
Документация СУБД «Квант-Гибрид» v.1.3.0
СУБД «Квант-Гибрид» представляет собой цифровую платформу общего назначения, применимую для широкого круга разработчиков государственных информационных систем, приложений, а также для корпоративных отделов по цифровой трансформации предприятий крупного и среднего бизнеса
Документация СУБД «Квант-Гибрид» (Quantum Hybrid Base, далее по тексту QHB) представлена в 3 частях и приложениях:
- Часть I - общее знакомство с внутренним строением QHB
- Часть II - рассматриваются темы, представляющие интерес для администратора базы данных QHB
- Часть III - рассматриваются темы, связанные с формальными знаниями языка SQL
- Приложения
Состояние документирования
Мы, разработчики QHB, с признательностью примем от Вас информацию об ошибках в Документации на почтовый адрес qhb.support@granit-concern.ru. Мы не скрываем, что продукт QHB создавался как форк от свободно распространяемого open source продукта PostgreSQL. Вероятные ошибки в документации могут быть связаны именно с этим.
О состоянии Документации и её перевода мы будем регулярно сообщать в сопроводительной документации к каждому релизу. Недостающие и/или непереведённые главы Вы можете найти на официальной странице документации PostgreSQL по адресу: https://www.postgresql.org/docs/.
Версия документации: 1.3.0
Номер ревизии: 38f946b2
Дополнительно
Вы можете скачать полный архив данной документации по ссылкам:
Ознакомьтесь со списком поддерживаемых платформ и замечаниями к релизу QHB.
Подключится к репозиториям бинарных пакетов и установить QHB можно на странице загрузки, воспользовавшись краткой инструкцией по начальной загрузке и установке.
Документация на СУБД «Квант-Гибрид» предыдущих версий:
Юридическое уведомление
Программное обеспечение СУБД «Квант-Гибрид» v.1.3.0
Предоставляются неисключительные права на использование данного Программного обеспечения и его документации исключительно для ознакомительных и учебных целей. Использование данной версии Программного обеспечения в коммерческих целях не допускается.
Программное обеспечение было создано в результате правомерной переработки Системы Управления Базами Данных PostgreSQL, распространяемой Калифорнийским университетом по открытой лицензии, и в отношении такой исходной программы применимы следующие условия ее использования по открытой лицензии:
Portions copyright (c) 1996-2011, PostgreSQL Global Development Group
Portions Copyright (c) 1994 Regents of the University of California
Предоставляются права на использование, копирование, изменение и распространение данного программного обеспечения и его документации для любых целей, бесплатно и без подписания какого-либо соглашения, при условии, что для каждой копии будут предоставлены данное выше замечание об авторских правах, текущий параграф и два следующих параграфа.
КАЛИФОРНИЙСКИЙ УНИВЕРСИТЕТ НЕ НЕСЕТ НИКАКОЙ ОТВЕТСТВЕННОСТИ ЗА ЛЮБЫЕ ПОВРЕЖДЕНИЯ, ВКЛЮЧАЯ ПОТЕРЮ ДОХОДА, НАНЕСЕННЫЕ ПРЯМЫМ ИЛИ НЕПРЯМЫМ, СПЕЦИАЛЬНЫМ ИЛИ СЛУЧАЙНЫМ ИСПОЛЬЗОВАНИЕМ ДАННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ИЛИ ЕГО ДОКУМЕНТАЦИИ, ДАЖЕ ЕСЛИ КАЛИФОРНИЙСКИЙ УНИВЕРСИТЕТ БЫЛ ИЗВЕЩЕН О ВОЗМОЖНОСТИ ТАКИХ ПОВРЕЖДЕНИЙ.
КАЛИФОРНИЙСКИЙ УНИВЕРСИТЕТ СПЕЦИАЛЬНО ОТКАЗЫВАЕТСЯ ПРЕДОСТАВЛЯТЬ ЛЮБЫЕ ГАРАНТИИ, ВКЛЮЧАЯ, НО НЕ ОГРАНИЧИВАЯСЬ ТОЛЬКО ЭТИМИ ГАРАНТИЯМИ: НЕЯВНЫЕ ГАРАНТИИ ПРИГОДНОСТИ ТОВАРА ИЛИ ПРИГОДНОСТИ ДЛЯ ОТДЕЛЬНОЙ ЦЕЛИ. ДАННОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ПРЕДОСТАВЛЯЕТСЯ НА ОСНОВЕ ПРИНЦИПА "КАК ЕСТЬ" И КАЛИФОРНИЙСКИЙ УНИВЕРСИТЕТ НЕ ОБЯЗАН ПРЕДОСТАВЛЯТЬ СОПРОВОЖДЕНИЕ, ПОДДЕРЖКУ, ОБНОВЛЕНИЯ, РАСШИРЕНИЯ ИЛИ ИЗМЕНЕНИЯ.
Кроме того, Программное обеспечение содержит модули собственной разработки:
- самобалансирующийся менеджер кэша дисковых блоков с автоматической компенсацией нагрузки на дисковую систему;
- QCP (балансировщик сетевой нагрузки предназначенный для оптимального использования серверных подключений);
- библиотечный кэш разобранных запросов;
- серверный процесс организующий фоновую запись диск;
- RBytea (модуль для внешнего хранения больших бинарных объектов с сохранением способа их обработки в прикладных системах);
- QSS (прозрачное шифрование данных с использованием алгоритма ГОСТ Р 3412-15 "Кузнечик" для произвольных объектов, включая внешние большие объекты);
- подсистема сбора и агрегации метрик;
- QSQL (пользовательская консоль для выполнения команд базы данных и запросов на языке SQL);
- QDL (модуль для прямой загрузки больших объёмов данных из текстового представления непосредственно в страницы данных);
- бинарные утилиты для управления СУБД;
- подсистема интернационализации i18n.
Программное обеспечение и все его компоненты предоставляются по принципу «как есть», что подразумевает: Пользователю известны важнейшие свойства Программного обеспечения, Пользователь несет риск соответствия Программного обеспечения его желаниям и потребностям, а также риск объема предоставляемых прав своим потребностям.
Пользователь принимает на себя обязательство не производить следующие действия с Программным обеспечением - эмулировать, декомпилировать, дизассемблировать, дешифровать, модифицировать и иные аналогичные действия.
Настоящее соглашение регулируется действующим законодательством Российской Федерации.
Правила сообщения об ошибках
Если вы найдёте ошибку в QHB, сообщите нам об этом. Ваши отчёты об ошибках играют важную роль в повышении надежности QHB, потому что даже при самом высоком качестве кода нельзя гарантировать, что каждая функция QHB будет работать на любой платформе и при любых обстоятельствах.
Следующие шаги призваны помочь вам в формировании отчётов об ошибках, которые могут быть обработаны эффективно. Мы не предлагаем выполнять их досконально, но лучше им следовать.
Мы не можем обещать немедленного исправления каждой ошибки. Если ошибка очевидна, критична или затрагивает большинство пользователей, то велика вероятность, что кто-то ею займется. Иногда мы рекомендуем вам обновить версию, чтобы увидеть, воспроизводится ли ошибка. Мы также можем решить, что данная ошибка не может быть исправлена до того, как будет выпущено какое-либо серьезное, запланированное обновление. Или, может быть, исправление слишком сложно, и на повестке дня есть более важные вещи. Если вам нужна немедленная помощь, подумайте о заключении договора о коммерческой поддержке.
Выявление ошибок
Прежде чем сообщать об ошибке, перечитайте документацию, чтобы убедиться, что вы действительно делаете, то что хотите. Если из документации не ясно, можете ли вы что-то сделать или нет, сообщите об этом - это ошибка в документации. Если программа делает что-то не так, как написано в документации, то это тоже ошибка.
Далее приведены лишь некоторые примеры возможных ошибок:
-
Программа завершается аварийным сигналом или сообщением об ошибке операционной системы, указывающем на проблему в программе. (Контрпримером может быть сообщение «Недостаточно места на диске» - эту проблему вы должны решить самостоятельно).
-
Программа отказывается принимать допустимые (согласно документации) данные.
-
Программа принимает недопустимые входные данные без предупреждения или сообщения об ошибке. Но имейте в виду, что данные, которые вы считаете некорректными, мы можем считать приемлемым расширением или совместимым с принятой практикой.
-
Не получается скомпилировать, собрать или установить QHB на поддерживаемых платформах в соответствии с инструкциями.
Здесь под определением «программа» подразумевается любой исполняемый файл, а не только серверный процесс.
Медленная работа - не обязательно ошибка. Прочитайте документацию или обратитесь в один из списков рассылки за помощью в настройке ваших приложений. Несоблюдение SQL-стандарта не обязательно является ошибкой, если соответствие для конкретной функции явно не заявлено.
Что сообщить
Самое важное, что следует помнить о сообщениях об ошибках, - сообщайте все факты и только факты. Не размышляйте о том, что, по вашему мнению, пошло не так, что «казалось, что оно делает» или какая часть программы содержит ошибку. Если вы не знакомы с реализацией, вы, скорее всего, ошибётесь и не поможете нам. Грамотные объяснения являются отличным дополнением к фактам, но не заменяют их. Если мы собираемся исправить ошибку, мы все равно должны будем посмотреть в чём она заключается. Сообщить голые факты относительно просто (можно просто скопировать и вставить текст с экрана), но слишком часто важные детали не упоминаются, потому что считаются незначительными и неважными или кажется, что отчет будет понятен и без них.
В каждом отчете об ошибке следует указать следующую информацию:
- Точная последовательность действий начиная с запуска программы, необходимая для воспроизведения проблемы. Она должна быть полной; если вывод зависит от данных в таблицах, то недостаточно указать только SELECT без предшествующих операторов CREATE TABLE и INSERT. У нас не будет времени на восстановление вашей схемы базы данных, и если предполагается, что мы должны создать собственные данные, мы, вероятно, пропустим эту проблему.
-
Если ваше приложение использует какой-либо другой клиентский интерфейс, например PHP, попробуйте изолировать ошибочные запросы. Вряд ли мы будем устанавливать веб-сервер для воспроизведения вашей ошибки. В любом случае не забудьте предоставить конкретные входные файлы; не гадайте о том, что проблема возникает для «больших файлов» или «баз данных среднего размера» и т. д., поскольку эта информация слишком расплывчата.
-
Результат выполнения. Пожалуйста, не пишите, что это "не работает" или "сломалось". Если есть сообщение об ошибке, покажите его, даже если оно выглядит непонятным. Если программа завершается ошибкой операционной системы, приведите эту ошибку. Если ничего не происходит, так и напишите. Даже если результатом вашего теста является сбой программы или что-то очевидное - на нашей платформе это может не произойти. Проще всего будет скопировать текст с терминала, если это возможно.
-
Важно описать результат, который вы ожидали получить. Если вы просто напишете "Эта команда выдает мне такой результат" Или "Это не то, что я ожидал", мы можем запустить ваш пример сами, просмотреть вывод и решить, что все в порядке и результат соответствует ожиданиям. Мы вряд ли будем тратить время на расшифровку точного смысла ваших команд. Особенно воздерживайтесь от простого заявления: "Это не то, что делает SQL/Oracle". Выяснение соответствия SQL-стандартам зачастую трудоёмкое и скучное занятие, а логика работы других реляционных баз данных может быть не полностью документирована или отличаться в нюансах. (Если ваша проблема - сбой программы, то вы, очевидно, можете пропустить этот пункт).
-
Все параметры командной строки и другие параметры запуска, включая все связанные переменные окружения или файлы конфигурации, которые вы изменяли со значений по умолчанию. Пожалуйста, предоставьте точную информацию. Если вы используете предварительно упакованный дистрибутив, который запускает сервер базы данных во время загрузки, вы должны попытаться выяснить, как это сделать.
-
Все что вы сделали не так, как написано в инструкции по установке.
-
Версия QHB. Чтобы узнать версию сервера, к которому вы подключены Вы можете запустить команду,
SELECT version();. Большинство исполняемых программ также поддерживает опцию--version; по крайней мереqhb --versionиqsql --versionдолжно работать. Если функция или параметры не существуют, значит скорее всего вашу версию пора обновить. Если вы запускаете предварительно упакованную версию, такую как RPM, укажите subversion, которую может иметь пакет. Если вы пишете о снимке Git, укажите это, а также хеш коммита. -
Если ваша версия старее актуальной, мы почти наверняка предложим вам её обновить. В каждом новом выпуске содержится много исправлений и улучшений, поэтому вполне возможно, что ошибка, с которой вы столкнулись в более старой версии QHB, уже исправлена. Мы можем предоставить только ограниченную поддержку для программ, использующих старые версии QHB; если вам этого недостаточно - рассмотрите возможность заключения договора о коммерческой поддержке.
-
Информация о платформе. Включает в себя имя и версию ядра, библиотеку C/RUST, процессор, информацию о памяти и так далее. В большинстве случаев достаточно сообщить поставщика и версию, но не следует предполагать, что все знают, что именно содержит «Debian» или что все работают на x86_64. Если у вас есть проблемы с установкой, то вам также необходима информация о наборе инструментов на вашем компьютере (компилятор, make и т.д.).
Не бойтесь, если ваш отчет об ошибке будет довольно большим. Лучше сообщить обо всем сразу, чем потом уточнять информацию у вас.
Не тратьте все свое время, чтобы выяснить, при каких входных данных ошибка исчезает. Скорее всего это не поможет решить проблему. Если окажется, что вам удалось найти решение раньше нас, пожалуйста, уделите немного времени и поделитесь своими решениями. Кроме того, не тратьте свое время на предположения о причине ошибки. Если ошибка воспроизводится, то мы установим причину.
При написании отчета об ошибке избегайте путаницы в терминологии. Официальное наименование Программного пакета - "КВАНТ-ГИБРИД", для краткости в документации скорее всего будет использовано название "QHB". Если вы говорите о бэкэнд-процессе, отметьте это, а не просто говорите «Сбои QHB». Сбой одного бэкэнд-процесса сильно отличается от сбоя родительского процесса "qhb"; пожалуйста, не пишите, что "процесс упал", когда имеется в виду, что один серверный процесс вышел из строя, или наоборот. Кроме того, клиентские программы, такие как интерактивный интерфейс "QSQL", полностью отделены от бэкэнда. Пожалуйста, постарайтесь указать, является ли проблема на стороне клиента или сервера.
Как сообщать об ошибках
Отправляйте отчёты об ошибках по адресу:
В теме письма желательно указать краткое описание проблемы, возможно, включив в неё часть сообщения об ошибке.
Часть I. Внутреннее устройство
Добро пожаловать в руководство по внутреннему устройству СУБД «Квант-Гибрид» (QHB). Основная цель этой части - познакомить вас на практике с основными аспектами системы QHB, без глубокого погружения в рассматриваемые темы.
Освоив это руководство, вы можете перейти к чтению части II для установки и администрирования своего собственного сервера или части III, для получения информации по использованию языка SQL в QHB.
-
- Краткая справка по индексам
- Типы индексов
- Многоколоночные индексы
- Индексы и ORDER BY
- Объединение нескольких индексов
- Уникальные индексы
- Индексы по выражениям
- Частичные индексы
- Сканирование только по индексу и покрывающие индексы
- Классы операторов и семейства операторов
- Индексы и правила сортировки
- Анализ использования индексов
- Индексы B-деревья
- Индексы GIN
- Индексы GiST
- Индексы SP-GiST
- Индексы BRIN
-
- Как работает расширяемость
- Система типов QHB
- Пользовательские функции
- Пользовательские процедуры
- Функции на языке запросов (SQL)
- Перегрузка функций
- Категории изменчивости функций
- Функции на процедурном языке
- Внутренние функции
- Функции на нативном языке
- Информация по оптимизации функций
- Пользовательские агрегаты
- Пользовательские типы
- Пользовательские операторы
- Информация по оптимизации оператора
- Интерфейсные расширения для индексов
- Упаковка связанных объектов в расширение
- Инфраструктура сборки расширений
-
- Обзор
- pg_aggregate
- pg_am
- pg_amop
- pg_amproc
- pg_attrdef
- pg_attribute
- pg_authid
- pg_auth_members
- pg_cast
- pg_class
- pg_collation
- pg_constraint
- pg_conversion
- pg_database
- pg_db_role_setting
- pg_default_acl
- pg_depend
- pg_description
- pg_enum
- pg_event_trigger
- pg_extension
- pg_foreign_data_wrapper
- pg_foreign_server
- pg_foreign_table
- pg_index
- pg_inherits
- pg_init_privs
- pg_language
- pg_largeobject
- pg_largeobject_metadata
- pg_namespace
- pg_opclass
- pg_operator
- pg_opfamily
- pg_partitioned_table
- pg_pltemplate
- pg_policy
- pg_proc
- pg_publication
- pg_publication_rel
- pg_range
- pg_replication_origin
- pg_rewrite
- pg_seclabel
- pg_sequence
- pg_shdepend
- pg_shdescription
- pg_shseclabel
- pg_statistic
- pg_statistic_ext
- pg_statistic_ext_data
- pg_subscription
- pg_subscription_rel
- pg_tablespace
- pg_transform
- pg_trigger
- pg_ts_config
- pg_ts_config_map
- pg_ts_dict
- pg_ts_parser
- pg_ts_template
- pg_type
- pg_user_mapping
-
- pg_available_extensions
- pg_available_extension_versions
- pg_config
- pg_cursors
- pg_file_settings
- pg_group
- pg_hba_file_rules
- pg_indexes
- pg_locks
- pg_matviews
- pg_policies
- pg_prepared_statements
- pg_prepared_xacts
- pg_publication_tables
- pg_replication_origin_status
- pg_replication_slots
- pg_roles
- pg_rules
- pg_seclabels
- pg_sequences
- pg_settings
- pg_shadow
- pg_stats
- pg_stats_ext
- pg_tables
- pg_timezone_abbrevs
- pg_timezone_names
- pg_user
- pg_user_mappings
- pg_views
Основы архитектуры
Прежде чем мы продолжим, необходимо понять основы архитектуры системы
QHB.
Понимание того, как взаимодействуют части QHB,
сделает эту главу несколько понятнее.
В терминах баз данных QHB использует модель клиент / сервер. Сессия QHB состоит из следующих взаимодействующих процессов (программ):
-
Процесс сервера, который управляет файлами базы данных, принимает подключения к базе данных от клиентских приложений и выполняет действия с базой данных от имени клиентов. Программа сервера базы данных называется qhb.
-
Клиентское приложение пользователя, которое будет выполнять операции с базой данных. Клиентские приложения могут быть очень разнообразными по своей природе: клиент может быть текстовым инструментом, графическим приложением, веб-сервером, который обращается к базе данных для отображения веб-страниц, или специализированным инструментом обслуживания базы данных. Некоторые клиентские приложения поставляются с дистрибутивом QHB, но большинство разработано пользователями.
Обычно для клиент-серверных приложений, клиент и сервер находятся на разных хостах. В этом случае они общаются через сетевое соединение по протоколу TCP/IP. Следует помнить об этом, поскольку файлы, к которым можно получить доступ на клиентском компьютере, могут быть недоступны (или могут быть доступны только с использованием другого имени файла) на сервере базы данных.
Сервер QHB может обрабатывать несколько одновременных подключений от клиентов. Для этого запускается (при помощи системного вызова "fork") новый процесс для каждого соединения. С этого момента клиент и новый серверный процесс обмениваются данными без вмешательства главного процесса qhb. Таким образом, главный процесс сервера всегда работает, ожидая клиентских подключений, тогда как процессы клиента и связанных серверов создаются и удаляются. (Все это происходит, конечно, прозрачно для пользователя.)
Модуль безопасного хранения QSS
- Описание
- Использование
- Утилита
qss_mgrи управление ключами - Утилита
qss_recryptиспользуется для перешифрования таблиц БД новым набором ключей - Утилита
qss_pinpadпредназначена для ввода пина криптотокена при использовании ключей в режиме pkcs11 - Утилита
magma_key_gen - Пример создания и включения шифрованной таблицы
- Получение тестовых ключей
- Инициализация QSS в режиме мастер ключа подписанного пользовательским ключем на файловой системе
- Инициализация QSS в режиме мастер ключа подписанного пользовательскимм ключем на крипто-токене
- Добавление возможности запуска сервера с другим пользовательским ключем
- Включение QSS на сервере
- Создание зашифрованной таблицы
- Подготовка к перешифровке БД новым мастер-ключем
Описание
Модуль безопасного хранения «КВАНТ-ГИБРИД» (Quantum Secure Storage, QSS) позволяет создавать таблицы, которые шифруются при записи на диск.
При старте сервера СУБД главный процесс QHB читает с диска мастер-ключ шифрования и сохраняет его в общей памяти, доступной дочерним процессам.
При чтении\записи блока\страницы на диск этот ключ используется для расшифровки\шифрования блока
Использование
Использование модуля в SQL:
create table t_qss(c1 int, c2 varchar) USING qss;
В qhb.conf добавляется параметр qss_mode: int с возможными режимами:
- 0 - отключено: попытки создания новых таблиц с
using qssили чтение\запись в уже существующие приводит к ошибкам, - 1 - включено: при старте сервера считывается qss.toml и производится загрузка актуального мастер-ключа с его расшифровкой, при любых ошибках сервер останавливается
Файлы, используемые в QSS:
.
└── PGDATA
├── base
├── qhb.conf
└── qss
├── 0.key
├── 1.key
└── qss.toml
В qss.toml хранятся общие настройки qss (например, путь к динамической библиотеке работы с крипто-токеном) и дополнительная информация по ключам, например, режим расшифровки ключа:
- не зашифрован,
- ключ расшифровки находится в файловой системе, например, на примонтированном usb, с указанием пути
- ключ расшифровки находится на криптотокене, с указанием его идентификатора
Бинарная версии ключа (файл .key) состоит из заголовка постоянного размера с информацией: версия (1),
режим расшифровки (должен совпадать с записью в файле-конфигурации) и 32 байтов зашифрованного мастер-ключа
Утилита qss_mgr и управление ключами
Для управления ключами используется утилита qss_mgr со следующими командами:
bash-4.2$ qss_mgr --help
qss_mgr 1.1.0
qss configures secured storage in QHB database
USAGE:
qss_mgr [FLAGS] [OPTIONS] <SUBCOMMAND>
FLAGS:
-h, --help
Prints help information
--new
Work with key group for key replacement
-V, --version
Prints version information
OPTIONS:
-d, --data-dir <data-dir>
Specifies the directory with database data [env: PGDATA=/tmp/qhb-data/]
SUBCOMMANDS:
add Add new version of master key encrypted with other secret key
del Remove key
help Prints this message or the help of the given subcommand(s)
init Initialize config and first encrypted master key
use-new Backup current key set and replace it with new
verify Verify key or keys
Общий флаг --new позволяет работать с "новым" набором ключей переключиться на которой можно командой use-new
Инициализация с добавлением первого мастер-ключа
Примечание!!!
в режиме pkcs11 для ввода пин-кода используется утилита qss-pinpad, запущенная на этом же компьютере в другом терминале.
Initialize config and first encrypted master key
USAGE:
qss_mgr init [OPTIONS] [master-key]
OPTIONS:
-k, --key <key> Key for encryption
-f, --key-format <key-format> Format of key for encryption: bin, base64, armored [default: bin]
--master-key-format <master-key-format> Source master key format: bin, base64, armored [default: bin]
-m, --mode <mode> Master key encrypt mode: fs, pkcs11 [default: pkcs11]
--module <pkcs11-module-path> PKCS11 module
--token-key-id <token-key-id> User key ID on token for pkcs11
--token-serial-number <token-serial-number> Token serial number for pkcs11
ARGS:
<master-key> Source master key file
Добавление мастер ключа, зашифрованного ключом другого пользователя
Add new version of master key encrypted with other secret key
USAGE:
qss_mgr add [OPTIONS] [master-key]
OPTIONS:
-k, --key <key> Key for encryption
-f, --key-format <key-format> Format of key for encryption: bin, base64, armored [default: bin]
--master-key-format <master-key-format> Source master key format: bin, base64, armored [default: bin]
-m, --mode <mode> Master key encrypt mode: fs, pkcs11 [default: pkcs11]
-n, --num <num> Previous key index to load master key from
--token-key-id <token-key-id> User key ID on token for pkcs11
--token-serial-number <token-serial-number> Token serial number for pkcs11
ARGS:
<master-key> Source master key file
Удаление ключа
Remove key
USAGE:
qss_mgr del [FLAGS] --num <num>
FLAGS:
-q, --quiet Quiet mode: don't ask for confirmation
OPTIONS:
-n, --num <num> Key index
Переключение на новый набор ключей
Backup current key set and replace it with new
USAGE:
qss_mgr use-new
Проверка ключей
Verify key or keys. If checking all keys, check that master keys is same
USAGE:
qss_mgr verify [OPTIONS]
OPTIONS:
-n, --num <num> Key index, if not specified, tries to check all keys
Утилита qss_recrypt используется для перешифрования таблиц БД новым набором ключей
Список команд
qss_reqcrypt 1.1.0
qss recrypt QHB cluster with new master key
USAGE:
qss_recrypt [FLAGS] --data-dir <data-dir> <SUBCOMMAND>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-v, --verbose Sets logging level to Debug [default: Info]
OPTIONS:
--data-dir <data-dir> Specifies the directory with database data [env: PGDATA=/tmp/qhb-data/]
SUBCOMMANDS:
add Scan database and add it to recrypt's config
help Prints this message or the help of the given subcommand(s)
recrypt Do database reencryption
Сканирование БД и сохранение данных о ее зашифрованных таблицах в файл конфигурации
Scan database and add it to recrypt's config
USAGE:
qss_recrypt --data-dir <data-dir> add [FLAGS] [OPTIONS]
FLAGS:
--no-timeout Run app with no timeout, use instead of -t 0s
OPTIONS:
-d, --dbname <dbname> Specifies the name of the database to connect to [env: PGDATABASE=]
-h, --host <host> Specifies the host name of the machine on which the server is running. If the value
begins with a slash, it is used as the directory for the Unix-domain socket [env:
PGHOST=/home/evgen/work/db/build/dbsockets]
-p, --port <port> Specifies the TCP port or the local Unix-domain socket file extension on which the
server is listening for connections [env: PGPORT=] [default: 5432]
-t, --timeout <timeout> Seconds to wait when attempting connection, supports "human time", -t 3s
-U, --username <username> Connect to the database as the user username instead of the default [env: PGUSER=]
Перешифрование кластера (экземпляра QHB)
При старте будет выполнена расшифровка старого мастер ключа (с запросом пина криптотокена при необходимости), а потом нового.
Do database reencryption
USAGE:
qss_recrypt --data-dir <data-dir> recrypt
Утилита qss_pinpad предназначена для ввода пина криптотокена при использовании ключей в режиме pkcs11
Запускать следует в отдельном терминале перед стартом сервера или использованием qss_mgr для добавления или проверки ключей
Утилита magma_key_gen
magma_key_gen предназначена для генерации пользовательских ключей QSS на крипто-токенах, поддерживающих аппаратное шифрование по ГОСТ 34.12-2018 и ГОСТ 34.13-2018
Утилита поставляется в пакете qhb-contrib
magma_key_gen принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
--id id | идентификатор создаваемого ключа |
--module pkcs11-module-path | путь к библиотеке крипто-токена. По-умолчанию используется /usr/lib64/librtpkcs11ecp.so |
Если ключ с таким идентификатором уже существует, программа выводит об этом сообщение и завершает работу.
Пример создания и включения шифрованной таблицы
Получение тестовых ключей
Создать мастер ключ и ключ пользователя:
head -c 32 /dev/urandom > master_key.bin
head -c 32 /dev/urandom > user1.bin
Инициализация QSS в режиме мастер ключа подписанного пользовательским ключем на файловой системе
qss_mgr init \
--module=/usr/lib64/librtpkcs11ecp.so \
--mode fs \
--key user1.bin \
master_key.bin
Инициализация QSS в режиме мастер ключа подписанного пользовательскимм ключем на крипто-токене
qss_mgr init \
--module=/usr/lib64/librtpkcs11ecp.so \
--mode pkcs11 \
--token-serial-number 3c4c6444 \
--token-key-id 1234 \
master_key.bin
Добавление возможности запуска сервера с другим пользовательским ключем
Должен быть доступен ключ первого пользователя.
qss_mgr add \
-mode fs \
-k user2.bin \
-n 0
Включение QSS на сервере
echo "qss_mode = 1" >> "${PGDATA}/qhb.conf"
qhb-ctl restart
Создание зашифрованной таблицы
create table t_qss(c1 int, c2 varchar) USING qss;
Подготовка к перешифровке БД новым мастер-ключем
Добавление нового мастер-ключа
qss_mgr --new init \
--module=/usr/lib64/librtpkcs11ecp.so \
--mode fs \
--key user1.bin \
new_master_key.bin
Сбор информации о зашифрованных таблицах в БД
Выполняется при запущенном кластере, надо повторить для всех БД в кластере, содержащих шифрованные таблицы
qss_recrypt --data-dir "${PGDATA}" add \
--dbname my
Запуск перешифровки кластера
Выполняется на остановленном кластере
qss_recrypt --data-dir "${PGDATA}" recrypt
Переключение на новый мастер-ключ
Выполняется на остановленном кластере. Переносит текущий набор ключей в папку old, заменяя его подготовленным набором ключей из папки new
qss_mgr --data-dir "${PGDATA}" use-new
Индексы
Индексы являются распространенным способом повышения производительности базы данных. Индекс позволяет серверу базы данных находить и извлекать определенные строки гораздо быстрее, чем без индекса. Но индексы также увеличивают нагрузку на систему баз данных в целом, поэтому их следует использовать разумно.
- Краткая справка по индексам
- Типы индексов
- Многоколоночные индексы
- Индексы и ORDER BY
- Объединение нескольких индексов
- Уникальные индексы
- Индексы по выражениям
- Частичные индексы
- Сканирование только по индексу и покрывающие индексы
- Классы операторов и семейства операторов
- Индексы и правила сортировки
- Анализ использования индексов
Краткая справка по индексам
Предположим, у нас есть таблица, подобная этой:
CREATE TABLE test1 (
id integer,
content varchar
);
и приложение делает много запросов вида
SELECT content FROM test1 WHERE id = constant;
Без предварительной подготовки система должна будет сканировать всю таблицу test1, строка за строкой, чтобы найти все соответствующие записи. Если в test1 есть много строк и только несколько из них (возможно, ноль или одна) будут возвращены таким запросом, то это явно неэффективный метод. Но если система получила указание поддерживать индекс для столбца id, она может использовать более эффективный метод для поиска подходящих строк. Например, достаточно будет пойти на несколько уровней вглубь дерева поиска.
Подобный подход используется в большинстве научно-популярных книг: термины и понятия, которые часто ищут читатели, собраны в алфавитном указателе в конце книги. Заинтересованный читатель может сравнительно быстро просканировать указатель и перейти к соответствующей странице (страницам), а не читать всю книгу целиком, чтобы найти интересующий материал. Подобно тому, как задача автора состоит в том, чтобы предвидеть элементы, которые читатели могут искать, задача программиста базы данных — предвидеть, какие индексы будут полезны.
Следующая команда может использоваться для создания подобного индекса для столбца id:
CREATE INDEX test1_id_index ON test1 (id);
Имя test1_id_index можно выбрать любое, но в идеале оно должно напоминать вам о назначении индекса.
Чтобы удалить индекс, используйте команду DROP INDEX. Индексы могут быть добавлены и удалены из таблиц в любое время.
После создания индекса дальнейшее вмешательство не требуется: система будет обновлять индекс при изменении таблицы и будет использовать индекс в запросах, когда считает, что это будет более эффективно, чем последовательное сканирование таблицы. Но вам, возможно, придется регулярно запускать команду ANALYZE для обновления статистики, чтобы планировщик запросов мог принимать обоснованные решения. См. главу Советы по производительности для получения информации о том, как узнать, используется ли индекс, и когда и почему планировщик может предпочесть не использовать индекс.
Индексы также могут использоваться командами UPDATE и DELETE с условиями фильтрации. Кроме того, индексы могут использоваться при соединении таблиц, поэтому индекс, определенный для столбца, который является частью условия соединения, также может значительно ускорить запросы с соединениями.
Создание индекса для большой таблицы может занять много времени. По умолчанию QHB позволяет выполнять чтение (SELECT) из таблицы параллельно с созданием индекса, но модификации (INSERT, UPDATE, DELETE) блокируются до завершения построения индекса. В нагруженной системе это часто недопустимо. Можно разрешить модификации параллельно с созданием индекса, но следует учитывать несколько моментов — для получения дополнительной информации см. раздел Неблокирующее построение индексов.
После создания индекса система должна постоянно синхронизировать его с таблицей. Это увеличивает накладные расходы на операции с данными. Поэтому индексы, которые редко или никогда не используются в запросах, должны быть удалены.
Типы индексов
QHB предоставляет несколько типов индексов: B-дерево, Hash, GiST, SP-GiST, GIN и BRIN. Каждый тип индекса использует свой алгоритм, который лучше всего подходит для разных типов запросов. По умолчанию команда CREATE INDEX создает B-дерево, потому что оно подходит в наиболее распространенных ситуациях.
B-деревья могут обрабатывать запросы на равенство, неравенство и принадлежность интервалу значений. В частности, планировщик запросов QHB будет рассматривать возможность использования индекса типа B-дерево всякий раз, когда индексированный столбец участвует в условии с одним из этих операторов:
<
<=
=
>=
>
Конструкции, эквивалентные комбинациям этих операторов, такие как BETWEEN и IN, также могут быть реализованы с помощью поиска по B-дереву. Кроме того, B-дерево может быть использовано при запросе условия IS NULL или IS NOT NULL на столбец индекса.
Оптимизатор также может использовать B-дерево для запросов,
включающих операторы сопоставления с образцом LIKE и ~, если шаблон
является константой и привязан к началу строки; например,
col LIKE 'foo%' or col ~ '^foo', но не col LIKE '%bar'. Однако, если ваша база
данных использует локаль, отличную от C, вам нужно будет создать индекс со
специальным классом операторов для поддержки индексации запросов на
сопоставление с образцом; см. раздел Классы операторов и семейства операторов ниже.
Также возможно использовать B-дерево для ILIKE и ~*, но только если шаблон
начинается с символов, для которых нет верхнего и нижнего регистра, например, цифр.
Индексы типа B-дерево также можно использовать для извлечения данных в отсортированном порядке. Это не всегда быстрее, чем простое сканирование и сортировка, но часто полезно.
Хеш-индексы могут обрабатывать только простые сравнения на равенство. Планировщик запросов рассмотрит возможность использование хеш-индекса, когда индексируемый столбец участвует в сравнении с использованием оператора =. Следующая команда создает хеш-индекс:
CREATE INDEX name ON table USING HASH (column);
Индексы GiST — это не единая категория индексов, а скорее инфраструктура, с помощью которой может быть реализовано множество различных стратегий индексации. Соответственно, конкретные операторы, с которыми может использоваться индекс GiST, варьируются в зависимости от стратегии индексации (класса операторов). Например, стандартный дистрибутив QHB включает классы операторов GiST для нескольких двумерных геометрических типов данных, которые поддерживают индексированные запросы с использованием следующих операторов:
<< &< &> >> <<| &<| |&> |>> @> <@ ~= &&
(Значение этих операторов см. в разделе Геометрические функции и операторы).
Многие другие классы операторов GiST доступны в коллекции contrib или в виде отдельных проектов.
Индексы GiST могут оптимизировать поиск «ближайшего соседа», например, такой запрос
SELECT * FROM places ORDER BY location <-> point '(101,456)' LIMIT 10;
находит десять мест, ближайших к заданной целевой точке. Возможность сделать это зависит от конкретного класса операторов, использованного при построении индекса.
Индексы SP-GiST, так же как и индексы GiST, предлагают инфраструктуру, которая поддерживает различные виды поиска. SP-GiST позволяет реализовать широкий спектр различных несбалансированных дисковых структур данных, таких как дерево квадрантов, k-мерные деревья и префиксные деревья (Tries). Например, стандартный дистрибутив QHB включает классы операторов SP-GiST для точек двумерного пространства, которые позволяют использовать индекс для запросов с использованием следующих операторов:
<< >> ~= <@ <^ >^
(Значение этих операторов см. в разделе Геометрические функции и операторы).
Как и GiST, SP-GiST поддерживает поиск «ближайшего соседа».
Индексы GIN — это «инвертированные индексы», которые подходят для индексации столбцов, значение которых представляет из себя коллекцию элементов, и последующего поиска по отдельным элементам. Инвертированный индекс содержит отдельную запись для каждого элемента и может эффективно обрабатывать запросы, которые проверяют наличие определенных элементов.
Подобно GiST и SP-GiST, GIN может поддерживать множество различных пользовательских стратегий индексирования, и конкретные операторы, с которыми может использоваться индекс GIN, различаются в зависимости от стратегии индексирования. Например, стандартный дистрибутив QHB включает класс операторов GIN для массивов, который поддерживает индексированные запросы с использованием операторов:
<@ @> = &&
Значение этих операторов см. в разделе Функции и операторы массива. Классы операторов GIN, включенные в стандартную поставку, а также входящие в коллекцию contrib, перечислены в разделе Встроенные классы операторов GIN.
Индексы BRIN (сокращение от Block Range INdexes, индекс диапазона блоков) хранят сводные
данные о значениях, хранящихся в последовательных диапазонах физических
блоков таблицы. Как и GiST, SP-GiST и GIN, BRIN может поддерживать
множество различных стратегий индексирования, и конкретные операторы, с
которыми может использоваться индекс BRIN, различаются в зависимости от
стратегии индексирования. Для типов данных, имеющих линейный порядок
сортировки, индекс хранит минимальные и
максимальные значения в столбце для каждого диапазона блоков.
Это позволяет использовать индекс для запросов, использующих следующие
операторы < <= = >= >. Для получения дополнительной информации см.
главу Индексы BRIN.
Многоколоночные индексы
Индекс может быть определен для более чем одного столбца таблицы. Например, если у вас есть такая таблица:
CREATE TABLE test2 (
major int,
minor int,
name varchar
);
(предположим, что вы так храните каталог /dev в базе данных), и вы часто делаете запросы вида
SELECT name FROM test2 WHERE major = constant AND minor = constant;
то может быть целесообразно создать индекс по столбцам major и minor вместе, например:
CREATE INDEX test2_mm_idx ON test2 (major, minor);
В настоящее время только индексы типа B-tree, GiST, GIN и BRIN поддерживают многоколоночные индексы. Можно указать до 32 столбцов.
Многоколоночный индекс типа B-дерево может использоваться с условиями запроса, которые включают любое подмножество столбцов индекса, но индекс наиболее эффективен, когда заданы ограничения на ведущие (крайние левые) столбцы.
Точное правило такое: должно быть ограничение равенства для нескольких (0+) первых столбцов индекса, плюс, возможно, ограничение неравенства на 1 следующий столбец — такие условия (т.н. "предикат поиска") позволяют сканировать узкий диапазон индекса.
Ограничения на прочие столбцы индекса ("дополнительный фильтр поиска") проверяются при сканировании индекса прямо в нем,
экономя обращения к таблице, но эти ограничения не уменьшают диапазон сканирования индекса.
Например, если есть индекс по (a, b, c), а условие запроса WHERE a = 5 AND b <= 50 AND c = 100,
то индекс будет сканироваться от первой записи a = 5 до последней записи a = 5 AND b <= 50,
и для каждой записи этого диапазона будет проверяться дополнительное условие с = 100.
Этот индекс в принципе может быть
использован и для запросов, которые имеют ограничения на b и/или c без
ограничения на a — но в этом случае будет сканироваться весь индекс,
и скорее всего планировщик предпочтет последовательное
сканирование таблицы такому использованию индекса.
Многоколоночный индекс GiST может использоваться с условиями запроса, которые включают любое подмножество столбцов индекса. Условия для дополнительных столбцов ограничивают записи, возвращаемые индексом, но условие для первого столбца является наиболее важным для определения того, какую часть индекса необходимо сканировать. Индекс GiST будет относительно неэффективным, если его первый столбец имеет мало вариантов различных значений, даже если в дополнительных столбцах много вариантов значений.
Многоколоночный индекс GIN может использоваться с условиями запроса, которые включают любое подмножество столбцов индекса. В отличие от B-дерева или GiST, эффективность поиска по индексу одинакова независимо от того, какие столбцы индекса входят в условие запроса.
Многоколоночный индекс BRIN может использоваться с условиями запроса, которые включают любое подмножество столбцов индекса. Подобно GIN и в отличие от B-дерева или GiST, эффективность поиска по индексу одинакова независимо от того, какие столбцы индекса входят в условие запроса. Единственная причина иметь несколько индексов BRIN в одной таблице вместо одного многоколоночного индекса BRIN — это задать для нескольких индексов разное значение параметра pages_per_range.
Конечно, каждый столбец должен использоваться с операторами, соответствующими типу индекса; если в условии используется другой оператор, то для него индекс не может быть использован.
Многоколоночные индексы следует использовать с осторожностью. В большинстве случаев достаточно одноколоночного индекса, который занимает меньше места и работает быстрее. Индексы с более чем тремя столбцами понадобятся только в экзотических ситуациях. См. также разделы Объединение нескольких индексов и Сканирование только по индексу и покрывающие индексы, где обсуждаются достоинства различных конфигураций индексов.
Индексы и ORDER BY
В дополнение к просто поиску строк, удовлетворяющих запросу, индекс может выдать их в определенном отсортированном порядке. Это позволяет реализовать указание ORDER BY без отдельного шага сортировки. Из всех типов индексов, поддерживаемых в настоящее время QHB, только B-дерево умеет сортированный вывод — другие типы индексов возвращают строки в неопределенном, зависящем от реализации порядке.
Даже если есть индекс, умеющий выдавать результаты в порядке, требуемом в ORDER BY, у планировщика всегда есть другой вариант: получить выборку другим способом, а потом отсортировать. Например, если в выборку попадает большая часть таблицы, будет выгоднее использовать сканирование таблицы с последующей досортировкой (последовательное чтение таблицы быстрее, чем хождение по ссылкам из индекса).
Важным частным случаем является ORDER BY в сочетании с LIMIT n: использование индекса позволит сразу отсечь n строк в порядке ORDER BY, а при использовании сканирования таблицы придётся достать и отсортировать всю выборку, чтобы получить первые n строк.
По умолчанию индексы B-дерева хранят свои записи в порядке возрастания, значения NULL после всех остальных (в случае равенства ссылка на строку в куче (TID) определяет порядок). Это означает, что прямое сканирование индекса по столбцу x приводит к выводу, удовлетворяющему ORDER BY x (точнее, ORDER BY x ASC NULLS LAST). Тот же индекс также можно сканировать в обратном направлении, получая выходные данные, удовлетворяющие ORDER BY x DESC (или, точнее, ORDER BY x DESC NULLS FIRST, именно такой порядок противоположен предыдущему).
Вы можете настроить порядок индекса B-дерево, включив опции ASC/DESC, NULLS FIRST/NULLS LAST при создании индекса, например:
CREATE INDEX test2_info_nulls_low ON test2 (info NULLS FIRST);
CREATE INDEX test3_desc_index ON test3 (id DESC NULLS LAST);
Индекс, созданный как ASC NULLS FIRST может удовлетворять либо ORDER BY x ASC NULLS FIRST либо ORDER BY x DESC NULLS LAST в зависимости от того, в каком направлении он сканируется.
Вы можете спросить, зачем предлагать все четыре варианта, когда два
варианта вместе с возможностью обратного сканирования будут охватывать
все варианты ORDER BY. В одноколоночных индексах параметры
действительно избыточны, но в многоколоночных индексах они могут быть
полезны. Рассмотрим индекс из двух столбцов для (x, y) : он подходит для
ORDER BY x, y если мы сканируем вперед, или ORDER BY x DESC, y DESC,
если мы сканируем назад. Но он не может поддержать порядок ORDER BY x ASC, y DESC.
Для такого порядка годится индекс (x ASC, y DESC) или (x DESC, y ASC)
Очевидно, что индексы с порядками сортировки, отличными от заданных по умолчанию, являются довольно специализированной функцией, но иногда они могут привести к значительному ускорению для определенных запросов. Стоит ли поддерживать такой индекс, зависит от того, как часто вы используете запросы, требующие специального порядка сортировки.
Объединение нескольких индексов
Простое сканирование индекса может использоваться для условий на отдельные столбцы
индекса, объединённых по AND. Например, при
наличии индекса (a, b) условие запроса WHERE a = 5 AND b = 6
может использовать индекс, но запрос, например, WHERE a = 5 OR b = 6 не
может напрямую использовать индекс.
К счастью, QHB имеет возможность комбинировать несколько индексов
(включая многократное использование одного и того же индекса) для
обработки случаев, которые не могут быть реализованы при сканировании
одного индекса. Система может реализовать условия AND и OR за
нескольких сканирований индекса. Например, запрос типа WHERE x = 42 OR x = 47 OR x = 53 OR x = 99 можно реализовать через сканирование четырех отдельных
диапазонов индекса по x, каждое по одному из условий x = ?.
Результаты этих сканирований затем объединяются для получения
результата. Другой пример: если у нас есть отдельные индексы для x и y,
одна из возможных реализаций запроса WHERE x = 5 AND y = 6
состоит в том, чтобы использовать каждый индекс для соответствующего условия,
а затем посчитать пересечение двух множеств строк.
Чтобы объединить несколько индексов, система сканирует каждый необходимый индекс и сохраняет множество строк, подходящий под эту часть условия, в памяти в виде битовой карты. Затем битовые карты можно объединять или пересекать в соответствии с запросом. Наконец, фактические строки таблицы посещаются и возвращаются. Строки таблицы посещаются в физическом порядке, потому что так они лежат в битовой карте; это означает, что любой порядок выдачи исходных индексов потерян, и поэтому потребуется отдельный шаг сортировки, если в запросе есть предложение ORDER BY. По этой причине, а также потому, что каждое дополнительное сканирование индекса добавляет дополнительное время, планировщик иногда предпочитает использовать простое сканирование индекса, даже если доступны дополнительные индексы, которые также можно было бы использовать.
Во всех приложениях, кроме самых простых, могут быть полезны различные
комбинации индексов, и разработчик базы данных должен найти
компромисс, какие индексы иметь. Иногда лучше
использовать многоколоночные индексы, а иногда лучше создавать
отдельные индексы и полагаться на функцию комбинирования индексов.
Например, если ваша рабочая нагрузка включает в себя набор запросов,
которые иногда содержат условие только на столбец x, иногда только на столбец y, а
иногда на оба столбца, вы можете создать два отдельных индекса для x и y,
полагаясь на комбинацию индексов для обработки запросов, которые
используйте оба столбца. Вы также можете создать многоколоночный индекс
для (x, y). Этот индекс эффективнее, чем комбинация
индексов, для запросов, включающих оба столбца, но, как обсуждалось в
разделе Многоколоночные индексы, он почти бесполезен для запросов, включающих только
y, поэтому он не должен быть единственным индексом. Комбинация
многоколоночного индекса и отдельного индекса по y будет неплохим вариантом.
Для запросов, включающих только x, можно использовать
многоколонный индекс, хотя он будет больше и, следовательно, медленнее,
чем индекс только для x. Третий вариант заключается в создании всех
трех индексов, но это разумно, только если поиск в таблице
происходит гораздо чаще, чем модификации, и все три типа запросов
одинаково частые. Если один из типов запросов встречается значительно реже,
чем другие, то лучше создать только два индекса,
которые лучше всего соответствуют двум более частым запросам.
Уникальные индексы
Индексы также можно использовать для обеспечения уникальности значения столбца или комбинации из нескольких столбцов.
CREATE UNIQUE INDEX name ON table (column [, ...]);
В настоящее время только индексы типа B-дерево могут быть объявлены уникальными.
Когда индекс объявляется уникальным, несколько строк таблицы с одинаковыми индексируемыми значениями не допускаются. Нулевые значения не считаются равными, т.е. уникальный индекс не мешает иметь несколько строк со значением NULL. Уникальный индекс из нескольких столбцов будет отклонять только те случаи, когда все индексируемые столбцы равны в нескольких строках.
QHB автоматически создает уникальный индекс, когда для таблицы определено уникальное ограничение или первичный ключ. Индекс охватывает столбцы, которые составляют первичный ключ или уникальное ограничение (это может быть многоколонный индекс, если необходимо), и он используется при проверке ограничения.
Заметка
Не надо вручную создавать индексы для уникальных столбцов; это создаст копию автоматически созданного индекса.
Индексы по выражениям
Столбец индекса необязательно должен быть просто столбцом базовой таблицы, но может быть функцией или скалярным выражением, вычисляемым от одного или нескольких столбцов таблицы. Эта опция полезна для быстрого доступа к таблице по результатам вычисления выражения.
Например, распространенный способ сравнения без учета регистра состоит в использовании функции lower:
SELECT * FROM test1 WHERE lower(col1) = 'value';
Этот запрос может использовать индекс, если он был определен по функции lower(col1) :
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));
Если объявить этот индекс уникальным, то это не позволит вставить в таблицу несколько строк,
значение col1 которых отличается только регистром. Т.о. индексы по выражениям
позволяют задавать нетривиальные ограничения уникальности.
Например, следующий уникальный индекс предотвращает сохранение
чисел с одинаковой целой частью в столбце с действительным числами:
CREATE UNIQUE INDEX test1_uniq_int ON tests ((floor(double_col)));
В качестве другого примера, если вы часто делаете запросы вроде
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';
тогда, возможно, стоит создать такой индекс:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));
Синтаксис команды CREATE INDEX обычно требует записи круглых скобок вокруг выражения, как показано в последнем примере. Скобки могут быть опущены, когда выражение является просто вызовом функции, как в первом примере.
Индексы по выражениям относительно дороги в обслуживании, поскольку
производные выражения должны вычисляться для каждой строки после вставки
и каждого изменения. Однако выражения индекса не
пересчитываются во время поиска по индексу, поскольку результат вычисления уже хранятся в
индексе. В обоих приведенных выше примерах система видит запрос как
WHERE indexed_column = ’constant’, поэтому скорость поиска эквивалентна
любому другому простому запросу индекса. Таким образом, индексы по выражениям
полезны, когда скорость поиска важнее скорости вставки и обновления.
Частичные индексы
Частичный индекс — это индекс, построенный на подмножестве таблицы; подмножество определяется условным выражением (называемым предикатом частичного индекса). Индекс содержит записи только для тех строк таблицы, которые удовлетворяют предикату. Частичные индексы являются специализированной функцией, но есть несколько ситуаций, в которых они полезны.
Одна из основных причин использования частичного индекса — избегать индексации наиболее популярных значений. Поскольку запрос, выполняющий поиск популярного значения (на которое приходится более скольких-то процентов от всей таблицы), все равно будет использовать сканирование таблицы, а не индекс, то нет смысла вообще сохранять эти строки в индексе. Это уменьшает размер индекса, что ускорит те запросы, которые используют индекс. Это также ускорит многие операции обновления таблиц, поскольку индекс нужно обновлять не всегда. Пример ниже показывает возможное применение этой идеи.
Пример. Настройка частичного индекса для исключения частых значений
Предположим, вы храните журналы доступа веб-сервера в базе данных. Большинство обращений происходит из диапазона IP-адресов вашей организации, но некоторые из других источников (например, сотрудники, подключающиеся по телефонной линии). Если вы ищете по IP-адресу в основном для внешних обращений, вам, вероятно, не нужно индексировать диапазон IP-адресов, который соответствует подсети вашей организации.
Предположим, что таблица такая:
CREATE TABLE access_log (
url varchar,
client_ip inet,
...
);
Чтобы создать частичный индекс, который соответствует нашему примеру, используйте такую команду:
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE NOT (client_ip > inet '192.168.100.0' AND
client_ip < inet '192.168.100.255');
Типичный запрос, который может использовать этот индекс:
SELECT *
FROM access_log
WHERE url = '/index.html' AND client_ip = inet '212.78.10.32';
Здесь IP-адрес из запроса покрывается частичным индексом. Следующий запрос не может использовать частичный индекс, так как он использует IP-адрес, который исключен из индекса:
SELECT *
FROM access_log
WHERE url = '/index.html' AND client_ip = inet '192.168.100.23';
Заметьте, что этот тип частичного индекса требует, чтобы общие значения были предопределены, поэтому такие частичные индексы лучше всего использовать для данных, распределение которых не меняются. Такие индексы можно время от времени пересоздавать, чтобы приспособиться к новым распределениям данных, но это добавляет усилий на обслуживание.
Другое возможное использование частичного индекса — включение в индекс только тех значений, которые участвуют в типичной рабочей нагрузке (как показано в следующем примере). Это дает преимущества, описанные выше, однако не позволяет использовать индекс при поиске по "нетипичным" значениям. Очевидно, что выбор частичных индексов в таком сценарии потребует большой осторожности и экспериментов.
Пример. Настройка частичного индекса для исключения «неинтересных» значений
Если у вас есть таблица, которая содержит как оплаченные, так и неоплаченные заказы, где неоплаченные заказы занимают небольшую долю в общей таблице, и при этом эти строки являются наиболее востребованными, вы можете повысить производительность, создав индекс только для неоплаченных заказов. Команда создания индекса будет выглядеть так:
CREATE INDEX orders_unbilled_index ON orders (order_nr)
WHERE billed is not true;
Возможный запрос, использующий этот индекс:
SELECT * FROM orders WHERE billed is not true AND order_nr < 10000;
Однако индекс также может использоваться в запросах, которые вообще не включают order_nr, например:
SELECT * FROM orders WHERE billed is not true AND amount > 5000.00;
Это не так эффективно, как частичный индекс по столбцу amount, поскольку система должна сканировать весь индекс. Тем не менее, если неоплаченных заказов относительно мало, использование этого частичного индекса для того, чтобы найти неоплаченные заказы с любым дополнительным условием может быть выигрышным.
Обратите внимание, что такой запрос не может использовать этот индекс:
SELECT * FROM orders WHERE order_nr = 3501;
Заказ 3501 может быть и оплачен, поэтому нельзя ограничиться поиском в частичном индексе.
Пример 3.2 также иллюстрирует, что индексированный столбец и столбец,
используемый в предикате, не обязаны совпадать. QHB поддерживает
частичные индексы с произвольными предикатами, при условии, что
задействованы только столбцы индексируемой таблицы. Однако имейте в
виду, что предикат должен соответствовать условиям, используемым в
запросах, которые должны использовать индекс. Чтобы быть точным,
частичный индекс может использоваться в запросе, только если система
может аналитически распознать, что из условия WHERE всегда следует
предикат индекса. QHB не имеет сложного средства проверки теорем,
способного распознавать математически эквивалентные выражения,
написанные в разных формах. (Мало того, что такое средство
чрезвычайно трудно создать, оно, вероятно, будет работать слишком медленно,
чтобы использоваться в планировщике запросов.) Система может распознавать
простые следствия из неравенства, например, x < 1 подразумевает
x < 2 . А в общем случае, лучше бы предиката индекса точно
соответствовал части WHERE, иначе индекс не будет
признан пригодным для использования. Сопоставление происходит во время
планирования запроса, а не во время выполнения. Как следствие,
параметризованные запросы могут не работать с частичным индексом. Например,
подготовленный запрос с параметром может иметь условие WHERE x < ?,
а предикат индекса x < 2 — индекс не будет использоваться для этого запроса,
т.к. для некоторых значений параметра это приводило бы к неправильным результатам.
Третье возможное использование для частичных индексов — не для запросов, а для поддержания уникальности. Идея заключается в том, чтобы создать уникальный индекс для подмножества таблицы, как в следующем примере. Это обеспечивает уникальность среди строк, которые удовлетворяют предикату индекса, без ограничения для тех, которые не удовлетворяют.
Пример. Настройка частичного уникального индекса
Предположим, у нас есть таблица с описанием результатов теста. Мы хотим убедиться, что для данной комбинации субъекта и цели хранится только одна «успешная» запись, а записей о «неудачных» испытаниях может храниться много. Вот один из способов сделать это:
CREATE TABLE tests (
subject text,
target text,
success boolean,
...
);
CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target)
WHERE success;
Это особенно эффективный подход, когда мало успешных тестов и много неудачных.
Следующий индекс запрещает создание более одной строки со значением NULL в данном столбце, используя предложение частичного индекса для обработки только значений нулевого столбца и используя выражение для перевода NULL в true:
CREATE UNIQUE INDEX tests_target_one_null ON tests ((target IS NULL)) WHERE target IS NULL;
Наконец, частичный индекс также можно использовать, чтобы запретить планировщику использовать этот индекс для конкретных запросов. Иногда особое распределение данных может привести к тому, что система будет использовать индекс, когда это на самом деле не нужно. В этом случае индекс можно настроить таким образом, чтобы он не был доступен для некорректного запроса. Обычно QHB делает разумный выбор в отношении использования индекса (например, он не использует при низкоселективной выборке, поэтому предыдущие примеры в первую очередь экономят место, занимаемое индексом, а не отваживают планировщик от использования индекса), а крайне неправильный выбор плана является, вероятно, ошибкой в системе.
Имейте в виду, что создание частичного индекса подразумевает, что вы знаете больше, чем планировщик запросов, в частности, вы знаете, когда использование индекса будет выгодным. Формирование этих знаний требует опыта и понимания того, как работают индексы в QHB. В большинстве случаев преимущество частичного индекса над обычным индексом будет минимальным.
Более подробную информацию о частичных индексах можно найти у Stonebraker, Seshadri.
Сканирование только по индексу и покрывающие индексы
Все индексы в QHB являются вторичными, то есть каждый индекс хранится отдельно от основной области данных таблицы (которая в терминологии QHB называется кучей(heap) таблицы). Это означает, что при обычном сканировании индекса каждый поиск строки требует извлечения данных как из индекса, так и из кучи. Кроме того, хотя записи индекса, которые соответствуют заданному индексируемому условию WHERE, обычно близки друг к другу в индексе, строки таблицы, на которые они ссылаются, могут находиться где угодно в куче. И та часть доступа по индексу, которая состоит из обращения к строкам в куче, включает в себя много произвольного доступа, который может быть медленным, особенно на традиционных вращающихся носителях. (Как описано в Разделе Объединение нескольких индексов, сканирования-на-битовых-картах пытаются уменьшить эту стоимость, делая доступ к куче последовательным, но он все равно производится.)
Чтобы решить эту проблему производительности, QHB поддерживает сканирование только по индексу, которое может реализовывать запросы только на основании индекса без какого-либо доступа к куче. Основная идея состоит в том, чтобы возвращать значения непосредственно из записи индекса, а не обращаться к соответствующей записи кучи. Существуют два фундаментальных ограничения на использование этого метода:
-
Тип индекса должен поддерживать сканирование только по индексу. Индексы B-дерева поддерживают. Индексы GiST и SP-GiST поддерживают сканирование только по индексу для некоторых классов операторов, но не для всех. Остальные типы индексов не поддерживают. Основным требованием является то, что индекс должен физически хранить или иметь возможность восстановить исходное значение данных для каждой записи индекса. В качестве контрпримера, индексы GIN не могут поддерживать сканирование только по индексу, поскольку каждая запись индекса содержит только часть исходного значения столбца.
-
Запрос должен ссылаться только на столбцы, хранящиеся в индексе. Например, предполагая индекс по столбцам
xиyтаблицы, которая также имеет столбецz, эти запросы могут использовать сканирование только по индексу:SELECT x, y FROM tab WHERE x = 'key'; SELECT x FROM tab WHERE x = 'key' AND y < 42;а эти запросы не могут:
SELECT x, z FROM tab WHERE x = 'key'; SELECT x FROM tab WHERE x = 'key' AND z < 42;(Для индексов по выражению и частичных индексов все сложнее, см. ниже.)
Если эти два фундаментальных требования выполнены, то все значения данных, требуемые запросом, доступны из индекса, поэтому физически возможно сканирование только по индексу. Но для любого сканирования таблицы в QHB есть дополнительное требование: система должна убедиться, что каждая извлеченная строка «видима» для MVCC-снимка текущего запроса, как описано в главе Параллельный контроль. Информация о видимости не хранится в записях индекса, а только в записях кучи; так что на первый взгляд может показаться, что для любого поиска в любом случае потребуется доступ к куче. И это действительно так, если строка таблицы была недавно изменена. Однако для редко меняющихся данных есть способ обойти эту проблему. QHB отслеживает для каждой страницы в куче таблицы, все ли строки, хранящиеся на этой странице, достаточно стары, чтобы быть видимыми для всех текущих и будущих транзакций. Эта информация сохраняется в виде одного бита в карте видимости таблицы. Сканирование только по индексу после нахождения подходящей записи индекса проверяет бит видимости для соответствующей страницы кучи. Если он установлен, строка определенно видимая, и поэтому данные могут быть возвращены без обращения к куче. Если он не установлен, запись кучи должна быть посещена, чтобы выяснить, видна ли строка, поэтому никакого преимущества в производительности по сравнению со стандартным сканированием индекса не достигается. Даже в успешном случае этот подход требует обращения к карте видимости; но поскольку карта видимости на четыре порядка меньше описываемой ею кучи, для доступа к ней требуется гораздо меньше операций ввода-вывода. В большинстве случаев карта видимости постоянно хранится в памяти.
Короче говоря, хотя сканирование только по индексу возможно с учетом двух фундаментальных требований, оно будет выигрышным, только если для значительной части страниц кучи таблицы установлены биты видимости. Такие таблицы, в которых большая часть строк неизменна, достаточно распространены, чтобы сделать этот тип сканирования очень полезным на практике.
Чтобы эффективно использовать функцию сканирования только по индексу, вы можете создать покрывающий индекс, т.е. индекс, специально включающий лишние столбцы, которые требуются конкретному запросу, который вы часто выполняете. Поскольку запросам обычно требуется получать больше столбцов, чем только те, по которым они осуществляют поиск, QHB позволяет создавать индекс, в котором некоторые столбцы являются просто «дополнительной нагрузкой», а не частью ключа поиска. Это делается путем добавления указания INCLUDE со списком дополнительных столбцов. Допустим, вы часто делаете запрос вида
SELECT z FROM tab WHERE x = 'key';
Традиционный подход к ускорению таких запросов заключается в создании
индекса только по x. Тем не менее, индекс, заданный как
CREATE INDEX tab_x_z ON tab(x) INCLUDE (z);
может обрабатывать эти запросы как сканирование только по индексу,
потому что z можно получить из индекса, не посещая кучу.
Поскольку столбец z не является частью ключа поиска индекса, он не
обязательно должен иметь тип данных, который может обрабатывать индекс;
он просто хранится в индексе и не обрабатывается механизмом индекса.
Кроме того, если индекс является уникальным, то есть
CREATE UNIQUE INDEX tab_x_z ON tab(x) INCLUDE (z);
условие уникальности применяется только к столбцу x, а не к комбинации x
и z. (При описании UNIQUE и PRIMARY KEY тоже можно задать INCLUDE,
это альтернативный синтаксис для создания такого индекса.)
Добавлять в индекс неключевые столбцы дополнительной нагрузки следует обдуманно, особенно если эти столбцы широкие. Если кортеж индекса превысит максимально допустимый размер для данного типа индекса, вставка данных завершится неудачно. В любом случае неключевые столбцы дублируют данные из таблицы и увеличивают размер индекса, что потенциально замедляет поиск. И помните, что нет никакого смысла включать столбцы полезной нагрузки в индекс, если таблица изменяется часто, т.к. все равно потребуется обращаться к куче. Если есть обращение к строке в куче, получить значение всех столбцов столбца можно оттуда, и это ничего не стоит. Другие ограничения заключаются в том, что в качестве дополнительных столбцов нельзя включать выражения, и что только B-деревья и GiST в настоящее время поддерживают включенные столбцы.
До того, как в QHB появилась функция INCLUDE, люди иногда создавали покрывающие индексы, записывая столбцы полезной нагрузки как обычные столбцы индекса, то есть
CREATE INDEX tab_x_y ON tab(x, y);
даже если они не собирались использовать y как часть WHERE. Это
прекрасно работает, если дополнительные столбцы являются конечными
столбцами; делать их ведущими столбцами неразумно по причинам,
изложенным в разделе Многоколоночные индексы. Однако этот метод
не подходит для уникальных индексов.
Усечение суффиксов всегда удаляет неключевые столбцы с верхних уровней B-Дерева. Как столбцы дополнительной нагрузки, они никогда не используются при сканировании индекса. Процесс усечения в принципе удаляет один или несколько конечных столбцов ключа из не-листьев B-Дерева, когда они не требуются для обхода дерева. Поэтому на практике покрытие индексов даже без предложения INCLUDE часто позволяет избежать хранения столбцов, которые являются дополнительной нагрузкой, на верхних уровнях. Однако явное определение столбцов дополнительной нагрузки в качестве неключевых столбцов надежно сохраняет кортежи на верхних уровнях небольшими.
Теоретически, сканирование только по индексу может использоваться с
индексами по выражениям. Например, имея индекс по f(x), где x — столбец
таблицы, можно выполнить запрос
SELECT f(x) FROM tab WHERE f(x) < 1;
как сканирование только по индексу; и это очень привлекательно, если f()
дорогая для вычисления функция. Однако планировщик QHB в
настоящее время не очень разбирается в таких случаях. Он считает, что
запрос потенциально может быть выполнен при сканировании только по
индексу, только когда из индекса доступны все столбцы, необходимые для
запроса. В этом примере x не требуется, кроме как в контексте f(x), но
планировщик этого не замечает и приходит к выводу, что сканирование
только по индексу невозможно. Если очень надо, то это ограничение можно обойти,
добавив x в качестве включенного столбца, например
CREATE INDEX tab_f_x ON tab (f(x)) INCLUDE (x);
Дополнительное предостережение. Если цель состоит в том, чтобы избежать
повторного вычисления f(x), то есть ещё одна проблема.
Не факт, что планировщик додумается использовать значение, взятое из индекса,
для всех вхождений f(x). Например, в запросе
SELECT B.name FROM tab join B on B.id = f(x) WHERE f(x) < 1;
даже если будет использовано сканирование только по индексу, значение f(x) для соединения
будет вычислено заново (x возьмут из дополнительной колонки индекса).
Этот недостаток может быть исправлен в будущих версиях
QHB.
Частичные индексы также интересны при сканировании только по индексам. Рассмотрим частичный индекс из примера выше:
CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target)
WHERE success;
Можем ли мы выполнить сканирование только по индексу, чтобы удовлетворить следующий запрос?
SELECT target FROM tests WHERE subject = 'some-subject' AND success;
Есть проблема: WHERE содержит success, который не является столбцом индекса.
Тем не менее, сканирование только
по индексу возможно, потому что плану не нужно перепроверять эту часть
WHERE во время выполнения: все записи, найденные в индексе, обязательно
имеют success = true поэтому в плане это не нужно явно проверять.
Классы операторов и семейства операторов
Определение индекса может указывать класс оператора для каждого столбца индекса.
CREATE INDEX name ON table (column opclass [sort options] [, ...]);
Класс операторов определяет операторы, которые будут использоваться индексом для этого столбца. Например, индекс B-дерева для типа int4 будет использовать класс int4_ops ; этот класс операторов включает функции сравнения для значений типа int4. На практике класс операторов по умолчанию для типа данных столбца обычно достаточен. Основная причина наличия классов операторов заключается в том, что для некоторых типов данных может быть более одного осмысленного поведения индекса. Например, мы могли бы захотеть отсортировать тип данных комплексного числа или по абсолютному значению или по реальной части. Мы могли бы сделать это, определив два класса операторов для типа данных, а затем выбрав подходящий класс при создании индекса. Класс оператора определяет основной порядок сортировки (который затем можно изменить, добавив параметры сортировки COLLATE, ASC/DESC, NULLS FIRST/NULLS LAST).
Есть также несколько встроенных классов операторов, кроме классов по умолчанию:
-
Классы операторов text_pattern_ops, varchar_pattern_ops и bpchar_pattern_ops поддерживают индексы B-дерева для типов text, varchar и char соответственно. Отличие от классов операторов по умолчанию состоит в том, что значения сравниваются строго символ за символом, а не в соответствии с правилами сортировки, специфичными для локали. Это делает эти классы операторов пригодными для использования в запросах, включающих выражения сопоставления с образцом (регулярные выражения LIKE или POSIX), когда база данных использует локаль, отличную от «C». Например, вы можете проиндексировать столбец varchar следующим образом:
CREATE INDEX test_index ON test_table (col varchar_pattern_ops);Обратите внимание, что вам придется создать еще и индекс с классом операторов по умолчанию, если вы хотите, чтобы запросы, включающие обычные сравнения <, <=, > или >= использовали индекс. Такие запросы не могут использовать операторы класса xxx_pattern_ops (сравнения на равенство — могут). Можно создать несколько индексов про один столбец, но с разными классами операторов. Если вы используете локаль C, вам не нужен индекс с операторами класса xxx_pattern_ops, т.к. в локали C индекс с операторами по умолчанию можно использовать и для запросов сопоставления с образцом.
Следующий запрос показывает все известные классы операторов:
SELECT am.amname AS index_method,
opc.opcname AS opclass_name,
opc.opcintype::regtype AS indexed_type,
opc.opcdefault AS is_default
FROM pg_am am, pg_opclass opc
WHERE opc.opcmethod = am.oid
ORDER BY index_method, opclass_name;
Класс операторов — это просто подмножество более крупной структуры, называемой семейством операторов. В тех случаях, когда несколько типов данных имеют сходное поведение, часто бывает полезно определить операторы над семейством типов данных и разрешить им работать с индексами. Для этого классы операторов для каждого из типов должны быть сгруппированы в одно и то же семейство операторов. Операторы семейства типов являются членами семейства, но не привязаны к конкретному классу в семействе.
Эта расширенная версия предыдущего запроса показывает семейство операторов, к которому принадлежит каждый класс операторов:
SELECT am.amname AS index_method,
opc.opcname AS opclass_name,
opf.opfname AS opfamily_name,
opc.opcintype::regtype AS indexed_type,
opc.opcdefault AS is_default
FROM pg_am am, pg_opclass opc, pg_opfamily opf
WHERE opc.opcmethod = am.oid AND
opc.opcfamily = opf.oid
ORDER BY index_method, opclass_name;
Этот запрос показывает все определенные семейства операторов и все операторы, включенные в каждое семейство:
SELECT am.amname AS index_method,
opf.opfname AS opfamily_name,
amop.amopopr::regoperator AS opfamily_operator
FROM pg_am am, pg_opfamily opf, pg_amop amop
WHERE opf.opfmethod = am.oid AND
amop.amopfamily = opf.oid
ORDER BY index_method, opfamily_name, opfamily_operator;
Индексы и правила сортировки
Индекс может использовать только одно правило сортировки (COLLATION) на столбец индекса. Если требуется поиск по столбцу с разными правилами сортировки, придется создать несколько индексов.
Рассмотрим следующие команды:
CREATE TABLE test1c (
id integer,
content varchar COLLATE "x"
);
CREATE INDEX test1c_content_index ON test1c (content);
Индекс унаследует правила сортировки от базового столбца content. Так что
запрос вида
SELECT * FROM test1c WHERE content > constant;
может использовать индекс, потому что сравнение столбца с константой по умолчанию использует правило сортировки столбца, и это соответствует индексу. Однако этот индекс не может ускорить запросы, в которых задано другое правило сортировки, например, такой:
SELECT * FROM test1c WHERE content > constant COLLATE "y";
Если такие запросы тоже нужны, то можно создать дополнительный индекс, который будет поддерживать правило сортировки "y", например:
CREATE INDEX test1c_content_y_index ON test1c (content COLLATE "y");
Анализ использования индексов
Хотя индексы в QHB не нуждаются в обслуживании или настройке, все же важно проверить, какие индексы действительно используются реальной рабочей нагрузкой запросов. Изучение использования индекса для отдельного запроса выполняется командой EXPLAIN; его применение для этой цели иллюстрируется в разделе Использование EXPLAIN. Также возможно собрать общую статистику об использовании индекса на работающем сервере, как описано в разделе Сборщик статистики.
Сложно сформулировать общую процедуру выбора индексов для создания. Существует ряд типичных случаев, которые были показаны в примерах в предыдущих разделах. Часто требуется много экспериментов. Остаток этого раздела содержит несколько советов на эту тему:
-
В первую очередь запустите ANALYZE. Эта команда собирает статистику о распределении значений в таблице. Эта информация необходима для оценки количества строк, возвращаемых запросом, которое необходимо планировщику для реалистичной оценки затрат для каждого возможного плана запроса. При отсутствии какой-либо реальной статистики предполагаются некоторые значения по умолчанию, которые почти наверняка будут неточными. Поэтому изучение планов выполнения без запуска ANALYZE является заведомо бесперспективным. См. разделы Обновление статистики планировщика и Процесс «Автовакуум» для получения дополнительной информации.
-
Используйте реальные данные для экспериментов. Использование тестовых данных для настройки индексов скажет вам, какие индексы вам нужны для тестовых данных, но не более того.
Особенно фатально использовать очень маленькие наборы тестовых данных. Выборка 1000 из 100000 строк может быть кандидатом на использование индекса, но если на тестовых данных вы выбираете 1 из 100 строк, то вы получите совсем другой результат. Все 100 строк, вероятно, помещаются на одной странице, и последовательное чтение всей таблицы будет безусловно быстрее на таком объеме,
Также будьте осторожны при генерации синтетических тестовых данных (это часто неизбежно, когда приложение еще не работает). Однородные значения, полностью случайные значения или значения, вставленные в порядке возрастания, исказят статистику по сравнению с реальными данными.
-
Когда индексы не используются, для тестирования может быть полезно форсировать их использование. Существуют параметры времени выполнения, которые могут отключать различные типы планов (см. раздел Конфигурация метода планирования). Например, отключение последовательного сканирования (enable_seqscan) и последовательных соединений (enable_nestloop), которые являются наиболее простыми планами, заставит систему использовать другой план. Если система все еще выбирает последовательное сканирование или последовательное соединение, то, вероятно, существует более фундаментальная причина, по которой индекс не используется, например, условие запроса не соответствует индексу. (Какой запрос можно использовать какой тип индекса объясняется в предыдущих разделах.)
-
Если искусственными ограничениями удалось заставить планировщик использовать индекс, то есть две варианта: либо планировщик прав, и использование индекса плохо подходит, либо оценки затрат планов запросов не отражают реальность. Посмотрите оценки стоимости планов с индексом и без индекса командой EXPLAIN ANALYZE, а также сравните реальное время выполнения.
-
Если окажется, что оценки затрат ошибочны, опять-таки есть несколько вариантов. Общая стоимость вычисляется умножением оценки количества строк на стоимость операций, производимых с каждой строкой. Стоимость операций можно скорректированы с помощью параметров (описано в разделе Константы стоимости планировщика). Неточная оценка количества строк(селективности) обычно связана с неточной статистикой. Это можно исправить, настроив параметры сбора статистики (см. ALTER TABLE).
Если вам не удастся скорректировать оценки стоимостей, чтобы они соответствовали реальности, вам, возможно, придется силой заставить планировщик использовать индекс. Вы также можете связаться с разработчиками QHB для изучения проблемы.
Индексы B-деревья
QHB включает в себя реализацию стандартной структуры данных индекса B-дерева (многонаправленного сбалансированного дерева — btree). Любой тип данных, который можно отсортировать в четком линейном порядке, может быть загружен в индекс B-дерево. Единственное ограничение заключается в том, что запись индекса не может превышать приблизительно одной трети страницы (после сжатия TOAST, если применимо).
Поскольку любой класс операторов B-дерева определяет порядок сортировки на своем типе данных, классы операторов B-дерева (точнее, на самом деле семейства операторов) стали использоваться в QHB для общего представления и понимания семантики сортировки. Поэтому они приобрели некоторые функции, которые выходят за рамки того, что было бы необходимо только для поддержки индексов B-деревьев, и их используют части системы, которые довольно далеки от методов доступа B-дерева.
Поведение классов операторов B-дерева
Класс операторов B-дерева должен предоставлять пять операторов сравнения: <, <=, =, >= и >. Можно было бы ожидать, что в эти операторы также должен входить <>, но это не так, потому что практически никогда не имеет смысл использовать <> в предложении WHERE для поиска по индексу. (Для некоторых целей планировщик обрабатывает <> как связанный с классом операторов B-дерева; но он находит данный оператор через отрицание оператора =, а не обращаясь к pg_amop).
Если несколько типов данных имеют почти одинаковую семантику сортировки, их классы операторов можно сгруппировать в семейство операторов. Это выгодно, потому что позволяет планировщику делать выводы о межтиповых сравнениях. Каждый класс операторов в семействе должен содержать однотиповые операторы (и связанные с ними вспомогательные функции) для своего типа входных данных, в то время как межтиповые операторы и вспомогательные функции «слабо» связаны с семейством. Рекомендуется включать в семейство полный набор межтиповых операторов, таким образом гарантируя, что планировщик сможет вызвать любые условия сравнения, которые выведет из транзитивности.
Существует несколько основных предположений, которым должно удовлетворять семейство операторов для B-деревьев:
-
Оператор = должен быть отношением эквивалентности, то есть для любых отличных от NULL значений A, B, C определенного типа данных:
-
A = A истинно (рефлексивность)
-
A = B влечет B = A (симметричность)
-
если A = B и B = C, то A = C (транзитивность)
-
-
Оператор < должен представлять из себя отношение строгого порядка, то есть для любых отличных от NULL значений A, B, C:
-
A < A ложно (антирефлексивность)
-
если A < B и B < C, то A < C (транзитивность)
-
-
Более того, порядок должен быть полным; то есть для любых отличных от NULL значений A, B должно быть верно ровно 1 утверждение из 3: A < B, либо B < A, либо A = B (закон трихотомии)
(Конечно, закон трихотомии обосновывает определение вспомогательной функции сравнения.)
Остальные три оператора определяются через операторы = и < очевидным образом и должны работать согласованно с последними.
Для семейства операторов, поддерживающих несколько типов данных, вышеуказанные законы должны выполняться, когда A, B, C берутся из любых типов данных в семействе. Закон транзитивности обеспечить сложнее всего, поскольку в ситуациях с разными типами это зависит от согласованности поведения двух или трех различных операторов. Для примера, нельзя поместить операторы для float8 и numeric в одно семейство, по крайней мере, не в сегодняшней ситуации, когда для сравнения с float8 значения numeric тоже преобразуются в тип float8. Из-за ограничения точности типа float8 различные значения numeric при приведении к float8 превращаются в одно и то же число, тем самым нарушая закон транзитивности.
Другое требование для семейства с несколькими типами данных заключается в том, что любые существующие неявные преобразования между типами данных, входящими в семейство операторов, должны сохранять результат сравнения.
Должно быть достаточно очевидно, почему индекс B-дерево требует выполнения вышеприведенных законов внутри одного типа данных: без этого просто не будет четкого упорядочивания ключей. Кроме того, индексный поиск, использующий сравнение с ключом другого типа данных, требует, чтобы сравнения вели себя разумно между двумя типами данных. Расширение семейства до трех или более типов данных не является обязательным для самого механизма индекса B-дерево, но планировщик полагается на них в целях оптимизации.
Вспомогательные функции B-дерева
B-дерево определяет одну обязательную и четыре факультативные вспомогательные функции:
order
Для каждой комбинации типов данных, для которых семейство операторов
B-дерева предоставляет операторы сравнения, оно должно предоставить и
вспомогательную функцию сравнения, зарегистрированную в ***pg\_amproc*** как вспомогательная функция номер 1
со свойствами *amproclefttype/amprocrighttype*, равными левому и правому
типу данных сравнения (т. е. тем же типам данных, с которыми
зарегистрированы соответствующие операторы в ***pg\_amop***). Функция
сравнения должна принимать отличные от *NULL* значения **A** и **B** и возвращать
целое число, которое < 0, 0 или > 0, когда **A < B**, **A = B** или **A > B** соответственно.
Результат *NULL* не допускается: все значения типа данных должны быть
сравнимы.
Если сравниваемые значения имеют сортируемый тип данных, то во
вспомогательную функцию сравнения будет передан соответствующий OID сортировки,
используя стандартный механизм **PG\_GET\_COLLATION()**.
<!-- not open source
Примеры реализации order ищите в файле *src/backend/access/nbtree/nbtcompare.c* -->
sortsupport
Опционально семейство операторов B-дерева может предоставлять *вспомогательную(ые) функцию(и) сортировки*, регистрируемую как
вспомогательная функция номер 2. Эти функции позволяют
реализовывать сравнения для целей сортировки более эффективно, чем
при простом вызове вспомогательной функции сравнения.
<!-- not open source
API, участвующие в этом, определены в: *src/include/utils/sortsupport.h*.
-->
<!-- "(или несколько функций)" как их различает система, если они все №2 ?! -->
in_range
Опционально семейство операторов B-дерева может предоставлять вспомогательную(ые) функцию(и) *in\_range*, регистрируемую как
вспомогательная функция номер 3.
Такие функции не используется при операциях B-дерева; они
расширяют семантику семейства операторов, чтобы оно могло поддерживать оконные предложения, содержащие типы границ рамки **RANGE *смещение* PRECEDING** и
**RANGE *смещение* FOLLOWING** (см. раздел [Вызовы оконных функций]). По сути, дополнительная информация позволяет добавлять или вычитать значение ***смещения*** способом, соответствующим принятому в семействе порядку сортировки.
Функция *in\_range* должна иметь сигнатуру
```sql
in_range(значение type1, база type1, смещение type2, вычитание bool, меньше bool)
returns bool
```
***Значение*** и ***база*** должны быть одинакового типа, одного из поддерживаемых семейством операторов
(т. е. типом, для которого задается порядок). Однако ***смещение*** может быть другого типа,
который никаким другим образом данным семейством может и не поддерживаться.
Например, встроенное семейство операторов *time\_ops* предоставляет
функцию *in\_range* которая имеет параметр ***смещение*** типа *interval*. Семейство может
иметь функцию *in\_range* для любого поддерживаемого типа и одного или нескольких типов ***смещения***.
Каждая вспомогательная функция *in\_range* должна быть
зарегистрирована в ***pg\_amproc*** с *amproclefttype* равным *type1* и *amprocrighttype*
равным *type2*.
Основополагающая семантика функции *in\_range* зависит от двух логических флаговых параметров. Она должна прибавить или вычесть из ***базы смещение*** и после этого сравнить результат со ***значением*** следующим образом:
- если !***вычитание*** и !***меньше***, возвращается ***значение*** >= (***база + смещение***)
- если !***вычитание*** и ***меньше***, возвращается ***значение*** <= (***база + смещение***)
- если ***вычитание*** и !***меньше***, возвращается ***значение*** >= (***база - смещение***)
- если ***вычитание*** и ***меньше***, возвращается ***значение*** <= (***база - смещение***)
Прежде чем делать это, функция должна проверить знак ***смещения***:
если оно отрицательное, выдавать ошибку *ERRCODE\_INVALID\_PRECEDING\_OR\_FOLLOWING\_SIZE* (22013) с текстом ошибки «invalid preceding or following size in window function». (Этого требует стандарт SQL, хотя нестандартные семейства операторов, вероятно, могут проигнорировать это ограничение, т. к., по-видимому, в нем нет особой семантической необходимости.)
Эта проверка возложена на *in_range*, чтобы основному коду не нужно было понимать, что для конкретного типа данных означает «отрицательное».
Дополнительно ожидается, что функции *in_range* должны, в частности, избегать возникновения ошибки в случае переполнения при вычислении ***база + смещение*** или ***база - смещение***. Правильный результат сравнения можно получить, даже если это значение выходит за границы диапазона типа данных.
Обратите внимание, что если тип данных включает такие понятия, как «бесконечность» или «NaN», может понадобиться повышенная осторожность для обеспечения согласованности результатов *in_range*
с обычным порядком сортировки этого семейства операторов.
Результаты функции *in_range* должны соответствовать порядку сортировки, установленному семейством операторов. Выражаясь точнее,
при любых фиксированных значениях ***смещения*** и ***вычитания*** справедливо следующее:
- Если *in_range* с ***меньше*** = true возвращает *true* для некоторого ***значения1*** и ***базы***, *true* должно возвращаться
для каждого ***значения2*** <= ***значению1*** с той же ***базой***.
- Если *in_range* с ***меньше*** = true возвращает *false* для некоторого ***значения1*** и ***базы***, *false* должно возвращаться
для каждого ***значения2*** >= ***значению1*** с той же ***базой***.
- Если *in_range* с ***меньше*** = true возвращает *true* для некоторого ***значения*** и ***базы1***, *true* должно возвращаться
для каждой ***базы2*** >= ***базе1*** с тем же ***значением***.
- Если *in_range* с ***меньше*** = true возвращает *false* для некоторого ***значения*** и ***базы1***, *false* должно возвращаться
для каждой ***базы2*** <= ***базе1*** с тем же ***значением***.
При ***меньше*** = false должны выполнятся аналогичные утверждения с противоположными условиями.
Если упорядочиваемый тип (*type1*) является сортируемым, функции *in_range* с помощью стандартного механизма *PG\_GET\_COLLATION()* будет передан OID соответствующего правила сортировки.
Функции *in_range* не обязаны обрабатывать значение аргументов *NULL* и обычно помечаются как строгие.
equalimage
Опционально семейство операторов В-дерева может предоставить вспомогательные функции *equalimage* («равенство подразумевает равенство образов»), регистрируемые как вспомогательная функция номер 4. Эти функции позволяют основному коду определять, безопасно ли применять оптимизацию с дедупликацией в В-дереве. На данный момент функции *equalimage* вызываются только при построении или перестроении индекса.
Функция *equalimage* должна иметь сигнатуру
```SQL
equalimage(opcintype oid) returns bool
```
Возвращаемое значение является статической информацией о классе операторов и правиле сортировки. Результат *true* показывает, что функция *order* для класса операторов гарантирует возвращать 0 («аргументы равны»), только когда его аргументы ***А*** и ***В*** также взаимозаменяемы без потери семантической информации. Если функция *equalimage* не зарегистрирована или возвращает *false*, это означает, что нельзя предполагать выполнение данного условия.
Аргумент ***opcintype*** является *pg_type.oid* типа данных, который индексируется данным классом операторов. Это удобство позволяет повторно использовать в разных классах операторов одну и ту же нижележащую функцию *equalimage*. Если ***opcintype*** относится к сортируемому типу данных, функции *equalimage* с помощью стандартного механизма *PG\_GET\_COLLATION()* будет передан OID соответствующего правила сортировки.
С точки зрения класса операторов результат *true* означает, что дедупликация безопасна (или безопасна для правила сортировки, чей OID был передан его функции *equalimage*). Однако основной код будет считать дедупликацию безопасной для индекса, только если **каждый** индексируемый столбец использует класс операторов, регистрирующий функцию *equalimage*, и все эти функции при вызове действительно возвращают *true*.
Равенство образов является условием, **почти** равнозначным простому битовому равенству. Есть лишь одно небольшое различие: при индексировании типа данных *valerna* представление двух равных образов на диске может отличаться в битовом отношении вследствие несогласованного применения сжатия TOAST к входным данным. Строго говоря, когда функция *equalimage* класса операторов возвращает *true*, безопасно предположить, что функция на С *datum_image_eq()* всегда будет согласована с функцией *order* класса операторов (при условии, что обеим функциям передан одинаковый OID правила сортировки).
Основной код совершенно не способен сделать какие-либо выводы относительно статуса класса операторов «равенство подразумевает равенство образов» в семействе операторов для множества типов данных на основе сведений о других классах операторов в том же семействе. Также семейству операторов нет смысла регистрировать межтиповую функцию *equalimage*, а попытка сделать это приведет к ошибке. Причина этого в том, что статус «равенство подразумевает равенство образов» зависит не только от семантик сортировки/равенства, которые более или менее определены на уровне семейства операторов. В целом, эти семантики, которые реализует один конкретный тип данных, должны рассматриваться по отдельности.
Для классов операторов, включенных в базовый продукт QHB, принято соглашение регистрировать стандартную универсальную функцию *equalimage*. Большинство классов операторов регистрирует функцию *btequalimage()*, которая указывает, что дедупликация безопасна без каких-либо условий. Классы операторов для сортируемых типов данных, таких как *text*, регистрируют функцию *btvarstrequalimage()*, которая указывает, что дедупликация безопасна с детерминированными правилами сортировки. Для сохранения контроля в сторонних расширениях наилучшим решением будет регистрировать их собственные специальные функции *equalimage*.
options
Опционально семейство операторов В-дерево может предоставлять вспомогательные функции *options* («параметры класса операторов»), регистрируемые как вспомогательная функция номер 5. Эти функции определяют набор видимых пользователю параметров, которые управляют поведением класса операторов.
Вспомогательная функция *options* должна иметь сигнатуру
```sql
options(relopts local_relopts *) returns void
```
Эта функция передает указатель на структуру ***local_relopts***, в которую нужно внести набор параметров класса операторов. К этим параметрам можно обращаться из других вспомогательных функций при помощи макросов *PG_HAS_OPCLASS_OPTIONS()* и *PG_GET_OPCLASS_OPTIONS()*.
На данный момент ни у одного класса операторов В-дерево нет вспомогательной функции *options*. В отличие от GiST, SP-GiST, GIN и BRIN, В-дерево не допускает гибкое представление ключей. Так что, вероятно, в актуальном методе доступа к индексу В-дереву у функции *options* нет практического применения. Тем не менее, эта вспомогательная функция была добавлена в В-дерево в целях единообразия и, возможно, станет полезной при дальнейшем развитии реализации В-дерева в QHB.
Реализация
В этом разделе изложена подробная информация о реализации индекса В-дерева, которая может быть полезна для специалистов.
Структура В-дерева
В QHB индексы В-деревья — это многоуровневые древовидные структуры, где каждый уровень дерева можно использовать в качестве двусвязного списка страниц. Единственная метастраница хранится в фиксированном положении в начале первого файла сегмента индекса. Все остальные страницы делятся на листовые и внутренние. Листовые страницы находятся на самом нижнем уровне дерева. Все остальные уровни состоят из внутренних страниц. Каждая листовая страница содержит кортежи, которые указывают на строки таблицы. Каждая внутренняя страница содержит кортежи, которые указывают на следующий уровень вниз по дереву. Обычно листовые страницы составляют более 99% всех страниц. Как внутренние, так и листовые страницы используют стандартный формат страницы, описанный в разделе Внутренняя структура страницы базы данных.
Новые листовые страницы добавляются в индекс В-дерево, когда существующая листовая страница не может вместить поступающий кортеж. Операция разделения страницы освобождает место для элементов, которые изначально принадлежали переполнившейся странице, перенося какую-то их часть на новую страницу. Разделение страницы также вставляет в родительскую страницу новую ссылку вниз, на новую страницу, что, в свою очередь, может вызвать разделение родительской страницы. Страницы разделяются «каскадно вверх» рекурсивным образом. Когда же в итоге и корневая страница не может вместить новую ссылку вниз, выполняется операция разделения корневой страницы. Это добавляет к структуре дерева новый уровень путем создания новой корневой страницы, которая находится на уровень выше исходной корневой страницы.
Дедупликация
Дубликат — это кортеж листовой страницы (кортеж, который указывает на строку таблицы), в котором все ключевые столбцы индекса содержат значения, совпадающие с соответствующими значениями столбца из по крайней мере еще одного кортежа листовой страницы в том же индексе. На практике дублирующиеся кортежи встречаются довольно часто. Индексы В-деревья могут использовать для дубликатов особое экономящее пространство представление при включении факультативного механизма — дедупликации.
Действие механизма дедупликации заключается в периодическом объединении групп дублирующихся кортежей с образованием одного кортежа со списком идентификаторов для каждой группы. В таком представлении ключевое(ые) значение(я) столбца находятся в единственном экземпляре. Затем идет отсортированный массив идентификаторов TID, которые указывают на строки в таблице. Это значительно уменьшает размер хранимых индексов, где каждое значение (или каждая отдельная комбинация значений столбца) появляется, в среднем, несколько раз. Это может значительно сократить время отклика запросов и в целом существенно повысить скорость их обработки. Также могут сильно снизиться издержки на регулярную очистку индекса.
Примечание
Дедупликация В-дерева также эффективна при работе с «дубликатами», которые содержат значение NULL, несмотря на то, что значения NULL, согласно операторам = из любого класса операторов В-дерева, не считаются равными друг другу. С точки зрения любой части реализации, которая понимает дисковую структуру В-дерева, NULL — это просто еще одно значение из домена значений индекса.
Процесс дедупликации запускается только по необходимости, когда вставляется новый элемент, который не помещается на существующую листовую страницу. Это предотвращает (или, по крайней мере, откладывает) разделение листовой страницы. В отличие от кортежей со списком идентификаторов GIN, в B-дереве этим кортежам не нужно расширяться всякий раз, когда вставляется новый дубликат; они просто являются альтернативным физическим представлением исходного логического содержимого листовой страницы. При смешанной нагрузке типа чтение/запись такая модель ставит во главу угла согласованную производительность. Для большинства клиентских приложений дедупликация должна обеспечить как минимум удовлетворительное увеличение производительности. По умолчанию она включена.
Команды CREATE INDEX и REINDEX используют дедупликацию, чтобы создать кортежи со списком идентификаторов, хотя применяемая ими стратегия слегка отличается. Каждая группа обычных дублирующихся кортежей, обнаруженных во взятых из таблицы отсортированных входных данных, объединяется в кортеж со списком идентификаторов до того, как добавляется на текущую ожидающую листовую страницу. В каждый такой кортеж упаковывается максимально возможное количество идентификаторов TID. Листовые страницы записываются обычным способом, без каких-либо отдельных проходов для исключения дубликатов. Эта стратегия очень подходит командам CREATE INDEX и REINDEX, поскольку они относятся к разовым групповым операциям.
При рабочих нагрузках с преобладанием записи, которые не получают преимуществ от дедупликации из-за малого количества или отсутствия дублированных значений в индексах, ее применение приведет к небольшому постоянному снижению производительности (если только она явно не отключена). Чтобы отключить дедупликацию в отдельных индексах, можно воспользоваться параметром хранения deduplicate_items. При рабочих нагрузках только на чтение производственных издержек не возникает, поскольку кортежи со списком идентификаторов читаются по меньшей мере так же эффективно, как и кортежи в стандартном представлении. Поэтому обычно в таких случаях отключать дедупликацию бесполезно.
Непосредственно индексы В-деревья не учитывают, что в среде MVCC может быть несколько сохранившихся версий одной логической строки таблицы; для индекса каждый кортеж является независимым объектом, которому требуется отдельный элемент индекса. Иногда «версионные дубликаты» могут накапливаться и негативно влиять на время отклика и скорость обработки запросов. Обычно это случается при нагрузках с преобладанием UPDATE, где большая часть отдельных обновлений не может применить оптимизацию HOT (обычно вследствие того, что как минимум один столбец индекса подвергается изменению, требующему новый набор версий индексного кортежа — по одному новому кортежу для каждого индекса). В действительности дедупликация В-дерева устраняет разбухание индекса, вызванное тиражированием версий. Обратите внимание, что из-за тиражирования версий даже кортежи уникального индекса не обязательно физически уникальны при хранении на диске. К уникальным индексам оптимизация путем дедупликации применяется выборочно и нацеливается на те страницы, на которых могут содержаться версионные дубликаты. Глобальная же цель — дать команде VACUUM больше времени на выполнение, прежде чем из-за тиражирования версий произойдет «ненужное» разделение страницы.
Совет
Для определения того, следует ли дедупликации выполняться в уникальном индексе, применяется специальный эвристический алгоритм. Зачастую он может перейти напрямую к разделению листовой страницы без расходов на лишние циклы холостых проходов дедупликации. Если вас беспокоят издержки на бесполезную дедупликацию, можете выборочно задать значениеdeduplicate_items = offдля отдельных индексов. В уникальных же индексах дедупликацию вполне можно оставить включенной — потери от этого будут невелики.
Из-за ограничений на уровне реализации дедупликацию можно использовать не везде. Безопасность ее применения определяется при выполнении команды CREATE INDEX или REINDEX.
Обратите внимание, что дедупликация считается небезопасной и не может применяться в следующих случаях, при которых имеются значительные семантические различия между равными значениями:
-
Дедупликация не может применяться с типами text, varchar и char при использовании недетерменированного правила сортировки, т. к. среди равных значений должны сохраняться различия в регистре и диакритических знаках.
-
Дедупликация не может применяться с типом numeric, т. к. среди равных значений должен сохраняться масштаб числового отображения.
-
Дедупликация не может применяться с типом jsonb, т. к. внутри класса операторов В-дерева jsonb используется тип numeric.
-
Дедупликация не может применяться с типами float4 и float8, т. к. у этих типов разное представление для значений -0 и 0, которые при этом все равно считаются равными. Это различие должно быть сохранено.
Есть еще одно дополнительное ограничение на уровне реализации, которое может быть убрано в будущих версиях QHB:
- Дедупликация не может применяться с типами-контейнерами (такими как составные или диапазонные типы или массивы).
Есть еще одно дополнительное ограничение на уровне реализации, которое действует независимо от используемого класса оператора или правила сортировки:
- Дедупликация не может применяться в индексах с INCLUDE.
Индексы GiST
Введение
GiST означает "обобщенное поисковое дерево" (Generalized Search Tree). Это сбалансированный, древовидный метод доступа, который работает как основа для произвольной схемы индексирования. B-деревья, R-деревья и многие другие схемы индексирования могут быть реализованы с помощью GiST.
Одним из преимуществ GiST является то, что он позволяет разрабатывать пользовательские типы данных вместе с соответствующими методами доступа эксперту предметной области без участия специалиста по базам данных.
Встроенные классы операторов
Основной дистрибутив QHB включает классы операторов GiST, показанные в следующей таблице:
| Имя | Индексируемый тип данных | Индексируемые операторы | Операторы сортировки |
|---|---|---|---|
| box_ops | box | && &> &< &<| >> << <<| <@ @> @ |&> | >> ~ ~= | <-> |
| circle_ops | circ | && &> &< &<| >> << <<| <@ @> @ |&> | >> ~ ~= | <-> |
| inet_ops | inet, cidr | && >> >>= > >= <> << <<= < <= = | |
| point_ops | point | >> >^ << <@ <@ <@ <^ ~= | <-> |
| poly_ops | polygon | && &> &< &<| >> << <<| <@ @> @ |&> | >> ~ ~= | <-> |
| range_ops | любой диапазонный тип | && &> &< >> << <@ -|- = @> @> | |
| tsquery_ops | tsquery | <@ @> | |
| tsvector_ops | tsvector | @@ |
По историческим причинам, класс операторов inet_ops не является классом по умолчанию для типов inet и cidr. Чтобы использовать его, указывайте имя класса явно в CREATE INDEX, например
CREATE INDEX ON my_table USING GIST (my_inet_column inet_ops);
Расширяемость
Традиционно, внедрение нового метода доступа к индексам означало много сложной работы. Необходимо было разобраться во внутренней работе базы данных: принципах работы менеджера блокировок и журнала упреждающей записи. Интерфейс GiST имеет высокий уровень абстракции, требующий от автора метода доступа только реализации семантики типа данных, к которому происходит обращение. Сам слой GiST заботится о параллелизме, журналировании и поиске в древовидной структуре.
Эту расширяемость не следует путать с расширяемостью других стандартных
поисковых деревьев в плане типов данных, которые они могут обрабатывать.
Например, QHB поддерживает расширяемые B-деревья и хэш-индексы.
Это означает, что в QHB вы можете построить
B-дерево или хэш-индекс над любым типом данных, каким захотите. Но
B-деревья поддерживают только предикаты диапазона (<, =, >), а
хэш-индексы только равенства.
Таким образом, если вы проиндексируете, скажем, коллекцию изображений с помощью B-дерева, вы сможете делать только запросы вида “изображение А равно изображению Б?”, “изображение А меньше изображения Б?” и т.п. В зависимости от того, как вы определяете “равно”, “меньше” и “больше” в этом контексте, это может иметь какой-то смысл. Однако, используя индекс на основе GiST, вы можете поддержать запросы, специфичные для предметной области, например "найти все изображения лошадей” или "найти все засвеченные фотографии".
Все, что требуется для запуска метода доступа GiST, — это реализовать несколько пользовательских методов, которые определяют поведение ключей в дереве. Конечно, эти методы должны быть довольно причудливыми, чтобы поддерживать причудливые запросы, но для всех стандартных запросов (B-деревья, R-деревья и т. д.) они довольно прямолинейны. Короче говоря, GiST сочетает в себе расширяемость с универсальностью, переиспользованием кода и чистым интерфейсом.
Существует пять методов, которые должен предоставить класс оператора индекса для GiST, и четыре, которые являются необязательными. Корректность индекса обеспечивается правильной реализацией методов same, consistent и union, а эффективность (размер и скорость работы) определяется методами penalty и picksplit.
Два из опциональных методов: compress и decompress позволяют индексу хранить во внутренних (т.е. нелистовых) вершинах дерева данные другого типа, нежели индексируемый тип. Листья в любом случае будут хранить данные такого же типа, как и индексируемый столбец, а другие узлы могут хранить произвольную структуру (C-style-struct), но все же в рамках общих ограничений QHB на типы данных (про данные переменной длины см. varlena). Если тот тип данных, что будет лежать в промежуточных вершинах дерева, существует на уровне SQL, то можно задать ему свойство STORAGE в команде CREATE OPERATOR CLASS. На самом деле, можно иметь много разных типов содержимого вершин. Есть главный тип, в котором производятся все вычисления при построении и навигации индекса, а при сохранении в вершины индекса вызывается compress, и в compress можно преобразовать в любой бинарный формат, в том числе с потерей информации. Если compress нет, то главный тип и содержимое всех вершин совпадает с индексируемым типом.
Необязательный метод №8 — distance, который нужен, если класс операторов хочет поддержать упорядоченные сканирования (поиск N ближайших соседей). Девятый метод fetch нужен, если класс операторов хочет поддерживать сканирование только по индексу, но при этом хранит альтернативный тип в промежуточных вершинах (использует compress/decompress).
-
consistent
Для значения
pв вершине индекса и поискового значенияq, эта функция возвращает, является ли запросq"согласованным" cо значениемp. Для листовых записей индекса это эквивалентно проверке индексируемого условия, а для внутренних вершин дерева это определяет, необходимо ли сканировать соответствующее поддерево. Когда функция возвращает истину, она должна также заполнить флаг перепроверки recheck. Это указывает, является лиqбезусловно подходящим или только возможно подходящим. Выставьте recheck = false, когда индекс полностью проверил условие предиката, а если recheck = true, то эта строка является только кандидатом на совпадение. В этом случае система будет перепроверять запрос на значении, взятом из строки. Такое соглашение позволяет GiST поддерживать как точные (lossless) так и грубые (lossy) индексы.SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_consistent(internal, data_type, smallint, oid, internal) RETURNS bool AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Примерный шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_consistent); Datum my_consistent(PG_FUNCTION_ARGS) { GISTENTRY *entry = (GISTENTRY *) PG_GETARG_POINTER(0); data_type *query = PG_GETARG_DATA_TYPE_P(1); StrategyNumber strategy = (StrategyNumber) PG_GETARG_UINT16(2); /* Oid subtype = PG_GETARG_OID(3); */ bool *recheck = (bool *) PG_GETARG_POINTER(4); data_type *key = DatumGetDataType(entry->key); bool retval; /* * Рассчитать возвращаемое значение как функцию от стратегии, ключа и запроса. * * Используйте GIST_LEAF(entry) чтобы понять, в каком месте дерева вас вызвали. * Это очень полезно. Например, при реализации оператора = * вы можете во внутренних вершинах проверять, что пересечение не пусто, * а в листьях проверять на точное равенство. */ *recheck = true; /* ну или false, если проверка была 100%-ная */ PG_RETURN_BOOL(retval); }Здесь, key является элементом в индексе, а query — значение, которое ищут. Параметр StrategyNumber указывает, какой из операторов вашего класса применяется: он соответствует номер одного из оператора из команды CREATE OPERATOR CLASS.
В зависимости от того, какие операторы вы включили в класс, тип данных query может быть разными, в том числе разным для разных операторов. В любом случае, он будет соответствовать типу второго аргумента оператора, а первый аргумент оператора будет главного типа содержимого индекса. (Приведенная выше заготовка кода предполагает, что все запросы будет одинакового типа data_type; если это не так, то сначала надо узнать тип второго параметра оператора, а потом доставать значение из query.) В SQL-объявлении функции consistent рекомендуется указывать тип данных query совпадающим с индексируемым типом данных, даже если реально передаваемый тип данных может быть другим в зависимости от оператора.
-
union
Этот метод объединяет информацию в дереве: получает на вход содержимое нескольких вершин, и создаёт подходящее содержимое для их общей родительской вершины.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_union(internal, internal) RETURNS storage_type AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Примерный шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_union); Datum my_union(PG_FUNCTION_ARGS) { GistEntryVector *entryvec = (GistEntryVector *) PG_GETARG_POINTER(0); GISTENTRY *ent = entryvec->vector; data_type *out, *tmp, *old; int numranges, i = 0; numranges = entryvec->n; tmp = DatumGetDataType(ent[0].key); out = tmp; if (numranges == 1) { out = data_type_deep_copy(tmp); PG_RETURN_DATA_TYPE_P(out); } for (i = 1; i < numranges; i++) { old = out; tmp = DatumGetDataType(ent[i].key); out = my_union_implementation(out, tmp); } PG_RETURN_DATA_TYPE_P(out); }Как вы можете видеть, в этой заготовке мы считаем, что для нашего типа данных
union (X, Y, Z) = union(union(X, Y), Z). Но поддержать типы данных, для которых это не так, тоже будет несложно.Результатом функции объединения должно быть значение главного типа содержимого индекса (как говорилось выше, он может отличаться или не отличаться от индексируемого типа). Функция union должна возвращать указатель на кусок памяти, выделенной с помощью palloc. Даже если результат совпадает с одним из входных аргументов, вы не может просто вернуть на него указатель, вы должны склонировать содержимое.
Как видно из примера, первый внутренний (internal) аргумент функции union — это указатель GistEntryVector. Второй аргумент является указателем на целочисленную переменную, которую можно игнорировать.
-
compress
Преобразует элемент данных в формат, подходящий для физического хранения на странице индекса. Если метод отсутствует, то элементы данных хранятся в индексе без изменений.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_compress(internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Примерный шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_compress); Datum my_compress(PG_FUNCTION_ARGS) { GISTENTRY *entry = (GISTENTRY *) PG_GETARG_POINTER(0); GISTENTRY *retval; if (entry->leafkey) { // заменить entry->key заархивированной версией compressed_data_type *compressed_data = palloc(sizeof(compressed_data_type)); /* здесь заполнить *compressed_data на основании entry->key ... */ retval = palloc(sizeof(GISTENTRY)); gistentryinit(*retval, PointerGetDatum(compressed_data), entry->rel, entry->page, entry->offset, FALSE); } else { // Как правило, для нелистовых вершин ничего не надо делать retval = entry; } PG_RETURN_POINTER(retval); }В этом коде нужно заменить compressed_data_type на индексируемый тип, так как содержимое листовых узлов должно быть такого типа.
-
decompress
Преобразует сохраненное представление данных в главный тип содержимого, которым могут манипулировать другие методы GiST в классе операторов. Если метод декомпрессии отсутствует, предполагается, что другие методы GiST могут работать непосредственно на сохраненном формате данных. Декомпрессия не обязательно противоположна компрессии; в частности, если сжатие с потерями, для декомпрессии невозможно точно восстановить исходные данные. Поведение decompress и fetch также могут различаться т.к. первое возвращает главный тип содержимого индекса (например, тип первого аргумента consistent), а второе — индексируемый тип, и эти типы могут различаться.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_decompress(internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Тривиальная реализация на C:
PG_FUNCTION_INFO_V1(my_decompress); Datum my_decompress(PG_FUNCTION_ARGS) { PG_RETURN_POINTER(PG_GETARG_POINTER(0)); }Приведенный выше пример подходит для случая, когда никакая декомпрессия не требуется. (Но в таком случае лучше, конечно, вообще отказаться от этого метода.)
-
penalty
Возвращает "штраф" за вставку новой записи в данную ветвь дерева. При вставке элемента его будут пихать по пути с наименьшим штрафом. Значение штрафа должно быть неотрицательным. Если вернуть отрицательное значение, оно будет рассматриваться как ноль.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_penalty(internal, internal, internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT; -- в некоторых случаях у вас получится нестрогая функцияШаблон реализации на C:
PG_FUNCTION_INFO_V1(my_penalty); Datum my_penalty(PG_FUNCTION_ARGS) { GISTENTRY *origentry = (GISTENTRY *) PG_GETARG_POINTER(0); GISTENTRY *newentry = (GISTENTRY *) PG_GETARG_POINTER(1); float *penalty = (float *) PG_GETARG_POINTER(2); data_type *orig = DatumGetDataType(origentry->key); data_type *new = DatumGetDataType(newentry->key); *penalty = my_penalty_implementation(orig, new); PG_RETURN_POINTER(penalty); }По историческим причинам, penalty не возвращает результат типа float, а кладет его по указателю, переданному третьим аргументом. А собственно возвращаемое значение функции игнорируется; но принято возвращать указатель на результат как в примере.
Функция penalty имеет решающее значение для хорошей работы индекса. Она используется во время вставки, чтобы определить, в какую ветвь пойти при выборе места для добавления новой записи в дереве. Во время выполнения запроса, чем больше сбалансирован индекс, тем быстрее выполняется поиск.
-
picksplit
При необходимости разбиения страницы индекса эта функция решает, какие записи на странице должны оставаться на старой странице, а какие должны быть перемещены на новую страницу.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_picksplit(internal, internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_picksplit); Datum my_picksplit(PG_FUNCTION_ARGS) { GistEntryVector *entryvec = (GistEntryVector *) PG_GETARG_POINTER(0); GIST_SPLITVEC *v = (GIST_SPLITVEC *) PG_GETARG_POINTER(1); OffsetNumber maxoff = entryvec->n - 1; GISTENTRY *ent = entryvec->vector; int i, nbytes; OffsetNumber *left, *right; data_type *tmp_union; data_type *unionL; data_type *unionR; GISTENTRY **raw_entryvec; maxoff = entryvec->n - 1; nbytes = (maxoff + 1) * sizeof(OffsetNumber); v->spl_left = (OffsetNumber *) palloc(nbytes); left = v->spl_left; v->spl_nleft = 0; v->spl_right = (OffsetNumber *) palloc(nbytes); right = v->spl_right; v->spl_nright = 0; unionL = NULL; unionR = NULL; /* Initialize the raw entry vector. */ raw_entryvec = (GISTENTRY **) palloc(entryvec->n * sizeof(void *)); for (i = FirstOffsetNumber; i <= maxoff; i = OffsetNumberNext(i)) raw_entryvec[i] = &(entryvec->vector[i]); for (i = FirstOffsetNumber; i <= maxoff; i = OffsetNumberNext(i)) { int real_index = raw_entryvec[i] - entryvec->vector; tmp_union = DatumGetDataType(entryvec->vector[real_index].key); Assert(tmp_union != NULL); /* * Выбрать, куда положить элемент индекса и соответственно изменить unionL и unionR * Добавить его в v->spl_left, либо в v->spl_right, и счетчики тоже изменить соответственно. */ if (my_choice_is_left(unionL, curl, unionR, curr)) { if (unionL == NULL) unionL = tmp_union; else unionL = my_union_implementation(unionL, tmp_union); *left = real_index; ++left; ++(v->spl_nleft); } else { // то же самое для направо... } } v->spl_ldatum = DataTypeGetDatum(unionL); v->spl_rdatum = DataTypeGetDatum(unionR); PG_RETURN_POINTER(v); }Обратите внимание, что результатом работы функции picksplit является изменение GIST_SPLITVEC-структуры, пришедшей параметром. Возвращаемое значение функции игнорируется, но принято возвращать указатель на эту структуру как в примере.
Как и penalty, функция picksplit имеет решающее значение для хорошей работы индекса. Придумать, как будут работать penalty и picksplit — самое сложное в дизайне GiST-индекса.
-
same
Возвращает true, если две записи индекса идентичны, в противном случае false.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_same(storage_type, storage_type, internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_same); Datum my_same(PG_FUNCTION_ARGS) { prefix_range *v1 = PG_GETARG_PREFIX_RANGE_P(0); prefix_range *v2 = PG_GETARG_PREFIX_RANGE_P(1); bool *result = (bool *) PG_GETARG_POINTER(2); *result = my_eq(v1, v2); PG_RETURN_POINTER(result); }По историческим причинам, функция same не просто возвращает логический результат, а помещает его по указателю, переданному третьим аргументом. Возвращаемое значение функции игнорируется, но принято возвращать этот же указатель как показано в примере.
-
distance
Для значения
pв вершине индекса и поискового значенияq, эта функция возвращает "расстояние" отqдоp. Для листовой вершины это скорее всего точное расстояние между двумя точками, а для нелистовой вершины следует понимать это как расстояние отqдо ближайшего элемента из поддерева (возможно, заниженное, но не завышенное). Эта функция должна быть предоставлена, если класс операторов содержит какие-либо операторы упорядочивания. Запрос, использующий оператор упорядочивания, будет реализован путем возврата записей индекса с наименьшими значениями "расстояния", поэтому работа distance должна быть согласованы с семантикой этого оператора.SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_distance(internal, data_type, smallint, oid, internal) RETURNS float8 AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Примерный шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_distance); Datum my_distance(PG_FUNCTION_ARGS) { GISTENTRY *entry = (GISTENTRY *) PG_GETARG_POINTER(0); data_type *query = PG_GETARG_DATA_TYPE_P(1); StrategyNumber strategy = (StrategyNumber) PG_GETARG_UINT16(2); /* Oid subtype = PG_GETARG_OID(3); */ /* bool *recheck = (bool *) PG_GETARG_POINTER(4); */ data_type *key = DatumGetDataType(entry->key); double retval; /* * Вычисление результата как функции от стратегии(оператора), ключа и поискового значения */ PG_RETURN_FLOAT8(retval); }Аргументы у distance такие же, как и у consistent.
Допускаются неточности при вычислении расстояния, главное вернуть не больше, чем реальное расстояние. Например, в геометрических приложениях расстояние до группы обычно считают как расстояние до ограничивающего группу параллелипипеда. Для внутренней вершины дерева возвращаемое расстояние не должно быть больше расстояния до любого из дочерних вершин. Если возвращенное расстояние не является точным, функция должна установить
*recheckв true. (Это не обязательно для внутренних вершин дерева; для них вычисление всегда предполагается неточным). В этом случае движок вычислит точное расстояние после извлечения строки из кучи и при необходимости пересортирует строки.Если функция расстояния хотя бы иногда возвращает
*recheck = true, то тип (float8/float4) и масштаб значений должны быть такие же как и у исходного оператора упорядочивания, потому что будут сортировать результаты distance с результатами оператора вперемешку. А если всегда*recheck = false, то результаты distance могут быть любыми float8 значениями, несогласованными с оператором, т.к. их будут сравнивать только между собой. (Бесконечность и минус бесконечность зарезервированы для обработки специальных случаев, таких как NULL, поэтому не надо возвращать такие значения). -
fetch
Преобразует сжатое индексное представление элемента данных в индексируемый тип данных для сканирования только по индексу. Возвращаемые данные должны быть точной копией исходного индексированного значения без искажений.
SQL-объявление функции должно выглядеть следующим образом:
CREATE OR REPLACE FUNCTION my_fetch(internal) RETURNS internal AS 'MODULE_PATHNAME' LANGUAGE C STRICT;Аргумент является указателем на структуру GISTENTRY. На входе, поле key — содержимое листа дерева в сжатом виде (т.е. результат работы compress), NOT NULL. Возвращаемое значение — другая GISTENTRY, чье поле key содержит те же данные в исходном, несжатом виде. Если функция compress класса операторов предостаелена, но ничего не делает для листовых записей, то метод fetch может возвращать аргумент без изменений. Если же функции compress вообще нет, тогда и fetch не нужна.
Шаблон реализации на C:
PG_FUNCTION_INFO_V1(my_fetch); Datum my_fetch(PG_FUNCTION_ARGS) { GISTENTRY *entry = (GISTENTRY *) PG_GETARG_POINTER(0); input_data_type *in = DatumGetPointer(entry->key); fetched_data_type *fetched_data; GISTENTRY *retval; retval = palloc(sizeof(GISTENTRY)); fetched_data = palloc(sizeof(fetched_data_type)); /* * Собственно преобразовать fetched_data в Datum исходного индексируемого типа */ /* fill *retval from fetched_data. */ gistentryinit(*retval, PointerGetDatum(converted_datum), entry->rel, entry->page, entry->offset, FALSE); PG_RETURN_POINTER(retval); }Если функция compress сохраняет данные в листах с искажением (с потерей информации), то класс оператора не может поддерживать сканирование только по индексу и не должен определять функцию fetch.
Все методы поддержки GiST обычно вызываются в короткоживущих контекстах памяти, то есть CurrentMemoryContext сбрасывается после обработки каждого кортежа. Это позволяет не беспокоиться о вызовах pfree. Однако в некоторых случаях хотелось бы иметь долгоживущий объект для кэширования данных при повторных вызовах. Чтобы сделать это, выделите память в контексте fcinfo->flinfo->fn_mcxt, и положите указатель в fcinfo->flinfo->fn_extra. Время жизни такого объекта — одна индексная операция (одно сканирование, одна вставка или построение индекса). Если вы заменяете fcinfo->flinfo->fn_extra, а там было ненулевое значение, то вы должны его освободить, иначе будут утечки.
Реализация
Построение больших индексов GiST путем простой последовательной вставки всех кортежей бывает медленным, потому что, когда индекс большой и вытесняется из памяти на диск, вставка очередного кортежа происходит в случайное место индекса и вызывает чтение/запись на диск случайных страниц. QHB поддерживает более эффективный, буферизованный метод построения индексов GiST, что может значительно уменьшить количество операций ввода-вывода при обработке неупорядоченного набора данных. Для упорядоченных наборов данных преимущество меньше или отсутствует, т.к. для них последовательная вставка тоже прекрасно работает (в каждый момент времени работа ведется только в нескольких страницах, которые влезают в память).
Однако для построения индекса с буферизацией будет больше вызовов penalty, т.е. больше нагрузка на процессор. Кроме того, требуется дополнительное временное пространство на диске, примерно равное итоговому размеру индекса. Также построение с буферизацией и без может приводить к разным по качеству индексам. Это зависит от реализации penalty, picksplit и операторов. Более качественный (сбалансированный) индекс может получиться как при одном, так и при другом алгоритме построения индекса.
Глобально поведение управляется параметром effective_cache_size: когда размер индекса превышает или явно собирается превысить effective_cache_size, построение GiST-индекса переключается на буферизованный метод. Также буферизацию можно включить/выключить явно для конкретного индекса. Для этого используется опция buffering команды CREATE INDEX. Поведение по умолчанию подходит для большинства случаев, но отключение буферизации может ускорить построение, если вам известно, что входные данные упорядочены.
Примеры
Исходный дистрибутив QHB содержит несколько примеров индексных методов, реализованных на основе GiST. В основной дистрибутив входит полнотекстовый поиск (типы tsvector и tsquery), а также R-Деревья для некоторых встроенных типов геометрических данных.
Следующие модули из contrib также содержат классы операторов GiST:
| Модуль | Описание функционала |
|---|---|
| btree_gist | Функциональность, эквивалентная B-дереву для некоторых типов данных |
| cube | Индексация многомерных кубов |
| hstore | Модуль для хранения пар (ключ, значение) |
| intarray | RD-дерево для одномерного массива int4 |
| ltree | Индексирование древовидных путей |
| pg_trgm | Степень сходства текстов в метрике триграмм |
| seg | Индексирование интервалов действительных чисел |
Индексы SP-GiST
Введение
SP-GiST — это сокращение от Space-partitioned GiST (обобщённое дерево по разбитому на партиции пространству). SP-GiST представляет собой дерево поиска, ветви которого не пересекаются (в отличие от GiST). В таком виде представимы многие несбалансированные структуры данных, в том числе деревья квадрантов, K-мерные деревья и префиксное деревья (Tries). Общая особенность этих структур заключается в том, что они многократно разбивают пространство поиска на непересекающиеся партиции, которые не обязательно должны быть одинакового размера. Поиск, хорошо соответствующий правилу разбиения, может быть очень быстрым.
Эти популярные структуры данных были первоначально разработаны для использования в оперативной памяти. В основной памяти они обычно проектируются как множество динамически выделенных узлов, связанных указателями. В отличие от B-Дерева у каждой вершины бывает всего по 2-4 дочерних, а высота дерева получается соответственно большая; большая высота — это проход большого количества вершин при поиске. Если хранить это прямо в таком виде на диске, то будет много чтений произвольного доступа. Для хранения на диске деревья должны наоборот сильно ветвиться. Основная задача, решаемая SP-GiST, заключается в размещении вершин поискового дерева на дисковых страницах таким образом, чтобы поиск требовал доступа только к нескольким дисковым страницам, даже если он проходит через много вершин.
Как и GiST, SP-GiST предназначена для разработки пользовательских типов данных с соответствующими методами доступа экспертом в прикладной области типа данных.
Встроенные классы операторов
Основной дистрибутив QHB включает классы операторов SP-GiST, показанные в таблице.
| Имя | Индексированный Тип Данных | Индексируемые Операторы | Операторы сортировки |
|---|---|---|---|
| kd_point_ops | point | << <@ <^ >> >^ ~= | <-> |
| quad_point_ops | point | << <@ <^ >> >^ ~= | <-> |
| range_ops | любой диапазонный тип | && &< &> -|- << <@ = >> @> | |
| box_ops | box | << &< && &> >> ~= @> <@ &<| <<| |>> |&> | <-> |
| poly_ops | polygon | << &< && &> >> ~= @> <@ &<| <<| |>> |&> | <-> |
| text_ops | text | < <= = > >= ~<=~ ~<~ ~>=~ ~>~ ^@ | |
| inet_ops | inet, cidr | && >> >>= > >= <> << <<= < <= = |
Из двух классов операторов для типа point, quad_point_ops — это класс по умолчанию. kd_point_ops поддерживает те же операторы, но использует другую структуру данных индекса, которая может обеспечить лучшую производительность в некоторых приложениях.
Классы операторов quad_point_ops, kd_point_ops и poly_ops
поддерживают оператор упорядочения <->, который позволяет выполнять поиск
k ближайших соседей (k-NN search) среди проиндексированных точек или многоугольников.
Расширяемость
SP-GiST предлагает интерфейс с высоким уровнем абстракции, требующий от разработчика реализовать только методы, специфичные для данного типа данных. Ядро SP-GiST обеспечивает эффективное хранение на диске и движок поиска в древовидной структуре, а также решает вопросы конкурентного доступа и логирования.
Листовые вершины SP-GiST-дерева содержат значения того же типа данных, что и индексируемый столбец. Однако они могут хранить значение не целиком, а только суффикс. В этом случае вспомогательные функции класса операторов должны уметь восстанавливать полное значение, собирая значения в родительских вершинах при проходе через них от корня к листу.
Содержимое внутренние вершин более сложное. Каждая внутренняя вершина содержит набор из одного или нескольких узлов (nodes), каждый из которых является ветвью дерева (= областью пространства). Узел содержит либо ссылку на внутреннюю вершину (если ветвь дерева большая), либо короткий список листьев, все из которых располагаются на одной странице индекса (если ветвь маленькая). Каждый узел обычно имеет метку (label) которая описывает его; например, в префиксном дереве метка узла может быть следующей буквой строкового значения. (Класс оператора может опустить метки узлов, если он работает с фиксированным набором узлов для всех внутренних вершин, см. SP-GiST без меток узлов).
Внутренняя вершина опционально может иметь префикс (prefix), описывающее все его члены. В префиксном дереве это может быть общий префикс представленных строк. Значение prefix не обязательно является действительно префиксом, но может быть любыми данными, необходимыми классу операторов; например, в дереве квадрантов в prefix хранится центральная точка, по которой происходит разбиение на квадранты. (А 4 узла соответствуют 4-ем областям пространства после разбиения.). Зачем существуют и префиксы, и метки? Метка нужна для того, чтобы решить, в какую из дочерних вершин пойти, не обращаясь к этим вершинам; метки хранятся в родительской вершине. Префикс наоборот хранится в самой вершине, и позволяет делать некоторые операции к ней, не обращаясь к родителю.
Некоторые алгоритмы работы с деревом требуют знания уровня ("глубины") текущей вершины, поэтому ядро SP-GiST предоставляет классам операторов возможность управлять подсчетом уровней при спуске по дереву. Как говорилось выше, есть поддержка восстановления значений по кусочкам, если это необходимо. И наконец, при спуске по дереву можно передавать дополнительный объект любого типа, он называется traverse value.
Примечание
Ядро SP-GiST берет на себя заботу о NULL-значения. Хотя индексы SP-GiST хранят записи для проиндексированных NULL'ов, это скрыто от кода класса оператора индекса: индексируемые NULL-значения никогда не будут переданы методам класса оператора, равно как и NULL-запросы. (Предполагается, что операторы SP-GiST являются строгими (STRICT), и NULL-значения заведомо не подходят под условия.) По этой причине NULL-значения больше не будут обсуждаться в этом разделе.
Существует пять пользовательских методов, которые должен предоставить класс оператора индекса для SP-GiST, и один необязательный. Все пять обязательных методов принимают 2 аргумента типа internal, это указатели на структуры, в первой расположены все входные значения, а во вторую надо поместить выходные значения. Возвращаемое значение из 4-ех методов void, а метод leaf_consistent возвращает bool. Методы не должны изменять какие-либо поля своих входных структур. Во всех случаях выходная структура инициализируется нулями перед вызовом пользовательского метода. Необязательный шестой метод compress принимает единственный аргумент datum — значение, которое индексируем, и возвращает его же в формате для хранения в листовой вершине.
Пять обязательных пользовательских методов:
-
config
Возвращает статическую информацию о реализации индекса, включая OID'ы типа данных префикса и типа данных меток узлов.
SQL-объявление функции должно выглядеть следующим образом:
CREATE FUNCTION my_config(internal, internal) RETURNS void ...Первый аргумент — это указатель на структуру spgConfigIn, содержащую входные данные для функции. Второй аргумент является указателем на структуру spgConfigOut, которую функция должна заполнить результирующими данными.
typedef struct spgConfigIn { Oid attType; /* Индексируемый тип данных*/ } spgConfigIn; typedef struct spgConfigOut { Oid prefixType; /* Какой будет тип данных префикса */ Oid labelType; /* Какой будет тип данных метки */ Oid leafType; /* Какой будет тип данных значений в листах */ bool canReturnData; /* Умеет реконструировать значения */ bool longValuesOK; /* Умеет обрабатывать длинные значения */ } spgConfigOut;Значение attType будет вам интересно, если ваш класс операторов умеет работать с несколькими типами данных.
Для классов операторов, которые не используют префиксы, prefixType следует задать VOIDOID. Аналогично, для классов операторов, которые не используют метки узлов, labelType следует задать VOIDOID. canReturnData должно быть установлено в true, если класс оператора способен восстанавливать исходное значение проиндексированного поля (для сканирования только по индексу). longValuesOK должно быть установлено true, только если attType имеет переменную длину, и класс оператора умеет нарезать длинные значения для размещения в нескольких узлах (см. Ограничения SP-GiST).
leafType обычно используют равный attType (оставить leafType нулевым работает так же, но лучше явно выставьте leafType = attType). Если attType и leafType различаются, должен быть предоставлен необязательный метод compress. Метод compress переводит индексируемые значения из attType в leafType. Примечание: leaf_consistent и inner_consistent получают в качестве аргументов attType, leafType на них не влияет.
-
choose
Решает, как именно будем вставлять новое значение в ветку дерева.
SQL-объявление функции должно выглядеть следующим образом:
CREATE FUNCTION my_choose(internal, internal) RETURNS void ...Первый аргумент — это указатель на структуру spgConfigIn, содержащую входные данные для функции. Второй аргумент является указателем на структуру spgConfigOut, которую функция должна заполнить результирующими данными.
typedef struct spgChooseIn { Datum datum; /* индексируемое значение */ Datum leafDatum; /* данные для записи в лист (все или суффикс) */ int level; /* текущая глубина в дереве, считая с 0 */ /* Содержимое текущей вершины */ bool allTheSame; /* вершина помечена all-the-same? */ bool hasPrefix; /* у вершины есть prefix? */ Datum prefixDatum; /* если да, то значение prefix */ int nNodes; /* количество дочерних узлов */ Datum *nodeLabels; /* label'ы дочерних узлов в виде линейного массива */ } spgChooseIn; typedef enum spgChooseResultType { spgMatchNode = 1, /* давайте спустимся в один из дочерних узлов */ spgAddNode, /* давайте добавим новый дочерний узел этой вершине */ spgSplitTuple /* давайте разобьем текущую вершину (поменяет ее prefix) */ } spgChooseResultType; typedef struct spgChooseOut { spgChooseResultType resultType; /* тип действия, 3 варианта, см. выше */ union { struct /* если тип spgMatchNode */ { int nodeN; /* номер узла, в который пойдем (от 0) */ int levelAdd; /* прибавить вот столько к глубине */ Datum restDatum; /* новое значение leafDatum */ } matchNode; struct /* если тип spgAddNode */ { Datum nodeLabel; /* label нового узла */ int nodeN; /* позиция вставки (от 0) */ } addNode; struct /* если тип spgSplitTuple */ { /* Информация для создания верхней из 2 вершин после разбиения */ bool prefixHasPrefix; /* вершина будет иметь prefix? */ Datum prefixPrefixDatum; /* если да, то значение prefix */ int prefixNNodes; /* число дочерних узлов */ Datum *prefixNodeLabels; /* их label'ы */ int childNodeN; /* номер дочернего узла, куда класть вторую вершину, * образующуюся при разбиении (от 0) */ /* Информация для создания нижней из 2 вершин (делается из текущей вершины и получает ее содержимое) */ bool postfixHasPrefix; /* вершина будет иметь prefix? */ Datum postfixPrefixDatum; /* если да, то значение prefix */ } splitTuple; } result; } spgChooseOut;datum — это исходное значение типа attType, которое должно был быть вставлено в индекс. Если есть метод compress, то leafDatum — это значение типа leafType, которое сперва получают вызовом compress, а потом при спуске по дереву методы choose или picksplit меняют его; когда процесс вставки достигает конечной страницы, текущее значение параметра leafDatum это то, что будет сохранено во вновь созданной листовой вершине. Если нет метода compress, то leafDatum не меняется при спуске по дереву и совпадает с datum. level — текущая глубина в дереве (прибавляется не всегда на +1, а вы ее меняете по своему усмотрению), для корня дерева 0. allTheSame имеет значение true, если текущая внутренняя вершина помечена как содержащая несколько эквивалентных узлов (см. Внутренние вершины "all-the-same"). hasPrefix имеет значение true, если текущая внутренняя вершина содержит префикс; и если содержит, то prefixDatum является его значением. nNodes — это число дочерних узлов, содержащихся в вершине, а nodeLabels — это массив значений их меток, или NULL, если нет никаких меток.
Функция choose может решить, что новое значение соответствует одному из существующих дочерних узлов, или что новый дочерний узел должен быть добавлен, или что новое значение несовместимо с префиксом вершины, и поэтому над ней нужно добавить родительскую вершину с менее ограничительным префиксом.
Если новое значение соответствует одному из существующих дочерних узлов, установите resultType равным spgMatchNode. Установите nodeN равным индексу (с нуля) этого узла в массиве узлов. levelAdd — сколько прибавить к глубине, например, если вашим методам глубина не интересна, то оставляйте ноль, и ее не будут считать. Если ваши методы реализуют хранение только суффикса, то в restDatum положите остаток суффикса, а если нет, то положите туда тоже, что и пришло (leafDatum).
Если необходимо добавить новый дочерний узел, установите resultType равным spgAddNode. Положите в nodeLabel метку, которая будет использоваться для нового узла, а в nodeN индекс (от нуля), в который необходимо вставить узел в массив узлов. После добавления узла метод choose будет вызван снова для той же самой вершины, и на этот раз должен привести к результату spgMatchNode.
Если новое значение не соответствует префиксу вершины, установите resultType равным spgSplitTuple. Это действие перемещает все существующие узлы в новую внутреннюю вершину более низкого уровня, а текущую вершину превращает в вершину, имеющую одну нисходящую ссылку, указывающую на новую вершину более низкого уровня. Установите prefixHasPrefix, чтобы указать, должна ли новая верхняя вершина иметь префикс, и если да, то заполните prefixPrefixDatum значением префикса. Это новое значение префикса должно быть менее строгим, чем исходное, достаточно нестрогим, чтобы новое значение подходило. Установите prefixNNodes равным числу узлов, необходимых в новой вершине, и сразу же задайте им всем метки: в prefixNodeLabels поместите указатель на массив, выделенный с помощью palloc, содержащий их метки, или, если метки не требуются, то prefixNodeLabels = NULL. Обратите внимание, что общий размер новой верхней вершины не должен превышать общего размера вершины, которую он замещает; это ограничивает длину нового префикса и новых меток. Задайте childNodeN — номер дочернего узла, соответствующего нижней вершине, образовавшейся при разбиении. Для нижнего узла нужно задать только postfixHasPrefix и postfixPrefixDatum. Сочетание префиксов двух вершин и, возможно, метки узла должно иметь такое же семантическое значение, что и префикс вершины до её разбиения, потому что нет возможности пойти в дочерние узлы и там что-то поправить. После того, как узел был разделен, то функция choose будет вызвана снова для верхней из двух вершин. Этот вызов скорее всего вернет результат spgAddNode: раз старая вершина не годилась для вставки, то после разбиения вы захотите создать ей сестринскую.
Итого, вы можете строить дерево, либо добавляя детей в текущую вершину, либо вставляя вершину над текущей, и добавлять детей уже к ней. Перебалансировку сделать нельзя.
-
picksplit
Решает, как создать новую внутреннюю вершину над набором листовых вершин. Вызывается, когда узел, содержащий листовые вершины, переполнился, и надо превратить его во внутреннюю вершину, содержащую несколько узлов с тем же контентом.
SQL-объявление функции должно выглядеть следующим образом:
CREATE FUNCTION my_picksplit(internal, internal) RETURNS void ...Первый аргумент — это указатель на структуру spgConfigIn, содержащую входные данные для функции. Второй аргумент является указателем на структуру spgConfigOut, которую функция должна заполнить результирующими данными.
typedef struct spgPickSplitIn { int nTuples; /* кол-во листовых вершин */ Datum *datums; /* их значения (линейный массив длины nTuples) */ int level; /* текущая глубина (считая от 0) */ } spgPickSplitIn; typedef struct spgPickSplitOut { bool hasPrefix; /* нужен ли prefix? */ Datum prefixDatum; /* если да, то значение prefix'а */ int nNodes; /* кол-во дочерних узлов */ Datum *nodeLabels; /* их label'ы (или NULL, если не надо меток) */ int *mapTuplesToNodes; /* раскладка листьев по дочерним узлам */ Datum *leafTupleDatums; /* новые значения листовых узлов */ } spgPickSplitOut;nTuples — количество листовых вершин, которые сейчас раскладываем. datums — это массив их значений типа leafType level это текущий уровень (глубина), одинаковый у всех листовых вершин, и у новой внутренней вершины, предположительно, будет такой же.
Установите hasPrefix, чтобы указать, должна ли новая внутренняя вершина иметь префикс, и если да, то заполните prefixDatum значением префикса. Поместите в nNodes количество дочерних узлов у новой вершины, а в nodeLabels массив их меток или NULL, если метки узлов не требуются. Задайте, в какой узел поместить каждую из листовых вершин — mapTuplesToNodes, длина равна nTuples, каждый элемент — номер узла (от 0). Заполните leafTupleDatums значениями, хранимыми в листах (если вы не храните только суффиксы для компактности, это будет тоже самое, что и входные данные datums, но все равно надо сделать копию). Обратите внимание, что picksplit должна выделить память под nodeLabels, mapTuplesToNodes и leafTupleDatums с помощью palloc.
Если во входных аргументах больше одного листа, то ожидается, что picksplit их как-то отклассифицирует и разделит на несколько узлов (picksplit вызывают с этой целью). Если picksplit поместит все предложенные листы в один узел, то ядро SP-GiST делает вывод, что они условно одинаковые, разделит их на узлы случайным образом (делить всё-таки надо из-за ограничения на количество дочерних листов). Эти несколько узлов все получат одинаковую метку (ту, которую вернула picksplit) и флаг allTheSame чтобы показать, что это произошло. Функции choose и inner_consistent должны проявлять надлежащую осторожность с такими внутренними вершинами. Дополнительную информацию смотрите в Внутренние вершины "all-the-same".
Функция picksplit может быть запущена для 1 листа только в том случае, если функция config установила longValuesOK = true, и встретилось значение длиннее, чем влезает на страницу. В этом случае смысл операции состоит в том, чтобы побить значение на префикс (который сохранят во внутренней вершине) и суффикс, который сохранят в листе или, если он всё ещё слишком длинный, снова вызовут picksplit. Дополнительную информацию смотрите в Ограничения SP-GiST.
-
inner_consistent
Возвращает набор ветвей, в которые следует сходить при поиске.
SQL-объявление функции должно выглядеть следующим образом:
CREATE FUNCTION my_inner_consistent(internal, internal) RETURNS void ...Первый аргумент — это указатель на структуру spgConfigIn, содержащую входные данные для функции. Второй аргумент является указателем на структуру spgConfigOut, которую функция должна заполнить результирующими данными.
typedef struct spgInnerConsistentIn { /* Свойства исходного поискового запроса */ ScanKey scankeys; /* массив значений, которые ищем, и предикатов (операторов) */ ScanKey orderbys; /* массив операторов упорядочивания и значений для них */ int nkeys; /* длина массива scankeys */ int norderbys; /* длина массива orderbys */ /* Состояние алгоритма обхода дерева */ Datum reconstructedValue; /* кумулятивный префикс родителей */ void *traversalValue; /* накопительный объект класса операторов */ MemoryContext traversalMemoryContext; /* контекст памяти, на котором аллокировать traversalValue */ int level; /* текущая глубина (от 0) */ bool returnData; /* нужно ли восстанавливать оригинальное значение? */ /* Свойства текущей внутренней вершины */ bool allTheSame; /* она помечена all-the-same? */ bool hasPrefix; /* у нее есть prefix? */ Datum prefixDatum; /* если да, то какой */ int nNodes; /* количество дочерних узлов */ Datum *nodeLabels; /* метки дочерних узлов (NULL, если нет меток) */ } spgInnerConsistentIn; typedef struct spgInnerConsistentOut { int nNodes; /* в сколько узлов (веток) надо сходить */ int *nodeNumbers; /* массив с номерами узлов длины nNodes */ int *levelAdds; /* на сколько увеличить глубину при входе в узел (массив длины nNodes) */ Datum *reconstructedValues; /* кумулятивный префикс при входе в узел (массив длины nNodes)*/ void **traversalValues; /* накопительные объекты (массив длины nNodes) */ double **distances; /* массив из nNodes массивов из norderbys расстояний до выбранных узлов */ } spgInnerConsistentOut;Массив scankeys длины nkeys описывает условия поиска в индексе. Эти условия объединяются по И(AND) — только строки, удовлетворяющие всем из них считаются подходящими. (Обратите внимание, что возможен вариант nkeys = 0, и это означает, что условия нет, и нужны просто все записи индекса). Обычно inner_consistent волнуют только поля sk_strategy и sk_argument каждой записи массива scankeys, которые соответственно дают оператор и значение сравнения. В частности, нет необходимости проверять sk_flags на предмет, является ли значение сравнения NULL, потому что основной код SP-GiST отфильтрует такие условия. Массив orderbys длины norderbys описывает операторы упорядочивания (если таковые имеются) аналогичным образом.
reconstructedValue — аккумулятор префикса, накапливаемый при проходе от корня (из префиксов вершин и, возможно, меток узлов). При заходе в корень это 0, а дальше зависит от выходных значений inner_consistent. Если ваш класс операторов не использует восстановление значений по префиксам внутренних вершин, то используйте 0 на всех уровнях. reconstructedValue всегда типа leafType.
traversalValue — указатель на любой ваш объект, который вы вернули из inner_consistent при заходе в родителя; для корня traversalValue == NULL. traversalMemoryContext — это контекст памяти, в котором надо аллокировать элементы traversalValues (см. ниже). level — текущая глубина. returnData имеет значение true, если в рамках запроса требуются восстановленные данные (если config вернула !canReturnData, то их не затребуют). allTheSame — свойство текущей вершины, в этом случае все узлы имеют одинаковую метку (если таковая имеется), и поэтому либо все, либо ни один из них не соответствует запросу (см. Внутренние вершины "all-the-same" ). hasPrefix + prefixDatum — префикс текущей вершины. nNodes — это число дочерних узлов, а nodeLabels — их метки.
В результате работы nNodes устанавливается в число дочерних узлов (ветвей дерева), которые надо посетить, потому что там могут быть результаты, подходящем под запрос. Часто это всего один узел, но потенциально может быть много, и это усложняет интерфейс: все выходные результаты являются массивами из nNodes элементов, индекс в которых — это номер узла среди рекомендуемых. nodeNumbers — номера рекомендуемых узлов среди дочерних узлов вершины. levelAdds — приращение глубины при спуске в данный узел; обычно это +1 для всех узлов, но вы можете решить, что какие-то узлы "особо заглубленные", например, на основании метки; если никакие методы вашего класса операторов не интересуется глубиной, то можете оставить указатель levelAdds нулевым. Если ваш класс операторов использует восстановление значений по префиксам внутренних вершин, то вам нужно заполнить reconstructedValues для передачи в дочерние вершины. Если происходит поиск ближайших соседей, заполните distances расстояниями до узлов, которые рекомендуете посетить (внешний массив по номеру узла, внутренний по номеру метрики из orderbys), если нет, то оставьте указатель distances нулевым; узлы с меньшим расстоянием будут посещены в первую очередь.
Если вам нужно передать какую-то дополнительную информацию в методы вашего класса операторов, заполните traversalValues, иначе оставьте его нулевым. Учтите, что массивы nodeNumbers, levelAdds, distances, reconstructedValues, и traversalValues надо выделять palloc'ом в текущем контексте, а элементы traversalValues надо выделять в контексте аллокации traversalMemoryContext, при этом каждый элемент должен быть отдельной единицей аллокации (нельзя использовать 1 единицу аллокации и положить в массив traversalValues указатель на ее середину).
-
leaf_consistent
Возвращает true, если листовая вершина удовлетворяет запросу.
SQL-объявление функции должно выглядеть следующим образом:
CREATE FUNCTION my_leaf_consistent(internal, internal) RETURNS bool ...Первый аргумент — это указатель на структуру spgConfigIn, содержащую входные данные для функции. Второй аргумент является указателем на структуру spgConfigOut, которую функция должна заполнить результирующими данными.
typedef struct spgLeafConsistentIn { /* Свойства исходного поискового запроса */ ScanKey scankeys; /* массив значений, которые ищем, и предикатов (операторов) */ ScanKey orderbys; /* массив операторов упорядочивания и значений для них */ int nkeys; /* длина массива scankeys */ int norderbys; /* длина массива orderbys */ /* Состояние алгоритма обхода дерева */ Datum reconstructedValue; /* кумулятивный префикс родителей */ void *traversalValue; /* накопительный объект класса операторов */ int level; /* текущая глубина (от 0) */ bool returnData; /* нужно ли возвращать оригинальное значение столбца? */ /* Свойства текущей листовой вершины */ Datum leafDatum; /* данные, хранящиеся в листе */ } spgLeafConsistentIn; typedef struct spgLeafConsistentOut { Datum leafValue; /* оригинальное значение столбца, если надо */ bool recheck; /* true, если надо перепроверить условие по значению из строки кучи */ bool recheckDistances; /* true, если расстояние надо уточнить по значению из строки кучи */ double *distances; /* массив из norderbys расстояний до данного листа */ } spgLeafConsistentOut;Массив scankeys длины nkeys описывает условия поиска в индексе. Эти условия объединяются по И(AND) — только строки, удовлетворяющие всем из них считаются подходящими. (Обратите внимание, что возможен вариант nkeys = 0, и это означает, что любой лист подходит). Обычно leaf_consistent волнуют только поля sk_strategy и sk_argument каждой записи массива scankeys, которые соответственно дают оператор и значение сравнения. В частности, нет необходимости проверять sk_flags на предмет, является ли значение сравнения NULL, потому что основной код SP-GiST отфильтрует такие условия. Массив orderbys длины norderbys описывает операторы упорядочивания (если таковые имеются) аналогичным образом.
reconstructedValue — аккумулятор префикса, накопленный при проходе от корня. Может быть NULL, если префикс не собирали; имеет тип leafType. traversalValue указатель на любой ваш объект, который вы вернули из inner_consistent при заходе в родителя. level — глубина листа (если вы ее считали). returnData имеет значение true, если нужно восстановить исходные данные столбца (если config вернула !canReturnData, то их не затребуют). leafDatum — это значение в листовой вершине типа leafType.
Функция должна возвращать true, если лист соответствует запросу, иначе false. Если результат true, и returnData true, тогда надо заполнить leafValue значением столбца (типа attType). Это может быть в точности leafDatum или комбинация из reconstructedValue и leafDatum. Также, recheck может быть установлено в true, если соответствие является не стопроцентным, и надо перепроверить условие на значении, взятом из строки кучи. Если выполняется упорядоченный поиск, заполните массив distances для массива значений расстояний в соответствии с массивом orderbys. В противном случае оставьте его NULL. Если хотя бы одно из возвращенных расстояний не является точным, установите recheckDistances в true; в этом случае исполнитель вычислит точные расстояния после извлечения строки из кучи и при необходимости переупорядочит строки.
Необязательный пользовательский метод:
-
compress
Преобразует индексируемое значение (типа attType) в формат для физического хранения в листовой вершине индекса (типа leafType). Выходное значение не должно быть помещенным в TOAST.
SQL-объявление функции может выглядеть следующим образом:
CREATE FUNCTION my_compress(internal) RETURNS internal ...
Все вспомогательные методы SP-GiST обычно вызываются в контексте кратковременной памяти; то есть, CurrentMemoryContext сбрасывается после обработки каждой вершины, поэтому можно не освобождать память. Метод config является исключением: он должен стараться избегать утечки памяти. Но обычно методу config незачем выделять память.
Если к типу индексируемого столбца применимы правила сортировки, то действующее для индекса правило сортировки будет передано всем вспомогательным методам через стандартный механизм PG_GET_COLLATION().
Реализация
В этом разделе рассматриваются детали реализации и другие хитрости, которые могут быть полезны для разработчиков классов операторов SP-GiST.
Ограничения SP-GiST
Ограничения вытекают из того, что любая листовая или внутренняя вершина должна помещаться на одной странице индекса (по умолчанию 8кБ). При индексировании столбцов переменной длины это может вызывать ошибку, когда встретится конкретное особо длинное значение. Ваш класс операторов может поддержать хранение длинных значений, если устроит что-то вроде префиксного дерева: исходное значение столбца делится между всеми вершинами на пути от корня до листа, при этом каждый отдельный кусок достаточно короткий, чтобы влезть на страницу; для этого можно искусственно создать цепочку из вершин с единственным потомком. Если ваш класс операторов готов всё это делать, то верните longValuesOK из config.
Для промежуточных вершин это ограничение означает, что не может быть слишком много дочерних узлов, и у них не могут быть слишком длинные префиксы. Далее, если узел внутренней вершины указывает на набор листов, эти листы должны находиться на одной странице (такое проектное решение принято для экономии места и более кучного размещения ветви в дисковой странице). Если набор дочерних узлов становится слишком большим, то добавляется новая внутренняя вершина, а листы разбиваются на несколько узлов этой вершины. На этом шаге вызывается picksplit для набора листов, которая должна их разбить, иначе ядро SP-GiST прибегает к чрезвычайным мерам, описанным в Внутренние вершины "all-the-same".
SP-GiST без меток узлов
Некоторые древовидные алгоритмы используют фиксированный набор узлов для каждой внутренней вершины; например, в дереве квадрантов всегда есть ровно четыре узла, соответствующие четырем квадрантам вокруг центральной точки внутренней вершины. В таком случае код обычно работает с узлами по номеру, и нет необходимости в явных метках узлов. Чтобы подавить метки узлов (и тем самым сэкономить место), функция picksplit может возвращать значение NULL для массива nodeLabels, и аналогично функция choose может возвращать значение NULL для массива prefixNodeLabels во время действия spgSplitTuple. Это, в свою очередь, приведет к тому, что nodeLabels станет NULL во время последующих вызовов choose и inner_consistent. Теоретически можно иметь часть внутренних вершин с метками узлов, а часть без.
Если у внутренней вершины нет меток узлов, то метод choose не должен возвращать spgAddNode, поскольку предполагается, что набор узлов в таких случаях является фиксированным.
Внутренние вершины "all-the-same"
Ядро SP-GiST может переопределять результаты вызова функции picksplit, если picksplit не удается разделить предоставленные листовые значения по крайней мере на две категории узлов. Когда это происходит, создается новая внутрення вершина с несколькими узлами, каждый из которых имеет ту же метку, что picksplit дал одному узлу, который он вернул, а конечные значения делятся случайным образом между этими эквивалентными узлами. Во внутренней вершине устанавливается флаг allTheSame, чтобы предупредить функции choose и inner_consistent о том, что разбиение внутренней вершины на узлы не такое, как они ожидают.
При работе choose с allTheSame-вершиной результат выбора spgMatchNode интерпретируется как "вставить в любой из узлов", значение nodeN игнорируется. Выбор spgAddNode вообще не допустим и вызовет ошибку (т.к. получилось бы, что часть узлов "all-the-same", а новый узел особенный).
При работе inner_consistent с allTheSame-вершиной она должна выбирать все узлы или не одного (т.к. формально они все одинаковые). Для этого может потребоваться или не потребоваться какой-либо специальный код.
Индексы GIN
- Введение
- Встроенные классы операторов
- Расширяемость
- Реализация
- GIN советы и хитрости
- Ограничения
- Примеры
Введение
GIN расшифровывается как «Generalized Inverted Index» (Обобщённый инвертированный индекс). GIN предназначается для случаев, когда индексируемые значения являются составными, а запросы, на обработку которых рассчитан индекс, ищут по наличию элементов в этих составных объектах. Например, такими объектами могут быть документы, а запросы могут выполнять поиск документов, содержащих определённые слова.
В этом разделе мы используем термин объект или элемент, говоря о составном значении, которое индексируется, и термин ключ, говоря о включённом в него элементе. GIN всегда хранит и ищет ключи, а не объекты как таковые.
Индекс GIN хранит пары (ключ => набор-строк), где набор-строк содержит идентификаторы строк, в которых есть данный ключ. Один и тот же идентификатор строки может фигурировать в нескольких списках, так как объект может содержать больше одного ключа. Значение каждого ключа хранится только один раз, так что индекс GIN очень компактен в случаях, когда один ключ встречается много раз.
GIN является обобщённым в том смысле, что ядро GIN не знает о конкретных операциях, которые он ускоряет. Конкретная семантика определяется вспомогательными методами (стратегиями), которые управляют тем, как извлекаются ключи из индексируемых объектов и условий запросов, и как установить, действительно ли удовлетворяет запросу строка, содержащая некоторые значения ключей. Как и GiST, GIN позволяет разрабатывать дополнительные типы данных с соответствующими методами доступа экспертам в предметной области типа данных.
Встроенные классы операторов
Основной дистрибутив QHB включает классы операторов GIN, показанные в следующей таблице. Некоторые из расширений, перечисленные в примерах, предоставляют дополнительные классы операторов GIN.
| Имя | Индексированный Тип Данных | Индексируемые Операторы |
|---|---|---|
| array_ops | anyarray | && = @< |
| jsonb_ops | jsonb | ? ?& ? @> @? @@ |
| jsonb_path_ops | jsonb | @> @? @@ |
| tsvector_ops | tsvector | @@ @@@ |
Из двух классов операторов для типа jsonb, jsonb_ops это значение по умолчанию. jsonb_path_ops поддерживает меньшее количество операторов, но обеспечивает лучшую производительность для этих операторов. Дополнительную информацию смотрите в разделе Индексация jsonb.
Расширяемость
Интерфейс GIN имеет высокий уровень абстракции, требующий от автора метода доступа только реализации семантики типа данных, с которым происходит работа. Слой GIN сам заботится о параллелизме, журналировании и поиске в древовидной структуре.
Все, что требуется для работы метода доступа GIN — это реализовать несколько пользовательских методов, которые определяют поведение ключей в дереве и отношения между ключами, индексируемыми элементами и индексируемыми запросами. Короче говоря, GIN сочетает расширяемость с универсальностью, повторным использованием кода и чистым интерфейсом.
Два метода, которые обязан предоставить класс операторов для GIN:
-
extractValue
Прототип метода на C:
Datum *extractValue(Datum itemValue, int32 *nkeys, bool **nullFlags)Возвращает массив ключей (выделенный с помощью palloc) индексируемого объекта. Количество возвращаемых ключей должно быть сохранено в *nkeys. Если какой-то из ключей может быть NULL, то необходимо также заполнить nullFlags (это массив типа bool длиной *nkeys, true означает, что этот ключ NULL; аллокировать тоже
palloc'ом). Если все ключи не NULL, то можно оставить *nullFlags нулевым. Возвращаемое значение тоже может быть нулевым, если объект вообще не содержит ключей. -
extractQuery
Прототип метода на C:
Datum *extractQuery(Datum query, int32 *nkeys, StrategyNumber n, bool **pmatch, Pointer **extra_data, bool **nullFlags, int32 *searchMode)Возвращает массив ключей (выделенный с помощью palloc) для запроса. query — это правый аргумент индексируемого оператора, где левый аргумент — это индексируемый столбец. Аргумент
nзадаёт номер стратегии оператора в классе операторов (см. раздел Стратегии методов индексов). Разные операторы могут иметь разный тип правой части, и, соответственно, query может быть разного типа — и даже при одинаковом типе запрос может интерпретироваться по-разному для разных операторов. Для различения и нужен параметрn.Количество возвращаемых ключей должно быть записано в *nkeys. Если какой-то из ключей может быть
NULL, то необходимо также заполнить nullFlags (это массив типа bool длиной *nkeys, true означает, что этот ключ NULL; аллокировать тожеpalloc'ом). Если все ключи неNULL, то можно оставить *nullFlags нулевым. Возвращаемое значение тоже может быть нулевым, если объект вообще не содержит ключей.Выходной аргумент searchMode позволяет функции extractQuery выбрать режим, в котором должен выполняться поиск. Если *searchMode установить в GIN_SEARCH_MODE_DEFAULT (это значение уже установлено перед вызовом), подходящими кандидатами считаются объекты, которые соответствуют хотя бы одному из возвращённых ключей. Если *searchMode установить в GIN_SEARCH_MODE_INCLUDE_EMPTY, то в дополнение к объектам с минимум одним совпадением ключа, подходящими кандидатами будут считаться и объекты, вообще не содержащие ключей. (Этот режим полезен для реализации, например, оператора является-подмножеством). Если *searchMode установить в GIN_SEARCH_MODE_ALL, подходящими кандидатами считаются все отличные от
NULLобъекты в индексе, независимо от того, встречаются ли в них возвращаемые ключи. (Этот режим намного медленнее других, так как он по сути требует сканирования всего индекса, но он может быть необходим для корректной обработки крайних случаев. Оператор, который часто выбирает этот режим, скорее всего не подходит для реализации в классе операторов GIN).Выходной аргумент pmatch используется, когда поддерживаются частичные ключи в запросах. Выделите массив из *nkeys элементов типа bool и задайте значение true для тех ключей, для которых выделенный ключ является частичным. Если *pmatch нулевой (а он нулевой перед вызовом), GIN полагает, что все ключи точные, а не частичные.
Выходной аргумент extra_data используется, чтобы привязать к каждому ключу дополнительную информацию, которая будет передана в методы consistent и comparePartial. Поместите в *extra_data массив из из *nkeys указателей на объекты производного типа. Перед вызовом указатель *extra_data нулевой, поэтому просто игнорируйте его, если не надо никакой дополнительной информации. Если массив *extra_data задан, то он передаётся в метод consistent целиком, а в comparePartial передаётся один соответствующий элемент.
Класс операторов должен также предоставить функцию для проверки, соответствует ли индексированный объект запросу. Поддерживаются две её вариации: булевская consistent и triConsistent с трехзначным результатом. Если предоставлена только consistent, то некоторые оптимизации, построенные на отбраковывании объектов до выборки всех ключей, отключаются. Если предоставлена только triConsistent, то она будет использоваться и вместо consistent, т.к. является более общей. Однако, если вычисление булевской вариации дешевле, то имеет смысл реализовать обе.
-
consistent
Прототип метода на C:
bool consistent(bool check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], bool *recheck, Datum queryKeys[], bool nullFlags[])Возвращает true, если индексированный элемент удовлетворяет оператору запроса с номером стратегии
n(или "возможно удовлетворяет", если дополнительно ставится флаг перепроверки). Проиндексированное значение в этом методе не доступно (GIN их нигде не хранит), есть только информация, какие из ключей запроса встретились в данном кортеже индекса. В метод передаётся всё, что вернула extractQuery при разборе запроса: массив ключей queryKeys, какие из нихNULL— nullFlags, дополнительную информацию extra_data, но главное — какие из этих ключей присутствуют в текущем кортеже индекса: check. Все эти массивы имеют длину nkeys, если ненулевые. На всякий случай передаётся и оригинальный запрос query.Если extractQuery выдала NULL-ключ, и в кортеже тоже есть NULL-ключ, то считается, что ключ найден (что является нетипичным при обработке
NULL-значений, и похоже на семантику IS NOT DISTINCT FROM). Если с точки зрения вашего класса операторов это особенная ситуация, то, встретивcheck[i] == true, вы можете проверитьnullFlags[i], чтобы понять, было ли это попадание в NULL-ключ. В случае положительного результата флаг *recheck следует оставить false, если вы уверены, что строка подходит, или выставить true, чтобы оператор перепроверили на данных, взятых из строки таблицы из кучи. -
triConsistent
Прототип метода на C:
GinTernaryValue triConsistent(GinTernaryValue check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], Datum queryKeys[], bool nullFlags[])Метод похож на consistent, но результат и входной аргумент check имеют тип GinTernaryValue, который состоит из 3-х вариантов: GIN_TRUE, GIN_FALSE и GIN_MAYBE. GIN_MAYBE означает "может быть подходит". Вы должны руководствоваться общими правилами тернарной логики: возвращать GIN_TRUE, только если строка подходит под запрос в предположении "худшего случая" для ключей, которые GIN_MAYBE, т.е. предполагая, что они все не подходят. И наоборот, возвращать GIN_FALSE, только если строка не подходит, даже в "лучшем случае" для GIN_MAYBE-ключей.
Выходного параметра recheck нет, вместо этого результат GIN_MAYBE трактуется как "надо перепроверить", а GIN_TRUE как "точно подходит".
Далее, ядру GIN нужно уметь сортировать ключи. Вы можете предоставить функцию сортировки compare. Если вы этого не сделаете, то GIN будет использовать сортировку по умолчанию для соответствующего типа данных.
-
compare
Прототип метода на C:
int compare(Datum a, Datum b)Сравнивать два ключа (а не исходных индексируемых значения) и вернуть целое число
< 0/0/> 0, когда первый ключ меньше/равен/больше второго. NULL-ключи никогда не передаются в эту функцию.
И ещё один необязательный метод:
-
comparePartial
Прототип метода на C:
int comparePartial(Datum partial_key, Datum key, StrategyNumber n, Pointer extra_data)Осуществляет проверку соответствия ключа индекса частичному ключу запроса. Результат 0 означает, что ключ подходит; меньше нуля — не подходит, но следует продолжить сканировать ключи; больше нуля — следует прекратить сканирование набора ключей, т.к. все остальные точно не подходят. NULL-ключи никогда не передаются в эту функцию.
Частичный ключ не обязательно является префиксом ключа, но так или иначе согласован с порядком сортировки, что позволяет выполнять не полное сканирование всех ключей, а только сканирование диапазона. Зная порядок сканирования ключей, вы можете прекратить сканирование досрочно, вернув положительное значение.
Для поддержки нечётких запросов класс операторов должен предоставлять comparePartial, а extractQuery должен выставлять флаг pmatch для частичных ключей. Дополнительную информацию смотрите в разделе Алгоритм нечёткого поиска.
Фактические типы переменных типа Datum, указанных выше, варьируются для разных классов операторов. Входное значение extractValue всегда имеет тип индексируемого столбца, а значения всех ключей имеют тип STORAGE класса операторов. Параметр query, передаваемый в extractQuery, consistent, triConsistent, будет такого типа, как правый аргумент поискового оператора; это не обязательно такой же тип, как у индексируемого столбца, главное, чтобы из него можно было извлечь ключи для поиска. Однако в SQL-объявлениях функций extractQuery, consistent, triConsistent рекомендуется указывать тип query совпадающим с типом столбца, если для разных операторов разный тип правой части.
Реализация
Внутри индекс GIN содержит B-дерево, построенное по ключам, где каждый ключ является элементом одного или нескольких проиндексированных объектов (например, элемент массива), и где каждая листовая вершина содержит либо массив("posting list") указателей на строки в куче (если этот массив достаточно маленький, чтобы поместиться в вершине индекса), либо указатель на B-дерево указателей кучи ("posting tree", “дерево рассылки”). На рис. 1 показаны эти компоненты индекса GIN.
В индекс может быть явно включён ключ со значением NULL. Кроме того, ключ NULL считается содержащимся во всех строках, в которых индексируемый столбец имеет значение NULL, либо если ExtractValue не выделила из значения ни одного ключа. Это сделано, чтобы можно было искать пустые значения.
Многоколоночные индексы GIN реализуются путем построения единого B-дерева, значения которого — пары (номер столбца, ключ), причём тип ключа может быть разным для разных столбцов.
Рисунок 1. Внутренняя структура GIN
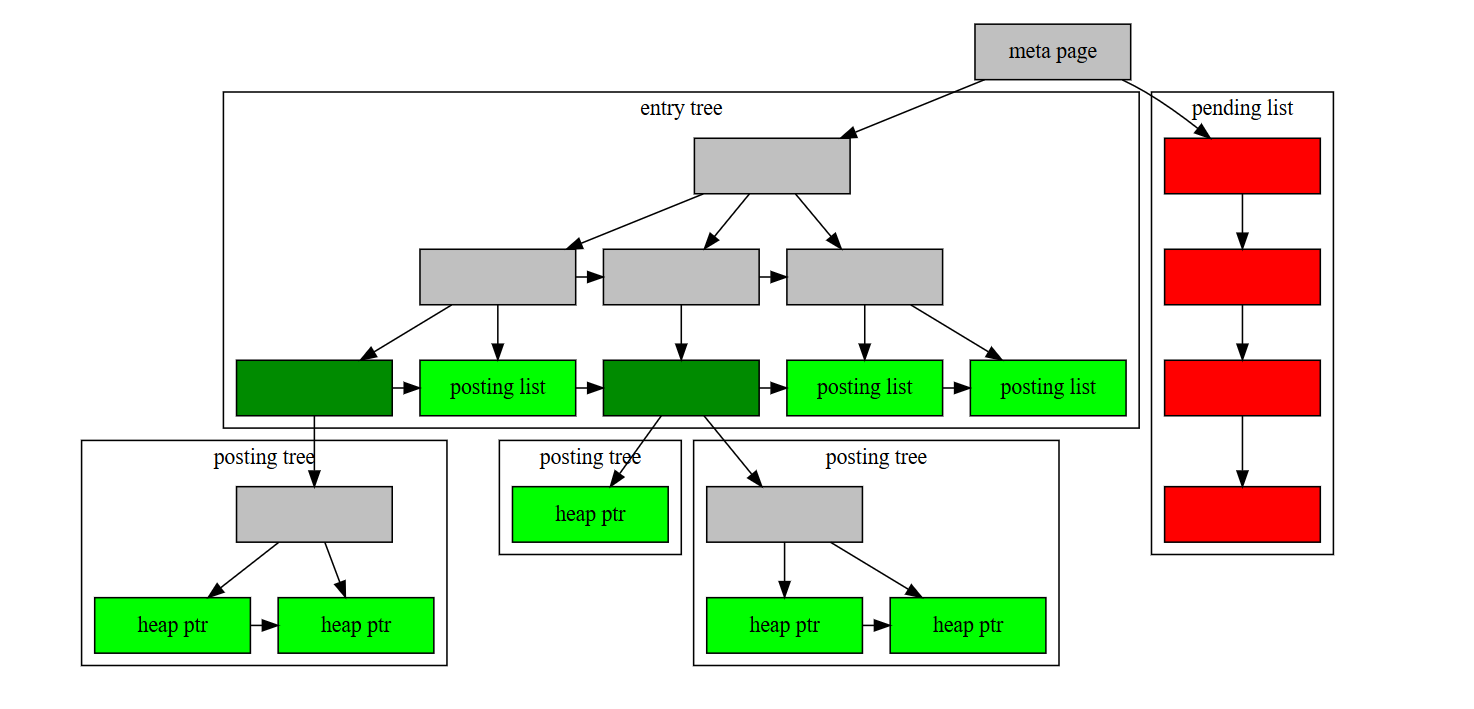
Быстрое обновление GIN
Обновление индекса GIN, как правило, происходит медленно, и это неотъемлемое свойство инвертированных индексов: вставка или обновление одной строки таблицы может вызвать множество вставок в индекс (по одной для каждого ключа, извлеченного из индексируемого элемента). Ядро GIN способно отложить большую часть этой работы, вставляя новые кортежи во временный, несортированный список ожидающих записей. Когда происходит VACUUM или VACUUM ANALYZE, или когда явно вызывается функция gin_clean_pending_list, или когда длина списка ожидания превышает значение параметра gin_pending_list_limit, все кортежи из списка ожидания помещаются в основное дерево, используя метод групповой вставки, такой же как и при первичном построении индекса. Это значительно увеличивает скорость обновления индекса GIN, даже считая дополнительные накладные расходы на вакуум. Кроме того, перестроение индекса можно вынести в отдельный фоновый процесс, чтобы избежать подвисания клиента во время вставки.
Главным недостатком этого подхода является замедление поиска. Кроме обычного поиска в индексе требуется также сканировать список ожидания, поэтому большой список ожидания значительно замедлит поиск. Еще один недостаток заключается в том, что, хотя амортизированное время модификации снижается, некоторое конкретное обновление может вызывать переполнение списка ожидания и подвиснуть надолго. Обе проблемы можно свести к минимуму, правильно настроив автовакуум, или вовремя запуская gin_clean_pending_list из другого служебного процесса.
Если максимальное время модификации важнее, чем среднее, использование отложенных записей можно отключить, изменив параметр fastupdate индекса GIN. Дополнительные сведения см. в разделе Параметры хранения индекса.
Алгоритм нечёткого поиска
GIN может поддерживать запросы "нечёткого поиска", в которых
вместо конкретного ключа указывается диапазон ключей для поиска.
Диапазон всегда согласованный с порядком сортировки ключей
(определяемым методом compare, либо сортировкой по умолчанию для типа ключа), и, желательно,
чтобы он не был слишком широким.
Как бы ни звучало указание нечёткого поиска в исходном запросе,
extractQuery должна установить флаг pmatch, а в значение ключа поместить нижнюю границу
диапазона ключей. Одновременно это должно быть поддержано методом comparePartial, который должен
определить верхнюю границу диапазона поиска (например, её можно передать через extra_data).
Дерево ключей сканируется начиная с нижней границы, и пока comparePartial не вернёт > 0;
все ключи, отобранные comparePartial, считаются подходящими.
Пример для поиска ключа по префиксу очень понятный: нижняя граница диапазона ключей совпадает с префиксом, метод comparePartial получает partial_key, равный этому префиксу, и его реализация тривиальна. В общем случае нижняя и верхняя граница, и условие поиска — разные вещи, и надо как-то их все передать в comparePartial. Например, поиск слов, получающихся из 'спорт' перестановкой двух соседних букв, может потребовать сканирования диапазона ['опрст'; 'тсрпо'] или ['о'; 'у').
GIN советы и хитрости
Создание или вставка
Если вы собираетесь вставить много данных, рассмотрите вариант удаления индекса и построения его с нуля. Этот совет верен для большинства индексов, но вставка в GIN-индекс может быть особенно медленной. См. также раздел Быстрое обновление GIN.
maintenance_work_mem
Время построения GIN-индекса сильно зависит от параметра maintenance_work_mem; рассмотрите вариант увеличения этого параметра в сессии, где выполняется создание индекса.
gin_pending_list_limit
Как уже было сказано в разделе Быстрое обновление GIN, параметр gin_pending_list_limit является основным средством настройки производительности GIN-индекса (вторым по значимости средством является частота запуска автовакуума). Параметр gin_pending_list_limit можно задать отдельно для каждого индекса, изменив его параметры хранения. Общее правило, что для редко меняющихся таблиц gin_pending_list_limit должен быть меньше.
gin_fuzzy_search_limit
Основной целью разработки GIN-индексов был полнотекстовый поиск. Полнотекстовый поиск часто возвращает огромное количество строк, особенно если искать частые слова. Прочитать такое количество строк с диска и отсортировать (отранжировать) их в памяти обычно неприемлемо в нагруженной системе. Чтобы облегчить контроль таких запросов, GIN имеет настраиваемый верхний предел на количество возвращаемых строк: параметр gin_fuzzy_search_limit. По умолчанию он установлен в 0 (то есть без ограничений). Если задано ненулевое ограничение, то все результаты поиска после заданного количества молча отбрасываются. Ограничение на количество результатов является "мягким" в том смысле, что фактическое число возвращаемых результатов может несколько отличаться от указанного предела в зависимости от запроса и качества генератора случайных чисел системы.
По опыту, значения в тысячах (например, 5000 — 20000) работают хорошо.
Ограничения
GIN предполагает, что индексируемые операторы являются строгими(STRICT). Это означает, что если значение столбца NULL, то extractValue не вызывается (но создаётся запись индекса, что эта строка содержит NULL-ключ); если поисковое значение NULL, то extractQuery не вызывается и результат поиска считается пустым. Однако запрос может содержать в себе что-то, что класс операторов истолкует как поиск NULL-ключа, например, пустую строку.
Примеры
Основной дистрибутив QHB включает классы операторов GIN, ранее перечисленные в таблице в разделе Встроенные классы операторов. Следующие расширения из contrib также содержат классы операторов GIN:
-
btree_gin
Функциональность B-дерева для некоторых типов данных
-
hstore
Расширение для хранения пар (ключ, значение)
-
intarray
Расширенная поддержка для int[ ]
-
pg_trgm
Сходство текста, основанное на сопоставлении триграмм
Индексы BRIN
Введение
BRIN обозначает индекс диапазона блоков (Block Range Index). BRIN предназначен для обработки очень больших таблиц, в которых некоторые столбцы имеют естественную корреляцию с их физическим расположением в таблице. Диапазон блоков — это группа страниц, которые физически соседствуют в таблице; для каждого диапазона блоков в индексе хранится некоторая сводная информация. Например, таблица, хранящая заказы на поставку, может иметь столбец даты, в который был помещен каждый заказ, и в большинстве случаев записи для более ранних заказов лежат раньше в таблице. Таблица, хранящая адреса, и имеющая столбец почтового индекса, будет хранить адреса одного города подряд, и почтовые индексы строк тоже окажутся сгруппированными.
Индексы BRIN отвечают на запросы посредством сканирования-на-битовых-картах, возвращая все строки всех страниц диапазона, если диапазон целиком был признан совместимым с условиями запросом. Исполнитель запроса (query executor) отвечает за перепроверку всех строк и удаление тех, которые не соответствуют условиям запроса — другими словами, эти индексы являются очень грубыми (большая ошибка первого рода). Но поскольку индекс BRIN очень мал, сканирование индекса добавляет лишь немного накладных расходов по сравнению с последовательным сканированием, при этом помогая избежать сканирования каких-то частей таблицы, если по BRIN-индексу понятно, что они точно не содержат подходящих строк.
Конкретные данные, которые будет хранить индекс BRIN, а также конкретные запросы, которые индекс сможет удовлетворить, зависят от класса оператора, выбранного для каждого столбца индекса. Например, типы данных, имеющие линейный порядок сортировки, могут иметь классы операторов, которые хранят минимальное и максимальное значение в каждом диапазоне блоков. Геометрические типы могут хранить ограничивающую рамку для всех объектов в диапазоне блоков.
Размер диапазона блоков определяется во время создания индекса параметром pages_per_range. Количество записей индекса будет равно размеру таблицы в страницах, деленному на выбранное значение pages_per_range. Чем меньше число, тем больше размер индекса, но и тем выше его точность.
Обслуживание индекса
В момент создания все существующие страницы кучи сканируются, и для каждого диапазона (включая неполный диапазон в конце) создается кортеж в индексе, содержащий сводку по этому диапазону.
При вставке новых строк требуется обновление сводной информации в BRIN-индексе. При вставке в "старые" диапазоны обновление происходит немедленно, а при вставке в "новые" диапазоны обновление индекса откладывается (в эти диапазоны вставляют постоянно, и пересчитывать кортеж индекса после каждой новой строчки было бы накладно). При поиске "новые" необсчитанные диапазоны считаются потенциально содержащими все что угодно.
Обсчёт "новых" диапазонов происходит при работе VACUUM. Вакуум можно запустить вручную, также обсчёт можно инициировать вызовом функции brin_summarize_new_values(regclass). Если включить параметр autosummarize, то "новые" диапазоны будут пересчитываться в фоне процессом Автовакуума. Если он не успевает это делать, то в журнале сервера могут появиться сообщения вида
LOG: request for BRIN range summarization for index "brin_wi_idx" page 128 was not recorded
По умолчанию параметр autosummarize выключен, т.к. это увеличивает нагрузку системы.
При удалении строк из таблицы не происходит пересчёта BRIN-индекса (это было бы слишком долго). После массовых удалений можно пересчитать BRIN-индекс по конкретным диапазонам, выполнив brin_desummarize_range (regclass, bigint) + brin_summarize_range (regclass, bigint), или по всей таблице, перестроив индекс целиком. Если этого не сделать, индекс будет говорить, что в таком-то диапазоне возможно есть такие-то данные даже после того, как вы удалите все такие данные.
Встроенные классы операторов
Основной дистрибутив QHB включает классы операторов BRIN, показанные в следующей таблице.
Классы операторов minmax хранят минимальные и максимальные значения среди значений индексируемого столбца по всем строкам диапазона. Классы операторов inclusion хранят значение, которое включает("обрамляет") все значения столбца в пределах диапазона.
| Имя | Индексируемый тип данных | Поддерживаемые операторы при поиске |
|---|---|---|
| int8_minmax_ops | bigint | < <= = >= > |
| bit_minmax_ops | bit | < <= = >= > |
| varbit_minmax_ops | bit varying | < <= = >= > |
| bytea_minmax_ops | bytea | < <= = >= > |
| bpchar_minmax_ops | character | < <= = >= > |
| char_minmax_ops | "char" | < <= = >= > |
| date_minmax_ops | date | < <= = >= > |
| float8_minmax_ops | double precision | < <= = >= > |
| inet_minmax_ops | inet | < <= = >= > |
| int4_minmax_ops | integer | < <= = >= > |
| interval_minmax_ops | interval | < <= = >= > |
| macaddr_minmax_ops | macaddr | < <= = >= > |
| macaddr8_minmax_ops | macaddr8 | < <= = >= > |
| name_minmax_ops | name | < <= = >= > |
| numeric_minmax_ops | numeric | < <= = >= > |
| pg_lsn_minmax_ops | pg_lsn | < <= = >= > |
| oid_minmax_ops | oid | < <= = >= > |
| float4_minmax_ops | real | < <= = >= > |
| int2_minmax_ops | smallint | < <= = >= > |
| text_minmax_ops | text | < <= = >= > |
| tid_minmax_ops | tid | < <= = >= > |
| date_minmax_ops | date | < <= = >= > |
| timestamp_minmax_ops | timestamp without time zone | < <= = >= > |
| timestamptz_minmax_ops | timestamp with time zone | < <= = >= > |
| time_minmax_ops | time without time zone | < <= = >= > |
| timetz_minmax_ops | time with time zone | < <= = >= > |
| uuid_minmax_ops | uuid | < <= = >= > |
| box_inclusion_ops | box | << &< && &> >> ~= @> <@ &<| <<| |>> |&> |
| network_inclusion_ops | inet | && >>= <<= = >> << |
| range_inclusion_ops | любой тип-диапазон | << &< && &> >> @> <@ -|- = < <= = > >= |
Расширяемость
Интерфейс BRIN имеет высокий уровень абстракции, требующий от разработчика описать только семантику данных. Большую часть работы выполняют универсальная реализация BRIN.
Все, что требуется, чтобы BRIN-индекс заработал, - это реализовать несколько пользовательских методов, которые определят поведение сводных значений, хранящихся в индексе, и их взаимодействие с ключами сканирования (= значениями в столбце таблицы). У BRIN-индексов четкий интерфейс, дающий хорошую расширяемость и переиспользование кода.
Существует четыре метода, которые должен предоставить класс оператора для использования в BRIN:
-
BrinOpcInfo *opcInfo(Oid type_oid)Возвращает внутреннюю информацию о сводных данных индексированных столбцов. Конкретнее, должна вернуть указатель на структуру BrinOpcInfo, выделенную с помощью palloc. Определение структуры такое:
typedef struct BrinOpcInfo { /* Количество совместно проиндексированных столбцов */ uint16 oi_nstored; /* Приватные данные класса оператора */ void *oi_opaque; /* Элементы кеша типов для проиндексированных столбцов */ TypeCacheEntry *oi_typcache[FLEXIBLE_ARRAY_MEMBER]; } BrinOpcInfo;Brinpcinfo::oi_opaque используется для передачи информации между методами класса операторов во время сканирования индекса.
-
bool consistent(BrinDesc *bdesc, BrinValues *column, ScanKey key)Вернуть, входит ли key (то, что ищут) в сводное значение column из индекса. key->sk_attno содержит номер столбца — это важно, если у вас многоколоночный индекс
-
bool addValue(BrinDesc *bdesc, BrinValues *column, Datum newval, bool isnull)Обновить сводную информацию диапазона column с учетом нового значения столбца newval. Вернуть true, если column изменилось
-
bool unionTuples(BrinDesc *bdesc, BrinValues *a, BrinValues *b)Объединить две сводки: изменить сводку
a, включив в нее сводкуb. Не надо менять сводкуb! Вернуть false, если не потребовалось менятьa(т.к. ужеaполностью включалоb).
Способы создания нового класса операторов, совместимого с BRIN:
-
Стандартный дистрибутив включает поддержку двух семейств классов операторов: minmax и inclusion. Есть реализация соответствующих классов операторов для всех встроенных типов данных. Аналогичные классы операторов для других типов могут быть выведены без написания какого-либо кода. Достаточно просто объявить этот класс в системном каталоге. Обратите внимание, что в код вспомогательных функций этих семейств встроены некоторые предположения о семантике стратегий операторов.
-
Вы можете создать классы операторов с совершенно другой семантикой, реализовав четыре основных вспомогательные функции, описанных выше. Обратите внимание, что обратная совместимость между мажорными релизами не гарантируется: в следующих версиях может измениться интерфейс этих функций.
-
Использовать вспомогательные функции от семейства minmax, вместе с набором операторов для типа данных.
Для создания класса операторов для типа данных, на котором определен полный порядок, можно использовать вспомогательные функции от minmax совместно с соответствующими операторами, как показано в следующей таблице. Все члены класса операторов (функции и операторы) являются обязательными.
Член класса операторов Какой объект использовать Вспомогательная функция 1 внутренняя функция brin_minmax_opcinfo() Вспомогательная функция 2 внутренняя функция brin_minmax_add_value() Вспомогательная функция 3 внутренняя функция brin_minmax_consistent() Вспомогательная функция 4 внутренняя функция brin_minmax_union() Стратегия 1 оператор меньше Стратегия 2 оператор меньше-или-равно Стратегия 3 оператор равно Стратегия 4 оператор больше-или-равно Стратегия 5 оператор больше -
Для создания класса оператора для сложного типа данных, наборы значений которого "обрамляются" "рамками" некоторого другого типа, можно использовать вспомогательные функции от семейства inclusion совместно с соответствующими операторами и дополнительными функциями, как показано в следующей таблице. Из них только одна дополнительная функция, которая может быть написана на любом языке, является обязательной. Реализация необязательных дополнительных функций позволяет некоторые оптимизации при работе индекса. Все операторы необязательные, но для некоторых операторов нужно реализовать другой для комплектности, как показано в таблице
Член класса операторов Какой объект использовать Требует наличия Вспомогательная функция 1 внутренняя функция brin_inclusion_opcinfo() Вспомогательная функция 2 внутренняя функция brin_inclusion_add_value() Вспомогательная функция 3 внутренняя функция brin_inclusion_consistent() Вспомогательная функция 4 внутренняя функция brin_inclusion_union() Вспомогательная функция 11 функция для объединения двух элементов (обязательная) Вспомогательная функция 12 дополнительная функция для проверки возможности слияния двух элементов Вспомогательная функция 13 дополнительная функция, чтобы проверить, если элемент содержится в другом Вспомогательная функция 14 необязательная функция для проверки, является ли элемент пустым Стратегия 1 оператор левее Стратегия 4 Стратегия 2 оператор не-выпирает-справа Стратегия 5 Стратегия 3 оператор перекрывается Стратегия 4 оператор не-выпирает-слева Стратегия 1 Стратегия 5 оператор правее Стратегия 2 Стратегия 6, 18 оператор такой-же-или-равен Стратегия 7 Стратегия 7, 13, 16, 24, 25 оператор охватывает-или-равен Стратегия 8, 14, 26, 27 оператор содержится-в-или-равен Стратегия 3 Стратегия 9 оператор не-выпирает-сверху Стратегия 11 Стратегия 10 оператор ниже Стратегия 12 Стратегия 11 оператор выше Стратегия 9 Стратегия 12 оператор не-выпирает-снизу Стратегия 10 Стратегия 20 оператор меньше Стратегия 5 Стратегия 21 оператор меньше-или-равно Стратегия 5 Стратегия 22 оператор больше Стратегия 1 Стратегия 23 оператор больше-или-равно Стратегия 1 Номера вспомогательных функций 1-10 зарезервированы для внутренних функций BRIN, поэтому функции уровня SQL начинаются с числа 11. Вспомогательная функция номер 11 является главной, обязательной для построения индекса. Она принимает два аргумента того же типа, что и класс оператора, и возвращать их объединение. Класс оператора семейства inclusion может хранить результат объединения в другом типа данных, он задается параметром STORAGE. Возвращаемое значение функции №11 должно быть типа STORAGE.
Вспомогательные функции №№ 12 и 14 введены для обработки неравномерностей во встроенных типах данных. Функция № 12 используется для поддержки сетевых адресов из различных семейств, которые нельзя объединять. Функция № 14 нужна для обработки пустых диапазонов. Функция № 13 необязательна, но ее реализация желательна, т.к. позволяет пропустить ряд шагов при построении индекса, если очередное значение не меняет сводку, хранящуюся в индексе.
И minmax, и inclusion поддерживают операторы, работающие с разными типами данных, хотя с ними зависимости становятся более сложными. Класс операторов minmax требует, чтобы был определен полный набор операторов с обоими аргументами, имеющими один и тот же тип. Это позволяет поддерживать дополнительные типы данных путем определения дополнительных наборов операторов. Стратегии класса операторов inclusion требуют, чтобы оператор принимал первый аргумент типа STORAGE, а второй аргумент типа данных столбца таблицы. Смотрите float4_minmax_ops в качестве примера расширения minmax, а также box_inclusion_ops в качестве примера расширения inclusion.
Параллельный контроль
В этой главе описывается поведение СУБД QHB, когда две или более сессий пытаются одновременно обратиться к одним и тем же данным. Задачи, стоящие перед СУБД в такой ситуации: обеспечить высокопроизводительный доступ к данным и сохранить их целостность. Материал данной статьи будет полезен всем разработчикам приложений баз данных.
- Многоверсионная модель
- Изоляция транзакций
- Явная блокировка
- Проверка согласованности данных на уровне приложения
- Ограничения
- Блокировка и индексы
Многоверсионная модель
QHB предоставляет разработчикам богатый набор инструментов для управления конкурентным доступом к данным. Внутренняя согласованность данных поддерживается с помощью многоверсионной модели (Multiversion Concurrency Control, MVCC). Она устроена таким образом, что в ходе исполнения каждой SQL-команды СУБД видит данные базы как бы "замороженными", определённой версии. Из этого следует, что те данные, которые были изменены или добавлены в ходе параллельной работы других транзакций, не нарушают целостности нашего представления о данных. MVCC, отказываясь от методологий блокировки традиционных систем баз данных, сводит к минимуму конфликты блокировок, чтобы обеспечить разумную производительность в многопользовательских средах.
Основное преимущество использования MVCC-модели управления параллелизмом, а не блокировок, состоит в том, что в MVCC блокировки, полученные для чтения данных, не конфликтуют с блокировками, взятыми для записи данных, а потому чтение никогда не блокирует запись, а запись чтение. QHB обеспечивает эту гарантию даже при использовании самого строгого уровня изоляции транзакций за счет использования Serializable Snapshot Isolation (SSI).
Средства блокировки на уровне таблиц и строк также доступны в QHB для приложений, которые обычно не нуждаются в полной изоляции транзакций и предпочитают явно управлять конкретными точками конфликта. Однако правильное использование MVCC обычно обеспечивает лучшую производительность, чем блокировки. Кроме того, определяемые приложением консультативные блокировки предоставляют механизм для получения блокировок, которые не привязаны к одной транзакции.
Изоляция транзакций
Стандарт SQL определяет четыре уровня изоляции транзакций. Наиболее строгим является Serializable, который определяется таким образом, что любое одновременное выполнение набора из нескольких Serializable транзакций гарантированно даст тот же эффект, что и запуск их по одному. Три других уровня определены в терминах явлений, возникающих в результате взаимодействия между параллельными транзакциями, которые не должны происходить на каждом уровне. Стандарт отмечает, что из-за определения Serializable, ни одно из этих явлений невозможно на этом уровне. (В этом нет ничего удивительного -- если эффект транзакций должен соответствовать тому, что они выполнялись по одному, как вы можете наблюдать какие-либо явления, вызванные их взаимодействием?)
Явления, которые запрещены на разных уровнях:
- Грязное чтение (Dirty read). Транзакция считывает данные, которые были записаны в результате выполнения параллельной незафиксированной транзакции.
- Неповторяемое чтение (Non-repeatable read). Транзакция считывает ранее прочитанные данные и замечает, что данные были изменены другой транзакцией (завершённой после первого чтения).
- Фантомное чтение (Phantom read). Транзакция повторно выполняет запрос, возвращающий набор строк для некоторого условия и обнаруживает, что набор строк, удовлетворяющих условию, изменился из-за транзакции, завершившейся за это время.
- Аномалии сериализации (Serialization anomaly). Результат успешной фиксации (commiting) группы транзакций оказывается несогласованным (inconsistent), отличающимся от результата полученного в ходе последовательного выполнения этих транзакций, независимо от порядка их выполнения. Результат успешной фиксации (commiting) группы транзакций конкурентно оказывается отличным от результата успешной фиксации группы транзаций выполнявшихся последовательно.
Уровни изолияции транзакций, описанные в стандарте SQL и реализованные в QHB:
| Уровень изоляции | Грязное чтение | Неповторимое чтение | Фантомное чтение | Аномалия сериализации |
|---|---|---|---|---|
| Read uncommitted | Разрешено, но не в QHB | Возможно | Возможно | Возможно |
| Read committed | Невозможно | Возможно | Возможно | Возможно |
| Repeatable read | Невозможно | Невозможно | Разрешено, но не в QHB | Возможно |
| Serializable | Невозможно | Невозможно | Невозможно | Невозможно |
В QHB вы можете запросить любой из четырех стандартных уровней изоляции транзакций, но внутренне реализованы только три различных уровня изоляции, то есть режим Read Uncommitted в QHB ведет себя как Read Committed. Это связано с тем, что это единственный разумный способ сопоставить стандартные уровни изоляции с архитектурой многоверсионного управления QHB.
Из таблицы также видно, что реализация Repeatable Read в QHB не позволяет выполнять фантомные чтения. Стандарт SQL допускает более строгое поведение: четыре уровня изоляции определяют только то, какие явления не должны происходить, а какие нет. Поведение доступных уровней изоляции подробно описано в следующих подразделах.
Чтобы установить уровень изоляции транзакции, используйте команду SET TRANSACTION.
Важно
Некоторые типы данных и функции QHB имеют специальные правила, касающиеся поведения транзакций. В частности, изменения, внесенные в последовательность (и, следовательно, счетчик столбца, объявленного с использованием serial), сразу видны всем другим транзакциям и не отменяются, если транзакция, которая внесла изменения, прерывается. См. главы Функции управления последовательностями и Серийные типы.
Уровень изоляции Read Committed
Read Committed - уровень изоляции по умолчанию в QHB. Когда
транзакция использует этот уровень изоляции, запрос SELECT (без
предложения FOR UPDATE/SHARE) видит только данные, зафиксированные до
начала запроса; он никогда не видит ни незафиксированные данные, ни
изменения, зафиксированные во время выполнения запроса параллельными
транзакциями. По сути, запрос SELECT видит снимок базы в моменте,
данные с начала выполнения запроса.
Однако SELECT видит результаты предыдущих обновлений, выполненных в его собственной
транзакции, даже если они еще не зафиксированы (commited). Также обратите внимание,
что две последовательные команды SELECT могут видеть разные данные, даже
если они находятся в пределах одной транзакции, если другие транзакции
производят изменения данных после запуска первого SELECT и до запуска второго
SELECT.
Команды UPDATE, DELETE, SELECT FOR UPDATE и SELECT FOR SHARE ведут себя
так же, как и SELECT, в плане поиска целевых строк: они будут
находить только те целевые строки, которые были зафиксированы на момент
запуска команды. Однако такая целевая строка, возможно, уже была
обновлена, удалена или заблокирована другой параллельной
транзакцией к моменту ее обнаружения. В этом случае запланированное
изменение будет дожидаться фиксации (commit) конкурентной трнзакции
или отмены (rollback) если та ещё выполняется.
Если конкурирующая транзакция откатывается (rollback), текущая транзакция
может продолжить изменения полученной строки (конкурирующая её не изменила).
Если конкурирующая транзакция зафиксировалась, но в результате её
работы строка была удалена -- она будет проигнорирована; в противном
случае она будет получена заново с повторной проверкой условия WHERE.
Применительно к SELECT FOR UPDATE и SELECT FOR SHARE это означает,
что обновлённая версия строки блокируется и возвращается клиенту.
INSERT с предложением ON CONFLICT DO UPDATE ведёт себя схожим образом:
в режиме Read Commited каждая строка, предлагаемая для вставки, будет
либо вставлена, либо изменена. Если не возникает несвязных ошибок, гарантируется
один из двух исходов: если конфликт вызван конкурирующей транзакцией, результат
который пока недоступен INSERT, UPDATE подействует на эту строку несмотря
на то, что эта команда не должна видеть никакую версию этой строки.
INSERT с предложением ON CONFLICT DO NOTHING может привести к тому, что
вставка не будет продолжена для строки из-за результата другой
транзакции, эффекты которой не видны для снимка INSERT. Опять же, это
характерно только для уровня Read Committed.
В силу вышеприведенных правил, команда обновления может увидеть несогласованное (inconsistent) состояние: она может видеть результаты выполнения конкурирующей команды. Вследствие этого, уровень Read Commited не подходит для команд со сложным сценарием поиска; однако, он вполне пригоден для простых случаев:
BEGIN;
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 12345;
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 7534;
COMMIT;
Если две такие транзакции одновременно пытаются изменить остаток на
счете 12345, мы явно хотим, чтобы вторая транзакция началась с
обновленной версии строки счета. Поскольку каждая команда влияет только
на заранее определенную строку, ее отображение в обновленной версии
строки не создает несогласованности.
Более сложное использование может привести к нежелательным результатам в
режиме Read Committed. Например, рассмотрим команду DELETE работающую с
данными, которые добавляются и удаляются согласно условиям другой
командой, например, предположим, что website представляет собой таблицу
из двух строк, где website.hits равны 9 и 10 :
BEGIN;
UPDATE website SET hits = hits + 1;
-- run from another session: DELETE FROM website WHERE hits = 10;
COMMIT;
DELETE не сможет произвести удаление записей до момента фиксации транзакции.
Запись с website.hits = 9 до выполнения UPDATE не будет подходить под условие DELETE,
а вторая запись, с website.hits = 10 будет заблокирована до момента фиксации.
После фиксации первой транзакции, первая запись получит website.hits = 10 и будет удалена во второй транзации.
Поскольку режим Read Committed запускает каждую команду с новым моментальным снимком, который включает в себя все транзакции, зафиксированные до этого момента, последующие команды в той же транзакции в любом случае будут видеть результаты совершенной параллельной транзакции.
Частичная изоляция транзакций, обеспечиваемая режимом Read Committed, подходит для многих приложений, и этот режим быстр и прост в использовании; однако, этого недостаточно для всех случаев. Приложениям, которые выполняют сложные запросы и обновления, может потребоваться более строго согласованное представление базы данных, чем обеспечивает режим Read Committed.
Уровень изоляции Repeatable Read
Уровень изоляции Repeatable Read видит только данные, зафиксированные до начала транзакции; он никогда не видит ни незафиксированные данные, ни изменения, зафиксированные во время выполнения транзакций параллельными транзакциями. (Тем не менее, запрос видит результаты предыдущих обновлений, выполненных в его собственной транзакции, даже если эти изменения еще не зафиксированы.) Это более надежная гарантия, чем требуется стандартом SQL для этого уровня изоляции, и предотвращает все явления описано в таблице 1 за исключением аномалий сериализации. Как упомянуто выше, это специально разрешено стандартом, который описывает только минимальную защиту, которую должен обеспечивать каждый уровень изоляции.
Этот уровень отличается от Read Committed тем, что запрос в повторяемой транзакции чтения видит моментальный снимок в начале первого оператора, не являющегося элементом управления транзакцией в транзакции, а не в начале текущего оператора в транзакции. Таким образом, последовательные команды SELECT в одной транзакции видят одни и те же данные, т.е. они не видят изменений, внесенных другими транзакциями, зафиксированными после запуска их собственной транзакции.
Приложения, использующие этот уровень, должны быть готовы повторить транзакции из-за ошибок сериализации.
Команды UPDATE, DELETE, SELECT FOR UPDATE и SELECT FOR SHARE ведут себя так же, как и команды SELECT с точки зрения поиска целевых строк: они найдут только целевые строки, которые были зафиксированы на момент начала транзакции. Однако такая целевая строка, возможно, уже была обновлена (или удалена, или заблокирована) другой параллельной транзакцией к моменту ее обнаружения. В этом случае повторяемая транзакция чтения будет ожидать, когда первая обновляющая транзакция будет зафиксирована или откатана (если она все еще выполняется). Если первый модуль обновления откатывается назад, то его эффекты сводятся на нет, и повторяемая транзакция чтения может продолжить обновление первоначально найденной строки. Но если первый обновитель фиксирует (и фактически обновил или удалил строку, а не просто заблокировал ее), то повторяемая транзакция чтения будет откатана с сообщением
ERROR: could not serialize access due to concurrent update
потому что повторяемая транзакция чтения не может изменять или блокировать строки, измененные другими транзакциями после начала повторяемой транзакции чтения.
Когда приложение получает это сообщение об ошибке, оно должно прервать текущую транзакцию и повторить всю транзакцию с самого начала. Во второй раз транзакция увидит ранее зафиксированное изменение как часть своего начального представления базы данных, поэтому нет логического конфликта при использовании новой версии строки в качестве отправной точки для обновления новой транзакции.
Обратите внимание, что только обновление транзакций может потребоваться повторить; Транзакции только для чтения никогда не будут иметь конфликтов сериализации.
Режим повторяемого чтения обеспечивает строгую гарантию того, что каждая транзакция видит полностью стабильное представление базы данных. Тем не менее, это представление не всегда будет соответствовать последовательному (по одному) выполнению параллельных транзакций одного и того же уровня. Например, даже транзакция только для чтения на этом уровне может видеть контрольную запись, обновленную, чтобы показать, что пакет был завершен, но не увидеть одну из подробных записей, которая логически является частью пакета, потому что она прочитала более раннюю версию контрольной записи., Попытки обеспечить выполнение бизнес-правил транзакциями, выполняющимися на этом уровне изоляции, вряд ли будут работать правильно без осторожного использования явных блокировок для блокировки конфликтующих транзакций.
Уровень изоляции Serializable
Уровень изоляции Serializable обеспечивает самую строгую изоляцию транзакций. Этот уровень эмулирует выполнение последовательных транзакций для всех зафиксированных транзакций; как если бы транзакции были выполнены одна за другой, поочередно, а не одновременно. Однако, как и уровень повторяемого чтения, приложения, использующие этот уровень, должны быть готовы повторить транзакции из-за сбоев сериализации. Фактически, этот уровень изоляции работает точно так же, как и Repeatable Read, за исключением того, что он отслеживает условия, которые могут привести к тому, что выполнение параллельного набора сериализуемых транзакций будет вести себя не так, как все возможные последовательные (по одному) выполнения этих транзакций. Этот мониторинг не вводит каких-либо блокировок, кроме присутствующих в повторяющемся чтении, но есть некоторые накладные расходы на мониторинг, и обнаружение условий, которые могут вызвать аномалию сериализации, вызовет сбой сериализации .
В качестве примера рассмотрим таблицу mytab, изначально содержащую:
class | value
------+-------
1 | 10
1 | 20
2 | 100
2 | 200
Предположим, что сериализуемая транзакция A вычисляет:
SELECT SUM(value) FROM mytab WHERE class = 1;
а затем вставляет результат 30 в качестве value в новую строку с class = 2. Одновременно сериализуемая транзакция B вычисляет:
SELECT SUM(value) FROM mytab WHERE class = 2;
и получает результат 300, который он вставляет в новую строку с class = 1. Затем обе транзакции пытаются зафиксировать. Если какая-либо
транзакция выполняется на уровне изоляции Repeatable Read, обеим будет
разрешено зафиксировать; но поскольку последовательный порядок
выполнения не согласуется с результатом, использование сериализуемых
транзакций позволит зафиксировать одну транзакцию и откатит другую с
этим сообщением:
ERROR: could not serialize access due to read/write dependencies among transactions
Это потому, что если бы A выполнилась до B, B вычислила бы сумму 330, а не
300, и аналогично другой порядок привел бы к другой сумме, вычисленной A.
Если для предотвращения аномалий Вы используете уровень изоляции Serializable, то важно помнить, что данные постоянной(persistant) пользовательской таблицы не явлются валидными до того момента, пока не произойдёт фиксация транзакцией. Это верно в том числе и для транзакций, которые выполняют только чтение, за исключением ситуаций, когда данные читаются отложенной(deffer)
Если вы используете уровень изоляции Serializable для предотвращения аномалий, важно, чтобы любые данные, считанные из постоянной пользовательской таблицы, не считались действительными до тех пор, пока производящая их транзакция не была успешно зафиксирована. Это верно даже для read-only транзакций, за исключением того, что данные, считанные в отложенной транзакции только для чтения, как известно, действительны, как только они прочитаны, потому что такая транзакция ожидает, пока она не сможет получить моментальный снимок, гарантированный свободный от такого проблемы, прежде чем начать читать какие-либо данные. Во всех других случаях приложения не должны зависеть от результатов, прочитанных во время транзакции, которая впоследствии была прервана; вместо этого они должны повторить транзакцию, пока она не завершится успешно.
Чтобы гарантировать истинную сериализуемость, QHB использует блокировку предикатов, что означает, что он сохраняет блокировки, которые позволяют ему определять, когда запись повлияла бы на результат предыдущего чтения из параллельной транзакции, если бы она выполнялась первой. В QHB эти блокировки не вызывают блокировку и, следовательно, не могут играть какую-либо роль в возникновении тупика. Они используются для идентификации и пометки зависимостей между параллельными сериализуемыми транзакциями, которые в определенных комбинациях могут привести к аномалиям сериализации. В отличие от транзакции Read Committed или Repeatable Read, которая хочет обеспечить согласованность данных, может потребоваться снять блокировку всей таблицы, что может заблокировать других пользователей, пытающихся использовать эту таблицу, или использовать SELECT FOR UPDATE или SELECT FOR SHARE который не только может заблокировать другие транзакции, но и вызвать доступ к диску.
Блокировки предикатов в QHB, как и в большинстве других систем баз данных, основаны на данных, фактически доступных транзакции. Они будут отображаться в системном представлении pg_locks в mode SIReadLock . Конкретные блокировки, полученные во время выполнения запроса, будут зависеть от плана, используемого запросом, и несколько более мелких блокировок (например, блокировок кортежей) могут быть объединены в меньшее количество более грубых блокировок (например, блокировок страниц) в течение транзакция для предотвращения исчерпания памяти, используемой для отслеживания блокировок. Транзакция READ ONLY может освободить свои блокировки SIRead до завершения, если обнаружит, что по-прежнему не может возникнуть конфликтов, которые могут привести к аномалии сериализации. Фактически транзакции READ ONLY часто могут установить этот факт при запуске и избежать каких-либо предикатных блокировок. Если вы явно запросите SERIALIZABLE READ ONLY DEFERRABLE, она будет блокирована, пока не сможет установить этот факт. (Это единственный случай, когда сериализуемые транзакции блокируют, а повторяющиеся транзакции чтения не делают.) С другой стороны, блокировки SIRead часто необходимо сохранять после принятия транзакции до тех пор, пока не завершатся перекрывающиеся транзакции чтения-записи.
Последовательное использование сериализуемых транзакций может упростить разработку. Гарантия того, что любой набор успешно совершенных параллельных сериализуемых транзакций будет иметь такой же эффект, как если бы они выполнялись по одной за раз, означает, что если вы сможете продемонстрировать, что отдельная транзакция, как написано, будет работать правильно при запуске сама по себе, вы может быть уверен, что он будет действовать правильно в любой комбинации сериализуемых транзакций, даже без какой-либо информации о том, что эти другие транзакции могут сделать, или он не будет успешно зафиксирован. Важно, чтобы среда, в которой используется этот метод, имела обобщенный способ обработки ошибок сериализации (которые всегда возвращаются со значением SQLSTATE ’40001’), поскольку будет очень сложно предсказать, какие именно транзакции могут способствовать чтению / записи. зависимости и необходимо откатить, чтобы предотвратить сериализацию аномалий. Мониторинг зависимостей чтения / записи имеет свою стоимость, также как и перезапуск транзакций, которые завершаются с ошибкой сериализации, но сбалансированы с затратами и блокировками, связанными с использованием явных блокировок и SELECT FOR UPDATE или SELECT FOR SHARE Сериализуемые транзакции лучший выбор производительности для некоторых сред.
Хотя уровень изоляции Sergizable в QHB позволяет фиксировать параллельные транзакции только в том случае, если он может доказать, что существует последовательный порядок выполнения, который даст тот же эффект, он не всегда предотвращает возникновение ошибок, которые не возникнут при истинном последовательном выполнении., В частности, можно увидеть уникальные нарушения ограничений, вызванные конфликтами с перекрывающимися сериализуемыми транзакциями, даже после явной проверки отсутствия ключа перед попыткой его вставки. Этого можно избежать, убедившись, что все сериализуемые транзакции, которые вставляют потенциально конфликтующие ключи, явно проверяют, могут ли они сделать это в первую очередь. Например, представьте приложение, которое запрашивает у пользователя новый ключ, а затем проверяет, что его еще не существует, сначала пытаясь выбрать его, или генерирует новый ключ, выбирая максимально существующий ключ и добавляя его. Если некоторые сериализуемые транзакции вставляют новые ключи напрямую, не следуя этому протоколу, нарушения уникальных ограничений могут быть зарегистрированы даже в тех случаях, когда они не могут произойти при последовательном выполнении параллельных транзакций.
Для обеспечения оптимальной производительности при использовании параллельных транзакций для управления параллелизмом следует учитывать следующие проблемы:
-
Объявите транзакции READ ONLY когда это возможно.
-
Управляйте количеством активных соединений, используя пул соединений, если это необходимо. Это всегда важный фактор производительности, но он может быть особенно важен в загруженной системе с использованием сериализуемых транзакций.
-
Не вкладывайте в одну транзакцию больше, чем необходимо для обеспечения целостности.
-
Не оставляйте соединения висящими « бездействующими в транзакции » дольше, чем это необходимо. Параметр конфигурации idle_in_transaction_session_timeout может использоваться для автоматического отключения длительных сеансов.
-
Устраните явные блокировки, SELECT FOR UPDATE и SELECT FOR SHARE где они больше не нужны, благодаря защитам, автоматически предоставляемым сериализуемыми транзакциями.
-
Когда система вынуждена объединять несколько блокировок предикатов на уровне страниц в одну блокировку предикатов на уровне отношений, поскольку в таблице блокировок предикатов не хватает памяти, может произойти увеличение частоты сбоев сериализации. Вы можете избежать этого, увеличив max_pred_locks_per_transaction, max_pred_locks_per_relation и / или max_pred_locks_per_page.
-
Последовательное сканирование всегда требует блокировки предиката на уровне отношений. Это может привести к увеличению частоты сбоев сериализации. Может быть полезно поощрять использование сканирования индекса путем уменьшения random_page_cost и / или увеличения cpu_tuple_cost. Обязательно сопоставьте любое уменьшение откатов транзакций и перезапусков с любым общим изменением времени выполнения запроса.
Явная блокировка
QHB предоставляет различные режимы блокировки для управления одновременным доступом к данным в таблицах. Эти режимы могут использоваться для управляемой приложением блокировки в ситуациях, когда MVCC не дает желаемого поведения. Кроме того, большинство команд QHB автоматически получают блокировки соответствующих режимов, чтобы гарантировать, что ссылочные таблицы не будут удалены или изменены несовместимыми способами во время выполнения команды. (Например, TRUNCATE не может безопасно выполняться одновременно с другими операциями в той же таблице, поэтому он получает эксклюзивную блокировку для таблицы, чтобы обеспечить это.)
Чтобы просмотреть список текущих незавершенных блокировок на сервере базы данных, используйте системное представление pg_locks. Для получения дополнительной информации о мониторинге состояния подсистемы диспетчера блокировки см. Главу 27 .
Блокировки на уровне таблицы
В приведенном ниже списке показаны доступные режимы блокировки и контексты, в которых они автоматически используются QHB. Вы также можете получить любую из этих блокировок явно с помощью команды LOCK. Помните, что все эти режимы блокировки являются блокировками на уровне таблицы, даже если имя содержит слово « строка » ; Названия режимов блокировки являются историческими. В некоторой степени имена отражают типичное использование каждого режима блокировки - но семантика все та же. Единственное реальное различие между одним режимом блокировки и другим - это набор режимов блокировки, с которыми конфликтует каждый (см. Таблицу 2). Две транзакции не могут одновременно удерживать блокировки конфликтующих режимов на одной и той же таблице. (Однако транзакция никогда не конфликтует сама с собой. Например, она может получить блокировку ACCESS EXCLUSIVE а затем получить блокировку ACCESS SHARE для той же таблицы.) Бесконфликтные режимы блокировки могут одновременно поддерживаться многими транзакциями. Обратите внимание, в частности, на то, что некоторые режимы блокировки являются конфликтующими друг с другом (например, блокировка ACCESS EXCLUSIVE не может удерживаться более чем одной транзакцией одновременно), в то время как другие не являются конфликтующими друг с другом (например, блокировка ACCESS SHARE может удерживаться несколько транзакций).
Режимы блокировки на уровне таблицы
- ACCESS SHARE
Конфликтует только с режимом блокировки ACCESS EXCLUSIVE .
Команда SELECT получает блокировку этого режима для ссылочных таблиц. В общем, любой запрос, который только читает таблицу и не изменяет ее, получает этот режим блокировки.
- ROW SHARE
Конфликты с режимами блокировки EXCLUSIVE и ACCESS EXCLUSIVE .
Команды SELECT FOR UPDATE и SELECT FOR SHARE получают блокировку этого режима для целевых таблиц (в дополнение к блокировкам ACCESS SHARE для любых других таблиц, на которые есть ссылки, но не выбранных FOR UPDATE/FOR SHARE ).
- ROW EXCLUSIVE
Конфликты с режимами блокировки SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE .
Команды UPDATE, DELETE и INSERT получают этот режим блокировки для целевой таблицы (в дополнение к блокировкам ACCESS SHARE для любых других ссылочных таблиц). В общем, этот режим блокировки будет активирован любой командой, которая изменяет данные в таблице.
- SHARE UPDATE EXCLUSIVE
Конфликты с режимами блокировки SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE. Этот режим защищает таблицу от одновременных изменений схемы и VACUUM .
Приобретен VACUUM (без FULL ), CREATE INDEX CONCURRENTLY, REINDEX CONCURRENTLY CREATE INDEX CONCURRENTLY, REINDEX CONCURRENTLY CREATE STATISTICS, а также некоторые варианты ALTER INDEX и ALTER TABLE (для полной информации см. ALTER INDEX и ALTER TABLE ).
- SHARE
Конфликты с режимами блокировки ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE. Этот режим защищает таблицу от одновременных изменений данных.
Приобретен по CREATE INDEX (без одновременного CONCURRENTLY ).
- SHARE ROW EXCLUSIVE
Конфликты с режимами блокировки ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE. Этот режим защищает таблицу от одновременных изменений данных и является самоисключающим, так что только один сеанс может удерживать его одновременно.
Приобретено CREATE TRIGGER и некоторыми формами ALTER TABLE (см. ALTER TABLE ).
- EXCLUSIVE
Конфликты с режимами блокировки ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE. Этот режим допускает только одновременные блокировки ACCESS SHARE, т. ACCESS SHARE Только чтение из таблицы может выполняться параллельно с транзакцией, удерживающей этот режим блокировки.
Приобретен REFRESH MATERIALIZED VIEW CONCURRENTLY .
- ACCESS EXCLUSIVE
Конфликтует с блокировками всех режимов ( ACCESS SHARE, ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE и ACCESS EXCLUSIVE ). Этот режим гарантирует, что держатель является единственной транзакцией, которая имеет доступ к таблице любым способом.
Получено REINDEX DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL и REFRESH MATERIALIZED VIEW (без CONCURRENTLY ). Многие формы ALTER INDEX и ALTER TABLE также получают блокировку на этом уровне. Это также режим блокировки по умолчанию для операторов LOCK TABLE которые не указывают режим явно.
Заметка
Только блокировка ACCESS EXCLUSIVE блокирует SELECT (без FOR UPDATE/SHARE).
После получения блокировка обычно удерживается до конца транзакции. Но если блокировка получена после установления точки сохранения, блокировка снимается немедленно, если точка отката возвращается к. Это согласуется с принципом, что ROLLBACK отменяет все эффекты команд, начиная с точки сохранения. То же самое относится и к блокировкам, полученным в блоке исключений PL/pgSQL: сбой ошибки из блока освобождает блокировки, полученные внутри него.
Таблица 2. Конфликтующие режимы блокировки
Запрошенный |
Текущий режим блокировки | ACCESS |
ROW |
ROW |
SHARE |
SHARE |
SHARE |
EXCLUSIVE |
ACCESS |
|---|---|---|---|---|---|---|---|---|
| ACCESS SHARE | X | |||||||
| ROW SHARE | X | X | ||||||
| ROW EXCLUSIVE | X | X | X | X | ||||
| SHARE UPDATE EXCLUSIVE | X | X | X | X | X | |||
| SHARE | X | X | X | X | X | |||
| SHARE ROW EXCLUSIVE | X | X | X | X | X | X | ||
| EXCLUSIVE | X | X | X | X | X | X | X | |
| ACCESS EXCLUSIVE | X | X | X | X | X | X | X | X |
Блокировки на уровне строк
В дополнение к блокировкам на уровне таблиц существуют блокировки на уровне строк, которые перечислены ниже с контекстами, в которых они автоматически используются QHB. См. Таблицу 3 для полной таблицы конфликтов блокировки на уровне строк. Обратите внимание, что транзакция может содержать конфликтующие блокировки в одной и той же строке, даже в разных субтранзакциях; но кроме этого, две транзакции не могут содержать конфликтующие блокировки в одной строке. Блокировки на уровне строк не влияют на запросы данных; они блокируют только писателей и шкафчиков в одном ряду.
Режимы блокировки на уровне строк
- FOR UPDATE
FOR UPDATE блокирует строки, извлеченные SELECT как если бы они были обновлены. Это предотвращает их блокировку, изменение или удаление другими транзакциями до завершения текущей транзакции. То есть другие транзакции, в которых предпринимаются попытки UPDATE, DELETE, SELECT FOR UPDATE, SELECT FOR NO KEY UPDATE, SELECT FOR SHARE или SELECT FOR KEY SHARE этих строк, будут заблокированы до завершения текущей транзакции; и наоборот, SELECT FOR UPDATE будет ожидать параллельной транзакции, которая выполнила любую из этих команд в той же строке, а затем заблокирует и вернет обновленную строку (или не строку, если строка была удалена). Однако в REPEATABLE READ или SERIALIZABLE сообщение об ошибке, если строка, подлежащая блокировке, изменилась с момента запуска транзакции. Для дальнейшего обсуждения см. Раздел "Проверка согласованности данных на уровне приложения".
Режим блокировки FOR UPDATE также вызывается любым DELETE в строке, а также UPDATE который изменяет значения в определенных столбцах. В настоящее время для случая UPDATE рассматривается набор столбцов с уникальным индексом, который можно использовать во внешнем ключе (поэтому частичные индексы и экспрессивные индексы не учитываются), но это может измениться в будущем.
- FOR NO KEY UPDATE
- Ведет себя аналогично FOR UPDATE, за исключением того, что полученная блокировка слабее: эта блокировка не будет блокировать команды SELECT FOR KEY SHARE которые пытаются получить блокировку в тех же строках. Этот режим блокировки также активируется любым UPDATE которое не получает блокировку FOR UPDATE .
- FOR SHARE
- Ведет себя аналогично FOR NO KEY UPDATE, за исключением того, что он получает общую блокировку, а не монопольную блокировку для каждой извлеченной строки. Общая блокировка блокирует выполнение другими транзакциями UPDATE, DELETE, SELECT FOR UPDATE или SELECT FOR NO KEY UPDATE в этих строках, но не мешает им выполнять SELECT FOR SHARE или SELECT FOR KEY SHARE .
- FOR KEY SHARE
- Ведет себя аналогично FOR SHARE, за исключением того, что блокировка слабее: SELECT FOR UPDATE заблокирован, но не SELECT FOR NO KEY UPDATE. Совместная блокировка ключом блокирует выполнение другими транзакциями DELETE или любого UPDATE который изменяет значения ключа, но не другого UPDATE, и это также не предотвращает SELECT FOR NO KEY UPDATE, SELECT FOR SHARE или SELECT FOR KEY SHARE .
QHB не запоминает какую-либо информацию об измененных строках в памяти, поэтому не существует ограничений на количество строк, заблокированных за один раз. Однако блокировка строки может привести к записи на диск, например, SELECT FOR UPDATE изменяет выбранные строки, чтобы пометить их как заблокированные, и, следовательно, приведет к записи на диск.
Таблица 3. Конфликтующие блокировки на уровне строк
| Запрошенный режим блокировки | Текущий режим блокировки | |||
|---|---|---|---|---|
| FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE | |
| FOR KEY SHARE | X | |||
| FOR SHARE | X | X | ||
| FOR NO KEY UPDATE | X | X | X | |
| FOR UPDATE | X | X | X | X |
Блокировки на уровне страницы
В дополнение к блокировкам таблиц и строк, общие / эксклюзивные блокировки на уровне страниц используются для управления доступом на чтение / запись к страницам таблицы в общем пуле буферов. Эти блокировки снимаются сразу после извлечения или обновления строки. Разработчикам приложений обычно не нужно беспокоиться о блокировках на уровне страниц, но они упомянуты здесь для полноты.
Взаимные блокировки
Использование явной блокировки может увеличить вероятность взаимоблокировок, при этом каждая из двух (или более) транзакций удерживает блокировки, которые нужны другой. Например, если транзакция 1 получает эксклюзивную блокировку для таблицы A, а затем пытается получить эксклюзивную блокировку для таблицы B, в то время как транзакция 2 уже имеет эксклюзивную блокировку таблицы B и теперь хочет получить эксклюзивную блокировку для таблицы A, ни одна из них не может продолжить, QHB автоматически обнаруживает тупиковые ситуации и разрешает их, прерывая одну из задействованных транзакций, позволяя другим завершить. (Точно, какая транзакция будет прервана, трудно предсказать, и на нее не следует полагаться.)
Обратите внимание, что взаимные блокировки также могут возникать в результате блокировок на уровне строк (и, следовательно, они могут возникать, даже если явная блокировка не используется). Рассмотрим случай, когда две параллельные транзакции изменяют таблицу. Первая транзакция выполняет:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 11111;
Это получает блокировку на уровне строк в строке с указанным номером учетной записи. Затем вторая транзакция выполняет:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 22222;
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 11111;
Первый оператор UPDATE успешно получает блокировку на уровне строк в указанной строке, поэтому он успешно обновляет эту строку. Однако второй оператор UPDATE обнаруживает, что строка, которую он пытается обновить, уже заблокирована, поэтому он ожидает завершения транзакции, получившей блокировку. Вторая транзакция теперь ожидает завершения первой транзакции, прежде чем продолжить выполнение. Теперь транзакция 1 выполняет:
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 22222;
Транзакция 1 пытается получить блокировку на уровне строки в указанной строке, но не может: транзакция 2 уже удерживает такую блокировку. Поэтому он ожидает завершения транзакции 2. Таким образом, транзакция 1 блокируется в транзакции 2, а транзакция 2 блокируется в транзакции 1: условие взаимоблокировки. QHB обнаружит эту ситуацию и прервет одну из транзакций.
Лучшая защита от взаимных блокировок, как правило, состоит в том, чтобы избежать их, будучи уверенным, что все приложения, использующие базу данных, получают блокировки для нескольких объектов в согласованном порядке. В приведенном выше примере, если обе транзакции обновили строки в одном и том же порядке, тупиковая ситуация не возникла бы. Следует также убедиться, что первая блокировка, полученная для объекта в транзакции, является наиболее ограничительным режимом, который будет необходим для этого объекта. Если это невозможно проверить заранее, то взаимные блокировки могут быть обработаны на лету, повторяя транзакции, которые прерываются из-за взаимных блокировок.
До тех пор, пока не будет обнаружена ситуация взаимоблокировки, транзакция, ищущая блокировку на уровне таблицы или на уровне строки, будет бесконечно долго ожидать освобождения конфликтующих блокировок. Это означает, что для приложений плохая идея держать транзакции открытыми в течение длительных периодов времени (например, во время ожидания ввода данных пользователем).
Консультативные блокировки
QHB предоставляет средства для создания блокировок, которые имеют значения, определенные приложением. Они называются консультативными блокировками, потому что система не навязывает их использование - это зависит от приложения, чтобы использовать их правильно. Консультативные блокировки могут быть полезны для стратегий блокировки, которые неудобно подходят для модели MVCC. Например, обычное использование консультативных блокировок состоит в том, чтобы эмулировать стратегии пессимистической блокировки, типичные для так называемых систем управления данными « плоских файлов ». Хотя флаг, хранящийся в таблице, можно использовать для той же цели, консультативные блокировки быстрее, избегают раздувания таблиц и автоматически очищаются сервером в конце сеанса.
Есть два способа получить консультативную блокировку в QHB : на уровне сеанса или на уровне транзакции. После получения на уровне сеанса консультативная блокировка удерживается до тех пор, пока явно не будет снята или сеанс не завершится. В отличие от стандартных запросов на блокировку, запросы на консультативную блокировку на уровне сеанса не учитывают семантику транзакции: блокировка, полученная во время обратной транзакции, будет по-прежнему удерживаться после отката, и аналогично разблокировка эффективна, даже если вызывающая транзакция завершится неудачей позже. Блокировка может быть получена несколько раз в процессе ее владения; для каждого выполненного запроса на блокировку должен быть соответствующий запрос на разблокировку до фактического снятия блокировки. С другой стороны, запросы на блокировку на уровне транзакции ведут себя больше как обычные запросы на блокировку: они автоматически освобождаются в конце транзакции и явной операции разблокировки не выполняется. Такое поведение часто более удобно, чем поведение на уровне сеанса, для кратковременного использования консультативной блокировки. Запросы на уровне сеанса и на уровне транзакции для одного и того же идентификатора консультативной блокировки будут блокировать друг друга ожидаемым образом. Если сеанс уже удерживает данную консультативную блокировку, дополнительные запросы от него всегда будут успешными, даже если другие сеансы ожидают блокировки; это утверждение верно независимо от того, находится ли существующая блокировка блокировки и новый запрос на уровне сеанса или уровне транзакции.
Как и все блокировки в QHB, полный список консультативных блокировок, удерживаемых в настоящее время любым сеансом, можно найти в системном представлении pg_locks .
Как консультативные, так и обычные блокировки хранятся в пуле общей памяти, размер которой определяется переменными конфигурации max_locks_per_transaction и max_connections. Необходимо соблюдать осторожность, чтобы не исчерпать эту память, иначе сервер вообще не сможет предоставить никаких блокировок. Это накладывает верхний предел на количество консультативных блокировок, предоставляемых сервером, обычно в пределах от десятков до сотен тысяч в зависимости от того, как настроен сервер.
В некоторых случаях, используя рекомендательные методы блокировки, особенно в запросах, включающих явное упорядочение и предложения LIMIT, необходимо соблюдать осторожность, чтобы контролировать блокировки, полученные из-за порядка, в котором оцениваются выражения SQL. Например:
SELECT pg_advisory_lock(id) FROM foo WHERE id = 12345; -- ok
SELECT pg_advisory_lock(id) FROM foo WHERE id > 12345 LIMIT 100; -- danger!
SELECT pg_advisory_lock(q.id) FROM
(
SELECT id FROM foo WHERE id > 12345 LIMIT 100
) q; -- ok
В приведенных выше запросах вторая форма опасна, поскольку не гарантируется применение LIMIT до выполнения функции блокировки. Это может привести к получению некоторых блокировок, которые приложение не ожидает, и, следовательно, не сможет освободить (пока не завершится сеанс). С точки зрения приложения, такие блокировки были бы висячими, хотя все еще видимыми в pg_locks.
Функции, предоставляемые для управления консультативными блокировками, описаны в разделе Функции консультативных блокировок.
Проверка согласованности данных на уровне приложения
Очень сложно обеспечить соблюдение бизнес-правил в отношении целостности данных с использованием транзакций Read Committed, поскольку представление данных смещается с каждым оператором, и даже один оператор не может ограничиваться снимком оператора, если возникает конфликт записи.
Хотя транзакция Repeatable Read имеет стабильное представление данных на протяжении всего своего выполнения, существует небольшая проблема с использованием моментальных снимков MVCC для проверок согласованности данных, связанных с так называемыми конфликтами чтения / записи. Если одна транзакция записывает данные, а параллельная транзакция пытается прочитать те же данные (до или после записи), она не может увидеть работу другой транзакции. Читатель тогда, кажется, выполнил сначала независимо от того, который начался первым или который совершил первым. Если это так далеко, это не проблема, но если считыватель также записывает данные, которые считываются параллельной транзакцией, то теперь есть транзакция, которая, кажется, выполнялась перед любой из ранее упомянутых транзакций. Если транзакция, которая, по-видимому, выполнила последнюю, на самом деле фиксируется первой, цикл очень легко отобразить на графике порядка выполнения транзакций. Когда появляется такой цикл, проверки целостности не будут работать правильно без посторонней помощи.
Как показано в разделе Подзапросы, сериализуемые транзакции - это просто повторяющиеся транзакции чтения, которые добавляют неблокирующий мониторинг опасных шаблонов конфликтов чтения / записи. Когда обнаружен шаблон, который может вызвать цикл в видимом порядке выполнения, одна из задействованных транзакций откатывается, чтобы прервать цикл.
Обеспечение согласованности с сериализуемыми транзакциями
Если уровень изоляции Сериализуемой транзакции используется для всех записей и для всех операций чтения, которые требуют согласованного просмотра данных, никаких других усилий не требуется для обеспечения согласованности. Программное обеспечение из других сред, написанное для использования сериализуемых транзакций для обеспечения согласованности, должно « просто работать » в этом отношении в QHB .
При использовании этого метода, это позволит избежать ненужной нагрузки для прикладных программистов, если прикладное программное обеспечение проходит через среду, которая автоматически повторяет транзакции, которые откатываются с ошибкой сериализации. Это может быть хорошей идеей, чтобы установить default_transaction_isolation в serializable. Также было бы целесообразно предпринять некоторые действия, чтобы гарантировать, что никакой другой уровень изоляции транзакции не используется, либо непреднамеренно, либо для подрыва проверок целостности, посредством проверок уровня изоляции транзакции в триггерах.
Смотрите главу Подзапросы для предложений по производительности.
!!! Предупреждение
Этот уровень защиты целостности с использованием сериализуемых
транзакций еще не распространяется на режим горячего резервирования.
Из-за этого те, кто использует горячее резервирование,
могут хотеть использовать *Repeatable Read* и явную блокировку на главном.
Обеспечение согласованности с помощью явных блокирующих блокировок
Когда возможны несериализуемые записи, чтобы обеспечить текущую достоверность строки и защитить ее от одновременных обновлений, необходимо использовать SELECT FOR UPDATE, SELECT FOR SHARE или соответствующую инструкцию LOCK TABLE. ( SELECT FOR UPDATE и SELECT FOR SHARE блокируют только возвращенные строки от одновременных обновлений, в то время как LOCK TABLE блокирует всю таблицу.) Это следует учитывать при переносе приложений на QHB из других сред.
Для тех, кто конвертирует из других сред, также следует отметить тот факт, что SELECT FOR UPDATE не гарантирует, что параллельная транзакция не будет обновлять или удалять выбранную строку. Для этого в QHB вы должны обновить строку, даже если значения не нужно менять. SELECT FOR UPDATE временно блокирует другие транзакции от получения той же блокировки или выполнения UPDATE или DELETE которые могут повлиять на заблокированную строку, но как только транзакция, удерживающая эту блокировку, фиксирует или откатывает назад, заблокированная транзакция продолжит конфликтующую операцию, если только фактическое UPDATE ряда был выполнен, пока замок удерживался.
Глобальные проверки достоверности требуют дополнительного внимания при несериализуемых MVCC. Например, банковское приложение может захотеть проверить, что сумма всех кредитов в одной таблице равна сумме дебетов в другой таблице, когда обе таблицы активно обновляются. Сравнение результатов двух последовательных команд SELECT sum(...) не будет надежно работать в режиме Read Committed, поскольку второй запрос, скорее всего, будет включать результаты транзакций, не учитываемые первой. Выполнение двух сумм в одной повторяемой транзакции чтения даст точную картину только последствий транзакций, совершенных до начала повторяемой транзакции чтения, но можно с полным основанием задаться вопросом, актуален ли ответ к моменту его доставки. Если повторяемая транзакция чтения сама применила некоторые изменения перед попыткой проверки согласованности, полезность проверки становится еще более дискуссионной, поскольку теперь она включает некоторые, но не все изменения после запуска транзакции. В таких случаях осторожный человек может захотеть заблокировать все таблицы, необходимые для проверки, чтобы получить бесспорную картину текущей реальности. Блокировка в режиме SHARE (или выше) гарантирует отсутствие незафиксированных изменений в заблокированной таблице, кроме изменений в текущей транзакции.
Также обратите внимание, что если кто-то полагается на явную блокировку для предотвращения одновременных изменений, следует либо использовать режим Read Committed, либо в режиме Repeatable Read, будьте осторожны, чтобы получить блокировки перед выполнением запросов. Блокировка, полученная повторяемой транзакцией чтения, гарантирует, что никакие другие транзакции, модифицирующие таблицу, все еще не запущены, но если моментальный снимок, видимый транзакцией, предшествует получению блокировки, он может предшествовать некоторым уже зафиксированным изменениям в таблице. Снимок повторяющейся транзакции чтения фактически замораживается в начале первого запроса или команды изменения данных ( SELECT, INSERT, UPDATE или DELETE), поэтому можно явно получить блокировки до того, как моментальный снимок будет заморожен.
Ограничения
Некоторые команды DDL, в настоящее время только TRUNCATE и формы переписывания таблиц ALTER TABLE, не являются безопасными для MVCC. Это означает, что после фиксации усечения или перезаписи таблица будет отображаться пустой для одновременных транзакций, если они используют снимок, сделанный до принятия команды DDL. Это будет проблемой только для транзакции, которая не обращалась к рассматриваемой таблице до запуска команды DDL - любая сделавшая транзакция содержала бы по меньшей мере блокировку таблицы ACCESS SHARE, которая блокировала бы команду DDL до завершения этой транзакции. Таким образом, эти команды не вызовут каких-либо явных несоответствий в содержании таблицы для последовательных запросов к целевой таблице, но они могут вызвать видимое несоответствие между содержимым целевой таблицы и другими таблицами в базе данных.
Поддержка уровня изоляции Serializable транзакций еще не была добавлена к целям репликации с горячим резервированием. Самым строгим уровнем изоляции, поддерживаемым в настоящее время в режиме горячего резервирования, является Repeatable Read. Хотя выполнение всех постоянных операций записи в базу данных в рамках сериализуемых транзакций на главном сервере гарантирует, что все резервные серверы в конечном итоге достигнут согласованного состояния, транзакция повторного чтения, выполняемая в режиме ожидания, может иногда видеть переходное состояние, несовместимое с любым последовательным выполнением транзакций на мастере.
Блокировка и индексы
Хотя QHB обеспечивает блокирующий доступ на чтение / запись к данным таблицы, блокирующему доступ на чтение / записи в настоящее время не предлагаются для каждого метода доступа индекса осуществляется в QHB. Различные типы индексов обрабатываются следующим образом:
| Индексы | Описание |
|---|---|
| Индексы | Краткосрочные блокировки / эксклюзивные блокировки на уровне страниц используются для доступа на чтение / запись. Блокировки снимаются сразу после извлечения или вставки каждой строки индекса. Эти типы индексов обеспечивают максимальный параллелизм без условий взаимоблокировки. |
| Хеш-индексы | Совместно используемые / эксклюзивные блокировки на уровне хеш-сегмента используются для доступа на чтение / запись. Замки снимаются после обработки всего ведра. Блокировки уровня сегмента обеспечивают лучший параллелизм, чем блокировки уровня индекса, но возможна взаимоблокировка, так как блокировки удерживаются дольше, чем одна операция индекса. |
| GIN индексы | Краткосрочные блокировки / эксклюзивные блокировки на уровне страниц используются для доступа на чтение / запись. Блокировки снимаются сразу после извлечения или вставки каждой строки индекса. Но обратите внимание, что вставка GIN-индексированного значения обычно приводит к нескольким вставкам индексного ключа на строку, поэтому GIN может выполнять существенную работу для вставки одного значения. |
В настоящее время B-деревья предлагают лучшую производительность для параллельных приложений; поскольку они также имеют больше возможностей, чем хеш-индексы, они являются рекомендуемым типом индекса для параллельных приложений, которым необходимо индексировать скалярные данные. При работе с нескалярными данными B-деревья бесполезны, и вместо них следует использовать индексы GiST, SP-GiST или GIN.
Большие объекты
- Краткая справка по большим объектам
- Особенности реализации
- Клиентские интерфейсы
- Создание большого объекта
- Импорт большого объекта
- Экспорт большого объекта
- Открытие существующего большого объекта
- Запись данных в большой объект
- Чтение данных из большого объекта
- Перемещение в большом объекте
- Получение текущего положения крупного объекта
- Усечение большого объекта
- Закрытие дескриптора большого объекта
- Удаление большого объекта
- Серверные функции
- Пример программы
QHB имеет функцию больших объектов, которая обеспечивает потоковый доступ к пользовательским данным, хранящимся в специальной структуре больших объектов. Потоковый доступ полезен при работе со значениями данных, которые слишком велики, чтобы удобно манипулировать ими в целом.
В этой главе описываются реализация и интерфейсы языка программирования
и запросов к данным больших объектов в QHB. Мы используем
библиотеку libpq, которая написана на языке C для примеров в этой главе, но большинство программных
интерфейсов, родных для QHB, поддерживают эквивалентную
функциональность. Другие интерфейсы могут использовать интерфейс больших
объектов для обеспечения универсальной поддержки больших
значений. Это здесь не описано.
Краткая справка по большим объектам
Все большие объекты хранятся в одной системной таблице с именем pg_largeobject. Каждый крупный объект также имеет запись в системной таблице pg_largeobject_metadata. Большие объекты можно создавать, изменять и удалять с помощью API чтения и записи, аналогичного стандартным операциям с файлами.
QHB также поддерживает систему хранения под названием TOAST, которая автоматически сохраняет значения, превышающие одну страницу базы данных, во вторичную область хранения для каждой таблицы. Это делает систему больших объектов частично устаревшими. Одно из оставшихся преимуществ больших объектов заключается в том, что они позволяют использовать значения размером до 4 ТБ, в то время как TOAST поля могут быть не более 1 ГБ. Кроме того, чтение и обновление частей большого объекта может быть выполнено эффективно, в то время как большинство операций над поджаренным полем будут читать или записывать все значение как единицу измерения.
Особенности реализации
Реализация больших объектов разбивает большие объекты на "куски" и сохраняет их в строках таблиц в базе данных. B-дерево гарантирует быстрый поиск правильного номера чанка при выполнении операций чтения и записи с произвольным доступом.
Куски сохраненного большого объекта необязательно должны быть смежными. Например, если приложение открывает новый большой объект и запишет несколько байт по смещению 1000000 байт, это не приводит к выделению дополнительных 1000000 байт; изменятся только куски, охватывающие диапазон фактически записанных байтов данных. Однако операция чтения будет считывать нули для любых нераспределенных местоположений, предшествующих последнему существующему фрагменту. Это соответствует обычному поведению "разреженных" файлов в файловых системах Unix.
Клиентские интерфейсы
В этом разделе описываются средства, которые библиотека клиентского
интерфейса libpq QHB предоставляет для доступа к большим
объектам. Интерфейс больших объектов QHB похож на
интерфейс файловой системы Unix, с аналогами open, read, write,
lseek и прочим.
Все манипуляции с большими объектами, использующие эти функции, должны выполняться в блоке транзакций SQL, поскольку дескрипторы файлов больших объектов действительны только в течение транзакции.
Если при выполнении какой-либо функции возникает ошибка, то функция возвращает значение, в противном случае невозможное, обычно это 0 или -1. Сообщение, описывающее ошибку, хранится в объекте connection и может быть извлечено с помощью PQerrorMessage.
Клиентские приложения, использующие эти функции, должны включать файл
заголовка libpq/libpq-fs.h и поставляться с библиотекой libpq.
Создание большого объекта
Функция
Oid lo_creat(PGconn *conn, int mode);
создает новый большой объект. Возвращаемое значение - это OID, присвоенный новому крупному объекту, или InvalidOid (ноль) при сбое (failure). Битовый аргумент mode определяет, будет ли объект открыт для чтения (INV_READ), записи (INV_WRITE), или и то и другое. (Эти символьные константы определены в заголовочном файле libpq/libpq-fs.х.)
Пример:
inv_oid = lo_creat(conn, INV_READ|INV_WRITE);
Функция
Oid lo_create(PGconn *conn, Oid lobjId);
также создает новый крупный объект. Назначаемый OID может быть задан с помощью lobjId; если этот OID уже используется для некоторого большого объекта, то происходит ошибка. Если lobjId является InvalidOid (ноль), тогда lo_create назначает неиспользуемый OID (это – то же самое поведение, что и lo_creat). Возвращаемое значение - это OID, присвоенный новому крупному объекту, или InvalidOid (ноль) при ошибке.
Пример:
inv_oid = lo_create(conn, desired_oid);
Импорт большого объекта
Чтобы импортировать файл из операционной системы в качестве большого объекта, вызовите:
Oid lo_import(PGconn *conn, const char *filename);
в filename указывается имя файла операционной системы, который будет импортирован как большой объект. Возвращаемое значение - это OID, присвоенный новому крупному объекту, или InvalidOid (ноль) при ошибке. Обратите внимание, что файл считывается библиотекой клиентского интерфейса, а не сервером; поэтому он должен существовать в файловой системе клиента и быть доступен для чтения клиентским приложением.
Функция
Oid lo_import_with_oid(PGconn *conn, const char *filename, Oid lobjId);
также импортирует новый крупный объект. Назначаемый OID может быть задан с помощью lobjId; если этот OID уже используется для некоторого большого объекта, то происходит ошибка. Если lobjId является InvalidOid (ноль) тогда lo_import_with_oid назначает неиспользуемый OID (это - то же самое поведение, что и lo_import). Возвращаемое значение - это OID, присвоенный новому крупному объекту, или InvalidOid (ноль) при ошибке.
Экспорт большого объекта
Чтобы экспортировать большой объект в файл операционной системы, вызовите
int lo_export(PGconn *conn, Oid lobjId, const char *filename);
в аргументе lobjId указывается идентификатор OID большого объекта для экспорта, а также имя файла аргумент указывает имя операционной системы файла. Обратите внимание, что файл записывается библиотекой клиентского интерфейса, а не сервером. Возвращает 1 при успешном выполнении, -1 при ошибке.
Открытие существующего большого объекта
Чтобы открыть существующий большой объект для чтения или записи, вызовите
int lo_open(PGconn *conn, Oid lobjId, int mode);
в аргументе lobjId указывается OID большого объекта для открытия. Битовый аргумент mode определяет, будет ли объект открыт для чтения (INV_READ), записи (INV_WRITE), или и то и другое. (Эти символьные константы определены в заголовочном файле libpq/libpq-fs.х.) lo_open возвращает дескриптор объекта (неотрицательный) для последующего использования в lo_read, lo_write, lo_lseek, lo_lseek64, lo_tell, lo_tell64, lo_truncate, lo_truncate64, и lo_close. Дескриптор действителен только в течение срока действия текущей транзакции. При ошибке возвращается значение -1.
В настоящее время сервер не различает режимы работы и INV_READ и INV_WRITE: вы можете читать из дескриптора в любом случае. Однако есть существенная разница между этими режимами. С INV_READ вы не можете записать дескриптор, и данные, считанные из него, будут отражать содержимое большого объекта во время моментального снимка транзакции, который был активен, когда lo_open была выполнена, независимо от последующих записей по тем или иным транзакциям. Чтение из дескриптора, открытого с помощью INV_WRITE возвращает данные, отражающие все операции записи других зафиксированных транзакций, а также операции записи текущей транзакции. Это похоже на отличия режимов REPEATABLE READ и READ COMMITTED для обычных команд SQL SELECT.
Вызов lo_open потерпит неудачу, если SELECT привилегия недоступна для большого объекта или параметр INV_WRITE не задан или UPDATE привилегии не представлены. Эти проверки привилегий можно отключить с помощью параметра времени выполнения lo_compat_privileges.
Пример:
inv_fd = lo_open(conn, inv_oid, INV_READ|INV_WRITE);
Запись данных в большой объект
Функция
int lo_write(PGconn *conn, int fd, const char *buf, size_t len);
пишет len байт из buf (который должен иметь размер len) к дескриптору большого объекта fd. Аргумент fd должен быть возвращен предыдущим lo_open. Количество фактически записанных байтов возвращается (в текущей реализации это всегда будет равно len если только нет ошибки). В случае ошибки возвращаемое значение равно -1.
Хотя len параметр объявляется как size_t, эта функция будет отклонять значения длины больше, чем INT_MAX. На практике, лучше всего передавать данные в кусках не более нескольких мегабайт в любом случае.
Чтение данных из большого объекта
Функция
int lo_read(PGconn *conn, int fd, char *buf, size_t len);
читает len байт из дескриптора большого объекта fd в buf (который должен иметь размер len). Аргумент fd должен быть возвращен предыдущим lo_open. Количество фактически прочитанных байт возвращается; это будет меньше, чем len если конец большого объекта достигнут первым. В случае ошибки возвращаемое значение равно -1.
Хотя len параметр объявляется как size_t, эта функция будет отклонять значения длины больше, чем INT_MAX. На практике, лучше всего передавать данные в кусках не более нескольких мегабайт в любом случае.
Перемещение в большом объекте
Чтобы изменить текущее местоположение чтения или записи, связанное с дескриптором большого объекта, вызовите
int lo_lseek(PGconn *conn, int fd, int offset, int whence);
Эта функция перемещает указатель текущего местоположения для большого дескриптора объекта, идентифицированного с помощью fd к новому местоположению, указанному с помощью offset. Допустимые значения для whence являются SEEK_SET (перемещение от начала объекта), SEEK_CUR (перемещение с текущей позиции), и SEEK_END (перемещение от конца объекта). Возвращаемое значение - это новый указатель местоположения, или -1 при ошибке.
При работе с большими объектами, размер которых может превышать 2 ГБ, вместо этого используйте
pg_int64 lo_lseek64(PGconn *conn, int fd, pg_int64 offset, int whence);
Эта функция имеет то же поведение, что и lo_lseek, но она может принять offset больше, чем 2 ГБ и/или доставить результат больше, чем 2 ГБ. Обратите внимание, что lo_lseek произойдет ошибка, если новый указатель местоположения будет больше, чем 2 ГБ.
Получение текущего положения крупного объекта
Чтобы получить текущее расположение для чтения или записи дескриптора большого объекта, вызовите
int lo_tell(PGconn *conn, int fd);
Если есть ошибка, возвращаемое значение равно -1.
При работе с большими объектами, размер которых может превышать 2 ГБ, вместо этого используйте
pg_int64 lo_tell64(PGconn *conn, int fd);
Эта функция имеет то же поведение, что и lo_tell, но она может доставить результат больше, чем 2 ГБ. Обратите внимание, что lo_tell произойдет ошибка, если текущее местоположение для чтения / записи больше 2 ГБ.
Усечение большого объекта
Чтобы обрезать большой объект до заданной длины, вызовите
int lo_truncate(PGcon *conn, int fd, size_t len);
Эта функция усекает дескриптор большого объекта fd по длине len. Аргумент fd должен быть возвращен предыдущим lo_open. Если len больше, чем текущая длина большого объекта, большой объект расширяется до указанной длины с нулевыми байтами (’\0’). При успехе, lo_truncate возвращать нуль. При ошибке возвращается значение -1.
Место чтения / записи, связанное с дескриптором fd не изменяется.
Хотя len параметр объявляется как size_t, lo_truncate будет отклонять значения длины больше, чем INT_MAX.
При работе с большими объектами, размер которых может превышать 2 ГБ, вместо этого используйте
int lo_truncate64(PGcon *conn, int fd, pg_int64 len);
Эта функция имеет то же поведение, что и lo_truncate, но он может принять a len значение, превышающее 2 ГБ.
Закрытие дескриптора большого объекта
Дескриптор большого объекта можно закрыть вызовом
int lo_close(PGconn *conn, int fd);
где fd является дескриптором большого объекта, возвращаемый lo_open. При успехе, lo_close возвращать нуль. При ошибке возвращается значение -1.
Все дескрипторы больших объектов, которые остаются открытыми в конце транзакции, будут закрыты автоматически.
Удаление большого объекта
Чтобы удалить большой объект из базы данных, вызовите
int lo_unlink(PGconn *conn, Oid lobjId);
Аргумент lobjId указывает OID большого объекта для удаления. Возвращает 1 в случае успеха, -1 при ошибке.
Серверные функции
Серверные функции, предназначенные для работы с большими объектами из SQL, перечислены в таблице 5.1.
Таблица 5.1. SQL-ориентированные функции больших объектов
| Функция | возвращаемый тип | Описание | Пример | Результат |
|---|---|---|---|---|
| lo_from_bytea(oid oid, string bytea) | oid | Создайте большой объект и храните там данные, возвращая его OID. Проходить 0 чтобы система могла выбрать OID. | lo_from_bytea(0, ’\xffffff00’) | 24528 |
| lo_put(loid oid, offset bigint, str bytea) | void | Запишите данные с заданным смещением. | lo_put(24528, 1, ’\xaa’) | |
| lo_get(loid oid [, from bigint, for int]) | bytea | Извлеките содержимое или его подстроку. | lo_get(24528, 0, 3) | \xffaaff |
Существуют дополнительные серверные функции, соответствующие каждой из описанных ранее клиентских функций; действительно, в большинстве случаев клиентские функции являются просто интерфейсами к эквивалентным серверным функциям. Те, которые так же удобно вызывать с помощью команд SQL являются lo_creat, lo_create, lo_unlink, lo_import, и lo_export. Вот примеры их использования:
CREATE TABLE image (
name text,
raster oid
);
SELECT lo_creat(-1); -- returns OID of new, empty large object
SELECT lo_create(43213); -- attempts to create large object with OID 43213
SELECT lo_unlink(173454); -- deletes large object with OID 173454
INSERT INTO image (name, raster)
VALUES ('beautiful image', lo_import('/etc/motd'));
INSERT INTO image (name, raster) -- same as above, but specify OID to use
VALUES ('beautiful image', lo_import('/etc/motd', 68583));
SELECT lo_export(image.raster, '/tmp/motd') FROM image
WHERE name = 'beautiful image';
Серверные функции lo_import и lo_export функции ведут себя значительно иначе, чем их клиентские аналоги. Эти две функции читают и записывают файлы в файловой системе сервера, используя разрешения пользователя-владельца базы данных. Поэтому по умолчанию их использование ограничено суперпользователями. Напротив, функции импорта и экспорта на стороне клиента считывают и записывают файлы в файловой системе клиента, используя разрешения клиентской программы. Клиентские функции не требуют никаких прав доступа к базе данных, за исключением права на чтение или запись большого объекта, о котором идет речь.
Примечание!!!
Можно предоставить использование серверной части lo_import и lo_export функции к non-superusers, но тщательное рассмотрение последствий обеспеченностью необходимо. Злонамеренный пользователь с такими привилегиями может легко использовать их в качестве суперпользователя (например, путем перезаписи файлов конфигурации сервера) или может атаковать остальную файловую систему сервера, не беспокоясь о получении привилегий суперпользователя базы данных как таковых. Доступ к ролям, имеющим такие привилегии, должен поэтому охраняться так же тщательно, как и доступ к ролям суперпользователя. Тем не менее, при использовании серверной части lo_import или lo_export это необходимо для некоторых рутинных задач, поэтому безопаснее использовать роль с такими привилегиями, чем с полными привилегиями суперпользователя, так как это помогает уменьшить риск повреждения от случайных ошибок.
Функциональные возможности: lo_read и lo_write также доступны через вызовы на стороне сервера, но имена функций на стороне сервера отличаются от интерфейсов на стороне клиента тем, что они не содержат подчеркиваний. Вы должны вызвать эти функции как loread и lowrite.
Пример программы
Пример 5.1 - это пример программы, которая показывает, как можно
использовать интерфейс больших объектов в libpq. Части программы
закомментированы, но оставлены в источнике для удобства читателя. Эта
программа также может быть найдена в src/test/примеры/testlo.с в
исходном дистрибутиве.
Пример 5.1. Большие объекты с примером программы libpq
/*-------------------------------------------------------------------------
*
* testlo.c
* test using large objects with libpq
*
* Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
* Portions Copyright (c) 1994, Regents of the University of California
*
*
* IDENTIFICATION
* src/test/examples/testlo.c
*
*-------------------------------------------------------------------------
*/
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include "libpq-fe.h"
#include "libpq/libpq-fs.h"
#define BUFSIZE 1024
/*
* importFile -
* import file "in_filename" into database as large object "lobjOid"
*
*/
static Oid
importFile(PGconn *conn, char *filename)
{
Oid lobjId;
int lobj_fd;
char buf[BUFSIZE];
int nbytes,
tmp;
int fd;
/*
* open the file to be read in
*/
fd = open(filename, O_RDONLY, 0666);
if (fd < 0)
{ /* error */
fprintf(stderr, "cannot open unix file\"%s\"\n", filename);
}
/*
* create the large object
*/
lobjId = lo_creat(conn, INV_READ | INV_WRITE);
if (lobjId == 0)
fprintf(stderr, "cannot create large object");
lobj_fd = lo_open(conn, lobjId, INV_WRITE);
/*
* read in from the Unix file and write to the inversion file
*/
while ((nbytes = read(fd, buf, BUFSIZE)) > 0)
{
tmp = lo_write(conn, lobj_fd, buf, nbytes);
if (tmp < nbytes)
fprintf(stderr, "error while reading \"%s\"", filename);
}
close(fd);
lo_close(conn, lobj_fd);
return lobjId;
}
static void
pickout(PGconn *conn, Oid lobjId, int start, int len)
{
int lobj_fd;
char *buf;
int nbytes;
int nread;
lobj_fd = lo_open(conn, lobjId, INV_READ);
if (lobj_fd < 0)
fprintf(stderr, "cannot open large object %u", lobjId);
lo_lseek(conn, lobj_fd, start, SEEK_SET);
buf = malloc(len + 1);
nread = 0;
while (len - nread > 0)
{
nbytes = lo_read(conn, lobj_fd, buf, len - nread);
buf[nbytes] = '\0';
fprintf(stderr, ">>> %s", buf);
nread += nbytes;
if (nbytes <= 0)
break; /* no more data? */
}
free(buf);
fprintf(stderr, "\n");
lo_close(conn, lobj_fd);
}
static void
overwrite(PGconn *conn, Oid lobjId, int start, int len)
{
int lobj_fd;
char *buf;
int nbytes;
int nwritten;
int i;
lobj_fd = lo_open(conn, lobjId, INV_WRITE);
if (lobj_fd < 0)
fprintf(stderr, "cannot open large object %u", lobjId);
lo_lseek(conn, lobj_fd, start, SEEK_SET);
buf = malloc(len + 1);
for (i = 0; i < len; i++)
buf[i] = 'X';
buf[i] = '\0';
nwritten = 0;
while (len - nwritten > 0)
{
nbytes = lo_write(conn, lobj_fd, buf + nwritten, len - nwritten);
nwritten += nbytes;
if (nbytes <= 0)
{
fprintf(stderr, "\nWRITE FAILED!\n");
break;
}
}
free(buf);
fprintf(stderr, "\n");
lo_close(conn, lobj_fd);
}
/*
* exportFile -
* export large object "lobjOid" to file "out_filename"
*
*/
static void
exportFile(PGconn *conn, Oid lobjId, char *filename)
{
int lobj_fd;
char buf[BUFSIZE];
int nbytes,
tmp;
int fd;
/*
* open the large object
*/
lobj_fd = lo_open(conn, lobjId, INV_READ);
if (lobj_fd < 0)
fprintf(stderr, "cannot open large object %u", lobjId);
/*
* open the file to be written to
*/
fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, 0666);
if (fd < 0)
{ /* error */
fprintf(stderr, "cannot open unix file\"%s\"",
filename);
}
/*
* read in from the inversion file and write to the Unix file
*/
while ((nbytes = lo_read(conn, lobj_fd, buf, BUFSIZE)) > 0)
{
tmp = write(fd, buf, nbytes);
if (tmp < nbytes)
{
fprintf(stderr, "error while writing \"%s\"",
filename);
}
}
lo_close(conn, lobj_fd);
close(fd);
return;
}
static void
exit_nicely(PGconn *conn)
{
PQfinish(conn);
exit(1);
}
int
main(int argc, char **argv)
{
char *in_filename,
*out_filename;
char *database;
Oid lobjOid;
PGconn *conn;
PGresult *res;
if (argc != 4)
{
fprintf(stderr, "Usage: %s database_name in_filename out_filename\n",
argv[0]);
exit(1);
}
database = argv[1];
in_filename = argv[2];
out_filename = argv[3];
/*
* set up the connection
*/
conn = PQsetdb(NULL, NULL, NULL, NULL, database);
/* check to see that the backend connection was successfully made */
if (PQstatus(conn) != CONNECTION_OK)
{
fprintf(stderr, "Connection to database failed: %s",
PQerrorMessage(conn));
exit_nicely(conn);
}
/* Set always-secure search path, so malicious users can't take control. */
res = PQexec(conn,
"SELECT pg_catalog.set_config('search_path', '', false)");
if (PQresultStatus(res) != PGRES_TUPLES_OK)
{
fprintf(stderr, "SET failed: %s", PQerrorMessage(conn));
PQclear(res);
exit_nicely(conn);
}
PQclear(res);
res = PQexec(conn, "begin");
PQclear(res);
printf("importing file \"%s\" ...\n", in_filename);
/* lobjOid = importFile(conn, in_filename); */
lobjOid = lo_import(conn, in_filename);
if (lobjOid == 0)
fprintf(stderr, "%s\n", PQerrorMessage(conn));
else
{
printf("\tas large object %u.\n", lobjOid);
printf("picking out bytes 1000-2000 of the large object\n");
pickout(conn, lobjOid, 1000, 1000);
printf("overwriting bytes 1000-2000 of the large object with X's\n");
overwrite(conn, lobjOid, 1000, 1000);
printf("exporting large object to file \"%s\" ...\n", out_filename);
/* exportFile(conn, lobjOid, out_filename); */
if (lo_export(conn, lobjOid, out_filename) < 0)
fprintf(stderr, "%s\n", PQerrorMessage(conn));
}
res = PQexec(conn, "end");
PQclear(res);
PQfinish(conn);
return 0;
}
Расширение SQL
- Как работает расширяемость
- Система типов QHB
- Пользовательские функции
- Пользовательские процедуры
- Функции на языке запросов (SQL)
- Аргументы для функций SQL
- Функции SQL c базовыми типами
- Функции SQL с составными типами
- Функции SQL с выходными параметрами
- Функции SQL с переменным числом аргументов
- Функции SQL со значениями аргументов по умолчанию
- Использование результата функции как таблицы
- Функции SQL, возвращающие множество строк
- Функции SQL, возвращающие таблицы
- Полиморфные функции SQL
- Функции SQL и правила сортировки
- Перегрузка функций
- Категории изменчивости функций
- Функции на процедурном языке
- Внутренние функции
- Функции на нативном языке
- Динамическая загрузка
- Базовые типы в функциях языка C/RUST
- Версия 1 Соглашение о вызовах
- Написание кода
- Компиляция и связывание динамически загружаемых функций
- Составные аргументы
- Возвращающиеся строки (составные типы)
- Возврат наборов
- Полиморфные аргументы и возвращаемые типы
- Общая память и LWLocks
- Использование C ++ для расширяемости
- Информация по оптимизации функций
- Пользовательские агрегаты
- Пользовательские типы
- Пользовательские операторы
- Информация по оптимизации оператора
- Интерфейсные расширения для индексов
- Упаковка связанных объектов в расширение
- Инфраструктура сборки расширений
В следующих разделах мы обсудим, как вы можете расширить язык запросов SQL, добавив:
- функции (начиная с раздела Пользовательские функции)
- агрегаты (начиная с раздела Пользовательские агрегаты)
- типы данных (начиная с раздела Пользовательские типы)
- операторы (начиная с раздела Пользовательские операторы)
- операторные классы для индексов (начиная с раздела Интерфейсные расширения для индексов)
- пакеты связанных объектов (начиная с раздела Упаковка связанных объектов в расширение)
Как работает расширяемость
QHB хорошо расширяем, потому что его работа основана на каталоге. Если вы знакомы со стандартными системами реляционных баз данных, вы знаете, что они хранят информацию о базах данных, таблицах, столбцах и т. д. в так называемых системных каталогах (иногда называемых словарём базы данных). Каталоги доступны пользователю в виде таблиц, похожих на любые другие таблицы, но СУБД хранит в них свою внутреннюю бухгалтерию. Одним из ключевых отличий между QHB и большинством систем баз данных является то, что QHB хранит гораздо больше информации в своих каталогах: не только информацию о таблицах и столбцах, но также информацию о всех существующих типах данных, функциях, методах доступа и так далее. Эти таблицы могут быть изменены пользователем, а поскольку QHB основывает свою работу на этих таблицах, то это означает, что QHB может быть расширен пользователями. Для сравнения, большинство систем баз данных могут быть расширены только путем изменения жестко закодированных процедур в их исходном коде или путем загрузки модулей, специально написанных поставщиком СУБД.
Кроме того, сервер QHB может включать в себя написанный пользователем код посредством динамической загрузки. То есть пользователь может указать файл с исполняемым кодом (например, разделяемую библиотеку), который реализует новый тип или функцию, и QHB загрузит его при необходимости. Код, написанный на SQL, еще проще добавить на сервер. Эта способность изменять свою работу «на лету» делает QHB прекрасно подходящим для быстрого создания прототипов новых приложений и систем хранения.
Система типов QHB
Типы данных QHB можно разделить на базовые, контейнерные, доменные типы и псевдотипы.
Базовые типы
Базовые типы, такие как integer, реализуются ниже уровня языка SQL (на низкоуровневом языке, например, C, Rust). Они обычно соответствуют тому, что называют абстрактными типами данных.
Встроенные базовые типы описаны в главе Типы данных.
Перечисления (enum) могут рассматриваться как подкатегория базовых типов. Но они могут быть созданы с использованием только SQL, без какого-либо низкоуровневого программирования. Обратитесь к разделу Перечисляемые типы за дополнительной информацией.
Контейнерные типы
QHB имеет три «контейнерных» типа, т.е. типа, который содержат внутри себя несколько значений другого типа. Это массивы, составные типы и диапазоны.
Массивы могут содержать несколько значений одного типа. Тип массива создается автоматически для каждого базового, составного, диапазонного и доменного типов. А вот массивов массивов нет. С точки зрения системы типов, многомерные массивы не отличаются от одномерных. Обратитесь к разделу Массивы за дополнительной информацией.
Составные типы(composite type), или кортежи — такой тип имеет одна строка таблицы. Для каждой таблицы автоматически создаётся тип её строки (его имя совпадает с именем таблицы), но составной тип может существовать и без привязки к таблице, его можно создать командой CREATE TYPE. Составной тип — это набор именованых полей некоторых других типов. Значением составного типа является строка или кортеж. Обратитесь к разделу Составные типы за дополнительной информацией.
Диапазонный тип состоит из двух значений одного типа, которые являются нижней и верхней границами диапазона. Диапазонные типы создаются пользователем, хотя существует несколько встроенных. Обратитесь к разделу Диапазонные типы за дополнительной информацией.
Доменные типы
Доменный тип основывается на конкретном базовом типе и во многих случаях взаимозаменяем с его базовым типом. Однако у домена могут быть ограничения, ограничивающие его допустимые значения подмножеством того, что допускает базовый тип. Домены создаются с помощью команды SQL CREATE DOMAIN. Обратитесь к разделу Доменные типы за дополнительной информацией.
Псевдо-типы
Есть несколько «псевдотипов» для специальных целей. Псевдотипы не могут быть столбцами таблиц или компонентами контейнерных типов, но их можно использовать для объявления аргументов и типов результатов функций. Это обеспечивает механизм в системе типов для идентификации особенного поведения функций. В таблице 27 перечислены существующие псевдотипы.
Полиморфные типы
Пять псевдотипов, представляющих особый интерес: anyelement, anyarray, anynonarray, anyenum и anyrange, которые в совокупности называются полиморфными типами. Любая функция, объявленная с использованием этих типов, называется полиморфной функцией. Полиморфная функция может работать со многими различными типами данных, причем конкретный тип выводится из данных, фактически переданных ей в конкретном вызове.
Полиморфные аргументы и результаты разрешаются в конкретный тип данных при разборе запроса, вызывающего полиморфную функцию. Они связаны друг с другом следующим образом: хотя anyelement может быть любого типа, все anyelement в конкретной функции должны быть того же типа. Аргументы и результаты, объявленные как anyarray/anyrange должны быть массивом/диапазоном, базовый тип (тип элементов) которых такой же, как и anyelement других аргументов.
anynonarray обрабатывается точно так же, как anyelement, но добавляет дополнительное ограничение, что фактический тип не должен быть типом массива. anyenum обрабатывается точно так же, как anyelement, но добавляет дополнительное ограничение, что фактический тип должен быть типом enum.
Таким образом, когда несколько аргументов объявлены с
полиморфным типом, выбирается только 1 конкретный тип, и все
anyelement/anyenum/anynonarray будут этого типа, а все anyarray
будут массивами этого типа. Например, функция,
объявленная как equal(anyelement, anyelement) будет принимать любые два
входных значения, но одинакового типа.
Функция equal2(anyelement, anyenum) тоже принимает два аргумента одинакового типа,
а значит оба из них должны быть одинаковыми перечислениями (enum).
Если возвращаемое значение функции объявляется как полиморфный тип, должен быть хотя бы один входной аргумента полиморфного типа, чтобы была возможность вывести конкретный тип из входных аргументов при вызове функции. Например, мы можем написать функцию индексирования массива (получение i-го элемента), её заголовок будет таким:
my_subscript(anyarray, integer) returns anyelement
Это объявление требует, чтобы первый аргумент был массивом и позволяет
анализатору выводить правильный тип результата из фактического типа
первого аргумента. А если объявить функцию как
f(anyarray) returns anyenum, то она будет принимать только массивы перечисляемых типов.
Функция с переменным числом аргументов (которая принимает переменное число аргументов, см. Функции SQL с переменным числом аргументов) тоже может быть полиморфной: для этого надо объявить ее последний параметр как VARIADIC anyarray. При сопоставлении аргументов и определения фактического типа такая функция ведет себя так же, как если бы вы записали соответствующее число параметров типа anynonarray.
Пользовательские функции
В QHB есть четыре вида функций:
-
функции на языке запросов (Функции на языке запросов (SQL))
-
функции на скриптовом языке (например, на PL/pgSQL или PL/Tcl, см. Функции на процедурном языке)
-
функции на нативном языке, см. Функции на нативном языке
Каждый тип функции может принимать базовые типы, составные типы или их комбинации в качестве аргументов (параметров). Кроме того, каждый тип функции может возвращать базовый тип, или составной тип, или множество базовых/составных типов (т.е. много строк, фактически таблицу).
Многие виды функций могут принимать или возвращать определенные псевдотипы (например, полиморфные типы); поддержка псевдотипов зависит от языка программирования, на котором написана функция, обратитесь к описанию каждого вида функций для более подробной информации.
Писать функции SQL проще всего, поэтому мы начнем с их обсуждения. Большинство концепций, представленных для функций SQL, переносятся и на другие типы функций. При чтении этой главе может быть полезно параллельно смотреть страницу команды CREATE FUNCTION, чтобы лучше понять примеры.
Пользовательские процедуры
Процедура — это объект базы данных, похожий на функцию. Различия следующие:
-
процедура не может возвращать значения (функция тоже может не возвращать, если не хочет);
-
функции вызываются как часть запроса или вообще любого DML, а процедура вызывается явно с помощью оператора CALL, также есть API для вызова именно процедуры, отдельное от API для выполнения произвольного DML;
-
в процедуре можно начать/зафиксировать/откатить транзакцию;
-
кроме этих моментов, функции можно использовать вместо процедур: в QHB функции могут иметь почти любые побочные эффекты.
Рекомендации по созданию пользовательских функций в оставшейся части этой главы также применимы к процедурам, за исключением того, что надо использовать команду CREATE PROCEDURE, нет возвращаемого значения и некоторые другие опции, такие как STRICT, неприменимы.
Функции и процедуры вместе также называются рутинами (ROUTINE). Существуют команды ALTER ROUTINE и DROP ROUTINE, которые можно применить, даже когда неизвестно, процедура это или функция. А команды CREATE ROUTINE нет, нужно выбрать, что именно хотите создать.
Функции на языке запросов (SQL)
Функции SQL выполняют произвольный список операторов SQL, возвращая результат последней выборки (SELECT) в списке. Если функция не помечена как возвращающая множество (SETOF), то будет возвращена только первая строка результата последней выборки. (Если не задан ORDER BY, то порядок строк не определён, и первая строка может выбираться недетерминировано.) Если последний запрос вообще не вернул строк, то результатом функции будет NULL. Также последняя команда может быть модификацией (INSERT, UPDATE или DELETE) с указанием RETURNING, опять же будет возвращена одна первая строка.
Второй вариант — функции, возвращающие SETOF sometype или, что тоже самое, TABLE(columns). В этом случае возвращаются все строки результата последней выборки (или модификации с указанием RETURNING). Более подробная информация приведена ниже.
Тело функции SQL должно быть списком операторов SQL, разделенных точкой с запятой. Точка с запятой после последнего оператора является необязательной. Если не объявлено, что функция возвращает void, последним оператором должен быть SELECT или INSERT, UPDATE или DELETE с указанием RETURNING.
Любой набор команд на языке SQL можно собрать вместе и объявить функцией. Помимо выборок SELECT, команды могут включать модификации (INSERT, UPDATE и DELETE), а также другие команды SQL. (В SQL-функциях вы не можете использовать команды управления транзакциями, например, COMMIT, SAVEPOINT и некоторые служебные команды, например, VACUUM). Однако последняя команда должна быть командой SELECT или иметь указание RETURNING, и что вернёт эта команд, то и будет возвращаемым значением функции. Можно сделать функцию, которая что-то делает, но ничего не возвращает, в этом случае объявите её как возвращающую void. Например, эта функция удаляет строки с отрицательными зарплатами из таблицы emp:
CREATE FUNCTION clean_emp() RETURNS void AS '
DELETE FROM emp
WHERE salary < 0;
' LANGUAGE SQL;
SELECT clean_emp();
clean_emp
-----------
(1 row)
Замечание
Тело SQL-функции анализируется целиком, прежде чем выполнить что-либо. Хотя функция SQL может содержать команды, которые изменяют системные каталоги (например, CREATE TABLE), эффекты таких команд не будут видны во время парсинга последующих команд в функции. Так, например, если функция начинается так:
CREATE TABLE foo (...);
INSERT INTO foo VALUES(...);
— она не запустится, потому что она содержит обращение к несуществующей таблицеfoo, а таблица не создастся, потому что функция невалидна целиком и не запускается. В такой ситуации рекомендуется переписать функцию наPL/pgSQL.
Синтаксис команды CREATE FUNCTION требует, чтобы тело функции было
записано как строковая константа. Обычно для строковой константы наиболее удобно использовать
знаки доллара (см. раздел Строковые константы с экранированием знаками доллара). Если
вы решите использовать обычный синтаксис строковой константы с
одинарными кавычками, следует удваивать одинарные кавычки (’) и
обратную косую черту (\)
в теле функции (согласно правилам экранирования, см. раздел Строковые константы).
Аргументы для функций SQL
На аргументы функции SQL можно ссылаться в теле функции, используя имена или номера. Примеры обоих методов приведены ниже.
Чтобы использовать имя, объявите аргумент функции с именем, а затем просто напишите это имя в теле функции. Если имя аргумента совпадает с именем любого столбца в текущей команде SQL, имя столбца будет иметь приоритет. Чтобы победить это, укажите имя аргумента с именем самой функции в качестве префикса, то есть function_name.argument_name. Если такое квалифицированное имя будет всё ещё конфликтовать с квалифицированным именем столбца, снова выберется столбец, а не аргумент. Чтобы преодолеть и это, присвойте алиас таблице, чтобы у столбца стало другое квалифицированное имя.
В более старом "нумерованном" подходе на аргументы ссылаются с использованием синтаксиса $n; тогда $1 относится к первому входному аргументу, $2 ко второму и т. д. Это будет работать независимо от того, был ли конкретный аргумент объявлен с именем.
Если аргумент имеет составной тип, то к полям можно обратиться через точку (т.н. dot notation), например, argname.fieldname или $1.fieldname. Здесь опять могут быть проблемы с совпадением имени, и может потребоваться указать имя аргумента с именем функции в качестве префикса, чтобы однозначно сослаться на поле аргумента.
Аргументы функции SQL могут использоваться только как значения данных, но не как идентификаторы. Так, например, это разумно:
INSERT INTO mytable VALUES ($1);
а это не сработает
INSERT INTO $1 VALUES (42);
Функции SQL c базовыми типами
Простейшая возможная функция SQL не имеет аргументов и просто возвращает значение базового типа, например, integer:
CREATE FUNCTION one() RETURNS integer AS $$
SELECT 1 AS rrres;
$$ LANGUAGE SQL;
-- Альтернативный синтаксис строкового литерала:
CREATE FUNCTION one() RETURNS integer AS '
SELECT 1 AS rrres;
' LANGUAGE SQL;
SELECT one();
one
-----
1
Обратите внимание, что внутри функции мы определили псевдоним rrres для столбца результата, но этот псевдоним не виден вне функции, и результат обозначен как one вместо rrres.
SQL-функции, которые принимают базовые типы в качестве аргументов тоже легко писать:
-- Вариант с именованными аргументами:
CREATE FUNCTION add_em(x integer, y integer) RETURNS integer AS $$
SELECT x + y;
$$ LANGUAGE SQL;
-- Альтернативый вариант с нумерованными аргументами:
CREATE FUNCTION add_em(integer, integer) RETURNS integer AS $$
SELECT $1 + $2;
$$ LANGUAGE SQL;
SELECT add_em(1, 2) AS answer;
answer
--------
3
Вот более полезная функция, которая может использоваться для дебетования банковского счета:
CREATE FUNCTION tf1 (accountno integer, debit numeric) RETURNS numeric AS $$
UPDATE bank
SET balance = balance - debit
WHERE accountno = tf1.accountno;
SELECT 1;
$$ LANGUAGE SQL;
Пользователь может выполнить эту функцию для дебетования счета 17 на 100 рублей следующим образом:
SELECT tf1(17, 100.0);
В этом примере мы выбрали имя accountno для первого аргумента, но оно совпадает с именем столбца в таблице bank. В команде UPDATE accountno ссылается на столбец bank.accountno, а для ссылки на аргумент необходимо использовать tf1.accountno. Конечно, мы могли бы избежать этого, использовав другое имя для аргумента.
На практике, вероятно, хотелось бы вернуть из функции что-то более полезное, чем константа 1, поэтому более вероятное определение:
CREATE FUNCTION tf1 (accountno integer, debit numeric) RETURNS numeric AS $$
UPDATE bank
SET balance = balance - debit
WHERE accountno = tf1.accountno;
SELECT balance FROM bank WHERE accountno = tf1.accountno;
$$ LANGUAGE SQL;
Функция корректирует баланс и возвращает новый баланс. То же самое можно сделать одной командой, используя RETURNING:
CREATE FUNCTION tf1 (accountno integer, debit numeric) RETURNS numeric AS $$
UPDATE bank
SET balance = balance - debit
WHERE accountno = tf1.accountno
RETURNING balance;
$$ LANGUAGE SQL;
Результат последнего SELECT или RETURNING не обязан в точности соответствовать типу результата. QHB может автоматически привести результат к нужному типу, если это можно сделать неявным преобразованием (implicit cast) или присваивающим преобразованием (assignment cast). Либо вы можете использовать явное преобразование типа. Например, предположим, что мы хотим, чтобы предыдущая функция add_em возвращала тип float8. Это не сработает:
CREATE FUNCTION add_em(integer, integer) RETURNS float8 AS $$
SELECT $1 + $2;
$$ LANGUAGE SQL;
потому что нет неявного преобразования integer во float. Нужно добавить явное преобразование:
CREATE FUNCTION add_em(integer, integer) RETURNS float8 AS $$
SELECT ($1 + $2)::float8;
$$ LANGUAGE SQL;
Функции SQL с составными типами
При написании функций, работающих с аргументами составных типов, нам придётся обращаться к конкретным полям аргумента. Например, предположим, что emp является таблицей, содержащей данные о сотрудниках и, следовательно, имя составного типа строки таблицы тоже emp. Вот функция double_salary которая вычисляет, какой была бы чья-то зарплата, если её удвоить:
CREATE TABLE emp (
name text,
salary numeric,
age integer,
cubicle point
);
INSERT INTO emp VALUES ('Bill', 4200, 45, '(2,1)');
CREATE FUNCTION double_salary(emp) RETURNS numeric AS $$
SELECT $1.salary * 2 AS salary;
$$ LANGUAGE SQL;
SELECT name, double_salary(emp.*) AS dream
FROM emp
WHERE emp.cubicle ~= point '(2,1)';
name | dream
------+-------
Bill | 8400
Обратите внимание на использование синтаксиса $1.salary для выбора
одного поля из аргумента-строки. Также обратите внимание, как
вызывающая команда SELECT использует table_name.*, чтобы взять всю
текущую строку таблицы в качестве значения составного типа. На строку таблицы
можно сослаться, используя только имя таблицы, например
так:
SELECT name, double_salary(emp) AS dream
FROM emp
WHERE emp.cubicle ~= point '(2,1)';
но этот альтернативный способ не рекомендуется. Вариант table_name.* лучше читается, сразу видно,
что передаётся строка таблицы, а не какая-то колонка. (См.
раздел Использование составных типов в запросах для получения подробной информации об этих двух
обозначениях для составного значения строки таблицы).
Иногда удобно создавать значение составного аргумента на лету. Это можно сделать с помощью конструктора типа ROW. Например, мы можем подправить данные перед передачей в функцию:
SELECT name, double_salary(ROW(name, salary * 1.1, age, cubicle)) AS dream
FROM emp;
Можно создать функцию, которая возвращает составной тип. Вот пример функции, которая возвращает одну строку emp:
CREATE FUNCTION new_emp() RETURNS emp AS $$
SELECT text 'None' AS name,
1000.0 AS salary,
25 AS age,
point '(2,2)' AS cubicle;
$$ LANGUAGE SQL;
В этом примере мы заполняем все поля константами, но вместо них могли быть произвольные вычисления.
Обратите внимание на две важные вещи в реализации функции:
-
Порядок значений в списке выборки должен точно соответствовать порядку полей составного типа (= порядку столбцов в таблице). Алиасы, которые мы дали константам в
new_emp(), ни на что не влияют. -
Мы должны убедиться, что тип каждого выражения соответствует соответствующему столбцу составного типа, при необходимости вставляя преобразование типа. В противном случае мы получим такие ошибки:
ERROR: function declared to return emp returns varchar instead of text at column 1
Как и в случае с базовым типом, функция будет автоматически
применять только неявные и присваивающие преобразования.
Другой способ определить ту же функцию:
CREATE FUNCTION new_emp() RETURNS emp AS $$
SELECT ROW('None', 1000.0, 25, '(2,2)')::emp;
$$ LANGUAGE SQL;
Здесь мы создали значение анонимного составного типа, а потом привели его к нужному типу emp. В данном примере это ни чем не лучше, но в некоторых случаях это удобная альтернатива — например, если мы возвращаем кортеж, который нам вернула другая функция. Другой пример: если возвращаемое значение нашей функции — доменный тип на основе составного, то мы обязаны сделать выброрку 1 составного значения, а не отдельных полей, т.к. в последнем случае не пройдёт преобразование в доменный тип.
Функцию, возвращающую составное значение, можно использовать как значение, и как таблицу:
-- Кортеж как значение
SELECT new_emp();
new_emp
--------------------------
(None,1000.0,25,"(2,2)")
-- Кортеж как таблица
SELECT * FROM new_emp();
name | salary | age | cubicle
------+--------+-----+---------
None | 1000.0 | 25 | (2,2)
Второй способ более подробно описан в разделе Использование результата функции как таблицы.
Когда вы вызываете функцию, которая возвращает составной тип, вам может потребоваться взять одно поле из ее результата. Вы можете сделать это с помощью следующего синтаксиса:
SELECT (new_emp()).name;
name
------
None
Дополнительные скобки необходимы, чтобы не запутать парсер. Без скобок вы получите что-то вроде этого:
SELECT new_emp().name;
ERROR: syntax error at or near "."
LINE 1: SELECT new_emp().name;
^
Другой вариант — использовать функциональную нотацию для извлечения поля:
SELECT name(new_emp());
name
------
None
Как объяснено в разделе Использование составных типов в запросах, эти две нотации эквивалентны.
Что ещё можно сделать с результатом работы такой функции? Можно передать его в другую функцию, которая как раз ожидает аргумент подходящего составного типа:
CREATE FUNCTION getname(emp) RETURNS text AS $$
SELECT $1.name;
$$ LANGUAGE SQL;
SELECT getname(new_emp());
getname
---------
None
(1 row)
Функции SQL с выходными параметрами
Альтернативный способ описания результатов функции — с помощью выходных параметров, как в этом примере:
CREATE FUNCTION add_em (IN x int, IN y int, OUT sum int)
AS 'SELECT x + y'
LANGUAGE SQL;
SELECT add_em(3,7);
add_em
--------
10
(1 row)
Это существенно не отличается от версии add_em показанной в предыдущем разделе. Реальное назначение выходных параметров заключается в том, чтобы предоставлять удобный способ определения функций, которые возвращают несколько значений. Например,
CREATE FUNCTION sum_n_product (x int, y int, OUT sum int, OUT product int)
AS 'SELECT x + y, x * y'
LANGUAGE SQL;
SELECT * FROM sum_n_product(11,42);
sum | product
-----+---------
53 | 462
(1 row)
По сути, мы здесь создали анонимный составной тип для результата функции. Приведенный выше пример имеет тот же конечный результат, что и
CREATE TYPE sum_prod AS (sum int, product int);
CREATE FUNCTION sum_n_product (int, int) RETURNS sum_prod
AS 'SELECT $1 + $2, $1 * $2'
LANGUAGE SQL;
но только без мороки с определением отдельного составного типа. Обратите внимание, что имена выходных параметров определяют имена столбцов анонимного составного типа. (Если вы опустите имя для выходного параметра, система выберет имя самостоятельно).
Также обратите внимание, что выходные параметры не указываются при вызове такой функции из SQL;
cнаружи функции выходные параметры ведут себя в точности как возвращаемые значения.
Сигнатура функции в QHB определяется только входными параметрами,
поэтому, например, вы можете удалить функцию sum_n_product любым из следующих вариантов:
DROP FUNCTION sum_n_product (x int, y int, OUT sum int, OUT product int);
DROP FUNCTION sum_n_product (int, int);
Параметры могут быть помечены как IN (по умолчанию), OUT, INOUT или VARIADIC. INOUT-параметр служит как входным параметром (частью списка входных аргументов), так и выходным параметром (частью кортежа результата). VARIADIC-параметр являются входными параметром, но обрабатываются особым образом, это описано в следующем разделе.
Замечание
Если у функции есть OUT- или INOUT-параметры, то у неё не может быть возвращаемого значения (RETURNS) и наоборот. Это два разных стиля описания возвращаемых значений; OUT-параметры — универсальный способ, а RETURNS — более красивый и наглядный.
Функции SQL с переменным числом аргументов
Функции SQL могут быть объявлены так, чтобы принимать переменное число аргументов, при условии, что все «необязательные» аргументы имеют один и тот же тип. Необязательные аргументы будут переданы функции в виде массива. Для этого последний аргумент функции должен быть массивом и помечен как VARIADIC. Например:
CREATE FUNCTION mleast(VARIADIC arr numeric[]) RETURNS numeric AS $$
SELECT min($1[i]) FROM generate_subscripts($1, 1) g(i);
$$ LANGUAGE SQL;
SELECT mleast(10, -1, 5, 4.4);
mleast
--------
-1
(1 row)
Технически все предоставленные аргументы от позиции VARIADIC и дальше собираются в одномерный массив, как если бы вы написали
SELECT mleast(ARRAY[10, -1, 5, 4.4]); -- прямо в таком виде не сработает
Однако вы не можете написать так — или, по крайней мере, это не будет соответствовать определению этой функции. VARIADIC-параметр ожидает один или несколько элементов базового типа массива, а не значение-массив.
Иногда полезно иметь возможность передавать уже имеющий массив в функцию с переменным числом аргументов; это особенно удобно, когда одна функция с переменным числом аргументов хочет передать свой переменный аргумент другой такой функции. Это можно сделать, воспользовавшись тем же ключевым словом VARIADIC:
SELECT mleast(VARIADIC ARRAY[10, -1, 5, 4.4]);
Массив, помеченный как VARIADIC может быть только последним аргументом вызова функции, и он сопоставится только с VARIADIC-аргументом функции, передавая массив. Указание VARIADIC в вызове также является единственным способом передачи пустого массива в функцию с переменным числом аргументов:
SELECT mleast(VARIADIC ARRAY[]::numeric[]);
Простое написание SELECT mleast() не работает, поскольку VARIADIC-аргумент должен соответствовать хотя бы одному фактическому значению. (Вы можете определить вторую функцию с именем mleast без параметров, если хотите разрешить такие вызовы).
Замечание по безопасности
Если есть схема в которой несознательные пользователи могут создавать функции, и вы вызываете функцию из этой схемы, и у неё есть VARIADIC-параметр, то всегда вызывайте её с использование синтаксиса VARIADIC ARRAY[...]. Так вы можете быть уверены, что вызываете именно эту функцию (если её не удалят, конечно). Если вы передаёте просто несколько чисел через запятую в VARIADIC-параметр, то злоумышленник может создать функцию с тем же именем, но с конкретным набором параметров, и ваш код начнёт вызывать эту функцию.
Даже если у VARIADIC-параметра есть имя, это имя не просто использовать для сопоставления параметров по именам при вызове функции (см. раздел Вызов функции). Например, следующие варианты все не работают:
SELECT mleast(arr => 10);
SELECT mleast(arr => 10, arr => 20);
SELECT mleast(arr => ARRAY[10, -1, 5, 4.4]);
Единственный работающий вариант опять использует ключевое слово VARIADIC:
SELECT mleast(VARIADIC arr => ARRAY[10, -1, 5, 4.4]);
Функции SQL со значениями аргументов по умолчанию
Функции могут быть объявлены со значениями по умолчанию для некоторых или всех входных аргументов. Значения по умолчанию подставляются, когда функция вызывается с недостаточным количеством фактических аргументов. Поскольку аргументы могут быть пропущены с конца списка, все параметры после параметра со значением по умолчанию также должны иметь значения по умолчанию. (Хотя при использовании связывания аргументов по именам при вызове функции можно задать любое подмножество аргументов, не только с конца, но надо всё-таки, чтобы позиционное задание аргументов тоже работало.)
QHB разрешает создание функций, у которых совпадает набор обязательных входных аргументов, а различается только набор факультативных (имеющих значение по умолчанию)! При вызове неоднозначности разрешаются определённым образом. Из-за этого нужно соблюдать меры предосторожности при вызове функций в базе данных, где несознательные пользователи могут создавать функции.
Примеры:
CREATE FUNCTION foo(a int, b int DEFAULT 2, c int DEFAULT 3)
RETURNS int
LANGUAGE SQL
AS $$
SELECT $1 + $2 + $3;
$$;
SELECT foo(10, 20, 30);
foo
-----
60
(1 row)
SELECT foo(10, 20);
foo
-----
33
(1 row)
SELECT foo(10);
foo
-----
15
(1 row)
SELECT foo(); -- не работает, потому что для первого аргумента нет умолчания
ERROR: function foo() does not exist
Вместо ключевого слова DEFAULT можно также использовать =:
CREATE FUNCTION foo(a int, b int = 2, c int = 3)
Использование результата функции как таблицы
Все функции SQL можно использовать в предложении FROM запроса, но это особенно полезно для функций, возвращающих составные типы. Если функция определена как возвращающая базовый тип, функция создает таблицу из одного столбца. Если функция определена для возврата составного типа, она создает столбец для каждого поля составного типа.
Вот пример:
CREATE TABLE foo (fooid int, foosubid int, fooname text);
INSERT INTO foo VALUES (1, 1, 'Joe');
INSERT INTO foo VALUES (1, 2, 'Ed');
INSERT INTO foo VALUES (2, 1, 'Mary');
CREATE FUNCTION getfoo(int) RETURNS foo AS $$
SELECT * FROM foo WHERE fooid = $1;
$$ LANGUAGE SQL;
SELECT *, upper(fooname) FROM getfoo(1) AS t1;
fooid | foosubid | fooname | upper
-------+----------+---------+-------
1 | 1 | Joe | JOE
(1 row)
Как показывает пример, мы можем работать со столбцами результата функции так же, как если бы они были столбцами обычной таблицы.
Обратите внимание, что мы получили только одну строку из функции. Это потому, что мы не использовали SETOF. Это описано в следующем разделе.
Функции SQL, возвращающие множество строк
Когда функция SQL объявляется как возвращающая SETOF sometype, последня выборка функции выполняется полностью, и каждая строка, которую она выводит, возвращается как элемент набора результатов.
Такие функции обычно используется в предложении FROM. В этом случае каждая строка, возвращаемая функцией, становится строкой псевдотаблицы, обрабатываемой запросом. Например, предположим, что таблица foo имеет то же содержимое, что и выше, и мы говорим:
CREATE FUNCTION getfoo(int) RETURNS SETOF foo AS $$
SELECT * FROM foo WHERE fooid = $1;
$$ LANGUAGE SQL;
SELECT * FROM getfoo(1) AS t1;
fooid | foosubid | fooname
-------+----------+---------
1 | 1 | Joe
1 | 2 | Ed
(2 rows)
Если функция возвращает результат посредством выходных параметров, тоже можно вернуть много строк:
CREATE TABLE tab (y int, z int);
INSERT INTO tab VALUES (1, 2), (3, 4), (5, 6), (7, 8);
CREATE FUNCTION sum_n_product_with_tab (x int, OUT sum int, OUT product int)
RETURNS SETOF record
AS $$
SELECT $1 + tab.y, $1 * tab.y FROM tab;
$$ LANGUAGE SQL;
SELECT * FROM sum_n_product_with_tab(10);
sum | product
-----+---------
11 | 10
13 | 30
15 | 50
17 | 70
(4 rows)
Ключевым моментом здесь является то, что вы должны написать RETURNS SETOF record, чтобы указать, что функция возвращает несколько строк, а не одну. Если имеется только один выходной параметр, то вместо record напишите его тип.
Часто бывает полезно сконструировать результат выборки, вызывая функцию, возвращающую таблицу, несколько раз, подставляя её аргументы из результатов подзапроса. Предпочтительный способ сделать это - использовать ключевое слово LATERAL, которое описано в разделе Подзапросы LATERAL. Вот пример использования возвращающей таблицу функции для перечисления элементов древовидной структуры:
SELECT * FROM nodes;
name | parent
-----------+--------
Top |
Child1 | Top
Child2 | Top
Child3 | Top
SubChild1 | Child1
SubChild2 | Child1
(6 rows)
CREATE FUNCTION listchildren(text) RETURNS SETOF text AS $$
SELECT name FROM nodes WHERE parent = $1
$$ LANGUAGE SQL STABLE;
SELECT * FROM listchildren('Top');
listchildren
--------------
Child1
Child2
Child3
(3 rows)
SELECT name, child FROM nodes, LATERAL listchildren(name) AS child;
name | child
--------+-----------
Top | Child1
Top | Child2
Top | Child3
Child1 | SubChild1
Child1 | SubChild2
(5 rows)
Этот пример не делает ничего такого, чего мы не могли бы сделать LATERAL-соединением без функции, но в более сложных случаях, когда для соединения требуются сложные вычисления, удобно поместить их в функцию.
Функции, возвращающие табличные результаты, также можно вызывать в списке выборки. Для каждой строки, которую запрос генерирует сам по себе, вызывается функция, возвращающая множество строк, и для каждого элемента этого множества генерируется выходная строка. Предыдущий пример также можно выполнить с помощью таких запросов:
SELECT listchildren('Top');
listchildren
--------------
Child1
Child2
Child3
(3 rows)
SELECT name, listchildren(name) FROM nodes;
name | listchildren
--------+--------------
Top | Child1
Top | Child2
Top | Child3
Child1 | SubChild1
Child1 | SubChild2
(5 rows)
В последнем SELECT обратите внимание, что для Child2, Child3 и т.д. нет выходных строк. Это происходит потому, что listchildren возвращает 0 строк для этих аргументов, поэтому строки результата не генерируются. Это такое же поведение, которое мы имели бы при внутреннем соединении с результатом функции при использовании синтаксиса LATERAL.
Поведение QHB для функции, возвращающей множество в списке выбора
запроса, почти такое же, как если бы функция, возвращающая множество,
была в LATERAL FROM. Например,
SELECT x, generate_series(1,5) AS g FROM tab;
почти эквивалентно
SELECT x, g FROM tab, LATERAL generate_series(1,5) AS g;
Разница проявляется только в свободе выбора планировщика.
Во втором варианте планировщик может поместить g во внешнюю цикл соединения вложенными циклами,
поскольку g на самом деле не зависит от tab.
Это приведет к другому порядку строк в итоговом результате.
Табличные функции в списке выборки всегда будут выполнятся самым внутренним циклом соединения,
т.е. результат функции (функций) пробегается до конца, а только потом переходят к следующей строке FROM.
Если в списке выбора запроса несколько функций, возвращающих
множество строк, то мы получим не декартово произведение их результатов,
как можно было подумать, а совмещение результатов функций по номерам:
для каждой строки из
базового запроса есть выходная строка, использующая первый результат из
каждой функции, затем выходная строка, использующая второй результат из
каждой функции и так далее; если результаты какой-то функция кончились раньше,
вместо них будут NULL, и так пока не кончится самая "результативная" функция.
Для каждой строки из базового запроса будет столько строк, сколько строк в самом большом
из результатов функций.
Такое поведение аналогично тому, что вы получите, поместив эти функции
в один LATERAL ROWS FROM( ... )
Табличные функции могут вызывать друг друга в списке выборки, хотя это не разрешено в секции FROM. В таких случаях каждый уровень вложенности обрабатывается отдельно, генерируя отдельные внутренний цикл, как если бы это был отдельный LATERAL ROWS FROM( ... ). Например, в
SELECT srf1(srf2(x), srf3(y)), srf4(srf5(z)) FROM tab;
функции возврата srf2, srf3 и srf5 будут запускаться в первом шаге для каждой строки tab, а затем для каждой строки того, что получилось, будут запускаться srf1 и srf4.
Функции, возвращающие множество, нельзя использовать в конструкциях условного вычисления, таких как CASE или COALESCE. Например, рассмотрим
SELECT x, CASE WHEN x > 0 THEN generate_series(1, 5) ELSE 0 END FROM tab;
Может показаться, что это должно привести к пяти повторениям входных
строк, которые имеют x > 0, и одному повторению прочих;
но на самом деле, поскольку generate_series(1, 5) будет
выполняться в неявном элементе LATERAL FROM до того, как выражение CASE
начнёт вычислять, запрос выдаст пять повторений
каждой строки из tab. Чтобы избежать путаницы, такие конструкции запрещены, и вызывают ошибку разбора.
Заметка
Если последней командой функции является INSERT, UPDATE или DELETE с RETURNING, эта команда всегда будет выполняться до конца, даже если функция не объявлена с помощью SETOF или вызывающий запрос не извлечёт все строки результата (например, у него есть LIMIT). Любые дополнительные строки, созданные указанием RETURNING отбрасываются, но изменения в заданной таблице производятся (и все завершаются до возврата из функции).
Функции SQL, возвращающие таблицы
Есть еще один способ объявить функцию как возвращающую набор: использовать синтаксис RETURNS TABLE(columns). Это эквивалентно использованию одного или нескольких OUT-параметров плюс маркировке функции как возвращающей SETOF record (или, если столбец единственный, SETOF тип-столбца). Нотация RETURNS TABLE(columns) указана в последних версиях стандарта SQL и, следовательно, может быть более переносимой, чем использование SETOF.
Например, предыдущий пример суммы и произведения может быть переписан так:
CREATE FUNCTION sum_n_product_with_tab (x int)
RETURNS TABLE(sum int, product int) AS $$
SELECT $1 + tab.y, $1 * tab.y FROM tab;
$$ LANGUAGE SQL;
Не допускается использование явных параметров OUT или INOUT с указанием RETURNS TABLE, надо выбрать один из вариантов нотации.
Полиморфные функции SQL
SQL-функции могут принимать и возвращать полиморфные типы anyelement, anyarray, anynonarray, anyenum и anyrange, обсуждавшиеся в разделе Полиморфные типы. Вот пример полиморфной функции make_array, которая создает массив из двух элементов произвольного типа данных:
CREATE FUNCTION make_array(anyelement, anyelement) RETURNS anyarray AS $$
SELECT ARRAY[$1, $2];
$$ LANGUAGE SQL;
SELECT make_array(1, 2) AS intarray, make_array('a'::text, 'b') AS textarray;
intarray | textarray
----------+-----------
{1,2} | {a,b}
(1 row)
Обратите внимание на использование приведения типа 'a'::text чтобы указать, что
аргумент имеет тип text. Это необходимо, потому что строковый литерал по умолчанию не относится
к какому-то конкретному строковому типу (имеет тип unknown). Без
приведения типа вы получите такую ошибку:
ERROR: could not determine polymorphic type because input has type "unknown"
Разрешается иметь полиморфные аргументы и фиксированный тип результата, но не наоборот:
CREATE FUNCTION is_greater(anyelement, anyelement) RETURNS boolean AS $$
SELECT $1 > $2;
$$ LANGUAGE SQL;
SELECT is_greater(1, 2);
is_greater
------------
f
(1 row)
CREATE FUNCTION invalid_func() RETURNS anyelement AS $$
SELECT 1;
$$ LANGUAGE SQL;
ERROR: cannot determine result data type
DETAIL: A function returning a polymorphic type must have at least one polymorphic argument.
Функции с выходными аргументами вполне могут использовать полиморфизм:
CREATE FUNCTION dup (f1 anyelement, OUT f2 anyelement, OUT f3 anyarray)
AS 'select $1, array[$1,$1]' LANGUAGE SQL;
SELECT * FROM dup(22);
f2 | f3
----+---------
22 | {22,22}
(1 row)
Полиморфизм может также использоваться функциями с переменным числом аргументов:
CREATE FUNCTION anyleast (VARIADIC anyarray) RETURNS anyelement AS $$
SELECT min($1[i]) FROM generate_subscripts($1, 1) g(i);
$$ LANGUAGE SQL;
SELECT anyleast(10, -1, 5, 4);
anyleast
----------
-1
(1 row)
SELECT anyleast('abc'::text, 'def');
anyleast
----------
abc
(1 row)
CREATE FUNCTION concat_values(text, VARIADIC anyarray) RETURNS text AS $$
SELECT array_to_string($2, $1);
$$ LANGUAGE SQL;
SELECT concat_values('|', 1, 4, 2);
concat_values
---------------
1|4|2
(1 row)
Функции SQL и правила сортировки
Когда SQL-функция имеет один или несколько параметров такого типа, для которого применимы правила сортировки (COLLATION), правила сортировки выбираются при каждом вызове на основании фактических аргументов функции. Алгоритм выбора описан в разделе Поддержка сортировки. Если правила сортировки успешно выбраны (т.е. нет конфликтов между неявно установленными правилами сортировки аргументов), то все параметры функции считаются имеющими такое правило сортировки, и обрабатываются соответственно. Это повлияет на поведение операций, связанных со сравнением и сортировкой, внутри функции. Например, для функции anyleast описанной выше, результат
SELECT anyleast('abc'::text, 'ABC');
будет зависеть от правил сортировки базы данных по умолчанию. В локали C результат будет ABC, но во многих других локалях это будет abc.
Правило сортировки можно установить принудительно при вызове функции, добавив указание COLLATE к любому из аргументов, например:
SELECT anyleast('abc'::text, 'ABC' COLLATE "C");
Либо, если вы хотите, чтобы функция работала по конкретным правилам, независимо от свойств аргументов, можно задавать правила сортировки внутри функции: при выполнении операции, а не при объявлении аргумента. Следующая версия anyleast всегда будет использовать локаль en_US для сравнения строк:
CREATE FUNCTION anyleast (VARIADIC anyarray) RETURNS anyelement AS $$
SELECT min($1[i] COLLATE "en_US") FROM generate_subscripts($1, 1) g(i);
$$ LANGUAGE SQL;
К сожалению, при вызове такой функций для не текстового типа будет ошибка при попытке применить к нему COLLATE...
Если среди фактических аргументов не могут быть выбраны общие правила сортировки, то параметры будут считаться имеющими правила сортировки по умолчанию для своих типов данных (которые обычно являются правилами сортировки по умолчанию базы данных, но могут отличаться для параметров доменных типов).
Поведение сопоставляемых параметров можно рассматривать как ограниченную форму полиморфизма, применяющуюся только к текстовым типам данных.
Перегрузка функций
С одним и тем же SQL-именем может быть определено несколько функций, если они принимают разные наборы входных аргументов. Другими словами, имена функций могут быть перегружены.
Это требует дополнительных мер предосторожности при работе в базах данных, где несознательные пользователи могут создавать функции. Например, вы можете вызвать совсем другую функцию, ошибившись в типе аргумента.
При выполнении запроса, сервер выбирает, какую именно функцию вызывать, исходя из количества и типов данных предоставленных аргументов. Перегрузка может также использоваться для эмуляции функций с переменным числом аргументов, вплоть до конечного максимального числа.
При создании семейства перегруженных функций следует соблюдать осторожность, чтобы не создавать двусмысленности выбора. Например, если есть функции
CREATE FUNCTION test(int, real) RETURNS ...
CREATE FUNCTION test(smallint, double precision) RETURNS ...
то не понятно, какая функция вызовется при тривиальном запросе SELECT test(1, 1.5).
Конечно, есть конкретные правила выбора, но они могут измениться в следующей версии, и вообще не стоит полагаться на такие зыбкие механизмы. Какая функция вызовется, должно быть очевидно для человека, читающего код.
Имя функции, принимающей один аргумент составного типа, не
должно совпадать с одним из полей этого составного типа!
Дело в том, что если кортеж типа T имеет поле attribute,
то attribute(t) означает тоже самое, что и t.attribute.
Если вы создадите свою функцию attribute(T), то вместо вашей функции
будет молча вызываться t.attribute. Пользовательскую функцию всё-таки можно вызвать,
используя квалифицированное имя schema.attribute(t), но лучше в такое не ввязываться.
Другой возможный конфликт — между вариативной и невариативной функциями. Например, можно создать foo(numeric) и foo(VARIADIC numeric[]). В этом случае неясно, какая из них должна вызываться в случае foo(10.1). Правило состоит в том, что используется функция, появляющаяся ранее в пути поиска, или, если две функции находятся в одной и той же схеме, выбирается невариативная.
При перегрузке функций на нативном языке существует дополнительное ограничение: имена связывания нативных функций не должны повторяться, и не должны совпадать с именами внутренних функций QHB, иначе это приведёт к неоднозначности при вызове функции, получится платформозависимое поведение: вы либо получите ошибку подгрузки библиотеки во время работы, либо вызовется не та функция (при совпадение с именем внутренней функции, скорее всего, вызовется внутренняя). По умолчанию имя связывания совпадает с именем функции, но это можно переопределить альтернативной формой указания AS команды CREATE FUNCTION:
CREATE FUNCTION test(int) RETURNS int
AS 'filename', 'test_1arg'
LANGUAGE C;
CREATE FUNCTION test(int, int) RETURNS int
AS 'filename', 'test_2arg'
LANGUAGE C;
test_2arg — имя нативной функции; такой формат имени — лишь одно из многих возможных соглашений, нет чётких правил на этот счёт.
Категории изменчивости функций
Каждая функция имеет категорию изменчивости с возможными вариантами VOLATILE, STABLE или IMMUTABLE. VOLATILE является значением по умолчанию, если в CREATE FUNCTION не указать явно другую категорию. Категория изменчивости — это обещания оптимизатору касательно поведения функции:
-
Функция VOLATILE может делать все, что угодно, включая изменение базы данных. Она может возвращать разные результаты при последовательных вызовах с одинаковыми аргументами. Оптимизатор не делает никаких предположений о поведении таких функций. Запрос, использующий изменчивую функцию, выполняет функцию для каждой строки, каждый раз, где она встречается.
-
Функция STABLE не может изменить данные и гарантированно возвращает одинаковые результаты при одинаковых входных значения — в рамках одного запроса. Эта категория позволяет оптимизатору заменить несколько вызовов функции с одними и теми же аргументами на один вызов. В частности, если стабильная функция содержится в "правой части" условия фильтрации, то можно вычислить функцию один раз, и потом искать результат в индексе. (Для изменчивых функций это недопустимо, потому что значение условия потенциально может меняться, и надо его вычислять для каждой строки).
-
Функция IMMUTABLE не может изменять данные и гарантированно будет возвращать одни и те же результаты, если всегда будут одни и те же аргументы. Эта категория позволяет оптимизатору предварительно оценить функцию, когда запрос вызывает ее с постоянными аргументами. Например, запрос типа SELECT ... WHERE x = 2 + 2 может быть упрощен на вид до SELECT ... WHERE x = 4, потому что функция, лежащая в основе оператора сложения целых чисел, помечена как IMMUTABLE.
Для достижения наилучших результатов оптимизации вы должны пометить свои функции категорией самой строгой изменчивости, какая для них выполняется.
Любая функция с побочными эффектами должна быть помечена как VOLATILE, чтобы оптимизатор не мог убрать ее вызов. Даже функция без побочных эффектов должна быть помечена как VOLATILE если ее значение может измениться в течение выполнения одного запроса: например, random(), currval(), timeofday(). Другим важным примером является то, что семейство функций current_timestamp квалифицируется как STABLE, поскольку их значения не изменяются в пределах транзакции.
Разница между категориями STABLE и IMMUTABLE почти незаметна, если рассуждать о простых интерактивных запросах, которые планируются и выполняются немедленно: не имеет большого значения, выполняется ли функция один раз во время планирования или один раз во время запуска запроса. Разница, если план будет сохранён и использован позже. Обозначение функции IMMUTABLE, когда это неправда, может привести к преждевременной оптимизации вызова на этапе планирования, а потом к повторному использованию устаревшего значения при использовании плана. Это опасно при использовании подготовленных операторов или внутри процедур, план которых кешируется (например, процедуры на PL/pgSQL).
Для функций, написанных на SQL или на одном из стандартных процедурных языков, существует еще одно важное свойство, определяемое категорией изменчивости, а именно видимость любых изменений данных, которые уже были внесены командой SQL, вызывающей функцию. Функция VOLATILE увидит такие изменения, функция STABLE или IMMUTABLE нет. Это поведение реализовано с использованием моментальных снимков MVCC: функции STABLE и IMMUTABLE используют моментальный снимок, созданный в начале вызывающего запроса, тогда как функции VOLATILE получают новый снимок в начале запроса, который они выполняют внутри себя.
Примечание
Если нативные функции обращаются к базе, им было бы неплохо вести себя так же, как описано выше, в плане видимости изменений, но обеспечить это сложно...
Из-за такого поведения моментального снимка функция, результат которой зависит от данных в таблицах, может считаться стабильной, даже если она берёт данные из таблиц, которые могут правиться параллельно выполняющимися запросами (если, конечно, нет других причин, почему она нестабильная). QHB будет выполнять все команды STABLE-функции, используя снимок, созданный для вызывающего запроса, и, таким образом, функция будет видеть фиксированное состояние базы данных в течение всего этого запроса.
Такое же поведение снимка используется для IMMUTABLE-функций. Однако, если результат вашей функции зависит от содержимого таблиц, то она, по-видимому, не IMMUTABLE! (Результат изменится, когда поменяют содержимое таблицы). Однако QHB не запретит вам объявить такую функцию IMMUTABLE.
Распространенной ошибкой является пометка функции IMMUTABLE когда ее результаты зависят от параметра конфигурации. Например, функция, которая манипулирует временем, вполне может выдавать результаты, которые зависят от настройки TimeZone. В целях безопасности такие функции должны быть помечены как STABLE.
Замечание
QHB проверяет, чтобы функции, помеченные STABLE или IMMUTABLE, не содержали никаких команд SQL, кроме SELECT, т.к. функции, меняющие данные явно нестабильные. Однако не проверят и не предотвращает вызвать изменчивую функцию (формально, если функция вызывает изменчивую, то она тоже волатильная). Если вы попробуете сделать это, то заметите, что изменения данных, сделанные вызванной волатильной функцией, не видны внешней стабильной функции: она работает с моментальным снимком базы.
Функции на процедурном языке
QHB позволяет писать пользовательские функции на различных интерпретируемых("скриптовых") языках. Эти языки обычно называются процедурными языками (PL). Процедурные языки не встроены в сервер QHB; они реализованы в подгружаемых модулях. См. главу Процедурные языки и последующие главы для получения дополнительной информации.
Внутренние функции
Внутренние функции - это функции, написанные на C или на Rust, которые статически скомпонованы в сервер QHB. Определение функции состоит из её имени на C, которое не обязательно совпадает с именем, объявленным для использования в SQL. (Из соображений обратной совместимости пустое "тело" функции воспринимается как то, что имя функции на C совпадает с SQL-именем).
Обычно все внутренние функции, присутствующие на сервере, объявляются во время инициализации кластера базы данных (см. раздел Создание кластера базы данных), но пользователь может использовать CREATE FUNCTION для создания дополнительного псевдонима внутренней функции. Внутренние функции объявляются в CREATE FUNCTION с LANGUAGE internal. Например, создадим псевдоним для функции sqrt:
CREATE FUNCTION square_root(double precision) RETURNS double precision
AS 'dsqrt'
LANGUAGE internal
STRICT;
Большинство внутренних функций «строгие» (STRICT).
Замечание
Не все предопределенные функции являются «внутренними» в вышеописанном смысле. Некоторые предопределенные функции написаны на SQL.
Функции на нативном языке
Пользовательские нативные функции могут быть написаны на C, Rust, С++ или других компилируемых unmanaged языках. Функции должны следовать соглашению о вызове C ("extern C", все означенные языки имеют возможность следовать такому соглашению) и соглашению QHB об именах функций, экспортируемых из библиотек. Это соглашение об именах называется "Version 1", и для разработки на языке C предоставляется макрос PG_FUNCTION_INFO_V1() для правильного оформления вашей функции (см. ниже).
Пользовательские функции компилируются в динамически загружаемые объекты (также называемые разделяемыми библиотеками) и загружаются сервером по требованию. Функция динамической загрузки — это то, что отличает «нативные» функции от «внутренних», а сами функции устроены одинаково.
Динамическая загрузка
При первом вызове пользовательской функции в конкретном загружаемом объектном файле в сеансе динамический загрузчик загружает этот объектный файл в память, чтобы вызвать функцию. Поэтому функция CREATE FUNCTION для пользовательской функции C должна указывать две части информации для функции: имя загружаемого объектного файла и C-имя (символ ссылки) конкретной функции, вызываемой в этом объектном файле. Если C-имя не указано явно, предполагается, что оно совпадает с именем функции SQL.
Следующий алгоритм используется для поиска файла общего объекта на основе имени, указанного в команде CREATE FUNCTION:
-
Если имя является абсолютным путем, данный файл загружается.
-
Если имя начинается со строки $libdir, эта часть заменяется именем каталога библиотеки пакетов QHB, которое определяется во время сборки.
-
Если имя не содержит часть каталога, поиск файла производится по пути, указанному в переменной конфигурации dynamic_library_path, см. dynamic_library_path.
-
В противном случае (файл не найден в пути или он содержит не абсолютную часть каталога), динамический загрузчик попытается принять имя, как указано, что, скорее всего, не удастся. (Ненадежно зависеть от текущего рабочего каталога).
Если эта последовательность не работает, к указанному имени добавляется расширение имени файла общей библиотеки для конкретной платформы (часто .so), и эта последовательность повторяется. Если это также не удается, загрузка не удастся.
Рекомендуется размещать разделяемые библиотеки относительно $libdir или по пути динамической библиотеки. Это упрощает обновление версий, если новая установка находится в другом месте. Действительный каталог, $libdir стоит $libdir можно узнать с помощью команды pg_config --pkglibdir.
Идентификатор пользователя, на котором работает сервер QHB, должен проходить путь к файлу, который вы собираетесь загрузить. Создание файла или каталога более высокого уровня нечитабельным и/или не исполняемым пользователем qhb является распространенной ошибкой.
В любом случае имя файла, указанное в команде CREATE FUNCTION записывается буквально в системных каталогах, поэтому, если файл необходимо загрузить снова, применяется та же процедура.
Заметка
QHB не будет компилировать функцию C/Rust автоматически. Объектный файл должен быть скомпилирован перед тем, как на него будет ссылаться команда CREATE FUNCTION. См. раздел Компиляция и связывание динамически загружаемых функций для получения дополнительной информации.
Чтобы гарантировать, что динамически загружаемый объектный файл не загружается на несовместимый сервер, QHB проверяет, что файл содержит «магический блок» с соответствующим содержимым. Это позволяет серверу обнаруживать очевидные несовместимости, такие как код, скомпилированный для другой основной версии QHB. Чтобы включить магический блок, запишите это в один (и только один) из исходных файлов модуля после включения заголовка fmgr.h:
PG_MODULE_MAGIC;
После первого использования динамически загруженный объектный файл сохраняется в памяти. Будущие вызовы в том же сеансе к функциям в этом файле приведут только к небольшим накладным расходам поиска таблицы символов. Если вам необходимо принудительно перезагрузить объектный файл, например, после его перекомпиляции, начните новый сеанс.
При желании динамически загружаемый файл может содержать функции инициализации и финализации. Если файл содержит функцию с именем _PG_init, эта функция будет вызываться сразу после загрузки файла. Функция не получает параметров и должна возвращать void. Если файл содержит функцию с именем _PG_fini, эта функция будет вызвана непосредственно перед выгрузкой файла. Аналогично, функция не получает параметров и должна возвращать void. Обратите внимание, что _PG_fini будет вызываться только во время выгрузки файла, а не во время завершения процесса. (В настоящее время выгрузки отключены и никогда не произойдут, но это может измениться в будущем).
Базовые типы в функциях языка C/RUST
Чтобы знать, как писать функции на языке C/RUST, вам необходимо знать, как QHB внутренне представляет базовые типы данных и как их можно передавать в функции и из функций. Внутри QHB рассматривает базовый тип как «блок памяти». Пользовательские функции, которые вы определяете для типа, в свою очередь, определяют способ работы QHB с ним. То есть QHB будет хранить и извлекать данные только с диска и использовать ваши пользовательские функции для ввода, обработки и вывода данных.
Базовые типы могут иметь один из трех внутренних форматов:
-
передача по значению с фиксированной длиной
-
передача по ссылке, фиксированной длины
-
передача по ссылке, переменной длины
Типы по значению могут иметь длину только 1, 2 или 4 байта (также 8 байтов, если sizeof(Datum) равен 8 на вашем сервере). Вы должны быть осторожны, чтобы определить ваши типы так, чтобы они были одинакового размера (в байтах) на всех архитектурах. Например, тип long опасен, потому что на одних машинах он составляет 4 байта, а на других - 8 байтов, тогда как тип int на большинстве машин Unix составляет 4 байта. int4 реализация типа int4 на машинах Unix может быть:
/* 4-byte integer, passed by value */
typedef int int4;
(Фактический код QHB C вызывает этот тип int32, потому что в C существует соглашение, согласно которому int XX означает XX бит . Поэтому обратите внимание также на то, что тип C int8 имеет размер 1 байт. SQL-тип int8 называется int64 в C. См. также таблицу 1).
С другой стороны, типы фиксированной длины любого размера могут передаваться по ссылке. Например, вот пример реализации типа QHB:
/* 16-byte structure, passed by reference */
typedef struct
{
double x, y;
} Point;
Только указатели на такие типы могут использоваться при передаче их в и из функций QHB. Чтобы вернуть значение такого типа, выделите правильный объем памяти с помощью palloc, заполните выделенную память и верните указатель на нее. (Также, если вы просто хотите вернуть то же значение, что и один из ваших входных аргументов того же типа данных, вы можете пропустить лишний palloc и просто вернуть указатель на входное значение).
Наконец, все типы переменной длины также должны передаваться по ссылке. Все типы переменной длины должны начинаться с непрозрачного поля длины ровно 4 байта, которое будет установлено SET_VARSIZE; никогда не устанавливайте это поле напрямую! Все данные, которые должны быть сохранены в этом типе, должны быть расположены в памяти сразу после этого поля длины. Поле длины содержит общую длину структуры, то есть включает в себя размер самого поля длины.
Еще один важный момент - избегать оставления неинициализированных битов в значениях типа данных; например, позаботьтесь об обнулении любых байтов заполнения выравнивания, которые могут присутствовать в структурах. Без этого планировщик может рассматривать логически эквивалентные константы вашего типа данных как неравные, что приводит к неэффективным (хотя и не неправильным) планам.
!!! Предупреждение
Никогда не изменяйте содержимое входного значения передачи по ссылке. Если вы это сделаете, вы, скорее всего, повредите данные на диске, поскольку указанный вами указатель может указывать прямо на буфер диска. Единственное исключение из этого правила объясняется в разделе Пользовательские агрегаты.
В качестве примера мы можем определить тип text следующим образом:
typedef struct {
int32 length;
char data[FLEXIBLE_ARRAY_MEMBER];
} text;
Нотация [FLEXIBLE_ARRAY_MEMBER] означает, что фактическая длина
части данных не указана в этом объявлении.
При манипулировании типами переменной длины мы должны быть осторожны, чтобы правильно распределить объем памяти и правильно задать поле длины. Например, если мы хотим сохранить 40 байтов в text структуре, мы можем использовать фрагмент кода, подобный этому:
#include "postgres.h"
...
char buffer[40]; /* our source data */
...
text *destination = (text *) palloc(VARHDRSZ + 40);
SET_VARSIZE(destination, VARHDRSZ + 40);
memcpy(destination->data, buffer, 40);
...
VARHDRSZ - это то же самое, что и sizeof(int32), но считается хорошим стилем использовать макрос VARHDRSZ для ссылки на размер служебной информации для типа переменной длины. Кроме того, поле длины должно быть установлено с SET_VARSIZE макроса SET_VARSIZE, а не путем простого присваивания.
Таблица 1 указывает, какой тип C/RUST соответствует какому типу SQL при написании функции на языке C/RUST, использующей встроенный тип QHB. В столбце «Определено в» указан заголовочный файл, который необходимо включить, чтобы получить определение типа. (Фактическое определение может быть в другом файле, который включен в указанный файл. Рекомендуется, чтобы пользователи придерживались определенного интерфейса). Обратите внимание, что вы всегда должны сначала включать postgres.h в любой исходный файл, поскольку он объявляет ряд вещей, которые вам понадобятся в любом случае.
Таблица 1. Эквивалентные типы C для встроенных типов SQL
| Тип SQL | Тип C | Определено в |
|---|---|---|
| boolean | bool | postgres.h (возможно встроенный компилятор) |
| box | BOX* | utils/geo_decls.h |
| bytea | bytea* | postgres.h |
| "char" | char | (встроенный компилятор) |
| character | BpChar* | postgres.h |
| cid | CommandId | postgres.h |
| date | DateADT | utils/date.h |
| smallint ( int2 ) | int16 | postgres.h |
| int2vector | int2vector* | postgres.h |
| integer ( int4 ) | int32 | postgres.h |
| real ( float4 ) | float4* | postgres.h |
| double precision ( float8 ) | float8* | postgres.h |
| interval | Interval* | datatype/timestamp.h |
| lseg | LSEG* | utils/geo_decls.h |
| name | Name | postgres.h |
| oid | Oid | postgres.h |
| oidvector | oidvector* | postgres.h |
| path | PATH* | utils/geo_decls.h |
| point | POINT* | utils/geo_decls.h |
| regproc | regproc | postgres.h |
| text | text* | postgres.h |
| tid | ItemPointer | storage/itemptr.h |
| time | TimeADT | utils/date.h |
| time with time zone | TimeTzADT | utils/date.h |
| timestamp | Timestamp* | datatype/timestamp.h |
| varchar | VarChar* | postgres.h |
| xid | TransactionId | postgres.h |
Теперь, когда мы рассмотрели все возможные структуры для базовых типов, мы можем показать некоторые примеры реальных функций.
Версия 1 Соглашение о вызовах
Соглашение о вызовах версии 1 опирается на макросы, которые подавляют большую часть сложности передачи аргументов и результатов. Объявление C функции версии-1 всегда:
Datum funcname(PG_FUNCTION_ARGS)
Кроме того, вызов макроса:
PG_FUNCTION_INFO_V1(funcname);
должен появиться в том же исходном файле. (Обычно он написан непосредственно перед самой функцией). Этот вызов макроса не требуется для внутренних функций языка, поскольку QHB предполагает, что все внутренние функции используют соглашение версии 1. Это, однако, требуется для динамически загружаемых функций.
В функции версии 1 каждый фактический аргумент выбирается с помощью PG_GETARG_ xxx () который соответствует типу данных аргумента. В нестрогих функциях необходимо предварительно проверить нулевой аргумент, используя PG_ARGNULL_ xxx (). Результат возвращается с использованием PG_RETURN_ xxx () для возвращаемого типа. PG_GETARG_ xxx () принимает в качестве аргумента номер аргумента функции для выборки, где счет начинается с 0. PG_RETURN_ xxx () принимает в качестве аргумента фактическое значение, которое нужно вернуть.
Вот несколько примеров использования соглашения о вызовах версии 1:
#include "postgres.h"
#include <string.h>
#include "fmgr.h"
#include "utils/geo_decls.h"
PG_MODULE_MAGIC;
/* by value */
PG_FUNCTION_INFO_V1(add_one);
Datum
add_one(PG_FUNCTION_ARGS)
{
int32 arg = PG_GETARG_INT32(0);
PG_RETURN_INT32(arg + 1);
}
/* by reference, fixed length */
PG_FUNCTION_INFO_V1(add_one_float8);
Datum
add_one_float8(PG_FUNCTION_ARGS)
{
/* The macros for FLOAT8 hide its pass-by-reference nature. */
float8 arg = PG_GETARG_FLOAT8(0);
PG_RETURN_FLOAT8(arg + 1.0);
}
PG_FUNCTION_INFO_V1(makepoint);
Datum
makepoint(PG_FUNCTION_ARGS)
{
/* Here, the pass-by-reference nature of Point is not hidden. */
Point *pointx = PG_GETARG_POINT_P(0);
Point *pointy = PG_GETARG_POINT_P(1);
Point *new_point = (Point *) palloc(sizeof(Point));
new_point->x = pointx->x;
new_point->y = pointy->y;
PG_RETURN_POINT_P(new_point);
}
/* by reference, variable length */
PG_FUNCTION_INFO_V1(copytext);
Datum
copytext(PG_FUNCTION_ARGS)
{
text *t = PG_GETARG_TEXT_PP(0);
/*
* VARSIZE_ANY_EXHDR is the size of the struct in bytes, minus the
* VARHDRSZ or VARHDRSZ_SHORT of its header. Construct the copy with a
* full-length header.
*/
text *new_t = (text *) palloc(VARSIZE_ANY_EXHDR(t) + VARHDRSZ);
SET_VARSIZE(new_t, VARSIZE_ANY_EXHDR(t) + VARHDRSZ);
/*
* VARDATA is a pointer to the data region of the new struct. The source
* could be a short datum, so retrieve its data through VARDATA_ANY.
*/
memcpy((void *) VARDATA(new_t), /* destination */
(void *) VARDATA_ANY(t), /* source */
VARSIZE_ANY_EXHDR(t)); /* how many bytes */
PG_RETURN_TEXT_P(new_t);
}
PG_FUNCTION_INFO_V1(concat_text);
Datum
concat_text(PG_FUNCTION_ARGS)
{
text *arg1 = PG_GETARG_TEXT_PP(0);
text *arg2 = PG_GETARG_TEXT_PP(1);
int32 arg1_size = VARSIZE_ANY_EXHDR(arg1);
int32 arg2_size = VARSIZE_ANY_EXHDR(arg2);
int32 new_text_size = arg1_size + arg2_size + VARHDRSZ;
text *new_text = (text *) palloc(new_text_size);
SET_VARSIZE(new_text, new_text_size);
memcpy(VARDATA(new_text), VARDATA_ANY(arg1), arg1_size);
memcpy(VARDATA(new_text) + arg1_size, VARDATA_ANY(arg2), arg2_size);
PG_RETURN_TEXT_P(new_text);
}
Предполагая, что приведенный выше код был подготовлен в файле funcs.c и скомпилирован в общий объект, мы могли бы определить функции для QHB с помощью таких команд:
CREATE FUNCTION add_one(integer) RETURNS integer
AS 'DIRECTORY/funcs', 'add_one'
LANGUAGE C STRICT;
-- note overloading of SQL function name "add_one"
CREATE FUNCTION add_one(double precision) RETURNS double precision
AS 'DIRECTORY/funcs', 'add_one_float8'
LANGUAGE C STRICT;
CREATE FUNCTION makepoint(point, point) RETURNS point
AS 'DIRECTORY/funcs', 'makepoint'
LANGUAGE C STRICT;
CREATE FUNCTION copytext(text) RETURNS text
AS 'DIRECTORY/funcs', 'copytext'
LANGUAGE C STRICT;
CREATE FUNCTION concat_text(text, text) RETURNS text
AS 'DIRECTORY/funcs', 'concat_text'
LANGUAGE C STRICT;
Здесь DIRECTORY обозначает каталог файла общей библиотеки (например,
каталог учебника по QHB, который содержит код для примеров,
используемых в этом разделе). (Лучше было бы использовать просто 'funcs'
в предложении AS после добавления DIRECTORY в путь поиска. В любом
случае мы можем опустить системное расширение для общей библиотеки,
обычно .so ).
Обратите внимание, что мы указали функции как «строгие», что означает, что система должна автоматически принимать нулевой результат, если любое входное значение равно нулю. Делая это, мы избегаем необходимости проверять нулевые входы в коде функции. Без этого нам пришлось бы явно проверять нулевые значения, используя PG_ARGISNULL().
На первый взгляд, соглашения о кодировании в версии 1 могут показаться просто бессмысленным мракобесием по сравнению с использованием простых соглашений о вызовах языка C/RUST. Тем не менее, они позволяют работать с NULL аргументами / возвращаемыми значениями и «поджаренными» (сжатыми или вне строки) значениями.
Макрос PG_ARGISNULL(n) позволяет функции проверять, является ли каждый вход нулевым. (Конечно, делать это необходимо только в функциях, не объявленных как «строгие»). Как и в PG_GETARG_ xxx (), входные аргументы считаются начиная с нуля. Обратите внимание, что следует воздерживаться от выполнения PG_GETARG_ xxx () пока не убедитесь что аргумент не является нулевым. Чтобы вернуть нулевой результат, выполните PG_RETURN_NULL(); это работает как в строгих, так и в нестрогих функциях.
Другие опции, предоставляемые интерфейсом версии 1, - это два варианта PG_GETARG_ xxx (). Первый из них, PG_GETARG_ xxx _COPY(), гарантирует возврат копии указанного аргумента, который является безопасным для записи. (Обычные макросы иногда возвращают указатель на значение, которое физически хранится в таблице, в которую нельзя записывать. Использование PG_GETARG_ xxx _COPY() гарантирует доступный для записи результат). Второй вариант состоит из PG_GETARG_ xxx _SLICE() макроса, который принимает три аргумента. Первый - это номер аргумента функции (как указано выше). Второе и третье - это смещение и длина возвращаемого сегмента. Смещения отсчитываются от нуля, а отрицательная длина требует возврата оставшейся части значения. Эти макросы обеспечивают более эффективный доступ к частям больших значений в том случае, если они имеют тип хранения «внешний». (Тип хранения столбца может быть указан с помощью ALTER TABLE tablename ALTER COLUMN colname SET STORAGE storagetype. storagetype - один из plain, external, extended или main).
Наконец, соглашения о вызовах функций версии 1 позволяют возвращать заданные результаты (раздел Возврат наборов) и реализовывать функции триггера (глава Триггеры)
Написание кода
Прежде чем перейти к более сложным темам, мы должны обсудить некоторые правила кодирования для функций языка C/RUST QHB. Хотя может быть возможно загрузить функции, написанные на языках, отличных от C, в QHB, это обычно сложно (когда это вообще возможно), потому что другие языки, такие как C++, FORTRAN или Pascal, часто не следуют тому же соглашению о вызовах, что и C. То есть другие языки не передают аргумент и возвращают значения между функциями одинаковым образом. По этой причине мы будем предполагать, что ваши функции языка C на самом деле написаны на C/RUST.
Основные правила написания и построения функций C/RUST следующие:
-
Используйте pg_config --includedir-server чтобы узнать, где установлены файлы заголовков сервера QHB в вашей системе (или системе, на которой будут работать ваши пользователи).
-
Компиляция и компоновка вашего кода для его динамической загрузки в QHB всегда требует специальных флагов. См. раздел Компиляция и связывание динамически загружаемых функций для подробного объяснения того, как это сделать для вашей конкретной операционной системы.
-
Не забудьте определить «магический блок» для вашей общей библиотеки, как описано в разделе 6.10.1.
-
При выделении памяти используйте функции QHB palloc и pfree вместо соответствующих библиотек C функции malloc и free. Память, выделенная palloc будет автоматически освобождаться в конце каждой транзакции, предотвращая утечки памяти.
-
Всегда обнуляйте байты ваших структур, используя memset (или выделяйте их сначала с помощью palloc0). Даже если вы назначите каждому полю вашей структуры, могут быть отступы выравнивания (отверстия в структуре), которые содержат значения мусора. Без этого трудно поддерживать хеш-индексы или хеш-объединения, так как для вычисления хеша необходимо выделить только значимые биты вашей структуры данных. Планировщик также иногда полагается на сравнение констант с помощью побитового равенства, поэтому вы можете получить нежелательные результаты планирования, если логически эквивалентные значения не являются побитовыми.
-
Большинство внутренних типов QHB объявлены в postgres.h, в то время как интерфейсы диспетчера функций ( PG_FUNCTION_ARGS и т. д.) Находятся в fmgr.h, поэтому вам нужно будет включить как минимум эти два файла. По причинам переносимости лучше сначала включить postgres.h, а не файлы заголовков других систем или пользователей. В том числе postgres.h также будет включать elog.h и palloc.h для вас.
-
Имена символов, определенные в объектных файлах, не должны конфликтовать друг с другом или с символами, определенными в исполняемом файле сервера QHB. Вам придется переименовать ваши функции или переменные, если вы получите сообщения об ошибках по этому поводу.
Компиляция и связывание динамически загружаемых функций
Прежде чем вы сможете использовать свои функции расширения QHB, написанные на C/RUST, они должны быть скомпилированы и связаны особым образом для создания файла, который может быть динамически загружен сервером. Чтобы быть точным, необходимо создать общую библиотеку .
Для получения информации, выходящей за рамки этого раздела, вам следует прочитать документацию по вашей операционной системе, в частности страницы руководства для компилятора C/RUST, cc и редактора ссылок, ld. Кроме того, исходный код QHB содержит несколько рабочих примеров в каталоге contrib. Однако, если вы будете полагаться на эти примеры, вы сделаете свои модули зависимыми от доступности исходного кода QHB.
Создание общих библиотек обычно аналогично связыванию исполняемых файлов: сначала исходные файлы компилируются в объектные файлы, затем объектные файлы связываются вместе. Объектные файлы должны быть созданы как позиционно-независимый код (PIC), что концептуально означает, что они могут быть размещены в произвольном месте в памяти, когда они загружаются исполняемым файлом. (Объектные файлы, предназначенные для исполняемых файлов, обычно не компилируются таким образом). Команда для связи общей библиотеки содержит специальные флаги, чтобы отличать ее от ссылки на исполняемый файл (по крайней мере, теоретически - в некоторых системах эта практика намного уродливее).
В следующих примерах мы предполагаем, что ваш исходный код находится в файле foo.c и мы создадим общую библиотеку foo.so Промежуточный объектный файл будет называться foo.o если не указано иное. Общая библиотека может содержать более одного объектного файла, но здесь мы используем только один.
Linux
- Флаг компилятора для создания PIC - -fPIC. Флаг компилятора для создания разделяемой библиотеки - -shared. Полный пример выглядит так:
cc -fPIC -c foo.c
cc -shared -o foo.so foo.o
Полученный файл общей библиотеки затем можно загрузить в QHB . При указании имени файла для команды CREATE FUNCTIONнеобходимо указать имя файла общей библиотеки, а не файла промежуточных объектов. Обратите внимание, что стандартное расширение разделяемой библиотеки системы (обычно .so или .sl ) может быть опущено в команде CREATE FUNCTION и обычно должно быть опущено для лучшей переносимости.
Обратитесь к разделу 6.10.1 о том, где сервер ожидает найти файлы общей библиотеки.
Составные аргументы
Составные типы не имеют фиксированного макета, как структуры C. Экземпляры составного типа могут содержать пустые поля. Кроме того, составные типы, являющиеся частью иерархии наследования, могут иметь поля, отличные от других членов той же иерархии наследования. Следовательно, QHB предоставляет функциональный интерфейс для доступа к полям составных типов из C.
Предположим, мы хотим написать функцию для ответа на запрос:
SELECT name, c_overpaid(emp, 1500) AS overpaid
FROM emp
WHERE name = 'Bill' OR name = 'Sam';
Используя соглашения о вызовах версии-1, мы можем определить c_overpaid как:
#include "postgres.h"
#include "executor/executor.h" /* for GetAttributeByName() */
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(c_overpaid);
Datum
c_overpaid(PG_FUNCTION_ARGS)
{
HeapTupleHeader t = PG_GETARG_HEAPTUPLEHEADER(0);
int32 limit = PG_GETARG_INT32(1);
bool isnull;
Datum salary;
salary = GetAttributeByName(t, "salary", &isnull);
if (isnull)
PG_RETURN_BOOL(false);
/* Alternatively, we might prefer to do PG_RETURN_NULL() for null salary. */
PG_RETURN_BOOL(DatumGetInt32(salary) > limit);
}
GetAttributeByName - системная функция QHB, которая возвращает атрибуты из указанной строки. Он имеет три аргумента: аргумент типа HeapTupleHeader передаваемый в функцию, имя требуемого атрибута и возвращаемый параметр, который сообщает, является ли атрибут null. GetAttributeByName возвращает значение Datum которое можно преобразовать в правильный тип данных с помощью соответствующего DatumGetXXX(). Обратите внимание, что возвращаемое значение не имеет смысла, если установлен null флаг; всегда проверяйте null флаг, прежде чем пытаться что-либо сделать с результатом.
Существует также GetAttributeByNum, который выбирает целевой атрибут по номеру столбца, а не по имени.
Следующая команда объявляет функцию c_overpaid в SQL:
CREATE FUNCTION c_overpaid(emp, integer) RETURNS boolean
AS 'DIRECTORY/funcs', 'c_overpaid'
LANGUAGE C STRICT;
Обратите внимание, что мы использовали STRICT чтобы нам не нужно было проверять, были ли входные аргументы NULL.
Возвращающиеся строки (составные типы)
Чтобы вернуть значение строки или составного типа из функции языка C/RUST, вы можете использовать специальный API, который предоставляет макросы и функции, чтобы скрыть большую часть сложности построения составных типов данных. Чтобы использовать этот API, исходный файл должен включать:
#include "funcapi.h"
Существует два способа создания составного значения данных (далее «кортеж»): вы можете построить его из массива значений Datum или из массива строк C/RUST, которые можно передать во входные функции преобразования столбца кортежа типы данных. В любом случае сначала необходимо получить или создать дескриптор TupleDesc для структуры кортежа. При работе с Datums вы передаете TupleDesc в BlessTupleDesc, а затем вызываете heap_form_tuple для каждой строки. При работе со строками C вы передаете TupleDesc в TupleDescGetAttInMetadata, а затем вызываете BuildTupleFromCStrings для каждой строки. В случае если функция возвращает набор кортежей, все шаги настройки могут быть выполнены один раз во время первого вызова функции.
Несколько вспомогательных функций доступны для настройки необходимого TupleDesc. Рекомендуемый способ сделать это в большинстве функций, возвращающих составные значения, это вызвать:
TypeFuncClass get_call_result_type(FunctionCallInfo fcinfo,
Oid *resultTypeId,
TupleDesc *resultTupleDesc)
передача той же самой структуры fcinfo переданной самой вызывающей функции. (Это, конечно, требует использования соглашений о вызовах версии-1). resultTypeId может быть задан как NULL или как адрес локальной переменной для получения OID типа результата функции. resultTupleDesc должен быть адресом локальной переменной TupleDesc. Убедитесь, что результатом является TYPEFUNC_COMPOSITE; если это так, resultTupleDesc был заполнен необходимым TupleDesc. (Если это не так, вы можете сообщить об ошибке в соответствии с «function returning record called in context that cannot accept type record» ).
Заметка
get_call_result_type может разрешить фактический тип результата полиморфной функции; так что это полезно в функциях, которые возвращают скалярные полиморфные результаты, а не только в функциях, которые возвращают композиты. Вывод resultTypeId в первую очередь полезен для функций, возвращающих полиморфные скаляры.
Заметка
get_call_result_type имеет одноуровневый get_expr_result_type, который можно использовать для разрешения ожидаемого выходного типа для вызова функции, представленного деревом выражений. Это может быть использовано при попытке определить тип результата вне самой функции. Существует также get_func_result_type, который можно использовать, когда доступен только OID функции. Однако эти функции не могут работать с функциями, объявленными для возврата record, и get_func_result_type не может разрешать полиморфные типы, поэтому вы должны преимущественно использовать get_call_result_type.
Старые устаревшие функции для получения TupleDesc:
TupleDesc RelationNameGetTupleDesc(const char *relname)
чтобы получить TupleDesc для типа строки именованного отношения, и:
TupleDesc TypeGetTupleDesc(Oid typeoid, List *colaliases)
чтобы получить TupleDesc на основе типа OID. Это может быть использовано для получения TupleDesc для базового или составного типа. Однако она не будет работать для функции, которая возвращает record, и не может разрешать полиморфные типы.
Когда у вас есть TupleDesc, вызовите:
TupleDesc BlessTupleDesc(TupleDesc tupdesc)
если вы планируете работать с Datums, или:
AttInMetadata *TupleDescGetAttInMetadata(TupleDesc tupdesc)
если вы планируете работать со строками C. Если вы пишете функцию, возвращающую набор, вы можете сохранить результаты этих функций в структуре FuncCallContext - используйте поле tuple_desc или attinmeta соответственно.
При работе с Datums используйте:
HeapTuple heap_form_tuple(TupleDesc tupdesc, Datum *values, bool *isnull)
построить HeapTuple заданных пользовательских данных в форме Datum.
При работе со строками Си используйте:
HeapTuple BuildTupleFromCStrings(AttInMetadata *attinmeta, char **values)
построить HeapTuple данных пользовательских данных в форме строки C. values это массив строк C, по одному на каждый атрибут возвращаемой строки. Каждая строка C должна иметь форму, ожидаемую функцией ввода типа данных атрибута. Чтобы вернуть null значение для одного из атрибутов, соответствующий указатель в массиве values должен быть установлен в NULL. Эту функцию нужно будет вызывать снова для каждой возвращаемой строки.
Как только вы построите кортеж для возврата из своей функции, он должен быть преобразован в элемент Datum. Использование:
HeapTupleGetDatum(HeapTuple tuple)
преобразовать HeapTuple в действительный элемент данных. Этот Datum может быть возвращен напрямую, если вы намереваетесь вернуть только одну строку, или он может использоваться как текущее возвращаемое значение в функции, возвращающей множество.
Пример появится в следующем разделе.
Возврат наборов
Существует также специальный API, который обеспечивает поддержку возврата наборов (нескольких строк) из функции языка Си. Функция, возвращающая множество, должна следовать соглашениям о вызовах версии-1. Кроме того, исходные файлы должны включать funcapi.h, как указано выше.
Функция возврата набора (SRF) вызывается один раз для каждого
возвращаемого элемента. Поэтому SRF должен сохранять достаточно
состояния, чтобы помнить, что он делал, и возвращать следующий элемент
при каждом вызове. Структура FuncCallContext предназначена для
управления этим процессом. Внутри функции
fcinfo->flinfo->fn_extra используется для хранения указателя на
FuncCallContext во всех вызовах.
typedef struct FuncCallContext
{
/*
* Number of times we've been called before
*
* call_cntr is initialized to 0 for you by SRF_FIRSTCALL_INIT(), and
* incremented for you every time SRF_RETURN_NEXT() is called.
*/
uint64 call_cntr;
/*
* OPTIONAL maximum number of calls
*
* max_calls is here for convenience only and setting it is optional.
* If not set, you must provide alternative means to know when the
* function is done.
*/
uint64 max_calls;
/*
* OPTIONAL pointer to miscellaneous user-provided context information
*
* user_fctx is for use as a pointer to your own data to retain
* arbitrary context information between calls of your function.
*/
void *user_fctx;
/*
* OPTIONAL pointer to struct containing attribute type input metadata
*
* attinmeta is for use when returning tuples (i.e., composite data types)
* and is not used when returning base data types. It is only needed
* if you intend to use BuildTupleFromCStrings() to create the return
* tuple.
*/
AttInMetadata *attinmeta;
/*
* memory context used for structures that must live for multiple calls
*
* multi_call_memory_ctx is set by SRF_FIRSTCALL_INIT() for you, and used
* by SRF_RETURN_DONE() for cleanup. It is the most appropriate memory
* context for any memory that is to be reused across multiple calls
* of the SRF.
*/
MemoryContext multi_call_memory_ctx;
/*
* OPTIONAL pointer to struct containing tuple description
*
* tuple_desc is for use when returning tuples (i.e., composite data types)
* and is only needed if you are going to build the tuples with
* heap_form_tuple() rather than with BuildTupleFromCStrings(). Note that
* the TupleDesc pointer stored here should usually have been run through
* BlessTupleDesc() first.
*/
TupleDesc tuple_desc;
} FuncCallContext;
SRF использует несколько функций и макросов, которые автоматически манипулируют структурой FuncCallContext (и ожидают найти ее через fn_extra). Использование:
SRF_IS_FIRSTCALL()
определить, вызывается ли ваша функция в первый или последующий раз. При первом вызове (только) используйте:
SRF_FIRSTCALL_INIT()
инициализировать FuncCallContext. При каждом вызове функции, включая первый, используйте:
SRF_PERCALL_SETUP()
правильно настроить использование FuncCallContext и очистку любых ранее возвращенных данных, оставшихся от предыдущего прохода.
Если ваша функция имеет данные для возврата, используйте:
SRF_RETURN_NEXT(funcctx, result)
вернуть его вызывающему. (результат должен иметь тип Datum, либо одно значение, либо кортеж, подготовленный, как описано выше). Наконец, когда ваша функция закончит возвращать данные, используйте:
SRF_RETURN_DONE(funcctx)
очистить и закончить SRF.
Текущий контекст памяти, когда вызывается SRF, является временным контекстом, который будет очищен между вызовами. Это означает, что вам не нужно вызывать pfree для всего, что вы выделили с помощью palloc; это все равно уйдет. Однако, если вы хотите распределить какие-либо структуры данных между вызовами, вам нужно поместить их в другое место. Контекст памяти, на который ссылается multi_call_memory_ctx, является подходящим местом для любых данных, которые должны сохраняться до завершения работы SRF. В большинстве случаев это означает, что вы должны переключиться на multi_call_memory_ctx при выполнении настройки первого вызова.
!!! Предупреждение
Хотя фактические аргументы функции остаются неизменными между вызовами, если вы сбрасываете значения аргументов (что обычно делается прозрачно с помощью макроса PG_GETARG_xxx) во временном контексте, то очищенные копии будут освобождаться в каждом цикле. Соответственно, если вы сохраняете ссылки на такие значения в вашем user_fctx, вы должны либо скопировать их в multi_call_memory_ctx после удаления, либо убедиться, что вы удалили значения только в этом контексте.
Полный пример псевдокода выглядит следующим образом:
Datum
my_set_returning_function(PG_FUNCTION_ARGS)
{
FuncCallContext *funcctx;
Datum result;
further declarations as needed
if (SRF_IS_FIRSTCALL())
{
MemoryContext oldcontext;
funcctx = SRF_FIRSTCALL_INIT();
oldcontext = MemoryContextSwitchTo(funcctx->multi_call_memory_ctx);
/* One-time setup code appears here: */
user code
if returning composite
build TupleDesc, and perhaps AttInMetadata
endif returning composite
user code
MemoryContextSwitchTo(oldcontext);
}
/* Each-time setup code appears here: */
user code
funcctx = SRF_PERCALL_SETUP();
user code
/* this is just one way we might test whether we are done: */
if (funcctx->call_cntr < funcctx->max_calls)
{
/* Here we want to return another item: */
user code
obtain result Datum
SRF_RETURN_NEXT(funcctx, result);
}
else
{
/* Here we are done returning items and just need to clean up: */
user code
SRF_RETURN_DONE(funcctx);
}
}
Полный пример простого SRF, возвращающего составной тип, выглядит следующим образом:
PG_FUNCTION_INFO_V1(retcomposite);
Datum
retcomposite(PG_FUNCTION_ARGS)
{
FuncCallContext *funcctx;
int call_cntr;
int max_calls;
TupleDesc tupdesc;
AttInMetadata *attinmeta;
/* stuff done only on the first call of the function */
if (SRF_IS_FIRSTCALL())
{
MemoryContext oldcontext;
/* create a function context for cross-call persistence */
funcctx = SRF_FIRSTCALL_INIT();
/* switch to memory context appropriate for multiple function calls */
oldcontext = MemoryContextSwitchTo(funcctx->multi_call_memory_ctx);
/* total number of tuples to be returned */
funcctx->max_calls = PG_GETARG_UINT32(0);
/* Build a tuple descriptor for our result type */
if (get_call_result_type(fcinfo, NULL, &tupdesc) != TYPEFUNC_COMPOSITE)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("function returning record called in context "
"that cannot accept type record")));
/*
* generate attribute metadata needed later to produce tuples from raw
* C strings
*/
attinmeta = TupleDescGetAttInMetadata(tupdesc);
funcctx->attinmeta = attinmeta;
MemoryContextSwitchTo(oldcontext);
}
/* stuff done on every call of the function */
funcctx = SRF_PERCALL_SETUP();
call_cntr = funcctx->call_cntr;
max_calls = funcctx->max_calls;
attinmeta = funcctx->attinmeta;
if (call_cntr < max_calls) /* do when there is more left to send */
{
char **values;
HeapTuple tuple;
Datum result;
/*
* Prepare a values array for building the returned tuple.
* This should be an array of C strings which will
* be processed later by the type input functions.
*/
values = (char **) palloc(3 * sizeof(char *));
values[0] = (char *) palloc(16 * sizeof(char));
values[1] = (char *) palloc(16 * sizeof(char));
values[2] = (char *) palloc(16 * sizeof(char));
snprintf(values[0], 16, "%d", 1 * PG_GETARG_INT32(1));
snprintf(values[1], 16, "%d", 2 * PG_GETARG_INT32(1));
snprintf(values[2], 16, "%d", 3 * PG_GETARG_INT32(1));
/* build a tuple */
tuple = BuildTupleFromCStrings(attinmeta, values);
/* make the tuple into a datum */
result = HeapTupleGetDatum(tuple);
/* clean up (this is not really necessary) */
pfree(values[0]);
pfree(values[1]);
pfree(values[2]);
pfree(values);
SRF_RETURN_NEXT(funcctx, result);
}
else /* do when there is no more left */
{
SRF_RETURN_DONE(funcctx);
}
}
Один из способов объявить эту функцию в SQL:
CREATE TYPE __retcomposite AS (f1 integer, f2 integer, f3 integer);
CREATE OR REPLACE FUNCTION retcomposite(integer, integer)
RETURNS SETOF __retcomposite
AS 'filename', 'retcomposite'
LANGUAGE C IMMUTABLE STRICT;
Другой способ - использовать параметры OUT:
CREATE OR REPLACE FUNCTION retcomposite(IN integer, IN integer,
OUT f1 integer, OUT f2 integer, OUT f3 integer)
RETURNS SETOF record
AS 'filename', 'retcomposite'
LANGUAGE C IMMUTABLE STRICT;
Обратите внимание, что в этом методе тип вывода функции формально является анонимным типом записи.
Модуль contrib/tablefunc каталога в исходном дистрибутиве содержит больше примеров возвращающих множество функций.
Полиморфные аргументы и возвращаемые типы
Можно объявить функции языка Си, чтобы они принимали и возвращали
полиморфные типы anyelement, anyarray, anynonarray, anyenum и anyrange.
См. Раздел Полиморфные типы для более подробного объяснения полиморфных функций.
Когда аргументы функции или возвращаемые типы определены как полиморфные
типы, автор функции не может заранее знать, с каким типом данных он
будет вызываться или должен возвращаться. В fmgr.h предусмотрены две
подпрограммы, позволяющие функции C версии 1 обнаружить фактические типы
данных своих аргументов и тип, который ожидается вернуть. Процедуры
называются get_fn_expr_rettype(FmgrInfo *flinfo) и
get_fn_expr_argtype(FmgrInfo *flinfo, int argnum). Они возвращают
OID типа результата или аргумента или InvalidOid, если информация
недоступна. Структура flinfo обычно доступна как fcinfo->flinfo.
Параметр argnum основан на zero. get_call_result_type также может
использоваться как альтернатива get_fn_expr_rettype. Существует также
get_fn_expr_variadic, который можно использовать для определения,
были ли переменные аргументы объединены в массив. Это в первую очередь
полезно для VARIADIC "any" функций, поскольку такое объединение всегда
будет происходить для функций с переменными числами, принимающих обычные
типы массивов.
Например, предположим, что мы хотим написать функцию, которая принимает один элемент любого типа, и возвращает одномерный массив этого типа:
PG_FUNCTION_INFO_V1(make_array);
Datum
make_array(PG_FUNCTION_ARGS)
{
ArrayType *result;
Oid element_type = get_fn_expr_argtype(fcinfo->flinfo, 0);
Datum element;
bool isnull;
int16 typlen;
bool typbyval;
char typalign;
int ndims;
int dims[MAXDIM];
int lbs[MAXDIM];
if (!OidIsValid(element_type))
elog(ERROR, "could not determine data type of input");
/* get the provided element, being careful in case it's NULL */
isnull = PG_ARGISNULL(0);
if (isnull)
element = (Datum) 0;
else
element = PG_GETARG_DATUM(0);
/* we have one dimension */
ndims = 1;
/* and one element */
dims[0] = 1;
/* and lower bound is 1 */
lbs[0] = 1;
/* get required info about the element type */
get_typlenbyvalalign(element_type, &typlen, &typbyval, &typalign);
/* now build the array */
result = construct_md_array(&element, &isnull, ndims, dims, lbs,
element_type, typlen, typbyval, typalign);
PG_RETURN_ARRAYTYPE_P(result);
}
Следующая команда объявляет функцию make_array в SQL:
CREATE FUNCTION make_array(anyelement) RETURNS anyarray
AS 'DIRECTORY/funcs', 'make_array'
LANGUAGE C IMMUTABLE;
Существует вариант полиморфизма, который доступен только для функций языка Си: они могут быть объявлены для получения параметров типа "any". (Обратите внимание, что это имя типа должно быть заключено в двойные кавычки, поскольку оно также является зарезервированным словом SQL). Это работает как любой элемент, за исключением того, что оно не ограничивает различные "any" аргументы одним и тем же типом и не помогает определить результат функции тип. Функция языка Си также может объявить свой последний параметр VARIADIC "any". Это будет соответствовать одному или нескольким фактическим аргументам любого типа (не обязательно того же типа). Эти аргументы не будут собраны в массив, как это происходит с обычными переменными функциями; они просто будут переданы функции отдельно. Макрос PG_NARGS () и методы, описанные выше, должны использоваться для определения количества фактических аргументов и их типов при использовании этой функции. Кроме того, пользователи такой функции могут захотеть использовать ключевое слово VARIADIC в своем вызове функции, ожидая, что функция будет рассматривать элементы массива как отдельные аргументы. Сама функция должна реализовать это поведение, если необходимо, после использования get_fn_expr_variadic, чтобы обнаружить, что фактический аргумент был помечен как VARIADIC.
Общая память и LWLocks
Надстройки могут резервировать LWLocks и распределение общей памяти при запуске сервера. Общая библиотека надстройки должна быть предварительно загружена, указав ее в shared_preload_libraries. Общая память резервируется путем вызова:
void RequestAddinShmemSpace(int size)
из вашей функции _PG_init.
LWLocks резервируются путем вызова:
void RequestNamedLWLockTranche(const char *tranche_name, int num_lwlocks)
из _PG_init. Это обеспечит доступность массива num_lwlocks LWLocks под именем tranche_name. Используйте GetNamedLWLockTranche, чтобы получить указатель на этот массив.
Чтобы избежать возможных условий гонки, каждый бэкэнд должен использовать LWLock AddinShmemInitLock при подключении и инициализации распределения общей памяти, как показано здесь:
static mystruct *ptr = NULL;
if (!ptr)
{
bool found;
LWLockAcquire(AddinShmemInitLock, LW_EXCLUSIVE);
ptr = ShmemInitStruct("my struct name", size, &found);
if (!found)
{
initialize contents of shmem area;
acquire any requested LWLocks using:
ptr->locks = GetNamedLWLockTranche("my tranche name");
}
LWLockRelease(AddinShmemInitLock);
}
Использование C ++ для расширяемости
Хотя серверная часть QHB написана на C/Rust, можно написать расширения на C++, если следовать этим рекомендациям:
-
Все функции, к которым обращается бэкэнд, должны представлять интерфейс C для бэкэнда; эти функции C могут затем вызывать функции C++. Например, внешняя связь C необходима для функций, к которым обращаются к серверу. Это также необходимо для любых функций, которые передаются в виде указателей между серверной частью и кодом C++.
-
Освободите память, используя соответствующий метод освобождения. Например, большая часть внутренней памяти выделяется с помощью palloc(), поэтому используйте pfree() для ее освобождения. Использование C++ удалить в таких случаях не удастся.
-
Не допускайте распространения исключений в коде C (используйте блок catch-all на верхнем уровне всех внешних функций C). Это необходимо, даже если код C++ явно не выбрасывает какие-либо исключения, потому что такие события, как нехватка памяти, могут по-прежнему генерировать исключения. Любые исключения должны быть перехвачены и соответствующие ошибки переданы обратно в интерфейс C. Если возможно, скомпилируйте C++ с -fno-exception, чтобы полностью исключить исключения; в таких случаях вы должны проверять ошибки в вашем C++ коде, например, проверять NULL, возвращаемый new().
-
При вызове внутренних функций из кода C++ убедитесь, что стек вызовов C++ содержит только простые старые структуры данных (POD). Это необходимо, потому что ошибки бэкэнда генерируют удаленный longjmp (), который неправильно разворачивает стек вызовов C++ с объектами не POD.
Таким образом, лучше всего поместить код C++ за стеной внешних функций C/RUST, которые взаимодействуют с бэкэндом и избегают утечек исключительных ситуаций, памяти и стека вызовов.
Информация по оптимизации функций
По умолчанию функция — это «черный ящик», система очень мало знает о её поведении. Из этого следует, что запросы, использующие функцию, могут выполняться менее эффективно, чем могли бы. Можно предоставить дополнительную информацию, которая поможет планировщику оптимизировать вызовы функций.
Некоторые основные факты могут быть предоставлены декларативными аннотациями в команде CREATE FUNCTION. Наиболее важным из них является категория волатильности функции (IMMUTABLE, STABLE или VOLATILE); всегда нужно быть осторожным, чтобы правильно указать это при определении функции. Свойство безопасности параллельного исполнения (PARALLEL UNSAFE, PARALLEL RESTRICTED или PARALLEL SAFE) также должно быть указано, если вы надеетесь на использование этой функции в параллельных запросах. Также может быть полезно указать оценочную стоимость выполнения функции и/или количество строк, которые она должна вернуть. Однако декларативный способ указания этих двух фактов позволяет указывать только константное значение, а это будет неадекватно.
Также можно прикрепить вспомогательную функцию для планировщика к любой функции, которую можно вызвать из SQL, для вспомогательной функции та функция, к которой она прикреплена, называется её целевой функцией. Вспомогателная функция предоставляет информацию планировщику о своей целевой функции. Вспомогаетльная функция — нативная (в то время как целевая функция — на любом языке), это делает её написание сложным, и они применяются редко.
Вспомогательная функция для планировщика должна иметь следующую SQL-сигнатуру:
supportfn(internal) returns internal
Чтобы подсоединить её к целевой функции, нужно при создании последней использовать указание SUPPORT.
Далее описано, какие "запросы" может делать планировщик ко вспомогательной функции, и какие оптимизации это позволяет. В будущих версиях могут появиться и другие запросы.
Если целевая функция возвращают boolean, то часто полезно оценить процент строк, для которых она вернёт истину. Вы можете реализовать SupportRequestSelectivity и вернуть оптимизатору примерный процент.
Если время выполнения целевой функции сильно зависит от ее входных данных, может быть полезно предоставить оценку непостоянных затрат для нее. Это можно сделать, реализовав тип запроса SupportRequestCost в вашей вспомогательной функции.
Для целевых функций, которые возвращают наборы, часто бывает полезно предоставить непостоянную оценку числа строк, которые будут возвращены. Это можно сделать с помощью вспомогательной функции, которая реализует тип запроса SupportRequestRows.
Самый сложный тип запроса SupportRequestSimplify позволяет переписать непосредственно дерево разбора, заменив вызов целевой функции на что-то ещё. Например, int4mul(n, 1) можно упростить до просто n, этого не знает планировщик, но знает вспомогательная функция, тесно связанная с int4mul. SupportRequestSimplify будет вызвано для каждого вхождения целевой функции в запрос, однако не гарантируется, что не смотря на советы вспомогательной функции, планировщик всё-таки не вызовет оригинальную целевую функцию как есть.
Когда целевая функций, возвращающая boolean, используются для фильтрации (например, в секции WHERE), из неё можно выделить другой, "грубый" фильтр, который позволит индексный поиск. Это делает вспомогательная функция по запросу SupportRequestIndexCondition; фильтр, который она вернёт, может быть в точности эквивалентным вызову целевой функции или быть более слабым, в последне случае для каждой строки будет перепроверяться оригинальный фильтр вызовом целевой функции. Планировщик может решить, что индексный поиск всё равно невозможен или невыгоден, — в этом случае фильтр, созданный вспомогательной функцией, не будет использоваться.
Пользовательские агрегаты
Агрегатные функции в QHB определяются в терминах состояний и функций перехода состояний. То есть агрегат работает с некоторым состоянием, которое обновляется при обработке каждой последующей входной строки. Чтобы создать новую агрегатную функцию, надо выбрать тип данных для состояния, его начальное значение и функцию перехода (свёртки). Функция перехода состояния принимает предыдущее значение состояния и агрегируемое значение(я) текущей строки и возвращает новое значение состояния. Если тип состояния агрегата отличен от желаемого типа результата агрегации, то нужно указать также функцию финализации, которая в конце преобразует одно в другое. В принципе, функции перехода и финализации — это просто обычные функции, которые могут использоваться и вне контекста агрегата. Но на практике, даже если можно использовать в качестве функции перехода существующую функцию, вы, возможно, заходите написать её специальную версию, оптимизированную именно для агрегации.
Таким образом, помимо типов данных аргумента и результата, видимых пользователю агрегата, существует внутренний тип данных состояния, который может отличаться как от типа аргумента, так и от типа результата.
В качестве примера определим агрегат суммы для комплексных чисел:
CREATE AGGREGATE sum (complex)
(
sfunc = complex_add,
stype = complex,
initcond = '(0,0)'
);
Здесь мы задали функцию перехода состояния, тип состояния и начальное состояние. Функцию финализации не задали, и поэтому результатом агрегации будет считаться конечное значение состояния. Как использовать этот агрегат:
SELECT sum(a) FROM test_complex;
sum
-----------
(34,53.9)
Обратите внимание, что мы полагаемся на перегрузку функций: существует более одной агрегатной функции с именем sum, но QHB может определить, какую из них применять к столбцу типа complex.
Приведенное выше определение sum вернет ноль (начальное состояние), если нет входных строк, или все они имеют значение NULL. А по стандарту SQL в таком случае положено вернуть NULL. Чтобы добиться этого, можно задать начальное состояние initcond = NULL или, что тоже самое, просто опустить initcond. Однако в этом случае функция перехода sfunc должна уметь обрабатывать текущее состояние NULL. Или можно объявить функцию перехода строгой (STRICT), в этом случае, если текущее состояние NULL, когда встретится строка со значнием NOT NULL, QHB поместит это первое NOT NULL значение в состояние агрегата (разумеется, типы входного значения и состояния должны быть одинаковыми). Для многих агрегатов, например, sum, min, max такое поведение — то, что нужно.
Еще одна особенность поведения «строгой» функции перехода заключается в том, что каждый раз, когда входное значение NULL, функция не вызывается, а состояние сохраняется прежним. Таким образом, NULL значения игнорируются. Если вам нужно другое поведение для входных NULL, не объявляйте вашу функцию перехода строгой, вместо этого закодируйте в ней обработку NULL.
avg (среднее арифметическое) — пример более сложного агрегата. Рабочее состояние должно состоять из суммы значений и их количества. Окончательный результат получается делением этих величин. Встроенная реализация avg хранит промежуточное состояние в виде массива, а не в виде кортежа. Например, определение avg(float8) выглядит так:
CREATE AGGREGATE avg (float8)
(
sfunc = float8_accum,
stype = float8[],
finalfunc = float8_avg,
initcond = '{0,0,0}'
);
Замечание
Для float8_accum требуется массив из трех элементов, а не из только двух, потому что она накапливает количество, сумму и сумму квадратов. Это сделано для того, чтобы ту же самую функцию float8_accum можно было использовать и для других агрегатов помимо avg.
Вызовы агрегатных функций в SQL позволяют использовать опции DISTINCT и ORDER BY, которые определяют, какие строки передаются в агрегирующую функцию и в каком порядке. Это происходит за кулисами, и агрегатная функция не может настраивать это поведение.
Для получения дополнительной информации см. описание команды CREATE AGGREGATE.
Режим движущегося агрегата
Агрегатные функции могут дополнительно поддерживать режим движущегося(скользящего) агрегата, который позволяет гораздо быстрее считать агрегат по окну с движущимся началом. (См. разделы Руководство по оконным функциям и Вызовы оконных функций для получения информации об использовании агрегатных функций в качестве оконных функций). Основная идея заключается в том, что в дополнение к обычной «прямой» функции перехода агрегат предоставляет обратную функцию перехода, которая позволяет удалять строки из текущего состояния агрегата, когда они выпадают из окна. Например, агрегат sum, который использует сложение в качестве функции прямого перехода, будет использовать вычитание в качестве функции обратного перехода. Без функции обратного перехода придётся пересчитывать агрегат с нуля при каждом перемещении рамки окна, в результате чего время выполнения будет пропорционально числу входных строк, умноженному на среднюю длину окна. При использовании функции обратного перехода время выполнения пропорционально просто количеству входных строк.
В функцию обратного перехода передаётся текущее состояние и значение выпадающей строки. Это обязательно первая из строк, добавленных в агрегат (и ещё не выпавших). Формально функция должна восстановить состояние агрегата, как если бы выпадающая строка никогда и не была добавлена в агрегат, а агрегацию начали со второй строки. Чтобы это реализовать, может потребоваться хранить в текущем состоянии агрегата больше информации, чем для агрегирования "только вперёд". По этой причине режим движущегося агрегата имеет независимый набор из типа данных, функций перехода прямой и обратной, и функции финализации, если нужна. А в простом случае этот набор будет совпадать с набором для "обыкновенного" режима агрегации.
В качестве примера опять определение агрегата sum для комплексных чисел, теперь поддерживается скользящий режим:
CREATE AGGREGATE sum (complex)
(
sfunc = complex_add,
stype = complex,
initcond = '(0,0)',
msfunc = complex_add,
minvfunc = complex_sub,
mstype = complex,
minitcond = '(0,0)'
);
Параметры, имена которых начинаются с m относятся к реализации движущегося агрегата. Все они (кроме функции обратного перехода minvfunc) имеют соотвествующий параметр без m, который относится к реализации "обычного " агрегата.
Функция прямого перехода для режима движущегося агрегата не может возвращать значение NULL в качестве нового значения состояния. Функция обратного перехода может вернуть NULL, но это будет воспринято как то, что она не может "убрать" данное значение — в этом случае агрегат пересчитают с нуля, начиная от нового начала окна. Это соглашение позволяет использовать функции движущегося агрегата, если иногда возникают ситуации, когда нельзя удалить значение из текущего состояния; в этих редких ситуациях функция обратного перехода "сдаётся", и агрегирование будет работать медленнее, но в большинстве ситуаций — быстро. Пример — агрегат, работающий с числами с плавающей запятой; функция обратного перехода будет вынуждена "сдаться", когда её попросят удалить значение NaN из текущего состояния агрегата.
При написании вспомогательных функций движущегося агрегата важно убедиться, что функция обратного перехода может точно восстановить правильное состояние. В противном случае могут быть заметные для пользователя различия в результатах в зависимости от того, используется ли режим скользящего агрегата. Примером агрегата, для которого добавление функции обратного перехода на первый взгляд кажется простым, а на самом деле имеет много подводных камней, является sum по float4 или float8. Наивное объявление sum(float8) может быть таким:
CREATE AGGREGATE unsafe_sum (float8)
(
stype = float8,
sfunc = float8pl,
mstype = float8,
msfunc = float8pl,
minvfunc = float8mi
);
Этот агрегат, однако, может дать неожиданные результаты при скользящем агрегировании:
SELECT
unsafe_sum(x) OVER (ORDER BY n ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING)
FROM (VALUES (1, 1.0e20::float8),
(2, 1.0::float8)) AS v (n,x);
Вторая строчка результата будет 0, а не 1. Причиной является ограниченная точность значений с плавающей запятой: добавление 1 к 1e20 даёт снова 1e20, и потом вычитание 1e20 из этого дает 0, а не 1. Обратите внимание, что это проблемы арифметики с плавающей запятой в целом, а не QHB.
Полиморфные агрегаты
Агрегатные функции могут использовать полиморфные функции перехода состояний или функции финализации, так что одни и те же функции могут использоваться для реализации нескольких агрегатов. См. раздел Полиморфные типы для объяснения полиморфных функций. Если пойти еще дальше, сама агрегатная функция может быть указана с полиморфными типами входного значения и состояния, что позволяет одному определению агрегата служить для нескольких типов входных данных. Вот пример полиморфного агрегата:
CREATE AGGREGATE array_accum (anyelement)
(
sfunc = array_append,
stype = anyarray,
initcond = '{}'
);
Здесь типом состояния для любого конкретного вызова агрегата является массив, элементы которого имеют тип, равный типу фактических входных данных. Поведение агрегата заключается в добавлении всех входных данных в массив. (Примечание: встроенный агрегат array_agg предоставляет аналогичную функциональность с лучшей производительностью, чем этот пример).
Протестируем этот агрегат на двух разных типах данных:
SELECT attrelid::regclass, array_accum(attname)
FROM pg_attribute
WHERE attnum > 0 AND attrelid = 'pg_tablespace'::regclass
GROUP BY attrelid;
attrelid | array_accum
---------------+---------------------------------------
pg_tablespace | {spcname,spcowner,spcacl,spcoptions}
(1 row)
SELECT attrelid::regclass, array_accum(atttypid::regtype)
FROM pg_attribute
WHERE attnum > 0 AND attrelid = 'pg_tablespace'::regclass
GROUP BY attrelid;
attrelid | array_accum
---------------+---------------------------
pg_tablespace | {name,oid,aclitem[],text[]}
(1 row)
Обычно у агрегатной функции с полиморфным типом результата тоже будет полиморфным, как в приведенном выше примере. Это необходимо, потому что иначе функция финализации не может быть разумно объявлена: у нее должен полиморфный тип результата (если, конечно, агрегирование разных типов не приводит к одинаковому типу результата), но нет полиморфного типа аргумента. Такую функцию CREATE FUNCTION не даст создать. Но иногда неудобно использовать тип полиморфного состояния. Наиболее распространенный случай, когда вспомогательные функции должны быть написаны на нативном языке, и тип состояния должен быть объявлен как internal поскольку для него нет эквивалента на уровне SQL. Для решения этой проблемы разшено добавить к функции финализации фиктивный аргумент полиморфного типа. В конце агрегации в функцию финализации будет передано состояние агрегата и NULL для всех аргументов кроме первого. Фактический тип фиктивного аргумента считается равным типу агрегируемого столбца, и из этого выводится тип результата агрегата. Вот почти настоящее определение встроенного агрегата array_agg:
CREATE FUNCTION array_agg_transfn(internal, anynonarray)
RETURNS internal ...;
CREATE FUNCTION array_agg_finalfn(internal, anynonarray)
RETURNS anyarray ...;
CREATE AGGREGATE array_agg (anynonarray)
(
sfunc = array_agg_transfn,
stype = internal,
finalfunc = array_agg_finalfn,
finalfunc_extra
);
Здесь опция finalfunc_extra указывает, что функция финализации получает в дополнение к значению состояния фиктивные аргументы. Дополнительный аргумент функции array_agg_finalfn делает её валидной и позволяет вывести итоговый тип агрегата (не из типа состояния, а непосредственно из входного типа).
Агрегатная функция может принимать различное количество аргументов, для этого надо объявить её последний аргумент как VARIADIC-массив, так же, как для обычных функций (см. раздел Функции SQL с переменным числом аргументов). Второй агрумент функции перехода должен быть таким же массивом (обычно тоже VARIADIC, но это не обязательно).
Замечание
VARIADIC-агрегаты подвержены ошибкам при использовании одновременно с опциейORDER BY(см. раздел Агрегатные выражения), т.к. не жалуются на неправильное количество аргументов. Помните, что все справа отORDER BY— ключи сортировки, а не значения для агрегирования. Например,
SELECT myaggregate(a ORDER BY a, b, c) FROM ...
— это агрегация 1 колонке и 3 ключа сортировки. А пользователь, возможно, имел в виду
SELECT myaggregate(a, b, c ORDER BY a) FROM ...
Еслиmyaggregateявляется VARIADIC, то оба этих вызова совершенно корректны.По той же причине стоит дважды подумать, прежде чем создавать агрегатные функции с одинаковыми именами, но разным количеством обычных аргументов.
Сортирующие агрегатные функции
Агрегаты, которые мы описывали до сих пор, являются «нормальными» агрегатами. QHB также поддерживает т.н. сортирующие агрегаты. Результат нормального агрегата может зависеть от порядка строк (например, string_agg) или не зависеть (наприме, min); в любом случае при его вызове в агрегатном выражении можно указать ORDER BY по любым столбцам, не обязательно тем, что передаются в агрегатную функцию, и сортировку осуществляет исполнитель запросов перед подачей в агрегатную функцию. Сортирующие агрегаты осуществляют сортировку сами, именно по тем столбцам, которые они обрабатывают, поэтому набор данных для передачи в них "совмещён" с ORDER BY (WITHIN GROUP(ORDER BY col)), а в агрегатную функцию передаются дополнительные "прямые" параметры. Предполагается, что сортирующий агрегат будет сортировать и накапливать данные внутри себя, и так делают все встроенные сортирующие агрегаты, но это не обязательно. Возможно, вам нужен сортирующий агрегат, если:
- требуется передать в функцию агрегирования дополнительный параметр,
- и результат агрегации не зависит от порядка строк.
Типичные примеры — подсчёт ранга или процентиля. Например, встроенное определение percentile_disc эквивалентно следующему:
CREATE FUNCTION ordered_set_transition(internal, anyelement)
RETURNS internal ...;
CREATE FUNCTION percentile_disc_final(internal, float8, anyelement)
RETURNS anyelement ...;
CREATE AGGREGATE percentile_disc (float8 ORDER BY anyelement)
(
sfunc = ordered_set_transition,
stype = internal,
finalfunc = percentile_disc_final,
finalfunc_extra
);
Этот агрегат принимает прямой аргумент float8 (процентная отсечка) и входные данные для агрегации, которые могут иметь любой сортируемый тип данных. Например, получение медианного семейного дохода:
SELECT percentile_disc(0.5) WITHIN GROUP (ORDER BY income) FROM households;
percentile_disc
-----------------
50489
Здесь 0.5 - прямой аргумент, т.к. процентная отсечка — это свойство всего агрегата, а не отдельных значений.
При реализации сортирующего агрегата вам придётся самостоятельно выполнять сортировку (если она вам нужна). Обычно это делают, храня ссылку на объект tuplesort внутри состояния агрегата, помещая туда все входные значения, и завершая сортировки и считывая данных в функции финализации. Такой дизайн позволяет в функции финализации добавлять «гипотетические» строки в данные в порядке сортировки. Хотя обычные агрегаты часто могут быть реализованы с помощью вспомогательных функций, написанных на PL/pgSQL или другом процедурном языке, сортирующие агрегаты должны записываться на нативном языке, хотя бы потому, что их состояние — сложный объект, который на SQL нельзя определить иначе как internal. Далее, поскольку функция финализации выполняет сортировку, после неё невозможно (или по крайней мере неэффективно) продолжить добавление входных строк. Поэтому функция финализации должна быть зарегистрирована в CREATE AGGREGATE не как READ_ONLY, а как READ_WRITE (или как SHAREABLE, если для дополнительных вызовов функции финализации возможно использование уже отсортированного состояния).
Функция перехода состояния для сортирующего агрегата получает текущее значение состояния, агрегириреумые входные значения каждой строки, и возвращает обновленное значение состояния. В принципе то же самое, что и для обычных агрегатов, но обратите внимание, что прямые аргументы (если таковые имеются) не передаются в функцию перехода; они передаются только в функцию финализации. Как и в случае с обычными агрегатами, опция finalfunc_extra может использоваться для определения полиморфоной агрегатной функции.
В настоящее время сортирующие агрегаты не могут использоваться в качестве оконных функций, поэтому им нет необходимости поддерживать режим движущегося агрегата.
Частичная агрегация
Опционально, агрегатная функция может поддерживать частичное агрегирование. Идея частичной агрегации состоит в том, чтобы независимо выполнять функцию перехода состояния агрегата над различными подмножествами входных данных, а затем объединять значения состояний, полученные из этих подмножеств, для получения одного и того же значения состояния, которое получилось бы при сканировании всех входных данных в разовая операция Этот режим можно использовать для параллельной агрегации, когда разные рабочие процессы сканируют разные части таблицы. Каждый процесс создает частичное значение состояния, и в конце эти значения состояния объединяются для получения окончательного значения состояния. (В будущем этот режим может также использоваться для таких целей, как объединение агрегирования по локальным и удаленным таблицам; но это еще не реализовано).
Для поддержки частичного агрегирования определение агрегата должно предоставлять функцию объединения, которая принимает два значения типа состояния агрегата (представляющих результаты агрегирования по двум подмножествам входных строк) и создает новое значение типа состояния, представляющее состояние было бы после агрегирования по комбинации этих наборов строк. Каким был бы относительный порядок строк из двух наборов — неизвестно. По этой причине для агрегатов, зависящих от порядка строк такую функцию нельзя определить.
В качестве простых примеров агрегаты MAX и MIN могут поддерживать частичного агрегирования, указав в качестве функции объединения максимум/минимум из двух, то же саамое, что и в функции перехода состояния.
Функция объединения используется также, как функция перехода, только входные аргументы имеют тип состояния, а не исходных данных; в частности такие же правила обработки NULL'ов в случае строгой/не сторгой функции. Кроме того, если у агрегата указана initcond, отличная от NULL, имейте в виду, что initcond будет стартовым значением для каждого частичного запуска агрегации и потом для функции объединения тоже.
Если тип состояния агрегата объявлен как internal, то функция объединения несет ответственность за то, чтобы ее результат был аллокирован в правильном контексте памяти; в частности, это означает, что, когда один из аргументов NULL, нельзя просто вернуть второй аргумент, поскольку это значение в неправильном контексте и имеет слишком короткий срок жизни.
Также, если тип состояния internal, нужно реализовать функции сериализации и десериализации, чтобы состояние можно было передать в другой процесс. Функция сериализации должна принимать один аргумент типа internal и возвращать результат типа bytea, который представляет собой упакованное значение состояния. И наоборот, функция десериализации выполняет это преобразование в обратном направлении. Она должна принимать два аргумента типов bytea и internal и возвращать результат типа internal. (Второй аргумент не используется и всегда равен нулю, но он необходим по соображениям безопасности типов). Результат функции десериализации должен быть просто размещен в текущем контексте памяти, поскольку в отличие от результата функции объединения, он короткоживущий.
Стоит также отметить, что для того, чтобы агрегат выполнялся параллельно, сам агрегат должен быть помечен как PARALLEL SAFE. А для его вспомогательных функциях такая пометка не обязательна.
Написание вспомогательных функций агрегатов
Функция, написанная на нативном языке, может обнаружить, что она вызывается как агрегатная вспомогательная функция, вызвав AggCheckCallContext, например:
if (AggCheckCallContext(fcinfo, NULL))
Представьте себе функцию, которая может вызываться и как функция перехода агрегата, так и как прост офункция. Если AggCheckCallContext вернуло true, то первый аргумент является временным значением, можно его исправить на месте и вернуть указатель на него же (а в общем случае надо аллокировать результат).
(В то время как агрегатным функциям перехода всегда разрешено изменять значение перехода на месте, агрегатным конечным функциям обычно не рекомендуется делать это; если они это делают, поведение должно быть объявлено при создании агрегата. См. CREATE AGGREGATE для более подробной информации).
Второй аргумент AggCheckCallContext может использоваться для получения контекста памяти, в котором хранятся значения агрегатного состояния. Это полезно для функций перехода, которые хотят использовать «расширенные» объекты (см. Раздел Использование TOAST) в качестве значений состояния. При первом вызове функция перехода должна вернуть расширенный объект, чей контекст памяти является дочерним по отношению к контексту совокупного состояния, и затем продолжать возвращать тот же расширенный объект при последующих вызовах. Смотрите array_append() для примера. (array_append() не является функцией перехода какого-либо встроенного агрегата, но написана так, чтобы вести себя эффективно при использовании в качестве функции перехода пользовательского агрегата).
Другая подпрограмма поддержки, доступная для агрегатных функций, написанных на нативном языке программирования, — это AggGetAggref, который возвращает узел разбора Aggref который определяет агрегированный вызов. Это в основном полезно для агрегатов с упорядоченным набором, которые могут проверить подструктуру узла Aggref чтобы выяснить, какой порядок сортировки они должны реализовать.
Пользовательские типы
Как описано в разделе Система типов QHB, QHB может быть расширен для поддержки новых типов данных. В этом разделе описывается, как определить новые базовые типы, определенные ниже уровня языка SQL. Создание нового базового типа требует реализации функций для работы с типом на нативном языке программирования.
Пользовательский тип должен всегда иметь функции ввода и вывода. Эти функции определяют, как тип отображается в строках (для ввода пользователем и вывода для пользователя) и как тип организован в памяти. Функция ввода принимает в качестве аргумента символьную строку с нулевым символом в конце и возвращает внутреннее (в памяти) представление типа. Функция вывода принимает внутреннее представление типа в качестве аргумента и возвращает символьную строку с нулевым символом в конце. Если мы хотим сделать что-то большее с типом, чем просто сохранить его, мы должны предоставить дополнительные функции для реализации любых операций, которые мы хотели бы иметь для этого типа.
Предположим, мы хотим определить тип complex, который представляет комплексные числа. Естественным способом представления комплексного числа в памяти будет следующая структура C:
typedef struct Complex {
double x;
double y;
} Complex;
Нам нужно будет сделать этот тип передаваемым по ссылке, поскольку он слишком велик, чтобы поместиться в одно значение Datum.
В качестве внешнего строкового представления типа мы выберем строку вида (x,y).
Функции ввода и вывода обычно не сложно написать, особенно функцию вывода. Но при определении внешнего строкового представления типа помните, что в конечном итоге вы должны написать полный и надежный синтаксический анализатор для этого представления в качестве входной функции. Например:
PG_FUNCTION_INFO_V1(complex_in);
Datum
complex_in(PG_FUNCTION_ARGS)
{
char *str = PG_GETARG_CSTRING(0);
double x,
y;
Complex *result;
if (sscanf(str, " ( %lf, %lf )", &x, &y) != 2)
ereport(ERROR,
(errcode(ERRCODE_INVALID_TEXT_REPRESENTATION),
errmsg("invalid input syntax for type %s: \"%s\"",
"complex", str)));
result = (Complex *) palloc(sizeof(Complex));
result->x = x;
result->y = y;
PG_RETURN_POINTER(result);
}
Функция вывода может быть просто
PG_FUNCTION_INFO_V1(complex_out);
Datum
complex_out(PG_FUNCTION_ARGS)
{
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
char *result;
result = psprintf("(%g,%g)", complex->x, complex->y);
PG_RETURN_CSTRING(result);
}
Вы должны быть внимательны, чтобы входные и выходные функции получились противоположны друг другу. Если вы этого не сделаете, у вас возникнут серьезные проблемы, когда вам нужно будет сохранить данные в файл и затем прочитать их обратно. Это особенно распространенная проблема при работе с числами с плавающей запятой.
Опционально, пользовательский тип может предоставлять процедуры ввода и вывода в бинарный формат. Двоичный ввод-вывод обычно быстрее, но менее переносим, чем текстовый ввод-вывод. Как и в случае с текстовым вводом/выводом, вы должны точно определить, что такое внешнее двоичное представление. Большинство встроенных типов данных пытаются обеспечить машинно-независимое двоичное представление. Для complex мы воспользуемся преобразователям в бинарное представление ввода/вывода типа float8:
PG_FUNCTION_INFO_V1(complex_recv);
Datum
complex_recv(PG_FUNCTION_ARGS)
{
StringInfo buf = (StringInfo) PG_GETARG_POINTER(0);
Complex *result;
result = (Complex *) palloc(sizeof(Complex));
result->x = pq_getmsgfloat8(buf);
result->y = pq_getmsgfloat8(buf);
PG_RETURN_POINTER(result);
}
PG_FUNCTION_INFO_V1(complex_send);
Datum
complex_send(PG_FUNCTION_ARGS)
{
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
StringInfoData buf;
pq_begintypsend(&buf);
pq_sendfloat8(&buf, complex->x);
pq_sendfloat8(&buf, complex->y);
PG_RETURN_BYTEA_P(pq_endtypsend(&buf));
}
После того, как мы написали функции ввода-вывода и скомпилировали их в разделяемую библиотеку, мы можем определить тип complex в SQL. Сначала мы объявим "оболочку" типа:
CREATE TYPE complex;
Она служит заполнителем, который позволяет нам ссылаться на тип при определении его функций ввода/вывода. Теперь мы можем определить функции ввода/вывода:
CREATE FUNCTION complex_in(cstring)
RETURNS complex
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_out(complex)
RETURNS cstring
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_recv(internal)
RETURNS complex
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
CREATE FUNCTION complex_send(complex)
RETURNS bytea
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
Наконец, мы можем предоставить полное определение типа данных:
CREATE TYPE complex (
internallength = 16,
input = complex_in,
output = complex_out,
receive = complex_recv,
send = complex_send,
alignment = double
);
Когда вы определяете новый базовый тип, QHB автоматически
обеспечивает поддержку массивов этого типа. Тип массива обычно имеет то
же имя, что и базовый тип, с добавлением символа подчеркивания (_) в начале.
Теперь, когда тип данных существует, мы можем объявить дополнительные функции для обеспечения полезных операций над типом данных. Потом, когда есть функции, могут быть определены операторы, работающие на этих функциях, созданы классы операторов для поддержки индексирования типа данных и т.д. Эти дополнительные слои обсуждаются в следующих разделах.
Если внутреннее представление типа данных имеет переменную длину, то его первые 4 байта должы хранить длину (на C это выглядит как поле char vl_len_[4]); к этому полю вы не должны никогда обращаться напрямую, но использовать специальные макросы (VARSIZE() и SET_VARSIZE()), эти макросы существуют, потому что поле длины может быть закодировано в зависимости от платформы. В SET_VARSIZE надо передавать общий размер элемента в байтах, включая 4 байта vl_len_.
Замечание
В более старом коде можно встретить объявления vl_len_ как int32 вместо char[4]. Это нормально, особенно если в структуре есть хотя бы одно другое поле с выравнивание 4+ байт. Если нет, то QHB может хранить структуру невыровено, для этого и char[4]
Для получения дополнительной информации см. Описание команды CREATE TYPE.
Использование TOAST
Если значения вашего типа данных сильно различаются по размеру (во внутреннем представлении), обычно желательно сделать тип данных сохраняющимся в TOAST (см. раздел TOAST). Стоит это сделать даже в том случае, когда значения всегда слишком малы для сжатия или внешнего хранения, поскольку TOAST может сэкономить пространство и для небольших данных, уменьшая издержки на заголовок.
Чтобы поддерживать сохранение в TOAST, функции C, работающие с типом данных, должны распаковать любые TOAST-значения, которые им передают с помощью PG_DETOAST_DATUM. (Эта деталь обычно скрывается путем определения макроса GETARG_DATATYPE_P для конкретного типа). Затем при запуске команды CREATE TYPE укажите внутреннюю длину как variable и выберите какой-либо подходящий вариант хранения, отличный от plain.
Если выравнивание данных неважно (для конкретной функции, либо потому, что тип данных имеет произвольное выравнивание (до 1 байта)), то можно избежать некоторых издержек PG_DETOAST_DATUM и вызывать вместо неё PG_DETOAST_DATUM_PACKED (обычно скрывается путем определения макроса GETARG_DATATYPE_PP ) и использовать макросы VARSIZE_ANY_EXHDR и VARDATA_ANY для доступа к потенциально упакованным данным. Опять же, данные, возвращаемые этими макросами, не выравниваются, даже если определение типа данных требует выравнивания. Если выравнивание важно, вы должны пройти через обычный интерфейс PG_DETOAST_DATUM.
Другая функция, включаемая поддержкой TOAST, - это возможность иметь
расширенное представление данных в памяти, с которым удобнее работать,
чем с форматом, хранящимся на диске. Обычный или «плоский» формат
хранения varlena - это, в конечном счете, просто blob of bytes; например,
он не может содержать указатели, так как он может быть скопирован в
другие места в памяти. Для сложных типов данных плоский формат может
быть довольно дорогим для работы, поэтому QHB предоставляет
способ «развернуть» плоский формат в представление, более подходящее
для вычислений, а затем передать этот формат в памяти между функциями
тип данных.
Чтобы использовать расширенное хранилище, тип данных должен определять расширенный формат, который следует правилам, приведенным в src/include/utils/expandeddatum.h, и предоставлять функции для «раскрытия» значения плоской переменной varlena в расширенный формат и «выравнивания» расширенного формата для возвращения к обычному представлению varlena. Затем убедитесь, что все функции C для типа данных могут принимать любое представление, возможно, путем преобразования одной в другую сразу после получения. Это не требует одновременного исправления всех существующих функций для типа данных, поскольку стандартный макрос PG_DETOAST_DATUM определен для преобразования расширенных входных данных в обычный плоский формат. Следовательно, существующие функции, работающие с форматом плоской varlena, будут продолжать работать, хотя и неэффективно, с расширенными входными данными; их не нужно преобразовывать до тех пор, пока не будет важна лучшая производительность.
Функции на C/RUST, которые знают, как работать с расширенным представлением, обычно делятся на две категории: те, которые могут обрабатывать только расширенный формат, и те, которые могут обрабатывать либо расширенные, либо плоские входные данные varlena. Первые легче написать, но могут быть менее эффективными в целом, потому что преобразование плоского ввода в расширенную форму для использования одной функцией может стоить больше, чем экономится при работе в расширенном формате. Когда требуется обрабатывать только расширенный формат, преобразование плоских входных данных в расширенную форму может быть скрыто внутри макроса выборки аргументов, так что функция выглядит не более сложной, чем та, которая работает с традиционным вводом varlena. Чтобы обработать оба типа ввода, напишите функцию выборки аргумента, которая будет сбрасывать внешние, короткие и сжатые входные данные, но не расширенные. Такая функция может быть определена как возвращение указателя на объединение плоского формата varlena и расширенного формата. Вызывающие могут использовать VARATT_IS_EXPANDED_HEADER() чтобы определить, какой формат они получили.
Инфраструктура TOAST не только позволяет отличать обычные значения varlena от расширенных значений, но также различает указатели «чтение-запись» и «только для чтения» на расширенные значения. Функции C/RUST, которые должны проверять только расширенное значение или будут изменять его только безопасным и не семантически видимым образом, не должны заботиться о том, какой тип указателя они получают. Функции на C/RUST, которые создают измененную версию входного значения, могут изменять расширенное входное значение на месте, если они получают указатель чтения-записи, но не должны изменять ввод, если они получают указатель только для чтения; в этом случае они должны сначала скопировать значение, создав новое значение для изменения. Функция C/RUST, которая создала новое расширенное значение, всегда должна возвращать указатель на чтение-запись. Кроме того, функция C/RUST, которая изменяет расширенное значение для чтения-записи на месте, должна позаботиться о том, чтобы оставить значение в нормальном состоянии, если оно не будет выполнено частично.
Примеры работы с расширенными значениями см. В стандартной инфраструктуре массива, в частности в src/backend/utils/adt/array_expanded.c.
Пользовательские операторы
Каждый оператор является «синтаксическим сахаром» для вызова базовой функции, которая выполняет реальную работу; поэтому вы должны сначала создать базовую функцию, прежде чем сможете создать оператор. Тем не менее, оператор не просто синтаксический сахар, потому что он несет дополнительную информацию, которая помогает планировщику запросов оптимизировать запросы, использующие оператор. Следующий раздел будет посвящен объяснению этой дополнительной информации.
QHB поддерживает левый унарный, правый унарный и бинарный операторы. Операторы могут быть перегружены; то есть одно и то же имя оператора может использоваться для разных операторов, которые имеют разное количество и типы операндов. Когда запрос выполняется, система определяет оператор для вызова по числу и типам предоставленных аргументов.
Вот пример создания оператора для сложения двух комплексных чисел. Мы предполагаем, что уже создали определение типа complex (см. раздел Пользовательские типы. Сначала нам нужна функция, которая будет выполнять работу, а затем мы сможем определить оператор:
CREATE FUNCTION complex_add(complex, complex)
RETURNS complex
AS 'filename', 'complex_add'
LANGUAGE C IMMUTABLE STRICT;
CREATE OPERATOR + (
leftarg = complex,
rightarg = complex,
function = complex_add,
commutator = +
);
Теперь мы можем выполнить запрос следующим образом:
SELECT (a + b) AS c FROM test_complex;
c
-----------------
(5.2,6.05)
(133.42,144.95)
Это мы показали, как создать бинарный оператор. Чтобы создать унарный оператор, просто опустите один из leftarg (для левого унарного) или rightarg (для правого унарного). function и leftarg/rightarg являются единственными обязательными элементами в CREATE OPERATOR. Указание commutator, показанное в примере, является дополнительной подсказкой оптимизатору запросов. Дальнейшие подробности о commutator и других указаниях оптимизации приведены в следующем разделе.
Информация по оптимизации оператора
Определение оператора QHB может включать несколько необязательных указаний, которые сообщают системе полезные сведения о поведении оператора. Эти пункты должны предоставляться всякий раз, когда это уместно, поскольку они могут значительно ускорить выполнение запросов, использующих оператор. Но если вы их предоставите, вы должны быть уверены, что они действительно имеют место быть! Неправильное использование предложения по оптимизации может привести к медленным запросам, неправильному выводу или другим плохим вещам. Вы всегда можете опустить указание оптимизации, если вы не уверены в нём; единственное последствие — запросы могут выполняться медленнее, чем нужно.
Дополнительные пункты оптимизации могут быть добавлены в будущих версиях QHB. Описанные здесь — это те, которые есть в релизе 1.3.0.
Также можно прикрепить вспомогательную функцию для планировщика к функции, которая лежит в основе оператора — это другой способ рассказать системе о поведении оператора. См. раздел Информация по оптимизации функций для получения дополнительной информации.
COMMUTATOR
Указание COMMUTATOR, если оно есть, задаёт имя оператора,
который является коммутатором данного. Мы говорим, что
оператор A является коммутатором оператора B, если (x A y) равно (y B x)
для всех возможных x, y. Обратите внимание, что B также
является коммутатором A. Например, операторы < и > для
определенного типа данных обычно являются коммутаторами друг друга, а
оператор + обычно коммутирует сам с собой, т.е. является коммутативным.
А вот оператор - не коммутирует ни с каким другим
(понятно, что коммутатор - существует, но его не принято делать оператором).
Тип левого операнда коммутируемого оператора такой же, как тип правого операнда его коммутатора, и наоборот. Таким образом, имя оператора коммутатора - это все, что нужно дать QHB для поиска коммутатора, и это все, что необходимо указать в указании COMMUTATOR.
Очень важно предоставлять информацию о коммутаторах для операторов,
которые будут использоваться в индексах и объединениях,
поскольку это позволяет оптимизатору запросов «перевернуть» условие,
чтобы привести его к форме, необходимой для различных типов планов.
В частности,
рассмотрим запрос с предложением WHERE, например tab1.x = tab2.y, где
tab1.x и tab2.y имеют пользовательский тип, и предположим, что по tab2.y
есть индекс. Чтобы сгенерировать сканирование индекса, оптимизатор должен
привести условие к виду tab2.y = tab1.x, поскольку механизм сканирования индекса ожидает
увидеть индексированный столбец слева от оператора, который ему дан.
QHB не будет по умолчанию считать, что = коммутативно
— создатель оператора = должен это указать, пометив оператор информацией коммутатора.
Когда вы определяете коммутативный оператор, вы просто делаете это. Когда вы определяете пару коммутативных операторов, все становится немного сложнее: как первый определяемый может ссылаться на другой, который вы еще не определили? Есть два решения этой проблемы:
-
Один из способов - опустить предложение COMMUTATOR в первом определяемом вами операторе, а затем указать его в определении второго оператора. Поскольку QHB знает, что коммутативные операторы идут парами, когда он увидит второе определение, он автоматически вернется и заполнит пропущенное предложение COMMUTATOR в первом определении.
-
Другой, более простой способ - просто включить предложения COMMUTATOR в оба определения. Когда QHB обрабатывает первое определение и понимает, что COMMUTATOR ссылается на несуществующий оператор, система сделает фиктивную запись для этого оператора в системном каталоге. Эта фиктивная запись будет содержать действительные данные только для имени оператора, левого и правого типов операндов и типа результата, поскольку это все, что QHB может вывести на данный момент. Первая запись в каталоге оператора будет связана с этой фиктивной записью. Позже, когда вы определяете второй оператор, система обновляет фиктивную запись дополнительной информацией из второго определения. Если вы попытаетесь использовать фиктивный оператор до его заполнения, вы просто получите сообщение об ошибке.
NEGATOR
Это понятие есть только для булевых операторов.
Указание NEGATOR, если оно есть, задаёт оператор, который
является отрицанием данного. Мы говорим, что оператор A
является отрицанием оператора B, если оба возвращают булевы результаты
и (x A y) равно NOT (x B y) для всех возможных x, y.
Обратите внимание, что B также является отрицанием A. Например, < и
>= являются парой отрицателей для большинства типов данных. Оператор
никогда не может быть собственным отрицателем.
В отличие от коммутаторов, пара унарных операторов может быть
действительно отмечена как отрицатели друг друга; это означало бы (A x)
равно NOT (B x) для всех x или эквивалент для правых унарных операторов.
Отрицатель оператора должен иметь те же типы левого и/или правого операнда, что и определяемый оператор, поэтому, как и в случае с COMMUTATOR предложении NEGATOR должно быть указано только имя оператора.
Предоставление отрицателя очень полезно для оптимизатора запросов,
поскольку оно позволяет упростить выражения типа NOT (x >= y) в x < y.
Это происходит чаще, чем вы думаете, потому что операции
NOT могут быть появляться вследствие других преобразований.
Пары взаимно противоположных операторов могут быть определены с использованием тех же методов, которые описаны выше для пар коммутаторов.
RESTRICT
Это понятие есть только для булевых операторов. Указание RESTRICT задаёт функцию оценки селективности ограничения для оператора. (Обратите внимание, что это имя функции, а не оператора). Идея этой оценки состоит в том, чтобы угадать, какая доля строк в таблице будет удовлетворять условию WHERE column OP constant для данного оператора и постоянного значения в правой части. Это помогает оптимизатору, давая ему некоторое представление о том, сколько строк будет отфильтровано таким WHERE. (А что, если константа будет слева, спросите вы? Ну, это одна из вещей, для которых предназначен COMMUTATOR...)
Написание новых функций оценки селективности ограничения выходит за рамки этой главы, но, к счастью, обычно вы можете просто использовать одну из стандартных функций оценки для многих ваших собственных операторов. Вот стандартные оценки селективности:
| Вспомогательная функция | Оператор |
|---|---|
| eqsel | = |
| neqsel | <> |
| scalarltsel | < |
| scalarlesel | <= |
| scalargtsel | > |
| scalargesel | >= |
Например, вы можете обойтись использованием eqsel / neqsel для операторов, которые имеют очень высокую / очень низкую селективность, даже если они на самом деле не имеют никакого отношения к равенсту/неравенству. Например, геометрические операторы приближенного равенства используют eqsel в предположении, что им обычно соответствует лишь небольшая часть записей в таблице.
Вы можете использовать scalarltsel, scalarlesel, scalargtsel и scalargesel для сравнения типов данных, которые имеют некоторые разумные средства преобразования в скалярные величины для сравнения диапазонов. В этом случае желательно добавить поддержку типа данных в функции convert_to_scalar().
Если вы этого не сделаете, все будет работать, но оценки оптимизатора не будет так хорошо, как они могли бы быть.
JOIN
Это понятие есть только для булевых операторов. Указание JOIN задаёт функцию оценки избирательности соединения для оператора. (Обратите внимание, что это имя функции, а не имя оператора). Идея оценки избирательности соединения состоит в том, чтобы угадать, какая доля строк в паре таблиц будет удовлетворять условию вида ON table1.column1 OP table2.column2 для данного оператора. Как и в случае с RESTRICT, это существенно помогает оптимизатору, позволяя ему выяснить, какая из нескольких возможных последовательностей объединения может потребовать меньше всего работы.
И опять здесь не рассказывается, как писать свой функции оценки селективности, а просто предлагается использовать одну из стандартных функций оценки, если она похожа на то, что нужно:
| Вспомогательная функция | Оператор |
|---|---|
| eqjoinsel | = |
| neqjoinsel | <> |
| scalarltjoinsel | < |
| scalarlejoinsel | <= |
| scalargtjoinsel | > |
| scalargejoinsel | >= |
| areajoinsel | 2D area-based comparisons |
| positionjoinsel | 2D position-based comparisons |
| contjoinsel | 2D containment-based comparisons |
HASHES
Предложение HASHES, если оно присутствует, сообщает системе, что для соединения, основанного на этом операторе, можно использовать метод hash join. HASHES имеет смысл только для двоичного оператора, который возвращает boolean, и на практике оператор должен представлять отношение эквивалентности, согласованное с хеширующей функцией.
Предположение, лежащее в основе хеш-соединения, заключается в том, что оператор соединения может возвращать true только для пары значений, которые хешируют один и тот же хеш-код. Если два значения помещаются в разные хэш-блоки, объединение никогда не сравнит их вообще, неявно предполагая, что результат оператора соединения должен быть ложным. Поэтому нельзя указывать HASHES для операторов, которые не представляют некоторую форму равенства. В большинстве случаев практично поддерживать хеширование для операторов, которые принимают одинаковый тип данных с обеих сторон. Однако иногда возможно разработать совместимые хеш-функции для двух или более типов данных, то есть функции, которые будут генерировать одинаковые хеш-коды для «равных» значений, даже если значения имеют разные представления. Например, довольно просто обеспечить это свойство при хешировании целых чисел различной ширины.
Чтобы иметь быть HASHES, оператор соединения должен принадлежать семейству операторов хеш-индекса. Это не проверяется при создании оператора, поскольку, конечно, в этот момент семейство ссылочных операторов еще не может существовать. Но попытки использовать оператор в хеш-соединениях потерпят неудачу во время выполнения, если такого семейства операторов не существует. Обращение к семейству операторов нужно, чтобы найти специфические для типа данных хеш-функции. Разумеется, нужно создать подходящие хеш-функции, прежде чем вы сможете создать семейство операторов.
При создании хэш-функции следует соблюдать осторожность, поскольку существуют машинно-зависимые обстоятельства, провоцирующие ошибки. которыми она может не справиться с задачей. Например, если ваш тип данных — это структура, в которой есть неинформативные байты (исклютельно для выравнивания), в них может быть случайный мусор, и вы не можете просто передать всю структуру hash_any. (Чтобы этого избежать, следует писать все функции так, чтобы неинформативные байты заполнялись нулями.) Другой пример — на машинах, использующих числа с плавающей запятой в соотвествии со стандартом IEEE отрицательный ноль и положительный ноль - это разные значения (разные битовые комбинации), но они должны считаться равными. Если значение с плавающей запятой может содержать отрицательный ноль, то нужен дополнительный шаг перед хешированием.
Оператор присоединения к хешу должен иметь коммутатор (сам, если два типа данных операндов одинаковы, или связанный оператор равенства, если они различны), принадлежащий тому же семейству операторов. Если коммутатор не пренадлежит семейству, могут вознуть ошибки планировщика. Кроме того, если семейство хеш-операторов поддерживает несколько типов данных, будет хорошей идеей иметь операторы равенства для всевозможных комбинаций типов, это позволит лучшую оптимизацию.
Замечание
Функция, лежащая в основе HASHES-оператора, должна быть помечена как IMMUTABLE или STABLE. Если он VOLATILE, система никогда не будет пытаться использовать оператор для хеш-соединения.
Замечание
И если эта функция строгая (STRICT), она должна быть всюдуопределенной, т.е. должна возвращать true или false для любых NOT NULL входных значений. Если это правило не соблюдается, хэш-оптимизация условийINможет привести к неверным результатам. (В частности,INможет вернутьfalse, когда правильный ответ в соответствии со стандартом NULL; или может выдать ошибку, сообщающую, что NULL — недопустимый результат).
MERGES
Предложение MERGES, если оно присутствует, сообщает системе, что для соединения, основанного на этом операторе, можно использовать метод merge-join. MERGES имеет смысл только для двоичного оператора, который возвращает boolean, и на практике оператор должен представлять равенство для некоторого типа данных или пары типов данных.
Объединение слиянием основано на идее упорядочения левой и правой таблиц по порядку и последующего их параллельного сканирования. Таким образом, оба типа данных должны быть полностью упорядочены, и оператор соединения должен иметь какой тип, который может быть успешным только для пар значений, попадающих в «одно и то же место» в порядке сортировки. На практике это означает, что оператор соединения должен вести себя как равенство. Но возможно объединить два разных типа данных, если они логически совместимы. Например, оператор равенства smallint -versus-integer является присоединяемым слиянием. Нам нужны только операторы сортировки, которые приведут оба типа данных в логически совместимую последовательность.
Чтобы пометить MERGES, оператор соединения должен появляться как член равенства семейства операторов индекса btree. Это не применяется при создании оператора, поскольку, конечно, семейство ссылочных операторов еще не могло существовать. Но оператор фактически не будет использоваться для объединений слиянием, если не будет найдено соответствующее семейство операторов. Флаг MERGES таким образом, служит подсказкой для планировщика, что стоит искать подходящее семейство операторов.
Оператор с объединением слиянием должен иметь коммутатор (сам, если два типа данных операндов одинаковы, или связанный оператор равенства, если они различны), который появляется в одном и том же семействе операторов. Если это не так, ошибки планировщика могут возникнуть при использовании оператора. Кроме того, это хорошая идея (но не обязательно) для семейства операторов btree которое поддерживает несколько типов данных, чтобы обеспечить операторы равенства для каждой комбинации типов данных; это позволяет лучше оптимизировать.
Заметка
Функция, лежащая в основе оператора объединения слиянием, должна быть помечена как неизменяемая или стабильная. Если он изменчив, система никогда не будет пытаться использовать оператор для объединения слиянием.
Интерфейсные расширения для индексов
Описанные выше процедуры позволяют вам определять новые типы, новые функции и новые операторы. Однако мы еще не можем определить индекс для столбца нового типа данных. Для этого мы должны определить класс операторов для нового типа данных. Позже в этом разделе мы проиллюстрируем эту концепцию на примере: новый класс операторов для метода индексирования B-дерева, который сохраняет и сортирует комплексные числа в порядке возрастания абсолютных значений.
Классы операторов могут быть сгруппированы в семейства операторов, чтобы показать взаимосвязи между семантически совместимыми классами. Когда задействован только один тип данных, достаточно класса операторов, поэтому мы сначала сосредоточимся на этом случае, а затем вернемся к семействам операторов.
Индексные методы и операторные классы
Таблица pg_am содержит одну строку для каждого индексного метода (внутренне известного как метод доступа). Поддержка регулярного доступа к таблицам встроена в QHB, но все индексные методы описаны в pg_am. Можно добавить новый метод доступа к индексу, написав необходимый код и затем создав запись в pg_am - но это выходит за рамки этой главы (см. Определение интерфейса метода доступа к индексу ).
Подпрограммы для индексного метода напрямую ничего не знают о типах данных, с которыми тот будет работать. Вместо этого операторский класс определяет набор операций, которые индексный метод должен использовать для работы с конкретным типом данных. Классы операторов называются так, потому что они указывают только одну вещь - набор операторов WHERE -предложения, которые можно использовать с индексом (то есть можно преобразовать в квалификацию сканирования индекса). Класс оператора также может указывать некоторую вспомогательную функцию, которая необходима внутренним операциям метода index, но не соответствует напрямую ни одному оператору WHERE-предложения, который может использоваться с индексом.
Можно определить несколько классов операторов для одного и того же типа данных и индексного метода. Благодаря этому для одного типа данных можно определить несколько наборов семантики индексирования. Например, для B-дерева требуется определить порядок сортировки для каждого типа данных, с которым он работает. Для типа данных с комплексным числом может быть полезно иметь один класс операторов B-дерева, который сортирует данные по комплексному абсолютному значению, другой, который сортирует по вещественной части, и так далее. Как правило, один из классов операторов считается наиболее полезным и помечается как класс операторов по умолчанию для этого типа данных и индексного метода.
Одно и то же имя класса оператора можно использовать для нескольких различных индексных методов (например, методы B-дерева и хеш-индекса имеют классы операторов с именем int4_ops), но каждый такой класс является независимой сущностью и должен определяться отдельно.
Стратегии индексного метода
Операторы, связанные с классом операторов, идентифицируются «номерами
стратегий», которые служат для идентификации семантики каждого
оператора в контексте его класса операторов. Например, B-деревья
накладывают строгий порядок на ключи, от меньшего к большему, и поэтому
операторы типа «меньше чем» и «больше или равно» интересны в
отношении B-дерева. Поскольку QHB позволяет пользователю
определять операторы, QHB не может посмотреть на имя оператора
(например, < или >= ) и сказать, какое это сравнение. Вместо этого
индексный метод определяет набор «стратегий», которые можно
рассматривать как обобщенные операторы. Каждый класс операторов
определяет, какой фактический оператор соответствует каждой стратегии
для конкретного типа данных и интерпретации семантики индекса.
Метод индексирования B-дерева определяет пять стратегий, показанных в таблице 2.
Таблица 2. B-Tree Стратегии
| Операция | Номер стратегии |
|---|---|
| меньше, чем | 1 |
| меньше или равно | 2 |
| равный | 3 |
| больше или равно | 4 |
| больше чем | 5 |
Хеш-индексы поддерживают только сравнения на равенство, поэтому они используют только одну стратегию, показанную в таблице 3.
Таблица 3. Хэш-стратегии
| Операция | Номер стратегии |
|---|---|
| равный | 1 |
Индексы GiST более гибкие: у них нет фиксированного набора стратегий вообще. Вместо этого подпрограмма поддержки «согласованности» каждого конкретного класса операторов GiST интерпретирует числа стратегий так, как им нравится. Например, некоторые из встроенных классов операторов индекса GiST индексируют двумерные геометрические объекты, предоставляя стратегии «R-дерева», показанные в таблице 4. Четыре из них являются настоящими двумерными тестами (перекрывается, то же самое, содержит, содержится в); четыре из них рассматривают только направление X; и другие четыре обеспечивают те же самые тесты в направлении Y.
Таблица 4. GiST двумерные стратегии R-дерева
| Операция | Номер стратегии |
|---|---|
| строго слева от | 1 |
| не распространяется на право | 2 |
| перекрывается | 3 |
| не распространяется на лево | 4 |
| строго справа от | 5 |
| одно и то же | 6 |
| содержит | 7 |
| содержится в | 8 |
| не распространяется выше | 9 |
| строго ниже | 10 |
| строго выше | 11 |
| не распространяется ниже | 12 |
По гибкости индексы SP-GiST аналогичны индексам GiST: у них нет фиксированного набора стратегий. Вместо этого подпрограммы поддержки каждого класса операторов интерпретируют номера стратегий в соответствии с определением класса операторов. Например, номера стратегий, используемые встроенными классами операторов для точек, показаны в таблице 5 .
Таблица 5. SP-GiST Point Strategies
| Операция | Номер стратегии |
|---|---|
| строго слева от | 1 |
| строго справа от | 5 |
| одно и то же | 6 |
| содержится в | 8 |
| строго ниже | 10 |
| строго выше | 11 |
Индексы GIN аналогичны индексам GiST и SP-GiST тем, что у них также нет фиксированного набора стратегий. Вместо этого подпрограммы поддержки каждого класса операторов интерпретируют номера стратегий в соответствии с определением класса операторов. Например, номера стратегий, используемые встроенным классом операторов для массивов, показаны в таблице 6.
Таблица 6. Стратегии GIN Array
| Операция | Номер стратегии |
|---|---|
| перекрытие | 1 |
| содержит | 2 |
| содержится в | 3 |
| равный | 4 |
Индексы BRIN аналогичны индексам GiST, SP-GiST и GIN тем, что они также не имеют фиксированного набора стратегий. Вместо этого подпрограммы поддержки каждого класса операторов интерпретируют номера стратегий в соответствии с определением класса операторов. В качестве примера, номера стратегий, используемые встроенными классами операторов Minmax, показаны в таблице 7.
Таблица 7. BRIN Minmax Стратегии
| Операция | Номер стратегии |
|---|---|
| меньше, чем | 1 |
| меньше или равно | 2 |
| равный | 3 |
| больше или равно | 4 |
| больше чем | 5 |
Обратите внимание, что все перечисленные выше операторы возвращают логические значения. На практике все операторы, определенные как операторы поиска индексного метода, должны возвращать тип boolean, так как они должны появляться на верхнем уровне WHERE для использования с индексом. (Некоторые методы доступа к индексу также поддерживают операторы упорядочения, которые обычно не возвращают логические значения; эта функция обсуждается в разделе Интерфейсные расширения для индексов).
Процедуры поддержки индексного метода
Стратегии обычно не достаточно информации для системы, чтобы понять, как использовать индекс. На практике индексные методы требуют дополнительных подпрограмм поддержки для работы. Например, метод индексирования B-дерева должен уметь сравнивать два ключа и определять, больше ли один, равен или меньше другого. Точно так же метод хэш-индекса должен иметь возможность вычислять хеш-коды для ключевых значений. Эти операции не соответствуют операторам, используемым в квалификациях в командах SQL; они являются административными процедурами, используемыми внутренними индексными методами.
Как и в случае стратегий, класс операторов определяет, какие конкретные функции должны играть каждую из этих ролей для данного типа данных и семантической интерпретации. Индексный метод определяет набор функций, которые ему нужны, а класс операторов определяет правильные функции для использования, назначая их «номерам функций поддержки», указанным в индексном методе.
B-деревья требуют функции поддержки сравнения и позволяют предоставлять две дополнительные функции поддержки по усмотрению автора класса оператора, как показано в таблице 8. Требования к этим функциям поддержки объясняются далее в разделе Вспомогательные функции B-дерева.
Таблица 8. Функции поддержки B-Tree
| Функция | Номер поддержки |
|---|---|
| Сравните два ключа и верните целое число меньше нуля, нуля или больше нуля, указывая, является ли первый ключ меньше, равен или больше второго | 1 |
| Возвратите адреса C-вызываемой функции поддержки сортировки (необязательно) | 2 |
| Сравните значение теста с базовым значением плюс / минус смещение и верните true или false в соответствии с результатом сравнения (необязательно) | 3 |
Для хеш-индексов требуется одна вспомогательная функция, и она может предоставляться по второму усмотрению по усмотрению автора класса оператора, как показано в таблице 9.
Таблица 9. Функции поддержки хэша
| Функция | Номер поддержки |
|---|---|
| Вычислить 32-битное хеш-значение для ключа | 1 |
| Вычислить 64-битное хеш-значение для ключа с учетом 64-битной соли; если соль равна 0, младшие 32 бита результата должны соответствовать значению, которое было бы вычислено функцией 1 (необязательно) | 2 |
Индексы GiST имеют девять вспомогательных функций, две из которых являются необязательными, как показано в таблице 10.
Таблица 10. GiST Поддержка Функции
| Функция | Описание | Номер поддержки |
|---|---|---|
| consistent | определить, удовлетворяет ли ключ квалификатору запроса | 1 |
| union | вычислить объединение набора ключей | 2 |
| compress | вычислить сжатое представление ключа или значения для индексации | 3 |
| decompress | вычислить распакованное представление сжатого ключа | 4 |
| penalty | вычислить штраф за вставку нового ключа в поддерево с заданным ключом поддерева | 5 |
| picksplit | определить, какие записи страницы должны быть перемещены на новую страницу, и вычислить ключи объединения для получающихся страниц | 6 |
| equal | сравнить два ключа и вернуть true, если они равны | 7 |
| distance | определить расстояние от ключа до значения запроса (необязательно) | 8 |
| fetch | вычислять исходное представление сжатого ключа для сканирования только по индексу (необязательно) | 9 |
Для индексов SP-GiST требуется пять вспомогательных функций, как показано в таблице 11.
Таблица 11. Функции поддержки SP-GiST
| Функция | Описание | Номер поддержки |
|---|---|---|
| config | предоставить основную информацию о классе оператора | 1 |
| choose | определить, как вставить новое значение во внутренний кортеж | 2 |
| picksplit | определить, как разбить набор значений | 3 |
| inner_consistent | определить, какие подразделы нужно искать для запроса | 4 |
| leaf_consistent | определить, удовлетворяет ли ключ квалификатору запроса | 5 |
Индексы GIN имеют шесть вспомогательных функций, три из которых являются необязательными, как показано в таблице 12.
Таблица 12. Функции поддержки GIN
| Функция | Описание | Номер поддержки |
|---|---|---|
| compare | сравнить два ключа и вернуть целое число меньше нуля, нуля или больше нуля, указывающее, является ли первый ключ меньше, равен или больше второго | 1 |
| extractValue | извлекать ключи из значения для индексации | 2 |
| extractQuery | извлекать ключи из условия запроса | 3 |
| consistent | определить, соответствует ли значение условию запроса (логический вариант) (необязательно, если присутствует функция поддержки 6) | 4 |
| comparePartial | сравнивать частичный ключ из запроса и ключ из индекса и возвращать целое число меньше нуля, нуля или больше нуля, указывающее, должен ли GIN игнорировать эту запись индекса, рассматривать запись как совпадение или остановить сканирование индекса (необязательно) | 5 |
| triConsistent | определить, соответствует ли значение условию запроса (троичный вариант) (необязательно, если присутствует функция поддержки 4) | 6 |
Индексы BRIN имеют четыре основные вспомогательные функции, как показано в таблице 13 ; эти основные функции могут потребовать предоставления дополнительных функций поддержки.
Таблица 13. Функции поддержки BRIN
| Функция | Описание | Номер поддержки |
|---|---|---|
| opcInfo | вернуть внутреннюю информацию, описывающую сводные данные индексированных столбцов | 1 |
| add_value | добавить новое значение в существующий кортеж итогового индекса | 2 |
| consistent | определить, соответствует ли значение условию запроса | 3 |
| union | вычислить объединение двух сводных кортежей | 4 |
В отличие от операторов поиска, функции поддержки возвращают тот тип данных, который ожидает конкретный индексный метод, например в случае функции сравнения для B-деревьев целое число со знаком. Количество и типы аргументов каждой вспомогательной функции также зависят от индексного метода. Для B-дерева и хеша функции поддержки сравнения и хеширования принимают те же типы входных данных, что и операторы, включенные в класс операторов, но это не относится к большинству функций поддержки GiST, SP-GiST, GIN и BRIN.
Пример
Теперь, когда мы увидели идеи, вот обещанный пример создания нового класса операторов. (Вы можете найти рабочую копию этого примера в src/tutorial/complex.c и src/tutorial/complex.sql в исходном выпуске). Класс операторов инкапсулирует операторы, которые сортируют комплексные числа в порядке абсолютных значений, поэтому мы выбираем имя complex_abs_ops. Во-первых, нам нужен набор операторов. Процедура определения операторов обсуждалась в разделе Пользовательские операторы. Для класса операторов на B-деревьях нам нужны следующие операторы:
-
абсолютное значение меньше чем (стратегия 1)
-
абсолютное значение меньше или равно (стратегия 2)
-
абсолютное значение равно (стратегия 3)
-
абсолютное значение больше или равно (стратегия 4)
-
абсолютное значение больше чем (стратегия 5)
Наименее подверженный ошибкам способ определения связанного набора операторов сравнения - сначала написать функцию поддержки сравнения B-деревьев, а затем написать другие функции в виде однострочных оболочек вокруг функции поддержки. Это уменьшает шансы получения противоречивых результатов для угловых случаев. Следуя этому подходу, мы сначала пишем:
#define Mag(c) ((c)->x*(c)->x + (c)->y*(c)->y)
static int
complex_abs_cmp_internal(Complex *a, Complex *b)
{
double amag = Mag(a),
bmag = Mag(b);
if (amag < bmag)
return -1;
if (amag > bmag)
return 1;
return 0;
}
Теперь функция меньше чем выглядит так:
PG_FUNCTION_INFO_V1(complex_abs_lt);
Datum
complex_abs_lt(PG_FUNCTION_ARGS)
{
Complex *a = (Complex *) PG_GETARG_POINTER(0);
Complex *b = (Complex *) PG_GETARG_POINTER(1);
PG_RETURN_BOOL(complex_abs_cmp_internal(a, b) < 0);
}
Другие четыре функции отличаются только тем, как они сравнивают результат внутренней функции с нулем.
Далее мы объявляем функции и операторы на основе этих функций в SQL:
CREATE FUNCTION complex_abs_lt(complex, complex) RETURNS bool
AS 'filename', 'complex_abs_lt'
LANGUAGE C IMMUTABLE STRICT;
CREATE OPERATOR < (
leftarg = complex, rightarg = complex, procedure = complex_abs_lt,
commutator = >, negator = >=,
restrict = scalarltsel, join = scalarltjoinsel
);
Важно указать правильные операторы коммутатора и отрицателя, а также подходящие функции ограничения и селективности, иначе оптимизатор не сможет эффективно использовать индекс.
Другие вещи, которые стоит отметить, происходят здесь:
-
Может быть только один оператор с именем, скажем,
=и принимающий complex типы для обоих операндов. В этом случае у нас нет никакого другого оператора=для complex, но если бы мы строили практический тип данных, мы бы, вероятно, хотели бы иметь=как обычную операцию равенства для комплексных чисел (а не равенства абсолютных значений). В этом случае нам нужно будет использовать другое имя оператора для complex_abs_eq. -
Хотя QHB может справляться с функциями, имеющими одинаковое имя SQL, при условии, что они имеют разные типы данных аргументов, C может справиться только с одной глобальной функцией, имеющей данное имя. Поэтому мы не должны называть функцию C чем-то простым, например, abs_eq. Обычно рекомендуется включать имя типа данных в имя функции C, чтобы не конфликтовать с функциями других типов данных.
-
Мы могли бы сделать имя SQL для функции abs_eq, полагаясь на QHB, чтобы отличать его по типу данных аргумента от любой другой функции SQL с тем же именем. Чтобы упростить пример, мы заставляем функцию иметь одинаковые имена на уровне C и уровне SQL.
Следующим шагом является регистрация подпрограммы поддержки, требуемой B-деревьями. Пример кода C, который реализует это, находится в том же файле, который содержит функции оператора. Вот как мы объявляем функцию:
CREATE FUNCTION complex_abs_cmp(complex, complex)
RETURNS integer
AS 'filename'
LANGUAGE C IMMUTABLE STRICT;
Теперь, когда у нас есть необходимые операторы и подпрограмма поддержки, мы наконец можем создать класс операторов:
CREATE OPERATOR CLASS complex_abs_ops
DEFAULT FOR TYPE complex USING btree AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 complex_abs_cmp(complex, complex);
И мы сделали! Теперь должна быть возможность создавать и использовать B-деревья для complex столбцов.
Мы могли бы написать записи оператора более подробно, как в:
OPERATOR 1 < (complex, complex),
но нет необходимости делать это, когда операторы принимают тот же тип данных, для которого мы определяем класс операторов.
В приведенном выше примере предполагается, что вы хотите сделать этот новый класс операторов классом операторов B-дерева по умолчанию для complex типа данных. Если вы этого не сделаете, просто пропустите слово DEFAULT.
Классы операторов и семейства операторов
До сих пор мы неявно предполагали, что класс операторов имеет дело только с одним типом данных. Хотя в определенном столбце индекса, безусловно, может быть только один тип данных, часто полезно индексировать операции, которые сравнивают индексированный столбец со значением другого типа данных. Кроме того, если используется оператор кросс-типа данных в связи с классом операторов, часто бывает так, что другой тип данных имеет собственный связанный класс операторов. Полезно сделать связи между связанными классами явными, потому что это может помочь планировщику в оптимизации запросов SQL (особенно для классов операторов B-дерева, поскольку планировщик содержит много знаний о том, как работать с ними).
Для удовлетворения этих потребностей QHB использует концепцию семейства операторов. Семейство операторов содержит один или несколько классов операторов, а также может содержать индексируемые операторы и соответствующие вспомогательные функции, которые принадлежат семейству в целом, но не относятся к какому-либо одному классу в семействе. Мы говорим, что такие операторы и функции «свободны» в семье, а не связаны с определенным классом. Как правило, каждый класс операторов содержит операторы с одним типом данных, в то время как операторы с несколькими типами данных в семействе отсутствуют.
Все операторы и функции в семействе операторов должны иметь совместимую семантику, где требования совместимости устанавливаются индексным методом. Поэтому вы можете спросить, зачем выделять отдельные подмножества семейства как операторные классы; и действительно, для многих целей классовые разделения не имеют значения, и семья является единственной интересной группировкой. Причиной определения классов операторов является то, что они указывают, сколько семейства необходимо для поддержки какого-либо конкретного индекса. Если существует индекс, использующий класс операторов, то этот класс операторов нельзя удалить без удаления индекса, но другие части семейства операторов, а именно другие классы операторов и свободные операторы, могут быть удалены. Таким образом, класс операторов должен быть указан, чтобы содержать минимальный набор операторов и функций, которые разумно необходимы для работы с индексом для определенного типа данных, и затем связанные, но несущественные операторы могут быть добавлены как свободные члены семейства операторов.
В качестве примера, QHB имеет встроенное семейство операторов B-дерева integer_ops, которое включает классы операторов int8_ops, int4_ops и int2_ops для индексов bigint (int8), integer (int4) и smallint (int2) соответственно. Семейство также содержит операторы сравнения между типами данных, позволяющие сравнивать любые два из этих типов, чтобы можно было искать индекс по одному из этих типов, используя значение сравнения другого типа. Семья может быть продублирована следующими определениями:
CREATE OPERATOR FAMILY integer_ops USING btree;
CREATE OPERATOR CLASS int8_ops
DEFAULT FOR TYPE int8 USING btree FAMILY integer_ops AS
-- standard int8 comparisons
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8, int8),
FUNCTION 2 btint8sortsupport(internal),
FUNCTION 3 in_range(int8, int8, int8, boolean, boolean) ;
CREATE OPERATOR CLASS int4_ops
DEFAULT FOR TYPE int4 USING btree FAMILY integer_ops AS
-- standard int4 comparisons
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4, int4),
FUNCTION 2 btint4sortsupport(internal),
FUNCTION 3 in_range(int4, int4, int4, boolean, boolean) ;
CREATE OPERATOR CLASS int2_ops
DEFAULT FOR TYPE int2 USING btree FAMILY integer_ops AS
-- standard int2 comparisons
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint2cmp(int2, int2),
FUNCTION 2 btint2sortsupport(internal),
FUNCTION 3 in_range(int2, int2, int2, boolean, boolean) ;
ALTER OPERATOR FAMILY integer_ops USING btree ADD
-- cross-type comparisons int8 vs int2
OPERATOR 1 < (int8, int2),
OPERATOR 2 <= (int8, int2),
OPERATOR 3 = (int8, int2),
OPERATOR 4 >= (int8, int2),
OPERATOR 5 > (int8, int2),
FUNCTION 1 btint82cmp(int8, int2),
-- cross-type comparisons int8 vs int4
OPERATOR 1 < (int8, int4),
OPERATOR 2 <= (int8, int4),
OPERATOR 3 = (int8, int4),
OPERATOR 4 >= (int8, int4),
OPERATOR 5 > (int8, int4),
FUNCTION 1 btint84cmp(int8, int4),
-- cross-type comparisons int4 vs int2
OPERATOR 1 < (int4, int2),
OPERATOR 2 <= (int4, int2),
OPERATOR 3 = (int4, int2),
OPERATOR 4 >= (int4, int2),
OPERATOR 5 > (int4, int2),
FUNCTION 1 btint42cmp(int4, int2),
-- cross-type comparisons int4 vs int8
OPERATOR 1 < (int4, int8),
OPERATOR 2 <= (int4, int8),
OPERATOR 3 = (int4, int8),
OPERATOR 4 >= (int4, int8),
OPERATOR 5 > (int4, int8),
FUNCTION 1 btint48cmp(int4, int8),
-- cross-type comparisons int2 vs int8
OPERATOR 1 < (int2, int8),
OPERATOR 2 <= (int2, int8),
OPERATOR 3 = (int2, int8),
OPERATOR 4 >= (int2, int8),
OPERATOR 5 > (int2, int8),
FUNCTION 1 btint28cmp(int2, int8),
-- cross-type comparisons int2 vs int4
OPERATOR 1 < (int2, int4),
OPERATOR 2 <= (int2, int4),
OPERATOR 3 = (int2, int4),
OPERATOR 4 >= (int2, int4),
OPERATOR 5 > (int2, int4),
FUNCTION 1 btint24cmp(int2, int4),
-- cross-type in_range functions
FUNCTION 3 in_range(int4, int4, int8, boolean, boolean),
FUNCTION 3 in_range(int4, int4, int2, boolean, boolean),
FUNCTION 3 in_range(int2, int2, int8, boolean, boolean),
FUNCTION 3 in_range(int2, int2, int4, boolean, boolean) ;
Обратите внимание, что это определение «перегружает» стратегию оператора и номера вспомогательных функций: каждое число встречается в семействе несколько раз. Это разрешено, если каждый экземпляр определенного числа имеет разные типы входных данных. Экземпляры, у которых оба типа ввода равны типу ввода класса оператора, являются основными операторами и функциями поддержки для этого класса операторов, и в большинстве случаев их следует объявлять как часть класса операторов, а не как свободные члены семейства.
В семействе операторов B-дерева все операторы в семействе должны сортироваться совместимо, как подробно описано в разделе Поведение классов операторов B-дерева. Для каждого оператора в семействе должна быть функция поддержки, имеющая те же два типа входных данных, что и оператор. Рекомендуется, чтобы семейство было полным, т.е. для каждой комбинации типов данных включены все операторы. Каждый класс операторов должен включать в себя только операторы не перекрестного типа и функцию поддержки для своего типа данных.
Чтобы создать семейство хеш-операторов с несколькими типами данных, необходимо создать совместимые функции поддержки хеш-функций для каждого типа данных, поддерживаемого этим семейством. Здесь совместимость означает, что функции гарантированно возвращают один и тот же хэш-код для любых двух значений, которые считаются равными операторами равенства семейства, даже когда значения имеют разные типы. Обычно это трудно сделать, когда типы имеют разные физические представления, но это может быть сделано в некоторых случаях. Кроме того, приведение значения из одного типа данных, представленного в семействе операторов, к другому типу данных, также представленному в семействе операторов через неявное или двоичное приведение приведения, не должно изменять вычисленное значение хеш-функции. Обратите внимание, что существует только одна вспомогательная функция для каждого типа данных, а не одна для оператора равенства. Рекомендуется, чтобы семейство было полным, т.е. предоставляло оператор равенства для каждой комбинации типов данных. Каждый класс операторов должен включать только оператор равенства без перекрестного типа и функцию поддержки для своего типа данных.
Индексы GiST, SP-GiST и GIN не имеют явного представления об операциях с кросс-типом данных. Набор поддерживаемых операторов - это то, что могут обрабатывать основные вспомогательные функции для данного класса операторов.
В BRIN требования зависят от структуры, предоставляющей классы операторов. Для классов операторов, основанных на minmax, требуемое поведение такое же, как и для семейств операторов B-дерева: все операторы в семействе должны выполнять совместимую сортировку, и приведение не должно изменять связанный порядок сортировки.
Системные зависимости от классов операторов
QHB использует классы операторов, чтобы выводить свойства операторов разными способами, а не просто использовать их с индексами. Поэтому вы можете захотеть создать классы операторов, даже если у вас нет намерения индексировать какие-либо столбцы вашего типа данных.
В частности, существуют функции SQL, такие как ORDER BY и DISTINCT которые требуют сравнения и сортировки значений. Чтобы реализовать эти функции для определенного пользователем типа данных, QHB ищет класс оператора B-дерева по умолчанию для типа данных. Член «равно» этого класса операторов определяет представление системы о равенстве значений для GROUP BY и DISTINCT, а порядок сортировки, налагаемый классом операторов, определяет порядок ORDER BY по умолчанию.
Если для типа данных не существует класса операторов B-дерева по умолчанию, система будет искать класс операторов хеша по умолчанию. Но поскольку этот класс операторов обеспечивает только равенство, он может поддерживать только группирование, а не сортировку.
Если для типа данных не существует класса операторов по умолчанию, вы получите ошибки типа «не удалось определить оператор упорядочения», если попытаетесь использовать эти функции SQL с типом данных.
Сортировка по классу операторов B-дерева, отличному от заданного по умолчанию, возможна, если указать, например, оператор класса меньше в опции USING, например:
SELECT * FROM mytable ORDER BY somecol USING ~<~;
В качестве альтернативы, указать оператор класса больше, чем в USING выбрать сортировку по убыванию.
Сравнение массивов определенного пользователем типа также основывается на семантике, определенной классом операторов B-дерева по умолчанию для этого типа. Если класс операторов B-дерева по умолчанию отсутствует, но есть класс операторов хеш-функций по умолчанию, то поддерживается равенство массивов, но не сравнение по порядку.
Еще одна особенность SQL, которая требует еще больших знаний о типе данных, - это опция кадрирования RANGE offset PRECEDING/FOLLOWING для оконных функций (см. раздел Вызовы оконных функций). Для запроса, такого как
SELECT sum(x) OVER (ORDER BY x RANGE BETWEEN 5 PRECEDING AND 10 FOLLOWING)
FROM mytable;
недостаточно знать, как упорядочить по x; база данных также должна
понимать, как «вычесть 5» или «добавить 10» к значению x текущей
строки, чтобы идентифицировать границы текущего фрейма окна. Сравнение
результирующих границ со значениями x других строк возможно с помощью
операторов сравнения, предоставляемых классом операторов B-дерева,
который определяет порядок ORDER BY, но операторы сложения и вычитания не
являются частью класса операторов, поэтому какие из них следует
использовать? Такой выбор был бы нежелателен, поскольку разные порядки
сортировки (разные классы операторов B-дерева) могут нуждаться в разном
поведении. Поэтому класс операторов B-дерева может указывать
вспомогательную функцию in_range, которая инкапсулирует поведения
сложения и вычитания, которые имеют смысл для порядка сортировки. Он
может даже обеспечить более одной функции поддержки in_range, если
имеется более одного типа данных, который имеет смысл использовать в
качестве смещения в предложениях RANGE. Если класс оператора B-дерева,
связанный с предложением окна ORDER BY, не имеет соответствующей
функции поддержки in_range, опция RANGE offset PRECEDING/FOLLOWING не
поддерживается.
Другим важным моментом является то, что оператор равенства, который появляется в семействе хеш-операторов, является кандидатом на хеш-объединения, агрегирование хеш-функций и связанные с ними оптимизации. Семейство хеш-операторов здесь важно, так как оно идентифицирует хеш-функцию (и) для использования.
Операторы сортировки
Некоторые методы доступа к индексу (в настоящее время только GiST и SP-GiST) поддерживают концепцию операторов упорядочения. До сих пор мы обсуждали поисковые операторы. Оператор поиска - это оператор, для которого можно выполнить поиск по индексу, чтобы найти все строки, удовлетворяющие WHERE indexed_column operator constant. Обратите внимание, что ничего не обещано о порядке, в котором будут возвращены соответствующие строки. Напротив, оператор упорядочения не ограничивает набор строк, которые могут быть возвращены, а вместо этого определяет их порядок. Оператор упорядочения - это оператор, для которого индекс может быть отсканирован для получения строк в порядке, представленном ORDER BY indexed_column operator constant. Причиной определения операторов упорядочения таким образом является то, что он поддерживает поиск ближайшего соседа, если оператор измеряет расстояние. Например, запрос типа
SELECT * FROM places ORDER BY location <-> point '(101,456)' LIMIT 10;
находит десять мест, ближайших к заданной целевой точке. Индекс GiST для
столбца местоположения может сделать это эффективно, потому что
<-> является оператором упорядочения.
В то время как операторы поиска должны возвращать логические результаты,
операторы упорядочения обычно возвращают некоторый другой тип, например,
с плавающей или числовой для расстояний. Этот тип обычно не совпадает с
индексируемым типом данных. Чтобы избежать жестких предположений о
поведении различных типов данных, определение оператора упорядочения
необходимо для именования семейства операторов B-дерева, которое
определяет порядок сортировки результирующего типа данных. Как было
сказано в предыдущем разделе, семейства операторов B-дерева определяют
понятие упорядочения в QHB, так что это естественное
представление. Поскольку оператор точки <-> возвращает float8,
его можно указать в команде создания класса оператора, например:
OPERATOR 15 <-> (point, point) FOR ORDER BY float_ops
где float_ops - это встроенное семейство операторов, которое включает
операции на float8. В этом объявлении говорится, что индекс может
возвращать строки в порядке возрастания значений оператора <->.
Особенности операторских классов
Есть две особенности классов операторов, которые мы еще не обсуждали, в основном потому, что они бесполезны с наиболее часто используемыми индексными методами.
Как правило, объявление оператора в качестве члена класса (или семейства) оператора означает, что индексный метод может извлечь именно набор строк, которые удовлетворяют условию WHERE, используя оператор. Например:
SELECT * FROM table WHERE integer_column < 4;
может быть точно удовлетворен B-деревом по целочисленному столбцу. Но бывают случаи, когда индекс полезен как неточное руководство для соответствующих строк. Например, если индекс GiST хранит только ограничивающие рамки для геометрических объектов, он не может точно удовлетворить условие WHERE, которое проверяет перекрытие между непрямоугольными объектами, такими как многоугольники. Тем не менее, мы могли бы использовать индекс для поиска объектов, ограничивающий прямоугольник которых перекрывает ограничивающий прямоугольник целевого объекта, а затем выполнить точный тест перекрытия только для объектов, найденных индексом. Если этот сценарий применим, индекс считается «потерянным» для оператора. Поиск по индексу с потерями реализуется с помощью индексного метода, возвращающего флаг перепроверки, когда строка может или не может действительно удовлетворять условию запроса. Базовая система затем проверит исходное условие запроса в извлеченной строке, чтобы увидеть, следует ли возвращать его в качестве действительного соответствия. Этот подход работает, если индекс гарантированно возвращает все необходимые строки плюс, возможно, некоторые дополнительные строки, которые можно устранить, выполнив исходный вызов оператора. Индексные методы, которые поддерживают поиск с потерями (в настоящее время GiST, SP-GiST и GIN), позволяют функциям поддержки отдельных классов операторов устанавливать флаг повторной проверки, и, таким образом, это по сути функция класса операторов.
Рассмотрим снова ситуацию, когда мы храним в индексе только ограничивающую рамку сложного объекта, такого как многоугольник. В этом случае нет смысла хранить весь многоугольник в элементе индекса - мы могли бы также хранить просто более простой объект типа box. Эта ситуация выражается опцией STORAGE в CREATE OPERATOR CLASS: мы напишем что-то вроде:
CREATE OPERATOR CLASS polygon_ops
DEFAULT FOR TYPE polygon USING gist AS
...
STORAGE box;
В настоящее время только индексные методы GiST, GIN и BRIN поддерживают тип STORAGE, который отличается от типа данных столбца. Процедуры поддержки сжатия и распаковки GiST должны иметь дело с преобразованием типов данных при использовании STORAGE. В GIN тип STORAGE идентифицирует тип значений «ключа», который обычно отличается от типа индексированного столбца - например, класс оператора для столбцов целочисленного массива может иметь ключи, которые являются просто целыми числами. Функции извлечения GIN extractValue и extractQuery отвечают за извлечение ключей из индексированных значений. BRIN аналогичен GIN: тип STORAGE определяет тип хранимых итоговых значений, а процедуры поддержки классов операторов отвечают за правильную интерпретацию итоговых значений.
Упаковка связанных объектов в расширение
Полезное расширение QHB обычно включает несколько объектов SQL; например, новый тип данных потребует новых функций, новых операторов и, возможно, новых классов операторов индекса. Полезно собрать все эти объекты в один пакет, чтобы упростить управление базой данных. QHB называет такой пакет расширением. Чтобы определить расширение, вам нужен как минимум файл сценария, который содержит команды SQL для создания объектов расширения, и управляющий файл, который задает несколько основных свойств самого расширения. Если расширение включает в себя C/RUST-код, обычно также будет файл общей библиотеки, в который был встроен C/RUST-код. Когда у вас есть эти файлы, простая команда (см. CREATE EXTENSION загружает объекты в вашу базу данных.
Основное преимущество использования расширения вместо простого запуска сценария SQL для загрузки группы «незакрепленных» объектов в вашу базу данных заключается в том, что QHB поймет, что объекты расширения объединяются. Вы можете удалить все объекты с помощью одной команды DROP EXTENSION (нет необходимости поддерживать отдельный сценарий «удаления»). Еще более полезно, что qhb_dump знает, что он не должен создавать дамп отдельных объектов-членов расширения - вместо этого он будет просто включать команду CREATE EXTENSION в дампы. Это значительно упрощает миграцию на новую версию расширения, которая может содержать больше объектов или отличаться от старой версии. Однако обратите внимание, что при загрузке такого дампа в новую базу данных вы должны иметь доступ к элементу управления, сценарию и другим файлам расширения.
QHB не позволит вам удалить отдельный объект, содержащийся в расширении, за исключением удаления всего расширения. Кроме того, хотя вы можете изменить определение объекта-члена расширения (например, с помощью функции CREATE OR REPLACE FUNCTION для функции), имейте в виду, что измененное определение не будет выгружено qhb_dump. Такое изменение обычно имеет смысл только в том случае, если вы одновременно вносите такое же изменение в файл сценария расширения. (Но есть специальные положения для таблиц, содержащих данные конфигурации; см. Раздел Упаковка связанных объектов в расширение). В производственных ситуациях, как правило, лучше создавать сценарий обновления расширения для выполнения изменений в объектах-членах расширения.
Сценарий расширения может устанавливать привилегии для объектов, являющихся частью расширения, с помощью операторов GRANT и REVOKE. Окончательный набор привилегий для каждого объекта (если они установлены) будет сохранен в системном каталоге pg_init_privs. Когда используется qhb_dump, команда CREATE EXTENSION будет включена в дамп, за которым следует набор операторов GRANT и REVOKE необходимых для того, чтобы установить привилегии для объектов такими, какими они были на момент получения дампа.
QHB в настоящее время не поддерживает сценарии расширения, выдающие операторы CREATE POLICY или SECURITY LABEL. Ожидается, что они будут установлены после создания расширения. Все политики RLS и метки безопасности на объектах расширения будут включены в дампы, созданные qhb_dump.
Механизм расширения также содержит положения для упаковки сценариев модификации, которые корректируют определения объектов SQL, содержащихся в расширении. Например, если версия 1.1 расширения добавляет одну функцию и изменяет тело другой функции по сравнению с 1.0, автор расширения может предоставить скрипт обновления, который вносит только эти два изменения. Затем можно применить команду ALTER EXTENSION UPDATE чтобы применить эти изменения и отследить, какая версия расширения фактически установлена в данной базе данных.
Виды объектов SQL, которые могут быть членами расширения, показаны в описании ALTER EXTENSION. В частности, объекты, относящиеся к общему кластеру базы данных, такие как базы данных, роли и табличные пространства, не могут быть членами расширения, поскольку расширение известно только в одной базе данных. (Хотя сценарию расширения не запрещено создавать такие объекты, в этом случае они не будут отслеживаться как часть расширения). Также обратите внимание, что хотя таблица может быть членом расширения, ее вспомогательные объекты, такие как индексы, непосредственно не считаются членами расширения. Другим важным моментом является то, что схемы могут принадлежать расширениям, но не наоборот: расширение как таковое имеет неквалифицированное имя и не существует «внутри» какой-либо схемы. Объекты-члены расширения, тем не менее, будут принадлежать схемам, когда это уместно для их типов объектов. Расширение может или не может быть подходящим для того, чтобы расширение владело схемой (схемами), в которой находятся его элементы-члены.
Если сценарий расширения создает какие-либо временные объекты (например, временные таблицы), эти объекты обрабатываются как элементы расширения для оставшейся части текущего сеанса, но автоматически удаляются в конце сеанса, как и любой временный объект. Это исключение из правила, что объекты-члены расширения не могут быть удалены без удаления всего расширения.
Определение объектов расширения
Широко распространенные расширения должны предполагать немного о базе данных, которую они занимают. В частности, если вы не указали SET search_path = pg_temp, предположите, что каждое неквалифицированное имя может преобразовываться в объект, определенный злоумышленником. Остерегайтесь конструкций, которые неявно зависят от search_path: выражения IN и CASE expression WHEN всегда выбирают оператор, используя путь поиска. Вместо них используйте OPERATOR(schema.=) ANY и CASE WHEN expression.
Файлы расширений
Команда CREATE EXTENSION опирается на управляющий файл для каждого
расширения, который должен называться так же, как расширение с суффиксом
.control, и должен быть помещен в каталог SHAREDIR/extension. Также должен
быть хотя бы один файл сценария SQL, который следует за расширению
шаблона именования extension--version.sql (например,
foo--1.0.sql для версии 1.0 расширения foo). По умолчанию файлы
сценариев также размещаются в каталог SHAREDIR/extension; но файл управления
может указывать другой каталог для файла(ов) сценария.
Формат файла для файла управления расширениями такой же, как и для файла
qhb.conf, а именно список назначений parameter_name = value,
по одному на строку. Пустые строки и комментарии, представленные #,
разрешены. Не забудьте указать любое значение, которое не является ни
одним словом или числом.
Управляющий файл может устанавливать следующие параметры:
- directory (string)
- Каталог, содержащий файл(ы) SQL- сценария расширения. Если не указан абсолютный путь, имя SHAREDIR каталога SHAREDIR установки. Поведение по умолчанию эквивалентно указанию directory = ’extension’.
- default_version (string)
- Версия расширения по умолчанию (та, которая будет установлена, если в CREATE EXTENSION не указана версия). Хотя это может быть опущено, это приведет к сбою CREATE EXTENSION если опция VERSION не появится, поэтому вы обычно не хотите этого делать.
- comment (string)
- Комментарий (любая строка) о расширении. Комментарий применяется при первоначальном создании расширения, но не при его обновлении (поскольку это может переопределить добавленные пользователем комментарии). Кроме того, комментарий расширения можно установить, написав команду COMMENT в файле сценария.
- encoding (string)
- Кодировка набора символов, используемая в файле(ах) скрипта. Это следует указывать, если файлы сценариев содержат символы, не относящиеся к ASCII. В противном случае предполагается, что файлы находятся в кодировке базы данных.
- module_pathname (string)
- Значение этого параметра будет заменено для каждого вхождения MODULE_PATHNAME в файлах скриптов. Если он не установлен, замена не производится. Как правило, это значение равно $libdir/shared_library_name а затем MODULE_PATHNAME используется в командах CREATE FUNCTION для функций языка C/RUST, поэтому файлам сценариев не нужно жестко связывать имя разделяемой библиотеки.
- requires (string)
- Список имен расширений, от которых зависит это расширение, например
requires = ’foo, bar’. Эти расширения должны быть установлены до того, как можно будет установить это расширение. - superuser (boolean)
- Если этот параметр имеет значение true (по умолчанию), только суперпользователи могут создать расширение или обновить его до новой версии. Если установлено значение false, требуются только те привилегии, которые необходимы для выполнения команд в сценарии установки или обновления.
- relocatable (boolean)
- Расширение можно перемещать, если возможно переместить содержащиеся в нем объекты в другую схему после первоначального создания расширения. По умолчанию установлено значение false, то есть расширение не может быть перемещено. См. Раздел Перемещаемость расширения для получения дополнительной информации.
- schema (string)
- Этот параметр может быть установлен только для не перемещаемых расширений. Это заставляет расширение загружаться в точно названную схему, а не в любую другую. Параметр schema используется только при первоначальном создании расширения, а не при его обновлении. См. Раздел Перемещаемость расширения для получения дополнительной информации.
В дополнение к основному управляющему файлу extension.control расширение может иметь вторичные управляющие файлы, названные в расширении стиля extension--version.control. Если они есть, они должны находиться в каталоге файлов сценариев. Вторичные управляющие файлы имеют тот же формат, что и основной управляющий файл. Любые параметры, установленные во вторичном управляющем файле, переопределяют первичный управляющий файл при установке или обновлении до этой версии расширения. Однако каталог параметров и default_version нельзя установить во вторичном управляющем файле.
Файлы сценариев SQL расширения могут содержать любые команды SQL, кроме команд управления транзакциями (BEGIN, COMMIT и т.д.) И команд, которые не могут быть выполнены внутри блока транзакции (например, VACUUM). Это связано с тем, что файлы сценариев неявно выполняются внутри блока транзакции.
Файлы сценариев SQL расширения также могут содержать строки,
начинающиеся с \echo, которые будут игнорироваться (обрабатываться как
комментарии) механизмом расширения. Это положение обычно используется
для выдачи ошибки, если файл сценария подается в qsql, а не загружается
через CREATE EXTENSION (см. Пример сценария в разделе Упаковка связанных объектов в расширение). Без
этого пользователи могут случайно загрузить содержимое расширения как
«незакрепленные» объекты, а не как расширение, - состояние дел, которое
немного утомительно восстанавливать.
Хотя файлы сценариев могут содержать любые символы, разрешенные указанной кодировкой, управляющие файлы должны содержать только простой ASCII, поскольку QHB не может узнать, в какой кодировке находится управляющий файл. На практике это проблема, только если вы хотите используйте не-ASCII символы в комментарии расширения. В этом случае рекомендуется не использовать параметр comment к контрольному файлу, а вместо этого использовать COMMENT ON EXTENSION в файле сценария для установки комментария.
Перемещаемость расширения
Пользователи часто хотят загружать объекты, содержащиеся в расширении, в другую схему, чем предполагал автор расширения. Существует три поддерживаемых уровня перемещаемости:
-
Полностью перемещаемое расширение может быть перемещено в другую схему в любое время, даже после его загрузки в базу данных. Это делается с помощью команды ALTER EXTENSION SET SCHEMA, которая автоматически переименовывает все объекты-члены в новую схему. Обычно это возможно только в том случае, если расширение не содержит внутренних предположений о том, в какой схеме находится какой-либо из его объектов. Кроме того, все объекты расширения должны начинаться с одной схемы (игнорируя объекты, которые не принадлежат какой-либо схеме, например: процедурные языки). Отметьте полностью перемещаемое расширение, установив relocatable = true в его контрольный файл.
-
Расширение может перемещаться во время установки, но не после. Обычно это происходит, если файл сценария расширения должен явно ссылаться на целевую схему, например, при настройке свойств search_path для функций SQL. Для такого расширения установите relocatable = false в его управляющем файле и используйте
@extschema@чтобы обратиться к целевой схеме в файле сценария. Все вхождения этой строки будут заменены фактическим именем целевой схемы перед выполнением сценария. Пользователь может установить целевую схему, используя опцию SCHEMA команды CREATE EXTENSION. -
Если расширение вообще не поддерживает перемещение, установите в его управляющем файле relocatable = false, а также задайте для schema имя предполагаемой целевой схемы. Это предотвратит использование опции SCHEMA CREATE EXTENSION, если только в ней не указана та же схема, что и в контрольном файле. Этот выбор обычно необходим, если расширение содержит внутренние предположения об именах схем, которые нельзя заменить использованием
@extschema@. Механизм замещения@extschema@доступен в этом случае, хотя он имеет ограниченное использование, поскольку имя схемы определяется управляющим файлом.
Во всех случаях файл сценария будет выполняться с параметром search_path, изначально установленным для указания на целевую схему; то есть CREATE EXTENSION делает эквивалент этого:
SET LOCAL search_path TO @extschema@;
Это позволяет объектам, созданным файлом сценария, перейти в целевую схему. Файл сценария может изменить search_path если пожелает, но это обычно нежелательно. search_path восстанавливается до прежнего значения после завершения CREATE EXTENSION.
Целевая схема определяется параметром schema в управляющем файле, если он указан, в противном случае - параметром SCHEMA в CREATE EXTENSION если он задан, в противном случае - текущей схемой создания объекта по умолчанию (первой в пути search_path вызывающего). Когда используется параметр schema управляющего файла, целевая схема будет создана, если она еще не существует, но в двух других случаях она уже должна существовать.
Если какие-либо обязательные расширения перечислены в requires в контрольном файле, их целевые схемы добавляются к начальному search_path. Это позволяет их объектам быть видимыми в файле сценария нового расширения.
Хотя не перемещаемое расширение может содержать объекты, распределенные по нескольким схемам, обычно желательно поместить все объекты, предназначенные для внешнего использования, в одну схему, которая считается целевой схемой расширения. Такое расположение удобно работает с настройкой по умолчанию search_path при создании зависимых расширений.
Таблицы конфигурации расширений
Некоторые расширения включают таблицы конфигурации, которые содержат данные, которые могут быть добавлены или изменены пользователем после установки расширения. Обычно, если таблица является частью расширения, ни определение таблицы, ни ее содержимое не будут выгружены qhb_dump. Но такое поведение нежелательно для таблицы конфигурации; любые изменения данных, сделанные пользователем, должны быть включены в дампы, иначе расширение будет вести себя по-другому после дампа и перезагрузки.
Чтобы решить эту проблему, файл сценария расширения может пометить созданную им таблицу или последовательность как отношение конфигурации, что заставит qhb_dump включить содержимое таблицы или последовательности (не ее определение) в дампы. Для этого вызовите функцию pg_extension_config_dump(regclass, text) после создания таблицы или последовательности, например
CREATE TABLE my_config (key text, value text);
CREATE SEQUENCE my_config_seq;
SELECT pg_catalog.pg_extension_config_dump('my_config', '');
SELECT pg_catalog.pg_extension_config_dump('my_config_seq', '');
Таким образом можно пометить любое количество таблиц или последовательностей. Последовательности, связанные с serial или bigserial столбцов, также могут быть отмечены.
Когда второй аргумент pg_extension_config_dump является пустой строкой, все содержимое таблицы выгружается с помощью qhb_dump. Обычно это верно только в том случае, если таблица изначально пуста, как это создано сценарием расширения. Если в таблице содержится смесь исходных данных и данных, предоставленных пользователем, второй аргумент pg_extension_config_dump предоставляет условие WHERE которое выбирает данные, которые должны быть выгружены. Например, вы можете сделать
CREATE TABLE my_config (key text, value text, standard_entry boolean);
SELECT pg_catalog.pg_extension_config_dump('my_config', 'WHERE NOT standard_entry');
и затем убедитесь, что standard_entry имеет значение true только в строках, созданных сценарием расширения.
Для последовательностей второй аргумент pg_extension_config_dump имеет никакого эффекта.
Более сложные ситуации, такие как изначально предоставленные строки, которые могут быть изменены пользователями, могут быть обработаны путем создания триггеров в таблице конфигурации, чтобы гарантировать, что измененные строки помечены правильно.
Вы можете изменить условие фильтра, связанное с таблицей конфигурации, снова вызвав pg_extension_config_dump. (Обычно это может быть полезно в скрипте обновления расширения). Единственный способ пометить таблицу как таблицу, которая больше не является таблицей конфигурации, - это отсоединить ее от расширения с помощью ALTER EXTENSION ... DROP TABLE.
Обратите внимание, что отношения внешнего ключа между этими таблицами будут определять порядок, в котором таблицы выгружаются qhb_dump. В частности, qhb_dump попытается вывести таблицу, на которую ссылаются, перед таблицей, на которую ссылаются. Поскольку отношения внешнего ключа устанавливаются во время CREATE EXTENSION (до загрузки данных в таблицы), циклические зависимости не поддерживаются. Когда существуют циклические зависимости, данные все равно будут выгружены, но дамп не сможет быть восстановлен напрямую, и потребуется вмешательство пользователя.
Последовательности, связанные с serial или bigserial столбцами, должны быть помечены напрямую, чтобы вывести их состояние. Маркировка их родительских отношений недостаточно для этой цели.
Обновления расширений
Одним из преимуществ механизма расширения является то, что он
предоставляет удобные способы управления обновлениями команд SQL,
которые определяют объекты расширения. Это делается путем привязки имени
или номера версии к каждой выпущенной версии сценария установки
расширения. Кроме того, если вы хотите, чтобы пользователи могли
динамически обновлять свои базы данных с одной версии на другую, вы
должны предоставить сценарии обновления, которые вносят необходимые
изменения для перехода с одной версии на другую. Сценарии обновления
имеют имена, следующего шаблона extension--old_version--target_version.sql
(например, foo--1.0--1.1.sql содержит команды для изменения версии 1.0
расширения foo в версию 1.1 ).
При наличии подходящего сценария обновления команда ALTER EXTENSION UPDATE обновит установленное расширение до указанной новой версии. Сценарий обновления выполняется в той же среде, которую CREATE EXTENSION предоставляет для сценариев установки: в частности, search_path настраивается таким же образом, и любые новые объекты, созданные сценарием, автоматически добавляются в расширение. Кроме того, если сценарий выбирает удаление объектов-членов расширения, они автоматически отсоединяются от расширения.
Если расширение имеет вторичные контрольные файлы, параметры управления, используемые для сценария обновления, являются теми, которые связаны с целевой (новой) версией сценария.
Механизм обновления может использоваться для решения важного особого случая: преобразования «свободной» коллекции объектов в расширение. До того, как механизм расширения был добавлен в PostgreSQL (в 9.1), многие люди писали модули расширения, которые просто создавали разные неупакованные объекты. Учитывая существующую базу данных, содержащую такие объекты, как мы можем преобразовать объекты в правильно упакованное расширение? Удаление их, а затем выполнение простого CREATE EXTENSION - один из способов, но нежелательно, если у объектов есть зависимости (например, если существуют столбцы таблицы типа данных, созданные расширением). Чтобы исправить эту ситуацию, нужно создать пустое расширение, затем использовать ALTER EXTENSION ADD чтобы присоединить каждый существующий объект к расширению, а затем, наконец, создать любые новые объекты, которые находятся в текущей версии расширения, но отсутствуют в распакованном выпуске. CREATE EXTENSION поддерживает этот случай с опцией FROM old_version, которая заставляет его не запускать обычный скрипт установки для целевой версии, а вместо этого сценарий обновления с именем extension--old_version--target_version.sql. Выбор имени фиктивной версии для использования в качестве old_version зависит от автора расширения, хотя unpackaged является общим соглашением. Если у вас есть несколько предыдущих версий, вы должны иметь возможность обновиться до стиля расширения, используйте несколько фиктивных названий версий для их идентификации.
ALTER EXTENSION может выполнять последовательности файлов сценариев
обновления для достижения запрошенного обновления. Например, если
доступны только foo--1.0--1.1.sql и foo--1.1--2.0.sql, ALTER EXTENSION
будет применять их последовательно, если будет запрошено обновление до
версии 2.0, а в данный момент установлена версия 1.0.
QHB ничего не говорит о свойствах имен версий: например, он не
знает, следует ли 1.1 за 1.0. Он просто сопоставляет доступные имена
версий и следует по пути, который требует применения наименьшего
количества сценариев обновления. (Имя версии может фактически быть любой
строкой, которая не содержит -- или начало или конец -).
Иногда полезно предоставить сценарии «понижения», например,
foo--1.1--1.0.sql чтобы позволить отменить изменения, связанные
с версией 1.1. Если вы это сделаете, будьте осторожны с возможностью
неожиданного применения скрипта понижения, поскольку он дает более
короткий путь. Рискованный случай - это сценарий обновления «быстрого
пути», который переходит вперед на несколько версий, а также сценарий
перехода к начальной точке быстрого пути. Может потребоваться меньше
шагов, чтобы применить понижение и затем быстрый путь, чем продвигаться
вперед по одной версии за раз. Если скрипт понижения удаляет незаменимые
объекты, это приведет к нежелательным результатам.
Чтобы проверить наличие неожиданных путей обновления, используйте эту команду:
SELECT * FROM pg_extension_update_paths('extension_name');
Это показывает каждую пару различных известных имен версий для
указанного расширения вместе с последовательностью пути обновления,
которая была бы принята, чтобы получить от исходной версии до целевой
версии, или NULL если нет доступного пути обновления. Путь показан в
текстовом виде с -- разделителями. Вы можете использовать
regexp_split_to_array(path,'--') если вы предпочитаете формат
массива.
Установка расширений с использованием скриптов обновления
Расширение, которое существует уже некоторое время, вероятно, будет
существовать в нескольких версиях, для которых автору потребуется
написать сценарии обновления. Например, если вы выпустили расширение foo
в версиях 1.0, 1.1 и 1.2, должны быть сценарии обновления
foo--1.0--1.1.sql и foo--1.1--1.2.sql. До PostgreSQL 10 необходимо было
также создавать новые файлы сценариев foo--1.1.sql и foo--1.2.sql
которые напрямую собирали более новые версии расширений, иначе более
новые версии не могли быть установлены напрямую, только путем установки
1.0 и затем обновление. Это было утомительно и дублировало, но теперь
это не нужно, потому что CREATE EXTENSION может автоматически следовать
цепочкам обновлений. Например, если доступны только файлы сценариев
foo--1.0.sql, foo--1.0--1.1.sql и foo--1.1--1.2.sql, то запрос на
установку версии 1.2 выполняется с помощью запуска этих трех сценарии в
последовательности. Обработка такая же, как если бы вы сначала
установили 1.0 а затем обновили до 1.2. (Как и в случае с ALTER
EXTENSION UPDATE, если доступно несколько путей, предпочтительнее
использовать кратчайший путь). Размещение файлов сценариев расширения в
этом стиле может уменьшить объем работ по обслуживанию, необходимых для
создания небольших обновлений.
Если вы используете вторичные (зависящие от версии) контрольные файлы с
расширением, поддерживаемым в этом стиле, имейте в виду, что каждой
версии нужен контрольный файл, даже если у него нет отдельного сценария
установки, поскольку этот контрольный файл будет определять, как неявное
обновление на эту версию выполняется. Например, если foo--1.0.control
указывает requires = 'bar' но другие управляющие файлы
foo этого не делают, зависимость расширения от bar будет сброшена при
обновлении с 1.0 до другой версии.
Пример расширения
Вот полный пример SQL- расширения, двухэлементного составного типа,
который может хранить значения любого типа в своих слотах, которые
называются k и v. Нетекстовые значения автоматически
преобразуются в текст для хранения.
Скриптовый файл pair--1.0.sql выглядит так:
-- complain if script is sourced in qsql, rather than via CREATE EXTENSION
\echo Use "CREATE EXTENSION pair" to load this file. \quit
CREATE TYPE pair AS ( k text, v text );
CREATE OR REPLACE FUNCTION pair(text, text)
RETURNS pair LANGUAGE SQL AS 'SELECT ROW($1, $2)::@extschema@.pair;';
CREATE OPERATOR ~> (LEFTARG = text, RIGHTARG = text, FUNCTION = pair);
-- "SET search_path" is easy to get right, but qualified names perform better.
CREATE OR REPLACE FUNCTION lower(pair)
RETURNS pair LANGUAGE SQL
AS 'SELECT ROW(lower($1.k), lower($1.v))::@extschema@.pair;'
SET search_path = pg_temp;
CREATE OR REPLACE FUNCTION pair_concat(pair, pair)
RETURNS pair LANGUAGE SQL
AS 'SELECT ROW($1.k OPERATOR(pg_catalog.||) $2.k,
$1.v OPERATOR(pg_catalog.||) $2.v)::@extschema@.pair;';
Управляющий файл pair.control выглядит так:
# pair extension
comment = 'A key/value pair data type'
default_version = '1.0'
relocatable = false
Хотя вам вряд ли нужен make-файл для установки этих двух файлов в правильный каталог, вы можете использовать Makefile содержащий это:
EXTENSION = pair
DATA = pair--1.0.sql
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
Этот make-файл основан на PGXS, что описано в следующем разделе. Команда make install установит управляющие файлы и файлы сценариев в правильный каталог, как сообщает pg_config.
Как только файлы установлены, используйте команду CREATE EXTENSION, чтобы загрузить объекты в любую конкретную базу данных.
Инфраструктура сборки расширений
Если вы думаете о распространении модулей расширения QHB, то для них может быть довольно сложно настроить переносную систему сборки. Поэтому установка QHB предоставляет инфраструктуру сборки для расширений, которая называется PGXS, так что простые модули расширения могут быть собраны просто на уже установленном сервере. PGXS в основном предназначен для расширений, которые включают в себя код на C, хотя он также может использоваться и для расширений чистого SQL. Обратите внимание, что PGXS не предназначен для того, чтобы быть универсальной структурой системы сборки, которая может использоваться для создания любого программного обеспечения, взаимодействующего с QHB; он просто автоматизирует общие правила сборки для простых модулей расширения сервера. Для более сложных пакетов вам может потребоваться написать собственную систему сборки.
Чтобы использовать инфраструктуру PGXS для вашего расширения, вы должны написать простой make-файл. В make- файле вам нужно установить некоторые переменные и включить глобальный make-файл PGXS. Вот пример, который создает модуль расширения с именем isbn_issn, состоящий из разделяемой библиотеки, содержащей некоторый код C/RUST, файл управления расширениями, сценарий SQL, файл включения (требуется только в том случае, если другим модулям может потребоваться доступ к функциям расширения без прохождения через SQL) и текстовый файл документации:
MODULES = isbn_issn
EXTENSION = isbn_issn
DATA = isbn_issn--1.0.sql
DOCS = README.isbn_issn
HEADERS_isbn_issn = isbn_issn.h
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
Последние три строки всегда должны быть одинаковыми. Ранее в файле вы назначаете переменные или добавляете пользовательские правила создания .
Установите одну из этих трех переменных, чтобы указать, что собирается:
- MODULES
- список объектов разделяемой библиотеки, которые будут построены из исходных файлов с одинаковым основанием (не включайте суффиксы библиотеки в этот список)
- MODULE_big
- общая библиотека для сборки из нескольких исходных файлов (список объектных файлов в OBJS )
- PROGRAM
- исполняемая программа для сборки (список объектных файлов в OBJS )
Следующие переменные также могут быть установлены:
- EXTENSION
- имена расширений; для каждого имени вы должны предоставить файл extension.control, который будет установлен в prefix/share/extension
- MODULEDIR
- подкаталог prefix/share в который должны быть установлены файлы DATA и DOCS (если не установлен, по умолчанию используется extension если установлено EXTENSION, или contrib если нет)
- DATA
- случайные файлы для установки в
prefix/share/$MODULEDIR - DATA_built
- случайные файлы для установки в
prefix/share/$MODULEDIR, которые нужно сначала собрать - DATA_TSEARCH
- случайные файлы для установки c
prefix/share/tsearch_data - DOCS
- случайные файлы для установки с
prefix/doc/$MODULEDIR - HEADERS
- HEADERS_built
- Файлы (возможно, для сборки и) устанавливаются с prefix/include/server/$MODULEDIR/$MODULE_big .
- В отличие от DATA_built, файлы в HEADERS_built не удаляются целью очистки; если вы хотите, чтобы они были удалены, также добавьте их в EXTRA_CLEAN или добавьте свои собственные правила, чтобы сделать это.
- HEADERS_$MODULE
- HEADERS_built_$MODULE
- Файлы для установки (после сборки, если указано) с prefix/include/server/$MODULEDIR/$MODULE , где $MODULE должно быть именем модуля, используемым в MODULES или MODULE_big.
- В отличие от DATA_built, файлы в HEADERS_built_$MODULE не удаляются с целью очистки; если вы хотите, чтобы они были удалены, также добавьте их в EXTRA_CLEAN или добавьте свои собственные правила, чтобы сделать это.
- Разрешается использовать обе переменные для одного и того же модуля или любой комбинации, если только в списке модулей нет двух имен модулей, которые отличаются только наличием префикса built_, что может привести к неоднозначности. В этом (надеюсь маловероятном) случае вы должны использовать только переменные HEADERS_built_$MODULE .
- SCRIPTS
- файлы сценариев (не двоичные файлы) для установки в prefix/bin
- SCRIPTS_built
- файлы сценариев (не двоичные файлы) для установки в prefix/bin, которые должны быть собраны в первую очередь
- REGRESS
- список регрессионных тестов (без суффикса), см. ниже
- REGRESS_OPTS
- дополнительные ключи для перехода на pg_regress
- ISOLATION
- список тестовых случаев изоляции, см. ниже для более подробной информации
- ISOLATION_OPTS
- дополнительные ключи для передачи в pg_isolation_regress
- TAP_TESTS
- переключатель, определяющий, нужно ли запускать тесты TAP, см. ниже
- NO_INSTALLCHECK
- не определять цель installcheck, полезно, например, если тесты требуют специальной конфигурации или не используют pg_regress
- EXTRA_CLEAN
- дополнительные файлы для удаления в make clean
- PG_CPPFLAGS
- будет добавлен к CPPFLAGS
- PG_CFLAGS
- будет добавлен к CFLAGS
- PG_CXXFLAGS
- будет добавлен в CXXFLAGS
- PG_LDFLAGS
- будет добавлен к LDFLAGS
- PG_LIBS
- будет добавлен в строку ссылки PROGRAM
- SHLIB_LINK
- будет добавлен в строку ссылки MODULE_big
- PG_CONFIG
- путь к программе pg_config для сборки установки QHB (обычно просто pg_config для использования первым в вашем PATH)
Поместите этот makefile как Makefile в каталог, содержащий ваше расширение. Затем вы можете выполнить make для компиляции, а затем make install для установки вашего модуля. По умолчанию расширение компилируется и устанавливается для установки QHB, которая соответствует первой программе pg_config найденной в вашем PATH. Вы можете использовать другую установку, установив PG_CONFIG чтобы он указывал на ее программу pg_config, либо внутри makefile, либо в командной строке make.
Вы также можете запустить make в каталоге за пределами исходного дерева вашего расширения, если вы хотите сохранить каталог сборки отдельно. Эта процедура также называется VPATH построить. Вот как:
mkdir build_dir
cd build_dir
make -f /path/to/extension/source/tree/Makefile
make -f /path/to/extension/source/tree/Makefile install
Кроме того, вы можете настроить каталог для сборки VPATH аналогично тому, как это делается для основного кода. Один из способов сделать это - использовать основной скрипт config/prep_buildtree. Как только это будет сделано, вы можете собрать, установив переменную make VPATH следующим образом:
make VPATH=/path/to/extension/source/tree
make VPATH=/path/to/extension/source/tree install
Эта процедура может работать с большим разнообразием макетов каталогов.
Сценарии, перечисленные в переменной REGRESS, используются для регрессионного тестирования вашего модуля, который может быть вызван командой make installcheck после выполнения команды make install. Чтобы это работало, у вас должен быть запущен сервер QHB. Файлы сценариев, перечисленные в REGRESS должны появляться в подкаталоге с именем sql/ в каталоге вашего расширения. Эти файлы должны иметь расширение .sql, которое не должно быть включено в список REGRESS в makefile. Для каждого теста также должен быть файл, содержащий ожидаемый результат в подкаталоге с именем expected/, с тем же основанием и расширением .out. make installcheck выполняет каждый тестовый сценарий с помощью qsql и сравнивает полученный результат с соответствующим ожидаемым файлом. Любые различия будут записаны в файл regression.diffs в формате diff -c. Обратите внимание, что попытка запустить тест, в котором отсутствует ожидаемый файл, будет отображаться как "trouble", поэтому убедитесь, что у вас есть все ожидаемые файлы.
Сценарии, перечисленные в переменной ISOLATION, используются для тестов, в которых подчеркивается поведение одновременной сессии с вашим модулем, которая может быть вызвана командой make installcheck после выполнения команды make install. Чтобы это работало, у вас должен быть запущенный сервер QHB. Файлы сценариев, перечисленные в ISOLATION должны появляться в подкаталоге с именем specs/ в каталоге вашего расширения. Эти файлы должны иметь расширение .spec, которое не должно быть включено в список ISOLATION в makefile. Для каждого теста также должен быть файл, содержащий ожидаемый результат в подкаталоге с именем expected/, с тем же основанием и расширением .out. make installcheck выполняет каждый тестовый сценарий и сравнивает полученный результат с соответствующим ожидаемым файлом. Любые различия будут записаны в файл output_iso/regression.diffs в формате diff -c. Обратите внимание, что попытка запустить тест, в котором отсутствует ожидаемый файл, будет отображаться как "trouble", поэтому убедитесь, что у вас есть все ожидаемые файлы.
TAP_TESTS позволяет использовать тесты TAP. Данные каждого прогона присутствуют в подкаталоге с именем tmp_check/.
Заметка
Самый простой способ создать ожидаемые файлы - создать пустые файлы, а затем выполнить тестовый прогон (который, конечно, сообщит о различиях). Проверьте фактические файлы результатов, найденные в каталоге results/ (для тестов в REGRESS) или в output_iso/results/ (для тестов в ISOLATION), а затем скопируйте их в expected/ если они соответствуют тому, что вы ожидаете от теста.
Триггеры
- Обзор триггерного поведения
- Видимость изменений данных
- Написание триггерных функций на C
- Полный пример запуска
Эта глава содержит общую информацию о написании триггерных функций. Триггерные функции могут быть написаны на большинстве доступных процедурных языков, включая PL/pgSQL. Прочитав текущую главу, вы можете обратиться к главе PL/pgSQL, чтобы узнать подробности о написании на нем триггера.
Также можно написать триггерную функцию на C или Rust, хотя большинству людей проще использовать один из процедурных языков. В настоящее время невозможно написать триггерную функцию на простом языке функций SQL.
Обзор триггерного поведения
Триггер - это указание, согласно которой база данных должна автоматически выполнять определенную функцию всякий раз, когда выполняется определенный тип операции. Триггеры могут быть прикреплены к таблицам (разделенным или нет), представлениям и сторонним таблицам.
В таблицах и внешних таблицах можно определить триггеры для выполнения до или после любой операции INSERT, UPDATE или DELETE, либо один раз для измененной строки, либо один раз для оператора SQL. Триггеры UPDATE могут быть установлены на срабатывание только в том случае, если в предложении SET UPDATE упоминаются определенные столбцы. Триггеры также могут быть TRUNCATE. Если происходит событие триггера, функция триггера вызывается в соответствующее время для обработки события.
В представлениях можно определить триггеры для выполнения вместо операций INSERT, UPDATE или DELETE. Такие триггеры INSTEAD OF запускаются один раз для каждой строки, которую необходимо изменить. Функция триггера отвечает за выполнение необходимых модификаций базовой таблицы (или таблиц) представления и при необходимости возвращает измененную строку, как она будет отображаться в представлении. Триггеры для представлений также могут быть определены для выполнения один раз для каждого оператора SQL, до или после операций INSERT, UPDATE или DELETE. Однако такие триггеры срабатывают только в том случае, если в представлении также имеется триггер INSTEAD OF. В противном случае любой оператор, нацеленный на представление должен быть переписан в оператор, влияющий на его базовую(ые) таблицу(ы), и тогда триггеры, которые будут срабатывать.
Функция триггера должна быть определена до создания триггера и объявлена как функция, не имеющая аргументов и возвращающая тип trigger. Функция триггера получает свой ввод через специально переданную структуру TriggerData, а не в виде аргументов обычной функции.
После создания подходящей триггерной функции триггер устанавливается с помощью CREATE TRIGGER. Одна и та же триггерная функция может использоваться для нескольких триггеров.
QHB предлагает как триггеры для каждой строки, так и триггеры для каждой инструкции. При использовании триггера, функция вызывается один раз для каждой строки, на которую влияет оператор, вызвавший триггер. Напротив, триггер для каждого оператора вызывается только один раз при выполнении, независимо от количества строк, затронутых этим оператором. В частности, оператор, который влияет на ноль строк, все равно будет приводить к выполнению любых применимых триггеров для каждого оператора. Эти два типа триггеров иногда называют триггерами уровня строки и триггерами уровня оператора, соответственно. Триггеры в TRUNCATE могут быть определены только на уровне оператора, а не для каждой строки.
Триггеры также классифицируются в зависимости от того, срабатывают они до, после или вместо операции. Они называются триггерами BEFORE, триггерами AFTER и триггерами INSTEAD OF соответственно. Триггеры уровня BEFORE естественным образом срабатывают до того, как оператор начинает что-либо делать, в то время как AFTER запускаются на самом конце оператора. Эти типы триггеров могут быть определены в таблицах, представлениях или внешних таблицах. Уровень BEFORE вызывает срабатывание непосредственно перед тем, как будет обработана определенная строка, в то время как уровень AFTER срабатывает в конце инструкции. Эти типы триггеров могут быть определены только для секционированных и внешних таблиц, но не для представлений. Триггеры INSTEAD OF могут быть определены только для представлений и только на уровне строк; они запускаются немедленно, так как каждая строка в представлении определяется как нуждающаяся в операции.
Оператор, нацеленный на родительскую таблицу в иерархии наследования или разбиения, не вызывает срабатывания триггеров уровня дочерних таблиц (запускаются только триггеры уровня операторов) родительской таблицы. Однако триггеры на уровне строк любых затронутых дочерних таблиц будут срабатывать.
Если INSERT содержит предложение ON CONFLICT DO UPDATE, возможно, что эффекты триггеров BEFORE INSERT и BEFORE UPDATE уровня строки могут быть применены так, как это видно из конечного состояния обновленной строки, если ссылка на столбец была EXCLUDED. Однако для выполнения обоих наборов триггеров уровня BEFORE необязательно указывать ссылку на столбец EXCLUDED. Возможность неожиданных результатов должна быть рассмотрена, когда есть триггеры уровня строки BEFORE INSERT и BEFORE UPDATE, которые изменяют вставляемую / обновляемую строку (это может быть проблематично, даже если изменения более или менее эквивалентны, или даже идемпотентны). Обратите внимание, что триггеры UPDATE на уровне оператора выполняются, когда указано ON CONFLICT DO UPDATE, независимо от того, затронул ли UPDATE какие-либо строки или нет, и независимо от того, выбирался ли альтернативный путь UPDATE. INSERT с предложением ON CONFLICT DO UPDATE сначала выполнит триггеры уровня BEFORE INSERT уровня INSERT, затем триггеры BEFORE UPDATE, затем триггеры AFTER UPDATE и, наконец, триггеры AFTER INSERT.
Если UPDATE в многораздельной таблице приводит к перемещению строки в другой раздел, он будет выполнен как DELETE из исходного раздела, за которым следует INSERT в новый раздел. В этом случае все триггеры BEFORE UPDATE уровня строки и все триггеры BEFORE DELETE уровня строки запускаются в исходном разделе. Затем все триггеры BEFORE INSERT уровня строки запускаются в целевом разделе. Возможность неожиданных результатов следует учитывать, когда все эти триггеры влияют на перемещение строки. Что касается триггеров AFTER ROW применяются триггеры AFTER DELETE и AFTER INSERT; но не AFTER UPDATE, потому что UPDATE было преобразовано в DELETE и INSERT. Что касается триггеров уровня оператора, ни один из триггеров DELETE или INSERT не запускается, даже если происходит перемещение строки; сработают только триггеры UPDATE определенные в целевой таблице, используемой в операторе UPDATE.
Триггерные функции, вызываемые триггерами для каждого оператора, всегда должны возвращать NULL. Триггерные функции, вызываемые триггерами для каждой строки, могут возвращать строку таблицы (значение типа HeapTuple) вызывающему исполнителю, если они того пожелают. Триггер на уровне строк, срабатывающий до операции, имеет следующие варианты:
-
Он может вернуть NULL, чтобы пропустить операцию для текущей строки. Это указывает исполнителю не выполнять операцию на уровне строк, которая вызвала триггер (вставка, изменение или удаление определенной строки таблицы).
-
Только для триггеров INSERT и UPDATE на уровне строк возвращаемая строка становится строкой, которая будет вставлена или заменит обновляемую строку. Это позволяет триггерной функции изменять вставляемую или обновляемую строку.
Триггер BEFORE уровня строки, который не имеет намерения вызвать какое-либо из этих поведений, должен быть аккуратен. В таком случае необходимо возвращать в качестве своего результата ту же самую строку, которая была передана. (то есть строка NEW для триггеров INSERT и UPDATE, строка OLD для триггеров DELETE).
Триггер INSTEAD OF уровня строк должен либо возвращать NULL, чтобы указать, что он не изменил никаких данных из базовых таблиц представления, либо возвращать строку представления, которая была передана (строка NEW для операций INSERT и UPDATE, или OLD ряд для DELETE операции). Ненулевое возвращаемое значение используется, чтобы сигнализировать, что триггер выполнил необходимые модификации данных в представлении. Это приведет к увеличению числа строк, на которые влияет команда. Для операций INSERT и UPDATE триггер может изменить строку NEW перед ее возвратом. Это изменит данные, возвращаемые INSERT RETURNING или UPDATE RETURNING, и будет полезно, когда представление не будет отображать точно те же данные, которые были предоставлены.
Возвращаемое значение игнорируется для триггеров уровня строки, срабатывающих после операции, и поэтому они могут возвращать NULL.
Некоторые соображения применимы к сгенерированным столбцам. Сохраненные сгенерированные столбцы вычисляются после триггеров BEFORE и до триггеров AFTER. Поэтому сгенерированное значение может быть проверено в триггерах AFTER. В триггерах BEFORE строка OLD содержит старое сгенерированное значение, как и следовало ожидать, но строка NEW еще не содержит нового сгенерированного значения и не должна быть доступна. В интерфейсе языка C содержимое столбца на этом этапе не определено; язык программирования более высокого уровня должен предотвращать доступ к сохраненному сгенерированному столбцу в строке NEW в триггере BEFORE. Изменения значения сгенерированного столбца в триггере BEFORE игнорируются и будут перезаписаны.
Если для одного и того же события в одном и том же отношении определено более одного триггера, триггеры сработают в алфавитном порядке по имени триггера. В случае триггеров BEFORE и INSTEAD OF возможно измененная строка, возвращаемая каждым триггером, становится входом для следующего триггера. Если какой-либо триггер BEFORE или INSTEAD OF возвращает NULL, операция прекращается для этой строки, и последующие триггеры не запускаются (для этой строки).
Определение триггера также может указывать логическое условие WHEN, которое будет проверено, чтобы увидеть, должен ли триггер срабатывать. В триггерах уровня строки условие WHEN может проверять старые и (или) новые значения столбцов строки. (Триггеры уровня оператора также могут иметь условия WHEN, хотя для них эта функция не так полезна.) В триггере BEFORE условие WHEN оценивается непосредственно перед выполнением функции, поэтому использование WHEN существенно не отличается от проверки того же условия в начале триггерной функции. Однако в триггере AFTER условие WHEN оценивается сразу после обновления строки и определяет, стоит ли в очереди событие для запуска триггера в конце оператора. Таким образом, когда условие WHEN триггера AFTER не возвращает истину, нет необходимости ставить в очередь событие или повторно извлекать строку в конце оператора. Это может привести к значительному ускорению операторов, которые изменяют множество строк, если триггер нужно запустить только для нескольких строк. INSTEAD OF не поддерживают условия WHEN.
Как правило, триггеры BEFORE уровня строки используются для проверки или изменения данных, которые будут вставлены или обновлены. Например, триггер BEFORE может использоваться для вставки текущего времени в столбец timestamp или для проверки согласованности двух элементов строки. Триггеры AFTER наиболее разумно используются для распространения обновлений на другие таблицы или для проверки согласованности с другими таблицами. Причина такого разделения заключается в том, что триггер AFTER должен быть уверен, что видит окончательное значение строки, а триггер BEFORE нет; после этого могут быть другие BEFORE триггерами. Если у вас нет особой причины для выполнения триггера BEFORE или AFTER, случай BEFORE более эффективен, поскольку информацию об операции не нужно сохранять до конца оператора.
Если триггерная функция выполняет команды SQL, эти команды могут снова запускать триггеры. Это известно как каскадные триггеры. Нет прямого ограничения на количество каскадных уровней. Каскады могут вызывать рекурсивный вызов одного и того же триггера; например, триггер INSERT может выполнить команду, которая вставляет дополнительную строку в ту же таблицу, вызывая повтор триггера INSERT. Программист триггера обязан избегать бесконечной рекурсии в таких сценариях.
Когда определяется триггер, для него могут быть указаны аргументы. Цель включения аргументов в определение триггера - разрешить различным триггерам с одинаковыми требованиями вызывать одну и ту же функцию. Например, может быть обобщенная триггерная функция, которая принимает в качестве аргументов два имени столбца и помещает текущего пользователя в один, а текущую метку времени - в другой. Правильно написанная триггерная функция не зависит от конкретной таблицы, для которой она запускается. Таким образом, эту же функцию можно использовать для событий INSERT в любой таблице с подходящими столбцами, например, для автоматического отслеживания создания записей в таблице транзакций. Он также может использоваться для отслеживания событий последнего обновления, если он определен как триггер UPDATE.
Каждый язык программирования, который поддерживает триггеры, имеет свой собственный метод, позволяющий сделать входные данные триггера доступными для функции триггера. Эти входные данные включают тип события триггера (например, INSERT или UPDATE), а также любые аргументы, которые были перечислены в CREATE TRIGGER. Для триггера уровня строки входные данные также включают строку NEW для триггеров INSERT и UPDATE и (или) или строку OLD для триггеров UPDATE и DELETE.
По умолчанию триггеры уровня оператора не имеют никакого способа проверить отдельные строки, измененные этим самым оператором. Но триггер AFTER STATEMENT может запросить создание таблиц переходов, чтобы сделать наборы затронутых строк доступными для триггера. AFTER ROW также могут запрашивать таблицы переходов, чтобы они могли видеть общие изменения в таблице, а также изменения в отдельной строке, для которой они в данный момент запускаются. Способ проверки таблиц переходов тоже зависит от используемого языка программирования, но типичный подход заключается в том, чтобы заставить таблицы переходов действовать как временные таблицы только для чтения, к которым могут обращаться команды SQL, выполненные в функции триггера.
Видимость изменений данных
Если вы выполняете команды SQL в своей функции триггера, и эти команды обращаются к таблице, вам необходимо знать правила видимости данных, поскольку они определяют, будут ли эти команды SQL видеть изменение данных, для которых сработал триггер. Кратко:
-
Триггеры уровня оператора следуют простым правилам видимости: ни одно из изменений, внесенных оператором, не видно триггерам BEFORE уровня оператора, тогда как все модификации видны триггерам AFTER уровня оператора.
-
Изменение данных (вставка, обновление или удаление), вызывающее срабатывание триггера, естественно, невидимо для команд SQL, выполняемых в триггере BEFORE уровне строк, поскольку это еще не произошло.
-
Однако команды SQL, выполняемые в триггере BEFORE на уровне строк, увидят влияние изменений данных для строк, ранее обработанных в той же внешней команде. Это требует осторожности, поскольку порядок этих событий изменений в общем случае не предсказуем; команда SQL, которая влияет на несколько строк, может посещать строки в любом порядке.
-
Аналогично, триггер INSTEAD OF уровня строк будет видеть влияние изменений данных, выполненных предыдущими срабатываниями триггеров INSTEAD OF в той же внешней команде.
-
Когда запускается триггер AFTER уровня строк, все изменения данных, сделанные внешней командой, уже завершены и видны для вызываемой функции триггера.
Если ваша триггерная функция написана на любом из стандартных процедурных языков, то приведенные выше операторы применимы, только если функция объявлена как VOLATILE. Функции, которые объявлены как STABLE или IMMUTABLE, не увидят изменений, внесенных вызывающей командой в любом случае.
Дополнительную информацию о правилах видимости данных можно найти в Видимость изменений данных SPI. Пример в разделе Полный пример запуска содержит демонстрацию этих правил.
Написание триггерных функций на C
В этом разделе описываются детали низкого уровня интерфейса для функции триггера. Эта информация необходима только при написании триггерных функций на языке C. Если вы используете язык более высокого уровня, то эти детали обрабатываются для вас автоматически. В большинстве случаев вам следует подумать об использовании процедурного языка, прежде чем писать свои триггеры на C. В документации каждого процедурного языка объясняется, как написать триггер на этом языке.
Функции запуска должны использовать интерфейс диспетчера функций «version 1».
Когда функция вызывается менеджером триггера, ей не передаются никакие обычные аргументы, но ей передается указатель «context», указывающий на структуру TriggerData. Функции на C могут проверить, были ли они вызваны из диспетчера триггеров или нет, выполнив макрос:
CALLED_AS_TRIGGER(fcinfo)
который распахивается в
((fcinfo)->context != NULL && IsA((fcinfo)->context, TriggerData))
Если это возвращает true, тогда безопасно привести fcinfo->context к типу TriggerData * и использовать структуру TriggerData. Функция не должна изменять структуру TriggerData или любые данные, на которые она указывает.
Структура TriggerData определена в commands/trigger.h:
typedef struct TriggerData
{
NodeTag type;
TriggerEvent tg_event;
Relation tg_relation;
HeapTuple tg_trigtuple;
HeapTuple tg_newtuple;
Trigger *tg_trigger;
TupleTableSlot *tg_trigslot;
TupleTableSlot *tg_newslot;
Tuplestorestate *tg_oldtable;
Tuplestorestate *tg_newtable;
} TriggerData;
где члены определены следующим образом:
-
type - всегда T_TriggerData.
-
tg_event - описывает событие, для которого вызывается функция. Вы можете использовать следующие макросы для проверки tg_event:
-
TRIGGER_FIRED_BEFORE(tg_event) - возвращает true, если триггер сработал до операции.
-
TRIGGER_FIRED_AFTER(tg_event) - возвращает true, если триггер сработал после операции.
-
TRIGGER_FIRED_INSTEAD(tg_event) - возвращает true, если сработал триггер вместо операции.
-
TRIGGER_FIRED_FOR_ROW(tg_event) - возвращает true, если триггер сработал для события уровня строки.
-
TRIGGER_FIRED_FOR_STATEMENT(tg_event) - возвращает true, если триггер сработал для события уровня оператора.
-
TRIGGER_FIRED_BY_INSERT(tg_event) возвращает true, если триггер был запущен командой INSERT.
-
TRIGGER_FIRED_BY_UPDATE(tg_event) - возвращает true, если триггер был запущен командой UPDATE.
-
TRIGGER_FIRED_BY_DELETE(tg_event) - возвращает true, если триггер был запущен командой DELETE.
-
TRIGGER_FIRED_BY_TRUNCATE(tg_event)_ - возвращает true, если триггер был запущен командой TRUNCATE.
-
-
tg_relation - это указатель на структуру, описывающую отношение, для которого сработал триггер. Посмотрите в utils/rel.h подробности об этой структуре. Наиболее интересными являются tg_relation->rd_att (дескриптор кортежей отношений) и tg_relation->rd_rel->relname (имя отношения; тип не char*, а NameData; используйте SPI_getrelname(tg_relation) для получения char*, если вам нужно копия имени).
-
tg_trigtuple - это указатель на строку, для которой сработал триггер. Эта строка вставляется, обновляется или удаляется. Если этот триггер был запущен для INSERT или DELETE. Это то, что вы должны вернуть из функции, если вы не хотите заменять строку другой (в случае INSERT) или пропустить операцию. Для триггеров во внешних таблицах значения системных столбцов здесь не указаны.
-
tg_newtuple - это указатель на новую версию строки, если триггер сработал для UPDATE, и NULL если он сработал для INSERT или DELETE. Это то, что вы должны вернуть из функции, если событие - UPDATE и вы не хотите заменять эту строку другой или пропустить операцию. Для триггеров во внешних таблицах значения системных столбцов здесь не указаны.
-
tg_trigger - это указатель на структуру типа Trigger, определенную в utils/reltrigger.h.
typedef struct Trigger
{
Oid tgoid;
char *tgname;
Oid tgfoid;
int16 tgtype;
char tgenabled;
bool tgisinternal;
Oid tgconstrrelid;
Oid tgconstrindid;
Oid tgconstraint;
bool tgdeferrable;
bool tginitdeferred;
int16 tgnargs;
int16 tgnattr;
int16 *tgattr;
char **tgargs;
char *tgqual;
char *tgoldtable;
char *tgnewtable;
} Trigger;
где:
-
tgname - это имя триггера.
-
tgnargs - это количество аргументов в tgargs.
-
tgargs - массив указателей на аргументы, указанные в операторе CREATE TRIGGER.
Другие члены предназначены только для внутреннего использования.
-
tg_trigtuplebuf - буфер, содержащий tg_trigtuple или InvalidBuffer если такого кортежа нет или он не хранится в дисковом буфере.
-
tg_newtuplebuf - буфер, содержащий tg_newtuple или InvalidBuffer если такого кортежа нет или он не хранится в буфере диска.
-
tg_oldtable - это указатель на структуру типа Tuplestorestate содержащую ноль или более строк в формате, заданном параметром tg_relation, или указатель NULL если нет отношения OLD TABLE.
-
tg_newtable - это указатель на структуру типа Tuplestorestate содержащую ноль или более строк в формате, заданном параметром tg_relation, или указатель NULL если нет отношения NEW TABLE.
Чтобы запросы, отправленные через SPI, ссылались на таблицы переходов, см. SPI_register_trigger_data.
Внимание! Функция триггера должна возвращать указатель NULL (но НЕ нулевое значение SQL, т.е. не устанавливать isNull как true). Будьте внимательны, возвращая либо tg_trigtuple либо tg_newtuple, в зависимости от ситуации, если вы не хотите изменять строку, с которой вы работаете.
Полный пример запуска
Вот очень простой пример триггерной функции, написанной на C. (Примеры триггеров, написанных на процедурных языках, можно найти в документации по процедурным языкам.)
Функция trigf сообщает количество строк в таблице ttest и пропускает фактическую операцию, если команда пытается вставить нулевое значение в столбец x. (Таким образом, триггер действует как ненулевое ограничение, но не прерывает транзакцию.)
Во-первых, определение таблицы:
CREATE TABLE ttest (
x integer
);
Это исходный код функции триггера:
#include "postgres.h"
#include "fmgr.h"
#include "executor/spi.h" /* this is what you need to work with SPI */
#include "commands/trigger.h" /* ... triggers ... */
#include "utils/rel.h" /* ... and relations */
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(trigf);
Datum
trigf(PG_FUNCTION_ARGS)
{
TriggerData *trigdata = (TriggerData *) fcinfo->context;
TupleDesc tupdesc;
HeapTuple rettuple;
char *when;
bool checknull = false;
bool isnull;
int ret, i;
/* make sure it's called as a trigger at all */
if (!CALLED_AS_TRIGGER(fcinfo))
elog(ERROR, "trigf: not called by trigger manager");
/* tuple to return to executor */
if (TRIGGER_FIRED_BY_UPDATE(trigdata->tg_event))
rettuple = trigdata->tg_newtuple;
else
rettuple = trigdata->tg_trigtuple;
/* check for null values */
if (!TRIGGER_FIRED_BY_DELETE(trigdata->tg_event)
&& TRIGGER_FIRED_BEFORE(trigdata->tg_event))
checknull = true;
if (TRIGGER_FIRED_BEFORE(trigdata->tg_event))
when = "before";
else
when = "after ";
tupdesc = trigdata->tg_relation->rd_att;
/* connect to SPI manager */
if ((ret = SPI_connect()) < 0)
elog(ERROR, "trigf (fired %s): SPI_connect returned %d", when, ret);
/* get number of rows in table */
ret = SPI_exec("SELECT count(*) FROM ttest", 0);
if (ret < 0)
elog(ERROR, "trigf (fired %s): SPI_exec returned %d", when, ret);
/* count(*) returns int8, so be careful to convert */
i = DatumGetInt64(SPI_getbinval(SPI_tuptable->vals[0],
SPI_tuptable->tupdesc,
1,
&isnull));
elog (INFO, "trigf (fired %s): there are %d rows in ttest", when, i);
SPI_finish();
if (checknull)
{
SPI_getbinval(rettuple, tupdesc, 1, &isnull);
if (isnull)
rettuple = NULL;
}
return PointerGetDatum(rettuple);
}
После того, как вы скомпилировали исходный код (см. Раздел 37.10.5), объявите функцию и триггеры:
CREATE FUNCTION trigf() RETURNS trigger
AS 'filename'
LANGUAGE C;
CREATE TRIGGER tbefore BEFORE INSERT OR UPDATE OR DELETE ON ttest
FOR EACH ROW EXECUTE FUNCTION trigf();
CREATE TRIGGER tafter AFTER INSERT OR UPDATE OR DELETE ON ttest
FOR EACH ROW EXECUTE FUNCTION trigf();
Теперь вы можете проверить работу триггера:
=> INSERT INTO ttest VALUES (NULL);
INFO: trigf (fired before): there are 0 rows in ttest
INSERT 0 0
-- Insertion skipped and AFTER trigger is not fired
=> SELECT * FROM ttest;
x
---
(0 rows)
=> INSERT INTO ttest VALUES (1);
INFO: trigf (fired before): there are 0 rows in ttest
INFO: trigf (fired after ): there are 1 rows in ttest
^^^^^^^^
remember what we said about visibility.
INSERT 167793 1
vac=> SELECT * FROM ttest;
x
---
1
(1 row)
=> INSERT INTO ttest SELECT x * 2 FROM ttest;
INFO: trigf (fired before): there are 1 rows in ttest
INFO: trigf (fired after ): there are 2 rows in ttest
^^^^^^
remember what we said about visibility.
INSERT 167794 1
=> SELECT * FROM ttest;
x
---
1
2
(2 rows)
=> UPDATE ttest SET x = NULL WHERE x = 2;
INFO: trigf (fired before): there are 2 rows in ttest
UPDATE 0
=> UPDATE ttest SET x = 4 WHERE x = 2;
INFO: trigf (fired before): there are 2 rows in ttest
INFO: trigf (fired after ): there are 2 rows in ttest
UPDATE 1
vac=> SELECT * FROM ttest;
x
---
1
4
(2 rows)
=> DELETE FROM ttest;
INFO: trigf (fired before): there are 2 rows in ttest
INFO: trigf (fired before): there are 1 rows in ttest
INFO: trigf (fired after ): there are 0 rows in ttest
INFO: trigf (fired after ): there are 0 rows in ttest
^^^^^^
remember what we said about visibility.
DELETE 2
=> SELECT * FROM ttest;
x
---
(0 rows)
Более сложные примеры доступны в src/test/regress/regress.c и SPI.
Триггеры событий
- Обзор поведения триггера событий
- Матрица запуска событий
- Написание функций запуска событий на C
- Полный пример запуска события
- Пример запуска события перезаписи таблицы
В дополнение к механизму триггера, описанному в главе 7, QHB. также предоставляет триггеры событий. В отличие от обычных триггеров, которые присоединяются к одной таблице и захватывают только события DML, триггеры событий являются глобальными для конкретной базы данных и способны захватывать события DDL.
Как и обычные триггеры, триггеры событий могут быть написаны на любом процедурном языке, который включает поддержку триггеров событий, на C или Rust, но не на простом SQL.
Обзор поведения триггера событий
Триггер события срабатывает всякий раз, когда событие, с которым оно связано, происходит в базе данных. В настоящее время поддерживаются только события ddl_command_start, ddl_command_end, table_rewrite и sql_drop. Поддержка дополнительных событий может быть добавлена в будущих выпусках.
Событие ddl_command_start наступает непосредственно перед выполнением ddl_command_start CREATE, ALTER, DROP, SECURITY LABEL, COMMENT, GRANT или REVOKE. Перед срабатыванием триггера события не проверяется, существует ли затронутый объект или нет. Однако это событие не возникает для команд DDL, нацеленных на общие объекты - базы данных, роли и табличные пространства - или для команд, нацеленных на сами триггеры событий. Механизм запуска событий не поддерживает эти типы объектов. ddl_command_start также происходит непосредственно перед выполнением команды SELECT INTO, поскольку это эквивалентно CREATE TABLE AS.
Событие ddl_command_end наступает сразу после выполнения этого же набора команд. Чтобы получить более подробную информацию о выполненных операциях DDL, используйте функцию возврата pg_event_trigger_ddl_commands() из ddl_command_end триггера события ddl_command_end (см. Раздел 9.28). Обратите внимание, что триггер срабатывает после выполнения действий (но до фиксации транзакции), и, таким образом, системные каталоги могут быть прочитаны как уже измененные.
Событие sql_drop происходит непосредственно перед ddl_command_end для любой операции, которая удаляет объекты базы данных. Функция pg_event_trigger_dropped_objects() возвращает список объектов, которые были удалены, используйте функцию возврата из триггера события sql_drop (см. Функции запуска событий). Обратите внимание, что триггер выполняется после того, как объекты были удалены из системных каталогов, поэтому их больше невозможно увидеть.
Событие table_rewrite наступает непосредственно перед перезаписью таблицы некоторыми действиями команд ALTER TABLE и ALTER TYPE. В то время как другие операторы управления доступны для перезаписи таблицы, такие как CLUSTER и VACUUM, событие table_rewrite не инициируют.
Триггеры событий (как и другие функции) не могут быть выполнены в прерванной транзакции. Таким образом, если команда DDL завершается с ошибкой, любые связанные триггеры ddl_command_end не будут выполнены. И наоборот, если триггер ddl_command_start завершился с ошибкой, дальнейшие триггеры событий ddl_command_start не будут предпринимать попыток выполнить саму команду. Точно так же, если триггер ddl_command_end завершается с ошибкой, эффекты оператора DDL будут откатываться, как и в любом другом случае, когда содержащая транзакция прерывается.
Полный список команд, поддерживаемых механизмом запуска событий, см. в главе Денежные Типы.
Триггеры событий создаются с помощью команды CREATE EVENT TRIGGER. Для того чтобы создать триггер события, вы должны сначала создать функцию со специальным типом возврата event_trigger. Эта функция не должна (и не может) возвращать значение; возвращаемый тип служит просто сигналом, что функция должна быть вызвана как триггер события.
Если для определенного события определено более одного триггера, они будут срабатывать в алфавитном порядке по имени триггера.
Определение триггера также может указывать условие WHEN так что, например, триггер ddl_command_start может быть запущен только для определенных команд, которые пользователь хочет перехватить. Обычно такие триггеры используются для ограничения диапазона операций DDL, которые могут выполнять пользователи.
Матрица запуска событий
В таблице 8.1 перечислены все команды, для которых поддерживаются триггеры событий.
Таблица 8.1. Поддержка триггеров событий по командам
| Командный тег | ddl_command_start | ddl_command_end | sql_drop | table_rewrite | Примечания |
|---|---|---|---|---|---|
| ALTER AGGREGATE | X | X | - | - | |
| ALTER COLLATION | X | X | - | - | |
| ALTER CONVERSION | X | X | - | - | |
| ALTER DOMAIN | X | X | - | - | |
| ALTER DEFAULT PRIVILEGES | X | X | - | - | |
| ALTER EXTENSION | X | X | - | - | |
| ALTER FOREIGN DATA WRAPPER | X | X | - | - | |
| ALTER FOREIGN TABLE | X | X | X | - | |
| ALTER FUNCTION | X | X | - | - | |
| ALTER LANGUAGE | X | X | - | - | |
| ALTER LARGE OBJECT | X | X | - | - | |
| ALTER MATERIALIZED VIEW | X | X | - | - | |
| ALTER OPERATOR | X | X | - | - | |
| ALTER OPERATOR CLASS | X | X | - | - | |
| ALTER OPERATOR FAMILY | X | X | - | - | |
| ALTER POLICY | X | X | - | - | |
| ALTER PROCEDURE | X | X | - | - | |
| ALTER PUBLICATION | X | X | - | - | |
| ALTER SCHEMA | X | X | - | - | |
| ALTER SEQUENCE | X | X | - | - | |
| ALTER SERVER | X | X | - | - | |
| ALTER STATISTICS | X | X | - | - | |
| ALTER SUBSCRIPTION | X | X | - | - | |
| ALTER TABLE | X | X | X | X | |
| ALTER TEXT SEARCH CONFIGURATION | X | X | - | - | |
| ALTER TEXT SEARCH DICTIONARY | X | X | - | - | |
| ALTER TEXT SEARCH PARSER | X | X | - | - | |
| ALTER TEXT SEARCH TEMPLATE | X | X | - | - | |
| ALTER TRIGGER | X | X | - | - | |
| ALTER TYPE | X | X | - | X | |
| ALTER USER MAPPING | X | X | - | - | |
| ALTER VIEW | X | X | - | - | |
| COMMENT | X | X | - | - | Только для локальных объектов |
| CREATE ACCESS METHOD | X | X | - | - | |
| CREATE AGGREGATE | X | X | - | - | |
| CREATE CAST | X | X | - | - | |
| CREATE COLLATION | X | X | - | - | |
| CREATE CONVERSION | X | X | - | - | |
| CREATE DOMAIN | X | X | - | - | |
| CREATE EXTENSION | X | X | - | - | |
| CREATE FOREIGN DATA WRAPPER | X | X | - | - | |
| CREATE FOREIGN TABLE | X | X | - | - | |
| CREATE FUNCTION | X | X | - | - | |
| CREATE INDEX | X | X | - | - | |
| CREATE LANGUAGE | X | X | - | - | |
| CREATE MATERIALIZED VIEW | X | X | - | - | |
| CREATE OPERATOR | X | X | - | - | |
| CREATE OPERATOR CLASS | X | X | - | - | |
| CREATE OPERATOR FAMILY | X | X | - | - | |
| CREATE POLICY | X | X | - | - | |
| CREATE PROCEDURE | X | X | - | - | |
| CREATE PUBLICATION | X | X | - | - | |
| CREATE RULE | X | X | - | - | |
| CREATE SCHEMA | X | X | - | - | |
| CREATE SEQUENCE | X | X | - | - | |
| CREATE SERVER | X | X | - | - | |
| CREATE STATISTICS | X | X | - | - | |
| CREATE SUBSCRIPTION | X | X | - | - | |
| CREATE TABLE | X | X | - | - | |
| CREATE TABLE AS | X | X | - | - | |
| CREATE TEXT SEARCH CONFIGURATION | X | X | - | - | |
| CREATE TEXT SEARCH DICTIONARY | X | X | - | - | |
| CREATE TEXT SEARCH PARSER | X | X | - | - | |
| CREATE TEXT SEARCH TEMPLATE | X | X | - | - | |
| CREATE TRIGGER | X | X | - | - | |
| CREATE TYPE | X | X | - | - | |
| CREATE USER MAPPING | X | X | - | - | |
| CREATE VIEW | X | X | - | - | |
| DROP ACCESS METHOD | X | X | X | - | |
| DROP AGGREGATE | X | X | X | - | |
| DROP CAST | X | X | X | - | |
| DROP COLLATION | X | X | X | - | |
| DROP CONVERSION | X | X | X | - | |
| DROP DOMAIN | X | X | X | - | |
| DROP EXTENSION | X | X | X | - | |
| DROP FOREIGN DATA WRAPPER | X | X | X | - | |
| DROP FOREIGN TABLE | X | X | X | - | |
| DROP FUNCTION | X | X | X | - | |
| DROP INDEX | X | X | X | - | |
| DROP LANGUAGE | X | X | X | - | |
| DROP MATERIALIZED VIEW | X | X | X | - | |
| DROP OPERATOR | X | X | X | - | |
| DROP OPERATOR CLASS | X | X | X | - | |
| DROP OPERATOR FAMILY | X | X | X | - | |
| DROP OWNED | X | X | X | - | |
| DROP POLICY | X | X | X | - | |
| DROP PROCEDURE | X | X | X | - | |
| DROP PUBLICATION | X | X | X | - | |
| DROP RULE | X | X | X | - | |
| DROP SCHEMA | X | X | X | - | |
| DROP SEQUENCE | X | X | X | - | |
| DROP SERVER | X | X | X | - | |
| DROP STATISTICS | X | X | X | - | |
| DROP SUBSCRIPTION | X | X | X | - | |
| DROP TABLE | X | X | X | - | |
| DROP TEXT SEARCH CONFIGURATION | X | X | X | - | |
| DROP TEXT SEARCH DICTIONARY | X | X | X | - | |
| DROP TEXT SEARCH PARSER | X | X | X | - | |
| DROP TEXT SEARCH TEMPLATE | X | X | X | - | |
| DROP TRIGGER | X | X | X | - | |
| DROP TYPE | X | X | X | - | |
| DROP USER MAPPING | X | X | X | - | |
| DROP VIEW | X | X | X | - | |
| GRANT | X | X | - | - | Только для локальных объектов |
| IMPORT FOREIGN SCHEMA | X | X | - | - | |
| REFRESH MATERIALIZED VIEW | X | X | - | - | |
| REVOKE | X | X | - | - | Только для локальных объектов |
| SECURITY LABEL | X | X | - | - | Только для локальных объектов |
| SELECT INTO | X | X | - | - |
Написание функций запуска событий на C
В этом разделе описываются подробности низкоуровневого интерфейса для функции запуска события. Эта информация необходима только при написании функций триггера событий на C. Если вы используете язык более высокого уровня, то эти детали обрабатываются автоматически. В большинстве случаев вам следует подумать об использовании процедурного языка, прежде чем писать свои триггеры событий на C. В документации каждого процедурного языка объясняется, как написать триггер событий на этом языке.
Функции триггера событий должны использовать интерфейс диспетчера «version 1».
Когда функция вызывается менеджером триггера события, ей не передаются никакие обычные аргументы кроме указателя «context», указывающий на структуру EventTriggerData. Функции на C могут проверить, были ли они вызваны из менеджера триггеров событий или нет, выполнив макрос:
CALLED_AS_EVENT_TRIGGER(fcinfo)
который распахивается в
((fcinfo)->context != NULL && IsA((fcinfo)->context, EventTriggerData))
Если это возвращает true, тогда безопасно привести fcinfo->context к типу EventTriggerData * и использовать структуру EventTriggerData. Функция не должна изменять структуру EventTriggerData или любые данные, на которые она указывает.
Структура EventTriggerData определена в commands/event_trigger.h:
typedef struct EventTriggerData
{
NodeTag type;
const char *event; /* event name */
Node *parsetree; /* parse tree */
const char *tag; /* command tag */
} EventTriggerData;
где члены определены следующим образом:
-
type - всегда T_EventTriggerData.
-
event описывает событие, для которого вызывается функция, одно из ddl_command_start, ddl_command_end, sql_drop, table_rewrite (см. Раздел 8.1 о значении этих событий).
-
parsetree - указатель на дерево разбора команды. Проверьте исходный код QHB для уточнения деталей. Структура дерева разбора может быть изменена без предварительного уведомления.
-
tag - тег команды, связанный с событием, для которого запускается триггер события, например "CREATE FUNCTION".
Внимание! Функция триггера события должна возвращать указатель NULL (но НЕ нулевое значение SQL, т.е. не устанавливать isNull как true).
Полный пример запуска события
Вот очень простой пример функции триггера события, написанной на C. (Примеры триггеров, написанных на процедурных языках, можно найти в документации по процедурным языкам.)
Функция noddl вызывает ошибку каждый раз, когда она вызывается. Определение триггера события связало функцию с событием ddl_command_start. В результате все команды DDL (с исключениями, упомянутыми в разделе 8.1) не могут быть запущены.
Это исходный код функции триггера:
#include "postgres.h"
#include "commands/event_trigger.h"
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(noddl);
Datum
noddl(PG_FUNCTION_ARGS)
{
EventTriggerData *trigdata;
if (!CALLED_AS_EVENT_TRIGGER(fcinfo)) /* internal error */
elog(ERROR, "not fired by event trigger manager");
trigdata = (EventTriggerData *) fcinfo->context;
ereport(ERROR,
(errcode(ERRCODE_INSUFFICIENT_PRIVILEGE),
errmsg("command \"%s\" denied", trigdata->tag)));
PG_RETURN_NULL();
}
После того, как вы скомпилировали исходный код (см. Раздел 37.10.5), объявите функцию и триггеры:
CREATE FUNCTION noddl() RETURNS event_trigger
AS 'noddl' LANGUAGE C;
CREATE EVENT TRIGGER noddl ON ddl_command_start
EXECUTE FUNCTION noddl();
Теперь вы можете проверить работу триггера:
=# \dy
List of event triggers
Name | Event | Owner | Enabled | Function | Tags
-------+-------------------+-------+---------+----------+------
noddl | ddl_command_start | dim | enabled | noddl |
(1 row)
=# CREATE TABLE foo(id serial);
ERROR: command "CREATE TABLE" denied
В этой ситуации, чтобы иметь возможность запускать некоторые команды DDL, когда вам нужно это сделать, вы должны либо сбросить триггер события, либо отключить его. Также может быть удобно отключить триггер только на время транзакции:
BEGIN;
ALTER EVENT TRIGGER noddl DISABLE;
CREATE TABLE foo (id serial);
ALTER EVENT TRIGGER noddl ENABLE;
COMMIT;
(Напомним, что на команды DDL самих триггеров событий не влияют триггеры событий.)
Пример запуска события перезаписи таблицы
Благодаря событию table_rewrite можно реализовать политику перезаписи таблицы, разрешив перезапись только в определенное время обслуживания.
Вот пример реализации такой политики.
CREATE OR REPLACE FUNCTION no_rewrite()
RETURNS event_trigger
LANGUAGE plpgsql AS
$$
---
--- Implement local Table Rewriting policy:
--- public.foo is not allowed rewriting, ever
--- other tables are only allowed rewriting between 1am and 6am
--- unless they have more than 100 blocks
---
DECLARE
table_oid oid := pg_event_trigger_table_rewrite_oid();
current_hour integer := extract('hour' from current_time);
pages integer;
max_pages integer := 100;
BEGIN
IF pg_event_trigger_table_rewrite_oid() = 'public.foo'::regclass
THEN
RAISE EXCEPTION 'you''re not allowed to rewrite the table %',
table_oid::regclass;
END IF;
SELECT INTO pages relpages FROM pg_class WHERE oid = table_oid;
IF pages > max_pages
THEN
RAISE EXCEPTION 'rewrites only allowed for table with less than % pages',
max_pages;
END IF;
IF current_hour NOT BETWEEN 1 AND 6
THEN
RAISE EXCEPTION 'rewrites only allowed between 1am and 6am';
END IF;
END;
$$;
CREATE EVENT TRIGGER no_rewrite_allowed
ON table_rewrite
EXECUTE FUNCTION no_rewrite();
Интерфейс программирования сервера
| Функция | Описание |
|---|---|
| SPI_connect | Подключиться к менеджеру SPI |
| SPI_finish | Отключиться от менеджера SPI |
| SPI_execute | Выполнить SQL команду |
| SPI_exec | Выполнить SQL команду, аналогично SPI_execute, но с параметром read_only=false |
| SPI_execute_with_args | Выполнить SQL команду, аналогично SPI_execute, но позволяет передать дополнительные параметры |
| SPI_prepare | Подготовить оператор, не выполняя его |
| SPI_prepare_cursor | Подготовить оператор, не выполняя его, аналогично SPI_prepare, но позволяет задать направление чтения |
| SPI_prepare_params | Подготовить оператор, не выполняя его, аналогично SPI_prepare_cursor, дополнительные параметры задаются через hook функцию |
| SPI_getargcount | Возвращает количество аргументов, необходимых для оператора, подготовленного методами SPI_prepare |
| SPI_getargtypeid | Возвращает OID типа данных для аргумента оператора, подготовленного методами SPI_prepare |
| SPI_is_cursor_plan | Возвращает true, если оператор, подготовленный SPI_prepare, может использоваться с SPI_cursor_open |
| SPI_execute_plan | Выполнить оператор, подготовленный SPI_prepare |
| SPI_execute_plan_with_paramlist | Выполнить оператор, подготовленный SPI_prepare_params, аналогично SPI_execute_plan, но позволяет передать значения дополнительных параметров |
| SPI_execp | Выполнить оператор, подготовленный SPI_prepare, аналогично SPI_execute_plan, но в режиме только чтения |
| SPI_cursor_open | Открыть курсор для оператора, созданного с помощью SPI_prepare |
| SPI_cursor_open_with_args | Открыть курсор, используя переданную команду и параметры |
| SPI_cursor_open_with_paramlist | Открыть курсор, подготовленный SPI_prepare_params, используя переданные параметры |
| SPI_cursor_find | Найти существующий курсор по имени |
| SPI_cursor_fetch | Прочитать несколько строк из курсора (только вперед/назад относительно текущей позиции) |
| SPI_cursor_move | Переместить курсор (только вперед/назад относительно текущей позиции) |
| SPI_scroll_cursor_fetch | Извлечь несколько строк из курсора |
| SPI_scroll_cursor_move | Переместить курсор |
| SPI_cursor_close | Закрыть курсор |
| SPI_keepplan | Сохранить оператор, подготовленный SPI_prepare, до конца сессии |
| SPI_saveplan | Возвращает копию оператора, подготовленного SPI_prepare |
| SPI_register_relation | Сделать эфемерное именованное отношение доступным по имени в запросах SPI |
| SPI_unregister_relation | Удалить эфемерное именованное отношение из реестра |
| SPI_register_trigger_data | Сделать доступными данные эфемерного триггера в запросах SPI |
| Функция | Описание |
|---|---|
| SPI_fname | Определить имя столбца для указанного номера столбца |
| SPI_fnumber | Определить номер столбца для указанного имени столбца |
| SPI_getvalue | Вернуть строковое значение указанного столбца |
| SPI_getbinval | Вернуть двоичное значение указанного столбца |
| SPI_gettype | Вернуть имя типа данных указанного столбца |
| SPI_gettypeid | Вернуть OID типа данных указанного столбца |
| SPI_getrelname | Вернуть имя указанного отношения |
| SPI_getnspname | Вернуть пространство имен указанного отношения |
| SPI_result_code_string | Вернуть код ошибки в виде строки |
| Функция | Описание |
|---|---|
| SPI_palloc | Выделить память] |
| SPI_repalloc | Перераспределить память |
| SPI_pfree | Освободить память |
| SPI_copytuple | Сделать копию строки |
| SPI_returntuple | Возвращает копию строки в качестве Datum |
| SPI_modifytuple | Создает новую запись, заменив выбранные поля исходной записи |
| SPI_freetuple | Освободить запись |
| SPI_freetuptable | Освободить строки, прочитанные SPI_execute или подобной функцией |
| SPI_freeplan | Освободить оператор, сохраненный с помощью SPI_keepplan, SPI_saveplan |
| Функция | Описание |
|---|---|
| SPI_commit | Зафиксировать текущую транзакцию |
| SPI_rollback | Отменить текущую транзакцию |
| SPI_start_transaction | Начать новую транзакцию |
Интерфейс программирования сервера (SPI) дает авторам пользовательских расширений, написанных на C или RUST, возможность запускать команды SQL внутри своих расширений. SPI - это набор интерфейсных функций, упрощающих доступ к анализатору, планировщику и исполнителю. SPI также осуществляет управление памятью.
Заметка
Доступные процедурные языки предоставляют различные средства для выполнения команд SQL из функций. Большинство этих средств основаны на SPI, поэтому эта документация может быть полезна и для пользователей этих языков.
Обратите внимание, что если команда, вызванная через SPI, завершиться с ошибкой, управление не будет возвращено вашей функции на C/RUST. Скорее всего, транзакция или субтранзакция, в которой выполняется ваша функция C/RUST, будет отменена. (Это может показаться удивительным, учитывая, что функции SPI в основном имеют документированные соглашения о возврате ошибок. Однако эти соглашения применяются только к ошибкам, обнаруженным в самих функциях SPI). Можно восстановить управление после ошибки, создав собственную субтранзакцию, окружающую вызовы SPI, которые могут быть неудачными.
Функции SPI возвращают неотрицательный результат в случае успеха (либо
через возвращаемое целочисленное значение, либо через глобальную
переменную SPI_result, как описано ниже). В случае ошибки будет
возвращен отрицательный результат или NULL .
Файлы исходного кода, использующие SPI, должны включать заголовочный файл executor/spi.h
Функции интерфейса
SPI_connect
SPI_connect, SPI_connect_ext - подключиться к менеджеру SPI
Синтаксис
int SPI_connect (void)
int SPI_connect_ext (int options )
Описание
SPI_connect открывает соединение к менеджеру SPI.
Вы должны вызвать эту функцию, если хотите выполнять команды через SPI.
Некоторые служебные SPI-функции можно вызывать без открытия соединения.
SPI_connect_ext делает то же самое, но имеет аргумент,
позволяющий передавать опциональные флаги. В настоящее время доступны следующие
значения:
SPI_OPT_NONATOMIC
- Устанавливает соединение SPI неатомарным, то есть
разрешает использование вызовов
SPI_commit,SPI_rollbackиSPI_startдля управления. В противном случае вызов данных функций приведет к немедленной ошибке.
SPI_connect() эквивалентно SPI_connect_ext(0).
Возвращаемое значение
SPI_OK_CONNECT
- при успехе
SPI_ERROR_CONNECT
- при ошибке
SPI_finish
SPI_finish - отключиться от менеджера SPI
Синтаксис
int SPI_finish (void)
Описание
SPI_finish закрывает существующее соединение с менеджером SPI. Вы
должны вызывать эту функцию после завершения всех операций со SPI, необходимых
во время текущего выполнения Вашей функции на C/RUST.
Вызов SPI_finish не требуется, если транзакция прервана
с помощью elog(ERROR). В этом случае SPI очистится автоматически.
Возвращаемое значение
SPI_OK_FINISH
- корректное отключение
SPI_ERROR_UNCONNECTED
- нет открытого соединения с менеджером SPI
SPI_execute
SPI_execute - выполнить SQL команду
Синтаксис
int SPI_execute(const char * command, bool read_only, long count)
Описание
SPI_execute выполняет указанную команду SQL для count строк. Если
read_only имеет значение true, команда должна только
читать данные, а накладные расходы на выполнение несколько уменьшаются.
Эта функция может быть вызвана только после подключения к менеджеру SPI.
Если count равно нулю, то команда выполняется для всех строк, удовлетворяющих
условиями запроса. Если count больше нуля, то будет получено не больше,
чем count строк; выполнение останавливается указанного количества, как
при добавлении оператора LIMIT к запросу. Например,
SPI_execute("SELECT * FROM foo", true, 5);
получит максимум 5 строк из таблицы. Обратите внимание, что такой предел действует только тогда, когда команда действительно возвращает строки. Например,
SPI_execute("INSERT INTO foo SELECT * FROM bar", false, 5);
вставляет все строки из bar, игнорируя параметр count. Однако запрос
SPI_execute("INSERT INTO foo SELECT * FROM bar RETURNING *", false, 5);
вставит не более 5 строк, поскольку выполнение будет остановлено после получения пятого результата RETURNING.
Вы можете передать несколько команд в одной строке, SPI_execute
возвращает результат для команды, выполненной последней. Ограничение количества строк count
применяется к каждой команды в отдельности (даже если будет возвращен
только последний результат). Ограничение не применяется к скрытым
командам, сгенерированным правилами.
Когда read_only имеет значение false, SPI_execute увеличивает счетчик
команд и вычисляет новый снимок перед выполнением каждой команды в
строке. Снимок фактически не изменяется, если текущий уровень изоляции
транзакции - SERIALIZABLE или REPEATABLE READ, но в режиме READ
COMMITTED обновление снимка позволяет каждой команде видеть результаты
вновь принятых транзакций из других сессий. Это важно для
согласованного поведения, когда команды изменяют базу данных.
Когда read_only имеет значение true, SPI_execute не обновляет ни
снимок, ни счетчик команд, а позволяет использовать в запросе только
команды SELECT. Команды выполняются с использованием
снимка, предварительно установленного для окружающего запроса. Этот
режим выполнения несколько быстрее, чем режим чтения / записи из-за
устранения накладных расходов на каждую команду. Это также позволяет
создавать действительно стабильные функции: поскольку все
последовательные выполнения будут использовать один и тот же
снимок, в результатах не будет никаких изменений.
Обычно неразумно смешивать команды только для чтения и чтения и записи в одной функции с использованием SPI; это может привести к очень запутанному поведению, поскольку запросы только для чтения не будут видеть результаты каких-либо обновлений базы данных, выполненных запросами чтения-записи.
Фактическое количество строк, для которых была выполнена (последняя)
команда, возвращается в глобальной переменной SPI_processed. Если
возвращаемое значение функции - SPI_OK_SELECT,
SPI_OK_INSERT_RETURNING, SPI_OK_DELETE_RETURNING или
SPI_OK_UPDATE_RETURNING, то вы можете использовать глобальный
указатель SPITupleTable *SPI_tuptable для доступа к строкам
результата. Некоторые служебные команды (такие как EXPLAIN) также
возвращают наборы строк, и SPI_tuptable будет содержать результат и в
этих случаях. Некоторые служебные команды (COPY, CREATE TABLE AS) не
возвращают набор строк, поэтому SPI_tuptable имеет значение NULL, но
они по-прежнему возвращают количество обработанных строк в
SPI_processed.
Структура SPITupleTable определяется таким образом:
typedef struct
{
MemoryContext tuptabcxt; /* memory context of result table */
uint64 alloced; /* number of alloced vals */
uint64 free; /* number of free vals */
TupleDesc tupdesc; /* row descriptor */
HeapTuple *vals; /* rows */
} SPITupleTable;
- vals - это массив указателей на строки. (Количество допустимых записей
задается
SPI_processed.); - tupdesc - это дескриптор строки, который вы можете передать функциям SPI, работающим со строками;
- tuptabcxt, alloced и free являются внутренними полями, не предназначенными для использования вызывающими SPI.
SPI_finish освобождает все SPITupleTable, выделенные во время текущего соединения с SPI.
Вы можете освободить определенную таблицу результатов ранее,
если закончили с ней работать, вызвав SPI_freetuptable.
Аргументы
const char * command
- строка, содержащая запрос для выполнения
bool read_only
- true для выполнения запросов только для чтения
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Если выполнение команды было успешным, то будет возвращено одно из следующих (неотрицательных) значений:
| Результат | Описание |
|---|---|
| SPI_OK_SELECT | если SELECT (но не SELECT INTO ) был выполнен |
| SPI_OK_SELINTO | если SELECT INTO был выполнен |
| SPI_OK_INSERT | если INSERT был выполнена |
| SPI_OK_DELETE | если DELETE был выполнено |
| SPI_OK_UPDATE | если UPDATE был выполнено |
| SPI_OK_INSERT_RETURNING | если INSERT RETURNING был выполнен |
| SPI_OK_DELETE_RETURNING | если DELETE RETURNING был выполнен |
| SPI_OK_UPDATE_RETURNING | если UPDATE RETURNING было выполнено |
| SPI_OK_UTILITY | если была выполнена служебная команда (например, CREATE TABLE ) |
| SPI_OK_REWRITTEN | если команда была переписана в другой тип команды (например, UPDATE стал INSERT ) по правилу. |
При ошибке возвращается одно из следующих отрицательных значений:
| Результат | Описание |
|---|---|
| SPI_ERROR_ARGUMENT | если command равен NULL или count меньше 0 |
| SPI_ERROR_COPY | если была предпринята попытка COPY TO stdout или COPY FROM stdin |
| SPI_ERROR_TRANSACTION | если была предпринята команда манипулирования транзакцией ( BEGIN, COMMIT, ROLLBACK, SAVEPOINT, PREPARE TRANSACTION, COMMIT PREPARED, ROLLBACK PREPARED или любой их вариант) |
| SPI_ERROR_OPUNKNOWN | если тип команды неизвестен (не должно происходить) |
| SPI_ERROR_UNCONNECTED | если не открыто подключение к менеджеру SPI |
Примечания
Все SPI функции, выполняющие запросы, устанавливают значения переменных SPI_processed и
SPI_tuptable (только указатель, а не содержимое структуры). Сохраните значения
этих двух глобальных переменных в локальные переменные в Вашей функции на C/RUST, если вам
нужно получить доступ к таблице результатов выполнения SPI_execute или другой
функции SPI_execute_xxx при последующих вызовах.
SPI_exec
SPI_exec - выполнить SQL команду, аналогично SPI_execute, но с параметром read_only=false
Синтаксис
int SPI_exec(const char * command, long count)
Описание
SPI_exec работает так же, как SPI_execute, но с последним параметром read_only
всегда принимаемым как false.
Аргументы
const char * command
- строка, содержащая запрос для выполнения
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Смотрите SPI_execute.
SPI_execute_with_args
SPI_execute_with_args - выполнить SQL команду, аналогично SPI_execute, но позволяет передать дополнительные параметры
Синтаксис
int SPI_execute_with_args(const char *command, int nargs, Oid *argtypes,
Datum *values, const char *nulls, bool read_only, long count)
Описание
SPI_execute_with_args выполняет запрос, который может включать
ссылки на внешние параметры. Текст команды ссылается на параметр как $n,
а вызов определяет типы данных и значения для каждого такого символа.
Параметры read_only и count имеют ту же интерпретацию, что и в SPI_execute.
Основное преимущество этой процедуры по сравнению со SPI_execute заключается в том, что значения данных могут быть вставлены в команду без утомительного заключения в кавычки/экранирования и, следовательно, сильно уменьшает риск атак с использованием SQL-инъекций.
Аналогичные результаты могут быть достигнуты со SPI_prepare, за которой
следует SPI_execute_plan; однако при использовании этой функции план
запроса всегда настраивается на конкретные значения параметров. Для
одноразового выполнения запроса SPI_execute_with_args
предпочтительней. Если одна и та же команда должна быть выполнена со
многими различными параметрами, любой из этих методов может быть более
быстрым, в зависимости от стоимости перепланирования по сравнению с
преимуществами специализированных планов.
Аргументы
const char * command
- SQL запрос
int nargs
- количество входных параметров ( $1, $2 и т. д.)
Oid * argtypes
- массив длинной
nargs, содержащий OID-ы типов данных входных параметров
Datum * values
- массив длинной
nargs, содержащий фактические значения параметров
const char * nulls
-
массив длинной
nargs, описывающий, какие параметры равны NULL -
Если параметр
nullsравен NULL тогдаSPI_execute_with_argsпредполагает, что ни один из параметров не содержит NULL. В противном случае каждая запись массиваnullsдолжна быть ’ ’, если значение соответствующего параметра не равно NULL, или ’n’ если значение соответствующего параметра равно NULL. (В последнем случае фактическое значение в соответствующей записи в параметреvaluesне имеет значения). Обратите внимание, чтоnulls- это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
bool read_only
- true для выполнения запросов только для чтения
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Возвращаемое значение такое же, как и для SPI_execute.
При успешном завершении SPI_processed и SPI_tuptable устанавливаются как в SPI_execute.
SPI_prepare
SPI_prepare - подготовить оператор, не выполняя его
Синтаксис
SPIPlanPtr SPI_prepare(const char * command, int nargs, Oid *argtypes)
Описание
SPI_prepare создает и возвращает подготовленный оператор для указанного
запроса, но не выполняет запрос. Подготовленный оператор может быть
впоследствии выполнен многократно с использованием SPI_execute_plan.
Когда одна и та же или аналогичная команда должна выполняться
многократно, обычно выгодно выполнять анализ разбора только один раз, и,
кроме того, может быть выгодно повторно использовать план выполнения для
команды. SPI_prepare преобразует строку запроса в подготовленный
оператор, который инкапсулирует результаты анализа.
Подготовленный оператор также предоставляет место для кэширования плана
выполнения, если выясняется, что вычисление специализированного плана для
каждого выполнения бесполезно.
Подготовленный запрос можно обобщить, используя параметры ( $1, $2 и т.д.) вместо констант в тексте запроса. Фактические значения параметров затем указываются при вызове SPI_execute_plan. Это позволяет использовать подготовленную команду в более широком диапазоне ситуаций, чем это было бы возможно без параметров.
Оператор, возвращаемый SPI_prepare, может использоваться только в
текущем соединении с менеджером SPI, поскольку SPI_finish освобождает память,
выделенную для такого оператора. Но оператор можно сохранить для дальнейшего использования,
используя функции SPI_keepplan или SPI_saveplan.
Аргументы
const char * command
- SQL запрос
int nargs
- количество входных параметров ( $1, $2 и т. д.)
Oid * argtypes
- указатель на массив длинной
nargs, содержащий OID-ы типов данных параметров
Возвращаемое значение
SPI_prepare возвращает ненулевой указатель на SPIPlan, который
является непрозрачной структурой, представляющей подготовленный
оператор. В случае ошибки будет возвращен NULL, а переменная SPI_result
будет содержать один из тех же кодов ошибок, которые используются
SPI_execute, или
SPI_ERROR_ARGUMENT, если command равен NULL, или nargs меньше 0,
или nargs больше чем 0 и argtypes равен NULL.
Примечания
Если параметры не определены, общий план будет создан при первом
использовании SPI_execute_plan и он же будет использоваться для всех
последующих выполнений. Если есть параметры, первые несколько
использований SPI_execute_plan сгенерируют специализированные планы,
которые являются специфическими для предоставленных значений параметров.
После достаточного использования одного и того же подготовленного
оператора SPI_execute_plan создаст общий план, и, если он не намного
дороже, чем специализированные планы, полученный общий план начнет использоваться
вместо перепланирования каждый раз. Если это поведение по умолчанию не
подходит, Вы можете изменить его, передав флаг
CURSOR_OPT_GENERIC_PLAN или CURSOR_OPT_CUSTOM_PLAN в
SPI_prepare_cursor, чтобы принудительно использовать общие или
специализированные планы соответственно.
Хотя основной смысл подготовленного оператора заключается в том, чтобы избежать повторного анализа и планирования оператора, QHB будет вынужден повторно анализировать и перепланировать оператор перед его использованием всякий раз, когда объекты базы данных, используемые в операторе, изменяются с помощью DDL команд с момента предыдущего использования подготовленного оператора. Кроме того, если значение параметра search_path изменяется от одного использования к следующему, оператор будет повторно проанализирован с использованием нового search_path. См. PREPARE для получения дополнительной информации о поведении подготовленных операторов.
Эта функция должна вызываться только после подключения к менеджеру SPI.
SPIPlanPtr объявлен как указатель на непрозрачный тип структуры в spi.h.
Неразумно пытаться получить доступ к его содержимому напрямую, так как
это повышает вероятность того, что ваш код сломается в будущих версиях
QHB.
Имя SPIPlanPtr несколько историческое, поскольку структура данных не обязательно содержит план выполнения.
SPI_prepare_cursor
SPI_prepare_cursor - подготовить оператор, не выполняя его, аналогично SPI_prepare, но позволяет задать направление чтения
Синтаксис
SPIPlanPtr SPI_prepare_cursor(const char * command, int nargs, Oid * argtypes, int cursorOptions)
Описание
Функция SPI_prepare_cursor идентична SPI_prepare, но
позволяет дополнительно передать планировщику «параметры
курсора». Это битовая маска, имеющая значения, перечисленные в
nodes/parsenodes.h для поля options структуры DeclareCursorStmt. SPI_prepare
Всегда принимает параметры курсора как ноль.
Аргументы
const char * command
- SQL запрос
int nargs
- количество входных параметров ( $1, $2 и т. д.)
Oid * argtypes
- указатель на массив длинной
nargs, содержащий OID-ы типов данных параметров
int cursorOptions
- целочисленная битовая маска параметров курсора; ноль - поведение по умолчанию
Возвращаемое значение
SPI_prepare_cursor имеет те же соглашения о возврате, что и
SPI_prepare.
Примечания
Полезные биты для установки в cursorOptions включают:
- CURSOR_OPT_SCROLL
- CURSOR_OPT_NO_SCROLL
- CURSOR_OPT_FAST_PLAN
- CURSOR_OPT_GENERIC_PLAN
- CURSOR_OPT_CUSTOM_PLAN.
Обратите внимание, в частности, что CURSOR\_OPT\_HOLD игнорируется.
SPI_prepare_params
SPI_prepare_params - подготовить оператор, не выполняя его, аналогично SPI_prepare_cursor, дополнительные параметры задаются через hook функцию
Синтаксис
SPIPlanPtr SPI_prepare_params(const char * command, ParserSetupHook parserSetup,
void * parserSetupArg, int cursorOptions)
Описание
SPI_prepare_params создает и возвращает подготовленный оператор для
указанного запроса, но не выполняет его. Эта функция эквивалентна
SPI_prepare_cursor, за исключением того, что вызывающая сторона
может передать hook функцию для контроля за разбором
ссылок на внешние параметры.
Аргументы
const char * command
- SQL запрос
ParserSetupHook parserSetup
- Функция настройки парсера
void * parserSetupArg
- сквозной аргумент для parserSetup
int cursorOptions
- целочисленная битовая маска параметров курсора; ноль - поведение по умолчанию
Возвращаемое значение
SPI\_prepare\_params имеет те же соглашения о возврате, что и
SPI_prepare.
SPI_getargcount
SPI_getargcount - возвращает количество аргументов, необходимых для оператора, подготовленного методами SPI_prepare
Синтаксис
int SPI_getargcount(SPIPlanPtr plan)
Описание
SPI\getargcount возвращает количество аргументов, необходимых для
выполнения оператора, подготовленного SPI_prepare.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Возвращаемое значение
Количество ожидаемых аргументов для plan. Если plan равен NULL или
недействителен, SPI_result устанавливается в SPI_ERROR_ARGUMENT и
возвращается -1.
SPI_getargtypeid
SPI_getargtypeid - возвращает OID типа данных для аргумента оператора, подготовленного методами SPI_prepare
Синтаксис
Oid SPI_getargtypeid(SPIPlanPtr plan, int argIndex)
Описание
SPI_getargtypeid возвращает OID типа аргумента с индексом argIndex
для оператора, подготовленного SPI_prepare. Нумерация аргументов начинается с нуля.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
int argIndex
- индекс аргумента
Возвращаемое значение
Тип OID аргумента с указанным индексом. Если plan равен NULL или
недействителен, или argIndex меньше 0 или больше или равен количеству аргументов,
объявленных для plan, SPI_result устанавливается в
SPI_ERROR_ARGUMENT и возвращается InvalidOid.
SPI_is_cursor_plan
SPI\_is\_cursor\_plan - возвращает true, если оператор, подготовленный SPI_prepare, может использоваться с SPI_cursor_open
Синтаксис
bool SPI_is_cursor_plan(SPIPlanPtr plan)
Описание
SPI_is_cursor_plan возвращает true, если оператор, подготовленный
SPI_prepare может быть передан в качестве аргумента SPI_cursor_open,
или false, если это не так. Функция возвращает true, если plan представляет
одну команду, и эта команда возвращает записи вызывающей стороне. Например, SELECT разрешен, если он не содержит предложение INTO, а
UPDATE разрешен, только если он содержит предложение RETURNING.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Возвращаемое значение
Если SPI_result содержит 0, тогда true или false указывает,
может ли plan создать курсор или нет. Если невозможно определить ответ
(например, если plan равен NULL или недействителен, или если
не открыто подключение к менеджеру SPI), тогда для SPI_result устанавливается
подходящий код ошибки, и возвращается значение false.
SPI_execute_plan
SPI_execute_plan - выполнить оператор, подготовленный SPI_prepare
Синтаксис
int SPI_execute_plan(SPIPlanPtr plan, Datum * values, const char * nulls,
bool read_only, long count)
Описание
SPI_execute_plan выполняет оператор, подготовленный SPI_prepare или
подобным методом. Параметры read_only и count имеют то же
назначение, что и в SPI_execute.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Datum * values
- Массив фактических значений параметров. Должен иметь ту же длину, что и число аргументов оператора.
const char * nulls
-
Массив, описывающий, какие параметры являются нулевыми. Должен иметь ту же длину, что и число аргументов оператора.
-
Если указатель
nullsравен NULL, тогдаSPI_execute_planпредполагает, что ни один из параметров не является нулевым. В противном случае каждый элемент массиваnullsдолжен быть ’ ’, если значение соответствующего параметра не равно нулю, или ’n’, если значение соответствующего параметра равно нулю. (В последнем случае фактическое значение в соответствующем элементеvaluesне имеет значения.) Обратите внимание, что nulls - это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
bool read_only
- true для выполнения запроса только читающего данные
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Возвращаемое значение такое же, как и для SPI_execute, со следующими возможными ошибочными (отрицательными) результатами:
SPI_ERROR_ARGUMENT
- если параметр
planравен NULL или недействителен, или параметрcountменьше 0
SPI_ERROR_PARAM
- если параметр
valuesравен NULL, иplanподготовлен с использованием параметров
В случае успешного завершения SPI_processed и SPI_tuptable устанавливаются как в SPI_execute.
SPI_execute_plan_with_paramlist
SPI_execute_plan_with_paramlist - выполняет оператор, подготовленный SPI_prepare_params, аналогично SPI_execute_plan, но позволяет передать значения дополнительных параметров.
Синтаксис
int SPI_execute_plan_with_paramlist(SPIPlanPtr plan,
ParamListInfo params, bool read_only, long count)
Описание
SPI_execute_plan_with_paramlist выполняет оператор, подготовленный
SPI_prepare. Эта функция эквивалентна SPI_execute_plan за
исключением того, что информация о значениях параметров, передаваемых в
запрос, передается по другом. Структура ParamListInfo может быть
удобна для передачи значений, которые уже доступны в этом формате. Функция
также поддерживает динамическую подстановку параметров через
hook функции, указанные в ParamListInfo.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
ParamListInfo params
- структура данных, содержащая типы параметров и значения; NULL, если параметров нет
bool read_only
- true для выполнения запроса только читающего данные
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Возвращаемое значение такое же, как у функции SPI_execute_plan.
В случае успешного завершения SPI_processed и SPI_tuptable устанавливаются как при вызове функции SPI_execute_plan.
SPI_execp
SPI_execp - выполнить оператор, подготовленный SPI_prepare, аналогично SPI_execute_plan, но в режиме только чтения
Синтаксис
int SPI_execp(SPIPlanPtr plan, Datum * values, const char * nulls, long count)
Описание
SPI_execp совпадает с SPI_execute_plan, но параметр read_only всегда принимается равным false.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Datum * values
- Массив фактических значений параметров. Должен иметь ту же длину, что и число аргументов оператора.
const char * nulls
-
Массив, описывающий, какие параметры являются нулевыми. Должен иметь ту же длину, что и число аргументов оператора.
-
Если указатель
nullsравен NULL, тогдаSPI_execpпредполагает, что ни один из параметров не является нулевым. В противном случае каждый элемент массиваnullsдолжeн быть ’ ’, если значение соответствующего параметра не равно нулю, или ’n’, если значение соответствующего параметра равно нулю. (В последнем случае фактическое значение в соответствующем элементеvaluesне имеет значения.) Обратите внимание, что nulls - это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
long count
- максимальное количество строк, которые нужно вернуть, или 0 без ограничений
Возвращаемое значение
Возвращаемое значение такое же, как у функции SPI_execute_plan.
В случае успешного завершения SPI_processed и SPI_tuptable устанавливаются как при вызове функции SPI_execute_plan.
SPI_cursor_open
SPI_cursor_open - открыть курсор для оператора, созданного с помощью SPI_prepare
Синтаксис
Portal SPI_cursor_open(const char * name, SPIPlanPtr plan,
Datum * values, const char * nulls, bool read_only)
Описание
SPI_cursor_open открывает курсор (называемый внутри базы данных порталом), который
будет выполнять оператор, подготовленный SPI_prepare. Входные параметры имеют
те же значения, что и соответствующие параметры для SPI_execute_plan.
Использование курсора вместо непосредственного выполнения оператора имеет два преимущества. Во-первых, результирующие строки могут быть получены по нескольку за раз, избегая переполнения памяти для запросов, которые возвращают много строк. Во-вторых, портал может пережить текущую функцию C/RUST (фактически он может дожить до конца текущей транзакции). Возврат имени портала в вызывающую функцию на C/RUST обеспечивает способ возврата набора строк в качестве результата.
Содержимое входных параметров будет скопировано в портал курсора, поэтому они могут быть освобождены, пока курсор еще существует.
Аргументы
const char * name
- имя для портала или NULL, чтобы система могла выбрать имя
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Datum * values
- Массив фактических значений параметров. Должен иметь ту же длину, что и число аргументов оператора.
const char * nulls
-
Массив, описывающий, какие параметры являются нулевыми. Должен иметь ту же длину, что и число аргументов оператора.
-
Если указатель
nullsравен NULL, тогдаSPI_cursor_openпредполагает, что ни один из параметров не является нулевым. В противном случае каждый элемент массиваnullsдолжeн быть ’ ’, если значение соответствующего параметра не равно нулю, или ’n’, если значение соответствующего параметра равно нулю. (В последнем случае фактическое значение в соответствующем элементеvaluesне имеет значения.) Обратите внимание, что nulls - это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
bool read_only
- true для выполнения запроса только читающего данные
Возвращаемое значение
Указатель на портал, содержащий курсор. Обратите внимание, что нет
соглашения о возврате ошибок; любая ошибка будет записана через elog.
SPI_cursor_open_with_args
SPI_cursor_open_with_args - открыть курсор, используя переданную команду и параметры
Синтаксис
Portal SPI_cursor_open_with_args(const char *name, const char *command,
int nargs, Oid *argtypes, Datum *values,
const char *nulls, bool read_only, int cursorOptions)
Описание
SPI_cursor_open_with_args открывает курсор (называемый внутри базы данных порталом),
который будет выполнять указанный запрос. Большинство параметров имеют
те же значения, что и соответствующие параметры для SPI_prepare_cursor
и SPI_cursor_open.
Для одноразового выполнения запроса эта функция должна быть предпочтительнее, чем последовательные вызовы SPI_prepare_cursor и SPI_cursor_open. Если один и тот же запрос выполняется с различными параметрами, любой из этих двух вариантов может быть быстрее, в зависимости от стоимости перепланирования по сравнению с преимуществами специализированных планов.
Содержимое входных параметров будет скопировано в портал курсора, поэтому они могут быть освобождены, пока курсор еще существует.
Аргументы
const char * name
- имя для портала или NULL, чтобы система могла выбрать имя
const char * command
- SQL запрос
int nargs
- количество входных параметров ( $1, $2 и т. д.)
Oid * argtypes
- массив длинной
nargs, содержащий OID-ы типов данных входных параметров
Datum * values
- массив длинной
nargs, содержащий фактические значения параметров
const char * nulls
-
массив длинной
nargs, описывающий, какие параметры равны NULL -
Если указатель
nullsравен NULL, тогдаSPI_cursor_open_with_argsпредполагает, что ни один из параметров не является нулевым. В противном случае каждый элемент массиваnullsдолжен быть ’ ’, если значение соответствующего параметра не равно нулю, или ’n’, если значение соответствующего параметра равно нулю. (В последнем случае фактическое значение в соответствующем элементеvaluesне имеет значения.) Обратите внимание, что nulls - это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
bool read_only
- true для выполнения запроса только читающего данные
int cursorOptions
- целочисленная битовая маска параметров курсора; ноль - поведение по умолчанию
Возвращаемое значение
Указатель на портал, содержащий курсор. Обратите внимание, что нет
соглашения о возврате ошибок; любая ошибка будет записана через elog.
SPI_cursor_open_with_paramlist
SPI_cursor_open_with_paramlist - открыть курсор, подготовленный SPI_prepare_params, используя переданные параметры
Синтаксис
Portal SPI_cursor_open_with_paramlist(const char *name,
SPIPlanPtr plan, ParamListInfo params, bool read_only)
Описание
SPI_cursor_open_with_paramlist открывает курсор (называемый внутри базы данных порталом),
который будет выполнять оператор, подготовленный SPI_prepare.
Эта функция эквивалентна SPI_cursor_open за исключением того, что
информация о значениях параметров, передаваемых в запрос, представлена
по другому. Структура ParamListInfo может быть
удобна для передачи значений, которые уже доступны в этом формате. Функция
также поддерживает динамическую подстановку параметров через
hook функции, указанные в ParamListInfo.
Содержимое входных параметров будет скопировано в портал курсора, поэтому они могут быть освобождены, пока курсор еще существует.
Аргументы
const char * name
- имя для портала или NULL, чтобы система могла выбрать имя
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
ParamListInfo params
- структура данных, содержащая типы параметров и значения; NULL, если параметров нет
bool read_only
- true для выполнения запроса только читающего данные
Возвращаемое значение
Указатель на портал, содержащий курсор. Обратите внимание, что нет
соглашения о возврате ошибок; любая ошибка будет записана через elog.
SPI_cursor_find
SPI_cursor_find - найти существующий курсор по имени
Синтаксис
Portal SPI_cursor_find(const char * name)
Описание
SPI_cursor_find находит существующий портал по имени. Это в первую
очередь полезно для разрешения имени курсора, возвращаемого в виде
текста другой функцией.
Аргументы
const char * name
- название портала
Возвращаемое значение
Указатель на портал с указанным именем или NULL, если ничего не найдено
SPI_cursor_fetch
SPI_cursor_fetch - прочитать несколько строк из курсора (только вперед/назад относительно текущей позиции)
Синтаксис
void SPI_cursor_fetch(Portal portal, bool forward, long count)
Описание
SPI_cursor_fetch извлекает несколько строк из курсора. Это
эквивалентно подмножеству SQL команды FETCH (для получения
дополнительной информации см. SPI_scroll_cursor_fetch).
Аргументы
Portal portal
- портал, содержащий курсор
bool forward
- true для извлечения вперед, false для извлечения назад
long count
- максимальное количество строк для извлечения
Возвращаемое значение
В случае успешного завершения SPI_processed и SPI_tuptable устанавливаются как в SPI_execute.
Примечания
Выборка в обратном направлении может завершиться с ошибкой, если план курсора не был создан с
опцией CURSOR_OPT_SCROLL.
SPI_cursor_move
SPI_cursor_move - переместить курсор (только вперед/назад относительно текущей позиции)
Синтаксис
void SPI_cursor_move(Portal portal, bool forward, long count)
Описание
SPI_cursor_move пропускает некоторое количество строк в курсоре. Это
эквивалентно подмножеству SQL команды MOVE (для получения дополнительной
информации см. SPI_scroll_cursor_move).
Аргументы
Portal portal
- портал, содержащий курсор
bool forward
- true для движения вперед, false для движения назад
long count
- максимальное количество строк для перемещения
Примечания
Перемещение в обратном направлении может завершиться с ошибкой, если план курсора не был создан с
опцией CURSOR_OPT_SCROLL.
SPI_scroll_cursor_fetch
SPI_scroll_cursor_fetch - извлечь несколько строк из курсора
Синтаксис
void SPI_scroll_cursor_fetch(Portal portal, FetchDirection direction, long count)
Описание
SPI_scroll_cursor_fetch извлекает несколько строк из курсора. Это
эквивалентно SQL команде FETCH .
Аргументы
Portal portal
- портал, содержащий курсор
FetchDirection direction
- одно из значений
FETCH_FORWARD,FETCH_BACKWARD,FETCH_ABSOLUTEилиFETCH_RELATIVE
long count
- количество строк для извлечения, если параметр
directionравенFETCH_FORWARDилиFETCH_BACKWARD - абсолютный номер строки для извлечения, если параметр
directionравенFETCH_ABSOLUTE - относительный номер строки для извлечения, если параметр
directionравенFETCH_RELATIVE
Возвращаемое значение
В случае успешного завершения SPI_processed и SPI_tuptable устанавливаются как в SPI_execute.
Примечания
См. SQL команду FETCH для получения подробной информации об
интерпретации параметров direction и count.
Если параметр direction имеет значение, отличное от FETCH_FORWARD, функция может завершиться с ошибкой,
если план курсора не был создан с опцией CURSOR_OPT_SCROLL.
SPI_scroll_cursor_move
SPI_scroll_cursor_move - переместить курсор
Синтаксис
void SPI_scroll_cursor_move(Portal portal, FetchDirection direction, long count)
Описание
SPI_scroll_cursor_move пропускает некоторое количество строк в
курсоре. Это эквивалентно SQL команде MOVE.
Аргументы
Portal portal
- портал, содержащий курсор
FetchDirection direction
- одно из значений
FETCH_FORWARD,FETCH_BACKWARD,FETCH_ABSOLUTEилиFETCH_RELATIVE
long count
- количество строк для перемещения, если параметр
directionравенFETCH_FORWARDилиFETCH_BACKWARD - абсолютный номер строки для перемещения, если параметр
directionравенFETCH_ABSOLUTE - относительный номер строки для извлечения, если параметр
directionравенFETCH_RELATIVE
Возвращаемое значение
В случае успешного завершения SPI_processed устанавливаются как в SPI_execute.
SPI_tuptable всегда устанавливается в NULL, поскольку эта функция не возвращает строк.
Примечания
См. SQL команду FETCH для получения подробной информации об
интерпретации параметров direction и count.
Если параметр direction имеет значение, отличное от FETCH_FORWARD, функция может завершиться с ошибкой,
если план курсора не был создан с опцией CURSOR_OPT_SCROLL.
SPI_cursor_close
SPI_cursor_close - закрыть курсор
Синтаксис
void SPI_cursor_close(Portal portal)
Описание
SPI_cursor_close закрывает ранее созданный курсор и освобождает
ресурсы, используемые порталом.
Все открытые курсоры закрываются автоматически в конце транзакции.
SPI_cursor_close нужно вызывать только в случае, если желательно
освободить ресурсы раньше.
Аргументы
Portal portal
- портал, содержащий курсор
SPI_keepplan
SPI_keepplan - сохранить оператор, подготовленный SPI_prepare, до конца сессии
Синтаксис
int SPI_keepplan(SPIPlanPtr plan)
Описание
SPI_keepplan сохраняет переданный оператор (подготовленный SPI_prepare
), чтобы он не был освобожден ни SPI_finish, ни менеджером транзакций.
Это дает Вам возможность повторно использовать подготовленные операторы
в последующих вызовах Вашей функции на C/RUST в текущей сессии.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Возвращаемое значение
0 в случае успеха; SPI_ERROR_ARGUMENT если параметр plan равен NULL или
недействителен
Примечания
Переданный оператор перемещается в постоянное хранилище с помощью копирования указателя (копирование данных не требуется). Если позже Вы захотите удалить его, используйте для этого SPI_freeplan.
SPI_saveplan
SPI_saveplan - возвращает копию оператора, подготовленного SPI_prepare
Синтаксис
SPIPlanPtr SPI_saveplan(SPIPlanPtr plan)
Описание
SPI_saveplan копирует переданный оператор (подготовленный SPI_prepare
) в память, которая не будет освобождена ни SPI_finish, ни менеджером
транзакций, и возвращает указатель на скопированный оператор. Это дает
Вам возможность повторно использовать подготовленные операторы в
последующих вызовах Вашей функции на C/RUST в текущей сессии.
Аргументы
SPIPlanPtr plan
- оператор, подготовленный вызовом SPI_prepare
Возвращаемое значение
Указатель на скопированный оператор; или NULL случае неудачи. В
случае ошибки SPI_result устанавливается следующим образом:
SPI_ERROR_ARGUMENT
- если параметр
planравен NULL или недействителен
SPI_ERROR_UNCONNECTED
- если не открыто подключение к менеджеру SPI
Примечания
Первоначально переданный оператор не освобождается, поэтому вы можете освободить его вручную вызовом SPI_freeplan, или он будет освобождён автоматически во время вызова SPI_finish.
В большинстве случаев SPI_keepplan предпочтительнее этой функции, поскольку не выполняется физическое копирование структур данных подготовленного оператора.
SPI_register_relation
SPI_register_relation - сделать эфемерное именованное отношение доступным по имени в запросах SPI
Синтаксис
int SPI_register_relation(EphemeralNamedRelation enr)
Описание
SPI_register_relation делает эфемерное именованное отношение, включая
связанную информацию, доступным для запросов, планируемых и выполняемых
через текущее соединение SPI.
Аргументы
EphemeralNamedRelation enr
- эфемерное именованное отношение
Возвращаемое значение
Если выполнение функции было успешным, то будет возвращено следующее (неотрицательное) значение:
SPI_OK_REL_REGISTER
- если отношение было успешно зарегистрировано по имени
При ошибке возвращается одно из следующих отрицательных значений:
SPI_ERROR_ARGUMENT
- если параметр
enrравен NULL или его полеnameравно NULL
SPI_ERROR_UNCONNECTED
- если не открыто подключение к менеджеру SPI
SPI_ERROR_REL_DUPLICATE
- если имя, указанное в поле
nameпараметраenr, уже зарегистрировано для этого соединения
SPI_unregister_relation
SPI_unregister_relation - удалить эфемерное именованное отношение из реестра
Синтаксис
int SPI_unregister_relation(const char * name)
Описание
SPI_unregister_relation удаляет эфемерное именованное отношение из
реестра для текущего соединения.
Аргументы
const char * name
- имя эфемерного именованного отношения
Возвращаемое значение
Если выполнение команды было успешным, то будет возвращено следующее (неотрицательное) значение:
SPI_OK_REL_UNREGISTER
- если запись об эфемерном именованном отношении успешно удалена из реестра
При ошибке возвращается одно из следующих отрицательных значений:
SPI_ERROR_ARGUMENT
- если параметр
nameравен NULL
SPI_ERROR_UNCONNECTED
- если не открыто подключение к менеджеру SPI
SPI_ERROR_REL_NOT_FOUND
- если эфемерное именованное отношение с именем
nameне найдено в реестре для текущего соединения
SPI_register_trigger_data
SPI_register_trigger_data - сделать доступными данные эфемерного триггера в запросах SPI
Синтаксис
int SPI_register_trigger_data(TriggerData *tdata)
Описание
SPI_register_trigger_data делает любые эфемерный отношения,
захваченные триггером, доступными для планирования запросов и
выполнения через текущее соединение SPI. В настоящее время это
обозначает таблицы переходов (transition relations), захваченные триггером AFTER определенным
с помощью предложения REFERENCING OLD/NEW TABLE AS. Эта функция
должна вызываться обработчиком PL триггера после подключения.
Аргументы
TriggerData * tdata
- объект
TriggerDataпередается в функцию-обработчик триггера черезfcinfo->context
Возвращаемое значение
Если выполнение команды было успешным, то будет возвращено следующее (неотрицательное) значение:
SPI_OK_TD_REGISTER
- если захваченные данные триггера (если такие есть) успешно зарегистрированы
При ошибке возвращается одно из следующих отрицательных значений:
SPI_ERROR_ARGUMENT
- если параметр
tdataравен NULL
SPI_ERROR_UNCONNECTED
- если не открыто подключение к менеджеру SPI
SPI_ERROR_REL_DUPLICATE
- если имя какого-либо временного отношения в данных триггера уже зарегистрировано для этого соединения
Функции поддержки интерфейса
Описанные здесь функции предоставляют интерфейс для извлечения информации из наборов результатов, возвращаемых SPI_execute и другими функциями SPI.
Все функции, описанные в этом разделе, могут использоваться с подключением и без подключения к менеджеру SPI.
SPI_fname
SPI_fname - определить имя столбца для указанного номера столбца
Синтаксис
char * SPI_fname(TupleDesc rowdesc, int colnumber)
Описание
SPI_fname возвращает копию имени столбца указанного номера столбца. (Вы можете
использовать pfree, чтобы освободить память, когда имя Вам больше не
нужно).
Аргументы
TupleDesc rowdesc
- описание входной строки
int colnumber
- номер столбца (отсчет начинается с 1)
Возвращаемое значение
Название столбца; NULL, если параметр colnumber находится вне диапазона.
В случае ошибки SPI_result установлен в SPI_ERROR_NOATTRIBUTE.
SPI_fnumber
SPI_fnumber - определить номер столбца для указанного имени столбца
Синтаксис
int SPI_fnumber(TupleDesc rowdesc, const char * colname)
Описание
SPI_fnumber возвращает номер столбца для столбца с указанным именем.
Если параметр colname ссылается на системный столбец (например, ctid), будет
возвращен соответствующий отрицательный номер столбца. Вызывающая сторона должна
проверить возвращаемое значение на точное
равенство SPI_ERROR_NOATTRIBUTE, чтобы обнаружить ошибку; проверка
результата, что значение меньше или равно 0 не является правильной, если только
системные столбцы не должны быть пропущены при обработке.
Аргументы
TupleDesc rowdesc
- описание входной строки
const char * colname
- имя столбца
Возвращаемое значение
Номер столбца (число начинается с 1 для пользовательских столбцов) или
SPI_ERROR_NOATTRIBUTE, если указанный столбец не найден.
SPI_getvalue
SPI_getvalue - вернуть строковое значение указанного столбца
Синтаксис
char * SPI_getvalue(HeapTuple row, TupleDesc rowdesc, int colnumber)
Описание
SPI_getvalue возвращает строковое представление значения указанного
столбца.
Результат возвращается в память, выделенную с помощью palloc. (Вы
можете использовать pfree для освобождения памяти, когда значение Вам больше
не нужно).
Аргументы
HeapTuple row
- входная строка для изучения
TupleDesc rowdesc
- описание входной строки
int colnumber
- номер столбца (отсчет начинается с 1)
Возвращаемое значение
Значение столбца или NULL, если:
- поле в строке равно NULL
- значение
colnumberвыходит за пределы диапазона (SPI_resultустановлен вSPI_ERROR_NOATTRIBUTE) - нет выходной функции (
SPI_resultустановлен вSPI_ERROR_NOOUTFUNC).
SPI_getbinval
SPI_getbinval - возвращает двоичное значение указанного столбца
Синтаксис
Datum SPI_getbinval(HeapTuple row, TupleDesc rowdesc, int colnumber, bool * isnull)
Описание
SPI_getbinval возвращает значение указанного столбца во внутренней
форме (как тип Datum).
Эта функция не выделяет новое пространство для данных. В случае типа данных «передача по ссылке» возвращаемое значение будет указателем на переданную строку.
Аргументы
HeapTuple row
- входная строка для изучения
TupleDesc rowdesc
- описание входной строки
int colnumber
- номер столбца (отсчет начинается с 1)
bool * isnull
- флаг для нулевого значения в столбце
Возвращаемое значение
Двоичное значение столбца. Переменная, на которую указывает
параметр isnull имеет значение true, если столбец равен нулю, иначе - false.
SPI_result устанавливается в SPI_ERROR_NOATTRIBUTE при ошибке.
SPI_gettype
SPI_gettype - возвращает имя типа данных указанного столбца
Синтаксис
char * SPI_gettype(TupleDesc rowdesc, int colnumber)
Описание
SPI_gettype возвращает копию имени типа данных указанного столбца. (Вы
можете использовать pfree, чтобы освободить память, когда имя типа Вам
больше не нужно).
Аргументы
TupleDesc rowdesc
- описание входной строки
int colnumber
- номер столбца (отсчет начинается с 1)
Возвращаемое значение
Имя типа данных указанного столбца или NULL при ошибке. При ошибке SPI_result
устанавливается в SPI_ERROR_NOATTRIBUTE.
SPI_gettypeid
SPI_gettypeid - возвращает OID типа данных указанного столбца
Синтаксис
Oid SPI_gettypeid(TupleDesc rowdesc, int colnumber)
Описание
SPI_gettypeid возвращает OID типа данных указанного столбца.
Аргументы
TupleDesc rowdesc
- описание входной строки
int colnumber
- номер столбца (отсчет начинается с 1)
Возвращаемое значение
OID типа данных указанного столбца или InvalidOid при ошибке. При ошибке
SPI_result устанавливается в SPI_ERROR_NOATTRIBUTE.
SPI_getrelname
SPI_getrelname - возвращает имя указанного отношения
Синтаксис
char * SPI_getrelname(Relation rel)
Описание
SPI_getrelname возвращает копию имени указанного отношения. (Вы можете
использовать pfree, чтобы освободить память, когда копия имени станет Вам больше не
нужна).
Аргументы
Relation rel
- входное отношение
Возвращаемое значение
Имя указанного отношения.
SPI_getnspname
SPI_getnspname - вернуть пространство имен указанного отношения
Синтаксис
char * SPI_getnspname(Relation rel)
Описание
SPI_getnspname возвращает копию имени пространства имен (схемы), которому
принадлежит указанное отношение. Вы
можете использовать pfree, чтобы освободить память, когда имя схемы станет Вам не нужно.
Аргументы
Relation rel
- входное отношение
Возвращаемое значение
Имя пространства имен указанного отношения.
SPI_result_code_string
SPI_result_code_string - возвращает код ошибки в виде строки
Синтаксис
const char * SPI_result_code_string(int code);
Описание
SPI_result_code_string выдает строковое представление кода
результата, возвращенного различными функциями SPI или сохраненного в
SPI_result.
Аргументы
int code
- код результата
Возвращаемое значение
Строковое представление кода результата.
Управление памятью
QHB выделяет память в контекстах памяти, предоставляющих
удобный метод управления распределениями, осуществляемыми во многих
разных местах, которые должны жить в различное количество времени.
Уничтожение контекста освобождает всю память, выделенную в нем. Таким
образом, нет необходимости отслеживать отдельные объекты, чтобы избежать
утечек памяти; вместо этого достаточно управлять только относительно
небольшим количеством контекстов. palloc и связанные функции выделяют
память из «текущего» контекста.
SPI_connect создает новый контекст памяти и делает его текущим. SPI_finish восстанавливает предыдущий текущий контекст памяти и уничтожает контекст, созданный SPI_connect. Эти действия гарантируют, что временные выделения памяти, сделанные внутри вашей функции на C/RUST, будут освобождены при выходе из функции на C/RUST, избегая утечки памяти.
Однако, если вашей функции на C/RUST необходимо вернуть объект в выделенной
памяти (например, значение типа данных с передачей по ссылке), вы не
можете выделить эту память, используя palloc, по крайней мере, пока вы
подключены к SPI. Если вы попытаетесь, объект будет освобожден с помощью
SPI_finish, и ваша функция на C/RUST не будет работать надежно. Чтобы решить
эту проблему, используйте SPI_palloc для выделения памяти для вашего
возвращаемого объекта. SPI_palloc выделяет память в «контексте вышестоящего
исполнителя», то есть в контексте памяти, который был текущим при
SPI_connect, что является точно правильным контекстом для значения,
возвращаемого вашей функцией на C/RUST. Некоторые из других служебных функций,
описанных в этом разделе, также возвращают объекты, созданные в
контексте вышестоящего исполнителя.
Когда вызывается SPI_connect, частный контекст функции C/RUST, создаваемый
SPI_connect, становится текущим контекстом. Все выделения сделанные
функциями palloc, repalloc или служебными функциями SPI (за исключением случаев,
описанных в этом разделе), выполняются в этом контексте. Когда функция на C/RUST
отключается от менеджера SPI через SPI_finish, текущий контекст
восстанавливается в контекст вышестоящего исполнителя, и все выделения,
сделанные в контексте памяти функции на C/RUST, освобождаются и больше не могут
использоваться.
SPI_palloc
SPI_palloc - выделить память
Синтаксис
void * SPI_palloc(Size size)
Описание
SPI_palloc выделяет память в контексте вышестоящего исполнителя.
Эта функция может использоваться только при подключении к менеджеру SPI. В противном случае выдает ошибку.
Аргументы
Size size
- размер в байтах памяти для размещения
Возвращаемое значение
указатель на новое место для хранения указанного размера
SPI_repalloc
SPI_repalloc - перераспределить память
Синтаксис
void * SPI_repalloc(void * pointer, Size size)
Описание
SPI_repalloc изменяет размер сегмента памяти, ранее выделенного с
помощью SPI_palloc.
Эта функция больше не отличается от обычного repalloc. Он сохраняется
только для обратной совместимости существующего кода.
Аргументы
void * pointer
- указатель на существующее хранилище для изменения
Size size
- размер в байтах памяти для размещения
Возвращаемое значение
указатель на новое пространство хранения указанного размера с содержимым, скопированным из существующей области
SPI_pfree
SPI_pfree - освободить память
Синтаксис
void SPI_pfree(void * pointer)
Описание
SPI_pfree освобождает память, ранее выделенную с помощью SPI_palloc
или SPI_repalloc.
Эта функция больше не отличается от обычного pfree. Он сохраняется
только для обратной совместимости существующего кода.
Аргументы
void * pointer
- указатель на существующее хранилище для освобождения
SPI_copytuple
SPI_copytuple - сделать копию записи
Синтаксис
HeapTuple SPI_copytuple(HeapTuple row)
Описание
SPI_copytuple создает копию записи в контексте вышестоящего исполнителя.
Обычно это используется для возврата измененной записи из триггера. В
функции, объявленной для возврата составного типа, используйте вместо
этого SPI_returntuple.
Эта функция может использоваться только при подключении к менеджеру SPI. В
противном случае он возвращает NULL и устанавливает SPI_result в
SPI_ERROR_UNCONNECTED.
Аргументы
HeapTuple row
- запись для копирования
Возвращаемое значение
скопированная строка или NULL в случае ошибки (см. SPI_result для
указания ошибки)
SPI_returntuple
SPI_returntuple - возвращает копию записи в качестве Datum
Синтаксис
HeapTupleHeader SPI_returntuple(HeapTuple row, TupleDesc rowdesc)
Описание
SPI_returntuple создает копию записи в контексте вышестоящего исполнителя,
возвращая ее в виде типа Datum. Полученный указатель должен
быть преобразован в Datum вызовом PointerGetDatum перед возвратом далее.
Эта функция может использоваться только при подключении к менеджеру SPI. В
противном случае он возвращает NULL и устанавливает SPI_result в
SPI_ERROR_UNCONNECTED.
Обратите внимание, что данный метод следует использовать для функций, которые
объявлены для возврата составных типов. SPI_returntuple нельзя применять для
триггеров; используйте SPI_copytuple для возврата измененной записи в
триггере.
Аргументы
HeapTuple row
- строка для копирования
TupleDesc rowdesc
- дескриптор для строки (передавайте один и тот же дескриптор каждый раз для наиболее эффективного кэширования)
Возвращаемое значение
HeapTupleHeader, указывающий на скопированную строку, или NULL при ошибке
(см. SPI_result для указания ошибки)
SPI_modifytuple
SPI_modifytuple - создает новую запись, заменив выбранные поля исходной записи
Синтаксис
HeapTuple SPI_modifytuple(Relation rel, HeapTuple row, int ncols,
int * colnum, Datum * values, const char * nulls)
Описание
SPI_modifytuple создает новую запись, подставляя новые значения для
выбранных столбцов, копируя остальные столбцы исходной строки.
Входная запись не изменяется. Новая запись возвращается в
контексте вышестоящего исполнителя.
Эта функция может использоваться только при подключении к менеджеру SPI. В
противном случае он возвращает NULL и устанавливает SPI_result в
SPI_ERROR_UNCONNECTED.
Аргументы
Relation rel
- Используется только как источник дескриптора строки для строки. (Передача отношения, а не дескриптора строки, является ошибкой.)
HeapTuple row
- строка для изменения
int ncols
- количество столбцов, которые нужно изменить
int * colnum
- массив длиной
ncols, содержащий номера столбцов для изменения (номера столбцов начинаются с 1)
Datum * values
- массив длиной
ncols, содержащий новые значения для указанных столбцов
const char * nulls
-
массив длиной
ncols, описывающий, какие новые значения равны нулю -
Если параметр
nullsравен NULL тогдаSPI_modifytupleпредполагает, что новые значения не равны NULL. В противном случае каждая запись массива nulls должна быть ’ ’, если соответствующее новое значение не равно нулю, или ’n’, если соответствующее новое значение равно нулю. (В последнем случае фактическое значение в соответствующей записиvaluesне имеет значения.) Обратите внимание, чтоnulls- это не текстовая строка, а массив, поэтому завершающий символ ’\0’ не нужен.
Возвращаемое значение
Новая строка с изменениями, размещенная в контексте вышестоящего исполнителя
или NULL при ошибке (см. SPI_result для указания ошибки)
В случае ошибки SPI_result устанавливается следующим образом:
SPI_ERROR_ARGUMENT
- если выполняется любое из условий:
- параметр
relравен NULL, - параметр
rowравен NULL, - параметр
ncolsменьше или равен 0, - параметр
colnumравен NULL, - параметр
valuesравен NULL.
- параметр
SPI_ERROR_NOATTRIBUTE
- если параметр
colnumсодержит недопустимый номер столбца (меньше или равно 0 или больше, чем количество столбцов в параметреrow)
SPI_ERROR_UNCONNECTED
- если нет подключения к менеджеру SPI
SPI_freetuple
SPI_freetuple - освободить запись
Синтаксис
void SPI_freetuple(HeapTuple row)
Описание
SPI_freetuple освобождает запись, ранее выделенную в контексте вышестоящего
исполнителя.
Эта функция больше не отличается от обычной heap_freetuple. Она
сохраняется только для обратной совместимости существующего кода.
Аргументы
HeapTuple row
- строка для освобождения
SPI_freetuptable
SPI_freetuptable - освободить строки, прочитанные SPI_execute или подобной функцией
Синтаксис
void SPI_freetuptable(SPITupleTable * tuptable)
Описание
SPI_freetuptable освобождает набор строк, созданный предыдущим вызовом функции
SPI, выполняющей запросы, такой как SPI_execute. Поэтому данная функция
часто вызывается с глобальной переменной SPI_tuptable качестве
аргумента.
Эта функция полезна, если функция на C/RUST, использующая SPI, должна выполнять несколько команд и не хочет сохранять результаты предыдущих команд до своего завершения. Обратите внимание, что любые наборы строк будут освобождены в любом случае при вызове SPI_finish. Кроме того, если субтранзакция запускается и затем прерывается при выполнении функции C/RUST, использующей SPI, SPI автоматически освобождает все наборы строк, созданные во время выполнения субтранзакции.
Аргументы
SPITupleTable * tuptable
- указатель на строку, которую нужно освободить, или NULL, если ничего не делать не нужно
SPI_freeplan
SPI_freeplan - освободить подготовленный оператор
Синтаксис
int SPI_freeplan(SPIPlanPtr plan)
Описание
SPI_freeplan освобождает подготовленный оператор, ранее возвращенный
SPI_prepare или сохраненный с помощью SPI_keepplan или SPI_saveplan.
Аргументы
SPIPlanPtr plan
- указатель на оператор, который нужно освободить
Возвращаемое значение
0 в случае успеха; SPI_ERROR_ARGUMENT, если параметр plan равен NULL или
недействителен.
Управление транзакциями
Невозможно выполнить команды управления транзакциями, такие как COMMIT и ROLLBACK через функции SPI, такие как SPI_execute. Однако существуют отдельные интерфейсные функции, позволяющие управлять транзакциями через SPI.
Обычно небезопасно и нецелесообразно запускать и завершать транзакции в произвольных пользовательских функциях, вызываемых из SQL, без учета контекста, в котором они вызываются. Например, граница транзакции в середине функции, которая является частью сложного SQL выражения, являющегося частью какой-либо другой SQL команды, вероятно, приведет к неясным внутренним ошибкам или сбоям. Представленные здесь интерфейсные функции предназначены, в первую очередь, для использования в реализациях на процедурных языках для поддержки управления транзакциями в процедурах уровня SQL, которые вызываются командой CALL, с учетом контекста вызова CALL. Функции, реализованные на C/RUST и использующие SPI, могут реализовывать ту же логику, но подробности этого выходят за рамки данной документации.
SPI_commit
SPI_commit, SPI_commit_and_chain - зафиксировать текущую транзакцию
Синтаксис
void SPI_commit(void)
void SPI_commit_and_chain(void)
Описание
SPI_commit фиксирует текущую транзакцию. Это примерно эквивалентно
выполнению SQL команды COMMIT. После того, как транзакция
зафиксирована, новая транзакция должна быть запущена с использованием
SPI_start_transaction прежде чем будут выполнены дальнейшие действия с
базой данных.
SPI_commit_and_chain - то же самое, но новая транзакция немедленно
начинается с теми же характеристиками транзакции, что и только что
завершенная, как с SQL командой COMMIT AND CHAIN.
Эти функции могут быть выполнены только в том случае, если соединение SPI было установлено как неатомарное в вызове SPI_connect_ext.
SPI_rollback
SPI_rollback, SPI_rollback_and_chain - отменить текущую транзакцию
Синтаксис
void SPI_rollback(void)
void SPI_rollback_and_chain(void)
Описание
SPI_rollback откатывает текущую транзакцию. Это приблизительно
эквивалентно выполнению SQL команды ROLLBACK. После отката транзакции
новая транзакция должна быть запущена с использованием
SPI_start_transaction прежде чем будут выполнены дальнейшие действия с
базой данных.
SPI_rollback_and_chain - то же самое, но новая транзакция немедленно
начинается с теми же характеристиками транзакции, что и только что
завершенная, как с SQL командой ROLLBACK AND CHAIN.
Эти функции могут быть выполнены только в том случае, если соединение SPI было установлено как неатомарное в вызове SPI_connect_ext.
SPI_start_transaction
SPI_start_transaction - начать новую транзакцию
Синтаксис
void SPI_start_transaction(void)
Описание
SPI_start_transaction запускает новую транзакцию. Функция может быть вызвана
только после SPI_commit или SPI_rollback, поскольку в этот момент
транзакция не активна. Обычно, когда вызывается процедура, использующая
SPI, уже существует активная транзакция, поэтому попытка запустить
другую перед закрытием текущей приведет к ошибке.
Эта функция может быть выполнена только в том случае, если соединение SPI было установлено как неатомное в вызове SPI_connect_ext.
Видимость изменений данных
Следующие правила регулируют видимость изменений данных в функциях, использующих SPI (или любых других функциях на C/RUST):
- Во время выполнения команды SQL любые изменения данных, сделанные этой командой, невидимы для самой команды. Например, в:
INSERT INTO a SELECT * FROM a;
вставленные строки невидимы для части SELECT.
-
Изменения, сделанные командой "C", видны всем командам, которые запускаются после "C", независимо от того, запущены ли они внутри "C" (во время выполнения "C") или после того, как "C" выполнена.
-
Изменения, выполненные через SPI внутри функции, вызванной командой SQL (обычной функцией или триггером), следуют одному или другому из приведенных выше правил в зависимости от флага чтения / записи, передаваемого в SPI. Команды, выполняемые в режиме только для чтения, следуют первому правилу: они не могут видеть изменения вызывающей команды. Команды, выполняемые в режиме чтения-записи, следуют второму правилу: они могут видеть все сделанные изменения.
-
Все стандартные процедурные языки устанавливают режим чтения-записи SPI в зависимости от атрибута волатильности функции. Команды функций STABLE и IMMUTABLE выполняются в режиме только для чтения, в то время как команды функций VOLATILE выполняются в режиме чтения-записи. Хотя авторы функций на C/RUST могут нарушать это соглашение, вряд ли это будет хорошей идеей.
Следующий раздел содержит пример, который иллюстрирует применение этих правил.
Примеры
Этот раздел содержит очень простой пример использования SPI. Функция C execq принимает команду SQL в качестве первого аргумента и число строк в качестве второго, выполняет команду с помощью SPI_exec и возвращает количество строк, обработанных командой. Вы можете найти более сложные примеры для SPI в дереве исходного кода в src/test/regress/regress.c и в модуле spi.
#include "postgres.h"
#include "executor/spi.h"
#include "utils/builtins.h"
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(execq);
Datum
execq(PG_FUNCTION_ARGS)
{
char *command;
int cnt;
int ret;
uint64 proc;
/* Convert given text object to a C string */
command = text_to_cstring(PG_GETARG_TEXT_PP(0));
cnt = PG_GETARG_INT32(1);
SPI_connect();
ret = SPI_exec(command, cnt);
proc = SPI_processed;
/*
* If some rows were fetched, print them via elog(INFO).
*/
if (ret > 0 && SPI_tuptable != NULL)
{
TupleDesc tupdesc = SPI_tuptable->tupdesc;
SPITupleTable *tuptable = SPI_tuptable;
char buf[8192];ержки управления транзакциями в процедурах уровня SQL, которые вызываются командой CALL, с учетом контекста вызова CALL. Функции, реализованные на C/RUST и использующие SPI, могут реализовывать ту же логику, но подробности этого выходят за рамки данной документации.
uint64 j;
for (j = 0; j < proc; j++)
{
HeapTuple tuple = tuptable->vals[j];
int i;
for (i = 1, buf[0] = 0; i <= tupdesc->natts; i++)
snprintf(buf + strlen(buf), sizeof(buf) - strlen(buf), " %s%s",
SPI_getvalue(tuple, tupdesc, i),
(i == tupdesc->natts) ? " " : " |");
elog(INFO, "EXECQ: %s", buf);
}
}
SPI_finish();
pfree(command);
PG_RETURN_INT64(proc);
}
Пример объявления функцию после компиляции ее в разделяемую библиотеку (подробности в разделе Компиляция и связывание динамически загружаемых функций):
CREATE FUNCTION execq(text, integer) RETURNS int8
AS 'filename'
LANGUAGE C STRICT;
Пример сессии:
=> SELECT execq('CREATE TABLE a (x integer)', 0);
execq
-------
0
(1 row)
=> INSERT INTO a VALUES (execq('INSERT INTO a VALUES (0)', 0));
INSERT 0 1
=> SELECT execq('SELECT * FROM a', 0);
INFO: EXECQ: 0 -- inserted by execq
INFO: EXECQ: 1 -- returned by execq and inserted by upper INSERT
execq
-------
2
(1 row)
=> SELECT execq('INSERT INTO a SELECT x + 2 FROM a', 1);
execq
-------
1
(1 row)
=> SELECT execq('SELECT * FROM a', 10);
INFO: EXECQ: 0
INFO: EXECQ: 1
INFO: EXECQ: 2 -- 0 + 2, only one row inserted - as specified
execq
-------
3 -- 10 is the max value only, 3 is the real number of rows
(1 row)
=> DELETE FROM a;
DELETE 3
=> INSERT INTO a VALUES (execq('SELECT * FROM a', 0) + 1);
INSERT 0 1
=> SELECT * FROM a;
x
---
1 -- no rows in a (0) + 1
(1 row)
=> INSERT INTO a VALUES (execq('SELECT * FROM a', 0) + 1);
INFO: EXECQ: 1
INSERT 0 1
=> SELECT * FROM a;
x
---
1
2 -- there was one row in a + 1
(2 rows)
-- This demonstrates the data changes visibility rule:
=> INSERT INTO a SELECT execq('SELECT * FROM a', 0) * x FROM a;
INFO: EXECQ: 1
INFO: EXECQ: 2
INFO: EXECQ: 1
INFO: EXECQ: 2
INFO: EXECQ: 2
INSERT 0 2
=> SELECT * FROM a;
x
---
1
2
2 -- 2 rows * 1 (x in first row)
6 -- 3 rows (2 + 1 just inserted) * 2 (x in second row)
(4 rows) ^^^^^^
rows visible to execq() in different invocations
Фоновые рабочие процессы
QHB может быть расширена для запуска пользовательского кода в отдельных процессах. Такие процессы запускаются, останавливаются и контролируются QHB, что позволяет им тесно связать время жизни со статусом сервера. Эти процессы имеют возможность подключаться к области общей памяти QHB и подключаться к базам данных, они также могут запускать последовательно, несколько транзакций как обычный серверный процесс, подключенный к клиенту. Также, связываясь с libpq, они могут подключаться к серверу и вести себя как обычное клиентское приложение.
Фоновые процессы могут быть инициализированы во время запуска QHB путем включения имени модуля в shared_preload_libraries. Модуль, желающий запустить фоновый рабочий, может зарегистрировать его, вызвав RegisterBackgroundWorker( BackgroundWorker *worker ) из своего _PG_init(). Фоновые рабочие также можно запустить после запуска системы, вызвав функцию RegisterDynamicBackgroundWorker( BackgroundWorker *worker, BackgroundWorkerHandle **handle ). В отличие от RegisterBackgroundWorker, который может вызываться только из postmaster, RegisterDynamicBackgroundWorker должен вызываться из обычного бэкэнда или другого фонового процесса.
Структура BackgroundWorker определяется таким образом:
typedef void (*bgworker_main_type)(Datum main_arg);
typedef struct BackgroundWorker
{
char bgw_name[BGW_MAXLEN];
char bgw_type[BGW_MAXLEN];
int bgw_flags;
BgWorkerStartTime bgw_start_time;
int bgw_restart_time; /* in seconds, or BGW_NEVER_RESTART */
char bgw_library_name[BGW_MAXLEN];
char bgw_function_name[BGW_MAXLEN];
Datum bgw_main_arg;
char bgw_extra[BGW_EXTRALEN];
int bgw_notify_pid;
} BackgroundWorker;
bgw_name и bgw_type - это строки, которые будут использоваться в сообщениях журнала, списках процессов и в подобных контекстах. bgw_type должен быть одинаковым для всех фоновых процессов одного типа, чтобы, например, можно было сгруппировать таких процессов в список процессов. bgw_name с другой стороны, может содержать дополнительную информацию о конкретном процессе. (Как правило, строка для bgw_name будет как-то идентифицировать фоновый процесс, но это не обязательно.)
bgw_flags - битовая маска или битовая маска, указывающая возможности, которые предоставляются модулю. Возможные значения:
| Флаг | Назначение |
|---|---|
| BGWORKER_SHMEM_ACCESS | Запрашивает доступ к общей памяти. Рабочие, не имеющие доступа к общей памяти, не могут получить доступ ни к одной из общих структур данных QHB, таких как тяжелые или облегченные блокировки, общие буферы, или к любым пользовательским структурам данных, которые рабочий может захотеть создать и использовать. |
| BGWORKER_BACKEND_DATABASE_CONNECTION | Запрашивает возможность установить соединение с базой данных, с помощью которого она может позже выполнять транзакции и запросы Фоновый процесс, использующий BGWORKER_BACKEND_DATABASE_CONNECTION для подключения к базе данных, должен также подключить разделяемую память с помощью BGWORKER_SHMEM_ACCESS, иначе запуск рабочего не удастся. |
bgw_start_time - состояние сервера, в течение которого QHB должна запустить процесс - это может быть BgWorkerStart_PostmasterStart (запускаться, как только сама QHB завершила свою собственную инициализацию, процессы, запускающиеся в этот момент, не подходят для соединений с базой данных), BgWorkerStart_ConsistentState (запускаться, как только достигнуто согласованное состояние, что позволяет процессам подключаться к базам данных и выполнять запросы только для чтения) и BgWorkerStart_RecoveryFinished (запускаться, как только система BgWorkerStart_RecoveryFinished перевела систему в нормальное состояние чтения-записи). Обратите внимание, что последние два значения эквивалентны на сервере, который не является standby. Обратите внимание, что этот параметр указывает только, когда фоновые процессы должны запускаться - они не будут останавливаться при переходе в другое состояния.
bgw_restart_time - это интервал в секундах, который QHB должна ждать перед перезапуском процесса в случае его сбоя. Это может быть любое положительное значение или BGW_NEVER_RESTART, указывающее не перезапускать процесс в случае сбоя.
bgw_library_name - это имя библиотеки, в которой следует искать начальную точку входа для фонового процесса. Именованная библиотека будет динамически загружена рабочим процессом, а имя-функции- bgw_function_name будет использоваться для идентификации вызываемой функции. При загрузке функции из основного кода должно быть установлено «QHB».
bgw_function_name - это имя функции в динамически загружаемой библиотеке, которая должна использоваться в качестве начальной точки входа для нового фонового процесса.
bgw_main_arg - это аргумент типа Datum для основной функции фонового процесса. Основная функция должна принимать один аргумент типа Datum и возвращать void. bgw_main_arg будет передан в качестве аргумента. Кроме того, глобальная переменная MyBgworkerEntry указывает на копию структуры BackgroundWorker переданную во время регистрации - процесс запуска может использовать эту структуру.
bgw_extra может содержать дополнительные данные для передачи фоновому процессу. В отличие от bgw_main_arg, эти данные не передаются в качестве аргумента основной функции worker-a, но к ним можно получить доступ через MyBgworkerEntry, как обсуждалось выше.
bgw_notify_pid - это PID бэкэнд-процесса QHB, которому qhbmaster должен отправить SIGUSR1 при запуске или выходе из процесса. Должен быть 0 для процессов, зарегистрированных во время запуска qhbmaster, или когда бэкэнд, регистрирующий процесса, не хочет ждать запуска процесса. В противном случае его следует инициализировать как MyProcPid.
После запуска процесс может подключиться к базе данных, вызвав BackgroundWorkerInitializeConnection( char *dbname, char *username , uint32 flags) или BackgroundWorkerInitializeConnectionByOid( Oid dboid, Oid useroid, uint32 flags). Это позволяет процессу выполнять транзакции и запросы с использованием интерфейса SPI. Если dbname имеет значение NULL или dboid имеет значение InvalidOid, сеанс не связан с какой-либо конкретной базой данных, но доступны общие каталоги. Если username NULL или useroid - InvalidOid, процесс будет работать как суперпользователь, созданный во время initdb. Если в качестве flags указано BGWORKER_BYPASS_ALLOWCONN можно обойти ограничение для подключения к базам данных, не разрешая пользовательские подключения. Фоновый рабочий может вызвать только одну из этих двух функций и только один раз. Невозможно переключить базы данных.
Сигналы изначально блокируются, когда управление достигает основной функции фонового процесса, и должны быть разблокированы самим процессом - это позволяет процессу при необходимости настраивать свои обработчики сигналов. Сигналы могут быть разблокированы в новом процессе путем вызова BackgroundWorkerUnblockSignals и заблокированы путем вызова BackgroundWorkerBlockSignals .
Если bgw_restart_time для фонового процесса сконфигурировано как
BGW_NEVER_RESTART, или если он завершается с кодом выхода 0 или
завершается TerminateBackgroundWorker, он будет автоматически отменен главным процессом при выходе. В противном случае он будет
перезапущен по истечении периода времени, настроенного с помощью
bgw_restart_time, или немедленно, если qhbmaster повторно
инициализирует кластер из-за сбоя бэкенда. Бэкэнды, которые должны
временно приостановить выполнение, должны использовать паузы
вместо выхода - это может быть достигнуто путем вызова WaitLatch().
Убедитесь, что при вызове этой функции установлен флаг
WL_POSTMASTER_DEATH, и проверьте код возврата для быстрого завершения
в аварийном случае, когда сама qhb завершилась.
Когда фоновый процесс зарегистрирован с помощью функции RegisterDynamicBackgroundWorker, сервер, выполняющий регистрацию, может получить информацию о статусе процесса. Бэкэнды, желающие сделать это, должны передать адрес BackgroundWorkerHandle * в качестве второго аргумента RegisterDynamicBackgroundWorker. Если процесс успешно зарегистрирован, этот указатель будет инициализирован с непрозрачным дескриптором, который впоследствии может быть передан в GetBackgroundWorkerPid( BackgroundWorkerHandle *, pid_t * ) или TerminateBackgroundWorker( BackgroundWorkerHandle * ) . GetBackgroundWorkerPid может использоваться для опроса статуса процесса: возвращаемое значение BGWH_NOT_YET_STARTED указывает, что процесс еще не был запущен qhbmaster - BGWH_STOPPED указывает, что он был запущен, но больше не работает и BGWH_STARTED указывает, что он в данный момент работает. В этом последнем случае PID также будет возвращен через второй аргумент. TerminateBackgroundWorker заставляет qhbmaster отправлять SIGTERM процессу, если он работает, и отменять его регистрацию, как только он завершится.
В некоторых случаях процесс, который регистрирует фоновый процесс, может дождаться его запуска. Это может быть достигнуто путем инициализации bgw_notify_pid для MyProcPid и последующей передачи BackgroundWorkerHandle * полученного во время регистрации, в WaitForBackgroundWorkerStartup( BackgroundWorkerHandle *handle, pid_t * ). Эта функция будет блокироваться до тех пор, пока qhbmaster не попытается запустить фоновый процесс снова, или пока qhbmaster не прекратит работу. Если фоновый процесс работает, возвращаемое значение будет BGWH_STARTED, а PID будет записан по указанному адресу. В противном случае возвращаемое значение будет BGWH_STOPPED или BGWH_POSTMASTER_DIED .
Процесс также может ожидать выключения фонового процесса, используя WaitForBackgroundWorkerShutdown( BackgroundWorkerHandle *handle ) и передавая BackgroundWorkerHandle * полученный при регистрации. Эта функция будет блокироваться до тех пор, пока не завершится фоновый процесс или qhbmaster не завершит работу. Когда фоновый процесс завершает работу, возвращаемое значение будет BGWH_STOPPED, если qhbmaster завершится, он вернет BGWH_POSTMASTER_DIED.
Если фоновый процесс отправляет асинхронные уведомления с помощью
команды NOTIFY через интерфейс программирования сервера SPI, он
должен явно вызывать ProcessCompletedNotifies после
ProcessCompletedNotifies включающей транзакции, чтобы можно было
доставлять любые уведомления. Если фоновый процесс регистрируется для
получения асинхронных уведомлений с LISTEN через SPI, процесс
регистрирует эти уведомления, но у него нет программного способа
перехватывать и отвечать на эти уведомления.
Максимальное количество зарегистрированных фоновых процессов ограничено
параметров max_worker_processes.
Процесс qhb
qhb - сервер базы данных QHB
- Синтаксис
- Описание
- Параметры
- Переменные окружения
- Диагностика
- Примечания
- Ошибки
- Примеры
- Смотрите Также
Синтаксис
qhb [option...]
или
qhbmaster [option...]
Описание
qhb - это сервер базы данных QHB. Чтобы клиентское приложение получило доступ к базе данных, оно подключается (по сети или локально) к работающему экземпляру qhb. Затем экземпляр qhb запускает отдельный процесс сервера для обработки соединения.
Один экземпляр qhb всегда управляет данными только одного кластера базы данных. Кластер баз данных - это набор баз данных, который хранится в общей папке файловой системы («область данных»). В системе одновременно может работать несколько экземпляров qhb, если они используют разные области данных и разные коммуникационные порты (см. ниже). Когда qhb запускается, он должен знать местоположение области данных. Местоположение должно быть указано с помощью опции -D или переменной среды PGDATA - значение по умолчанию отсутствует. Как правило, -D или PGDATA указывает непосредственно на каталог области данных, созданный qhb_bootstrap. Другие возможные шаблоны файлов обсуждаются в главе Расположение файлов.
По умолчанию qhb запускается на консоли и печатает сообщения журнала в стандартный поток ошибок. В продуктивном окружении qhb должен запускаться как фоновый процесс, возможно, во время загрузки системы.
Команда qhb также может быть вызвана в однопользовательском режиме. Основное использование этого режима во время начального создания базы при помощи qhb_bootstrap. Иногда этот режим используется для отладки или аварийного восстановления; обратите внимание, что использование однопользовательского режима не совсем подходит для полноценной отладки сервера, так как не будет реалистичного межпроцессного взаимодействия, блокировок и т.п. При вызове в однопользовательском режиме из оболочки пользователь может вводить запросы, и результаты будут выводиться на экран, но в форме, которая более полезна для разработчиков, чем для конечных пользователей. В однопользовательском режиме пользователь сеанса будет установлен на пользователя с ID 1, и этому пользователю будут предоставлены неявные полномочия суперпользователя. Этот пользователь фактически не должен существовать, поэтому однопользовательский режим можно использовать для ручного восстановления после определенных видов случайного повреждения системных каталогов.
Параметры
qhb принимает следующие аргументы командной строки. Для подробного обсуждения вариантов обратитесь к разделу Конфигурация сервера. Вы можете сохранить ввод большинства этих параметров, настроив файл конфигурации. Некоторые (безопасные) параметры также могут быть установлены из подключающегося клиента в зависимости от приложения, чтобы применяться только для этого сеанса. Например, если установлена переменная среды PGOPTIONS, клиенты на основе libpq передадут эту строку на сервер, который будет интерпретировать ее как параметры командной строки qhb.
Общие параметры
| Параметр | Описание |
|---|---|
| -B nbuffers | Устанавливает количество общих буферов для использования процессами сервера. Значение по умолчанию для этого параметра выбирается автоматически qhb_bootstrap. Указание этой опции эквивалентно установке параметра конфигурации shared_buffers |
| -c name = value | Устанавливает именованный параметр времени выполнения. Параметры конфигурации, поддерживаемые QHB, описаны в главе 19. Большинство других параметров командной строки на самом деле являются краткими формами такого назначения параметров. -c может появляться несколько раз для установки нескольких параметров |
| -C name | Печатает значение указанного параметра времени выполнения и завершает работу. (Подробности смотрите в опции -c выше.) Это может быть использовано на работающем сервере и возвращает значения из qhb.conf, модифицированные любыми параметрами, предоставленными в этом вызове. Он не отражает параметры, предоставленные при запуске кластера. Этот параметр предназначен для других программ, которые взаимодействуют с экземпляром сервера, например qhb_ctl, для запроса значений параметров конфигурации. Пользовательские приложения должны вместо этого использовать SHOW или представление pg_settings |
| -d debug-level | Устанавливает уровень отладки. Чем выше установлено это значение, тем больше выходных данных отладки записывается в журнал сервера. Значения находятся в диапазоне от 1 до 5. Также возможно передать -d 0 для определенного сеанса, что предотвратит распространение уровня журнала родительского процесса qhb на этот сеанс |
| -D datadir | Определяет расположение файловой системы файлов конфигурации базы данных |
| -e | Устанавливает стиль даты по умолчанию « Европейский », то есть DMY порядок полей ввода даты. Это также приводит к тому, что день печатается до месяца в определенных форматах вывода даты |
| -F | Отключает вызовы fsync для повышения производительности, что может привести к повреждению данных в случае сбоя системы. Указание этого параметра эквивалентно отключению параметра конфигурации fsync. Прочтите подробную документацию перед использованием! |
| -h hostname | Указывает IP-имя хоста или адрес, по которому qhb должен прослушивать соединения TCP / IP от клиентских приложений. Значением также может быть список адресов через запятую или * для указания прослушивания на всех доступных интерфейсах. Пустое значение указывает, что не прослушивается ни один IP-адрес, и в этом случае для подключения к серверу могут использоваться только сокеты Unix-домена. По умолчанию прослушивание только на локальном хосте. Указание этой опции эквивалентно установке параметра конфигурации listen_addresses |
| -i | Позволяет удаленным клиентам подключаться через соединения TCP / IP (интернет-домен). Без этой опции принимаются только локальные соединения. Эта опция эквивалентна установке *listen_addresses * * в qhb.conf или через -h .Эта опция устарела, так как она не позволяет получить доступ ко всем функциям listen_addresses. Обычно лучше установить listen_addresses напрямую |
| -k directory | Указывает каталог сокета Unix-домена, в котором qhb должен прослушивать соединения от клиентских приложений. Значение также может быть разделенным запятыми списком каталогов. Пустое значение указывает, что прослушивание не происходит ни в одном из сокетов Unix-домена, и в этом случае для подключения к серверу могут использоваться только сокеты TCP / IP. Значением по умолчанию обычно является /tmp, но его можно изменить во время сборки. Указание этой опции эквивалентно установке параметра конфигурации unix_socket_directories |
| -l | Включает безопасные соединения с использованием SSL. QHB должен быть скомпилирован с поддержкой SSL, чтобы эта опция была доступна |
| -N max-connections | Устанавливает максимальное количество клиентских подключений, которые принимает этот сервер. Значение по умолчанию для этого параметра выбирается автоматически qhb_bootstrap. Указание этой опции эквивалентно установке параметра конфигурации max_connections |
| -o extra-options | Аргументы в стиле командной строки, указанные в extra-options, передаются всем процессам сервера, запущенным этим процессом qhb. Пробелы внутри extra-options считаются отдельными аргументами, если они не экранированы обратной косой чертой ( \ ) - написать \\ для представления буквального символа обратного слеша. Несколько аргументов также могут быть указаны с помощью многократного использования -o .Использование этой опции устарело- все параметры командной строки для серверных процессов можно указать непосредственно в командной строке qhb |
| -p port | Указывает порт TCP / IP или расширение файла локального сокета домена Unix, на котором qhb должен прослушивать соединения от клиентских приложений. По умолчанию используется значение переменной среды PGPORT или, если PGPORT не установлен, то по умолчанию используется значение, установленное во время компиляции (обычно 5432). Если вы указываете порт, отличный от порта по умолчанию, то все клиентские приложения должны указывать один и тот же порт, используя либо параметры командной строки, либо PGPORT |
| -s | Выводит информацию о времени и другую статистику в конце каждой команды. Это полезно для бенчмаркинга или для настройки количества буферов. |
| -S work-mem | Определяет объем памяти, который будет использоваться внутренними сортировками и хэшами перед использованием временных файлов на диске |
| -V | Показать версию qhb и выйти |
| --name = value | Устанавливает именованный параметр времени выполнения - более короткая форма -c |
| --describe-config | Эта опция выводит внутренние переменные конфигурации сервера, описания и значения по умолчанию в формате COPY разделителями табуляцией. Он предназначен в первую очередь для использования инструментами администрирования |
| -? | Показать справку об аргументах командной строки qhb и выйти |
Параметры для разработки
Описанные здесь параметры используются в основном для целей отладки, а в некоторых случаях для помощи в восстановлении сильно поврежденных баз данных. Не должно быть никаких причин использовать их в настройке производственной базы данных. Они перечислены здесь только для использования разработчиками системы QHB. Кроме того, эти параметры могут быть изменены или удалены в будущем выпуске без предварительного уведомления.
| Параметр | Описание |
|---|---|
| -f { s i o b t n m h } | Запрещает использование определенных методов сканирования и объединения: s и i отключают последовательное и индексное сканирование соответственно, o, b и t отключают сканирование только по индексу, сканирование по растровому индексу и сканирование TID соответственно, в то время как n, m и h отключают nested- loop, merge и hash присоединяются соответственно.Ни последовательное сканирование, ни объединение с вложенным циклом не могут быть полностью отключены; параметры -fs и -fn просто не -fn оптимизатору использовать эти типы планов, если у него есть какая-либо другая альтернатива |
| -n | Эта опция предназначена для отладки проблем, которые приводят к аварийному завершению процесса сервера. Обычная стратегия в этой ситуации состоит в том, чтобы уведомить все другие серверные процессы о том, что они должны завершиться, а затем повторно инициализировать общую память и семафоры. Это связано с тем, что ошибочный процесс на сервере мог повредить некоторое общее состояние перед завершением. Эта опция указывает, что qhb не будет повторно инициализировать общие структуры данных. Опытный системный программист может затем использовать отладчик для проверки состояния совместно используемой памяти и семафора |
| -O | Позволяет изменять структуру системных таблиц. Это используется qhb_bootstrap |
| -P | Игнорируйте системные индексы при чтении системных таблиц, но обновляйте индексы при изменении таблиц. Это полезно при восстановлении с поврежденных системных индексов |
| -t pa | Вывести статистику по времени для каждого запроса, относящегося к каждому из основных системных модулей. Эта опция не может использоваться вместе с опцией -s |
| -T | Эта опция предназначена для отладки проблем, которые приводят к аварийному завершению процесса сервера. Обычная стратегия в этой ситуации состоит в том, чтобы уведомить все другие серверные процессы о том, что они должны завершиться, а затем повторно инициализировать общую память и семафоры. Это связано с тем, что ошибочный процесс на сервере мог повредить некоторое общее состояние перед завершением. Эта опция указывает, что qhb остановит все другие процессы сервера, отправив сигнал SIGSTOP, но не приведет к их завершению. Это позволяет системным программистам собирать дампы ядра всех процессов сервера вручную. |
| -v protocol | Задает номер версии протокола внешнего / внутреннего интерфейса, который будет использоваться для определенного сеанса. Эта опция предназначена только для внутреннего использования |
| -W seconds | Задержка, равная многим секундам, возникает при запуске нового серверного процесса после проведения процедуры аутентификации. Это сделано для того, чтобы дать возможность подключить к серверу процесс с помощью отладчика |
Параметры для однопользовательского режима
Следующие параметры применимы только к однопользовательскому режиму (см. Однопользовательский режим).
| Параметр | Описание |
|---|---|
| --single | Выбирает однопользовательский режим. Это должен быть первый аргумент в командной строке. |
| database | Определяет имя базы данных для доступа. Это должен быть последний аргумент в командной строке. Если он опущен, по умолчанию используется имя пользователя. |
| -E | Выведите все команды на стандартный вывод перед их выполнением. |
| -j | Используйте точку с запятой, за которой следуют две новые строки, а не просто новая, в качестве ограничителя ввода команды. |
| -r filename | Отправьте весь вывод журнала сервера на filename. Эта опция учитывается только в том случае, если она указана в командной строке. |
Переменные окружения
| Переменная | Описание |
|---|---|
| PGCLIENTENCODING | Кодировка символов по умолчанию, используемая клиентами. (Клиенты могут переопределить это индивидуально.) Это значение также можно установить в файле конфигурации. |
| PGDATA | Местоположение каталога данных по умолчанию |
| PGDATESTYLE | Значение по умолчанию для параметра времени выполнения DateStyle. (Использование этой переменной среды устарело.) |
| PGPORT | Номер порта по умолчанию (желательно установить в файле конфигурации) |
Диагностика
Сообщение об ошибке, в котором упоминается semget или shmget, вероятно, указывает на
то, что вам необходимо настроить ядро для предоставления достаточной
общей памяти и семафоров. Вы можете отложить перенастройку ядра, уменьшив параметр
shared_buffers, чтобы уменьшить потребление разделяемой памяти
QHB, и / или уменьшить max_connections, чтобы уменьшить
потребление семафора.
Сообщение об ошибке, указывающее на то, что другой сервер уже запущен, следует тщательно проверить, например, с помощью команды
$ ps ax | grep qhb
или
$ ps -ef | grep qhb
в зависимости от вашей системы. Если вы уверены, что конфликтующий сервер не запущен, вы можете удалить файл блокировки, указанный в сообщении, и повторить попытку.
Сообщение об ошибке, указывающее на невозможность привязки к порту, может указывать на то, что этот порт уже используется некоторым процессом, не связанным с QHB. Вы также можете получить эту ошибку, если завершите работу QHB и немедленно перезапустите его, используя тот же порт; в этом случае вы должны просто подождать несколько секунд, пока операционная система не закроет порт, прежде чем пытаться снова. Наконец, вы можете получить эту ошибку, если указать номер порта, который ваша операционная система считает зарезервированным. Например, многие версии Unix считают номера портов менее 1024 «доверенными» и разрешают только суперпользователю Unix доступ к ним.
Примечания
Командную утилиту qhb_ctl можно использовать для безопасного и удобного запуска и выключения сервера qhb.
Если это вообще возможно, не используйте SIGKILL для уничтожения основного сервера qhb. Это предотвратит освобождение qhb системных ресурсов (например, разделяемой памяти и семафоров), которые он хранит до завершения. Это может вызвать проблемы при запуске нового экземпляра qhb.
Для нормального завершения работы сервера qhb можно использовать сигналы SIGTERM, SIGINT или SIGQUIT. Первый будет ожидать завершения работы всех клиентов перед выходом, второй принудительно отключит все клиенты, а третий немедленно завершит работу без надлежащего завершения работы, что приведет к запуску восстановления во время перезапуска.
Сигнал SIGHUP перезагрузит файлы конфигурации сервера. Также возможно отправить SIGHUP на отдельный процесс сервера, но это обычно не имеет смысла.
Чтобы отменить текущий запрос, отправьте сигнал SIGINT процессу, выполняющему эту команду. Чтобы завершить внутренний процесс, отправьте SIGTERM этому процессу. Смотрите также pg_cancel_backend и pg_terminate_backend в главе Функции сигнализации сервера для вызываемых SQL эквивалентов этих двух действий.
Сервер qhb использует SIGQUIT, чтобы указать подчиненным процессам
сервера завершиться без обычной очистки. Этот сигнал не должен
использоваться пользователями. Также неразумно отправлять SIGKILL на
серверный процесс - основной процесс qhb будет интерпретировать это
как сбой и заставит все родственные процессы завершиться как часть
стандартной процедуры восстановления после сбоя.
Ошибки
Однопользовательский режим
Чтобы запустить сервер в однопользовательском режиме, используйте команду, например
qhb --single -D /usr/local/qhb/data other-options my_database
Укажите правильный путь к каталогу базы данных с помощью -D или
убедитесь, что установлена переменная среды PGDATA. Также укажите имя
конкретной базы данных, в которой вы хотите работать.
Обычно сервер однопользовательского режима обрабатывает символ новой строки как окончание ввода команды - о точка с запятой не является синтаксическим разделителем, как в qsql. Чтобы продолжить команду через несколько строк, надо использовать обратную косую черту перед каждой новой строкой, кроме последней. Обратная косая черта и соседний символ новой строки удаляются из команды ввода. Обратите внимание, что это произойдет, даже внутри строкового литерала или комментария.
Но если вы используете ключ командной строки -j, одиночная новая строка не завершает ввод команды, вместо этого используется последовательность: точка с запятой - и начало новой строки. То есть введите точку с запятой, за которой сразу следует полностью пустая строка. Обратная косая черта и последующая новая строка не обрабатывается специально в этом режиме. Опять же, нет никаких гарантий если такая последовательность появляется внутри строкового литерала или комментария.
В любом из режимов ввода, если вы вводите точку с запятой, которая не является предшествующей или является частью окончания ввода команды, она считается разделителем команд. Когда вы вводите окончание ввода команды, несколько введенных вами операторов будут выполняться как одна транзакция.
Чтобы выйти из сеанса, введите EOF (обычно Control + D). Если вы ввели
какой-либо текст со времени последнего терминатора ввода команды, тогда
EOF будет принят как терминатор ввода команды, и для выхода потребуется
другой EOF.
Обратите внимание, что сервер однопользовательского режима не предоставляет сложных функций редактирования строк (например, без истории команд). В однопользовательском режиме также не выполняется фоновая обработка, например автоматические контрольные точки или репликация.
Примеры
Чтобы запустить qhb в фоновом режиме, используя значения по умолчанию, введите:
$ nohup qhb >logfile 2>&1 </dev/null &
Чтобы запустить qhb с определенным портом, например, 1234:
$ qhb -p 1234
Чтобы подключиться к этому серверу с помощью qsql, укажите этот порт с параметром -p:
$ qsql -p 1234
или установите переменную окружения PGPORT :
$ export PGPORT=1234
$ qsql
Именованные параметры времени выполнения могут быть установлены в любом из следующих стилей:
$ qhb -c work_mem=1234
$ qhb --work-mem=1234
Любая форма переопределяет любую настройку для work_mem в qhb.conf. Обратите внимание, что подчеркивания в именах параметров могут быть записаны как подчеркивание или тире в командной строке. За исключением краткосрочных экспериментов, вероятно, лучше отредактировать параметр в qhb.conf чем полагаться на параметр командной строки для установки параметра.
Смотрите Также
Системные каталоги
Системные каталоги — это место, где система управления реляционными
базами данных хранит метаданные схемы, такие как сведения о таблицах и
столбцах, а также информацию о внутреннем бухгалтерском учете. Системные
каталоги QHB — это обычные таблицы. Вы можете удалить и
пересоздать их, добавить столбцы, вставить и обновить значения
— и тем самым сильно испортить свою систему. В большинстве случаев не следует
изменять системные каталоги вручную, для этого обычно существуют команды
SQL. (Например, CREATE DATABASE вставляет строку в каталог pg_database
и фактически создает базу данных на диске.) Есть некоторые
исключения для особенно сложных операций, но многие из них с течением времени становятся доступны в виде команд SQL, и поэтому
необходимость в прямом манипулировании системными каталогами постоянно
уменьшается.
- Обзор
- pg_aggregate
- pg_am
- pg_amop
- pg_amproc
- pg_attrdef
- pg_attribute
- pg_authid
- pg_auth_members
- pg_cast
- pg_class
- pg_collation
- pg_constraint
- pg_conversion
- pg_database
- pg_db_role_setting
- pg_default_acl
- pg_depend
- pg_description
- pg_enum
- pg_event_trigger
- pg_extension
- pg_foreign_data_wrapper
- pg_foreign_server
- pg_foreign_table
- pg_index
- pg_inherits
- pg_init_privs
- pg_language
- pg_largeobject
- pg_largeobject_metadata
- pg_namespace
- pg_opclass
- pg_operator
- pg_opfamily
- pg_partitioned_table
- pg_pltemplate
- pg_policy
- pg_proc
- pg_publication
- pg_publication_rel
- pg_range
- pg_replication_origin
- pg_rewrite
- pg_seclabel
- pg_sequence
- pg_shdepend
- pg_shdescription
- pg_shseclabel
- pg_statistic
- pg_statistic_ext
- pg_statistic_ext_data
- pg_subscription
- pg_subscription_rel
- pg_tablespace
- pg_transform
- pg_trigger
- pg_ts_config
- pg_ts_config_map
- pg_ts_dict
- pg_ts_parser
- pg_ts_template
- pg_type
- pg_user_mapping
- Системные представления
- pg_available_extensions
- pg_available_extensions_versions
- pg_config
- pg_cursors
- pg_file_settings
- pg_group
- pg_hba_file_rules
- pg_indexes
- pg_locks
- pg_matviews
- pg_policies
- pg_prepared_statements
- pg_prepared_xacts
- pg_publication_tables
- pg_replication_origin_status
- pg_replication_slots
- pg_roles
- pg_rules
- pg_seclabels
- pg_sequences
- pg_settings
- pg_shadow
- pg_stats
- pg_stats_ext
- pg_tables
- pg_timezone_abbrevs
- pg_timezone_names
- pg_user
- pg_user_mappings
- pg_views
Обзор
В таблице Системные каталоги перечислены системные каталоги. Более подробная документация по каждому каталогу приводится ниже.
Большинство системных каталогов копируются из шаблона базы данных во время ее создания и затем зависят от конкретной базы данных. Несколько каталогов физически совместно используются во всех базах данных в кластере — они отмечаются в описаниях отдельных каталогов.
Таблица: Системные каталоги
| имя каталога | Цель |
|---|---|
| pg_aggregate | агрегатные функции |
| pg_am | методы доступа отношений |
| pg_amop | операторы метода доступа |
| pg_amproc | функции поддержки метода доступа |
| pg_attrdef | значения столбца по умолчанию |
| pg_attribute | столбцы таблицы («атрибуты») |
| pg_authid | идентификаторы авторизации (роли) |
| pg_auth_members | отношения членства идентификатора авторизации |
| pg_cast | приведения (преобразования типов данных) |
| pg_class | таблицы, индексы, последовательности, представления («отношения») |
| pg_collation | параметры сортировки (сведения о локали) |
| pg_constraint | проверочные ограничения, ограничения уникальности, ограничения первичного ключа, ограничения внешнего ключа |
| pg_conversion | кодирование информация о преобразовании |
| pg_database | базы данных в этом кластере |
| pg_db_role_setting | параметры для каждой роли и базы данных |
| pg_default_acl | права доступа по умолчанию для типов объектов |
| pg_depend | зависимости между объектами базы данных |
| pg_description | описания или комментарии объектов базы данных |
| pg_enum | определения меток и значений перечислений |
| pg_event_trigger | триггеры событий |
| pg_extension | установленные расширения |
| pg_foreign_data_wrapper | определения оберток сторонних данных |
| pg_foreign_server | определения сторонних серверов |
| pg_foreign_table | дополнительная информация по сторонней таблице |
| pg_index | дополнительная информация по индексам |
| pg_inherits | иерархия наследования таблиц |
| pg_init_privs | начальные права объекта |
| pg_language | языки для написания функций |
| pg_largeobject | страницы данных для больших объектов |
| pg_largeobject_metadata | метаданные для больших объектов |
| pg_namespace | схемы |
| pg_opclass | классы операторов метода доступа |
| pg_operator | операторы |
| pg_opfamily | семейства операторов метода доступа |
| pg_partitioned_table | информация о ключе разбиения таблиц |
| pg_policy | политики защиты на уровне строк |
| pg_proc | функции и процедуры |
| pg_publication | публикации для логической репликации |
| pg_publication_rel | сопоставление отношения с публикацией |
| pg_range | информация о типах диапазонов |
| pg_replication_origin | зарегистрированные источники репликации |
| pg_rewrite | правила перезаписи запроса |
| pg_seclabel | метки безопасности для объектов базы данных |
| pg_sequence | информация о последовательностях |
| pg_shdepend | зависимости от общих объектов |
| pg_shdescription | комментарии к общим объектам |
| pg_shseclabel | метки безопасности для общих объектов базы данных |
| pg_statistic | статистика планировщика |
| pg_statistic_ext | расширенная статистика планировщика (определение) |
| pg_statistic_ext_data | расширенная статистика планировщика (собранная статистика) |
| pg_subscription | подписки на логическую репликацию |
| pg_subscription_rel | состояние связи для подписок |
| pg_tablespace | табличные пространства в кластере базы данных |
| pg_transform | преобразования (преобразование типа данных в процедурный язык) |
| pg_trigger | триггеры |
| pg_ts_config | конфигурации текстового поиска |
| pg_ts_config_map | сопоставления маркеров конфигураций текстового поиска |
| pg_ts_dict | словари текстового поиска |
| pg_ts_parser | анализаторы текстового поиска |
| pg_ts_template | шаблоны текстового поиска |
| pg_type | типы данных |
| pg_user_mapping | сопоставления пользователей для сторонних серверов |
pg_aggregate
Каталог pg_aggregate хранит информацию об агрегатных функциях. Агрегатная функция — это функция, которая работает с набором значений (как правило, с одним столбцом из каждой строки, которая соответствует условию запроса) и возвращает одно значение, вычисленное из всех этих значений. Типичными агрегатными функциями являются sum, count и max. Каждая запись внутри pg_aggregate представляет собой расширение записи в pg_proc. Запись в pg_proc содержит имя агрегата, типы входных и выходных данных, а также другую информацию, аналогичную имеющейся у обычных функций.
Столбцы pg_aggregate
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| aggfnoid | regproc | pg_proc.oid | OID агрегатной функции в pg_proc |
| aggkind | char | Вид агрегатной функции: n для обычной (normal), o для сортирующей (ordered-set) или h для гипотезирующей (hypothetical-set) | |
| aggnumdirectargs | int2 | Число прямых (неагрегированных) аргументов сортирующей или гипотезирующей агрегатной функции, считая переменный массив аргументов за один аргумент. Если равняется pronargs, агрегатная функция должна принимать переменный массив, и этот массив описывает как агрегированные аргументы, так и конечные прямые аргументы. Всегда равно 0 для обычных агрегатных функций. | |
| aggtransfn | regproc | pg_proc.oid | Функция перехода |
| aggfinalfn | regproc | pg_proc.oid | Функция завершения (0, если ее нет) |
| aggcombinefn | regproc | pg_proc.oid | Функция совмещения (0, если ее нет) |
| aggserialfn | regproc | pg_proc.oid | Функция сериализации (0, если ее нет) |
| aggdeserialfn | regproc | pg_proc.oid | Функция десериализации (0, если ее нет) |
| aggmtransfn | regproc | pg_proc.oid | Функция прямого перехода для режима движущегося агрегата (0, если ее нет) |
| agminvtransfn | regproc | pg_proc.oid | Функция обратного перехода для режима движущегося агрегата (0, если ее нет) |
| aggmfinalfn | regproc | pg_proc.oid | Функция завершения для режима движущегося агрегата (0, если ее нет) |
| aggfinalextra | bool | При значении true в aggfinalfn передаются дополнительные фиктивные аргументы | |
| aggmfinalextra | bool | При значении true в aggmfinalfn передаются дополнительные фиктивные аргументы | |
| aggfinalmodify | char | Изменяет ли aggfinalfn значение состояния перехода: r, если состояние доступно только для чтения, s, если aggtransfn не может быть применена после *aggfinalfn, или w, если состояние перезаписывается | |
| aggmfinalmodify | char | Сходно с aggfinalmodify, но для самого aggmfinalfn | |
| aggsortop | oid | pg_operator.oid | Связанный оператор сортировки (0, если его нет) |
| aggtranstype | oid | pg_type.oid | Тип данных внутреннего перехода (состояния) агрегатной функции |
| aggtransspace | int4 | Приблизительный средний размер (в байтах) данных о состоянии перехода или 0 для использования оценки по умолчанию | |
| aggmtranstype | oid | pg_type.oid | Тип данных внутреннего перехода (состояния) агрегатной функции для режима движущегося агрегата (0, если его нет) |
| aggmtransspace | int4 | Приблизительный средний размер (в байтах) данных о состоянии перехода для режима движущегося агрегата или 0 для использования оценки по умолчанию | |
| agginitval | text | Начальное значение переходного состояния. Это текстовое поле, содержащее начальное значение во внешнем строковом представлении. Если это поле имеет значение *NULL, то значение состояния перехода начнется с NULL. | |
| agginitval | text | Начальное значение переходного состояния для режима движущегося агрегата. Это текстовое поле, содержащее начальное значение во внешнем строковом представлении. Если это поле имеет значение NULL, то значение состояния перехода начнется с NULL. |
Новые агрегатные функции регистрируются с помощью команды CREATE AGGREGATE. Дополнительную информацию о написании агрегатных функций и значении функций перехода см. в разделе Пользовательские агрегаты.
pg_am
Каталог pg_am хранит информацию о методах доступа к отношениям. Существует одна строка для каждого метода доступа, поддерживаемого системой. В настоящее время только таблицы и индексы имеют методы доступа. Требования к методам доступа к таблицам и индексам подробно рассматриваются в главах Интерфейс доступа к таблице и Интерфейс доступа индекса соответственно.
Столбцы pg_am
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| amname | name | Имя метода доступа | |
| amhandler | regproc | pg_proc.oid | OID функции обработчика, ответственного за предоставление информации о методе доступа |
| amtype | char | t = таблица (включая материализованные представления), i = индекс. |
Примечание
Данные о свойствах индексных методов доступа напрямую видны только на уровне кода С. Однако запросы SQL могут проверять эти свойства с помощью pg_index_column_has_property() и связанных функций.
pg_amop
Каталог pg_amop хранит информацию об операторах, связанных с семействами операторов метода доступа. Существует одна строка для каждого оператора, который является членом семейства операторов. Членом семейства может быть либо оператор поиска, либо оператор упорядочивания. Оператор может принадлежать нескольким семействам, но в пределах одного семейства не может находиться более чем в одной позиции поиска или позиции упорядочивания. (Допустимо, хотя и маловероятно, что оператор будет использоваться как для поиска, так и для сравнения.)
Столбцы pg_amop
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| amopfamily | oid | pg_opfamily.oid | Семейство операторов, для которых эта запись предназначена |
| amoplefttype | oid | pg_type.oid | Левый тип входных данных оператора |
| amoprighttype | oid | pg_type.oid | Правый тип входных данных оператора |
| amopstrategy | int2 | Номер стратегии оператора | |
| amoppurpose | char | Назначение оператора: s для поиска, о для сравнения | |
| amopopr | oid | pg_operator.oid | OID оператора |
| amopmethod | oid | pg_am.oid | Семейство операторов метода индексного доступа |
| amopsortfamily | oid | pg_opfamily.oid | Семейство операторов B-дерева, в соответствии с которым данный оператор сортирует, если это оператор упорядочивания, и 0, если это оператор поиска |
Запись оператора «поиска» указывает, что индекс этого семейства операторов может быть использован для поиска всех строк, удовлетворяющих требованию WHERE столбец_индекса оператор константа. Очевидно, что такой оператор должен вернуть тип boolean, а тип его левого операнда должен соответствовать типу данных столбца индекса.
Запись оператора «упорядочивания» указывает, что индекс этого семейства операторов может быть отсканирован для возврата строк в порядке, представленном ORDER BY столбец_индекса оператор константа. Такой оператор может возвращать любой сортируемый тип данных, хотя, опять же, тип его левого операнда должен соответствовать типу данных столбца индекса. Точная семантика выражения ORDER BY определяется по столбцу amopsortfamily, который должен указывать на семейство операторов B-дерева для типа, возвращаемого оператором.
Примечание
В настоящее время предполагается, что порядок сортировки для оператора упорядочивания является значением по умолчанию для указанного семейства операторов, т. е. ASC NULLS LAST. Возможно, когда-нибудь для придания большей гибкости будут добавлены дополнительные столбцы, чтобы явно указать параметры сортировки.
Поле amopmethod в записи оператора должно соответствовать полю opfmethod содержащего его семейства операторов (в данном случае включение amopmethod является преднамеренной денормализацией структуры каталога из соображений производительности). Кроме того, поля amoplefttype и amoprighttype должны соответствовать полям oprleft и oprright соответствующей записи в pg_operator.
pg_amproc
Каталог pg_amproc хранит информацию о функциях поддерживаемых оператором и связанных с семействами операторов метода доступа. Существует одна строка для каждой опорной функции, принадлежащей семейству операторов.
pg_amproc столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| amprocfamily | oid | pg_opfamily.oid | Семейство операторов для которых предназначается эта запись |
| amproclefttype | oid | pg_type.oid | Левый тип входных данных ассоциированного оператора |
| amprocrighttype | oid | pg_type.oid | Правый тип входных данных ассоциированного оператора |
| amprocnum | int2 | Номер поддерживаемой функции | |
| amproc | regproc | pg_proc.oid | OID функции |
Пояснить эту структуру можно так amproclefttype и amprocrighttype поля - которые идентифицируют левый и правый типы входных данных оператора(ов), поддерживающие определенную функцию. Для некоторых методов доступа они соответствуют типам входных данных самой функции, для других-нет. Существует понятие функции для индекса "по умолчанию" это такая функция, для которой amproclefttype и amprocrighttype оба равны классу оператора индекса opcintype.
pg_attrdef
Каталог pg_attrdef сохраняет значения столбца по умолчанию. Основная информация о столбцах хранится в каталоге pg_attribute. Только столбцы, для которых значение по умолчанию было явно установлено, хранятся в этом каталоге.
pg_attrdef столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| adrelid | oid | pg_class.oid | Таблица, к которой принадлежит этот столбец |
| adnum | int2 | pg_attribute.attnum | Номер столбца: |
| adbin | pg_node_tree | Значение столбца по умолчанию, в nodeToString() представлении. Воспользуйтесь pg_get_expr(adbin, adrelid) чтобы преобразовать его в выражение SQL. |
pg_attribute
Каталог pg_attribute хранит информацию о столбцах таблицы. Хранится ровно одна строка для каждого столбца в каждой таблице базы данных. (Также хранятся записи атрибутов для индексов, и всех объектов, которые имеют записи в pg_class).
Термин атрибут эквивалентен столбцу и используется по историческим причинам.
pg_attribute столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| attrelid | oid | pg_class.oid | Таблица, к которой принадлежит этот столбец |
| attname | name | Имя столбца | |
| atttypid | oid | pg_type.oid | Тип данных этого столбца |
| attstattarget | int4 | attstattarget управляет уровнем детализации статистики, накопленной для данного столбца методом ANALYZE. Нулевое значение указывает на то, что статистика не должна собираться. Отрицательное значение указывает на использование статистики по умолчанию. Точное значение положительных значений зависит от типа данных. Для скалярных типов данных, attstattarget является как числом "наиболее распространенных значений" для сбора, так и числом ячеек гистограммы для создания. | |
| attlen | int2 | Копия pg_type.typlen типа этого столбца | |
| attnum | int2 | Номер столбца. Обычные столбцы пронумерованы от 1 и выше. Системные столбцы, такие как ctid, имеют (произвольные) отрицательные числа. | |
| attndims | int4 | Число измерений, если столбец имеет тип массива; в противном случае 0. (В настоящее время число измерений массива не обязательно, поэтому любое ненулевое значение означает “это массив”.) | |
| attcacheof | int4 | Всегда -1 в хранилище, но при загрузке в дескриптор строки в памяти он может быть обновлен для кэширования смещения атрибута в строке | |
| atttypmod | int4 | atttypmod записи специфичные для типа данных, предоставляемых во время создания таблицы (например, максимальная длина для varchar) Передается в функции ввода определенного типа и функции ограничения длины. Значение обычно будет равно -1 для типов, которые не нуждаются в atttypmod. | |
| attbyval | bool | Копия pg_type.typbyval типа этого столбца | |
| attstorage | char | Обычно это копия pg_type.typsize типа этого столбца. Для TOAST типов данных этот атрибут можно изменить после создания столбца для управления политикой хранения. | |
| attalign | char | Копия pg_type.typalign типа этого столбца | |
| attnotnull | bool | Ограничение not-null. | |
| atthasdef | bool | Показывает, что столбец имеет выражение по умолчанию или выражение генерации, в этом случае будет соответствующая запись в поле pg_attrdef из каталога, который фактически определяет выражение. (Необходимо проверять attgenerated чтобы определить, является ли это выражение по умолчанию или значение.) | |
| atthasmissing | bool | Показывает, что столбец имеет значение, которое используется, когда столбец полностью отсутствует в строке, это происходит, когда столбец добавляется с значением ПО УМОЛЧАНИЮ после создания строки. Используемое фактическое значение хранится в колонке attmissingval . | |
| attidentity | char | Если пусто (”), то столбец идентификаторов отсутствует. Иначе, a = генерируется всегда, d = генерируется по умолчанию. | |
| attgenerated | char | Если пусто (”), то столбец не сгенерированный. Иначе, с = на хранении. (В будущем могут быть добавлены и другие значения.) | |
| attisdropped | bool | Этот столбец был удален и больше не является допустимым. Удалённый столбец все еще физически присутствует в таблице, но игнорируется синтаксическим анализатором и поэтому не может быть доступен через SQL. | |
| attislocal | bool | Этот столбец определяется локально в отношении. Обратите внимание, что столбец может быть локально определен и унаследован одновременно. | |
| attinhcount | int4 | Число прямых предков, которые есть в этой колонке. Столбец с ненулевым числом предков нельзя удалить или переименовать. | |
| attcollation | oid | pg_collation.oid | Заданные параметры сортировки столбца или ноль, если столбец не является типом данных с возможностью сортировки. |
| attacl | aclitem[] | Права доступа на уровне столбца, если они были предоставлены специально для этого столбца | |
| attoptions | text[] | Параметры уровня атрибута, в виде строки "ключ=значение" | |
| attfdwoptions | text[] | Параметры внешней оболочки данных уровня атрибута, в виде строки "ключ=значение" | |
| attmissingval | anyarray | Этот столбец имеет массив из одного элемента, содержащий значение, используемое, когда столбец полностью отсутствует в строке, как это происходит, когда в столбец добавляется значение по умолчанию после создания строки. Значение используется только тогда, когда atthasmissing установлен в true. Если значение отсутствует, столбец имеет значение null. |
Для удалённого(ых) столбца(ов) в pg_attribute, atttypid колонка сбрасывается в null, но
attlen а остальные поля скопированные из pg_type все еще
действительны. Это необходимо, чтобы справиться с
ситуацией, когда тип данных удалённого столбца был позже удалён, и
поэтому не существует соответствующий pg_type
и не возникает конфликта при повторном использовании OID,
а attlen и другие поля можно использовать для интерпретации содержимого строки таблицы.
pg_authid
Каталог pg_authid содержит информацию об идентификаторах авторизации базы данных (ролях). Роль включает в себя понятия “пользователи” и “группы”. Пользователь-это просто роль с установленным флагом rolcanlogin. Любая роль (С или без rolcanlogin) может иметь другие роли в качестве членов - см. pg_auth_members.
Поскольку этот каталог содержит пароли, он не должен быть общедоступным
для чтения. pg_roles-это публично доступное представление (VIEW) для pg_authid,
для того чтобы скрыть поле пароля.
В Роли в базе данных содержатся подробные сведения об управлении правами пользователей и привилегиями.
Поскольку аутентификация пользователей проводится для всего кластера, pg_authid является общим каталогом для всех баз данных кластера: существует только одна копия pg_authid на кластер, а не собственная для каждой базы данных.
pg_authid столбцы
| Имя | Тип | Описание |
|---|---|---|
| oid | oid | Идентификатор строки |
| rolname | name | Имя роли |
| rolsuper | bool | Роль имеет привилегии суперпользователя |
| rolinherit | bool | Роль автоматически наследует привилегии ролей, членом которых она является |
| rolcreaterole | bool | Роль может создавать другие роли |
| rolcreatedb | bool | Роль может создавать базы данных |
| rolcanlogin | bool | Роль может войти в систему. То есть эта роль может быть задана в качестве идентификатора авторизации начального сеанса |
| rolreplication | bool | Роль - это роль репликации. Роль репликации может инициировать подключения репликации и создавать и удалять слоты репликации. |
| rolbypassrls | bool | Роль обходит политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. |
| rolconnlimit | int4 | Для ролей, которые могут войти в систему, задает максимальное число одновременных подключений, которые может создать эта роль. -1 означает отсутствие ограничений. |
| rolpassword | text | Пароль (возможно зашифрованный), null, если нет. Формат зависит от используемой формы шифрования. |
| rolvaliduntil | timestamptz | Срок действия пароля (используется только для аутентификации по паролю); null, если нет срока действия |
Для зашифрованного пароля MD5, rolpassword столбец будет начинаться со строки md5 далее следует 32-символьный шестнадцатеричный хэш MD5. Хэш MD5 будет содержать пароль пользователя, связанный с его именем. Например, если пользователь Джо имеет пароль xyzzy, QHB будет хранить хэш md5 из xyzzyjoe.
Если пароль зашифрован с помощью SCRAM-SHA-256, он имеет следующий формат:
SCRAM-SHA-256$<iteration count>:<salt>$<StoredKey>:<ServerKey>
где salt, StoredKey и ServerKey строки в формате Base64. Этот формат совпадает с форматом, указанным в документе RFC5803.
Пароль, который не соответствует ни одному из этих форматов, считается незашифрованным.
pg_auth_members
Каталог pg_auth_members содержит отношения членства между ролями. Допускается любой нециклический набор отношений.
Поскольку авторизация пользователей является кластерной, pg_auth_members является общим каталогом для всех баз данных кластера: существует только одна копия pg_auth_members на кластер, а не для каждой базы данных.
pg_auth_members столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| roleid | oid | pg_authid.oid | Идентификатор роли, имеющей участника |
| member | oid | pg_authid.oid | Идентификатор роли, которая является членом roleid |
| grantor | oid | pg_authid.oid | Идентификатор роли, предоставившей это членство |
| admin_option | bool | True, если member может предоставить членство в компании roleid для других |
pg_cast
Каталог pg_cast хранит пути преобразования типов данных, как встроенные, так и определяемые пользователем.
Следует отметить, что pg_cast не содержит все преобразования типов, которые система умеет выполнять, а только те, которые не могут быть выведены из некоторого общего правила. Например, приведение между доменом и его базовым типом явно не представлено в виде pg_cast. Еще одним важным исключением является то, что каталог pg_cast не содержит "автоматическое преобразование ввода-вывода", те преобразования, которые выполняются с использованием собственных функций ввода-вывода типа данных для преобразования в/из текста или других строковых типов, явно не представленные в pg_cast.
pg_cast столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| castsource | oid | pg_type.oid | OID типа исходных данных |
| casttarget | oid | pg_type.oid | OID целевого типа данных |
| castfunc | oid | pg_proc.oid | OID функции, которая будет использоваться для выполнения этого приведения. Null, если метод cast не требует функции. |
| castcontext | char | Указывает, в каких контекстах приведение может быть вызвано - e означает только явное приведение (использование синтаксиса CAST или :: ) а означает неявно при присвоении целевому столбцу, а также явно, i означает неявно в выражениях, а также в других случаях. | |
| castmethod | char | Указывает, как выполняется приведение. а означает, что используется функция, указанная в столбце castfunc, i означает, что используются функции ввода/вывода. b означает, что типы являются двоично-совместимыми, поэтому преобразование не требуется. |
Функции, перечисленные в pg_cast должны всегда использовать тип источника приведения в качестве первого аргумента и возвращать тип назначения приведения в качестве типа результата. Приведенная функция может иметь до трех аргументов. Второй аргумент, если он присутствует, должен быть типом integer; он получает модификатор типа, связанный с целевым типом, или -1, если его нет. Третий аргумент, если он присутствует, должен быть логическим типом - он получает значение true если приведение является явным приведением, иначе false.
Возможно создать в pg_cast запись, в которой исходные и целевые типы совпадают, если связанная функция принимает более одного аргумента. Такие функции представляют собой "функции приведения длины", которые принуждают значения типа быть приемлимым для определенного значения модификатора типа.
Когда a pg_cast запись имеет различные исходные и целевые типы, а функция, принимающая более одного аргумента, представляет собой преобразование из одного типа в другой и применение приведения длины за один шаг. Если такая запись недоступна, приведение к типу, использующему модификатор типа, включает два шага: один для преобразования между типами данных и второй для применения модификатора.
pg_class
Каталог pg_class содержит информацию о таблицах и всех других объектах, которые имеет столбцы или иным образом похожи на таблицу. Этот каталог включает в себя индексы (см. также pg_index), последовательности (см. также pg_sequence), представления, материализованные представления, составные типы и таблицы TOAST (см. relkind). Когда мы имеем в виду все эти виды объектов, мы говорим об “отношениях”. Не все столбцы в каталоге имеют значение для всех типов отношений.
pg_class столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| relname | name | Имя таблицы, индекса, представления и т.д. | |
| relnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего это отношение |
| reltype | oid | pg_type.oid | OID типа данных, который соответствует типу строки этой таблицы, если таковой имеется (ноль для индексов, у которых нет pg_type вход) |
| reloftype | oid | pg_type.oid | Для типизированных таблиц OID базового составного типа NULL для всех других отношений |
| relowner | oid | pg_authid.oid | Владелец отношения |
| relam | oid | pg_am.oid | Если это таблица или индекс, то используется метод доступа (куча, B-дерево, хэш и т. д.) |
| relfilenode | oid | Имя файла на диске для этого отношения - NULL означает, что это “сопоставленное” отношение, имя файла на диске для которого определяется низкоуровневым состоянием | |
| reltablespace | oid | pg_tablespace.oid | Табличное пространство, в котором хранится это отношение. Если NULL, подразумевается табличное пространство базы данных по умолчанию . (Не имеет смысла, если отношение не имеет файла на диске.) |
| relpages | int4 | Размер представления этой таблицы на диске в страницах (размера BLCKSZ). Это только оценка, используемая планировщиком, столбец обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. | |
| reltuples | float4 | Количество "живых" строк в таблице. Это только оценка, используемая планировщиком. Она обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. | |
| relallvisible | int4 | Количество страниц, отмеченных как все видимые на карте видимости таблицы. Это только оценка, используемая планировщиком. Она обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. | |
| reltoastrelid | oid | pg_class.oid | OID таблицы TOAST, связанной с этой таблицей, 0, если нет. Таблица TOAST хранит большие атрибуты "вне строки" во вторичной таблице. |
| relhasindex | bool | True, если это таблица и она имеет (или недавно имела) какие-либо индексы | |
| relisshared | bool | True, если эта таблица является общей для всех баз данных в кластере. Только определенные системные каталоги (такие как pg_database) разделяемы. | |
| relpersistence | char | p = постоянная таблица, u = незарегистрированная таблица, t = временная таблица | |
| relkind | char | r = Обычная таблица, i = индекс, s = последовательность, t = Таблица TOAST, v = представление, m = материализованное представление, c = составной тип, f = внешняя таблица, p = партиционированная таблица, I = партиционированный индекс | |
| relnatts | int2 | Количество пользовательских столбцов в связи (системные столбцы не учитываются). Должно быть такое количество соответствующих записей в pg_attribute. См. также pg_attribute.attnum. | |
| relchecks | int2 | Количество CHECK (порверок) ограничений для таблицы; см. каталог pg_constraint | |
| relhasrules | bool | True, если таблица имеет (или когда-то имела) правила; см. каталог pg_rewrite | |
| relhastriggers | bool | True, если таблица имеет (или когда-то имела) триггеры; см. каталог pg_trigger | |
| relhassubclass | bool | True, если у таблицы или индекса есть (или когда-то были) "дети" в результате наследования | |
| relrowsecurity | bool | True, если в таблице включена защита на уровне строк; см. каталог pg_policy | |
| relforcerowsecurity | bool | True, если безопасность на уровне строк (если она включена) будет также применяться к владельцу таблицы; см. каталог pg_policy | |
| relispopulated | bool | True, если отношение заполнено (это справедливо для всех отношений, кроме некоторых материализованных представлений) | |
| relreplident | char | Столбцы, используемые для формирования "идентичности реплики" для строк: d = по умолчанию (первичный ключ, если есть), n = ничего, f = все столбцы i = индекс с indisreplident или по умолчанию | |
| relispartition | bool | True, если таблица или индекс является партицией | |
| relrewrite | oid | pg_class.oid | Для новых отношений, записываемых во время операции DDL, которая требует перезаписи таблицы, это содержит OID исходного отношения; в противном случае 0. Это состояние является видимым только dyenhb - это поле никогда не должно содержать ничего, кроме 0 для отношения пользователя. |
| relfrozenxid | xid | Все идентификаторы транзакций до этого были заменены на постоянный (”замороженный") идентификатор транзакции в этой таблице. Используется для отслеживания того, нужно ли очистить таблицу, чтобы предотвратить "оборачивание" идентификатора транзакции или разрешить уменьшение pg_xact. NULL (InvalidTransactionId) если отношение не является таблицей. | |
| relminmxid | xid | Все идентификаторы multixact перед этим были заменены на постоянный (”замороженный") идентификатор транзакции в этой таблице. Это используется для отслеживания того, нужно ли вакуумировать таблицу, чтобы предотвратить "оборачивание" multixact ID или разрешить уменьшение pg_multixact. Ноль (InvalidMultiXactId) если отношение не является таблицей. | |
| relacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации | |
| reloptions | text[] | Параметры, зависящие от метода доступа, в виде строки "ключ=значение" | |
| relpartbound | pg_node_tree | Если таблица является партицией (см. relispartition), внутреннее представление связанной партиции |
Несколько логических флагов внутри pg_class поддерживаются "лениво" : они гарантированно будут истинными, если это правильное состояние, но не сбрасываются на false сразу же, когда условие больше не является истинным. Например, relhasindex устанавливается с помощью CREATE INDEX, но никогда не очищается с помощью DROP INDEX. Вместо этого, вакуум очищает relhasindex если он обнаружит, что таблица не имеет индексов. Это расположение позволяет избежать условий гонки и улучшает параллелизм.
pg_collation
Каталог pg_collation описывает доступные параметры сортировки, которые представляют собой сопоставления между именем SQL и категориями локали операционной системы.
pg_collation столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| collname | name | Имя сортировки (уникальное для каждого пространства имен и кодировки) | |
| collnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего эту сортировку |
| collowner | oid | pg_authid.oid | Владелец сортировки |
| collprovider | char | Поставщик сортировки: d = database по умолчанию, c = libc, i = icu | |
| collisdeterministic | bool | Является ли сортировка детерминированной? | |
| collencoding | int4 | Кодировка, в которой применяется сортировка, или -1, если она работает для любой кодировки | |
| collcollate | name | LC_COLLATE для этого объекта сортировки | |
| collctype | name | LC_CTYPE для этого объекта сортировки | |
| collversion | text | Версия параметров сортировки для конкретного поставщика. Записывается при создании параметров сортировки, а затем проверяется при их использовании для обнаружения изменений в определении параметров сортировки, которые могут привести к повреждению данных. |
Обратите внимание, что уникальным ключем в этом каталоге является (collname, collencoding, collnamespace) а не только (collname, collnamespace). QHB обычно игнорирует все параметры сортировки, которые не имеют collencoding равным либо кодировке текущей базы данных, либо -1, кроме того, создание новых записей с тем же именем, что и запись с collencoding = -1 запрещено. Поэтому достаточно использовать полное имя SQL (schema.name) для определения параметров сортировки, даже если оно не является уникальным в соответствии с определением каталога. Причина определения каталога таким образом заключается в том, что qhb_bootstrap заполняет его во время инициализации кластера записями для всех локалей, доступных в системе, поэтому он должен иметь возможность хранить записи для всех кодировок, которые могут когда-либо использоваться в кластере.
В шаблоне template0 может быть полезно для создать параметры сортировки, кодировка которых не соответствует кодировке базы данных, так как они могут соответствовать кодировкам баз данных, клонированных позже из template0. В настоящее время это можно сделать вручную.
pg_constraint
Каталог pg_constraint хранит ограничения check, primary key, unique,
foreign key и exclusion для таблиц. (Ограничения столбцов не
обрабатываются специально. Каждое ограничение столбца эквивалентно
некоторому ограничению таблицы.) Ограничения Not-null представлены
не здесь, а в каталоге pg_attribute.
Определяемые пользователем триггеры ограничений (созданные с помощью триггера CREATE CONSTRAINT) также приводят к появлению записи в этой таблице.
Здесь также хранятся проверочные ограничения для доменов.
pg_constraint столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| conname | name | Имя ограничения (не обязательно уникальное!) | |
| connamespace | oid | pg_namespace.oid | OID пространства имен, содержащего это ограничение |
| contype | char | c = проверочное ограничение, f = ограничение внешнего ключа, p = ограничение первичного ключа, u = ограничение уникальности, t = триггер ограничения, x = ограничение на исключение | |
| condeferrable | bool | Может ли это ограничение быть отложенным? | |
| condeferred | bool | Является ли ограничение отложенным по умолчанию? | |
| convalidated | bool | Было ли это ограничение проверено? В настоящее время может быть false только для внешних ключей и проверочных ограничений | |
| conrelid | oid | pg_class.oid | Таблица, на которую наложено это ограничение; 0 если нет ограничения таблицы |
| contypid | oid | pg_type.oid | Домен, на который наложено это ограничение; 0 если нет ограничения домена |
| conindid | oid | pg_class.oid | Индекс, поддерживающий это ограничение, если это уникальный, первичный ключ, внешний ключ или ограничение исключения - в противном случае 0 |
| conparentid | oid | pg_constraint.oid | Соответствующее ограничение в родительской партиционированной таблице, если это ограничение для партиции в противном случае 0 |
| confrelid | oid | pg_class.oid | Если это внешний ключ, то ссылочная таблица (на которую ссылается ключ) - в противном случае 0 |
| confupdtype | char | Код действия при обновлении внешнего ключа: a = нет действия, r = ограничивать, c = каскад, n = установить значение null, d = установить по умолчанию | |
| confdeltype | char | Код действия при удалении внешнего ключа: a = нет действия, r = ограничивать, c = каскад, n = установить значение null, d = установить по умолчанию | |
| confmatchtype | char | Тип соответствия для внешнего ключа: f = полный, p = частичный, s = простой | |
| conislocal | bool | Определяется ли ограничение локально для отношения. Обратите внимание, что ограничение может быть локально определено и унаследовано одновременно. | |
| coninhcount | int4 | Число предков прямого наследования от ограничения. Ограничение с ненулевым числом предков не может быть удалено или переименовано. | |
| connoinherit | bool | True если не наследуемое ограничение (определяется локально для отношения). | |
| conkey | int2[] | pg_attribute.attnum | Если ограничение таблицы (включая внешние ключи, но не триггеры ограничений), то список ограниченных столбцов |
| confkey | int2[] | pg_attribute.attnum | Если это внешний ключ, то список ссылочных столбцов |
| conpfeqop | oid[] | pg_operator.oid | Если ограничение - внешний ключ, то список операторов равенства для сравнений PK = FK |
| conppeqop | oid[] | pg_operator.oid | Если ограничение - внешний ключ, то список операторов равенства для сравнений PK = PK |
| conffeqop | oid[] | pg_operator.oid | Если ограничение - внешний ключ, то список операторов равенства для сравнений FK = FK |
| conexclop | oid[] | pg_operator.oid | Если ограничение исключения, то список операторов исключения для каждого столбца |
| conbin | pg_node_tree | Если это проверочное ограничение (CHECK), то внутреннее представление выражения. (Чтобы извлечь определение проверочного ограничения рекомендуется использовать pg_get_constraintdef()) |
В случае ограничения исключения, столбец conkey полезен только для элементов
ограничений, которые являются простыми ссылками на столбец. Для других
случаев, значение conkey будет NULL и необходимо просмотреть связный индекс,
чтобы обнаружить выражение ограничения (conkey таким образом,
имеет то же содержание, что и pg_index.indkey для индекса.)
Примечание!!!
pg_class.relchecks необходимо согласовать с количеством записей check-constraint, найденных в этой таблице для каждого отношения.
pg_conversion
Каталог pg_conversion описывает функции преобразования кодировки. Дополнительную информацию смотрите в разделе CREATE CONVERSION.
pg_conversion столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| conname | name | Имя преобразования (уникальное в пределах пространства имен) | |
| connamespace | oid | pg_namespace.oid | OID пространства имен, содержащего это преобразование |
| conowner | oid | pg_authid.oid | Владелец преобразования |
| conforencoding | int4 | ID кодировки источника | |
| contoencoding | int4 | ID кодировки назначения | |
| conproc | regproc | pg_proc.oid | Функция преобразования |
| condefault | bool | True, если это преобразование по умолчанию |
pg_database
Каталог pg_database хранит информацию о доступных базах данных. Базы данных создаются с помощью команды CREATE DATABASE. Дополнительную информацию о значении некоторых параметров см. в главе Управление базами данных.
В отличие от большинства системных каталогов, pg_database является общим для всех баз данных кластера: существует только одна копия pg_database на кластер, а не по одному на каждую базу данных.
pg_database столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| datname | name | Имя базы данных | |
| datdba | oid | pg_authid.oid | Владелец базы данных, как правило, пользователь, который ее создал |
| encoding | int4 | Кодировка символов для этой базы данных (при помощи pg_encoding_to_char() можно перевести число в имя кодировки) | |
| datcollate | name | LC_COLLATE для этой базы данных | |
| datctype | name | LC_CTYPE для этой базы данных | |
| datistemplate | bool | Если true, то эта база данных может быть клонирована любым пользователем обладающим привилегией CREATEDB, если значение false, то клонировать его могут только суперпользователи или владелец базы данных. | |
| datallowconn | bool | Если false, то никто не может подключиться к этой базе данных. Используется для защиты базы данных template0 от изменения. | |
| datconnlimit | int4 | Задает максимальное число одновременных подключений, которые могут быть выполнены для этой базы данных. -1 означает отсутствие ограничений. | |
| datlastsysoid | oid | Последний системный OID в базе данных - необходимо, в частности, для qhb_dump | |
| datfrozenxid | xid | Все идентификаторы транзакций до этого были заменены на постоянный (”замороженный") идентификатор транзакции в этой базе данных. Используется для отслеживания того, должна ли база данных быть очищена для предотвращения "оборачивания" идентификатора транзакции или для разрешения уменьшения pg_xact. Это минимальное значение pg_class.relfrozenxid для каждой таблицы. | |
| datminmxid | xid | Все идентификаторы multixact перед этим были заменены на постоянный (”замороженный") идентификатор транзакции в этой базе данных. Используется для отслеживания того, должна ли база данных быть очищена для предотвращения "оборачивания" multixact или для разрешения уменьшения pg_multixact. Это минимальное значение pg_class.relminmxid для каждой таблицы. | |
| dattablespace | oid | pg_tablespace.oid | Табличное пространство по умолчанию для этой базы данных. Если в пределах этой базы данных pg_class.reltablespace - NULL там будут находиться все общие системные каталоги |
| datacl | aclitem[] | Права доступа- смотрите раздел Привилегии для получения дополнительной информации |
pg_db_role_setting
Каталог pg_db_role_setting хранит значения по умолчанию, заданные для переменных конфигурации времени выполнения, для каждой комбинации роли и базы данных.
В отличие от большинства системных каталогов, pg_db_role_setting является общим для всех баз данных кластера: существует только одна копия pg_db_role_setting на кластер, а не по одному на каждую базу данных.
pg_db_role_setting столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| setdatabase | oid | pg_database.oid | OID базы данных, к которой применяется этот параметр, или NULL, если он не относится к конкретной базе данных |
| setrole | oid | pg_authid.oid | OID роли, к которой применяется этот параметр, или NULL, если он не относится к конкретной роли |
| setconfig | text[] | Значения по умолчанию для переменных конфигурации времени выполнения |
pg_default_acl
Каталог pg_default_acl сохраняет начальные привилегии, назначаемые вновь созданным объектам.
pg_default_acl столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| defaclrole | oid | pg_authid.oid | OID роли, связанной с этой записью |
| defaclnamespace | oid | pg_namespace.oid | OID пространства имен, связанного с этой записью, или 0 для глобальной записи |
| defaclobjtype | char | Тип объекта для которого эта запись предназначена для: r = отношение (таблица, представление), S = последовательность, f = функция, T = тип, n = схема | |
| defaclacl | aclitem[] | Права доступа, которые этот тип объекта должен иметь при создании |
Одна запись в pg_default_acl показывает начальные привилегии, которые должны быть назначены объекту, принадлежащему указанному пользователю. В настоящее время существует два типа записей: "глобальные" записи с defaclnamespace = 0 и записи "схемы", ссылающиеся на конкретную схему. Если глобальная запись присутствует, то она переопределяет обычные жесткие привилегии задаваемые по умолчанию для типа объекта. Запись для каждой схемы, если она присутствует, представляет привилегии, которые должны быть добавлены к глобальным или жестко привязанным привилегиям по умолчанию.
Обратите внимание, что если запись ACL в другом каталоге имеет значение NULL, то она используется для представления жестко привязанных привилегий по умолчанию для ее объекта, а не того, что может быть внутри pg_default_acl в данный момент. pg_default_acl считывается только во время создания объекта.
pg_depend
Каталог pg_depend записывает отношения зависимости между объектами базы данных. Эта информация позволяет командам DROP находить, какие другие объекты должны быть удалены с помощью DROP CASCADE, или предотвращать удаление в случае DROP RESTRICT.
Смотрите также раздел pg_shdepend, который выполняет аналогичную функцию для зависимостей, включающих объекты, совместно используемые в кластере баз данных.
pg_depend столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| classid | oid | pg_class.oid | OID системного каталога, в котором находится зависимый объект |
| objid | oid | OID для любого столбца | OID конкретного зависимого объекта |
| objsubid | int4 | Для столбца таблицы это номер столбца (objid и classid задают саму таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| refclassid | oid | pg_class.oid | OID системного каталога, в котором находится объект ссылки |
| refobjid | oid | OID для любого столбца | OID конкретного объекта ссылки |
| refobjsubid | int4 | Для столбца таблицы это номер столбца (refobjid и refclassid задают саму таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| deptype | char | Код, определяющий конкретную семантику этого отношения зависимости | |
Во всех случаях a pg_depend запись указывает, что объект ссылки не может быть удален без удаления также зависимого объекта. Тем не менее, есть несколько подвидов зависимостей, задаваемых с помощью deptype:
DEPENDENCY_NORMAL (n)
Обычное отношение между раздельно созданными объектами. Зависимый объект можно удалить, не затрагивая объект который на него ссылается. Объект который ссылается может быть удален только путем указания CASCADE и в этом случае зависимый объект также удаляется. Пример: столбец таблицы имеет нормальную зависимость от своего типа данных.
DEPENDENCY_AUTO (a)
Зависимый объект может быть удален отдельно от объекта который на него ссылается и должен быть автоматически удален (независимо от того выбран режим, RESTRICT или CASCADE). Пример: именованное ограничение из таблицы становится автоматически зависимым от таблицы, так что оно исчезнет автоматически , если таблица будет удалена.
DEPENDENCY_INTERNAL (i)
Зависимый объект был создан как часть другого объекта, и на самом деле является только частью его внутренней реализации. Удаление при помощи DROP такого зависимого объекта будет запрещено (вместо этого пользователю будет выдано сообщение о том что необходимо вызвать DROP для основного объекта). Удаление объекта который ссылается на данный, приведет к автоматическому удалению зависимого объекта вне зависимости от того указывается CASCADE при удалении или нет. Если зависимый объект должен быть удален из-за зависимости от какого-либо другого удаляемого объекта, его удаление преобразуется в удаление объекта который создал ссылки, так что зависимости NORMAL и AUTO, зависимого объекта ведут себя так же, как и зависимости объекта который ссылается на данный. Пример: Правило ON SELECT для представления (VIEW) становится внутренне зависимым от представления, предотвращая его удаление, пока представление остается в системе. Зависимости для этого правила (например, таблицы, на которые оно ссылается) действуют так, как если бы они были зависимостями представления (VIEW).
DEPENDENCY_PARTITION_PRI (P) и DEPENDENCY_PARTITION_SEC (S)
Зависимый объект был создан как часть создания партиции и на самом деле является только частью его внутренней реализации - однако, в отличие от INTERNAL, существует более одного объекта ссылающегося на данный. Зависимый объект не должен быть удален, пока не будет удален хотя бы один из этих объектов - если какой-либо из них удаляется, зависимый объект должен быть удален вне зависимости от указания CASCADE. Также в отличие от INTERNAL, удаление некоторого другого объекта, от которого зависит объект, не приводит к автоматическому удалению какого-либо объекта, на который он ссылается. Следовательно, если удаление не касается хотя бы одного из этих объектов каким либо способом, оно не будет затрагивать зависимый объект. (В большинстве случаев зависимый объект совместно использует все свои зависимости связанные с партициями по крайней мере с одним объектом, на который ссылается партиция, так что это ограничение не приводит к блокированию каскадного удаления.) Первичные и вторичные зависимости партиций ведут себя одинаково, за исключением того, что первичная зависимость предпочтительна для использования в сообщениях об ошибках - следовательно, объект, зависящий от партиции, должен иметь одну первичную зависимость партиции и одну или несколько вторичных зависимостей партиции. Обратите внимание, что зависимости партиций создаются в дополнение к любым зависимостям, которые обычно имеются у объекта, а не вместо них. Это упрощает задачу Операции присоединения / отсоединения партиций: необходимо только добавить или удалить зависимости. Пример: дочерний партиционированный индекс становится зависимым от партиционирования как таблицы, в которой он находится, так и от родительского партиционированного индекса, так что он удаляется, если любой из этих объектов удаляется, но не иначе. Зависимость от родительского индекса является основной, так что если пользователь пытается удалить дочерний партиционированный индекс, сообщение об ошибке будет предлагать вместо этого удалить родительский индекс (а не таблицу).
DEPENDENCY_EXTENSION (е)
Зависимый объект является элементом расширения, на которое ссылается объект (см. раздел pg_extension). Зависимый объект можно удалить только с помощью DROP EXTENSION для объекта который ссылается. Функционально этот тип зависимости действует так же, как и INTERNAL зависимость, но она хранится отдельно для ясности и упрощения qhb_dump.
DEPENDENCY_AUTO_EXTENSION (x)
Зависимый объект не является элементом расширения, на которое ссылается объект (и поэтому он не должен игнорироваться qhb_dump), но он не может функционировать без расширения и должен автоматически удаляться, если расширение удаляется. Зависимый объект также может быть удалён сам по себе. Функционально этот тип зависимости действует так же, как и AUTO зависимость, но она хранится отдельно для ясности и упрощения qhb_dump.
DEPENDENCY_PIN (p)
Зависимого объекта нет - этот тип записи означает, что сама система зависит от объекта, и поэтому этот объект никогда не должен быть удален. Записи этого типа создаются только в команде qhb_bootstrap. Столбцы для зависимого объекта содержат нули.
Обратите внимание, что вполне возможно, что два объекта будут связаны более чем одной зависимостью в pg_depend. Например, дочерний партиционированный индекс будет иметь зависимость от партиции связанной таблицы, и автозависимость от каждого столбца той таблицы, которую он индексирует. Такая ситуация нужна для выражения семантики множественной зависимости. Зависимый объект можно удалить без CASCADE если какая-либо из его зависимостей удовлетворяет его условию автоматического сброса. И наоборот, должны быть выполнены все ограничения зависимостей, относительно которых объекты должны быть удалены вместе.
pg_description
Каталог pg_description хранит комментарий для каждого объекта базы данных. Описаниями можно манипулировать с помощью команды COMMENT и просматривать с помощью qsql \d команды.
Смотрите также раздел pg_shdescription, который выполняет аналогичную функцию для описаний объектов, совместно используемых в кластере баз данных.
pg_description столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID объекта, к которому относится данное описание |
| classoid | oid | pg_class.oid | Идентификатор OID системного каталога, в котором отображается этот объект |
| objsubid | int4 | Для комментария к столбцу таблицы это номер столбца (objoid и classoid задают таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| description | text | Произвольный текст, который служит необязательным описанием (комментарием) данного объекта |
pg_enum
Каталог pg_enum содержит записи, показывающие значения и текстовые метки для каждого типа enum. Внутренним представлением значения enum фактически является OID связанной строки в pg_enum.
pg_enum столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| enumtypid | oid | pg_type.oid | OID записи в pg_type владеющей этим значением enum |
| enumsortorder | float4 | Положение сортировки этого значения enum в пределах его типа enum | |
| enumlabel | name | Текстовая метка для этого перечисления значения |
OIDs для pg_enum строки следуют специальному правилу: четные OID гарантированно упорядочиваются таким же образом, как и порядок сортировки их типа enum. То есть, если два четных OID принадлежат к одному и тому же типу перечисления, меньший OID должен иметь меньший размер enumsortorder значение. Нечетные значения OID не должны иметь никакого отношения к порядку сортировки. Это правило позволяет подпрограммам сравнения перечислений избегать поиска в каталоге во многих распространенных случаях. Подпрограммы, которые создают и изменяют типы перечислений, пытаются назначить чётный OID для значений перечисления, когда это возможно.
При создании типа перечисления его членам присваиваются позиции порядка
сортировки 1..n. Но элементы, добавленные позже, могут иметь
отрицательные или дробные значения enumsortorder. Единственное
требование к этим значениям состоит в том, чтобы они были правильно
упорядочены и уникальны в каждом типе перечисления.
pg_event_trigger
Каталог pg_event_trigger хранит триггеры событий БД.
pg_event_trigger столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| evtname | name | Имя триггера (должно быть уникальным) | |
| evtevent | name | Определяет событие, для которого срабатывает этот триггер | |
| evtowner | oid | pg_authid.oid | Владелец триггера события |
| evtfoid | oid | pg_proc.oid | Вызываемая функция |
| evtenabled | char | Задаёт режимы session_replication_role в которых срабатывает триггер события. О = триггер срабатывает в режимах origin и local, D = триггер отключен, R = триггер срабатывает в режиме replica, A = триггер срабатывает всегда. | |
| evttags | text[] | Метки команд, для которых этот триггер будет срабатывать. Если NULL, то запуск этого триггера не ограничен тегом команды. |
pg_extension
Каталог pg_extension сохраняет информацию об установленных расширениях. Смотрите раздел Упаковка связанных объектов в расширение для получения подробной информации о расширениях.
pg_extension столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| extname | name | Имя расширения | |
| extowner | oid | pg_authid.oid | Владелец расширения |
| extnamespace | oid | pg_namespace.oid | Схема, содержащая экспортируемые объекты расширения |
| extrelocatable | bool | True, если расширение можно переместить в другую схему | |
| extversion | text | Имя версии для расширения | |
| extconfig | oid[] | pg_class.oid | Массив из regclass OID для таблиц конфигурации расширения, или NULL если у расширения нет таблиц |
| extcondition | text[] | Массив для условия фильтра WHERE предложений для таблиц конфигурации расширения, или NULL если условий нет |
Обратите внимание, что в отличие от большинства каталогов со столбцами namespace, extnamespace их наличие в этом каталоге не означает, что расширение принадлежит к этой схеме. Имена расширений никогда не определяются схемой. Скорее, extnamespace указывает схему, содержащую большинство или все объекты расширения. Если extrelocatable true, тогда эта схема должна содержать все объекты, принадлежащие расширению.
pg_foreign_data_wrapper
Каталог pg_foreign_data_wrapper сохраняет определения внешних данных. Внешние данные - это механизм, с помощью которого осуществляется доступ к данным находящимся на внешних серверах.
pg_foreign_data_wrapper столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| fdwname | name | Имя источника внешних данных | |
| fdwowner | oid | pg_authid.oid | Владелец источника внешних данных |
| fdwhandler | oid | pg_proc.oid | Ссылается на функцию обработчика, которая отвечает за предоставление подпрограмм для обработки внешних данных. Ноль, если обработчик не предусмотрен |
| fdwvalidator | oid | pg_proc.oid | Ссылается на функцию валидатора, которая отвечает за проверку правильности параметров, заданных вне СУБД, а также параметров для внешних серверов и сопоставлений пользователей, использующих внешние данные. Ноль, если валидатор не предусмотрен |
| fdwacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации | |
| fdwoptions | text[] | Конкретные параметры внешних данных, в виде строки "ключ=значение" |
pg_foreign_server
Каталог pg_foreign_server сохраняет определения внешних серверов. Внешний сервер описывает источник внешних данных, например удаленный сервер. Доступ к внешним серверам осуществляется через foreign_data_wrapper.
pg_foreign_server столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| srvname | name | Имя внешнего сервера | |
| srvowner | oid | pg_authid.oid | Владелец внешнего сервера |
| srvfdw | oid | pg_foreign_data_wrapper.oid | OID foreign_data_wrapper этого внешнего сервера |
| srvtype | text | Тип сервера (необязательно) | |
| srvversion | text | Версия сервера (необязательно) | |
| srvacl | aclitem[] | Права доступа - смотрите раздел Привилегии для получения дополнительной информации | |
| srvoptions | text[] | Конкретные параметры внешнего сервера, в виде строки "ключ=значение" |
pg_foreign_table
Каталог pg_foreign_table содержит дополнительную информацию о внешних таблицах. Внешняя таблица в основном представлена в каталоге pg_class, как обычная таблица. Запись соответствующая ей в pg_foreign_table содержит информацию, относящуюся только к внешним таблицам, а не к какому-либо другому виду связи.
pg_foreign_table столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| ftrelid | oid | pg_class.oid | OID записи из pg_class для этой внешней таблицы |
| ftserver | oid | pg_foreign_server.oid | OID внешнего сервера для этой внешней таблицы |
| ftoptions | text[] | Параметры внешней таблицы, в виде строки "ключ=значение" |
pg_index
Каталог pg_index содержит часть информации об индексах. Остальное - в основном каталоге pg_class.
pg_index столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| indexrelid | oid | pg_class.oid | OID записи из pg_class для этого индекса |
| indrelid | oid | pg_class.oid | OID записи pg_class таблицы для которой индекс предназначен |
| indnatts | int2 | Общее количество столбцов в индексе (повторяет pg_class.relnatts) это число включает в себя как ключевые, так и включенные атрибуты | |
| indnkeyatts | int2 | Количество ключевых столбцов в индексе, не считая каких-либо включенных столбцов, которые просто хранятся и не участвуют в семантике индекса | |
| indisunique | bool | Если true, то это уникальный индекс | |
| indisprimary | bool | Если true, то этот индекс представляет собой первичный ключ таблицы (indisunique в этом случае должно быть true) | |
| indisexclusion | bool | Если значение true, то этот индекс поддерживает ограничение исключения | |
| indimmediate | bool | Если true, то проверка уникальности применяется сразу после вставки (не имеет значения, если indisunique false) | |
| indisclustered | bool | Если true, то таблица была кластеризованной по этому индексу | |
| indisvalid | bool | Если значение true, то индекс в настоящее время является допустимым для запросов. False означает, что индекс может быть неполным: и еще должен быть изменен с помощью операций вставки / обновления, но он не может безопасно использоваться для запросов. Если он обозначен как уникальный, свойство уникальности также не гарантируется. | |
| indcheckxmin | bool | Если значение true, запросы не должны использовать индекс до тех пор, пока поле xmin находится ниже их горизонта событий (TransactionXmin) , поскольку таблица может содержать разорванные HOT цепочки с несовместимыми строками, которые запросы могут видеть | |
| indisready | bool | Если true, то индекс в настоящее время готов к вставкам. False означает, что индекс должен быть проигнорирован операциями вставки / обновления. | |
| indislive | bool | Если значение false, индекс находится в процессе удаления и должен игнорироваться при любой попытке использования (включая использования в HOT цепочках) | |
| indisreplident | bool | Если true, то этот индекс был выбран в качестве "идентификатора реплики" с помощью команд ALTER TABLE ... REPLICA IDENTITY USING INDEX ... | |
| indkey | int2vector | pg_attribute.attnum | Массив из значений indnatts, указывающий, на столбцы таблицы которые этот индекс обрабатывает. Например, значение параметра 1 3 означает, что первый и третий столбцы таблицы составляют записи индекса. Ключевые столбцы предшествуют неключевым (включенным) столбцам. Ноль в этом массиве указывает, что соответствующий атрибут индекса является выражением над столбцами таблицы, а не просто ссылкой на столбец. |
| indcollation | oidvector | pg_collation.oid | Для каждого столбца в ключе индекса (indnkeyatts values),содержит OID параметров сортировки, используемых для индекса,или ноль, если столбец не является типом данных с возможностью сортировки. |
| indclass | oidvector | pg_opclass.oid | Для каждого столбца в ключе индекса (indnkeyatts values), содержит OID класса оператора для использования. Смотрите дополнительную информацию в разделе pg_opclass. |
| indoption | int2vector | Массив из indnkeyatts значений, хранящие биты флагов для каждого столбца. Значение битов определяется методом доступа индекса. | |
| indexprs | pg_node_tree | Деревья выражений (nodeToString() представление) для атрибутов индекса, которые не являются простыми ссылками на столбец. Это список с одним элементом для каждой нулевой записи в indkey. Null, если все атрибуты индекса являются простыми ссылками. | |
| indpred | pg_node_tree | Дерево выражений (nodeToString() представление) для частичного индексного предиката. Null, если не является частичным индексом. |
pg_inherits
Каталог pg_inherits записывает информацию об иерархиях наследования таблиц. Существует одна запись для каждой прямой связи родительской и дочерней таблиц в базе данных. (Косвенное наследование может быть определено цепочками записей.)
pg_inherits столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| inhrelid | oid | pg_class.oid | OID дочерней таблицы |
| inparent | oid | pg_class.oid | OID родительской таблицы |
| inhseqno | int4 | Если для дочерней таблицы существует более одного прямого родителя (множественное наследование), это число указывает порядок, в котором должны быть упорядочены наследуемые столбцы. Отсчет начинается с 1. |
pg_init_privs
Каталог pg_init_privs записывает информацию о начальных привилегиях объектов в системе. Существует одна запись для каждого объекта в базе данных, имеющего начальный набор привилегий отличных от привилегий по умолчанию (не-NULL).
Объекты могут иметь начальные привилегии, задавая эти привилегии при инициализации системы (с помощью qhb_bootstrap) или при создании объекта при выполнении CREATE EXTENSION, а сценарий расширения устанавливает начальные привилегии с помощью системы предоставления привилегий (GRANT). Обратите внимание, что система автоматически обрабатывает запись привилегий во время сценария расширения и что авторам расширения нужно только использовать инструкции GRANT и REVOKE в своем сценарии, чтобы иметь записанные привилегии. Столбец privtype указывает, была ли начальная привилегия установлена qhb_bootstrap или во время выполнения команды CREATE EXTENSION.
Объекты, которые имеют начальные привилегии, установленные qhb_bootstrap, будут
иметь записи, где privtype помечается как i, в то время как объекты,
которые имеют начальные привилегии, установленные при помощи CREATE EXTENSION,
будут помечаться как e.
pg_init_privs столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID конкретного объекта |
| classoid | oid | pg_class.oid | OID системного каталога, в котором находится объект |
| objsubid | int4 | Для столбца таблицы это номер столбца (objoid и classoid заданы от самой таблицы). Для всех других типов объектов этот столбец равен нулю. | |
| privtype | char | Код, определяющий тип начальной привилегии этого объекта - i или e | |
| initprivs | aclitem[] | Начальные права доступа - смотрите раздел Привилегии для получения дополнительной информации |
pg_language
Каталог pg_language регистрирует языки, на которых можно писать функции или хранимые процедуры. Дополнительную информацию об обработчиках языка смотрите в разделе CREATE LANGUAGE.
pg_language столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| lanname | name | Название языка | |
| lanowner | oid | pg_authid.oid | Владелец языка |
| lanispl | bool | Это значение false для внутренних языков (таких как SQL) и true для пользовательских языков. В настоящее время qhb_dump все еще использует это, чтобы определить, какие языки должны быть сохранены, Но это может быть заменено другим механизмом в будущем. | |
| lanplusted | bool | True, если это доверенный язык, пердполагается, что он, не предоставляет доступ к чему-либо за пределами обычной среды выполнения SQL. Только суперпользователи могут создавать функции на ненадежных языках. | |
| lanplcallfoid | oid | pg_proc.oid | Для языков не использующих внутренние механизмы это ссылка на обработчик языка - специальную функцию, ответственную за выполнение всех предложений, написанных на определенном языке |
| laninline | oid | pg_proc.oid | Ссылка на функцию, которая отвечает за выполнение “встроенных” анонимных блоков кода ( DO блоков). Ноль, если анонимные блоки не поддерживаются. |
| lanvalidator | oid | pg_proc.oid | Ссылка на функцию-валидатор языка, которая отвечает за проверку синтаксиса и валидности новых функций при их создании. Ноль, если валидатор не предусмотрен. |
| lanacl | aclitem[] | Права доступа - смотрите раздел Привилегии для получения дополнительной информации |
pg_largeobject
Каталог pg_largeobject содержит данные, составляющие "большие объекты".
Большой объект идентифицируется OID, назначенным при его создании.
Каждый большой объект разбивается на сегменты или "страницы" достаточно
маленькие, чтобы удобно хранить их в виде строк внутри pg_largeobject.
Количество данных на странице определяется как LOBLKSIZE (который в
настоящее время BLCKSZ / 4, или обычно 2 кб).
Для получения списка OID больших объектов используйте pg_largeobject_metadata.
pg_largeobject столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| loid | oid | pg_largeobject_metadata.oid | Идентификатор большого объекта, включающий страницу |
| pageno | int4 | Номер страницы в пределах ее большого объекта (отсчет от нуля) | |
| data | bytea | Фактические данные, хранящиеся в большом объекте. Никогда не будет больше, чем LOBLKSIZE байт а может быть и меньше. |
Каждая строка из pg_largeobject содержит данные для одной страницы большого объекта, начиная со смещения в байтах (pageno * LOBLKSIZE) внутри объекта. Реализация позволяет использовать разреженное хранилище: страницы могут отсутствовать и быть короче, чем LOBLKSIZE байты, даже если они не являются последней страницей объекта. Отсутствующие области внутри большого объекта считываются как нули.
pg_largeobject_metadata
Каталог pg_largeobject_metadata содержит метаданные, связанные с большими объектами. Фактические данные большого объекта хранятся в pg_largeobject.
pg_largeobject_metadata столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| lomowner | oid | pg_authid.oid | Владелец большого объекта |
| lomacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации |
pg_namespace
Каталог pg_namespace хранит пространства имен. Пространство имен-это структура, лежащая в основе схем SQL - каждое пространство имен может иметь отдельную коллекцию отношений, типов и т. д.
pg_namespace столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| nspname | name | Имя пространства имен | |
| nspowner | oid | pg_authid.oid | Владелец пространства имен |
| nspacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации |
pg_opclass
Каталог pg_opclass определяет классы операторов метода доступа к индексу. Каждый класс операторов определяет семантику для индексных столбцов определенного типа данных и конкретного метода доступа к индексам. Класс оператора по существу определяет, что определенное семейство операторов применимо к определенному типу данных индексируемого столбца. Набор операторов из семейства, которые фактически используются с индексированным столбцом, являются теми, которые принимают тип данных столбца в качестве их аргумента.
Классы операторов подробно описаны в разделе Расширения для индексов.
pg_opclass столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| opcmethod | oid | pg_am.oid | Класс оператора для метода индексного доступа |
| opcname | name | Имя класса оператора | |
| opcnamespace | oid | pg_namespace.oid | Пространство имен класса оператора |
| opcowner | oid | pg_authid.oid | Владелец класса оператора |
| opcfamily | oid | pg_opfamily.oid | Семейство операторов, содержащее класс оператора |
| opcintype | oid | pg_type.oid | Тип данных, который индексирует класс оператора |
| opcdefault | bool | True, если этот класс оператора является значением по умолчанию для opcintype | |
| opckeytype | oid | pg_type.oid | Тип данных, хранящихся в индексе, или ноль, если он совпадает с opcintype |
Класс оператора должен соответствовать opfmethod содержащего его семейства операторов. Кроме того, должно быть не более одной строки в pg_opclass у которой opcdefault true для любой заданной комбинации opcmethod и opcintype.
pg_operator
Каталог pg_operator хранит информацию об операторах. Дополнительную информацию смотрите в разделах CREATE OPERATOR и Пользовательские операторы.
pg_operator столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| oprname | name | Наименование оператора | |
| oprnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот оператор |
| oprowner | oid | pg_authid.oid | Владелец оператора |
| oprkind | char | b = инфикс ("оба”), l = префикс ("слева”), r = постфикс ("справа”) | |
| oprcanmerge | bool | Этот оператор поддерживает объединения слиянием | |
| oprcanhash | bool | Этот оператор поддерживает хэш-соединения | |
| oprleft | oid | pg_type.oid | Тип левого операнда |
| oprright | oid | pg_type.oid | Тип правого операнда |
| oprresult | oid | pg_type.oid | Тип результата |
| oprcom | oid | pg_operator.oid | Коммутатор оператора этого типа, если таковой имеется |
| oprnegate | oid | pg_operator.oid | Отрицание оператора этого типа, если таковое имеется |
| oprcode | regproc | pg_proc.oid | Функция, реализующая этот оператор |
| oprrest | regproc | pg_proc.oid | Функция оценки селективности ограничения для данного оператора |
| oprjoin | regproc | pg_proc.oid | Функция оценки селективности соединения для этого оператора |
Неиспользуемые столбцы содержат нули. Например, oprleft равно нулю для префиксного оператора.
pg_opfamily
Каталог pg_opfamily определяет семейства операторов. Каждое семейство операторов представляет собой набор операторов и связанных с ними основных процедур, реализующих семантику, заданную для конкретного метода доступа к индексу. Кроме того, операторы в семействе все “совместимы”, тем способом, который определяет метод доступа. Концепция семейства операторов позволяет использовать операторы разного типа с индексами и использовать знания о семантике метода доступа.
Семейства операторов подробно описаны в разделе Расширения для индексов.
pg_opfamily столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| opfmethod | oid | pg_am.oid | Метода индексного доступа для которго предназначено семейство операторов |
| opfname | name | Имя этого семейства операторов | |
| opfnamespace | oid | pg_namespace.oid | Пространство имен этого семейства операторов |
| opfowner | oid | pg_authid.oid | Владелец семейства операторов |
Большая часть информации, определяющей семейство операторов, не входит в pg_opfamily, а находится в связанных строках в pg_amop, pg_amproc и pg_opclass.
pg_partitioned_table
Каталог pg_partitioned_table хранит информацию о способе партиционирования таблиц.
pg_partitioned_table столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| partrelid | oid | pg_class.oid | OID партиционированой таблицы, запись из pg_class |
| partstrat | char | Стратегия партиционирования; h = хэш партиционирование, l = партиционирование по списку, r = партиционирование по диапазону | |
| partnatts | int2 | Количество столбцов в ключе партиции | |
| partdefid | oid | pg_class.oid | OID из pg_class для партиции по умолчанию этой партиционированой таблицы или ноль, если эта партиционированная таблица не имеет партиции по умолчанию. |
| partattrs | int2vector | pg_attribute.attnum | Массив из значений partnatts , указывающий, какие столбцы таблицы являются частью ключа партиции. Например, значение параметра 1 3 означает, что первый и третий столбцы таблицы составляют ключ партиции. Ноль в этом массиве указывает, что соответствующий столбец ключа партиции является выражением, а не простой ссылкой на столбец. |
| partclass | oidvector | pg_opclass.oid | Для каждого столбца в ключе партиционирования содержит OID класса оператора для использования. Смотрите дополнительную информацию в разделе pg_opclass. |
| partcollation | oidvector | pg_opclass.oid | Для каждого столбца в ключе партиционирования содержит OID параметров сортировки, используемых для партиционирования, или ноль, если столбец не является типом данных с возможностью сортировки. |
| partexprs | pg_node_tree | Деревья выражений (nodeToString() представление) для столбцов ключа партиции, которые не являются простыми ссылками на столбцы. Это список с одним элементом для каждой нулевой записи в partattrs. Null, если все столбцы ключа партиции являются простыми ссылками. |
pg_pltemplate
Каталог pg_pltemplate хранит информацию о "шаблоне" для процедурных языков. Шаблон для языка позволяет создать язык в конкретной базе данных с помощью простой команды CREATE LANGUAGE, без необходимости указывать детали реализации.
В отличие от большинства системных каталогов, pg_pltemplate является общим для всех баз данных кластера: существует только одна копия pg_pltemplate на кластер, а не по одному на каждую базу данных. Это позволяет получить доступ к информации в каждой базе данных по мере необходимости.
pg_pltemplate столбцы
| Имя | Тип | Описание |
|---|---|---|
| tmplname | name | Название языка для которого предназначен данный шаблон |
| tmpltrusted | boolean | True, если язык считается доверенным |
| tmpldbacreate | boolean | True, если язык может быть создан владельцем базы данных |
| tmplhandler | text | Имя функции обработчика вызовов |
| tmplinline | text | Имя функции обработчика анонимных блоков или null, если анонимных блоков нет |
| tmplvalidator | text | Имя функции валидатора, или null, если валидатора нет |
| tmpllibrary | text | Путь к разделяемой библиотеке, реализующей язык |
| tmplacl | aclitem[] | Права доступа для шаблона (фактически не используется) |
В настоящее время нет никаких команд, которые управляют шаблонами процедурного языка; чтобы изменить встроенную информацию, суперпользователь должен изменить таблицу с помощью обычных команд INSERT, DELETE или UPDATE.
Примечание!!!
Вполне вероятно, что pg_pltemplate будет удален в некоторых будущих выпусках QHB, в пользу сохранения этих знаний о процедурных языках в их соответствующих сценариях установки расширений.
pg_policy
Каталог pg_policy сохраняет политики безопасности на уровне строк для таблиц. Политика включает тип команды, к которой она применяется (возможно, все команды), роли, к которым она применяется, выражение, которое должно быть добавлено в качестве квалификационного барьера безопасности к запросам, включающим таблицу, и выражение, которое должно быть добавлено в опцию WITH CHECK для запросов, которые пытаются добавить новые записи в таблицу.
pg_policy столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| polname | name | Название политики | |
| polrelid | oid | pg_class.oid | Таблица, к которой применяется политика |
| polcmd | char | Тип команды, к которой применяется политика: r для SELECT, a для INSERT, w для UPDATE, d для DELETE, или * для всех | |
| polpermissive | boolean | Является ли эта политика разрешительной или ограничительной? | |
| polroles | oid[] | pg_authid.oid | Роли, к которым применяется политика |
| polqual | pg_node_tree | Дерево выражений, добавляемое к квалификациям барьеров безопасности для запросов, использующих таблицу | |
| polwithcheck | pg_node_tree | Дерево выражений, которое будет добавлено в квалификацию WITH CHECK для запросов, пытающихся добавить строки в таблицу |
Примечание!!!
Политики, хранящиеся в pg_policy применяются только тогда, когда pg_class.relrowsecurity установлено для соот. таблицы.
pg_proc
Каталог pg_proc хранит информацию о функциях, процедурах, агрегатных функциях и оконных функциях (в совокупности также известных как подпрограммы). Дополнительную информацию смотрите в разделах CREATE FUNCTION, CREATE PROCEDURE и Пользовательские функции.
Если prokind указывает, что запись предназначена для агрегатной функции, в ней должна быть соответствующая строка из pg_aggregate.
pg_proc столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| proname | name | Имя функции | |
| pronamespace | oid | pg_namespace.oid | OID пространства имен, содержащего эту функцию |
| proowner | oid | pg_authid.oid | Владелец функции |
| prolang | oid | pg_language.oid | Язык реализации или интерфейс вызова этой функции |
| procost | float4 | Расчетная стоимость исполнения (в единицах cpu_operator_cost ), если установлен признак proretset, это стоимость за одну возвращенную строку | |
| prorows | float4 | Предполагаемое количество строк результатов (ноль, если не задан proretset) | |
| provariadic | oid | pg_type.oid | Тип данных элементов масива параметров переменной длинны, либо ноль, если функция не имеет переменного числа параметров |
| prosupport | regproc | pg_proc.oid | Дополнительная функция поддержки планировщика для этой функции (см. раздел Оптимизация функций) |
| prokind | char | f для нормальной функции, p для процедуры, a для агрегатной функции, или w для оконной функции | |
| prosecdef | bool | Функция- определитель контекста безопасности (т. е. функция "setuid") | |
| proleakproof | bool | Функция не имеет никаких побочных эффектов. Никакая информация о аргументах не передается, иначе чем через возвращаемое значение. Любая функция, которая может вызвать ошибку в зависимости от значений ее аргументов, не является герметичной. | |
| proisstrict | bool | Функция возвращает значение null, если любой аргумент вызова имеет значение null. В этом случае функция по факту не будет вызвана вообще. Функции, которые не являются "строгими"(strict), должны быть подготовлены для обработки нулевых входных данных. | |
| proretset | bool | Функция возвращает набор (т. е. несколько значений указанного типа данных) | |
| provolatile | char | provolatile указывает, зависит ли результат функции только от ее входных аргументов или на него влияют внешние факторы. Для "неизменяемых" функций , которые всегда дают один и тот же результат для одних и тех же входных данных устанавливается значение i. Для "стабильных" функций, результаты которых (для фиксированных входных аргументов) не изменяются в пределах сканирования устанавливается значение s. Для "изменчивых" (volatile) функций, результаты которых могут измениться в любое время устанавливается значение v. (Также v используется для функций с побочными эффектами, так их вызовы не могут быть исключены в процессе оптимизации.) | |
| proparallel | char | Указывает, можно ли безопасно запускать функцию в параллельном режиме. Для функций, которые безопасно запускать в параллельном режиме без ограничений устанавливается значение s.Для функций, которые могут выполняться в параллельном режиме, но их выполнение ограничено процессом - параллельные рабочие процессы не могут вызывать эти функции устанавливается значение r. Для функций, которые небезопасны в параллельном режиме устанавливается значение u - наличие такой функции заставляет оптимизатор строить план последовательного выполнения. | |
| pronargs | int2 | Количество входных аргументов | |
| pronargdefaults | int2 | Количество аргументов, имеющих значения по умолчанию | |
| prorettype | oid | pg_type.oid | Тип данных возвращаемого значения |
| proargtypes | oidvector | pg_type.oid | Массив с типами данных аргументов функции. Включает только входные аргументы (включая INOUT и VARIADIC Аргументы), и таким образом представляет сигнатуру вызова функции. |
| proallargtypes | oid[] | pg_type.oid | Массив с типами данных аргументов функции. Включает в себя все аргументы (в том числе IN и INOUT аргументы), однако, если все аргументы являются IN, это поле будет иметь значение null. Обратите внимание, что индексация массива обычно начинается с 1, тогда как по историческим причинам proargtypes индексируется от 0. |
| proargmodes | char[] | Массив с режимами аргументов функции, закодированными как i для IN аргументов, о для OUT аргументы, b для INOUT аргументов, v для VARIADIC аргументов, t для TABLE аргументов. Если все аргументы это IN аргументы, это поле будет иметь значение null. Обратите внимание, что индексы соответствуют позициям proallargtypes нет proargtypes. | |
| proargnames | text[] | Массив с именами аргументов функции. Аргументы без имени представляют собой пустые строки в массиве. Если ни один из аргументов не имеет имени, это поле будет иметь значение null. Обратите внимание, что индексы соответствуют позициям proallargtypes но не proargtypes. | |
| proargdefaults | pg_node_tree | Деревья выражений (nodeToString() представление) для значений по умолчанию. Это список pronargdefaults элементов, соответствующих последнему N входным аргументам (т. е. последним N позициям в proargtypes). Если ни один из аргументов не имеет значений по умолчанию, это поле будет иметь значение null. | |
| protrftypes | oid[] | Типы OID данных, для которых необходимо применить преобразования. | |
| prosrc | text | Способ вызвать функцию. Может быть фактический исходный код функции для интерпретируемых языков, символ ссылки, имя файла или почти все остальное, в зависимости от языка и реализации/соглашения о вызове. | |
| probin | text | Дополнительная информация о том, как вызвать эту функцию. Интерпретация зависит от языка. | |
| proconfig | text[] | Локальные настройки функции для переменных конфигурации времени выполнения | |
| proacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации |
Для скомпилированных функций, как встроенных, так и динамически загружаемых, prosrc содержит имя функции на языке C (объектную ссылку). Для всех других известных на данный момент типов языков, prosrc содержит исходный текст функции. probin не используется, за исключением динамически загружаемых функций C/RUST, для которых он дает имя файла общей библиотеки, содержащего функцию.
pg_publication
Каталог pg_publication содержит все публикации для логической репликации, созданные в базе данных.
pg_publication столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| pubname | name | Название публикации | |
| pubname | oid | pg_authid.oid | Владелец публикации |
| puballtables | bool | Если задано значение true, эта публикация автоматически включает все таблицы в базе данных включая те которые созданы в будущем. | |
| pubinsert | bool | При значении true операции вставки реплицируются для таблиц в публикации. | |
| pubupdate | bool | При значении true операции обновления реплицируются для таблиц в публикации. | |
| pubdelete | bool | При значении true операции удаления реплицируются для таблиц в публикации. | |
| pubtruncate | bool | Если задано значение true, то операции truncate реплицируются для таблиц в публикации. |
pg_publication_rel
Каталог pg_publication_rel содержит сопоставление между отношениями и
публикациями в базе данных в виде отображения многие-ко-многим. Смотрите
также раздел pg_publication_tables для более удобного просмотра этой информации.
pg_publication_rel столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| prpubid | oid | pg_publication.oid | Ссылка на публикацию |
| prrelid | oid | pg_class.oid | Ссылка на связь |
pg_range
Каталог pg_range хранит информацию о типах диапазона в дополнение к записям типов в pg_type.
pg_range столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| rngtypid | oid | pg_type.oid | OID типа диапазона |
| rngsubtype | oid | pg_type.oid | OID типа элемента (подтипа) данного типа диапазона |
| rngcollation | oid | pg_collation.oid | OID параметров сортировки, используемых для сравнения диапазонов, или 0, если нет |
| rngsubopc | oid | pg_opclass.oid | OID класса оператора подтипа, используемого для сравнения диапазонов |
| rngcanonic | regproc | pg_proc.oid | OID функции для преобразования значения диапазона в каноническую форму или 0, если нет |
| rngsubdiff | regproc | pg_proc.oid | OID функции для возврата разницы между двумя значениями элементов в виде двойная точность, или 0, если нет |
rngsubopc (плюс rngcollation, если тип элемента является collatable) определяет порядок сортировки, используемый типом диапазона. rngcanonic используется, когда тип элемента является дискретным. rngsubdiff является необязательным, но может задаваться для повышения производительности индексов GiST по типу диапазона.
pg_replication_origin
Каталог pg_replication_origin содержит все созданные источники репликации. Дополнительные сведения об источниках репликации.
В отличие от большинства системных каталогов, pg_replication_origin является общим для всех баз данных кластера: существует только одна копия pg_replication_origin на кластер, а не по одному на каждую базу данных.
pg_replication_origin столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| roident | oid | Уникальный кластерный идентификатор источника репликации. Никогда должен выходить за границы системы. | |
| roname | text | Внешнее, определяемое пользователем, имя источника репликации. |
pg_rewrite
Каталог pg_rewrite хранит правила перезаписи для таблиц и представлений.
pg_rewrite столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| rulename | name | Имя правила | |
| ev_class | oid | pg_class.oid | Таблица для которой предназначено это правило |
| ev_type | char | Тип события, для которого используется правило: 1 = SELECT, 2 = UPDATE, 3 = INSERT, 4 = DELETE | |
| ev_enabled | char | Элементы управления, в которых срабатывает правило режимы session_replication_role. О = правило срабатывает в режимах origin и local, D = правило отключено, R = правило срабатывает в режиме replica, A = правило срабатывает всегда. | |
| is_instead | bool | True, если правило INSTEAD | |
| ev_qual | pg_node_tree | Дерево выражений (nodeToString() представление) для квалификационного условия правила | |
| ev_action | pg_node_tree | Дерево запросов (nodeToString() представление) для действия правила |
Примечание!!!
pg_class.relhasrules должно быть true, если таблица имеет какие-либо правила в этом каталоге.
pg_seclabel
Каталог pg_seclabel сохраняет метки безопасности на объектах базы данных. Метками безопасности можно управлять с помощью команды SECURITY LABEL. Для более простого способа просмотра меток безопасности см. раздел pg_seclabels, а также раздел pg_shseclabel, который содержит аналогичную информацию для меток безопасности объектов базы данных, совместно используемых в кластере баз данных.
pg_seclabel столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID объекта, к которому относится эта метка безопасности |
| classoid | oid | pg_class.oid | Идентификатор OID системного каталога, в котором отображается этот объект |
| objsubid | int4 | Для метки безопасности в столбце таблицы это номер столбца (в этом случае objoid и classoid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| provider | text | Поставщик меток безопасности, связанный с этой меткой. | |
| label | text | Метка безопасности, применяемая к этому объекту. |
pg_sequence
Каталог pg_sequence содержит информацию о последовательностях (sequence). Некоторые сведения о последовательностях, такие как имя и схема, находятся в разделе pg_class.
pg_sequence столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| seqrelid | oid | pg_class.oid | OID в pg_class для этой последовательности |
| seqtypid | oid | pg_type.oid | Тип данных последовательности |
| seqstart | int8 | Начальное значение последовательности | |
| seqincrement | int8 | Значение приращения последовательности | |
| seqmax | int8 | Максимальное значение последовательности | |
| seqmin | int8 | Минимальное значение последовательности | |
| seqcache | int8 | Размер кэша последовательности | |
| seqcycle | bool | Циклы последовательности |
pg_shdepend
Каталог pg_shdepend содержит зависимости между объектами базы данных и общими объектами, такими как роли. Эта информация позволяет QHB убедиться в том, что эти объекты не используются перед попыткой их удаления.
См. также раздел pg_depend, который содержит аналогичную информацию для зависимостей, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shdepend является общим для всех баз данных кластера: существует только одна копия pg_shdepend на кластер, а не по одному на каждую базу данных.
pg_shdepend столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| dbid | oid | pg_database.oid | Идентификатор OID базы данных, в которой находится зависимый объект, или ноль для общего объекта |
| classid | oid | pg_class.oid | OID системного каталога, в котором находится зависимый объект |
| objid | oid | OID для любого столбца | OID конкретного зависимого объекта |
| objsubid | int4 | Для столбца таблицы это номер столбца (objid и classid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| refclassid | oid | pg_class.oid | OID системного каталога, в котором находится объект ссылки (должен быть общим каталогом) |
| refobjid | oid | OID для любого столбца | OID конкретного ссылки на объект |
| deptype | char | Код, определяющий конкретную семантику этого отношения зависимости - см. ниже детальное описание |
Во всех случаях запись в pg_shdepend указывает, что объект ссылки не может быть удален без удаления также зависимого объекта. Тем не менее, есть несколько подвидов, которые задаются с помощью deptype:
SHARED_DEPENDENCY_OWNER (о)
Объект на который ссылаются (должен быть ролью) является владельцем зависимого объекта.
SHARED_DEPENDENCY_ACL (a)
Объект на который ссылаются (должен быть ролью) упоминается в списке ACL (access control list, т. е. список привилегий) зависимого объекта. (Запись SHARED_DEPENDENCY_ACL не создаётся для владельца объекта, так как у владельца в любом случае будет SHARED_DEPENDENCY_OWNER .)
SHARED_DEPENDENCY_POLICY (r)
Объект на который ссылаются (должен быть ролью) является целью для зависимого объекта политики.
SHARED_DEPENDENCY_PIN (p)
Не зависимого объекта - этот тип записи означает то, что сама система зависит от объекта на который ссылается, и поэтому этот объект никогда не должен быть удален. Записи этого типа создаются только в команде qhb_bootstrap. Столбцы для зависимого объекта у этой записи содержат нули.
В будущем могут потребоваться и другие виды зависимостей. Обратите внимание, сейчас для объекта на который ссылаются поддерживаются только роли.
pg_shdescription
Каталог pg_shdescription хранит необязательные описания (комментарии) для общих объектов базы данных. Описаниями можно манипулировать с помощью команды COMMENT и просматривать с помощью qsql \d команды.
См. также раздел pg_description, который содержит аналогичную информацию для описаний, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shdescription является общим для всех баз данных кластера: существует только одна копия pg_shdescription на кластер, а не по одному на каждую базу данных.
pg_shdescription столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID объекта, к которому относится данное описание |
| classoid | oid | pg_class.oid | Идентификатор OID системного каталога, в котором отображается этот объект |
| description | text | Произвольный текст, который служит описанием данного объекта |
pg_shseclabel
Каталог pg_shseclabel сохраняет метки безопасности на общих объектах базы данных. Метками безопасности можно управлять с помощью команды SECURITY LABEL. Для простого способа просмотра меток безопасности см. раздел pg_seclabels.
Смотрите также раздел pg_seclabel, который выполняет аналогичную функцию для меток безопасности, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shseclabel является общим для всех баз данных кластера: существует только одна копия pg_shseclabel на кластер, а не по одному на каждую базу данных.
pg_shseclabel столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID объекта, к которому относится эта метка безопасности |
| classoid | oid | pg_class.oid | Идентификатор OID системного каталога, в котором отображается этот объект |
| provider | text | Поставщик, связанный с этой меткой. | |
| label | text | Метка безопасности, применяемая к этому объекту. |
pg_statistic
Каталог pg_statistic хранит статистические данные о содержимом базы данных. Записи создаются при помощи команды ANALYZE и впоследствии используются планировщиком запросов. Обратите внимание, что все статистические данные по своей сути являются приблизительными, даже если они являются актуальными.
Обычно есть одна запись, с stainherit = false, для каждого столбца таблицы, который был проанализирован. Если таблица имеет дочерние элементы наследования, тотакже создается вторая запись с stainherit = true . Эта строка представляет статистику для столбца по всему дереву наследования, т. е. статистику для данных, которые вы видите с помощью SELECT column FROM table*, в то время как stainherit = false строка представляет собой результаты выполнения SELECT column FROM ONLY table.
В pg_statistic также хранятся статистические данные о значениях индексных выражений. Они описываются так, как если бы они были реальными столбцами данных - в частности, starelid ссылается на индекс. Однако для обычного столбца индекса, не содержащего выражения, запись не производится, поскольку она была бы избыточной для записи для базового столбца таблицы. В настоящее время записи для выражений индекса всегда имеют stainherit = false.
Поскольку различные виды статистики подходят для различных видов данных, pg_statistic предназначен не для того, чтобы строить очень много предположений о том, какую статистику он хранит. Только очень общие статистические данные (такие как nullness) приведены в отдельных столбцах в pg_statistic. Все остальное хранится в "слотах", которые представляют собой группы связанных столбцов, содержимое которых определяется кодовым номером в одном из слотов.
pg_statistic она не должна быть доступной для чтения любым пользователем, поскольку даже статистическая информация о содержании таблицы может считаться конфиденциальной. (Например: минимальные и максимальные значения столбца зарплаты могут представлять интерес.) pg_stats - это доступное для чтения всем пользователям представление для pg_statistic оно предоставляет только информацию о тех таблицах, которые доступны на чтение текущему пользователю.
pg_statistic столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| starelid | oid | pg_class.oid | Таблица или индекс, к которому принадлежит описываемый столбец |
| staattnum | int2 | pg_attribute.attnum | Номер описываемой колонки |
| stainherit | bool | Если значение true, то статистика включает дочерние столбцы наследования, а не только значения в указанном отношении | |
| stanullfrac | float4 | Доля записей в которых столбец не заполнен | |
| stawidth | int4 | Средняя сохраненная ширина записей для ненулевых столбцов в байтах | |
| stadistinct | float4 | Число различных значений данных в ненулевом в столбце. Значение больше нуля-это фактическое число различных значений. Значение меньше нуля- взятое по модулю это количество строк в таблице; например, столбец, в котором около 80% значений не имеют значения NULL и каждое ненулевое значение появляется в среднем примерно два раза , может быть представлен следующим образом: stadistinct = -0.4. Нулевое значение означает, что число различных значений неизвестно. | |
| stakindN | int2 | Кодовый номер, указывающий вид статистики, хранящейся в N-м "слоте" строки из pg_statistic. | |
| staopN | oid | pg_operator.oid | Оператор, используемый для получения статистики, хранящейся в N-м "слоте". Например, для "слота гистограммы" это будет оператор <, определяющий порядок сортировки данных. |
| stacollN | oid | pg_collation.oid | Параметры сортировки, используемые для получения статистики, хранящейся в N-м "слоте". Например, "слот гистограммы" для столбца с возможностью сортировки будет отображать параметры сортировки, определяющие порядок сортировки данных. Ноль для непроверяемых данных. |
| stanumbersN | float4[] | Числовая статистика соответствующего вида для N-го "слота", или null, если вид "слот" не содержит числовых значений | |
| stavaluesN | anyarray | Значения данных столбца соответствующего вида для N-го "слота", или null, если этот вид "слота" не хранит никаких значений для данных. Значения каждого элемента массива фактически относятся к определенному типу данных столбца или связанному типу, такому как тип элемента массива, поэтому нет способа определить тип этих столбцов более конкретно, чем anyarray. |
pg_statistic_ext
Каталог pg_statistic_ext содержит определения расширенной статистики планировщика. Каждая строка в этом каталоге соответствует объекту статистики, созданному с помощью команды CREATE STATISTICS.
pg_statistic_ext столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| stxrelid | oid | pg_class.oid | Таблица, содержащая столбцы, описываемые данным объектом |
| stxname | name | Имя объекта статистики | |
| stxnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот объект статистики |
| stxowner | oid | pg_authid.oid | Владелец объекта статистики |
| stxkeys | int2vector | pg_attribute.attnum | Массив номеров атрибутов, указывающих, какие столбцы таблицы покрываются этим объектом статистики; например, значение 1 3 это означает, что будут покрыты первый и третий столбцы таблицы |
| stxkind | char[] | Массив, содержащий коды для включенных типов статистики; допустимыми значениями являются: d для n-различных статистических данных, f для статистики функциональной зависимости, а также m для статистики списка наиболее часто встречающихся значений (MCV) |
pg_statistic_ext запись полностью заполняется при выполнении команды CREATE STATISTICS, но фактические статистические значения не вычисляются. Последующие команды ANALYZE вычисляют требуемые значения и заполняют запись в каталоге pg_statistic_ext_data.
pg_statistic_ext_data
Каталог pg_statistic_ext_data содержит данные для расширенной статистики планировщика, определенной в pg_statistic_ext. Каждая строка в этом каталоге соответствует объекту статистики, созданному с помощью команды CREATE STATISTICS.
Так же как pg_statistic, pg_statistic_ext_data этот каталог не должен быть доступен для чтения всем пользователям, поскольку его содержимое может считаться конфиденциальным. (Пример: наиболее распространенные комбинации значений в столбцах базы данных могут предоставлять определённый интерес.) pg_stats_ext-это доступное для чтения представление (view) bp pg_statistic_ext_data (после соединения с pg_statistic_ext) которое предоставляет только информацию о тех таблицах и столбцах, которые могут быть прочитаны текущим пользователем.
pg_statistic_ext_data столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| stxoid | oid | pg_statistic_ext.oid | Расширенный статистический объект, содержащий определение для данных |
| stxdndistinct | pg_ndistinct | количество значений сохранённая как тип pg_ndistinct | |
| stxddependencies | pg_dependencies | Статистика функциональных зависимостей, сохранённая как тип pg_dependenciesп | |
| stxdmcv | pg_mcv_list | Статистика списка MCV (most-common values), сохранённая как тип pg_mcv_list Тип |
pg_subscription
Каталог pg_subscription содержит все существующие подписки на логическую репликацию.
В отличие от большинства системных каталогов, pg_subscription является общим для всех баз данных кластера: существует только одна копия pg_subscription на кластер, а не по одному на каждую базу данных.
Доступ к колонке subconninfo отзывается у обычных пользователей, поскольку он может содержать простые текстовые пароли.
pg_subscription столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| subdbid | oid | pg_database.oid | OID базы данных, в которой находится подписка |
| subname | name | Название подписки | |
| subowner | oid | pg_authid.oid | Владелец подписки |
| subenabled | bool | Если задано значение true, подписка включена и должна реплицироваться. | |
| subsynccommit | text | Содержит значение параметра настройка synchronous_commit для процессов подписки. | |
| subconninfo | text | Строка подключения к вышестоящей базе данных | |
| subslotname | name | Имя слота репликации в вышестоящей базе данных. Также используется при локальной репликации имя источника. | |
| subpublications | text[] | Массив подписанных имен публикаций которые ссылаются на публикации на сервере. |
pg_subscription_rel
Каталог pg_subscription_rel содержит состояние для каждого реплицируемого отношения в каждой подписке. Это отображение хранится как многие-ко-многим.
Этот каталог содержит только таблицы, известные подписке после выполнения команды CREATE SUBSCRIPTION или ALTER SUBSCRIPTION или REFRESH PUBLICATION.
pg_subscription_rel столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| srsubid | oid | pg_subscription.oid | Ссылка на подписку |
| srrelid | oid | pg_class.oid | Ссылка на связь |
| srsubstate | char | Код состояния: i = инициализация, d = данные копируются, s = синхронизированно, r = готов (нормальная репликация) | |
| srsublsn | pg_lsn | LSN принимающей стороны для состояния s и r. |
pg_tablespace
Каталог pg_tablespace хранит информацию о доступных табличных пространствах. Таблицы могут быть размещены в определенных табличных пространствах для облегчения администрирования хранилища.
В отличие от большинства системных каталогов, pg_tablespace является общим для всех баз данных кластера - существует только одна копия pg_tablespace на кластер, а не по одному на каждую базу данных.
pg_tablespace столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| spcname | name | Имя табличного пространства | |
| spcowner | oid | pg_authid.oid | Владелец табличного пространства, обычно пользователь, который его создал |
| spcacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации | |
| spcoptions | text[] | Параметры табличного пространства, в виде строки "ключ=значение" |
pg_transform
Каталог pg_transform хранит информацию о преобразованиях, которые являются механизмом для адаптации типов данных к процедурным языкам.
pg_transform столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| trftype | oid | pg_type.oid | OID типа данных, для которого предназначено это преобразование |
| trflang | oid | pg_language.oid | OID языка, для которого это преобразование предназначено |
| trffromsql | regproc | pg_proc.oid | OID функции, используемый при преобразовании типа данных для передачи в процедурный язык (например, параметры функции). Ноль - если эта операция не поддерживается. |
| trftosql | regproc | pg_proc.oid | OID функции, используемый при преобразовании полученных из процедурного языка (например, возвращаемых значений) в тип данных. Ноль - если эта операция не поддерживается. |
pg_trigger
Каталог pg_trigger содержит информацию о триггерах в таблицах и представлениях.
pg_trigger столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| tgrelid | oid | pg_class.oid | Таблица, в которой находится этот триггер |
| tgname | name | Имя триггера (должно быть уникальным среди триггеров одной таблицы) | |
| tgfoid | oid | pg_proc.oid | Вызываемая функция |
| tgtype | int2 | Битовая маска, идентифицирующая условия срабатывания триггера | |
| tgenabled | char | Элементы управления, для которых срабатывает триггер в режиму session_replication_role . О = триггер срабатывает в режимах origin и local, D = триггер отключен, R = триггер срабатывает в режиме replica, A = триггер срабатывает всегда. | |
| tgisinternal | bool | True, если триггер генерируется внутри системы (обычно для принудительного применения ограничения, определенного tgconstraint) | |
| tgconstrrelid | oid | pg_class.oid | Таблица, на которую ссылается ограничение ссылочной целостности |
| tgconstrindid | oid | pg_class.oid | Индекс, поддерживающий ограничение уникальности, первичного ключа, ссылочной целостности или исключения |
| tgconstraint | oid | pg_constraint.oid | pg_constraint запись, связанная с триггером, если таковая имеется |
| tgdeferrable | bool | True, если триггер ограничения является отложенным | |
| tginitdeferred | bool | True, если триггер ограничения изначально отложен | |
| tgnargs | int2 | Количество строк аргументов, переданных в функцию trigger | |
| tgattr | int2vector | pg_attribute.attnum | Номера столбцов, если триггер является специфичным для столбца - в противном случае пустой массив |
| tgargs | bytea | Строки аргументов для передачи триггеру, завершается NULL | |
| tgqual | pg_node_tree | Дерево выражений (nodeToString() представление) для условие триггера WHEN, или NULL, если условия нет | |
| tgoldtable | name | имя предложения REFERENCING для СТАРОЙ ТАБЛИЦЫ, или NULL, если нет | |
| tgnewtable | name | имя предложения REFERENCING для НОВОЙ ТАБЛИЦЫ, или NULL, если условия нет |
В настоящее время специфичный для столбца запуск триггера поддерживается только для UPDATE события, соот. tgattr актуально только для этого типа событий. tgtype может также содержать биты для других типов событий, но они считаются независимы от того, что находится внутри tgattr.
Примечание!!!
Когда tgconstraint ненулевое значение оно ссылается на строки из pg_constraint, т.о. tgconstrrelid, tgconstrindid, tgdeferrable, и tginitdeferred избыточны . Тем не менее, возможно, что не отложенный триггер будет связан с ограничением deferrable - ограничения внешнего ключа могут иметь некоторые отложенные и некоторые не отложенные триггеры.
Примечание!!!
pg_class.relhastriggers должно быть true, если отношение имеет какие-либо триггеры в этом каталоге.
pg_ts_config
Каталог *pg_ts_config содержит записи конфигурации полнотекстового поиска. Конфигурация задает определенный синтаксический анализатор полнотекстового поиска и список словарей, которые будут использоваться для каждого из типов выходных маркеров синтаксического анализатора. Синтаксический анализатор хранится в записи pg_ts_config, но сопоставление токен-словарь определяется дочерними записями в pg_ts_config_map.
pg_ts_config столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| cfgname | name | Имя конфигурации текстового поиска | |
| cfgnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего эту конфигурацию |
| cfgowner | oid | pg_authid.oid | Владелец конфигурации |
| cfgparser | oid | pg_ts_parser.oid | OID синтаксического анализатора текстового поиска для этой конфигурации |
pg_ts_config_map
Каталог pg_ts_config_map содержит записи, показывающие, с какими словарями текстового поиска следует обращаться и в каком порядке, для каждого типа выходного токена синтаксического анализатора каждой конфигурации текстового поиска.
pg_ts_config_map столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| mapcfg | oid | pg_ts_config.oid | OID записи из pg_ts_config, владеющий этим отображением |
| maptokentype | integer | Тип маркера, создаваемого синтаксическим анализатором конфигурации | |
| mapseqno | integer | Порядок, в котором следует ознакомиться с этой записью (ниже mapseqnos первый) | |
| mapdict | oid | pg_ts_dict.oid | OID словаря текстового поиска для консультации |
pg_ts_dict
Каталог pg_ts_dict содержит записи, определяющие словари текстового поиска. Словарь зависит от шаблона текстового поиска, который задает все необходимые функции реализации - сам словарь предоставляет значения для настраиваемых пользователем параметров, поддерживаемых шаблоном. Такое разделение позволяет создавать словари непривилегированным пользователям. Параметры задаются текстовой строкой dictinitoption, формат и значение которой различаются в зависимости от шаблона.
pg_ts_dict столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| dictname | name | Название словаря текстового поиска | |
| dictnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот словарь |
| dictowner | oid | pg_authid.oid | Владелец словаря |
| dicttemplate | oid | pg_ts_template.oid | OID шаблона текстового поиска для этого справочника |
| dictinitoption | text | Строка параметра инициализации для шаблона |
pg_ts_parser
Каталог pg_ts_parser содержит записи, определяющие синтаксические анализаторы текстового поиска. Синтаксический анализатор отвечает за разбиение входного текста на лексемы и присвоение каждой лексеме типа токена. Поскольку синтаксический анализатор должен быть реализован с помощью функций на языке C\RUST, создание новых синтаксических анализаторов возможно только для суперпользователей базы данных.
pg_ts_parser столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| prsname | name | Имя синтаксического анализатора для поиска текста | |
| prsnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот синтаксический анализатор |
| prsstart | regproc | pg_proc.oid | OID функции запуска синтаксического анализатора |
| prstoken | regproc | pg_proc.oid | OID функции поиска следующего маркера синтаксического анализатора |
| prsend | regproc | pg_proc.oid | OID функции завершения работы синтаксического анализатора |
| prsheadline | regproc | pg_proc.oid | OID функции заголовка синтаксического анализатора |
| prslextype | regproc | pg_proc.oid | OID функции анализатора лексического типа |
pg_ts_template
Каталог pg_ts_template содержит записи, определяющие шаблоны текстового поиска. Шаблон-это скелет реализации для класса словарей текстового поиска. Поскольку шаблон должен быть реализован с помощью функций на языке C\RUST, создание новых шаблонов возможно только для суперпользователей базы данных.
pg_ts_template столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| tmplname | name | Имя шаблона текстового поиска | |
| tmplnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот шаблон |
| tmplinit | regproc | pg_proc.oid | OID функции инициализации шаблона |
| tmpllexize | regproc | pg_proc.oid | OID функции лексера |
pg_type
Каталог pg_type хранит информацию о типах данных. Базовые типы и типы перечислений (скалярные типы) создаются с помощью CREATE TYPE, а домены-с помощью CREATE DOMAIN. Составной тип автоматически создается для каждой таблицы в базе данных, чтобы представить структуру строк таблицы. Кроме того, можно создать составные типы с помощью CREATE TYPE AS.
pg_type столбцы
| Имя | Тип | Ссылка | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| typname | name | Имя типа данных | |
| typnamespace | oid | pg_namespace.oid | OID пространства имен, содержащего этот тип |
| typowner | oid | pg_authid.oid | Владелец данного типа |
| typlen | int2 | Для типа фиксированного размера, typlen это число байтов во внутреннем представлении типа. Для типа переменной длины, typlen отрицательный. -1 указывает на тип "varlena" (тип переменного размера с указанием длины), -2 указывает на C-строку завершающуюся нулевым символом. | |
| typbyval | bool | typbyval определяет, будут ли внутренние функции передавать значение этого типа по значению или по ссылке. typbyval предпочтительно иметь значение false - если typlen это не 1, 2 или 4 (или 8 на машинах, где Datum составляет 8 байт). Типы переменной длины всегда передаются по ссылке. Обратите внимание, что typbyval может быть false, даже если длина позволит передачу по значению. | |
| typtype | char | typtype имеет значения b для базового типа, s для составного типа (например, тип строки таблицы), d для домена, e для перечислимого типа, p для псевдо-типа, или r для типа диапазона. См/ также typrelid и typbasetype. | |
| typcategory | char | typcategory это произвольная классификация типов данных, которая используется синтаксическим анализатором для определения того, какие неявные приведения должны быть “предпочтительными”. См typcategory Коды. | |
| typispreferred | bool | True, если тип является предпочтительным объектом приведения в пределах его typcategory | |
| typisdefined | bool | True, если тип определен, false, если это запись "заготовка" для еще не определенного типа. Когда typisdefined имеет значение false, ни на что, кроме имени типа, пространства имен и OID, нельзя полагаться. | |
| typdelim | char | Символ, который разделяет два значения этого типа при разборе данных массива. Обратите внимание, что разделитель связан с типом данных элемента массива, а не с самим типом массив. | |
| typrelid | oid | pg_class.oid | Если это составной тип (см. typtype), то этот столбец указывает на то, запись из pg_class которая определяет соответствующую таблицу. (Для отдельно стоящего композитного типа: запись из pg_class на самом деле не представляет собой таблицу, но она все равно необходима для записи из pg_attribute для ссылки на них.) Для несоставных типов значение столбца - Ноль. |
| typelem | oid | pg_type.oid | Если typelem не равно 0, то он ссылается на другую строку в pg_type. В этом случае текущий тип может использоваться как массив, значений типа typelem. "Настоящий" массив при этом имеет переменную длину (typlen = -1), но некоторые типы фиксированной длины (typlen > 0) также имеют ненулевое значение typelem, например Name и Point. Если для типа фиксированной длины задан typelem тогда его внутреннее представление должно быть некоторым количеством значений (кортежем) с типом данных typelem без каких-либо других данных. Типы массивов переменной длины имеют заголовок, определяемый подпрограммами массива. |
| typarray | oid | pg_type.oid | Если typarray не равно 0, то он ссылается на другую строку в pg_type, которая и является ”настоящим" массивом, с этотим типом в качестве элемента |
| typinput | regproc | pg_proc.oid | Функция преобразования ввода (из текста) |
| typoutput | regproc | pg_proc.oid | Функция преобразования вывода (в текст) |
| typreceive | regproc | pg_proc.oid | Функция преобразования ввода (двоичный формат), или 0 если такой функции нет |
| typsend | regproc | pg_proc.oid | Функция преобразования вывода (двоичный формат), или 0, если такой функции нет |
| typmodin | regproc | pg_proc.oid | Функция модификатора ввода, или 0, если тип не поддерживает модификаторы |
| typmodout | regproc | pg_proc.oid | Функция модификатора вывода или 0 для использования стандартного формата |
| typanalyze | regproc | pg_proc.oid | Пользовательская функция ANALYZE, или 0 для использования стандартной функции |
| typalign | char | Показывает требуется ли выравнивание при хранении значения этого типа. Это относится к хранилищу на диске, а также к большинству представлений значения внутри QHB. Когда несколько значений хранятся последовательно, например в представлении строки данных на диске, заполнение числами вставляется перед Datum для этого типа так, чтобы он начинался на указанной границе. Ссылка на выравнивание является началом первого Datum в последовательности. Возможные значения::
ПримечаниеДля типов, используемых в системных таблицах, очень важно, чтобы размер и выравнивание определённые в pg_type были согласованы с тем, как компилятор будет упаковывать столбец в структуру, представляющую строку таблицы. |
|
| typstorage | char | typstorage сообщает о типах varlena (те с typlen = -1) подготовлен ли тип к TOAST и какова должна быть стратегия по умолчанию для атрибутов этого типа. Возможные значения:
Обратите внимание, что столбцы "m" также можно переместить во вторичное хранилище, но только в крайнем случае ("e" и "x" столбцы перемещаются первыми). |
|
| typnotnull | bool | typnotnull представляет собой не нулевое ограничение для типа. Используется только для доменов. | |
| typbasetype | oid | pg_type.oid | Если это домен (см. typtype), тогда typbasetype определяет тип, на котором основан этот вариант. Ноль, если этот тип не является доменом. |
| typtypmod | int4 | Если тип это домен typtypmod нужен для того чтобы задать модификатор приведения к его базовому типу (-1 если базовый тип не typtypmod). -1, если этот тип не является доменом. | |
| typndims | int4 | typndims это число измерений массива из доменов (то есть, если typbasetype является массивом). Ноль для типов, отличных от массива из доменов. | |
| typcollation | oid | pg_collation.oid | typcollation задает параметры сортировки типа. Если тип не поддерживает параметры сортировки, столбец равен нулю. Базовый тип, который поддерживает параметры сортировки будет иметь ненулевое значение, как правило DEFAULT_COLLATION_OID. Домен над типом collatable вкачестве значения может иметь OID параметров сортировки, отличный от базового типа, если он был указан для домена. |
| typdefaultbin | pg_node_tree | Если typdefaultbin не ноль, это то nodeToString() для выражения по умолчанию данного типа. Используется только для доменов. | |
| typdefault | text | typdefault имеет значение null, если тип не имеет связанного значения по умолчанию. Если typdefaultbin не равно нулю, typdefault должно содержать удобочитаемую версию выражения по умолчанию, представленного в typdefaultbin. Если typdefaultbin имеет значение null а typdefault нет, значит typdefault является внешним представлением значения по умолчанию типа, которое может быть подано в функцию преобразования типа для получения константы. | |
| typacl | aclitem[] | Права доступа; смотрите раздел Привилегии для получения дополнительной информации |
В таблице pg_type столбцы перечислены определяемые системой значения следующих параметров: typcategory. Любые будущие дополнения к этому списку также будут прописными буквами ASCII. Все остальные символы ASCII зарезервированы для пользовательских категорий.
| Код | Категория |
|---|---|
| A | Массив |
| B | Булевый тип |
| C | Составной тип |
| D | Типы даты / времени |
| E | Тип enum |
| G | Геометрические типы |
| I | Типы сетевых адресов |
| N | Числовой тип |
| P | Псевдо-типы |
| R | Тип диапазон |
| S | Строковый тип |
| T | Типы Timespan |
| U | Определяемые пользователем типы |
| V | Типы битовых строк |
| X | Неизвестный тип |
pg_user_mapping
Каталог pg_user_mapping содержит сопоставления для локального и удаленного пользователя. Доступ к этому каталогу ограничен для обычных пользователей, используйте вместо этого представление pg_user_mappings.
pg_user_mapping столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| oid | oid | Идентификатор строки | |
| umuser | oid | pg_authid.oid | OID сопоставляемой локальной роли, 0, если пользовательское сопоставление является общедоступным |
| umserver | oid | pg_foreign_server.oid | OID внешнего сервера, содержащий это сопоставление |
| umoptions | text[] | Параметры сопоставления, в виде строки "ключ=значение" |
Системные представления
Помимо системных каталогов, QHB предоставляет ряд встроенных представлений. Некоторые системные представления обеспечивают удобный доступ к некоторым часто используемым запросам в системных каталогах. Другие представления предоставляют доступ к внутреннему состоянию сервера.
Информационная схема (information_schema) предоставляет альтернативный набор представлений, которые перекрывают функциональные возможности системных представлений. Поскольку информационная схема является частью стандарта SQL, а представления, описанные здесь, являются специфичными для QHB, обычно лучше использовать информационную схему, если она предоставляет всю необходимую информацию.
В таблице "системные представления" перечислены системные представления, описанные в этом разделе. Более подробная документация по каждому представлению приведена ниже. Существуют некоторые дополнительные представления, обеспечивающие доступ к результатам работы сборщика статистических данных; они описаны в разделе Сборщик статистики
За исключением тех случаев, когда это отмечено, все представления, описанные здесь, доступны только для чтения.
системные представления
| имя представления | Цель |
|---|---|
| pg_available_extensions | доступные расширения |
| pg_available_extension_versions | доступные версии расширений |
| pg_config | параметры конфигурации во время компиляции |
| pg_cursors | открытый курсор |
| pg_file_settings | сводка содержимого файла конфигурации |
| pg_group | группы пользователей баз данных |
| pg_hba_file_rules | сводка содержимого файла конфигурации проверки подлинности клиента |
| pg_indexes | индексы |
| pg_locks | замки в настоящее время удерживаются или ожидаются |
| pg_matviews | материализованное представление |
| pg_policies | политики |
| pg_prepared_statements | подготовленное заявление |
| pg_prepared_xacts | подготовленные сделки |
| pg_publication_tables | публикации и связанные с ними таблицы |
| pg_replication_origin_status | сведения об источниках репликации, включая ход выполнения репликации |
| pg_replication_slots | сведения о слоте репликации |
| pg_roles | роль базы данных |
| pg_rules | правила |
| pg_seclabels | метка безопасности |
| pg_sequences | последовательности |
| pg_settings | настройка параметров |
| pg_shadow | пользователь базы данных |
| pg_stats | статистика планировщика |
| pg_stats_ext | расширенная статистика планировщика |
| pg_tables | таблицы |
| pg_timezone_abbrevs | сокращения часовых поясов |
| pg_timezone_names | названия часовых поясов |
| pg_user | пользователь базы данных |
| pg_user_mappings | сопоставление пользователей |
| pg_views | число просмотров |
pg_available_extensions
Представление pg_available_extensions содержит список расширений, доступных для установки. См. также каталог pg_extension, в котором отображаются установленные в данный момент расширения.
pg_available_extensions столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | name | Имя расширения |
| default_version | text | Имя версии по умолчанию, или NULL если версия не указана |
| installed_version | text | Версия расширения установленного сейчас, или NULL если расширение не установлено |
| comment | text | Строка комментария из управляющего файла расширения |
Представление pg_available_extensions доступно только для чтения.
pg_available_extensions_versions
Представление pg_available_extension_versions содержит список конкретных версий расширений, доступных для установки. См. также каталог pg_extension, в котором отображаются установленные в данный момент расширения.
pg_available_extension_versions столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | name | Имя расширения |
| version | text | Версия |
| installed | bool | True, если эта версия данного расширения уже установлена |
| superuser | bool | True, если только суперпользователям разрешено устанавливать это расширение |
| relocatable | bool | True, если расширение можно переместить в другую схему |
| schema | name | Имя схемы, в которую необходимо установить расширение, или NULL при частичном или полном перемещении |
| requires | name[] | Имена необходимых для работы расширений (зависимости), или NULL если зависимостей нет |
| comment | text | Строка комментария из управляющего файла расширения |
Представление pg_available_extension_versions доступно только для чтения.
pg_config
Представление pg_config описывает параметры конфигурации во время компиляции текущей установленной версии QHB. Оно предназначено, например, для использования программными пакетами, которые хотят взаимодействовать с QHB, чтобы облегчить поиск необходимых заголовочных файлов и библиотек. Оно предоставляет ту же основную информацию, что и утилита qhb_config из поставки QHB.
По умолчанию, представление pg_config может быть прочитано только суперпользователями.
pg_config столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | text | Имя параметра |
| setting | text | Значение параметра |
pg_cursors
Представление pg_cursors - список курсоров, которые в настоящее время доступны. Курсоры могут быть определены несколькими способами:
-
через оператор DECLARE в SQL
-
через сообщение привязки в сетевом протоколе QHB
-
через интерфейс программирования сервера (SPI), как описано в соот. разделе документации SPI
Представление pg_cursors отображает курсоры, созданные любым из этих средств. Курсоры существуют только в течение транзакции, которая их определяет, если они не были объявлены WITH HOLD. Таким образом, не удерживаемые курсоры присутствуют в представлении только до конца транзакции их создавшей.
Примечание!!!
Курсоры используются в системе для реализации некоторых компонентов QHB, таких как процедурные языки. Поэтому представление pg_cursors может содержать курсоры, которые не были явно созданы пользователем.
pg_cursors столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | text | Имя курсора |
| statement | text | Строка запроса (полностью), отправленная для объявления этого курсора |
| is_holdable | boolean | True если курсор является удерживаемым (то есть он может быть доступен после транзакции, объявшей курсор) - иначе false |
| is_binary | boolean | True если курсор был объявлен BINARY - иначе false |
| is_scrollable | boolean | True если курсор двунаправленный (то есть он позволяет извлекать строки непоследовательным образом)- иначе false |
| creation_time | timestamptz | Время когда был объявлен курсор |
Представление pg_cursors доступно только для чтения.
pg_file_settings
Представление pg_file_settings предоставляет сводку содержимого файла(ов) конфигурации сервера. В этом представлении отображается строка для каждой записи "имя = значение", появляющейся в файлах, с примечаниями, указывающими, может ли это значение быть успешно применено. Дополнительные строки могут отображаться для проблем, не связанных с записью "имя = значение", например синтаксических ошибок в файлах.
Это представление полезно для проверки того, будут ли работать запланированные изменения в файлах конфигурации, или для диагностики предыдущего сбоя. Обратите внимание, что это представление сообщает о текущем содержимом файлов, а не о том, что было применено сервером в последний раз. (Для этого обычно достаточно представления pg_settings).
По умолчанию, представление pg_file_settings может быть прочитано только суперпользователями.
pg_file_settings столбцы
| Имя | Тип | Описание |
|---|---|---|
| sourcefile | text | Полный путь к файлу конфигурации |
| sourceline | integer | Номер строки в файле конфигурации, где появляется запись |
| seqno | integer | Порядок, в котором обрабатываются операции (1..N) |
| name | text | Имя параметра конфигурации |
| setting | text | Значение, которое будет присвоено параметру |
| applied | boolean | True, если значение может быть применено успешно |
| error | text | Если не null - в столбце содержится сообщение об ошибке, указывающее, почему эта запись не может быть применена |
Если файл конфигурации содержит синтаксические ошибки или недопустимые имена параметров, сервер не будет пытаться применить какие-либо параметры из файла, а следовательно, все значения поля applied будут false. В таком случае в представлении будет одна или несколько строк с ненулевым значением error, указывающие на проблему(ы). В противном случае, если это возможно, будут применены отдельные настройки. Если индивидуальный параметр не может быть применен (например, недопустимое значение или параметр не может быть изменен после запуска сервера), он будет иметь соответствующее сообщение в поле error. Другой способ, при котором applied = false означает, что параметр переопределяется более поздней записью для того же имени параметра; этот случай не считается ошибкой, поэтому ничто не появляется в поле error.
Дополнительную информацию о различных способах изменения параметров времени выполнения см. в разделе Настройка параметров
pg_group
Представление pg_group показывает имена и члены всех ролей, которые помечены как not rolcanlogin, т.е. отображает роли как группы.
pg_group столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| groname | name | pg_authid.rolname | Название группы |
| grosysid | oid | pg_authid.oid | ID этой группы |
| grolist | oid[] | pg_authid.oid | Массив, содержащий идентификаторы ролей в этой группе |
pg_hba_file_rules
Представление pg_hba_file_rules предоставляет сводку содержимого файла конфигурации для проверки подлинности клиента, qhb_hba.conf. В этом представлении отображается строка для каждой непустой строки файла, не содержащей комментариев, с примечаниями, указывающими на возможность успешного применения правила.
Это представление может быть полезно для проверки того, будут ли работать запланированные изменения в файле конфигурации проверки подлинности, или для диагностики предыдущего сбоя. Обратите внимание, что это представление сообщает о текущем содержимом файла, а не о том, что было загружено последним сервером.
По умолчанию, представление pg_hba_file_rules может быть прочитано только суперпользователями.
pg_hba_file_rules столбцы
| Имя | Тип | Описание |
|---|---|---|
| line_number | integer | Номер строки этого правила в qhb_hba.conf |
| type | text | Тип соединения |
| database | text[] | Список имен баз данных, к которым применяется данное правило |
| user_name | text[] | Список имен пользователей и ролей, к которым применяется данное правило |
| address | text | Имя хоста или IP-адрес, либо одно из значений all, samehost, или samenet, или null для локальных соединений |
| netmask | text | Маска IP-адреса, или null, если не применимо |
| auth_method | text | Способ аутентификации |
| options | text[] | Параметры, указанные для метода аутентификации, если таковые имеются |
| error | text | Если не null, то сообщение об ошибке, указывающее, почему эта строка не может быть обработана |
Обычно строка, отражающая неверную запись, будет иметь значения только для line_number и error.
pg_indexes
Представление pg_indexes предоставляет доступ к полезной информации о каждом индексе в базе данных.
pg_indexes столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу и индекс |
| tablename | name | pg_class.relname | Имя таблицы, для которой используется индекс |
| indexname | name | pg_class.relname | Имя индекса |
| tablespace | name | pg_tablespace.spcname | Имя табличного пространства, содержащего индекс (null, если пространство по умолчанию для базы данных) |
| indexdef | text | Определение индекса (восстановленная команда CREATE INDEX) |
pg_locks
Представление pg_locks предоставляет доступ к информации о блокировках, удерживаемых активными процессами на сервере базы данных. Дополнительную информацию о блокировке смотрите в разделе посвященном блокировкам
pg_locks содержит одну строку на активный блокируемый объект, запрошенный режим блокировки и соответствующий процесс. Таким образом, один и тот же блокируемый объект может появляться много раз, если несколько процессов удерживают или ожидают блокировки на нем. Однако объект, который в настоящее время не имеет блокировок - не будет отображаться вообще.
Существует несколько различных типов блокируемых объектов: отношения целиком (например, таблицы), отдельные страницы отношений, отдельные кортежи отношений, идентификаторы транзакций (как виртуальные, так и постоянные идентификаторы) и общие объекты базы данных (идентифицируемые классом OID и объектным OID, таким же образом, как и в pg_description или pg_depend). Также запрос на расширение отношения представляется в виде отдельного блокируемого объекта. Кроме того, "необязательные" блокировки могут быть иметь номера, значения которых определяет пользователь.
pg_locks столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| locktype | text | Тип блокируемого объекта: отношение (relation), расширение (extend), Страница (page), кортеж (tuple), транзакция ( transactionid, virtualxid), объект (object), userlock, или необязательная (advisory) | |
| database | oid | pg_database.oid | OID базы данных, в которой существует цель блокировки, или ноль, если цель является общим объектом, или null, если цель является идентификатором транзакции |
| relation | oid | pg_class.oid | OID отношения, на которое направлена блокировка, или null, если цель не является отношением или частью отношения |
| page | integer | Номер страницы, на которую направлена блокировка в пределах отношения, или значение null, если цель не является страницей отношения или кортежем | |
| tuple | smallint | Номер кортежа, на который направлена блокировка внутри страницы, или значение null, если цель не является кортежем | |
| virtualxid | text | Виртуальный идентификатор транзакции, на которую направлена блокировка, или значение null, если цель не является виртуальным идентификатором транзакции | |
| transactionid | xid | Идентификатор транзакции, на которую направлена блокировка, или значение null, если цель не является идентификатором транзакции | |
| classid | oid | pg_class.oid | OID системного каталога, содержащего целевой объект блокировки, или значение null, если целевой объект не является общим объектом базы данных |
| objid | oid | OID для любого столбца | OID целевого объекта блокировки в системном каталоге или значение null, если целевой объект не является общим объектом базы данных |
| objsubid | smallint | Номер столбца, на который направлена блокировка (classid и objid определяет саму таблицу), или ноль, если целевой объект является каким-либо другим общим объектом базы данных, или null, если целевой объект не является общим объектом базы данных | |
| virtualtransaction | text | Виртуальный идентификатор транзакции, которая удерживает или ожидает эту блокировку | |
| pid | integer | Идентификатор серверного процесса (PID), удерживающего или ожидающего эту блокировку, или значение null, если блокировка удерживается подготовленной транзакцией | |
| mode | text | Название режима блокировки, удерживаемого или ожидаемого этим процессом (см. раздел Блокировки на уровне таблицы и раздел Уровень изоляции Serializable) | |
| granted | boolean | True, если блокировка удерживается, false, если блокировка ожидается | |
| fastpath | boolean | True, если блокировка была получена через fastpath, false, если получена через главную таблицу блокировки |
granted имеет значение true в строке, представляющей блокировку, удерживаемую указанным процессом. Значение False указывает, что этот процесс в настоящее время ожидает получения этой блокировки, что означает, что по крайней мере один другой процесс удерживает или ожидает разрешения конфликтного режима блокировки на том же самом заблокированном объекте. Процесс ожидания будет находиться в спящем режиме до тех пор, пока не будет снята другая блокировка (или обнаружена ситуация взаимоблокировки). Один процесс может ожидать получения не более одной блокировки за один раз.
Во время выполнения транзакции серверный процесс удерживает монопольную блокировку виртуального идентификатора транзакции. Если постоянному идентификатору присваивается транзакция (что обычно происходит только в том случае, если транзакция изменяет состояние базы данных), он также удерживает монопольную блокировку на постоянном идентификаторе транзакции до ее завершения. Когда процесс считает необходимым специально дождаться окончания другой транзакции, он делает это, пытаясь получить общую блокировку идентификатора другой транзакции (виртуальный или постоянный идентификатор в зависимости от ситуации). Это произойдет только тогда, когда другая транзакция завершится и освободит свои блокировки.
Хотя кортежи являются блокируемым типом объекта, информация о блокировках на уровне строк хранится на диске, а не в памяти, и поэтому блокировки на уровне строк обычно не отображаются в этом представлении. Если процесс ожидает блокировки уровня строки, он обычно отображается в представлении как Ожидание постоянного идентификатора транзакции текущего держателя блокировки этой строки.
Необязательные блокировки можно приобрести для ключей состоящих из любого одиночного значения bigint или двух integer. Старшая часть отображается в колонке classid, младшая в objid, а objsubid равно 1. Оригинал значения bigint можно собрать заново с помощью выражения (classid::bigint << 32) | objid::bigint. Ключи integer отображаются так: первый в столбце classid колонка, второй в столбце objid, а objsubid равно 2. Фактическое значение ключей зависит от пользователя. Необязательные блокировки являются локальными для каждой базы данных, поэтому столбец database имеет значение для необязательной блокировки.
pg_locks обеспечивает глобальное представление всех блокировок в кластере баз данных, а не только тех, которые относятся к текущей базе данных. Хотя через соединение по столбцу relation с pg_class.oid можно определить заблокированные отношения, это будет правильно работать только для отношений в текущей базе данных (те, для которых столбец database - это либо OID текущей базы данных, либо ноль).
Столбец pid можно соединить со столбцом pid представления pg_stat_activity, что позволяет получить дополнительную информацию о сессии для каждой блокировки, например
SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa
ON pl.pid = psa.pid;
Кроме того, если вы используете подготовленные транзакции, то virtualtransaction столбец можно соединить со столбцом transaction представления pg_prepared_xacts, что позволяет получить дополнительную информацию о подготовленных транзакциях, содержащих блокировки. (Подготовленная транзакция никогда не может ждать блокировки, но она продолжает удерживать блокировки, полученные во время выполнения)
Например:
SELECT * FROM pg_locks pl LEFT JOIN pg_prepared_xacts ppx
ON pl.virtualtransaction = '-1/' || ppx.transaction;
При этом можно получить информацию о том, какие процессы блокируют какие другие процессы путем присоединения pg_locks с самим собой, но у такого соединения много сложных деталей - такой запрос должен был бы кодировать знания о том, какие режимы блокировки конфликтуют с другими. Хуже того, чем pg_locks представление не предоставляет сведения о том, какие процессы опережают другие в очереди ожидания блокировки, а также сведения о том, какие процессы являются параллельными рабочими (workers), выполняющимися от имени каких других сеансов клиента. Это лучше всего использовать при помощи функции pg_blocking_pids() (см. раздел Системные информационные функции и операторы) для определения того, какой процесс (ы) процесс ожидают каких блокировок.
Представление pg_locks отображает данные как из обычного диспетчера блокировки, так и из диспетчера блокировки предикатов, которые являются отдельными системами, кроме того, обычный менеджер блокировки подразделяет свои блокировки на регулярные и быстрые блокировки (fastpath). Т.о. данные в pg_locks не гарантируют полной согласованности. Когда представление запрашивает, данные о блокировках быстрого доступа (с fastpath = true) данные собираются с каждого бэкенда последовательно, не "замораживая" состояние всего менеджера блокировок, поэтому можно устанвить или снять блокировки во время сбора информации. Обратите внимание, что эти блокировки, как известно, не конфликтуют с любой другой блокировкой во время получения информации. После того, как все бэкенды были опрошены для получения быстрых блокировок, оставшаяся часть обычного менеджера блокировок блокируется как единое целое, и согласованный снимок всех оставшихся блокировок собирается атомарно. После разблокировки обычного диспетчера блокировки диспетчер блокировки предикатов точно также блокируется, и все блокировки предикатов собираются как атомарно. Таким образом, за исключением быстрых блокировок, каждый менеджер блокировок будет выдавать последовательные наборы результатов, но поскольку мы не блокируем оба менеджера блокировок одновременно, возможно, что блокировки будут захвачены или освобождены после опроса обычного менеджера блокировок и до опроса менеджера блокировки предикатов.
Блокировка обычного и / или диспетчера блокировки и / или диспетчера предикатов может оказать некоторое влияние на производительность базы данных, если к этому представлению очень часто обращаются. Блокировки удерживаются только в течение минимального количества времени, необходимого для получения данных от менеджеров блокировки, но это полностью не исключает возможность влияния на производительность.
pg_matviews
Представление pg_matviews предоставляет доступ к полезной информации о каждом материализованном представлении в базе данных.
pg_matviews столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей материализованное представление |
| matviewname | name | pg_class.relname | Имя материализованного представления |
| matviewowner | name | pg_authid.rolname | Имя владельца материализованного представления |
| tablespace | name | pg_tablespace.spcname | Имя табличного пространства, содержащего материализованное представление (null, если пространство по умолчанию для базы данных) |
| hasindexes | boolean | True, если материализованное представление имеет (или недавно имело) какие-либо индексы | |
| ISP populated | boolean | True, если материализованное представление заполнено в данный момент | |
| definition | text | Определение материализованного представления (реконструированный запрос SELECT) |
pg_policies
Представление pg_policies предоставляет доступ к полезной информации о каждой политике безопасности на уровне строк в базе данных.
pg_policies столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей табличную политику включено |
| tablename | name | pg_class.relname | Имя таблицы с включённой политикой |
| policyname | name | pg_policy.polname | Название политики |
| polpermissive | text | Является ли эта политика разрешительной или ограничительной? | |
| roles | name[] | Роли, к которым применяется эта политика | |
| cmd | text | Тип команды, к которой применяется политика | |
| qual | text | Выражение, добавленное к условиям барьеров безопасности для запросов, к которым применяется эта политика | |
| with_check | text | Выражение, добавленное в условие WITH CHECK для запросов, которые пытаются добавить строки в эту таблицу |
pg_prepared_statements
Представление pg_prepared_statements отображает все подготовленные инструкции, доступные в текущем сеансе.
pg_prepared_statements содержит одну строку для каждого подготовленного оператора. Строки добавляются в представление при создании нового подготовленного оператора и удаляются при освобождении подготовленного оператора (например, с помощью команды DEALLOCATE).
pg_prepared_statements столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | text | Идентификатор подготовленного заявления |
| statement | text | Строка запроса, отправленная клиентом для создания этого подготовленного оператора. Для подготовленных операторов, созданных с помощью SQL, это оператор PREPARE, представленный клиентом. Для подготовленных операторов, созданных с помощью сетевого протокола, это текст самого подготовленного оператора. |
| prepare_time | timestamptz | Время, в которое был создан prepared оператор |
| parameter_types | regtype[] | Ожидаемые типы параметров для подготовленного оператора в виде массива regtype. OID, соответствующий элементу этого массива, может быть получен путем приведения regtype значение к oid. |
| from_sql | boolean | True, если подготовленный оператор был создан с помощью SQL команды PREPARE - False если оператор было подготовлен через сетевой протокол |
Представление pg_prepared_statements доступно только для чтения.
pg_prepared_xacts
Представление pg_prepared_xacts отображает информацию о транзакциях, которые в настоящее время подготовлены для двухфазной фиксации (см. раздел PREPARE TRANSACTION для получения подробной информации).
pg_prepared_xacts содержит одну строку на подготовленную транзакцию. Запись удаляется при фиксации или откате транзакции.
pg_prepared_xacts столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| transaction | xid | Числовой идентификатор подготовленной транзакции | |
| gid | text | Глобальный идентификатор, присвоенный транзакции | |
| prepared | timestamp with time zone | Время, в которое транзакция была подготовлена к фиксации | |
| owner | name | pg_authid.rolname | Имя пользователя, выполнившего транзакцию |
| database | name | pg_database.datname | Имя базы данных, в которой была выполнена транзакция |
Когда осуществляется доступ к представлению pg_prepared_xacts, внутренние структуры данных диспетчера транзакций на мгновение блокируются, а для отображения d представлении создается копия. Это гарантирует, что представление создает согласованный набор результатов, не блокируя при этом обычные операции дольше, чем это необходимо. Тем не менее, если к этому представлению часто обращаться, это может оказать определенное влияние на производительность базы данных.
pg_publication_tables
Представление pg_publication_tables предоставляет информацию о сопоставлении публикаций и таблиц, которые они содержат. В отличие от базового каталога pg_publication_rel, это представление расширяет список публикаций, определённых как FOR ALL TABLES, таким образом, для таких публикаций будет строка для каждой подходящей таблицы.
pg_publication_tables столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| pubname | name | pg_publication.pubname | Название публикации |
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу |
| tablename | name | pg_class.relname | Имя таблицы |
pg_replication_origin_status
Представление pg_replication_origin_status содержит информацию о том, как далеко продвинулось воспроизведение изменений для определенного источника.
pg_replication_origin_status столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| local_id | oid | pg_replication_origin.roident | внутренний идентификатор узла |
| external_id | text | pg_replication_origin.roname | идентификатор внешнего узла |
| remote_lsn | pg_lsn | Номер LSN исходного узла, до которого были реплицированы данные. | |
| local_lsn | pg_lsn | Номер LSN этого узла, в котором remote_lsn был реплицирован. Используется для очистки записей фиксации транзакции (COMMIT) перед сохранением данных на диске при использовании асинхронных commit. |
pg_replication_slots
Представление pg_replication_slots предоставляет список всех слотов репликации, которые в настоящее время существуют в кластере баз данных, а также их текущее состояние.
pg_replication_slots столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| slot_name | name | Уникальный кластерный идентификатор для слота репликации | |
| plugin | name | Базовое имя разделяемого объекта, содержащего модуль вывода, который использует этот логический слот, или null для физических слотов. | |
| slot_type | text | Тип слота - физический или логический | |
| datoid | oid | pg_database.oid | Идентификатор OID базы данных, с которой связан этот слот, или значение null. Только логические слоты имеют связанную базу данных. |
| database | text | pg_database.datname | Имя базы данных, с которой связан этот слот, или null. Только логические слоты имеют связанную базу данных. |
| temporary | boolean | True, если это слот временной репликации. Временные слоты не сохраняются на диске и автоматически сбрасываются при ошибке или по завершении сеанса. | |
| active | boolean | True, если этот слот в настоящее время активно используется | |
| active_pid | integer | Идентификатор процесса сеанса, использующего этот слот, если слот в настоящее время активно используется. NULL если неактивен. | |
| xmin | xid | Самая старая транзакция, которую этот слот должен сохранить в базе данных. VACUUM не сможет удалить кортежи, удаленные любой более поздней транзакцией. | |
| catalog_xmin | xid | Самая старая транзакция, влияющая на системные каталоги, которые этот слот должен сохранить в базе данных. VACUUM не сможет удалить кортежи каталога, удаленные любой более поздней транзакцией. | |
| restart_lsn | pg_lsn | Адрес (номер LSN) самого старого WAL, который все еще может потребоваться потребителю этого слота и, следовательно, не будет автоматически удален во время контрольных точек. NULL если номер LSN этого слота никогда не был зарезервирован. | |
| confirmed_flush_lsn | pg_lsn | Адрес (номер LSN) до которого потребитель логического слота подтвердил получение данных. Данные старше этого больше не доступны. NULL для физических слотов. |
pg_roles
Представление pg_roles предоставляет доступ к информации о ролях базы данных. Это просто общедоступное представление pg_authid, которое скрывает поле пароля.
pg_roles столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| rolname | name | Имя роли | |
| rolsuper | bool | Роль имеет привилегии суперпользователя | |
| rolinherit | bool | Роль автоматически наследует привилегии ролей, членом которых она является | |
| rolcreaterole | bool | Роль может создавать другие роли | |
| rolcreatedb | bool | Роль может создавать базы данных | |
| rolcanlogin | bool | Роль может войти в систему. То есть эта роль может быть задана в качестве идентификатора авторизации начального сеанса | |
| rolreplication | bool | Роль - это роль репликации. Роль репликации может инициировать подключения репликации и создавать и удалять слоты репликации. | |
| rolconnlimit | int4 | Для ролей, которые могут войти в систему, задает максимальное число одновременных подключений, которые может создать эта роль. -1 означает отсутствие ограничений. | |
| rolpassword | text | Скрытый пароль (всегда читается как ********) | |
| rolvaliduntil | timestamptz | Срок действия пароля (используется только для парольной аутентификации - null, если нет срока действия | |
| rolbypassrls | bool | Роль обходит любую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. | |
| rolconfig | text[] | Значения в роли по умолчанию для переменных конфигурации времени выполнения | |
| oid | oid | pg_authid.oid | Идентификатор роли |
pg_rules
Вид pg_rules предоставляет доступ к полезной информации о правилах перезаписи запросов.
pg_rules столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу |
| tablename | name | pg_class.relname | Имя таблицы, для которой используется правило |
| rulename | name | pg_rewrite.rulename | Название правила |
| definition | text | Определение правила (восстановленная команда создания) |
Из представления pg_rules исключены возможности правил ON SELECT для представлений и материализованных представлений те, которые можно увидеть в pg_views и pg_matviews.
pg_seclabels
Представление pg_seclabels предоставляет информацию о метках безопасности. Это как более простая для запроса версия каталога pg_seclabel.
pg_seclabels столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| objoid | oid | OID для любого столбца | OID объекта, к которому относится эта метка безопасности |
| classoid | oid | pg_class.oid | Идентификатор OID системного каталога, в котором отображается этот объект |
| objsubid | int4 | Для метки безопасности в столбце таблицы это номер столбца (objoid и classoid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. | |
| objtype | text | Тип объекта, к которому применяется эта метка (текст). | |
| objnamespace | oid | pg_namespace.oid | OID пространства имен для этого объекта, если применимо; в противном случае значение NULL. |
| objname | text | Имя объекта, к которому применяется эта метка (текст). | |
| provider | text | pg_seclabel.provider | Поставщик меток, связанный с этой меткой. |
| label | text | pg_seclabel.label | Метка безопасности, применяемая к этому объекту. |
pg_sequences
Представление pg_sequences предоставляет доступ к полезной информации о каждой последовательности в базе данных.
pg_sequences столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей последовательность |
| sequencename | name | pg_class.relname | Имя последовательности |
| sequenceowner | name | pg_authid.rolname | Имя владельца последовательности |
| data_type | regtype | pg_type.oid | Тип данных последовательности |
| start_value | bigint | Начальное значение последовательности | |
| min_value | bigint | Минимальное значение последовательности | |
| max_value | bigint | Максимальное значение последовательности | |
| increment_by | bigint | Значение приращения последовательности | |
| cycle | boolean | Цикличность последовательности (возможность) | |
| cache_size | bigint | Размер кэша последовательности | |
| last_value | bigint | Последнее значение последовательности, записанное на диск. Если используется кэширование, это значение может быть больше, чем последнее значение, выдаваемое из последовательности. Значение Null, если последовательность еще не была прочитана. Кроме того, если текущий пользователь не имеет прав USAGE или SELECT на последовательность, значение равно null. |
pg_settings
Представление pg_settings предоставляет доступ к параметрам времени выполнения сервера. Это по существу альтернативный интерфейс к командам SHOW и SET. Оно также предоставляет доступ к некоторым фактам о каждом параметре, которые непосредственно не доступны из SHOW, таким как минимальные и максимальные значения.
pg_settings столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | text | Имя параметра конфигурации времени выполнения |
| setting | text | Текущее значение параметра |
| unit | text | Неявная единица измерения параметра |
| category | text | Логическая группа параметра |
| short_desc | text | Краткое описание параметра |
| extra_desc | text | Дополнительное, более детальное, описание параметра |
| context | text | Контекст, необходимый для установки значения параметра (см. ниже) |
| vartype | text | Тип параметра (bool, перечисление, integer, real, или строка) |
| source | text | Источник текущего значения параметра |
| min_val | text | Минимальное допустимое значение параметра (null для нечисловых значений) |
| max_val | text | Максимально допустимое значение параметра (null для нечисловых значений) |
| enumvals | text[] | Допустимые значения параметра enum (null для значений, отличных от enum) |
| boot_val | text | Значение параметра принимается при запуске сервера, если параметр не задан иным образом |
| reset_val | text | Значение, которое будет сброшено для параметра в текущем сеансе |
| sourcefile | text | Файл конфигурации в котором текущее значение было установлено (null для значений, заданных из источников, отличных от файлов конфигурации, или при проверке пользователем, который не является ни суперпользователем, ни членом pg_read_all_settings); полезно при использовании использовать директивы include в файлах конфигурации |
| sourceline | integer | Номер строки в файле конфигурации в котором текущее значение было установлено (null для значений, заданных из источников, отличных от файлов конфигурации, или при проверке пользователем, который не является ни суперпользователем, ни членом pg_read_all_settings). |
| pending_restart | boolean | True если значение было изменено в файле конфигурации, но нуждается в перезапуске; иначе False. |
Существует несколько возможных значений: контекста. В порядке уменьшения сложности изменения настроек, ими являются:
internal
Эти параметры не могут быть изменены непосредственно; они отражают внутренне определенные значения. Некоторые из них могут быть изменены через изменения параметров, предоставляемых в qhb_bootstrap.
postmaster
Эти параметры могут применяться только при запуске сервера, поэтому любое изменение требует перезагрузки сервера. Значения для этих параметров обычно хранятся в qhb.conf файл, либо передаются в командной строке при запуске сервера. Конечно же, настройки с любым из нижеследующих контекстов типы также могут быть установлены во время запуска сервера.
sighup
Изменения в этих настройках могут быть внесены в qhb.conf без
перезагрузки сервера. Пошлите сигнал SIGHUP к qhbmaster для того
чтобы перечитать qhb.conf и применить изменения.
Qhbmaster также переадресует сигнал SIGHUP своим дочерним процессам,
чтобы все они приняли новое значение.
superuser-backend
Изменения в этих настройках могут быть внесены в qhb.conf без перезагрузки сервера. Они также могут быть установлены для определенного сеанса в пакете запроса на подключение (например, через переменную окружения PGOPTIONS), но только если подключающийся пользователь является суперпользователем. Однако эти параметры никогда не изменяются в сеансе после его запуска. Если вы измените их внутри qhb.conf, необходимо отправить сигнал SIGHUP к qhbmaster, для того чтобы инициировать перечитывание qhb.conf. Новые значения будут влиять только на последующие запущенные сеансы.
backend
Изменения в этих настройках могут быть внесены в qhb.conf без перезагрузки сервера. Они также могут быть установлены для определенного сеанса в пакете запроса на подключение (например, через переменную окружения PGOPTIONS); любой пользователь может внести такое изменение для своей сессии. Однако эти параметры никогда не изменяются в сеансе после его запуска. Если вы измените их внутри qhb.conf, пошлите сигнал SIGHUP к qhbmaster для того чтобы инициировать перечитывание qhb.conf. Новые значения будут влиять только на последующие запущенные сеансы.
superuser
Эти настройки можно установить из qhb.conf, или в течение сеанса с помощью команды SET; но только суперпользователи могут изменить их с помощью SET. Изменения в составе qhb.conf будет влиять на существующие сеансы только в том случае, если не было установлено значение session-local с WITH SET.
user
Эти настройки можно установить из qhb.conf, или в течение сеанса с помощью команды SET. Любой пользователь может изменить свое локальное значение сеанса. Изменения в составе qhb.conf будет влиять на существующие сеансы только в том случае, если не было установлено значение session-local с WITH SET.
Представление pg_settings не может быть вставлено или удалено, но его можно обновить. UPDATE, для pg_settings эквивалентен выполнению команды SET для этого именованного параметра. Это изменение влияет только на значение, используемое в текущем сеансе. Если обновление выполняется в рамках транзакции, которая позже прерывается, последствия команды UPDATE исчезают при откате транзакции. После фиксации окружающей транзакции эффекты будут сохраняться до конца сеанса, если только они не будут переопределены другим UPDATE или SET.
pg_shadow
Представление pg_shadow показывает свойства всех ролей, которые помечены как rolcanlogin в pg_authid.
Это имя связано с тем, что эта таблица не должна быть доступна для чтения любыми пользователями, поскольку она содержит пароли. pg_user-это доступное всем представление для pg_shadow, но со скрытым полем пароля.
pg_shadow столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| usename | name | pg_authid.rolname | Имя пользователя |
| usesysid | oid | pg_authid.oid | ID этого пользователя |
| usecreatedb | bool | Пользователь может создавать базы данных | |
| usesuper | bool | Пользователь является суперпользователем | |
| userepl | bool | Пользователь может инициировать потоковую репликацию и вывести систему из режима резервного копирования. | |
| usebypassrls | bool | Пользователь игнорирует любую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. | |
| passwd | text | Пароль (возможно зашифрованный); null, если нет. Смотрите pg_authid для получения подробной информации о том, как хранятся зашифрованные пароли. | |
| valuntil | timestamptz | Срок действия пароля (используется только для аутентификации пароля) | |
| useconfig | text[] | Значения по умолчанию сеанса для переменных конфигурации времени выполнения |
pg_stats
Представление pg_stats предоставляет доступ к информации, хранящейся в каталоге pg_statistic. Это представление позволяет получить доступ только к строкам pg_statistic это соответствует таблицам, на которые у пользователя есть разрешение для чтения, и поэтому безопасно разрешать публичный доступ для чтения к этому представлению.
pg_stats также предназначена для представления информации в более удобочитаемом формате, чем базовый каталог — за счет того, что его схема должна быть расширена всякий раз, когда определяются новые типы слотов для pg_statistic.
pg_stats столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу |
| tablename | name | pg_class.relname | Имя таблицы |
| attname | name | pg_attribute.attname | Имя столбца, описываемого этой строкой |
| inherited | bool | Если true, то эта строка содержит дочерние столбцы наследования, а не только значения в указанной таблице | |
| null_frac | real | Доля записей столбцов, имеющих значение null | |
| avg_width | integer | Средняя ширина в байтах записей столбца | |
| n_distinct | real | Если больше нуля, то показывает примерное число различных значений в столбце. Если меньше нуля, то модуль числа показывает количество различных значений разделённое на число строк. (Отрицательная форма используется, когда ANALYZE считает, что число различных значений, вероятно, будет увеличиваться по мере роста таблицы; положительная форма используется, когда считается, что столбец имеет фиксированное число возможных значений.) Например, значение -1 указывает на уникальный столбец, в котором число различных значений совпадает с числом строк. | |
| most_common_vals | anyarray | Список наиболее распространенных значений в столбце. (Null, если никакие значения не более распространенны, чем любые другие.) | |
| most_common_freqs | real[] | Список частот наиболее частых значений, т. е. количество вхождений каждого значения делится на общее количество строк. (Null, если most_common_vals тоже null.) | |
| histogram_bounds | anyarray | Список значений, разделяющих значения столбца на группы примерно одинаковой наборы называемые "популяции". Значения внутри most_common_vals, если они присутствует, то они исключаются из этого расчета гистограммы. (Столбец имеет значение null, если тип данных столбца не имеет оператора < или если most_common_vals список охватывает все популяции.) | |
| correlation | real | Статистическая корреляция между физическим упорядочением строк и логическим упорядочением значений столбцов. Значение колеблется от -1 до +1. Когда значение близко к -1 или +1, сканирование индекса по столбцу будет оценено как более дешевое, чем когда оно близко к нулю, из-за уменьшения случайного доступа к диску. (Столбец имеет значение null, если тип данных столбца не имеет оператора <.) | |
| most_common_elems | anyarray | Список ненулевых значений элементов, наиболее часто появляющихся в пределах значений столбца. (Null для скалярных типов.) | |
| most_common_elem_freqs | real[] | Список частот наиболее распространенных значений элементов, т. е. доля строк, содержащих хотя бы один экземпляр данного значения. Два или три дополнительных значения следуют за частотами каждого элемента; это минимум и максимум предыдущих частот каждого элемента и, возможно, частота нулевых элементов. (Null, когда заполнен most_common_elems.) | |
| elem_count_histogram | real[] | Гистограмма подсчетов различных ненулевых значений элементов в пределах значений столбца, за которыми следует среднее число различных ненулевых элементов. (Null для скалярных типов.) |
Максимальное число записей в полях массива можно контролировать по столбцам с помощью команды ALTER TABLE SET STATISTICS или глобально, задавая параметр времени выполнения default_statistics_target.
pg_stats_ext
Представление pg_stats_ext предоставляет доступ к информации, хранящейся в каталогах pg_statistic_ext и pg_statistic_ext_data. Это представление позволяет получить доступ к строкам pg_statistic_ext и pg_statistic_ext_data которые соответствует таблицам, для которые у пользователя есть разрешение на чтение, и поэтому безопасно разрешить доступ на чтение к этому представлению.
pg_stats_ext также предназначена для представления информации в более удобочитаемом формате, чем базовые каталоги — и потому должна быть расширена всякий раз, когда добавляются новые типы расширенной статистики pg_statistic_ext.
pg_stats_ext столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу |
| tablename | name | pg_class.relname | Имя таблицы |
| statistics_schemaname | name | pg_namespace.nspname | Имя схемы, содержащей расширенную статистику |
| statistics_name | name | pg_statistic_ext.stxname | Наименование расширенной статистики |
| statistics_owner | oid | pg_authid.oid | Владелец расширенной статистики |
| attnames | name[] | pg_attribute.attname | Имена столбцов, на которых определяется расширенная статистика |
| kinds | text[] | Типы расширенной статистики, включенной для этой записи | |
| n_distinct | pg_ndistinct | Если больше нуля, то показывает примерное число различных значений в столбце. Если меньше нуля, то модуль числа показывает количество различных значений разделённое на число строк. (Отрицательная форма используется, когда ANALYZE считает, что число различных значений, вероятно, будет увеличиваться по мере роста таблицы; положительная форма используется, когда считается, что столбец имеет фиксированное число возможных значений.) Например, значение -1 указывает на уникальный столбец, в котором число различных значений совпадает с числом строк. | |
| dependencies | pg_dependencies | Статистика для функциональной зависимости | |
| most_common_vals | anyarray | Список наиболее распространенных комбинаций значений в столбцах. (Null, если никакие комбинации не считаются более распространенными, чем любые другие.) | |
| most_common_val_nulls | anyarray | Список нулевых флагов для наиболее распространенных комбинаций значений. (Null, если задан most_common_vals) | |
| most_common_freqs | real[] | Список частот наиболее распространенных комбинаций, т. е. количество вхождений каждой делится на общее количество строк. (Null, если задан most_common_vals) | |
| most_common_base_freqs | real[] | Список базовых частот наиболее распространенных комбинаций, т. е. произведение частот на значение. (Null, если задан most_common_vals) |
Максимальное число записей в полях массива можно контролировать для столбцов с помощью команды ALTER TABLE SET STATISTICS или глобально, задавая параметр времени выполнения default_statistics_target.
pg_tables
Представление pg_tables предоставляет доступ к полезной информации о каждой таблице в базе данных.
pg_tables столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей таблицу |
| tablename | name | pg_class.relname | Имя таблицы |
| tableowner | name | pg_authid.rolname | Имя владельца таблицы |
| tablespace | name | pg_tablespace.spcname | Имя табличного пространства, содержащего таблицу (null, если пространство по умолчанию для базы данных) |
| hasindexes | boolean | pg_class.relhasindex | True, если таблица имеет (или недавно имела) какие-либо индексы |
| hasrules | boolean | pg_class.relhasrules | True, если таблица имеет (или когда-то имела) правила |
| hastriggers | boolean | pg_class.реластриггеры | True, если таблица имеет (или когда-то имела) триггеры |
| rowsecurity | boolean | pg_class.relrowsecurity | True, если в таблице включена защита строк |
pg_timezone_abbrevs
Представление pg_timezone_abbrevs предоставляет список сокращений часовых поясов, которые в настоящее время распознаются как корректные для функций datetime. Содержание этого представления изменяется при изменении параметра времени выполнения timezone_abbreviations.
pg_timezone_abbrevs столбцы
| Имя | Тип | Описание |
|---|---|---|
| abbrev | text | Аббревиатура часового пояса |
| utc_offset | интервал | Смещение от UTC (положительное значение означает на восток от Гринвича) |
| is_dst | boolean | True, если это аббревиатура необходима для перехода на летнее время |
Хотя большинство сокращений часовых поясов представляют собой фиксированные смещения от UTC, есть некоторые, которые исторически менялись в таких случаях этот представление содержит их текущее значение.
pg_timezone_names
Представление pg_timezone_names предоставляет список имен часовых поясов, которые распознаются командой SET TIMEZONE, а также связанные с ними сокращения, смещения UTC и состояние летнего времени. (Технически QHB не использует UTC, потому что координация для високосных секунд не обрабатываются). В отличие от сокращений, показанных в pg_timezone_abbrevs, многие из этих имен подразумевают набор правил перехода на летнее время. Таким образом, связанная информация изменяется через локальные границы для летнего времени. Отображаемая информация вычисляется на основе текущего значения параметра CURRENT_TIMESTAMP.
pg_timezone_names столбцы
| Имя | Тип | Описание |
|---|---|---|
| name | text | Название часового пояса |
| abbrev | text | Аббревиатура часового пояса |
| utc_offset | интервал | Смещение от UTC (положительное значение означает восток от Гринвича) |
| is_dst | boolean | True, если в настоящее время наблюдается переход на летнее время |
pg_user
Представление pg_user доступ к информации о пользователях базы данных. Это просто общедоступное представление pg_shadow которое скрывает поле пароля.
pg_user столбцы
| Имя | Тип | Описание |
|---|---|---|
| usename | name | Имя пользователя |
| usesysid | oid | ID этого пользователя |
| usecreatedb | bool | Пользователь может создавать базы данных |
| usesuper | bool | Пользователь является суперпользователем |
| userepl | bool | Пользователь может инициировать потоковую репликацию и вывести систему из режима резервного копирования. |
| usebypassrls | bool | Пользователь обходит каждую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. |
| passwd | text | Не пароль (всегда читается как ********) |
| valuntil | timestamptz | Срок действия пароля (используется только для парольной аутентификации) |
| useconfig | text[] | Значения по умолчанию сеанса для переменных конфигурации времени выполнения |
pg_user_mappings
Представление pg_user_mappings доступ к информации о сопоставлениях пользователей. Это по существу общедоступное представление pg_user_mapping, которое оставляет столбец umoptions, если у пользователя нет прав на его использование.
pg_user_mappings столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| umid | oid | pg_user_mapping.oid | OID сопоставления пользователей |
| srvid | oid | pg_foreign_server.oid | OID внешнего сервера, содержащий это сопоставление |
| srvname | name | pg_foreign_server.srvname | Имя внешнего сервера |
| umuser | oid | pg_authid.oid | OID сопоставляемой локальной роли, 0, если пользовательское сопоставление является общедоступным |
| usename | name | Имя локального пользователя для сопоставления | |
| umoptions | text[] | Пользователь сопоставляет определенные параметры, в виде строки "ключ=значение" |
Чтобы защитить информацию о пароле, сохраненную в качестве параметра сопоставления пользователей, umoptions столбец будет считываться как null, если не применяется одно из следующих условий:
-
текущий пользователь-это сопоставляемый пользователь, который владеет сервером или имеет USAGE для него
-
текущий пользователь является владельцем сервера и сопоставление для PUBLIC
-
текущий пользователь является суперпользователем
pg_views
Представление pg_views предоставляет доступ к полезной информации о каждом представлении (view) в базе данных.
pg_views столбцы
| Имя | Тип | Ссылки | Описание |
|---|---|---|---|
| schemaname | name | pg_namespace.nspname | Имя схемы, содержащей представление |
| viewname | name | pg_class.relname | Имя представления |
| viewowner | name | pg_authid.rolname | Имя владельца объекта (view) |
| определение | text | Определение представления (реконструированный запрос SELECT) |
Определение интерфейса метода доступа к таблице
В этой главе описывается интерфейс между основной системой QHB и методами доступа к таблицам (access method), которые управляют хранилищем для таблиц. Основная система мало что знает об этих методах доступа, кроме того, что описано в этой главе. Поэтому можно разработать новые типы методов доступа, написав дополнительный код.
Каждый метод доступа к таблице описывается строкой в системном каталоге pg_am. Запись в pg_am задает имя и функцию-обработчик (handler function) для метода доступа к таблице. Эти записи могут быть созданы и удалены с помощью команд SQL CREATE ACCESS METHOD и DROP ACCESS METHOD.
Функция обработчика метода доступа к таблице должна быть объявлена, чтобы принять один аргумент типа internal и чтобы вернуть псевдо-тип table_am_handler. Аргумент является фиктивным значением, которое необходимо для предотвращения вызова функции непосредственно из команд SQL. Результатом работы функции должен быть указатель на структуру типа TableAmRoutine, который содержит все необходимое для использования метода доступа к таблице. Возвращаемое значение должно иметь время жизни самого сервера, что обычно достигается путем определения его как static const переменной в глобальной области видимости. Структура TableAmRoutine, также называемая API-структурой метода доступа, определяет поведение метода доступа с помощью функций обратного вызовова. Эти обратные вызовы являются указателями на обычные C-функции и не являются видимыми или вызываемыми на уровне SQL. Все обратные вызовы и их поведение определяются в структурe TableAmRoutine (с комментариями внутри структуры, определяющими требования к обратным вызовам). Большинство обратных вызовов имеют оберточные функции, которые документируются для пользователя (а не исполнителя) метода доступа к таблице. Для получения дополнительной информации обратитесь к файлу src/include/access/tableam.h.
Для реализации метода доступа исполнителю, как правило, требуется реализовать определенный для этого метода тип слота таблицы кортежей (см. src/include/executor/tuptable.h), который позволяет реализации иметь ссылки на кортежи метода доступа и получать доступ к столбцам кортежа.
В настоящее время способ, которым метод доступа фактически хранит данные, довольно неограничен. Например, можно, но не обязательно, использовать общий буферный кэш. В случае его использования, вероятно, имеет смысл использовать стандартную структуру страницы QHB, как описано в разделе Внутренняя структура страницы базы данных.
Одно довольно большое ограничение API метода доступа к таблице заключается в том, что в настоящее время, если метод доступа хочет поддерживать модификации и/или индексы, то необходимо, чтобы каждый кортеж имел идентификатор кортежа (TID), состоящий из номера блока и номера элемента (см. также раздел Внутренняя структура страницы базы данных). Нет строгой необходимости в том, чтобы части TIDs имели то же значение, которое они, например, имеют для кучи, но если требуется опциональная поддержка битового сканирования, тогда номер блока должен обеспечивать локальность.
Для обработки аварийного завершения метод доступа может использовать WAL или же пользовательские механизмы. Если выбран параметр WAL, можно использовать Общие записи WAL или реализовать новый тип записей WAL. Общие записи WAL просты, но требуют большего объема данных. Реализация нового типа записи WAL в настоящее время требует внесения изменений в основной код (в частности, src/include/access/rmgrlist.h).
Для реализации транзакционной поддержки таким образом, чтобы различные методы доступа к таблицам были доступны в рамках одной транзакции, вероятно, необходимо тесно интегрироваться с механизмом в src/backend/access/transam/xlog.c.
Любой разработчик нового способа доступа к таблице может обратиться к существующей реализации кучи, которая находится в src/backend/access/heap/ heapam_handler.c.
Определение интерфейса метода доступа к индексу
- Базовая структура API для индексов
- Функции доступа к индексу
- Индексное сканирование
- Вопросы блокировки индекса
- Проверка уникальности индекса
- Функции оценки стоимости индекса
В этой главе описывается интерфейс между ядром QHB и методами доступа к индексам, которые управляют отдельными типами индексов. Ядро системы ничего не знает об индексах, кроме того, что описано здесь, поэтому можно разработать совершенно новые типы индексов, написав дополнительный код.
Все индексы в QHB - это то, что технически известно как вторичные индексы, то есть индекс физически отделен от файла таблицы, который он описывает. Каждый индекс хранится как собственное физическое отношение и описывается записью в каталоге pg_class. Содержание индекса полностью находится под контролем его метода доступа к индексу. На практике все методы доступа к индексам разделяют индексы на страницы стандартного размера, чтобы они могли использовать обычный диспетчер хранилища и диспетчер буферов для доступа к содержимому индекса. (Все существующие методы доступа к индексам, кроме того, используют стандартный макет страницы, описанный в разделе Внутренняя структура страницы базы данных, и большинство используют тот же формат для заголовков индексных записей, но эти решения не являются обязательными для метода доступа).
Индекс это средство эффективного сопоставления некоторых значений ключей с идентификаторами записей (TID) версий строк (записей) в родительской таблице индекса. TID состоит из номера блока и номера записи внутри этого блока (см. раздел Внутренняя структура страницы базы данных). Этой информации достаточно для извлечения определенной версии строки из таблицы. Индексы непосредственно не знают, что при использовании MVCC, может существовать несколько версий одной и той же логической строки; для индекса каждая запись является независимым объектом, который требует своей собственной записи в индексе. Таким образом, обновление строки всегда создает новые записи для всех индексов, в которых участвует запись, даже если значения ключей не изменились. (HOT оптимизация обновления записей является исключением из этого утверждения, но индексы не имеют с ней дело). Индексные записи для мертвых записей в таблице удаляются во время вакуума вместе с удалением самих мертвых записей.
Базовая структура API для индексов
Каждый метод доступа к индексу описывается строкой в системном каталоге pg_am. Запись в pg_am содержит имя и функцию-обработчик метода доступа к индексу. Эти записи могут быть созданы и удалены с помощью SQL команд CREATE ACCESS METHOD и DROP ACCESS METHOD.
Функция-обработчик индексного метода доступа должна принимать один аргумент типа internal и возвращать псевдо-тип index_am_handler. Аргумент является фиктивным значением, предназначенным для предотвращения вызова функций обработчика непосредственно из команд SQL. Результатом работы функции должна быть структура типа IndexAmRoutine, размещенная в куче с помощью palloc и содержащая всё, что ядро должно знать, чтобы использовать метод доступа к индексу. Структура IndexAmRoutine, также называемая API-структурой метода доступа, включает поля, задающие различные фиксированные свойства метода доступа, например, возможность поддержки многоколоночных индексов. Что еще более важно, она содержит указатели на функции, выполняющие всю реальную работу для индексного метода доступа. Эти вспомогательные функции являются простыми функциями на C и не видны и не вызываются на уровне SQL. Вспомогательные функции описаны в разделе Функции доступа к индексу .
Структура IndexAmRoutine определяется таким образом:
typedef struct IndexAmRoutine
{
NodeTag type;
/*
* Total number of strategies (operators) by which we can traverse/search
* this AM. Zero if AM does not have a fixed set of strategy assignments.
*/
uint16 amstrategies;
/* total number of support functions that this AM uses */
uint16 amsupport;
/* does AM support ORDER BY indexed column's value? */
bool amcanorder;
/* does AM support ORDER BY result of an operator on indexed column? */
bool amcanorderbyop;
/* does AM support backward scanning? */
bool amcanbackward;
/* does AM support UNIQUE indexes? */
bool amcanunique;
/* does AM support multi-column indexes? */
bool amcanmulticol;
/* does AM require scans to have a constraint on the first index column? */
bool amoptionalkey;
/* does AM handle ScalarArrayOpExpr quals? */
bool amsearcharray;
/* does AM handle IS NULL/IS NOT NULL quals? */
bool amsearchnulls;
/* can index storage data type differ from column data type? */
bool amstorage;
/* can an index of this type be clustered on? */
bool amclusterable;
/* does AM handle predicate locks? */
bool ampredlocks;
/* does AM support parallel scan? */
bool amcanparallel;
/* does AM support columns included with clause INCLUDE? */
bool amcaninclude;
/* type of data stored in index, or InvalidOid if variable */
Oid amkeytype;
/* interface functions */
ambuild_function ambuild;
ambuildempty_function ambuildempty;
aminsert_function aminsert;
ambulkdelete_function ambulkdelete;
amvacuumcleanup_function amvacuumcleanup;
amcanreturn_function amcanreturn; /* can be NULL */
amcostestimate_function amcostestimate;
amoptions_function amoptions;
amproperty_function amproperty; /* can be NULL */
ambuildphasename_function ambuildphasename; /* can be NULL */
amvalidate_function amvalidate;
ambeginscan_function ambeginscan;
amrescan_function amrescan;
amgettuple_function amgettuple; /* can be NULL */
amgetbitmap_function amgetbitmap; /* can be NULL */
amendscan_function amendscan;
ammarkpos_function ammarkpos; /* can be NULL */
amrestrpos_function amrestrpos; /* can be NULL */
/* interface functions to support parallel index scans */
amestimateparallelscan_function amestimateparallelscan; /* can be NULL */
aminitparallelscan_function aminitparallelscan; /* can be NULL */
amparallelrescan_function amparallelrescan; /* can be NULL */
} IndexAmRoutine;
Чтобы быть полезным, метод доступа к индексу также должен иметь одно или несколько семейств операторов и классов операторов, определенных в pg_opfamily, pg_opclass, pg_amop и pg_amproc. Эти записи позволяют планировщику определить, какие виды запросов могут использоваться с индексами данного метода доступа. Семейства операторов и классы описаны в Интерфейсные расширения для индексов, который является необходимым материалом для чтения этой главы.
Индивидуальный индекс определяется записью в pg_class, описывающей его как физическое отношение, плюс запись в pg_index, показывающей логическое содержимое индекса, то есть набор столбцов входящих в индекс, и семантику этих столбцов, то есть связь с классами операторов. Столбцы индекса (ключевые значения) могут быть либо простыми столбцами таблицы, для которой строится индекс, либо выражениями над строками этой таблицы. Обычно для индексного метода доступа не имеет значения, откуда берутся значения ключей индекса (ему всегда передаются предварительно вычисленные значения ключей), но очень важна информация о классе оператора в pg_index. Обе эти записи каталога могут быть доступны в составе структуры данных Relation, которая передается всем операциям с индексом.
Некоторые из полей флагов структуры IndexAmRoutine имеют нетривиальное назначение. Требования, предъявляемые к amcanunique, обсуждаются в разделе Проверка уникальности индекса. Флаг amcanmulticol утверждает, что метод доступа поддерживает многоколоночные индексы, в то время как amoptionalkey указывает, что метод доступа разрешает сканирование, когда для первого столбца индекса не задано ограничение. Когда amcanmulticol равен false, amoptionalkey, говорит, что метод доступа поддерживает сканирование с полным перебором без каких-либо ограничительных условий. Методы доступа, поддерживающие несколько столбцов в индексе, должны поддерживать сканирования, позволяющие пропускать ограничения для любого или всех столбцов после первого; однако им разрешено требовать, чтобы использовались ограничения для первого столбца индекса, об этом сигнализирует флаг amoptionalkey равный false. Одна из причин, по которой метод доступа может установить значение amoptionalkey равным false, если он не индексирует нулевые значения. Поскольку большинство индексируемых операторов являются строгими и, следовательно, не могут возвращать true, если поле содержит NULL, на первый взгляд кажется правильным не хранить записи индекса для нулевых значений: они никогда не могут быть возвращены при сканировании индекса. Однако этот аргумент неверен, если проверка индекса не содержит условия ограничения для данного столбца индекса. На практике это означает, что индексы, у которых amoptionalkey равным true, должен индексировать значения NULL, так как планировщик может решить использовать такой индекс без ключей сканирования вообще. Связанное с этим ограничение заключается в том, что метод доступа к индексам, поддерживающий несколько столбцов индекса, должен поддерживать индексирование NULL значений в столбцах после первого, поскольку планировщик будет предполагать, что индекс может использоваться для запросов, которые не ограничивают эти столбцы. Например, рассмотрим индекс на (a, b) и запрос с WHERE a = 4. Система будет считать, что индекс может быть использован для сканирования строк с помощью а = 4, что неверно, если индекс пропускает строки, где b - это null. Однако допустимо пропускать строки, в которых первый индексированный столбец имеет значение NULL. Метод доступа к индексу, позволяющий индексировать значения NULL, также может установить значение amsearchnulls в true, указывая, что он поддерживает предложения IS NULL и IS NOT NULL в условиях поиска.
Функции доступа к индексу
Функции построения и обслуживания индекса
Функции построения и обслуживания индекса, которые должен предоставить метод доступа к индексу в структуре IndexAmRoutine:
ambuild
IndexBuildResult *
ambuild (Relation heapRelation,
Relation indexRelation,
IndexInfo *indexInfo);
Создает новый индекс. Отношение индекса физически создано, но является пустым. Метод должен заполнить отношение любыми фиксированными данными, необходимыми для собственного функционирования, а также записями для всех строк, уже существующих в таблице. Обычно функция ambuild будет вызывать table_index_build_scan() для сканирования таблицы на наличие существующих записей и вычисления ключей, которые необходимо вставить в индекс. Функция должна возвращать структуру, размещенную в куче с помощью palloc и содержащую статистику о новом индексе.
ambuildempty
void
ambuildempty (Relation indexRelation);
Создает пустой индекс и записывает его в слой инициализации (INIT_FORKNUM) данного отношения. Этот метод вызывается только для нежурналируемых индексов. Пустой индекс, записанный в слой инициализации, будет скопирован поверх основного слоя отношения при каждом перезапуске сервера.
aminsert
bool
aminsert (Relation indexRelation,
Datum *values,
bool *isnull,
ItemPointer heap_tid,
Relation heapRelation,
IndexUniqueCheck checkUnique,
IndexInfo *indexInfo);
Вставляет новую запись в существующий индекс. Входные массивы values и isnull задают значения ключей для индексирования, heap_tid - это TID для индексации. Если метод доступа поддерживает уникальные индексы (его флаг amcanunique равен true), тогда аргумент checkUnique указывает выполняется или нет проверка уникальности. Это зависит от того, является ли ограничение уникальности откладываемым; смотрите раздел Проверка уникальности индекса для получения подробной информации. Обычно метод доступа требует только параметр heapRelation при выполнении проверки уникальности (так как должен будет заглянуть в таблицу, чтобы проверить живучесть записи).
Логическое значение результата функции является значимым только тогда, когда значение параметра checkUnique является UNIQUE_CHECK_PARTIAL. В этом случае true означает, что новая запись является уникальной, тогда как false означает, что она может быть неуникальной (и отложенная проверка уникальности должна быть запланирована). В других случаях рекомендуется всегда возвращать false.
Некоторые индексы могут индексировать не все записи. Если запись не будет индексироваться, параметр aminsert надо просто вернуть, ничего не делая.
Если индексный метод доступа хочет кэшировать данные через последовательные вставки индекса в инструкции SQL, он может выделить пространство в indexInfo->ii_Context и хранить указатель на данные внутри indexInfo->ii_AmCache (который изначально будет равен нулю).
ambulkdelete
IndexBulkDeleteResult *
ambulkdelete (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats,
IndexBulkDeleteCallback callback,
void *callback_state);
Удаляет запись(и) из индекса. Это операция "массового удаления", которая
должна быть реализована путем сканирования всего индекса и проверки
каждой записи, чтобы определить, следует ли ее удалить. Для каждой записи нужно вызвать функцию обратного
вызова: callback( __TID__, callback_state) и проверить возвращаемое значение типа bool.
Если возвращаемое значение равно true, запись необходимо удалить из индекса.
Метод ambulkdelete должен возвращать либо NULL, либо структуру, размещенную в куче с помощью palloc и содержащую статистику
о результатах операции удаления. Можно вернуть NULL,
если индекс не был изменен в процессе операции VACUUM, в противном случае
должна быть возвращена корректная статистика.
Из-за ограничения maintenance_work_mem, функцию ambulkdelete, возможно, потребуется вызывать несколько раз, когда требуется удалить много записей. Аргумент stats является результатом предыдущего вызова для этого индекса (он равен NULL для первого вызова в рамках операции VACUUM). Это позволяет методу доступа накапливать статистику по всей операции. Как правило, ambulkdelete будет изменять и возвращать ту же структуру, если переданная stats не является нулем.
amvacuumcleanup
IndexBulkDeleteResult *
amvacuumcleanup (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats);
Выполнить очистку после операции VACUUM (до этого могло быть 0 или больше вызовов ambulkdelete). Функция не должна делать ничего, кроме возврата статистики, но может выполнить массовую очистку, такую как удаление пустых страниц индекса. Параметр stats содержит результат последнего вызова метода ambulkdelete, или NULL, если ambulkdelete не был вызван, потому что никакие записи не нужно было удалять. Результат функции является структурой, размещенной в куче с помощью palloc. Содержащаяся в нем статистика будет использована для обновления pg_class и выводится операцией VACUUM, если задан ключ VERBOSE. Метод может вернуть NULL, если индекс не изменялся во время операции VACUUM, в противном случае должна возвращаться корректная статистика..
Метод amvacuumcleanup также будет вызван по завершении операции ANALYZE. В этом случае параметр stats всегда имеет значение NULL, и любое возвращаемое значение игнорируется. Этот случай можно отличить проверкой info->analyze_only. Рекомендуется, чтобы в таком вызове метод доступа не делал ничего, кроме очистки после вставки, и это только в рабочем процессе autovacuum.
amcanreturn
bool
amcanreturn (Relation indexRelation, int attno);
Проверяет, поддерживает ли индекс сканирование только по индексу для данного столбца, возвращая его значение из индексной записи в виде структуры IndexTuple. Нумерация атрибутов начинается с 1, т.е. параметр attno для первого столбца должен быть равен 1. Метод возвращает true, если поддерживается, иначе false. Если метод доступа вообще не поддерживает сканирование только по индексу, то поле amcanreturn в его структуре IndexAmRoutine можно установить в значение NULL.
amcostestimate
void
amcostestimate (PlannerInfo *root,
IndexPath *path,
double loop_count,
Cost *indexStartupCost,
Cost *indexTotalCost,
Selectivity *indexSelectivity,
double *indexCorrelation,
double *indexPages);
Оценивает стоимость на сканирование индекса. Эта функция полностью описана в разделе Функции оценки стоимости индекса ниже.
amoptions
bytea *
amoptions (ArrayType *reloptions,
bool validate);
Разбирает и анализирует массив reloptions. Метод вызывается только, когда для индекса существует ненулевой массив reloptions. Аргумент reloptions это текстовый массив, содержащий записи форме name=value. Функция должна сформировать bytea значение, которое будет скопировано в поле rd_options записи индекса в relcache. Содержимое bytea определяется самим методом доступа; большинство стандартных методов доступа используют структуру StdRdOptions. Когда аргумент validate равен true, функция должна выдавать соответствующее сообщение об ошибке, если какой-либо из параметров в массиве reloptions не распознан или имеет недопустимое значение; если validate имеет значение false, недопустимые значения должны молча игнорироваться. (validate имеет значение false при загрузке уже сохраненных параметров из pg_catalog; недопустимая запись может быть найдена только в том случае, если метод доступа изменил свои правила для опций, и в этом случае игнорирование устаревших записей является уместным). Можно вернуть значение NULL, если требуется поведение по умолчанию.
amproperty
bool
amproperty (Oid index_oid, int attno,
IndexAMProperty prop, const char *propname,
bool *res, bool *isnull);
Метод amproperty позволяет методу доступа
переопределить поведение по умолчанию
pg_index_column_has_property и связанных функций. Если метод
доступа не имеет никакого специального поведения для запросов свойств
индекса, то поле amproperty в структуре IndexAmRoutine можно
установить в значение NULL. В противном случае, метод amproperty
будет вызван с аргументами index_oid и attno равными нулю для
pg_indexam_has_property, или с валидным значением в index_oid
и attno больше нуля для
pg_index_column_has_property. Атрибут prop является значением
enum, идентифицирующим проверяемое свойство, в то время как атрибут propname
является исходной строкой имени свойства. Если ядро не
распознает имя свойства, то параметр prop будет содержать AMPROP_UNKNOWN.
Методы доступа могут определять имена настраиваемых свойств путем
проверки propname на соответствие (используйте pg_strcasecmp, чтобы
проверить соответствие единообразно с основным кодом); для имен,
известных ядру базы данных, лучше проверить параметр prop. Если метод amproperty
возвращает true, значит он определил результат проверки свойства. В этом случае
он должен установить значение res или
значение *isnull в true, чтобы вернуть NULL. (Обе
указанные переменные инициализируются в false перед вызовом). Если
метод amproperty возвращает false, тогда ядро базы данных продолжит свою
обычную логику для определения результата проверки свойства.
Методы доступа, поддерживающие операторы сортировки, должны реализовывать проверку свойства AMPROP_DISTANCE_ORDERABLE, так как ядро не знает, как это сделать, и вернет значение NULL. Также стоит реализовать проверку AMPROP_RETURNABLE, если это можно сделать дешевле, чем открыть индекс и вызвать метод amcanreturn, что является поведением ядра базы данных по умолчанию. Поведение по умолчанию должно быть удовлетворительным для всех других стандартных свойств.
ambuildphasename
char *
ambuildphasename (int64 phasenum);
Возвращает текстовое имя заданного номера фазы сборки. Номера фаз-это те, которые сообщаются во время построения индекса через вызов pgstat_progress_update_param. Названия фаз затем доступны во view pg_stat_progress_create_index.
amvalidate
bool
amvalidate (Oid opclassoid);
Проверяет записи каталога для указанного класса операторов, насколько метод доступа может сделать это. Например, может убедится, что реализованы всех обязательные функций в методе доступа. Метод amvalidate должен вернуть false, если opclass является недопустимым. О проблемах следует сообщать с помощью вызова ereport.
Функции поддержки сканирования
Цель индекса, конечно же, заключается в поддержке сканирования для записей, соответствующих индексируемому условию WHERE, часто называемым квалификатором или ключом сканирования. Семантика индексного сканирования более подробно описана в разделе Индексное сканирование ниже. Метод доступа к индексу может поддерживать "простые" индексные сканирования, bitmap индексные сканирования или оба. Связанные со сканированием функции, которые должен или может предоставить метод доступа к индексам:
ambeginscan
IndexScanDesc
ambeginscan (Relation indexRelation,
int nkeys,
int norderbys);
Выполняет подготовку к сканированию индекса. Параметры nkeys и norderbys указывают количество операторов сравнения и сортировки, которые будут использоваться в сканировании; это может быть полезно для целей выделения памяти. Обратите внимание, что фактические значения ключей сканирования еще не предоставлены. Результатом работы должна быть структура, выделенная в куче с помощью palloc. В связи с особенностями реализации, метод доступа к индексу должен создать эту структуру путем вызова функции RelationGetIndexScan(). В большинстве случаев ambeginscan мало что делает, кроме данного вызова и, возможно, получения блокировок; интересные части запуска сканирования индекса находятся в функции amrescan.
amrescan
void
amrescan (IndexScanDesc scan,
ScanKey keys,
int nkeys,
ScanKey orderbys,
int norderbys);
Запускает или перезапускает сканирование индекса, возможно, с новыми ключами сканирования. (Для перезапуска с использованием ранее переданных ключей параметры keys и/или orderbys устанавливаются в NULL). Обратите внимание, что не допускается, чтобы количество ключей или операторов сортировки было больше, чем то, что передано ambeginscan. На практике функция перезапуска используется, когда в соединении со вложенным циклом выбирается новая внешняя запись и, поэтому, требуется новое сравнение с ключем, но структура, содержащая состояние сканирования, остается прежней.
amgettuple
boolean
amgettuple (IndexScanDesc scan,
ScanDirection direction);
Выбирает следующую запись в заданном сканировании, двигаясь в указанном направлении (вперед или назад в индексе). Возвращает true, если запись получена, false, если не осталось совпадающих записей. Если запись найдена, ее TID сохраняется в структуре сканирования. Обратите внимание, что "успех" означает только то, что индекс содержит запись, соответствующую ключам сканирования, а не то, что запись обязательно все еще существует в таблице или пройдет тест видимости в снимке вызывающего объекта. В случае успеха, функция amgettuple должна также установить scan->xs_recheck в true или false. False означает, что запись индекса обязательно соответствует ключам сканирования. True означает, что это не обязательно, и условия, представленные ключами сканирования, должны быть повторно проверены после извлечения записи из таблицы. Это условие поддерживает операторы индекса c ”потерями". Обратите внимание, что повторная проверка будет распространяться только на условия сканирования; частичный индексный предикат (если таковой имеется) никогда не перепроверяется кодом, который вызывал amgettuple.
Если индекс поддерживает сканирование только по индексу (т.е. функция amcanreturn возвращает true для соответствующего свойства), тогда в случае успешного сканирования, метод доступа также должен проверить значение scan->xs_want_itup, и оно равно true, метод доступа обязан вернуть исходные индексированные данные для записи индекса. Данные могут быть возвращены в виде указателя IndexTuple, сохраненного в scan->xs_itup, с дескриптором записи scan->xs_itupdesc; или в форме указателя HeapTuple, сохраненного в scan->xs_hitup, с дескриптором записи scan->xs_hitupdesc. (Последний формат следует использовать при возврате данных, которые могут не вписываться в IndexTuple). В любом случае, управление данными, на которые ссылается указатель, является ответственностью метода доступа. Данные должны оставаться хорошими по крайней мере до следующего вызова amgettuple, amrescan, или amendscan.
Функция amgettuple должна быть реализована только в том случае, если метод доступа поддерживает “простые” индексные сканирования. Если это не так, то поле amgettuple в структуре IndexAmRoutine необходимо установить в значение NULL.
amgetbitmap
int64
amgetbitmap (IndexScanDesc scan,
TIDBitmap *tbm);
Извлекает все записи в данном сканировании и добавляет их в TIDBitmap, переданной на вход (то есть добавляет TID найденных записей к уже находящимся в битовой карте). Функция возвращает количество извлеченных записей (это может быть только приблизительное значение, например, некоторые методы доступа не обнаруживают дубликаты). При вставке идентификаторов записей в коллекцию, amgettbitmap может сигнализировать, что для некоторых записей требуется повторная проверка условий сканирования. Это аналогично выходному параметру xs_recheck функции amgettuple. Примечание: в текущей реализации поддержка этой функции объединена с поддержкой хранилища с потерями самой битовой карты, поэтому вызывающий код повторно проверяет и условия сканирования, и частичный индексный предикат (если таковой имеется) для записей, помеченных для повторной проверки. Однако это не всегда может быть правдой. Функции amgettbitmap и amgettuple нельзя использовать в одном и том же сканировании индекса; есть и другие ограничения при использовании amgettbitmap, более подробно они описаны в разделе Индексное сканирование .
Функция amgettbitmap должна быть реализована только в том случае, если метод доступа поддерживает “bitmap” сканирование индекса. Если это не так, то поле amgettbitmap в его структуре IndexAmRoutine необходимо установить в значение NULL.
amendscan
void
amendscan (IndexScanDesc scan);
Завершает сканирование и освобождает ресурсы. Сама структура сканирования не должна быть освобождена, но любые блокировки и закрепления, полеченные внутри метода доступа, должны быть освобождены, а также любая другая память, выделенная методом ambeginscan и другими функциями поддержки сканирования.
ammarkpos
void
ammarkpos (IndexScanDesc scan);
Отмечает текущее положение сканирования. Метод доступа должен поддерживать только одно запоминание позиции на сканирование.
Функция ammarkpos должна быть реализована только в том случае, если метод доступа поддерживает упорядоченные сканирования. Если это не так, то поле ammarkpos в его структуре IndexAmRoutine можно установить в значение NULL.
amrestrpos
void
amrestrpos (IndexScanDesc scan);
Восстанавливает сканирование до самой последней отмеченной позиции.
функция amrestrpos должна быть реализована только в том случае, если метод доступа поддерживает упорядоченные сканирования. Если это не так, то поле amrestrpos в его структуре IndexAmRoutine можно установить в значение NULL.
Функции поддержки параллельного сканирования
В дополнение к поддержке обычных индексных сканирований, некоторые типы индексов могут поддерживать параллельные индексные сканирования, позволяющие нескольким бэкендам совместно выполнять сканирования индекса. Метод доступа к индексам должен организовать все так, чтобы каждый взаимодействующий процесс возвращал подмножество записей, полученных обычным, непараллельным сканированием индекса, но таким образом, чтобы объединение этих подмножеств было равно набору записей, которые будут возвращены обычным, непараллельным сканированием индекса. Кроме того, хотя не требуется никакого глобального упорядочения записей, возвращаемых параллельным сканированием, порядок внутри этих подмножеств записей, возвращаемых в каждом взаимодействующем процессе, должен соответствовать запрошенному порядку. Для поддержки параллельного сканирования индексов могут быть реализованы следующие функции:
amestimateparallelscan
Size
amestimateparallelscan (void);
Оценивает и возвращает количество байт в динамической общей памяти, которое необходимо методу доступа для выполнения параллельного сканирования. (Это число является дополнением, а не заменой, объема памяти, необходимого для хранения независимой от метода доступа данных структуры ParallelIndexScanDescData).
Нет необходимости реализовывать эту функцию для методов доступа, которые не поддерживают параллельное сканирование или для которых требуется нулевое количество дополнительных байт памяти.
aminitparallelscan
void
aminitparallelscan (void *target);
Эта функция вызывается для инициализации динамической общей памяти в начале параллельного сканирования. Параметр target будет указывать, по крайней мере, на количество байт, возвращенных ранее функцией amestimateparallelscan, и эта функция может использовать данное количество памяти для хранения любых данных, которые ей требуются.
Нет необходимости реализовывать эту функцию для методов доступа, которые не поддерживают параллельное сканирование, или в тех случаях, когда требуемая общая память, не требует инициализации.
amparallelrescan
void
amparallelrescan (IndexScanDesc scan);
Эта функция, если она реализована, будет вызвана при необходимости перезапуска параллельного сканирования индекса. Она должен сбросить любое общее состояние, настроенное с помощью aminitparallelscan таким образом, чтобы перезапустить сканирование с самого начала.
Индексное сканирование
В индексном сканировании метод доступа отвечает за возврат TID всех записей, соответствующих ключам сканирования. Метод доступа не участвует в фактической выборке этих записей из родительской таблицы индекса, а также в определении того, проходят ли они проверку видимости сканирования в снимке данных или другие условия.
Ключ сканирования-это внутреннее представление условия WHERE в форме index_key operator constant, где ключ индекса является одним из столбцов индекса, а оператор-одним из членов семейства операторов, связанных с этим столбцом индекса. Сканирование индекса имеет ноль или более ключей сканирования, связанных через И, то есть ожидается, что возвращенные записи, удовлетворяют всем указанным условиям.
Метод доступа может сообщить, что индекс является индексом с потерями или требует повторных проверок для конкретного запроса. Это означает, что сканирование индекса вернет все записи, удовлетворяющие ключу сканирования, а также, возможно, дополнительные записи, которые не удовлетворяют. Часть ядра базы данных, отвечающая за индексное сканирование, затем снова применит условия индекса к записи из таблицы, чтобы проверить, действительно ли она должна быть выбрана. Если опция повторной проверки не задана, сканирование индекса должно возвращать набор данных, полученный от метода доступа.
Обратите внимание, что метод доступа обязан убедиться, что он правильно находит все и только удовлетворяющие всем заданным ключам сканирования записи. Кроме того, ядро базы данных просто передаст все условия WHERE, соответствующие ключам индекса, и семейства операторов, без какого-либо семантического анализа на избыточность или противоречивовсть. Например, в выражении WHERE x>4 AND x>14, где x является столбцом в B-tree индексе, только в функции amrescan функции B-tree индекса можно понять, что первый ключ сканирования является избыточным и может быть отброшен. Необходимая степень предварительной обработки в функции amrescan зависит от степени, которая требуется методу доступа к индексу, чтобы уменьшить ключи сканирования до ”нормализованной" формы.
Некоторые методы доступа возвращают записи индекса в строго определенном порядке, другие-нет. Существует, фактически, два различных способа, которые метод доступа может поддерживать для сортировки вывода:
-
Методы доступа, всегда возвращающие записи в порядке хранения данных в индексе (например, btree), должны установить amcanorder в true. В настоящее время такие методы доступа должны использовать btree-совместимые стратегии для их операторов равенства и сортировки.
-
Методы доступа, поддерживающие операторы сортировки должны установить amcanorderbyop в true. Это указывает на то, что индекс способен возвращать записи в порядке, удовлетворяющем ORDER BY index_key operator constant. Модификаторы сканирования этой формы могут быть переданы в функцию amrescan как описано ранее.
Функция amgettuple имеет аргумент direction, который может принимать значения или ForwardScanDirection (обычный случай), или BackwardScanDirection. Если первый вызов после amrescan получит BackwardScanDirection, тогда набор совпадающих индексных записей должен сканироваться назад-вперед, а не в обычном направлении вперед-назад, поэтому методу amgettuple необходимо вернуть последнюю совпадающую запись в индексе, а не первую, как это обычно делается. (Это будет происходить только для методов доступа, установивших флаг amcanorder в true). После первого вызова, функции amgettuple необходимо быть готовым к дальнейшему сканированию в любом направлении от последней возвращенной записи. (Но если флаг amcanbackward имеет значение false, все последующие вызовы будут иметь то же направление, что и первый).
Методы доступа, поддерживающие упорядоченное сканирование, должны поддерживать "маркировку" позиции в сканировании и последующий возврат к отмеченной позиции. Одна и та же позиция может быть восстановлена несколько раз. Однако, необходимо сохранять только одно положение на сканирование; новый вызов функции ammarkpos переопределяет ранее отмеченную позицию. Методам доступа, не поддерживающим упорядоченное сканирование, не нужно реализовывать функции ammarkpos и amrestrpos внутри IndexAmRoutine; вместо этого установите эти указатели в значение NULL.
Текущее положение сканирования и отмеченная позиция (если такая есть) должны оставаться в согласованном состоянии во время одновременных вставок или удалений из индекса. Это нормально, если только что вставленная запись не возвращается сканированием, которое обнаружило бы запись, если бы она существовала, когда сканирование началось. Так же нормально для сканирования вернуть такую запись при повторном сканировании или возврате, даже если она не была возвращена в первый раз. Аналогично, одновременное удаление может быть отражено или не отражено в результатах сканирования. Важно, чтобы вставки или удаления не приводили к пропуску или к дублированию возвращаемых записей, которые не были вставлены или удалены.
Если индекс хранит исходные значения индексированных данных (а не некоторое их представление с потерями), полезно поддерживать сканирование только по индексу, в котором индекс возвращает фактические данные, а не только TID записи в таблице. Это позволит избежать ввода-вывода только в том случае, если карта видимости показывает, что TID находится на полностью видимой странице; в противном случае требуется прочитать запись из таблицы, чтобы проверить видимость согласно MVCC. Но это уже не касается метода доступа.
Вместо использования функции amgettuple, сканирование индекса можно выполнить с помощью вызова amgettbitmap, чтобы получить все записи в одном вызове. Это может быть заметно более эффективным, чем amgettuple, потому что это позволяет избежать циклов блокировки/разблокировки в рамках метода доступа. В принципе, вызов amgettbitmap должен иметь такие же последствия, как и последовательные вызовы amgettuple, но есть несколько ограничений, чтобы упростить дело. Прежде всего, amgettbitmap возвращает все записи сразу и маркировка или восстановление позиции сканирования не поддерживается. Во-вторых, записи возвращаются в виде битовой карты, которая не имеет никакой сортировки, поэтому amgettbitmap не принимает аргумент direction. (Операторы сортировки также никогда не будут предоставлены для такого сканирования). Кроме того, не предусмотрено использование только индексных сканирований с помощью amgettbitmap, так как нет никакого способа вернуть содержимое индексных записей. В-третьих, amgettbitmap не гарантирует никакой блокировки возвращенных записей, с последствиями, указанными в разделе Вопросы блокировки индекса .
Обратите внимание, что для метода доступа разрешено реализовать только amgettbitmap и не реализовывать amgettuple или наоборот, если его внутренняя реализация не подходит для одного API или другого.
Вопросы блокировки индекса
Методы доступа к индексам должны обрабатывать одновременные обновления индекса несколькими процессами. Ядро QHB получает AccessShareLock на индекс во время сканирования индекса и RowExclusiveLock при обновлении индекса (включая обычный VACUUM). Поскольку эти типы блокировок не конфликтуют, метод доступа отвечает за обработку любых более мелких блокировок, которые можгут потребоваться. Исключительная блокировка индекса целиком может потребоваться только во время его создания, уничтожения или REINDEX .
Реализация типа индекса, поддерживающего одновременные обновления, обычно требует тщательного и подробного анализа требуемого поведения.
Помимо собственных внутренних требований к согласованности индекса, параллельные обновления создают проблемы согласованности между родительской таблицей и индексом. Поскольку QHB отделяет доступ и обновления таблицы от доступа и обновления индекса, существуют окна, в которых индекс может быть несовместим с таблицей. Эта проблема решается с помощью следующих правил:
-
Новая запись в таблице создается перед созданием для нее записи в индексе. (Поэтому одновременное сканирование индекса, скорее всего, не сможет увидеть запись в таблице. Это нормально, потому что читатель индекса не заинтересован в получении незафиксированной строки в любом случае. Для более детальной информации смотрите раздел Проверка уникальности индекса).
-
Когда запись удаляется из таблицы (с помощью VACUUM), все ее индексные записи должны быть удалены первыми.
-
Сканирование индекса должно закреплять страницу индекса, содержащую элемент, возвращенный последним вызовом amgettuple, и функция ambulkdelete не может удалить записи со страниц, закрепленных другими бэкэндами. Необходимость в этом правиле объясняется ниже.
Без третьего правила читатель индекса может видеть запись индекса непосредственно перед ее удалением VACUUM, а затем получить соответствующую запись из таблицы после того, как она была удалена VACUUM. Это не создает никаких серьезных проблем, если этот номер элемента еще не используется (после очистки), когда читатель достигает его, так как пустой слот элемента будет игнорироваться при извлечении записей из таблицы. Но что делать, если третий сервер уже повторно использовал данный слот элемента для чего-то другого? При использовании моментального снимка, совместимого с MVCC, нет никаких проблем, потому что новый пользователь слота наверняка будет слишком новым, чтобы пройти тест видимости для моментального снимка. Однако с моментальным снимком, не совместимым с MVCC (например SnapshotAny), возможна ситуация, когда будет принята и возвращена строка, которая фактически не соответствует ключам сканирования. Можно защититься от этого сценария, требуя, перепроверки ключей сканирования для записи из таблицы во всех случаях, но это слишком дорого. Вместо этого используется закрепление страницы индекса в качестве прокси, как указание, что читатель все еще может быть “в процессе” обращение от записи индекса к соответствующей записи в таблице. Создание таких блоков функцией ambulkdelete гарантирует, что VACUUM не сможет удалить запись из таблицы до того, как читатель закончит работать с ней. Это решение не требует больших затрат во время выполнения и добавляет накладные расходы на блокировку только в редких случаях, когда на самом деле существует конфликт.
Такое решение требует, чтобы сканирование индекса было “синхронным”: необходимо прочитать запись из таблицы сразу после сканирования соответствующей записи индекса. Это дорого по ряду причин. "Асинхронное" сканирование, при котором собирается много TID из индекса, a только через некоторое время выполняется чтение таблицы, требует гораздо меньше накладных расходов на блокировку индекса и позволяет более эффективно реализовать доступ к таблице. В соответствии с приведенным выше анализом, синхронный подход необходимо использовать для не-MVCC-совместимых снимков, а асинхронное сканирование применимо для запроса, использующего снимок MVCC.
В функции amgetbitmap, метод доступа не сохраняет защелок индексных страниц для возвращенных записей. Поэтому безопасно использовать такие сканирования только с MVCC-совместимыми моментальными снимками.
Когда флаг ampredlocks не установлен, любое сканирование, использующее этот метод доступа к индексу в сериализуемой транзакции, получит неблокирующую блокировку предиката на весь индекс. Это приведет к возникновению конфликта чтения и записи при вставке любой записи в этот индекс в параллельной сериализуемой транзакции. Если определенные шаблоны конфликтов чтения и записи обнаруживаются среди набора параллельных сериализуемых транзакций, одна из этих транзакций может быть отменена для защиты целостности данных. Когда флаг установлен, это указывает, что метод доступа к индексу реализует более мелкую блокировку предиката, которая будет стремиться к уменьшению частоты таких отмен транзакций.
Проверка уникальности индекса
QHB реализует ограничения уникальности SQL через использование уникальных индексов, которые являются индексами, запрещающими несколько записей с одинаковыми ключами. Метод доступа, поддерживающий эту функцию, устанавливает для флага amcanunique значение true. (В настоящее время его поддерживают только B-tree индексы). Столбцы, перечисленные в предложении INCLUDE не учитываются при обеспечении уникальности.
Из-за MVCC необходимо всегда разрешать наличие повторяющихся записей в индексе: записи могут ссылаться на последовательные версии одной логической строки. Поведение, которое требуется добиться, заключается в том, что ни один снимок MVCC не может включать две строки с одинаковыми ключами индекса. Это разбивается на следующие случаи, которые необходимо проверить при вставке новой строки в уникальный индекс:
-
Если конфликтующая валидная строка была удалена текущей транзакцией, это нормально. (В частности, поскольку обновление всегда удаляет старую версию строки перед вставкой новой версии, это позволит обновить строку без изменения ключа).
-
Если конфликтующая строка была вставлена пока еще незафиксированной транзакцией, необходимо дождаться, завершения этой транзакции. Если она откатывается назад, тогда нет никакого конфликта. Если транзакция фиксируется, не удаляя конфликтующую строку снова, существует нарушение уникальности. (На практике просто выполняется ожидание другой транзакции, а затем повторение проверки видимости).
-
Аналогично, если конфликтующая допустимая строка была удалена пока еще незафиксированной транзакцией, необходимо дождаться фиксации или прерывания этой транзакции, а затем повторить тест.
Кроме того, непосредственно перед сообщением о нарушении уникальности в соответствии с вышеуказанными правилами, метод доступа должен повторно проверить жизнеспособность вставляемой строки. Если запись мертва, то не нужно сообщать о каких-либо нарушениях. (Этот случай не может произойти во время обычного сценария вставки строки, только что созданной текущей транзакцией. Однако, это может произойти при выполнении CREATE UNIQUE INDEX CONCURRENTLY.)
Метод доступа к индексу обязан выполнять данные тесты сам, а это означает, что он должен проверить в таблице состояние фиксации любой строки, которая имеет дубликат ключа в соответствии с содержимым индекса. Это, без сомнения, некрасиво и немодульно, но это позволяет избежать избыточной работы: если бы ядро базы данных делало отдельную проверку, то поиск конфликтующей строки в индексе был бы фактически повторен в процессе поиска места для вставки новой записи индекса строки. Более того, нет очевидного способа избежать гонок, если только проверка конфликта не является неотъемлемой частью вставки новой записи индекса.
Если ограничение уникальности является отложенным, возникает дополнительная сложность: нужно иметь возможность вставлять запись индекса для новой строки, но откладывать любую ошибку нарушения уникальности до конца оператора или даже позже. Чтобы избежать ненужных повторных поисков индекса, метод доступа к индексу должен выполнить предварительную проверку уникальности во время начальной вставки. Если проверка показывает, что нет конфликтующей живой записи, дальнейшие проверки не проводятся. В противном случае планируется повторная проверка, когда придет время применить ограничение. Если во время повторной проверки и вставленный запись, и какая-то другая запись с тем же ключом являются живыми, то необходимо сообщить об ошибке. (Обратите внимание, что в данном случае “живая” фактически означает “в HOT цепочке в индексе существует живая запись”). Чтобы реализовать повторные проверки, в функцию aminsert передается параметр checkUnique, имеющий одно из следующих значений:
-
UNIQUE_CHECK_NO указывает, что проверка уникальности не должна выполняться (это не уникальный индекс).
-
UNIQUE_CHECK_YES указывает, что этот уникальный индекс без отложенной проверки, и проверка уникальности должна быть выполнена немедленно, как описано выше.
-
UNIQUE_CHECK_PARTIAL указывает, что ограничение уникальности является отложенным. QHB будет использовать этот режим для вставки каждой строки в индекс. Метод доступа должен разрешать повторяющиеся записи в индексе и сообщать о любых потенциальных дубликатах, возвращая false из aminsert. Для каждой строки, для которой возвращается false, будет запланирована отложенная повторная проверка.
Метод доступа должен идентифицировать любые строки, которые могут нарушить ограничение уникальности. Ложные срабатывания не являются ошибкой. Это позволяет выполнить проверку, не дожидаясь завершения других транзакций; конфликты, сообщенные здесь, не рассматриваются как ошибки и будут перепроверены позже, к этому времени они могут больше не быть конфликтами.
-
UNIQUE_CHECK_EXISTING указывает, что это отложенная повторная проверка строки, промеченной как потенциальное нарушение уникальности. Хотя это реализуется путем вызова aminsert, метод доступа не должен вставлять новую запись индекса в этом случае. Запись индекса уже присутствует. Вместо этого метод доступа должен проверить, есть ли другая "живая" запись в индексе. Если это так, и если целевая строка также все еще активна, сообщить об ошибке.
Рекомендуется, чтобы в вызове UNIQUE_CHECK_EXISTING, метод доступа далее проверял, что целевая строка, действительно, имеет существующую запись в индексе, и сообщает об ошибке, если ее нет. Это хорошая идея, потому что значения индексной записи, переданной в aminsert, будут пересчитаны. Если определение индекса включает в себя функции, которые на самом деле не являются неизменяемыми, возможна проверка неправильной области индекса. Верификация того, что целевая строка найдена при повторной проверке, убеждается, что сканируются те же значения записи, которые использовались в исходной вставке.
Функции оценки стоимости индекса
Функция amcostestimate предоставляет информацию, описывающую возможное сканирование индекса, включая списки Where и ORDER BY, которые были определены для использования с индексом. Метод должен возвращать оценку стоимости доступа к индексу и селективность предложений WHERE (то есть доли строк родительской таблицы, которые будут получены во время сканирования индекса). Для простых случаев почти вся работа оценщика затрат может быть выполнена путем вызова стандартных подпрограмм в оптимизаторе; смысл наличия функции amcostestimate заключается в том, чтобы позволить методу доступа к индексам предоставлять специфические знания о конкретных типах индексов, если это может улучшить стандартные оценки.
Каждая функция amcostestimate должна иметь следующие параметры:
void
amcostestimate (PlannerInfo *root,
IndexPath *path,
double loop_count,
Cost *indexStartupCost,
Cost *indexTotalCost,
Selectivity *indexSelectivity,
double *indexCorrelation,
double *indexPages);
Первые три параметра являются входными данными:
root
- Информация планировщика об обрабатываемом запросе.
path
- Рассматривается путь доступа к индексу. Все поля, кроме indexTotalCost и indexSelectivity являются валидными.
loop_count
- Число повторений сканирования индекса, которое должно быть учтено в оценке стоимости. Значение обычно будет больше единицы при рассмотрении параметризованного сканирования для использования внутри соединения с помощью вложенных запросов. Обратите внимание, что оценка стоимости все еще должна быть только для одного сканирования; большое значение loop_count означает, что его можно учесть для планирования кэширования при нескольких сканированиях.
Последние пять параметров являются выходными данными по ссылке:
indexStartupCost
- Значение стоимость начальной обработки индекса
indexTotalCost
- Общая стоимость обработки индекса
indexSelectivity
- Индекс селективности
indexCorrelation
- Коэффициент корреляции между порядком сканирования индекса и порядком базовой таблицы
indexPages
- Число листовых страниц индекса
Обратите внимание, что функции оценки затрат необходимо писать на C/RUST, а не на SQL или любом другом доступном процедурном языке, поскольку они должны иметь доступ к внутренним структурам данных планировщика/оптимизатора.
Стоимость доступа к индексу должна быть рассчитана с использованием параметров, используемых src/backend/optimizer/path/costsize.c: последовательная выборка дискового блока имеет стоимость seq_page_cost, произвольная выборка имеет стоимость random_page_cost, и стоимость обработки одной строки индекса обычно следует принимать как cpu_index_tuple_cost. Кроме того, следует использовать соответствующее умножение на cpu_operator_cost для любых операторов сравнения, вызываемых во время обработки индекса (особенно вычисление самих условий индекса).
Затраты на доступ должны включать все дисковые и процессорные затраты, связанные со сканированием самого индекса, но не затраты на извлечение или обработку строк родительской таблицы, идентифицированных индексом.
indexStartupCost - это часть общей стоимости сканирования, которая должна быть израсходована, прежде чем станет возможно извлечь первую строку. Для большинства индексов это значение можно принять равным нулю, но тип индекса с высокой начальной стоимостью может захотеть установить его ненулевым.
В indexSelectivity должно быть записано значение предполагаемой доли строк родительской таблицы, которая будет получена во время сканирования индекса. В случае запроса с потерями, как правило, значение будет выше, чем доля строк, которые фактически удовлетворяют условиям сравнения.
В indexCorrelation следует записать корреляцию (в диапазоне от -1,0 до 1,0) между порядком индекса и порядком таблицы. Это используется для корректировки оценки стоимости извлечения строк из родительской таблицы.
В indexPages необходимо записать количество листовых страниц. Значение используется для оценки количества рабочих процессов для параллельного сканирования индекса.
Когда loop_count больше единицы, возвращаемые числа должны быть средними, ожидаемыми для любого одного сканирования индекса.
Оценка стоимости
Типичный оценщик стоимости будет действовать следующим образом:
- Оценивает и возвращает долю строк родительской таблицы, которые будут посещены на основе заданных условий сравнения. При отсутствии каких-либо специфических знаний для данного типа индекса нужно использовать стандартную функцию оптимизатора clauselist_selectivity():
*indexSelectivity = clauselist_selectivity(root, path->indexquals,
path->indexinfo->rel->relid,
JOIN_INNER, NULL);
-
Оценивает количество строк индекса, которые будут посещены во время сканирования. Для многих типов индексов это то же самое, что indexSelectivity, умноженное на число строк в индексе, но может быть и больше. (Обратите внимание, что размер индекса в страницах и строках доступен из входного параметра path->indexinfo).
-
Оценивает количество индексных страниц, которые будут прочитаны во время сканирования. Это может быть просто indexSelectivity умноженное на размер индекса в страницах.
-
Вычисляет стоимость доступа к индексу. Универсальный оценщик может сделать это так:
/*
* Our generic assumption is that the index pages will be read
* sequentially, so they cost seq_page_cost each, not random_page_cost.
* Also, we charge for evaluation of the indexquals at each index row.
* All the costs are assumed to be paid incrementally during the scan.
*/
cost_qual_eval(&index_qual_cost, path->indexquals, root);
*indexStartupCost = index_qual_cost.startup;
*indexTotalCost = seq_page_cost * numIndexPages +
(cpu_index_tuple_cost + index_qual_cost.per_tuple) * numIndexTuples;
Однако вышеизложенное не учитывает амортизацию операций чтения индекса при повторных сканированиях индекса.
- Оценивает коэффициент корреляции. Для простого упорядоченного индекса по одному полю значение можно получить из pg_statistic. Если корреляция неизвестна, то консервативная оценка равна нулю (без корреляции).
Примеры функций оценки стоимости можно найти в разделе src/backend/utils/adt/selfuncs.c.
Общие записи WAL
Хотя все встроенные модули, использующие упреждающую запись, поддерживают свои собственные типы записей WAL, существует также общий тип записи WAL, который описывает изменения страниц в общем виде. Это полезно для расширений, предоставляющих пользовательские методы доступа, поскольку они не могут зарегистрировать свои собственные процедуры восстановления через WAL.
API для построения универсальных записей WAL определяется в access/generic_xlog.h.
Чтобы выполнить обновление данных защищённых WAL с помощью универсального средства записи WAL, выполните следующие действия:
-
state = GenericXLogStart(relation) - начать построение общей записи WAL для данного отношения.
-
page = GenericXLogRegisterBuffer(state, buffer, flags) - зарегистрируйте буфер, который будет изменен в текущей общей записи WAL. Эта функция возвращает указатель на временную копию страницы буфера, где должны быть сделаны изменения. (Не изменяйте содержимое буфера напрямую). Третий аргумент-это битовая маска флагов, применимая к данной операции. В настоящее время единственным таким флагом является GENERIC_XLOG_FULL_IMAGE, что означает, что в запись WAL должен быть включены не конкретные изменения, а полностраничный образ. Обычно этот флаг устанавливается, если страница является новой или была полностью переписана. GenericXLogRegisterBuffer можно повторить, если при помощи журналированного действия необходимо изменить несколько страниц.
-
Примените изменения к образам страниц, полученным на предыдущем шаге.
-
GenericXLogFinish(state) - примените изменения к буферам и выдайте общую запись WAL.
Построение записи WAL может быть отменено между любыми из вышеперечисленных шагов путем вызова GenericXLogAbort(state). Это приведет к отмене всех изменений в копии изображения страницы.
Пожалуйста, обратите внимание на следующие моменты при использовании общего средства записи WAL:
-
Никакие прямые модификации буферов не допускаются! Все изменения должны быть сделаны в копиях, полученных от GenericXLogRegisterBuffer(). Другими словами, код, который делает универсальные записи WAL, никогда не должен вызывать BufferGetPage(). Тем не менее, это остается обязанностью вызывающей стороны закрепить/открепить (pin/unpin) и заблокировать/разблокировать (lock/unlock) буферы в нужный момент. Исключительная блокировка должна быть удержана на каждом целевом буфере перед вызовом GenericXLogRegisterBuffer() до тех пор, пока не будет вызван GenericXLogFinish().
-
Регистрация буферов (шаг 2) и модификация изображений страниц (шаг 3) могут быть вызваны в любой последовательности. Имейте в виду, что буферы должны быть зарегистрированы в том же порядке, в котором блокировки должны быть получены на них во время воспроизведения.
-
Максимальное число буферов, которые могут быть зарегистрированы для универсальной записи WAL является MAX_GENERIC_XLOG_PAGES. При превышении этого предела будет выдана ошибка.
-
Generic WAL предполагает, что изменяемые страницы имеют стандартную компоновку, и в частности, что между ними нет полезных данных pd_lower и pd_upper.
-
Так как вы изменяете копии буферных страниц, GenericXLogStart() не запускает критическую секцию. Таким образом, вы можете безопасно выполнять выделение памяти, возврат ошибок и т. д. между GenericXLogStart() и GenericXLogFinish(). Единственная критическая секция присутствует внутри GenericXLogFinish(), но находясь внутринеё нет необходимости беспокоиться о вызове GenericXLogAbort() во время выхода из-за ошибки.
-
GenericXLogFinish() заботится о маркировке грязных буферов и настройке их LSNs. Вам не нужно делать это явно.
-
Для незарегистрированных отношений все работает одинаково, за исключением того, что не порождается фактическая запись WAL. Таким образом, обычно нет необходимости выполнять явные проверки незарегистрированных отношений.
-
Универсальная функция восстановления по Wal будет получать эксклюзивные блокировки для буферов в том же порядке, в котором они были зарегистрированы. После повторного внесения всех изменений, блокировки будут освобождены в том же порядке.
-
Если GENERIC_XLOG_FULL_IMAGE не задается для зарегистрированного буфера, общая запись WAL содержит разницу между старым и новым образами страниц. Эта разность основана на байтовом сравнении. Это не очень компактно для случая перемещения данных в пределах страницы и может быть улучшено в будущем.
Физическое хранилище базы данных
- Структура файлов базы данных
- TOAST
- Карта свободного пространства
- Карта видимости
- Слой инициализации
- Внутренняя структура страницы базы данных
В этой главе представлен обзор формата физического хранилища, используемого базами данных QHB.
Структура файлов базы данных
В этом разделе описывается формат хранения на уровне файлов и каталогов.
Файлы конфигурации и данных, используемые СУБД, обычно хранятся в одном
каталоге называемом PGDATA (аналогично имени переменной среды).
Обычно PGDATA располагается по следующему пути: /var/lib/qhb/data.
Несколько кластеров, управляемых различными экземплярами сервера,
могут существовать на одной и той же машине.
Каталог PGDATA содержит несколько подкаталогов и управляющих файлов,
как показано в таблице 1. В дополнение к этим
необходимым элементам, файлы конфигурации кластера qhb.conf, qhb_hba.conf,
и qhb_ident.conf традиционно хранятся в PGDATA, хотя можно разместить их и
в другом месте.
Таблица 1. Содержание PGDATA
| Файл/каталог | Описание |
|---|---|
| QHB_VERSION | Файл, содержащий основной номер версии QHB |
| base | Каталог в котором содержатся подкаталоги для каждой базы данных |
| current_logfiles | Файл содержащий пути файлов для ведения журнала логгирования |
| global | Подкаталог, содержащий таблицы общие для кластера, такие как pg_database |
| pg_commit_ts | Подкаталог, содержащий данные временной метки фиксации транзакций |
| pg_dynshmem | Подкаталог, содержащий файлы, используемые динамической подсистемой общей памяти |
| pg_logical | Подкаталог, содержащий статусные данные для логического декодирования |
| pg_multixact | Подкаталог, содержащий данные о состоянии мультитранзакций (используется для общих блокировок строк) |
| pg_notify | Подкаталог, содержащий данные о состоянии LISTEN/NOTIFY |
| pg_replslot | Подкаталог, содержащий данные слота репликации |
| pg_serial | Подкаталог, содержащий информацию о совершенных сериализуемых транзакциях |
| pg_snapshots | Подкаталог, содержащий экспортированные снимки |
| pg_stat | Подкаталог, содержащий постоянные файлы для подсистемы статистики |
| pg_stat_tmp | Подкаталог, содержащий временные файлы для подсистемы статистики |
| pg_subtrans | Подкаталог, содержащий данные о состоянии подтранзакции |
| pg_tblspc | Подкаталог, содержащий символьные ссылки на табличные пространства |
| pg_twophase | Подкаталог, содержащий файлы состояний для подготовленных транзакций |
| pg_wal | Подкаталог, содержащий файлы WAL (Журнал упреждающей записи) |
| pg_xact | Подкаталог, содержащий данные о состоянии фиксации транзакций |
| qhb.auto.conf | Файл, используемый для хранения параметров конфигурации, которые задаются ALTER SYSTEM |
| postmaster.opts | Файл, записывающий параметры командной строки, с которыми сервер был запущен в последний раз |
| qhbmaster.pid | Файл блокировки, записывающий текущий идентификатор процесса postmaster (PID), путь к каталогу данных кластера, метку времени запуска postmaster, номер порта, путь к каталогу сокета Unix-домена, первый допустимый адрес listen_address (IP-адрес или * или пустой, если не прослушивает TCP), и идентификатор сегмента общей памяти (этот файл не присутствует после завершения работы сервера) |
Для каждой базы данных в кластере существует подкаталог внутри PGDATA/base, названный по номеру OID базы данных в pg_database. Этот подкаталог по умолчанию используется для файлов базы данных; в частности, там хранятся ее системные каталоги.
Обратите внимание, что в следующих разделах описано поведение встроенного устройства кучи метод доступа к таблице и методы доступа к встроенному индексу. Поскольку QHB является расширяемой системой, другие методы доступа могут работать по-другому.
Каждая таблица и индекс хранятся в отдельном файле. Для обычных отношений эти файлы называются по номеру таблицы или индекса filenode, который можно найти в pg_class.relfilenode. Но для временных отношений имя файла имеет вид tBBB_FFF, где BBB является идентификатором внутреннего сервера, который создал файл, и FFF является номером filenode. В любом случае, помимо основного файла (слоя), каждая таблица и индекс имеют карту свободного пространства (см. раздел Карта свободного пространства), в которой хранится информация о свободном пространстве, доступном в отношении. Карта свободного пространства хранится в файле с именем с номером filenode с суффиксом _fsm. Таблицы также имеют карту видимости, хранящуюся в файле с суффиксом _vm для отслеживания страниц без "мертвых" кортежей. Карта видимости описана далее в разделе Карта видимости. Незарегистрированные таблицы и индексы имеют третий файл, известный как слой инициализации с суффиксом \init (см. раздел Слой инициализации).
!!!! Предупреждение
Обратите внимание, что хотя filenode таблицы часто совпадает с ее OID, это не обязательно так. Некоторые операции, такие как усечение, переиндексация, кластеризация и некоторые формы ALTER TABLE, могут изменить filenode, сохраняя OID. Избегайте предположения, что filenode и table OID-это одно и то же. Кроме того, для некоторых системных каталогов, в частности pg_class, pg_class.relfilenode содержит ноль. Фактическое число filenode этих каталогов хранится в структуре данных более низкого уровня и может быть получен с помощью pg_relation_filenode() функция.
Если объем таблицы или индекса превышает 1 гб, он делится на сегменты размером в гигабайт. Имя файла первого сегмента совпадает с именем filenode; последующие сегменты называются filenode.1, filenode.2, и т.д. Это позволяет избежать проблем на платформах, имеющих ограничения по размеру файлов. (На самом деле, 1 гб-это только размер сегмента по умолчанию. Размер сегмента можно регулировать с помощью опции конфигурации --with-segsize при сборки QHB). В теории, для карт свободного пространства и карт видимости также может потребоваться несколько сегментов, хотя на практике это вряд ли произойдет.
Таблица, содержащая столбцы с потенциально большими записями, будет иметь связанную с ней таблицу TOAST, которая используется для внешнего хранения полей, которые слишком велики, чтобы хранить их непосредственно в строках таблицы. pg_class.reltoastrelid связывает таблицу с ее TOAST таблицами, если таковые имеются. Дополнительную информацию смотрите в разделе TOAST.
Содержание таблиц и индексов рассматривается далее в разделе Внутренняя структура страницы базы данных.
Табличные пространства делают устройство базы данных более сложным. Каждое пользовательское табличное пространство имеет символическую ссылку внутри каталога PGDATA/pg_tblspc, который указывает на физический каталог табличного пространства (т.е. расположение, указанное в команде CREATE TABLESPACE табличного пространства). Эта символьная ссылка названа по номеру OID табличного пространства. Внутри физического каталога табличных пространств есть подкаталог с именем, которое зависит от версии сервера QHB. (Этот подкаталог необходим для того, чтобы последовательные версии базы данных могли использовать одни и те же значение для CREATE TABLESPACE без конфликтов). В подкаталоге для конкретной версии для каждой базы данных, которая имеет элементы в табличном пространстве, существует подкаталог названный по номеру OID базы данных. Таблицы и индексы хранятся в этом каталоге, используя схему именования filenode. Табличное пространство pg_default недоступно через pg_tblspc, но находится в PGDATA/base. Точно так же, как pg_global табличное пространство недоступно через pg_tblspc, но находится в PGDATA/global.
pg_relation_filepath() функция показывает весь путь (относительно
PGDATA) любого отношения. Это часто полезно в качестве альтернативы для
запоминания многих из вышеперечисленных правил. Но имейте в виду, что
эта функция просто дает название первого сегмента основного слоя
отношения — вам может понадобиться добавить номер сегмента и/или
_fsm, _vm, или _init чтобы найти все файлы,
связанные с этим отношением.
Временные файлы (для таких операций как сортировка данных большего размера, чем может поместиться в памяти) создаются внутри PGDATA/base/pgsql_tmp, или в подкаталоге табличного пространства внутри pgsql_tmp, если табличное пространство отличается от pg_default. Имя временного файла имеет вид pgsql_tmpPPP.NNN, где PPP это PID владеющего бэкенда и NNN идентифицирует различные временные файлы этого бэкенда.
TOAST
В этом разделе представлен обзор TOAST (The Oversized-Attribute Storage Technique, техника хранения сверхбольших атрибутов).
QHB использует фиксированный размер страницы (обычно 8 кб) и не позволяет кортежам занимать несколько страниц. Поэтому невозможно хранить очень большие значения полей непосредственно. Чтобы преодолеть это ограничение, большие значения полей сжимаются и/или разбиваются на несколько физических строк. Это происходит прозрачно для пользователя, только с небольшим влиянием на большую часть внутреннего кода. Этот прием называют TOAST. Инфраструктура TOAST также используется для улучшения обработки больших значений данных в памяти.
Только некоторые типы данных поддерживают TOAST — нет необходимости накладывать накладные расходы на типы данных, которые не могут создавать большие значения полей. Для поддержки TOAST тип данных должен иметь представление переменной длины (varlena), в котором обычно первое четырехбайтовое слово содержит общую длину значения в байтах (включая сам размер). TOAST не ограничивает остальную часть представления типа данных. Специальные представления работают путем изменения или интерпретации этого начального слова длины. Поэтому функции уровня C/RUST, использующие тип данных, поддерживающий TOAST, должны быть аккуратны с тем, как они обрабатывают входные значения TOAST: входные данные могут фактически не состоять из четырехбайтового слова длины и содержимого до тех пор, пока они не будут детализированы. (Обычно это делается путем вызова PG_DETOAST_DATUM прежде, чем делать что-либо с входным значением, но в некоторых случаях возможны более эффективные подходы. Дополнительную информацию смотрите в разделе Использование TOAST).
TOAST использует два бита из длины слова varlena (биты старшего порядка на big-endian архитектурах и биты младшего порядка на little-endian архитектурах), тем самым ограничивая логический размер любого значения типа данных с поддержкой TOAST до 1 гб (230 - 1 байт). Когда оба бита равны нулю, значение является обычным значением соответствующего типа данных, а оставшиеся биты длины содержат общий размер типа данных (включая размер типа длины) в байтах. Когда выставлен бит самого старшего или самого младшего порядка, значение имеет только однобайтовый заголовок вместо обычного четырехбайтового заголовка, а оставшиеся биты этого байта дают общий размер типа данных (включая байт длины) в байтах. Этот подход предоставляет экономичное хранение значений размером менее 127 байт, но при этом позволяет увеличить тип данных до 1 гб при необходимости. Значения с однобайтовыми заголовками не выровнены по какой-либо определенной границе, тогда как значения с четырехбайтовыми заголовками выровнены по крайней мере по четырехбайтовой границе; это отсутствие выравнивания обеспечивает дополнительную экономию пространства, что значительно для коротких значений. В частном случае, если все оставшиеся биты однобайтового заголовка равны нулю (что было бы невозможно для самодостаточной длины), значение является указателем на исходные данные с несколькими возможными альтернативами, как описано ниже. Тип и размер такого а TOAST-указателя определяется кодом, хранящимся во втором байте данных. Наконец, когда бит самого старшего или самого младшего порядка равен нулю, а соседний бит установлен, то содержимое данных сжато и должно быть распаковано перед использованием. В этом случае оставшиеся биты четырехбайтового слова длины дают общий размер сжатых данных, а не исходные данные. Обратите внимание, что сжатие также возможно для данных разделенных на несколько страниц. Это определяется не заголовком varlena, а содержимым по TOAST-указателю.
Как уже упоминалось, существует несколько типов данных для TOAST указателя. Наиболее распространенный тип — это указатель на разделенные по страницам данные, хранящиеся в таблице TOAST. Эта таблица отделена от таблицы, содержащая TOAST-указатель на данные, но связана с ней. Эта информация указателя на диске создается с помощью кода управления TOAST (в access/heap/tuptoaster.c) когда кортеж, который будет храниться на диске, слишком велик, чтобы быть сохраненным как есть. Более подробная информация приводится в разделе Внешнее хранилище TOAST на диске. Кроме того, TOAST-указатель на данные может содержать указатель на исходящие данные, которые отображаются в другом месте в памяти. Такие данные обязательно временны и никогда не появляются на диске, но они очень полезны для предотвращения копирования и избыточной обработки больших значений данных. Более подробная информация приводится в разделе Внешнее хранилище TOAST в памяти.
Метод сжатия, используемый как для одностраничных, так и для многостраничных данных, является довольно простой и очень быстрой реализацией алгоритма из семейства методов сжатия LZ, реализация представлена в src/common/pg_lzcompress.c.
Внешнее хранилище TOAST на диске
Если любой из столбцов таблицы поддерживает TOAST, таблица будет иметь связанную таблицу TOAST, OID которой хранится в записи таблицы pg_class.reltoastrelid. Значения TOAST на диске хранятся в таблице TOAST, как описано ниже более подробно.
Разделенные значения делятся (если используется сжатие) на порции длиной не более чем TOAST_MAX_CHUNK_SIZE байт (по умолчанию это значение выбрано таким образом, что четыре строки chunk поместятся на странице, что составляет около 2000 байт). Каждый фрагмент хранится в виде отдельной строки в таблице TOAST, принадлежащей таблице-владельцу. Каждая таблица TOAST имеет столбцы chunk_id (OID, определяющий конкретное TOAST значение), chunk_seq (порядковый номер для фрагмента в пределах его значения), и chunk_data (фактические данные фрагмента). Уникальный индекс на chunk_id и chunk_seq обеспечивает быстрое доступ к значениям. Таким образом, указатель на данные, представляющий собой устаревшее значение на диске, должен хранить OID таблицы TOAST, в которой нужно искать, и OID конкретного значения (его chunk_id). Для удобства, указатели на данные также хранят логический размер данных (исходная несжатая длина) и физический сохраненный размер (различен, если сжатие было применено). Учитывая байты заголовка varlena, общий размер TOAST-указателя на диске составляет 18 байт независимо от фактического размера представленного значения.
Код для обработки TOAST запускается только тогда, когда значение строки,
подлежащее хранению в таблице, больше, чем TOAST_TUPLE_THRESHOLD байт
(обычно 2 кб). Код TOAST будет сжимать и/или перемещать значения полей
из строки до тех пор, пока значение строки не станет короче, чем
TOAST_TUPLE_TARGET байт (также 2 кб по-умолчанию) или до тех пор,
пока объем строки будет невозможно уменьшить. Во время операции UPDATE
значения неизмененных полей обычно сохраняются как есть; поэтому
обновление строки с значениями разделенных на несколько страниц не несет никаких
дополнительных затрат, если ни одно из таких значений не
изменилось.
Код для обработки TOAST определяет четыре различных стратегии для хранения столбцов с поддержкой TOAST на диске:
-
PLAIN предотвращает сжатие или хранение вне строки; кроме того, он отключает использование однобайтовых заголовков для типов varlena. Это единственная возможная стратегия для столбцов типов данных, не допускающих TOAST.
-
EXTENDED позволяет как сжатие, так и хранение вне строки. Это значение по умолчанию для большинства типов данных с поддержкой TOAST. Сначала будет предпринята попытка сжатия, затем хранение вне строки, если строка все еще слишком велика.
-
EXTERNAL позволяет хранить вне строки, но не сжимать. Использование EXTERNAL сделает операции с подстрокой в больших text и bytea столбцах быстрее (в ущерб большему требованию к памяти), потому что такие операции оптимизированы для выборки только необходимых частей вне строки, когда оно не сжато.
-
MAIN позволяет сжатие, но не вне хранилища. (На самом деле, для таких столбцов по-прежнему будет выполняться автономное хранение, но только в крайнем случае, когда нет другого способа сделать строку достаточно маленькой, чтобы поместиться на странице).
Каждый тип данных поддерживающий TOAST задает стратегию по умолчанию для столбцов этого типа данных. Также стратегию для указанного столбца таблицы можно изменить с помощью ALTER TABLE ... SET STORAGE.
TOAST_TUPLE_TARGET можно настроить для каждой таблицы с помощью ALTER TABLE ... SET (toast_tuple_target = N)
По сравнению с более простым подходом, который позволяет значениям строк пересекать границы странцы, эта схема имеет ряд преимуществ. Предполагая, что запросы обычно имеют сравнения с относительно маленькими значениями ключа, большая часть работы будет выполнена с использованием записи основной строки. Большие значения TOAST-атрибутов будут извлечены только (если они вообще выбраны) во время отправки результата клиенту. Таким образом, основная таблица намного меньше, а значит больше строк помещается в общий буферный кэш, чем могло быть без использования внешнего хранения аттрибутов. Данные для сортировки также уменьшаются, и сортировка чаще всего будет выполняться полностью в памяти. Небольшой тест показал, что в таблице, которая содержит типичные HTML-страницы и их URL-адреса, хранится примерно в два раза меньший объем необработанных данных, включая таблицу TOAST, и что основная таблица содержит только около 10% всех данных (URL-адреса и некоторые небольшие HTML-страницы). При этом не было никакой разницы во времени выполнения по сравнению с таблицей без TOAST аттрибутов, в которой все HTML-страницы были сокращены до 7 КБ, для соответствия.
Внешнее хранилище TOAST в памяти
TOAST-указатели могут указывать на данные, которые не находятся на диске, а находятся в другом месте в памяти текущего серверного процесса. Такие указатели, очевидно, не могут быть долговечными, но они тем не менее полезны. В настоящее время существует два вида: указатели на косвенные (indirect) данные и указатели на расширенные (expanded) данные.
Косвенный указатель TOAST указывает на значение varlena, хранящееся где-то в памяти. Изначально он был создан просто как доказательство концепции, но в настоящее время он используется во время логического декодирования, чтобы избежать потенциального создания физических кортежей более 1 гб (что может произойти при объединении всех разделенных полей в один кортеж). У такого способа весьма ограниченное применение: владелец такого указателя самостоятельно должен учитывать, что ссылаемые данные существуют до тех пор, пока существует указатель.
Расширенные TOAST-указатели полезны для сложных типов данных, представление которых на диске не особенно подходит для вычислительных целей. Например, стандартное представление varlena массива включает информацию о размерности, битовый массив с null-значениями, если таковые имеются и далее все значения по порядку. Когда сам тип элемента имеет переменную длину, единственный способ найти N-ный элемент — это просмотреть все предыдущие элементы. Такое представление подходит для хранения на диске из-за его компактности, но для вычислений с массивом гораздо лучше иметь “расширенное” или “деконструированное” представление, в котором определены все начальные местоположения элементов. Механизм TOAST-указателя поддерживает эту потребность, позволяя данным, переданным по ссылке, указывать либо на стандартное значение varlena (представленного на диске), либо на TOAST-указатель, который указывает на расширенное представление где-то в памяти. Детали этого расширенного представления зависят от типа данных, тем не менее он должен иметь стандартный заголовок и соответствовать другим требованиям API, приведенным в src/include/utils/expandeddatum.h. функции уровня C/RUST, работающие с типом данных, могут выбрать для обработки любое представление. Функции, которые не знают о расширенном представлении, а просто применяют PG_DETOAST_DATUM к их входам будет, прозрачно получают обычное представление varlena; поэтому поддержка расширенного представления может вводиться постепенно, по одной функции за раз.
Указатели TOAST на расширенные значения далее разбиваются на указатели для чтения-записи и только для чтения. Представление с указанием на объект является одинаковым в любом случае, но функция, получающая указатель на чтение и запись, может изменять указанное значение на месте, тогда как функция, получающая указатель только на чтение, не должна этого делать; она должна сначала создать копию, если она хочет сделать измененную версию значения. Это различие и некоторые связанные с ним соглашения позволяют избежать ненужного копирования расширенных значений во время выполнения запроса.
Для всех типов указателей TOAST в памяти код управления TOAST гарантирует, что никакие данные указателя не может оказаться на диске. Указатели TOAST в памяти автоматически расширяются до обычных линейных значений varlena перед хранением, и затем, возможно, преобразуются в указатели TOAST на диске, если содержащийся кортеж был слишком большим.
Карта свободного пространства
Каждое отношение кучи и индекса, за исключением хэш-индексов, имеет карту свободного пространства (FSM) для отслеживания доступного пространства в отношении. Она хранится вместе с основными данными отношения в отдельном слое отношений, названной по номеру filenode отношения вместе с _fsm суффиксом. Например, если filenode отношения равен 12345, то FSM хранится в файле с именем 12345_fsm, в том же каталоге, что и основной файл отношения.
Карта свободного пространства организована в виде дерева страниц FSM. Страницы FSM нижнего уровня хранят свободное пространство, доступное на каждой странице кучи (или индекса), используя один байт для представления каждой такой страницы. Верхние уровни агрегируют информацию с нижних уровней.
Внутри каждой страницы FSM находится двоичное дерево, хранящееся в массиве с одним байтом на узел. Каждый конечный узел представляет собой страницу кучи или страницу FSM более низкого уровня. В каждом не-листовом узле хранится максимум из его дочерних значений. Поэтому максимальное значение всех листовых узлах хранится в корне.
Посмотрите src/backend/storage/freespace/README для получения более подробной информации о том, как структурирован FSM, и как он обновляется и ищется. Модуль pg_freespacemap может использоваться для изучения информации, хранящейся на картах свободного пространства.
Карта видимости
Каждое отношение кучи имеет карту видимости (VM), чтобы отслеживать, какие страницы содержат только кортежи, которые, как известно, видны для всех активных транзакций; она также отслеживает, какие страницы содержат только замороженные кортежи. Она хранится вместе с основными данными отношения в отдельном слое отношений, названной по номеру filenode отношения вместе с _vm суффиксом. Например, если filenode отношения равен 12345, то VM хранится в файле с именем 12345_vm, в том же каталоге, что и основной файл отношения. Обратите внимание, что индексы не имеют карту видимости.
Карта видимости хранит два бита на странице кучи. Первый бит, если он установлен, указывает, что страница является полностью видимой, или другими словами, что страница не содержит никаких кортежей, которые необходимо очистить. Эта информация также может использоваться сканированиями по индексу для ответа на запросы, с использованием только кортежа индекса. Второй бит, если он установлен, означает, что все Кортежи на странице были заморожены. Это означает, что даже вакуум с защитой от переполнения счетчика транзакции не должен повторно просматривать страницу.
Карта является консервативной в том смысле, что мы удостоверяемся, что всякий раз, когда бит установлен, мы знаем, что условие истинно, но если бит не установлен, он может быть или не быть истинным. Биты карты видимости задаются только вакуумом, но очищаются любыми операциями изменения данных на странице.
Модуль pg_visibility можно использовать для изучения информации, хранящейся в карте видимости.
Слой инициализации
Каждая нежурналируемая таблица и каждый индекс нежурналируемой таблицы имеют слой инициализации. Слой инициализации — это пустая таблица или индекс соответствующего типа. Когда нежурналируемая таблица должна быть сброшена к пустому состоянию из-за сбоя, слой инициализации копируется поверх основного слоя, а все другие слои стираются (они будут автоматически воссозданы по мере необходимости).
Внутренняя структура страницы базы данных
В этом разделе представлен обзор формата страницы, используемого в таблицах и индексах QHB1. Последовательности и таблицы TOAST представляются так же, как обычная таблица.
В следующем объяснении предполагается, что байт содержит 8 битов. Кроме того, термин элемент относится к значению данных, которое хранится на странице. В таблице элемент является строкой; в индексе элемент является записью индекса.
Каждая таблица и индекс хранятся в виде массива страниц фиксированного размера (обычно 8 кб, хотя при компиляции сервера можно выбрать другой размер страницы). В таблице все страницы логически эквивалентны, поэтому определенный элемент (строка) может храниться на любой странице. В индексах первая страница обычно зарезервирована как метастраница, содержащая управляющую информацию, и в индексе могут быть разные типы страниц, в зависимости от метода доступа к индексу.
В таблице 2 показана общая компоновка страницы. На каждой странице есть 5 частей.
Таблица 2. Общая Структура Страницы
| Предмет | Описание |
|---|---|
| PageHeaderData | 24 байта длиной. Содержит общую информацию о странице, включая указатели на свободное места. |
| ItemIdData | Массив идентификаторов элементов, указывающих на фактические элементы. Каждая запись является парой (смещение,длина). 4 байта на элемент. |
| Free space | Свободное пространство. Новые идентификаторы элементов выделяются с начала этой области, новые элементы — с конца. |
| Items | Собственно сами элементы. |
| Special space | Специальная область для методов индексного доступа. Различные методы хранят различные данные. Пустое поле для обычных таблиц. |
Первые 24 байта каждой страницы состоят из заголовка страницы (PageHeaderData). Его формат подробно описан в таблице 3. Первое поле отслеживает самую последнюю запись WAL, связанную с этой страницей. Второе поле содержит контрольную сумму страницы, если контрольные суммы включены. Далее идет 2-байтовое поле, содержащее биты флагов. Далее следуют три 2-байтных целочисленных поля (pd_lower, pd_upper, и pd_special). Они содержат смещения в байтах от начала страницы до начала свободного пространства, до конца свободного пространства и до начала специального пространства. Следующие 2 байта заголовка страницы, pd_pagesize_version, содержат размер страницы и индикатор версии.
Размер страницы в основном присутствует только в качестве перекрестной проверки; нет поддержки страниц разных размеров при установке. Последнее поле служит подсказкой для того, будет ли полезно очистить страницу: он отслеживает самый старый XMAX на странице, из тех что не был очищен.
Таблица 3. Структура PageHeaderData
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| pd_lsn | PageXLogRecPtr | 8 байт | LSN: следующий байт после последнего байта WAL-записи для последнего изменения на этой странице |
| pd_checksum | uint16 | 2 байта | Контрольная сумма страницы |
| pd_flags | uint16 | 2 байта | Биты флагов |
| pd_lower | LocationIndex | 2 байта | Смещение до начала свободного места |
| pd_upper | LocationIndex | 2 байта | Смещение до конца свободного пространства |
| pd_special | LocationIndex | 2 байта | Смещение до начала специального пространства |
| pd_pagesize_version | uint16 | 2 байта | Размер страницы и номер версии макета информация |
| pd_prune_xid | TransactionId | 4 байта | Самый старый неочищенный XMAX на странице, или ноль, если отсутствует |
Все подробности можно узнать в разделе src/include/storage/bufpage.h.
После заголовка страницы идут идентификаторы элементов (ItemIdData), каждый из которых требует четыре байта. Идентификатор элемента содержит смещение в байтах до начала элемента, его длину в байтах и несколько битов атрибутов, влияющих на его интерпретацию. Новые идентификаторы элементов выделяются по мере необходимости с начала свободного пространства. Количество присутствующих идентификаторов элементов можно определить, посмотрев на pd_lower, который увеличивается при выделении нового идентификатора. Поскольку идентификатор элемента никогда не перемещается до тех пор, пока он не будет освобожден, его индекс можно использовать в долгосрочной основе для ссылки на элемент, даже если сам элемент перемещается по странице для сжатия свободного пространства. На самом деле, каждый указатель на элемент (ItemPointer, также известный как CTID) созданный QHB состоит из номера страницы и индекса идентификатора элемента.
Сами элементы хранятся в пространстве, выделенном с конца свободного пространства. Точная структура варьируется в зависимости от того, что должна содержать таблица. В таблицах и последовательностях используется структура с именем HeapTupleHeaderData, описанная ниже.
Последний раздел - это "специальный раздел", который может содержать все, что метод доступа желает сохранить. Например, B-дерево хранит ссылки на левый и правый родственные элементы страницы, а также некоторые другие данные, относящиеся к структуре индекса. Обычные таблицы вообще не используют специальный раздел (указывается при настройке pd_special для выравнивания размера страницы).
На рис. 1 показано, как эти части располагаются на странице.
Рис. 1. Структура страницы
Расположение Строк Таблицы
Все строки таблицы структурированы аналогичным образом. Существует заголовок фиксированного размера (занимающий 23 байта на большинстве машинах), за которым следует необязательное битовый массив с null-элементами, необязательное поле с идентификатором объекта и пользовательские данные. Заголовок подробно описан в таблице 4. Сами же пользовательские данные (столбцы строки) начинаются со смещения, указанного в t_hoff, который всегда должен быть кратен MAXALIGN для платформы. Битовый массив с null-элементами присутствует только в том случае, если установлен бит HEAP_HASNULL в t_infomask. Если он присутствует, то он начинается сразу после фиксированного заголовка и занимает достаточно байт, чтобы иметь один бит на столбец данных (т.е. количество битов, равное количеству атрибутов в столбце). t_infomask2). В этом списке битов выставленный бит указывает, что элемент не null, пустой - null. Когда битовый массив отсутствует, все столбцы считаются не null. Идентификатор объекта присутствует только в том случае, если установлен бит HEAP_HASOID_OLD в t_infomask. Если присутствует, то он появляется непосредственно перед смещением t_hoff. Чтобы сделать t_hoff кратным MAXALIGN между битовым массивом и идентификатором объекта добавляется отступ произвольного размера. (Это в свою очередь гарантирует, что идентификатор объекта соответствующим образом выровнен.)
Таблица 4. Структура Heaptupleheaderdata
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| t_xmin | TransactionId | 4 байта | значение XID при вставке |
| t_xmax | TransactionId | 4 байта | значение XID при удалении |
| t_cid | CommandId | 4 байта | значение CID при вставке и/или удалении (пересекается с t_xvac) |
| t_xvac | TransactionId | 4 байта | XID для операции вакума при перемещении версии строки |
| t_ctid | ItemPointerData | 6 байт | TID текущий или более новой версии строки |
| t_infomask2 | uint16 | 2 байта | количество атрибутов плюс различные флаговые биты |
| t_infomask | uint16 | 2 байта | различные флаговые биты |
| t_hoff | uint8 | 1-байтовый | смещение до данных пользователя |
Все подробности можно узнать в разделе src/include/access/htup_details.h.
Интерпретация фактических данных может быть выполнена только с помощью информации, полученной из других таблиц, в основном pg_attribute. Ключевые значения, необходимые для определения местоположения полей: attlen и attalign. Доступ к произвольному атрибуту возможен только тогда, когда все поля имеют фиксированную длину и нет нулевых значений. Все эти особенности определены в функциях heap_getattr, fastgetattr и heap_getsysattr.
Чтобы прочитать данные, необходимо прочитать каждый атрибут по очереди. Первым делом нужно проверить, является ли поле NULL в соответствии с битовым массивом null-значений. Если это так, то элемент отсутствует в данных. После этого необходимо убедиться, что есть правильное выравнивание. Если поле имеет фиксированную ширину, то все байты помещаются как есть. Если это поле переменной длины (attlen = -1), то это немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка struct varlena, который включает в себя общую длину сохраненного значения и некоторые флаговые биты. В зависимости от флагов, данные могут быть либо встроенными, либо хранится отдельно в таблице TOAST; они также могут быть сжаты (см. раздел TOAST).
На самом деле, использование этого формата страницы не требуется ни для методов доступа к таблице, ни для методов доступа к индексу. Метод heap доступа к таблице всегда использует этот формат. Все существующие методы индексирования также используют базовый формат, но данные, хранящиеся на мета-страницах индекса, обычно не следуют правилам компоновки элементов.
Как планировщик использует статистику
Эта глава основана на материалах, описанных в разделах Использование EXPLAIN и Статистика, используемая планировщиком, чтобы описать некоторые детали о том, как планировщик использует системную статистику для оценки количества строк, которые может возвратить каждая часть запроса. Это существенная часть процесса планирования, обеспечивающая большую часть информации для расчета стоимости запроса.
Цель этой главы состоит не в том, чтобы подробно документировать код, а в том, чтобы представить обзор того, как он работает. Это, возможно, сгладит кривую обучения для тех, кто впоследствии захочет изучить код.
Примеры оценок строк
В приведенных ниже примерах используются таблицы в базе данных регрессионного теста QHB. Обратите также внимание, что поскольку ANALYZE использует случайную выборку при создании статистики, результаты немного изменятся после нового анализа.
Начнем с очень простого запроса:
EXPLAIN SELECT * FROM tenk1;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..458.00 rows=10000 width=244)
Как планировщик определяет размер (мощность) таблицы tenk1 рассматривается в разделе Статистика, используемая планировщиком, но повторяется здесь для полноты картины. Количество страниц и строк находится в поле pg_class:
SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1';
relpages | reltuples
----------+-----------
358 | 10000
Эти числа являются текущими по состоянию на последний вызов VACUUM или ANALYZE в таблице. Затем планировщик выбирает фактическое количество страниц в таблице (это дешевая операция, не требующая сканирования таблицы). Если это значение отличается от relpages тогда reltuples пропорционально изменяется, чтобы получить текущую оценку количества строк. В приведенном выше примере значение параметра relpages является актуальным, поэтому оценка строк такая же, как reltuples.
Давайте перейдем к примеру с диапазоном в условии WHERE:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=24.06..394.64 rows=1007 width=244)
Recheck Cond: (unique1 < 1000)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000)
Планировщик проверяет условие WHERE и ищет функцию
селективности (оценка размера выборки) для оператора < в pg_operator.
Это проводится в
колонке oprrest, и запись в этом случае является scalarltsel.
scalarltsel функция извлекает гистограмму для unique1 из pg_statistic.
Для запросов выполняемых вручную удобнее искать информацию в более простом
pg_stats:
SELECT histogram_bounds FROM pg_stats
WHERE tablename='tenk1' AND attname='unique1';
histogram_bounds
------------------------------------------------------
{0,993,1997,3050,4040,5036,5957,7057,8029,9016,9995}
Далее обрабатывается доля гистограммы в пределах 1000. Это и есть селективность. Гистограмма делит диапазон на равные частотные сегменты, поэтому все, что нам нужно сделать, это найти группу, в которой находится наше значение, и подсчитать пропорциональную долю и все предыдущие группы. Значение 1000 явно находится во второй группе (993-1997). Предполагая линейное распределение значений внутри каждой группы, мы можем рассчитать селективность как:
selectivity = (1 + (1000 - bucket[2].min)/(bucket[2].max - bucket[2].min))/num_buckets
= (1 + (1000 - 993)/(1997 - 993))/10
= 0.100697
то есть одна целая группа плюс пропорциональная доля второй, разделенная на количество групп. Конечное число строк теперь может быть рассчитано как произведение селективности и мощности tenk1:
rows = rel_cardinality * selectivity
= 10000 * 0.100697
= 1007 (rounding off)
Далее рассмотрим пример с условием равенства в WHERE:
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'CRAAAA';
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=30 width=244)
Filter: (stringu1 = 'CRAAAA'::name)
Опять же, планировщик изучает условие в WHERE и ищет функцию
селективности для =, который является eqsel. Для оценки равенства
гистограмма не полезна; вместо этого для определения селективности
используется список наиболее распространенных значений (most common
value - MCV). Давайте
посмотрим на MCV, с некоторыми дополнительными столбцами, которые будут
полезны позже:
SELECT null_frac, n_distinct, most_common_vals, most_common_freqs FROM pg_stats
WHERE tablename='tenk1' AND attname='stringu1';
null_frac | 0
n_distinct | 676
most_common_vals | {EJAAAA,BBAAAA,CRAAAA,FCAAAA,FEAAAA,GSAAAA,JOAAAA,MCAAAA,NAAAAA,WGAAAA}
most_common_freqs | {0.00333333,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003,0.003}
Селективность определяется записью соответствующей записью CRAAAA в списке наиболее распространенных частот (MCFs):
selectivity = mcf[3]
= 0.003
Как и прежде, расчетное число строк — это просто произведение селективности с кардинальностью tenk1:
rows = 10000 * 0.003
= 30
Теперь рассмотрим тот же запрос, но с константой, которая не находится в списке MCV:
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 = 'xxx';
QUERY PLAN
----------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=15 width=244)
Filter: (stringu1 = 'xxx'::name)
Это совсем другая проблема: как оценить селективность, когда значение не находится в списке MCV. Для решения можно использовать знание о том, что искомое значение не находится в списке вместе со всем значениями частот для MCV:
selectivity = (1 - sum(mvf))/(num_distinct - num_mcv)
= (1 - (0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003 +
0.003 + 0.003 + 0.003 + 0.003))/(676 - 10)
= 0.0014559
Нужно сложить все частоты для MCV и вычесть их из единицы, а затем разделить на количество других различных значений. Это равнозначно, что часть столбца, которая не является ни одним из MCV, равномерно распределена между всеми другими различными значениями. Обратите внимание, что нет никаких нулевых значений, поэтому нам не нужно беспокоиться о них (в противном случае мы бы вычитали нулевую дробь из числителя). Приблизительное число строк затем вычисляется как обычно:
rows = 10000 * 0.0014559
= 15 (rounding off)
В предыдущем примере с условием unique1 < 1000 было упрощением того, что действительно делает scalarltsel. Теперь, когда мы увидели пример использования MCVs, мы можем описать процесс более детально. Этот пример был верен, поскольку unique1 это уникальный столбец, а значит у него нет MCV (очевидно, что никакое значение не встречается чаще, чем любое другое значение). Для неуникального столбца обычно существуют гистограмма и список MCV, и гистограмма не включает значения из списка MCV. Это сделано для более точной оценки. В этой ситуации scalarltsel непосредственно применяет данное условие (например, "<1000") к каждому значению списка MCV и суммирует частоты MCV, для которых условие является истинным. Это дает точную оценку селективности для той части таблицы, которая содержит значения MCVs. Аналогичным образом используется гистограмма для оценки селективности в той части таблицы, которая не содержит значения MCVs, а затем эти два числа складываются для оценки общей селективности. Например, рассмотрим
EXPLAIN SELECT * FROM tenk1 WHERE stringu1 < 'IAAAAA';
QUERY PLAN
------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=3077 width=244)
Filter: (stringu1 < 'IAAAAA'::name)
Мы уже видели информацию MCV для stringu1, и вот его гистограмма:
SELECT histogram_bounds FROM pg_stats
WHERE tablename='tenk1' AND attname='stringu1';
histogram_bounds
--------------------------------------------------------------------------------
{AAAAAA,CQAAAA,FRAAAA,IBAAAA,KRAAAA,NFAAAA,PSAAAA,SGAAAA,VAAAAA,XLAAAA,ZZAAAA}
Проверяя список MCV, мы обраруживаем, что условие stringu1 удовлетворяется первыми шестью записями, а не последними четырьмя, поэтому селективность для значений из множества MCV определяется как
selectivity = sum(relevant mvfs)
= 0.00333333 + 0.003 + 0.003 + 0.003 + 0.003 + 0.003
= 0.01833333
Суммирование всех MCFs также говорит нам, что общая доля значений из множества MCVs, составляет 0.03033333, и поэтому доля значений, представленная гистограммой, составляет 0.96966667 (опять же, нет NULL-значений, иначе мы должны были бы их здесь исключить). Видно, что значение IAAAAA расположено почти в конце третьей группы гистограммы. Используя довольно грубые предположения о частоте различных символов, планировщик приходит к оценке 0,298387 для части значений из гистограммы, которая меньше, чем IAAAAA. Затем мы объединяем оценки для MCV и не-MCV значений:
selectivity = mcv_selectivity + histogram_selectivity * histogram_fraction
= 0.01833333 + 0.298387 * 0.96966667
= 0.307669
rows = 10000 * 0.307669
= 3077 (rounding off)
В этом конкретном примере коррекция полученная из списка MCV незначительна, потому что распределение столбцов на самом деле довольно плоское (статистика, показывающая эти конкретные значения как более распространенные, чем другие, в основном из-за ошибки выборки). В более типичном случае, когда некоторые значения являются значительно более распространенными, чем другие, этот сложный процесс повышает точность, поскольку селективность для MVC найдена точно.
Теперь рассмотрим случай с несколькими условиями в WHERE:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 1000 AND stringu1 = 'xxx';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=23.80..396.91 rows=1 width=244)
Recheck Cond: (unique1 < 1000)
Filter: (stringu1 = 'xxx'::name)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..23.80 rows=1007 width=0)
Index Cond: (unique1 < 1000)
Планировщик предполагает, что эти два условия являются независимыми, так что селективности их оценок могут быть умножены:
selectivity = selectivity(unique1 < 1000) * selectivity(stringu1 = 'xxx')
= 0.100697 * 0.0014559
= 0.0001466
rows = 10000 * 0.0001466
= 1 (rounding off)
Обратите внимание, что количество строк, которые должны быть возвращены при сканирования битового индекса, отражает только условие, используемое в индексе. Это важно, так как оно влияет на оценку стоимости для последующих выборок из таблицы.
Наконец, мы рассмотрим запрос, который включает в себя соединение таблиц:
EXPLAIN SELECT * FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 50 AND t1.unique2 = t2.unique2;
QUERY PLAN
--------------------------------------------------------------------------------------
Nested Loop (cost=4.64..456.23 rows=50 width=488)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.64..142.17 rows=50 width=244)
Recheck Cond: (unique1 < 50)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.63 rows=50 width=0)
Index Cond: (unique1 < 50)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.00..6.27 rows=1 width=244)
Index Cond: (unique2 = t1.unique2)
Ограничение на tenk1, unique1< 50, вычисляется перед циклом соединения. Это обрабатывается аналогично предыдущему примеру с диапазоном. На этот раз значение 50 попадает в первую корзину гистограммы unique1:
selectivity = (0 + (50 - bucket[1].min)/(bucket[1].max - bucket[1].min))/num_buckets
= (0 + (50 - 0)/(993 - 0))/10
= 0.005035
rows = 10000 * 0.005035
= 50 (rounding off)
Ограничение для соединения является t2.unique2 = t1.unique2. Оператор — это уже разобранный =, однако функцию селективности (eqjoinsel.eqjoinsel) находится в столбце oprjoin таблицы pg_operator. Эта функция ищет статистическую информацию для обоих tenk2 и tenk1:
SELECT tablename, null_frac,n_distinct, most_common_vals FROM pg_stats
WHERE tablename IN ('tenk1', 'tenk2') AND attname='unique2';
tablename | null_frac | n_distinct | most_common_vals
-----------+-----------+------------+------------------
tenk1 | 0 | -1 |
tenk2 | 0 | -1 |
В этом случае отсутствует информация MCV для unique2 поскольку все значения выглядят уникальными, а значит используется алгоритм, который полагается только на число различных значений для обоих отношений вместе с их нулевыми фракциями:
selectivity = (1 - null_frac1) * (1 - null_frac2) * min(1/num_distinct1, 1/num_distinct2)
= (1 - 0) * (1 - 0) / max(10000, 10000)
= 0.0001
В этом случае это определяется как вычитание доли null элеменов из единицы для каждого из отношений и деление на максимальное число различных значений. Число строк, которые будет получиено при соединении, вычисляется как мощность декартова произведения двух входных данных, умноженная на селективность:
rows = (outer_cardinality * inner_cardinality) * selectivity
= (50 * 10000) * 0.0001
= 50
Если бы существовали списки MCV для двух столбцов, eqjoinsel использовал бы прямое сравнение списков MCV для определения селективности соединения для той части значений, что содержится в MCVs. Оценка для остальной части данных следует по такому же подходу.
Обратите внимание, что мы показали inner_cardinality как 10000, то есть неизмененный размер tenk2. При проверке выходных данных EXPLAIN может показаться, что оценка соединяемых строк исходит из 50 * 1, то есть число внешних строк умножается на предполагаемое число строк, полученных каждым внутренним индексным сканированием на tenk2. Но это не так: размер отношения соединения оценивается до того, как был рассмотрен какой-либо конкретный план соединения. Если все работает хорошо, то два способа оценки размера соединения дадут примерно один и тот же результат, но из-за ошибки округления и других факторов они иногда значительно расходятся.
Для тех, кто заинтересован в более подробной информации, оценка размера таблицы (перед любым условием WHERE) делается в src/backend/ optimizer/util/plancat.с. Общая логика для селективности условий находится в src/backend/optimizer/path/clausesel.с. Специфичные для операторов функции селективности можно найти внутри src/backend/utils/adt/selfuncs.с.
Примеры многомерной статистики
Функциональная зависимость
Многомерная корреляция может быть продемонстрирована с помощью очень простого набора данных — таблицы с двумя столбцами, содержащими одинаковые значения:
CREATE TABLE t (a INT, b INT);
INSERT INTO t SELECT i % 100, i % 100 FROM generate_series(1, 10000) s(i);
ANALYZE t;
Как объяснено в разделе Статистика, используемая планировщиком, планировщик может определить размер таблицы t используя количество страниц и строк, полученных из pg_class:
SELECT relpages, reltuples FROM pg_class WHERE relname = 't';
relpages | reltuples
----------+-----------
45 | 10000
Распределение данных очень простое; в каждом столбце есть только 100 различных значений распределенных равномерно.
В следующем примере показан результат оценки условия WHERE для столбца a:
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..170.00 rows=100 width=8) (actual rows=100 loops=1)
Filter: (a = 1)
Rows Removed by Filter: 9900
Планировщик изучает условие и определяет, что селективность равна 1% Сравнивая эту оценку и фактическое число строк, мы видим, что оценка является очень точной (фактической, так как таблица очень мала). При использования столбца b в условии WHERE генерируется идентичный план. Но обратите внимание, что произойдет, если мы применим одно и то же условие к обоим столбцам, объединив их с AND:
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1 AND b = 1;
QUERY PLAN
-----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=1 width=8) (actual rows=100 loops=1)
Filter: ((a = 1) AND (b = 1))
Rows Removed by Filter: 9900
Планировщик оценивает селективность для каждого условия индивидуально, приходя к тем же самым оценкам 1%, что и выше. Затем он предполагает, что условия независимы, и поэтому он умножает их селективность, производя окончательную оценку селективности равной всего 0,01%. Это является значительной недооценкой, поскольку фактическое число строк, соответствующих условиям (100), на два порядка выше.
Эта проблема может быть решена путем создания объекта статистики, который укажет ANALYZE вычислить многомерную статистику функциональной зависимости по двум столбцам:
CREATE STATISTICS stts (dependencies) ON a, b FROM t;
ANALYZE t;
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1 AND b = 1;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=100 width=8) (actual rows=100 loops=1)
Filter: ((a = 1) AND (b = 1))
Rows Removed by Filter: 9900
Подсчет групп многомерных значений
Аналогичная проблема возникает с оценкой мощности множеств нескольких столбцов, таких как число групп, которые будут генерироваться выражением GROUP BY. Когда GROUP BY передан один столбец, оценка различных значений (которые можно увидеть в значении количества строк, возвращаемых узлом HashAggregate) очень точна:
EXPLAIN (ANALYZE, TIMING OFF) SELECT COUNT(*) FROM t GROUP BY a;
QUERY PLAN
-----------------------------------------------------------------------------------------
HashAggregate (cost=195.00..196.00 rows=100 width=12) (actual rows=100 loops=1)
Group Key: a
-> Seq Scan on t (cost=0.00..145.00 rows=10000 width=4) (actual rows=10000 loops=1)
Но без многомерной статистики оценка количества групп в запросе с двумя столбцами в GROUP BY, в частности в следующем примере, отклоняется на порядок:
EXPLAIN (ANALYZE, TIMING OFF) SELECT COUNT(*) FROM t GROUP BY a, b;
QUERY PLAN
--------------------------------------------------------------------------------------------
HashAggregate (cost=220.00..230.00 rows=1000 width=16) (actual rows=100 loops=1)
Group Key: a, b
-> Seq Scan on t (cost=0.00..145.00 rows=10000 width=8) (actual rows=10000 loops=1)
При переопределении объекта статистики для включения подсчета групп для двух столбцов оценка значительно улучшается:
DROP STATISTICS stts;
CREATE STATISTICS stts (dependencies, ndistinct) ON a, b FROM t;
ANALYZE t;
EXPLAIN (ANALYZE, TIMING OFF) SELECT COUNT(*) FROM t GROUP BY a, b;
QUERY PLAN
--------------------------------------------------------------------------------------------
HashAggregate (cost=220.00..221.00 rows=100 width=16) (actual rows=100 loops=1)
Group Key: a, b
-> Seq Scan on t (cost=0.00..145.00 rows=10000 width=8) (actual rows=10000 loops=1)
MCV списки
Как пояснялось в разделе ранее, функциональные зависимости являются очень дешевым и эффективным классом статистики, но у них есть основное ограничение в глобальном характере (отслеживается зависимости на уровне столбцов, а не между отдельными значениями столбцов).
Этот раздел вводит многомерный вариант множеств MCV (наиболее распространенных значений), расширение статистики по столбцам, описанной в разделе, с примерами оценок строк. Этот вариант решают проблему путем хранения отдельных значений, но это, естественно, более дорого, как с точки зрения построения статистики в ходе ANALYZE, так и времени затрачиваемом на хранение и планирование.
Давайте еще раз посмотрим на запрос из раздела функциональной зависимости, но на этот раз со списком MCV, созданным на том же наборе столбцов (не забудьте удалить функциональные зависимости, чтобы убедиться, что планировщик использует только новую статистику).
DROP STATISTICS stts;
CREATE STATISTICS stts2 (mcv) ON a, b FROM t;
ANALYZE t;
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1 AND b = 1;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=100 width=8) (actual rows=100 loops=1)
Filter: ((a = 1) AND (b = 1))
Rows Removed by Filter: 9900
Оценка так же точна, как и с функциональными зависимостями, в основном благодаря тому, что таблица довольно мала и имеет простое распределение с небольшим количеством различных значений. Прежде чем рассматривать второй запрос, который не так хорошо работают функциональные зависимости, давайте немного рассмотрим список MCV.
Проверка списка MCV возможна с помощью функции pg_mcv_list_items.
SELECT m.* FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid),
pg_mcv_list_items(stxdmcv) m WHERE stxname = 'stts2';
index | values | nulls | frequency | base_frequency
-------+----------+-------+-----------+----------------
0 | {0, 0} | {f,f} | 0.01 | 0.0001
1 | {1, 1} | {f,f} | 0.01 | 0.0001
...
49 | {49, 49} | {f,f} | 0.01 | 0.0001
50 | {50, 50} | {f,f} | 0.01 | 0.0001
...
97 | {97, 97} | {f,f} | 0.01 | 0.0001
98 | {98, 98} | {f,f} | 0.01 | 0.0001
99 | {99, 99} | {f,f} | 0.01 | 0.0001
(100 rows)
Это подтверждает, что в двух столбцах есть 100 различных комбинаций, и
все они примерно равновероятны (частота 1% для каждого из них).
base_frequency — это частота, вычисляемая из статистики по каждому
столбцу независимо от статистики по нескольким столбцам. Если бы
в любом из столбцов были какие-либо нулевые значения, это было бы
указано в столбце nulls.
При оценке селективности планировщик применяет все условия для элементов в списке MCV, а затем суммирует частоты эквивалентных элементов. За подробностями можно обратиться к функции mcv_clauselist_selectivity в файле src/backend/статистика/mcv.с.
По сравнению с функциональными зависимостями, списки MCV имеют два основных преимущества. Во-первых, в списке хранятся фактические значения, что позволяет решить, какие комбинации совместимы.
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1 AND b = 10;
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=1 width=8) (actual rows=0 loops=1)
Filter: ((a = 1) AND (b = 10))
Rows Removed by Filter: 10000
Во-вторых, списки MCV обрабатывают больше видов условий, а не только условия равенства как функциональные зависимости. Например, взгляните на следующий запрос с диапазоном значений для той же таблицы:
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a <= 49 AND b > 49;
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=1 width=8) (actual rows=0 loops=1)
Filter: ((a <= 49) AND (b > 49))
Rows Removed by Filter: 10000
Планировщик статистики и безопасности
Доступ к таблице pg_statistic ограничивается суперпользователями, так
что обычные пользователи не могут узнать о содержании таблиц других
пользователей из него. Некоторые функции оценки селективности будут
использовать предоставленный пользователем оператор (либо оператор,
появляющийся в запросе, либо связанный с ним оператор) для анализа
сохраненной статистики. Например, чтобы определить, применимо ли
сохраненное MCV, оценщик селективности должен будет
выполнить соответствующее оператор = для сравнения константы в
запросе с сохраненным значением. Таким образом, данные в pg_statistic
потенциально могут передаваться пользовательским операторам. Правильно
созданный оператор может намеренно пропускать переданные операнды
(например, регистрируя их или записывая в другую таблицу), или случайно
пропускать их, показывая их значения в сообщениях об ошибках, в обоих
случаях возможно получить данные из pg_statistic для
пользователя, который не должен видеть его.
Чтобы предотвратить это, к всем встроенным функциям оценки селективности применяется следующее. При планировании запроса, чтобы иметь возможность использовать сохраненную статистику, текущий пользователь должен либо иметь привилегию SELECT на таблицу или вовлеченные столбцы, или используемый оператор должны быть LEAKPROOF (точнее, функция, на которой основан оператор). Если нет, то оценщик селективности будет вести себя так, как если бы никакой статистики не было доступно, и планировщик будет продолжать использовать предположения по умолчанию.
Если пользователь не имеет необходимых прав доступа к таблице или столбцам, то во многих случаях запрос в конечном итоге получит ошибку прав доступа, и в этом случае такой механизм на практике невидим. Но если пользователь читает из представления с барьером безопасности, то планировщик может захотеть проверить статистику базовой таблицы, которая в противном случае недоступна для пользователя. В этом случае оператор должен быть leak-proof, иначе статистика не будет использоваться. Единственное в чем могут быть наблюдаемые отличия это неоптимальность плана. Если кто-то подозревает, что это так, можно попробовать запустить запрос от имени более привилегированного пользователя, чтобы увидеть, выбирается ли другой план.
Это ограничение применяется только в тех случаях, когда планировщику необходимо выполнить оператор, определенный пользователем, для одного или нескольких значений из pg_statistic. Таким образом, планировщику разрешается использовать общую статистическую информацию, такую как доля нулевых значений или количество различных значений в столбце, независимо от прав доступа.
Содержащиеся в сторонних расширениях функции оценки селективности, которые потенциально работают со статистикой с пользовательскими операторами, должны следовать тем же правилам безопасности. Обратитесь к исходному коду QHB для получения подробных деталей.
Асинхронный пул соединений QCP
Асинхронный пул соединений (Quantum Connection Pool или QCP) обеспечивает подключение и поддержку связи с удаленными клиентами.
Общий принцип работы
QCP принимает входящие подключения от удалённых клиентов по адресу listening_address
(по умолчанию — 0.0.0.0:8080) и "проксирует" их серверам баз данных, перечисленных
в настройке servers. Соединения до серверов устанавливаются (и завершаются) автоматически, по мере необходимости.
В зависимости от режима работы, задаваемого параметром relay_mode, проксирование данных от
клиентов к серверам осуществляется одним из следующих способов:
relay_mode: Session: при первом обращении к серверу, клиенту выделяется уникальное соединение до базы данных, которое возвращается в пул только при отключении клиента.relay_mode: Smart: при обращении к серверу, клиенту выделяется уникальное соединение до базы данных, которое возвращается в пул тогда и только тогда, когда в ответе от сервера будет стоять флаг "Idle" (PostgreSQL Documentation: Message Formats, сообщениеReadyForQuery).
С полным описанием настроек можно ознакомиться в примере конфигурационного файла qcp/config-example.yaml.
Запуск и работа
Запуск осуществляется с помощью утилиты qcp (qcp --help для списка опций), остановка — утилитой
qcp-ctrl (qcp-ctrl --help для списка опций). Например, чтобы остановить запущенный экземпляр
QCP, необходимо выполнить команду qcp-ctrl quit.
Вывод логов в процессе работы QCP контролируется настройкой log_output (см.
qcp/config-example.yaml), при этом уровень логирования задаётся настройкой log_level (подробнее
про уровни логирования смотри — LevelFilter). Например,
чтобы выводить логи уровня Info и выше в файл /tmp/qcp.log, необходимо задать следующие
настройки в файле конфигурации:
log_level: Info
log_output:
file: /tmp/qcp.log
Потребление памяти
При старте программы единовременно выделяется количество памяти, указанное в разделе arena файла
конфигурации:
# Конфигурация памяти (опционально)
arena:
chunk_size: 66560 # Размер одного "куска" памяти, в байтах
# Общее количество потребляемой памяти можно указать либо используя параметр
# "количество кусков памяти":
chunks_count: 3150 # Количество таких "кусков"
# ... или указав общее количество напрямую:
total_size: 3.1 GB # Поддерживаются суффиксы B, KB, MB, GB
Внешнее хранение двоичных данных Rbytea
- Тип данных rbytea
- Установка расширения
- Функции для работы с типом rbytea
- Фоновый процесс очистки устаревших копий
- Параметры конфигурации расширения
Тип данных rbytea
Тип данных rbytea предназначен для хранения двоичных данных. Он аналогичен типу bytea, с той лишь разницей, что сами данные хранятся не в табличном пространстве базы, а во внешнем хранилище. В качестве внешнего хранилища, в текущей версии QHB, выступает файловая система. Это может быть смонтированный в определённую точку файловой системы сервера внешний том или символическая ссылка.
Основной целью расширения является вынос двоичных данных из таблиц базы данных в нетранзакционное хранилище, разгрузив тем самым саму базу данных. Зачастую, двоичные данные имеют большой объём, который занимает значительный процент от общего размера базы, усложняя администрирование и обслуживание.
Тип данных rbytea в записи базы данных оставляет только небольшой заголовок, в котором содержатся служебные поля и ссылку на файл во внешнем хранилище. В качестве ссылки используется тип данных uuid, а генерация случайных идентификаторов использует возможности модулем pgcrypto.
Данные во внешнем хранилище могут быть зашифрованы алгоритмом Кузнечик.
Установка расширения
Установка расширения производится командой CREATE EXTENSION:
create extension rbytea cascade;
Установку должен запускать суперпользователь баз данных. Эту команду следует запускать в той базе данных, в которой предполагается использовать модуль. Для работы фонового процесса необходимо обеспечить предварительную загрузку разделяемой библиотеки расширения, указав к конфигурации параметр:
shared_preload_libraries = 'librbytea'
Описание параметров расширения приведены ниже в разделе Параметры конфигурации расширения
Функции для работы с типом rbytea
| Имя | Тип результата | Описание |
|---|---|---|
| uuid(col rbytea) | uuid | Получить идентификатор данных |
| len(col rbytea) | bigint | Получить длину данных в байтах |
| len_full(col rbytea) | bigint | Получить длину в байтах данных с учетом выравнивания для шифрования |
| qss_mode(col rbytea) | bigint | Возвращает признак шифрования данных (1) или его отсутствия (0) |
| md5sum(col rbytea) | text | Возвращает md5 сумму данных |
| sha256sum(col rbytea) | text | Возвращает sha256 сумму данных |
| md5store(col rbytea) | text | Возвращает md5 сумму зашифрованных данных во внешнем хранилище |
| sha256store(col rbytea) | text | Возвращает sha256 сумму зашифрованных данных во внешнем хранилище |
| rvacuum() | bigint | Выполняет очистку устаревших данных в хранилище |
Фоновый процесс очистки устаревших копий
Поскольку на файловую систему не распространяется транзакционность базы данных, во внешнем хранилище могут оставаться
данные полей таблиц типа rbytea, которые удалены или были сохранены в незаконченных, отмененных транзакциях.
Фоновый процесс очистки периодически запускается, проходит по некоторому диапазону транзакций, очищая данные.
Файлы перемещаются в каталог TRASH, который создаётся для каждой базы данных указанной в параметре rbytea.databases_for_vacuuming.
После каждого запуска максимальный номер транзакции запоминается и при следующем запуске используется как минимальный для диапазона сканирования. В качестве максимального номера диапазона сканирования используется последняя завершённая транзакция.
Параметры запуска указаны в разделе Параметры конфигурации расширения
Параметры конфигурации расширения
Для работы расширений нужно установить несколько параметров в конфигурационном файле:
Определение каталога (точки монтирования файловой системы / тома) для сохранения образов данных
rbytea.filesystem_storage_path = '/mnt/fs'
Двоичные данные будут сохранятся в данном каталоге сервера. Для каждой базы будет создаваться свой подкаталог (по oid базы), а внутри него, во множестве подкаталогов - собственно файлы с данными.
Имена вложенных каталогов от каталога базы данных до файла будут составлять uuid типа rbytea, а расширение файла - номер транзакции, в которой данные впервые появились в системе.
Каталог должен быть доступен на чтение и запись в него для пользователя, от имени которого запускается сервер базы данных.
По-умолчанию, если параметр опущен или пуст, каталогом для сохранения двоичных данных назначается <каталог базы данных>/rbytea.
Загрузка разделяемой библиотеки при старте QHB:
shared_preload_libraries = 'librbytea'
Данный параметр обеспечивает загрузку разделяемой библиотеки при старте QHB и инициализацию фонового процесса для очистки устаревших образов. В противном случае, автоочистка устаревших образов производится не будет.
Внимание*
Если параметрshared_preload_librariesуже содержит указание на загрузку других библиотек, нужно не перезаписать его значение, а добавить через разделительlibrbytea
Интервал запуска фонового процесса очистки
rbytea.worker_restart_time = 86400
Фоновый процесс не работает постоянно. Поскольку данные достаточно статичны, запускать процесс очистки с большой частотой не требуется. Задержка от окончания предыдущего запуска до следующего запуска задаётся в данном параметре.
Значение указано в секундах. По умолчанию, параметр устанавливается в значение 86400 секунд (сутки).
Задание баз данных для фонового процесса очистки
rbytea.databases_for_vacuuming = 'qhb'
Параметр указывает, какие базы данных подлежат очистке. Указываются названия баз данных через запятую. Главный процесс базы данных будет запускать столько фоновых процессов очистки, сколько баз данных перечислено в данном параметре.
Включение фонового шифрования
rbytea.filesystem_qss_mode = 0
Если в системе доступно фоновое шифрование при записи на диск, данный параметр позволяет зашифровывать также и двоичные данные rbytea. Для шифрования параметр необходимо установить в значение 1.
При шифровании данных, данные дополняются (выравниваются) до границы 16-байтных блоков. Поэтому функции
len(rbytea) и len_full(rbytea) для одних и тех же данных могут возвращать разное значение.
А функции md5store(rbytea) и sha256store(rbytea) подсчитывают контрольные суммы для зашифрованных данных,
дополненных до границы 16-байтного блока.
Вопросы смены ключа шифрования должны решаться администратором базы данных.
По-умолчанию, параметр устанавливается в значение 0.
Модуль прямой загрузки данных QDL
Модуль прямой загрузки данных (Quantum Direct Loader, QDL) - утилита, позволяющая осуществить загрузку из файла формата CSV в таблицу формата QHB согласно конфигурации. Скорость работы существенно превосходит INSERT и COPY за счёт использования оптимизированного многопоточного кода, отсутствия блокировок таблицы и обхода транзакционного ядра.
- Поддерживаемые типы полей
- Синтаксис
- Команда
create_table - Команда
insert_values - Команда
validate - Файл конфигурации
- Сценарий использования
Поддерживаемые типы полей
| Типы | Названия |
|---|---|
| Целочисленные | smallint, int2, integer, int4, int, bigint, int8 |
| Числовые с плавающей запятой | float4, real, float8, double precision |
| Текстовые | character, char, varchar, character varying, text |
| Числа с указанной точностью | decimal, numeric, dec |
| Булевы | bool, boolean |
| Идентификаторы | uuid |
| Временные | timestamp, date |
Примечание.
В текущей версии QDL допускается использование значений NaN (Not a Number) в таких типах данных как float (числовые с плавающей запятой) и numeric (числа с указанной точностью). В дополнение к обычным числовым значениям и NaN, float также имеют специальные значения: Infinity и -Infinity. Обратите внимание, что все значения находящиеся в файле формата CSV не заключаются в кавычки.
Идентификаторы UUID записываются в виде последовательности шестнадцатеричных цифр в нижнем регистре, разделенных знаками минуса на несколько групп, в таком порядке: группа из 8 цифр, за ней три группы из 4 цифр и, наконец, группа из 12 цифр, что в сумме составляет 32 цифры. Пример UUID в этом стандартном виде:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
Временные типы поддерживают такие специальные значения как infinity, -infinity и epoch.
Синтаксис
USAGE:
qdl <SUBCOMMAND>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
SUBCOMMANDS:
create_table Generate SQL script to create a table
insert_values Populate a table file with values
validate Validates csv data file
help Prints this message or the help of the given subcommand(s)
Команда create_table
Генерирует SQL-скрипт, создающий таблицу СУБД согласно конфигурации, а также заполняет её первыми тремя кортежами CSV-таблицы. Это требуется для создания структуры таблицы, которая будет заполнена данными. Также это позволяет нам получить пути расположения файлов и их названия(OID, требуемый для генерации командой insert_values).
USAGE:
qdl create_table [FLAGS] [OPTIONS] --config <config>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-v, --verbose Display debug messages
OPTIONS:
-c, --config <config> Path to config
-d, --data <data> Path to csv file with data
Примечание.
В формате CSV все символы являются значимыми. Значение в таблице, дополненное пробелами или любыми другими символами, кроме DELIMITER, будет включать эти символы. Это может приводить к ошибкам при заполнении таблицы данными из системы, дополняющей строки CSV пробельными символами до некоторой фиксированной ширины. В случае возникновения такой проблемы необходимо обработать файл CSV и удалить из него замыкающие пробельные символы, прежде чем загружать данные из него в QHB.
Пример использования
qdl create_table \
--config config.yml \
--data data.csv
Команда insert_values
Производит загрузку из файла в формате CSV в таблицу формата используемого QHB. Данная команда выполняется многопоточно; количество ядер, отводимое под параллельную обработку, указывается в файле конфигурации.
Также рекомендуется предварительно удостовериться, что версия компоновки страницы QHB равна 4. Сделать это можно, например, при помощи расширения pageinspect::page_header.
USAGE:
qdl insert_values [FLAGS] [OPTIONS] --config <config> --out-dir <out-dir>
FLAGS:
-h, --help Prints help information
-s, --skip-errors Continue adding rows despite errors
-V, --version Prints version information
-v, --verbose Display debug messages
OPTIONS:
-c, --config <config> Path to config
-d, --data <data> Path to csv file with data
-o, --out-dir <out-dir> Output directory
Пример использования
qdl insert_values \
--config config.yml \
--data data.csv \
--out-dir output/
Команда validate
Проверяет логическую целостность CSV-файла и согласованность структуры данных с файлом конфигурации, сигнализируя об ошибках соответствующим кодом возврата. Сообщение об успехе выводится только в случае, если был активирован флаг --verbose, в противном случае выполнение этой команды не сопровождается выводом сообщений в консоль.
USAGE:
qdl validate [FLAGS] [OPTIONS] --config <config>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-v, --verbose Display debug messages
OPTIONS:
-c, --config <config> Path to config
-d, --data <data> Path to csv file with data
Пример использования
qdl validate \
--config config.yml \
--data data.csv
Файл конфигурации
Файл конфигурации имеет следующие партиции:
- general -- базовая конфигурация приложения. Содержит поля
threads(целочисленное) иchunk_size(целочисленное, опциональное). Первое ответственно за количество потоков-обработчиков сырых данных. Второе ответственно за размер внутреннего буфера передачи данных, данный параметр может меняться с целью оптимизации в нестандартных аппаратных конфигурациях. - input -- конфигурация входных данных. Содержит поля
path(путь),encoding(строковое),delimiter(строковое, опциональное). Первое -- путь до входного файла; второе -- кодировка; третье -- разделитель столбцов для человекочитаемых входных форматов. - output -- конфигурация выходных данных. Содержит поля
segment_size(целочисленное, опциональное) иoid(целочисленное). Первое -- максимальное количество страниц в сегменте БД; второе -- Object IDentifier, который составит часть пути до сегментов. - table -- конфигурация таблицы. Содержит поля
name(строковое) иfields(повторяющиесяfield). Первое -- имя таблицы; второе -- описание каждого из полей(field_1 : varcharи опциональной пометки[nullable]).
Пример конфигурации:
# Конфигурация системы:
general:
# Количество потоков, выделяемых для парсинга и сериализации строк.
# Прошу обратить внимание, что помимо этих потоков обязательно выделяются ещё два:
# поток чтения и поток записи в файл.
threads: 2
# Конфигурация исходных данных:
input:
# Кодировка:
encoding: "utf8"
# Разделитель столбцов для CSV:
delimiter: ";"
# Конфигурация получаемых данных:
output:
# Object IDentifier. Определяет целочисленный идентификатор для группы файлов целевой таблицы.
oid: 16385
# Конфигурация целевой таблицы:
table:
# Имя таблицы. Требуется для `generate_sql`, чтобы задать имя создаваемой таблицы.
name: "t_qdl"
# Колонки в формате "имя": "тип"
fields:
id : integer
social_id : integer [nullable]
first_name : varchar
last_name : varchar
city : varchar (30)
profession : varchar (30) [nullable]
salary : double precision
description : varchar [nullable]
Сценарий использования
ВНИМАНИЕ. Во избежание проблем с правами доступа, все последующие операции требуется производить от имени пользователя, который запускает экземпляр БД.
ШАГ 0(опциональный). qdl validate --config config.yml --data data.csv -- Валидируем CSV файл, проверяем на согласованность с конфигурацией. Это может сэкономить большое количество времени в случаях, когда мы конвертируем CSV-файл большого объёма, т.к. если в ходе работы функции insert_values будет обнаружена ошибка, её выполнение придётся повторить после исправления причин её возникновения.
ШАГ 1. qdl create_table --config config.yml --data data.csv -- Создаём SQL-скрипт создания таблицы, в которую мы хотим загрузить, а в последствии использовать в СУБД. Также этот скрипт получает OID (Object Identifier; потребуется для файла конфигурации insert_values) и пути файлов БД. Эти операции могут быть произведены вручную, но во избежание возможных ошибок рекомендуется использовать скрипт.
ШАГ 2. Исполнение SQL-скрипта. OID, полученный в ходе выполнения, требуется разместить в файле конфигурации config.yml.
ШАГ 3. qdl insert_values --config config.yml --data data.csv --out-dir ./output_dir/ -- Загружаем таблицу - этот процесс может занять значительное время в зависимости от объёма загружаемых данных. Потоки, выполняющие чтение/конвертацию/запись, имеют определённые названия; это позволит системному администратору оценить загруженность каждого отдельно взятого потока\ядра и определить их количеством таким образом, чтобы добиться оптимальной производительности. Также нужно заметить, что внутренние буфера qdl не имеют ограничения размера, а значит при очень медленной записи на диск возможна ситуация, когда эти буфера займут всю оперативную память.
ШАГ 4. Заменяем файлы СУБД сгенерированными при помощи qdl - копируем файлы при помощи команд операционной системы. После этого нам нужно выполнить переподключение БД на вновь сгенерированные файлы, для этого можно выполнить перезагрузку СУБД или выполнить SELECT qhb_drop_rel_cache('table_name');.
Пример использования QDL
Описание задачи
Допустим, у нас имеется таблица, партиционированная по диапазонам дат. Пусть каждый диапазон охватывает один год. В качестве примера возьмем таблицу, у которой три поля c типами timestamp, int и text. Пусть на данный момент имеется две партиции с данными за 2019 и 2020 годы. Предположим, необходимо максимально быстро и эффективно загрузить данные за 2021 год. Для этих целей можно использовать утилиту QDL (Quantum Direct Loader). Утилита позволяет на основе заданного описания структуры таблицы и соответствующих данных в CSV-файле сформировать в многопоточном режиме файл таблицы, минуя обычные механизмы базы данных. Полученный файл может быть скопирован в качестве файла таблицы в директорию базы данных.
Установка модуля, ссылки на документацию
QDL - формально совершенно отдельный модуль, который можно поставить даже независимо от QHB (хотя при этом все-таки подразумевается, что база должна уже быть установлена и доступна).
Описание модуля в документации представлено в разделе Модуль прямой загрузки данных QDL, но далее будут подробно рассмотрены все типовые шаги использования инструмента на основе законченного примера.
Формирование данных тестовой таблицы
-- Партиционированная таблица qdl_test
DROP TABLE IF EXISTS qdl_test;
CREATE TABLE qdl_test (
timestamp_value timestamp not null,
int_value int not null,
text_value text
) PARTITION BY RANGE (timestamp_value);
-- Тестовые данные за 2019 год
DROP TABLE IF EXISTS qdl_test_y2019;
CREATE TABLE qdl_test_y2019 PARTITION OF qdl_test
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
INSERT INTO qdl_test_y2019
SELECT to_timestamp(extract('epoch' FROM to_timestamp('2019-01-01','yyyy-mm-dd')) + random()*60*60*24*365)::timestamp AS timestamp_value,
round(random()*1000000)::int AS int_value,
substr(md5(random()::text), 0, 30) AS text_value
FROM generate_series(1,1000);
-- Тестовые данные за 2020 год
DROP TABLE IF EXISTS qdl_test_y2020;
CREATE TABLE qdl_test_y2020 PARTITION OF qdl_test
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
INSERT INTO qdl_test_y2020
SELECT to_timestamp(extract('epoch' from to_timestamp('2020-01-01','yyyy-mm-dd')) + random()*60*60*24*365)::timestamp AS timestamp_value,
round(random()*1000000)::int AS int_value,
substr(md5(random()::text), 0, 30) AS text_value
FROM generate_series(1,1000);
Генерация загружаемых из CSV-файла данных
В целях тестирования сгенерируем данные за 2021 год в файле /tmp/qdl_data.csv, используя возможности команды COPY. В качестве символа разделителя выберем точку с запятой.
Этот же символ необходимо будет использовать в файле конфигурации QDL.
Примечание
При работе QDL подразумевается, что первая строка должна содержать заголовок строки, поэтому необходимо добавить параметр header со значением true для формата CSV. Иначе первая строка с данными будет пропущена вместо заголовка и не попадет в загружаемую таблицу.
COPY (SELECT to_timestamp(extract('epoch' from to_timestamp('2021-01-01','yyyy-mm-dd')) + random()*60*60*24*365)::timestamp AS timestamp_value
, round(random()*1000000) AS int_value
, substr(md5(random()::text), 0, 30) AS text_value
FROM generate_series(1,1000))
TO '/tmp/qdl_data.csv'
WITH (format csv, delimiter ';', header true);
Создание конфигурационного файла /tmp/config.yml, содержащего описание загружаемой таблицы для QDL
Следует отметить, что на первом этапе параметр oid в секции output не играет роли, поэтому его значение можно оставить нулевым
Важными здесь являются параметры кодировки, символа-разделителя, описание таблицы и ее полей.
Если поле может принимать пустое значение, после наименования типа нужно добавить ключевое слово [nullable].
# Конфигурация системы:
general:
# Количество потоков, выделяемых для парсинга и сериализации строк.
# Следует обратить внимание, что помимо этих потоков обязательно выделяются ещё два:
# поток чтения и поток записи в файл.
threads: 2
# Конфигурация исходных данных:
input:
# Кодировка:
encoding: "utf8"
# Разделитель столбцов для CSV:
delimiter: ";"
# Конфигурация получаемых данных:
output:
# Object IDentifier. Определяет целочисленный идентификатор для группы файлов целевой таблицы.
# Не важен до выполнения этапа создания таблицы
oid: 0
# Конфигурация целевой таблицы:
table:
# Имя таблицы. Требуется для `generate_sql`, чтобы задать имя создаваемой таблицы.
name: "qdl_test_y2021"
# Колонки в формате "имя": "тип"
fields:
timestamp_value : timestamp
int_value : integer
text_value : text [nullable]
Проверка целостности описания таблицы и данных в CSV-файле
Это опциональный шаг, но его желательно выполнить для того, чтобы не терять результаты, быть может, многочасовой работы в процессе формирования данных таблицы, если вдруг формат данных в какой-то строке окажется неверным.
Следующая команда проверяет логическую целостность CSV-файла и согласованность структуры данных с файлом конфигурации, сигнализируя об ошибках соответствующим кодом возврата.
/usr/bin/qdl validate --config /tmp/config.yml --data /tmp/qdl_data.csv --verbose
В случае успешной проверки сообщение, похожее на следующее:
[20210319_140056][qdl::validate_csv][DEBUG] /tmp/qdl_data.csv is valid csv file
Получение скрипта для создания таблицы и вывода значения OID
/usr/bin/qdl create_table --config /tmp/config.yml --data /tmp/qdl_data.csv > /tmp/table_script.sql
Вывод результата работы команды выглядит следующим образом:
create table qdl_test_y2021("timestamp_value" timestamp NOT NULL, "int_value" integer NOT NULL, "text_value" text);
BEGIN TRANSACTION;
insert into qdl_test_y2021("timestamp_value", "int_value", "text_value")
values ('2021-01-22 18:48:32.683962', 135563, '5eb8ab78966be8bf2048e9a4bd83a');
insert into qdl_test_y2021("timestamp_value", "int_value", "text_value")
values ('2021-03-08 22:54:53.465401', 899737, '21926559632ba26460cc2eafcf3c7');
insert into qdl_test_y2021("timestamp_value", "int_value", "text_value")
values ('2021-02-02 16:45:35.763331', 742323, '37ea89be376354fe2f0797aa8b471');
COMMIT TRANSACTION;
checkpoint;
SELECT pg_relation_filepath('qdl_test_y2021');
Скрипт нужно выполнить в базе данных. Если имеются реплики, команды выполнятся там автоматически. В данный скрипт попадают команды INSERT только для первых трех строк загружаемых данных. Впоследствии мы заменим данные этой таблицы на те, которые будут сформированы утилитой QDL, поэтому вставка этих трех строк в итоге ни на что не повлияет. Последний запрос скрипта выведет путь к таблице относительно каталога кластера баз данных.
Формирование файла таблицы
Это основная и самая ресурсоемкая операция. Важно выбрать эффективное значение для количества параллельных потоков (параметр threads в секции general), участвующих в формировании файла таблицы. Это значение будет зависеть от количества процессоров на используемой машине.
Значение OID таблицы нужно прописать в файле /tmp/config.yml в качестве значения параметра oid в секции output.
Допустим, в приведенном скрипте в результате последнего запроса функция pg_relation_filepath вывела значение base/13676/16463, тогда для OID таблицы пропишем значение 16463. Имя сформированного в результате файла таблицы будет соответствовать этому параметру.
В результате работы утилиты в директории --out-dir появится файл с заданным OID в качестве имени, в приведенном примере это будет файл 16463. В случае, если размер данных окажется более 1 Gb, создадутся дополнительные файлы с соответствующими расширениями (16463.1, 16463.2 и так далее).
/usr/bin/qdl insert_values --config /tmp/config.yml --data /tmp/qdl_data.csv --out-dir /tmp
Копирование полученного файла средствами OS в директорию базы данных на главном сервере и на репликах
Если обработка данных происходит непосредственно на сервере базы данных, команда копирования может выглядеть приблизительно следующим образом:
cp /tmp/16463 <путь к каталогу данных>/base/13676/16463
Данные, скопированные через команду операционной системы, не попадут через репликацию на сервера реплик. Чтобы они там оказались, необходимо также скопировать их в соответствующие директории на каждом из этих серверов. Если этого не сделать, на серверах реплик останутся те три строки, которые были внесены в таблицу на главном сервере скриптом, созданным в результате работы команды QDL create_table.
Сброс данных таблицы
Этот шаг необходим для того, чтобы закешированные данные таблицы сбросились. Если имеются реплики, необходимо выполнить приведенный запрос как на главном сервере, так и на серверах реплик.
SELECT qhb_drop_rel_cache('qdl_test_y2021');
Проверка данных таблицы
Можно убедиться, что данные доступны как на главном сервере, так и на серверах реплик, если они имеются.
select * from qdl_test_y2021 limit 10;
select count(*) from qdl_test_y2021; -- опционально можно убедиться в соответствии количеству строк в файле
Если нужно, теперь можно построить необходимые индексы.
Примечание
Следует отметить, что загрузка данных в обход стандартных механизмов работы базы данных сказывается на том, что при восстановлении базы из бэкапа и при применении архивных журналов данные в таблицах, загруженных через QDL, не восстановятся. При выполнении массовой загрузки данных через QDL желательно сразу после этого выполнить полный бэкап базы.
Включение данных в партиционированную таблицу
Сделаем таблицу qdl_test_y2021 частью таблицы qdl_test, превратив ее в партицию и добавив ограничения по диапазону дат.
ALTER TABLE qdl_test ATTACH PARTITION qdl_test_y2021
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
При этом на серверах реплик уже будет иметься заранее подготовленная таблица qdl_test_y2021 и команда успешно выполнится на репликах.
Теперь при запросе данных 2021 года в таблице qdl_test используется обращение к новой партиции.
qhb=# explain select count(*) from qdl_test where timestamp_value >= to_timestamp('2021-01-01','YYYY-MM_DD');
QUERY PLAN
-------------------------------------------------------------------------------------------------
Aggregate (cost=79.79..79.80 rows=1 width=8)
-> Append (cost=0.00..78.84 rows=379 width=0)
Subplans Removed: 2
-> Seq Scan on qdl_test_y2021 (cost=0.00..26.95 rows=377 width=0)
Filter: (timestamp_value >= to_timestamp('2021-01-01'::text, 'YYYY-MM_DD'::text))
(5 rows)
В плане запроса отражено обращение к партиции qdl_test_y2021.
Заключение
Таким образом, используя QDL, можно эффективно загружать в базу объемные дынные. Тестирование показывает, что общее время загрузки данных с помощью QDL и время копирования полученного файла в три с половиной раза меньше по сравнению с продолжительностью загрузки тех же данных с помощью команды COPY.
Приведенный подход может быть использован в хранилищах и витринах данных, где время загрузки новых данных является критичным показателем, а данные, как правило, поступают из других источников.
Менеджер кеша дисковых блоков TARQ
Менеджер кеша дисковых блоков - самобалансирующийся менеджер кеша дисковых блоков с автоматической компенсацией нагрузки на дисковую систему.
Алгоритм вытеснения из кеша нужен для работы в среде где, для ускорения операций с диском, часть быстродействующей памяти используется для размещения наиболее часто востребованных блоков. Алгоритм служит для определения блока который можно выбросить с наименьшими потерями для общей производительности. Т.е. такого блока, который будет использоваться не так часто и/или интенсивно как остальные.
QHB может запускаться с усовершенствованным алгоритмом вытеснения - TARQ.
Алгоритм предполагает поддержку двух списков страниц - L1 и L2.
Максимальная длина обоих списков составляет 2c, где c - размер кэша
в страницах. Оба списка формируются в стиле LRU. При перемещении в кэш
страницы, номер которой отсутствует в обоих списках, этот номер заносится
в начало списка L1. При обращении к странице, номер которой фигурирует
в одном из списков, этот номер переносится в начало списка L2.
Важной особенностью алгоритма является то, что только в начале каждого
из списков (подсписках T1 и T2) находятся номера страниц, находящихся
в кэше, т.е. поддерживается история страниц, недавно вытесненных из кэша.
Страница для замещения выбирается из конца списка T1 или T2 в
зависимости от значения параметра p, определяющего текущую допустимую
длину списка T1, а тем самым, и длину T2. Адаптивность алгоритма
состоит в том, что значение p изменяется в зависимости от вида рабочей
нагрузки.
Для включения и управления новым алгоритмом вытеснения используются параметры в конфигурационном файле:
-
use_qhb_cache - булевый параметр при установке значения в TRUE будет использоваться новая версия кеша
-
qhb_cache_size - общий размер буферного кеша (при включении use_qhb_cache=true значение shared_buffers не используется)
-
shared_buffers_partition - размер фрагментов кеша (партиций, не имеют отношения к партициям таблицы), обращение к каждому фрагменту происходит независимо от остальных, слишком большой размер приведёт к возрастанию конкуренции за блокировки, слишком маленький может привести к задержкам если в партиции не окажется пригодных к вытеснению блоков (все грязные или занятые фоновым процессом).
Рекомендуемое значение:128 -
tarq_cache.touch_queue_ignore - целое число от 1 до 100, процент заполнения фрагмента кеша при котором обращения начинают приводить к операциям балансировки, для незаполненного или заполненного немного фрагмента балансировок не требуется.
Рекомендуемое значение:50
Ребалансировка - дорогая операция, в нагруженной среде к некоторым буферам (содержимое системных таблиц, словари, последовательности) может быть много тысяч обращений в секунду, существенно не влияющих на общий баланс. Для сглаживания можно использовать следующие параметры:
-
tarq_cache.touch_window - время в секундах, все обращения в течение этого "окна" считаются одним обращением.
Рекомендуемое значение:3 -
tarq_cache.touch_threshold - количество обращений к буферу по достижению которого происходит операция ребалансировки. \ Рекомендуемое значение:
5
Параметр HOLDMEM и дополнительные кэши дисковых блоков
Внимание! Эта функциональность QHB является экспериментальной, её использование в инсталляциях на продуктивной среде не рекомендовано.
В QHB для ускорения работы с таблицами имеется возможность создавать их особым параметром HOLDMEM,
который указывает, где они будут размещаться. Существуют три параметра: OFF, POSSIBLY и ONLY.
Примеры создания таблиц:
CREATE TABLE cats (id int) WITH (HOLDMEM = OFF);
-- то же самое, что и CREATE TABLE cats (id int);
CREATE TABLE dogs (id int) WITH (HOLDMEM = POSSIBLY);
CREATE UNLOGGED TABLE cows (id int) WITH (HOLDMEM = ONLY);
-- обратите внимание, что таблицы с HOLDMEM = ONLY должны быть UNLOGGED;
Описание параметров HOLDMEM:
-
OFF— это обычные таблицы. При создании таблицы этот параметр можно опустить. Обычно он нужен, когда требуется изменить свойство таблицы:ALTER TABLE dogs SET (HOLDMEM = OFF); -
POSSIBLY— это таблицы, которые по возможности находятся в памяти:ALTER TABLE dogs SET (HOLDMEM = POSSIBLY); -
ONLY— это таблицы, которые всегда находятся в памяти:ALTER TABLE dogs SET UNLOGGED, SET (HOLDMEM = ONLY);Примечание Все таблицы с параметром
HOLDMEM = ONLYдолжны бытьUNLOGGED.
HOLDMEM = POSSIBLY
Таблицы, созданные с параметром HOLDMEM = POSSIBLY, предназначены для хранения данных, к которым требуется быстрый доступ. Для них используется отдельный LRU cache, за счёт простоты которого достигается быстродействие при обращении к нему во время поиска страницы. Однако данный кэш менее качественный, чем TARQ, поэтому его использование нужно в особых случаях: при работе с данными, к которым требуется частое обращение.
Для включения и управления алгоритмом вытеснения для таблиц, по возможности хранящихся в памяти, используются параметры в конфигурационном файле:
-
use_possible_buffer — логический параметр. При установке значения в TRUE будет использоваться этот кэш.
-
qhb_possible_buffers_size — общий размер буферного кэша.
-
shared_buffers_partition (используется общий параметр с TARQ) — размер фрагментов кеша (партиций; не имеют отношения к партициям таблицы), обращение к каждому фрагменту происходит независимо от остальных, слишком большой размер приведёт к возрастанию конкуренции за блокировки, слишком маленький может привести к задержкам, если в партиции не окажется пригодных к вытеснению блоков (все «грязные» или занятые фоновым процессом).
Рекомендуемое значение:128.
HOLDMEM = ONLY
Таблицы, созданные с параметром HOLDMEM = ONLY, предназначены для хранения данных, к которым требуется максимально быстрый доступ.
Однако нужно знать некоторые особенности при работе с ним. Так как все данные хранятся в памяти, переполнение этого буфера приведёт к ошибке. Также при сбое или экстренном завершении данные не могут быть и не будут восстановлены.
Для включения и управления алгоритмом вытеснения для таблиц, по возможности хранящихся в памяти, используются параметры в конфигурационном файле:
-
use_qhb_onlymem_cache — логический параметр. При установке значения в TRUE будет использоваться этот кэш.
-
qhb_onlymem_cache_size — общий размер буферного кэша.
Совместимость
Параметр HOLDMEM, так же как и значения OFF, POSSIBLY и ONLY, реализованные в QHB, является расширением стандарта SQL.
Таблицы APPEND_ONLY
В QHB для ускорения работы с таблицами имеется возможность создавать их с особым параметром APPEND_ONLY.
Параметр предназначен для таблиц, с которыми не производятся модификаций, например журналы, данные с датчиков и т.п.
В такие таблицы можно только добавлять записи, но делается это с максимальной скоростью,
т.к. не выполняется полноценного MVCC анализа.
Для этого варианта хранилища характерны также следующие свойства:
- Отсутствует необходимость в автоочистке.
- Поддерживаются все типы индексов.
- Для удаления старых данных можно использовать секционирование таблицы и удалять данные секциями, либо использовать команду
TRUNCATE. - Не поддерживается механизм
TOAST.
Создание APPEND_ONLY таблицы выполняется запросом:
CREATE TABLE TABLE_NAME (...) USING APPEND_ONLY;
Сервер метрик
Сервер метрик используется в инфраструктуре QHB для сбора, агрегации и пересылки метрик в систему мониторинга Graphite.
Тема установки и настройки Graphite выходит за рамки данной документации. Пожалуйста, обратитесь к документации Graphite, доступной по адресу https://graphite.readthedocs.io/en/latest/.
Сервер метрик должен быть установлен и настроен на каждой машине, где работают компоненты QHB (сам сервер баз данных или QCP), смотрите раздел Установка.
Настройка сервера метрик
Пример файла конфигурации устанавливается по пути /etc/metricsd/config-example.yaml.
Для работы сервиса, необходимо скопировать его в /etc/metricsd/config.yaml и подправить необходимые параметры. Особого внимания требует секция aggregation → backends:
# Backends configuration. At least one backend must be configured.
backends:
# Configuration of graphite backend
- graphite:
# The address of the Graphite TCP endpoint for text protocol. Default port is 2003.
# Only TCP protocol is available, so if Graphite is not listening on this port, you will get an error!
address: "graphite:2003"
# A prefix which is prepended to the name of each metric. Optional, defaults to empty string.
prefix: ""
# Connection timeout. Optional, defaults to 30 seconds.
connection_timeout: "30 sec"
# Send data timeout. Optional, defaults to 5 seconds.
send_timeout: "5 sec"
Исправьте параметр address на реальный адрес сервера Graphite в вашей сети, также рекомендуется изменить значение параметра prefix на, например, имя машины, на которой запущен сервис. Этот префикс будет добавляться ко всем генерируемым метрикам.
Для автоматического запуска сервера при старте системы, активируйте соответствующий сервис systemd:
$ sudo systemctl enable --now metricsd.service
Часть II. Установка и настройка
В этой части рассматриваются темы, представляющие интерес для администратора базы данных QHB. Это включает в себя установку программного обеспечения, настройку сервера, управление пользователями и базами данных, а также задачи по обслуживанию. Любой, кто запускает сервер QHB, даже для личного использования, особенно в производственной среде, должен быть знаком с темами, описанными в этой части.
Информация в этой части расположена приблизительно в том порядке, в котором её должен прочитать новый пользователь. Однако главы являются автономными и, по желанию, могут быть прочитаны независимо друг от друга в любом порядке. Информация в этой части представлена в повествовательной форме. Читателям, ищущим полное описание конкретной команды, следует обратиться к главе Команды SQL.
Первые несколько глав написаны так, чтобы их можно было понять без предварительных знаний, чтобы новые пользователи, которым необходимо настроить собственный сервер, спокойно могли начать свое исследование. Остальные же главы этой — о настройке и управлении — предполагают, что читатель уже знаком с общими принципами использования базы данных QHB. Для получения дополнительной информации, рекомендуется ознакомиться с внутренним устройством и языком SQL.
-
- Настройка параметров
- Расположение файлов
- Соединения и Аутентификация
- Потребление ресурсов
- Журнал упреждающей записи (wal)
- Копирование
- Планирование запросов
- Отчеты об ошибках и ведение журнала
- Статистика выполнения
- Автоматическая очистка
- Клиентское соединение по умолчанию
- Управление блокировками
- Совместимость версий и платформ
- Обработка ошибок
- Предустановленные параметры
- Индивидуальные параметры
- Параметры разработчика
- Сокращения командной строки
-
- clusterdb - кластеризация базы данных QHB
- createdb - создать новую базу данных QHB
- createuser - определить новую учетную запись пользователя QHB
- dropdb - удалить базу данных QHB
- dropuser - удалить учетную запись пользователя QHB
- vacuumdb сбор мусора и анализ базы данных QHB
- qhb_basebackup - сделать базовую резервную копию кластера QHB
- reindexdb - переиндексировать базу данных QHB
- qhb_config - получить информацию об установленной версии QHB
- qhb_dump - извлекает базу данных QHB в файл сценария или другой архив
- qhb_dumpall - извлекает кластер базы данных QHB в файл сценария
- qhb_isready - проверить состояние соединения с сервером QHB
- qhb_receivewal - потоковые журналы записи с сервера QHB
- qhb_recvlogical - управление потоками логического декодирования QHB
- qhb_restore - восстанавливает базу данных QHB из файла архива, созданного qhb_dump
- qsql - QHB интерактивный терминал
-
- initdb - создать новый кластер базы данных QHB
- qhb_archivecleanup - очистить архивные файлы QHB WAL
- qhb_checksums - включить, отключить или проверить контрольные суммы данных в кластере базы данных QHB
- qhb_controldata - отображать управляющую информацию кластера базы данных QHB
- qhb_ctl - инициализация, запуск, остановка или управление сервером QHB
- qhb_resetwal - сбросить журнал предварительной записи и другую управляющую информацию кластера базы данных QHB
- qhb_rewind - синхронизирует каталог данных QHB с другим каталогом данных, который был разветвлен из него
- qhb_upgrade - обновить экземпляр сервера QHB
- qhb_waldump - отображает удобочитаемый рендеринг журнала записи с опережением кластера базы данных QHB
Установка
Поддерживаемые платформы
Платформа, то есть комбинация архитектуры процессора и операционной системы, считается поддерживаемой сообществом разработчиков QHB.
Для QHB версии 1.3.0 поддерживаются:
- Centos Linux 7, x86_64
- Centos Linux 8, x86_64
- Альт Сервер 9, x86_64
- Fedora 32, x86_64
- Fedora 33, x86_64
- Linux Debian 9, x86_64
- Astra Linux Special Edition, «Смоленск» 1.6, x86_64
- в docker контейнере
Состав поставки
QHB поставляется в виде следующих пакетов
- qhb-core - ядро QHB
- qhb-contrib - расширения QHB
- qcp - пулер соединений
- qdl - средство быстрой загрузки
- qbackup - инструмент резервного копирования
- metricsd - сервер метрик
Установка из репозитория пакетов
Внимание!
Если вы обновляете версию QHB или мигрируете базы данных с других СУБД, обратитесь к разделу Установка с обновлением.
В этой главе описывается установка QHB из предварительно упакованного дистрибутива. Двоичные пакеты QHB для поддерживаемых платформ можно найти на Странице загрузки
Стандартная процедура установки QHB выглядит так:
Подключение репозитория и установка пакетов
Подключите репозиторий пакетов и установите пакеты для выбранной платформы со Страницы загрузки.
Инициализация кластера базы данных
Инициализируйте кластер базы данных при помощи утилиты initdb или qhb_bootstrap. В данном примере /opt/qhb/data — расположение каталога базы данных:
Внимание!
Запуск утилит необходимо производить из под пользователяqhb, владельца экземпляра.
Или предворять запуск командойsudo -u qhb.
/usr/local/qhb/bin/initdb -D /opt/qhb/data -U qhb
или
/usr/local/qhb/bin/qhb_bootstrap -D /opt/qhb/data -U qhb
Замечание.
Использование утилитыqhb_bootstrapпредпочтительно.
Утилитаinitdbпланируется к удалению в будущих версиях QHB.
Настройка сервиса
Если необходимо, настройте сервис базы данных, см. Настройка сервиса базы данных.
Создание базы данных и конфигурирование
Следуйте инструкция по созданию и настройке базы данных, см. Начало работы.
Установка с обновлением
Обновление версии QHB и миграция баз данных с других СУБД.
При переходе с одной версии QHB к другой, иногда происходят такие изменения в структурах данных каталога СУБД, которые делают невозможным функционирование новой версии без преобразования данных старой базы.
Для такого преобразованияя предусмотрена специальная утилита обновления экземпляра qhb_upgrade.
Некоторые обновления не требуют запуска qhb_upgrade:
- обновление пакетов из репозитория, если база данных ещё не была создана или планируется создание новой, а старая не важна,
- установка QHB впервые или
- миграция базы с помощью утилит qhb_dump / qhb_dumpall.
Если же планируется перенос или миграция базы данных, перед обновлением нужно обратиться утилите qhb_upgrade. Утилита может обновлять данные не только при обновлении версии QHB, но даже при миграции с PostgreSQL некоторых версий.
Некоторые минорные обновления QHB не меняют структуру данных, и их установка не требуют каких-то специальных действий. В этом случае, утилита qhb_upgrade об этом сообщит.
Начало работы
Создание базы данных
Первый тест, чтобы увидеть, можете ли вы получить доступ к серверу базы данных - попытаться создать базу данных. Работающий сервер QHB может управлять многими базами данных. Как правило, отдельная база данных используется для каждого проекта или для каждого пользователя.
Возможно, ваш администратор уже создал базу данных для вашего использования. В этом случае вы можете пропустить этот шаг и перейти к следующему разделу.
Чтобы создать новую базу данных, в этом примере с именем mydb, вы используете следующую команду:
createdb mydb -h localhost
Если в ответ на такой запуск нет ошибки, то этот шаг был успешным, и вы можете пропустить оставшуюся часть этого раздела.
Если вы видите сообщение, похожее на:
createdb: command not found
тогда QHB не был установлен должным образом. Либо он вообще не был установлен, либо путь поиска вашей оболочки не был настроен на его включение. Попробуйте вместо этого вызвать команду с абсолютным путем:
/usr/local/qhb/bin/createdb mydb
Ваш путь может быть другим. Обратитесь к вашему администратору или ознакомьтесь с инструкциями по установке, чтобы исправить ситуацию.
Другой ответ может быть таким:
createdb: could not connect to database qhb: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
Это означает, что сервер не был запущен или не был запущен там, где
ожидал createdb. Снова, проверьте инструкции по установке или
проконсультируйтесь с администратором.
Другой ответ может быть таким:
createdb: could not connect to database qhb: FATAL: role "joe" does not exist
где упоминается ваше имя пользователя. Это произойдет, если администратор не создал для вас учетную запись пользователя QHB. (Учетные записи пользователей QHB отличаются от учетных записей пользователей операционной системы). Если вы являетесь администратором, обратитесь к главе Роли в базе данных за помощью в создании учетных записей. Вам нужно стать пользователем операционной системы, под которой был установлен QHB (обычно qhb), чтобы создать первую учетную запись пользователя. Возможно также, что вам было присвоено имя пользователя QHB, отличающееся от имени пользователя вашей операционной системы; в этом случае вам нужно использовать ключ -U или установить окружение PGUSER, чтобы указать свое имя пользователя в QHB.
Если у вас есть учетная запись пользователя, но у нее нет прав, необходимых для создания базы данных, вы увидите следующее:
createdb: database creation failed: ERROR: permission denied to create database
Не каждый пользователь имеет право создавать новые базы данных. Если QHB отказывается создавать базы данных для вас, ваш администратор должен предоставить вам разрешение на создание баз данных. Обратитесь к вашему администратору, если это произойдет. Если вы установили QHB самостоятельно, вы должны войти в систему в целях данного руководства под учетной записью пользователя, с которой вы запустили сервер1.
Вы также можете создавать базы данных с другими именами. QHB позволяет создавать любое количество баз данных. Имена баз данных должны иметь алфавитный первый символ и иметь длину не более 63 байтов. Удобный выбор - создать базу данных с тем же именем, что и ваше текущее имя пользователя. Многие инструменты предполагают, что имя базы данных используется как имя по умолчанию, поэтому оно поможет вам сэкономить время при наборе текста. Чтобы создать эту базу данных, просто введите:
createdb
Если вы больше не хотите использовать свою базу данных, вы можете удалить ее. Например, если вы являетесь владельцем (создателем) базы данных mydb, вы можете уничтожить ее, используя следующую команду:
dropdb mydb
(Для этой команды имя базы данных по умолчанию не совпадает с именем учетной записи пользователя. Вы всегда должны указывать его.) Это действие физически удаляет все файлы, связанные с базой данных, и не может быть отменено, так что это должно быть сделано только с большим количеством предусмотрительности.
Больше информации по командам createdb и dropdb можно найти в соответствующих разделах.
В качестве объяснения того, почему это работает: имена пользователей QHB отделены от учетных записей пользователей операционной системы. Когда вы подключаетесь к базе данных, вы можете выбрать, какое имя пользователя QHB будет подключаться; если вы этого не сделаете, по умолчанию будет использоваться то же имя, что и ваша текущая учетная запись операционной системы. Как это бывает, всегда будет учетная запись пользователя QHB, имя которой совпадает с именем пользователя операционной системы, запустившего сервер, и также бывает, что этот пользователь всегда имеет разрешение на создание баз данных. Вместо входа в систему под этим пользователем вы также можете указать опцию -U везде, чтобы выбрать имя пользователя QHB для подключения.
Доступ к базе данных
Создав базу данных, вы можете получить к ней доступ одним из следующих способов:
-
С помощью интерактивного терминала QHB, называемого qsql, который позволяет в интерактивном режиме вводить, редактировать и выполнять команды SQL.
-
С использованием существующего графического инструмента внешнего интерфейса, например, pgAdmin, DBeaver или офисного пакета с поддержкой ODBC или JDBC. Эти возможности не рассматриваются в этом руководстве.
-
Написав собственное приложение с использованием одной из нескольких доступных языковых привязок.
Возможно, вы захотите запустить qsql, чтобы попробовать примеры из этого урока. Его можно запустить для базы данных mydb, набрав команду:
$ qsql -h localhost -d mydb
Если вы не укажете имя базы данных, по умолчанию будет использоваться имя вашей учетной записи. Мы уже сталкивались с этой схемой в предыдущем разделе, при работе с createdb.
Внутри qsql вы увидите следующее сообщение:
qsql - Interactive terminal qhb (1.2.0)
Enter "\help" in order to get help
mydb(username)=#
Это будет означать, что вы являетесь суперпользователем базы данных, что наиболее вероятно, если вы установили экземпляр QHB самостоятельно. Суперпользователь имеет неограниченный доступ к базе данных; впрочем, для целей урока это не имеет значения.
Если вы столкнулись с проблемами при запуске qsql, вернитесь к предыдущему разделу. Диагностика createdb и qsql схожи, и если первый сработал, последний также должен сработать.
Последняя строка, напечатанная qsql является приглашением и указывает, что qsql ожидает ввод, то есть вы можете вводить запросы SQL в рабочее пространство. Попробуйте эти команды:
mydb(username)=# select version();
version
----------
QHB 1.2.0
(1 строка)
mydb(username)=# SELECT current_date;
date
------------
2020-10-07
mydb(username)=# SELECT 2 + 2;
?column?
----------
4
(1 строка)
Программа qsql имеет ряд внутренних команд, которые не являются
командами SQL. Они начинаются с символа обратной косой черты "\".
Например, чтобы выйти из qsql, введите:
mydb(username)=# \q
и qsql завершит работу и вернёт вас в командную оболочку.
Все возможности qsql описаны в соответствующем разделе: qsql.
Настройка и эксплуатация сервера
В этой главе рассказывается, как настроить и запустить сервер базы данных и как он взаимодействует с операционной системой.
- Учетная запись пользователя
- Создание кластера базы данных
- Запуск сервера базы данных
- Завершение работы сервера
Учетная запись пользователя
Как и любой серверный процесс, доступный для внешнего мира, рекомендуется запускать QHB под отдельной учетной записью пользователя. Эта учетная запись пользователя должна владеть только данными, которыми управляет сервер, и не должна использоваться совместно с другими демонами. (Например, использование пользователя nobody является плохой идеей). Не рекомендуется устанавливать исполняемые файлы, принадлежащие этому пользователю, потому что скомпрометированные системы могут затем изменить свои собственные двоичные файлы.
Чтобы добавить учетную запись пользователя Unix в вашу систему, используйте команду useradd или adduser. Имя пользователя qhb часто используется, и предполагается в этой книге, но возможно использовать другое имя, если необходимо.
Создание кластера базы данных
Прежде чем что-либо делать, вы должны инициализировать область хранения базы данных на диске. В документации это называется кластером базы данных. (В стандарте SQL используется термин кластер каталога). Кластер баз данных — это набор баз данных, который управляется одним экземпляром работающего сервера баз данных. После инициализации кластер базы данных будет содержать базу данных с именем qhb, которая является базой данных по умолчанию для использования утилитами, пользователями и сторонними приложениями. Сам сервер базы данных не требует существования базы данных qhb, но многие внешние утилиты предполагают, что она существует. Другая база данных, созданная в каждом кластере во время инициализации, называется template1. Как следует из названия, она будет использоваться в качестве шаблона для впоследствии созданных баз данных и не должна использоваться для фактической работы. (Информацию о создании новых баз данных в кластере см. в главе Управление базами данных).
С точки зрения файловой системы, кластер базы данных - это один каталог, в котором будут храниться все данные. Он называется каталогом данных или областью данных. Где хранить свои данные - полностью зависит от пользователя. Каких-либо жёстких установок не существует, хотя популярны такие места, как /usr/local/qhb/data или /var/lib/qhb/data. Чтобы инициализировать кластер базы данных, используйте команду qhb_bootstrap, которая устанавливается с QHB. Расположение файловой системы вашего кластера баз данных указывается с помощью опции -D, например:
qhb_bootstrap -D /usr/local/qhb/data
Обратите внимание, что вы должны выполнить эту команду при входе в учетную запись пользовател, которая описана в предыдущем разделе.
Заметка
В качестве альтернативы опции -D вы можете установить переменную окружения PGDATA..
qhb_bootstrap попытается создать указанную вами директорию, если она еще не существует. Конечно, это не удастся, если у qhb_bootstrap нет прав на запись в родительский каталог. Обычно рекомендуется, чтобы пользователь QHB владел не только каталогом данных, но и своим родительским каталогом, чтобы это не было проблемой. Если желаемый родительский каталог тоже не существует, вам сначала нужно его создать, используя привилегии суперпользователя, если каталог прародителя недоступен для записи. Так что процесс может выглядеть так:
root# mkdir /usr/local/qhb
root# chown qhb /usr/local/qhb
root# su qhb
qhb$ qhb_bootstrap -D /usr/local/qhb/data
Если работаем от root используем:
root# mkdir /usr/local/qhb/data
root# chown qhb /usr/local/qhb
root# sudo -u qhb ./qhb_bootstrap -D /usr/local/qhb/data
qhb_bootstrap откажется запускаться, если каталог данных существует и уже содержит файлы, что предотвратит случайную перезапись существующей установки.
Поскольку каталог данных содержит все данные, хранящиеся в базе данных, важно, чтобы он был защищен от несанкционированного доступа. Поэтому qhb_bootstrap отзывает права доступа у всех, кроме пользователя QHB и, при необходимости, группы. Групповой доступ, если он включен, доступен только для чтения. Это позволяет непривилегированному пользователю в той же группе, что и владелец кластера, создавать резервную копию данных кластера или выполнять другие операции, для которых требуется только чтение.
Обратите внимание, что включение или отключение группового доступа в существующем кластере требует выключения кластера и установки соответствующего режима для всех каталогов и файлов перед перезапуском QHB. В противном случае в каталоге данных может существовать комбинация режимов. Для кластеров, которые разрешают доступ только владельцу, соответствующие режимы - 0700 для каталогов и 0600 для файлов. Для кластеров, которые также разрешают чтение по группе, соответствующие режимы - 0750 для каталогов и 0640 для файлов.
Однако, хотя содержимое каталога является безопасным, настройка аутентификации клиента по умолчанию позволяет любому локальному пользователю подключаться к базе данных и даже стать суперпользователем базы данных. Если вы не доверяете другим локальным пользователям, мы рекомендуем использовать один из параметров qhb_bootstrap -W, --pwprompt или --pwfile, чтобы назначить пароль суперпользователю базы данных. Кроме того, укажите пароль -A md5 или -A password чтобы режим проверки подлинности по умолчанию не использовался; или измените созданный файл qhb_hba.conf после запуска qhb_bootstrap, но перед первым запуском сервера. Другие разумные подходы включают использование peer аутентификации или разрешений файловой системы для ограничения соединений.
qhb_bootstrap также инициализирует локаль по умолчанию для кластера базы данных. Обычно берет используются параметры локали из среды и применяет их к инициализированной базе данных. Можно указать другую локаль для базы данных - более подробную информацию об этом можно найти в разделе Поддержка локали. Порядок сортировки по умолчанию, используемый в конкретном кластере баз данных, устанавливается qhb_bootstrap, и, хотя вы можете создавать новые базы данных, используя другой порядок сортировки, порядок, используемый в базах данных шаблонов, которые создает qhb_bootstrap, нельзя изменить без их удаления и повторного создания. Существует также влияние на производительность при использовании локалей, отличных от C(RUST) или POSIX. Поэтому важно правильно сделать этот выбор с первого раза.
qhb_bootstrap также устанавливает кодировку набора символов по умолчанию для кластера базы данных. Обычно это следует выбирать в соответствии с настройками локали. Подробнее см. раздел Поддержка набора символов.
Языки, отличные от C\RUST полагаются на библиотеку сортировки операционной системы для упорядочения набора символов. Это контролирует порядок ключей, хранящийся в индексах. По этой причине кластер не может переключиться на несовместимую версию библиотеки сортировки, используя восстановление моментальных снимков, двоичную потоковую репликацию, другую операционную систему или обновление операционной системы.
Использование вторичных файловых систем
Многие установки создают свои кластеры базы данных в файловых системах (томах), отличных от «корневого» тома. Если вы решите сделать это, не рекомендуется пытаться использовать самый верхний каталог тома (точку монтирования) в качестве каталога для хранения данных. Рекомендуется создать каталог в каталоге для монтирования, который принадлежит пользователю QHB, а затем создать в нем каталог данных. Это позволяет избежать проблем с разрешениями, особенно для таких операций, как qhb_upgrade, а также гарантирует понятные сообщения об ошибках, если том отключен.
Файловые Системы
Как правило, любая файловая система с семантикой POSIX может использоваться для QHB. Пользователи предпочитают разные файловые системы по разным причинам, включая поддержку поставщиков, производительность и личную экспертизу. Опыт показывает, что при прочих равных условиях не следует ожидать значительных изменений в производительности или в поведении просто от переключения файловых систем или незначительных изменений конфигурации файловой системы.
NFS
Для хранения каталога данных QHB можно использовать файловую систему NFS. QHB не делает ничего неприемлимого для файловых систем NFS, то есть предполагает, что NFS ведет себя точно так же, как локально подключенные диски. QHB не использует никаких функций, о которых известно, что они имеют нестандартное поведение в NFS, таких как блокировка файлов и т.п.
Единственное жесткое требование для использования NFS с QHB - это монтирование файловой системы с использованием опции hard. С помощью опции hard процессы могут «зависать» на неопределенное время, если возникают проблемы с сетью, поэтому такая конфигурация потребует тщательной настройки мониторинга. Опция soft будет прерывать системные вызовы в случае сетевых проблем, но QHB не будет повторять системные вызовы, прерванные таким образом, поэтому любое такое прерывание приведет к сообщению об ошибке ввода-вывода.
Нет необходимости использовать опцию sync. Поведение опции async является достаточным, поскольку QHB делает вызовы fsync в нужное время для очистки кэшей записи, аналогично тому, как это происходит в локальной файловой системе. Однако настоятельно рекомендуется использовать параметр экспорта sync на сервере NFS в системах, где он существует. В противном случае fsync или его эквивалент на клиенте NFS не гарантируют того, что данные достигнут постоянного хранилища на сервере, что может привести к повреждению, аналогично тому которое может случится на сервере с отключенным параметром fsync. Значения по умолчанию этих параметров монтирования и экспорта различаются у разных поставщиков и версий, поэтому рекомендуется в любом случае проверить и, возможно, указать их явно, чтобы избежать двусмысленности.
В некоторых случаях к внешнему храненилищу можно получить доступ через NFS или протокол более низкого уровня, например iSCSI. В последнем случае хранилище выглядит как блочное устройство, и на нем может быть создана любая поддерживаемая файловая система. Такой подход может избавить администратора базы данных от необходимости иметь дело с некоторыми особенностями NFS, но, конечно, сложность управления удаленным хранилищем возникает на других уровнях.
Запуск сервера базы данных
Прежде чем кто-либо сможет получить доступ к базе данных, вы должны запустить сервер базы данных. Программа сервера базы данных называется qhb. Программа qhb должна знать, где найти файлы базы данных, которые она должна использовать. Это делается с помощью опции -D. Таким образом, самый простой способ запустить сервер:
qhb# qhb -D /usr/local/qhb/data
root# sudo -u qhb ./qhb -D /usr/local/qhb/data
эта команда оставит сервер на консоли. Она должна выполнятся из учётной записи пользователя qhb. Без -D сервер попытается использовать каталог данных, названный переменной окружения PGDATA. Если эта переменная также не указана, произойдет сбой.
Обычно лучше запускать qhb в фоновом режиме. Для этого используйте обычный синтаксис оболочки (shell) Unix:
$ qhb -D /usr/local/qhb/data >logfile 2>&1 &
Важно где-то хранить выходные данные сервера stdout и stderr, как показано выше для целей аудита и диагностики проблем. (См. раздел Обслуживание файла журнала для более подробного обсуждения обработки файла журнала).
Программа qhb также принимает ряд других параметров командной строки. Для получения дополнительной информации см. Справочную страницу qhb и главу Конфигурация сервера.
Этот синтаксис трудно запомнить и повторить. Поэтому программа-обертка qhb_ctl предоставляется для упрощения некоторых задач. Например:
qhb_ctl start -l logfile
запустит сервер в фоновом режиме и поместит вывод в именованный файл журнала. Параметр -D имеет то же значение, что и для qhb. qhb_ctl также может остановливать сервер.
Обычно вы хотите запустить сервер базы данных при загрузке компьютера. Сценарии автозапуска зависят от операционной системы. Некоторые из них распространяются с пакетами QHB.
Различные системы имеют разные соглашения для запуска демонов во время
загрузки. Многие системы имеют файл /etc/rc.local или /etc/rc.d/rc.local.
Другие используют каталоги init.d или rc.d Что бы вы ни делали, сервер
должен работать под учетной записью пользователя QHB, а не под
учетной записью root или любого другого пользователя. Поэтому вы,
вероятно, должны формировать свои команды, используя
su qhb -c '...'. Например:
su qhb -c 'qhb_ctl start -D /usr/local/qhb/data -l serverlog'
Вот еще несколько предложений для запуска :
- добавьте в /etc/rc.d/rc.local или /etc/rc.local
/usr/local/qhb/bin/qhb_ctl start -l logfile -D /usr/local/qhb/data
-
или используйте файл contrib/start-scripts/linux в исходном дистрибутиве QHB.
-
при использовании systemd вы можете использовать следующий файл для systemd (например, в /etc/systemd/system/qhb.service):
[Unit] Description=QHB database server Documentation=man:qhb(1) [Service] Type=notify User=qhb ExecStart=/usr/local/qhb/bin/qhb -D /usr/local/qhb/data ExecReload=/bin/kill -HUP $MAINPID KillMode=mixed KillSignal=SIGINT TimeoutSec=90 [Install] WantedBy=multi-user.targetТщательно продумайте настройку тайм-аута. На настоящий момент системный тайм-аут по умолчанию составляет 90 секунд и завершит процесс, который не уведомит о готовности в течение этого времени. Но серверу QHB, который может выполнить восстановление после сбоя при запуске, может потребоваться гораздо больше времени, чтобы подготовиться. Предлагаемое значение 0 отключает логику тайм-аута.
Во время работы сервера его PID хранится в файле qhbmaster.pid в каталоге данных. Это используется для предотвращения запуска нескольких экземпляров сервера в одном каталоге данных, а также может использоваться для выключения сервера.
Сбои при запуске сервера
Существует несколько распространенных причин, по которым сервер может не запуститься. Проверьте файл журнала сервера или запустите его вручную (без перенаправления стандартного вывода или стандартной ошибки) и посмотрите, какие сообщения об ошибках появляются. Ниже мы объясним некоторые из наиболее распространенных сообщений об ошибках более подробно.
LOG: could not bind IPv4 address "127.0.0.1": Address already in use
HINT: Is another postmaster already running on port 5432? If not, wait a few seconds and retry.
FATAL: could not create any TCP/IP sockets
Обычно это означает только то, что вы попытались запустить другой сервер на том же порту, на котором он уже запущен. Однако, если сообщение об ошибке в ядре не является Address already in use или каким-либо другим вариантом, это может быть другой проблемой. Например, попытка запустить сервер с зарезервированным номером порта может выдать что-то вроде:
$ qhb -p 777
LOG: could not bind IPv4 address "127.0.0.1": Permission denied
HINT: Is another postmaster already running on port 777? If not, wait a few seconds and retry.
FATAL: could not create any TCP/IP sockets
Сообщение :
FATAL: could not create shared memory segment: Invalid argument
DETAIL: Failed system call was shmget(key=5440001, size=4011376640, 03600).
вероятно, означает, что ограничение вашего ядра на размер разделяемой памяти меньше, чем рабочая область, которую пытается создать QHB (4011376640 байт в этом примере). Или это может означать, что в вашем ядре вообще не настроена поддержка разделяемой памяти System V. В качестве временного решения можно попробовать запустить сервер с меньшим, чем обычно, числом буферов ( shared_buffers). В конечном итоге необходимо перенастроить ядро ОС, чтобы увеличить допустимый размер разделяемой памяти. Это сообщение также может появиться при попытке запустить несколько серверов на одном компьютере, если их общее запрошенное пространство превышает ограничение ядра.
Ошибка :
FATAL: could not create semaphores: No space left on device
DETAIL: Failed system call was semget(5440126, 17, 03600).
не означает, что вам не хватает места на диске. Это означает, что ограничение вашего ядра на число семафоров System V меньше, чем число, которое QHB хочет создать. Как и в случае выше, можно обойти эту проблему, запустив сервер с меньшим количеством разрешенных соединений ( max_connections), но в конечном итоге необходимо увеличить ограничение ядра.
Если вы получили ошибку «illegal system call», вполне вероятно, что разделяемая память или семафоры вообще не поддерживаются в вашем ядре. В этом случае единственный вариант - перенастроить ядро, чтобы включить эти функции.
Проблемы с клиентским подключением
Хотя возможные ошибки на стороне клиента довольно разнообразны и зависят от приложения, некоторые из них могут быть напрямую связаны с тем, как был запущен сервер. Условия, отличные от указанных ниже, должны быть задокументированы в соответствующем клиентском приложении.
qsql: could not connect to server: Connection refused
Is the server running on host "server.joe.com" and accepting
TCP/IP connections on port 5432?
Это общая ошибка «Я не могу найти сервер для связи». Выглядит как ошибка при попытке установить связь TCP/IP. Распространенная ошибка - забыть включить настройки сервера для разрешения соединений по TCP/IP.
В качестве альтернативы, при попытке соединения с локальным сервером с использованием доменных сокетов Unix вы получите:
qsql: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
Последняя строка полезна для проверки того, что клиент пытается подключиться в нужное место. Если на самом деле не работает ни один сервер, сообщение об ошибке в ядре обычно будет либо « onnection refused либо No such file or directory, важно понимать, что в этом контексте Connection refused в соединении, не означает, что сервер получил ваш запрос на соединение и отклонил его. В этом случае будет выдано другое сообщение, которое указывают на более фундаментальные проблемы, такие как отсутствие сетевого подключения.
Завершение работы сервера
Есть несколько способов выключить сервер базы данных. Вы управляете типом выключения, посылая различные сигналы основному процессу qhb.
-
SIGTERM Это режим Smart Shutdown. После получения сигнала SIGTERM сервер запрещает новые подключения, но позволяет существующим сеансам нормально завершать свою работу. Сервер отключается только после завершения всех сеансов. Если сервер находится в режиме горячего резервного копирования, он дополнительно ожидает, пока режим резервного копирования в перестанет быть активным. При активном режиме резервного копирования новые подключения будут по-прежнему разрешены, но только для суперпользователей (это исключение позволяет суперпользователю подключаться для завершения горячего копирования). Если сервер находится в состоянии восстановления, когда запрашивается интеллектуальное отключение, восстановление и потоковая репликация будут остановлены только после завершения всех обычных сеансов.
-
SIGINT Это режим быстрого отключения. Сервер запрещает новые подключения и отправляет всем существующим серверным процессам сигнал SIGTERM, что заставит их прервать свои текущие транзакции и быстро завершить работу. Затем он ожидает завершения всех серверных процессов и, наконец, сам завершает работу. Если сервер находится в режиме горячего резервного копирования, режим резервного копирования будет прерван, что сделает резервную копированию бесполезной.
-
SIGQUIT Это режим немедленного отключения. Сервер отправит сигнал SIGQUIT всем дочерним процессам и будет ждать их завершения. Если они не прекратятся в течение 5 секунд, им будут отправлены сигналы SIGKILL. Главный процесс сервера завершается сразу же после завершения всех дочерних процессов без выполнения обычной обработки завершения работы базы данных. Это приведет к восстановлению (путем воспроизведения журнала WAL) при следующем запуске. Рекомендуется только в чрезвычайных ситуациях.
Программа qhb_ctl предоставляет удобный интерфейс для отправки этих сигналов для завершение работы сервера. Кроме того, вы можете отправить сигнал напрямую, используя kill. PID процесса qhb можно найти с помощью программы ps или из файла qhbmaster.pid в каталоге данных. Например, чтобы сделать быстрое отключение:
$ kill -INT `head -1 /usr/local/qhb/data/qhbmaster.pid`
Важно!!!
Лучше не использовать SIGKILL для выключения сервера так как в этом случае не будет выполнено освобождение сервером разделяемой памяти и семафоров. Кроме того, SIGKILL убивает процесс qhb не позволяя ему передавать сигнал своим подпроцессам, поэтому может потребоваться также уничтожить отдельные подпроцессы вручную.
Чтобы завершить отдельный сеанс, одновременно продолжая другие сеансы, используйте pg_terminate_backend() (см. Таблицу ) или отправьте сигнал SIGTERM дочернему процессу, связанному с сеансом.
Конфигурация сервера
Есть много параметров конфигурации, которые влияют на поведение системы базы данных. В первом разделе этой главы мы опишем, как взаимодействовать с параметрами конфигурации. В последующих разделах подробно обсуждается каждый параметр.
- Настройка параметров
- Расположение файлов
- Соединения и Аутентификация
- Настройки соединения
- listen_addresses (string)
- port (integer)
- max_connections (integer)
- superuser_reserved_connections (integer)
- unix_socket_directories (string)
- unix_socket_group (string)
- unix_socket_permissions (integer)
- bonjour (boolean)
- bonjour_name (string)
- tcp_keepalives_idle (integer)
- tcp_keepalives_interval (integer)
- tcp_keepalives_count (integer)
- tcp_user_timeout (integer)
- Аутентификация
- SSL
- ssl (boolean)
- ssl_ca_file (string)
- ssl_cert_file (string)
- ssl_crl_file (string)
- ssl_key_file (string)
- ssl_ciphers (string)
- ssl_prefer_server_ciphers (boolean)
- ssl_ecdh_curve (string)
- ssl_min_protocol_version (enum)
- ssl_max_protocol_version (enum)
- ssl_dh_params_file (string)
- ssl_passphrase_command (string)
- ssl_passphrase_command_supports_reload (boolean)
- Настройки соединения
- Потребление ресурсов
- Журнал упреждающей записи (wal)
- Копирование
- Передающий сервер
- Мастер сервер
- Резервные серверы
- primary_conninfo (string)
- primary_slot_name (string)
- promote_trigger_file (string)
- hot_standby (boolean)
- max_standby_archive_delay (integer)
- max_standby_streaming_delay (integer)
- wal_receiver_status_interval (integer)
- hot_standby_feedback (boolean)
- wal_receiver_timeout (integer)
- wal_retrieve_retry_interval (integer)
- recovery_min_apply_delay (integer)
- Подписчики
- Планирование запросов
- Конфигурация метода планирования
- enable_bitmapscan (boolean)
- enable_gathermerge (boolean)
- enable_hashagg (boolean)
- enable_hashjoin (boolean)
- enable_indexscan (boolean)
- enable_indexonlyscan (boolean)
- enable_material (boolean)
- enable_mergejoin (boolean)
- enable_nestloop (boolean)
- enable_parallel_append (boolean)
- enable_parallel_hash (boolean)
- enable_partition_pruning (boolean)
- enable_partitionwise_join (boolean)
- enable_partitionwise_aggregate (boolean)
- enable_seqscan (boolean)
- enable_sort (boolean)
- enable_tidscan (boolean)
- Константы стоимости планировщика
- seq_page_cost (с floating point)
- random_page_cost (с floating point)
- cpu_tuple_cost (с floating point)
- cpu_index_tuple_cost (с floating point)
- cpu_operator_cost (с floating point)
- parallel_setup_cost (с floating point)
- parallel_tuple_cost (с floating point)
- min_parallel_table_scan_size (integer)
- min_parallel_index_scan_size (integer)
- effective_cache_size (integer)
- jit_above_cost (с floating point)
- jit_inline_above_cost (с floating point)
- jit_optimize_above_cost (с floating point)
- Генетический оптимизатор запросов
- Другие варианты планировщика
- Конфигурация метода планирования
- Отчеты об ошибках и ведение журнала
- Расположение журнала
- log_destination (string)
- logging_collector (boolean)
- log_directory (string)
- log_filename (string)
- log_file_mode (integer)
- log_rotation_age (integer)
- log_rotation_size (integer)
- log_truncate_on_rotation (boolean)
- syslog_facility (enum)
- syslog_ident (string)
- syslog_sequence_numbers (boolean)
- syslog_split_messages (boolean)
- event_source (string)
- Когда писать в журнал
- Что писать в журнал
- application_name (string)
- debug_pretty_print (boolean)
- log_checkpoints (boolean)
- log_connections (boolean)
- log_disconnections (boolean)
- log_duration (boolean)
- log_error_verbosity (enum)
- log_hostname (boolean)
- log_line_prefix (string)
- log_lock_waits (boolean)
- log_statement (enum)
- log_replication_commands (boolean)
- log_temp_files (integer)
- log_timezone (string)
- Использование вывода журнала в формате CSV
- Название процесса
- Расположение журнала
- Статистика выполнения
- Автоматическая очистка
- autovacuum (boolean)
- log_autovacuum_min_duration (integer)
- autovacuum_max_workers (integer)
- autovacuum_naptime (integer)
- autovacuum_vacuum_threshold (integer)
- autovacuum_vacuum_insert_threshold (integer)
- autovacuum_analyze_threshold (integer)
- autovacuum_vacuum_scale_factor (floating point)
- autovacuum_vacuum_insert_scale_factor (floating point)
- autovacuum_analyze_scale_factor (floating point)
- autovacuum_freeze_max_age (integer)
- autovacuum_multixact_freeze_max_age (integer)
- autovacuum_vacuum_cost_delay (floating point)
- autovacuum_vacuum_cost_limit (integer)
- Клиентское соединение по умолчанию
- Поведение команд
- client_min_messages (enum)
- search_path (string)
- row_security (boolean)
- default_table_access_method (string)
- default_tablespace (string)
- temp_tablespaces (string)
- check_function_bodies (boolean)
- default_transaction_isolation (enum)
- default_transaction_read_only (boolean)
- default_transaction_deferrable (boolean)
- session_replication_role (enum)
- statement_timeout (integer)
- lock_timeout (integer)
- idle_in_transaction_session_timeout (integer)
- vacuum_freeze_table_age (integer)
- vacuum_freeze_min_age (integer)
- vacuum_multixact_freeze_table_age (integer)
- vacuum_multixact_freeze_min_age (integer)
- vacuum_cleanup_index_scale_factor (с floating point)
- bytea_output (enum)
- xmlbinary (enum)
- xmloption (enum)
- gin_pending_list_limit (integer)
- Язык и форматирование
- Предварительная загрузка общей библиотеки
- Другие значения по умолчанию
- Поведение команд
- Управление блокировками
- Совместимость версий и платформ
- Обработка ошибок
- Предустановленные параметры
- block_size (integer)
- data_checksums (boolean)
- data_directory_mode (integer)
- debug_assertions (boolean)
- integer_datetimes (boolean)
- lc_collate (string)
- lc_ctype (string)
- max_function_args (integer)
- max_identifier_length (integer)
- max_index_keys (integer)
- segment_size (integer)
- server_encoding (string)
- server_version (string)
- server_version_num (integer)
- ssl_library (string)
- wal_block_size (integer)
- wal_segment_size (integer)
- Индивидуальные параметры
- Параметры разработчика
- allow_system_table_mods (boolean)
- ignore_system_indexes (boolean)
- post_auth_delay (integer)
- pre_auth_delay (integer)
- trace_notify (boolean)
- trace_recovery_messages (enum)
- trace_sort (boolean)
- trace_locks (boolean)
- trace_lwlocks (boolean)
- trace_userlocks (boolean)
- trace_lock_oidmin (integer)
- trace_lock_table (integer)
- debug_deadlocks (boolean)
- log_btree_build_stats (boolean)
- wal_consistency_checking (string)
- wal_debug (boolean)
- ignore_checksum_failure (boolean)
- zero_damaged_pages (boolean)
- jit_debugging_support (boolean)
- jit_dump_bitcode (boolean)
- jit_expressions (boolean)
- jit_profiling_support (boolean)
- jit_tuple_deforming (boolean)
- Сокращения командной строки
Настройка параметров
Имена параметров и значения
Все имена параметров не чувствительны к регистру. Каждый параметр
принимает значение одного из пяти типов: логическое, строковое, целое, с
плавающей запятой или перечисляемое (enum). Тип определяет синтаксис для
установки параметра:
-
Boolean: значения могут быть записаны как
on,off,true,false,yes,no,1,0(без учета регистра) или любым однозначным префиксом одного из них. -
String: в общем случае заключайте значение в одинарные кавычки, удваивая любые одинарные кавычки внутри значения. Однако кавычки обычно можно опустить, если значение представляет собой простое число или идентификатор. (Значения, которые соответствуют ключевому слову SQL, требуют кавычек в некоторых контекстах).
-
Numeric (целое число и число с плавающей запятой): числовые параметры могут быть указаны в обычном формате целого числа и числа с плавающей запятой; дробные значения округляются до ближайшего целого числа, если параметр имеет целочисленный тип. Целочисленные параметры дополнительно принимают шестнадцатеричный ввод (начиная с 0x ) и восьмеричный ввод (начиная с 0), но эти форматы не могут иметь дроби. Не используйте тысячи разделителей. Кавычки не обязательны, за исключением шестнадцатеричного ввода.
-
Numeric with Unit: некоторые числовые параметры имеют неявную единицу, потому что они описывают количество памяти или времени. Единицей может быть байты, килобайты, блоки (обычно восемь килобайт), миллисекунды, секунды или минуты. Неукрашенное числовое значение для одной из этих настроек будет использовать единицу измерения по умолчанию, которую можно узнать из pg_settings.unit. Для удобства настройки могут быть заданы с явно заданной единицей измерения, например, ’120 ms’ для значения времени, и они будут преобразованы в любую фактическую единицу измерения параметра. Обратите внимание, что значение должно быть записано в виде строки (с кавычками), чтобы использовать эту функцию. Имя устройства чувствительно к регистру, и между числовым значением и единицей может быть пробел.
-
Допустимые единицы памяти: B (байты), kB (килобайты), MB (мегабайты), GB (гигабайты) и TB (терабайты). Множитель для блоков памяти равен 1024, а не 1000.
-
Допустимые единицы времени: us (микросекунды), ms (миллисекунды), s (секунды), min (минуты), h (часы) и d (дни).
-
-
Если дробное значение указано с единицей, оно будет округлено до кратного следующей меньшей единицы, если таковая имеется. Например, 30.1 GB будут преобразованы в 30822 MB не 32319628902 B Если параметр имеет целочисленный тип, окончательное округление до целого числа происходит после любого преобразования единиц.
-
Enumerated: параметры перечислимого типа записываются так же, как строковые параметры, но имеют ограниченный набор значений. Допустимые значения для такого параметра можно найти в pg_settings.enumvals. Перечисленные значения параметров не чувствительны к регистру.
Взаимодействие параметров через файл конфигурации
Самый фундаментальный способ установить эти параметры - отредактировать файл qhb.conf, который обычно хранится в каталоге данных. Копия по умолчанию устанавливается при инициализации каталога кластера базы данных. Пример того, как может выглядеть этот файл:
# This is a comment
log_connections = yes
log_destination = 'syslog'
search_path = '"$user", public'
shared_buffers = 128MB
В каждой строке указывается один параметр. Знак равенства между именем и значением необязателен. Пробелы незначительны (кроме как в значении параметра в кавычках), а пустые строки игнорируются. Хеш-метки (#) обозначают оставшуюся часть строки как комментарий. Значения параметров, которые не являются простыми идентификаторами или числами, должны быть заключены в одинарные кавычки. Чтобы вставить одинарную кавычку в значение параметра, напишите две кавычки (желательно) или обратную косую черту. Если файл содержит несколько записей для одного и того же параметра, все, кроме последнего, игнорируются.
Параметры, установленные таким образом, предоставляют значения по умолчанию для кластера. Настройки, видимые активными сеансами, будут этими значениями, если они не будут переопределены. В следующих разделах описываются способы, которыми администратор или пользователь могут переопределить эти значения по умолчанию.
Файл конфигурации перечитывается всякий раз, когда основной процесс
сервера получает сигнал SIGHUP; этот сигнал легче всего отправить,
запустив qhb_ctl reload из командной строки или вызвав функцию SQL
pg_reload_conf(). Процесс основного сервера также передает этот
сигнал всем запущенным в данный момент процессам сервера, так что
существующие сеансы также принимают новые значения (это произойдет после
того, как они выполнят любую выполняемую в настоящее время клиентскую
команду). Кроме того, вы можете отправить сигнал непосредственно на один
серверный процесс. Некоторые параметры могут быть установлены только при
запуске сервера; любые изменения их записей в файле конфигурации будут
игнорироваться до перезапуска сервера. Неверные настройки параметров в
файле конфигурации также игнорируются (но регистрируются) во время
обработки SIGHUP.
В дополнение к qhb.conf каталог данных QHB содержит файл qhb.auto.conf, который имеет тот же формат, что и qhb.conf но предназначен для редактирования автоматически, а не вручную. Этот файл содержит настройки, предоставленные командой ALTER SYSTEM. Этот файл читается всякий раз, когда есть qhb.conf, и его настройки действуют аналогичным образом. Настройки в qhb.auto.conf переопределяют настройки в qhb.conf.
Внешние инструменты также могут изменять qhb.auto.conf. Не рекомендуется делать это во время работы сервера, поскольку одновременная команда ALTER SYSTEM может перезаписать такие изменения. Такие инструменты могут просто добавлять новые настройки в конец, или они могут удалить дубликаты настроек и / или комментарии (как ALTER SYSTEM ).
Системное представление pg_file_settings может быть полезно для предварительного тестирования изменений в файлах конфигурации или для диагностики проблем, если сигнал SIGHUP не pg_file_settings желаемых результатов.
Взаимодействие параметров через SQL
QHB предоставляет три команды SQL для установки параметров конфигурации по умолчанию. Уже упомянутая команда ALTER SYSTEM предоставляет доступные для SQL средства изменения глобальных значений по умолчанию; это функционально эквивалентно редактированию qhb.conf. Кроме того, есть две команды, которые позволяют устанавливать значения по умолчанию для каждой базы данных или для каждой роли:
-
Команда ALTER DATABASE позволяет переопределять глобальные параметры для каждой базы данных.
-
Команда ALTER ROLE позволяет как глобальным настройкам, так и настройкам для каждой базы данных быть переопределенными пользовательскими значениями.
Значения, установленные с помощью ALTER DATABASE и ALTER ROLE, применяются только при запуске нового сеанса базы данных. Они переопределяют значения, полученные из файлов конфигурации или командной строки сервера, и составляют значения по умолчанию для оставшейся части сеанса. Обратите внимание, что некоторые параметры не могут быть изменены после запуска сервера, и поэтому не могут быть установлены с помощью этих команд (или перечисленных ниже).
После подключения клиента к базе данных QHB предоставляет две дополнительные команды SQL (и эквивалентные функции) для взаимодействия с локальными настройками конфигурации сеанса:
-
Команда SHOW позволяет проверить текущее значение всех параметров. Соответствующая функция - current_setting(setting_name text).
-
Команда SET позволяет изменять текущее значение тех параметров, которые могут быть установлены локально для сеанса; это не влияет на другие сеансы. Соответствующая функция set_config(setting_name, new_value, is_local).
Кроме того, системное представление pg_settings может использоваться для просмотра и изменения локальных значений сеанса:
-
Запрос этого представления аналогичен использованию SHOW ALL но предоставляет более подробную информацию. Это также более гибко, так как можно задавать условия фильтрации или объединяться с другими отношениями.
-
Использование UPDATE в этом представлении, в частности обновление столбца setting, эквивалентно выдаче команд SET. Например, эквивалентом
SET configuration_parameter TO DEFAULT;
является:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
Взаимодействие параметров через оболочку
Помимо установки глобальных значений по умолчанию или добавления переопределений на уровне базы данных или роли, вы можете передавать настройки в QHB с помощью средств оболочки. И сервер, и клиентская библиотека libpq принимают значения параметров через оболочку.
- Во время запуска сервера настройки параметров могут быть переданы команде qhb через параметр командной строки -c. Например,
qhb -c log_connections=yes -c log_destination='syslog'
Параметры, предоставляемые таким образом, переопределяют параметры, заданные с помощью qhb.conf или ALTER SYSTEM, поэтому их нельзя изменить глобально без перезапуска сервера.
- При запуске клиентского сеанса через libpq настройки параметров можно указать с помощью переменной среды PGOPTIONS. Установленные таким образом настройки представляют собой значения по умолчанию для жизни сеанса, но не влияют на другие сеансы. По историческим причинам формат PGOPTIONS похож на тот, который используется при запуске команды qhb ; в частности, должен быть указан флаг -c. Например,
env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Другие клиенты и библиотеки могут предоставлять свои собственные механизмы через оболочку или иным образом, которые позволяют пользователю изменять настройки сеанса без непосредственного использования команд SQL.
Управление содержимым файла конфигурации
QHB предоставляет несколько функций для разбиения сложных файлов qhb.conf на вложенные файлы. Эти функции особенно полезны при управлении несколькими серверами со связанными, но не идентичными конфигурациями.
В дополнение к отдельным настройкам параметров файл qhb.conf может содержать директивы include, которые определяют другой файл для чтения и обработки, как если бы он был вставлен в файл конфигурации на данном этапе. Эта функция позволяет разделить файл конфигурации на физически отдельные части. Директивы include просто выглядят так:
include ’filename’
Если имя файла не является абсолютным путем, оно берется относительно каталога, содержащего ссылочный файл конфигурации. Включения могут быть вложенными.
Существует также директива include_if_exists, которая действует так же, как директива include, за исключением случаев, когда указанный файл не существует или не может быть прочитан. Обычное include будет считать это условием ошибки, но include_if_exists просто регистрирует сообщение и продолжает обрабатывать файл конфигурации, на который ссылаются.
Файл qhb.conf также может содержать директивы include_dir, которые указывают весь каталог файлов конфигурации, который нужно включить. Это выглядит как
include_dir 'directory'
Неабсолютные имена каталогов берутся относительно каталога, содержащего
ссылочный файл конфигурации. В указанном каталоге будут включены только
файлы, не являющиеся каталогами, имена которых заканчиваются суффиксом
.conf. Имена файлов, начинающиеся с cимвола . также игнорируется, чтобы
избежать ошибок, поскольку такие файлы скрыты на некоторых платформах.
Несколько файлов в каталоге include обрабатываются в порядке имен файлов
(в соответствии с правилами языка C, т.е. цифрами перед буквами и
заглавными буквами перед строчными).
Включаемые файлы или каталоги могут использоваться для логического разделения частей конфигурации базы данных, вместо того, чтобы иметь один большой файл qhb.conf. Рассмотрим компанию с двумя серверами баз данных, каждый с разным объемом памяти. Есть вероятные элементы конфигурации, которые будут совместно использоваться для таких вещей, как ведение журнала. Но связанные с памятью параметры на сервере будут различаться между двумя. И там могут быть специфические настройки сервера тоже. Один из способов справиться с этой ситуацией - разбить пользовательские изменения конфигурации вашего сайта на три файла. Вы можете добавить это в конец вашего файла qhb.conf чтобы включить их:
include 'shared.conf'
include 'memory.conf'
include 'server.conf'
Все системы будут иметь одинаковый shared.conf. Каждый сервер с определенным объемом памяти может использовать один и тот же memory.conf; у вас может быть один для всех серверов с 8 ГБ ОЗУ, другой для тех, у кого 16 ГБ. И, наконец, server.conf может содержать действительно специфическую для сервера информацию о конфигурации.
Другая возможность - создать каталог с файлами конфигурации и поместить эту информацию в файлы. Например, на каталог conf.d можно ссылаться в конце qhb.conf :
include_dir 'conf.d'
Затем вы можете назвать файлы в каталоге conf.d следующим образом:
00shared.conf
01memory.conf
02server.conf
Это соглашение об именах устанавливает четкий порядок загрузки этих файлов. Это важно, потому что будет использоваться только последний параметр, обнаруженный для определенного параметра, когда сервер читает файлы конфигурации. В этом примере что-то, установленное в conf.d/02server.conf, переопределит значение, установленное в .d/01memory.conf.
Вместо этого вы могли бы использовать этот подход для описательного именования файлов:
00shared.conf
01memory-8GB.conf
02server-foo.conf
Такое расположение дает уникальное имя для каждого варианта файла конфигурации. Это может помочь устранить неоднозначность, когда конфигурации нескольких серверов хранятся в одном месте, например в репозитории контроля версий. (Хранение файлов конфигурации базы данных под управлением версиями - это еще одна полезная практика).
Расположение файлов
В дополнение к уже упомянутому файлу qhb.conf QHB использует два других редактируемых вручную файла конфигурации, которые управляют аутентификацией клиента. По умолчанию все три файла конфигурации хранятся в каталоге данных кластера базы данных. Параметры, описанные в этом разделе, позволяют размещать файлы конфигурации в другом месте. (Это может упростить администрирование. В частности, зачастую проще обеспечить правильное резервное копирование файлов конфигурации, если они хранятся отдельно).
Параметры расположения файлов конфигурации
data_directory (string)
Определяет основной файл конфигурации сервера (обычно называется qhb.conf). Этот параметр можно установить только при запуске сервера.
config_file (string)
Определяет основной файл конфигурации сервера (обычно называется qhb.conf). Этот параметр можно установить только в командной строке .
hba_file (string)
Указывает файл конфигурации для аутентификации на основе хоста (обычно называется qhb_hba.conf). Этот параметр можно установить только при запуске сервера.
external_pid_file (string)
Задает имя дополнительного файла идентификатора процесса (PID), который сервер должен создать для использования программами администрирования сервера. Этот параметр можно установить только при запуске сервера.
При установке по умолчанию ни один из вышеперечисленных параметров не устанавливается явно. Вместо этого каталог данных указывается параметром командной строки -D или переменной среды PGDATA, и все файлы конфигурации находятся в каталоге данных.
Если вы хотите сохранить файлы конфигурации в другом месте, кроме каталога данных, параметр командной строки qhb -D или переменная среды PGDATA должны указывать на каталог, содержащий файлы конфигурации, а параметр data_directory должен быть установлен в qhb.conf (или в командная строка), чтобы показать, где на самом деле находится каталог данных. Обратите внимание, что data_directory переопределяет -D и PGDATA для расположения каталога данных, но не для расположения файлов конфигурации.
При желании вы можете указать имена файлов конфигурации и их расположение по отдельности, используя параметры config_file, hba_file и/или ident_file. config_file может быть указан только в командной строке qhb, но остальные могут быть установлены в основном файле конфигурации. Если все три параметра плюс data_directory установлены явно, указывать -D или PGDATA не обязательно.
При установке любого из этих параметров относительный путь будет интерпретироваться относительно каталога, в котором запущен qhb.
Соединения и Аутентификация
Настройки соединения
listen_addresses (string)
- Указывает адрес (а) TCP / IP, на котором сервер должен прослушивать соединения от клиентских приложений. Значение принимает форму разделенного запятыми списка имен хостов и / или числовых IP-адресов. Специальная запись * соответствует всем доступным IP-интерфейсам. Запись 0.0.0.0 позволяет прослушивать все адреса IPv4 и :: позволяет прослушивать все адреса IPv6. Если список пуст, сервер вообще не прослушивает ни один IP-интерфейс, и в этом случае для подключения к нему можно использовать только сокеты Unix-домена. Значением по умолчанию является localhost, что позволяет устанавливать только локальные « петлевые » соединения TCP / IP. В то время как аутентификация клиента (глава 20) позволяет детально контролировать, кто может получить доступ к серверу, listen_addresses контролирует, какие интерфейсы принимают попытки соединения, что может помочь предотвратить повторные запросы злонамеренного соединения на незащищенных сетевых интерфейсах. Этот параметр можно установить только при запуске сервера.
port (integer)
- TCP-порт, который прослушивает сервер; 5432 по умолчанию. Обратите внимание, что один и тот же номер порта используется для всех IP-адресов, которые прослушивает сервер. Этот параметр можно установить только при запуске сервера.
max_connections (integer)
-
Определяет максимальное количество одновременных подключений к серверу базы данных. По умолчанию обычно используется 100 соединений, но может быть и меньше, если настройки ядра не будут его поддерживать (как определено во время initdb). Этот параметр можно установить только при запуске сервера.
-
При запуске резервного сервера вы должны установить для этого параметра то же или более высокое значение, чем на главном сервере. В противном случае запросы не будут разрешены на резервном сервере.
superuser_reserved_connections (integer)
-
Определяет количество « слотов » для соединений, которые зарезервированы для соединений суперпользователями QHB. В большинстве случаев соединения max_connections могут быть активными одновременно. Всякий раз, когда число активных одновременных подключений составляет не менее max_connections минус superuser_reserved_connections, новые подключения будут приниматься только для суперпользователей, и новые подключения репликации не будут приниматься.
-
Значение по умолчанию - три соединения. Значение должно быть меньше, чем max_connections. Этот параметр можно установить только при запуске сервера.
unix_socket_directories (string)
-
Указывает каталог сокетов Unix-домена, в которых сервер должен прослушивать соединения от клиентских приложений. Можно создать несколько сокетов, перечислив несколько каталогов, разделенных запятыми. Пробелы между записями игнорируются; окружите имя каталога двойными кавычками, если вам нужно включить в имя пробел или запятые. Пустое значение указывает, что прослушивание не происходит ни в одном из сокетов Unix-домена, и в этом случае для подключения к серверу могут использоваться только сокеты TCP / IP. Значением по умолчанию обычно является /tmp, но его можно изменить во время сборки. Этот параметр можно установить только при запуске сервера.
-
В дополнение к самому файлу сокета, который называется .s.PGSQL. nnnn .s.PGSQL. nnnn где nnnn - номер порта сервера, обычный файл с именем .s.PGSQL. nnnn .lock .s.PGSQL. nnnn .lock будет создан в каждом из каталогов unix_socket_directories. Ни один файл не должен быть удален вручную.
unix_socket_group (string)
- Устанавливает группу-владельца сокетов Unix-домена. (Владельцем пользователя сокетов всегда является пользователь, запускающий сервер). В сочетании с параметром unix_socket_permissions это может использоваться в качестве дополнительного механизма контроля доступа для соединений Unix-домена. По умолчанию это пустая строка, которая использует группу по умолчанию пользователя сервера. Этот параметр можно установить только при запуске сервера.
unix_socket_permissions (integer)
-
Устанавливает права доступа для сокетов Unix-домена. Сокеты домена Unix используют обычный набор разрешений файловой системы Unix. Ожидается, что значением параметра будет числовой режим, указанный в формате, принятом системными вызовами chmod и umask. (Для использования обычного восьмеричного формата число должно начинаться с 0 (ноль)).
-
Разрешения по умолчанию - 0777, что означает, что любой может подключиться. Разумными альтернативами являются 0770 (только пользователь и группа, см. Также unix_socket_group ) и 0700 (только пользователь). (Обратите внимание, что для сокета Unix-домена только права на запись имеют значение, поэтому нет смысла устанавливать или отзывать разрешения на чтение или выполнение).
-
Этот параметр можно установить только при запуске сервера.
-
Этот параметр не имеет отношения к системам, особенно Solaris с Solaris 10, которые полностью игнорируют разрешения сокетов. Там можно достичь аналогичного эффекта, указав unix_socket_directories на каталог с разрешением поиска, ограниченным желаемой аудиторией. Этот параметр также не имеет значения в Windows, где нет сокетов Unix-домена.
bonjour (boolean)
- Позволяет рекламировать существование сервера через Bonjour. По умолчанию выключено. Этот параметр можно установить только при запуске сервера.
bonjour_name (string)
- Указывает имя службы Bonjour. Имя компьютера используется, если для этого параметра задана пустая строка ” (по умолчанию). Этот параметр игнорируется, если сервер не был скомпилирован с поддержкой Bonjour. Этот параметр можно установить только при запуске сервера.
tcp_keepalives_idle (integer)
- Задает время бездействия сети, по истечении которого операционная система должна отправлять клиенту сообщение поддержки активности TCP. Если это значение указано без единиц измерения, оно принимается за секунды. Значение 0 (по умолчанию) выбирает операционную систему по умолчанию. Этот параметр поддерживается только в системах, которые поддерживают TCP_KEEPIDLE или эквивалентный параметр сокета, и в Windows; в других системах оно должно быть равно нулю. В сеансах, подключенных через сокет Unix-домена, этот параметр игнорируется и всегда читается как ноль.
tcp_keepalives_interval (integer)
- Задает время, по истечении которого сообщение подтверждения активности TCP, которое не было подтверждено клиентом, должно быть повторно передано. Если это значение указано без единиц измерения, оно принимается за секунды. Значение 0 (по умолчанию) выбирает операционную систему по умолчанию. Этот параметр поддерживается только в системах, которые поддерживают TCP_KEEPINTVL или эквивалентный параметр сокета, и в Windows; в других системах оно должно быть равно нулю. В сеансах, подключенных через сокет Unix-домена, этот параметр игнорируется и всегда читается как ноль.
tcp_keepalives_count (integer)
- Задает количество сообщений поддержки активности TCP, которые могут быть потеряны до того, как соединение сервера с клиентом будет считаться разорванным. Значение 0 (по умолчанию) выбирает операционную систему по умолчанию. Этот параметр поддерживается только в системах, которые поддерживают TCP_KEEPCNT или эквивалентную опцию сокета; в других системах оно должно быть равно нулю. В сеансах, подключенных через сокет Unix-домена, этот параметр игнорируется и всегда читается как ноль.
tcp_user_timeout (integer)
- Задает время, в течение которого передаваемые данные могут оставаться неподтвержденными до принудительного закрытия TCP-соединения. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение 0 (по умолчанию) выбирает операционную систему по умолчанию. Этот параметр поддерживается только в системах, которые поддерживают TCP_USER_TIMEOUT ; в других системах оно должно быть равно нулю. В сеансах, подключенных через сокет Unix-домена, этот параметр игнорируется и всегда читается как ноль.
Аутентификация
authentication_timeout (integer)
- Максимальное время, необходимое для завершения аутентификации клиента. Если потенциальный клиент не завершил протокол аутентификации за это время, сервер закрывает соединение. Это не позволяет зависшим клиентам занимать соединение бесконечно. Если это значение указано без единиц измерения, оно принимается за секунды. Значение по умолчанию составляет одну минуту (1m). Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
password_encryption (enum)
-
Если в CREATE ROLE или ALTER ROLE указан пароль, этот параметр определяет алгоритм, который будет использоваться для шифрования пароля. Значением по умолчанию является md5, в котором пароль хранится в виде хэша MD5 (также допускается on качестве псевдонима для md5 ). Установка этого параметра в scram-sha-256 зашифрует пароль с помощью SCRAM-SHA-256.
-
Обратите внимание, что старые клиенты могут не поддерживать механизм аутентификации SCRAM и, следовательно, не работать с паролями, зашифрованными с помощью SCRAM-SHA-256.
krb_server_keyfile (string)
- Устанавливает расположение файла ключа сервера Kerberos. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
krb_caseins_users (boolean)
- Устанавливает, должны ли имена пользователей GSSAPI обрабатываться без учета регистра. По умолчанию off (чувствительно к регистру). Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
db_user_namespace (boolean)
-
Этот параметр включает имена пользователей для каждой базы данных. По умолчанию он выключен. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Если это включено, вы должны создавать пользователей как username@dbname. Когда username передается подключающимся клиентом, @ и имя базы данных добавляются к имени пользователя, и это специфичное для базы данных имя пользователя ищется сервером. Обратите внимание, что когда вы создаете пользователей с именами, содержащими @ в среде SQL, вам нужно будет указывать имя пользователя в кавычках.
-
Если этот параметр включен, вы все равно можете создавать обычных глобальных пользователей. Просто добавьте @ при указании имени пользователя в клиенте, например, joe@. Символ @ будет удален до того, как сервер найдет имя пользователя.
-
db_user_namespace вызывает различия в представлении имени пользователя клиента и сервера. Проверка подлинности всегда выполняется с именем пользователя сервера, поэтому методы проверки подлинности должны быть настроены для имени пользователя сервера, а не клиента. Поскольку md5 использует имя пользователя в качестве соли как на клиенте, так и на сервере, md5 нельзя использовать с db_user_namespace.
SSL
ssl (boolean)
- Включает SSL- соединения. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию off.
ssl_ca_file (string)
- Указывает имя файла, содержащего центр сертификации сервера SSL (CA). Относительные пути относятся к каталогу данных. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию пусто, что означает, что файл CA не загружен, и проверка сертификата клиента не выполняется.
ssl_cert_file (string)
- Указывает имя файла, содержащего сертификат сервера SSL. Относительные пути относятся к каталогу данных. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию это server.crt.
ssl_crl_file (string)
- Указывает имя файла, содержащего список отзыва сертификатов сервера SSL (CRL). Относительные пути относятся к каталогу данных. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию пусто, что означает, что файл CRL не загружен.
ssl_key_file (string)
- Задает имя файла, содержащего закрытый ключ сервера SSL. Относительные пути относятся к каталогу данных. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию это server.key.
ssl_ciphers (string)
-
Задает список наборов шифров SSL, которые разрешено использовать для защищенных соединений. См. Страницу руководства по шифрам в пакете OpenSSL для ознакомления с синтаксисом этого параметра и списком поддерживаемых значений. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. Значением по умолчанию является HIGH:MEDIUM:+3DES:!aNULL. По умолчанию это обычно разумный выбор, если у вас нет особых требований к безопасности.
Объяснение значения по умолчанию:-
HIGH - Наборы шифров, которые используют шифры из группы HIGH (например, AES, Camellia, 3DES)
-
MEDIUM - Наборы шифров, которые используют шифры из группы MEDIUM (например, RC4, SEED)
-
+3DES - Порядок OpenSSL по умолчанию для HIGH проблематичен, потому что он заказывает 3DES выше, чем AES128. Это неправильно, потому что 3DES предлагает меньше безопасности, чем AES128, и это также намного медленнее. +3DES переупорядочивает его после всех других шифров HIGH и MEDIUM.
-
!aNULL - Отключает анонимные наборы шифров, которые не выполняют аутентификацию. Такие комплекты шифров уязвимы для атак «человек посередине» и поэтому не должны использоваться.
-
-
Доступные подробности комплекта шифров зависят от версии OpenSSL. Используйте команду
openssl ciphers -v 'HIGH:MEDIUM:+3DES:!aNULL'чтобы увидеть фактические данные для текущей установленной версии OpenSSL. Обратите внимание, что этот список фильтруется во время выполнения в зависимости от типа ключа сервера.
ssl_prefer_server_ciphers (boolean)
- Указывает, следует ли использовать настройки шифрования SSL сервера, а не настройки клиента. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию включено.
ssl_ecdh_curve (string)
-
Задает имя кривой для использования в обмене ключами ECDH. Он должен поддерживаться всеми подключенными клиентами. Это не обязательно должна быть та же кривая, которая используется ключом эллиптической кривой сервера. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. Значение по умолчанию - prime256v1.
-
Имена OpenSSL для наиболее распространенных кривых: prime256v1 (NIST P-256), secp384r1 (NIST P-384), secp521r1 (NIST P-521). Полный список доступных кривых можно openssl ecparam -list_curves с помощью команды openssl ecparam -list_curves. Не все из них можно использовать в TLS.
ssl_min_protocol_version (enum)
-
Устанавливает минимальную версию протокола SSL / TLS для использования. Допустимые значения: TLSv1, TLSv1.1, TLSv1.2, TLSv1.3. Старые версии библиотеки OpenSSL не поддерживают все значения; ошибка будет возникать, если выбрана неподдерживаемая настройка. Версии протокола до TLS 1.0, а именно версии 2 и 3 SSL, всегда отключены.
-
По умолчанию используется TLSv1, в основном для поддержки старых версий библиотеки OpenSSL. Возможно, вы захотите установить более высокое значение, если все программные компоненты могут поддерживать более новые версии протокола.
ssl_max_protocol_version (enum)
- Устанавливает максимальную версию протокола SSL / TLS для использования. Допустимые значения такие же, как для ssl_min_protocol_version, с добавлением пустой строки, которая допускает любую версию протокола. По умолчанию разрешена любая версия. Установка максимальной версии протокола в основном полезна для тестирования или если у некоторых компонентов возникают проблемы при работе с более новым протоколом.
ssl_dh_params_file (string)
-
Указывает имя файла, содержащего параметры Диффи-Хеллмана, используемые для так называемого эфемерного семейства DH-шифров SSL. По умолчанию пусто, и в этом случае используются скомпилированные по умолчанию параметры DH. Использование пользовательских параметров DH уменьшает воздействие, если злоумышленнику удается взломать хорошо известные скомпилированные параметры DH. Вы можете создать свой собственный файл параметров DH с помощью команды openssl dhparam -out dhparams.pem 2048.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
ssl_passphrase_command (string)
-
Устанавливает внешнюю команду, которая будет вызываться, когда требуется получить ключевую фразу для расшифровки файла SSL, такого как закрытый ключ. По умолчанию этот параметр пуст, что означает, что используется встроенный механизм подсказок.
-
Команда должна распечатать парольную фразу на стандартный вывод и выйти с кодом 0. В значении параметра %p заменяется строкой приглашения. (Напишите %% для литерала %). Обратите внимание, что строка приглашения, вероятно, будет содержать пробелы, поэтому убедитесь, что в ней указаны соответствующие кавычки. Единственная новая строка удаляется с конца вывода, если она есть.
-
На самом деле команда не должна запрашивать у пользователя пароль. Он может прочитать его из файла, получить его из цепочки для ключей или подобного. Пользователь сам должен убедиться, что выбранный механизм надежно защищен.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
ssl_passphrase_command_supports_reload (boolean)
-
Этот параметр определяет, будет ли команда passphrase, установленная ssl_passphrase_comman, также вызываться во время перезагрузки конфигурации, если файл ключа нуждается в парольной фразе. Если этот параметр отключен (по умолчанию), то ssl_passphrase_command будет игнорироваться во время перезагрузки, и конфигурация SSL не будет перезагружаться, если требуется пароль. Этот параметр подходит для команды, для запроса которой требуется TTY, который может быть недоступен во время работы сервера. Установка этого параметра в on может быть целесообразной, если, например, пароль получен из файла.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Потребление ресурсов
Память
shared_buffers (integer)
-
Устанавливает объем памяти, используемый сервером базы данных для буферов общей памяти. Значение по умолчанию обычно составляет 128 мегабайт (128MB), но может быть меньше, если настройки ядра не будут его поддерживать (как определено во время initdb). Этот параметр должен быть не менее 128 килобайт. Тем не менее, настройки, значительно превышающие минимальные, обычно необходимы для хорошей производительности. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. (Значения BLCKSZ от значений по BLCKSZ изменяют минимальное значение). Этот параметр можно установить только при запуске сервера.
-
Если у вас есть выделенный сервер базы данных с 1 ГБ или более ОЗУ, разумное начальное значение для shared_buffers составляет 25% памяти в вашей системе. Существуют некоторые рабочие нагрузки, в которых эффективны даже большие настройки для shared_buffers, но поскольку QHB также опирается на кэш операционной системы, маловероятно, что выделение более 40% ОЗУ для shared_buffers будет работать лучше, чем меньшее количество. Большие настройки для shared_buffers обычно требуют соответствующего увеличения max_wal_size, чтобы распространить процесс записи большого количества новых или измененных данных на более длительный период времени.
-
В системах с менее чем 1 ГБ ОЗУ необходим меньший процент ОЗУ, чтобы оставить достаточно места для операционной системы.
huge_pages (enum)
-
Определяет, запрашиваются ли огромные страницы для основной области общей памяти. Допустимые значения: try (по умолчанию), on и off. Если huge_pages настроили try huge_pages, сервер попытается запросить огромные страницы, но в случае сбоя вернется к huge_pages по умолчанию. При on, запрос больших страниц будет препятствовать запуску сервера. С off огромные страницы не будут запрашиваться.
-
В настоящее время этот параметр поддерживается только в Linux. Эта настройка игнорируется в других системах, если задана try.
-
Использование огромных страниц приводит к уменьшению таблиц страниц и сокращению затрат времени ЦП на управление памятью, что повышает производительность.
-
Обратите внимание, что этот параметр влияет только на основную область общей памяти. Операционные системы, такие как Linux, FreeBSD и Illumos, также могут автоматически использовать огромные страницы (также известные как « супер » или « большие » страницы) для обычного распределения памяти без явного запроса QHB. В Linux это называется « прозрачные огромные страницы » (ТНР). Известно, что эта функция может привести к снижению производительности QHB для некоторых пользователей в некоторых версиях Linux, поэтому ее использование в настоящее время не рекомендуется (в отличие от явного использования huge_pages).
temp_buffers (integer)
-
Устанавливает максимальный объем памяти, используемый для временных буферов в каждом сеансе базы данных. Это локальные буферы сеанса, используемые только для доступа к временным таблицам. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. По умолчанию используется восемь мегабайт (8MB). (Если BLCKSZ не равен 8 КБ, значение по умолчанию масштабируется пропорционально ему). Этот параметр можно изменить в отдельных сеансах, но только перед первым использованием временных таблиц в сеансе; Последующие попытки изменить значение не будут влиять на этот сеанс.
-
Сеанс будет распределять временные буферы по мере необходимости до предела, заданного temp_buffers. Стоимость установки большого значения в сеансах, которые на самом деле не нуждаются во многих временных буферах, составляет только дескриптор буфера, или около 64 байтов, за приращение в temp_buffers. Однако, если буфер фактически используется, для него будут использованы дополнительные 8192 байта (или, как BLCKSZ байты BLCKSZ).
max_prepared_transactions (integer)
-
Устанавливает максимальное количество транзакций, которые могут одновременно находиться в « подготовленном » состоянии (см. PREPARE TRANSACTION ). Установка этого параметра в ноль (по умолчанию) отключает функцию подготовленной транзакции. Этот параметр можно установить только при запуске сервера.
-
Если вы не планируете использовать подготовленные транзакции, этот параметр должен быть установлен на ноль, чтобы предотвратить случайное создание подготовленных транзакций. Если вы используете подготовленные транзакции, вы, вероятно, захотите, чтобы max_prepared_transactions был по крайней мере таким же большим, как max_connections, чтобы у каждого сеанса могла быть ожидающая подготовленная транзакция.
-
При запуске резервного сервера вы должны установить для этого параметра то же или более высокое значение, чем на главном сервере. В противном случае запросы не будут разрешены на резервном сервере.
work_mem (integer)
- Устанавливает максимальный объем памяти, который будет использоваться операцией запроса (такой как сортировка или хеш-таблица) перед записью во временные файлы на диске. Если это значение указано без единиц измерения, оно принимается за килобайты. Значение по умолчанию составляет четыре мегабайта (4MB). Обратите внимание, что для сложного запроса несколько операций сортировки или хеширования могут выполняться параллельно; каждой операции будет разрешено использовать столько памяти, сколько указано в этом значении, прежде чем она начнет записывать данные во временные файлы. Кроме того, несколько запущенных сеансов могут выполнять такие операции одновременно. Следовательно, общая используемая память может многократно превышать значение work_mem ; этот факт необходимо учитывать при выборе значения. Операции сортировки используются для ORDER BY, DISTINCT и объединений слиянием. Хеш-таблицы используются в хеш-соединениях, агрегации на основе хеша и обработке подзапросов IN основе хеша.
maintenance_work_mem (integer)
-
Задает максимальный объем памяти, который будет использоваться операциями обслуживания, такими как VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY. Если это значение указано без единиц измерения, оно принимается за килобайты. По умолчанию это 64 мегабайта (64MB). Поскольку только одна из этих операций может быть выполнена за один раз сеансом базы данных, и у установки обычно нет многих из них, работающих одновременно, можно безопасно установить это значение значительно больше, чем work_mem. Большие настройки могут повысить производительность для очистки и восстановления дампов базы данных.
-
Обратите внимание, что при запуске autovacuum, до времени autovacuum_max_workers эта память может быть выделена, поэтому будьте осторожны, чтобы не установить слишком высокое значение по умолчанию. Это может быть полезно для контроля, отдельно устанавливая autovacuum_work_mem.
autovacuum_work_mem (integer)
- Указывает максимальный объем памяти, который будет использоваться каждым рабочим процессом автоочистки. Если это значение указано без единиц измерения, оно принимается за килобайты. По умолчанию используется значение -1, указывающее, что вместо этого следует использовать значение maintenance_work_mem. Этот параметр не влияет на поведение VACUUM при запуске в других контекстах.
max_stack_depth (integer)
-
Задает максимальную безопасную глубину стека выполнения сервера. Идеальным параметром для этого параметра является фактический предел размера стека, установленный ядром (установленный ulimit -s или локальным эквивалентом), за вычетом запаса прочности в мегабайте или около того. Запас безопасности необходим, потому что глубина стека проверяется не в каждой подпрограмме на сервере, а только в ключевых потенциально-рекурсивных подпрограммах. Если это значение указано без единиц измерения, оно принимается за килобайты. Значение по умолчанию составляет два мегабайта (2MB), что является консервативно небольшим и вряд ли приведет к сбою. Однако он может быть слишком маленьким, чтобы разрешить выполнение сложных функций. Только суперпользователи могут изменять эту настройку.
-
Установка max_stack_depth выше фактического лимита ядра будет означать, что убегающая рекурсивная функция может привести к сбою отдельного внутреннего процесса. На платформах, где QHB может определить ограничение ядра, сервер не допустит, чтобы для этой переменной было установлено небезопасное значение. Однако не все платформы предоставляют информацию, поэтому при выборе значения рекомендуется соблюдать осторожность.
shared_memory_type (enum)
- Определяет реализацию совместно используемой памяти, которую сервер должен использовать для основной области совместно используемой памяти, которая содержит совместно используемые буферы QHB и другие совместно используемые данные. Возможные значения: mmap (для анонимной разделяемой памяти, выделенной с помощью mmap ), sysv (для разделяемой памяти System V, выделенной с помощью shmget ). Не все значения поддерживаются на всех платформах; первая поддерживаемая опция используется по умолчанию для этой платформы. Использование опции sysv, которая не используется по умолчанию на какой-либо платформе, обычно не рекомендуется, потому что обычно для нее требуются нестандартные настройки ядра для больших выделений .
dynamic_shared_memory_type (enum)
- Определяет реализацию динамической разделяемой памяти, которую должен использовать сервер. Возможные значения: posix (для разделяемой памяти POSIX, выделенной с помощью shm_open ), sysv (для разделяемой памяти System V, выделенной с помощью shmget), windows (для разделяемой памяти Windows) и mmap (для имитации разделяемой памяти с использованием отображенных в памяти файлов, хранящихся в данных каталог). Не все значения поддерживаются на всех платформах; первая поддерживаемая опция используется по умолчанию для этой платформы. Использование параметра mmap, который не используется по умолчанию на любой платформе, обычно не рекомендуется, поскольку операционная система может многократно записывать измененные страницы на диск, увеличивая нагрузку на ввод-вывод системы; однако это может быть полезно для отладки, когда каталог pg_dynshmem хранится на диске RAM, или когда другие средства общей памяти недоступны.
Диск
temp_file_limit (integer)
-
Задает максимальный объем дискового пространства, который процесс может использовать для временных файлов, таких как временные файлы сортировки и хэширования, или файл хранилища для удерживаемого курсора. Транзакция, пытающаяся превысить этот лимит, будет отменена. Если это значение указано без единиц измерения, оно принимается за килобайты. -1 (по умолчанию) означает отсутствие ограничений. Только суперпользователи могут изменять эту настройку.
-
Этот параметр ограничивает общее пространство, используемое в любой момент всеми временными файлами, используемыми данным процессом QHB. Следует отметить, что дисковое пространство, используемое для явных временных таблиц, в отличие от временных файлов, используемых за кулисами при выполнении запросов, не учитывается в этом ограничении.
Использование ресурсов ядра
max_files_per_process (integer)
- Устанавливает максимальное количество одновременно открытых файлов, разрешенное для каждого подпроцесса сервера. По умолчанию используется тысяча файлов. Если ядро применяет безопасный лимит для каждого процесса, вам не нужно беспокоиться об этом параметре. Но на некоторых платформах (особенно в большинстве систем BSD) ядро позволяет отдельным процессам открывать гораздо больше файлов, чем может реально поддерживать система, если все процессы пытаются открыть такое количество файлов. Если вы обнаружите, что видите « Слишком много открытых файлов », попробуйте уменьшить этот параметр. Этот параметр можно установить только при запуске сервера.
Определение предела стоимости работы процесса очистки
Во время выполнения команд VACUUM и ANALYZE система поддерживает внутренний счетчик, который отслеживает оценочную стоимость различных выполняемых операций ввода-вывода. Когда накопленная стоимость достигает предела (указанного в vacuum_cost_limit), процесс, выполняющий операцию, будет vacuum_cost_limit в спящем режиме в течение короткого периода времени, как указано в vacuum_cost_delay. Затем он сбросит счетчик и продолжит выполнение.
Цель этой функции - позволить администраторам уменьшить влияние ввода / вывода этих команд на одновременную работу базы данных. Во многих ситуациях не важно, чтобы команды обслуживания, такие как VACUUM и ANALYZE быстро заканчивались; однако, как правило, очень важно, чтобы эти команды не оказывали значительного влияния на способность системы выполнять другие операции с базой данных. Задержка вакуума, основанная на затратах, позволяет администраторам достичь этого.
Эта функция по умолчанию отключена для команд VACUUM введенных вручную. Чтобы включить его, установите для переменной vacuum_cost_delay ненулевое значение.
vacuum_cost_delay (floating point)
-
Время, в течение которого процесс будет находиться в спящем режиме после превышения предела стоимости. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию равно нулю, что отключает функцию задержки вакуума на основе стоимости. Положительные значения позволяют производить VACUUM на основе затрат.
-
При использовании vacuum, основанного на стоимости, подходящие значения для vacuum_cost_delay обычно довольно малы, возможно, менее 1 миллисекунды. Несмотря на то, что в параметре vacuum_cost_delay можно задать значения в долях миллисекунды, такие задержки могут не измеряться точно на старых платформах. На таких платформах увеличение расхода ресурсов VACUUM превышающее то, что вы получаете на 1 мс, потребует изменения других параметров стоимости вакуума. Тем не менее, вы должны сохранять vacuum_cost_delay таким же небольшим, как ваша платформа будет постоянно измерять; большие задержки не помогают.
vacuum_cost_page_hit (integer)
- Ориентировочная стоимость очистки буфера в общем буферном кеше. Он представляет собой стоимость блокировки пула буферов, поиска общей хеш-таблицы и сканирования содержимого страницы. Значением по умолчанию является один.
vacuum_cost_page_miss (integer)
- Ориентировочная стоимость очистки буфера, который должен быть прочитан с диска. Это представляет собой попытку заблокировать пул буферов, найти общую хеш-таблицу, прочитать нужный блок с диска и просканировать его содержимое. Значение по умолчанию 10.
vacuum_cost_page_dirty (integer)
- Ориентировочная стоимость взимается, когда вакуум модифицирует блок, который был ранее чистым. Он представляет собой дополнительный ввод / вывод, необходимый для повторной очистки грязного блока на диске. Значением по умолчанию является 20.
vacuum_cost_limit (integer)
- Накопленная стоимость, которая заставит процесс уборки спать. Значение по умолчанию составляет 200.
Заметка
Существуют определенные операции, которые удерживают критические блокировки и поэтому должны завершаться как можно быстрее. Вакуумные задержки на основе затрат не возникают во время таких операций. Поэтому возможно, что стоимость накапливается намного выше, чем указанный предел. Чтобы избежать бесполезно длительных задержек в таких случаях, фактическая задержка рассчитывается как vacuum_cost_delay * accumulated_balance / vacuum_cost_limit с максимумом vacuum_cost_delay * 4.
Фоновая запись
Существует отдельный серверный процесс, называемый фоновым модулем записи, функция которого заключается в выдаче записей «грязных» (новых или измененных) общих буферов. Он записывает общие буферы, поэтому серверные процессы обрабатывают пользовательские запросы редко или никогда не должны ждать, пока произойдет запись. Тем не менее, средство записи в фоновом режиме приводит к общему увеличению нагрузки ввода-вывода, поскольку в противном случае страница с многократным загрязнением могла бы быть записана только один раз за интервал контрольной точки, средство записи в фоновом режиме может записать ее несколько раз, так как она загрязнена за тот же интервал, Параметры, обсуждаемые в этом подразделе, могут использоваться для настройки поведения для местных нужд.
bgwriter_delay (integer)
- Определяет задержку между раундами активности для фонового писателя. В каждом раунде писатель выдает записи для некоторого количества грязных буферов (управляемых следующими параметрами). Затем он спит по длине bgwriter_delay и повторяется. Когда в пуле буферов нет грязных буферов, он переходит в более длительный режим bgwriter_delay независимо от bgwriter_delay. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет 200 миллисекунд (200 200ms). Обратите внимание, что во многих системах эффективное разрешение задержек сна составляет 10 миллисекунд; установка значения bgwriter_delay, не кратного 10, может иметь те же результаты, что и установка следующего более высокого значения, кратного 10. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
bgwriter_lru_maxpages (integer)
- В каждом раунде фоновый писатель будет записывать не более этого количества буферов. Установка этого значения в ноль отключает фоновую запись. (Обратите внимание, что контрольные точки, которые управляются отдельным выделенным вспомогательным процессом, не затрагиваются). Значение по умолчанию - 100 буферов. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
bgwriter_lru_multiplier (с floating point)
- Количество грязных буферов, записанных в каждом раунде, основано на количестве новых буферов, которые были необходимы серверным процессам во время последних раундов. Средняя потребность за последнее время умножается на bgwriter_lru_multiplier чтобы получить оценку количества буферов, которое потребуется в следующем раунде. Грязные буферы записываются до тех пор, пока не появится столько чистых, многоразовых буферов. (Тем не менее, не более чем буферы bgwriter_lru_maxpages будут записываться за раунд). Таким образом, настройка 1.0 представляет « своевременную » политику записи именно того количества буферов, которое, по прогнозам, необходимо. Большие значения обеспечивают некоторую защиту от всплесков спроса, в то время как меньшие значения преднамеренно оставляют записи для серверных процессов. По умолчанию это 2.0. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
bgwriter_flush_after (integer)
- Всякий раз, когда фоновое устройство записи записывает больше этого объема данных, попытайтесь заставить ОС выполнить эти записи в основное хранилище. Это ограничит количество «грязных» данных в кеше страниц ядра, уменьшая вероятность зависаний при fsync в конце контрольной точки или когда ОС записывает данные большими пакетами в фоновом режиме. Зачастую это приводит к значительному снижению задержки транзакций, но также есть некоторые случаи, особенно с рабочими нагрузками, которые больше, чем shared_buffers, но меньше, чем кеш страниц ОС, где производительность может снизиться. Этот параметр может не повлиять на некоторые платформы. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. Допустимый диапазон: от 0, что отключает принудительную обратную запись, до 2MB. По умолчанию 512kB в Linux, 0 другом месте. (Если BLCKSZ не равен 8 КБ, значения по умолчанию и максимальные значения масштабируются пропорционально ему). Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Меньшие значения bgwriter_lru_maxpages и bgwriter_lru_multiplier уменьшают дополнительную нагрузку ввода-вывода, вызываемую фоновым bgwriter_lru_maxpages bgwriter_lru_multiplier, но повышают вероятность того, что серверным процессам придется выполнять записи для себя, что задерживает интерактивные запросы.
Асинхронное поведение
effective_io_concurrency (integer)
Устанавливает количество одновременных операций дискового ввода-вывода, которые, как ожидает QHB, могут выполняться одновременно. Увеличение этого значения приведет к увеличению числа операций ввода-вывода, которые каждый отдельный сеанс QHB пытается инициировать параллельно. Допустимый диапазон: от 1 до 1000 или ноль для отключения выдачи асинхронных запросов ввода-вывода. В настоящее время этот параметр влияет только на сканирование кучи растровых изображений.
Для магнитных дисков хорошей отправной точкой для этого параметра является количество отдельных дисков, содержащих полосу RAID 0 или зеркало RAID 1, используемое для базы данных. (Для RAID 5 диск четности не должен учитываться). Однако, если база данных часто занята несколькими запросами, выполняемыми в параллельных сеансах, более низких значений может быть достаточно для сохранения дискового массива занятым. Значение выше, чем необходимо, чтобы диски были заняты, приведет только к дополнительной загрузке ЦП. SSD-накопители и другие хранилища на основе памяти часто могут обрабатывать много одновременных запросов, поэтому наилучшим значением могут быть сотни.
Асинхронный ввод-вывод зависит от эффективной функции posix_fadvise, которой нет в некоторых операционных системах. Если функция отсутствует, то установка этого параметра в любое значение, кроме нуля, приведет к ошибке. В некоторых операционных системах (например, Solaris) функция присутствует, но фактически ничего не делает.
В поддерживаемых системах по умолчанию установлено значение 1, в противном случае - 0. Это значение можно переопределить для таблиц в определенном табличном пространстве, установив параметр табличного пространства с тем же именем (см. ALTER TABLESPACE).
maintenance_io_concurrency (integer)
Схоже с effective_io_concurrency, но используется в работах по обслуживанию БД, которые совершаются в пользу множества клиентских сеансов.
В поддерживаемых системах по умолчанию установлено значение 10, в противном случае - 0. Это значение можно переопределить для таблиц в определенном табличном пространстве, установив параметр табличного пространства с тем же именем (см. ALTER TABLESPACE).
max_worker_processes (integer)
Устанавливает максимальное количество фоновых процессов, которые может поддерживать система. Этот параметр можно установить только при запуске сервера. По умолчанию это 8.
При запуске резервного сервера вы должны установить для этого параметра то же или более высокое значение, чем на главном сервере. В противном случае запросы не будут разрешены на резервном сервере.
Изменяя это значение, рассмотрите также настройку max_parallel_workers, max_parallel_maintenance_workers и max_parallel_workers_per_gather.
max_parallel_workers_per_gather (integer)
Устанавливает максимальное количество рабочих, которое может быть запущено одним узлом Gather или Gather Merge. Параллельные рабочие берутся из пула процессов, установленных max_worker_processes, ограниченного max_parallel_workers. Обратите внимание, что запрошенное количество потоков может быть недоступно во время выполнения. Если это произойдет, план будет работать с меньшим количеством потоков, чем ожидалось, что может быть неэффективным. Значение по умолчанию - 2. Установка этого значения в 0 отключает параллельное выполнение запроса.
Обратите внимание, что параллельные запросы могут потреблять значительно больше ресурсов, чем непараллельные запросы, потому что каждый рабочий процесс является совершенно отдельным процессом, который оказывает примерно то же влияние на систему, что и дополнительный пользовательский сеанс. Это следует учитывать при выборе значения для этого параметра, а также при настройке других параметров, управляющих использованием ресурсов, таких как work_mem. Ограничения ресурсов, такие как work_mem, применяются индивидуально к каждому потоку, что означает, что общее использование может быть намного выше для всех процессов, чем обычно для любого отдельного процесса. Например, параллельный запрос с использованием 4 рабочих может использовать до 5 раз больше процессорного времени, памяти, пропускной способности ввода / вывода и т. д. Как запрос, который вообще не использует рабочих.
max_parallel_maintenance_workers (integer)
Устанавливает максимальное количество параллельных рабочих, которые могут быть запущены одной служебной командой. В настоящее время единственной командой параллельной утилиты, которая поддерживает использование параллельных рабочих, является CREATE INDEX, и только при построении индекса B-дерева. Параллельные рабочие берутся из пула процессов, установленных max_worker_processes, ограниченного max_parallel_workers. Обратите внимание, что запрошенное количество потоков может быть недоступно во время выполнения. Если это произойдет, работа утилиты будет выполняться с меньшим количеством потоков, чем ожидалось. Значение по умолчанию - 2. Установка этого значения в 0 отключает использование параллельных рабочих утилитными командами.
Обратите внимание, что параллельные служебные команды не должны занимать существенно больше памяти, чем эквивалентные непараллельные операции. Эта стратегия отличается от стратегии параллельного запроса, где ограничения ресурсов обычно применяются для каждого рабочего процесса. Параллельные служебные команды рассматривают ограничение ресурса maintenance_work_mem как ограничение, которое применяется ко всей служебной команде независимо от количества параллельных рабочих процессов. Однако параллельные служебные команды могут по-прежнему потреблять значительно больше ресурсов ЦП и пропускной способности ввода-вывода.
max_parallel_workers (integer)
Устанавливает максимальное количество рабочих, которое система может поддерживать для параллельных операций. Значение по умолчанию равно 8. При увеличении или уменьшении этого значения также следует рассмотреть возможность настройки max_parallel_maintenance_workers и max_parallel_workers_per_gather. Также обратите внимание, что настройка для этого значения, которая больше, чем max_worker_processes, не будет иметь никакого эффекта, поскольку параллельные рабочие берутся из пула рабочих процессов, созданного этим параметром.
backend_flush_after (integer)
Всякий раз, когда за один сервер было записано больше этого объема данных, попытайтесь заставить ОС выполнить эти записи в базовое хранилище. Это ограничит количество «грязных» данных в кеше страниц ядра, уменьшая вероятность зависаний при fsync в конце контрольной точки или когда ОС записывает данные большими пакетами в фоновом режиме. Зачастую это приводит к значительному снижению задержки транзакций, но также есть некоторые случаи, особенно с рабочими нагрузками, которые больше, чем shared_buffers, но меньше, чем кеш страниц ОС, где производительность может снизиться. Этот параметр может не повлиять на некоторые платформы. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. Допустимый диапазон: от 0, что отключает принудительную обратную запись, до 2MB. По умолчанию 0, т. е. принудительная обратная запись отсутствует. (Если BLCKSZ не 8 КБ, максимальное значение пропорционально ему).
old_snapshot_threshold (integer)
Устанавливает минимальный период времени, в течение которого снимок запроса может использоваться без риска возникновения ошибки « снимок слишком старый » при использовании снимка. Данные, которые были мертвы дольше, чем этот порог, могут быть удалены. Это может помочь предотвратить вздутие живота на снимках, которые остаются в использовании в течение длительного времени. Чтобы предотвратить неверные результаты из-за очистки данных, которые в противном случае были бы видны для снимка, генерируется ошибка, когда снимок старше этого порога, и снимок используется для чтения страницы, которая была изменена с момента создания снимка.
Если это значение указано без единиц измерения, оно принимается за минуты. Значение -1 (по умолчанию) отключает эту функцию, эффективно устанавливая предел возраста снимка бесконечность. Этот параметр можно установить только при запуске сервера.
Полезные значения для производственной работы, вероятно, варьируются от небольшого количества часов до нескольких дней. Небольшие значения (например, 0 или 1min) допустимы только потому, что иногда они могут быть полезны для тестирования. Несмотря на то, что допустимо значение до 60d, имейте в виду, что во многих рабочих нагрузках экстремальное раздувание или изменение идентификатора транзакции может происходить в гораздо более короткие периоды времени.
Когда эта функция включена, освобожденное пространство в конце отношения не может быть освобождено для операционной системы, так как это может удалить информацию, необходимую для обнаружения условия « снимок слишком старый ». Все пространство, выделенное для отношения, остается связанным с этим отношением для повторного использования только в этом отношении, если только оно явно не освобождено (например, с VACUUM FULL ).
Этот параметр не пытается гарантировать, что ошибка будет сгенерирована при любых конкретных обстоятельствах. Фактически, если правильные результаты могут быть сгенерированы из (например) курсора, который материализовал набор результатов, не будет сгенерировано никакой ошибки, даже если нижележащие строки в ссылочной таблице были удалены. Некоторые таблицы невозможно безопасно очистить на ранней стадии, поэтому этот параметр не будет затронут, например системные каталоги. Для таких таблиц этот параметр не уменьшит раздувание и не создаст возможность ошибки « снимок слишком старый » при сканировании.
Журнал упреждающей записи (wal)
Для получения дополнительной информации о настройке этих параметров см. раздел Конфигурация WAL.
Настройки
wal_level (enum)
-
wal_level определяет, сколько информации записывается в WAL. Значение по умолчанию - replica, которая записывает достаточно данных для поддержки архивации и репликации WAL, включая выполнение запросов только для чтения на резервном сервере. minimal удаляет все журналы, кроме информации, необходимой для восстановления после сбоя или немедленного выключения. Наконец, logical добавляет информацию, необходимую для поддержки логического декодирования. Каждый уровень включает информацию, зарегистрированную на всех более низких уровнях. Этот параметр можно установить только при запуске сервера.
-
На minimal уровне WAL-протоколирование некоторых массовых операций может быть безопасно пропущено, что может значительно ускорить эти операции (см. раздел Отключить архивацию WAL и потоковую репликацию). Операции, в которых может применяться эта оптимизация, включают в себя:
-
CREATE TABLE AS
-
CREATE INDEX
-
CLUSTER
-
COPY в таблицы, которые были созданы или усечены в одной транзакции
-
-
Но минимальный WAL не содержит достаточно информации для восстановления данных из базовой резервной копии и журналов WAL, поэтому для включения архивации WAL (archive_mode) и потоковой репликации необходимо использовать replica или более позднюю версию.
-
На logical уровне регистрируется та же информация, что и для replica, плюс информация, необходимая для извлечения наборов логических изменений из WAL. Использование logical уровня увеличит объем WAL, особенно если многие таблицы сконфигурированы для REPLICA IDENTITY FULL и выполняется много операторов UPDATE и DELETE.
fsync (boolean)
-
Если этот параметр включен, сервер QHB попытается убедиться, что обновления физически записаны на диск, fsync() системные вызовы fsync() или различные эквивалентные методы (см. Wal_sync_method). Это гарантирует, что кластер базы данных сможет вернуться в согласованное состояние после сбоя операционной системы или оборудования.
-
Хотя отключение fsync часто приводит к повышению производительности, это может привести к неустранимому повреждению данных в случае сбоя питания или сбоя системы. Таким образом, рекомендуется отключать fsync случае, если вы можете легко воссоздать всю базу данных из внешних данных.
-
Примеры безопасных обстоятельств для отключения fsync включают начальную загрузку нового кластера базы данных из файла резервной копии, использование кластера базы данных для обработки пакета данных, после которого база данных будет выброшена и воссоздана, или для базы данных только для чтения клон, который часто воссоздается и не используется для отработки отказа. Высококачественное оборудование само по себе не является достаточным основанием для отключения fsync.
-
Для надежного восстановления при включении fsync необходимо принудительно установить все измененные буферы в ядре в долговременное хранилище. Это можно сделать, когда кластер выключен или когда fsync, запустив initdb --sync-only, sync, размонтирование файловой системы или перезагрузку сервера.
-
Во многих ситуациях отключение synchronous_commit для некритических транзакций может обеспечить большую потенциальную выгоду производительности при отключении fsync без сопутствующего риска повреждения данных.
-
fsync можно установить только в файле qhb.conf или в командной строке сервера. Если вы отключите этот параметр, также рассмотрите возможность отключения full_page_writes.
synchronous_commit (enum)
-
Указывает, будет ли фиксация транзакции ожидать записи WAL на диск, прежде чем команда вернет клиенту указание «успех». Допустимые значения: on, remote_apply, remote_write, local и off. По умолчанию безопасная настройка включена. В off состоянии возможна задержка между тем, когда клиенту сообщается об успехе, и когда транзакция действительно гарантированно защищена от сбоя сервера. (Максимальная задержка в три раза больше wal_writer_delay). В отличие от fsync, off этого параметра не создает риска несогласованности базы данных: сбой операционной системы или базы данных может привести к потере некоторых недавних якобы зафиксированных транзакций, но состояние базы данных будет быть так же, как если бы эти транзакции были прерваны чисто. Таким образом, отключение synchronous_commit может быть полезной альтернативой, когда производительность важнее точной уверенности в долговечности транзакции. Для получения дополнительной информации см. раздел Асинхронный коммит.
-
Если synchronous_standby_names не является пустым, этот параметр также определяет, будет ли фиксация транзакции ожидать репликацию своих записей WAL на резервный сервер (ы). При on фиксация будет ожидать до тех пор, пока ответы из текущих синхронных резервных копий не укажут, что они получили запись фиксации транзакции и сбросили ее на диск. Это гарантирует, что транзакция не будет потеряна, если как основной, так и все синхронные резервные серверы не повредят хранилище своей базы данных. Если задано значение remote_apply, коммиты будут ждать, пока ответы из текущего синхронного резерва (-ов) не укажут, что они получили запись фиксации транзакции и применили ее, так что она стала видимой для запросов в резервах. Когда установлено значение remote_write, коммиты будут ждать, пока ответы из текущего синхронного резерва (-ов) не remote_write, что они получили запись фиксации транзакции и записали ее в свою операционную систему. Этот параметр достаточен для обеспечения сохранения данных даже в случае сбоя резервного экземпляра QHB, но не в том случае, если резервный переносит сбой на уровне операционной системы, поскольку данные не обязательно достигли стабильного хранилища в резервном режиме. Наконец, настройка local заставляет коммиты ждать локального сброса на диск, но не репликации. Это обычно нежелательно, когда используется синхронная репликация, но предоставляется для полноты.
-
Если synchronous_standby_names пусто, параметры on, remote_apply, remote_write и local обеспечивают одинаковый уровень синхронизации: транзакция фиксирует только ожидание локальной загрузки на диск.
-
Этот параметр может быть изменен в любое время; Поведение любой транзакции определяется настройкой, действующей при ее фиксации. Поэтому возможно и полезно, чтобы некоторые транзакции выполнялись синхронно, а другие - асинхронно. Например, чтобы одна транзакция с несколькими состояниями фиксировалась асинхронно, когда значение по умолчанию противоположное, введите SET LOCAL synchronous_commit TO OFF в транзакции.
wal_sync_method (enum)
-
Метод, используемый для принудительного обновления WAL на диск. Если fsync выключен, то этот параметр не имеет значения, поскольку обновления файла WAL вообще не будут принудительно обновляться. Возможные значения:
-
open_datasync (запись файлов WAL с опцией open() O_DSYNC)
-
fdatasync (вызывать fdatasync() при каждом коммите)
-
fsync (вызывать fsync() при каждом коммите)
-
fsync_writethrough (вызывать fsync() при каждом fsync_writethrough, вызывая сквозную запись любого дискового кэша записи)
-
open_sync (запись файлов WAL с опцией open() O_SYNC)
-
-
open_* также используют O_DIRECT если доступно. Не все эти варианты доступны на всех платформах. По умолчанию это первый метод в приведенном выше списке, который поддерживается платформой, за исключением того, что fdatasync является значением по умолчанию в Linux. Значение по умолчанию не обязательно идеально; может потребоваться изменить этот параметр или другие аспекты конфигурации вашей системы, чтобы создать безопасную конфигурацию или достичь оптимальной производительности. Эти аспекты обсуждаются в разделе Надежность. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
full_page_writes (boolean)
-
Когда этот параметр включен, сервер QHB записывает все содержимое каждой страницы диска в WAL во время первой модификации этой страницы после контрольной точки. Это необходимо, поскольку запись страницы, которая выполняется во время сбоя операционной системы, может быть завершена только частично, что приводит к появлению на диске страницы, содержащей смесь старых и новых данных. Данные изменения уровня строки, обычно хранящиеся в WAL, не будут достаточны для полного восстановления такой страницы во время восстановления после сбоя. Хранение полного изображения страницы гарантирует, что страница может быть правильно восстановлена, но за счет увеличения объема данных, которые должны быть записаны в WAL. (Поскольку воспроизведение WAL всегда начинается с контрольной точки, этого достаточно сделать при первом изменении каждой страницы после контрольной точки. Поэтому одним из способов снижения стоимости полностраничных записей является увеличение параметров интервала контрольной точки).
-
Отключение этого параметра ускоряет нормальную работу, но может привести к неисправимому повреждению данных или повреждению данных без вывода сообщений после сбоя системы. Риски аналогичны отключению fsync, хотя и меньше, и его следует отключать только на основании тех же обстоятельств, которые рекомендованы для этого параметра.
-
Отключение этого параметра не влияет на использование архивации WAL для восстановления на определенный момент времени (PITR) (см. раздел Непрерывное архивирование и восстановление на момент времени (PITR)).
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию включено.
wal_log_hints (boolean)
-
Когда этот параметр включен, сервер QHB записывает все содержимое каждой страницы диска в WAL во время первой модификации этой страницы после контрольной точки, даже для некритических модификаций так называемых битов подсказок.
-
Если контрольные суммы данных включены, обновления битов подсказок всегда регистрируются в WAL, и этот параметр игнорируется. Вы можете использовать этот параметр, чтобы проверить, сколько дополнительных журналов WAL произойдет, если в вашей базе данных будут включены контрольные суммы данных.
-
Этот параметр можно установить только при запуске сервера. Значение по умолчанию off.
wal_compression (boolean)
-
Когда этот параметр включен, сервер QHB сжимает полный образ страницы, записанный в WAL, когда full_page_writes включен или во время основного резервного копирования. Сжатый образ страницы будет распакован во время воспроизведения WAL. Значение по умолчанию off. Только суперпользователи могут изменять эту настройку.
-
Включение этого параметра может уменьшить объем WAL без увеличения риска неустранимого повреждения данных, но за счет некоторого дополнительного ЦП, потраченного на сжатие во время ведения журнала WAL и на декомпрессию во время воспроизведения WAL.
wal_buffers (integer)
-
Объем общей памяти, используемой для данных WAL, которые еще не были записаны на диск. Значение по умолчанию -1 выбирает размер, равный 1/32 (около 3%) shared_buffers, но не менее 64kB не больше, чем размер одного сегмента WAL, обычно 16MB. Это значение может быть установлено вручную, если автоматический выбор слишком велик или слишком мал, но любое положительное значение менее 32kB будет рассматриваться как 32kB. Если это значение указано без единиц измерения, оно принимается как блоки WAL, то есть байты XLOG_BLCKSZ, обычно 8 КБ. Этот параметр можно установить только при запуске сервера.
-
Содержимое буферов WAL записывается на диск при каждой фиксации транзакции, поэтому крайне большие значения вряд ли обеспечат значительное преимущество. Однако установка этого значения как минимум в несколько мегабайт может улучшить производительность записи на занятом сервере, где одновременно фиксируются многие клиенты. Автонастройка, выбранная по умолчанию, равной -1, должна в большинстве случаев давать приемлемые результаты.
wal_writer_delay (integer)
- Определяет, как часто писатель WAL сбрасывает WAL во временных терминах. После сброса WAL писатель спит в течение отрезка времени, указанного в wal_writer_delay, если только он не проснулся раньше из-за асинхронной фиксации транзакции. Если последний сброс произошел меньше, чем wal_writer_delay назад, и с тех пор был произведен WAL меньше, чем wal_writer_flush_after, то WAL записывается только в операционную систему, а не на диск. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет 200 миллисекунд (200 200ms ). Обратите внимание, что во многих системах эффективное разрешение задержек сна составляет 10 миллисекунд; установка для wal_writer_delay значения, не кратного 10, может иметь те же результаты, что и установка следующего более высокого значения, кратного 10. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
wal_writer_flush_after (integer)
- Определяет, как часто писатель WAL сбрасывает WAL в объемном выражении. Если последний сброс произошел меньше, чем wal_writer_delay назад, и с тех пор был произведен WAL меньше, чем wal_writer_flush_after, то WAL записывается только в операционную систему, а не на диск. Если wal_writer_flush_after установлен в 0 то данные WAL всегда сбрасываются немедленно. Если это значение указано без единиц измерения, оно принимается как блоки WAL, то есть байты XLOG_BLCKSZ, обычно 8 КБ. По умолчанию это 1MB. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
commit_delay (integer)
-
Установка commit_delay добавляет задержку перед началом commit_delay WAL. Это может улучшить пропускную способность групповой фиксации, позволяя большему количеству транзакций фиксироваться через один сброс WAL, если загрузка системы достаточно высока, чтобы дополнительные транзакции были готовы к фиксации в течение заданного интервала. Однако это также увеличивает задержку вплоть до commit_delay для каждого commit_delay WAL. Поскольку задержка просто теряется, если никакие другие транзакции не готовы к фиксации, задержка выполняется только в том случае, если по крайней мере commit_siblings другие транзакции активны, когда собирается инициировать сброс. Кроме того, никакие задержки не выполняются, если fsync отключен. Если это значение указано без единиц измерения, оно принимается за микросекунды. По умолчанию commit_delay равен нулю (без задержки). Только суперпользователи могут изменять эту настройку.
-
В QHB первый процесс, который становится готовым к очистке, ожидает установленный интервал, в то время как последующие процессы ждут только до тех пор, пока лидер не завершит операцию очистки.
commit_siblings (integer)
- Минимальное количество одновременных открытых транзакций, которое требуется для выполнения задержки commit_delay. Большее значение повышает вероятность того, что хотя бы еще одна транзакция будет готова к фиксации в течение интервала задержки. По умолчанию используется пять транзакций.
Контрольные точки
checkpoint_timeout (integer)
- Максимальное время между автоматическими контрольными точками WAL. Если это значение указано без единиц измерения, оно принимается за секунды. Допустимый диапазон составляет от 30 секунд до одного дня. По умолчанию это пять минут (5min минут). Увеличение этого параметра может увеличить время, необходимое для восстановления после сбоя. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
checkpoint_completion_target (с floating point)
- Определяет цель завершения контрольной точки, как часть общего времени между контрольными точками. По умолчанию это 0,5. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
checkpoint_flush_after (integer)
- Всякий раз, когда во время выполнения контрольной точки было записано больше этого объема данных, попытайтесь заставить ОС выполнить эти записи в базовое хранилище. Это ограничит количество «грязных» данных в кеше страниц ядра, уменьшая вероятность зависаний при fsync в конце контрольной точки или когда ОС записывает данные большими пакетами в фоновом режиме. Зачастую это приводит к значительному снижению задержки транзакций, но также есть некоторые случаи, особенно с рабочими нагрузками, которые больше, чем shared_buffers, но меньше, чем кеш страниц ОС, где производительность может снизиться. Этот параметр может не повлиять на некоторые платформы. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. Допустимый диапазон: от 0, что отключает принудительную обратную запись, до 2MB. По умолчанию 256kB в Linux, 0 другом месте. (Если BLCKSZ не равен 8 КБ, значения по умолчанию и максимальные значения масштабируются пропорционально ему). Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
checkpoint_warning (integer)
- Записать сообщение в журнал сервера, если контрольные точки, вызванные заполнением файлов сегментов WAL, max_wal_size ближе друг к другу, чем это количество времени (что говорит о том, что max_wal_size должен быть повышен). Если это значение указано без единиц измерения, оно принимается за секунды. Значение по умолчанию составляет 30 секунд (30s). Ноль отключает предупреждение. Предупреждения не будут генерироваться, если checkpoint_timeout меньше, чем checkpoint_warning. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
max_wal_size (integer)
- Максимальный размер, позволяющий WAL расти между автоматическими контрольными точками WAL. Это мягкий предел; Размер WAL может превышать max_wal_size при особых обстоятельствах, таких как большая нагрузка, сбой команды archive_command или высокий параметр wal_keep_segments. Если это значение указано без единиц измерения, оно принимается за мегабайты. По умолчанию это 1 ГБ. Увеличение этого параметра может увеличить время, необходимое для восстановления после сбоя. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
min_wal_size (integer)
- Пока использование диска WAL остается ниже этого параметра, старые файлы WAL всегда перерабатываются для использования в будущем на контрольной точке, а не удаляются. Это можно использовать для гарантии того, что достаточно места WAL зарезервировано для обработки пиков при использовании WAL, например, при выполнении больших пакетных заданий. Если это значение указано без единиц измерения, оно принимается за мегабайты. По умолчанию установлено 80 МБ. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Архивирование
archive_mode (enum)
-
Когда archive_mode включен, заполненные сегменты WAL отправляются в архивное хранилище с помощью параметра archive_command. Помимо off, для отключения есть два режима: on и always. Во время нормальной работы нет никакой разницы между этими двумя режимами, но при установке на always архиватор WAL включается также во время восстановления архива или режима ожидания. В always режиме все файлы, восстановленные из архива или переданные с потоковой репликацией, будут заархивированы (снова). Смотрите раздел 26.2.9 для деталей.
-
archive_mode и archive_command являются отдельными переменными, так что archive_command можно изменять, не выходя из режима архивирования. Этот параметр можно установить только при запуске сервера. archive_mode не может быть включен, когда wal_level установлен на minimal.
archive_command (string)
-
Команда локальной оболочки, выполняемая для архивирования завершенного сегмента файла WAL. Любой %p в строке заменяется путем к файлу, который нужно заархивировать, а любой %f заменяется только именем файла. (Путь указывается относительно рабочего каталога сервера, т. %% Каталога данных кластера). Используйте %% для встраивания фактического символа % в команду. Для команды важно возвратить нулевой статус выхода, только если это успешно. Для получения дополнительной информации см. Раздел 25.3.1.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. Он игнорируется, если archive_mode был включен при запуске сервера. Если archive_command является пустой строкой (по умолчанию), а archive_mode включен, архивация WAL временно отключается, но сервер продолжает накапливать файлы сегментов WAL в ожидании, что в ближайшее время будет предоставлена команда. Задание команды archive_command, которая ничего не делает, но возвращает значение true, например /bin/true (REM в Windows), эффективно отключает архивирование, но также разрывает цепочку файлов WAL, необходимых для восстановления архива, поэтому ее следует использовать только в необычных случаях.
archive_timeout (integer)
- Команда archive_command вызывается только для завершенных сегментов WAL. Следовательно, если ваш сервер генерирует небольшой трафик WAL (или имеет периоды простоя, когда это происходит), может быть длительная задержка между завершением транзакции и ее безопасной записью в архивном хранилище. Чтобы ограничить возраст неархивированных данных, вы можете установить archive_timeout чтобы сервер периодически переключался на новый файл сегмента WAL. Если этот параметр больше нуля, сервер будет переключаться на новый файл сегмента по истечении этого промежутка времени с момента последнего переключения файла сегмента, и когда-либо было выполнено какое-либо действие с базой данных, включая одну контрольную точку (контрольные точки пропускаются, если есть нет активности базы данных). Обратите внимание, что архивные файлы, которые закрываются рано из-за принудительного переключения, имеют ту же длину, что и полностью заполненные файлы. Следовательно, неразумно использовать очень короткое значение archive_timeout - это приведет к переполнению вашего архивного хранилища. Параметры archive_timeout минуты или около того обычно разумны. Следует рассмотреть возможность использования потоковой репликации вместо архивирования, если вы хотите, чтобы данные копировались с главного сервера быстрее, чем это. Если это значение указано без единиц измерения, оно принимается за секунды. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Восстановление из архива
В этом разделе описываются параметры, которые применяются только на время восстановления. Они должны быть сброшены для любого последующего восстановления, которое вы хотите выполнить.
«Восстановление» охватывает использование сервера в качестве резервного или для целевого восстановления. Как правило, режим ожидания используется для обеспечения высокой доступности и / или масштабируемости чтения, тогда как целевое восстановление используется для восстановления после потери данных.
Чтобы запустить сервер в режиме ожидания, создайте файл с именем standby.signal в каталоге данных. Сервер войдет в режим восстановления и не остановит восстановление после достижения конца архивированной WAL, но будет продолжать пытаться продолжить восстановление, подключившись к серверу-отправителю, как указано параметром primary_conninfo и / или выбрав новые сегменты WAL с помощью команды restore_command. Для этого режима интерес представляют параметры из этого раздела и раздела Резервные серверы. Параметры из раздела Точки восстановления также будут применяться, но, как правило, бесполезны в этом режиме.
Чтобы запустить сервер в целевом режиме восстановления, создайте файл с именем recovery.signal в каталоге данных. Если созданы файлы standby.signal и recovery.signal, режим ожидания имеет приоритет. Целевой режим восстановления заканчивается, когда архивированная WAL полностью воспроизводится или когда достигается recovery_target. В этом режиме будут использоваться параметры из этого раздела и раздела Точки восстановления.
restore_command (string)
-
Команда локальной оболочки, выполняемая для извлечения заархивированного сегмента серии файлов WAL. Этот параметр необходим для восстановления архива, но необязателен для потоковой репликации. Любой %f в строке заменяется именем файла для извлечения из архива, а любой %p заменяется именем пути назначения копирования на сервере. (Путь указывается относительно текущего рабочего каталога, т.е. Каталога данных кластера). Любой %r заменяется именем файла, содержащего последнюю действительную точку перезапуска. Это самый ранний файл, который необходимо сохранить, чтобы обеспечить возможность перезапуска восстановления, поэтому эту информацию можно использовать для усечения архива до минимума, необходимого для поддержки перезапуска из текущего восстановления. %r обычно используется только в конфигурациях с теплым резервированием . Напишите %% для вставки фактического символа %.
-
Для команды важно возвратить нулевой статус выхода, только если это успешно. У команды будут запрошены имена файлов, которых нет в архиве; он должен возвращать ненулевое значение, когда это требуется Пример:
restore_command = 'cp /mnt/server/archivedir/%f "%p"'
-
Исключением является то, что если команда была прервана сигналом (отличным от SIGTERM, который используется как часть отключения сервера базы данных) или ошибкой оболочки (например, команда не найдена), то восстановление будет прервано, и сервер будет не пускай
-
Этот параметр можно установить только при запуске сервера.
archive_cleanup_command (string)
- Этот необязательный параметр указывает команду оболочки, которая будет выполняться при каждой точке перезапуска. Цель archive_cleanup_command - предоставить механизм для очистки старых заархивированных файлов WAL, которые больше не нужны резервному серверу. Любой %r заменяется именем файла, содержащего последнюю действительную точку перезапуска. Это самый ранний файл, который необходимо сохранить, чтобы обеспечить возможность перезапуска восстановления, и поэтому все файлы ранее, чем %r могут быть безопасно удалены. Эта информация может быть использована для усечения архива до минимума, необходимого для поддержки перезапуска из текущего восстановления. Модуль qhb_archivecleanup часто используется в archive_cleanup_command для конфигураций с одним резервом, например:
archive_cleanup_command = 'qhb-archivecleanup /mnt/server/archivedir %r'
-
Однако обратите внимание, что если несколько резервных серверов восстанавливаются из одного и того же архивного каталога, вам необходимо убедиться, что вы не удаляете файлы WAL, пока они больше не нужны ни одному из серверов. archive_cleanup_command обычно используется в конфигурации с горячим archive_cleanup_command . Напишите %% для вставки фактического символа % в команду.
-
Если команда возвращает ненулевой статус выхода, будет записано сообщение с предупреждением. Исключением является то, что если команда была прервана сигналом или ошибкой оболочки (например, команда не найдена), возникнет фатальная ошибка.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
recovery_end_command (string)
-
Этот параметр указывает команду оболочки, которая будет выполнена только один раз в конце восстановления. Этот параметр не является обязательным. Цель recovery_end_command - предоставить механизм для очистки после репликации или восстановления. Любой %r заменяется именем файла, содержащего последнюю действительную точку перезапуска, как в archive_cleanup_command.
-
Если команда возвращает ненулевой статус выхода, то будет записано сообщение журнала предупреждений, и база данных все равно продолжит запуск. Исключением является то, что если команда была прервана сигналом или ошибкой со стороны оболочки (например, команда не найдена), база данных не продолжит запуск.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Точки восстановления
По умолчанию восстановление будет восстановлено до конца журнала WAL. Следующие параметры могут использоваться для указания более ранней точки остановки. Можно использовать самое большее из recovery_target, recovery_target_lsn, recovery_target_name, recovery_target_time или recovery_target_xid; если в файле конфигурации указано более одного из них, возникнет ошибка. Эти параметры могут быть установлены только при запуске сервера.
recovery_target = ’immediate’
-
Этот параметр указывает, что восстановление должно завершиться, как только будет достигнуто согласованное состояние, т. Е. Как можно раньше. При восстановлении из оперативной резервной копии это означает точку, на которой завершилось создание резервной копии.
-
Технически это строковый параметр, но в данный момент допустимым является только значение ’immediate’.
recovery_target_name (string)
- Этот параметр указывает именованную точку восстановления (созданную с помощью pg_create_restore_point()), к которой будет продолжено восстановление.
recovery_target_time (timestamp)
- Этот параметр указывает метку времени, до которой будет продолжаться восстановление. Точная точка остановки также зависит от recovery_target_inclusive.
recovery_target_xid (string)
- Этот параметр указывает идентификатор транзакции, до которой будет продолжаться восстановление. Имейте в виду, что хотя идентификаторы транзакций назначаются последовательно в начале транзакции, транзакции могут выполняться в другом числовом порядке. Будут восстановлены транзакции, совершенные до (и, возможно, включая) указанной транзакции. Точная точка остановки также зависит от recovery_target_inclusive.
recovery_target_lsn (pg_lsn)
- Этот параметр указывает номер LSN расположения журнала записи с опережением, до которого будет продолжаться восстановление. Точная точка остановки также зависит от recovery_target_inclusive. Этот параметр анализируется с использованием системного типа данных pg_lsn.
Следующие параметры дополнительно определяют цель восстановления и влияют на то, что происходит при достижении цели:
recovery_target_inclusive (boolean)
- Указывает, следует ли останавливаться сразу после указанной цели восстановления (on) Или непосредственно перед целью восстановления (off). Применяется, когда указаны recovery_target_lsn, recovery_target_time или recovery_target_xid. Этот параметр определяет, будут ли транзакции, имеющие точно целевое местоположение WAL (LSN), время фиксации или идентификатор транзакции, соответственно, включаться в восстановление. По умолчанию включено.
recovery_target_timeline (string)
-
Определяет восстановление в конкретную временную шкалу. Значение может быть числовым идентификатором временной шкалы или специальным значением. current значение восстанавливается по той же временной шкале, которая была текущей, когда была сделана базовая резервная копия. Значение latest восстанавливается до последней временной шкалы, найденной в архиве, что полезно на резервном сервере. latest по умолчанию.
-
Обычно этот параметр нужно устанавливать только в сложных ситуациях повторного восстановления, когда вам необходимо вернуться в состояние, которое само было достигнуто после восстановления на определенный момент времени. См. Раздел 25.3.5 для обсуждения.
recovery_target_action (enum)
-
Указывает, какое действие должен предпринять сервер после достижения цели восстановления. По умолчанию используется pause, что означает, что восстановление будет приостановлено. promote означает, что процесс восстановления завершится, и сервер начнет принимать подключения. Наконец, shutdown остановит сервер после достижения цели восстановления.
-
Предполагаемое использование параметра pause - разрешить выполнение запросов к базе данных, чтобы проверить, является ли эта цель восстановления наиболее желательной точкой для восстановления. Приостановленное состояние может быть восстановлено с помощью pg_wal_replay_resume() (см. Таблицу III.8.86), которая затем приводит к завершению восстановления. Если эта цель восстановления не является желаемой точкой остановки, затем выключите сервер, измените настройки цели восстановления на более позднюю цель и перезапустите, чтобы продолжить восстановление.
-
Параметр shutdown полезен для того, чтобы экземпляр был готов в нужной точке воспроизведения. Экземпляр по-прежнему сможет воспроизводить больше записей WAL (и фактически должен будет воспроизводить записи WAL с момента последней контрольной точки при следующем запуске).
-
Обратите внимание, что поскольку recovery.signal не будет удален, если для recovery_target_action задано значение shutdown, любой последующий запуск будет завершен немедленным завершением работы, если не будет изменена конфигурация или файл recovery.signal будет удален вручную.
-
Этот параметр не действует, если цель восстановления не установлена. Если hot_standby не включен, настройка pause будет действовать так же, как shutdown.
Копирование
Эти параметры управляют поведением встроенной функции потоковой репликации . Серверы будут либо главным, либо резервным сервером. Мастера могут отправлять данные, в то время как резервные всегда являются получателями реплицированных данных. При использовании каскадной репликации резервные серверы также могут быть отправителями и получателями. Параметры в основном для отправляющего и резервного серверов, хотя некоторые параметры имеют значение только на главном сервере. Настройки могут меняться по кластеру без проблем, если это требуется.
Передающий сервер
Эти параметры могут быть установлены на любом сервере, который должен отправлять данные репликации на один или несколько резервных серверов. Мастер всегда является передающим сервером, поэтому эти параметры всегда должны быть установлены на мастере. Роль и значение этих параметров не изменяются после того, как резерв становится главным.
max_wal_senders (integer)
-
Задает максимальное количество одновременных подключений с резервных серверов или клиентов потокового резервного копирования (т. Е. Максимальное количество одновременно работающих процессов отправителя WAL). По умолчанию 10. Значение 0 означает, что репликация отключена. При резком отключении потокового клиента оставшийся слот подключения может остаться позади до истечения времени ожидания, поэтому этот параметр следует установить немного выше, чем максимальное число ожидаемых клиентов, чтобы отключенные клиенты могли немедленно восстановить соединение. Этот параметр можно установить только при запуске сервера. Кроме того, wal_level должен иметь значение replica или выше, чтобы разрешить подключения с резервных серверов.
-
При запуске резервного сервера вы должны установить для этого параметра то же или более высокое значение, чем на главном сервере. В противном случае запросы не будут разрешены на резервном сервере.
max_replication_slots (integer)
- Задает максимальное количество слотов репликации , которое может поддерживать сервер. По умолчанию установлено значение 10. Этот параметр можно установить только при запуске сервера. Если установить значение, меньшее, чем количество существующих в настоящее время слотов репликации, сервер не запустится. Кроме того, wal_level должен быть установлен на replica или выше, чтобы можно было использовать слоты репликации.
wal_keep_segments (integer)
-
Задает минимальное количество прошлых сегментов файла журнала, хранящихся в каталоге pg_wal, в случае, если резервному серверу необходимо извлечь их для потоковой репликации. Каждый сегмент обычно составляет 16 мегабайт. Если резервный сервер, подключенный к отправляющему серверу, отстает более чем на сегменты wal_keep_segments, отправляющий сервер может удалить сегмент WAL, все еще необходимый резервному, и в этом случае подключение репликации будет прервано. В результате нисходящие соединения также в конечном итоге потерпят неудачу. (Однако резервный сервер может восстановиться путем извлечения сегмента из архива, если используется архивация WAL).
-
Это устанавливает только минимальное количество сегментов, сохраняемых в pg_wal ; системе может потребоваться сохранить больше сегментов для архивации WAL или для восстановления с контрольной точки. Если wal_keep_segments равен нулю (по умолчанию), система не сохраняет никаких дополнительных сегментов для резервных целей, поэтому количество старых сегментов WAL, доступных резервным серверам, зависит от местоположения предыдущей контрольной точки и состояния архивации WAL. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
wal_init_zero (boolean)
- Если установлено значение on (по умолчанию), эта опция заставляет новые файлы WAL заполняться нулями. В некоторых файловых системах это обеспечивает выделение места перед тем, как нам нужно будет писать записи WAL. Однако файловые системы Copy-On-Write (COW) могут не воспользоваться этой методикой, поэтому предоставляется возможность пропустить ненужную работу. Если установлено значение off, при создании файла записывается только последний байт, так что он имеет ожидаемый размер.
wal_recycle (boolean)
- Если этот параметр включен (по умолчанию), этот параметр вызывает перезапись файлов WAL путем их переименования, избегая необходимости создавать новые. В файловых системах COW может быть быстрее создавать новые, поэтому предоставляется возможность отключить это поведение.
wal_sender_timeout (integer)
-
Завершите соединения репликации, которые неактивны дольше, чем это количество времени. Это полезно для отправляющего сервера для обнаружения аварийного сбоя или отключения сети. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет 60 секунд. Нулевое значение отключает механизм тайм-аута.
-
С кластером, распределенным по нескольким географическим местоположениям, использование различных значений для местоположения обеспечивает большую гибкость в управлении кластером. Меньшее значение полезно для более быстрого обнаружения сбоев в режиме ожидания с сетевым подключением с низкой задержкой, а большее значение помогает лучше оценить работоспособность режима ожидания, если он находится в удаленном месте, с сетевым подключением с высокой задержкой.
track_commit_timestamp (boolean)
- Запись времени фиксации транзакций. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. Значение по умолчанию off.
Мастер сервер
Эти параметры могут быть установлены на главном / основном сервере, который должен отправлять данные репликации на один или несколько резервных серверов. Обратите внимание, что в дополнение к этим параметрам wal_level должен быть соответствующим образом установлен на главном сервере, и при желании также может быть включена архивация WAL (см. раздел Архивирование). Значения этих параметров на резервных серверах не имеют значения, хотя вы можете установить их там, чтобы подготовиться к тому, чтобы резервный сервер стал главным.
synchronous_standby_names (string)
-
Задает список резервных серверов, которые могут поддерживать синхронную репликацию, как описано в разделе 26.2.8. Будет один или несколько активных синхронных резервных серверов; транзакции, ожидающие принятия, будут разрешены после того, как эти резервные серверы подтвердят получение своих данных. Синхронными резервными копиями будут те, чьи имена появляются в этом списке, и которые в настоящее время подключены и передают данные в режиме реального времени (как показано состоянием streaming в представлении pg_stat_replication ). Указание более одного синхронного режима ожидания может обеспечить очень высокую доступность и защиту от потери данных.
-
Имя резервного сервера для этой цели является параметром application_name для резервного, как установлено в информации о подключении резервного. В случае ожидания физической репликации это должно быть установлено в параметре primary_conninfo ; по умолчанию используется настройка cluster_name, если установлено, иначе walreceiver. Для логической репликации это может быть установлено в информации о соединении подписки, и по умолчанию это имя подписки. Для других потребителей потока репликации обратитесь к их документации.
-
Этот параметр указывает список резервных серверов, используя любой из следующих синтаксисов:
[FIRST] num_sync ( standby_name [, ...] )
ANY num_sync ( standby_name [, ...] )
standby_name [, ...]
-
где num_sync - это количество синхронных резервных серверов, от которых транзакции должны ждать ответов, а standby_name - это имя резервного сервера. FIRST и ANY указывают способ выбора синхронных резервных серверов из перечисленных серверов.
-
Ключевое слово FIRST сочетании с num_sync задает синхронную репликацию на основе приоритетов и заставляет коммиты транзакций ждать, пока их записи WAL реплицируются в синхронные резервные копии num_sync, выбранные на основе их приоритетов. Например, установка FIRST 3 (s1, s2, s3, s4) заставит каждый коммит ожидать ответов от трех резервных серверов с более высоким приоритетом, выбранных из резервных серверов s1, s2, s3 и s4. Резервные устройства, имена которых появляются ранее в списке, имеют более высокий приоритет и будут рассматриваться как синхронные. Другие резервные серверы, появившиеся позже в этом списке, представляют потенциальные синхронные резервы. Если какой-либо из текущих синхронных резервных серверов отключится по какой-либо причине, он будет немедленно заменен следующим резервным сервером с наивысшим приоритетом. Ключевое слово FIRST является необязательным.
-
Ключевое слово ANY сочетании с num_sync задает синхронную репликацию на основе кворума и заставляет коммиты транзакций ждать, пока их записи WAL будут реплицированы, по крайней мере, в список standbys, указанный в num_sync. Например, установка ANY 3 (s1, s2, s3, s4) заставит каждую фиксацию продолжаться, как только ответят по крайней мере любые три резервных элемента s1, s2, s3 и s4.
-
FIRST и ANY нечувствительны к регистру. Если эти ключевые слова используются в качестве имени резервного сервера, его имя в режиме ожидания должно быть заключено в двойные кавычки.
-
Третий синтаксис поддерживается в QHB. Это так же, как первый синтаксис с FIRST и num_sync равными 1. Например, FIRST 1 (s1, s2) и s1, s2 имеют то же значение: либо s1 либо s2 выбран в качестве синхронного режима ожидания.
-
Специальная запись * соответствует любому резервному имени.
-
Не существует механизма для обеспечения уникальности резервных имен. В случае дубликатов один из подходящих резервных копий будет рассматриваться как более высокий приоритет, хотя какой именно является неопределенным.
Заметка
Каждое имя standby_name должно иметь форму действительного идентификатора SQL, если это не *. При необходимости вы можете использовать двойные кавычки. Но обратите внимание, что имена в режиме ожидания сравниваются с именами приложений в режиме ожидания без учета регистра, в двойных кавычках или нет.
-
Если здесь не указаны синхронные резервные имена, синхронная репликация не включена и транзакции не будут ждать репликации. Это конфигурация по умолчанию. Даже когда синхронная репликация включена, отдельные транзакции можно настроить так, чтобы они не ожидали репликации, установив для параметра synchronous_commit значение local или off.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
vacuum_defer_cleanup_age (integer)
-
Определяет количество транзакций, на которые обновления VACUUM и HOT будут откладывать очистку версий мертвых строк. По умолчанию транзакции равны нулю, это означает, что версии мертвых строк могут быть удалены как можно скорее, то есть, как только они больше не видны для любой открытой транзакции. Вы можете установить ненулевое значение на основном сервере, который поддерживает серверы горячего резервирования, как описано в разделе 26.5. Это дает больше времени для выполнения запросов в режиме ожидания без возникновения конфликтов из-за ранней очистки строк. Тем не менее, поскольку значение измеряется с точки зрения количества транзакций записи, происходящих на первичном сервере, трудно предсказать, сколько дополнительного времени будет предоставлено для резервных запросов. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Вам также следует рассмотреть возможность установки hot_standby_feedback на резервных серверах в качестве альтернативы использованию этого параметра.
-
Это не предотвращает очистку мертвых строк, которые достигли возраста, указанного в old_snapshot_threshold.
Резервные серверы
Эти параметры управляют поведением резервного сервера, который должен получать данные репликации. Их значения на главном сервере не имеют значения.
primary_conninfo (string)
-
Задает строку подключения, которая будет использоваться резервным сервером для соединения с отправляющим сервером. Если переменная окружения также не установлена, то используются значения по умолчанию.
-
Строка подключения должна указывать имя хоста (или адрес) отправляющего сервера, а также номер порта, если он не совпадает со значением резервного сервера по умолчанию. Также укажите имя пользователя, соответствующее роли с соответствующей привилегией на отправляющем сервере . Пароль также необходимо указать, если отправитель требует аутентификации по паролю. Его можно указать в строке primary_conninfo или в отдельном файле ~/.pgpass на резервном сервере (используйте replication качестве имени базы данных). Не указывайте имя базы данных в строке primary_conninfo.
-
Этот параметр можно установить только при запуске сервера. Этот параметр не действует, если сервер не находится в режиме ожидания.
primary_slot_name (string)
- Опционально указывает существующий слот репликации, который будет использоваться при подключении к отправляющему серверу посредством потоковой репликации для управления удалением ресурсов на вышестоящем узле . Этот параметр можно установить только при запуске сервера. Этот параметр не имеет эффекта, если primary_conninfo не установлен.
promote_trigger_file (string)
- Указывает файл триггера, присутствие которого завершает восстановление в режиме ожидания. Даже если это значение не установлено, вы все равно можете продвинуть режим ожидания с помощью qhb_ctl promote или вызова pg_promote. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
hot_standby (boolean)
- Указывает, можете ли вы подключаться и выполнять запросы во время восстановления, как описано в разделе 26.5. Значение по умолчанию включено. Этот параметр можно установить только при запуске сервера. Это действует только во время восстановления архива или в режиме ожидания.
max_standby_archive_delay (integer)
-
Когда активен горячий резерв, этот параметр определяет, как долго резервный сервер должен ждать, прежде чем отменять резервные запросы, конфликтующие с записями WAL, подлежащими применению. max_standby_archive_delay применяется, когда данные WAL читаются из архива WAL (и, следовательно, не являются текущими). Если это значение указано без единиц измерения, оно принимается за миллисекунды. По умолчанию 30 секунд. Значение -1 позволяет ждущему клиенту бесконечно ждать завершения конфликтующих запросов. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Обратите внимание, что max_standby_archive_delay отличается от максимальной продолжительности времени, в течение которого запрос может выполняться до отмены; скорее это максимальное общее время, разрешенное для применения данных одного сегмента WAL. Таким образом, если один запрос привел к значительной задержке ранее в сегменте WAL, последующие конфликтующие запросы будут иметь гораздо меньше льготного времени.
max_standby_streaming_delay (integer)
-
Когда активен горячий резерв, этот параметр определяет, как долго резервный сервер должен ждать, прежде чем отменять резервные запросы, конфликтующие с записями WAL, подлежащими применению. max_standby_streaming_delay применяется, когда данные WAL принимаются посредством потоковой репликации. Если это значение указано без единиц измерения, оно принимается за миллисекунды. По умолчанию 30 секунд. Значение -1 позволяет ждущему клиенту бесконечно ждать завершения конфликтующих запросов. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Обратите внимание, что max_standby_streaming_delay отличается от максимальной продолжительности времени, в течение которого запрос может выполняться до отмены; скорее это максимальное общее время, разрешенное для применения данных WAL после их получения от основного сервера. Таким образом, если один запрос привел к значительной задержке, последующие конфликтующие запросы будут иметь гораздо меньше льготного времени до тех пор, пока резервный сервер не перехватит снова.
wal_receiver_status_interval (integer)
- Задает минимальную частоту для процесса приемника WAL в режиме ожидания для отправки информации о ходе репликации в основной или восходящий режим ожидания, где это можно увидеть с помощью представления pg_stat_replication. Резервный сервер сообщит о последнем записанном в журнал месте записи с опережением записи, о последней позиции, которую он записал на диск, и о последней позиции, которую он применил. Значение этого параметра - максимальное время между отчетами. Обновления отправляются каждый раз, когда меняются позиции записи или очистки, или, по крайней мере, так часто, как указано в этом параметре. Таким образом, позиция применения может немного отставать от истинной позиции. Если это значение указано без единиц измерения, оно принимается за секунды. Значение по умолчанию составляет 10 секунд. Установка этого параметра в ноль полностью отключает обновления статуса. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
hot_standby_feedback (boolean)
-
Указывает, будет ли горячий резерв отправлять отзывы первичному или восходящему резерву о запросах, выполняющихся в данный момент в резерве. Этот параметр можно использовать для устранения отмен запросов, вызванных записями очистки, но может вызвать переполнение базы данных на первичном сервере для некоторых рабочих нагрузок. Сообщения обратной связи не будут отправляться чаще, чем один раз за wal_receiver_status_interval. Значение по умолчанию off. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Если используется каскадная репликация, обратная связь передается в восходящем направлении, пока в конце концов не достигнет первичной. Standbys не использует никакой обратной связи, которую они получают, кроме как для передачи в обратном направлении.
-
Этот параметр не переопределяет поведение old_snapshot_threshold на первичном сервере; моментальный снимок в режиме ожидания, который превышает возрастной порог основного устройства, может стать недействительным, что приведет к отмене транзакций в режиме ожидания. Это связано с тем, что old_snapshot_threshold предназначен для предоставления абсолютного предела времени, в течение которого мертвые строки могут способствовать раздуванию, что в противном случае было бы нарушено из-за конфигурации режима ожидания.
wal_receiver_timeout (integer)
- Завершите соединения репликации, которые неактивны дольше, чем это количество времени. Это полезно для принимающего резервного сервера, чтобы обнаружить сбой первичного узла или отключение сети. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет 60 секунд. Нулевое значение отключает механизм тайм-аута. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
wal_retrieve_retry_interval (integer)
-
Указывает, как долго резервный сервер должен ждать, когда данные WAL недоступны из каких-либо источников (потоковая репликация, локальный pg_wal или архив WAL), прежде чем пытаться снова получить данные WAL. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет 5 секунд. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Этот параметр полезен в конфигурациях, где узлу в процессе восстановления необходимо контролировать время ожидания доступности новых данных WAL. Например, при восстановлении архива можно сделать восстановление более отзывчивым при обнаружении нового файла журнала WAL, уменьшив значение этого параметра. В системе с низкой активностью WAL ее увеличение уменьшает количество запросов, необходимых для доступа к архивам WAL, что полезно, например, в облачных средах, где учитывается количество обращений к инфраструктуре.
recovery_min_apply_delay (integer)
-
По умолчанию резервный сервер восстанавливает записи WAL с отправляющего сервера как можно скорее. Может оказаться полезным иметь копию данных с задержкой по времени, что дает возможность исправить ошибки потери данных. Этот параметр позволяет отложить восстановление на указанное количество времени. Например, если вы установите для этого параметра значение 5min минут, резервный сервер будет воспроизводить каждую транзакцию, только если системное время в режиме ожидания не менее чем через пять минут после времени фиксации, сообщенного мастером. Если это значение указано без единиц измерения, оно принимается за миллисекунды. По умолчанию ноль, добавление без задержки.
-
Возможно, что задержка репликации между серверами превышает значение этого параметра, и в этом случае задержка не добавляется. Обратите внимание, что задержка рассчитывается между отметкой времени WAL, записанной на главном устройстве, и текущим временем в режиме ожидания. Задержки передачи из-за задержек в сети или каскадных конфигураций репликации могут значительно сократить фактическое время ожидания. Если системные часы на главном и в режиме ожидания не синхронизированы, это может привести к восстановлению, применяя записи раньше, чем ожидалось; но это не главная проблема, потому что полезные настройки этого параметра намного больше, чем типичные временные отклонения между серверами.
-
Задержка происходит только в записях WAL для фиксации транзакции. Другие записи воспроизводятся как можно быстрее, что не является проблемой, поскольку правила видимости MVCC гарантируют, что их эффекты не видны до тех пор, пока не будет применена соответствующая запись фиксации.
-
Задержка наступает, когда база данных в процессе восстановления достигает согласованного состояния, пока резервный ресурс не будет повышен или запущен. После этого восстановление завершится без ожидания.
-
Этот параметр предназначен для использования с развертываниями потоковой репликации; однако, если указан параметр, он будет учитываться во всех случаях, кроме восстановления после сбоя. hot_standby_feedback будет задержан использованием этой функции, которая может привести к раздутию на мастер; используйте оба вместе с осторожностью.
!!! Предупреждение
Этот параметр затрагивает синхронную репликацию, когда для synchronous_commit задано значение remote_apply ; каждый COMMIT должен ждать, пока его не применят.
- Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Подписчики
Эти параметры управляют поведением подписчика логической репликации. Их значения для издателя не имеют значения.
Обратите внимание, что параметры конфигурации wal_receiver_timeout, wal_receiver_status_interval и wal_retrieve_retry_interval влияют на потоки логической репликации.
max_logical_replication_workers (int)
-
Задает максимальное количество потоков логической репликации. Это включает в себя как прикладные потоки, так и потоки синхронизации таблиц.
-
Потоки логической репликации берутся из пула, определенного max_worker_processes.
-
Значение по умолчанию 4.
max_sync_workers_per_subscription (integer)
-
Максимальное количество потоков синхронизации на подписку. Этот параметр управляет степенью параллелизма исходной копии данных во время инициализации подписки или при добавлении новых таблиц.
-
В настоящее время в таблице может быть только один поток синхронизации.
-
Рабочие синхронизации взяты из пула, определенного max_logical_replication_workers.
-
Значением по умолчанию является 2.
Планирование запросов
Конфигурация метода планирования
Эти параметры конфигурации предоставляют грубый метод воздействия на планы запросов, выбранные оптимизатором запросов. Если план по умолчанию, выбранный оптимизатором для определенного запроса, не является оптимальным, временное решение состоит в том, чтобы использовать один из этих параметров конфигурации, чтобы заставить оптимизатор выбрать другой план. Улучшенные способы улучшения качества планов, выбранного оптимизатор включают корректировки констант затрат планировщика (см раздел Константы стоимости планировщика), работают ANALYZE вручную, увеличивая значение default_statistics_target параметра конфигурации, а также увеличение количества статистических данных, собранное для отдельных столбцов используя ALTER TABLE SET STATISTICS.
enable_bitmapscan (boolean)
Включает или отключает использование планировщиком запросов типов планов растрового сканирования. По умолчанию включено.
enable_gathermerge (boolean)
Включает или отключает использование планировщиком запросов типов планов слияния. По умолчанию включено.
enable_hashagg (boolean)
Включает или отключает использование планировщиком запросов типов плана хэширования. По умолчанию включено.
enable_hashjoin (boolean)
Включает или отключает использование планировщиком запросов типов планов хэш-соединения. По умолчанию включено.
enable_indexscan (boolean)
Включает или отключает использование планировщиком запросов типов планов сканирования индекса. По умолчанию включено.
enable_indexonlyscan (boolean)
Включает или отключает использование планировщиком запросов типов планов проверки только для индекса (см. раздел Сканирование только по индексу и покрывающие индексы). По умолчанию включено.
enable_material (boolean)
Включает или отключает использование материализации в планировщике запросов. Невозможно полностью подавить материализацию, но отключение этой переменной не позволяет планировщику вставить узлы материализации, за исключением случаев, когда это требуется для корректности. По умолчанию включено.
enable_mergejoin (boolean)
Включает или отключает использование планировщиком запросов типов планов слиянием и объединением. По умолчанию включено.
enable_nestloop (boolean)
Включает или отключает использование плановиком запросов планов соединения с вложенными циклами. Невозможно полностью исключить соединения с вложенными циклами, но отключение этой переменной не позволяет планировщику использовать ее, если есть другие доступные методы. По умолчанию включено.
enable_parallel_append (boolean)
Включает или отключает использование планировщиком запросов типов планов добавления с параллельной поддержкой. По умолчанию включено.
enable_parallel_hash (boolean)
Включает или отключает использование в планировщике запросов типов планов хеш-соединения с параллельным хешем. Не имеет эффекта, если планы хеш-соединения также не включены. По умолчанию включено.
enable_partition_pruning (boolean)
Включает или отключает возможность планировщика запросов исключать разделы разделенной таблицы из планов запросов. Это также контролирует способность планировщика генерировать планы запросов, которые позволяют исполнителю запросов удалять (игнорировать) разделы во время выполнения запроса. По умолчанию включено. Смотрите раздел Сокращение партиций для деталей.
enable_partitionwise_join (boolean)
Включает или отключает использование планировщиком запросов разбиения по частям, что позволяет выполнять соединение между многораздельными таблицами путем объединения соответствующих разделов. В настоящее время объединение по частям применяется только в том случае, если в условия объединения входят все ключи разделов, которые должны быть одного типа данных и иметь точно совпадающие наборы дочерних разделов. Поскольку планирование объединения по частям может использовать значительно больше процессорного времени и памяти во время планирования, по умолчанию off.
enable_partitionwise_aggregate (boolean)
Включает или отключает использование планировщиком запросов групповой группировки или агрегации по секциям, что позволяет группировать или агрегировать по секционированным таблицам, выполняемым отдельно для каждой секции. Если предложение GROUP BY не включает ключи разделов, только частичное агрегирование может быть выполнено для каждого раздела, а финализация должна быть выполнена позже. Поскольку группировка или агрегация по частям могут использовать значительно больше процессорного времени и памяти во время планирования, по умолчанию off.
enable_seqscan (boolean)
Включает или отключает использование планировщиком запросов типов планов последовательного сканирования. Невозможно полностью отключить последовательное сканирование, но отключение этой переменной не позволяет планировщику использовать один, если есть другие доступные методы. По умолчанию включено.
enable_sort (boolean)
Включает или отключает использование планировщиком запросов явных шагов сортировки. Невозможно полностью исключить явные сортировки, но отключение этой переменной не позволяет планировщику использовать ее, если есть другие доступные методы. По умолчанию включено.
enable_tidscan (boolean)
Включает или отключает использование планировщиком запросов типов планов сканирования TID. По умолчанию включено.
Константы стоимости планировщика
Переменные стоимости, описанные в этом разделе, измеряются в произвольном масштабе. Только их относительные значения имеют значение, следовательно, масштабирование их всех вверх или вниз на один и тот же коэффициент не приведет к изменению выбора планировщика. По умолчанию эти переменные стоимости основаны на стоимости последовательных выборок страниц; то есть seq_page_cost обычно устанавливается seq_page_cost 1.0 а другие переменные стоимости устанавливаются со ссылкой на это. Но вы можете использовать другой масштаб, если хотите, например, фактическое время выполнения в миллисекундах на конкретной машине.
Заметка
К сожалению, нет четко определенного метода определения идеальных значений для переменных стоимости. Их лучше всего рассматривать как средние значения для всего набора запросов, которые получит конкретная установка. Это означает, что менять их на основании всего лишь нескольких экспериментов очень рискованно.
seq_page_cost (с floating point)
- Устанавливает оценку планировщика стоимости выборки страницы на диске, которая является частью серии последовательных выборок. По умолчанию это 1.0. Это значение можно переопределить для таблиц и индексов в определенном табличном пространстве, установив параметр табличного пространства с тем же именем (см.ALTER TABLESPACE).
random_page_cost (с floating point)
-
Устанавливает оценку планировщика стоимости непоследовательной выборки страницы диска. По умолчанию это 4.0. Это значение можно переопределить для таблиц и индексов в определенном табличном пространстве, установив параметр табличного пространства с тем же именем (см. ALTER TABLESPACE).
-
Уменьшение этого значения относительно seq_page_cost приведет к тому, что система предпочтет сканирование индекса; его увеличение сделает просмотр индекса относительно более дорогим. Вы можете увеличить или уменьшить оба значения вместе, чтобы изменить важность затрат на дисковый ввод-вывод относительно затрат на ЦП, которые описываются следующими параметрами.
-
Произвольный доступ к механическому дисковому хранилищу обычно намного дороже, чем четырехкратный последовательный доступ. Однако используется более низкий уровень по умолчанию (4.0), поскольку предполагается, что большинство случайных обращений к диску, таких как индексированные операции чтения, находятся в кеше. Значение по умолчанию можно рассматривать как моделирование произвольного доступа как в 40 раз медленнее, чем последовательное, при этом ожидается, что 90% случайных чтений будут кэшироваться.
-
Если вы считаете, что кэш-память в 90% является неверным допущением для вашей рабочей нагрузки, вы можете увеличить random_page_cost, чтобы лучше отражать истинную стоимость случайного чтения из хранилища. Соответственно, если ваши данные, вероятно, будут полностью в кеше, например, когда база данных меньше общей памяти сервера, может быть целесообразно уменьшение random_page_cost. Хранилище с низкой стоимостью случайного чтения относительно последовательных, например, твердотельных накопителей, также может быть лучше смоделировано с более низким значением random_page_cost.
Заметка
Хотя система позволит вам установить random_page_cost меньше, чем seq_page_cost, это физически seq_page_cost. Однако установка их равными имеет смысл, если база данных полностью кэшируется в ОЗУ, поскольку в этом случае штраф за несоответствие страниц не взимается. Кроме того, в сильно кэшированной базе данных вы должны снизить оба значения относительно параметров ЦП, поскольку стоимость извлечения страницы уже в ОЗУ намного меньше, чем обычно.
cpu_tuple_cost (с floating point)
- Устанавливает плановую оценку стоимости обработки каждой строки во время запроса. По умолчанию это 0,01.
cpu_index_tuple_cost (с floating point)
- Устанавливает плановую оценку стоимости обработки каждой записи индекса во время сканирования индекса. По умолчанию это 0,005.
cpu_operator_cost (с floating point)
- Устанавливает плановую оценку стоимости обработки каждого оператора или функции, выполняемой во время запроса. По умолчанию это 0,0025.
parallel_setup_cost (с floating point)
- Устанавливает плановую оценку стоимости запуска параллельных рабочих процессов. По умолчанию это 1000.
parallel_tuple_cost (с floating point)
- Устанавливает плановую оценку стоимости переноса одного кортежа из параллельного рабочего процесса в другой процесс. По умолчанию это 0,1.
min_parallel_table_scan_size (integer)
- Устанавливает минимальный объем табличных данных, которые необходимо сканировать, чтобы можно было рассмотреть параллельное сканирование. При параллельном последовательном сканировании количество проверенных данных таблицы всегда равно размеру таблицы, но при использовании индексов количество проверенных данных таблицы обычно будет меньше. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. По умолчанию используется 8 мегабайт (8 МБ).
min_parallel_index_scan_size (integer)
- Устанавливает минимальный объем индексных данных, которые должны быть отсканированы, чтобы можно было рассмотреть параллельное сканирование. Обратите внимание, что параллельное сканирование индекса обычно не затрагивает весь индекс; это число страниц, которое, по мнению плановика, будет действительно затронуто сканированием. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. По умолчанию используется 512 килобайт (512kB).
effective_cache_size (integer)
- Устанавливает предположение планировщика об эффективном размере дискового кэша, доступного для одного запроса. Это учитывается при оценке стоимости использования индекса; чем выше значение, тем выше вероятность того, что будет использоваться индексное сканирование, чем ниже значение, тем больше вероятность того, что будет использовано последовательное сканирование. При установке этого параметра вы должны учитывать как общие буферы QHB, так и часть дискового кэша ядра, которая будет использоваться для файлов данных QHB, хотя некоторые данные могут существовать в обоих местах. Также учитывайте ожидаемое количество одновременных запросов к разным таблицам, так как им придется совместно использовать доступное пространство. Этот параметр не влияет на размер разделяемой памяти, выделяемой QHB, а также не резервирует кэш-память ядра; он используется только для целей оценки. Система также не предполагает, что данные остаются в кеше диска между запросами. Если это значение указано без единиц измерения, оно принимается как блоки, то есть байты BLCKSZ, обычно 8 КБ. По умолчанию используется 4 гигабайта (4GB). (Если BLCKSZ не равен 8 КБ, значение по умолчанию масштабируется пропорционально ему).
jit_above_cost (с floating point)
- Задает стоимость запроса, выше которой активируется JIT-компиляция, если она включена . Выполнение JIT стоит времени планирования, но может ускорить выполнение запроса. Установка этого параметра в -1 отключает компиляцию JIT. По умолчанию это 100000.
jit_inline_above_cost (с floating point)
- Устанавливает стоимость запроса, выше которой JIT-компиляция пытается встроить функции и операторы. Встраивание добавляет время планирования, но может улучшить скорость выполнения. Не имеет смысла устанавливать это значение меньше, чем jit_above_cost. Установка этого в -1 отключает встраивание. По умолчанию это 500000.
jit_optimize_above_cost (с floating point)
- Устанавливает стоимость запроса, выше которой JIT-компиляция применяет дорогостоящие оптимизации. Такая оптимизация добавляет время планирования, но может улучшить скорость выполнения. Не имеет смысла устанавливать это значение меньше, чем jit_above_cost, и вряд ли будет полезно установить его больше, чем jit_inline_above_cost. Установка этого значения в -1 отключает дорогостоящие оптимизации. По умолчанию это 500000.
Генетический оптимизатор запросов
Оптимизатор генетических запросов (GEQO) - это алгоритм, который выполняет планирование запросов с использованием эвристического поиска. Это сокращает время планирования сложных запросов (тех, которые объединяют многие отношения) за счет создания планов, которые иногда уступают тем, которые обнаруживаются обычным алгоритмом исчерпывающего поиска. Для получения дополнительной информации см. Главу 59.
geqo (boolean)
- Включает или отключает генетическую оптимизацию запросов. Это включено по умолчанию. Обычно лучше не выключать его в производстве; переменная geqo_threshold обеспечивает более детальный контроль над GEQO.
geqo_threshold (integer)
- Используйте генетическую оптимизацию запросов для планирования запросов, по крайней мере, с таким количеством элементов FROM. (Обратите внимание, что конструкция FULL OUTER JOIN считается только одним элементом FROM ). По умолчанию используется значение 12. Для более простых запросов обычно лучше использовать обычный планировщик исчерпывающего поиска, но для запросов со многими таблицами исчерпывающий поиск занимает слишком много времени., часто дольше, чем штраф за выполнение неоптимального плана. Таким образом, пороговое значение размера запроса является удобным способом управления использованием GEQO.
geqo_effort (integer)
-
Управляет компромиссом между временем планирования и качеством плана запроса в GEQO. Эта переменная должна быть целым числом в диапазоне от 1 до 10. Значением по умолчанию является пять. Большие значения увеличивают время, затрачиваемое на планирование запросов, но также повышают вероятность выбора эффективного плана запросов.
-
geqo_effort самом деле ничего не делает напрямую; он используется только для вычисления значений по умолчанию для других переменных, которые влияют на поведение GEQO (описано ниже). Если вы предпочитаете, вы можете установить другие параметры вручную.
geqo_pool_size (integer)
- Контролирует размер пула, используемого GEQO, то есть количество особей в генетической популяции. Оно должно быть не менее двух, а полезные значения обычно составляют от 100 до 1000. Если оно установлено на ноль (настройка по умолчанию), то подходящее значение выбирается на основе geqo_effort и количества таблиц в запросе.
geqo_generations (integer)
- Управляет количеством поколений, используемых GEQO, то есть количеством итераций алгоритма. Должно быть хотя бы одно, а полезные значения находятся в том же диапазоне, что и размер пула. Если он установлен на ноль (настройка по умолчанию), то подходящее значение выбирается на основе geqo_pool_size.
geqo_selection_bias (с floating point)
- Управляет смещением выбора, используемым GEQO. Смещение выбора - это избирательное давление в популяции. Значения могут быть от 1,50 до 2,00; последний по умолчанию.
geqo_seed (с floating point)
- Управляет начальным значением генератора случайных чисел, используемого GEQO для выбора случайных путей в пространстве поиска порядка соединения. Значение может варьироваться от нуля (по умолчанию) до единицы. Изменение значения изменяет набор исследуемых путей соединения и может привести к тому, что будет найден лучший или худший лучший путь.
Другие варианты планировщика
default_statistics_target (integer)
- Устанавливает целевой показатель статистики по умолчанию для столбцов таблицы без определенного для столбца целевого значения через ALTER TABLE SET STATISTICS. Большие значения увеличивают время, необходимое для ANALYZE, но могут улучшить качество оценок планировщика. По умолчанию установлено значение 100. Для получения дополнительной информации об использовании статистики планировщиком запросов QHB см. раздел Статистика, используемая планировщиком.
constraint_exclusion (enum)
-
Управляет использованием в планировщике запросов ограничений таблиц для оптимизации запросов. Допустимые значения constraint_exclusion : включено (проверить ограничения для всех таблиц), off (никогда не проверять ограничения) и partition (изучить ограничения только для дочерних таблиц наследования и подзапросов UNION ALL ). partition является настройкой по умолчанию. Он часто используется с традиционными деревьями наследования для улучшения производительности.
-
Когда этот параметр разрешает его для конкретной таблицы, планировщик сравнивает условия запроса с ограничениями таблицы CHECK и пропускает таблицы сканирования, для которых условия противоречат ограничениям. Например:
CREATE TABLE parent(key integer, ...);
CREATE TABLE child1000(check (key between 1000 and 1999)) INHERITS(parent);
CREATE TABLE child2000(check (key between 2000 and 2999)) INHERITS(parent);
...
SELECT * FROM parent WHERE key = 2400;
-
С включенным исключением ограничений этот SELECT не будет сканировать child1000 вообще, улучшая производительность.
-
В настоящее время исключение ограничений по умолчанию включено только для случаев, которые часто используются для реализации разбиения таблиц через деревья наследования. Включение его для всех таблиц приводит к дополнительным затратам на планирование, что заметно при простых запросах и чаще всего не дает никаких преимуществ для простых запросов. Если у вас нет таблиц, которые разделены с использованием традиционного наследования, вы можете отключить его полностью. (Обратите внимание, что эквивалентная функция для партиционированных таблиц управляется отдельным параметром enable_partition_pruning).
-
Обратитесь к разделу Партиционирование и исключение ограничений для получения дополнительной информации об использовании исключения ограничений для реализации разделения.
cursor_tuple_fraction (с floating point)
- Устанавливает оценку планировщика доли строк курсора, которые будут получены. По умолчанию это 0,1. Меньшие значения этого параметра смещают планировщик в сторону использования планов «быстрого запуска» для курсоров, которые будут быстро извлекать первые несколько строк, и, возможно, потребуется много времени для извлечения всех строк. Большие значения делают больший акцент на общее расчетное время. При максимальном значении 1,0 курсоры планируются точно так же, как и обычные запросы, с учетом только общего расчетного времени, а не того, как скоро могут быть доставлены первые строки.
from_collapse_limit (integer)
-
Планировщик объединит подзапросы в верхние запросы, если итоговый список FROM будет содержать не более этого количества элементов. Меньшие значения сокращают время планирования, но могут привести к ухудшению планов запросов. По умолчанию установлено восемь. Для получения дополнительной информации см. раздел Управление планировщиком с помощью явных предложений JOIN.
-
Установка этого значения в geqo_threshold или более может инициировать использование планировщика GEQO, что приведет к неоптимальным планам. См. раздел Генетический оптимизатор запросов.
jit (boolean)
- Определяет, может ли компиляция JIT использоваться QHB, если она доступна . По умолчанию включено.
join_collapse_limit (integer)
-
Планировщик переписывает явные конструкции JOIN (кроме FULL JOIN) в списки элементов FROM всякий раз, когда получается список, содержащий не более этого количества элементов. Меньшие значения сокращают время планирования, но могут привести к ухудшению планов запросов.
-
По умолчанию эта переменная установлена так же, как from_collapse_limit, что подходит для большинства применений. Установка его в 1 предотвращает любое изменение порядка явных JOIN. Таким образом, явный порядок соединения, указанный в запросе, будет фактическим порядком, в котором соединяются отношения. Поскольку планировщик запросов не всегда выбирает оптимальный порядок соединения, опытные пользователи могут временно выбрать для этой переменной значение 1, а затем явно указать желаемый порядок соединения. Для получения дополнительной информации см. раздел Управление планировщиком с помощью явных предложений JOIN.
-
Установка этого значения в geqo_threshold или более может инициировать использование планировщика GEQO, что приведет к неоптимальным планам. См. раздел Генетический оптимизатор запросов.
parallel_leader_participation (boolean)
- Позволяет процессу-руководителю выполнять план запроса в узлах Gather и Gather Merge вместо ожидания рабочих процессов. По умолчанию включено. Если для этого значения установлено значение off вероятность того, что потоки будут заблокированы, снижает вероятность того, что лидер не достаточно быстро читает кортежи, но требует, чтобы процесс лидера ожидал запуска рабочих процессов, прежде чем будут созданы первые кортежи. Степень, в которой лидер может помочь или снизить производительность, зависит от типа плана, количества потоков и продолжительности запроса.
force_parallel_mode (enum)
-
Позволяет использовать параллельные запросы для целей тестирования даже в тех случаях, когда повышение производительности не ожидается. Допустимые значения force_parallel_mode off (использовать параллельный режим только тогда, когда ожидается повышение производительности), on (принудительный параллельный запрос для всех запросов, для которых он считается безопасным), и regress (например, on, но с дополнительными изменениями поведения как объяснено ниже).
-
Более конкретно, установка этого значения on добавит Gather узел в верхней части любого плана запроса, для которых это является безопасным, так что выполняется запрос внутри параллельного рабочего. Даже если параллельный поток недоступен или не может использоваться, такие операции, как запуск субтранзакции, которая будет запрещена в контексте параллельного запроса, будут запрещены, если только планировщик не считает, что это приведет к сбою запроса. Если при установке этого параметра возникают сбои или неожиданные результаты, возможно, некоторые функции, используемые запросом, должны быть помечены как PARALLEL UNSAFE (или, возможно, PARALLEL RESTRICTED ).
-
Установка этого значения для regress имеет все те же эффекты, что и его on плюс некоторые дополнительные эффекты, предназначенные для облегчения автоматического регрессионного тестирования. Обычно сообщения от параллельного потока включают в себя строку контекста, указывающую на это, но настройка regress подавляет эту строку, так что выходные данные такие же, как при непараллельном выполнении. Кроме того, узлы Gather добавленные в планы с помощью этого параметра, скрыты в выводе EXPLAIN поэтому выходные данные соответствуют тому, что было бы получено, если этот параметр был off.
plan_cache_mode (enum)
- Подготовленные операторы (явно подготовленные или неявно сгенерированные, например, PL / pgSQL) могут быть выполнены с использованием пользовательских или общих планов. Пользовательские планы создаются заново для каждого выполнения с использованием его определенного набора значений параметров, в то время как общие планы не зависят от значений параметров и могут быть повторно использованы при выполнении. Таким образом, использование общего плана экономит время планирования, но если идеальный план сильно зависит от значений параметров, то общий план может быть неэффективным. Выбор между этими параметрами обычно выполняется автоматически, но его можно переопределить с помощью plan_cache_mode. Допустимые значения: auto (по умолчанию), force_custom_plan и force_generic_plan. Этот параметр учитывается при выполнении кэшированного плана, а не при его подготовке. Для получения дополнительной информации см. PREPARE.
Отчеты об ошибках и ведение журнала
Расположение журнала
log_destination (string)
-
QHB поддерживает несколько методов регистрации сообщений сервера, включая stderr, csvlog и syslog. Задайте для этого параметра список желаемых пунктов назначения журнала, разделенных запятыми. По умолчанию вход только в stderr. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Если csvlog включен в log_destination, записи журнала выводятся в формате "CSV"), что удобно для загрузки журналов в программы. См. раздел Использование вывода журнала в формате CSV для деталей. logging_collector должен быть включен для генерации вывода журнала в формате CSV.
-
Если включены либо stderr, либо csvlog, создается файл current_logfiles для записи местоположения файла (ов) журнала, который в данный момент используется сборщиком журналов, и связанного с ним места назначения журналирования. Это обеспечивает удобный способ поиска журналов, используемых в данный момент экземпляром. Вот пример содержимого этого файла:
stderr log/qhb.log
csvlog log/qhb.csv
- current_logfiles воссоздается при создании нового файла журнала в результате поворота и при перезагрузке log_destination. Он удаляется, когда ни stderr, ни csvlog не включены в log_destination и когда сборщик журналов отключен.
Заметка
В большинстве систем Unix вам потребуется изменить конфигурацию демона системного журнала вашей системы, чтобы использовать параметр системного журнала для log_destination. QHB может регистрироваться в средствах системного журнала с LOCAL0 по LOCAL7 (см. Syslog_facility ), но конфигурация системного журнала по умолчанию на большинстве платформ отбрасывает все такие сообщения. Вам нужно будет добавить что-то вроде:local0. \* / var / log / qhbв файл конфигурации демона системного журнала, чтобы заставить его работать.
logging_collector (boolean)
- Этот параметр включает сборщик журналов, который является фоновым процессом, который собирает сообщения журнала, отправленные в stderr, и перенаправляет их в файлы журнала. Этот подход часто более полезен, чем запись в системный журнал, поскольку некоторые типы сообщений могут не отображаться в выходных данных системного журнала. (Один из распространенных примеров - сообщения об ошибках динамического компоновщика; другой - сообщения об ошибках, создаваемые такими сценариями, как archive_command ). Этот параметр можно установить только при запуске сервера.
Заметка
Можно войти в stderr без использования сборщика журналов; сообщения журнала будут отправляться туда, куда направлен серверный stderr. Однако этот метод подходит только для небольших томов журналов, поскольку он не предоставляет удобного способа вращения файлов журналов. Кроме того, на некоторых платформах, не использующих сборщик журналов, может привести к потере или искажению вывода журнала, потому что несколько процессов, записывающих одновременно в один и тот же файл журнала, могут перезаписать вывод друг друга.
Заметка
Сборщик журналов предназначен для того, чтобы никогда не терять сообщения. Это означает, что в случае чрезвычайно высокой нагрузки серверные процессы могут быть заблокированы при попытке отправить дополнительные сообщения журнала, если сборщик отстал. Напротив, системный журнал предпочитает отбрасывать сообщения, если он не может их записать, а это означает, что он может не записывать некоторые сообщения в таких случаях, но не блокирует остальную часть системы.
log_directory (string)
- Когда logging_collector включен, этот параметр определяет каталог, в котором будут создаваться файлы журнала. Его можно указать как абсолютный путь или относительно каталога данных кластера. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию это log.
log_filename (string)
-
Когда logging_collector включен, этот параметр устанавливает имена созданных файлов журнала. Значение обрабатывается как шаблон strftime, поэтому % -escapes можно использовать для указания изменяющихся во времени имен файлов. (Обратите внимание, что при наличии % -escapes, зависящих от часового пояса, вычисления выполняются в зоне, указанной в log_timezone ). Поддерживаемые % -escapes аналогичны тем, которые перечислены в спецификации strftime Open Group. Обратите внимание, что системное время strftime не используется напрямую, поэтому специфичные для платформы (нестандартные) расширения не работают. По умолчанию используется qhb-%Y-%m-%d_%H%M%S.log.
-
Если вы указываете имя файла без экранирования, вы должны запланировать использование утилиты ротации журналов, чтобы в конечном итоге не заполнить весь диск. В выпусках до 8.4, если бы не было % escape, QHB добавлял бы эпоху времени создания нового файла журнала, но это больше не так.
-
Если вывод в формате ".csv" включен в log_destination, .csv будет добавлен к имени файла журнала с меткой времени, чтобы создать имя файла для вывода в формате CSV. (Если log_filename оканчивается на .log, вместо него заменяется суффикс).
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
log_file_mode (integer)
-
В системах Unix этот параметр устанавливает разрешения для файлов журнала, когда включен logging_collector. (В Microsoft Windows этот параметр игнорируется). Ожидается, что значением параметра будет числовой режим, указанный в формате, принятом системными вызовами chmod и umask. (Для использования обычного восьмеричного формата число должно начинаться с 0 (ноль)).
-
Разрешения по умолчанию - 0600, что означает, что только владелец сервера может читать или записывать файлы журнала. Другой обычно полезный параметр - 0640, позволяющий членам группы владельца читать файлы. Однако обратите внимание, что для использования такой настройки вам нужно изменить log_directory, чтобы хранить файлы где-то за пределами каталога данных кластера. В любом случае неразумно делать файлы журналов доступными для чтения всем, поскольку они могут содержать конфиденциальные данные.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
log_rotation_age (integer)
- Когда logging_collector включен, этот параметр определяет максимальное время использования отдельного файла журнала, после которого будет создан новый файл журнала. Если это значение указано без единиц измерения, оно принимается за минуты. По умолчанию это 24 часа. Установите в ноль, чтобы отключить создание новых файлов журнала на основе времени. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
log_rotation_size (integer)
- Когда logging_collector включен, этот параметр определяет максимальный размер отдельного файла журнала. После того, как этот объем данных будет записан в файл журнала, будет создан новый файл журнала. Если это значение указано без единиц измерения, оно принимается за килобайты. По умолчанию 10 мегабайт. Установите в ноль, чтобы отключить создание новых файлов журнала на основе размера. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
log_truncate_on_rotation (boolean)
-
Когда logging_collector включен, этот параметр заставит QHB усекать (перезаписывать), а не добавлять к любому существующему файлу журнала с таким же именем. Однако усечение будет происходить только при открытии нового файла из-за ротации по времени, а не при запуске сервера или ротации по размеру. Если этот параметр отключен, во все случаи будут добавляться уже существующие файлы. Например, использование этого параметра в сочетании с qhb-%H.log например qhb-%H.log приведет к qhb-%H.log 24-часовых файлов журнала и их циклической перезаписи. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
-
Пример: чтобы хранить 7 дней журналов, один файл журнала в день с именем server_log.Mon, server_log.Tue и т. Д., И автоматически перезаписывать журнал прошлой недели с журналом этой недели, установите для log_filename значение server_log.%a log_truncate_on_rotation, log_truncate_on_rotation в on и log_rotation_age до 1440 .
-
Пример: чтобы хранить журналы в течение 24 часов, один файл журнала в час, но также вращаться раньше, если размер файла журнала превышает 1 ГБ, задайте для log_filename значение server_log.%H%M, log_truncate_on_rotation - on, log_rotation_age - 60 и log_rotation_size - 1000000. Включение %M в log_filename позволяет при любых вращениях на основе размера выбирать имя файла, отличное от начального имени файла часа.
syslog_facility (enum)
- Когда вход в системный журнал включен, этот параметр определяет « средство » системного журнала, которое будет использоваться. Вы можете выбрать из LOCAL0, LOCAL1, LOCAL2, LOCAL3, LOCAL4, LOCAL5, LOCAL6, LOCAL7 ; по умолчанию это LOCAL0. Смотрите также документацию о системном демоне вашей системы. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
syslog_ident (string)
- Когда вход в системный журнал включен, этот параметр определяет имя программы, используемое для идентификации сообщений QHB в журналах системного журнала. По умолчанию используется qhb . Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
syslog_sequence_numbers (boolean)
-
При входе в системный журнал, который включен (по умолчанию), каждое сообщение будет иметь префикс возрастающего порядкового номера (например, [2]). Это позволяет обойти « --- последнее сообщение, повторенное N раз --- », которое многие реализации системного журнала выполняют по умолчанию. В более современных реализациях системного журнала можно настроить повторное подавление сообщений (например, $RepeatedMsgReduction RepeatedMsgReduction в rsyslog), поэтому это может быть необязательно. Кроме того, вы можете отключить это, если вы действительно хотите подавить повторяющиеся сообщения.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
syslog_split_messages (boolean)
-
Когда запись в системный журнал включена, этот параметр определяет способ доставки сообщений в системный журнал. При включении (по умолчанию) сообщения разделяются на строки, а длинные строки разделяются так, что они помещаются в 1024 байта, что является типичным пределом размера для традиционных реализаций системного журнала. Когда он выключен, сообщения журнала сервера QHB доставляются в службу системного журнала как есть, и служба системного журнала должна обрабатывать потенциально громоздкие сообщения.
-
Если в конечном итоге системный журнал регистрируется в текстовом файле, то эффект будет одинаковым в любом случае, и лучше оставить этот параметр включенным, поскольку большинство реализаций системного журнала либо не могут обрабатывать большие сообщения, либо их необходимо специально настраивать для их обработки. Но если системный журнал в конечном итоге записывает данные на какой-либо другой носитель, может оказаться необходимым или более полезным хранить сообщения логически вместе.
-
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
event_source (string)
- Когда включена запись в журнал событий, этот параметр определяет имя программы, используемое для идентификации сообщений QHB в журнале. По умолчанию используется QHB. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Когда писать в журнал
log_min_messages (enum)
- Управляет тем, какие уровни сообщений записываются в журнал сервера. Допустимые значения: DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL и PANIC. Каждый уровень включает в себя все уровни, которые следуют за ним. Чем позже уровень, тем меньше сообщений отправляется в журнал. По умолчанию установлено WARNING. Обратите внимание, что LOG имеет другой ранг, чем в client_min_messages. Только суперпользователи могут изменять эту настройку.
log_min_error_statement (enum)
- Управляет тем, какие операторы SQL, вызывающие ошибку, записываются в журнал сервера. Текущий оператор SQL включается в запись журнала для любого сообщения указанной серьезности или выше. Допустимые значения: DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL и PANIC. По умолчанию установлено значение ERROR, что означает, что в журнал будут записываться операторы, вызывающие ошибки, сообщения журнала, фатальные ошибки или паники. Чтобы эффективно отключить запись неудачных операторов, установите для этого параметра значение PANIC. Только суперпользователи могут изменять эту настройку.
log_min_duration_statement (integer)
-
Приводит к записи продолжительности каждого выполненного оператора, если оператор выполнялся как минимум указанное количество времени. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Установка этого значения в ноль печатает все длительности операторов. Минус один (по умолчанию) отключает продолжительность записи оператора. Например, если вы установите значение 250ms все операторы SQL, выполняющие 250 мс или более, будут записываться в журнал. Включение этого параметра может быть полезно для отслеживания неоптимизированных запросов в ваших приложениях. Только суперпользователи могут изменять эту настройку.
-
Для клиентов, использующих расширенный протокол запросов, длительности шагов Parse, Bind и Execute регистрируются независимо.
Заметка
При использовании этой опции вместе с log_statement текст операторов, которые регистрируются из-за log_statement, не будет повторяться в сообщении журнала продолжительности. Если вы не используете syslog, рекомендуется зарегистрировать PID или идентификатор сеанса с помощью log_line_prefix, чтобы можно было связать сообщение оператора с более поздним сообщением продолжительности, используя идентификатор процесса или идентификатор сеанса.
log_transaction_sample_rate (real)
- Установите долю транзакций, чьи выписки все регистрируются, в дополнение к выпискам, зарегистрированным по другим причинам. Это применяется к каждой новой транзакции независимо от продолжительности ее заявлений. По умолчанию 0, что означает не регистрировать операторы от какой-либо дополнительной транзакции Установка этого значения в 1 регистрирует все операторы для всех транзакций. log_transaction_sample_rate полезен для отслеживания образца транзакции. Только суперпользователи могут изменять эту настройку.
Заметка
Как и все параметры ведения журнала выписок, эта опция может значительно увеличить накладные расходы.
Таблица 1 объясняет уровни серьезности сообщений, используемые QHB. Если выходные данные журнала отправляются в системный журнал или журнал событий Windows, уровни серьезности переводятся, как показано в таблице.
Таблица 1. Уровни серьезности сообщений
| Строгость | Использование | Системный журнал | Журнал событий |
|---|---|---|---|
| DEBUG1..DEBUG5 | Предоставляет последовательно-более подробную информацию для использования разработчиками. | DEBUG | INFORMATION |
| INFO | Предоставляет информацию, неявно запрашиваемую пользователем, например, вывод из VACUUM VERBOSE. | INFO | INFORMATION |
| NOTICE | Предоставляет информацию, которая может быть полезна пользователям, например, уведомление об усечении длинных идентификаторов. | NOTICE | INFORMATION |
| WARNING | Предоставляет предупреждения о возможных проблемах, например, COMMIT вне блока транзакции. | NOTICE | WARNING |
| ERROR | Сообщает об ошибке, которая привела к прерыванию текущей команды. | WARNING | ERROR |
| LOG | Сообщает информацию, представляющую интерес для администраторов, например, действия контрольных точек. | INFO | INFORMATION |
| FATAL | Сообщает об ошибке, которая привела к прерыванию текущего сеанса. | ERR | ERROR |
| PANIC | Сообщает об ошибке, которая привела к прерыванию всех сеансов базы данных. | CRIT | ERROR |
Что писать в журнал
application_name (string)
-
NAMEDATALEN может содержать любую строку длиной не более NAMEDATALEN символов (64 символа в стандартной сборке). Обычно он устанавливается приложением при подключении к серверу. Имя будет отображено в представлении pg_stat_activity и включено в записи журнала CSV. Она также может быть включен в регулярные записи в журнале через log_line_prefix параметра. В значении application_name могут использоваться только печатные символы ASCII. Другие символы будут заменены на вопросительные знаки (?).
-
debug_print_parse (boolean)
-
debug_print_rewritten (boolean)
-
debug_print_plan (boolean)
-
-
Эти параметры позволяют выводить различные выходные данные отладки. Когда установлено, они печатают результирующее дерево разбора, выходные данные программы переписывания запросов или план выполнения для каждого выполненного запроса. Эти сообщения отправляются на уровне сообщений LOG, поэтому по умолчанию они отображаются в журнале сервера, но не отправляются клиенту. Вы можете изменить это, настроив client_min_messages и / или log_min_messages. Эти параметры по умолчанию отключены.
debug_pretty_print (boolean)
- Если установлено, debug_pretty_print от сообщений, созданных debug_print_parse, debug_print_rewritten или debug_print_plan. Это приводит к более удобочитаемому, но намного более длинному выводу, чем « компактный » формат, используемый, когда он выключен. Он включен по умолчанию.
log_checkpoints (boolean)
- Заставляет контрольные точки и точки перезапуска регистрироваться в журнале сервера. Некоторая статистика включена в сообщения журнала, включая количество записанных буферов и время, потраченное на их запись. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию выключено.
log_connections (boolean)
- Приводит к регистрации каждой попытки подключения к серверу, а также успешного завершения аутентификации клиента. Только суперпользователи могут изменять этот параметр при запуске сеанса, и его нельзя изменить вообще в течение сеанса. По умолчанию off .
Заметка
Некоторые клиентские программы, такие как psql, пытаются подключиться дважды, определяя, требуется ли пароль, поэтому повторяющиеся сообщения « соединение получено » не обязательно указывают на проблему.
log_disconnections (boolean)
- Заставляет завершения сеанса регистрироваться. Вывод журнала предоставляет информацию, аналогичную log_connections, плюс продолжительность сеанса. Только суперпользователи могут изменять этот параметр при запуске сеанса, и его нельзя изменить вообще в течение сеанса. По умолчанию off .
log_duration (boolean)
-
Вызывает продолжительность каждого выполненного оператора для регистрации. По умолчанию off. Только суперпользователи могут изменять эту настройку.
-
Для клиентов, использующих расширенный протокол запросов, длительности шагов Parse, Bind и Execute регистрируются независимо.
Заметка
Разница между включением log_duration и установкой log_min_duration_statement в ноль заключается в том, что превышение log_min_duration_statement заставляет регистрировать текст запроса, но эта опция не делает. Таким образом, если log_duration и log_min_duration_statement имеет положительное значение, все длительности регистрируются, но текст запроса включается только для операторов, превышающих пороговое значение. Такое поведение может быть полезно для сбора статистики в установках с высокой нагрузкой.
log_error_verbosity (enum)
- Управляет количеством сведений, записанных в журнале сервера для каждого зарегистрированного сообщения. Допустимые значения: TERSE, DEFAULT и VERBOSE, каждое из которых добавляет дополнительные поля к отображаемым сообщениям. TERSE исключает регистрацию информации об ошибках DETAIL, HINT, QUERY и CONTEXT. Вывод VERBOSE включает код ошибки SQLSTATE , а также имя файла исходного кода, имя функции и номер строки, которая вызвала ошибку. Только суперпользователи могут изменять эту настройку.
log_hostname (boolean)
- По умолчанию в сообщениях журнала подключений отображается только IP-адрес подключающегося хоста. Включение этого параметра также приводит к регистрации имени хоста. Обратите внимание, что в зависимости от настройки разрешения имени вашего хоста это может привести к значительному снижению производительности. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
log_line_prefix (string)
- Это строка в стиле printf которая выводится в начале каждой строки журнала. Символы % начинаются с « escape-последовательностей », которые заменяются информацией о состоянии, как показано ниже. Нераспознанные последовательности игнорируются. Другие символы копируются прямо в строку журнала. Некоторые экранирования распознаются только сессионными процессами и будут рассматриваться как пустые фоновыми процессами, такими как процесс основного сервера. Информация о состоянии может быть выровнена влево или вправо, указав числовой литерал после% и перед параметром. Отрицательное значение приведет к тому, что информация о состоянии будет дополнена справа пробелами для придания ей минимальной ширины, тогда как положительное значение будет дополнено слева. Заполнение может быть полезно для облегчения восприятия человеком файлов журнала. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера. По умолчанию используется значение ’%m [%p] ’ которое регистрирует отметку времени и идентификатор процесса.
| Последовательность | Эффект | Только сессия |
|---|---|---|
| %a | Имя приложения | да |
| %u | Имя пользователя | да |
| %d | Имя базы данных | да |
| %r | Имя удаленного хоста или IP-адрес, а также удаленный порт | да |
| %h | Имя удаленного хоста или IP-адрес | да |
| %p | Идентификатор процесса | нет |
| %t | Отметка времени без миллисекунд | нет |
| %m | Отметка времени с миллисекундами | нет |
| %n | Отметка времени с миллисекундами (как эпоха Unix) | нет |
| %i | Тег команды: тип текущей команды сеанса | да |
| %e | Код ошибки SQLSTATE | нет |
| %c | Идентификатор сеанса: см. Ниже | нет |
| %l | Номер строки журнала для каждого сеанса или процесса, начиная с 1 | нет |
| %s | Отметка времени начала процесса | нет |
| %v | Идентификатор виртуальной транзакции (backendID / localXID) | нет |
| %x | ID транзакции (0, если ни один не назначен) | нет |
| %q | Не выводит никаких данных, но указывает несессионным процессам остановиться в этой точке строки; игнорируется сессионными процессами | нет |
| %% | Буквальный % | нет |
- %c escape печатает квазиуникальный идентификатор сеанса, состоящий из двух 4-байтовых шестнадцатеричных чисел (без начальных нулей), разделенных точкой. Числа - это время начала процесса и идентификатор процесса, поэтому %c также можно использовать как способ экономии места для печати этих элементов. Например, чтобы сгенерировать идентификатор сеанса из pg_stat_activity, используйте этот запрос:
SELECT to_hex(trunc(EXTRACT(EPOCH FROM backend_start))::integer) || '.' ||
to_hex(pid)
FROM pg_stat_activity;
Заметка
Если вы устанавливаете непустое значение для log_line_prefix, вы обычно должны сделать его последний символ пробелом, чтобы обеспечить визуальное отделение от остальной части строки журнала. Также можно использовать знак пунктуации.
Заметка
Системный журнал создает свою собственную метку времени и информацию об идентификаторе процесса, так что вы, вероятно, не захотите включать эти экранированные символы при входе в системный журнал.
Заметка
Экранирование %q полезно при включении информации, доступной только в контексте сеанса (бэкенда), например имени пользователя или базы данных. Например:log_line_prefix = '%m [%p] %q%u@%d/%a '
log_lock_waits (boolean)
- Управляет созданием сообщения журнала, когда сеанс ожидает дольше, чем deadlock_timeout, чтобы получить блокировку. Это полезно при определении того, вызывает ли ожидание блокировки низкую производительность. По умолчанию off. Только суперпользователи могут изменять эту настройку.
log_statement (enum)
-
Управляет тем, какие операторы SQL регистрируются. Допустимые значения: none (off), ddl, mod и all (все операторы). ddl регистрирует все операторы определения данных, такие как операторы CREATE, ALTER и DROP. mod регистрирует все операторы ddl, а также операторы изменения данных, такие как INSERT, UPDATE, DELETE, TRUNCATE и COPY FROM. PREPARE, EXECUTE и EXPLAIN ANALYZE также регистрируются, если содержащиеся в них команды имеют соответствующий тип. Для клиентов, использующих расширенный протокол запросов, ведение журнала происходит при получении сообщения Execute и включении значений параметров Bind (с удвоением всех встроенных одинарных кавычек).
-
По умолчанию none. Только суперпользователи могут изменять эту настройку.
Заметка
Операторы, которые содержат простые синтаксические ошибки, не регистрируются даже параметром log_statement = all, потому что сообщение журнала log_statement только после того, как был выполнен базовый анализ для определения типа оператора. В случае протокола расширенного запроса этот параметр также не регистрирует операторы, которые не выполняются до фазы выполнения (т. Е. Во время анализа анализа или планирования). Установите log_min_error_statement в ERROR (или ниже) для записи таких операторов.
log_replication_commands (boolean)
- Заставляет каждую команду репликации регистрироваться в журнале сервера. Значение по умолчанию off. Только суперпользователи могут изменять эту настройку.
log_temp_files (integer)
- Управляет регистрацией временных имен файлов и размеров. Временные файлы могут быть созданы для сортировки, хэшей и результатов временных запросов. Если этот параметр включен, запись журнала создается для каждого временного файла при его удалении. Нулевое значение записывает всю информацию временного файла, в то время как положительные значения регистрируют только файлы, размер которых больше или равен указанному объему данных. Если это значение указано без единиц измерения, оно принимается за килобайты. По умолчанию установлено значение -1, что запрещает такую регистрацию. Только суперпользователи могут изменять эту настройку.
log_timezone (string)
- Устанавливает часовой пояс, используемый для отметок времени, записанных в журнале сервера. В отличие от TimeZone, это значение распространяется на весь кластер, поэтому все сеансы будут сообщать метки времени единообразно. Встроенное значение по умолчанию - GMT, но обычно оно переопределяется в qhb.conf; initdb установит там настройку, соответствующую системному окружению. См. раздел Часовые пояса для получения дополнительной информации. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Использование вывода журнала в формате CSV
В том числе csvlog в log_destination списке обеспечивает удобный способ для импорта файлов журнала в таблицу базы данных. Эта опция генерирует строки журнала в формате значений, разделенных запятыми (CSV), со следующими столбцами: отметка времени с миллисекундами, имя пользователя, имя базы данных, идентификатор процесса, хост клиента: номер порта, идентификатор сеанса, номер строки для сеанса, команда тег, время начала сеанса, идентификатор виртуальной транзакции, идентификатор обычной транзакции, серьезность ошибки, код SQLSTATE, сообщение об ошибке, подробность сообщения об ошибке, подсказка, внутренний запрос, который привел к ошибке (если есть), количество символов в позиции ошибки, ошибка контекст, пользовательский запрос, который привел к ошибке (если таковой имеется и активирован log_min_error_statement), количество символов в позиции ошибки в нем, местоположение ошибки в исходном коде QHB (если для log_error_verbosity задано verbose ) и имя приложения. Вот пример определения таблицы для хранения вывода журнала в формате CSV:
CREATE TABLE postgres_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)
);
Чтобы импортировать файл журнала в эту таблицу, используйте команду COPY FROM :
COPY postgres_log FROM '/full/path/to/logfile.csv' WITH csv;
Есть несколько вещей, которые необходимо сделать, чтобы упростить импорт файлов журнала CSV:
-
Установите log_filename и log_rotation_age чтобы обеспечить согласованную, предсказуемую схему именования для ваших файлов журнала. Это позволяет вам предсказать, каким будет имя файла, и узнать, когда отдельный файл журнала будет завершен и, следовательно, готов к импорту.
-
Установите для log_rotation_size значение 0, чтобы отключить ротацию журналов на основе размера, поскольку это затрудняет прогнозирование имени файла журнала.
-
Установите для log_truncate_on_rotation значение on чтобы старые данные журнала не смешивались с новыми в том же файле.
-
Приведенное выше определение таблицы содержит спецификацию первичного ключа. Это полезно для защиты от случайного импорта одной и той же информации дважды. Команда COPY фиксирует все импортируемые данные за один раз, поэтому любая ошибка приведет к сбою всего импорта. Если вы импортируете частичный файл журнала, а затем снова импортируете файл после его завершения, нарушение первичного ключа приведет к сбою импорта. Дождитесь завершения и закрытия журнала, прежде чем импортировать. Эта процедура также защитит от случайного импорта неполной строки, которая была написана не полностью, что также приведет к сбою COPY .
Название процесса
Эти параметры определяют, как изменяются заголовки процессов сервера. Названия процессов обычно просматриваются с помощью таких программ, как ps. Смотрите раздел Стандартные инструменты Unix для деталей.
cluster_name (string)
-
Устанавливает имя, которое идентифицирует этот кластер базы данных (экземпляр) для различных целей. Имя кластера появляется в заголовке процесса для всех процессов сервера в этом кластере. Кроме того, это имя приложения по умолчанию для резервного соединения (см. synchronous_standby_names ).
-
Имя может быть любой строкой длиной не более NAMEDATALEN символов (64 символа в стандартной сборке). В значении cluster_name можно использовать только печатные символы ASCII. Другие символы будут заменены на вопросительные знаки (?). Имя не отображается, если для этого параметра задана пустая строка ” (по умолчанию). Этот параметр можно установить только при запуске сервера.
update_process_title (boolean)
- Позволяет обновлять заголовок процесса каждый раз, когда сервер получает новую команду SQL. Этот параметр по умолчанию включен на большинстве платформ, но по умолчанию он off в Windows из-за больших накладных расходов этой платформы при обновлении заголовка процесса. Только суперпользователи могут изменять эту настройку.
Статистика выполнения
Сборщик статистики запросов и индексов
Эти параметры управляют функциями сбора статистики на уровне сервера. Когда сбор статистики включен, к полученным данным можно получить доступ через семейство системных представлений pg_stat и pg_statio . Обратитесь к главе Мониторинг активности базы данных за дополнительной информацией.
track_activities (boolean)
- Включает сбор информации о текущей выполняемой команде каждого сеанса, а также время, когда эта команда начала выполнение. Этот параметр включен по умолчанию. Обратите внимание, что даже если эта опция включена, эта информация не видна всем пользователям, только суперпользователям и пользователю, которому принадлежит сеанс, о котором сообщается, поэтому она не должна представлять угрозу безопасности. Только суперпользователи могут изменять эту настройку.
track_activity_query_size (integer)
- Определяет объем памяти, зарезервированный для хранения текста текущей выполняемой команды для каждого активного сеанса, для поля pg_stat_activity.query. Если это значение указано без единиц измерения, оно принимается как байты. Значение по умолчанию составляет 1024 байта. Этот параметр можно установить только при запуске сервера.
track_counts (boolean)
- Включает сбор статистики о работе базы данных. Этот параметр включен по умолчанию, поскольку демону autovacuum требуется собранная информация. Только суперпользователи могут изменять эту настройку.
track_io_timing (boolean)
- Включает синхронизацию вызовов ввода-вывода базы данных. По умолчанию этот параметр отключен, поскольку он будет периодически запрашивать у операционной системы текущее время, что может вызвать значительные издержки на некоторых платформах. Вы можете использовать инструмент pg_test_timing для измерения затрат времени в вашей системе. Информация о времени ввода / вывода отображается в pg_stat_database, в выходных данных EXPLAIN, когда используется опция BUFFERS, и в pg_stat_statements. Только суперпользователи могут изменять эту настройку.
track_functions (enum)
- Позволяет отслеживать количество вызовов функций и использованное время. Укажите pl для отслеживания только функций процедурного языка, all также для отслеживания функций языка SQL и C/RUST. По умолчанию установлено значение none, что отключает отслеживание статистики функций. Только суперпользователи могут изменять эту настройку.
Заметка
Функции языка SQL, которые достаточно просты для « встраивания » в вызывающий запрос, отслеживаться не будут, независимо от этого параметра.
stats_temp_directory (string)
- Устанавливает каталог для хранения временных данных статистики. Это может быть путь относительно каталога данных или абсолютный путь. По умолчанию используется pg_stat_tmp. Указание этого на файловую систему на основе ОЗУ снизит требования к физическому вводу-выводу и может привести к повышению производительности. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Мониторинг статистики
log_statement_stats (boolean)
log_parser_stats (boolean)
log_planner_stats (boolean)
log_executor_stats (boolean)
Для каждого запроса выведите статистику производительности соответствующего модуля в журнал сервера. Это грубый инструмент профилирования, похожий на средство операционной системы Unix getrusage(). log_statement_stats сообщает общую статистику операторов, в то время как другие представляют статистику по модулям. log_statement_stats нельзя включить вместе с какими-либо опциями для каждого модуля. Все эти параметры по умолчанию отключены. Только суперпользователи могут изменять эти настройки.
Автоматическая очистка
Эти настройки управляют поведением функции автоочистки. Дополнительную информацию см в разделе Процесс «Автовакуум». Обратите внимание, что многие из этих настроек могут быть переопределены для каждой таблицы отдельно; см. подраздел Параметры хранения.
autovacuum (boolean)
Управляет тем, должен ли сервер запускать демон запуска автоочистки. Это включено по умолчанию; однако для работы автоочистки также необходимо включить track_counts. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера; тем не менее, автоочистку можно отключить для отдельных таблиц, изменив их параметры хранения.
Обратите внимание, что даже когда этот параметр отключен, система будет при необходимости запускать процессы автоочистки, чтобы предотвратить зацикливание идентификатора транзакции. Дополнительную информацию см. в разделе Предотвращение ошибок зацикливания идентификатора транзакции.
log_autovacuum_min_duration (integer)
Заставляет регистрировать каждое действие, выполненное автоочисткой, если оно выполнялось как минимум указанное количество времени. Установка значения в ноль регистрирует все действия автоочистки. -1 (по умолчанию) отключает запись действий автоочистки. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Например, если установить значение 250ms, будут регистрироваться все автоматические операции очистки и анализа, которые выполняются в течение 250 мс или более. Кроме того, если для этого параметра установлено любое значение, отличное от -1, сообщение будет записано в журнал, если действие автоочистки пропущено из-за конфликтующей блокировки или одновременного удаления отношения. Включение этого параметра может быть полезным для отслеживания активности автоочистки. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера; тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_max_workers (integer)
Задает максимальное количество процессов автоочистки (кроме собственно ее запуска), которые могут выполняться одновременно. По умолчанию это три. Этот параметр можно установить только при запуске сервера.
autovacuum_naptime (integer)
Определяет минимальную задержку между запусками автоочистки в любой отдельно взятой базе данных.
В каждом раунде демон проверяет базу данных и при необходимости выдает команды VACUUM и ANALYZE для таблиц в этой базе данных.
Если это значение указано без единиц измерения, оно принимается за секунды.
По умолчанию используется одна минута (1min).
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
autovacuum_vacuum_threshold (integer)
Задает минимальное количество обновленных или удаленных кортежей, необходимое для запуска VACUUM в отдельно взятой таблице.
По умолчанию это 50 кортежей. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера;
тем не менее, его значение можно переопределить для отдельных таблиц,
изменив их параметры хранения.
autovacuum_vacuum_insert_threshold (integer)
Задает количество добавленных кортежей, требующееся для запуска VACUUM в отдельно взятой таблице. По умолчанию это 100 кортежей. Если указано -1, автоочистка не запустит операцию VACUUM с таблицами, основываясь на количестве добавлений. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера; тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_analyze_threshold (integer)
Задает минимальное количество добавленных, обновленных или удаленных кортежей, необходимое для запуска ANALYZE
в любой отдельно взятой таблице. По умолчанию это 50 кортежей. Этот параметр можно установить только в файле qhb.conf
или в командной строке сервера; тем не менее, его значение можно
переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_vacuum_scale_factor (floating point)
Задает часть размера таблицы, добавляемую к autovacuum_vacuum_threshold при принятии
решения о запуске VACUUM. По умолчанию это 0,2 (20% от размера таблицы).
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера;
тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_vacuum_insert_scale_factor (floating point)
Задает часть размера таблицы, добавляемую к autovacuum_vacuum_insert_threshold при принятии
решения о запуске VACUUM. По умолчанию это 0,2 (20% от размера таблицы).
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера;
тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_analyze_scale_factor (floating point)
Задает часть размера таблицы, добавляемую к autovacuum_analyze_threshold при принятии
решения о запуске ANALYZE. По умолчанию это 0,1 (10% от размера таблицы).
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера; тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_freeze_max_age (integer)
Задает максимальный возраст (в транзакциях), которого может достичь поле таблицы pg_class.relfrozenxid, прежде чем
операция VACUUM будет вынуждена предотвратить зацикливание идентификатора транзакции в этой таблице.
Обратите внимание, что система будет запускать процессы автоочистки, чтобы предотвратить зацикливание,
даже если автоочистка отключена.
Очистка также позволяет удалять старые файлы из подкаталога pg_xact, поэтому по умолчанию это относительно небольшие 200 миллионов транзакций. Этот параметр можно установить только при запуске сервера; тем не менее, его значение можно уменьшить для отдельных таблиц, изменив их параметры хранения. Дополнительную информацию см. в подразделе Предотвращение ошибок зацикливания идентификатора транзакции.
autovacuum_multixact_freeze_max_age (integer)
Задает максимальный возраст (в мультитранзакциях), которого может достичь поле таблицы pg_class.relminmxid, прежде чем
операция VACUUM будет вынуждена предотвратить зацикливание идентификаторов мультитранзакций в этой таблице.
Обратите внимание, что система будет запускать процессы автоочистки, чтобы предотвратить зацикливание,
даже если автоочистка отключена.
Очистка мультитранзакций также позволяет удалять старые файлы из pg_multixact/members и pg_multixact/offsets, поэтому по умолчанию это относительно небольшие 400 миллионов мультитранзакций. Этот параметр можно установить только при запуске сервера; тем не менее, его можно уменьшить для отдельных таблиц, изменив их параметры хранения. Дополнительную информацию см. в подразделе Мультитранзакции и зацикливание.
autovacuum_vacuum_cost_delay (floating point)
Задает значение задержки стоимости, которое будет использоваться в автоматических операциях VACUUM.
Если указано -1, будет использовано обычное значение vacuum_cost_delay.
Если это значение указано без единиц измерения, оно принимается за миллисекунды.
Значение по умолчанию составляет 2 миллисекунды.
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера;
тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
autovacuum_vacuum_cost_limit (integer)
Указывает предельное значение стоимости, которое будет использоваться в автоматических операциях VACUUM.
Если указано -1 (по умолчанию), будет использовано обычное значение vacuum_cost_limit.
Обратите внимание, что если работающих потоков автоочистки больше одного, это значение распределяется между ними пропорционально,
так что сумма пределов для каждого потока не превышает значения этой переменной.
Этот параметр можно установить только в файле qhb.conf или в командной строке сервера;
тем не менее, его значение можно переопределить для отдельных таблиц, изменив их параметры хранения.
Клиентское соединение по умолчанию
Поведение команд
client_min_messages (enum)
-
Управляет тем, какие уровни сообщений отправляются клиенту. Допустимые значения: DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, LOG, NOTICE, WARNING и ERROR. Каждый уровень включает в себя все уровни, которые следуют за ним. Чем позже уровень, тем меньше сообщений отправляется. По умолчанию это NOTICE. Обратите внимание, что LOG имеет другой ранг, чем в log_min_messages .
-
Сообщения уровня INFO всегда отправляются клиенту.
search_path (string)
-
Эта переменная указывает порядок поиска схем, когда на объект (таблицу, тип данных, функцию и т. д). Ссылается простое имя без указания схемы. Когда в разных схемах есть объекты с одинаковыми именами, используется тот, который был найден первым в пути поиска. На объект, который не входит ни в одну из схем в пути поиска, можно ссылаться только путем указания его содержащей схемы с квалифицированным (пунктирным) именем.
-
Значение для search_path должно быть разделенным запятыми списком имен схем. Любое имя, которое не является существующей схемой или является схемой, для которой у пользователя нет разрешения USAGE, игнорируется.
-
Если одним из элементов списка является специальное имя $user, то схема с именем, возвращаемым CURRENT_USER, заменяется, если такая схема существует и у пользователя есть разрешение USAGE для нее. (Если нет, $user игнорируется).
-
Схема системного каталога, pg_catalog, всегда ищется, независимо от того, упоминается она в пути или нет. Если оно упомянуто в пути, то оно будет найдено в указанном порядке. Если pg_catalog не находится в пути, он будет pg_catalog перед поиском любого из элементов пути.
-
Аналогично, схема временной таблицы текущего сеанса, pg_temp_ nnn, всегда ищется, если она существует. Он может быть явно указан в пути с помощью псевдонима pg_temp, Если он не указан в пути, то он ищется первым (даже до pg_catalog). Однако во временной схеме ищутся только имена отношений (таблица, представление, последовательность и т.д). И имена типов данных. Никогда не ищется имя функции или оператора.
-
Когда объекты создаются без указания конкретной целевой схемы, они будут помещены в первую действительную схему с именем в search_path. Об ошибке сообщается, если путь поиска пуст.
-
Значением по умолчанию для этого параметра является "$user", public. Этот параметр поддерживает совместное использование базы данных (когда ни один пользователь не имеет частных схем, и все используют общее использование public ), частные схемы для каждого пользователя и их комбинации. Другие эффекты можно получить, изменив настройку пути поиска по умолчанию, глобально или для каждого пользователя.
-
Для получения дополнительной информации об обработке схемы см. Раздел 5.9. В частности, конфигурация по умолчанию подходит только тогда, когда в базе данных есть один пользователь или несколько доверяющих друг другу пользователей.
-
Текущее эффективное значение пути поиска можно проверить с помощью функции SQL current_schemas (см. Раздел 9.25). Это не совсем то же самое, что изучение значения search_path, поскольку current_schemas показывает, как были разрешены элементы, появляющиеся в search_path .
row_security (boolean)
-
Эта переменная определяет, будет ли возникать ошибка вместо применения политики безопасности строк. Когда включено, политики применяются нормально. Если установлено значение off, запросы не выполняются, что в противном случае применило бы хотя бы одну политику. По умолчанию включено. off если ограниченная видимость строки может привести к неверным результатам; например, qhb_dump делает это изменение по умолчанию. Эта переменная не влияет на роли, которые обходят каждую политику безопасности строк, то есть на суперпользователей и роли с атрибутом BYPASSRLS .
-
Для получения дополнительной информации о политиках безопасности строк см. СОЗДАНИЕ ПОЛИТИКИ .
default_table_access_method (string)
- Этот параметр указывает метод доступа к таблице по умолчанию, который используется при создании таблиц или материализованных представлений, если команда CREATE явно не указывает метод доступа или когда используется SELECT ... INTO, что не позволяет указать метод доступа к таблице. По умолчанию это heap .
default_tablespace (string)
-
Эта переменная задает табличное пространство по умолчанию, в котором создаются объекты (таблицы и индексы), когда команда CREATE явно не указывает табличное пространство. Он также определяет табличное пространство, в которое разделенное отношение будет направлять будущие разделы.
-
Значением является либо имя табличного пространства, либо пустая строка, указанная с использованием табличного пространства по умолчанию для текущей базы данных. Если значение не соответствует имени какого-либо существующего табличного пространства, QHB автоматически будет использовать табличное пространство по умолчанию для текущей базы данных. Если указано табличное пространство не по умолчанию, у пользователя должна быть привилегия CREATE, иначе попытки создания будут неудачными.
-
Эта переменная не используется для временных таблиц; для них вместо этого используется temp_tablespaces .
-
Эта переменная также не используется при создании баз данных. По умолчанию новая база данных наследует настройки табличного пространства из базы данных шаблонов, из которой она скопирована.
-
Для получения дополнительной информации о табличных пространствах см. раздел Табличные пространства.
temp_tablespaces (string)
-
Эта переменная задает табличные пространства, в которых создаются временные объекты (временные таблицы и индексы для временных таблиц), когда команда CREATE явно не указывает табличное пространство. Временные файлы для таких целей, как сортировка больших наборов данных, также создаются в этих табличных пространствах.
-
Значение представляет собой список имен табличных пространств. Когда в списке более одного имени, QHB выбирает случайного члена списка каждый раз, когда создается временный объект; за исключением того, что внутри транзакции последовательно созданные временные объекты помещаются в последовательные табличные пространства из списка. Если выбранный элемент списка представляет собой пустую строку, QHB автоматически будет использовать табличное пространство по умолчанию для текущей базы данных.
-
Когда temp_tablespaces устанавливается интерактивно, указание несуществующего табличного пространства является ошибкой, как и указание табличного пространства, для которого у пользователя нет привилегии CREATE. Однако при использовании ранее установленного значения несуществующие табличные пространства игнорируются, как и табличные пространства, для которых у пользователя нет привилегии CREATE. В частности, это правило применяется при использовании значения, заданного в qhb.conf .
-
Значением по умолчанию является пустая строка, в результате чего все временные объекты создаются в табличном пространстве по умолчанию текущей базы данных.
-
Смотрите также default_tablespace .
check_function_bodies (boolean)
- Этот параметр обычно включен. Если установлено значение off, отключается проверка строки тела функции во время CREATE FUNCTION . Отключение проверки позволяет избежать побочных эффектов процесса проверки и избежать ложных срабатываний из-за проблем, таких как прямые ссылки. off этот параметр перед загрузкой функций от имени других пользователей; qhb_dump делает это автоматически.
default_transaction_isolation (enum)
-
Каждая транзакция SQL имеет уровень изоляции, который может быть « прочитано незафиксировано », « зафиксировано чтение », « повторяемое чтение » или « сериализуемо ». Этот параметр контролирует уровень изоляции по умолчанию для каждой новой транзакции. По умолчанию « передано на чтение » .
-
Обратитесь к главе Параллельный контроль и SET TRANSACTION для получения дополнительной информации.
default_transaction_read_only (boolean)
-
Доступная только для чтения транзакция SQL не может изменять временные таблицы. Этот параметр контролирует состояние по умолчанию только для чтения каждой новой транзакции. По умолчанию off (чтение / запись).
-
Обратитесь к SET TRANSACTION для получения дополнительной информации.
default_transaction_deferrable (boolean)
-
При выполнении на уровне serializable изоляции отложенная транзакция SQL только для чтения может быть отложена до того, как ей будет разрешено продолжить. Однако, как только он начинает выполняться, он не несет никаких накладных расходов, необходимых для обеспечения сериализуемости; поэтому у кода сериализации не будет причин принудительно прерывать его из-за одновременных обновлений, что делает эту опцию подходящей для длительных транзакций только для чтения.
-
Этот параметр управляет отложенным статусом по умолчанию для каждой новой транзакции. В настоящее время он не влияет на транзакции чтения-записи или те, которые работают на уровнях изоляции ниже, чем serializable. По умолчанию off .
-
Обратитесь к SET TRANSACTION для получения дополнительной информации.
session_replication_role (enum)
-
Управляет срабатыванием связанных с репликацией триггеров и правил для текущего сеанса. Установка этой переменной требует привилегий суперпользователя и приводит к отмене любых ранее кэшированных планов запросов. Возможные значения: origin (по умолчанию), replica и local .
-
Предполагаемое использование этого параметра заключается в том, что системы логической репликации устанавливают его для replica когда они применяют реплицированные изменения. В результате триггеры и правила (которые не были изменены из их конфигурации по умолчанию) не будут срабатывать на реплике. См. Разделы ALTER TABLE ENABLE TRIGGER и ENABLE RULE для получения дополнительной информации.
-
QHB обрабатывает исходные и local настройки одинаково. Сторонние системы репликации могут использовать эти два значения для своих внутренних целей, например, используя local для обозначения сеанса, изменения которого не должны реплицироваться.
-
Поскольку внешние ключи реализованы в виде триггеров, установка этого параметра на replica также отключает все проверки внешних ключей, которые могут привести к несогласованности данных в случае неправильного использования.
statement_timeout (integer)
-
Прервите любое утверждение, которое занимает больше указанного времени. Если для log_min_error_statement задано значение ERROR или ниже, тайм-аут оператора также будет записан в журнал. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Нулевое значение (по умолчанию) отключает тайм-аут.
-
Время ожидания измеряется с момента поступления команды на сервер до ее завершения сервером. В протоколе расширенных запросов тайм-аут начинает работать, когда поступает какое-либо связанное с запросом сообщение (Parse, Bind, Execute, Describe), и оно отменяется при завершении сообщения Execute или Sync.
-
Установка statement_timeout в qhb.conf не рекомендуется, потому что это повлияет на все сеансы.
lock_timeout (integer)
-
Прервите любой оператор, который ожидает дольше указанного времени, пытаясь получить блокировку таблицы, индекса, строки или другого объекта базы данных. Ограничение по времени применяется отдельно для каждой попытки получения блокировки. Ограничение применяется как к явным запросам блокировки (таким как LOCK TABLE или SELECT FOR UPDATE без NOWAIT ), так и к неявно полученным блокировкам. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Нулевое значение (по умолчанию) отключает тайм-аут.
-
В отличие от statement_timeout, этот тайм-аут может происходить только во время ожидания блокировок. Обратите внимание, что если lock_timeout отличен от нуля, бессмысленно устанавливать для lock_timeout то же самое или большее значение, поскольку время ожидания оператора всегда срабатывает первым. Если для log_min_error_statement задано значение ERROR или ниже, то выдержка времени будет записана в журнал.
-
Установка lock_timeout в qhb.conf не рекомендуется, потому что это повлияет на все сеансы.
idle_in_transaction_session_timeout (integer)
-
Завершите любой сеанс открытой транзакцией, которая простаивала дольше указанного времени. Это позволяет снять любые блокировки, удерживаемые этим сеансом, и повторно использовать слот подключения; это также позволяет вакуумировать кортежи, видимые только для этой транзакции. См. раздел Регулярная очистка для более подробной информации об этом.
-
Если это значение указано без единиц измерения, оно принимается за миллисекунды. Нулевое значение (по умолчанию) отключает тайм-аут.
vacuum_freeze_table_age (integer)
- VACUUM выполняет агрессивное сканирование, если таблица pg_class . relfrozenxid достигло возраста, указанного в этом параметре. Агрессивное сканирование отличается от обычного VACUUM тем, что оно посещает каждую страницу, которая может содержать незамерзающие XID или MXID, а не только те, которые могут содержать мертвые кортежи. По умолчанию 150 миллионов транзакций. Хотя пользователи могут установить это значение в диапазоне от нуля до двух миллиардов, VACUUM будет молча ограничивать эффективное значение до 95% autovacuum_freeze_max_age, чтобы периодическое руководство VACUUM могло запускаться до того, как для таблицы будет запущена автоочистка с обходом. Для получения дополнительной информации см. раздел Предотвращение ошибок зацикливания идентификатора транзакции.
vacuum_freeze_min_age (integer)
Определяет конечный возраст (в транзакциях), который VACUUM должен
использовать, чтобы решить, следует ли заморозить версии строк при
сканировании таблицы. По умолчанию 50 миллионов транзакций. Хотя
пользователи могут установить это значение в диапазоне от нуля до
одного миллиарда, `VACUUM` будет молча ограничивать эффективное
значение до половины значения *autovacuum_freeze_max_age*, чтобы не
было неоправданно короткого промежутка времени между принудительными
автоочистками. Для получения дополнительной информации
см. раздел [Предотвращение ошибок зацикливания идентификатора транзакции].
vacuum_multixact_freeze_table_age (integer)
`VACUUM` выполняет агрессивное сканирование, если поле таблицы ***pg_class.
relminmxid*** достигло возраста, указанного в этом параметре.
Агрессивное сканирование отличается от обычной операции `VACUUM` тем, что оно
посещает каждую страницу, которая может содержать незамороженные XID
или MXID, а не только те, которые могут содержать мертвые кортежи.
По умолчанию установлено 150 миллионов мультитранзакций. Хотя
пользователи могут установить это значение в диапазоне от нуля до
двух миллиардов, `VACUUM` будет молча ограничивать эффективное
значение до 95% от [autovacuum\_multixact\_freeze\_max\_age], чтобы
у периодически запускаемой вручную команды `VACUUM` были шансы выполниться до того, как для
таблицы будет запущена автоочистка, предотвращающая зацикливание.
Дополнительную информацию см. в подразделе [Мультитранзакции и зацикливание].
vacuum_multixact_freeze_min_age (integer)
Определяет предельный возраст (в мультитранзакциях), который команда `VACUUM`
должна использовать при решении о том, заменять ли
идентификатор мультитранзакции более новым идентификатором транзакции или
мультитранзакции при сканировании таблицы. По
умолчанию установлено 5 миллионов мультитранзакций. Хотя пользователи
могут установить это значение в диапазоне от нуля до одного
миллиарда, `VACUUM` будет молча ограничивать эффективное значение
половиной значения [autovacuum\_multixact\_freeze\_max\_age], чтобы не
допустить неоправданно коротких периодов между принудительными
автоочистками. Дополнительную информацию см. в
подразделе [Мультитранзакции и зацикливание].
vacuum_cleanup_index_scale_factor (с floating point)
-
Указывает долю от общего числа кортежей кучи, подсчитанных в предыдущем сборе статистики, которые можно вставить без сканирования индекса на этапе очистки VACUUM. Этот параметр в настоящее время применяется только к B-деревьям.
-
Если из кучи не было удалено ни одного кортежа, B-деревья по-прежнему сканируются на этапе очистки VACUUM когда выполняется хотя бы одно из следующих условий: статистика индекса устарела или индекс содержит удаленные страницы, которые можно повторно использовать во время очистки, Статистика индекса считается устаревшей, если число вновь вставленных кортежей превышает долю в vacuum_cleanup_index_scale_factor от общего числа кортежей кучи, обнаруженных предыдущим сбором статистики. Общее количество кортежей кучи хранится на мета-странице индекса. Обратите внимание, что мета-страница не включает эти данные до тех пор, пока VACUUM не найдет мертвые кортежи, поэтому сканирование B-дерева на этапе очистки может быть пропущено, только если второй и последующие циклы VACUUM не обнаруживают мертвых кортежей.
-
Значение может варьироваться от 0 до 10000000000. Если в vacuum_cleanup_index_scale_factor установлено значение 0, сканирование индекса никогда не пропускается во время очистки VACUUM. Значение по умолчанию составляет 0.1 .
bytea_output (enum)
- Устанавливает формат вывода для значений типа bytea. Допустимые значения: hex (по умолчанию) и escape (традиционный формат QHB). См. Раздел 8.4 для получения дополнительной информации. Тип bytea всегда принимает оба формата на входе, независимо от этого параметра.
xmlbinary (enum)
-
Устанавливает, как двоичные значения должны быть закодированы в XML. Это применимо, например, когда значения bytea конвертируются в XML с помощью функций xmlelement или xmlforest. Возможные значения: base64 и hex, которые определены в стандарте XML-схемы. По умолчанию используется base64. Для получения дополнительной информации о функциях, связанных с XML, см. Раздел 9.14 .
-
Фактический выбор здесь в основном зависит от вкуса, ограниченного только возможными ограничениями в клиентских приложениях. Оба метода поддерживают все возможные значения, хотя шестнадцатеричная кодировка будет несколько больше, чем кодировка base64.
xmloption (enum)
-
Устанавливает, является ли DOCUMENT или CONTENT неявным при преобразовании между значениями XML и символьных строк. См. раздел Тип XML для описания этого. Допустимые значения: DOCUMENT и CONTENT . По умолчанию используется CONTENT .
-
Согласно стандарту SQL, команда для установки этой опции
SET XML OPTION { DOCUMENT | CONTENT };
Этот синтаксис также доступен в QHB.
gin_pending_list_limit (integer)
- Устанавливает максимальный размер списка ожидания индекса GIN, который используется при fastupdate. Если список становится больше этого максимального размера, он очищается путем массового перемещения записей в нем в основную структуру данных индекса GIN. Если это значение указано без единиц измерения, оно принимается за килобайты. По умолчанию используется четыре мегабайта (4MB). Этот параметр можно переопределить для отдельных индексов GIN, изменив параметры хранения индекса. См. раздел Быстрое обновление GIN и раздел GIN советы и хитрости для получения дополнительной информации.
Язык и форматирование
DateStyle (string)
- Устанавливает формат отображения значений даты и времени, а также правила интерпретации неоднозначных значений ввода даты. По историческим причинам эта переменная содержит два независимых компонента: спецификацию выходного формата (ISO, Postgres, SQL или German) и спецификацию ввода / вывода для упорядочивания года / месяца / дня (DMY, MDY или YMD). Они могут быть установлены отдельно или вместе. Ключевые слова Euro и European являются синонимами для DMY; ключевые слова US, NonEuro и NonEuropean являются синонимами для MDY. См. раздел Типы даты / времени для получения дополнительной информации. По умолчанию встроенным является ISO, MDY, но initdb инициализирует файл конфигурации с настройкой, соответствующей поведению выбранного lc_time стандарта lc_time .
IntervalStyle (enum)
-
Устанавливает формат отображения для значений интервала. Значение sql_standard будет выдавать выходные данные, соответствующие литералам стандартного интервала SQL. Значение iso_8601 будет выдавать выходные данные, соответствующие временному интервалу «формат с указателями», определенному в разделе 4.4.3.2 ISO 8601.
-
Параметр IntervalStyle также влияет на интерпретацию ввода неоднозначных интервалов. См. раздел Формат ввода интервалов для получения дополнительной информации.
TimeZone (string)
- Устанавливает часовой пояс для отображения и интерпретации меток времени. Встроенное значение по умолчанию - GMT, но обычно оно переопределяется в qhb.conf; initdb установит там настройку, соответствующую системному окружению. См. раздел Часовые пояса для получения дополнительной информации.
timezone_abbreviations (string)
- Устанавливает коллекцию сокращений часовых поясов, которые будут приняты сервером для ввода даты и времени. По умолчанию используется значение ’Default’, которое является коллекцией, которая работает в большинстве стран мира; Есть также ’Australia’ и ’India’, и другие коллекции могут быть определены для конкретной установки. См. Раздел B.4 для получения дополнительной информации.
extra_float_digits (integer)
-
Этот параметр регулирует количество цифр, используемых для текстового вывода значений с плавающей запятой, включая float4, float8 и геометрические.
-
Если значение равно 1 (по умолчанию) или выше, значения с плавающей запятой выводятся в кратчайшем точном формате; см. раздел Типы с плавающей точкой. Фактическое количество генерируемых цифр зависит только от выводимого значения, а не от значения этого параметра. float8 значений float8 требуется не более 17 цифр, а для значений float4 9. Этот формат является быстрым и точным, сохраняя исходное двоичное значение с плавающей точкой точно при правильном чтении. Для исторической совместимости допустимы значения до 3.
-
Если значение равно нулю или отрицательно, то результат округляется до заданной десятичной точности. Используемая точность - это стандартное количество цифр для типа ( FLT_DIG или DBL_DIG в зависимости от ситуации), уменьшенное в соответствии со значением этого параметра. (Например, указание -1 приведет к float4 значения float4 будут округлены до 5 значащих цифр, а значения float8 округлены до 14 цифр). Этот формат медленнее и не сохраняет все биты двоичного значения с плавающей точкой, но может быть больше человек читаемый.
Заметка
см. раздел Типы с плавающей точкой для дальнейшего обсуждения.
client_encoding (string)
- Устанавливает кодировку на стороне клиента (набор символов). По умолчанию используется кодировка базы данных. Наборы символов, поддерживаемые сервером QHB, описаны в разделе Поддерживаемые наборы символов.
lc_messages (string)
-
Устанавливает язык, на котором отображаются сообщения. Допустимые значения зависят от системы; см. раздел Поддержка локали для получения дополнительной информации. Если для этой переменной задана пустая строка (которая является значением по умолчанию), то значение наследуется от среды выполнения сервера системно-зависимым способом.
-
В некоторых системах эта категория локали не существует. Установка этой переменной все равно будет работать, но эффекта не будет. Кроме того, существует вероятность того, что переведенных сообщений на желаемом языке не существует. В этом случае вы будете продолжать видеть английские сообщения.
-
Только суперпользователи могут изменять этот параметр, поскольку он влияет на сообщения, отправляемые в журнал сервера, а также на клиент, и неправильное значение может затенить читаемость журналов сервера.
lc_monetary (string)
- Устанавливает языковой стандарт для форматирования денежных сумм, например, с to_char семейства функций to_char. Допустимые значения зависят от системы; см. раздел Поддержка локали для получения дополнительной информации. Если для этой переменной задана пустая строка (которая является значением по умолчанию), то значение наследуется от среды выполнения сервера системно-зависимым способом.
lc_numeric (string)
- Устанавливает языковой стандарт для форматирования чисел, например, с to_char семейства функций to_char. Допустимые значения зависят от системы; см. раздел Поддержка локали для получения дополнительной информации. Если для этой переменной задана пустая строка (которая является значением по умолчанию), то значение наследуется от среды выполнения сервера системно-зависимым способом.
lc_time (string)
- Устанавливает языковой стандарт для форматирования даты и времени, например, с to_char семейства функций to_char. Допустимые значения зависят от системы; см. раздел Поддержка локали для получения дополнительной информации. Если для этой переменной задана пустая строка (которая является значением по умолчанию), то значение наследуется от среды выполнения сервера системно-зависимым способом.
default_text_search_config (string)
- Выбирает конфигурацию текстового поиска, которая используется теми вариантами функций текстового поиска, у которых нет явного аргумента, определяющего конфигурацию. См. Главу 12 для получения дополнительной информации. Встроенное значение по умолчанию - pg_catalog.simple, но initdb инициализирует файл конфигурации с настройкой, соответствующей выбранной локали lc_ctype, если можно определить конфигурацию, соответствующую этой локали.
Предварительная загрузка общей библиотеки
Для предварительной загрузки общих библиотек на сервер доступно несколько параметров, чтобы загрузить дополнительные функции или повысить производительность. Например, установка ’$libdir/mylib’ приведет к mylib.so (или на некоторых платформах mylib.sl) из каталога стандартной библиотеки установки. Различия между настройками заключаются в том, когда они вступают в силу и какие привилегии требуются для их изменения.
Таким образом можно предварительно ’$libdir/plXXX’ библиотеки процедурного языка QHB, обычно используя синтаксис ’$libdir/plXXX’ где XXX - это pgsql, perl, tcl или python .
Только общие библиотеки, специально предназначенные для использования с QHB, могут быть загружены таким образом. Каждая библиотека, поддерживаемая QHB, имеет «магический блок», который проверяется на совместимость. По этой причине не-QHB библиотеки не могут быть загружены таким образом. Для этого вы можете использовать средства операционной системы, такие как LD_PRELOAD .
В общем, обратитесь к документации конкретного модуля за рекомендуемым способом загрузки этого модуля.
local_preload_libraries (string)
-
Эта переменная указывает одну или несколько общих библиотек, которые должны быть предварительно загружены при запуске подключения. Он содержит разделенный запятыми список имен библиотек, где каждое имя интерпретируется как для команды LOAD. Пробелы между записями игнорируются; окружите имя библиотеки двойными кавычками, если вам нужно включить пробел или запятые в имени. Значение параметра вступает в силу только в начале соединения. Последующие изменения не имеют никакого эффекта. Если указанная библиотека не найдена, попытка подключения завершится неудачно.
-
Эта опция может быть установлена любым пользователем. Из-за этого загружаемые библиотеки ограничены теми, которые появляются в подкаталоге plugins каталога стандартной библиотеки установки. (Администратор базы данных должен убедиться, что там установлены только « безопасные » библиотеки). Записи в local_preload_libraries могут явно указывать этот каталог, например, $libdir/plugins/mylib, или просто указывать имя библиотеки - mylib будет иметь то же самое эффект как $libdir/plugins/mylib .
-
Цель этой функции - позволить непривилегированным пользователям загружать библиотеки отладки или измерения производительности в конкретные сеансы, не требуя явной команды LOAD. Для этого было бы типично установить этот параметр с помощью переменной среды PGOPTIONS на клиенте или с помощью ALTER ROLE SET .
-
Однако, если модуль специально не предназначен для такого использования пользователями, не являющимися суперпользователями, обычно это неправильная настройка для использования. Вместо этого посмотрите на session_preload_libraries .
session_preload_libraries (string)
-
Эта переменная указывает одну или несколько общих библиотек, которые должны быть предварительно загружены при запуске подключения. Он содержит разделенный запятыми список имен библиотек, где каждое имя интерпретируется как для команды LOAD. Пробелы между записями игнорируются; окружите имя библиотеки двойными кавычками, если вам нужно включить пробел или запятые в имени. Значение параметра вступает в силу только в начале соединения. Последующие изменения не имеют никакого эффекта. Если указанная библиотека не найдена, попытка подключения завершится неудачно. Только суперпользователи могут изменять эту настройку.
-
Цель этой функции - позволить библиотекам отладки или измерения производительности загружаться в конкретные сеансы без явной команды LOAD. Например, auto_explain можно включить для всех сеансов с данным именем пользователя, установив этот параметр с помощью ALTER ROLE SET. Кроме того, этот параметр может быть изменен без перезапуска сервера (но изменения вступают в силу только при запуске нового сеанса), поэтому проще добавлять новые модули таким образом, даже если они должны применяться ко всем сеансам.
-
В отличие от shared_preload_libraries, нет большого преимущества в производительности при загрузке библиотеки при запуске сеанса, а не при его первом использовании. Однако при использовании пула соединений есть некоторое преимущество.
shared_preload_libraries (string)
-
Эта переменная указывает одну или несколько общих библиотек, которые должны быть предварительно загружены при запуске сервера. Он содержит разделенный запятыми список имен библиотек, где каждое имя интерпретируется как для команды LOAD. Пробелы между записями игнорируются; окружите имя библиотеки двойными кавычками, если вам нужно включить пробел или запятые в имени. Этот параметр можно установить только при запуске сервера. Если указанная библиотека не найдена, сервер не запустится.
-
Некоторые библиотеки должны выполнять определенные операции, которые могут выполняться только при запуске postmaster, такие как выделение общей памяти, резервирование легких блокировок или запуск фоновых рабочих. Эти библиотеки должны быть загружены при запуске сервера через этот параметр. Подробности смотрите в документации каждой библиотеки.
-
Другие библиотеки также могут быть предварительно загружены. За счет предварительной загрузки общей библиотеки время запуска библиотеки сокращается при первом использовании библиотеки. Однако время запуска каждого нового серверного процесса может немного увеличиться, даже если этот процесс никогда не использует библиотеку. Поэтому этот параметр рекомендуется только для библиотек, которые будут использоваться в большинстве сеансов. Кроме того, изменение этого параметра требует перезапуска сервера, так что, скажем, это неправильная настройка для краткосрочных задач отладки. Вместо этого используйте для этого session_preload_libraries .
Заметка
На хостах Windows предварительная загрузка библиотеки при запуске сервера не сократит время, необходимое для запуска каждого нового процесса сервера; каждый процесс сервера перезагрузит все библиотеки предварительной загрузки. Тем не менее, shared_preload_libraries все еще полезен на хостах Windows для библиотек, которые должны выполнять операции во время запуска postmaster.
jit_provider (string)
-
Эта переменная является именем используемой библиотеки провайдера JIT . По умолчанию используется llvmjit. Этот параметр можно установить только при запуске сервера.
-
Если задана несуществующая библиотека, JIT будет недоступен, но ошибки не возникнет. Это позволяет устанавливать поддержку JIT отдельно от основного пакета QHB .
Другие значения по умолчанию
dynamic_library_path (string)
-
Если необходимо открыть динамически загружаемый модуль и имя файла, указанное в команде CREATE FUNCTION или LOAD, не имеет компонента каталога (т. Е. Имя не содержит косую черту), система будет искать этот путь для поиска требуемого файла.
-
Значение для dynamic_library_path должно быть списком абсолютных путей к каталогам, разделенных двоеточиями (или точками с запятой в Windows). Если элемент списка начинается со специальной строки $libdir, $libdir скомпилированной библиотеки пакетов QHB заменяется на $libdir; Здесь устанавливаются модули, предоставляемые стандартным дистрибутивом QHB. (Используйте pg_config --pkglibdir чтобы узнать имя этого каталога). Например:
dynamic_library_path = '/usr/local/qhb/lib:/home/my_project/lib:$libdir'
-
Значением по умолчанию для этого параметра является ’$libdir’. Если в качестве значения задана пустая строка, автоматический поиск пути отключается.
-
Этот параметр может быть изменен суперпользователями во время выполнения, но настройка, выполненная таким образом, будет сохраняться только до конца клиентского соединения, поэтому этот метод должен быть зарезервирован для целей разработки. Рекомендуемый способ установить этот параметр - в файле конфигурации qhb.conf .
gin_fuzzy_search_limit (integer)
- Мягкий верхний предел размера набора, возвращаемого при сканировании индекса GIN. Для получения дополнительной информации см. раздел GIN советы и хитрости.
Управление блокировками
deadlock_timeout (integer)
-
Это время ожидания блокировки перед проверкой наличия тупиковой ситуации. Проверка на взаимоблокировку является относительно дорогой, поэтому сервер не запускает ее каждый раз, когда ожидает блокировки. Мы с оптимизмом предполагаем, что взаимные блокировки не распространены в рабочих приложениях, и просто подождем некоторое время, прежде чем проверять наличие взаимоблокировок. Увеличение этого значения уменьшает количество времени, затрачиваемого на ненужные проверки взаимоблокировок, но замедляет сообщение о реальных ошибках взаимоблокировок. Если это значение указано без единиц измерения, оно принимается за миллисекунды. Значение по умолчанию составляет одну секунду (1s), что, вероятно, соответствует наименьшему значению, которое вы хотели бы получить на практике. На сильно загруженном сервере вы можете поднять его. В идеале настройка должна превышать ваше типичное время транзакции, чтобы повысить вероятность того, что блокировка будет снята до того, как официант решит проверить тупик. Только суперпользователи могут изменять эту настройку.
-
Когда установлен параметр log_lock_waits, этот параметр также определяет время ожидания, прежде чем будет выдано сообщение журнала об ожидании блокировки. Если вы пытаетесь исследовать задержки блокировки, вы можете установить короче обычного deadlock_timeout .
max_locks_per_transaction (integer)
-
Таблица общих блокировок отслеживает блокировки max_locks_per_transaction * ( max_connections + max_prepared_transactions ) (например, таблиц); следовательно, не больше, чем это множество различных объектов могут быть заблокированы одновременно. Этот параметр контролирует среднее количество блокировок объектов, выделенных для каждой транзакции; отдельные транзакции могут блокировать больше объектов, если блокировки всех транзакций помещаются в таблицу блокировок. Это не количество строк, которые могут быть заблокированы; эта ценность не ограничена. Значение по умолчанию, 64, исторически доказано достаточным, но вам может потребоваться повысить это значение, если у вас есть запросы, которые касаются множества разных таблиц в одной транзакции, например, запрос родительской таблицы с множеством дочерних элементов. Этот параметр можно установить только при запуске сервера.
-
При запуске резервного сервера вы должны установить для этого параметра то же или более высокое значение, чем на главном сервере. В противном случае запросы не будут разрешены на резервном сервере.
max_pred_locks_per_transaction (integer)
- Общая таблица блокировки предикатов отслеживает блокировки max_pred_locks_per_transaction * ( max_connections + max_prepared_transactions ) (например, таблиц); следовательно, не больше, чем это множество различных объектов могут быть заблокированы одновременно. Этот параметр контролирует среднее количество блокировок объектов, выделенных для каждой транзакции; отдельные транзакции могут блокировать больше объектов, если блокировки всех транзакций помещаются в таблицу блокировок. Это не количество строк, которые могут быть заблокированы; эта ценность не ограничена. Стандартное значение 64 обычно достаточно для тестирования, но вам может потребоваться увеличить это значение, если у вас есть клиенты, которые касаются множества разных таблиц в одной сериализуемой транзакции. Этот параметр можно установить только при запуске сервера.
max_pred_locks_per_relation (integer)
- Это контролирует, сколько страниц или кортежей одного отношения может быть заблокировано предикатом, прежде чем блокировка будет повышена до полного отношения. Значения, большие или равные нулю, означают абсолютный предел, а отрицательные значения означают max_pred_locks_per_transaction, деленное на абсолютное значение этого параметра. По умолчанию используется значение -2, которое сохраняет поведение предыдущих версий QHB. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
max_pred_locks_per_page (integer)
- Это контролирует, сколько строк на одной странице может быть заблокировано предикатом, прежде чем блокировка будет повышена до всей страницы. Значение по умолчанию - 2. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
Совместимость версий и платформ
Предыдущие версии QHB
array_nulls (boolean)
-
Определяет, распознает ли входной синтаксический анализатор массива NULL кавычек как указание элемента массива null. По умолчанию это включено, что позволяет вводить значения массива, содержащие нулевые значения.
-
Обратите внимание, что можно создавать значения массива, содержащие нулевые значения, даже если эта переменная off.
backslash_quote (enum)
-
Это определяет, может ли знак кавычки быть представлен \’ в строковом литерале. Предпочтительный стандартный способ представления знака кавычки в SQL - это удвоение его (”), но QHB также принимает \’. Однако использование \’ создает риски безопасности, потому что в некоторых кодировках клиентского набора символов существуют многобайтовые символы, в которых последний байт численно эквивалентен ASCII \. Если код на стороне клиента экранирует некорректно, то возможна атака SQL-инъекцией. Этот риск можно предотвратить, заставив сервер отклонять запросы, в которых знак кавычки, по-видимому, экранирован обратной косой чертой. Допустимые значения backslash_quote : safe_encoding (всегда разрешено), off (всегда отклонено) и безопасное safe_encoding (разрешено только в том случае, если клиентское кодирование не позволяет ASCII \ в многобайтовом символе). safe_encoding является настройкой по умолчанию.
-
Обратите внимание, что в строковом литерале, соответствующем стандарту, в любом случае \ just означает \. Этот параметр влияет только на обработку нестандартных литералов, включая синтаксис escape-строки (E’...’).
escape_string_warning (boolean)
-
Когда включено, выдается предупреждение, если в обычном строковом литерале (’...’ синтаксис) появляется обратная косая черта (\), а standard_conforming_strings выключено. По умолчанию включено.
-
Приложения, которые хотят использовать обратную косую черту в качестве escape, должны быть модифицированы для использования синтаксиса escape-строки (E’...’), потому что поведение обычных строк по умолчанию теперь обрабатывает обратную косую черту как обычный символ в соответствии со стандартом SQL. Эта переменная может быть включена, чтобы помочь найти код, который необходимо изменить.
lo_compat_privileges (boolean)
-
Установка этой переменной в положение on отключает новые проверки привилегий для совместимости с предыдущими выпусками. По умолчанию off. Только суперпользователи могут изменять эту настройку.
-
Установка этой переменной отключает не все проверки безопасности, связанные с большими объектами.
operator_precedence_warning (boolean)
-
Когда он включен, синтаксический анализатор будет выдавать предупреждение для любой конструкции, которая могла бы изменить значения, в результате изменений в приоритетах операторов. Это полезно для аудита приложений, чтобы увидеть, не изменились ли изменения приоритета; но он не предназначен для того, чтобы его оставляли включенным в работе, поскольку он будет предупреждать о каком-то совершенно корректном, стандартно совместимом коде SQL. По умолчанию off .
-
См. раздел Приоритет оператора для получения дополнительной информации.
quote_all_identifiers (boolean)
- Когда база данных генерирует SQL, принудительно заключите в кавычки все идентификаторы, даже если они не являются (в настоящее время) ключевыми словами. Это повлияет на вывод EXPLAIN а также на результаты функций, таких как pg_get_viewdef. Смотрите также параметр --quote-all-identifiers в qhb_dump и qhb_dumpall.
standard_conforming_strings (boolean)
- Контролирует, будут ли обычные строковые литералы (’...’) обрабатывать обратную косую черту буквально, как указано в стандарте SQL. По умолчанию включено. Приложения могут проверить этот параметр, чтобы определить, как будут обрабатываться строковые литералы. Наличие этого параметра также может рассматриваться как указание на то, что синтаксис escape-строки (E’...’) поддерживается. Синтаксис Escape-строки (раздел Строковые константы с экранированием в стиле C) следует использовать, если приложение хочет, чтобы обратные слэши обрабатывались как escape-символы.
synchronize_seqscans (boolean)
Это позволяет синхронизировать друг с другом последовательное сканирование больших таблиц, так что одновременное сканирование считывает один и тот же блок примерно в одно и то же время и, следовательно, разделяет рабочую нагрузку ввода-вывода. Когда это включено, сканирование может начаться в середине таблицы, а затем « обернуться» вокруг конца, чтобы покрыть все строки, чтобы синхронизироваться с активностью сканирований, которые уже выполняются. Это может привести к непредсказуемым изменениям порядка строк, возвращаемых запросами, в которых нет предложения ORDER BY. Отключение этого параметра обеспечивает поведение до 8.3, при котором последовательное сканирование всегда начинается с начала таблицы. По умолчанию включено.
Совместимость платформы и клиента
transform_null_equals (boolean)
-
Когда включено, выражения вида expr = NULL (или NULL = expr) обрабатываются как expr IS NULL, то есть они возвращают true, если expr оценивается как нулевое значение, и false в противном случае. Правильное SQL-совместимое поведение expr = NULL - всегда возвращать ноль (неизвестно). Поэтому этот параметр по умолчанию off .
-
Однако отфильтрованные формы в Microsoft Access генерируют запросы, которые, по-видимому, используют expr = NULL для проверки на нулевые значения, поэтому, если вы используете этот интерфейс для доступа к базе данных, вы можете включить эту опцию. Поскольку выражения вида expr = NULL всегда возвращают нулевое значение (используя стандартную интерпретацию SQL), они не очень полезны и не часто появляются в обычных приложениях, поэтому этот параметр на практике приносит мало вреда. Но новых пользователей часто смущает семантика выражений, содержащих нулевые значения, поэтому по умолчанию эта опция отключена.
-
Обратите внимание, что этот параметр влияет только на точную форму = NULL, но не на другие операторы сравнения или другие выражения, которые в вычислительном отношении эквивалентны некоторому выражению, включающему оператор равенства (например, IN). Таким образом, эта опция не является общим исправлением для плохого программирования.
-
Обратитесь к разделу Функции сравнения и операторы за соответствующей информацией.
Обработка ошибок
exit_on_error (boolean)
- Если включено, любая ошибка прервет текущий сеанс. По умолчанию это отключено, так что только ФАТАЛЬНЫЕ ошибки прервут сеанс.
restart_after_crash (boolean)
- Если установлено значение on, которое используется по умолчанию, QHB автоматически переинициализируется после сбоя бэкэнда. Если оставить это значение включенным, обычно это лучший способ максимизировать доступность базы данных. Однако в некоторых обстоятельствах, например, когда QHB вызывается кластерным программным обеспечением, может быть полезно отключить перезапуск, чтобы кластерное программное обеспечение могло получить контроль и предпринимать любые действия, которые оно сочтет целесообразными.
data_sync_retry (boolean)
-
Если установлено значение off, которое используется по умолчанию, QHB выдаст ошибку уровня PANIC при невозможности сброса измененных файлов данных в файловую систему. Это приводит к сбою сервера базы данных. Этот параметр можно установить только при запуске сервера.
-
В некоторых операционных системах состояние данных в кеше страниц ядра после сбоя обратной записи неизвестно. В некоторых случаях это могло быть полностью забыто, что делает небезопасным повторение; вторая попытка может быть объявлена успешной, когда фактически данные были потеряны. В этих обстоятельствах единственный способ избежать потери данных - это восстановление из WAL после того, как сообщается о любом сбое, предпочтительно после расследования основной причины сбоя и замены любого неисправного оборудования.
-
Если установлено значение on, QHB будет вместо этого сообщать об ошибке, но продолжит работу, чтобы можно было повторить операцию сброса данных на более поздней контрольной точке. Включайте его только после изучения обработки операционной системы буферизованных данных в случае сбоя обратной записи.
Предустановленные параметры
Следующие « параметры » доступны только для чтения и определяются при компиляции QHB или при его установке. Как таковые, они были исключены из примера файла qhb.conf. Эти опции сообщают о различных аспектах поведения QHB, которые могут представлять интерес для определенных приложений, в частности, административных интерфейсов.
block_size (integer)
- Сообщает размер блока диска. Это определяется значением BLCKSZ при сборке сервера. Значение по умолчанию составляет 8192 байта. Значение некоторых переменных конфигурации (например, shared_buffers ) зависит от block_size. См. раздел Потребление ресурсов для информации.
data_checksums (boolean)
- Сообщает, включены ли контрольные суммы данных для этого кластера. Смотрите контрольные суммы данных для получения дополнительной информации.
data_directory_mode (integer)
- В системах Unix этот параметр сообщает о разрешениях каталога данных, определенных (data_directory) при запуске. (В Microsoft Windows этот параметр всегда будет отображать 0700 ). Смотрите групповой доступ для получения дополнительной информации.
debug_assertions (boolean)
- Сообщает, был ли QHB собран с включенными утверждениями. Это тот случай, если макрос USE_ASSERT_CHECKING определен при USE_ASSERT_CHECKING QHB (выполняется, например, с configure параметра configure --enable-cassert ). По умолчанию QHB собран без утверждений.
integer_datetimes (boolean)
- Сообщает, был ли построен QHB с поддержкой 64-битных целых дат и времени. По умолчанию - on.
lc_collate (string)
- Сообщает локаль, в которой выполняется сортировка текстовых данных. См. раздел Поддержка локали для получения дополнительной информации. Это значение определяется при создании базы данных.
lc_ctype (string)
- Сообщает о локали, определяющей классификации персонажей. См. Раздел 23.1 для получения дополнительной информации. Это значение определяется при создании базы данных. Обычно это будет то же самое, что и lc_collate, но для специальных приложений он может быть установлен по-другому.
max_function_args (integer)
- Сообщает максимальное количество аргументов функции. Это определяется значением FUNC_MAX_ARGS при сборке сервера. Значение по умолчанию составляет 100 аргументов.
max_identifier_length (integer)
- Сообщает максимальную длину идентификатора. Он определяется на единицу меньше значения NAMEDATALEN при сборке сервера. Значение по умолчанию NAMEDATALEN - 64; поэтому значение по умолчанию max_identifier_length составляет 63 байта, что может быть меньше 63 символов при использовании многобайтовых кодировок.
max_index_keys (integer)
- Сообщает максимальное количество индексных ключей. Это определяется значением INDEX_MAX_KEYS при сборке сервера. Значение по умолчанию составляет 32 ключа.
segment_size (integer)
- Сообщает о количестве блоков (страниц), которые могут быть сохранены в сегменте файла. Это определяется значением RELSEG_SIZE при сборке сервера. Максимальный размер файла сегмента в байтах равен block_size умноженному на block_size; по умолчанию это 1 ГБ.
server_encoding (string)
- Сообщает кодировку базы данных (набор символов). Определяется при создании базы данных. Обычно клиенты должны иметь дело только со значением client_encoding .
server_version (string)
- Сообщает номер версии сервера. Это определяется значением PG_VERSION при сборке сервера.
server_version_num (integer)
- Сообщает номер версии сервера как целое число. Это определяется значением PG_VERSION_NUM при сборке сервера.
ssl_library (string)
- Сообщает имя библиотеки SSL, с которой был построен этот сервер QHB (даже если SSL в настоящее время не настроен или не используется в этом экземпляре), например OpenSSL, или пустая строка, если ее нет.
wal_block_size (integer)
- Сообщает размер блока диска WAL. Это определяется значением XLOG_BLCKSZ при сборке сервера. Значение по умолчанию составляет 8192 байта.
wal_segment_size (integer)
- Сообщает размер сегментов журнала записи вперед. Значение по умолчанию составляет 16 МБ. См. Раздел 29.4 для получения дополнительной информации.
Индивидуальные параметры
Эта функция была разработана для того, чтобы позволить параметрам, обычно не известным QHB, добавляться дополнительными модулями (такими как процедурные языки). Это позволяет настраивать модули расширения стандартными способами.
У пользовательских параметров есть имена из двух частей: имя расширения, затем точка, затем собственно имя параметра, очень похожее на квалифицированные имена в SQL. Примером является plpgsql.variable_conflict .
Поскольку в процессах, которые не загрузили соответствующий модуль расширения, может потребоваться установка пользовательских параметров, QHB примет настройку для любого имени параметра из двух частей. Такие переменные рассматриваются как заполнители и не имеют функции до тех пор, пока модуль, который их определяет, не будет загружен. Когда модуль расширения загружается, он добавляет свои определения переменных, преобразует любые значения заполнителей в соответствии с этими определениями и выдает предупреждения для любых нераспознанных заполнителей, начинающихся с его имени расширения.
Параметры разработчика
Следующие параметры предназначены для работы с исходным кодом QHB, а в некоторых случаях - для восстановления сильно поврежденных баз данных. Не должно быть никаких причин использовать их в производственной базе данных. Как таковые, они были исключены из примера файла qhb.conf. Обратите внимание, что для многих из этих параметров требуются специальные флаги компиляции исходного кода.
allow_system_table_mods (boolean)
- Позволяет изменять структуру системных таблиц. Это используется initdb. Этот параметр можно установить только при запуске сервера.
ignore_system_indexes (boolean)
- Игнорировать системные индексы при чтении системных таблиц (но все же обновлять индексы при изменении таблиц). Это полезно при восстановлении с поврежденных системных индексов. Этот параметр нельзя изменить после начала сеанса.
post_auth_delay (integer)
- Время задержки при запуске нового серверного процесса после проведения процедуры аутентификации. Это предназначено, чтобы дать разработчикам возможность присоединить к серверу процесс с помощью отладчика. Если это значение указано без единиц измерения, оно принимается за секунды. Нулевое значение (по умолчанию) отключает задержку. Этот параметр нельзя изменить после начала сеанса.
pre_auth_delay (integer)
- Время задержки сразу после того, как новый процесс сервера разветвлен, прежде чем он выполнит процедуру аутентификации. Это предназначено для того, чтобы дать разработчикам возможность подключиться к процессу сервера с помощью отладчика для отслеживания неправильного поведения при аутентификации. Если это значение указано без единиц измерения, оно принимается за секунды. Нулевое значение (по умолчанию) отключает задержку. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
trace_notify (boolean)
- Создает большое количество результатов отладки для команд LISTEN и NOTIFY. client_min_messages или log_min_messages должны быть DEBUG1 или ниже, чтобы отправлять эти выходные данные в журналы клиента или сервера соответственно.
trace_recovery_messages (enum)
- Включает запись результатов отладки, связанных с восстановлением, которые в противном случае не были бы зарегистрированы. Этот параметр позволяет пользователю переопределить обычную настройку log_min_messages, но только для определенных сообщений. Это предназначено для использования при отладке горячего резервирования. Допустимые значения: DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1 и LOG . Значение по умолчанию, LOG, вообще не влияет на решения по протоколированию. Другие значения приводят к тому, что связанные с восстановлением отладочные сообщения этого приоритета или выше регистрируются так, как если бы они имели приоритет LOG; для общих настроек log_min_messages это приводит к безоговорочной отправке их в журнал сервера. Этот параметр можно установить только в файле qhb.conf или в командной строке сервера.
trace_sort (boolean)
- Если включено, выдавать информацию об использовании ресурсов во время операций сортировки. Этот параметр доступен, только если макрос TRACE_SORT был определен при компиляции QHB. (Однако TRACE_SORT в настоящее время определен по умолчанию).
trace_locks (boolean)
- Если включено, выдать информацию об использовании блокировки. Сбрасываемая информация включает тип операции блокировки, тип блокировки и уникальный идентификатор заблокированного или разблокированного объекта. Также включены битовые маски для типов блокировки, уже предоставленных для этого объекта, а также для типов блокировки, ожидаемых для этого объекта. Для каждого типа блокировки также подсчитывается количество предоставленных блокировок и ожидающих блокировок, а также итоговые значения. Пример вывода файла журнала показан здесь:
LOG: LockAcquire: new: lock(0xb7acd844) id(24688,24696,0,0,0,1)
grantMask(0) req(0,0,0,0,0,0,0)=0 grant(0,0,0,0,0,0,0)=0
wait(0) type(AccessShareLock)
LOG: GrantLock: lock(0xb7acd844) id(24688,24696,0,0,0,1)
grantMask(2) req(1,0,0,0,0,0,0)=1 grant(1,0,0,0,0,0,0)=1
wait(0) type(AccessShareLock)
LOG: UnGrantLock: updated: lock(0xb7acd844) id(24688,24696,0,0,0,1)
grantMask(0) req(0,0,0,0,0,0,0)=0 grant(0,0,0,0,0,0,0)=0
wait(0) type(AccessShareLock)
LOG: CleanUpLock: deleting: lock(0xb7acd844) id(24688,24696,0,0,0,1)
grantMask(0) req(0,0,0,0,0,0,0)=0 grant(0,0,0,0,0,0,0)=0
wait(0) type(INVALID)
-
Подробная информация о сбрасываемой структуре может быть найдена в src/include/storage/lock.h
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
trace_lwlocks (boolean)
-
Если включено, выдать информацию об использовании легкого замка. Облегченные блокировки предназначены главным образом для обеспечения взаимного исключения доступа к структурам данных с общей памятью.
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
trace_userlocks (boolean)
-
Если включено, выдать информацию об использовании блокировки пользователя. Вывод такой же, как для trace_locks, только для консультативных блокировок.
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
trace_lock_oidmin (integer)
-
Если установлено, не отслеживайте блокировки для таблиц ниже этого OID. (используйте, чтобы избежать вывода на системные таблицы)
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
trace_lock_table (integer)
-
Безоговорочно проследите блокировки на этой таблице (OID).
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
debug_deadlocks (boolean)
-
Если установлено, выдает информацию обо всех текущих блокировках при возникновении тайм-аута блокировки.
-
Этот параметр доступен только в том случае, если макрос LOCK_DEBUG был определен при компиляции QHB .
log_btree_build_stats (boolean)
-
Если установлено, регистрирует статистику использования системных ресурсов (память и ЦП) для различных операций B-дерева.
-
Этот параметр доступен только в том случае, если макрос BTREE_BUILD_STATS был определен при компиляции QHB .
wal_consistency_checking (string)
-
Этот параметр предназначен для проверки ошибок в процедурах повторного выполнения WAL. Когда этот параметр включен, полностраничные изображения любых буферов, измененных вместе с записью WAL, добавляются в запись. Если запись впоследствии воспроизводится, система сначала применяет каждую запись, а затем проверяет, соответствуют ли буферы, измененные записью, сохраненным изображениям. В некоторых случаях (например, биты подсказок) допустимы незначительные изменения, которые будут игнорироваться. Любые неожиданные различия приведут к фатальной ошибке, что приведет к прекращению восстановления.
-
Значением этого параметра по умолчанию является пустая строка, которая отключает эту функцию. Для проверки всех записей может быть установлено значение all или список менеджеров ресурсов, разделенный запятыми, для проверки только тех записей, которые исходят от этих менеджеров ресурсов. В настоящее время поддерживаются следующие менеджеры ресурсов: heap, heap2, btree, hash, gin, gist, sequence, spgist, brin и generic. Только суперпользователи могут изменять эту настройку.
wal_debug (boolean)
- Если включено, выдает отладочный вывод, связанный с WAL. Этот параметр доступен только в том случае, если макрос WAL_DEBUG был определен при компиляции QHB .
ignore_checksum_failure (boolean)
-
Имеет эффект только если контрольные суммы данных включены.
-
Обнаружение ошибки контрольной суммы во время чтения обычно заставляет QHB сообщать об ошибке, прерывая текущую транзакцию. Если для параметра ignore_checksum_failure установлено ignore_checksum_failure on, система игнорирует ошибку (но все равно ignore_checksum_failure предупреждение) и продолжает обработку. Такое поведение может вызвать сбои, распространение или скрытие коррупции или других серьезных проблем. Тем не менее, это может позволить вам обойти ошибку и извлечь неповрежденные кортежи, которые все еще могут присутствовать в таблице, если заголовок блока все еще в здравом уме. Если заголовок поврежден, будет сообщено об ошибке, даже если эта опция включена. Настройка по умолчанию off, и она может быть изменена только суперпользователем.
zero_damaged_pages (boolean)
- Обнаружение поврежденного заголовка страницы обычно заставляет QHB сообщать об ошибке, прерывая текущую транзакцию. Если для параметра zero_damaged_pages установлено zero_damaged_pages on, система вместо этого отправит предупреждение, zero_damaged_pages поврежденную страницу в памяти и продолжит обработку. Такое поведение уничтожит данные, а именно все строки на поврежденной странице. Однако он позволяет обойти ошибку и извлечь строки из любых неповрежденных страниц, которые могут присутствовать в таблице. Это полезно для восстановления данных, если произошло повреждение из-за аппаратной или программной ошибки. Обычно вы не должны устанавливать это, пока не оставите надежду восстановить данные с поврежденных страниц таблицы. Страницы с нулевым удалением не записываются на диск, поэтому рекомендуется заново создать таблицу или индекс, прежде чем снова отключить этот параметр. Настройка по умолчанию off, и она может быть изменена только суперпользователем.
jit_debugging_support (boolean)
- Если LLVM обладает необходимой функциональностью, зарегистрируйте сгенерированные функции в GDB. Это облегчает отладку. Настройка по умолчанию off. Этот параметр можно установить только при запуске сервера.
jit_dump_bitcode (boolean)
- Записывает сгенерированный IR LLVM в файловую систему внутри data_directory. Это полезно только для работы над внутренними компонентами реализации JIT. Настройка по умолчанию off. Этот параметр может быть изменен только суперпользователем.
jit_expressions (boolean)
- Определяет, скомпилированы ли выражения JIT, когда JIT-компиляция активирована . По умолчанию включено.
jit_profiling_support (boolean)
- Если LLVM обладает необходимой функциональностью, отправьте данные,
необходимые для разрешения функции профилирования, сгенерированной
JIT. Это записывает файлы в
$HOME/.debug/jit/; пользователь несет ответственность за выполнение очистки при желании. Настройка по умолчанию off. Этот параметр можно установить только при запуске сервера.
jit_tuple_deforming (boolean)
- Определяет, деформируется ли кортеж JIT, когда JIT-компиляция активирована . По умолчанию включено.
Сокращения командной строки
Для удобства имеются также однобуквенные параметры командной строки, доступные для некоторых параметров. Они описаны в таблице 4.2 . Некоторые из этих опций существуют по историческим причинам, и их наличие в виде однобуквенной опции не обязательно означает одобрение использования этой опции.
Таблица 2. Короткий ключ
| Короткий вариант | Эквивалент |
|---|---|
| -B x | shared_buffers = x |
| -d x | log_min_messages = DEBUG x |
| -e | datestyle = euro |
| -fb, -fb, -fh, -fm, -fn, -fo, -fs, -ft | enable_bitmapscan = off, enable_hashjoin = off, enable_indexscan = off, enable_mergejoin = off, enable_nestloop = off, enable_indexonlyscan = off, enable_seqscan = off, enable_tidscan = off |
| -F | fsync = off |
| -h x | listen_addresses = x |
| -i | listen_addresses = ’*’ |
| -k x | unix_socket_directories = x |
| -l | ssl = on |
| -N x | max_connections = x |
| -O | allow_system_table_mods = on |
| -p x | port = x |
| -P | ignore_system_indexes = on |
| -s | log_statement_stats = on |
| -S x | work_mem = x |
| -tpa, -tpl, -te | log_parser_stats = on log_planner_stats = on, log_executor_stats = on, log_executor_stats = on |
| -W x | post_auth_delay = x |
Советы по производительности
На производительность запроса могут влиять многие факторы. Некоторые из них могут контролироваться пользователем, в то время как другие имеют основополагающее значение для базовой структуры системы. В этой главе даются некоторые советы по пониманию и настройке производительности QHB.
- Создание демонстрационных таблиц
- Использование EXPLAIN
- Статистика, используемая планировщиком
- Управление планировщиком с помощью явных предложений JOIN
- Заполнение базы данных
- Настройки снижающие надежность
Создание демонстрационных таблиц
Для создания демонстрационных таблиц используйте команды :
CREATE TABLE tenk1 (
unique1 int4,
unique2 int4,
two int4,
four int4,
ten int4,
twenty int4,
hundred int4,
thousand int4,
twothousand int4,
fivethous int4,
tenthous int4,
odd int4,
even int4,
stringu1 name,
stringu2 name,
string4 name
);
CREATE TABLE tenk2 (
unique1 int4,
unique2 int4,
two int4,
four int4,
ten int4,
twenty int4,
hundred int4,
thousand int4,
twothousand int4,
fivethous int4,
tenthous int4,
odd int4,
even int4,
stringu1 name,
stringu2 name,
string4 name
);
CREATE TABLE onek (
unique1 int4,
unique2 int4,
two int4,
four int4,
ten int4,
twenty int4,
hundred int4,
thousand int4,
twothousand int4,
fivethous int4,
tenthous int4,
odd int4,
even int4,
stringu1 name,
stringu2 name,
string4 name
);
Для заполнения используйте SQL команды из приложения Данные для анализа производительности
ВНИМАНИЕ!!!
Приведённый выше файл, содержащий демонстрационные данные для анализа производительности, довольно большого размера и открытие его для просмотра и попытка выполнить, находящиеся в нём команды при помощи графических утилит может занять значительное время и закончится ошибкой поэтому рекомендуется скачать файл на диск и использовать утилиту qsql для загрузки данных из интерфейса командной строки.
После загрузки данных необходимо выполнить заполнение таблицы и создание необходимых индексов при помощи команд :
INSERT INTO tenk2 SELECT * FROM tenk1;
CREATE INDEX tenk1_unique1 ON tenk1 USING btree(unique1 int4_ops);
CREATE INDEX tenk1_unique2 ON tenk1 USING btree(unique2 int4_ops);
CREATE INDEX tenk1_hundred ON tenk1 USING btree(hundred int4_ops);
CREATE INDEX tenk1_thous_tenthous ON tenk1 (thousand, tenthous);
CREATE INDEX tenk2_unique1 ON tenk2 USING btree(unique1 int4_ops);
CREATE INDEX tenk2_unique2 ON tenk2 USING btree(unique2 int4_ops);
CREATE INDEX tenk2_hundred ON tenk2 USING btree(hundred int4_ops);
CREATE INDEX onek_unique1 ON onek USING btree(unique1 int4_ops);
CREATE INDEX IF NOT EXISTS onek_unique1 ON onek USING btree(unique1 int4_ops);
CREATE INDEX IF NOT EXISTS ON onek USING btree(unique1 int4_ops);
CREATE INDEX onek_unique2 ON onek USING btree(unique2 int4_ops);
CREATE INDEX onek_hundred ON onek USING btree(hundred int4_ops);
CREATE INDEX onek_stringu1 ON onek USING btree(stringu1 name_ops);
Теперь необходим провести очистку таблиц при помощи комманд :
vacuum analyze tenk1;
vacuum analyze tenk2;
vacuum analyze onek;
Таблицы созданы и заполнены
Выполняя примеры запросов приведённые ниже в этом разделе вы сможете получить аналогичные результаты, но ваши предполагаемые оценки затрат (COST) и количества строк могут незначительно отличаться, потому что статистика ANALYZE является случайной выборкой, а не точной, и поскольку оценки затрат по своей природе в некоторой степени зависят от платформы.
Использование EXPLAIN
QHB строит план запросов для каждого запроса, который получен от пользователя. Выбор правильного плана, соответствующего структуре запроса и свойствам данных, абсолютно необходим для хорошей производительности, поэтому в систему входит комплексный планировщик, который пытается выбрать хорошие планы. Вы можете использовать команду EXPLAIN, чтобы увидеть, какой план запроса создает планировщик для любого запроса. Чтение планов - это искусство, которое требует некоторого опыта, чтобы овладеть им, и в этом разделе описаны только основы.
В примерах используется стандартный текстовый формат EXPLAIN, который компактен и удобен для чтения человеком. Если вы хотите передать выходные данные EXPLAIN в программу для дальнейшего анализа, вы должны использовать вместо этого один из машиночитаемых форматов вывода (XML, JSON или YAML).
EXPLAIN Основы
Структура плана запроса представляет собой дерево узлов плана. Узлы на самом нижнем уровне дерева являются узлами сканирования: они возвращают необработанные строки из таблицы. Существуют разные типы узлов сканирования для разных методов доступа к таблице: последовательное сканирование (sequential scans), индексное сканирование (index scans) и индексное сканирование битовых карт (bitmap index scans). В части SQL запроса после FROM есть также источники строк, не являющиеся таблицами, такие как предложения VALUES и функции, возвращающие наборы, которые имеют свои собственные типы узлов сканирования. Если запрос требует объединения, агрегирования, сортировки или других операций с необработанными строками, то над узлами сканирования будут дополнительные узлы для выполнения этих операций. Опять же, как правило, существует несколько возможных способов выполнения этих операций, поэтому и здесь могут появляться разные типы узлов. Вывод EXPLAIN содержит одну строку для каждого узла в дереве плана, показывая базовый тип узла плюс оценки затрат, которые планировщик сделал для выполнения этого узла плана. Могут появиться дополнительные строки с отступом от итоговой строки узла, чтобы показать дополнительные свойства узла. Самая первая строка (итоговая строка для самого верхнего узла) содержит приблизительную общую стоимость выполнения плана (COST) - именно это число планировщик стремится свести к минимуму.
Вот простой пример, чтобы показать, как выглядит результат:
EXPLAIN SELECT * FROM tenk1;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..445.00 rows=10000 width=244)
Поскольку в этом запросе нет WHERE, необходимо просматривать все строки таблицы, поэтому планировщик решил использовать простой план последовательного сканирования (Seq Scan). Числа после (слева направо):
-
cost=0.00..445.00 rows=10000 width=244
Ориентировочная стоимость запуска. Это время, затрачиваемое до начала фазы вывода, например, время на выполнение сортировки в узле сортировки. -
cost=0.00..445.00 rows=10000 width=244
Ориентировочная общая стоимость. Предполагается, что узел плана выполнен до конца, то есть извлечены все доступные строки. На практике родительский узел может прервать чтение всех доступных строк (см. Пример LIMIT ниже). -
cost=0.00..445.00 rows=10000 width=244
Расчетное количество строк, выводимых этим узлом плана. Опять же, предполагается, что узел полностью выполнился. -
cost=0.00..445.00 rows=10000 width=244
Расчетная средняя "ширина" строк, выводимых этим узлом плана (в байтах).
Затраты измеряются в произвольных единицах, определяемых параметрами затрат планировщика (см. раздел Константы стоимости планировщика). Как правило затрат выборки чтение страниц с диска то есть параметр seq_page_cost обычно устанавливается равным 1.0, а другие параметры стоимости устанавливаются относительно него. Примеры в этом разделе выполняются с параметрами стоимости по умолчанию.
Важно понимать, что стоимость узла верхнего уровня включает стоимость всех его дочерних узлов. Также важно понимать, что стоимость отражает только то, что интересует планировщик. В частности, стоимость не учитывает время, потраченное на передачу строк результатов клиенту, что может быть важным фактором в реальном окружении, но планировщик игнорирует это, потому что он не может скорректировать эту величину, изменив план. (Считается, что каждый правильный план будет выводить один и тот же набор строк).
Значение rows немного сложнее, потому что это не количество строк, обработанных или отсканированных узлом плана, а число, выдаваемое узлом. Это число часто меньше, чем число сканируемых строк, в результате фильтрации по любым условиям WHERE условия, которые применяются на узле. В идеальном случае оценка строк верхнего уровня будет приблизительно соответствовать количеству строк, фактически возвращенных, обновленных или удаленных запросом.
Возвращаясь к нашему примеру:
EXPLAIN SELECT * FROM tenk1;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..445.00 rows=10000 width=244)
Эти числа получены очень просто. Если вы делаете:
SELECT relpages, reltuples FROM pg_class WHERE relname = 'tenk1';
вы обнаружите, что tenk1 имеет 345 страниц на диске и 10000 строк. Ориентировочная стоимость рассчитывается как (disk pages read * seq_page_cost ) + (rows scanned * cpu_tuple_cost ). По умолчанию seq_page_cost равно 1,0, а cpu_tuple_cost равно 0,01, поэтому предполагаемая стоимость составляет (445 * 1,0) + (10000 * 0,01) = 445.
Теперь давайте изменим запрос, добавив условие WHERE :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 7000;
QUERY PLAN
------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..470.00 rows=7000 width=244)
Filter: (unique1 < 7000)
(2 rows)
Обратите внимание, что вывод EXPLAIN показывает WHERE, применяемое в качестве условия Filter, присоединённого к узлу плана Seq Scan. Это означает, что узел плана проверяет условие для каждой сканируемой строки и выводит только те, которые подходят под условие. Оценка количества выходных строк была уменьшена из-за WHERE. Тем не менее,все равно придется просмотреть все 10000 строк, поэтому стоимость не снизилась; на самом деле он немного увеличилась (на 10000 * cpu_operator_cost, если точно), чтобы отразить дополнительное время ЦП, затраченное на проверку условия WHERE .
Фактическое количество строк, которое выберет этот запрос, равно 7000, но оценка количества rows только приблизительная. Если вы попытаетесь повторить этот эксперимент, вы, вероятно, получите немного другую оценку - более того, он может меняться после каждой команды ANALYZE, потому что статистика, полученная с помощью ANALYZE для таблицы, берется из случайной выборки строк.
Теперь давайте сделаем условие более ограничительным:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0)
Index Cond: (unique1 < 100)
(4 rows)
Здесь планировщик решил использовать двухэтапный план: дочерний узел плана просматривает индекс, чтобы найти местоположене строк в страницах таблицы, соответствующих условию индекса, а затем родительский узел плана фактически выбирает эти строки из самой таблицы. Извлечение строк по отдельности намного дороже, чем их последовательное чтение, но поскольку не все страницы таблицы нужно считывать, это все же дешевле, чем последовательное сканирование. (Причина использования двух уровней плана состоит в том, что узел верхнего плана сортирует местоположения строк, идентифицированные индексом, в некторый физический порядок перед их чтением, чтобы минимизировать стоимость отдельных выборок. Bitmap Index Scan, упомянутый в имени узлоа, - это и есть механизм, который выполняет сортировку).
Теперь давайте добавим еще одно условие к WHERE :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND stringu1 = 'xxx';
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=5.04..225.20 rows=1 width=244)
Recheck Cond: (unique1 < 100)
Filter: (stringu1 = 'xxx'::name)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0)
Index Cond: (unique1 < 100)
(5 rows)
Добавленное условие stringu1 = 'xxx' уменьшает оценку количества
выходных строк, но не стоимость, потому что нам все еще приходится
считывать тот же набор строк. Обратите внимание, что столбец stringu1
нельзя применять для использования индекса, поскольку этот индекс
только для столбца unique1. Вместо этого он применяется в качестве
фильтра для строк, извлекаемых индексом. Таким образом, стоимость
фактически немного увеличилась, чтобы отразить эту дополнительную
проверку.
В некоторых случаях планировщик предпочтет « простой » план сканирования индекса Index Scan :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 = 42;
QUERY PLAN
-----------------------------------------------------------------------------
Index Scan using tenk1_unique1 on tenk1 (cost=0.29..8.30 rows=1 width=244)
Index Cond: (unique1 = 42)
(2 rows)
В этом плане строки таблицы выбираются при помощи индекса, что делает их еще более дорогими для чтения, но их так мало, что дополнительные затраты на сортировку местоположений строк не изменят производительность. Чаще всего план такого типа используется для запросов, которые выбирают только одну строку. Он также часто используется для запросов, которые имеют условие ORDER BY, соответствующее порядку индекса, потому что тогда не требуется никакого дополнительного шага сортировки для выполнения сортировки указанной в ORDER BY .
Если в нескольких столбцах, на которые есть ссылки в WHERE, имеются отдельные индексы, планировщик может выбрать использование комбинации индексов AND или OR:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000;
QUERY PLAN
-------------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=25.07..60.11 rows=10 width=244)
Recheck Cond: ((unique1 < 100) AND (unique2 > 9000))
-> BitmapAnd (cost=25.07..25.07 rows=10 width=0)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0)
Index Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique2 (cost=0.00..19.78 rows=999 width=0)
Index Cond: (unique2 > 9000)
(7 rows)
Такой план требует чтения из обоих индексов, поэтому он не обязательно даст выигрыш по сравнению с использованием только одного индекса и обработкой другого условия как фильтра. Если вы измените соответствующие диапазоны, вы увидите, что план изменится соответствующим образом.
Вот пример, показывающий влияние LIMIT :
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2;
QUERY PLAN
-------------------------------------------------------------------------------------
Limit (cost=0.29..14.28 rows=2 width=244)
-> Index Scan using tenk1_unique2 on tenk1 (cost=0.29..70.27 rows=10 width=244)
Index Cond: (unique2 > 9000)
Filter: (unique1 < 100)
(4 rows)
Это тот же запрос, что и выше, но мы добавили LIMIT чтобы не все строки были извлечены, и планировщик передумал, это делать. Обратите внимание, что общая стоимость и количество строк узла сканирования индекса (Index Scan) отображаются так, как если бы он был выполнен до конца. Однако ожидается, что узел Limit остановится после получения только одной пятой из этих строк, поэтому его общая стоимость составляет всего одну пятую, и это фактическая оценочная стоимость запроса. Этот план предпочтительнее, чем добавление узла Limit к предыдущему плану, потому что Limit не мог избежать начальной стоимости Bitmap Index Scan, поэтому общая стоимость, при таком подходе, будет примерно 14 единиц.
Давайте попробуем объединить две таблицы, используя столбцы, которые мы обсуждали:
EXPLAIN SELECT *
FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 10 AND t1.unique2 = t2.unique2;
QUERY PLAN
--------------------------------------------------------------------------------------
Nested Loop (cost=4.65..118.50 rows=10 width=488)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.38 rows=10 width=244)
Recheck Cond: (unique1 < 10)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0)
Index Cond: (unique1 < 10)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..7.90 rows=1 width=244)
Index Cond: (unique2 = t1.unique2)
(7 rows)
В этом плане у нас есть узел соединения с вложенным циклом (Nested Loop) с двумя
дочерними сканированиями таблиц (tenk1 t1 и tenk2 t2) в качестве входных. Отступ
строки сводки узла отражает структуру дерева плана. Первый, или «внешний»,
дочерний объект объединения - это Bitmap Index Scan, похожее на
то, что мы видели ранее. Его стоимость и количество строк такие же, как
мы получили бы из SELECT ... WHERE unique1 < 10 потому что мы
применяем WHERE unique1 <> 10 для этого узла. Предложение t1.unique2 =
t2.unique2 пока не актуально, поэтому оно не влияет на количество строк
внешнего сканирования. Узел соединения с вложенным циклом (Nested Loop) будет
запускать свой второй или «внутренний» дочерний элемент один раз для
каждой строки, полученной из внешнего дочернего элемента. Значения
столбцов из текущего внешней строки могут быть включены во внутреннее
сканирование; здесь доступно значение t1.unique2 из внешней строки,
поэтому мы получаем план и затраты, аналогичные тем, что мы видели выше
для простого случая SELECT ... WHERE t2.unique2 = constant.
(Предполагаемая стоимость на самом деле немного ниже, чем было показано
выше, в результате кэширования, которое, как ожидается, произойдет во
время повторного сканирования индекса в t2 ). Затем стоимость узла цикла
устанавливается на основе стоимости внешнего сканирование, плюс одно
повторение внутреннего сканирования для каждой внешней строки (это 10 *
7,90), а также немного процессорного времени для обработки
соединения.
В этом примере число выходных строк в соединении совпадает с произведением количества строк в двух сканированиях, но это почти всегда не так, потому что могут быть дополнительные WHERE которые упоминают обе таблицы и поэтому могут применяться только в точке соединения, а не для входного сканирования. Вот пример:
EXPLAIN SELECT *
FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 10 AND t2.unique2 < 10 AND t1.hundred < t2.hundred;
QUERY PLAN
---------------------------------------------------------------------------------------------
Nested Loop (cost=4.65..49.36 rows=33 width=488)
Join Filter: (t1.hundred < t2.hundred)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.38 rows=10 width=244)
Recheck Cond: (unique1 < 10)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0)
Index Cond: (unique1 < 10)
-> Materialize (cost=0.29..8.51 rows=10 width=244)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..8.46 rows=10 width=244)
Index Cond: (unique2 < 10)
(9 rows)
Условие t1.hundred < t2.hundred не может быть проверено в индексе tenk2_unique2, поэтому оно применяется на узле соединения. Это уменьшает приблизительное количество выходных строк узла соединения, но не изменяет ни сканирование в дочерних узлах.
Обратите внимание, что здесь планировщик решил «материализовать» внутреннее отношение объединения, поместив поверх него узел плана Materialize. Это означает, что сканирование индекса t2 будет выполнено только один раз, даже если узел соединения с вложенным циклом должен прочитать эти данные десять раз, по одному разу для каждой строки из внешнего отношения. Узел Materialise сохраняет данные в памяти при чтении, а затем возвращает данные из памяти при каждом последующем проходе.
При работе с внешними объединениями вы можете увидеть узлы плана соединения с присоединенными фильтром объединения Join Filter . Условия фильтра объединения взяты из предложения ON внешнего соединения, поэтому строка, которая не соответствует условию фильтра соединения, все равно может быть выдана как строка с нулевым расширением.
Если мы немного изменим избирательность запроса, мы можем получить совсем другой план соединения:
EXPLAIN SELECT *
FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2;
QUERY PLAN
------------------------------------------------------------------------------------------
Hash Join (cost=226.23..709.73 rows=100 width=488)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244)
-> Hash (cost=224.98..224.98 rows=100 width=244)
-> Bitmap Heap Scan on tenk1 t1 (cost=5.06..224.98 rows=100 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0)
Index Cond: (unique1 < 100)
(8 rows)
Здесь планировщик выбрал использование хэш-соединения, в котором строки одной таблицы заносятся в хэш-таблицу в памяти, после чего сканируется другая таблица и проверяется на совпадение каждой строки в хэш-таблице. Снова обратите внимание, как отступ отражает структуру плана: Bitmap Heap Scan on tenk1 является входом для узла Hash, который построил хеш-таблицу для tenk1 Затем он возвращается в узел Hash Join, который читает строки из своего внешнего дочернего плана и ищет в каждой хеш-таблице.
Другой возможный тип объединения - это соединение слиянием, показанное здесь:
EXPLAIN SELECT *
FROM tenk1 t1, onek t2
WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2;
QUERY PLAN
------------------------------------------------------------------------------------------
Merge Join (cost=95.11..164.54 rows=10 width=488)
Merge Cond: (t1.unique2 = t2.unique2)
-> Index Scan using tenk1_unique2 on tenk1 t1 (cost=0.29..643.28 rows=100 width=244)
Filter: (unique1 < 100)
-> Sort (cost=94.83..97.33 rows=1000 width=244)
Sort Key: t2.unique2
-> Seq Scan on onek t2 (cost=0.00..45.00 rows=1000 width=244)
(7 rows)
Объединение слиянием (Merge Join) требует, чтобы его входные данные были отсортированы по ключам объединения. В этом плане данные tenk1 сортируются с использованием сканирования индекса для обхода строк в правильном порядке, но для onek предпочтительнее последовательное сканирование (Seq Scan) и сортировка (Sort), поскольку в этой таблице нужно посетить еще много строк. (Последовательное сканирование-сортировка часто превосходит сканирование индекса для сортировки множества строк из-за непоследовательного доступа к диску, необходимого для сканирования индекса).
Один из способов посмотреть на варианты планов - заставить планировщика игнорировать любую стратегию, которая, по его мнению, была самой дешевой, используя флаги включения / выключения, описанные в разделе Конфигурация метода планирования. (Это грубый, но полезный инструмент см. также раздел Управление планировщиком с помощью явных предложений JOIN). Например, если мы не уверены, что последовательное сканирование и сортировка - лучший способ справиться с таблицей onek в предыдущем примере, мы можем попробовать
SET enable_sort = off;
EXPLAIN SELECT *
FROM tenk1 t1, onek t2
WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2;
QUERY PLAN
------------------------------------------------------------------------------------------
Hash Join (cost=226.23..275.08 rows=10 width=488)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on onek t2 (cost=0.00..45.00 rows=1000 width=244)
-> Hash (cost=224.98..224.98 rows=100 width=244)
-> Bitmap Heap Scan on tenk1 t1 (cost=5.06..224.98 rows=100 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0)
Index Cond: (unique1 < 100)
(8 rows)
что показывает, что планировщик считает, что сортировка onek помощью сканирования по индексу примерно на 12% дороже, чем последовательное сканирование и сортировка. Конечно, следующий вопрос - правильно ли это? Мы можем исследовать это, используя EXPLAIN ANALYZE, как описано ниже.
EXPLAIN ANALYZE
Можно проверить точность оценок планировщика, используя опцию EXPLAIN ’s ANALYZE. С помощью этой опции EXPLAIN фактически выполняет запрос, а затем отображает истинное количество строк и истинное время выполнения, накопленные в каждом узле плана, а также те же оценки, которые показывает обычный EXPLAIN. Например, мы можем получить такой результат:
EXPLAIN ANALYZE SELECT *
FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 10 AND t1.unique2 = t2.unique2;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=4.65..118.50 rows=10 width=488) (actual time=0.108..0.406 rows=10 loops=1)
-> Bitmap Heap Scan on tenk1 t1 (cost=4.36..39.38 rows=10 width=244) (actual time=0.061..0.135 rows=10 loops=1)
Recheck Cond: (unique1 < 10)
Heap Blocks: exact=10
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..4.36 rows=10 width=0) (actual time=0.038..0.038 rows=10 loops=1)
Index Cond: (unique1 < 10)
-> Index Scan using tenk2_unique2 on tenk2 t2 (cost=0.29..7.90 rows=1 width=244) (actual time=0.022..0.023 rows=1 loops=10)
Index Cond: (unique2 = t1.unique2)
Planning Time: 0.953 ms
Execution Time: 0.517 ms
(10 rows)
Обратите внимание, что значения «фактического времени» actual time приведены в миллисекундах реального времени, тогда как оценки cost выражены в произвольных единицах; поэтому они вряд ли совпадают. Обычно наиболее важно искать, достаточно ли приблизительное число строк соответствует действительности. В этом примере все оценки были точными, но на практике это довольно необычно.
В некоторых планах запросов узел подплана может выполняться более одного раза. Например, сканирование внутреннего индекса будет выполняться один раз для каждой внешней строки в приведенном выше плане вложенного цикла. В таких случаях значение цикла сообщает об общем количестве выполнений узла, а показанные фактические значения времени и строк представляют собой средние значения для каждого выполнения. Это сделано для того, чтобы сделать числа сопоставимыми с тем, как отображаются оценки затрат. Умножьте на значение цикла, чтобы получить общее время, фактически потраченное на узел. В приведенном выше примере мы потратили 0,220 миллисекунды на выполнение сканирования индекса на tenk2 .
В некоторых случаях EXPLAIN ANALYZE показывает дополнительную статистику выполнения помимо времени выполнения узла плана и количества строк. Например, узлы Sort и Hash предоставляют дополнительную информацию:
EXPLAIN ANALYZE SELECT *
FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2 ORDER BY t1.fivethous;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=713.05..713.30 rows=100 width=488) (actual time=4.184..4.195 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
-> Hash Join (cost=226.23..709.73 rows=100 width=488) (actual time=0.387..4.019 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.011..1.688 rows=10000 loops=1)
-> Hash (cost=224.98..224.98 rows=100 width=244) (actual time=0.350..0.350 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 35kB
-> Bitmap Heap Scan on tenk1 t1 (cost=5.06..224.98 rows=100 width=244) (actual time=0.039..0.300 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
Heap Blocks: exact=90
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) (actual time=0.022..0.022 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning Time: 1.542 ms
Execution Time: 4.327 ms
(15 rows)
Узел Sort показывает используемый метод сортировки (в частности, была ли сортировка в памяти или на диске) и необходимый объем памяти или дискового пространства. Узел Hash показывает количество хэш-партиций и пакетов, а также пиковый объем памяти, используемый для хэш-таблицы. (Если количество пакетов превышает единицу, также будет задействовано использование дискового пространства, но это не показано).
Другой тип дополнительной информации - это количество строк, удаленных условием фильтра:
EXPLAIN ANALYZE SELECT * FROM tenk1 WHERE ten < 7;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..470.00 rows=7000 width=244) (actual time=0.038..42.547 rows=7000 loops=1)
Filter: (ten < 7)
Rows Removed by Filter: 3000
Planning Time: 0.176 ms
Execution Time: 43.762 ms
(5 rows)
Эти подсчеты могут быть особенно полезны для условий фильтрации, применяемых в узлах соединения. Строка «Rows Removed» появляется только тогда, когда хотя бы одна отсканированная строка или пара возможных соединений в случае узла соединения отклонена условием фильтрации.
У EXPLAIN есть опция BUFFERS которую можно использовать с ANALYZE для получения еще большей статистики времени выполнения:
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=25.07..60.11 rows=10 width=244) (actual time=0.964..1.033 rows=10 loops=1)
Recheck Cond: ((unique1 < 100) AND (unique2 > 9000))
Heap Blocks: exact=10
Buffers: shared hit=14 read=3
-> BitmapAnd (cost=25.07..25.07 rows=10 width=0) (actual time=0.942..0.943 rows=0 loops=1)
Buffers: shared hit=4 read=3
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) (actual time=0.056..0.056 rows=100 loops=1)
Index Cond: (unique1 < 100)
Buffers: shared hit=2
-> Bitmap Index Scan on tenk1_unique2 (cost=0.00..19.78 rows=999 width=0) (actual time=0.863..0.863 rows=999 loops=1)
Index Cond: (unique2 > 9000)
Buffers: shared hit=2 read=3
Planning Time: 0.400 ms
Execution Time: 1.113 ms
(14 rows)
Число BUFFERS помогает определить, какие части запроса наиболее интенсивны при вводе-выводе.
Имейте в виду, что поскольку EXPLAIN ANALYZE фактически выполняет запрос, любые побочные эффекты будут происходить как и при обычном выполнении запроса, даже если любые результаты, которые может выдать запрос, будут отброшены и вместо них выводится EXPLAIN. Если вы хотите проанализировать запрос на изменение данных без изменения таблиц, вы можете откатить команду позже, например:
BEGIN;
EXPLAIN ANALYZE UPDATE tenk1 SET hundred = hundred + 1 WHERE unique1 < 100;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Update on tenk1 (cost=5.07..229.46 rows=101 width=250) (actual time=14.628..14.628 rows=0 loops=1)
-> Bitmap Heap Scan on tenk1 (cost=5.07..229.46 rows=101 width=250) (actual time=0.101..0.439 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.043..0.043 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.079 ms
Execution time: 14.727 ms
ROLLBACK;
Как видно из этого примера, когда запрос представляет собой команду INSERT, UPDATE или DELETE, фактическая работа по изменению данных таблицы выполняется узлом плана INSERT, UPDATE или DELETE. Узлы плана под этим узлом выполняют поиск строк и / или вычисляют новые данные. Итак, выше мы видим тот же Bitmap Index Scan, который мы уже видели, и его выходные данные передаются в узел update, в котором хранятся обновленные строки. Стоит отметить, что хотя узел, модифицирующий данные, может выполнятся значительное время (в этом примере он занимает основную долю времени) выполнения, планировщик в настоящее время ничего не добавляет к оценкам затрат для учета этой работы. Это связано с тем, что выполняемая работа одинакова для каждого правильного плана запроса, поэтому она не влияет на решения по планированию.
Предостережения
Существует два основных случая, когда время выполнения, измеренное с помощью EXPLAIN ANALYZE может отличаться от нормального выполнения того же запроса. Во-первых, поскольку выходные строки не доставляются клиенту, затраты на передачу по сети и затраты на преобразование ввода / вывода не включены. Во-вторых, накладные расходы на измерения, добавленные EXPLAIN ANALYZE могут быть значительными, особенно на машинах с медленными системными вызовами операционной системы gettimeofday().
Результаты EXPLAIN не следует экстраполировать на ситуации, сильно отличающиеся от тех, которые вы фактически проверяете, например, нельзя предполагать, что результаты на таблице с крошечным количеством тестовых данных применимы к большим таблицам. Оценки стоимости планировщика не являются линейными, и поэтому он может выбрать другой план для таблицы большего или меньшего размера. Граничным условием, например, является то, что для таблицы, занимающей только одну страницу диска, почти всегда выбирается план с последовательным сканированием, независимо от того, доступны индексы или нет. Планировщик понимает, что для обработки таблицы в любом случае потребуется одно чтение страницы на диске, поэтому нет смысла тратить дополнительные операции чтения страницы для просмотра индекса.
Есть случаи, когда фактические и оценочные значения не совпадают, но на самом деле все в порядке. Один из таких случаев возникает, когда выполнение узла плана останавливается с помощью LIMIT или аналогичного эффекта. Например, в запросе LIMIT мы использовали ранее,
EXPLAIN ANALYZE SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.29..14.28 rows=2 width=244) (actual time=1.196..1.321 rows=2 loops=1)
-> Index Scan using tenk1_unique2 on tenk1 (cost=0.29..70.27 rows=10 width=244) (actual time=1.194..1.319 rows=2 loops=1)
Index Cond: (unique2 > 9000)
Filter: (unique1 < 100)
Rows Removed by Filter: 287
Planning Time: 7.903 ms
Execution Time: 1.557 ms
(7 rows)
оценочнка стоимости и количества строк для узла Index Scan отображаются так, как если бы он был выполнен до конца. Но в действительности узел Limit прекратил запрашивать строки после того, как он получил две строки, поэтому фактическое количество строк составляет только 2, а время выполнения меньше, чем можно предположить в оценке затрат. Это не ошибка оценки, а только несоответствие в способе отображения оценок и истинных значений.
Объединения слиянием (Merge Join) также имеют артефакты измерения, которые могут запутать. Объединение слиянием прекратит чтение одного ввода, если оно исчерпало другой ввод, а следующее значение ключа в одном входе больше, чем значение последнего ключа другого ввода; в таком случае больше не может быть совпадений, поэтому нет необходимости сканировать оставшуюся часть первого ввода. Это приводит к тому, что не выполняется полное чтение одного дочернего элемента, с результатами, подобными упомянутым для LIMIT. Кроме того, если внешний (первый) дочерний элемент содержит строки с дублирующимися значениями ключа, внутренний (второй) дочерний объект резервируется и повторно сканируется для части его строк, соответствующей этому значению ключа. EXPLAIN ANALYZE считает эти повторные исключения одних и тех же внутренних рядов, как если бы они были настоящими дополнительными рядами. Когда существует много внешних дубликатов, сообщаемое фактическое число строк для внутреннего дочернего узла плана может быть значительно больше, чем число строк, которые фактически находятся во внутреннем отношении.
BitmapAnd и BitmapOr nвсегда сообщают, что их фактическое число строк равно нулю из-за ограничений реализации.
Обычно EXPLAIN отображает каждый узел плана, созданный планировщиком. Однако в некоторых случаях исполнитель (executor) может определить, что определенные узлы не нужно выполнять, поскольку они не могут создавать строки, основываясь на значениях параметров, которые были недоступны во время планирования. (В настоящее время это может происходить только для дочерних узлов узла Append или MergeAppend, который сканирует таблицу с партициями). Когда это происходит, эти узлы плана исключаются из вывода EXPLAIN, и вместо этого появляется аннотация Subplans Removed: N.
Статистика, используемая планировщиком
Статистика по одному столбцу
Как мы видели в предыдущем разделе, планировщик запросов должен оценить количество строк, извлеченных запросом, чтобы сделать правильный выбор плана запроса. В этом разделе приводится краткий обзор статистики, которую система использует для этих оценок.
Одним из компонентов статистики - общее количество записей в каждой таблице и индексе, а также количество дисковых блоков, занимаемых каждой таблицей и индексом. Эта информация хранится в таблице pg_class, в столбцах reltuples и relpages. Мы можем посмотреть на это с помощью запросов, похожих на этот:
SELECT relname, relkind, reltuples, relpages
FROM pg_class
WHERE relname LIKE 'tenk1%';
relname | relkind | reltuples | relpages
----------------------+---------+-----------+----------
tenk1 | r | 10000 | 345
tenk1_hundred | i | 10000 | 30
tenk1_thous_tenthous | i | 10000 | 30
tenk1_unique1 | i | 10000 | 30
tenk1_unique2 | i | 10000 | 30
(5 rows)
Здесь мы можем видеть, что tenk1 содержит 10000 строк, как и его индексы, но индексы (что неудивительно) намного меньше таблицы.
По соображениям эффективности reltuples и relpages не обновляются на лету, и поэтому они обычно содержат несколько устаревших значений. Они обновляются с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. Операция VACUUM или ANALYZE, которая не сканирует всю таблицу (что обычно имеет место), будет постепенно обновлять число reltuples на основе части таблицы, которую она просканировала, что приведет к приблизительному значению. В любом случае планировщик будет масштабировать значения, которые он находит в pg_class чтобы соответствовать текущему размеру физической таблицы, таким образом получая более точное приближение.
Большинство запросов извлекают только часть строк в таблице из-за WHERE которые ограничивают строки, подлежащие проверке. Таким образом, планировщик должен оценить селективность WHERE, то есть долю строк, соответствующих каждому условию в WHERE. Информация, используемая для этой задачи, хранится в системном каталоге pg_statistic. Записи в pg_statistic обновляются командами ANALYZE и VACUUM ANALYZE и всегда являются приблизительными, даже если они обновлены.
Вместо непосредственного просмотра pg_statistic лучше взглянуть на его представление pg_stats при ручном анализе статистики. pg_stats предназначен для более удобного чтения. Кроме того, pg_stats доступен для чтения всем, тогда как pg_statistic доступен для чтения только суперпользователю. (Это не позволяет непривилегированным пользователям узнавать что-либо о содержимом таблиц других людей из статистики. Представление pg_stats ограничено отображением только строк о таблицах, которые может прочитать текущий пользователь).
Объем информации, хранимой в pg_statistic функцией ANALYZE, в частности максимальное количество записей в массивах most_common_vals и histogram_bounds для каждого столбца, можно установить для каждого столбца с помощью команды ALTER TABLE SET STATISTICS или глобально, установив переменной конфигурации default_statistics_target. Предел по умолчанию в настоящее время составляет 100 записей. Повышение лимита может позволить сделать более точные оценки планировщика, особенно для столбцов с нерегулярным распределением данных, за счет того, что они потребляют больше места в pg_statistic и немного больше времени для вычисления оценок. И наоборот, нижний предел может быть достаточным для столбцов с простым распределением данных.
Более подробную информацию об использовании статистики планировщиком можно найти в главе Как планировщик использует статистику.
Расширенная статистика
Обычно медленные запросы выполняются по плохим планы выполнения, поскольку несколько столбцов, используемых в предложениях запросов, коррелированы. Планировщик обычно предполагает, что несколько условий не зависят друг от друга, предположение, которое не выполняется, когда значения столбцов коррелируют между собой. Регулярные статистические данные из-за того, что они собраны для отдельных столбцов не могут собирать какие-либо данные о корреляции между столбцами. Однако у QHB есть возможность вычислять многомерную статистику, которая может собирать такую информацию.
Поскольку число возможных комбинаций столбцов очень велико, нецелесообразно автоматически рассчитывать многомерную статистику. Вместо этого можно создавать расширенные объекты статистики, которые чаще всего называют просто объектами статистики, чтобы дать серверу команду получать статистику по интересующим наборам столбцов.
Объекты статистики создаются с помощью команды CREATE STATISTICS . Создание такого объекта просто создает запись каталога, обозначающую интерес к статистике. Сбор фактических данных выполняется ANALYZE (либо ручной командой, либо в фоне привыполнении автоматических процессов). Собранные значения можно просмотреть в каталоге pg_statistic_ext_data.
ANALYZE вычисляет расширенную статистику на основе той же выборки строк таблицы, которая используется для вычисления обычной статистики из одного столбца. Поскольку размер выборки увеличивается за счет увеличения цели статистики для таблицы или любого из ее столбцов (как описано в предыдущем разделе), большая цель статистики обычно приводит к более точной расширенной статистике, а также к большему времени, затрачиваемому на ее вычисление.
В следующих подразделах описываются виды расширенной статистики, которые в настоящее время поддерживаются.
Функциональные зависимости
Самый простой вид расширенной статистики отслеживает функциональные зависимости, понятие, используемое в определениях нормальных форм базы данных. Мы говорим, что столбец b функционально зависит от столбца a если знание значения a достаточно для определения значения b, то есть нет двух строк, имеющих одинаковое значение a но разные значения b. В полностью нормализованной базе данных функциональные зависимости должны существовать только от первичных ключей и суперключей. Однако на практике многие наборы данных не полностью нормализованы по разным причинам - преднамеренная денормализация по причинам производительности является распространенным примером. Даже в полностью нормализованной базе данных между некоторыми столбцами может быть частичная корреляция, которая может быть выражена как частичная функциональная зависимость.
Наличие функциональных зависимостей напрямую влияет на точность оценок в определенных запросах. Если запрос содержит условия как для независимого, так и для зависимого столбца (столбцов), условия для зависимых столбцов не уменьшают размер результата, но без знания функциональной зависимости планировщик запросов будет предполагать, что условия независимы, что приводит к занижению размера результата.
Чтобы сообщить планировщику о функциональных зависимостях, ANALYZE может собирать измерения зависимости между столбцами. Оценка степени зависимости между всеми наборами столбцов была бы чрезмерно дорогой, поэтому сбор данных ограничивается теми группами столбцов, которые появляются вместе в статистическом объекте, определенном с помощью параметра dependencies. Желательно создавать статистику с dependencies только для групп столбцов, которые сильно коррелированы, чтобы избежать ненужных накладных расходов как при ANALYZE и при дальнейшем планировании запросов.
Вот пример сбора статистики функциональной зависимости:
CREATE STATISTICS stts (dependencies) ON city, zip FROM zipcodes;
ANALYZE zipcodes;
SELECT stxname, stxkeys, stxddependencies
FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid)
WHERE stxname = 'stts';
stxname | stxkeys | stxddependencies
---------+---------+------------------------------------------
stts | 1 5 | {"1 => 5": 1.000000, "5 => 1": 0.423130}
(1 row)
Здесь видно, что столбец 1 (почтовый индекс) полностью определяет столбец 5 (город), поэтому коэффициент равен 1,0, тогда как город определяет почтовый индекс только в 42% случаев, что означает, что существует много городов (58%), которые представлены более чем одним почтовым индексом.
При вычислении селективности для запроса, включающего функционально зависимые столбцы, планировщик корректирует оценки селективности для каждого условия, используя коэффициенты зависимости, чтобы не создавать заниженную оценку.
Ограничения функциональных зависимостей
Функциональные зависимости в настоящее время применяются только при рассмотрении простых условий равенства, которые сравнивают столбцы с постоянными значениями. Они не используются для улучшения оценок условий равенства, сравнивающих два столбца или сравнения столбца с выражением, ни для предложений диапазона, LIKE или любого другого типа условия.
При оценке с использованием функциональных зависимостей планировщик предполагает, что условия на задействованных столбцах являются совместимыми и, следовательно, избыточными. Если они несовместимы, правильная оценка будет равна нулю строк, но эта возможность не рассматривается. Например, учитывая запрос как
SELECT * FROM zipcodes WHERE city = 'San Francisco' AND zip = '94105';
планировщик игнорирует пункт о city как не изменяющий избирательность, что является правильным. Тем не менее, он будет делать то же самое предположение о
SELECT * FROM zipcodes WHERE city = 'San Francisco' AND zip = '90210';
даже если на самом деле будет ноль строк, удовлетворяющих этому запросу. Однако статистика функциональной зависимости не дает достаточно информации, чтобы сделать вывод, что это так.
Во многих практических ситуациях это предположение обычно выполняется; например, в приложении может быть графический интерфейс, который позволяет выбирать только совместимые значения города и почтового индекса для использования в запросе. Но если это не так, функциональные зависимости не могут быть приемлемым вариантом.
Многовариантное N-мерное число уникальных значений
Статистика по одному столбцу хранит количество различных значений в каждом столбце. Оценки количества различных значений при объединении нескольких столбцов (например, для GROUP BY a, b ) часто неверны, когда у планировщика есть только статистические данные из одного столбца, что приводит к выбору плохих планов.
Чтобы улучшить такие оценки, ANALYZE может собирать n-различных статистических данных для групп столбцов. Как и прежде, это нецелесообразно делать для каждой возможной группировки столбцов, поэтому данные собираются только для тех групп столбцов, которые появляются вместе в объекте статистики, определенном с помощью опции ndistinct. Данные будут собираться для каждой возможной комбинации двух или более столбцов из набора перечисленных столбцов.
Продолжая предыдущий пример, n-мерные различные значения в таблице почтовых индексов могут выглядеть следующим образом:
CREATE STATISTICS stts2 (ndistinct) ON city, state, zip FROM zipcodes;
ANALYZE zipcodes;
SELECT stxkeys AS k, stxdndistinct AS nd
FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid)
WHERE stxname = 'stts2';
-[ RECORD 1 ]--------------------------------------------------------
k | 1 2 5
nd | {"1, 2": 33178, "1, 5": 33178, "2, 5": 27435, "1, 2, 5": 33178}
(1 row)
Это означает, что существует три комбинации столбцов, которые имеют 33178 различных значений: почтовый индекс и состояние; Почтовый индекс и город; и почтовый индекс, город и штат (ожидается, что все они равны, учитывая, что только один почтовый индекс уникален в этой таблице). С другой стороны, комбинация города и штата имеет только 27435 различных значений.
Целесообразно создавать ndistinct объекты статистики только по тем комбинациям столбцов, которые фактически используются для группировки и для которых неправильная оценка количества групп приводит к плохим планам. В противном случае расчёты статистики внутри ANALYZE будут напрасны.
Многомерные списки MCV
Другим типом статистики, хранимой для каждого столбца, являются наиболее распространенные списки значений. Это позволяет получить очень точные оценки для отдельных столбцов, но может привести к значительным занижениям для запросов с условиями для нескольких столбцов.
Чтобы улучшить такие оценки, ANALYZE может собирать списки MCV по комбинациям столбцов. Подобно функциональным зависимостям и n-мерным уникальным значениям, это нецелесообразно делать для каждой возможной группировки столбцов. Тем более для MCV, поскольку список MCV (в отличие от функциональных зависимостей и n-различных коэффициентов) хранит общие значения столбцов. Таким образом, данные собираются только для тех групп столбцов, которые появляются вместе в объекте статистики, определенном с опцией mcv .
Продолжая предыдущий пример, список MCV для таблицы почтовых индексов может выглядеть следующим образом (в отличие от более простых типов статистики, для проверки содержимого MCV требуется функция):
CREATE STATISTICS stts3 (mcv) ON city, state FROM zipcodes;
ANALYZE zipcodes;
SELECT m.* FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid),
pg_mcv_list_items(stxdmcv) m WHERE stxname = 'stts3';
index | values | nulls | frequency | base_frequency
-------+------------------------+-------+-----------+----------------
0 | {Washington, DC} | {f,f} | 0.003467 | 2.7e-05
1 | {Apo, AE} | {f,f} | 0.003067 | 1.9e-05
2 | {Houston, TX} | {f,f} | 0.002167 | 0.000133
3 | {El Paso, TX} | {f,f} | 0.002 | 0.000113
4 | {New York, NY} | {f,f} | 0.001967 | 0.000114
5 | {Atlanta, GA} | {f,f} | 0.001633 | 3.3e-05
6 | {Sacramento, CA} | {f,f} | 0.001433 | 7.8e-05
7 | {Miami, FL} | {f,f} | 0.0014 | 6e-05
8 | {Dallas, TX} | {f,f} | 0.001367 | 8.8e-05
9 | {Chicago, IL} | {f,f} | 0.001333 | 5.1e-05
...
(99 rows)
Это указывает на то, что наиболее распространенной комбинацией города и штата является Вашингтон, округ Колумбия, с фактической частотой (в выборке) около 0,35%. Базовая частота комбинации (рассчитанная по простым частотам на столбец) составляет всего 0,0027%, что приводит к заниженным оценкам на два порядка.
Желательно создавать объекты статистики MCV только на комбинациях столбцов, которые фактически используются в условиях вместе, и для которых неправильная оценка количества групп приводит к плохим планам. В противном случае расчёты статистики внутри ANALYZE будут напрасны.
Управление планировщиком с помощью явных предложений JOIN
Можно в определенной степени управлять планировщиком запросов, используя явный синтаксис JOIN. Чтобы понять, почему это важно, нам сначала нужно немного предыстории.
В простом запросе с соедиенением, таком как:
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
Планировщик может соединять таблицы в любом порядке. Например, он может сгенерировать план запроса, который соединяет A с B, используя условие WHERE a.id = b.id, а затем присоединить C к этой объединенной таблице, используя другое условие WHERE. Или он может соединить B с C, а затем присоединить A к этому результату. Или он может соединить A с C, а затем соединить их с B - но это будет неэффективно, поскольку должно быть сформировано полное декартово произведение A и C, поскольку в WHERE нет применимого условия, позволяющего оптимизировать объединение., (Все объединения в исполнителе происходят между двумя входными таблицами, поэтому необходимо создать результат одним или другим из этих способов). Важным моментом является то, что эти различные возможности объединения дают семантически эквивалентные результаты, но могут иметь очень разные затраты на выполнение. Поэтому планировщик изучит все из них, чтобы попытаться найти наиболее эффективный план запроса.
Когда в запросе используются только две или три таблицы, не о чем беспокоиться. Но количество возможных порядков соединения растет по экспоненте по мере увеличения количества таблиц. После десяти или более входных таблиц более нецелесообразно проводить исчерпывающий поиск всех возможностей, и даже для шести или семи таблиц планирование может занять очень много времени. Когда входных таблиц слишком много, планировщик QHB переключается с полного поиска на генетический вероятностный поиск с ограниченным числом возможностей. (Порог переключения задается параметром времени выполнения geqo_threshold). Генетический поиск занимает меньше времени, но он не обязательно находит наилучший возможный план.
Когда запрос включает внешние объединения, у планировщика имеется меньше свободы, чем для простых (внутренних) объединений. Например, рассмотрим:
SELECT * FROM a LEFT JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
Хотя ограничения этого запроса внешне похожи на предыдущий пример, семантика отличается, потому что для каждой строки A, которая не имеет совпадающей строки в соединении B и C, должна быть выделена строка. Поэтому у планировщика нет выбора порядка соединения здесь : он должен соединить B с C и затем присоединить A к этому результату. Соответственно, этот запрос занимает меньше времени для планирования, чем предыдущий запрос. В других случаях планировщик может определить, что более одного варианта соединения является достаточным. Например, учитывая:
SELECT * FROM a LEFT JOIN b ON (a.bid = b.id) LEFT JOIN c ON (a.cid = c.id);
сначала можно присоединить A к B или C. В настоящее время только FULL JOIN полностью ограничивает порядок соединения. Большинство практических случаев, связанных с LEFT JOIN или RIGHT JOIN могут быть в некоторой степени перестроены.
Явный синтаксис внутреннего соединения ( INNER JOIN, CROSS JOIN или JOIN ) семантически аналогичен перечислению входных отношений в FROM, поэтому он не ограничивает порядок соединения.
Несмотря на то, что большинство видов JOIN не полностью ограничивают порядок соединения, можно поручить планировщику запросов QHB обрабатывать все предложения JOIN как ограничивающие порядок соединения. Например, эти три запроса логически эквивалентны:
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
Но если мы скажем планировщику построить план для JOIN, то для второго и третьего плана потребуется меньше времени, чем для первого. Этот эффект не имеет большого смысла только для трех таблиц, но он может помочь для запросов в которых много таблиц.
Чтобы планировщик следовал порядку соединения, установленному явными соединениями JOIN, установите для параметра времени выполнения join_collapse_limit значение 1. (Другие возможные значения обсуждаются ниже).
Вам не нужно полностью ограничивать порядок соединения, чтобы сократить время поиска, потому что можно использовать операторы JOIN в элементах простого списка FROM. Например, рассмотрим:
SELECT * FROM a CROSS JOIN b, c, d, e WHERE ...;
Значение параметра join_collapse_limit = 1 заставляет планировщика соединять A с B, прежде чем соединять их с другими таблицами, но не ограничивает его выбор в противном случае. В этом примере количество возможных способов объединения уменьшается в 5 раз.
Ограничение таким способом поиска вариантов для планировщика является полезным методом как для сокращения времени планирования, так и для "направления" планировщика к хорошему плану запросов. Если планировщик выбирает неправильный порядок соединения по умолчанию, вы можете заставить его выбрать лучший порядок с помощью синтаксиса JOIN - при условии, что вы знаете лучший порядок.
Тесно связанной проблемой, которая влияет на время планирования, является объединение подзапросов в их родительский запрос. Например, рассмотрим:
SELECT *
FROM x, y,
(SELECT * FROM a, b, c WHERE something) AS ss
WHERE somethingelse;
Эта ситуация может возникнуть из-за использования представления, содержащего соединение - SELECT будет вставлено вместо ссылки на представление, в результате чего будет получен запрос, аналогичный приведенному выше. Обычно планировщик будет пытаться свернуть подзапрос в родительский, получив:
SELECT * FROM x, y, a, b, c WHERE something AND somethingelse;
Это обычно приводит к лучшему плану, чем планирование подзапроса отдельно. (Например, внешние условия WHERE могут быть такими, что при присоединении X к A сначала удаляются многие строки из A, что позволяет избежать необходимости формировать полный логический вывод подзапроса), но в то же время мы увеличили время планирования - здесь мы имеем проблему пятистороннего соединения, заменяющую две отдельные проблемы трехстороннего соединения. Из-за экспоненциального роста числа возможностей соединения это имеет большое значение. Планировщик старается не зацикливаться на огромных проблемах поиска объединений, не сворачивая подзапрос, если в родительском запросе больше таблиц чем указано в параметре from_collapse_limit. Вы можете соотнести время планирования с качеством плана, настроив уменьшив или увеличив этот параметр времени выполнения.
from_collapse_limit и join_collapse_limit имеют похожие имена, потому что они выполняют почти одно и то же: один контролирует, когда планировщик "сгладит" подзапросы, а другой контролирует, когда он "сгладит" явные объединения. Обычно вы либо устанавливаете join_collapse_limit равным from_collapse_limit (чтобы явные объединения и подзапросы действовали аналогично), либо устанавливаете join_collapse_limit 1 (если вы хотите управлять порядком соединения с помощью явных указаний). Но вы можете установить их по-разному, если вы пытаетесь настроить компромисс между временем планирования и временем выполнения.
Заполнение базы данных
Может потребоваться вставить большой объем данных при первом заполнении базы данных. Этот раздел содержит некоторые предложения о том, как сделать этот процесс максимально эффективным.
Отключить автокоммит
При использовании нескольких INSERT выключите автокоммит и просто сделайте один коммит в конце. (В обычном SQL это означает команду BEGIN в начале и COMMIT в конце. Некоторые клиентские библиотеки могут делать это во внутренней реализации, и в этом случае вам нужно убедиться, что библиотека делает это, только когда вы этого хотите). Дополнительным преимуществом выполнения всех вставок в одной транзакции является то, что если при вставке одной строки произошел сбой, вставка всех строк, вставленных до этой точки, будет откатываться, поэтому вы не получите базу данных с частично загруженными данными.
Используйте COPY
Используйте команду COPY, чтобы загрузить все строки в одной команде, вместо использования серии команд INSERT. Команда COPY оптимизирована для загрузки большого количества строк; он менее гибок, чем INSERT, но значительно снижает накладные расходы при большой загрузке данных. Поскольку COPY - это одна команда, нет необходимости отключать автокоммит, если вы используете этот метод для заполнения таблицы.
Если вы не можете использовать COPY, это может помочь использовать PREPARE для создания подготовленного оператора INSERT, а затем использовать EXECUTE столько раз, сколько требуется. Это позволяет избежать некоторых накладных расходов, связанных с многократным анализом и планированием INSERT. Различные интерфейсы предоставляют эту возможность по-разному; ищите « подготовленные заявления » в документации интерфейса.
Обратите внимание, что загрузка большого количества строк с помощью COPY почти всегда быстрее, чем с помощью INSERT, даже если используется PREPARE и несколько вставок объединяются в одну транзакцию.
COPY быстрее всего используется в той же транзакции, что и предыдущая команда CREATE TABLE или TRUNCATE. В таких случаях не нужно писать в WAL, потому что в случае ошибки файлы, содержащие вновь загруженные данные, все равно будут удалены. Однако это соображение применимо только в том случае, если wal_level minimal для однораздельных таблиц, так как в противном случае все команды должны писать WAL.
Удалить индексы
Если вы загружаете только что созданную таблицу, самый быстрый способ - создать таблицу, выполнить массовую загрузку данных таблицы с помощью COPY, а затем создать любые индексы, необходимые для этой таблицы. Создание индекса для уже существующих данных происходит быстрее, чем его постепенное обновление по мере загрузки каждой строки.
Если вы добавляете большие объемы данных в существующую таблицу, может быть выгодно удалить индексы, загрузить таблицу, а затем воссоздать индексы. Конечно, производительность базы данных для других пользователей может снизиться во время отсутствия индексов. Следует проявить осторожность, прежде чем отбрасывать уникальный индекс, поскольку проверка ошибок, предоставляемая ограничением уникальности, будет потеряна, пока индекс отсутствует.
Удалить ограничения внешнего ключа
Как и в случае с индексами, ограничение внешнего ключа может быть "массово" проверено более эффективно, чем строка за строкой. Поэтому может быть полезно удалить ограничения внешнего ключа, загрузить данные и заново создать ограничения. Опять же, существует компромисс между скоростью загрузки данных и потерей проверки ошибок, в то время как ограничение отсутствует.
Более того, когда вы загружаете данные в таблицу с существующими ограничениями внешнего ключа, каждая новая строка требует записи в списке ожидающих событий триггера на сервере (так как это запуск триггера, который проверяет ограничение внешнего ключа строки). Загрузка многих миллионов строк может привести к переполнению очереди событий триггера доступной памяти, что приведет к недопустимому обмену или даже полному отказу команды. Поэтому может быть необходимо, а не просто желательно удалить и повторно применить внешние ключи при загрузке больших объемов данных. Если временное удаление ограничения неприемлемо, единственным другим выходом может быть разделение операции загрузки на более мелкие транзакции.
Увеличьте maintenance_work_mem
Временное увеличение параметра конфигурации maintenance_work_mem при загрузке больших объемов данных может привести к повышению производительности. Это поможет ускорить выполнение команд CREATE INDEX и ALTER TABLE ADD FOREIGN KEY. Это не будет иметь большого значения для самой COPY, поэтому этот совет полезен только при использовании одного или обоих из перечисленных методов.
Увеличить max_wal_size
Временное увеличение переменной конфигурации max_wal_size также может ускорить загрузку больших объемов данных. Это связано с тем, что загрузка большого количества данных в QHB приводит к тому, что контрольные точки появляются чаще, чем обычная частота контрольных точек (указывается в переменной конфигурации checkpoint_timeout). Всякий раз, когда возникает контрольная точка, все грязные страницы должны быть сброшены на диск. Временное увеличение max_wal_size во время массовой загрузки данных позволяет уменьшить количество необходимых контрольных точек.
Отключить архивацию WAL и потоковую репликацию
При загрузке больших объемов данных в установку, которая использует архивирование WAL или потоковую репликацию, может быть быстрее создать новую базовую резервную копию после завершения загрузки, чем обрабатывать большой объем добавочных данных WAL. Чтобы предотвратить добавочное ведение журнала WAL при загрузке, отключите архивацию и потоковую репликацию, установив для wal_level значение minimal, для параметра archive_mode off, а для max_wal_senders - ноль. Но учтите, что изменение этих настроек требует перезагрузки сервера.
Помимо сокращения времени обработки данных WAL архиватором или отправителем WAL, выполнение этого на самом деле ускорит выполнение определенных команд, поскольку они вообще не предназначены для записи WAL, если wal_level minimal. (Они могут гарантировать безопасность при fsync дешевле, выполнив fsync в конце, чем написав WAL). Это относится к следующим командам:
-
CREATE TABLE AS SELECT
-
CREATE INDEX (и варианты, такие как ALTER TABLE ADD PRIMARY KEY )
-
ALTER TABLE SET TABLESPACE
-
CLUSTER
-
COPY FROM, когда целевая таблица была создана или усечена ранее в той же транзакции
Запустите ANALYZE
Всякий раз, когда вы значительно изменили распределение данных в таблице, настоятельно рекомендуется использовать ANALYZE. Изменение распределения включает в себя в том числе и массовую загрузку больших объемов данных в таблицу. Запуск ANALYZE (или VACUUM ANALYZE ) гарантирует, что планировщик будет иметь актуальную статистику о таблице. При отсутствии статистики или устаревшей статистики планировщик может принимать неправильные решения во время планирования запросов, что приведёт к низкой производительности для любых таблиц с неточной или несуществующей статистикой. Обратите внимание, что если фоновый процесс autovacuum включен, он может автоматически запустить ANALYZE, см. разделы Обновление статистики планировщика и Процесс «Автовакуум» для получения дополнительной информации.
Некоторые заметки о qhb_dump
Сценарии дампа, сгенерированные qhb_dump, автоматически применяют несколько, но не все, из приведенных выше рекомендаций. Чтобы загрузить дамп qhb_dump как можно быстрее, вам нужно сделать несколько дополнительных действий вручную. (Обратите внимание, что эти пункты применяются при восстановлении дампа, а не при его создании. Те же пункты применяются при загрузке текстового дампа с помощью qsql или использовании qhb_restore для загрузки из файла архива qhb_dump).
По умолчанию qhb_dump использует COPY, а когда он генерирует полный дамп схемы и данных, следует осторожно загружать данные перед созданием индексов и внешних ключей. Таким образом, в этом случае несколько рекомендаций обрабатываются автоматически. Что вам остается сделать, так это:
-
Установить соответствующие (т. max_wal_size, чем обычно) значения для maintenance_work_mem и max_wal_size .
-
Если используется архивация WAL или потоковая репликация, рассмотреть возможность их отключения во время восстановления. Для этого установить для параметра archive_mode значение off, для wal_level значение minimal, а для max_wal_senders - ноль, прежде чем загружать дамп. После этого установить для них правильные значения и создайть новую базовую резервную копию.
-
Поэкспериментируйте с режимами параллельного дампа и восстановления qhb_dump и qhb_restore и найдите оптимальное количество одновременных заданий для использования. Параллельное сохранение и восстановление с помощью опции -j должен обеспечить значительно более высокую производительность по сравнению с последовательным режимом.
-
Подумайте, должен ли весь дамп быть восстановлен как одна транзакция. Для этого передайте параметр командной строки -1 или --single-transaction в qsql или qhb_restore. При использовании этого режима даже самые маленькие ошибки будут отменять все восстановление, возможно, отбрасывая многие часы обработки. В зависимости от того, насколько взаимосвязаны данные, это может показаться предпочтительным или нет. Команды COPY будут выполняться быстрее, если вы используете одну транзакцию и отключили архивирование WAL.
-
Если на сервере базы данных доступно несколько процессоров, попробуйте использовать параметр --jobs в qhb_restore. Это позволяет одновременно загружать данные и создавать индексы.
-
Запустите ANALYZE после всех операций.
Дамп только для данных будет по-прежнему использовать COPY, но он не удаляет и не воссоздает индексы и обычно не касается внешних ключей1. Таким образом, при загрузке дампа только для данных, вы можете удалить и воссоздать индексы и внешние ключи, если вы хотите использовать эти методы. По-прежнему полезно увеличивать max_wal_size при загрузке данных, но не беспокойтесь об увеличении maintenance_work_mem; скорее, вы сделаете это при ручном воссоздании индексов и внешних ключей впоследствии. И не забудьте ANALYZE когда вы закончите; см. разделы Обновление статистики планировщика и Процесс «Автовакуум» для получения дополнительной информации.
Настройки снижающие надежность
Надежность - это функция базы данных, которая гарантирует запись совершенных транзакций, даже если сервер выходит из строя или теряет питание. Однако надежность добавляет значительную нагрузку на базу данных, поэтому, если ваш сайт не требует такой гарантии, QHB может быть настроена для намного быстрой работы. Ниже приведены изменения конфигурации, которые можно внести для повышения производительности в таких случаях. За исключением отмеченного ниже, надежность все еще гарантируется в случае сбоя программного обеспечения базы данных - только внезапное прекращение работы операционной системы создает риск потери или повреждения данных при использовании этих настроек.
-
Поместите каталог данных кластера базы данных в файловую систему с поддержкой памяти (то есть RAM- диск). Это исключает все операции ввода-вывода на диске базы данных, но ограничивает объем хранения данных до объема доступной памяти (и, возможно, подкачки).
-
Выключите fsync - нет необходимости сбрасывать данные на диск.
-
Выключите synchronous_commit - может не потребоваться форсировать запись WAL на диск при каждом коммите. Этот параметр создает риск потери транзакции (но не повреждения данных) в случае сбоя базы данных.
-
Отключите full_page_writes - нет необходимости принимать меры против частичной записи страницы.
-
Увеличьте max_wal_size и checkpoint_timeout - это уменьшает частоту контрольных точек, но увеличивает требования к хранилищу /pg_wal.
-
Создавайте unlogged tables, чтобы избежать записи WAL, хотя это сделает таблицы не защищенными от сбоев.
Вы можете получить эффект отключения внешних ключей, используя опцию --disable-triggers но понимайте, что это устраняет, а не просто откладывает, проверку внешнего ключа, и поэтому можно вставлять неверные данные, если вы используете эту опцию.
Провайдер пользовательского сканирования
- Создание пользовательских путей сканирования
- Создание пользовательских планов сканирования
- Выполнение пользовательских сканирований
QHB поддерживает набор экспериментальных объектов, которые позволяют расширять модули путем добавления новых типов сканирования в систему. В отличие от оболочки внешних данных, которая отвечает только за то, как сканировать свои собственные внешние таблицы, пользовательский провайдер сканирования может предоставить альтернативный метод сканирования любого отношения в системе. Как правило, мотивация для написания пользовательского провайдера сканирования будет состоять в том, чтобы разрешить использование некоторой оптимизации, не поддерживаемой основной системой, такой как кэширование или некоторая форма аппаратного ускорения. В этой главе описывается, как создать новый пользовательский провайдер сканирования.
Реализация нового типа пользовательского сканирования - это трехэтапный процесс. Во-первых, во время планирования необходимо сгенерировать пути доступа, представляющие собой сканирование с использованием предложенной стратегии. Во-вторых, если один из этих путей доступа выбран планировщиком в качестве оптимальной стратегии для сканирования конкретного отношения, путь доступа должен быть преобразован в план. Наконец, должна быть предусмотрена возможность выполнения плана и получения тех же результатов, которые были бы получены для любого другого пути доступа, нацеленного на то же отношение.
Создание пользовательских путей сканирования
Пользовательский провайдер сканирования обычно добавляет пути для базового отношения, устанавливая следующий обработчик, который вызывается после того, как основной код создал все пути доступа, которые он может для отношения (за исключением путей Gather, которые создаются после этого вызова, чтобы они могли использовать частичные пути, добавленные обработчиком):
typedef void (*set_rel_pathlist_hook_type) (PlannerInfo *root,
RelOptInfo *rel,
Index rti,
RangeTblEntry *rte);
extern PGDLLIMPORT set_rel_pathlist_hook_type set_rel_pathlist_hook;
Хотя функция подключения может использоваться для проверки, изменения или удаления путей, созданных основной системой, пользовательский провайдер сканирования обычно ограничивается созданием CustomPath объектов и добавление их к rel с помощью add_path. провайдер пользовательского сканирования отвечает за инициализацию CustomPath объекта, который объявляется следующим образом:
typedef struct CustomPath
{
Path path;
uint32 flags;
List *custom_paths;
List *custom_private;
const CustomPathMethods *methods;
} CustomPath;
path необходимо инициализировать как и для любого другого пути, включая оценку количества строк, начальную и общую стоимость, а также порядок сортировки, предоставляемый этим путем. flags это битовая маска, которая должна включать в себя CUSTOMPATH_SUPPORT_BACKWARD_SCAN если пользовательский путь может поддерживать обратную проверку и CUSTOMPATH_SUPPORT_MARK_RESTORE если он может поддерживать пометку и восстановление. Обе возможности являются необязательными. Необязательный параметр custom_paths это список Path узлов, используемых этим узлом пользовательского пути; они будут преобразованы в Plan узлы планировщиком. custom_private может использоваться для хранения собственных данных пользовательского пути. Собственные данные должны храниться в форме, которая может быть обработана с помощью nodeToString, так что отладочные процедуры, которые пытаются напечатать пользовательский путь, будут работать как задумано. methods должен указывать на объект (обычно статически выделенный), реализующий необходимые методы пользовательского пути, из которых в настоящее время существует только один.
Пользовательский провайдер сканирования также может предоставить пути соединения. Так же, как и для базовых отношений, такой путь должен давать тот же результат, что и при соединении, которое он заменяет. Для этого провайдер соединения должен установить следующий обработчик, а затем в ней создать CustomPath путь(и) для связи соединения.
typedef void (* set_join_pathlist_hook_type) (PlannerInfo * root,
RelOptInfo * joinrel,
RelOptInfo * externalrel,
RelOptInfo * innerrel,
JoinType jointype,
JoinPathExtraData * extra);
extern PGDLLIMPORT set_join_pathlist_hook_type set_join_pathlist_hook;
Этот обработчик будет вызываться повторно для одного и того же отношения соединения, с различными комбинациями внутренних и внешних отношений; это ответственность обработчика, чтобы минимумизировать лишнюю работу.
Обратные вызовы пользовательских путей сканирования
Plan *(*PlanCustomPath) (PlannerInfo *root,
RelOptInfo *rel,
CustomPath *best_path,
List *tlist,
List *clauses,
List *custom_plans);
Преобразует пользовательский путь в готовый план. Возвращаемое значение обычно будет CustomScan объектом, который аллоцируется и инициализируется обратным вызовом. Смотрите раздел Создание пользовательских планов сканирования для получения более подробной информации.
Создание пользовательских планов сканирования
Пользовательское сканирование представлено в конечном дереве планов в виде следующей структуры:
typedef struct CustomScan
{
Scan scan;
uint32 flags;
List *custom_plans;
List *custom_exprs;
List *custom_private;
List *custom_scan_tlist;
Bitmapset *custom_relids;
const CustomScanMethods *methods;
} CustomScan;
scan необходимо инициализировать, как и для любого другого сканирования, включая расчетные затраты, списки целевых объектов, и т.д. Битовая маска flags имеет тот же смысл, что и в CustomPath. custom_plans может использоваться для хранения дочерних Plan узлов. custom_exprs следует использовать для хранения деревьев выражений, которые необходимо будет исправить с помощью setrefs.c и subselect.c, в то время как custom_private следует использовать для хранения других личных данных, которые используются только самим провайдером пользовательского сканирования. custom_scan_tlist может иметь значение NIL при сканировании базового отношения, указывающее, что пользовательское сканирование возвращает кортежи сканирования, соответствующие типу строки базового отношения. В противном случае это целевой список, описывающий фактические кортежи сканирования. custom_scan_tlist должен быть указан для соединений, а также может быть предоставлено для сканирования, если пользовательский провайдер сканирования может вычислить некоторые выражения без переменных. custom_relids устанавливается ядром и задается для набора отношений (индексов таблицы диапазонов), которые обрабатывает этот узел сканирования; за исключением случаев, когда это сканирование заменяет соединение, оно будет иметь только один элемент. methods необходимо указать на объект (обычно статически выделенный), реализующий необходимые пользовательские методы сканирования, которые более подробно описаны ниже.
Когда CustomScan сканирует отношение, scan.scanrelid должен быть индексом таблицы диапазонов сканируемой таблицы. Когда он заменяет соединение, scan.scanrelid должен быть нулевым.
Деревья плана должны иметь возможность быть продублированы с помощью copyObject, поэтому все данные, хранящиеся в "пользовательских" полях, должны состоять из узлов, которые эта функция может обрабатывать. Кроме того, настраиваемые провайдеры сканирования не могут заменить более крупную структуру, которая встраивает CustomScan для самой структуры, как это было бы возможно для CustomPath или CustomScanState.
Обратный вызов пользовательского плана сканирования
Node *(*CreateCustomScanState) (CustomScan *cscan);
Выделяет CustomScanState для переданного объекта CustomScan. Фактический размер выделенной памяти часто будет больше, чем требуется для обычного CustomScanState, потому что многие провайдеры захотят встроить этот объект в качестве поля более крупной структуры. Возвращаемое значение должно иметь метку узла и методы установите соответствующим образом, но другие поля должны быть оставлены как нули на этом этапе; после базовой инициализации в ExecInitCustomScan, будет вызван BeginCustomScan обработчику, для передачи управления провайдеру пользовательского сканирования.
Выполнение пользовательских сканирований
Когда CustomScan выполняется, его состояние исполнения находится в CustomScanState, который определен следующим образом:
typedef struct CustomScanState
{
ScanState ss;
uint32 flags;
const CustomExecMethods *methods;
} CustomScanState;
ss инициализируется как и для любого другого состояния сканирования, за
исключением того, что сканирование выполняется для соединения, а не для
базового отношения, ss.ss_currentRelation остается NULL. flags — это
битовая маска аналогичная соответствующему полю в CustomPath и CustomScan.
methods должен указывать на объект (обычно статически выделенный),
реализующий требуемые пользовательские методы состояния сканирования,
которые более подробно описаны ниже. Как правило, CustomScanState,
который не обязан поддерживать copyObject, на самом деле будет
являться частью большей структуры.
Обратные вызовы выполнения пользовательского сканирования
void (*BeginCustomScan) (CustomScanState *node,
EState *estate,
int eflags);
Инициализирует переданный объект CustomScanState. Стандартные поля инициализируются с помощью ExecInitCustomScan, но любые собственные поля должны быть инициализированы в этом месте.
TupleTableSlot *(*ExecCustomScan) (CustomScanState *node);
Выбирает следующий кортеж для сканирования. Если какие-либо кортежи остаются, функция заполняет ps_ResultTupleSlot следующим кортежем в текущем направлении сканирования, а затем возвращает слот кортежа. Если кортежи закончились, должен быть возвращаен NULL или пустой слот.
void (*EndCustomScan) (CustomScanState *node);
Очищает данные, связанные с CustomScanState. Этот метод является обязательным, но он ничего не обязан делать, если нет никаких связанных данных или он будет очищен автоматически.
void (*ReScanCustomScan) (CustomScanState *node);
Смещение текущего указателя сканирование в начало и подготовка к повторному сканированию отношения.
void (*MarkPosCustomScan) (CustomScanState *node);
Сохраняет текущее положение сканирования, чтобы впоследствии его можно было восстановить с помощью обработчика RestrPosCustomScan. Этот обратный вызов является необязательным и должен быть предоставлен только в том случае, если установлен флаг CUSTOMPATH_SUPPORT_MARK_RESTORE.
void (*RestrPosCustomScan) (CustomScanState *node);
Восстанавливает предыдущую позицию сканирования, сохраненную с помощью обработчика MarkPosCustomScan. Этот обратный вызов является необязательным и должен быть предоставлен только в том случае, если установлен флаг CUSTOMPATH_SUPPORT_MARK_RESTORE.
Size (*EstimateDSMCustomScan) (CustomScanState *node,
ParallelContext *pcxt);
Оценивает объем общей динамической памяти, который потребуется для параллельной работы. Значение может быть больше, чем фактически использованная сумма, но она не должна быть меньше. Возвращаемое значение представлено в байтах. Этот обратный вызов является необязательным и должен быть предоставлен только в том случае, если этот пользовательский провайдер сканирования поддерживает параллельное выполнение.
void (*InitializeDSMCustomScan) (CustomScanState *node,
ParallelContext *pcxt,
void *coordinate);
Инициализирует общую динамическую память, которая необходима для
параллельной работы. coordinate указывает на общую область памяти
размером равным возвращаемым значением EstimateDSMCustomScan. Этот
обратный вызов является необязательным и должен быть предоставлен только
в том случае, если этот пользовательский провайдер сканирования
поддерживает параллельное выполнение.
void (*ReInitializeDSMCustomScan) (CustomScanState *node,
ParallelContext *pcxt,
void *coordinate);
Повторно инициализирует общую динамическую память, необходимую для параллельной работы, когда узел пользовательского плана сканирования будет повторно сканироваться. Этот обратный вызов является необязательным и должен быть предоставлен только в том случае, если этот пользовательский провайдер сканирования поддерживает параллельное выполнение. Рекомендуемая практика заключается в том, что этот обратный вызов сбрасывает только общее состояние, в то время как обработчик ReScanCustomScan сбрасывает только локальное состояние. В настоящее время этот обратный вызов будет вызван перед вызовом ReScanCustomScan но лучше всего не полагаться на этот порядок.
void (*InitializeWorkerCustomScan) (CustomScanState *node,
shm_toc *toc,
void *coordinate);
Инициализирует локальное состояние параллельного процесса на основе общего состояния, заданного лидером во время выполнения InitializeDSMCustomScan. Этот обратный вызов является необязательным и должен быть предоставлен только в том случае, если этот пользовательский провайдер сканирования поддерживает параллельное выполнение.
void (*ShutdownCustomScan) (CustomScanState *node);
Высвобождает ресурсы, когда ожидается, что узел не будет выполнен до завершения. Функция вызывается не во всех случаях; иногда, EndCustomScan может вызываться без предшествующего вызова ShutdownCustomScan. Поскольку сегмент DSM, используемый параллельным запросом, уничтожается сразу после вызова этого обратного вызова, этот метод следует реализовать пользовательским провайдерам сканирования, которые хотят предпринять некоторые действия до исчезновения сегмента DSM.
void (*ExplainCustomScan) (CustomScanState *node,
List *ancestors,
ExplainState *es);
Выводит дополнительную информацию для EXPLAIN узла пользовательского плана сканирования. Этот обратный вызов является необязательным. Общие данные, хранящиеся в ScanState, такие как целевой список и отношение сканирования, будут показаны даже без этого обратного вызова, но обратный вызов позволяет отображать дополнительную информацию о внутреннем состоянии.
Роли в базе данных
- Роли базы данных
- Атрибуты ролей
- Ролевая модель управления доступом
- Удаление ролей
- Роли по умолчанию
- Функция безопасности
QHB управляет правами доступа к базе данных, используя концепцию ролей. Роль может рассматриваться как пользователь базы данных или группа пользователей базы данных, в зависимости от того, как установлена роль. Роли могут владеть объектами базы данных (например, таблицами и функциями) и могут назначать привилегии для этих объектов другим ролям, чтобы контролировать, кто имеет доступ к каким объектам. Кроме того, можно предоставить членство в роли другой роли, что позволяет роли участника использовать привилегии, назначенные другой роли.
Понятие ролей объединяет понятия «пользователи» и «группы». Любая роль может выступать в роли пользователя, группы или обоих.
В этой главе описывается, как создавать и управлять ролями. Более подробную информацию о влиянии привилегий ролей на различные объекты базы данных можно найти в разделе Привилегии.
Роли базы данных
Роли базы данных концептуально полностью отделены от пользователей операционной системы. На практике может быть удобно ввести соответствие, но это не обязательно. Роли базы данных являются глобальными для установленного экземпляра базы данных (а не для отдельной базы данных). Чтобы создать роль, используйте команду SQL CREATE ROLE:
CREATE ROLE name;
name соответствует правилам для идентификаторов SQL: без украшений без специальных символов или в двойных кавычках. (На практике обычно требуется добавить в команду дополнительные параметры, такие как LOGIN. Подробнее см. ниже) Чтобы удалить существующую роль, используйте аналогичную команду DROP ROLE:
DROP ROLE name;
Для удобства программы createuser и dropuser предоставляются в качестве оберток вокруг этих команд SQL, которые можно вызывать из командной строки оболочки:
createuser name
dropuser name
Чтобы определить набор существующих ролей, изучите системный каталог pg_roles, например
SELECT rolname FROM pg_roles;
Метакоманда \du программы qsql также полезна для просмотра существующих
ролей.
Для начальной загрузки системы базы данных, недавно инициализированная система всегда содержит одну предопределенную роль. Эта роль всегда является «суперпользователем», и по умолчанию (если она не изменена при запуске initdb) она будет иметь то же имя, что и пользователь операционной системы, который инициализировал экземпляр базы данных. Обычно эта роль будет называться qhb. Чтобы создать больше ролей, сначала необходимо подключиться c этой начальной ролью к БД.
Каждое соединение с сервером базы данных выполняется с использованием имени определенной роли, и эта роль определяет начальные привилегии доступа для команд, выполненных в этом соединении. Имя роли, которое будет использоваться для конкретного подключения к базе данных, указывается клиентом, который инициирует запрос на подключение в зависимости от приложения. Например, программа qsql использует параметр командной строки -U чтобы указать роль для подключения. Многие приложения по умолчанию принимают имя текущего пользователя операционной системы (включая createuser и psq). Поэтому часто удобно поддерживать соответствие имен между ролями и пользователями операционной системы.
Набор ролей базы данных, к которым может подключаться данное клиентское соединение, определяется настройкой аутентификации клиента. (Таким образом, клиент не ограничен подключением в качестве роли, соответствующей пользователю операционной системы, так же, как имя пользователя не обязательно должно совпадать с его или ее настоящим именем) Поскольку идентификация роли определяет набор привилегий, доступных подключенному клиенту, важно тщательно настроить привилегии при настройке многопользовательской среды.
Атрибуты ролей
Роль в базе данных может иметь ряд атрибутов, которые определяют ее привилегии и взаимодействуют с системой аутентификации клиента.
| Атрибут | Описание |
|---|---|
| LOGIN (вход в систему) | Только роли с атрибутом LOGIN могут использоваться в качестве начального имени роли для подключения к базе данных. Роль с атрибутом LOGIN может рассматриваться как «пользователь базы данных». Чтобы создать роль с правами входа в систему, используйте: CREATE ROLE name LOGIN; CREATE USER name; CREATE USER эквивалентен CREATE ROLE за исключением того, что CREATE USER по умолчанию включает LOGIN, а CREATE ROLE - нет) |
| SUPERUSER (статус суперпользователя) | Суперпользователь базы данных обходит все проверки разрешений, кроме права на вход. Это опасная привилегия, и ее не следует использовать небрежно. Лучше всего выполнять большую часть своей работы в роли, которая не является суперпользователем. Чтобы создать нового суперпользователя базы данных, используйте CREATE ROLE name SUPERUSER. Вы должны сделать это под ролью, которая уже является суперпользователем. |
| CREATEDB (создание базы данных) | Роль должна быть явно предоставлена разрешение на создание баз данных (за исключением суперпользователей, поскольку они обходят все проверки разрешений). Чтобы создать такую роль, используйте CREATE ROLE name CREATEDB. |
| CREATEROLE (создание ролей) | Роли должно быть явно предоставлено разрешение на создание большего количества ролей (за исключением суперпользователей, так как они обходят все проверки разрешений). Чтобы создать такую роль, используйте CREATE ROLE name CREATEROLE. Роль с привилегией CREATEROLE может изменять и CREATEROLE другие роли, а также предоставлять или отзывать членство в них. Однако для создания, изменения, удаления или изменения принадлежности к роли суперпользователя требуется статус суперпользователя; CREATEROLE недостаточно для этого. |
| REPLICATION (инициирование репликации) | Роль должна быть явно предоставлена разрешение на инициирование потоковой репликации (за исключением суперпользователей, так как они обходят все проверки разрешений). Роль, используемая для потоковой репликации, также должна иметь разрешение LOGIN. Чтобы создать такую роль, используйте CREATE ROLE name REPLICATION LOGIN. |
| PASSWORD (пароль) | Пароль имеет значение только в том случае, если метод аутентификации клиента требует от пользователя ввода пароля при подключении к базе данных. password и методы аутентификации md5 используют пароли. Пароли базы данных отделены от паролей операционной системы. Укажите пароль при создании роли с помощью CREATE ROLE name PASSWORD ’ string ’. |
Подсказка!!!
Рекомендуется создать роль с привилегиями CREATEDB и CREATEROLE, которая не является суперпользователем, а затем использовать эту роль для всего рутинного управления базами данных и ролями. Такой подход позволяет избежать опасностей работы в качестве суперпользователя для задач, которые на самом деле этого не требуют.
Атрибуты роли могут быть изменены после создания с помощью ALTER ROLE. См. справочные страницы для команд CREATE ROLE и ALTER ROLE для получения подробной информации.
Роль также может иметь специфичные для роли значения «по умолчанию» для многих параметров конфигурации настроек сервера, описанных в главе Конфигурация сервера. Например, если по какой-то причине необходимо отключить сканирование индекса (не очень хорошая идея) при каждом подключении, можно использовать:
ALTER ROLE myname SET enable_indexscan TO off;
Это сохранит настройку (но не установит ее сразу). В последующих
соединениях с этой ролью будет выглядеть, как будто
SET enable_indexscan TO off был выполнен непосредственно перед началом
сеанса. Вы все еще можете изменить этот параметр во время сеанса; это
будет только по умолчанию. Чтобы удалить настройку по умолчанию для
конкретной роли, используйте ALTER ROLE rolename RESET varname. Обратите
внимание, что специфичные для роли значения по умолчанию, прикрепленные
к ролям без привилегии LOGIN, довольно бесполезны, поскольку они никогда
не будут вызваны.
Ролевая модель управления доступом
Часто удобно группировать пользователей, чтобы упростить управление привилегиями: таким образом, привилегии могут быть предоставлены или отменены для группы в целом. В QHB это достигается созданием роли, представляющей группу, а затем предоставлением членства в роли группы отдельным ролям пользователей.
Чтобы настроить групповую роль, сначала создайте роль:
CREATE ROLE name;
Обычно роль, используемая в качестве группы, не имеет атрибута LOGIN, хотя вы можете установить ее, если хотите.
Когда роль группы существует, вы можете добавлять и удалять участников, используя команды GRANT и REVOKE:
GRANT group_role TO role1, ... ;
REVOKE group_role FROM role1, ... ;
Вы можете предоставить членство и другим групповым ролям (поскольку на самом деле нет различий между групповыми ролями и не групповыми ролями). База данных не позволит вам настроить циклические циклы членства. Кроме того, не разрешено предоставлять членство в роли для PUBLIC.
Члены групповой роли могут использовать привилегии роли двумя способами. Во-первых, каждый член группы может явно выполнить SET ROLE, чтобы временно «стать» групповой ролью. В этом состоянии сеанс базы данных имеет доступ к привилегиям роли группы, а не к исходной роли входа, и любые созданные объекты базы данных считаются принадлежащими роли группы, а не роли входа. Во-вторых, роли участников, имеющие атрибут INHERIT автоматически используют привилегии ролей, членами которых они являются, включая любые привилегии, унаследованные этими ролями. В качестве примера предположим, что мы сделали:
CREATE ROLE joe LOGIN INHERIT;
CREATE ROLE admin NOINHERIT;
CREATE ROLE wheel NOINHERIT;
GRANT admin TO joe;
GRANT wheel TO admin;
Сразу после подключения в качестве роли joe сеанс базы данных будет использовать привилегии, предоставленные непосредственно joe, а также любые привилегии, предоставленные admin, поскольку joe «наследует» привилегии admin. Однако привилегии, предоставленные wheel, ему недоступны, потому что, хотя joe косвенно является членом wheel, членство осуществляется через роль admin которая имеет атрибут NOINHERIT. После:
SET ROLE admin;
сеанс будет использовать только те привилегии, которые предоставлены admin, а не те, которые предоставлены joe. После:
SET ROLE wheel;
сеанс будет использовать только те привилегии, которые предоставлены wheel, а не те, которые предоставлены либо joe либо admin. Исходное состояние привилегий может быть восстановлено любым способом из:
SET ROLE joe;
SET ROLE NONE;
RESET ROLE;
Заметка
Команда SET ROLE всегда позволяет выбрать любую роль, в которую прямо или косвенно входит исходная роль входа. Таким образом, в приведенном выше примере нет необходимости становиться admin, прежде чем стать wheel.
Заметка
В стандарте SQL существует четкое различие между пользователями и ролями, и пользователи не наследуют привилегии автоматически, в то время как роли делают. Такое поведение может быть получено в QHB, если для ролей, используемых в качестве ролей SQL, используется атрибут INHERIT, а для ролей, используемых в качестве пользователей SQL, - атрибут NOINHERIT. В QHB по умолчанию всем ролям предоставляет атрибут INHERIT.
Атрибуты роли LOGIN, SUPERUSER, CREATEDB и CREATEROLE могут
рассматриваться как специальные привилегии, но они никогда не
наследуются, как обычные привилегии для объектов базы данных. Вы должны
на самом деле установить роль для конкретной роли, имеющей один из этих
атрибутов, чтобы использовать этот атрибут. Продолжая приведенный выше
пример, мы можем предоставить CREATEDB и CREATEROLE роль admin. Тогда
сеанс, соединяющийся как роль joe, не будет иметь этих привилегий сразу,
а только после выполнения SET ROLE admin.
Чтобы уничтожить групповую роль, используйте DROP ROLE:
DROP ROLE name;
Любое членство в групповой роли автоматически отменяется (но роли участников не затрагиваются иным образом).
Удаление ролей
Поскольку роли могут владеть объектами базы данных и могут иметь привилегии для доступа к другим объектам, удаление роли часто является не просто вопросом быстрого DROP ROLE. Любые объекты, принадлежащие этой роли, должны быть сначала отброшены или переназначены другим владельцам; и любые разрешения, предоставленные этой роли, должны быть аннулированы.
Право собственности на объекты может передаваться по одному с помощью команд ALTER, например:
ALTER TABLE bobs_table OWNER TO alice;
В качестве альтернативы, можно использовать команду REASSIGN OWNED для переназначения владения всеми объектами, принадлежащими роли, которая должна быть удалена, другой роли. Поскольку REASSIGN OWNED не может получить доступ к объектам в других базах данных, необходимо запускать его в каждой базе данных, содержащей объекты, принадлежащие этой роли. (Обратите внимание, что первый такой REASSIGN OWNED изменит владельца любых совместно используемых между базами данных объектов, то есть баз данных или табличных пространств, которые принадлежат роли, подлежащей удалению)
Как только любые ценные объекты были переданы новым владельцам, любые оставшиеся объекты, принадлежащие подлежащей удалению роли, могут быть удалены с помощью команды DROP OWNED. Опять же, эта команда не может получить доступ к объектам в других базах данных, поэтому необходимо запускать ее в каждой базе данных, содержащей объекты, принадлежащие этой роли. Кроме того, DROP OWNED не удаляет целые базы данных или табличные пространства, поэтому это необходимо делать вручную, если роли принадлежат какие-либо базы данных или табличные пространства, которые не были переданы новым владельцам.
DROP OWNED также заботится об удалении любых привилегий, предоставленных целевой роли для объектов, которые ей не принадлежат. Поскольку REASSIGN OWNED не касается таких объектов, как правило, необходимо запустить как REASSIGN OWNED и DROP OWNED (в таком порядке!), чтобы полностью удалить зависимости роли, которую необходимо удалить.
Итого, самый общий рецепт удаления роли, которая использовалась для владения объектами:
REASSIGN OWNED BY doomed_role TO successor_role;
DROP OWNED BY doomed_role;
-- repeat the above commands in each database of the cluster
DROP ROLE doomed_role;
Когда не все принадлежащие объекты должны быть переданы одному и тому же владельцу-преемнику, лучше всего обработать исключения вручную, а затем выполнить описанные выше шаги для полной очистки.
Если попытка DROP ROLE выполняется, пока зависимые объекты все еще остаются, она выдаст сообщения, определяющие, какие объекты необходимо переназначить или отбросить.
Роли по умолчанию
QHB предоставляет набор ролей по умолчанию, которые обеспечивают доступ к определенным, часто необходимым, привилегированным возможностям и информации. Администраторы могут предоставлять эти роли пользователям и/или другим ролям в их среде, предоставляя этим пользователям доступ к указанным возможностям и информации.
Роли по умолчанию описаны в таблице 7.1. Обратите внимание, что конкретные разрешения для каждой роли по умолчанию могут измениться в будущем при добавлении дополнительных возможностей. Администраторы должны отслеживать заметки о выпуске на предмет изменений.
Таблица 7.1. Роли по умолчанию
| Роль | Разрешенный доступ |
|---|---|
| pg_read_all_settings | Прочитайте все переменные конфигурации, даже те, которые обычно видны только суперпользователям. |
| pg_read_all_stats | Прочитайте все представления pg_stat_ * и используйте различные статистические расширения, даже те, которые обычно видны только суперпользователям. |
| pg_stat_scan_tables | Выполните функции мониторинга, которые могут блокировать ACCESS SHARE для таблиц, возможно, в течение длительного времени. |
| pg_monitor | Читать / выполнять различные виды мониторинга и функции. Эта роль является членом групп pg_read_all_settings, pg_read_all_stats и pg_stat_scan_tables. |
| pg_signal_backend | Подайте сигнал другому бэкэнду, чтобы отменить запрос или завершить сеанс. |
| pg_read_server_files | Разрешить чтение файлов из любого места, к которому база данных может получить доступ на сервере с помощью COPY и других функций доступа к файлам. |
| pg_write_server_files | Разрешить запись в файлы в любом месте, к которому база данных может получить доступ на сервере с помощью COPY и других функций доступа к файлам. |
| pg_execute_server_program | Разрешить выполнение программ на сервере базы данных как пользователь, база данных запускается так же, как с COPY и другими функциями, которые позволяют выполнять программу на стороне сервера. |
pg_monitor, pg_read_all_settings, pg_read_all_stats и pg_stat_scan_tables предназначены для того, чтобы администраторы могли легко настроить роль для мониторинга сервера базы данных. Они предоставляют набор общих привилегий, позволяющих роли читать различные полезные параметры конфигурации, статистику и другую системную информацию, обычно доступную только суперпользователям.
Роль pg_signal_backend предназначена для того, чтобы администраторы могли включать доверенные, но не суперпользовательские роли, для отправки сигналов другим бэкэндам. В настоящее время эта роль позволяет отправлять сигналы для отмены запроса на другом сервере или завершения его сеанса. Однако пользователь, которому предоставлена эта роль, не может отправлять сигналы бэкэнду, принадлежащему суперпользователю. См. раздел Функции сигнализации сервера.
pg_read_server_files, pg_write_server_files и pg_execute_server_program предназначены для того, чтобы администраторы могли иметь доверенные, но не суперпользовательские роли, которые могут получать доступ к файлам и запускать программы на сервере базы данных в качестве пользователя базы данных. Поскольку эти роли могут получить доступ к любому файлу в файловой системе сервера, они пропускают все проверки разрешений на уровне базы данных при непосредственном доступе к файлам и могут использоваться для получения доступа на уровне суперпользователя, поэтому при предоставлении этих ролей следует соблюдать особую осторожность.
При предоставлении этих ролей следует соблюдать осторожность, чтобы гарантировать, что они используются только там, где это необходимо, и при том понимании, что эти роли предоставляют доступ к конфиденциальной информации.
Администраторы могут предоставить доступ к этим ролям пользователям с помощью команды GRANT, например:
GRANT pg_signal_backend TO admin_user;
Функция безопасности
Функции, триггеры и политики безопасности на уровне строк позволяют пользователям вставлять код на внутренний сервер, который другие пользователи могут выполнять непреднамеренно. Следовательно, эти механизмы позволяют создавать «троянских коней» относительно легко. Самая сильная защита - жесткий контроль над тем, кто может определять объекты. Там, где это невозможно, пишите запросы, относящиеся только к объектам, имеющим доверенных владельцев. Удалите из search_path общедоступную схему и любые другие схемы, которые позволяют не доверенным пользователям создавать объекты.
Функции выполняются внутри процесса внутреннего сервера с разрешениями операционной системы демона сервера баз данных. Если язык программирования, используемый для функции, допускает неконтролируемый доступ к памяти, можно изменить внутренние структуры данных сервера. Следовательно, среди прочего, такие функции могут обойти любые системы контроля доступа. Языки функций, которые разрешают такой доступ, считаются «ненадежными», а QHB позволяет только суперпользователям создавать функции, написанные на этих языках.
Управление базами данных
- Обзор
- Создание базы данных
- Базы данных шаблонов
- Конфигурация базы данных
- Удаление базы данных
- Табличные пространства
Каждый экземпляр работающего сервера QHB управляет одной или несколькими базами данных. Таким образом, базы данных являются высшим иерархическим уровнем для организации объектов SQL («объектов базы данных»). В этой главе описываются свойства баз данных, а также способы их создания, управления и уничтожения.
Обзор
База данных — это именованная коллекция объектов SQL («объекты базы данных»). Как правило, каждый объект базы данных (таблицы, функции и т. д.) принадлежит одной и только одной базе данных. (Однако есть несколько системных каталогов, например, pg_database, которые принадлежат всему экземпляру и доступны из каждой базы данных внутри экземпляра). Точнее, база данных представляет собой набор схем, а схемы содержат таблицы, функции и т. д. Таким образом, полная иерархия: сервер, база данных, схема, таблица (или какой-либо другой вид объекта, например функция).
При подключении к серверу базы данных клиент должен указать в своем запросе на подключение имя базы данных, к которой он хочет подключиться. Невозможно получить доступ к более чем одной базе данных для одного соединения. Тем не менее, приложение не ограничено по количеству подключений, которые оно открывает к той же или другим базам данных. Базы данных физически разделены, а управление доступом осуществляется на уровне соединения. Если один экземпляр сервера QHB предназначен для размещения проектов или пользователей, которые должны быть отдельными и по большей части не осведомленными друг о друге, поэтому рекомендуется поместить их в отдельные базы данных. Если проекты или пользователи взаимосвязаны и должны иметь возможность использовать ресурсы друг друга, они должны быть помещены в одну и ту же базу данных, но, возможно, в отдельные схемы. Схемы — это чисто логическая структура, и кто может получить доступ к тому, что управляется системой привилегий. Более подробная информация об управлении схемами находится в разделе Схемы.
Базы данных создаются с помощью команды CREATE DATABASE (см. раздел Создание базы данных) и уничтожаются с помощью команды DROP DATABASE (см. раздел Удаление базы данных). Чтобы определить набор существующих баз данных, изучите системный каталог pg_database, например
SELECT datname FROM pg_database;
Команда \l программы qsql также полезна для вывода списка существующих
баз данных.
Создание базы данных
Чтобы создать базу данных, сервер QHB должен быть запущен (см. раздел Запуск сервера базы данных).
Базы данных создаются с помощью команды SQL CREATE DATABASE:
CREATE DATABASE name;
где name следует обычным правилам для идентификаторов SQL. Текущая роль автоматически становится владельцем новой базы данных. Владелец базы данных имеет право удалить ее позже (что также удаляет все объекты в ней, даже если у них другой владелец).
Создание баз данных - ограниченная операция. См. раздел Атрибуты ролей для получения разрешения.
Поскольку вам необходимо подключиться к серверу базы данных, чтобы выполнить команду CREATE DATABASE, остается вопрос, как можно создать первую базу данных на любом указанном месте. Первая база данных всегда создается командой initdb при инициализации области хранения данных. (См. раздел Создание кластера базы данных). Эта база данных называется qhb. Таким образом, чтобы создать первую «обычную» базу данных, вы можете подключиться к qhb.
Вторая база данных, template1, также создается во время инициализации экземпляра базы данных. Всякий раз, когда в экземпляре создается новая база данных, template1 по существу клонируется. Это означает, что любые изменения, которые вы делаете в template1, распространяются на все впоследствии созданные базы данных. Из-за этого избегайте создания объектов в template1 если вы не хотите, чтобы они распространялись на каждую вновь созданную базу данных. Более подробная информация представлена в разделе Базы данных шаблонов.
Для удобства есть программа createdb, которую вы можете запустить из оболочки для создания новых баз данных.
createdb dbname
createdb подключается к базе данных qhb и выдает команду CREATE DATABASE, как описано выше. Справочная страница createdb содержит детали вызова. Обратите внимание, что createdb без аргументов создаст базу данных с текущим именем пользователя.
Иногда вы хотите создать базу данных для кого-то другого, и они станут владельцами новой базы данных, чтобы они могли сами настраивать и управлять ею. Для этого используйте одну из следующих команд:
CREATE DATABASE dbname OWNER rolename;
из среды SQL или:
createdb -O rolename dbname
из оболочки ОС. Только суперпользователь может создавать базу данных для кого-то другого (то есть для роли, в которой вы не участвуете).
Базы данных шаблонов
CREATE DATABASE фактически работает путем копирования существующей базы данных. По умолчанию он копирует стандартную системную базу данных с именем template1. Таким образом, эта база данных является «шаблоном», из которого создаются новые базы данных. Если вы добавите объекты в template1, эти объекты будут скопированы в впоследствии созданные пользовательские базы данных. Такое поведение допускает локальные модификации стандартного набора объектов в базах данных. Например, если вы установите процедурный язык PL/Perl в template1, он автоматически будет доступен в пользовательских базах данных без каких-либо дополнительных действий при создании этих баз данных.
Существует вторая стандартная системная база данных с именем template0. Эта база данных содержит те же данные, что и исходное содержимое template1, то есть только стандартные объекты, предопределенные вашей версией QHB. template0 никогда не должен изменяться после инициализации экземпляра базы данных. CREATE DATABASE скопировав template0 вместо template1, вы можете создать «первичную» пользовательскую базу данных, которая не содержит никаких локальных дополнений из template1. Это особенно удобно при восстановлении дампа qhb_dump: сценарий дампа должен быть восстановлен в первичной базе данных, чтобы гарантировать, что каждый воссоздает правильное содержимое базы данных дампа, не конфликтуя с объектами, которые могли быть добавлены в template1 позже.
Другая распространенная причина копирования template0 вместо template1 заключается в том, что при копировании template0 можно указать новые настройки кодирования и локали, тогда как для копии template1 должны использоваться те же настройки, что и для нее. Это связано с тем, что template1 может содержать данные, специфичной кодировки или локали, а template0 как известно, нет.
Чтобы создать базу данных путем копирования template0, используйте:
CREATE DATABASE dbname TEMPLATE template0;
из среды SQL или:
createdb -T template0 dbname
из оболочки ОС
Можно создать дополнительные базы данных шаблонов, и в действительности можно скопировать любую базу данных в экземпляре, указав ее имя в качестве шаблона для CREATE DATABASE. Тем не менее, важно понимать, что это не предназначено для универсального средства «COPY DATABASE». Основным ограничением является то, что никакие другие сеансы не могут быть подключены к исходной базе данных, пока она копируется. Создание базы данных завершится ошибкой, если при ее запуске возникнет какое-либо другое соединение; во время операции копирования новые соединения с исходной базой данных будут запрещены.
В pg_database есть два полезных флага для каждой базы данных: столбцы datistemplate и datallowconn. datistemplate может быть установлен, чтобы указать, что база данных предназначена в качестве шаблона для CREATE DATABASE. Если этот флаг установлен, база данных может быть клонирована любым пользователем с привилегиями CREATEDB; если он не установлен, клонировать могут только суперпользователи и владелец базы данных. Если datallowconn имеет значение false, то новые подключения к этой базе данных не будут разрешены (но существующие сеансы не прекращаются просто путем установки флага false). База данных template0 обычно помечается как datallowconn = false чтобы предотвратить ее модификацию. И template0 и template1 всегда должны быть помечены datistemplate = true.
Заметка
template1 и template0 не имеют особого статуса, кроме того факта, что имя template1 является именем исходной базы данных по умолчанию для CREATE DATABASE. Например, можно удалить template1 и воссоздать его из template0 без каких-либо вредных последствий. Этот путь действий может быть целесообразным, если кто-то небрежно добавил кучу мусора в template1. (Чтобы удалить template1, он должен иметь pg_database.datistemplate = false).
База данных qhb также создается при инициализации экземпляра базы данных. Эта база данных является базой данных по умолчанию для пользователей и приложений для подключения. Это просто копия template1 и может быть удалена и воссоздана при необходимости.
Конфигурация базы данных
Сервер QHB предоставляет большое количество переменных конфигурации во время выполнения (см. главу Конфигурация сервера). Для многих из этих настроек вы можете установить значения по умолчанию для базы данных.
Например, если по какой-то причине вы хотите отключить оптимизатор GEQO
для данной базы данных, вам обычно нужно либо отключить его для всех баз
данных, либо убедиться, что каждый подключающийся клиент осторожно
выдает SET geqo TO off. Чтобы установить этот параметр по умолчанию в
конкретной базе данных, вы можете выполнить команду:
ALTER DATABASE mydb SET geqo TO off;
Это сохранит настройку (но не установит ее сразу). При последующих
подключениях к этой базе данных это будет выглядеть так, как будто
SET geqo TO off; был выполнен незадолго до начала сеанса. Обратите внимание,
что пользователи все еще могут изменять этот параметр во время своих
сеансов; это будет только значение по умолчанию. Чтобы отменить любую
такую настройку, используйте ALTER DATABASE dbname RESET varname.
Удаление базы данных
Базы данных удаляются командой DROP DATABASE:
DROP DATABASE name;
Только владелец базы данных или суперпользователь может удалить базу данных. Удаление базы данных удаляет все объекты, которые содержались в базе данных. Уничтожение базы данных не может быть отменено.
Вы не можете выполнить команду DROP DATABASE когда подключены к удаляемой базе данных. Однако вы можете подключиться к любой другой базе данных, включая базу данных template1. template1 будет единственным вариантом для удаления последней пользовательской базы данных данного экземпляра.
Для удобства есть также программа оболочки для удаления баз данных, dropdb:
dropdb dbname
(В отличие от createdb, удаление базы данных с текущим именем пользователя не является действием по умолчанию).
Табличные пространства
Табличные пространства в QHB позволяют администраторам баз данных определять места в файловой системе, где могут храниться файлы, представляющие объекты базы данных. После создания, на табличное пространство можно ссылаться по имени при создании объектов базы данных.
Используя табличные пространства, администратор может управлять разметкой диска установки QHB. Это полезно по крайней мере в двух случаях. Во-первых, если раздел или том, на котором был инициализирован экземпляр, исчерпал пространство и не может быть расширен, табличное пространство можно создать в другом разделе и использовать до тех пор, пока система не будет перенастроена.
Во-вторых, табличные пространства позволяют администратору использовать знания об использовании объектов базы данных для оптимизации производительности. Например, индекс, который очень интенсивно используется, может быть размещен на очень быстром, высокодоступном диске, таком как дорогостоящее твердотельное устройство. В то же время таблица, в которой хранятся архивные данные, которые редко используются или не критичны по производительности, могут храниться в менее дорогой, более медленной дисковой системе.
Предупреждение!!!
Несмотря на то, что табличные пространства расположены вне основного каталога данных QHB, они являются неотъемлемой частью экземпляра базы данных и не могут рассматриваться как автономный набор файлов данных. Они зависят от метаданных, содержащихся в главном каталоге данных, и поэтому не могут быть присоединены к другому экземпляру базы данных или сохранены отдельно. Аналогичным образом, если вы потеряете табличное пространство (удаление файла, сбой диска и т. д.), экземпляр базы данных может стать нечитаемым или не сможет запуститься. Размещение табличного пространства во временной файловой системе, такой как RAM-диск, ставит под угрозу надежность всего экземпляра.
Чтобы определить табличное пространство, используйте команду CREATE TABLESPACE, например:
CREATE TABLESPACE fastspace LOCATION '/ssd1/qhb/data';
Расположение должно быть существующим пустым каталогом, который принадлежит пользователю операционной системы QHB. Все объекты, впоследствии созданные в табличном пространстве, будут храниться в файлах под этим каталогом. Расположение не должно быть в съемном или временном хранилище, поскольку экземпляр может не функционировать, если табличное пространство отсутствует или потеряно.
Заметка
Обычно нет смысла создавать более одного табличного пространства на логическую файловую систему, поскольку вы не можете контролировать расположение отдельных файлов в логической файловой системе. Однако QHB не налагает никаких подобных ограничений, и на самом деле он не знает напрямую о границах файловой системы в вашей ОС. Он просто хранит файлы в каталогах, которые вы указали для использования.
Само создание табличного пространства должно выполняться под суперпользователем базы данных, но после этого вы можете разрешить его использовать обычным пользователям базы данных. Для этого предоставьте им привилегию CREATE.
Таблицы, индексы и целые базы данных могут быть назначены конкретным табличным пространствам. Для этого пользователь с привилегией CREATE в заданном табличном пространстве должен передать имя табличного пространства в качестве параметра соответствующей команде. Например, следующая команда создает таблицу в табличном пространстве space1:
CREATE TABLE foo(i int) TABLESPACE space1;
В качестве альтернативы используйте параметр default_tablespace:
SET default_tablespace = space1;
CREATE TABLE foo(i int);
Если для default_tablespace задано значение, отличное от пустой строки, оно предоставляет неявное предложение TABLESPACE для команд CREATE TABLE и CREATE INDEX которые не имеют явной команды.
Существует также параметр temp_tablespaces, который определяет размещение временных таблиц и индексов, а также временных файлов, которые используются для таких целей, как сортировка больших наборов данных. Это может быть список имен табличных пространств, а не только одно имя, так что нагрузка, связанная с временными объектами, может быть распределена по нескольким табличным пространствам. Случайный член списка выбирается каждый раз, когда создается временный объект.
Табличное пространство, связанное с базой данных, используется для хранения системных каталогов этой базы данных. Кроме того, это табличное пространство по умолчанию, используемое для таблиц, индексов и временных файлов, созданных в базе данных, если не задано предложение TABLESPACE и никакие другие параметры не определены в default_tablespace или temp_tablespaces (в зависимости от ситуации). Если база данных создается без указания для нее табличного пространства, она использует то же самое табличное пространство, что и база данных шаблонов, из которой она копируется.
Два табличных пространства создаются автоматически при инициализации экземпляра базы данных. Пространство pg_global используется для общих системных каталогов. Пространство pg_default является табличным пространством по умолчанию для баз данных template1 и template0 (и, следовательно, будет табличным пространством по умолчанию и для других баз данных, если оно не переопределено предложением TABLESPACE в CREATE DATABASE).
После создания табличное пространство можно использовать из любой базы данных, при условии, что запрашивающий пользователь имеет достаточные привилегии. Это означает, что табличное пространство нельзя отбросить, пока не будут удалены все объекты во всех базах данных, использующих табличное пространство.
Чтобы удалить пустое табличное пространство, используйте команду DROP TABLESPACE.
Чтобы определить набор существующих табличных пространств, изучите системный каталог pg_tablespace, например
SELECT spcname FROM pg_tablespace;
Метакоманда \db программы qsql также полезна для перечисления
существующих табличных пространств.
QHB использует символические ссылки для упрощения реализации табличных пространств. Это означает, что табличные пространства могут использоваться только в системах, которые поддерживают символические ссылки.
Каталог $PGDATA/pg_tblspc содержит символические ссылки, которые указывают на каждое из встроенных табличных пространств, определенных в экземпляре. Хотя это и не рекомендуется, но можно вручную настроить макет табличного пространства, переопределив эти ссылки. Ни при каких обстоятельствах не выполняйте эту операцию во время работы сервера.
Локализация
В этой главе описываются доступные функции локализации с точки зрения администратора. QHB поддерживает два средства локализации:
-
Использование локализационных средств операционной системы для обеспечения порядка сортировки, форматирования чисел, перевода сообщений и других аспектов для конкретного языка. Это описано в разделах Поддержка локализаций и Поддержка сортировки.
-
Предоставление ряда в различных кодировках для поддержки хранения текста на всех видах языков и обеспечения перевода набора символов между клиентом и сервером. Это описано в разделе Поддержка набора символов.
Внимание!!!
Текущая версия QHB поддерживает наборы символов, перечисленные в разделе Поддержка набора символов. Однако предпочтительной кодировкой базы данных является UTF-8, и в следующих релизах QHB поддержка других кодировок может быть удалена.
Поддержка локализаций
Поддержка локализаций относится к приложению, учитывающему культурные
предпочтения в отношении алфавитов, сортировки, форматирования чисел и
т. д. QHB использует стандартные средства локализации
ISO C и POSIX, предоставляемые операционной системой сервера.
Для получения дополнительной информации обратитесь к документации вашей системы.
Обзор
Поддержка локализаций автоматически инициализируется при создании экземпляра
базы данных с использованием initdb. По умолчанию initdb инициализирует
экземпляр базы данных с настройкой локализации среды выполнения,
поэтому, если ваша система уже настроена на использование языкового
стандарта, который вы хотите использовать в своем экземпляре базы
данных, вам больше ничего не нужно делать. Если вы хотите использовать
другую локализацию (или вы не уверены, для какой локализации настроена ваша система),
вы можете указать initdb, какую именно локализацию использовать, указав
параметр --locale. Например:
initdb --locale=ru_RU
Этот пример для систем Unix устанавливает язык русского языка (ru), который
используют в России (RU). Другие возможности могут включать en_US
(американский английский) и fr_CA (французский канадский). Если для
локализации можно использовать более одного набора символов, тогда
спецификации могут принимать форму language_territory.codeset.
Например, ru_RU.utf8 представляет русский язык (ru), на котором говорят
в России (RU), с кодировкой набора символов UTF-8.
Какие локализации доступны в вашей системе, под какими именами зависит от
того, что было предоставлено поставщиком операционной системы и что было
установлено. В большинстве систем Unix команда locale -a предоставит
список доступных локализаций. Windows использует более подробные названия
German_Germany, например German_Germany или Swedish_Sweden.1252, но
принципы те же.
Иногда полезно смешивать правила из нескольких языков, например, использовать правила сортировки на английском языке, но сообщения на испанском языке. Для поддержки этого существует набор подкатегорий языковых стандартов, которые контролируют только определённые аспекты правил локализации:
| Категория | |
|---|---|
LC_COLLATE | Порядок сортировки строк |
LC_CTYPE | Классификация символов (Что это за буква? Каков её эквивалент в верхнем регистре?) |
LC_MESSAGES | Язык сообщений |
LC_MONETARY | Форматирование денежных сумм |
LC_NUMERIC | Форматирование чисел |
LC_TIME | Форматирование даты и времени |
Имена категорий переводятся в имена параметров initdb, чтобы
переопределить выбор локализации для конкретной категории. Например, чтобы
установить языковой стандарт французско-канадский, но использовать
правила США для форматирования валюты, используйте initdb --locale=fr_CA --lc-monetary=en_US.
Если вы хотите, чтобы система работала без поддержки локализаций,
используйте специальное имя локализации C её эквивалент POSIX.
Некоторые категории локализаций должны иметь фиксированные значения при
создании базы данных. Вы можете использовать разные настройки для разных
баз данных, но как только база данных будет создана, вы больше не
сможете их изменить. LC_COLLATE и LC_CTYPE — эти категории. Они влияют
на порядок сортировки индексов, поэтому они должны оставаться
фиксированными, иначе индексы в текстовых столбцах будут повреждены. (Но
вы можете ослабить это ограничение, используя параметры сортировки, как
описано в разделе Поддержка сортировки). Значения по умолчанию для этих категорий
определяются при запуске initdb, и эти значения используются при
создании новых баз данных, если не указано иное в команде CREATE DATABASE.
Другие категории языковых стандартов могут быть изменены в любое время
путём установки параметров конфигурации сервера, которые имеют то же
имя, что и категории локализаций (подробности см. в разделе
Язык и форматирование). Значения, выбранные initdb, на самом деле записываются
только в файл конфигурации qhb.conf, чтобы служить значениями по умолчанию при
запуске сервера. Если вы удалите эти назначения из qhb.conf, то сервер
унаследует настройки из среды, в которой он выполняется.
Обратите внимание, что локализацию поведения сервера определяется переменными среды, видимыми сервером, а не средой какого-либо клиента. Поэтому будьте осторожны, чтобы настроить правильные параметры локализации перед запуском сервера. Если клиент и сервер настроены в разных локализациях, сообщения могут показываться на разных языках в зависимости от того, где они возникли.
Наследование языкового стандарта от среды выполнения, означает следующее
в большинстве операционных систем: для данной локализации, скажем,
сортировки, следующие переменные среды анализируются в приведённом ниже
порядке, пока одна из них не окажется заданной LC_ALL, LC_COLLATE (или
переменная, соответствующая соответствующей категории), LANG. Если ни
одна из этих переменных среды не установлена, то по умолчанию в качестве
локализации используется значение C.
Некоторые библиотеки локализации сообщений также обращают внимание на
переменную среды LANGUAGE которая переопределяет все остальные настройки
локализации с целью установки языка сообщений. Если вы сомневаетесь,
пожалуйста, обратитесь к документации вашей операционной системы, в
частности к документации по gettext.
Чтобы разрешить перевод сообщений на предпочитаемый пользователем язык,
во время сборки должен быть выбран NLS (configure --enable-nls). Все
остальные языковые поддержки встроены автоматически.
Поведение
Настройки локализации влияют на следующие SQL-функции:
-
Порядок сортировки в запросах с использованием
ORDER BYили стандартных операторов сравнения текстовых данных; -
upper,lowerиinitcapфункции; -
операторы сортировки с образцом (регулярные выражения в стиле
LIKE,SIMILAR TOиPOSIX); локализации влияют на поиск без учёта регистра и на классификацию символов по регулярным выражениям; -
семейство функций
to_char; -
возможность использовать индексы с предложениями
LIKE.
Недостатком использования в QHB локализаций,
отличных от C или POSIX является его влияние на производительность.
Это замедляет обработку символов и предотвращает использование LIKE
обычных индексов. По этой причине используйте локализации только в том
случае, если они вам действительно нужны.
В качестве обходного пути, позволяющего QHB использовать индексы с
предложениями LIKE в локализации, отличной от C, существует несколько
пользовательских классов операторов. Это позволяет создать индекс,
который выполняет строгое посимвольное сравнение, игнорируя правила
сравнения локализаций. Обратитесь к разделу
Классы операторов и семейства операторов за дополнительной
информацией. Другой подход заключается в создании индексов с
использованием сортировки C, как обсуждалось в разделе Поддержка сортировки.
Проблемы
Если поддержка локализации не работает в соответствии с приведённым выше
объяснением, проверьте, правильно ли настроена поддержка локализации в вашей
операционной системе. Чтобы проверить, какие языковые стандарты
установлены в вашей системе, вы можете использовать команду locale -a
если ваша операционная система предоставляет её.
Убедитесь, что QHB действительно использует локализацию,
которая вам нужна. Параметры LC_COLLATE и LC_CTYPE определяются при
создании базы данных и не могут быть изменены, кроме как путем создания
новой базы данных. Другие настройки локализации, включая LC_MESSAGES и
LC_MONETARY, первоначально определяются средой, в которой запущен
сервер, но могут быть изменены на лету. Вы можете проверить параметры
активной локализации, используя команду SHOW.
Поддержка набора символов
Поддержка набора символов в QHB позволяет хранить текст в различных
наборах символов (также называемых кодировками), включая однобайтовые
наборы символов, такие как серии ISO 8859, и многобайтовые наборы
символов, такие как EUC (расширенный код Unix), UTF-8 и внутренний код
Mule. Все поддерживаемые наборы символов могут прозрачно использоваться
клиентами, но некоторые из них не поддерживаются для использования на
сервере (то есть в качестве кодировки на стороне сервера). Набор
символов по умолчанию выбирается при инициализации экземпляра базы
данных QHB с помощью initdb. Он может быть
переопределен при создании базы данных, поэтому вы можете иметь
несколько баз данных, каждая из которых имеет свой набор символов.
Однако важным ограничением является то, что каждый набор символов базы
данных должен быть совместим с настройками языкового стандарта базы
данных LC_CTYPE (классификация символов) и LC_COLLATE (порядок
сортировки строк). Для локализации C или POSIX разрешен любой набор символов,
но для других локализаций, предоставляемых libc, есть только один набор
символов, который будет работать правильно. (Однако в Windows кодировка
UTF-8 может использоваться с любой локализацией) Если у вас настроена
поддержка ICU, локализации, предоставляемые ICU, можно использовать с
большинством, но не со всеми кодировками на стороне сервера.
Поддерживаемые наборы символов
Таблица 1 показывает наборы символов, доступные для использования в QHB
| имя | Описание | язык | Поддержка на сервере | ICU? | Байтов на символ | Псевдонимы |
|---|---|---|---|---|---|---|
| BIG5 | Большая Пятерка | Традиционный китайский | нет | нет | 1-2 | WIN950, Windows950 |
| EUC_CN | Расширенный код UNIX-CN | Упрощенный китайский | да | да | 1-3 | |
| EUC_JP | Расширенный код UNIX-JP | Японский | да | да | 1-3 | |
| EUC_JIS_2004 | Расширенный код UNIX-JP, JIS X 0213 | Японский | да | нет | 1-3 | |
| EUC_KR | Расширенный код UNIX-KR | корейский язык | да | да | 1-3 | |
| EUC_TW | Расширенный код UNIX-TW | Традиционный китайский, тайваньский | да | да | 1-3 | |
| GB18030 | Национальный стандарт | китайский язык | нет | нет | 1-4 | |
| GBK | Расширенный национальный стандарт | Упрощенный китайский | нет | нет | 1-2 | WIN936, Windows936 |
| ISO_8859_5 | ISO 8859-5, ECMA 113 | Латинский / Кириллица | да | да | 1 | |
| ISO_8859_6 | ISO 8859-6, ECMA 114 | Латинский / Арабский | да | да | 1 | |
| ISO_8859_7 | ISO 8859-7, ECMA 118 | Латинский / греческий | да | да | 1 | |
| ISO_8859_8 | ISO 8859-8, ECMA 121 | Latin / Hebrew | да | да | 1 | |
| JOHAB | JOHAB | Корейский (хангыль) | нет | нет | 1-3 | |
| KOI8R | KOI 8-R | Кириллица | да | да | 1 | KOI8 |
| KOI8U | KOI 8-У | Кириллица (украинский) | да | да | 1 | |
| LATIN1 | ISO 8859-1, ECMA 94 | Западноевропейский | да | да | 1 | ISO88591 |
| LATIN2 | ISO 8859-2, ECMA 94 | Центральноевропейский | да | да | 1 | ISO88592 |
| LATIN3 | ISO 8859-3, ECMA 94 | Южноевропейский | да | да | 1 | ISO88593 |
| LATIN4 | ISO 8859-4, ECMA 94 | Североевропейский | да | да | 1 | ISO88594 |
| LATIN5 | ISO 8859-9, ECMA 128 | турецкий | да | да | 1 | ISO88599 |
| LATIN6 | ISO 8859-10, ECMA 144 | нордический | да | да | 1 | ISO885910 |
| LATIN7 | ISO 8859-13 | балтийский | да | да | 1 | ISO885913 |
| LATIN8 | ISO 8859-14 | кельтский | да | да | 1 | ISO885914 |
| LATIN9 | ISO 8859-15 | LATIN1 с евро и акцентами | да | да | 1 | ISO885915 |
| LATIN10 | ISO 8859-16, ASRO SR 14111 | румынский | да | нет | 1 | ISO885916 |
| MULE_INTERNAL | Внутренний код Mule | Многоязычный Emacs | да | нет | 1-4 | |
| SJIS | Shift JIS | Японский | нет | нет | 1-2 | Mskanji, ShiftJIS, WIN932, Windows932 |
| SHIFT_JIS_2004 | Shift JIS, JIS X 0213 | Японский | нет | нет | 1-2 | |
| SQL_ASCII | не указано (см. текст) | Любые | да | нет | 1 | |
| UHC | Унифицированный код Хангыль | корейский язык | нет | нет | 1-2 | WIN949, Windows949 |
| UTF8 | Юникод, 8 бит | все | да | да | 1-4 | Unicode |
| WIN866 | Windows CP866 | кириллица | да | да | 1 | ALT |
| WIN874 | Windows CP874 | тайский | да | нет | 1 | |
| WIN1250 | Windows CP1250 | Центральноевропейский | да | да | 1 | |
| WIN1251 | Windows CP1251 | кириллица | да | да | 1 | WIN |
| WIN1252 | Windows CP1252 | Западноевропейский | да | да | 1 | |
| WIN1253 | Windows CP1253 | греческий | да | да | 1 | |
| WIN1254 | Windows CP1254 | турецкий | да | да | 1 | |
| WIN1255 | Windows CP1255 | иврит | да | да | 1 | |
| WIN1256 | Windows CP1256 | арабский | да | да | 1 | |
| WIN1257 | Windows CP1257 | балтийский | да | да | 1 | |
| WIN1258 | Windows CP1258 | вьетнамский | да | да | 1 | ABC, TCVN, TCVN5712, VSCII |
Не все клиентские API поддерживают все перечисленные наборы символов.
Например, драйвер JDBC не поддерживает MULE_INTERNAL,
LATIN6, LATIN8 и LATIN10.
Параметр SQL_ASCII ведет себя значительно иначе, чем другие параметры.
Когда набор символов сервера - SQL_ASCII, сервер интерпретирует
байтовые значения 0-127 в соответствии со стандартом ASCII, а байтовые
значения 128-255 принимаются как неинтерпретированные символы. При
настройке SQL_ASCII преобразование кодировки не выполняется. Таким
образом, этот параметр является не столько декларацией, что используется
конкретная кодировка, сколько объявлением о незнании кодировки. В
большинстве случаев, если вы работаете с любыми данными, отличными от
ASCII, неразумно использовать параметр SQL_ASCII поскольку QHB
не сможет помочь вам в преобразовании или проверке не-ASCII символов.
Настройка набора символов
initdb определяет набор символов (кодировку) по умолчанию для экземпляра QHB. Например,
initdb -E EUC_JP
устанавливает набор символов по умолчанию EUC_JP (расширенный код Unix
для японского языка). Вы можете использовать --encoding вместо -E если
вы предпочитаете полные параметры. Если опция -E или
--encoding не указана, initdb пытается определить подходящую кодировку
для использования на основе указанной локализации или локализации по умолчанию.
Вы можете указать кодировку не по умолчанию во время создания базы данных, при условии, что кодировка совместима с выбранной локализацией:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr
--lc-ctype=ko_KR.euckr korean
Это создаст базу данных с именем korean которая использует набор символов EUC_KR и локализацию ko_KR. Другой способ сделать это - использовать команду SQL:
CREATE DATABASE korean WITH ENCODING 'EUC_KR'
`LC_COLLATE`='ko_KR.euckr' `LC_CTYPE`='ko_KR.euckr'
TEMPLATE=template0;
Обратите внимание, что приведенные выше команды указывают на копирование
базы данных template0. При копировании любой другой базы данных
параметры кодировки и локализации нельзя изменить по сравнению с исходной
базой данных, поскольку это может привести к повреждению данных. Для
получения дополнительной информации см. раздел Базы данных шаблонов.
Кодировка для базы данных хранится в системном каталоге pg_database. Вы
можете увидеть это, используя команду psql \l.
$ psql -l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
------------+-------+----------+-------------+-------------+------------------------------------
mydb | qhb | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
qhb | qhb | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | qhb | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/qhb + qhb=CTc/qhb
template1 | qhb | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/qhb + qhb=CTc/qhb
tpc | qhb | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/qhb + qhb=CTc/qhb + tpc=CTc/qhb
(5 rows)
Важно!!!
В большинстве современных операционных систем QHB может определить, какой набор символов подразумевается настройкойLC_CTYPE, и он будет обеспечивать использование только соответствующей кодировки базы данных. В старых системах вы обязаны убедиться, что используете кодировку, ожидаемую выбранной вами локализацией. Ошибка в этой области может привести к странному поведению зависящих от локализации операций, таких как сортировка.
QHB позволит суперпользователям создавать базы данных с кодировкой
SQL_ASCII даже если LC_CTYPE не назначен на C или POSIX. Как отмечалось
выше, SQL_ASCII не требует, чтобы данные, хранящиеся в базе данных,
имели какую-либо конкретную кодировку, и поэтому этот выбор создаёт
риски неправильного поведения, зависящего от локализации. Использование этой
комбинации настроек не рекомендуется и может когда-нибудь быть полностью
запрещено.
Автоматическое преобразование набора символов между сервером и клиентом
QHB поддерживает автоматическое преобразование набора символов между
сервером и клиентом для определенных комбинаций набора символов.
Информация о преобразовании хранится в системном каталоге
pg_conversion. QHB поставляется с некоторыми предопределенными
преобразованиями, как показано в таблице 2. Вы можете создать новое
преобразование с помощью SQL-команды CREATE CONVERSION.
Таблица 2. Преобразование набора символов клиент/сервер
| Набор символов сервера | Доступные клиентские наборы символов |
|---|---|
| BIG5 | не поддерживается в качестве серверной кодировки |
| EUC_CN | EUC_CN, MULE_INTERNAL, UTF8 |
| EUC_JP | EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
| EUC_JIS_2004 | EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
| EUC_KR | EUC_KR, MULE_INTERNAL, UTF8 |
| EUC_TW | EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
| GB18030 | не поддерживается в качестве серверной кодировки |
| GBK | не поддерживается в качестве серверной кодировки |
| ISO_8859_5 | ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
| ISO_8859_6 | ISO_8859_6, UTF8 |
| ISO_8859_7 | ISO_8859_7, UTF8 |
| ISO_8859_8 | ISO_8859_8, UTF8 |
| JOHAB | не поддерживается в качестве серверной кодировки |
| KOI8R | KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
| KOI8U | KOI8U, UTF8 |
| LATIN1 | LATIN1, MULE_INTERNAL, UTF8 |
| LATIN2 | LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
| LATIN3 | LATIN3, MULE_INTERNAL, UTF8 |
| LATIN4 | LATIN4, MULE_INTERNAL, UTF8 |
| LATIN5 | ЛАТИН5, UTF8 |
| LATIN6 | LATIN6, UTF8 |
| LATIN7 | LATIN7, UTF8 |
| LATIN8 | LATIN8, UTF8 |
| LATIN9 | LATIN9, UTF8 |
| LATIN10 | LATIN10, UTF8 |
| MULE_INTERNAL | MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 - LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
| SJIS | не поддерживается в качестве серверной кодировки |
| SHIFT_JIS_2004 | не поддерживается в качестве серверной кодировки |
| SQL_ASCII | любой (преобразование не будет выполнено) |
| UHC | не поддерживается в качестве серверной кодировки |
| UTF8 | все поддерживаемые кодировки |
| WIN866 | WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
| WIN874 | WIN874, UTF8 |
| WIN1250 | WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
| WIN1251 | WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
| WIN1252 | WIN1252, UTF8 |
| WIN1253 | WIN1253, UTF8 |
| WIN1254 | WIN1254, UTF8 |
| WIN1255 | WIN1255, UTF8 |
| WIN1256 | WIN1256, UTF8 |
| WIN1257 | WIN1257, UTF8 |
| WIN1258 | WIN1258, UTF8 |
Чтобы включить автоматическое преобразование набора символов, вы должны указать QHB набор символов (кодировку), который вы хотели бы использовать в клиенте. Есть несколько способов сделать это:
- Используя команду
\encodingв psql.\encodingпозволяет менять кодировку клиента на лету. Например, чтобы изменить кодировку наSJIS, введите:
\encoding SJIS
-
libpqимеет функции для управления кодировкой клиента. -
Использование
SET client_encoding TO. Установка кодировки клиента может быть выполнена с помощью этой SQL-команды:
SET CLIENT_ENCODING TO 'value';
- Также вы можете использовать стандартный синтаксис
SET NAMESдля этой цели:
SET NAMES 'value';
- Чтобы запросить текущую кодировку клиента:
SHOW client_encoding;
- Чтобы вернуться к кодировке по умолчанию:
RESET client_encoding;
-
Использование
PGCLIENTENCODING. Если переменная средыPGCLIENTENCODINGопределена в среде клиента, эта кодировка клиента выбирается автоматически при установлении соединения с сервером. (Это может впоследствии быть переопределено, используя любой из других методов, упомянутых выше). -
Использование переменной конфигурации
client_encoding. Если переменнаяclient_encodingустановлена, то эта кодировка клиента автоматически выбирается при установлении соединения с сервером. (Это может впоследствии быть переопределено, используя любой из других методов, упомянутых выше).
Если преобразование определенного символа невозможно - предположим, что
вы выбрали EUC_JP для сервера и LATIN1 для клиента, и возвращаются
некоторые японские символы, которые не имеют представления в LATIN1 -
сообщается об ошибке.
Если клиентский набор символов определен как SQL_ASCII, преобразование
кодировки отключается независимо от набора символов сервера. Как и для
сервера, использование SQL_ASCII неразумно, если вы не работаете с
полностью ASCII-данными.
Дальнейшее чтение
Следующие источники можно использовать для начала изучения различных видов систем кодирования.
CJKV Information Processing: Chinese, Japanese, Korean & Vietnamese
Computing. Содержит подробные объяснения EUC_JP, EUC_CN, EUC_KR, EUC_TW .
http://www.unicode.org/. Веб-сайт Консорциума Unicode.
RFC 3629. UTF-8 (8-битный формат преобразования UCS / Unicode) определяется здесь.
Поддержка сортировки
Функция сортировки позволяет указать порядок сортировки и классификацию
символов для каждого столбца или даже для каждой операции. Это
LC_COLLATE ограничение на то, что LC_COLLATE и LC_CTYPE базы данных
не могут быть изменены после её создания.
Концепции
Концептуально, каждое выражение данных с возможностью сортировки
имеет параметры сортировки. (Встроенные типы данных - text, varchar
и char. Определяемые пользователем базовые типы также
могут быть помечены как совместимые, и, конечно же, область данных для
сопоставляемых типов данных может быть отсортирована.) Если выражение
является ссылкой на столбец, сортировка выражения является определённой
сортировкой столбца. Если выражение является константой, сопоставление
является сопоставлением по умолчанию для типа данных константы.
Сопоставление более сложного выражения получается из сопоставлений его
входных данных, как описано ниже.
Параметры сортировки выражения могут быть параметрами сортировки «по умолчанию», что означает настройки локализации, определенные для базы данных. Кроме того, сопоставление выражения может быть неопределённым. В таких случаях операции сортировки и другие операции, которые должны знать параметры сортировки, завершатся неудачно.
Когда система базы данных должна выполнить упорядочивание или
классификацию символов, она использует сопоставление входного выражения.
Это происходит, например, с предложениями ORDER BY и вызовами функций
или операторов, такими как <. Правила сортировки, применяемые для
предложения ORDER BY, - это просто параметры сортировки сортированного
ключа. Параметры сортировки, применяемые для вызова функции или
оператора, получаются из аргументов, как описано ниже. В дополнение к
операторам сравнения, параметры сортировки учитываются функциями,
которые преобразуют буквы в нижний и верхний регистр, такие как lower,
upper и initcap, с помощью операторов сортировки с образцом,
to_char и связанных функций.
Для операции вызова функции или оператора, сопоставление кодировок, которое определяется из сортировки аргументов вызова, будет использовано во время исполнения операции. Если результат вызова функции или оператора относится к типу данных с возможностью сортировки, то сортировка также используется во время синтаксического анализа в качестве определённого сортировки выражения функции или оператора, если существует окружающее выражение, которое требует знания его сортировки.
Сортировка выражения может быть явной или неявной. Это
различие влияет на то, как объединяются параметры сортировки, когда в
выражении появляется несколько различных параметров сортировки. Явное
определение правил сортировки происходит, когда используется COLLATE.
Все остальные сортировки являются неявными. Когда необходимо
объединить несколько параметров сортировки, например, при вызове
функции, используются следующие правила:
-
Если какое-либо входное выражение задано с явным сопоставлением, то все явно определённые сортировки среди входных выражений должны быть одинаковыми, в противном случае возникает ошибка. Если присутствует какое-либо явно полученное сопоставление, оно является результатом сочетания сопоставлений.
-
В противном случае все входные выражения должны иметь одинаковое неявное сопоставление или сопоставление по умолчанию. Если присутствует какое-либо сопоставление, отличное от значения по умолчанию, то оно является результатом комбинации сортировки. В противном случае результатом является сопоставление по умолчанию.
-
Если среди входных выражений существуют конфликтующие неявные параметры сортировки, то считается, что комбинация имеет неопределённый порядок сортировки. Это не ошибочное условие, если конкретная вызываемая функция не требует знания параметров сортировки, которые она должна применять. Если это произойдет, ошибка будет возникать во время выполнения.
Например, рассмотрим это определение таблицы:
CREATE TABLE test1 (
a text COLLATE "de_DE",
b text COLLATE "es_ES",
...
);
Затем в
SELECT a < 'foo' FROM test1;
< сравнение выполняется в соответствии с правилами de_DE, потому что
выражение объединяет неявное сопоставление с сопоставлением
по умолчанию. Но в
SELECT a < ('foo' COLLATE "fr_FR") FROM test1;
сравнение выполняется с использованием правил fr_FR, потому что явный
вывод правила сортировки переопределяет неявный. Кроме того, в следующем примере
SELECT a < b FROM test1;
синтаксический анализатор не может определить, какое сопоставление
применить, поскольку столбцы a и b имеют конфликтующие неявные
сортировки. Поскольку оператору < необходимо знать, какое
сопоставление использовать, это приведет к ошибке. Ошибка может быть
устранена путём добавления явного спецификатора правила сортировки к любому
входному запросу, таким образом:
SELECT a < b COLLATE "de_DE" FROM test1;
или эквивалентно
SELECT a COLLATE "de_DE" < b FROM test1;
С другой стороны, структурно похожий случай
SELECT a || b FROM test1;
не приводит к ошибке, потому что оператор || не заботится о правилах
сортировок: его результат одинаков независимо от параметров сортировки.
Сортировка, назначенная объединённым входным выражениям функции или оператора, также считается применимой к результату функции или оператора, если функция или оператор выдает результат типа данных с возможностью переноса. Итак, запрос
SELECT * FROM test1 ORDER BY a || 'foo';
будет выполнен в соответствии с правилами de_DE . Но запрос:
SELECT * FROM test1 ORDER BY a || b;
приводит к ошибке, потому что даже если оператору || не нужно знать
параметры сортировки, то ORDER BY это важно. Как и прежде,
конфликт может быть разрешён с помощью явного спецификатора
сортировки:
SELECT * FROM test1 ORDER BY a || b COLLATE "fr_FR";
Управление сортировкой
Сортировка - это объект схемы SQL, который соотносит SQL-имя на локализации,
предоставляемые библиотеками, установленными в операционной системе. У
определения параметров сортировки есть поставщик, который указывает,
какая библиотека предоставляет данные локализации. Одно имя стандартного
провайдера - libc, в котором используются локализации, предоставляемые
библиотекой C операционной системы. Это локализации, которые используют
большинство инструментов, предоставляемых операционной системой. Другой
провайдер - icu, который использует внешнюю ICU библиотеку. Локализации
ICU можно использовать только в том случае, если при создании
QHB была настроена поддержка ICU.
Правило сортировки, предоставляемое libc сопоставляется с комбинацией
LC_COLLATE и LC_CTYPE, как принято вызовом системной библиотеки
setlocale() . (Как следует из названия, основная цель правила сортировки
состоит в том, чтобы установить LC_COLLATE, который управляет порядком
сортировки. Но на практике редко требуется иметь параметр LC_CTYPE,
отличный от LC_COLLATE, поэтому его удобнее собирать согласно одной
концепции, чем создание другой инфраструктуры для установки LC_CTYPE
каждого выражения.) Кроме того, сопоставление libc связано с кодировкой
набора символов (см. раздел Поддержка набора символов). Одно и то же имя
правила сортировки может существовать для разных кодировок.
Объект сортировки, предоставляемый icu отображается на именованный
сборщик, предоставляемый библиотекой ICU. ICU не поддерживает отдельные
параметры «collate» и «ctype», поэтому они всегда одинаковы.
Кроме того, параметры сортировки ICU не зависят от кодировки, поэтому в
базе данных всегда есть только один параметр сортировки ICU для данного
имени.
Стандартные правила сортировки
На всех платформах доступны параметры сортировки с именами default, C и
POSIX. Дополнительные параметры сортировки могут быть доступны в
зависимости от поддержки операционной системы. Параметры сортировки по
default выбирают значения LC_COLLATE и LC_CTYPE указанные во время
создания базы данных. Оба правила C и POSIX задают «традиционное
поведение C», при котором только буквы ASCII от «A» до «Z»
обрабатываются как буквы, а сортировка выполняется строго по значениям
байтов кода символа.
Кроме того, стандартное имя сортировки SQL ucs_basic доступно для
кодировки UTF8. Это эквивалентно C и сортирует по кодовой точке
Unicode.
Предопределенные правила сортировки
Если операционная система обеспечивает поддержку использования
нескольких языковых стандартов в рамках одной программы (newlocale и
связанных функций) или если настроена поддержка ICU, то при
инициализации кластера базы данных initdb заполняет системный каталог
pg_collation правилами на основе всех языковых стандартов, которые он
находит в операционной системе во время инициализации.
Чтобы проверить доступные в настоящее время локализации, используйте запрос
SELECT * FROM pg_collation или команду \dOS+ в qsql.
Стандартные правила сортировки
Например, операционная система может предоставить локализацию с именем
de_DE.utf8. Тогда initdb создаст сопоставление с именем de_DE.utf8
для кодировки UTF8, для которого LC_COLLATE и LC_CTYPE установлены
в значение de_DE.utf8. Это также создаст сопоставление с
тегом .utf8 из имени. Таким образом, вы также можете использовать
параметры сортировки под именем de_DE, что не так громоздко для
написания и делает имя менее зависимым от кодировки. Обратите внимание,
что, тем не менее, начальный набор имен параметров сортировки зависит от
платформы.
Набор параметров сортировки по умолчанию, предоставляемый libc
сопоставляется непосредственно с локализациями, установленными в операционной
системе, которые можно узнать с помощью команды locale -a . В
случае, если требуется сопоставление libc, имеющее разные значения для
LC_COLLATE и LC_CTYPE, или если в операционной системе после
инициализации системы баз данных установлены новые локализации, то можно
создать новое сопоставление с помощью команды CREATE COLLATION. Новые
локализации операционной системы также можно массово импортировать
с помощью функции pg_import_system_collations().
В любой конкретной базе данных представляют интерес только
правила сортировки, использующие кодировку этой базы данных. Другие записи в
pg_collation игнорируются. Таким образом, de_DE имя правила,
такое как de_DE может считаться уникальным в данной базе данных, даже
если оно не будет уникальным в глобальном масштабе. Рекомендуется
использовать сокращенные имена параметров сортировки, так как вам придётся
делать на одну вещь меньше, если вы решите перейти на другую кодировку базы
данных. Однако обратите внимание, что праивла default, C и POSIX
могут использоваться независимо от кодировки базы данных.
QHB считает, что отдельные объекты сортировки несовместимы, даже если они имеют идентичные свойства. Так, например,
SELECT a COLLATE "C" < b COLLATE "POSIX" FROM test1;
выдаст ошибку, даже если параметры сортировки C и POSIX имеют идентичное
поведение. Поэтому не рекомендуется смешивать имена сортировок с
разделителями и без них.
Правила сортировки ICU
С ICU не имеет смысла перечислять все возможные названия локализаций. ICU
использует определённую систему именования для локализаций, но существует
гораздо больше названий локализаций, чем на самом деле разных локализаций.
initdb использует API ICU для извлечения набора различных локализаций для
заполнения начального набора параметров сортировки. Правила сортировки,
предоставляемые ICU, создаются в среде SQL с именами в формате языкового
тега BCP 47, с добавлением расширения «для частного использования»
-x-icu, чтобы отличать их от языковых стандартов libc.
Вот несколько примеров правил сортировки, которые могут быть созданы:
de-x-icu
Немецкое правило сортировки, вариант по умолчанию
de-AT-x-icu
Немецкое правило сортировки для Австрии, вариант по умолчанию
(Есть также, de-DE-x-icu или de-CH-x-icu, но на момент написания
статьи они эквивалентны de-x-icu).
und-x-icu (for “undefined”)
«Корневое» правило сортировки ICU. Используйте его, чтобы получить разумный
порядок сортировки, не зависящий от языка.
Некоторые (менее часто используемые) кодировки не поддерживаются ICU.
Когда кодировка базы данных является одной из них, записи сортировки ICU
в pg_collation игнорируются. Попытка его использовать приведет к
появлению ошибки в строке: «сопоставление «de-x-icu» для
кодировки «WIN874» не существует».
Создание новых правил сортировки
Если стандартных и предопределённых параметров сортировки недостаточно,
пользователи могут создавать свои собственные правила сортировки с помощью
команды SQL CREATE COLLATION.
Стандартные и предопределённые параметры сортировки находятся в схеме
pg_catalog, как и все предопределённые объекты. Пользовательские
параметры сортировки должны создаваться в пользовательских схемах. Это
также гарантирует, что они сохраняются pg_dump.
Правила сортировки libc
Новые правила сортировки libc могут быть созданы следующим образом:
CREATE COLLATION german (provider = libc, locale = 'de_DE');
Точные значения, приемлемые для предложения locale в этой команде,
зависят от операционной системы. В Unix-подобных системах команда
locale -a покажет список.
Поскольку предопределенные параметры сортировки libc уже включают в себя
все параметры сортировки, определенные в операционной системе при
инициализации экземпляра базы данных, нет необходимости создавать новые
вручную. Причины могут быть в том случае, если желательна другая система
именования (в этом случае см. раздел Копирование правил сортировки ) или если
операционная система была обновлена для предоставления новых определений
локализации (в этом случае см. Также pg_import_system_collations()).
Правила сортировки ICU
ICU позволяет настраивать параметры сортировки вне базового набора
языка+страны, который предварительно загружен initdb. Пользователям
рекомендуется определять свои собственные правила сортировки, которые
используют базовые средства для соответствия поведению сортировки их
требованиям. См. http://userguide.icu-project.org/locale и
http://userguide.icu-project.org/collation/api
для получения информации о наименовании локализации ICU. Набор допустимых имён
и атрибутов зависит от конкретной версии ICU.
Вот некоторые примеры:
CREATE COLLATION "de-u-co-phonebk-x-icu" (provider = icu, locale = 'de-u-co-phonebk');
CREATE COLLATION "de-u-co-phonebk-x-icu" (provider = icu, locale = 'de@collation=phonebook');
-
Немецкая сортировка с типом сортировки телефонной книги
-
В первом примере выбирается языковой стандарт
ICUс использованием
«языкового тега» форматаBCP 47. Во втором примере используется традиционный синтаксис локализации, специфичный дляICU. Первый стиль предпочтительнее в дальнейшем, но он не поддерживается старыми версиямиICU. -
Обратите внимание, что вы можете называть правила сортировки в среде SQL как угодно. В этом примере мы следуем стилю именования, который используют предопределенные параметры сортировки, которые, в свою очередь, также следуют
BCP 47, но это не требуется для пользовательских параметров сортировки.
CREATE COLLATION "und-u-co-emoji-x-icu" (provider = icu, locale = 'und-u-co-emoji');
CREATE COLLATION "und-u-co-emoji-x-icu" (provider = icu, locale = '@collation=emoji');
- Корневое правило сортировки с типом сортировки
Emoji, в соответствии с Техническим стандартомUnicode #51
Заметка В традиционной системе именования локализаций
ICUкорневая локализация выбирается пустой строкой.
CREATE COLLATION digitslast (provider = icu, locale =
'en-u-kr-latn-digit');
CREATE COLLATION digitslast (provider = icu, locale =
'en@colReorder=latn-digit');
- Сортировка цифр после латинских букв. (По умолчанию цифры перед буквами.)
CREATE COLLATION upperfirst (provider = icu, locale =
'en-u-kf-upper');
CREATE COLLATION upperfirst (provider = icu, locale =
'en@colCaseFirst=upper');
- Сортировка заглавных буквы перед строчными. (По умолчанию сначала используются строчные буквы.)
CREATE COLLATION special (provider = icu, locale =
'en-u-kf-upper-kr-latn-digit');
CREATE COLLATION special (provider = icu, locale =
'en@colCaseFirst=upper;colReorder=latn-digit');
- Сочетает в себе оба вышеуказанных варианта.
CREATE COLLATION numeric (provider = icu, locale = 'en-u-kn-true');
CREATE COLLATION numeric (provider = icu, locale =
'en@colNumeric=yes');
- Числовой порядок сортирует последовательности цифр по их числовому значению, например: A-21 < A-123 (также известный как «естественная сортировка»).
Подробности смотрите в Техническом стандарте Unicode #35 и BCP 47.
Список возможных типов сортировки (вложенный тег co) можно найти в
репозитории CLDR. ICU Locale Explorer можно использовать для проверки
подробностей конкретного определения локализации. Для примеров, использующих
вложенные теги k* требуется ICU как минимум версии 54.
Обратите внимание, что хотя эта система позволяет создавать параметры
сортировки, которые «игнорируют регистр» или «игнорируют ударения»
или аналогичные (с использованием ключа ks), для того, чтобы такие
параметры сортировки действовали по-настоящему без учета регистра или
акцента, они также должны быть объявлены недетерминированными в CREATE COLLATION; см. раздел Недетерминированные правила сортировки.
В противном случае любые строки, которые являются равными в
соответствии с правилом сортировки, но не являются побайтово равными,
будут отсортированы в соответствии со своими байтовыми значениями.
Заметка
По своей конструкцииICUбудет принимать практически любую строку в качестве имени локализации и сопоставлять её с ближайшей локализацией, которую он может предоставить, используя процедуру, описанную в его документации. Таким образом, прямой обратной связи не будет, если спецификация правила сортировки составлена с использованием функций, которые данная установкаICUфактически не поддерживает. Поэтому рекомендуется создавать контрольные примеры на уровне приложения, чтобы проверить, что определения параметров сортировки удовлетворяют требованиям.
Копирование правил сортировки
Команду CREATE COLLATION можно также использовать для создания нового
правила сортировки из существующего правила, что может быть полезно для
возможности использовать независимые от операционной системы имена
правил в приложениях, создавать имена для совместимости или
использования правил, предоставляемых ICU в более читаемом формате.
Например:
CREATE COLLATION german FROM "de_DE";
CREATE COLLATION french FROM "fr-x-icu";
Недетерминированные правила сортировки
Правило сортировки является либо детерминированным, либо недетерминированным.
Детерминированное правило использует детерминированные сравнения, что означает,
что оно считает строки равными, только если они состоят из одной и той же
последовательности байтов. Недетерминированное сравнение может определить
строки равными, даже если они состоят из разных байтов. Типичные ситуации
включают сравнение без учета регистра, сравнение без учета акцента, а также
сравнение строк в различных нормальных формах Unicode. Поведение этих операций
определяется поставщиком правил сравнения; флаг детерминированности только
определяет, следует ли использовать байтовое сравнение для равенства.
См. Также Технический стандарт Unicode 10 для получения дополнительной информации о терминологии.
Чтобы создать недетерминированный порядок сортировки, укажите для
свойства CREATE COLLATION свойство deterministic = false,
например:
CREATE COLLATION ndcoll (provider = icu, locale = 'und', deterministic
= false);
В этом примере стандартная сортировка Unicode будет работать
недетерминированным способом. В частности, это позволило бы правильно
сравнивать строки в разных нормальных формах. Более интересные примеры
используют средства настройки ICU, описанные выше. Например:
CREATE COLLATION case_insensitive (provider = icu, locale =
'und-u-ks-level2', deterministic = false);
CREATE COLLATION ignore_accents (provider = icu, locale =
'und-u-ks-level1-kc-true', deterministic = false);
Все стандартные и предопределённые параметры сортировки являются
детерминированными, по умолчанию все определяемые пользователем
параметры сортировки являются детерминированными. Хотя
недетерминированные правила сортировки дают более «правильное» поведение,
особенно если учитывать всю мощь Unicode и его множество особых случаев,
у них также есть некоторые недостатки. Прежде всего, их использование
приводит к снижению производительности. Кроме того, некоторые операции
невозможны с недетерминированными правилами, такими как операции
сортировки с образцом. Поэтому их следует использовать только в тех
случаях, когда они конкретно востребованы.
Методы извлечения выборки из таблицы
В дополнение к методам BERNOULLI и SYSTEM, требуемыми стандартом SQL, реализация предложения
TABLESAMPLE в QHB поддерживает пользовательские методы извлечения выборки из
таблицы. Метод извлечения выборки определяет, какие строки таблицы будут выбраны, при использовании
предложения TABLESAMPLE.
На уровне SQL, метод извлечения выборки представлен единственной функцией (как правило, реализованной на C или Rust) с сигнатурой
имя_метода(internal) RETURNS tsm_handler
Имя функции совпадает с именем метода, используемым в предложении TABLESAMPLE. Аргумент internal
является фиктивным (всегда принимающим нулевое значение) — он предотвращает вызов этой функции
непосредственно из команды SQL. Результатом функции должна быть аллоцированная palloc структура,
имеющая тип TsmRoutine, который содержит указатели на опорные функции для метода извлечения
выборки. Опорные функции описаны в разделе Опорные функции метода извлечения выборки.
Кроме указателей на функций, структура TsmRoutine должна содержать следующие поля:
-
List *parameterTypesЭто список содержит OID типов данных параметров, принимаемых предложением
TABLESAMPLEпри использовании данного метода извлечения выборки. Например, у встроенных методов этот список содержит один элемент со значениемFLOAT4OID, представлющий собой процент выборки. Пользовательские методы могут иметь дополнительные или иные параметры. -
bool repeatable_across_queriesЗначение
trueозначает, что метод извлечения выборки возвращает идентичные выборки в последовательных запросах, если в каждом запросе предоставляются одни и те же параметры и начальное значениеREPEATABLE, а содержимое таблицы не изменяется. Если же значение равноfalse, предложениеREPEATABLEне принимается для использования с методом выборки. -
bool repeatable_acrossЕсли
true, то метод извлечения выборки способен возвращать идентичные выборки в последовательных сканирования внутри одного и того же запроса (при неизменных параметрах, начальном значении и снимке). Если же значение равноfalse, то планировщик не будет выбирать планы запроса, требующие более одного сканирования семплированной таблицы, так как они может приводить к неконсистентным результатам запроса.
Для дополнительной информации, см. тип структуры TsmRoutine объявленный в
src/include/access/tsmapi.h.
Методы извлечения выборки, входящие в стандартный дистрибутив, могут послужить хорошим примером при
реализации собственных методов выборки. Код встроенных методов находится в подкаталоге
src/backend/access/tablesample дерева исходного кода, а в подкаталоге contrib можно найти методы
извлечения выборки расширений.
Опорные функции метода извлечения выборки
Функция обработчика TSM возвращает аллоцированную palloc структуру TsmRoutine, содержащую
указатели на опорные функции, описанные ниже. Большинство этих функций являются обязательными,
однако некоторые являются опциональными, и соответствующие им указатели могут быть NULL.
void
SampleScanGetSampleSize (PlannerInfo *root,
RelOptInfo *baserel,
List *paramexprs,
BlockNumber *pages,
double *tuples);
Эта функция вызывается во время планирования запроса. Она должна оценить количество страниц
отношения, которые будут прочитаны во время сканирования выборки, и количество кортежей, которые
будут выбраны при сканировании. (Например, они могут быть определены оценкой процента выборки и
умножением baserel->pages и baserel->tuples на этот процент с округлением к целому.) Список
paramexprs содержит выражения, являющиеся параметрами к предложению TABLESAMPLE. Рекомендуется
использовать estimate_expression_value(), чтобы редуцировать эти выражения до констант, когда они
используются для оценки, однако функция должна вернуть оценку и в случае, когда выражения не могут
быть редуцированны. Более того, функция должна успершно вернуть оценку даже в случае, когда
соответствующие значения выглядят некорректными (помните, что это только приблизительные оценки
чисел, которые будут получены во время выполнения). pages и tuples являются выходными
параметрами.
void
InitSampleScan (SampleScanState *node,
int eflags);
Инициализация для выполнения узла плана SampleScan. Эта функция вызывается во время запуска
исполнителя. Её полагается выполнить любую инициализацию, необходимую перед началом обработки. Узел
SampleScanState уже создан, но его поле tsm_state ещё равно NULL. Функция InitSampleScan может
аллоцировать с помощью palloc любое внутренее состояние, требуемое для метода извлечения выборки, и
присвоить node->tsm_state указатель на это состояние. Информация о том, какие страницы
сканировать, доступна через иные поля узла SampleScanState (но обратите внимание, что дескриптор
сканирования node->ss.ss_currentScanDesc ещё не установлен). eflags содержит битовые флаги,
описывающие рабочий режим исполнителя для данного узла плана.
Когда (eflags & EXEC_FLAG_EXPLAIN_ONLY) истино, сканирование фактически не будет выполняться, и
функция должна выполнить только минимум, необходимый, чтобы состояние узла было корректным для
EXPLAIN и EndSampleScan.
Эта функция может быть опущена (присваиванием указателю значение NULL), в этом случае функция
BeginSampleScan должна выполнять всю инициализацию, необходимую методу извлечения выборки.
void
BeginSampleScan (SampleScanState *node,
Datum *params,
int nparams,
uint32 seed);
Начать выполнение сканирования выборки. Это функция вызывается непосредственно перед первой попыткой
извлечения кортежа и может быть вызвана снова, если сканирование необходимо перезапустить.
Информация о таблице, подлежащей сканированию, доступна через поля структуры node (но обратите
внимание, что node->ss.ss_currentScanDesc в этот момент ещё не инициализирован). Массив params,
длины nparams, содержит значения параметров переданных предложению TABLESAMPLE. Они будут иметь
номер и тип, определённые списком patameterTypes метода извлечения выборки, и будут проверены на
неравенство NULL. seed содержит начальное значение для всех псевдослучайных чисел,
сгенерированных внутри метода. Оно представляет собой или хеш на основе значения REPEATABLE, или
результат вызова random().
Эта функция может менять значения полей node->use_bulkread и node->use_pagemode. Если
node->use_pagemode истино, что по-умолчанию так, то сканирование будет использовать стратегию
доступа к буферу, которая поощряет переиспользование буферов. Может иметь смысл установить это поле
в false, если сканирование будет выбирать лишь малую часть всех кортежей в каждой посещённой
таблице. Это приведет к меньшему количеству выполняемых проверок видимости кортежей, хотя каждая из
них будет стоить дороже, так как потребует больше блокировок.
Если метод извлечения выборки помечен как repeatable_across_scans, он обязан выбирать один и тот
же набор кортежей во время повторного сканирования, как и во время первоначального, то есть вызов
BeginSampleScan должен приводить к выбору тех же кортежей, что и раньше (если параметры
TABLESPACE и начальное значение не изменились).
BlockNumber
NextSampleBlock (SampleScanState *node, BlockNumber nblocks);
Возвращает номер блока следующей сканируемой страницы, или InvalidBlockNumber если не осталось страниц для сканирования.
Эта функция может быть опущена (присваиванием указателю значение NULL), тогда основной код выполнит последовательное сканирование всего отношения. Такая проверка может использовать синхронизацию сканирования, так что метод извлечения выборки не может предполагать, что страницы отношения посещаются в одном и том же порядке при каждом сканировании.
OffsetNumber
NextSampleTuple (SampleScanState *node,
BlockNumber blockno,
OffsetNumber maxoffset);
Для данной страницы, возвращает номер смещения следующего кортежа, добавляемого в выборку, или
InvalidOffsetNumber если не осталось кортежей для выборки. maxoffset является наибольшей
величиной смещения на этой странице.
Примечание!!!
NextSampleTuple явно не говорится, какие номера смещения в диапазоне1 .. maxoffsetв действительности соответствуют корректным кортежам. Как правило, это не является проблемой, поскольку основной код игнорирует запросы к семплированию не существующих или скрытых кортежей, это не должно привести ни к какому смещению в выборке. Однако, если необходимо, функция может использоватьnode->donetuples, чтобы проверить, сколько из возвращённых кортежей были корректны и видимы.
Примечание!!!
NextSampleTuple не следует предполагать, что blockno это тот же номер страницы, что был возвращен самым последним вызовомNextSampleBlock. Он был возвращен каким-то предыдущим вызовомNextSampleBlockвызовом, однако основной код может вызывать NextSampleBlock до фактического сканирования страниц, для поддержки предварительной выборки. Допустимо предположить, что когда выборка данной страницы начнётся, все последующие вызовы вызовыNextSampleTupleссылаются на одну и ту же страницу, до тех пор, пока не будет возвращен InvalidOffsetNumber.
void
EndSampleScan (SampleScanState *node);
Завершить сканирование и освободить ресурсы. Как правило, освобождать аллоцированную с помощью palloc память не обязательно, однако любые ресурсы, видымые извне, должны быть очищины. Эта функция может быть опущена (присваиванием указателю значение NULL) в обычном случае, когда подобных ресурсов нет.
Регулярные задачи обслуживания базы данных
QHB, как и любое программное обеспечение для баз данных, для достижения оптимальной производительности требует, чтобы определенные задачи выполнялись регулярно . Обсуждаемые здесь задачи являются обязательными, но они повторяемые и могут быть легко автоматизированы с помощью стандартных инструментов, таких как сценарии cron. Администратор базы данных отвечает за установку соответствующих сценариев и проверку их успешного выполнения.
Одной из очевидных задач обслуживания является создание резервных копий данных на регулярной основе. Без последней резервной копии у вас нет шансов на восстановление после катастрофы (сбой диска, пожар, ошибочное удаление критической таблицы и т. д.). Механизмы резервного копирования и восстановления, доступные в QHB, подробно обсуждаются в главе Резервное копирование и восстановление.
Другой основной категорией задачи обслуживания является периодическая очистка базы данных. Эта задача обсуждается в разделе Регулярная очистка. С ней тесно связана задача обновления статистики, которая будет использоваться планировщиком запросов, как описано в разделе Обновление статистики планировщика.
Другая задача, которая может потребовать периодического внимания, — это управление файлами журналов. Она обсуждается в разделе Обслуживание файла журнала.
QHB не требует значительного обслуживания по сравнению с другими системами управления базами данных. Тем не менее, надлежащее внимание к этим задачам позволит обеспечить комфортный и продуктивный опыт работы с системой.
Регулярная очистка
Базы данных QHB требуют периодического обслуживания, известного как очистка («vacuum»). Для многих установок достаточно, чтобы процесс vacuum выполнял только автоматическую очистку, как описано в разделе Процесс «Автовакуум». Возможно, вам придется настроить параметры autovacuum, описанные там, чтобы получить наилучшие результаты для вашей установки. Некоторые администраторы баз данных захотят дополнить или заменить действия автоочистки командами VACUUM с ручным управлением, которые обычно выполняются в соответствии с расписанием с помощью сценариев cron. Чтобы правильно настроить процесс vacuum с ручным управлением, важно понимать вопросы, обсуждаемые в следующих нескольких подразделах. Администраторы, которые полагаются на автоочистку, могут ознакомится с этим материалом, чтобы лучше понять как настроить autovacuum.
Основы vacuum
Команда QHB VACUUM должна обрабатывать каждую таблицу на регулярной основе по нескольким причинам:
-
для восстановления или повторного использования дискового пространства, занятого обновленными или удаленными строками;
-
для обновления статистики данных используемых планировщиком запросов QHB;
-
для обновления карты видимости, которая ускоряет Сканирование только по индексу и покрывающие индексы;
-
для защиты от потери очень старых данных из-за "закольцовывания" идентификатора транзакции или мультранзакционного идентификатора.
Каждая из этих причин требует выполнение операций VACUUM различной частоты и объема, что будет объяснено в следующих подразделах.
Существует два варианта VACUUM: стандартный VACUUM и VACUUM FULL. VACUUM FULL может освободить больше места на диске, но работает намного медленнее. Кроме того, стандартная форма VACUUM может работать параллельно с другими операциями базы данных. (Такие команды, как SELECT, INSERT, UPDATE и DELETE, продолжат нормально функционировать, хотя вы не сможете изменять определение таблицы с помощью команд, таких как ALTER TABLE во время очистки). VACUUM FULL требует эксклюзивной блокировки на таблицы, с которыми он работает, и, следовательно, не может быть выполнен параллельно с другим использованием таблицы. Поэтому, как правило, администраторы должны стремиться использовать стандартный VACUUM и избегать VACUUM FULL.
VACUUM создает значительный объем трафика ввода-вывода, что может привести к снижению производительности других активных сеансов. Существуют параметры конфигурации, которые можно регулировать, чтобы снизить влияние фоновой очистки на производительность - см. раздел Определение предела стоимости работы процесса очистки.
Восстановление дискового пространства
В QHB UPDATE или DELETE строки не сразу удаляют старую версию строки. Этот подход необходим для получения преимуществ многоверсионного управления параллелизмом: нельзя удалять версию строки, пока она потенциально может быть видна другим транзакциям. Но в конце концов устаревшая или удаленная версия строки больше не представляет интереса для какой-либо транзакции. Затем занимаемое им пространство должно стать доступно для повторного использования новыми строками, чтобы избежать неограниченного роста требований к дисковому пространству. Это достигается с помощью процесса VACUUM.
Стандартная форма VACUUM удаляет версии "мертвых" строк в таблицах и индексах и отмечает пространство, доступное для повторного использования в будущем. Однако он не вернет пространство операционной системе, за исключением особого случая, когда одна или несколько страниц в конце таблицы становятся полностью свободными, и можно легко получить эксклюзивную блокировку таблицы. Напротив, VACUUM FULL активно уплотняет таблицы, записывая полную новую версию файла таблицы без пустого пространства. Это минимизирует размер таблицы, но может занять очень много времени. Также требуется дополнительное дисковое пространство для новой копии таблицы, пока операция не завершится.
Обычно, цель очистки состоит в том, чтобы выполняьб стандартный VACUUM достаточно часто, чтобы избежать необходимости запуска VACUUM FULL. Фоновый процесс autovacuum пытается работать таким образом, и фактически никогда не применяет VACUUM FULL. Идея такого подхода состоит не в том, чтобы поддерживать минимальный размер таблиц, а в том, чтобы поддерживать устойчивое равномерное использование дискового пространства: каждая таблица занимает пространство, эквивалентное ее минимальному размеру, тем не менее, много места может использоваться между очистками. Хотя VACUUM FULL можно использовать для сокращения таблицы до минимального размера и возврата дискового пространства в операционную систему, в этом нет особого смысла, если таблица в будущем снова будет расти. Таким образом, стандартные прогоны VACUUM с умеренной частотой являются лучше, чем редкие прогоны VACUUM FULL, для обрабоки значительно обновленных таблиц.
Некоторые администраторы предпочитают планировать VACUUM самостоятельно, например, выполняя всю работу ночью при низкой нагрузке. Сложность выполнения очистки по фиксированному расписанию состоит в том, что если в таблице неожиданно наблюдается всплеск активности обновления, она может раздуться до такой степени, что VACUUM FULL станет действительно необходим для освобождения места. Использование фонового процесса autovacuum облегчает эту задачу, поскольку фоновый процесс планирует динамическое удаление "мёртвых" строк в ответ на действия по обновлению. Неразумно полностью отключать фоновый процесс, если у вас нет стопроцентно предсказуемой рабочей нагрузки. Одним из возможных компромиссов является установка параметров фонового процесса так, чтобы он реагировал только на необычайно интенсивную деятельность по обновлению, таким образом не давая системе выйти из-под контроля, в то время как запланированные процессы VACUUM должны выполнять основную часть работы, когда нагрузка является типичной.
Для тех, кто не использует автоочистку, типичный подход - планирование VACUUM всей базы данных один раз в сутки в течение периода наименьшего использования, дополненного, по мере необходимости, более частой очисткой сильно обновленных таблиц. (В некоторых установках с чрезвычайно высокой частотой обновления самые загруженные таблицы вакуумируются каждые несколько минут). Если у вас в кластере несколько баз данных, не забудьте настроить VACUUM для каждой. Здесь может быть полезна программа vacuumdb.
Заметка
Результаты простого VACUUM могут быть неудовлетворительными, если в таблице содержится большое количество версий "мертвых" строк в результате массового обновления или удаления. Если у вас есть такая таблица и вам нужно освободить занимаемое ею избыточное дисковое пространство, вам нужно будет использовать VACUUM FULL или, альтернативно, CLUSTER или один из вариантов перезаписи таблицы ALTER TABLE. Эти команды переписывают новую копию таблицы и строят для нее новые индексы. Все эти опции требуют эксклюзивной блокировки. Обратите внимание, что они также временно используют дополнительное дисковое пространство, приблизительно равное размеру таблицы, поскольку старые копии таблицы и индексов не могут быть освобождены, пока не будут созданы новые.
Заметка
Если у вас есть таблица, все содержимое которой периодически удаляется, попробуйте сделать это с помощью TRUNCATE, а не с помощью DELETE а затем выполните VACUUM. TRUNCATE немедленно удаляет все содержимое таблицы, не требуя последующего VACUUM или VACUUM FULL для восстановления неиспользуемого дискового пространства. Недостатком является то, что строгая семантика MVCC нарушается.
Обновление статистики планировщика
Планировщик запросов QHB полагается на статистическую информацию о содержимом таблиц для создания хороших планов для запросов. Эти статистические данные собираются с помощью команды ANALYZE, которую можно вызвать отдельно или в качестве необязательного шага в VACUUM. Важно иметь достаточно точную статистику, иначе неверный выбор планов выполнения может значительно снизить производительность базы данных.
Фоновый процесс autovacuum, если он включен, будет автоматически запускать команды ANALYZE всякий раз, когда содержимое таблицы в достаточной степени изменяется . Однако администраторы могут предпочесть полагаться на запланированные вручную операции ANALYZE, особенно если известно, что активность обновления таблицы не повлияет на статистику «интересующих» планировщик столбцов (которые интенсивно используются в WHERE). Фоновый процесс autovacuum планирует ANALYZE строго в зависимости от количества вставленных или обновленных строк - он не знает, приведет ли это к значимым статистическим изменениям.
Как и в случае с VACUUM для восстановления пространства, частые обновления статистики более полезны для сильно обновленных таблиц, чем для редко обновляемых. Но даже для сильно обновленной таблицы может не потребоваться обновление статистики, если статистическое распределение данных сильно не меняется. Простое правило - подумать о том, насколько изменяются минимальное и максимальное значения столбцов в таблице. Например, столбец timestamp который содержит время обновления строки, будет иметь постоянно увеличивающееся максимальное значение при добавлении и обновлении строк; такой столбец, вероятно, будет нуждаться в более частых обновлениях статистики, чем, скажем, столбец, содержащий URL-адреса для страниц, доступных на веб-сайте. Столбец URL может получать изменения так же часто, но статистическое распределение его значений, вероятно, изменяется слабо.
Можно запустить ANALYZE для определенных таблиц и даже только для определенных столбцов таблицы, поэтому существует возможность обновлять некоторые статистические данные чаще, чем другие, если этого требует ваше приложение. На практике, однако, обычно лучше всего проанализировать всю базу данных, потому что это быстрая операция. ANALYZE использует статистически случайную выборку строк таблицы, а не читает каждую строку.
Заметка
Хотя подстройка частоты ANALYZE каждого столбца может быть и не очень продуктивной, может оказаться целесообразным выполнить для каждого столбца настройку уровня детализации статистики, собираемой ANALYZE. Столбцы, которые интенсивно используются в WHERE и имеют очень нерегулярное распределение данных, могут потребовать более детальной гистограммы данных, чем другие столбцы. См. ALTER TABLE SET STATISTICS или можно изменить значение по умолчанию для всей базы данных, используя параметр конфигурации default_statistics_target.
Также по умолчанию имеется ограниченная информация о селективности функций. Однако если вы создадите индекс по выражению, использующий вызов функции, будет собрана полезная статистика о функции, которая может значительно улучшить планы запросов, использующие индекс по выражению.
Заметка
Фоновый процесс autovacuum не запускает команды ANALYZE для внешних таблиц, так как не имеет возможности определить, как часто это может быть сделано. Если ваши запросы для правильного планирования требуют статистики внешних таблиц , рекомендуется запускать вручную команды ANALYZE для этих таблиц по расписанию.
Обновление карты видимости
VACUUM поддерживает карту видимости для каждой таблицы, чтобы отслеживать, какие страницы содержат только кортежи, которые, как известно, видны всем активным транзакциям (и всем будущим транзакциям, пока страница не будет снова изменена). Это реализовано для двух целей.
-
Во-первых, сам VACUUM может пропустить такие страницы при следующем запуске, так как нечего убирать.
-
Во-вторых, страницы видимости позволяют QHB отвечать на некоторые запросы, используя только индекс, без ссылки на базовую таблицу. Поскольку индексы QHB не содержат информации о видимости строки, при обычном сканировании индекса строка выбирается для каждой соответствующей записи индекса, чтобы проверить, должна ли она быть видимой текущей транзакцией. С другой стороны, сканирование только по индексу сначала проверяет карту видимости. Если известно, что все кортежи на странице видны, выборка может быть пропущена. Это наиболее полезно для больших наборов данных, где карта видимости может предотвратить лишний доступ к диску. Карта видимости значительно меньше списка всех блоков, поэтому ее можно легко кэшировать, даже если блоков очень много.
Предотвращение ошибок зацикливания идентификатора транзакции
Семантика транзакции MVCC в QHB зависит от возможности сравнения номеров идентификаторов транзакций (XID): версия строки с XID вставки, превышающим XID текущей транзакции, находится «в будущем» и не должна быть видимой для текущей транзакции. Но поскольку идентификаторы транзакций имеют ограниченный размер 32 бита, кластер, работающий в течение длительного времени (более 4 миллиардов транзакций), будет подвергаться циклическому изменению идентификатора транзакции (закольцовывание, wraparound): счетчик XID обнуляется, и все транзакции, которые были в прошлом внезапно окажутся в будущем - что означает, что их значения становится невидимы. В итоге произойдёт катастрофическая потеря данных. (На самом деле данные все еще там, но это не поможет, если нет возможности их получить). Чтобы избежать этого, необходимо запустить VACUUM для каждой таблицы в каждой базе данных как минимум один раз каждые два миллиарда транзакций.
Причина, по которой периодический запуск VACUUM решает проблему, состоит в том, что VACUUM помечает строки как "замороженные" (freeze), указывая на то, что они были установлены транзакцией, зафиксированной достаточно давно, и что изменения этой транзакции будут видны для всех текущих и будущих транзакций., Нормальные XID сравниваются с использованием арифметики по модулю 2 **32 **. Это означает, что для каждого нормального XID существует два миллиарда «более старых» и два миллиарда «более новых» значений. После создания версии строки с определенным нормальным XID версия строки будет «в прошлом» для следующих двух миллиардов транзакций, независимо от того, о каком XID идет речь. Если версия строки все еще существует после более чем двух миллиардов транзакций, она внезапно появится в будущем. Чтобы предотвратить это, QHB резервирует специальный XID, FrozenTransactionId, который не следует нормальным правилам сравнения XID и всегда считается старше любого обычного XID. Версии замороженных строк обрабатываются так, как если бы XID вставки был FrozenTransactionId, так что они будут казаться «в прошлом» для всех обычных транзакций, независимо от проблем с переносом, и поэтому такие версии строк будут действительными до тех пор, пока они не будут удалены, независимо от того, как долго они хранятся.
vacuum_freeze_min_age контролирует, какой возраст должен быть у значения XID, прежде чем строки, содержащие этот XID, будут "заморожены". Увеличение этого параметра поможет избежать ненужной работы, если строки, которые в противном случае были бы заморожены, вскоре будут снова изменены, но уменьшение этого параметра увеличивает количество транзакций, которые могут пройти, прежде чем таблицу необходимо будет снова очистить.
VACUUM использует карту видимости, чтобы определить, какие страницы таблицы необходимо сканировать. Обычно он пропускает страницы, которые не имеют версий "мертвых" строк, даже если на этих страницах все еще могут быть версии строк со старыми значениями XID. Поэтому обычные VACUUM не всегда замораживают каждую старую версию строки в таблице. Периодически VACUUM будет иницировать агрессивный вакуум, пропуская только те страницы, которые не содержат ни пустых строк, ни незамерзших значений XID или MXID. vacuum_freeze_table_age контролирует, когда VACUUM выполнит след. действия: сканируются все видимые, но не полностью замороженные страницы, если количество транзакций, прошедших с момента последнего такого сканирования, больше, чем vacuum_freeze_table_age минус vacuum_freeze_min_age. Установка 0 в vacuum_freeze_table_age заставляет VACUUM использовать эту более агрессивную стратегию для всех сканирований.
Максимальное время, в течение которого таблица может оставаться невостребованной, составляет два миллиарда транзакций минус значение vacuum_freeze_min_age во время последнего агрессивного вакуума. Если бы она оставалась невостребованной дольше, это могло бы привести к потере данных. Чтобы этого не происходило, autovacuum вызывается для любой таблицы, которая может содержать незамерзающие строки с XID старше, чем возраст, указанный в параметре конфигурации autovacuum_freeze_max_age. (Вызов произойдет, даже если автоочистка отключен).
Подразумевается, что если таблица не будет очищена VACUUM, то для ее обработки будет вызываться autovacuum примерно один раз за autovacuum_freeze_max_age минус vacuum_freeze_min_age транзакцию. Для таблиц, которые регулярно очищает VACUUM в целях освобождения пространства, это не имеет большого значения. Однако для статических таблиц (включая таблицы, для которых вызываются операции вставки, но не обновления и не удаления), нет необходимости в VACUUM для восстановления пространства, поэтому может быть полезно попытаться максимально увеличить интервал между принудительными сеансами автоочистки для очень больших статических таблиц. Очевидно, что это можно сделать, либо увеличив autovacuum_freeze_max_age либо уменьшив vacuum_freeze_min_age.
Сколько-нибудь эффективным максимальным значением vacuum_freeze_table_age является 0.95*autovacuum_freeze_max_age. Большее значение будет упираться в возможный максимум. А значение равное autovacuum_freeze_max_age вообще не имеет смысла, потому что процедура очистки для предотвращения "закольцовывания" (прохода через ноль номера транзакции) запустится к этому моменту сама. Таким образом множитель 0,95 оставляет некоторое пространство для манёвра и запуска VACUUM в ручном режиме, до момента, когда произойдёт закольцовывание. Основным правилом можно считать следующее: Параметр vacuum_freeze_table_age нужно выставить несколько ниже, чем autovacuum_freeze_max_age, оставляя промежуток для штатно-запланированного запуска VACUUM или autovacuum вызываемого нормальными процедурами DELETE и UPDATE. Таким образом, ставя значения слишком близко, возможно повлечь запуск autovacuum для устранения закольцовываний, даже если таблица была недавно очищена для целей восстановления свободного места. Установка же низких значений ведёт к агрессивному и более частому вакуумированию таблицы.
Единственный недостаток увеличения autovacuum_freeze_max_age (и в сочетании с vacuum_freeze_table_age) заключается в том, что подкаталоги pg_xact и pg_commit_ts кластера базы данных будут занимать больше места, поскольку они должны хранить статус фиксации и (если track_commit_timestamp включена) временную метку всех транзакций возрастом меньше чем autovacuum_freeze_max_age. Состояние фиксации использует два бита на транзакцию, поэтому, если для autovacuum_freeze_max_age установлено максимально допустимое значение в два миллиарда, можно ожидать, что pg_xact вырастет примерно до половины гигабайта, а pg_commit_ts - примерно до 20 ГБ. Если это малозначимо по сравнению с вашим общим размером базы данных, рекомендуется установить для autovacuum_freeze_max_age максимально допустимое значение. В противном случае установите его в зависимости от того, что вы хотите разрешить для pg_xact и pg_commit_ts. (Значение по умолчанию, 200 миллионов транзакций, означает около 50 МБ хранилища pg_xact и около 2 ГБ хранилища pg_commit_ts).
Одним из недостатков уменьшения vacuum_freeze_min_age является то, что это может привести к тому, что VACUUM сделает бесполезную работу: замораживания версии строки - пустая трата времени, если строка будет вскоре изменена (что приведет к приобретению строкой нового XID). Таким образом, настройка должна быть достаточно большой, чтобы строки не были заморожены до тех пор, пока они, скорее всего, не изменятся.
Чтобы отследить возраст самых старых незамерзших XID в базе данных, VACUUM сохраняет статистику XID в системных таблицах pg_class и pg_database. В частности, столбец relfrozenxid в строке таблицы pg_class содержит XID отсечки замораживания, который использовался последним агрессивным VACUUM для этой таблицы. Все строки, вставленные транзакциями с XID старше этого XID с отсечкой, гарантированно будут заморожены. Точно так столбец datfrozenxid строки базы данных pg_database является нижней границей незамерзших XID, появляющихся в этой базе данных, — это только минимум значений relfrozenxid каждой таблицы в базе данных. Удобный способ проверить эту информацию - выполнить такие запросы:
SELECT c.oid::regclass as table_name,
greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind IN ('r', 'm');
SELECT datname, age(datfrozenxid) FROM pg_database;
Столбец age показывает количество транзакций от XID среза до XID текущей транзакции.
VACUUM обычно сканирует только те страницы, которые были изменены с момента последнего вакуума, но relfrozenxid может быть расширен только после сканирования каждой страницы таблицы, которая может содержать незамерзщие XID. Это происходит, когда relfrozenxid больше, чем vacuum_freeze_table_age транзакции, когда используется опция FREEZE VACUUM, или когда все страницы, которые еще не полностью заморожены, требуют очистки для удаления версий мертвых строк. Когда VACUUM сканирует каждую страницу в таблице, которая еще не полностью заморожена, ему следует установить значение для age(relfrozenxid) чуть превышающее vacuum_freeze_min_age. Если VACUUM, устанавливающий relfrozenxid, не будет выдан на таблицу до тех пор, пока autovacuum_freeze_max_age не будет достигнут, то для таблицы будет автоматически запущена автоочистка.
Если по какой-то причине автоочистке не удастся удалить старые XID из таблицы, система начнет выдавать предупреждающие сообщения, подобные этому, когда самые старые XID базы данных достигнут десяти миллионов транзакций с точки прохода VACUUM:
WARNING: database "mydb" must be vacuumed within 177009986 transactions
HINT: To avoid a database shutdown, execute a database-wide VACUUM in "mydb".
(Ручной VACUUM должен решить проблему, как подсказано в сообщении, но учтите, что VACUUM должен выполняться суперпользователем, иначе он не сможет обрабатывать системные каталоги и, следовательно, не сможет продвигать datfrozenxid базы данных). Если эти предупреждения игнорируются, система завершит работу и откажется начинать любые новые транзакции, если до завершения процедуры останется менее 1 миллиона транзакций:
ERROR: database is not accepting commands to avoid wraparound data loss in database "mydb"
HINT: Stop the postmaster and vacuum that database in single-user mode.
Запас безопасности в 1 миллион транзакций предусмотрен, чтобы позволить администратору восстановиться без потери данных, выполнив вручную необходимые команды VACUUM. Однако, поскольку система не будет выполнять команды после перехода в режим безопасного отключения, единственный способ сделать это - остановить сервер и запустить сервер в однопользовательском режиме для выполнения VACUUM.
Мультитранзакции и зацикливание
Идентификаторы мультитранзакций используются для поддержки блокировки строк несколькими транзакциями. Поскольку в заголовке кортежа имеется только ограниченное пространство для хранения информации о блокировке, эта информация кодируется как «идентификатор множественной транзакции» или идентификатор мультитранзакции, когда существует более одной транзакции, одновременно блокирующей строку. Информация о том, какие идентификаторы транзакций включены в любой конкретный идентификатор мультитранзакции, хранится отдельно в подкаталоге pg_multixact, и в поле xmax в заголовке кортежа отображается только идентификатор мультитранзакции. Как и идентификаторы транзакций, идентификаторы мультитранзакций реализованы в виде 32-разрядного счетчика и соответствующего хранилища, что требует тщательного управления устареванием, очистки хранилища и обработки изменений при зацикливаниях. Существует отдельная область хранения, которая содержит список элементов для каждой мультитранзакции, которая также использует 32-разрядный счетчик и которым также необходимо управлять.
Всякий раз, когда VACUUM сканирует какую-либо часть таблицы, он заменяет любой обнаруженный им идентификатор мультитранзакции, который старше, чем vacuum_multixact_freeze_min_age, на другое значение, которое может быть нулевым значением, идентификатором отдельной транзакции или новым идентификатором мультитранзакции. Для каждой таблицы pg_class.relminmxid хранит самый старый из возможных идентификаторов мультитранзакций, которые все еще присутствуют в любом кортеже этой таблицы. Если это значение старше, чем vacuum_multixact_freeze_table_age, агрессивный вакуум запускается принудительно. Как обсуждалось в предыдущем разделе, агрессивный вакуум означает, что будут пропущены только те страницы, про которые известно, что они полностью заморожены. Функция mxid_age() может использоваться для pg_class.relminmxid для определения возраста.
Агрессивное сканирование VACUUM, независимо от того, что его вызывает, позволяет повысить доступность дискового пространства. В конце концов, так как все таблицы во всех базах данных сканируются и их самые старые значения мультитранзакций обновляются, пространство на диске для старых файлов мультитранзакций может быть освобождено.
В качестве защитного устройства агрессивное сканирование VACUUM будет выполняться для любой таблицы, возраст мультитранзакций которой больше, чем autovacuum_multixact_freeze_max_age. Агрессивное VACUUM сканирование также будет происходить постепенно для всех таблиц, начиная с тех, которые имеют самые старые мультитранзакции, если объем используемого пространства хранения элементов превышает 50% адресуемого пространства хранения. Оба этих вида агрессивного сканирования будут происходить даже в том случае, если автоочистка формально отключена.
Процесс «Автовакуум»
QHB имеет необязательную, но настоятельно рекомендуемую функцию, называемую Автовакуум (autovacuum), цель которой - автоматизировать выполнение команд VACUUM и ANALYZE. При включении autovacuum проверяет таблицы, в которые было вставлено, обновлено или удалено большое количество кортежей. Эти проверки используют средства сбора статистики; поэтому, autovacuum нельзя использовать, если для track_counts не установлено значение true. В конфигурации по умолчанию автоочистка включена, и соответствующие параметры конфигурации установлены соответствующим образом.
Процесс autovacuum на самом деле состоит из нескольких процессов. Существует постоянный фоновый процесс, называемый средством запуска autovacuum (autovacuum executor), который отвечает за запуск рабочих процессов autovacuum для всех баз данных. Модуль запуска будет распределять работу по времени, пытаясь запускать по одному процессу в каждой базе данных каждые autovacuum_naptime секунд. (Следовательно, если в установке имеется N баз данных, новый процесс будет запускаться каждые autovacuum_naptime/N секунд). Одновременно разрешено запускать максимум autovacuum_max_workers рабочих процессов. Если запущено больше баз данных, чем установленное значение autovacuum_max_workers, то следующая база данных будет обработана, как только закончится первый процесс. Каждый рабочий процесс будет проверять каждую таблицу в своей базе данных и выполнять VACUUM и/или ANALYZE по мере необходимости. log_autovacuum_min_duration может быть установлен для мониторинга активности процессов автоочистки.
Если несколько больших таблиц становятся доступны для вакуума за короткий промежуток времени, все процессы автоочистки, могут быть заняты очисткой в течение длительного времени. Это приведет к тому, что другие таблицы и базы данных не будут очищены до тех пор, пока процесс не станет доступным. Нет ограничений на количество процессов в одной базе данных, но процессы стараются избегать повторения уже выполненной работы. Обратите внимание, что количество работающих процессов не учитывается в рамках ограничений max_connections или superuser_reserved_connections.
Таблицы, у которых значение relfrozenxid больше, чем autovacuum_freeze_max_age старых транзакций, всегда очищаются VACUUM (это также относится к тем таблицам, чей максимальный срок замораживания был изменен с помощью параметров хранилища; см. ниже). В противном случае, если количество кортежей, устаревших с момента последнего VACUUM, превышает «порог», таблица очищается VACUUM. Порог вакуума (vacuum threshold) определяется как:
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
где базовый порог вакуума (vacuum base threshold) - autovacuum_vacuum_threshold, коэффициент масштабирования вакуума (vacuum scale factor)- autovacuum_vacuum_scale_factor, а число кортежей (number of tuples) - pg_class.reltuples. Количество устаревших кортежей котрое получается из сборщика статистики - это примерный расчет, обновляемый каждой операцией UPDATE и DELETE. (Расчет приблизительный, потому, что некоторая информация может быть потеряна при большой нагрузке). Если значение relfrozenxid в таблице больше, чем vacuum_freeze_table_age транзакции, агрессивный вакуум выполняется для замораживания старых кортежей и продвижения relfrozenxid, в противном случае сканируются только страницы, которые были изменены с момента последнего вакуума.
Для анализа используется аналогичное условие: порог, определяемый как:
analyze threshold = analyze base threshold + analyze scale factor * number of tuples
сравнивается с общим количеством вставленных, обновленных или удаленных кортежей со времени последнего ANALYZE.
Временные таблицы не доступны для автоочистки. Следовательно, соответствующие операции вакуума и анализа для них должны выполняться с помощью команд сеанса SQL.
Пороговые значения по умолчанию и масштабные коэффициенты взяты из qhb.conf, но их можно переопределить (и многие другие параметры управления автоочисткой) для каждой таблицы; см. Параметры хранения для получения дополнительной информации. Если параметр управляющий autovacuum был изменен с помощью параметров хранения таблицы, это значение используется при обработке этой таблицы - в противном случае используются глобальные настройки. См. раздел Автоматическая очистка для более подробной информации о глобальных настройках.
Когда работают несколько процессов autovacuum, параметры задержки затрат на автоочистку (см. раздел Определение предела стоимости работы процесса очистки) «сбалансированы» между всеми работающими процессами, так что общее влияние ввода/вывода на систему одинаково независимо от количества фактически работающих процессов, Однако любые рабочие таблицы, для которых были установлены собственные параметры хранения autovacuum_vacuum_cost_delay или autovacuum_vacuum_cost_limit, не учитываются в алгоритме балансировки.
Процессы autovacuum обычно не блокируют другие команды. Если процесс попытается получить блокировку, которая конфликтует с блокировкой SHARE UPDATE EXCLUSIVE удерживаемой автоочисткой, получение блокировки прервет autovacuum. Конфликтующие режимы блокировки см. в таблице. Однако, если автоочистка работает для предотвращения закольцовывания идентификатора транзакции (т. е. имя запроса автоочистки в представлении pg_stat_activity заканчивается текстом to prevent wraparound), автоочистка автоматически не прерывается.
Предупреждение!!!
Регулярно выполняемые команды, которые получают блокировки, конфликтующие с блокировкой SHARE UPDATE EXCLUSIVE (например, ANALYZE), могут эффективно предотвращать завершение autovacuum.
Регулярная переиндексация
В некоторых ситуациях целесообразно периодически перестраивать индексы с помощью команды REINDEX или ряда отдельных шагов перестройки.
Страницы индекса B-tree, которые стали полностью пустыми, возвращаются для повторного использования. Однако все еще существует вероятность неэффективного использования пространства: если все, кроме нескольких индексных ключей на странице, были удалены, страница остается выделенной. Следовательно, шаблон использования, при котором большинство, но не все ключи в каждом диапазоне в конечном итоге будут удалены, приведет к неэффективному использованию пространства. Для таких моделей использования рекомендуется периодическая переиндексация.
Потенциал раздувания (bloat) в индексах отличных от B-tree не был достаточно исследован. Рекомендуется периодически отслеживать физический размер индекса при использовании любого типа индекса, отличного от B-tree.
Кроме того, для индексов B-tree доступ к недавно сконструированному индексу немного быстрее, чем к индексу, который много раз обновлялся, потому что логически смежные страницы обычно также физически соседствуют во вновь созданном индексе. (Это соображение не относится к индексам, не относящимся к B-tree). Возможно, есть смысл периодически переиндексировать таблицы для повышения скорости доступа.
REINDEX может использоваться легко и безопасно во всех случаях. Эта команда требует блокировки ACCESS EXCLUSIVE по умолчанию, поэтому часто предпочтительно выполнять ее с параметром CONCURRENTLY, который требует только блокировки SHARE UPDATE EXCLUSIVE.
Обслуживание файла журнала
Хорошей идеей будет сохранить куда-нибудь вывод журнала сервера базы данных, а не просто отбрасывать его через /dev/null. Вывод журнала очень важен при диагностике проблем. Однако вывод журнала имеет тенденцию к росту объемов (особенно на более высоких уровнях детализации), поэтому его нет смысла сохранять его бесконечно долго. Желательно настроить файлы журнала так, чтобы новые файлы журнала запускались, а старые удалялись через разумный период времени.
Если вы просто направите stderr процесса qhb в файл, у вас будет вывод журнала, но единственный способ обрезать файл журнала — это остановить и перезапустить сервер. Это может быть приемлемо, если вы используете QHB в среде разработки, но немногие продукционные серверы сочтут это поведение приемлемым.
Лучшим подходом является отправка вывода stderr сервера в какую-либо программу ротации журналов. Существует встроенная logging_collector ротации журналов, которую вы можете использовать, установив для параметра конфигурации logging_collector значение true в qhb.conf. Параметры управления для этой программы описаны в разделе Расположение журнала. Вы также можете использовать этот подход для захвата данных журнала в машиночитаемом формате CSV (значения, разделенные запятыми).
В качестве альтернативы вы можете использовать внешнюю программу ротации журналов, если у вас есть такая, которую вы уже используете с другим серверным программным обеспечением. Например, инструмент rotatelogs, включенный в дистрибутив Apache, может использоваться с QHB. Один из способов сделать это - направить вывод сервера stderr в нужную программу. Если вы запускаете сервер с qhb_ctl, то stderr уже перенаправлен на stdout, поэтому вам просто нужна команда pipe, например:
qhb_ctl start | rotatelogs /var/log/pgsql_log 86400
Вы можете объединить эти подходы, настроив logrotate для сбора файлов журналов, создаваемых встроенным сборщиком журналов QHB. В этом случае сборщик журналов определяет имена и расположение файлов журналов, а logrotate периодически архивирует эти файлы. При запуске ротации журнала logrotate должен убедиться, что приложение отправляет дальнейшие выходные данные в новый файл. Обычно это делается с помощью сценария postrotate который отправляет сигнал SIGHUP приложению, которое затем повторно открывает файл журнала. В QHB вы можете запустить qhb_ctl с опцией logrotate. Когда сервер получает эту команду, сервер либо переключается на новый файл журнала, либо повторно открывает существующий файл, в зависимости от конфигурации ведения журнала (см. Раздел Расположение журнала).
Заметка
При использовании статических имен файлов журнала сервер может не открыть файл журнала, если достигнут максимальный лимит открытых файлов в системе или произошло переполнение таблицы файлов. В этом случае сообщения журнала отправляются в старый файл до успешной ротации журнала. Если logrotate настроен на сжатие файла журнала и его удаление, сервер может потерять сообщения, зарегистрированные в этот период времени. Чтобы избежать этой проблемы, вы можете настроить сборщик журналов на динамическое назначение имен файлов журналов и использовать сценарий предварительной prerotate чтобы игнорировать открытые файлы журналов.
Другой производственный подход к управлению выводом журнала - отправить его в системный журнал и позволить системному журналу работать с ротацией файлов. Для этого установите для параметра конфигурации log_destination значение syslog (для вывода только в syslog) в qhb.conf. Затем вы можете отправить сигнал SIGHUP демону syslog всякий раз, когда вы хотите заставить его начать запись нового файла журнала. Если вы хотите автоматизировать ротацию журналов, программа logrotate может быть настроена для работы с файлами журналов на системном уровне.
Однако во многих установках системный журнал не очень надежен, особенно с большими сообщениями, он может обрезать или отбрасывать сообщения именно тогда, когда они вам нужны больше всего. Кроме того, в Linux системный журнал сбрасывает каждое сообщение на диск, что приводит к снижению производительности. (Вы можете использовать «-» в начале имени файла в файле конфигурации системного журнала, чтобы отключить синхронизацию).
Обратите внимание, что все решения, описанные выше, предусматривают запуск новых файлов журнала через настраиваемые интервалы, но они не обрабатывают удаление старых, бесполезных файлов журнала. Возможно, вы захотите настроить пакетное задание для периодического удаления старых файлов журнала. Другая возможность - настроить программу ротации так, чтобы старые файлы журналов циклически перезаписывались.
Резервное копирование и восстановление
- SQL-дамп
- Резервное копирование на уровне файловой системы
- Непрерывное архивирование и восстановление на момент времени
- Советы и примеры
- Предостережения
Как и все, что содержит ценные данные, базы данных QHB должны регулярно подвергаться резервному копированию. Существует три принципиально разных подхода к резервному копированию данных QHB:
У каждого есть свои сильные и слабые стороны, которые обсуждается в следующих разделах.
SQL-дамп
Идея этого метода дампа состоит в том, чтобы создать файл с SQL-командами, которые при применении на сервере воссоздают базу данных в том же состоянии, в котором она находилась во время создания дампа. QHB предоставляет для этой цели служебную программу qhb_dump. Простейшее использование этой программы выглядит следующим образом:
qhb_dump dbname > dumpfile
qhb_dump записывает свой результат в стандартный вывод. Ниже мы увидим, когда это может быть полезно. В то время как вышеуказанная команда создаёт текстовый файл, qhb_dump может создавать файлы в других форматах, которые обеспечивают параллелизм и более детальный контроль над восстановлением объектов.
qhb_dump — это обычное клиентское приложение QHB. Это означает, что можно выполнить процедуру резервного копирования с любого удалённого хоста, который имеет доступ к базе данных. Но помните, что qhb_dump не работает с использованием специальных привилегий. В частности, требуется доступ на чтение ко всем таблицам, для которых выполняется резервное копирование, поэтому для резервного копирования всей базы данных почти всегда требуется запуск с правами суперпользователя базы данных.
Заметка
Если у вас недостаточно прав для резервного копирования всей базы данных, вы всё равно можете создавать резервные копии тех частей базы данных, к которым у вас есть доступ, используя такие параметры, как-n schemaили-t table).
Чтобы указать, к какому серверу баз данных должен обращаться qhb_dump,
используйте параметры командной строки -h host и -p port. Хост по
умолчанию — это локальный хост или то значение, которое указано в переменной среды PGHOST.
Точно так же порт по умолчанию указывается переменной окружения PGPORT
или, если она не задана, значением, принятым по умолчанию.
Заметка
При компиляции сервер обычно имеет те же значения параметров по умолчанию
Как и любое другое клиентское приложение QHB, qhb_dump по умолчанию
соединяется с базой данных используя имя пользователя, которое совпадает с текущим именем пользователя операционной системы. Чтобы переопределить это, либо укажите опцию -U либо установите переменную окружения PGUSER.
Помните, что соединения qhb_dump подчиняются обычным механизмам
аутентификации клиента.
Важное преимущество qhb_dump перед другими методами резервного копирования, описанными ниже, заключается в том, что выходные данные qhb_dump, как правило, могут загружаться в более новые версии QHB, тогда как резервные копии на уровне файлов и непрерывное архивирование являются исключительно специфичными для версии сервера. qhb_dump также является единственным методом, который будет работать при переносе базы данных на другую архитектуру компьютера, например при переходе с 32-разрядного на 64-разрядный сервер.
Дампы, созданные qhb_dump, являются внутренне непротиворечивыми, то есть дамп представляет собой снимок базы данных во время запуска qhb_dump. qhb_dump не блокирует другие операции с базой данных во время работы.
Заметка
Исключением являются те операции, которым требуется полная блокировка, например, большинство формALTER TABLE.
Восстановление дампа
Текстовые файлы, созданные qhb_dump, предназначены для чтения программой qsql. Общая форма команды для восстановления дампа:
qsql dbname < dumpfile
где dumpfile — это файл, содержащий вывод команды qhb_dump. Эта команда не будет создавать базу данных dbname, поэтому вы должны создать её самостоятельно из template0 перед выполнением qsql (например, с помощью createdb -T template0 dbname). qsql поддерживает параметры, аналогичные
qhb_dump, для указания сервера базы данных, к которому нужно
подключиться, и имени пользователя для использования (см. подробнее в qsql). Дампы нетекстовых файлов восстанавливаются с помощью утилиты qhb_restore.
Перед восстановлением дампа SQL все пользователи, которым принадлежали объекты или права на них в выгруженной базе данных, уже должны существовать. Если их нет, при восстановлении не удастся воссоздать объекты с первоначальным владельцем и / или правами. (Иногда это желаемое поведение, но обычно это не так).
По умолчанию сценарий qsql будет продолжать выполняться после
возникновения ошибки SQL. Если запустить qsql с переменной ON_ERROR_STOP установленной для изменения этого поведения, то qsql завершится кодом 3, если возникает ошибка SQL:
qsql --set ON_ERROR_STOP=on dbname < dumpfile
В любом случае, у вас будет только частично восстановленная база данных. В качестве альтернативы вы можете указать, что весь дамп должен быть восстановлен за одну транзакцию, поэтому восстановление будет либо полностью завершено, либо полностью отменено. Этот режим может быть указан путём передачи параметров командной строки -1 или --single-transaction в qsql. При использовании этого режима помните, что даже небольшая ошибка может послужить причиной отката восстановления, которое уже выполняется в течение многих часов. Однако это все же может быть предпочтительнее, чем ручная очистка сложной базы данных после частично восстановленного дампа.
Возможность qhb_dump и qsql использовать каналы ввода/вывода позволяет скопировать базу данных напрямую с одного сервера на другой, например:
qhb_dump -h host1 dbname | qsql -h host2 dbname
Важно!!!
Дампы, создаваемые qhb_dump, относятся к template0. Это означает, что любые языки, процедуры и т. д., добавленные через template1, также будут выгружены qhb_dump. В результате при восстановлении, если вы используете настроенный template1, вы должны создать пустую базу данных из template0, как в примере выше.
После восстановления резервной копии целесообразно запустить ANALYZE для каждой базы данных, чтобы оптимизатор запросов имел полезную статистику. См. раздел Обновление статистики планировщика и раздел Процесс «Автовакуум» для получения дополнительной информации. Дополнительные советы о том, как эффективно загружать большие объёмы данных в QHB, см. в разделе Заполнение базы данных.
Использование qhb_dumpall
qhb_dump одновременно создаёт дамп только одной базы данных, который не содержит информацию о ролях или табличных пространствах (потому что они относятся к экземпляру, а не к базе данных). Для создания удобного дампа всего содержимого экземпляра базы данных предусмотрена программа qhb_dumpall. qhb_dumpall выполняет резервное копирование каждой базы данных в данном кластере, а также сохраняет данные для всего кластера, такие как определения ролей и табличных пространств. Простой вариант использования этой программы:
qhb_dumpall > dumpfile
Полученный дамп можно восстановить с помощью qsql:
qsql -f dumpfile qhb
Заметка
На самом деле вы можете указать любое существующее имя базы данных для запуска, но если вы загружаете в пустой экземпляр, обычно следует использовать qhb.
Восстановление дампа qhb_dumpall необходимо производить с правами суперпользователя, поскольку это требуется для восстановления информации о ролях и табличных пространствах. Если вы используете табличные пространства, убедитесь, что их пути в дампе соответствуют новой среде.
qhb_dumpall работает, выполняя команды для воссоздания ролей, табличных пространств и пустых баз данных, затем вызывая qhb_dump для каждой базы данных. Это означает, что хотя каждая база данных будет внутренне согласованной, снимки разных баз данных не синхронизируются.
Данные всего экземпляра могут быть выгружены отдельно, используя опцию
--globals-only. Это необходимо для полного резервного копирования
экземпляра при выполнении команды qhb_dump в отдельных базах данных.
Обработка больших баз данных
Некоторые операционные системы имеют ограничения по максимальному размеру файла, которые вызывают проблемы при создании больших выходных файлов qhb_dump. К счастью, qhb_dump может записывать в стандартный вывод, поэтому вы можете использовать стандартные инструменты Unix для решения этой потенциальной проблемы. Есть несколько возможных методов:
Используйте сжатые дампы. Вы можете использовать вашу предпочитаемую программу сжатия, например, gzip:
qhb_dump dbname | gzip > filename.gz
Восстановление дампа с помощью:
gunzip -c filename.gz | qsql dbname
или:
cat filename.gz | gunzip | qsql dbname
Команда split позволяет разбить вывод на более мелкие файлы, приемлемые по размеру для базовой файловой системы. Например, чтобы сделать куски по 1 мегабайту:
qhb_dump dbname | split -b 1m - filename
Восстановление дампа с помощью:
cat filename* | qsql dbname
Используйте специальный формат дампа qhb_dump. Если QHB был собран в системе с установленной библиотекой сжатия zlib, пользовательский формат дампа будет сжимать данные по мере их записи в выходной файл. Это приведет к размеру файла дампа, аналогичному использованию gzip, но у него есть дополнительное преимущество: таблицы могут восстанавливаться выборочно. Следующая команда создаёт дамп базы данных с использованием специального формата дампа:
qhb_dump -Fc dbname > filename
Дамп специального формата не является сценарием для qsql, а должен быть восстановлен с помощью qhb_restore, например:
qhb_restore -d dbname filename
Для очень больших баз данных вам может потребоваться объединить split с одним из двух других подходов.
Используйте функцию параллельного дампа qhb_dump. Чтобы ускорить дамп большой базы данных, вы можете использовать параллельный режим qhb_dump. Этот режим позволит сбросить несколько таблиц одновременно. Вы можете контролировать количество потоков с помощью параметра -j. Параллельные дампы поддерживаются только для архива в формате каталога.
qhb_dump -j num -F d -f out.dir dbname
Вы можете использовать qhb_restore -j для параллельного восстановления
дампа. Это будет работать для любого архива, созданном в специальном формате
или в формате каталога, независимо от того, был ли он создан с помощью qhb_dump -j.
Резервное копирование на уровне файловой системы
Альтернативная стратегия резервного копирования заключается в прямом копировании файлов, которые QHB использует для хранения данных в базе данных; Вы можете использовать любой метод для резервного копирования файловой системы; например:
tar -cf backup.tar /usr/local/qhb/data
Однако есть два ограничения, которые делают этот метод непрактичным или, по крайней мере, уступают методу qhb_dump:
-
Сервер базы данных должен быть выключен, чтобы получить правильную резервную копию. Промежуточные меры, такие как запрещение всех подключений, работать не будут (отчасти потому, что tar и подобные инструменты не делают атомарный снимок состояния файловой системы, но также из-за внутренней буферизации внутри сервера). Информацию об остановке сервера можно найти в разделе завершение работы сервера. Излишне говорить, что вам также необходимо выключить сервер перед восстановлением данных.
-
Если вы вникли в детали структуры файловой системы базы данных, у вас может возникнуть соблазн попытаться выполнить резервное копирование или восстановление только определенных отдельных таблиц или баз данных из их соответствующих файлов или каталогов. Это не будет работать, потому что информация, содержащаяся в этих файлах, не может быть использована без файлов журнала транзакций
pg_xact/*, которые содержат статус фиксации всех транзакций. Файл таблицы может использоваться только с этой информацией. Конечно, также невозможно восстановить только таблицу и связанные сpg_xactданные, потому что это сделает все остальные таблицы в экземпляре базы данных бесполезными. Таким образом, резервные копии файловой системы работают только для полного резервного копирования и восстановления всего экземпляра базы данных.
Альтернативный подход к резервному копированию файловой системы заключается в создании «согласованного снимка» каталога данных, если файловая система поддерживает эту функцию (и вы уверены, что она реализована правильно). Типичная процедура - сделать «замороженный снимок» тома, содержащего базу данных, затем скопировать весь каталог данных (не только части, см. выше) из моментального снимка на устройство резервного копирования, а затем освободить замороженный снимок. Это будет работать даже во время работы сервера базы данных. Однако созданная таким образом резервная копия сохраняет файлы базы данных в таком состоянии, как если бы сервер базы данных был неправильно остановлен; поэтому, когда вы запускаете сервер базы данных с резервной копией данных, он будет считать, что предыдущий экземпляр сервера завершился аварийно, и применит данные журналов WAL. Это не проблема, однако это стоит иметь в виду.
Внимание!!!
Обязательно включите файлы WAL в свою резервную копию!
Заметка
Вы можете выполнить CHECKPOINT перед созданием снимка, чтобы сократить время восстановления.
Если ваша база данных распределена по нескольким файловым системам, то способа получить строго одновременно замороженные снимки всех томов может не оказаться. Например, если ваши файлы данных и журнал WAL находятся на разных дисках, или если табличные пространства находятся в разных файловых системах, может оказаться невозможным использование резервного копирования «моментального снимка», поскольку моментальные снимки должны быть одновременными. Внимательно прочитайте документацию по файловой системе, прежде чем доверять технологии согласованных снимков в таких ситуациях.
Если согласованные снимки невозможны, один из вариантов - отключить сервер базы данных на достаточно длительное время, чтобы скопировать все замороженные снимки. Другим вариантом является выполнение непрерывного архивирования (раздел Создание базовой резервной копии), поскольку такие резервные копии не пострадают от изменений файловой системы во время резервного копирования. Это требует работы непрерывного архивирования на время процесса резервного копирования. Восстановление выполняется с использованием непрерывного восстановления архива (См. раздел Восстановление с помощью непрерывного архива).
Другой вариант - использовать rsync для резервного копирования файловой
системы. Для этого сначала нужно запустить rsync во время работы сервера
базы данных, а затем завершить работу сервера базы данных на время, достаточное,
чтобы выполнить rsync --checksum. (--checksum необходим, потому
что rsync различает время с точностью до секунды).
Второй запуск rsync отработает быстрее, чем первый, потому что ему останется
относительно мало данных для передачи, и конечный результат будет
согласованным, поскольку сервер был выключен. Этот метод позволяет
выполнять резервное копирование файловой системы с минимальным временем
простоя.
Обратите внимание, что резервная копия файловой системы обычно больше, чем дамп SQL. (Например, qhb_dump не нужно записывать содержимое индексов, только команды для их восстановления). Однако создание резервной копии файловой системы может выполняться быстрее.
Непрерывное архивирование и восстановление на момент времени
QHB поддерживает журнал упреждающей записи (WAL) в подкаталоге
pg_wal/ каталога данных экземпляра. В журнал записываются все изменения,
внесённые в файлы данных базы. Этот журнал существует главным
образом в целях обеспечения безопасности при сбоях: в случае сбоя
системы базы данных могут быть восстановлена до состояния согласованности путём
«воспроизведения» записей журнала, созданных с момента последней
контрольной точки. Однако наличие журнала позволяет использовать третью
стратегию резервного копирования баз данных: можно объединить резервное
копирование на уровне файловой системы с резервным копированием файлов
WAL. Если требуется восстановление, то восстанавливается резервная копия
файловой системы, а затем воспроизводятся изменения из резервных копий
файлов WAL, чтобы привести систему к актуальному состоянию. Этот подход
сложнее в администрировании, чем любой из предыдущих подходов, но он
имеет некоторые существенные преимущества:
-
не требуется идеально согласованное резервное копирование файловой системы в качестве отправной точки. Любое внутреннее несоответствие в резервной копии будет исправлено путём воспроизведения журнала (это существенно не отличается от того, что происходит во время восстановления после сбоя). Поэтому не нужна возможность создания снимков файловой системы, просто
tarили аналогичный инструмент архивирования. -
Поскольку можно комбинировать неограниченно длинную последовательность файлов WAL для воспроизведения, непрерывное резервное копирование может быть достигнуто простым продолжением архивирования файлов WAL. Это особенно ценно для больших баз данных, где не всегда удобно делать полное резервное копирование.
-
Нет необходимости воспроизводить записи WAL до самого конца. Можно остановить воспроизведение в любой момент и получить согласованный снимок базы данных на заданный момент времени. Таким образом, этот метод поддерживает восстановление на определенный момент времени: восстановление базы данных до её состояния возможно в любое время с момента создания резервной копии базы.
-
Если непрерывно передавать серии файлов WAL на другой компьютер, который был загружен с одними и теми же базовыми данными резервной копии, то появляется система тёплого резервирования: в любой момент можно запустить второй сервер, и у него будет практически текущая копия база данных.
Заметка
qhb_dump и qhb_dumpall не создают резервные копии на уровне файловой системы и не могут использоваться как часть решения для непрерывного архивирования. Это логические дампы, и они не содержат достаточно информации для использования при воспроизведении WAL.
Как и в случае простого метода резервного копирования файловой системы, этот метод может поддерживать только восстановление всего экземпляра базы данных, но не его части. Кроме того, для этого требуется большое архивное хранилище: базовая резервная копия может быть громоздкой, а занятая система будет генерировать много мегабайт трафика WAL, который необходимо архивировать. Тем не менее, это предпочтительный метод резервного копирования во многих ситуациях, когда требуется высокая надёжность.
Для успешного восстановления с использованием непрерывного архивирования (также называемого «оперативным резервным копированием» многими разработчиками баз данных) нужна непрерывная последовательность архивированных WAL-файлов история которой, по крайней мере, начинается со времени начала резервного копирования. Итак, для начала необходимо настроить и протестировать процедуру архивации файлов WAL, прежде чем делать первую базовую резервную копию. Соответственно, сначала рассмотрим механизм архивирования файлов WAL.
Настройка архивации WAL
В абстрактном смысле работающая система QHB создаёт бесконечно длинную последовательность записей WAL. Система физически делит эту последовательность на файлы сегментов WAL, которые обычно имеют размер 16 МБ (хотя размер сегмента можно изменить во время создания нового кластера базы данных через параметры initdb). Сегменты получают числовые имена, которые отражают их положение в абстрактной последовательности WAL. Когда архивация WAL не используется, система обычно создаёт только несколько файлов сегментов, а затем «перезаписывает» их, меняя имена ставших ненужными файлов WAL на новые, с бо́льшими номерами. Предполагается, что файлы сегментов, содержимое которых предшествует последней контрольной точке, больше не представляют интереса и могут быть использованы заново.
При архивировании данных WAL нам нужно захватить содержимое каждого
файла сегмента после его заполнения и сохранить эти данные где-то перед
тем, как файл сегмента будет повторно использован. В
зависимости от приложения и доступного оборудования, может быть много
разных способов «сохранения данных где-то»: мы можем скопировать файлы
сегментов в каталог, смонтированный NFS на другом компьютере, записать
на ленточный накопитель (гарантируя, что у вас есть способ
идентификации исходного имени каждого файла), или собрать вместе
и записать на компакт-диски, или что-то ещё. Чтобы
предоставить администратору базы данных гибкость, QHB старается не
делать никаких предположений о том, как будет осуществляться
архивирование. Вместо этого QHB позволяет администратору указать команду
оболочки, которая будет выполняться, чтобы скопировать заполненный файл
сегмента туда, куда он должен попасть. Команда может быть такой же
простой, как cp, или может вызывать сложный сценарий оболочки - все
зависит от администратора.
Чтобы включить архивирование WAL, установите для параметра конфигурации
wal_level значение replica или выше, для параметра archive_mode -
значение on и укажите команду оболочки для использования в параметре
конфигурации archive_command. На практике эти настройки всегда будут
помещаться в файл qhb.conf. В archive_command %p заменяется путём к
файлу для архивирования, а %f заменяется только именем файла. (Путь
указывается относительно текущего рабочего каталога, т. е. каталога
данных экземпляра). Используйте %% если вам нужно вставить символ % в команду.
Самая простая полезная команда выглядит примерно так:
archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f' # Unix
она скопирует архивируемые сегменты WAL в каталог /mnt/server/archivedir.
(Это пример, а не рекомендация, и он может работать не на всех
платформах). После замены параметров %p и %f действительная команда
может выглядеть следующим образом:
test ! -f /mnt/server/archivedir/00000001000000A900000065 && cp qhb_wal/00000001000000A900000065 /mnt/server/archivedir/00000001000000A900000065
Аналогичная команда будет сгенерирована для каждого нового файла, подлежащего архивированию.
Команда архивирования будет выполняться под управлением того же пользователя, на котором работает сервер QHB. Поскольку серия архивируемых файлов WAL содержит практически всё, что есть в вашей базе данных, вы должны быть уверены, что заархивированные данные защищены от посторонних глаз. Например, архивируйте в каталог, с ограниченными правами доступа на чтение для группы и других пользователей.
Важно, чтобы команда архивирования возвращала нулевой статус выхода, только если копирование произошло успешно. Получив нулевой результат, QHB предположит, что файл был успешно заархивирован, и удалит или переиспользует его. Однако ненулевой статус говорит QHB, что файл не был заархивирован и будут периодически предприниматься попытки его архивации заново, пока это не удастся.
Обычно команда архивирования должна предотвращать перезапись любого ранее существующего архивного файла. Это важная функция безопасности для сохранения целостности вашего архива в случае ошибки администратора (например, отправка вывода двух разных серверов в один и тот же каталог архива).
Рекомендуется протестировать предложенную вами команду архивирования,
чтобы убедиться, что она действительно не перезаписывает существующий
файл, а если это так, то возвращает ненулевой статус. Приведённый выше
пример команды для Unix обеспечивает это путём включения отдельного шага
test. На некоторых платформах Unix в cp есть такие переключатели, как -i,
которые можно использовать для выполнения тех же операций менее явно,
но вы не должны полагаться на них, не убедившись, что возвращён
правильный код статуса. (В частности, GNU cp вернет нулевой код статуса,
когда используется -i и целевой файл уже существует, что не является
желаемым поведением).
При разработке вашей конфигурации архивации рассмотрите, что произойдёт,
если команда архивирования не будет выполнена повторно, потому что
какие-то обстоятельства требуют вмешательства оператора или архиву не хватает
места. Например, это может произойти, если вы пишете на ленту без
автоматической смены; когда лента заполняется, ничто больше не может
быть заархивировано, пока лента не будет заменена. Вы должны убедиться,
что о любой ошибке или запросе оператору-человеку сообщается надлежащим
образом, чтобы ситуация могла быть разрешена достаточно быстро. pg_wal/
будет продолжать заполняться файлами сегментов WAL, пока ситуация не
будет решена. (Если файловая система, содержащая pg_wal/ заполняется,
QHB завершит работу аварийно. Никакие зафиксированные транзакции не
будут потеряны, но база данных останется в автономном режиме, пока вы не
освободите некоторое пространство).
Скорость команды архивации не имеет значения, пока она может
соответствовать средней скорости, с которой ваш сервер генерирует данные
WAL. Нормальная работа продолжается, даже если процесс архивирования
немного отстаёт. Если архивирование значительно отстаёт, это увеличит
объём данных, которые могут быть потеряны в случае аварии. Это также будет
означать, что pg_wal/ будет содержать большое количество ещё не
заархивированных файлов сегментов, которые в конечном итоге могут
превысить доступное дисковое пространство. Рекомендуется следить за
процессом архивации, чтобы убедиться, что он работает так, как вы
рассчитываете.
При написании команды архивирования вы должны исходить из того, что имена файлов, подлежащих архивированию, могут быть длиной до 64 символов и могут содержать любую комбинацию букв ASCII, цифр и точек. Нет необходимости сохранять исходный относительный путь (%p), но необходимо сохранить имя файла (%f).
Обратите внимание, что несмотря на то, что архивация WAL позволит вам восстановить
любые изменения, внесенные в данные в вашей базе данных QHB, она не
восстановит изменения, внесённые в файлы конфигурации (то есть qhb.conf,
qhb_hba.conf и qhb_ident.conf), так как они редактируются вручную, а не
с помощью операций SQL. Возможно, вы захотите сохранить файлы
конфигурации в том же месте, где будут храниться результаты ваших обычных процедур
резервного копирования файловой системы. расположение файлов
Команда архивирования вызывается только для завершённых сегментов WAL.
Следовательно, если ваш сервер генерирует только небольшой трафик WAL
(или имеет периоды простоя, когда это происходит), может возникнуть длительная
задержка между завершением транзакции и ее безопасной записью в архивное
хранилище. Чтобы установить ограничение на срок хранения
неархивированных данных, вы можете установить archive_timeout, чтобы
заставить сервер переключаться на новый файл сегмента WAL так часто,
насколько это необходимо. Обратите внимание, что архивные файлы, которые
архивируются раньше из-за принудительного переключения, имеют ту же длину,
что и полностью заполненные файлы. Поэтому неразумно устанавливать очень
короткое значение archive_timeout — это приведёт к переполнению вашего
архивного хранилища. Параметр archive_timeout установленный на минутный
промежуток или около того обычно бывает корректен.
Кроме того, можно принудительно переключить сегмент с помощью
pg_switch_wal если вы хотите, чтобы только что завершённая транзакция
была заархивирована как можно скорее. Другие функции утилит, относящиеся
к управлению WAL, перечислены в таблице 1.
Таблица 1. Функции управления резервным копированием
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_create_restore_point(name text) | pg_lsn | Создать именованную точку для выполнения восстановления* |
| pg_current_wal_flush_lsn() | pg_lsn | Получить текущее местоположение сброса журнала предзаписи. |
| pg_current_wal_insert_lsn() | pg_lsn | Получить текущее местоположение вставки журнала предзаписи. |
| pg_current_wal_lsn() | pg_lsn | Получить текущее местоположение записи в журнал предзаписи. |
| pg_start_backup(label text [, fast boolean [, exclusive boolean ] ]) | pg_lsn | Подготовление к выполнению резервному копированию* |
| pg_stop_backup() | pg_lsn | Завершить выполнение монопольного резервного копирования* |
| pg_stop_backup(exclusive boolean [, wait_for_archive boolean ]) | set of record | Завершить выполнение монопольного резервного копирования* |
| pg_is_in_backup() | bool | Истинно, если монопольное резервное копирование все еще выполняется. |
| pg_backup_start_time() | timestamp with time zone | Получить время запуска монопольного резервного копирования. |
| pg_switch_wal() | pg_lsn | Принудительное переключение на новый файл журнала с опережением записи* |
| pg_walfile_name(lsn pg_lsn) | text | Преобразовать местоположение журнала предзаписи в имя файла. |
| pg_walfile_name_offset(lsn pg_lsn) | text, integer | Преобразовать местоположение журнала предзаписи в имя файла и десятичное смещение байта в нём. |
| pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) | numeric | Рассчитать разницу между двумя местоположениями журнала записи. |
Заметка
* - (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешениеEXECUTEдля запуска функции).
Когда wal_level - minimal некоторые команды SQL оптимизированы, чтобы
избежать ведения журнала WAL. Если архивация или потоковая репликация
были включены во время выполнения одного из этих операторов, WAL не
будет содержать достаточно информации для восстановления архива.
(На восстановление после аварийного завершения это не распространяется).
По этой причине wal_level может быть изменен только при запуске сервера.
Тем не менее, параметр archive_command может быть изменен с перезагрузкой файла конфигурации.
Если вы хотите временно остановить архивирование, один из способов
сделать это - установить для archive_command пустую строку (’ ’). Это
приведет к тому, что файлы WAL будут накапливаться в pg_wal/ пока
не будет восстановлена рабочая команда archive_command.
Создание базовой резервной копии
Самый простой способ выполнить базовое резервное копирование - использовать инструмент qhb_basebackup. Он может создавать базовую резервную копию в виде обычных файлов или в виде архива tar. Альтернативой этому инструменту служит qbackup. Эта программа позволяет сохранять ваши резервные копии в структурированный каталог, при этом поддерживается инкрементальное копирование и сжатие, а также параллельный режим работы.
Если требуется больше гибкости, чем могут обеспечить эти программы, то вы также можете сделать базовую резервную копию, используя низкоуровневый API (см. раздел Создание базовой резервной копии с использованием API низкого уровня).
Нет необходимости беспокоиться о количестве времени, необходимого для
создания базовой резервной копии. Однако если вы обычно запускаете
сервер с отключенными full_page_writes, вы можете заметить падение
производительности во время резервного копирования, так как
full_page_writes включается автоматически в режиме резервного
копирования.
Чтобы в последующем использовать резервную копию, вам необходимо
сохранить все файлы сегментов WAL, созданные во время и после
резервного копирования файловой системы. Чтобы помочь вам в этом,
процесс базового резервного копирования создаёт файл истории
резервного копирования, который немедленно сохраняется в области
архивации WAL. Этот файл назван как первый файл сегмента WAL,
который необходим для резервного копирования файловой системы.
Например, если начальный файл WAL -
0000000100001234000055CD файл истории резервного копирования будет иметь
имя, например, 0000000100001234000055CD.007C9330.backup. (Вторая часть
имени файла обозначает точную позицию в файле WAL и обычно может
игнорироваться). После того, как вы благополучно заархивировали
резервную копию файловой системы и файлы сегментов WAL, использованные
во время резервного копирования (как указано в истории резервного
копирования файла), все архивные сегменты WAL с численно меньшими
именами больше не нужны для восстановления резервной копии файловой
системы и могут быть удалены. Однако вам следует подумать о том, чтобы
сохранить несколько наборов резервных копий, чтобы быть абсолютно
уверенным, что возможно восстановить нужные данные.
Файл истории резервного копирования — это небольшой текстовый файл. Он
содержит строку метки, которую вы дали qhb_basebackup, а также начальное
и конечное время и имена начального и конечного сегментов WAL, относящихся к резервной копии. Если вы использовали
метку для идентификации связанного файла дампа, то заархивированного файла
истории достаточно, чтобы указать, какой файл дампа нужно восстановить.
Поскольку вы должны хранить все архивные файлы WAL начиная с первой базовой резервной копии, интервал между повторными резервными копированиями копиями обычно следует выбирать исходя из того, сколько памяти вы хотите потратить на архивные файлы WAL. Вам также следует учитывать, сколько времени вы готовы потратить на восстановление, ведь система должна будет воспроизвести все эти сегменты WAL, а это может занять некоторое время, если прошло много времени с момента последнего резервного копирования базы.
Создание базовой резервной копии с использованием API низкого уровня
Процедура создания базовой резервной копии с использованием
низкоуровневых API-интерфейсов содержит на несколько шагов больше, чем
метод qhb_basebackup или qbackup, но относительно проста. Очень важно, чтобы эти
шаги выполнялись последовательно, и чтобы каждый шаг был успешен перед
переходом к следующему шагу.
Резервные копии низкого уровня могут быть сделаны немонопольным способом.
Создание немонопольной резервной копии на низком уровне
Немонопольное резервное копирование низкого уровня позволяет
запускать другие параллельные резервные копии (через API-интерфейс или qhb_basebackup).
-
Убедитесь, что архивация WAL включена и работает.
-
Подключитесь к серверу (не имеет значения, к какой базе данных) как пользователь с правами на запуск
pg_start_backup(суперпользователь или пользователь, которому предоставлена привилегияEXECUTEдля функции) и выполните команду:SELECT pg_start_backup('label', false, false);где
label- любая строка, которую вы хотите использовать в качестве идентификатора этой операции резервного копирования. Соединение, вызывающееpg_start_backupдолжно поддерживаться до конца резервного копирования, иначе резервное копирование будет автоматически прервано.По умолчанию
pg_start_backupможет занять много времени до завершения. Это связано с тем, что он выполняет контрольную точку, а операции ввода-вывода, требуемые для этого, распределяются в интервале времени, равного по умолчанию половине вашего интервала между контрольными точками (см. параметр конфигурацииcheckpoint_completion_targetв разделе Контрольные точки). Обычно это то, что и требуется, потому что это минимизирует влияние на обработку запросов. Если вы хотите начать резервное копирование как можно скорее, измените второй параметр наtrue, который немедленно выдаст контрольную точку с использованием максимально возможного количества операций ввода-вывода.Третий параметр
falseуказываетpg_start_backupинициировать немонопольную базовую резервную копию. -
Выполните резервное копирование, используя любой удобный инструмент для резервного копирования файловой системы, такой как tar или cpio (не qhb_dump или qhb_dumpall). Нет необходимости останавливать нормальную работу базы данных, пока вы делаете это. См. раздел Резервное копирование каталога данных о том, какие нюансы следует учитывать при выполнении резервного копирования.
-
В том же соединении, что и раньше, введите команду:
SELECT * FROM pg_stop_backup(false, true);Это прекращает режим резервного копирования. На ведущем сервере также выполняется автоматическое переключение на следующий сегмент WAL. В режиме ожидания невозможно автоматическое переключение сегментов WAL, поэтому вы можете запустить
pg_switch_walчтобы выполнить ручное переключение. Цель переключения заключается в том, чтобы последний файл сегмента WAL, записанный в течение интервала резервного копирования, был готов к архивированию.pg_stop_backupвернет одну строку с тремя значениями. Второе из этих полей должно быть записано в файл с именемbackup_labelв корневом каталоге резервной копии. Третье поле должно быть записано в файл с именемtablespace_mapесли поле не пустое. Эти значения крайне важны для резервного копирования и должны быть записаны без изменений. -
Как только файлы сегментов WAL, активные во время резервного копирования, будут заархивированы, всё готово. Файл, идентифицируемый первым возвращаемым значением
pg_stop_backupявляется последним сегментом, который требуется для формирования полного набора файлов резервных копий. Если параметрarchive_modeвключен и параметрwait_for_archiveфункцииpg_stop_backupравенtrue,pg_stop_backupне выполнится до тех пор, пока не будет заархивирован последний сегмент. На ведомом сервере параметрarchive_modeпри этом должен иметь значениеalways. Архивирование этих файлов происходит автоматически, так как вы уже настроилиarchive_command. В большинстве случаев это происходит быстро, но рекомендуется следить за системой архивирования, чтобы убедиться в отсутствии задержек. Если процесс архивирования отстал из-за сбоев команды архивирования, он будет повторять попытки до тех пор, пока архив не будет успешно завершен и резервное копирование не будет завершено. Если вы хотите установить ограничение по времени выполненияpg_stop_backup, установите соответствующее значениеstatement_timeout, но учтите, что еслиpg_stop_backupзавершит работу из-за этого, ваша резервная копия может потерять целостность.Если процесс резервного копирования отслеживает и гарантирует, что все файлы сегментов WAL, необходимые для резервного копирования, успешно заархивированы, то для параметра
wait_for_archive(по умолчанию устанавливается значениеtrue) можно установить значениеfalse, чтобыpg_stop_backupзавершался, как только запись остановки резервного копирования записывается в WAL. По умолчаниюpg_stop_backupбудет ждать, пока все WAL будут заархивированы, что может занять некоторое время. Эту опцию следует использовать с осторожностью: если архивирование WAL не контролируется должным образом, резервная копия может не включать все файлы WAL и, следовательно, будет неполной и не сможет быть восстановлена.
Создание монопольной резервной копии на низком уровне
Заметка
Монопольный метод резервного копирования устарел и обычно его следует избегать.
Процесс для монопольной резервной копии в основном такой же, как и для немонопольной, но отличается в нескольких ключевых шагах. Этот тип резервного копирования может выполняться только на первичном сервере и не допускает одновременного резервного копирования. Более того, поскольку он создает файл метки резервной копии, как описано ниже, он может заблокировать автоматический перезапуск главного сервера после сбоя. С другой стороны, ошибочное удаление этого файла из резервной копии является распространенной ошибкой, которая может привести к серьезному повреждению данных. Если необходимо использовать этот метод, могут быть выполнены следующие шаги.
-
Убедитесь, что архивация WAL включена и работает.
-
Подключитесь к серверу (не имеет значения, какая база данных) как пользователь с правами на запуск
pg_start_backup(суперпользователь или пользователь, которому предоставлена привилегияEXECUTEдля функции) и выполните команду:SELECT pg_start_backup('label');где
label- любая строка, которую вы хотите использовать для уникальной идентификации этой операции резервного копирования.pg_start_backupсоздает файл метки резервной копии с именемbackup_labelв каталоге кластера с информацией о вашей резервной копии, включая время начала и строку метки. Функция также создает файл карты табличных пространств, называемыйtablespace_map, в каталоге кластера с информацией о символических ссылках табличных пространств вpg_tblspc/, если присутствует одна или несколько таких ссылок. Оба файла имеют решающее значение для целостности резервной копии, если вам необходимо восстановить базу из нее.По умолчанию вызов
pg_start_backupможет занять довольно продолжительное время. Это связано с тем, что при этом выполняется контрольная точка, и ввод-вывод, необходимый для выполнения контрольной точки, будет распределен в течение значительного периода времени, по умолчанию в течение половины установленного интервала между контрольными точками (см. параметр конфигурацииcheckpoint_completion_targetв разделе Контрольные точки). Обычно это то, что требуется, так как это минимизирует влияние на обработку запросов. Если вы хотите начать резервное копирование как можно скорее, используйте:SELECT pg_start_backup ('label', true);Это заставляет контрольную точку выполниться как можно быстрее.
-
Выполните резервное копирование, используя любой удобный инструмент для резервного копирования файловой системы, такой как tar или cpio (не pg_dump или pg_dumpall ). Нет необходимости останавливать нормальную работу базы данных, пока вы делаете это. См. раздел Резервное копирование каталога данных о том, какие нюансы следует учитывать при выполнении резервного копирования.
Как отмечалось выше, если во время резервного копирования происходит сбой сервера, перезапуск может оказаться невозможным, пока файл
backup_labelне будет удален вручную из каталогаPGDATA. Обратите внимание, что очень важно никогда не удалять файлbackup_labelпри восстановлении резервной копии, поскольку это приведет к повреждению. Путаница в том, когда следует удалить этот файл, является частой причиной повреждения данных при использовании этого метода; убедитесь, что вы удаляете файл только на существующем главном сервере и никогда не удаляйте его при создании резервного сервера или при восстановлении из резервной копии, даже если вы создаете резервный сервер, который впоследствии будет преобразован в новый главный серчер. -
Снова подключитесь к базе данных как пользователь с правами на запуск
pg_stop_backup(суперпользователь или пользователь, которому предоставлена привилегия EXECUTE для этой функции) и выполните команду:SELECT pg_stop_backup();Эта функция завершает режим резервного копирования и выполняет автоматический переход к следующему сегменту WAL. Цель переключения заключается в том, чтобы последний сегмент WAL, записанный в течение интервала резервного копирования, был бы готов к архивированию.
-
Как только файлы сегментов WAL, активные во время резервного копирования, будут заархивированы, процедура резервирования будет завершена. WAL-файл, идентифицируемый результатом выполнения
pg_stop_backup, является последним сегментом, который требуется для формирования полного набора файлов резервных копий. Если опцияarchive_modeвключена,pg_stop_backupне завершается, пока не будет заархивирован последний сегмент. Архивирование этих файлов происходит автоматически, поскольку уже должна быть настроена командаarchive_command. В большинстве случаев это происходит быстро, но рекомендуется следить за системой архивирования, чтобы убедиться в отсутствии задержек. Если процесс архивирования отстал из-за сбоев команды архивирования, он будет повторять попытки до тех пор, пока архивация не будет успешно завершена, и только в этом случае резервное копирование закончится.При использовании монопольного режима резервного копирования абсолютно необходимо убедиться, что
pg_stop_backupуспешно завершится в конце резервного копирования. Даже в случае сбоя самой резервной копии, например, из-за недостатка дискового пространства, сбой вызоваpg_stop_backupоставит сервер в режиме резервного копирования на неопределенное время, что приведет к сбою будущих резервных копий и увеличит риск сбоя перезапуска сервера при остающемся файлеbackup_label.
Резервное копирование каталога данных
Некоторые инструменты резервного копирования файловой системы выдают
предупреждения или ошибки, если файлы, которые они пытаются скопировать,
изменяются в процессе копирования. При создании базовой резервной копии
активной базы данных это нормальная ситуация, а не ошибка. Однако вы
должны убедиться, что вы можете отличить логи такого рода от реальных
ошибок. Например, некоторые версии rsync возвращают отдельный код
завершения для «исчезнувших исходных файлов», и вы можете написать
скрипт, чтобы принять этот код завершения как случай, не
связанный с ошибкой. Кроме того, некоторые версии GNU tar возвращают код
ошибки, неотличимый от фатальной ошибки, если файл был усечён во время его
копирования через tar. К счастью, GNU tar версии 1.16 и
выше завершается с кодом 1, если файл был изменен во время резервного
копирования, и 2 для других ошибок.
Заметка
В GNUtarверсии 1.23 и более поздних версиях вы можете использовать параметры предупреждений--warning=no-file-changed,--warning=no-file-removed, чтобы скрыть соответствующие предупреждающие сообщения.
Убедитесь, что ваша резервная копия содержит все файлы из каталога экземпляра базы данных (например, /usr/local/qhb/data). Если вы используете табличные пространства, которые не находятся под этим каталогом, будьте осторожны и включайте их (убедитесь, что ваша резервная копия архивирует символические ссылки в виде ссылок, иначе восстановление повредит ваши табличные пространства).
Однако вы должны исключить из резервной копии файлы в подкаталоге
экземпляра pg_wal/. Эта небольшая корректировка имеет смысл, поскольку
снижает риск ошибок при восстановлении. Это легко организовать, если
pg_wal/ является символической ссылкой, указывающей куда-то за пределы
каталога экземпляра, что в любом случае является обычной настройкой из
соображений производительности. Вы также можете исключить
qhbmaster.pid и postmaster.opts, которые записывают информацию о
работающем qhbmaster, а не о qhbmaster, который в конечном итоге будет
использовать эту резервную копию. (Эти файлы могут запутать qhb_ctl).
Также стоит исключать из резервной копии каталог pg_replslot/ кластера, чтобы слоты репликации, существующие на главном сервере, не попадали в копию. В противном случае последующее использование резервной копии на резервном сервере может привести к неопределенному сроку хранения файлов WAL в резервной системе и, возможно, к раздутию на главном сервере, если включена обратная связь с горячим резервом, поскольку клиенты, использующие эти слоты репликации, все равно будут подключаться и обновлять слоты на мастере, а не на резервном сервере. Даже если резервная копия предназначена только для использования при создании нового мастера, копирование слотов репликации не будет особенно полезным, поскольку содержимое этих слотов, вероятно, будет сильно устаревшим к тому времени, когда новый мастер войдет в сеть.
Содержимое каталогов pg_dynshmem/, pg_notify/, pg_serial/,
pg_snapshots/, pg_stat_tmp/ и pg_subtrans/ (но не сами каталоги)
может быть исключено из резервной копии, поскольку оно будет
инициализировано при запуске qhbmaster. Если stats_temp_directory
(см. Статистика выполнения) установлен и указывает на подкаталог
внутри каталога данных, то содержимое этого каталога также может быть опущено.
Любой файл или каталог, начинающийся с pgsql_tmp может быть опущен из
резервной копии. Эти файлы удаляются при запуске qhbmaster, а каталоги
восстанавливаются по мере необходимости.
Файлы pg_internal.init могут быть исключены из резервной копии всякий
раз, когда найден файл с таким именем. Эти файлы содержат данные кэша
отношений, которые всегда восстанавливаются при восстановлении.
Файл метки резервной копии содержит строку метки, которую вы задали
во время вызова pg_start_backup, а также имя начального файла WAL.
Поэтому в случае путаницы можно заглянуть внутрь архива
резервной копии и точно определить, в каком сеансе резервного
копирования он был получен. Файл карты табличных пространств
содержит имена символических ссылок, поскольку они существуют в каталоге
pg_tblspc/ и полный путь каждой символической ссылки. Эти файлы не
только для информации, их наличие и содержание имеют решающее
значение для правильной работы процесса восстановления системы.
Также возможно сделать резервную копию, когда сервер остановлен, например
с помощью qbackup. В этом случае вы, очевидно, не можете использовать
pg_start_backup или pg_stop_backup, и поэтому вы будете предоставлены
вашим собственным устройствам для отслеживания того, какая резервная копия
является какой, и как далеко назад идут связанные файлы WAL
(qbackup делает это автоматически). Как правило, лучше
следовать процедуре непрерывного архивирования, описанной выше.
Восстановление с помощью непрерывного архива
Процедура восстановления из резервной копии:
-
Остановите сервер, если он работает.
-
Если у вас есть место для этого, скопируйте весь каталог данных экземпляра и все табличные пространства во временную папку на случай, если они понадобятся вам позже. Обратите внимание, что эта мера предосторожности потребует, чтобы у вас было достаточно свободного места в вашей системе для хранения двух копий вашей существующей базы данных. Если у вас недостаточно места, вы должны как минимум сохранить содержимое подкаталога экземпляра pg_wal, так как он может содержать журналы, которые не были заархивированы до завершения работы системы.
-
Удалите все существующие файлы и подкаталоги в каталоге данных экземпляра и в корневых каталогах всех используемых вами табличных пространств.
-
Восстановите файлы базы данных из резервной копии вашей файловой системы. Убедитесь, что они восстановлены с правами владельца (пользователя системы баз данных, а не root!) и с правами доступа. Если вы используете табличные пространства, вы должны убедиться, что символические ссылки в
pg_tblspc/были правильно восстановлены. -
Удалите все файлы, присутствующие в
pg_wal/, которые были получены из резервной копии потому что, вероятно, они устарели и не являются актуальными. Если вы не архивировалиpg_wal/, то заново создайте его с надлежащими разрешениями, соблюдая осторожность, чтобы убедиться, что вы восстановили его в качестве символической ссылки, если вы его так настроили ранее. -
Если у вас есть разархивированные файлы сегментов WAL, которые вы сохранили на шаге 2, скопируйте их в
pg_wal/. (Лучше всего их копировать, а не перемещать, т.к. у вас остаются неизмененные файлы, и, если возникает проблема, и придется начать заново). -
Задайте параметры конфигурации восстановления в
qhb.confи создайте файлrecovery.signalв каталоге данных экземпляра. Вы также можете временно изменитьqhb_hba.conf, чтобы обычные пользователи не могли подключаться, пока вы не убедитесь, что восстановление прошло успешно. -
Запустите сервер. Сервер перейдет в режим восстановления и продолжит чтение нужных ему архивированных файлов WAL. Если восстановление будет прервано из-за внешней ошибки, сервер можно просто перезапустить, он продолжит восстановление. По завершении процесса восстановления сервер удалит
recovery.signal(для предотвращения случайного повторного входа в режим восстановления позже), а затем начнет обычные операции с базой данных. -
Проверьте содержимое базы данных, чтобы убедиться, что вы восстановились до нужного состояния. Если нет, вернитесь к шагу 1. Если все в порядке, разрешите пользователям подключаться, восстановив
qhb_hba.confв нормальном состоянии.
Ключевой частью всего этого является настройка конфигурации
восстановления, которая описывает, как вы хотите восстановить и как
далеко должно пройти восстановление. Единственное, что вы обязательно
должны указать, это restore_command, которая сообщает QHB, как
извлекать заархивированные сегменты файла WAL. Как и archive_command,
это командная строка оболочки. Она может содержать %f, который заменяется
именем нужного файла журнала, и %p, который заменяется путём, по
которому нужно скопировать файл журнала. (Путь указывается относительно
текущего рабочего каталога, т.е. каталога данных экземпляра). Напишите
%%, если вам нужно вставить фактический символ % в команду. Самая простая
полезная команда выглядит примерно так:
restore_command = 'cp /mnt/server/archivedir/%f %p'
который скопирует ранее заархивированные сегменты WAL из каталога
/mnt/server/archivedir. Конечно, вы можете использовать что-то гораздо
более сложное, возможно, даже сценарий оболочки, который просит
оператора смонтировать соответствующую ленту. Например, qbackup делает это
автоматически, используя встроенную подкоманду.
Важно, чтобы команда возвращала ненулевой статус выхода при ошибке. Эта
команда будет вызвана так же для запроса файлов, которых нет в архиве, она должна
вернуть ненулевое значение, если их нет. Однако это не должно считаться
за ошибку. Исключением является, если команда была прервана сигналом
(отличным от SIGTERM, который используется для отключения сервера
базы данных) или ошибкой оболочки (например, команда не найдена), то
восстановление будет прервано, и сервер не запустится.
Не все запрошенные файлы будут файлами сегментов WAL; также следует
ожидать запросов на файлы с суффиксом .history. Также помните, что
базовое имя пути %p будет отличаться от %f, не ожидайте, что они будут
взаимозаменяемыми.
Сегменты WAL, которые нельзя найти в архиве, будут искать в pg_wal/;
это позволяет использовать последние неархивированные сегменты. Однако
сегменты, доступные из архива, будут использоваться вместо файлов в
pg_wal/, так как имеют приоритет над ними.
Обычно восстановление выполняется через все доступные сегменты WAL, тем
самым восстанавливая базу данных до текущего момента времени (или
максимально близко, учитывая доступные сегменты WAL). Поэтому нормальное
восстановление заканчивается сообщением «файл не найден», точный текст
сообщения об ошибке зависит от выбранного вами параметра
restore_command. Вы также можете увидеть сообщение об ошибке в начале
восстановления для файла с именем что-то вроде 00000001.history. Это
также нормально и не указывает на проблему в простых ситуациях
восстановления (см. линии времени)
Если вы хотите восстановить данные до некоторого предыдущего момента времени (скажем, непосредственно перед тем, как младший администратор баз данных отбросил вашу основную таблицу транзакций), просто укажите необходимую точку остановки. Вы можете указать точку остановки, известную как «цель восстановления», либо по дате/времени, названной точке восстановления, либо по завершению транзакции c определенным идентификатором. (см. подробнее в recovery target)
Заметка
Точка остановки должна быть указана после времени окончания основного резервного копирования, то есть времени окончанияpg_stop_backup. Нельзя использовать базовую резервную копию для восстановления до того времени, когда эта резервная копия выполнилась. (Чтобы восстановиться до такого времени, вы должны вернуться к своей предыдущей базовой резервной копии и начать восстановление оттуда).
Заметка
В команде restore в qbackup существуют опции, позволяющие выбрать эти настройки. Ими можно будет воспользоваться только если резервная копия была сделана при помощи backup
Если восстановление обнаружит поврежденные данные WAL, восстановление
будет остановлено в этот момент, и сервер не запустится. В таком случае
процесс восстановления может быть перезапущен с самого начала с
указанием «цели восстановления» до точки повреждения, чтобы
восстановление могло завершиться нормально. Если восстановление
завершится неудачно по внешней причине, такой как сбой системы или если
архив WAL стал недоступен, то восстановление можно просто перезапустить,
и оно будет перезапущено почти с того места, где произошел сбой.
Перезапуск восстановления работает так же, как контрольная точка в
обычной работе: сервер периодически передает все свое состояние на диск,
а затем обновляет файл pg_control, чтобы указать, что уже обработанные
данные WAL не нужно снова сканировать.
Линии времени
Возможность восстановить базу данных до предыдущего момента времени создаёт некоторые сложности, сродни научно-фантастическим рассказам о путешествиях во времени и параллельных вселенных. Например, в исходной истории базы данных предположим, что вы удалили критическую таблицу в 17:15 во вторник вечером, но не осознали свою ошибку до полудня среды. Однако вы можете получить свою резервную копию, и восстановиться к моменту времени 17:14 во вторник и запустить сервер. В этой истории базы данных вы никогда не удаляли таблицу. Но, предположим, позже вы поймете, что это не такая уж хорошая идея, и необходимо вернуться к утру среды из оригинальной истории. К сожалению. в данной ситуации этого сделать уже не получится, т.к. пока ваша база данных была запущена и работала, она перезаписала некоторые файлы сегментов WAL, которые вели к тому времени, к которому вы теперь хотели бы вернуться. Таким образом, чтобы избежать этого, необходимо отличать серии записей WAL, сгенерированные после восстановления на определенный момент времени, от тех, которые были сгенерированы в исходной истории базы данных.
Чтобы справиться с этой проблемой, в QHB есть понятие линия времени.
Всякий раз, когда восстановление архива завершается, создаётся новая
временная линия для определения последовательности записей WAL,
созданной после этого восстановления. Идентификационный номер
линии времени является частью имён файлов сегментов WAL, поэтому
новая линия времени не перезаписывает данные WAL, созданные предыдущими
линиями времени. Фактически возможно архивировать много различных линий
времени. Хотя это может показаться бесполезной функцией, это часто помогает.
Рассмотрим ситуацию, когда вы не совсем уверены, к какому моменту
времени необходимо восстанавливаться, и поэтому вам приходится делать несколько
попыток восстановления на определенный момент времени методом проб и
ошибок, пока не найдется лучшее место для ветвления из старой истории.
Без линий времени этот процесс быстро приведет к неуправляемому беспорядку.
С помощью линий времени вы можете восстановить любое предыдущее
состояние, в том числе состояния в ветвях линий времени, от которых вы
отказались ранее.
Каждый раз, когда создаётся новая линия времени, QHB создаёт файл «истории линии времени», который показывает, с какой линии времени он вышел и когда. Эти файлы истории необходимы для того, чтобы система могла выбрать правильные файлы сегментов WAL при восстановлении из архива, который содержит несколько линий времени. Поэтому они архивируются в область архивирования WAL, как и файлы сегментов WAL. Файлы истории — это просто небольшие текстовые файлы, поэтому их целесообразно хранить на протяжении долгого времени (в отличие от больших файлов сегментов). Вы можете, если хотите, добавлять комментарии в файлы истории, чтобы записывать свои собственные заметки о том, как и почему была создана эта конкретная линия времени. Такие комментарии будут особенно полезны, когда в результате экспериментов у вас будет череда различных линий времени.
По умолчанию восстановление происходит на ту же линию времени,
которая была текущей, когда была сделана базовая резервная копия.
Если вы хотите восстановить какую-либо дочернюю линию времени
(то есть вы хотите вернуться к некоторому состоянию, которое само
было получено после попытки восстановления), вам нужно
указать целевой идентификатор временной шкалы в
recovery_target_timeline.
Важно!!! Вы не можете восстановиться в состояние, которое находится в линии времени, ответвившейся раньше, чем базовая резервная копия началась.
Советы и примеры
Некоторые советы по настройке непрерывного архивирования приведены здесь.
Автономные горячие резервные копии
Для создания автономных оперативных резервных копий можно использовать средства резервного копирования QHB. Это резервные копии, которые нельзя использовать для восстановления на определенный момент времени, но, как правило, ими гораздо быстрее выполнять резервное копирование и восстановление, чем дампы qhb_dump. (Они также намного больше, чем дампы qhb_dump, поэтому в некоторых случаях преимущество в скорости может быть сведено на нет.)
Как и в случае базовых резервных копий, самый простой способ создать
автономное горячее резервное копирование - использовать инструмент
qhb_basebackup. Если при вызове задать параметр -X, весь журнал
предварительной записи, необходимый для использования резервной копии,
будет автоматически включен в резервную копию, и никаких специальных
действий для её восстановления не требуется.
Если требуется больше гибкости при копировании файлов резервных копий,
процесс более низкого уровня можно использовать и для автономных
оперативных резервных копий. Чтобы подготовиться к низкоуровневым
автономным горячим резервным копиям, убедитесь, что для wal_level
задано значение replica или выше, для параметра archive_mode значение
on, и настройте команду archive_command которая выполняет архивирование
только при наличии файла переключателя. Например:
archive_command = 'test ! -f /var/lib/qhb/backup_in_progress || (test ! -f /var/lib/qhb/archive/%f && cp %p /var/lib/qhb/archive/%f)'
Заметка
Вqbackupесть подкомандаbackup-wal, которую можно использовать для этих целей см. подробнее в qbackup backup-wal
Эта команда выполняет архивирование, когда существует
/var/lib/qhb/backup_in_progress, и в противном случае молча
возвращает нулевое состояние выхода (что позволяет QHB
переиспользовать ненужный файл WAL).
С помощью этой подготовки можно сделать резервную копию с помощью сценария, подобного следующему:
touch /var/lib/qhb/backup_in_progress
qsql -c "select pg_start_backup('hot_backup');"
tar -cf /var/lib/qhb/backup.tar /var/lib/qhb/data/
qsql -c "select pg_stop_backup();"
rm /var/lib/qhb/backup_in_progress
tar -rf /var/lib/qhb/backup.tar /var/lib/qhb/archive/
Файл-переключатель /var/lib/qhb/backup_in_progress создаётся первым,
что позволяет архивировать заполненные файлы WAL. После резервного
копирования файл переключателя удаляется. Архивные файлы WAL затем
добавляются в резервную копию, чтобы как базовая резервная копия, так и
все необходимые файлы WAL были частью одного и того же tar-файла.
Пожалуйста, не забудьте добавить обработку ошибок в ваши скрипты
резервного копирования.
Существует альтернативный подход к горячему резервному копированию в виде утилиты qbackup. Эта утилита комбинирует архивирование WAL-записей и постраничное инкрементальное резервное копирование, что позволяет добиться более компактных резервных копий за счёт сохранения только тех данных, которые изменились с момента предыдущей автономной резервной копии.
Сжатие архивных журналов
Если размер архивного хранилища имеет значение, вы можете использовать gzip для сжатия архивных файлов:
archive_command = 'gzip < %p > /var/lib/qhb/archive/%f'
Затем вам нужно будет использовать gunzip во время восстановления:
restore_command = 'gunzip < /mnt/server/archivedir/%f > %p'
Скрипты archive_command
Многие люди предпочитают использовать сценарии для определения своей
команды archive_command, поэтому их запись в qhb.conf выглядит
очень просто:
archive_command = 'local_backup_script.sh "%p" "%f"'
Использование отдельного файла сценария целесообразно тогда,
когда вы хотите использовать более одной команды в процессе
архивирования. Это позволяет управлять всей сложностью скрипта, который
может быть написан на популярном языке сценариев, таком как bash или
perl.
Примеры задач, которые могут быть решены в сценарии:
-
Копирование данных для безопасного хранения данных за пределами площадки.
-
Пакетное копирование WAL, так что они передаются каждые три часа, а не по одному.
-
Взаимодействие с другим программным обеспечением для резервного копирования и восстановления.
-
Взаимодействие с программным обеспечением для мониторинга ошибок.
Заметка
При использовании сценария archive_command желательно включить logging_collector. Любые сообщения, записанные в сценарий stderr, будут затем отображаться в журнале сервера базы данных, что позволяет легко диагностировать сложные конфигурации в случае сбоев.
Заметка
Вы можете использовать qbackup backup-wal для этих целей.
Предостережения
На момент написания статьи существует несколько ограничений техники непрерывного архивирования. Это, вероятно, будет исправлено в следующих выпусках:
-
Если команда CREATE DATABASE выполняется во время создания базовой резервной копии, а затем шаблонная база данных, которую скопировала
CREATE DATABASEизменяется, пока базовая резервная копия все ещё выполняется, возможно, что восстановление приведёт к распространению этих изменений на созданную базу данных. Это, конечно, нежелательно. Чтобы избежать этого риска, лучше не изменять шаблонные базы данных при создании базовой резервной копии. -
Команды CREATE TABLESPACE регистрируются в WAL с буквальным абсолютным путём и поэтому будут воспроизведены как создания табличного пространства с тем же абсолютным путём. Это может быть нежелательно, если журнал воспроизводится на другом компьютере. Это может быть опасно, даже если журнал воспроизводится на том же компьютере, но в новом каталоге данных: воспроизведение все равно перезапишет содержимое исходного табличного пространства. Чтобы избежать потенциальных ошибок такого рода, рекомендуется создавать новую базовую резервную копию после создания или удаления табличных пространств.
Следует также отметить, что формат WAL по умолчанию довольно громоздкий,
поскольку включает в себя множество снимков страницы диска. Эти снимки
страниц предназначены для поддержки восстановления после сбоя, поскольку
нам может потребоваться исправить частично записанные страницы диска. В
зависимости от аппаратного и программного обеспечения системы риск
частичной записи может быть достаточно мал, чтобы его можно было
игнорировать, и в этом случае вы можете значительно уменьшить общий
объём архивированных журналов, отключив снимки страниц с помощью
параметра full_page_writes. (Прочтите примечания и предупреждения к WAL
перед тем, как сделать это.) Отключение снимков страницы не
мешает использованию журналов для операций PITR.
Возможность для последующего улучшения - сжатие архивных данных WAL путём удаления ненужных
копий страниц, даже если установлен параметр full_page_writes. В то же время
администраторы могут захотеть уменьшить количество снимков страниц,
включенных в WAL, максимально увеличив параметры интервала контрольных
точек.
Мониторинг активности базы данных
- Стандартные инструменты Unix
- Сборщик статистики
- Конфигурация сбора статистики
- Просмотр статистики
- Таблица 1. Динамические статистические представления
- Таблица 2. Представления по собранной статистике
- Таблица 3. Представление pg_stat_activity
- Таблица 4. Описание значений столбца wait_event
- Таблица 5. Представление pg_stat_replication
- Таблица 6. Представление pg_stat_wal_receiver
- Таблица 7. Представление pg_stat_subscription
- Таблица 8. Представление pg_stat_ssl
- Таблица 9. Представление pg_stat_gssapi
- Таблица 10. Представление pg_stat_archiver
- Таблица 11. Представление pg_stat_bgwriter
- Таблица 12. Представление pg_stat_database
- Таблица 13. Представление pg_stat_database_conflicts
- Таблица 14. Представление pg_stat_all_tables
- Таблица 15. Представление pg_stat_all_indexes
- Таблица 16. Представление pg_statio_all_tables
- Таблица 17. Представление pg_statio_all_indexes
- Таблица 18. Представление pg_statio_all_sequence
- Таблица 19. Представление pg_stat_user_functions
- Функции статистики
- Просмотр блокировок
- Отчеты о ходе выполнения команд
- Метрики QHB
- Дашборды метрик QHB для Grafana
Администратор базы данных часто задается вопросом: "Что сейчас делает система"? В этой главе рассказывается, как это выяснить.
Доступны несколько инструментов для мониторинга активности базы данных и
анализа производительности. Большая часть этой главы посвящена описанию
сборщика статистики QHB , но не следует пренебрегать обычными
программами мониторинга Unix, такими как ps, top, iostat и vmstat.
Кроме того, как только вы определили неэффективный запрос, может
потребоваться дальнейшее исследование с помощью команды EXPLAIN в
QHB . В разделе Использование EXPLAIN обсуждается EXPLAIN и другие методы для понимания
поведения отдельного запроса.
Стандартные инструменты Unix
В большинстве платформ Unix QHB изменяет заголовок своей
команды, сообщаемый ps, так что отдельные процессы сервера могут быть
легко идентифицированы. Пример вывода команды:
$ ps auxww | grep ^qhb
qhb 15551 0.0 0.1 57536 7132 pts/0 S 18:02 0:00 qhb -i
qhb 15554 0.0 0.0 57536 1184 ? Ss 18:02 0:00 qhb: background writer
qhb 15555 0.0 0.0 57536 916 ? Ss 18:02 0:00 qhb: checkpointer
qhb 15556 0.0 0.0 57536 916 ? Ss 18:02 0:00 qhb: walwriter
qhb 15557 0.0 0.0 58504 2244 ? Ss 18:02 0:00 qhb: autovacuum launcher
qhb 15558 0.0 0.0 17512 1068 ? Ss 18:02 0:00 qhb: stats collector
qhb 15582 0.0 0.0 58772 3080 ? Ss 18:04 0:00 qhb: joe runbug 127.0.0.1 idle
qhb 15606 0.0 0.0 58772 3052 ? Ss 18:07 0:00 qhb: tgl regression [local] SELECT waiting
qhb 15610 0.0 0.0 58772 3056 ? Ss 18:07 0:00 qhb : tgl regression [local] idle in transaction
(Формат вызова ps может отличаться для разных платформ, как и детали
отображаемой информации. Этот пример приведен для одной из последних версий системы Linux.) Первым
процессом из перечисленных здесь является процесс главного сервера. Аргументы
команды, приведенные здесь для него, те же, что использовались при
запуске. Следующие пять процессов являются фоновыми рабочими процессами,
автоматически запускаемыми главным процессом. (Процесс «stats-collector» не будет показан, если его запуск отключен;
аналогично процесс «autovacuum launcher» (фоновый процесс автоочистки) также можно отключить.) Каждый из оставшихся
процессов является серверным процессом, обрабатывающим одно клиентское
соединение. Для каждого такого процесса устанавливается отображение командной
строки в виде
qhb: user database host activity
Элементы имени пользователя, базы данных и хоста остаются неизменными на протяжении всего жизненного цикла клиентского соединения, а индикатор активности изменяется. Он может принимать значение idle ( ожидание клиентской команды), idle in transaction (ожидание клиента внутри блока BEGIN) или имя типа команды, например, SELECT. Кроме того, добавляется waiting если серверный процесс в настоящее время ожидает высвобождения блокировки, которую удерживает другой сеанс. В приведенном выше примере мы можем сделать вывод, что процесс 15606 ожидает, пока процесс 15610 завершит свою транзакцию и тем самым снимет некоторую блокировку. (Процесс 15610 должен быть блокирующим, потому что нет другого активного сеанса. В более сложных случаях необходимо было бы обратиться к системному представлению pg_locks чтобы определить, кто кого блокирует.)
Если параметр cluster_name настроен, имя кластера также будет показано в выводе
ps:
$ psql -c 'SHOW cluster_name'
cluster_name
--------------
server1
(1 row)
$ ps aux|grep server1
qhb 27093 0.0 0.0 30096 2752 ? Ss 11:34 0:00 qhb: server1: background writer
...
Если вы отключили параметр update_process_title, то индикатор активности не обновляется; заголовок процесса устанавливается только один раз при запуске нового процесса. На некоторых платформах это снижает существенные накладные расходы, на других влияние обновления этого индикатора незначительно.
Сборщик статистики
Сборщик статистики QHB - это подсистема, которая поддерживает сбор и передачу информации о работе сервера. В настоящее время сборщик может учитывать обращения к таблицам и индексам как по дисковым блокам, так и по отдельным строкам. Он также отслеживает общее количество строк в каждой таблице, информацию о выполнении вакуума и анализирует действия для каждой таблицы. Также он может подсчитывать вызовы пользовательских функций и общее время, потраченное на каждую из них.
QHB также поддерживает выдачу динамической информации о том, что именно происходит в системе в данный момент, например, о точной команде, выполняемой в настоящее время другими процессами сервера, и о том, какие другие соединения имеются в системе. Эта возможность не зависит от сборщика статистики.
Конфигурация сбора статистики
Поскольку сбор статистики добавляет некоторые накладные расходы к выполнению запроса, система может быть настроена или не настроена на сбор информации. Это контролируется параметрами конфигурации, которые обычно устанавливаются в qhb.conf. (Подробнее о настройке параметров конфигурации см. в главе Конфигурация сервера).
Параметр track_activities позволяет отслеживать текущие команды, выполняемые любым серверным процессом.
Параметр track_counts контролирует, собирается ли статистика по обращениям к таблицам и индексам.
Параметр track_functions позволяет отслеживать использование пользовательских функций.
Параметр track_io_timing включает мониторинг времени чтения и записи блоков.
Обычно эти параметры устанавливаются в qhb.conf так, что они применяются ко всем процессам сервера, но их можно включить или отключить в отдельных сеансах с помощью команды SET. (Чтобы обычные пользователи не могли скрывать свою активность от администратора, только суперпользователи могут изменять эти параметры с помощью SET.)
Сборщик статистики передает собранные данные другим процессам QHB через временные файлы. Эти файлы хранятся в каталоге, название которого задается параметром stats_temp_directory, по умолчанию содержит значение pg_stat_tmp. Для повышения производительности stats_temp_directory может указывать на файловую систему на основе ОЗУ, что сокращает время физического ввода/вывода. Когда сервер отключается, постоянная копия статистических данных сохраняется в подкаталоге pg_stat, так что статистика может быть сохранена при перезапусках сервера. Когда восстановление выполняется при запуске сервера (например, после немедленного выключения, сбоя сервера и восстановления на определенный момент времени), все счетчики статистики сбрасываются.
Просмотр статистики
Несколько предопределенных представлений, перечисленных в Таблице 1, доступны для отображения текущего состояния системы. Есть также несколько других представлений, перечисленных в Таблице 2, доступных для отображения результатов сбора статистики. В качестве альтернативы можно создавать собственные представления с использованием базовых статистических функций, как описано в разделе Функции статистики.
При использовании статистики для мониторинга собранных данных важно понимать, что информация не обновляется мгновенно. Каждый отдельный процесс сервера передает новые статистические значения сборщику непосредственно перед тем, как перейти в режим ожидания; таким образом, запрос или транзакция, которая еще выполняется, не влияет на отображаемые итоги. Кроме того, сам сборщик генерирует новый отчет не чаще одного раза в PGSTAT_STAT_INTERVAL миллисекунд (500 мс, если значение параметра не было изменено при компиляции сервера). Таким образом, отображаемая информация отстает от фактической активности. Однако информация о текущем запросе, собираемая при установке параметра track_activities, всегда актуальна.
Другим важным моментом является то, что когда серверный процесс
запрашивает статистические данные, он
сначала получает самый последний снимок от сборщика статистики, а
затем продолжает использовать этот снимок для всех статистических
представлений и функций до окончания текущей транзакции. Таким
образом, статистика не изменится до окончания текущей транзакции.
Точно так же собирается информация о текущих запросах всех
сеансов, когда она запрашивается в начале транзакции, и эта же информация будет отображаться в течение всей
транзакции. Это функциональность, а не ошибка, она позволяет вам
выполнять несколько запросов к статистике и сопоставлять результаты, не
беспокоясь о том, что данные по статистике изменяются. Но если вы хотите видеть
новые результаты при выполнении каждого запроса, обязательно выполняйте запросы вне
транзакционных блоков. Или вы можете вызвать
pg_stat_clear_snapshot(), что сбросит снимок статистики текущей
транзакции (если он был). При следующем обращении к статистической
информации будет получен новый снимок.
Транзакция также может видеть свою собственную статистику (пока еще не переданную сборщику) в представлениях pg_stat_xact_all_tables, pg_stat_xact_sys_tables, pg_stat_xact_user_tables и pg_stat_xact_user_functions. Эти данные ведут себя не так, как указано выше. Напротив, они постоянно обновляются на протяжении всей транзакции.
Некоторая информация в представлениях динамической статистики, показанных в Таблице 1, имеет ограничения по безопасности. Обычные пользователи могут видеть только всю информацию о своих собственных сеансах (сеансах, принадлежащих к роли, членом которой они являются). В строках о других сеансах многие столбцы будут нулевыми. Однако обратите внимание, что существование сеанса и его общие свойства, такие как пользователь сеанса и база данных, видны всем пользователям. Суперпользователи и члены встроенной роли pg_read_all_stats (см. также раздел Роли по умолчанию) могут видеть всю информацию обо всех сеансах.
Таблица 1. Динамические статистические представления
| Посмотреть имя | Описание |
|---|---|
| pg_stat_activity | Одна строка для каждого серверного процесса, отображающая информацию, связанную с текущей активностью этого процесса, например состояние и текущий запрос. См. pg_stat_activity |
| pg_stat_replication | Одна строка на процесс отправителя WAL, показывающая статистику репликации на подключенный резервный сервер этого отправителя. См. pg_stat_replication |
| pg_stat_wal_receiver | Только одна строка, показывающая статистику о приемнике WAL с подключенного сервера этого приемника. См. pg_stat_wal_receiver |
| pg_stat_subscription | Как минимум одна строка на подписку, показывающая информацию о процессах подписки. См. pg_stat_subscription. |
| pg_stat_ssl | Одна строка для каждого подключения (обычного и реплицирующего), показывающая информацию о SSL, используемом для этого соединения См. pg_stat_ssl. |
| pg_stat_gssapi | Одна строка для каждого подключения (обычного и реплицирующего), показывающая информацию об аутентификации и шифровании GSSAPI, используемых в этом соединении. См. pg_stat_gssapi |
| pg_stat_progress_create_index | Одна строка для каждого бэкэнда, выполняющего CREATE INDEX или REINDEX, показывающая ход выполнения команды. См. раздел Отчет о ходе выполнения CREATE INDEX. |
| pg_stat_progress_vacuum | Одна строка для каждого бэкэнда (включая рабочие процессы автоочистки), на котором выполняется VACUUM, показывающая ход выполнения команды. См. раздел Отчет о ходе выполнения VACUUM. |
| pg_stat_progress_cluster | Одна строка для каждого бэкэнда, в котором работает CLUSTER или VACUUM FULL, показывающая ход выполнения команды. См. раздел Отчет о ходе выполнения CLUSTER. |
Таблица 2. Представления по собранной статистике
| Посмотреть имя | Описание |
|---|---|
| pg_stat_archiver | Только одна строка, показывающая статистику о работе процесса архиватора WAL. См. pg_stat_archiver. |
| pg_stat_bgwriter | Только одна строка, показывающая статистику о работе фонового процесса записи. См. pg_stat_bgwriter. |
| pg_stat_database | Одна строка на базу данных, показывающая статистику всей базы данных. См. pg_stat_database. |
| pg_stat_database_conflicts | Одна строка на базу данных, показывающая статистику всей базы данных по отменам запросов из-за конфликта с восстановлением на резервных серверах. См. pg_stat_database_conflicts. |
| pg_stat_all_tables | Одна строка для каждой таблицы в текущей базе данных, показывающая статистику доступа к этой конкретной таблице. См. pg_stat_all_tables. |
| pg_stat_sys_tables | То же, что pg_stat_all_tables, за исключением того, что отображаются только системные таблицы. |
| pg_stat_user_tables | То же, что pg_stat_all_tables, за исключением того, что отображаются только пользовательские таблицы. |
| pg_stat_xact_all_tables | Аналогичен pg_stat_all_tables, но подсчитывает статистику по операциям, совершенным до настоящего момента в текущей транзакции (которые еще не включены в pg_stat_all_tables и связанные представления). Столбцы с количеством живых и мертвых строк, а также с данными по выполнению очистки и сбора статистики в этом представлении отсутствуют. |
| pg_stat_xact_sys_tables | То же, что pg_stat_xact_all_tables, за исключением того, что отображаются только системные таблицы. |
| pg_stat_xact_user_tables | То же, что pg_stat_xact_all_tables, за исключением того, что отображаются только пользовательские таблицы. |
| pg_stat_all_indexes | Одна строка для каждого индекса в текущей базе данных, показывающая статистику доступа к этому конкретному индексу. См. pg_stat_all_indexes. |
| pg_stat_sys_indexes | То же, что pg_stat_all_indexes, за исключением того, что pg_stat_all_indexes представлены только индексы в системных таблицах. |
| pg_stat_user_indexes | То же, что pg_stat_all_indexes, за исключением того, что pg_stat_all_indexes представлены только индексы пользовательских таблиц. |
| pg_statio_all_tables | Одна строка для каждой таблицы в текущей базе данных, показывающая статистику ввода-вывода для этой конкретной таблицы. См. pg_statio_all_tables. |
| pg_statio_sys_tables | То же, что pg_statio_all_tables, за исключением того, что отображаются только системные таблицы. |
| pg_statio_user_tables | То же, что pg_statio_all_tables, за исключением того, что отображаются только пользовательские таблицы. |
| pg_statio_all_indexes | Одна строка для каждого индекса в текущей базе данных, показывающая статистику ввода-вывода для этого конкретного индекса. См. pg_statio_all_indexes. |
| pg_statio_sys_indexes | То же, что pg_statio_all_indexes, за исключением того, что pg_statio_all_indexes представлены только индексы в системных таблицах. |
| pg_statio_user_indexes | То же, что pg_statio_all_indexes, за исключением того, что pg_statio_all_indexes представлены только индексы пользовательских таблиц. |
| pg_statio_all_sequences | Одна строка для каждой последовательности в текущей базе данных, показывающая статистику ввода-вывода для этой конкретной последовательности. См. pg_statio_all_sequence для получения подробной информации. |
| pg_statio_sys_sequences | То же, что pg_statio_all_sequences, за исключением того, что отображаются только системные последовательности. (В настоящее время системные последовательности не определены, поэтому это представление всегда пусто.) |
| pg_statio_user_sequences | То же, что pg_statio_all_sequences, за исключением того, что отображаются только пользовательские последовательности. |
| pg_stat_user_functions | Одна строка для каждой отслеживаемой функции, показывающая статистику выполнения этой функции. См. pg_stat_user_functions. |
| pg_stat_xact_user_functions | Аналогичен pg_stat_user_functions, но учитывает только вызовы во время текущей транзакции (которые еще не включены в pg_stat_user_functions ). |
Статистика по индексу особенно полезна для определения того, какие индексы используются и насколько они эффективны.
Представления pg_statio_ в первую очередь полезны для определения эффективности буферного кеша. Когда количество фактических операций чтения с диска намного меньше числа обращений к буферу, кеш удовлетворяет большинству запросов на чтение без вызова ядра операционной системы. Однако эти статистические данные не дают полной картины: из-за того, как QHB обрабатывает дисковый ввод-вывод, данные, которых нет в буферном кеше QHB , могут по-прежнему находиться в кэше ввода/вывода ядра и, следовательно, могут по-прежнему выбираться, не требуя физического чтения. Пользователям, заинтересованным в получении более подробной информации о поведении ввода/вывода QHB , рекомендуется использовать сборщик статистики QHB в сочетании с утилитами операционной системы, которые позволяют лучше понять, как ядро обрабатывает ввод/вывод.
Таблица 3. Представление pg_stat_activity
| колонка | Тип | Описание |
|---|---|---|
| datid | oid | OID базы данных, с которой связан этот бэкэнд |
| datname | name | Имя базы данных, с которой связан этот бэкэнд |
| pid | integer | Идентификатор процесса этого бэкэнда |
| usesysid | oid | OID пользователя, вошедшего в этот бэкэнд |
| usename | name | Имя пользователя, вошедшего в этот бэкэнд |
| application_name | text | Имя приложения, которое подключено к этому бэкэнду |
| client_addr | inet | IP-адрес клиента, подключенного к этому бэкэнду. Если это поле пустое, это означает, что клиент подключен через сокет Unix на серверном компьютере или это внутренний процесс, такой как autovacuum. |
| client_hostname | text | Имя хоста подключенного клиента, сообщаемое при обратном поиске DNS client_addr. Это поле будет отличным от NULL для IP-соединений и только при включенном режиме log_hostname. |
| client_port | integer | Номер порта TCP, который клиент использует для связи с этим бэкэндом, или -1 если используется сокет Unix |
| backend_start | timestamp with time zone | Время, когда этот процесс был запущен. Для клиентских бэкэндов это время, когда клиент подключается к серверу. |
| xact_start | timestamp with time zone | Время, когда была запущена текущая транзакция этого процесса, или ноль, если транзакция не активна. Если текущий запрос является первой из его транзакций, этот столбец равен столбцу query_start . |
| query_start | timestamp with time zone | Время, когда был запущен текущий активный запрос, или если state не active, когда был запущен последний запрос |
| state_change | timestamp with time zone | Время последнего изменения состояния |
| wait_event_type | text | Тип события, которого ожидает серверная часть, если это имеет место; в противном случае NULL. Возможные значения: |
| - LWLock: бэкэнд ждет легкую блокировку. Каждая такая блокировка защищает определенную структуру данных в разделяемой памяти. wait_event будет содержать имя, идентифицирующее цель получения легкой блокировки. (У некоторых блокировок есть особые имена; другие являются частью группы блокировок со схожим назначением.) | ||
| - Lock: бэкэнд ждет тяжелую блокировку. Тяжелые блокировки, также известные как блокировки или просто блокировки менеджера блокировок, в основном защищают видимые SQL-объекты, такие как таблицы. Однако они также используются для обеспечения взаимоисключающего обновления для некоторых внутренних операций, таких как расширение отношений. В wait_event обозначается конкретное место ожидания. | ||
| - BufferPin: серверный процесс ожидает доступа к буферу данных в течение периода, когда никакой другой процесс не может обращаться к этому буферу. Ожидания закрепления буфера могут быть длительными, если другой процесс удерживает открытый курсор, который последним читал данные из рассматриваемого буфера. | ||
| - Activity: Серверный процесс простаивает. Используется системными процессами, ожидающими активности в основном цикле обработки. В wait_event обозначается конкретное место ожидания. | ||
| - Extension: серверный процесс ожидает активности в модуле расширения. Эта категория полезна при использовании модулей для отслеживания нестандартных мест ожидания. | ||
| - Client: серверный процесс ожидает в сокете некоторой активности от пользовательских приложений. Сервер ожидает, что произойдет что-то, что не зависит от его внутренних процессов. В wait_event обозначается конкретное место ожидания. | ||
| - IPC: серверный процесс ожидает некоторой активности от другого процесса на сервере. В wait_event обозначается конкретное место ожидания. | ||
| - Timeout: процесс сервера ожидает истечения времени ожидания. В wait_event обозначается конкретное место ожидания. | ||
| - IO: серверный процесс ожидает завершения ввода-вывода. В wait_event обозначается конкретное место ожидания. | ||
| wait_event | text | Имя события ожидания, если бэкэнд в данный момент в ожидании, иначе NULL. Детали в Таблице 4. |
| state | text | Текущее общее состояние этого бэкэнда. Возможные значения: |
| - active: бэкэнд выполняет запрос. | ||
| - idle: бэкэнд ожидает новой команды от клиента. | ||
| - idle in transaction: бэкэнд находится внутри транзакции, но в данный момент не выполняет запрос. | ||
| - idle in transaction (aborted): это состояние подобно idle in transaction, за исключением того, что один из операторов в транзакции вызвал ошибку. | ||
| - fastpath function call: бэкэнд выполняет функцию fast-path. | ||
| - disabled: об этом состоянии сообщается, если track_activities отключен в этом бэкэнде. | ||
| backend_xid | xid | Идентификатор транзакции верхнего уровня этого бэкэнда, если он имеется. |
| backend_xmin | xid | Граница xmin для данного бэкэнда. |
| query | text | Текст последнего запроса этого бэкэнда. Если поле state содержит значение active, в этом поле отображается текущий выполняемый запрос. Во всех других состояниях он показывает последний запрос, который был выполнен ранее. По умолчанию текст запроса усекается до 1024 символов; это значение можно изменить с помощью параметра track_activity_query_size. |
| backend_type | text | Тип текущего бэкэнда. Возможные типы: autovacuum launcher, autovacuum worker, logical replication launcher, logical replication worker, parallel worker, background writer, client backend, checkpointer, startup, walreceiver, walsender и walwriter. Кроме того, фоновые процессы, зарегистрированные расширениям, могут иметь дополнительные типы. |
Представление pg_stat_activity будет иметь одну строку для каждого серверного процесса, показывая информацию, связанную с текущей активностью этого процесса.
Примечание
Столбцы wait_event и state независимы. Если бэкэнд находится в состоянии active, он может быть или не быть в состоянии ожидания какого-либо события. Если состояние active а wait_event не NULL, это означает, что запрос выполняется, но блокируется где-то в системе.
Таблица 4. Описание значений столбца wait_event
| Тип события ожидания | Имя события ожидания | Описание |
|---|---|---|
| LWLock | ShmemIndexLock | Ожидание поиска и выделения места в разделяемой памяти. |
| OidGenLock | Ожидание выделения или назначения OID. | |
| XidGenLock | Ожидание выделения или назначения идентификатора транзакции. | |
| ProcArrayLock | Ожидание получения снимка или очистки идентификатора транзакции в конце транзакции. | |
| SInvalReadLock | Ожидание получения или удаления сообщений из общей очереди инвалидации. | |
| SInvalWriteLock | Ожидание добавления сообщения в общую очередь инвалидации. | |
| WALBufMappingLock | Ожидание замены страницы в буферах WAL. | |
| WALWriteLock | Ожидание записи буферов WAL на диск. | |
| ControlFileLock | Ожидание чтения или обновления контрольного файла или создания нового файла WAL. | |
| CheckpointLock | Ожидание выполнения контрольной точки. | |
| CLogControlLock | Ожидание чтения или обновления статуса транзакции. | |
| SubtransControlLock | Ожидание чтения или обновления информации подтранзакции. | |
| MultiXactGenLock | Ожидание чтения или обновления общего состояния мультитранзакций. | |
| MultiXactOffsetControlLock | Ожидание чтения или обновления смещений мультитранзакций. | |
| MultiXactMemberControlLock | Ожидание чтения или обновления членов мультитранзакций. | |
| RelCacheInitLock | Ожидание чтения или записи файла инициализации кэша отношения. | |
| CheckpointerCommLock | Ожидание при выполнении запросов fsync. | |
| TwoPhaseStateLock | Ожидание чтения или обновления состояния подготовленных транзакций. | |
| TablespaceCreateLock | Ожидание создания или удаления табличного пространства. | |
| BtreeVacuumLock | Ожидание чтения или обновления связанной с вакуумом информации для индекса B-дерева. | |
| AddinShmemInitLock | Ожидание управления распределением пространства в разделяемой памяти. | |
| AutovacuumLock | Рабочий процесс автовакуума или процесс запуска автовакуума в ожидании обновления или чтения текущего состояния рабочих процессов автоочистки. | |
| AutovacuumScheduleLock | Ожидание при проверке, что таблица, которая выбрана для очистки, все еще нуждается в ней. | |
| SyncScanLock | Ожидание получения начального местоположения сканирования таблицы для синхронизированных сканирований. | |
| RelationMappingLock | Ожидание обновления файла карты отношения, используемого для сохранения в каталоге данных о файловых узлах. | |
| AsyncCtlLock | Ожидание чтения или обновления общего состояния уведомлений. | |
| AsyncQueueLock | Ожидание чтения или обновления уведомлений. | |
| SerializableXactHashLock | Ожидание получения или сохранения информации о сериализуемых транзакциях. | |
| SerializableFinishedListLock | Ожидание доступа к списку завершенных сериализуемых транзакций. | |
| SerializablePredicateLockListLock | Ожидание выполнения операции со списком блокировок, удерживаемых сериализуемыми транзакциями. | |
| OldSerXidLock | Ожидание чтения или записи конфликтующих сериализуемых транзакций. | |
| SyncRepLock | Ожидание чтения или обновления информации о синхронных репликах. | |
| BackgroundWorkerLock | Ожидание чтения или обновления состония фонового процесса. | |
| DynamicSharedMemoryControlLock | Ожидание чтения или обновления состояния динамической разделяемой памяти. | |
| AutoFileLock | Ожидание обновления файла qhb.auto.conf. | |
| ReplicationSlotAllocationLock | Ожидание выделения или освобождения слота репликации. | |
| ReplicationSlotControlLock | Ожидание чтения или обновления состояния слота репликации. | |
| CommitTsControlLock | Ожидание чтения или обновления отметок времени подтверждения транзакции. | |
| CommitTsLock | Ожидание чтения или обновления последнего значения, установленного для отметки времени транзакции. | |
| ReplicationOriginLock | Ожидание установки, удаления или использования источника репликации. | |
| MultiXactTruncationLock | Ожидание чтения или очистки информации мультитранзакций. | |
| OldSnapshotTimeMapLock | Ожидание чтения или обновления информации о старых снимках. | |
| LogicalRepWorkerLock | Ожидание завершения действия процесса логической репликации. | |
| CLogTruncationLock | Ожидание выполнения функции txid_status или обновления самого старого идентификатора транзакции, доступного для неё. | |
| clog | Ожидание ввода-вывода в clog (буфере состояния транзакций). | |
| commit_timestamp | Ожидание ввода-вывода в буфере отметок времени фиксации транзакций. | |
| subtrans | Ожидание ввода-вывода буфера подтранзакций. | |
| multixact_offset | Ожидание ввода-вывода в буфере смещения мультитранзакций. | |
| multixact_member | Ожидание ввода-вывода в буфере multixact_member. | |
| async | Ожидание ввода-вывода в асинхронном (уведомляющем) буфере. | |
| oldserxid | Ожидание ввода-вывода в буфере oldserxid. | |
| wal_insert | Ожидание вставки WAL в буфер памяти. | |
| buffer_content | Ожидание чтения или записи страницы данных в памяти. | |
| buffer_io | Ожидание ввода-вывода страницы данных. | |
| replication_origin | Ожидание чтения или обновления состояния процесса репликации. | |
| replication_slot_io | Ожидание ввода-вывода данных слота репликации. | |
| proc | Ожидание чтения или обновления информации о блокировке по быстрому пути. | |
| buffer_mapping | Ожидание связывания блока данных с буфером в буферном пуле. | |
| lock_manager | Ожидание добавления или проверки блокировок для бэкэндов или ожидание присоединения или выхода из группы блокировок (используется параллельными запросами). | |
| predicate_lock_manager | Ожидание добавления или проверки информации предикатных блокировок. | |
| serializable_xact | Ожидание выполнения операции сериализуемой транзакцией в параллельном запросе. | |
| parallel_query_dsa | Ожидание блокировки выделения динамической общей памяти в параллельном запросе. | |
| tbm | Ожидание блокировки общего итератора TBM. | |
| parallel_append | Ожидание выбора следующего подплана во время выполнения плана параллельного добавления. | |
| parallel_hash_join | Ожидание выделения или обмена части памяти или обновления счетчиков во время выполнения плана параллельного хеширования. | |
| Lock | relation | Ожидание получения блокировки в отношении. |
| extend | Ожидание расширения отношения. | |
| page | Ожидание получения блокировки для страницы отношения. | |
| tuple | Ожидание получения блокировки для кортежа. | |
| transactionid | Ожидание завершения транзакции. | |
| virtualxid | Ожидание получения блокировки виртуального XID. | |
| speculative token | Ожидание получения блокировки спекулятивной вставки. | |
| object | Ожидание получения блокировки для объекта, не относящегося к базе данных. | |
| userlock | Ожидание получения пользовательской блокировки. | |
| advisory | Ожидание получения рекомендательной пользовательской блокировки. | |
| BufferPin | BufferPin | Ожидание закрепления буфера. |
| Activity | ArchiverMain | Ожидание в основном цикле процесса архивирования. |
| AutoVacuumMain | Ожидание в главном цикле процесса запуска автоочистки. | |
| BgWriterHibernate | Ожидание в фоновом процессе записи в режиме бездействия. | |
| BgWriterMain | Ожидание в основном цикле рабочего рпоцесса фоновой записи. | |
| CheckpointerMain | Ожидание в основном цикле процесса контрольной точки. | |
| LogicalApplyMain | Ожидание в основном цикле процесса применения логической репликации. | |
| LogicalLauncherMain | Ожидание в основном цикле процесса запуска логической репликации. | |
| PgStatMain | Ожидание в основном цикле процесса сбора статистики. | |
| RecoveryWalAll | Ожидание восстановления WAL из любого источника (локального, архивного или потокового) при восстановлении. | |
| RecoveryWalStream | Ожидание WAL из потока при восстановлении. | |
| SysLoggerMain | Ожидание в основном цикле процесса syslogger. | |
| WalReceiverMain | Ожидание в основном цикле процесса приема WAL. | |
| WalSenderMain | Ожидание в основном цикле процесса отправителя WAL. | |
| WalWriterMain | Ожидание в основном цикле процесса записи WAL. | |
| Client | ClientRead | Ожидание чтения данных от клиента. |
| ClientWrite | Ожидание записи данных, отправляемых клиенту. | |
| LibPQWalReceiverConnect | Ожидание в приемнике WAL для установления соединения с удаленным сервером. | |
| LibPQWalReceiverReceive | Ожидание в приемнике WAL для получения данных с удаленного сервера. | |
| SSLOpenServer | Ожидание SSL при попытке подключения. | |
| WalReceiverWaitStart | Ожидание запуска процесса отправки начальных данных для потоковой репликации. | |
| WalSenderWaitForWAL | Ожидание сброса WAL в процессе отправки WAL. | |
| WalSenderWriteData | Ожидание любого действия при обработке ответов от получателя WAL в процессе отправителя WAL. | |
| Extension | Extension | Ожидание в расширении. |
| IPC | BgWorkerShutdown | Ожидание выключения фонового рабочего процесса. |
| BgWorkerStartup | Ожидание запуска фонового рабочего процесса. | |
| BtreePage | Ожидание появления номера страницы, необходимой для продолжения параллельного сканирования B-дерева. | |
| CheckpointDone | Ожидание контрольной точки для завершения. | |
| CheckpointStart | Ожидание контрольной точки для запуска. | |
| ClogGroupUpdate | Ожидание, когда ведущий процесс группы обновит статус транзакции в конце транзакции. | |
| ExecuteGather | Ожидание активности от дочернего процесса при выполнении узла сбора данных(Gather). | |
| Hash/Batch/Allocating | Ожидание, когда выбранный участник параллельного хеширования разместит хеш-таблицу. | |
| Hash/Batch/Electing | Выбор участника параллельного хеширования для размещения хеш-таблицы. | |
| Hash/Batch/Loading | Ожидание, пока другие участники параллельного хеширования завершат загрузку хеш-таблицы. | |
| Hash/Build/Allocating | Ожидание, когда выбранный участник параллельного хеширования выделит начальную хеш-таблицу. | |
| Hash/Build/Electing | Выбор участника параллельного хеширования для размещения начальной хеш-таблицы. | |
| Hash/Build/HashingInner | Ожидание, пока другие участники параллельного хеширования завершат хеширование внутреннего отношения. | |
| Hash/Build/HashingOuter | Ожидание, пока другие участники параллельного хеширования завершат разбиение внешнего отношения. | |
| Hash/GrowBatches/Allocating | Ожидание выделения выбранным участником параллельного хеширования большего количества пакетов. | |
| Hash/GrowBatches/Deciding | Выбор участника параллельного хеширования для принятия решения о будущем добавлении пакетов. | |
| Hash/GrowBatches/Electing | Выбор участника параллельного хеширования для добавления большего количества пакетов. | |
| Hash/GrowBatches/Finishing | Ожидание выбранного участника параллельного хеширования для принятия решения о добавлении дополнительных пакетов. | |
| Hash/GrowBatches/Repartitioning | Ожидание, пока другие участники параллельного хеширования завершат перераспределение. | |
| Hash/GrowBuckets/Allocating | Ожидание, когда выбранный участник параллельного хеширования закончит выделять дополнительные группы. | |
| Hash/GrowBuckets/Electing | Выбор участника параллельного хеширования для выделения дополнительнывх групп. | |
| Hash/GrowBuckets/Reinserting | Ожидание, пока другие участники паралллеьного хеширования закончат вставлять кортежи в новые группы. | |
| LogicalSyncData | Ожидание, когда удаленный сервер логической репликации отправит данные для начальной синхронизации таблицы. | |
| LogicalSyncStateChange | Ожидание, когда удаленный сервер логической репликации изменит состояние. | |
| MessageQueueInternal | Ожидание присоединения другого процесса к общей очереди сообщений. | |
| MessageQueuePutMessage | Ожидание записи сообщения протокола в общую очередь сообщений. | |
| MessageQueueReceive | Ожидание получения байтов из общей очереди сообщений. | |
| MessageQueueSend | Ожидание отправки байтов в общую очередь сообщений. | |
| ParallelBitmapScan | Ожидание инициализации параллельного сканирования по битовой карте. | |
| ParallelCreateIndexScan | Ожидание завершения сканирования параллельными процессами CREATE INDEX. | |
| ParallelFinish | Ожидание окончания вычислений параллельных рабочих процессов. | |
| ProcArrayGroupUpdate | Ожидание, пока ведущий процесс в группе не очистит идентификатор транзакции в конце транзакции. | |
| Promote | В ожидании продвижения ведомых. | |
| ReplicationOriginDrop | Ожидание, когда источник репликации станет неактивным и будет удален. | |
| ReplicationSlotDrop | Ожидание, когда слот репликации станет неактивным и будет удален. | |
| SafeSnapshot | Ожидание снимка транзакции READ ONLY DEFERRABLE. | |
| SyncRep | Ожидание подтверждения от удаленного сервера во время синхронной репликации. | |
| Timeout | BaseBackupThrottle | Ожидание во время резервного копирования базы при ограничении активности. |
| PgSleep | Ожидание в процессе, который вызвал pg_sleep. | |
| RecoveryApplyDelay | Ожидание применения WAL при восстановлении из-за задержки. | |
| IO | BufFileRead | Ожидание чтения из буферизованного файла. |
| BufFileWrite | Ожидание записи в буферизованный файл. | |
| ControlFileRead | Ожидание чтения из контрольного файла. | |
| ControlFileSync | Ожидание помещения контрольного файла в стабильное хранилище. | |
| ControlFileSyncUpdate | Ожидание обновления контрольного файла в стабильном хранилище. | |
| ControlFileWrite | Ожидание записи в контрольный файл. | |
| ControlFileWriteUpdate | Ожидание записи для обновления контрольного файла. | |
| CopyFileRead | Ожидание чтения во время операции копирования файла. | |
| CopyFileWrite | Ожидание записи во время операции копирования файла. | |
| DataFileExtend | Ожидание расширения файла данных отношения. | |
| DataFileFlush | Ожидание помещения файла данных отношения в стабильное хранилище. | |
| DataFileImmediateSync | Ожидание немедленной синхронизации файла данных отношения со стабильным хранилищем. | |
| DataFilePrefetch | Ожидание асинхронной предварительной выборки из файла данных отношений. | |
| DataFileRead | Ожидание чтения из файла данных отношения. | |
| DataFileSync | Ожидание переноса изменений в файле реляционных данных в стабильное хранилище. | |
| DataFileTruncate | Ожидание усечения файла данных отношения. | |
| DataFileWrite | Ожидание записи в файл данных отношений. | |
| DSMFillZeroWrite | Ожидание записи нулевых байтов в файл поддержки динамической разделяемой памяти. | |
| LockFileAddToDataDirRead | Ожидание чтения при добавлении строки в файл блокировки каталога данных. | |
| LockFileAddToDataDirSync | Ожидание поступления данных в стабильное хранилище при добавлении строки в файл блокировки каталога данных. | |
| LockFileAddToDataDirWrite | Ожидание записи при добавлении строки в файл блокировки каталога данных. | |
| LockFileCreateRead | Ожидание чтения при создании файла блокировки каталога данных. | |
| LockFileCreateSync | Ожидание поступления данных в стабильное хранилище при создании файла блокировки каталога данных. | |
| LockFileCreateWrite | Ожидание записи при создании файла блокировки каталога данных. | |
| LockFileReCheckDataDirRead | Ожидание чтения во время повторной проверки файла блокировки каталога данных. | |
| LogicalRewriteCheckpointSync | Ожидание сопоставления логической перезаписи для достижения стабильного хранилища во время контрольной точки. | |
| LogicalRewriteMappingSync | Ожидание сопоставления данных для достижения стабильного хранилища во время логической перезаписи. | |
| LogicalRewriteMappingWrite | Ожидание записи данных сопоставления во время логической перезаписи. | |
| LogicalRewriteSync | Ожидание сопоставления логической перезаписи для достижения стабильного хранилища. | |
| LogicalRewriteWrite | Ожидание записи логических сопоставлений перезаписи. | |
| RelationMapRead | Ожидание чтения файла карты отношений. | |
| RelationMapSync | Ожидание, пока файл карты отношений не будет записан в стабильное хранилище. | |
| RelationMapWrite | Ожидание записи в файл карты отношений. | |
| ReorderBufferRead | Ожидание чтения во время переупорядочения буфера управления. | |
| ReorderBufferWrite | Ожидание записи во время переупорядочения буфера управления. | |
| ReorderLogicalMappingRead | Ожидание чтения логического отображения во время управления буфером переупорядочения. | |
| ReplicationSlotRead | Ожидание чтения из управляющего файла слота репликации. | |
| ReplicationSlotRestoreSync | Ожидание, пока контрольный файл слота репликации не будет помещен в стабильное хранилище при восстановлении его в памяти | |
| ReplicationSlotSync | Ожидание, когда контрольный файл слота репликации будет помещен в стабильное хранилище. | |
| ReplicationSlotWrite | Ожидание записи в управляющий файл слота репликации. | |
| SLRUFlushSync | Ожидание, пока данные SLRU будут записаны в стабильное хранилище во время проверки или остановки базы данных. | |
| SLRURead | Ожидание чтения страницы SLRU. | |
| SLRUSync | Ожидание, пока данные SLRU будут записаны в стабильное хранилище после записи страницы. | |
| SLRUWrite | В ожидании записи страницы SLRU. | |
| SnapbuildRead | Ожидание чтения снимка сериализованного исторического каталога. | |
| SnapbuildSync | Ожидание получения сериализованного моментального снимка каталога для записи в стабильное хранилище. | |
| SnapbuildWrite | Ожидание записи сериализованного исторического снимка каталога. | |
| TimelineHistoryFileSync | Ожидание файла хронологии, полученного посредством потоковой репликации, для записи в стабильное хранилище. | |
| TimelineHistoryFileWrite | Ожидание записи файла истории линии времени, полученной посредством потоковой репликации. | |
| TimelineHistoryRead | Ожидание чтения файла истории линии времени. | |
| TimelineHistorySync | Ожидание, когда вновь созданный файл истории линии времени будет записан в стабильное хранилище. | |
| TimelineHistoryWrite | Ожидание записи нового файла истории. | |
| TwophaseFileRead | Ожидание чтения файла двухфазного состояния. | |
| TwophaseFileSync | Ожидание помещения файла двухфазного состояния в стабильное хранилище. | |
| TwophaseFileWrite | Ожидание записи файла двухфазного состояния. | |
| WALBootstrapSync | Ожидание, пока WAL будет записан в стабильное хранилище во время начальной загрузки. | |
| WALBootstrapWrite | Ожидание записи WAL-страницы во время начальной загрузки. | |
| WALCopyRead | Ожидание чтения при создании нового сегмента WAL путем копирования существующего. | |
| WALCopySync | Ожидание нового сегмента WAL, созданного путем копирования существующего для записи в стабильное хранилище. | |
| WALCopyWrite | Ожидание записи при создании нового сегмента WAL путем копирования существующего. | |
| WALInitSync | Ожидание, пока недавно инициализированный файл WAL будет записан в стабильное хранилище. | |
| WALInitWrite | Ожидание записи при инициализации нового файла WAL. | |
| WALRead | Ожидание чтения из файла WAL. | |
| WALSenderTimelineHistoryRead | Ожидание чтения из файла истории линии времени при выполнении команды timeline процессом walsender. | |
| WALSync | Ожидание, пока файл WAL будет записан в стабильное хранилище. | |
| WALSyncMethodAssign | Ожидание, пока данные будут записаны в стабильное хранилище при назначении метода синхронизации WAL. | |
| WALWrite | Ожидание записи в файл WAL. |
Примечание
Для траншей, зарегистрированных расширениями, имя указывается по названию расширения, и именно оно будет отображаться в поле wait_event. Вполне возможно, что пользователь зарегистрировал транш в одном из бэкэндов (используя динамическую разделяемую память), и в этом случае другие бэкэнды не получат эту информацию, поэтому в таких случаях выводитсяextension.
Вот пример того, как события ожидания могут быть просмотрены
SELECT pid, wait_event_type, wait_event FROM pg_stat_activity WHERE wait_event is NOT NULL;
pid | wait_event_type | wait_event
------+-----------------+---------------
2540 | Lock | relation
6644 | LWLock | ProcArrayLock
(2 rows)
Таблица 5. Представление pg_stat_replication
| Колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса отправителя WAL |
| usesysid | oid | OID пользователя, вошедшего в этот процесс-отправитель WAL |
| usename | name | Имя пользователя, подключенного к процессу-отправителю WAL |
| application_name | text | Имя приложения, подключенного к этому процессу-отправителю WAL |
| client_addr | inet | IP-адрес клиента, подключенного к этому процессу-отправителю WAL. Если это поле пустое, это означает, что клиент подключен через сокет Unix на сервере. |
| client_hostname | text | Имя хоста подключенного клиента, получаемое при обратном поиске в DNS по client_addr. Это поле будет отличным от NULL для IP-соединений и только при включенном log_hostname. |
| client_port | integer | Номер TCP-порта, который клиент использует для связи с процессом-отправителем WAL, или -1, если используется сокет Unix. |
| backend_start | timestamp with time zone | Время, когда этот процесс был запущен, т.е. когда клиент подключился к этому процессу-отправителю WAL. |
| backend_xmin | xid | Значение xmin, полученное от сервера-реплики при включенном hot_standby_feedback. |
| state | text | Текущее состояние отправителя WAL. Возможные значения: |
| - startup: этот отправитель WAL запускается. | ||
| - catchup: подключенный к процессу-отправителю сервер-реплика догоняет основной. | ||
| - streaming: процесс-отправитель WAL выполняет потоковую передачу изменений после того, как его подключенный резервный сервер обнаружил основной. | ||
| - backup: процесс-отправитель WAL передает резервную копию. | ||
| - stopping: процесс-отправитель WAL останавливается. | ||
| sent_lsn | pg_lsn | Последняя позиция WAL, отправленная по этому соединению |
| write_lsn | pg_lsn | Последняя позиция WAL, записанная на диск этим резервным сервером |
| flush_lsn | pg_lsn | Последняя позиция WAL, сброшенная на диск этим резервным сервером |
| replay_lsn | pg_lsn | Последняя позиция WAL, примененная в базе данных на этом резервном сервере |
| write_lag | interval | Время, прошедшее между локальным сбросом последних данных WAL и получением уведомления о том, что этот резервный сервер записал их (но еще не сбросил или применил их). Это может быть использовано для измерения задержки, которая произошла при фиксации транзакции, когда в synchronous_commit выбран уровень remote_write, если этот сервер был настроен как синхронный резервный сервер. |
| flush_lag | interval | Время, прошедшее между локальным сбросом последних данных WAL и получением уведомления о том, что этот резервный сервер записал и сбросил их (но еще не применил). Это может быть использовано для определения задержки, когда в synchronous_commit выбран уровень on при фиксации, если этот сервер был настроен как синхронный резервный сервер. |
| replay_lag | interval | Прошло время между локальной очисткой последней WAL и получением уведомления о том, что этот резервный сервер написал, сбросил и применил ее. Это может быть использовано для определения задержки, когда в synchronous_commit выбран уровень remote_apply при фиксации, если этот сервер был настроен как синхронный резервный сервер. |
| sync_priority | integer | Приоритет этого резервного сервера для выбора в качестве синхронного резервного в синхронной репликации на основе приоритетов. Не имеет значения при синхронной репликации с учетом кворума. |
| sync_state | text | Состояние синхронизации этого резервного сервера. Возможные значения: |
| - async: этот резервный сервер является асинхронным. | ||
| - potential: этот резервный сервер теперь асинхронный, но потенциально может стать синхронным, если произойдет сбой одного из текущих синхронных серверов. | ||
| - sync: этот резервный сервер является синхронным. | ||
| - quorum: этот резервный сервер считается кандидатом на участие в кворуме. | ||
| reply_time | timestamp with time zone | Время отправки последнего ответного сообщения, полученного от резервного сервера |
Представление pg_stat_replication будет содержать по одной строке на процесс-отправитель WAL, показывающий статистику репликации на соответствующий резервный сервер. Перечислены только напрямую подключенные резервные сервера; информация о резервных серверах, подключенных опосредованно, недоступна.
Время задержки, указанное в представлении pg_stat_replication, представляет время, затраченное на запись, сброс и повторное воспроизведение последнего WAL, а также на то, чтобы отправитель узнал об этом. Эти длительность представляет задержку фиксации, которая была (или должна была быть) добавлена каждым уровнем синхронной фиксации, если удаленный сервер был настроен как синхронный резервный сервер. Для асинхронного режима ожидания столбец replay_lag приблизительно определяет задержку перед тем, как последние транзакции стали видимыми для запросов. Если резервный сервер полностью догнал отправляющий сервер и активность WAL больше не наблюдается, последнее измеренное значение времени задержки будет продолжать отображаться в течение короткого времени, а затем показывать NULL.
Время задержки определяется автоматически для физической репликации. Модули логического декодирования могут не отправлять сообщения отслеживания; в этм случае механизм отслеживания просто отобразит в качестве времени задержки значение NULL.
Примечание
Сообщаемое время задержки не является прогнозом того, сколько времени потребуется резервному серверу, чтобы догнать отправляющий сервер, учитывая текущую скорость воспроизведения. Такая система будет показывать аналогичные значения времени, когда будет генерироваться новый WAL, но не тогда, когда отправляющий сервер будет простаивать. В частности, когда резервный сервер полностью догнал ведущий, pg_stat_replication показывает время, затраченное на запись, очистку и воспроизведение самого последнего переданного изменения WAL, а не ноль, как могут ожидать некоторые пользователи. Это соответствует целям измерения синхронных фиксаций и задержек видимости транзакций для недавних записанных транзакций. Чтобы уменьшить путаницу для пользователей, ожидающих другое поведение при запаздывании, значения запаздывания возвращаются в NULL через короткое время в системе, которая уже воспроизвела все изменения и находится в ожидании. Системы мониторинга должны выбрать, следует ли представлять это как отсутствующие данные, обнулять их или продолжать отображать последнее известное значение.
Таблица 6. Представление pg_stat_wal_receiver
| колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса-получателя WAL |
| status | text | Состояние активности процесса-получателя WAL |
| receive_start_lsn | pg_lsn | Первая позиция WAL, используемая при запуске приемника WAL |
| receive_start_tli | integer | Первый номер линии времени, используемый при запуске приемника WAL |
| received_lsn | pg_lsn | Последняя позиция WAL, уже полученная и записанная на диск, начальное значение этого поля является первой позицией журнала при запуске приемника WAL |
| received_tli | integer | Номер линии времени последней позиции WAL, полученной и записанной на диск, начальное значение этого поля является номером линии времени первой позиции журнала, использованной при запуске приемника WAL |
| last_msg_send_time | timestamp with time zone | Время отправки последнего сообщения, полученного от отправителя WAL |
| last_msg_receipt_time | timestamp with time zone | Время получения последнего сообщения, полученного от отправителя WAL |
| latest_end_lsn | pg_lsn | Последняя позиция WAL, о которой был уведомлен отправитель WAL |
| latest_end_time | timestamp with time zone | Время последней записи WAL, о которой был уведомлен отправитель WAL |
| slot_name | text | Имя слота репликации, используемое этим приемником WAL |
| sender_host | text | Хост экземпляра QHB , к которому подключен этот приемник WAL. Это может быть имя хоста, IP-адрес или путь к каталогу, если соединение осуществляется через сокет Unix. (Подключение к сокету можно распознать, поскольку он всегда будет абсолютным путем, начинающимся с /.) |
| sender_port | integer | Номер порта экземпляра QHB , к которому подключен получатель WAL. |
| conninfo | text | Строка соединения, используемая этим приемником WAL, со скрытыми секретными полями. |
Представление pg_stat_wal_receiver будет содержать только одну строку, показывающую статистику о получателе WAL с подключенного сервера этого получателя.
Таблица 7. Представление pg_stat_subscription
| колонка | Тип | Описание |
|---|---|---|
| subid | oid | OID подписки |
| subname | text | Название подписки |
| pid | integer | Идентификатор процесса рабочего процесса подписки |
| relid | Oid | OID отношения, которое процесс синхронизирует; для основного процесса применения |
| received_lsn | pg_lsn | Последняя полученная запись WAL, начальное значение этого поля 0 |
| last_msg_send_time | timestamp with time zone | Время отправки последнего сообщения, полученного от отправителя WAL |
| last_msg_receipt_time | timestamp with time zone | Время получения последнего сообщения, полученного от отправителя WAL |
| latest_end_lsn | pg_lsn | Последняя запись WAL, о которой был уведомлен отправитель WAL |
| latest_end_time | timestamp with time zone | Время последней записи в WAL, о которой был уведомлен отправитель WAL |
Представление pg_stat_subscription будет содержать одну строку для каждой подписки для основного процесса (с NULL в PID, если процесс не работает) и дополнительные строки для процессов, обрабатывающих начальные данные для таблиц в подписке.
Таблица 8. Представление pg_stat_ssl
| колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса бэкенда или процесса отправителя WAL |
| ssl | boolean | True, если SSL используется для этого соединения |
| version | text | Используемая версия SSL или NULL, если SSL в этом соединении не используется. |
| cipher | text | Имя используемого шифра SSL или NULL, если SSL не используется в этом соединении |
| bits | integer | Количество бит в используемом алгоритме шифрования или NULL, если SSL не используется в этом соединении |
| compression | boolean | True, если используется сжатие SSL, false, если нет, или NULL, если SSL не используется в этом соединении. |
| client_dn | text | Поле «Уникальное имя» (DN) из используемого клиентского сертификата или NULL, если клиентский сертификат не был предоставлен или SSL не используется в этом соединении. Это поле усекается, если поле DN длиннее, чем NAMEDATALEN (64 символа в стандартной сборке). |
| client_serial | numeric | Серийный номер сертификата клиента или NULL, если сертификат клиента не предоставлен или SSL не используется в этом соединении. Комбинация серийного номера сертификата и эмитента сертификата однозначно идентифицирует сертификат (если только эмитент ошибочно не использует серийные номера). |
| issuer_dn | text | DN эмитента клиентского сертификата или NULL, если клиентский сертификат не был предоставлен или SSL не используется в этом соединении. Это поле усекается как client_dn. |
Представление pg_stat_ssl будет содержать по одной строке для каждого бэкенда или процесса отправителя WAL, показывая статистику использования SSL для этого соединения. Его можно объединить с pg_stat_activity или pg_stat_replication в столбце pid, чтобы получить более подробную информацию о соединении.
Таблица 9. Представление pg_stat_gssapi
| колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса бэкэнда |
| gss_authenticated | boolean | Истинно, если для этого соединения использовалась аутентификация GSSAPI |
| principal | text | Принципал, используемый для аутентификации этого соединения, или NULL, если GSSAPI не использовался для аутентификации этого соединения. Это поле усекается, если участник длиннее, чем NAMEDATALEN (64 символа в стандартной сборке). |
| encrypted | boolean | True, если в этом соединении используется шифрование GSSAPI |
Представление pg_stat_gssapi будет содержать одну строку для каждого бэкэнда, показывающую информацию об использовании GSSAPI для этого соединения. Его можно объединить с pg_stat_activity или pg_stat_replication в столбце pid, чтобы получить более подробную информацию о соединении.
Таблица 10. Представление pg_stat_archiver
| колонка | Тип | Описание |
|---|---|---|
| archived_count | bigint | Количество файлов WAL, которые были успешно заархивированы |
| last_archived_wal | text | Имя последнего файла WAL, успешно заархивированного |
| last_archived_time | timestamp with time zone | Время последней успешной операции архивирования |
| failed_count | bigint | Количество неудачных попыток архивирования файлов WAL |
| last_failed_wal | text | Имя файла WAL последней неудачной операции архивирования |
| last_failed_time | timestamp with time zone | Время последней неудачной архивной операции |
| stats_reset | timestamp with time zone | Время последнего сброса этой статистики |
Представление pg_stat_archiver всегда будет содержать одну строку, содержащую данные о процессе архивации кластера.
Таблица 11. Представление pg_stat_bgwriter
| колонка | Тип | Описание |
|---|---|---|
| checkpoints_timed | bigint | Количество запланированных контрольных точек, которые были выполнены |
| checkpoints_req | bigint | Количество запрошенных контрольных точек, которые были выполнены |
| checkpoint_write_time | double precision | Общее время, потраченное на этап обработки контрольной точки, где файлы записываются на диск, в миллисекундах |
| checkpoint_sync_time | double precision | Общее количество времени, потраченное на часть обработки контрольной точки, где файлы синхронизируются с диском, в миллисекундах |
| buffers_checkpoint | bigint | Количество буферов, записанных во время контрольных точек |
| buffers_clean | bigint | Количество буферов, записанных фоновым процессом записи |
| maxwritten_clean | bigint | Количество раз, когда процесс записи в фоновом режиме останавливал сброс грязных страниц, поскольку записывал слишком много буферов |
| buffers_backend | bigint | Количество буферов, записанных непосредственно бэкэндом |
| buffers_backend_fsync | bigint | Сколько раз бэкэнд выполнял вызов fsync сам (обычно их обрабатывает фоновый процесс записи, даже когда бэкэнд выполняет запись самостоятельно) |
| buffers_alloc | bigint | Количество выделенных буферов |
| stats_reset | timestamp with time zone | Время последнего сброса этой статистики |
Представление pg_stat_bgwriter всегда будет содержать одну строку, содержащую общие данные для всего кластера.
Таблица 12. Представление pg_stat_database
| колонка | Тип | Описание |
|---|---|---|
| datid | oid | OID базы данных или 0 для объектов, принадлежащих к общим отношениям |
| datname | name | Имя базы данных или NULL для общих объектов. |
| numbackends | integer | Количество бэкэндов, которые в данный момент подключены к этой базе данных, или NULL для общих объектов. Это единственный столбец в этом представлении, который возвращает значение, отражающее текущее состояние; все остальные столбцы возвращают накопленные значения с момента последнего сброса. |
| xact_commit | bigint | Количество транзакций в этой базе данных, которые были совершены |
| xact_rollback | bigint | Количество транзакций в этой базе данных, которые были отменены |
| blks_read | bigint | Количество дисковых блоков, прочитанных в этой базе данных |
| blks_hit | bigint | Количество обнаружений дисковых блоков в буферном кеше, так что чтение не было необходимо (это включает только попадания в буферный кеш QHB , а не в кэш файловой системы операционной системы) |
| tup_returned | bigint | Количество строк, возвращенных запросами в этой базе данных |
| tup_fetched | bigint | Количество строк, извлеченными запросами в этой базе данных |
| tup_inserted | bigint | Количество строк, вставленных запросами в этой базе данных |
| tup_updated | bigint | Количество строк, обновленных запросами в этой базе данных |
| tup_deleted | bigint | Количество строк, удаленных запросами в этой базе данных |
| conflicts | bigint | Количество запросов отменено из-за конфликтов при восстановлении в этой базе данных. (Конфликты возникают только на резервных серверах; подробности смотрите в pg_stat_database_conflicts.) |
| temp_files | bigint | Количество временных файлов, созданных запросами в этой базе данных. Подсчитываются все временные файлы, независимо от того, почему был создан временный файл (например, при сортировке или хэшировании), и независимо от настройки log_temp_files. |
| temp_bytes | bigint | Общий объем данных, записанных во временные файлы по запросам в этой базе данных. Учитываются все временные файлы, независимо от того, почему был создан временный файл, и независимо от настройки log_temp_files. |
| deadlocks | bigint | Количество взаимоблокировок, обнаруженных в этой базе данных |
| checksum_failures | bigint | Число ошибок контрольной суммы страницы данных, обнаруженных в этой базе данных (или в общем объекте), или NULL, если контрольные суммы данных не включены. |
| checksum_last_failure | timestamp with time zone | Время, когда в этой базе данных (или в общем объекте) был обнаружен последний сбой контрольной суммы страницы данных, или NULL, если контрольные суммы данных не включены. |
| blk_read_time | double precision | Время, затраченное на чтение блоков файлов данных бэкэндами в этой базе данных, в миллисекундах |
| blk_write_time | double precision | Время, затрачиваемое на запись блоков файлов данных бэкэндами в этой базе данных, в миллисекундах |
| stats_reset | timestamp with time zone | Время последнего сброса этой статистики |
Представление pg_stat_database будет содержать одну строку для каждой базы данных в кластере, плюс одну для общих объектов, показывающую общую статистику на уровне всей базы данных.
Таблица 13. Представление pg_stat_database_conflicts
| колонка | Тип | Описание |
|---|---|---|
| datid | oid | OID базы данных |
| datname | name | Имя базы данных |
| confl_tablespace | bigint | Количество запросов в этой базе данных, которые были отменены из-за удаленных табличных пространств |
| confl_lock | bigint | Количество запросов в этой базе данных, которые были отменены из-за тайм-аутов блокировки |
| confl_snapshot | bigint | Количество запросов в этой базе данных, которые были отменены из-за устаревших снимков данных |
| confl_bufferpin | bigint | Количество запросов в этой базе данных, которые были отменены из-за закрепленных буферов |
| confl_deadlock | bigint | Количество запросов в этой базе данных, которые были отменены из-за взаимных блокировок |
Представление pg_stat_database_conflicts будет содержать одну строку для каждой базы данных, показывающую статистику всей базы данных об отменах запросов, возникающих из-за конфликтов с восстановлением на резервных серверах. Это представление будет содержать информацию только о резервных серверах, поскольку конфликты не возникают на главных серверах.
Таблица 14. Представление pg_stat_all_tables
| колонка | Тип | Описание |
|---|---|---|
| relid | oid | OID таблицы |
| schemaname | name | Имя схемы, в которой находится эта таблица |
| relname | name | Имя этой таблицы |
| seq_scan | bigint | Количество последовательных сканирований, выполненных по этой таблице |
| seq_tup_read | bigint | Количество живых строк, выбранных при последовательном сканировании |
| idx_scan | bigint | Количество сканирований индекса, выполненных для этой таблицы |
| idx_tup_fetch | bigint | Количество живых строк, выбранных при сканировании индекса |
| n_tup_ins | bigint | Количество вставленных строк |
| n_tup_upd | bigint | Количество обновленных строк (включая обновленные в режиме HOT) |
| n_tup_del | bigint | Количество удаленных строк |
| n_tup_hot_upd | bigint | Количество строк, обновленных в режиме HOT (т.е. не требуется отдельное обновление индекса) |
| n_live_tup | bigint | Расчетное количество живых строк |
| n_dead_tup | bigint | Расчетное количество мертвых строк |
| n_mod_since_analyze | bigint | Предполагаемое количество строк, измененных с момента последнего анализа этой таблицы |
| last_vacuum | timestamp with time zone | Последний раз, когда эта таблица была очищена вручную (не считая VACUUM FULL) |
| last_autovacuum | timestamp with time zone | Последний раз, когда эта таблица была очищена фоновым процессом автоочистки |
| last_analyze | timestamp with time zone | Последний раз, когда эта таблица анализировалась вручную |
| last_autoanalyze | timestamp with time zone | Последний раз, когда эта таблица анализировалась фоновым процессом автоочистки |
| vacuum_count | bigint | Сколько раз эта таблица очищалась вручную (не считая VACUUM FULL) |
| autovacuum_count | bigint | Сколько раз эта таблица очищалась фоновым процессом автоочистки |
| analyze_count | bigint | Сколько раз эта таблица была проанализирована вручную |
| autoanalyze_count | bigint | Сколько раз эта таблица анализировалась фоновым процессом автоочистки |
Представление pg_stat_all_tables будет содержать одну строку для каждой таблицы в текущей базе данных (включая таблицы TOAST), показывающую статистику доступа к этой конкретной таблице. Представления pg_stat_user_tables и pg_stat_sys_tables содержат ту же информацию, но отображают только пользовательские и системные таблицы соответственно.
Таблица 15. Представление pg_stat_all_indexes
| колонка | Тип | Описание |
|---|---|---|
| relid | oid | OID таблицы для этого индекса |
| indexrelid | oid | OID этого индекса |
| schemaname | name | Имя схемы, в которой находится этот индекс |
| relname | name | Имя таблицы для этого индекса |
| indexrelname | name | Наименование этого индекса |
| idx_scan | bigint | Количество сканирований индекса, выполненных по этому индексу |
| idx_tup_read | bigint | Количество записей индекса, возвращенных сканированием по этому индексу |
| idx_tup_fetch | bigint | Количество живых строк таблицы, выбранных при простом сканировании индекса с использованием этого индекса |
Представление pg_stat_all_indexes будет содержать одну строку для каждого индекса в текущей базе данных, показывающую статистику доступа к этому конкретному индексу. Представления pg_stat_user_indexes и pg_stat_sys_indexes содержат ту же информацию, но показывают только пользовательские и системные индексы соответственно.
Индексы могут использоваться при простом сканировании индекса, сканировании битовых карт индекса и в работе оптимизатора. При сканировании битовых карт выходные данные нескольких индексов можно комбинировать с помощью правил И или ИЛИ, поэтому сложно связать выборки отдельных строк с конкретными индексами при использовании битовых карт. Следовательно, сканирование битовых карт увеличивает значение pg_stat_all_indexes.idx_tup_read для индексов, которые оно использует, и оно увеличивает значение pg_stat_all_tables.idx_tup_fetch count для таблиц, но не влияет при этом на pg_stat_all_indexes.idx_tup_fetch. Оптимизатор также обращается к индексам при использовании переданных констант, значения которых находятся за пределами имеющегося диапазона статистики оптимизатора, поскольку статистика оптимизатора может быть устаревшей.
Примечание
Значения счетчиков idx_tup_read и idx_tup_fetch могут отличаться даже без использования сканирований битовых карт, поскольку idx_tup_read подсчитывает записи индекса, извлеченные из индекса, в то время как idx_tup_fetch подсчитывает число живых строк, извлеченных из таблицы. Последнее значение будет меньше, если какие-либо мертвые или еще не зафиксированные строки извлекаются с использованием индекса или если какие-либо выборки из таблицы не производятся при выполнении сканирования только по индексу.
Таблица 16. Представление pg_statio_all_tables
| колонка | Тип | Описание |
|---|---|---|
| relid | oid | OID таблицы |
| schemaname | name | Имя схемы, в которой находится эта таблица |
| relname | name | Имя этой таблицы |
| heap_blks_read | bigint | Количество дисковых блоков, прочитанных из этой таблицы |
| heap_blks_hit | bigint | Количество попаданий в буфер в этой таблице |
| idx_blks_read | bigint | Количество дисковых блоков, прочитанных по всем индексам в этой таблице |
| idx_blks_hit | bigint | Количество попаданий в буфер во всех индексах этой таблицы |
| toast_blks_read | bigint | Количество дисковых блоков, прочитанных из таблицы TOAST этой таблицы (если есть) |
| toast_blks_hit | bigint | Количество попаданий в буфер в таблице TOAST этой таблицы (если есть) |
| tidx_blks_read | bigint | Количество дисковых блоков, прочитанных из индексов таблицы TOAST этой таблицы (если есть) |
| tidx_blks_hit | bigint | Количество попаданий в буфер в индексах таблицы TOAST этой таблицы (если есть) |
Представление pg_statio_all_tables будет содержать по одной строке для каждой таблицы в текущей базе данных (включая таблицы TOAST), показывая статистику ввода-вывода для этой конкретной таблицы. Представления pg_statio_user_tables и pg_statio_sys_tables содержат ту же информацию, но отображают только пользовательские и системные таблицы соответственно.
Таблица 17. Представление pg_statio_all_indexes
| колонка | Тип | Описание |
|---|---|---|
| relid | oid | OID таблицы для этого индекса |
| indexrelid | oid | OID этого индекса |
| schemaname | name | Имя схемы, в которой находится этот индекс |
| relname | name | Имя таблицы для этого индекса |
| indexrelname | name | Наименование этого индекса |
| idx_blks_read | bigint | Количество дисковых блоков, прочитанных из этого индекса |
| idx_blks_hit | bigint | Количество попаданий в буфер в этом индексе |
Представление pg_statio_all_indexes будет содержать по одной строке для каждого индекса в текущей базе данных, показывая статистику ввода-вывода для этого конкретного индекса. Представления pg_statio_user_indexes и pg_statio_sys_indexes содержат ту же информацию, но отфильтрованы так, чтобы показывать только пользовательские и системные индексы соответственно.
Таблица 18. Представление pg_statio_all_sequence
| колонка | Тип | Описание |
|---|---|---|
| relid | oid | OID последовательности |
| schemaname | name | Имя схемы, в которой находится эта последовательность |
| relname | name | Имя этой последовательности |
| blks_read | bigint | Количество дисковых блоков, прочитанных из этой последовательности |
| blks_hit | bigint | Количество попаданий в буфер в этой последовательности |
Представление pg_statio_all_sequence будет содержать по одной строке для каждой последовательности в текущей базе данных, показывая статистику ввода-вывода для этой конкретной последовательности.
Таблица 19. Представление pg_stat_user_functions
| колонка | Тип | Описание |
|---|---|---|
| funcid | oid | OID функции |
| schemaname | name | Имя схемы, в которой находится эта функция |
| funcname | name | Имя этой функции |
| calls | bigint | Сколько раз эта функция была вызвана |
| total_time | double precision | Общее время, потраченное на эту функцию и все другие функции, вызываемые ею, в миллисекундах |
| self_time | double precision | Общее время, потраченное на саму функцию, не включая другие вызываемые ею функции, в миллисекундах |
Представление pg_stat_user_functions будет содержать одну строку для каждой отслеживаемой функции, показывающую статистику о выполнении этой функции. Параметр track_functions определяет, какие именно функции отслеживаются.
Функции статистики
Другие способы просмотра статистики можно настроить, написав запросы,
которые используют те же базовые функции доступа к статистике, которые
используются стандартными представлениями, показанными выше. За
подробностями, такими как имена функций, обращайтесь к определениям
стандартных представлений. (Например, в qsql вы можете выполнить
\\d+ pg\_stat\_activity.) Функции доступа к статистике для каждой базы данных
принимают OID базы данных в качестве аргумента, чтобы определить, в
какой базе данных будет выполняться их работа. Функции для каждой таблицы и для
индекса принимают OID таблицы или индекса. Функции для статистики по
функциям принимают функцию OID. Обратите внимание, что с этими функциями
можно видеть только таблицы, индексы и функции лишь в текущей базе данных.
Дополнительные функции, связанные со сбором статистики, перечислены в таблице 20.
Таблица 20. Дополнительные статистические функции
| функция | Return Type | Описание |
|---|---|---|
| pg_backend_pid() | integer | Идентификатор процесса сервера, обрабатывающего текущий сеанс |
| pg_stat_get_activity ( integer ) | setof record | Возвращает запись информации о бэкэнде с указанным PID или одну запись для каждого активного бэкенда в системе, если указано NULL. Возвращенные поля являются подмножеством полей в представлении pg_stat_activity. |
| pg_stat_get_snapshot_timestamp() | timestamp with time zone | Возвращает время снимка текущей статистики |
| pg_stat_clear_snapshot() | void | Сбросить текущий снимок статистики |
| pg_stat_reset() | void | Сброс всех счетчиков статистики для текущей базы данных до нуля (по умолчанию требуются привилегии суперпользователя, но EXECUTE для этой функции может быть предоставлен другим.) |
| pg_stat_reset_shared (text) | void | Сброс некоторых счетчиков статистики для всего кластера на ноль, в зависимости от аргумента (по умолчанию требуются привилегии суперпользователя, но EXECUTE для этой функции может быть предоставлен другим). Вызов pg_stat_reset_shared (’bgwriter’) обнулит все счетчики, показанные в представлении pg_stat_bgwriter. Вызов pg_stat_reset_shared (’archiver’) обнулит все счетчики, показанные в представлении pg_stat_archiver. |
| pg_stat_reset_single_table_counters (oid) | void | Сброс статистики для отдельной таблицы или индекса в текущей базе данных до нуля (по умолчанию требуются привилегии суперпользователя, но EXECUTE для этой функции может быть предоставлен другим) |
| pg_stat_reset_single_function_counters (oid) | void | Сброс статистики для одной функции в текущей базе данных до нуля (по умолчанию требуются привилегии суперпользователя, но EXECUTE для этой функции может быть предоставлен другим) |
pg_stat_get_activity, основная функция представления pg_stat_activity, возвращает набор записей, содержащих всю доступную информацию о каждом бэкэнд-процессе. Иногда бывает удобнее получить только часть этой информации. В таких случаях может использоваться более старый набор функций доступа к статистике на уровне серверных процессов; они приведены в таблице 21. Эти функции доступа используют идентификационный номер бэкэнда, который варьируется от одного до количества текущих активных бэкэндов. Функция pg_stat_get_backend_idset предоставляет удобный способ генерации одной строки для каждого активного бэкэнда для вызова этих функций. Например, чтобы показать PID и текущие запросы всех бэкэндов:
SELECT pg_stat_get_backend_pid(s.backendid) AS pid,
pg_stat_get_backend_activity(s.backendid) AS query
FROM (SELECT pg_stat_get_backend_idset() AS backendid) AS s;
Таблица 21. Статистические функции на уровне бэкэндов
| функция | Return Type | Описание |
|---|---|---|
| pg_stat_get_backend_idset() | setof integer | Набор текущих активных идентификационных номеров бэкэнда (от 1 до количества активных бэкэндов) |
| pg_stat_get_backend_activity(integer) | text | Текст последнего запроса этого бэкэнда |
| pg_stat_get_backend_activity_start(integer) | timestamp with time zone | Время, когда был запущен самый последний запрос |
| pg_stat_get_backend_client_addr(integer) | inet | IP-адрес клиента, подключенного к этому бэкэнду |
| pg_stat_get_backend_client_port(integer) | integer | Номер порта TCP, который клиент использует для связи |
| pg_stat_get_backend_dbid(integer) | oid | OID базы данных, с которой связан этот бэкэнд |
| pg_stat_get_backend_pid(integer) | integer | Идентификатор процесса этого бэкэнда |
| pg_stat_get_backend_start(integer) | timestamp with time zone | Время, когда этот процесс был запущен |
| pg_stat_get_backend_userid(integer) | oid | OID пользователя, подключенного к этому бэкэнду |
| pg_stat_get_backend_wait_event_type(integer) | text | Имя типа события ожидания, если бэкэнд в данный момент ожидает, иначе NULL. См. Таблицу 4 для получения деталей. |
| pg_stat_get_backend_wait_event(integer) | text | Имя события ожидания, если бэкэнд в данный момент ожидает, иначе NULL. См. Таблицу 4 для получения деталей. |
| pg_stat_get_backend_xact_start(integer) | timestamp with time zone | Время начала текущей транзакции |
Просмотр блокировок
Еще одним полезным инструментом для мониторинга активности базы данных является системная таблица pg_locks. Это позволяет администратору базы данных просматривать информацию о блокировках в менеджере блокировок. Например, эту возможность можно использовать для того, чтобы:
-
Просмотреть все имеющиеся блокировки, все блокировки отношений в конкретной базе данных, все блокировки определенного отношения или все блокировки, удерживаемые определенным сеансом QHB .
-
Определить отношение в текущей базе данных с наибольшим количеством блокировок (которые могут быть источником проблем среди пользователей базы данных).
-
Определить влияние конкуренции за блокировку на общую производительность базы данных, а также как меняется конкуренция в зависимости от общей нагрузки базы данных.
Детали представления pg_locks см. в разделе pg_locks. Для получения дополнительной информации о блокировке и управлении параллелизмом с QHB обратитесь к главе Параллельный контроль.
Отчеты о ходе выполнения команд
QHB имеет возможность сообщать о ходе выполнения определенных команд во время их выполнения. В настоящее время командами, которые поддерживают отчеты о ходе выполнения, являются CREATE INDEX, VACUUM и CLUSTER. Этот список может быть расширен в будущем.
Отчет о ходе выполнения CREATE INDEX
Для каждой выполняемой команды CREATE INDEX или REINDEX представление pg_stat_progress_create_index будет содержать одну строку для каждого из бэкэндов, создающих в данный момент индексы. Таблицы ниже описывают информацию, которая будет выведена, и предоставляют информацию о том, как ее интерпретировать.
Таблица 22. Просмотр pg_stat_progress_create_index
| колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса бэкэнда. |
| datid | oid | OID базы данных, с которой связан этот бэкэнд. |
| datname | name | Имя базы данных, с которой связан этот бэкэнд. |
| relid | oid | OID таблицы, для которой создается индекс. |
| index_relid | oid | OID создаваемого или переиндексированного индекса. Во время выполнения CREATE INDEX в неблокирующем режиме значение 0. |
| command | text | Команда, которая выполняется: CREATE INDEX, CREATE INDEX CONCURRENTLY, REINDEX или REINDEX CONCURRENTLY. |
| phase | text | Текущая фаза обработки создания индекса. Смотри таблицу 23. |
| lockers_total | bigint | Общее число процессов, требующих ожидания, когда они есть. |
| lockers_done | bigint | Число процессов, которые завершили ожидание. |
| current_locker_pid | bigint | Идентификатор процесса, удерживающего блокировку в данный момент. |
| blocks_total | bigint | Общее количество блоков, подлежащих обработке. |
| blocks_done | bigint | Количество блоков, уже обработанных на текущем этапе. |
| tuples_total | bigint | Общее количество кортежей, которые должны быть обработаны в текущей фазе. |
| tuples_done | bigint | Количество кортежей, уже обработанных в текущей фазе. |
| partitions_total | bigint | При создании индекса для партицированной таблицы в этом столбце указывается общее количество партиций, для которых создается индекс. |
| partitions_done | bigint | При создании индекса для партицированной таблицы в этом столбце указывается количество партиций, для которых индекс был заполнен. |
Таблица 23. Фазы CREATE INDEX
| Фаза | Описание |
|---|---|
| initializing | Инициализация. CREATE INDEX или REINDEX готовится к созданию индекса. Ожидается, что этот этап будет очень коротким. |
| waiting for writers before build | Ожидание окончания записи перед построением. CREATE INDEX CONCURRENTLY или REINDEX CONCURRENTLY ожидает транзакции с блокировками записи, которые могут читать таблицу. Эта фаза пропускается, когда идет работа в неблокирующем режиме. Столбцы lockers_total, lockers_done и current_locker_pid содержат информацию о ходе выполнения этой фазы. |
| building index | Построение индекса. Индекс строится с помощью кода, реализующего метод доступа. На этом этапе методы доступа, которые поддерживают отчеты о ходе выполнения, заполняют свои собственные данные о ходе выполнения, и в этом столбце указывается внутренняя фаза. Как правило, данные о ходе выполнения будут содержать столбцы blocks_total и blocks_done, а также могут меняться значения в столбцах tuples_total и tuples_done. |
| waiting for writers before validation | Ожидание окончания записи перед проверкой. CREATE INDEX CONCURRENTLY или REINDEX CONCURRENTLY ожидают транзакции с блокироваками записей, которые потенциально могут завершить обновление данных в таблице. Эта фаза пропускается при выполнении операции в неблокирующем режиме. Столбцы lockers_total, lockers_done и current_locker_pid содержат информацию о ходе выполнения этой фазы. |
| index validation: scanning index | Проверка индекса: сканирование. CREATE INDEX CONCURRENTLY сканирует индекс в поисках кортежей, которые необходимо проверить. Эта фаза пропускается, когда не в параллельном режиме. Столбцы blocks_total (для общего размера индекса) и blocks_done содержат информацию о ходе выполнения этой фазы. |
| index validation: sorting tuples | Проверка индекса: сортировка кортежей. CREATE INDEX CONCURRENTLY сортирует выходные данные фазы сканирования индекса. |
| index validation: scanning table | Проверка индекса: сканирование таблицы. CREATE INDEX CONCURRENTLY сканирует таблицу для проверки кортежей индексов, собранных на предыдущих двух этапах. Эта фаза пропускается, когда не в параллельном режиме. Столбцы blocks_total (для общего размера таблицы) и blocks_done содержат информацию о ходе выполнения этой фазы. |
| waiting for old snapshots | Ожидание старых снимков. CREATE INDEX CONCURRENTLY или REINDEX CONCURRENTLY ожидает транзакций, которые потенциально могут увидеть таблицу, чтобы выпустить их моментальные снимки. Эта фаза пропускается при выполнении операции в неблокирующем режиме. Столбцы lockers_total, lockers_done и current_locker_pid содержат информацию о ходе выполнения этой фазы. |
| waiting for readers before marking dead | Ожидание завершения чтения перед отключением старого индекса. REINDEX CONCURRENTLY ожидает завершение транзакций, удерживающих блокировки чтения, прежде чем пометить старый индекс как нерабочий. Эта фаза пропускается при выполнении операции в неблокирующем режиме. Столбцы lockers_total, lockers_done и current_locker_pid содержат информацию о ходе выполнения этой фазы. |
| waiting for readers before dropping | Ожидание завершения чтения перед удалением старого индекса. REINDEX CONCURRENTLY ожидает завершение транзакций, удерживающих блокировки чтения, прежде чем удалить старый индекс. Эта фаза пропускается при выполнении операции в неблокирующем режиме. Столбцы lockers_total, lockers_done и current_locker_pid содержат информацию о ходе выполнения этой фазы. |
Отчет о ходе выполнения VACUUM
Всякий раз, когда VACUUM работает, представление pg_stat_progress_vacuum будет содержать одну строку для каждого бэкэнда (включая рабочие процессы автоочистки), который в данный момент производит очистку. Таблицы ниже описывают информацию, которая будет предоставлена, и поясняют, как ее интерпретировать. О ходе выполнения команд VACUUM FULL сообщается через pg_stat_progress_cluster поскольку VACUUM FULL и CLUSTER перезаписывают таблицу, в то время как обычный VACUUM только изменяет ее на месте. См. раздел Отчет о ходе выполнения CLUSTER.
Таблица 24. Просмотр pg_stat_progress_vacuum
| колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса бэкэнда. |
| datid | oid | OID базы данных, с которой связан этот бэкэнд. |
| datname | name | Имя базы данных, с которой связан этот бэкэнд. |
| relid | oid | OID стола пылесосят. |
| phase | text | Текущая фаза обработки вакуума. Смотри Таблицу 25. |
| heap_blks_total | bigint | Общее количество блоков кучи в таблице. Этот номер сообщается с начала сканирования; добавленные позже блоки не будут (и не обязательно) посещаться этим VACUUM. |
| heap_blks_scanned | bigint | Количество отсканированных блоков кучи. Поскольку карта видимости используется для оптимизации сканирования, некоторые блоки будут пропущены без проверки; пропущенные блоки включены в это общее количество, так что это число в конечном итоге станет равным heap_blks_total когда вакуум будет завершен. Этот счетчик активируется только тогда, когда фаза scanning heap. |
| heap_blks_vacuumed | bigint | Количество блоков кучи вакуумировано. Если таблица не имеет индексов, этот счетчик увеличивается только тогда, когда фаза vacuuming heap. Блоки, которые не содержат мертвых кортежей, пропускаются, поэтому счетчик может иногда пропускать вперед с большими приращениями. |
| index_vacuum_count | bigint | Количество выполненных индексных вакуумных циклов. |
| max_dead_tuples | bigint | Количество мертвых кортежей, которые мы можем сохранить перед выполнением цикла индекса вакуума, основываясь на maintenance_work_mem. |
| num_dead_tuples | bigint | Количество мертвых кортежей, собранных с момента последнего индекса вакуумного цикла. |
Таблица 25. Фазы VACUUM
| фаза | Описание |
|---|---|
| initializing | VACUUM готовится начать сканирование кучи. Ожидается, что этот этап будет очень коротким. |
| scanning heap | VACUUM в настоящее время сканирует кучу. Он будет обрезать и дефрагментировать каждую страницу, если потребуется, и, возможно, выполнять замораживание. heap_blks_scanned можно использовать для отслеживания хода сканирования. |
| vacuuming indexes | VACUUM в настоящее время пылесосит индексы. Если в таблице есть какие-либо индексы, это будет происходить как минимум один раз за вакуум после полного сканирования кучи. Это может происходить несколько раз за вакуум, если maintenance_work_mem недостаточно для хранения количества найденных мертвых кортежей. |
| vacuuming heap | VACUUM в настоящее время пылесосит кучу. Вакуумирование кучи отличается от сканирования кучи и происходит после каждого случая очистки индексов. Если heap_blks_scanned меньше, чем heap_blks_total, система вернется к сканированию кучи после завершения этой фазы; в противном случае он начнет очищать индексы после завершения этой фазы. |
| cleaning up indexes | VACUUM в настоящее время очищает индексы. Это происходит после того, как куча была полностью отсканирована и вся очистка индексов и кучи была завершена. |
| truncating heap | VACUUM в настоящее время урезает кучу, чтобы вернуть пустые страницы в конце отношения к операционной системе. Это происходит после очистки индексов. |
| performing final cleanup | VACUUM выполняет окончательную очистку. На этом этапе VACUUM будет пылесосить карту свободного пространства, обновлять статистику в pg_class и сообщать статистику pg_class статистики. Когда эта фаза будет завершена, VACUUM закончится. |
Отчет о ходе выполнения CLUSTER
Всякий раз, когда CLUSTER или VACUUM FULL работает, представление pg_stat_progress_cluster будет содержать строку для каждого бэкэнда, который в данный момент выполняет любую из команд. Таблицы ниже описывают информацию, которая будет сообщена, и предоставляют информацию о том, как ее интерпретировать.
Таблица 26. просмотр pg_stat_progress_cluster
| Колонка | Тип | Описание |
|---|---|---|
| pid | integer | Идентификатор процесса бэкэнда. |
| datid | oid | OID базы данных, с которой связан этот бэкэнд. |
| datname | name | Имя базы данных, с которой связан этот бэкэнд. |
| relid | oid | OID кластеризованной таблицы. |
| command | text | Команда, которая выполняется. Либо CLUSTER либо VACUUM FULL. |
| phase | text | Текущая фаза обработки. Смотри Таблицу 27. |
| cluster_index_relid | oid | Если таблица сканируется с использованием индекса, это OID используемого индекса; в противном случае это ноль. |
| heap_tuples_scanned | bigint | Количество отсканированных кучи. Этот счетчик увеличивается только тогда, когда фаза является последовательной seq scanning heap, index scanning heap или writing new heap. |
| heap_tuples_written | bigint | Количество написанных кучи кортежей. Этот счетчик увеличивается только тогда, когда фаза является последовательной seq scanning heap, index scanning heap или writing new heap. |
| heap_blks_total | bigint | Общее количество блоков кучи в таблице. Это число сообщается как начало seq scanning heap. |
| heap_blks_scanned | bigint | Количество отсканированных блоков кучи. Этот счетчик активируется только тогда, когда фаза является последовательной seq scanning heap. |
| index_rebuild_count | bigint | Количество перестроенных индексов. Этот счетчик увеличивается только тогда, когда фаза rebuilding index. |
Таблица 27. Фазы CLUSTER и VACUUM FULL
| Фаза | Описание |
|---|---|
| initializing | Команда готовится начать сканирование кучи. Этот этап должен быть очень коротким. |
| seq scanning heap | Команда сканирует таблицу с использованием последовательного сканирования. |
| index scanning heap | CLUSTER в настоящее время сканирует таблицу, используя сканирование индекса. |
| sorting tuples | CLUSTER в настоящее время сортирует кортежи. |
| writing new heap | CLUSTER в настоящее время пишет новую кучу. |
| swapping relation files | В настоящее время команда встраивает вновь созданные файлы. |
| rebuilding index | В настоящее время команда перестраивает индекс. |
| performing final cleanup | Команда выполняет окончательную очистку. Когда эта фаза будет завершена, CLUSTER или VACUUM FULL завершатся. |
Метрики QHB
Общие замечания
В настоящее время метрики в QHB собираются на уровне всего кластера баз данных и относятся ко всему набору процессов QHB, независимо от того, являются ли они фоновыми или поддерживающими пользовательские подключения. Данные метрик поступают в сборщик и агрегатор метрик metricsd, далее агрегируются и записываются в Graphite, в качестве интерфейса к которому выступает Grafana.
Типы метрик
- Gauge. Неотрицательное целое значение. Может быть установлено, увеличено или уменьшено на заданное число.
- Counter. Неотрицательное целое значение. Может быть только увеличено на заданное число.
- Timer. Неотрицательное целое значение, длительность в наносекундах. Значение может быть только записано, во время агрегации вычисляется ряд
статистических характеристик:
- sum. Сумма значений
- count. Число записанных значений
- max. Максимальное из записанных значений
- min. Минимальное из записанных значений
- mean. Арифметическое среднее
- median. Медиана
- std. Стандартное квадратичное отклонение
- Опционально, список перцентилей
Группы метрик
Системные метрики
Сбор системных метрик регулируется двумя глобальными константами:
- qhb_os_monitoring - логическая константа, по умолчанию значение off. При значении on выполняется периодический сбор метрик.
- qhb_os_stat_period - период сбора системной статистики в секундах, по умолчанию 30 секунд.
Загрузка и CPU
| Наименование | Описание | Тип метрики |
|---|---|---|
| sys.load_average.1min | load average за последнюю минуту | gauge |
| sys.load_average.5min | то же за последние 5 минут | gauge |
| sys.load_average.15min | то же за последние 15 минут | gauge |
| sys.cpu.1min | Процент загрузки процессоров за последнюю минуту | gauge |
| sys.cpu.5min | то же за последние 5 минут | gauge |
| sys.cpu.15min | то же за последние 15 минут | gauge |
Примечание
Значения метрик load average содержат значения с точностью до сотых, однако при передаче данных в силу технических особенностей исходные значения умножаются на 100 и передаются как целые. Поэтому необходимо при выводе данных учитывать эту особенность и делить значения на 100.
load average - усреднённое количество исполняемых и ожидающих потоков за заданный интервал времени (1, 5 и 15 минут).
Обычно соответствующие значения выводятся через команды uptime, top либо cat /proc/loadavg
Чтобы детальнее ознакомиться с особенностями, связанными с этим показателем, можно ознакомиться с переводом статьи Brendan Gregg: https://habr.com/ru/company/mailru/blog/335326
Если значение этого показателя за последнюю минуту больше, чем за последние 5 и 15 минут, нагрузка растет, если меньше - падает. Однако, этот показатель важен не сам по себе, а по отношению к общему числу процессоров. Дополнительные и производные от load average метрики по загрузке процессоров sys.cpu.
sys.cpu.<N>min = sys.load_average.<N>min / cpu_count * 100
где cpu_count - количество процессоров в системе, а N принимает значения 1,5 или 15.
Количество процессоров рассчитывается как произведение количества физических сокетов, ядер на сокет и нитей на ядро. Команда lscpu выводит все необходимые данные в следующих строках (пример вывода):
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
В данном случае cpu_count = 2 * 4 * 1 = 8.
Альтернативным и более простым методом может быть получение этого значения через команду nproc.
Таким образом, загрузка в 100% будет достигнута в данном случае, если величина load average будет стремиться к 8. Однако, эти расчеты и значения будут иметь довольно приблизительный и даже условный характер, что показывает приведенная выше по ссылке статья.
Использование памяти
| Наименование | Описание | Тип метрики |
|---|---|---|
| sys.mem.total | общий размер установленной памяти RAM | gauge |
| sys.mem.used | используемая память | gauge |
| sys.mem.free | неиспользуемая память | gauge |
| sys.mem.available | память, доступная для запускаемых приложений (не включая swap, но учитывая потенциально освобождаемую память, занимаемую страничным кэшем) | gauge |
| sys.swap.total | общий размер файла подкачки | gauge |
| sys.swap.free | неиспользуемая память файла подкачки | gauge |
Значения метрик соответствуют следующим полям из вывода утилиты free (значения в kB, т.е. соответствуют выводу free -k):
| Метрика | Поле утилиты free |
|---|---|
| sys.mem.total | Mem:total |
| sys.mem.used | Mem:used |
| sys.mem.free | Mem:free |
| sys.mem.available | Mem:available |
| sys.swap.total | Swap:total |
| sys.swap.free | Swap:free |
Величину, соответствующую выводимому в утилите free значению Mem:buff/cache, можно рассчитать по формуле:
Mem:buff/cache = Mem:total - Mem:used - Mem:free
Таким образом, в Графане можно, используя функцию diffSeries, рассчитывать и выводить это значение на основании других имеющихся данных.
Значение Mem:shared (данные виртуальной файловой системы tmpfs) не выводится через метрики.
Значение Swap:used можно рассчитать по формуле:
Swap:used = Swap:total - Swap:free
Это значение можно выводить в Графане также в виде рассчитываемой величины через функцию diffSeries.
Более детальное описание этих показателей может быть получено через справочную систему операционной системы для утилиты free (Для этого вызовите man free).
Использование дискового пространства
| Наименование | Описание | Тип метрики |
|---|---|---|
| sys.disk_space.total | объем дисковой системы, на которой находится каталог с данными (в байтах) | gauge |
| sys.disk_space.free | свободное пространство дисковой системы, на которой находится каталог с данными (в байтах) | gauge |
Метрики относятся к дисковой системе, на которой расположен каталог с файлами базы данных. Этот каталог определяется параметром командной строки -D при запуске базы данных либо переменной среды $PGDATA. Параметр data_directory в файле параметров qhb.conf может переопределять расположение каталога с данными.
Другие системные метрики
| Наименование | Описание | Тип метрики |
|---|---|---|
| sys.processes | общее количество запущенных в системе процессов | gauge |
| sys.uptime | количество секунд, прошедших с начала запуска системы | gauge |
Метрики по вводу-выводу
Метрики чтения блоков на уровне инстанса QHB
| Наименование | Описание | Тип метрики |
|---|---|---|
| qhb.db_stat.blocks_fetched | количество полученных при чтении блоков | counter |
| qhb.db_stat.blocks_hit | количество блоков, найденных в кэше при чтении | counter |
| qhb.db_stat.blocks_read_time | время чтения блоков, в миллисекундах | counter |
| qhb.db_stat.blocks_write_time | время чтения блоков, в миллисекундах | counter |
На основании метрик qhb.db_stat.blocks_fetched и qhb.db_stat.blocks_hit рассчитывается коэффициент попадания в кэш:
k = blocks_hit / blocks_fetched * 100%
Хорошим уровнем обычно считается значение более 90%. Если значение коэффициента существенно ниже этой отметки, желательно рассмотреть возможность увеличения объема буферного кэша.
Метрики процесса bgwriter
| Наименование | Описание | Тип метрики |
|---|---|---|
| qhb.bgwr.checkpoints_timed | количество запланированных контрольных точек, которые были выполнены | counter |
| qhb.bgwr.checkpoints_req | количество запрошенных контрольных точек, выполненных вне очереди запланированных | counter |
| qhb.bgwr.checkpoint_write_time | время, потраченное на этап обработки контрольной точки, где файлы записываются на диск, в миллисекундах | counter |
| qhb.bgwr.checkpoint_sync_time | количество времени, потраченное на часть обработки контрольной точки, где файлы синхронизируются с диском, в миллисекундах | counter |
| qhb.bgwr.buffers_checkpoint | количество буферов, записанных во время контрольных точек | counter |
| qhb.bgwr.buffers_clean | количество буферов, записанных фоновым процессом записи | counter |
| qhb.bgwr.maxwritten_clean | количество раз, когда процесс записи в фоновом режиме останавливал сброс грязных страниц, поскольку записывал слишком много буферов | counter |
| qhb.bgwr.buffers_backend | количество буферов, записанных непосредственно бэкэндом | counter |
| qhb.bgwr.buffers_backend_fsync | сколько раз бэкэнд выполнял вызов fsync сам (обычно их обрабатывает фоновый процесс записи, даже когда бэкэнд выполняет запись самостоятельно) | counter |
| qhb.bgwr.buffers_alloc | количество выделенных буферов | counter |
Данные по перечисленным метрикам отображаются в разделе "Контрольные точки и операции с буферами" дашборда "QHB". Обычно при выполнении запланированных контрольных точек сначала происходит запись информации о начале контрольной точки, затем в течение некоторого времени идет сброс блоков на диск и по окончании контрольной точки фиксируется информация о продолжительности записи и синхронизации данных. В случае обработки запланированной контрольной точки запись блоков равномерно распределяется во времени согласно параметрам настройки, чтобы снизить влияние этого процесса на общий ввод-вывод. При запрошенных через команду контрольных точках сброс блоков происходит сразу, без искусственной задержки.
Метрики процесса архивации WAL-файлов
| Наименование | Описание | Тип метрики |
|---|---|---|
| qhb.wal.archived | количество успешно выполненных операций архивации WAL-файлов | counter |
| qhb.wal.failed | количество попыток архивации, завершившихся сбоем | counter |
| qhb.wal.archive_time | время, потраченное на копирование файлов журналов, в наносекундах | counter |
Эти метрики работают в том случае, если настроена архивация WAL. Для этого необходимо установить archive_mode в значение on и определить команду архивации в параметре archive_command.
Метрики по транзакциям
Метрики по завершениям и отменах транзакций. Данные метрик собираются непосредственно при выполнении команд завершения и отмены транзакций на уровне всего кластера баз данных
| Наименование | Описание | Тип метрики |
|---|---|---|
| qhb.transaction.commit | количество фиксаций транзакций | counter |
| qhb.transaction.rollback | количество отмен транзакций | counter |
| qhb.transaction.deadlocks | количество дедлоков | counter |
Коэффициент подтверждения транзакций рассчитывается как процентное отношение успешных завершений транзакций к сумме подтверждений и откатов транзакций:
k = commit/(commit + rollback)*100%
Обычно значение стремится к 100%, т.к. чаще всего транзакции завершаются успешно. Существенная доля отмен транзакций может говорить о том, что в системе существуют проблемы.
Дедлоки возникают при взаимных блокировках, когда между различными сессиями возникают ситуации взаимного ожидания освобождения заблокированных данных. В этом случае после автоматического определения дедлока происходит отмена одной из транзакций.
Метрики событий ожиданий
Данный набор метрик полностью соответствует набору стандартных событий ожидания. Метрики имеют префикс qhb.wait. Далее в наименовании идет класс события ожидания и через точку название события ожидания. В текщем релизе имена метрик ограничены в размере и имеют в наименовании максимум 31 символ. Все метрики по событиям ожиданий имеют тип counter, однако, значение содержит продолжительность времени в микросекундах, которые эти ожидания заняли в совокупности во всех сессиях за период агрегации.
Примечание
Если в течение периода наблюдения работало множество пользовательских подключений, которые находились в состоянии ожидания, суммарное значение времени ожидания может многократно превзойти этот период. Например, если в течение 10 секунд 1000 сессий провели в ожиданиях по одной секунде, суммарное время ожиданий составит 1000 секунд.
Метрики с типами событий ожидания Lock, LWLock, IO и IPC отображаются в разделе "События ожидания" дашборда QHB. Значения метрик выводятся в микросекундах (автоматически переводясь в другие единицы при увеличении значений). На существующих графиках выводятся не все события ожиданий, а только по пять самых значимых по величине на каждом графике. Разные события ожиданий могут иметь сильно отличающиеся по величине продолжительности. Значительные колебания значений могут отражать возникающие проблемы.
Наиболее значимые события ожиданий
- Lock.extend, ожидание расширения отношения. Становится заметным при активном росте таблиц. Необходимость выделения новых блоков приводит к некоторым задержкам, которые отражаются в этой метрике.
- Lock.transactionid, ожидание завершения транзакции. Событие ожидания возникает в том случае, если транзакция вынуждена ждать окончания обработки предыдущих транзакций, которые также получают подтверждение своего окончания.
- Lock.tuple, ожидание получения блокировки для кортежа. Возникает в случае одновременной работы с теми же данными нескольких транзакций.
- LWLock.WALWriteLock, ожидание записи буферов WAL на диск. Часто является лидером среди событий ожиданий этого типа, т.к. операции с диском являются наиболее медленными в этой группе событий ожидания.
- LWLock.wal_insert, ожидание вставки WAL в буфер памяти.
- LWLock.buffer_content, ожидание чтения или записи страницы данных в памяти. Возникает и становится существенным при интенсивном вводе-выводе.
- LWLock.buffer_mapping, ожидание связывания блока данных с буфером в буферном пуле.
- LWLock.lock_manager, ожидание добавления или проверки блокировок для бэкэндов. Событие становится значимым при частых транзакциях.
Метрики буферного менеджера
Ниже представлены метрики, касающиеся механизмов управления памятью.
| Наименование | Операция | Описание | Тип метрики | Агрегат |
|---|---|---|---|---|
| qhb.bufmgr.BufferAlloc | чтение данных | количество поисков буфера | timer | count |
| qhb.bufmgr.BufferAlloc | чтение данных | сумма времени на поиск буфера | timer | sum |
| qhb.bufmgr.happy_path | чтение данных | количество поисков, когда буфер нашёлся сразу | timer | count |
| qhb.bufmgr.happy_path | чтение данных | сумма времени на поиск, когда буфер нашёлся сразу | timer | sum |
| qhb.bufmgr.cache_miss | чтение данных | количество промахов кеша буферов | timer | count |
| qhb.bufmgr.cache_miss | чтение данных | сумма времени обработки промахов кеша буферов | timer | sum |
| qhb.bufmgr.disk_read | чтение данных | количество чтений страницы с диска (асинхронно) | timer | count |
| qhb.bufmgr.flush_dirty | чтение данных | количество выгрузки страницы на диск (асинхронно) | timer | count |
| qhb.bufmgr.retry_counter | чтение данных | количество повторных обработок промаха | counter | |
| qhb.bufmgr.strategy_pop_cnt | чтение данных | количество срабатываний специальной стратегии получения или вытеснения буфера | counter | |
| qhb.bufmgr.strategy_reject_cnt | чтение данных | количество забракованных буферов, предложенных специальной стратегией | counter | |
| tarq_cache.allocate | чтение данных | количество поисков в TARQ | timer | count |
| tarq_cache.allocate | чтение данных | сумма времени на поиск в TARQ | timer | sum |
| tarq_cache.allocate_new | чтение данных | количество выборов исключаемого блока в TARQ | timer | count |
| tarq_cache.rollback | чтение данных | количество откатов вытеснения в TARQ | timer | count |
| tarq_cache.rollback | чтение данных | сумма времени на откаты вытеснения в TARQ | timer | sum |
| tarq_cache.touch | чтение данных | сумма времени на учёт популярных страниц в TARQ | timer | sum |
Метрики пула соединений QCP
Ниже описаны метрики пула соединений, характеризующие работу пула.
| Наименование | Операция | Описание | Тип метрики |
|---|---|---|---|
| backend_held | выполнение запроса | время, в течение которого qcp удерживает соединение к серверу привязанным к какому-то клиенту | timer |
| queue | выполнение запроса | количество запросов в очереди на текущий момент | gauge |
| relay.wait_request | выполнение запроса | время ожидания получения запроса от клиента | timer |
| relay.wait_response | выполнение запроса | время ожидания ответа на запрос от сервера | timer |
Дашборды метрик QHB для Grafana
Дашборды QHB для Grafana расположены в репозитории по следующей ссылке.
QHB поставляется совместно с сервером метрик, который записывает данные метрик в Graphite и интерфейсом к которым служит Grafana. Текущий набор дашбордов для Grafana поставляется в качестве самодокументируемых образцов, на основе которых пользователи, при необходимости, могут самостоятельно создать дашборда, более соответствующие их потребностям. Вместе с тем, поставляемые дашборды могут использоваться и в исходном виде.
Импорт дашбордов
Экспорт JSON-описания дашбордов выполнен в Grafana 6.7.2.
Перед импортом JSON-описания необходимо решить, будут ли названия метрик содержали в качестве префикса имя хоста.
Именно таким образом устроены наименования метрик внутри дашбордов и этот вариант рекомендуется оставить.
В начале имен метрик добавлена переменная $server_name, по умолчанию для нее выбрано значение your_host_name.
Перед импортом можно заменить в JSON-файлах это значение на наименование одного из хостов.
В дальнейшем в этой переменной через интерфейс Grafana можно будет добавить через запятую все имена хостов,
с которых будут собираться метрики. Это позволит быстро переключаться при просмотре метрик с одного хоста на другой.
Если такая схема использоваться не будет (в случае, если метрики будут использоваться с единственного хоста),
можно удалить в файлах JSON во всех именах метрик префикс $server_name до проведения импорта описания JSON.
Однако, это более трудоемкий вариант и его выбирать не рекомендуется.
Для импорта описаний дашбордов необходимо выполнить следующие шаги:
- В меню "Dashboards" вашего сайта Grafana выбрать пункт "Manage".
- В открывшемся списке папок и дашбордов выбрать существующую или создать новую папку.
- Находясь в выбранной папке, выбрать в правой верхней части страницы пункт "Import".
- На открывшейся странице можно либо нажать справа вверху кнопку "Upload .json file" и загрузить файл либо вставить содержание JSON-файла в поле под заголовком "Or paste JSON" и нажать кнопку "Load". После этого нужно заполнить необходимые параметры и выполнить загрузку JSON-описания.
Дашборд "Операционная система"
Дашборд представляет основные системные показатели:
- Время работы инстанаса QHB
- Load Average
- Исполользование CPU
- Использование памяти
- Использование дисковой системы, на которой расположен каталог баз данных
Дашборд "QHB"
Дашборд содержит несколько разделов:
- Транзакции
- Чтение и запись блоков
- События ожидания
- Контрольные точки и операции с буферами
- Архивация WAL
В каждом разделе представлены наборы тематических панелей, отражающие основные показатели.
Настройка сбора метрик
Для того, чтобы дашборды отображали данные метрик, необходимо выполнить некоторые настройки.
Настройка сервера метрик
Настройка сервера метрик описана в разделе Сервер метрик.
Рекомендуется в параметре prefix конфига /etc/metricsd/config.yaml сервера метрик прописать имя хоста,
на котором он работает. Если сделать это для каждого сервера, все метрики будут организованы иерархически,
и первый уровень иерархии будет уровнем серверов. В именах метрик в предлагаемых дашбордах для этих целей присутствует
переменная $server_name. Подразумевается, что на хосте работает только один кластер баз данных.
Настройка параметров базы данных
Для настройки отправки метрик необходимо в qhb.conf указать параметр metrics_collector_id в значение, с которым запускается сборщик метрик, например, 1001 (актуально до релиза QHB 1.3.0). Начиная с релиза QHB 1.3.0 вместо metrics_collector_id используется collector_addr, по умолчанию имеет значение @metrics-collector (представляет собой адрес unix domain socket'а), сервер метрик по умолчанию запускается именно на этом адресе.
Для настройки отправки аннотаций необходимо в qhb.conf прописать следующие параметры:
grafana.address - адрес Графаны, например http://localhost:3000
grafana.token - необходимо указать токен, полученный в Графане по адресу http://localhost:3000/org/apikeys
Пример настроек в qhb.conf для отправки метрик и аннотаций
# До релиза QHB 1.3.0
# metrics_collector_id = 1001
# С релиза QHB 1.3.0:
collector_addr = @metrics-collector
grafana.address = 'http://localhost:3000'
grafana.token = 'eyJrIjoiNGxTaloxMUNTQkFUMTN0blZqUTN6REN6OWI5YjM1MzMiLCJuIjoidGVzdCIsImlkIjoxfQ=='
Для сбора системных метрик (Дашборд "Операционная система") необходимо установить параметр qhb_os_monitoring в значение on. Можно также задать период сбора системной статистики qhb_os_stat_period, значение по умолчанию которого равно 30 секундам. Не рекомендуется задавать слишком низкое значение для этого параметра, т.к. сбор системной статистики требует некоторых ресурсов.
В файле параметров можно прописать:
qhb_os_monitoring = on
qhb_os_stat_period = 60 # если период по умолчанию в 30 секунд не устраивает
Либо выполнить команды:
alter system set qhb_os_monitoring = on;
alter system set qhb_os_stat_period = 60;
select pg_reload_conf();
Примеры использования метрик в SQL-функциях
Помимо встроенных метрик, пользователи могут использовать свои метрики через следующие функции SQL.
Тип метрик Timer
Используется при фиксации промежутка времени, единицы измерения - наносекунды.
select qhb_timer_report('qhb.timer.nano',10000000000 /* 10 секунд в наносекундах */);
Тип метрик Counter
Используется, когда нужно зафиксировать количество произошедших за промежуток времени событий.
select qhb_counter_increase_by('qhb.example.counter',10);
Тип метрик Gauge
Используется, когда нужно установить некий статичный показатель в определенное значение или изменить его.
select qhb_gauge_update('qhb.gauge_example.value', 10); /* Установка значения */
select qhb_gauge_add('qhb.gauge_example.value',1); /* Увеличение значения */
select qhb_gauge_sub('qhb.gauge_example.value',1); /* Уменьшение значения */
Аннотации
Используются, если нужно добавить комментарий к данным метрик. Первый параметр функции - текст комментария, последующие параметры - теги.
select qhb_annotation('Начало выполнения теста', 'test','billing'); /* Текст аннотации и два тега */
Мониторинг использования диска
В этой главе рассказывается, как отслеживать использование диска в системе баз данных QHB.
Определение использования диска
У каждой таблицы есть основной файл кучи, где хранится большая часть данных. Если в таблице есть какие-либо столбцы с потенциально широкими значениями, также может быть файл TOAST, связанный с таблицей, который используется для хранения значений, которые слишком широки, чтобы удобно помещаться в основной таблице (см. раздел TOAST). В таблице TOAST будет один действительный индекс, если он есть. Также могут быть индексы, связанные с базовой таблицей. Каждая таблица и индекс хранятся в отдельном файле на диске - возможно, в нескольких файлах, если размер файла превышает один гигабайт. Соглашения об именах этих файлов описаны в разделе Структура файлов базы данных.
Вы можете отслеживать дисковое пространство тремя способами: с помощью функций SQL, перечисленных в разделе Функции управления объектами базы данных, с помощью модуля oid2name или с помощью ручной проверки системных каталогов. Функции SQL являются самыми простыми в использовании и обычно рекомендуются. В оставшейся части этого раздела показано, как это сделать путем проверки системных каталогов.
Используя qsql в недавно очищенной или проанализированной базе данных, вы можете создавать запросы, чтобы увидеть использование диском любой таблицы:
SELECT pg_relation_filepath(oid), relpages FROM pg_class WHERE relname = 'customer';
pg_relation_filepath | relpages
----------------------+----------
base/16384/16806 | 60
(1 row)
Каждая страница обычно составляет 8 килобайт. (Помните, что relpages обновляется только с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX). Путь к файлу представляет интерес, если вы хотите проверить файл таблицы непосредственно.
Чтобы показать пространство, используемое таблицами TOAST, используйте запрос, подобный следующему:
SELECT relname, relpages
FROM pg_class,
(SELECT reltoastrelid
FROM pg_class
WHERE relname = 'customer') AS ss
WHERE oid = ss.reltoastrelid OR
oid = (SELECT indexrelid
FROM pg_index
WHERE indrelid = ss.reltoastrelid)
ORDER BY relname;
relname | relpages
----------------------+----------
pg_toast_16806 | 0
pg_toast_16806_index | 1
Вы также можете легко отобразить размеры индекса:
SELECT c2.relname, c2.relpages
FROM pg_class c, pg_class c2, pg_index i
WHERE c.relname = 'customer' AND
c.oid = i.indrelid AND
c2.oid = i.indexrelid
ORDER BY c2.relname;
relname | relpages
-------------------+----------
customer_id_index | 26
С помощью этой информации легко найти самые большие таблицы и индексы:
SELECT relname, relpages
FROM pg_class
ORDER BY relpages DESC;
relname | relpages
----------------------+----------
bigtable | 3290
customer | 3144
Ошибка диска
Самая важная задача администратора диска для администратора базы данных - убедиться, что диск не переполнен. Заполненный диск с данными не приведет к повреждению данных, но может помешать выполнению полезных действий. Если диск с файлами WAL заполнится, может возникнуть паника сервера базы данных и последующее отключение.
Если вы не можете освободить дополнительное место на диске, удалив другие объекты, вы можете переместить некоторые файлы базы данных в другие файловые системы, используя табличные пространства. См. раздел Табличные пространства для получения дополнительной информации об этом.
Заметка
Некоторые файловые системы работают плохо, когда они почти заполнены, поэтому не ждите, пока диск полностью не заполнится, чтобы принять меры.
Если ваша система поддерживает дисковые квоты для каждого пользователя, то на базу данных, естественно, будет распространяться любая квота, установленная для пользователя, от которого работает сервер. Превышение квоты будет иметь те же негативные последствия, что и полное отсутствие места на диске.
Надежность и журнал упреждающей записи
В этой главе объясняется, как журнал упреждающей записи (Write Ahead Log, WAL) используется для обеспечения эффективной и надежной работы.
Надежность
Надежность является важным свойством любой серьезной системы баз данных, и QHB делает все возможное, чтобы гарантировать надежную работу. Одним из аспектов надежной работы является то, что все данные, записанные в завершенной транзакции, должны храниться в энергонезависимой памяти, защищенной от потери питания, сбоя операционной системы и аппаратного сбоя (за исключением, разумеется, отказа самой энергонезависимой области). Успешная запись данных в постоянное хранилище компьютера (дисковое или аналогичное) обычно соответствует этому требованию. На самом деле, даже если компьютер серьезно поврежден, если диски сохранились, их можно перенести на другой компьютер с аналогичным оборудованием, и все зафиксированные транзакции останутся без изменений.
Хотя принудительное периодическое сохранение данных на дисках и других устройствах может показаться простой операцией, это не так. Поскольку дисковые такие значительно медленнее, чем основная память и процессор, существует несколько уровней кэширования между основной памятью компьютера и дисками. Во-первых, это буферный кеш операционной системы, который кеширует часто запрашиваемые дисковые блоки и объединяет записи на диск. К счастью, все операционные системы предоставляют приложениям возможность форсировать запись из буферного кэша на диск, и QHB использует эти функции. (См. параметр wal_sync_method, для тонкой настройки).
Далее,кеш может быть в дисковом контроллере - это особенно распространено на RAID-контроллерах. Некоторые из этих кэшей являются сквозными, что означает, что записи отправляются на диск сразу после их поступления. У другие есть обратная запись, то есть данные отправляются на диск через некоторое время. Такие кеши могут быть угрозой надежности, поскольку память в кеше дискового контроллера может оказаться энергозависимой и теряет свое содержимое при сбое питания - качественные контроллеры имеют резервные блоки батарей (Battery Backup Unit, BBU), это означает, что в составе контроллера есть батарея, которая поддерживает питание кеша в случае потери питания системы. После восстановления питания данные будут корректно записаны на дисководы.
И, наконец, большинство дисководов имеют внутренный кеш. Некоторые из них имеют кеш со сквозной, а другие с обратной записью, и для кэшей дисков с обратной записью существуют те же проблемы, что и для дисковых кэшей контроллера. Диски IDE и SATA потребительского уровня особенно часто имеют кэши обратной записи, который не выдержат сбоя питания. Многие твердотельные накопители (SSD) также имеют энергозависимые кэши обратной записи.
Эти кэши обычно можно отключить - однако способ сделать это зависит от
операционной системы и типа диска. В Linux диски IDE и SATA можно запрашивать с помощью hdparm -I.
Кэширование записи включено, если рядом с Write cache есть *.
hdparm -W 0 может использоваться для отключения кэширования записи.
Диски SCSI могут быть запрошены с помощью sdparm. Используйте
sdparm --get=WCE чтобы проверить, включен ли кэш записи, и
sdparm --clear=WCE чтобы отключить его.
Диски SATA последних моделей (те, которые следуют стандарту ATAPI-6 или более новому) предлагают команду очистки кэша диска FLUSH CACHE EXT, в то время как диски SCSI уже давно поддерживают аналогичную команду SYNCHRONIZE CACHE. Эти команды не доступны напрямую для QHB, но некоторые файловые системы (например, ZFS, ext4 ) могут использовать их для сброса данных на диски на дисках с обратной записью. К сожалению, такие файловые системы ведут себя неоптимально в сочетании с дисковыми контроллерами с BBU. В таких системах команда синхронизации направляет все данные из кэша контроллера на диски, что исключает большую часть преимуществ BBU. Если QHB установлена в такую среду, преимущества BBU для производительности можно восстановить, отключив барьеры записи в файловой системе или перенастроив контроллер диска, если это возможно. Если барьеры записи отключены, убедитесь, что батарея остается работоспособной - неисправный аккумулятор может привести к потере данных.
Когда операционная система отправляет запрос на запись в оборудование обеспечивающее долгосрочное хранение, есть мало способов для того , чтобы убедиться, что данные поступили в действительно энергонезависимую область хранения. Скорее, администратор обязан убедиться, что все компоненты хранилища обеспечивают целостность как данных, так и метаданных файловой системы. Избегайте дисковых контроллеров, которые имеют кэши записи без батарейного питания. На уровне диска отключите кэширование с обратной записью, если диск не может гарантировать, что данные будут записаны перед выключением. Если вы используете твердотельные накопители, помните, что многие из них по умолчанию не поддерживают команды очистки кэша.
Еще один риск потери данных связан с самими операциями записи на диск. Пластины механического устройства хранения, как правило, разделены на сектора, обычно по 512 байт каждый. Каждая физическая операция чтения или записи обрабатывает целый сектор. Когда на диск поступает запрос на запись, он может быть кратен 512 байтам ( QHB обычно записывает 8192 байт или 16 секторов за раз), и в процессе записи может произойти сбой из-за потери питания в любое время, что означает, что некоторые из 512-байтовых секторов были записаны, а другие нет. Чтобы защититься от таких сбоев, QHB периодически записывает полностраничные образы в постоянное хранилище WAL перед изменением фактической страницы на диске. Таким образом, во время восстановления после сбоя QHB может восстановить частично записанные страницы из WAL. Если используется файловая система, которая предотвращает частичную запись страниц (например, ZFS), вы можете отключить полностраничное представление (запись 8 КБ или 16 секторов за раз), отключив параметр full_page_writes. Дисковые контроллеры с батарейным блоком (BBU) не предотвращают частичную запись страниц, если они не гарантируют, что данные записываются в BBU как полные (8 КБ) страницы.
QHB также защищает от некоторых видов повреждения данных на устройствах хранения, которые могут возникнуть из-за аппаратных ошибок или сбоя носителя с течением времени, таких как чтение / запись мусорных данных.
-
Каждая отдельная запись в файле WAL защищена проверкой CRC-32 (32-разрядная версия), которая позволяет нам определить правильность содержимого записи. Значение CRC устанавливается при записи каждой записи WAL и проверяется во время восстановления после сбоя, восстановления архива и репликации.
-
Страницы данных в конфигурации по умолчанию не имеют контрольной суммы , хотя образы страниц, сохранённые в записях WAL, будут защищены - смотрите qhb_bootstrap для подробностей о включении контрольных сумм длястраниц данных.
-
Внутренние структуры данных хранящиеся на диске, такие как pg_xact, pg_subtrans, pg_multixact, pg_serial, pg_notify, pg_stat, pg_snapshots, не проверяются при помощи контрольных сумм, а страницы не защищены полными записями страниц (по 8Кб). Однако там, где такие структуры данных являются постоянными, записываются записи WAL, которые позволяют точно выстроить заново последние изменения при восстановлении после сбоя, и эти записи WAL защищены, как обсуждалось выше.
-
Отдельные файлы состояний в pg_twophase защищены CRC-32.
-
Временные файлы данных, используемые в больших запросах SQL для сортировки, материализации и промежуточных результатов, в настоящее время не проверяются, и в WAL не будут записываться изменения в этих файлах.
QHB не защищает от исправляемых ошибок памяти, и предполагается, что вы будете работать с ОЗУ, которое использует отраслевой стандарт исправления ошибок (ECC) или более эффективную защиту.
Журнал упреждающей записи
Запись в журнал упреждающей записи (Write Ahead Log, WAL ) - это стандартный метод обеспечения целостности данных. Подробное описание можно найти в большинстве (если не во всех) справочных и учебных пособиях по обработке транзакций. Центральная концепция WAL заключается в том, что изменения в файлах данных (в которых находятся таблицы и индексы) должны записываться только после того, как эти изменения были зарегистрированы, то есть после того, как записи журнала, описывающие изменения, были сброшены в постоянное хранилище. Если мы следуем этой процедуре, нам не нужно сбрасывать страницы данных на диск при каждой фиксации транзакции, потому что мы знаем, что в случае сбоя мы сможем восстановить базу данных, используя журнал: любые изменения, которые не были применены на страницы данных могут быть восстановлены из записей журнала. (Это восстановление с повтором транзакций, также известно как REDO).
Заметка
Поскольку WAL восстанавливает содержимое файла базы данных после сбоя, журнальные файловые системы не нужны для надежного хранения файлов данных или файлов WAL. Фактически, издержки журналирования могут снизить производительность, особенно если журналирование часто приводит к сбросу данных файловой системы на диск. Сброс данных журнала часто может быть отключен с помощью опции монтирования файловой системы, например data=writeback в файловой системе Linux ext3. Журналированные файловые системы улучшают скорость загрузки после сбоя.
Использование WAL приводит к значительному сокращению числа операций записи на диск, поскольку для сохранения транзакции требуется только файл журнала, а не каждый файл данных, измененный транзакцией. Файл журнала записывается последовательно, поэтому стоимость синхронизации журнала намного ниже, чем стоимость сброса на диск страниц файлов данных. Это особенно верно для серверов, обрабатывающих множество небольших транзакций, затрагивающих разные части хранилища данных. Кроме того, когда сервер обрабатывает много небольших параллельных транзакций, одной фиксации файла журнала может быть достаточно для фиксации многих транзакций.
WAL также позволяет поддерживать оперативное резервное копирование и восстановление на определенный момент времени, как описано в разделе Выполнение восстановления на момент времени (PITR). Архивируя данные WAL, мы можем поддерживать возврат к любому моменту времени, охваченному доступными данными WAL: мы просто устанавливаем предварительную физическую резервную копию базы данных и "воспроизводим" изменения из журнала столько раз, сколько необходимо. Более того, физическое резервное копирование не должно быть мгновенным снимком состояния базы данных - если оно выполнено в течение некоторого периода времени, то повторное воспроизведение журнала за этот период устранит любые внутренние несоответствия.
Асинхронный коммит
Асинхронная фиксация (asynchronous commit) - это опция, которая позволяет транзакциям завершаться быстрее, за счет того, что самые последние транзакции могут быть потеряны в случае сбоя базы данных. Во многих приложениях это приемлемый компромисс.
Как описано в предыдущем разделе, фиксация транзакции обычно выполняется синхронно: сервер ожидает сброса записей WAL транзакции в постоянное хранилище, а затем возвращает клиенту указание об успешном выполнении. Поэтому клиенту гарантируется, что транзакция, о которой было сообщено, будет сохранена даже в случае сбоя сервера сразу после этого. Однако для коротких транзакций эта задержка является основным компонентом общего времени транзакции. Выбор режима асинхронной фиксации означает, что сервер возвращает сообщение об успешной фиксации, как только транзакция логически завершена, до того, как сгенерированные ею записи WAL действительно попадут на диск. Это может обеспечить значительное увеличение пропускной способности для небольших транзакций.
Асинхронная фиксация транзакций создает риск потери данных. Существует короткое временное окно между отчетом о завершении транзакции для клиента и временем, когда транзакция действительно зафиксирована (то есть она гарантированно не будет потеряна в случае сбоя сервера). Таким образом, асинхронная фиксация транзакций не должна использоваться, если клиент будет выполнять внешние действия, полагаясь на то, что транзакция будет завершена. Например, банк, безусловно, не будет использовать асинхронную фиксацию транзакции, регистрирующей выдачу наличных в банкомате. Но во многих сценариях, таких как регистрация событий, нет необходимости в сильных гарантиях такого рода.
Риск, связанный с использованием асинхронной фиксации транзакций, - это потеря данных, а не их повреждение. Если база данных выйдет из строя, она восстановится путем воспроизведения WAL до последней записи, которая была сохранена. Поэтому база данных будет восстановлена в самосогласованном состоянии, но любые транзакции, которые еще не были записаны на диск, не будут отражены в этом состоянии. Таким образом, минимальные последствия - потеря нескольких последних транзакций. Поскольку транзакции воспроизводятся в порядке фиксации, может быть внесено несоответствие - например, если транзакция B внесла изменения, полагаясь на изменения внесённые предыдущей транзакцией A, невозможно восстановить эффекты A, в то время как эффекты B сохранены.
Пользователь может выбрать режим фиксации каждой транзакции, чтобы можно было одновременно выполнять синхронные и асинхронные фиксации транзакции. Это обеспечивает гибкие компромиссы между производительностью и уверенностью в согласованности транзакций. Режим фиксации управляется настраиваемым пользователем параметром synchronous_commit, который может быть изменен любым из способов настройки параметра конфигурации. Режим, используемый для любой транзакции, зависит от значения synchronous_commit когда начинается фиксация транзакции.
Некоторые служебные команды, например DROP TABLE, принудительно фиксируются синхронно, независимо от значения параметра synchronous_commit. Это необходимо для обеспечения согласованности между файловой системой сервера и логическим состоянием базы данных. Команды, поддерживающие двухфазную фиксацию, такие как PREPARE TRANSACTION, также всегда являются синхронными.
Если во время окна риска между асинхронной фиксацией и записью изменений в WAL транзакции происходит сбой базы данных, изменения, сделанные во время этой транзакции, будут потеряны. Продолжительность окна риска ограничена, потому что фоновый процесс ( WAL writer) сбрасывает новые записи WAL на диск каждые миллисекунды wal_writer_delay . Фактическая максимальная продолжительность окна риска в три раза больше wal_writer_delay потому что средство записи WAL предназначено для записи целых страниц за раз в периоды нагрузки.
Предосторожение!!!
Выключение в немедленном режиме эквивалентно сбою сервера и, следовательно, приведет к потере любых невыполненных асинхронных фиксаций транзакций.
Асинхронная фиксация транзакции обеспечивает поведение, отличное от установки fsync = off. fsync - это параметр для всего сервера, который будет изменять поведение всех транзакций. Он отключает всю логику в QHB, которая пытается синхронизировать записи в различные части базы данных, и, следовательно, сбой системы (то есть сбой оборудования или операционной системы, а не сбой самого QHB) может привести к сколь угодно плохому повреждению состояния базы данных - от потери отдельных таблиц до полной непригодности. Во многих сценариях асинхронная фиксация транзакций обеспечивает значительное улучшение производительности, которое можно получить, отключив fsync, но без риска повреждения данных.
Действие параметра commit_delay также очень похоже на асинхронную фиксацию транзакций, но на самом деле это метод синхронной фиксации (фактически, commit_delay игнорируется во время асинхронной фиксации). commit_delay вызывает задержку непосредственно перед тем, как транзакция сбрасывает WAL на диск, в надежде, что один сброс, выполненный одной такой транзакцией, может также обслуживить другие транзакции, фиксируемые примерно в одно и то же время. Этот параметр можно рассматривать как способ увеличения временного окна, в котором транзакции могут присоединиться к группе, собирающейся участвовать в одном сохраненнии, чтобы амортизировать стоимость сброса между несколькими транзакциями.
Конфигурация WAL
Существует несколько параметров конфигурации, связанных с WAL, которые влияют на производительность базы данных. Этот раздел объясняет их использование. Обратитесь к Главе Конфигурация сервера за общей информацией о настройке параметров конфигурации сервера.
Checkpoints это "точки" в последовательности транзакций, при которых гарантируется, что файлы данных и индекса были обновлены и сохранена вся информация, записанная до этой контрольной точки. Во время контрольной точки все грязные страницы данных сбрасываются на диск, и в файл журнала записывается специальная запись контрольной точки. (Записи изменений ранее были сброшены в файлы WAL). В случае сбоя процедура восстановления после сбоя находит последнюю запись контрольной точки, чтобы определить точку в журнале (известную как запись REDO), с которой она должна начать REDO операции. Любые изменения, внесенные в файлы данных до этого момента, гарантированно будут уже на диске. Следовательно, после контрольной точки сегменты журнала, предшествующие тому, в котором содержится повторная запись, больше не нужны и могут быть использованы повторно или удалены. (Когда выполняется архивация WAL , сегменты журнала должны быть заархивированы перед тем, как их повторно используют или удалят).
Требование контрольной точки - сброс всех грязных страниц данных на диск может вызвать значительную нагрузку на подсистему ввода-вывода. По этой причине активность контрольной точки регулируется таким образом, что ввод-вывод начинался при запуске контрольной точки и завершался до начала следующей контрольной точки - это минимизирует снижение производительности во время контрольных точек.
Процесс контрольной точки сервера автоматически выполняет контрольную точку очень часто. Контрольная точка начинается каждые секунды checkpoint_timeout, или, если будет превышено значение max_wal_size , в зависимости от того, что наступит раньше. Настройки по умолчанию - 5 минут и 1 ГБ соответственно. Если с предыдущей контрольной точки не было записи в WAL, новые контрольные точки будут пропущены, даже если checkpoint_timeout прошла. (Если используется архивация WAL, и вы хотите установить более низкий предел частоты архивирования файлов, чтобы ограничить возможную потерю данных, вам следует настроить параметр archive_timeout, а не параметры контрольной точки). Также можно принудительно установить контрольную точку с помощью команды SQL CHECKPOINT.
Уменьшение checkpoint_timeout и / или max_wal_size приводит к тому, что контрольные точки возникают чаще. Это позволяет быстрее восстанавливаться после сбоя, так как потребуется меньше работы. Тем не менее, необходимо сбалансировать это с возросшей стоимостью очистки грязных страниц данных. Если задано full_page_writes (по умолчанию включено), необходимо учитывать еще один фактор. Чтобы обеспечить согласованность страницы данных, первая модификация страницы данных после каждой контрольной точки приводит к регистрации всего содержимого страницы. В этом случае меньший интервал контрольных точек увеличивает объем вывода в журнал WAL, частично сводя на нет цель использовать меньший интервал и в любом случае вызывая больший дисковый ввод-вывод.
Контрольные точки довольно дороги, во-первых, потому что они требуют записи всех текущих грязных буферов, а во-вторых, потому что они приводят к дополнительному последующему трафику WAL, как обсуждалось выше. Поэтому целесообразно устанавливать параметры контрольных точек достаточно высокими, чтобы контрольные точки не возникали слишком часто. В качестве простой проверки работоспособности параметров вашей контрольной точки вы можете установить параметр checkpoint_warning. Если контрольные точки расположены ближе друг к другу, чем секунды checkpoint_warning, в журнал сервера будет выведено сообщение с рекомендацией увеличить max_wal_size. Случайное появление такого сообщения не является причиной для тревоги, но если оно появляется часто, то параметры контроля контрольной точки должны быть увеличены. Массовые операции, такие как чтения больщих таблиц с помощью COPY могут вызвать появление ряда таких предупреждений, если вы не установили max_wal_size достаточно высоким.
Чтобы избежать переполнения системы ввода-вывода с помощью записи страниц, запись грязных буферов во время контрольной точки распределяется на некоторый период времени. Этот период контролируется checkpoint_completion_target, который задается как часть интервала контрольных точек. Скорость ввода-вывода регулируется таким образом, чтобы контрольная точка заканчивалась по истечении заданной доли секунды checkpoint_timeout или до превышения max_wal_size, в зависимости от того, что наступит раньше. При значении по умолчанию 0,5 QHB может завершить каждую контрольную точку примерно за половину времени до запуска следующей контрольной точки. В системе, которая очень близка к максимальной пропускной способности ввода-вывода при нормальной работе, вы можете увеличить checkpoint_completion_target чтобы уменьшить нагрузку ввода-вывода с контрольных точек. Недостатком этого является то, что продление контрольных точек влияет на время восстановления, поскольку необходимо будет хранить больше сегментов WAL для возможного использования для восстановления. Хотя checkpoint_completion_target может быть установлено до 1,0, лучше оставить его меньше этого значения (возможно, не более 0,9), поскольку контрольные точки включают в себя некоторые другие действия помимо записи грязных буферов. Значение 1.0 вполне может привести к тому, что контрольные точки не будут выполнены вовремя, что приведет к снижению производительности из-за неожиданного изменения количества необходимых сегментов WAL.
На платформах Linux и POSIX checkpoint_flush_after позволяет принудительно заставить ОС, сбрасывать страницы, записанные контрольной точкой, на диск после определённого количества байтов. В противном случае эти страницы могут храниться в кеше страниц ОС, вызывая остановку при вызове fsync в конце контрольной точки. Этот параметр часто помогает уменьшить задержку транзакции, но также может негативно повлиять на производительность - особенно для рабочих нагрузок, которые больше, чем shared_buffers, но меньше, чем кеш страниц ОС.
Количество файлов сегментов WAL в pg_wal зависит от min_wal_size , max_wal_size и количества WAL, сгенерированного в предыдущих циклах контрольных точек. Когда старые файлы сегментов журнала больше не нужны, они удаляются или повторно используются (то есть переименовываются, чтобы стать будущими сегментами в пронумерованной последовательности). Если из-за кратковременного пика скорости вывода журнала превышен max_wal_size, ненужные файлы сегментов будут удаляться, пока система не вернется к этому пределу. Ниже этого предела система повторно использует достаточно файлов WAL для покрытия предполагаемой потребности до следующей контрольной точки и удаляет остальные. Оценка основана на скользящей средней числа файлов WAL, использованных в предыдущих циклах контрольных точек. Скользящее среднее значение немедленно увеличивается, если фактическое использование превышает оценку, поэтому оно в некоторой степени учитывает пиковое использование, а не среднее использование. min_wal_size устанавливает минимальное количество файлов WAL для будущего использования - столько WAL всегда будет использовано повторно , даже если система простаивает и оценка использования WAL предполагает, что сегментов требуется мало.
Независимо от max_wal_size, wal_keep_segments + 1 самые последние файлы WAL хранятся всегда. Кроме того, если используется архивация WAL, старые сегменты не могут быть удалены или повторно использованы, пока они не будут заархивированы. Если архивация WAL не может идти одновременно со скоростью, с которой генерируется WAL, или если archive_command неоднократно завершается с ошибкой, старые файлы WAL будут накапливаться в pg_wal до тех пор, пока ситуация не разрешиться. Медленный или сбойный резервный сервер, который использует слот репликации, будет давать такой же эффект.
В режиме восстановления архива или в режиме ожидания сервер периодически выполняет точки перезапуска, которые аналогичны контрольным точкам в обычной работе: сервер переносит все свое состояние на диск, обновляет файл pg_control чтобы указать, что уже обработанные данные WAL не нужно снова сканировать, а затем переиспользует любые старые файлы сегментов журнала в каталоге pg_wal. Точки перезапуска не могут выполняться чаще, чем контрольные точки в мастере, потому что точки перезапуска могут выполняться только в записях контрольных точек. Точка перезапуска срабатывает при достижении записи контрольной точки, если прошло не менее checkpoint_timeout секунд с момента последней точки перезапуска или если размер WAL собирается превысить max_wal_size. Однако из-за ограничений на время, когда может быть выполнена точка перезапуска, max_wal_size часто превышается во время восстановления на величину WAL до одного контрольного пункта. ( max_wal_size никогда не бывает жестким ограничением, поэтому вы всегда должны оставлять достаточно места, чтобы избежать нехватки дискового пространства для файлов журнала).
Есть две обычно используемые внутренние функции WAL: XLogInsertRecord и XLogFlush. XLogInsertRecord используется для помещения новой записи в буферы WAL в разделяемой памяти. Если для новой записи нет места, XLogInsertRecord должен будет записать (переместить в кеш ядра ОС) несколько заполненных буферов WAL. Это нежелательно, поскольку XLogInsertRecord используется для каждой низкоуровневой модификации базы данных (например, вставка строки) в то время, когда на затронутых страницах данных удерживается монопольная блокировка, поэтому операция должна быть максимально быстрой. Что еще хуже, запись в буферы WAL также может привести к созданию нового сегмента журнала, что занимает еще больше времени. Обычно буферы WAL должны записываться и очищаться с помощью запроса XLogFlush, который, по большей части, выполняется во время фиксации транзакции, чтобы гарантировать, что записи транзакции сбрасываются в постоянное хранилище. В системах с высокой скоростью заполнения журнала запросы XLogFlush могут возникать недостаточно часто, чтобы запретить XLogInsertRecord выполнять записи. В таких системах следует увеличить количество буферов WAL, изменив параметр wal_buffers. Когда full_page_writes установлен и система сильно нагружена, установка wal_buffers выше поможет сгладить время отклика в течение периода, следующего сразу за каждой контрольной точкой.
Параметр commit_delay определяет, на сколько микросекунд процесс лидера групповой фиксации транзакции будет находиться в спящем режиме после получения блокировки в XLogFlush, пока последователи групповой фиксации стоят в очереди после лидера. Эта задержка позволяет другим процессам сервера добавлять свои записи фиксации в буферы WAL, чтобы все они были сброшены возможной синхронизирующей операцией лидера. Спящий режим не будет использоваться, если fsync не включен или если в текущий момент в активных транзакциях меньше, чем commit_siblings - это позволяет избежать ожидания в спящем режиме, когда маловероятно, что какой-либо другой сеанс совершится в ближайшее время. Обратите внимание, что на некоторых платформах разрешение неактивного запроса составляет десять миллисекунд, поэтому любой ненулевой параметр commit_delay от 1 до 10000 микросекунд будет иметь тот же эффект. Также обратите внимание, что на некоторых платформах операции сна могут занимать немного больше времени, чем запрошено параметром.
Поскольку цель commit_delay состоит в том, чтобы позволить амортизировать стоимость каждой операции обращения к диску для одновременной фиксации транзакций (возможно, за счет задержки транзакции), необходимо количественно оценить эту стоимость, прежде чем параметр можно будет выбрать с достаточной точностью. Чем выше эта стоимость, тем эффективнее будет ожидаемая commit_delay для увеличения пропускной способности транзакций до определенного уровня. Значение, составляющее половину среднего времени, операции записи 8 КБ, часто является наиболее эффективным параметром для commit_delay , поэтому это значение рекомендуется в качестве отправной точки для использования при оптимизации для конкретной рабочей нагрузки. Хотя настройка commit_delay особенно полезна, когда журнал WAL хранится на механических вращающихся дисках с высокой задержкой, преимущества могут быть значительными даже для носителей с очень быстрым временем синхронизации, таких как твердотельные накопители или массивы RAID с кэш-памятью с резервным питанием от аккумулятора, но это, безусловно, должно быть проверено на репрезентативной нагрузке. В таких случаях следует использовать более высокие значения commit_siblings, тогда как меньшие значения commit_siblings часто полезны на носителях с более высокой задержкой. Обратите внимание, что вполне возможно, что слишком высокая установка commit_delay может значительно увеличить задержку фиксации транзакции, в связи с чем пострадает общая пропускная способность.
Когда commit_delay установлен в ноль (по умолчанию), все еще возможно, групповая фиксации, но каждая группа будет состоять только из сессий, которые достигают точки, где они должны сбрасывать свои записи фиксации во время окна, в котором выполняется предыдущая операция сохранения (если она была). При большем количестве клиентов, как правило, возникает «давка» между сеансами, так что эффекты групповой фиксации становятся значительными, даже когда commit_delay равен нулю, и, таким образом, явная установка commit_delay оказывает меньще влияния на производительность. Установка commit_delay может помочь, только когда
- есть некоторые одновременно завершающиеся транзакции
- пропускная способность системы ввода-вывода ограничена до некоторой степени скоростью фиксации транзакции, но с высокой задержкой для механических устройств хранения этот параметр может быть эффективен для увеличения пропускной способности транзакций даже всего с двумя клиентами (то есть одним фиксирующим транзакуию клиентом с одной дочерней транзакцией).
Параметр wal_sync_method определяет, как QHB будет запрашивать ядро ОС для принудительного обновления WAL на диск. Все параметры должны быть одинаковыми с точки зрения надежности, за исключением fsync_writethrough, который иногда может вызвать очистку дискового кэша, даже если другие параметры этого не делают это зависит от платформы, на которой работает QHB. Обратите внимание, что этот параметр не имеет значения, если fsync отключен.
WAL детали реализации
WAL включается автоматически; никаких действий со стороны администратора не требуется, за исключением обеспечения соблюдения требований к дисковому пространству для журналов WAL и выполнения необходимой настройки (см. раздел Конфигурация WAL).
Записи WAL добавляются в журналы WAL по мере возникновения каждой новой записи. Позиция вставки описывается порядковым номером журнала (LSN), который представляет собой байтовое смещение в журналах, монотонно увеличивающееся с каждой новой записью. Значения LSN имеют тип данных pg_lsn. Значения можно сравнивать для расчета объема данных WAL, которые их разделяют, поэтому они используются для измерения объёмов и процесса репликации и восстановления.
Журналы WAL хранятся на диске в каталоге pg_wal в виде набора файлов сегментов, обычно каждый размером 16 МБ (но размер можно изменить, изменив параметр --wal-segsize qhb_bootstrap). Каждый сегмент делится на страницы, обычно по 8 кБ каждая (этот размер можно изменить с помощью параметра конфигурации --with-wal-blocksize). Cодержание записи зависит от типа регистрируемого события. Сегментным файлам присваиваются постоянно растущие числа в качестве имен, начиная с 000000010000000000000000. Числа не переносятся при переполнении, но потребуется очень и очень много времени, чтобы исчерпать доступный запас чисел.
Бывает выгодно для производительности, когда журнал расположен на диске, отличном от основных файлов базы данных. Это может быть достигнуто путем перемещения каталога pg_wal в другое место (конечно, когда сервер выключен) и создания символической ссылки из исходного местоположения в главном каталоге данных на новое местоположение.
Задача QHB - обеспечить, запись журнала до записей изменения в файлах базы данных, но это может быть нарушено драйверами устройств хранения которые ложно сообщают об успешной записи, когда на самом деле они только кэшировали данные в ядре ОС и еще не сохранили их на диске. Сбой питания в такой ситуации может привести к неисправимому повреждению данных. Администраторы должны убедиться, что диски, содержащие файлы журнала WAL QHB, не создают таких ситуаций. (См. раздел Надежность).
После создания контрольной точки журнала ее позиция сохраняется в файле pg_control. Поэтому в начале восстановления сервер сначала читает pg_control а затем запись контрольной точки, затем он выполняет операцию REDO путем сканирования вперед по файлу из местоположения журнала, указанного в записи контрольной точки. Поскольку всё содержимое всех изменений страниц данных, сохраняется в журнале после контрольной точки (при условии, что full_page_writes не отключен) все изменения после контрольной точки будут восстановлены в согласованном состоянии.
Чтобы справиться со случаем, когда pg_control поврежден, мы должны поддерживать возможность сканирования существующих сегментов журнала в обратном порядке - от самого нового к старому - чтобы найти последнюю контрольную точку. Это еще не реализовано. pg_control достаточно мал (менее одной страницы диска), чтобы не создавать проблем с частичной записью, и на момент написания этой статьи не было сообщений о сбоях базы данных только из-за невозможности чтения самого pg_control. Таким образом, хотя теоретически это слабое место, кажется pg_control не является проблемой на практике.
Процедурные языки
QHB позволяет писать пользовательские функции на других языках, кроме SQL и C/RUST. Эти другие языки обычно называются процедурными языкам (PL). Для функции, написанной на процедурном языке, сервер базы данных не имеет встроенных методов, для интерпретации исходного текста функции. Вместо этого задача передается специальному обработчику, который обрабатывает детали языка. Обработчик может либо выполнять всю работу по синтаксическому анализу, синтаксическому анализу, выполнению и т. д., Либо он может служить «связующим звеном» между QHB и существующей реализацией языка программирования. Сам обработчик является функцией языка C/RUST, скомпилированной в общий объект и загружается по требованию, как и любая другая функция C/RUST.
В настоящее время в стандартном выпуске QHB доступен язык: PL/pgSQL (глава PL/pgSQL), другие языки могут быть созданы пользователями самостоятельно.
Установка процедурных языков
Процедурный язык должен быть «установлен» в каждой базе данных, где он будет использоваться. Процедурные языки, установленные в базе данных template1, автоматически доступны во всех впоследствии созданных базах данных, так как их записи в template1 будут скопированы командой CREATE DATABASE. Таким образом, администратор базы данных может решить, какие языки доступны в каких базах данных, и при желании может сделать некоторые языки доступными по умолчанию.
Для языков, поставляемых со стандартным дистрибутивом, необходимо только
выполнить CREATE EXTENSION language_name чтобы установить язык в
текущей базе данных. Описанная ниже ручная процедура рекомендуется
только для установки языков, которые не были упакованы как расширения.
Ручная процедура установки процедурных языков
Процедурный язык устанавливается в базе данных в пять этапов, которые должны выполняться суперпользователем базы данных. В большинстве случаев требуемые команды SQL должны быть упакованы как установочный скрипт «расширения», чтобы их можно было использовать для CREATE EXTENSION.
-
Общий объект для языкового обработчика (динамически подключаемая библиотека) должен быть скомпилирован и установлен в соответствующий каталог библиотеки, так же, как сборка и установка модулей с обычными пользовательскими функциями C\RUST - см. раздел Компиляция и связывание динамически загружаемых функций. Часто обработчик языка зависит от внешней библиотеки, которая обеспечивает реальный движок языка программирования - в этом случае он также должен быть установлен.
-
Обработчик должен быть создан командой
CREATE FUNCTION handler_function_name()
RETURNS language_handler
AS 'path-to-shared-object'
LANGUAGE C;
Специальный возвращаемый тип language_handler сообщает системе баз данных, что эта функция не возвращает ни один из определенных типов данных SQL и не может напрямую использоваться в инструкциях SQL .
- При желании обработчик языка может предоставлять встроенную функцию обработчика, предназначенную для выполнения блоков анонимного кода (команды DO), написанных на этом языке. Если встроенная функция обработчика предоставляется языком, необходимо объявить ее командой
CREATE FUNCTION inline_function_name(internal)
RETURNS void
AS 'path-to-shared-object'
LANGUAGE C;
- При желании обработчик языка может предоставить функцию «валидатора», которая проверяет правильность определения функции, фактически не выполняя ее. Функция валидатора,если она существует, вызывается командой CREATE FUNCTION. Если язык предоставляет функцию валидатора, необходимо объявить ее командой
CREATE FUNCTION validator_function_name(oid)
RETURNS void
AS 'path-to-shared-object'
LANGUAGE C STRICT;
- Наконец, сам процедурный язык, должен быть объявлен с командой
CREATE [TRUSTED] LANGUAGE language_name
HANDLER handler_function_name
[INLINE inline_function_name]
[VALIDATOR validator_function_name] ;
Необязательное ключевое слово TRUSTED указывает, что язык не предоставляет доступ к данным,к которым в противном случае, у пользователя нет доступа. Доверенные языки предназначены для обычных пользователей баз данных (без привилегий суперпользователя) и позволяют им безопасно создавать функции и процедуры. Поскольку функции процедурного языка выполняются внутри сервера базы данных, флаг TRUSTED следует указывать только для языков, которые не разрешают доступ к внутренним компонентам сервера базы данных или файловой системе. Язык PL/pgSQL считается доверенным.
При установке QHB по умолчанию обработчик для языка PL/pgSQL создается и устанавливается в каталог «library». Более того, сам язык PL/pgSQL установлен во всех базах данных.
Клиентские приложения QHB
Эта часть содержит справочную информацию для клиентских приложениях и утилитах QHB. Некоторые приложения могут требовать особых привилегий. Общей особенностью этих приложений является то, что они могут быть запущены на любом хосте, независимо от того, где находится сервер базы данных.
При указании в командной строке имени пользователя и базы данных, они передаются без изменения регистра - все пробелы или специальные символы требуется заключать в кавычки. Имена таблиц и другие идентификаторы не зависят от регистра, за исключением случаев, когда это отдельно задокументировано и может потребоваться заключение в кавычки.
- clusterdb - кластеризация базы данных QHB
- createdb - создать новую базу данных QHB
- createuser - определить новую учетную запись пользователя QHB
- dropdb - удалить базу данных QHB
- dropuser - удалить учетную запись пользователя QHB
- vacuumdb сбор мусора и анализ базы данных QHB
- qhb_basebackup - сделать базовую резервную копию кластера QHB
- reindexdb - переиндексировать базу данных QHB
- qhb_config - получить информацию об установленной версии QHB
- qhb_dump - извлекает базу данных QHB в файл сценария или другой архив
- qhb_dumpall - извлекает кластер базы данных QHB в файл сценария
- qhb_isready - проверить состояние соединения с сервером QHB
- qhb_receivewal - потоковые журналы записи с сервера QHB
- qhb_recvlogical - управление потоками логического декодирования QHB
- qhb_restore - восстанавливает базу данных QHB из файла архива, созданного qhb_dump
- qsql - QHB интерактивный терминал
clusterdb - кластеризация базы данных QHB
clusterdb - кластеризация базы данных QHB
Синтаксис
clusterdb [connection-option...] [ --verbose | -v ] [ --table | -t table ] ... [dbname]
clusterdb [connection-option...] [ --verbose | -v ] --all | -a
Описание
clusterdb - это утилита для перекластеризации таблиц в базе данных QHB. Она находит таблицы, которые ранее были кластеризованы, и снова группирует их по тому же индексу, который использовался в последний раз. Таблицы, которые никогда не группировались, не затрагиваются.
clusterdb - это "обёртка" над SQL командой CLUSTER. Нет разницы между кластеризацией баз данных с помощью этой утилиты или же иным способом при обращении к серверу.
Параметры
clusterdb принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
-a, --all | Кластеризация всех баз данных |
[-d] dbname, [--dbname=]dbname | Определяет имя базы данных для кластеризации. Если не указывать и не использовать параметр -a (или --all), имя базы данных считывается из переменной окружения PGDATABASE. Если не установлена переменная окружения, используется имя пользователя, указанное в параметрах подключения |
-e, --echo | Выводить команды, которые clusterdb генерирует и отправляет на сервер. |
-q, --quiet | Не отображать сообщения о прогрессе выполнения |
-t table, --table=table | Кластеризовать конкретную таблицу. Несколько таблиц можно кластеризовать, написав несколько ключей -t |
-v, --verbose | Показать подробную информацию во время процесса |
-V, --version | Показать версию clusterdb и выйти |
-?, --help | Показать справку об аргументах командной строки clusterdb и выйти |
clusterdb также принимает следующие аргументы командной строки для параметров подключения:
| Аргумент | Описание |
|---|---|
-h host, --host=host | Указывает имя или адрес компьютера, на котором работает сервер. Если значение начинается с косой черты, то оно используется в качестве каталога для Unix-сокета |
-p port, --port=port | Указывает порт TCP или расширение файла локального Unix-сокета, на котором сервер прослушивает соединения |
-U username, --username=username | Имя пользователя |
-w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
-W, --password | Эта опция не является существенной, так как clusterdb автоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее, clusterdb потратит одну дополнительную попытку подключения для аутентификации. В некоторых случаях стоит ввести -W, чтобы не делать эту попытку. |
--maintenance-db=dbname | Задает имя базы данных для подключения, чтобы определить какие другие базы данных должны быть кластеризованы. Если не указано иное, будет использоваться база данных qhb, а если она не существует, будет использоваться template1 |
Окружение
PGDATABASE
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never .
Эта утилита, как и большинство других утилит QHB, также использует переменные окружения, поддерживаемые libpq .
Диагностика
В случае затруднений см. CLUSTER и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, при запуске утилиты, будут применяться параметры подключения и переменные окружения, которые используются библиотекой libpq.
Примеры
Чтобы кластеризовать базу данных test:
$ clusterdb test
Чтобы кластеризировать отдельную таблицу foo в базе данных xyzzy:
$ clusterdb --table=foo xyzzy
См. также
createdb - создать новую базу данных QHB
createdb - утилита, позволяющая создать новую базу данных.
Синтаксис
createdb [FLAGS] [OPTIONS] --host <host> [ARGS]
Описание
createdb - это "обёртка" надо SQL командой CREATE DATABASE. Нет разницы между созданием базы данных с помощью этой утилиты или же иным способом при обращении к серверу.
Если имя БД не указано, то используется имя пользователя, от которого выполняется программа, аналогичный алгоритм с владельцем БД.
Если БД невозможно создать, то программа выведет сообщение об ошибке, иногда предлагая решение проблемы.
Обычно пользователь базы данных, который выполняет эту команду,
становится владельцем новой базы данных. Однако другой владелец может
быть указан с помощью опции -O, если исполняющий пользователь имеет
соответствующие привилегии.
Параметры
createdb принимает следующие аргументы командной строки:
FLAGS:
| Аргумент | Описание |
|---|---|
| --help | Показать справку об аргументах командной строки и выйти |
| -w, --no-password | Никогда не запрашивать ввод пароля |
| -W, --password | Принудительно запрашивать пароль |
| -V, --version | Распечатать версию createdb и выйти |
| -v, --verbose | Устанавливает уровень ведения журнала в Debug [default: Info] |
OPTIONS:
| Аргумент | Описание |
|---|---|
| -E, --encoding <encoding> | Определяет схему кодировки символов, которая будет использоваться в этой базе данных |
| -h, --host <host> | Указывает имя хоста или директорию сокета, на котором работает сервер [env: PGHOST=] |
| --lc-collate <lc-collate> | Задает параметр LC_COLLATE, который будет использоваться в этой базе данных. |
| --lc-ctype <lc-ctype> | Задает параметр LC_CTYPE, который будет использоваться в этой базе данных. |
| -l, --locale <locale> | Определяет язык, который будет использоваться в этой базе данных. |
| --maintenance-db <m-dbname> | Задает имя базы данных, к которой необходимо подключиться при создании новой базы данных. |
| -O, --owner <owner> | Указывает пользователя базы данных, которому будет принадлежать новая база данных |
| -p, --port <port> | Указывает порт TCP или расширение файла локального сокета домена Unix, на котором сервер прослушивает соединения. [default: 5432] |
| -D, --tablespace <tablespace> | Задает табличное пространство по умолчанию для базы данных. |
| -T, --template <template> | Определяет базу данных шаблонов, из которой можно построить эту базу данных. |
| -U, --username <username> | Имя пользователя для подключения. |
ARGS:
| Аргумент | Описание |
|---|---|
| dbname | Определяет имя базы данных, которая будет создана. Имя должно быть уникальным среди всех баз данных QHB в этом кластере. По умолчанию создается база данных с тем же именем, что и текущий системный пользователь. [env: PGDATABASE=] |
| comment | Ввод комментария для базы данных. |
Параметры -D, -l, -E, -O и -T соответствуют параметрам базовой
команды SQL CREATE DATABASE; ознакомьтесь с соответствующим разделом документации
для получения дополнительной информации.
Переменные Окружение
PGDATABASE
- Если установлено, имя базы данных для создания, если не переопределено в командной строке.
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию. PGUSER также определяет имя базы данных для создания, если оно не указано в командной строке или PGDATABASE.
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never.
Диагностика
В случае затруднений см. CREATE DATABASE и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте.
Примеры
Сценарии использования
$ createdb new
- создаёт новую базу данных с именем "new"
$ createdb
- создаёт новую базу данных с именем пользователя, от которого запущена программа
$ createdb new -l en_US.UTF-8 -T template0 --maintenance-db qhb
- создаёт новую базу данных с именем "new", с локалью en_US.UTF-8, беря за основу базу template0, подключаясь к обслуживающей базе qhb`
$ createdb new "my comment" -l en_US -E LATIN1 -T template0 -v
- создаёт новую базу данных с именем "new", настройками LC_COLLATE и LC_CTYPE - en_us,
кодировкой LATIN1, беря за основу базу template0.
После создания на базу накладывается комментарий "my comment".
Флаг -v обеспечивает вывод отладочной информации:[DEBUG] Running getpwuid_r for user #1000 [DEBUG] Loading user with uid 1000 [DEBUG] executing statement batch: SELECT pg_catalog.set_config('search_path', '', false); [DEBUG] executing statement batch: CREATE DATABASE new2 ENCODING 'LATIN1' TEMPLATE template0 LC_COLLATE 'en_US' LC_CTYPE 'en_US'; [DEBUG] executing statement batch: COMMENT ON DATABASE new2 IS 'my comment'; [DEBUG] Database has been successfully created
Особенности использования
createdb new -l en_US.UTF-8 -T template0
и
createdb new -l en_US -E UTF-8 -T template0
- не одно и то же. В первом случае БД успешно создастся, во втором варианте будет выведена ошибка.
[ERROR] db error: ERROR: encoding "UTF8" does not match locale "en_US": SQL: "CREATE DATABASE new3 ENCODING 'UTF-8' TEMPLATE template0 LC_COLLATE 'en_US' LC_CTYPE 'en_US';"
DETAIL: The chosen LC_CTYPE setting requires encoding "LATIN1".
-
Невозможно указать комментарий к базе данных, не указав её имя.
-
Флаг
-l, --localeобъединяет в себе--lc-collateи--lc-ctype- вместе их указать нельзя. Пример:
createdb new -l en_US = CREATE DATABASE new LC_COLLATE 'en_US' LC_CTYPE 'en_US';
createdb new4 --lc-collate en_US --lc-ctype en_US - ошибка
- По умолчанию утилита пытается использовать
template1как обсуживающую БД (maintenance-db), если подключится к ней не выходит, то используется БДqhb.
-v, --verbose
- помимо отладочной информации исполняет роль
ECHO, выводя SQL-команды, отправленные на сервер для исполнения
Смотрите Также
createuser
createuser - определить новую учетную запись пользователя QHB
Синтаксис
createuser [connection-option...] [option...] [ROLENAME]
Описание
createuser создает нового пользователя QHB (или, точнее, роль).
Только суперпользователи и пользователи с привилегией CREATEROLE могут
создавать новых пользователей, поэтому createuser должен вызывать тот,
кто может подключиться как суперпользователь или пользователь с привилегией CREATEROLE .
Если вы хотите создать нового суперпользователя, вы должны подключиться как уже существующий суперпользователь, а не просто с привилегией CREATEROLE. Быть суперпользователем подразумевает возможность обходить все проверки прав доступа в базе данных, поэтому права суперпользователя не следует предоставлять легкомысленно.
createuser - это "обертка" над SQL командой CREATE ROLE. Нет
разницы между созданием пользователей с помощью этой утилиты или же иным способом при обращении к серверу. Подробнее про атрибуты ролей описано в ROLE ATTRIBUTES.
Параметры
createuser принимает следующие аргументы командной строки:
FLAGS:
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти |
| -V, --version | Распечатать версию createuser и выйти |
| -e, --echo | Выводит на экран команды, которые createuser генерирует и отправляет на сервер. |
CONNECTION OPTIONS:
| Аргумент | Описание |
|---|---|
| -h, --host=HOSTNAME | Указывает имя хоста компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. |
| -p, --port=PORT | Указывает порт TCP или расширение файла локального сокета домена Unix, на котором сервер прослушивает соединения. |
| -U, --username=USERNAME | Имя пользователя для подключения (не имя пользователя роли которое будет создано) |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | Эта опция не является существенной, так как createuser автоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее, createuser будет тратить попытки подключения, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
OPTIONS:
| Аргумент | Описание |
|---|---|
| -c, --connection-limit=N | Устанавливает максимальное количество подключений для нового пользователя. По умолчанию установлено без ограничений. |
| -d, --createdb | Новому пользователю будет разрешено создавать базы данных. |
| -D, --no-createdb | Новому пользователю не будет разрешено создавать базы данных. Это поведение используется по умолчанию. |
| -g, --role=ROLE | Указывает роль, к которой эта роль будет немедленно добавлена в качестве нового участника. Несколько ролей, можно указать, указав несколько ключей -g . |
| -i, --inherit | Новая роль автоматически наследует привилегии ролей, членом которых она является. Это поведение используется по умолчанию. |
| -I, --no-inherit | Новая роль не будет автоматически наследовать привилегии ролей, членом которых она является. |
| -l, --login | Новому пользователю будет разрешено войти в систему (то есть имя пользователя может использоваться в качестве начального идентификатора пользователя сеанса). Это по умолчанию. |
| -L, --no-login | Новому пользователю не будет разрешено войти в систему. (Роль без привилегий входа по-прежнему полезна в качестве средства управления разрешениями базы данных.) |
| -P, --pwprompt | Если указано, createuser выдаст запрос на ввод пароля нового пользователя. В этом нет необходимости, если вы не планируете использовать аутентификацию по паролю. |
| -r, --createrole | Новому пользователю будет разрешено создавать новые роли (то есть этот пользователь будет иметь привилегию CREATEROLE |
| -R, --no-createrole | Новый пользователь не сможет создавать новые роли. Это поведение используется по умолчанию. |
| -s, --superuser | Новый пользователь будет суперпользователем. |
| -S, --no-superuser | Новый пользователь не будет суперпользователем. Это поведение используется по умолчанию. |
| --interactive | Запрашивать имя пользователя, если оно не указано в командной строке, а также запрашивать, параметров -d / -D, -r / -R, -s / -S если не указаны в командной строке. |
| --replication | Новый пользователь будет иметь привилегию REPLICATION, которая более подробно описана в документации по CREATE ROLE. |
| --no-replication | У нового пользователя не будет привилегии REPLICATION. |
ARGS:
| Аргумент | Описание |
|---|---|
| ROLENAME | Определяет имя пользователя QHB, который будет создан. Это имя должно отличаться от всех существующих ролей в этой установке QHB. |
Окружение
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never .
Диагностика
В случае затруднений см. CREATE ROLE и qsql для ознакомления потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, будут применяться любые параметры подключения по умолчанию и переменные среды.
Примеры
Создание пользователя joe на сервере базы данных по умолчанию:
$ createuser joe
Создание пользователя joe на сервере базы данных по умолчанию с запросом дополнительных атрибутов:
$ createuser --interactive joe
Shall the new role be a superuser? (y/n) n
Shall the new role be allowed to create databases? (y/n) n
Shall the new role be allowed to create more new roles? (y/n) n
Чтобы создать того же пользователя joe используя сервер на хосте eden , порт 5000, с явно заданными атрибутами, взглянем на базовую команду:
$ createuser -h eden -p 5000 -S -D -R -e joe
CREATE ROLE joe NOSUPERUSER NOCREATEDB NOCREATEROLE INHERIT LOGIN;
Создание пользователя joe в качестве суперпользователя и сразу назначить пароль:
$ createuser -P -s -e joe
Enter password for new role: xyzzy
Enter it again: xyzzy
CREATE ROLE joe PASSWORD 'md5b5f5ba1a423792b526f799ae4eb3d59e' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;
В приведенном выше примере новый пароль фактически не отображается при вводе, но мы показываем, что было введено для ясности. Как видите, пароль зашифрован перед отправкой клиенту.
Смотрите также
dropuser, CREATE ROLE, ROLE ATTRIBUTES
dropdb - удалить базу данных QHB
dropdb - утилита, позволяющая удалить ранее созданную базу данных.
Синтаксис
dropdb [FLAGS] [OPTIONS] <dbname> --host <host>
Описание
dropdb - это "обертка" над SQL командой DROP DATABASE. Нет разницы между удалением баз данных с помощью этой утилиты или же иным способом при обращении к серверу. Пользователь, который выполняет эту команду, должен быть суперпользователем или владельцем базы данных. Также для сохранения подключения необходимо подключиться к обслуживающей БД (maintenance-db), так как удалить БД, к которой подключён - нельзя, также нельзя удалить базу template1 и/или template0.
Параметры
dropdb принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
dbname | Имя удаляемой базы данных |
-e, --echo | Выводить команды, которые dropdb генерирует и отправляет на сервер |
-i, --interactive | Запросить подтверждение перед удалением |
-V, --version | Показать версию dropdb и выйти |
--if-exists | Не выдавать ошибку, если базы данных не существует. В этом случае выдается уведомление |
-?, --help | Показать справку об аргументах командной строки dropdb и выйти |
dropdb также принимает следующие параметры командной строки для параметров подключения:
| Аргумент | Описание |
|---|---|
-h host, --host=host | Указывает имя или адрес компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для Unix-сокета |
-p port, --port=port | Указывает порт TCP или расширение файла локального Unix-сокета, на котором сервер прослушивает соединения |
-U username, --username=username | Имя пользователя |
-w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля |
-W, --password | Эта опция не является существенной, так как dropdb автоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее, dropdb потратит одну дополнительную попытку подключения для аутентификации. В некоторых случаях стоит ввести -W, чтобы не делать эту попытку |
--maintenance-db=dbname | Задает имя базы данных, к которой нужно подключиться, чтобы удалить целевую базу данных. Если не указано иное, будет использоваться база данных qhb, а если и её не существует, то будет использоваться template1 |
Окружение
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never.
Диагностика
В случае затруднений см. DROP DATABASE и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, при запуске утилиты, будут применяться параметры подключения и переменные окружения, которые используются библиотекой libpq.
Примеры
Удаление базы new_db. Информацию о подключении берётся из окружения:
$ dropdb new_db
Удаление базы new_db с указанием параметров соединения в интерактивном режиме
$ dropdb -h localhost -p 5432 -i new_db
Database "new_db" will be permanently removed.
Are you sure? (Y/n):
Смотрите также
dropuser - удалить учетную запись пользователя QHB
dropuser - удалить учетную запись пользователя QHB
Синтаксис
dropuser [connection-option...] [option...] [username]
Описание
dropuser удаляет существующего пользователя QHB. Только
суперпользователи и пользователи с привилегией CREATEROLE могут удалять
пользователей QHB. Чтобы удалить суперпользователя, вы должны
быть самим суперпользователем.
dropuser - это "обертка" над SQL командой DROP ROLE. Нет
разницы между удалением пользователей с помощью этой утилиты или же иным способом при обращении к серверу
Параметры
dropuser принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
username | Указывает имя удаляемого пользователя QHB. Вам будет предложено ввести имя, если оно не указано в командной строке и используется параметр -i / --interactive |
-e, --echo | Выводить команды, которые dropuser генерирует и отправляет на сервер |
-i, --interactive | Запросить подтверждение перед удалением пользователя и запрашивать его, если оно не было указано в командной строке |
-V, --version | Показать версию dropuser и выйти |
--if-exists | Не выдавать ошибку, если пользователя не существует. В этом случае выдается уведомление |
-?, --help | Показать справку об аргументах командной строки dropuser и выйти |
dropuser также принимает следующие параметры командной строки для
параметров подключения:
| Аргумент | Описание |
|---|---|
-h host, --host=host | Указывает имя или адрес компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для Unix-сокета |
-p port, --port=port | Указывает порт TCP или расширение файла локального Unix-сокета, на котором сервер прослушивает соединения |
-U username, --username=username | Имя пользователя для подключения. (А не удаляемого пользователя) |
-w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля |
-W, --password | Эта опция не является существенной, так как dropuser автоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее, dropuser потратит одну дополнительную попытку подключения для аутентификации. В некоторых случаях стоит ввести -W, чтобы не делать эту попытку |
Окружение
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never.
Эта утилита, как и большинство других утилит QHB, также использует переменные среды, поддерживаемые libpq.
Диагностика
В случае затруднений см. DROP ROLE и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, при запуске утилиты, будут применяться параметры подключения и переменные окружения, которые используются библиотекой libpq.
Примеры
Чтобы удалить пользователя alex с сервера базы данных по умолчанию:
$ dropuser alex
Чтобы удалить пользователя alex используя сервер на хосте eden, порт
5000, с проверкой и просмотром основной команды:
$ dropuser -p 5000 -h eden -i -e alex
Role "alex" will be permanently removed.
Are you sure? (y/n) y
DROP ROLE alex;
Смотрите также
vacuumdb сборка мусора и анализ базы данных QHB
vacuumdb - сборка мусора и анализ базы данных QHB
Синтаксис
vacuumdb [connection-option...] [option...] [ --table | -t table [( column [,...] )] ] ... [dbname]
vacuumdb [connection-option...] [option...] --all | -a
Описание
vacuumdb утилита для очистки базы данных QHB. vacuumdb также
генерирует внутреннюю статистику, используемую оптимизатором запросов
QHB.
ⓘ
vacuumdb- это "обертка" над SQL командой VACUUM. Нет разницы между очисткой и анализом баз данных с помощью этой утилиты или же иным способом при обращении к серверу
Параметры
vacuumdb принимает следующие аргументы командной строки:
-
-a
--allОбрабатывать все базы данных.
-
[-d]dbname
[--dbname=]dbnameУказывает имя базы данных, которая будет очищена или проанализирована. Если не указывать и не использовать параметр
-a(или--all), имя базы данных считывается из переменной окружения PGDATABASE. Если не установлена переменная окружения, используется имя пользователя, указанное в параметрах подключения. -
--disable-page-skippingОтключить пропуск страниц на основе содержимого карты видимости.
-
-e
--echoВыводить команды, которые
vacuumdbгенерирует и отправляет на сервер. -
-f
--fullВыполнить «полную» очистку.
-
-F
--freezeАгрессивно «замораживать» кортежи.
-
-jnjobs
--jobs=njobsВыполняет вакуум или анализ параллельно, запуская несколько (в количестве njobs) команд одновременно. Этот параметр сокращает время обработки, но также увеличивает нагрузку на сервер базы данных.
vacuumdbоткрывает njobs соединений с базой данных, поэтому убедитесь, что параметрmax_connectionsдостаточно высок, чтобы принять все соединения.Обратите внимание, что использование этого режима вместе с параметром
-f(FULL) может привести к сбоям из-за взаимоблокировки, если определенные системные каталоги обрабатываются параллельно. -
--min-mxid-age mxid_ageВыполняет вакуум или анализ только для таблиц с возрастом идентификатора мультитранзакции не менее
mxid_age. Этот параметр полезен для определения приоритетности таблиц для обработки, чтобы предотвратить зацикливание при обходе идентификатора мультитранзакции. (см. раздел Мультитранзакции и зацикливание).Для этого параметра возраст идентификатора мультитранзакции для отношения является наибольшим из возрастов основного отношения и связанной с ним таблицы TOAST, если такая существует. Так как команды, выполняемые
vacuumdbтакже будут при необходимости обрабатывать таблицу TOAST для отношений, их возрасты не нужно рассматривать по отдельности. -
--min-xid-age xid_ageВыполняет вакуум или анализ только для таблиц с возрастом идентификатора транзакции не менее
xid_age. Этот параметр полезен для определения приоритетности таблиц для обработки, чтобы предотвратить зацикливание идентификатора транзакции (см. раздел Предотвращение ошибок зацикливания идентификатора транзакции).Для этого параметра возраст идентификатора транзакции для отношения является наибольшим из возрастов основного отношения и связанной с ним таблицы TOAST, если такая существует. Поскольку команды, выполняемые
vacuumdb, также при необходимости будут обрабатывать таблицу TOAST для отношений, их возрасты не нужно рассматривать по отдельности. -
-q
--quietНе отображать сообщения о прогрессе выполнения.
-
--skip-lockedПропускать отношения, которые неудаётся немедленно заблокировать для обработки.
-
-ttable[ (column[,...]) ]
--table=table[ (column[,...]) ]Очистить или проанализировать конкретные таблицы. Имена столбцов могут быть указаны только вместе с
--analyzeили--analyze-only. Несколько таблиц можно очищать, написав несколько параметров-t.
Заметка
Если вы укажете столбцы, вам, вероятно, придется экранировать скобки в коносли. (См. Примеры ниже.)
-
-v
--verboseПоказать подробную информацию во время процесса.
-
-V
--versionПоказать версию
vacuumdbи выйти. -
-z
--analyzeРассчитать статистику для оптимизатора.
-
-Z
--analyze-onlyРассчитать статистику для оптимизатора (без вакуума).
-
--analyze-in-stagesРассчитать статистику для оптимизатора (без вакуума), наподобие
--analyze-only. Чтобы быстрее получить полезную статистику, выполняется в несколько этапов (в настоящее время в три этапа) с различными настройками конфигурации.Этот параметр полезен для анализа базы данных, которая была заполнена путем восстановлением из дампа или с помощью утилиты
qhb_upgrade. С нимvacuumdbпопытается собрать некоторую статистику как можно быстрее, чтобы как можно скорее сделать базу данных пригодной для использования. А затем, рассчитать полную статистику на последующих этапах. -
-?
--helpПоказать справку об аргументах командной строки
vacuumdbи выйти.
vacuumdb также принимает следующие аргументы командной строки для
параметров подключения:
-
-hhost
--host=hostУказывает имя или адрес компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для Unix-сокета.
-
-pport
--port=portУказывает порт TCP или расширение файла локального Unix-сокета, на котором сервер прослушивает соединения.
-
-Uusername
--username=usernameИмя пользователя для подключения как.
-
-w
--no-passwordНе запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля.
-
-W
--passwordЭта опция не является существенной, так как
vacuumdbавтоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее,vacuumdbпотратит одну дополнительную попытку подключения для аутентификации. В некоторых случаях стоит ввести-W, чтобы не делать эту попытку. -
--maintenance-db=dbnameЗадает имя базы данных для подключения, чтобы определить какие другие базы данных должны быть очищены или проанализированны. Если не указано иное, будет использоваться база данных QHB, а если и её не существует, то будет использоваться
template1.
Окружение
PGDATABASE
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never.
Эта утилита, как и большинство других утилит QHB, также использует переменные среды, поддерживаемые libpq.
Диагностика
В случае затруднений см. VACUUM и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, будут применяться любые параметры подключения по умолчанию и переменные среды, используемые интерфейсной библиотекой libpq.
Примечания
vacuumdb может потребоваться несколько раз подключиться к серверу QHB, каждый раз запрашивая пароль. В таких случаях удобно иметь файл ~/.pgpass.
Примеры
Очистка базы данных test:
$ vacuumdb test
Очистка и анализ для оптимизатора базы данных с именем bigdb:
$ vacuumdb --analyze bigdb
Чтобы очистить одну таблицу foo в базе данных с именем xyzzy и
проанализировать один столбец таблицы для оптимизатора:
$ vacuumdb --analyze --verbose --table='foo(bar)' xyzzy
Смотрите Также
qhb_basebackup - резервное копирование кластера QHB
qhb_basebackup - создать резервную копию кластера QHB
Синтаксис
qhb_basebackup [option...]
Описание
qhb_basebackup используется для создания резервных копий работающего кластера баз данных QHB. Резервное копирование производится без влияния на другие клиенты базы данных и могут использоваться как для восстановления на определенный момент времени (см. раздел Непрерывное архивирование и восстановление на момент времени (PITR) ), так и в качестве отправной точки для ведомого сервера при реализации трансляции файлов или потоковой репликации.
qhb_basebackup создает побитовую копию файлов кластера, обеспечивая автоматическое переключение системы в режим резервного копирования. Резервные копии всегда берутся для целого кластера баз данных; резервное копирование отдельных баз данных или объектов базы данных невозможно. Для отдельных резервных копий объектов базы данных необходимо использовать qhb_dump.
Резервное копирование выполняется через обычное соединение QHB и
использует протокол репликации. Соединение должно быть установлено под
суперпользователем или пользователем, имеющим разрешения REPLICATION
(см. раздел Атрибуты ролей), а qhb_hba.conf должен позволять соединение
репликации. Сервер также должен быть настроен с параметром max_wal_senders,
установленным достаточно высоко, чтобы оставить хотя бы один сеанс
доступным для резервного копирования и одним для потоковой передачи WAL
(если используется).
Может быть запущено несколько qhb_basebackup'ов одновременно, но с точки зрения производительности лучше выполнять одно резервное копирование и скопировать его результат.
qhb_basebackup может сделать резервную копию не только с
ведущего, но и с ведомого кластера. Чтобы сделать резервную копию ведомого
кластера, настройте его, чтобы он мог принимать подключения
репликации (установите параметры max_wal_senders и hot_standby, и
настройте аутентификацию). Вам также нужно будет
включить full_page_writes на ведущем кластере.
Обратите внимание, что при резервном копировании ведомого кластера есть некоторые ограничения:
-
Файл истории резервного копирования не создаётся в целевом кластере баз данных
-
Если вы используете
-X none, нет гарантии, что все файлы WAL, необходимые для резервного копирования, будут архивированы в конце резервного копирования. -
Если ведомый сервер становится ведущим во время резервного копирования, резервное копирование завершится неудачно.
-
Все записи WAL, необходимые для резервного копирования, должны содержать достаточное количество полностраничных записей, для чего необходимо включить full_page_writes на ведущем кластере и не использовать инструменты pg_compresslog или archive_command для удаления полностраничных записей из файлов WAL.
Параметры
| Параметр | Описание |
|---|---|
-D directory --pgdata=directory | Каталог для резервной копии. qhb_basebackup создаст каталог и родительские каталоги, если это необходимо. Каталог может уже существовать, но должен быть пуст, иначе произойдёт ошибка. Когда резервная копия создаётся в tar режиме и каталог указан как - (тире), файл tar будет записан в стандартный поток вывода (stdout). Эта опция обязательна. |
| -F format --format=format | Выбор формата вывода. format может быть одним из следующих: p plain : Записать результат в виде простых файлов с той же компоновкой, что и исходном каталоге данных с сохранением табличных пространств. Если в кластере нет дополнительных табличных пространств, вся база данных будет помещена в целевой каталог. Если кластер содержит дополнительные табличные пространства, основной каталог данных будет помещен в целевой каталог, а все остальные табличные пространства будут размещены в том же абсолютном пути, что и на сервере. Это формат по умолчанию t tar : Запишите результат в виде tar-файлов в целевой каталог. Основной каталог данных будет записан в файл с именем base.tar, а все остальные табличные пространства будут названы в соответствии с их OID. Если в качестве целевого каталога указано значение - (тире), содержимое tar будет записано в стандартный вывод, подходящий для передачи, например, в gzip. Это возможно только в том случае, если в кластере нет дополнительных табличных пространств и потоковая передача WAL не используется. |
-r rate --max-rate=rate | Максимальная скорость передачи данных, передаваемых с сервера. Значения указаны в килобайтах в секунду. Используйте суффикс M чтобы указать мегабайт в секунду. Суффикс k также принимается и не имеет никакого эффекта. Допустимые значения: от 32 килобайт в секунду до 1024 мегабайт в секунду. Цель состоит в том, чтобы ограничить влияние qhb_basebackup на работающий сервер. Эта опция всегда влияет на передачу каталога данных. На передачу файлов WAL влияет только метод fetch. |
-R --write-recovery-conf | Создайте файл standby.signal и добавьте параметры подключения в qhb.auto.conf в выходном каталоге (или в файле базового архива при использовании формата tar), чтобы упростить настройку ведомого сервера. В файле qhb.auto.conf будут записаны параметры подключения и, если указан, слот репликации, который использует qhb_basebackup, то потоковая репликация будет использовать те же параметры. |
-T olddir=newdir --tablespace-mapping=olddir=newdir | Переместите табличное пространство из каталога olddir в newdir во время резервного копирования. olddir должен точно соответствовать пути табличного пространства, как оно определено. (Однако ошибкой не является, если в olddir нет табличного пространства.) И olddir и newdir должны быть абсолютными путями. Если путь содержит знак =, экранируйте его обратной косой чертой \. Эта опция может быть указана несколько раз для нескольких табличных пространств (см. примеры ниже). Если табличное пространство перемещается таким образом, символические ссылки внутри основного каталога данных обновляются, чтобы указывать на новое местоположение. Таким образом, новый каталог данных готов к использованию для нового экземпляра сервера со всеми табличными пространствами в обновлённых местоположениях. |
--waldir=waldir | Указывает местоположение для каталога журнала WAL. waldir должен быть абсолютным путем. Каталог журнала предзаписи можно указывать только если резервная копия находится в обычном режиме. |
-X method --wal-method=method | Включает в резервную копию необходимые файлы журнала предзаписи (файлы WAL). Включает в себя журналы упреждающей записи, созданные во время резервного копирования. Если выбран метод none, можно запускать qhbmaster непосредственно в извлеченном каталоге без необходимости обращаться к архиву журналов, что делает его полностью автономной резервной копией. Поддерживаются следующие методы сбора журналов предзаписи: n none : Не включать журнал предзаписи в резервную копию. f fetch : Файлы журнала предзаписи собираются в конце резервного копирования. Поэтому необходимо, чтобы параметр wal_keep_segments был рассчитан и установлен правильно, чтобы журнал не удалялся до окончания резервного копирования. Если журнал был удалён, когда пришло время передать его, резервное копирование не удастся и станет непригодным для использования. Когда используется формат tar, файлы журнала с предзаписи записи будут записаны в файл base.tar. s stream : Потоковая запись журнала предзаписи при создании резервной копии. Открывает второе соединение с сервером и начинает потоковую передачу журнала предзаписи параллельно при выполнении резервного копирования. Поэтому будет использоваться два соединения, настроенных параметром max_wal_senders. Пока клиент может отслеживать поступивший журнал предзаписи, использование этого режима не требует сохранения дополнительных журналов записи на главном сервере. При использовании формата tar файлы журналов предзаписи будут записываться в отдельный файл с именем pg_wal.tar. Это значение по умолчанию. |
-z --gzip | Включает gzip-сжатие результирующего tar-файла с уровнем сжатия по умолчанию. Сжатие доступно только при использовании формата tar, и суффикс .gz будет автоматически добавлен ко всем именам файлов tar. |
-Z level --compress=level | Включает gzip-сжатие вывода tar-файла и указывает уровень сжатия (от 0 до 9, 0 - без сжатия и 9 - с наилучшим сжатием). Сжатие доступно только при использовании формата tar, и суффикс .gz будет автоматически добавлен ко всем именам файлов tar. |
Окружение
Эта утилита, как и большинство других утилит QHB, использует переменные окружения, поддерживаемые libpq. (см. переменные окружения)
Переменная окружения PG_COLOR указывает, использовать ли цвет в
диагностических сообщениях.
Возможные значения always, auto, never.
Примечания
В начале резервного копирования на сервере, с которого берется резервная
копия, должна быть зафиксирована контрольная точка. Особенно, если опция
--checkpoint=fast не используется, это может занять некоторое время, в
течение которого qhb_basebackup будет казаться бездействующим.
Резервная копия будет включать все файлы в каталоге данных и табличных пространствах, включая файлы конфигурации и любые дополнительные файлы, за исключением некоторых временных файлов, управляемых QHB. Копируются только обычные файлы и каталоги, за исключением того, что символические ссылки, используемые для табличных пространств, сохраняются. Символьные ссылки, указывающие на определенные каталоги, известные QHB, копируются как пустые каталоги. Другие символические ссылки и специальные файлы устройств пропускаются.
По умолчанию для табличных пространств в простом формате будут
создаваться резервные копии на тот же путь, что и на сервере, если не
используется опция --tablespace-mapping. Без этой опции резервное копирование
в простом формате на том же хосте, что и на сервере, не
будет работать, если используются табличные пространства, поскольку
резервная копия должна быть записана в те же каталоги, что и исходные
табличные пространства.
Когда используется режим tar, пользователь должен распаковать каждый
tar-файл перед запуском сервера QHB. Если есть дополнительные
табличные пространства, их tar-файлы необходимо распаковать в
правильных местах. В этом случае символические ссылки для этих табличных
пространств будут создаваться сервером в соответствии с содержимым файла
tablespace_map который включен в файл base.tar.
qhb_basebackup работает с серверами QHB версии 1.1 и выше.
qhb_basebackup сохранит разрешения группы как в plain и в tar формате, если разрешения группы включены в исходном кластере.
Примеры
Создать базовую резервную копию сервера на mydbserver и сохранить ее в локальном каталоге /usr/local/qhb/data:
$ qhb_basebackup -h mydbserver -D /usr/local/qhb/data
Создать резервную копию локального сервера в формате tar
для каждого табличного пространства и сохранить его в backup
каталоге, отображая отчет о ходе выполнения во время работы:
$ qhb_basebackup -D backup -Ft -z -P
Создать резервную копию локальной базы данных с одним табличным пространством и сжать ее с помощью bzip2:
$ qhb_basebackup -D - -Ft -X fetch | bzip2 > backup.tar.bz2
(Эта команда не будет выполнена, если в базе данных есть несколько табличных пространств.)
Создать резервную копию локальной базы данных с перемещением табличного пространства из /opt/ts в ./backup/ts :
$ qhb_basebackup -D backup/data -T /opt/ts=$(pwd)/backup/ts
Смотрите Также
reindexdb - переиндексировать базу данных QHB
reindexdb - переиндексировать базу данных QHB
Синтаксис
reindexdb [connection-option...] [option...] [ --schema | -S schema ] ...
[ --table | -t table ] ... [ --index | -i index ] ... [dbname]
reindexdb [connection-option...] [option...] --all | -a
reindexdb [connection-option...] [option...] --system | -s [dbname]
Описание
reindexdb - это утилита для перестроения индексов в базе данных QHB.
reindexdb - это "обертка" над SQL командой REINDEX. Нет разницы между переиндексацией базы данных с помощью этой утилиты или же иным способом при обращении к серверу.
Параметры
reindexdb принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
-a, --all | Переиндексировать все базы данных |
--concurrently | Использовать параметр CONCURRENTLY. См. REINDEX для получения дополнительной информации |
[-d] dbname, [--dbname=]dbname | Указывает имя базы данных для переиндексации. Если не указывать и не использовать параметр -a (или --all), имя базы данных считывается из переменной окружения PGDATABASE. Если не установлена переменная окружения, используется имя пользователя, указанное в параметрах подключения |
-e, --echo | Выводить команды, которые reindexdb генерирует и отправляет на сервер |
-i index, --index=index | Пересоздать конкретный индекс. Несколько индексов можно воссоздать, написав несколько ключей -i |
-q, --quiet | Не отображать сообщения о прогрессе выполнения |
-s, --system | Переиднексировать системные каталоги |
-S schema, --schema=schema | Переиндексировать конкретную схему. Несколько схем можно переиндексировать, написав несколько ключей -S |
-t table, --table=table | Переиндексировать конкретную таблицу. Несколько таблиц можно переиндексировать, написав несколько ключей -t |
-v, --verbose | Показать подробную информацию во время процесса |
-V, --version | Показать версию reindexdb и выйти |
-?, --help | Показать справку об аргументах командной строки reindexdb и выйти |
reindexdb также принимает следующие параметры командной строки для параметров подключения:
| Аргумент | Описание |
|---|---|
-h host, --host=host | Указывает имя или адрес компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для Unix-сокета |
-p port, --port=port | Указывает порт TCP или расширение файла локального Unix-сокета, на котором сервер прослушивает соединения |
-U username, --username=username | Имя пользователя |
-w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля |
-W, --password | Эта опция не является существенной, так как reindexdb автоматически запросит пароль, если сервер требует аутентификацию по паролю. Тем не менее, reindexdb потратит одну дополнительную попытку подключения для аутентификации. В некоторых случаях стоит ввести -W, чтобы не делать эту попытку |
--maintenance-db=dbname | Задает имя базы данных для подключения, чтобы определить какие другие базы данных должны быть переиндексированы. Если не указано иное, будет использоваться база данных qhb, а если и её не существует, то будет использоваться template1 |
Окружение
PGDATABASE
PGHOST
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never .
Эта утилита, как и большинство других утилит QHB, также использует переменные окружения, поддерживаемые libpq.
Диагностика
В случае затруднений см. REINDEX и qsql для обсуждения потенциальных проблем и сообщений об ошибках. Сервер базы данных должен работать на целевом хосте. Кроме того, при запуске утилиты, будут применяться параметры подключения и переменные окружения, которые используются библиотекой libpq.
Примечания
С помощью reindexdb может потребоваться несколько раз подключиться к серверу QHB, каждый раз запрашивая пароль. В таких случаях удобно иметь файл ~/.pgpass.
Примеры
Чтобы переиндексировать базу данных test:
$ reindexdb test`
Чтобы переиндексировать таблицу foo и индекса bar в базе данных
abcd:
$ reindexdb --table=foo --index=bar abcd`
Смотрите Также
qhb_config - получить информацию об установленной версии QHB
qhb_config - получить информацию об установленной версии QHB
Синтаксис
qhb_config [option...]
Описание
Утилита qhb_config выводит параметры конфигурации текущей установленной
версии QHB. Он предназначен, например, для использования
программными пакетами, которые хотят взаимодействовать с QHB для
облегчения поиска необходимых заголовочных файлов и библиотек.
Параметры
Чтобы использовать qhb_config, укажите один или несколько из следующих
параметров:
| Аргумент | Описание |
|---|---|
--bindir | Вывести расположение пользовательских исполняемых файлов. Например, чтобы найти программу qsql. Обычно это то же место, где находится сама qhb_config |
--docdir | Вывести расположение файлов документации |
--htmldir | Вывести расположение файлов документации в формате HTML |
--includedir | Вывести расположение заголовочных файлов C клиентских интерфейсов |
--pkgincludedir | Вывести расположение других заголовочных файлов C |
--includedir-server | Вывести расположение заголовочных файлов C для программирования сервера |
--libdir | Вывести расположение библиотек объектного кода |
--pkglibdir | Вывести расположение динамически загружаемых модулей либо путь где сервер будет искать их. (Другие файлы данных, зависящие от архитектуры, также могут быть установлены в этом каталоге) |
--localedir | Вывести расположение файлов поддержки локали. (Это будет пустая строка, если поддержка локали не была настроена при сборке QHB) |
--mandir | Вывести расположение страниц руководства |
--sharedir | Вывести расположение архитектурно-независимых вспомогательных файлов |
--sysconfdir | Вывести расположение общесистемных файлов конфигурации |
--pgxs | Вывести расположение make-файлов расширений |
--configure | Вывести параметры, которые были заданы сценарию configure при сборке QHB. Этот параметр можно использовать для последующего воспроизведения идентичной конфигурации или для выяснения того, с какими параметрами был собран используемый бинарный пакет. (Тем не менее, обратите внимание, что бинарные пакеты часто содержат специфичные патчи конкретного производителя). Смотрите также примеры ниже |
--cc | Вывести значение переменной CC которая использовалась для сборки QHB. Показывает используемый компилятор Си |
--cppflags | Вывести значение переменной CPPFLAGS, которая использовалась при сборки QHB. Это показывает флаги компилятора C, примененные для препроцессора (обычно флаги -I) |
--cflags | Вывести значение переменной CFLAGS, которая использовалась при сборки QHB. Показывает флаги компилятора C которые использовались при сборке |
--cflags_sl | Вывести значение переменной CFLAGS_SL, которая использовалась для сборки QHB. Показывает дополнительные флаги компилятора C, используемые для сборки разделяемых библиотек |
--ldflags | Вывести значение переменной LDFLAGS, которая использовалась для сборки QHB. Показывает флаги компоновщика, которые использовались. |
--ldflags_ex | Вывести значение переменной LDFLAGS_EX, которая использовалась для сборки QHB. Показывает флаги компоновщика, которые использовались только для сборки исполняемых файлов |
--ldflags_sl | Вывести значение переменной LDFLAGS_SL, которая использовалась для сборки QHB. Здесь показаны флаги компоновщика, которые использовались только для создания разделяемых библиотек |
--libs | Вывести значение переменной LIBS, которая использовалась для сборки QHB. Обычно он содержит флаги -l для внешних библиотек, прилинкованных к QHB |
--version | Вывести версию QHB |
-?, --help | Показать справку об аргументах командной строки qhb_config и выйти |
Если указано более одного параметра, информация печатается в указанном порядке, по одному элементу в строке. Если параметры не переданы, выводится вся доступная информация с подписями к чему она относится.
Пример
Чтобы воспроизвести конфигурацию сборки текущей установки QHB, выполните следующую команду:
eval ./configure `qhb_config --configure`
Вывод qhb_config --configure оборачивается в кавычки, соответственно
аргументы с пробелами представляются правильно. Поэтому для получения корректного результата использование eval необходимо.
qhb_dump - извлекает базу данных QHB в файл сценария или другой архив
qhb_dump - утилита извлечения базы данных QHB в файл сценария или другой
архив.
- Описание
- Синтаксис
- Параметры
- Дополнительная информация по параметрам
- Уровень сжатия
- TIMEOUT
- no sync
- ROLENAME
- Форматы дампов
- Выгрузка блобов
- Clean
- Создание базы
- no owner
- schema only
- Параллельные дампы
- Шаблоны выгрузки
- column inserts
- Отключение триггеров
- Защита строк
- exclude table data
- inserts
- load via partition root
- Экранирование идентификаторов
- section
- serializable deferrable
- snapshot
- strict names
- use set session authorization
- Устаревшие опции
- Окружение
- Диагностика
- Примечания
- Примеры
- Смотрите Также
Описание
qhb_dump - это утилита для резервного копирования базы данных QHB.
Создаёт последовательные резервные копии, даже если база данных
используется.
qhb_dump не блокирует доступ других
пользователей к базе данных (читателей или писателей).
qhb_dump снимает дамп только с одной базы данных. Для резервного копирования
всего кластера или для резервного копирования глобальных объектов, общих
для всех баз данных в кластере (таких, как роли и табличные
пространства), следует использовать qhb_dumpall.
Дамп может быть создан в формате SQL-сценария или файла архива.
SQL-сценарий - это текстовый файл, содержащие команды SQL, необходимые для
восстановления базы данных до состояния, в котором она находилась на
момент сохранения. Чтобы восстановить БД используя такой скрипт, выполните его
используя утилиту qsql.
Файлы сценариев могут использоваться для восстановления базы
данных даже на других машинах и других архитектурах; с некоторыми
изменениями, на других SQL-совместимых базах данных.
Альтернативные форматы архивных файлов должны использоваться с
qhb_restore для перестройки базы данных. Они позволяют qhb_restore избирательно
восстанавливать данные, или изменять порядок элементов перед восстановлением.
Форматы архивных файлов предназначены для переноса между различными архитектурами.
При использовании с одним из форматов архивных файлов и в сочетании с
qhb_restore, qhb_dump обеспечивает гибкий механизм архивирования и
передачи. qhb_dump может использоваться для резервного копирования всей
базы данных, затем qhb_restore может использоваться для проверки архива
и/или выбора того, какие части базы данных должны быть восстановлены.
Наиболее гибкими форматами выходного файла являются «пользовательский»
формат ( -Fc ) и «каталог» ( -Fd ). Эти форматы позволяют выбирать и
переупорядочивать все заархивированные элементы, поддерживают
параллельное восстановление и, по умолчанию, сжимаются.
Формат «каталог» единственный, поддерживающий параллельные дампы.
Во время работы qhb_dump необходимо внимательно проверять консольный вывод на наличие
предупреждений или ошибок (stderr), особенно в свете ограничений, перечисленных ниже.
Синтаксис
qhb_dump [connection-option...] [OPTION]... [DBNAME]
Параметры
Обратите внимание на то что для многих параметров существуют особенности использования и ознакомьтесь с расширенной справкой в разделе Дополнительная информация по параметрам.
Следующие параметры командной строки управляют содержимым и форматом вывода.
COMMON OPTIONS
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти. |
| -V, --version | Вывести версию qhb_dump и выйти |
| -v, --verbose | Выводит на экран команды, которые createuser генерирует и отправляет на сервер. |
GENERAL OPTIONS
| Аргумент | Описание |
|---|---|
| -f, --file=FILENAME | Перенаправить вывод в указанный файл. Можно не указывать для файловых форматов вывода, тогда используется стандартный вывод. Необходимо задать для формата вывода каталога, т.к. указывает целевой каталог вместо файла. В этом случае каталог создается qhb_dump. |
-F, --format=c, d, t, p | Задать формат вывода дампа. Форматы дампов |
| -j, --jobs=NUM | Запустить создание дампа в NUM потоков. Можно использовать только с выходным форматом каталога. Подробнее. |
| -Z, --compress=0-9 | Уровень сжатия для дампа. Подробнее |
| --lock-wait-timeout=TIMEOUT | Таймаут, на получение блокировки таблиц. Если невозможно заблокировать таблицу в течение указанного времени - выдаётся ошибка. Подробнее |
| --no-sync | Не дожидаться синхронизации записи файлов на диск Подробнее |
CONNECTION OPTIONS
| Аргумент | Описание |
|---|---|
| -d, --dbname=DBNAME | Имя базы данных для подключения. Эквивалентно указанию dbname в качестве первого не опционального аргумента |
| -h, --host=HOSTNAME | Имя хоста, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Значение по умолчанию берется из переменной среды PGHOST, далее предпринимается попытка подключения через сокет домена Unix. |
| -p, --port=PORT | TCP порт или расширение файла локального сокета домена Unix. По умолчанию берётся переменная среды PGPORT, или порт заданный при компиляции. |
| -U, --username=USERNAME | Имя пользователя для подключения. |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | qhb_dump автоматически запросит пароль, если сервер требует аутентификацию по паролю. qhb_dump будет пытаться подключиться, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
| --role=ROLENAME | Задает имя роли, которая будет использоваться для создания дампа. Подробнее |
OPTIONS
| Аргумент | Описание |
|---|---|
| -a, --data-only | Дамп только данных, а не схемы (DDL определения данных). Данные таблицы, большие объекты и значения последовательности сбрасываются. Эта опция похожа на --section=data, но по историческим причинам не идентична. |
| -b, --blobs | Включить большие объекты в дамп. Это поведение по умолчанию Подробнее |
| -B, --no-blobs | Исключить выгрузку блобов в дамп. Когда заданы оба параметра -b и -B, больших объектов включаются в дамп. |
| -c, --clean | Дополняет выходной файл командами для очистки (DROP) объектов базы данных перед выводом команд для их создания. Подробнее |
| -C, --create | Формирует команду на создание инстанса БД и подключение к нему. Подробнее |
| -E, --encoding=ENCODING | Создать дамп в указанной кодировке набора символов. По умолчанию дамп создается в кодировке базы данных. (Другой способ получить тот же результат - установить для переменной среды PGCLIENTENCODING желаемую кодировку дампа.) |
| -n, --schema=PATTERN | Включать в Дамп только схемы, соответствующие pattern Подробнее |
| -N, --exclude-schema=PATTERN | Исключать из Дампа схемы, соответствующие pattern Подробнее |
| -O, --no-owner | Не формировать команды для установки владельца объектов как в исходной базе данных. Подробнее |
| -s, --schema-only | Включает в Дамп только определения объектов (схема), но не сами данные. Подробнее |
| -S, --superuser=NAME | Указать имя суперпользователя, которое будет использоваться при отключении триггеров. Актуально, только если используется --disable-triggers. (Обычно лучше вместо этого запускать полученный скрипт как суперпользователь.) |
| -t, --table=PATTERN | Включать в Дамп только таблицы, соответствующие pattern Подробнее |
| -T, --exclude-table=PATTERN | Исключать из Дампа таблицы, соответствующие pattern Подробнее |
| -x, --no-privileges, --no-acl | Запретить сброс прав доступа (команды GRANT / REVOKE). |
| --binary-upgrade | Эта опция предназначена для использования утилитами обновления на месте. Использование в других целях не рекомендуется и не поддерживается. Поведение опции может измениться в будущих выпусках без предварительного уведомления. |
| --column-inserts | Формировать Дамп данных в виде команды INSERT с явными указанием столбцов Подробнее |
| --disable-dollar-quoting | Этот параметр отключает использование долларовых кавычек для тел функций; можно использовать кавычки из стандартного синтаксиса SQL. |
| --disable-triggers | Включать в дамп команды на отключение триггеров. Подробнее |
| --enable-row-security | Выгружать данные из таблиц с защитой строк. Подробнее |
| --exclude-table-data=PATTERN | Не сбрасывайте данные для таблиц, соответствующих pattern. Подробнее |
| --extra-float-digits=NUM | Использовать заданное значение extra_float_digits для чисел с плавающей запятой вместо максимально доступной точности. Обычные дампы, созданные для резервного копирования, не должны использовать эту опцию. |
| --if-exists | Используйте условные команды (добавить IF EXISTS ) при очистке объектов базы данных. Не работает без --clean. |
| --inserts | Создаёт дамп через команды INSERT Подробнее |
| --load-via-partition-root | Для партиции таблицы ссылаться на корневую таблицу в иерархии партицирования, а не на эту партицию. Подробнее |
| --no-comments | Не включать в дамп комментарии. |
| --no-publications | Не включать в дамп публикации. |
| --no-security-labels | Не включать в дамп защитные метки. |
| --no-subscriptions | Не включать в дамп подписки. |
| --no-synchronized-snapshots | Эта опция позволяет запускать qhb_dump -j на сервере до 9.2, более подробную информацию смотрите в документации по параметру -j. |
| --no-tablespaces | Не формировать команды для указания табличных пространств. Все объекты будут создаваться в табличном пространстве по умолчанию при восстановлении. Эта опция применима для простого текстового формата. Для форматов архива вы можете указать эту опцию при вызове qhb_restore. |
| --no-unlogged-table-data | Не выгружать данные нежурналируемых таблицы в дамп. Не влияет на выгрузку определений таблиц. На резервном сервере данные нежурналируемых таблиц никогда не выгружаются. |
| --on-conflict-do-nothing | Добавить ON CONFLICT DO NOTHING к командам INSERT. Работает только вместе с --inserts, --rows-per-insert, --rows-per-insert. |
| --quote-all-identifiers | Включить принудительно Экранирование идентификаторов при создании дампа Подробнее. |
| --rows-per-insert=NROWS | Выставляет максимально количество строк для INSERT (не COPY). Должно быть больше нуля. Любая ошибка во время загрузки приведет к потере только строк, которые являются частью проблемной INSERT. |
| --section=SECTION | Выбор разделов для включения в дамп Подробнее |
| --serializable-deferrable | Подробнее |
| --snapshot=SNAPSHOT | Подробнее |
| --strict-names | Подробнее |
| --use-set-session-authorization | Подробнее |
ARGS
| Аргумент | Описание |
|---|---|
| DBNAME | Определяет имя базы данных, которая будет выгружена. Если это не указано, используется переменная окружения PGDATABASE. Если переменная не установлена, используется имя пользователя, указанное для подключения. |
Дополнительная информация по параметрам
В этом разделе описана дополнительная информация, по параметрам командной строки утилиты qhb_dump.
Уровень сжатия
-Z, --compress=0-9
Уровень сжатия для дампа. Ноль означает отсутствие сжатия. Для пользовательского формата архива это указывает сжатие отдельных сегментов табличных данных, и по умолчанию используется сжатие на умеренном уровне. Для формата простого текста установка ненулевого уровня сжатия приводит к сжатию выходного файла, как если бы он был передан через gzip; по умолчанию не сжимать.
В настоящее время формат архива tar не поддерживается.
TIMEOUT
--lock-wait-timeout=TIMEOUT
Таймаут, на получение блокировки таблиц в начале дампа. Если невозможно заблокировать таблицу в течение указанного времени - выдаётся ошибка.
Тайм-аут может быть указан в любом из форматов,
принятых с помощью SET statement_timeout.
(Разрешенные форматы различаются в зависимости от версии сервера,
с которого выгружается дамп; целое число миллисекунд принимается всеми версиями.)
no sync
--no-sync
По умолчанию qhb_dump будет ожидать безопасной записи всех файлов на
диск. Эта опция заставляет qhb_dump возвращаться без ожидания, что
быстрее, но означает, что последующий сбой операционной системы
может привести к повреждению дампа. Как правило, этот параметр
полезен для тестирования, но его не следует использовать при сбросе
данных из производственной установки.
ROLENAME
--role=ROLENAME
Задает имя роли, которая будет использоваться для создания дампа.
qhb_dump выполнит команду SET ROLE rolename после подключения к базе данных.
Это полезно, когда пользователю (указанному ключом -U) не хватает привилегий,
необходимых для снятия дампа, но возможно переключиться на роль с необходимыми правами.
В некоторых установках задана политика, запрещающая вход в систему от имени суперпользователя, использование этой опции позволяет создавать дампы без нарушения политики.
Форматы дампов
-F format, --format= format - Параметр формата вывода. format может быть одним из следующих:
| Формат | Описание |
|---|---|
p, plain | Текстовый файл сценария SQL (по умолчанию) |
c, custom | Пользовательский формат |
d, directory | Дамп в формате каталога, подходящий для qhb_restore |
t, tar | Дамп tar формата, подходящий для ввода в qhb_restore |
custom
Пользовательский формат, подходящий для qhb_restore.
Вместе с форматом каталога это наиболее гибкий формат вывода,
поскольку он позволяет вручную выбирать и переупорядочивать
заархивированные элементы во время восстановления.
Этот формат также сжат по умолчанию.
directory
Дамп в формате каталога, подходящий для qhb_restore.
Создаёт каталог с одним файлом для каждой таблицы и исключает blob объекты,
создаёт файл оглавления, описывающий выгруженные объекты в машиночитаемом формате, для qhb_restore.
Архив формата каталогов может управляться стандартными инструментами Unix; например, файлы в несжатом архиве могут быть сжаты с помощью инструмента gzip.
Этот формат сжат по умолчанию, а также поддерживает параллельные дампы.
tar-dump
Дамп tar формата, подходящий для ввода в qhb_restore.
Формат tar совместим с форматом каталога:
при извлечении архива в формате tar создается действительный архив
в формате каталога.
Однако формат tar не поддерживает сжатие.
Кроме того, при использовании формата tar относительный порядок элементов данных таблицы не может быть изменен во время восстановления.
Выгрузка блобов
-b, --blobs
Включить большие объекты в дамп.
Это поведение по умолчанию, за исключением случаев,
когда указаны ключи --schema, --table или --schema-only.
Поэтому ключ -b полезен только для добавления больших объектов в дампы,
где запрошена конкретная схема или таблица.
Обратите внимание, что --schema-only считаются данными и поэтому будут включены,
когда используется --data-only, но не с ключом --schema-only.
Clean
-c, --clean
Дополняет выходной файл командами для очистки (DROP)
объектов базы данных перед выводом команд для их создания.
Если также не указано --if-exists, восстановление может выводить
сообщения о несуществующих объектах в целевой базе данных при попытке удаления.
Эта опция имеет смысл только для простого текстового формата.
Для других форматов архива вы можете указать эту опцию при вызове qhb_restore.
Создание базы
-C, --create
Формирует команду на создание инстанса БД и подключение к нему. В этом случае будет не важно какая БД указывается в параметрах подключения при восстановлении.
Если указан параметр --clean, сценарий удаляет и создаёт
заново целевую базу данных перед повторным подключением к ней.
С параметром --create выходные данные также формирует комментарий базы данных, если он есть,
и любые параметры переменных конфигурации, специфичные для этой базы данных,
то есть любые ALTER DATABASE ... SET ... и ALTER ROLE ... IN DATABASE ... SET ... команды,
которые ссылаются на эту базу.
Права доступа к самой базе данных также выгружаются в дамп, если не применён --no-acl.
Эта опция применима только для простого текстового формата.
Для других форматов архива вы можете указать эту опцию при вызове qhb_restore.
no owner
-O, --no-owner
Не формировать команды для установки владельца объектов как в исходной базе данных.
По умолчанию qhb_dump создаёт операторы ALTER OWNER или SET SESSION AUTHORIZATION
для установки владельца объектов.
Эти команды успешно выполнятся только при запуске сценария суперпользователем
(или тем же пользователем, которому принадлежат все объекты в сценарии).
Чтобы создать сценарий, который может быть восстановлен любым пользователем,
но предоставит ему право владения всеми объектами, укажите -O.
Эта опция имеет смысл только для простого текстового формата.
Для форматов архива вы можете указать эту опцию при вызове qhb_restore.
schema only
-s, --schema-only
Включает в Дамп только определения объектов (схема), но не сами данные.
Эта опция является обратной к --data-only.
Применение похоже на использование аргументов --section=pre-data --section=post-data,
но не идентично по историческим причинам.
Не путайте это с параметром --schema, который использует термин «схема» в другом значении,
чтобы исключить данные таблицы только для подмножества таблиц в базе данных,
смотрите --exclude-table-data.
Параллельные дампы
При использовании опции -j, --jobs=NUM утилита qhb_dump запустит
создание дампа параллельно, одновременно в NUM потоков.
Эта опция сокращает время дампа, но также увеличивает нагрузку на сервер базы данных.
Вы можете использовать эту опцию только с выходным
форматом каталога, потому что это единственный выходной формат, в
котором несколько процессов могут записывать свои данные
одновременно.
qhb_dump откроет NUM + 1 соединений с базой данных, поэтому
убедитесь, что ваш параметр max_connections соответствует,
и обеспечивает достаточное количество соединений.
Запрос монопольных блокировок к объектам базы данных при выполнении
параллельного дампа может привести к сбою. Причина в том, что
мастер-процесс qhb_dump запрашивает общие блокировки для объектов,
которые рабочие процессы будут выгружать позже, чтобы
удостовериться, что их никто не удалит и не удалит их во время
выполнения дампа. Если другой клиент затем запрашивает монопольную
блокировку таблицы, эта блокировка не будет предоставлена, но будет
поставлена в очередь в ожидании снятия общей блокировки главного
процесса. Следовательно, любой другой доступ к таблице также не
будет предоставлен и будет поставлен в очередь после запроса
исключительной блокировки. Это включает в себя рабочий процесс,
пытающийся сбросить таблицу. Без каких-либо мер предосторожности это
будет классическая тупиковая ситуация. Чтобы обнаружить этот
конфликт, рабочий процесс qhb_dump запрашивает другую общую
блокировку, используя опцию NOWAIT. Если рабочему процессу не
предоставлена эта общая блокировка, кто-то другой должен тем
временем запросить эксклюзивную блокировку, и нет никакого способа
продолжить работу с дампом, поэтому у qhb_dump нет другого выбора,
кроме как прервать дамп.
Для согласованного резервного копирования сервер базы данных должен
поддерживать синхронизированные моментальные снимки. С помощью этой функции клиенты базы данных могут
убедиться, что они видят один и тот же набор данных, даже если они
используют разные соединения. qhb_dump -j использует несколько
соединений с базой данных; он подключается к базе данных один раз с
главным процессом и еще раз для каждого рабочего задания. Без
функции синхронизированного моментального снимка различные рабочие
задания не гарантируют, что в каждом соединении будут отображаться
одни и те же данные, что может привести к непоследовательному
резервному копированию.
Шаблоны выгрузки
Шаблоны Схем
Включение Схем
-n pattern, --schema= pattern
Включать в Дамп только схемы, соответствующие pattern;
включает как саму схему, так и все содержащиеся в ней объекты.
Если эта опция не указана, все несистемные схемы в целевой базе данных будут
выгружены. Несколько схем можно выбрать, написав несколько ключей -n.
Параметр pattern интерпретируется как шаблон по тем же правилам,
которые используются командами qsql
, поэтому можно также выбрать несколько схем, написав в шаблоне символы подстановки. При использовании подстановочных знаков, будьте осторожны, если необходимо, указывайте шаблон, чтобы предотвратить расширение оболочки подстановочными знаками; см. примеры.
Заметка
Если указан параметр -n,qhb_dumpне будет пытаться создать дамп каких-либо других объектов базы данных, от которых могут зависеть выбранные схемы. Следовательно, нет никакой гарантии, что результаты дампа определенной схемы могут быть успешно восстановлены в чистую базу данных.
Заметка
Объекты, не являющиеся схемами, такие как BLOB-объекты, не выводятся, если указан параметр -n. Вы можете добавить BLOB-объекты обратно в дамп с помощью переключателя --blobs.
Исключение Схем
-N pattern , --exclude-schema= pattern
Не включать в Дамп схемы, соответствующие pattern. Шаблон
интерпретируется по тем же правилам, что и для -n.
Аргумент-N может быть задан более одного раза, чтобы исключить схемы,
соответствующие любому из нескольких шаблонов.
Когда заданы и -n и -N, в дамп включаются схемы,
которые соответствуют как минимум одному -n, но не -N.
Если аргумент -N задаётся без -n, то схемы, соответствующие -N,
исключаются из обычного дампа.
Шаблоны Таблиц
-t pattern, --table= pattern
Включать в Дамп только таблицы с именами, соответствующими pattern.
Здесь определение «таблица» включает в себя представления, материализованные
представления, последовательности и сторонние таблицы. Несколько
таблиц можно выбрать, написав несколько ключей -t. Параметр pattern
интерпретируется как шаблон тем же правилам,
которые используются в командах qsql
, поэтому можно также выбрать несколько таблиц, написав в шаблоне символы подстановки. При использовании подстановочных знаков, будьте осторожны, если необходимо, указывайте шаблон, чтобы предотвратить расширение оболочки подстановочными знаками; см. примеры.
-n и -N не действуют при использовании -t, поскольку таблицы,
выбранные с помощью -t будут выгружаться независимо от этих ключей,
а объекты, не являющиеся таблицами, не будут выгружаться.
Заметка
Если указан параметр -t,qhb_dumpне пытается создать дамп каких-либо других объектов базы данных, от которых могут зависеть выбранные таблицы. Следовательно, нет никакой гарантии, что результаты дампа конкретной таблицы могут быть успешно восстановлены в чистую базу данных.
Исключение Схем
-N pattern , --exclude-schema= pattern
-T pattern, --exclude-table= pattern
Не включать в Дамп схемы, соответствующие pattern.
Шаблон интерпретируется по тем же правилам, что и для -t.
Аргумент-T может быть задан более одного раза, чтобы исключить таблицы,
соответствующие любому из нескольких шаблонов.
Когда заданы и -t и -T, в дамп включаются таблицы,
которые соответствуют как минимум одному -t, но не -T.
Если аргумент -T используется без -t, то таблицы, соответствующие -T,
исключаются из обычного дампа.
column inserts
--column-inserts
Дамп данных в виде команды INSERT с явными указанием столбцов
(INSERT INTO table ( column, ...) VALUES ... ).
Восстановление по такому дампу очень медленное; в основном полезно для создания дампов, которые можно загружать в СУБД, отличные от QHB.
Любая ошибка во время перезагрузки приведет к потере только тех строк,
которые являются частью проблемной INSERT, а не всего содержимого таблицы.
Отключение триггеров
--disable-triggers
Эта опция актуальна только при создании дампа содержащего только данные. Формирует команды для временного отключения триггеров на целевых таблицах во время восстановления данных. Используйте, если есть проверки ссылочной целостности или другие триггеры для таблиц, которые не нужно вызывать во время восстановления данных.
В настоящее время команды, создаваемые с ключом --disable-triggers
должны выполняться суперпользователем. Таким образом, вы должны
также указать имя суперпользователя с помощью -S или,
запустить полученный скрипт как суперпользователь.
Эта опция имеет смысл только для простого текстового формата. Для
форматов архива вы можете указать эту опцию при вызове qhb_restore .
Защита строк
--enable-row-security
Эта опция актуальна только при выводе содержимого таблицы, в которой
есть защита строк. По умолчанию qhb_dump выключит row_security,
чтобы все данные были сброшены из таблицы. Если у пользователя
недостаточно прав для обхода защиты строк, выдается ошибка. Этот
параметр инструктирует qhb_dump установить вместо свойства
row_security значение, позволяющее пользователю выгружать части
содержимого таблицы, к которым у него есть доступ.
Обратите внимание, что если вы используете эту опцию в настоящее время, вы, вероятно, также захотите, чтобы дамп был в формате INSERT так как COPY FROM во время восстановления не поддерживает защиту строк.
exclude table data
--exclude-table-data= pattern
Не сбрасывайте данные для таблиц, соответствующих pattern.
Шаблон интерпретируется по тем же правилам, что и для -t.
--exclude-table-data аргумент может быть задан более одного раза, чтобы
исключить таблицы, соответствующие любому из нескольких шаблонов.
Эта опция полезна, когда вам нужно определение конкретной таблицы, даже если вам не нужны данные в ней.
Чтобы исключить данные для всех таблиц в базе данных, см. --schema-only.
inserts
--inserts
Создаёт дамп через команды INSERT (а не COPY ). Это сделает
восстановление очень медленным; в основном полезно для создания
дампов, которые можно загружать в базы данных, отличные от
QHB.
Любая ошибка во время перезагрузки приведет к потере только строк, которые являются частью проблемной INSERT, а не всего содержимого таблицы.
Обратите внимание, что восстановление может завершиться неудачей, если вы изменили порядок столбцов.
Опция --column-inserts безопасна от изменений порядка столбцов, хотя и медленнее.
load via partition root
--load-via-partition-root
Для партиции таблицы, в дамп формируются команды COPY или INSERT, ссылающиеся на корневую таблицу в иерархии партицирования, а не на эту партицию.
В результате при загрузке данных подходящая партиция будет выбираться заново для каждой строки. Это может быть полезно при перезагрузке данных, когда на целевом сервере строки не всегда попадают в те же партиции, в которых они находились на исходном.
Это возможно, когда столбец по которому выполнено партицирование имеет текстовый тип, а правило сортировки определено иначе на стороне системы куда выгружается дамп.
Лучше не использовать параллелизм при восстановлении из архива,
созданного с помощью этой опции, потому что qhb_restore не будет
точно знать, в какой раздел (ы) данный элемент данных архива будет
загружать данные. Это может привести к существенному замедлению из-за
конфликтов блокировок между параллельными заданиями.
Возможен даже сбой восстановления из-за того что ограничение по внешнему ключу,
вступит в силу до загрузки всех нужных данных.
Экранирование идентификаторов
--quote-all-identifiers
Включает принудительное экранирование всех идентификаторов при формировании дампа.
Эта опция рекомендуется при выгрузке базы данных с сервера, основная версия
QHB которого отличается от версии qhb_dump,
или в случае если дамп предназначен для загрузки на сервер другой версии.
По умолчанию qhb_dump заключает в кавычки только идентификаторы,
которые являются зарезервированными словами в своей основной версии.
Это иногда приводит к проблемам совместимости при работе с серверами
других версий, которые имеют разные наборы зарезервированных слов.
Использование --quote-all-identifiers предотвращает такие проблемы
ценой более сложного для чтения сценария дампа.
section
--section= pre-data | data | post-data
Только дамп названого раздела. Имя раздела может быть pre-data,
data или post-data. Эта опция может быть указана более одного раза,
чтобы выбрать несколько разделов. По умолчанию дамп всех разделов.
Раздел данных содержит фактические данные таблицы, содержимое больших объектов и значения последовательности. Элементы после данных включают определения индексов, триггеров, правил и ограничений, отличных от проверенных проверочных ограничений. Элементы предварительных данных включают все остальные элементы определения данных.
serializable deferrable
--serializable-deferrable
Используйте serializable транзакцию для дампа, чтобы гарантировать,
что используемый снимок соответствует более поздним состояниям базы
данных; но делайте это, ожидая точки в потоке транзакций, в которой
не может быть никаких аномалий, чтобы не было риска сбоя дампа или
откатывания других транзакций с serialization_failure.
См. Главу 13 для получения дополнительной информации об изоляции транзакций и управлении параллелизмом.
Эта опция не выгодна для дампа, который предназначен только для аварийного восстановления. Это может быть полезно для дампа, используемого для загрузки копии базы данных для отчетов или другого совместного использования загрузки только для чтения, в то время как исходная база данных продолжает обновляться. Без этого дамп может отражать состояние, которое не согласуется с каким-либо последовательным выполнением транзакций, в конечном итоге совершенных. Например, если используются методы пакетной обработки, партия может отображаться как закрытая в дампе без отображения всех элементов, входящих в пакет.
Эта опция не будет иметь значения, если при запуске qhb_dump нет
активных транзакций чтения-записи. Если транзакции чтения-записи
активны, начало дампа может быть отложено на неопределенный
промежуток времени. После запуска производительность с
переключателем или без него одинакова.
snapshot
--snapshot=SNAPSHOT
Используйте указанный синхронизированный моментальный снимок при создании дампа базы данных (подробности см. В таблице 9.87 ).
Эта опция полезна, когда необходимо синхронизировать дамп со слотом логической репликации (см. Главу 48 ) или с одновременным сеансом.
В случае параллельного дампа имя снимка, определенное этим параметром, используется вместо создания нового снимка.
strict names
--strict-names
Требуется, чтобы каждая --schema схемы ( -n / --schema ) и таблица (
-t / --table ) соответствовала хотя бы одной схеме / таблице в базе
данных, которую нужно вывести.
Обратите внимание, что если ни один из квалификаторов схемы / таблицы не найдет совпадения, qhb_dump
выдаст ошибку даже без --strict-names.
Эта опция не влияет на -N / --exclude-schema, -T / --exclude-table
или --exclude-table-data.
Шаблон исключения, не соответствующий ни одному объекту, не считается ошибкой.
use set session authorization
--use-set-session-authorization
Вывести стандартные команды SQL SET SESSION AUTHORIZATION вместо
команд ALTER OWNER для определения принадлежности объекта. Это
делает дамп более совместимым со стандартами, но в зависимости от
истории объектов в дампе может не восстановиться должным образом.
Кроме того, дамп с использованием SET SESSION AUTHORIZATION,
безусловно, потребует привилегий суперпользователя для правильного
восстановления, тогда как ALTER OWNER требует меньших привилегий.
Устаревшие опции
-R --no-reconnect
Эта опция устарела, но все же принята для обратной совместимости.
Окружение
PGDATABASE
PGHOST
PGOPTIONS
PGPORT
PGUSER
- Параметры подключения по умолчанию.
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never.
Диагностика
qhb_dump при работе выполняет операции SELECT. Если у вас есть проблемы с
запуском qhb_dump, убедитесь, что вы можете запросить информацию из базы
данных, например, с помощью qsql. Кроме того, будут применяться любые
параметры подключения по умолчанию и переменные среды, используемые
интерфейсной библиотекой libpq .
Активность базы данных qhb_dump обычно собирается сборщиком статистики.
Если это нежелательно, вы можете установить для параметра track_counts
значение false с помощью PGOPTIONS или команды ALTER USER.
Примечания
Если в вашем кластере баз данных есть какие-либо локальные дополнения к
базе данных template1, будьте осторожны, чтобы восстановить вывод
qhb_dump в действительно пустую базу данных; в противном случае вы
можете получить ошибки из-за дублирования определений добавленных
объектов. Чтобы создать пустую базу данных без каких-либо локальных
дополнений, делайте копию используя template0 , а не template1, например:
CREATE DATABASE foo WITH TEMPLATE template0;
Если выбран дамп только для данных и используется параметр
--disable-triggers,
qhb_dump отправляет команды для отключения триггеров
в пользовательских таблицах перед вставкой данных, а затем
команды для их повторного включения после вставки данных. Если
восстановление остановлено в середине, системные каталоги могут остаться
в неправильном состоянии.
Файл дампа, созданный qhb_dump, не содержит статистику, используемую
оптимизатором для принятия решений по планированию запросов. Поэтому
целесообразно запускать ANALYZE после восстановления из файла дампа,
чтобы обеспечить оптимальную производительность;
см. раздел Обновление статистики планировщика и
раздел Процесс «Автовакуум» для получения дополнительной информации.
Поскольку qhb_dump используется для передачи данных в более новые версии
QHB, можно ожидать, что выходные данные qhb_dump загрузятся в
версии сервера QHB, более новые, чем версия qhb_dump. qhb_dump
также может создавать дампы с серверов QHB, которые старше его
собственной версии.
Однако qhb_dump не может создавать дампы с серверов QHB,
более новых, чем его собственная основная версия; он откажется даже
попытаться, вместо того, чтобы рискнуть сделать неправильный сброс.
Кроме того, не гарантируется, что вывод qhb_dump может быть загружен на
сервер более старой основной версии, даже если дамп был взят с сервера
этой версии. Загрузка файла дампа на старый сервер может потребовать
ручного редактирования файла дампа для удаления синтаксиса, не понятного
старому серверу.
Использование опции --quote-all-identifiers
рекомендуется в кросс-версиях, поскольку это может предотвратить
проблемы, возникающие из-за изменения списков зарезервированных слов в
разных версиях QHB .
При дампе подписок логической репликации qhb_dump будет генерировать
команды CREATE SUBSCRIPTION которые используют опцию connect = false,
так что при восстановлении подписки не создаются удаленные подключения
для создания слота репликации или для начальной копии таблицы. Таким
образом, дамп может быть восстановлен без необходимости сетевого доступа
к удаленным серверам. Затем пользователь должен повторно активировать
подписки подходящим способом. Если задействованные хосты изменились,
возможно, потребуется изменить информацию о соединении. Также может быть
целесообразно обрезать целевые таблицы перед началом новой полной копии
таблицы.
Примеры
Чтобы вывести базу данных mydb в файл SQL-скрипта:
$ qhb_dump mydb > db.sql
Чтобы вывести базу данных в архивный файл нестандартного формата:
$ qhb_dump -Fc mydb > db.dump
Чтобы вывести базу данных в архив формата каталогов:
$ qhb_dump -Fd mydb -f dumpdir
Чтобы вывести базу данных в архив в формате каталога параллельно с 5 рабочими заданиями:
$ qhb_dump -Fd mydb -j 5 -f dumpdir
Чтобы перезагрузить архивный файл в (только что созданную) базу данных с именем newdb :
$ qhb_restore -d newdb db.dump
Чтобы перезагрузить архивный файл в ту же базу данных, из которой он был выгружен, отбрасывая текущее содержимое этой базы данных:
$ qhb_restore -d qhb --clean --create db.dump
Выгрузить одну таблицу с именем mytab :
$ qhb_dump -t mytab mydb > db.sql
Для вывода всех таблиц, имена которых начинаются с emp в detroit схеме, кроме таблицы employee_log :
$ qhb_dump -t 'detroit.emp*' -T detroit.employee_log mydb > db.sql
Чтобы вывести все схемы, имена которых начинаются с east или west, а заканчиваются на gsm, при этом исключая любые схемы, содержащие в имени слово test :
$ qhb_dump -n 'east*gsm' -n 'west*gsm' -N '*test*' mydb > db.sql
То же самое, используя запись регулярного выражения для объединения ключей:
$ qhb_dump -n '(east|west)*gsm' -N '*test*' mydb > db.sql
Чтобы вывести все объекты базы данных, кроме таблиц, имена которых начинаются с ts_ :
$ qhb_dump -T 'ts_*' mydb > db.sql
Чтобы указать имя в верхнем или смешанном регистре в -t и связанных с
ним ключах, вам нужно заключить имя в двойные кавычки; иначе шаблон будет
свёрнут в нижний регистр см. Шаблоны . Но двойные кавычки являются
особенными для оболочки поэтому в свою очередь, они должны быть
заключены в кавычки. Таким образом, чтобы вывести одну таблицу с именем
в смешанном регистре, вам нужно что-то вроде
$ qhb_dump -t "\"MixedCaseName\"" mydb > mytab.sql
Смотрите Также
qhb_dumpall, qhb_restore, qsql
qhb_dumpall - извлекает кластер базы данных QHB в файл сценария
qhb_dumpall - извлекает кластер базы данных QHB в файл сценария
Описание
qhb_dumpall - это утилита для записи ( « дампа » ) всех баз данных
QHB кластера в один файл сценария. Файл сценария содержит команды
SQL, которые можно использовать в качестве входных данных для qsql для
восстановления баз данных. Это делается путем вызова qhb_dump для каждой
базы данных в кластере. qhb_dumpall также выводит глобальные объекты,
которые являются общими для всех баз данных, то есть роли базы данных и
табличные пространства. ( qhb_dump не сохраняет эти объекты.)
Поскольку qhb_dumpall читает таблицы из всех баз данных, вам, скорее
всего, придется подключиться как суперпользователь базы данных, чтобы
получить полный дамп. Также вам понадобятся привилегии суперпользователя
для выполнения сохраненного скрипта, чтобы иметь возможность добавлять
роли и создавать базы данных.
Сценарий SQL будет записан в стандартный вывод. Используйте параметр -f / --file или операторы оболочки, чтобы перенаправить его в файл.
qhb_dumpall необходимо несколько раз подключиться к серверу QHB
(один раз для каждой базы данных). Если вы используете аутентификацию по
паролю, он будет запрашивать пароль каждый раз. В таких случаях удобно
иметь файл ~/.pgpass.
Синтаксис
qhb_dumpall [connection-option...] [OPTION...]
Параметры
Следующие параметры командной строки управляют содержимым и форматом вывода.
COMMON OPTIONS
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти. |
| -V, --version | Вывести версию qhb_dumpall и выйти |
| -v, --verbose | Выводит на экран команды, которые qhb_dumpall генерирует и отправляет на сервер. |
GENERAL OPTIONS
| Аргумент | Описание |
|---|---|
| -f, --file=FILENAME | Перенаправить вывод в указанный файл для qhb_dumpall. Иначе используется стандартный вывод. |
| --lock-wait-timeout=TIMEOUT | Таймаут, на получение блокировки таблиц. Если невозможно заблокировать таблицу в течение указанного времени - выдаётся ошибка. Подробнее |
| --no-sync | Не дожидаться синхронизации записи файлов на диск Подробнее |
CONNECTION OPTIONS
| Аргумент | Описание |
|---|---|
| -d, --dbname=DBNAME | Ознакомиться с отличиями от стандартного поведения |
| -h, --host=HOSTNAME | Имя хоста, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Значение по умолчанию берется из переменной среды PGHOST, далее предпринимается попытка подключения через сокет домена Unix. |
| -l, --database=DBNAME | alternative-dbname |
| -p, --port=PORT | TCP порт или расширение файла локального сокета домена Unix. По умолчанию берётся переменная среды PGPORT, или порт заданный при компиляции. |
| -U, --username=USERNAME | Имя пользователя для подключения. |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | qhb_dumpall автоматически запросит пароль, если сервер требует аутентификацию по паролю. qhb_dumpall будет пытаться подключиться, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
| --role=ROLENAME | Задает имя роли, которая будет использоваться для создания дампа. Подробнее |
OPTIONS
| Аргумент | Описание |
|---|---|
| -a, --data-only | Дамп только данных, а не схемы (DDL определения данных). |
| -c, --clean | Включите команды SQL для очистки (удаления) баз данных перед их воссозданием. В дамп будут добавлены команды DROP для ролей и табличных пространств. |
| -E encoding, --encoding=encoding | Создать дамп в указанной кодировке. По умолчанию дамп создается в кодировке базы данных. (Другой способ - установить для переменной среды PGCLIENTENCODING желаемую кодировку дампа.) |
| -g, --globals-only | Дамп только глобальные объекты (роли и табличные пространства), без баз данных. |
| -O, --no-owner | Не создавать команды для установки владельца объектов Подробнее |
| -r, --roles-only | Дамп только ролей, без баз данных или табличных пространств. |
| -s, --schema-only | Дамп только определения объектов (схема), а не данные. |
| -S NAME, --superuser=NAME | Имя суперпользователя, которое будет использоваться при отключении триггеров. Подробнее |
| -t, --tablespaces-only | Дамп только табличные пространства, без баз данных или ролей. |
| -x, --no-privileges | Запретить сброс прав доступа (команды GRANT / REVOKE). |
| --binary-upgrade | Эта опция предназначена для использования утилитами обновления на месте. Использование в других целях не рекомендуется и не поддерживается. Поведение опции может измениться в будущих выпусках без предварительного уведомления. |
| --column-inserts | Формировать Дамп данных в виде команды INSERT с явными указанием столбцов Подробнее |
| --disable-dollar-quoting | Этот параметр отключает использование долларовых кавычек для тел функций; можно использовать кавычки из стандартного синтаксиса SQL. |
| --disable-triggers | Включать в дамп команды на отключение триггеров. Подробнее |
| --extra-float-digits=NUM | Использовать заданное значение extra_float_digits для чисел с плавающей запятой вместо максимально доступной точности. Обычные дампы, созданные для резервного копирования, не должны использовать эту опцию. |
| --exclude-database=pattern | Не Включать в Дамп базы данных, соответствующие pattern Подробнее |
| --if-exists | Используйте условные команды (добавить IF EXISTS ) при очистке объектов базы данных и других объектов. Не работает без --clean. |
| --inserts | Создаёт дамп через команды INSERT Подробнее |
| --load-via-partition-root | Для партиции таблицы ссылаться на корневую таблицу в иерархии партицирования, а не на эту партицию. Подробнее |
| --no-comments | Не включать в дамп комментарии. |
| --no-publications | Не включать в дамп публикации. |
| --no-security-labels | Не включать в дамп защитные метки. |
| --no-subscriptions | Не включать в дамп подписки. |
| --no-role-passwords | Не сбрасывайте пароли для ролей. Подробнее |
| --no-sync | Не дожидаться синхронизации записи файлов на диск Подробнее |
| --no-tablespaces | Не формировать команды для указания табличных пространств. Все объекты будут создаваться в табличном пространстве по умолчанию при восстановлении. |
| --no-unlogged-table-data | Не выгружать данные нежурналируемых таблицы в дамп. Не влияет на выгрузку определений таблиц. |
| --on-conflict-do-nothing | Добавить ON CONFLICT DO NOTHING к командам INSERT. Работает только с --inserts или --column-inserts. |
| --quote-all-identifiers | Включить принудительно Экранирование идентификаторов при создании дампа Подробнее. |
| --rows-per-insert=NROWS | Выставляет максимально количество строк для INSERT (не COPY). Должно быть больше нуля. Любая ошибка во время загрузки приведет к потере только строк, которые являются частью проблемной INSERT. |
| --use-set-session-authorization | Подробнее |
Дополнительная информация по параметрам
TIMEOUT
--lock-wait-timeout=TIMEOUT
Таймаут, на получение блокировки таблиц в начале дампа. Если невозможно заблокировать таблицу в течение указанного времени - выдаётся ошибка.
Тайм-аут может быть указан в любом из форматов,
принятых с помощью SET statement_timeout.
(Разрешенные форматы различаются в зависимости от версии сервера,
с которого выгружается дамп; целое число миллисекунд принимается всеми версиями.)
no sync
--no-sync
По умолчанию qhb_dumpall будет ожидать безопасной записи всех файлов на
диск. Эта опция заставляет qhb_dumpall возвращаться без ожидания, что
быстрее, но означает, что последующий сбой операционной системы
может привести к повреждению дампа. Как правило, этот параметр
полезен для тестирования, но его не следует использовать при сбросе
данных из производственной установки.
dbname
-d connstr, --dbname=connstr
Задает параметры, используемые для подключения к серверу, в виде строки подключения.
Параметр называется --dbname для согласованности с другими клиентскими приложениями,
но поскольку qhb_dumpall необходимо подключаться ко многим базам данных,
имя базы данных в строке подключения будет игнорироваться.
Используйте параметр -l чтобы указать имя базы данных, используемой для начального соединения,
которая будет создавать дамп глобальных объектов и определять, какие другие базы данных должны быть дампированы.
alternative-dbname
-l dbname, --database=dbname
Задает имя базы данных, к которой необходимо подключиться для создания
дампов глобальных объектов и определения того, какие другие базы данных должны быть выгружены.
Если не указано иное, будет использоваться база данных qhb,
если она не существует, будет использоваться template1 .
ROLENAME
--role=ROLENAME
Задает имя роли, которая будет использоваться для создания дампа.
qhb_dumpall выполнит команду SET ROLE rolename после подключения к базе данных.
Это полезно, когда пользователю (указанному ключом -U) не хватает привилегий,
необходимых для снятия дампа, но возможно переключиться на роль с необходимыми правами.
В некоторых установках задана политика, запрещающая вход в систему от имени суперпользователя, использование этой опции позволяет создавать дампы без нарушения политики.
no owner
-O, --no-owner
Не создавать команды для установки владельца объектов в соответствии с исходной базой данных.
По умолчанию qhb_dumpall выдает операторы ALTER OWNER или SET SESSION AUTHORIZATION
чтобы установить владельца созданных элементов схемы.
Эти операторы не будут выполнены при запуске сценария,
если он не запущен суперпользователем (или тем же пользователем,
которому принадлежат все объекты в сценарии).
Чтобы создать сценарий, который может быть восстановлен любым пользователем,
но предоставит ему право владения всеми объектами, укажите -O .
superuser
Имя суперпользователя, которое будет использоваться при отключении триггеров.
Это актуально, только если используется --disable-triggers.
(Обычно лучше не указывать это и вместо этого запускать полученный скрипт как суперпользователь.)
column inserts
--column-inserts
Дамп данных в виде команды INSERT с явными указанием столбцов
(INSERT INTO table ( column, ...) VALUES ... ).
Восстановление по такому дампу очень медленное; в основном полезно для создания дампов, которые можно загружать в СУБД, отличные от QHB.
Отключение триггеров
--disable-triggers
Эта опция актуальна только при создании дампа содержащего только данные. Формирует команды для временного отключения триггеров на целевых таблицах во время восстановления данных. Используйте, если есть проверки ссылочной целостности или другие триггеры для таблиц, которые не нужно вызывать во время восстановления данных.
В настоящее время команды, создаваемые с ключом --disable-triggers
должны выполняться суперпользователем. Таким образом, вы должны
также указать имя суперпользователя с помощью -S или,
запустить полученный скрипт как суперпользователь.
exclude database
--exclude-database=pattern
Не Включать в Дамп базы данных, соответствующие pattern;
Несколько баз можно исключить, написав несколько ключей --exclude-database.
Параметр pattern интерпретируется как шаблон по тем же правилам,
которые используются командами qsql, поэтому несколько баз данных также можно исключить,
написав в шаблоне символы подстановки. При использовании подстановочных
знаков, будьте осторожны, если необходимо, указывайте шаблон, чтобы
предотвратить расширение оболочки подстановочными знаками.
inserts
--inserts
Создаёт дамп через команды INSERT (а не COPY ). Это сделает
восстановление очень медленным; в основном полезно для создания
дампов, которые можно загружать в базы данных, отличные от
QHB.
Любая ошибка во время перезагрузки приведет к потере только строк, которые являются частью проблемной INSERT, а не всего содержимого таблицы.
Обратите внимание, что восстановление может завершиться неудачей, если вы изменили порядок столбцов.
Опция --column-inserts безопасна от изменений порядка столбцов, хотя и медленнее.
load via partition root
--load-via-partition-root
Для партиции таблицы, в дамп формируются команды COPY или INSERT,
ссылающиеся на корневую таблицу в иерархии партицирования,
а не на эту партицию.
В результате при загрузке данных подходящая партиция будет выбираться заново для каждой строки. Это может быть полезно при перезагрузке данных, когда на целевом сервере строки не всегда попадают в те же партиции, в которых они находились на исходном.
Это возможно, когда столбец по которому выполнено партицирование имеет текстовый тип, а правило сортировки определено иначе на стороне системы куда выгружается дамп.
no role passwords
--no-role-passwords
Не сбрасывать пароли для ролей.
После восстановления роли будут иметь нулевой пароль,
и проверка подлинности по паролю всегда будет неуспешной,
пока пароль не будет установлен.
Поскольку при pg_authid этой опции значения пароля не нужны,
информация о роли читается из представления каталога pg_roles, а не pg_authid.
Следовательно, эта опция также помогает, если доступ к pg_authid ограничен какой-либо политикой безопасности.
Экранирование идентификаторов
--quote-all-identifiers
Включает принудительное экранирование всех идентификаторов при формировании дампа.
Эта опция рекомендуется при выгрузке базы данных с сервера, основная версия
QHB которого отличается от версии qhb_dumpall,
или в случае если дамп предназначен для загрузки на сервер другой версии.
По умолчанию qhb_dumpall заключает в кавычки только идентификаторы,
которые являются зарезервированными словами в своей основной версии.
Это иногда приводит к проблемам совместимости при работе с серверами
других версий, которые имеют разные наборы зарезервированных слов.
Использование --quote-all-identifiers предотвращает такие проблемы
ценой более сложного для чтения сценария дампа.
use set session authorization
--use-set-session-authorization
Вывести стандартные команды SQL SET SESSION AUTHORIZATION вместо
команд ALTER OWNER для определения принадлежности объекта. Это
делает дамп более совместимым со стандартами, но в зависимости от
истории объектов в дампе может не восстановиться должным образом.
Кроме того, дамп с использованием SET SESSION AUTHORIZATION,
безусловно, потребует привилегий суперпользователя для правильного
восстановления, тогда как ALTER OWNER требует меньших привилегий.
Окружение
PGHOST
PGOPTIONS
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never .
Эта утилита, как и большинство других утилит QHB, также использует переменные среды, поддерживаемые libpq .
Примечания
Поскольку qhb_dumpall вызывает qhb_dump для каждой БД, некоторые
диагностические сообщения будут ссылаться на qhb_dump .
Опция --clean может быть полезна, даже если вы собираетесь восстановить
скрипт дампа в новый кластер. Использование --clean разрешает сценарию
удалять и заново создавать встроенные базы данных qhb и template1,
гарантируя, что эти базы данных сохранят те же свойства (например,
языковой стандарт и кодировку), которые были у них в исходном кластере.
Без этой опции эти базы данных сохранят свои существующие свойства
уровня базы данных, а также любое ранее существующее содержимое.
После восстановления рекомендуется запускать ANALYZE для каждой базы данных,
чтобы оптимизатор имел полезную статистику. Вы также можете запустить
vacuumdb -a -z для анализа всех баз данных.
Не следует ожидать, что скрипт дампа будет работать полностью без
ошибок. В частности, поскольку сценарий будет выдавать команду CREATE ROLE для каждой роли, существующей в исходном кластере, он обязательно
получит ошибку « роль уже существует » для суперпользователя начальной
загрузки, если только целевой кластер не был инициализирован с другим
именем суперпользователя начальной загрузки. Эта ошибка безвредна и
должна игнорироваться. Использование опции --if-exists может привести к
ряду дополнительных безобидных сообщений об ошибках о
несуществующих объектах.
qhb_dumpall требует, чтобы все необходимые каталоги табличного
пространства существовали до восстановления; в противном случае создание
базы данных завершится неудачно для баз данных, расположенных не по
умолчанию.
Примеры
Чтобы сбросить все базы данных:
$ qhb_dumpall > db.out
Неважно, к какой базе данных вы подключаетесь, поскольку файл сценария,
созданный qhb_dumpall, будет содержать соответствующие команды для
создания и подключения к сохраненным базам данных.
Исключением является случай, если вы указали --clean,
вы должны сначала подключиться к базе данных qhb;
сценарий попытается немедленно удалить другие базы
данных, и это не удастся для базы данных, к которой вы подключены.
Смотрите Также
Проверьте qhb_dump для подробной информации о возможных состояниях ошибки.
qhb_isready - проверка состояние соединения с сервером QHB
Синтаксис
qhb_isready [FLAGS] [OPTIONS]
Описание
qhb_isready - это утилита для проверки состояния соединения с сервером
базы данных QHB. Статус выхода определяет результат проверки
соединения.
Параметры
FLAGS:
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти. |
| --no-timeout | Запустить приложение без тайм-аута, используется вместо -t 0s |
| -q, --quiet | Устанавливает уровень ведения журнала в Error, конфликтует с флагом verbose. |
| -V, --version | Вывести версию qhb_isready и выйти. |
| -v, --verbose | Устанавливает уровень ведения журнала в Debug (по умолчанию: Info). |
OPTIONS:
| Аргумент | Описание |
|---|---|
| -d, --dbname DBNAME | Определяет имя базы данных для подключения (env: PGDATABASE). |
| -h, --host HOST | Указывает имя хоста компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется как каталог для сокета Unix-домена. (env:PGHOST) |
| -p, --port PORT | Указывает порт TCP или расширение файла локального сокета Unix-домена, на котором сервер прослушивает соединения. По умолчанию используется значение переменной среды (env: PGPORT) или, если не установлено, значение порта, указанного во время компиляции, обычно 5432. |
| -t, --timeout TIMEOUT | Максимальное количество секунд ожидания при попытке соединения, поддерживает «человеческое время», например -t 3s. |
| -U, --username USERNAME | Подключение к базе данных с использованием имени пользователя вместо имени по умолчанию. (env: PGUSER) |
Статус выхода
qhb_isready возвращает оболочке:
| Код выхода | Условия |
|---|---|
| 0 | сервер принимает соединения нормально |
| 1 | сервер отклоняет соединения (например, во время запуска или неверно заданных аргументов: --no-existent-arg) |
| 2 | не было ответа на попытку соединения |
| 3 | попытка не была предпринята (например, из-за неверных параметров аргумента(ов)) |
Примечания
Для получения статуса сервера необязательно указывать правильные значения имени пользователя, пароля или имени базы данных; однако, если указаны неправильные значения, сервер зарегистрирует неудачную попытку подключения.
Примеры
Стандартное использование:
$ qhb_isready echo $?
[INFO] /home/user/qhb/core_db/build/dbsockets:5432 - accepting connections
0
Запуск с параметрами подключения к неотвечающему кластеру QHB:
$ qhb_isready --host localhost --port 22; echo $?
[WARN] Unable to load login packet: Provided buffer (66560) is shorter than a packet length (body_length = 1397239086, packet_id = 83 (S), raw_length = 1397239090).
[ERROR] localhost:22 - connection rejected
1
Ошибка при попытке установить подключение
$ qhb_isready --host localhost --port 42; echo $?
[WARN] ConnectionError: failed to connect to 127.0.0.1:42: Failed to establish connection to 127.0.0.1:42: Connection refused (os error 111)
[ERROR] localhost:42 - no response
2
Запуск с некорректными параметрами
$ qhb_isready --host asd; echo $?
[WARN] Failed to lookup address asd: failed to lookup address information: Name or service not known
[ERROR] asd:5432 - incorrect parameters
3
qhb_receivewal - потоковые журналы записи с сервера QHB
qhb_receivewal - потоковые журналы записи с сервера QHB
Описание
qhb_receivewal используется для потоковой передачи журнала
предварительной записи (Write Ahead Log, WAL)
из работающего кластера QHB.
Журнал упреждающей записи передается по протоколу потоковой репликации и
записывается в локальный каталог. Этот каталог можно использовать
в качестве расположения архива для восстановления с использованием
восстановления на определенный момент времени
(см. раздел Непрерывное архивирование и восстановление на момент времени).
qhb_receivewal направляет журнал упреждающей записи в режиме реального
времени, поскольку он генерируется на сервере, и не ожидает завершения
сегментов, как это делает archive_command. По этой причине нет
необходимости устанавливать archive_timeout при использовании
qhb_receivewal.
В отличие от приемника WAL резервного сервера QHB, qhb_receivewal
по умолчанию сбрасывает данные WAL только тогда, когда файл WAL закрыт.
Опция --synchronous должна быть указана для сброса данных WAL в режиме
реального времени. Так как qhb_receivewal не применяет WAL, вы не должны
допускать, чтобы он стал синхронным резервом, когда synchronous_commit
равен remote_apply. Если это произойдет, он окажется резервным,
который никогда не догонит, и приведет к блокировке фиксации транзакции.
Чтобы избежать этого, вы должны либо настроить подходящее значение для
synchronous_standby_names, либо указать application_name для
qhb_receivewal, который ему не соответствует, либо изменить значение
synchronous_commit на что-то отличное от remote_apply .
Журнал предварительной записи передается по обычному соединению
QHB и использует протокол репликации. Соединение должно быть
установлено суперпользователем или пользователем, имеющим разрешения
REPLICATION (см. раздел Атрибуты ролей), а qhb_hba.conf должен разрешить
соединение репликации. Сервер также должен быть настроен с
max_wal_senders, установленным достаточно высоко, чтобы оставить хотя
бы один сеанс доступным для потока.
Если соединение потеряно или если оно не может быть изначально
установлено, с нефатальной ошибкой, qhb_receivewal будет повторять
попытку подключения бесконечно и восстанавливать потоковую передачу как
можно скорее. Чтобы избежать этого, используйте параметр -n.
При отсутствии фатальных ошибок qhb_receivewal будет работать до тех
пор, пока не прекратится сигналом SIGINT (Control + C).
Синтаксис
qhb_receivewal [OPTION] ...
Параметры
CONNECTION OPTIONS
| Аргумент | Описание |
|---|---|
| -d, --dbname=CONNSTR | Имя базы данных для подключения. |
| -h, --host=HOSTNAME | Имя хоста, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Значение по умолчанию берется из переменной среды PGHOST, далее предпринимается попытка подключения через сокет домена Unix. |
| -p, --port=PORT | TCP порт или расширение файла локального сокета домена Unix. По умолчанию берётся переменная среды PGPORT, или порт заданный при компиляции. |
| -U, --username=NAME | Имя пользователя для подключения. |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | Автоматически запросить пароль, если сервер требует аутентификацию по паролю. Утилита будет пытаться подключиться, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
OPTIONS
| Аргумент | Описание |
|---|---|
| -D, --directory=DIR | Каталог для записи вывода. Обязательный параметр. |
| -E, --endpos=LSN | Автоматически останавливать репликацию и выходить с кодом выхода 0, когда приём достигает указанного номера LSN. Если есть запись с LSN, равным lsn, запись будет обработана. |
| --if-not-exists | Не генерировать ошибку, если при опции create-slot будет найден уже существующий слот с указанным именем. |
| -n, --no-loop | Завершить работу с ошибкой, и не выполнять новую попытку подключения при ошибках соединения. |
| --no-sync | Отключить принудительный сброс на диск WAL-журналов. Последующий сбой операционной системы может привести к повреждению сегментов WAL. Полезно для тестирования, но не следует использовать при архивации WAL в производственной среде. Эта опция несовместима с --synchronous. |
| -s, --status-interval=SECS | Интервал отправки пакетов состояния. Подробнее |
| -S, --slot=SLOTNAME | Требовать от qhb_receivewal использования существующего слота репликации. Подробнее |
| --synchronous | Записать данные WAL на диск сразу же после их получения. Подробнее |
| -v, --verbose | Включает подробный режим. |
| -V, --version | Вывести версию qhb_receivewal и выйти |
| -Z, --compress=0-9 | Включает gzip-сжатие журналов записи с опережением и указывает уровень сжатия (от 0 до 9, 0 - без сжатия и 9 - с наилучшим сжатием). Суффикс .gz будет автоматически добавлен ко всем именам файлов. |
| -?, --help | Показать справку об аргументах командной строки qhb_receivewal и выйти. |
status interval
-s SECS, --status-interval=SECS
Задает количество секунд между пакетами состояния, отправляемыми обратно на сервер. Это позволяет упростить мониторинг прогресса с сервера. Нулевое значение полностью отключает периодические обновления статуса, хотя обновление по-прежнему будет отправляться по запросу сервера, чтобы избежать отключения по тайм-ауту. Значение по умолчанию составляет 10 секунд.
SLOTNAME
-S SLOTNAME, --slot=SLOTNAME
Требовать от qhb_receivewal использования существующего слота репликации.
Когда используется эта опция, qhb_receivewal будет сообщать серверу позицию сброса,
указывая, когда каждый сегмент был синхронизирован с диском,
чтобы сервер мог удалить этот сегмент, если в этом нет необходимости.
Когда клиент репликации qhb_receivewal настроен на сервере как синхронный резерв,
то использование слота репликации сообщит серверу позицию сброса,
но только когда файл WAL закрыт. Следовательно, такая конфигурация
приведет к тому, что транзакции на первичном сервере ожидают долгое время
и эффективно не будут работать удовлетворительно.
Опция --synchronous должна быть указана дополнительно для правильной работы.
synchronous
--synchronous
Записать данные WAL на диск сразу после их получения.
Также отправьте пакет состояния обратно на сервер сразу после очистки независимо от --status-interval.
Эта опция должна быть указана, если клиент репликации qhb_receivewal
настроен на сервере как синхронный резерв, чтобы обеспечить
своевременную отправку обратной связи на сервер.
Дополнительные опции
qhb_receivewal может выполнить одно из двух следующих действий для
управления слотами физической репликации:
| Параметр | Описание |
|---|---|
| --create-slot | Создать новый слот физической репликации с именем, указанным в параметре --slot, и выйти. |
| --drop-slot | Удалить слот репликации с именем, указанным в --slot, и выйти. |
Статус Выхода
qhb_receivewal выйдет со статусом 0, когда завершится сигналом SIGINT .
(Это нормальный способ завершить его. Следовательно, это не ошибка.) Для
фатальных ошибок или других сигналов состояние выхода будет отличным от
нуля.
Окружение
Эта утилита, как и большинство других утилит QHB, использует переменные окружения, поддерживаемые libpq .
Переменная окружения PG_COLOR указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never.
Примечания
При использовании qhb_receivewal вместо archive_command в качестве
основного метода резервного копирования WAL настоятельно рекомендуется
использовать слоты репликации. В противном случае сервер может свободно
перезаписывать или удалять файлы журналов WAL перед их
резервным копированием, поскольку он не имеет никакой информации ни от
архива, ни от слотов репликации о том, как далеко заархивирован поток
WAL. Однако обратите внимание, что слот репликации заполнит дисковое
пространство сервера, если получатель не успевает за извлечением данных
WAL.
qhb_receivewal сохранит разрешения группы для полученных файлов WAL,
если разрешения группы включены в исходном кластере.
Примеры
Для потоковой передачи журнала предварительной записи с сервера mydbserver и его сохранения в локальном каталоге /usr/local/qhb/archive :
$ qhb_receivewal -h mydbserver -D /usr/local/qhb/archive
Смотрите Также
qhb_recvlogical - управление потоками логического декодирования QHB
qhb_recvlogical - управление потоками логического декодирования QHB
Описание
qhb_recvlogical управляет слотами репликации с логическим декодированием
и передает данные из таких слотов репликации.
Он создает соединение в режиме репликации, поэтому к нему применяются те же ограничения, что и для qhb_receivewal, плюс ограничения для логической репликации.
qhb_recvlogical не имеет эквивалента режимам просмотра и получения
интерфейса SQL логического декодирования. Утилита отправляет подтверждения
воспроизведения для данных в "ленивом режиме", по мере их получения и при чистом
выходе. Чтобы проверить ожидающие данные в слоте, не используя их,
используйте pg_logical_slot_peek_changes.
Синтаксис
qhb_recvlogical [option...]
Параметры
Для выбора действия необходимо указать хотя бы один из следующих параметров:
Возможные действия
--create-slot
Создайте новый слот логической репликации с именем,
заданным параметром --slot, используя плагин вывода,
заданный параметром --plugin, для базы данных,
заданной параметром --dbname.
--drop-slot
Удалить слот репликации с именем, указанным параметром --slot, затем выйти.
--start
Начать запись потока в слот логической репликации,
указанный в параметре --slot, продолжая до сигнала отмены.
Если поток изменений на стороне сервера заканчивается
отключением или отключением сервера, повторите цикл, если не указан параметр --no-loop.
Формат потока определяется выходным плагином, указанным при создании слота. Соединение должно быть с той же базой данных, которая использовалась для создания слота.
--create-slotи--startмогут быть указаны вместе.--drop-slotне может быть объединено с другим действием.
Options
Следующие параметры командной строки управляют расположением и форматом вывода и другим поведением репликации:
| Аргумент | Описание |
|---|---|
| -S, --slot=SLOTNAME | Имя слота логической репликации для режимов --create-slot, --create-slot, --drop-slot. |
| -E, --endpos=LSN | Автоматически останавливать репликацию и выходить с кодом выхода 0, когда приём достигает указанного номера LSN. Подробнее |
| -f, --file=FILE | Записать полученные и декодированные данные транзакций в файл. Используйте -(минус) для стандартного вывода (stdout). |
| -F --fsync-interval=SECS | Частота вызова fsync() Подробнее |
| --if-not-exists | Не создавать ошибку, если --create-slot указан, а слот с таким именем уже существует. |
| -I, --startpos=LSN | В режиме --start начать репликацию с указанного номера LSN. Игнорируется в других режимах. |
| -n, --no-loop | Завершить работу с ошибкой, и не выполнять новую попытку подключения при ошибках соединения. |
| -o, --option=NAME[=VALUE] | Передать пару Name:Value в плагин вывода, указание Value опционально. Существующие параметры и их поведение зависит от используемого выходного плагина. |
| -P, --plugin=PLUGIN | Использовать указанный плагин вывода логического декодирования при создании слота репликации. Не действует, если слот уже существует. |
| -s, --status-interval=SECS | Интервал отправки пакетов состояния. Аналогично параметру qhb_receivewal - status interval |
End position
-E lsn, --endpos=lsn
Автоматически останавливать репликацию и выходить с кодом выхода 0,
когда приём достигает указанного номера LSN.
Если есть запись с LSN, равным lsn, запись будет обработана.
Опция --endpos не знает границ транзакции и может обрезать вывод во время транзакции.
Любая частично выводимая транзакция не будет использована и будет воспроизведена снова,
когда слот будет считан в следующий раз. Отдельные сообщения никогда не усекаются.
fsync-interval
-F SECS, --fsync-interval=SECS
Определяет, как часто qhb_recvlogical должен вызывать вызовы fsync()
чтобы убедиться, что выходной файл безопасно записан на диск.
Сервер иногда запрашивает у клиента очистку и сообщает серверу о положении очистки.
Этот параметр необходим для более частого выполнения сбросов. Задание интервала 0 отключает вызовы fsync() полностью, в то же время сообщая о ходе выполнения на сервер. В этом случае данные могут быть потеряны в случае сбоя.
CONNECTION OPTIONS
Следующие параметры командной строки управляют параметрами подключения к базе данных.
| Аргумент | Описание |
|---|---|
| -d, --dbname=DBNAME | Имя базы данных для подключения. |
| -h, --host=HOSTNAME | Имя хоста, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Значение по умолчанию берется из переменной среды PGHOST, далее предпринимается попытка подключения через сокет домена Unix. |
| -p, --port=PORT | TCP порт или расширение файла локального сокета домена Unix. По умолчанию берётся переменная среды PGPORT, или порт заданный при компиляции. |
| -U, --username=NAME | Имя пользователя для подключения. |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | Автоматически запросить пароль, если сервер требует аутентификацию по паролю. Утилита будет пытаться подключиться, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
COMMON OPTIONS
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти. |
| -V, --version | Вывести версию утилиты и выйти. |
| -v, --verbose | Включает подробный режим. |
Окружение
Эта утилита, как и большинство других утилит QHB, использует переменные окружения, поддерживаемые libpq .
Переменная окружения PG_COLOR указывает, использовать ли цвет в
диагностических сообщениях. Возможные значения always, auto, never .
Примечания
qhb_recvlogical сохранит разрешения группы для полученных файлов WAL,
если разрешения группы включены в исходном кластере.
Смотрите также
qhb_restore
qhb_restore - восстанавливает базу данных QHB из файла архива, созданного qhb_dump
Описание
qhb_restore - это утилита для восстановления базы данных QHB из
архива, созданного qhb_dump в одном из текстовых форматов. Он выдаст
команды, необходимые для восстановления базы данных до состояния, в
котором она находилась на момент сохранения. Архивные файлы также
позволяют qhb_restore избирательно выбирать то, что восстанавливается,
или даже переупорядочивать элементы перед восстановлением. Архивные
файлы предназначены для переноса между архитектурами.
qhb_restore может работать в двух режимах. Если указано имя базы данных,
qhb_restore подключается к этой базе данных и восстанавливает содержимое
архива непосредственно в базу данных. В противном случае сценарий,
содержащий команды SQL, необходимые для перестройки базы данных,
создается и записывается в файл или стандартный вывод. Этот вывод
сценария эквивалентен формату вывода простого текста qhb_dump. Поэтому
некоторые параметры, управляющие выводом, аналогичны параметрам qhb_dump
.
Очевидно, что qhb_restore не может восстановить информацию, которой нет
в файле архива. Например, если архив был создан с использованием опции «
сбросить данные как команды INSERT »( qhb_dump --insert ),
qhb_restore не сможет загружать данные с помощью операторов COPY.
Синтаксис
qhb_restore [connection-option...] [option...] [filename]
Параметры
qhb_restore принимает следующие аргументы командной строки.
Обратите внимание на то что для многих параметров существуют особенности использования и ознакомьтесь с расширенной справкой в разделе Дополнительная информация по параметрам.
COMMON OPTIONS
| Аргумент | Описание |
|---|---|
| -?, --help | Показать справку об аргументах командной строки и выйти. |
| -V, --version | Вывести версию qhb_restore и выйти. |
| -v, --verbose | Включить подробный режим. |
GENERAL OPTIONS
| Аргумент | Описание |
|---|---|
| -f, --file=FILENAME | Укажите выходной файл для сгенерированного скрипта или для листинга (ключ -l). Используйте - для стандартного вывода. |
-F, --format=c, d, t | Укажите формат архива. Обычно нет необходимости указывать формат, так как qhb_restore определит формат автоматически. См Форматы дампов |
| -j, --jobs=NUM | Запустить восстановление дампа в NUM потоков. Подробнее. |
CONNECTION OPTIONS
| Аргумент | Описание |
|---|---|
| -d, --dbname=DBNAME | Имя базы данных для подключения. qhb_restore не использует переменную PGDATABASE. |
| -h, --host=HOSTNAME | Имя хоста, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Значение по умолчанию берется из переменной среды PGHOST, далее предпринимается попытка подключения через сокет домена Unix. |
| -p, --port=PORT | TCP порт или расширение файла локального сокета домена Unix. По умолчанию берётся переменная среды PGPORT, или порт заданный при компиляции. |
| -U, --username=USERNAME | Имя пользователя для подключения. |
| -w, --no-password | Не запрашивать ввод пароля. Если серверу требуется аутентификация по паролю, а пароль недоступен другими способами, такими как файл .pgpass, попытка подключения завершится неудачно. Эта опция может быть полезна в пакетных заданиях и сценариях, где нет ни одного пользователя для ввода пароля. |
| -W, --password | qhb_restore автоматически запросит пароль, если сервер требует аутентификацию по паролю. qhb_restore будет пытаться подключиться, для аутентификации. В некоторых случаях стоит ввести -W чтобы избежать дополнительной попытки подключения. |
| --role=ROLENAME | Задает имя роли, которая будет использоваться для восстановления. Подробнее |
OPTIONS
| Аргумент | Описание |
|---|---|
| -a, --data-only | Восстановить только данные, а не схему (определения данных). Данные таблицы, крупные объекты и значения последовательности восстанавливаются, если они присутствуют в архиве. Эта опция похожа, но по историческим причинам не идентична --section=data . |
| -c, --clean | Очистить (DROP) объекты базы данных перед их воссозданием. (Если не используется --if-exists это может привести к сообщениям об ошибках, если какие-либо объекты не присутствуют в целевой базе данных.) |
| -C, --create | Создать базу данных перед ее восстановлением. Подробнее |
| -e, --exit-on-error | Выйти, если при отправке команд SQL в базу данных возникла ошибка. По умолчанию работа продолжается, а количество ошибок отображается в конце восстановления. |
| -I index, --index=index | Восстановить определение только именованного индекса. Несколько индексов могут быть указаны с несколькими ключами -I. |
| -l, --list | Создать оглавление архива Подробнее |
| -L, --use-list=FILENAME | Восстановление по оглавлению Подробнее |
| -n, --schema=SCHEMA | Восстановить объекты только из указанной схемы. Несколько схем могут быть указаны с несколькими ключами -n . Комбинируется с опцией -t чтобы восстановить только определенную таблицу. |
| -N, --exclude-schema=SCHEMA | Не восстанавливать объекты из указанной схеме. Исключает несколько схем, с несколькими ключами -N. Ключ -N приоритетнее чем-n, при одновременном указании - схема исключается. |
| -O, --no-owner | Не выполнять команды для установки владельца объектов в соответствии с исходной базой данных. Подробнее |
| -P, --function=NAME(args) | Восстановить только указанную функцию. Указывайте имя функции и аргументы в точности, как они указаны в оглавлении файла дампа. Несколько функций могут быть указаны с несколькими ключами -P . |
| -s, --schema-only | Восстановить только схему (определения данных), а не данные. Подробнее |
| -S, --superuser=NAME | Имя суперпользователя, которое будет использоваться при отключении триггеров. Актуально, только для --disable-triggers. |
| -t, --table=NAME | Восстановить определение и/или данные только указанной таблицы. Подробнее |
| -T, --trigger=NAME | Восстановить только названый триггер. Несколько триггеров могут быть указаны с несколькими ключами -T. |
| -x, --no-privileges | Пропустить восстановление прав доступа (команды GRANT / REVOKE). |
| -1, --single-transaction | Выполнить восстановление как одну транзакцию (обернуть отправленные команды в BEGIN / COMMIT ). Гарантирует что все команды завершаться успешно, либо изменения не применяются. Эта опция подразумевает --exit-on-error. |
| --disable-triggers | Отключение триггеров при восстановлении. Подробнее |
| --enable-row-security | Восстанавливать данные из таблиц с защитой строк. Подробнее |
| --if-exists | Использовать условные команды (добавить IF EXISTS ) при очистке объектов базы данных. Не работает без --clean. |
| --no-comments | Не восстанавливать комментарии даже если архив содержит их. |
| --no-publications | Не восстанавливать публикации даже если архив содержит их. |
| --no-security-labels | Не восстанавливать защитные метки даже если архив содержит их. |
| --no-subscriptions | Не восстанавливать подписки даже если архив содержит их. |
| --no-tablespaces | Не восстанавливать табличные пространства. Все объекты будут восстановлены в табличном пространстве по умолчанию. |
| --no-data-for-failed-tables | Не восстанавливать данные в таблицы которые не удалось создать Подробнее |
| --section=SECTION | Восстановить только указанный раздел. Имя раздела может быть pre-data, data, post-data. Подробнее |
| --strict-names | Требовать строго соответствия схем и таблиц таковым в файле резервной копии. Подробнее |
| --use-set-session-authorization | Использовать стандартные SQL команды для назначения владельцев объектов. Подробнее |
Дополнительная информация по параметрам
ROLENAME
--role=rolename
Указывает имя роли, которое будет использоваться для восстановления.
Эта опция заставляет qhb_restore выдавать команду SET ROLE rolename
после подключения к базе данных. Это полезно, когда
аутентифицированному пользователю (указанному -U ) не хватает
привилегий, необходимых для qhb_restore, но он может переключиться
на роль с необходимыми правами. В некоторых установках есть
политика, запрещающая вход в систему непосредственно от имени
суперпользователя, и использование этого параметра позволяет
выполнять восстановление без нарушения политики.
create
-C, --create
Создать базу данных перед ее восстановлением. Если также указан
параметр --clean удалить и заново создать целевую базу данных
перед подключением к ней.
С помощью qhb_restore --create также восстанавливаются комментарий
базы данных, если он есть, и любые параметры переменной
конфигурации, специфичные для этой базы данных, то есть любые ALTER DATABASE ... SET ... и ALTER ROLE ... IN DATABASE ... SET ...
команды, которые упоминают эту базу данных. Права доступа к самой
базе данных также восстанавливаются, если не указан параметр
--no-acl .
Когда используется эта опция, база данных с именем -d используется
только для выдачи начальных команд DROP DATABASE и CREATE DATABASE .
Все данные восстанавливаются в базу данных по имени которое указано
в архиве.
Параллельное восстановление
-j NUM, --jobs=NUM
Запускайте самые трудоемкие части qhb_restore - те, которые
загружают данные, создают индексы или создают ограничения -
используя несколько одновременных заданий. Эта опция может
значительно сократить время восстановления большой базы данных на
сервере, работающем на многопроцессорной машине.
Каждое задание представляет собой один процесс или один поток, в зависимости от операционной системы, и использует отдельное соединение с сервером.
Оптимальное значение для этого параметра зависит от аппаратной настройки сервера, клиента и сети. Факторы включают количество ядер ЦП и настройку диска. Как правило, можно установить параметр равным количеству ядер ЦП на сервере, но значения, превышающие это, во многих случаях также могут привести к более быстрому восстановлению. Конечно, слишком высокие значения приведут к снижению производительности из-за перегрузки.
Эта опция поддерживает только пользовательские форматы и форматы
каталогов. Входными данными должен быть обычный файл или каталог
(не, например, канал). Этот параметр игнорируется при создании
сценария, а не при подключении напрямую к серверу базы данных. Кроме
того, несколько заданий нельзя использовать вместе с опцией --single-transaction .
Оглавление архива
-l, --list
Вывести оглавление архива. Выходные данные этой операции могут
использоваться как входные данные для опции -L. Обратите внимание,
что если с -l используются переключатели фильтрации, такие как -n
или -t, они ограничат перечисленные элементы.
-L FILENAME, --use-list=FILENAME
Восстановите только те элементы архива, которые перечислены в
FILENAME, и восстановите их в порядке их появления в файле.
Обратите внимание, что если с -L используются переключатели
фильтрации, такие как -n или -t, они еще больше ограничат
восстановленные элементы.
Входной файл обычно создается путем редактирования вывода предыдущей
операции -l. Строки можно перемещать или удалять, а также
закомментировать, поместив точку с запятой ( ; ) в начале строки.
Смотрите ниже примеры.
no owner
-O, --no-owner
Не выполнять команды для установки владельца объектов в соответствии
с исходной базой данных. По умолчанию qhb_restore выдает операторы
ALTER OWNER или SET SESSION AUTHORIZATION чтобы установить владельца
созданных элементов схемы. Эти операторы потерпят неудачу, если
исходное соединение с базой данных установлено не суперпользователем
(или пользователем, которому принадлежат все объекты в сценарии).
С ключом -O любой пользователь может использоваться для
начального соединения, и этот пользователь будет владеть всеми
созданными объектами.
schema only
-s, --schema-only
Восстановить только схему (определения данных), а не данные, в той степени, в которой записи схемы присутствуют в архиве.
Эта опция является обратной к --data-only. Это похоже на, но по
историческим причинам не идентично указанию --section=pre-data
--section=post-data .
(Не путайте это с параметром --schema, который использует слово «
схема » в другом значении.)
table
-t table, --table= table
Восстановить определение и / или данные только указанной таблицы.
В этом случае «таблица» включает в себя представления,
материализованные представления, последовательности и сторонние
таблицы. Несколько таблиц можно выбрать, написав несколько ключей -t.
Эта опция может быть объединена с опцией -n для указания таблиц в
конкретной схеме.
Заметка
Если указан параметр-t,qhb_restoreне пытается восстановить какие-либо другие объекты базы данных, от которых могут зависеть выбранные таблицы. Следовательно, нет гарантии, что восстановление определенной таблицы в чистую базу данных будет успешным.
Заметка
Этот флаг не ведет себя идентично флагу -tqhb_dump. В настоящее время вqhb_restoreнет условий для подстановочных знаков, и вы не можете включить имя схемы в его -t. И хотя флаг -tqhb_dumpтакже будет выгружать вспомогательные объекты (например, индексы) выбранных таблиц, флаг-tqhb_restoreне включает такие вспомогательные объекты.
Отключение триггеров
--disable-triggers
Эта опция актуальна только при выполнении восстановления только
данных. Опция инструктирует qhb_restore выполнять команды для
временного отключения триггеров на целевых таблицах во время
загрузки данных. Используйте, если есть проверки ссылочной целостности или
другие триггеры для таблиц, которые не нужно вызывать во время
восстановления данных.
В настоящее время команды, отправляемые для --disable-triggers
должны выполняться как суперпользователь. Поэтому вы должны также
указать имя суперпользователя с помощью -S или, предпочтительно,
запустить qhb_restore как суперпользователь.
Защита строк
--enable-row-security
Эта опция актуальна только при восстановлении содержимого таблицы с
защитой строк. По умолчанию qhb_restore выключит row_security,
чтобы все данные были восстановлены в таблице. Если у пользователя
недостаточно прав для обхода защиты строк, выдается ошибка. Этот
параметр указывает qhb_restore включить вместо row_security
значение, позволяющее пользователю попытаться восстановить
содержимое таблицы с включенной защитой строк. Это может по-прежнему
не работать, если пользователь не имеет права вставлять строки из
дампа в таблицу.
Обратите внимание, что этот параметр также требует, чтобы дамп был в формате INSERT, так как COPY FROM не поддерживает безопасность строк.
no-data-for-failed-tables
--no-data-for-failed-tables
По умолчанию данные таблицы восстанавливаются, даже если команда создания таблицы не выполнена (например, потому что она уже существует). С этой опцией данные для такой таблицы пропускаются. Это поведение полезно, если целевая база данных уже содержит требуемое содержимое таблицы. Например, вспомогательные таблицы для расширений QHB, таких, как PostGIS, могут быть уже загружены в целевую базу данных; указание этого параметра предотвращает загрузку в них дубликатов или устаревших данных.
Этот параметр действует только при восстановлении непосредственно в базу данных, но не при выводе сценария SQL.
Section
--section=SECTION
Восстановить только указанный раздел. Имя раздела может быть
pre-data, data, post-data. Эта опция может быть указана более
одного раза, чтобы выбрать несколько разделов. По умолчанию
восстанавливается все разделы.
Раздел данных содержит фактические данные таблиц, а также определения крупных объектов. Элементы после данных состоят из определений индексов, триггеров, правил и ограничений, отличных от проверенных проверочных ограничений. Элементы предварительных данных состоят из всех других элементов определения данных.
strict-names
--strict-names
Проверять в обязательном порядке, чтобы каждая схема ( -n / --schema )
и --schema таблицы (-t / --table ) соответствовали
хотя бы одной схеме / таблице в файле резервной копии.
use-set-session-authorization
--use-set-session-authorization
Использовать стандартные команды SQL SET SESSION AUTHORIZATION вместо
команд ALTER OWNER для назначения принадлежности объектов.
Это делает скрипт более совместимым со стандартами, но в зависимости от
истории объектов в дампе, восстановление может произойти не должным образом.
Окружение
qhb_restoreне использует переменную PGDATABASE, если имя базы данных не указано.
PGHOST
PGOPTIONS
PGPORT
PGUSER
- Параметры подключения по умолчанию
PG_COLOR
- Указывает, использовать ли цвет в диагностических сообщениях. Возможные значения always, auto, never .
Эта утилита, как и большинство других утилит QHB, также использует переменные среды, поддерживаемые libpq.
Диагностика
Когда прямое соединение с базой данных указывается с помощью опции -d,
qhb_restore внутренне выполняет операторы SQL. Если у вас возникли
проблемы с запуском qhb_restore, убедитесь, что вы можете выбирать
информацию из базы данных, используя, например, qsql. Кроме того, будут
применяться любые параметры подключения по умолчанию и переменные среды,
используемые интерфейсной библиотекой libpq .
Примечания
Если в вашей установке есть какие-либо локальные дополнения к базе
данных template1, будьте осторожны, чтобы загрузить вывод qhb_restore в
действительно пустую базу данных; в противном случае вы можете получить
ошибки из-за дублирования определений добавленных объектов. Чтобы
создать пустую базу данных без каких-либо локальных дополнений,
скопируйте из template0 не из template1, например:
CREATE DATABASE foo WITH TEMPLATE template0;
Ограничения
Ограничения qhb_restore подробно описаны ниже.
При восстановлении данных в существующей таблице и использовании
опции --disable-triggers, утилита qhb_restore генерирует команды для
отключения триггеров в пользовательских таблицах перед вставкой
данных, а затем выполняет команды для их повторного включения после
вставки данных. Если восстановление остановлено в середине,
системные каталоги могут остаться в неправильном состоянии.
qhb_restore не может выборочно восстанавливать большие объекты;
например, только для определенной таблицы. Если в архиве содержатся
большие объекты, то все большие объекты будут восстановлены, или ни
один из них, если они исключены с помощью -L, -t или других
параметров.
Смотрите также документацию по qhb_dump для подробностей об ограничениях
qhb_dump .
Файл дампа, созданный qhb_dump, не содержит статистику, используемую
оптимизатором для принятия решений по планированию запросов. Поэтому
целесообразно запускать ANALYZE после восстановления из дампа,
чтобы обеспечить оптимальную производительность;
см. раздел Обновление статистики планировщика и
раздел Процесс «Автовакуум» для получения дополнительной информации.
Примеры
Предположим, мы сделали дамп базы данных mydb в пользовательском формате:
$ qhb_dump -Fc mydb > db.dump
Чтобы удалить базу данных и воссоздать ее из дампа:
$ dropdb mydb
$ qhb_restore -C -d qhb db.dump
База данных, указанная в -d может быть любой базой данных, существующей
в кластере; qhb_restore использует его только для выдачи команды CREATE DATABASE для mydb. С ключом -C данные всегда восстанавливаются в имя базы
данных, которое появляется в файле дампа.
Чтобы перезагрузить дамп в новую базу данных с именем newdb :
$ createdb -T template0 newdb
$ qhb_restore -d newdb db.dump
Обратите внимание, что мы не используем -C, а вместо этого подключаемся
непосредственно к базе данных, в которую нужно восстановить. Также
обратите внимание, что мы клонируем новую базу данных из template0 не
template1, чтобы убедиться, что она изначально пуста.
Чтобы изменить порядок элементов базы данных, сначала необходимо вывести содержимое архива:
$ qhb_restore -l db.dump > db.list
Файл списка состоит из заголовка и одной строки для каждого элемента, например:
;
; Archive created at Mon Sep 14 13:55:39 2019
; dbname: DBDEMOS
; TOC Entries: 81
; Compression: 9
; Dump Version: 1.10-0
; Format: CUSTOM
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 8.3.5
; Dumped by qhb_dump version: 8.3.8
;
;
; Selected TOC Entries:
;
3; 2615 2200 SCHEMA - public pasha
1861; 0 0 COMMENT - SCHEMA public pasha
1862; 0 0 ACL - public pasha
317; 1247 17715 TYPE public composite pasha
319; 1247 25899 DOMAIN public domain0 pasha
Точки с запятой начинаются с комментария, а цифры в начале строк относятся к внутреннему идентификатору архива, назначенному каждому элементу.
Строки в файле могут быть закомментированы, удалены и переупорядочены. Например:
10; 145433 TABLE map_resolutions qhb
;2; 145344 TABLE species qhb
;4; 145359 TABLE nt_header qhb
6; 145402 TABLE species_records qhb
;8; 145416 TABLE ss_old qhb
может использоваться в качестве входных данных для qhb_restore и
восстанавливает только элементы 10 и 6 в следующем порядке:
qhb_restore -L db.list db.dump
Смотрите Также
qsql - Интерактивный терминал QHB
qsql - интерактивный терминал QHB.
Синтаксис
qsql [параметры]
Описание
qsql - это консольный интерфейс QHB. Он позволяет вводить запросы в интерактивном режиме, выполнять их в QHB и просматривать результаты запроса. Альтернативно, ввод запросов может осуществляться из файла, конвеера ранее запущенной программы или из аргументов командной строки. Кроме того, qsql предоставляет несколько метакоманд и различные функции для облегчения написания сценариев и автоматизации широкого спектра задач.
Параметры
- -h <ХОСТ>
- --host <ХОСТ>
- Определяет хост сервера баз данных. Если значение начинается с косой черты, оно используется как каталог для доменного сокета Unix. [default: /var/run/postgresql/]
- -d <БД>
- --database <БД>
- Определяет имя базы данных для подключения. [default: параметр --username]
- -p <ПОРТ>
- --port <ПОРТ>
- Указывает порт TCP или расширение файла локального сокета Unix-домена, на котором сервер прослушивает соединения. По умолчанию используется значение 5432
- -U <ПОЛЬЗОВАТЕЛЬ>
- --username <ПОЛЬЗОВАТЕЛЬ>
- Имя пользователя [default: Пользователь ОС]
- -W <ПАРОЛЬ>
- --password <ПАРОЛЬ>
- Явное указание пароля [deprecated]
- -l, <УРОВЕНЬ>
- --log-level <УРОВЕНЬ>
- Уровень логирования (Off, Error, Warn, Info, Debug, Trace) [default: Info]
Дополнительные параметры (флаги)
- --help
- Показать справку о qsql и выйти.
- -w
- --no-password
- Отменяет запрос пароля. В текущей версии при неудачном подключении пароль, тем не менее, будет запрошен.
- --version
- Распечатать версию qsql и выйти.
- Переменная отвечает за значение параметра
--hostприменяемое при запуске qsql по умолчанию - initdb - создать новый кластер базы данных QHB
- qhb_archivecleanup - очистить архивные файлы QHB WAL
- qhb_checksums - включить, отключить или проверить контрольные суммы данных в кластере базы данных QHB
- qhb_controldata - отображать управляющую информацию кластера базы данных QHB
- qhb_ctl - инициализировать, запустить, остановить или управлять сервером QHB
- qhb_resetwal - сбросить журнал предварительной записи и другую управляющую информацию кластера базы данных QHB
- qhb_rewind - синхронизирует каталог данных QHB с другим каталогом данных, который был ответвлен от него
- qhb_upgrade - обновить экземпляр сервера QHB
- qhb_waldump - отображает WAL кластера базы данных QHB в удобочитаемом виде
-
-Aauthmethod
--auth=authmethodЭтот параметр определяет метод аутентификации по умолчанию для локальных пользователей, используемый в
qhb_hba.conf(строкиhostиlocal).initdbпредварительно внесет вqhb_hba.confуказанный метод аутентификации для обычный и репликационных соединений.Не используйте
trustесли вы не доверяете всем локальным пользователям в вашей системе.trustиспользуется по умолчанию для простоты установки. -
--auth-host=authmethodЭтот параметр определяет метод аутентификации для локальных пользователей для соединения по TCP/IP, используемый в
qhb_hba.conf(строки host). -
--auth-local=authmethodЭтот параметр указывает метод аутентификации для локальных пользователей для соединения по Unix-сокет, используемые в
qhb_hba.conf(строкиlocal). -
-Ddirectory
--pgdata=directoryЭтот параметр указывает каталог, в котором должен храниться кластер базы данных. Это единственный обязательный параметр, необходимый для
initdb. Но его можно не вводить, если установить переменную окруженияPGDATA. При дальнейшем использовании, так может быть удобно, поскольку сервер базы данных (qhb) может позже найти каталог базы данных по этой переменной окружения. -
-Eencoding
--encoding=encodingОпределяет кодировку шаблона базы данных. Эта будет кодировка будет использоваться по умолчанию для любой базы данных, которую вы создадите в дальнейшем, если вы не переопределите ее. Значение по умолчанию определяется на основе локали. Если локаль не удалось определить, то выбирается
SQL_ASCII. Наборы символов, поддерживаемые сервером QHB, описаны в разделе Поддержка набора символов. -
-g
--allow-group-accessПозволяет пользователям в той же группе, что и владелец кластера, читать все файлы кластера, созданные
initdb. Этот параметр игнорируется в Windows, так как в ней не поддерживаются разрешения группы в стиле POSIX. -
-k
--data-checksumsИспользовать контрольные суммы на страницах данных, чтобы помочь обнаружить повреждения системы при вводе-выводе, которая в противном случае были бы незамеченными. Включение контрольных сумм может повлечь за собой заметное снижение производительности. Если этот параметр установлен, то контрольные суммы будут рассчитываться для всех объектов и во всех базах данных. Все ошибки контрольной суммы будут видны в представлении
pg_stat_database. -
--locale=localeУстанавливает локаль по умолчанию для кластера базы данных. Если этот параметр не указан, локаль наследуется от окружения, в которой запускается
initdb. Поддержка локали описана в Разделе 9.1. -
--lc-collate=locale
--lc-ctype=locale
--lc-messages=locale
--lc-monetary=locale
--lc-numeric=locale
--lc-time=localeПодобно
--locale, но устанавливает локаль только в указанной категории. -
--no-localeЭквивалентно
--locale=C -
-N
--no-syncПо умолчанию
initdbождиает пока все файлы будут надёжно записаны на диск. Этот параметр позволитinitdbзавершаться быстрее - без ожидания, но в случае падения операционной системы может привести к повреждению каталога данных. Как правило, этот параметр полезен для тестирования, и его не следует использовать в продакшене. -
--pwfile=filenameЗаставляет
initdbчитать пароль суперпользователя базы данных из файла. Первая строка файла берется в качестве пароля. -
-S
--sync-onlyБезопасно записать все файлы базы данных на диск и выйти. Не выполняет никаких других обычных операций
initdb. -
-Tconfig
--text-search-config=configУстанавливает конфигурацию текстового поиска по умолчанию. См. default_text_search_config для получения дополнительной информации.
-
-Uusername
--username=usernameУстанавливает имя пользователя базы данных суперпользователя. По умолчанию это имя пользователя операционной системы, запускающего
initdb. На самом деле, имя суперпользователя неважно, и этот параметр позволяет использовать привычное имяqhb, если имя пользователя операционной системы отличается. -
-W
--pwpromptЗаставляет
initdbзапросить пароль, предназначенный для суперпользователя базы данных. Если вы не планируете использовать аутентификацию по паролю, это не важно. В противном случае вы не сможете использовать аутентификацию по паролю, пока не настроите пароль. -
-Xdirectory
--waldir=directoryЭтот параметр указывает каталог, в котором должен храниться WAL.
-
--wal-segsize=sizeУстанавливает размер сегмента WAL в мегабайтах, то есть размер каждого отдельного файла в журнале WAL. По умолчанию составляет 16 мегабайт. Значение должно быть степенью 2 от 1 до 1024 (мегабайт). Этот параметр может быть установлен только во время инициализации и не может быть изменен.
Этот пареметр может быть полезно настроить для контроля степени гранулярности и архивации журнала WAL. Кроме того, в базах данных с большим объемом WAL большое количество файлов WAL в каталоге может стать проблемой производительности и управления. Увеличение размера файла WAL приведет к уменьшению количества файлов WAL.
-
-d
--debugВыводит отладочные и другие сообщения загрузчика, представляющие наименьший интерес. Загрузчик - это программа, которую
initdbиспользует для создания таблиц каталога. С этим параметром генерируется большое количество чрезвычайно скучных сообщений. -
-LdirectoryУказывает, где
initdbдолжен искать входные файлы для инициализации кластера базы данных. Обычно в этом нет необходимости. В случае необходмости, вам будет предложено указать их местоположение явно. -
-n
--no-cleanПо умолчанию, если ошибка помешала создать кластер базы данных,
initdbудаляет все файлы, которые он создал. Этот параметр запрещает удаление файлов в цеялх отладки. -
-V
--versionПоказать версию
initdbи выйти. -
-?
--helpПоказать справку об аргументах командной строки
initdbи выйти. - Указывает каталог, в котором должен храниться кластер базы данных; может быть переопределено с помощью опции -D.
- Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never.
- Указывает часовой пояс по умолчанию для созданного кластера базы данных. Значением должно быть полное имя часового пояса (см. раздел Часовые пояса).
- Синтаксис
- Описание
- Безопасность
- Локализация
- Параметры
- Флаги
- Опции
- Сценарии использования
- Окружение
- Смотрите также
-D,--data-dir <data-dir>Каталог хранения данных кластера. Это единственный обязательный параметр для утилитыqhb_bootstrap. Может быть задан или с флагами -D, --data-dir, или последним параметром, тогда флаги -D, --data-dir можно опустить. При этом его можно указать в переменной окружения PGDATA, что будет удобным при дальнейшем использовании (QHB обращается к этой же переменной).-
-h,--help
Вывод справочной информации -
-g,--allow-group-access
Позволяет пользователям, входящим в группу владельца кластера, читать все файлы кластера, создаваемые программой qhb_bootstrap.
По-умолчанию: false. -
-k,--data-checksums
Применять контрольные суммы на страницах данных для выявления сбоев при вводе/выводе, которые иначе останутся незамеченными. Расчёт контрольных сумм может повлечь заметное снижение производительности. Когда контрольные суммы включены, они рассчитываются для всех объектов и во всех базах данных. Все ошибки контрольных сумм будут видны в представлении pg_stat_database.
По-умолчанию: false. -
-n,--no-clean
По умолчанию, при выявлении ошибки на этапе развёртывания кластера,qhb_bootstrapудаляет все файлы, которые к тому моменту были созданы. Параметр отменяет очистку файлов для целей отладки.
По-умолчанию: false (то есть очищать). -
-N,--no-sync
По умолчаниюqhb_bootstrapждёт, пока все файлы не будут надёжно записаны на диск. С данным параметромqhb_bootstrapзавершается быстрее, без ожидания, но в случае неожиданного сбоя операционной системы каталог данных может оказаться испорченным. Этот параметр может быть полезен при тестировании, в производственной среде применять его не следует.
По-умолчанию: false. -
-W,--pwprompt
Указываетqhb_bootstrapзапросить пароль, который будет назначен суперпользователю базы данных. -
-s,--show
Выводит конфигурацию без создания кластера. Другие операции при этом не выполняются.
По-умолчанию: false. -
-S,--sync-only
Безопасно записывает все файлы базы на диск и останавливается. Другие операции при этом не выполняются.
По-умолчанию: false. -
-d,--debug
Выводит отладочные сообщения.
По-умолчанию: false. -
-V,--version
Выводит текущую версию -
-A,--auth
Метод аутентификации по умолчанию для локальных пользователей, используемый в файле qhb_hba.conf (строки local и host).
По-умолчанию: trust. -
--auth-host
Метод аутентификации по умолчанию для локальных пользователей, подключающихся по TCP/IP, используемый в файле qhb_hba.conf (строки host).
Доступные варианты: trust, reject, scram_sha_256, md5, password, radius, pam, bsd, ldap, ident, gss, sspi, cert.
По-умолчанию: из опции --auth. -
--auth-local
Метод аутентификации по умолчанию для локальных пользователей, подключающихся через Unix-сокет, используемый в файле qhb_hba.conf (строки local).
Доступные варианты: trust, reject, scram_sha_256, md5, password, radius, pam, bsd, ldap, peer.
По-умолчанию: из опции --auth. -
-E,--encoding
Кодировка шаблона и новых баз данных по умолчанию, если не указать иное при их создании. В настоящий момент поддерживается только UTF8.
По-умолчанию: UTF8. -
--locale
Локаль кластера по умолчанию.
По-умолчанию: нейтральная локаль (Си-локаль). -
--lc-collate
Локаль для порядка сортировки строк.
По-умолчанию: из опции --locale. -
--lc-ctype
Локаль для классификации символов.
По-умолчанию: из опции --locale. -
--lc-messages
Язык сообщений.
По-умолчанию: из опции --locale. -
--lc-monetary
Локаль для форматирования валют.
По-умолчанию: из опции --locale. -
--lc-numeric
Локаль для форматирования чисел.
По-умолчанию: из опции --locale. -
--lc-time
Локаль для форматирования даты и времени.
По-умолчанию: из опции --locale. -
--no-locale
Равносильно--locale=C, то установка нейтральной локали по умолчанию. Нельзя задать одновременно с параметром--locale. -
--pwfile
Чтение пароля суперпользователя базы данных из первой строки указанного файлa. Опцииpwpromptиpwfileявляются взаимоисключающими. Если в опцияхauth-hostилиauth-localуказан метод аутентификации, отличный отtrust, то наличие одной из опцийpwpromptилиpwfileявляется обязательным. -
-L,--share-dir
Каталог, где необходимо искать входные файлы для развёртывания кластера.
По-умолчанию: "share" внутри каталога, указанного в опцииdata-dir. -
-T,--text-search-config
Конфигурация текстового поиска по умолчанию. См. default_text_search_config для получения дополнительной информации.
По-умолчанию: соответствующее выбранной локалиlc_ctype, если не удалось найти, то "simple". -
-U,--username
Имя суперпользователя базы данных.
По-умолчанию: имя пользователя ОС, запустившегоqhb_bootstrap. Позволяет оставить привычноеqhb, если имя пользователя ОС другое. -
-X,--waldir
Каталог для хранения журнала предзаписи.
По-умолчанию: "pg_wal" внутри каталога, указанного в опцииdata-dir. -
--wal_segsize
Размер сегмента WAL, в мегабайтах. Такой размер будет иметь каждый отдельный файл в журнале WAL. Значение должно задаваться степенью 2 от 1 до 1024 (в мегабайтах). Параметр можно установить только во время инициализации и нельзя изменить позже.Этот размер бывает полезно поменять при тонкой настройке трансляции или архивации WAL. Кроме того, в базах данных с WAL большого объёма огромное количество файлов WAL в каталоге может стать проблемой с точки зрения производительности и администрирования. Увеличение размера файлов WAL приводит к уменьшению числа этих файлов.
По-умолчанию: 16. - Указывает каталог, в котором должен храниться кластер базы данных;
может быть переопределено с помощью опции-D. - Указывает, использовать ли цвета в диагностических сообщениях.
Возможные значения always, auto, never. - выводить отладочную информацию в cleanup.log
- удалять ставшие ненужными файлы из каталога архива
-
-ffilenode
--filenode=filenodeПроверить контрольнные суммы только для отношения с указанным
filenode -
-Ddirectory
--pgdata=directoryУказывает каталог, в котором хранится кластер базы данных. (env: PGDATA=/tmp/qhb-data/)
-
-c
--checkПроверяет контрольные суммы. Это режим по умолчанию, если ничего не указано.
-
-d
--disable
Отключить контрольные суммы. -
-e
--enable
Включить контрольные суммы. -
-h
--helpВывести справочную информацию.
-
-N
--no-syncНе ждать, пока изменения будут безопасно записаны на диск. По умолчанию
qhb_checksumsбудет ожидать безопасной записи всех файлов на диск. Этот параметр позволяетqhb_checksumsзавершаться без ожидания, что быстрее, но в случае сбоя операционной системы может привести к повреждению обновленного каталога данных. Как правило, этот параметр полезен для тестирования, но его не следует использовать в продакшене. -
-P
--progressВыводить сообщения о прогрессе выполнения. Сообщения будут выводиться при проверке или включении контрольных сумм.
-
-V
--versionПоказать информацию о версии и выйти
-
-v
--verboseВыводить подробные сообщения. Уровень отладки по умолчанию: Warn
- Указывает каталог, в котором хранится кластер базы данных; может
быть переопределено с помощью параметра
-D. - Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never .
-
qhb_checksums -e
первый запуск, включение контрольных сумм, в конце выводится статистика с количеством обработанных блоков и файлов, любая ошибка приводит к остановке и выходу с кодом 1. -
qhb_checksums -с
проверка уже включённых контрольных сумм, отношение к статистике и ошибкам такое же, как у--enable -
qhb_checksums -d
последний запуск программы, выключает контрольные суммы, несмотря на любые ошибки, кромеPermission deniedна/global/pg_control -
--verboseдля вывода отладочной информации -
--no-syncдля отключения сброса изменений на диск -
--progressдля отображения хода выполнения - Местоположение каталога данных по умолчанию
- Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never .
-
PGCTLTIMEOUT
Ограничение по умолчанию на количество секунд ожидания при ожидании запуска или завершения работы. Если не установлено, то по умолчанию используется значение 60 секунд.
-
PGDATA
Расположение каталога данных по умолчанию.
-
qhbmaster.pid
qhb_ctlпроверяет этот файл в каталоге данных, чтобы определить, работает ли сервер в данный момент. -
postmaster.opts
Если этот файл существует в каталоге данных,
qhb_ctl(в режимеrestart) передаст содержимое файла в качестве аргументов qhb, если он не переопределен параметром-o. Содержимое этого файла также отображается в режимеstatus. -
-f
--forceПринудительное выполнение
qhb_resetwalдаже если он не может получить приемлимые данные изpg_control, как объяснено выше. -
-n
--dry-runВывести значения, восстановленные из
pg_controlи значения, которые должны быть изменены, и выйим ничего не изменяя. В основном используется как инструмент отладки, но он также может быть полезен для проверки корректности параметров, прежде чем позволитьqhb_resetwalначать работу по-настоящему. -
-V
--versionПоказать версию и выйти.
-
-?
--helpПоказать справку и выйти.
-
-cxid, xid
--commit-timestamp-ids=xid, xidВручную установить самые старые и новейшие ID транзакций, для которых можно получить время фиксации.
Безопасное значение для самого старого ID транзакции, для которого можно получить время фиксации, можно определить найдя наименьшее в числовом виде имя файла в подкаталоге
pg_commit_tsкаталога данных. И наоборот, безопасное значение для новейшего ID транзакции, для которого можно получить время фиксации (вторая часть), можно определить найдя наибольшое в числовом виде имя файла. Числа в именах файлов представлены в шестнадцатеричном формате. -
-exid_epoch
--epoch=xid_epoch
Вручную установить эпоху идентификатора следующей транзакции.Эпоха идентификатора транзакции фактически не сохраняется нигде в базе данных, кроме поля, устанавленного параметром
qhb_resetwal, поэтому любое значение будет допустимым в отношении самой базы данных. Возможно, вам придется настроить это значение, чтобы обеспечить правильную работу систем репликации, таких как Slony-I и Skytools, - для такого случая соответствующее значение должно быть получено из состояния нижележащей реплицированной базы данных. -
-lwalfile
--next-wal-file=walfileВручную установить начальную позицию WAL, указав имя файла следующего сегмента WAL.
Имя файла следующего сегмента WAL должно быть больше, любых других имен файлов сегментов WAL, которые в настоящее время находятся в подкаталоге
pg_walкаталога данных. Эти имена также в представлены шестнадцатеричном виде и состоят из трех частей. Первая часть является «ID линии времени» и обычно должна оставаться неизменной. Например, если00000001000000320000004Aявляется самой большой записью вpg_wal, используйте-l 00000001000000320000004Bили большее число.Обратите внимание, что при использовании нестандартных размеров сегментов WAL числа в именах файлов WAL отличаются от номеров LSN, выдаваемых системными функциями и представлениями. Этот параметр принимает имя файла WAL, а не LSN.
Заметка
Самqhb_resetwalпросматривает файлы вpg_walи по умолчанию выбирает для параметра-lзначение идущее следующим после найденного. Поэтому задвать параметр-lвручную необходимо только в том случае, если вам известно о существовании сегментов WAL, которые в данный момент отсутствуют вpg_wal, например если лежат в отдельном архиве, либо если содержимоеpg_walполностью утеряно. -
-mmxid, mxid
--multixact-ids=mxid, mxidВручную установить ID следующей и самой старой мультитранзакции.
Безопасное значение для следующего идентификатора мультитранзакции может быть определено путем поиска самого большого в числовом виде имени файла в подкаталоге
pg_multixact/offsetsв каталоге данных. К найденному числу надо прибавить один и умножить на 65536 (0x10000). И наоборот, безопасное значение идентификатора самой старой мультитранзакции (вторая часть-m) можно определить, найдя наименьшее в числовом виде имя файла в том же каталоге и его умножив на 65536. Имена файлов представлены в шестнадцатеричном формате, поэтому самый простой способ умножить это добавить четыре нуля к имени файлу. -
-ooid
--next-oid=oidВручную установить следующий OID.
Не существует сравнительно простого способа определить следующий за наибольшим из существующих значений OID, но, к счастью, это не критично.
-
-Omxoff
--multixact-offset=mxoffВручную установить смещение следующей мультитранзакции.
Безопасное значение может быть определено, найдя наибольшее в числовом виде имя файла в подкаталоге
pg_multixact/membersкаталога данных, прибавив один и умножив на 52352 (0xCC80). Имена файлов представлены в шестнадцатеричном формате. Простого рецепта, как для других параметров с добавленией нулей, здесь нет. -
--wal-segsize=wal_segment_sizeУстановить новый размер сегмента WAL в мегабайтах. Значение должно быть степенью 2 от 1 до 1024 (мегабайт). Смотрите тот же параметр в initdb для получения дополнительной информации.
Заметка
В то время какqhb_resetwalустанавливает начальный адрес WAL, превышающий номер последнего существующего файла сегмента WAL, при некоторых изменениях размера предыдущие имена файлов WAL могут использоваться повторно. Вместе с этим параметром, рекомендуется использовать-l, чтобы вручную установить начальный адрес WAL, если наложение имен файлов WAL вызывает проблемы для вашей стратегией архивирования. -
-xxid
--next-transaction-id=xidВручную установить идентификатор следующей транзакции.
Безопасное значение можно определить, найдя наибольшее в числовом виде имя файла в подкаталоге
pg_xactкаталога данных, прибавив один и умножив на 1048576 (0x100000). Обратите внимание, что имена файлов представлены в шестнадцатеричном формате. Обычно проще всего указать значение параметра в шестнадцатеричном формате. Например, если0011наибольшее значение вpg_xact, то подходящим значение будет-x 0x1200000(пять последних нулей обеспечивают правильный множитель). - Указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never.
-
Сканируется журнал WAL целевого кластера, начиная с последней контрольной точки до момента расхождения истории линии времени исходного кластера и целевого кластера. Для каждой записи WAL отмечается каждый затронутый блок данных. В результате получается список всех блоков данных, которые были изменены в целевом кластере после того, как исходный кластер отделился.
-
Копируются все эти измененные блоки из исходного кластера в целевой кластер, напрямую через файловую систему (
--source-pgdata) или через SQL (--source-server). -
Копируются все остальные файлы, такие как pg_xact и файлы конфигурации, из исходного кластера в целевой (исключая файлы отношений). Как и при базовом копировании, содержимое каталогов
pg_dynshmem/,pg_notify/,pg_replslot/,pg_serial/,pg_snapshots/,pg_stat_tmp/иpg_subtrans/исключается из данных, копируемых из исходного кластера. Также исключаются файлы или каталоги, начинающиеся сpgsql_tmp, а также файлыbackup_label,tablespace_map,pg_internal.init,postmaster.optsиqhbmaster.pid. -
Применяется WAL из исходного кластера, начиная с контрольной точки, созданной при отработке отказа. (Строго говоря,
qhb_rewindне применяет WAL, он просто создает файл метки резервной копии, который запускает QHB и воспроизводит все WAL с этой контрольной точки). -
Переместить старый кластер
Если ваш используете установочный каталог привязан к конкретной версии, например
/opt/QHB/1, то вам не требуется перемещать старый кластер. Все графические установщики используют директории установки привязанные к конкретной версии.Если ваш установочный каталог не зависит от версии, например
/usr/local/qhb, необходимо переместить текущий установочный каталог QHB, чтобы он не мешал новой установке QHB. Когда текущий сервер QHB выключен, каталог этой установки QHB можно безопасно переместить; если старый каталог -/usr/local/qhb, вы можете переименовать его:mv /usr/local/qhb /usr/local/qhb.old -
Установите новые исполняемые файлы QHB
Установите новый исполняемые файлы сервера и вспомогательные файлы.
qhb_upgradeвключен в установку по умолчанию. -
Инициализировать новый кластер QHB
Инициализируйте новый кластер, используя qhb_bootstrap. Используйте совместимые флаги
qhb_bootstrapкоторые соответствуют флагам старого кластера. Многие готовые установщики делают этот шаг автоматически. Нет необходимости запускать новый кластер. -
Установите дополнительные разделяемые объектные файлы
Установите любые дополнительные общие объектные файлы (или DLL), используемые старым кластером, в новый кластер, например,
pgcrypto.so, независимо от того, находились ли вcontribили другом месте. Не устанавливайте определения схемы, (например,CREATE EXTENSION pgcrypto), потому что они будут перенесены из старого кластера. Кроме того, все нестандартные файлы поддержки полнотекстового поиска (словарь, синоним, тезаурус, стоп-слова) также должны быть скопированы в новый кластер. -
Настройте аутентификацию
qhb_upgradeбудет подключаться к старому и новому серверам несколько раз, так что возможно имеет смысл установить режим аутентификацииpeerвqhb_hba.confили использовать файл~/.pgpass. -
Остановить оба сервера
Убедитесь, что оба сервера базы данных остановлены. Для Unix, можно выполнить:
pg_ctl -D /opt/pgsql/12 stop qhb_ctl -D /opt/PostgreSQL stopведомые серверы потоковой репликации и доставки журналов могут оставаться запущенными до следующего шага.
-
Подготовка к обновлению резервного сервера
Если вы обновляете ведомые серверы, используя методы, описанные в разделе Шаг 10, убедитесь, что старые ведомые серверы заняты, запустив
qhb_controldataсо старым основным и резервным кластерами. Убедитесь, что значения «Последнее положение контрольной точки» совпадают во всех кластерах. (Будет несоответствие, если старые ведомые серверы были закрыты до старого основного или старые ведомые серверы все еще работают). Также изменитеwal_levelнаreplicaв файлеqhb.confна новом основном кластере. -
Запустите
qhb_upgradeВсегда запускайте
qhb_upgradeот нового сервера, а не от старого. Дляqhb_upgradeтребуется указать каталоги данных и исполняемых файлов (bin) старого и нового кластера. Вы также можете указать имя пользователя.После запуска
qhb_upgradeпроверит совместимость двух кластеров, а затем выполнит обновление. Вы можете использоватьqhb_upgrade--checkдля выполнения только проверок.qhb_upgrade --checkтакже сообщит какие настройки, нужно будет сделать вручную после обновления.Очевидно, что никто не должен иметь доступ к кластерам во время обновления.
qhb_upgradeзапускает серверы на порту 50432, чтобы избежать непреднамеренных клиентских подключений.Если при восстановлении схемы базы данных произошла ошибка,
qhb_upgradeзавершится, и вам придется вернуться к старому кластеру, как описано в шаге 16 ниже. Чтобы повторить попыткуqhb_upgrade, вам потребуется внести коррективы в старый кластер, чтобыqhb_upgradeмогла успешно восстановить схему. Если проблема возникла с модулемcontrib, вам может потребоваться удалить его в старом кластере, и затем установить его в новом после обновления, (предполагается, что модуль не используется для хранения пользовательских данных). -
Обновление ведомых серверов с потоковой репликацией и трансляцией журнала
Если у вас настроена потоковая репликация или трансляция журнала для ведомых серверов, вы можете выполнить следующие шаги, чтобы быстро обновить их. Вам не придётся запускать
qhb_upgradeна ведомых серверах. Вместо этого используйте rsync на ведущем сервере. Не запускайте пока никаких серверов на этом этапе.Если вы не хотите использовать rsync (или у вас его нет), либо вам нужно более простое решение, пропустите инструкции этого раздела и просто заново создайте ведомые серверы после завершения
qhb_upgradeи запуска нового ведущего сервера. -
Установите новые исполняемые файлы QHB на ведомых серверах
Убедитесь, что новые исполняемые и вспомогательные файлы установлены на всех ведомых серверах.
-
Убедитесь, что на ведомых серверах новых каталогов данных не существует (или они пустые)
Если запускалась
qhb_bootstrap, удалите новые каталоги данных на ведомых серверах. -
Установите дополнительные разделяемые объектные файлы
Установите те же дополнительные разделяемые объектные файлы на новых ведомых серверах, что вы установили в новом ведущем кластере.
-
Остановите ведомые серверы
Если ведомые серверы все еще работают, остановите их сейчас, используя приведенные выше инструкции.
-
Сохраните файлы конфигурации
Сохраните все файлы конфигурации из старых каталогов конфигурации ведомых серверов, такие как,
qhb.conf,qhb_hba.conf, потому что они будут перезаписаны или удалены на следующем этапе. -
Запустите
rsyncПри использовании режима ссылок ведомые серверы можно быстро обновить с помощью rsync. Для этого в каталоге, внутри которого находятся каталоги старого и нового кластера, для каждого ведомого сервера выполните на ведущем:
rsync --archive --delete --hard-links --size-only --no-inc-recursive old_cluster new_cluster remote_dirгде
old_clusterиnew_clusterзадаются относительно текущего каталога на ведущем, аremote_dirнаходится на ведомом над каталогами старого и нового кластера. Структура подкаталогов в указанных каталогах на ведущем и ведомом серверах должна совпадать. Обратитесь к руководствуrsyncза подробной информацией как указать удаленный каталог, например так:rsync --archive --delete --hard-links --size-only --no-inc-recursive /opt/PostgreSQL \ /opt/PostgreSQL standby.example.com:/opt/PostgreSQLВы можете проверить, что будет делать команда, используя параметр rsync
--dry-run.rsyncдолжен быть запущен на ведущем сервере как минимум с одним ведомым. Затем, пока обновленный ведомоый сервер остаётся остановленным, на этом ведомом сервере можно запустить rsync для обновления других ведомых серверов.Во время этой операции записываются ссылки, созданные в режиме ссылок
qhb_upgrade, которые связывают файлы в старом и новом кластерах на ведущем сервере. Затем находятся соответствующие файлы в старом кластере ведомого и в новом кластере ведомого создаются ссылки на них. Файлы, которые не были связаны ссылками на ведущем, просто копируются с него на ведомый. (Обычно они маленькие). Это обеспечивает быстрое обновление ведомого сервера. К сожалению,rsyncбез необходимости копирует файлы, связанные с временными и незарегистрированными таблицами, потому что эти файлы обычно не существуют на ведомых серверах.Если у вас есть табличные пространства, вам нужно будет выполнить аналогичную команду
rsyncдля каждого каталога табличного пространства, например:rsync --archive --delete --hard-links --size-only --no-inc-recursive /vol1/pg_tblsp/PG_9.5_201510051 \ /vol1/pg_tblsp/PG_9.6_201608131 standby.example.com:/vol1/pg_tblspЕсли вы переместили
pg_walза пределы каталогов данных,rsyncдолжен быть запущен и в этих каталогах. -
Настройка ведомого сервера с потоковой репликации и трансляцией журнала
Настройте серверы для трансляции журнала. (Не требуется запускать
pg_start_backup()иpg_stop_backup()или делать резервную копию файловой системы, так как ведомые устройства все еще синхронизируются с ведущим). -
Восстановите
qhb_hba.confЕсли вы изменили
qhb_hba.conf, восстановите его исходные настройки. Также может потребоваться настроить другие файлы конфигурации в новом кластере в соответствии со старым кластером, напримерqhb.conf. -
Запустите новый сервер
Теперь можно безопасно запустить новый сервер, а затем и любые ведомые серверы синхронизированные с помощью
rsync. -
Действия после обновления
Если требуются какие-либо действия после обновления,
qhb_upgradeвыдаст предупреждения по завершении. Также будут сгенерированы файлы скриптов, которые должен будет запустить администратор. Скрипты будут подключаться к каждой базе данных, которой требуются дополнительные действия после обновления. Каждый скрипт должен быть запущен командой:psql --username=qhb --file=script.sql qhbОни могут быть выполнены в любом порядке и могут быть удалены после выполнения.
Предостережение
Как правило, небезопасно обращаться к таблицам, которые задействованы в перестраивающих базу данных скриптах, пока эти скрипты не завершат свою работу; это может привести к некорректным результатам или плохой производительности. К таблицам, которые не задействованы в скриптах, можно обращаться немедленно. -
Статистика
Поскольку статистика оптимизатора не передается
qhb_upgrade, вам будет предложено выполнить команду для восстановления этой информации после обновления. Возможно, вам придется установить параметры подключения к новому кластеру. -
Удалить старый кластер
Если вы удовлетворены обновлением, вы можете удалить каталоги данных старого кластера. Вы также можете удалить старые каталоги установки (например,
bin,share). -
Возврат к старому кластеру
Если после запуска
qhb_upgradeвы хотите вернуться к старому кластеру, есть несколько вариантов: -
Если использовался параметр
--check, то старый кластер не изменился; просто перезапустите его. -
Если
qhb_upgradeпрервана до начала связывания, старый кластер не изменился; просто перезапустите его. - Каталог данных; смотрите также опцию
-p. - Указывает, использовать ли цвета в диагностических сообщениях.
Возможные значения
always,auto,never. - Функции обёрток сторонних данных
- Процедуры обратного вызова сторонних данных
- Процедуры FDW для сканирования сторонних таблиц
- Процедуры FDW для сканирования сторонних соединений
- Процедуры FDW для планирования обработки после сканирования / соединения
- Процедуры FDW для обновления сторонних таблиц
- FDW-процедуры для блокировки строк
- Процедуры FDW для EXPLAIN
- Процедуры FDW для ANALYZE
- Процедуры FDW для IMPORT FOREIGN SCHEMA
- Программы FDW для параллельного выполнения
- Процедуры FDW для репараметризации путей
- Вспомогательные функции для обёртки сторонних данных
- Планирование запросов на обработку сторонних данных
- Блокировка строк в обёртках сторонних данных
- Синтаксис
- Описание
- Обзор
- Ограничения
- Установка и подготовка
- Использование
- Справка по командной строке
- Версионирование
-
Постраничное инкрементальное копирование: позволяет сэкономить место на диске и создавать копии быстрее, чем при полном копировании. Восстановление инкрементальных копий также осуществляется быстрее, чем воспроизведение файлов WAL.
-
Параллельное выполнение: выполнение внутренних процессов команд
backupиrestoreв несколько параллельных потоков. -
Сжатие: хранение копируемых данных в сжатом состоянии для экономии дискового пространства.
-
Каталогизация резервных копий: получение списка резервных копий и соответствующей метаинформации в виде простого текста или JSON.
-
Полные резервные копии содержат все файлы, необходимые для восстановления кластера баз данных с нуля.
-
Инкрементальные копии создаются на уровне страниц и включают только те данные, которые изменились со времени последнего копирования. Это позволяет сэкономить место на диске и создавать копии быстрее, чем при полном копировании. Восстановление инкрементальных копий также осуществляется быстрее, чем воспроизведение файлов WAL.
-
qbackupработает с серверами QHB версии 1.3.0 и новее. -
Поддержка табличных пространств ограничена.
-
Поддержка линий времени ограничена.
-
На сервере QHB, где была сделана копия, и на сервере, где она будет восстанавливаться, должны быть одинаковые значения параметров
block_sizeиwal_block_sizeи одинаковая основная версия. В зависимости от конфигурации кластера, QHB может накладывать дополнительные ограничения, например, по архитектуре процессора и версии libc/libicu. -
Установите параметр
wal_levelв значение вышеminimal. -
Установите параметр
archive_modeв значениеonилиalways. -
Установите параметр
archive_command:archive_command = 'путь_инсталляции/qbackup backup-wal -B каталог_копий -f %f -p %p'Здесь
путь_инсталляции— путь к каталогу установленной версии qbackup, которую вы хотите использовать. - Полные копии. Содержимое
каталога_данныхкопируется вкаталог_копий, за исключением необязательных файлов. Вкаталоге_копийможет содержаться любое количество независимых резервных копий. - Инкрементальные копии. При передаче флага
--incrementalqbackupавтоматически находит последнюю подходящую копию вкаталоге_копийи выполняет сравнение её содержимого с содержимымкаталога_данных. В Инкрементальной копии хранятся только те файлы (или части файлов), которые изменились с момента создания Полной копии. Это значительно сокращает размер резервной копии, но может потребовать больше времени для выполнения операций сравнения файлов. -
каталог_копий— каталог, в котором хранятся все файлы резервных копий и метаданные. -
каталог_данных— каталог, в котором будут храниться данные восстановленного кластера. Каталог должен быть создан перед выполнением команды, быть пустым и доступен для записи. -
идентификатор_копииопределяет, из какой резервной копии будет восстановлен кластер. Если вы выбираете для восстановления инкрементальную копию, qbackup автоматически восстанавливает нижележащую полную копию и затем последовательно применяет все необходимые добавления. -
Чтобы восстановить состояние кластера на определённый момент времени, укажите это время в параметре
--target-time, в формате timestamp. Например:qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии --target-time='2017-05-18 14:18:11+03' -
Чтобы восстановить состояние кластера до определённой транзакции, воспользуйтесь ключом
--target-xid:qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии --target-xid=687 -
Чтобы восстановить состояние кластера до определённой позиции в журнале (LSN), воспользуйтесь ключом
--target-lsn:qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии --target-lsn=16/B374D848 -
Чтобы восстановить состояние кластера до заданной именованной точки восстановления, воспользуйтесь ключом
--target-name:qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии --target-name='before_app_upgrade' -
Чтобы восстановить самое раннее из возможных согласованное состояние кластера, передайте в флаг
--immediate:qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии --immediate -
ID— уникальный идентификатор копии. -
status— состояние резервной копии. Возможные варианты:Done- резервная копия выполнена и готова к использованиюIn Progress- резервное копирование ещё выполняетсяError- резервное копирование завершилось с ошибкой
-
size- размер резервной копии (в несжатом виде). -
compressed size- размер резервной копии на диске (только для сжатых копий). -
kind- тип резервной копии. Возможные варианты:Full- полная резервная копия.Incremental- инкрементальная резервная копия.
-
is compressed- сжата ли копия. -
start lsn- LSN (Line Sequence Number) в момент начала копирования. Отсутствует для копий остановленного кластера. -
parent- идентификатор предыдущей копии для инкрементальных копий. -
start time- системное время начала резервного копирования. -
end time- системное время окончания резервного копирования. -
- Числовые Типы
- Денежные Типы
- Символьные типы
- Двоичные типы данных
- Типы даты / времени
- Логический тип
- Перечисляемые типы
- Геометрические типы
- Типы сетевых адресов
- Типы битовых строк
- Типы текстового поиска
- Тип UUID
- Тип XML
- Типы JSON
- Массивы
- Составные типы
- Диапазонные типы
- Типы доменов
- Типы идентификаторов объектов
- Тип pg_lsn
- Псевдо-типы
-
- Логические операторы
- Функции сравнения и операторы
- Математические функции и операторы
- Строковые функции и операторы
- Двоичные строковые функции и операторы
- Функции и операторы битовых строк
- Сопоставление с образцом
- Функции форматирования типов данных
- Функции и операторы даты / времени
- Функции поддержки Enum
- Геометрические функции и операторы
- Функции и операторы сетевых адресов
- Функции текстового поиска и операторы
- Функции XML
- Функции и операторы JSON
- Функции управления последовательностями
- Условные выражения
- Функции и операторы массива
- Функции диапазона и операторы
- Агрегатные функции
- Оконные функции
- Выражения подзапроса
- Сравнение строк и массивов
- Функции возврата наборов (SET)
- Системные информационные функции и операторы
- Функции системного администрирования
- Триггерные функции
- Функции запуска событий
- Функции статистической информации
-
- ABORT
- ALTER AGGREGATE
- ALTER COLLATION
- ALTER CONVERSION
- ALTER DATABASE
- ALTER DEFAULT PRIVILEGES
- ALTER DOMAIN
- ALTER EVENT TRIGGER
- ALTER EXTENSION
- ALTER FOREIGN DATA WRAPPER
- ALTER FOREIGN TABLE
- ALTER FUNCTION
- ALTER GROUP
- ALTER INDEX
- ALTER LANGUAGE
- ALTER LARGE OBJECT
- ALTER MATERIALIZED VIEW
- ALTER OPERATOR
- ALTER OPERATOR CLASS
- ALTER OPERATOR FAMILY
- ALTER POLICY
- ALTER PROCEDURE
- ALTER PUBLICATION
- ALTER ROLE
- ALTER ROUTINE
- ALTER RULE
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER STATISTICS
- ALTER SUBSCRIPTION
- ALTER SYSTEM
- ALTER TABLE
- ALTER TABLESPACE
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TEXT SEARCH PARSER
- ALTER TEXT SEARCH TEMPLATE
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER USER MAPPING
- ALTER VIEW
- ANALYZE
- BEGIN
- CALL
- CHECKPOINT
- CLOSE
- CLUSTER
- COMMENT
- COMMIT
- COMMIT PREPARED
- COPY
- CREATE ACCESS METHOD
- CREATE AGGREGATE
- CREATE CAST
- CREATE COLLATION
- CREATE CONVERSION
- CREATE DATABASE
- CREATE DOMAIN
- CREATE EVENT TRIGGER
- CREATE EXTENSION
- CREATE FOREIGN DATA WRAPPER
- CREATE FOREIGN TABLE
- CREATE FUNCTION
- CREATE GROUP
- CREATE INDEX
- CREATE LANGUAGE
- CREATE MATERIALIZED VIEW
- CREATE OPERATOR
- CREATE OPERATOR CLASS
- CREATE OPERATOR FAMILY
- CREATE POLICY
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE ROLE
- CREATE RULE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE STATISTICS
- CREATE SUBSCRIPTION
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLESPACE
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TEXT SEARCH PARSER
- CREATE TEXT SEARCH TEMPLATE
- CREATE TRANSFORM
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE USER MAPPING
- CREATE VIEW
- DEALLOCATE
- DECLARE
- DELETE
- DISCARD
- DO
- DROP ACCESS METHOD
- DROP AGGREGATE
- DROP CAST
- DROP COLLATION
- DROP CONVERSION
- DROP DATABASE
- DROP DOMAIN
- DROP EVENT TRIGGER
- DROP EXTENSION
- DROP FOREIGN DATA WRAPPER
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GROUP
- DROP INDEX
- DROP LANGUAGE
- DROP MATERIALIZED VIEW
- DROP OPERATOR
- DROP OPERATOR CLASS
- DROP OPERATOR FAMILY
- DROP OWNED
- DROP POLICY
- DROP PROCEDURE
- DROP PUBLICATION
- DROP ROLE
- DROP ROUTINE
- DROP RULE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP STATISTICS
- DROP SUBSCRIPTION
- DROP TABLE
- DROP TABLESPACE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TEXT SEARCH PARSER
- DROP TEXT SEARCH TEMPLATE
- DROP TRANSFORM
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP USER MAPPING
- DROP VIEW
- END
- EXECUTE
- EXPLAIN
- FETCH
- GRANT
- IMPORT FOREIGN SCHEMA
- INSERT
- LISTEN
- LOAD
- LOCK
- MOVE
- NOTIFY
- PREPARE
- PREPARE TRANSACTION
- REASSIGN OWNED
- REFRESH MATERIALIZED VIEW
- REINDEX
- RELEASE SAVEPOINT
- RESET
- REVOKE
- ROLLBACK
- ROLLBACK PREPARED
- ROLLBACK TO SAVEPOINT
- SAVEPOINT
- SECURITY LABEL
- SELECT
- SELECT INTO
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SET TRANSACTION
- SHOW
- START TRANSACTION
- TRUNCATE
- UNLISTEN
- UPDATE
- VACUUM
- VALUES
- Язык SQL. Введение
- Основные принципы
- Создание таблицы
- Ввод данных
- Запросы к таблице
- Соединения таблиц
- Агрегатные функции
- Изменение строк
- Удаление строк
-
varchar(80) - тип данных, который может хранить произвольные строки символов длиной до 80 символов.
-
int - обычный целочисленный тип;
-
real - числа с плавающей точкой одинарной точности;
-
date тип для хранения даты.
-
Город Хейвард (Hayward) отсуствует в результатах. Это связано с тем, что в таблице cities для Хейвард нет соответствующей записи, поэтому соединение игнорирует эту строку в таблице weather. Такое соединение называется внутренним. Далее мы увидим, как это можно исправить.
-
Присутствуют 2 столбца с названием города. Это правильно, т.к. столбцы из таблиц weather и cities объединяются. На практике такое поведение нежелательно, поэтому лучше перечислять результирующие столбцы явно, а не с помощью *:
- Лексическая структура
- Выражения значения
- Вызов функции
-
--и/*нигде не могут появляться в имени оператора, так как они будут приняты в качестве начала комментария. -
Имя оператора из нескольких символов не может заканчиваться на + или -, если только имя не содержит хотя бы один из следующих символов:
-
Знак доллара ($), за которым следуют цифры, используется для представления позиционного параметра в теле определения функции или подготовленного оператора. В других контекстах знак доллара может быть частью идентификатора или строковой константы в кавычках.
-
Круглые скобки (()) имеют обычное значение для группирования выражений и обеспечения приоритета. В некоторых случаях скобки требуются как часть фиксированного синтаксиса конкретной команды SQL.
-
Скобки ([]) используются для выбора элементов массива. См. раздел Массивы для получения дополнительной информации о массивах.
-
Запятые (,) используются в некоторых синтаксических конструкциях для разделения элементов списка.
-
Точка с запятой (;) завершает команду SQL. Он не может появляться где-либо внутри команды, кроме как внутри строковой константы или идентификатора в кавычках.
-
Двоеточие (:) используется для выбора «кусочков» из массивов. (См. раздел Массивы. В некоторых диалектах SQL (таких как Embedded SQL) двоеточие используется для добавления префиксов к именам переменных.
-
Звездочка (*) используется в некоторых контекстах для обозначения всех полей строки таблицы или составного значения. Он также имеет особое значение при использовании в качестве аргумента агрегатной функции, а именно, что агрегат не требует какого-либо явного параметра.
-
Точка (.) Используется в числовых константах и для разделения имен схем, таблиц и столбцов.
-
Постоянное или буквальное значение;
-
Ссылка на столбец;
-
Ссылка на позиционный параметр в теле определения функции или подготовленного оператора;
-
Выражение подзапроса;
-
Выражение выбора поля;
-
Вызов оператора;
-
Вызов функции;
-
Агрегатное выражение;
-
Вызов оконной функции;
-
Приведение типа;
-
Сортировка выражения;
-
Скалярный подзапрос;
-
Конструктор массива;
-
Конструктор строк.
-
Другое выражение значения в скобках (используется для группировки подвыражений и переопределения приоритета).
-
В режиме ROWS offset должно давать ненулевое, неотрицательное целое число, а параметр означает, что кадр начинается или заканчивается указанным числом строк до или после текущей строки.
-
В режиме GROUPS offset снова должно давать ненулевое, неотрицательное целое число, а параметр означает, что кадр начинается или заканчивается за указанное число одноранговых групп до или после группы текущей строки, где одноранговые группы представляют набор строк, которые эквивалентных в порядке ORDER BY. (Для использования режима GROUPS в определении окна должно быть предложение ORDER BY).
-
В режиме RANGE эти параметры требуют, чтобы предложение ORDER BY указывало ровно один столбец. offset определяет максимальную разницу между значением этого столбца в текущей строке и его значением в предыдущих или последующих строках кадра. Тип данных выражения offset варьируется в зависимости от типа данных столбца упорядочения. Для числовых упорядочивающих столбцов обычно это тот же тип, что и упорядочивающий столбец, но для столбцов с упорядочиванием даты и времени это интервал. Например, если столбец заказа имеет тип date или timestamp, можно написать
RANGE BETWEEN '1 day' PRECEDING AND '10 days' FOLLOWING. offset по-прежнему должно быть ненулевым и неотрицательным, хотя значение «неотрицательный» зависит от его типа данных. - Базовая информация по таблицам
- Значения по умолчанию
- Сгенерированные столбцы
- Ограничения
- Системные столбцы
- Изменение таблиц
- Привилегии
- Политики безопасности строк
- Схемы
- Наследование
- Партиционирование таблиц
- Внешние данные
- Другие объекты базы данных
- Отслеживание зависимостей
-
Выражение используемое для генерации может использовать только неизменяемые функции и не может использовать подзапросы или ссылаться на что-либо, кроме текущей строки.
-
Выражение используемое для генерации не может ссылаться на другой сгенерированный столбец.
-
Выражение используемое для генерации не может ссылаться на системный столбец, кроме tableoid.
-
Сгенерированный столбец не может иметь значение по умолчанию по умолчанию или определение идентификатора.
-
Сгенерированный столбец не может быть частью ключа разбиения.
-
Внешние таблицы могут иметь сгенерированные столбцы. См. CREATE FOREIGN TABLE для деталей.
-
Сгенерированные столбцы поддерживают права доступа отдельно от базовых столбцов, лежащих в их основе. Таким образом, можно расположить его так, чтобы определенная роль могла считываться из сгенерированного столбца, но не из нижележащих базовых столбцов.
-
Сгенерированные столбцы обновляются после запуска триггеров. Поэтому изменения, внесенные в базовые столбцы в триггере BEFORE будут отражены в сгенерированных столбцах. Но, наоборот, не допускается доступ к сгенерированным столбцам в триггерах BEFORE.
-
запретить удаление указанного продукта;
-
удалить также и соот. заказы;
-
что-то другое?
- Добавить столбцы
- Удалить столбцы
- Добавить ограничения
- Удалить ограничения
- Изменить значения по умолчанию
- Изменить типы данных столбца
- Переименовать столбцы
- Переименовать таблицы
- привилегии CONNECT и TEMPORARY (создание временных таблиц) для баз данных; EXECUTE привилегию для функций и процедур;
- привилегия USAGE для языков и типов данных(включая домены).
-
позволить многим пользователям использовать одну базу данных, не мешая друг другу;
-
организовать объекты базы данных в логические группы, чтобы сделать их более управляемыми;
-
сторонние приложения могут быть помещены в отдельные схемы, чтобы они не конфликтовали с именами других объектов.
-
Ограничить обычных пользователей частными схемами. Для этого выполните REVOKE CREATE ON SCHEMA public FROM PUBLIC и создайте схему для каждого пользователя с тем же именем, что и у этого пользователя. Напомним, что путь поиска по умолчанию начинается с $user, который преобразуется в имя пользователя. Поэтому, если у каждого пользователя есть отдельная схема, он получает доступ к своим собственным схемам по умолчанию. После принятия этого шаблона в базе данных, в которую уже вошли ненадежные пользователи, рассмотрите возможность аудита схемы public для объектов с именами, подобными объектам в схеме pg_catalog. Этот шаблон является шаблоном использования защищенной схемы, если только недоверенный пользователь не является владельцем базы данных или не имеет привилегии CREATEROLE, в этом случае шаблон использования защищенной схемы не работает.
-
Удалите общедоступную схему из пути поиска по умолчанию, изменив qhb.conf или введя команду ALTER ROLE ALL SET search_path = "$user". Каждый пользователь сохраняет возможность создавать объекты в схеме public, но выбирать эти объекты возможно только используя квалифицированные имена. Несмотря на то, что ссылки на квалифицированные таблицы в порядке, вызовы функций в схеме public будут небезопасными или ненадежными. Если вы создаете функции или расширения в схеме public, используйте вместо этого первый шаблон. В противном случае, как и в первом шаблоне, это безопасно, если только ненадежный пользователь не является владельцем базы данных или не имеет привилегии CREATEROLE.
-
Конфигурайия по умолчанию. Все пользователи имеют доступ к схеме public неявно. Это моделирует ситуацию, когда схемы вообще недоступны, обеспечивая плавный переход из мира, не знающего схемы. Однако это не является безопасным шаблоном. Это допустимо только в том случае, если база данных имеет одного пользователя или несколько взаимно доверяющих пользователей.
-
В случае объявления cities.name как UNIQUE или PRIMARY KEY, это не помешает таблице capitals иметь строки с именами, дублирующими строки в cities. И эти повторяющиеся строки по умолчанию будут отображаться в запросах из cities. На самом деле, по умолчанию таблица capitals вообще не имеет уникального ограничения и поэтому может содержать несколько строк с одинаковыми именами. Вы можете добавить уникальное ограничение для capitals, но это не предотвратит дублирование в связке с таблицей cities.
-
Точно так же, если бы мы указали что cities.name ссылается на какую-то другую таблицу, это ограничение не будет автоматически распространяться на capitals. В этом случае вы можете обойти это, вручную добавив такое же ограничение REFERENCES в capitals.
-
Указание на то, что столбец из другой таблицы ссылается на cities(name) позволит другой таблице содержать названия городов, но не названия столиц. Для этого случая нет хорошего пути решения.
-
Производительность запросов может быть значительно улучшена в определенных ситуациях, особенно когда большинство часто используемых строк таблицы находятся в одной партиции или небольшом количестве партиций. Партиционирование заменяет ведущие столбцы индексов, уменьшая размер индекса и повышая вероятность того, что интенсивно используемые части индексов помещаются в памяти.
-
Когда запросы или обновления обращаются к большому проценту одной партиции, производительность можно улучшить, воспользовавшись преимуществом последовательного сканирования этой партиции вместо использования индекса и чтения с произвольным доступом, разбросанного по всей таблице.
-
Массовая загрузка и удаление могут быть выполнены путем добавления или удаления партиций, если это требование запланировано в проекте партиционирования. Выполнение команды ALTER TABLE DETACH PARTITION или удаление отдельной партиции с помощью DROP TABLE намного быстрее, чем массовая операция. Эти команды также избавлены от накладных расходов вакуума, вызванных массовым удалением.
-
Редко используемые данные могут быть перенесены на более дешевые и медленные носители данных.
-
Ограничения CHECK и NOT NULL для партиционированной таблицы всегда наследуются всеми ее партициями. Контрольные ограничения, помеченные как NO INHERIT, не могут быть созданы для партиционированных таблиц.
-
Использование ONLY для добавления или удаления ограничения в партиционированной таблице поддерживается только до тех пор, пока у нее нет партиций. Как только партиции возникают, использование ONLY приведет к ошибке, поскольку добавление или удаление ограничений только для партиционированной таблицы, когда партиции существуют, не поддерживается. Вместо этого могут быть добавлены ограничения на сами партиции и (если они отсутствуют в родительской таблице) удалить их.
-
Поскольку партиционированная таблица не имеет никаких данных непосредственно, попытки использовать TRUNCATE ONLY в партиционированной таблице всегда будут возвращать ошибку.
-
Партиции не могут иметь столбцы, отсутствующие в родительском элементе. Невозможно указать столбцы при создании партиций с помощью CREATE TABLE, а также невозможно добавить столбцы к партициям после использования ALTER TABLE. Таблицы могут быть добавлены как партиции с помощью ALTER TABLE ... ATTACH PARTITION только если их столбцы точно соответствуют родительскому.
-
Вы не можете удалить ограничение NOT NULL для столбца партиции, если ограничение присутствует в родительской таблице.
- Создайте таблицу measurement как партиционированную таблицу, указав
условие PARTITION BY, которое включает метод партиционирования (в
данном случае RANGE) и список столбцов, которые следует использовать
в качестве ключа разбиения.
При желании вы можете использовать несколько столбцов в ключе разбиения для разделения диапазона. Конечно, это часто приводит к большему количеству партиций, каждый из которых в отдельности меньше. С другой стороны, использование меньшего количества столбцов может привести к более грубым критериям партиционирования с меньшим числом партиций. Запрос, обращающийся к партиционированной таблице, должен будет сканировать меньшее количество партиций, если условия включают некоторые или все эти столбцы. Например, рассмотрите диапазон таблицы, разделенный с использованием столбцов lastname и firstname (в этом порядке) в качестве ключа разбиения. - Создать партиции. Определение каждой партиции должно указывать границы, которые соответствуют методу и ключу разбиения родителя. Обратите внимание, что указание границ таким образом, что значения новой партиции будут совпадать со значениями в одном или нескольких существующих партициях, приведет к ошибке. Вставка данных в родительскую таблицу, которая не сопоставлена ни с одной из существующих партиций, приведет к ошибке - соответствующие партиции должны быть добавлены вручную. Созданные таким образом партиции во всех смыслах являются обычными таблицами QHB (или, возможно, внешними таблицами). Можно указать табличное пространство и параметры хранения для каждой партиции отдельно. Нет необходимости создавать ограничения таблицы, описывающие граничные условия для партиций. Напротив, ограничения партиции генерируются неявно из спецификации границ партиции, когда есть необходимость обратиться к ним.
-
Создайте индекс для ключевого столбца (столбцов), а также любые другие индексы, которые вам могут понадобиться, для партиционированной таблицы. (Ключевой индекс не является строго необходимым, но в большинстве сценариев он полезен). Это автоматически создает один индекс для каждой партиции, и любые партиции, которые вы создаете или присоединяете позже, также будут содержать индекс.
CREATE INDEX ON measurement (logdate); -
Убедитесь, что параметр конфигурации enable_partition_pruning не отключен в qhb.conf. Если это так, запросы не будут оптимизированы должным образом.
-
Невозможно создать ограничение исключения, охватывающее все партиции; можно ограничить каждую отдельную партицию индивидуально.
-
Ограничения уникальности для партиционированных таблиц должны включать все столбцы ключей разбиения. Это ограничение существует, потому что QHB может применять уникальность только в каждой партиции отдельно.
-
Триггеры BEFORE ROW, если необходимо, должны быть определены на отдельных партициях, а не на партиционированной таблице.
-
Смешивание временных и постоянных отношений в одном дереве партиций не допускается. Следовательно, если партиционированная таблица является постоянной, то такими же должны быть и ее партиции и, аналогично, если партиционированная таблица является временной. При использовании временных отношений все члены дерева партиций должны быть из одного сеанса.
-
Для декларативного партиционирования у партиций должен быть точно такой же набор столбцов, что и у партиционированной таблицы, тогда как при наследовании таблиц у дочерних таблиц могут быть дополнительные столбцы, отсутствующие в родительской.
-
Наследование таблиц допускает множественное наследование.
-
Декларативное партиционирование поддерживает только партиционирование по диапазонам, спискам и хэшам, тогда как наследование таблиц позволяет разделять данные способом, выбранным пользователем. (Тем не менее, обратите внимание, что, если ограничение исключения не может эффективно сократить дочерние таблицы, производительность запросов может быть низкой).
-
Некоторые операции требуют более сильной блокировки при использовании декларативного партиционирования, чем при использовании наследования таблиц. Например, добавление или удаление партиции в или из партиционированной таблицы требует установки блокировки ACCESS EXCLUSIVE на родительскую таблицу, тогда как в случае обычного наследования достаточно блокировки SHARE UPDATE EXCLUSIVE.
-
Создайте «главную» таблицу, от которой будут наследоваться все «дочерние» таблицы. Эта таблица не будет содержать данных. Не определяйте никакие контрольные ограничения для этой таблицы, если только вы не собираетесь применять их одинаково ко всем дочерним таблицам. Также нет смысла определять какие-либо индексы или ограничения уникальности для неё. В нашем примере главная таблица — это таблица measurement, как она была определена изначально.
-
Создайте несколько «дочерних» таблиц, каждая из которых наследуется от основной таблицы. Обычно эти таблицы не добавляют столбцы в набор, унаследованный от главной. Как и при декларативном разбиении, эти таблицы во всех отношениях являются обычными таблицами QHB (или внешними таблицами).
- Добавьте неперекрывающиеся ограничения таблиц в дочерние таблицы,
чтобы определить допустимые значения ключей в каждой.
Типичные примеры: - Для каждой дочерней таблицы создайте индекс по ключевым столбцам, а также любые другие индексы, которые вам могут понадобиться.
- Для того, чтобы приложение могло сказать INSERT INTO measurement... и чтобы данные были перенаправлены в соответствующую дочернюю таблицу можно прикрепить подходящую триггерную функцию к главной таблице. Если данные будут добавлены только к последнему дочернему элементу, можно использовать очень простую триггерную функцию:
- Убедитесь, что параметр конфигурации constraint_exclusion не отключен в QHB.conf в противном случае к дочерним таблицам можно получить доступ без необходимости.
-
Не существует автоматического способа проверить, что все контрольные ограничения являются взаимоисключающими. Безопаснее создавать код, который генерирует дочерние таблицы и создает и/или изменяет связанные объекты, чем писать каждый из них вручную.
-
Индексы и ограничения внешнего ключа применяются к отдельным таблицам, а не к их дочерним наследованиям, поэтому они должны учитывать некоторые предостережения.
-
Схемы, показанные здесь, предполагают, что значения ключевых столбцов строки никогда не меняются или, по крайней мере, не меняются настолько, чтобы требовать его перемещения в другую партицию. UPDATE которое пытается сделать это, закончится с ошибкой из-за ограничений CHECK. Если вам нужно обработать такие случаи, вы можете поместить подходящие триггеры обновления в дочерние таблицы, но это значительно усложняет управление структурой.
-
Если вы используете команды VACUUM или ANALYZE вручную, не забывайте, что вам нужно запускать их для каждой дочерней таблицы отдельно. Например, следующая команда будет обрабатывать только основную таблицу:
ANALYZE measurement; -
Операторы INSERT с предложениями ON CONFLICT вряд ли будут работать должным образом, поскольку действие ON CONFLICT выполняется только в случае уникальных нарушений в указанном целевом отношении, а не в его дочерних отношениях.
-
Триггеры или правила будут необходимы для маршрутизации строк в нужную дочернюю таблицу, если приложение явно не осведомлено о схеме партиционирования. Триггеры могут быть сложными для написания и будут намного медленнее, чем маршрутизация кортежей, выполняемая внутренне посредством декларативного разбиения.
-
Во время инициализации плана запроса. Здесь можно выполнить сокращение партиций для значений параметров, которые известны на этапе инициализации выполнения. Партиции, которые были сокращены на этом этапе, не будут отображаться в запросе EXPLAIN или EXPLAIN ANALYZE. Можно определить количество партиций, которые были удалены на этом этапе, наблюдая за свойством «Subplans Removed» в выводе EXPLAIN.
-
Во время фактического выполнения плана запроса. Здесь также может быть выполнено удаление партиций, чтобы удалить партиции, используя значения, которые известны только во время фактического выполнения запроса. Это включает в себя значения из подзапросов и значения из параметров времени выполнения, например, из параметризованных объединений вложенных циклов. Поскольку значение этих параметров может изменяться много раз во время выполнения запроса, сокращение партиции выполняется всякий раз, когда один из параметров выполнения, используемых для сокращения партиции, изменяется. Определение того, были ли партиции сокращены на этом этапе, требует тщательной проверки loops свойства в выходных данных EXPLAIN ANALYZE. Подпланы, соответствующие различным партициям, могут иметь разные значения для него в зависимости от того, сколько раз каждый из них был сокращен во время выполнения. Некоторые могут быть показаны, как (never executed) если они были обрезаны каждый раз.
-
Исключение ограничений применяется только при планировании запросов, в отличие от сокращения партиций, которое также может применяться при выполнении запросов.
-
Исключение ограничений работает только тогда, когда предложение запроса WHERE содержит константы (или внешние параметры). Например, сравнение с неизменяемой функцией, например, CURRENT_TIMESTAMP не может быть оптимизировано, поскольку планировщик не может знать, в какую дочернюю таблицу может попасть значение функции во время выполнения.
-
Сохраняйте простые ограничения на партиции, иначе планировщик не сможет доказать, что дочерние таблицы могут не посещаться. Используйте простые условия равенства для разбиения списка или простые тесты диапазона для разбиения диапазона, как показано в предыдущих примерах. Хорошее эмпирическое правило заключается в том, что ограничения партиционирования должны содержать только сравнения столбца (-ов) партиционирования с константами с помощью операторов, индексируемых по B-дереву, поскольку в ключе разбиения допускаются только столбцы, индексируемые по B-дереву.
-
Все ограничения для всех дочерних элементов родительской таблицы проверяются во время исключения ограничений, поэтому большое количество дочерних элементов может значительно увеличить время планирования запросов. Таким образом, партиционирование с использованием наследования будет хорошо работать, возможно, с сотней дочерних таблиц - не пытайтесь использовать много тысяч дочерних таблиц.
-
Представления (views);
-
Функции, процедуры и операторы (functions, procedures, and operators);
-
Типы данных и домены (data types and domains);
-
Триггеры и правила перезаписи (triggers and rewrite rules).
-
Имя таблицы и столбца для обновления;
-
Новое значение столбца;
-
Условия задающее список строк для обновления.
- Обзор
- Табличные выражения
- Списки выборки
- Объединение запросов
- Сортировка строк
- LIMIT и OFFSET
- Списки VALUES
- Запросы WITH (общие табличные выражения)
-
Для каждой возможной комбинации строк из таблиц
T1иT2(декартово произведение) объединённая таблица будет содержать строку, состоящую из всех столбцов таблицыT1за которыми следуют все столбцы таблицыT2. Если таблицы имеютNиMстрок соответственно, объединенная таблица будет иметь размерN * Mстрок. -
FROM T1 CROSS JOIN T2эквивалентноFROM T1 INNER JOIN T2 ON TRUE(см. ниже). А также эквивалентноFROM T1, T2. -
Слова
INNERиOUTERявляются необязательными во всех типах соединений.INNER— это значение по умолчанию;LEFT,RIGHTиFULLподразумевают внешнее соединение. -
Условие соединения указывается в предложении
ONилиUSINGили неявно словомNATURAL. Условие соединения определяет, какие строки из двух исходных таблиц считаются «совпадающими», как подробно описано ниже. -
Возможные типы квалифицированного соединения:
-
INNER JOIN- каждая строкаR1изT1в объединенной таблице соединена со строкой изT2, которая удовлетворяет условию соединения сR1. -
LEFT OUTER JOIN- сначала выполняется внутреннее соединение. Затем в результирующую таблицу добавляются все строкиT1, которым не соответствует ни одной строкиT2. Вместо значенийT2вставляютсяNULL. В итоге, в результирующей таблице всегда будет присутствовать хотя бы одна строкаT1. -
RIGHT OUTER JOIN- сначала выполняется внутреннее соединение. Затем в результирующую таблицу добавляются все строкиT2, которым не соответствует ни одной строкиT1. Вместо значенийT1вставляютсяNULL. Это соединение обратно левому: В итоге, в результирующей таблице всегда будет присутствовать хотя бы одна строкаT2. -
FULL OUTER JOIN- сначала выполняется внутреннее соединение. Затем в результирующую таблицу добавляются все строкиT1, которым не соответствует ни одной строкиT2(вместо значенийT2вставляютсяNULL). И все строкиT2, которым не соответствует ни одной строкиT1(вместо значенийT1вставляютсяNULL).
-
-
Предложение
ONявляется наиболее общим видом условия соединения: тут указываются выражения логического типа, аналогично предложениюWHERE. Две строки изT1иT2совпадают, если выражениеONвозвращаетtrue. -
Предложение
USINGэто сокращение, которое используется, когда обе стороны соединения используют одинаковые имена столбцов. Оно принимает разделённый запятыми список имен общих столбцов и формирует условие соединения с равенством этих столбцов. Например, соединениеT1иT2с помощьюUSING (a, b)создает условиеON T1.a = T2.a AND T1.b = T2.b. -
Кроме того, использование
JOIN USINGоставляет только уникальные столбцы: нет необходимости печатать оба сопоставленных столбца, т.к. они имеют одинаковые значения. В противоположностиJOIN ON, который выводит все столбцы изT1и затем все столбцы изT2,JOIN USINGсоздает один столбец для каждой из перечисленных пар столбцов (в указанном порядке), за которыми следуют все оставшиеся столбцы изT1, а затем все оставшиеся столбцы изT2. -
Наконец,
NATURAL— это сокращенная формаUSING: он формирует списокUSINGсостоящий из всех имен столбцов, которые появляются в обеих входных таблицах. Как и при использованииUSING, эти столбцы появляются только один раз в результирующей таблице. Если нет общих имён столбцов,NATURAL JOINведет себя какJOIN ... ON TRUE, создавая кросс-объединение между таблицами. - это список выражений значения через запятую, (как определено в разделе Выражения значения). Например, список имён столбцов:
-
Вычисление нерекурсивной части. Для UNION (но не UNION ALL) отбрасываются дублирующиеся строки. В результат рекурсивного запроса добавляются все оставшиеся строки и также помещаются во временную рабочую таблицу.
-
Пока рабочий стол не пуст, повторите эти шаги:
-
Оцените рекурсивный термин, подставив текущее содержимое рабочей таблицы для рекурсивной самореференции. Для UNION (но не UNION ALL) отбросьте дублирующиеся строки и строки, которые дублируют любую предыдущую строку результата. Все оставшиеся строки добавляются в результат рекурсивного запроса, и также помещаются во временную промежуточную таблицу.
-
Содержимое рабочей таблицы заменяется содержимым промежуточной таблицы, затем промежуточная таблица очищается.
-
- Числовые Типы
- Денежные Типы
- Символьные типы
- Двоичные типы данных
- Типы даты/времени
- Логический тип
- Перечисляемые типы
- Геометрические типы
- Типы сетевых адресов
- Типы битовых строк
- Типы текстового поиска
- Тип UUID
- Тип XML
- Типы JSON
- Массивы
- Составные типы
- Диапазонные типы
- Типы доменов
- Типы идентификаторов объектов
- Тип pg_lsn
- Псевдо-типы
-
Если вам требуется точное хранение и расчеты (например, для денежных сумм), используйте вместо этого числовой тип.
-
Если вы хотите выполнять сложные вычисления с этими типами для чего-то важного, особенно если вы полагаетесь на определенное поведение в граничных случаях (бесконечность, недостаточность), вам следует тщательно оценить реализацию.
-
Сравнение двух значений с плавающей точкой на равенство не всегда может работать как ожидалось.
-
Infinity
-
-Infinity
-
NaN
-
Хотя тип date не может иметь связанный часовой пояс, тип time может. Часовые пояса в реальном мире не имеют большого значения, если они не связаны ни с датой, ни с временем, поскольку смещение может изменяться в течение года с переходом на летнее время.
-
Часовой пояс по умолчанию задается в виде постоянного числового смещения от UTC. Таким образом, невозможно адаптироваться к летнему времени при выполнении арифметических операций по датам и временам в пределах границ летнего времени.
-
Полное название часового пояса, например, America/New_York. Распознанные имена часовых поясов перечислены в представлении pg_timezone_names (см. pg_timezone_names). Для этой цели QHB использует широко используемые данные часового пояса IANA, поэтому те же имена часовых поясов также распознаются другим программным обеспечением.
-
Сокращение часового пояса, например PST. Такая спецификация просто определяет конкретное смещение от UTC, в отличие от полных имен часовых поясов, которые также могут подразумевать набор правил перехода на летнее время. Распознанные сокращения перечислены в представлении pg_timezone_abbrevs (см. раздел pg_timezone_abbrevs). Вы не можете задать параметры конфигурации TimeZone или log_timezone для сокращения часового пояса, но вы можете использовать сокращения во входных значениях даты/времени и с оператором AT TIME ZONE.
-
В дополнение к названиям и аббревиатурам часовых поясов QHB будет принимать спецификации часовых поясов в стиле POSIX в виде STDoffset или STDoffsetDST, где STD - сокращение зоны, offset - числовое смещение в часах к западу от UTC, а DST - это необязательное сокращение зоны перехода на летнее время, предполагаемое на один час впереди заданного смещения. Например, если EST5EDT еще не является распознанным названием зоны, оно будет принято и будет функционально эквивалентно времени Восточного побережья США. В этом синтаксисе сокращение зоны может быть строкой букв или произвольной строкой, заключенной в угловые скобки (<>). Когда присутствует сокращение зоны перехода на летнее время, предполагается, что оно будет использоваться в соответствии с теми же правилами перехода на летнее время, которые используются в записи posixrules базы данных часовых поясов IANA. В стандартной установке QHB posixrules совпадает с US/Eastern, поэтому спецификации часовых поясов в стиле POSIX соответствуют правилам перехода на летнее время в США. При необходимости вы можете изменить это поведение, заменив файл posixrules.
-
SQL-команда SET TIME ZONE устанавливает часовой пояс для сеанса. Это альтернативное написание команды SET TIMEZONE TO с синтаксисом более совместимым со спецификацией SQL.
-
Переменная окружения PGTZ используется клиентами libpq для отправки команды SET TIME ZONE на сервер при подключении.
-
Точка (
.) Используется для доступа членов. -
Квадратные скобки (
[]) используются для доступа к массиву. -
Массивы SQL/JSON начинаются с 0, в отличие от обычных массивов SQL, которые начинаются с 1.
-
Литералы пути примитивных типов JSON:Unicode text, numeric, true, false или null.
-
Переменные пути, перечисленные в Таблице 24.
-
Операторы доступа перечислены в Таблице 25.
-
Операторы и методы jsonpath, перечисленные в разделе Операторы пути и методы SQL/JSON
-
Круглые скобки, которые можно использовать для предоставления выражений фильтра или определения порядка вычисления пути.
- int4range - диапазон integer
- int8range - диапазон от bigint
- numrange - диапазон numeric значений
- tsrange - диапазон timestamp without time zone
- tstzrange - диапазон timestamp with time zone
- daterange - диапазон date
- Логические операторы
- Функции сравнения и операторы
- Математические функции и операторы
- Строковые функции и операторы
- Двоичные строковые функции и операторы
- Функции и операторы битовых строк
- Сопоставление с образцом
- Функции форматирования типов данных
- Функции и операторы даты/времени
- Функции поддержки Enum
- Геометрические функции и операторы
- Функции и операторы сетевых адресов
- Функции текстового поиска и операторы
- Функции XML
- Функции и операторы JSON
- Функции управления последовательностями
- Условные выражения
- Функции и операторы массива
- Функции диапазона и операторы
- Агрегатные функции
- Оконные функции
- Выражения подзапроса
- Сравнение строк и массивов
- Функции возврата наборов (SET)
- Системные информационные функции и операторы
- Функции системного администрирования
- Функции настройки конфигурации
- Функции сигнализации сервера
- Функции управления резервным копированием
- Функции управления восстановлением
- Функции синхронизации снимков
- Функции репликации
- Функции управления объектами базы данных
- Функции обслуживания индекса
- Общие функции доступа к файлам
- Функции консультативных блокировок
- Отправка метрик и аннотаций
- Триггерные функции
- Функции запуска событий
- Функции статистической информации
- position (необязательно)
- Строка вида n$ где n - индекс аргумента для печати. Индекс 1 означает первый аргумент после formatstr. Если position опущена, по умолчанию используется следующий аргумент в последовательности.
- flags (необязательно)
- Дополнительные параметры, управляющие форматированием вывода спецификатора формата. В настоящее время единственным поддерживаемым флагом является знак минус (-), который приведет к выравниванию вывода спецификатора формата. Это не имеет никакого эффекта, если поле width также не указано.
- width (необязательно)
Задает минимальное количество символов, которое используется для отображения выходных данных спецификатора формата. Выходные данные дополняются слева или справа (в зависимости от флага -) с пробелами, необходимыми для заполнения ширины. Слишком маленькая ширина не приводит к усечению вывода, а просто игнорируется. Ширина может быть указана с использованием любого из следующего: положительное целое число; звездочка (\*) для использования следующего аргумента функции в качестве ширины; или строка вида * n $ для использования аргумента n й функции в качестве ширины.
Если ширина берется из аргумента функции, этот аргумент используется перед аргументом, который используется для значения спецификатора формата. Если аргумент width является отрицательным, результат выравнивается по левому краю (как если бы был указан флаг -) в поле длины abs (width).
- type (обязательно)
Тип преобразования формата, используемый для создания выходных данных спецификатора формата. Поддерживаются следующие типы:
s форматирует значение аргумента как простую строку. Нулевое значение рассматривается как пустая строка.
I рассматриваю значение аргумента как идентификатор SQL, заключая его в двойные кавычки, если это необходимо. Ошибка в значении, quote_ident нулю (эквиваленту quote_ident).
L указывает значение аргумента как литерал SQL. Нулевое значение отображается в виде строки NULL, без кавычек (эквивалент quote_nullable).
-
|обозначает чередование (любой из двух вариантов). -
*обозначает повторение предыдущего пункта ноль или более раз. -
+обозначает повторение предыдущего пункта один или несколько раз. -
?обозначает повторение предыдущего пункта ноль или один раз. -
{m}обозначает повторение предыдущего элемента ровно m раз. -
{m,}обозначает повторение предыдущего элемента m или более раз. -
{m,n}обозначает повторение предыдущего элемента не менее m и не более n раз. -
Круглые скобки
()могут использоваться для группировки элементов в один логический элемент. -
Выражение в скобках
[...]определяет класс символов, как в регулярных выражениях POSIX. -
символ пробела или
#, которому предшествует\, сохраняется -
пробел или
#в выражении в скобках сохраняется -
пробел и комментарии не могут появляться в многосимвольных обозначениях, таких как
(?: -
Большинство атомов и все ограничения не имеют атрибута жадности (поскольку в любом случае они не могут соответствовать переменным объемам текста).
-
Добавление скобок вокруг RE не меняет его жадности.
-
Квантованный атом с квантификатором с фиксированным повторением (
{m}или{m}?) Имеет такую же жадность (возможно, нет), как сам атом. -
Количественный атом с другими нормальными квантификаторами (включая
{m,n}сm, равнымn) является жадным (предпочитает самое длинное совпадение). -
Количественный атом с не жадным квантификатором (включая
{m, n}?Сm, равнымn) не является жадным (предпочитает кратчайшее совпадение). -
Ветвь - то есть RE, у которого нет верхнего уровня оператор - имеет ту же жадность, что и первый квантифицированный атом, имеющий атрибут жадности.
-
RE, состоящее из двух или более ветвей, соединенных оператор всегда жадный.
-
Вычитание класса символов XQuery не поддерживается. Примером этой функции является использование следующего для соответствия только английским согласным:
[a-z-[aeiou]]. -
Сокращения класса символов XQuery
\c,\C,\iи\Iне поддерживаются. -
Элементы класса символов XQuery, использующие
\p{UnicodeProperty}или обратное\P{UnicodeProperty}, не поддерживаются. -
POSIX интерпретирует классы символов, такие как
\w(см. таблицу 20), в соответствии с преобладающим языковым стандартом (которым вы можете управлять, прикрепляя предложение COLLATE к оператору или функции). XQuery определяет эти классы с помощью ссылок на свойства символов Unicode, поэтому эквивалентное поведение получается только с языком, который следует правилам Unicode. -
Стандарт SQL (не сам XQuery) пытается обслуживать больше вариантов «новой строки», чем POSIX. Описанные выше варианты соответствия с учетом новой строки рассматривают только ASCII NL (
\n) как новую строку, но SQL заставил бы нас рассматривать CR (\r), CRLF (\r\n) (новую строку в стиле Windows) и некоторые cимволы только для Unicode, такие как LINE SEPARATOR (U + 2028), а также перевод строки. Примечательно, что.и\sдолжен считаться\r\nкак один символ, а не два в соответствии с SQL. -
Из экранирования ввода символов, описанного в таблице 19, XQuery поддерживает только
\n,\rи\t. -
XQuery не поддерживает синтаксис
[:name:]для классов символов в выражениях в скобках. -
XQuery не имеет ограничений на просмотр или просмотр назад, а также не выходит за пределы ограничений, описанных в таблице 21.
-
Метасинтаксические формы, описанные в разделе Метасинтаксис регулярных выражений, не существуют в XQuery.
-
Буквы флагов регулярного выражения, определенные в XQuery, относятся к буквам опций для POSIX, но не совпадают с ними (Таблица 23). В то время как параметры
iиqведут себя одинаково, другие не делают: -
Флаги XQuery (разрешить точку для совпадения с новой строкой) и
m(разрешить совпадение^и$для совпадения на новой строке) обеспечивают доступ к тем же режимам поведения, что и флаги POSIXn,pиw, но они не соответствуют поведению флагов POSIXsиm, В частности, обратите внимание, что точка-совпадение-новая строка является поведением по умолчанию в POSIX, но не в XQuery. -
Флаг XQuery
x(игнорировать пробелы в шаблоне) заметно отличается от флага расширенного режима POSIX. ФлагxPOSIX также позволяет#начинать комментарий в шаблоне, и POSIX не будет игнорировать символ пробела после обратной косой черты. -
FM подавляет начальные нули и конечные пробелы, которые в противном случае были бы добавлены, чтобы сделать вывод шаблона фиксированной ширины. В QHB FM изменяет только следующую спецификацию, а в Oracle FM влияет на все последующие спецификации, а повторные модификаторы FM включают и выключают режим заполнения.
-
TM не включает в себя конечные заготовки. to_timestamp и to_date игнорируют модификатор TM .
-
- to_timestamp* и to_date пропускают несколько пробелов в начале
строки ввода и вокруг значений даты и времени, если не используется
опция FX. Например,
to_timestamp(’ 2000 JUN’, ’YYYY MON’)иto_timestamp(’2000 - JUN’, ’YYYY-MON’)работают, ноto_timestamp('2000 JUN', 'FXYYYY MON')возвращает ошибку, поскольку to_timestamp ожидает только один пробел. FX должен быть указан как первый элемент в шаблоне.
- to_timestamp* и to_date пропускают несколько пробелов в начале
строки ввода и вокруг значений даты и времени, если не используется
опция FX. Например,
-
Разделитель (пробел, или не буквенный / нецифровый символ) в строке шаблона to_timestamp и to_date соответствует любому отдельному разделителю во входной строке или пропускается, если не используется опция FX. Например,
to_timestamp('2000JUN', 'YYYY///MON')иto_timestamp('2000/JUN', 'YYYY MON')работают, ноto_timestamp('2000//JUN', 'YYYY/MON')возвращает ошибка, так как количество разделителей во входной строке превышает количество разделителей в шаблоне. -
Шаблон TZH может соответствовать номеру со знаком. Без опции FX знаки минус могут быть неоднозначными и могут интерпретироваться как разделитель. Эта неоднозначность разрешается следующим образом: если число разделителей перед TZH в строке шаблона меньше, чем число разделителей перед знаком минус во входной строке, знак минус интерпретируется как часть TZH. В противном случае знак минус считается разделителем между значениями. Например,
to_timestamp('2000 -10', 'YYYY TZH')соответствует -10 для TZH, ноto_timestamp('2000 -10', 'YYYY TZH')соответствует 10 для TZH. -
Обычный текст разрешен в шаблонах to_char и будет выводиться буквально. Вы можете поместить подстроку в двойные кавычки, чтобы она интерпретировалась как буквальный текст, даже если она содержит шаблоны. Например, в
'"Hello Year "YYYY', YYYY будет заменен данными года, а одиночный Y в Year не будет. В to_date, to_number и to_timestamp буквенный текст и строки в двойных кавычках приводят к пропуску количества символов, содержащихся в строке; например,"XX"пропускает два входных символа (независимо от того, являются ли они XX). -
Если вы хотите, чтобы в выводе была двойная кавычка, вы должны поставить перед ней обратную косую черту, например
'\"YYYY Month\"'. Обратные слеши не являются чем-то особенным вне строк в двойных кавычках. Внутри строки в двойных кавычках обратный слеш заставляет следующий символ восприниматься буквально, каким бы он ни был (но это не имеет особого эффекта, если следующий символ не является двойной кавычкой или другим обратным слешем). -
В to_timestamp и to_date, если спецификация формата года меньше четырех цифр, например, YYY, а введенный год меньше четырех цифр, год будет скорректирован так, чтобы быть ближайшим к 2020 году, например, 95 станет 1995 годом.
-
В to_timestamp и to_date преобразование YYYY имеет ограничение при обработке лет с более чем 4 цифрами. Вы должны использовать какой-либо нецифровый символ или шаблон после YYYY, в противном случае год всегда интерпретируется как 4 цифры. Например (с 20000 годом):
to_date('200001131', 'YYYYMMDD')будет интерпретироваться как год с 4 цифрами; вместо этого используйте разделитель без цифр после года, напримерto_date('20000-1131', 'YYYY-MMDD')илиto_date('20000Nov31', 'YYYYMonDD'). -
В to_timestamp и to_date поле CC (столетие) принимается, но игнорируется, если есть поле YYY, YYYY или Y,YYY. Если CC используется с YY или Y то результат вычисляется как этот год в указанном столетии. Если указан век, а год - нет, то подразумевается первый год столетия.
-
В to_timestamp и to_date имена или номера дней недели (DAY, D и связанные типы полей) принимаются, но игнорируются для целей вычисления результата. То же самое верно для полей квартала (Q).
-
В to_timestamp и to_date дату нумерации недели ISO 8601 (в отличие от григорианской даты) можно указать одним из двух способов:
-
Год, номер недели и день недели: например,
to_date('2006-42-4', 'IYYY-IW-ID')возвращает дату 2006-10-19. Если вы опускаете день недели, он считается равным 1 (понедельник). -
Год и день года: например,
to_date(’2006-291’, ’IYYY-IDDD’)также возвращает 2006-10-19.
Попытка ввести дату, используя сочетание полей нумерации недели ISO 8601 и полей григорианской даты, не имеет смысла и приведет к ошибке. В контексте года нумерации по ISO 8601 понятие «месяц» или «день месяца» не имеет смысла. В контексте григорианского года неделя ИСО не имеет смысла. -
В to_timestamp, миллисекунды (MS) или микросекунды (US) используются как цифры секунд после десятичной точки. Например,
to_timestamp('12.3', 'SS.MS')составляет не 3 миллисекунды, а 300, потому что преобразование обрабатывает его как 12 + 0,3 секунды. Таким образом, для формата SS.MS входные значения12.3,12.30и12.300указывают одинаковое количество миллисекунд. Чтобы получить три миллисекунды, нужно записать12.003, что для преобразования означает 12 + 0,003 = 12,003 секунды.
Вот более сложный пример:to_timestamp('15:12:02.020.001230', 'HH24:MI:SS.MS.US')составляет 15 часов, 12 минут и 2 секунды + 20 миллисекунд + 1230 микросекунд = 2,021230 секунд, -
Нумерация дня недели в to_char(..., ’ID’) соответствует функции extract(isodow from ...), а в to_char(..., ’D’) - не соответствует extract(dow from ...) день нумерации.
-
to_char(interval) форматирует HH и HH12 как показано на 12-часовых часах, например, ноль часов и 36 часов выводят как 12, в то время как HH24 выводит значение полного часа, которое может превышать 23 в значении interval.
-
0 указывает позицию цифры, которая будет всегда печататься, даже если она содержит начальный / конечный ноль. 9 также указывает позицию цифры, но если это ведущий ноль, то он будет заменен пробелом, а если это конечный ноль и указан режим заполнения, то он будет удален. (Для to_number() эти два символа шаблона эквивалентны).
-
Шаблонные символы S, L, D и G представляют знак, символ валюты, десятичную точку и символы разделителя тысяч, определенные текущей локалью (см. Lc_monetary и lc_numeric). Шаблон символов точки и запятая представляют эти точные символы со значениями десятичной точки и разделителя тысяч независимо от локали.
-
Если в to_char() явного положения не предусмотрено, для знака будет зарезервирован один столбец, и он будет привязан (отображается слева от номера). Если S появляется слева от некоторых из 9, он также будет привязан к числу.
-
Знак, отформатированный с использованием SG, PL или MI, не привязан к номеру; например,
to_char(-12, 'MI9999')выдает'- 12'to_char(-12, 'S9999')выдает' -12'. (Реализация Oracle не позволяет использовать MI до 9, а требует, чтобы 9 предшествовал MI). -
TH не преобразует значения меньше нуля и не преобразует дробные числа.
-
PL, SG и TH являются расширениями QHB.
-
В to_number, если используются лекала шаблонов без данных, такие как L или TH, соответствующее количество входных символов пропускается независимо от того, соответствуют ли они шаблону шаблона, если только они не являются символами данных (то есть цифрами, знаком, десятичной точкой или запятой). Например, TH пропустит два символа без данных.
-
V с to_char умножает входные значения на 10^n, где n - количество цифр после V. V с to_number делится аналогичным образом. to_char и to_number не поддерживают использование V сочетании с десятичной точкой (например, 99.9V99 не допускается).
-
EEEE (научная запись) не может использоваться в сочетании с любым другим шаблоном форматирования или модификаторами, кроме шаблонов цифр и десятичных точек, и должен находиться в конце строки формата (например, 9.99EEEE является допустимым шаблоном).
- Век
- Для значений timestamp - поле дня (месяца) (1 - 31); для значений interval количество дней
- день недели с воскресенья (0) по субботу (6)
- день года (1 - 365/366)
- эпоха UNIX. Для timestamp with time zone значениями timestamp with time zone - количество секунд с 1970-01-01 00:00:00 UTC (может быть отрицательным); для значений date и timestamp - количество секунд с 1970-01-01 по 00:00:00 по местному времени; для значений interval общее количество секунд в интервале
- поле часа (0 - 23)
- день недели с понедельника (1) по воскресенье (7)
-
годовой номер недели в ISO 8601, к которому относится дата (не относится к интервалам)
SELECT EXTRACT(ISOYEAR FROM DATE ’2006-01-01’); Result: 2005 SELECT EXTRACT(ISOYEAR FROM DATE ’2006-01-02’); Result: 2006Каждый год нумерации ISO 8601 начинается с понедельника недели, содержащей 4 января, поэтому в начале января или конце декабря год ISO может отличаться от григорианского года. Смотрите поле week для получения дополнительной информации.
-
поле секунд, включая дробные части, умноженное на 1 000 000; обратите внимание, что это включает в себя полные секунды
SELECT EXTRACT(MICROSECONDS FROM TIME ’17:12:28.5’); Result: 28500000 -
миллениум
SELECT EXTRACT(MILLENNIUM FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 3Годы в 1900-х годах во втором тысячелетии. Третье тысячелетие началось 1 января 2001 года.
-
поле секунд, включая дробные части, умножается на 1000. Обратите внимание, что это включает полные секунды.
SELECT EXTRACT(MILLISECONDS FROM TIME ’17:12:28.5’); Result: 28500 -
поле минут (0 - 59)
SELECT EXTRACT(MINUTE FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 38 -
для значений timestamp - номер месяца в году (1 - 12); для interval значений число месяцев по модулю 12 (0 - 11)
SELECT EXTRACT(MONTH FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 2 SELECT EXTRACT(MONTH FROM INTERVAL ’2 years 3 months’); Result: 3 SELECT EXTRACT(MONTH FROM INTERVAL ’2 years 13 months’); Result: 1 -
Квартал года (1 - 4)
SELECT EXTRACT(QUARTER FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 1 -
поле секунд, включая дробные части (0 - 592)
SELECT EXTRACT(SECOND FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 40 SELECT EXTRACT(SECOND FROM TIME ’17:12:28.5’); Result: 28.5 - смещение часового пояса от UTC, измеряется в секундах. Положительные значения соответствуют часовым поясам к востоку от UTC, отрицательные значения - к западу от UTC. (Технически, QHB не использует UTC, потому что секундные секунды не обрабатываются).
- часовая составляющая смещения часового пояса
- минутная составляющая смещения часового пояса
-
номер недели в году по нумерации ISO 8601. По определению, недели ISO начинаются по понедельникам, а первая неделя года содержит 4 января этого года. Другими словами, первый четверг года - первая неделя этого года.
В системе нумерации недель ИСО даты начала января могут быть частью 52-й или 53-й недели предыдущего года, а даты конца декабря - частью первой недели следующего года. Например, 2005-01-01 является частью 53-й недели 2004 года, а 2006-01-01 является частью 52-й недели 2005 года, а 2012-12-31 является частью первой недели 2013 года. Рекомендуется использовать поле isoyear вместе с week чтобы получить согласованные результаты.
SELECT EXTRACT(WEEK FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 7 -
поле года. Имейте в виду, что отсутствует 0 год нашей эры (AD), поэтому вычитать годы до Р. Х. (BC) из лет после Р. Х. (AD) следует с осторожностью.
SELECT EXTRACT(YEAR FROM TIMESTAMP ’2001-02-16 20:38:40’); Result: 2001 -
функции и операторы для обработки и создания данных JSON
-
язык путей SQL/JSON
- NULL значение JSON во всех случаях преобразуется в нулевое значение SQL.
- Если выходной столбец имеет тип json или jsonb, значение JSON точно воспроизводится.
- Если выходной столбец является составным (строковым) типом, а значение JSON является JSON-объектом, поля объекта преобразуются в столбцы выходного строкового типа путем рекурсивного применения этих правил.
- Аналогично, если выходной столбец является типом массива, а значение JSON является массивом JSON, элементы массива JSON преобразуются в элементы выходного массива путем рекурсивного применения этих правил.
- В противном случае, если значение JSON является строковым литералом, содержимое строки передается в функцию преобразования ввода для типа данных столбца.
- В противном случае обычное текстовое представление значения JSON подается в функцию преобразования ввода для типа данных столбца. Хотя в примерах для этих функций используются константы, обычно используется ссылка на таблицу в предложении FROM и использование одного из ее столбцов json или jsonb в качестве аргумента функции. Затем на извлеченные значения ключей можно ссылаться в других частях запроса, таких как WHERE и целевые списки. Таким образом, извлечение нескольких значений может повысить производительность по сравнению с извлечением их отдельно с помощью ключевых операторов.
-
Метод элемента .datetime() еще не реализован, главным образом потому, что неизменяемые функции и операторы jsonpath не могут ссылаться на часовой пояс сеанса, который используется в некоторых операциях datetime. Поддержка даты и времени будет добавлена в jsonpath в будущих версиях QHB.
-
Выражение пути может быть логическим предикатом, хотя стандарт SQL/JSON допускает предикаты только в фильтрах. Это необходимо для реализации оператора @@. Например, следующее выражение jsonpath допустимо в QHB:
- Существуют небольшие различия в интерпретации шаблонов регулярных выражений, используемых в фильтрах like_regex, как описано в разделе Регулярные выражения.
-
lax (по умолчанию) - механизм пути неявно адаптирует запрошенные данные к указанному пути. Все оставшиеся структурные ошибки подавляются и преобразуются в пустые последовательности SQL/JSON.
-
strict - при возникновении структурной ошибки формируется ошибка.
-
Выражение пути содержит методы type() или size() которые возвращают тип и количество элементов в массиве соответственно.
-
Запрашиваемые данные JSON содержат вложенные массивы. В этом случае развернут только самый внешний массив, а все внутренние массивы остаются неизменными. Таким образом, неявное развертывание может идти только на один уровень вниз на каждом этапе оценки пути.
- это те, которые будут использоваться в системных каталогах, таких как pg_depend, и могут быть переданы другим системным функциям, таким как pg_identify_object или pg_describe_object. classid - OID системного каталога, содержащего объект; objid - это OID самого объекта, а objsubid
- это идентификатор подобъекта, или ноль, если его нет. Эта функция является обратной к pg_identify_object_as_address.
-
pg_cancel_backend и pg_terminate_backend отправляют сигналы (SIGINT или SIGTERM соответственно) на внутренние процессы, идентифицируемые по идентификатору процесса. Идентификатор процесса активного бэкэнда можно найти в столбце pid представления pg_stat_activity или в списке процессов qhb на сервере (используя ps в Unix). Роль активного бэкенда можно найти в столбце usename представления pg_stat_activity.
-
pg_reload_conf отправляет сигнал SIGHUP на сервер, вызывая перезагрузку файлов конфигурации всеми процессами сервера.
-
pg_rotate_logfile сигнализирует менеджеру файлов журнала о немедленном переключении на новый выходной файл. Это работает, только когда работает встроенный сборщик журналов, так как в противном случае нет подпроцесса менеджера файлов журнала.
-
’main’ возвращает размер основного ответвления данных отношения.
-
’fsm’ возвращает размер карты свободного пространства (см. раздел Карта свободного пространства ), связанной с отношением.
-
’vm’ возвращает размер карты видимости (см. раздел Карта видимости), связанной с отношением.
-
’init’ возвращает размер форка инициализации, если он есть, связанный с отношением.
- Обзор
- Структура PL/pgSQL
- Объявления
- Выражения
- Основные положения
- Управляющие структуры
- Курсоры
- Управление транзакциями
- Ошибки и сообщения
- Триггерные функции
- PL/pgSQL под капотом
- Советы по разработке на PL/pgSQL
- Портирование из Oracle PL/SQL
- может быть использован для создания функций и триггеров,
- добавляет структуры управления к языку SQL,
- может выполнять сложные вычисления,
- наследует все пользовательские типы, функции и операторы,
- может быть определен как доверенный сервером,
- прост в использовании.
- Дополнительные обходы между клиентом и сервером исключены
- Промежуточные результаты, которые не нужны клиенту, не нужно передавать между сервером и клиентом
- Можно избежать нескольких раундов разбора запроса
-
Оператор SELECT INTO устанавливает FOUND true, если назначена строка, и false, если строка не возвращается.
-
Оператор PERFORM устанавливает FOUND true, если он создает (и отбрасывает) одну или несколько строк, и false, если строка не создается.
-
Операторы UPDATE, INSERT и DELETE устанавливают FOUND true, если затронута хотя бы одна строка, и false, если строка не затрагивается.
-
FETCH устанавливает FOUND true, если возвращает строку, и false, если строка не возвращается.
-
Оператор MOVE устанавливает FOUND true, если он успешно перемещает курсор, в противном случае - false.
-
FOREACH FOR или FOREACH устанавливает FOUND true, если он повторяется один или несколько раз, в противном случае - false. FOUND устанавливается таким образом при выходе из цикла; внутри выполнения цикла FOUND не изменяется оператором цикла, хотя он может быть изменен выполнением других операторов в теле цикла.
-
Операторы RETURN QUERY и RETURN QUERY EXECUTE устанавливают FOUND true, если запрос возвращает хотя бы одну строку, и false, если строка не возвращается.
-
IF ... THEN ... END IF -
IF ... THEN ... ELSE ... END IF -
IF ... THEN ... ELSIF ... THEN ... ELSE ... END IF -
CASE ... WHEN ... THEN ... ELSE ... END CASE -
CASE WHEN ... THEN ... ELSE ... END CASE - автоматически определяются для описания условия, которое вызвало вызов.
- Тип данных text; строка, представляющая событие, для которого запускается триггер.
- Тип данных text; переменная, содержащая тег команды, для которого срабатывает триггер.
- Чтобы начать и закончить тело функции, например:
- Для строковых литералов внутри тела функции, например:
- Когда вам нужна одиночная кавычка в строковой константе внутри тела функции, например:
- Когда одна кавычка в строке внутри тела функции находится рядом с концом этой строковой константы, например:
- Когда вам нужно две одинарные кавычки в строковой константе (на которую приходится 8 кавычек), и это рядом с концом этой строковой константы (еще 2). Это, вероятно, понадобится вам, только если вы пишете функцию, которая генерирует другие функции, как в примере 9.10. Например:
- Проверяет, скрывает ли объявление ранее определенную переменную.
- Некоторые команды PL/pgSQL позволяют присваивать значения более чем одной переменной одновременно, например, SELECT INTO. Как правило, число целевых переменных и количество исходных переменных должны совпадать, хотя PL/pgSQL будет использовать NULL для пропущенных значений, а дополнительные переменные игнорируются. Включение этой проверки приведет к тому, что PL/pgSQL будет выдавать WARNING или ERROR всякий раз, когда число целевых переменных и количество исходных переменных различаются.
- Включение этой проверки заставит PL/pgSQL проверять, возвращает ли данный запрос более одной строки, когда используется предложение INTO. Поскольку оператор INTO будет когда-либо использовать только одну строку, запрос, возвращающий несколько строк, как правило, либо неэффективен, либо недетерминирован, и, следовательно, вероятно, является ошибкой.
-
Если имя, используемое в команде SQL, может быть либо именем столбца таблицы, либо ссылкой на переменную функции, PL/SQL обрабатывает его как имя столбца. Это соответствует поведению PL/pgSQL plpgsql.variable_conflict = use_column, которое не является значением по умолчанию, как описано в разделе Подстановка переменных. Во-первых, во-первых, часто лучше избегать таких неоднозначностей, но если вам нужно портировать большой объем кода, который зависит от этого поведения, настройка variable_conflict может быть лучшим решением.
-
В QHB тело функции должно быть записано как строковый литерал. Поэтому вам нужно использовать знаки доллара или экранировать одинарные кавычки в теле функции. (См. раздел Обработка кавычек).
-
Имена типов данных часто нуждаются в переводе. Например, в Oracle строковые значения обычно объявляются как имеющие тип varchar2, который является нестандартным типом SQL. В QHB вместо этого используйте тип varchar или text. Аналогично, замените тип number на numeric или используйте другой тип числовых данных, если есть более подходящий.
-
Вместо пакетов используйте схемы для организации ваших функций в группы.
-
Поскольку пакетов нет, переменных уровня пакета тоже нет. Это несколько раздражает. Вместо этого вы можете сохранить состояние сеанса во временных таблицах.
-
Целочисленные циклы FOR с REVERSE работают по-разному: PL/SQL ведет обратный отсчет от второго числа к первому, а PL/pgSQL ведет обратный отсчет от первого числа ко второму, что требует замены границ цикла при переносе. Эта несовместимость вызывает сожаление, но вряд ли изменится. (См. раздел FOR (целочисленный вариант)).
-
Циклы FOR запросов (кроме курсоров) также работают по-другому: целевая переменная (и) должна быть объявлена, тогда как PL/SQL всегда объявляет их неявно. Преимущество этого состоит в том, что значения переменных все еще доступны после выхода из цикла.
-
Существуют различные нотационные различия для использования переменных курсора.
-
Имя типа varchar2 должно быть изменено на varchar или text. В примерах в этом разделе мы будем использовать varchar, но text часто является лучшим выбором, если вам не нужны определенные ограничения длины строки.
-
Ключевое слово RETURN в прототипе функции (а не в теле функции) становится RETURNS в QHB. Кроме того, IS становится AS, и вам нужно добавить предложение LANGUAGE, поскольку PL/pgSQL не является единственным возможным языком функций.
-
В QHB тело функции считается строковым литералом, поэтому вокруг него нужно использовать кавычки или знаки доллара. Это заменяет прекращение / в подходе Oracle.
-
Команда show errors не существует в QHB и не нужна, поскольку ошибки сообщаются автоматически.
- ABORT — прервать текущую транзакцию
- ALTER AGGREGATE — изменить определение агрегатной функции
- ALTER COLLATION — изменить определение правила сортировки
- ALTER CONVERSION — изменить определение перекодировки
- ALTER DATABASE — изменить базу данных
- ALTER DEFAULT PRIVILEGES — определить права доступа по умолчанию
- ALTER DOMAIN — изменить определение домена
- ALTER EVENT TRIGGER — изменить определение событийного триггера
- ALTER EXTENSION — изменить определение расширения
- ALTER FOREIGN DATA WRAPPER — изменить определение обертки сторонних данных
- ALTER FOREIGN TABLE — изменить определение сторонней таблицы
- ALTER FUNCTION — изменить определение функции
- ALTER GROUP — изменить имя роли или членство
- ALTER INDEX — изменить определение индекса
- ALTER LANGUAGE — изменить определение процедурного языка
- ALTER LARGE OBJECT — изменить определение большого объекта
- ALTER MATERIALIZED VIEW — изменить определение материализованного представления
- ALTER OPERATOR — изменить определение оператора
- ALTER OPERATOR CLASS — изменить определение класса операторов
- ALTER OPERATOR FAMILY — изменить определение семейства операторов
- ALTER POLICY — изменить определение политики защиты на уровне строк
- ALTER PROCEDURE — изменить определение процедуры
- ALTER PUBLICATION — изменить определение публикации
- ALTER ROLE — изменить роль в базе данных
- ALTER ROUTINE — изменить определение подпрограммы
- ALTER RULE — изменить определение правила
- ALTER SCHEMA — изменить определение схемы
- ALTER SEQUENCE — изменить определение генератора последовательности
- ALTER SERVER — изменить определение стороннего сервера
- ALTER STATISTICS — изменить определение объекта расширенной статистики
- ALTER SUBSCRIPTION — изменить определение подписки
- ALTER SYSTEM — изменить параметр конфигурации сервера
- ALTER TABLE — изменить определение таблицы
- ALTER TABLESPACE — изменить определение табличного пространства
- ALTER TEXT SEARCH CONFIGURATION — изменить определение конфигурации текстового поиска
- ALTER TEXT SEARCH DICTIONARY — изменить определение словаря текстового поиска
- ALTER TEXT SEARCH PARSER — изменить определение анализатора текстового поиска
- ALTER TEXT SEARCH TEMPLATE — изменить определение шаблона текстового поиска
- ALTER TRIGGER — изменить определение триггера
- ALTER TYPE — изменить определение типа
- ALTER USER — изменить роль в базе данных
- ALTER USER MAPPING — изменить определение сопоставления пользователей
- ALTER VIEW — изменить определение представления
- ANALYZE — собрать статистику по базе данных
- BEGIN — начать блок транзакции
- CALL — вызвать процедуру
- CHECKPOINT — принудительно выполнить контрольную точку в журнале с упреждающей записью
- CLOSE — закрыть курсор
- CLUSTER — кластеризовать таблицу согласно индексу
- COMMENT — определить или изменить комментарий объекта
- COMMIT — зафиксировать текущую транзакцию
- COMMIT PREPARED — зафиксировать транзакцию, которая ранее была подготовлена для двухфазной фиксации
- COPY — копировать данные между файлом и таблицей
- CREATE ACCESS METHOD — определить новый метод доступа
- CREATE AGGREGATE — определить новую агрегатную функцию
- CREATE CAST — определить новое приведение
- CREATE COLLATION — определить новое правило сортировки
- CREATE CONVERSION — определить новую перекодировку
- CREATE DATABASE — создать новую базу данных
- CREATE DOMAIN — определить новый домен
- CREATE EVENT TRIGGER — определить новый событийный триггер
- CREATE EXTENSION — определить новое расширение
- CREATE FOREIGN DATA WRAPPER — определить новую обертку сторонних данных
- CREATE FOREIGN TABLE — определить новую стороннюю таблицу
- CREATE FUNCTION — определить новую функцию
- CREATE GROUP — определить новую роль в базе данных
- CREATE INDEX — определить новый индекс
- CREATE LANGUAGE — определить новый процедурный язык
- CREATE MATERIALIZED VIEW — определить новое материализованное представление
- CREATE OPERATOR — определить новый оператор
- CREATE OPERATOR CLASS — определить новый класс операторов
- CREATE OPERATOR FAMILY — определить новое семейство операторов
- CREATE POLICY — определить для таблицы новую политику защиты на уровне строк
- CREATE PROCEDURE — определить новую процедуру
- CREATE PUBLICATION — определить новую публикацию
- CREATE ROLE — определить новую роль в базе данных
- CREATE RULE — определить новое правило перезаписи
- CREATE SCHEMA — определить новую схему
- CREATE SEQUENCE — определить новый генератор последовательности
- CREATE SERVER — определить новый сторонний сервер
- CREATE STATISTICS — определить новую расширенную статистику
- CREATE SUBSCRIPTION — определить новую подписку
- CREATE TABLE — определить новую таблицу
- CREATE TABLE AS — определить новую таблицу из результатов запроса
- CREATE TABLESPACE — определить новое табличное пространство
- CREATE TEXT SEARCH CONFIGURATION — определить новую конфигурацию текстового поиска
- CREATE TEXT SEARCH DICTIONARY — определить новый словарь текстового поиска
- CREATE TEXT SEARCH PARSER — определить новый анализатор текстового поиска
- CREATE TEXT SEARCH TEMPLATE — определить новый шаблон текстового поиска
- CREATE TRANSFORM — определить новую трансформацию
- CREATE TRIGGER — определить новый триггер
- CREATE TYPE — определить новый тип данных
- CREATE USER — определить новую роль в базе данных
- CREATE USER MAPPING — определить новое сопоставление пользователей для стороннего сервера
- CREATE VIEW — определить новое представление
- DEALLOCATE — освободить подготовленный оператор
- DECLARE — определить курсор
- DELETE — удалить строки в таблице
- DISCARD — сбросить состояние сеанса
- DO — выполнить анонимный блок кода
- DROP ACCESS METHOD — удалить метод доступа
- DROP AGGREGATE — удалить агрегатную функцию
- DROP CAST — удалить приведение
- DROP COLLATION — удалить правило сортировки
- DROP CONVERSION — удалить перекодировку
- DROP DATABASE — удалить базу данных
- DROP DOMAIN — удалить домен
- DROP EVENT TRIGGER — удалить событийный триггер
- DROP EXTENSION — удалить расширение
- DROP FOREIGN DATA WRAPPER — удалить обертку сторонних данных
- DROP FOREIGN TABLE — удалить стороннюю таблицу
- DROP FUNCTION — удалить функцию
- DROP GROUP — удалить роль в базе данных
- DROP INDEX — удалить индекс
- DROP LANGUAGE — удалить процедурный язык
- DROP MATERIALIZED VIEW — удалить материализованное представление
- DROP OPERATOR — удалить оператор
- DROP OPERATOR CLASS — удалить класс операторов
- DROP OPERATOR FAMILY — удалить семейство операторов
- DROP OWNED — удалить объекты базы данных, принадлежащие роли в базе данных
- DROP POLICY — удалить из таблицы политику защиты на уровне строк
- DROP PROCEDURE — удалить процедуру
- DROP PUBLICATION — удалить публикацию
- DROP ROLE — удалить роль в базе данных
- DROP ROUTINE — удалить подпрограмму
- DROP RULE — удалить правило перезаписи
- DROP SCHEMA — удалить схему
- DROP SEQUENCE — удалить последовательность
- DROP SERVER — удалить дескриптор стороннего сервера
- DROP STATISTICS — удалить расширенную статистику
- DROP SUBSCRIPTION — удалить подписку
- DROP TABLE — удалить таблицу
- DROP TABLESPACE — удалить табличное пространство
- DROP TEXT SEARCH CONFIGURATION — удалить конфигурацию текстового поиска
- DROP TEXT SEARCH DICTIONARY — удалить словарь текстового поиска
- DROP TEXT SEARCH PARSER — удалить анализатор текстового поиска
- DROP TEXT SEARCH TEMPLATE — удалить шаблон текстового поиска
- DROP TRANSFORM — удалить трансформацию
- DROP TRIGGER — удалить триггер
- DROP TYPE — удалить тип данных
- DROP USER — удалить роль в базе данных
- DROP USER MAPPING — удалить сопоставление пользователей для стороннего сервера
- DROP VIEW — удалить представление
- END — зафиксировать текущую транзакцию
- EXECUTE — выполнить подготовленный оператор
- EXPLAIN — показать план выполнения оператора
- FETCH — получить строки из запроса при помощи курсора
- GRANT — определить права доступа
- IMPORT FOREIGN SCHEMA — импортировать определения таблицы со стороннего сервера
- INSERT — добавить в таблицу новые строки
- LISTEN — ожидать уведомления
- LOAD — загрузить файл разделяемой библиотеки
- LOCK — заблокировать таблицу
- MOVE — переместить курсор
- NOTIFY — создать уведомление
- PREPARE — подготовить оператор к выполнению
- PREPARE TRANSACTION — подготовить текущую транзакцию для двухфазной фиксации
- REASSIGN OWNED — сменить владельца объектов базы данных, принадлежащих роли в базе данных
- REFRESH MATERIALIZED VIEW — заменить содержимое материализованного представления
- REINDEX — перестроить индексы
- RELEASE SAVEPOINT — уничтожить определенную ранее точку сохранения
- RESET — восстановить значение по умолчанию параметра периода выполнения
- REVOKE — аннулировать права доступа
- ROLLBACK — прервать текущую транзакцию
- ROLLBACK PREPARED — отменить транзакцию, которая ранее была подготовлена для двухфазной фиксации
- ROLLBACK TO SAVEPOINT — откатиться к точке сохранения
- SAVEPOINT — определить новую точку сохранения в текущей транзакции
- SECURITY LABEL — определить или изменить примененную к объекту метку безопасности
- SELECT — получить строки из таблицы или представления
- SELECT INTO — определить новую таблицу из результатов запроса
- SET — изменить параметр периода выполнения
- SET CONSTRAINTS — установить время проверки ограничений для текущей транзакции
- SET ROLE — установить идентификатор текущего пользователя для текущей транзакции
- SET SESSION AUTHORIZATION — установить идентификатор пользователя сеанса и идентификатор текущего пользователя текущего сеанса
- SET TRANSACTION — установить характеристики текущей транзакции
- SHOW — показать значение параметра периода выполнения
- START TRANSACTION — начать блок транзакции
- TRUNCATE — опустошить таблицу или набор таблиц
- UNLISTEN — прекратить ожидание уведомления
- UPDATE — изменить строки таблицы
- VACUUM — почистить память и при необходимости проанализировать базу данных
- VALUES — вычислить набор строк
- refresh (boolean)
- copy_data (boolean)
-
RECEIVE позволяет задать имя функции двоичного ввода, а NONE удаляет ссылку на такую функцию. Для изменения этого свойства требуются права суперпользователя.
-
SEND позволяет задать имя функции двоичного вывода, а NONE удаляет ссылку на такую функцию. Для изменения этого свойства требуются права суперпользователя.
-
TYPMOD_IN позволяет задать имя функции ввода модификатора типа, а NONE удаляет ссылку на такую функцию. Для изменения этого свойства требуются права суперпользователя.
-
TYPMOD_OUT позволяет задать имя функции вывода модификатора типа, а NONE удаляет ссылку на такую функцию. Для изменения этого свойства требуются права суперпользователя.
-
ANALYZE позволяет задать имя функции сбора статистики типа, а NONE удаляет ссылку на такую функцию. Для изменения этого свойства требуются права суперпользователя.
-
STORAGE может принимать значения plain, extended, external или main (более подробную информацию о том, что они означают, см. в разделе TOAST). Однако для изменения значения с plain на все остальные требуются права суперпользователя (т. к. для этого изменения нужно, чтобы все функции, реализующие типа на С, поддерживали TOAST), а изменение других значений на plain не разрешено вовсе (поскольку значения этого типа в базе данных могут уже храниться в виде TOAST). Обратите внимание, что изменение этого свойства само по себе не меняет никакие сохраненные данные; оно просто задает стратегию TOAST по умолчанию, которая будет использоваться для столбцов, создаваемых в будущем. Изменение стратегии TOAST для существующих столбцов таблицы описано в разделе ALTER TABLE.
-
check_option (string)
Изменяет параметр проверки представления. Допустимые значения: local (локальная) или cascaded (каскадная)
-
security_barrier (boolean)
Изменяет свойство представления, включающее барьер безопасности. Значение должно быть логическим: true или false.
- Бит 16
- Синтаксис
- Описание
- Параметры
- Перегрузка
- Примечания
- Примеры
- Разработка защищенных функций SECURITY DEFINER
- Совместимость
- См. также
-
-- и /* в имени оператора присутствовать не могут, так как они приняты в качестве начала комментария.
-
Многосимвольное имя оператора не может заканчиваться на + или -, если только имя также не содержит хотя бы один из этих символов:
- Использование => в качестве имени оператора считается устаревшим и может быть окончательно запрещено в будущих выпусках.
- publish (string)
- publish_via_partition_root (boolean)
-
Получение следующего значения производится с помощью функции nextval() вместо стандартного выражения NEXT VALUE FOR.
-
Предложение OWNED BY является расширением QHB.
- Запрещена модификация данных (update и delete).
- Осуществляется максимально быстрая вставка данных.
- Отсутствует необходимость в автоочистке.
- Поддерживаются все типы индексов.
- Для удаления старых данных можно использовать секционирование таблицы и удалять данные секциями, либо использовать команду TRUNCATE.
- Не поддерживается механизм TOAST.
-
PRESERVE ROWS
По завершении транзакции никаких специальных действий не предпринимается. Это поведение по умолчанию.
-
DELETE ROWS
В конце каждого блока транзакций все строки во временной таблице будут удалены. По существу, при каждой фиксации выполняется автоматическое TRUNCATE.
-
DROP
В конце текущего блока транзакций временная таблица будет удалена.
-
Стандарт требует заключать предложение подзапроса в круглые скобки; в QHB эти скобки необязательны.
-
В стандарте требуется указывать предложение WITH [ NO ] DATA; в QHB это необязательно.
-
QHB обрабатывает временные таблицы не так, как указано в стандарте; подробную информацию см. в разделе CREATE TABLE.
-
Предложение WITH является расширением QHB; параметры хранения не входят в стандарт.
-
Концепция табличных пространств QHB не является частью стандарта. Следовательно, предложение TABLESPACE является расширением.
- Синтаксис
- Описание
- Параметры
- Примечания
- Примеры
- Совместимость
- Временная таблица
- Неотложные ограничения уникальности
- Ограничения-тесты для столбцов
- Ограничение EXCLUDE
- «Ограничение» NULL
- Ограничение именования
- Наследование
- Таблицы с нулевыми столбцами
- Множество столбцов идентификаторов
- Генерируемые столбцы
- Предложение LIKE
- Предложение USING qss
- Предложение USING append_only
- Предложение WITH
- TABLESPACE
- Типизированная таблица
- Предложение PARTITION BY
- Предложение PARTITION OF
- См. также
- Запрещена модификация данных (update и delete).
- Осуществляется максимально быстрая вставка данных.
- Отсутствует необходимость в автоочистке.
- Поддерживаются все типы индексов.
- Для удаления старых данных можно использовать секционирование таблицы и удалять данные секциями, либо использовать команду TRUNCATE.
- Не поддерживается механизм TOAST.
- PRESERVE ROWS
- DELETE ROWS
- DROP
-
Функция «из SQL», которая преобразует тип из среды SQL в среду языка. Эта функция будет вызываться для аргументов функции, написанной на этом языке.
-
Функция «в SQL», которая преобразует тип из среды языка в среду SQL. Эта функция будет вызываться для значения, возвращаемого из функции, написанной на этом языке.
-
В то время как имена переходных таблиц для триггеров AFTER задаются с помощью предложения REFERENCING стандартным образом, переменные строк, используемые в триггерах FOR EACH ROW нельзя указывать в предложении REFERENCING. Порядок обращения к таким строкам зависит от языка, на котором написана функция триггера, но для каждого языка он вполне определенный. Некоторые языки действуют так, как будто предложение REFERENCING присутствует в команде, и содержит указание OLD ROW AS OLD NEW ROW AS NEW.
-
Стандарт позволяет использовать переходные таблицы со специфичными для столбцов триггерами UPDATE, но тогда набор строк, которые должны быть видны в переходных таблицах, должен зависеть от списка целевых столбцов триггера. В настоящее время в QHB это не реализовано.
-
QHB разрешает задавать в качестве действия триггера только пользовательскую функцию. Стандарт же позволяет выполнять в качестве действия триггера ряд других команд SQL, таких как
CREATE TABLE. Это ограничение нетрудно обойти, создав пользовательскую функцию, которая выполняет нужные команды. -
Список *FROM в запросе, определяющем представление, должен содержать ровно один элемент, и это должна быть таблица или другое изменяемое представление.
-
Определение представления не должно содержать WITH, DISTINCT, GROUP BY, HAVING, LIMIT и OFFSET BY на верхнем уровне запроса.
-
Определение представления не должно содержать операций с множествами (UNION, INTERSECT или EXCEPT) на верхнем уровне запроса.
-
Список выборки в запросе не должен содержать агрегатные и оконные функции, а также функции, возвращающие множества.
-
Стандарт позволяет удалить командой только одну функцию.
-
Параметр IF EXISTS
-
Возможность задавать режимы и имена аргументов
-
Стандарт позволяет удалить командой только одну процедуру.
-
Параметр IF EXISTS
-
Возможность задавать режимы и имена аргументов
-
Стандарт позволяет удалить командой только одну подпрограмму.
-
Параметр IF EXISTS
-
Возможность задавать режимы и имена аргументов
-
Агрегатные функции.
- SELECT
- INSERT
- UPDATE
- DELETE
- TRUNCATE
- REFERENCES
- TRIGGER
- CREATE
- CONNECT
- TEMPORARY
- EXECUTE
- USAGE
-
Индекс был поврежден, и его содержимое стало некорректным. Хотя в теории этого никогда не должно произойти, на практике индексы могут быть повреждены из-за ошибок программного обеспечения или аппаратных сбоев. В таких случаях
REINDEXпредоставляет метод восстановления. -
Индекс стал «раздутым», то есть содержит много пустых или почти пустых страниц. Это может произойти с индексами B-деревьями в QHB при определенных необычных сценариях использования.
REINDEXпредоставляет способ сократить объем, занимаемый индексом, записывая новую версию индекса без «мертвых» страниц. Дополнительную информацию см. в разделе Регулярная переиндексация. -
Вы изменили для индекса параметр хранения (например, коэффициент заполнения) и хотите убедиться, что изменение вступило в силу.
-
Если построение индекса завершается неудачно в режиме CONCURRENTLY, этот индекс остается в «нерабочем» состоянии. Такие индексы бесполезны, но с помощью
REINDEXих можно легко перестроить. Обратите внимание, что перестраивать индекс в неблокирующем режиме способна только командаREINDEX INDEX. -
В каталог pg_index добавляется новое определение временного индекса. Это определение будет использовано для замены старого индекса. Чтобы предотвратить любые изменения в схеме во время обработки, на уровне сеанса выполняется блокировка SHARE UPDATE EXCLUSIVE переиндексируемых индексов, а также связанных с ними таблиц.
-
Первый проход для построения индекса выполняется для каждого нового индекса. После того, как индекс построен, его флаг pg_index.indisready переключается в «true», чтобы этот индекс был готов к добавлениям, тем самым делая его видимым для других сеансов сразу после окончания построившей его транзакции. Этот шаг выполняется в отдельной транзакции для каждого индекса.
-
Затем выполняется второй проход для внесения в индекс кортежей, которые были добавлены во время выполнения первого прохода. Этот шаг также выполняется в отдельной транзакции для каждого индекса.
-
Все ограничения, относящиеся к индексу, переключаются на определение нового индекса; также изменяются имена индексов. В этот момент флаг pg_index.indisvalid переключается в «true» для нового индекса и в «false» для старого, и производится сброс кэша, в результате чего все сеансы, которые ссылались на старый индекс, становятся недействительными.
-
Старые индексы имеют флаг pg_index.indisready, который переключается в «false», чтобы предотвратить новые добавления кортежей, как только завершатся текущие запросы, которые могут ссылаться на старый индекс.
-
Старые индексы удаляются. Блокировки SHARE UPDATE EXCLUSIVE уровня сеанса, установленные для индексов и таблиц, снимаются.
- Синтаксис
- Описание
- Параметры
- Примеры
- Совместимость
- Необязательное предложение FROM
- Пустые списки SELECT
- Необязательное ключевое слово AS
- ONLY и наследование
- Ограничения предложения TABLESAMPLE
- Вызовы функций в предложении FROM
- Пространства имен в GROUP BY и ORDER BY
- Функциональные зависимости
- LIMIT и OFFSET
- FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE, FOR KEY SHARE
- Изменение данных в WITH
- Нестандартные предложения
-
Вычисляются все запросы в списке WITH. Они фактически служат временными таблицами, к которым можно обращаться в списке FROM. Запрос WITH, на который в FROM обращаются более одного раза, вычисляется только один раз, если иное не указано в параметре NOT MATERIALIZED. (См. подраздел Предложение WITH ниже.)
-
Вычисляются все элементы в списке FROM. (Каждый элемент в списке FROM — это реальная или виртуальная таблица.) Если в списке
указано более одного элемента, они объединяются перекрестным соединением. (См. подраздел Предложение FROM ниже.) -
Если указано предложение WHERE, все строки, которые не удовлетворяют условию, исключаются из результата. (См. подраздел Предложение WHERE ниже.)
-
Если указано предложение GROUP BY или вызываются агрегатные функции, то вывод объединяется в группы строк, соответствующие одному или нескольким значениям, и вычисляются результаты агрегатных функций. Если присутствует предложение HAVING, оно исключает группы, не удовлетворяющие данному условию. (См. подразделы Предложение GROUP BY и Предложение HAVING ниже.)
-
Вычисляются фактические выходные строки по заданным в
SELECTвыходным выражениям для каждой выбранной строки или группы строк. (См. подраздел Список SELECT ниже.) -
SELECT DISTINCTудаляет повторяющиеся строки из результата.SELECT DISTINCT ONудаляет строки, соответствующие всем указанным выражениям.SELECT ALL(значение по умолчанию) возвращает все строки-кандидаты, включая дубликаты. (См. подраздел Предложение DISTINCT ниже.) -
Операторы UNION, INTERSECT и EXCEPT объединяют выходные данные нескольких команд
SELECTв один результирующий набор. Оператор UNION возвращает все строки, находящиеся в одном или обоих результирующих наборах. Оператор INTERSECT возвращает все строки, которые строго находятся в обоих результирующих наборах. Оператор EXCEPT возвращает строки, которые находятся в первом результирующем наборе, но не во втором. Во всех трех случаях повторяющиеся строки исключаются, если только явно не задан оператор ALL. Можно добавить необязательный оператор DISTINCT, чтобы явно указать, что требуется устранение повторяющихся строк. Заметьте, что в данном случае DISTINCT — это поведение по умолчанию, хотя в самой командеSELECTпо умолчанию подразумевается ALL. (См. подразделы Предложение UNION, Предложение INTERSECT и Предложение EXCEPT ниже.) -
Если указано предложение ORDER BY, возвращаемые строки сортируются в указанном порядке. Если ORDER BY не задается, строки возвращаются в любом порядке, который система считает наиболее быстрым для получения. (См. подраздел Предложение ORDER BY ниже.)
-
Если указано предложение LIMIT (или FETCH FIRST) или OFFSET, команда
SELECTвозвращает только подмножество результирующих строк. (См. подраздел Предложение LIMIT ниже.) -
Если указано FOR UPDATE, FOR NO KEY UPDATE, FOR SHARE или FOR KEY SHARE, команда
SELECTблокирует выбранные строки от одновременных обновлений. (См. подраздел Предложение блокировки ниже.) -
[INNER ] JOIN
-
LEFT [OUTER ] JOIN
-
RIGHT [OUTER ] JOIN
-
FULL [OUTER ] JOIN
-
CROSS JOIN
- Коды ошибок
- Расширения
- Ключевые слова
- Поддерживаемые платформы
- Страница загрузки
- Поддержка прикладных платформ
- Краткие инструкции
- Расширенный SQL
- Замечания к релизу
- x86_64
- Linux
Возможна работа на всех последних дистрибутивах, но пока бинарные пакеты собираются только для операционных систем, перечисленных на странице загрузки. - QHB для CentOs 7 и 8
- QHB для Альт Сервер 9
- QHB для Fedora 32 и 33
- QHB для Debian 9 и Astra Linux Special Edition «Смоленск» 1.6
- QHB в виде docker контейнера
- Дополнительные типы данных для совместимости с Microsoft SQL Server
- Дополнительный оператор равенства для совместимости с Microsoft SQL Server
- Быстрое усечение временных таблиц
- Немедленное обновление статистики отдельных таблиц
- Поддержка указаний для планировщика, позволяющих отключать или подключать определённые индексы при выполнении запроса
- сравнение без учёта регистра, в том числе, если один из аргументов mchar/mvarchar, а второй нет;
для сравнения с учётом регистра вводятся специальные версии операторов сравнения:
&<,&<=,&=,&>=и&> - mchar фиксированной длины дополняется пробелами справа, но при сравнениях пробелы справа игнорируются;
- данные типа mchar/mvarchar хранятся в кодировке utf-16 (для пользователя это не важно);
- для сравнения и приведения к верхнему/нижнему регистру используется ICU, поэтому результат не зависит от операционной системы;
- функция получения подстроки substr(str, pos [, length]), а не substring
- mchar и mvarchar без указания длины трактуются как строки неопределённой, неограниченной длины (похоже на nvarchar(max)); mchar неопределённой длины не дополняется пробелами справа (но явно заданные пробелы всё-таки хранятся)
- функция вычисления длины строки length(string), а не len как в Microsoft SQL Server.
- bool
- bytea
- char
- mchar
- varchar
- mvarchar
- name
- int2
- int4
- int8
- int2vector
- text
- oid
- xid
- cid
- oidvector
- float4
- float8
- macaddr
- inet
- cidr
- date
- time
- timestamp
- timestamptz
- interval
- timetz
- Краткая инструкция по начальной загрузке и установке
- Краткая инструкция по обновлению
- Запуск и остановка сервера с помощью сервиса systemd
- Пример настройки синхронной реплики
- Инструкция по использованию QSS в режиме хранения пользовательского ключа на USB носителе
- Инструкция по использованию QSS в режиме хранения пользовательского ключа на крипто-токене
- Инструкция по установке и использованию QCP
- необходимо обновление или миграция (бинарная) с других СУБД, или с младших версий СУБД «Квант-Гибрид»,
- когда каталог базы данных уже существует и не может быть создан заново,
- когда необходимо сохранить данные уже используемой базы данных в бинарном виде,
- Загрузка и установка бинарных пакетов
- Инициализация кластера базы данных
- Запуск и остановка сервера
- Создание базы данных
- Доступ к базе данных
-
С помощью интерактивного терминала QHB, называемого qsql, который позволяет в интерактивном режиме вводить, редактировать и выполнять команды SQL.
-
С использованием существующего графического инструмента внешнего интерфейса, например, pgAdmin, DBeaver или офисного пакета с поддержкой ODBC или JDBC. Эти возможности не рассматриваются в этом руководстве.
-
Написав собственное приложение с использованием одной из нескольких доступных языковых привязок.
- Создаем пользователя PostgreSQL для репликации
- Устанавливаем необходимые параметры в файле конфигурации
vi /u01/qhb/db/qhb.conf - Устанавливаем параметры доступа к БД с standby машины
- Производим рестарт сервиса СУБД
- Останавливаем сервис СУБД на сервере реплики
- Удаляем директорию с данными БД
- Если объём данных в БД большой, то рекомендовано воспользоваться копией данных, при её наличии. В случае если ситуация позволяет, выполняем восстановление через бэкап.
- запуску сервера СУБД в режиме, стендбай. Для этого требуется создать файл standby.signal в директории кластера БД (рядом с qhb.conf).
- в файле конфигурации
qhb.confнеобходимо указать строку подключения к мастер-серверу: - В обоих случаях, параметры СУБД в файле конфигурации будут скопированы с мастера, и следует изменить некоторые значения, на соответствующие реплике. \ Параметры на реплике указываем такие:
- Теперь и только теперь, можно запустить СУБД на втором сервере, реплике.
- Проверяем на мастере:
- Создадим таблицу на мастере:
- Заполним случайными значениями на миллион строк:
- На слейве проверяем чтение из таблицы:
-
Подключить USB носитель Админа
-
Выполнить запуск сервера БД с помощью утилиты qhb_ctl от имени пользователя QHB:
- Отключить USB носитель
-
В отдельном терминале запустить qss_pinpad (будет использоваться для ввода пин-кода токена)
-
Подключить USB носитель Админа с токеном
-
Выполнить запуск сервера БД с помощью утилиты qhb_ctl от имени пользователя QHB:
-
Ввести пин-код в терминале с qss_pinpad
-
Отключить USB носитель (токен)
- Поддержка HOLDMEM = ONLY таблиц
- Множество новых метрик в merticsd
- Утилита magma_key_gen для генерации пользовательских ключей QSS на крипто-токенах, поддерживающих аппаратное шифрование по ГОСТ 34.12-2018 и ГОСТ 34.13-2018
- QDL: Поддержка типа UUID
- QDL: Широкая поддержка специальных значений для date и timestamp: Epoch, Infinity, -Infinity
- QBackup: Добавлены механизмы поддержки и актуализации предыдущих версий каталога
- QBackup: В каталог добавлена информация о версии базы данных и каталога версий
- QCP: Отмена текущего запроса на сервере при отключении клиента
- QCP: "Проброс" запроса на отмену текущего запроса от клиента к конечному серверу
- QCP: Автоматическая отмена всех текущих запросов при остановке QCP
- QCP: Отправка heartbeat-сообщений неактивным подключениям к БД
- QCP: Клиенты могут подключаться к QCP через unix domain socket
- Оптимизирована работа с памятью в Tarq
- Локализация в qhb_upgrade
- MChar в 2B научился работать с like escape
- QDL: Зафиксирован формат записи для float, double precision, numeric
- QDL: Увеличена производительность генератора значений NULL
- QDL: Увеличена производительность парсера значений с плавающей точкой и numeric
- QDL: Уменьшен размер исполняемого файла за счёт удаления легаси-кода
- QDL: Упрощён генератор скрипта для create_table, уменьшена вероятность ошибок времени исполнения
- QCP: Более гибкая настройка логирования
- QCP: Более подробные сообщения об ошибках, возникающих в процессе работы
- Утечки в вакууме при использовании Tarq
- Параметры настройки rbytea
- Ошибка неправильного параметра auth в qhb_bootstrap под названием scram_sha_256
- В 2B удалена рекурсия из MChar like
- shared_buffers_partitions: правильная обработка параметра
- Запуск qhb_upgrade от пользователя root (запрещен)
- Ошибка при инициализации кластера с помощью qhb_bootstrap при указании флага --waldir
- QBackup: Ошибка повторяющегося идентификатора копии при быстром последовательном создании нескольких резервных копий
- QBackup: Ошибка несовпадения директории каталога копий с метаинформацией каталога при ручном перемещении файла каталога
- QBackup: Пути в метаинформации каталога теперь всегда абсолютные
- QBackup: Ошибки во время резервного копирования теперь всегда отражаются в статусе копии
- QCP:
qcp, иqcp-ctrlпри ошибках теперь возвращают ненулевой код завершения - Проверена работоспособность имеющихся пакетов в дистрибутиве Альт Сервер 9
- Добавлена поддержка дистрибутивов Fedora 32 и 33
QSSпополнился функциямиqhb_get_qss_tablesиqhb_get_qss_indexes.- Улучшился вывод в случае ошибки.
- Добавился новый режим работы с параллельным набором ключей,
qss_recryptс командой сбора зашифрованных таблиц и их индексов. - Добавлена поддержка
base64-encodingключей, "Кузнечика" в CTR режиме. - Добавлена поддержка
rbytea. - Добавлена утилита
QSS Pinpad. - Добавлена поддержка
RuToken. - Поддержка мета-команд
\passwordи\include. - Параллельный режим работы
QDL. - Пользовательская документация.
- Демонстрационный конфиг в пакете
RPM. - Более не нужен результат работы с СУБД, для того чтобы создать базу.
- Стабилизирована поддержка основных типов.
- Переделана работа со страницами и кортежами для улучшения стабильности.
- Стандартизировано API записи во всех компонентах
QDL. - Ряд системных функций, работа которых приводила к записи некорректных размеров кортежей в мета-информацию страницы.
qhb_archivecleanup: обновлены зависимости и добавлена русская локализация.qhb_checksum: добавлен режим параллельной работы и нормальный вывод прогресс-бара с флагом--verbose.qhb_checksum: теперь корректно работает с файлами больших размеров.- Реализована утилита
createdb. - Реализована утилита
dropdb. - Метрики добавлены в буфер-менеджер
TARQ. grafanaбольше не инициализирует рантайм под каждый вызовwith_grafana.- Перещёлкивание "часов" буфера назад при переводе системных часов.
- Оптимизирован буфер-менеджер
TARQ. - Из релизной сборки удалены debug-символы.
- Исправлены параметры сборки, приводившие к просадке производительности.
- Реализация чекпоинтера на Rust.
- Убраны многие раздражающие ограничения и устранены критические ошибки.
Статус выхода
qsql возвращает 0 оболочке (shell), если программа завершилась нормально; или 1, если происходит ошибка.
Использование
Подключение к базе данных
qsql является обычным клиентским приложением QHB. Чтобы подключиться к базе данных, вам необходимо знать имя целевой базы данных, имя хоста и номер порта сервера, а также какое имя пользователя вы хотите использовать. Для qsql можно указать эти значения через параметры командной строки, а именно -d, -h, -p и -U соответственно. Не все эти опции обязательны. Если вы опустите имя хоста, qsql подключится через сокет Unix-домена к серверу на локальном хосте или через TCP/IP к localhost на машинах, на которых нет сокетов Unix-домена. Номер порта по умолчанию определяется во время компиляции. Поскольку сервер баз данных использует ту же настройку по умолчанию, в большинстве случаев вам не нужно указывать порт. Имя пользователя по умолчанию - это имя пользователя вашей операционной системы, а также имя базы данных по умолчанию. Обратите внимание, что вы не можете просто подключиться к любой базе данных под любым именем пользователя. Администратор вашей базы данных должен сообщить вам о ваших правах доступа.
Если соединение не может быть установлено по какой-либо причине (например, недостаточно прав, сервер не работает на целевом хосте и т.д.) qsql вернет ошибку и завершит работу.
Ввод команд SQL
В обычной работе qsql отображает строку-приглашение (prompt) с именем базы данных, к которой в настоящее время подключен qsql, за которой следует строка =>. Например:
$ qsql testdb
qsql (1.0)
Type "help" for help.
testdb=>
Далее, пользователь может вводить команды SQL. Обычно входные строки отправляются на сервер при достижении точки с запятой в конце команды. Конец строки не завершает команду. Таким образом, команды могут быть разбиты на несколько строк для ясности. Если команда была отправлена и выполнена без ошибок, ее результаты отображаются на экране.
Если у недоверенных пользователей есть доступ к базе данных, начните сеанс, удалив
общедоступные схемы из search_path. Можно выполнить
SELECT pg_catalog.set_config('search_path', '', false) перед другими
командами SQL. Это соображение относится не только к qsql, а ко
всем интерфейсам для выполнения произвольных команд SQL.
Всякий раз, когда команда выполняется, qsql также опрашивает асинхронные события уведомления, генерируемые LISTEN и NOTIFY .
Метакоманды
Все, что вы вводите в qsql, начинающееся с обратной косой черты без кавычек, является метакомандой qsql, которая обрабатывается самой qsql . Эти команды делают qsql более полезным для администрирования или написания скриптов. Мета-команды часто называют командами слэша или обратной косой черты.
Доступные метакоманды:
help
Вывести основные команды
\q, \quit, quit
Выйти из qsql
\h, \help
Вывести команды SQL
\?
Вывести команды qsql
\l, \list
Вывести список баз данных
\c, \connect [ -reuse-previous=on|off ] [ имя_бд [ имя_пользователя ] [ компьютер ] [ порт ] | строка_подключения ]
Устанавливает новое подключение к серверу QHB. Параметры подключения можно указывать как позиционно (в показанном порядке), так и передавая аргумент строка_подключения.
Когда в команде опускается имя базы данных, пользователь, компьютер или порт, для нового подключения могут использоваться значения от предыдущего. По умолчанию значения от предыдущего подключения используются повторно, если только не указывается строка подключения (строка_подключения). Если передать в первом аргументе -reuse-previous=on или -reuse-previous=off, это поведение переопределяется.
Если новое подключение успешно установлено, предыдущее подключение закрывается. Если попытка подключения не удалась (неверное имя пользователя, доступ запрещён и т. д.), то предыдущее соединение останется активным.
Примеры:
=> \c mydb myuser host.dom 6432
=> \c service=foo
=> \c "host=localhost port=5432 dbname=mydb connect_timeout=10 sslmode=disable"
=> \c qhb://tom@localhost/mydb?application_name=myapp
\! [ команда ]
Метакоманда позволяет перейти в процесс оболочки (без указания параметра "команда") либо выполнить произвольную команду оболочки (указанную в параметре)
При исполнении команды, указанной в параметре "команда", не происходит интерполяции и подстановок значений средствами qsql - команда передается для исполнения "как есть". По завершении процесса оболочки либо указанной команды, qsql продолжает выполнение
\o или \out [ файл ] или [|команда ]
При вводе метакоманды qsql перенаправляет результаты последующих запросов в "файл" или команду оболочки "команда" при помощи конвеера.
Исключением являются сообщения об ошибках, на которые не влияет данная опция.
\g [ файл ] или [ |команда ]
Отправляет буфер запросов (предыдущий запрос) на исполнение серверу баз данных. При наличии аргументов "файл" или "команда" используются для перенаправления вывода результата запроса в файл или конвейер соответственно.
Данная метакоманда \g может использоваться для получения эффекта, подобного команде \out, без изменения направления вывода результатов запроса на постоянной основе
\i или \include файл
Чтение и выполнение команд из указанного файла
\password [ username ]
Смена пароля для указанного пользователя. Если параметр "username" отсутствует, то смена пароля затрагивает текущего пользователя. Данная команда запрашивает новое значение пароля, шифрует его и отсылает на сервер в виде команды ALTER ROLE.
\copy { table [ ( column_list ) ] } from { 'filename' | program 'command' | stdin | pstdin } [ [ with ] ( option [, ...] ) ]
\copy { table [ ( column_list ) ] | ( query ) } to { 'filename' | program 'command' | stdout | pstdout } [ [ with ] ( option [, ...] ) ]
Выполнение команды SQL COPY при помощи терминала qsql. Здесь чтение и запись файлов производит клиентская программа-терминал, пересылая данные по специальному протоколу на сервер баз данных.
Доступны также источники/приемники данных запроса в виде конвейера (для параметра 'command') или декскрипторов стандартного ввода-вывода.
В остальном, данная форма команды \copy принимает те же параметры, что и SQL COPY на сервере БД.
\cd [ каталог ]
Переключает текущий каталог файловой системы для процесса qsql
Подсказка:
Для получения значения текущего каталога (до или после команды \cd) используйте команду \!, например:
\! pwd
\da[S] [ шаблон ]
Выводит список агрегатных функций вместе с типом возвращаемого значения и типами данных, которыми они оперируют. Если указан шаблон, показываются только те агрегатные функции, имена которых соответствуют ему. По умолчанию показываются только объекты, созданные пользователями. Для включения системных объектов нужно задать шаблон или добавить модификатор S.
\dA[+] [ шаблон ]
Выводит список методов доступа. Если указан шаблон, показываются только те методы доступа, имена которых соответствуют ему. При добавлении + к имени команды для каждого метода доступа показывается его описание и связанная функция-обработчик.
\db[+] [ шаблон ]
Выводит список табличных пространств. Если указан шаблон, показываются только те табличные пространства, имена которых соответствуют ему. При добавлении + к имени команды для каждого объекта дополнительно выводятся параметры, объём на диске, права доступа и описание.
\dc[S+] [ шаблон ]
Выводит список преобразований между кодировками наборов символов. Если указан шаблон, показываются только те преобразования кодировок, имена которых соответствуют ему. По умолчанию показываются только объекты, созданные пользователями. Для включения системных объектов нужно задать шаблон или добавить модификатор S. При добавлении + к имени команды для каждого объекта дополнительно будет выводиться описание.
\dC[+] [ шаблон ]
Выводит список приведений типов. Если указан шаблон, показываются только те приведения типов, имена которых соответствуют ему. При добавлении + к имени команды для каждого объекта дополнительно будет выводиться описание.
\dd[S] [ шаблон ]
Показывает описания объектов следующих видов: ограничение, класс операторов, семейство операторов, правило и триггер. Описания остальных объектов можно посмотреть соответствующими метакомандами для этих типов объектов. \dd показывает описания для объектов, соответствующих шаблону, или для доступных объектов указанных типов, если аргументы не заданы. Но в любом случае выводятся только те объекты, которые имеют описание. По умолчанию показываются только объекты, созданные пользователями. Для включения системных объектов нужно задать шаблон или добавить модификатор S.
Описания объектов создаются SQL-командой COMMENT.
\ddp [ шаблон ]
Выводит список прав доступа по умолчанию. Выводится строка для каждой роли (и схемы, если применимо), для которой права доступа по умолчанию отличаются от встроенных. Если указан шаблон, выводятся строки только для тех ролей и схем, имена которых соответствуют ему. Права доступа по умолчанию устанавливаются командой ALTER DEFAULT PRIVILEGES. Смысл отображаемых привилегий объясняется в описании GRANT.
\dD[S+] [ шаблон ]
Выводит список доменов. Если указан шаблон, показываются только те домены, имена которых соответствуют ему. По умолчанию показываются только объекты, созданные пользователями. Для включения системных объектов нужно задать шаблон или добавить модификатор S. При добавлении + к имени команды для каждого объекта дополнительно будут выводиться права доступа и описание.
\dE[S+] [ шаблон ]
\di[S+] [ шаблон ]
\dm[S+] [ шаблон ]
\ds[S+] [ шаблон ]
\dt[S+] [ шаблон ]
\dv[S+] [ шаблон ]
ВНИМАНИЕ! Шаблон не поддерживаестя в настоящий момент В этой группе команд буквы E, i, m, s, t и v обозначают соответственно: внешнюю таблицу, индекс, материализованное представление, последовательность, таблицу и представление. Можно указывать все или часть этих букв, в произвольном порядке, чтобы получить список объектов этих типов. Например, \dit выводит список индексов и таблиц. При добавлении + к имени команды для каждого объекта дополнительно будут выводиться физический размер на диске и описание, при наличии. Если указан шаблон, выводятся только объекты, имена которых соответствуют ему. По умолчанию показываются только объекты, созданные пользователями. Для включения системных объектов нужно задать шаблон или добавить модификатор S.
\des[+] [ шаблон ]
Выводит список сторонних серверов (мнемоника: «external servers»). Если указан шаблон, выводятся только те серверы, имена которых соответствуют ему. Если используется форма \des+, то выводится полное описание каждого сервера, включая права доступа, тип, версию, параметры и описание.
\det[+] [ шаблон ]
Выводит список сторонних таблиц (мнемоника: «external tables»). Если указан шаблон, выводятся только те записи, имя таблицы или схемы которых соответствуют ему. Если используется форма \det+, то дополнительно выводятся общие параметры и описание сторонней таблицы.
\deu[+] [ шаблон ]
Выводит список сопоставлений пользователей (мнемоника: «external users»). Если указан шаблон, выводятся только сопоставления, в которых имена пользователей соответствуют ему. Если используется форма \deu+, то выводится дополнительная информация о каждом сопоставлении пользователей.
Внимание!!!
\deu+ также может отображать имя и пароль удалённого пользователя, поэтому следует позаботиться о том, чтобы не раскрывать их.
\dew[+] [ шаблон ]
Выводит список обёрток сторонних данных (мнемоника: «external wrappers»). Если указан шаблон, выводятся только те обёртки сторонних данных, имена которых соответствуют ему. Если используется форма \dew+, то дополнительно выводятся права доступа, параметры и описание обёртки.
\df[antwS+] [ шаблон ]
Выводит список функций с типами данных их результатов, аргументов и классификацией: «agg» (агрегатная), «normal» (обычная), «trigger» (триггерная) или «window» (оконная). Чтобы получить функции только определённого вида (видов), добавьте в команду соответствующие буквы a, n, t или w. Если задан шаблон, показываются только те функции, имена которых соответствуют ему. По умолчанию показываются только функции, созданные пользователями; для включения системных объектов нужно задать шаблон или добавить модификатор S. Если используется форма \df+, то дополнительно выводятся характеристики каждой функции: изменчивость, допустимость распараллеливания, владелец, классификация по безопасности, права доступа, язык, исходный код и описание.
Подсказка!!!
Чтобы найти функции с аргументами или возвращаемыми значениями определённого типа данных, воспользуйтесь имеющейся в постраничнике возможностью поиска в выводе \df.
\dF[+] [ шаблон ]
Выводит список конфигураций текстового поиска. Если указан шаблон, показываются только те конфигурации, имена которых соответствуют ему. Если используется форма \dF+, то выводится полное описание для каждой конфигурации, включая базовый синтаксический анализатор и используемые словари для каждого типа фрагментов.
\dFd[+] [ шаблон ]
Выводит список словарей текстового поиска. Если указан шаблон, показываются только словари, имена которых соответствуют ему. Если используется форма \dFd+, то выводится дополнительная информация о каждом словаре, включая базовый шаблон текстового поиска и параметры инициализации.
\dFp[+] [ шаблон ]
Выводит список анализаторов текстового поиска. Если указан шаблон, показываются только те анализаторы, имена которых соответствуют ему. Если используется форма \dFp+, то выводится полное описание для каждого анализатора, включая базовые функции и список типов фрагментов.
\dFt[+] [ шаблон ]
Выводит список шаблонов текстового поиска. Если указан шаблон, показываются только шаблоны, имена которых соответствуют ему. Если используется форма \dFt+, то выводится дополнительная информация о каждом шаблоне, включая имена основных функций.
\du
Вывести всех пользователей.
qsql
rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcanlogin | rolconnlimit | rolvaliduntil | memberof | rolreplication | rolbypassrls
---------+----------+------------+---------------+-------------+-------------+--------------+---------------+----------------------------------------------------------------------------------------------------------------------------------+----------------+--------------
qhb | true | true | true | true | true | -1 | <null> | <null>: error deserializing column 8: cannot convert between the Rust type `alloc::string::String` and the Postgres type `_name` | true | true
Окружение
PGHOST
Примеры
Первый пример показывает, как распределить команду по нескольким строкам ввода:
testdb=> CREATE TABLE my_table (
testdb(> first integer not null default 0,
testdb(> second text)
testdb-> ;
CREATE TABLE
Давайте предположим, что вы заполнили таблицу данными и хотите посмотреть на нее:
testdb=> SELECT * FROM my_table;
first | second
-------+--------
1 | one
2 | two
3 | three
4 | four
(4 rows)
или:
testdb=> SELECT first, second, first > 2 AS gt2 FROM my_table;
first | second | gt2
-------+--------+-----
1 | one | f
2 | two | f
3 | three | t
4 | four | t
(4 rows)
Серверные приложения QHB
Эта часть содержит справочную информацию для серверных приложений QHB и вспомогательных утилит. Эти команды можно запускать только на том хосте, где находится сервер баз данных. Другие служебные программы перечислены в клиентских приложениях QHB.
initdb
initdb - создать новый кластер базы данных QHB
Синтаксис
initdb [option...] [ --pgdata | -D ] directory
Описание
initdb создает новый кластер базы данных QHB. Кластер баз данных -
это набор баз данных, которые управляются одним экземпляром сервера.
Создание кластера базы данных состоит из создания каталогов, в которых
будут храниться данные базы данных, создания таблиц общего каталога
(таблиц, которые принадлежат всему кластеру, а не какой-либо конкретной
базе данных), и создания баз данных template1 и qhb. Когда вы
позже создадите новую базу данных, все в базе данных template1 будет
скопировано. (Следовательно, все, что установлено в template1,
автоматически копируется в каждую созданную позже базу данных). База
данных qhb - это база данных по умолчанию, предназначенная для
использования пользователями, утилитами и сторонними приложениями.
Хотя initdb попытается создать указанный каталог данных, он может не
иметь разрешения, если родительский каталог нужного каталога данных
принадлежит пользователю root. Чтобы инициализировать в такой настройке,
создайте пустой каталог данных как root, затем используйте chown чтобы
назначить владение этим каталогом учетной записи пользователя базы
данных, затем su чтобы стать пользователем базы данных для запуска
initdb.
initdb должен быть запущен от имени пользователя, которому будет
принадлежать серверный процесс, потому что сервер должен иметь доступ к
файлам и каталогам, которые создает initdb. Поскольку сервер не может
быть запущен от имени пользователя root, вы также не должны запускать
initdb от имени пользователя root. (Это на самом деле откажется сделать
это).
По соображениям безопасности новый кластер, созданный initdb будет
доступен только владельцу кластера по умолчанию. Параметр
--allow-group-access позволяет любому пользователю в той же группе, что
и владелец кластера, читать файлы в кластере. Это полезно для выполнения
резервного копирования как непривилегированный пользователь.
initdb инициализирует стандартную локаль кластера базы данных и
кодировку набора символов Кодировка набора символов, порядок
сопоставления (LC_COLLATE) и классы набора символов ( LC_CTYPE,
например, верхняя, нижняя, цифра) могут быть установлены отдельно для
базы данных при ее создании. initdb определяет эти настройки для базы
данных template1, которая будет использоваться по умолчанию для всех
других баз данных.
Чтобы изменить порядок сортировки по умолчанию или классы набора
символов, используйте параметры --lc-collate, --lc-ctype и --lc-ctype.
Порядок сопоставления, отличный от C или POSIX также снижает
производительность. По этим причинам важно правильно выбрать локаль при
запуске initdb .
Остальные категории локалей могут быть изменены позже при запуске
сервера. Вы также можете использовать --locale чтобы установить значение
по умолчанию для всех категорий языковых стандартов, включая порядок
сопоставления и классы набора символов. Все значения локали сервера
(lc_) могут отображаться через SHOW ALL. Более подробную информацию
можно найти в разделе Поддержка локали.
Чтобы изменить кодировку по умолчанию, используйте --encoding. Более
подробную информацию можно найти в разделе Поддержка набора символов.
Параметры
Другие, менее часто используемые параметры также доступны:
Другие опции:
Окружение
PGDATA
PG_COLOR
TZ
Эта утилита, как и большинство других утилит QHB, также использует переменные окружения, поддерживаемые libpq.
Примечания
initdb также может быть вызван через qhb_ctl initdb.
Смотрите также
qhb_bootstrap
Утилита qhb_bootstrap создаёт новый кластер баз данных QHB.
Синтаксис
qhb_bootstrap [FLAGS] [OPTIONS] <data-dir>
Описание
qhb_bootstrap создает новый кластер базы данных QHB. Кластер — это коллекция баз данных под управлением единого экземпляра сервера.
Инициализация кластера базы данных заключается в создании каталогов для хранения данных, формировании общих системных таблиц (относящихся ко всему кластеру, а не к какой-либо базе) и создании баз данных template1 и qhb. Впоследствии все новые базы создаются на основе шаблона template1 (все дополнения, установленные в template1 автоматически копируются в каждую новую базу данных). База qhb используется пользователями, утилитами и сторонними приложениями по умолчанию.
Безопасность
Утилита qhb_bootstrap должна выполняться от имени пользователя, под которым будет запускаться сервер, так как ему необходим полный доступ к файлам и каталогам, создаваемым qhb_bootstrap. Сервер не может запускаться от имени суперпользователя, поэтому выполнение утилиты qhb_bootstrap от его лица будет отклонено.
Из соображений безопасности новый кластер, созданный утилитой qhb_bootstrap, будет доступен только для владельца кластера. Ключ --allow-group-access позволяет разрешить чтение файлов в кластере всем пользователям, входящим в группу владельца кластера. Это полезно для выполнения резервного копирования от имени непривилегированного пользователя.
Не используйте метод аутентификации trust, если не можете доверять всем локальным пользователям в вашей системе. Режим trust используется по умолчанию для облегчения процесса установки.
Локализация
qhb_bootstrap инициализирует локали и кодировки баз данных кластера, которые будут использоваться по умолчанию. Кодировка, порядок сортировки (LC_COLLATE), классы наборов символов (LC_CTYPE, например, заглавные, строчные буквы, цифры) могут устанавливаться раздельно при создании новой базы данных. qhb_bootstrap определяет параметры локали для шаблона template1, которые будут применяться по умолчанию для новых баз.
Указанная локаль должна быть установлена в системе (locale -a).
Чтобы изменить порядок сортировки по умолчанию или классы наборов символов, используются параметры --lc-collate и --lc-ctype. Порядок сортировки, отличающийся от C или POSIX, оказывает влияние на производительность. Поэтому необходимо тщательно выбирать необходимую и достаточную локаль при выполнении qhb_bootstrap. См. https://simply.name/ru/pg-lc-collate.html.
Другие категории локали можно изменить и после старта сервера. Также можно использовать параметр --locale, чтобы задать локаль для всех категорий одновременно, включая порядок сортировки и классы наборов символов. Значения локалей сервера (lc_*) можно вывести командой SHOW ALL. Более подробную информацию можно найти в разделе Поддержка локали.
Параметры
Флаги
Опции
Сценарии использования
qhb_bootstrap --data-dir /qhb/qhb-data
создает кластер в каталоге /qhb/qhb-data с параметрами по-умолчанию
qhb_bootstrap --data-dir /qhb/qhb-data --locale ru_RU --auth scram_sha_256 -d
создает кластер в каталоге /qhb/qhb-data с кодировкой ru_RU и шифрованием SCRAM-SHA-256 с выводом подробной отладочной информации
Окружение
PGDATA
PG_COLOR
Смотрите также
qhb_archivecleanup
qhb_archivecleanup - очистка архивных файлов QHB WAL.
Синтаксис
qhb_archivecleanup [option...] archivelocation oldestkeptwalfile
Описание
qhb_archivecleanup предназначен для использования в качестве
archive_cleanup_command для очистки файловых архивов WAL при работе в
качестве резервного сервера. qhb_archivecleanup также
может использоваться как самостоятельная программа для очистки файловых
архивов WAL.
Чтобы настроить резервный сервер для использования qhb_archivecleanup,
добавьте в файл конфигурации qhb.conf следующую строку:
archive_cleanup_command = 'qhb_archivecleanup archivelocation %r'
где archivelocation - это каталог, из которого должны быть удалены файлы сегментов WAL.
Важно!!!
Чтобыqhb_archivecleanupиспользвать как отдельную программу, нужно в файле конфигурации qhb.conf добавить следующие строки:archive_mode = on; archive_command = 'test ! -f archivelocation %f && cp %p archivelocation %f';Это относится только к мастер-серверу, так как именно он передает логи.
При использовании в archive_cleanup_command все файлы WAL, логически предшествующие значению аргумента %r
будут удалены из расположения archivelocation. Это минимизирует количество файлов, которые необходимо сохранить,
сохраняя возможность аварийного перезапуска. Использование этого параметра целесообразно,
если расположение archivelocation указывает на область файлов конкретного
резервного сервера, но не в том случае, когда
archivelocation какталог с архивом WAL, предназначенный для долговременного хранения, или
когда несколько резервных серверов восстанавливаются из одного и того же archivelocation.
При использовании в качестве самостоятельной программы все файлы WAL,
логически предшествующие файлу oldestkeptwalfile будут удалены из
каталога archivelocation. В этом режиме, если вы укажете имя файла с расширением .partial
или .backup, oldestkeptwalfile будет определяться без расширения.
использоваться только префикс файла. Благодаря такой интерпретации расширения .backup будут корректно удалены все файлы WAL, заархивированные до определённой базовой копии. Например, следующий пример удалит
все файлы старше WAL с именем 000000010000003700000010:
qhb_archivecleanup -d archive 000000010000003700000010.00000020.backup
qhb_archivecleanup: keep WAL file "archive/000000010000003700000010" and later
qhb_archivecleanup: removing file "archive/00000001000000370000000F"
qhb_archivecleanup: removing file "archive/00000001000000370000000E"
qhb_archivecleanup предполагает, что расположение archivelocation
является каталогом, доступным для чтения и записи пользователем,
владеющим сервером.
Параметры
qhb_archivecleanup принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
-d | Выводить подробные отладочные сообщения в stderr |
-n | Вывести имена файлов, которые будут удалены в stdout (выполняет пробный запуск). |
-V, --version | Показать версию qhb_archivecleanup и выйти. |
-x extension | Указать расширение, которое будет убрано из всех имен файлов, прежде чем принимать решение об их удалении. Это обычно полезно для очистки архивов, которые были сжаты и, следовательно, имеют расширение, добавленное программой сжатия. Например: -x .gz. |
-?, --help | Показать справку об аргументах командной строки qhb_archivecleanup и выйти. |
Примеры
В системах Linux или Unix вы можете использовать:
archive_cleanup_command = 'qhb_archivecleanup -d /mnt/standby/archive %r 2>>cleanup.log'
где каталог архива физически расположен на резервном сервере, так что
команда archive_command обращается к нему через NFS, но файлы являются
локальными для резервного сервера. Это команда будет:
qhb_checksums
qhb_checksums - включить, отключить или проверить контрольные суммы
данных в кластере базы данных QHB
Синтаксис
qhb_checksums [FLAGS] [OPTIONS] --pgdata <pgdata>
qhb_checksums [option...] [[ -D | --pgdata ] datadir]
Описание
qhb_checksums - утилита для проверки, включения и выключения контрольных
сумм данных в кластере QHB. Сервер должен быть штатным образом выключен перед запуском
qhb_checksums. При проверке контрольных сумм код завершения равен нулю,
если ошибок нет, и ненулевой, если обнаружена хотя бы
одна ошибка контрольной суммы. При включении или отключении контрольных
сумм ненулевой код завершения, означает, что операция не удалась.
У всех файлов таблиц есть заголовок, по умолчанию поле с контрольной суммой в нём равно 0, также в общем файле ControlFile "версия чексумм" = 0 (1 - включена). При первом запуске нужно включить эти чексуммы с помощью флага --enable, который поставит версию чексумм "1" и изменит поле чексуммы во всех заголовках файлов таблиц БД (папки global, base, pg_tblspc). Если нужно проверить, правильные ли чексуммы в файлах, то программа запоминает значение чексуммы из файла, обнуляет его, считает новое, сравнивает и возвращает на место старое значение (если оно не совпало с подсчитанным - выводится ошибка с указанием места происшествия). Если чексуммы надо выключить - программа меняет значение версии чексумм на 0 и ничего не делает с файлами таблиц
При проверке контрольных сумм сканируется каждый файл в кластере.При
включении контрольных сумм каждый файл в кластере перезаписывается.
Отключение контрольных сумм обновляет только файл pg_control.
Параметры
Доступны следующие параметры командной строки:
Флаги (FLAGS)
Окружение
PGDATA
PG_COLOR
Примечания
Включение контрольных сумм в большом кластере может занять много времени. Во время этой операции кластер или другие программы, выполняющие запись в каталог данных, не должны запускаться, иначе может произойти потеря данных.
При использовании репликации, которая выполняется путем неспосредственного копирования блоков отношений на уровне файлов отношений (например, qhb_rewind), включение или отключение контрольных сумм может привести к повреждению страниц в виде расхождения контрольных сумм, если эта операция не будет выполнена согласованно на всех узлах. Поэтому при включении или отключении контрольных сумм рекомендуется остановить все кластеры, для того чтобы переключить их в другой режим. Удаление всех ведомых серверов, выполнение операции на основном сервере и создание ведомых серверов заново, также является безопасным методом.
Если qhb_checksums прерывается или уничтожается при включении или
отключении контрольных сумм, конфигурация контрольной суммы данных
кластера остается неизменной, и qhb_checksums можно повторно запустить
для выполнения той же операции.
Обработка ошибок
Ошибка Possibly encrypted block, проявляется либо при шифровке файла, либо при очень серьёзном повреждении файла, подразумевая под собой MismatchBlockChecksum.
Примеры
--enable, --check и --disable - три главных аргумента, к которым могут быть применены следующие флаги:
qhb_controldata
qhb_controldata - показать управляющую информацию кластера базы данных QHB.
Синтаксис
qhb_controldata [option] [[ --pgdata | -D ] datadir]
Описание
qhb_controldata показывает информацию, установленную после выполнения initdb,
например версию каталога. Она также показывает информацию о работе WAL и контрольных точек. Эта информация относится ко всему кластеру и не относится к какой-либо одной базе данных.
Эта утилита может быть запущена только тем пользователем, который
инициализировал кластер, поскольку требует права на чтения в каталоге
данных. Вы можете указать каталог данных в командной строке или
использовать переменную окружения PGDATA. Эта утилита поддерживает
параметр -V(--version), который выводит версию, и -? (--help), который
отображают поддерживаемые qhb_controldata аргументы.
Окружение
PGDATA
PG_COLOR
qhb_ctl
qhb_ctl - инициализировать, запустить, остановить или управлять сервером QHB.
Синтаксис
qhb_ctl init[db] [-D datadir] [-s] [-o initdb-options]
qhb_ctl start [-D datadir] [-l filename] [-W] [-t seconds] [-s] [-o options] [-p path] [-c]
qhb_ctl stop [-D datadir] [-m s[mart] | f[ast] | i[mmediate] ] [-W] [-t seconds] [-s]
qhb_ctl restart [-D datadir] [-m s[mart] | f[ast] | i[mmediate] ] [-W] [-t seconds] [-s] [-o options] [-c]
qhb_ctl reload [-D datadir] [-s]
qhb_ctl status [-D datadir]
qhb_ctl promote [-D datadir] [-W] [-t seconds] [-s]
qhb_ctl logrotate [-D datadir] [-s]
qhb_ctl kill signal_name process_id
Описание
qhb_ctl - это утилита для инициализации,
запуска, остановки или перезапуска кластера базы данных QHB
(qhb) или отображения состояния работающего сервера. Хотя сервер
можно запустить вручную, qhb_ctl берёт на себя такие задачи, как
направление вывода в журнал и корректное отключение от терминала и
группы процессов, и, также, предоставляет удобный интерфейс для
остановки кластера.
Команда init или initdb создает новый кластер баз данных QHB, то
есть коллекцию баз данных, которая будет управляться одним экземпляром
сервера. Эта команда вызывает initdb. Смотрите initdb для
подробной информации.
Команда start запускает сервер. Сервер запускается в фоновом режиме,
а его стандартный ввод подключается к /dev/null. В
Unix-подобных системах по умолчанию стандартный вывод и стандартные ошибки отправляются в стандартный вывод qhb_ctl (не ошибок). Затем стандартный вывод qhb_ctl должен быть
перенаправлен в файл или в другой процесс, например программе
ротации журналов rotatelogs; в противном случае qhb
будет писать свой вывод в управляющий терминал (в фоновом режиме) и останется в группе
процессов оболочки.
Режим stop останавливает сервер, который работает в указанном каталоге
данных. Существует три разных метода остановки, которые могут быть выбраны с параметром -m.
Режим "Smart" ожидает отключения всех активных клиентов и завершения
всех процессов резервного копирования в онлайн-хранилище. Если сервер находится
в режиме горячего резервирования, восстановление и потоковая репликация
будут прерваны после отключения всех клиентов. «Fast» режим (по
умолчанию) не ожидает отключения клиентов и прекращает выполнение
резервного копирования в онлайн-хранилище. Все активные транзакции
откатываются, клиенты принудительно отключаются, и затем сервер
останавливается. Режим «Immediate» немедленно прервет все процессы на
сервере, не выполняя процедуру штатной остаонки. Такой вариант приведет к
восстановлению после сбоя при следующем запуске сервера.
Команда restart выполняет остановку с последующим запуском сервера. Это
позволяет изменить параметры командной строки qhb или параметры
файла конфигурации, которые нельзя изменить без перезапуска сервера.
Если в командной строке были использованы относительные пути при
запуске сервера, команда restart может завершиться ошибкой, если вызывать qhb_ctl не в том же каталоге, как это было во время запуска
сервера.
Команда reload просто отправляет процессу сервера qhb сигнал SIGHUP,
заставляя его перечитать свои файлы конфигурации (qhb.conf,
qhb_hba.conf и т. д.). Это позволяет изменять параметры файла
конфигурации, которые не требуют полного перезапуска сервера для
вступления в силу.
Команда status проверяет, работает ли сервер в указанном каталоге данных.
Если да, отображаются PID сервера и параметры командной строки,
которые использовались для его запуска. Если сервер не запущен, qhb_ctl
возвращает код завершения 3. Если доступный каталог данных не указан,
qhb_ctl возвращает код завершения 4.
Команда promote дает команду резервному серверу, работающему в указанном
каталоге данных, выйти из режима резеврирования и начать операции
чтения-записи.
Команда logrotate прокручивает файл журнала сервера. Подробнее о том, как
использовать этот режим с внешними инструментами ротации журналов, смотрите в
разделе Обслуживание файла журнала.
Команда kill отправляет сигнал указанному процессу. Используйте
--help чтобы увидеть поддерживаемые имена сигналов.
Параметры
| Аргумент | Описание |
|---|---|
-c,--core-files | Позволяет при сбоях сервера генерировать файлы дампа памяти на платформах, где это возможно, путем снятия любых мягких ограничений ресурсов, установленных для core-файлов. Это полезно при отладке или диагностике проблем, позволяя получить трассировку стека от упавшего процесса сервера |
-D datadir, --pgdata=datadir | Указывает расположение файлов конфигурации базы данных. Если этот параметр не указан, используется переменная окружения PGDATA |
-l filename,--log=filename | Направляет вывод сообщений в файл filename. Если файл не существует, то он создается. Значение umask равно 077, поэтому доступ к файлу журнала по умолчанию запрещен другим пользователям |
-m mode, --mode=mode | Определяет режим остановки кластера. mode может быть smart, fast или immediate (или первой буквой одного из этих вариантов). Если этот параметр не указан, по умолчанию используется значение fast |
-o options, --options=options | Указывает параметры, которые должны быть переданы непосредственно команде qhb. -o можно указывать несколько раз, передавая все заданные параметры. options обычно должны быть заключены в одинарные или двойные кавычки, чтобы гарантировать, что они передаются как группа |
-o initdb-options, --options=initdb-options | Определяет параметры, которые должны быть переданы непосредственно команде initdb. -o можно указывать несколько раз, передавая все заданные параметры. initdb-options обычно должны быть заключены в одинарные или двойные кавычки, чтобы они передавались как группа |
-p path | Указывает расположение исполняемого файла qhb. По умолчанию исполняемый файл qhb берется из того же каталога, что и qhb_ctl, или, если это не так, из зашитого каталога установки. Нет необходимости использовать эту опцию, если вы не делаете что-то необычное и не получаете ошибок о том, что исполняемый файл qhb не найден. В режиме init этот параметр аналогично указывает на расположение исполняемого файла initdb |
-s, --silent | Выводить только ошибки, без информационных сообщений |
-t seconds,--timeout=seconds | Задает максимальное время ожидания (в секундах) ожидания завершения операции (см. -w). По умолчанию используется значение переменной окружения PGCTLTIMEOUT или, если она не задана, 60 секунд |
-V,--version | Вывести версию qhb_ctl и выйти |
-w,--wait | Ждать, пока операция завершится. По умолчанию поддерживается для команд start, stop, restart, promote и register. Во время ожидания qhb_ctl несколько раз проверяет PID-файл сервера, засыпая на короткий промежуток времени между проверками. Остановка считается завершенной, когда сервер удаляет свой PID-файл. qhb_ctl возвращает код завершения, в зависимости от успеха запуска или остановки. Если операция не завершается в течение времени ожидания (см. параметр -t), то qhb_ctl завершается с ненулевым кодом выхода. Но обратите внимание, что операция может продолжаться в фоновом режиме и в конечном итоге завершится успешно |
-W, --no-wait | Не ждать завершения операции. Этот параметр противоположен параметру -w. Если ожидание отключено, запрошенное действие инициируется, но нет информации о его успешности. В этом случае файл журнала сервера или внешняя система мониторинга должны будут использоваться для проверки текущего состояния успешности операции. |
-?,--help | Показать справку об аргументах командной строки qhb_ctl и выйти |
Если указана опция, которая действительна, но не относится к выбранному
режиму работы, qhb_ctl игнорирует ее.
Окружение
Большинству режимов qhb_ctl требуются знать расположение каталога
данных; следовательно, опция -D обязательна, если не установлена PGDATA.
qhb_ctl, как и большинство других утилит QHB, также использует
переменные окружения, поддерживаемые qhb.
Для дополнительных переменных, которые влияют на сервер, смотрите qhb.
Файлы
Примеры
Запуск сервера
Запуск сервер и ожидание им приема соединений:
$ qhb_ctl start
Запуск сервера на порте 5433 и без fsync:
$ qhb_ctl -o "-F -p 5433" start
Остановка сервера
Чтобы остановить сервер, используйте:
$ qhb_ctl stop
Параметр -m позволяет контролировать, как сервер будет остановлен:
$ qhb_ctl stop -m smart
Перезапуск сервера
Перезапуск сервера практически эквивалентен его остановке и повторному
запуску, за исключением того, что по умолчанию qhb_ctl сохраняет и
повторно использует параметры командной строки, которые были переданы
ранее запущенному экземпляру. Чтобы перезапустить сервер, используя те
же параметры, что и раньше, используйте:
$ qhb_ctl restart
Но если указан параметр -o, он заменяет все предыдущие параметры. Чтобы
перезапустить сервер на порте 5433 и отключить fsync при перезапуске, используйте:
$ qhb_ctl -o "-F -p 5433" restart
Отображение статуса сервера
Вот пример вывода статуса из qhb_ctl:
$ qhb_ctl status
qhb_ctl: server is running (PID: 13718)
/usr/local/qhb/bin/qhb "-D" "/usr/local/qhb/data" "-p" "5433" "-B" "128"
Во второй строке показна команда, которая будет выполненена в режиме перезапуска.
Смотрите также
qhb_resetwal
qhb_resetwal - очищает журнал предзаписи (WAL) и другую
управляющую информацию кластера базы данных QHB
Синтаксис
qhb_resetwal [ --force | -f ] [ --dry-run | -n ] [option...] [ --pgdata | -D ] datadir
Описание
qhb_resetwal очищает журнал предзаписи (WAL) и, при необходимости,
сбрасывает некоторую другую управляющую информацию, хранящуюся в файле
pg_control. Эта функция бывает необходима, когда эти файлы повреждены.
Её следует использовать как крайнюю меру, когда сервер не
может запуститься из-за таких повреждений.
После выполнения этой команды станет возможным запустить сервер, но имейте в виду, что база данных может содержать несогласованные данные из-за частично зафиксированных транзакций. Вы должны немедленно выгрузить ваши данные, запустить initdb и восстановить данные. После этого проверьте согласованность базы данных и при необходимости внесите коррективы.
Эта утилита может быть запущена только тем пользователем, который
установил сервер, поскольку ей требуется доступ на чтение/запись
к каталогу данных. По соображениям безопасности вы должны указать
каталог данных в командной строке. qhb_resetwal не использует переменную
окружения PGDATA.
Если qhb_resetwal выводит сообщение о том, что он не может определить
действительные данные из pg_control, вы можете принудительно
запустить его, указав параметр -f (--force). В этом случае, отсутствующие данные будут заменены наиболее вероятными
значениями. Для большинства полей это нормально, но может потребоваться ручное вмешательство для: следующего значения
OID, следующего ID транзакции и времени, следующего
ID мультитранзакции и смещения и начальной
позиции WAL. Эти поля могут быть указаны с помощью
параметров, описанных ниже. Если вы не можете определить правильные
значения для всех этих полей, можно использовать -f, однако, к
восстановленной базе данных следует относиться с еще большим
подозрением, чем обычно: нужно будет немедленно выгрузить и затем востанновить данные. Не выполняйте никакие операции по изменению данных до того, как вы создадите дамп, так как любое такое действие
может усугубить повреждение.
Параметры
Следующие параметры нужны только тогда, когда qhb_resetwal не может
определить подходящие значения, читая pg_control. Безопасные значения
могут быть определены, как описано ниже. Для значений, которые принимают
числовые аргументы, с
помощью префикса 0x могут быть указаны шестнадцатеричные значения.
Окружение
PG_COLOR
Примечания
Эту команду нельзя использовать во время работы сервера. qhb_resetwal
не станет запускаться, при обнаруженном блокирующем файле в каталоге хранения данных. Если произошел сбой сервера, блокирующий файл может остаться в системе; в этом случае вы можете вручную удалить его, чтобы
запустить qhb_resetwal. Но прежде чем сделать это, дважды удостоверьтесь, что серверный процесс не запущен.
qhb_resetwal работает только с серверами той же основной версии.
Смотрите также
qhb_rewind
qhb_rewind - синхронизирует каталог данных QHB с другим каталогом
данных, который был ответвлён от него
Синтаксис
qhb_rewind [option...] { -D | --target-pgdata } directory { --source-pgdata=directory | --source-server=connstr }
Описание
qhb_rewind - это инструмент для синхронизации кластера QHB с
другой копией того же кластера после того, как временные линии кластеров
разошлись. Типичным сценарием является возвращение к работе после отказа бывшего главного сервера в качестве ведомого к другому серверу, ставшего новым главным.
Результат эквивалентен замене целевого каталога данных на исходный.
Копируются только измененные блоки из файлов отношений; все остальные
файлы копируются полностью, включая файлы конфигурации. Преимущество
qhb_rewind перед созданием новой базовой резервной копии или таких
инструментов, как rsync, заключается в том, что qhb_rewind не требует
чтения неизмененных блоков в кластере. Это делает синхронизацию намного быстрее,
когда база данных большая, и только небольшая часть блоков отличается
между кластерами.
qhb_rewind анализирует историю линии времени исходного и целевого
кластеров, чтобы определить точку их расхождения, и ожидает найти WAL в
каталоге pg_wal целевого кластера, pg_wal до точки расхождения. Точку
расхождения можно найти либо на целевой или на исходной
временной линии, либо у их общего предка. В типичном сценарии отработки
отказа, когда целевой кластер был отключен вскоре после расхождения, это
не проблема, но если целевой кластер работал в течение длительного
времени после расхождения, старые файлы WAL могут быть удалены. В этом случае их можно вручную скопировать из архива WAL
в каталог pg_wal или считать при запуске, настроив primary_conninfo
или restore_command. Использование qhb_rewind не ограничивается
переключением при отказе. Например, резервный сервер может быть повышен и
выполняет несколько записывающих транзакций, затем, после синхронизации, снова
становится резервным.
Когда целевой сервер запускается впервые после запуска qhb_rewind, он
переходит в режим восстановления и воспроизводит все изменения из WAL,
сгенерированные на исходном сервере, после точки расхождения. Если
какие-то сегменты WAL не доступны на исходном сервере при запуске
qhb_rewind, и, следовательно, не могли быть скопированы, то их необходимо предоставить при запуске целевого
сервера. Это можно сделать, создав файл recovery.signal в целевом
каталоге данных и настроив подходящую команду restore_command в
qhb.conf.
qhb_rewind требует, чтобы на целевом сервере был включен режим
wal_log_hints в qhb.conf, либо включены контрольные суммы данных, когда
кластер был инициализирован с помощью initdb. Ни один из этих режимов в
настоящее время не включен по умолчанию. full_page_writes также должен
быть включен (по умолчанию он включен).
Предупреждение
Если во время обработки происходит сбойqhb_rewind, вероятно, целевой каталог данных будет в таком состоянии, которое не подойдёт для восстановления. В таком случае рекомендуется сделать новую резервную копию.
qhb_rewindсразу прекратит работу, если найдет файлы, непосредственная запись в которые невозможна. Это может произойти, например, когда исходный и целевой сервер используют одинаковые пути файлов для ключей и сертификатов SSL, доступных только для чтения. Если такие файлы существуют на целевом сервере, рекомендуется их удалить перед запускомqhb_rewind. После синхронизации некоторые из этих файлов могут быть скопированы из источника, и в этом случае может потребоваться удалить скопированные данные и восстановить ссылки, использовавшиеся до синхронизации.
Параметры
qhb_rewind принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
-D directory, --target-pgdata=directory | Указывает целевой каталог данных, который синхронизируется с источником. Целевой сервер должен быть штатно остановлен перед запуском qhb_rewind |
--source-pgdata=directory | Задает путь файловой системы к каталогу данных исходного сервера, с которым нужно синхронизировать целевой. Этот параметр требует, чтобы исходный сервер был штатно остановлен |
--source-server=connstr | Указывает строку подключения libpq для подключения к исходному серверу QHB, с которым нужно синхронизировать целевой. Соединение должно быть обычным (без репликации) от имени роли, имеющей достаточные разрешения для выполнения функций, используемых qhb_rewind на исходном сервере (см. Раздел «Примечания»), или от имени суперпользователя. Этот параметр требует, чтобы исходный сервер был запущен, и работал не в режиме восстановления |
-n, --dry-run | Делать все, кроме внесения изменений в целевой каталог |
-N, --no-sync | По умолчанию qhb_rewind будет ожидать записи всех файлов на диск. С этим параметром qhb_rewind будет завершаться без ожидания, что несколько быстрее, но в случае сбоя операционной системы может привести к повреждению каталога синхронизированных данных. Как правило, этот параметр полезен для тестирования, но его не следует использовать в продакшене |
-P, --progress | Выводить сообщения о прогрессе. Включение этого параметра даст приблизительный отчет о ходе выполнения при копировании данных из исходного кластера. |
--debug | Выводить отладочную информацию. (Полезно для разработчиков при отладке qhb_rewind) |
-V, --version | Показать версию qhb_rewind и выйти |
-?, --help | Показать справку об аргументах командной строки qhb_rewind и выйти |
Окружение
Когда используется параметр --source-server, qhb_rewind также
использует переменные окружения, поддерживаемые libpq.
Переменная окружения PG_COLOR указывает, использовать ли цвета в диагностических сообщениях. Возможные значения always, auto, never .
Примечания
Если при выполнении qhb_rewind исходным кластером является работающий сервер, вместо суперпользователя может использоваться роль, имеющая
достаточные права в исходном кластере для выполнения функций, используемых qhb_rewind. Вот как можно создать такую роль с именем
rewind_user:
CREATE USER rewind_user LOGIN;
GRANT EXECUTE ON function pg_catalog.pg_ls_dir(text, boolean, boolean) TO rewind_user;
GRANT EXECUTE ON function pg_catalog.pg_stat_file(text, boolean) TO rewind_user;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text) TO rewind_user;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text, bigint, bigint, boolean) TO rewind_user;
Если при выполнении qhb_rewind исходным кластером является работающий сервер, который был недавно повышен, то на нём необходимо выполнить
CHECKPOINT, чтобы его управляющий файл содержал
актуальную информацию о временной линии, которая используется
qhb_rewind, чтобы проверить, может ли целевой кластер синхронизироваться с
выбранным исходным кластером.
Как это устроено
Основная идея - скопировать все изменения на уровне файловой системы из исходного кластера в целевой кластер:
qhb_upgrade
qhb_upgrade - обновить экземпляр сервера QHB
Синтаксис
qhb_upgrade -b oldbindir -B newbindir -d oldconfigdir -D newconfigdir [option...]
Описание
qhb_upgrade позволяет обновлять данные,
хранящиеся в файлах данных QHB, до более поздней версии
QHB, а также в файлах данных PostgreSQL 12 без создания дампа/перезагрузки данных, которая обычно требуется для
обновлений минорных версий. Это не требуется для обновлений версии, исправляющих ошибки.
В основных выпусках QHB регулярно добавляются новые функции,
которые часто меняют структуру системных таблиц, но формат внутреннего
хранилища данных редко меняется. qhb_upgrade использует этот факт для
быстрого обновления путем создания новых системных таблиц и простого
повторного использования старых файлов пользовательских данных. Если
будущий основной выпуск когда-либо изменит формат хранения данных таким
образом, что старый формат данных станет нечитаемым, qhb_upgrade не
будет использоваться для таких обновлений.
qhb_upgrade делает все возможное, чтобы убедиться, что старый и новый
кластеры совместимы в бинарном формате, например, путем проверки
совместимых настроек времени компиляции, включая 32/64-битные двоичные
файлы. Важно, чтобы любые внешние модули также были
бинарно-совместимыми, хотя это не может быть проверено qhb_upgrade .
Параметры
qhb_upgrade принимает следующие аргументы командной строки:
| Аргумент | Описание |
|---|---|
-b bindir, --old-bindir=bindir | каталог исполняемых файлов старой версии QHB; переменная окружения PGBINOLD |
-B bindir, --new-bindir=bindir | каталог исполняемых файлов новой версии QHB; переменная окружения PGBINNEW |
-c, --check | только проверить кластеры, не изменять данные |
-d configdir, --old-datadir=configdir | каталог конфигурации старого кластера базы данных; переменная окружения PGDATAOLD |
-D configdir, --new-datadir=configdir | каталог конфигурации нового кластера базы данных; переменная окружения PGDATANEW |
-s dir, --socketdir=dir | каталог, используемый для сокетов postmaster во время обновления; по умолчанию текущий рабочий каталог; переменная окружения PGSOCKETDIR |
-U username, --username=username | имя пользователя для установки кластера; переменная окружения PGUSER |
-v, --verbose | включить подробное внутренние сообщения |
-V, --version | показать версию и выйти |
--help | показать справку и выйти |
Использование
Далее описаны шаги, чтобы выполнить обновление с qhb_upgrade:
Примечания
Запускайте qhb_upgrade пользователем, от имени которого будет запускаться новый сервер, или укажите его параметром -U.
qhb_upgrade нельзя запускать под пользователем root.
qhb_upgrade создает различные файлы, такие как дампы схем, в
текущем рабочем каталоге, поэтому текущий пользователь должен иметь права на запись в него. Также в целях безопасности убедитесь, что этот
каталог не доступен для чтения или записи другим пользователям.
qhb_upgrade запускает на короткое время процессы postmaster со старым и новым
каталогом данных. Временные файлы Unix-сокетов для работы с этими
процессами по умолчанию создаются в текущем рабочем каталоге. В
некоторых ситуациях путь к текущему каталогу может быть слишком длинным,
чтобы быть допустимым именем сокета. В этом случае вы можете
использовать опцию -s чтобы поместить файлы сокетов в другой каталог
с коротким путем. В целях безопасности убедитесь, что этот каталог
не доступен для чтения или записи другим пользователям.
qhb_upgrade сообщит обо всех случаях сбоя, перестроения и
переиндексации, если они влияют на вашу установку; скрипты после
обновления для восстановления таблиц и индексов будут создаваться
автоматически. Если вы пытаетесь автоматизировать обновление многих
кластеров, вы должны обнаружить, что кластеры с одинаковыми схемами баз
данных требуют одинаковых шагов после обновления для всех обновлений
кластера; Это связано с тем, что действия после обновления основаны на
схемах базы данных, а не на пользовательских данных.
Для тестирования развертывания создайте копию старого кластера только для схемы, вставьте фиктивные данные и обновите их.
qhb_upgrade не поддерживает обновление баз данных, содержащих столбцы
таблиц, с использованием этих системных типов данных reg* OID-ссылки:
regproc, regprocedure, regoper, regoperator, regconfig и
regdictionary. (regtype может быть обновлен).
Смотрите также
qhb_bootstrap, qhb_ctl, qhb_dump, qhb
qhb_waldump
qhb_waldump - отображает WAL кластера базы данных QHB в удобочитаемом виде
Синтаксис
qhb_waldump [option...] [startseg [endseg]]
Описание
qhb_waldump отображает журнал предзаписи (WAL) и в основном используется для
отладки или в целях обучения.
Эта утилита может быть запущена только тем пользователем, который установил сервер, поскольку для нее требуется доступ только для чтения к каталогу данных.
Параметры
Следующие параметры командной строки управляют расположением и форматом вывода:
| Аргумент | Описание |
|---|---|
startseg | Начать чтение с указанного файла сегмента журнала. Это неявно определяет путь, по которому будут выполняться поиск файлов, и временную шкалу для использования |
endseg | Остановиться после прочтения указанного файла сегмента журнала |
-b, --bkp-details | Выводить подробную информацию о резервных блоках |
-e end, --end=end | Прекратить чтение в указанном месте WAL, вместо чтения потока журнала до конца |
-f, --follow | Продолжать опрашивать (раз в секунду) появление новых записей WAL, после достижения конца WAL |
-n limit, --limit=limit | Отобразите указанное количество записей и остановиться |
-p path, --path=path | Указывает каталог для поиска файлов сегментов журнала, либо каталог с подкаталогом pg_wal который содержит такие файлы. По умолчанию выполняется поиск в текущем каталоге, подкаталоге pg_wal текущего каталога и подкаталоге pg_wal PGDATA |
-r rmgr, --rmgr=rmgr | Выводить только записи, созданные указанным менеджером ресурсов. Если list передан в качестве имени, то вывести список допустимых имен менеджера ресурсов и завершить работу |
-s start, --start=start | место в WAL, с которого нужно начать чтение. По умолчанию начинается чтение первой корректной записи журнала в самом первом найденном файле |
-t timeline, --timeline=timeline | Временная шкала, с которой нужно читать записи журнала. По умолчанию, если указано используется значение startseg,. Если же и оно не указано, то значение равно 1 |
-V, --version | Показать версию qhb_waldump и выйти |
-x xid, --xid=xid | Вывести только те записи, которые отмечены указанным идентификатором транзакции |
-z, --stats[=record] | Вывести сводную статистику (количество и размер записей и образов полных страниц) вместо отдельных записей. Опционально генерировать статистику для каждой записи, а не по per-rmgr |
-?, --help | Показать справку об аргументах командной строки qhb_waldump и выйти |
Окружение
PGDATA
PG_COLOR
Примечания
Во время работы сервера может дать неправильные результаты.
Отображается только указанная временная шкала (или по умолчанию, если она не указана). Записи в другие сроки игнорируются.
qhb_waldump не может читать файлы WAL с суффиксом .partial. Если эти
файлы должны быть прочитаны, суффикс .partial должен быть удален из
имени файла.
Смотрите также
Написание обёртки сторонних данных
Все операции над сторонней таблицей производятся через созданную для неё обёртку сторонних данных, которая состоит из набора функций, вызываемых основным сервером. Обёртка сторонних данных отвечает за извлечение данных из удаленного источника данных и передачу их исполнителю запросов QHB. Если обновление сторонних таблиц должно поддерживаться, обёртка также должна поддерживать это. В этой главе описывается, как написать обёртку сторонних данных.
Обёртки сторонних данных, включенные в дистрибутив, являются хорошими примерами для написания собственных обёрток (см. каталог contrib дерева исходного кода). Справочная страница CREATE FOREIGN DATA WRAPPER также содержит некоторые полезные сведения.
Примечание!!!
Стандарт SQL определяет интерфейс для написания обёрток сторонних данных. Однако QHB не реализует этот API, потому что усилия по его размещению в QHB были бы большими, а стандартизованный API все равно не получил широкого распространения.
Функции обёрток сторонних данных
Автор FDW1 должен реализовать функцию обработчика и (опционально) функцию валидатора. Обе функции должны быть написаны на компилируемом языке, таком как C/RUST, с использованием интерфейса версии 1. Дополнительные сведения о соглашениях о вызовах языка C и динамической загрузке см. в разделе Функции на нативном языке.
Функция обработчика просто возвращает структуру указателей функций для функций обратного вызова, которые будут вызваны планировщиком, исполнителем и различными командами обслуживания. Большая часть усилий по написанию FDW1 заключается в реализации этих функций обратного вызова. Функция обработчика должна быть зарегистрирована в QHB как не имеющая аргументов и возвращающая специальный псевдотип fdw_handler. Функции обратного вызова являются простыми функциями C/RUST и не видны или не вызываются на уровне SQL. Функции обратного вызова описаны в разделе Процедуры обратного вызова сторонних данных.
Функция validator отвечает за проверку параметров, указанных в командах CREATE и ALTER для обёртки сторонних данных, а также сторонних серверов, сопоставлений пользователей и сторонних таблиц, использующих обёртку. Функция validator должна быть зарегистрирована как принимающая два аргумента, текстовый массив, содержащий параметры для проверки, и OID, представляющий тип объекта, с которым связаны параметры (в виде OID системного каталога объект будет сохранен либо ForeignDataWrapperRelationId, ForeignServerRelationId, UserMappingRelationId, или ForeignTableRelationId). Если функция валидатора не задана, параметры не проверяются во время создания объекта или во время изменения объекта.
Процедуры обратного вызова сторонних данных
Функция обработчика FDW1 возвращает структуру palloc’D FdwRoutine, содержащая указатели на функции обратного вызова, описанные ниже. Функции, связанные со сканированием, являются обязательными, остальные-необязательными.
Тип структуры FdwRoutine объявлен в src/include/foreign/fdwapi.h, который см. для получения дополнительных сведений.
Процедуры FDW для сканирования сторонних таблиц
void
GetForeignRelSize(PlannerInfo *root,
RelOptInfo *baserel,
Oid foreigntableid);
Получение оценки размера отношения для сторонней таблицы. Функция вызывается в начале планирования запроса, который сканирует стороннюю таблицу. root - глобальная информация планировщика о запросе; baserel - информация планировщика об этой таблице; и foreigntableid это pg_class OID из сторонней таблицы. (foreigntableid может быть получен из структур данных планировщика, но он передается явно, чтобы сэкономить усилия).
Эта функция должна выставлять baserel->rows в ожидаемое количество строк,
возвращаемых сканированием таблицы, с учётом фильтра, заданного ограничением выборки.
Начальное значение baserel->rows — некая константа по умолчанию, которую
следует заменить, если это вообще возможно. Эта функция также может
изменять baserel->width, если есть возможность улучшить оценку ширины строки результата.
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных
void
GetForeignPaths(PlannerInfo *root,
RelOptInfo *baserel,
Oid foreigntableid);
Создаёт возможные пути доступа для сканирования сторонней таблицы. Вызывается во время планирования запросов. Параметры такие же, как и для GetForeignRelSize (см. выше).
Эта функция должна генерировать по крайней мере один путь доступа
(ForeignPath узел) для сканирования сторонней таблицы и должна вызвать
add_path, чтобы добавить каждый такой путь к baserel->pathlist.
Рекомендуется использовать create_foreignscan_path для того, чтобы
построить ForeignPath узлы. Функция может генерировать несколько
путей доступа, например, путь, который имеет допустимый pathkeys для
представления предварительно отсортированного результата. Каждый путь
доступа должен содержать смету расходов и может содержать любую
конфиденциальную информацию FDW1, необходимую для идентификации
конкретного метода сканирования.
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
ForeignScan *
GetForeignPlan(PlannerInfo *root,
RelOptInfo *baserel,
Oid foreigntableid,
ForeignPath *best_path,
List *tlist,
List *scan_clauses,
Plan *outer_plan);
Создать ForeignScan планирование узла из выбранного внешнего пути доступа. Это называется в конце планирования запросов. Параметры как для GetForeignRelSize, плюс выбранные ForeignPath (ранее произведенный мимо GetForeignPaths, GetForeignJoinPaths, или GetForeignUpperPaths), целевой список, создаваемый узлом плана, условия ограничения, применяемые узлом плана, и внешний подплан узла плана. ForeignScan, который используется для перепроверок, выполняемых RecheckForeignScan. (Если путь предназначен для соединения, а не для базового отношения, foreigntableid является InvalidOid).
Эта функция должна создавать и возвращать a ForeignScan узел планирования; рекомендуется использовать его make_foreignscan для того чтобы построить the ForeignScan узел.
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
void
BeginForeignScan(ForeignScanState *node,
int eflags);
Начните выполнять внешнее сканирование. Это называется во время запуска исполнителя. Он должен выполнить любую инициализацию, необходимую перед началом сканирования, но не начать выполнение фактического сканирования (это должно быть сделано при первом вызове к IterateForeignScan). То ForeignScanState узел уже был создан, но его fdw_state поле по-прежнему имеет значение NULL. Информация о таблице, подлежащей сканированию, доступна через ForeignScanState узел (в частности, от нижележащего ForeignScan узел плана, который содержит любую FDW1-частную информацию, предоставляемую компанией GetForeignPlan). eflags содержит флаговые биты, описывающие рабочий режим исполнителя для данного узла плана.
Обратите внимание, что когда (eflags & EXEC_FLAG_EXPLAIN_ONLY) верно,
что эта функция не должна выполнять никаких внешне видимых действий; она
должна выполнять только минимум, необходимый для того, чтобы сделать
состояние узла допустимым для ExplainForeignScan и EndForeignScan.
TupleTableSlot *
IterateForeignScan(ForeignScanState *node);
Извлеките одну строку из внешнего источника, возвращая ее в слот таблицы кортежей (узел ScanTupleSlot следует использовать для этой цели). Возвращайте значение NULL, если больше нет доступных строк. Инфраструктура слотов таблиц кортежей позволяет возвращать либо физический, либо виртуальный Кортеж; в большинстве случаев последний вариант предпочтительнее с точки зрения производительности. Обратите внимание, что это вызывается в контексте кратковременной памяти, который будет сброшен между вызовами. Создайте контекст памяти в BeginForeignScan если вам нужно более долговечное хранение, или используйте es_query_cxt узлы EState.
Возвращаемые строки должны соответствовать целевому списку fdw_scan_tlist, если он был предоставлен, в противном случае они должны соответствовать типу строки сканируемой внешней таблицы. Если вы решите оптимизировать удаленную выборку столбцов, которые не нужны, вы должны вставить значения NULL в эти позиции столбцов, или же сгенерировать a fdw_scan_tlist список с опущенными столбцами.
Обратите внимание, что исполнителю QHB все равно, нарушают ли возвращенные строки какие — либо ограничения, определенные для внешней таблицы, но планировщик заботится и может неправильно оптимизировать запросы, если в внешней таблице есть строки, которые не удовлетворяют объявленному ограничению. Если ограничение нарушается, когда пользователь объявил, что ограничение должно иметь значение true, может быть целесообразно вызвать ошибку (так же, как это необходимо сделать в случае несоответствия типа данных).
void
ReScanForeignScan(ForeignScanState *node);
Перезапустите сканирование с самого начала. Обратите внимание, что любые параметры, от которых зависит проверка, могут иметь измененное значение, поэтому новое сканирование не обязательно возвращает точно такие же строки.
void
EndForeignScan(ForeignScanState *node);
Завершите сканирование и освободите ресурсы. Как правило, не важно, чтобы освободить palloc’D память, но, например, открытые файлы и соединения с удаленными серверами должны быть очищены.
Процедуры FDW для сканирования сторонних соединений
Если FDW1 поддерживает выполнение внешних соединений удаленно (а не путем извлечения данных обеих таблиц и выполнения соединения локально), он должен предоставить эту функцию обратного вызова:
void
GetForeignJoinPaths(PlannerInfo *root,
RelOptInfo *joinrel,
RelOptInfo *outerrel,
RelOptInfo *innerrel,
JoinType jointype,
JoinPathExtraData *extra);
Создайте возможные пути доступа для объединения двух (или более) внешних таблиц, принадлежащих одному и тому же внешнему серверу. Эта необязательная функция вызывается во время планирования запроса. Как и в случае с GetForeignPaths, эта функция должна генерировать ForeignPath путь(ы) для поставляемого устройства joinrel (использовать create_foreign_join_path чтобы построить их), и вызовите add_path чтобы добавить эти пути к набору путей, рассматриваемых для объединения. Но в отличие от него GetForeignPaths, нет необходимости, чтобы эта функция успешно создавала хотя бы один путь, поскольку пути, включающие локальное присоединение, всегда возможны.
Следует отметить, что эта функция будет повторно вызываться для одного и того же отношения соединения при различных сочетаниях внутренних и внешних отношений; ответственность за сведение к минимуму дублируемой работы лежит на FDW1.
Если a ForeignPath путь выбирается для соединения, он будет представлять весь процесс соединения; пути, созданные для таблиц компонентов и дочерних соединений, использоваться не будут. Последующая обработка пути соединения выполняется во многом так же, как и для пути сканирования одной внешней таблицы. Одно отличие заключается в том, что scanrelid из полученных результатов: ForeignScan узел плана должен быть установлен в ноль, так как нет ни одного отношения, которое он представляет; вместо этого, узел плана должен быть установлен в ноль. fs_relids область применения: ForeignScan узел представляет собой набор отношений, которые были соединены. (Последнее поле автоматически настраивается кодом основного планировщика и не должно заполняться FDW1). Другое отличие состоит в том, что поскольку список столбцов для удаленного соединения не может быть найден из системных каталогов, FDW1 должен заполнить fdw_scan_tlist с соответствующим перечнем TargetEntry узлы, представляющие набор столбцов, которые он будет предоставлять во время выполнения в кортежах, которые он возвращает.
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
Процедуры FDW для планирования обработки после сканирования / соединения
Если FDW1 поддерживает выполнение удаленной обработки после сканирования/соединения, такой как удаленная агрегация, он должен предоставить эту функцию обратного вызова:
void
GetForeignUpperPaths(PlannerInfo *root,
UpperRelationKind stage,
RelOptInfo *input_rel,
RelOptInfo *output_rel,
void *extra);
Создайте возможные пути доступа для обработки верхних отношений, которая является термином планировщика для всех процессов обработки запросов после сканирования/объединения, таких как агрегация, функции окон, сортировка и обновления таблиц. Эта необязательная функция вызывается во время планирования запроса. В настоящее время он вызывается только в том случае, если все базовые отношения, участвующие в запросе, принадлежат одному и тому же FDW1. Эта функция должна генерировать ForeignPath путь(ы) для любой обработки post-scan/join, которую FDW1 умеет выполнять удаленно (используйте create_foreign_upper_path чтобы построить их), и вызовите add_path чтобы добавить эти пути к указанному верхнему отношению. Как и в случае с GetForeignJoinPaths, нет необходимости, чтобы эта функция успешно создавала какие-либо пути, поскольку пути, включающие локальную обработку, всегда возможны.
Параметр stage определяет, какой шаг post-scan/join в настоящее время рассматривается. output_rel является ли верхнее отношение, которое должно принимать пути, представляющие вычисление этого шага, и input_rel является отношением, представляющим входные данные для этого шага. То дополнительный параметр предоставляет дополнительную информацию, в настоящее время он установлен только для UPPERREL_PARTIAL_GROUP_AGG или UPPERREL_GROUP_AGG, и в этом случае он указывает на GroupPathExtraData структура; или для UPPERREL_FINAL, и в этом случае он указывает на a FinalPathExtraData структура. (Заметить что ForeignPath пути, добавленные в output_rel как правило, не будет иметь никакой прямой зависимости от путей input_rel, поскольку их обработка, как ожидается, будет осуществляться извне. Однако изучение путей, ранее созданных для предыдущего этапа обработки, может быть полезно во избежание избыточной работы по планированию).
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
Процедуры FDW для обновления сторонних таблиц
Если FDW1 поддерживает записываемые внешние таблицы, он должен предоставлять некоторые или все из следующих функций обратного вызова в зависимости от потребностей и возможностей FDW1:
void
AddForeignUpdateTargets(Query *parsetree,
RangeTblEntry *target_rte,
Relation target_relation);
Операции UPDATE и DELETE выполняются для строк, ранее извлеченных функциями сканирования таблиц. FDW1 может потребоваться дополнительная информация, такая как идентификатор строки или значения столбцов первичного ключа, чтобы гарантировать, что он может идентифицировать точную строку для обновления или удаления. Чтобы поддержать это, эта функция может добавить дополнительные скрытые или “мусорные” целевые столбцы в список столбцов, которые должны быть получены из внешней таблицы во время UPDATE или DELETE .
Чтобы сделать это, добавьте TargetEntry пункты к parsetree -
>targetList, содержащий выражения для получения дополнительных
значений. Каждая такая запись должна быть отмечена resjunk = true, и
должны иметь различное resname это позволит идентифицировать его во
время выполнения. Избегайте использования сопоставления имен ctidN,
wholerow, или wholerowN, поскольку основная система может генерировать
ненужные столбцы этих имен. Если дополнительные выражения являются более
сложными, чем простые Vars, они должны быть выполнены через
eval_const_expressions перед добавлением их в targetlist.
Хотя эта функция вызывается во время планирования, предоставленная информация немного отличается от той, которая доступна для других процедур планирования. parsetree является ли дерево синтаксического анализа для команды UPDATE или DELETE, в то время как target_rte и target_relation опишите целевую внешнюю таблицу.
Если AddForeignUpdateTargets указатель установлен в значение NULL, никакие дополнительные целевые выражения не добавляются. (Это сделает невозможным выполнение операций удаления, хотя UPDATE все еще может быть осуществимо, если FDW1 использует неизменяемый первичный ключ для идентификации строк).
List *
PlanForeignModify(PlannerInfo *root,
ModifyTable *plan,
Index resultRelation,
int subplan_index);
Выполните все дополнительные действия планирования, необходимые для вставки, обновления или удаления во внешней таблице. Эта функция генерирует FDW1-закрытую информацию, которая будет присоединена к ModifyTable запланируйте узел, который выполняет действие обновления. Эта частная информация должна иметь вид: Список, и будет поставлен к BeginForeignModify во время стадии исполнения.
root это глобальная информация планировщика о запросе. plan это ModifyTable узел плана, который является полным за исключением fdwPrivLists поле. resultRelation определяет целевую внешнюю таблицу по индексу таблицы диапазонов. subplan_index определяет, какая это цель ModifyTable узла плана, считая от нуля; используйте это, если вы хотите индексировать в намеченные планы или другой субструктуры план узел.
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
Если PlanForeignModify указатель установлен в значение NULL, никакие дополнительные действия план-времени не приняты, и fdw_private список доставленных в BeginForeignModify будет ноль.
void
BeginForeignModify(ModifyTableState *mtstate,
ResultRelInfo *rinfo,
List *fdw_private,
int subplan_index,
int eflags);
Начните выполнение операции изменения внешней таблицы. Эта процедура вызывается во время запуска исполнителя. Он должен выполнить любую инициализацию, необходимую до фактического изменения таблицы. Впоследствии, ExecForeignInsert, ExecForeignUpdate или ExecForeignDelete будет вызван для каждого кортежа, который будет вставлен, обновлен или удален.
mtstate является ли общее состояние ModifyTable выполняется узел плана; глобальные данные о состоянии плана и выполнения доступны через эту структуру. rinfo это ResultRelInfo структура, описывающая целевую внешнюю таблицу. (Этот ri_FdwState область применения: ResultRelInfo доступен для FDW1, чтобы хранить любое частное государство, которое ему нужно для этой операции). fdw_private содержит личные данные, созданные с помощью PlanForeignModify если вообще есть. subplan_index определяет, какой целевой объект ModifyTable план узла такой есть. eflags содержит флаговые биты, описывающие рабочий режим исполнителя для данного узла плана.
Обратите внимание, что когда (eflags & EXEC_FLAG_EXPLAIN_ONLY) верно,
что эта функция не должна выполнять никаких внешне видимых действий; она
должна выполнять только минимум, необходимый для того, чтобы сделать
состояние узла допустимым для ExplainForeignModify и EndForeignModify.
Если BeginForeignModify указатель установлен в значение NULL, никакие действия не выполняются во время запуска исполнителя.
TupleTableSlot *
ExecForeignInsert(EState *estate,
ResultRelInfo *rinfo,
TupleTableSlot *slot,
TupleTableSlot *planSlot);
Вставьте один Кортеж во внешнюю таблицу. estate является глобальным состоянием выполнения для запроса. rinfo это ResultRelInfo структура, описывающая целевую внешнюю таблицу. slot содержит Кортеж, который будет вставлен; он будет соответствовать определению типа строки внешней таблицы. planSlot содержит Кортеж, который был создан с помощью ModifyTable подплан узла плана; он отличается от slot в возможно содержащих дополнительные "мусорные" колонки. (Этот planSlot обычно представляет небольшой интерес для случаев вставки, но предоставляется для полноты).
Возвращаемое значение является либо слотом, содержащим данные, которые были фактически вставлены (это может отличаться от данных, предоставленных, например, в результате действий триггера), либо NULL, если строка фактически не была вставлена (опять же, как правило, в результате триггеров). passed-in slot может быть повторно использован для этой цели.
Данные в возвращаемом слоте используются только в том случае, если инструкция INSERT имеет вид RETURNING предложение или включает в себя представление WITH CHECK OPTION; или если внешняя таблица имеет вид AFTER ROW спусковой крючок. Триггеры требуют все столбцы, но FDW1 может выбрать оптимизацию, возвращающую некоторые или все столбцы в зависимости от содержимого RETURNING статья или WITH CHECK OPTION ограничения. Независимо от этого, некоторый слот должен быть возвращен, чтобы указать на успех, или отчетное число строк запроса будет неверным.
Если ExecForeignInsert указатель установлен в значение NULL, попытки вставки во внешнюю таблицу завершатся ошибкой с сообщением об ошибке.
Обратите внимание, что эта функция также вызывается при вставке маршрутизируемых кортежей в раздел внешней таблицы или выполнении COPY FROM внешней таблицы, и в этом случае она вызывается иначе, чем в случае вставки. Смотрите функции обратного вызова, описанные ниже, которые позволяют FDW1 поддерживать это.
TupleTableSlot *
ExecForeignUpdate(EState *estate,
ResultRelInfo *rinfo,
TupleTableSlot *slot,
TupleTableSlot *planSlot);
Обновите один Кортеж во внешней таблице. estate является глобальным состоянием выполнения для запроса. rinfo это ResultRelInfo структура, описывающая целевую внешнюю таблицу. slot содержит новые данные для кортежа; он будет соответствовать определению типа строки внешней таблицы. planSlot содержит Кортеж, который был создан с помощью ModifyTable подплан узла плана; он отличается от slot в возможно содержащих дополнительные” мусорные " колонки. В частности, любые ненужные столбцы, которые были запрошены AddForeignUpdateTargets будет доступен из этого слота.
Возвращаемое значение является либо слотом, содержащим строку, как она была фактически обновлена (это может отличаться от данных, предоставленных, например, в результате действий триггера), либо NULL, если ни одна строка не была фактически обновлена (снова, как правило, в результате триггеров). passed-in slot может быть повторно использован для этой цели.
Данные в возвращаемом слоте используются только в том случае, если инструкция UPDATE имеет RETURNING предложение или включает в себя представление WITH CHECK OPTION; или если внешняя таблица имеет вид AFTER ROW спусковой крючок. Триггеры требуют все столбцы, но FDW1 может выбрать оптимизацию, возвращающую некоторые или все столбцы в зависимости от содержимого RETURNING статья или WITH CHECK OPTION ограничения. Независимо от этого, некоторый слот должен быть возвращен, чтобы указать на успех, или отчетное число строк запроса будет неверным.
Если ExecForeignUpdate указатель установлен в значение NULL, попытки обновить внешнюю таблицу завершатся ошибкой с сообщением об ошибке.
TupleTableSlot *
ExecForeignDelete(EState *estate,
ResultRelInfo *rinfo,
TupleTableSlot *slot,
TupleTableSlot *planSlot);
Удалите один кортеж из внешней таблицы. estate является глобальным состоянием выполнения для запроса. rinfo это ResultRelInfo структура, описывающая целевую внешнюю таблицу. slot не содержит ничего полезного при вызове, но может использоваться для удержания возвращенного кортежа. planSlot содержит Кортеж, который был создан с помощью ModifyTable подплан узла plan; в частности, он будет содержать любые ненужные столбцы, которые были запрошены с помощью AddForeignUpdateTargets. Для идентификации удаляемого кортежа необходимо использовать столбец(ы) нежелательной почты.
Возвращаемое значение является либо слотом, содержащим строку, которая была удалена, либо NULL, если ни одна строка не была удалена (как правило, в результате триггеров). passed-in slot может использоваться для удержания кортежа, подлежащего возврату.
Данные в возвращаемом слоте используются только в том случае, если запрос на удаление имеет вид RETURNING предложение или внешняя таблица имеет вид AFTER ROW спусковой крючок. Триггеры требуют все столбцы, но FDW1 может выбрать оптимизацию, возвращающую некоторые или все столбцы в зависимости от содержимого RETURNING пункт. Независимо от этого, некоторый слот должен быть возвращен, чтобы указать на успех, или отчетное число строк запроса будет неверным.
Если ExecForeignDelete указатель установлен в значение NULL, попытки удаления из внешней таблицы завершатся ошибкой с сообщением об ошибке.
void
EndForeignModify(EState *estate,
ResultRelInfo *rinfo);
Завершите обновление таблицы и освободите ресурсы. Как правило, не важно, чтобы освободить palloc’D память, но, например, открытые файлы и соединения с удаленными серверами должны быть очищены.
Если EndForeignModify указатель установлен в значение NULL, никакие действия не предпринимаются во время завершения работы исполнителя.
Кортежи, вставленные в партицированную таблицу с помощью INSERT или COPY FROM, направляются в партиции. Если FDW1 поддерживает маршрутизируемые разделы внешней таблицы, он также должен предоставлять следующие функции обратного вызова. Эти функции также вызываются, когда COPY FROM выполняется на внешней таблице.
void
BeginForeignInsert(ModifyTableState *mtstate,
ResultRelInfo *rinfo);
Начните выполнение операции вставки во внешнюю таблицу. Эта процедура вызывается непосредственно перед первым кортежем, вставленным во внешнюю таблицу, в обоих случаях, когда это партиция, выбранная для маршрутизации кортежа, и цель, указанная в команде COPY FROM. Он должен выполнить любую инициализацию, необходимую до фактической вставки. Впоследствии, ExecForeignInsert будет вызван для каждого кортежа, который будет вставлен во внешнюю таблицу.
mtstate является ли общее состояние ModifyTable выполняется узел плана; глобальные данные о состоянии плана и выполнения доступны через эту структуру. rinfo это ResultRelInfo структура, описывающая целевую внешнюю таблицу. (Этот ri_FdwState область применения: ResultRelInfo доступен для FDW1, чтобы хранить любое частное государство, которое ему нужно для этой операции).
Когда это вызывается командой COPY FROM, глобальные данные, связанные с планом, в mtstate не предусмотрено и то planSlot параметр из ExecForeignInsert впоследствии вызывается для каждого вставленного Кортежа является NULL, является ли внешняя таблица партицией, выбранной для маршрутизации кортежа, или целевым объектом, указанным в команде.
Если Beginforeignsert указатель установлен в значение NULL, для инициализации не предпринимается никаких действий.
Обратите внимание, что если FDW1 не поддерживает маршрутизируемые разделы внешней таблицы и / или выполнение COPY FROM внешних таблиц, эта функция или ExecForeignInsert впоследствии вызванный должен бросить ошибку по мере необходимости.
void
EndForeignInsert(EState *estate,
ResultRelInfo *rinfo);
Завершите операцию вставки и освободите ресурсы. Как правило, не важно, чтобы освободить palloc’D память, но, например, открытые файлы и соединения с удаленными серверами должны быть очищены.
Если Endforeignsert указатель установлен в значение NULL, никакие действия не принимаются для прекращения.
int
IsForeignRelUpdatable(Relation rel);
Отчет о том, какие операции обновления поддерживает указанная внешняя
таблица. Возвращаемое значение должно представлять собой битовую маску
номеров событий правила, указывающую, какие операции поддерживаются
внешней таблицей, с помощью CmdType перечисление; то есть, (1 << CMD_UPDATE) = 4 для
UPDATE, (1 << CMD_INSERT) = 8 для INSERT, и (1 << CMD_DELETE) = 16 для DELETE.
Если IsForeignRelUpdatable указатель установлен в значение NULL, внешние таблицы считаются вставляемыми, обновляемыми или удаляемыми, если FDW1 предоставляет ExecForeignInsert, ExecForeignUpdate, или ExecForeignDelete соответственно. Эта функция необходима только в том случае, если FDW1 поддерживает некоторые таблицы, которые можно обновить, а некоторые-нет. (Даже в этом случае допустимо выбросить ошибку в подпрограмму выполнения вместо проверки этой функции. Однако эта функция используется для определения возможности обновления для отображения в information_schema число просмотров).
Некоторые вставки, обновления и удаления во внешние таблицы можно оптимизировать, реализовав альтернативный набор интерфейсов. Обычные интерфейсы для вставки, обновления и удаления строк выборки с удаленного сервера и последующего изменения этих строк по одному за раз. В некоторых случаях такой пошаговый подход необходим, но он может быть неэффективным. Если внешний сервер может определить, какие строки следует изменить, фактически не извлекая их, и если нет локальных структур, которые могли бы повлиять на операцию (локальные триггеры на уровне строк, сохраненные сгенерированные столбцы или WITH CHECK OPTION ограничения из родительских представлений), то можно организовать вещи так, что вся операция выполняется на удаленном сервере. Интерфейсы, описанные ниже, делают это возможным.
bool
PlanDirectModify(PlannerInfo *root,
ModifyTable *plan,
Index resultRelation,
int subplan_index);
Решите, безопасно ли выполнять прямую модификацию на удаленном сервере. Если да, то вернитесь истинный после выполнения необходимых для этого плановых действий. В противном случае, возврат ложный. Эта необязательная функция вызывается во время планирования запроса. Если эта функция выполняется успешно, BeginDirectModify, IterateDirectModify и EndDirectModify будет вызван на этапе выполнения, вместо этого. В противном случае модификация таблицы будет выполнена с использованием функций обновления таблиц, описанных выше. Параметры такие же, как и для PlanForeignModify.
Чтобы выполнить прямое изменение на удаленном сервере, эта функция должна переписать целевой подплан с ForeignScan узлом планирования, который выполняет прямое изменение на удаленном сервере. То операция область применения: ForeignScan должно быть установлено на CmdType перечисление соответственно; то есть, CMD_UPDATE для UPDATE, CMD_INSERT для INSERT, и CMD_DELETE для DELETE .
Дополнительную информацию смотрите в разделе Планирование запросов на обработку сторонних данных.
Если PlanDirectModify указатель установлен в значение NULL, никакие попытки выполнить прямое изменение на удаленном сервере не предпринимаются.
void
BeginDirectModify(ForeignScanState *node,
int eflags);
Подготовьтесь к выполнению прямого изменения на удаленном сервере. Это называется во время запуска исполнителя. Он должен выполнить любую инициализацию, необходимую до прямого изменения (это должно быть сделано при первом вызове к IterateDirectModify). ForeignScanState узел уже был создан, но его fdw_state поле по-прежнему имеет значение NULL. Информация о таблице, которую необходимо изменить, доступна через ForeignScanState узел (в частности, от нижележащего ForeignScan узел плана, который содержит любую FDW1-частную информацию, предоставляемую компанией PlanDirectModify). eflags содержит флаговые биты, описывающие рабочий режим исполнителя для данного узла плана.
Обратите внимание, что когда (eflags & EXEC_FLAG_EXPLAIN_ONLY) верно,
что эта функция не должна выполнять никаких внешне видимых действий; она
должна выполнять только минимум, необходимый для того, чтобы сделать
состояние узла допустимым для ExplainDirectModify и EndDirectModify.
Если BeginDirectModify указатель установлен в значение NULL, никакие попытки выполнить прямое изменение на удаленном сервере не предпринимаются.
TupleTableSlot *
IterateDirectModify(ForeignScanState *node);
Когда запрос INSERT, UPDATE или DELETE не имеет a RETURNING предложение, просто возвращает NULL после прямого изменения на удаленном сервере. Когда запрос содержит предложение, извлеките один результат, содержащий данные, необходимые для выполнения запроса. RETURNING вычисление, возвращая его в слот таблицы кортежа (узел ScanTupleSlot следует использовать для этой цели). Данные, которые были фактически вставлены, обновлены или удалены, должны храниться в системе es_result_relation_info - >ri_projectReturning - >>pi_exprContext->>>ecxt_scantuple из узла s EState. Возвращайте значение NULL, если больше нет доступных строк. Обратите внимание, что это вызывается в контексте кратковременной памяти, который будет сброшен между вызовами. Создайте контекст памяти в BeginDirectModify если вам нужно более долговечное хранение, или используйте es_query_cxt из узла s EState.
Возвращаемые строки должны соответствовать fdw_scan_tlist целевой список, если он был предоставлен, в противном случае они должны соответствовать типу строки обновляемой внешней таблицы. Если вы решите оптимизировать удаленную выборку столбцов, которые не нужны для RETURNING вычисление, вы должны вставить значения NULL в этих позициях столбца, или же сгенерировать a fdw_scan_tlist список с опущенными столбцами.
Независимо от того, содержит ли запрос предложение или нет, количество строк в отчете запроса должно быть увеличено самим FDW1. Если запрос не содержит предложения, то FDW1 также должен увеличить количество строк для запроса. ForeignScanState узел в случае объяснения анализа.
Если IterateDirectModify указатель установлен в значение NULL, никакие попытки выполнить прямое изменение на удаленном сервере не предпринимаются.
void
EndDirectModify(ForeignScanState *node);
Очистка после прямого изменения на удаленном сервере. Как правило, не важно, чтобы освободить palloc’D память, но, например, открытые файлы и соединения с удаленным сервером должны быть очищены.
Если EndDirectModify указатель установлен в значение NULL, никакие попытки выполнить прямое изменение на удаленном сервере не предпринимаются.
FDW-процедуры для блокировки строк
Если FDW1 желает поддерживать late row locking (как описано в разделе Блокировка строк в обёртках сторонних данных), он должен предоставить следующие функции обратного вызова:
RowMarkType
GetForeignRowMarkType(RangeTblEntry *rte,
LockClauseStrength strength);
Сообщите, какой параметр маркировки строк следует использовать для внешней таблицы. rte это RangeTblEntry узел для таблицы и strength описывает силу блокировки, запрошенную соответствующим предложением FOR UPDATE/SHARE, если таковой имеется. Результат должен быть членом группы RowMarkType тип enum.
Эта функция вызывается во время планирования запроса для каждой внешней таблицы, которая появляется в запросе UPDATE, DELETE или SELECT FOR UPDATE/SHARE и не является целью UPDATE или DELETE .
Если GetForeignRowMarkType указатель установлен в значение NULL, ROW_MARK_COPY опция всегда используется. (Это подразумевает, что RefetchForeignRow никогда не будет называться, поэтому его не нужно предоставлять также).
Дополнительную информацию смотрите в разделе Блокировка строк в обёртках сторонних данных.
void
RefetchForeignRow(EState *estate,
ExecRowMark *erm,
Datum rowid,
TupleTableSlot *slot,
bool *updated);
Повторно извлеките один слот кортежа из внешней таблицы, после блокировки его, если это требуется. EState является глобальным состоянием выполнения для запроса. erm - ExecRowMark структура, описывающая целевую внешнюю таблицу и тип блокировки строк (если таковой имеется) для получения. rowid определяет Кортеж, который будет извлечен. slot не содержит ничего полезного при вызове, но может использоваться для удержания возвращенного кортежа. updated является выходным параметром.
Эта функция должна хранить Кортеж в предоставленном слоте или очистить его, если блокировка строк не может быть получена. Тип блокировки строки для получения определяется с помощью erm - >markType, который является значением, ранее возвращенным с помощью GetForeignRowMarkType. (ROW_MARK_REFERENCE означает просто повторно забрать кортеж, не приобретая никакой блокировки, и ROW_MARK_COPY никогда не будет видна эта процедура).
Кроме того, *updated должно быть установлено true если то, что было извлечено, было обновленной версией кортежа, а не той же самой версией, полученной ранее. (Если FDW1 не может быть уверен в этом, всегда рекомендовано возвращать true).
Обратите внимание, что по умолчанию неспособность получить блокировку строки должна привести к возникновению ошибки; возврат с пустым слотом подходит только в том случае, если SKIP LOCKED опция указывается путем erm - >waitPolicy.
rowid это ctid значение, ранее считанное для строки, которая будет повторно извлечена. Хотя rowid значение передается как Datum величина, в настоящее время это может быть только tid. API функции выбран в надежде, что в будущем можно будет разрешить другие типы данных для идентификаторов строк.
Если RefetchForeignRow указатель установлен в значение NULL, попытки повторно извлечь строки завершатся ошибкой с сообщением об ошибке.
Дополнительную информацию смотрите в разделе Блокировка строк в обёртках сторонних данных.
bool
RecheckForeignScan(ForeignScanState *node,
TupleTableSlot *slot);
Еще раз проверьте, что ранее возвращенный Кортеж все еще соответствует соответствующим квалификаторам сканирования и соединения, и, возможно, предоставит измененную версию кортежа. Для обёрток сторонних данных, которые не выполняют функцию объединения, обычно будет удобнее установить это значение NULL а вместо этого поставили fdw_recheck_quals соответственно. Однако когда внешние объединения выталкиваются вниз, недостаточно повторно применить проверки, относящиеся ко всем базовым таблицам, к результирующему кортежу, даже если все необходимые атрибуты присутствуют, потому что неспособность соответствовать некоторому квалификатору может привести к тому, что некоторые атрибуты будут иметь значение NULL, а не к отсутствию возвращаемого кортежа. RecheckForeignScan может перепроверять квалификаторы и возвращать true, если они все еще удовлетворены, и false в противном случае, но он также может хранить кортеж замены в поставляемом слоте.
Для реализации функции push-соединения обёртка сторонних данных обычно создает альтернативный локальный план соединения, который используется только для повторных проверок; он становится внешним подпланом объекта ForeignScan. Когда требуется перепроверка, этот подплан может быть выполнен, и полученный Кортеж может быть сохранен в слоте. Этот план не должен быть эффективным, так как ни одна базовая таблица не будет возвращать более одной строки; например, он может реализовать все соединения как вложенные циклы. Функция GetExistingLocalJoinPath может использоваться для поиска существующих путей для подходящего локального пути соединения, который может использоваться в качестве альтернативного локального плана соединения. GetExistingLocalJoinPath выполняет поиск непараметризованного пути в списке путей указанного отношения соединения. (Если он не находит такой путь, он возвращает NULL, и в этом случае обёртка сторонних данных может построить локальный путь самостоятельно или может решить не создавать пути доступа для этого соединения).
Процедуры FDW для EXPLAIN
void
ExplainForeignScan(ForeignScanState *node,
ExplainState *es);
Печать дополнительных EXPLAIN вывода для сканирования внешней таблицы. Эта функция может вызывать ExplainPropertyText и связанные функции для добавления полей в выходные данные EXPLAIN. Поля флага внутри es может использоваться для определения того, что нужно распечатать, и состояния объекта ForeignScanState узел может быть проверен для предоставления статистики времени выполнения в случае объяснения анализа.
Если ExplainForeignScan указатель установлен в значение NULL, никакая дополнительная информация не печатается во время EXPLAIN .
void
ExplainForeignModify(ModifyTableState *mtstate,
ResultRelInfo *rinfo,
List *fdw_private,
int subplan_index,
struct ExplainState *es);
Печать дополнительных выходных данных объяснения для обновления внешней таблицы. Эта функция может вызывать ExplainPropertyText и связанные функции для добавления полей в выходные данные EXPLAIN. Поля флага внутри es может использоваться для определения того, что нужно распечатать, и состояния объекта ModifyTableState узел может быть проверен для предоставления статистики времени выполнения в случае объяснения анализа. Первые четыре аргумента такие же, как и для BeginForeignModify.
Если ExplainForeignModify указатель установлен в значение NULL, никакая дополнительная информация не печатается во время EXPLAIN.
void
ExplainDirectModify(ForeignScanState *node,
ExplainState *es);
Распечатайте дополнительные EXPLAIN выходные данные для прямого изменения на удаленном сервере. Эта функция может вызывать ExplainPropertyText и связанные функции для добавления полей в выходные данные EXPLAIN. Поля флага внутри es может использоваться для определения того, что нужно распечатать, и состояния объекта ForeignScanState узел может быть проверен для предоставления статистики времени выполнения в случае объяснения анализа.
Если ExplainDirectModify указатель установлен в значение NULL, никакая дополнительная информация не печатается во время EXPLAIN .
Процедуры FDW для ANALYZE
bool
AnalyzeForeignTable(Relation relation,
AcquireSampleRowsFunc *func,
BlockNumber *totalpages);
Эта функция вызывается, когда ANALYZE выполняется на внешней таблице. Если FDW1 может собирать статистику для этой внешней таблицы, он должен вернуться истинный, и предоставляет указатель на функцию, которая будет собирать образцы строк из таблицы в функция, плюс предполагаемый размер таблицы в страницах в всего страниц. В противном случае, возврат ложный.
Если FDW1 не поддерживает сбор статистических данных для любых таблиц, то AnalyzeForeignTable указатель может быть установлен на NULL.
Если это предусмотрено, функция выборки образцов должна иметь подпись
int
AcquireSampleRowsFunc(Relation relation,
int elevel,
HeapTuple *rows,
int targrows,
double *totalrows,
double *totaldeadrows);
Случайная выборка до targrows строки должны быть собраны из таблицы и сохранены в предоставленной вызывающей стороне rows массив. Должно быть возвращено фактическое количество собранных строк. Кроме того, сохраните оценки общего числа живых и мертвых строк в таблице в выходные параметры totalrows и totaldeadrows. (Набор totaldeadrows до нуля, если FDW1 не имеет никакого понятия мертвых строк).
Процедуры FDW для IMPORT FOREIGN SCHEMA
List *
ImportForeignSchema(ImportForeignSchemaStmt *stmt, Oid serverOid);
Получите список команд для создания внешней таблицы. Эта функция вызывается при выполнении IMPORT FOREIGN SCHEMA, и передается дерево синтаксического анализа для этого оператора, а также OID внешнего сервера для использования. Он должен возвращать список строк C, каждая из которых должна содержать команду CREATE FOREIGN TABLE. Эти строки будут проанализированы и выполнены главным сервером.
Внутри же ImportForeignSchemaStmt структуры, remote_schema это имя удаленной схемы, из которой должны быть импортированы таблицы. тип списка определяет способ фильтрации имен таблиц: FDW_IMPORT_SCHEMA_ALL означает, что все таблицы в удаленной схеме должны быть импортированы (в этом случае table_list быть пустой), FDW_IMPORT_SCHEMA_LIMIT_TO средства для включения только таблиц, перечисленных в table_list, и FDW_IMPORT_SCHEMA_EXCEPT средства для исключения таблиц, перечисленных в table_list. Возможности это список параметров, используемых для процесса импорта. Значения этих вариантов зависят от FDW1. Например, FDW1 может использовать параметр для определения того, является ли NOT NULL атрибуты столбцов должны быть импортированы. Эти параметры не должны иметь ничего общего с теми, которые поддерживаются FDW1 в качестве параметров объекта базы данных.
FDW1 может проигнорировать локальная схема область применения: ImportForeignSchemaStmt, потому что главный сервер автоматически вставит это имя в анализируемые команды CREATE FOREIGN TABLE.
FDW1 не должен заботиться о реализации фильтрации, указанной выше тип списка и table_list, либо, поскольку главный сервер автоматически пропустит все возвращенные команды для таблиц, исключенных в соответствии с этими опциями. Однако часто бывает полезно избегать работы по созданию команд для исключенных таблиц в первую очередь. Функция IsImportableForeignTable() может быть полезна для проверки того, будет ли данное имя внешней таблицы проходить фильтр.
Если FDW1 не поддерживает импорт определений таблиц, то указатель ImportForeignSchema может быть установлен на NULL.
Программы FDW для параллельного выполнения
Один ForeignScan узел может, дополнительно, поддерживать параллельное выполнение. Параллель ForeignScan будет выполняться в нескольких процессах и должен возвращать каждую строку ровно один раз через все взаимодействующие процессы. Для этого процессы могут координироваться через блоки динамической общей памяти фиксированного размера. Эта общая память не обязательно должна быть сопоставлена с одним и тем же адресом в каждом процессе, поэтому она не должна содержать указателей. Все перечисленные ниже функции являются необязательными, но большинство из них необходимы для поддержки параллельного выполнения.
bool
IsForeignScanParallelSafe(PlannerInfo *root, RelOptInfo *rel,
RangeTblEntry *rte);
Проверьте, можно ли выполнить сканирование в параллельном процессе. Эта функция будет вызываться только тогда, когда планировщик считает, что параллельный план может быть возможен, и должен возвращать true, если это безопасно для выполнения сканирования в параллельном процессе. Как правило, это не будет иметь место, если удаленный источник данных имеет семантику транзакций, если только соединение процесса с данными не может быть каким-то образом сделано для совместного использования того же контекста транзакции, что и лидер.
Если эта функция не определена, предполагается, что сканирование должно выполняться в пределах параллельной выноски. Обратите внимание, что возврат true не означает, что само сканирование может быть выполнено параллельно, только то, что сканирование может быть выполнено в параллельном процессе. Поэтому может быть полезно определить этот метод, даже если параллельное выполнение не поддерживается.
Size
EstimateDSMForeignScan(ForeignScanState *node, ParallelContext *pcxt);
Оцените объем динамической общей памяти, который потребуется для параллельной работы. Это может быть больше, чем сумма, которая будет фактически использована, но она не должна быть ниже. Возвращаемое значение находится в байтах. Эта функция является необязательной и может быть опущена, если она не требуется; но если она опущена, то следующие три функции также должны быть опущены, поскольку общая память не будет выделена для использования FDW1.
void
InitializeDSMForeignScan(ForeignScanState *node, ParallelContext *pcxt,
void *coordinate);
Инициализируйте динамическую общую память, которая будет необходима для параллельной работы. координировать указывает на общую область памяти размером, равным возвращаемому значению EstimateDSMForeignScan. Эта функция является необязательной и может быть опущена, если это не требуется.
void
ReInitializeDSMForeignScan(ForeignScanState *node, ParallelContext *pcxt,
void *coordinate);
Повторно инициализируйте динамическую общую память, необходимую для параллельной работы, когда узел плана внешнего сканирования готовится к повторному сканированию. Эта функция является необязательной и может быть опущена, если это не требуется. Рекомендуемая практика заключается в том, что эта функция сбрасывает только общее состояние, в то время как ReScanForeignScan функция сбрасывает только локальное состояние. В настоящее время эта функция будет вызвана раньше ReScanForeignScan но лучше всего не полагаться на этот заказ.
void
InitializeWorkerForeignScan(ForeignScanState *node, shm_toc *toc,
void *coordinate);
Инициализируйте локальное состояние параллельного процесса на основе общего состояния, заданного руководителем во время выполнения InitializeDSMForeignScan. Эта функция является необязательной и может быть опущена, если это не требуется.
void
ShutdownForeignScan(ForeignScanState *node);
Высвобождайте ресурсы, когда ожидается, что узел не будет выполнен до завершения. Это называется не во всех случаях; иногда, EndForeignScan может вызываться без того, чтобы эта функция была вызвана первой. Поскольку сегмент DSM, используемый параллельным запросом, уничтожается сразу же после вызова этого обратного вызова, внешние обертки данных, которые хотят предпринять некоторые действия, прежде чем сегмент DSM исчезнет, должны реализовать этот метод.
Процедуры FDW для репараметризации путей
List *
ReparameterizeForeignPathByChild(PlannerInfo *root, List *fdw_private,
RelOptInfo *child_rel);
Эта функция вызывается при преобразовании пути, параметризованного самым верхним родителем данного дочернего отношения child_rel быть параметризованным по отношению к ребенку. Эта функция используется для перезамера любых путей или преобразования любых узлов выражения, сохраненных в данном файле fdw_private член а ForeignPath. Обратный вызов может использовать reparameterize_path_by_child, adjust_appendrel_attrs или adjust_appendrel_attrs_multilevel как и положено.
Вспомогательные функции для обёртки сторонних данных
Несколько вспомогательных функций экспортируются с главного сервера, чтобы авторы обёрток сторонних данных могли легко получить доступ к атрибутам объектов, связанных с FDW1, таким как параметры FDW1. Чтобы использовать любую из этих функций, необходимо включить файл заголовка foreign/foreign.h в вашем исходном файле. Этот заголовок также определяет типы структур, возвращаемые этими функциями.
ForeignDataWrapper *
GetForeignDataWrapperExtended(Oid fdwid, bits16 flags);
Эта функция возвращает объект ForeignDataWrapper для обёртки сторонних данных с заданным OID. ForeignDataWrapper объект содержит свойства FDW1 (см. foreign/foreign.h относительно деталей). флаги это побитовая или битовая маска, указывающая на дополнительный набор опций. Он может принять значение FDW_MISSING_OK, и в этом случае a NULL результат возвращается вызывающему объекту вместо ошибки для неопределенного объекта.
ForeignDataWrapper *
GetForeignDataWrapper(Oid fdwid);
Эта функция возвращает a объект ForeignDataWrapper для обёртки сторонних данных с заданным OID. ForeignDataWrapper объект содержит свойства FDW1 (см. foreign/foreign.h относительно деталей).
ForeignServer *
GetForeignServerExtended(Oid serverid, bits16 flags);
Эта функция возвращает ForeignServer объект для внешнего сервера с заданным OID. ForeignServer объект содержит свойства сервера (см. foreign/foreign.h относительно деталей). флаги это побитовая или битовая маска, указывающая на дополнительный набор опций. Он может принять значение FSV_MISSING_OK, и в этом случае a NULL результат возвращается вызывающему объекту вместо ошибки для неопределенного объекта.
ForeignServer *
GetForeignServer(Oid serverid);
Эта функция возвращает ForeignServer объект для внешнего сервера с заданным OID. Один ForeignServer объект содержит свойства сервера (см. foreign/foreign.h относительно деталей).
UserMapping *
GetUserMapping(Oid userid, Oid serverid);
Эта функция возвращает объект UserMapping для отображения пользователя данной роли на данном сервере. (Если нет никакого сопоставления для конкретного пользователя, он вернет сопоставление для PUBLIC, или бросьте ошибку, если ее нет). UserMapping объект содержит свойства пользовательского сопоставления (см. foreign/foreign.h относительно деталей).
ForeignTable *
GetForeignTable(Oid relid);
Эта функция возвращает объект ForeignTable для внешней таблицы с заданным OID. ForeignTable объект содержит свойства внешней таблицы (см. foreign/foreign.h относительно деталей).
List *
GetForeignColumnOptions(Oid relid, AttrNumber attnum);
Эта функция возвращает параметры FDW1 для каждого столбца для столбца с заданным внешним OID таблицы и номером атрибута, в виде списка DefElem. Значение NIL возвращается, если столбец не имеет параметров.
Некоторые типы объектов имеют функции поиска на основе имен в дополнение к основанным на OID функциям:
ForeignDataWrapper *
GetForeignDataWrapperByName(const char *name, bool missing_ok);
Эта функция возвращает объект ForeignDataWrapper для обёртки сторонних данных с заданным именем. Если обёртка не найдена, верните значение NULL, если missing_ok имеет значение true, иначе возникнет ошибка.
ForeignServer *
GetForeignServerByName(const char *name, bool missing_ok);
Эта функция возвращает ForeignServer объект для внешнего сервера с заданным именем. Если сервер не найден, верните значение NULL, если missing_ok имеет значение true, иначе возникнет ошибка.
Планирование запросов на обработку сторонних данных
Функции обратного вызова FDW1 GetForeignRelSize, GetForeignPaths, GetForeignPlan, PlanForeignModify, GetForeignJoinPaths, GetForeignUpperPaths, и PlanDirectModify должны вписываться в работу планировщика QHB. Вот некоторые заметки о том, что они должны делать.
Информация внутри корень и подложка может использоваться для уменьшения объема информации, которая должна быть извлечена из внешней таблицы (и, следовательно, снизить стоимость). baserel - >baserestrictinfo это особенно интересно, так как содержит ограничительные кавычки (WHERE предложения), которые должны использоваться для фильтрации строк, подлежащих извлечению. (Сам FDW1 не требуется для принудительного применения этих тестов, поскольку основной исполнитель может проверить их вместо этого). baserel- > reltarget - >>exprs можно использовать, чтобы определить, какие столбцы должны быть извлечены; но обратите внимание, что он только перечисляет столбцы, которые должны быть испущены ForeignScan узел плана, а не столбцы, которые используются при квалификационной оценке, но не выводятся запросом.
Различные частные поля доступны для функций планирования FDW1, чтобы сохранить информацию. Как правило, все, что вы храните в частных полях FDW1, должно быть убрано, чтобы оно было исправлено в конце планирования.
baserel - >fdw_private это void указатель, доступный для функций планирования FDW1 для хранения информации, относящейся к конкретной внешней таблице. Основной планировщик не трогает его, кроме как для инициализации его в ноль, когда RelOptInfo узел будет создан. Это полезно для передачи информации вперед от GetForeignRelSize Для GetForeignPaths и-или GetForeignPaths Для GetForeignPlan, тем самым избегая пересчета.
GetForeignPaths можно определить значение различных путей доступа, храня личную информацию в fdw_private область применения: ForeignPath узлы. fdw_private объявляется как a Список указатель, но на самом деле может содержать что-либо, так как основной планировщик не касается его. Тем не менее, рекомендуется использовать представление, котороеможет быть выгружено nodeToString, для использования с поддержкой отладки, доступной в бэкэнде.
GetForeignPlan может исследовать fdw_private поле выбранного ForeignPath узла, и может произвести fdw_exprs и fdw_private списки, подлежащие размещению в ForeignScan запланируйте узел, где они будут доступны во время выполнения. Оба эти списка должны быть представлены в такой форме, чтобы copyObject умеет копировать. fdw_private список не имеет никаких других ограничений и никоим образом не интерпретируется ядром backend. То fdw_exprs список, если он не равен NIL, должен содержать деревья выражений, предназначенные для выполнения во время выполнения. Эти деревья будут проходить пост-обработку планировщиком, чтобы сделать их полностью исполняемыми.
В GetForeignPlan, как правило, переданный целевой список можно скопировать в узел плана как есть. Переданный scan_clauses список содержит те же пункты, что и baserel - >baserestrictinfo, но может быть переупорядочен для для лучшей эффективности выполнения. В простых случаях FDW1 может просто удалить RestrictInfo узлы из списка scan_clauses (с помощью extract_actual_clauses) и поместить все предложения в список квалификации узла плана, что означает, что все предложения будут проверены исполнителем во время выполнения. Более сложные FDW1 могут быть в состоянии проверить некоторые пункты внутренне, и в этом случае эти пункты могут быть удалены из списка квалификации узла плана, чтобы исполнитель не тратил время на повторную проверку их.
Например, FDW1 может идентифицировать некоторые положения об ограничении формы foreign_variable = sub_expression, который он определяет, может быть выполнен на удаленном сервере с учетом локально оцененного значения sub_expression. Фактическая идентификация такой оговорки должна произойти во время GetForeignPaths, так как это повлияло бы на смету расходов для пути. Путь fdw_private поле, вероятно, будет содержать указатель на идентифицированное предложение RestrictInfo узел. Затем GetForeignPlan удалил бы это положение из scan_clauses, но добавить то sub_expression Для fdw_exprs чтобы убедиться, что он получает массаж в исполняемую форму. Это, вероятно, также поместит управляющую информацию в узел плана fdw_private поле, указывающее функциям выполнения, что следует делать во время выполнения. Запрос, передаваемый на удаленный сервер, будет включать что-то вроде Где foreign_variable = $1, при этом значение параметра получено во время выполнения из оценки fdw_exprs дерево выражения.
Все предложения, удаленные из списка квалификации узла плана, должны быть добавлены вместо этого fdw_recheck_quals или перепроверить с помощью RecheckForeignScan для того чтобы обеспечить правильное поведение на READ COMMITTED уровень изоляции. Когда параллельное обновление происходит для некоторой другой таблицы, вовлеченной в запрос, исполнителю может потребоваться проверить, что все исходные тесты все еще удовлетворены для кортежа, возможно, против другого набора значений параметров. С помощью fdw_recheck_quals обычно это проще, чем реализовать проверки внутри RecheckForeignScan, но этот метод будет недостаточным, когда внешние соединения были вытеснены, так как кортежи соединения в этом случае могут иметь некоторые поля, переходящие в NULL, не отвергая кортеж полностью.
Другой ForeignScan поле, которое может быть заполнено FDWs1 является fdw_scan_tlist, который описывает кортежи, возвращенные FDW1 для этого узла плана. Для простых сканирований внешней таблицы это может быть установлено в NULL, подразумевая, что возвращенные кортежи имеют тип строки, объявленный для внешней таблицы. non-NIL значение должно быть целевым списком (списком TargetEntry) содержащие Vars и / или выражения, представляющие возвращаемые столбцы. Это может быть использовано, например, чтобы показать, что FDW1 пропустил некоторые столбцы, которые он заметил, не будут нужны для запроса. Кроме того, если FDW1 может вычислять выражения, используемые запросом, дешевле, чем это можно сделать локально, он может добавить эти выражения в fdw_scan_tlist. Обратите внимание, что планы объединения (созданные из путей, сделанных GetForeignJoinPaths) должны всегда поставлять fdw_scan_tlist чтобы описать набор столбцов, которые они вернут.
FDW1 всегда должен создавать по крайней мере один путь, который зависит только от предложений ограничения таблицы. В запросах join он также может создавать пути, которые зависят от предложений join, например foreign_variable = локальная переменная. Такие пункты не будут найдены в baserel - >baserestrictinfo но нужно искать в списках присоединения к отношениям. Путь, использующий такое предложение, называется "параметризованным путем". Он должен идентифицировать другие отношения, используемые в выбранном предложении соединения с подходящим значением param_info; использовать get_baserel_parampathinfo чтобы вычислить это значение. В GetForeignPlan, этот локальная переменная часть предложения соединения будет добавлена к fdw_exprs, и тогда во время выполнения дело работает так же, как и для обычного предложения об ограничении.
Если FDW1 поддерживает удаленные соединения, GetForeignJoinPaths должен производить ForeignPaths для потенциальных удаленных соединений во многом таким же образом, как GetForeignPaths работает для базовых таблиц. Информацию о предполагаемом присоединении можно передать вперед GetForeignPlan точно так же, как описано выше. Однако, baserestrictinfo не относится к отношениям соединения; вместо этого соответствующие условия соединения для конкретного соединения передаются в GetForeignJoinPaths как отдельный параметр (extra - >restrictlist).
FDW1 может дополнительно поддерживать прямое выполнение некоторых действий плана, которые находятся выше уровня сканирования и объединения, таких как группирование или агрегирование. Чтобы предложить такие варианты, FDW1 должен генерировать пути и вставлять их в соответствующее верхнее отношение. Например, путь, представляющий удаленную агрегацию, должен быть вставлен в поле UPPERREL_GROUP_AGG связь, используя add_path. Этот путь будет сравниваться по стоимости с локальным агрегированием, выполненным путем считывания простого пути сканирования для внешней связи (обратите внимание, что такой путь также должен быть указан, иначе будет ошибка во время планирования). Если путь удаленной агрегации выигрывает, что обычно и происходит, то он будет преобразован в план обычным способом, путем вызова GetForeignPlan. Рекомендуемое место для создания таких путей находится в GetForeignUpperPaths функция обратного вызова, которая вызывается для каждого верхнего отношения (т. е. для каждого шага обработки после сканирования/соединения), если все базовые отношения запроса исходят из одного и того же FDW1.
PlanForeignModify и другие обратные вызовы, описанные в разделе Процедуры FDW для обновления сторонних таблиц, разработаны вокруг предположения, что внешнее отношение будет сканироваться обычным способом, а затем отдельные обновления строк будут управляться локальным ModifyTable план узла. Этот подход необходим для общего случая, когда обновление требует чтения локальных таблиц, а также внешних таблиц. Тем не менее, если операция может быть выполнена полностью внешним сервером, FDW1 может создать путь, представляющий это, и вставить его в поле UPPERREL_FINAL верхнее отношение, где он будет конкурировать с ModifyTable подход. Этот подход также может быть использован для реализации удаленного доступа SELECT FOR UPDATE, а не использовать обратные вызовы блокировки строк, описанные в разделе FDW-процедуры для блокировки строк. Имейте в виду, что путь вставляется в UPPERREL_FINAL отвечает за реализацию всего поведения запроса.
При планировании UPDATE или DELETE, PlanForeignModify и PlanDirectModify может искать RelOptInfo структуру для внешней таблицы и использовать baserel - >fdw_private данные, ранее созданные функциями планирования сканирования. Однако в INSERT целевая таблица не сканируется, поэтому ее нет RelOptInfo для него. То List возвращаемый PlanForeignModify имеет те же ограничения, что и fdw_private список a ForeignScan узел плана, то есть он должен содержать только структуры, которые copyObject умеет копировать.
INSERT с ON CONFLICT предложением не поддерживает указание целевого объекта конфликта, поскольку уникальные ограничения или ограничения исключения для удаленных таблиц не известны локально. Это в свою очередь подразумевает, что ON CONFLICT DO UPDATE не поддерживается, так как спецификация там обязательна.
Блокировка строк в обёртках сторонних данных
Если базовый механизм хранения FDW1 имеет концепцию блокировки отдельных строк для предотвращения одновременного обновления этих строк, обычно целесообразно, чтобы FDW1 выполнял блокировку на уровне строк с максимально близким приближением к семантике, используемой в обычных таблицах QHB. Есть несколько соображений, связанных с этим.
Одним из ключевых решений, которые необходимо принять, является ли выполнять раннюю блокировку (early locking) или позднюю блокировку (late locking). В ранней блокировке строка блокируется, когда она впервые извлекается из базового хранилища, в то время как в поздней блокировке строка блокируется только тогда, когда известно, что она должна быть заблокирована. (Разница возникает потому, что некоторые строки могут быть отброшены локально проверенным ограничением или условиями соединения). Ранняя блокировка намного проще и позволяет избежать дополнительных обходов в удаленный магазин, но она может привести к блокировке строк, которые не должны были быть заблокированы, что приводит к снижению параллелизма или даже неожиданным тупикам. Кроме того, поздняя блокировка возможна только в том случае, если строка, подлежащая блокировке, может быть однозначно повторно идентифицирована позже. Предпочтительно идентификатор строки должен идентифицировать конкретную версию строки, как это делают TIDs QHB.
По умолчанию QHB игнорирует соображения блокировки при взаимодействии с FDW1, но FDW1 может выполнять раннюю блокировку без какой-либо явной поддержки со стороны основного кода. Функции API, описанные в разделе FDW-процедуры для блокировки строк, позволяют FDW1 использовать позднюю блокировку, если она пожелает.
Дополнительным соображением является то, что в READ COMMITTED режим изоляции, QHB, возможно, потребуется повторно проверить ограничение и условия соединения с обновленной версией некоторого целевого кортежа. Повторная проверка условий соединения требует повторного получения копий нецелевых строк, которые ранее были присоединены к целевому кортежу. При работе со стандартными таблицами QHB это делается путем включения tid нецелевых таблиц в список столбцов, проецируемых через соединение, а затем повторной выборки нецелевых строк, когда это требуется. Этот подход сохраняет компактность набора данных соединения, но требует недорогой возможности повторного извлечения, а также TID, который может однозначно определить версию строки, подлежащую повторному извлечению. Поэтому по умолчанию метод, используемый с внешними таблицами, заключается в том, чтобы включить копию всей строки, извлеченной из внешней таблицы, в список столбцов, проецируемых через соединение. Это не ставит никаких особых требований к FDW1, но может привести к снижению производительности слияния и хэш-соединений. FDW1, способный удовлетворять требованиям повторной выборки, может выбрать для этого первый способ.
Для UPDATE или DELETE на внешней таблице рекомендуется, чтобы ForeignScan операция над целевой таблицей выполняет раннюю блокировку строк, которые она извлекает, возможно, через эквивалент SELECT FOR UPDATE. FDW1 может определить, является ли таблица целью UPDATE/DELETE во время плана, сравнивая ее relid с root- > parse - >>resultRelation, или во время выполнения с помощью ExecRelationIsTargetRelation(). Альтернативной возможностью является выполнение поздней блокировки в пределах ExecForeignUpdate или ExecForeignDelete обратный вызов, но никакой специальной поддержки для этого не предусмотрено.
Для внешних таблиц, которые должны быть заблокированы с помощью команды SELECT FOR UPDATE/SHARE, ForeignScan операция может снова выполнить раннюю блокировку путем выборки кортежей с эквивалентом SELECT FOR UPDATE/SHARE. Для выполнения поздней блокировки вместо этого, предоставьте функции обратного вызова, определенные в разделе FDW-процедуры для блокировки строк. В GetForeignRowMarkType, выберите параметр rowmark ROW_MARK_EXCLUSIVE, ROW_MARK_NOKEYEXCLUSIVE, ROW_MARK_SHARE, или ROW_MARK_KEYSHARE в зависимости от требуемого режима блокировки. (Основной код будет действовать одинаково независимо от того, какой из этих четырех вариантов вы выберете). В других местах вы можете определить, была ли внешняя таблица заблокирована этим типом команды с помощью get_plan_rowmark в запланированное время, или ExecFindRowMark во время выполнения; вы должны проверить не только то, возвращается ли ненулевая структура rowmark, но и то, что нет ее strength поля LCS_NONE.
Наконец, для внешних таблиц, которые используются в команде UPDATE, DELETE или SELECT FOR UPDATE/SHARE, но не заданы для блокировки строк, можно переопределить выбор по умолчанию для копирования целых строк, имея GetForeignRowMarkType выбранный вариант ROW_MARK_REFERENCE когда он видит режима блокировки LCS_NONE. Это приведет к тому, что RefetchForeignRow быть вызванным с этим значением для markType; затем он должен повторно получить строку, не приобретая никакого нового замка. (Если у вас есть a GetForeignRowMarkType функция, но не хотите, чтобы повторно получить разблокированные строки, выберите опцию ROW_MARK_COPY для LCS_NONE).
Смотрите src/include/nodes/lockoptions.h, комментарии для RowMarkType и PlanRowMark в src/include/nodes/plannodes.h, и комментарии для ExecRowMark в src/include/nodes/execnodes.h для дополнительной информации.
Foreign Data Wrapper, обёртка сторонних данных
Инструмент резервного копирования qbackup
Синтаксис
qbackup version
qbackup help [команда]
qbackup list -B каталог_копий [параметр...]
qbackup backup -B каталог_копий -D каталог_данных [--incremental]
[--compress] [параметр...]
qbackup restore -B каталог_копий -D каталог_данных
-i идентификатор_копии [параметр...]
qbackup remove -B каталог_копий -i идентификатор_копии
[--single] [параметр...]
qbackup backup-wal -B каталог_копий -D каталог_данных -p путь_файла_wal
-f имя_файла_wal [параметр...]
Описание
qbackup — инструмент для управления резервным копированием и восстановлением кластеров баз данных QHB.
Обзор
По сравнению с другими средствами резервного копирования qbackup имеет следующие преимущества, полезные
для реализации различных стратегий резервного копирования и работы с базами данных большого объёма:
Для управления резервными копиями qbackup создаёт каталог резервных копий. В этом каталоге сохраняются все
файлы резервных копий с дополнительной метаинформацией, а также архивы WAL, необходимые для восстановления
на момент времени.
Используя qbackup, вы можете выполнять полное или инкрементальное резервное копирование:
qbackup может производить копирование как работающего, так и остановленного экземпляра. Для копирования WAL
используются внутренние механизмы QHB (archive_command).
Ограничения
В настоящее время qbackup версии 1.3.0 имеет следующие ограничения:
Установка и подготовка
Установив qbackup, выполните следующие действия:
Создание каталога копий
qbackup хранит резервные копии в каталоге копий, путь к которому указывается в переменной среды BACKUPS_DIR
или в аргументе командной строки -B (--backups-dir). Каталог копий должен быть создан пользователем
перед началом работы с утилитой и не должен содержать никаких файлов. Ручное редактирование файлов в каталоге
копий не допускается.
Пользователь, запускающий qbackup, должен иметь полный доступ к каталогу_копий и как минимум доступ
на чтение всего содержимого каталога_данных.
Настройка кластера баз данных
Хотя qbackup можно использовать от имени суперпользователя, рекомендуется создать отдельную роль
с минимальными правами, необходимыми для выбранной стратегии копирования. В этих инструкциях по настройке
такой ролью служит роль backup.
Для выполнения резервного копирования роль backup должна иметь следующие разрешения
на сервере QHB (только в базе данных, к которой производится подключение):
BEGIN;
CREATE ROLE backup WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO backup;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO backup;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO backup;
COMMIT;
В файле qhb_hba.conf разрешите подключение к кластеру баз данных пользователю с именем backup.
Программа qbackup должна читать непосредственно файлы кластера, поэтому запускать qbackup
(или подключаться к нему удалённо) нужно от имени пользователя ОС, который имеет доступ на чтение всех
файлов и каталогов внутри каталога данных кластера (PGDATA), подлежащего копированию.
Модифицируйте файл конфигурации qhb.conf:
Установка archive_command необходима для резервного копирования работающего кластера.
Для копирования остановленного кластера устанавливать этот параметр не требуется.
Пример минимально возможной конфигурации для копирования работающего кластера:
# qhb.conf
wal_level = 'replica'
archive_mode = 'on'
archive_command = '/usr/bin/qbackup backup-wal -B /opt/backup_dir -f %f -p %p'
Использование
Создание резервной копии
Для создания резервной копии выполните следующую команду:
qbackup backup -B каталог_копий -D каталог_данных [--compress] [--incremental]
[параметры подключения...] [параметр...]
qbackup поддерживает два основных режима создания резервных копий:
При восстановлении кластера из инкрементальной копии qbackup использует родительскую полную копию и все инкрементальные копии между ними, которые в совокупности образуют «цепочку копий». Таким образом, прежде чем делать инкрементальные копии, необходимо сделать как минимум одну полную.
Флаг --compress значительно уменьшает размер резервной копии, но может привести к замедлению процесса копирования.
Восстановление кластера
Чтобы восстановить кластер баз данных из резервной копии, выполните команду restore:
qbackup restore -B каталог_копий -D каталог_данных
-i идентификатор_копии [параметры...]
Здесь:
После окончания работы команды restore запустите службу базы данных, используя qhb_ctl.
Выполнение восстановления на момент времени (PITR)
Вы можете восстановить состояние кластера на любой момент времени (до заданной точки восстановления),
используя с командой restore параметры точки восстановления.
Параметры --action, --timeline и --inclusive могут указываться в дополнение к параметрам,
устанавливающим точку восстановления.
Обратитесь к соответствующим пунктам документации за подробностями.
Запуск qbackup в параллельных потоках
Команды backup и restore могут выполняться в несколько параллельных потоков. Это может существенно
ускорять работу qbackup при наличии достаточных ресурсов (ядер процессора, производительности
дисковой подсистемы и сети).
Параллельным выполнением управляет ключ командной строки -j/--threads. Например, чтобы запустить
резервное копирование в четыре параллельных потока, выполните:
qbackup backup -B каталог_копий -D каталог_данных [--compress] [--incremental] -j 4
По умолчанию, или если заданное число потоков равно 0, qbackup автоматически выбирает число потоков,
которое обеспечит максимальную производительность копирования (в ущерб другим операциям).
Управление каталогом резервных копий
С помощью qbackup вы можете управлять резервными копиями в командной строке:
Просмотр информации о резервных копиях
Чтобы просмотреть список существующих копий для каждого экземпляра, выполните команду:
qbackup list -B каталог_копий
qbackup выводит список всех имеющихся резервных копий. Например:
+--------+--------+---------+-----------------+-------------+-------------+-----------+--------+---------------------+---------------------+
| ID | status | size | compressed size | kind | is archived | start lsn | parent | start time | end time |
+--------+--------+---------+-----------------+-------------+-------------+-----------+--------+---------------------+---------------------+
| QH05YZ | Done | 30.02MB | 4.54MB | Full | true | — | — | 2020-09-21 09:49:47 | 2020-09-21 09:49:48 |
+--------+--------+---------+-----------------+-------------+-------------+-----------+--------+---------------------+---------------------+
| QH05ZK | Done | 68.64KB | — | Incremental | false | — | QH05YZ | 2020-09-21 09:50:08 | 2020-09-21 09:50:11 |
+--------+--------+---------+-----------------+-------------+-------------+-----------+--------+---------------------+---------------------+
Для каждой копии выдаются следующие сведения:
Вы также можете получить подробную информацию о резервных копиях в формате JSON:
qbackup list -B каталог_копий --json
Пример вывода:
[
{
"identifier": "QH05YZ",
"status": "Ok",
"size": 31478420,
"compressed_size": 4764910,
"compressed": true,
"kind": "Full",
"start_lsn": null,
"start_time": "2020-09-21T09:49:47.333017715Z",
"end_time": "2020-09-21T09:49:48.475500730Z",
"parent": null
},
{
"identifier": "QH05ZK",
"status": "Ok",
"size": 70292,
"compressed_size": null,
"compressed": false,
"kind": "Incremental",
"start_lsn": null,
"start_time": "2020-09-21T09:50:08.233053635Z",
"end_time": "2020-09-21T09:50:11.105948603Z",
"parent": "QH05YZ"
}
]
Удаление резервных копий
Для удаления резервной копии, ставшей ненужной, выполните команду:
qbackup remove -B каталог_копий -i идентификатор_копии
Эта команда удалит резервную копию с заданным идентификатор_копии вместе со всеми инкрементальными копиями,
которые от неё зависят (если таковые найдутся). Таким образом вы можете удалить некоторые последние
инкрементальные копии из "цепочки копий".
Справка по командной строке
Команды
В этом подразделе описываются команды qbackup. Необязательные параметры этих команд
заключаются в квадратные скобки. В подробностях все параметры описываются в подразделе Параметры.
version
qbackup version
Выводит версию qbackup.
help
qbackup help [команда]
Выдаёт справку по командам qbackup. Если в параметрах задаётся одна из команд qbackup,
выводит подробную информацию по параметрам, которые принимает эта команда.
Аналогичную роль выполняет флаг --help, доступный для любой из команд.
list
qbackup list -B каталог_копий [--json] [--help]
Показывает содержимое каталога копий.
По умолчанию содержимое каталога представляется в виде обычного текста. Вы можете передать флаг --json,
чтобы получить результат в формате JSON.
Более подробно использование этой команды описывается в подразделе Управление каталогом резервных копий.
backup
qbackup backup -B каталог_копий -D каталог_данных
[--compress] [--incremental]
[--help] [-j число_потоков] [--progress]
Создаёт резервную копию экземпляра QHB.
За подробностями обратитесь к подразделу Создание резервной копии.
restore
qbackup restore -B каталог_копий -D каталог_данных -i идентификатор_копии
[--help]
[-j число_потоков] [--progress]
[параметры точки восстановления...]
Восстанавливает экземпляр QHB из резервной копии, расположенной в каталоге каталог_копий.
За подробностями обратитесь к подразделу Восстановление кластера.
remove
qbackup remove -B каталог_копий -i идентификатор_копии [--single]
[--help] [--progress]
Удаляет копию с заданным идентификатором (идентификатор_копии) и все инкрементальные копии,
которые от неё зависят. Удаляет только указанную копию, если передан флаг --single.
За подробностями обратитесь к подразделу Удаление резервных копий.
backup-wal
qbackup backup-wal -B каталог_копий --wal-file-name=имя_файла_wal --wal-file-path=путь_к_файлу_wal
[--help]
Копирует файлы WAL в соответствующий подкаталог каталога копий.
Команду backup-wal можно использовать в значении параметра archive_command QHB при
настройке непрерывного архивирования WAL.
Параметры
Общие параметры
Общие параметры поддерживаются большей частью команд qbackup.
-j --threads
Позволяет указать количество потоков для операций, которые поддерживают параллельное выполнение (backup и restore).
По умолчанию, если значение параметра не установлено или равно 0, используется оптимальное число потоков
для данной системы.
-P --progress
Выводит интерактивную информацию о процессе выполнения операции. Предназначено для отображения пользователям.
-v --verbose
Выводит более подробную информацию о процессе выполнения операции.
Параметры подключения
Для подключения к базе необходимо указать ряд параметров. Обязательными для успешного подключения являются только два из них: имя пользователя и имя хоста базы. Необходимость остальных параметров определяется настройками кластера.
Параметры подключения используются только для резервного копирования работающего кластера.
Используются только в команде backup. Необходимы для резервного копирования работающего кластера.
-u --user
Обязательный параметр.
Имя пользователя базы, от имени которого выполняется копирование.
Если переменная среды QBACKUP_USER установлена, используется её значение. Указанный параметр в командной
строке имеет приоритет над переменной среды.
-h --host
Обязательный параметр.
Указывает имя хоста компьютера, на котором работает сервер. Если значение начинается с косой черты, оно используется в качестве каталога для сокета домена Unix. Множественные имена хоста могут быть перечисленны через запятую. Каждое из имен будет опробовано последовательно.
Если переменная среды QBACKUP_HOST установлена, используется её значение. Указанный параметр в командной
строке имеет приоритет над переменной среды.
--db-name
Имя базы данных для подключения. По умолчанию равняется имени пользователя базы.
Если переменная среды QBACKUP_DBNAME установлена, используется её значение. Указанный параметр в командной
строке имеет приоритет над переменной среды.
-p --port
Порт для подключения к базе. Несколько портов могут быть перечислены через запятую.
Число указанных портов может быть равно 1, в этом случае один и тот же порт используется для всех хостов,
или же должно соответствовать указанному число хостов.
Значение по умолчанию равно 5432.
Если переменная среды QBACKUP_PORT установлена, используется её значение. Указанный параметр в командной
строке имеет приоритет над переменной среды.
--password
Пароль пользователя для подключения к базе.
Если переменная среды QBACKUP_PASSWORD установлена, используется её значение. Указанный параметр в командной
строке имеет приоритет над переменной среды.
Параметры точки восстановления
Для команды restore могут быть указаны дополнительные параметры, регулирующие восстановление
до определенной точки (PITR).
Используются только в команде restore.
--target-time=момент_времени
Восстановление до определенного момента времени в формате timestamp.
Значение этого параметра задаётся в том же формате, что принимается типом данных timestamp with time zone, за исключением того, что в нём нельзя использовать сокращённое название часового пояса. Поэтому рекомендуется задавать числовое смещение от UTC или записывать название часового пояса полностью, например Europe/Helsinki (но не EEST).
--target-xid = xid_транзакции
Восстановление на определенный идентификатор транзакции.
Имейте в виду, что числовое значение идентификатора отражает последовательность именно старта транзакций,
а фиксироваться они могут в ином порядке. Восстановлению будут подлежать все транзакции, что были
зафиксированы до указанной (и, возможно, включая её, в зависимости от значения параметра --inclusive).
--target-lsn = LSN
Восстановление на определенный LSN (Line Sequence Number). Этот параметр принимает значение системного типа данных pg_lsn.
--target-name = имя_точки_восстановления
Восстановление на определенную именованную точку восстановления, созданную с помощью pg_create_restore_point().
--immediate
Данный параметр указывает, что процесс восстановления должен завершиться, как только будет достигнуто целостное состояние, т. е. как можно раньше. При восстановлении из оперативной резервной копии, это будет точкой, в которой завершился процесс резервного копирования.
--action = [ pause | promote | shutdown ]
Указывает, какое действие должен предпринять сервер после достижения цели восстановления.
Вариант по умолчанию — pause, что означает приостановку восстановления. Второй вариант, promote,
означает, что процесс восстановления завершится, и сервер начнёт принимать подключения.
Наконец, с вариантом shutdown сервер остановится, как только цель восстановления будет достигнута.
Вариант pause позволяет выполнить запросы к базе данных и убедиться в том, что достигнутая
цель оказалась желаемой точкой восстановления. Для снятия с паузы нужно вызвать pg_wal_replay_resume(),
что в итоге приведёт к завершению восстановления. Если окажется, что мы ещё не достигли
желаемой точки восстановления, нужно остановить сервер, установить более позднюю цель
и перезапустить сервер для продолжения восстановления.
Вариант shutdown полезен для получения готового экземпляра сервера в желаемой точке.
При этом данный экземпляр сможет воспроизводить дополнительные записи WAL (а при перезапуске
ему придётся воспроизводить записи WAL после последней контрольной точки).
Заметьте, что так как recovery.signal не переименовывается, когда в --action выбран вариант shutdown,
при последующем запуске будет происходить немедленная остановка, пока вы не измените конфигурацию
или не удалите файл recovery.signal вручную.
Этот параметр не действует, если цель восстановления не установлена.
--timeline = [ current | latest | timeline_id ]
Указывает линию времени для восстановления. Значение может задаваться числовым идентификатором линии времени
или ключевым словом (timeline_id). С ключевым словом current восстанавливается та линия времени, которая была активной
при создании базовой резервной копии. С ключевым словом latest восстанавливаться будет последняя линия времени,
найденная в архиве, что полезно для ведомого сервера. По умолчанию подразумевается latest.
--inclusive = [ on | off ]
Прекратить восстановление в момент достижения заданной точки (on) или непосредственно перед её достижением (off).
По умолчанию on.
Версионирование
При разработке qbackup используется семантическое версионирование.
Часть III. Язык SQL
В этой части описывается использование языка SQL в QHB. Мы начнем с общего синтаксиса SQL, затем объясним, как создавать структуры для хранения данных, как наполнять базу данных и как выполнять к ней запросы. Далее перечислим существующие типы данных и функции, применяемые с командами SQL. И закончим рассмотрением нескольких важных для оптимальной производительности аспектов.
Главы, представленные в этой части упорядочены определенным образом, чтобы
даже новичок мог проработать информацию последовательно, от начала до конца.
При этом главы самодостаточны, так что опытные пользователи
могут читать их так, как им будет удобно.
Полное описание конкретных команд представлено в главе Команды SQL.
Читатели этой части должны знать, как подключиться к базе данных QHB и выполнять команды SQL. Если вы этого еще не знаете, то рекомендуется сначала прочитать первую и вторую часть. Команды SQL обычно вводятся с использованием интерактивного терминала QHB qsql, но также можно использовать и другие программы с аналогичной функциональностью.
Язык SQL. Общие сведения
Язык SQL. Введение
В этой главе рассматриваются простейшие команды SQL. Эта глава знакомит вас с SQL, но никоим образом не является полным справочным руководством. Вам следует учитывать, что некоторые возможности языка QHB являются расширениями стандарта.
В следующих примерах мы предполагаем, что вы создали базу данных mydb, как описано в разделе Начало работы, и смогли запустить qsql, как описано в разделе qsql.
Примеры в этом руководстве также можно найти в дистрибутиве исходного кода QHB в каталоге src/tutorial/. (Бинарные дистрибутивы QHB могут не компилировать эти файлы). Чтобы использовать эти файлы, перейдите в этот каталог и запустите make:
$ cd ..../src/tutorial
$ make
Эта команда создает сценарии и компилирует файлы C/RUST, содержащие пользовательские функции и типы. Затем, чтобы начать обучение, выполните следующее:
$ cd ..../tutorial
$ qsql -s mydb
...
mydb=> \i basics.sql
Команда \i считывает команды из указанного файла. Параметр qsql -s переводит \qsql в пошаговый режим, с задержкой перед отправкой каждого оператора на сервер. Команды, используемые в этом разделе, находятся в файле basics.sql.
Основные принципы
QHB — это реляционная система управления базами данных (РСУБД). Это означает, что это система управления данными, представленными в виде отношений. Отношение — это, по сути, двумерная таблица. Хранение данных в таблицах на сегодняшний день очень распространено, но вместе с тем существует ряд других способов организации баз данных. К примеру, файлы и каталоги в Unix-подобных операционных системах образуют иерархическую базу данных. Также существуют объектно-ориентированные базы данных.
Любая таблица представляет собой именованный набор строк. Все строки таблицы имеет одинаковый набор именованных столбцов, и каждый столбец имеет определенный тип данных. Несмотря на то что порядок столбцов фиксированный, важно помнить, что SQL никоим образом не гарантирует порядок строк в таблице (хотя им можно задать правила сортировки при выводе).
Таблицы объединены в базы данных, а набор баз данных, управляемых одним сервером QHB, составляет кластер баз данных.
Создание таблицы
Вы можете создать таблицу, указав имя таблицы и все именами столбцов, с указанием их типов:
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- low temperature
temp_hi int, -- high temperature
prcp real, -- precipitation
date date
);
Этот текст можно также ввести в в qsql вместе с переносами строк. qsql поймет, что команда продожается до точки с запятой.
В командах можно использовать пробельные символы (пробелы, табуляции и переводы строк). То есть вы можете ввести команду, выровняв её иначе, или даже уместив в одной строке. Два минуса («--») обозначают начало комментария. Все, что идёт за ними до конца строки игнорируется. SQL нечувствителен к регистру ключевых слов и идентификаторов, за исключением случаев, когда идентификаторы заключены в двойные кавычки.
Используемые типы данных:
QHB поддерживает стандартные типы SQL int, smallint, real, double precision, char(N), varchar(N), date, time, timestamp и interval, а также другие общие типы и богатый набор геометрических типов. QHB может быть расширен произвольными наборами пользовательских типов данных. Поэтому имена типов не являются ключевыми словами, кроме тех случаев, когда это требуется для поддержки особых случаев в стандарте SQL.
Во второй таблице будут храниться города и их географическое местоположение:
CREATE TABLE cities (
name varchar(80),
location point
);
Тип point - пример специфического типа данных QHB.
Наконец, следует упомянуть, что если вам больше не нужна таблица или вы хотите пересоздать ее по-другому, вы можете удалить ее с помощью следующей команды:
DROP TABLE tablename;
Ввод данных
Для добавления строк в таблицу используется команда INSERT:
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
Обратите внимание, что для всех типов данных используются довольно очевидные форматы. Константы, за исключением простых числовых значений, должны быть заключены в одинарные кавычки (’), аналогично примеру выше. Тип date самом деле очень гибкий и принимает разные форматы, но лучше придерживаться формата, показанного здесь.
Тип point требует ввода пары координат:
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
Используемый здесь синтаксис, требует, чтобы вы помнили порядок столбцов, однако можно использовать альтернативную запись, перечислив столбцы явно:
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
Также можно перечислить столбцы в другом порядке или даже пропустить некоторые столбцы, например, если осадки нам неизвестны:
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
Многие разработчики предпочитают перечислять столбцы явно, не полагаясь на их изначальный порядок в таблице.
Пожалуйста, введите все команды, представленные выше, чтобы у вас были данные, с которыми можно будет работать в последующих разделах.
Чтобы загрузить большой объем данных из текстовых файлов можно использовать команду COPY. Часто такая загрузка проходит быстрее, потому что команда COPY оптимизирована для этого применения, хотя и менее гибка, чем INSERT. Например, COPY можно применить так:
COPY weather FROM '/home/user/weather.txt';
Файл weather.txt должен быть доступен на компьютере, где выполняется
серверный процесс, а не на клиенте, т.к. файл будет прочитан непосредственно на сервере.
Запросы к таблице
Для выборки информации из таблиц баз данных используется оператор SQL SELECT. Общий вид оператора представлен ниже
[WITH запросы_with]
SELECT [DISTINCT] перечень_столбцов
FROM перечень_таблиц
[WHERE условия]
[GROUP BY список_группировки]
[HAVING условия_группировки]
[ORDER BY условия_сортировки]
Следующий запрос позволяет получить все строки таблицы weather:
SELECT * FROM weather;
Здесь символ * означает «все столбцы1». Этот же результат можно получить с помощью запроса:
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
Результат будет следующий:
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
San Francisco | 43 | 57 | 0 | 1994-11-29
Hayward | 37 | 54 | | 1994-11-29
(3 rows)
Можно вывести результат выражения, а не просто значение поля в столбце. Например, можно вывести среднюю температуру:
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
Результат:
city | temp_avg | date
---------------+----------+------------
San Francisco | 48 | 1994-11-27
San Francisco | 50 | 1994-11-29
Hayward | 45 | 1994-11-29
(3 rows)
Для переименования заголовков столбцов можно использовать не обязательное ключевое слово AS, как в примере выше.
Множество выбираемых строк можно ограничить с помощью ключевого слова WHERE. За предложением WHERE следует логическое выражение (условия поиска), и возвращаются только те строки, для которых логическое выражение имеет значение true. В предложении WHERE можно использовать обычные логические операторы (AND, OR и NOT).
Например, следующий запрос вернет температуру города Сан-Франциско в дождливые дни:
SELECT * FROM weather
WHERE city = 'San Francisco' AND prcp > 0.0;
Результат:
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
(1 row)
С помощью :
SELECT * FROM weather
ORDER BY city;
Результат:
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
Hayward | 37 | 54 | | 1994-11-29
San Francisco | 43 | 57 | 0 | 1994-11-29
San Francisco | 46 | 50 | 0.25 | 1994-11-27
В общем случае выводимые в результирующей таблице строки не упорядочены, однако их можно отсортировать используя преложение ORDER BY (не обязательный):
SELECT * FROM weather
ORDER BY city, temp_lo;
Получить уникальные строки из результирующего набора можно с помощью предложения DISTINCT:
SELECT DISTINCT city
FROM weather;
Результат:
city
---------------
Hayward
San Francisco
(2 rows)
Порядок вывода строк результирующей таблицы может отличаться. Вы можете задать правильную сортировку, используя DISTINCT и ORDER BY вместе2:
SELECT DISTINCT city
FROM weather
ORDER BY city;
Хотя SELECT * полезен общих запросов, в рабочем коде это плохая практика, поскольку добавление столбца в таблицу приведет к изменению результатов.
В некоторых базах данных, предложение DISTINCT автоматически упорядочивает строки, поэтому ORDER BY не требуется. Но это не требуется стандартом SQL, и QHB не гарантирует, что DISTINCT отсортирует выводимые строки.
Соединения таблиц
До сих пор мы строили запросы только к одной таблице. Но запросы могут обращаться сразу к нескольким таблицам или к одной и той же таблице так, что одновременно будут обрабатываться разные наборы её строк. Запрос, который обращается к нескольким строкам одной или разных таблиц одновременно, называется соединением (JOIN).
Например, вы хотите увидеть параметры погоды вместе с местонахождением соответствующего города. Для этого нужно сравнить столбец city каждой строки таблицы weather со столбцом name всех строк таблицы cities и выбрать строки, в которых эти значения совпадают.
SELECT *
FROM weather, cities
WHERE city = name;
Результат:
city | temp_lo | temp_hi | prcp | date | name | location
--------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
San Francisco | 43 | 57 | 0 | 1994-11-29 | San Francisco | (-194,53)
(2 rows)
Обратите внимание на две вещи в результирующей выборке:
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
Результат:
city | temp_lo | temp_hi | prcp | date | location
--------------+---------+---------+------+------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | (-194,53)
San Francisco | 43 | 57 | 0 | 1994-11-29 | (-194,53)
(2 rows)
Т.к. у всех столбцов имена различаются, парсер автоматически обнаружил, к какой таблице они принадлежат. Если в двух таблицах имена столбцов повторяются, то необходимо явно указать какой столбец имеется в виду, например:
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
Считается хорошим стилем специфицировать именя столбцов в запросе с соединениями, чтобы запрос не завершился ошибкой, если позднее в одну из таблиц будет добавлено имя столбца, совпадающее с уже существующим в другой таблице.
Предыдущий запрос также может быть записан в следующем виде:
SELECT *
FROM weather INNER JOIN cities ON (weather.city = cities.name);
Теперь мы выясним, как получить в результирующем наборе город Хейвард. Мы хотим, чтобы запрос для каждой строки таблицы weather находил соответствующие строки cities. Если подходящей строки не найдено, мы хотим, чтобы вместо столбцов таблицы cities были выведены некоторые «пустые значения». Этот вид запроса называется внешним соединением.
Запрос выглядит так:
SELECT *
FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name);
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
Hayward | 37 | 54 | | 1994-11-29 | |
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
San Francisco | 43 | 57 | 0 | 1994-11-29 | San Francisco | (-194,53)
(3 rows)
Этот запрос называется левым внешним соединением, поскольку в результирующий набор попадут все строки таблицы, указанной слева от оператора JOIN, и только те строки таблицы указанной справа, которые соответствуют условию указанному в предложении ON. Для записей левой таблицы, которые не соответствуют условию, значение столбца из правой таблицы будет пустыми (NULL).
Также можно соединить таблицу саму с собой. Это называется самосоединением. К примеру, если мы хотим найти все записи о погоде, которые находятся в диапазоне температур других записей о погоде. Поэтому нам нужно сравнить temp_lo temp_hi каждой строки weather с temp_lo и temp_hi всех других строк weather.
Мы можем сделать это с помощью следующего запроса:
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
city | low | high | city | low | high
---------------+-----+------+---------------+-----+------
San Francisco | 43 | 57 | San Francisco | 46 | 50
Hayward | 37 | 54 | San Francisco | 46 | 50
(2 rows)
Здесь мы переименовали таблицу погоды на W1 и W2 чтобы можно было различить левую и правую стороны соединения. Подобные псевдонимы можно использовать в любых запросах, чтобы сохранить некоторую типизацию, например:
SELECT *
FROM weather w, cities c
WHERE w.city = c.name;
Этот стиль сокращения встречается довольно часто.
Агрегатные функции
Как и большинство других реляционных баз данных, QHB поддерживает агрегатные функции. Агрегатная функция вычисляет единственное результирующее значение из множества входных строк. Например, есть агрегаты для вычисления количества (COUNT), суммы (SUM), среднего (AVG), максимального (MAX) и минимального (MIN) набора строк.
Например, мы можем найти максимум температуры из всех низких температур (столбец temp_lo):
SELECT max(temp_lo) FROM weather;
max
-----
46
(1 row)
Если мы хотим узнать, в каком городе (или городах) было это значение температуры, мы можем попробовать ввести следующий код:
SELECT city FROM weather WHERE temp_lo = max(temp_lo); -- WRONG
Этот запрос не будет работать, так как функция MAX не может использоваться в WHERE. (Это ограничение объясняется тем, что WHERE определяет, какие строки будут рассчитаны с помощью агрегатной функции, так что оно должно вычисляться до агрегатных функций). Однако, можно переписать запрос с помощью подзапроса:
SELECT city FROM weather
WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
city
---------------
San Francisco
(1 row)
Теперь все работает, т.к. подзапрос с агрегатной функцией выполняется отдельно от внешнего запроса.
Агрегатные функции также очень полезны в сочетании с предложением GROUP BY. Например, мы можем получить максимум низкой температуры, для каждого города:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city;
city | max
--------------+-----
Hayward | 37
San Francisco | 46
(2 rows)
В итоге мы получаем одну результирующую строку для каждого города. Каждый сагрегированный результат вычисляется по строкам таблицы, соответствующим этому городу. Теперь можно отфильтровать эти строки, используя HAVING:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
city | max
---------+-----
Hayward | 37
(1 row)
получив те же результаты только для тех городов, у которых значения temp_lo ниже 40.
Наконец, если нам нужны только города, названия которых начинаются с «S», можно написать:
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' (1)
GROUP BY city
HAVING max(temp_lo) < 40;
city | max
------+-----
(0 rows)
(1): Синтаксис оператора LIKE (выполняющий сравнение по шаблону) рассматривается в разделе Функции и операторы.
Важно понимать взаимодействие между агрегатными функциями и предложениями WHERE и HAVING. Принципиальное различие между WHERE и HAVING заключается в том, что WHERE сначала выбирает строки, а потом их группирует и вычисляет агрегатные функции (таким образом, оно фильтрует строки для вычисления агрегатов), тогда как HAVING выбирает группы строк, после вычисления группировки и вычисления агрегатных функций. Поэтому, WHERE не должно содержать агрегатных функций - нет смысла использовать агрегатную функцию, для определения входных строки для агрегатов. Предложение же HAVING всегда содержит агрегатные функции. (Строго говоря, вы можете написать HAVING, в котором нет агрегатных функций, но вряд ли этотбудет полезно. То же самое условие скорее всего будет работать более эффективно на стадии WHERE).
В предыдущем примере мы применили фильтр по имени города в WHERE, так как это не агрегатная функция. Это правильней, чем добавлять условие к HAVING, т.к. в этом случае не требуется выполнять группировки и вычислять агрегаты для строк, не удовлетворяющих условию WHERE.
Изменение строк
Вы можете модифицировать строки таблицы с помощью команды UPDATE. Предположим, вы обнаружили, что показания температуры завышены на 2 градуса после 28 ноября. Вы можете исправить данные следующим образом:
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
Теперь запрос вернёт обновленные данные:
SELECT * FROM weather;
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
San Francisco | 41 | 55 | 0 | 1994-11-29
Hayward | 35 | 52 | | 1994-11-29
(3 rows)
Удаление строк
Строки можно удалить из таблицы с помощью оператора DELETE. Предположим, вас больше не интересует погода в Хейварде. Вы можете удалить эти строки из таблицы:
DELETE FROM weather WHERE city = 'Hayward';
Все записи наблюдений для города Хейворд, удалены.
SELECT * FROM weather;
city | temp_lo | temp_hi | prcp | date
--------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
San Francisco | 41 | 55 | 0 | 1994-11-29
(2 rows)
Остерегайтесь использования оператора DELETE без предложения WHERE
DELETE FROM tablename;
Без дополнительных условий, DELETE удалит все строки таблицы. Дополнительного подтверждения при этом выдаваться не будет!
Расширенные функции
Расширенные функции. Вступление
В главе Язык SQL. Общие сведения рассмотрены основы использования SQL для хранения и доступа к данным в QHB. Теперь мы обсудим некоторые более продвинутые функции SQL, которые упрощают управление и предотвращают потерю или повреждение ваших данных. Также, мы рассмотрим некоторые расширения QHB.
В этой главе иногда приводятся ссылки на примеры, из главы Язык SQL. Общие сведения, для их изменения или улучшения, поэтому будет полезно прочитать эту главу. Некоторые примеры из этой главы также можно найти в приложении Расширенный SQL. Это приложение также содержит некоторые примеры данных и таблицы, которые повторно в этой главе не описываются.
Представления (VIEW)
В разделе Соединения таблиц мы рассматривали запросы из нескольких таблиц. Предположим, что комбинированный список записей о погоде и местоположения города представляет особый интерес для вашего приложения, но вы не хотите использовать весь запрос каждый раз, когда он вам нужен. Вы можете создать представление запроса (VIEW), которое создаёт уникальное имя для запроса, и теперь вы можете обращаться к этому имени, как к обычной таблице:
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
Использование представлений (VIEW) является ключевым аспектом хорошего дизайна базы данных. Представления позволяют инкапсулировать детали структуры таблиц, которые могут меняться по мере развития приложения, за согласованными интерфейсами.
Представления могут использоваться практически в любом месте, где можно использовать реальную таблицу. Также можно создавать представления из других представлений.
Внешние ключи
Вспомните таблицы weather и cities из главы Язык SQL. Рассмотрим следующую проблему: Вы хотите убедиться, что никто не сможет вставить в таблицу погоды (weather) строки, у которых нет соответствующей записи в таблице городов (cities). Это ограничение называется поддержанием ссылочной целостности данных. В упрощенных системах баз данных это будет реализовано (если вообще будет реализовано) путем просмотра таблицы городов (cities) перед вставкой, чтобы проверить, существует ли соответствующая запись, а затем будут вставлены или отклонены новые записи о погоде. Этот подход имеет ряд проблем и очень неудобен, поэтому QHB может сделать это за вас.
Новое объявление таблиц будет выглядеть так:
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
Теперь попробуйте вставить неверную запись:
INSERT INTO weather VALUES ('Berkeley', 45, 53, 0.0, '1994-11-28');
ERROR: insert or update on table "weather" violates foreign key constraint "weather_city_fkey"
DETAIL: Key (city)=(Berkeley) is not present in table "cities".
Поведение внешних ключей может быть настроено для вашего приложения, см. дополнительную информацию в главе Определение данных. Правильное использование внешних ключей улучшит качество ваших приложений баз данных, поэтому вам настоятельно рекомендуется узнать о них.
Транзакции
Транзакции являются фундаментальной концепцией любых систем баз данных. Важным моментом транзакции является то, что она объединяет несколько последовательных операций в одну операцию «все или ничего». Промежуточные состояния между операциями не видны другим параллельным транзакциям, и если происходит какой-либо сбой, препятствующий завершению транзакции, то ни одна из операций никак не влияет на базу данных.
Например, рассмотрим банковскую базу данных, которая содержит остатки по различным счетам клиентов, а также общие остатки по депозитам для филиалов. Предположим, что мы хотим записать платеж в размере 100 долларов со счета Алисы на счет Боба. Сильно упрощая, SQL-команды для этого могут выглядеть так:
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
UPDATE branches SET balance = balance - 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Alice');
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
UPDATE branches SET balance = balance + 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Bob');
Детали этих команд здесь не важны; важно отметить, что для выполнения этой довольно простой операции требуется несколько отдельных обновлений. Сотрудники банка хотят быть уверены, что либо все эти обновления произойдут, либо ни одно из них не произойдет. Конечно, не годится, чтобы системный сбой привел к тому, что Боб получит 100 долларов, которые не были списаны со счёта Алисы. Также Алиса не останется счастливым клиентом, если у нее со счёта будет списана сумма без зачисления Бобу. Нам нужна гарантия того, что если во время операции что-то пойдет не так, то ни одна из выполненных до сих пор операций не вступит в силу. Группировка обновлений в транзакцию дает нам эту гарантию. Транзакция называется атомарной: с точки зрения других транзакций она либо происходит полностью, либо вообще не происходит.
Мы также хотим гарантировать, что после того, как транзакция будет завершена и подтверждена системой базы данных, она действительно будет записана в долговременное хранилище и не будет потеряна, даже если вскоре после этого произойдет сбой системы. Например, если мы записываем снятие наличных Бобом, мы не хотим иметь никаких шансов на то, что дебет его счета исчезнет в результате аварии сразу после того, как он выйдет из двери банка. Транзакционная база данных гарантирует, что все обновления, сделанные транзакцией, будут зарегистрированы в постоянном хранилище (то есть, на диске) до того, как будет сообщено о завершении транзакции.
Еще одно важное свойство транзакционных баз данных тесно связано с понятием атомарных обновлений: когда одновременно выполняется несколько транзакций, каждая из них не должна видеть неполные изменения, внесенные другими. Например, если одна транзакция занята суммированием всех остатков в филиалах, не годится, чтобы она включала дебет из филиала Алисы, но не включила кредит из филиала Боба, и наоборот. Таким образом, транзакции должны выполнять «все или ничего» не только с точки зрения их постоянного воздействия на базу данных, но также с точки зрения видимости во время их исполнения. Обновления, сделанные открытой транзакцией, невидимы для других транзакций, до тех пор, пока транзакция не завершится, после чего все обновления станут видимыми одновременно.
В QHB транзакция устанавливается путем окружения команд SQL транзакции командами BEGIN и COMMIT. Таким образом, наша банковская транзакция будет выглядеть так:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
-- etc etc
COMMIT;
Если в ходе транзакции мы решили, что не хотим фиксировать (возможно, мы только что заметили, что баланс Алисы стал отрицательным), мы можем выполнить команду ROLLBACK вместо COMMIT, и все наши обновления будут отменены.
QHB фактически обрабатывает каждый оператор SQL как выполняемый в транзакции. Если вы не выполните команду BEGIN, то каждый отдельный оператор имеет неявный BEGIN и (в случае успеха) COMMIT обернутый вокруг него. Группу операторов, окруженную BEGIN и COMMIT, иногда называют блоком транзакции.
Заметка
Некоторые клиентские библиотеки выдают команды BEGIN и COMMIT автоматически, так что вы можете получить эффект блоков транзакций без запроса. Проверьте документацию для прикладного интерфейса, который вы используете.
Можно управлять транзакциями более детально, используя точки сохранения. Точки сохранения позволяют вам выборочно отбрасывать части транзакции, в то же время фиксируя остальные. После определения точки сохранения с помощью SAVEPOINT вы можете при необходимости откатиться до точки сохранения с помощью ROLLBACK TO. Все изменения базы данных транзакции между определением точки сохранения и откатом к ней отбрасываются, но изменения, сохраненные раньше, чем точка сохранения, сохраняются.
После отката к точке сохранения она продолжает оставаться определённой, поэтому вы можете откатиться к ней несколько раз. И наоборот, если вы уверены, что вам не нужно будет снова возвращаться к определенной точке сохранения, она может быть освобождена, для того что бы освободить некоторые ресурсы системы. Имейте в виду, что освобождение или откат к точке сохранения автоматически сбросит все точки сохранения, которые были определены после нее.
Все это происходит внутри блока транзакции, поэтому ни одно из тзменений не видно другим сеансам базы данных. Когда и если вы фиксируете блок транзакции, зафиксированные действия становятся видимыми как единое целое для других сеансов, тогда как отмененные действия никогда не становятся видимыми вообще.
Вспоминая банковскую базу данных, предположим, что мы списываем 100,00 долларов со счета Алисы и зачисляем на счет Боба, чтобы потом выяснить, что мы должны были зачислить счет Уолли. Мы могли бы сделать это, используя точки сохранения, например:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
Этот пример, конечно, упрощен, но в блоке транзакций возможен больший контроль с помощью точек сохранения. Более того, ROLLBACK TO — это единственный способ восстановить контроль над блоком транзакции, который был переведен системой в прерванное состояние из-за ошибки, если не считать полного отката и повторного запуска.
Руководство по оконным функциям
Оконная функция выполняет различные вычисление для набора строк таблицы, которые так или иначе связаны с текущей строкой. Это сопоставимо с таким расчетом, который можно выполнить с помощью агрегатной функции. Однако оконные функции не приводят к тому, что строки группируются в одну выходную строку, как это сделали бы обычные,неоконные агрегатные вызовы. Вместо этого строки сохраняют свои отдельные идентичности. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса.
Вот пример, который показывает, как сравнить зарплату каждого сотрудника со средней зарплатой в его или ее отделе:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)
Первые три выходных столбца взяты непосредственно из таблицы empsalary, и для каждой строки в таблице есть одна выходная строка. Четвертый столбец представляет среднее значение по всем строкам таблицы, которые имеют то же значение depname что и текущая строка. (На самом деле это та же функция, что и обычный агрегат avg, но предложение OVER приводит к тому, что она обрабатывается как оконная функция и вычисляет результат в рамках тех значений, что выделены для расчета в окне).
Вызов оконной функции всегда содержит предложение OVER непосредственно после имени и аргумента(ов) оконной функции. Это то, что синтаксически отличает её от обычной функции или обычного агрегата. Предложение OVER точно определяет, как строки запроса разделяются для обработки оконной функцией. Предложение PARTITION BY в OVER делит строки на группы или разделы, которые имеют одинаковые выражения значений PARTITION BY. Для каждой строки оконная функция вычисляется по строкам, которые попадают в тот же раздел, что и текущая строка.
Вы также можете контролировать порядок, в котором строки обрабатываются оконными функциями, используя ORDER BY в OVER. (Окно ORDER BY даже не должно соответствовать порядку, в котором выводятся строки). Вот пример:
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
depname | empno | salary | rank
-----------+-------+--------+------
develop | 8 | 6000 | 1
develop | 10 | 5200 | 2
develop | 11 | 5200 | 2
develop | 9 | 4500 | 4
develop | 7 | 4200 | 5
personnel | 2 | 3900 | 1
personnel | 5 | 3500 | 2
sales | 1 | 5000 | 1
sales | 4 | 4800 | 2
sales | 3 | 4800 | 2
(10 rows)
Как видно из результата, функция rank формирует числовой ранг текущей строки, в рамках заданных партиций, для каждого уникального значения параметра, используя порядок сортировки, определенный в предложении ORDER BY. Для rank не требуется явный параметр, поскольку его поведение полностью определяется предложением OVER.
Строки, рассматриваемые оконной функцией, являются строками «виртуальной таблицы», созданной предложением FROM запроса, отфильтрованным по его WHERE, GROUP BY и HAVING если таковые имеются. Например, строка, удаленная из резултата из-за несоответствия условию WHERE не видна ни одной оконной функции. Запрос может содержать несколько оконных функций, которые по-разному разбивают данные на части с использованием разных предложений OVER, но все они действуют на одну и ту же коллекцию строк, определенных этой виртуальной таблицей.
Мы уже видели, что ORDER BY можно опустить, если порядок строк не важен. Также возможно опустить PARTITION BY, и в этом случае будет один раздел, содержащий все строки.
Есть еще одна важная концепция, связанная с оконными функциями: для каждой строки в ее разделе есть набор строк, называемый кадром окна. Некоторые оконные функции действуют только на строки кадра окна, а не на весь раздел. По умолчанию, если задано ORDER BY, то кадр состоит из всех строк от начала раздела до текущей строки, а также любых последующих строк, которые равны текущей строке в соответствии с предложением ORDER BY. Если ORDER BY опущен, кадр по умолчанию состоит из всех строк в разделе1. Вот пример использования sum:
SELECT salary, sum(salary) OVER () FROM empsalary;
salary | sum
--------+-------
5200 | 47100
5000 | 47100
3500 | 47100
4800 | 47100
3900 | 47100
4200 | 47100
4500 | 47100
4800 | 47100
6000 | 47100
5200 | 47100
(10 rows)
Мы видим что, поскольку в предложении OVER нет ORDER BY, кадр окна совпадает с разделом, который в отсутствие PARTITION BY и представляет собой всю таблицу; другими словами, каждая сумма берется по всей таблице, и поэтому мы получаем одинаковый результат для каждой выходной строки. Но если мы добавим предложение ORDER BY, мы получим совсем другие результаты:
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum
--------+-------
3500 | 3500
3900 | 7400
4200 | 11600
4500 | 16100
4800 | 25700
4800 | 25700
5000 | 30700
5200 | 41100
5200 | 41100
6000 | 47100
(10 rows)
Здесь сумма берется с первого (самого низкого) оклада до текущего, включая любые дубликаты текущего (обратите внимание на результаты для дублированных окладов).
Оконные функции разрешены только в списке SELECT и предложении ORDER BY запроса. Они запрещены в других местах, например в предложениях GROUP BY, HAVING и WHERE. Это потому, что они логически выполняются после обработки этих предложений. Кроме того, оконные функции выполняются после обычных агрегатных функций. Это означает, что допустимо включать вызов агрегатной функции в аргументы оконной функции, но не наоборот.
Если есть необходимость отфильтровать или сгруппировать строки после выполнения расчетов в окне, вы можете использовать дополнительный выбор. Например:
SELECT depname, empno, salary, enroll_date
FROM
(SELECT depname, empno, salary, enroll_date,
rank() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos
FROM empsalary
) AS ss
WHERE pos < 3;
Приведенный выше запрос показывает только строки из внутреннего запроса, имеющие ранг менее 3.
Когда запрос включает несколько оконных функций, можно записать каждую из них с отдельным предложением OVER, но это является дублированием и приводит к ошибкам, если требуется одинаковое поведение окон для нескольких функций. Вместо этого каждый оконный блок может быть указан в предложении WINDOW, а затем использован в OVER. Например:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
Более подробную информацию об оконных функциях можно найти в раздел Вызовы оконных функций, раздел Оконные функции, раздел Обработка оконных функций и на странице справки SELECT.
Синтаксис SQL
В этой главе описывается синтаксис SQL. Он формирует основу для понимания следующих глав, в которых подробно рассматриваются способы применения команд SQL для определения и изменения данных.
Мы также советуем пользователям, которые уже знакомы с SQL, внимательно прочитать эту главу, поскольку она содержит несколько правил и концепций, которые непоследовательно реализованы в базах данных SQL или относятся к QHB.
Лексическая структура
Предложение на SQL состоит из последовательности команд. Команда состоит из последовательности токенов, оканчивающейся точкой с запятой («;»). Конец потока ввода также завершает команду. Какие токены являются действительными, зависит от синтаксиса конкретной команды.
Токен может быть ключевым словом, идентификатором, идентификатором в кавычках, литералом (или константой) или специальным символом. Токены разделяются символами-разделителями (пробел, табуляция, новая строка), но это необязательно, если нет двусмысленности (что обычно имеет место только в том случае, если специальный символ соседствует с каким-либо другим типом токена).
Например, следующее (синтаксически) допустимый ввод SQL:
SELECT * FROM MY_TABLE;
UPDATE MY_TABLE SET A = 5;
INSERT INTO MY_TABLE VALUES (3, 'hi there');
Это последовательность из трех команд, по одной на строку (хотя это и не требуется; в одной строке может быть несколько команд, и команды могут быть с пользой разбиты на строки).
Кроме того, комментарии могут появляться во входных данных SQL. Они не являются токенами, фактически они эквивалентны пробелам.
Синтаксис SQL не очень согласован относительно того, какие токены идентифицируют команды, а какие являются операндами или параметрами. Первые несколько токенов обычно являются именем команды, поэтому в приведенном выше примере мы обычно говорим о командах «SELECT», «UPDATE» и «INSERT». Но, например, команда UPDATE всегда требует, чтобы токен SET появлялся в определенной позиции, и этот конкретный вариант INSERT также требует VALUES для завершения. Точные правила синтаксиса для каждой команды описаны в главе Команды SQL.
Идентификаторы и ключевые слова
Токены, такие как SELECT, UPDATE или VALUES в приведенном выше примере, являются примерами ключевых слов, то есть слов, которые имеют фиксированное значение в языке SQL. MY_TABLE и A являются примерами идентификаторов. Они идентифицируют имена таблиц, столбцов или других объектов базы данных в зависимости от команды, в которой они используются. Поэтому их иногда просто называют «именами». Ключевые слова и идентификаторы имеют одинаковую лексическую структуру, что означает, что невозможно знать, является ли токен идентификатором или ключевым словом, не зная языка. Полный список ключевых слов, используемых стандарте SQL и в QHB можно найти в Ключевые слова SQL
Идентификаторы SQL и ключевые слова должны начинаться с буквы (a - z, но также с букв с диакритическими знаками и нелатинскими буквами) или подчеркивания (_). Последующие символы в идентификаторе или ключевом слове могут быть буквами, подчеркиванием, цифрами (0 - 9) или знаками доллара ($). Обратите внимание, что знаки доллара не допускаются в идентификаторах в соответствии с буквой стандарта SQL, поэтому их использование может сделать приложения менее переносимыми. Стандарт SQL не будет определять ключевое слово, которое содержит цифры, начинается или заканчивается подчеркиванием, поэтому идентификаторы этой формы защищены от возможного конфликта с будущими расширениями стандарта.
Система использует не более NAMEDATALEN-1 байтов идентификатора; более длинные имена могут быть записаны в командах, но они будут усечены. По умолчанию NAMEDATALEN равен 64, поэтому максимальная длина идентификатора составляет 63 байта.
Ключевые слова и идентификаторы без кавычек не чувствительны к регистру. Следовательно:
UPDATE MY_TABLE SET A = 5;
можно эквивалентно записать как:
uPDaTE my_TabLE SeT a = 5;
Часто используемое соглашение заключается в написании ключевых слов в верхнем регистре и имен в нижнем регистре, например:
UPDATE my_table SET a = 5;
Существует второй тип идентификатора: идентификатор с разделителями (delimited identifier) или идентификатор в кавычках (quoted identifier). Он формируется путем включения произвольной последовательности символов в двойные кавычки ("). Идентификатор с разделителями всегда является идентификатором, а не ключевым словом. Таким образом, "select" может использоваться для ссылки на столбец или таблицу с именем "select", тогда как select без кавычек был бы взят как ключевое слово и поэтому вызвал бы ошибку синтаксического анализа при использовании там, где ожидается имя таблицы или столбца. Пример может быть написан с помощью заключенных в кавычки идентификаторов как это:
UPDATE "my_table" SET "a" = 5;
Идентификаторы в кавычках могут содержать любой символ, кроме символа с нулевым кодом. (Чтобы включить двойные кавычки, напишите две двойные кавычки). Это позволяет создавать имена таблиц или столбцов, которые в противном случае были бы невозможны, например, содержащие пробелы или амперсанды. Ограничение длины все еще применяется.
Вариант заключенных в кавычки идентификаторов позволяет включать экранированные символы Юникода, идентифицируемые их кодовыми точками. Этот вариант рассмотрен в разделе Строковые константы с экранированием Unicode. Заключение в кавычки идентификатора также делает его чувствительным к регистру, тогда как имена без кавычек всегда свертываются в нижний регистр. Например, идентификаторы FOO, foo и "foo" в QHB считаются одинаковыми, но "Foo" и "FOO" отличаются друг от друга. (Свертывание имен без кавычек в нижний регистр в QHB несовместимо со стандартом SQL, который говорит, что имена без кавычек должны быть приведены в верхний регистр. Таким образом, foo должен быть эквивалентен "FOO", а не "foo" в соответствии со стандартом. Если Вы хотите писать переносимые приложения. Рекомендуется всегда указывать конкретное имя или никогда его не указывать).
Константы
В QHB есть три типа неявно типизированных констант: строки, битовые строки и числа. Константы также могут быть указаны с явными типами, которые могут обеспечить более точное представление и более эффективную обработку системой. Эти альтернативы обсуждаются в следующих подразделах.
Строковые константы
Строковая константа в SQL — это произвольная последовательность символов, ограниченная одинарными кавычками (’), например, ’This is a string’. Чтобы включить символ одинарной кавычки в строковую константу, напишите две соседние одинарные кавычки, например, ’Dianne”s horse’. Обратите внимание, что это не то же самое, что символ двойной кавычки (").
Две строковые константы, которые разделены только пробелами хотя бы с одной новой строкой, объединяются и эффективно обрабатываются так, как если бы строка была записана как одна константа. Например:
SELECT 'foo'
'bar';
эквивалентно:
SELECT ’foobar’;
но:
SELECT 'foo' 'bar';
неверный синтаксис (Это немного странное поведение определяется SQL и QHB следует стандарту).
Строковые константы с экранированием в стиле C
QHB также принимает строковые константы с экранированием, которые являются расширением стандарта SQL. Константная строка с экранированием указывается путем написания буквы E (в верхнем или нижнем регистре) непосредственно перед открывающей одинарной кавычкой, например, E’foo’. (При продолжении строковые константы с экранированием через строки пишите E только перед первой открывающей кавычкой). Внутри строки с экранированием символ обратной косой черты (\) начинает C-подобную escape- последовательность с обратной косой чертой, в которой комбинация обратной косой черты и следующего(их) символа(ов) представляет специальное байтовое значение, как показано в таблице:
Escape-последовательности с обратной косой чертой
| Escape-последовательность с обратной косой чертой | Описание |
|---|---|
| \b | backspace |
| \f | form feed |
| \n | newline |
| \r | carriage return |
| \t | tab |
| \o, \oo, \ooo (o = 0 - 7) | octal byte value |
| \xh, \xhh (h = 0 - 9, A - F) | hexadecimal byte value |
| \uxxxx, \Uxxxxxxxx (x = 0 - 9, A - F) | 16 or 32-bit hexadecimal Unicode character value |
Любой другой символ после обратной косой черты воспринимается буквально. Таким образом, чтобы включить символ обратной косой черты, напишите две обратные косые черты (\\). Кроме того, одиночная кавычка может быть включена в escape-строку, с помощью \’, в дополнение к обычному способу ''.
Вы несете ответственность за то, что создаваемые вами последовательности байтов, особенно при использовании восьмеричного или шестнадцатеричного экранирования, составляют допустимые символы в кодировке набора символов сервера. Если кодировкой сервера является UTF-8, вместо этого следует использовать кодировку Unicode или альтернативный синтаксис escape Unicode, описанный в разделе Строковые константы с экранированием Unicode. Альтернативой может быть ручное кодирование UTF-8 и запись байтов, что будет очень громоздким.
Экранирующий синтаксис Unicode работает полностью, только если кодировка сервера UTF8. При использовании других серверных кодировок можно указывать только кодовые точки в диапазоне ASCII (до \u007F). Как 4-значная, так и 8-значная форма могут использоваться для указания суррогатных пар UTF-16 для составления символов с кодовыми точками, большими, чем U + FFFF, хотя наличие 8-значной формы технически делает это ненужным. (Если суррогатные пары используются, когда кодировкой сервера является UTF8, они сначала объединяются в одну кодовую точку, которая затем кодируется в UTF-8).
Символ с нулевым кодом не может быть строковой константой.
Строковые константы с экранированием Unicode
QHB также поддерживает другой тип синтаксиса с экранированием для строк, который позволяет указывать произвольные символы Юникода по кодовой точке. Константа escape-строки Unicode начинается с U& (заглавная или строчная буква U, за которой следует амперсанд) непосредственно перед открывающей кавычкой, без пробелов между ними, например, U&’foo’. (Обратите внимание, что это создает неоднозначность с оператором &. Используйте пробелы вокруг оператора, чтобы избежать этой проблемы). Внутри кавычек символы Unicode могут быть указаны в экранированной форме путем написания обратной косой черты с последующим четырехзначным шестнадцатеричным номером кодовой точки или в качестве альтернативы обратный слеш, за которым следует знак плюс, за которым следует шестизначный шестнадцатеричный номер кода. Например, строка ’data’ может быть записана как
U&'d\0061t\+000061'
Следующий менее тривиальный пример пишет русское слово «слон» кириллическими буквами:
U&'\0441\043B\043E\043D'
Если требуется другой escape-символ, чем обратная косая черта, его можно указать с помощью оператора UESCAPE после строки, например:
U&'d!0061t!+000061' UESCAPE '!'
Экранирующим символом может быть любой отдельный символ, кроме шестнадцатеричной цифры, знака плюс, одинарной кавычки, двойной кавычки или пробела. Обратите внимание, что escape-символ пишется в одинарных кавычках, а не в двойных.
Экранирующий синтаксис Unicode работает только в том случае, если кодировка сервера UTF8. При использовании других серверных кодировок можно указывать только кодовые точки в диапазоне ASCII (до \007F). Как 4-значная, так и 6-значная форма могут использоваться для указания суррогатных пар UTF-16 для составления символов с кодовыми точками, большими, чем U + FFFF, хотя технически наличие 6-значной формы делает это ненужным. (Если суррогатные пары используются, когда кодировкой сервера является UTF8, они сначала объединяются в одну кодовую точку, которая затем кодируется в UTF-8).
Кроме того, escape-синтаксис Unicode для строковых констант работает только при включенном параметре конфигурации standard_conforming_strings. Это связано с тем, что в противном случае этот синтаксис может запутать клиентов, которые анализируют операторы SQL, до такой степени, что это может привести к инъекциям SQL и аналогичным проблемам безопасности. Если параметр отключен, этот синтаксис будет отклонен с сообщением об ошибке.
Чтобы буквально включить escape-символ в строку, напишите его дважды.
Строковые константы с экранированием знаками доллара
Хотя стандартный синтаксис для указания строковых констант обычно удобен, бывает трудно понять, когда нужная строка содержит много одинарных кавычек или обратных косых черт, поскольку каждая из них должна быть удвоена. Чтобы разрешить более удобочитаемые запросы в таких ситуациях, QHB предоставляет другой способ записи строковых констант, называемый «экранирование знаками доллара». Строковая константа, заключенная в такие «кавычки», состоит из знака доллара ($), необязательного «тега», состоящего из нуля или более символов, еще одного знака доллара, произвольной последовательности символов, составляющих содержимое строки, знака доллара, того же тега, которым началась эта цитата, и знака доллара. Например, вот два разных способа указать строку «Dianne's horse» с использованием экранирования знаками доллара:
$$Dianne's horse$$
$SomeTag$Dianne's horse$SomeTag$
Обратите внимание, что внутри строки, заключенной в знаки доллара, можно использовать одинарные кавычки без экранирования. Действительно, ни один символ внутри строки в кавычках не экранируется: содержимое строки всегда пишется буквально. Обратные косые черты, как и знаки доллара, не являются особыми, если они не являются частью последовательности, соответствующей открывающему тегу.
Можно вкладывать строковые константы в знаках доллара, выбирая разные теги на каждом уровне вложенности. Это чаще всего используется при написании определений функций. Например:
$function$
BEGIN
RETURN ($1 ~ $q$[\t\r\n\v\\]$q$);
END;
$function$
Здесь последовательность $q$[\t\r\n\v\\]$q$ представляет
заключенную в знаки доллара текстовую строку [\t\r\n\v\\], которая
будет распознаваться, когда тело функции будет выполняться QHB. Но так
как последовательность не соответствует внешнему разделителю долларовых
кавычек $function$, это просто еще несколько символов внутри константы,
поскольку речь идет о внешней строке.
Тэг строки в кавычках, если таковой имеется, следует тем же правилам, что и идентификатор без кавычек, за исключением того, что он не может содержать знак доллара. Теги чувствительны к регистру, поэтому $tag$String content$tag$ является правильным, но $TAG$String content$tag$ - нет.
Строка в знаках доллара, следующая за ключевым словом или идентификатором, должна отделяться от нее пробелами; в противном случае разделитель долларовых кавычек будет взят как часть предыдущего идентификатора.
Экранирование знаками доллара не являются частью стандарта SQL, но зачастую это более удобный способ написания сложных строковых литералов, чем синтаксис с одинарными кавычками, соответствующий стандарту. Это особенно полезно при представлении строковых констант внутри других констант, что часто требуется в определениях процедурных функций. В синтаксисе с одинарными кавычками каждая обратная черта в приведенном выше примере должна быть записана как четыре обратных черты, которые будут уменьшены до двух обратных черт при разборе исходной строковой константы, а затем до одного, когда внутренняя строковая константа будет повторно проанализирована во время выполнения функции.
Константы битовых строк
Константы битовых строк выглядят как обычные строковые константы с
буквой B (в верхнем или нижнем регистре) непосредственно перед
открывающей кавычкой (без пробелов), например, B'1001'. В битовых
строковых константах допускаются только символы 0 и 1.
В качестве альтернативы константы битовой строки могут быть указаны в
шестнадцатеричном формате с использованием начального X (верхний или
нижний регистр), например, X'1FF'. Это обозначение эквивалентно
константе битовой строки с четырьмя двоичными цифрами для каждой
шестнадцатеричной цифры.
Обе формы константы битовой строки могут быть продолжены между строками так же, как обычные строковые константы. «Экранирование знаками доллара» нельзя использовать в константе битовой строки.
Числовые константы
Числовые константы принимаются в следующих общих формах:
digits
digits.[digits][e[+-]digits]
[digits].digits[e[+-]digits]
digitse[+-]digits
где digits — это одна или несколько десятичных цифр (от 0 до 9). Как минимум одна цифра должна быть до или после десятичной точки, если она используется. По крайней мере одна цифра должна следовать за маркером экспоненты (e), если таковая имеется. В константе не должно быть пробелов или других символов. Обратите внимание, что любой ведущий знак плюс или минус на самом деле не считается частью константы; это оператор, применяемый к константе.
Вот несколько примеров допустимых числовых констант:
42
3.5
4.
.001
5e2
1.925e-3
Числовая константа, которая не содержит ни десятичной точки, ни экспоненты, изначально считается типом integer если ее значение соответствует типу integer (32 бита); в противном случае предполагается, что это тип bigint если его значение соответствует типу bigint (64 бита); в противном случае он считается типом numeric. Константы, которые содержат десятичные точки и/или показатели, всегда изначально считаются numeric.
Первоначально назначенный тип данных числовой константы является лишь отправной точкой для алгоритмов разрешения типов. В большинстве случаев константа будет автоматически приведена к наиболее подходящему типу в зависимости от контекста. При необходимости вы можете принудительно интерпретировать числовое значение как определенный тип данных путем его приведения. Например, вы можете заставить числовое значение обрабатываться как тип real (float4), написав:
REAL '1.23' -- string style
1.23::REAL -- PostgreSQL (historical) style
На самом деле это просто особые случаи общих обозначений приведения, обсуждаемых далее.
Константы других типов
Константа произвольного типа может быть введена с использованием любого из следующих обозначений:
type 'string'
'string'::type
CAST ( 'string' AS type )
Текст строковой константы передается на вход процедуры преобразования для маркировки в соответствии с указанным типом. Результатом является константа указанного типа. Явное приведение типов может быть опущено, если нет неопределенности относительно типа, которым должна быть константа (например, когда она назначается непосредственно столбцу таблицы), и в этом случае она будет автоматически приведена к нужному типу.
Строковая константа может быть записана с использованием обычной записи SQL или знаков доллара.
Также можно указать приведение типа с использованием функционально-подобного синтаксиса:
typename ( 'string' )
но не все имена типов могут быть использованы таким образом; детальную информацию см. в разделе Приведение типов.
CAST(), «::» и функционально-подобный синтаксис также можно использовать
для указания преобразований типов во время выполнения произвольных
выражений, как обсуждается в разделе Приведение типов. Чтобы избежать синтаксической
неоднозначности, синтаксис type 'string' может использоваться только для
указания типа простой литеральной константы. Другое ограничение
синтаксиса type type 'string' заключается в том, что он не работает для типов
массивов; используйте «::» или CAST() чтобы указать тип константы
массива.
Синтаксис CAST() соответствует SQL. Синтаксис type 'string' является
обобщением стандарта: SQL определяет этот синтаксис только для
нескольких типов данных, но QHB допускает его для всех типов.
Операторы
Имя оператора — это последовательность символов длиной до 63 символов из следующего списка:
+ - * / < > = ~ ! @ # % ^ & | ` ?
Однако есть несколько ограничений на имена операторов:
~ ! @ # % ^ & | ` ?
Например, @- это разрешенное имя оператора, а *- нет. Это
ограничение позволяет QHB анализировать SQL-совместимые запросы без
пробелов между токенами.
При работе с нестандартными именами операторов вам обычно нужно
разделять соседние операторы пробелами, чтобы избежать двусмысленности.
Например, если вы определили левый унарный оператор с именем @, вы не
можете написать X*@Y; вы должны написать X* @Y чтобы QHB прочитал его
как два оператора, а не как один.
Специальные символы
Некоторые символы, которые не являются буквенно-цифровыми, имеют особое значение, отличное от оператора. Подробную информацию об использовании можно найти в том месте, где описан соответствующий элемент синтаксиса. Этот раздел существует только для того, чтобы сообщить о существовании и обобщить назначение этих символов.
Комментарии
Комментарий — это последовательность символов, начинающаяся с двойных черт и продолжающаяся до конца строки, например:
-- This is a standard SQL comment
В качестве альтернативы можно использовать комментарии блока в стиле C:
/* multiline comment
* with nesting: /* nested block comment */
*/
где комментарий начинается с /* и распространяется на совпадение вхождения */. Эти блочные комментарии вложены, как указано в стандарте SQL, но в отличие от C, так что можно закомментировать большие блоки кода, которые могут содержать существующие блочные комментарии.
Комментарий удаляется из входного потока перед дальнейшим синтаксическим анализом и фактически заменяется пробелом.
Приоритет оператора
Таблица "Приоритет оператора" показывает приоритет и ассоциативность операторов в QHB. Большинство операторов имеют одинаковый приоритет и являются левоассоциативными. Приоритет и ассоциативность операторов встроены в синтаксический анализатор.
Иногда вам нужно будет добавить скобки при использовании комбинаций бинарных и унарных операторов. Например:
SELECT 5 ! - 6;
будет проанализирован как:
SELECT 5 ! (- 6);
потому что синтаксический анализатор понятия не имеет - пока не стало слишком поздно – «!» определяется как постфиксный оператор, а не как инфиксный. Чтобы получить желаемое поведение в этом случае, вы должны написать:
SELECT (5 !) - 6;
Приоритет оператора (от высшего к низшему)
| Оператор / Элемент | Ассоциативность | Описание |
|---|---|---|
| . | left | разделитель имени таблицы/столбца |
| :: | left | определение типа в стиле QHB |
| [ ] | left | выбор элемента массива |
| + - | right | унарный плюс, унарный минус |
| ^ | left | экспоненцирование |
| * / % | left | умножение, деление, по модулю |
| + - | left | сложение, вычитание |
| (любой другой оператор) | left | все остальные собственные и пользовательские операторы |
| BETWEEN IN LIKE ILIKE SIMILAR | ограничение диапазона, набор членов, сопоставление строк | |
| < > = <= >= <> | операторы сравнения | |
| IS ISNULL NOT NULL | IS TRUE, IS FALSE, IS NULL, IS DISTINCT FROM т.д. | |
| NOT | right | логическое отрицание |
| AND | left | логическое соединение |
| OR | left | логическая дизъюнкция |
Обратите внимание, что правила приоритета операторов также применяются к пользовательским операторам, имена которых совпадают с именами встроенных операторов, упомянутых выше. Например, если вы определите оператор «+» для некоторого пользовательского типа данных, он будет иметь тот же приоритет, что и встроенный оператор «+», независимо от того, что делает ваш.
Когда полное имя схемы используется в синтаксисе OPERATOR, как, например, в:
SELECT 3 OPERATOR(pg_catalog.+) 4;
конструкция OPERATOR имеет приоритет по умолчанию, показанный в таблице 9 для «любого другого оператора». Это верно независимо от того, какой конкретный оператор появляется внутри OPERATOR().
Выражения значения
Выражение значения используются в различных контекстах, таких как список целей команды SELECT, в качестве новых значений столбцов в INSERT или UPDATE или в условиях поиска в ряде команд. Результат вычисления выражения значений иногда называют скаляром, чтобы отличить его от результата табличного выражения (которое является таблицей). Поэтому выражения значений также называют скалярными выражениями (или даже просто выражениями). Синтаксис выражения позволяет вычислять значения из примитивных частей, используя арифметические, логические, множественные и другие операции.
Выражением значения может быть:
В дополнение к этому списку, существует ряд конструкций, которые могут быть классифицированы как выражения, но не следуют никаким общим правилам синтаксиса. Как правило, они имеют семантику функции или оператора и объясняются в соответствующем месте в главе Функции и операторы. Примером является предложение IS NULL.
Константы уже обсуждались в разделе Константы. В следующих подразделах обсуждаются остальные варианты.
Ссылки на столбец
На столбец можно ссылаться в виде:
correlation.columnname
correlation — это имя таблицы (возможно, дополненной именем схемы) или псевдонима для таблицы, определенного с помощью предложения FROM. Имя таблицы и разделяющая точка могут быть опущены, если имя столбца уникально во всех таблицах, используемых в текущем запросе. (См. также главу Запросы).
Позиционные параметры
Ссылка на позиционный параметр используется для указания значения, которое подается извне в оператор SQL. Параметры используются в определениях функций SQL и в подготовленных запросах. Некоторые клиентские библиотеки также поддерживают указание значений данных отдельно от командной строки SQL, и в этом случае параметры используются для ссылки на внешние значения данных. Форма ссылки на параметр:
$number
Например, рассмотрим определение функции dept как:
CREATE FUNCTION dept(text) RETURNS dept
AS $$ SELECT * FROM dept WHERE name = $1 $$
LANGUAGE SQL;
Здесь $1 ссылка на значение первого аргумента функции при каждом её вызове.
Подзапросы
Если выражение дает значение типа массива, то конкретный элемент значения массива можно извлечь, написав
expression[subscript]
или несколько смежных элементов («срез массива») можно извлечь, написав
expression[lower_subscript:upper_subscript]
(Здесь скобки [ ] должны появляться буквально). Каждый подзапрос сам по себе является выражением, которое должно давать целочисленное значение.
В общем случае массив expression должен быть заключен в скобки, но круглые скобки могут быть опущены, когда выражение, которое должно быть подписано, является просто ссылкой на столбец или позиционным параметром. Кроме того, несколько подзапросов могут быть объединены, если исходный массив является многомерным. Например:
mytable.arraycolumn[4]
mytable.two_d_column[17][34]
$1[10:42]
(arrayfunction(a,b))[42]
Скобки в последнем примере обязательны. См. раздел Массивы для получения дополнительной информации о массивах.
Выбор поля
Если выражение возвращает значение составного типа (тип строки), то конкретное поле строки можно извлечь, написав
expression fieldname
В общем случае expression строки должно быть заключено в скобки, но скобки можно опустить, если выбранное выражение является просто ссылкой на таблицу или позиционным параметром. Например:
mytable.mycolumn
$1.somecolumn
(rowfunction(a,b)).col3
(Таким образом, квалифицированная ссылка на столбец на самом деле является просто частным случаем синтаксиса выбора поля). Важным частным случаем является извлечение поля из столбца таблицы составного типа:
(compositecol).somefield
(mytable.compositecol).somefield
Скобки здесь обязательны для того, чтобы показать, что compositecol — это имя столбца, а не имя таблицы, или что mytable — это имя таблицы, а не имя схемы во втором случае.
Вы можете запросить все поля составного значения, написав .*:
(compositecol).*
Это обозначение ведет себя по-разному в зависимости от контекста; см. раздел Использование составных типов в запросах для деталей.
Операторы вызова
Существует три возможных синтаксиса для вызова оператора:
expression operator expression (binary infix operator)
operator expression (unary prefix operator)
expression operator (unary postfix operator)
где маркер operator следует синтаксическим правилам раздел Операторы, или является одним из ключевых слов AND, OR и NOT, или является квалифицированным именем оператора в форме:
OPERATOR(schema.operatorname)
Какие конкретные операторы существуют и являются ли они унарными или двоичными, зависит от того, какие операторы были определены системой или пользователем. В главе Функции и операторы описываются встроенные операторы.
Вызов функции
Синтаксис для вызова функции — это имя функции (возможно, дополненное именем схемы), за которым следует список аргументов, заключенный в скобки:
function_name ([expression [, expression ... ]] )
Например, вычисление квадратного корня из 2:
sqrt(2)
Список всех встроенных функций см. в главе Функции и операторы. Другие необходимые функции могут быть добавлены пользователем.
При отправке запросов в базу данных, когда некоторые пользователи не доверяют другим пользователям, соблюдайте меры безопасности при написании вызовов таких функций.
К аргументам необязательно могут быть прикреплены имена. Детальную информацию см. в разделе Вызов функции.
Функция, которая принимает один аргумент составного типа, может вызываться с использованием синтаксиса выбора поля, и наоборот, выбор поля может быть написан в функциональном стиле. То есть обозначения col(table) и table.col являются взаимозаменяемыми. Такое поведение не является стандартом SQL, но предоставляется в QHB, поскольку позволяет использовать функции для эмуляции «вычисляемых полей».
Агрегатные выражения
Агрегатное выражение представляет собой применение агрегатной функции для строк, выбранных запросом. Агрегатная функция преобразует несколько входных значений к одному результирующему, например, сумме или среднему значению исходных данных. Синтаксис статистического выражения является одним из следующих:
aggregate_name (expression [, ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (ALL expression [, ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (DISTINCT expression [, ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( * ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( [ expression [, ... ] ] ) WITHIN GROUP ( order_by_clause ) [ FILTER ( WHERE filter_clause ) ]
где aggregate_name — это ранее определенный агрегат (возможно, с указанием имени схемы), а expression — это любое выражение значения, которое само не содержит выражения агрегации или вызова оконной функции. Необязательные order_by_clause и filter_clause описаны ниже.
Первая форма агрегатного выражения вызывает агрегат один раз для каждой
входной строки. Вторая форма такая же, как и первая, поскольку по
умолчанию используется ALL. Третья форма вызывает агрегат один раз для
каждого отдельного выражения значения (или отдельного набора значений
для нескольких выражений), найденных во входных строках. Четвертая форма
вызывает агрегат один раз для каждой входной строки; поскольку
конкретное входное значение не указано, оно обычно используется только
для агрегатной функции count(*). Последняя форма используется с
агрегатными функциями с упорядоченным набором, которые описаны ниже.
Большинство агрегатных функций игнорируют нулевые входные данные, поэтому строки, в которых одно или несколько выражений дают нулевое значение, отбрасываются. Это можно считать верным для всех встроенных агрегатов, если не указано иное.
Например, count(*) дает общее количество входных строк; count(f1)
возвращает количество входных строк, в которых f1 не равно нулю,
поскольку count игнорирует нули; и count(distinct f1) дает количество
различных ненулевых значений f1.
Обычно входные строки подаются в агрегатную функцию в неопределенном порядке. Во многих случаях это не имеет значения; например, min выдает один и тот же результат независимо от того, в каком порядке он принимает входные данные. Однако некоторые агрегатные функции (например, array_agg и string_agg) выдают результаты, которые зависят от упорядочения входных строк. При использовании такого агрегата необязательный order_by_clause может использоваться для указания желаемого порядка. У order_by_clause тот же синтаксис, что и для предложения ORDER BY уровня запроса, как описано в разделе Сортировка строк, за исключением того, что его выражения всегда являются просто выражениями и не могут быть именами или числами выходных столбцов. Например:
SELECT array_agg(a ORDER BY b DESC) FROM table;
При работе с агрегатными функциями с несколькими аргументами обратите внимание, что предложение ORDER BY идет после всех аргументов агрегации. Например, напишите это:
SELECT string_agg(a, ',' ORDER BY a) FROM table;
но не это:
SELECT string_agg(a ORDER BY a, ',') FROM table; -- неверно
Последний синтаксически допустим, но он представляет собой вызов однопараметрической агрегатной функции с двумя ключами ORDER BY (второй является довольно бесполезным, поскольку он является константой).
Если DISTINCT указан в дополнение к order_by_clause, то все выражения ORDER BY должны соответствовать обычным аргументам агрегата; то есть вы не можете сортировать выражения, которые не включены в список DISTINCT.
Помещение ORDER BY в обычный список аргументов агрегата, как описано выше, используется при упорядочении входных строк для универсальных и статистических агрегатов, для которых упорядочение необязательно. Существует подкласс агрегатных функций, называемых агрегатами упорядоченного набора, для которых требуется order_by_clause, обычно потому, что вычисление агрегата имеет смысл только с точки зрения конкретного порядка его входных строк. Типичными примерами агрегатов с упорядоченным набором являются вычисления ранга и процентиля. Для агрегата упорядоченного набора order_by_clause записывается внутри WITHIN GROUP (...), как показано в финальной альтернативе синтаксиса выше. Выражения в order_by_clause вычисляются один раз для каждой входной строки, как обычные агрегатные аргументы, сортируются в соответствии с требованиями order_by_clause и передаются в агрегатную функцию в качестве входных аргументов. (Это непохоже на случай non-WITHIN GROUP order_by_clause, которой не рассматривается как аргумент(ы) для агрегатной функции). Выражения аргументов, предшествующие WITHIN GROUP, если таковые имеются, называются прямыми аргументами, чтобы отличать их от агрегатных аргументов, перечисленных в order_by_clause. В отличие от обычных агрегатных аргументов, прямые аргументы вычисляются только один раз за вызов агрегата, а не один раз на каждую входную строку. Это означает, что они могут содержать переменные, только если эти переменные сгруппированы по GROUP BY; это ограничение такое же, как если бы прямые аргументы вообще не были внутри агрегатного выражения. Прямые аргументы обычно используются для таких вещей, как процентильные дроби, которые имеют смысл только как одно значение для расчета агрегации. Список прямых аргументов может быть пустым; в этом случае просто напишите () не (*). (QHB фактически принимает любое написание, но только первый способ соответствует стандарту SQL).
Пример агрегатного вызова с упорядоченным набором:
SELECT percentile_cont(0.5) WITHIN GROUP (ORDER BY income) FROM households;
percentile_cont
-----------------
50489
которая получает 50-й процентиль, или медиану, значения столбца income из таблицы households. Здесь 0.5 - прямой аргумент; не имеет смысла, чтобы процентная доля была значением, варьирующимся по строкам.
Если указан FILTER, то в агрегатную функцию передаются только входные строки, для которых filter_clause оценивается как «истина»; другие строки отбрасываются. Например:
SELECT
count(*) AS unfiltered,
count(*) FILTER (WHERE i < 5) AS filtered
FROM generate_series(1,10) AS s(i);
unfiltered | filtered
------------+----------
10 | 4
(1 row)
Предопределенные агрегатные функции описаны в разделе Агрегатные функции. Другие агрегатные функции могут быть добавлены пользователем.
Агрегатное выражение может появляться только в списке результатов или в предложении HAVING команды SELECT. Это запрещено в других разделах, таких как WHERE, поскольку эти разделы логически оцениваются до формирования результатов агрегатов.
Когда агрегатное выражение появляется в подзапросе (см.раздел Скалярные подзапросы и раздел Выражения подзапроса, агрегат обычно вычисляется по строкам подзапроса. Но возникает исключение, если аргументы агрегата (и filter_clause при наличии) содержат только переменные внешнего уровня: агрегат в этом случае принадлежит такому ближайшему внешнему уровню и вычисляется поверх строк этого запроса. Агрегатное выражение в целом является тогда внешней ссылкой для подзапроса, в котором оно появляется, и действует как константа поверх любого вычисления этого подзапроса. Ограничение относительно отображения только в списке результатов или предложении HAVING применяется к уровню запроса, к которому принадлежит агрегат.
Вызовы оконных функций
Вызов оконной функции представляет собой применение агрегатоподобной функции над некоторой частью строк, выбранных запросом. В отличие от агрегатных вызовов, это не связано с группировкой выбранных строк в одну выходную строку - каждая строка остается отдельной в выходных данных запроса. Однако оконная функция имеет доступ ко всем строкам, которые будут частью группы текущей строки в соответствии со спецификацией группировки (список PARTITION BY) вызова оконной функции. Синтаксис вызова оконной функции один из следующих:
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
где window_definition имеет синтаксис:
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]
Необязательный frame_clause может быть одним из:
{ RANGE | ROWS | GROUPS } frame_start [ frame_exclusion ]
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end [ frame_exclusion ]
где frame_start и frame_end могут быть одним из:
UNBOUNDED PRECEDING
offset PRECEDING
CURRENT ROW
offset FOLLOWING
UNBOUNDED FOLLOWING
и frame_exclusion может быть одним из:
EXCLUDE CURRENT ROW
EXCLUDE GROUP
EXCLUDE TIES
EXCLUDE NO OTHERS
Здесь expression представляет любое выражение значения, которое само не содержит вызовов оконных функций.
window_name является ссылкой на именованную спецификацию окна, определенную в предложении WINDOW запроса. В качестве альтернативы полное определение window_definition может быть указано в скобках, используя тот же синтаксис, что и для определения именованного окна в предложении WINDOW; см. страницу выбора SELECT для деталей. Стоит отметить, что OVER wname не совсем эквивалентно OVER (wname ...); последнее подразумевает копирование и изменение определения окна и будет отклонено, если спецификация окна, на которое ссылается ссылка, включает предложение frame.
Предложение PARTITION BY группирует строки запроса в разделы, которые обрабатываются отдельно оконной функцией. PARTITION BY работает аналогично предложению GROUP BY уровня запроса, за исключением того, что его выражения всегда являются просто выражениями и не могут быть именами или числами выходных столбцов. Без PARTITION BY все строки, созданные запросом, обрабатываются как один раздел. Предложение ORDER BY определяет порядок, в котором строки раздела обрабатываются оконной функцией. Он работает аналогично предложению ORDER BY уровня запроса, но также не может использовать имена или номера выходных столбцов. Без ORDER BY строки обрабатываются в неопределенном порядке.
frame_clause определяет набор строк, составляющих кадр окна, который является подмножеством текущего раздела, для тех оконных функций, которые действуют на кадр, а не на весь раздел. Набор строк в кадре может варьироваться в зависимости от того, какая строка является текущей. Кадр может быть указан в режиме RANGE, ROWS или GROUPS; в каждом случае он выполняется от frame_start до frame_end. Если frame_end опущен, конец по умолчанию равен CURRENT ROW.
frame_start с UNBOUNDED PRECEDING означает, что кадр начинается с первой строки раздела, и аналогично frame_end с UNBOUNDED FOLLOWING означает, что кадр заканчивается последней строкой раздела.
В режиме RANGE или GROUPS, frame_start с CURRENT ROW означает, что кадр начинается с первой строки однорангового соединения текущей строки (строка, которую предложение ORDER BY окна сортирует как эквивалентную текущей строке), в то время как frame_end с CURRENT ROW означает, что кадр заканчивается с последней равноправной строкой для текущей строки. В режиме ROWS с CURRENT ROW просто означает текущую строку.
В опциях offset PRECEDING и offset FOLLOWING offset должно быть выражением, не содержащим никаких переменных, агрегатных функций или оконных функций. Значение offset зависит от режима кадра:
В любом случае расстояние до конца кадра ограничено расстоянием до конца раздела, поэтому для строк рядом с концом раздела кадр может содержать меньше строк, чем в других местах.
Обратите внимание, что в режимах ROWS и GROUPS, 0 PRECEDING и 0 FOLLOWING эквивалентны CURRENT ROW. Это обычно выполняется и в режиме RANGE для соответствующего значения специфического типа данных “zero”.
Опция frame_exclusion позволяет исключить строки вокруг текущей строки из кадра, даже если они будут включены в соответствии с параметрами начала и конца кадра. EXCLUDE CURRENT ROW исключает текущую строку из кадра. EXCLUDE GROUP исключает текущую строку и ее упорядоченные одноранговые элементы из кадра. EXCLUDE TIES исключает любые одноранговые элементы текущей строки из фрейма, но не саму текущую строку. EXCLUDE NO OTHERS просто явно указывает поведение по умолчанию - не исключать текущую строку или ее одноранговые узлы.
Опция кадрирования по умолчанию - RANGE UNBOUNDED PRECEDING, которая совпадает с RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. С ORDER BY это устанавливает кадр, для всех строк от начала раздела до последнего однорангового узла текущей строки с учетом ORDER BY. Без ORDER BY это означает, что все строки раздела включены в кадр окна, так как все строки становятся равноправными в текущей строке.
Ограничения состоят в том, что frame_start не может быть UNBOUNDED
FOLLOWING, frame_end не может быть UNBOUNDED PRECEDING, а выбор
frame_end не может появляться раньше в приведенном выше списке
frame_start и frame_end, чем выбор frame_start - например, RANGE BETWEEN CURRENT ROW AND offset PRECEDING не допускается. Но, например,
ROWS BETWEEN 7 PRECEDING AND 8 PRECEDING разрешены, даже если они
никогда не будут выбирать какие-либо строки.
Если указан параметр FILTER, то только входные строки, для которых filter_clause оценивается как «истина», передаются оконной функции; другие строки отбрасываются. Только оконные функции, которые являются агрегатами, принимают предложение FILTER.
Встроенные оконные функции описаны в таблице Оконные функции. Другие оконные функции могут быть добавлены пользователем. Кроме того, любой встроенный или определяемый пользователем универсальный или статистический агрегат может использоваться в качестве оконной функции. (Агрегаты упорядоченного набора и гипотетического набора в настоящее время не могут использоваться в качестве оконных функций).
Синтаксисы, использующие *, используются для вызова агрегатных функций
без параметров в качестве оконных функций, например, count(*) OVER (PARTITION BY x ORDER BY y). Звездочка (*) обычно не используется для
оконных функций. Специфичные оконные функции не позволяют использовать
DISTINCT или ORDER BY в списке аргументов функции.
Вызовы оконных функций разрешены только в списке SELECT и предложении ORDER BY запроса.
Более подробную информацию о оконных функциях можно найти в разделе Руководство по оконным функциям, разделе Оконные функции и разделе Обработка оконных функций.
Приведение типов
Приведение типов определяет преобразование из одного типа данных в другой. QHB принимает два эквивалентных синтаксиса для приведения типов:
CAST ( expression AS type )
expression::type
Синтаксис CAST соответствует SQL; синтаксис с «::» является историческим наследием QHB.
Когда приведение применяется к выражению значения известного типа, оно представляет преобразование типа во время выполнения. Приведение будет успешным, только если определена подходящая операция преобразования типа. Обратите внимание, что это немного отличается от использования приведений с константами, как показано в разделе Константы других типов. Приведение, примененное к произвольному строковому литералу, представляет собой начальное присвоение типа постоянному значению литерала, и поэтому оно выполнится успешно для любого типа (если содержимое строкового литерала является приемлемым входным синтаксисом для используемого типа данных).
Явное приведение типов обычно может быть опущено, если нет двусмысленности относительно типа, который должно генерировать выражение значения (например, когда оно назначено столбцу таблицы); система автоматически применяет приведение типа в таких случаях. Однако автоматическое приведение выполняется только для приведений, помеченных как «OK to apply implicitly» в системных каталогах. Другие приведения должны вызываться с явным синтаксисом приведения. Это ограничение предназначено для того, чтобы предотвратить неожиданные преобразования, применяемые автоматически.
Также возможно указать приведение типа с использованием функционально-подобного синтаксиса:
typename (expression)
Однако это работает только для типов, имена которых также допустимы в качестве имен функций. Например, double precision не может быть использована таким образом, но эквивалентный float8 может. Кроме того, имена interval, time и timestamp могут использоваться таким образом, только если они заключены в двойные кавычки, из-за синтаксических конфликтов. Следовательно, использование функционально-подобного синтаксиса приведений приводит к несоответствиям, и его, вероятно, следует избегать.
Функционально-подобный синтаксис на самом деле является просто вызовом функции. Когда один из двух стандартных синтаксисов преобразования используется для выполнения преобразования во время выполнения, он будет внутренне вызывать зарегистрированную функцию для выполнения преобразования. По соглашению, эти функции преобразования имеют то же имя, что и их тип вывода, и, таким образом, «функционально-подобный синтаксис» является не чем иным, как прямым вызовом базовой функции преобразования. Очевидно, что это не то, на что портативное приложение должно положиться. Для получения дополнительной информации см. CREATE CAST.
Сортировка выражений
Предложение COLLATE переопределяет параметры сортировки выражения. Он добавляется к выражению, к которому он относится:
expr COLLATE collation
где collation — это идентификатор, который может быть определен схемой. Предложение COLLATE связывает крепче, чем операторы; при необходимости могут быть использованы круглые скобки.
Если параметры сортировки явно не указаны, система баз данных либо получит параметры сортировки из столбцов, участвующих в выражении, либо использует параметры сортировки базы данных по умолчанию, если в выражении нет столбцов.
Два типовых варианта использования предложения COLLATE переопределяют порядок сортировки в предложении ORDER BY, например:
SELECT a, b, c FROM tbl WHERE ... ORDER BY a COLLATE "C";
и переопределение сортировки вызова функции или оператора, который имеет чувствительные к настройкам локализации результаты, например:
SELECT * FROM tbl WHERE a > 'foo' COLLATE "C";
Обратите внимание, что в последнем случае предложение COLLATE присоединяется к входному аргументу оператора, на который необходимо повлиять. Неважно, к какому аргументу оператора или функции, вызывающей предложение COLLATE, присоединено, потому что сортировка, применяемая оператором или функцией, получается с учетом всех аргументов, и явное предложение COLLATE будет переопределять сортировку всех других аргументы. (Однако присоединение несоответствующих предложений COLLATE к более чем одному аргументу является ошибкой. Более подробную информацию см. в разделе Поддержка сортировки. Таким образом, это дает тот же результат, что и в предыдущем примере:
SELECT * FROM tbl WHERE a COLLATE "C" > 'foo';
Но этот вариант будет ошибкой:
SELECT * FROM tbl WHERE (a > 'foo') COLLATE "C";
потому что он пытается применить параметры сортировки к результату оператора «>», который является логическим типом данных без сортировки.
Скалярные подзапросы
Скалярный подзапрос — это обычный запрос SELECT в скобках, который возвращает ровно одну строку с одним столбцом. (См. главу Запросы для получения информации о написании запросов). Запрос SELECT выполняется, и единственное возвращаемое значение используется в контексте его вызова. Ошибочно использовать запрос, который возвращает более одной строки или более одного столбца в качестве скалярного подзапроса. (Но, если во время конкретного выполнения подзапрос не возвращает строк, ошибки нет; скалярный результат принимается равным нулю). Подзапрос может ссылаться на переменные из окружающего запроса, которые будут действовать как константы во время любого разового вызова подзапроса.
Например, следующий запрос находит наибольшее население города в каждом штате:
SELECT name, (SELECT max(pop) FROM cities WHERE cities.state = states.name)
FROM states;
Конструкторы массивов
Конструктор массива — это выражение, которое создает значение массива,
используя значения для его элементов-членов. Простой конструктор массива
состоит из ключевого слова «ARRAY», левой квадратной скобки [, списка
выражений (разделенных запятыми) для значений элементов массива и,
наконец, правой квадратной скобки ]. Например:
SELECT ARRAY[1,2,3+4];
array
---------
{1,2,7}
(1 row)
По умолчанию тип элемента массива является общим типом выражений-членов, определяемых с использованием тех же правил, что и для конструкций UNION или CASE. Вы можете переопределить это, явно приведя конструктор массива к желаемому типу, например:
SELECT ARRAY[1,2,22.7]::integer[];
array
----------
{1,2,23}
(1 row)
Это имеет тот же эффект, что и приведение каждого выражения к типу элемента массива по отдельности. Подробнее о приведении см. раздел Приведение типов.
Значения многомерного массива можно построить с помощью вложенных конструкторов массива. Во внутренних конструкторах ключевое слово ARRAY может быть опущено. Например, следующие варианты дают один и тот же результат:
SELECT ARRAY[ARRAY[1,2], ARRAY[3,4]];
array
---------------
{{1,2},{3,4}}
(1 row)
SELECT ARRAY[[1,2],[3,4]];
array
---------------
{{1,2},{3,4}}
(1 row)
Поскольку многомерные массивы должны быть прямоугольными, внутренние конструкторы на одном уровне должны создавать вложенные массивы одинаковых размеров. Любое приведение, примененное к внешнему конструктору массива, автоматически распространяется на все внутренние конструкторы.
Элементы конструктора многомерного массива могут быть чем угодно, дающим массив правильного вида, а не только конструкцией sub-ARRAY. Например:
CREATE TABLE arr(f1 int[], f2 int[]);
INSERT INTO arr VALUES (ARRAY[[1,2],[3,4]], ARRAY[[5,6],[7,8]]);
SELECT ARRAY[f1, f2, '{{9,10},{11,12}}'::int[]] FROM arr;
array
------------------------------------------------
{{{1,2},{3,4}},{{5,6},{7,8}},{{9,10},{11,12}}}
(1 row)
Вы можете создать пустой массив, но так как невозможно иметь массив без типа, вы должны явно привести пустой массив к нужному типу. Например:
SELECT ARRAY[]::integer[];
array
-------
{}
(1 row)
Также возможно построить массив из результатов подзапроса. В этой форме конструктор массива записывается с ключевым словом ARRAY за которым следует подзапрос (не заключенный в скобки). Например:
SELECT ARRAY(SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%');
array
-----------------------------------------------------------------------
{2011,1954,1948,1952,1951,1244,1950,2005,1949,1953,2006,31,2412,2413}
(1 row)
SELECT ARRAY(SELECT ARRAY[i, i*2] FROM generate_series(1,5) AS a(i));
array
----------------------------------
{{1,2},{2,4},{3,6},{4,8},{5,10}}
(1 row)
Подзапрос должен возвращать один столбец. Если выходной столбец подзапроса не является типом массива, результирующий одномерный массив будет иметь элемент для каждой строки в результате подзапроса, причем тип элемента соответствует типу выходного столбца подзапроса. Если выходной столбец подзапроса имеет тип массива, результатом будет массив того же типа, но с одним более высоким измерением; в этом случае все строки подзапроса должны давать массивы одинаковой размерности, иначе результат не будет прямоугольным.
Индексы значения массива, построенного с помощью ARRAY, всегда начинаются с единицы. Для получения дополнительной информации о массивах см. раздел Массивы.
Конструкторы строк
Конструктор строки — это выражение, которое создает значение строки (также называемое составным значением), используя значения для его полей-членов. Конструктор строки состоит из ключевого слова ROW, левой круглой скобки, нуля или более выражений (разделенных запятыми) для значений поля строки и, наконец, правой круглой скобки. Например:
SELECT ROW(1,2.5,'this is a test');
Ключевое слово ROW является необязательным, если в списке более одного выражения.
Конструктор строки может включать синтаксис rowvalue.*, который будет
расширен до списка элементов значения строки, как это происходит, когда
синтаксис .* используется на верхнем уровне списка SELECT (см. раздел Использование составных типов в запросах). Например, если таблица t имеет столбцы f1 и f2, следующие записи выдают идентичные результаты:
SELECT ROW(t.*, 42) FROM t;
SELECT ROW(t.f1, t.f2, 42) FROM t;
По умолчанию значение, созданное ROW-выражением, относится к анонимному типу записи. При необходимости его можно привести к названному составному типу - либо к типу строки таблицы, либо к составному типу, созданному с помощью CREATE TYPE AS. Чтобы избежать двусмысленности, может потребоваться явное приведение. Например:
CREATE TABLE mytable(f1 int, f2 float, f3 text);
CREATE FUNCTION getf1(mytable) RETURNS int AS 'SELECT $1.f1' LANGUAGE SQL;
-- No cast needed since only one getf1() exists
SELECT getf1(ROW(1,2.5,'this is a test'));
getf1
-------
1
(1 row)
CREATE TYPE myrowtype AS (f1 int, f2 text, f3 numeric);
CREATE FUNCTION getf1(myrowtype) RETURNS int AS 'SELECT $1.f1' LANGUAGE SQL;
-- Now we need a cast to indicate which function to call:
SELECT getf1(ROW(1,2.5,'this is a test'));
ERROR: function getf1(record) is not unique
SELECT getf1(ROW(1,2.5,'this is a test')::mytable);
getf1
-------
1
(1 row)
SELECT getf1(CAST(ROW(11,'this is a test',2.5) AS myrowtype));
getf1
-------
11
(1 row)
Конструкторы строк можно использовать для построения составных значений, которые будут храниться в столбце таблицы составного типа или передаваться в функцию, которая принимает составной параметр. Кроме того, можно сравнить два значения строки или проверить строку с помощью IS NULL или IS NOT NULL, например:
SELECT ROW(1,2.5,'this is a test') = ROW(1, 3, 'not the same');
SELECT ROW(table.*) IS NULL FROM table; -- detect all-null rows
Подробнее см. раздел Сравнение строк и массивов. Конструкторы строк также могут использоваться в связи с подзапросами, как обсуждается в разделе Выражения подзапроса.
Правила вычисления выражений
Порядок вычисления подвыражений не определен. В частности, входные данные оператора или функции не обязательно оцениваются слева направо или в любом другом фиксированном порядке.
Кроме того, если результат выражения может быть определен путем вычисления только некоторых его частей, тогда другие подвыражения могут вообще не оцениваться. Например, в выражении:
SELECT true OR somefunc();
параметр somefunc() (вероятно) не будет вызван вообще. То же самое будет, если написать:
SELECT somefunc() OR true;
Обратите внимание, что это не то же самое, что «оптимизация» логических операторов слева направо, встречающееся в некоторых языках программирования.
Как следствие, неразумно использовать функции с побочными эффектами как
часть сложных выражений. Особенно опасно полагаться на побочные эффекты
или порядок вычисления в предложениях WHERE и HAVING предложениях, так как
эти пункты тщательно обрабатываются как часть построения плана
выполнения. Булевы выражения (комбинации AND/OR/NOT) в этих
предложениях могут быть реорганизованы любым способом, разрешенным
законами булевой алгебры.
Когда необходимо форсировать порядок вычислений, можно использовать CASE конструкцию (см. раздел Условные выражения). Например, это ненадежный способ избежать деления на ноль в WHERE предложении:
SELECT ... WHERE x > 0 AND y/x > 1.5;
Но это безопасно:
SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;
CASE-конструкция используемая таким образом, будет препятствовать
попыткам оптимизации, так что это должно быть сделано только в случае
необходимости. (В этом конкретном примере было бы лучше обойти проблему,
написав y > 1.5*x).
Однако CASE, это не панацея от подобных проблем. Одним из ограничений метода, показанного выше, является то, что он не препятствует раннему вычислению постоянных подвыражений. Как описано в разделе Категории изменчивости функций, функции и операторы, помеченные как IMMUTABLE могут быть вычислены при планировании запроса, а не при его выполнении. Так например:
SELECT CASE WHEN x > 0 THEN x ELSE 1/0 END FROM tab;
скорее всего, это приведет к ошибке деления на ноль из-за того, что
планировщик пытается упростить постоянное подвыражение, даже если в
каждой строке таблицы есть x > 0 так, что вариант с ELSE никогда не
будет обработан во время выполнения.
Хотя этот конкретный пример может показаться глупым, связанные запросы, которые явно не включают константы, могут возникать в запросах, выполняемых внутри функций, поскольку значения аргументов функции и локальных переменных могут быть вставлены в запросы в качестве констант для целей планирования. Например, в функциях PL/pgSQL использование оператора IF-THEN-ELSE для защиты рискованных вычислений намного безопаснее, чем просто вложить его в выражение CASE.
Другое ограничение того же типа состоит в том, что CASE не может предотвратить вычисление содержащегося в нем агрегатного выражения, потому что агрегатные выражения вычисляются до того, как будут рассмотрены другие выражения в списке SELECT или предложении HAVING. Например, следующий запрос может вызвать ошибку деления на ноль, несмотря на кажущуюся защиту от нее:
SELECT CASE WHEN min(employees) > 0
THEN avg(expenses / employees)
END
FROM departments;
Агрегаты min() и avg() вычисляются одновременно по всем входным строкам, так что, если любая строка имеет employees равное нулю, то ошибка деления на ноль будет происходить до того, как появится возможность проверить результат min(). Вместо этого используйте предложение WHERE или FILTER, чтобы предотвратить попадание проблемных входных строк в агрегатную функцию.
Вызов функции
QHB позволяет вызывать функции с именованными параметрами с использованием позиционной или именованной нотации. Именованная нотация особенно полезна для функций, которые имеют большое количество параметров, поскольку она делает ассоциации между параметрами и фактическими аргументами более явными и надежными. В позиционной нотации вызов функции записывается со значениями аргументов в том же порядке, в котором они определены в объявлении функции. В именованной нотации аргументы сопоставляются с параметрами функции по имени и могут быть записаны в любом порядке.
В любой нотации параметры, которые имеют значения по умолчанию, указанные в объявлении функции, вообще не должны записываться в вызове. Но это особенно полезно в именованной нотации, поскольку любая комбинация параметров может быть опущена; в то время как в позиционной нотации параметры могут быть пропущены только справа налево.
QHB также поддерживает смешанную нотацию, которая объединяет позиционную и именованную нотацию. В этом случае позиционные параметры записываются первыми, а именованные параметры появляются после них.
Следующие примеры иллюстрируют использование всех трех обозначений, используя следующее определение функции:
CREATE FUNCTION concat_lower_or_upper(a text, b text, uppercase boolean DEFAULT false)
RETURNS text
AS
$$
SELECT CASE
WHEN $3 THEN UPPER($1 || ' ' || $2)
ELSE LOWER($1 || ' ' || $2)
END;
$$
LANGUAGE SQL IMMUTABLE STRICT;
Функция concat_lower_or_upper имеет два обязательных параметра, a и
b. Кроме того, есть один необязательный параметр uppercase который по
умолчанию равен false. Входы a и b будут объединены и переведены в
верхний или нижний регистр в зависимости от параметра uppercase.
Остальные детали этого определения функции здесь не важны
(см. главу Расширение SQL для получения дополнительной информации).
Использование позиционной нотации
Позиционная нотация — это традиционный механизм передачи аргументов функциям в QHB. Примером является:
SELECT concat_lower_or_upper('Hello', 'World', true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
Все аргументы указаны в порядке. Результат - верхний регистр, поскольку uppercase указан как true. Другой пример:
SELECT concat_lower_or_upper('Hello', 'World');
concat_lower_or_upper
-----------------------
hello world
(1 row)
Здесь параметр uppercase пропущен, поэтому он получает значение по умолчанию false, что приводит к выводу в нижнем регистре. В позиционной нотации аргументы могут быть опущены справа налево, если они имеют значения по умолчанию.
Использование именованных обозначений
В именованной нотации имя каждого аргумента указывается с помощью
=> чтобы отделить его от выражения аргумента. Например:
SELECT concat_lower_or_upper(a => 'Hello', b => 'World');
concat_lower_or_upper
-----------------------
hello world
(1 row)
Опять же, аргумент в uppercase был опущен, поэтому он неявно установлен в значение false. Одно из преимуществ использования именованных обозначений заключается в том, что аргументы могут быть указаны в любом порядке, например:
SELECT concat_lower_or_upper(a => 'Hello', b => 'World', uppercase => true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
SELECT concat_lower_or_upper(a => 'Hello', uppercase => true, b => 'World');
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
Более старый синтаксис, основанный на ":=", поддерживается для обратной совместимости:
SELECT concat_lower_or_upper(a := 'Hello', uppercase := true, b := 'World');
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
Использование смешанной нотации
Смешанная нотация объединяет позиционную и именованную нотацию. Однако, как уже упоминалось, именованные аргументы не могут предшествовать позиционным аргументам. Например:
SELECT concat_lower_or_upper('Hello', 'World', uppercase => true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
В приведенном выше запросе аргументы a и b указываются позиционно, а
uppercase - именем. В этом примере это мало что добавляет, кроме
документации. С более сложной функцией, имеющей многочисленные параметры
со значениями по умолчанию, именованные или смешанные обозначения могут
сэкономить много времени и уменьшить вероятность ошибок.
Именованные и смешанные нотации вызовов в настоящее время не могут использоваться при вызове агрегатной функции (но они работают, когда агрегатная функция используется в качестве оконной функции).
Определение данных
В этой главе рассказывается, как создать структуры в которых будут храниться данные. В реляционной базе данных необработанные данные хранятся в таблицах, поэтому большая часть этой главы посвящена объяснению того, как создаются и изменяются таблицы, и какие функции доступны для управления тем, какие данные хранятся в таблицах. Затем мы обсудим, как таблицы могут быть организованы в схемы, и как могут быть назначены привилегии для таблиц. Наконец, мы кратко рассмотрим другие функции, которые влияют на хранение данных, такие как наследование, партиционирование (разбиение таблиц на фрагменты), представления, функции и триггеры.
Базовая информация по таблицам
Таблица в реляционной базе данных внешне очень похожа на таблицу на бумаге: она состоит из строк и столбцов. Количество и порядок столбцов фиксированы, и у каждого столбца есть имя. Количество строк является переменным - оно отражает, сколько данных хранится в данный момент. SQL не дает никаких гарантий относительно порядка строк в таблице. Когда таблица прочитана, строки появятся в неуказанном порядке, если сортировка явно не задана, см. главу Запросы. Кроме того, SQL не присваивает уникальные идентификаторы строкам, поэтому в таблице может быть несколько полностью идентичных строк. Это является следствием математической модели, которая лежит в основе реляционных СУБД, но обычно это нежелательно. Далее в этой главе мы увидим, как бороться с этой проблемой.
Каждый столбец имеет тип данных. Тип данных ограничивает набор возможных значений, которые могут быть назначены столбцу, и определяет семантику данных, хранящимся в столбце, чтобы его можно было использовать для вычисления выражений. Например, столбец, объявленный как числовой, не будет принимать произвольные текстовые строки, и данные, хранящиеся в таком столбце, могут использоваться для математических вычислений. Напротив, столбец с типом символьной строки, будет принимать практически любые данные, но он не поддается математическим вычислениям, хотя длянего доступны и другие операции, такие как конкатенация строк.
QHB включает в себя значительный набор встроенных типов данных, которые подходят для многих приложений. Пользователи также могут определять свои собственные типы данных. Большинство встроенных типов данных имеют очевидные имена и семантику, подробное объяснение см. главу Типы данных. Некоторыми из часто используемых типов данных являются integer для целых чисел, numeric для возможно дробных чисел, text для символьных строк, date для дат, time для значений timestamp дня и timestamp для значений, содержащих как дату, так и время.
Чтобы создать таблицу, используйте команду CREATE TABLE с подходящим названием. В этой команде вы указываете как минимум имя новой таблицы, имена столбцов и тип данных каждого столбца. Например:
CREATE TABLE my_first_table (
first_column text,
second_column integer
);
Это создает таблицу с именем my_first_table с двумя столбцами. Первый столбец называется first_column и имеет тип данных text, второй столбец имеет имя second_column и тип integer. Имена таблиц и столбцов соответствуют синтаксису идентификатора см. раздел Идентификаторы и ключевые слова. Имена типов обычно также являются идентификаторами, но есть некоторые исключения. Обратите внимание, что список столбцов разделен запятыми и заключен в скобки.
Конечно, предыдущий пример был сильно надуманным. Обычно таблицам и столбцам дают имена, которые передают, какие данные они хранят. Итак, давайте посмотрим на более реалистичный пример:
CREATE TABLE products (
product_no integer,
name text,
price numeric
);
(тип numeric может хранить дробные компоненты, как это было бы типично для денежных сумм).
В случае, когда создается много взаимосвязанных таблиц, разумно выбрать единый шаблон именования таблиц и столбцов. Например, существует выбор использования имен существительных в единственном или множественном числе для имен таблиц, которые предпочитают те или иные проектировщики баз данных.
Существует ограничение на количество столбцов в таблице. В зависимости от типов столбцов оно составляет от 250 до 1600. Однако определение таблицы с таким количеством столбцов весьма необычно и часто вызывает сомнение в правильности модели данных.
Если вам больше не нужна таблица, вы можете удалить ее с помощью команды DROP TABLE. Например:
DROP TABLE my_first_table;
DROP TABLE products;
Попытка удалить несуществующую таблицу является ошибкой. Тем не менее в файлах сценариев SQL принято удалять каждую таблицу перед ее созданием, игнорируя любые сообщения об ошибках, чтобы скрипт работал независимо от того, существует таблица или нет. (При необходмости, вы можете использовать вариант DROP TABLE IF EXISTS чтобы избежать сообщений об ошибках, но это не стандартный SQL).
Если вам нужно изменить таблицу, которая уже существует, см. раздел Изменение таблиц.
Используя описанные выше команды, вы можете создавать полностью функциональные таблицы. Остальная часть этой главы посвящена командам для добавления в определение таблицы возможностей для обеспечения целостности, безопасности или удобства данных. Если вы хотите заполнить ваши таблицы данными сейчас, вы можете перейти к главе Манипулирование данными и прочитать остальную часть этой главы позже.
Значения по умолчанию
Столбцу может быть назначено значение по умолчанию. Когда создается новая строка и для некоторых столбцов не указаны значения, эти столбцы будут заполнены соответствующими значениями по умолчанию. Команда манипулирования данными может также явно запросить, чтобы для столбца было установлено значение по умолчанию, без необходимости знать, что это за значение. (Подробности о командах манипулирования данными находятся в главе Манипулирование данными.
Если никакое значение по умолчанию не объявлено явно, значением по умолчанию является null значение. Обычно это имеет смысл, поскольку null значение может рассматриваться как представляющее неизвестные данные.
В определении таблицы значения по умолчанию перечислены после типа данных столбца. Например:
CREATE TABLE products (
product_no integer,
name text,
price numeric DEFAULT 9.99
);
Значением по умолчанию может быть выражение, которое будет вычисляться всякий раз, когда вставляется значение по умолчанию (а не при создании таблицы). Типичный пример - для столбца timestamp по умолчанию задано значение CURRENT_TIMESTAMP, поэтому для него устанавливается время вставки строки. Другим распространенным примером является генерация «серийного номера» для каждой строки. В QHB это обычно делается примерно так:
CREATE TABLE products (
product_no integer DEFAULT nextval('products_product_no_seq'),
...
);
где функция nextval() предоставляет последовательные значения из объекта последовательности (см. раздел Функции управления последовательностями). Такое объявление достаточно распространено, поэтому для него есть специальное сокращение:
CREATE TABLE products (
product_no SERIAL,
...
);
Сокращение SERIAL обсуждается далее в разделе Серийные типы.
Сгенерированные столбцы
Сгенерированный столбец — это специальный столбец, который всегда вычисляется из других столбцов. Таким образом, для столбцов это то же самое, что представление для таблиц. Существует два вида генерируемых столбцов: хранимые и виртуальные. Сохраненный сгенерированный столбец вычисляется, когда он записывается в хранилище (вставляется или обновляется) и занимает пространство в хранилище, как если бы это был обычный столбец. Виртуальный сгенерированный столбец не занимает места в хранилище и вычисляется при чтении. Таким образом, виртуальный сгенерированный столбец похож на представление, а сохраненный сгенерированный столбец похож на материализованное представление (за исключением того, что оно всегда обновляется автоматически). В настоящее время QHB реализует только хранимые сгенерированные столбцы.
Чтобы создать сгенерированный столбец, используйте предложение GENERATED ALWAYS AS в CREATE TABLE, например:
CREATE TABLE people (
...,
height_cm numeric,
height_in numeric GENERATED ALWAYS AS (height_cm / 2.54) STORED
);
Ключевое слово STORED должно быть указано, чтобы выбрать сохраненный вид сгенерированного столбца. Смотрите CREATE TABLE для более подробной информации.
Сгенерированный столбец не может быть записан напрямую. В командах INSERT или UPDATE значение не может быть указано для сгенерированного столбца, но может быть указано ключевое слово DEFAULT.
Рассмотрим различия между столбцом с заданным по умолчанию и сгенерированным столбцом. Столбец по умолчанию вычисляется один раз, когда строка впервые вставляется, если не было предоставлено никакого другого значения - сгенерированный столбец обновляется при каждом изменении строки и не может быть переопределен. Столбец по умолчанию может не ссылаться на другие столбцы таблицы, сгенерированный столбец обычно имеет такие ссылки. В столбце по умолчанию могут использоваться нестабильные функции, например random() или функции, относящиеся к текущему времени - которые не допускаются для сгенерированных столбцов.
Несколько ограничений применяются к определению сгенерированных столбцов и таблиц, включающих сгенерированные столбцы:
Дополнительные ограничения относятся к использованию сгенерированных столбцов.
Ограничения
Типы данных — это способ ограничения возможных значений данных, которые могут храниться в таблице. Однако для многих приложений ограничение, которое они предоставляют, слишком грубое. Например, столбец, содержащий цену товара, вероятно, должен принимать только положительные значения. Но нет стандартного типа данных, который принимает только положительные числа. Другая проблема заключается в том, что может потребоваться ограничить данные столбца относительно других столбцов или строк. Например, в таблице, содержащей информацию о продукте, должна быть только одна строка для каждого номера продукта.
Для этого SQL позволяет определять ограничения для столбцов и таблиц. Ограничения дают вам больше контроля над данными в ваших таблицах. Если пользователь пытается сохранить в столбце данные, которые нарушают ограничение, возникает ошибка. Это выполняется, даже если значение пришло из определения значения по умолчанию.
Контрольные ограничения
Контрольное ограничение (CHECK constraints) является наиболее общим типом ограничения. Оно позволяет указать, что значение в определенном столбце должно удовлетворять логическому выражению (истинностному значению). Например, чтобы требовать положительных цен на товары, можно использовать:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0)
);
Определение ограничения идет после типа данных, также как и определения значений по умолчанию. Значения и ограничения по умолчанию могут быть перечислены в любом порядке. Контрольное ограничение состоит из ключевого слова CHECK за которым следует выражение в скобках. Выражение контрольного ограничения должно включать огстолбец, для которого задаётся выражение, иначе ограничение не будет иметь большого смысла.
Также можно задать ограничению отдельное имя. Это уточняет сообщения об ошибках и позволяет ссылаться на ограничение, когда вам нужно его изменить. Синтаксис:
CREATE TABLE products (
product_no integer,
name text,
price numeric CONSTRAINT positive_price CHECK (price > 0)
);
Чтобы указать именованное ограничение, используйте ключевое слово CONSTRAINT за которым следует идентификатор, за которым следует определение ограничения. (Если вы не указали имя ограничения, система сгенерирует имя).
Контрольное ограничение также может ссылаться на несколько столбцов. Допустим, вы храните обычную цену и цену со скидкой и хотите, чтобы цена со скидкой была ниже обычной цены:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0),
discounted_price numeric CHECK (discounted_price > 0),
CHECK (price > discounted_price)
);
Первые два ограничения описаны выше. Третье использует новый синтаксис. Он не привязан к определенному столбцу, а отображается как отдельный элемент в списке столбцов, разделенных запятыми. Определения столбцов и эти определения ограничений могут быть перечислены в смешанном порядке.
Мы говорим, что первые два ограничения являются ограничениями столбца, тогда как третье ограничение является ограничением таблицы, потому что оно написано отдельно от любого определения одного столбца. Ограничения столбца также могут быть записаны как ограничения таблицы, тогда как обратное не обязательно возможно, поскольку предполагается, что ограничение столбца относится только к столбцу, к которому оно прикреплено. (QHB не применяет это правило, но вы должны следовать ему, если хотите, чтобы определения таблиц работали с другими системами баз данных). Приведенный выше пример также можно записать так:
CREATE TABLE products (
product_no integer,
name text,
price numeric,
CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0),
CHECK (price > discounted_price)
);
или даже:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0 AND price > discounted_price)
);
Имена могут быть назначены ограничениям таблицы так же, как ограничения столбцов:
CREATE TABLE products (
product_no integer,
name text,
price numeric,
CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0),
CONSTRAINT valid_discount CHECK (price > discounted_price)
);
Важно отметить, что контрольное ограничение выполняется, если контрольное выражение имеет значение true или значение null. Поскольку большинство выражений будут иметь нулевое значение, если какой-либо операнд будет нулевым, они не будут предотвращать нулевые значения в ограниченных столбцах. Чтобы столбец не содержал нулевых значений, можно использовать ограничение NOT NULL, описанное в следующем разделе.
Примечание!!!
QHB не поддерживает контрольные ограничения, которые ссылаются на данные таблицы, кроме проверяемой новой или обновленной строки. Хотя контрольное ограничение которое нарушает это правило, может показаться работающим в простых тестах, оно не может гарантировать, что база данных не достигнет состояния, в котором условие ограничения ложно (из-за последующих изменений другой строки (строк)). Это может привести к сбою - база данных может завершиться с ошибкой, даже если полное состояние базы данных соответствует ограничению из-за того, что строки не загружаются в порядке, который будет удовлетворять ограничению. Если возможно, используйте ограничения UNIQUE, EXCLUDE или FOREIGN KEY для выражения ограничений между строками и таблицами.
Если вам требуется одноразовая проверка по отношению к другим строкам при вставке строки, а не постоянная гарантия согласованности, для ее реализации можно использовать пользовательский триггер. (Этот подход позволяет избежать проблемы сброса/перезагрузки, поскольку qhb_dump не переустанавливает триггеры до перезагрузки данных, поэтому проверка не будет выполняться во время выполнения дампа / перезагрузки).
Примечание!!!
QHB предполагает, что условия ограничений CHECK неизменны, то есть они всегда будут давать один и тот же результат для одной и той же входной строки. Это предположение оправдывает выполнение проверки на контрольное ограничение только при вставке или обновлении строки, а не в других случаях. (Вышеприведенное предупреждение о том, что не следует ссылаться на другие данные таблицы является частным случаем этого ограничения). Примером распространенного способа нарушить это предположение является ссылка на пользовательскую функцию в выражении CHECK, а затем изменение поведения этой функции. QHB не запрещает этого, но не заметит, есть ли в таблице строки, которые теперь нарушают ограничение CHECK. Это может вызвать сбой последующего дампа базы данных. Рекомендуемый способ обработки такого изменения состоит в том, чтобы удалить ограничение (используя ALTER TABLE), скорректировать определение функции и повторно добавить ограничение, таким образом перепроверив его для всех строк таблицы.
Ограничения not-null
Ограничение not-null (Not-Null constraints) указывает, что столбец не должен принимать null значение. Пример синтаксиса:
CREATE TABLE products (
product_no integer NOT NULL,
name text NOT NULL,
price numeric
);
Ограничение not-null всегда записывается как ограничение столбца. Ограничение not-null функционально эквивалентно созданию контрольного ограничения CHECK (column_name IS NOT NULL), но в QHB создание явного ограничения not-null более эффективно. Недостатком является то, что вы не можете дать явные имена ограничениям not-null, созданным таким образом.
Столбец может иметь более одного ограничения. Просто напишите ограничения один за другим:
CREATE TABLE products (
product_no integer NOT NULL,
name text NOT NULL,
price numeric NOT NULL CHECK (price > 0)
);
Порядок не имеет значения-ограничения могут проверяться в любом порядке.
Ограничение NOT NULL имеет обратное ограничение NULL. Это не означает, что столбец должен всегда быть нулевым - в таком случае он бесполезен. Вместо этого просто выбирается поведение по умолчанию, согласно которому столбец может быть пустым. Ограничение NULL отсутствует в стандарте SQL и не должно использоваться в переносимых приложениях. (Оно было добавлено только в QHB для совместимости с некоторыми системами баз данных). Однако такой синтаксис позволяет легко переключать ограничение в файле сценария. Например, вы можете начать с:
CREATE TABLE products (
product_no integer NULL,
name text NULL,
price numeric NULL
);
и затем вставьте ключевое слово NOT, где это необходимо.
Ограничения уникальности
Ограничения уникальности (UNIQUE constraints) гарантируют, что данные, содержащиеся в столбце или группе столбцов, являются уникальными среди всех строк в таблице. Синтаксис:
CREATE TABLE products (
product_no integer UNIQUE,
name text,
price numeric
);
когда задаётся как ограничение столбца, и:
CREATE TABLE products (
product_no integer,
name text,
price numeric,
UNIQUE (product_no)
);
когда задаётся, как ограничение таблицы.
Чтобы определить ограничение уникальности для группы столбцов, запишите его как ограничение таблицы с именами столбцов, разделенными запятыми:
CREATE TABLE example (
a integer,
b integer,
c integer,
UNIQUE (a, c)
);
Это указывает на то, что комбинация значений в указанных столбцах уникальна для всей таблицы, хотя любой из столбцов не обязательно должен быть (и обычно не является) уникальным.
Вы можете назначить свое собственное имя для ограничения уникальности обычным способом:
CREATE TABLE products (
product_no integer CONSTRAINT must_be_different UNIQUE,
name text,
price numeric
);
Добавление ограничения уникальности автоматически создаст уникальный индекс B-дерево для столбца или группы столбцов, перечисленных в ограничении. Ограничение уникальности, охватывающее только некоторые строки, не может быть записано как ограничения уникальности, но можно применить такое же ограничение, создав уникальный частичный индекс.
Как правило, ограничения уникальности нарушается, если в таблице имеется более одной строки, в которой значения всех столбцов, входящих в ограничение, равны. Однако два null значения никогда не считаются равными в этом сравнении. Это означает, что даже при наличии уникального ограничения можно хранить повторяющиеся строки, которые содержат null значение, по крайней мере, в одном из ограниченных столбцов. Такое поведение соответствует стандарту SQL, но другие базы данных SQL могут не следовать этому правилу. Поэтому будьте осторожны при разработке приложений, предназначенных для переносимости.
Ограничение первичного ключа
Ограничение первичного ключа (Primary Keys constraint) указывает, что столбец или группа столбцов могут использоваться в качестве уникального идентификатора для строк в таблице. Необходимо, чтобы значения были как уникальными, так и не нулевыми. Итак, следующие два определения таблицы принимают одинаковые данные:
CREATE TABLE products (
product_no integer UNIQUE NOT NULL,
name text,
price numeric
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
Первичные ключи могут занимать более одного столбца в этом случае синтаксис похож на ограничения уникальности:
CREATE TABLE example (
a integer,
b integer,
c integer,
PRIMARY KEY (a, c)
);
Добавление первичного ключа автоматически создаст уникальный индекс B-дерево для столбца или группы столбцов, перечисленных в первичном ключе, и заставит столбцы соответствовать ограничению NOT NULL.
Таблица не может иметь более одного первичного ключа. (Может быть любое количество уникальных и ненулевых ограничений, которые функционально почти одинаковы, но только одно может быть идентифицировано как первичный ключ). Теория реляционных баз данных требует, чтобы у каждой таблицы был первичный ключ. QHB не применяет это правило, но обычно его соблюдают.
Первичные ключи полезны как для целей документирования, так и для клиентских приложений. Например, приложение с графическим интерфейсом, которое позволяет изменять значения строк, скорее всего, должно знать первичный ключ таблицы, чтобы иметь возможность уникально идентифицировать строки. Существуют различные способы, которыми система баз данных использует первичный ключ, если он был объявлен, например, первичный ключ определяет целевой столбец (столбцы) по умолчанию для внешних ключей, ссылающихся на его таблицу.
Ограничение внешнего ключа
Ограничение внешнего ключа (foreign key constraint) указывает, что значения в столбце (или группе столбцов) должны соответствовать значениям, появляющимся в некоторой строке другой таблицы. Это ограничение поддерживает ссылочную целостность между двумя связанными таблицами.
Допустим, у вас есть таблица продуктов, которую мы уже использовали несколько раз:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
Предположим также, что у вас есть таблица с заказами этих продуктов. Мы хотим убедиться, что таблица заказов содержит только те заказы продуктов, которые действительно существуют. Для этого мы определяем ограничение внешнего ключа в таблице заказов, которая ссылается на таблицу продуктов:
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products (product_no),
quantity integer
);
Теперь невозможно создавать заказы с номерами продуктов отличными от NULL, которые отсутствуют в таблице продуктов.
В этой ситуации таблица заказов является дочерней таблицей, а таблица продуктов - родительской таблицей. Аналогично, есть ссылающиеся и упоминаемые столбцы.
Указанную выше команду можно сократить до:
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products,
quantity integer
);
потому что при отсутствии списка столбцов первичный ключ родительской таблицы используется в качестве упоминаемого столбца (столбцов).
Внешний ключ также может ограничивать и ссылаться на группу столбцов. Как обычно, его необходимо записать в виде табличного ограничения. Вот пример надуманного синтаксиса:
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
);
Количество и тип столбцов ограничения обязательно должны соответствовать количеству и типу ссылочных столбцов.
Вы можете назначить собственное имя для ограничения внешнего ключа обычным способом.
Таблица может иметь более одного ограничения внешнего ключа. Это используется для реализации отношений «многие ко многим» между таблицами. Скажем, у вас есть таблицы о продуктах и заказах, но теперь вы хотите, чтобы один заказ мог содержать много продуктов (что не разрешено в приведенной выше структуре). Вы можете использовать следующую структуру таблиц:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products,
order_id integer REFERENCES orders,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
Обратите внимание, что первичный ключ накладывается на внешние ключи в последней таблице.
Внешние ключи запрещают создание заказов, которые не относятся ни к каким продуктам. Но если продукт будет удален после создания заказа, который ссылается на него? SQL позволяет вам справиться и с этим. У нас есть несколько вариантов:
Чтобы проиллюстрировать это, давайте реализуем следующую политику в приведенном выше примере отношения «многие ко многим»: когда кто-то хочет удалить продукт, на который все еще ссылается заказ (через order_items), мы запрещаем его. Если кто-то удаляет заказ, элементы заказа также удаляются:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT,
order_id integer REFERENCES orders ON DELETE CASCADE,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
Ограничение внешнего ключа и каскадное удаление являются двумя наиболее распространенными вариантами. RESTRICT предотвращает удаление упоминаемой строки. NO ACTION означает, что если при проверке ограничения все еще существуют какие-либо ссылающиеся строки, то возникает ошибка - это поведение по умолчанию, если вы ничего не указали. (Существенное различие между этими двумя вариантами заключается в том, что NO ACTION позволяет отложить проверку до более поздней стадии в транзакции, тогда как RESTRICT этого не позволяет). CASCADE указывает, что при удалении строки, на которую есть ссылка, строки, ссылающиеся на нее, также должны быть автоматически удалены. Есть два других варианта: SET NULL и SET DEFAULT. Это приводит к тому, что ссылающиеся столбцы в ссылающейся строке становятся равными null или их значениям по умолчанию, соответственно, при удалении упоминаемой строки. Обратите внимание, что это не освобождает вас от соблюдения каких-либо других ограничений. Например, если действие указывает SET DEFAULT, но значение по умолчанию не удовлетворяет ограничению внешнего ключа, операция завершится ошибкой.
Аналогично ON DELETE также существует опция ON UPDATE которая вызывается при изменении (обновлении) упоминаемого столбца. Возможные действия одинаковы. В этом случае CASCADE означает, что обновленные значения упоминаемых столбцов должны быть скопированы также и в ссылающуюся строку.
Как правило, ссылающаяся строка не должна удовлетворять ограничению внешнего ключа, если какой-либо из ее ссылающихся столбцов равен null. Если к объявлению внешнего ключа добавляется MATCH FULL, то ссылающаяся строка экранируется, удовлетворяя ограничению, только если все ее ссылочные столбцы равны null (таким образом, сочетание нулевых и ненулевых значений гарантированно приведет к сбою ограничения MATCH FULL). Если вы не хотите, чтобы ссылающиеся строки не удовлетворяли ограничению внешнего ключа, объявите ссылающиеся столбцы как NOT NULL.
Внешний ключ должен ссылаться на столбцы, которые являются первичным ключом или образуют уникальное ограничение. Это означает, что упоминаемые столбцы всегда имеютсвязанный индекс (тот, который лежит в основе первичного ключа или ограничения уникальности) - поэтому проверка на соответствие ссылающейся строки будет эффективной. Поскольку удаление строки из упоминаемой таблицы или обновление упоминаемого столбца потребуется сканирование ссылающейся таблицы на наличие строк, соответствующих старому значению, часто рекомендуется также индексировать ссылающиеся столбцы. Поскольку это не всегда необходимо, и существует множество вариантов индексации, объявление ограничения внешнего ключа не создает автоматически индекс для ссылающихся столбцов.
Более подробная информация об обновлении и удалении данных приведена в главе Манипулирование данными. Также см. Описание синтаксиса ограничения внешнего ключа в справочной документации по CREATE TABLE.
Ограничения исключения
Ограничения исключения (Exclusion constraints) гарантируют, что, если любые две строки сравниваются по указанным столбцам или выражениям с использованием указанных операторов, то по крайней мере один из этих операторов сравнения вернет false или null. Синтаксис:
CREATE TABLE circles (
c circle,
EXCLUDE USING gist (c WITH &&)
);
Смотрите также CREATE TABLE ... CONSTRAINT ... EXCLUDE для подробностей.
Добавление ограничения исключения автоматически создаст индекс типа, указанного в объявлении ограничения.
Системные столбцы
Каждая таблица имеет несколько системных столбцов, которые неявно определяются системой. Следовательно, эти имена нельзя использовать в качестве имен пользовательских столбцов. (Обратите внимание, что эти ограничения не зависят от того, является ли имя ключевым словом или нет - цитирование имени не позволит вам обойти эти ограничения).
Системные столбцы
| Имя столбца | Назначение |
|---|---|
| tableoid | OID таблицы, содержащей эту строку. Этот столбец особенно удобен для запросов, которые выбираются из иерархий наследования (см. раздел Наследование, поскольку без него трудно определить, из какой отдельной таблицы получена строка. tableoid можно объединить со столбцом oid из таблицы pg_class чтобы получить имя таблицы |
| xmin | Идентификатор (идентификатор транзакции) вставляющей транзакции для этой версии строки. (Версия строки - это отдельное состояние строки, каждое обновление строки создает новую версию строки для той же логической строки) |
| cmin | Идентификатор команды (начиная с нуля) внутри транзакции |
| xmax | Идентификатор (идентификатор транзакции) удаляющей транзакции или ноль для неустановленной версии строки. Этот столбец может быть ненулевым в видимой версии строки. Обычно это означает, что транзакция удаления еще не зафиксирована или что попытка удаления была отменена |
| cmax | Идентификатор команды в транзакции удаления или ноль если запись не удалялась |
| ctid | Физическое местоположение версии строки в ее таблице. Обратите внимание, что хотя ctid можно использовать для быстрого поиска версии строки, ctid изменится, если он будет обновлен или перемещен с помощью операции VACUUM FULL. Поэтому ctid бесполезен в качестве долгосрочного идентификатора строки. Для логической идентификации строк должен использоваться первичный ключ |
Идентификаторы транзакций также являются 32-битными величинами. В долгоживущей базе данных можно начинать заново нумерацию для идентификаторов транзакций. Это не фатальная проблема с учетом соответствующих процедур обслуживания - см. главу Регулярные задачи обслуживания базы данных для деталей. Однако плохим решением будет зависеть от уникальности идентификаторов транзакций при длительной эксплуатации БД (более одного миллиарда транзакций).
Идентификаторы команд также являются 32-битными величинами. Это создает жесткий предел в 2^32 (примерно 4 миллиарда) команд SQL в одной транзакции. На практике это ограничение не является проблемой - обратите внимание, что ограничение на количество команд SQL, а не количество обработанных строк. Кроме того, только команды, которые фактически изменяют содержимое базы данных, будут использовать идентификатор команды.
Изменение таблиц
Когда вы создаете таблицу и понимаете, что допустили ошибку или изменились требования приложения, вы можете удалить таблицу и создать ее заново. Но это несамый удобный вариант, если таблица уже заполнена данными, или если на таблицу ссылаются другие объекты базы данных (например, ограничение внешнего ключа). Поэтому QHB предоставляет семейство команд для внесения изменений в существующие таблицы. Обратите внимание, что это принципиально отличается от изменения данных, содержащихся в таблице: здесь мы заинтересованы в изменении структуры таблицы.
Можно вносить следующие изменения в структуру таблицы:
Все эти действия выполняются с помощью команды ALTER TABLE, справочная страница которой содержит дополнительные подробности, кроме приведенных ниже.
Добавление столбца
Чтобы добавить столбец, используйте команду, например:
ALTER TABLE products ADD COLUMN description text;
Новый столбец изначально заполняется любым заданным значением по умолчанию (null, если вы не указано предложение DEFAULT).
Можно одновременно установить ограничения для столбца, используя обычный синтаксис:
ALTER TABLE products ADD COLUMN description text CHECK (description <> '');
Фактически все параметры, которые можно применить к описанию столбца в CREATE TABLE можно использовать в этой команде. Имейте в виду, однако, что значение по умолчанию должно удовлетворять заданным ограничениям, иначе ADD завершится с ошибкой. Кроме того, можно добавить ограничения позже (см. ниже) после того, как вы правильно заполнили новый столбец.
Удаление столбца
Чтобы удалить столбец, используйте команду, например:
ALTER TABLE products DROP COLUMN description;
Какие бы данные ни были в столбце, они исчезнут. Ограничения таблицы, включающие столбец, также удалятся. Однако, если на столбец ссылается ограничение внешнего ключа другой таблицы, QHB не будет автоматически отброшено это ограничение. Вы можете разрешить удаление всего, что зависит от столбца, добавив CASCADE:
ALTER TABLE products DROP COLUMN description CASCADE;
См. раздел Отслеживание зависимостей для знакомства с общим механизмом отслеживания зависимостей.
Добавление ограничения
Чтобы добавить ограничение, используется синтаксис ограничения таблицы. Например:
ALTER TABLE products ADD CHECK (name <> '');
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
Чтобы добавить ограничение not-null, которое нельзя записать как ограничение таблицы, используйте этот синтаксис:
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
Ограничение будет проверено немедленно, поэтому данные таблицы должны удовлетворять ограничению, прежде чем его можно будет добавить.
Снятие ограничения
Чтобы удалить ограничение, нужно знать его имя. Если имя задано, это легко. В противном случае система присваивает сгенерированное имя, которое необходимо выяснить. Команда для снятия ограничения может выглядить так:
ALTER TABLE products DROP CONSTRAINT some_name;
(Если вы имеете дело с сгенерированным именем ограничения, таким как $2, не забывайте, что вам нужно будет заключить его в двойные кавычки, чтобы сделать его действительным идентификатором).
Как и в случае удаления столбца, вам нужно добавить CASCADE если вы хотите удалить ограничение, от которого зависит что-то еще. Примером является то, что ограничение внешнего ключа зависит от ограничения уникального или первичного ключа для столбцов, на которые имеются ссылки.
Это работает одинаково для всех типов ограничений, кроме ограничений not-null, в связи с тем, что ограничения not-null не имеют имен. Чтобы удалить ограничение not-null, используйте:
ALTER TABLE products ALTER COLUMN product_no DROP NOT NULL;
Изменение значения столбца по умолчанию
Чтобы установить новое значение по умолчанию для столбца, используйте команду, например:
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
Обратите внимание, что выполнение этой команды не влияет на существующие строки в таблице, она просто меняет значение по умолчанию для будущих команд INSERT.
Чтобы удалить любое значение по умолчанию, используйте:
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
Это практически то же самое, что установка по умолчанию на null. Как следствие, не является ошибкой сбрасывать значение по умолчанию, если оно не было определено, потому что значение по умолчанию является неявным null значением.
Изменение типа данных столбца
Чтобы преобразовать столбец в другой тип данных, используйте команду, например:
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
Команда завершится успешно, только если каждая существующая запись в столбце может быть преобразована в новый тип путем неявного приведения. Если требуется более сложное преобразование, вы можете добавить предложение USING, в котором указано, как получить новые значения из старых.
QHB будет пытаться преобразовать значение столбца по умолчанию (если оно есть) в новый тип, а также проверить любые ограничения, связанные со столбцом. Но эти преобразования и проверки могут потерпеть неудачу или могут привести к неожиданным результатам. Часто лучше удалить любые ограничения на столбец перед изменением его типа, а затем добавить измененные ограничения.
Переименование столбца
Чтобы переименовать столбец:
ALTER TABLE products RENAME COLUMN product_no TO product_number;
Переименование таблицы
Чтобы переименовать таблицу:
ALTER TABLE products RENAME TO items;
Привилегии
При создании объекта ему назначается владелец. Обычно владельцем является роль, выполнившая команды создания. Для большинства типов объектов начальное состояние таково, что только владелец (или суперпользователь) может что-либо делать с объектом. Чтобы другие роли могли его использовать, необходимо предоставить привилегии.
Существуют различные виды привилегий: SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER, CREATE, CONNECT, TEMPORARY, EXECUTE и USAGE. Привилегии, применимые к конкретному объекту, различаются в зависимости от типа объекта (таблица, функция и т. д.). Более подробная информация о значениях этих привилегий приведена ниже. В следующих разделах и главах также будет показано, как используются эти привилегии.
Право изменять или уничтожать объект всегда является привилегией только владельца.
Объект может быть назначен новому владельцу с помощью команды ALTER соответствующего вида для объекта, например:
ALTER TABLE table_name OWNER TO new_owner;
Суперпользователи всегда могут это сделать, обычные роли могут делать это только в том случае, если они являются одновременно текущим владельцем объекта (или членом роли-владельца) и членом новой роли-владельца.
Для назначения привилегий используется команда GRANT. Например, если joe является существующей ролью, а accounts - существующей таблицей, привилегия для обновления таблицы может быть предоставлена с помощью:
GRANT UPDATE ON accounts TO joe;
Запись ALL вместо определенной привилегии предоставляет все привилегии, которые относятся к типу объекта.
Специальное имя роли «PUBLIC» можно использовать для предоставления привилегии каждой роли в системе. Кроме того, «групповые» роли могут быть установлены, чтобы помочь управлять привилегиями, когда существует много пользователей базы данных - подробности см. в главе Роли в базе данных.
Чтобы отозвать привилегию, используйте подходящую команду REVOKE:
REVOKE ALL ON accounts FROM PUBLIC;
Специальные привилегии владельца объекта (т.е. право выполнять DROP, GRANT, REVOKE и т. д.) всегда подразумеваются для владельца и не могут быть предоставлены или отозваны. Но владелец объекта может отозвать свои обычные привилегии, например, сделать таблицу доступной только для чтения как для себя, так и для других.
Обычно, только владелец объекта (или суперпользователь) может предоставить или отозвать привилегии для объекта. Тем не менее, можно предоставить привилегию «с опцией предоставления», которая дает получателю право предоставлять её в свою очередь другим лицам. Если опция предоставления впоследствии аннулируется, тогда все, кто получил привилегию от этого получателя (напрямую или через цепочку грантов), потеряют эту привилегию. Подробнее см. Справочные страницы GRANT и REVOKE.
Доступные привилегии:
| Привилегия | Описание |
|---|---|
| SELECT | Позволяет выполнять выбор из любого столбца или определенного столбца (столбцов) таблицы, представления, материализованного представления или другого табличного объекта. Также позволяет использовать *COPY TO. Эта привилегия также необходима для ссылки на существующие значения столбца в *UPDATE или DELETE. Для последовательностей эта привилегия также позволяет использовать функцию currval. Для больших объектов эта привилегия позволяет объекту быть прочитанным. |
| INSERT | Разрешает вставку новой строки в таблицу, представление и т. д. Может быть предоставлено определенным столбцам, в этом случае только командам INSERT могут быть назначены только эти столбцы (поэтому другие столбцы будут получать значения по умолчанию). Также позволяет использовать COPY FROM |
| UPDATE | Разрешает обновление любого столбца или определенного столбца (столбцов) таблицы, представления и т. Д. (На практике любая нетривиальная команда UPDATE также требует привилегии SELECT, поскольку она должна ссылаться на столбцы таблицы, чтобы определить, какие строки обновлять, и / или для вычисления новых значений для столбцов). SELECT ... FOR UPDATE и SELECT ... FOR SHARE также требуют эту привилегию как минимум для одного столбца в дополнение к привилегии SELECT. Для последовательностей эта привилегия позволяет использовать функции nextval и setval. Для больших объектов эта привилегия позволяет писать или очищать (TRUNCATE) объект. |
| DELETE | Позволяет удалить строки из таблицы, представления и т. д. (На практике любой нетривиальной команде DELETE также потребуется привилегия SELECT, поскольку она должна ссылаться на столбцы таблицы, чтобы определить, какие строки следует удалить). |
| TRUNCATE | Позволяет очистить таблицы, представления и т. д. |
| REFERENCES | Позволяет создать ограничение внешнего ключа, ссылающегося на таблицу или определенные столбцы таблицы. |
| TRIGGER | Позволяет создать триггер для таблицы, представления и т. д. |
| CREATE | Для баз данных позволяет создавать новые схемы и публикации в базе данных. Для схем позволяет создавать новые объекты внутри схемы. Чтобы переименовать существующий объект, вы должны владеть объектом и иметь эту привилегию для содержащей схемы.Для табличных пространств позволяет создавать таблицы, индексы и временные файлы в табличном пространстве и позволяет создавать базы данных, в которых табличное пространство является табличным пространством по умолчанию. (Обратите внимание, что отзыв этой привилегии не изменит размещение существующих объектов). |
| CONNECT | Позволяет грантополучателю подключаться к базе данных. Эта привилегия проверяется при запуске соединения (в дополнение к проверке любых ограничений, налагаемых qhb_hba.conf). |
| TEMPORARY | Позволяет создавать временные таблицы при использовании базы данных. |
| EXECUTE | Позволяет вызывать функцию или процедуру, включая использование любых операторов, которые реализованы поверх функции. Это единственный тип привилегий, применимый к функциям и процедурам. |
| USAGE | Для процедурных языков позволяет использовать язык для создания функций на этом языке. Это единственный тип привилегий, применимый к процедурным языкам.Для схем разрешает доступ к объектам, содержащимся в схеме (при условии, что собственные требования к привилегиям объектов также выполнены). По сути, это позволяет получателю « искать » объекты в схеме. Без этого разрешения все еще можно увидеть имена объектов, например, путем запроса системных каталогов. Кроме того, после отзыва этого разрешения существующие сеансы могут иметь операторы, которые ранее выполняли этот поиск, так что это не является полностью безопасным способом предотвращения доступа к объекту.Для последовательностей позволяет использовать функции currval и nextval.Для типов и доменов позволяет использовать тип или домен при создании таблиц, функций и других объектов схемы. (Обратите внимание, что эта привилегия не управляет всем « использованием » типа, например значениями типа, появляющимися в запросах. Она только предотвращает создание объектов, зависящих от типа. Основная цель этой привилегии - контролировать, какие пользователи могут создать зависимости от типа, которые могут помешать владельцу изменить тип позже).Для оболочек сторонних данных позволяет создавать новые серверы с использованием *foreign-data wrapper. Для сторонних серверов позволяет создавать сторонние таблицы с использованием сервера. Получатели могут также создавать, изменять или удалять свои собственные сопоставления пользователей, связанные с этим сервером. |
Права, требуемые для других команд, перечислены на странице ссылок соответствующей команды.
QHB предоставляет привилегии для некоторых типов объектов PUBLIC по умолчанию при создании объектов. PUBLIC по умолчанию не предоставляет никаких привилегий для таблиц, столбцов таблиц, последовательностей, внешних источников данных, внешних серверов, больших объектов, схем или табличных пространств. Для других типов объектов привилегиями по умолчанию, предоставляемыми PUBLIC являются:
Владелец объекта может, конечно, отозвать права по умолчанию и явно предоставленные привилегии. (Для обеспечения максимальной безопасности выполните команду REVOKE в той же транзакции, в которой создается объект тогда не будет промежутка, в котором другой пользователь может использовать объект). Кроме того, эти настройки привилегий по умолчанию можно изменить с помощью команды ALTER DEFAULT PRIVILEGES.
Таблица "Сокращения привилегий ACL" показывает однобуквенные сокращения, которые используются для этих типов привилегий в значениях ACL (Access Control List). Вы увидите эти буквы в выходных данных команд qsql, перечисленных ниже, или при просмотре столбцов ACL системных каталогов.
Таблица Сокращения привилегий ACL
| Льгота | Сокращенное название | Применимые типы объектов |
|---|---|---|
| SELECT | r («читать») | LARGE OBJECT, SEQUENCE, TABLE (и табличные объекты), столбец таблицы |
| INSERT | a («добавить») | TABLE, столбец таблицы |
| UPDATE | w («написать») | LARGE OBJECT, SEQUENCE, TABLE, столбец таблицы |
| DELETE | d | TABLE |
| TRUNCATE | D | TABLE |
| REFERENCES | x | TABLE, столбец таблицы |
| TRIGGER | t | TABLE |
| CREATE | C | DATABASE, SCHEMA, TABLESPACE |
| CONNECT | c | DATABASE |
| TEMPORARY | T | DATABASE |
| EXECUTE | X | FUNCTION, PROCEDURE |
| USAGE | U | DOMAIN, FOREIGN DATA WRAPPER, FOREIGN SERVER, LANGUAGE, SCHEMA, SEQUENCE, TYPE |
Таблица "Сводка прав доступа" объединяет привилегии, доступные для каждого типа объекта SQL, с использованием приведенных выше сокращений.
Таблица 4.2. Сводка прав доступа
| Тип объекта | Все привилегии | PUBLIC привилегии по умолчанию |
|---|---|---|
| DATABASE | CTc | Tc |
| DOMAIN | U | U |
| FUNCTION или PROCEDURE | X | X |
| FOREIGN DATA WRAPPER | U | none |
| FOREIGN SERVER | U | none |
| LANGUAGE | U | U |
| LARGE OBJECT | rw | none |
| SCHEMA | UC | none |
| SEQUENCE | rwU | none |
| TABLE (и табличные объекты) | arwdDxt | none |
| Столбец таблицы | arwx | none |
| TABLESPACE | C | none |
| TYPE | U | U |
Привилегии, которые были предоставлены для определенного объекта, отображаются в виде списка записей aclitem, где каждый aclitem описывает разрешения одного грантополучателя, которые были предоставлены конкретным лицом, предоставляющим право. Например, calvin=r*w/hobbes указывает, что роль calvin имеет привилегию SELECT (r) с опцией её предоставления (*), а также не подлежащую предоставлению привилегию UPDATE (w), обе из которых предоставлены ролью hobbes. Если calvin также имеет некоторые привилегии на тот же объект, предоставленные другим лицом, предоставляющим право, они будут отображаться как отдельная запись aclitem. Пустое поле грантополучателя в aclitem означает PUBLIC.
В качестве примера предположим, что пользователь miriam создает таблицу mytable и выполняет:
GRANT SELECT ON mytable TO PUBLIC;
GRANT SELECT, UPDATE, INSERT ON mytable TO admin;
GRANT SELECT (col1), UPDATE (col1) ON mytable TO miriam_rw;
Тогда команда qsql \dp покажет:
=> \dp mytable
Access privileges
Schema | Name | Type | Access privileges | Column privileges | Policies
--------+---------+-------+-----------------------+-----------------------+----------
public | mytable | table | miriam=arwdDxt/miriam+| col1: +|
| | | =r/miriam +| miriam_rw=rw/miriam |
| | | admin=arw/miriam | |
(1 row)
Если столбец «Access privileges» для данного объекта пуст, это означает, что объект имеет права по умолчанию (то есть запись его привилегий в соответствующем системном каталоге равна null). Привилегии по умолчанию всегда включают все привилегии для владельца и могут включать некоторые привилегии для PUBLIC в зависимости от типа объекта, как описано выше. При первом предоставлении или отзыве объекта создаются экземпляры привилегий по умолчанию (например, miriam=arwdDxt/miriam), а затем они изменяются в соответствии с указанным запросом. Аналогично, записи отображаются в «Column privileges» только для столбцов с привилегиями не по умолчанию. (Примечание: для этой цели «привилегии по умолчанию» всегда означают встроенные привилегии по умолчанию для типа объекта. Объект, чьи привилегии были затронуты командой ALTER DEFAULT PRIVILEGES, всегда будет отображаться с явной записью привилегии, включающей эффекты ALTER).
Обратите внимание, что неявные параметры предоставления прав владельца не отмечены в выводе привилегий доступа. А * появится только тогда, когда параметры прав были кому-либо явно предоставлены.
Политики безопасности строк
В дополнение к стандартной системе привилегий SQL, доступной через GRANT, таблицы могут иметь политики безопасности строк, которые ограничивают для каждого пользователя возможность того какие строки могут быть возвращены обычными запросами или вставлены, обновлены или удалены с помощью команд изменения данных. Эта функция также известна как «безопасность на уровне строк». По умолчанию таблицы не имеют никаких политик, поэтому, если у пользователя есть права доступа к таблице в соответствии с системой привилегий SQL, все строки в ней одинаково доступны для запроса или обновления.
Когда в таблице включена защита строк (с помощью ALTER TABLE ... ENABLE ROW LEVEL SECURITY), любой нормальный доступ к таблице для выбора строк или изменения строк должен быть разрешен политикой безопасности строк. (Однако владелец таблицы обычно не подчиняется политикам безопасности строк). Если для таблицы не существует политики, используется политика запрета по умолчанию, что означает, что строки не видны или не могут быть изменены. Операции, которые применяются ко всей таблице, такие как TRUNCATE и REFERENCES, не подлежат защите строк.
Политики безопасности строк могут быть специфичными для команд, ролей или для того и другого. Можно указать политику, применяемую ко всем командам или к SELECT, INSERT, UPDATE или DELETE. Несколько политик могут быть назначены для данной политики, и применяются нормальные правила членства и наследования ролей.
Чтобы указать, какие строки являются видимыми или изменяемыми в соответствии с политикой, требуется выражение, которое возвращает логический результат. Это выражение будет оцениваться для каждой строки перед проверкой любых условий или выполнения функций, поступающих из пользовательского запроса. (Единственным исключением из этого правила являются герметичные функции, которые гарантированно не допускают утечки информации - оптимизатор может выбрать применение таких функций перед проверкой безопасности строк). Строки, для которых выражение не возвращает true, не будут обрабатываться. Отдельные выражения могут быть указаны для обеспечения независимого контроля над видимыми строками и строками, которые могут быть изменены. Выражения политики выполняются как часть запроса с привилегиями пользователя, выполняющего запрос, хотя функции определения безопасности могут использоваться для доступа к данным, недоступным для вызывающего пользователя.
Суперпользователи и роли с атрибутом BYPASSRLS всегда обходят систему безопасности строк при доступе к таблице. Владельцы таблиц обычно также обходят защиту строк, хотя владелец таблицы может выбрать защиту строк с помощью ALTER TABLE ... FORCE ROW LOWEL SECURITY.
Включение и отключение защиты строк, а также добавление политик в таблицу всегда является привилегией только владельца таблицы.
Политики создаются с помощью команды CREATE POLICY, изменяются с помощью команды ALTER POLICY и удаляются с помощью команды DROP POLICY. Чтобы включить и отключить защиту строк для данной таблицы, используйте команду ALTER TABLE.
У каждой политики есть имя, и для таблицы можно определить несколько политик. Поскольку политики зависят от таблицы, каждая политика для таблицы должна иметь уникальное имя. Разные таблицы могут иметь политики с одинаковым именем.
Когда к данному запросу применяются несколько политик, они объединяются либо с помощью OR (для разрешающих политик, которые используются по умолчанию), либо с помощью AND (для ограничительных политик). Это похоже на правило, согласно которому данная роль обладает привилегиями всех ролей, членом которых они являются. Разрешительные и ограничительные политики обсуждаются ниже.
В качестве простого примера ниже показано, как создать политику в отношении account чтобы разрешить доступ к строкам только членам роли managers и только строкам их учетных записей:
CREATE TABLE accounts (manager text, company text, contact_email text);
ALTER TABLE accounts ENABLE ROW LEVEL SECURITY;
CREATE POLICY account_managers ON accounts TO managers
USING (manager = current_user);
Приведенная выше политика неявно предоставляет предложение WITH CHECK, идентичное его предложению USING, так что ограничение применяется как к строкам, выбранным командой (таким образом, менеджер не может SELECT, UPDATE или DELETE существующих строк, принадлежащих другому менеджеру), так и к строкам, измененным командой (таким образом, строки, принадлежащие другому менеджеру, не могут быть созданы с помощью INSERT или UPDATE).
Если роль не указана или используется специальное имя пользователя PUBLIC, то политика применяется ко всем пользователям в системе. Чтобы разрешить всем пользователям доступ только к своей строке в таблице users, можно использовать простую политику:
CREATE POLICY user_policy ON users
USING (user_name = current_user);
Это работает аналогично предыдущему примеру.
Чтобы использовать другую политику для строк, добавляемых в таблицу, по сравнению с видимыми строками, можно объединить несколько политик. Эта пара политик позволит всем пользователям просматривать все строки в таблице users, но изменять только свои собственные:
CREATE POLICY user_sel_policy ON users
FOR SELECT
USING (true);
CREATE POLICY user_mod_policy ON users
USING (user_name = current_user);
В команде SELECT эти две политики объединяются с использованием OR, в результате чего можно выбрать все строки. В других типах команд применяется только вторая политика, так что эффекты такие же, как и раньше.
Защита строк также может быть отключена с помощью команды ALTER TABLE. Отключение защиты строк не приводит к удалению политик, определенных в таблице - они просто игнорируются. Затем все строки в таблице становятся видимыми и изменяемыми в соответствии со стандартной системой привилегий SQL.
Ниже приведен более крупный пример того, как эту функцию можно использовать в производственных средах. Таблица passwd эмулирует файл паролей Unix:
-- Simple passwd-file based example
CREATE TABLE passwd (
user_name text UNIQUE NOT NULL,
pwhash text,
uid int PRIMARY KEY,
gid int NOT NULL,
real_name text NOT NULL,
home_phone text,
extra_info text,
home_dir text NOT NULL,
shell text NOT NULL
);
CREATE ROLE admin; -- Administrator
CREATE ROLE bob; -- Normal user
CREATE ROLE alice; -- Normal user
-- Populate the table
INSERT INTO passwd VALUES
('admin','xxx',0,0,'Admin','111-222-3333',null,'/root','/bin/dash');
INSERT INTO passwd VALUES
('bob','xxx',1,1,'Bob','123-456-7890',null,'/home/bob','/bin/zsh');
INSERT INTO passwd VALUES
('alice','xxx',2,1,'Alice','098-765-4321',null,'/home/alice','/bin/zsh');
-- Be sure to enable row level security on the table
ALTER TABLE passwd ENABLE ROW LEVEL SECURITY;
-- Create policies
-- Administrator can see all rows and add any rows
CREATE POLICY admin_all ON passwd TO admin USING (true) WITH CHECK (true);
-- Normal users can view all rows
CREATE POLICY all_view ON passwd FOR SELECT USING (true);
-- Normal users can update their own records, but
-- limit which shells a normal user is allowed to set
CREATE POLICY user_mod ON passwd FOR UPDATE
USING (current_user = user_name)
WITH CHECK (
current_user = user_name AND
shell IN ('/bin/bash','/bin/sh','/bin/dash','/bin/zsh','/bin/tcsh')
);
-- Allow admin all normal rights
GRANT SELECT, INSERT, UPDATE, DELETE ON passwd TO admin;
-- Users only get select access on public columns
GRANT SELECT
(user_name, uid, gid, real_name, home_phone, extra_info, home_dir, shell)
ON passwd TO public;
-- Allow users to update certain columns
GRANT UPDATE
(pwhash, real_name, home_phone, extra_info, shell)
ON passwd TO public;
Как и при любых настройках безопасности, важно протестировать и убедиться, что система работает должным образом. В приведенном выше примере показано, что система разрешений работает правильно.
-- admin can view all rows and fields
qhb=> set role admin;
SET
qhb=> table passwd;
user_name | pwhash | uid | gid | real_name | home_phone | extra_info | home_dir | shell
-----------+--------+-----+-----+-----------+--------------+------------+-------------+-----------
admin | xxx | 0 | 0 | Admin | 111-222-3333 | | /root | /bin/dash
bob | xxx | 1 | 1 | Bob | 123-456-7890 | | /home/bob | /bin/zsh
alice | xxx | 2 | 1 | Alice | 098-765-4321 | | /home/alice | /bin/zsh
(3 rows)
-- Test what Alice is able to do
qhb=> set role alice;
SET
qhb=> table passwd;
ERROR: permission denied for relation passwd
qhb=> select user_name,real_name,home_phone,extra_info,home_dir,shell from passwd;
user_name | real_name | home_phone | extra_info | home_dir | shell
-----------+-----------+--------------+------------+-------------+-----------
admin | Admin | 111-222-3333 | | /root | /bin/dash
bob | Bob | 123-456-7890 | | /home/bob | /bin/zsh
alice | Alice | 098-765-4321 | | /home/alice | /bin/zsh
(3 rows)
qhb=> update passwd set user_name = 'joe';
ERROR: permission denied for relation passwd
-- Alice is allowed to change her own real_name, but no others
qhb=> update passwd set real_name = 'Alice Doe';
UPDATE 1
qhb=> update passwd set real_name = 'John Doe' where user_name = 'admin';
UPDATE 0
qhb=> update passwd set shell = '/bin/xx';
ERROR: new row violates WITH CHECK OPTION for "passwd"
qhb=> delete from passwd;
ERROR: permission denied for relation passwd
qhb=> insert into passwd (user_name) values ('xxx');
ERROR: permission denied for relation passwd
-- Alice can change her own password; RLS silently prevents updating other rows
qhb=> update passwd set pwhash = 'abc';
UPDATE 1
Все созданные до сих пор политики были разрешающими, то есть при применении нескольких политик они объединяются с использованием логического оператора «ИЛИ». Хотя разрешающие политики могут создаваться так, чтобы разрешать доступ к строкам только в намеченных случаях, может быть проще объединить разрешающие политики с ограничительными политиками (которые должны пропускать записи и которые объединяются с использованием логического оператора «И»). Основываясь на приведенном выше примере, мы добавляем ограничительную политику, требующую подключения администратора через локальный сокет Unix для доступа к записям таблицы passwd:
CREATE POLICY admin_local_only ON passwd AS RESTRICTIVE TO admin
USING (pg_catalog.inet_client_addr() IS NULL);
Затем мы можем увидеть, что администратор, подключающийся по сети, не увидит никаких записей из-за ограничительной политики:
=> SELECT current_user;
current_user
--------------
admin
(1 row)
=> select inet_client_addr();
inet_client_addr
------------------
127.0.0.1
(1 row)
=> SELECT current_user;
current_user
--------------
admin
(1 row)
=> TABLE passwd;
user_name | pwhash | uid | gid | real_name | home_phone | extra_info | home_dir | shell
-----------+--------+-----+-----+-----------+------------+------------+----------+-------
(0 rows)
=> UPDATE passwd set pwhash = NULL;
UPDATE 0
Проверки ссылочной целостности, такие как ограничения уникальных или первичных ключей и ссылки на внешние ключи, всегда обходят защиту строк, чтобы обеспечить целостность данных. При разработке схем и политик на уровне строк необходимо соблюдать осторожность, чтобы избежать утечек информации по «скрытому каналу» посредством таких проверок ссылочной целостности.
В некоторых случаях важно быть уверенным, что защита строк не применяется. Например, при создании резервной копии это может привести к катастрофическим последствиям, если политика безопасности строк приведет к исключению некоторых строк из резервной копии. В такой ситуации вы можете отключить параметр конфигурации row_security. Это само по себе не обходит безопасность строк - он выдает ошибку, если результаты какого-либо запроса будут отфильтрованы политикой. Причина ошибки может быть затем исследована и исправлена.
В приведенных выше примерах политики учитывают только текущие значения в строке, к которым осуществляется доступ или которые обновляются. Это самый простой и наиболее эффективный случай - когда это возможно, лучше всего разрабатывать приложения для защиты строк таким образом. Если необходимо обратиться к другим строкам или другим таблицам для принятия решения о политике, это может быть выполнено с использованием вложенных элементов SELECT или функций, содержащих SELECT**, в выражениях политики. Имейте в виду, однако, что такой доступ может создать условия, которые могут привести к утечке информации, если не принять меры предосторожности. В качестве примера рассмотрим следующую конструкцию таблицы:
-- definition of privilege groups
CREATE TABLE groups (group_id int PRIMARY KEY,
group_name text NOT NULL);
INSERT INTO groups VALUES
(1, 'low'),
(2, 'medium'),
(5, 'high');
GRANT ALL ON groups TO alice; -- alice is the administrator
GRANT SELECT ON groups TO public;
-- definition of users' privilege levels
CREATE TABLE users (user_name text PRIMARY KEY,
group_id int NOT NULL REFERENCES groups);
INSERT INTO users VALUES
('alice', 5),
('bob', 2),
('mallory', 2);
GRANT ALL ON users TO alice;
GRANT SELECT ON users TO public;
-- table holding the information to be protected
CREATE TABLE information (info text,
group_id int NOT NULL REFERENCES groups);
INSERT INTO information VALUES
('barely secret', 1),
('slightly secret', 2),
('very secret', 5);
ALTER TABLE information ENABLE ROW LEVEL SECURITY;
-- a row should be visible to/updatable by users whose security group_id is
-- greater than or equal to the row's group_id
CREATE POLICY fp_s ON information FOR SELECT
USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
CREATE POLICY fp_u ON information FOR UPDATE
USING (group_id <= (SELECT group_id FROM users WHERE user_name = current_user));
-- we rely only on RLS to protect the information table
GRANT ALL ON information TO public;
Теперь предположим, что alice хочет изменить «слегка партиретную» информацию, но решает, что mallory не следует доверять новое содержимое этой строки, поэтому она делает:
BEGIN;
UPDATE users SET group_id = 1 WHERE user_name = 'mallory';
UPDATE information SET info = 'secret from mallory' WHERE group_id = 2;
COMMIT;
Это выглядит безопасно - нет промежутка между выполнением команд, в котором mallory должен видеть строку «secret от mallory». Тем не менее, здесь есть условия гонки. Если mallory одновременно делает, скажем,
SELECT * FROM information WHERE group_id = 2 FOR UPDATE;
и его транзакция находится в режиме READ COMMITTED, он может видеть «секрет от mallory». Это происходит, если его транзакция достигает информационной строки сразу после транзакции alice. Он блокирует ожидание фиксации транзакции alice, а затем извлекает обновленное содержимое строки благодаря предложению FOR UPDATE. Однако он не извлекает обновленную строку для неявного SELECT from users, потому что этот sub-SELECT не имел FOR UPDATE - вместо этого строка users читается из снимка, сделанного в начале запроса. Поэтому выражение политики проверяет старое значение уровня привилегий mallory и позволяет ему видеть обновленную строку.
Есть несколько способов обойти эту проблему. Одним простым ответом является использование SELECT ... FOR SHARE в параметрах SELECT в политиках безопасности строк. Однако для этого необходимо предоставить привилегию UPDATE для ссылочной таблицы (в данном случае users) заинтересованным пользователям, что может быть нежелательным. (Но можно применить другую политику безопасности строк, чтобы предотвратить их фактическое использование этой привилегии или встроить подзапрос в функцию определения безопасности). Кроме того, интенсивное одновременное использование блокировок общего ресурса строки в ссылочной таблице может привести к снижению производительности, особенно если строку часто обновляют. Другое практическое решение, если обновления ссылочной таблицы происходят нечасто — установить исключительную блокировку ссылочной таблицы при ее обновлении, чтобы никакие параллельные транзакции не могли проверять старые значения строк. Или можно просто дождаться завершения всех одновременных транзакций после фиксации обновления таблицы, на которую есть ссылка, начавшихся до внесения изменений, основанных на новой ситуации безопасности.
Для получения дополнительной информации см. CREATE POLICY и ALTER TABLE.
Схемы
Кластер баз данных QHB содержит одну или несколько именованных баз данных. Пользователи и группы пользователей являются общими для всего кластера, но никакие другие данные не передаются между базами данных. Любое данное клиентское соединение с сервером может получить доступ только к объектам в одной базе данных, указанной в запросе на соединение.
Пользователи кластера не обязательно имеют право доступа к каждой базе данных в кластере. Совместное использование имен пользователей означает, что не может быть разных пользователей с именем, скажем, joe в двух базах данных в одном кластере, но система может быть настроена так, чтобы позволить joe доступ только к некоторым базам данных.
База данных содержит одну или несколько именованных схем, которые в свою очередь содержат таблицы. Схемы также содержат другие виды именованных объектов, включая типы данных, функции и операторы. Одно и то же имя объекта может использоваться в разных схемах без конфликтов - например, и schema1 и myschema могут содержать таблицы с именем mytable. В отличие от баз данных, схемы жестко не разделены: пользователь может получить доступ к объектам в любой из схем в базе данных, к которой он подключен, если у него есть права для этого.
Существует несколько причин, по которым можно использовать схемы:
Схемы аналогичны каталогам на уровне операционной системы, за исключением того, что схемы не могут быть вложенными.
Создание схемы
Чтобы создать схему, используйте команду CREATE SCHEMA. Дайте схеме имя по вашему выбору. Например:
CREATE SCHEMA myschema;
Чтобы создать или получить доступ к объектам в схеме, напишите полное имя, состоящее из имени схемы и имени таблицы, разделенных точкой:
schema.table
Это работает везде, где ожидается имя таблицы, включая команды изменения таблицы и команды доступа к данным, обсуждаемые в следующих главах. (Для краткости мы будем говорить только о таблицах, но те же идеи применимы и к другим видам именованных объектов, таких как типы и функции).
На самом деле, даже более общий синтаксис
database.schema.table
тоже можно использовать, но в настоящее время это только для формального соответствия стандарту SQL. Если вы пишете имя базы данных, оно должно совпадать с именем базы данных, к которой вы подключены.
Итак, чтобы создать таблицу в новой схеме, используйте:
CREATE TABLE myschema.mytable (
...
);
Чтобы удалить схему, если она пуста (все объекты в ней удалены), используйте:
DROP SCHEMA myschema;
Чтобы удалить схему, включающую все содержащиеся в ней объекты, используйте:
DROP SCHEMA myschema CASCADE;
См. раздел Отслеживание зависимостей для знакомства с общим механизмом отслеживания зависимостей.
Часто необходимо создать схему, принадлежащую кому-то другому (поскольку это один из способов ограничить действия ваших пользователей четко определенными пространствами имен). Синтаксис для этого следующий:
CREATE SCHEMA schema_name AUTHORIZATION user_name;
Вы даже можете опустить имя схемы, и в этом случае имя схемы будет таким же, как имя пользователя. См. раздел Шаблоны использования о том, как это может быть полезно.
Имена схем, начинающиеся с pg_, зарезервированы для системных целей и не могут быть созданы пользователями.
Схема Public
В предыдущих разделах мы создавали таблицы без указания имен схем. По умолчанию такие таблицы (и другие объекты) автоматически помещаются в схему с именем public. Каждая новая база данных содержит такую схему. Таким образом, следующее эквивалентно:
CREATE TABLE products (...);
и:
CREATE TABLE public.products (...);
Путь поиска схемы
Квалифицированные имена загромождают текст, и зачастую лучше не связывать конкретное имя схемы с приложениями. Поэтому таблицы часто называются неквалифицированными именами, которые состоят только из имени таблицы. Система определяет, какая таблица имеется в виду, следуя "пути поиска" (search_path), который представляет собой список схем для поиска нужного объекта. Первая подходящая таблица в пути поиска считается обнаруженной. Если в пути поиска нет совпадений, сообщается об ошибке, даже если совпадающие имена таблиц существуют в других схемах в базе данных.
Возможность создавать объекты с одинаковыми именами в разных схемах усложняет написание запроса, который каждый раз ссылается на одни и те же объекты. Это также открывает возможность для пользователей изменять поведение запросов других пользователей, злонамеренно или случайно. Из-за преобладания неквалифицированных имен в запросах и их использования во внутренних структурах QHB, добавление схемы в search_path эффективно доверяет всем пользователям, имеющим привилегию CREATE для этой схемы. Когда вы запускаете обычный запрос, злонамеренный пользователь, способный создавать объекты в схеме вашего пути поиска, может взять на себя управление и выполнять произвольные функции SQL, как если бы вы их выполняли.
Первая схема, названная в пути поиска, называется текущей схемой. Помимо первой найденной схемы, это также схема, в которой будут создаваться новые таблицы, если команда CREATE TABLE не задает имя схемы.
Чтобы показать текущий путь поиска, используйте следующую команду:
SHOW search_path;
В настройках по умолчанию это возвращает:
search_path
--------------
"$user", public
Первый элемент указывает, что схема с тем же именем, что и текущий пользователь, должна быть найдена. Если такой схемы не существует, запись игнорируется. Второй элемент относится к публичной схеме, которую мы уже видели.
Первая схема в пути поиска является местоположением по умолчанию для создания новых объектов. По этой причине по умолчанию объекты создаются в общедоступной схеме. Когда на объекты ссылаются в любом другом контексте без квалификации схемы (изменение таблицы, изменение данных или команды запроса), путь поиска проходится до тех пор, пока не будет найден соответствующий объект. Следовательно, в конфигурации по умолчанию любой неквалифицированный доступ снова может ссылаться только на общедоступную схему.
Чтобы поместить нашу новую схему в путь, необходимо использовать:
SET search_path TO myschema,public;
(Мы опускаем здесь $user потому что нам это не нужно). И тогда мы можем получить доступ к таблице без уточнения схемы:
DROP TABLE mytable;
Кроме того, поскольку myschema является первым элементом в пути, в нем по умолчанию будут создаваться новые объекты.
Мы могли бы также написать:
SET search_path TO myschema;
Теперь у нас больше нет доступа к публичной схеме без явной квалификации. В общедоступной схеме нет ничего особенного, кроме того, что она существует по умолчанию. Его тоже можно отбросить.
Смотрите также раздел Системные информационные функции и операторы для знакомства с другими способами управления путем поиска схемы.
Путь поиска работает таким же образом для имен типов данных, имен функций и операторов, как и для имен таблиц. Типы данных и имена функций могут быть определены точно так же, как и имена таблиц. Если вам нужно записать в выражение квалифицированное имя оператора, существует специальное условие: вы должны написать:
OPERATOR(schema.operator)
Это необходимо, чтобы избежать синтаксической неоднозначности. Примером является:
SELECT 3 OPERATOR(pg_catalog.+) 4;
На практике каждый обычно полагается на путь поиска операторов, чтобы не было необходимости писать что-то наподобие этого.
Схемы и привилегии
По умолчанию пользователи не могут получить доступ к объектам в схемах, которыми они не владеют. Для этого владелец схемы должен предоставить привилегию USAGE для этой схемы. Чтобы разрешить пользователям использовать объекты в схеме, могут потребоваться дополнительные привилегии в зависимости от объекта.
Пользователю также может быть разрешено создавать объекты в чужой схеме. Для этого необходимо предоставить привилегию CREATE для схемы. Обратите внимание, что по умолчанию все имеют привилегии CREATE и USAGE в схеме public. Это позволяет всем пользователям, которые могут подключаться к определенной базе данных, создавать объекты в ее схеме public. Некоторые шаблоны использования требуют отзыва этой привилегии:
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
(Первый «public» — это схема, второй «public» означает «каждый пользователь». В первую очередь это идентификатор, во вторую очередь это ключевое слово, отсюда и другая заглавная буква см. раздел Идентификаторы и ключевые слова.
Схема системного каталога
В дополнение к public и созданным пользователем схемам каждая база данных содержит схему pg_catalog, которая содержит системные таблицы и все встроенные типы данных, функции и операторы. pg_catalog всегда является эффективной частью пути поиска. Если он не указан явно в пути, тогда он неявно ищется перед поиском схем пути. Это гарантирует, что встроенные имена всегда будут доступны для поиска. Тем не менее, вы можете явно разместить pg_catalog в конце вашего пути поиска, если вы предпочитаете, чтобы определяемые пользователем имена переопределяли встроенные имена.
Поскольку имена системных таблиц начинаются с pg_, лучше избегать таких имен, чтобы избежать конфликта, если в какой-то будущей версии будет определена системная таблица с именем, совпадающим с вашей таблицей. (При использовании пути поиска по умолчанию неквалифицированная ссылка на имя вашей таблицы будет разрешена как системная таблица). Системные таблицы будут продолжать следовать условию иметь имена, начинающиеся с pg_, так что они не будут конфликтовать с неквалифицированными именами пользовательских таблиц, если пользователи избегают префикса pg_.
Шаблоны использования
Схемы могут быть использованы для организации ваших данных различными способами. Шаблон использования защищенной схемы не позволяет ненадежным пользователям изменять поведение запросов других пользователей. Когда база данных не использует шаблон использования защищенной схемы, пользователи, желающие безопасно запросить объекты этй базы данных, будут предпринимать необходимые действия в начале каждого сеанса. В частности, они будут начинать каждый сеанс, устанавливая search_path в пустую строку или иным образом удаляя схемы, не доступные для записи суперпользователем, из search_path. Существует несколько шаблонов использования, поддерживаемых конфигурацией по умолчанию:
Для любого шаблона, чтобы установить общие приложения (таблицы, которые будут использоваться всеми, дополнительные функции, предоставленные третьими лицами и т. д.), поместите их в отдельные схемы. Не забудьте предоставить соответствующие привилегии, чтобы позволить другим пользователям доступ к ним. Затем пользователи могут ссылаться на эти дополнительные объекты, квалифицируя имена с помощью имени схемы, или они могут помещать дополнительные схемы в свой путь поиска по своему выбору.
Возможность переноса
В стандарте SQL понятие объектов в одной и той же схеме, принадлежащих разным пользователям, не существует. Более того, некоторые реализации не позволяют создавать схемы, имена которых отличаются от их владельцев. Фактически, понятия схемы и пользователя почти эквивалентны в системе баз данных, которая реализует только базовую поддержку схемы, указанную в стандарте. Поэтому многие пользователи считают, что квалифицированные имена действительно состоят из user_name.table_name. Именно так будет вести себя QHB, если вы создадите схему для каждого пользователя.
Кроме того, в стандарте SQL отсутствует понятие public схемы. Для максимального соответствия стандарту не следует использовать public схему.
Конечно, некоторые системы баз данных SQL могут вообще не реализовывать схемы или предоставлять поддержку пространства имен, разрешая (возможно ограниченный) доступ к базе данных. Если вам нужно работать с этими системами, максимальная переносимость будет достигнута, если вообще не использовать схемы.
Наследование
QHB реализует наследование таблиц, что может быть полезным инструментом для разработчиков баз данных. (SQL: 1999 и более поздние версии определяют функцию наследования типов, которая во многих отношениях отличается от функций, описанных здесь).
Давайте начнем с примера: предположим, что мы пытаемся построить модель данных для городов. В каждом штате много городов, но только одна столица. Мы хотим иметь возможность быстро получить столицу для любого конкретного штата. Это можно сделать, создав две таблицы: одну для столиц штатов и одну для городов, которые не являются столицами. Однако, что происходит, когда мы хотим запросить данные о городе, независимо от того, является ли он столицей или нет? Функция наследования может помочь решить эту проблему. Мы определяем таблицу capitals чтобы она наследовала от cities:
CREATE TABLE cities (
name text,
population float,
altitude int -- in feet
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
В этом случае таблица capitals наследует все столбцы своей родительской таблицы, cities. Столицы штатов также имеют дополнительный столбец, в котором указано их состояние.
В QHB таблица может наследовать от нуля или более других таблиц, а запрос может ссылаться либо на все строки таблицы, либо на все строки таблицы плюс все ее потомки. Последнее поведение по умолчанию. Например, следующий запрос находит названия всех городов, включая столицы штатов, которые расположены на высоте более 500 футов:
SELECT name, altitude
FROM cities
WHERE altitude > 500;
Учитывая пример данных из руководства (см. раздел Вступление), этот запрос возвращает:
name | altitude
----------+----------
Las Vegas | 2174
Mariposa | 1953
Madison | 845
С другой стороны, следующий запрос находит все города, которые не являются столицами штатов и расположены на высоте более 500 футов:
SELECT name, altitude
FROM ONLY cities
WHERE altitude > 500;
name | altitude
-----------+----------
Las Vegas | 2174
Mariposa | 1953
Здесь ключевое слово ONLY указывает, что запрос должен применяться только к cities, а не к таблицам ниже cities в иерархии наследования. Многие из команд, которые мы уже обсуждали - SELECT, UPDATE и DELETE - поддерживают ключевое слово ONLY.
Вы также можете написать имя таблицы с завершающим * чтобы явно указать, что таблицы-потомки включены:
SELECT name, altitude
FROM cities*
WHERE altitude > 500;
Запись * не обязательна, так как это поведение всегда по умолчанию.
В некоторых случаях вы можете узнать, из какой таблицы произошла конкретная строка. В каждой таблице есть системный столбец с именем tableoid который может указать tableoid таблицу:
SELECT c.tableoid, c.name, c.altitude
FROM cities c
WHERE c.altitude > 500;
который возвращает:
tableoid | name | altitude
----------+-----------+----------
139793 | Las Vegas | 2174
139793 | Mariposa | 1953
139798 | Madison | 845
(Если вы попытаетесь воспроизвести этот пример, вы, вероятно, получите разные числовые OID) jбъединенив oid с pg_class вы увидите фактические имена таблиц:
SELECT p.relname, c.name, c.altitude
FROM cities c, pg_class p
WHERE c.altitude > 500 AND c.tableoid = p.oid;
который возвращает:
relname | name | altitude
----------+-----------+----------
cities | Las Vegas | 2174
cities | Mariposa | 1953
capitals | Madison | 845
Другой способ получить тот же эффект - использовать псевдоним типа regclass, который будет символически печатать OID таблицы:
SELECT c.tableoid::regclass, c.name, c.altitude
FROM cities c
WHERE c.altitude > 500;
Наследование автоматически не распространяет данные из команд INSERT или COPY в другие таблицы в иерархии наследования. В нашем примере следующая INSERT завершится ошибкой:
INSERT INTO cities (name, population, altitude, state)
VALUES ('Albany', NULL, NULL, 'NY');
Мы можем надеяться, что данные будут каким-то образом перенаправлены в таблицу capitals, но этого не происходит: INSERT всегда вставляет именно в указанную таблицу.
Все контрольные ограничения и ограничения not-null родительской таблицы автоматически наследуются ее дочерними элементами, если явно не указано иное с предложениями NO INHERIT. Другие типы ограничений (уникальный, первичный ключ и ограничения внешнего ключа) не наследуются.
Таблица может наследоваться от нескольких родительских таблиц, в этом случае она имеет объединение столбцов, определенных родительскими таблицами. К ним добавляются все столбцы, объявленные в определении дочерней таблицы. Если одно и то же имя столбца появляется в нескольких родительских таблицах или в родительской таблице, и в определении дочернего элемента, то эти столбцы «объединяются» таким образом, чтобы в дочерней таблице был только один такой столбец. Для объединения столбцы должны иметь одинаковые типы данных, иначе возникает ошибка. Наследуемые контрольные ограничения и ограничения not-null объединяются аналогичным образом. Так, например, объединенный столбец будет помечен как not-null, если любое из определений столбца, из которого он получен, будет помечен как not-null. Контрольные ограничения объединяются, если они имеют одинаковые имена, и объединение не будет выполнено, если их условия различны.
Наследование таблиц обычно устанавливается при создании дочерней таблицы, используя предложение INHERITS оператора CREATE TABLE. В качестве альтернативы, к таблице, которая уже определена совместимым способом, может быть добавлено новое родительское отношение, используя INHERIT вариант ALTER TABLE. Для этого новая дочерняя таблица должна уже включать столбцы с теми же именами и типами, что и столбцы родительской таблицы. Она также должна включать контрольные ограничения с теми же именами и контрольными выражениями, что и у родительской. Аналогично ссылка наследования может быть удалена из дочернего элемента, используя NO INHERIT вариант ALTER TABLE. Динамическое добавление и удаление таких связей на наследование, может быть полезно, когда отношение наследования используется для разбиения таблиц (см. раздел Партиционирование таблиц).
Одним из удобных способов создания совместимой таблицы, которая впоследствии станет новым дочерним элементом, является использование предложения LIKE в CREATE TABLE. Это создаст новую таблицу с теми же столбцами, что и исходная таблица. Если в исходной таблице есть какие-либо контрольные ограничения, то следует указать параметр INCLUDING CONSTRAINTS для LIKE, поскольку новый потомок должен иметь ограничения, соответствующие родительским чтобы считаться совместимым.
Родительская таблица не может быть удалена, пока остаются ее дочерние элементы. Столбцы или контрольные ограничения дочерних таблиц также не могут быть удалены или изменены, если они унаследованы от каких-либо родительских таблиц. Если вы хотите удалить таблицу и всех ее потомков, одним из простых способов является удаление родительской таблицы с опцией CASCADE(см. раздел Отслеживание зависимостей).
ALTER TABLE будет распространять любые изменения в определениях данных столбцов и проверит ограничения вниз по иерархии наследования. Опять же, удаление столбцов, зависящих от других таблиц, возможно только при использовании опции CASCADE. ALTER TABLE следует тем же правилам объединения и отклонения дубликатов столбцов, которые применяются в команде CREATE TABLE.
Унаследованные запросы выполняют проверки прав доступа только для родительской таблицы. Так, например, предоставление разрешения UPDATE для таблицы cities подразумевает также разрешение на обновление строк в таблице capitals при обращении к ним через cities. Это сохраняет видимость того, что данные находятся также и в родительской таблице. Но таблица capitals не может быть обновлена напрямую без дополнительных прав. Аналогичным образом политики безопасности строк родительской таблицы (см. раздел Политики безопасности строк) применяются к строкам, приходящим из дочерних таблиц во время унаследованного запроса. Политики дочерней таблицы, если таковые имеются, применяются только в том случае, если она является таблицей с явным именем в запросе и в этом случае любые политики, связанные с его родителем(ями), игнорируются.
Внешние таблицы (см. раздел Внешние данные) также могут быть частью иерархий наследования, как родительские или дочерние таблицы так же, как обычные таблицы. Если сторонняя таблица является частью иерархии наследования, то любые операции, не поддерживаемые сторонней таблицей, также не поддерживаются во всей иерархии.
Предостережения при наследовании
Обратите внимание, что не все команды SQL могут работать в иерархиях наследования. Команды, которые используются для запроса данных, изменения данных или изменения схемы (например,SELECT, UPDATE, DELETE, большинство вариантов ALTER TABLE, но не INSERT или ALTER TABLE ... RENAME), обычно по умолчанию включают дочерние таблицы и поддерживают ONLY обозначение, чтобы исключить их. Команды, которые выполняют обслуживание и настройку базы данных (например, REINDEX, VACUUM), обычно работают только с отдельными физическими таблицами и не поддерживают рекурсию по иерархиям наследования. Соответствующее поведение каждой отдельной команды задокументировано на ее справочной странице ( глава Команды SQL).
Серьезным ограничением функции наследования является то, что индексы (включая ограничения уникальности) и ограничения внешнего ключа применяются только к отдельным таблицам, а не к их дочерним элементам. Это верно как для ссылающихся, так и для указываемых сторон ограничения внешнего ключа. Таким образом, в условиях приведенного выше примера:
Некоторые функции, не реализованные для иерархий наследования, реализованы для декларативного партиционирования. При принятии решения о том, полезно ли разбиение на партиции с помощью наследования для вашего приложения, требуется осторожность.
Партиционирование таблиц
QHB поддерживает базовое партиционирование таблиц. В этом разделе описывается, почему и как реализовать партиционирование в вашей базе данных.
Обзор
Партиционирование позволяет логически разделить одну большую таблицу на более мелкие физические части. Партиционирование может дать несколько преимуществ:
Преимущества партиционирования, как правило, имеют смысл только тогда, когда целая таблица будет очень большой. Точный размер, при достижении которого таблица получит выгоду от партиционирования, зависит от приложения, хотя эмпирическое правило заключается в том, что размер таблицы должен превысить физическую память сервера базы данных.
QHB предлагает встроенную поддержку для следующих форм партиционирования:
| Форма партиционирования | Описание |
|---|---|
| По диапазону | Таблица разбивается на «диапазоны», определяемые ключевым столбцом или набором столбцов, без перекрытия диапазонов значений, назначенных различным партициям. Например, можно разделить по диапазонам дат или диапазонам идентификаторов для определенных бизнес-объектов. |
| По списку | Таблица разбивается путем явного перечисления значений ключей, которые появляются в каждой партиции. |
| По хэшу | Таблица разбивается путем указания модуля и остатка для каждой партиции. Каждая партиция будет содержать строки, для которых хэш-значение ключа разбиения, разделенное на указанный модуль, приведет к указанному остатку. |
Если вашему приложению нужно использовать другие формы партиционирования, не перечисленные выше, вместо них можно использовать альтернативные методы, такие как наследование и представления UNION ALL. Такие методы предлагают гибкость, но не имеют некоторых преимуществ в производительности по сравнению с партиционированием.
Декларативное партиционирование
QHB предлагает способ указать, как поделить таблицу на части, называемые партициями. Такая таблица называется партиционированной таблицей. Определение партиции состоит из метода партиционирования и списка столбцов или выражений, которые будут использоваться в качестве ключа разбиения.
Все строки, вставленные в партиционированную таблицу, будут перенаправлены в одну из партиций в зависимости от значения ключа разбиения. Каждая партиция имеет подмножество данных, определенных границами партиционирования.
В настоящее время поддерживаются следующие методы партиционирования: по диапазонам (range), по списку (list) и по хэшу (hash).
Сами партиции могут быть определены как партиционированные таблицы, используя то, что называется субпартиционированием. Партиции могут иметь свои собственные индексы, ограничения и значения по умолчанию, отличные от других партиций. Смотрите CREATE TABLE для более подробной информации о создании партиционированных таблиц и субпартиций.
Невозможно превратить обычную таблицу в партиционированную таблицу или наоборот. Тем не менее, можно добавить обычную или партиционированную таблицу, содержащую данные, как партицию партиционированной таблицы, или удалить партицию из партиционированной таблицы, превратив его в отдельную таблицу см. ALTER TABLE, чтобы узнать больше о командах ATTACH PARTITION и DETACH PARTITION.
Отдельные партиции связаны с партиционированной таблицей с помощью скрытого наследования- однако, невозможно использовать общие свойства наследования (обсуждаемые ниже) с декларативно партиционированными таблицами или их партициями. Например, партиция не может иметь никаких родителей, кроме партиции таблицы, частью которой она является, и обычная таблица не может наследовать от партиционированной таблицы. Это означает, что партиционированные таблицы и их партиции не участвуют в наследовании обычных таблиц. Поскольку иерархия партиций, состоящая из партиционированной таблицы и ее партиций, по-прежнему является иерархией наследования, все обычные правила наследования применяются, как описано в разделе Наследование, с некоторыми исключениями, в частности:
Партиции также могут быть внешними таблицами, хотя у них есть некоторые ограничения, которых нет у обычных таблиц см. CREATE FOREIGN TABLE для получения дополнительной информации.
Обновление ключа разбиения в строке может привести к её перемещению в другую партицию, где эта строка будет удовлетворять условиям на границы партиции.
Пример декларативного партиционирования
Предположим, мы создаем базу данных для большой компании по производству мороженого. Компания измеряет пиковые температуры каждый день, а также продажи мороженого в каждом регионе. Создадим таблицу:
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
);
Мы знаем, что большинство запросов получат доступ только к данным за последнюю неделю, месяц или квартал, поскольку основное использование этой таблицы будет заключаться в подготовке онлайн-отчетов для руководства. Чтобы уменьшить объем старых данных, которые необходимо хранить, мы решили сохранить данные за последние 3 года. В начале каждого месяца мы будем удалять данные самого старого месяца. В этой ситуации мы можем использовать партиционирование, чтобы помочь нам удовлетворить все наши различные требования к таблице измерений (measurement).
Чтобы использовать декларативное партиционирование в этом случае, выполните следующие действия:
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
CREATE TABLE measurement_y2006m02 PARTITION OF measurement
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');
...
CREATE TABLE measurement_y2007m11 PARTITION OF measurement
FOR VALUES FROM ('2007-11-01') TO ('2007-12-01');
CREATE TABLE measurement_y2007m12 PARTITION OF measurement
FOR VALUES FROM ('2007-12-01') TO ('2008-01-01')
TABLESPACE fasttablespace;
CREATE TABLE measurement_y2008m01 PARTITION OF measurement
FOR VALUES FROM ('2008-01-01') TO ('2008-02-01')
WITH (parallel_workers = 4)
TABLESPACE fasttablespace;
Чтобы реализовать разбиение на партиции, укажите предложение PARTITION BY в командах, используемых для создания отдельных партиций, например:
CREATE TABLE measurement_y2006m02 PARTITION OF measurement
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01')
PARTITION BY RANGE (peaktemp);
После создания партиции measurement_y2006m02 любые данные, вставленные в партицию, которая сопоставлена с measurement_y2006m02 (или данные, которые непосредственно вставлены в measurement_y2006m02, при условии, что оно удовлетворяет ограничению на партиции), будут дополнительно перенаправлены в одну из партиций на основе столбца peaktemp. Указанный ключ разбиения может перекрываться с ключом разбиения родителя, хотя следует соблюдать осторожность при указании границ партиции, чтобы набор данных, которые он принимает, составлял подмножество того, что позволяют собственные границы партиции - система не пытается проверить, так ли это на самом деле.
В приведенном выше примере мы будем создавать новую партицию каждый месяц, поэтому было бы разумно написать скрипт, который автоматически генерирует необходимый DDL.
Обслуживание партиций
Обычно набор партиций, созданный при первоначальном определении таблицы, не должен оставаться статическим. Обычно требуется удалить старые партиции и периодически добавлять новые партиции для новых данных. Одним из наиболее важных преимуществ партиционирования является именно то, что оно позволяет практически мгновенно выполнить эту болезненную задачу, манипулируя структурой партиции, а не физически перемещая большие объемы данных.
Самый простой вариант удаления старых данных - удалить ненужную партицию:
DROP TABLE measurement_y2006m02;
Так можно очень быстро удалить миллионы записей, потому что не нужно индивидуально удалять каждую запись. Однако обратите внимание, что приведенная выше команда требует установки блокировки ACCESS EXCLUSIVE на родительскую таблицу.
Другой вариант, который часто предпочтительнее, состоит в том, чтобы удалить партицию из партиционированной таблицы, но сохранить доступ к нему как к таблице самостоятельно:
ALTER TABLE measurement DETACH PARTITION measurement_y2006m02;
Теперь можно выполнять дальнейшие операции с данными до их удаления. Например, это позволит провести резервное копирование данных с помощью COPY, qhb_dump или аналогичных инструментов также отдельная таблица может быть полезной для агрегации данных или выполнения других манипуляций с данными или запуска отчетов.
Точно так же мы можем добавить новую партицию для обработки новых данных. Мы можем создать пустую партицию в партиционированной таблице так же, как исходные партиции были созданы выше:
CREATE TABLE measurement_y2008m02 PARTITION OF measurement
FOR VALUES FROM ('2008-02-01') TO ('2008-03-01')
TABLESPACE fasttablespace;
В качестве альтернативы иногда удобнее создать новую таблицу вне структуры партиций, а затем сделать ей подходящую партицию. Это позволяет загружать, проверять и преобразовывать данные до их появления в партиционированной таблице:
CREATE TABLE measurement_y2008m02
(LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS)
TABLESPACE fasttablespace;
ALTER TABLE measurement_y2008m02 ADD CONSTRAINT y2008m02
CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' );
\copy measurement_y2008m02 from 'measurement_y2008m02'
-- possibly some other data preparation work
ALTER TABLE measurement ATTACH PARTITION measurement_y2008m02
FOR VALUES FROM ('2008-02-01') TO ('2008-03-01' );
Перед запуском команды ATTACH PARTITION рекомендуется создать контрольное ограничение для присоединяемой таблицы, соответствующее требуемому ограничению партиции. Таким образом, система сможет пропустить сканирование, чтобы проверить неявное ограничение партиции. Без контрольного ограничения таблица будет сканироваться для проверки ограничения партиции, при этом удерживая блокировку ACCESS EXCLUSIVE для этой партиции и блокировку SHARE UPDATE EXCLUSIVE в родительской таблице. Может потребоваться сбросить избыточное контрольное ограничение после завершения ATTACH PARTITION.
Как объяснено выше, можно создавать индексы для партиционированных таблиц, и они автоматически применяются ко всей иерархии. Это очень удобно, так как не только существующие партиции будут проиндексированы, но и любые партиции, которые будут созданы в будущем. Одно ограничение заключается в том, что при создании такого партиционированного индекса невозможно использовать CONCURRENTLY. Чтобы преодолеть длительное время блокировки, можно использовать CREATE INDEX ON ONLY для партиционированной таблицы - такой индекс помечается как недействительный, и партиции не получают индекс автоматически. Индексы на партициях можно создавать отдельно с помощью CONCURRENTLY, а затем прикреплять к индексу на родительском CONCURRENTLY с помощью ALTER INDEX .. ATTACH PARTITION. Как только индексы для всех партиций присоединены к родительскому индексу, родительский индекс помечается как действительный автоматически. Пример:
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales);
CREATE INDEX measurement_usls_200602_idx
ON measurement_y2006m02 (unitsales);
ALTER INDEX measurement_usls_idx
ATTACH PARTITION measurement_usls_200602_idx;
...
Этот метод также может использоваться с ограничениями UNIQUE и PRIMARY KEY индексы создаются неявно при создании ограничения. Пример:
ALTER TABLE ONLY measurement ADD UNIQUE (city_id, logdate);
ALTER TABLE measurement_y2006m02 ADD UNIQUE (city_id, logdate);
ALTER INDEX measurement_city_id_logdate_key
ATTACH PARTITION measurement_y2006m02_city_id_logdate_key;
...
Ограничения декларативного партиционирования
К партиционированным таблицам применяются следующие ограничения:
Реализация с использованием наследования
Хотя встроенное декларативное партиционирование подходит для большинства общих случаев использования, в некоторых случаях может оказаться полезным более гибкий подход, партиционирование может быть реализовано с использованием наследования таблиц, что позволяет использовать несколько функций, не поддерживаемых декларативным партиционированием, таких как:
Пример партиционирования с использованием наследования
Мы используем ту же таблицу измерений, которую использовали выше. Чтобы реализовать партиционирование с использованием наследования, выполните следующие действия:
CREATE TABLE measurement_y2006m02 () INHERITS (measurement);
CREATE TABLE measurement_y2006m03 () INHERITS (measurement);
...
CREATE TABLE measurement_y2007m11 () INHERITS (measurement);
CREATE TABLE measurement_y2007m12 () INHERITS (measurement);
CREATE TABLE measurement_y2008m01 () INHERITS (measurement);
CHECK ( x = 1 )
CHECK ( county IN ( 'Oxfordshire', 'Buckinghamshire', 'Warwickshire' ))
CHECK ( outletID >= 100 AND outletID < 200 )
Убедитесь, что ограничения гарантируют, что не будет перекрытия между значениями ключей, разрешенными в разных дочерних таблицах. Распространенной ошибкой является установка ограничений диапазона, таких как:
CHECK ( outletID BETWEEN 100 AND 200 )
CHECK ( outletID BETWEEN 200 AND 300 )
Это неправильно, так как неясно, к какой дочерней таблице относится значение ключа 200. Вместо этого было бы лучше создать дочерние таблицы следующим образом:
CREATE TABLE measurement_y2006m02 (
CHECK ( logdate >= DATE '2006-02-01' AND logdate < DATE '2006-03-01' )
) INHERITS (measurement);
CREATE TABLE measurement_y2006m03 (
CHECK ( logdate >= DATE '2006-03-01' AND logdate < DATE '2006-04-01' )
) INHERITS (measurement);
...
CREATE TABLE measurement_y2007m11 (
CHECK ( logdate >= DATE '2007-11-01' AND logdate < DATE '2007-12-01' )
) INHERITS (measurement);
CREATE TABLE measurement_y2007m12 (
CHECK ( logdate >= DATE '2007-12-01' AND logdate < DATE '2008-01-01' )
) INHERITS (measurement);
CREATE TABLE measurement_y2008m01 (
CHECK ( logdate >= DATE '2008-01-01' AND logdate < DATE '2008-02-01' )
) INHERITS (measurement);
CREATE INDEX measurement_y2006m02_logdate ON measurement_y2006m02 (logdate);
CREATE INDEX measurement_y2006m03_logdate ON measurement_y2006m03 (logdate);
CREATE INDEX measurement_y2007m11_logdate ON measurement_y2007m11 (logdate);
CREATE INDEX measurement_y2007m12_logdate ON measurement_y2007m12 (logdate);
CREATE INDEX measurement_y2008m01_logdate ON measurement_y2008m01 (logdate);
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO measurement_y2008m01 VALUES (NEW.*);
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
После создания функции создаем триггер, который вызывает эту функцию:
CREATE TRIGGER insert_measurement_trigger
BEFORE INSERT ON measurement
FOR EACH ROW EXECUTE FUNCTION measurement_insert_trigger();
В данном случае необходимо переопределять "триггерную" функцию каждый месяц, чтобы она всегда указывала на текущую дочернюю таблицу. Однако определение самого триггера обновлять не нужно.
Для того чтобы при вставке данных, сервер автоматически находил дочернюю таблицу, в которую должна быть добавлена строка, можно сформировать более сложную триггерную функцию, например:
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF ( NEW.logdate >= DATE '2006-02-01' AND
NEW.logdate < DATE '2006-03-01' ) THEN
INSERT INTO measurement_y2006m02 VALUES (NEW.*);
ELSIF ( NEW.logdate >= DATE '2006-03-01' AND
NEW.logdate < DATE '2006-04-01' ) THEN
INSERT INTO measurement_y2006m03 VALUES (NEW.*);
...
ELSIF ( NEW.logdate >= DATE '2008-01-01' AND
NEW.logdate < DATE '2008-02-01' ) THEN
INSERT INTO measurement_y2008m01 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
Определение триггера такое же, как и раньше. Обратите внимание, что каждое условие IF должен точно соответствовать ограничению CHECK для его дочерней таблицы.
Хотя эта функция более сложная, чем в случае одного месяца, ее не нужно обновлять так часто, поскольку ветки исполнения могут быть добавлены заранее.
Другой подход к перенаправлению вставок в соответствующую дочернюю таблицу заключается в установке правил вместо триггера в главной таблице. Например:
CREATE RULE measurement_insert_y2006m02 AS
ON INSERT TO measurement WHERE
( logdate >= DATE '2006-02-01' AND logdate < DATE '2006-03-01' )
DO INSTEAD
INSERT INTO measurement_y2006m02 VALUES (NEW.*);
...
CREATE RULE measurement_insert_y2008m01 AS
ON INSERT TO measurement WHERE
( logdate >= DATE '2008-01-01' AND logdate < DATE '2008-02-01' )
DO INSTEAD
INSERT INTO measurement_y2008m01 VALUES (NEW.*);
У правила значительно больше накладных расходов, чем у триггера, но накладные расходы оплачиваются один раз за запрос, а не один раз за строку, поэтому этот метод может быть полезен для ситуаций массовой вставки. В большинстве случаев, однако, метод триггера будет предлагать лучшую производительность. Помните, что COPY игнорирует правила. Если вы хотите использовать COPY для вставки данных, вам нужно будет копировать в правильную дочернюю таблицу, а не прямо в мастер. COPY запускает триггеры, поэтому вы можете использовать их как обычно, если вы используете триггерный подход.
Другой недостаток подхода с использованием правил заключается в том, что не существует простого способа вызвать ошибку, если набор правил не охватывает дату вставки - вместо этого данные будут автоматически отправлены в основную таблицу.
Как мы видим, сложная иерархия таблиц может потребовать значительного количества DDL. В приведенном выше примере необходимо создавать новую дочернюю таблицу каждый месяц, поэтому было бы разумно написать скрипт, который автоматически генерирует необходимый DDL.
Обслуживание для наследования
Чтобы быстро удалить старые данные, просто удалите дочернюю таблицу, которая больше не нужна:
DROP TABLE measurement_y2006m02;
Чтобы удалить дочернюю таблицу из таблицы иерархии наследования, но сохранить доступ к ней как к отдельной таблице:
ALTER TABLE measurement_y2006m02 NO INHERIT measurement;
Чтобы добавить новую дочернюю таблицу для обработки новых данных, создайте пустую дочернюю таблицу так же, как исходные дочерние таблицы были созданы выше:
CREATE TABLE measurement_y2008m02 (
CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' )
) INHERITS (measurement);
В качестве альтернативы можно создать и заполнить новую дочернюю таблицу, прежде чем добавлять ее в иерархию таблиц. Это может позволить загружать, проверять и преобразовывать данные, прежде чем они станут видимыми для запросов в родительской таблице.
CREATE TABLE measurement_y2008m02
(LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
ALTER TABLE measurement_y2008m02 ADD CONSTRAINT y2008m02
CHECK ( logdate >= DATE '2008-02-01' AND logdate < DATE '2008-03-01' );
\copy measurement_y2008m02 from 'measurement_y2008m02'
-- possibly some other data preparation work
ALTER TABLE measurement_y2008m02 INHERIT measurement;
Предостережения
Следующие предостережения применяются к партиционированию, реализованному с использованием наследования:
Сокращение партиций
Сокращение партиций — это метод оптимизации запросов, который повышает производительность для декларативно партиционированных таблиц. В качестве примера:
SET enable_partition_pruning = on; -- the default
SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
Без сокращения партиций вышеупомянутый запрос будет сканировать каждую из партиций таблицы measurement. При включенном сокращении партиций планировщик изучит определение каждой партиции и докажет, что ее не нужно сканировать, поскольку в ней не может быть строк, соответствующих условию WHERE из запроса. Когда планировщик может доказать это, он исключает (обрезает) партицию из плана запроса.
Используя команду EXPLAIN и параметр конфигурации enable_partition_pruning, можно показать разницу между планом, для которого партиции были сокращены, и планом, для которого они не сокращались. Типичный неоптимизированный план для этого типа установки таблицы:
SET enable_partition_pruning = off;
EXPLAIN SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
QUERY PLAN
-----------------------------------------------------------------------------------
Aggregate (cost=188.76..188.77 rows=1 width=8)
-> Append (cost=0.00..181.05 rows=3085 width=0)
-> Seq Scan on measurement_y2006m02 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
-> Seq Scan on measurement_y2006m03 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
...
-> Seq Scan on measurement_y2007m11 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
-> Seq Scan on measurement_y2007m12 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
-> Seq Scan on measurement_y2008m01 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
Некоторые или все партиции могут использовать сканирование индекса вместо последовательного сканирования полной таблицы, но суть в том, что вообще нет необходимости сканировать более старые партиции, чтобы ответить на этот запрос. Когда мы включаем сокращение партиций, мы получаем значительно более дешевый план, который даст тот же ответ:
SET enable_partition_pruning = on;
EXPLAIN SELECT count(*) FROM measurement WHERE logdate >= DATE '2008-01-01';
QUERY PLAN
-----------------------------------------------------------------------------------
Aggregate (cost=37.75..37.76 rows=1 width=8)
-> Seq Scan on measurement_y2008m01 (cost=0.00..33.12 rows=617 width=0)
Filter: (logdate >= '2008-01-01'::date)
Обратите внимание, что сокращение партиций обусловлено только ограничениями, неявно определенными ключами разбиения, а не наличием индексов. Поэтому нет необходимости определять индексы по ключевым столбцам. Необходимость создания индекса для данной партиции зависит от того, ожидаете ли вы, что запросы, сканирующие эту партицию, обычно сканируют большую часть партиции или только небольшую часть. Индекс будет полезен в последнем случае, но не в первом.
Сокращение партиций может быть выполнено не только во время планирования данного запроса, но и во время его выполнения. Это полезно, поскольку позволяет сократить количество партиций, когда предложения содержат выражения, значения которых неизвестны во время планирования запроса, например, параметры, определенные в операторе PREPARE, с использованием значения, полученного из подзапроса, или используя параметризованное значение на внутренней стороне вложенного соединения цикла. Сокращение партиций во время выполнения может быть выполнено в любой из следующих моментов времени:
Сокращение партиций может быть отключено с помощью параметра enable_partition_pruning.
В настоящее время обрезка партиций во время выполнения выполняется только для типов узлов Append и MergeAppend. Он еще не реализован для типа узлов ModifyTable, но, вероятно, будет изменен в будущем выпуске QHB.
Партиционирование и исключение ограничений
Исключение ограничений — это метод оптимизации запросов, аналогичный сокращению партиций. Хотя он в основном используется для разбиения, реализованного с использованием унаследованного метода наследования, он может использоваться для других целей, в том числе с декларативным партиционированием.
Исключение ограничений работает очень похоже на сокращение партиций, за исключением того, что оно использует контрольные ограничения каждой таблицы – откуда и получило свое имя - в то время как сокращение партиций использует границы партиций таблицы, которые существуют только в случае декларативного партиционирования. Другое отличие состоит в том, что исключение ограничений применяется только во время планирования не бывает попытки удалить партиции во время выполнения.
В исключении ограничений используются контрольные ограничения, что делает его медленным по сравнению с сокращением партиций, но иногда это может быть использовано в качестве преимущества: поскольку ограничения могут быть определены даже для декларативно партиционированных таблиц, в дополнение к их внутренним границам партиций, исключение ограничений может исключить дополнительные партиции из плана запроса.
Значение по умолчанию (и рекомендуемое) для параметра constraint_exclusion - не включен и не выключен, а является промежуточным параметром, называемым partition, который вызывает применение метода только к запросам, которые, вероятно, будут работать с партиционированными таблицами наследования Параметр on заставляет планировщик проверять контрольные ограничения во всех запросах, в том числе простых, что вряд ли принесет пользу.
Следующие предостережения относятся к исключению ограничений:
Декларативные методы партиционирования
Выбор способа партиционирования таблицы должен быть сделан тщательно, так как плохой дизайн может негативно повлиять на производительность планирования и выполнения запросов.
Одним из наиболее важных проектных решений является выбор столбца(ов), по которым вы партиционируете свои данные. Часто лучшим выбором будет партиционирование по столбцу или набору столбцов, которые чаще всего встречаются в WHERE предложениях запросов, выполняемых в партиционированной таблице. Элементы предложения WHERE, которые соответствуют и совместимы с ключом разбиения, могут использоваться для удаления ненужных партиций. Тем не менее, вы можете быть вынуждены принимать другие решения в соответствии с требованиями первичному ключу или уникальному ограничению. Удаление нежелательных данных также является фактором, который следует учитывать при планировании стратегии партиционирования. Партиция может быть отсоединена довольно быстро, поэтому может быть полезно разработать стратегию партиционирования таким образом, чтобы все данные, которые должны быть удалены одновременно, находились в одной партиции.
Выбор целевого числа партиций, на которые следует разделить таблицу, также является критически важным решением. Отсутствие достаточного количества партиций может означать, что индексы остаются слишком большими, а локальность данных остается плохой, что может привести к низким коэффициентам попадания в кэш. Однако разделение таблицы на слишком много партиций также может вызвать проблемы. Слишком большое количество партиций может привести к более длительному времени планирования запросов и более высокому потреблению памяти при планировании и выполнении запросов. При выборе способа партиционирования таблицы также важно учитывать, какие изменения могут произойти в будущем. Например, если вы выбрали одну партицию для каждого клиента и в настоящее время у вас небольшое количество крупных клиентов, подумайте о последствиях, если через несколько лет вы окажетесь с большим количеством мелких клиентов. В таком случае, может быть лучше выбрать разбиение по хэшу и выбрать разумное количество партиций вместо того, чтобы пытаться разделить их, по списку и надеяться, что количество клиентов не превысит порог, по которому целесообразно разделить данные.
Разбиение на субпартиции может быть полезным для дополнительного партиционирования, которые, как ожидается, станут большими, чем другие партиции, хотя чрезмерное разбиение на субпартиции может легко привести к большому количеству партиций и может вызвать проблемы, уже упомянутые в предыдущем абзаце.
Также важно учитывать издержки партиционирования при планировании и выполнении запросов. Планировщик запросов обычно способен достаточно хорошо обрабатывать иерархии партиций с несколькими тысячами партиций, при условии, что типичные запросы позволяют планировщику запросов удалять все партиции, кроме небольшого числа. Время планирования увеличивается, а потребление памяти возрастает, когда остается много партиций после того, как планировщик выполнил удаление партиций. Это особенно верно для команд UPDATE и DELETE. Еще одна причина для беспокойства по поводу наличия большого количества партиций заключается в том, что потребление памяти сервером может значительно возрасти в течение определенного периода времени, особенно если многие сеансы касаются большого количества партиций. Это связано с тем, что каждая партиция требует загрузки своих метаданных в локальную память каждого сеанса, который его касается.
С рабочими нагрузками типа OLAP имеет смысл использовать большее количество партиций, чем с рабочей нагрузкой типа OLTP. Как правило, в хранилищах данных планирование запросов занимает меньше времени, так как большая часть времени обработки тратится на выполнение запросов. При любом из этих двух типов рабочих нагрузок важно принимать правильные решения как можно раньше, поскольку перераспределение больших объемов данных может быть болезненно медленным. Моделирование предполагаемой рабочей нагрузки часто полезно для оптимизации стратегии партиционирования. Никогда не думайте, что больше партиций лучше, чем меньше партиций, и наоборот.
Внешние данные
QHB реализует части спецификации SQL/MED, позволяя вам получать доступ к данным, находящимся вне QHB, используя обычные SQL-запросы. Такие данные называются «внешние данные». (Обратите внимание, что это использование не следует путать с внешними ключами, которые являются типом ограничения в базе данных).
Доступ к внешним данным осуществляется с помощью обёртки сторонних данных (foreign data wrapper). Обёртка сторонних данных — это библиотека, которая может взаимодействовать с внешним источником данных, скрывая детали подключения к источнику данных и получения данных из него. В качестве модулей contrib доступны некоторые сторонние обертки данных. Другие виды сторонних упаковщиков данных могут быть найдены как сторонние продукты. Если ни одна из существующих сторонних обёрток данных не соответствует вашим потребностям, вы можете написать свою собственную см. главу Написание обёртки сторонних данных.
Для доступа к сторонним данным необходимо создать объект внешнего сервера, который определяет способ подключения к определенному внешнему источнику данных в соответствии с набором параметров, используемых его поддерживающей обёрткой сторонних данных. Затем нужно создать одну или несколько сторонних таблиц, которые определяют структуру удаленных данных. Внешняя таблица может использоваться в запросах так же, как обычная таблица, но внешняя таблица не хранит данные на сервере QHB. Всякий раз, когда он используется, QHB запрашивает обёртку сторонних данных для выборки данных из внешнего источника или передачи данных во внешний источник в случае команд обновления.
Доступ к удаленным данным может потребовать аутентификации для внешнего источника данных. Эта информация может быть предоставлена сопоставлением пользователей, которое может предоставить дополнительные данные, такие как имена пользователей и пароли, на основе текущей роли QHB.
Для получения дополнительной информации см.CREATE FOREIGN DATA WRAPPER, CREATE SERVER, CREATE USER MAPPING, CREATE FOREIGN TABLE и IMPORT FOREIGN SCHEMA.
Другие объекты базы данных
Таблицы являются центральными объектами в структуре реляционной базы данных, потому что они содержат ваши данные. Но они не единственные объекты, которые существуют в базе данных. Многие другие виды объектов могут быть созданы, чтобы сделать использование и управление данными более эффективным или удобным. Они не обсуждаются в этой главе:
Отслеживание зависимостей
Когда вы создаете сложные структуры базы данных, включающие множество таблиц с ограничениями внешнего ключа, представлениями, триггерами, функциями и т. д., вы неявно создаете сеть зависимостей между объектами. Например, таблица с ограничением внешнего ключа зависит от таблицы, на которую она ссылается.
Чтобы гарантировать целостность всей структуры базы данных, QHB гарантирует, что вы не можете удалить объекты, от которых все еще зависят другие объекты. Например, попытка удалить таблицу продуктов, которая рассматривалась в разделе Ограничение внешнего ключа, с таблицей заказов, зависящей от нее, приведет к появлению сообщения об ошибке, подобного этому:
DROP TABLE products;
ERROR: cannot drop table products because other objects depend on it
DETAIL: constraint orders_product_no_fkey on table orders depends on table products
HINT: Use DROP ... CASCADE to drop the dependent objects too.
Сообщение об ошибке содержит полезную подсказку: если вы не хотите удалять все зависимые объекты по отдельности, вы можете запустить:
DROP TABLE products CASCADE;
и все зависимые объекты будут удалены, как и любые объекты, которые рекурсивно зависят от них. В этом случае не удаляется таблица заказов, производится только удаление ограничений внешнего ключа. На этом все заканчивается, потому что ничто не зависит от ограничения внешнего ключа. (Можно проверить, что будет делать DROP ... CASCADE, запустите DROP без CASCADE и прочитайте вывод DETAIL).
Почти все команды DROP в QHB поддерживают указание CASCADE. Конечно, характер возможных зависимостей зависит от типа объекта. Вы также можете написать RESTRICT вместо CASCADE чтобы получить поведение по умолчанию, которое должно предотвратить удаление объектов, от которых зависят любые другие объекты.
Если в команде DROP перечисленно несколько объектов, CASCADE требуется только при наличии зависимостей вне указанной группы. Например, когда вы говорите DROP TABLE tab1, tab2 наличие внешнего ключа, ссылающегося на tab1 из tab2, не будет означать, что CASCADE необходим для успеха.
Для пользовательских функций QHB отслеживает зависимости, связанные с внешне видимыми свойствами функции, такими как ее аргументы и типы результатов, но не зависимости, которые могут быть обнаружены только путем анализа тела функции. В качестве примера рассмотрим следующую ситуацию:
CREATE TYPE rainbow AS ENUM ('red', 'orange', 'yellow',
'green', 'blue', 'purple');
CREATE TABLE my_colors (color rainbow, note text);
CREATE FUNCTION get_color_note (rainbow) RETURNS text AS
'SELECT note FROM my_colors WHERE color = $1'
LANGUAGE SQL;
(См. раздел Функции на языке запросов (SQL) для объяснения функций языка SQL). QHB будет знать, что функция get_color_note зависит от типа rainbow: удаление типа приведет к принудительному удалению функции, поскольку ее тип аргумента больше не будет определяться. Но QHB не будет считать, что get_color_note зависит от таблицы my_colors, и поэтому не будет удалять функцию, если таблица будет удалена. Хотя у этого подхода есть недостатки, есть и преимущества. Функция все еще допустима в некотором смысле, если таблица отсутствует, хотя ее выполнение может вызвать ошибку - создание новой таблицы с тем же именем позволит функции работать снова.
Манипулирование данными
В этой главе рассматривается, как вставлять, обновлять и удалять данные таблиц. В этой главе, также, будет объяснено, как извлечь изменённые данные из базы данных.
Вставка данных
Когда таблица создана, она не содержит данных. Первое, что нужно сделать перед тем, как база данных станет полезной, — это вставить данные. Данные всегда вставляются как минимум по одной строке за раз. Конечно, возможно вставить более одной строки, но нет способа вставить менее одной строки. Даже если известны только некоторые значения столбцов, необходимо создать строку целиком.
Чтобы создать новую строку, используйте команду INSERT. Команда требует имя таблицы и значение столбца. Например, рассмотрим таблицу продуктов (products) из главы Определение данных:
CREATE TABLE products (
product_no integer,
name text,
price numeric
);
Пример команды для вставки строки:
INSERT INTO products VALUES (1, 'Cheese', 9.99);
Значения данных перечислены в порядке появления столбцов в таблице, разделенных запятыми. Обычно значения данных будут литералами (константами), но также допустимы скалярные выражения.
Вышеуказанный синтаксис имеет недостаток - нужно знать порядок столбцов в таблице. Чтобы избежать этого, вы можно явно перечислить столбцы. Например, обе следующие команды делают то же самок, что и приведенная выше:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99);
INSERT INTO products (name, price, product_no) VALUES ('Cheese', 9.99, 1);
Многие пользователи считают хорошей практикой всегда указывать имена столбцов.
Если у вас нет значений для всех столбцов, вы можете опустить некоторые из них. В этом случае столбцы будут заполнены значениями по умолчанию. Например:
INSERT INTO products (product_no, name) VALUES (1, 'Cheese');
INSERT INTO products VALUES (1, 'Cheese');
Вторая форма - это расширение QHB.Столбцы слева заполняются указанными значениями, а остальные столбцы получают значения по умолчанию.
Для ясности вы также можете запросить значения по умолчанию явно, для отдельных столбцов или для всей строки:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', DEFAULT);
INSERT INTO products DEFAULT VALUES;
Можно вставить несколько строк одной командой:
INSERT INTO products (product_no, name, price) VALUES
(1, 'Cheese', 9.99),
(2, 'Bread', 1.99),
(3, 'Milk', 2.99);
Также возможно вставить результат запроса (который может не иметь ни одной строки, состоять из одной строки или из нескольких строк):
INSERT INTO products (product_no, name, price)
SELECT product_no, name, price FROM new_products
WHERE release_date = 'today';
Поддерживаются все возможности SQL-запросов (глава Запросы) для вычисления строк, которые нужно вставить.
Обновление данных
Модификация данных, которые уже находятся в базе данных, называется обновлением. Можно обновить отдельные строки, все строки в таблице или подмножество всех строк. Каждый столбец может быть обновлен отдельно; другие столбцы не затрагиваются.
Чтобы обновить существующие строки, используйте команду UPDATE. Для этого требуется:
SQL, как правило, не предоставляет уникальный идентификатор для строк (см. главу Определение данных). Поэтому не всегда возможно напрямую указать, какую строку обновлять. Вместо этого указывается, каким условиям должна соответствовать строка для обновления. Только если существуеть первичный ключ в таблице (независимо от того, объявлен он или нет), можно надежно обращаться к отдельным строкам, выбирая условие, соответствующее первичному ключу. Графические инструменты доступа к базе данных полагаются на этот факт, чтобы стало возможно обновлять строки по отдельности.
Например, эта команда обновляет все продукты с ценой 5 до цены 10:
UPDATE products SET price = 10 WHERE price = 5;
Это может привести к обновлению нуля, одной или нескольких строк. Попытка обновления, которое не соответствует ни одной строке, не является ошибкой.
Давайте посмотрим на эту команду подробно. Сначала следует ключевое слово UPDATE за которым следует имя таблицы. Как обычно, имя таблицы может быть дополнено схемой, в противном случае оно ищется в пути по умолчанию (search_path). Далее следует ключевое слово SET за которым следуют имя столбца, знак равенства и новое значение столбца. Новое значение столбца может быть любым скалярным выражением или просто константой. Например, если нужно поднять цену на все товары на 10%, можно использовать:
UPDATE products SET price = price * 1.10;
Как видно, выражение для нового значения может ссылаться на
существующие значения в строке. Мы также пропустили WHERE. Если условие не задано,
это означает, что все строки в таблице будут обновлены. Если условие
присутствует, обновляются только те строки, которые соответствуют
условию WHERE. Обратите внимание, что знак равенства в предложении SET
является присваиванием, а знак в предложении WHERE - сравнением, но это
не создает никакой двусмысленности. Конечно, условие WHERE не
обязательно должно быть критерием равенства. Доступны многие другие
операторы (см. главу Функции и операторы). Но выражение должно вычисляться до
логического результата.
Вы можете обновить более одного столбца в команде UPDATE, перечислив более одного назначения в предложении SET. Например:
UPDATE mytable SET a = 5, b = 3, c = 1 WHERE a > 0;
Удаление данных
До сих пор рассматривалось, как добавлять данные в таблицы и как их
изменять. Осталось обсудить, как удалить данные, которые больше не
нужны. Так же, как добавление данных возможно только для целых строк, можно
удалить только целые строки из таблицы. В предыдущем разделе было рассмотрено,
что SQL не предоставляет способ напрямую обращаться к
отдельным строкам. Поэтому удаление строк может быть сделано только
путем указания условий, которым должны соответствовать удаляемые строки.
Если в таблице есть первичный ключ, возможно
указать точную строку. Но также возможно удалить группы строк,
соответствующие условию, или удалить все строки в таблице
одновременно.
Используйте команду DELETE для удаления строк; синтаксис очень похож на команду UPDATE. Например, чтобы удалить все строки из таблицы товаров с ценой 10, используйте:
DELETE FROM products WHERE price = 10;
Если просто написать:
DELETE FROM products;
тогда все строки в таблице будут удалены! БУДЬТЕ ОСТОРОЖНЫ.
Возврат данных из измененных строк
Иногда полезно получить данные из измененных строк, когда ими манипулируют. Все команды INSERT, UPDATE и DELETE имеют необязательное предложение RETURNING, для поддержки этой возможности. Использование RETURNING позволяет избежать выполнения дополнительного запроса к базе данных для сбора данных и является особенно ценным - в противном случае было бы трудно надежно идентифицировать измененные строки.
Разрешенное содержимое предложения RETURNING совпадает с выходным
списком команды SELECT (см. раздел Списки выборки). Он может содержать имена столбцов
целевой таблицы команды или выражения значений, использующие эти
столбцы. Обычным сокращением является RETURNING *, которое выбирает все
столбцы целевой таблицы по порядку.
В INSERT доступными для RETURNING данными является строка, в которой она была вставлена. Это не очень полезно в тривиальных вставках - возвращаются данные, предоставленные клиентом. Но это может быть очень удобно при использовании вычисленных значений по умолчанию. Например, при использовании serial столбца для предоставления уникальных идентификаторов RETURNING может вернуть идентификатор, назначенный новой строке:
CREATE TABLE users (firstname text, lastname text, id serial primary key);
INSERT INTO users (firstname, lastname) VALUES ('Joe', 'Cool') RETURNING id;
Предложение RETURNING также очень полезно с INSERT ... SELECT.
В UPDATE данные, доступные для RETURNING являются новым содержимым измененной строки. Например:
UPDATE products SET price = price * 1.10
WHERE price <= 99.99
RETURNING name, price AS new_price;
В DELETE данные, доступные для RETURNING являются содержимым удаленной строки. Например:
DELETE FROM products
WHERE obsoletion_date = 'today'
RETURNING *;
Если в целевой таблице есть триггеры (глава Триггеры), данные, доступные для RETURNING — это строка, измененная триггерами. Таким образом, проверка столбцов, вычисленных триггерами, является еще одним распространенным вариантом использования RETURNING.
Запросы
В данном разделе показано, как получить данные из базы данных.
Обзор
Процесс получения данных из базы данных называется запросом.
В SQL для создания запросов используется команда SELECT.
Общий вид команды SELECT следующий:
[WITH запросы_with]
SELECT список_выборки
FROM табличное_выражение
[определение_сортировки]
Далее будут подробно описаны список выборки, табличное
выражение и определение сортировки. Запросы WITH
являются расширенной функцией, поэтому рассматриваются
в последнюю очередь.
Простейший запрос имеет следующий вид:
SELECT * FROM table1;
Если существует таблица с именем table1, то вышеупомянутая команда
извлечёт все строки с содержимым всех столбцов из table1. (Метод
выдачи результата зависит от клиентского приложения. Например, программа qsql
отобразит на экране таблицу ASCII-art, хотя клиентские
библиотеки могут извлекать отдельные значения из
результата запроса). В качестве списка выборки указан символ * он означает,
что в результате выполнения запроса вернутся все столбцы
табличного выражения. В списке выборки можно также
указать подмножество доступных столбцов или выполнить вычисления с
использованием столбцов. Например, если в table1 есть столбцы с именами
a, b и c (и, возможно, другие), вы можете выполнить следующий запрос:
SELECT a, b + c FROM table1;
(тут считается, что b и c числовые типы данных).
См. раздел Списки выборки для более подробной информации.
FROM table1 — это простейший вид табличного выражения, который читает
только одну таблицу. В общем случае табличные выражения могут быть сложными
комбинациями базовых таблиц, соединений и подзапросов. Но вы также
можете не использовать табличное выражение и использовать только команду
SELECT в качестве калькулятора:
SELECT 3 * 4;
Это вырожденный пример, но бывает полезно, когда выражения в списке выборки возвращают различные результаты. Например, можно вызвать функцию, возвращающую случайные значения:
SELECT random();
Табличные выражения
Табличное выражение вычисляет таблицу. Оно содержит предложение FROM, за
которым могут следовать WHERE, GROUP BY и HAVING. Простые табличные
выражения просто ссылаются на конкретную (базовую) таблицу на диске,
но в более сложных выражениях можно модифицировать или
комбинировать базовые таблицы различными способами.
Необязательные предложения WHERE, GROUP BY и HAVING в табличных выражениях задают
последовательность преобразований, выполняемых с данными,
полученными в предложении FROM. В результате этих преобразований создается
виртуальная таблица, строки которой передаются в
список выборки для вычисления выходных строк запроса.
Условие FROM
Предложение FROM формирует таблицу из одной или нескольких ссылок на таблицы,
разделённых запятыми.
FROM ссылка_на_таблицу [, ссылка_на_таблицу [, ...]]
Ссылка на таблицу может быть именем таблицы (возможно,
с именем схемы) или производной таблицей (подзапрос,
конструкция JOIN или их сложные комбинации). Если в предложении FROM
указано более одной ссылки на таблицу, таблицы соединяются перёкрестно
(то есть формируется декартово произведение их строк; см. ниже).
Результатом списка FROM является промежуточная виртуальная таблица,
которая затем может преобразовываться с помощью WHERE, GROUP BY и HAVING, и, в итоге, является результатом общего табличного
выражения.
Если ссылка на таблицу указывает на таблицу, являющаяся
родительской в табличной иерархии наследования, то в результате
выводятся строки не только этой таблицы, но и всех ее таблиц-потомков
Если вы хотите получить только столбцы родительской таблицы, то перед
именем нужно указать ключевое слово ONLY). При этом
в результате будут получены только столбцы родительской таблицы -
столбцы дочерних таблиц будут проигнорированы.
Соединение таблиц
Соединённая таблица — это таблица, полученная из двух других (реальных или производных) таблиц в соответствии с правилами соединения. Возможны внутренние, внешние и перекрёстные соединения. Общий синтаксис соединения таблиц:
T1 тип_соединения T2 [ условие_соединения ]
Соединения всех типов могут быть объединены в цепочку или вложены друг в друга - любая
из таблиц или даже обе таблицы T1 и T2 могут быть уже соединёнными
таблицами. Для указания точного порядка соединения предложения JOIN можно заключать в скобки.
При отсутствии скобок предложения JOIN обрабатываются слева направо.
Типы соединения
Перекрёстное соединение (CROSS JOIN):
T1 CROSS JOIN T2
Заметка
Последний вариант не полностью эквивалентен первым двум, если в объединении указано более двух таблиц, т.к.JOINсвязывает более плотно, чем запятая. Например, условиеFROM T1 CROSS JOIN T2 INNER JOIN T3 ON conditionне совпадает с условиемFROM T1, T2 INNER JOIN T3 ON conditionпосколькуconditionможет ссылаться наT1в первом случае, но не во втором.
Квалифицированные соединение (Qualified joins)
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 ON boolean_expression
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 USING ( join column list )
T1 NATURAL { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2
Заметка
ПредложениеUSINGзащищено от изменений столбцов в соединяемых отношениях, поскольку соединяются только перечисленные столбцы. использованиеNATURALболее рисковано, поскольку любые изменения схем, приводящие к появлению нового совпадающего имени столбца, приведут к объединению этого нового столбца.
Рассмотрим вышеизложенное на примерах. Пусть у нас есть таблицы t1:
num | name
-----+------
1 | a
2 | b
3 | c
и t2:
num | value
-----+-------
1 | xxx
3 | yyy
5 | zzz
Для различных их соединений мы получим следующие результаты:
=> SELECT * FROM t1 CROSS JOIN t2;
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
1 | a | 3 | yyy
1 | a | 5 | zzz
2 | b | 1 | xxx
2 | b | 3 | yyy
2 | b | 5 | zzz
3 | c | 1 | xxx
3 | c | 3 | yyy
3 | c | 5 | zzz
(9 rows)
=> SELECT * FROM t1 INNER JOIN t2 ON t1.num = t2.num;
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
3 | c | 3 | yyy
(2 rows)
=> SELECT * FROM t1 INNER JOIN t2 USING (num);
num | name | value
-----+------+-------
1 | a | xxx
3 | c | yyy
(2 rows)
=> SELECT * FROM t1 NATURAL INNER JOIN t2;
num | name | value
-----+------+-------
1 | a | xxx
3 | c | yyy
(2 rows)
=> SELECT * FROM t1 LEFT JOIN t2 ON t1.num = t2.num;
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
2 | b | |
3 | c | 3 | yyy
(3 rows)
=> SELECT * FROM t1 LEFT JOIN t2 USING (num);
num | name | value
-----+------+-------
1 | a | xxx
2 | b |
3 | c | yyy
(3 rows)
=> SELECT * FROM t1 RIGHT JOIN t2 ON t1.num = t2.num;
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
3 | c | 3 | yyy
| | 5 | zzz
(3 rows)
=> SELECT * FROM t1 FULL JOIN t2 ON t1.num = t2.num;
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
2 | b | |
3 | c | 3 | yyy
| | 5 | zzz
(4 rows)
Условие соединения, указанное с помощью ON может также содержать
условия, которые не имеют прямого отношения к соединению. Это может
быть полезным для некоторых запросов, но должно быть тщательно
продумано. Например:
=> SELECT * FROM t1 LEFT JOIN t2 ON t1.num = t2.num AND t2.value = 'xxx';
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
2 | b | |
3 | c | |
(3 rows)
Обратите внимание, что аналогичное условие в WHERE приводит к иному
результату:
=> SELECT * FROM t1 LEFT JOIN t2 ON t1.num = t2.num WHERE t2.value = 'xxx';
num | name | num | value
-----+------+-----+-------
1 | a | 1 | xxx
(1 row)
Это связано с тем, что условие, указанное в предложение ON,
обрабатывается до соединения, а условие, указанное в WHERE,
обрабатывается после соединения. Это не имеет значения для внутренних
объединений, но очень важно для внешних объединений.
Псевдонимы таблиц и столбцов
Таблицам и сложным ссылкам на таблицы можно дать временные имена, по которым можно обращаться к таблицам в запросе. Это временное имя называется псевдонимом таблицы.
Псевдоним можно создать с помощью ключевого слова AS:
FROM table_reference AS alias
Или:
FROM table_reference alias
Ключевое слово AS является необязательным. alias может быть любым
идентификатором.
Стандартно псевдонимы создаются в качестве коротких идентификаторов для длинных имён таблиц, чтобы улучшить читаемость запросов. Например:
SELECT * FROM some_very_long_table_name s JOIN another_fairly_long_name a ON s.id = a.num;
Псевдоним становится новым именем таблицы в текущем запросе - после объявления псевдонима нельзя сослаться на таблицу по исходному имени. Следующий пример недопустим:
SELECT * FROM my_table AS m WHERE my_table.a > 5; -- wrong
Псевдонимы таблиц в основном используется для улучшения читаемости, но также их использование обязательно самосоединении таблицы, например:
SELECT * FROM people AS mother JOIN people AS child ON mother.id = child.mother_id;
Кроме того, псевдоним обязателен, если вы используете подзапрос (см. раздел Подзапросы).
В случае неоднозначных объявлений псевдонимов стоит использовать скобки. В следующем
примере первому оператору присваивается псевдоним b, второму экземпляру
my_table, но второй оператор присваивает псевдоним результату
соединения:
SELECT * FROM my_table AS a CROSS JOIN my_table AS b ...
SELECT * FROM (my_table AS a CROSS JOIN my_table) AS b ...
Также псевдонимы можно давать столбцам таблицы, а не только самим таблицам:
FROM table_reference [AS] alias ( column1 [, column2 [, ...]] )
Если псевдонимов меньше, чем столбцов в таблице, то остальные столбцы сохраняют свои исходные имена. Такой синтаксис особенно полезен для самосоединений или подзапросов.
Когда псевдоним применяется к результату JOIN, он
скрывает изначальные имена таблиц внутри JOIN.
Например следующий запрос возможен:
SELECT a.* FROM my_table AS a JOIN your_table AS b ON ...
но запрос:
SELECT a.* FROM (my_table AS a JOIN your_table AS b ON ...) AS c
выдаст ошибку, т.к. псевдоним таблицы a не доступен вне
псевдонима c.
Подзапросы
Подзапросы, которые образуют таблицу, должны быть заключены в круглые скобки и должны иметь псевдоним (как в разделе Псевдонимы таблиц и столбцов). Например:
FROM (SELECT * FROM table1) AS alias_name
Этот пример эквивалентен FROM table1 AS alias_name. Более интересные
случаи, которые нельзя свести к простому соединению, возникают, когда
подзапрос включает в себя группировку или агрегирующие функции.
Подзапрос также может быть списком VALUES:
FROM (VALUES ('anne', 'smith'), ('bob', 'jones'), ('joe', 'blow'))
AS names(first, last)
Опять же, тут требуется псевдоним таблицы. Указывать псевдонимы столбцам
списка VALUES необязательно, но это хорошая практика. Для получения
дополнительной информации см. раздел Списки VALUES.
Табличные функции
Табличные функции — это функции, создающие набор строк, состоящий
из базовых типов данных (скалярных типов) или составных типов данных
(строк таблицы). Они используются как таблицы, представления или
подзапросы в предложении FROM. Столбцы, возвращаемые табличными
функциями, могут быть включены в предложения SELECT, JOIN или WHERE
так же, как столбцы таблиц, представлений или подзапросов.
Табличные функции также могут быть соединены с использованием
синтаксиса ROWS FROM. Результаты будут возвращены в параллельных
столбцах, количество строк в результате будет равно наибольшему из результатов функций,
а результаты с меньшим количеством строк дополнятся значениями NULL.
function_call [WITH ORDINALITY] [[AS] table_alias [(column_alias [, ... ])]]
ROWS FROM( function_call [, ... ] )
[WITH ORDINALITY] [[AS] table_alias [(column_alias [, ... ])]]
Если указано предложение WITH ORDINALITY, то в результирующие столбцы
функции будет добавлен дополнительный столбец типа bigint с пронумерованными строками результатов.
(Это обобщение стандартного синтаксиса SQL для UNNEST ... WITH ORDINALITY).
По умолчанию данный столбец называется ordinality, но
ему может быть присвоено другое имя с помощью предложения AS.
В специальную табличную функцию UNNEST передается массив с любым
количеством параметров. Функция возвращает соответствующее
количество столбцов, как если бы UNNEST (см. раздел Функции и операторы массива) был вызван для
каждого параметра по отдельности и объединен с использованием конструкции
ROWS FROM.
UNNEST( array_expression [, ... ] ) [WITH ORDINALITY] [[AS] table_alias [(column_alias [, ... ])]]
Если table_alias не указан, то в качестве имени
таблицы используется имя функции, а в случае c конструкцией ROWS FROM() используется имя первой
функции.
Если псевдонимы столбцов не указаны, то для функции, возвращающей базовый тип данных, имя столбца также совпадает с именем функции. Для функции, возвращающей составной тип, результирующие столбцы получают имена отдельных атрибутов типа.
Несколько примеров:
CREATE TABLE foo (fooid int, foosubid int, fooname text);
CREATE FUNCTION getfoo(int) RETURNS SETOF foo AS $$
SELECT * FROM foo WHERE fooid = $1;
$$ LANGUAGE SQL;
SELECT * FROM getfoo(1) AS t1;
SELECT * FROM foo
WHERE foosubid IN (
SELECT foosubid
FROM getfoo(foo.fooid) z
WHERE z.fooid = foo.fooid
);
CREATE VIEW vw_getfoo AS SELECT * FROM getfoo(1);
SELECT * FROM vw_getfoo;
В некоторых случаях полезно определить табличную функцию, возвращающую
различные наборы столбцов для разных вариантов вызова.
Для этого необходимо объявить табличную функцию
как возвращающую псевдотип record. Когда такая функция используется в
запросе, ожидаемая структура строк должна быть указана в самом запросе,
чтобы система могла знать, как анализировать запрос и составить план запроса. Этот
синтаксис выглядит так:
function_call [AS] alias (column_definition [, ... ])
function_call AS [alias] (column_definition [, ... ])
ROWS FROM( ... function_call AS (column_definition [, ... ]) [, ... ] )
Если синтаксис ROWS FROM() не используется, список column_definition
заменяет список псевдонимов, который в противном случае можно
было бы добавить в предложение FROM; имена в определениях столбцов
служат псевдонимами. При использовании ROWS FROM()
список column_definition может быть добавлен к каждой функции
отдельно; или если существует только одна функция и нет предложения
WITH ORDINALITY, список column_definition можно записать вместо
списка псевдонимов после ROWS FROM().
Посмотрим на этот пример:
SELECT *
FROM dblink('dbname=mydb', 'SELECT proname, prosrc FROM pg_proc')
AS t1(proname name, prosrc text)
WHERE proname LIKE 'bytea%';
Функция dblink (часть модуля dblink) выполняет удаленный запрос.
Она объявлена, как возвращающая record, т.к. он может использоваться для
любого запроса. Здесь фактический набор столбцов необходимо указать в
вызывающем запросе, чтобы анализатор запроса знал, например, как преобразовать
*.
Подзапросы LATERAL
Перед подзапросами в предложении FROM можно указать ключевое слово
LATERAL. Оно позволит им ссылаться на столбцы,
предшествующих элементов FROM. (Без LATERAL каждый подзапрос
выполняется независимо и не может ссылаться на
другие элементы FROM).
Перед табличными функциями в предложении FROM, также можно указать
LATERAL, но для функций оно не необязательно;
в аргументах функций можно обращаться к столбцам в предыдущих элементах
FROM в любом случае.
LATERAL элемент может появиться на верхнем уровне в списке FROM или в
дереве JOIN. В последнем случае он может также ссылаться на любые
элементы, левой части дерева JOIN, к которому он присоединен с правой
стороны.
Когда элемент FROM содержит LATERAL, запрос выполняется
следующим образом: для каждой строки элемента FROM со
столбцами подзапроса, или набора строк из нескольких элементов FROM,
содержащих столбцы, вычисляется LATERAL со значениеми столбцов этой строки или набора строк.
Затем результирующие строки соединяются как обычно со строками, из которых
они были вычислены. И процедура повторяется для всех строк или наборов строк
из исходной таблицы.
Обычный пример LATERAL:
SELECT * FROM foo, LATERAL (SELECT * FROM bar WHERE bar.id = foo.bar_id) ss;
Тут использование LATERAL не имеет смысла, т.к. тот же результат можно
получить более простым способом:
SELECT * FROM foo, bar WHERE bar.id = foo.bar_id;
LATERAL в первую очередь полезен, когда столбец с перекрестной
ссылкой необходим для соединения с вычисляемой строкой (набором строк).
Например когда нужно передать значение аргумента для функции,
возвращающей набор. Например, предположив, что vertices(polygon)
возвращают множество вершин многоугольника, мы могли бы получить
близко расположенные вершины многоугольников, хранящиеся в polygon, с
помощью:
SELECT p1.id, p2.id, v1, v2
FROM polygons p1, polygons p2,
LATERAL vertices(p1.poly) v1,
LATERAL vertices(p2.poly) v2
WHERE (v1 <-> v2) < 10 AND p1.id != p2.id;
Этот запрос можно также записать так:
SELECT p1.id, p2.id, v1, v2
FROM polygons p1 CROSS JOIN LATERAL vertices(p1.poly) v1,
polygons p2 CROSS JOIN LATERAL vertices(p2.poly) v2
WHERE (v1 <-> v2) < 10 AND p1.id != p2.id;
или в нескольких других эквивалентных формулировках. (Как уже
упоминалось, ключевое слово LATERAL в этом примере не нужно, но оно
добавлено, чтобы было понятней).
Часто очень удобно использовать LEFT JOIN с LATERAL, чтобы
исходные строки появлялись в результате, даже если подзапрос LATERAL
не возвращает для них строк. Например, если функция
get_product_names() возвращает названия продуктов, выпускаемых конкретным
производителем, но при этом некоторые производители в настоящее
время не выпускают продукты, мы можем узнать это следующим образом:
SELECT m.name
FROM manufacturers m LEFT JOIN LATERAL get_product_names(m.id) pname ON true
WHERE pname IS NULL;
Условие WHERE
Синтаксис WHERE:
WHERE search_condition
где search_condition - любое выражение значения (см. раздел Выражения значения), которое возвращает значение типа boolean.
После обработки предложения FROM каждая строка производной виртуальной
таблицы проверяется на соответствие условиям в WHERE. Если результат
условия равен true, строка сохраняется в выходной таблице, в противном
случае (т. е. если результат false или null), она отбрасывается.
В условии поиска обычно указывается хотя бы один столбец из таблицы,
созданной в предложении FROM; это не обязательно, но иначе
предложение WHERE будет бесполезным.
Вот несколько примеров использования WHERE:
SELECT ... FROM fdt WHERE c1 > 5
SELECT ... FROM fdt WHERE c1 IN (1, 2, 3)
SELECT ... FROM fdt WHERE c1 IN (SELECT c1 FROM t2)
SELECT ... FROM fdt WHERE c1 IN (SELECT c3 FROM t2 WHERE c2 = fdt.c1 + 10)
SELECT ... FROM fdt WHERE c1 BETWEEN (SELECT c3 FROM t2 WHERE c2 = fdt.c1 + 10) AND 100
SELECT ... FROM fdt WHERE EXISTS (SELECT c1 FROM t2 WHERE c2 > fdt.c1)
fdt — это таблица, полученная в предложении FROM. Строки, которые не
удовлетворяют условию поиска WHERE, удаляются из fdt. Обратите внимание
на использование скалярных подзапросов в качестве выражений значений.
Как и любой другой запрос, подзапросы могут использовать сложные
табличные выражения. Обратите также внимание на то, как fdt используется
в подзапросах. Определение c1 как fdt.c1 необходимо только в том случае,
если в таблице подзапроса также имеется столбецc1.
Но уточнение имени столбца добавляет читаемости, даже когда оно
не нужно. В этом примере показано, как область именования столбцов
внешнего запроса распространяется на его подзапросы.
Предложения GROUP BY и HAVING
После прохождения фильтра WHERE строки полученной таблицы могут быть
сгруппированы с использованием предложения GROUP BY и затем
сгруппированные строки могут быть отфильтрованы с помощью предложения HAVING.
SELECT select_list
FROM ...
[WHERE ...]
GROUP BY grouping_column_reference [, grouping_column_reference]...
Предложение GROUP BY группирует строки таблицы по всем
перечисленным в GROUP BY столбцам. Порядок, в
котором перечислены столбцы, неважен. Смысл заключается в
объединении каждого набора строк, имеющих общие значения, в одну строку
группы, которая представляет все строки в группе. Это делается для
устранения избыточности в результирующих данных и/или вычисления агрегированных функций,
которые применяются к этим группам. Например:
=> SELECT * FROM test1;
x | y
---+---
a | 3
c | 2
b | 5
a | 1
(4 rows)
=> SELECT x FROM test1 GROUP BY x;
x
---
a
b
c
(3 rows)
Во втором примере нельзя записать SELECT * FROM test1 GROUP BY x,
потому что не существует единственного значения для y которое
можно было бы связать с каждой группой. Сгруппированные столбцы можно
использовать в списке выборки, т.к. они имеют единое значение в каждой
группе.
В целом, если таблица сгруппирована, то столбцы, которые не перечислены
в GROUP BY можно использовать только в агрегатных выражениях. Например:
=> SELECT x, sum(y) FROM test1 GROUP BY x;
x | sum
---+-----
a | 4
b | 5
c | 2
(3 rows)
Здесь sum - агрегатная функция, которая вычисляет одно значение для всей
группы. Более подробную информацию о видах агрегатных функций можно
найти в разделе Агрегатные функции.
Группировка без агрегатных выражений по сути выдает набор
различающихся значений столбцов. Тот же результат можно получить используя
предложение DISTINCT (см. раздел Выбор уникальных записей).
Ещё один пример, который вычисляет общую сумму продаж по каждому продукту (а не общую сумму продаж всех продуктов):
SELECT product_id, p.name, (sum(s.units) * p.price) AS sales
FROM products p LEFT JOIN sales s USING (product_id)
GROUP BY product_id, p.name, p.price;
В этом примере столбцы product_id, p.name и p.price должны находиться в
предложении GROUP BY, поскольку на них есть ссылки в списке выборки
запросов (но см. ниже). Столбец s.units не обязательно должен быть в
списке GROUP BY поскольку он используется только в агрегатном выражении
(sum(...)), которое представляет количество проданных единиц.
Для каждого продукта запрос возвращает итоговую строку обо всех его продажах.
Если бы в таблице продуктов product_id являлся бы первичным ключом, то в примере выше
достаточно было бы группировки по product_id, поскольку название и цена функционально
зависят от идентификатора продукта, и название и цена однозначно
определяются по идентификатору продукта.
В стандарте SQL GROUP BY может группировать только по столбцам исходной
таблицы, но QHB расширяет эту возможность, разрешая GROUP BY
группировать по столбцам в списке выборки. Также допустима группировка
по выражениям вместо имен столбцов.
Если таблица была сгруппирована с использованием GROUP BY, но вам нужны
только определенные группы, можно отфильтровать группы с использованием
HAVING, работающего аналогично WHERE.
Синтаксис:
SELECT select_list FROM ... [WHERE ...] GROUP BY ... HAVING boolean_expression
Выражения в предложении HAVING могут использовать как сгруппированные
выражения, так и выражения не участвующие в группировке ( но в этом случае это должны быть агрегирующие функции).
Пример:
=> SELECT x, sum(y) FROM test1 GROUP BY x HAVING sum(y) > 3;
x | sum
---+-----
a | 4
b | 5
(2 rows)
=> SELECT x, sum(y) FROM test1 GROUP BY x HAVING x < 'c';
x | sum
---+-----
a | 4
b | 5
(2 rows)
Более реалистичный пример:
SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit
FROM products p LEFT JOIN sales s USING (product_id)
WHERE s.date > CURRENT_DATE - INTERVAL '4 weeks'
GROUP BY product_id, p.name, p.price, p.cost
HAVING sum(p.price * s.units) > 5000;
В примере выше WHERE выбирает строки по столбцу, который не
участвует в группировке (выражение верно только для продаж в течение последних
четырех недель), в то время как предложение HAVING отфильтровывает
группы с общим объемом продаж более 5000. Обратите внимание, что
агрегатные выражения не обязательно должны быть одинаковыми во всех
частях запроса.
Если в запросе есть вызовы агрегатных функций, но нет предложения
GROUP BY, то данные все равно будут сгруппированы в результате будет
отдельная строка группы (или, возможно, ни одной строки, если эта
строка затем отсекается условиями из HAVING). То же самое верно, если
запрос содержит предложение HAVING, но не содержит агрегатных
функций или предложения GROUP BY.
GROUPING SETS, CUBE и ROLLUP
Более сложные операции группировки, нежели описанные выше, возможны с применением концепции наборов группирования.
GROUPING SETS
Данные, выбранные с помощью предложений FROM и WHERE, группируются по
отдельности для каждого заданного набора группирования, агрегатные функции
вычисляются для каждой группы как для простых предложений GROUP BY, а затем
возвращаются результаты. Например:
=> SELECT * FROM items_sold;
brand | size | sales
-------+------+-------
Foo | L | 10
Foo | M | 20
Bar | M | 15
Bar | L | 5
(4 rows)
=> SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
brand | size | sum
-------+------+-----
Foo | | 30
Bar | | 20
| L | 15
| M | 35
| | 50
(5 rows)
В каждом внутреннем списке GROUPING SETS можно перечислить ноль (пустой столбец) или более столбцов
или выражений, которые интерпретируется так же, как если бы они были указаны непосредственно
в предложении GROUP BY. Пустой набор группирования означает, что
все строки собраны в одну группу (которая выводится, даже
если не было входных строк), как описано выше для агрегатных
функций без предложения GROUP BY.
Ссылки на группирующие столбцы или выражения заменяются значениями NULL в результирующих строках тех наборов группирования, в которых эти столбцы не появляются. Чтобы распознавать, результатом какого группирования стала конкретная строка вывода, см. таблицу Группировка операций.
Существуют более краткие записи для указания двух распространенных видов наборов группирования.
ROLLUP
Предложение формы
ROLLUP ( e1, e2, e3, ... )
представляет собой заданный список выражений и всех префиксов списка, включая пустой список, т. е. оно равнозначно:
GROUPING SETS (
( e1, e2, e3, ... ),
...
( e1, e2 ),
( e1 ),
( )
)
Часто ROLLUP используется для анализа иерархических данных, например,
для отображения общей зарплаты по отделам, подразделениями и по всей компании в целом.
CUBE
Предложение формы
CUBE (e1, e2, ...)
представляет заданный список и все его возможные подмножества (т. е. степенное множество). Таким образом,
CUBE (a, b, c)
равносильно
GROUPING SETS (
( a, b, c ),
( a, b ),
( a, c ),
( a ),
( b, c ),
( b ),
( c ),
( )
)
Отдельными элементами предложения CUBE или ROLLUP могут быть либо
отдельные выражения, либо вложенные списки элементов в скобках. В
последнем случае списки обрабатываются как цельные единицы, участвующие
в создании отдельных наборов группирования. Например:
CUBE ((a, b), (c, d))
равнозначно
GROUPING SETS (
( a, b, c, d ),
( a, b ),
( c, d ),
( )
)
и
ROLLUP (a, (b, c), d)
равнозначно
GROUPING SETS (
( a, b, c, d ),
( a, b, c ),
( a ),
( )
)
Конструкции CUBE и ROLLUP могут либо использоваться непосредственно в
предложении GROUP BY, либо вкладываться внутрь GROUPING SETS. Если
одно предложение GROUPING SETS вложено в другое, результат будет таким же,
как если бы все элементы внутреннего GROUPING SETS были записаны непосредственно во внешнем.
Если в одном предложении GROUP BY указано несколько элементов
группирования, то окончательный список является
прямым произведением этих элементов. Например:
GROUP BY a, CUBE (b, c), GROUPING SETS ((d), (e))
равнозначно
GROUP BY GROUPING SETS (
(a, b, c, d), (a, b, c, e),
(a, b, d), (a, b, e),
(a, c, d), (a, c, e),
(a, d), (a, e)
)
Примечание
Конструкция(a, b)обычно распознается в выражениях как конструктор строки. Но в предложенииGROUP BYэто не распространяется на верхние уровни выражений, и(a, b)анализируется как список выражений, как описано выше. Если по какой-то причине вам нужен конструктор строки в выражении группировки, используйтеROW(a, b).
Обработка оконных функций
Если запрос содержит какие-либо оконные функции (см. раздел Руководство по оконным функциям,
раздел Оконные функции и раздел Вызовы оконных функций), эти функции вычисляются после каждой
группировки, агрегации и фильтрации HAVING. То есть, если запрос
использует какие-либо агрегатные функции, предложеия GROUP BY или HAVING, тогда строки,
видимые оконными функциями, являются сгруппированными строками, а не исходными
строками таблицы из FROM/WHERE.
При использовании нескольких оконных функций все оконные функции,
имеющие синтаксически эквивалентные предложения PARTITION BY и ORDER BY,
гарантированно обрабатывают данные за один проход. Следовательно, они увидят единый
порядок сортировки, даже если ORDER BY не определяет однозначный порядок.
Однако для функций имеющих различные предложения PARTITION BY и ORDER BY
никаких гарантий не дается. (В таких случаях между проходами оценок оконной функции
шаг сортировки обычно требуется между проходами оценок оконной функции, и сортировка не
гарантирует сохранение порядка строк, который ее ORDER BY считает
эквивалентным).
На данный момент оконные функции всегда требуют предварительно
отсортированные данные, и поэтому результат запроса будет
упорядочен в соответствии с тем или иным условием PARTITION BY/ORDER BY
оконных функций, однако полагаться на это не стоит. Используйте
явно предложение ORDER BY, если хотите быть уверены в порядке сортировки.
Списки выборки
Как было упомянуто в разделе Табличные выражения, табличное выражение в команде SELECT создает промежуточную виртуальную таблицу, возможно, комбинируя таблицы, представления, удаляя строки, группируя и т.д. Итоговая таблица передаётся на обработку в список выборки. Список выборки определяет, какие столбцы промежуточной таблицы фактически выводятся.
Элементы списка выборки
Простейший тип списка выборки — это * который выдает все столбцы,
созданные табличным выражением. В общем случае список выборки
SELECT a, b, c FROM ...
Имена столбцов a, b и c это либо фактические имена столбцов
таблиц, перечисленных в предложении FROM, либо псевдонимы,
описанные в соотвествии с разделом Псевдонимы таблиц и столбцов. Пространство имён в
списке выборки то же самое, что и в предложении WHERE, если не было
группировки, в этом случае оно совпадает с пространством имён в предложении HAVING.
Если в нескольких таблицах существует столбец с одинаковым именем, то необходимо указать имя таблицы:
SELECT tbl1.a, tbl2.a, tbl1.b FROM ...
При работе с несколькими таблицами может быть полезно запросить все столбцы конкретной таблицы:
SELECT tbl1.*, tbl2.a FROM ...
Для получения подробной информации о типе записи table_name.* см. раздел Использование составных типов в запросах.
Если в списке выборки используется произвольное выражение значения, концептуально в результирующую таблицу добавляется новый виртуальный столбец в. Выражение значения вычисляется для каждой возвращаемой строки, подменяя ссылки на соответствующие значения из колонок. Однако выражение в запросе не обязательно должно ссылаться на данные, указываемые в предложении FROM, оно также может представлять собой простое арифметическое действие или иное действие возвращающее скалярную величину.
Переименование столбцов
Записям в списке выборки могут быть назначены имена для последующей обработки, например, для использования в предложении ORDER BY или для отображения клиентским приложением. Например:
SELECT a AS value, b + c AS sum FROM ...
Если имя столбца не указано с помощью AS, система назначает имя столбца по умолчанию. Для простых ссылок на столбцы это имя столбца, для вызовов функций это имя функции. Для сложных выражений система сгенерирует подходящее имя.
Ключевое слово AS можно опустить, если имя нового столбца не является ключевым словом QHB (см. раздел Ключевые слова SQL). Чтобы избежать случайного совпадения с ключевым словом, вы можете заключить имя столбца в кавычки. Например, VALUE является ключевым словом, поэтому такой вариант выдаст ошибку:
SELECT a value, b + c AS sum FROM ...
но можно использовать такой вариант:
SELECT a "value", b + c AS sum FROM ...
Для защиты от случайных совпадений с ключевыми словами, которые могут появиться в будущем рекомендуется либо всегда писать AS либо использовать кавычки.
Переименование столбцов, описанное в этом разделе отличается от именования, описанного в предложении FROM (см. раздел Псевдонимы таблиц и столбцов). Можно переименовать столбец дважды, но имя, указанное в списке выборки, будет иметь приоритет.
Выбор уникальных записей
После того, как список выборки обработан, из итоговой таблицы можно дополнительно исключить дублирующиеся строки, используя DISTINCT. Ключевое слово DISTINCT пишется сразу после предложения SELECT:
SELECT DISTINCT select_list ...
(Чтобы включить поведение по умолчанию и отобразить все строки можно использовать ключевое слово ALL.)
Две строки считаются разными, если они отличаются хотя бы
одним значением столбца, при этом значения NULL считаются одинаковыми.
Можно явно определить какие строки считать разными:
SELECT DISTINCT ON (expression [, expression ...]) select_list ...
Здесь expression — это выражение значения, которое вычисляется для всех строк. Набор строк, для которых все выражения равны, считаются дубликатами, и в результате сохраняется только первая строка набора. Обратите внимание, «первая строка» набора может быть произвольной если запрос не отсортирован или сортировка не гарантирует уникальное упорядочение строк, поступающих в фильтр DISTINCT. (Обработка DISTINCT ON происходит после сортировки ORDER BY).
Предложение DISTINCT ON не является частью стандарта SQL и иногда его использование считается плохим стилем из-за неопределенности в результатах . При разумном использовании GROUP BY и подзапросов в FROM можно избежать этой конструкции, но часто она является наиболее удобной альтернативой.
Объединение запросов
Результаты двух запросов могут быть объединены с использованием операций объединения, пересечения и разности. Синтаксис следующий:
query1 UNION [ALL] query2
query1 INTERSECT [ALL] query2
query1 EXCEPT [ALL] query2
query1 и query2 — это запросы, в которых могут использоваться любые функции,
упомянутые ранее.
Операции над множествами могут быть вложенными и связанными, например:
query1 UNION query2 UNION query3
Этот запрос выполнится следующим образом:
(query1 UNION query2) UNION query3
Предложение UNION добавляет результат query2 к результату query1
(порядок строк не гарантирован).
Кроме того, он исключает дублирующиеся строки аналогично DISTINCT,
если только не указано предложение UNION ALL.
Предложение INTERSECT возвращает все строки, которые находятся в результатах обоих запросов. Дублирующиеся строки фильтруются, если не указано INTERSECT ALL.
Предложение EXCEPT возвращает все строки, которые есть в результате query1 но отсутствуют в
результате query2. (Это иногда называют разницей двух запросов).
Опять же, дубликаты удаляются, если не используется EXCEPT ALL.
Чтобы вычислить объединение, пересечение или разность двух запросов, эти два запроса должны быть «совместимыми», это значит что они должны возвращать одинаковое количество столбцов и соответствующие столбцы должны иметь совпадающие типы данных.
Сортировка строк
После того, как запрос выдал таблицу с результатами (после обработки списка выборки), она может быть дополнительно отсортирована. Если сортировка не указана, то строки будут возвращены в произвольном порядке. Фактический порядок в этом случае будет зависеть от типов планов сканирования и соединения, а также от порядка хранения данных на диске, но на него нельзя полагаться. Конкретный порядок вывода гарантируется, только если этап сортировки указан явно.
Порядок сортировки задается с помощью предложения ORDER BY:
SELECT select_list
FROM table_expression
ORDER BY sort_expression1 [ASC | DESC] [NULLS { FIRST | LAST }]
[, sort_expression2 [ASC | DESC] [NULLS { FIRST | LAST }] ...]
Выражениями сортировки могут быть любые выражения, которые будет допустимым в списке выборки запроса. К примеру:
SELECT a, b FROM table1 ORDER BY a + b, c;
Если задано несколько выражений, то последующие значения позволяют отсортировать
строки, которые равны по предыдущим значениям. За каждым
выражением может следовать необязательное ключевое слово ASC или DESC,
которое задает направление сортировки по возрастанию или убыванию, соответственно.
По умолчанию используется порядок по возрастанию (ASC)
При сортировке по возрастанию сначала ставятся меньшие значения, где «меньший» определяется оператором
<. Аналогично, в сортировке по убыванию порядок определяется с помощью оператора1
> .
Для указания места вывода значений NULL используют предложения NULLS FIRST и NULLS LAST, которые
указывают как отображать значения NULL - до или после ненулевых значений.
По умолчанию значения NULL сортируются, как если
бы они были больше, чем любое неNULL значение, т.е. NULLS FIRST
является значением по умолчанию для порядка DESC, а NULLS LAST для ASK.
Обратите внимание, что параметры сортировки определяются
для каждого столбца отдельно. К примеру, ORDER BY x, y DESC
означает ORDER BY x ASC, y DESC, а не ORDER BY x DESC, y DESC.
Выражение sort_expression также может быть меткой столбца или номером итогового столбца, например:
SELECT a + b AS sum, c FROM table1 ORDER BY sum;
SELECT a, max(b) FROM table1 GROUP BY a ORDER BY 1;
оба из которых сортируются по первому столбцу. Обратите внимание, что имя столбца в выражении сортировки должно стоять отдельно, его нельзя использовать в выражении - например, это ошибка:
SELECT a + b AS sum, c FROM table1 ORDER BY sum + c;
Это ограничение позволяет уменьшить двусмысленность. Возможен вариант, когда в ORDER BY указано простое имя, которое совпадает с именем результирующего столбца или столбца из табличного выражения. В таких случаях используется результирующий столбец. Путаница может возничь в том случае, если вы используете AS для переименования результирующего столбца, совпадающее с именем другого столбца таблицы.
ORDER BY может также применяться к результату UNION, INTERSECT или EXCEPT, но в этом случае разрешается сортировать только по именам или номерам столбцов, а не по выражениям.
LIMIT и OFFSET
LIMIT и OFFSET позволяют вам получить только часть строк результирующей таблицы:
SELECT select_list
FROM table_expression
[ ORDER BY ... ]
[ LIMIT { number | ALL } ] [ OFFSET number ]
Если задано численное значение LIMIT, то будет возвращено не более указанного количества строк
(возможно, меньше, если сам запрос выдаст меньше строк). Указание LIMIT ALL — аналогичен
варианту, когда предложение LIMIT отсутствует, а также варианту LIMIT с аргументом NULL.
OFFSET используется, чтобы пропустить заданное количество строк, прежде чем начать возвращать строки. OFFSET 0 — аналогичен варианту когда предложение OFFSET отсуствует, а также варианту OFFSET с аргументом NULL.
Если указаны и OFFSET и LIMIT, то сначала пропускается указанное количество строк OFFSET пропускаются перед началом подсчета возвращаемых строк LIMIT.
При использовании LIMIT необходимо также указывать предложение ORDER BY, чтобы обеспечить определённый порядок выдаваемых результатов, иначе мы получим непредсказуемое подмножество результирующих строк. Можно запросить от десятой до двадцатой строки, но какой порядок имелся в виду? Если вы не указали ORDER BY, порядок будет произвольным.
Оптимизатор запросов учитывает LIMIT, при построении планов запросов, поэтому для разных LIMIT и OFFSET, скорее всего, вы получите разные планы (с разными порядками строк). Таким образом, разные LIMIT/OFFSET без использования ORDER BY, будут выбирать разные подмножества результатов, приводя к противоречивым результатам. Это не ошибка, а неотъемлемое следствие того факта, что SQL не гарантирует порядка выводов результатов запроса, если порядок вывода не определен предолжением ORDER BY.
Строки, пропускаемые предложением OFFSET, все равно вычисляются на сервере, поэтому задавать большое значение OFFSET неэффективно.
Списки VALUES
Предложение VALUES позволяет создать «постоянную таблицу», которую можно использовать в запросе, без необходимости создания таблицы на диске. Имеет следующий синтаксис:
VALUES ( expression [, ...] ) [, ...]
Для каждого заключенного в скобки списка выражений оздается строка в таблице. Все списки должны иметь одинаковое количество элементов (т.е. количество столбцов в таблице), а соответствующие записи в каждом списке должны иметь совместимые типы данных. Фактический тип данных, назначенный каждому столбцу результата, определяется с использованием тех же правил, что и для UNION .
Например:
VALUES (1, 'one'), (2, 'two'), (3, 'three');
вернет таблицу из двух столбцов и трех строк. Этот пример эквивалентен следующему запросу:
SELECT 1 AS column1, 'one' AS column2
UNION ALL
SELECT 2, 'two'
UNION ALL
SELECT 3, 'three';
По умолчанию QHB назначает столбцам таблицы VALUES имена
column1, column2 и т.д. . Имена столбцов не определены стандартом SQL,
и разные СУБД могут именовать столбцы другим образом, поэтому хорошим стилем считается
переопределение имен по умолчанию списком псевдонимов таблицы, например
так:
=> SELECT * FROM (VALUES (1, 'one'), (2, 'two'), (3, 'three')) AS t (num,letter);
num | letter
-----+--------
1 | one
2 | two
3 | three
(3 rows)
Синтаксически спискок VALUES равнозначен следующей записи:
SELECT select_list FROM table_expression
и может использоваться везде, где допустим SELECT. Например, вы можете использовать его как часть UNION или присоединить к нему sort_specification (ORDER BY, LIMIT и/или OFFSET). Также VALUES часто используется в качестве источника данных в команде INSERT и в качестве подзапроса.
Для получения дополнительной информации см. VALUES.
Запросы WITH (общие табличные выражения)
WITH предоставляет способ написания дополнительных операторов для использования в больших запросах. Эти операторы, которые часто называют общими табличными выражениями или CTE (Common Table Expressions), можно рассматривать как определения временных таблиц, которые существуют в рамках одного запроса. Дополнительным оператором в предложении WITH может быть SELECT, INSERT, UPDATE или DELETE, а само предложение WITH присоединяется к основному оператору (которым также может быть SELECT, INSERT, UPDATE или DELETE).
SELECT в WITH
Основное назначение SELECT в WITH - разбивать сложные запросы на простые части. Например:
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
Этот запрос отображает итоги продаж по отдельным продуктам для топовых регионов. Предложение WITH определяет два вспомогательных оператора с именами regional_sales и top_regions, где данные, полученные в regional_sales, используются в top_regions а данные, полученные в top_regions, используются в основном запросе SELECT. Этот пример можно было бы написать без использования WITH, но нам потребовалось бы два уровня вложенных подзапросов. Вариант с WITH выглядит намного проще.
Необязательный модификатор RECURSIVE превращает WITH из простой синтаксической конструкции в функцию, выполняющую вещи невозможные в стандартном SQL. С RECURSIVE, запрос WITH может обращаться к своему собственному результату. Это видно на очень простом примере — запрос для вычисления суммы целых чисел от 1 до 100:
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100
)
SELECT sum(n) FROM t;
В рекурсивном запросе WITH всегда вначале записывается нерекурсивная чать, затем UNION (или UNION ALL), а затем рекурсивная часть, где можно обратиться к своим собственным результатам запроса. Порядок выполнения таких запросов следующий:
Вычисление рекурсивных запросов
В приведенном выше примере в рабочей таблице на каждом шаге существует только одна строка,
которая накапливает значения от 1 до 100 в последовательных
шагах. На 100-м шаге из-за условию в WHERE нет выводимых данных, и поэтому запрос
завершается.
Рекурсивные запросы обычно используются для обработки иерархических или древовидных данных. Полезным примером является следующий запрос для поиска всех прямых и косвенных частей продукта, используя только таблицу с ямыми связами:
WITH RECURSIVE included_parts(sub_part, part, quantity) AS (
SELECT sub_part, part, quantity FROM parts WHERE part = 'our_product'
UNION ALL
SELECT p.sub_part, p.part, p.quantity
FROM included_parts pr, parts p
WHERE p.part = pr.sub_part
)
SELECT sub_part, SUM(quantity) as total_quantity
FROM included_parts
GROUP BY sub_part
При работе с рекурсивными запросами важно быть уверенным, что рекурсивная часть запроса в конце не будет возвращать кортежи (строки), иначе запрос будет бесконечным. Иногда, можно добиться этого используя UNION вместо UNION ALL, т.к. при этом отбрасываются строки, которые дублируют предыдущие выходные строки. Однако часто в цикле не встречаются строки, которые совпадают полностью, поэтому можно проверить только одно или несколько полей, чтобы узнать, не была ли ранее достигнута текущая точка. Стандартный метод решения таких задач состоит в том, чтобы вычислить массив уже обработанных значений. Например, рассмотрим следующий запрос, который ищет таблицу с помощью поля link:
WITH RECURSIVE search_graph(id, link, data, depth) AS (
SELECT g.id, g.link, g.data, 1
FROM graph g
UNION ALL
SELECT g.id, g.link, g.data, sg.depth + 1
FROM graph g, search_graph sg
WHERE g.id = sg.link
)
SELECT * FROM search_graph;
Этот запрос зацикливается, если связи link содержат циклы.
Поскольку нам требуется вывод depth, простое изменение UNION ALL на
UNION не поможет. Вместо этого нам нужно определить,
достигали ли мы текущей строки ранее, следуя определенному пути. Мы
добавляем два столбца path и cycle к результату и получаем:
WITH RECURSIVE search_graph(id, link, data, depth, path, cycle) AS (
SELECT g.id, g.link, g.data, 1,
ARRAY[g.id],
false
FROM graph g
UNION ALL
SELECT g.id, g.link, g.data, sg.depth + 1,
path || g.id,
g.id = ANY(path)
FROM graph g, search_graph sg
WHERE g.id = sg.link AND NOT cycle
)
SELECT * FROM search_graph;
Помимо предотвращения циклов, значения массива часто бывают полезны сами по себе для представление «пути», используемого для достижения какой-либо конкретной строки.
В общем случае если для распознавания цикла, необходимо проверить более одного поля,
можно использовать массив строк. Например, если нам нужно
сравнить поля f1 и f2:
WITH RECURSIVE search_graph(id, link, data, depth, path, cycle) AS (
SELECT g.id, g.link, g.data, 1,
ARRAY[ROW(g.f1, g.f2)],
false
FROM graph g
UNION ALL
SELECT g.id, g.link, g.data, sg.depth + 1,
path || ROW(g.f1, g.f2),
ROW(g.f1, g.f2) = ANY(path)
FROM graph g, search_graph sg
WHERE g.id = sg.link AND NOT cycle
)
SELECT * FROM search_graph;
Опустите синтаксис ROW() в общем случае, когда нужно проверить только одно поле для распознавания цикла. Это позволяет использовать простой массив, а не массив составного типа, что повышает эффективность.
Алгоритм рекурсивного вычисления запроса выводит результаты в порядке поиска в ширину (BFS). Вы можете также получить результаты, отсортированные в порядке поиска в глубину (DFS), сделав внешний запрос ORDER BY по столбцу «path», как в примере выше.
Полезный приём для тестирования запросов, когда вы не уверены, что они могут зацикливаться, - это поместить LIMIT в родительский запрос. Например, этот запрос будет зацикливаться без LIMIT:
WITH RECURSIVE t(n) AS (
SELECT 1
UNION ALL
SELECT n+1 FROM t
)
SELECT n FROM t LIMIT 100;
В данном случае зацикливания не происходит, поскольку QHB выдает столько строк запроса WITH сколько фактически возвращает родительский запрос. Использование этого трюка в производственной среде не рекомендуется, потому что другие СУБД могут работать по-другому. Кроме того, подобный запрос не будет работать, если вы выполните внешний запрос сортировки результатов рекурсивного запроса или присоедините их к какой-либо другой таблице, потому что в таких случаях внешний запрос обычно пытается извлечь все данные запроса WITH.
Полезным свойством запросов WITH является то, что они обычно вычисляются только один раз для родительского запроса, даже если родительский запрос или одноуровневый запрос WITH ссылается на них более одного раза. Таким образом, долгие вычисления, которые необходимы в нескольких местах, могут быть помещены в запрос WITH для ускорения работы запроса. Другим возможным применением является предотвращение нежелательных множественных вычислений функций с побочными эффектами. Однако есть и обратная сторона этой монеты - оптимизатор не может перенести ограничения из родительского запроса в запрос WITH с множественными ссылками, поскольку это может повлиять использование WITH во всех местах, когда должно повлиять только на один. Запрос WITH с множественными ссылками будет выполняться как записан и возвращать все строки, включая те которые родительский запрос может впоследствии отбросить. (Но, как упоминалось выше, вычисление может остановиться раньше, если в ссылке на запрос потребуется ограниченное количество строк).
Однако, если запрос WITH является нерекурсивным и не имеет побочных эффектов (то есть, это SELECT без зменчивых функций), его можно сложить в родительский запрос, что позволяет оптимизировать совместно два уровня запроса. По умолчанию это происходит, только если родительский запрос ссылается на запрос WITH один раз, а не несколько. Вы можете переопределить это решение, указав MATERIALIZED, чтобы вычислять запрос WITH отдельно, или указав NOT MATERIALIZED, чтобы принудительно включить его в родительский запрос. Последний вариант может привести к дублированию вычислений запроса WITH, но это все равно может оказаться выгодным, если при каждом использовании запроса WITH требуется только небольшая часть полного результата запроса WITH.
Простой пример этих правил:
WITH w AS (
SELECT * FROM big_table
)
SELECT * FROM w WHERE key = 123;
Этот запрос WITH будет свернут в родительский и создаст тот же план выполнения, что и:
SELECT * FROM big_table WHERE key = 123;
В частности, если в таблице есть индекс по key, он, вероятно, будет использоваться
для выборки строк с key = 123. С другой стороны, в:
WITH w AS (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
запрос WITH будет материализован, создавая временную копию big_table которая затем соединяется сама с собой без использования какого-либо индекса. Этот запрос будет выполнен намного эффективнее, если он будет записан как:
WITH w AS NOT MATERIALIZED (
SELECT * FROM big_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.key = w2.ref
WHERE w2.key = 123;
так что ограничения родительского запроса могут быть применены непосредственно к просмотрам big_table.
Следующий пример показывает случай, когда NOT MATERIALIZED нежелателен:
WITH w AS (
SELECT key, very_expensive_function(val) as f FROM some_table
)
SELECT * FROM w AS w1 JOIN w AS w2 ON w1.f = w2.f;
Здесь материализация запроса WITH гарантирует, что very_expensive_function вычисляется только один раз для каждой строки таблицы, а не дважды.
В приведенных выше примерах показано, что WITH используется с SELECT, но его можно присоединить также к INSERT, UPDATE или DELETE. В каждом случае он создает временную таблицу(ы), на которую можно ссылаться в основной команде.
Операторы изменения данных в WITH
Вы можете использовать операторы изменения данных (INSERT, UPDATE или DELETE) в WITH. Это позволяет вам выполнять несколько разных операций в одном запросе. Например:
WITH moved_rows AS (
DELETE FROM products
WHERE
"date" >= '2010-10-01' AND
"date" < '2010-11-01'
RETURNING *
)
INSERT INTO products_log
SELECT * FROM moved_rows;
Этот запрос перемещает строки из products в products_log. Оператор DELETE в WITH удаляет указанные строки из products и возвращает их содержимое с помощью предложения RETURNING. А затем основной запрос читает этот вывод и вставляет его в products_log.
Изюминкой вышеприведенного примера является то, что предложение WITH присоединяется к INSERT, а не к SELECT в INSERT. Это необходимо, т.к. WITH может содержать операторы, изменяющие данные, только на верхнем уровне. Тем не менее, при этом применяются обычные правила видимости WITH, поэтому можно обратиться к выводу оператора WITH из подзапроса.
Операторы изменения данных в WITH обычно дополняются предложением RETURNING (см. раздел Возврат данных из измененных строк), как показано в примере выше. Именно результат данные предложения RETURNING, а не таблица назначения оператора изменения данных, формируют временную таблицу, на которую может ссылаться остальная часть запроса. Если в операторе изменения данных в WITH отсутствует предложение RETURNING, то оно не образует временную таблицу и не может быть использовано в остальной части запроса. Тем не менее, такой запрос, будет выполнен. Вырожденный пример:
WITH t AS (
DELETE FROM foo
)
DELETE FROM bar;
Этот пример удалит все строки из таблиц foo и bar. Количество затронутых строк, о которых будет сообщено клиенту, будет посчитано только по строкам, удаленным из bar.
Рекурсивные ссылки в операторах, изменяющих данные, не допускаются. В некоторых случаях можно обойти это ограничение, обратившись к выводу рекурсивного оператора WITH, например:
WITH RECURSIVE included_parts(sub_part, part) AS (
SELECT sub_part, part FROM parts WHERE part = 'our_product'
UNION ALL
SELECT p.sub_part, p.part
FROM included_parts pr, parts p
WHERE p.part = pr.sub_part
)
DELETE FROM parts
WHERE part IN (SELECT part FROM included_parts);
Этот запрос удалит все прямые и косвенные части продукта.
Операторы, изменяющие данные в WITH выполняются ровно один раз и всегда до завершения, независимо от того, считывает ли первичный запрос все (или вообще любые) их выходные данные. Обратите внимание, что это отличается от правила для SELECT в WITH: как говорилось ранее, выполнение SELECT выполняется только до тех пор, пока основной запрос требует его вывода.
Вложенные операторы в WITH выполняются одновременно друг с другом и с основным запросом. Следовательно, при использовании операторов, изменяющих данные в WITH порядок, в котором операторы фактически будут изменять данные, непредсказуем. Все операторы выполняются с одним и тем же снимком данных (см. главу Параллельный контроль), поэтому они не могут «видеть» влияние друг друга на целевые таблицы. Это увеличивает предсказуемость фактического порядка обновлений строк и означает, что RETURNING является единственным способом передачи изменений между различными вложенными операторами WITH и основным запросом. Например в следующем примере:
WITH t AS (
UPDATE products SET price = price * 1.05
RETURNING *
)
SELECT * FROM products;
внешний SELECT будет возвращать исходные цены, которые были до действия UPDATE, в то время как в
WITH t AS (
UPDATE products SET price = price * 1.05
RETURNING *
)
SELECT * FROM t;
внешний SELECT вернет обновлённые данные.
Многократное обновление строк в одном операторе не поддерживается. Происходит только одна из модификаций, но сложно (а иногда и невозможно) предсказать, какая именно. То же самое с удалением строки, которая обновляется в том же самом операторе: в результате выполнится только обновление. Поэтому не следует пытаться модифицировать одну строку дважды в одном выражении. В частности, избегайте написания вложенных операторов WITH которые могут повлиять на строки, измененные основным оператором или дочерним вложенным оператором. Результаты таких запросов будут непредсказуемыми.
В настоящее время любая таблица, используемая как цель оператора изменения данных в WITH не должна иметь ни условного правила, ни правила ALSO, ни правила INSTEAD которое расширяется до нескольких операторов.
На самом деле QHB использует класс оператора B-дерева, чтобы определить порядок сортировки для ASC и DESC.
Обычно типы данных устанавливаются так, чтобы порядку сортировки соотвествовали операторы < и >,
можно разработать собственный тип данных с иным поведением.
Типы данных
QHB имеет богатый набор собственных типов данных, доступных пользователям. Пользователи могут добавлять новые типы в QHB с помощью команды CREATE TYPE.
В Таблице 1 показаны все встроенные типы данных общего назначения. Большинство альтернативных имен, перечисленных в столбце «Псевдонимы», являются именами, используемыми внутри QHB по историческим причинам. Кроме того, доступны некоторые используемые или устаревшие типы, но они не перечислены здесь.
| Имя | Псевдонимы | Описание |
|---|---|---|
| bigint | int8 | 8-байтовое целое со знаком |
| bigserial | serial8 | автоинкрементное восьмибайтовое целое число |
| bit [ (n) ] | битовая строка фиксированной длины | |
| bit varying [ (n) ] | varbit [ (n) ] | битовая строка переменной длины |
| boolean | bool | логический логический (истина / ложь) |
| box | прямоугольная коробка на плоскости | |
| bytea | двоичные данные («байтовый массив») | |
| character [ (n) ] | char [ (n) ] | символьная строка фиксированной длины |
| character varying [ (n) ] | varchar [ (n) ] | символьная строка переменной длины |
| cidr | сетевой адрес IPv4 или IPv6 | |
| circle | круг на плоскости | |
| date | календарная дата (год, месяц, день) | |
| double precision | float8 | число с плавающей запятой двойной точности (8 байт) |
| inet | адрес хоста IPv4 или IPv6 | |
| integer | int, int4 | четырехбайтовое целое со знаком |
| interval [ fields ] [ (p) ] | промежуток времени | |
| json | текстовые данные JSON | |
| jsonb | двоичные данные JSON, разложенные | |
| line | бесконечная линия на плоскости | |
| lseg | отрезок на плоскости | |
| macaddr | MAC (Media Access Control) адрес | |
| macaddr8 | MAC (Media Access Control) адрес (формат EUI-64) | |
| money | сумма в валюте | |
| numeric [ (p, s) ] | decimal [ (p, s) ] | точное число выбираемой точности |
| path | геометрический путь на плоскости | |
| pg_lsn | порядковый номер журнала QHB | |
| point | геометрическая точка на плоскости | |
| polygon | замкнутый геометрический путь на плоскости | |
| real | float4 | число с плавающей точкой одинарной точности (4 байта) |
| smallint | int2 | двухбайтовое целое со знаком |
| smallserial | serial2 | автоинкрементное двухбайтовое целое число |
| serial | serial4 | автоинкрементное четырехбайтовое целое число |
| text | символьная строка переменной длины | |
| time [ (p) ] [ without time zone ] | время суток (без часового пояса) | |
| time [ (p) ] with time zone | timetz | время суток, включая часовой пояс |
| timestamp [ (p) ] [ without time zone ] | дата и время (без часового пояса) | |
| timestamp [ (p) ] with time zone | timestamptz | дата и время, включая часовой пояс |
| tsquery | запрос текстового поиска | |
| tsvector | документ текстового поиска | |
| txid_snapshot | снимок идентификатора транзакции на уровне пользователя | |
| uuid | универсально уникальный идентификатор | |
| xml | данные XML |
Каждый тип данных имеет внешнее представление, определяемое его входными и выходными функциями. Многие из встроенных типов имеют очевидные внешние форматы. Однако несколько типов являются уникальными для QHB, например, геометрические пути, или имеют несколько возможных форматов, таких как типы даты и времени. Некоторые из функций ввода и вывода не являются обратимыми, т. е. результат функции вывода может потерять точность по сравнению с исходным вводом.
Числовые Типы
Числовые типы состоят из двух-, четырех- и восьмибайтовых целых чисел, четырех- и восьмибайтовых чисел с плавающей запятой и десятичных дробей с выбираемой точностью. В Таблице 2 перечислены доступные типы.
| Имя | Размер хранилища | Описание | Ассортимент |
|---|---|---|---|
| smallint | 2 байта | целое число малого диапазона | От -32768 до +32767 |
| integer | 4 байта | типичный выбор для целого числа | От -2147483648 до +2147483647 |
| bigint | 8 байт | большое целое число | От -9223372036854775808 до +9223372036854775807 |
| decimal | переменная | указанная пользователем точность, точная | до 131072 цифр перед десятичной точкой; до 16383 цифр после запятой |
| numeric | переменная | указанная пользователем точность, точная | до 131072 цифр перед десятичной точкой; до 16383 цифр после запятой |
| real | 4 байта | переменная точность, неточная | Точность 6 десятичных цифр |
| double precision | 8 байт | переменная точность, неточная | Точность 15 десятичных цифр |
| smallserial | 2 байта | небольшое автоинкрементное целое число | От 1 до 32767 |
| serial | 4 байта | автоинкрементное целое число | 1 до 2147483647 |
| bigserial | 8 байт | большое автоинкрементное целое число | 1 до 9223372036854775807 |
Синтаксис констант для числовых типов описан в разделе Константы. Числовые типы имеют полный набор соответствующих арифметических операторов и функций. Обратитесь к главе Функции и операторы за дополнительной информацией. В следующих разделах подробно описаны типы.
Целочисленные типы
Типы smallint, integer и bigint хранят целые числа, то есть числа без дробных компонент, различных диапазонов. Попытки сохранить значения за пределами допустимого диапазона приведут к ошибке.
Тип integer является наиболее распространенным, поскольку он обеспечивает наилучший баланс между диапазоном, размером хранилища и производительностью. Тип smallint обычно используется только в том случае, если объем дискового пространства выше. Тип bigint предназначен для использования, когда диапазон типа integer недостаточен.
В SQL определены только целочисленные типы integer (или int), smallint и bigint. Имена типов int2, int4 и int8 являются расширениями, которые также используются некоторыми другими системами баз данных SQL.
Числа произвольной точности
Числовой тип (numeric) может хранить числа с очень большим количеством цифр. Особенно рекомендуется для хранения денежных сумм и других количественных величин, где требуется точность. Расчеты с числовыми значениями дают точные результаты, где это возможно, например: сложение, вычитание, умножение. Однако вычисления для числовых значений очень медленны по сравнению с целочисленными типами или с типами с плавающей запятой, описанными в следующем разделе.
Следующие термины используются ниже: Точность (precision) числа — это общее количество значащих цифр во всем числе, то есть количество цифр по обеим сторонам десятичной точки. Масштаб (scale) числа — это количество десятичных цифр в дробной части, справа от десятичной точки. Таким образом, число 23,5141 имеет точность 6 и масштаб 4. Целые числа можно считать имеющими нулевой масштаб.
Можно настроить как максимальную точность, так и максимальный масштаб числового столбца. Чтобы объявить столбец числового типа, используйте синтаксис:
NUMERIC(precision, scale)
Точность должна быть положительной, масштаб должен быть неотрицательным. Альтернативный вариант:
NUMERIC(precision)
устанавливает масштаб 0. Форма:
NUMERIC
без какой-либо точности или масштаба создает столбец, в котором могут быть сохранены числовые значения любой точности и масштаба, вплоть до предела реализации по точности. Столбец такого типа не будет приводить входные значения к какому-либо конкретному масштабу, тогда как numeric столбцы с объявленным масштабом будут приводить входные значения к этому масштабу. (Стандарт SQL требует, чтобы масштаб по умолчанию был равен 0, что соответствует приведению к целочисленной точности. Если вы беспокоитесь о переносимости, всегда указывайте точность и масштаб явно).
Заметка
Максимально допустимая точность, если она явно указана в объявлении типа, составляет 1000; NUMERIC без указанной точности подпадает под ограничения, описанные в Таблице 2.
Если масштаб сохраняемого значения больше, чем объявленный масштаб столбца, система округляет значение до указанного числа дробных цифр. Затем, если число цифр слева от десятичной точки превышает объявленную точность минус заявленная шкала, возникает ошибка.
Числовые значения физически сохраняются без каких-либо дополнительных начальных или конечных нулей. Таким образом, заявленная точность и масштаб столбца являются максимальными, а не фиксированными распределениями. (В этом смысле числовой тип больше похож на varchar(n) чем на char(n)). Фактическое требование к хранилищу составляет два байта для каждой группы из четырех десятичных разрядов, плюс три-восемь байтов служебных данных.
В дополнение к обычным числовым значениям, числовой тип допускает
специальное значение NaN, означающее «не число». Любая операция с NaN
приводит к другому NaN. При записи этого значения в качестве константы в
команду SQL вы должны заключать в кавычки, например, UPDATE table SET x = 'NaN'.
При вводе строка NaN распознается без учета регистра.
Заметка
В большинстве реализаций концепции «не число» NaN не считается равным любому другому числовому значению (включая NaN). Чтобы разрешить сортировку и использование числовых значений в древовидных индексах, QHB рассматривает значения NaN как равные и превышающие все значения, отличные от NaN.
Типы decimal и numeric эквивалентны. Оба типа являются частью стандарта SQL.
При округлении значений числовой тип округляет связи от нуля в то время как (на большинстве машин) типы real и double precision округляют до ближайшего четного числа. Например:
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.5, 3.5, 1) as x;
x | num_round | dbl_round
------+-----------+-----------
-3.5 | -4 | -4
-2.5 | -3 | -2
-1.5 | -2 | -2
-0.5 | -1 | -0
0.5 | 1 | 0
1.5 | 2 | 2
2.5 | 3 | 2
3.5 | 4 | 4
(8 rows)
Типы с плавающей точкой
Типы данных real и double precision являются неточными числовыми типами переменной точности. На всех поддерживаемых в настоящее время платформах эти типы являются реализациями стандарта IEEE 754 для двоичной арифметики с плавающей запятой (одинарной и двойной точности соответственно) в той степени, в которой это поддерживается базовым процессором, операционной системой и компилятором.
Неточное означает, что некоторые значения не могут быть преобразованы точно во внутренний формат и хранятся в виде приближений, поэтому при сохранении и извлечении значения могут обнаруживаться небольшие расхождения. Управление этими ошибками и то, как они распространяются посредством вычислений, является предметом целой отрасли математики и информатики и не будет обсуждаться здесь, за исключением следующих моментов:
На всех поддерживаемых в настоящее время платформах real тип имеет диапазон от 1E**-37** до 1E**+37** с точностью не менее 6 десятичных цифр. Тип double precision имеет диапазон от 1E**-307** до 1E**+308** с точностью не менее 15 цифр. Значения, которые являются слишком большими или слишком маленькими, вызовут ошибку. Округление может иметь место, если точность введенного числа слишком высока. Числа, слишком близкие к нулю, которые не могут быть представлены отличными от нуля, вызовут ошибку недостаточного значения.
По умолчанию значения с плавающей запятой выводятся в текстовой форме в самом кратком десятичном представлении; полученное десятичное значение ближе к истинному сохраненному двоичному значению, чем к любому другому значению, представляемому с той же двоичной точностью. (Однако выходное значение в настоящее время никогда не бывает точно посередине между двумя представимыми значениями, чтобы избежать широко распространенной ошибки, когда входные подпрограммы не соблюдают должным образом правило округления до ближайшего четного). Это значение будет использовать не более 17 значащих десятичных цифр для значения float8 и не более 9 цифр для значений float4.
Заметка
Этот формат вывода с наименьшей точностью вывода генерируется намного быстрее, чем исторически сложившийся формат округления.
Для снижения точности вывода, можно использовать параметр extra_float_digits для выбора округления десятичного числа. Установка значения 0 восстанавливает предыдущее значение округления по умолчанию до 6 (для float4) или 15 (для float8) значащих десятичных цифр. Установка отрицательного значения уменьшает количество цифр; например, -2 округляет вывод до 4 или 13 цифр соответственно.
Любое значение extra_float_digits больше 0 выбирает формат с наименьшей точностью.
В дополнение к обычным числовым значениям типы с плавающей точкой имеют несколько специальных значений:
Они представляют специальные значения IEEE 754 «бесконечность»,
«отрицательная бесконечность» и «не число» соответственно. При записи
этих значений в качестве констант в SQL-команде необходимо заключить их
в кавычки, например, UPDATE table SET x = '-Infinity'. При вводе эти
строки распознаются без учета регистра.
Заметка
IEEE754 указывает, что NaN не должен сравниваться с любым другим значением с плавающей запятой (включая NaN). Чтобы позволить значениям с плавающей точкой сортироваться и использоваться в древовидных индексах, QHB рассматривает значения NaN как равные и превышающие все значения, отличные от NaN.
QHB также поддерживает стандартные обозначения SQL float и float(p) для указания неточных (inexact) числовых типов. Здесь p указывает минимально допустимую точность в двоичных разрядах. QHB принимает значения от float(1) до float(24) как выбор типа real, в то время как значения от float(25) до float(53) как выбор типа double precision. Значения p вне допустимого диапазона формируют ошибку. float без заданной точности считается double precision.
Серийные типы
В этом разделе описывается специфичный для QHB способ создания столбца автоинкрементирования. Другой способ - использовать функцию столбца идентификаторов стандарта SQL, см. в описании CREATE TABLE.
Типы данных smallserial, serial и bigserial — это не настоящие типы, а просто удобство записи для создания столбцов уникальных идентификаторов (аналогично свойству AUTO_INCREMENT поддерживаемому некоторыми другими базами данных). В текущей реализации, указание:
CREATE TABLE tablename (
colname SERIAL
);
эквивалентно указанию:
CREATE SEQUENCE tablename_colname_seq AS integer;
CREATE TABLE tablename (
colname integer NOT NULL DEFAULT nextval('tablename_colname_seq')
);
ALTER SEQUENCE tablename_colname_seq OWNED BY tablename.colname;
Таким образом, создаётся целочисленный столбец и его значения по умолчанию организованы для назначения из генератора последовательности. Ограничение NOT NULL применяется, чтобы гарантировать, что нулевое значение не может быть вставлено. (В большинстве случаев вы также хотели бы присоединить ограничение UNIQUE или PRIMARY KEY чтобы предотвратить случайную вставку дублирующихся значений, но это не происходит автоматически). Наконец, последовательность помечается как «принадлежащая» столбцу, так что она будет удалена, если столбец или таблица будут удалены.
Заметка
Поскольку smallserial, serial и bigserial реализованы с использованием последовательностей, в последовательности значений, которая появляется в столбце, могут быть «дыры» или пробелы, даже если строки никогда не удаляются. Значение, выделенное из последовательности, все равно будет «израсходовано», даже если строка, содержащая это значение, никогда не будет успешно вставлена в столбец таблицы. Это может произойти, например, если транзакция вставки откатывается. Подробности смотрите в nextval() в разделе Функции управления последовательностями.
Чтобы вставить следующее значение последовательности в столбец последовательности, укажите, что столбцу последовательности должно быть присвоено его значение по умолчанию. Это можно сделать либо путем исключения столбца из списка столбцов в инструкции INSERT, либо с помощью ключевого слова DEFAULT.
Имена типов serial и serial4 эквивалентны: оба создают столбцы типа integer. Имена типов bigserial и serial8 работают аналогично, за исключением того, что они создают столбец bigint. Следует использовать bigserial, если вы предполагаете использовать более 2**31** идентификаторов за время существования таблицы. Имена типов smallserial и serial2 также работают аналогично, за исключением того, что они создают столбец smallint.
Последовательность, созданная для столбца последовательности, автоматически удаляется при удалении столбца-владельца. Вы можете удалить последовательность без удаления столбца, но это приведет к удалению выражения по умолчанию для столбца.
Денежные Типы
Тип money хранит сумму в валюте с фиксированной дробной точностью; см. таблицу 3. Дробная точность определяется настройкой базы данных lc_monetary. Диапазон, указанный в таблице, предполагает наличие двух дробных цифр. Ввод принимается в различных форматах, включая целочисленные литералы и литералы с плавающей запятой, а также типичное форматирование валюты, например, ’$1,000.00’. Вывод обычно в последней форме, но зависит от локали.
| Имя | Размер хранилища | Описание | Ассортимент |
|---|---|---|---|
| money | 8 байт | сумма в валюте | От -92233720368547758.08 до +92233720368547758.07 |
Так как выходные данные этого типа чувствительны к локали, они могут не работать, при загрузке данных money в базу данных, которая имеет другой параметр lc_monetary. Чтобы избежать проблем, перед восстановлением дампа в новую базу данных убедитесь, что lc_monetary имеет то же или эквивалентное значение, что и в базе данных, которая была выгружена.
Значения типов данных numeric, int и bigint могут быть приведены к money. Преобразование из типов данных real и double precision можно выполнить, если сначала привести к типу numeric, например:
SELECT '12.34'::float8::numeric::money;
Однако это не рекомендуется. Числа с плавающей запятой не должны использоваться для обработки денег из-за возможной ошибки округления.
Денежное значение может быть приведено к числовому без потери точности. Преобразование в другие типы потенциально может привести к потере точности и также должно выполняться в два этапа:
SELECT '52093.89'::money::numeric::float8;
Деление денежной величины на целое число производится с усечением дробной части в сторону нуля. Чтобы получить округленный результат, разделите на значение с плавающей запятой или преобразуйте денежное значение в числовое перед делением и обратно в денежное после этого. (Последнее предпочтительнее, чтобы избежать риска потери точности). Когда денежная стоимость делится на другую денежную стоимость, результат получается double precision (т. е. чистое число, а не деньги); денежные единицы отменяют друг друга при делении.
Символьные типы
| Имя | Описание |
|---|---|
| character varying(n), varchar(n) | переменная длина с ограничением |
| character(n), char(n) | фиксированная длина, с дополнением |
| text | переменная неограниченная длина |
Таблица 4 показывает типы символов общего назначения, доступные в QHB.
SQL определяет два основных типа символов: character varying(n) и character(n), где n - положительное целое число. Оба этих типа могут хранить строки длиной до n символов (не байтов). Попытка сохранить более длинную строку в столбце этих типов приведет к ошибке, если только избыточные символы не являются пробелами, в этом случае строка будет усечена до максимальной длины. (Это несколько странное исключение требуется стандартом SQL). Если строка, которая должна быть сохранена, короче объявленной длины, значения character будут дополнены пробелами; Значения типа character varying просто сохранят более короткую строку.
Если кто-либо явно преобразует значение в character varying(n) или character(n), то значение чрезмерной длины будет усечено до n символов без возникновения ошибки. (Это также требуется стандартом SQL).
Обозначения varchar(n) и char(n) являются псевдонимами для character varying(n) и character(n), соответственно. character без спецификатора длины эквивалентен character(1). Если character varying используется без спецификатора длины, тип принимает строки любого размера. Последнее является расширением QHB.
Кроме того, QHB предоставляет тип text, в котором хранятся строки любой длины. Хотя тип text не соответствует стандарту SQL, он есть и в некоторых других системах управления базами данных SQL.
Значения типа character физически дополняются пробелами до указанной
ширины n и сохраняются и отображаются таким образом. Однако конечные
пробелы обрабатываются как семантически несущественные и не учитываются
при сравнении двух значений типа character. В сопоставлениях, где пробел
является значительным, такое поведение может привести к неожиданным
результатам; например, SELECT 'a '::CHAR(2) collate "C" < E'a\n'::CHAR(2)
возвращает true, даже если в локали C пробел будет
больше новой строки. Конечные пробелы удаляются при преобразовании
character значения в один из других типов строк. Обратите внимание, что
конечные пробелы семантически значимы в character varying и text
значениях, а также при использовании сопоставления с шаблоном оператором
LIKE и в регулярных выражениях.
Потребность в памяти для короткой строки (до 126 байт) составляет 1 байт плюс фактическая строка, которая включает заполнение пробелами в случае character. Более длинные строки имеют 4 байта служебной информации вместо 1. Длинные строки сжимаются системой автоматически, поэтому физические требования к диску могут быть меньше. Очень длинные значения также хранятся в фоновых таблицах, чтобы они не мешали быстрому доступу к более коротким значениям столбцов. В любом случае самая длинная строка символов, которую можно сохранить, составляет около 1 ГБ. (Максимальное значение, которое будет разрешено для n в объявлении типа данных, меньше этого. Менять это было бы бесполезно, поскольку в многобайтовых кодировках число символов и байтов может быть совершенно разным. Если вы хотите сохранить длинные строки без определенного верхнего предела, используйте text или character varying без спецификатора длины вместо того, чтобы создавать произвольный предел длины).
Заметка
Между этими тремя типами нет разницы в производительности, за исключением увеличения места для хранения при использовании типа с пробелом и нескольких дополнительных циклов ЦП для проверки длины при сохранении в столбце с ограниченной длиной. Хотя character(n) имеет преимущества в производительности в некоторых других системах баз данных, в QHB такого преимущества нет; на самом деле character(n) обычно самый медленный из трех из-за его дополнительных затрат на хранение. В большинстве случаев вместо этого следует использовать text или character varying.
Обратитесь к разделу Строковые константы за информацией о синтаксисе строковых литералов, а также к главе Функции и операторы за информацией о доступных операторах и функциях. Набор символов базы данных определяет набор символов, используемый для хранения текстовых значений; для получения дополнительной информации о поддержке набора символов обратитесь к разделу Поддержка набора символов.
Пример 7.1. Использование типов символов
CREATE TABLE test1 (a character(4));
INSERT INTO test1 VALUES ('ok');
SELECT a, char_length(a) FROM test1; -- (1)
a | char_length
------+-------------
ok | 2
CREATE TABLE test2 (b varchar(5));
INSERT INTO test2 VALUES ('ok');
INSERT INTO test2 VALUES ('good ');
INSERT INTO test2 VALUES ('too long');
ERROR: value too long for type character varying(5)
INSERT INTO test2 VALUES ('too long'::varchar(5)); -- explicit truncation
SELECT b, char_length(b) FROM test2;
b | char_length
-------+-------------
ok | 2
good | 5
too l | 5
Заметка
Функцияchar_lengthобсуждается в разделе Строковые функции и операторы
В QHB есть два других символьных типа фиксированной длины, показанных в Таблице 5. Тип name существует только для хранения идентификаторов во внутренних системных каталогах и не предназначен для использования обычными пользователями. Его длина в настоящее время определяется как 64 байта (63 используемых символа плюс терминатор), но на него следует ссылаться, используя константу NAMEDATALEN в исходном коде C/RUST. Длина устанавливается во время компиляции (и, следовательно, настраивается для специальных целей); максимальная длина по умолчанию может измениться в будущем выпуске. Тип "char" (обратите внимание на кавычки) отличается от char(1) тем, что он использует только один байт памяти. Он используется внутри системных каталогов как упрощенный тип перечисления.
Таблица 5. Специальные типы символов
| Имя | Размер хранилища | Описание |
|---|---|---|
| "char" | 1 байт | однобайтовый внутренний тип |
| name | 64 байта | внутренний тип для имен объектов |
Двоичные типы данных
Тип данных bytea позволяет хранить двоичные строки; см. таблицу 7.6.
Таблица 6. Двоичные типы данных
| имя | Размер хранилища | Описание |
|---|---|---|
| bytea | 1 или 4 байта плюс фактическая двоичная строка | двоичная строка переменной длины |
Бинарная строка — это последовательность октетов (или байтов). Двоичные строки отличаются от символьных строк двумя способами. Во-первых, двоичные строки специально позволяют хранить октеты с нулевым значением и другие «непечатные» октеты (как правило, октеты вне десятичного диапазона от 32 до 126). Строки символов запрещают нулевые октеты, а также запрещают любые другие значения октетов и последовательности значений октетов, которые являются недопустимыми в соответствии с выбранной кодировкой набора символов базы данных. Во-вторых, операции над двоичными строками обрабатывают фактические байты, тогда как обработка символьных строк зависит от настроек локали. Короче говоря, двоичные строки подходят для хранения данных, которые программист считает «необработанными байтами», тогда как символьные строки подходят для хранения текста.
Тип bytea поддерживает два формата для ввода и вывода: формат «hex» (шестнадцатеричный) и исторический формат QHB «escape» (экранированный). Они оба всегда принимаются на вход. Формат вывода зависит от параметра конфигурации bytea_output; по умолчанию используется «hex».
Стандарт SQL определяет другой тип двоичной строки, который называется BLOB или BINARY LARGE OBJECT. Формат ввода отличается от bytea, но предоставляемые функции и операторы в основном одинаковы.
«Шестнадцатеричный» формат bytea
«Шестнадцатеричный» формат кодирует двоичные данные в виде 2
шестнадцатеричных цифр на байт, наиболее значимые из которых являются
первыми. Всей строке предшествует последовательность \x (чтобы отличить
ее от escape-формата). В некоторых контекстах первоначальный обратный
слеш, возможно, должен быть экранирован путем его удвоения (см.
раздел Строковые константы). Для ввода шестнадцатеричные цифры могут быть в верхнем или
нижнем регистре, и пробел допускается между парами цифр (но не внутри
пары цифр и не в начальной последовательности \x). Шестнадцатеричный
формат совместим с широким спектром внешних приложений и протоколов, и
он, как правило, быстрее преобразуется, чем escape-формат, поэтому его
использование является предпочтительным.
Пример:
SELECT '\xDEADBEEF';
Экранированный формат bytea
Экранированный формат является традиционным форматом QHB для типа bytea. В нем используется подход, представляющий двоичную строку как последовательность символов ASCII, при этом преобразовываются те байты, которые не могут быть представлены в виде символа ASCII, в специальные escape-последовательности. Если с точки зрения приложения представление байтов в виде символов имеет смысл, то такое представление может быть удобным. Но на практике это обычно сбивает с толку, поскольку стирает различия между двоичными строками и символьными строками, а также конкретный выбранный управляющий механизм несколько громоздок. Следовательно, этого формата, вероятно, следует избегать для большинства новых приложений.
При вводе значений bytea в escape-формате, октеты определенных значений должны быть экранированы, тогда как все октетные значения могут быть экранированы. В общем случае, чтобы экранировать октет, преобразуйте его в трехзначное восьмеричное значение и поставьте перед ним обратную косую черту. Сама обратная косая черта (десятичное значение октета 92) альтернативно может быть представлена двойной обратной косой чертой. Таблица 7 показывает символы, которые должны быть экранированы, и дает альтернативные escape-последовательности, где это применимо.
Таблица 7. Экранированные символы октета bytea
| Десятичное значение октета | Описание | Экранированное входное представление | Пример | Шестнадцатеричное представление |
|---|---|---|---|---|
| 0 | нулевой октет | ’\000’ | SELECT ’\000’::bytea; | \x00 |
| 39 | одинарная кавычка | ”” или ’\047’ | SELECT ””::bytea; | \x27 |
| 92 | обратный слэш | ’\\’ или ’\134’ | SELECT ’\\’::bytea; | \x5c |
| От 0 до 31 и от 127 до 255 | «Непечатные» октеты | ’\ xxx’ (восьмеричное значение) | SELECT ’\001’::bytea; | \x01 |
Требование экранирования не печатаемых октетов зависит от настроек локали. В некоторых случаях вы можете оставить их без экранирования.
Причина, по которой одинарные кавычки должны быть удвоены, как показано в Таблице 7, заключается в том, что это верно для любого строкового литерала в команде SQL. Универсальный синтаксический анализатор строковых литералов использует самые крайние одинарные кавычки и сводит любую пару одинарных кавычек к одному символу данных. То, что функция ввода bytea видит, — это всего лишь одна одинарная кавычка, которую она обрабатывает как простой символ данных. Однако входная функция bytea обрабатывает обратную косую черту как спецсимвол, и другие действия, показанные в Таблице 7, реализуются этой функцией.
В некоторых контекстах обратная косая черта должна быть удвоена по сравнению с показанной выше, потому что общий анализатор строковых литералов также сократит пары обратной косой черты до одного символа данных; см. раздел Строковые константы.
Октеты bytea выводятся в шестнадцатеричном формате по умолчанию. Если вы измените bytea_output на escape, «непечатные» октеты преобразуются в их эквивалентные трехзначные восьмеричные значения и им предшествует один обратный слеш. Большинство «печатаемых» октетов выводятся по их стандартному представлению в клиентском наборе символов, например:
SET bytea_output = 'escape';
SELECT 'abc \153\154\155 \052\251\124'::bytea;
bytea
----------------
abc klm *\251T
Октет с десятичным значением 92 (обратная косая черта) удваивается в выходных данных. Подробности в Таблице 8.
Таблица 8. Выходные экранированные октеты bytea
| Десятичное значение октета | Описание | Выходное представление с выходом | Пример | Результат на выходе |
|---|---|---|---|---|
| 92 | обратный слэш | \\ | SELECT ’\134’::bytea; | \\ |
| От 0 до 31 и от 127 до 255 | «Непечатные» октеты | \ xxx (восьмеричное значение) | SELECT ’\001’::bytea; | \001 |
| От 32 до 126 | «Печатаемые» октеты | представление набора символов клиента | SELECT ’\176’::bytea; | ~ |
В зависимости от используемого интерфейса QHB, вам может потребоваться выполнить дополнительную работу, связанную с экранированием и деэкранированием строк bytea. Например, вам также может потребоваться экранировать перевод строки и возврат каретки, если ваш интерфейс автоматически их переводит.
Типы даты/времени
QHB поддерживает полный набор типов даты и времени SQL, показанных в Таблице 9. Операции, доступные для этих типов данных, описаны в разделе Функции и операторы даты/времени. Даты подсчитываются в соответствии с григорианским календарем, даже за годы до того, как этот календарь был введен .
Таблица 9. Типы даты / времени
| Имя | Размер хранилища | Описание | Низкая стоимость | Высокое значение | разрешение |
|---|---|---|---|---|---|
| timestamp [ (p) ] [ without time zone ] | 8 байт | дата и время (без часового пояса) | 4713 г. до н.э. | 294276 н.э. | 1 микросекунда |
| timestamp [ (p) ] with time zone | 8 байт | дата и время с часовым поясом | 4713 г. до н.э. | 294276 н.э. | 1 микросекунда |
| date | 4 байта | дата (без времени суток) | 4713 г. до н.э. | 5874897 н.э. | 1 день |
| time [ (p) ] [ without time zone ] | 8 байт | время суток (без даты) | 00:00:00 | 24:00:00 | 1 микросекунда |
| time [ (p) ] with time zone | 12 байт | время суток (без даты) с часовым поясом | 00: 00: 00 + 1459 | 24: 00: 00-1459 | 1 микросекунда |
| interval [ fields ] [ (p) ] | 16 байт | интервал времени | -178000000 лет | 178000000 лет | 1 микросекунда |
Заметка
Стандарт SQL требует, чтобы запись только timestamp была эквивалентна timestamp without time zone, и QHB соблюдает это поведение. timestamptz принимается как сокращение от timestamp with time zone; это расширение QHB.
time, timestamp и interval принимают необязательное значение точности p которое указывает количество дробных цифр, сохраняемых в поле секунд. По умолчанию нет явного ограничения точности. Допустимый диапазон p составляет от 0 до 6.
Тип interval имеет дополнительную опцию, которая заключается в ограничении набора хранимых полей, путем записи одной из этих фраз:
YEAR
MONTH
DAY
HOUR
MINUTE
SECOND
YEAR TO MONTH
DAY TO HOUR
DAY TO MINUTE
DAY TO SECOND
HOUR TO MINUTE
HOUR TO SECOND
MINUTE TO SECOND
Обратите внимание, если при выборе интервала, указаны оба поля fields и p, то fields должен содержать SECOND, поскольку точность применяется только к секундам.
Тип time with time zone определяется стандартом SQL, но определение обладает свойствами, которые приводят к сомнительной полезности. В большинстве случаев сочетание date, time, timestamp without time zone и timestamp with time zone должно обеспечивать полный диапазон функциональных возможностей даты/времени, требуемых для любого приложения.
Ввод даты / времени
Ввод даты и времени допускается практически в любом приемлемом формате, включая ISO 8601, SQL- совместимый, традиционный POSTGRES и другие. Для некоторых форматов порядок ввода даты, месяца и года в дате является неоднозначным, и существует поддержка для определения ожидаемого порядка этих полей. Установите для параметра DateStyle значение MDY чтобы выбрать интерпретацию месяц-день-год, DMY для выбора интерпретации день-месяц-год или YMD чтобы выбрать интерпретацию год-месяц-день.
Помните, что любые литералы даты или времени должны быть заключены в одинарные кавычки, как текстовые строки. Обратитесь в раздел Константы других типов за дополнительной информацией. SQL требует следующий синтаксис
type [ (p) ] 'value'
где p - необязательная спецификация точности, дающая количество дробных цифр в поле секунд. Точность может быть указана для типов time, timestamp и interval и может варьироваться от 0 до 6. Если точность не указана в спецификации константы, по умолчанию используется точность литерального значения (но не более 6 цифр).
Даты
Таблица 10 показывает некоторые возможные входные данные для типа даты.
Таблица 10. Ввод даты
| Пример | Описание |
|---|---|
| 1999-01-08 | ISO 8601; 8 января в любом режиме (рекомендуемый формат) |
| January 8, 1999 | однозначно в любом datestyle ввода datestyle |
| 1/8/1999 | 8 января в режиме MDY; 1 августа в режиме DMY |
| 1/18/1999 | 18 января в режиме MDY; отклонено в других режимах |
| 01/02/03 | 2 января 2003 г. в режиме MDY; 1 февраля 2003 г. в режиме DMY; 3 февраля 2001 г. в режиме YMD |
| 1999-Jan-08 | 8 января в любом режиме |
| Jan-08-1999 | 8 января в любом режиме |
| 08-Jan-1999 | 8 января в любом режиме |
| 99-Jan-08 | 8 января в режиме YMD, в других ошибка |
| 08-Jan-99 | 8 января, кроме ошибки в режиме YMD |
| Jan-08-99 | 8 января, кроме ошибки в режиме YMD |
| 19990108 | ISO 8601; 8 января 1999 года в любом режиме |
| 990108 | ISO 8601; 8 января 1999 года в любом режиме |
| 1999.008 | год и день года |
| J2451187 | Юлианская дата |
| January 8, 99 BC | 99 год до нашей эры |
Время
Типы времени суток -это time [ (p) ] without time zone и
time [ (p) ] with time zone. «time» эквивалентно «time without time zone».
Допустимые входные данные для этих типов состоят из времени суток, за которым следует необязательный часовой пояс. (См. таблицу 11 и таблицу 12). Если часовой пояс указан во входных данных для time without time zone, он игнорируется. Вы также можете указать дату, но она будет игнорироваться, за исключением случаев, когда вы используете имя часового пояса, которое включает правило перехода на летнее время, например America/New_York. В этом случае указание даты требуется для определения того, применяется ли стандартное или летнее время. Соответствующее смещение часового пояса записывается в поле со значением time with time zone.
| Пример | Описание |
|---|---|
| 04:05:06.789 | ISO 8601 |
| 04:05:06 | ISO 8601 |
| 04:05 | ISO 8601 |
| 040506 | ISO 8601 |
| 04:05 AM | такой же, как 04:05; AM не влияет на значение |
| 04:05 PM | такой же, как 16:05; входной час должен быть <= 12 |
| 04:05:06.789-8 | ISO 8601 |
| 04:05:06-08:00 | ISO 8601 |
| 04:05-08:00 | ISO 8601 |
| 040506-08 | ISO 8601 |
| 04:05:06 PST | часовой пояс указан аббревиатурой |
| 2003-04-12 04:05:06 America/New_York | часовой пояс указан полным именем |
Таблица 12. Ввод часового пояса
| Пример | Описание |
|---|---|
| PST | Сокращение (для тихоокеанского стандартного времени) |
| America/New_York | Полное название часового пояса |
| PST8PDT | Спецификация часового пояса в стиле POSIX |
| -8:00 | Смещение ISO-8601 для PST |
| -800 | Смещение ISO-8601 для PST |
| -8 | Смещение ISO-8601 для PST |
| zulu | Военная аббревиатура для UTC |
| z | Короткая форма zulu |
Обратитесь к разделу Часовые пояса за дополнительной информацией о том, как указать часовые пояса.
Отметки времени
Допустимые входные данные для типов отметок времени состоят из объединения даты и времени, за которым следует необязательный часовой пояс, за которым следует необязательный AD или BC. (В качестве альтернативы AD/BC могут появляться перед часовым поясом, но это не предпочтительный порядок). Таким образом:
1999-01-08 04:05:06
и:
1999-01-08 04:05:06 -8:00
действительные значения, соответствующие стандарту ISO 8601. Кроме того, поддерживается общий формат:
January 8 04:05:06 1999 PST
Стандарт SQL различает метку времени без часового пояса и метку времени с литералами часового пояса по наличию символа «+» или «-» и смещению часового пояса после времени. Следовательно, согласно стандарту,
TIMESTAMP '2004-10-19 10:23:54'
это метка времени без часового пояса, в то время как
TIMESTAMP '2004-10-19 10:23:54+02'
это метка времени со значением часового пояса. QHB никогда не проверяет содержимое литеральной строки перед определением ее типа, и поэтому будет обрабатывать оба вышеперечисленные выражения как метку времени без часового пояса. Чтобы литерал обрабатывался как метка времени со значением часового пояса, присвойте ему правильный явный тип:
TIMESTAMP WITH TIME ZONE '2004-10-19 10:23:54+02'
В литерале, который был определен как метка времени без часового пояса, QHB будет молча игнорировать любую индикацию часового пояса. Таким образом, результирующее значение получается из полей даты/времени во входном значении и не корректируется для часового пояса.
Для метки времени со значением часового пояса внутреннее сохраненное значение всегда указывается в формате UTC (универсальное координированное время, традиционно известное как среднее время по Гринвичу, GMT). Входное значение с указанным явным часовым поясом преобразуется в UTC с использованием соответствующего смещения для этого часового пояса. Если во входной строке не указан часовой пояс, предполагается, что он находится в часовом поясе, указанном системным параметром TimeZone, и преобразуется в UTC с использованием смещения для зоны часового пояса.
Когда выводится метка времени со значением часового пояса, она всегда преобразуется из UTC в текущую зону часового пояса и отображается как местное время в этой зоне. Чтобы увидеть время в другом часовом поясе, измените часовой пояс или используйте конструкцию AT TIME ZONE (см. раздел AT TIME ZONE).
Преобразования между меткой времени без часового пояса и меткой времени с часовым поясом обычно предполагают, что значение метки времени без часового пояса должно быть принято или задано как местное время часового пояса. Для преобразования можно указать другой часовой пояс, используя AT TIME ZONE.
Специальные значения
QHB для удобства поддерживает несколько специальных значений ввода даты/времени, как показано в Таблице 13. Значения infinity и -infinity специально представлены внутри системы и будут отображаться без изменений; другие же - просто сокращенные обозначения, которые при чтении будут преобразованы в обычные значения даты/времени. (В частности, now и связанные строки преобразуются в определенное значение времени, как только они будут прочитаны). Все эти значения должны быть заключены в одинарные кавычки при использовании в качестве констант в командах SQL.
Таблица 13. Специальные даты / времени
| Строка ввода | Действительные типы | Описание |
|---|---|---|
| epoch | date, timestamp | 1970-01-01 00: 00: 00 + 00 (системное время Unix ноль) |
| infinity | date, timestamp | позже всех других отметок времени |
| -infinity | date, timestamp | раньше всех других отметок времени |
| now | date, time, timestamp | время начала текущей транзакции |
| today | date, timestamp | полночь (00:00) сегодня |
| tomorrow | date, timestamp | полночь (00:00) завтра |
| yesterday | date, timestamp | полночь (00:00) вчера |
| allballs | time | 00: 00: 00.00 UTC |
Следующие SQL- совместимые функции также можно использовать для получения текущего значения времени для соответствующего типа данных: CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP, LOCALTIME, LOCALTIMESTAMP. Последние четыре принимают необязательную спецификацию с точностью до секунды. (См. раздел Текущая дата/время). Обратите внимание, что они являются функциями SQL и не распознаются в строках ввода данных.
Формат вывода типов дата/время
Формат вывода типов даты / времени может быть установлен в один из четырех стилей ISO 8601, SQL (Ingres), традиционный POSTGRES (формат даты Unix) или немецкий. По умолчанию используется формат ISO. (Стандарт SQL требует использования формата ISO 8601. Название формата вывода «SQL» является исторической случайностью). В Таблице 14 приведены примеры каждого стиля вывода. Выходные данные типов date и time как правило, представляет собой только часть даты или времени в соответствии с приведенными примерами. Однако стиль POSTGRES выводит значения только для даты в формате ISO.
Таблица 14. Стили вывода даты / времени
| Спецификация стиля | Описание | пример |
|---|---|---|
| ISO | ISO 8601, стандарт SQL | 1997-12-17 07:37:16-08 |
| SQL | традиционный стиль | 12/17/1997 07:37:16.00 PST |
| Postgres | оригинальный стиль | Wed Dec 17 07:37:16 1997 PST |
| German | региональный стиль | 17.12.1997 07:37:16.00 PST |
Заметка
ISO 8601 определяет использование заглавной буквы T для разделения даты и времени. QHB принимает этот формат на входе, но на выходе он использует пробел, а не T, как показано выше. Это для удобочитаемости и для соответствия RFC 3339, а также некоторым другим системам баз данных.
В стилях SQL и POSTGRES день отображается перед месяцем, если указан порядок полей DMY, в противном случае месяц отображается перед днем. (См. раздел Формат вывода типов дата/время о том, как этот параметр также влияет на интерпретацию входных значений). В Таблице 15 приведены примеры.
Таблица 15. Соглашение о дате заказа
| Установка datestyle | Порядок ввода | Пример вывода |
|---|---|---|
| SQL, DMY | day/month/year | 17/12/1997 15:37:16.00 CET |
| SQL, MDY | month/day/year | 12/17/1997 07:37:16.00 PST |
| Postgres, DMY | day/month/year | Wed 17 Dec 07:37:16 1997 PST |
Стиль даты/времени может быть выбран пользователем с помощью команды SET datestyle, параметра DateStyle в файле конфигурации qhb.conf или используя переменную среды PGDATESTYLE на сервере или клиенте.
Функция форматирования to_char (см. раздел Функции форматирования типов данных) также доступна как более гибкий способ форматирования данных даты/времени.
Часовые пояса
Часовые пояса и условности часовых поясов зависят от политических решений, а не только от геометрии Земли. В 1900-х годах часовые пояса во всем мире стали несколько стандартизированы, но по-прежнему подвержены произвольным изменениям, особенно в отношении правил перехода на летнее время. QHB использует широко используемую базу данных часовых поясов IANA (Olson) для получения информации о исторических правилах часовых поясов. Что касается времени в будущем, предполагается, что последние известные правила для данного часового пояса будут продолжать соблюдаться в течение неопределенного времени в будущем.
QHB стремится быть совместимым со стандартными определениями SQL для типичного использования. Однако стандарт SQL имеет странное сочетание типов и возможностей даты и времени. Есть две очевидные проблемы:
Чтобы устранить эти трудности, мы рекомендуем использовать типы даты/времени, которые содержат дату и время при использовании часовых поясов. Мы не рекомендуем использовать тип time with time zone (хотя он поддерживается QHB для соответствия стандарту SQL). QHB предполагает ваш местный часовой пояс для любого типа, содержащего только дату или время.
Все даты и время с учетом часового пояса хранятся внутри в формате UTC. Они преобразуются в местное время в зоне, указанной параметром конфигурации TimeZone перед отображением клиенту.
QHB позволяет указывать часовые пояса в трех разных формах:
Короче говоря, в этом разница между сокращениями и полными именами: сокращения представляют конкретное смещение от UTC, тогда как многие полные имена подразумевают локальное правило перехода на летнее время и поэтому имеют два возможных смещения UTC. Например, 2014-06-04 12:00 America/New_York представляет полуденное местное время в Нью-Йорке, которое для этой конкретной даты было восточным летним временем (UTC-4). Итак, 2014-06-04 12:00 EDT указывает тот же момент времени. Но 2014-06-04 12:00 EST указывает полдень по восточному поясному времени (UTC-5), независимо от того, было ли летнее время номинально действующим на эту дату.
Чтобы усложнить ситуацию, некоторые юрисдикции использовали одно и то же сокращение часового пояса для обозначения разных смещений UTC в разное время; например, в Москве MSK означало UTC + 3 в некоторые годы и UTC + 4 в другие. QHB интерпретирует такие сокращения в соответствии с тем, что они имели в виду (или имели в виду совсем недавно) в указанную дату; но, как и в приведенном выше примере EST, это не обязательно совпадает с местным гражданским временем этой даты.
Следует опасаться, что функция часового пояса в стиле POSIX может привести к молчаливому принятию фиктивного ввода, поскольку нет никакой проверки на правильность сокращений зон. Например, SET TIMEZONE TO FOOBAR0 будет работать, оставляя систему эффективно использующей довольно своеобразное сокращение для UTC. Другая проблема, о которой следует помнить, заключается в том, что в именах часовых поясов POSIX положительные смещения используются для местоположений к западу от Гринвича. В любом другом месте QHB следует соглашению ISO-8601, согласно которому положительные смещения часовых поясов находятся к востоку от Гринвича.
Во всех случаях названия и сокращения часовых поясов распознаются без учета регистра.
Ни имена часовых поясов, ни сокращения не встроены в сервер; они получены из файлов конфигурации, хранящихся в папках .../share/timezone/ и .../share/timezonesets/ установочного каталога .
Параметр конфигурации TimeZone можно установить в файле qhb.conf или любым другим стандартным способом, описанным в главе Конфигурация сервера. Есть также несколько специальных способов установить его:
Формат ввода интервалов
Интервальные значения могут быть записаны с использованием следующего подробного синтаксиса:
[@] quantity unit [quantity unit...] [direction]
где quantity (количество) — это число (возможно, подписанное); unit (единица измерения) - microsecond, millisecond, second, minute, hour, day, week, month, year, decade, century, millennium или сокращения или множественные числа этих единиц; direction (направление) может быть ago (назад) или пустым. Знак (@) является необязательным. Суммы различных единиц неявно суммируются с помощью соответствующего знака учета. ago меняет знак всех полей. Этот синтаксис также используется для вывода интервала, если для IntervalStyle установлено значение postgres_verbose.
Количество дней, часов, минут и секунд может быть указано без явной маркировки единиц измерения. Например, ’1 12:59:10’ читается так же, как ’1 day 12 hours 59 min 10 sec’. Кроме того, комбинация лет и месяцев может быть указана с тире; например, ’200-10’ читается так же, как "200 years 10 months". (Эти более короткие формы фактически являются единственными, разрешенными стандартом SQL, и используются для вывода, когда для IntervalStyle установлено значение sql_standard).
Значения интервалов также можно записать в виде временных интервалов ISO 8601, используя либо «формат с обозначениями» раздела 4.4.3.2 стандарта, либо «альтернативный формат» раздела 4.4.3.3. Формат с обозначениями выглядит так:
P quantity unit [ quantity unit ...] [ T [ quantity unit ...]]
Строка должна начинаться с буквы P и может содержать букву T которая вводит единицы времени дня. Доступные сокращения единиц приведены в Таблице 16. Единицы могут быть опущены и могут быть указаны в любом порядке, но после T должны появляться единицы меньше, чем день. В частности, значение M зависит от того, находится ли он до или после T
Таблица 16. Сокращения единиц интервала ISO 8601
| Сокращенное название | Смысл |
|---|---|
| Y | Лет |
| M | Месяцы (в части даты) |
| W | Недели |
| D | Дни |
| H | Часы |
| M | Минуты (во временной части) |
| S | Секунд |
В альтернативном формате:
P [ years-months-days ] [ T hours:minutes:seconds ]
строка должна начинаться с P, а T разделяет части интервала даты и времени. Значения приведены в виде чисел, аналогичных датам ISO 8601.
При записи интервальной константы со спецификацией полей или при
назначении строки интервальному столбцу, определенному спецификацией
полей, интерпретация немаркированных величин зависит от полей. Например,
INTERVAL '1' YEAR читается как 1 год, тогда как INTERVAL '1' означает 1
секунду. Кроме того, значения полей «справа» от наименее значимого поля,
разрешенного спецификацией полей, молча отбрасываются. Например, запись
INTERVAL '1 day 2:03:04' HOUR TO MINUTE приводит к удалению поля секунд,
но не поля дня.
Согласно стандарту SQL все поля интервального значения должны иметь одинаковый знак, поэтому ведущий отрицательный знак применяется ко всем полям; например, знак минус в интервальном литерале ’-1 2:03:04’ применяется как к дням, так и к часам/минутам/секундам. QHB позволяет полям иметь разные знаки и традиционно обрабатывает каждое поле в текстовом представлении как независимо подписанное, так что часть часа/минуты/секунды считается положительной в этом примере. Если для IntervalStyle установлено значение sql_standard то ведущий знак считается применимым ко всем полям (но только если дополнительные знаки не появляются). В противном случае используется традиционная интерпретация QHB. Чтобы избежать неоднозначности, рекомендуется прикреплять явный знак к каждому полю, если какое-либо поле является отрицательным.
В подробном формате ввода и в некоторых полях более компактных форматов ввода значения полей могут иметь дробные части; например, ’1.5 week’ или ’01:02:03.45’. Такой ввод преобразуется в соответствующее количество месяцев, дней и секунд для хранения. Когда это приводит к дробному числу месяцев или дней, дробь добавляется в поля нижнего порядка с использованием коэффициентов преобразования 1 месяц = 30 дней и 1 день = 24 часа. Например, ’1.5 month’ становится 1 месяц и 15 дней. Только секунды будут отображаться как дробные на выходе.
В Таблице 17 приведены некоторые примеры правильных interval ввода.
| Пример | Описание |
|---|---|
| 1-2 | Стандартный формат SQL: 1 год 2 месяца |
| 3 4:05:06 | Стандартный формат SQL: 3 дня 4 часа 5 минут 6 секунд |
| 1 year 2 months 3 days 4 hours 5 minutes 6 seconds | Традиционный формат Postgres: 1 год 2 месяца 3 дня 4 часа 5 минут 6 секунд |
| P1Y2M3DT4H5M6S | ISO 8601 «формат с обозначениями»: то же значение, что и выше |
| P0001-02-03T04: 05: 06 | ISO 8601 «альтернативный формат»: то же значение, что и выше |
Внутренние интервальные значения хранятся в виде месяцев, дней и секунд. Это сделано потому, что число дней в месяце варьируется, и день может иметь 23 или 25 часов, если требуется корректировка перехода на летнее время. Поля месяца и дня являются целыми числами, а поле секунд может хранить дроби. Поскольку интервалы обычно создаются из константных строк или вычитания меток времени, этот метод хранения в большинстве случаев работает хорошо, но может привести к неожиданным результатам:
SELECT EXTRACT(hours from '80 minutes'::interval);
date_part
-----------
1
SELECT EXTRACT(days from '80 hours'::interval);
date_part
-----------
0
Функции justify_days и justify_hours доступны для настройки дней и часов, которые выходят за пределы их нормальных диапазонов.
Формат вывода интервалов
Формат вывода типа интервала может быть установлен в один из четырех стилей sql_standard, postgres, postgres_verbose или iso_8601 с помощью команды SET intervalstyle. По умолчанию используется формат postgres. В Таблице 18 приведены примеры каждого стиля вывода.
Стиль sql_standard создает выходные данные, которые соответствуют спецификации стандарта SQL для строковых литеральных интервалов, если значение интервала соответствует ограничениям стандарта (только год-месяц или только дневное время, без смешивания положительных и отрицательных компонентов). В противном случае выходные данные выглядят как стандартная буквенная строка год-месяц, за которой следует дневная буквенная строка с явными знаками, добавленными для устранения неоднозначности интервалов со смешанными знаками.
Вывод стиля postgres совпадает с выводом выпусков PostgreSQL до 8.4, когда для параметра DateStyle было установлено значение ISO.
Вывод стиля postgres_verbose совпадает с выводом выпусков PostgreSQL до 8.4, когда для параметра DateStyle был установлен в значение, отличное от ISO.
Вывод стиля iso_8601 соответствует «формату с указателями», описанному в разделе 4.4.3.2 стандарта ISO 8601.
Таблица 18. Примеры стиля вывода интервала
| Спецификация стиля | Год-Месяц Интервал | Дневной интервал | Смешанный интервал |
|---|---|---|---|
| sql_standard | 1-2 | 3 4:05:06 | -1-2 +3 -4: 05: 06 |
| postgres | 1 year 2 mons | 3 days 04:05:06 | -1 year -2 mons +3 days -04:05:06 |
| postgres_verbose | @ 1 year 2 mons | @ 3 days 4 hours 5 mins 6 secs | @ 1 year 2 mons -3 days 4 hours 5 mins 6 secs ago |
| iso_8601 | P1Y2M | P3DT4H5M6S | Р-1Y-2M3DT-4H-5М-6S |
Логический тип
QHB предоставляет стандартный логический (boolean) тип SQL; см. таблицу 19. Логический тип может иметь несколько состояний: «истина» (TRUE), «ложь» (FALSE) и третье состояние «неизвестно», которое представлено NULL значением SQL.
Таблица 19. Логический тип данных
| Имя | Размер хранилища | Описание |
|---|---|---|
| boolean | 1 байт | состояние истинно или ложно |
Булевы константы могут быть представлены в запросах SQL ключевыми словами SQL TRUE, FALSE и NULL.
Функция ввода типа данных для логического типа принимает эти строковые представления для «истинного» состояния:
true
yes
on
1
и эти представления для «ложного» состояния:
false
no
off
0
Также допускаются уникальные префиксы этих строк, например, t или n. Начальные или конечные пробелы игнорируются, и регистр не имеет значения.
Функция вывода типа данных для логического типа всегда выдает либо t либо f, как показано в примере 7.2.
Пример 7.2. Использование логического типа
CREATE TABLE test1 (a boolean, b text);
INSERT INTO test1 VALUES (TRUE, 'sic est');
INSERT INTO test1 VALUES (FALSE, 'non est');
SELECT * FROM test1;
a | b
---+---------
t | sic est
f | non est
SELECT * FROM test1 WHERE a;
a | b
---+---------
t | sic est
Ключевые слова TRUE и FALSE являются предпочтительным (SQL- совместимым) методом для записи логических констант в запросах SQL. Но вы также можете использовать строковые представления, следуя общему синтаксису строковой литеральной константы, описанному в раздел Константы других типов, например, ’yes’::boolean.
Обратите внимание, что синтаксический анализатор автоматически понимает, что TRUE и FALSE имеют логический тип, но это не так для NULL, потому что он может иметь любой тип. Поэтому в некоторых контекстах вам, возможно, придется явным образом привести NULL к логическому значению, например NULL::boolean. И наоборот, приведение может быть опущено из строково-литерального логического значения в контекстах, где анализатор может сделать вывод, что литерал должен иметь логический тип.
Перечисляемые типы
Перечислимые (enum) типы — это типы данных, которые содержат статический упорядоченный набор значений. Они эквивалентны перечислимым типам поддерживаемым во многих языках программирования. Примером перечисляемого типа могут быть дни недели или набор значений состояния для фрагмента данных.
Объявление перечислимых типов
Типы перечислений создаются с помощью команды CREATE TYPE, например:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
После создания перечислимый тип может использоваться в определениях таблиц и функций так же, как и любой другой тип:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
name | current_mood
------+--------------
Moe | happy
(1 row)
Порядок
Порядок значений в перечисляемом типе— это порядок, в котором значения были перечислены при создании типа. Все стандартные операторы сравнения и связанные агрегатные функции поддерживаются для перечислений. Например:
INSERT INTO person VALUES ('Larry', 'sad');
INSERT INTO person VALUES ('Curly', 'ok');
SELECT * FROM person WHERE current_mood > 'sad';
name | current_mood
-------+--------------
Moe | happy
Curly | ok
(2 rows)
SELECT * FROM person WHERE current_mood > 'sad' ORDER BY current_mood;
name | current_mood
-------+--------------
Curly | ok
Moe | happy
(2 rows)
SELECT name
FROM person
WHERE current_mood = (SELECT MIN(current_mood) FROM person);
name
-------
Larry
(1 row)
Надежность типа
Каждый перечисляемый тип данных является отдельным и не может сравниваться с другими перечисляемыми типами. Смотрите этот пример:
CREATE TYPE happiness AS ENUM ('happy', 'very happy', 'ecstatic');
CREATE TABLE holidays (
num_weeks integer,
happiness happiness
);
INSERT INTO holidays(num_weeks,happiness) VALUES (4, 'happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (6, 'very happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (8, 'ecstatic');
INSERT INTO holidays(num_weeks,happiness) VALUES (2, 'sad');
ERROR: invalid input value for enum happiness: "sad"
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood = holidays.happiness;
ERROR: operator does not exist: mood = happiness
Если вам действительно нужно сделать что-то подобное, вы можете написать собственный оператор или добавить явные приведения к вашему запросу:
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood::text = holidays.happiness::text;
name | num_weeks
------+-----------
Moe | 4
(1 row)
Детали реализации
Метки перечисления чувствительны к регистру, поэтому ’happy’ — это не то же самое, что ’HAPPY’. Пробелы в метках тоже значимы.
Хотя перечисляемые типы в основном предназначены для статических наборов значений, существует поддержка добавления новых значений в существующий тип перечисления и переименования значений (см. ALTER TYPE). Существующие значения нельзя удалить из типа перечисления, равно как нельзя изменить порядок сортировки таких значений, исключая удаление и повторное создание типа перечисления.
Значение перечисляемого типа занимает четыре байта на диске. Длина текстовой метки значения перечисления ограничена настройкой NAMEDATALEN скомпилированной в QHB; в стандартных сборках это означает максимум 63 байта.
Переводы из внутренних значений перечисления в текстовые метки хранятся в системном каталоге pg_enum. Запросы к этому каталогу напрямую могут быть полезны.
Геометрические типы
Геометрические типы данных представляют собой двумерные пространственные объекты. Таблица 20 показывает геометрические типы, доступные в QHB.
Таблица 20. Геометрические типы
| Имя | Размер хранилища | Описание | Представление |
|---|---|---|---|
| point | 16 байт | Точка на плоскости | (x,y) |
| line | 32 байта | Бесконечная линия | {A, B, C}, |
| lseg | 32 байта | Конечный отрезок | ((x1,y1),(x2,y2)) |
| box | 32 байта | Прямоугольная коробка | ((x1,y1),(x2,y2)) |
| path | 16 + 16n байт | Закрытый путь (похож на полигон) | ((x1,y1),...) |
| path | 16 + 16n байт | Открытый путь | [(x1,y1),...] |
| polygon | 40 + 16n байт | Полигон (похож на замкнутый путь) | ((x1,y1),...) |
| circle | 24 байта | Круг | <(x, y), r> (центральная точка и радиус) |
Богатый набор функций и операторов доступен для выполнения различных геометрических операций, таких как масштабирование, перемещение, вращение и определение пересечений. Они объяснены в раздел Геометрические функции и операторы.
Точки
Точки являются фундаментальным двумерным строительным блоком для геометрических типов. Значения типа точка указываются с использованием одного из следующих синтаксисов:
( x, y )
x, y
где x и y - соответствующие координаты в виде чисел с плавающей точкой.
Точки выводятся с использованием первого синтаксиса.
Линии
Линии представлены линейным уравнением Ax + By + C = 0, где A и B не равны нулю одновременно. Значения типа line вводятся и выводятся в следующем виде:
{ A, B, C }
В качестве альтернативы для ввода можно использовать любую из следующих форм:
[ ( x1, y1 ), ( x2, y2 ) ]
( ( x1, y1 ), ( x2, y2 ) )
( x1, y1 ), ( x2, y2 )
x1, y1 , x2, y2
где (x1, y1) и (x2, y2) две разные точки на линии.
Отрезки линии
Отрезки линии представлены парами точек, которые являются конечными точками отрезка. Значения типа lseg указываются с использованием любого из следующих синтаксисов:
[ ( x1, y1 ), ( x2, y2 ) ]
( ( x1, y1 ), ( x2, y2 ) )
( x1, y1 ), ( x2, y2 )
x1, y1 , x2, y2
где (x1, y1) и (x2, y2) - конечные точки отрезка линии.
Отрезки линии выводятся с использованием первого синтаксиса.
Рамки (boxes)
Рамки представлены парами точек, которые находятся в противоположных углах рамки. Значения типа box указываются с использованием любого из следующих синтаксисов:
( ( x1, y1 ), ( x2, y2 ) )
( x1, y1 ), ( x2, y2 )
x1, y1 , x2, y2
где (x1, y1) и (x2, y2) - любые два противоположных угла рамки.
Рамки выводятся с использованием второго синтаксиса.
Любые два противоположных угла могут быть предоставлены на входе, но значения будут по мере необходимости переупорядочены, для сохранения в порядке верхнего правого и нижнего левого угла.
Пути
Пути представлены списками связанных точек. Пути могут быть открытыми, если первая и последняя точки в списке считаются несвязанными, или закрытыми, если первая и последняя точки считаются связанными.
Значения типа path указываются с использованием любого из следующих синтаксисов:
[ ( x1, y1 ), ..., ( xn, yn ) ]
( ( x1, y1 ), ..., ( xn, yn ) )
( x1, y1 ), ..., ( xn, yn )
( x1, y1 , ..., xn, yn )
x1, y1 , ..., xn, yn
где точки являются конечными точками отрезков, составляющих путь.
Квадратные скобки ([]) указывают открытый путь, а круглые скобки (())
указывают закрытый путь. Когда внешние скобки опущены, как в синтаксисах
с третьего по пятый, предполагается закрытый путь.
Пути выводятся с использованием первого или второго синтаксиса, в зависимости от ситуации.
Полигоны
Полигоны представлены списками точек (вершины многоугольника). Полигоны очень похожи на закрытые пути, но хранятся по-разному и имеют собственный набор подпрограмм поддержки.
Значения типа polygon указываются с использованием любого из следующих синтаксисов:
( ( x1, y1 ), ..., ( xn, yn ) )
( x1, y1 ), ..., ( xn, yn )
( x1, y1 , ..., xn, yn )
x1, y1 , ..., xn, yn
где точки являются конечными точками отрезков, составляющих границу многоугольника.
Полигоны выводятся с использованием первого синтаксиса.
Круги
Круги представлены центральной точкой и радиусом. Значения типа circle указываются с использованием любого из следующих синтаксисов:
< ( x, y ), r >
( ( x, y ), r )
( x, y ), r
x, y , r
где (x, y) - центральная точка, а r - радиус окружности.
Круги выводятся с использованием первого синтаксиса.
Типы сетевых адресов
QHB предлагает типы данных для хранения адресов IPv4, IPv6 и MAC, как показано в Таблице 21. Лучше использовать эти типы вместо обычных текстовых типов для хранения сетевых адресов, потому что эти типы предлагают проверку ошибок ввода, а так же специализированные операторы и функции (см. раздел Функции и операторы сетевых адресов).
Таблица 21. Типы сетевых адресов
| Имя | Размер хранилища | Описание |
|---|---|---|
| cidr | 7 или 19 байт | Сети IPv4 и IPv6 |
| inet | 7 или 19 байт | IPv4 и IPv6 хосты и сети |
| macaddr | 6 байт | MAC-адреса |
| macaddr8 | 8 байт | MAC-адреса (формат EUI-64) |
При сортировке типов данных inet или cidr адреса IPv4 всегда будут сортироваться до адресов IPv6, включая адреса IPv4, инкапсулированные или сопоставленные с адресами IPv6, например ::10.2.3.4 или ::ffff:10.4.3.2.
inet
Тип inet содержит адрес хоста IPv4 или IPv6 и, возможно, его подсеть, все в одном поле. Подсеть представлена количеством битов сетевого адреса, присутствующих в адресе хоста («маска сети»). Если маска сети равна 32, а адрес - IPv4, то это значение не указывает на подсеть, только на один хост. В IPv6 длина адреса составляет 128 бит, поэтому 128 бит указывают уникальный адрес хоста. Обратите внимание, что, если вы хотите принимать только сети, вы должны использовать тип cidr а не inet.
Формат ввода для этого типа: address/y где address - это адрес IPv4 или IPv6, а y - количество бит в маске сети. Если часть /y отсутствует, маска сети равна 32 для IPv4 и 128 для IPv6, поэтому значение представляет только один хост. На дисплее часть /y подавляется, если маска сети указывает один хост.
cidr
Тип cidr содержит спецификацию сети IPv4 или IPv6. Форматы ввода и вывода соответствуют правилам маршрутизации бесклассового интернет-домена. Форматом для указания сетей является address/y где address - это сеть, представленная в виде адреса IPv4 или IPv6, а y - количество битов в маске сети. Если y опущен, он рассчитывается с использованием допущений из старой классовой системы нумерации сети, за исключением того, что он будет по крайней мере достаточно большим, чтобы включать все октеты, записанные во входных данных. Указывать сетевой адрес, биты которого установлены справа от указанной маски, является ошибкой.
Таблица 22 показывает несколько примеров.
Таблица 22. Примеры ввода типа cidr
| ввод cidr | вывод cidr | abbrev(cidr) |
|---|---|---|
| 192.168.100.128/25 | 192.168.100.128/25 | 192.168.100.128/25 |
| 192.168/24 | 192.168.0.0/24 | 192.168.0/24 |
| 192.168/25 | 192.168.0.0/25 | 192.168.0.0/25 |
| 192.168.1 | 192.168.1.0/24 | 192.168.1/24 |
| 192.168 | 192.168.0.0/24 | 192.168.0/24 |
| 128.1 | 128.1.0.0/16 | 128.1/16 |
| 128 | 128.0.0.0/16 | 128.0/16 |
| 128.1.2 | 128.1.2.0/24 | 128.1.2/24 |
| 10.1.2 | 10.1.2.0/24 | 10.1.2/24 |
| 10.1 | 10.1.0.0/16 | 10.1/16 |
| 10 | 10.0.0.0/8 | 10/8 |
| 10.1.2.3/32 | 10.1.2.3/32 | 10.1.2.3/32 |
| 2001:4f8:3:ba::/64 | 2001:4f8:3:ba::/64 | 2001:4f8:3:ba::/64 |
| 2001:4f8:3:ba:2e0:81ff:fe22:d1f1/128 | 2001:4f8:3:ba:2e0:81ff:fe22:d1f1/128 | 2001:4f8:3:ba:2e0:81ff:fe22:d1f1 |
| ::ffff:1.2.3.0/120 | ::ffff:1.2.3.0/120 | ::ffff:1.2.3/120 |
| ::ffff:1.2.3.0/128 | ::ffff:1.2.3.0/128 | ::ffff:1.2.3.0/128 |
inet и cidr
Существенное различие между типами данных inet и cidr заключается в том, что inet принимает значения с ненулевыми битами справа от маски сети, а cidr - нет. Например, 192.168.0.1/24 действителен для inet но не для cidr.
Если вас не устраивает формат вывода inet или cidr, попробуйте функции host, text и abbrev.
macaddr
Тип macaddr хранит MAC-адреса, известные, например, по аппаратным адресам карты Ethernet (хотя MAC-адреса используются и для других целей). Ввод принимается в следующих форматах:
'08:00:2b:01:02:03'
'08-00-2b-01-02-03'
'08002b:010203'
'08002b-010203'
'0800.2b01.0203'
'0800-2b01-0203'
'08002b010203'
Все эти примеры будут указывать один и тот же адрес. Верхний и нижний регистр допускается для цифр от a до f. Вывод всегда в первой из показанных форм.
IEEE Std 802-2001 определяет вторую показанную форму (с дефисами) в
качестве канонической формы для MAC-адресов и определяет первую форму (с
двоеточиями) в качестве обратной битовой нотации, так что
08-00-2b-01-02-03 = 01:00:4D:08:04:0C. В настоящее время это
соглашение широко игнорируется и относится только к устаревшим сетевым
протоколам (таким как Token Ring). QHB не содержит положений об
обращении битов, и все принятые форматы используют канонический порядок
LSB.
Остальные пять форматов ввода не являются частью какого-либо стандарта.
macaddr8
Тип macaddr8 хранит MAC-адреса в формате EUI-64, известном, например, по
аппаратным адресам платы Ethernet (хотя MAC-адреса также используются и
для других целей). Этот тип может принимать MAC-адреса длиной 6 и 8
байтов и сохранять их в формате длины 8 байтов. MAC-адреса,
предоставленные в 6-байтовом формате, будут сохраняться в 8-байтовом
формате с 4-м и 5-м байтами, установленными в FF и FE соответственно.
Обратите внимание, что IPv6 использует модифицированный формат EUI-64,
где 7-й бит должен быть установлен в единицу после преобразования из
EUI-48. Для этого изменения предусмотрена функция macaddr8_set7bit.
Вообще говоря, доступен любой ввод, который состоит из пар
шестнадцатеричных цифр (на границах байтов), необязательно
последовательно разделяемых одним из ':', '-' или '.'. Количество
шестнадцатеричных цифр должно быть 16 (8 байт) или 12 (6 байт).
Начальные и конечные пробелы игнорируются. Ниже приведены примеры
допустимых форматов ввода:
'08:00:2b:01:02:03:04:05'
'08-00-2b-01-02-03-04-05'
'08002b:0102030405'
'08002b-0102030405'
'0800.2b01.0203.0405'
'0800-2b01-0203-0405'
'08002b01:02030405'
'08002b0102030405'
Все эти примеры будут указывать один и тот же адрес. Верхний и нижний регистр допускается для цифр от a до f. Вывод всегда в первой из показанных форм. Последние шесть форматов ввода, которые упомянуты выше, не являются частью какого-либо стандарта. Чтобы преобразовать традиционный 48-битный MAC-адрес в формате EUI-48 в модифицированный формат EUI-64, который будет включен в качестве части хоста адреса IPv6, используйте macaddr8_set7bit как показано ниже:
SELECT macaddr8_set7bit('08:00:2b:01:02:03');
macaddr8_set7bit
-------------------------
0a:00:2b:ff:fe:01:02:03
(1 row)
Типы битовых строк
Битовые строки — это строки 1 и 0. Их можно использовать для хранения или визуализации битовых масок. Существует два типа битовых строк SQL: bit(n) и bit varying(n), где n - положительное целое число.
Данные типа bit должны точно соответствовать длине n; попытка сохранить более короткие или более длинные битовые строки является ошибкой. bit varying данные имеют переменную длину вплоть до максимальной длины n; более длинные строки будут отклонены. Запись bit без длины эквивалентна bit(1), тогда как bit varying без указания длины означает неограниченную длину.
Заметка
Если явно привести значение битовой строки в bit(n), оно будет усечено или дополнено нулями справа, чтобы быть равно точно n битами, без возникновения ошибки. Аналогично, если явно привести значение битовой строки в bit varying(n), оно будет усечено справа, если оно больше, чем n бит.
Обратитесь к разделу Константы битовых строк за информацией о синтаксисе битовых строковых констант. Доступны битовые логические операторы и функции манипуляции со строками, см. раздел Функции и операторы битовых строк.
Пример 7.3. Использование типов битовых строк
CREATE TABLE test (a BIT(3), b BIT VARYING(5));
INSERT INTO test VALUES (B'101', B'00');
INSERT INTO test VALUES (B'10', B'101');
ERROR: bit string length 2 does not match type bit(3)
INSERT INTO test VALUES (B'10'::bit(3), B'101');
SELECT * FROM test;
a | b
-----+-----
101 | 00
100 | 101
Значение битовой строки требует 1 байт для каждой группы из 8 битов, плюс 5 или 8 байтов служебной информации в зависимости от длины строки (но длинные значения могут быть сжаты или перемещены вне строки, как объяснено в разделе Символьные типы для символьных строк).
Типы текстового поиска
QHB предоставляет два типа данных, предназначенных для поддержки полнотекстового поиска, который представляет собой поиск по коллекции документов на естественном языке для поиска документов, которые лучше всего соответствуют запросу. Тип tsvector представляет документ в форме, оптимизированной для текстового поиска; тип tsquery аналогично представляет текстовый запрос. В разделе Функции текстового поиска и операторы обобщаются связанные функции и операторы.
tsvector
Значение tsvector — это упорядоченный список различных лексем, которые представляют собой слова, которые были нормализованы для объединения различных вариантов одного и того же слова . Сортировка и удаление дубликатов выполняются автоматически во время ввода, как показано в этом примере:
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
Чтобы представить лексемы, содержащие пробелы или знаки пунктуации, заключите их в кавычки:
SELECT $$the lexeme ' ' contains spaces$$::tsvector;
tsvector
-------------------------------------------
' ' 'contains' 'lexeme' 'spaces' 'the'
(Мы используем строковые литералы, заключенные в кавычки в этом и следующем примере, чтобы избежать путаницы с двойными кавычками внутри литералов). Встроенные кавычки и обратные слэши должны быть удвоены:
SELECT $$the lexeme 'Joe''s' contains a quote$$::tsvector;
tsvector
------------------------------------------------
'Joe''s' 'a' 'contains' 'lexeme' 'quote' 'the'
По желанию, целочисленные позиции могут быть прикреплены к лексемам:
SELECT 'a:1 fat:2 cat:3 sat:4 on:5 a:6 mat:7 and:8 ate:9 a:10 fat:11 rat:12'::tsvector;
tsvector
-------------------------------------------------------------------------------
'a':1,6,10 'and':8 'ate':9 'cat':3 'fat':2,11 'mat':7 'on':5 'rat':12 'sat':4
Позиция обычно указывает местоположение исходного слова в документе. Позиционная информация может использоваться для ранжирования близости. Значения положения могут варьироваться от 1 до 16383; большие числа автоматически устанавливаются на 16383. Дублирующие позиции для одной и той же лексемы отбрасываются.
Лексемы, имеющие позиции, могут быть дополнительно помечены весом,
который может быть A, B, C или D. D является значением по умолчанию и,
следовательно, не отображается на выходе:
SELECT 'a:1A fat:2B,4C cat:5D'::tsvector;
tsvector
----------------------------
'a':1A 'cat':5 'fat':2B,4C
Весовые коэффициенты, как правило, используются для отражения структуры документа, например, путем выделения слов заголовка, отличных от слов основного текста. Функции ранжирования текстового поиска могут назначать разные приоритеты различным маркерам веса.
Важно понимать, что тип tsvector сам по себе не выполняет нормализацию слов; он предполагает, что слова, которые ему даны, нормализованы соответствующим образом для приложения. Например,
SELECT 'The Fat Rats'::tsvector;
tsvector
--------------------
'Fat' 'Rats' 'The'
Для большинства приложений для поиска текста на английском языке вышеприведенные слова будут считаться ненормализованными, но tsvector это не волнует. Необработанный текст документа обычно должен быть передан через to_tsvector для нормализации слов, подходящих для поиска:
SELECT to_tsvector('english', 'The Fat Rats');
to_tsvector
-----------------
'fat':2 'rat':3
tsquery
Значение tsquery хранит лексемы, которые нужно искать, и может
комбинировать их, используя логические операторы & (AND), | (OR) и !
(NOT), а также оператор поиска фразы <->; (FOLLOWED BY). Существует
также вариант <N>; оператора FOLLOWED BY, где N - целочисленная
константа, которая определяет расстояние между двумя искомыми лексемами.
<-> эквивалентно <1>;.
Скобки могут быть использованы для принудительной группировки этих
операторов. При отсутствии скобок, ! (NOT) связывается наиболее плотно,
затем <->; (FOLLOWED BY) следующий наиболее плотно, затем & (AND),
с | (OR) связываются наименее плотно.
Вот некоторые примеры:
SELECT 'fat & rat'::tsquery;
tsquery
---------------
'fat' & 'rat'
SELECT 'fat & (rat | cat)'::tsquery;
tsquery
---------------------------
'fat' & ( 'rat' | 'cat' )
SELECT 'fat & rat & ! cat'::tsquery;
tsquery
------------------------
'fat' & 'rat' & !'cat'
При желании лексемы в tsquery могут быть помечены одной или несколькими весовыми буквами, что ограничивает их совпадением только с лексемами tsvector с одним из этих весов:
SELECT 'fat:ab & cat'::tsquery;
tsquery
------------------
'fat':AB & 'cat'
Кроме того, лексемы в tsquery могут быть помечены * для указания
соответствия префикса:
SELECT 'super:*'::tsquery;
tsquery
-----------
'super':*
Этот запрос будет соответствовать любому слову в tsvector который начинается с «super».
Правила цитирования для лексем такие же, как описано ранее для лексем в tsvector; и, как и в случае с tsvector, любая необходимая нормализация слов должна быть выполнена перед преобразованием в тип tsquery. Функция to_tsquery удобна для выполнения такой нормализации:
SELECT to_tsquery('Fat:ab & Cats');
to_tsquery
------------------
'fat':AB & 'cat'
Обратите внимание, что to_tsquery будет обрабатывать префиксы так же, как и другие слова, что означает, что это сравнение возвращает true:
SELECT to_tsvector( 'postgraduate' ) @@ to_tsquery( 'postgres:*' );
?column?
----------
t
потому что postgres будет связан с postgr:
SELECT to_tsvector( 'postgraduate' ), to_tsquery( 'postgres:*' );
to_tsvector | to_tsquery
---------------+------------
'postgradu':1 | 'postgr':*
который будет соответствовать основной форме postgraduate.
Тип UUID
Тип данных uuid хранит универсальные уникальные идентификаторы (UUID) в соответствии с RFC 4122, ISO / IEC 9834-8: 2005 и соответствующими стандартами. (Некоторые системы называют этот тип данных глобально уникальным идентификатором или GUID, вместо этого). Этот идентификатор является 128-битной величиной, которая генерируется алгоритмом, выбранным для того, чтобы сделать очень маловероятным, что этот же идентификатор будет сгенерирован кем-либо еще в известной вселенной с использованием того же алгоритма. Поэтому для распределенных систем эти идентификаторы обеспечивают лучшую гарантию уникальности, чем генераторы последовательностей, которые уникальны только в одной базе данных.
UUID записывается в виде последовательности шестнадцатеричных цифр в нижнем регистре, в нескольких группах, разделенных дефисами, в частности, в группе из 8 цифр, за которой следуют три группы из 4 цифр, за которыми следует группа из 12 цифр, всего 32 цифры, представляющие 128 бит Пример UUID в этой стандартной форме:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
QHB также принимает следующие альтернативные формы для ввода: использование цифр в верхнем регистре, стандартный формат, заключенный в фигурные скобки, пропуск некоторых или всех дефисов, добавление дефиса после любой группы из четырех цифр. Примеры:
A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11
{a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11}
a0eebc999c0b4ef8bb6d6bb9bd380a11
a0ee-bc99-9c0b-4ef8-bb6d-6bb9-bd38-0a11
{a0eebc99-9c0b4ef8-bb6d6bb9-bd380a11}
Вывод всегда в стандартной форме.
QHB предоставляет функции хранения и сравнения для UUID, но основная база данных не содержит никакой функции для генерации UUID, потому что ни один алгоритм не подходит для каждого приложения. Модуль uuid-ossp предоставляет функции, которые реализуют несколько стандартных алгоритмов. Модуль pgcrypto также предоставляет функцию генерации случайных UUID. В качестве альтернативы UUID могут генерироваться клиентскими приложениями или другими библиотеками, вызываемыми через функцию на стороне сервера.
Тип XML
Тип данных xml может использоваться для хранения данных XML. Его
преимущество перед хранением данных XML в текстовом поле состоит в том,
что он проверяет входные значения на предмет корректности, и существуют
вспомогательные функции для выполнения над ним безопасных операций; см.
раздел Функции XML. Использование этого типа данных требует, чтобы установка
была построена с помощью configure --with-libxml.
Тип xml может хранить правильно сформированные «документы», как
определено стандартом XML, а также фрагменты «содержимого», которые
определяются посредством ссылки на более разрешительный «document node»
модели данных XQuery и XPath. Грубо говоря, это означает, что фрагменты
контента могут иметь более одного элемента верхнего уровня или
символьного узла. Выражение xmlvalue IS DOCUMENT можно использовать для
оценки того, является ли конкретное значение xml полным документом или
только фрагментом содержимого.
Создание значений XML
Чтобы получить значение типа xml из символьных данных, используйте функцию xmlparse:
XMLPARSE ( { DOCUMENT | CONTENT } value)
Примеры:
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>')
XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>')
Хотя это единственный способ преобразовать символьной строки в значения XML в соответствии со стандартом SQL, специфичные для QHB синтаксисы:
xml '<foo>bar</foo>'
'<foo>bar</foo>'::xml
также могут быть использованы.
Тип xml не проверяет входные значения по декларации типа документа (DTD), даже когда входное значение указывает DTD. В настоящее время также отсутствует встроенная поддержка проверки на соответствие другим языкам XML схем, например XML Schema.
Обратная операция, производящая символьное строковое значение из xml, использует функцию xmlserialize:
XMLSERIALIZE ( { DOCUMENT | CONTENT } value AS type )
type может быть character, character varying или text (или псевдонимом для одного из них). Опять же, согласно стандарту SQL, это единственный способ преобразования между типами xml и символьными типами, но QHB также позволяет просто приводить значение.
Когда значение символьной строки приводится к типу xml или из него без прохождения XMLPARSE или XMLSERIALIZE, соответственно, выбор DOCUMENT вместо CONTENT определяется параметром конфигурации сеанса «XML option», который можно установить с помощью стандартной команды:
SET XML OPTION { DOCUMENT | CONTENT };
или более похожий на QHB синтаксис:
SET xmloption TO { DOCUMENT | CONTENT };
По умолчанию используется CONTENT, поэтому разрешены все формы XML-данных.
Обработка кодировки
Необходимо соблюдать осторожность при работе с несколькими кодировками символов на клиенте, сервере и в данных XML, передаваемых через них. При использовании текстового режима для передачи запросов на сервер и запроса результатов к клиенту (что является нормальным режимом), QHB преобразует все символьные данные, передаваемые между клиентом и сервером, и наоборот, в кодировку символов соответствующей цели; см. раздел Поддержка набора символов. Это включает в себя строковые представления значений XML, как в приведенных выше примерах. Обычно это означает, что объявления кодировки, содержащиеся в данных XML, могут стать недействительными, поскольку символьные данные преобразуются в другие кодировки при перемещении между клиентом и сервером, поскольку объявление встроенной кодировки не изменяется. Чтобы справиться с этим поведением, объявления кодировки, содержащиеся в символьных строках, представленных для ввода в тип xml, игнорируются, и предполагается, что содержимое находится в текущей серверной кодировке. Следовательно, для правильной обработки символьные строки данных XML должны отправляться от клиента в текущей клиентской кодировке. В обязанности клиента входит либо преобразование документов в текущую клиентскую кодировку перед отправкой их на сервер, либо соответствующая настройка клиентской кодировки. На выходе значения типа xml не будут иметь объявления кодировки, и клиенты должны предполагать, что все данные находятся в текущей клиентской кодировке.
При использовании двоичного режима для передачи параметров запроса на сервер и запроса результатов обратно клиенту преобразование кодировки не выполняется, поэтому ситуация отличается. В этом случае будет соблюдаться объявление кодировки в данных XML, и если оно отсутствует, предполагается, что данные находятся в UTF-8 (как требуется стандартом XML; обратите внимание, что QHB не поддерживает UTF-16). На выходе данные будут иметь объявление кодировки, определяющее кодировку клиента, если только кодировка клиента не является UTF-8, в этом случае она будет опущена.
Нет необходимости говорить, что обработка данных XML с помощью QHB будет менее подвержена ошибкам и более эффективна, если кодировка данных XML, кодировка клиента и серверная кодировка совпадают. Поскольку данные XML обрабатываются внутри UTF-8, вычисления будут наиболее эффективными, если кодировка сервера также UTF-8.
Предупреждение!!!
Некоторые функции, связанные с XML, могут вообще не работать с данными, отличными от ASCII, если кодировка сервера не соответствует UTF-8. Известно, что это проблема, в частности, для xmltable() и xpath().
Доступ к значениям XML
Тип данных xml необычен тем, что не предоставляет операторов сравнения. Это потому, что не существует четко определенного и универсально полезного алгоритма сравнения для данных XML. Одним из следствий этого является то, что вы не можете получить строки, сравнивая столбец xml со значением поиска. Поэтому значения XML, как правило, должны сопровождаться отдельным ключевым полем, таким как идентификатор. Альтернативное решение для сравнения значений XML состоит в том, чтобы сначала преобразовать их в символьные строки, но обратите внимание, что сравнение символьных строк не имеет ничего общего с полезным методом сравнения XML.
Поскольку для типа данных xml нет операторов сравнения, невозможно создать индекс непосредственно для столбца этого типа. Если требуется быстрый поиск в данных XML, возможные обходные пути включают приведение выражения к типу символьной строки и его индексацию или индексирование выражения XPath. Конечно, фактический запрос должен быть скорректирован для поиска по индексируемому выражению.
Функциональность текстового поиска в QHB также может быть использована для ускорения полного поиска документов в XML-данных. Однако необходимая поддержка предварительной обработки еще не доступна в дистрибутиве QHB.
Типы JSON
Типы данных JSON предназначены для хранения данных JSON (нотации объектов JavaScript), как указано в RFC 7159. Такие данные также могут храниться в виде текста, но у типов данных JSON есть преимущество, заключающееся в том, что каждое сохраненное значение является действительным в соответствии с правилами JSON. Есть также различные JSON-специфические функции и операторы, доступные для данных, хранящихся в этих типах данных; см. раздел Функции и операторы JSON.
QHB предлагает два типа для хранения данных JSON: json и jsonb. Для реализации эффективных механизмов запросов для этих типов данных QHB также предоставляет тип данных jsonpath описанный в разделе Тип jsonpath.
Типы данных json и jsonb принимают почти идентичные наборы значений в качестве входных данных. Основное практическое отличие заключается в эффективности. Тип данных json хранит точную копию входного текста, функции обработки которого должны обрабатываться при каждом выполнении; в то время как данные jsonb хранятся в разложенном двоичном формате, что делает его немного медленнее при вводе из-за дополнительных издержек преобразования, но значительно быстрее при обработке, так как повторная обработка не требуется. jsonb также поддерживает индексирование, что может быть существенным преимуществом.
Поскольку тип json хранит точную копию входного текста, он сохраняет семантически незначимые пробелы между токенами, а также порядок ключей в объектах JSON. Кроме того, если объект JSON внутри значения содержит один и тот же ключ более одного раза, то все пары ключ/значение сохраняются. (Функции обработки считают последнее значение как оперативное). В отличие от этого, jsonb не сохраняет пробел, не сохраняет порядок ключей объекта и не сохраняет дубликаты ключей объекта. Если во входных данных указаны дубликаты ключей, сохраняется только последнее значение.
В целом, большинство приложений предпочитают хранить данные JSON в формате jsonb, если только нет специализированных требований, таких как устаревшие предположения о порядке расположения ключей объекта.
QHB допускает только одну кодировку набора символов для каждой базы данных. Поэтому типы JSON не могут жестко соответствовать спецификации JSON, если кодировка базы данных не является UTF8. Попытки напрямую включить символы, которые не могут быть представлены в кодировке базы данных, потерпят неудачу; наоборот, символы, которые могут быть представлены в кодировке базы данных, но не в UTF8, будут разрешены.
RFC 7159 позволяет строкам JSON содержать escape-последовательности Unicode, обозначенные \uXXXX. В функции ввода для типа json экранирование Unicode разрешено независимо от кодировки базы данных и проверяется только на синтаксическую корректность (то есть, что четыре шестнадцатеричные цифры следуют за \u). Однако функция ввода для jsonb более строгая: она запрещает экранирование Unicode для символов, не относящихся к ASCII (те, что выше U+007F), если только кодировка базы данных не UTF8. Тип jsonb также отклоняет \u0000 (потому что это не может быть представлено в текстовом типе QHB) и настаивает на том, что любое использование суррогатных пар Unicode для обозначения символов вне базовой многоязычной плоскости Unicode является правильным. Допустимые экранированные символы Юникода преобразуются в эквивалентные символы ASCII или UTF8 для хранения; это включает в себя складывание суррогатных пар в один символ.
Заметка
Многие из функций обработки JSON, описанные в разделе Функции и операторы JSON, преобразуют экранирование Unicode в обычные символы и, следовательно, будут выдавать те же типы ошибок, которые только что были описаны, даже если их ввод имеет тип json не jsonb. Тот факт, что функция ввода json не выполняет эти проверки, может рассматриваться как исторический артефакт, хотя он допускает простое хранение (без обработки) экранирования JSON Unicode в кодировке базы данных отличной от UTF8. В общем, по возможности лучше избегать смешивания экранирования Unicode в JSON с кодировкой базы данных отличной от -UTF8, если это возможно.
При преобразовании текстового ввода JSON в jsonb примитивные типы, описанные в RFC 7159, эффективно отображаются на собственные типы QHB, как показано в Таблице 23. Следовательно, существуют некоторые незначительные дополнительные ограничения на то, что составляет допустимые данные jsonb которые не применяются ни к типу json, ни к JSON в абстрактном виде, что соответствует ограничениям на то, что может быть представлено базовым типом данных. В частности, jsonb будет отклонять числа, выходящие за пределы numeric типа данных QHB, а json - нет. Такие ограничения, определенные реализацией, разрешены RFC 7159. Однако на практике такие проблемы гораздо чаще встречаются в других реализациях, поскольку обычно тип примитива JSON представляется в виде типа с плавающей запятой двойной точности IEEE 754 (что явно предусмотрено и позволяет RFC 7159). При использовании JSON в качестве формата обмена с такими системами следует учитывать опасность потери числовой точности по сравнению с данными, изначально сохраняемыми в QHB.
И наоборот, как отмечено в таблице, существуют некоторые незначительные ограничения на формат ввода примитивных типов JSON, которые не применяются к соответствующим типам QHB.
Таблица 23. Примитивные типы JSON и соответствующие им типы QHB
| Примитивный тип JSON | Тип QHB | Примечания |
|---|---|---|
| string | text | \u0000 не \u0000, как и не-ASCII Unicode, если кодировка базы данных не UTF8 |
| number | numeric | Значения NaN и infinity не допускаются |
| boolean | boolean | Допускается только строчное true и false написание |
| null | (none) | SQL NULL — это другое понятие |
Синтаксис ввода и вывода JSON
Синтаксис ввода/вывода для типов данных JSON соответствует RFC 7159.
Ниже приведены все допустимые выражения json (или jsonb):
-- Simple scalar/primitive value
-- Primitive values can be numbers, quoted strings, true, false, or null
SELECT '5'::json;
-- Array of zero or more elements (elements need not be of same type)
SELECT '[1, 2, "foo", null]'::json;
-- Object containing pairs of keys and values
-- Note that object keys must always be quoted strings
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;
-- Arrays and objects can be nested arbitrarily
SELECT '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::json;
Как указывалось ранее, когда значение JSON вводится, а затем печатается без какой-либо дополнительной обработки, json выводит тот же текст, который был введен, в то время как jsonb не сохраняет семантически незначимые детали, такие как пробелы. Например, обратите внимание на различия здесь:
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::json;
json
-------------------------------------------------
{"bar": "baz", "balance": 7.77, "active":false}
(1 row)
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::jsonb;
jsonb
--------------------------------------------------
{"bar": "baz", "active": false, "balance": 7.77}
(1 row)
Одна семантически незначительная деталь, на которую стоит обратить внимание, состоит в том, что в jsonb числа будут печататься в соответствии с поведением базового numeric типа. На практике это означает, что числа, введенные с пометкой E будут напечатаны без нее, например:
SELECT '{"reading": 1.230e-5}'::json, '{"reading": 1.230e-5}'::jsonb;
json | jsonb
-----------------------+-------------------------
{"reading": 1.230e-5} | {"reading": 0.00001230}
(1 row)
Однако jsonb сохранит конечные дробные нули, как видно в этом примере, даже если они семантически незначимы для таких целей, как проверки на равенство.
Список встроенных функций и операторов, доступных для построения и обработки значений JSON, см. в разделе Функции и операторы JSON.
Разработка документов JSON
Представление данных в виде JSON может быть значительно более гибким, чем традиционная модель реляционных данных, что особенно важно в средах с изменчивыми требованиями. Оба подхода вполне могут сосуществовать и дополнять друг друга в одном приложении. Однако даже для приложений, где требуется максимальная гибкость, все же рекомендуется, чтобы документы JSON имели несколько фиксированную структуру. Структура, как правило, не является принудительной (хотя применение некоторых бизнес-правил возможно), но наличие предсказуемой структуры облегчает написание запросов, которые эффективно суммируют набор «документов» (данных) в таблице.
Данные JSON подчиняются тем же соображениям управления параллелизмом, что и любой другой тип данных при хранении в таблице. Хотя хранение больших документов практически возможно, имейте в виду, что любое обновление получает блокировку на уровне строки для всей строки. Рассмотрите возможность ограничения документов JSON до управляемого размера, чтобы уменьшить конфликт блокировок между транзакциями обновления. В идеале каждый документ JSON должен представлять собой соответствующий бизнес-правилам атомарные элементы данных, которые не могут быть разумно разделены на более мелкие элементы, и могут быть изменены независимо.
Анализ вложений и наличия в jsonb
Анализ вложений является важной возможностью jsonb. Не существует параллельного набора средств для типа json. Анализ вложений определяет, содержится ли один документ jsonb внутри другого. Эти примеры возвращают значение true, за исключением отмеченных случаев:
-- Simple scalar/primitive values contain only the identical value:
SELECT '"foo"'::jsonb @> '"foo"'::jsonb;
-- The array on the right side is contained within the one on the left:
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
-- Order of array elements is not significant, so this is also true:
SELECT '[1, 2, 3]'::jsonb @> '[3, 1]'::jsonb;
-- Duplicate array elements don't matter either:
SELECT '[1, 2, 3]'::jsonb @> '[1, 2, 2]'::jsonb;
-- The object with a single pair on the right side is contained
-- within the object on the left side:
SELECT '{"product": "PostgreSQL", "version": 9.4, "jsonb": true}'::jsonb @> '{"version": 9.4}'::jsonb;
-- The array on the right side is not considered contained within the
-- array on the left, even though a similar array is nested within it:
SELECT '[1, 2, [1, 3]]'::jsonb @> '[1, 3]'::jsonb; -- yields false
-- But with a layer of nesting, it is contained:
SELECT '[1, 2, [1, 3]]'::jsonb @> '[[1, 3]]'::jsonb;
-- Similarly, containment is not reported here:
SELECT '{"foo": {"bar": "baz"}}'::jsonb @> '{"bar": "baz"}'::jsonb; -- yields false
-- A top-level key and an empty object is contained:
SELECT '{"foo": {"bar": "baz"}}'::jsonb @> '{"foo": {}}'::jsonb;
Общий принцип заключается в том, что вложенный объект должен соответствовать содержащему его объекту по структуре и содержимому данных, возможно, после отбрасывания некоторых несоответствующих элементов массива или пар ключ/значение объекта из содержащего объекта. Но помните, что порядок элементов массива не имеет значения при сопоставлении вложений, и повторяющиеся элементы массива эффективно учитываются только один раз.
В качестве специального исключения из общего принципа, что структуры должны совпадать, массив может содержать примитивное значение:
-- This array contains the primitive string value:
SELECT '["foo", "bar"]'::jsonb @> '"bar"'::jsonb;
-- This exception is not reciprocal -- non-containment is reported here:
SELECT '"bar"'::jsonb @> '["bar"]'::jsonb; -- yields false
В jsonb также есть оператор наличия (existence), который является вариацией темы вложения: он проверяет, отображается ли строка (заданная как текстовое значение) как ключ объекта или элемент массива на верхнем уровне значения jsonb. Эти примеры возвращают значение true, за исключением отмеченных случаев:
-- String exists as array element:
SELECT '["foo", "bar", "baz"]'::jsonb ? 'bar';
-- String exists as object key:
SELECT '{"foo": "bar"}'::jsonb ? 'foo';
-- Object values are not considered:
SELECT '{"foo": "bar"}'::jsonb ? 'bar'; -- yields false
-- As with containment, existence must match at the top level:
SELECT '{"foo": {"bar": "baz"}}'::jsonb ? 'bar'; -- yields false
-- A string is considered to exist if it matches a primitive JSON string:
SELECT '"foo"'::jsonb ? 'foo';
Объекты JSON лучше, чем массивы, подходят для анализа вложений или наличия, когда задействовано много ключей или элементов, поскольку в отличие от массивов они внутренне оптимизированы для поиска и не требуют линейного поиска.
Заметка
Поскольку содержимое JSON является вложенным, соответствующий запрос может пропустить явный выбор подобъектов. В качестве примера предположим, что у нас есть столбец doc содержащий объекты на верхнем уровне, а большинство объектов содержат поля tags которые содержат массивы подобъектов. Этот запрос находит записи, в которых появляются "term":"paris" содержащие как "term":"paris" и "term":"food", игнорируя любые такие ключи вне массива tags:
```sql
SELECT doc->'site_name' FROM websites
WHERE doc @> '{"tags":[{"term":"paris"}, {"term":"food"}]}';
```
Можно сделать то же самое, скажем,
```sql
SELECT doc->'site_name' FROM websites
WHERE doc->'tags' @> '[{"term":"paris"}, {"term":"food"}]';
```
но такой подход менее гибок, а зачастую и менее эффективен.
С другой стороны, оператор наличия JSON не является вложенным: он будет искать только указанный ключ или элемент массива на верхнем уровне значения JSON.
Различные операторы вложений и наличия, а также все другие операторы и функции JSON описаны в разделе Функции и операторы JSON.
Индексация jsonb
Индексы GIN можно использовать для эффективного поиска ключей или пар ключ/значение, встречающихся в большом количестве документов jsonb (датумов). Предоставляются два «класса операторов» GIN, предлагающих различные компромиссы производительности и гибкости.
Класс операторов GIN по умолчанию для jsonb поддерживает запросы с
операторами верхнего уровня наличия ключей: ?, ?& и ?| и оператор наличия
пути/значения @>. (Подробнее о семантике, которую реализуют эти
операторы, см. таблицу 45). Пример создания индекса с помощью
этого класса операторов:
CREATE INDEX idxgin ON api USING GIN (jdoc);
Нестандартный класс операторов GIN jsonb_path_ops поддерживает
индексирование только оператора @>. Пример создания индекса с
помощью этого класса операторов:
CREATE INDEX idxginp ON api USING GIN (jdoc jsonb_path_ops);
Рассмотрим пример таблицы, в которой хранятся документы JSON, извлеченные из стороннего веб-сервиса, с документированным определением схемы. Типичный документ:
{
"guid": "9c36adc1-7fb5-4d5b-83b4-90356a46061a",
"name": "Angela Barton",
"is_active": true,
"company": "Magnafone",
"address": "178 Howard Place, Gulf, Washington, 702",
"registered": "2009-11-07T08:53:22 +08:00",
"latitude": 19.793713,
"longitude": 86.513373,
"tags": [
"enim",
"aliquip",
"qui"
]
}
Мы храним эти документы в таблице с именем api, в столбце jsonb именем jdoc. Если для этого столбца создается индекс GIN, индекс может использовать такие запросы:
-- Find documents in which the key "company" has value "Magnafone"
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @> '{"company": "Magnafone"}';
Тем не менее, индекс не может быть использован для запросов, подобных
следующему, потому что хотя оператор ? индексируется, он не применяется
непосредственно к индексируемому столбцу jdoc:
-- Find documents in which the key "tags" contains key or array element "qui"
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc -> 'tags' ? 'qui';
Тем не менее, при надлежащем использовании индексов выражений в приведенном выше запросе может использоваться индекс. Если запросы к определенным элементам в ключе "tags" распространены, определение индекса, подобного этому, может быть целесообразным:
CREATE INDEX idxgintags ON api USING GIN ((jdoc -> 'tags'));
Теперь, WHERE предложение jdoc -> 'tags' ? 'qui' будет распознаваться
как приложение индексируемого оператора ? к индексированному выражению
jdoc -> 'tags'. (Более подробную информацию об индексах выражений
можно найти в разделе Индексы по выражениям).
Кроме того, индекс GIN поддерживает @@ и @? операторы, которые выполняют
сопоставление jsonpath.
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @@ '$.tags[*] == "qui"';
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @@ '$.tags[*] ? (@ == "qui")';
Индекс GIN извлекает из jsonpath операторы следующей формы:
accessors_chain = const. Цепочка доступа может состоять из методов
доступа .key, [*] и [index]. jsonb_ops дополнительно поддерживает
методы доступа .* и .**.
Другой подход к запросам заключается в использовании вложений, например:
-- Find documents in which the key "tags" contains array element "qui"
SELECT jdoc->'guid', jdoc->'name' FROM api WHERE jdoc @> '{"tags": ["qui"]}';
Простой индекс GIN для столбца jdoc может поддержать этот запрос. Но обратите внимание, что такой индекс будет хранить копии каждого ключа и значения в столбце jdoc, в то время как индекс выражения предыдущего примера хранит только данные, найденные под ключом tags. Хотя подход с простым индексом является гораздо более гибким (поскольку он поддерживает запросы по любому ключу), целевые индексы выражений, вероятно, будут меньше и быстрее для поиска, чем простой индекс.
Хотя класс операторов jsonb_path_ops поддерживает только запросы с
операторами @>, @@ и @?, он имеет заметные преимущества в
производительности по сравнению с классом операторов по умолчанию
jsonb_ops. Индекс jsonb_path_ops обычно намного меньше индекса
jsonb_ops на тех же данных, и специфика поиска лучше, особенно когда
запросы содержат ключи, которые часто появляются в данных. Поэтому
поисковые операции с индексом jsonb_path_ops обычно выполняются лучше,
чем с классом операторов по умолчанию.
Техническое различие между индексами GIN jsonb_ops и jsonb_path_ops
состоит в том, что первый создает независимые элементы индекса для
каждого ключа и значения в данных, а второй создает элементы индекса
только для каждого значения в данных.1 По сути, каждый элемент
индекса jsonb_path_ops является хешем значения и ключа (ключей),
ведущих к нему; например, чтобы индексировать {"foo": {"bar": "baz"}},
будет создан один элемент индекса, включающий все три элемента foo, bar
и baz в хеш- значение. Таким образом, запрос вложений, ищущий эту
структуру, приведет к чрезвычайно специфичному поиску по индексу; но нет
никакого способа узнать, является ли foo ключом. С другой стороны,
индекс jsonb_ops будет создавать три элемента индекса, представляющих
foo, bar и baz отдельно; затем, чтобы выполнить запрос вложений, он
будет искать строки, содержащие все три этих элемента. Хотя индексы GIN
могут выполнять такой поиск довольно эффективно, он все равно будет
менее конкретным и более медленным, чем эквивалентный поиск
jsonb_path_ops, особенно если существует очень большое количество
строк, содержащих какой-либо один из трех элементов индекса.
Недостаток подхода jsonb_path_ops заключается в том, что он не создает
индексных записей для структур JSON, не содержащих никаких значений,
таких как {"a": {}}. Если запрашивается поиск документов, содержащих
такую структуру, то для этого потребуется полное индексное сканирование,
которое выполняется довольно медленно. Поэтому jsonb_path_ops не
подходит для приложений, которые часто выполняют такой поиск.
jsonb также поддерживает индексы btree и hash. Обычно они полезны, только если важно проверить равенство полных документов JSON. Упорядочение btree для данных jsonb редко представляет большой интерес, но для полноты он является:
Object > Array > Boolean > Number > String > Null
Object with n pairs > object with n - 1 pairs
Array with n elements > array with n - 1 elements
Объекты с одинаковым количеством пар сравниваются в следующем порядке:
key-1, value-1, key-2 ...
Обратите внимание, что ключи объектов сравниваются в порядке их хранения; в частности, поскольку более короткие ключи хранятся перед более длинными ключами, это может привести к неинтуитивным результатам, таким как:
{ "aa": 1, "c": 1} > {"b": 1, "d": 1}
Аналогично, массивы с равным количеством элементов сравниваются в следующем порядке:
element-1, element-2 ...
Примитивные значения JSON сравниваются с использованием тех же правил сравнения, что и для базового типа данных QHB. Строки сравниваются с использованием параметров сортировки базы данных по умолчанию.
Трансформации
Доступны дополнительные расширения, которые реализуют преобразования для типа jsonb для разных процедурных языков.
Тип jsonpath
Тип jsonpath реализует поддержку языка путей SQL/JSON в QHB для эффективного запроса данных JSON. Он предоставляет двоичное представление разобранного выражения пути SQL/JSON, которое указывает элементы, которые должны быть извлечены механизмом пути из данных JSON для дальнейшей обработки с помощью функций запроса SQL/JSON.
Семантика предикатов и операторов пути SQL/JSON обычно соответствует SQL. В то же время, чтобы обеспечить наиболее естественный способ работы с данными JSON, синтаксис пути SQL/JSON использует некоторые соглашения JavaScript:
Выражение пути SQL/JSON обычно пишется в запросе SQL в виде строкового
литерала SQL, поэтому его необходимо заключить в одинарные кавычки, а
любые одинарные кавычки, требуемые в пределах значения, должны быть
удвоены (см. раздел Строковые константы). Некоторые формы выражений пути требуют
строковых литералов внутри них. Эти встроенные строковые литералы
следуют соглашениям JavaScript/ECMAScript: они должны быть заключены в
двойные кавычки, и в них могут использоваться экранированные символы
обратной косой черты для представления символов, трудно поддающихся
вводу. В частности, способ написать двойную кавычку во встроенном
строковом литерале — это \", а чтобы написать обратную косую черту,
нужно написать \\. Другие специальные последовательности обратной
косой черты включают в себя те, которые распознаются в строках JSON:
\b, \f, \n, \r, \t, \v для различных управляющих символов ASCII и
\uNNNN для символа Unicode, идентифицируемого его кодовой точкой из 4
шестнадцатеричных цифр. Синтаксис обратной косой черты также включает
два случая, которые не допускаются JSON: \xNN для символьного кода,
написанного только с двумя шестнадцатеричными цифрами, и \u{N...} для
символьного кода, записанного с помощью от 1 до 6 шестнадцатеричных
цифр.
Выражение пути состоит из последовательности элементов пути, которая может быть следующей:
Подробнее об использовании выражений jsonpath с функциями запросов SQL/JSON см. раздел Язык путей SQL/JSON.
Таблица 24. Переменные jsonpath
| Переменная | Описание |
|---|---|
| $ | Переменная, представляющая текст JSON для запроса (элемент контекста). |
| $varname | Именованная переменная. Его значение может быть установлено с помощью параметра vars нескольких функций обработки JSON. См. таблицу 47 и ее примечания для деталей. |
| @ | Переменная, представляющая результат оценки пути в выражениях фильтра. |
Таблица 25. Операторы доступа jsonpath
| Оператор доступа | Описание |
|---|---|
.key ."$varname" |
Метод доступа к элементу, который возвращает элемент объекта с указанным ключом. Если имя ключа является именованной переменной, начинающейся с $ или не соответствует правилам JavaScript идентификатора, оно должно быть заключено в двойные кавычки в виде строкового литерала. |
| .∗ | Средство доступа к элементу подстановочного знака, которое возвращает значения всех элементов, расположенных на верхнем уровне текущего объекта. |
| .∗∗ | Рекурсивный метод доступа к элементу с подстановочными знаками, который обрабатывает все уровни иерархии JSON текущего объекта и возвращает все значения элементов, независимо от уровня их вложенности. Это расширение QHB стандарта SQL/JSON. |
| .∗∗{level}
.∗∗{start_level to end_level} |
То же, что и .∗∗, но с фильтром по уровням вложенности иерархии JSON. Уровни вложенности указываются как целые числа. Нулевой уровень соответствует текущему объекту. Чтобы получить доступ к самому низкому уровню вложенности, вы можете использовать last ключевое слово. Это расширение QHB стандарта SQL/JSON. |
| subscript, ...] | Метод доступа к элементу массива. subscript может быть задан в двух формах: от index или start_index to end_index. Первая форма возвращает один элемент массива по его индексу. Вторая форма возвращает срез массива по диапазону индексов, включая элементы, которые соответствуют предоставленным start_index и end_index . Указанный index может быть целым числом, а также выражением, возвращающим одно числовое значение, которое автоматически приводится к целому числу. Нулевой индекс соответствует первому элементу массива. Вы также можете использовать last ключевое слово для обозначения последнего элемента массива, что полезно для обработки массивов неизвестной длины. |
| [∗] | Метод доступа к элементу массива с подстановочными символами, который возвращает все элементы массива. |
Массивы
QHB позволяет определять столбцы таблицы как многомерные массивы переменной длины. Могут быть созданы массивы любого встроенного или определенного пользователем базового типа, типа перечисления, составного типа, типа диапазона или домена.
Объявление типов массивов
Чтобы проиллюстрировать использование типов массивов, мы создадим эту таблицу:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
Как показано, тип данных массива именуется путем добавления квадратных
скобок ([]) к имени типа данных элементов массива. Приведенная выше
команда создаст таблицу с именем sal_emp со столбцом типа text (name),
одномерным массивом типа integer (pay_by_quarter), который
представляет квартальную зарплату сотрудника, и двумерным массивом text
(schedule), который представляет недельный график сотрудника.
Синтаксис CREATE TABLE позволяет указывать точный размер массивов, например:
CREATE TABLE tictactoe (
squares integer[3][3]
);
Однако текущая реализация игнорирует любые предоставленные ограничения размера массива, т. е. поведение такое же, как и для массивов неопределенной длины.
Текущая реализация также не применяет заявленное количество измерений. Все массивы определенного типа элементов считаются одинаковыми, независимо от размера или количества измерений. Итак, объявление размера массива или числа измерений в CREATE TABLE — это просто документация; это не влияет на поведение во время выполнения.
Альтернативный синтаксис, который соответствует стандарту SQL с помощью ключевого слова ARRAY, может использоваться для одномерных массивов. pay_by_quarter мог быть определен как:
pay_by_quarter integer ARRAY[4],
Или, если не указан размер массива:
pay_by_quarter integer ARRAY,
Однако, как и прежде, QHB не налагает ограничения на размер в любом случае.
Ввод значений массива
Чтобы записать значение массива в виде литеральной константы, заключите значения элементов в фигурные скобки и разделите их запятыми. (Если вы знаете C/RUST, это мало чем отличается от синтаксиса C для инициализации структур). Вы можете поставить двойные кавычки вокруг любого значения элемента и должны сделать это, если он содержит запятые или фигурные скобки. (Подробнее см. ниже). Таким образом, общий формат константы массива следующий:
'{ val1 delim val2 delim ... }'
где delim - символ разделителя для типа, как отмечено в записи pg_type. Среди стандартных типов данных, представленных в дистрибутиве QHB, все используют запятую (,), за исключением типа box, в котором используется точка с запятой (;). Каждый val является либо константой типа элемента массива, либо подмножеством. Пример константы массива:
'{{1,2,3},{4,5,6},{7,8,9}}'
Эта константа представляет собой двумерный массив размером 3 на 3, состоящий из трех подмножеств целых чисел.
Чтобы установить для элемента константы массива значение NULL, напишите NULL для значения элемента. (Подойдет любой вариант NULL верхнем или нижнем регистре). Если вам нужно фактическое строковое значение «NULL», вы должны заключить его в двойные кавычки.
(Эти виды констант массива на самом деле являются лишь частным случаем констант универсального типа, обсуждаемых в разделе Константы других типов. Константа первоначально обрабатывается как строка и передается в процедуру преобразования входных данных массива. Может потребоваться явная спецификация типа).
Теперь мы можем показать некоторые операторы INSERT:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
Результат двух предыдущих вставок выглядит так:
SELECT * FROM sal_emp;
name | pay_by_quarter | schedule
-------+---------------------------+-------------------------------------------
Bill | {10000,10000,10000,10000} | {{meeting,lunch},{training,presentation}}
Carol | {20000,25000,25000,25000} | {{breakfast,consulting},{meeting,lunch}}
(2 rows)
Многомерные массивы должны иметь соответствующие экстенты для каждого измерения. Несоответствие вызывает ошибку, например:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"meeting"}}');
ERROR: multidimensional arrays must have array expressions with matching dimensions
Синтаксис конструктора ARRAY также может быть использован:
INSERT INTO sal_emp
VALUES ('Bill',
ARRAY[10000, 10000, 10000, 10000],
ARRAY[['meeting', 'lunch'], ['training', 'presentation']]);
INSERT INTO sal_emp
VALUES ('Carol',
ARRAY[20000, 25000, 25000, 25000],
ARRAY[['breakfast', 'consulting'], ['meeting', 'lunch']]);
Обратите внимание, что элементы массива являются обычными константами или выражениями SQL; например, строковые литералы заключаются в одинарные кавычки, а не в двойные, как это было бы в литерале массива. Синтаксис конструктора ARRAY более подробно обсуждается в разделе Конструкторы массивов.
Доступ к массивам
Теперь мы можем выполнить несколько запросов к таблице. Сначала мы покажем, как получить доступ к одному элементу массива. Этот запрос извлекает имена сотрудников, зарплата которых изменилась во втором квартале:
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
name
-------
Carol
(1 row)
Номера индексов массива пишутся в квадратных скобках. По умолчанию QHB
использует для массивов соглашение об одинарной нумерации, то есть
массив из n элементов начинается с array[1] и заканчивается array[n].
Этот запрос возвращает заработную плату всех сотрудников за третий квартал:
SELECT pay_by_quarter[3] FROM sal_emp;
pay_by_quarter
----------------
10000
25000
(2 rows)
Мы также можем получить доступ к произвольным прямоугольным фрагментам массива или подмассива. Срез массива обозначается записью «нижняя граница»:«верхняя граница» для одного или нескольких измерений массива. Например, этот запрос извлекает первый элемент в расписании Билла за первые два дня недели:
SELECT schedule[1:2][1:1] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{meeting},{training}}
(1 row)
Если какое-либо измерение записывается как срез, т. е. содержит
двоеточие, то все измерения рассматриваются как срезы. Любое измерение,
которое имеет только одно число (без двоеточия), рассматривается как
значение от 1 до указанного числа. Например, [2] обрабатывается как
[1:2], как в этом примере:
SELECT schedule[1:2][2] FROM sal_emp WHERE name = 'Bill';
schedule
-------------------------------------------
{{meeting,lunch},{training,presentation}}
(1 row)
Чтобы избежать путаницы со случаем без срезов, лучше использовать
синтаксис срезов для всех измерений, например, [1:2][1:1], а не
[2][1:1].
Можно опустить нижнюю и/или верхнюю границу спецификатора слайса; отсутствующая граница заменяется нижним или верхним пределом индексов массива. Например:
SELECT schedule[:2][2:] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{lunch},{presentation}}
(1 row)
SELECT schedule[:][1:1] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{meeting},{training}}
(1 row)
Выражение индекса массива вернет значение NULL, если либо сам массив,
либо любое из выражений индекса равно NULL. Кроме того, null
возвращается, если индекс находится за пределами границ массива (в этом
случае ошибка не возникает). Например, если schedule в настоящее время
имеет размеры [1:3][1:2] то ссылка на schedule[3][3] выдает
NULL. Точно так же ссылка на массив с неправильным числом индексов дает
NULL значение, а не ошибку.
Выражение среза массива также дает NULL, если сам массив или любое из подстрочных выражений являются NULL. Однако в других случаях, таких как выбор среза массива, который полностью находится за пределами текущих границ массива, выражение среза выдает пустой (нулевой) массив вместо NULL. (Это не соответствует поведению без срезов и выполняется по историческим причинам). Если запрашиваемый срез частично перекрывает границы массива, то он автоматически сокращается до перекрывающейся области вместо возврата NULL.
Текущие измерения любого значения массива можно получить с помощью функции array_dims:
SELECT array_dims(schedule) FROM sal_emp WHERE name = 'Carol';
array_dims
------------
[1:2][1:2]
(1 row)
array_dims дает текстовый результат, который удобен для чтения людьми, но, возможно, неудобен для программ. Измерения также можно получить с помощью array_upper и array_lower, которые возвращают верхнюю и нижнюю границу указанного размера массива соответственно:
SELECT array_lower(schedule, 1), array_upper(schedule, 1) FROM sal_emp WHERE name = 'Carol';
array_lower array_upper
--------------------------
1 2
(1 row)
array_length вернет длину указанного размера массива:
SELECT array_length(schedule, 1) FROM sal_emp WHERE name = 'Carol';
array_length
--------------
2
(1 row)
cardinality возвращает общее количество элементов в массиве по каждому измерению. Это фактическое число строк, которое возвращает вызов unnest:
SELECT cardinality(schedule) FROM sal_emp WHERE name = 'Carol';
cardinality
-------------
4
(1 row)
Модификация массивов
Значение массива можно полностью заменить:
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Carol';
или используя синтаксис выражения ARRAY:
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
Массив также можно обновить в одном элементе:
UPDATE sal_emp SET pay_by_quarter[4] = 15000
WHERE name = 'Bill';
или обновить в срезе:
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
Синтаксис среза с опущенной нижней и/или верхней границами может быть использован, но только при обновлении значения массива, которое не является NULL или нульмерным (в противном случае не существует ограничения по нижнему индексу для замены).
Сохраненный массив можно расширять, добавляя элементы, которые еще не
присутствуют. Любые позиции между ранее присутствующими и вновь
назначенными элементами будут заполнены null. Например, если массив
myarray в настоящее время имеет 4 элемента, он будет иметь шесть
элементов после обновления, которое присваивается myarray[6];
myarray[5]будет содержать null. В настоящее время расширение таким
способом допускается только для одномерных, а не многомерных массивов.
Назначение индексов позволяет создавать массивы, в которых не
используются одинарная нумерация. Например, можно назначить
myarray[-2:7] для создания массива со значениями индекса от -2 до 7.
Новые значения массива также могут быть созданы с помощью оператора конкатенации, :
SELECT ARRAY[1,2] || ARRAY[3,4];
?column?
-----------
{1,2,3,4}
(1 row)
SELECT ARRAY[5,6] || ARRAY[[1,2],[3,4]];
?column?
---------------------
{{5,6},{1,2},{3,4}}
(1 row)
Оператор конкатенации позволяет помещать отдельный элемент в начало или
конец одномерного массива. Он также принимает два N-мерных массива или
N-мерный и N+1-мерный массив.
Когда отдельный элемент помещается в начало или конец одномерного массива, результатом является массив с тем же нижним индексом, что и у операнда массива. Например:
SELECT array_dims(1 || '[0:1]={2,3}'::int[]);
array_dims
------------
[0:2]
(1 row)
SELECT array_dims(ARRAY[1,2] || 3);
array_dims
------------
[1:3]
(1 row)
Когда два массива с равным числом измерений объединяются, результат сохраняет нижнюю границу индекса внешнего измерения левого операнда. Результатом является массив, содержащий каждый элемент левого операнда, за которым следует каждый элемент правого операнда. Например:
SELECT array_dims(ARRAY[1,2] || ARRAY[3,4,5]);
array_dims
------------
[1:5]
(1 row)
SELECT array_dims(ARRAY[[1,2],[3,4]] || ARRAY[[5,6],[7,8],[9,0]]);
array_dims
------------
[1:5][1:2]
(1 row)
Когда N-мерный массив помещается в начало или конец N+1-мерного массива,
результат аналогичен описанному выше случаю массива элементов. Каждый
N-мерный подмассив по сути является элементом внешнего измерения
N+1-мерного массива. Например:
SELECT array_dims(ARRAY[1,2] || ARRAY[[3,4],[5,6]]);
array_dims
------------
[1:3][1:2]
(1 row)
Массив также может быть создан с использованием функций array_prepend, array_append или array_cat. Первые два поддерживают только одномерные массивы, но array_cat поддерживает многомерные массивы. Несколько примеров:
SELECT array_prepend(1, ARRAY[2,3]);
array_prepend
---------------
{1,2,3}
(1 row)
SELECT array_append(ARRAY[1,2], 3);
array_append
--------------
{1,2,3}
(1 row)
SELECT array_cat(ARRAY[1,2], ARRAY[3,4]);
array_cat
-----------
{1,2,3,4}
(1 row)
SELECT array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6]);
array_cat
---------------------
{{1,2},{3,4},{5,6}}
(1 row)
SELECT array_cat(ARRAY[5,6], ARRAY[[1,2],[3,4]]);
array_cat
---------------------
{{5,6},{1,2},{3,4}}
В простых случаях оператор конкатенации, рассмотренный выше, предпочтительнее прямого использования этих функций. Однако, поскольку оператор конкатенации перегружен для обслуживания всех трех случаев, существуют ситуации, когда использование одной из функций помогает избежать двусмысленности. Например, рассмотрим:
SELECT ARRAY[1, 2] || '{3, 4}'; -- the untyped literal is taken as an array
?column?
-----------
{1,2,3,4}
SELECT ARRAY[1, 2] || '7'; -- so is this one
ERROR: malformed array literal: "7"
SELECT ARRAY[1, 2] || NULL; -- so is an undecorated NULL
?column?
----------
{1,2}
(1 row)
SELECT array_append(ARRAY[1, 2], NULL); -- this might have been meant
array_append
--------------
{1,2,NULL}
В приведенных выше примерах анализатор видит целочисленный массив на одной стороне оператора конкатенации и константу неопределенного типа с другой. Эвристика, которую он использует для разрешения типа константы, предполагает, что она того же типа, что и другие входные данные оператора - в данном случае, целочисленный массив. Поэтому предполагается, что оператор конкатенации представляет array_cat, а не array_append. Если это неправильный выбор, его можно исправить, приведя константу к типу элемента массива; но явное использование array_append может быть предпочтительным решением.
Поиск в массивах
Для поиска значения в массиве необходимо проверить каждое значение. Это можно сделать вручную, если вы знаете размер массива. Например:
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
Однако это быстро становится утомительным для больших массивов и бесполезно, если размер массива неизвестен. Альтернативный метод описан в разделе Сравнение строк и массивов. Приведенный выше запрос может быть заменен на:
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter);
Кроме того, вы можете найти строки, где массив имеет все значения, равные 10000, с помощью:
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
В качестве альтернативы можно использовать функцию generate_subscripts. Например:
SELECT * FROM
(SELECT pay_by_quarter,
generate_subscripts(pay_by_quarter, 1) AS s
FROM sal_emp) AS foo
WHERE pay_by_quarter[s] = 10000;
Эта функция описана в разделе Функции возврата наборов (SET).
Вы также можете искать в массиве с помощью оператора &&, который
проверяет, перекрывает ли левый операнд правый операнд. Например:
SELECT * FROM sal_emp WHERE pay_by_quarter && ARRAY[10000];
Этот и другие операторы массива более подробно описаны в разделе Функции и операторы массива. Его можно ускорить с помощью соответствующего индекса, как описано в разделе Типы индексов.
Вы также можете искать конкретные значения в массиве, используя функции array_position и array_positions. Первый возвращает индекс первого вхождения значения в массиве; последний возвращает массив с индексами всех вхождений значения в массиве. Например:
SELECT array_position(ARRAY['sun','mon','tue','wed','thu','fri','sat'], 'mon');
array_positions
-----------------
2
SELECT array_positions(ARRAY[1, 4, 3, 1, 3, 4, 2, 1], 1);
array_positions
-----------------
{1,4,8}
Заметка
Массивы не являются наборами; поиск определенных элементов массива может быть признаком неправильного проектирования базы данных. Попробуйте использовать отдельную таблицу со строкой для каждого элемента, который будет являться элементом массива. Это будет легче для поиска, и, вероятно, позволит лучше масштабировать большое количество элементов.
Синтаксис ввода и вывода массива
Внешнее текстовое представление значения массива состоит из элементов,
которые интерпретируются в соответствии с правилами преобразования
ввода-вывода для типа элемента массива, а также элементов оформления,
которые указывают на структуру массива. Оформление состоит из фигурных
скобок ({ и }) вокруг значения массива и символов-разделителей между
смежными элементами. Символ-разделитель обычно представляет собой
запятую (,), но может быть и другим: он определяется настройкой typdelim
для типа элемента массива. Среди стандартных типов данных,
представленных в дистрибутиве QHB, все используют запятую, за
исключением типа box, в котором используется точка с запятой (;). В
многомерном массиве каждое измерение (строка, плоскость, куб и т. д.)
получает свой собственный уровень фигурных скобок, и разделители должны
быть записаны между смежными фигурными скобками сущностями одного
уровня.
Процедура вывода массива помещает двойные кавычки вокруг значений элемента, если они являются пустыми строками, содержат фигурные скобки, символы-разделители, двойные кавычки, обратную косую черту или пробел или соответствуют слову NULL. Двойные кавычки и обратные косые черты, встроенные в значения элементов, будут экранированы соответствующей обратной косой чертой. Для числовых типов данных можно с уверенностью предположить, что двойные кавычки никогда не появятся, но для текстовых типов данных следует быть готовыми справиться с наличием или отсутствием кавычек.
По умолчанию значение индекса нижней границы измерений массива равно
единице. Для представления массивов с другими нижними границами
диапазоны индексов массива могут быть указаны явно перед записью
содержимого массива. Это оформление состоит из квадратных скобок ([])
вокруг нижней и верхней границ каждого измерения массива, между которыми
стоит символ разделителя (:). Оформление размера массива сопровождается
знаком равенства (=). Например:
SELECT f1[1][-2][3] AS e1, f1[1][-1][5] AS e2
FROM (SELECT '[1:1][-2:-1][3:5]={{{1,2,3},{4,5,6}}}'::int[] AS f1) AS ss;
e1 | e2
----+----
1 | 6
(1 row)
Процедура вывода массива будет включать в свой результат явные измерения только в том случае, если одна или несколько нижних границ отличаются от единицы.
Если значение, записанное для элемента, равно NULL (в любом случае), элемент считается равным NULL. Наличие любых кавычек или обратной косой черты отключает это и позволяет вводить буквальное строковое значение литерала «NULL».
Как показано ранее, при записи значения массива вы можете использовать двойные кавычки вокруг любого отдельного элемента массива. Вы должны сделать это, если значение элемента в противном случае приведет к путанице синтаксического анализатора значений массива. Например, элементы, содержащие фигурные скобки, запятые (или символ-разделитель типа данных), двойные кавычки, обратные слэши или начальные или конечные пробелы должны быть заключены в двойные кавычки. Пустые строки и строки, соответствующие слову NULL, также должны быть заключены в кавычки. Чтобы поместить двойную кавычку или обратную косую черту в значение элемента массива заключенного в кавычки, поставьте перед ним обратную косую черту. Кроме того, можно избежать кавычек и использовать обратную косую черту для защиты всех символов данных, которые в противном случае были бы приняты за синтаксис массива.
Вы можете добавить пробел перед левой или правой скобкой. Вы также можете добавить пробел до или после любой отдельной строки элемента. Во всех этих случаях пробелы будут игнорироваться. Однако пропуски внутри элементов в двойных кавычках, или окруженные с обеих сторон символами, не являющимися пробелами, не игнорируются.
Заметка
Синтаксис конструктора массива (см. раздел Конструкторы массивов) часто проще в работе, чем синтаксис массива-литерала при записи значений массива в командах SQL. В массиве значения отдельных элементов записываются так же, как если бы они не были членами массива.
Составные типы
Составной тип представляет структуру строки или записи; по существу, это просто список имен полей и их типов данных. QHB позволяет использовать составные типы во многом так же, как и простые типы. Например, столбец таблицы может быть объявлен как составной тип.
Декларация составных типов
Вот два простых примера определения составных типов:
CREATE TYPE complex AS (
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
Синтаксис сопоставим с CREATE TABLE, за исключением того, что можно указывать только имена и типы полей; никакие ограничения (такие как NOT NULL) в настоящее время не могут быть включены. Обратите внимание, что ключевое слово AS имеет важное значение; без этого система будет думать, что подразумевается другого вид команды CREATE TYPE, и вы получите странные синтаксические ошибки.
Определив типы, мы можем использовать их для создания таблиц:
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
или функции:
CREATE FUNCTION price_extension(inventory_item, integer) RETURNS numeric
AS 'SELECT $1.price * $2' LANGUAGE SQL;
SELECT price_extension(item, 10) FROM on_hand;
Каждый раз, когда вы создаете таблицу, составной тип также автоматически создается с тем же именем, что и таблица, для представления типа строки таблицы. Например, если бы мы сказали:
CREATE TABLE inventory_item (
name text,
supplier_id integer REFERENCES suppliers,
price numeric CHECK (price > 0)
);
тогда тот же составной тип inventory_item показанный выше, возникнет как побочный продукт и может быть использован так же, как и выше. Однако обратите внимание на важное ограничение текущей реализации: поскольку с составным типом не связаны никакие ограничения, ограничения, показанные в определении таблицы, не применяются к значениям составного типа вне таблицы. (Чтобы обойти это, создайте домен поверх составного типа и примените требуемые ограничения как контрольные ограничения для домена).
Построение составных значений
Чтобы записать составное значение в виде литеральной константы, заключите значения полей в круглые скобки и разделите их запятыми. Вы можете поместить двойные кавычки вокруг любого значения поля, и это необходимо делать, если оно содержит запятые или скобки. (Подробнее см. ниже). Таким образом, общий формат составной константы следующий:
'( val1, val2, ... )'
Примером является:
'("fuzzy dice",42,1.99)'
что будет допустимым значением типа inventory_item определенного выше. Чтобы сделать поле пустым, не пишите никаких символов в его позиции в списке. Например, эта константа задает третье поле NULL:
'("fuzzy dice",42,)'
Если нужна пустая строка, а не NULL, напишите двойные кавычки:
'("",42,)'
Здесь первое поле является не-NULL пустой строкой, третье - NULL.
(Эти константы на самом деле являются лишь частным случаем констант универсального типа, обсуждаемых в разделе Константы других типов. Константа первоначально обрабатывается как строка и передается в процедуру преобразования ввода составного типа. Может потребоваться явная спецификация типа, чтобы определить, к какому типу следует преобразовать константу).
Синтаксис конструктора строки также можно использовать для создания составных значений. В большинстве случаев это значительно проще в использовании, чем синтаксис строкового литерала, поскольку вам не нужно беспокоиться о нескольких уровнях цитирования. Мы уже использовали этот метод выше:
ROW('fuzzy dice', 42, 1.99)
ROW('', 42, NULL)
Ключевое слово ROW на самом деле является необязательным, если в выражении указано более одного поля, поэтому его можно упростить до:
('fuzzy dice', 42, 1.99)
('', 42, NULL)
Синтаксис конструктора строки более подробно обсуждается в разделе Конструкторы строк.
Доступ к составным типам
Чтобы получить доступ к полю составного столбца, нужно написать точку и имя поля, как при выборе поля из имени таблицы. На самом деле, это так похоже на выбор из имени таблицы, что вам часто приходится использовать круглые скобки, чтобы не запутать парсер. Например, вы можете попробовать выбрать некоторые подполя из нашей таблицы примеров on_hand например:
SELECT item.name FROM on_hand WHERE item.price > 9.99;
Это не будет работать, так как элемент item считается именем таблицы, а не именем столбца on_hand, согласно правилам синтаксиса SQL. Вы должны написать это так:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
или если вам нужно использовать имя таблицы (например, в запросе с несколькими таблицами), например так:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
Теперь заключенный в скобки объект правильно интерпретируется как ссылка на столбец item, а затем из него можно выбрать субполе.
Подобные синтаксические проблемы применяются всякий раз, когда вы выбираете поле из составного значения. Например, чтобы выбрать только одно поле из результата функции, которая возвращает составное значение, вам нужно написать что-то вроде:
SELECT (my_func(...)).field FROM ...
Без лишних скобок это приведет к синтаксической ошибке.
Название специального поля * означает «все поля», как более подробно
описано в разделе Использование составных типов в запросах.
Модификация составных типов
Вот несколько примеров правильного синтаксиса для вставки и обновления составных столбцов. Во-первых, вставка или обновление целого столбца:
INSERT INTO mytab (complex_col) VALUES((1.1,2.2));
UPDATE mytab SET complex_col = ROW(1.1,2.2) WHERE ...;
Первый пример пропускает ROW, второй использует его; мы могли бы сделать это в любом случае.
Мы можем обновить отдельное подполе составного столбца:
UPDATE mytab SET complex_col.r = (complex_col).r + 1 WHERE ...;
Обратите внимание, что нам не нужно (и мы действительно не можем) ставить скобки вокруг имени столбца, появляющегося сразу после SET, но нам нужны скобки при обращении к тому же столбцу в выражении справа от знака равенства.
И мы можем указать подполя как цели для INSERT:
INSERT INTO mytab (complex_col.r, complex_col.i) VALUES(1.1, 2.2);
Если бы мы не указали значения для всех подполей столбца, оставшиеся подполя были бы заполнены нулевыми значениями.
Использование составных типов в запросах
Существуют различные специальные синтаксические правила и поведения, связанные с составными типами в запросах. Эти правила предоставляют полезные ярлыки, но могут сбивать с толку, если вы не знаете логику, стоящую за ними.
В QHB ссылка на имя таблицы (или псевдоним) в запросе фактически является ссылкой на составное значение текущей строки таблицы. Например, если бы у нас была таблица inventory_item как показано в разделе Декларация составных типов, мы могли бы написать:
SELECT c FROM inventory_item c;
Этот запрос создает один составной столбец, поэтому мы можем получить вывод, например:
c
------------------------
("fuzzy dice",42,1.99)
(1 row)
Однако обратите внимание, что простые имена сопоставляются с именами столбцов перед именами таблиц, поэтому этот пример работает только потому, что в таблицах запроса нет столбца с именем c.
Обычный синтаксис имени квалифицированного столбца
table_name.column_name можно понимать как применение выбора поля к
составному значению текущей строки таблицы. (Из соображений
эффективности это не реализовано таким образом).
Когда мы пишем
SELECT c.* FROM inventory_item c;
тогда, согласно стандарту SQL, мы должны расширить содержимое таблицы на отдельные столбцы:
name | supplier_id | price
-----------+-------------+-------
fuzzy dice | 42 | 1.99
(1 row)
как будто выполнялся запрос:
SELECT c.name, c.supplier_id, c.price FROM inventory_item c;
QHB будет применять это поведение раскрытия к любому составному
выражению, хотя, как показано выше, вам нужно писать круглые скобки
вокруг значения, к которому применяется .*, когда это не простое имя
таблицы. Например, если myfunc() - это функция, возвращающая составной
тип со столбцами a, b и c, то эти два запроса имеют одинаковый
результат:
SELECT (myfunc(x)).* FROM some_table;
SELECT (myfunc(x)).a, (myfunc(x)).b, (myfunc(x)).c FROM some_table;
Заметка
QHB обрабатывает расширение столбцов, фактически превращая первую форму во вторую. Таким образом, в этом примере myfunc() будет вызываться три раза в строке с любым синтаксисом. Если это дорогая функция, вы можете избежать этого, с помощью запроса:
`SELECT m.* FROM some_table, LATERAL myfunc(x) AS m;`
Помещение функции в боковой элемент FROM позволяет вызывать ее более
одного раза в строке. `m.*` все еще разворачивается в `m.a`, `m.b`, `m.c`, но
теперь эти переменные являются просто ссылками на выходные данные
элемента *FROM*. (Ключевое слово *LATERAL* здесь необязательно, но мы
показываем его, чтобы уточнить, что функция получает `x` из *some_table*).
Синтаксис composite_value.* приводит к расширению столбца такого
типа, когда он появляется на верхнем уровне выходного списка SELECT,
списка RETURNING в INSERT/UPDATE/DELETE,
предложения VALUES или
конструктора строки. Во всех других контекстах (в том числе, когда они
вложены в одну из этих конструкций), присоединение .* к составному
значению не меняет значение, поскольку означает «все столбцы», и поэтому
то же составное значение создается снова. Например, если somefunc()
принимает составной аргумент, эти запросы совпадают:
SELECT somefunc(c.*) FROM inventory_item c;
SELECT somefunc(c) FROM inventory_item c;
В обоих случаях текущая строка inventory_item передается функции в виде
одного составного аргумента. Несмотря на то, что .* ничего не делает
в таких случаях, это хороший стиль, поскольку он ясно показывает, что
предполагается составное значение. В частности, синтаксический
анализатор будет рассматривать c как c.* для ссылки на имя таблицы
или псевдоним, а не на имя столбца, так что нет никакой двусмысленности;
тогда как без .* неясно, означает ли c имя таблицы или имя столбца,
и на самом деле интерпретация имени столбца будет предпочтительнее, если
есть столбец с именем c.
Другим примером, демонстрирующим эти концепции, является то, что все эти запросы означают одно и то же:
SELECT * FROM inventory_item c ORDER BY c;
SELECT * FROM inventory_item c ORDER BY c.*;
SELECT * FROM inventory_item c ORDER BY ROW(c.*);
Все эти предложения ORDER BY задают составное значение строки, в результате чего строки сортируются в соответствии с правилами, описанными в разделе Сравнение составных типов. Однако если inventory_item элемент содержит столбец с именем «c», то первый случай будет отличаться от других, поскольку это означало бы сортировку только по этому столбцу. Учитывая имена столбцов, показанные ранее, эти запросы также эквивалентны приведенным выше:
SELECT * FROM inventory_item c ORDER BY ROW(c.name, c.supplier_id, c.price);
SELECT * FROM inventory_item c ORDER BY (c.name, c.supplier_id, c.price);
(В последнем случае используется конструктор строки с опущенным ключевым словом ROW).
Другое специальное синтаксическое поведение, связанное с составными значениями, заключается в том, что мы можем использовать функциональную нотацию для извлечения поля составного значения. Простой способ объяснить это состоит в том, что нотации field(table) и table.field являются взаимозаменяемыми. Например, эти запросы эквивалентны:
SELECT c.name FROM inventory_item c WHERE c.price > 1000;
SELECT name(c) FROM inventory_item c WHERE price(c) > 1000;
Более того, если у нас есть функция, которая принимает один аргумент составного типа, мы можем вызвать ее с любой нотацией. Все эти запросы эквивалентны:
SELECT somefunc(c) FROM inventory_item c;
SELECT somefunc(c.*) FROM inventory_item c;
SELECT c.somefunc FROM inventory_item c;
Эта эквивалентность между функциональной нотацией и нотацией полей позволяет использовать функции на составных типах для реализации «вычисляемых полей». Приложению, использующему последний запрос выше, не нужно знать, что somefunc не является реальным столбцом таблицы.
Синтаксис ввода и вывода составного типа
Внешнее текстовое представление составного значения состоит из
элементов, которые интерпретируются в соответствии с правилами
преобразования ввода-вывода для отдельных типов полей, плюс оформление,
которое указывает составную структуру. Оформление состоит из круглых
скобок ((и)) вокруг всего значения, а также запятых (,) между соседними
элементами. Пробелы вне скобок игнорируются, но в скобках они считаются
частью значения поля и могут иметь или не иметь существенного значения в
зависимости от правил преобразования входных данных для типа данных
поля. Например, в:
'( 42)'
пробел будет игнорироваться, если тип поля целочисленный, но не текстовый.
Как показано ранее, при написании составного значения вы можете писать двойные кавычки вокруг любого отдельного значения поля. Вы должны сделать это, если значение поля в противном случае могло бы запутать синтаксический анализатор составного значения. В частности, поля, содержащие скобки, запятые, двойные кавычки или обратную косую черту, должны быть заключены в двойные кавычки. Чтобы поместить двойную кавычку или обратную косую черту в значение составного поля в кавычках, поставьте перед ним обратную косую черту. (Кроме того, пара двойных кавычек в значении поля с двойными кавычками используется для представления символа двойной кавычки, аналогично правилам для одинарных кавычек в строковых литералах SQL). В качестве альтернативы вы можете избежать кавычек и использовать экранирование обратной косой чертой для защиты всех символов данных, которые в противном случае были бы приняты в качестве составного синтаксиса.
Абсолютно пустое значение поля (без запятых или круглых скобок) означает
NULL. Чтобы записать значение, которое является пустой строкой, а не
NULL, напишите "".
Программа составного вывода помещает двойные кавычки вокруг значений полей, если они являются пустыми строками или содержат круглые скобки, запятые, двойные кавычки, обратную косую черту или пробел. (Делать это для пустого пространства не обязательно, но помогает удобочитаемости). Двойные кавычки и обратные слэши, встроенные в значения полей, будут удвоены.
Заметка
Помните, что то, что вы пишете в команде SQL, сначала будет интерпретироваться как строковый литерал, а затем как составной. Это удваивает количество обратных косых черт, которые вам нужны (при условии использования синтаксиса escape-строки). Например, чтобы вставить текстовое поле, содержащее двойную кавычку и обратную косую черту в составном значении, вам нужно написать:
```sql
INSERT ... VALUES ('("\"\\")');
```
Обработчик строковых литералов удаляет один уровень обратной косой
черты, так что то, что поступает в синтаксический анализатор составных
значений, выглядит как ("\"\\"). В свою очередь, строка, переданная
подпрограмме ввода типа данных text, становится "\. (Если бы мы
работали с типом данных, чья подпрограмма ввода также обрабатывала
обратную косую черту, например, bytea, нам может потребоваться до восьми
обратных косых черт в команде, чтобы получить одну обратную косую черту
в сохраненном составном поле). Кавычки из знаков доллара (см.
раздел Строковые константы с экранированием знаками доллара) могут использоваться, чтобы избежать необходимости
удваивать обратную косую черту.
Заметка
Синтаксис конструктора строк обычно проще в работе, чем синтаксис составного литерала при записи составных значений в командах SQL. В конструкторе строк значения отдельных полей записываются так же, как если бы они не были составными.
Диапазонные типы
Диапазонные типы — это типы данных, представляющие диапазон значений некоторого типа элемента (называемый подтипом диапазона). Например, диапазоны меток времени могут использоваться для представления диапазонов времени, зарезервированных для комнаты собраний. В этом случае тип данных - tsrange (сокращение от «timestamp range»), а timestamp — это подтип. Подтип должен иметь общий порядок, чтобы было четко определено, находятся ли значения элемента в пределах, до или после диапазона значений.
Диапазонные типы полезны, поскольку они представляют множество значений элементов в одном значении диапазона, а также потому, что такие понятия, как перекрывающиеся диапазоны, могут быть четко выражены. Использование диапазонов времени и даты для целей планирования является наиболее ярким примером; но диапазоны цен, диапазоны измерений от инструмента и т. д. также могут быть полезны.
Типы встроенных диапазонов
QHB поставляется со следующими встроенными типами диапазонов:
Кроме того, вы можете определить свои собственные диапазоные типы; см. CREATE TYPE для получения дополнительной информации.
Примеры
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- Containment
SELECT int4range(10, 20) @> 3;
-- Overlaps
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
-- Extract the upper bound
SELECT upper(int8range(15, 25));
-- Compute the intersection
SELECT int4range(10, 20) * int4range(15, 25);
-- Is the range empty?
SELECT isempty(numrange(1, 5));
См. раздел Функции диапазона и операторы для получения полного списка операторов и функций для типов диапазонов.
Инклюзивные и эксклюзивные границы
Каждый непустой диапазон имеет две границы: нижнюю и верхнюю. Все точки между этими значениями включены в диапазон. Инклюзивная граница означает, что сама граничная точка также включена в диапазон, а эксклюзивная граница означает, что граничная точка не включена в диапазон.
В текстовой форме диапазона включающая нижняя граница представлена как
"[", в то время как исключительная нижняя граница представлена как "(".
Аналогично, включающая верхняя граница представлена как "]", тогда как
исключительная верхняя граница представлена на ")". (Подробнее см.
раздел Диапазон ввода/вывода).
Функции lower_inc и upper_inc проверяют включенность нижней и верхней границ значения диапазона, соответственно.
Бесконечные (неограниченные) диапазоны
Нижняя граница диапазона может быть опущена, что означает, что все
точки, меньшие верхней границы, включены в диапазон, например, (,3].
Аналогично, если верхняя граница диапазона опущена, то все точки,
превышающие нижнюю границу, включаются в диапазон. Если нижняя и верхняя
границы опущены, все значения типа элемента считаются находящимися в
диапазоне. Указание отсутствующей границы как включающей автоматически
преобразуется в исключительную, например, [,] преобразуется в (,).
Можно думать об этих пропущенных значениях как +/-infinity, но они
представляют собой специальные значения типа диапазона и считаются
выходящими за пределы значений +/-infinity любого типа элемента
диапазона.
Типы элементов, имеющие понятие «бесконечность», могут использовать их в
качестве явных связанных значений. Например, в диапазонах меток времени
[today,infinity) исключает специальное значение метки времени
бесконечность, тогда как [today,infinity] включает его, аналогично
[today,) and [today,].
Функции lower_inf и upper_inf проверяют бесконечную нижнюю и верхнюю границы диапазона соответственно.
Диапазон ввода/вывода
Входные данные для значения диапазона должны соответствовать одному из следующих шаблонов:
(lower-bound,upper-bound)
(lower-bound,upper-bound]
[lower-bound,upper-bound)
[lower-bound,upper-bound]
empty
Скобки или квадратные скобки указывают, являются ли нижняя и верхняя границы исключающими или включающими, как описано ранее. Обратите внимание, что последний шаблон пуст, он представляет пустой диапазон (диапазон, не содержащий точек).
Нижняя граница (lower-bound) может быть либо строкой, которая является допустимым вводом для подтипа, либо пустой, чтобы указать отсутствие нижней границы. Аналогично, верхняя граница (upper-bound) может быть либо строкой, которая является допустимым вводом для подтипа, либо пустой, чтобы указать отсутствие верхней границы.
Каждое связанное значение может быть заключено в кавычки с использованием символов " (двойная кавычка). Это необходимо, если связанное значение содержит круглые скобки, скобки, запятые, двойные кавычки или обратную косую черту, поскольку в противном случае эти символы были бы приняты как часть синтаксиса диапазона. Чтобы поместить двойную кавычку или обратную косую черту в указанное значение в кавычках, поставьте перед ним обратную косую черту. (Кроме того, пара двойных кавычек внутри связанного значения в двойных кавычках используется для представления символа двойной кавычки, аналогично правилам для одинарных кавычек в строках литералов SQL.). Кроме того, вы можете избежать кавычек и использовать экранирование обратной косой черты для защиты всех символов данных, которые в противном случае были бы приняты как синтаксис диапазона. Кроме того, чтобы написать связанное значение, которое является пустой строкой, напишите "", так как запись «ничего» означает бесконечная граница.
Пробел допускается до и после значения диапазона, но любой пробел между скобками или квадратными скобками принимается как часть нижнего или верхнего граничного значения. (В зависимости от типа элемента это может иметь или не иметь значения).
Заметка
Эти правила очень похожи на правила записи значений полей в литералах составного типа. См. раздел Синтаксис ввода и вывода составного типа для дополнительных комментариев.
Примеры:
-- includes 3, does not include 7, and does include all points in between
SELECT '[3,7)'::int4range;
-- does not include either 3 or 7, but includes all points in between
SELECT '(3,7)'::int4range;
-- includes only the single point 4
SELECT '[4,4]'::int4range;
-- includes no points (and will be normalized to 'empty')
SELECT '[4,4)'::int4range;
Построение рядов
Каждый тип диапазона имеет функцию-конструктор с тем же именем, что и
тип диапазона. Использование функции конструктора часто более удобно,
чем запись литеральной константы диапазона, поскольку она устраняет
необходимость в дополнительных кавычках связанных значений. Функция
конструктора принимает два или три аргумента. Форма с двумя аргументами
создает диапазон в стандартной форме (включая нижнюю границу,
исключающую верхнюю границу), тогда как форма с тремя аргументами
создает диапазон с границами формы, указанной в третьем аргументе.
Третий аргумент должен быть одной из строк "()", "(]", "[)" или
"[]". Например:
-- The full form is: lower bound, upper bound, and text argument indicating
-- inclusivity/exclusivity of bounds.
SELECT numrange(1.0, 14.0, '(]');
-- If the third argument is omitted, '[)' is assumed.
SELECT numrange(1.0, 14.0);
-- Although '(]' is specified here, on display the value will be converted to
-- canonical form, since int8range is a discrete range type (see below).
SELECT int8range(1, 14, '(]');
-- Using NULL for either bound causes the range to be unbounded on that side.
SELECT numrange(NULL, 2.2);
Типы дискретных диапазонов
Дискретный диапазон — это тот, чей тип элемента имеет четко определенный «шаг», такой как integer или date. В этих типах можно сказать, что два элемента являются смежными, когда между ними нет допустимых значений. Это отличается от непрерывных диапазонов, где всегда (или почти всегда) можно идентифицировать другие значения элемента между двумя заданными значениями. Например, диапазон по типу numeric является непрерывным, как и диапазон по timestamp. (Хотя метка времени (timestamp) имеет ограниченную точность и поэтому теоретически может рассматриваться как дискретная, лучше считать ее непрерывной, поскольку размер шага обычно не представляет интереса).
Другой способ думать о типе дискретного диапазона состоит в том, что
существует четкое представление о «следующем» или «предыдущем» значении
для каждого значения элемента. Зная это, можно выполнить преобразование
между инклюзивным и эксклюзивным представлениями границ диапазона,
выбрав следующее или предыдущее значение элемента вместо заданного
первоначально. Например, в целочисленном диапазоне типов [4,8] и (3,9)
обозначают одинаковый набор значений; но это не так для числового
диапазона.
Тип дискретного диапазона должен иметь функцию канонизации, которая знает желаемый размер шага для типа элемента. Функция канонизации отвечает за преобразование эквивалентных значений типа диапазона в идентичные представления, в частности, последовательно включающие или исключающие границы. Если функция канонизации не указана, то диапазоны с различным форматированием всегда будут рассматриваться как неравные, даже если в действительности они могут представлять один и тот же набор значений.
Все встроенные диапазонные типы int4range, int8range и daterange
используют каноническую форму, которая включает нижнюю границу и
исключает верхнюю границу; то есть [). Однако определяемые
пользователем диапазонные типы могут использовать другие соглашения.
Определение новых диапазонных типов
Пользователи могут определять свои собственные диапазонные типы. Наиболее распространенная причина для этого - использовать диапазоны по подтипам, не предусмотренным среди встроенных диапазонных типов. Например, чтобы определить новый диапазонный тип подтипа float8:
CREATE TYPE floatrange AS RANGE (
subtype = float8,
subtype_diff = float8mi
);
SELECT '[1.234, 5.678]'::floatrange;
Поскольку float8 не имеет значимого «шага», мы не определяем функцию канонизации в этом примере.
Определение вашего собственного диапазонного типа также позволяет вам указать для использования другой подтип оператора класса B-дерева или его сопоставления, чтобы изменить порядок сортировки, определяющий, какие значения попадают в данный диапазон.
Если считается, что подтип имеет дискретные, а не непрерывные значения,
команда CREATE TYPE должна указывать функцию канонизации. Функция
канонизации принимает значение входного диапазона и должна возвращать
эквивалентное значение диапазона, которое может иметь различные границы
и форматирование. Канонический вывод для двух диапазонов, представляющих
один и тот же набор значений, например целочисленные диапазоны [1, 7]
и [1, 8), должен быть одинаковым. Неважно, какое представление вы
выберете как каноническое, если два эквивалентных значения с разными
форматами всегда отображаются на одно и то же значение с одинаковым
форматированием. В дополнение к настройке формата включающих/исключающих
границ функция канонизации может округлять граничные значения в случае,
если желаемый размер шага больше, чем тот, который способен хранить
подтип. Например, диапазонный тип по метке времени может быть определен
так, чтобы иметь размер шага в час, и в этом случае функция канонизации
должна будет округлить границы, не кратные часу, или, возможно, вместо
этого выдавать ошибку.
Кроме того, любой диапазонный тип, который предназначен для использования
с индексами GiST или SP-GiST, должен определять разность подтипов или
функцию subtype_diff. (Индекс по-прежнему будет работать без
subtype_diff, но он, вероятно, будет значительно менее эффективным, чем
если бы была предусмотрена разностная функция). Разностная функция
подтипа принимает два входных значения подтипа и возвращает их разность
(то есть X минус Y) представляется как значение float8. В примере выше
может использоваться функция float8mi которая лежит в основе обычного
оператора float8 minus; но для любого другого подтипа необходимо
преобразование некоторых типов. Кроме того, может потребоваться
творческая мысль о том, как представить различия в виде чисел. В
максимально возможной степени функция subtype_diff должна
согласовываться с порядком сортировки, подразумеваемым выбранным классом
оператора и параметрами сортировки; то есть её результат должен быть
положительным всякий раз, когда первый аргумент больше второго в
соответствии с порядком сортировки.
Менее упрощенный пример функции subtype_diff:
CREATE FUNCTION time_subtype_diff(x time, y time) RETURNS float8 AS
'SELECT EXTRACT(EPOCH FROM (x - y))' LANGUAGE sql STRICT IMMUTABLE;
CREATE TYPE timerange AS RANGE (
subtype = time,
subtype_diff = time_subtype_diff
);
SELECT '[11:10, 23:00]'::timerange;
См. CREATE TYPE для получения дополнительной информации о создании диапазонных типов.
Индексирование
Индексы GiST и SP-GiST могут быть созданы для столбцов таблицы диапазонных типов. Например, чтобы создать индекс GiST:
CREATE INDEX reservation_idx ON reservation USING GIST (during);
Индекс GiST или SP-GiST может ускорять запросы с участием следующих
операторов диапазона: =, &&, <@, @>, <<, >>, -|-, &<
и &> (дополнительную информацию см. в разделе Функции диапазона и операторы).
Кроме того, B-дерев и хэш-индексы могут быть созданы для столбцов
таблицы диапазонных типов. Для этих типов индексов единственная полезная
операция диапазона — это равенство. Для значений диапазона определен
порядок сортировки B-деревьев с соответствующими операторами < и
>, но этот порядок довольно произвольный и обычно не используется в
реальном мире. Поддержка B-деревьев и хеш-типов диапазонов в первую
очередь предназначена для внутренней сортировки и хеширования в
запросах, а не для создания фактических индексов.
Ограничения для диапазонов
В то время как UNIQUE является естественным ограничением для скалярных значений, обычно он не подходит для диапазонных типов. Вместо этого, часто более подходящим является ограничение исключения (см. CREATE TABLE ... CONSTRAINT ... EXCLUDE). Ограничения исключения позволяют задавать такие ограничения, как «неперекрывающиеся» для диапазонного типа. Например:
CREATE TABLE reservation (
during tsrange,
EXCLUDE USING GIST (during WITH &&)
);
Это ограничение предотвратит одновременное существование любых перекрывающихся значений в таблице:
INSERT INTO reservation VALUES
('[2010-01-01 11:30, 2010-01-01 15:00)');
INSERT 0 1
INSERT INTO reservation VALUES
('[2010-01-01 14:45, 2010-01-01 15:45)');
ERROR: conflicting key value violates exclusion constraint "reservation_during_excl"
DETAIL: Key (during)=(["2010-01-01 14:45:00","2010-01-01 15:45:00")) conflicts
with existing key (during)=(["2010-01-01 11:30:00","2010-01-01 15:00:00")).
Расширение btree_gist можно использовать для определения ограничений исключения для простых скалярных типов данных, которые затем можно комбинировать с исключениями диапазона для максимальной гибкости. Например, после установки btree_gist следующее ограничение будет отклонять перекрывающиеся диапазоны, только если номера комнат собраний равны:
CREATE EXTENSION btree_gist;
CREATE TABLE room_reservation (
room text,
during tsrange,
EXCLUDE USING GIST (room WITH =, during WITH &&)
);
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:00, 2010-01-01 15:00)');
INSERT 0 1
INSERT INTO room_reservation VALUES
('123A', '[2010-01-01 14:30, 2010-01-01 15:30)');
ERROR: conflicting key value violates exclusion constraint "room_reservation_room_during_excl"
DETAIL: Key (room, during)=(123A, ["2010-01-01 14:30:00","2010-01-01 15:30:00")) conflicts
with existing key (room, during)=(123A, ["2010-01-01 14:00:00","2010-01-01 15:00:00")).
INSERT INTO room_reservation VALUES
('123B', '[2010-01-01 14:30, 2010-01-01 15:30)');
INSERT 0 1
Типы доменов
Домен — это определенный пользователем тип данных, основанный на другом базовом типе. Необязательно, он может иметь условия, ограничивающие его допустимые значения подмножеством того, что допускает базовый тип. В противном случае он ведет себя как базовый тип - например, любой оператор или функция, которые могут быть применены к базовому типу, будут работать с типом домена. Базовым типом может быть любой встроенный или определенный пользователем базовый тип, тип перечисления, тип массива, составной тип, тип диапазона или другой домен.
Например, мы могли бы создать домен над целыми числами, который принимает только положительные целые числа:
CREATE DOMAIN posint AS integer CHECK (VALUE > 0);
CREATE TABLE mytable (id posint);
INSERT INTO mytable VALUES(1); -- works
INSERT INTO mytable VALUES(-1); -- fails
Когда оператор или функция базового типа применяется к значению домена,
домен автоматически преобразуется в базовый тип. Так, например, считается, что
результат mytable.id - 1 имеет тип integer, а не posint.
Мы могли бы написать (mytable.id - 1)::posint чтобы привести результат
обратно к posint, в результате чего ограничения домена будут
перепроверены. В этом случае это приведет к ошибке, если выражение было
применено к значению идентификатора 1. Присвоение значения базового типа
полю или переменной типа домена допускается без написания явного
приведения, но ограничения домена будут проверены.
Для получения дополнительной информации см. CREATE DOMAIN.
Типы идентификаторов объектов
Идентификаторы объектов (OID) используются внутри QHB в качестве первичных ключей для различных системных таблиц. Тип oid представляет идентификатор объекта. Существует также несколько типов псевдонимов для oid: regproc, regprocedure, regoper, regoperator, regclass, regtype, regrole, regnamespace, regconfig и regdictionary. В Таблице 26 приведена общая информация по типам идентификаторов объектов.
Тип oid в настоящее время реализован как беззнаковое четырехбайтовое целое число. Следовательно, он недостаточно велик, чтобы обеспечить уникальность всей базы данных в больших базах данных или даже в больших отдельных таблицах.
Сам по себе тип oid имеет несколько операций, не поддающихся сравнению. Однако его можно привести к целому числу, а затем манипулировать с помощью стандартных целочисленных операторов. (Остерегайтесь возможной путаницы со знаком и без знака, если вы сделаете это).
Типы псевдонимов OID не имеют собственных операций, кроме специализированных процедур ввода и вывода. Эти подпрограммы могут принимать и отображать символические имена для системных объектов, а не исходное числовое значение, которое будет использовать тип oid. Типы псевдонимов позволяют упростить поиск значений OID для объектов. Например, чтобы проверить строки pg_attribute относящиеся к таблице mytable, можно написать:
SELECT * FROM pg_attribute WHERE attrelid = 'mytable'::regclass;
скорее, чем:
SELECT * FROM pg_attribute
WHERE attrelid = (SELECT oid FROM pg_class WHERE relname = 'mytable');
Хотя это само по себе выглядит не так уж и плохо, все же упрощенно. Для выбора правильного OID потребуется гораздо более сложный суб-выбор, если в разных схемах есть несколько таблиц с именем mytable. Преобразователь ввода regclass обрабатывает поиск в таблице в соответствии с настройкой пути к схеме, поэтому автоматически выполняет «правильные действия». Точно так же приведение OID таблицы к regclass удобно для символического отображения числового OID.
Таблица 26. Типы идентификаторов объектов
| Имя | Ссылки | Описание | Пример значения |
|---|---|---|---|
| oid | Любые | числовой идентификатор объекта | 564182 |
| regproc | pg_proc | имя функции | sum |
| regprocedure | pg_proc | функция с типами аргументов | sum(int4) |
| regoper | pg_operator | имя оператора | + |
| regoperator | pg_operator | оператор с типами аргументов | *(integer,integer) или -(NONE,integer) |
| regclass | pg_class | имя отношения | pg_type |
| regtype | pg_type | имя типа данных | integer |
| regrole | pg_authid | название роли | smithee |
| regnamespace | pg_namespace | имя пространства имен | pg_catalog |
| regconfig | pg_ts_config | конфигурация текстового поиска | english |
| regdictionary | pg_ts_dict | словарь текстового поиска | simple |
Все типы псевдонимов OID для объектов, сгруппированных по пространству имен, принимают имена, соответствующие схеме, и будут отображать имена, соответствующие схеме, при выводе, если объект не будет найден в текущем пути поиска без проверки. Типы псевдонимов regproc и regoper будут принимать только входные имена, которые являются уникальными (не перегруженными), поэтому они имеют ограниченное использование; для большинства применений более подходящими являются regprocedure или regoperator. Для regoperator унарные операторы идентифицируются путем написания NONE для неиспользованного операнда.
Дополнительным свойством большинства типов псевдонимов OID является создание зависимостей. Если константа одного из этих типов появляется в сохраненном выражении (например, в выражении по умолчанию для столбца или в представлении), она создает зависимость от ссылочного объекта. Например, если столбец имеет выражение по умолчанию nextval(’my_seq’::regclass), QHB понимает, что выражение по умолчанию зависит от последовательности my_seq; система не позволит удалить последовательность без предварительного удаления выражения по умолчанию. regrole является единственным исключением для свойства. Константы этого типа не допускаются в таких выражениях.
Заметка
Типы псевдонимов OID не полностью соответствуют правилам изоляции транзакций. Планировщик также рассматривает их как простые константы, что может привести к неоптимальному планированию.
Другим типом идентификатора, используемым системой, является xid или идентификатор транзакции (сокращенно xact). Это тип данных системных столбцов xmin и xmax. Идентификаторы транзакции являются 32-битными величинами.
Третий тип идентификатора, используемый системой - cid, или идентификатор команды. Это тип данных системных столбцов cmin и cmax. Идентификаторы команд также являются 32-битными величинами.
Последний тип идентификатора, используемый системой — это tid, или идентификатор кортежа (идентификатор строки). Это тип данных системного столбца ctid. Идентификатор кортежа — это пара (номер блока, индекс кортежа в блоке), который идентифицирует физическое местоположение строки в своей таблице.
(Системные столбцы более подробно описаны в разделе Системные столбцы).
Тип pg_lsn
Тип данных pg_lsn может использоваться для хранения данных LSN (порядкового номера журнала - Log Sequence Number), которые являются указателем на местоположение в WAL. Этот тип является представлением XLogRecPtr и внутренним системным типом QHB.
Внутренне LSN представляет собой 64-разрядное целое число,
представляющее позицию байта в потоке журнала упреждающей записи. Он
печатается в виде двух шестнадцатеричных чисел длиной до 8 цифр,
разделенных косой чертой; например, 16/B374D848. Тип pg_lsn
поддерживает стандартные операторы сравнения, такие как = и >. Два
номера LSN могут быть вычтены с помощью оператора -; результат - число
байтов, разделяющих эти местоположения в wal-журнале.
Псевдо-типы
Система типов QHB содержит ряд записей специального назначения, которые в совокупности называются псевдотипами. Псевдотип нельзя использовать в качестве типа данных столбца, но его можно использовать для объявления аргумента функции или типа результата. Каждый из доступных псевдотипов полезен в ситуациях, когда поведение функции не соответствует простому взятию или возвращению значения определенного типа данных SQL. В таблице 7.27 перечислены существующие псевдотипы.
| Имя | Описание |
|---|---|
| any | Указывает, что функция принимает любой тип входных данных. |
| anyelement | Указывает, что функция принимает любой тип данных (см. раздел Полиморфные типы). |
| anyarray | Указывает, что функция принимает любой тип данных массива (см. раздел Полиморфные типы). |
| anynonarray | Указывает, что функция принимает любой тип данных, отличный от массива (см. раздел Полиморфные типы). |
| anyenum | Указывает, что функция принимает любой тип данных enum (см. разделы Полиморфные типы и Перечисляемые типы). |
| anyrange | Указывает, что функция принимает любой тип данных диапазона (см. разделы Полиморфные типы и Диапазонные типы). |
| cstring | Указывает, что функция принимает или возвращает строку C с нулевым символом в конце. |
| internal | Указывает, что функция принимает или возвращает внутренний тип данных сервера. |
| language_handler | Обработчик вызова процедурного языка объявляется как возвращающий language_handler. |
| fdw_handler | Обработчик обёртки fdw_handler данных объявляется как возвращающий fdw_handler. |
| index_am_handler | Обработчик метода доступа к индексу объявлен как возвращающий index_am_handler. |
| tsm_handler | Обработчик метода tableample объявлен как возвращающий tsm_handler. |
| record | Определяет функцию, принимающую или возвращающую неопределенный тип строки. |
| trigger | Объявлена триггерную функция для возврата trigger. |
| event_trigger | Объявлена функция запуска события, которая возвращает event_trigger. |
| pg_ddl_command | Определяет представление команд DDL, доступных для триггеров событий. |
| void | Указывает, что функция не возвращает значения. |
| unknown | Определяет еще не разрешенный тип, например, недекорированный строковый литерал. |
| opaque | Устаревшее имя типа, которое раньше служило многим из вышеперечисленных целей. |
Функции, закодированные в C/Rust (встроенные или динамически загружаемые), могут быть объявлены для принятия или возврата любого из этих псевдо-типов данных. Автор функции должен гарантировать, что функция будет вести себя безопасно, когда псевдотип используется в качестве типа аргумента.
Функции, закодированные в процедурных языках, могут использовать псевдотипы только в соответствии с их языками реализации. В настоящее время большинство процедурных языков запрещают использование псевдотипа в качестве типа аргумента и разрешают только void и record в качестве типа результата (плюс trigger или event_trigger когда функция используется в качестве триггера или триггера события). Некоторые также поддерживают полиморфные функции, используя типы anyelement, anyarray, anynonarray, anyenum и anyrange.
Псевдотип internal используется для объявления функций, предназначенных только для внутреннего вызова системой базы данных, а не путем прямого вызова в запросе SQL. Если у функции есть хотя бы один аргумент типа internal, ее нельзя вызвать из SQL. Чтобы сохранить безопасность типов этого ограничения, важно следовать этому правилу кодирования: не создавайте никакую функцию, которая объявляется возвращающей internal если у нее нет хотя бы одного internal аргумента.
Для этой цели термин « значение » включает элементы массива, хотя в терминологии JSON иногда элементы массива отличаются от значений внутри объектов.
Функции и операторы
QHB предоставляет большое количество функций и операторов для встроенных
типов данных. Пользователи также могут определять свои собственные
функции и операторы, как описано в части V. Команды qsql \df и \do
могут использоваться для вывода списка всех доступных функций и
операторов соответственно.
Большинство функций и операторов, описанных в этой главе, за исключением самых простых арифметических операторов и операторов сравнения и некоторых явно помеченных функций, не определены стандартом SQL. Некоторые из этих расширенных функциональных возможностей присутствуют в других системах управления базами данных SQL, и во многих случаях эти функциональные возможности совместимы и согласованы между различными реализациями. Эта глава также не является исчерпывающей; дополнительные функции указаны в соответствующих разделах руководства.
Логические операторы
Доступны обычные логические операторы: AND, OR, NOT.
SQL использует трехзначную логическую систему с истиной (TRUE), ложью (FALSE) и неизвестностью (NULL). Соблюдайте следующие таблицы истинности:
| a | b | a AND b | a OR b |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| TRUE | NULL | NULL | TRUE |
| FALSE | FALSE | FALSE | FALSE |
| FALSE | NULL | FALSE | NULL |
| NULL | NULL | NULL | NULL |
| a | NOT a |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| NULL | NULL |
Операторы AND и OR являются коммутативными, то есть вы можете переключать левый и правый операнд, не влияя на результат. Но см. раздел Правила вычисления выражений для получения дополнительной информации о порядке вычисления подвыражений.
Функции сравнения и операторы
Доступны обычные операторы сравнения, как показано в таблице 1.
Таблица 1. Операторы сравнения
| оператор | Описание |
|---|---|
| < | меньше, чем |
| > | больше чем |
| <= | меньше или равно |
| >= | больше или равно |
| = | равный |
| <> или != | не равный |
Операторы сравнения доступны для всех соответствующих типов данных. Все
операторы сравнения являются бинарными операторами, которые возвращают
значения типа boolean; выражения типа 1 < 2 < 3 недопустимы
(потому что нет оператора < для сравнения логического значения с 3).
Есть также некоторые предикаты сравнения, как показано в таблице 2. Они ведут себя подобно операторам, но имеют специальный синтаксис, предписанный стандартом SQL.
Таблица 2. Предикаты сравнения
| Выражение | Описание |
|---|---|
| a BETWEEN x AND y | между |
| a NOT BETWEEN x AND y | не между |
| a BETWEEN SYMMETRIC x AND y | между, после сортировки значений сравнения |
| a NOT BETWEEN SYMMETRIC x AND y | не между, после сортировки значений сравнения |
| a IS DISTINCT FROM b | не равно, рассматривая null как обычное значение |
| a IS NOT DISTINCT FROM b | равно, рассматривая null как обычное значение |
| expression IS NULL | null |
| expression IS NOT NULL | не null |
| expression ISNULL | является null (нестандартный синтаксис) |
| expression NOTNULL | не равно null (нестандартный синтаксис) |
| boolean_expression IS TRUE | правда |
| boolean_expression IS NOT TRUE | ложно или неизвестно |
| boolean_expression IS FALSE | ложно |
| boolean_expression IS NOT FALSE | правда или неизвестно |
| boolean_expression IS UNKNOWN | неизвестно |
| boolean_expression IS NOT UNKNOWN | верно или неверно |
Предикат BETWEEN упрощает тестирование диапазона:
a BETWEEN x AND y
эквивалентно
a >= x AND a <= y
Обратите внимание, что BETWEEN обрабатывает значения конечных точек как включенные в диапазон. NOT BETWEEN делает противоположное сравнение:
a NOT BETWEEN x AND y
эквивалентно
a < x OR a > y
BETWEEN SYMMETRIC аналогичен BETWEEN за исключением того, что не требуется, чтобы аргумент слева от AND был меньше или равен аргументу справа. Если это не так, эти два аргумента автоматически меняются местами, поэтому всегда подразумевается непустой диапазон.
Обычные операторы сравнения выдают null (что означает «неизвестно»), а
не истину или ложь, когда любой из входных операндов null. Например,
7 = NULL возвращает null, как и 7 <> NULL. Когда это поведение не
подходит, используйте предикаты IS [NOT] DISTINCT FROM:
a IS DISTINCT FROM b
a IS NOT DISTINCT FROM b
Для не-null входных аргументов IS DISTINCT FROM аналогичен оператору
<>. Однако, если оба входных аргумента имеют значение null, он возвращает false,
а если только один аргумент имеет null значение, он возвращает true.
Аналогично, IS NOT DISTINCT FROM идентичен = для не-null аргументов, но
возвращает true, если оба аргумента имеют значение null, и false, если
только один аргумент имеет значение null. Таким образом, эти предикаты
эффективно действуют так, как если бы null был нормальным значением
данных, а не «неизвестным».
Чтобы проверить, является ли значение пустым, используйте предикаты:
expression IS NULL
expression IS NOT NULL
или эквивалентные, но нестандартные предикаты:
expression ISNULL
expression NOTNULL
Не пишите expression = NULL, потому что NULL "не равно" NULL. (NULL
значение представляет неизвестное значение, и неизвестно, равны ли два
неизвестных значения).
Заметка
Некоторые приложения могут ожидать, чтоexpression = NULLвозвращает true, еслиexpressionоценивается как null значение. Настоятельно рекомендуется изменить эти приложения в соответствии со стандартом SQL. Однако, если это невозможно, доступна переменная конфигурации transform_null_equals. Если он включен, QHB преобразует предложенияx = NULLвx IS NULL.
Если expression имеет строковое значение, то IS NULL равно true, если
само выражение строки равно нулю или когда все поля строки имеют
значение null, а IS NOT NULL равно true, если само выражение строки не
равно нулю и все поля строки имеют значение ненулевой. Из-за этого
поведения IS NULL и IS NOT NULL не всегда возвращают обратные результаты
для выражений со значениями строк; в частности, строковое выражение,
содержащее как null, так и не-null поля, вернет false для обоих
тестов. В некоторых случаях может быть предпочтительнее записать row IS DISTINCT FROM NULL или row IS NOT DISTINCT FROM NULL, которая просто
проверит, является ли значение строки в целом нулевым, без каких-либо
дополнительных тестов для полей строки.
Булевы значения также могут быть проверены с использованием предикатов
boolean_expression IS TRUE
boolean_expression IS NOT TRUE
boolean_expression IS FALSE
boolean_expression IS NOT FALSE
boolean_expression IS UNKNOWN
boolean_expression IS NOT UNKNOWN
Они всегда будут возвращать истину или ложь, никогда не принимать null значение, даже если операнд null. null вход рассматривается как логическое значение «неизвестно». Обратите внимание, что IS UNKNOWN и IS NOT UNKNOWN фактически совпадают с IS NULL и IS NOT NULL, соответственно, за исключением того, что входное выражение должно иметь логический тип.
Некоторые функции сравнения также доступны, как показано в таблице 3.
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| num_nonnulls(VARIADIC "any") | возвращает количество ненулевых аргументов | num_nonnulls(1, NULL, 2) | 2 |
| num_nulls(VARIADIC "any") | возвращает количество нулевых аргументов | num_nulls(1, NULL, 2) | 1 |
Математические функции и операторы
Математические операторы предоставляются для многих типов QHB. Для типов без стандартных математических соглашений (например, типы даты / времени) мы описываем фактическое поведение в последующих разделах.
Таблица 4 показывает доступные математические операторы.
Таблица 4. Математические операторы
| Оператор | Описание | пример | Результат |
|---|---|---|---|
| + | суммирование | 2 + 3 | 5 |
| - | вычитание | 2 - 3 | -1 |
| * | умножение | 2 * 3 | 6 |
| / | деление (целочисленное деление усекает результат) | 4 / 2 | 2 |
| % | по модулю (остаток) | 5 % 4 | 1 |
| ^ | возведение в степень (партнеры слева направо) | 2.0 ^ 3.0 | 8 |
| / | квадратный корень | / 25.0 | 5 |
| / | кубический корень | / 27.0 | 3 |
| ! | факториал | 5 ! | 120 |
| !! | факториал (префиксный оператор) | !! 5 | 120 |
| @ | абсолютная величина | @ -5.0 | 5 |
| & | побитовое И | 91 & 15 | 11 |
| | | побитовое ИЛИ | 32 | 3 | 35 |
| # | побитовый XOR | 17 # 5 | 20 |
| ~ | побитовое НЕ | ~1 | -2 |
| << | битовое смещение влево | 1 << 4 | 16 |
| >> | битовое смещение вправо | 8 >> 2 | 2 |
Битовые операторы работают только с целочисленными типами данных, тогда как остальные доступны для всех числовых типов данных. Побитовые операторы также доступны для битовых типов bit и bit varying, как показано в таблице 8.14.
Таблица 5 показывает доступные математические функции. В таблице dp
указывает на double precision. Многие из этих функций представлены в
нескольких формах с различными типами аргументов. Если не указано иное,
любая форма функции возвращает тот же тип данных, что и ее аргумент.
Функции, работающие с данными double precision, в основном реализованы
поверх библиотеки C/RUST хост-системы; поэтому точность и поведение в
граничных случаях могут варьироваться в зависимости от хост-системы.
Таблица 5. Математические функции
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| abs(x) | (так же, как вход) | абсолютная величина | abs(-17.4) | 17.4 |
| cbrt(dp) | dp | кубический корень | cbrt(27.0) | 3 |
| ceil(dp or numeric) | (так же, как вход) | ближайшее целое число больше или равно аргументу | ceil(-42.8) | -42 |
| ceiling(dp or numeric) | (так же, как вход) | ближайшее целое число больше или равно аргументу (то же, что и ceil) | ceiling(-95.3) | -95 |
| degrees(dp) | dp | радианы в градусы | degrees(0.5) | 28.6478897565412 |
| div(y numeric, x numeric) | numeric | целое отношение y / x | div(9,4) | 2 |
| exp(dp or numeric) | (так же, как вход) | экспоненциальный | exp(1.0) | 2.71828182845905 |
| floor(dp or numeric) | (так же, как вход) | ближайшее целое число меньше или равно аргументу | floor(-42.8) | -43 |
| ln(dp or numeric) | (так же, как вход) | натуральный логарифм | ln(2.0) | 0.693147180559945 |
| log(dp or numeric) | (так же, как вход) | основание 10 логарифм | log(100.0) | 2 |
| log10(dp or numeric) | (так же, как вход) | основание 10 логарифм | log10(100.0) | 2 |
| log(b numeric, x numeric) | numeric | логарифм по основанию b | log(2.0, 64.0) | 6.0000000000 |
| mod(y, x) | (так же, как типы аргументов) | остаток от y / x | mod(9,4) | 1 |
| pi() | dp | Константа π | pi() | 3.14159265358979 |
| power(a dp, b dp) | dp | возведенный в степень b | power(9.0, 3.0) | 729 |
| power(a numeric, b numeric) | numeric | возведенный в степень b | power(9.0, 3.0) | 729 |
| radians(dp) | dp | градусы в радианы | radians(45.0) | 0.785398163397448 |
| round(dp or numeric) | (так же, как вход) | округлить до ближайшего целого | round(42.4) | 42 |
| round(v numeric, s int) | numeric | округлить до десятичных знаков | round(42.4382, 2) | 42.44 |
| scale(numeric) | integer | масштаб аргумента (количество десятичных цифр в дробной части) | scale(8.41) | 2 |
| sign(dp or numeric) | (так же, как вход) | знак аргумента (-1, 0, +1) | sign(-8.4) | -1 |
| sqrt(dp or numeric) | (так же, как вход) | квадратный корень | sqrt(2.0) | 1.4142135623731 |
| trunc(dp or numeric) | (так же, как вход) | усечь до нуля | trunc(42.8) | 42 |
| trunc(v numeric, s int) | numeric | усечь до десятичных знаков | trunc(42.4382, 2) | 42.43 |
| width_bucket(operand dp, b1 dp, b2 dp, count int) | int | вернуть номер сегмента, которому будет назначен operand в гистограмме, имеющей count сегментов равной ширины, охватывающих диапазон от b1 до b2 ; возвращает 0 или count +1 для входа вне диапазона | width_bucket(5.35, 0.024, 10.06, 5) | 3 |
| width_bucket(operand numeric, b1 numeric, b2 numeric, count int) | int | вернуть номер сегмента, которому будет назначен operand в гистограмме, имеющей count сегментов равной ширины, охватывающих диапазон от b1 до b2 ; возвращает 0 или count +1 для входа вне диапазона | width_bucket(5.35, 0.024, 10.06, 5) | 3 |
| width_bucket(operand anyelement, thresholds anyarray) | int | вернуть номер сегмента, которому будет назначен operand, с помощью массива, в котором перечислены нижние границы сегментов; возвращает 0 для входа меньше первой нижней границы; массив thresholds должен быть отсортирован, сначала наименьший, иначе будут получены неожиданные результаты | width_bucket(now(), array[’yesterday’, ’today’, ’tomorrow’]::timestamptz[]) | 2 |
В таблице 6 показаны функции для генерации случайных чисел.
| Функция | Тип ответа | Описание |
|---|---|---|
| random() | dp | случайное значение в диапазоне 0,0 <= x <1,0 |
| setseed(dp) | void | установить начальное значение для последующих вызовов random() (значение от -1,0 до 1,0 включительно) |
Функция random() использует простой линейный конгруэнтный алгоритм. Это быстро, но не подходит для криптографических приложений; см. модуль qhbcrypto для более безопасной альтернативы. Если вызывается setseed(), то результаты последующих вызовов random() в текущем сеансе повторяются путем повторной выдачи setseed() с тем же аргументом.
В таблице 7 показаны доступные тригонометрические функции. Все эти функции принимают аргументы и возвращают значения типа double precision. Каждая из тригонометрических функций представлена в двух вариантах: один измеряет углы в радианах, а другой - углы в градусах.
Таблица 7. Тригонометрические функции
| Функция (радианы) | Функция (градусы) | Описание |
|---|---|---|
| acos(x) | acosd(x) | обратный косинус |
| asin(x) | asind(x) | обратный синус |
| atan(x) | atand(x) | обратный тангенс |
| atan2(y, x) | atan2d(y, x) | обратный тангенс y / x |
| cos(x) | cosd(x) | косинус |
| cot(x) | cotd(x) | котангенс |
| sin(x) | sind(x) | синус |
| tan(x) | tand(x) | тангенс |
Заметка
Другой способ работы с углами, измеряемыми в градусах, состоит в использовании функций преобразования единиц измеренияradians()иdegrees()показанных ранее. Однако использование тригонометрических функций, основанных на градусах, является предпочтительным, поскольку этот способ позволяет избежать ошибки округления в особых случаях, таких какsind(30).
Таблица 8 показывает доступные гиперболические функции. Все эти функции принимают аргументы и возвращают значения типа double precision.
Таблица 8. Гиперболические функции
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| sinh(x) | гиперболический синус | sinh(0) | 0 |
| cosh(x) | гиперболический косинус | cosh(0) | 1 |
| tanh(x) | тангенс гиперболический | tanh(0) | 0 |
| asinh(x) | обратный гиперболический синус | asinh(0) | 0 |
| acosh(x) | обратный гиперболический косинус | acosh(1) | 0 |
| atanh(x) | обратный гиперболический тангенс | atanh(0) | 0 |
Строковые функции и операторы
В этом разделе описываются функции и операторы для проверки и манипулирования строковыми значениями. Строки в этом контексте включают значения типов character, character varying и text. Если не указано иное, все перечисленные ниже функции работают со всеми этими типами, но с осторожностью относитесь к возможным эффектам автоматического заполнения пробелами при использовании типа character. Некоторые функции также существуют изначально для типов битовых строк.
SQL определяет некоторые строковые функции, которые используют ключевые слова, а не запятые, для разделения аргументов. Подробности приведены в таблице 9. QHB также предоставляет версии этих функций, которые используют обычный синтаксис вызова функций (см. Таблицу 10).
Таблица 9. Строковые функции и операторы SQL
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| string | | string | text | Конкатенация строк | ’Post’ | | ’greSQL’ | PostgreSQL |
| string | | non-string или non-string | | string | text | Конкатенация строк с одним нестроковым вводом | ’Value: ’ | | 42 | Value: 42 |
| bit_length(string) | int | Количество бит в строке | bit_length(’jose’) | 32 |
| char_length(string) или character_length(string) | int | Количество символов в строке | char_length(’jose’) | 4 |
| lower(string) | text | Преобразовать строку в нижний регистр | lower(’TOM’) | tom |
| octet_length(string) | int | Количество байтов в строке | octet_length(’jose’) | 4 |
| overlay(string placing string from int [ for int ]) | text | Заменить подстроку | overlay(’Txxxxas’ placing ’hom’ from 2 for 4) | Thomas |
| position(substring in string) | int | Расположение указанной подстроки | position(’om’ in ’Thomas’) | 3 |
| substring(string [ from int ] [ for int ]) | text | Извлечь подстроку | substring(’Thomas’ from 2 for 3) | hom |
| substring(string from pattern) | text | Извлечь подстроку, соответствующую регулярному выражению POSIX. См. раздел Сопоставление с образцом для получения дополнительной информации о сопоставлении с образцом. | substring('Thomas' from '...$') | mas |
| substring(string from pattern for escape) | text | Извлечь подстроку, соответствующую регулярному выражению SQL. См. раздел Сопоставление с образцом для получения дополнительной информации о сопоставлении с образцом. | substring('Thomas' from '%#"o_a#"_' for '#') | oma |
| trim([ leading | trailing | both ] [ characters ] from string) | text | Удалите самую длинную строку, содержащую только символы из characters (по умолчанию пробел) из начала, конца или обоих концов (both по умолчанию) строки | trim(both ’xyz’ from ’yxTomxx’) | Tom |
| trim([ leading | trailing | both ] [ from ] string [, characters ]) | text | Нестандартный синтаксис для trim() | trim(both from ’yxTomxx’, ’xyz’) | Tom |
| upper(string) | text | Преобразовать строку в верхний регистр | upper(’tom’) | TOM |
Доступны дополнительные функции работы со строками, которые перечислены в таблице 10. Некоторые из них используются для реализации стандартных строковых функций SQL, перечисленных в таблице 9.
Таблица 10. Другие строковые функции
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
ascii(string) | int | Код ASCII первого символа аргумента. Для UTF8 возвращает кодовую точку Unicode символа. Для других многобайтовых кодировок аргумент должен быть символом ASCII. | ascii(’x’) | 120 |
btrim(string text [, characters text ]) | text | Удалите самую длинную строку, состоящую только из символов в characters (по умолчанию пробел) из начала и конца string | cbtrim(’xyxtrimyyx’, ’xyz’) | trim |
chr(int) | text | Символ с заданным кодом. Для UTF8 аргумент обрабатывается как кодовая точка Unicode. Для других многобайтовых кодировок аргумент должен обозначать символ ASCII. Символ NULL (0) недопустим, поскольку текстовые типы данных не могут хранить такие байты. | chr(65) | A |
concat(str "any" [, str "any" [, ...] ]) | text | Объединить текстовые представления всех аргументов. NULL аргументы игнорируются. | concat(’abcde’, 2, NULL, 22) | abcde222 |
concat_ws(sep text, str "any" [, str "any" [, ...] ]) | text | Объедините все, кроме первого аргумента, с разделителями. Первый аргумент используется в качестве строки разделителя. NULL аргументы игнорируются. | concat_ws(’,’, ’abcde’, 2, NULL, 22) | abcde,2,22 |
convert(string bytea, src_encoding name, dest_encoding name) | bytea | Преобразовать строку в dest_encoding. Исходная кодировка указывается с помощью src_encoding. string должна быть действительной в этой кодировке. Конверсии могут быть определены с помощью CREATE CONVERSION. Также есть несколько предопределенных конверсий. Смотрите Таблицу 8.11 для доступных преобразований. | convert (’text_in_utf8’, ’UTF8’, ’LATIN1’) | text_in_utf8 представлен в кодировке Latin-1 (ISO 8859-1) |
convert_from(string bytea, src_encoding name) | text | Преобразовать строку в кодировку базы данных. Исходная кодировка указывается с помощью src_encoding. string должна быть действительной в этой кодировке. | convert_from (’text_in_utf8’, ’UTF8’) | text_in_utf8 представлен в текущей кодировке базы данных |
convert_to(string text, dest_encoding name) | bytea | Преобразовать строку в dest_encoding. | convert_to (’some text’, ’UTF8’) | some text представленный в кодировке UTF8 |
decode(string text, format text) | bytea | Декодировать двоичные данные из текстового представления в string. Параметры для format такие же, как в encode. | decode (’MTIzAAE=’, ’base64’) | \x3132330001 |
encode(data bytea, format text) | text | Кодировать двоичные данные в текстовое представление. Поддерживаемые форматы: base64, hex, escape. escape преобразует нулевые байты и старшие биты в восьмеричные последовательности (\ nnn) и удваивает обратную косую черту. | encode (’123\000\001’, ’base64’) | MTIzAAE= |
format (formatstr text [, formatarg "any" [, ...] ]) | text | Отформатируйте аргументы в соответствии со строкой формата. Эта функция похожа на функцию C sprintf. См. раздел FORMAT. | format (’Hello %s, %1$s’, ’World’) | Hello World, World |
initcap(string) | text | Преобразуйте первую букву каждого слова в верхний регистр, а остальные в нижний регистр. Слова — это последовательности буквенно-цифровых символов, разделенных не буквенно-цифровыми символами. | initcap (’hi THOMAS’) | Hi Thomas |
left(str text, n int) | text | Вернуть первые n символов в строке. Когда n отрицательно, вернуть все, кроме последних | n | символов. | left(’abcde’, 2) | ab |
length(string) | int | Количество символов в string | length(’jose’) | 4 |
length(string bytea, encoding name) | int | Количество символов в строке в заданной кодировке. Строка должна быть действительной в этой кодировке. | length(’jose’, ’UTF8’) | 4 |
lpad(string text, length int [, fill text ]) | text | Заполнить строку до указанной длины, указанными символами fill (по умолчанию пробел). Если строка уже длиннее length она усекается (справа). | lpad(’hi’, 5, ’xy’) | xyxhi |
ltrim(string text [, characters text ]) | text | Удалить из начала строки, наибольшую подстроку, содержащую символы указанные в characters (по умолчанию пробел) | ltrim(’zzzytest’, ’xyz’) | test |
md5(string) | text | Вычисляет MD5-хеш строки, возвращая результат в шестнадцатеричном виде | md5(’abc’) | 900150983cd24fb0 d6963f7d28e17f72 |
parse_ident(qualified_identifier text [, strictmode boolean DEFAULT true ]) | text[] | Разбить qualified_identifier на массив идентификаторов, удаляя кавычки вокруг идентификаторов. По умолчанию дополнительные символы после последнего идентификатора считаются ошибкой, но если второй параметр имеет значение false, такие символы игнорируются. (Такое поведение полезно для анализа имён таких объектов как функции). Учтите, что эта функция не усекает длинные идентификаторы. Если вам нужны усеченные имена, вы можете привести результат к name[]. | parse_ident (’"SomeSchema".someTable’) | {SomeSchema,sometable} |
pg_client_encoding() | name | Текущее имя кодировки клиента | pg_client_encoding() | SQL_ASCII |
quote_ident(string text) | text | Вернуть указанную строку, заключенную в кавычки, для использования в качестве идентификатора в строке оператора SQL. Кавычки добавляются только в случае необходимости (т.е. если строка содержит неидентифицирующие символы или будет сложена регистром). Встроенные цитаты правильно удвоены. Смотрите также пример - Цитирование значений в динамических запросах. | quote_ident(’Foo bar’) | "Foo bar" |
quote_literal(string text) | text | Вернуть указанную строку, заключенную в кавычки, для использования в качестве строкового литерала в строке оператора SQL. Встроенные одинарные кавычки и обратные слэши корректно удваиваются. Обратите внимание, что quote_literal возвращает null при null входе; если аргумент может быть null, quote_nullable часто более подходит. Смотрите также пример - Цитирование значений в динамических запросах. | quote_literal(E’O\’Reilly’) | ’O”Reilly’ |
quote_literal(value anyelement) | text | Приведите указанное значение к тексту и затем процитируйте его как литерал. Встроенные одинарные кавычки и обратные слэши корректно удваиваются. | quote_literal(42.5) | ’42.5’ |
quote_nullable(string text) | text | Возврат заданной строки, заключенной в кавычки, для использования в качестве строкового литерала в строке оператора SQL; или, если аргумент null, вернуть NULL. Встроенные одинарные кавычки и обратные слэши корректно удваиваются. Смотрите также пример - Цитирование значений в динамических запросах. | quote_nullable(NULL) | NULL |
quote_nullable(value anyelement) | text | Приведите данное значение к тексту и затем процитируйте его как литерал; или, если аргумент null, вернуть NULL. Встроенные одинарные кавычки и обратные слэши корректно удваиваются. | quote_nullable(42.5) | ’42.5’ |
regexp_match(string text, pattern text [, flags text ]) | text[] | Вернуть захваченные подстроки, полученные в результате первого совпадения регулярного выражения POSIX со string. См. раздел Регулярные выражения POSIX для получения дополнительной информации. | regexp_match(’foobarbequebaz’, ’(bar)(beque)’) | {bar,beque} |
regexp_matches(string text, pattern text [, flags text ]) | setof text[] | Вернуть захваченные подстроки, полученные в результате сопоставления регулярного выражения POSIX со строкой. См. раздел Регулярные выражения POSIX для получения дополнительной информации. | regexp_matches(’foobarbequebaz’, ’ba.’, ’g’) | {bar} {baz} (2 rows) |
regexp_replace(string text, pattern text, replacement text [, flags text ]) | text | Заменить подстроку(и), соответствующие регулярному выражению POSIX. См. раздел Регулярные выражения POSIX для получения дополнительной информации. | regexp_replace(’Thomas’, ’.[mN]a.’, ’M’) | ThM |
regexp_split_to_array(string text, pattern text [, flags text ]) | text[] | Разделить строку используя регулярное выражение POSIX в качестве разделителя. См. раздел Регулярные выражения POSIX для получения дополнительной информации. | regexp_split_to_array(’hello world’, ’\s+’) | {hello,world} |
regexp_split_to_table(string text, pattern text [, flags text ]) | setof text | Разделить строку используя регулярное выражение POSIX в качестве разделителя. См. раздел Регулярные выражения POSIX для получения дополнительной информации. | regexp_split_to_table(’hello world’, ’\s+’) | hello world (2 rows) |
repeat(string text, number int) | text | Повторите строку указанное число раз | repeat(’Pg’, 4) | PgPgPgPg |
replace(string text, from text, to text) | text | Заменить все вхождения в строку подстроки from на подстроку to | replace(’abcdefabcdef’, ’cd’, ’XX’) | abXXefabXXef |
reverse(str) | text | Вернуть обратную строку. | reverse(’abcde’) | edcba |
right(str text, n int) | text | Вернуть последние n символов в строке. Когда n отрицательно, вернуть все, кроме первых | n | символов. | right(’abcde’, 2) | de |
rpad(string text, length int [, fill text ]) | text | Заполнить строку до длины, добавив символы fill (пробел по умолчанию). Если строка уже длиннее length она усекается. | rpad(’hi’, 5, ’xy’) | hixyx |
rtrim(string text [, characters text ]) | text | Удалить из конца строки, наибольшую подстроку, содержащую символы указанные в characters (по умолчанию пробел) | rtrim(’testxxzx’, ’xyz’) | test |
split_part(string text, delimiter text, field int) | text | Разбить строку на разделителем delimiter и вернуть заданное поле (считая от единицы) | split_part(’abc~@~def~@~ghi’, ’~@~’, 2) | def |
strpos(string, substring) | int | Расположение указанной подстроки (аналогично position(substring in string), но обратите внимание на обратный порядок аргументов) | strpos(’high’, ’ig’) | 2 |
substr(string, from [, count ]) | text | Извлечь подстроку (так же, как substring(string from from for count)) | substr(’alphabet’, 3, 2) | ph |
starts_with(string, prefix) | bool | Возвращает true, если строка начинается с prefix. | starts_with(’alphabet’, ’alph’) | t |
to_ascii(string text [, encoding text ]) | text | Преобразовать строку в ASCII из другой кодировки (поддерживает только преобразование из LATIN1, LATIN2, LATIN9 и WIN1250) | to_ascii(’Karel’) | Karel |
to_hex(number int or bigint) | text | Преобразовать число в его эквивалентное шестнадцатеричное представление | to_hex(2147483647) | 7fffffff |
translate(string text, from text, to text) | text | Любой символ в строке который соответствует символу из набора from заменяется соответствующим символом в наборе. Если значений from больше, чем to, вхождения дополнительных символов в from удаляются. | translate(’12345’, ’143’, ’ax’) | a2x5 |
Функции concat, concat_ws и format являются переменными, поэтому можно передавать значения для объединения или форматирования в виде массива, помеченного ключевым словом VARIADIC (см. раздел Функции SQL с переменным числом аргументов). Элементы массива обрабатываются так, как если бы они были отдельными обычными аргументами функции. Если аргумент массива variadic имеет значение NULL, concat и concat_ws возвращают NULL, но format рассматривает NULL как массив с нулевым элементом.
Смотрите также string_agg функцию string_agg в разделе Агрегатные функции.
Таблица 11. Встроенные преобразования
| Имя конверсии1 | Кодировка источника | Кодировка назначения |
|---|---|---|
| ascii_to_mic | SQL_ASCII | MULE_INTERNAL |
| ascii_to_utf8 | SQL_ASCII | UTF8 |
| big5_to_euc_tw | BIG5 | EUC_TW |
| big5_to_mic | BIG5 | MULE_INTERNAL |
| big5_to_utf8 | BIG5 | UTF8 |
| euc_cn_to_mic | EUC_CN | MULE_INTERNAL |
| euc_cn_to_utf8 | EUC_CN | UTF8 |
| euc_jp_to_mic | EUC_JP | MULE_INTERNAL |
| euc_jp_to_sjis | EUC_JP | SJIS |
| euc_jp_to_utf8 | EUC_JP | UTF8 |
| euc_kr_to_mic | EUC_KR | MULE_INTERNAL |
| euc_kr_to_utf8 | EUC_KR | UTF8 |
| euc_tw_to_big5 | EUC_TW | BIG5 |
| euc_tw_to_mic | EUC_TW | MULE_INTERNAL |
| euc_tw_to_utf8 | EUC_TW | UTF8 |
| gb18030_to_utf8 | GB18030 | UTF8 |
| gbk_to_utf8 | GBK | UTF8 |
| iso_8859_10_to_utf8 | LATIN6 | UTF8 |
| iso_8859_13_to_utf8 | LATIN7 | UTF8 |
| iso_8859_14_to_utf8 | LATIN8 | UTF8 |
| iso_8859_15_to_utf8 | LATIN9 | UTF8 |
| iso_8859_16_to_utf8 | LATIN10 | UTF8 |
| iso_8859_1_to_mic | LATIN1 | MULE_INTERNAL |
| iso_8859_1_to_utf8 | LATIN1 | UTF8 |
| iso_8859_2_to_mic | LATIN2 | MULE_INTERNAL |
| iso_8859_2_to_utf8 | LATIN2 | UTF8 |
| iso_8859_2_to_windows_1250 | LATIN2 | WIN1250 |
| iso_8859_3_to_mic | LATIN3 | MULE_INTERNAL |
| iso_8859_3_to_utf8 | LATIN3 | UTF8 |
| iso_8859_4_to_mic | LATIN4 | MULE_INTERNAL |
| iso_8859_4_to_utf8 | LATIN4 | UTF8 |
| iso_8859_5_to_koi8_r | ISO_8859_5 | KOI8R |
| iso_8859_5_to_mic | ISO_8859_5 | MULE_INTERNAL |
| iso_8859_5_to_utf8 | ISO_8859_5 | UTF8 |
| iso_8859_5_to_windows_1251 | ISO_8859_5 | WIN1251 |
| iso_8859_5_to_windows_866 | ISO_8859_5 | WIN866 |
| iso_8859_6_to_utf8 | ISO_8859_6 | UTF8 |
| iso_8859_7_to_utf8 | ISO_8859_7 | UTF8 |
| iso_8859_8_to_utf8 | ISO_8859_8 | UTF8 |
| iso_8859_9_to_utf8 | LATIN5 | UTF8 |
| johab_to_utf8 | JOHAB | UTF8 |
| koi8_r_to_iso_8859_5 | KOI8R | ISO_8859_5 |
| koi8_r_to_mic | KOI8R | MULE_INTERNAL |
| koi8_r_to_utf8 | KOI8R | UTF8 |
| koi8_r_to_windows_1251 | KOI8R | WIN1251 |
| koi8_r_to_windows_866 | KOI8R | WIN866 |
| koi8_u_to_utf8 | KOI8U | UTF8 |
| mic_to_ascii | MULE_INTERNAL | SQL_ASCII |
| mic_to_big5 | MULE_INTERNAL | BIG5 |
| mic_to_euc_cn | MULE_INTERNAL | EUC_CN |
| mic_to_euc_jp | MULE_INTERNAL | EUC_JP |
| mic_to_euc_kr | MULE_INTERNAL | EUC_KR |
| mic_to_euc_tw | MULE_INTERNAL | EUC_TW |
| mic_to_iso_8859_1 | MULE_INTERNAL | LATIN1 |
| mic_to_iso_8859_2 | MULE_INTERNAL | LATIN2 |
| mic_to_iso_8859_3 | MULE_INTERNAL | LATIN3 |
| mic_to_iso_8859_4 | MULE_INTERNAL | LATIN4 |
| mic_to_iso_8859_5 | MULE_INTERNAL | ISO_8859_5 |
| mic_to_koi8_r | MULE_INTERNAL | KOI8R |
| mic_to_sjis | MULE_INTERNAL | SJIS |
| mic_to_windows_1250 | MULE_INTERNAL | WIN1250 |
| mic_to_windows_1251 | MULE_INTERNAL | WIN1251 |
| mic_to_windows_866 | MULE_INTERNAL | WIN866 |
| sjis_to_euc_jp | SJIS | EUC_JP |
| sjis_to_mic | SJIS | MULE_INTERNAL |
| sjis_to_utf8 | SJIS | UTF8 |
| windows_1258_to_utf8 | WIN1258 | UTF8 |
| uhc_to_utf8 | UHC | UTF8 |
| utf8_to_ascii | UTF8 | SQL_ASCII |
| utf8_to_big5 | UTF8 | BIG5 |
| utf8_to_euc_cn | UTF8 | EUC_CN |
| utf8_to_euc_jp | UTF8 | EUC_JP |
| utf8_to_euc_kr | UTF8 | EUC_KR |
| utf8_to_euc_tw | UTF8 | EUC_TW |
| utf8_to_gb18030 | UTF8 | GB18030 |
| utf8_to_gbk | UTF8 | GBK |
| utf8_to_iso_8859_1 | UTF8 | LATIN1 |
| utf8_to_iso_8859_10 | UTF8 | LATIN6 |
| utf8_to_iso_8859_13 | UTF8 | LATIN7 |
| utf8_to_iso_8859_14 | UTF8 | LATIN8 |
| utf8_to_iso_8859_15 | UTF8 | LATIN9 |
| utf8_to_iso_8859_16 | UTF8 | LATIN10 |
| utf8_to_iso_8859_2 | UTF8 | LATIN2 |
| utf8_to_iso_8859_3 | UTF8 | LATIN3 |
| utf8_to_iso_8859_4 | UTF8 | LATIN4 |
| utf8_to_iso_8859_5 | UTF8 | ISO_8859_5 |
| utf8_to_iso_8859_6 | UTF8 | ISO_8859_6 |
| utf8_to_iso_8859_7 | UTF8 | ISO_8859_7 |
| utf8_to_iso_8859_8 | UTF8 | ISO_8859_8 |
| utf8_to_iso_8859_9 | UTF8 | LATIN5 |
| utf8_to_johab | UTF8 | JOHAB |
| utf8_to_koi8_r | UTF8 | KOI8R |
| utf8_to_koi8_u | UTF8 | KOI8U |
| utf8_to_sjis | UTF8 | SJIS |
| utf8_to_windows_1258 | UTF8 | WIN1258 |
| utf8_to_uhc | UTF8 | UHC |
| utf8_to_windows_1250 | UTF8 | WIN1250 |
| utf8_to_windows_1251 | UTF8 | WIN1251 |
| utf8_to_windows_1252 | UTF8 | WIN1252 |
| utf8_to_windows_1253 | UTF8 | WIN1253 |
| utf8_to_windows_1254 | UTF8 | WIN1254 |
| utf8_to_windows_1255 | UTF8 | WIN1255 |
| utf8_to_windows_1256 | UTF8 | WIN1256 |
| utf8_to_windows_1257 | UTF8 | WIN1257 |
| utf8_to_windows_866 | UTF8 | WIN866 |
| utf8_to_windows_874 | UTF8 | WIN874 |
| windows_1250_to_iso_8859_2 | WIN1250 | LATIN2 |
| windows_1250_to_mic | WIN1250 | MULE_INTERNAL |
| windows_1250_to_utf8 | WIN1250 | UTF8 |
| windows_1251_to_iso_8859_5 | WIN1251 | ISO_8859_5 |
| windows_1251_to_koi8_r | WIN1251 | KOI8R |
| windows_1251_to_mic | WIN1251 | MULE_INTERNAL |
| windows_1251_to_utf8 | WIN1251 | UTF8 |
| windows_1251_to_windows_866 | WIN1251 | WIN866 |
| windows_1252_to_utf8 | WIN1252 | UTF8 |
| windows_1256_to_utf8 | WIN1256 | UTF8 |
| windows_866_to_iso_8859_5 | WIN866 | ISO_8859_5 |
| windows_866_to_koi8_r | WIN866 | KOI8R |
| windows_866_to_mic | WIN866 | MULE_INTERNAL |
| windows_866_to_utf8 | WIN866 | UTF8 |
| windows_866_to_windows_1251 | WIN866 | WIN |
| windows_874_to_utf8 | WIN874 | UTF8 |
| euc_jis_2004_to_utf8 | EUC_JIS_2004 | UTF8 |
| utf8_to_euc_jis_2004 | UTF8 | EUC_JIS_2004 |
| shift_jis_2004_to_utf8 | SHIFT_JIS_2004 | UTF8 |
| utf8_to_shift_jis_2004 | UTF8 | SHIFT_JIS_2004 |
| euc_jis_2004_to_shift_jis_2004 | EUC_JIS_2004 | SHIFT_JIS_2004 |
| shift_jis_2004_to_euc_jis_2004 | SHIFT_JIS_2004 | EUC_JIS_2004 |
FORMAT
Функция FORMAT создает выходные данные, отформатированные в соответствии со строкой формата, в стиле, аналогичном функции C sprintf.
format(formatstr text [, formatarg "any" [, ...] ])
formatstr - строка формата, которая определяет, как результат должен быть отформатирован. Текст в строке формата копируется непосредственно в результат, кроме случаев, когда используются спецификаторы формата. Спецификаторы формата действуют как заполнители в строке, определяя, как последующие аргументы функции должны быть отформатированы и вставлены в результат. Каждый аргумент formatarg преобразуется в текст в соответствии с обычными правилами вывода для его типа данных, а затем форматируется и вставляется в результирующую строку в соответствии со спецификаторами формата.
Спецификаторы формата вводятся символом % и имеют форму
%[position][flags][width]type
где поля компонента:
В дополнение к описателям формата, описанным выше, специальная
последовательность %% может использоваться для вывода буквального
символа %.
Вот несколько примеров преобразования основных форматов:
SELECT format('Hello% s', 'World');
Result: Hello World
SELECT format('Testing %s, %s, %s, %%', 'one', 'two', 'three');
Result: Testing one, two, three, %
SELECT format('INSERT INTO %I VALUES(%L)', 'Foo bar', E'O\'Reilly');
Result: INSERT INTO "Foo bar" VALUES('O''Reilly')
SELECT format('INSERT INTO %I VALUES(%L)', 'locations', 'C:\Program Files');
Result: INSERT INTO locations VALUES('C:\Program Files')
Вот примеры использования полей width и флага -:
SELECT format('|%10s|', 'foo');
Result: | foo|
SELECT format('|%-10s|', 'foo');
Result: |foo |
SELECT format('|%*s|', 10, 'foo');
Result: | foo|
SELECT format('|%*s|', -10, 'foo');
Result: |foo |
SELECT format('|%-*s|', 10, 'foo');
Result: |foo |
SELECT format('|%-*s|', -10, 'foo');
Result: |foo |
Эти примеры показывают использование полей position:
SELECT format('Testing %3$s, %2$s, %1$s', 'one', 'two', 'three');
Result: Testing three, two, one
SELECT format('|%*2$s|', 'foo', 10, 'bar');
Result: | bar|
SELECT format('|%1$*2$s|', 'foo', 10, 'bar');
Result: | foo|
В отличие от стандартной функции C sprintf, функция форматирования QHB позволяет смешивать спецификаторы формата с полями position и без них в одной строке формата. Спецификатор формата без поля position всегда использует следующий аргумент после последнего использованного аргумента. Кроме того, функция format не требует использования всех аргументов функции в строке формата. Например:
SELECT format('Testing %3$s, %2$s, %s', 'one', 'two', 'three');
Result: Testing three, two, three
Спецификаторы формата %I и %L особенно полезны для безопасного
построения динамических операторов SQL. См. Пример 42.1.
Двоичные строковые функции и операторы
В этом разделе описываются функции и операторы для изучения и манипулирования значениями типа bytea.
SQL определяет некоторые строковые функции, которые используют ключевые слова, а не запятые, для разделения аргументов. Подробности приведены в таблице 12. QHB также предоставляет версии этих функций, которые используют обычный синтаксис вызова функций (см. Таблицу 8.13).
Заметка
В примере результатов, показанных на этой странице, предполагается, что параметр сервераbytea_outputустановлен наescape(традиционный формат QHB).
Таблица 12. Двоичные строковые функции и операторы SQL
| Функция | Тип ответа | Описание | пример | Результат |
|---|---|---|---|---|
| string | | string | bytea | Конкатенация строк | ’\\Post’::bytea | | ’\047gres\000’::bytea | \\Post’gres\000 |
| octet_length(string) | int | Количество байтов в двоичной строке | octet_length(’jo\000se’::bytea) | 5 |
| overlay(string placing string from int [ for int ]) | bytea | Заменить подстроку | overlay(’Th\000omas’::bytea placing ’\002\003’::bytea from 2 for 3) | T\\002\\003mas |
| position(substring in string) | int | Расположение указанной подстроки | position(’\000om’::bytea in ’Th\000omas’::bytea) | 3 |
| substring(string [ from int ] [ for int ]) | bytea | Извлечь подстроку | substring(’Th\000omas’::bytea from 2 for 3) | h\000o |
| trim([ both ] bytes from string) | bytea | Удалить самую длинную строку, содержащую только байты, появляющиеся в bytes из начала и конца строки | trim(’\000\001’::bytea from ’\000Tom\001’::bytea) | Tom |
Доступны дополнительные функции манипуляции с двоичными строками, которые перечислены в таблице 13. Некоторые из них используются для реализации стандартных строковых функций SQL, перечисленных в таблице 8.12.
Таблица 13. Другие бинарные строковые функции
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
btrim(string bytea, bytes bytea) | bytea | Удалить самую длинную строку, содержащую только байты, появляющиеся в bytes из начала и конца string | btrim(’\\000trim\\001’::bytea, ’\\000\\001’::bytea) | trim |
decode(string text, format text) | bytea | Декодировать двоичные данные из текстового представления в string. Параметры для format такие же, как в encode. | decode(’123\\000456’, ’escape’) | 123\\000456 |
encode(data bytea, format text) | text | Кодировать двоичные данные в текстовое представление. Поддерживаемые форматы: base64, hex, escape. escape преобразует нулевые байты и старшие биты в восьмеричные последовательности (\ nnn) и удваивает обратную косую черту. | encode(’123\\000456’::bytea, ’escape’) | 123\\000456 |
get_bit(string, offset) | int | Извлечь бит из строки | get_bit(’Th\\000omas’::bytea, 45) | 1 |
get_byte(string, offset) | int | Извлечь байт из строки | get_byte(’Th\\000omas’::bytea, 4) | 109 |
length(string) | int | Длина двоичной строки | length(’jo\\000se’::bytea) | 5 |
md5(string) | text | Вычисляет хеш string MD5, возвращая результат в шестнадцатеричном виде | md5(’Th\\000omas’::bytea) | 8ab2d3c9689aaf18b4958c334c82d8b1 |
set_bit(string, offset, newvalue) | bytea | Установить бит в строке | set_bit(’Th\\000omas’::bytea, 45, 0) | Th\\000omAs |
| ```set_byte(string, offset, newvalue) | bytea``` | Установить байт в строке | set_byte(’Th\\000omas’::bytea, 4, 64) | Th\\000o@as |
sha224(bytea) | bytea | SHA-224 хеш | sha224(’abc’) | \\x23097d223405d8228642a477bda255b32aadbce4bda0b3f7e36c9da7 |
sha256(bytea) | bytea | SHA-256 хеш | sha256(’abc’) | \\xba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad |
sha384(bytea) | bytea | SHA-384 хеш | sha384(’abc’) | \\xcb00753f45a35e8bb5a03d699ac65007272c32ab0eded1631a8b605a43ff5bed8086072ba1e7cc2358baeca134c825a7 |
sha512(bytea) | bytea | SHA-512 хеш | sha512(’abc’) | \\xddaf35a193617abacc417349ae20413112e6fa4e89a97ea20a9eeee64b55d39a2192992a274fc1a836ba3c23a3feebbd454d4423643ce80e2a9ac94fa54ca49f |
get_byte и set_byte нумеруют первый байт двоичной строки как байт 0. get_bit и set_bit нумеруют биты справа внутри каждого байта; например, бит 0 является младшим битом первого байта, а бит 15 является старшим битом второго байта.
Обратите внимание, что по историческим причинам функция md5 возвращает
шестнадцатеричное значение типа text тогда как функции SHA-2 возвращают
тип bytea. Используйте функции encode и decode для преобразования между
ними, например, encode(sha256(’abc’), ’hex’) чтобы получить
шестнадцатеричное текстовое представление.
См. Также агрегатную функцию string_agg в разделе Агрегатные функции и функции больших объектов в разделе Серверные функции.
Функции и операторы битовых строк
В этом разделе описываются функции и операторы для проверки и обработки
битовых строк, то есть значений типов bit и bit varying. Помимо обычных
операторов сравнения можно использовать операторы, показанные в таблице
8.14. Битовые операнды &, и # должны быть одинаковой длины. При сдвиге
битов первоначальная длина строки сохраняется, как показано в примерах.
Таблица 14. Операторы битовых строк
| Оператор | Описание | Пример | Результат |
|---|---|---|---|
| | | | конкатенация | B’10001’ | | B’011’ | 10001011 |
| & | побитовое И | B’10001’ & B’01101’ | 00001 |
| | | побитовое ИЛИ | B’10001’ | B’01101’ | 11101 |
| # | побитовый XOR | B’10001’ # B’01101’ | 11100 |
| ~ | побитовое НЕ | ~ B’10001’ | 01110 |
| << | битовое смещение влево | B’10001’ << 3 | 01000 |
| >> | битовое смещение вправо | B’10001’ >> 2 | 00100 |
Следующие стандартные функции SQL работают как с битовыми строками, так и с символьными строками: length, bit_length, octet_length, position, substring, overlay.
Следующие функции работают как с битовыми строками, так и с двоичными строками: get_bit, set_bit. При работе с битовой строкой эти функции нумеруют первый (самый левый) бит строки как бит 0.
Кроме того, можно приводить целочисленные значения к bit типа и из них. Несколько примеров:
44::bit(10) 0000101100
44::bit(3) 100
cast(-44 as bit(12)) 111111010100
'1110'::bit(4)::integer 14
Обратите внимание, что приведение к bit означает приведение к bit(1) и, следовательно, выдаст только младший значащий бит целого числа.
Преобразование целого числа в bit(n) копирует самые правые n битов. Преобразование целого числа в битовую строку, ширина которой шире, чем само целое число, будет расширяться знаком слева.
Сопоставление с образцом
QHB предлагает три отдельных подхода к сопоставлению с образцом: традиционный оператор SQL LIKE, более поздний оператор SIMILAR TO (добавлен в SQL: 1999) и регулярные выражения в стиле POSIX. Помимо основного «эта строка соответствует этому шаблону?» Операторы, функции доступны для извлечения или замены соответствующих подстрок и для разделения строки в соответствующих местах.
Заметка
Если у вас есть потребности в сопоставлении с образцом, которые выходят за рамки этого, подумайте о написании пользовательской функции на Perl или Tcl.
Предостережение
Хотя большинство поисков по регулярным выражениям могут выполняться очень быстро, могут быть изобретены регулярные выражения, которые занимают произвольное количество времени и памяти для обработки. Остерегайтесь принятия шаблонов поиска регулярных выражений из неблагоприятных источников. Если вы должны сделать это, желательно установить тайм-аут заявления. Поиск с использованием шаблонов SIMILAR TO имеет те же угрозы безопасности, поскольку SIMILAR TO предоставляет многие из тех же возможностей, что и регулярные выражения в стиле POSIX. Поиски типа LIKE, которые намного проще двух других вариантов, безопаснее использовать с возможно неблагоприятными источниками паттернов.
Операторы сопоставления с образцом всех трех видов не поддерживают недетерминированные сопоставления. При необходимости примените к выражению другое сопоставление, чтобы обойти это ограничение.
LIKE
string LIKE pattern [ESCAPE escape-character]
string NOT LIKE pattern [ESCAPE escape-character]
Выражение LIKE возвращает true, если string соответствует предоставленному pattern. (Как и ожидалось, выражение NOT LIKE возвращает false, если LIKE возвращает true, и наоборот. Эквивалентное выражение NOT (string LIKE pattern).)
Если pattern не содержит знаков процента или подчеркивания, то шаблон
представляет только саму строку; в этом случае LIKE действует как
оператор равенства. Подчеркивание (_) в pattern обозначает
(соответствует) любой отдельный символ; знак процента (%) соответствует
любой последовательности из нуля или более символов.
Несколько примеров:
'abc' LIKE 'abc' true
'abc' LIKE 'a%' true
'abc' LIKE '_b_' true
'abc' LIKE 'c' false
LIKE сопоставление с образцом всегда покрывает всю строку. Следовательно, если требуется сопоставить последовательность в любом месте строки, шаблон должен начинаться и заканчиваться знаком процента.
Чтобы сопоставить буквенное подчеркивание или знак процента без сопоставления с другими символами, соответствующему символу в pattern должен предшествовать escape-символ. Экранирующим символом по умолчанию является обратный слеш, но другой можно выбрать с помощью предложения ESCAPE. Чтобы соответствовать самому escape-символу, напишите два escape-символа.
Заметка
Если у вас отключеныstandard_conforming_strings, любые обратные слеши, которые вы пишете в константах литеральных строк, должны быть удвоены. См. раздел Строковые константы для получения дополнительной информации.
Также можно выбрать не escape-символ, написав ESCAPE ''. Это эффективно
отключает механизм выхода, что делает невозможным отключение
специального значения знаков подчеркивания и процентов в шаблоне.
Ключевое слово ILIKE можно использовать вместо LIKE чтобы сопоставить регистр без учета регистра в соответствии с активной локалью. Это не в стандарте SQL, но является расширением QHB.
Оператор ~~ эквивалентен LIKE, а ~~* соответствует ILIKE. Также есть
операторы !~~ и !~~* которые представляют NOT LIKE и NOT ILIKE
соответственно. Все эти операторы специфичны для QHB.
Также есть префиксный оператор ^@ и соответствующая функция starts_with
которая охватывает случаи, когда необходим только поиск по началу
строки.
Регулярные выражения SIMILAR TO
string SIMILAR TO pattern [ESCAPE escape-character]
string NOT SIMILAR TO pattern [ESCAPE escape-character]
Оператор SIMILAR TO возвращает true или false в зависимости от того, соответствует ли его шаблон заданной строке. Он похож на LIKE, за исключением того, что он интерпретирует шаблон, используя определение регулярного выражения в стандарте SQL. Регулярные выражения SQL представляют собой любопытную смесь между нотацией LIKE нотацией обычного регулярного выражения.
Как и LIKE, оператор SIMILAR TO успешно выполняется, только если его
шаблон соответствует всей строке; это не похоже на обычное поведение
регулярных выражений, когда шаблон может соответствовать любой части
строки. Также как LIKE, SIMILAR TO использует символы _ и %
качестве подстановочных символов, обозначающих любой отдельный символ и
любую строку соответственно (они сопоставимы с . и .* в регулярных
выражениях POSIX).
В дополнение к этим возможностям, заимствованным из LIKE, SIMILAR TO поддерживает метасимволы сопоставления с образцом, заимствованные из регулярных выражений POSIX:
Обратите внимание, что точка (.) Не является метасимволом для SIMILAR
TO.
Как и в случае с LIKE, обратная косая черта отключает специальное значение любого из этих метасимволов; или другой escape-символ может быть указан с помощью ESCAPE.
Несколько примеров:
'abc' SIMILAR TO 'abc' true
'abc' SIMILAR TO 'a' false
'abc' SIMILAR TO '%(b|d)%' true
'abc' SIMILAR TO '(b|c)%' false
Функция substring с тремя параметрами обеспечивает извлечение подстроки, которая соответствует шаблону регулярного выражения SQL. Функция может быть написана в соответствии с синтаксисом SQL99:
substring(string from pattern for escape-character)
или как простая функция с тремя аргументами:
substring(string, pattern, escape-character)
Как и в случае SIMILAR TO, указанный шаблон должен соответствовать всей
строке данных, иначе функция завершится ошибкой и вернет значение NULL.
Чтобы указать часть шаблона, для которой интересует соответствующая
подстрока данных, шаблон должен содержать два вхождения escape-символа,
за которым следует двойная кавычка ("). Текст, соответствующий части
шаблона между этими разделителями: возвращается после успешного
завершения сравнения.
Escape- символы двойные кавычки фактически делят шаблон substring на три
независимых регулярных выражения; например, вертикальная черта (|) в
любом из трех разделов влияет только на этот раздел. Кроме того, первое
и третье из этих регулярных выражений определяются так, чтобы они
соответствовали наименьшему возможному объему текста, а не самому
большому, когда есть некоторая неоднозначность относительно того, какая
часть строки данных соответствует какому шаблону. (На языке POSIX первое
и третье регулярные выражения должны быть не жадными).
В качестве расширения стандарта SQL QHB позволяет использовать только один escape-разделитель с двойными кавычками, и в этом случае третье регулярное выражение считается пустым; или нет разделителей, и в этом случае первое и третье регулярные выражения считаются пустыми.
Несколько примеров с #" разделяющим возвращаемую строку:
substring('foobar' from '%#"o_b#"%' for '#') oob
substring('foobar' from '#"o_b#"%' for '#') NULL
Регулярные выражения POSIX
В таблице 15 перечислены доступные операторы для сопоставления с образцом с использованием регулярных выражений POSIX.
Таблица 15. Операторы соответствия регулярного выражения
| Оператор | Описание | Пример |
|---|---|---|
| ~ | Соответствует регулярному выражению с учетом регистра | ’thomas’ ~ ’.*thomas.*’ |
| ~* | Соответствует регулярному выражению без учета регистра | ’thomas’ ~* ’.*Thomas.*’ |
| !~ | Не соответствует регулярному выражению, чувствительно к регистру | ’thomas’ !~ ’.*Thomas.*’ |
| !~* | Не соответствует регулярному выражению, без учета регистра | ’thomas’ !~* ’.*vadim.*’ |
Регулярные выражения POSIX предоставляют более мощные средства для сопоставления с образцом, чем операторы LIKE и SIMILAR TO. Многие инструменты Unix, такие как egrep, sed или awk используют язык сопоставления с шаблоном, который похож на описанный здесь.
Регулярное выражение — это последовательность символов, которая является сокращенным определением набора строк (регулярного набора). Говорят, что строка соответствует регулярному выражению, если она является членом регулярного набора, описанного регулярным выражением. Как и в LIKE, символы шаблона точно соответствуют строковым символам, если они не являются специальными символами в языке регулярных выражений, но в регулярных выражениях используются другие специальные символы, чем в LIKE. В отличие от шаблонов LIKE, регулярному выражению разрешено совпадать в любом месте строки, если только оно не привязано явно к началу или концу строки.
Несколько примеров:
'abc' ~ 'abc' true
'abc' ~ '^a' true
'abc' ~ '(b|d)' true
'abc' ~ '^(b|c)' false
Язык паттернов POSIX описан более подробно ниже.
Функция substring с двумя параметрами substring(string from pattern) обеспечивает извлечение подстроки, соответствующей шаблону регулярного выражения POSIX. Возвращает null, если совпадения нет, в противном случае та часть текста, которая соответствует шаблону. Но если шаблон содержит какие-либо круглые скобки, возвращается часть текста, которая соответствует первому подвыражению в скобках (та, чья левая скобка стоит первой). Вы можете поместить круглые скобки вокруг всего выражения, если хотите использовать внутри него круглые скобки, не вызывая этого исключения. Если вам нужны круглые скобки в шаблоне перед подвыражением, которое вы хотите извлечь, смотрите описанные ниже скобки без захвата.
Несколько примеров:
substring('foobar' from 'o.b') oob
substring('foobar' from 'o(.)b') o
Функция regexp_replace обеспечивает подстановку нового текста для
подстрок, которые соответствуют шаблонам регулярных выражений POSIX. Он
имеет синтаксис regexp_replace(source, pattern, replacement [, flags ]).
source строка возвращается без изменений, если нет совпадения
с pattern. Если есть совпадение, source строка возвращается с
replacement строкой, заменяющей соответствующую подстроку. Строка
replacement может содержать \n, где n 1 до 9, чтобы указать, что
должна быть вставлена исходная подстрока, соответствующая n-му
заключенному в скобки подвыражению шаблона, и она может содержать \&
чтобы указать, что подстрока соответствия всему шаблону должна быть
вставлена. Напишите \\ если вам нужно вставить буквальный слеш в тексте
замены. Параметр flags представляет собой необязательную текстовую
строку, содержащую ноль или более однобуквенных флагов, которые изменяют
поведение функции. Флаг i указывает совпадение без учета регистра, а
флаг g указывает замену каждой подходящей подстроки, а не только первой.
Поддерживаемые флаги (хотя и не g) описаны в таблице 23.
Несколько примеров:
regexp_replace('foobarbaz', 'b..', 'X')
fooXbaz
regexp_replace('foobarbaz', 'b..', 'X', 'g')
fooXX
regexp_replace('foobarbaz', 'b(..)', 'X\1Y', 'g')
fooXarYXazY
Функция regexp_match возвращает текстовый массив захваченных подстрок,
полученных в результате первого совпадения шаблона регулярного выражения
POSIX со строкой. Он имеет синтаксис regexp_match(string, pattern [, flags ]).
Если совпадений нет, результат равен NULL. Если совпадение
найдено, и pattern содержит вложенные выражения в скобках, то
результатом является текстовый массив из одного элемента, содержащий
подстроку, соответствующую всему шаблону. Если совпадение найдено, и
pattern содержит вложенные выражения, заключенные в скобки, то
результатом является текстовый массив, чей n-й элемент является
подстрокой, соответствующей вложенному выражению в скобках n-го pattern
(не считая «не захватывающих» скобок; см. ниже). для деталей). Параметр
flags представляет собой необязательную текстовую строку, содержащую
ноль или более однобуквенных флагов, которые изменяют поведение функции.
Поддерживаемые флаги описаны в таблице 23.
Несколько примеров:
SELECT regexp_match('foobarbequebaz', 'bar.*que');
regexp_match
--------------
{barbeque}
(1 row)
SELECT regexp_match('foobarbequebaz', '(bar)(beque)');
regexp_match
--------------
{bar,beque}
(1 row)
В общем случае, когда вы просто хотите, чтобы вся совпадающая подстрока или NULL не совпадали, напишите что-то вроде
SELECT (regexp_match('foobarbequebaz', 'bar.*que'))[1];
regexp_match
--------------
barbeque
(1 row)
Функция regexp_matches возвращает набор текстовых массивов захваченных подстрок, полученных в результате сопоставления шаблона регулярного выражения POSIX со строкой. Он имеет тот же синтаксис, что и regexp_match. Эта функция не возвращает ни одной строки, если совпадения нет, одна строка, если есть совпадение и флаг g не задан, или N строк, если есть N совпадений и задан флаг g. Каждая возвращаемая строка является текстовым массивом, содержащим всю совпавшую подстроку или подстроки, соответствующие заключенным в скобки подвыражениям pattern, как описано выше для regexp_match. regexp_matches принимает все флаги, показанные в таблице 23, плюс флаг g который выдает команду на возврат всех совпадений, а не только первого.
Несколько примеров:
SELECT regexp_matches('foo', 'not there');
regexp_matches
----------------
(0 rows)
SELECT regexp_matches('foobarbequebazilbarfbonk', '(b[^b]+)(b[^b]+)', 'g');
regexp_matches
----------------
{bar,beque}
{bazil,barf}
(2 rows)
Функция regexp_split_to_table разбивает строку, используя шаблон
регулярного выражения POSIX в качестве разделителя. Он имеет синтаксис
regexp_split_to_table(string, pattern [, flags ]). Если нет
совпадения с pattern, функция возвращает string. Если найдется хотя бы
одно совпадение, для каждого совпадения он возвращает текст с конца
последнего совпадения (или начала строки) до начала совпадения. Когда
совпадений больше нет, он возвращает текст от конца последнего
совпадения до конца строки. Параметр flags представляет собой
необязательную текстовую строку, содержащую ноль или более однобуквенных
флагов, которые изменяют поведение функции. regexp_split_to_table
поддерживает флаги, описанные в таблице 23.
Функция regexp_split_to_array ведет себя так же, как и
regexp_split_to_table, за исключением того, что
regexp_split_to_array возвращает свой результат в виде массива text.
Он имеет синтаксис regexp_split_to_array(string, pattern [, flags ]).
Параметры те же, что и для regexp_split_to_table.
Несколько примеров:
SELECT foo FROM regexp_split_to_table('the quick brown fox jumps over the lazy dog', '\s+') AS foo;
foo
-------
the
quick
brown
fox
jumps
over
the
lazy
dog
(9 rows)
SELECT regexp_split_to_array('the quick brown fox jumps over the lazy dog', '\s+');
regexp_split_to_array
-----------------------------------------------
{the,quick,brown,fox,jumps,over,the,lazy,dog}
(1 row)
SELECT foo FROM regexp_split_to_table('the quick brown fox', '\s*') AS foo;
foo
-----
t
h
e
q
u
i
c
k
b
r
o
w
n
f
o
x
(16 rows)
Как показывает последний пример, функции разбиения regexp игнорируют совпадения нулевой длины, которые происходят в начале или конце строки или сразу после предыдущего совпадения. Это противоречит строгому определению соответствия регулярному выражению, которое реализуется с помощью regexp_match и regexp_matches, но обычно является наиболее удобным поведением на практике. Другие программные системы, такие как Perl, используют аналогичные определения.
Детали регулярных выражений
Регулярные выражения QHB реализованы с использованием программного пакета, написанного Генри Спенсером. Большая часть описания регулярных выражений ниже дословно скопирована из его руководства.
Регулярные выражения (RE), как определено в POSIX 1003.2, имеют две формы: расширенные RE или ERE (примерно такие же, как у egrep) и базовые RE или BRE (примерно те, что у ed). QHB поддерживает обе формы, а также реализует некоторые расширения, которые не входят в стандарт POSIX, но стали широко использоваться благодаря их доступности в таких языках программирования, как Perl и Tcl. RE, использующие эти расширения, отличные от POSIX, в данной документации называются расширенными RE или ARE. ARE являются почти точным набором ERE, но BRE имеют несколько обозначений несовместимости (а также гораздо более ограничены). Сначала мы опишем формы ARE и ERE, отметив функции, которые применяются только к ARE, а затем опишем, как отличаются BRE.
Заметка
QHB всегда изначально предполагает, что регулярное выражение следует правилам ARE. Однако более ограниченные правила ERE или BRE можно выбрать, добавив встроенную опцию к шаблону RE, как описано в разделе Метасинтаксис регулярных выражений. Это может быть полезно для совместимости с приложениями, которые ожидают в точности правил POSIX 1003.2.
Регулярное выражение определяется как одна или несколько ветвей,
разделенных знаком |. Это соответствует всему, что соответствует одной
из ветвей.
Ветвь — это ноль или более количественных атомов или ограничений, связанных друг с другом. Соответствует совпадению для первого, за которым следует совпадение для второго и т. д.; пустая ветвь соответствует пустой строке.
Количественный атом — это атом, за которым может следовать один квантификатор. Без квантификатора он соответствует совпадению для атома. С квантификатором он может соответствовать некоторому количеству совпадений атома. Атом может быть любой из возможностей, показанных в таблице 16. Возможные квантификаторы и их значения приведены в таблице 8.17.
Ограничение соответствует пустой строке, но соответствует только при выполнении определенных условий. Ограничение может использоваться там, где может использоваться атом, за исключением того, что за ним не может следовать квантификатор. Простые ограничения показаны в таблице 18; некоторые другие ограничения описаны ниже.
Таблица 16. Атомы регулярного выражения
| Атом | Описание |
|---|---|
| (re) | (где re - любое регулярное выражение) соответствует совпадению для re, причем совпадение отмечено для возможного сообщения |
| (?: re) | как указано выше, но совпадение не отмечено для отчетности (набор «без захвата» скобок) (только ARE) |
| . | соответствует любому отдельному символу |
| [ chars ] | выражение в скобках, соответствующее любому из chars (см. раздел Выражения в скобках для более подробной информации) |
| \ k | (где k не алфавитно-цифровой символ) соответствует этому символу, взятому как обычный символ, например, \\ соответствует символу обратной косой черты |
| \ c | где c - буквенно-цифровой (возможно, за которым следуют другие символы) - escape, см. раздел Экранирование в регулярных выражениях (только ARE; в ERE и BRE это соответствует c) |
| { | когда за ним следует символ, отличный от цифры, соответствует символу левой скобки {; после цифры следует начало bound (см. ниже) |
| x | где x - это один символ без другого значения, соответствует этому символу |
RE не может заканчиваться обратной косой чертой (\).
Заметка
Если у вас отключеныstandard_conforming_strings, любые обратные слеши, которые вы пишете в константах литеральных строк, должны быть удвоены. См. раздел Строковые константы для получения дополнительной информации.
Таблица 17. Квантификаторы регулярных выражений
| Квантор | Совпадения |
|---|---|
* | последовательность из 0 или более совпадений атома |
+ | последовательность из 1 или более совпадений атома |
? | последовательность из 0 или 1 совпадений атома |
{m} | последовательность ровно m совпадений атома |
{m,} | последовательность из m или более совпадений атома |
{m,n} | последовательность от m до n (включительно) совпадений атома; m не может превышать n |
*? | не жадная версия * |
+? | не жадная версия + |
?? | не жадная версия ? |
{m}? | не жадная версия { m } |
{m,}? | не жадная версия { m,} |
{m,n}? | не жадная версия { m, n } |
Формы, использующие {...}, называются границами. Числа m и n пределах
являются десятичными целыми числами без знака с допустимыми значениями
от 0 до 255 включительно.
Нежадные квантификаторы (доступные только в ARE) соответствуют тем же возможностям, что и их соответствующие нормальные (жадные) аналоги, но предпочитают наименьшее число, а не наибольшее количество совпадений. См. раздел Правила сопоставления регулярных выражений для более подробной информации.
Квантификатор не может сразу следовать за другим квантификатором,
например, ** является недействительным. Квантор не может начинать
выражение или подвыражение или следовать за ^ или |.
Таблица 18. Ограничения регулярного выражения
| Ограничения | Описание |
|---|---|
| ^ | соответствует началу строки |
| $ | совпадения в конце строки |
| (?= re) | положительное совпадение в любой точке, где начинается повтор совпадения подстроки (только ARE) |
| (?! re) | совпадения с отрицательным прогнозом в любой точке, где не начинается повтор совпадения подстрок (только ARE) |
| (?<= re) | положительное совпадение за спиной в любой точке, где заканчивается совпадение подстроки (только ARE) |
| (?<! re) | Отрицательное совпадение за спиной в любой точке, где нет совпадений подстроки (только ARE) |
Ограничения Lookahead и Lookbehind не могут содержать обратных ссылок (см. раздел Экранирование в регулярных выражениях), и все скобки в них считаются не захватывающими.
Выражения в скобках
Выражение в скобках — это список символов, заключенных в []. Обычно он
соответствует любому отдельному символу из списка (но см. ниже). Если
список начинается с ^, он соответствует любому отдельному символу, не
относящемуся к остальной части списка. Если два символа в списке
разделены знаком -, это сокращение для полного диапазона символов между
этими двумя (включительно) в последовательности сортировки, например,
[0-9] в ASCII соответствует любой десятичной цифре. Недопустимо, чтобы
два диапазона совместно использовали конечную точку, например, a-c-e.
Диапазоны очень сильно зависят от последовательности сортировки, поэтому
переносимые программы не должны полагаться на них.
Чтобы включить литерал ] в список, сделайте его первым символом
(после ^, если он используется). Чтобы включить литерал -, сделайте
его первым или последним символом или второй конечной точкой диапазона.
Чтобы использовать литерал - в качестве первой конечной точки
диапазона, заключите его в [. и .] сделать его упорядочивающим
элементом (см. ниже). За исключением этих символов, некоторых комбинаций
с использованием [ (см. следующие абзацы) и экранировок (только для
ARE), все другие специальные символы теряют свое особое значение в
выражении в скобках. В частности, \ не является особенным, когда
следует правилам ERE или BRE, хотя он является особенным (как введение
escape) в ARE.
Внутри выражения в скобках элемент сортировки (символ, многосимвольная
последовательность, которая сопоставляется, как если бы это был один
символ, или имя последовательности сопоставления для любого из них),
заключенный в [. и .] обозначает последовательность символов этого
элемента сортировки. Последовательность рассматривается как отдельный
элемент списка выражения в скобках. Это позволяет выражению в скобках,
содержащему многосимвольный элемент сортировки, соответствовать более
чем одному символу, например, если последовательность сортировки
включает в себя элемент сортировки ch, то RE [[.ch.]]*c
соответствует первым пяти символам chchcc,
Заметка
В настоящее время QHB не поддерживает многосимвольные элементы сортировки. Эта информация описывает возможное будущее поведение.
В выражении в скобках элемент сортировки, заключенный в [= и =]
является классом эквивалентности, обозначающим последовательности
символов всех элементов сопоставления, эквивалентных этому элементу,
включая самого себя. (Если нет других эквивалентных элементов
сортировки, обработка выглядит так, как если бы в качестве разделителей
использовались [. и .]). Например, если o и ^ являются членами
класса эквивалентности, то [[=o=]], [[=^=]] и [o^]
являются синонимами. Класс эквивалентности не может быть конечной точкой
диапазона.
В выражении в скобках имя класса символов, заключенное в [: и :]
обозначает список всех символов, принадлежащих этому классу. Класс
символов не может использоваться в качестве конечной точки диапазона.
Стандарт POSIX определяет следующие имена классов символов: alnum (буквы
и цифры), alpha (буквы), blank (пробел и табуляция), cntrl (символы
управления), digit (цифры), graph (печатные символы, кроме пробела),
lower (строчные буквы), print (печатаемые символы, включая пробел),
пунктуация (пунктуация), space (любой пробел), upper (заглавные буквы) и
xdigit (шестнадцатеричные цифры). Поведение этих стандартных классов
символов обычно одинаково для разных платформ для символов в 7-битном
наборе ASCII. То, считается ли данный не-ASCII символ принадлежащим
одному из этих классов, зависит от параметров сортировки, используемых
для функции или оператора регулярного выражения (см. раздел Поддержка сортировки), или
по умолчанию от настройки языка LC_CTYPE базы данных (см. раздел Поддержка локали).
Классификация символов, отличных от ASCII, может варьироваться в
зависимости от платформы даже в локалях с одинаковыми именами. (Но
языковой стандарт C никогда не считает, что любые не-ASCII-символы
принадлежат какому-либо из этих классов). В дополнение к этим
стандартным классам символов QHB определяет класс символов ascii,
который содержит ровно 7-битный набор ASCII.
Существует два особых случая выражений в скобках: выражения в скобках
[[:<:]] и [[:>:]] являются ограничениями,
соответствующими пустым строкам в начале и конце слова соответственно.
Слово определяется как последовательность символов слова, которая не
предшествует и не сопровождается символами слова. Символ слова — это
символ alnum (как определено классом символов POSIX, описанным выше) или
знак подчеркивания. Это расширение, совместимое с POSIX 1003.2, но не
указанное в нем, и его следует использовать с осторожностью в
программном обеспечении, предназначенном для переноса на другие системы.
Описанные ниже экранирующие ограничения, обычно предпочтительнее; они не
являются более стандартными, но их легче набирать.
Экранирование в регулярных выражениях
Экранирование — это специальные последовательности, начинающиеся с \ за
которым следует буквенно-цифровой символ. Экраны могут быть нескольких
видов: ввод символов, сокращения классов, экранирование ограничений и
обратные ссылки. Символ \ сопровождаемый буквенно-цифровым символом, но
не являющийся допустимым выходом, является недопустимым в ARE. В ERE нет
выходов: вне выражения в скобках символ \ за которым следует
буквенно-цифровой символ, просто обозначает этот символ как обычный
символ, а внутри выражения в скобках \ - обычный символ. (Последнее
является единственной фактической несовместимостью между ERE и ARE).
Существуют экранирование ввода символов, чтобы упростить указание непечатаемых и других неудобных символов в RE. Они показаны в таблице 8.19.
Сокращения класса обеспечивают сокращения для некоторых обычно используемых классов символов. Они показаны в таблице 20.
Экранирование ограничения — это ограничение, соответствующее пустой строке, если выполняются определенные условия, записываемое как escape. Они показаны в таблице 21.
Обратная ссылка (\n) соответствует той же строке, которая соответствует
предыдущему заключенному в скобки подвыражению, указанному числом n (см.
Таблицу 8.22). Например, ([bc])\1 соответствует bb или cc но не bc
или cb. Подвыражение должно полностью предшествовать обратной ссылке в
RE. Субэкспрессии нумеруются в порядке их ведущих скобок. Неполные
скобки не определяют подвыражения.
Таблица 19. Регулярное выражение E-Entry Escape
| Выделение | Описание |
|---|---|
\a | предупреждающий (звонок) символ, как в C |
\b | Backspace, как в C |
\B | синоним обратной косой черты (\), чтобы уменьшить необходимость удвоения обратной косой черты |
\cX | (где X - любой символ) символ, чьи 5 младших битов такие же, как у X, а все остальные биты равны нулю |
\e | символ с именем последовательности упорядочения ESC или, если это не так, символ с восьмеричным значением 033 |
\f | подача формы, как в C |
\n | перевод строки, как в C |
\r | возврат каретки, как в C |
\t | горизонтальная вкладка, как в C |
\uwxyz | (где wxyz - ровно четыре шестнадцатеричные цифры) символ, шестнадцатеричное значение которого равно 0x wxyz |
\Ustuvwxyz | (где stuvwxyz ровно восемь шестнадцатеричных цифр) символ, шестнадцатеричное значение которого равно 0x stuvwxyz |
\v | вертикальная вкладка, как в C |
\xhhh | (где hhh - любая последовательность шестнадцатеричных цифр) символ, шестнадцатеричное значение которого равно 0x hhh (один символ независимо от того, сколько шестнадцатеричных цифр используется) |
\0 | символ, значение которого равно 0 (нулевой байт) |
\xy | (где xy - это ровно две восьмеричные цифры, а не обратная ссылка) символ, восьмеричное значение которого равно 0 xy |
\xyz | (где xyz - ровно три восьмеричных цифры, а не обратная ссылка) символ, восьмеричное значение которого равно 0 xyz |
Шестнадцатеричные цифры 0-9, a-f и A-F Восьмеричные цифры 0-7.
Цифровая символьная запись выходит за пределы, указывая значения вне
диапазона ASCII (0-127), значения которых зависят от кодировки базы
данных. Когда кодировка UTF-8, escape-значения эквивалентны кодовым
точкам Unicode, например, \u1234 означает символ U+1234. Для других
многобайтовых кодировок экранирование ввода символов обычно просто
указывает конкатенацию байтовых значений для символа. Если
escape-значение не соответствует никакому допустимому символу в
кодировке базы данных, ошибка не возникает, но она никогда не будет
соответствовать никаким данным.
Экранирование ввода символов всегда принимается как обычные символы.
Например, \135 является ] в ASCII, но \135 не завершает выражение в
скобках.
Таблица 20. Класс регулярных выражений - Сокращения
| Выделение | Описание |
|---|---|
\d | [[:digit:]] |
\s | [[:space:]] |
\w | [[:alnum:]_] (примечание подчеркивание включено) |
\D | [^[:digit:]] |
\S | [^[:space:]] |
\W | [^[:alnum:]_] (примечание подчеркивание включено) |
В выражениях в скобках \d, \s и \w теряют свои внешние скобки, а \D,
\S и \W недопустимы. (Так, например, [a-c\d] эквивалентно
[a-c[:digit:]]. Кроме того, [a-c\D], что эквивалентно
[a-c^[:digit:]], является недопустимым).
Таблица 21. Ограничение регулярных выражений
| Выделение | Описание |
|---|---|
| \A | соответствует только в начале строки (см. раздел Правила сопоставления регулярных выражений о том, как это отличается от ^) |
| \m | соответствует только в начале слова |
| \M | соответствует только в конце слова |
| \y | соответствует только в начале или конце слова |
| \Y | соответствует только в точке, которая не является началом или концом слова |
| \Z | соответствует только в конце строки (см. раздел Правила сопоставления регулярных выражений о том, как это отличается от $) |
Слово определяется как в спецификации [[:<:]] и [[:>:]]
выше. Экранирование ограничений в выражениях в скобках недопустимо.
Таблица 22. Регулярное выражение обратные ссылки
| Выделение | Описание |
|---|---|
| \m | (где m - ненулевая цифра) обратная ссылка на m -е подвыражение |
| \mnn | (где* m* - ненулевая цифра, а nn - еще несколько цифр, а десятичное значение mnn не больше, чем число закрывающих скобок, замеченных до сих пор) обратная ссылка на mnn -ый подвыражение |
Существует неоднозначность между экранированием восьмеричных символов и обратными ссылками, которая разрешается следующей эвристикой, как указано выше. Ведущий ноль всегда указывает на восьмеричный выход. Одна ненулевая цифра, за которой не следует другая цифра, всегда принимается в качестве обратной ссылки. Последовательность из нескольких цифр, не начинающаяся с нуля, берется в качестве обратной ссылки, если она идет после подходящего подвыражения (т. е. число находится в допустимом диапазоне для обратной ссылки), а в противном случае принимается за восьмеричное.
Метасинтаксис регулярных выражений
В дополнение к основному синтаксису, описанному выше, существуют некоторые специальные формы и различные синтаксические средства.
RE может начинаться с одного из двух специальных префиксов директора.
Если RE начинается с ***:, остальная часть RE берется как ARE. (Это
обычно не имеет никакого эффекта в QHB, поскольку предполагается, что RE
являются ARE; но это имеет эффект, если параметром flags для функции
regex был задан режим ERE или BRE). Если RE начинается с ***=
остальная часть RE принимается за буквальную строку, причем все символы
считаются обычными символами.
ARE может начинаться со встроенных опций: последовательность (?xyz)
(где xyz - один или несколько буквенных символов) определяет опции,
влияющие на остальную часть RE. Эти параметры переопределяют любые ранее
определенные параметры - в частности, они могут переопределять поведение
с учетом регистра, подразумеваемое оператором регулярного выражения, или
параметр flags для функции регулярного выражения. Доступные буквы опций
показаны в таблице 23. Обратите внимание, что эти же буквы параметров
используются в параметрах флагов функций регулярных выражений.
Таблица 23. ARE символы с встроенными опциями
| Вариант | Описание |
|---|---|
| b | Остальная часть RE - BRE |
| c | Сопоставление с учетом регистра (переопределяет тип оператора) |
| e | Остальная часть RE — это ERE |
| i | сопоставление без учета регистра (см. раздел Правила сопоставления регулярных выражений) (переопределяет тип оператора) |
| m | исторический синоним для n |
| n | сопоставление с учетом новой строки (см. раздел Правила сопоставления регулярных выражений) |
| p | частичное совпадение с учетом новой строки (см. раздел Правила сопоставления регулярных выражений) |
| q | Остальная часть RE является литеральной («кавычкой») строкой, все обычные символы |
| s | сопоставление, не зависящее от перевода строки (по умолчанию) |
| t | жесткий синтаксис (по умолчанию; см. ниже) |
| w | частичное обратное частичное совпадение с учетом новой строки («странное») (см. раздел Правила сопоставления регулярных выражений) |
| x | расширенный синтаксис (см. ниже) |
Встроенные параметры вступают в силу после завершения
последовательности. Они могут появляться только в начале ARE (после директора
***: если таковой имеется).
В дополнение к обычному (строгому) синтаксису RE, в котором значимы все
символы, существует расширенный синтаксис, доступный путем указания
встроенной опции x. В расширенном синтаксисе символы пробела в RE
игнорируются, как и все символы между # и следующей новой строкой (или
концом RE). Это позволяет создавать абзацы и комментировать сложные RE.
Из этого основного правила есть три исключения:
Для этой цели пробелами являются пробелы, символы табуляции, перевода строки и любые символы, принадлежащие классу пробелов.
Наконец, в ARE, вне выражений в скобках, последовательность (?#ttt)
(где ttt - любой текст, не содержащий )) — это комментарий, полностью
игнорируемый. Опять же, это не допускается между символами
многосимвольных обозначений, например (?:. Такие комментарии являются
скорее историческим артефактом, чем полезным средством, и их
использование не рекомендуется; вместо этого используйте расширенный
синтаксис.
Ни одно из этих расширений метасинтаксиса не доступно, если начальный
директор ***= указал, что ввод пользователя будет обрабатываться как
литеральная строка, а не как RE.
Правила сопоставления регулярных выражений
В случае, когда RE может соответствовать более чем одной подстроке данной строки, RE соответствует той, которая начинается раньше в строке. Если RE может соответствовать более чем одной подстроке, начинающейся в этой точке, то будет выполнено либо самое длинное, либо самое короткое совпадение, в зависимости от того, является ли RE жадным или не жадным.
Является ли RE жадным или нет, определяется следующими правилами:
Приведенные выше правила связывают атрибуты жадности не только с отдельными количественными атомами, но и с ветвями и целыми RE, содержащими количественные атомы. Это означает, что сопоставление выполняется таким образом, что ветвь или целое RE совпадает с самой длинной или самой короткой из возможных подстрок в целом. Как только длина полного совпадения определена, его часть, которая соответствует любому конкретному подвыражению, определяется на основе атрибута жадности этого подвыражения, причем подвыражения, начинающиеся раньше в RE, имеют приоритет над теми, которые начинаются позже.
Пример того, что это значит:
SELECT SUBSTRING('XY1234Z', 'Y*([0-9]{1,3})');
Result: 123
SELECT SUBSTRING('XY1234Z', 'Y*?([0-9]{1,3})');
Result: 1
В первом случае RE в целом жадный, потому что Y* жадный. Он может
совпадать, начиная с Y, и соответствовать самой длинной строке,
начинающейся там, то есть Y123. Выводом является часть этого в скобках,
или 123. Во втором случае RE в целом не является жадным, потому что Y*?
не жадный Он может совпадать, начиная с Y, и соответствовать самой
короткой строке, начинающейся там, то есть Y1. Подвыражение [0-9]{1,3}
является жадным, но не может изменить решение относительно общей
длины совпадения; поэтому он вынужден совпадать только с 1.
Вкратце, когда RE содержит как жадные, так и не жадные подвыражения, общая длина совпадения либо максимально длинная, либо максимально короткая, в соответствии с атрибутом, назначенным всему RE. Атрибуты, назначенные подвыражениям, влияют только на то, сколько из этого соответствия им разрешено «съесть» относительно друг друга.
Квантификаторы {1,1} и {1,1}? могут быть использован, чтобы вызвать
жадность или не жадность, соответственно, для подвыражения или целого
RE. Это полезно, когда вам нужно, чтобы весь RE имел атрибут жадности,
отличный от того, что выводится из его элементов. В качестве примера
предположим, что мы пытаемся разделить строку, содержащую несколько
цифр, на цифры и части до и после них. Мы можем попытаться сделать это
так:
SELECT regexp_match('abc01234xyz', '(.*)(\d+)(.*)');
Result: {abc0123,4,xyz}
Это не сработало: первый .* Жадный, поэтому он «съедает» столько,
сколько может, оставляя \d+ совпадать с последним возможным местом,
последней цифрой. Мы можем попытаться исправить это, сделав его не
жадным:
SELECT regexp_match('abc01234xyz', '(.*?)(\d+)(.*)');
Result: {abc,0,""}
Это тоже не сработало, потому что теперь RE в целом не жадный, и поэтому он заканчивает сравнение как можно скорее. Мы можем получить то, что хотим, заставив RE в целом быть жадным:
SELECT regexp_match('abc01234xyz', '(?:(.*?)(\d+)(.*)){1,1}');
Result: {abc,01234,xyz}
Контроль общей жадности RE отдельно от жадности его компонентов обеспечивает большую гибкость при работе с образцами переменной длины.
При принятии решения о том, какое совпадение длиннее или короче, длины
совпадений измеряются в символах, а не в элементах сортировки. Пустая
строка считается более длинной, чем не совпадающей. Например: bb*
соответствует трем средним символам abbbc; (week|wee) (night|knights)
соответствует всем десяти символам weeknights; когда (.*).*
сопоставляется с abc, подвыражение в скобках соответствует всем трем
символам; и когда (a*)* сопоставляется с bc, и все RE, и
подвыражение в скобках соответствуют пустой строке.
Если задано независимое от регистра совпадение, эффект будет таким же,
как если бы все алфавитные различия исчезли из алфавита. Когда алфавит,
существующий во многих случаях, появляется как обычный символ вне
выражения в скобках, он фактически преобразуется в выражение в скобках,
содержащее оба случая, например, x становится [xX]. Когда оно
появляется внутри выражения в скобках, все его аналоги в регистре
добавляются в выражение в скобках, например, [x] становится [xX] и
[^x] становится [^xX].
Если указано совпадение с учетом новой строки, . и выражения в скобках,
использующие ^, никогда не будут совпадать с символом новой строки (так
что совпадения никогда не будут пересекать символы новой строки, если RE
явно не упорядочит его), а ^ и $ будут совпадать с пустой строкой после
и до новой строки соответственно, в дополнение к совпадению в начале и в
конце строки соответственно. Но экранированные символы ARE \A и \Z
продолжают соответствовать только началу или концу строки.
Если указано частичное совпадение с учетом новой строки, это влияние . и
выражения в скобках, как при сопоставлении с учетом новой строки, но не
^ и $.
Если указано обратное частичное совпадение с учетом новой строки, это
влияет на ^ и $, как и при сопоставлении с учетом новой строки, но не
влияет . и выражения в скобках. Это не очень полезно, но предусмотрено
для симметрии.
Пределы и совместимость
В этой реализации нет конкретных ограничений на длину RE. Однако программы, предназначенные для обеспечения высокой переносимости, не должны использовать RE длиной более 256 байт, поскольку реализация, совместимая с POSIX, может отказаться принимать такие RE.
Единственная особенность ARE, которая на самом деле несовместима с POSIX
ERE, заключается в том, что \ не теряет своего особого значения в
выражениях в скобках. Все остальные функции ARE используют синтаксис,
который является недопустимым или имеет неопределенные или
неопределенные эффекты в ERE POSIX; *** синтаксис директоров также
находится за пределами синтаксиса POSIX как для BRE, так и для ERE.
Многие из расширений ARE заимствованы из Perl, но некоторые были
изменены, чтобы очистить их, а некоторые расширения Perl отсутствуют.
Заметные несовместимости включают в себя \b, \B, отсутствие
специальной обработки для завершающего символа новой строки, добавление
дополненных выражений в скобках к тем вещам, на которые влияет
сопоставление с учетом новой строки, ограничения на круглые скобки и
обратные ссылки в ограничениях lookahead/lookbehind, и семантика
соответствия самого длинного/самого короткого совпадения (а не первого
совпадения).
Основные регулярные выражения
BRE отличаются от ERE в нескольких отношениях. В BREs, |, + и ? являются
обычными символами, и их функциональность не имеет аналогов.
Ограничителями для границ являются \{ и \}, причем { и } сами по себе
являются обычными символами. Круглые скобки для вложенных подвыражений:
\( и \), с ( и ) сами по себе обычными символами. ^ - обычный символ, за
исключением начала RE или начала заключенного в скобки подвыражения, $ -
обычный символ, за исключением конца RE или конца заключенного в скобки
подвыражения, а * - обычный символ, если он появляется в начале RE или
начале заключенного в скобки подвыражения (после возможного начала ^).
Наконец, доступны однозначные обратные ссылки, и \< и \>
являются синонимами для [[:<:]] и [[:>:]] соответственно;
в BRE нет других выходов.
Отличия от XQuery (LIKE_REGEX)
Начиная с SQL: 2008, стандарт SQL включает в себя оператор LIKE_REGEX, который выполняет сопоставление с шаблоном в соответствии со стандартом регулярных выражений XQuery. QHB еще не реализует этот оператор, но вы можете получить очень похожее поведение, используя функцию regexp_match(), поскольку регулярные выражения XQuery довольно близки к синтаксису ARE, описанному выше.
Существенные различия между существующей функцией регулярных выражений на основе POSIX и регулярными выражениями XQuery включают:
Функции форматирования типов данных
Функции форматирования QHB предоставляют мощный набор инструментов для преобразования различных типов данных (дата / время, целые числа, числа с плавающей запятой, числовые) в форматированные строки и для преобразования форматированных строк в конкретные типы данных. Таблица 8.24 перечисляет их. Все эти функции следуют общему соглашению о вызовах: первый аргумент — это значение, которое нужно отформатировать, а второй аргумент — это шаблон, который определяет формат вывода или ввода.
Таблица 24. Функции форматирования
| Функция | Тип ответа | Описание | Пример |
|---|---|---|---|
| to_char(timestamp, text) | text | конвертировать метку времени в строку | to_char(current_timestamp, ’HH12:MI:SS’) |
| to_char(interval, text) | text | преобразовать интервал в строку | to_char(interval ’15h 2m 12s’, ’HH24:MI:SS’) |
| to_char(int, text) | text | конвертировать целое число в строку | to_char(125, ’999’) |
| to_char (double precision, text) | text | преобразовать реальную / двойную точность в строку | to_char(125.8::real, ’999D9’) |
| to_char(numeric, text) | text | преобразовать число в строку | to_char(-125.8, ’999D99S’) |
| to_date(text, text) | date | преобразовать строку в дату | to_date(’05 Dec 2000’, ’DD Mon YYYY’) |
| to_number(text, text) | numeric | преобразовать строку в число | to_number(’12,454.8-’, ’99G999D9S’) |
| to_timestamp(text, text) | timestamp with time zone | преобразовать строку в метку времени | to_timestamp(’05 Dec 2000’, ’DD Mon YYYY’) |
Заметка
Существует также функция to_timestamp с одним аргументом; см. таблицу 31.
Совет
Существуютto_timestampиto_dateдля обработки входных форматов, которые нельзя преобразовать простым преобразованием. Для большинства стандартных форматов даты/времени работает простое приведение исходной строки к требуемому типу данных, и это намного проще. Аналогично,to_numberне требуется для стандартных числовых представлений.
В строке выходного шаблона to_char есть определенные шаблоны, которые распознаются и заменяются данными соответствующего формата на основе заданного значения. Любой текст, который не является лекалом шаблона, просто дословно копируется. Точно так же во входной строке шаблона (для других функций) лекала шаблона идентифицируют значения, которые будут предоставлены строкой входных данных. Если в строке шаблона есть символы, которые не являются лекалами шаблонами, соответствующие символы во входной строке данных просто пропускаются (независимо от того, равны они символам строки шаблона или нет).
В таблице 25 показаны лекала шаблонов, доступные для форматирования значений даты и времени.
Таблица 25. Лекала шаблонов для форматирования даты / времени
| Шаблон | Описание |
|---|---|
| HH | час дня (01-12) |
| HH12 | час дня (01-12) |
| HH24 | час дня (00-23) |
| MI | минута (00-59) |
| SS | второй (00-59) |
| MS | миллисекунда (000-999) |
| US | микросекунда (000000-999999) |
| SSSS | секунд после полуночи (0-86399) |
| AM, am, PM или pm | индикатор меридием (без периодов) |
| A.M., a.m., P.M. или p.m. | индикатор меридием (с периодами) |
| Y,YYY | год (4 или более цифр) с запятой |
| YYYY | год (4 или более цифр) |
| YYY | последние 3 цифры года |
| YY | последние 2 цифры года |
| Y | последняя цифра года |
| IYYY | Недельный год нумерации ISO 8601 (4 или более цифр) |
| IYY | последние 3 цифры года нумерации ISO 8601 |
| IY | последние 2 цифры года нумерации ISO 8601 |
| I | последняя цифра ISO 8601 год нумерации недели |
| BC, bc, AD или ad | индикатор эры (без периодов) |
| B.C., b.c., A.D. или a.d. | индикатор эры (с периодами) |
| MONTH | полное название месяца в верхнем регистре (с пробелами до 9 символов) |
| Month | полное заглавное название месяца (с пробелами до 9 символов) |
| month | полное название месяца в нижнем регистре (с пробелами до 9 символов) |
| MON | сокращенное название месяца в верхнем регистре (3 буквы на английском языке, длина может отличаться) |
| Mon | сокращенное заглавное название месяца (3 буквы на английском языке, длина может отличаться) |
| mon | сокращенное название месяца в нижнем регистре (3 буквы в английском, длина может быть разной) |
| MM | номер месяца (01-12) |
| DAY | полное название дня в верхнем регистре (с пробелами до 9 символов) |
| Day | полное заглавное название дня (с пробелами до 9 символов) |
| day | полное название дня в нижнем регистре (с пробелами до 9 символов) |
| DY | сокращенное название дня в верхнем регистре (3 буквы на английском языке, длина может отличаться) |
| Dy | сокращенное заглавное название дня (3 буквы на английском языке, длина может быть разной) |
| dy | сокращенное название дня в нижнем регистре (3 буквы на английском языке, длина может отличаться) |
| DDD | день года (001-366) |
| IDDD | день недели по номеру ISO 8601 (001-371; 1-й день года - понедельник первой недели ISO) |
| DD | день месяца (01-31) |
| D | день недели, с воскресенья (1) по субботу (7) |
| ID | ISO 8601 день недели, с понедельника (1) по воскресенье (7) |
| W | неделя месяца (1-5) (первая неделя начинается в первый день месяца) |
| WW | номер недели в году (1-53) (первая неделя начинается в первый день года) |
| IW | номер недели в году по номеру недели ISO 8601 (01-53; первый четверг года на первой неделе) |
| CC | век (2 цифры) (XXI век начинается с 2001-01-01) |
| J | Юлианский день (целые дни с 24 ноября 4714 г. до н.э. в полночь UTC) |
| Q | квартал |
| RM | месяц прописными буквами римскими цифрами (I-XII; I = январь) |
| rm | месяц строчными буквами римскими цифрами (i-xii; i = январь) |
| TZ | сокращение верхнего пояса в верхнем регистре (поддерживается только в to_char) |
| tz | to_char сокращение часового пояса (поддерживается только в to_char) |
| TZH | часы часового пояса |
| TZM | минуты часового пояса |
| OF | смещение часового пояса от UTC (поддерживается только в to_char) |
Модификаторы можно применять к любому лекалу шаблона, чтобы изменить
его поведение. Например, FMMonth — это шаблон Month с модификатором FM.
В таблице 26 показаны шаблоны модификаторов для форматирования
даты/времени.
Таблица 26. Модификаторы лекала шаблонов для форматирования даты / времени
| Модификатор | Описание | пример |
|---|---|---|
| Префикс FM | режим заполнения (подавление начальных нулей и отступов) | FMMonth |
| Суффикс TH | суффикс порядкового номера в верхнем регистре | DDTH, например, 12 |
| суффикс th | строчный суффикс порядкового номера | DDth, например, 12th |
| Префикс FX | глобальная опция фиксированного формата (см. примечания по использованию) | FX Month DD Day |
| Префикс TM | режим перевода (печатать локализованные названия дней и месяцев на основе lc_time) | TMMonth |
| Суффикс SP | режим заклинания (не реализован) | DDSP |
Замечания по использованию для форматирования даты / времени:
Если указан параметр FX, то разделитель в строке шаблона соответствует ровно
одному символу во входной строке. Но обратите внимание, что символ
входной строки не обязательно должен совпадать с разделителем из
строки шаблона. Например, to_timestamp('2000/JUN', 'FXYYYY MON')
работает, но to_timestamp('2000/JUN', 'FXYYYY MON') возвращает
ошибку, поскольку второй пробел в строке шаблона занимает букву J из
строки ввода.
Предостережение
В то время какto_dateбудет отклонять смесь полей даты нумерации недели по григорианскому стандарту и ISO,to_charне будет, поскольку могут быть полезны спецификации выходного формата, такие какYYYY-MM-DD (IYYY-IDDD). Но избегайте писать что-то вродеIYYY-MM-DD; это дало бы удивительные результаты в начале года. (См. раздел EXTRACT, date_part для получения дополнительной информации).
В таблице 27 показаны лекала шаблонов, доступные для форматирования числовых значений.
Таблица 27. Лекала шаблонов для числового форматирования
| Шаблон | Описание |
|---|---|
| 9 | цифровая позиция (может быть отброшена, если она незначительна) |
| 0 | позиция цифры (не будет удалена, даже если она незначительна) |
| . (Точка) | десятичная точка |
| , (запятая) | разделитель групп (тысяч) |
| PR | отрицательное значение в угловых скобках |
| S | знак привязан к номеру (использует локаль) |
| L | символ валюты (использует локаль) |
| D | десятичная точка (использует локаль) |
| G | разделитель группы (использует локаль) |
| MI | знак минус в указанной позиции (если число <0) |
| PL | знак плюс в указанной позиции (если число> 0) |
| SG | знак плюс / минус в указанной позиции |
| RN | Римская цифра (ввод от 1 до 3999) |
| TH или th | суффикс порядкового номера |
| V | сдвинуть указанное количество цифр (см. примечания) |
| EEEE | показатель для научной записи |
Замечания по использованию для числового форматирования:
Некоторые модификаторы могут быть применены к любому лекалу шаблона, чтобы изменить его поведение. Например, FM99.99 — это шаблон 99.99 с модификатором FM. В таблице 28 показаны шаблоны модификаторов для числового форматирования.
Таблица 28. Модификаторы шаблонов для числового форматирования
| Модификатор | Описание | пример |
|---|---|---|
| Префикс FM | режим заполнения (подавление концевых нулей и пробелов заполнения) | FM99.99 |
| Суффикс TH | суффикс порядкового номера в верхнем регистре | 999TH |
| Суффикс th | строчный суффикс порядкового номера | 999th |
В таблице 29 приведены некоторые примеры использования функции to_char.
| Выражение | Результат |
|---|---|
| to_char(current_timestamp, ’Day, DD HH12:MI:SS’) | ’Tuesday, 06 05:39:18’ |
| to_char(current_timestamp, ’FMDay, FMDD HH12:MI:SS’) | ’Tuesday, 6 05:39:18’ |
| to_char(-0.1, ’99.99’) | ’ -.10’ |
| to_char(-0.1, ’FM9.99’) | ’-.1’ |
| to_char(-0.1, ’FM90.99’) | ’-0.1’ |
| to_char(0.1, ’0.9’) | ’ 0.1’ |
| to_char(12, ’9990999.9’) | ' 0012.0' |
| to_char(12, ’FM9990999.9’) | ’0012.’ |
| to_char(485, ’999’) | ’ 485’ |
| to_char(-485, ’999’) | ’-485’ |
| to_char(485, ’9 9 9’) | ’ 4 8 5’ |
| to_char(1485, ’9,999’) | ’ 1,485’ |
| to_char(1485, ’9G999’) | ’ 1 485’ |
| to_char(148.5, ’999.999’) | ’ 148.500’ |
| to_char(148.5, ’FM999.999’) | ’148.5’ |
| to_char(148.5, ’FM999.990’) | ’148.500’ |
| to_char(148.5, ’999D999’) | ’ 148,500’ |
| to_char(3148.5, ’9G999D999’) | ’ 3 148,500’ |
| to_char(-485, ’999S’) | ’485-’ |
| to_char(-485, ’999MI’) | ’485-’ |
| to_char(485, ’999MI’) | ’485 ’ |
| to_char(485, ’FM999MI’) | ’485’ |
| to_char(485, ’PL999’) | ’+485’ |
| to_char(485, ’SG999’) | ’+485’ |
| to_char(-485, ’SG999’) | ’-485’ |
| to_char(-485, ’9SG99’) | ’4-85’ |
| to_char(-485, ’999PR’) | ’<485>’ |
| to_char(485, ’L999’) | ’DM 485’ |
| to_char(485, ’RN’) | ' CDLXXXV' |
| to_char(485, ’FMRN’) | ’CDLXXXV’ |
| to_char(5.2, ’FMRN’) | ’V’ |
| to_char(482, ’999th’) | ’ 482nd’ |
| to_char(485, ’"Good number:"999’) | ’Good number: 485’ |
| to_char(485.8, ’"Pre:"999" Post:" .999’) | ’Pre: 485 Post: .800’ |
| to_char(12, ’99V999’) | ’ 12000’ |
| to_char(12.4, ’99V999’) | ’ 12400’ |
| to_char(12.45, ’99V9’) | ’ 125’ |
| to_char(0.0004859, ’9.99EEEE’) | ’ 4.86e-04’ |
Функции и операторы даты/времени
В таблице 31 показаны доступные функции для обработки значения
даты/времени, подробности представлены в следующих подразделах. Таблица
8.30 иллюстрирует поведение основных арифметических операторов (+, * и
т.д.). Функции форматирования см. в разделе Функции форматирования типов данных. Вы должны быть знакомы с
исходной информацией о типах данных даты/времени из раздела Типы даты/времени.
Все функции и операторы, описанные ниже, которые принимают входные
данные time или timestamp фактически бывают двух вариантов: один,
который требует time with time zone или timestamp with time zone, и
один, который требует time without time zone или timestamp without time
zone. Для краткости эти варианты не показаны отдельно. Кроме того,
операторы + и * входят в коммутативные пары (например, и дата + целое
число и целое число + дата); мы показываем только одну из каждой такой
пары.
Таблица 30. Операторы даты/времени
| Оператор | Пример | Результат |
|---|---|---|
| + | date ’2001-09-28’ + integer ’7’ | date ’2001-10-05’ |
| + | date ’2001-09-28’ + interval ’1 hour’ | timestamp ’2001-09-28 01:00:00’ |
| + | date ’2001-09-28’ + time ’03:00’ | timestamp ’2001-09-28 03:00:00’ |
| + | interval ’1 day’ + interval ’1 hour’ | interval ’1 day 01:00:00’ |
| + | timestamp ’2001-09-28 01:00’ + interval ’23 hours’ | timestamp ’2001-09-29 00:00:00’ |
| + | time ’01:00’ + interval ’3 hours’ | time ’04:00:00’ |
| - | - interval ’23 hours’ | interval ’-23:00:00’ |
| - | date ’2001-10-01’ - date ’2001-09-28’ | integer ’3’ (дни) |
| - | date ’2001-10-01’ - integer ’7’ | date ’2001-09-24’ |
| - | date ’2001-09-28’ - interval ’1 hour’ | timestamp ’2001-09-27 23:00:00’ |
| - | time ’05:00’ - time ’03:00’ | interval ’02:00:00’ |
| - | time ’05:00’ - interval ’2 hours’ | time ’03:00:00’ |
| - | timestamp ’2001-09-28 23:00’ - interval ’23 hours’ | timestamp ’2001-09-28 00:00:00’ |
| - | interval ’1 day’ - interval ’1 hour’ | interval ’1 day -01:00:00’ |
| - | timestamp ’2001-09-29 03:00’ - timestamp ’2001-09-27 12:00’ | interval ’1 day 15:00:00’ |
| * | 900 * interval ’1 second’ | interval ’00:15:00’ |
| * | 21 * interval ’1 day’ | interval ’21 days’ |
| * | double precision ’3.5’ * interval ’1 hour’ | interval ’03:30:00’ |
| / | interval ’1 hour’ / double precision ’1.5’ | interval ’00:40:00’ |
Таблица 31. Функции даты/времени
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| age(timestamp, timestamp) | interval | Вычтите аргументы, получив «символический» результат, который использует годы и месяцы, а не дни | age(timestamp ’2001-04-10’, timestamp ’1957-06-13’) | 43 years 9 mons 27 days |
| age(timestamp) | interval | Вычесть из current_date (в полночь) | age(timestamp ’1957-06-13’) | 43 years 8 mons 3 days |
| clock_timestamp() | timestamp with time zone | Текущая дата и время (изменения во время выполнения выписки); см. раздел Текущая дата / время | ||
| current_date | date | Текущая дата см. раздел Текущая дата / время | ||
| current_time | time with time zone | Текущее время суток; см. раздел Текущая дата / время | ||
| current_timestamp | timestamp with time zone | Текущая дата и время (начало текущей транзакции); см. раздел Текущая дата / время | ||
| date_part(text, timestamp) | double precision | Получить подполе (эквивалентное extract); см. раздел EXTRACT, date_part | date_part(’hour’, timestamp ’2001-02-16 20:38:40’) | 20 |
| date_part(text, interval) | double precision | Получить подполе (эквивалентное extract); см. раздел EXTRACT, date_part | date_part(’month’, interval ’2 years 3 months’) | 3 |
| date_trunc(text, timestamp) | timestamp | Усечь до указанной точности; см. раздел date_trunc | date_trunc(’hour’, timestamp ’2001-02-16 20:38:40’) | 2001-02-16 20:00:00 |
| date_trunc(text, timestamp with time zone, text) | timestamp with time zone | Усечь до указанной точности в указанном часовом поясе; см. раздел date_trunc | date_trunc(’day’, timestamptz ’2001-02-16 20:38:40+00’, ’Australia/Sydney’) | 2001-02-16 13:00:00+00 |
| date_trunc(text, interval) | interval | Усечь до указанной точности; см. раздел date_trunc | date_trunc(’hour’, interval ’2 days 3 hours 40 minutes’) | 2 days 03:00:00 |
| extract (field from timestamp) | double precision | Получить подполе; см. раздел EXTRACT, date_part | extract(hour from timestamp ’2001-02-16 20:38:40’) | 20 |
| extract (field from interval) | double precision | Получить подполе; см см. раздел EXTRACT, date_part | extract(month from interval ’2 years 3 months’) | 3 |
| isfinite(date) | boolean | Тест на конечную дату (не +/- бесконечность) | isfinite(date ’2001-02-16’) | true |
| isfinite(timestamp) | boolean | Тест для конечной отметки времени (не +/- бесконечность) | isfinite(timestamp ’2001-02-16 21:28:30’) | true |
| isfinite(interval) | boolean | Тест на конечный интервал | isfinite(interval ’4 hours’) | true |
| justify_days(interval) | interval | Настройте интервал так, чтобы 30-дневные периоды времени представлялись в месяцах | justify_days(interval ’35 days’) | 1 mon 5 days |
| justify_hours(interval) | interval | Настройте интервал, чтобы 24-часовой период времени был представлен в днях. | justify_hours(interval ’27 hours’) | 1 day 03:00:00 |
| justify_interval(interval) | interval | Отрегулируйте интервал, используя justify_days и justify_hours, с дополнительными настройками знака | justify_interval(interval ’1 mon -1 hour’) | 29 days 23:00:00 |
| localtime | time | Текущее время суток; см. раздел Текущая дата / время | ||
| localtimestamp | timestamp | Текущая дата и время (начало текущей транзакции); см. раздел Текущая дата / время | ||
| make_date(year int, month int, day int) | date | Создать дату из поля год, месяц и день | make_date(2013, 7, 15) | 2013-07-15 |
| make_interval(years int DEFAULT 0, months int DEFAULT 0, weeks int DEFAULT 0, days int DEFAULT 0, hours int DEFAULT 0, mins int DEFAULT 0, secs double precision DEFAULT 0.0) | interval | Создайте интервал из полей лет, месяцев, недель, дней, часов, минут и секунд | make_interval(days => 10) | 10 days |
| make_time(hour int, min int, sec double precision) | time | Создать время из часовых, минутных и секундных полей | make_time(8, 15, 23.5) | 08:15:23.5 |
| make_timestamp(year int, month int, day int, hour int, min int, sec double precision) | timestamp | Создать метку времени из полей год, месяц, день, час, минуты и секунды | make_timestamp(2013, 7, 15, 8, 15, 23.5) | 2013-07-15 08:15:23.5 |
| make_timestamptz(year int, month int, day int, hour int, min int, sec double precision, [ timezone text ]) | timestamp with time zone | Создать временную метку с часовым поясом из полей год, месяц, день, час, минуты и секунды; если timezone не указан, используется текущий часовой пояс | make_timestamptz(2013, 7, 15, 8, 15, 23.5) | 2013-07-15 08:15:23.5+01 |
| now() | timestamp with time zone | Текущая дата и время (начало текущей транзакции); см. раздел Текущая дата / время | ||
| statement_timestamp() | timestamp with time zone | Текущая дата и время (начало текущей выписки); см. раздел Текущая дата / время | ||
| timeofday() | text | Текущая дата и время (например, clock_timestamp, но в виде text строки); см. раздел Текущая дата / время | ||
| transaction_timestamp() | timestamp with time zone | Текущая дата и время (начало текущей транзакции); см. раздел Текущая дата / время | ||
| to_timestamp(double precision) | timestamp with time zone | Преобразовать эпоху Unix (секунды с 1970-01-01 00: 00: 00 + 00) в метку времени | to_timestamp(1284352323) | 2010-09-13 04:32:03+00 |
В дополнение к этим функциям поддерживается оператор SQL OVERLAPS:
(start1, end1) OVERLAPS (start2, end2)
(start1, length1) OVERLAPS (start2, length2)
Это выражение дает истину, когда два периода времени (определенные их
конечными точками) перекрываются, ложь, когда они не перекрываются.
Конечные точки могут быть указаны как пары дат, времени или отметок
времени; или как дата, время или отметка времени с последующим
интервалом. Когда предоставляется пара значений, сначала можно записать
начало или конец; OVERLAPS автоматически принимает более раннее значение
пары в качестве начала. Каждый период времени считается представляющим
начало полуоткрытого интервала start <= time < end если только start и
end не равны, и в этом случае он представляет этот единственный момент
времени. Это означает, например, что два периода времени с общей
конечной точкой не перекрываются.
SELECT (DATE '2001-02-16', DATE '2001-12-21') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: true
SELECT (DATE '2001-02-16', INTERVAL '100 days') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: false
SELECT (DATE '2001-10-29', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: false
SELECT (DATE '2001-10-30', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: true
При добавлении значения interval к (или вычитании значения interval из)
значению timestamp with time zone компонент
дней увеличивает или уменьшает дату timestamp with time zone
на указанное количество дней. В зависимости от
изменения летнего времени (когда часовой пояс сеанса установлен на
часовой пояс, который распознает летнее время), это означает, что
interval '1 day' не обязательно равен interval '24 hours'. Например,
если для часового пояса сеанса установлено значение CST7CDT,
timestamp with time zone '2005-04-02 12:00-07' + interval '1 day' будет
выводитьtimestamp with time zone '2005-04-03 12:00-06', при
добавлении interval '24 hours' к тому же начальному значению, получим
timestamp with time zone '2005-04-03 13:00-06', поскольку в
часовом поясе CST7CDT происходит изменение летнего времени в 2005-04-03 02:00.
Обратите внимание, что может быть неоднозначность в поле months
возвращаемом по age, потому что разные месяцы имеют разное количество
дней. Подход QHB использует месяц от более ранней из двух дат при
расчете неполных месяцев. Например, age('2004-06-01', '2004-04-30')
использует апрель, чтобы получить 1 mon 1 day, в то время как
использование мая даст 1 mon 2 days потому что май имеет 31 день, а
апрель - только 30,
Вычитание дат и временных меток также может быть сложным. Один концептуально простой способ выполнить вычитание - преобразовать каждое значение в количество секунд, используя EXTRACT(EPOCH FROM ...), а затем вычесть результаты; это производит количество секунд между двумя значениями. Это позволит настроить количество дней в каждом месяце, изменения часового пояса и настройки летнего времени. Вычитание значений даты или метки времени с помощью оператора « - » возвращает количество дней (24 часа) и часов / минут / секунд между значениями, выполняя те же настройки. Функция age возвращает годы, месяцы, дни и часы / минуты / секунды, выполняя вычитание от поля к полю и затем корректируя отрицательные значения поля. Следующие запросы иллюстрируют различия в этих подходах. Результаты выборки были получены с timezone = ’US/Eastern’; существует переход на летнее время между двумя использованными датами:
SELECT EXTRACT(EPOCH FROM timestamptz '2013-07-01 12:00:00') -
EXTRACT(EPOCH FROM timestamptz '2013-03-01 12:00:00');
Result: 10537200
SELECT (EXTRACT(EPOCH FROM timestamptz '2013-07-01 12:00:00') -
EXTRACT(EPOCH FROM timestamptz '2013-03-01 12:00:00'))
/ 60 / 60 / 24;
Result: 121.958333333333
SELECT timestamptz '2013-07-01 12:00:00' - timestamptz '2013-03-01 12:00:00';
Result: 121 days 23:00:00
SELECT age(timestamptz '2013-07-01 12:00:00', timestamptz '2013-03-01 12:00:00');
Result: 4 mons
EXTRACT, date_part
EXTRACT(field FROM source)
Функция extract извлекает подполя, такие как год или час, из значений даты / времени. source должен быть выражением значения типа timestamp, time или interval. (Выражения типа date приводятся к timestamp и поэтому могут также использоваться). field - это идентификатор или строка, которая выбирает, какое поле извлечь из исходного значения. Функция extract возвращает значения типа double precision. Ниже приведены допустимые имена полей:
Century
SELECT EXTRACT(CENTURY FROM TIMESTAMP ’2000-12-16 12:21:13’);
Result: 20
SELECT EXTRACT(CENTURY FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 21
Первый век начинается в 0001-01-01 00:00:00 нашей эры, хотя они не знали этого в то время. Это определение относится ко всем странам григорианского календаря. Нет века № 0, вы переходите от -1 века к 1 веку.
day
SELECT EXTRACT(DAY FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 16
SELECT EXTRACT(DAY FROM INTERVAL ’40 days 1 minute’);
Result: 40
decade
– номер текущего десятилетия (поле года, разделенное на 10)
SELECT EXTRACT(DECADE FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 200
dow
SELECT EXTRACT(DOW FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 5
Обратите внимание, что нумерация дней недели в extract отличается от функции to_char(..., ’D’) .
doy
SELECT EXTRACT(DOY FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 47
epoch
SELECT EXTRACT(EPOCH FROM TIMESTAMP WITH TIME ZONE ’2001-02-16
20:38:40.12-08’);
Result: 982384720.12
SELECT EXTRACT(EPOCH FROM INTERVAL ’5 days 3 hours’);
Result: 442800
Вы можете преобразовать значение эпохи обратно во временную to_timestamp с помощью to_timestamp:
SELECT to_timestamp(982384720.12);
Result: 2001-02-17 04:38:40.12+00
hour
SELECT EXTRACT(HOUR FROM TIMESTAMP ’2001-02-16 20:38:40’);
Result: 20
isodow
SELECT EXTRACT(ISODOW FROM TIMESTAMP ’2001-02-18 20:38:40’);
Result: 7
Идентично dow кроме воскресенья. Это соответствует дню нумерации недели по ISO 8601.
isoyear
microseconds
millennium
milliseconds
minute
month
quarter
second
timezone
timezone_hour
timezone_minute
week
year
Заметка
Когда входное значение равно +/- Бесконечность, extract возвращает +/- Бесконечность для монотонно увеличивающихся полей (epoch, julian, year, isoyear, decade, century и millennium). Для других полей возвращается NULL.
Функция extract в первую очередь предназначена для вычислительной обработки. Форматирование значений даты / времени для отображения см. в разделе Функции форматирования типов данных.
Функция date_part смоделирована на традиционном Ingres, эквивалентном extract стандартной SQL- функции:
date_part('field', source)
Обратите внимание, что здесь параметр field должен быть строковым значением, а не именем. Допустимые имена полей для date_part такие же, как и для extract.
SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
Result: 16
SELECT date_part('hour', INTERVAL '4 hours 3 minutes');
Result: 4
date_trunc
Функция date_trunc концептуально аналогична функции trunc для чисел.
date_trunc(field, source [, time_zone ])
source - это выражение значения типа timestamp, timestamp with time zone
или interval. (Значения типа date и time автоматически timestamp в
timestamp или interval, соответственно). field выбирает, с какой
точностью обрезать входное значение. Возвращаемое значение также имеет
тип timestamp, timestamp with time zone или interval, и оно имеет все
поля, которые менее значимы, чем выбранное, установленное в ноль (или
одно, для дня и месяца).
Допустимые значения для field:
microseconds
milliseconds
second
minute
hour
day
week
month
quarter
year
decade
century
millennium
Когда входное значение имеет тип timestamp with time zone, усечение выполняется относительно определенного часового пояса; например, усечение до day приводит к значению полуночи в этой зоне. По умолчанию усечение выполняется относительно текущей настройки TimeZone, но можно указать необязательный аргумент time_zone чтобы указать другой часовой пояс. Название часового пояса можно указать любым из способов, описанных в разделе Часовые пояса.
Часовой пояс не может быть указан при обработке timestamp without time zone ввода timestamp without time zone или interval.
Примеры (при условии, что местный часовой пояс - America/New_York):
SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40');
Result: 2001-02-16 20:00:00
SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40');
Result: 2001-01-01 00:00:00
SELECT date_trunc('day', TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40+00');
Result: 2001-02-16 00:00:00-05
SELECT date_trunc('day', TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40+00', 'Australia/Sydney');
Result: 2001-02-16 08:00:00-05
SELECT date_trunc('hour', INTERVAL '3 days 02:47:33');
Result: 3 days 02:00:00
AT TIME ZONE
AT TIME ZONE преобразует временную метку без временной зоны в/из временной метки с часовым поясом и значениями времени в разные часовые пояса. Таблица 32 показывает его варианты.
Таблица 32. AT TIME ZONE Варианты
| Выражение | Тип ответа | Описание |
|---|---|---|
| timestamp without time zone AT TIME ZONE zone | timestamp with time zone | Рассматривать данную метку времени без часового пояса как расположенную в указанном часовом поясе |
| timestamp with time zone AT TIME ZONE zone | timestamp without time zone | Преобразовать данную временную метку с часовым поясом в новый часовой пояс без указания часового пояса |
| time with time zone AT TIME ZONE zone | time with time zone | Преобразовать данное время с часовым поясом в новый часовой пояс |
В этих выражениях желаемый часовой пояс может быть указан либо в виде
текстовой строки (например, ’America/Los_Angeles’), либо в качестве
интервала (например, INTERVAL ’-08:00’). В текстовом случае имя часового
пояса можно указать любым из способов, описанных в разделе Часовые пояса.
Примеры (при условии, что местным часовым поясом является
America/Los_Angeles):
SELECT TIMESTAMP '2001-02-16 20:38:40' AT TIME ZONE 'America/Denver';
Result: 2001-02-16 19:38:40-08
SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40-05' AT TIME ZONE 'America/Denver';
Result: 2001-02-16 18:38:40
SELECT TIMESTAMP '2001-02-16 20:38:40-05' AT TIME ZONE 'Asia/Tokyo' AT TIME ZONE 'America/Chicago';
Result: 2001-02-16 05:38:40
В первом примере добавляется часовой пояс к значению, в котором он отсутствует, и отображает значение с использованием текущего параметра TimeZone. Во втором примере метка времени со значением часового пояса перемещается в указанный часовой пояс и возвращает значение без часового пояса. Это позволяет хранить и отображать значения, отличные от текущей настройки TimeZone. Третий пример переводит время Токио во время Чикаго. Преобразование значений времени в другие часовые пояса использует текущие действующие правила часовых поясов, поскольку дата не указана.
Функция timezone (zone, timestamp) эквивалентна timestamp AT TIME ZONE zone соответствующей конструкции SQL, в timestamp AT TIME ZONE zone.
Текущая дата / время
QHB предоставляет ряд функций, которые возвращают значения, связанные с текущей датой и временем. Все эти стандартные функции SQL возвращают значения, основанные на времени начала текущей транзакции:
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURRENT_TIME(precision)
CURRENT_TIMESTAMP(precision)
LOCALTIME
LOCALTIMESTAMP
LOCALTIME(precision)
LOCALTIMESTAMP(precision)
CURRENT_TIME и CURRENT_TIMESTAMP доставляют значения с часовым поясом; LOCALTIME и LOCALTIMESTAMP доставляют значения без часового пояса.
CURRENT_TIME, CURRENT_TIMESTAMP, LOCALTIME и LOCALTIMESTAMP могут дополнительно принимать параметр точности, который приводит к тому, что результат округляется до такого количества дробных цифр в поле секунд. Без параметра точности результат дается с полной доступной точностью.
Несколько примеров:
SELECT CURRENT_TIME;
Result: 14:39:53.662522-05
SELECT CURRENT_DATE;
Result: 2001-12-23
SELECT CURRENT_TIMESTAMP;
Result: 2001-12-23 14:39:53.662522-05
SELECT CURRENT_TIMESTAMP(2);
Result: 2001-12-23 14:39:53.66-05
SELECT LOCALTIMESTAMP;
Result: 2001-12-23 14:39:53.662522
Поскольку эти функции возвращают время начала текущей транзакции, их значения не изменяются во время транзакции. Это считается особенностью: цель состоит в том, чтобы позволить одной транзакции иметь согласованное представление о «текущем» времени, так чтобы несколько модификаций в одной транзакции имели одинаковую отметку времени.
QHB также предоставляет функции, которые возвращают время начала текущего оператора, а также фактическое текущее время в момент вызова функции. Полный список нестандартных функций времени:
transaction_timestamp()
statement_timestamp()
clock_timestamp()
timeofday()
now()
| transaction_timestamp() | эквивалентен CURRENT_TIMESTAMP, но назван так, чтобы четко отражать то, что он возвращает. |
|---|---|
| statement_timestamp() | возвращает время начала текущего оператора (более конкретно, время получения последнего командного сообщения от клиента). |
| statement_timestamp() и transaction_timestamp() | возвращают одно и то же значение во время первой команды транзакции, но могут отличаться во время последующих команд. |
| clock_timestamp() | возвращает фактическое текущее время, поэтому его значение изменяется даже в пределах одной команды SQL. |
| timeofday() | это историческая функция QHB. Как и clock_timestamp(), он возвращает фактическое текущее время, но в виде отформатированной text строки, а не как метка времени со значением часового пояса |
| now() | это традиционный QHB, эквивалентный transaction_timestamp(). |
Все типы данных даты / времени также принимают специальное литеральное значение для указания текущей даты и времени (опять же, интерпретируется как время начала транзакции). Таким образом, все три следующие запроса возвращают один и тот же результат:
SELECT CURRENT_TIMESTAMP;
SELECT now();
SELECT TIMESTAMP ’now’; -- incorrect for use with DEFAULT
Задержка исполнения
Следующие функции доступны для задержки выполнения процесса сервера:
pg_sleep(seconds)
pg_sleep_for(interval)
pg_sleep_until(timestamp with time zone)
pg_sleep переводит процесс текущего сеанса в спящий режим до тех пор, пока не истекут указанные секунды. seconds это значение типа double precision, поэтому можно указать задержки в долях секунды. pg_sleep_for - это удобная функция для больших времен ожидания указанных в качестве интервала. pg_sleep_until - это удобная функция, когда требуется определенное время пробуждения. Например:
SELECT pg_sleep(1.5);
SELECT pg_sleep_for('5 minutes');
SELECT pg_sleep_until('tomorrow 03:00');
Эффективное разрешение интервала ожидания зависит от платформы; 0,01 секунды — это обычное значение. Задержка сна будет по крайней мере такой же, как указано. Это может быть дольше в зависимости от таких факторов, как нагрузка на сервер. В частности, pg_sleep_until не гарантированно проснется точно в указанное время, но не проснется раньше.
Убедитесь, что ваш сеанс не содержит больше блокировок, чем необходимо при вызове pg_sleep или его вариантов. В противном случае другим сеансам, возможно, придется ждать вашего спящего процесса, замедляя работу всей системы.
Функции поддержки Enum
Для типов enum (описанных в разделе Перечисляемые типы), есть несколько функций, которые позволяют более чистое программирование без жесткого кодирования определенных значений типа enum. Они перечислены в таблице 33. В примерах предполагается, что тип enum создан как:
CREATE TYPE rainbow AS ENUM (’red’, ’orange’, ’yellow’, ’green’, ’blue’, ’purple’);
Таблица 33. Функции поддержки Enum
| Функция | Описание | Пример | Результат |
|---|---|---|---|
enum_first(anyenum) | Возвращает первое значение типа входного перечисления | enum_first(null::rainbow) | red |
enum_last(anyenum) | Возвращает последнее значение типа входного перечисления | enum_last(null::rainbow) | purple |
enum_range(anyenum) | Возвращает все значения типа входного перечисления в упорядоченном массиве | enum_range(null::rainbow) | {red,orange,yellow,green,blue,purple} |
enum_range(anyenum, anyenum) | Возвращает диапазон между двумя заданными значениями перечисления в виде упорядоченного массива. Значения должны быть из того же типа перечисления. Если первый параметр имеет значение null, результат будет начинаться с первого значения типа enum. Если второй параметр имеет значение null, результат заканчивается последним значением типа enum. | enum_range(’orange’::rainbow, ’green’::rainbow) | {orange,yellow,green} |
enum_range(NULL, ’green’::rainbow) | {red,orange,yellow,green} | ||
enum_range(’orange’::rainbow, NULL) | {orange,yellow,green,blue,purple} |
Обратите внимание, что за исключением формы enum_range с двумя аргументами, эти функции игнорируют определенное значение, переданное им; они заботятся только о своем объявленном типе данных. Может быть передано либо нулевое, либо определенное значение типа с тем же результатом. Как правило, эти функции применяются к столбцу таблицы или аргументу функции, а не к имени типа с проводным подключением, как показано в примерах.
Геометрические функции и операторы
Геометрические типы point, box, lseg, line, path, polygon и circle имеют большой набор собственных вспомогательных функций и операторов, показанных в таблице 34, таблице 35 и таблице 36.
Предупреждение
Обратите внимание, что оператор «тот же, что и», ~=, представляет обычное понятие равенства для типов point, box, polygon и circle. Некоторые из этих типов также имеют оператор =, но = сравнивает только для равных областей. Другие скалярные операторы сравнения (<= и т. д.) также сравнивают области для этих типов.
Таблица 34. Геометрические операторы
| Оператор | Описание | Пример |
|---|---|---|
| + | Перевод | box ’((0,0),(1,1))’ + point ’(2.0,0)’ |
| - | Перевод | box ’((0,0),(1,1))’ - point ’(2.0,0)’ |
| * | Масштабирование / поворот | box ’((0,0),(1,1))’ * point ’(2.0,0)’ |
| / | Масштабирование / поворот | box ’((0,0),(2,2))’ / point ’(2.0,0)’ |
| # | Точка или рамка пересечения | box ’((1,-1),(-1,1))’ # box ’((1,1),(-2,-2))’ |
| # | Количество точек на пути или полигоне | # path ’((1,0),(0,1),(-1,0))’ |
| @-@ | Длина или окружность | @-@ path ’((0,0),(1,0))’ |
| @@ | Центр | @@ circle ’((0,0),10)’ |
| ## | Ближайшая точка к первому операнду второго операнда | point ’(0,0)’ ## lseg ’((2,0),(0,2))’ |
| <-> | Дистанция между | circle ’((0,0),1)’ <-> circle ’((5,0),1)’ |
| && | Совмещение? (Одна общая черта делает это правдой). | box ’((0,0),(1,1))’ && box ’((0,0),(2,2))’ |
| << | Строго осталось от? | circle ’((0,0),1)’ << circle ’((5,0),1)’ |
| >> | Это строго право? | circle ’((5,0),1)’ >> circle ’((0,0),1)’ |
| &< | Не распространяется на право? | box ’((0,0),(1,1))’ &< box ’((0,0),(2,2))’ |
| &> | Не распространяется влево от? | box ’((0,0),(3,3))’ &> box ’((0,0),(2,2))’ |
| << | Строго ниже? | box ’((0,0),(3,3))’ << box ’((3,4),(5,5))’ |
| >> | Строго выше? | box ’((3,4),(5,5))’ >> box ’((0,0),(3,3))’ |
| &< | Не распространяется выше? | box ’((0,0),(1,1))’ &< box ’((0,0),(2,2))’ |
| &> | Не распространяется ниже? | box ’((0,0),(3,3))’ &> box ’((0,0),(2,2))’ |
| <^ | Ниже (позволяет трогать)? | circle ’((0,0),1)’ <^ circle ’((0,5),1)’ |
| >^ | Выше (позволяет трогать)? | circle ’((0,5),1)’ >^ circle ’((0,0),1)’ |
| ?# | Intersects? | lseg ’((-1,0),(1,0))’ ?# box ’((-2,-2),(2,2))’ |
| ?- | Горизонтальный? | ?- lseg ’((-1,0),(1,0))’ |
| ?- | Выровнены по горизонтали? | point ’(1,0)’ ?- point ’(0,0)’ |
| ? | Вертикально? | ? lseg ’((-1,0),(1,0))’ |
| ? | Выровнены по вертикали? | point ’(0,1)’ ? point ’(0,0)’ |
| ?- | Перпендикулярно? | lseg ’((0,0),(0,1))’ ?- lseg ’((0,0),(1,0))’ |
| ? | Параллельны? | lseg ’((-1,0),(1,0))’ ? lseg ’((-1,2),(1,2))’ |
| @> | Содержит? | circle ’((0,0),2)’ @> point ’(1,1)’ |
| <@ | Содержится в или на? | point ’(1,1)’ <@ circle ’((0,0),2)’ |
| ~= | Такой же как? | polygon ’((0,0),(1,1))’ ~= polygon ’((1,1),(0,0))’ |
Таблица 35. Геометрические функции
| Функция | Тип ответа | Описание | Пример |
|---|---|---|---|
| area(object) | double precision | площадь | area(box ’((0,0),(1,1))’) |
| center(object) | point | центр | center(box ’((0,0),(1,2))’) |
| diameter(circle) | double precision | диаметр круга | diameter(circle ’((0,0),2.0)’) |
| height(box) | double precision | вертикальный размер коробки | height(box ’((0,0),(1,1))’) |
| isclosed(path) | boolean | закрытый путь? | isclosed(path ’((0,0),(1,1),(2,0))’) |
| isopen(path) | boolean | открытый путь? | isopen(path ’[(0,0),(1,1),(2,0)]’) |
| length(object) | double precision | длина | length(path ’((-1,0),(1,0))’) |
| npoints(path) | int | количество баллов | npoints(path ’[(0,0),(1,1),(2,0)]’) |
| npoints(polygon) | int | количество баллов | npoints(polygon ’((1,1),(0,0))’) |
| pclose(path) | path | преобразовать путь в закрытый | pclose(path ’[(0,0),(1,1),(2,0)]’) |
| popen(path) | path | преобразовать путь в открытый | popen(path ’((0,0),(1,1),(2,0))’) |
| radius(circle) | double precision | радиус круга | radius(circle ’((0,0),2.0)’) |
| width(box) | double precision | горизонтальный размер коробки | width(box ’((0,0),(1,1))’) |
Таблица 36. Функции преобразования геометрических типов
| Функция | Тип ответа | Описание | Пример |
|---|---|---|---|
| box(circle) | box | круг к рамке | box(circle ’((0,0),2.0)’) |
| box(point) | box | указать на пустое поле | box(point ’(0,0)’) |
| box(point, point) | box | указывает на рамку | box(point ’(0,0)’, point ’(1,1)’) |
| box(polygon) | box | полигон в рамку | box(polygon ’((0,0),(1,1),(2,0))’) |
| bound_box(box, box) | box | рамка к ограничительной рамке | bound_box(box ’((0,0),(1,1))’, box ’((3,3),(4,4))’) |
| circle(box) | circle | рамка в круг | circle(box ’((0,0),(1,1))’) |
| circle(point, double precision) | circle | центр и радиус окружности | circle(point ’(0,0)’, 2.0) |
| circle(polygon) | circle | многоугольник в круг | circle(polygon ’((0,0),(1,1),(2,0))’) |
| line(point, point) | line | указывает на линию | line(point ’(-1,0)’, point ’(1,0)’) |
| lseg(box) | lseg | диагональ прямоугольника к отрезку | lseg(box ’((-1,0),(1,0))’) |
| lseg(point, point) | lseg | указывает на отрезок | lseg(point ’(-1,0)’, point ’(1,0)’) |
| path(polygon) | path | полигон к пути | path(polygon ’((0,0),(1,1),(2,0))’) |
| point (double precision, double precision) | point | построить точку | point(23.4, -44.5) |
| point(box) | point | центр рамки | point(box ’((-1,0),(1,0))’) |
| point(circle) | point | центр круга | point(circle ’((0,0),2.0)’) |
| point(lseg) | point | центр отрезка | point(lseg ’((-1,0),(1,0))’) |
| point(polygon) | point | центр многоугольника | point(polygon ’((0,0),(1,1),(2,0))’) |
| polygon(box) | polygon | коробка к 4-х точечному многоугольнику | polygon(box ’((0,0),(1,1))’) |
| polygon(circle) | polygon | окружность до 12-точечного многоугольника | polygon(circle ’((0,0),2.0)’) |
| polygon(npts, circle) | polygon | окружность в npts -точечный многоугольник | polygon(12, circle ’((0,0),2.0)’) |
| polygon(path) | polygon | путь к многоугольнику | polygon(path ’((0,0),(1,1),(2,0))’) |
Можно получить доступ к двум номерам компонентов point как если бы точка
была массивом с индексами 0 и 1. Например, если t.p является столбцом
point то SELECT p\[0\] FROM t извлекает координату X и UPDATE t SET p[1] = ... изменяет координату Y. Таким же образом значение типа box
или lseg можно рассматривать как массив из двух point значений.
Функция area работает для типов box, circle и path. Функция area
работает только с типом данных path если точки в path не пересекаются.
Например, path ’((0,0),(0,1),(2,1),(2,2),(1,2),(1,0),(0,0))’::PATH не
будет работать; однако следующий визуально идентичный path ’((0,0),(0,1),(1,1),(1,2),(2,2),(2,1),(1,1),(1,0),(0,0))’::PATH будет
работать. Если концепция пересекающегося и непересекающегося path вводит
в заблуждение, нарисуйте оба вышеупомянутых path рядом на листе
миллиметровки.
Функции и операторы сетевых адресов
В таблице 37 показаны операторы, доступные для типов cidr и inet. Операторы <<, <<=, >>, >>= и && проверяют наличие подсети. Они рассматривают только сетевые части двух адресов (игнорируя любую часть хоста) и определяют, является ли одна сеть идентичной или подсетью другой.
| Оператор | Описание | Пример |
|---|---|---|
| < | меньше чем | inet ’192.168.1.5’ < inet ’192.168.1.6’ |
| <= | меньше или равно | inet ’192.168.1.5’ <= inet ’192.168.1.5’ |
| = | равно | inet ’192.168.1.5’ = inet ’192.168.1.5’ |
| >= | больше или равно | inet ’192.168.1.5’ >= inet ’192.168.1.5’ |
| > | больше, чем | inet ’192.168.1.5’ > inet ’192.168.1.4’ |
| <> | не равно | inet ’192.168.1.5’ <> inet ’192.168.1.4’ |
| << | содержится в | inet ’192.168.1.5’ << inet ’192.168.1/24’ |
| <<= | содержится или равно | inet ’192.168.1/24’ <<= inet ’192.168.1/24’ |
| >> | содержит | inet ’192.168.1/24’ >> inet ’192.168.1.5’ |
| >>= | содержит или равно | inet ’192.168.1/24’ >>= inet ’192.168.1/24’ |
| && | содержит или содержится | inet ’192.168.1/24’ && inet ’192.168.1.80/28’ |
| ~ | поразрядно НЕ | ~ inet ’192.168.1.6’ |
| & | побитовое И | inet ’192.168.1.6’ & inet ’0.0.0.255’ |
| побитовое ИЛИ | inet ’192.168.1.6’ inet ’0.0.0.255’ | |
| + | прибавление | inet ’192.168.1.6’ + 25 |
| - | вычитание | inet ’192.168.1.43’ - 36 |
| - | вычитание | inet ’192.168.1.43’ - inet ’192.168.1.19’ |
В таблице 38 показаны функции, доступные для использования с типам cidr и inet. Функции abbrev, host и text в первую очередь предназначены для предоставления альтернативных форматов отображения.
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| abbrev(inet) | text | сокращенный формат отображения в виде текста | abbrev(inet ’10.1.0.0/16’) | 10.1.0.0/16 |
| abbrev(cidr) | text | сокращенный формат отображения в виде текста | abbrev(cidr ’10.1.0.0/16’) | 10.1/16 |
| broadcast(inet) | inet | широковещательный адрес для сети | broadcast(’192.168.1.5/24’) | 192.168.1.255/24 |
| family(inet) | int | извлечь семейство адресов; 4 для IPv4, 6 для IPv6 | family(’::1’) | 6 |
| host(inet) | text | извлечь IP-адрес в виде текста | host(’192.168.1.5/24’) | 192.168.1.5 |
| hostmask(inet) | inet | построить маску хоста для сети | hostmask(’192.168.23.20/30’) | 0.0.0.3 |
| masklen(inet) | int | извлекать длину маски | masklen(’192.168.1.5/24’) | 24 |
| netmask(inet) | inet | построить сетевую маску для сети | netmask(’192.168.1.5/24’) | 255.255.255.0 |
| network(inet) | cidr | извлечь сетевую часть адреса | network(’192.168.1.5/24’) | 192.168.1.0/24 |
| set_masklen(inet, int) | inet | установить длину маски для значения inet | set_masklen(’192.168.1.5/24’, 16) | 192.168.1.5/16 |
| set_masklen(cidr, int) | cidr | установить длину маски маски для значения cidr | set_masklen(’192.168.1.0/24’::cidr, 16) | 192.168.0.0/16 |
| text(inet) | text | извлечь IP-адрес и длину маски в виде текста | text(inet ’192.168.1.5’) | 192.168.1.5/32 |
| inet_same_family(inet, inet) | boolean | адреса из одной семьи? | inet_same_family(’192.168.1.5/24’, ’::1’) | false |
| inet_merge(inet, inet) | cidr | самая маленькая сеть, которая включает в себя обе из указанных сетей | inet_merge(’192.168.1.5/24’, ’192.168.2.5/24’) | 192.168.0.0/22 |
Любое значение cidr может быть приведено к inet неявно или явно;
следовательно, функции, показанные выше, как работающие с inet также
работают со значениями cidr. (Там, где есть отдельные функции для inet и
cidr, это происходит потому, что поведение должно отличаться для двух
случаев). Кроме того, разрешено приводить значение inet к cidr. Когда
это будет сделано, любые биты справа от маски маски будут cidr обнулены
для создания действительного значения cidr. Кроме того, вы можете
преобразовать текстовое значение в inet или cidr используя обычный
синтаксис приведения: например, inet(expression) или colname::cidr.
В таблице 39 показаны функции, доступные для использования с типом macaddr. Функция trunc(macaddr) возвращает MAC-адрес с последними 3 байтами, установленными в ноль. Это может быть использовано для связи оставшегося префикса с производителем.
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| trunc(macaddr) | macaddr | установить последние 3 байта в ноль | trunc(macaddr ’12:34:56:78:90:ab’) | 12:34:56:00:00:00 |
Тип macaddr также поддерживает стандартные реляционные операторы (>, <= и т. Д). Для лексикографического упорядочения и побитовые арифметические операторы (~, & и ) для NOT, AND и OR.
В таблице 40 показаны функции, доступные для использования с типом macaddr8. Функция trunc(macaddr8) возвращает MAC-адрес с последними 5 байтами, установленными в ноль. Это может быть использовано для связи оставшегося префикса с производителем.
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
trunc(macaddr8) | macaddr8 | установить последние 5 байтов в ноль | trunc(macaddr8 ’12:34:56:78:90:ab:cd:ef’) | 12:34:56:00:00:00:00:00 |
macaddr8_set7bit(macaddr8) | macaddr8 | установите 7-й бит в единицу, также известный как модифицированный EUI-64, для включения в адрес IPv6 | macaddr8_set7bit(macaddr8 ’00:34:56:ab:cd:ef’) | 02:34:56:ff:fe:ab:cd:ef |
Тип macaddr8 также поддерживает стандартные реляционные операторы (>, <= и т. д). Для упорядочения и побитовые арифметические операторы (~, & и ) для NOT, AND и OR.
Функции текстового поиска и операторы
В таблице 41, таблице 42 и таблице 43 обобщены функции и операторы, которые предоставляются для полнотекстового поиска.
Таблица 41. Операторы текстового поиска
| Оператор | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| @@ | boolean | tsvector соответствует tsquery ? | to_tsvector(’fat cats ate rats’) @@ to_tsquery(’cat & rat’) | t |
| @@@ | boolean | устарел синоним @@ | to_tsvector(’fat cats ate rats’) @@@ to_tsquery(’cat & rat’) | t |
| tsvector | tsvector с | ’a:1 b:2’::tsvector ’c:1 d:2 b:3’::tsvector | ’a’:1 ’b’:2,5 ’c’:3 ’d’:4 | |
| && | tsquery | И tsquery с вместе | ’fat rat’::tsquery && ’cat’::tsquery | (’fat’ ’rat’) & ’cat’ |
| tsquery | ИЛИ tsquery с вместе | ’fat rat’::tsquery ’cat’::tsquery | (’fat’ ’rat’) ’cat’ | |
| !! | tsquery | отрицать tsquery | !! ’cat’::tsquery | !’cat’ |
| <-> | tsquery | tsquery последующим tsquery | to_tsquery(’fat’) <-> to_tsquery(’rat’) | ’fat’ <-> ’rat’ |
| @> | boolean | tsquery содержит другое? | ’cat’::tsquery @> ’cat & rat’::tsquery | f |
| <@ | boolean | tsquery содержится в? | ’cat’::tsquery <@ ’cat & rat’::tsquery | t |
Операторы содержания tsquery учитывают только лексемы, перечисленные в двух запросах, игнорируя операторы объединения.
В дополнение к операторам, показанным в таблице, обычные операторы сравнения B-деревьев (=, < и т.д.). Определены для типов tsvector и tsquery. Они не очень полезны для текстового поиска, но позволяют, например, создавать уникальные индексы на столбцах этих типов.
Таблица 42. Функции текстового поиска
| Функция | Тип ответа | Описание | пример | Результат |
|---|---|---|---|---|
array_to_tsvector (text[]) | tsvector | конвертировать массив лексем в tsvector | array_to_tsvector(’{fat,cat,rat}’::text[]) | ’cat’ ’fat’ ’rat’ |
get_current_ts_config() | regconfig | получить конфигурацию текстового поиска по умолчанию | get_current_ts_config() | english |
length (tsvector) | integer | количество лексем в tsvector | length(’fat:2,4 cat:3 rat:5A’::tsvector) | 3 |
numnode (tsquery) | integer | количество лексем плюс операторов в tsquery | numnode(’(fat & rat) cat’::tsquery) | 5 |
plainto_tsquery ([ config regconfig, ] query text) | tsquery | производить tsquery игнорируя пунктуацию | plainto_tsquery(’english’, ’The Fat Rats’) | ’fat’ & ’rat’ |
phraseto_tsquery ([ config regconfig, ] query text) | tsquery | производить tsquery который ищет фразу, игнорируя пунктуацию | phraseto_tsquery(’english’, ’The Fat Rats’) | ’fat’ <-> ’rat’ |
websearch_to_tsquery ([ config regconfig, ] query text) | tsquery | создать tsquery из запроса в стиле веб-поиска | websearch_to_tsquery(’english’, ’"fat rat" or rat’) | ’fat’ <-> ’rat’ ’rat’ |
querytree(query tsquery) | text | получить индексируемую часть tsquery | querytree(’foo & ! bar’::tsquery) | ’foo’ |
setweight(vector tsvector, weight "char") | tsvector | назначить weight каждому элементу vector | setweight(’fat:2,4 cat:3 rat:5B’::tsvector, ’A’) | ’cat’:3A ’fat’:2A,4A ’rat’:5A |
setweight(vector tsvector, weight "char", lexemes text[]) | tsvector | присваивать weight элементам vector, перечисленным в lexemes | setweight(’fat:2,4 cat:3 rat:5B’::tsvector, ’A’, ’{cat,rat}’) | ’cat’:3A ’fat’:2,4 ’rat’:5A |
strip(tsvector) | tsvector | убрать позиции и веса с tsvector | strip(’fat:2,4 cat:3 rat:5A’::tsvector) | ’cat’ ’fat’ ’rat’ |
to_tsquery([ config regconfig, ] query text) | tsquery | нормализуйте слова и конвертируйте в tsquery | to_tsquery(’english’, ’The & Fat & Rats’) | ’fat’ & ’rat’ |
to_tsvector([ config regconfig, ] document text) | tsvector | уменьшить текст документа до tsvector | to_tsvector(’english’, ’The Fat Rats’) | ’fat’:2 ’rat’:3 |
to_tsvector([ config regconfig, ] document json(b)) | tsvector | уменьшите каждое строковое значение в документе до tsvector, а затем tsvector их в порядке документа для получения одного tsvector | to_tsvector(’english’, ’{"a": "The Fat Rats"}’::json) | ’fat’:2 ’rat’:3 |
json(b)_to_tsvector([ config regconfig, ] document json(b), filter json(b)) | tsvector | уменьшите каждое значение в документе, заданном filter до tsvector, а затем tsvector их в порядке документа, чтобы получить один tsvector. filter - это массив jsonb, который перечисляет, какие элементы должны быть включены в результирующий tsvector. Возможные значения для filter: "string" (чтобы включить все строковые значения), "numeric" (чтобы включить все числовые значения в строковом формате), "boolean" (чтобы включить все логические значения в строковом формате "true" / "false"), "key" (чтобы включить все ключи) или "all" (чтобы включить все выше). Эти значения можно объединить, чтобы включить, например, все строковые и числовые значения. | json_to_tsvector(’english’, ’{"a": "The Fat Rats", "b": 123}’::json, ’["string", "numeric"]’) | ’123’:5 ’fat’:2 ’rat’:3 |
ts_delete(vector tsvector, lexeme text) | tsvector | удалить данную lexeme из vector | ts_delete(’fat:2,4 cat:3 rat:5A’::tsvector, ’fat’) | ’cat’:3 ’rat’:5A |
ts_delete(vector tsvector, lexemes text[]) | tsvector | удалить любое вхождение лексем в lexemes из vector | ts_delete(’fat:2,4 cat:3 rat:5A’::tsvector, ARRAY[’fat’,’rat’]) | ’cat’:3 |
ts_filter(vector tsvector, weights "char"[]) | tsvector | выбрать только элементы с заданными weights из vector | ts_filter(’fat:2,4 cat:3b rat:5A’::tsvector, ’{a,b}’) | ’cat’:3B ’rat’:5A |
ts_headline([ config regconfig, ] document text, query tsquery [, options text ]) | text | отобразить соответствие запроса | ts_headline(’xy z’, ’z’::tsquery) | xy <b>z</b> |
ts_headline([ config regconfig, ] document json(b), query tsquery [, options text ]) | text | отобразить соответствие запроса | ts_headline(’{"a":"xyz"}’::json, ’z’::tsquery) | {"a":"xy <b>z</b>"} |
ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) | float4 | ранжировать документ по запросу | ts_rank(textsearch, query) | 0.818 |
ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) | float4 | ранжировать документ для запроса с использованием плотности покрытия | ts_rank_cd(’{0.1, 0.2, 0.4, 1.0}’, textsearch, query) | 2.01317 |
ts_rewrite(query tsquery, target tsquery, substitute tsquery) | tsquery | заменить target substitute в запросе | ts_rewrite(’a & b’::tsquery, ’a’::tsquery, ’foobar’::tsquery) | ’b’ & (’foo’ ’bar’) |
ts_rewrite(query tsquery, select text) | tsquery | заменить, используя цели и замены из команды SELECT | SELECT ts_rewrite(’a & b’::tsquery, ’SELECT t,s FROM aliases’) | ’b’ & (’foo’ ’bar’) |
tsquery_phrase(query1 tsquery, query2 tsquery) | tsquery | создать запрос, который ищет query1 за которым следует query2 (аналогично оператору <->) | tsquery_phrase(to_tsquery(’fat’), to_tsquery(’cat’)) | ’fat’ <-> ’cat’ |
tsquery_phrase(query1 tsquery, query2 tsquery, distance integer) | tsquery | создать запрос, который ищет query1 за которым следует query2 на distance | tsquery_phrase(to_tsquery(’fat’), to_tsquery(’cat’), 10) | ’fat’ <10> ’cat’ |
tsvector_to_array(tsvector) | text[] | конвертировать tsvector в массив лексем | tsvector_to_array(’fat:2,4 cat:3 rat:5A’::tsvector) | {cat,fat,rat} |
tsvector_update_trigger() | trigger | функция триггера для автоматического обновления столбца tsvector | CREATE TRIGGER ... tsvector_update_trigger(tsvcol, ’pg_catalog.swedish’, title, body) | |
tsvector_update_trigger_column() | trigger | функция триггера для автоматического обновления столбца tsvector | CREATE TRIGGER ... tsvector_update_trigger_column(tsvcol, configcol, title, body) | |
unnest(tsvector, OUT lexeme text, OUT positions smallint[], OUT weights text) | setof record | разверните tsvector до набора строк | unnest(’fat:2,4 cat:3 rat:5A’::tsvector) | (cat,{3},{D}) ... |
Все функции текстового поиска, которые принимают необязательный аргумент regconfig будут использовать конфигурацию, заданную параметром default_text_search_config, когда этот аргумент пропущен.
Функции в таблице 43 перечислены отдельно, потому что они обычно не используются в повседневных операциях текстового поиска. Они полезны для разработки и отладки новых конфигураций текстового поиска.
Таблица 43. Функции отладки текстового поиска
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
ts_debug(\[ config regconfig, \] document text, OUT alias text, OUT description text, OUT token text, OUT dictionaries regdictionary\[\], OUT dictionary regdictionary, OUT lexemes text\[\]) | setof record | протестировать конфигурацию | ts_debug (’english’, ’The Brightest supernovaes’) | (asciiword,"Word, all ASCII",The, {english_stem}, english_stem,{}) ... |
ts_lexize(dict regdictionary, token text) | text[] | проверить словарь | ts_lexize (’english_stem’, ’stars’) | {star} |
ts_parse(parser_name text, document text, OUT tokid integer, OUT token text) | setof record | проверить парсер | ts_parse (’default’, ’foo - bar’) | (1,foo) ... |
ts_parse(parser_oid oid, document text, OUT tokid integer, OUT token text) | setof record | проверить парсер | ts_parse (3722, ’foo - bar’) | (1,foo) ... |
ts_token_type(parser_name text, OUT tokid integer, OUT alias text, OUT description text) | setof record | получить типы токенов, определенные парсером | ts_token_type (’default’) | (1,asciiword, "Word, all ASCII") ... |
ts_token_type(parser_oid oid, OUT tokid integer, OUT alias text, OUT description text) | setof record | получить типы токенов, определенные парсером | ts_token_type (3722) | (1,asciiword, "Word, all ASCII") ... |
ts_stat(sqlquery text, \[ weights text, \] OUT word text, OUT ndoc integer, OUT nentry integer) | setof record | получить статистику столбца tsvector | ts_stat (’SELECT vector from apod’) | (foo,10,15) ... |
Функции XML
Функции и функционально-подобные выражения, описанные в этом разделе, работают со значениями типа xml. См. раздел Тип XML для получения информации о типе xml. Функциональные выражения xmlparse и xmlserialize для преобразования в тип xml и из него описаны там, а не в этом разделе.
Использование большинства этих функций требует, чтобы QHB был собран с помощью configure --with-libxml.
Создание XML-контента
Набор функций и функциональных выражений доступен для создания XML-контента из данных SQL. Как таковые, они особенно подходят для форматирования результатов запросов в XML-документы для обработки в клиентских приложениях.
xmlcomment
xmlcomment(text)
Функция xmlcomment создает значение XML, содержащее комментарий XML с
указанным текстом в качестве содержимого. Текст не может содержать «--»
или заканчиваться на «-», поэтому полученная конструкция является
допустимым комментарием XML. Если аргумент равен нулю, результат равен
нулю.
Пример:
SELECT xmlcomment('hello');
xmlcomment
--------------
<!--hello-->
xmlconcat
xmlconcat(xml[, ...])
Функция xmlconcat объединяет список отдельных значений XML, чтобы создать одно значение, содержащее фрагмент содержимого XML. Нулевые значения опущены; результат будет нулевым, если нет ненулевых аргументов.
Пример:
SELECT xmlconcat('<abc/>', '<bar>foo</bar>');
xmlconcat
----------------------
<abc/><bar>foo</bar>
Объявления XML, если они есть, объединяются следующим образом. Если все значения аргументов имеют одно и то же объявление версии XML, эта версия используется в результате, иначе версия не используется. Если все значения аргумента имеют отдельное значение объявления «да», то это значение используется в результате. Если все значения аргумента имеют отдельное значение объявления и по крайней мере одно - «нет», то это используется в результате. В противном случае результат не будет иметь отдельной декларации. Если для результата определено, что требуется отдельное объявление, но нет объявления версии, будет использоваться объявление версии с версией 1.0, поскольку для XML требуется, чтобы объявление XML содержало объявление версии. Декларации кодирования игнорируются и удаляются во всех случаях.
Пример:
SELECT xmlconcat('<?xml version="1.1"?><foo/>', '<?xml version="1.1" standalone="no"?><bar/>');
xmlconcat
-----------------------------------
<?xml version="1.1"?><foo/><bar/>
xmlelement
xmlelement(name name [, xmlattributes(value [AS attname] [, ... ])] [, content, ...])
Выражение xmlelement создает элемент XML с заданным именем, атрибутами и содержимым.
Примеры:
SELECT xmlelement(name foo);
xmlelement
------------
<foo/>
SELECT xmlelement(name foo, xmlattributes('xyz' as bar));
xmlelement
------------------
<foo bar="xyz"/>
SELECT xmlelement(name foo, xmlattributes(current_date as bar), 'cont', 'ent');
xmlelement
-------------------------------------
<foo bar="2007-01-26">content</foo>
Имена элементов и атрибутов, которые не являются допустимыми именами
XML, экранируются путем замены нарушающих символов последовательностью
_x HHHH _, где HHHH - это HHHH Unicode символа в шестнадцатеричной
записи. Например:
SELECT xmlelement(name "foo$bar", xmlattributes('xyz' as "a&b"));
xmlelement
----------------------------------
<foo_x0024_bar a_x0026_b="xyz"/>
Явное имя атрибута указывать не нужно, если значение атрибута является ссылкой на столбец, и в этом случае имя столбца будет использоваться в качестве имени атрибута по умолчанию. В других случаях атрибуту должно быть дано явное имя. Так что этот пример действителен:
CREATE TABLE test (a xml, b xml);
SELECT xmlelement(name test, xmlattributes(a, b)) FROM test;
Но это не так:
SELECT xmlelement(name test, xmlattributes('constant'), a, b) FROM test;
SELECT xmlelement(name test, xmlattributes(func(a, b))) FROM test;
Содержимое элемента, если оно указано, будет отформатировано в соответствии с его типом данных. Если сам контент имеет тип xml, можно создавать сложные XML-документы. Например:
SELECT xmlelement(name foo, xmlattributes('xyz' as bar),
xmlelement(name abc),
xmlcomment('test'),
xmlelement(name xyz));
xmlelement
----------------------------------------------
<foo bar="xyz"><abc/><!--test--><xyz/></foo>
Содержимое других типов будет отформатировано в допустимые символьные данные XML. В частности, это означает, что символы <,> и & будут преобразованы в объекты. Двоичные данные (тип данных bytea) будут представлены в bytea base64 или hex, в зависимости от настройки параметра конфигурации xmlbinary. Ожидается, что конкретное поведение для отдельных типов данных будет развиваться, чтобы выровнять сопоставления QHB с сопоставлениями, указанными в SQL: 2006 и более поздних версия.
xmlforest
xmlforest(content [AS name] [, ...])
Выражение xmlforest создает XML-лес (последовательность) элементов с использованием заданных имен и содержимого.
Примеры:
SELECT xmlforest('abc' AS foo, 123 AS bar);
xmlforest
------------------------------
<foo>abc</foo><bar>123</bar>
SELECT xmlforest(table_name, column_name)
FROM information_schema.columns
WHERE table_schema = 'pg_catalog';
xmlforest
-------------------------------------------------------------------------------------------
<table_name>pg_authid</table_name><column_name>rolname</column_name>
<table_name>pg_authid</table_name><column_name>rolsuper</column_name>
...
Как видно из второго примера, имя элемента может быть опущено, если значение содержимого является ссылкой на столбец, и в этом случае имя столбца используется по умолчанию. В противном случае имя должно быть указано.
Имена элементов, которые не являются допустимыми именами XML, экранируются, как показано выше для xmlelement. Точно так же данные содержимого экранируются для создания допустимого содержимого XML, если оно уже не имеет тип xml.
Обратите внимание, что деревья XML не являются действительными документами XML, если они состоят из более чем одного элемента, поэтому может быть полезно обернуть выражения xmlforest в xmlelement.
xmlpi
xmlpi(name target [, content])
Выражение xmlpi создает инструкцию обработки XML. Содержимое, если оно присутствует, не должно содержать последовательность символов ?>.
Пример:
SELECT xmlpi(name php, 'echo "hello world";');
xmlpi
-----------------------------
<?php echo "hello world";?>
xmlroot
xmlroot(xml, version text | no value [, standalone yes|no|no value])
Выражение xmlroot изменяет свойства корневого узла значения XML. Если указана версия, она заменяет значение в объявлении версии корневого узла; если указан автономный параметр, он заменяет значение в автономном объявлении корневого узла.
SELECT xmlroot(xmlparse(document '<?xml version="1.1"?><content>abc</content>'),
version '1.0', standalone yes);
xmlroot
----------------------------------------
<?xml version="1.0" standalone="yes"?>
<content>abc</content>
xmlagg
xmlagg(xml)
Функция xmlagg, в отличие от других функций, описанных здесь, является агрегатной функцией. Он объединяет входные значения с вызовом агрегатной функции, во многом как xmlconcat, за исключением того, что объединение происходит по строкам, а не по выражениям в одной строке. См. раздел Агрегатные функции для получения дополнительной информации о агрегатных функциях.
Пример:
CREATE TABLE test (y int, x xml);
INSERT INTO test VALUES (1, '<foo>abc</foo>');
INSERT INTO test VALUES (2, '<bar/>');
SELECT xmlagg(x) FROM test;
xmlagg
----------------------
<foo>abc</foo><bar/>
Чтобы определить порядок объединения, в совокупный вызов может быть добавлено предложение ORDER BY как описано в разделе Агрегатные выражения. Например:
SELECT xmlagg(x ORDER BY y DESC) FROM test;
xmlagg
----------------------
<bar/><foo>abc</foo>
Следующий нестандартный подход рекомендовался в предыдущих версиях и может быть полезен в определенных случаях:
SELECT xmlagg(x) FROM (SELECT * FROM test ORDER BY y DESC) AS tab;
xmlagg
----------------------
<bar/><foo>abc</foo>
Предикаты XML
Выражения, описанные в этом разделе, проверяют свойства значений xml.
IS DOCUMENT
xml IS DOCUMENT
Выражение IS DOCUMENT возвращает значение true, если значение аргумента XML является правильным документом XML, значение false, если это не так (то есть фрагмент содержимого), или значение null, если аргумент равен null. См. раздел Тип XML о разнице между документами и фрагментами контента.
IS NOT DOCUMENT
xml IS NOT DOCUMENT
Выражение IS NOT DOCUMENT возвращает значение false, если значение аргумента XML является правильным документом XML, значение true, если это не так (то есть фрагмент содержимого), или значение NULL, если аргумент равен NULL.
XMLEXISTS
XMLEXISTS(text PASSING [BY { REF | VALUE }] xml [BY { REF | VALUE }])
Функция xmlexists оценивает выражение XPath 1.0 (первый аргумент) с переданным значением XML в качестве элемента контекста. Функция возвращает false, если в результате этой оценки получен пустой набор узлов, true, если она возвращает любое другое значение. Функция возвращает ноль, если любой аргумент равен нулю. Ненулевое значение, передаваемое в качестве элемента контекста, должно быть документом XML, а не фрагментом содержимого или любым не-XML-значением.
Пример:
SELECT xmlexists('//town[text() = ''Toronto'']' PASSING BY VALUE '<towns><town>Toronto</town><town>Ottawa</town></towns>');
xmlexists
------------
t
(1 row)
Предложения BY REF и BY VALUE принимаются в QHB, но игнорируются. В стандарте SQL функция xmlexists оценивает выражение на языке XML Query, но QHB допускает только выражение XPath 1.0.
xml_is_well_formed
xml_is_well_formed(text)
xml_is_well_formed_document(text)
xml_is_well_formed_content(text)
Эти функции проверяют, является ли text строка правильно сформированным XML, возвращая логический результат. xml_is_well_formed_document проверяет правильно сформированный документ, а xml_is_well_formed_content проверяет правильно сформированный контент. xml_is_well_formed выполняет первое, если для параметра конфигурации xmloption задано значение DOCUMENT, или второе, если для него задано CONTENT. Это означает, что xml_is_well_formed полезен для определения успешности простого приведения к типу xml, тогда как две другие функции полезны для определения того, будут ли успешными соответствующие варианты XMLPARSE.
Примеры:
SET xmloption TO DOCUMENT;
SELECT xml_is_well_formed('<>');
xml_is_well_formed
--------------------
f
(1 row)
SELECT xml_is_well_formed('<abc/>');
xml_is_well_formed
--------------------
t
(1 row)
SET xmloption TO CONTENT;
SELECT xml_is_well_formed('abc');
xml_is_well_formed
--------------------
t
(1 row)
SELECT xml_is_well_formed_document('<pg:foo xmlns:pg="http://postgresql.org/stuff">bar</pg:foo>');
xml_is_well_formed_document
-----------------------------
t
(1 row)
SELECT xml_is_well_formed_document('<pg:foo xmlns:pg="http://postgresql.org/stuff">bar</my:foo>');
xml_is_well_formed_document
-----------------------------
f
(1 row)
Последний пример показывает, что проверки включают в себя правильное совпадение пространств имен.
Обработка XML
Для обработки значений типа данных xml QHB предлагает функции xpath и xpath_exists, которые оценивают выражения XPath 1.0, и XMLTABLE функцию XMLTABLE.
xpath
xpath(xpath, xml [, nsarray])
Функция xpath вычисляет выражение XPath 1.0 xpath (text значение) по отношению к XML-значению xml. Он возвращает массив XML-значений, соответствующих набору узлов, созданному выражением XPath. Если выражение XPath возвращает скалярное значение, а не набор узлов, то возвращается массив из одного элемента.
Второй аргумент должен быть правильно сформированным документом XML. В частности, он должен иметь один элемент корневого узла.
Необязательный третий аргумент функции — это массив отображений пространства имен. Этот массив должен быть двумерным text массивом с длиной второй оси, равной 2 (т.е. это должен быть массив массивов, каждый из которых состоит ровно из 2 элементов). Первый элемент каждой записи массива — это имя пространства имен (псевдоним), второй - URI пространства имен. Не требуется, чтобы псевдонимы, предоставленные в этом массиве, были такими же, как и используемые в самом документе XML (другими словами, как в документе XML, так и в контексте функции xpath, псевдонимы являются локальными).
Пример:
SELECT xpath('/my:a/text()', '<my:a xmlns:my="http://example.com">test</my:a>',
ARRAY[ARRAY['my', 'http://example.com']]);
xpath
--------
{test}
(1 row)
Чтобы работать с пространствами имен по умолчанию (анонимными), сделайте что-то вроде этого:
SELECT xpath('//mydefns:b/text()', '<a xmlns="http://example.com"><b>test</b></a>',
ARRAY[ARRAY['mydefns', 'http://example.com']]);
xpath
--------
{test}
(1 row)
xpath_exists {#}
xpath_exists(xpath, xml [, nsarray])
Функция xpath_exists является специализированной формой функции xpath. Вместо того чтобы возвращать отдельные значения XML, которые удовлетворяют выражению XPath 1.0, эта функция возвращает логическое значение, указывающее, был ли выполнен запрос или нет (в частности, было ли получено какое-либо значение, отличное от пустого набора узлов). Эта функция эквивалентна предикату XMLEXISTS, за исключением того, что она также поддерживает аргумент сопоставления пространства имен.
Пример:
SELECT xpath_exists('/my:a/text()', '<my:a xmlns:my="http://example.com">test</my:a>',
ARRAY[ARRAY['my', 'http://example.com']]);
xpath_exists
--------------
t
(1 row)
xmltable
xmltable( [XMLNAMESPACES(namespace uri AS namespace name[, ...]), ]
row_expression PASSING [BY { REF | VALUE }] document_expression [BY { REF | VALUE }]
COLUMNS name { type [PATH column_expression] [DEFAULT default_expression] [NOT NULL | NULL]
| FOR ORDINALITY }
[, ...]
)
Функция xmltable создает таблицу на основе заданного значения XML, фильтра XPath для извлечения строк и набора определений столбцов.
Необязательное предложение XMLNAMESPACES представляет собой список пространств имен, разделенных запятыми. Он определяет пространства имен XML, используемые в документе, и их псевдонимы. Спецификация пространства имен по умолчанию в настоящее время не поддерживается.
Обязательный аргумент row_expression — это выражение XPath 1.0, которое оценивается, передавая document_expression в качестве элемента контекста, для получения набора узлов XML. Эти узлы - то, что xmltable превращает в выходные строки. Строки не будут создаваться, если document_expression имеет значение null, а также если row_expression создает пустой набор узлов или любое значение, отличное от набора узлов.
document_expression предоставляет элемент контекста для row_expression. Это должен быть правильно сформированный XML-документ; фрагменты/леса не принимаются. Предложения BY REF и BY VALUE принимаются, но игнорируются. В стандарте SQL функция xmltable оценивает выражения на языке XML Query, но QHB допускает только выражения XPath 1.0.
Обязательное предложение COLUMNS указывает список столбцов в выходной таблице. Каждая запись описывает один столбец. Смотрите краткое описание синтаксиса для формата выше. Имя и тип столбца обязательны; предложения path, default и nullability являются необязательными.
Столбец, помеченный FOR ORDINALITY будет заполнен номерами строк, начиная с 1, в порядке узлов, полученных из результирующего набора строк row_expression. Максимум один столбец может быть помечен FOR ORDINALITY.
column_expression для столбца — это выражение XPath 1.0, которое оценивается для каждой строки, с текущим узлом из результата row_expression качестве элемента контекста, чтобы найти значение столбца. Если column_expression не указано, то имя столбца используется как неявный путь.
Если выражение XPath столбца возвращает не XML-значение (ограничено строкой, логическим или двойным в XPath 1.0) и столбец имеет тип QHB, отличный от xml, столбец будет установлен так, как если бы строковое представление значения было присвоено типу QHB. (Если значение является логическим, его строковое представление принимается равным 1 или 0 если категория типа выходного столбца является числовой, в противном случае - true или false).
Если выражение XPath столбца возвращает непустой набор узлов XML и тип столбца QHB - xml, столбцу будет точно присвоен результат выражения, если он имеет форму документа или содержимого3.
Результат не в формате XML, назначенный выходному столбцу xml создает содержимое, отдельный текстовый узел со строковым значением результата. Результат XML, назначенный столбцу любого другого типа, может содержать не более одного узла, или возникает ошибка. Если существует ровно один узел, столбец будет установлен так, как если бы он присваивал строковое значение узла (как определено для string функции XPath 1.0) типу QHB.
Строковое значение элемента XML представляет собой объединение в порядке документа всех текстовых узлов, содержащихся в этом элементе и его потомках. Строковое значение элемента без текстовых узлов-потомков является пустой строкой (не NULL). Любые атрибуты xsi:nil игнорируются. Обратите внимание, что text() только для пробелов text() узел text() между двумя нетекстовыми элементами сохраняется, а начальные пробелы в text() узле не сглаживаются. string функция XPath 1.0 может использоваться для правил, определяющих строковое значение других типов узлов XML и не-XML-значений.
Представленные здесь правила преобразования не совсем соответствуют стандарту SQL.
Если выражение пути возвращает пустой набор узлов (обычно, когда он не совпадает) для данной строки, столбцу будет присвоено NULL, если не указано default_expression; затем используется значение, полученное в результате оценки этого выражения.
Столбцы могут быть помечены как NOT NULL. Если column_expression для столбца NOT NULL ничего не соответствует и отсутствует DEFAULT или default_expression также имеет значение null, выдается сообщение об ошибке.
default_expression вместо немедленной оценки при xmltable оценивается каждый раз, когда для столбца требуется значение по умолчанию. Если выражение квалифицируется как стабильное или неизменное, повторная оценка может быть пропущена. Это означает, что вы можете с пользой использовать изменчивые функции, такие как nextval в default_expression.
Примеры:
CREATE TABLE xmldata AS SELECT
xml $$
<ROWS>
<ROW id="1">
<COUNTRY_ID>AU</COUNTRY_ID>
<COUNTRY_NAME>Australia</COUNTRY_NAME>
</ROW>
<ROW id="5">
<COUNTRY_ID>JP</COUNTRY_ID>
<COUNTRY_NAME>Japan</COUNTRY_NAME>
<PREMIER_NAME>Shinzo Abe</PREMIER_NAME>
<SIZE unit="sq_mi">145935</SIZE>
</ROW>
<ROW id="6">
<COUNTRY_ID>SG</COUNTRY_ID>
<COUNTRY_NAME>Singapore</COUNTRY_NAME>
<SIZE unit="sq_km">697</SIZE>
</ROW>
</ROWS>
$$ AS data;
SELECT xmltable.*
FROM xmldata,
XMLTABLE('//ROWS/ROW'
PASSING data
COLUMNS id int PATH '@id',
ordinality FOR ORDINALITY,
"COUNTRY_NAME" text,
country_id text PATH 'COUNTRY_ID',
size_sq_km float PATH 'SIZE[@unit = "sq_km"]',
size_other text PATH
'concat(SIZE[@unit!="sq_km"], " ", SIZE[@unit!="sq_km"]/@unit)',
premier_name text PATH 'PREMIER_NAME' DEFAULT 'not specified') ;
id | ordinality | COUNTRY_NAME | country_id | size_sq_km | size_other | premier_name
----+------------+--------------+------------+------------+--------------+---------------
1 | 1 | Australia | AU | | | not specified
5 | 2 | Japan | JP | | 145935 sq_mi | Shinzo Abe
6 | 3 | Singapore | SG | 697 | | not specified
В следующем примере показано объединение нескольких узлов text (), использование имени столбца в качестве фильтра XPath, а также обработка пробелов, комментариев XML и инструкций по обработке:
REATE TABLE xmlelements AS SELECT
xml $$
<root>
<element> Hello<!-- xyxxz -->2a2<?aaaaa?> <!--x--> bbb<x>xxx</x>CC </element>
</root>
$$ AS data;
SELECT xmltable.*
FROM xmlelements, XMLTABLE('/root' PASSING data COLUMNS element text);
element
-------------------------
Hello2a2 bbbxxxCC
В следующем примере показано, как можно использовать предложение XMLNAMESPACES для указания списка пространств имен, используемых в документе XML, а также в выражениях XPath:
WITH xmldata(data) AS (VALUES ('
<example xmlns="http://example.com/myns" xmlns:B="http://example.com/b">
<item foo="1" B:bar="2"/>
<item foo="3" B:bar="4"/>
<item foo="4" B:bar="5"/>
</example>'::xml)
)
SELECT xmltable.*
FROM XMLTABLE(XMLNAMESPACES('http://example.com/myns' AS x,
'http://example.com/b' AS "B"),
'/x:example/x:item'
PASSING (SELECT data FROM xmldata)
COLUMNS foo int PATH '@foo',
bar int PATH '@B:bar');
foo | bar
-----+-----
1 | 2
3 | 4
4 | 5
(3 rows)
Отображение таблиц в XML
Следующие функции отображают содержимое реляционных таблиц в значения XML. Их можно рассматривать как функцию экспорта XML:
table_to_xml(tbl regclass, nulls boolean, tableforest boolean, targetns text)
query_to_xml(query text, nulls boolean, tableforest boolean, targetns text)
cursor_to_xml(cursor refcursor, count int, nulls boolean,
tableforest boolean, targetns text)
Тип ответа каждой функции - xml.
table_to_xml отображает содержимое именованной таблицы, передаваемой как параметр tbl. Тип regclass принимает строки, идентифицирующие таблицы, используя обычные обозначения, включая необязательные квалификации схемы и двойные кавычки. query_to_xml выполняет запрос, текст которого передается как query параметра, и отображает набор результатов. cursor_to_xml извлекает указанное количество строк из курсора, указанного параметром cursor. Этот вариант рекомендуется, если необходимо сопоставить большие таблицы, поскольку значение результата создается в памяти каждой функцией.
Если tableforest имеет значение false, итоговый XML-документ выглядит следующим образом:
<tablename>
<row>
<columnname1>data</columnname1>
<columnname2>data</columnname2>
</row>
<row>
...
</row>
...
</tablename>
Если tableforest имеет значение true, результатом является фрагмент содержимого XML, который выглядит следующим образом:
<tablename>
<columnname1>data</columnname1>
<columnname2>data</columnname2>
</tablename>
<tablename>
...
</tablename>
...
Если имя таблицы недоступно, то есть при отображении запроса или курсора table строк используется в первом формате, row во втором.
Выбор между этими форматами остается за пользователем. Первый формат — это правильный XML-документ, который будет важен во многих приложениях. Второй формат имеет тенденцию быть более полезным в функции cursor_to_xml если значения результата должны быть впоследствии собраны в один документ. Обсуждаемые выше функции для создания содержимого XML, в частности xmlelement, могут использоваться для изменения результатов по вкусу.
Значения данных отображаются так же, как описано выше для функции xmlelement.
Параметр nulls определяет, должны ли нулевые значения быть включены в выходные данные. Если true, нулевые значения в столбцах представлены как:
<columnname xsi:nil="true"/>
где xsi - префикс пространства имен XML для экземпляра схемы XML. Соответствующее объявление пространства имен будет добавлено к значению результата. Если false, столбцы, содержащие нулевые значения, просто не включаются в вывод.
Параметр targetns указывает желаемое пространство имен XML для результата. Если конкретное пространство имен не требуется, должна быть передана пустая строка.
Следующие функции возвращают документы схемы XML, описывающие сопоставления, выполняемые соответствующими функциями выше:
table_to_xmlschema(tbl regclass, nulls boolean, tableforest boolean, targetns text)
query_to_xmlschema(query text, nulls boolean, tableforest boolean, targetns text)
cursor_to_xmlschema(cursor refcursor, nulls boolean, tableforest boolean, targetns text)
Важно, чтобы одни и те же параметры были переданы для получения соответствующих сопоставлений данных XML и документов схемы XML.
Следующие функции создают сопоставления данных XML и соответствующую схему XML в одном документе (или лесу), связанных вместе. Они могут быть полезны, когда требуются автономные и самоописываемые результаты:
table_to_xml_and_xmlschema(tbl regclass, nulls boolean, tableforest boolean, targetns text)
query_to_xml_and_xmlschema(query text, nulls boolean, tableforest boolean, targetns text)
Кроме того, доступны следующие функции для создания аналогичных отображений всей схемы или всей текущей базы данных:
schema_to_xml(schema name, nulls boolean, tableforest boolean, targetns text)
schema_to_xmlschema(schema name, nulls boolean, tableforest boolean, targetns text)
schema_to_xml_and_xmlschema(schema name, nulls boolean, tableforest boolean, targetns text)
database_to_xml(nulls boolean, tableforest boolean, targetns text)
database_to_xmlschema(nulls boolean, tableforest boolean, targetns text)
database_to_xml_and_xmlschema(nulls boolean, tableforest boolean, targetns text)
Обратите внимание, что они потенциально производят много данных, которые должны быть встроены в память. При запросе сопоставлений содержимого больших схем или баз данных может оказаться целесообразным вместо этого рассмотреть сопоставление таблиц отдельно, возможно даже через курсор.
Результат отображения содержимого схемы выглядит следующим образом:
<schemaname>
table1-mapping
table2-mapping
...
</schemaname>
где формат отображения таблицы зависит от параметра tableforest как описано выше.
Результат отображения содержимого базы данных выглядит следующим образом:
<dbname>
<schema1name>
...
</schema1name>
<schema2name>
...
</schema2name>
...
</dbname>
где отображение схемы такое же, как указано выше.
В качестве примера использования выходных данных, создаваемых этими функциями, на рисунке 1 показана table_to_xml_and_xmlschema стилей XSLT, которая преобразует выходные данные table_to_xml_and_xmlschema в документ HTML, содержащий табличное представление данных таблицы. Аналогичным образом результаты этих функций могут быть преобразованы в другие форматы на основе XML.
Рисунок 1. Таблица стилей XSLT для преобразования вывода SQL/XML в HTML
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="http://www.w3.org/1999/xhtml"
>
<xsl:output method="xml"
doctype-system="http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"
doctype-public="-//W3C/DTD XHTML 1.0 Strict//EN"
indent="yes"/>
<xsl:template match="/*">
<xsl:variable name="schema" select="//xsd:schema"/>
<xsl:variable name="tabletypename"
select="$schema/xsd:element[@name=name(current())]/@type"/>
<xsl:variable name="rowtypename"
select="$schema/xsd:complexType[@name=$tabletypename]/xsd:sequence/xsd:element[@name='row']/@type"/>
<html>
<head>
<title><xsl:value-of select="name(current())"/></title>
</head>
<body>
<table>
<tr>
<xsl:for-each select="$schema/xsd:complexType[@name=$rowtypename]/xsd:sequence/xsd:element/@name">
<th><xsl:value-of select="."/></th>
</xsl:for-each>
</tr>
<xsl:for-each select="row">
<tr>
<xsl:for-each select="*">
<td><xsl:value-of select="."/></td>
</xsl:for-each>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Функции и операторы JSON
Этот раздел описывает:
Чтобы узнать больше о стандарте SQL/JSON, обратитесь к стандарту ISO/IEC TR 19075-6.
Обработка и создание данных JSON
В таблице 44 показаны операторы, доступные для использования с типами данных JSON (см. в разделе Типы JSON).
Таблица 44. jsonb и jsonb Операторы
| Оператор | Тип правого операнда | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|---|
-> | int | json или jsonb | Получить элемент массива JSON (индексируется с нуля, отрицательные целые числа считаются с конца) | '[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json->2 | {"c":"baz"} |
-> | text | json или jsonb | Получить поле объекта JSON по ключу | '{"a": {"b":"foo"}}'::json->'a' | {"b":"foo"} |
->> | int | text | Получить элемент массива JSON в виде text | '[1,2,3]'::json->>2 | 3 |
->> | text | text | Получить поле объекта JSON как text | '{"a":1,"b":2}'::json->>'b' | 2 |
#> | text[] | json или jsonb | Получить объект JSON по указанному пути | '{"a": {"b":{"c": "foo"}}}'::json#>'{a,b}' | {"c": "foo"} |
#>> | text[] | text | Получить объект JSON по указанному пути в виде text | '{"a":[1,2,3],"b":[4,5,6]}'::json#>>'{a,2}' | 3 |
Существуют параллельные варианты этих операторов для типов json и jsonb. Операторы извлечения поля/элемента/пути возвращают тот же тип, что и их левый ввод (json или jsonb), за исключением тех, которые указаны как возвращающий text, которые приводят значение к тексту. Операторы извлечения поля/элемента/пути возвращают NULL вместо сбоя, если вход JSON не имеет правильной структуры, соответствующей запросу; например, если такого элемента не существует. Все операторы извлечения поля/элемента/пути, которые принимают индексы целочисленных JSON-массивов, поддерживают отрицательную подписку с конца массивов.
Стандартные операторы сравнения, показанные в таблице 1, доступны для jsonb, но не для json. Они следуют правилам упорядочения операций B-дерева, изложенным в разделе Индексирование jsonb.
Некоторые дополнительные операторы также существуют только для jsonb, как показано в таблице 45. Многие из этих операторов могут быть проиндексированы jsonb операторов jsonb. Полное описание jsonb содержания и существования jsonb см. в разделе Анализ вложений и наличия в jsonb. Раздел Индексирование jsonb описывает, как эти операторы могут использоваться для эффективной индексации данных jsonb.
Таблица 45. Дополнительные операторы jsonb
| Оператор | Тип правого операнда | Описание | Пример |
|---|---|---|---|
| @> | jsonb | Содержит ли левое значение JSON правильные записи пути / значения JSON на верхнем уровне? | ’{"a":1, "b":2}’::jsonb @> ’{"b":2}’::jsonb |
| <@ | jsonb | Содержатся ли левые записи пути / значения JSON на верхнем уровне в правом значении JSON? | ’{"b":2}’::jsonb <@ ’{"a":1, "b":2}’::jsonb |
| ? | text | Существует ли строка как ключ верхнего уровня в значении JSON? | ’{"a":1, "b":2}’::jsonb ? ’b’ |
| ? | text[] | Существуют ли какие-либо из этих строк массива в качестве ключей верхнего уровня? | ’{"a":1, "b":2, "c":3}’::jsonb ? array[’b’, ’c’] |
| ?& | text[] | Все ли эти строки массива существуют как ключи верхнего уровня? | ’["a", "b"]’::jsonb ?& array[’a’, ’b’] |
| jsonb | jsonb два значения jsonb в новое значение jsonb | ’["a", "b"]’::jsonb ’["c", "d"]’::jsonb | |
| - | text | Удалить пару ключ / значение или строковый элемент из левого операнда. Пары ключ / значение сопоставляются на основе их значения ключа. | ’{"a": "b"}’::jsonb - ’a’ |
| - | text[] | Удалите несколько пар ключ / значение или строковые элементы из левого операнда. Пары ключ / значение сопоставляются на основе их значения ключа. | ’{"a": "b", "c": "d"}’::jsonb - ’{a,c}’::text[] |
| - | integer | Удалить элемент массива с указанным индексом (отрицательные целые числа считаются с конца). Выдает ошибку, если контейнер верхнего уровня не является массивом. | ’["a", "b"]’::jsonb - 1 |
| #- | text[] | Удалить поле или элемент с указанным путем (для массивов JSON отрицательные целые числа считаются с конца) | ’["a", {"b":1}]’::jsonb #- ’{1,b}’ |
| @? | jsonpath | Возвращает ли путь JSON какой-либо элемент для указанного значения JSON? | ’{"a":[1,2,3,4,5]}’::jsonb @? ’$.a[*] ? (@ > 2)’ |
| @@ | jsonpath | Возвращает результат проверки предиката пути JSON для указанного значения JSON. Только первый элемент результата учитывается. Если результат не является логическим, возвращается null. | ’{"a":[1,2,3,4,5]}’::jsonb @@ ’$.a[*] > 2’ |
Оператор ||» объединяет элементы на верхнем уровне каждого из своих операндов. Он не работает рекурсивно. Например, если оба операнда являются объектами с именем поля общего ключа, значением поля в результате будет просто значение из правого операнда.
Операторы «@?» и «@@» подавляют следующие ошибки: отсутствие поля объекта или элемента массива, непредвиденный тип элемента JSON и числовые ошибки. Это может быть полезно при поиске в коллекциях документов JSON различной структуры.
В таблице 46 показаны функции, доступные для создания значений json и jsonb. (Не существует эквивалентных функций для jsonb, функций row_to_json и array_to_json. Однако функция to_jsonb предоставляет практически те же функции, что и эти функции).
Таблица 46. Функции создания JSON
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| to_json(anyelement) to_jsonb(anyelement) | Возвращает значение в виде json или jsonb. Массивы и композиты преобразуются (рекурсивно) в массивы и объекты; в противном случае, если приведение приведено к типу json, функция преобразования будет использована для выполнения преобразования; в противном случае получается скалярное значение. Для любого скалярного типа, отличного от числа, логического или нулевого значения, будет использоваться текстовое представление таким образом, чтобы оно было допустимым значением json или jsonb. | to_json (’Fred said "Hi."’::text) | "Fred said \"Hi.\"" |
| array_to_json(anyarray [, pretty_bool]) | Возвращает массив в виде массива JSON. Многомерный массив QHB становится массивом массивов JSON. pretty_bool строки будет добавлен между элементами измерения 1, если pretty_bool имеет значение true. | array_to_json (’{{1,5},{99,100}}’::int[]) | [[1,5],[99,100]] |
| row_to_json(record [, pretty_bool]) | Возвращает строку в виде объекта JSON. pretty_bool строки будет добавлен между элементами уровня 1, если pretty_bool имеет значение true. | row_to_json (row(1,’foo’)) | {"f1":1,"f2":"foo"} |
| json_build_array(VARIADIC "any") jsonb_build_array(VARIADIC "any") | Создает возможно разнородный тип JSON-массива из списка переменных аргументов. | json_build_array (1,2,’3’,4,5) | [1, 2, "3", 4, 5] |
| json_build_object(VARIADIC "any") jsonb_build_object(VARIADIC "any") | Создает объект JSON из списка переменных аргументов. По соглашению список аргументов состоит из чередующихся ключей и значений. | json_build_object (’foo’,1,’bar’,2) | {"foo": 1, "bar": 2} |
| json_object(text[]) jsonb_object(text[]) | Создает объект JSON из текстового массива. Массив должен иметь либо одно измерение с четным числом элементов, в этом случае они рассматриваются как чередующиеся пары ключ / значение, либо два измерения, так что каждый внутренний массив имеет ровно два элемента, которые принимаются как пара ключ / значение., | json_object (’{a, 1, b, "def", c, 3.5}’)
json_object (’{{a, 1},{b, "def"},{c, 3.5}}’) |
{"a": "1", "b": "def", "c": "3.5"} |
| json_object(keys text[], values text[]) jsonb_object(keys text[], values text[]) | Эта форма json_object получает ключи и значения попарно из двух отдельных массивов. Во всем остальном он идентичен форме с одним аргументом. | json_object (’{a, b}’, ’{1,2}’) | {"a": "1", "b": "2"} |
Примечание
array_to_json и row_to_json ведут себя так же, как to_json за исключением того, что предлагают красивую опцию печати. Поведение, описанное для to_json также применимо к каждому отдельному значению, преобразованному другими функциями создания JSON.
Примечание
Расширение hstore имеет приведение от hstore к json, поэтому значения hstore преобразованные с помощью функций создания JSON, будут представлены как объекты JSON, а не как примитивные строковые значения.
В таблице 47 показаны функции, доступные для обработки значений json и jsonb.
Таблица 47. Функции обработки JSON
| Функция | Тип результата | Описание | Пример | Результат |
|---|---|---|---|---|
| int | Возвращает число элементов во внешнем массиве JSON. | json_array_length('[1,2,3,{"f1":1,"f2":[5,6]},4]') | 5 |
|
| Разворачивает внешний объект JSON в набор пар ключ/значение (key/value). | select * from json_each('{"a":"foo", "b":"bar"}') | key | value -----+------- a | "foo" b | "bar" |
| setof key text, value text | Разворачивает внешний объект JSON в набор пар ключ/значение (key/value). Возвращаемые значения будут иметь тип text. | select * from json_each_text('{"a":"foo", "b":"bar"}') | key | value -----+------- a | foo b | bar |
|
| Возвращает значение JSON по пути, заданному элементами пути (path_elems) (равнозначно оператору #> operator). | json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4') | {"f5":99,"f6":"foo"} |
| text | Возвращает значение JSON по пути, заданному элементами пути path_elems, как text (равнозначно оператору #>>). | json_extract_path_text('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4', 'f6') | foo |
| setof text | Возвращает набор ключей во внешнем объекте JSON. | json_object_keys('{"f1":"abc","f2":{"f3":"a", "f4":"b"}}') | json_object_keys ----------------- f1 f2 |
| anyelement | Разворачивает объект из from_json в табличную строку, в которой столбцы соответствуют типу строки, заданному параметром base (см. примечания ниже). |
| a | b | c
---+-----------+-------------
1 | {2,"a b"} | (4,"a b c") |
| setof anyelement | Разворачивает внешний массив объектов из from_json в набор табличных строк, в котором столбцы соответствуют типу строки, заданному параметром base (см. примечания ниже). |
| a | b ---+--- 1 | 2 3 | 4 |
|
| Разворачивает массив JSON в набор значений JSON. | select * from json_array_elements('[1,true, [2,false]]') | value ----------- 1 true [2,false] |
| setof text | Разворачивает массив JSON в набор значений text. | select * from json_array_elements_text('["foo", "bar"]') | value ----------- foo bar |
| text | Возвращает тип внешнего значения JSON в виде текстовой строки. Возможные типы: object, array, string, number, boolean и null. | json_typeof('-123.4') | number |
| record | Формирует обычную запись из объекта JSON (см. примечания ниже). Как и со всеми функциями, возвращающими record, при вызове необходимо явно определить структуру записи с помощью предложения AS. |
| |
| setof record | Формирует обычный набор записей из массива объекта JSON (см. примечания ниже). Как и со всеми функциями, возвращающими record, при вызове необходимо явно определить структуру записи с помощью предложения AS. | select * from json_to_recordset('[{"a":1,"b":"foo"},{"a":"2","c":"bar"}]') as x(a int, b text); | a | b ---+----- 1 | foo 2 | |
|
| Возвращает значение from_json, из которого исключаются все поля объекта, содержащие значения NULL. Другие значения NULL остаются нетронутыми. | json_strip_nulls('[{"f1":1,"f2":null},2,null,3]') | [{"f1":1},2,null,3] |
|
| Возвращает значение target, в котором раздел с заданным путём (path) заменяется новым значением (new_value), либо в него добавляется значение new_value, если аргумент create_missing равен true (это значение по умолчанию) и элемент, на который ссылается path, не существует. Как и с операторами, рассчитанными на пути, отрицательные числа в пути (path) обозначают отсчёт от конца массивов JSON. |
|
|
|
| Возвращает значение target с вставленным в него новым значением new_value. Если место в target, выбранное путём path, оказывается в массиве JSONB, new_value будет вставлен до (по умолчанию) или после (если параметр insert_after равен true) выбранной позиции. Если место в target, выбранное путём path, оказывается в объекте JSONB, значение new_value будет вставлено в него, только если заданный путь path не существует. Как и с операторами, рассчитанными на пути, отрицательные числа в пути (path) обозначают отсчёт от конца массивов JSON. |
|
|
|
| Возвращает значение from_json в виде текста JSON с отступами. | jsonb_pretty('[{"f1":1,"f2":null},2,null,3]') | [
{
"f1": 1,
"f2": null
},
2,
null,
3
] |
| boolean | Определяет, выдаёт ли путь JSON какой-либо элемент при заданном значении JSON. |
|
|
| boolean | Возвращает результат проверки предиката пути JSON для заданного значения JSON. При этом учитывается только первый элемент результата. Если результат не является булевским, возвращается null. |
|
|
| setof jsonb | Возвращает все элементы JSON, которые выдаёт путь JSON для заданного значения JSON. |
| jsonb_path_query ------------------ 2 3 4 |
| jsonb | Возвращает все элементы JSON, которые выдаёт путь JSON для заданного значения JSON, оборачивая их в массив. |
|
|
| jsonb | Возвращает первый элемент JSON, который выдаётся выражением пути для заданного значения JSON. В случае отсутствия результатов возвращает NULL. |
|
|
Примечание
Многие из этих функций и операторов преобразуют экранирование Unicode в строках JSON в соответствующий одиночный символ. Это не проблема, если вход имеет тип jsonb, потому что преобразование уже выполнено; но для ввода json это может привести к ошибке, как отмечено в разделе Типы JSON.
Примечание
Функции json[b]_populate_record, json[b]_populate_recordset, json[b]_to_record и json[b]_to_recordset работают с объектом JSON или массивом объектов и извлекают значения, связанные с ключами, имена которых соответствуют именам столбцов тип выходной строки. Поля объекта, которые не соответствуют ни одному имени выходного столбца, игнорируются, а выходные столбцы, которые не соответствуют ни одному полю объекта, будут заполнены пустыми значениями. Для преобразования значения JSON в тип SQL выходного столбца последовательно применяются следующие правила:
Примечание
Все элементы параметра path jsonb_set а также jsonb_insert кроме последнего, должны присутствовать в target. Если create_missing имеет значение false, должны присутствовать все элементы параметра path jsonb_set. Если эти условия не выполнены, target возвращается без изменений.
Примечание
Если последний элемент пути является ключом объекта, он будет создан, если он отсутствует, и ему будет присвоено новое значение. Если последний элемент пути является индексом массива, если он положительный, то элемент для установки определяется путем подсчета слева, а если отрицательный - путем подсчета справа - -1 обозначает самый правый элемент и так далее. Если элемент выходит за пределы диапазона -array_length .. array_length -1, а create_missing имеет значение true, новое значение добавляется в начало массива, если элемент отрицательный, и в конец массива, если он положительный.
Примечание
json_typeof возвращаемое значение функции json_typeof не следует путать с SQL NULL. В то время как вызов json_typeof(’null’::json) вернет null, вызов json_typeof(NULL::json) вернет SQL NULL.
Примечание
Если аргумент json_strip_nulls содержит повторяющиеся имена полей в любом объекте, результат может быть семантически несколько другим, в зависимости от порядка их появления. Это не проблема для jsonb_strip_nulls так jsonb значения jsonb никогда не имеют повторяющихся имен полей объекта.
Примечание
Функции jsonb_path_exists, jsonb_path_match, jsonb_path_query, jsonb_path_query_array и jsonb_path_query_first имеют необязательные vars и silent аргументы. Если указан аргумент vars, он предоставляет объект, содержащий именованные переменные, для подстановки в выражение jsonpath.Если silent аргумент указан и имеет true значение, эти функции подавляют те же ошибки, что и @? и @@ операторы.
См. также раздел Агрегатные функции, где приведена агрегатная функция json_agg которая агрегирует значения записей в виде JSON, и агрегатная функция json_object_agg которая агрегирует пары значений в объект JSON и их эквиваленты jsonb_agg, jsonb_agg и jsonb_object_agg.
Язык путей SQL/JSON
Выражения пути SQL/JSON задают элементы, которые нужно извлечь из данных JSON, аналогично выражениям XPath, используемым для доступа SQL к XML. В QHB выражения пути реализованы как тип данных jsonpath и могут использовать любые элементы, описанные в разделе Тип jsonpath.
Функции и операторы запросов JSON передают предоставленное выражение пути механизму пути для оценки. Если выражение соответствует запрашиваемым данным JSON, возвращается соответствующий элемент SQL/JSON. Выражения пути написаны на языке путей SQL/JSON и могут также включать арифметические выражения и функции. Функции запросов обрабатывают предоставленное выражение как текстовую строку, поэтому оно должно быть заключено в одинарные кавычки.
Выражение пути состоит из последовательности элементов, разрешенных типом данных jsonpath. Выражение пути оценивается слева направо, но вы можете использовать скобки, чтобы изменить порядок операций. Если оценка прошла успешно, создается последовательность элементов SQL/JSON (последовательность SQL/JSON), и результат оценки возвращается в функцию запроса JSON, которая завершает указанное вычисление.
Чтобы сослаться на данные JSON, которые нужно запросить (элемент контекста), используйте знак $ в выражении пути. За ним могут следовать один или несколько операторов доступа, которые понижают структуру структуры JSON уровень за уровнем для получения содержимого элемента контекста. Каждый следующий оператор имеет дело с результатом предыдущего шага оценки.
Например, предположим, у вас есть некоторые данные JSON с GPS-трекера, которые вы хотели бы проанализировать, например:
{
"track": {
"segments": [
{
"location": [ 47.763, 13.4034 ],
"start time": "2018-10-14 10:05:14",
"HR": 73
},
{
"location": [ 47.706, 13.2635 ],
"start time": "2018-10-14 10:39:21",
"HR": 135
}
]
}
}
Чтобы получить доступные сегменты дорожки, вам нужно использовать. оператор доступа .key для всех предыдущих объектов JSON:
'$.track.segments'
Если элемент для извлечения является элементом массива, вы должны удалить этот массив с помощью оператора [*]. Например, следующий путь вернет координаты местоположения для всех доступных сегментов дорожки:
'$.track.segments[*].location'
Чтобы вернуть координаты только первого сегмента, вы можете указать соответствующий индекс в операторе доступа []. Обратите внимание, что массивы SQL/JSON являются 0-относительными:
'$.track.segments[0].location'
Результат каждого шага оценки пути может обрабатываться одним или несколькими операторами и методами jsonpath, перечисленными в разделе Операторы пути и методы SQL/JSON. Каждому имени метода должна предшествовать точка. Например, вы можете получить размер массива:
'$.track.segments.size()'
Дополнительные примеры использования операторов и методов jsonpath в выражениях пути см. раздел Операторы пути и методы SQL/JSON.
При определении пути вы также можете использовать одно или несколько выражений фильтра, которые работают аналогично WHERE в SQL. Выражение фильтра начинается со знака вопроса и содержит условие в скобках:
? (condition)
Выражения фильтра должны быть указаны сразу после шага оценки пути, к которому они применяются. Результат этого шага фильтруется, чтобы включить только те элементы, которые удовлетворяют предоставленному условию. SQL/JSON определяет трехзначную логику, поэтому условие может быть true, false или unknown. unknown значение играет ту же роль, что и SQL NULL и его можно проверить с помощью неизвестного предиката. Дальнейшие шаги оценки пути используют только те элементы, для которых выражения фильтра возвращают true.
Функции и операторы, которые можно использовать в выражениях фильтра,
перечислены в таблице 49. Результат оценки пути, подлежащий
фильтрации, обозначается переменной @. Чтобы сослаться на элемент JSON,
хранящийся на более низком уровне вложенности, добавьте один или
несколько операторов доступа после @.
Предположим, вы хотите получить все значения сердечного ритма, превышающие 130. Это можно сделать с помощью следующего выражения:
'$.track.segments[*].HR ? (@ > 130)'
Чтобы вместо этого получить время начала сегментов с такими значениями, вы должны отфильтровать ненужные сегменты перед возвратом времени начала, поэтому выражение фильтра применяется к предыдущему шагу, а путь, используемый в условии, отличается:
'$.track.segments[*] ? (@.HR > 130)."start time"'
При необходимости вы можете использовать несколько выражений фильтра на одном уровне вложенности. Например, следующее выражение выбирает все сегменты, которые содержат местоположения с соответствующими координатами и высокими значениями сердечного ритма:
'$.track.segments[*] ? (@.location[1] < 13.4) ? (@.HR > 130)."start time"'
Использование выражений фильтра на разных уровнях вложенности также допускается. В следующем примере сначала фильтруются все сегменты по местоположению, а затем возвращаются высокие значения частоты сердечных сокращений для этих сегментов, если они доступны:
'$.track.segments[*] ? (@.location[1] < 13.4).HR ? (@ > 130)'`
Вы также можете вкладывать выражения фильтра друг в друга:
'$.track ? (exists(@.segments[*] ? (@.HR > 130))).segments.size()'`
Это выражение возвращает размер дорожки, если оно содержит сегменты с высокими значениями сердечного ритма, или пустую последовательность в противном случае.
Реализация QHB языка путей SQL/JSON имеет следующие отклонения от стандарта SQL/JSON:
'$.track.segments[*].HR < 70'
Строгий и слабый режимы
При запросе данных JSON выражение пути может не соответствовать фактической структуре данных JSON. Попытка получить доступ к несуществующему члену объекта или элемента массива приводит к структурной ошибке. У выражений пути SQL/JSON есть два режима обработки структурных ошибок:
Режим lax облегчает сопоставление структуры документа JSON и выражения пути, если данные JSON не соответствуют ожидаемой схеме. Если операнд не соответствует требованиям конкретной операции, он может быть автоматически упакован в массив SQL/JSON или развернут путем преобразования его элементов в последовательность SQL/JSON перед выполнением этой операции. Кроме того, операторы сравнения автоматически распаковывают свои операнды в режиме lax, поэтому вы можете сравнивать массивы SQL/JSON "из коробки". Массив размером 1 считается равным своему единственному элементу. Автоматическое развертывание не выполняется только тогда, когда:
Например, при запросе данных GPS, перечисленных выше, вы можете абстрагироваться от того факта, что при использовании режима lax он хранит массив сегментов:
lax $.track.segments.location’
В строгом strict режиме указанный путь должен точно соответствовать структуре запрашиваемого документа JSON, чтобы вернуть элемент SQL/JSON, поэтому использование этого выражения пути приведет к ошибке. Чтобы получить тот же результат, что и в режиме lax, вы должны явно развернуть массив segments:
’strict $.track.segments\[\*\].location’
Регулярные выражения
Выражения пути SQL/JSON позволяют сопоставлять текст с регулярным выражением с помощью фильтра like_regex. Например, следующий запрос пути SQL/JSON будет без учета регистра совпадать со всеми строками в массиве, которые начинаются с английской гласной:
'$[*] ? (@ like_regex "^[aeiou]" flag "i")'
Необязательная строка флага может включать один или несколько символов i для соответствия без учета регистра, m для разрешения ^ и $ для соответствия в новых строках, s для разрешения, чтобы соответствовать новой строке и q, чтобы процитировать весь шаблон (сводя поведение к простому совпадению подстроки).
Стандарт SQL/JSON заимствует свое определение для регулярных выражений из оператора LIKE_REGEX, который, в свою очередь, использует стандарт XQuery. QHB в настоящее время не поддерживает оператор LIKE_REGEX. Поэтому фильтр like_regex реализован с использованием механизма регулярных выражений POSIX, описанного в разделе Регулярные выражения POSIX. Это приводит к различным незначительным несоответствиям стандартного поведения SQL/JSON, которые каталогизированы в разделе Отличия от XQuery (LIKE_REGEX). Однако обратите внимание, что описанные здесь несовместимости флаговых букв не применяются к SQL/JSON, поскольку он переводит буквенные символы XQuery в соответствие с тем, что ожидает механизм POSIX.
Имейте в виду, что аргумент шаблона like_regex является строковым литералом пути JSON, написанным в соответствии с правилами, приведенными в разделе Тип jsonpath. В частности, это означает, что любые обратные слеши, которые вы хотите использовать в регулярном выражении, должны быть удвоены. Например, чтобы сопоставить строки, содержащие только цифры:
'$ ? (@ like_regex "^\\d+$")'
Операторы пути и методы SQL/JSON
В таблице 48 показаны операторы и методы, доступные в jsonpath. Таблица 49 показывает доступные элементы выражения фильтра.
Таблица 48. Операторы и методы jsonpath
| Оператор / Метод | Описание | Пример JSON | Пример запроса | Результат |
|---|---|---|---|---|
| + (одинарный) | Плюс оператор, который выполняет итерацию по последовательности SQL/JSON | {"x": [2.85, -14.7, -9.4]} | + $.x.floor() | 2, -15, -10 |
| - (одинарный) | Оператор минус, который перебирает последовательность SQL/JSON | {"x": [2.85, -14.7, -9.4]} | - $.x.floor() | -2, 15, 10 |
| + (двоичный) | прибавление | [2] | 2 + $[0] | 4 |
| - (двоичный) | Вычитание | [2] | 4 - $[0] | 2 |
| * | умножение | [4] | 2 * $[0] | 8 |
| / | разделение | [8] | $[0] / 2 | 4 |
| % | модуль | [32] | $[0] % 10 | 2 |
| type() | Тип элемента SQL/JSON | [1, "2", {}] | $[*].type() | "number", "string", "object" |
| size() | Размер элемента SQL/JSON | {"m": [11, 15]} | $.m.size() | 2 |
| double() | Приблизительное число с плавающей точкой, преобразованное из числа SQL/JSON или строки | {"len": "1.9"} | $.len.double() * 2 | 3.8 |
| ceiling() | Ближайшее целое число больше или равно номеру SQL/JSON | {"h": 1.3} | $.h.ceiling() | 2 |
| floor() | Ближайшее целое число меньше или равно номеру SQL/JSON | {"h": 1.3} | $.h.floor() | 1 |
| abs() | Абсолютное значение числа SQL/JSON | {"z": -0.3} | $.z.abs() | 0.3 |
| keyvalue() | Последовательность пар ключ-значение объекта, представленная в виде массива элементов, содержащего три поля ("key", "value" и "id"). "id" - это уникальный идентификатор пары «ключ-значение», которой принадлежит объект. | {"x": "20", "y": 32} | $.keyvalue() | {"key": "x", "value": "20", "id": 0}, {"key": "y", "value": 32, "id": 0} |
Таблица 49. Элементы выражения фильтра jsonpath
| Значение / Predicate | Описание | Пример JSON | Пример запроса | Результат |
|---|---|---|---|---|
| == | Оператор равенства | [1, 2, 1, 3] | $[*] ? (@ == 1) | 1, 1 |
| != | Оператор неравенства | [1, 2, 1, 3] | $[*] ? (@ != 1) | 2, 3 |
| <> | Оператор неравенства (такой же как !=) | [1, 2, 1, 3] | $[*] ? (@ <> 1) | 2, 3 |
| < | Менее чем оператор | [1, 2, 3] | $[*] ? (@ < 2) | 1 |
| <= | Оператор "меньше или равно" | [1, 2, 3] | $[*] ? (@ <= 2) | 1, 2 |
| > | Больше чем оператор | [1, 2, 3] | $[*] ? (@ > 2) | 3 |
| >= | Оператор «больше чем или равно» | [1, 2, 3] | $[*] ? (@ >= 2) | 2, 3 |
| true | Значение, используемое для сравнения с true литералом JSON | [{"name": "John", "parent": false}, {"name": "Chris", "parent": true}] | $[*] ? (@.parent == true) | {"name": "Chris", "parent": true} |
| false | Значение, используемое для сравнения с false литералом JSON | [{"name": "John", "parent": false}, {"name": "Chris", "parent": true}] | $[*] ? (@.parent == false) | {"name": "John", "parent": false} |
| null | Значение, используемое для сравнения с null значением JSON | [{"name": "Mary", "job": null}, {"name": "Michael", "job": "driver"}] | $[*] ? (@.job == null) .name | "Mary" |
| && | Логическое И | [1, 3, 7] | $[*] ? (@ > 1 && @ < 5) | 3 |
| Логическое ИЛИ | [1, 3, 7] | $[*] ? (@ < 1 @ > 5) | 7 | |
| ! | Логическое НЕ | [1, 3, 7] | $[*] ? (!(@ < 5)) | 7 |
| like_regex | Проверяет, соответствует ли первый операнд регулярному выражению, данному вторым операндом, при необходимости с изменениями, описанными строкой flag символов (см. п. 4.1.15.2.2) | ["abc", "abd", "aBdC", "abdacb", "babc"] | $[*] ? (@ like_regex "^ab.*c" flag "i") | "abc", "aBdC", "abdacb" |
| starts with | Проверяет, является ли второй операнд начальной подстрокой первого операнда | ["John Smith", "Mary Stone", "Bob Johnson"] | $[*] ? (@ starts with "John") | "John Smith" |
| exists | Проверяет, соответствует ли выражение пути хотя бы одному элементу SQL/JSON | {"x": [1, 2], "y": [2, 4]} | strict $.* ? (exists (@ ? (@[*] > 2))) | 2, 4 |
| is unknown | Проверяет, неизвестно ли логическое условие | [-1, 2, 7, "infinity"] | $[*] ? ((@ > 0) is unknown) | "infinity" |
Функции управления последовательностями
В этом разделе описываются функции для работы с объектами последовательности, также называемыми генераторами последовательностей или просто последовательностями. Объекты последовательности — это специальные однорядные таблицы, созданные с помощью CREATE SEQUENCE. Объекты последовательности обычно используются для генерации уникальных идентификаторов для строк таблицы. Функции последовательности, перечисленные в таблице 50, предоставляют простые, многопользовательские безопасные методы для получения последовательных значений последовательности из объектов последовательности.
Таблица 50. Функции последовательности
| Функция | Тип ответа | Описание |
|---|---|---|
| currval(regclass) | bigint | Возвращаемое значение, полученное последним с помощью nextval для указанной последовательности |
| lastval() | bigint | Возвращаемое значение, полученное последним с помощью nextval для любой последовательности |
| nextval(regclass) | bigint | Прогрессировать последовательность и вернуть новое значение |
| setval(regclass, bigint) | bigint | Установить текущее значение последовательности |
| setval(regclass, bigint, boolean) | bigint | Установить текущее значение последовательности и флаг is_called |
Последовательность, которой должна управлять функция последовательности, задается аргументом regclass, который является просто OID последовательности в системном каталоге pg_class. Однако вам не нужно искать OID вручную, так как преобразователь ввода типа данных regclass сделает всю работу за вас. Просто напишите имя последовательности, заключенное в одинарные кавычки, чтобы оно выглядело как буквальная константа. Для совместимости с обработкой обычных имен SQL строка будет преобразована в нижний регистр, если она не содержит двойных кавычек вокруг имени последовательности. Таким образом:
nextval(’foo’) operates on sequence foo
nextval(’FOO’) operates on sequence foo
nextval(’"Foo"’) operates on sequence Foo
При необходимости имя последовательности может быть дополнено схемой:
nextval(’myschema.foo’) operates on myschema.foo
nextval(’"myschema".foo’) same as above
nextval(’foo’) searches search path for foo
См. раздел Типы идентификаторов объектов для получения дополнительной информации о regclass.
Конечно, аргумент функции последовательности может быть как выражением, так и константой. Если это текстовое выражение, то неявное приведение приведет к поиску во время выполнения.
Доступны следующие функции последовательности:
nextval
Переместите объект последовательности к следующему значению и верните это значение. Это делается атомарно: даже если несколько сессий выполняются nextval одновременно, каждый из них безопасно получит отдельное значение последовательности. Если объект последовательности был создан с параметрами по умолчанию, последовательные вызовы nextval будут возвращать последовательные значения, начинающиеся с 1. Другие варианты поведения могут быть получены с помощью специальных параметров в команде CREATE SEQUENCE; см. справочную страницу команд для получения дополнительной информации.
Важно!!!
Чтобы избежать блокировки параллельных транзакций, которые получают числа из той же последовательности, операция nextval никогда не откатывается; то есть, как только значение было получено, оно считается использованным и больше не будет возвращено. Это верно, даже если окружающая транзакция позднее прерывается, или если вызывающий запрос заканчивается тем, что не использует значение. Например, INSERT с предложением ON CONFLICT будет вычислять вставляемый кортеж, включая выполнение любых необходимых вызовов nextval, прежде чем обнаруживать любой конфликт, который заставит его следовать правилу ON CONFLICT. Такие случаи оставят неиспользованные «дыры» в последовательности назначенных значений. Таким образом, объекты последовательностей QHB не могут использоваться для получения последовательностей «без промежутков». Эта функция требует привилегии USAGE или UPDATE для последовательности.
currval
Вернуть значение, полученное последним значением nextval для этой последовательности в текущем сеансе. (Сообщается об ошибке, если nextval никогда не вызывался для этой последовательности в этом сеансе). Поскольку он возвращает локальное значение сеанса, он дает предсказуемый ответ, выполняли ли другие сеансы nextval после текущего сеанса. Эта функция требует привилегии USAGE или SELECT для последовательности.
lastval
Вернуть значение, которое было возвращено последним значением nextval в текущем сеансе. Эта функция идентична currval, за исключением того, что вместо того, чтобы принимать имя последовательности в качестве аргумента, она ссылается на любую nextval последовательность, к которой nextval был применен в текущем сеансе. lastval будет lastval если nextval еще не был вызван в текущем сеансе. Эта функция требует привилегии USAGE или SELECT для последней использованной последовательности.
setval
Сброс значения счетчика объекта последовательности. last_value форма устанавливает в поле last_value последовательности указанное значение и устанавливает для его поля is_called значение true, что означает, что следующий nextval будет продвигать последовательность перед возвратом значения. Значение, сообщаемое currval, также устанавливается на указанное значение. В форме с тремя параметрами is_called может быть установлен в true или false. true имеет тот же эффект, что и форма с двумя параметрами. Если для этого параметра установлено значение false, следующее следующее значение вернет точно указанное значение, и продвижение последовательности начинается со следующего следующего nextval. Кроме того, значение, сообщаемое currval, в этом случае не изменяется. Например,
SELECT setval(’foo’, 42); Next nextval will return 43
SELECT setval(’foo’, 42, true); Same as above
SELECT setval(’foo’, 42, false); Next nextval will return 42
Результат, возвращаемый setval является просто значением его второго аргумента.
Важно!!!
Поскольку последовательности не являются транзакционными, изменения, сделанные setval, не отменяются, если транзакция откатывается. Эта функция требует привилегии UPDATE для последовательности.
Условные выражения
В этом разделе описываются SQL- совместимые условные выражения, доступные в QHB
Хотя COALESCE, GREATEST и LEAST синтаксически похожи на функции, они не являются обычными функциями и поэтому не могут использоваться с явными VARIADIC массива VARIADIC.
CASE
Выражение SQL CASE является общим условным выражением, аналогичным операторам if/else в других языках программирования:
CASE WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
CASE могут использоваться везде, где выражение допустимо. Каждое условие «condition» является выражением, которое возвращает логический результат. Если результат условия равен true, значением выражения CASE является result, следующий за условием, а остальная часть выражения CASE не обрабатывается. Если результат условия неверен, любые последующие предложения WHEN проверяются таким же образом. Если условия WHEN не возвращает true, значением выражения CASE является результатом предложения ELSE. Если предложение ELSE опущено и ни одно из условий не является истинным, результат будет нулевым.
Пример:
SELECT * FROM test;
a
---
1
2
3
SELECT a,
CASE WHEN a=1 THEN 'one'
WHEN a=2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
Типы данных всех выражений result должны быть преобразованы в один тип вывода.
Существует «простая» форма выражения CASE которая является вариантом общей формы выше:
CASE expression
WHEN value THEN result
[WHEN ...]
[ELSE result]
END
Первое expression вычисляется, затем сравнивается с каждым из выражений value в предложениях WHEN пока не будет найдено одно значение, равное ему. Если совпадений не найдено, возвращается result предложения ELSE (или нулевое значение). Это похоже на оператор switch в C.
Приведенный выше пример может быть написан с использованием простого синтаксиса CASE:
SELECT a,
CASE a WHEN 1 THEN 'one'
WHEN 2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
Выражение CASE не оценивает какие-либо подвыражения, которые не нужны для определения результата. Например, это возможный способ избежать сбоя деления на ноль:
SELECT ... WHERE CASE WHEN x <> 0 THEN y/x > 1.5 ELSE false END;`
Как описано в разделе Правила вычисления выражений, существуют различные ситуации, в
которых подвыражения выражения оцениваются в разное время, поэтому
принцип «CASE оценивает только необходимые подвыражения» не является
гарантированным. Например, постоянное подвыражение 1/0 обычно приводит к
сбою деления на ноль во время планирования, даже если он находится
внутри плеча CASE, которое никогда не будет задействовано во время
выполнения.
COALESCE
COALESCE(value [, ...])
Функция COALESCE возвращает первый из своих аргументов, который не является нулевым. Нуль возвращается, только если все аргументы являются нулевыми. Он часто используется для замены значения по умолчанию нулевыми значениями, когда данные извлекаются для отображения, например:
SELECT COALESCE(description, short_description, '(none)') ...
Это возвращает description если оно не равно нулю, иначе short_description если оно не равно нулю, иначе (none).
Как и выражение CASE, COALESCE оценивает только те аргументы, которые необходимы для определения результата; то есть аргументы справа от первого ненулевого аргумента не оцениваются. Эта стандартная функция SQL предоставляет возможности, аналогичные NVL и IFNULL, которые используются в некоторых других системах баз данных.
NULLIF
NULLIF(value1, value2)
Функция NULLIF возвращает нулевое значение, если value1 равно value2; в противном случае он возвращает value1. Это может быть использовано для выполнения обратной операции примера COALESCE приведенного выше:
SELECT NULLIF(value, ’(none)’) ...
В этом примере, если value равно (none), возвращается значение null, в противном случае возвращается значение value.
GREATEST и LEAST
GREATEST(value [, ...])
LEAST(value [, ...])
Функции GREATEST и LEAST выбирают наибольшее или наименьшее значение из списка любого числа выражений. Все выражения должны быть преобразованы в общий тип данных, который будет типом результата . Значения NULL в списке игнорируются. Результатом будет NULL, только если все выражения оцениваются как NULL.
Обратите внимание, что GREATEST и LEAST не входят в стандарт SQL, но являются распространенным расширением. Некоторые другие базы данных заставляют их возвращать NULL, если любой аргумент равен NULL, а не только тогда, когда все имеют значение NULL.
Функции и операторы массива
В таблице 51 показаны операторы, доступные для типов массивов.
| Оператор | Описание | Пример | Результат |
|---|---|---|---|
| = | равный | ARRAY[1.1,2.1,3.1]::int[] = ARRAY[1,2,3] | t |
| <> | не равный | ARRAY[1,2,3] <> ARRAY[1,2,4] | t |
| < | меньше, чем | ARRAY[1,2,3] < ARRAY[1,2,4] | t |
| > | больше чем | ARRAY[1,4,3] > ARRAY[1,2,4] | t |
| <= | меньше или равно | ARRAY[1,2,3] <= ARRAY[1,2,3] | t |
| >= | больше или равно | ARRAY[1,4,3] >= ARRAY[1,4,3] | t |
| @> | содержит | ARRAY[1,4,3] @> ARRAY[3,1,3] | t |
| <@ | содержится в | ARRAY[2,2,7] <@ ARRAY[1,7,4,2,6] | t |
| && | перекрытия (имеют общие элементы) | ARRAY[1,4,3] && ARRAY[2,1] | t |
| || | конкатенация между массивами | ARRAY[1,2,3] || ARRAY[4,5,6] | {1,2,3,4,5,6} |
| || | конкатенация между массивами | ARRAY[1,2,3] || ARRAY[[4,5,6],[7,8,9]] | {{1,2,3},{4,5,6},{7,8,9}} |
| || | объединение элементов в массив | 3 || ARRAY[4,5,6] | {3,4,5,6} |
| || | конкатенация массивов к элементам | ARRAY[4,5,6] || 7 | {4,5,6,7} |
Операторы упорядочения массива (<, >= и т.д.) сравнивают содержимое массива поэлементно, используя функцию сравнения B-дерева по умолчанию для типа данных элемента, и сортируют на основе первого различия. В многомерных массивах элементы посещаются в главном порядке строк (последний индекс изменяется наиболее быстро). Если содержимое двух массивов одинаково, но размерность отличается, первое различие в информации о размерности определяет порядок сортировки.
Операторы содержания массива (<@ и @>) считают, что один массив должен содержаться в другом, если каждый из его элементов появляется в другом. Дубликаты специально не обрабатываются, поэтому считается, что ARRAY[1] и ARRAY[1,1] содержат друг друга.
См. раздел Массивы для более подробной информации о поведении оператора массива. См. раздел Типы индексов для более подробной информации о том, какие операторы поддерживают индексированные операции.
В таблице 52 показаны функции, доступные для использования с типами массивов. См. раздел Массивы для получения дополнительной информации и примеров использования этих функций.
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| array_append(anyarray, anyelement) | anyarray | добавить элемент в конец массива | array_append (ARRAY [1,2], 3) | {1,2,3} |
| array_cat(anyarray, anyarray) | anyarray | объединить два массива | array_cat (ARRAY [1,2,3], ARRAY[4,5]) | {1,2,3,4,5} |
| array_ndims(anyarray) | int | возвращает количество измерений массива | array_ndims (ARRAY [[1,2,3], [4,5,6]]) | 2 |
| array_dims(anyarray) | text | возвращает текстовое представление размеров массива | array_dims (ARRAY [[1,2,3], [4,5,6]]) | [1:2][1:3] |
| array_fill(anyelement, int[] [, int[]]) | anyarray | возвращает массив, инициализированный с предоставленными значением и размерами, необязательно с нижними границами, отличными от 1 | array_fill (7, ARRAY[3], ARRAY[2]) | [2:4]={7,7,7} |
| array_length(anyarray, int) | int | возвращает длину запрошенного размера массива | array_length (array[1,2,3], 1) | 3 |
| array_lower(anyarray, int) | int | возвращает нижнюю границу запрошенного размера массива | array_lower (’[0:2]= {1,2,3}’::int[], 1) | 0 |
| array_position(anyarray, anyelement [, int]) | int | возвращает индекс первого вхождения второго аргумента в массиве, начиная с элемента, указанного третьим аргументом, или с первого элемента (массив должен быть одномерным) | array_position (ARRAY [’sun’,’mon’,’tue’,’wed’,’thu’,’fri’, ’sat’], ’mon’) | 2 |
| array_positions(anyarray, anyelement) | int[] | возвращает массив индексов всех вхождений второго аргумента в массиве, заданного в качестве первого аргумента (массив должен быть одномерным) | array_positions (ARRAY [’A’,’A’,’B’,’A’], ’A’) | {1,2,4} |
| array_prepend(anyelement, anyarray) | anyarray | добавить элемент в начало массива | array_prepend (1, ARRAY[2,3]) | {1,2,3} |
| array_remove(anyarray, anyelement) | anyarray | удалить все элементы, равные заданному значению, из массива (массив должен быть одномерным) | array_remove (ARRAY[1,2,3,2], 2) | {1,3} |
| array_replace(anyarray, anyelement, anyelement) | anyarray | заменить каждый элемент массива, равный заданному значению, новым значением | array_replace (ARRAY[1,2,5,4], 5, 3) | {1,2,3,4} |
| array_to_string(anyarray, text [, text]) | text | объединяет элементы массива, используя предоставленный разделитель и необязательную пустую строку | array_to_string (ARRAY[1, 2, 3, NULL, 5], ’,’, ’*’) | 1,2,3,*,5 |
| array_upper(anyarray, int) | int | возвращает верхнюю границу запрошенного размера массива | array_upper (ARRAY[1,8,3,7], 1) | 4 |
| cardinality(anyarray) | int | возвращает общее количество элементов в массиве или 0, если массив пуст | Cardinality (ARRAY[[1,2],[3,4]]) | 4 |
| string_to_array(text, text [, text]) | text[] | разбивает строку на элементы массива, используя предоставленный разделитель и необязательную пустую строку | string_to_array (’xx~^~yy~^~zz’, ’~^~’, ’yy’) | {xx,NULL,zz} |
unnest(anyarray) |
setof anyelement |
расширить массив до набора строк |
unnest(ARRAY[1,2]) |
1 2 (2 rows) |
unnest(anyarray, anyarray [, ...]) |
setof anyelement, anyelement [, ...] |
разверните несколько массивов (возможно, разных типов) до набора строк. Это разрешено только в предложении FROM; см. раздел 6.2.1.4 |
Unnest (ARRAY[1,2], ARRAY[’foo’,’bar’,’baz’]) |
1 foo 2 bar NULL baz (3 rows) |
В array_position и array_positions каждый элемент массива сравнивается с искомым значением с использованием семантики IS NOT DISTINCT FROM.
В array_position возвращается NULL если значение не найдено.
В array_positions NULL возвращается, только если массив NULL; если значение не найдено в массиве, вместо него возвращается пустой массив.
В string_to_array, если параметр разделителя равен NULL, каждый символ во входной строке станет отдельным элементом в результирующем массиве. Если разделитель является пустой строкой, тогда вся входная строка возвращается как массив из одного элемента. В противном случае входная строка разделяется при каждом появлении строки-разделителя.
В string_to_array, если параметр null-string пропущен или равен NULL, ни одна из подстрок ввода не будет заменена на NULL. В array_to_string, если параметр null-string опущен или равен NULL, любые нулевые элементы в массиве просто пропускаются и не представляются в выходной строке.
См. также раздел Агрегатные функции для использования с массивами агрегатной функции array_agg.
Функции диапазона и операторы
См. раздел Диапазонные типы для обзора диапазонных типов.
В таблице 53 показаны операторы, доступные для диапазонных типов.
Таблица 53. Операторы диапазона
| Оператор | Описание | Пример | Результат |
|---|---|---|---|
| = | равный | int4range(1,5) = ’[1,4]’::int4range | t |
| <> | не равный | numrange(1.1,2.2) <> numrange(1.1,2.3) | t |
| < | меньше, чем | int4range(1,10) < int4range(2,3) | t |
| > | больше чем | int4range(1,10) > int4range(1,5) | t |
| <= | меньше или равно | numrange(1.1,2.2) <= numrange(1.1,2.2) | t |
| >= | больше или равно | numrange(1.1,2.2) >= numrange(1.1,2.0) | t |
| @> | содержит диапазон | int4range(2,4) @> int4range(2,3) | t |
| @> | содержит элемент | ’[2011-01-01,2011-03-01)’::tsrange @> ’2011-01-10’::timestamp | t |
| <@ | диапазон содержит | int4range(2,4) <@ int4range(1,7) | t |
| <@ | элемент содержится | 42 <@ int4range(1,7) | f |
| && | перекрытия (есть общие точки) | int8range(3,7) && int8range(4,12) | t |
| << | строго слева от | int8range(1,10) << int8range(100,110) | t |
| >> | строго право | int8range(50,60) >> int8range(20,30) | t |
| &< | не распространяется на право | int8range(1,20) &< int8range(18,20) | t |
| &> | не распространяется слева от | int8range(7,20) &> int8range(5,10) | t |
| -- | соседствует с | numrange(1.1,2.2) -- numrange(2.2,3.3) | t |
| + | союз | numrange(5,15) + numrange(10,20) | [5,20) |
| * | пересечение | int8range(5,15) * int8range(10,20) | [10,15) |
| - | разница | int8range(5,15) - int8range(10,20) | [5,10) |
Простые операторы сравнения <, >, <= и >= сначала сравнивают нижние границы, и только если они равны, сравнивают верхние границы. Эти сравнения обычно не очень полезны для диапазонов, но предоставлены, чтобы позволить строить B-деревья на диапазонах.
Операторы left-of/right-of/adjacent всегда возвращают false, когда задействован пустой диапазон; то есть пустой диапазон не считается ни до, ни после любого другого диапазона.
Операторы объединения и разности не будут работать, если результирующий диапазон должен будет содержать два непересекающихся поддиапазона, поскольку такой диапазон не может быть представлен.
В таблице 54 показаны функции, доступные для использования с диапазонными типами.
| Функция | Тип ответа | Описание | Пример | Результат |
|---|---|---|---|---|
| lower (anyrange) | тип элемента диапазона | нижняя граница диапазона | lower(numrange(1.1,2.2)) | 1.1 |
| upper (anyrange) | тип элемента диапазона | верхняя граница диапазона | upper(numrange(1.1,2.2)) | 2.2 |
| isempty (anyrange) | boolean | диапазон пуст? | isempty(numrange(1.1,2.2)) | false |
| lower_inc (anyrange) | boolean | нижняя граница включительно? | lower_inc(numrange(1.1,2.2)) | true |
| upper_inc (anyrange) | boolean | верхняя граница включительно? | upper_inc(numrange(1.1,2.2)) | false |
| lower_inf (anyrange) | boolean | нижняя граница бесконечна? | lower_inf(’(,)’::daterange) | true |
| upper_inf (anyrange) | boolean | верхняя граница бесконечна? | upper_inf(’(,)’::daterange) | true |
| range_merge (anyrange, anyrange) | anyrange | наименьший диапазон, который включает оба из указанных диапазонов | range_merge(’[1,2)’::int4range, ’[3,4)’::int4range) | [1,4) |
lower и upper функции возвращают ноль, если диапазон пуст или запрошенная граница бесконечна. Функции lower_inc, upper_inc, lower_inf и upper_inf возвращают false для пустого диапазона.
Агрегатные функции
Агрегатные функции вычисляют один результат из набора входных значений. Встроенные агрегатные функции общего назначения перечислены в таблице 8.55, а статистические агрегаты - в таблице 56. Встроенные внутригрупповые агрегатные функции упорядоченного набора перечислены в таблице 57, а встроенные внутригрупповые гипотетически заданные функции - в таблице 58. Операции группировки, которые тесно связаны с агрегатными функциями, перечислены в таблице 59. Особые синтаксические соображения для агрегатных функций описаны в «Руководстве пользователя» в разделе Агрегатные выражения. Обратитесь к разделу руководства "Агрегатные функции" за дополнительной вводной информацией.
Таблица 55. Агрегатные функции общего назначения
| Функция | Тип аргумента (ов) | Тип ответа | Частичный режим | Описание |
|---|---|---|---|---|
| array_agg(expression) | любой не массив | массив типа аргумента | нет | входные значения, включая нули, объединяются в массив |
| array_agg(expression) | любой тип массива | такой же как тип данных аргумента | нет | входные массивы объединяются в массив одного более высокого измерения (все входные данные должны иметь одинаковую размерность и не могут быть пустыми или нулевыми) |
| avg(expression) | smallint, int, bigint, real, double precision, numeric или interval | numeric для любого аргумента целочисленного типа, double precision для аргумента с плавающей запятой, в остальном такой же, как тип данных аргумента | да | среднее (среднее арифметическое) всех ненулевых входных значений |
| bit_and(expression) | smallint, int, bigint или bit | такой же как тип данных аргумента | да | побитовое И всех ненулевых входных значений или ноль, если нет |
| bit_or(expression) | smallint, int, bigint или bit | такой же как тип данных аргумента | да | побитовое ИЛИ всех ненулевых входных значений или ноль, если нет |
| bool_and(expression) | bool | bool | да | истина, если все входные значения верны, иначе ложь |
| bool_or(expression) | bool | bool | да | истина, если хотя бы одно входное значение истинно, иначе ложь |
| count(*) | bigint | да | количество входных строк | |
| count(expression) | Любые | bigint | да | количество входных строк, для которых значение expression не равно нулю |
| every(expression) | bool | bool | да | эквивалентно bool_and |
| json_agg(expression) | any | json | нет | агрегирует значения, включая нули, в виде массива JSON |
| jsonb_agg(expression) | any | jsonb | нет | агрегирует значения, включая нули, в виде массива JSON |
| json_object_agg(name, value) | (any, any) | json | нет | объединяет пары имя / значение в виде объекта JSON; значения могут быть нулевыми, но не именами |
| jsonb_object_agg(name, value) | (any, any) | jsonb | нет | объединяет пары имя / значение в виде объекта JSON; значения могут быть нулевыми, но не именами |
| max(expression) | любой числовой, строковый, дата / время, тип сети или перечисления или массивы этих типов | такой же как тип аргумента | да | максимальное значение expression для всех ненулевых входных значений |
| min(expression) | любой числовой, строковый, дата / время, тип сети или перечисления или массивы этих типов | такой же как тип аргумента | да | минимальное значение expression для всех ненулевых входных значений |
| string_agg(expression, delimiter) | (text, text) или (bytea, bytea) | такой же как типы аргументов | нет | ненулевые входные значения объединяются в строку, разделенные разделителем |
| sum(expression) | smallint, int, bigint, real, double precision, numeric, interval или money | bigint для аргументов smallint или int, numeric для аргументов bigint, в остальном совпадает с типом данных аргумента | да | сумма expression по всем ненулевым входным значениям |
| xmlagg(expression) | xml | xml | нет | конкатенация ненулевых значений XML (см. также раздел xmlagg ) |
Следует отметить, что кроме count эти функции возвращают нулевое значение, когда строки не выбраны. В частности, sum без строк возвращает null, а не ноль, как можно было ожидать, и array_agg возвращает null, а не пустой массив, когда нет входных строк. Функция coalesce может использоваться для замены нуля или пустого массива на ноль при необходимости.
Агрегатные функции, которые поддерживают частичный режим, могут участвовать в различных оптимизациях, таких как параллельная агрегация.
Агрегатные функции array_agg, json_agg, jsonb_agg, json_object_agg, jsonb_object_agg, string_agg и xmlagg, а также аналогичные пользовательские агрегатные функции выдают значимо разные значения результата в зависимости от порядка входных значений. Этот порядок не указан по умолчанию, но им можно управлять, написав предложение ORDER BY в совокупном вызове, как показано в «Руководстве пользователя» в разделе Агрегатные выражения. Альтернативно, подача входных значений из отсортированного подзапроса обычно работает. Например:
SELECT xmlagg(x) FROM (SELECT x FROM test ORDER BY y DESC) AS tab;
Помните, что этот подход может дать сбой, если внешний уровень запроса содержит дополнительную обработку, такую как объединение, поскольку это может привести к переупорядочению вывода подзапроса до вычисления агрегата.
В таблице 56 показаны агрегатные функции, обычно используемые в статистическом анализе. (Они отделены просто для того, чтобы избежать загромождения списка наиболее часто используемых агрегатов). Если в описании упоминается N, это означает количество входных строк, для которых все входные выражения не равны NULL. Во всех случаях ноль возвращается, если вычисление не имеет смысла, например, когда N равно нулю.
Таблица 56. Агрегатные функции для статистики
| Функция | Тип аргумента | Тип ответа | Частичный режим | Описание |
|---|---|---|---|---|
| corr(Y, X) | double precision | double precision | да | коэффициент корреляции |
| covar_pop(Y, X) | double precision | double precision | да | ковариация населения |
| covar_samp(Y, X) | double precision | double precision | да | ковариация образца |
| regr_avgx(Y, X) | double precision | double precision | да | среднее значение независимой переменной (sum(X)/ N) |
| regr_avgy(Y, X) | double precision | double precision | да | среднее значение зависимой переменной (sum(Y)/ N) |
| regr_count(Y, X) | double precision | bigint | да | количество строк ввода, в которых оба выражения не равны нулю |
| regr_intercept(Y, X) | double precision | double precision | да | y-пересечение линейного уравнения с наименьшими квадратами, определяемого парами (X, Y) |
| regr_r2(Y, X) | double precision | double precision | да | квадрат коэффициента корреляции |
| regr_slope(Y, X) | double precision | double precision | да | наклон линейного уравнения с наименьшими квадратами, определяемый парами (X, Y) |
| regr_sxx(Y, X) | double precision | double precision | да | sum(X ^2) - sum(X)^2/ N (« сумма квадратов » независимой переменной) |
| regr_sxy(Y, X) | double precision | double precision | да | sum(X * Y) - sum(X) * sum(Y)/ N (« сумма произведений » независимой переменной, зависящей от времени) |
| regr_syy(Y, X) | double precision | double precision | да | sum(Y ^2) - sum(Y)^2/ N (« сумма квадратов » зависимой переменной) |
| stddev(expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | исторический псевдоним для stddev_samp |
| stddev_pop(expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | популяционное стандартное отклонение входных значений |
| stddev_samp(expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | выборочное стандартное отклонение входных значений |
| variance (expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | исторический псевдоним для var_samp |
| var_pop (expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | Популяционная дисперсия входных значений (квадрат стандартного отклонения населения) |
| var_samp (expression) | smallint, int, bigint, real, double precision или numeric | double precision для аргументов с плавающей точкой, иначе numeric | да | выборочная дисперсия входных значений (квадрат стандартного отклонения выборки) |
В таблице 57 показаны некоторые агрегатные функции, которые используют синтаксис упорядоченного набора. Эти функции иногда называют функциями «обратного распределения».
Таблица 57. Упорядоченные-совокупные функции
| Функция | Тип (ы) прямого аргумента | Тип агрегированных аргументов | Тип ответа | Частичный режим | Описание |
|---|---|---|---|---|---|
mode() WITHIN GROUP (ORDER BY sort_expression) | любой сортируемый тип | такое же как выражение сортировки | нет | возвращает наиболее частое входное значение (произвольно выбирая первое, если есть несколько одинаково частых результатов) | |
percentile_cont(fraction) WITHIN GROUP (ORDER BY sort_expression) | double precision | double precision или interval | такое же как выражение сортировки | нет | непрерывный процентиль: возвращает значение, соответствующее указанной дроби в порядке, при необходимости интерполируя между смежными входными элементами |
percentile_cont(fractions) WITHIN GROUP (ORDER BY sort_expression) | double precision\[\] | double precision или interval | массив типа выражения сортировки | нет | множественный непрерывный процентиль: возвращает массив результатов, соответствующих форме параметра fractions, причем каждый ненулевой элемент заменяется значением, соответствующим этому процентилю |
percentile_disc(fraction) WITHIN GROUP (ORDER BY sort_expression) | double precision | любой сортируемый тип | такое же как выражение сортировки | нет | дискретный процентиль: возвращает первое входное значение, позиция которого в заказе равна или превышает указанную дробь |
percentile_disc(fractions) WITHIN GROUP (ORDER BY sort_expression) | double precision\[\] | любой сортируемый тип | массив типа выражения сортировки | нет | множественный дискретный процентиль: возвращает массив результатов, соответствующих форме параметра fractions, при этом каждый ненулевой элемент заменяется входным значением, соответствующим этому процентилю |
Все агрегаты, перечисленные в таблице 57, игнорируют нулевые значения
в своих отсортированных входных данных. Для тех, которые принимают
параметр дроби, значение дроби должно быть между 0 и 1; если нет, то
возникает ошибка. Однако нулевое значение дроби дает просто нулевой
результат.
Каждый из агрегатов, перечисленных в таблице 58, связан с оконной функцией с тем же именем, определенной в разделе Оконные функции. В каждом случае совокупный результат — это значение, которое соответствующая оконная функция возвратила бы для «гипотетической» строки, построенной из args, если бы такая строка была добавлена в отсортированную группу строк, вычисленную из sorted_args.
Таблица 58. Агрегатные функции гипотетического множества
| Функция | Тип (ы) прямого аргумента | Тип агрегированных аргументов | Тип ответа | Частичный режим | Описание |
|---|---|---|---|---|---|
rank(args) WITHIN GROUP (ORDER BY sorted_args) | VARIADIC "any" | VARIADIC "any" | bigint | нет | ранг гипотетического ряда с пробелами для повторяющихся рядов |
dense_rank(args) WITHIN GROUP (ORDER BY sorted_args) | VARIADIC "any" | VARIADIC "any" | bigint | нет | ранг гипотетического ряда, без пробелов |
percent_rank(args) WITHIN GROUP (ORDER BY sorted_args) | VARIADIC "any" | VARIADIC "any" | double precision | нет | относительный ранг гипотетического ряда, от 0 до 1 |
cume_dist(args) WITHIN GROUP (ORDER BY sorted_args) | VARIADIC "any" | VARIADIC "any" | double precision | нет | относительный ранг гипотетического ряда, варьирующийся от 1 / N до 1 |
Для каждого из этих агрегатов гипотетического набора список прямых аргументов, указанных в args должен соответствовать количеству и типам агрегированных аргументов, указанных в sorted_args. В отличие от большинства встроенных агрегатов, эти агрегаты не являются строгими, то есть они не отбрасывают входные строки, содержащие nulls. Пустые значения сортируются в соответствии с правилом, указанным в предложении ORDER BY.
Таблица 59. Группировка операций
| Функция | Тип ответа | Описание |
|---|---|---|
| GROUPING(args...) | integer | Целочисленная битовая маска, указывающая, какие аргументы не включены в текущий набор группировки |
Операции группировки используются вместе с наборами группировки
(см. раздел GROUPING SETS, CUBE и ROLLUP) для различения строк результатов. Аргументы операции
группировки фактически не вычисляются, но они должны точно
соответствовать выражениям, приведенным в предложении GROUP BY
соответствующего уровня запроса. Биты назначаются с самым правым
аргументом, являющимся младшим значащим битом; каждый бит равен 0, если
соответствующее выражение включено в критерии группировки набора групп,
генерирующего строку результата, и 1, если это не так. Например:
=> SELECT * FROM items_sold;
make | model | sales
-------+-------+-------
Foo | GT | 10
Foo | Tour | 20
Bar | City | 15
Bar | Sport | 5
(4 rows)
=> SELECT make, model, GROUPING(make,model), sum(sales) FROM items_sold GROUP BY ROLLUP(make,model);
make | model | grouping | sum
-------+-------+----------+-----
Foo | GT | 0 | 10
Foo | Tour | 0 | 20
Bar | City | 0 | 15
Bar | Sport | 0 | 5
Foo | | 1 | 30
Bar | | 1 | 20
| | 3 | 50
(7 rows)
Оконные функции
Оконные функции предоставляют возможность выполнять вычисления по наборам строк, которые связаны с текущей строкой запроса. См. раздел Руководство по оконным функциям для ознакомления с этой функцией и раздел Вызовы оконных функций для деталей синтаксиса.
Встроенные функции окна перечислены в таблице 60. Обратите внимание, что эти функции должны вызываться с использованием синтаксиса оконной функции, то есть требуется предложение OVER.
В дополнение к этим функциям в качестве оконной функции может использоваться любой встроенный или определенный пользователем агрегат общего назначения или статистический агрегат (т.е. агрегаты неупорядоченного набора или гипотетического набора); см. раздел Агрегатные функции для получения списка встроенных агрегатов. Агрегатные функции действуют как оконные функции только тогда, когда предложение OVER следует за вызовом; в противном случае они действуют как неоконные агрегаты и возвращают одну строку для всего набора.
Таблица 60. Универсальные оконные функции
| Функция | Тип ответа | Описание |
|---|---|---|
| row_number() | bigint | номер текущей строки в его сегменте, считая от 1 |
| rank() | bigint | ранг текущей строки с пробелами; такой же, как row_number его первого партнера |
| dense_rank() | bigint | ранг текущей строки без пробелов; эта функция считает группы пиров |
| percent_rank() | double precision | относительный ранг текущей строки: (rank - 1)/(всего строк в сегменте - 1) |
| cume_dist() | double precision | кумулятивное распределение: (количество предшествующих или равных строк разделов)/общее количество строк разделов |
| ntile(num_buckets integer) | integer | целое число в диапазоне от 1 до значения аргумента, делающее раздел как можно более равномерно |
| lag(value anyelement [, offset integer [, default anyelement ]]) | same type as value | возвращает value оцененное в строке, которая offset строки перед текущей строкой в сегменте; если такой строки нет, вместо этого возвращаем default (который должен быть того же типа, что и value). И offset и default оцениваются относительно текущей строки. Если опущено, offset умолчанию равно 1 и по default равно нулю |
| lead(value anyelement [, offset integer [, default anyelement ]]) | same type as value | возвращает value оцененное в строке, которая является offset строкой после текущей строки в разделе; если такой строки нет, вместо этого возвращаем default (который должен быть того же типа, что и value). И offset и default оцениваются относительно текущей строки. Если опущено, offset умолчанию равно 1 и по default равно нулю |
| first_value(value any) | same type as value | возвращает value оцененное в строке, являющейся первой строкой оконного фрейма |
| last_value(value any) | same type as value | возвращает value оцененное в строке, которая является последней строкой оконного фрейма |
| nth_value(value any, nth integer) | same type as value | возвращает value оцененное в строке, которая является nth строкой оконного фрейма (считая от 1); ноль, если такой строки нет |
Все функции, перечисленные в таблице 60, зависят от порядка сортировки, указанного в предложении ORDER BY соответствующего определения окна. Строки, которые не различаются при рассмотрении только столбцов ORDER BY называются равноправными. Четыре функции ранжирования (включая cume_dist) определены так, чтобы они давали одинаковый ответ для всех одноранговых строк.
Обратите внимание, что first_value, last_value и nth_value учитывают только строки в «кадре окна», который по умолчанию содержит строки от начала раздела до последнего узла текущей строки. Это может дать бесполезные результаты для last_value а иногда и nth_value. Вы можете переопределить кадр, добавив подходящую спецификацию кадра (RANGE, ROWS или GROUPS) в предложение OVER. См. раздел Вызовы оконных функций для получения дополнительной информации о спецификациях кадров.
Когда агрегатная функция используется в качестве оконной функции, она агрегирует по строкам в рамке окна текущей строки. Агрегат, используемый с ORDER BY и определением кадра окна по умолчанию, создает тип поведения «промежуточная сумма», который может соответствовать или не соответствовать желаемому. Чтобы получить агрегацию по всему разделу, опустите ORDER BY или используйте ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING Другие характеристики кадра могут быть использованы для получения других эффектов.
cume_dist вычисляет долю строк раздела, которые меньше или равны текущей строке, тогда как percent_rank вычисляет долю строк раздела, которые меньше текущей строки, предполагая, что текущая строка не существует в разделе.
Выражения подзапроса
В этом разделе описываются SQL- совместимые выражения подзапроса, доступные в QHB. Все формы выражений, описанные в этом разделе, возвращают логические (true/false) результаты.
EXISTS
EXISTS (subquery)
Аргумент EXISTS — это произвольный оператор SELECT или подзапрос. Подзапрос оценивается, чтобы определить, возвращает ли он какие-либо строки. Если он возвращает хотя бы одну строку, результат EXISTS равен true; если подзапрос не возвращает строк, результатом EXISTS будет false.
Подзапрос может ссылаться на переменные из окружающего запроса, которые будут действовать как константы во время любой оценки подзапроса.
Подзапрос, как правило, выполняется только до момента, когда можно определить, возвращена ли хотя бы одна строка, а не до завершения. Неразумно писать подзапрос с побочными эффектами (например, вызывая функции последовательности); возникновение побочных эффектов может быть непредсказуемым.
Поскольку результат зависит только от того, возвращаются ли какие-либо строки, а не от содержимого этих строк, выходной список подзапроса обычно не важен. Обычное соглашение о кодировании - записывать все тесты EXISTS в форме EXISTS(SELECT 1 WHERE ...). Однако есть исключения из этого правила, такие как подзапросы, которые используют INTERSECT.
Этот простой пример похож на внутреннее соединение по col2, но он
генерирует не более одной выходной строки для каждой строки tab1, даже
если есть несколько совпадающих строк tab2:
SELECT col1
FROM tab1
WHERE EXISTS (SELECT 1 FROM tab2 WHERE col2 = tab1.col2);
IN
expression IN (subquery)
Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно один столбец. Левое выражение оценивается и сравнивается с каждой строкой результата подзапроса. Результатом IN является «истина», если найдена какая-либо одинаковая строка подзапроса. Результатом является «ложь», если не найдено ни одной равной строки (включая случай, когда подзапрос не возвращает строк).
Обратите внимание, что если левое выражение возвращает null или если нет равных правых значений и хотя бы одна правая строка возвращает null, результатом конструкции IN будет null, а не ложь. Это соответствует нормальным правилам SQL для логических комбинаций null значений.
Как и в случае с EXISTS, неразумно предполагать, что подзапрос будет оценен полностью.
row_constructor IN (subquery)
Левая часть этой формы IN является конструктором строки, как описано в «Руководстве пользователя» в разделе Конструкторы строк. Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно столько столбцов, сколько имеется выражений в левой строке. Левые выражения оцениваются и сравниваются построчно с каждой строкой результата подзапроса. Результатом IN является «истина», если найдена какая-либо одинаковая строка подзапроса. Результатом является «ложь», если не найдено ни одной равной строки (включая случай, когда подзапрос не возвращает строк).
Как обычно, null значения в строках объединяются в соответствии с обычными правилами логических выражений SQL. Две строки считаются равными, если все их соответствующие члены ненулевые и равные; строки являются неравными, если любые соответствующие члены ненулевые и неравные; в противном случае результат сравнения строк неизвестен (null). Если все результаты для каждой строки являются неравными или null, хотя бы с одним null, то результат IN является null.
NOT IN
expression NOT IN (subquery)
Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно один столбец. Левое выражение оценивается и сравнивается с каждой строкой результата подзапроса. Результатом NOT IN является «истина», если найдены только неравные строки подзапроса (включая случай, когда подзапрос не возвращает строк). Результатом является «ложь», если найдена какая-либо равная строка.
Обратите внимание, что если левое выражение возвращает null или если нет равных правых значений и хотя бы одна правая строка дает null, результатом конструкции NOT IN будет null, а не истина. Это соответствует нормальным правилам SQL для логических комбинаций null значений.
Как и в случае с EXISTS, неразумно предполагать, что подзапрос будет оценен полностью.
row_constructor NOT IN (subquery)
Левая часть этой формы NOT IN является конструктором строки, как описано в «Руководстве пользователя» в разделе Конструкторы строк. Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно столько столбцов, сколько имеется выражений в левой строке. Левые выражения оцениваются и сравниваются построчно с каждой строкой результата подзапроса. Результатом NOT IN является «истина», если найдены только неравные строки подзапроса (включая случай, когда подзапрос не возвращает строк). Результатом является «ложь», если найдена какая-либо равная строка.
Как обычно, null значения в строках объединяются в соответствии с обычными правилами логических выражений SQL. Две строки считаются равными, если все их соответствующие члены ненулевые и равные; строки являются неравными, если любые соответствующие члены ненулевые и неравные; в противном случае результат сравнения строк неизвестен (null). Если все результаты для каждой строки являются неравными или null, хотя бы с одним null, то результат NOT IN будет null.
ANY/SOME
expression operator ANY (subquery)
expression operator SOME (subquery)
Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно один столбец. Левое выражение оценивается и сравнивается с каждой строкой результата подзапроса с использованием данного оператора, который должен давать логический результат. Результат ANY является «истинным», если получен какой-либо истинный результат. Результатом является «ложь», если истинный результат не найден (включая случай, когда подзапрос не возвращает строк).
SOME является синонимом для ANY. IN эквивалентно = ANY.
Обратите внимание, что, если нет никаких успехов, и хотя бы одна правая строка возвращает null для результата оператора, результат ANY конструкции будет null, а не ложным. Это соответствует нормальным правилам SQL для логических комбинаций null значений.
Как и в случае с EXISTS, неразумно предполагать, что подзапрос будет оценен полностью.
row_constructor operator ANY (subquery)
row_constructor operator SOME (subquery)
Левая часть этой формы ANY является конструктором строки, как описано в «Руководстве пользователя» в разделе Конструкторы строк. Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно столько столбцов, сколько имеется выражений в левой строке. Левые выражения оцениваются и сравниваются построчно с каждой строкой результата подзапроса, используя данный оператор. Результатом ANY является true, если сравнение возвращает true для любой строки подзапроса. Результат - «ложь», если сравнение возвращает ложь для каждой строки подзапроса (включая случай, когда подзапрос не возвращает строк). Результат равен NULL, если сравнение со строкой подзапроса не возвращает true, и хотя бы одно сравнение возвращает NULL.
См. раздел Сравнение конструкторов строк для получения подробной информации о значении сравнения конструктора строки.
ALL
expression operator ALL (subquery)
Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно один столбец. Левое выражение оценивается и сравнивается с каждой строкой результата подзапроса с использованием данного оператора, который должен давать логический результат. Результатом ALL является true, если все строки возвращают true (включая случай, когда подзапрос не возвращает строк). Результат «ложь», если найден какой-либо ложный результат. Результат равен NULL, если сравнение со строкой подзапроса не возвращает false, и хотя бы одно сравнение возвращает NULL.
NOT IN эквивалентно <> ALL.
Как и в случае с EXISTS, неразумно предполагать, что подзапрос будет оценен полностью.
row_constructor operator ALL (subquery)
Левая часть этой формы ALL является конструктором строк, как описано в «Руководстве пользователя» в разделе Конструкторы строк. Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно столько столбцов, сколько имеется выражений в левой строке. Левые выражения оцениваются и сравниваются построчно с каждой строкой результата подзапроса, используя данный оператор. Результатом ALL является true, если сравнение возвращает true для всех строк подзапроса (включая случай, когда подзапрос не возвращает строк). Результатом является «ложь», если сравнение возвращает ложь для любой строки подзапроса. Результат равен NULL, если сравнение со строкой подзапроса не возвращает false, и хотя бы одно сравнение возвращает NULL.
См. раздел Сравнение конструкторов строк для получения подробной информации о значении сравнения конструктора строки.
Сравнение по одной строке
row_constructor operator (subquery)
Левая часть — это конструктор строк, как описано в «Руководстве пользователя» в разделе Конструкторы строк. Правая часть — это вложенный в скобки подзапрос, который должен возвращать ровно столько столбцов, сколько имеется выражений в левой строке. Кроме того, подзапрос не может возвращать более одной строки. (Если он возвращает ноль строк, результат принимается равным null). Левая часть вычисляется и сравнивается по строкам с одной строкой результата подзапроса.
См. раздел Сравнение конструкторов строк для получения подробной информации о значении сравнения конструктора строки.
Сравнение строк и массивов
В этом разделе описывается несколько специализированных конструкций для множественных сравнений между группами значений. Эти формы синтаксически связаны с формами подзапросов предыдущего раздела, но не включают подзапросы. Формы, включающие подвыражения массива, являются расширениями QHB; Остальные SQL- совместимы. Все формы выражений, описанные в этом разделе, возвращают логические (true/false) результаты.
IN
expression IN (value [, ...])
Правая часть — это заключенный в скобки список скалярных выражений. Результат true, если результат левого выражения равен любому из правых выражений. Это сокращенное обозначение для
expression = value1
OR
expression = value2
OR
...
Обратите внимание, что если левое выражение возвращает null или если нет равных правых значений и хотя бы одно правое выражение дает null, результатом конструкции IN будет null, а не ложь. Это соответствует нормальным правилам SQL для логических комбинаций null значений.
NOT IN
expression NOT IN (value [, ...])
Правая часть — это заключенный в скобки список скалярных выражений. Результат true, если результат левого выражения не равен всем правым выражениям. Это сокращенное обозначение для
expression <> value1
AND
expression <> value2
AND
...
Обратите внимание, что если левое выражение возвращает null или если нет равных правых значений и хотя бы одно правое выражение возвращает null, результат конструкции NOT IN будет null, а не истинным, как можно было ожидать. Это соответствует нормальным правилам SQL для логических комбинаций null значений.
x NOT IN y во всех случаях эквивалентно NOT (x IN y). Тем не менее,
нулевые значения гораздо чаще приводят в замешательство новичка при
работе с NOT IN чем при работе с IN. Лучше всего выразить ваше состояние
положительно, если это возможно.
ANY/SOME (массив)
expression operator ANY (array expression)
expression operator SOME (array expression)
Правая часть — это выражение в скобках, которое должно давать значение массива. Левое выражение вычисляется и сравнивается с каждым элементом массива с использованием данного оператора, который должен давать логический результат. Результат ANY является «истинным», если получен какой-либо истинный результат. Результатом является «ложь», если истинный результат не найден (включая случай, когда массив имеет нулевые элементы).
Если выражение массива дает null массив, результат ANY будет null. Если левое выражение возвращает null, то результат ANY обычно равен null (хотя оператор нестрогого сравнения может привести к другому результату). Кроме того, если правый массив содержит какие-либо null элементы и не получен истинный результат сравнения, результат ANY будет null, а не ложным (опять-таки, предполагая оператор строгого сравнения). Это соответствует нормальным правилам SQL для логических комбинаций null значений.
SOME является синонимом для ANY.
ALL (массив)
expression operator ALL (array expression)
Правая часть — это выражение в скобках, которое должно давать значение массива. Левое выражение вычисляется и сравнивается с каждым элементом массива с использованием данного оператора, который должен давать логический результат. Результатом ALL является «истина», если все сравнения дают истину (включая случай, когда массив имеет нулевые элементы). Результат «ложь», если найден какой-либо ложный результат.
Если выражение массива дает null массив, результат ALL будет null. Если левое выражение возвращает null, результат ALL обычно равен null (хотя оператор нестрогого сравнения может привести к другому результату). Кроме того, если правый массив содержит какие-либо null элементы и не получен ложный результат сравнения, результат ALL будет null, а не истинным (опять-таки, при условии использования оператора строгого сравнения). Это соответствует нормальным правилам SQL для логических комбинаций null значений.
Сравнение конструкторов строк
row_constructor operator row_constructor
Каждая сторона является конструктором строки, как описано в «Руководстве
пользователя» в разделе Конструкторы строк. Два значения строки должны иметь одинаковое
количество полей. Каждая сторона оценивается, и они сравниваются по
строкам. Сравнение конструкторов строк допускается, когда оператором
является =, <>, <, <=, > или >= . Каждый элемент
строки должен иметь тип, который имеет класс оператора B-дерева по
умолчанию, иначе попытка сравнения может вызвать ошибку.
Случаи = и <> работают немного по-другому. Две строки считаются равными, если все их соответствующие члены ненулевые и равные; строки являются неравными, если любые соответствующие члены ненулевые и неравные; в противном случае результат сравнения строк неизвестен (null).
Для случаев <, <=, > и >= элементы строки сравниваются слева
направо, останавливаясь, как только обнаруживается неравная или null
пара элементов. Если любой из этой пары элементов является null,
результат сравнения строк неизвестен (null); в противном случае
сравнение этой пары элементов определяет результат. Например,
ROW(1,2,NULL) < ROW(1,3,0) дает значение true, а не null, поскольку
третья пара элементов не рассматривается.
row_constructor IS DISTINCT FROM row_constructor
Эта конструкция похожа на сравнение строк <>, но не дает null значения для null входных данных. Вместо этого любое null значение считается неравным (отличным от) любого ненулевого значения, а любые два null значения считаются равными (не отличными). Таким образом, результат будет либо истинным, либо ложным, а не null.
row_constructor IS NOT DISTINCT FROM row_constructor
Эта конструкция похожа на сравнение строк =, но она не дает null значения для null входных данных. Вместо этого любое null значение считается неравным (отличным от) любого ненулевого значения, а любые два null значения считаются равными (не отличными). Таким образом, результат всегда будет либо истинным, либо ложным, а не null.
Сравнение составных типов
record operator record
Спецификация SQL требует сравнения строк для возврата NULL, если результат зависит от сравнения двух значений NULL или NULL и не NULL. QHB делает это только при сравнении результатов двух конструкторов строк (как в разделе Сравнение конструкторов строк) или при сравнении конструктора строк с выходными данными подзапроса (как в разделе Выражения подзапроса). В других контекстах, где сравниваются два значения составного типа, два значения поля NULL считаются равными, а NULL считается большим, чем ненулевое. Это необходимо для согласованного поведения сортировки и индексации составных типов.
Каждая сторона оценивается, и они сравниваются по строкам. Сравнения составных типов допускаются, когда оператором является =, <>, <, <=, > или >= или имеет семантику, аналогичную одной из них. (Точнее говоря, оператор может быть оператором сравнения строк, если он является членом класса операторов B-дерева или является отрицателем члена = класса операторов B-дерева). Поведение по умолчанию вышеупомянутых операторов такое же, как для IS [NOT] DISTINCT FROM для конструкторов строк (см. раздел Сравнение конструкторов строк).
Для поддержки сопоставления строк, которые включают элементы без класса операторов B-дерева по умолчанию, для сравнения составных типов определены следующие операторы: *=, *<>, *<, *<=, *> и *>=. Эти операторы сравнивают внутреннее двоичное представление двух строк. Две строки могут иметь различное двоичное представление, даже если сравнение двух строк с оператором равенства верно. Порядок строк в этих операторах сравнения является детерминированным, но не имеет иного смысла. Эти операторы используются внутри для материализованных представлений и могут быть полезны для других специализированных целей, таких как репликация, но не предназначены для общего использования при написании запросов.
Функции возврата наборов (SET)
В этом разделе описываются функции, которые могут возвращать более одной строки. Наиболее широко используемые функции в этом классе — это функции, генерирующие ряды, как подробно описано в таблице 61 и таблице 62. Другие, более специализированные функции, возвращающие множество, описаны в «Руководстве пользователя», например в разделе Табличные функции приведены способы объединения нескольких функций возврата набора.
Таблица 61. Функции генерации серий
| Функция | Тип аргумента | Тип ответа | Описание |
|---|---|---|---|
| generate_series(start, stop) | int, bigint или numeric | setof int, setof bigint или setof numeric (аналогично типу аргумента) | Создайте серию значений от start до stop с размером шага один |
| generate_series(start, stop, step) | int, bigint или numeric | setof int, setof bigint или setof numeric (аналогично типу аргумента) | Генерация серии значений от start до stop с шагом step |
| generate_series(start, stop, step interval) | timestamp или timestamp with time zone | setof timestamp или setof timestamp with time zone (такой же, как тип аргумента) | Генерация серии значений от start до stop с шагом step |
Если шаг положителен, возвращается ноль строк, если start больше, чем stop. И наоборот, когда шаг отрицательный, нулевые строки возвращаются, если start меньше stop. Нулевые строки также возвращаются для NULL входных данных. Это ошибка, когда шаг равен нулю. Вот несколько примеров:
SELECT * FROM generate_series(2,4);
generate_series
-----------------
2
3
4
(3 rows)
SELECT * FROM generate_series(5,1,-2);
generate_series
-----------------
5
3
1
(3 rows)
SELECT * FROM generate_series(4,3);
generate_series
-----------------
(0 rows)
SELECT generate_series(1.1, 4, 1.3);
generate_series
-----------------
1.1
2.4
3.7
(3 rows)
-- this example relies on the date-plus-integer operator
SELECT current_date + s.a AS dates FROM generate_series(0,14,7) AS s(a);
dates
------------
2004-02-05
2004-02-12
2004-02-19
(3 rows)
SELECT * FROM generate_series('2008-03-01 00:00'::timestamp,
'2008-03-04 12:00', '10 hours');
generate_series
---------------------
2008-03-01 00:00:00
2008-03-01 10:00:00
2008-03-01 20:00:00
2008-03-02 06:00:00
2008-03-02 16:00:00
2008-03-03 02:00:00
2008-03-03 12:00:00
2008-03-03 22:00:00
2008-03-04 08:00:00
(9 rows)
Таблица 62. Функции генерации нижнего индекса
| Функция | Тип ответа | Описание |
|---|---|---|
| generate_subscripts(array anyarray, dim int) | setof int | Создайте серию, содержащую индексы данного массива. |
| generate_subscripts(array anyarray, dim int, reverse boolean) | setof int | Создайте серию, содержащую индексы данного массива. Когда reverse верно, серия возвращается в обратном порядке. |
generate_subscripts — это вспомогательная функция, которая генерирует набор допустимых подписок для указанного измерения данного массива. Нулевые строки возвращаются для массивов, у которых нет запрошенного измерения, или для массивов NULL (но действительные индексы возвращаются для элементов массива NULL). Вот несколько примеров:
-- basic usage
SELECT generate_subscripts('{NULL,1,NULL,2}'::int[], 1) AS s;
s
---
1
2
3
4
(4 rows)
-- presenting an array, the subscript and the subscripted
-- value requires a subquery
SELECT * FROM arrays;
a
--------------------
{-1,-2}
{100,200,300}
(2 rows)
SELECT a AS array, s AS subscript, a[s] AS value
FROM (SELECT generate_subscripts(a, 1) AS s, a FROM arrays) foo;
array | subscript | value
---------------+-----------+-------
{-1,-2} | 1 | -1
{-1,-2} | 2 | -2
{100,200,300} | 1 | 100
{100,200,300} | 2 | 200
{100,200,300} | 3 | 300
(5 rows)
-- unnest a 2D array
CREATE OR REPLACE FUNCTION unnest2(anyarray)
RETURNS SETOF anyelement AS $$
select $1[i][j]
from generate_subscripts($1,1) g1(i),
generate_subscripts($1,2) g2(j);
$$ LANGUAGE sql IMMUTABLE;
CREATE FUNCTION
SELECT * FROM unnest2(ARRAY[[1,2],[3,4]]);
unnest2
---------
1
2
3
4
(4 rows)
Когда к функции в предложении FROM добавляется суффикс WITH ORDINALITY, к bigint добавляется столбец WITH ORDINALITY, который начинается с 1 и увеличивается на 1 для каждой строки вывода функции. Это наиболее полезно в случае набора возвращающих функций, таких как unnest().
-- set returning function WITH ORDINALITY
SELECT * FROM pg_ls_dir('.') WITH ORDINALITY AS t(ls,n);
ls | n
-----------------+----
pg_serial | 1
pg_twophase | 2
postmaster.opts | 3
pg_notify | 4
qhb.conf | 5
pg_tblspc | 6
logfile | 7
base | 8
qhbmaster.pid | 9
qhb_ident.conf | 10
global | 11
pg_xact | 12
pg_snapshots | 13
pg_multixact | 14
QHB_VERSION | 15
pg_wal | 16
qhb_hba.conf | 17
pg_stat_tmp | 18
pg_subtrans | 19
(19 rows)
Системные информационные функции и операторы
Таблица 63 показывает несколько функций, которые извлекают информацию о сеансе и системе.
В дополнение к функциям, перечисленным в этом разделе, существует ряд функций, связанных с системой статистики, которые также предоставляют системную информацию. См. раздел Просмотр статистики для получения дополнительной информации.
Таблица 63. Информационные функции сеанса
| Имя | Тип ответа | Описание |
|---|---|---|
| current_catalog | name | имя текущей базы данных (в стандарте SQL называется « каталог ») |
| current_database() | name | название текущей базы данных |
| current_query() | text | текст текущего выполняемого запроса, отправленный клиентом (может содержать более одного оператора) |
| current_role | name | эквивалентно current_user |
| current_schema [()] | name | имя текущей схемы |
| current_schemas(boolean) | name[] | имена схем в пути поиска, необязательно включая неявные схемы |
| current_user | name | имя пользователя текущего контекста выполнения |
| inet_client_addr() | inet | адрес удаленного соединения |
| inet_client_port() | int | порт удаленного подключения |
| inet_server_addr() | inet | адрес локальной связи |
| inet_server_port() | int | порт локальной связи |
| pg_backend_pid() | int | Идентификатор процесса сервера, присоединенного к текущему сеансу |
| pg_blocking_pids(int) | int[] | Идентификаторы процесса, которые блокируют указанный идентификатор процесса сервера от получения блокировки |
| pg_conf_load_time() | timestamp with time zone | время загрузки конфигурации |
| pg_current_logfile([ text ]) | text | Основное имя файла журнала или журнал в запрошенном формате, который в данный момент используется сборщиком журналов. |
| pg_my_temp_schema() | oid | OID временной схемы сеанса или 0, если нет |
| pg_is_other_temp_schema(oid) | boolean | Схема временная схема другого сеанса? |
| pg_jit_available() | boolean | доступна ли компиляция JIT в этом сеансе? Возвращает false если для jit установлено значение false. |
| pg_listening_channels() | setof text | названия каналов, которые слушает в данный момент сеанс |
| pg_notification_queue_usage() | double | доля асинхронной очереди уведомлений, занятой в данный момент (0-1) |
| pg_postmaster_start_time() | timestamp with time zone | время запуска сервера |
| pg_safe_snapshot_blocking_pids(int) | int[] | Идентификаторы процессов, которые блокируют указанный идентификатор процесса сервера от получения безопасного снимка |
| pg_trigger_depth() | int | текущий уровень вложенности триггеров QHB (0, если не вызывается, прямо или косвенно, из триггера) |
| session_user | name | имя пользователя сеанса |
| user | name | эквивалентно current_user |
| version() | text | Информация о версии QHB. Смотрите также server_version_num для машиночитаемой версии. |
| qhb_commit_id() | text | Возвращает текущий номер зафиксированной транзакции. |
current_catalog, current_role, current_schema, current_user, session_user и user имеют специальный синтаксический статус в SQL: они должны вызываться без завершающих скобок. (В QHB скобки можно использовать с current_schema, но не с остальными).
session_user обычно является пользователем, который инициировал текущее соединение с базой данных; но суперпользователи могут изменить эту настройку с помощью SET SESSION AUTHORIZATION. current_user — это идентификатор пользователя, который применим для проверки прав доступа. Обычно он равен пользователю сеанса, но его можно изменить с помощью SET ROLE. Он также изменяется во время выполнения функций с атрибутом SECURITY DEFINER. На языке Unix пользователь сеанса - это «реальный пользователь», а текущий пользователь - «эффективный пользователь». current_role и user являются синонимами для current_user. (Стандарт SQL проводит различие между current_role и current_user, но QHB этого не делает, поскольку объединяет пользователей и роли в единый вид сущностей).
current_schema возвращает имя схемы, которая является первой в пути поиска (или нулевое значение, если путь поиска пуст). Это схема, которая будет использоваться для любых таблиц или других именованных объектов, которые создаются без указания целевой схемы. current_schemas(boolean) возвращает массив имен всех схем, присутствующих в настоящее время в пути поиска. Опция Boolean определяет, включены ли в возвращаемый путь поиска неявно включенные системные схемы, такие как pg_catalog.
inet_client_addr возвращает IP-адрес текущего клиента, а inet_client_port возвращает номер порта. inet_server_addr возвращает IP-адрес, на котором сервер принял текущее соединение, а inet_server_port возвращает номер порта. Все эти функции возвращают NULL, если текущее соединение происходит через сокет Unix-домена.
pg_blocking_pids возвращает массив идентификаторов процессов сеансов, которые блокируют серверный процесс с указанным идентификатором процесса, или пустой массив, если такого серверного процесса нет или он не заблокирован. Один серверный процесс блокирует другой, если он либо содержит блокировку, которая конфликтует с запросом блокировки заблокированного процесса (жесткий блок), либо ожидает блокировку, которая будет конфликтовать с запросом блокировки заблокированного процесса, и находится впереди него в очереди ожидания (мягкий блок). При использовании параллельных запросов результат всегда содержит видимые клиентом идентификаторы процессов (то есть результаты pg_backend_pid), даже если фактическая блокировка удерживается или ожидается дочерним рабочим процессом. Соответственно в результате могут быть продублированы идентификаторы PID. Также обратите внимание, когда подготовленная транзакция содержит конфликтующую блокировку, она будет представлена нулевым идентификатором процесса в результате выполнения этой функции. Частые вызовы этой функции могут оказать некоторое влияние на производительность базы данных, поскольку для нее требуется кратковременный эксклюзивный доступ к общему состоянию диспетчера блокировки.
pg_conf_load_time возвращает временную метку с часовым поясом, когда файлы конфигурации сервера были загружены в последний раз. (Если текущий сеанс был жив в то время, это будет время, когда сам сеанс перечитывал файлы конфигурации, поэтому чтение будет немного отличаться в разных сеансах. В противном случае это время, когда процесс postmaster перечитывал файлы конфигурации).
pg_current_logfile возвращает в виде текста путь к файлам журналов, которые в данный момент используются сборщиком журналов. Путь включает каталог log_directory и имя файла журнала. Сбор журнала должен быть включен или возвращаемое значение равно NULL. Когда существует несколько файлов журнала, каждый в своем формате, pg_current_logfile вызываемый без аргументов, возвращает путь к файлу с первым форматом, найденным в упорядоченном списке: stderr, csvlog. NULL возвращается, когда ни один файл журнала не имеет ни одного из этих форматов. Чтобы запросить конкретный формат файла, укажите текстовое значение csvlog или stderr в качестве значения необязательного параметра. Возвращаемое значение равно NULL если запрошенный формат журнала не настроен как log_destination. pg_current_logfile отражает содержимое файла current_logfiles.
pg_my_temp_schema возвращает OID временной схемы текущего сеанса или ноль, если ее нет (потому что она не создала никаких временных таблиц). pg_is_other_temp_schema возвращает true, если данный OID является OID временной схемы другого сеанса. (Это может быть полезно, например, для исключения временных таблиц других сеансов из каталога).
pg_listening_channels возвращает набор имен асинхронных каналов уведомлений, которые прослушивает текущий сеанс. pg_notification_queue_usage возвращает долю от общего доступного пространства для уведомлений, которое в данный момент занято уведомлениями, ожидающими обработки, в виде double в диапазоне 0-1. См LISTEN и NOTIFY для получения дополнительной информации.
pg_postmaster_start_time возвращает временную метку с часовым поясом при запуске сервера.
pg_safe_snapshot_blocking_pids возвращает массив идентификаторов процессов сеансов, которые блокируют процесс сервера с указанным идентификатором процесса от получения безопасного снимка, или пустой массив, если такого серверного процесса нет или он не заблокирован. Сеанс, выполняющий транзакцию SERIALIZABLE блокирует транзакцию SERIALIZABLE READ ONLY DEFERRABLE от получения моментального снимка до тех пор, пока последний не определит, что безопасно избегать любых предикатных блокировок. См. раздел Уровень изоляции Serializable для получения дополнительной информации о сериализуемых и отложенных транзакциях. Частые вызовы этой функции могут оказать некоторое влияние на производительность базы данных, поскольку для нее требуется кратковременный доступ к общему состоянию менеджера блокировки предикатов.
version возвращает строку, описывающую версию сервера QHB. Вы также можете получить эту информацию из server_version или для машиночитаемой версии server_version_num. Разработчики программного обеспечения должны использовать server_version_num или PQserverVersion вместо анализа текстовой версии.
В таблице 64 перечислены функции, которые позволяют пользователю запрашивать привилегии доступа к объекту программным способом. См. раздел Привилегии для получения дополнительной информации о привилегиях.
Таблица 64. Доступ к функциям запроса привилегий
| Имя | Тип ответа | Описание |
|---|---|---|
| has_any_column_privilege(user, table, privilege) | boolean | имеет ли пользователь привилегию для любого столбца таблицы |
| has_any_column_privilege (table, privilege) | boolean | имеет ли текущий пользователь привилегию для любого столбца таблицы |
| has_column_privilege (user, table, column, privilege) | boolean | имеет ли пользователь привилегию для столбца |
| has_column_privilege (table, column, privilege) | boolean | имеет ли текущий пользователь привилегию для столбца |
| has_database_privilege (user, database, privilege) | boolean | имеет ли пользователь привилегию для базы данных |
| has_database_privilege (database, privilege) | boolean | имеет ли текущий пользователь привилегию для базы данных |
| has_foreign_data_wrapper_privilege (user, fdw, privilege) | boolean | имеет ли пользователь привилегию для обёртки сторонних данных |
| has_foreign_data_wrapper_privilege (fdw, privilege) | boolean | имеет ли текущий пользователь привилегию для обёртки сторонних данных |
| has_function_privilege (user, function, privilege) | boolean | имеет ли пользователь привилегию для функции |
| has_function_privilege (function, privilege) | boolean | имеет ли текущий пользователь привилегию для функции |
| has_language_privilege (user, language, privilege) | boolean | имеет ли пользователь право на язык |
| has_language_privilege (language, privilege) | boolean | имеет ли текущий пользователь привилегию для языка |
| has_schema_privilege (user, schema, privilege) | boolean | имеет ли пользователь привилегию для схемы |
| has_schema_privilege (schema, privilege) | boolean | имеет ли текущий пользователь привилегию для схемы |
| has_sequence_privilege (user, sequence, privilege) | boolean | имеет ли пользователь привилегию для последовательности |
| has_sequence_privilege (sequence, privilege) | boolean | имеет ли текущий пользователь привилегию для последовательности |
| has_server_privilege (user, server, privilege) | boolean | имеет ли пользователь привилегию для стороннего сервера |
| has_server_privilege (server, privilege) | boolean | имеет ли текущий пользователь привилегию для стороннего сервера |
| has_table_privilege (user, table, privilege) | boolean | имеет ли пользователь привилегию для таблицы |
| has_table_privilege (table, privilege) | boolean | имеет ли текущий пользователь привилегию для таблицы |
| has_tablespace_privilege (user, tablespace, privilege) | boolean | имеет ли пользователь привилегию для табличного пространства |
| has_tablespace_privilege (tablespace, privilege) | boolean | имеет ли текущий пользователь привилегию для табличного пространства |
| has_type_privilege (user, type, privilege) | boolean | имеет ли пользователь привилегию для типа |
| has_type_privilege (type, privilege) | boolean | имеет ли текущий пользователь привилегию для типа |
| pg_has_role (user, role, privilege) | boolean | имеет ли пользователь право на роль |
| pg_has_role (role, privilege) | boolean | имеет ли текущий пользователь право на роль |
| row_security_active (table) | boolean | у текущего пользователя активна защита на уровне строк для таблицы |
has_table_privilege проверяет, может ли пользователь получить доступ к таблице определенным образом. Пользователь может быть указан по имени, по OID (pg_authid.oid), public чтобы указать псевдоролевую роль PUBLIC, или, если аргумент опущен, предполагается current_user. Таблица может быть указана по имени или по OID. (Таким образом, на самом деле существует шесть вариантов has_table_privilege, которые можно различить по количеству и типам их аргументов). При указании по имени имя может быть дополнено схемой при необходимости. Требуемый тип привилегий доступа указывается текстовой строкой, которая должна принимать одно из значений SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES или TRIGGER. Опционально, с WITH GRANT OPTION можно добавить тип привилегии, чтобы проверить, удерживается ли привилегия с опцией grant. Кроме того, несколько типов привилегий могут быть перечислены через запятую, и в этом случае результат будет true если удерживается какая-либо из перечисленных привилегий. (Случай строки привилегий не имеет значения, и допускается наличие дополнительного пробела между именами привилегий, но не внутри них). Некоторые примеры:
SELECT has_table_privilege('myschema.mytable', 'select');
SELECT has_table_privilege('joe', 'mytable', 'INSERT, SELECT WITH GRANT OPTION');
has_sequence_privilege проверяет, может ли пользователь получить доступ к последовательности определенным образом. Возможности его аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен оцениваться как USAGE, SELECT или UPDATE.
has_any_column_privilege проверяет, может ли пользователь получить доступ к любому столбцу таблицы определенным образом. Возможности его аргументов аналогичны has_table_privilege, за исключением того, что требуемый тип привилегий доступа должен соответствовать некоторой комбинации SELECT, INSERT, UPDATE или REFERENCES. Обратите внимание, что наличие любой из этих привилегий на уровне таблицы неявно предоставляет ее для каждого столбца таблицы, поэтому has_any_column_privilege всегда будет возвращать true если has_table_privilege делает для это тех же аргументов. Но has_any_column_privilege также успешно выполняется если существует предоставление привилегии на уровне столбца хотя бы для одного столбца.
has_column_privilege проверяет, может ли пользователь получить доступ к столбцу определенным образом. Возможности его аргументов аналогичны has_table_privilege, с добавлением, что столбец может быть указан либо по имени, либо по номеру атрибута. Требуемый тип привилегий доступа должен соответствовать некоторой комбинации SELECT, INSERT, UPDATE или REFERENCES. Обратите внимание, что наличие любой из этих привилегий на уровне таблицы неявно предоставляет ее для каждого столбца таблицы.
has_database_privilege проверяет, может ли пользователь получить доступ к базе данных определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен соответствовать некоторой комбинации CREATE, CONNECT, TEMPORARY или TEMP (которая эквивалентна TEMPORARY).
has_function_privilege проверяет, может ли пользователь получить доступ к функции определенным образом. Возможности аргументов аналогичны has_table_privilege. При указании функции текстовой строкой, а не OID, допустимый ввод такой же, как для типа данных regprocedure (см. раздел Типы идентификаторов объектов). Требуемый тип привилегий доступа должен оцениваться как EXECUTE. Примером является:
SELECT has_function_privilege('joeuser', 'myfunc(int, text)', 'execute');
has_foreign_data_wrapper_privilege проверяет, может ли пользователь получить доступ к оболочке внешних данных определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен быть USAGE.
has_language_privilege проверяет, может ли пользователь получить доступ к процедурному языку определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен быть USAGE.
has_schema_privilege проверяет, может ли пользователь получить доступ к схеме определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен соответствовать некоторой комбинации CREATE или USAGE.
has_server_privilege проверяет, может ли пользователь получить доступ к внешнему серверу определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен быть USAGE.
has_tablespace_privilege проверяет, может ли пользователь получить доступ к табличному пространству определенным образом. Возможности аргументов аналогичны has_table_privilege. Требуемый тип привилегий доступа должен оцениваться как CREATE.
has_type_privilege проверяет, может ли пользователь получить доступ к типу определенным образом. Возможности аргументов аналогичны has_table_privilege. При указании типа текстовой строкой, а не OID, допустимый ввод такой же, как для типа данных regtype (см. раздел Типы идентификаторов объектов). Требуемый тип привилегий доступа должен быть USAGE.
pg_has_role проверяет, может ли пользователь получить доступ к роли определенным образом. Возможности его аргументов аналогичны has_table_privilege, за исключением того, что public не допускается в качестве имени пользователя. Требуемый тип привилегий доступа должен соответствовать некоторой комбинации MEMBER или USAGE. MEMBER обозначает прямое или косвенное членство в роли (то есть право делать SET ROLE), а USAGE обозначает, доступны ли привилегии роли немедленно без выполнения SET ROLE.
row_security_active проверяет, активна ли защита на уровне строк для указанной таблицы в контексте current_user и среды. Таблица может быть указана по имени или по OID.
В таблице 65 показаны операторы, доступные для типа aclitem, который представляет собой представление прав доступа в каталоге. См. раздел Привилегии для получения информации о том, как читать значения привилегий доступа.
| Оператор | Описание | Пример | Результат |
|---|---|---|---|
| = | равный | ’calvin=r*w/hobbes’::aclitem = ’calvin=r*w*/hobbes’::aclitem | f |
| @> | содержит элемент | ’{calvin=r*w/hobbes, hobbes=r*w*/postgres}’::aclitem[] @> ’calvin=r*w/hobbes’::aclitem | t |
| ~ | содержит элемент | ’{calvin=r*w/hobbes, hobbes=r*w*/postgres}’::aclitem[] ~ ’calvin=r*w/hobbes’::aclitem | t |
В таблице 66 показаны некоторые дополнительные функции для управления типом aclitem.
| Имя | Тип ответа | Описание |
|---|---|---|
| acldefault (type, ownerId) | aclitem[] | получить права доступа по умолчанию для объекта, принадлежащего ownerId |
| aclexplode (aclitem[]) | setof record | получить массив aclitem виде кортежей |
| makeaclitem (grantee, grantor, privilege, grantable) | aclitem | построить aclitem из ввода |
acldefault возвращает встроенные права доступа по умолчанию для объекта
типа type принадлежащего роли ownerId. Они представляют привилегии
доступа, которые будут приняты, когда запись ACL объекта равна нулю.
(Права доступа по умолчанию описаны в разделе Привилегии). Типом параметра
является CHAR: напишите ’c’ для COLUMN, ’r’ для TABLE и табличных
объектов, ’s’ для SEQUENCE, ’d’ для DATABASE, ’f’ для FUNCTION или
PROCEDURE, ’l’ для LANGUAGE, ’L’ для LARGE OBJECT, ’n для SCHEMA,’t ’ для TABLESPACE, ’F’ для FOREIGN DATA WRAPPER, ’S’ для FOREIGN SERVER
или ’T' для TYPE или DOMAIN.
aclexplode возвращает массив aclitem в виде набора строк. В качестве выходных столбцов указываются oid grantor, oid grantee (0 для PUBLIC), предоставляется привилегия в виде текста (SELECT, ...) и является ли привилегия логически допустимой. makeaclitem выполняет обратную операцию.
В таблице 67 показаны функции, которые определяют, является ли определенный объект видимым в текущем пути поиска схемы. Например, таблица считается видимой, если содержащая ее схема находится в пути поиска, и таблица с таким именем не появляется ранее в пути поиска. Это эквивалентно утверждению, что на таблицу можно ссылаться по имени без явного уточнения схемы. Чтобы перечислить имена всех видимых таблиц:
SELECT relname FROM pg_class WHERE pg_table_is_visible(oid);
Таблица 67. Функции запроса видимости схемы
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_collation_is_visible(collation_oid) | boolean | сортировка видна в пути поиска |
| pg_conversion_is_visible(conversion_oid) | boolean | конверсия видна в пути поиска |
| pg_function_is_visible(function_oid) | boolean | функция видна в пути поиска |
| pg_opclass_is_visible(opclass_oid) | boolean | класс оператора виден в пути поиска |
| pg_operator_is_visible(operator_oid) | boolean | оператор виден в пути поиска |
| pg_opfamily_is_visible(opclass_oid) | boolean | видно ли семейство операторов в пути поиска |
| pg_statistics_obj_is_visible(stat_oid) | boolean | виден ли объект статистики в пути поиска |
| pg_table_is_visible(table_oid) | boolean | таблица видна в пути поиска |
| pg_ts_config_is_visible(config_oid) | boolean | видна ли конфигурация текстового поиска в пути поиска |
| pg_ts_dict_is_visible(dict_oid) | boolean | виден словарь текстового поиска в пути поиска |
| pg_ts_parser_is_visible(parser_oid) | boolean | виден ли анализатор текстового поиска в пути поиска |
| pg_ts_template_is_visible(template_oid) | boolean | виден ли шаблон текстового поиска в пути поиска |
| pg_type_is_visible(type_oid) | boolean | тип (или домен) виден в пути поиска |
Каждая функция выполняет проверку видимости для одного типа объекта базы данных. Обратите внимание, что pg_table_is_visible также может использоваться с представлениями, материализованными представлениями, индексами, последовательностями и внешними таблицами; pg_function_is_visible также может использоваться с процедурами и агрегатами; pg_type_is_visible также может использоваться с доменами. Для функций и операторов объект в пути поиска виден, если ранее в пути нет объекта с таким же именем и типом данных аргумента. Для классов операторов рассматриваются как имя, так и связанный метод доступа к индексу.
Все эти функции требуют OID объекта для идентификации объекта, подлежащего проверке. Если вы хотите проверить объект по имени, удобно использовать псевдонимы OID (regclass, regtype, regprocedure, regoperator, regconfig или regdictionary), например:
SELECT pg_type_is_visible('myschema.widget'::regtype);
Обратите внимание, что не имеет смысла тестировать имя типа, не являющееся схемой, таким образом - если имя вообще можно распознать, оно должно быть видимым.
В таблице 68 перечислены функции, которые извлекают информацию из системных каталогов.
Таблица 68. Информационные функции системного каталога
| Имя | Тип ответа | Описание |
|---|---|---|
| format_type(type_oid, typemod) | text | получить имя SQL типа данных |
| pg_get_constraintdef(constraint_oid) | text | получить определение ограничения |
| pg_get_constraintdef(constraint_oid, pretty_bool) | text | получить определение ограничения |
| pg_get_expr(pg_node_tree, relation_oid) | text | декомпилировать внутреннюю форму выражения, предполагая, что любые переменные в нем относятся к отношению, указанному вторым параметром |
| pg_get_expr(pg_node_tree, relation_oid, pretty_bool) | text | декомпилировать внутреннюю форму выражения, предполагая, что любые переменные в нем относятся к отношению, указанному вторым параметром |
| pg_get_functiondef(func_oid) | text | получить определение функции или процедуры |
| pg_get_function_arguments(func_oid) | text | получить список аргументов определения функции или процедуры (со значениями по умолчанию) |
| pg_get_function_identity_arguments(func_oid) | text | получить список аргументов для идентификации функции или процедуры (без значений по умолчанию) |
| pg_get_function_result(func_oid) | text | получить предложение RETURNS для функции (возвращает ноль для процедуры) |
| pg_get_indexdef(index_oid) | text | получить команду CREATE INDEX для индекса |
| pg_get_indexdef(index_oid, column_no, pretty_bool) | text | получить команду CREATE INDEX для индекса или определение только одного столбца индекса, когда column_no не равно нулю |
| pg_get_keywords() | setof record | получить список ключевых слов SQL и их категорий |
| pg_get_ruledef(rule_oid) | text | получить команду CREATE RULE для правила |
| pg_get_ruledef(rule_oid, pretty_bool) | text | получить команду CREATE RULE для правила |
| pg_get_serial_sequence(table_name, column_name) | text | получить имя последовательности, которую использует столбец серийного номера или идентификатора |
| pg_get_statisticsobjdef(statobj_oid) | text | получить команду CREATE STATISTICS для объекта расширенной статистики |
| pg_get_triggerdef (trigger_oid) | text | CREATE [ CONSTRAINT ] TRIGGER get CREATE [ CONSTRAINT ] TRIGGER для триггера |
| pg_get_triggerdef (trigger_oid, pretty_bool) | text | CREATE [ CONSTRAINT ] TRIGGER get CREATE [ CONSTRAINT ] TRIGGER для триггера |
| pg_get_userbyid(role_oid) | name | получить имя роли с заданным OID |
| pg_get_viewdef(view_name) | text | получить базовую команду SELECT для представления или материализованного представления (устарело) |
| pg_get_viewdef(view_name, pretty_bool) | text | получить базовую команду SELECT для представления или материализованного представления (устарело) |
| pg_get_viewdef(view_oid) | text | получить базовую команду SELECT для представления или материализованного представления |
| pg_get_viewdef(view_oid, pretty_bool) | text | получить базовую команду SELECT для представления или материализованного представления |
| pg_get_viewdef(view_oid, wrap_column_int) | text | получить базовую команду SELECT для представления или материализованного представления; строки с полями переносятся в указанное количество столбцов, подразумевается симпатичная печать |
| pg_index_column_has_property(index_oid, column_no, prop_name) | boolean | проверить, имеет ли столбец индекса указанное свойство |
| pg_index_has_property(index_oid, prop_name) | boolean | проверить, имеет ли индекс указанное свойство |
| pg_indexam_has_property(am_oid, prop_name) | boolean | проверить, есть ли у метода доступа к индексу указанное свойство |
| pg_options_to_table(reloptions) | setof record | получить набор пар имя / значение опции хранения |
| pg_tablespace_databases(tablespace_oid) | setof oid | получить набор OID базы данных, которые имеют объекты в табличном пространстве |
| pg_tablespace_location(tablespace_oid) | text | получить путь в файловой системе, в которой находится это табличное пространство |
| pg_typeof(any) | regtype | получить тип данных любого значения |
| collation for (any) | text | получить сопоставление аргумента |
| to_regclass(rel_name) | regclass | получить OID названного отношения |
| to_regproc(func_name) | regproc | получить OID названной функции |
| to_regprocedure(func_name) | regprocedure | получить OID названной функции |
| to_regoper(operator_name) | regoper | получить OID указанного оператора |
| to_regoperator(operator_name) | regoperator | получить OID указанного оператора |
| to_regtype(type_name) | regtype | получить OID названного типа |
| to_regnamespace(schema_name) | regnamespace | получить OID названной схемы |
| to_regrole(role_name) | regrole | получить OID указанной роли |
format_type возвращает имя SQL типа данных, идентифицируемого его типом OID и, возможно, модификатором типа. Передайте NULL для модификатора типа, если конкретный модификатор не известен.
pg_get_keywords возвращает набор записей, описывающих ключевые слова
SQL, распознаваемые сервером. Столбец word содержит ключевое слово.
catcode содержит код категории: U для незарезервированного, C для имени
столбца, T для имени типа или функции или R для зарезервированного.
catdesc содержит возможно локализованную строку, описывающую категорию.
pg_get_constraintdef, pg_get_indexdef, pg_get_ruledef, pg_get_statisticsobjdef и pg_get_triggerdef соответственно восстанавливают команду создания для ограничения, индекса, правила, расширенного объекта статистики или триггера. (Обратите внимание, что это декомпилированная реконструкция, а не исходный текст команды). pg_get_expr декомпилирует внутреннюю форму отдельного выражения, например значение по умолчанию для столбца. Это может быть полезно при проверке содержимого системных каталогов. Если выражение может содержать Vars, укажите OID отношения, на которое они ссылаются, как на второй параметр; если не ожидаются Vars, достаточно нуля. pg_get_viewdef восстанавливает запрос SELECT который определяет представление. Большинство этих функций представлены в двух вариантах, один из которых может при желании «красиво распечатать» результат. Формат pretty-printed более читабелен, но формат по умолчанию, скорее всего, будет интерпретирован аналогичным образом в будущих версиях QHB; Избегайте использования pretty-printed вывода для дампа. Передача значения false для параметра pretty-print дает тот же результат, что и для варианта, в котором этот параметр вообще отсутствует.
pg_get_functiondef возвращает полный оператор CREATE OR REPLACE FUNCTION для функции. pg_get_function_arguments возвращает список аргументов функции в той форме, в которой она должна отображаться в CREATE FUNCTION. pg_get_function_result аналогичным образом возвращает соответствующее предложение RETURNS для функции. pg_get_function_identity_arguments возвращает список аргументов, необходимый для идентификации функции, например, в той форме, в которой она должна отображаться в ALTER FUNCTION. Эта форма опускает значения по умолчанию.
pg_get_serial_sequence возвращает имя последовательности, связанной со столбцом, или NULL, если последовательность не связана со столбцом. Если столбец является столбцом идентификаторов, связанная последовательность представляет собой последовательность, внутренне созданную для столбца идентификаторов. Для столбцов, созданных с использованием одного из серийных типов (serial, smallserial, bigserial), это последовательность, созданная для этого определения последовательного столбца. В последнем случае эта связь может быть изменена или удалена с помощью команды ALTER SEQUENCE OWNED BY. Первый входной параметр — это имя таблицы с необязательной схемой, а второй параметр - имя столбца. Поскольку первый параметр потенциально является схемой и таблицей, он не обрабатывается как идентификатор в двойных кавычках, то есть по умолчанию он находится в нижнем регистре, а второй параметр, являющийся просто именем столбца, рассматривается как дважды заключенный в кавычки и его регистр сохраняется. Функция возвращает значение, соответствующим образом отформатированное для передачи в функции последовательности (см. раздел Функции управления последовательностями). Типичное использование - чтение текущего значения последовательности для идентификатора или последовательного столбца, например:
SELECT currval(pg_get_serial_sequence('sometable', 'id'));
pg_get_userbyid извлекает имя роли с учетом ее OID.
pg_index_column_has_property, pg_index_has_property и pg_indexam_has_property возвращают, обладает ли указанный столбец индекса, метод индекса или метод доступа к индексу указанным свойством. NULL возвращается, если имя свойства неизвестно или не относится к конкретному объекту, или если OID или номер столбца не идентифицируют допустимый объект. См. Таблицу 8.69 для свойств столбца, Таблицу 8.70 для свойств индекса и Таблицу 8.71 для свойств метода доступа. (Обратите внимание, что методы доступа расширения могут определять дополнительные имена свойств для своих индексов).
Таблица 69. Свойства столбца индекса
| Имя | Описание |
|---|---|
| asc | Сортирует ли столбец в порядке возрастания при сканировании вперед? |
| desc | Сортирует ли столбец в порядке убывания при сканировании вперед? |
| nulls_first | Сортирует ли столбец сначала пустые значения при сканировании вперед? |
| nulls_last | Сортируется ли столбец с нулями в последний раз при сканировании вперед? |
| orderable | Имеет ли столбец какой-либо определенный порядок сортировки? |
| distance_orderable | Может ли столбец сканироваться по порядку оператором « расстояния », например, ORDER BY col <-> constant ? |
| returnable | Может ли значение столбца быть возвращено при сканировании только по индексу? |
| search_array | Поддерживает ли данный столбец поиск col = ANY(array) ? |
| search_nulls | Поддерживает ли столбец поиск IS NULL и IS NOT NULL ? |
| Имя | Описание |
|---|---|
| clusterable | Можно ли использовать индекс в команде CLUSTER ? |
| index_scan | Поддерживает ли индекс обычное (не растровое) сканирование? |
| bitmap_scan | Индекс поддерживает растровое сканирование? |
| backward_scan | Можно ли изменить направление сканирования в середине сканирования (для поддержки FETCH BACKWARD на курсоре без необходимости материализации)? |
Таблица 71. Свойства метода доступа индекса
| Имя | Описание |
|---|---|
| can_order | Поддерживает ли метод доступа ASC, DESC и связанные ключевые слова в CREATE INDEX ? |
| can_unique | Поддерживает ли метод доступа уникальные индексы? |
| can_multi_col | Поддерживает ли метод доступа индексы с несколькими столбцами? |
| can_exclude | Поддерживает ли метод доступа ограничения исключения? |
| can_include | Поддерживает ли метод доступа предложение INCLUDE в CREATE INDEX ? |
pg_options_to_table возвращает набор пар имя/значение параметра хранения (option_name/option_value) при передаче pg_class.reloptions или pg_attribute.attoptions.
pg_tablespace_databases позволяет исследовать табличное пространство. Он возвращает набор OID баз данных, имеющих объекты, хранящиеся в табличном пространстве. Если эта функция возвращает какие-либо строки, табличное пространство не является пустым и не может быть удалено. Для отображения конкретных объектов, заполняющих табличное пространство, вам необходимо подключиться к базам данных, идентифицированным pg_tablespace_databases и запросить их каталоги pg_class.
pg_typeof возвращает OID типа данных переданного ему значения. Это может быть полезно для устранения неполадок или динамического построения запросов SQL. Функция объявлена как возвращающая regtype, который является типом псевдонима OID (см. раздел Типы идентификаторов объектов); это означает, что он совпадает с OID для сравнения, но отображается как имя типа. Например:
SELECT pg_typeof(33);
pg_typeof
-----------
integer
(1 row)
SELECT typlen FROM pg_type WHERE oid = pg_typeof(33);
typlen
--------
4
(1 row)
Выражение collation for возвращает сличение переданного ему значения. Пример:
SELECT collation for (description) FROM pg_description LIMIT 1;
pg_collation_for
------------------
"default"
(1 row)
SELECT collation for ('foo' COLLATE "de_DE");
pg_collation_for
------------------
"de_DE"
(1 row)
Значение может быть заключено в кавычки и дополнено схемой. Если параметры сортировки не выводятся для выражения аргумента, то возвращается null значение. Если аргумент не имеет сопоставимого типа данных, то возникает ошибка.
Функции to_regclass, to_regproc, to_regprocedure, to_regoper, to_regoperator, to_regtype, to_regnamespace и to_regrole выполняют преобразование имен отношений, функций, операторов, типов, схем, и ролей (заданных в виде текста) в объекты типа regclass, regproc, regprocedure, regoper, regoperator, regtype, regnamespace и regrole соответственно. Эти функции отличаются от преобразования из текста тем, что они не принимают числовой OID, и что они возвращают null а не выдают ошибку, если имя не найдено (или, например, to_regproc и to_regoper, если данное имя соответствует нескольким объектам).
В таблице 72 перечислены функции, связанные с идентификацией и адресацией объекта базы данных.
Таблица 72. Информация об объекте и функции адресации
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_describe_object(classid oid, objid oid, objsubid integer) | text | получить описание объекта базы данных |
| pg_identify_object(classid oid, objid oid, objsubid integer) | type text, text schema text name text identity | получить идентификатор объекта базы данных |
| pg_identify_object_as_address(classid oid, objid oid, objsubid integer) | type text, object_names text[], object_args text[] | получить внешнее представление адреса объекта базы данных |
| pg_get_object_address(type text, object_names text[], object_args text[]) | classid, objid, objsubid integer | получить адрес объекта базы данных из его внешнего представления |
pg_describe_object возвращает текстовое описание объекта базы данных, указанного в OID каталога, OID объекта и идентификаторе pg_describe_object (например, номер столбца в таблице; идентификатор подобъекта равен нулю при обращении к целому объекту). Это описание предназначено для чтения человеком и может быть переведено в зависимости от конфигурации сервера. Это полезно для определения идентичности объекта, хранящегося в каталоге pg_depend.
pg_identify_object возвращает строку, содержащую достаточно информации для уникальной идентификации объекта базы данных, указанного в OID каталога, OID объекта и идентификатора pg_identify_object. Эта информация предназначена для машинного чтения и никогда не переводится. type определяет тип объекта базы данных; schema - это имя схемы, к которой принадлежит объект, или NULL для типов объектов, которые не принадлежат схемам; name - это имя объекта, которое при необходимости указывается в кавычках, если имя (вместе с именем схемы, если это уместно) достаточно для однозначной идентификации объекта, в противном случае NULL; identity - это полная идентичность объекта, с точным форматом, зависящим от типа объекта, и каждое имя в формате уточняется схемой и при необходимости указывается в кавычках.
pg_identify_object_as_address возвращает строку, содержащую достаточно информации, чтобы однозначно идентифицировать объект базы данных, указанный в OID каталога, OID объекта и ID подобъекта. Возвращаемая информация не зависит от текущего сервера, то есть ее можно использовать для идентификации объекта с таким же именем на другом сервере. type определяет тип объекта базы данных; object_names и object_args - это текстовые массивы, которые вместе образуют ссылку на объект. Эти три значения могут быть переданы в pg_get_object_address для получения внутреннего адреса объекта. Эта функция является обратной к pg_get_object_address.
pg_get_object_address возвращает строку, содержащую достаточно информации для уникальной идентификации объекта базы данных, указанного его типом, именем объекта и массивами аргументов. Возвращаемые значения
Функции, показанные в таблице 73, извлекают комментарии, ранее сохраненные с помощью команды COMMENT. Возвращается нулевое значение, если для указанных параметров не найдено ни одного комментария.
Таблица 73. Comment Information Functions
| Имя | Тип ответа | Описание |
|---|---|---|
| col_description(table_oid, column_number) | text | получить комментарий к столбцу таблицы |
| obj_description(object_oid, catalog_name) | text | получить комментарий для объекта базы данных |
| obj_description(object_oid) | text | получить комментарий для объекта базы данных (не рекомендуется) |
| shobj_description(object_oid, catalog_name) | text | получить комментарий для общего объекта базы данных |
col_description возвращает комментарий для столбца таблицы, который определяется OID ее таблицы и номером столбца. (obj_description нельзя использовать для столбцов таблицы, поскольку столбцы не имеют собственных идентификаторов OID).
Двухпараметрическая форма bj_description возвращает комментарий для
объекта базы данных, указанного его OID и именем содержащего системный
каталог. Например, obj_description (123456, ’pg_class’) извлекает
комментарий для таблицы с OID 123456. Форма obj_description с одним
параметром требует только OID объекта. Он не рекомендуется, поскольку
нет гарантии, что OID уникальны в разных системных каталогах;
следовательно, может быть возвращен неверный комментарий.
shobj_description используется точно так же, как obj_description, за исключением того, что он используется для получения комментариев к общим объектам. Некоторые системные каталоги являются глобальными для всех баз данных в каждом кластере, и описания объектов в них также хранятся глобально.
Функции, показанные в таблице 74, предоставляют информацию о транзакциях сервера в экспортируемой форме. Основное использование этих функций - определить, какие транзакции были совершены между двумя моментальными снимками.
Таблица 74. Идентификаторы транзакций и снимки
| Имя | Тип ответа | Описание |
|---|---|---|
| txid_current() | bigint | получить идентификатор текущей транзакции, назначив новый, если у текущей транзакции его нет |
| txid_current_if_assigned() | bigint | то же самое, что и txid_current (), но возвращает ноль вместо назначения нового идентификатора транзакции, если ни один уже не назначен |
| txid_current_snapshot() | txid_snapshot | получить текущий снимок |
| txid_snapshot_xip(txid_snapshot) | setof bigint | получить текущие идентификаторы транзакций в снимке |
| txid_snapshot_xmax(txid_snapshot) | bigint | получить xmax снимка |
| txid_snapshot_xmin(txid_snapshot) | bigint | получить xmin снимка |
| txid_visible_in_snapshot(bigint, txid_snapshot) | boolean | виден идентификатор транзакции в снимке? (не используйте с идентификаторами субтранзакций) |
| txid_status(bigint) | text | сообщить о статусе данной транзакции: зафиксировано, прервано, выполняется или пусто, если идентификатор транзакции слишком старый |
Внутренний тип идентификатора транзакции (xid) имеет ширину 32 бита и охватывает каждые 4 миллиарда транзакций. Тем не менее, эти функции экспортируют 64-битный формат, который расширен счетчиком «эпох», поэтому он не будет меняться в течение срока службы установки. Тип данных, используемый этими функциями, txid_snapshot, хранит информацию о видимости идентификатора транзакции в определенный момент времени. Его компоненты описаны в таблице 75.
| Имя | Описание |
|---|---|
| xmin | Самый ранний идентификатор транзакции (txid), который все еще активен. Все более ранние транзакции будут либо зафиксированы и видимы, либо отменены. |
| xmax | Первый пока не назначенный txid. Все txids, больше или равные этому, еще не запущены на момент моментального снимка и поэтому невидимы. |
| xip_list | Активные txids во время снимка. Список включает только те активные txids между xmin и xmax; там могут быть активные txids выше, чем xmax. Txid с xmin <= txid <xmax, которого нет в этом списке, уже был завершен во время моментального снимка и, таким образом, либо видим, либо мертв в соответствии с его состоянием фиксации. Список не включает txids субтранзакций. |
Текстовое представление txid_snapshot - это xmin: xmax: xip_list.
Например, 10: 20: 10,14,15 означает *xmin = 10, xmax = 20, xip_list = 10, 14, 15.
txid_status (bigint) сообщает о состоянии фиксации недавней транзакции. Приложения могут использовать его для определения того, была ли транзакция совершена или прервана, когда сервер приложений и базы данных отключился во время выполнения COMMIT. О статусе транзакции будет сообщено как о том, что она выполняется, зафиксирована или прервана, при условии, что транзакция достаточно недавняя, чтобы система сохранила статус фиксации этой транзакции. Если статус достаточно стар, чтобы в системе не сохранилось ни одной ссылки на эту транзакцию, а информация о состоянии фиксации была отброшена, эта функция вернет NULL. Обратите внимание, что подготовленные транзакции отображаются как выполняемые; приложения должны проверить pg_prepared_xacts, если им нужно определить, является ли txid подготовленной транзакцией.
Функции, показанные в таблице 76, предоставляют информацию о транзакциях, которые уже были совершены. Эти функции в основном предоставляют информацию о том, когда транзакции были совершены. Они предоставляют полезные данные только при включенной опции конфигурации track_commit_timestamp и только для транзакций, которые были зафиксированы после его включения.
Таблица 76. Информация о совершенной транзакции
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_xact_commit_timestamp(xid) | timestamp with time zone | получить фиксацию времени транзакции |
| pg_last_committed_xact() | xid xid, timestamp timestamp with time zone | получить идентификатор транзакции и метку времени последней совершенной транзакции |
Функции, показанные в таблице 77, печатают информацию, инициализированную во время initdb, такую как версия каталога. Они также показывают информацию о записи в журнал упреждающей записи и обработке контрольных точек. Эта информация распространяется на весь кластер и не относится к какой-либо одной базе данных. Они предоставляют большую часть той же информации из того же источника, что и qhb_controldata, хотя в форме, лучше подходящей для функций SQL.
Таблица 77. Функции управления данными
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_control_checkpoint() | record | Возвращает информацию о текущем состоянии контрольной точки. |
| pg_control_system() | record | Возвращает информацию о текущем состоянии контрольного файла. |
| pg_control_init() | record | Возвращает информацию о состоянии инициализации кластера. |
| pg_control_recovery() | record | Возвращает информацию о состоянии восстановления. |
pg_control_checkpoint возвращает запись, показанную в таблице 78
Таблица 78. pg_control_checkpoint Columns
| Имя столбца | Тип данных |
|---|---|
| checkpoint_lsn | pg_lsn |
| redo_lsn | pg_lsn |
| redo_wal_file | text |
| timeline_id | integer |
| prev_timeline_id | integer |
| full_page_writes | boolean |
| next_xid | text |
| next_oid | oid |
| next_multixact_id | xid |
| next_multi_offset | xid |
| oldest_xid | xid |
| oldest_xid_dbid | oid |
| oldest_active_xid | xid |
| oldest_multi_xid | xid |
| oldest_multi_dbid | oid |
| oldest_commit_ts_xid | xid |
| newest_commit_ts_xid | xid |
| checkpoint_time | timestamp with time zone |
pg_control_system возвращает запись, показанную в таблице 79
Таблица 79. Столбцы pg_control_system
| Имя столбца | Тип данных |
|---|---|
| pg_control_version | integer |
| catalog_version_no | integer |
| system_identifier | bigint |
| pg_control_last_modified | timestamp with time zone |
pg_control_init возвращает запись, показанную в таблице 80
Таблица 80. Столбцы pg_control_init
| Имя столбца | Тип данных |
|---|---|
| max_data_alignment | integer |
| database_block_size | integer |
| blocks_per_segment | integer |
| wal_block_size | integer |
| bytes_per_wal_segment | integer |
| max_identifier_length | integer |
| max_index_columns | integer |
| max_toast_chunk_size | integer |
| large_object_chunk_size | integer |
| float4_pass_by_value | boolean |
| float8_pass_by_value | boolean |
| data_page_checksum_version | integer |
pg_control_recovery возвращает запись, показанную в таблице 81
Таблица 81. Столбцы pg_control_recovery
| Имя столбца | Тип данных |
|---|---|
| min_recovery_end_lsn | pg_lsn |
| min_recovery_end_timeline | integer |
| backup_start_lsn | pg_lsn |
| backup_end_lsn | pg_lsn |
| end_of_backup_record_required | boolean |
Функции системного администрирования
Функции, описанные в этом разделе, используются для контроля и мониторинга установки QHB.
Функции настройки конфигурации
В таблице 82 показаны функции, доступные для запроса и изменения параметров конфигурации во время выполнения.
Таблица 82. Функции настройки конфигурации
| Имя | Тип ответа | Описание |
|---|---|---|
| current_setting(setting_name [, missing_ok ]) | text | получить текущее значение настройки |
| set_config(setting_name, new_value, is_local) | text | установить параметр и вернуть новое значение |
Функция current_setting выдает текущее значение параметра setting_name. Это соответствует команде SQL SHOW. Пример:
SELECT current_setting('datestyle');
current_setting
-----------------
ISO, MDY
(1 row)
Если параметр с именем setting_name отсутствует, current_setting выдает ошибку, если не указано значение missing_ok и значение true.
set_config устанавливает параметр setting_name в new_value. Если is_local имеет значение true, новое значение будет применяться только к текущей транзакции. Если вы хотите, чтобы новое значение применялось к текущему сеансу, используйте вместо этого false. Функция соответствует SQL-команде SET. Пример:
SELECT set_config('log_statement_stats', 'off', false);
set_config
------------
off
(1 row)
Функции сигнализации сервера
Функции, показанные в таблице 83, отправляют управляющие сигналы другим процессам сервера. Использование этих функций ограничено суперпользователями по умолчанию, но доступ может быть предоставлен другим, использующим GRANT, с отмеченными исключениями.
Таблица 83. Функции сигнализации сервера
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_cancel_backend(pid int) | boolean | Отмените текущий запрос бэкэнда. Это также допустимо, если вызывающая роль является членом роли, бэкэнд которой отменяется, или вызывающая роль была предоставлена pg_signal_backend, однако только суперпользователи могут отменять pg_signal_backend суперпользователя. |
| pg_reload_conf() | boolean | Заставить процессы сервера перезагрузить свои файлы конфигурации |
| pg_rotate_logfile() | boolean | Повернуть файл журнала сервера |
| pg_terminate_backend(pid int) | boolean | Завершить бэкэнд. Это также разрешено, если вызывающая роль является членом роли, бэкэнд которой завершается, или вызывающей роли был предоставлен pg_signal_backend, однако только суперпользователи могут завершить pg_signal_backend суперпользователя. |
Каждая из этих функций возвращает true случае успеха и false противном случае.
Функции управления резервным копированием
Функции, показанные в таблице 84, помогают создавать резервные копии в режиме онлайн. Эти функции не могут быть выполнены во время восстановления (кроме неисключительных pg_start_backup, неисключительных pg_stop_backup, pg_is_in_backup, pg_backup_start_time и pg_wal_lsn_diff).
Таблица 84. Функции управления резервным копированием
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_create_restore_point(name text) | pg_lsn | Создать именованную точку для выполнения восстановления (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции). |
| pg_current_wal_flush_lsn() | pg_lsn | Получить текущее местоположение для записи журнала впереди |
| pg_current_wal_insert_lsn() | pg_lsn | Получить текущее местоположение вставки журнала записи |
| pg_current_wal_lsn() | pg_lsn | Получить текущее местоположение записи в журнал записи |
| pg_start_backup(label text [, fast boolean [, exclusive boolean ] ]) | pg_lsn | Подготовьтесь к выполнению резервного копирования в онлайн-хранилище (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции) |
| pg_stop_backup() | pg_lsn | Завершите выполнение эксклюзивного резервного копирования в онлайн-хранилище (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции) |
| pg_stop_backup(exclusive boolean [, wait_for_archive boolean ]) | setof record | Завершите выполнение эксклюзивного или неисключительного резервного копирования в режиме онлайн (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции) |
| pg_is_in_backup() | bool | Истинно, если онлайновое эксклюзивное резервное копирование все еще выполняется. |
| pg_backup_start_time() | timestamp with time zone | Получите время запуска эксклюзивного резервного копирования онлайн. |
| pg_switch_wal() | pg_lsn | Принудительное переключение на новый файл журнала с опережением записи (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено EXECUTE для запуска функции). |
| pg_walfile_name(lsn pg_lsn) | text | Преобразовать местоположение журнала записи вперед в имя файла |
| pg_walfile_name_offset(lsn pg_lsn) | text, integer | Преобразовать местоположение журнала упреждающей записи в имя файла и десятичное смещение байта в файле |
| pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) | numeric | Рассчитайте разницу между двумя местоположениями журнала записи |
pg_start_backup принимает произвольную пользовательскую метку для резервной копии. (Обычно это имя, под которым будет сохранен файл резервного дампа). При использовании в монопольном режиме функция записывает файл метки резервной копии (backup_label) и, если есть какие-либо ссылки в каталоге pg_tblspc/, карты табличного пространства (tablespace_map) в каталог данных кластера базы данных, выполняет контрольную точку, а затем возвращает начальное местоположение резервной копии журнала упреждающей записи в виде текста. Пользователь может игнорировать это значение результата, но оно предоставляется в случае, если оно полезно. При использовании в неисключительном режиме содержимое этих файлов вместо этого возвращается функцией pg_stop_backup и должно быть записано вызывающей стороной в резервную копию.
qhb=# select pg_start_backup('label_goes_here');
pg_start_backup
-----------------
0/D4445B8
(1 row)
Существует необязательный второй параметр типа boolean. Если true, это указывает на выполнение pg_start_backup как можно быстрее. Это форсирует немедленную контрольную точку, которая вызовет всплеск операций ввода-вывода, замедляя любые параллельно выполняющиеся запросы.
В исключительной резервной копии pg_stop_backup удаляет файл метки и, если он существует, файл tablespace_map созданный pg_start_backup. В неисключительной резервной копии содержимое backup_label и ablespace_map возвращается в результате работы функции и должно быть записано в файлы резервной копии (а не в каталог данных). Существует необязательный второй параметр типа boolean. Если false, pg_stop_backup вернется сразу после завершения резервного копирования, не дожидаясь архивирования WAL. Такое поведение полезно только для программного обеспечения резервного копирования, которое независимо контролирует архивирование WAL. В противном случае WAL, необходимый для обеспечения согласованности резервного копирования, может отсутствовать и сделать резервную копию бесполезной. Если для этого параметра установлено значение true, pg_stop_backup будет ожидать архивирования WAL, когда включено архивирование; в режиме ожидания это означает, что он будет ждать только, когда archive_mode = always. Если активность записи на основной стороне низкая, может быть полезно запустить pg_switch_wal на основной стороне, чтобы инициировать немедленное переключение сегмента.
При выполнении на первичном сервере функция также создает файл истории резервного копирования в области архива журнала упреждающей записи. Файл истории содержит метку, присвоенную pg_start_backup, начальный и конечный местоположения журналов упреждающей записи для резервной копии, а также время начала и окончания резервного копирования. Возвращаемое значение — это конечное местоположение журнала записи с опережением записи (которое снова можно игнорировать). После записи конечного местоположения текущая точка вставки журнала с опережением записи автоматически перемещается к следующему файлу журнала с опережением записи, так что конечный файл журнала с опережением записи может быть немедленно заархивирован для завершения резервного копирования.
pg_switch_wal переходит к следующему файлу журнала с опережением записи, что позволяет архивировать текущий файл (при условии, что вы используете непрерывное архивирование). Возвращаемое значение - конечное местоположение журнала записи с опережением + 1 в только что завершенном файле журнала записи с опережением. Если с момента последнего переключения журнала с опережением записи не было никаких действий с опережением записи, pg_switch_wal ничего не делает и возвращает начальное местоположение файла журнала с опережением записи, который используется в данный момент.
pg_create_restore_point создает именованную запись журнала предварительной записи, которую можно использовать в качестве цели восстановления, и возвращает соответствующее местоположение журнала предварительной записи. Затем указанное имя можно использовать с recovery_target_name, чтобы указать точку, до которой будет продолжаться восстановление. Избегайте создания нескольких точек восстановления с одним и тем же именем, поскольку восстановление остановится на первой точке, имя которой соответствует цели восстановления.
pg_current_wal_lsn отображает текущее местоположение записи в журнал записи вперед в том же формате, что и вышеуказанные функции. Аналогично, pg_current_wal_insert_lsn отображает текущее местоположение вставки журнала с опережением записи, а pg_current_wal_flush_lsn отображает текущее местоположение pg_current_wal_flush_lsn журнала с опережением записи. Место вставки является «логическим» концом журнала упреждающей записи в любой момент, тогда как место записи — это конец того, что было фактически записано из внутренних буферов сервера, а место сброса — это место, которое гарантированно будет записано в долговременный место хранения. Расположение записи — это конец того, что можно проверить извне сервера, и обычно это то, что вам нужно, если вы заинтересованы в архивировании частично полных файлов журнала с опережением записи. Места для вставки и сброса доступны главным образом для отладки сервера. Обе эти операции предназначены только для чтения и не требуют прав суперпользователя.
Вы можете использовать pg_walfile_name_offset для извлечения соответствующего имени файла журнала записи с опережением записи и смещения байтов из результатов любой из вышеперечисленных функций. Например:
qhb=# SELECT * FROM pg_walfile_name_offset(pg_stop_backup());
file_name | file_offset
--------------------------+-------------
00000001000000000000000D | 4039624
(1 row)
Аналогично, pg_walfile_name извлекает только имя файла журнала записи с опережением. Когда указанное местоположение журнала предварительной записи находится точно на границе файла журнала предварительной записи, обе эти функции возвращают имя предыдущего файла журнала предварительной записи. Обычно это желаемое поведение для управления поведением архивирования журнала с опережением записи, поскольку предыдущий файл является последним, который в настоящее время необходимо архивировать.
pg_wal_lsn_diff вычисляет разницу в байтах между двумя местоположениями журнала записи с опережением. Его можно использовать с pg_stat_replication или некоторыми функциями, показанными в таблице 4.84, для получения задержки репликации.
Подробнее о правильном использовании этих функций см. в разделе Непрерывное архивирование и восстановление на момент времени.
Функции управления восстановлением
Функции, показанные в таблице 85, предоставляют информацию о текущем состоянии режима ожидания. Эти функции могут выполняться как во время восстановления, так и в нормальном режиме.
Таблица 85. Функции восстановления информации
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_is_in_recovery() | bool | Верно, если восстановление все еще продолжается. |
| pg_last_wal_receive_lsn() | pg_lsn | Получите последнее местоположение журнала предварительной записи, полученное и синхронизированное на диск потоковой репликацией. Пока идет потоковая репликация, она будет монотонно возрастать. Если восстановление завершено, оно останется неизменным со значением последней записи WAL, полученной и синхронизированной с диском во время восстановления. Если потоковая репликация отключена или она еще не запущена, функция возвращает NULL. |
| pg_last_wal_replay_lsn() | pg_lsn | Получите последнюю запись журнала перед воспроизведением во время восстановления. Если восстановление еще продолжается, оно будет монотонно возрастать. Если восстановление завершено, то это значение останется неизменным на уровне последней записи WAL, примененной во время этого восстановления. Когда сервер был запущен нормально без восстановления, функция возвращает NULL. |
| pg_last_xact_replay_timestamp() | timestamp with time zone | Получить метку времени последней транзакции, воспроизведенной во время восстановления. Это время, когда на первичном сервере была сгенерирована запись WAL для этой транзакции. Если ни одна транзакция не была воспроизведена во время восстановления, эта функция возвращает NULL. В противном случае, если восстановление еще продолжается, оно будет увеличиваться монотонно. Если восстановление завершено, то это значение останется неизменным на уровне последней транзакции, примененной во время этого восстановления. Когда сервер был запущен нормально без восстановления, функция возвращает NULL. |
Функции, показанные в таблице 86, контролируют ход восстановления. Эти функции могут быть выполнены только во время восстановления.
Таблица 86. Функции управления восстановлением
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_is_wal_replay_paused() | bool | Истинно, если восстановление приостановлено. |
| pg_promote(wait boolean DEFAULT true, wait_seconds integer DEFAULT 60) | boolean | Продвигает физический резервный сервер. Если для параметра wait установлено значение true (по умолчанию), функция ожидает, пока продвижение будет завершено или wait_seconds секунды wait_seconds, и возвращает true если продвижение прошло успешно, и false противном случае. Если для wait установлено значение false, функция возвращает значение true сразу после отправки сообщения SIGUSR1 администратору почты, чтобы запустить повышение. По умолчанию эта функция доступна только суперпользователям, но другим пользователям может быть предоставлено разрешение EXECUTE для ее запуска. |
| pg_wal_replay_pause() | void | Немедленно приостанавливает восстановление (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции). |
| pg_wal_replay_resume() | void | Перезапускает восстановление, если оно было приостановлено (по умолчанию ограничено суперпользователями, но другим пользователям может быть предоставлено разрешение EXECUTE для запуска функции). |
Пока восстановление приостановлено, дальнейшие изменения в базе данных не применяются. В режиме горячего резервирования все новые запросы будут видеть одинаковый непротиворечивый снимок базы данных, и никакие дальнейшие конфликты запросов не будут создаваться до возобновления восстановления.
Если потоковая репликация отключена, состояние паузы может продолжаться бесконечно без проблем. Во время потоковой репликации записи WAL будут по-прежнему приниматься, что в конечном итоге заполнит доступное дисковое пространство в зависимости от длительности паузы, скорости генерации WAL и доступного дискового пространства.
Функции синхронизации снимков
QHB позволяет сеансам базы данных синхронизировать свои снимки. Снимок определяет, какие данные видны для транзакции, которая использует снимок. Синхронизированные снимки необходимы, когда два или более сеанса должны видеть идентичный контент в базе данных. Если две сессии просто начинают свои транзакции независимо, всегда существует вероятность того, что какая-то третья транзакция совершит транзакцию между выполнением двух команд START TRANSACTION, так что одна сессия видит результаты этой транзакции, а другая - нет.
Чтобы решить эту проблему, QHB позволяет транзакции экспортировать используемый снимок. Пока экспортируемая транзакция остается открытой, другие транзакции могут импортировать ее моментальный снимок, и тем самым гарантируется, что они видят точно такое же представление базы данных, что и первая транзакция. Но обратите внимание, что любые изменения в базе данных, сделанные любой из этих транзакций, остаются невидимыми для других транзакций, как это обычно бывает для изменений, сделанных незафиксированными транзакциями. Таким образом, транзакции синхронизируются по отношению к ранее существующим данным, но действуют нормально для изменений, которые они вносят сами.
Снимки экспортируются с pg_export_snapshot функции pg_export_snapshot, показанной в таблице 87, и импортируются с помощью команды SET TRANSACTION.
Таблица 87. Функции синхронизации снимков
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_export_snapshot() | text | Сохранить текущий снимок и вернуть его идентификатор |
Функция pg_export_snapshot сохраняет текущий снимок и возвращает text строку, идентифицирующую снимок. Эта строка должна быть передана (вне базы данных) клиентам, которые хотят импортировать снимок. Снимок доступен для импорта только до конца транзакции, которая его экспортировала. Транзакция может экспортировать более одного снимка, если это необходимо. Обратите внимание, что это полезно только в транзакциях READ COMMITTED, поскольку в REPEATABLE READ и на более высоких уровнях изоляции транзакции используют один и тот же моментальный снимок в течение всего срока службы. После того, как транзакция экспортировала какие-либо моментальные снимки, ее нельзя подготовить с помощью PREPARE TRANSACTION.
См. SET TRANSACTION для деталей о том, как использовать экспортированный снимок.
Функции репликации
Функции, показанные в таблице 88, предназначены для управления функциями репликации и взаимодействия с ними.
Использование функций для начала репликации разрешено только суперпользователям. Использование функций для слота репликации ограничено суперпользователями и пользователями, имеющими привилегию REPLICATION.
Функции, описанные в разделе Функции управления резервным копированием, разделе Функции управления восстановлением и разделе Функции синхронизации снимков, также имеют отношение к репликации.
Таблица 88. Функции SQL репликации
| Функция | Тип ответа | Описание |
|---|---|---|
| pg_create_physical_replication_slot(slot_name name [, immediately_reserve boolean, temporary boolean ]) | (name slot_name, lsn pg_lsn) | Создает новый физический слот репликации с именем slot_name. Необязательный второй параметр, если он равен true, указывает, что LSN для этого слота репликации будет зарезервирован немедленно; в противном случае номер LSN зарезервирован при первом подключении от клиента потоковой репликации. Потоковые изменения из физического слота возможны только с протоколом потоковой репликации. Необязательный третий параметр temporary, если он установлен в значение true, указывает, что слот не должен постоянно храниться на диске и предназначен только для использования в текущем сеансе. Временные слоты также освобождаются при любой ошибке. Эта функция соответствует команде протокола репликации CREATE_REPLICATION_SLOT ... PHYSICAL. |
| pg_drop_replication_slot(slot_name name) | void | Удаляет физический или логический слот репликации с именем slot_name. То же, что команда протокола репликации DROP_REPLICATION_SLOT. Для логических слотов это должно вызываться при подключении к той же базе данных, в которой был создан слот. |
| pg_create_logical_replication_slot(slot_name name, plugin name [, temporary boolean ]) | (name slot_name, lsn pg_lsn) | Создает новый логический (декодирующий) слот репликации с именем slot_name используя плагин вывода plugin. Необязательный третий параметр temporary, если он установлен в значение true, указывает, что слот не должен постоянно храниться на диске и предназначен только для использования в текущем сеансе. Временные слоты также освобождаются при любой ошибке. Вызов этой функции имеет тот же эффект, что и команда протокола репликации CREATE_REPLICATION_SLOT ... LOGICAL. |
| pg_copy_physical_replication_slot(src_slot_name name, dst_slot_name name [, temporary boolean ]) | (name slot_name, lsn pg_lsn) | Копирует существующий физический слот репликации с именем src_slot_name в физический слот репликации с именем dst_slot_name. Скопированный физический слот начинает резервировать WAL из того же LSN, что и исходный слот. temporary является обязательным. Если temporary опущено, используется то же значение, что и для исходного слота. |
| pg_copy_logical_replication_slot(src_slot_name name, dst_slot_name name [, temporary boolean [, plugin name ] ]) | (name slot_name, lsn pg_lsn) | Копирует существующее имя слота логической репликации src_slot_name в слот логической репликации с именем dst_slot_name, изменяя выходной плагин и постоянство. Скопированный логический слот начинается с того же номера LSN, что и исходный логический слот. И temporary и plugin являются обязательными. Если temporary или plugin не указан, используются те же значения, что и для исходного логического слота. |
| pg_logical_slot_get_changes(slot_name name, upto_lsn pg_lsn, upto_nchanges int, VARIADIC options text[]) | (lsn pg_lsn, xid xid, text data) | Возвращает изменения в слоте slot_name, начиная с точки, с которой изменения использовались последними. Если upto_lsn и upto_nchanges равны NULL, логическое декодирование будет продолжаться до конца WAL. Если upto_lsn не NULL, декодирование будет включать только те транзакции, которые совершаются до указанного LSN. Если upto_nchanges равен NULL, декодирование остановится, когда число строк, полученных в результате декодирования, превысит указанное значение. Однако обратите внимание, что фактическое количество возвращаемых строк может быть больше, поскольку этот предел проверяется только после добавления строк, полученных при декодировании каждой новой транзакции. |
| pg_logical_slot_peek_changes(slot_name name, upto_lsn pg_lsn, upto_nchanges int, VARIADIC options text[]) | (lsn pg_lsn, xid xid, text data) | Ведет себя так же, как pg_logical_slot_get_changes(), за исключением того, что изменения не используются; то есть они будут возвращены снова при будущих вызовах. |
| pg_logical_slot_get_binary_changes(slot_name name, upto_lsn pg_lsn, upto_nchanges int, VARIADIC options text[]) | (lsn pg_lsn, xid xid, data bytea) | Работает так же, как pg_logical_slot_get_changes(), за исключением того, что изменения возвращаются как bytea. |
| pg_logical_slot_peek_binary_changes(slot_name name, upto_lsn pg_lsn, upto_nchanges int, VARIADIC options text[]) | (lsn pg_lsn, xid xid, data bytea) | Ведет себя так же, как pg_logical_slot_get_changes(), за исключением того, что изменения возвращаются как bytea и что изменения не используются; то есть они будут возвращены снова при будущих вызовах. |
| pg_replication_slot_advance(slot_name name, upto_lsn pg_lsn) | (name slot_name, end_lsn pg_lsn) bool | Продвигает текущую подтвержденную позицию слота репликации с именем slot_name. Слот не будет перемещен назад, и он не будет перемещен за пределы текущей позиции вставки. Возвращает название слота и реальную позицию, до которой он был продвинут. |
| pg_replication_origin_create(node_name text) | oid | Создайте источник репликации с заданным внешним именем и верните присвоенный ему внутренний идентификатор. |
| pg_replication_origin_drop(node_name text) | void | Удалите ранее созданный источник репликации, включая любой связанный процесс воспроизведения. |
| pg_replication_origin_oid(node_name text) | oid | Найдите источник репликации по имени и верните внутренний идентификатор. Если соответствующий источник репликации не найден, выдается ошибка. |
| pg_replication_origin_session_setup(node_name text) | void | Пометить текущий сеанс как воспроизведение с заданным источником, позволяя отслеживать ход воспроизведения. Используйте pg_replication_origin_session_reset чтобы вернуться. Может использоваться, только если не настроено предыдущее происхождение. |
| pg_replication_origin_session_reset() | void | Отмените эффекты pg_replication_origin_session_setup(). |
| pg_replication_origin_session_is_setup() | bool | Был ли настроен источник репликации в текущем сеансе? |
| pg_replication_origin_session_progress(flush bool) | pg_lsn | Верните местоположение воспроизведения для источника репликации, настроенного в текущем сеансе. Параметр flush определяет, будет ли соответствующая локальная транзакция записана на диск или нет. |
| pg_replication_origin_xact_setup(origin_lsn pg_lsn, origin_timestamp timestamptz) | void | Пометить текущую транзакцию как воспроизведение транзакции, которая зафиксирована в данном LSN и отметке времени. Может вызываться только в том случае, если источник репликации был предварительно настроен с помощью pg_replication_origin_session_setup(). |
| pg_replication_origin_xact_reset() | void | Отмените эффекты pg_replication_origin_xact_setup(). |
| pg_replication_origin_advance (node_name text, lsn pg_lsn) | void | Установить процесс репликации для данного узла в заданном месте. Это в первую очередь полезно для настройки исходного местоположения или нового местоположения после изменений конфигурации и т.п. Помните, что неосторожное использование этой функции может привести к непоследовательному копированию данных. |
| pg_replication_origin_progress(node_name text, flush bool) | pg_lsn | Вернуть местоположение воспроизведения для данного источника репликации. Параметр flush определяет, будет ли соответствующая локальная транзакция записана на диск или нет. |
| pg_logical_emit_message(transactional bool, prefix text, content text) | pg_lsn | Выдать текстовое логическое сообщение декодирования. Это можно использовать для передачи общих сообщений в плагины логического декодирования через WAL. Параметр transactional указывает, должно ли сообщение быть частью текущей транзакции или оно должно быть записано немедленно и декодировано, как только логическое декодирование прочитает запись. prefix - это текстовый префикс, используемый плагинами логического декодирования для простого распознавания для них интересных сообщений. content - это текст сообщения. |
| pg_logical_emit_message(transactional bool, prefix text, content bytea) | pg_lsn | Издайте двоичное сообщение логического декодирования. Это можно использовать для передачи общих сообщений в плагины логического декодирования через WAL. Параметр transactional указывает, должно ли сообщение быть частью текущей транзакции или оно должно быть записано немедленно и декодировано, как только логическое декодирование прочитает запись. prefix - это текстовый префикс, используемый плагинами логического декодирования для простого распознавания для них интересных сообщений. content - это двоичное содержимое сообщения. |
Функции управления объектами базы данных
Функции, показанные в таблице 89, рассчитывают использование дискового пространства объектов базы данных.
Таблица 89. Функции размера объекта базы данных
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_column_size(any) | int | Количество байтов, используемых для хранения определенного значения (возможно сжатого) |
| pg_database_size(oid) | bigint | Дисковое пространство, используемое базой данных с указанным OID |
| pg_database_size(name) | bigint | Дисковое пространство, используемое базой данных с указанным именем |
| pg_indexes_size(regclass) | bigint | Общее дисковое пространство, используемое индексами, прикрепленными к указанной таблице |
| pg_relation_size(relation regclass, fork text) | bigint | Дисковое пространство, используемое указанным ответвлением (’main’, ’fsm’, ’vm’ или ’init’) указанной таблицы или индекса |
| pg_relation_size(relation regclass) | bigint | pg_relation_size(..., ’main’) для pg_relation_size(..., ’main’) |
| pg_size_bytes(text) | bigint | Преобразует размер в удобочитаемом формате с единицами измерения размера в байтах |
| pg_size_pretty(bigint) | text | Преобразует размер в байтах, выраженный как 64-разрядное целое число, в читаемый человеком формат с единицами размера |
| pg_size_pretty(numeric) | text | Преобразует размер в байтах, выраженный в виде числового значения, в удобочитаемый формат с единицами измерения размера |
| pg_table_size(regclass) | bigint | Дисковое пространство, используемое указанной таблицей, за исключением индексов (но включая TOAST, карту свободного пространства и карту видимости) |
| pg_tablespace_size(oid) | bigint | Дисковое пространство, используемое табличным пространством с указанным OID |
| pg_tablespace_size(name) | bigint | Дисковое пространство, используемое табличным пространством с указанным именем |
| pg_total_relation_size(regclass) | bigint | Общее дисковое пространство, используемое указанной таблицей, включая все индексы и данные TOAST |
pg_column_size показывает пространство, используемое для хранения любого отдельного значения данных.
pg_total_relation_size принимает OID или имя таблицы или таблицы тостов и возвращает общее дисковое пространство, используемое для этой таблицы, включая все связанные индексы. Эта функция эквивалентна pg_table_size + pg_indexes_size.
pg_table_size принимает OID или имя таблицы и возвращает дисковое пространство, необходимое для этой таблицы, исключая индексы. (TOAST space, карта свободного пространства и карта видимости включены).
pg_indexes_size принимает OID или имя таблицы и возвращает общее дисковое пространство, используемое всеми индексами, прикрепленными к этой таблице.
pg_database_size и pg_tablespace_size принимают OID или имя базы данных или табличного пространства и возвращают общее дисковое пространство, используемое в них. Чтобы использовать pg_database_size, вы должны иметь разрешение CONNECT для указанной базы данных (которая предоставляется по умолчанию) или быть членом роли pg_read_all_stats. Чтобы использовать pg_tablespace_size, вы должны иметь разрешение CREATE для указанного табличного пространства или быть членом роли pg_read_all_stats если только это не табличное пространство по умолчанию для текущей базы данных.
pg_relation_size принимает OID или имя таблицы, индекса или таблицы тостов и возвращает размер на диске в байтах одного разветвления этого отношения. (Обратите внимание, что для большинства целей удобнее использовать функции более высокого уровня pg_total_relation_size или pg_table_size, которые суммируют размеры всех вилок). С одним аргументом он возвращает размер основного форка данных отношения. Второй аргумент может быть предоставлен, чтобы указать, какой форк нужно исследовать:
pg_size_pretty может использоваться для форматирования результата одной из других функций в удобочитаемом виде с использованием байтов, КБ, МБ, ГБ или ТБ в зависимости от ситуации.
pg_size_bytes может использоваться для получения размера в байтах из строки в удобочитаемом формате. Входные данные могут иметь единицы байтов, кБ, МБ, ГБ или ТБ и анализируются без учета регистра. Если единицы не указаны, подразумеваются байты.
Приведенные выше функции, работающие с таблицами или индексами, принимают аргумент regclass, который является просто OID таблицы или индекса в системном каталоге pg_class. Однако вам не нужно искать OID вручную, так как преобразователь ввода типа данных regclass сделает всю работу за вас. Просто напишите имя таблицы, заключенное в одинарные кавычки, чтобы оно выглядело как буквальная константа. Для совместимости с обработкой обычных имен SQL строка будет преобразована в нижний регистр, если она не содержит двойных кавычек вокруг имени таблицы.
Если OID, который не представляет существующий объект, передается в качестве аргумента одной из вышеуказанных функций, возвращается NULL.
Функции, показанные в таблице 90, помогают идентифицировать конкретные файлы на диске, связанные с объектами базы данных.
Таблица 90. Функции расположения объектов базы данных
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_relation_filenode(relation regclass) | oid | Номер файлового узла указанного отношения |
| pg_relation_filepath(relation regclass) | text | Путь к файлу с указанным отношением |
| pg_filenode_relation(tablespace oid, filenode oid) | regclass | Найти отношение, связанное с данным табличным пространством и файловым узлом |
pg_relation_filenode принимает OID или имя таблицы, индекса, последовательности или таблицы тостов и возвращает номер «файлового узла», назначенный в данный момент. FileNode — это базовый компонент имен файлов, используемых для отношения (см. раздел Структура файлов базы данных для получения дополнительной информации). Для большинства таблиц результат такой же, как у pg_class. relfilenode, но для некоторых системных каталогов relfilenode равен нулю, и эту функцию необходимо использовать для получения правильного значения. Функция возвращает NULL, если передано отношение, которое не имеет хранилища, такое как представление.
pg_relation_filepath похож на pg_relation_filenode, но возвращает полное имя пути файла (относительно каталога данных кластера базы данных PGDATA) отношения.
pg_filenode_relation является противоположностью pg_relation_filenode. При наличии OID «табличного пространства» и «filenode» он возвращает OID связанного отношения. Для таблицы в табличном пространстве базы данных по умолчанию табличное пространство может быть указано как 0.
В таблице 91 перечислены функции, используемые для управления сопоставлениями.
Таблица 91. Функции управления сопоставлением
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_collation_actual_version(oid) | text | Вернуть актуальную версию сличения из операционной системы |
| pg_import_system_collations(schema regnamespace) | integer | Импорт сопоставлений операционной системы |
pg_collation_actual_version возвращает актуальную версию объекта сортировки, так как он в настоящее время установлен в операционной системе. Если это отличается от значения в pg_collation.collversion, то объекты, зависящие от параметров сортировки, возможно, потребуется перестроить. Смотрите также ALTER COLLATION.
pg_import_system_collations добавляет параметры сортировки в системный каталог pg_collation на основе всех локалей, найденных в операционной системе. Это то, что использует initdb; см. раздел Управление сортировкой для более подробной информации-->. Если впоследствии в операционную систему будут установлены дополнительные локали, эту функцию можно будет запустить снова, чтобы добавить параметры сортировки для новых локалей. Локали, соответствующие существующим записям в pg_collation будут пропущены. (Но объекты сопоставления, основанные на локалях, которых больше нет в операционной системе, не удаляются этой функцией). Параметром schema обычно будет pg_catalog, но это не является обязательным требованием; параметры сортировки могут быть установлены и в другую схему. Функция возвращает количество новых созданных объектов сопоставления.
Таблица 92. Функции разделения информации
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_partition_tree(regclass) | setof record | Вывести информацию о таблицах или индексах в дереве разделов для данной разделенной таблицы или разделенного индекса, с одной строкой для каждого раздела. Предоставленная информация включает имя раздела, имя его непосредственного родителя, логическое значение, указывающее, является ли раздел листом, и целое число, указывающее его уровень в иерархии. Значение уровня начинается с 0 для входной таблицы или индекса в его роли в качестве корня дерева разделов, 1 для его разделов, 2 для их разделов и т. Д. |
| pg_partition_ancestors(regclass) | setof regclass | Перечислите отношения предков данного раздела, включая сам раздел. |
| pg_partition_root(regclass) | regclass | Вернуть самого верхнего родителя дерева разделов, которому принадлежит данное отношение. |
Чтобы проверить общий размер данных, содержащихся в таблице измерений, описанной в разделе Пример декларативного партиционирования, можно использовать следующий запрос:
=# SELECT pg_size_pretty(sum(pg_relation_size(relid))) AS total_size
FROM pg_partition_tree('measurement');
total_size
------------
24 kB
(1 row)
Функции обслуживания индекса
В таблице 93 показаны функции, доступные для задач обслуживания индекса. Эти функции не могут быть выполнены во время восстановления. Использование этих функций ограничено суперпользователями и владельцем данного индекса.
Таблица 93. Функции обслуживания индекса
| Имя | Тип ответа | Описание |
|---|---|---|
| brin_summarize_new_values(index regclass) | integer | суммировать диапазоны страниц, еще не суммированные |
| brin_summarize_range(index regclass, blockNumber bigint) | integer | суммировать диапазон страниц, охватывающий данный блок, если он еще не суммирован |
| brin_desummarize_range(index regclass, blockNumber bigint) | integer | разбиение диапазона страниц, охватывающих данный блок, если он суммирован |
| gin_clean_pending_list(index regclass) | bigint | переместить записи из списка ожидания GIN в основную структуру индекса |
brin_summarize_new_values принимает OID или имя индекса BRIN и проверяет индекс, чтобы найти диапазоны страниц в базовой таблице, которые в данный момент не суммируются индексом; для любого такого диапазона он создает новый кортеж сводного индекса путем сканирования страниц таблицы. Возвращает количество новых сводок диапазона страниц, которые были вставлены в индекс. brin_summarize_range делает то же самое, за исключением того, что он только суммирует диапазон, который охватывает данный номер блока.
gin_clean_pending_list принимает OID или имя индекса GIN и очищает ожидающий список указанного индекса, перемещая записи в нем в основную структуру данных GIN. Возвращает количество страниц, удаленных из списка ожидания. Обратите внимание, если аргумент является индексом GIN, созданным с отключенной опцией fastupdate, очистка не происходит, и возвращаемое значение равно 0, поскольку у индекса нет списка ожидания. Пожалуйста, смотрите раздел Быстрое обновление GIN и раздел GIN советы и хитрости для получения подробной информации об ожидающем списке и опции fastupdate.
Общие функции доступа к файлам
Функции, показанные в таблице 94, предоставляют собственный доступ к файлам на компьютере, на котором размещен сервер. Только файлы в каталоге кластера базы данных и log_directory могут быть доступны, если пользователю не назначена роль pg_read_server_files. Используйте относительный путь для файлов в каталоге кластера и путь, соответствующий параметру конфигурации log_directory для файлов журнала.
Обратите внимание, что предоставление пользователям привилегии EXECUTE для pg_read_file () или связанных функций дает им возможность читать любой файл на сервере, который может прочитать база данных, и что эти чтения обходят все проверки привилегий в базе данных. Это означает, что, помимо прочего, пользователь с таким доступом может читать содержимое таблицы pg_authid, в которой содержится информация для аутентификации, а также читать любой файл в базе данных. Поэтому предоставление доступа к этим функциям должно быть тщательно продумано.
Таблица 94. Общие функции доступа к файлам
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_ls_dir(dirname text [, missing_ok boolean, include_dot_dirs boolean]) | setof text | Список содержимого каталога. По умолчанию ограничен суперпользователями, но другим пользователям может быть предоставлено EXECUTE для запуска функции. |
| pg_ls_logdir() | setof record | Укажите имя, размер и время последнего изменения файлов в каталоге журнала. Доступ предоставляется членам роли pg_monitor и может предоставляться другим ролям, не являющимся суперпользователем. |
| pg_ls_waldir() | setof record | Укажите имя, размер и время последнего изменения файлов в каталоге WAL. Доступ предоставляется членам роли pg_monitor и может предоставляться другим ролям, не являющимся суперпользователем. |
| pg_ls_archive_statusdir() | setof record | Укажите имя, размер и время последнего изменения файлов в каталоге состояния архива WAL. Доступ предоставляется членам роли pg_monitor и может предоставляться другим ролям, не являющимся суперпользователем. |
| pg_ls_tmpdir([tablespace oid]) | setof record | Укажите имя, размер и время последнего изменения файлов во временном каталоге табличного пространства. Если табличное пространство не предусмотрено, используется табличное пространство pg_default. Доступ предоставляется членам роли pg_monitor и может предоставляться другим ролям, не являющимся суперпользователем. |
| pg_read_file(filename text [, offset bigint, length bigint [, missing_ok boolean] ]) | text | Вернуть содержимое текстового файла. По умолчанию ограничен суперпользователями, но другим пользователям может быть предоставлено EXECUTE для запуска функции. |
| pg_read_binary_file(filename text [, offset bigint, length bigint [, missing_ok boolean] ]) | bytea | Вернуть содержимое файла. По умолчанию ограничен суперпользователями, но другим пользователям может быть предоставлено EXECUTE для запуска функции. |
| pg_stat_file(filename text[, missing_ok boolean]) | record | Вернуть информацию о файле. По умолчанию ограничен суперпользователями, но другим пользователям может быть предоставлено EXECUTE для запуска функции. |
Некоторые из этих функций принимают необязательный параметр missing_ok, который определяет поведение, когда файл или каталог не существует. Если true, функция возвращает NULL (кроме pg_ls_dir, который возвращает пустой набор результатов). Если false, возникает ошибка. По умолчанию установлено значение false.
pg_ls_dir возвращает имена всех файлов (и каталогов и других специальных файлов) в указанном каталоге. Include_dot_dirs указывает, включены ли «.» И «..» в набор результатов. По умолчанию они исключаются (ложь), но их включение может быть полезно, если для параметра missing_ok задано значение true, чтобы отличать пустой каталог от несуществующего каталога.
pg_ls_logdir возвращает имя, размер и время последнего изменения (mtime) каждого файла в каталоге журнала. По умолчанию только суперпользователи и члены роли pg_monitor могут использовать эту функцию. Доступ может быть предоставлен другим лицам, использующим GRANT.
pg_ls_waldir возвращает имя, размер и время последнего изменения (mtime) каждого файла в каталоге WAL. По умолчанию только суперпользователи и члены роли pg_monitor могут использовать эту функцию. Доступ может быть предоставлен другим лицам, использующим GRANT.
pg_ls_archive_statusdir возвращает имя, размер и время последнего изменения (mtime) каждого файла в каталоге состояния архива WAL pg_wal / archive_status. По умолчанию только суперпользователи и члены роли pg_monitor могут использовать эту функцию. Доступ может быть предоставлен другим лицам, использующим GRANT.
pg_ls_tmpdir возвращает имя, размер и время последнего изменения (mtime) каждого файла во временном каталоге файлов для указанного табличного пространства. Если табличное пространство не предусмотрено, используется табличное пространство pg_default. По умолчанию только суперпользователи и члены роли pg_monitor могут использовать эту функцию. Доступ может быть предоставлен другим лицам, использующим GRANT.
pg_read_file возвращает часть текстового файла, начиная с заданного смещения, возвращая не более байтов длины (меньше, если конец файла достигнут первым). Если смещение отрицательно, это относительно конца файла. Если смещение и длина не указаны, возвращается весь файл. Считанные из файла байты интерпретируются как строка в кодировке сервера; выдается ошибка, если они недопустимы в этой кодировке.
pg_read_binary_file похож на pg_read_file, за исключением того, что результатом является значение bytea; соответственно проверки кодирования не выполняются. В сочетании с функцией convert_from эту функцию можно использовать для чтения файла в указанной кодировке:
SELECT convert_from(pg_read_binary_file('file_in_utf8.txt'), 'UTF8');
pg_stat_file возвращает запись, содержащую размер файла, отметку времени последнего доступа, отметку времени последнего изменения, отметку времени последнего изменения статуса файла (только для платформ Unix), отметку времени создания файла (только для Windows) и boolean указание, является ли он каталогом. Типичные использования включают в себя:
SELECT * FROM pg_stat_file ('имя файла');
SELECT (pg_stat_file ('filename')). Модификация;
Функции консультативных блокировок
Функции, показанные в таблице 95, управляют консультативными блокировками. Подробнее о правильном использовании этих функций см. в разделе Консультативные блокировки.
Таблица 95. Консультативные функции блокировки
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_advisory_lock(key bigint) | void | Получить эксклюзивную блокировку на уровне сеанса |
| pg_advisory_lock(key1 int, key2 int) | void | Получить эксклюзивную блокировку на уровне сеанса |
| pg_advisory_lock_shared(key bigint) | void | Получить общую блокировку на уровне сеанса |
| pg_advisory_lock_shared(key1 int, key2 int) | void | Получить общую блокировку на уровне сеанса |
| pg_advisory_unlock(key bigint) | boolean | Освободить эксклюзивную блокировку на уровне сеанса |
| pg_advisory_unlock(key1 int, key2 int) | boolean | Освободить эксклюзивную блокировку на уровне сеанса |
| pg_advisory_unlock_all() | void | Освободить все консультативные блокировки уровня сеанса, удерживаемые текущим сеансом |
| pg_advisory_unlock_shared(key bigint) | boolean | Освободить общую блокировку на уровне сеанса |
| pg_advisory_unlock_shared(key1 int, key2 int) | boolean | Освободить общую блокировку на уровне сеанса |
| pg_advisory_xact_lock(key bigint) | void | Получите эксклюзивную блокировку на уровне транзакции |
| pg_advisory_xact_lock(key1 int, key2 int) | void | Получите эксклюзивную блокировку на уровне транзакции |
| pg_advisory_xact_lock_shared(key bigint) | void | Получить общую блокировку на уровне транзакций |
| pg_advisory_xact_lock_shared(key1 int, key2 int) | void | Получить общую блокировку на уровне транзакций |
| pg_try_advisory_lock(key bigint) | boolean | Получите эксклюзивную блокировку на уровне сеанса, если она доступна |
| pg_try_advisory_lock(key1 int, key2 int) | boolean | Получите эксклюзивную блокировку на уровне сеанса, если она доступна |
| pg_try_advisory_lock_shared(key bigint) | boolean | Получите общую блокировку на уровне сеанса, если она доступна |
| pg_try_advisory_lock_shared(key1 int, key2 int) | boolean | Получите общую блокировку на уровне сеанса, если она доступна |
| pg_try_advisory_xact_lock(key bigint) | boolean | Получите эксклюзивную консультативную блокировку уровня транзакции, если она доступна |
| pg_try_advisory_xact_lock(key1 int, key2 int) | boolean | Получите эксклюзивную консультативную блокировку уровня транзакции, если она доступна |
| pg_try_advisory_xact_lock_shared(key bigint) | boolean | Получите совместную блокировку уровня транзакции, если она доступна |
| pg_try_advisory_xact_lock_shared(key1 int, key2 int) | boolean | Получите совместную блокировку уровня транзакции, если она доступна |
pg_advisory_lock блокирует определяемый приложением ресурс, который может быть идентифицирован либо одним 64-битным значением ключа, либо двумя 32-битными значениями ключа (обратите внимание, что эти два пространства ключей не перекрываются). Если другой сеанс уже удерживает блокировку того же идентификатора ресурса, эта функция будет ожидать, пока ресурс не станет доступным. Замок эксклюзивный. Несколько запросов на блокировку стека, так что если один и тот же ресурс заблокирован три раза, его нужно разблокировать три раза, чтобы освободить для использования другими сеансами.
pg_advisory_lock_shared работает так же, как и pg_advisory_lock, за исключением того, что блокировка может использоваться совместно с другими сеансами, запрашивающими общие блокировки. Только потенциальные эксклюзивные шкафчики заблокированы.
pg_try_advisory_lock аналогична pg_advisory_lock, за исключением того, что функция не будет ожидать, когда блокировка станет доступной. Он либо получит блокировку немедленно и вернет true, либо вернет false, если блокировка не может быть получена немедленно.
pg_try_advisory_lock_shared работает так же, как и pg_try_advisory_lock, за исключением того, что он пытается получить разделяемую, а не эксклюзивную блокировку.
pg_advisory_unlock снимет ранее приобретенную эксклюзивную консультативную блокировку уровня сеанса. Возвращает true, если блокировка успешно снята. Если блокировка не была удержана, она вернет false и, кроме того, сервер сообщит о предупреждении SQL.
pg_advisory_unlock_shared работает так же, как и pg_advisory_unlock, за исключением того, что освобождает общую консультативную блокировку на уровне сеанса.
pg_advisory_unlock_all освободит все консультативные блокировки уровня сеанса, удерживаемые текущим сеансом. (Эта функция неявно вызывается в конце сеанса, даже если клиент отключается некорректно).
pg_advisory_xact_lock работает так же, как и pg_advisory_lock, за исключением того, что блокировка автоматически снимается в конце текущей транзакции.
pg_advisory_xact_lock_shared работает так же, как pg_advisory_lock_shared, за исключением того, что блокировка автоматически снимается в конце текущей транзакции и не может быть снята явно.
pg_try_advisory_xact_lock работает так же, как и pg_try_advisory_lock, за исключением того, что блокировка, если она получена, автоматически снимается в конце текущей транзакции и не может быть снята явно.
pg_try_advisory_xact_lock_shared работает так же, как и pg_try_advisory_lock_shared, за исключением того, что блокировка, если она получена, автоматически снимается в конце текущей транзакции и не может быть разблокирована явно.
Отправка метрик и аннотаций
Отправка метрики таймера
qhb_timer_report <name> <value>, где <name> — имя метрики (text), <value> — значение таймера в наносекундах (int8).
Увеличение значения "счётчика"
qhb_counter_increase_by <name> <value>, где <name> — имя метрики (text), <value> — значение (int8), на которое надо увеличить значение счётчика.
Увеличение значения типа "gauge"
qhb_gauge_add <name> <value>, где <name> — имя метрики (text), <value> — значение (int8), на которое надо увеличить значение "gauge".
Уменьшение значения типа "gauge"
qhb_gauge_sub <name> <value>, где <name> — имя метрики (text), <value> — значение (int8), на которое надо уменьшить значение "gauge".
Установка значение типа "gauge"
qhb_gauge_update <name> <value>, где <name> — имя метрики (text), <value> — значение (int8), в которое надо установить значение "gauge".
Отправка аннотации в графану
qhb_annotation <text> [<tag> ...], где <text> — текст аннотации для графаны, <tag> — опциональное значение тега (или тегов) для аннотации; можно указать произвольное количество тегов.
Триггерные функции
В настоящее время QHB предоставляет одну встроенную триггерную функцию, suppress_redundant_updates_trigger, которая предотвращает любое обновление, которое фактически не изменяет данные в строке, в отличие от обычного поведения, которое всегда выполняет обновление независимо от того, изменились ли данные, (Это нормальное поведение ускоряет запуск обновлений, поскольку проверка не требуется, а также полезно в некоторых случаях).
В идеале вам следует избегать запуска обновлений, которые фактически не изменяют данные в записи. Избыточные обновления могут повлечь значительные ненужные расходы времени, особенно если нужно изменить множество индексов, а также пространство в мертвых строках, которое в конечном итоге придется очистить. Однако обнаружение таких ситуаций в клиентском коде не всегда легко или даже невозможно, и написание выражений для их обнаружения может быть подвержено ошибкам. Альтернативой является использование suppress_redundant_updates_trigger, который будет пропускать обновления, которые не изменяют данные. Вы должны использовать это с осторожностью, как бы то ни было. Триггер занимает небольшое, но нетривиальное время для каждой записи, поэтому, если большинство записей, затронутых обновлением, фактически изменено, использование этого триггера фактически замедлит запуск обновления.
Функция suppress_redundant_updates_trigger может быть добавлена в таблицу следующим образом:
CREATE TRIGGER z_min_update
BEFORE UPDATE ON tablename
FOR EACH ROW EXECUTE FUNCTION suppress_redundant_updates_trigger();
В большинстве случаев вы захотите использовать этот триггер последним для каждой строки. Принимая во внимание, что триггеры срабатывают в порядке имен, вы должны затем выбрать имя триггера, которое следует за именем любого другого триггера, который вы можете иметь на столе.
Для получения дополнительной информации о создании триггеров см. CREATE TRIGGER.
Функции запуска событий
QHB предоставляет эти вспомогательные функции для извлечения информации из триггеров событий.
Для получения дополнительной информации о триггерах событий см. главу Триггеры событий.
Захват изменений в конце команды
pg_event_trigger_ddl_commands возвращает список команд DDL, выполняемых каждым действием пользователя при вызове в функции, связанной с триггером события ddl_command_end. Если вызывается в любом другом контексте, возникает ошибка. pg_event_trigger_ddl_commands возвращает одну строку для каждой выполненной базовой команды; некоторые команды, представляющие собой одно предложение SQL, могут возвращать более одной строки. Эта функция возвращает следующие столбцы:
| Имя | Тип | Описание |
|---|---|---|
| classid | oid | OID каталога, в который входит объект |
| objid | oid | OID самого объекта |
| objsubid | integer | Идентификатор подобъекта (например, номер атрибута для столбца) |
| command_tag | text | Командный тег |
| object_type | text | Тип объекта |
| schema_name | text | Имя схемы, к которой принадлежит объект, если есть; в противном случае NULL. Цитирование не применяется. |
| object_identity | text | Текстовое отображение идентификатора объекта, дополненное схемой. Каждый идентификатор, включенный в личность, указывается в случае необходимости. |
| in_extension | bool | true, если команда является частью сценария расширения |
| command | pg_ddl_command | Полное представление команды, во внутреннем формате. Это не может быть выведено напрямую, но может быть передано другим функциям для получения различной информации о команде. |
Обработка объектов, отброшенных командой DDL
pg_event_trigger_dropped_objects возвращает список всех объектов, удаленных командой, для которой вызывается событие sql_drop. Если вызвано в любом другом контексте, pg_event_trigger_dropped_objects вызывает ошибку. pg_event_trigger_dropped_objects возвращает следующие столбцы:
| Имя | Тип | Описание |
|---|---|---|
| classid | oid | OID каталога, в котором находился объект |
| objid | oid | OID самого объекта |
| objsubid | integer | Идентификатор подобъекта (например, номер атрибута для столбца) |
| original | bool | Истинно, если это был один из корневых объектов удаления |
| normal | bool | Истинно, если в графе зависимостей было нормальное отношение зависимости, ведущее к этому объекту |
| is_temporary | bool | true, если это был временный объект |
| object_type | text | Тип объекта |
| schema_name | text | Имя схемы, к которой принадлежит объект, если есть; в противном случае NULL. Цитирование не применяется. |
| object_name | text | Имя объекта, если комбинация схемы и имени может использоваться в качестве уникального идентификатора для объекта; в противном случае NULL. Кавычки не применяются, а имя никогда не указывается в схеме. |
| object_identity | text | Текстовое отображение идентификатора объекта, дополненное схемой. Каждый идентификатор, включенный в личность, указывается в случае необходимости. |
| address_names | text[] | Массив, который вместе с object_type и address_args может использоваться pg_get_object_address() для воссоздания адреса объекта на удаленном сервере, содержащем объект с таким же именем того же вида |
| address_args | text[] | Дополнение для address_names |
pg_event_trigger_dropped_objects можно использовать в триггере событий, например так:
CREATE FUNCTION test_event_trigger_for_drops()
RETURNS event_trigger LANGUAGE plpgsql AS $$
DECLARE
obj record;
BEGIN
FOR obj IN SELECT * FROM pg_event_trigger_dropped_objects()
LOOP
RAISE NOTICE '% dropped object: % %.% %',
tg_tag,
obj.object_type,
obj.schema_name,
obj.object_name,
obj.object_identity;
END LOOP;
END
$$;
CREATE EVENT TRIGGER test_event_trigger_for_drops
ON sql_drop
EXECUTE FUNCTION test_event_trigger_for_drops();
Обработка события перезаписи таблицы
Функции, показанные в таблице 96, предоставляют информацию о таблице, для которой только что было вызвано событие table_rewrite. Если вызывается в любом другом контексте, возникает ошибка.
Таблица 96. Информация перезаписи таблицы
| Имя | Тип ответа | Описание |
|---|---|---|
| pg_event_trigger_table_rewrite_oid() | Oid | OID таблицы, которая должна быть переписана. |
| pg_event_trigger_table_rewrite_reason() | int | Код (ы) причины, объясняющие причину перезаписи. Точное значение кодов зависит от версии. |
pg_event_trigger_table_rewrite_oid можно использовать в триггере событий, например так:
CREATE FUNCTION test_event_trigger_table_rewrite_oid()
RETURNS event_trigger
LANGUAGE plpgsql AS
$$
BEGIN
RAISE NOTICE 'rewriting table % for reason %',
pg_event_trigger_table_rewrite_oid()::regclass,
pg_event_trigger_table_rewrite_reason();
END;
$$;
CREATE EVENT TRIGGER test_table_rewrite_oid
ON table_rewrite
EXECUTE FUNCTION test_event_trigger_table_rewrite_oid();
Функции статистической информации
QHB предоставляет функцию для проверки сложной статистики, определенной с помощью команды CREATE STATISTICS.
Проверка списков MCV
pg_mcv_list_items возвращает список всех элементов, хранящихся в многостолбцовом списке MCV, и возвращает следующие столбцы:
| Имя | Тип | Описание |
|---|---|---|
| index | int | индекс элемента в списке MCV |
| values | text[] | значения, хранящиеся в элементе MCV |
| nulls | boolean[] | флаги, идентифицирующие значения NULL |
| frequency | double precision | частота этого элемента MCV |
| base_frequency | double precision | базовая частота этого элемента MCV |
pg_mcv_list_items можно использовать так:
SELECT m.* FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid),
pg_mcv_list_items(stxdmcv) m WHERE stxname = 'stts';
Значения pg_mcv_list могут быть получены только из столбца pg_statistic_ext_data.stxdmcv.
Имена преобразований следуют стандартной схеме именования: официальное имя исходной кодировки со всеми не алфавитно-цифровыми символами, замененными подчеркиванием, за которым следует _to_, за которым следует аналогично обработанное имя кодировки назначения. Следовательно, имена могут отличаться от обычных имен кодирования.
60, если операционная система реализует дополнительные секунды
Результат, содержащий более одного узла элемента на верхнем уровне, или непробельный текст вне элемента, является примером формы содержимого. Результат XPath не может иметь форму, например, если он возвращает узел атрибута, выбранный из элемента, который его содержит. Такой результат будет помещен в форму содержимого, где каждый такой запрещенный узел будет заменен его строковым значением, как определено для string функции XPath 1.0.
PL/pgSQL - процедурный язык SQL
Обзор
PL/pgSQL - это загружаемый процедурный язык для системы баз данных QHB. Цели разработки PL/pgSQL заключались в создании загружаемого процедурного языка, который
Функции, созданные с помощью PL/pgSQL, можно использовать везде, где могут использоваться встроенные функции. Например, можно создавать сложные функции условного вычисления, а затем использовать их для определения операторов или использовать их в выражениях индекса.
В QHB PL/pgSQL устанавливается по умолчанию. Однако это все еще загружаемый модуль, поэтому администраторы, особенно заботящиеся о безопасности, могут удалить его.
Преимущества использования PL/pgSQL
SQL - это язык QHB, и большинство других реляционных баз данных используют его в качестве языка запросов. Это портативный и легкий в освоении. Но каждый оператор SQL должен выполняться сервером базы данных индивидуально.
Это означает, что ваше клиентское приложение должно отправлять каждый запрос на сервер базы данных, ждать его обработки, получать и обрабатывать результаты, выполнять некоторые вычисления, а затем отправлять дополнительные запросы на сервер. Все это требует межпроцессного взаимодействия, а также повлечет за собой нагрузку на сеть, если ваш клиент находится на другом компьютере, а не на сервере базы данных.
С PL/pgSQL вы можете сгруппировать блок вычислений и серию запросов на сервере базы данных, таким образом обладая мощью процедурного языка и простотой использования SQL, но при этом значительно экономя накладные расходы на связь клиент-сервер.
Это может привести к значительному увеличению производительности по сравнению с приложением, которое не использует хранимые функции.
Кроме того, с PL/pgSQL вы можете использовать все типы данных, операторы и функции SQL.
Поддерживаемые типы данных аргумента и результата
Функции, написанные на PL/pgSQL, могут принимать в качестве аргументов любой скалярный или массив данных, поддерживаемый сервером, и они могут возвращать результат любого из этих типов. Они также могут принимать или возвращать любой составной тип (тип строки), указанный именем. Также возможно объявить функцию PL/pgSQL как принимающую record, что означает, что любой составной тип будет делать как ввод, или как возвращающую record, что означает, что результатом является тип строки, столбцы которой определяются спецификацией в вызывающем запросе, как описано в разделе Табличные функции.
Функции PL/pgSQL могут быть объявлены для приема переменного числа аргументов с помощью маркера VARIADIC. Это работает точно так же, как и для функций SQL, как описано в разделе Функции SQL с переменным числом аргументов.
Функции PL/pgSQL также могут быть объявлены для приема и возврата
полиморфных типов anyelement, anyarray, anynonarray, anyenum и
anyrange. Фактические типы данных, обрабатываемые полиморфной функцией,
могут варьироваться от вызова к вызову, как описано в разделе Полиморфные типы.
Пример показан в разделе Объявление параметров функции.
Функции PL/pgSQL также могут быть объявлены так, чтобы они возвращали «набор» (или таблицу) любого типа данных, который может быть возвращен как один экземпляр. Такая функция генерирует свои выходные данные, выполняя RETURN NEXT для каждого требуемого элемента набора результатов или используя RETURN QUERY для вывода результата оценки запроса.
Наконец, можно объявить функцию PL/pgSQL, которая возвращает void если она не имеет полезного возвращаемого значения. (В качестве альтернативы, это может быть написано как процедура в этом случае).
Функции PL/pgSQL также могут быть объявлены с выходными параметрами вместо явной спецификации возвращаемого типа. Это не добавляет фундаментальной возможности к языку, но это часто удобно, особенно для возврата нескольких значений. Обозначение RETURNS TABLE также может использоваться вместо RETURNS SETOF.
Конкретные примеры приведены в разделе Объявление параметров функции и разделе Возврат из функции.
Структура PL/pgSQL
Функции, написанные на PL/pgSQL, определяются сервером путем выполнения команд CREATE FUNCTION. Такая команда обычно выглядит, скажем,
CREATE FUNCTION somefunc(integer, text) RETURNS integer
AS 'function body text'
LANGUAGE plpgsql;
Тело функции - это просто строковый литерал в отношении CREATE FUNCTION. Часто для написания тела функции полезно использовать знаки доллара (см. раздел Строковые константы с экранированием знаками доллара), а не обычный синтаксис с одинарными кавычками. Без использования знаков доллара любые одиночные кавычки или обратные черты в теле функции должны быть экранированы путем их удвоения. Почти все примеры в этой главе используют литералы в кавычках для своих функций.
PL/pgSQL - это блочно-структурированный язык. Полный текст тела функции должен быть блоком. Блок определяется как:
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END [ label ];
Каждое объявление и каждый оператор в блоке заканчиваются точкой с запятой. Блок, который появляется внутри другого блока, должен иметь точку с запятой после END, как показано выше; однако последний END который завершает тело функции, не требует точки с запятой.
Заметка
Распространенная ошибка - писать точку с запятой сразу после BEGIN. Это неверно и приведет к синтаксической ошибке.
label нужна только в том случае, если вы хотите идентифицировать блок для использования в операторе EXIT или указать имена переменных, объявленных в блоке. Если метка дается после END, она должна совпадать с меткой в начале блока.
Все ключевые слова не чувствительны к регистру. Идентификаторы неявно преобразуются в нижний регистр, если они не заключены в двойные кавычки, как в обычных командах SQL.
Комментарии работают в коде PL/pgSQL так же, как и в обычном SQL.
Двойная черта ( -- ) начинает комментарий, который простирается до конца
строки. /* запускает комментарий блока, который распространяется до
появления символов */.
Любой оператор в разделе операторов блока может быть субблоком. Подблоки могут использоваться для логической группировки или для локализации переменных в небольшой группе операторов. Переменные, объявленные в подблоке, маскируют любые переменные с одинаковыми именами внешних блоков на время действия субблока; но вы все равно можете получить доступ к внешним переменным, если укажете их имена с меткой их блока. Например:
CREATE FUNCTION somefunc() RETURNS integer AS $$
<< outerblock >>
DECLARE
quantity integer := 30;
BEGIN
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 30
quantity := 50;
--
-- Create a subblock
--
DECLARE
quantity integer := 80;
BEGIN
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 80
RAISE NOTICE 'Outer quantity here is %', outerblock.quantity; -- Prints 50
END;
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 50
RETURN quantity;
END;
$$ LANGUAGE plpgsql;
Заметка
На самом деле существует скрытый «внешний блок», окружающий тело любой функции PL/pgSQL. Этот блок предоставляет объявления параметров функции (если есть), а также некоторые специальные переменные, такие как FOUND (см. раздел Получение статуса результата). Внешний блок помечен именем функции, что означает, что параметры и специальные переменные могут быть дополнены именем функции.
Важно не путать использование BEGIN/END для группировки операторов в PL/pgSQL с одноименными командами SQL для управления транзакциями. PL/pgSQL BEGIN/END предназначены только для группировки; они не начинают и не заканчивают транзакцию. См. раздел Управление транзакциями для получения информации об управлении транзакциями в PL/pgSQL. Кроме того, блок, содержащий предложение EXCEPTION, эффективно формирует субтранзакцию, которую можно откатить без влияния на внешнюю транзакцию. Подробнее об этом см. раздел Ошибки захвата.
Объявления
Все переменные, используемые в блоке, должны быть объявлены в разделе объявлений блока. (Единственное исключение состоит в том, что переменная цикла FOR повторяющегося по диапазону целочисленных значений, автоматически объявляется как целочисленная переменная, и аналогично переменная цикла FOR повторяющегося по результату курсора, автоматически объявляется как переменная записи).
Переменные PL/pgSQL могут иметь любой тип данных SQL, например, integer, varchar и char.
Вот несколько примеров объявлений переменных:
user_id integer;
quantity numeric(5);
url varchar;
myrow tablename%ROWTYPE;
myfield tablename.columnname%TYPE;
arow RECORD;
Общий синтаксис объявления переменной:
name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
Предложение DEFAULT, если оно задано, задает начальное значение, назначенное переменной при вводе блока. Если предложение DEFAULT не задано, переменная инициализируется нулевым значением SQL. Опция CONSTANT предотвращает присвоение переменной после инициализации, так что ее значение будет оставаться постоянным на протяжении всего блока. Опция COLLATE указывает параметры сортировки, которые следует использовать для переменной (см. раздел Сортировка переменных PL/pgSQL). Если указано NOT NULL, присвоение нулевого значения приводит к ошибке во время выполнения. Все переменные, объявленные как NOT NULL должны иметь ненулевое значение по умолчанию. Равно ( = ) может использоваться вместо PL/SQL-совместимого :=.
Значение переменной по умолчанию оценивается и присваивается переменной каждый раз, когда вводится блок (не только один раз за вызов функции). Так, например, присвоение now() переменной типа timestamp приводит к тому, что переменная будет иметь время текущего вызова функции, а не время, когда функция была предварительно скомпилирована.
Примеры:
quantity integer DEFAULT 32;
url varchar := 'http://mysite.com';
user_id CONSTANT integer := 10;
Объявление параметров функции
Параметры, передаваемые в функции, именуются с помощью идентификаторов $1, $2 и т.д. При желании псевдонимы могут быть объявлены для $n имен параметров с целью повышения читабельности. Затем можно использовать псевдоним или числовой идентификатор для ссылки на значение параметра.
Есть два способа создать псевдоним. Предпочтительным способом является присвоение имени параметру в команде CREATE FUNCTION, например:
CREATE FUNCTION sales_tax(subtotal real) RETURNS real AS $$
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
Другой способ - явно объявить псевдоним, используя синтаксис объявления.
name ALIAS FOR $n;
Тот же пример в этом стиле выглядит так:
CREATE FUNCTION sales_tax(real) RETURNS real AS $$
DECLARE
subtotal ALIAS FOR $1;
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
Заметка
Эти два примера не являются полностью эквивалентными. В первом случае на промежуточный итог можно ссылаться как на sales_tax.subtotal, но во втором случае это невозможно. (Если бы мы прикрепили метку к внутреннему блоку, subtotal можно было бы квалифицировать с этой меткой).
Еще несколько примеров:
CREATE FUNCTION instr(varchar, integer) RETURNS integer AS $$
DECLARE
v_string ALIAS FOR $1;
index ALIAS FOR $2;
BEGIN
-- some computations using v_string and index here
END;
$$ LANGUAGE plpgsql;
CREATE FUNCTION concat_selected_fields(in_t sometablename) RETURNS text AS $$
BEGIN
RETURN in_t.f1 || in_t.f3 || in_t.f5 || in_t.f7;
END;
$$ LANGUAGE plpgsql;
Когда функция PL/pgSQL объявляется с выходными параметрами, выходным параметрам присваиваются имена $n и необязательные псевдонимы точно так же, как обычные входные параметры. Выходной параметр фактически является переменной, которая начинается с NULL; это должно быть назначено во время выполнения функции. Конечное значение параметра - это то, что возвращается. Например, расчет налога с продаж также может быть сделан следующим образом:
CREATE FUNCTION sales_tax(subtotal real, OUT tax real) AS $$
BEGIN
tax := subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
Обратите внимание, что мы пропустили RETURNS real - мы могли бы включить его, но это было бы излишним.
Выходные параметры наиболее полезны при возврате нескольких значений. Тривиальный пример:
CREATE FUNCTION sum_n_product(x int, y int, OUT sum int, OUT prod int) AS $$
BEGIN
sum := x + y;
prod := x * y;
END;
$$ LANGUAGE plpgsql;
Как обсуждалось в разделе Функции SQL с выходными параметрами, это эффективно создает анонимный тип записи для результатов функции. Если задано предложение RETURNS, оно должно типа record.
Другой способ объявить функцию PL/pgSQL - использовать RETURNS TABLE, например:
CREATE FUNCTION extended_sales(p_itemno int)
RETURNS TABLE(quantity int, total numeric) AS $$
BEGIN
RETURN QUERY SELECT s.quantity, s.quantity * s.price FROM sales AS s
WHERE s.itemno = p_itemno;
END;
$$ LANGUAGE plpgsql;
Это в точности эквивалентно объявлению одного или нескольких параметров OUT и указанию RETURNS SETOF sometype.
Когда возвращаемый тип функции PL/pgSQL объявлен как полиморфный тип ( anyelement, anyarray, anynonarray, anyenum или anyrange), создается специальный параметр $0. Тип данных - это фактический тип возвращаемого значения функции, выведенный из фактических типов ввода (см. раздел Полиморфные типы). Это позволяет функции получить доступ к ее фактическому типу возврата, как показано в разделе Типы копирования. $0 инициализируется нулевым значением и может быть изменено функцией, поэтому его можно использовать для хранения возвращаемого значения, если это необходимо, хотя это не требуется. $0 также может быть присвоен псевдоним. Например, эта функция работает с любым типом данных, который имеет оператор + :
CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement)
RETURNS anyelement AS $$
DECLARE
result ALIAS FOR $0;
BEGIN
result := v1 + v2 + v3;
RETURN result;
END;
$$ LANGUAGE plpgsql;
Тот же эффект можно получить, объявив один или несколько выходных параметров как полиморфные типы. В этом случае специальный параметр $0 не используется; Сами выходные параметры служат той же цели. Например:
CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement,
OUT sum anyelement)
AS $$
BEGIN
sum := v1 + v2 + v3;
END;
$$ LANGUAGE plpgsql;
ALIAS
newname ALIAS FOR oldname;
Синтаксис ALIAS является более общим, чем предлагается в предыдущем разделе: вы можете объявить псевдоним для любой переменной, а не только для параметров функции. Основное практическое использование для этого состоит в назначении другого имени для переменных с предопределенными именами, таких как NEW или OLD в функции триггера.
Примеры:
DECLARE
prior ALIAS FOR old;
updated ALIAS FOR new;
Поскольку ALIAS создает два разных способа именования одного и того же объекта, неограниченное использование может привести к путанице. Лучше всего использовать его только с целью переопределения заранее определенных имен.
Типы копирования
variable%TYPE
%TYPE предоставляет тип данных переменной или столбца таблицы. Вы можете использовать это для объявления переменных, которые будут содержать значения базы данных. Например, предположим, у вас есть столбец с именем user_id в вашей таблице users. Чтобы объявить переменную с тем же типом данных, что и users.user_id вы пишете:
user_id users.user_id%TYPE;
Используя %TYPE вам не нужно знать тип данных структуры, на которую вы ссылаетесь, и, самое главное, если тип данных ссылочного элемента изменится в будущем (например: вы меняете тип user_id с integer на real), вам может не потребоваться изменить определение функции.
%TYPE особенно полезен в полиморфных функциях, поскольку типы данных, необходимые для внутренних переменных, могут меняться от одного вызова к другому. Подходящие переменные могут быть созданы путем применения %TYPE к аргументам функции или местозаполнителям результата.
Типы строк
name table_name%ROWTYPE;
name composite_type_name;
Переменная составного типа называется переменной строки (или переменной типа строки). Такая переменная может содержать целую строку результата запроса SELECT или FOR, если набор столбцов этого запроса соответствует объявленному типу переменной. Доступ к отдельным полям значения строки осуществляется с использованием обычной точечной нотации, например rowvar.field.
Переменная строки может быть объявлена для того же типа, что и строки
существующей таблицы или представления, используя нотацию table_name%ROWTYPE;
или это может быть объявлено путем указания имени составного
типа. (Поскольку каждая таблица имеет связанный составной тип с одним и
тем же именем, в QHB не имеет значения, пишете ли вы %ROWTYPE или
нет. Но форма с %ROWTYPE более переносима).
Параметрами функции могут быть составные типы (полные строки таблицы). В этом случае соответствующий идентификатор $n будет переменной строки, и из него можно выбрать поля, например, $1.user_id.
Вот пример использования составных типов. table1 и table2 являются существующими таблицами, имеющими по крайней мере упомянутые поля:
CREATE FUNCTION merge_fields(t_row table1) RETURNS text AS $$
DECLARE
t2_row table2%ROWTYPE;
BEGIN
SELECT * INTO t2_row FROM table2 WHERE ... ;
RETURN t_row.f1 || t2_row.f3 || t_row.f5 || t2_row.f7;
END;
$$ LANGUAGE plpgsql;
SELECT merge_fields(t.*) FROM table1 t WHERE ... ;
Типы записей
name RECORD;
Переменные записи аналогичны переменным типа строки, но не имеют предопределенной структуры. Они принимают фактическую структуру строк, назначенных им при выполнении команды SELECT или FOR. Подструктура переменной записи может меняться каждый раз, когда ей назначается. Следствием этого является то, что до тех пор, пока переменная записи не будет впервые назначена, она не имеет подструктуры, и любая попытка доступа к полю в ней вызовет ошибку во время выполнения.
Обратите внимание, что RECORD не является истинным типом данных, а только заполнителем. Следует также понимать, что когда объявляется функция PL/pgSQL, возвращающая record типа, это не совсем то же самое, что и переменная записи, даже если такая функция может использовать переменную записи для хранения своего результата. В обоих случаях фактическая структура строки неизвестна при написании функции, но для функции, возвращающей record фактическая структура определяется при разборе вызывающего запроса, тогда как переменная записи может изменить свою структуру строки на лету.
Сортировка переменных PL/pgSQL
Когда функция PL/pgSQL имеет один или несколько параметров типов данных для сопоставления, для каждого вызова функции определяется сопоставление в зависимости от сопоставлений, назначенных фактическим аргументам, как описано в разделе Поддержка сортировки. Если сопоставление успешно идентифицировано (т.е. между аргументами нет конфликтов неявных сопоставлений), то все параметры сопоставления обрабатываются как имеющие такое сопоставление неявно. Это повлияет на поведение чувствительных к сбору операций внутри функции. Например, рассмотрим
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b;
END;
$$ LANGUAGE plpgsql;
SELECT less_than(text_field_1, text_field_2) FROM table1;
SELECT less_than(text_field_1, text_field_2 COLLATE "C") FROM table1;
Первое использование less_than будет использовать общее сравнение text_field_1 и text_field_2 для сравнения, в то время как второе использование будет использовать C сортировку.
Кроме того, идентифицированное сопоставление также предполагается как сопоставление любых локальных переменных, относящихся к разводимым типам. Таким образом, эта функция не будет работать по-другому, если она была написана как
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
DECLARE
local_a text := a;
local_b text := b;
BEGIN
RETURN local_a < local_b;
END;
$$ LANGUAGE plpgsql;
Если параметры типов данных для сопоставления отсутствуют или для них нельзя определить общие параметры сортировки, то параметры и локальные переменные используют параметры сортировки по умолчанию для своего типа данных (обычно это параметры сортировки базы данных по умолчанию, но могут отличаться для переменных типа домена).
Локальная переменная типа данных с возможностью сопоставления может иметь другой сопоставление, связанное с включением опции COLLATE в ее объявление, например
DECLARE
local_a text COLLATE "en_US";
Этот параметр переопределяет параметры сортировки, которые в противном случае были бы переданы переменной в соответствии с приведенными выше правилами.
Также, конечно, явные предложения COLLATE могут быть записаны внутри функции, если требуется принудительно использовать конкретное сопоставление в конкретной операции. Например,
CREATE FUNCTION less_than_c(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b COLLATE "C";
END;
$$ LANGUAGE plpgsql;
Это переопределяет параметры сортировки, связанные со столбцами таблицы, параметрами или локальными переменными, используемыми в выражении, так же, как это происходит в простой команде SQL.
Выражения
Все выражения, используемые в инструкциях PL/pgSQL, обрабатываются с использованием основного SQL- исполнителя сервера. Например, когда вы пишете оператор PL/pgSQL, как
IF expression THEN ...
PL/pgSQL оценит выражение, подав запрос
SELECT expression
на основной движок SQL. При формировании команды SELECT любые вхождения имен переменных PL/pgSQL заменяются параметрами, как подробно описано в разделе Подстановка переменных. Это позволяет составить план запроса для SELECT только один раз, а затем повторно использовать для последующих оценок с различными значениями переменных. Таким образом, то, что действительно происходит при первом использовании выражения, по сути, является командой PREPARE. Например, если мы объявили две целочисленные переменные x и y, и мы напишем
IF x < y THEN ...
то, что происходит за кулисами, эквивалентно
PREPARE statement_name(integer, integer) AS SELECT $1 < $2;
и затем этот подготовленный оператор будет EXECUTE d для каждого выполнения оператора IF, с текущими значениями переменных PL/pgSQL, предоставленными в качестве значений параметров. Обычно эти детали не важны для пользователя PL/pgSQL, но их полезно знать при попытке диагностировать проблему. Более подробная информация представлена в разделе Планирование кеширования.
Основные положения
В этом и следующих разделах мы опишем все типы операторов, которые явно понятны PL/pgSQL. Все, что не распознается как один из этих типов операторов, считается командой SQL и отправляется на выполнение главному ядру базы данных, как описано в разделе Выполнение команды без результата и разделе Выполнение запроса с результатом в одну строку.
Присваивание
Присвоение значения переменной PL/pgSQL записывается так:
variable { := | = } expression;
Как объяснено ранее, выражение в таком выражении оценивается с помощью команды SQL SELECT отправляемой основному ядру базы данных. Выражение должно давать одно значение (возможно, значение строки, если переменная является строкой или переменной записи). Целевая переменная может быть простой переменной (необязательно квалифицируемой именем блока), полем строки или переменной записи или элементом массива, который является простой переменной или полем. Равное ( = ) может использоваться вместо PL/SQL-совместимого :=.
Если тип данных результата выражения не совпадает с типом данных переменной, значение будет приведено, как если бы было приведено присваивание . Если для пары задействованных типов данных неизвестно приведение присваивания, интерпретатор PL/pgSQL попытается преобразовать значение результата в текстовом виде, то есть применяя функцию вывода типа результата, за которой следует функция ввода типа переменной. Обратите внимание, что это может привести к ошибкам во время выполнения, сгенерированным функцией ввода, если строковая форма значения результата не приемлема для функции ввода.
Примеры:
tax := subtotal * 0.06;
my_record.user_id := 20;
Выполнение команды без результата
Для любой команды SQL, которая не возвращает строки, например, INSERT без предложения RETURNING, вы можете выполнить команду в функции PL / pgSQL, просто написав команду.
Любое имя переменной PL/pgSQL, отображаемое в тексте команды, рассматривается как параметр, а затем текущее значение переменной предоставляется в качестве значения параметра во время выполнения. Это точно так же, как обработка, описанная ранее для выражений; подробности см. в разделе Подстановка переменных.
При выполнении команды SQL таким способом PL/pgSQL может кэшировать и повторно использовать план выполнения для команды, как обсуждалось в разделе Планирование кеширования.
Иногда полезно оценить выражение или запрос SELECT но отбросить результат, например, при вызове функции, которая имеет побочные эффекты, но не имеет полезного значения результата. Чтобы сделать это в PL / pgSQL, используйте оператор PERFORM:
PERFORM query;
Это выполняет query и отбрасывает результат. Напишите query, как и команду SQL SELECT, но замените исходное ключевое слово SELECT на PERFORM. Для запросов WITH используйте PERFORM а затем поместите запрос в скобки. (В этом случае запрос может вернуть только одну строку). Переменные PL/pgSQL будут подставлены в запрос так же, как для команд, которые не возвращают результата, и план кэшируется таким же образом. Кроме того, специальная переменная FOUND устанавливается в значение true, если запрос выдал хотя бы одну строку, или в значение false, если не было строк (см. раздел Получение статуса результата).
Заметка
Можно было бы ожидать, что написание SELECT напрямую приведет к этому результату, но в настоящее время единственный приемлемый способ сделать это - PERFORM. Команда SQL, которая может возвращать строки, например, SELECT, будет отклонена как ошибка, если в ней нет предложения INTO, как описано в следующем разделе.
Пример:
PERFORM create_mv('cs_session_page_requests_mv', my_query);
Выполнение запроса с результатом в одну строку
Результат команды SQL, дающей одну строку (возможно, из нескольких столбцов), может быть присвоен переменной записи, переменной типа строки или списку скалярных переменных. Это делается путем написания базовой команды SQL и добавления предложения INTO. Например,
SELECT select_expressions INTO [STRICT] target FROM ...;
INSERT ... RETURNING expressions INTO [STRICT] target;
UPDATE ... RETURNING expressions INTO [STRICT] target;
DELETE ... RETURNING expressions INTO [STRICT] target;
где target может быть переменной записи, переменной строки или разделенным запятыми списком простых переменных и полей записи / строки. Переменные PL/pgSQL будут подставлены в остальную часть запроса, и план будет кэширован, как описано выше для команд, которые не возвращают строки. Это работает для SELECT, INSERT / UPDATE / DELETE с RETURNING и служебных команд, которые возвращают результаты набора строк (например, EXPLAIN). За исключением предложения INTO, команда SQL такая же, как она написана вне PL/pgSQL.
Заметка
Обратите внимание, что эта интерпретация SELECT с INTO сильно отличается от обычной команды SELECT INTO QHB, в которой целью INTO является вновь созданная таблица. Если вы хотите создать таблицу из результата SELECT внутри функции PL/pgSQL, используйте синтаксис CREATE TABLE... AS SELECT.
Если в качестве цели используется строка или список переменных, столбцы результата запроса должны точно соответствовать структуре цели в отношении числа и типов данных, иначе произойдет ошибка времени выполнения. Когда переменная записи является целью, она автоматически настраивается на тип строки столбцов результата запроса.
Предложение INTO может появляться практически в любом месте команды SQL. Обычно он записывается либо непосредственно перед, либо сразу после списка select_expressions в команде SELECT, либо в конце команды для других типов команд. Рекомендуется следовать этому соглашению на случай, если парсер PL/pgSQL станет более строгим в будущих версиях.
Если STRICT не указан в предложении INTO, тогда target будет установлен на первую строку, возвращаемую запросом, или на нули, если запрос не вернул ни одной строки. (Обратите внимание, что « первая строка » не является четко определенной, если вы не использовали ORDER BY). Любые строки результатов после первой строки отбрасываются. Вы можете проверить специальную переменную FOUND (см. раздел Получение статуса результата), чтобы определить, была ли возвращена строка:
SELECT * INTO myrec FROM emp WHERE empname = myname;
IF NOT FOUND THEN
RAISE EXCEPTION 'employee % not found', myname;
END IF;
Если указан параметр STRICT, запрос должен возвращать ровно одну строку, иначе будет сообщено об ошибке во время выполнения, NO_DATA_FOUND (без строк) или TOO_MANY_ROWS (более одной строки). Вы можете использовать блок исключения, если хотите перехватить ошибку, например:
BEGIN
SELECT * INTO STRICT myrec FROM emp WHERE empname = myname;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RAISE EXCEPTION 'employee % not found', myname;
WHEN TOO_MANY_ROWS THEN
RAISE EXCEPTION 'employee % not unique', myname;
END;
Успешное выполнение команды с помощью STRICT всегда устанавливает FOUND в значение true.
Для INSERT / UPDATE / DELETE с RETURNING PL/pgSQL сообщает об ошибке для более чем одной возвращенной строки, даже если STRICT не указан. Это связано с тем, что нет такой опции, как ORDER BY с помощью которой можно определить, какая затронутая строка должна быть возвращена.
Если для функции включен print_strict_params, то при возникновении ошибки из-за несоблюдения требований STRICT часть DETAIL в сообщении об ошибке будет содержать информацию о параметрах, переданных в запрос. Вы можете изменить параметр print_strict_params для всех функций, установив plpgsql.print_strict_params, хотя это plpgsql.print_strict_params только на последующие компиляции функций. Вы также можете включить его для каждой функции, используя опцию компилятора, например:
CREATE FUNCTION get_userid(username text) RETURNS int
AS $$
#print_strict_params on
DECLARE
userid int;
BEGIN
SELECT users.userid INTO STRICT userid
FROM users WHERE users.username = get_userid.username;
RETURN userid;
END
$$ LANGUAGE plpgsql;
При сбое эта функция может выдавать сообщение об ошибке, например
ERROR: query returned no rows
DETAIL: parameters: $1 = 'nosuchuser'
CONTEXT: PL/pgSQL function get_userid(text) line 6 at SQL statement
Заметка
Опция STRICT соответствует поведению SELECT INTO и связанных операторов Oracle PL/SQL.
Для обработки случаев, когда вам нужно обработать несколько строк результатов из запроса SQL, см. раздел Цикл по результатам запроса.
Выполнение динамических команд
Часто вы захотите генерировать динамические команды внутри ваших функций PL/pgSQL, то есть команды, которые будут включать разные таблицы или разные типы данных при каждом их выполнении. Обычные попытки PL/pgSQL кешировать планы для команд (как описано в разделе Планирование кеширования) не будут работать в таких сценариях. Для решения такого рода проблем предусмотрен оператор EXECUTE :
EXECUTE command-string [ INTO [STRICT] target ] [ USING expression [, ... ] ];
где command-string - это выражение, дающее строку (типа text ), содержащую команду, которая должна быть выполнена. Необязательной target является переменная записи, переменная строки или разделенный запятыми список простых переменных и полей записи / строки, в которые будут сохраняться результаты команды. Необязательные выражения USING предоставляют значения для вставки в команду.
Подстановка переменных PL/pgSQL в вычисляемой командной строке не производится. Любые обязательные значения переменных должны быть вставлены в командную строку по мере ее создания; или вы можете использовать параметры, как описано ниже.
Также нет кэширования плана для команд, выполняемых через EXECUTE. Вместо этого команда всегда планируется каждый раз, когда выполняется оператор. Таким образом, командная строка может быть динамически создана внутри функции для выполнения действий над различными таблицами и столбцами.
Предложение INTO указывает, где должны быть назначены результаты команды SQL, возвращающей строки. Если указан список строк или переменных, он должен точно соответствовать структуре результатов запроса (когда используется переменная записи, он автоматически настраивается на соответствие структуре результатов). Если возвращается несколько строк, только первая будет назначена переменной INTO. Если строки не возвращаются, NULL присваивается переменной (ам) INTO. Если предложение INTO не указано, результаты запроса отбрасываются.
Если задана опция STRICT выдается сообщение об ошибке, если запрос не создает ровно одну строку.
В командной строке могут использоваться значения параметров, на которые в команде ссылаются как $1, $2 и т. Д. Эти символы относятся к значениям, указанным в предложении USING. Этот метод часто предпочтительнее вставки значений данных в командную строку в виде текста: он позволяет избежать накладных расходов во время выполнения преобразования значений в текст и обратно, и он гораздо менее подвержен атакам с использованием SQL-инъекций, поскольку нет необходимости заключать в кавычки или побега. Примером является:
EXECUTE 'SELECT count(*) FROM mytable WHERE inserted_by = $1 AND inserted <= $2'
INTO c
USING checked_user, checked_date;
Обратите внимание, что символы параметров могут использоваться только для значений данных - если вы хотите использовать динамически определяемые имена таблиц или столбцов, вы должны вставить их в командную строку в текстовом виде. Например, если предыдущий запрос необходимо выполнить для динамически выбранной таблицы, вы можете сделать это:
EXECUTE 'SELECT count(*) FROM '
|| quote_ident(tabname)
|| ' WHERE inserted_by = $1 AND inserted <= $2'
INTO c
USING checked_user, checked_date;
Более чистый подход заключается в использовании %I спецификации format() для имен таблиц или столбцов (строки, разделенные новой строкой, объединяются):
EXECUTE format('SELECT count(*) FROM %I '
'WHERE inserted_by = $1 AND inserted <= $2', tabname)
INTO c
USING checked_user, checked_date;
Другое ограничение на символы параметров заключается в том, что они работают только в командах SELECT, INSERT, UPDATE и DELETE. В других типах операторов (обычно называемых служебными операторами) вы должны вставлять значения текстуально, даже если они являются просто значениями данных.
EXECUTE с простой константой командной строки и некоторыми параметрами USING, как в первом примере выше, функционально эквивалентен простому написанию команды непосредственно в PL/pgSQL и позволяет автоматической замене переменных PL/pgSQL. Важным отличием является то, что EXECUTE будет перепланировать команду при каждом выполнении, генерируя план, специфичный для текущих значений параметров; в то время как PL/pgSQL может создать общий план и кэшировать его для повторного использования. В ситуациях, когда лучший план сильно зависит от значений параметров, может быть полезно использовать EXECUTE чтобы убедиться, что общий план не выбран.
SELECT INTO в настоящее время не поддерживается в EXECUTE; вместо этого выполните простую команду SELECT и укажите INTO как часть самого EXECUTE.
Заметка
Оператор PL/pgSQL EXECUTE не связан с оператором EXECUTE SQL, поддерживаемым сервером QHB. Оператор EXECUTE сервера нельзя использовать непосредственно в функциях PL/pgSQL (и не нужен).
Пример 1. Цитирование значений в динамических запросах
При работе с динамическими командами вам часто приходится обрабатывать экранирование одинарных кавычек. Рекомендованный метод для цитирования фиксированного текста в теле функции - это экранирование знаками доллара. (Если у вас есть устаревший код, который не использует долларовые кавычки, обратитесь к обзору в разделе Обработка кавычек, который может сэкономить некоторые усилия при переводе указанного кода в более разумную схему).
Динамические значения требуют тщательной обработки, поскольку они могут содержать символы кавычек. Пример использования format() (предполагается, что вы заключили в кавычки тело функции, поэтому кавычки не нужно удваивать):
EXECUTE format('UPDATE tbl SET %I = $1 '
'WHERE key = $2', colname) USING newvalue, keyvalue;
Также можно напрямую вызывать функции цитирования:
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = '
|| quote_literal(newvalue)
|| ' WHERE key = '
|| quote_literal(keyvalue);
Этот пример демонстрирует использование функций quote_ident и quote_literal (см. раздел Строковые функции и операторы). В целях безопасности выражения, содержащие идентификаторы столбцов или таблиц, должны передаваться через quote_ident перед вставкой в динамический запрос. Выражения, содержащие значения, которые должны быть литеральными строками в построенной команде, должны передаваться через quote_literal. Эти функции предпринимают соответствующие шаги для возврата входного текста, заключенного в двойные или одинарные кавычки соответственно, с любыми встроенными специальными символами, должным образом экранированными.
Поскольку quote_literal помечен как STRICT, он всегда будет возвращать ноль при вызове с нулевым аргументом. В приведенном выше примере, если newvalue или keyvalue были нулевыми, вся строка динамического запроса станет нулевой, что приведет к ошибке EXECUTE. Вы можете избежать этой проблемы, используя функцию quote_nullable, которая работает так же, как и quote_literal за исключением того, что при вызове с нулевым аргументом она возвращает строку NULL. Например,
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = '
|| quote_nullable(newvalue)
|| ' WHERE key = '
|| quote_nullable(keyvalue);
Если вы имеете дело со значениями, которые могут быть нулевыми, вы должны обычно использовать quote_nullable вместо quote_literal.
Как всегда, нужно позаботиться о том, чтобы нулевые значения в запросе не давали непредвиденных результатов. Например, WHERE
'WHERE key = ' || quote_nullable(keyvalue)
никогда не будет успешным, если значение keyvalue равно нулю, потому что результат использования оператора равенства = с нулевым операндом всегда равен нулю. Если вы хотите, чтобы значение null работало как обычное значение ключа, вам необходимо переписать приведенное выше как
'WHERE key IS NOT DISTINCT FROM ' || quote_nullable(keyvalue)
(В настоящее время IS NOT DISTINCT FROM обрабатывается гораздо менее эффективно, чем =, поэтому не делайте этого, если не нужно. См. раздел Функции сравнения и операторы для получения дополнительной информации о пустых значениях и IS DISTINCT).
Обратите внимание, что цитирование в знаках доллара полезно только для цитирования фиксированного текста. Было бы очень плохой идеей написать этот пример так:
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = $$'
|| newvalue
|| '$$ WHERE key = '
|| quote_literal(keyvalue);
потому что он сломался бы, если бы содержимое newvalue содержало $$. То же самое возражение будет относиться к любому другому ограничителю в знаках доллара, который вы можете выбрать. Таким образом, для безопасного цитирования текста, который не известен заранее, вы должны использовать quote_literal, quote_nullable или quote_ident, в зависимости от ситуации.
Динамические операторы SQL также можно безопасно создавать с помощью функции format (см. раздел FORMAT). Например:
EXECUTE format('UPDATE tbl SET %I = %L '
'WHERE key = %L', colname, newvalue, keyvalue);
%I эквивалентен quote_ident, а %L эквивалентен quote_nullable. Функция format может использоваться вместе с предложением USING :
EXECUTE format('UPDATE tbl SET %I = $1 WHERE key = $2', colname)
USING newvalue, keyvalue;
Эта форма лучше, потому что переменные обрабатываются в их собственном формате типа данных, а не безоговорочно преобразуют их в текст и заключают их в кавычки через %L Это также более эффективно.
Гораздо больший пример динамической команды и EXECUTE можно увидеть в Примере 10, который создает и выполняет команду CREATE FUNCTION для определения новой функции.
Получение статуса результата
Есть несколько способов определить эффект команды. Первый метод заключается в использовании команды GET DIAGNOSTICS, которая имеет вид:
GET [ CURRENT ] DIAGNOSTICS variable { = | := } item [, ... ];
Эта команда позволяет получить индикаторы состояния системы. CURRENT - это шумовое слово (но см. Также GET STACKED DIAGNOSTICS в разделе Получение информации об ошибке). Каждый item является ключевым словом, идентифицирующим значение состояния, которое должно быть назначено указанной variable (которое должно иметь правильный тип данных для его получения). Доступные в настоящее время элементы состояния показаны в таблице 1. Вместо токена SQL-standard = можно использовать двоеточие ( := ). Пример:
GET DIAGNOSTICS integer_var = ROW_COUNT;
Таблица 1. Доступные элементы диагностики
| Имя | Тип | Описание |
|---|---|---|
| ROW_COUNT | bigint | количество строк, обработанных самой последней командой SQL |
| PG_CONTEXT | text | строка (и) текста, описывающего текущий стек вызовов (см. раздел Получение информации о месте выполнения) |
Второй метод определения эффектов команды - это проверка специальной переменной с именем FOUND, которая имеет тип boolean. FOUND начинает false в каждом вызове функции PL/pgSQL. Он устанавливается каждым из следующих типов утверждений:
Другие операторы PL/pgSQL не изменяют состояние FOUND. В частности, обратите внимание, что EXECUTE изменяет вывод GET DIAGNOSTICS, но не меняет FOUND.
FOUND - локальная переменная в каждой функции PL/pgSQL ; любые изменения в ней влияют только на текущую функцию.
Пустой оператор
Иногда полезен пустой оператор. Например, когда одно плечо условия if / then / else намеренно пусто. Для этого используйте оператор NULL :
NULL;
Например, следующие два фрагмента кода эквивалентны:
BEGIN
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
NULL; -- ignore the error
END;
BEGIN
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN -- ignore the error
END;
Что предпочтительнее, это вопрос вкуса.
Заметка
В Oracle PL/SQL пустые списки операторов недопустимы, поэтому для таких ситуаций требуются операторы NULL. PL/pgSQL позволяет просто ничего не писать.
Управляющие структуры
Управляющие структуры, вероятно, самая полезная (и важная) часть PL/pgSQL. С управляющими структурами PL/pgSQL вы можете манипулировать данными QHB очень гибким и мощным способом.
Возврат из функции
Доступны две команды, которые позволяют вам возвращать данные из функции: RETURN и RETURN NEXT.
RETURN
RETURN expression;
RETURN с выражением завершает функцию и возвращает значение expression вызывающей стороне. Эта форма используется для функций PL/pgSQL, которые не возвращают набор.
В функции, которая возвращает скалярный тип, результат выражения будет автоматически преобразован в тип возврата функции, как описано для назначений. Но чтобы вернуть составное (строковое) значение, вы должны написать выражение, доставляющее точно запрошенный набор столбцов. Это может потребовать использования явного приведения.
Если вы объявили функцию с выходными параметрами, напишите просто RETURN без выражения. Текущие значения переменных выходного параметра будут возвращены.
Если вы объявили функцию, возвращающую void, оператор RETURN может быть использован для досрочного выхода из функции; но не пишите выражение после RETURN.
Возвращаемое значение функции нельзя оставлять неопределенным. Если управление достигает конца блока верхнего уровня функции, не нажимая оператор RETURN, произойдет ошибка времени выполнения. Однако это ограничение не распространяется на функции с выходными параметрами и на функции, возвращающие void. В этих случаях оператор RETURN автоматически выполняется, если заканчивается блок верхнего уровня.
Несколько примеров:
-- functions returning a scalar type
RETURN 1 + 2;
RETURN scalar_var;
-- functions returning a composite type
RETURN composite_type_var;
RETURN (1, 2, 'three'::text); -- must cast columns to correct types
RETURN NEXT и RETURN QUERY
RETURN NEXT expression;
RETURN QUERY query;
RETURN QUERY EXECUTE command-string [ USING expression [, ... ] ];
Когда объявляется, что функция PL/pgSQL возвращает SETOF sometype, процедура, которой нужно следовать, немного отличается. В этом случае отдельные возвращаемые элементы указываются с помощью последовательности команд RETURN NEXT или RETURN QUERY, а затем используется последняя команда RETURN без аргумента, указывающая, что функция завершилась. RETURN NEXT может использоваться как со скалярными, так и с составными типами данных; с составным типом результата будет возвращена вся «таблица» результатов. RETURN QUERY добавляет результаты выполнения запроса к набору результатов функции. RETURN NEXT и RETURN QUERY можно свободно смешивать в одной функции, возвращающей множество, и в этом случае их результаты будут объединены.
RETURN NEXT и RETURN QUERY фактически не возвращаются из функции - они просто добавляют ноль или более строк в набор результатов функции. Затем выполнение продолжается со следующего оператора в функции PL/pgSQL. По мере выполнения последовательных команд RETURN NEXT или RETURN QUERY набор результатов формируется. Окончательный RETURN, который не должен иметь аргументов, заставляет элемент управления выйти из функции (или вы можете просто позволить элементу управления достигнуть конца функции).
RETURN QUERY имеет вариант RETURN QUERY EXECUTE, который указывает, что запрос должен выполняться динамически. Выражения параметров могут быть вставлены в вычисляемую строку запроса через USING, точно так же, как в команде EXECUTE.
Если вы объявили функцию с выходными параметрами, напишите просто RETURN NEXT без выражения. При каждом выполнении текущие значения переменной (ов) выходного параметра будут сохраняться для возможного возврата в виде строки результата. Обратите внимание, что вы должны объявить функцию как возвращающую SETOF record когда есть несколько выходных параметров, или SETOF sometype когда есть только один выходной параметр типа sometype, чтобы создать функцию, возвращающую множество с выходными параметрами.
Вот пример функции, использующей RETURN NEXT :
CREATE TABLE foo (fooid INT, foosubid INT, fooname TEXT);
INSERT INTO foo VALUES (1, 2, 'three');
INSERT INTO foo VALUES (4, 5, 'six');
CREATE OR REPLACE FUNCTION get_all_foo() RETURNS SETOF foo AS
$BODY$
DECLARE
r foo%rowtype;
BEGIN
FOR r IN
SELECT * FROM foo WHERE fooid > 0
LOOP
-- can do some processing here
RETURN NEXT r; -- return current row of SELECT
END LOOP;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
SELECT * FROM get_all_foo();
Вот пример функции, использующей RETURN QUERY :
CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS
$BODY$
BEGIN
RETURN QUERY SELECT flightid
FROM flight
WHERE flightdate >= $1
AND flightdate < ($1 + 1);
-- Since execution is not finished, we can check whether rows were returned
-- and raise exception if not.
IF NOT FOUND THEN
RAISE EXCEPTION 'No flight at %.', $1;
END IF;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
-- Returns available flights or raises exception if there are no
-- available flights.
SELECT * FROM get_available_flightid(CURRENT_DATE);
Заметка
Текущая реализация RETURN NEXT и RETURN QUERY сохраняет весь набор результатов перед возвратом из функции, как обсуждалось выше. Это означает, что если функция PL/pgSQL выдает очень большой набор результатов, производительность может быть низкой: данные будут записаны на диск во избежание исчерпания памяти, но сама функция не вернется, пока не будет сгенерирован весь набор результатов. Будущая версия PL/pgSQL может позволить пользователям определять функции, возвращающие множество, которые не имеют этого ограничения. В настоящее время точка, с которой данные начинают записываться на диск, контролируется переменной конфигурации work_mem. Администраторам, которые имеют достаточно памяти для хранения больших наборов результатов в памяти, следует рассмотреть возможность увеличения этого параметра.
Возврат из процедуры
Процедура не имеет возвращаемого значения. Поэтому процедура может завершиться без оператора RETURN. Если вы хотите использовать инструкцию RETURN для досрочного выхода из кода, напишите просто RETURN без выражения.
Если процедура имеет выходные параметры, окончательные значения переменных выходных параметров будут возвращены вызывающей стороне.
Вызов процедуры
Функция, процедура или блок PL/pgSQL могут вызывать процедуру, используя CALL. Выходные параметры обрабатываются иначе, чем CALL работает в простом SQL. Каждый параметр INOUT процедуры должен соответствовать переменной в операторе CALL, и все, что возвращает процедура, присваивается этой переменной после ее возврата. Например:
CREATE PROCEDURE triple(INOUT x int)
LANGUAGE plpgsql
AS $$
BEGIN
x := x * 3;
END;
$$;
DO $$
DECLARE myvar int := 5;
BEGIN
CALL triple(myvar);
RAISE NOTICE 'myvar = %', myvar; -- prints 15
END
$$;
Условные операторы
Операторы IF и CASE позволяют выполнять альтернативные команды в зависимости от определенных условий. PL/pgSQL имеет три формы IF:
и две формы CASE :
IF-THEN
IF boolean-expression THEN
statements
END IF;
IF-THEN оператор являются простейшей формой IF. Операторы между THEN и END IF будут выполнены, если условие истинно. В противном случае они пропускаются.
Пример:
IF v_user_id <> 0 THEN
UPDATE users SET email = v_email WHERE user_id = v_user_id;
END IF;
IF-THEN-ELSE
IF boolean-expression THEN
statements
ELSE
statements
END IF;
Операторы IF-THEN-ELSE добавляют к IF-THEN, позволяя вам указать альтернативный набор операторов, которые должны выполняться, если условие не выполняется. (Обратите внимание, что это включает случай, когда условие оценивается как NULL).
Примеры:
IF parentid IS NULL OR parentid = ''
THEN
RETURN fullname;
ELSE
RETURN hp_true_filename(parentid) || '/' || fullname;
END IF;
IF v_count > 0 THEN
INSERT INTO users_count (count) VALUES (v_count);
RETURN 't';
ELSE
RETURN 'f';
END IF;
IF-THEN-ELSIF
IF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
...
]
]
[ ELSE
statements ]
END IF;
Иногда есть больше, чем просто две альтернативы. IF-THEN-ELSIF предоставляет удобный метод проверки нескольких альтернатив по очереди. Условия IF проверяются последовательно, пока не будет найдено первое истинное условие. Затем выполняются соответствующие операторы, после чего управление переходит к следующему оператору после END IF. (Любые последующие условия IF не проверяются). Если ни одно из условий IF выполняется, выполняется блок ELSE (если есть).
Вот пример:
IF number = 0 THEN
result := 'zero';
ELSIF number > 0 THEN
result := 'positive';
ELSIF number < 0 THEN
result := 'negative';
ELSE
-- hmm, the only other possibility is that number is null
result := 'NULL';
END IF;
Ключевое слово ELSIF также может быть написано как ELSEIF.
Альтернативный способ выполнения той же задачи - вложение операторов IF-THEN-ELSE, как в следующем примере:
IF demo_row.sex = 'm' THEN
pretty_sex := 'man';
ELSE
IF demo_row.sex = 'f' THEN
pretty_sex := 'woman';
END IF;
END IF;
Однако этот метод требует написания соответствующего END IF для каждого IF, поэтому он намного более громоздкий, чем использование ELSIF когда есть много альтернатив.
Простой CASE
CASE search-expression
WHEN expression [, expression [ ... ]] THEN
statements
[ WHEN expression [, expression [ ... ]] THEN
statements
... ]
[ ELSE
statements ]
END CASE;
Простая форма CASE обеспечивает условное выполнение, основанное на
равенстве операндов. search-expression оценивается (один раз) и
последовательно сравнивается с каждым expression в предложениях WHEN.
Если совпадение найдено, то соответствующие statements выполняются, а
затем управление переходит к следующему оператору после END CASE.
(Последующие выражения WHEN не оцениваются). Если совпадений не найдено,
выполняются операторы ELSE; но если ELSE нет, то возникает
исключение CASE_NOT_FOUND.
Простой пример:
CASE x
WHEN 1, 2 THEN
msg := 'one or two';
ELSE
msg := 'other value than one or two';
END CASE;
Поисковое выражение CASE
CASE
WHEN boolean-expression THEN
statements
[ WHEN boolean-expression THEN
statements
... ]
[ ELSE
statements ]
END CASE;
Поисковое выражение CASE обеспечивает условное выполнение, основанное на
истинности логических выражений. boolean-expression каждого предложения
WHEN вычисляется по очереди, пока не будет найдено одно, которое выдает
true. Затем выполняются соответствующие statements, а затем управление
переходит к следующему оператору после END CASE. (Последующие выражения
WHEN не оцениваются). Если истинный результат не найден, выполняются
statements в блоке ELSE ; но если ELSE нет, то возникает исключение
CASE_NOT_FOUND.
Пример:
CASE
WHEN x BETWEEN 0 AND 10 THEN
msg := 'value is between zero and ten';
WHEN x BETWEEN 11 AND 20 THEN
msg := 'value is between eleven and twenty';
END CASE;
Эта форма CASE полностью эквивалентна IF-THEN-ELSIF, за исключением правила, согласно которому достижение пропущенного предложения ELSE приводит к ошибке, а не к бездействию.
Простые циклы
С помощью операторов LOOP, EXIT, CONTINUE, WHILE, FOR и FOREACH вы можете настроить функцию PL/pgSQL на повторение ряда команд.
LOOP
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
LOOP определяет безусловный цикл, который повторяется бесконечно, пока
не будет завершен с помощью оператора EXIT или RETURN. Необязательная
label может использоваться операторами EXIT и CONTINUE во вложенных
циклах, чтобы указать, к какому циклу относятся эти операторы.
EXIT
EXIT [ label ] [ WHEN boolean-expression ];
Если label не указана, самый внутренний цикл завершается, а затем
выполняется оператор, следующий за END LOOP. Если указана label, это
должна быть метка текущего или некоторого внешнего уровня вложенного
цикла или блока. Затем именованный цикл или блок завершается, и
управление продолжается оператором после соответствующего END цикла /
блока.
Если указано WHEN, выход из цикла происходит только в том случае, если
boolean-expression имеет значение true. В противном случае управление
передается оператору после EXIT.
EXIT может использоваться со всеми типами циклов; он не ограничен использованием с безусловными циклами.
При использовании с блоком BEGIN, EXIT передает управление следующему оператору после конца блока. Обратите внимание, что для этой цели должна использоваться метка; немаркированный EXIT никогда не считается совпадающим с блоком BEGIN.
Примеры:
LOOP
-- some computations
IF count > 0 THEN
EXIT; -- exit loop
END IF;
END LOOP;
LOOP
-- some computations
EXIT WHEN count > 0; -- same result as previous example
END LOOP;
<<ablock>>
BEGIN
-- some computations
IF stocks > 100000 THEN
EXIT ablock; -- causes exit from the BEGIN block
END IF;
-- computations here will be skipped when stocks > 100000
END;
CONTINUE
CONTINUE [ label ] [ WHEN boolean-expression ];
Если label не указана, начинается следующая итерация самого внутреннего
цикла. То есть все операторы, оставшиеся в теле цикла, пропускаются, и
управление возвращается к выражению управления цикла (если оно есть),
чтобы определить, нужна ли еще одна итерация цикла. Если присутствует
label, она указывает метку цикла, выполнение которого будет продолжено.
Если указано WHEN, следующая итерация цикла начинается только в том
случае, если boolean-expression имеет значение true. В противном случае
управление переходит к оператору после CONTINUE.
CONTINUE можно использовать со всеми типами циклов; он не ограничен использованием с безусловными циклами.
Примеры:
LOOP
-- some computations
EXIT WHEN count > 100;
CONTINUE WHEN count < 50;
-- some computations for count IN [50 .. 100]
END LOOP;
WHILE
[ <<label>> ]
WHILE boolean-expression LOOP
statements
END LOOP [ label ];
Оператор WHILE повторяет последовательность операторов до тех пор, пока
boolean-expression оценивается как true. Выражение проверяется перед
каждой записью в теле цикла.
Например:
WHILE amount_owed > 0 AND gift_certificate_balance > 0 LOOP
-- some computations here
END LOOP;
WHILE NOT done LOOP
-- some computations here
END LOOP;
FOR (целочисленный вариант)
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
statements
END LOOP [ label ];
Эта форма FOR создает цикл, который перебирает диапазон целых значений.
Имя переменной автоматически определяется как тип integer и существует
только внутри цикла (любое существующее определение имени переменной
игнорируется в цикле). Два выражения, дающие нижнюю и верхнюю границы
диапазона, оцениваются один раз при входе в цикл. Если предложение BY не
указано, шаг итерации равен 1, в противном случае это значение,
указанное в предложении BY, которое снова оценивается один раз при
входе в цикл. Если указано REVERSE то значение шага вычитается, а не
добавляется после каждой итерации.
Некоторые примеры целочисленных циклов FOR :
FOR i IN 1..10 LOOP
-- i will take on the values 1,2,3,4,5,6,7,8,9,10 within the loop
END LOOP;
FOR i IN REVERSE 10..1 LOOP
-- i will take on the values 10,9,8,7,6,5,4,3,2,1 within the loop
END LOOP;
FOR i IN REVERSE 10..1 BY 2 LOOP
-- i will take on the values 10,8,6,4,2 within the loop
END LOOP;
Если нижняя граница больше, чем верхняя граница (или меньше, в случае REVERSE), тело цикла вообще не выполняется. Ошибка не возникает.
Если к циклу FOR прикреплена label то на целочисленную переменную цикла
можно ссылаться с помощью квалифицированного имени, используя эту label.
Цикл по результатам запроса
Используя цикл FOR другого типа, вы можете перебирать результаты запроса и соответствующим образом манипулировать этими данными. Синтаксис:
[ <<label>> ]
FOR target IN query LOOP
statements
END LOOP [ label ];
target - это переменная записи, переменная строки или разделенный запятыми список скалярных переменных. target назначается последовательно каждой строке, полученной в результате query и тело цикла выполняется для каждой строки.
Пример:
CREATE FUNCTION refresh_mviews() RETURNS integer AS $$
DECLARE
mviews RECORD;
BEGIN
RAISE NOTICE 'Refreshing all materialized views...';
FOR mviews IN
SELECT n.nspname AS mv_schema,
c.relname AS mv_name,
pg_catalog.pg_get_userbyid(c.relowner) AS owner
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON (n.oid = c.relnamespace)
WHERE c.relkind = 'm'
ORDER BY 1
LOOP
-- Now "mviews" has one record with information about the materialized view
RAISE NOTICE 'Refreshing materialized view %.% (owner: %)...',
quote_ident(mviews.mv_schema),
quote_ident(mviews.mv_name),
quote_ident(mviews.owner);
EXECUTE format('REFRESH MATERIALIZED VIEW %I.%I', mviews.mv_schema, mviews.mv_name);
END LOOP;
RAISE NOTICE 'Done refreshing materialized views.';
RETURN 1;
END;
$$ LANGUAGE plpgsql;
Если цикл завершается оператором EXIT, последнее назначенное значение строки все еще доступно после цикла.
Запрос, используемый в операторе FOR этого типа, может быть любой командой SQL, которая возвращает строки вызывающей стороне: SELECT является наиболее распространенным случаем, но вы также можете использовать INSERT, UPDATE или DELETE с предложением RETURNING. Некоторые служебные команды, такие как EXPLAIN, тоже будут работать.
Переменные PL/pgSQL подставляются в текст запроса, и план запроса кэшируется для возможного повторного использования, как подробно описано в разделе Подстановка переменных и разделе Планирование кеширования.
FOR-IN-EXECUTE - это еще один способ перебора строк:
[ <<label>> ]
FOR target IN EXECUTE text_expression [ USING expression [, ... ] ] LOOP
statements
END LOOP [ label ];
Это похоже на предыдущую форму, за исключением того, что исходный запрос указан как строковое выражение, которое оценивается и перепланируется для каждой записи в цикле FOR. Это позволяет программисту выбирать скорость заранее спланированного запроса или гибкость динамического запроса, как с простым оператором EXECUTE. Как и в случае EXECUTE, значения параметров могут быть вставлены в динамическую команду через USING.
Другой способ указать запрос, результаты которого должны быть повторены, объявить его как курсор. Это описано в разделе Цикл по результату курсора.
Цикл по массивам
Цикл FOREACH во многом похож на цикл FOR, но вместо итерации по строкам, возвращаемым запросом SQL, он выполняет итерацию по элементам значения массива. (Как правило, FOREACH предназначен для циклического прохождения по компонентам составного выражения; в будущем могут быть добавлены варианты циклического перемещения по композитам, кроме массивов). Оператор FOREACH для циклического перемещения по массиву:
[ <<label>> ]
FOREACH target [ SLICE number ] IN ARRAY expression LOOP
statements
END LOOP [ label ];
Без SLICE или, если SLICE 0, цикл перебирает отдельные элементы массива, созданного путем вычисления expression. target переменная назначается каждому значению элемента в последовательности, и тело цикла выполняется для каждого элемента. Вот пример зацикливания элементов целочисленного массива:
CREATE FUNCTION sum(int[]) RETURNS int8 AS $$
DECLARE
s int8 := 0;
x int;
BEGIN
FOREACH x IN ARRAY $1
LOOP
s := s + x;
END LOOP;
RETURN s;
END;
$$ LANGUAGE plpgsql;
Элементы посещаются в порядке хранения, независимо от количества измерений массива. Хотя target обычно является только одна переменная, она может быть списком переменных при циклическом просмотре массива составных значений (записей). В этом случае для каждого элемента массива переменные назначаются из последовательных столбцов составного значения.
При положительном значении FOREACH выполняет итерации по фрагментам массива, а не по отдельным элементам. Значение SLICE должно быть целочисленной константой, не превышающей количество измерений массива. target переменная должна быть массивом, и она получает последовательные срезы значения массива, где каждый срез имеет количество измерений, указанных в SLICE. Вот пример итерации по одномерным слайсам:
CREATE FUNCTION scan_rows(int[]) RETURNS void AS $$
DECLARE
x int[];
BEGIN
FOREACH x SLICE 1 IN ARRAY $1
LOOP
RAISE NOTICE 'row = %', x;
END LOOP;
END;
$$ LANGUAGE plpgsql;
SELECT scan_rows(ARRAY[[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
NOTICE: row = {1,2,3}
NOTICE: row = {4,5,6}
NOTICE: row = {7,8,9}
NOTICE: row = {10,11,12}
Ошибки захвата
По умолчанию любая ошибка, возникающая в функции PL/pgSQL, прерывает выполнение функции, а также окружающей транзакции. Вы можете перехватывать ошибки и восстанавливать их, используя блок BEGIN с предложением EXCEPTION. Синтаксис является расширением нормального синтаксиса для блока BEGIN :
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
EXCEPTION
WHEN condition [ OR condition ... ] THEN
handler_statements
[ WHEN condition [ OR condition ... ] THEN
handler_statements
... ]
END;
Если ошибки не возникает, эта форма блока просто выполняет все операторы statements, а затем управление переходит к следующему оператору после END. Но если в операторах возникает ошибка, дальнейшая обработка statements прекращается, и управление переходит в список EXCEPTION. В списке ищется первое условие condition соответствующее возникшей ошибке. Если совпадение найдено, выполняются соответствующие handler_statements, а затем управление переходит к следующему оператору после END. Если совпадение не найдено, ошибка распространяется так, как если бы предложение EXCEPTION вообще не было: ошибка может быть перехвачена включающим блоком с помощью EXCEPTION, или, если его нет, он прерывает обработку функции.
Имена condition могут быть любыми из указанных в Приложении A. Название категории соответствует любой ошибке в ее категории. Имя специального условия OTHERS соответствует каждому типу ошибки, кроме QUERY_CANCELED и ASSERT_FAILURE. (Можно, но часто неразумно, отлавливать эти два типа ошибок по имени). Имена условий не чувствительны к регистру. Кроме того, условие ошибки может быть указано кодом SQLSTATE; например это эквивалентно:
WHEN division_by_zero THEN ...
WHEN SQLSTATE '22012' THEN ...
Если в выбранном handler_statements возникает новая ошибка, она не может быть перехвачена этим предложением EXCEPTION, но может передаваться через среду. Окружающее предложение EXCEPTION может его поймать.
Когда в предложении EXCEPTION обнаружена ошибка, локальные переменные функции PL/pgSQL остаются такими же, какими они были при возникновении ошибки, но все изменения в постоянном состоянии базы данных в блоке откатываются. В качестве примера рассмотрим этот фрагмент:
INSERT INTO mytab(firstname, lastname) VALUES('Tom', 'Jones');
BEGIN
UPDATE mytab SET firstname = 'Joe' WHERE lastname = 'Jones';
x := x + 1;
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
RAISE NOTICE 'caught division_by_zero';
RETURN x;
END;
Когда элемент управления достигает назначения для y, он потерпит неудачу с ошибкой Division_by_zero. Это будет поймано предложением EXCEPTION. Значение, возвращаемое в операторе RETURN будет увеличенным значением x, но влияние команды UPDATE будет отменено. Однако команда INSERT предшествующая блоку, не откатывается, поэтому в результате база данных содержит Tom Jones, а не Joe Jones.
Заметка
Блок, содержащий предложение EXCEPTION, значительно дороже для входа и выхода, чем для блока без такового. Поэтому не используйте EXCEPTION без необходимости.
Пример 2. Исключения с UPDATE/INSERT
В этом примере используется обработка исключений для выполнения UPDATE или INSERT, в зависимости от ситуации. Рекомендуется, чтобы приложения использовали INSERT с ON CONFLICT DO UPDATE а не использовали этот шаблон. Этот пример служит главным образом для иллюстрации использования структур потока управления PL/pgSQL :
CREATE TABLE db (a INT PRIMARY KEY, b TEXT);
CREATE FUNCTION merge_db(key INT, data TEXT) RETURNS VOID AS
$$
BEGIN
LOOP
-- first try to update the key
UPDATE db SET b = data WHERE a = key;
IF found THEN
RETURN;
END IF;
-- not there, so try to insert the key
-- if someone else inserts the same key concurrently,
-- we could get a unique-key failure
BEGIN
INSERT INTO db(a,b) VALUES (key, data);
RETURN;
EXCEPTION WHEN unique_violation THEN
-- Do nothing, and loop to try the UPDATE again.
END;
END LOOP;
END;
$$
LANGUAGE plpgsql;
SELECT merge_db(1, 'david');
SELECT merge_db(1, 'dennis');
Это кодирование предполагает, что ошибка unique_violation вызвана INSERT, а не, скажем, INSERT в триггерной функции таблицы. Это может также привести к неправильной работе, если в таблице имеется более одного уникального индекса, поскольку он будет повторять операцию независимо от того, какой индекс вызвал ошибку. Больше безопасности можно было бы получить, используя функции, обсуждаемые далее, чтобы проверить, была ли ожидаемая ошибка в ловушке.
Получение информации об ошибке
Обработчикам исключений часто требуется идентифицировать конкретную возникшую ошибку. Есть два способа получить информацию о текущем исключении в PL/pgSQL: специальные переменные и команда GET STACKED DIAGNOSTICS.
В обработчике исключений специальная переменная SQLSTATE содержит код ошибки, соответствующий SQLSTATE исключению . Специальная переменная SQLERRM содержит сообщение об ошибке, связанной с исключением. Эти переменные не определены вне обработчиков исключений.
Внутри обработчика исключений можно также получить информацию о текущем исключении с помощью команды GET STACKED DIAGNOSTICS, которая имеет вид:
GET STACKED DIAGNOSTICS variable { = | := } item [, ... ];
Каждый item является ключевым словом, идентифицирующим значение состояния, которое должно быть назначено указанной variable (которое должно иметь правильный тип данных для его получения). Доступные в настоящее время элементы состояния показаны в таблице 2.
Таблица 2. Элементы диагностики ошибок
| Имя | Тип | Описание |
|---|---|---|
| RETURNED_SQLSTATE | text | код ошибки SQLSTATE исключения |
| COLUMN_NAME | text | имя столбца, связанного с исключением |
| CONSTRAINT_NAME | text | имя ограничения, связанного с исключением |
| PG_DATATYPE_NAME | text | имя типа данных, связанного с исключением |
| MESSAGE_TEXT | text | текст основного сообщения об исключении |
| TABLE_NAME | text | имя таблицы, связанной с исключением |
| SCHEMA_NAME | text | имя схемы, связанной с исключением |
| PG_EXCEPTION_DETAIL | text | текст подробного сообщения об исключении, если оно есть |
| PG_EXCEPTION_HINT | text | текст сообщения с подсказкой исключения, если таковое имеется |
| PG_EXCEPTION_CONTEXT | text | строка (и) текста, описывающего стек вызовов во время исключения (см. раздел Получение информации о месте выполнения) |
Если исключение не установило значение для элемента, будет возвращена пустая строка.
Вот пример:
DECLARE
text_var1 text;
text_var2 text;
text_var3 text;
BEGIN
-- some processing which might cause an exception
...
EXCEPTION WHEN OTHERS THEN
GET STACKED DIAGNOSTICS text_var1 = MESSAGE_TEXT,
text_var2 = PG_EXCEPTION_DETAIL,
text_var3 = PG_EXCEPTION_HINT;
END;
Получение информации о месте выполнения
Команда GET DIAGNOSTICS, ранее описанная в разделе Получение статуса результата, извлекает информацию о текущем состоянии выполнения (в то время как команда GET STACKED DIAGNOSTICS рассмотренная выше, сообщает информацию о состоянии выполнения на момент предыдущей ошибки). Его элемент состояния PG_CONTEXT полезен для определения текущего местоположения выполнения. PG_CONTEXT возвращает текстовую строку со строками (строками), описывающими стек вызовов. Первая строка ссылается на текущую функцию и текущую команду GET DIAGNOSTICS. Вторая и любые последующие строки относятся к вызывающим функциям дальше по стеку вызовов. Например:
CREATE OR REPLACE FUNCTION outer_func() RETURNS integer AS $$
BEGIN
RETURN inner_func();
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION inner_func() RETURNS integer AS $$
DECLARE
stack text;
BEGIN
GET DIAGNOSTICS stack = PG_CONTEXT;
RAISE NOTICE E'--- Call Stack ---\n%', stack;
RETURN 1;
END;
$$ LANGUAGE plpgsql;
SELECT outer_func();
NOTICE: --- Call Stack ---
PL/pgSQL function inner_func() line 5 at GET DIAGNOSTICS
PL/pgSQL function outer_func() line 3 at RETURN
CONTEXT: PL/pgSQL function outer_func() line 3 at RETURN
outer_func
------------
1
(1 row)
GET STACKED DIAGNOSTICS ... PG_EXCEPTION_CONTEXT возвращает тот же вид трассировки стека, но описывает местоположение, в котором была обнаружена ошибка, а не текущее местоположение.
Курсоры
Вместо одновременного выполнения всего запроса можно установить курсор, который инкапсулирует запрос, и затем прочитать результат запроса по несколько строк за раз. Одна из причин этого состоит в том, чтобы избежать переполнения памяти, когда результат содержит большое количество строк. (Однако пользователям PL/pgSQL обычно не нужно беспокоиться об этом, поскольку циклы FOR автоматически используют курсор внутри, чтобы избежать проблем с памятью). Более интересным является возвращение ссылки на курсор, созданный функцией, что позволяет звонящий, чтобы прочитать строки. Это обеспечивает эффективный способ возврата больших наборов строк из функций.
Объявление переменных курсора
Весь доступ к курсорам в PL/pgSQL осуществляется через переменные курсора, которые всегда имеют специальный тип данных refcursor. Один из способов создать курсорную переменную - просто объявить ее как переменную типа refcursor. Другой способ - использовать синтаксис объявления курсора, который в общем случае:
name [ [ NO ] SCROLL ] CURSOR [ ( arguments ) ] FOR query;
(FOR может быть заменен на IS для совместимости с Oracle). Если указан SCROLL, курсор будет способен прокручиваться назад; если не указан NO SCROLL, обратные выборки будут отклонены; если ни одна из спецификаций не появляется, это зависит от запроса, будут ли разрешены обратные выборки. arguments, если указан, представляет собой разделенный запятыми список типов name datatype пар, которые определяют имена, которые должны быть заменены значениями параметров в данном запросе. Фактические значения для замены этих имен будут указаны позже, когда курсор будет открыт.
Несколько примеров:
DECLARE
curs1 refcursor;
curs2 CURSOR FOR SELECT * FROM tenk1;
curs3 CURSOR (key integer) FOR SELECT * FROM tenk1 WHERE unique1 = key;
Все три из этих переменных имеют тип данных refcursor, но первая может использоваться с любым запросом, в то время как вторая имеет полностью определенный запрос, уже связанный с ним, а последняя имеет параметризованный запрос, связанный с ним. ( key будет заменен целочисленным значением параметра при открытии курсора). Переменная curs1 называется несвязанной, поскольку она не связана ни с каким конкретным запросом.
Открытие курсоров
Прежде чем курсор можно использовать для извлечения строк, его необходимо открыть. (Это действие эквивалентно команде SQL DECLARE CURSOR). PL/pgSQL имеет три формы оператора OPEN, две из которых используют несвязанные переменные курсора, а третья использует связанную переменную курсора.
Заметка
Переменные связанного курсора также можно использовать без явного открытия курсора с помощью оператора FOR описанного в разделе Цикл по результату курсора.
OPEN FOR query
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR query;
Переменная курсора открывается и получает заданный запрос для выполнения. Курсор уже нельзя открыть, и он должен быть объявлен как несвязанная переменная курсора (то есть как простая переменная refcursor ). Запрос должен быть SELECT или чем-то еще, что возвращает строки (например, EXPLAIN ). Запрос обрабатывается так же, как и другие команды SQL в PL/pgSQL : имена переменных PL/pgSQL заменяются, и план запроса кэшируется для возможного повторного использования. Когда переменная PL/pgSQL подставляется в запрос курсора, подставляется значение, которое она имеет во время OPEN ; Последующие изменения в переменной не влияют на поведение курсора. Параметры SCROLL и NO SCROLL имеют те же значения, что и для привязанного курсора.
Пример:
OPEN curs1 FOR SELECT * FROM foo WHERE key = mykey;
OPEN FOR EXECUTE
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR EXECUTE query_string
[ USING expression [, ... ] ];
Переменная курсора открывается и получает заданный запрос для выполнения. Курсор уже нельзя открыть, и он должен быть объявлен как несвязанная переменная курсора (то есть как простая переменная refcursor ). Запрос указывается как строковое выражение, так же, как в команде EXECUTE. Как обычно, это обеспечивает гибкость, поэтому план запроса может варьироваться от одного прогона к следующему (см. раздел Планирование кеширования ), а также означает, что в командной строке не производится подстановка переменных. Как и в случае EXECUTE, значения параметров могут быть вставлены в динамическую команду через format() и USING. Параметры SCROLL и NO SCROLL имеют те же значения, что и для привязанного курсора.
Пример:
OPEN curs1 FOR EXECUTE format('SELECT * FROM %I WHERE col1 = $1',tabname) USING keyvalue;
В этом примере имя таблицы вставляется в запрос через format(). Значение сравнения для col1 вставляется через параметр USING, поэтому не нужно col1.
Открытие связанного курсора
OPEN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ];
Эта форма OPEN используется для открытия переменной курсора, запрос которой был связан с ней, когда она была объявлена. Курсор уже не может быть открыт. Список фактических выражений значений аргументов должен появляться тогда и только тогда, когда указывалось, что курсор принимает аргументы. Эти значения будут подставлены в запрос.
План запроса для привязанного курсора всегда считается кэшируемым; в этом случае нет эквивалента EXECUTE. Обратите внимание, что SCROLL и NO SCROLL не могут быть указаны в OPEN, поскольку поведение прокрутки курсора уже было определено.
Значения аргумента могут быть переданы с использованием позиционной или именованной нотации. В позиционной нотации все аргументы указываются по порядку. В именованной нотации имя каждого аргумента указывается с помощью := чтобы отделить его от выражения аргумента. Как и в случае вызова функций, описанных в разделе Вызов функции, также допускается смешивание позиционной и именованной нотации.
Примеры (они используют примеры объявления курсора выше):
OPEN curs2;
OPEN curs3(42);
OPEN curs3(key := 42);
Поскольку подстановка переменных выполняется в запросе связанного курсора, на самом деле существует два способа передачи значений в курсор: либо с явным аргументом OPEN, либо неявным образом путем ссылки на переменную PL/pgSQL в запросе. Однако в него будут подставлены только переменные, объявленные до объявления ограниченного курсора. В любом случае передаваемое значение определяется во время OPEN. Например, другой способ получить тот же эффект, что и в приведенном выше примере с curs3 :
DECLARE
key integer;
curs4 CURSOR FOR SELECT * FROM tenk1 WHERE unique1 = key;
BEGIN
key := 42;
OPEN curs4;
Использование курсоров
Когда курсор открыт, им можно манипулировать с помощью описанных здесь операторов.
Эти манипуляции не обязательно должны выполняться в той же функции, которая открывала курсор для начала. Вы можете вернуть значение refcursor из функции и позволить вызывающей стороне воздействовать на курсор. (Внутренне значение refcursor - это просто строковое имя так называемого портала, содержащего активный запрос для курсора. Это имя можно передавать, присваивать другим переменным refcursor и т. д., Не нарушая портал).
Все порталы неявно закрываются в конце транзакции. Поэтому значение refcursor можно использовать для ссылки на открытый курсор только до конца транзакции.
FETCH
FETCH [ direction { FROM | IN } ] cursor INTO target;
FETCH извлекает следующую строку из курсора в цель, которая может быть переменной строки, переменной записи или списком простых переменных, разделенных запятыми, подобно SELECT INTO. Если следующей строки нет, для цели устанавливается значение NULL. Как и в случае SELECT INTO, специальная переменная FOUND может быть проверена, чтобы увидеть, была ли получена строка или нет.
Предложение direction может быть любым из вариантов, разрешенных в команде SQL FETCH, кроме тех, которые могут извлекать более одной строки; а именно, это может быть NEXT, PRIOR, FIRST, LAST, ABSOLUTE count, RELATIVE count, FORWARD или BACKWARD. direction пропуска совпадает с указанием NEXT. В формах, использующих count, count может быть любым целочисленным выражением (в отличие от команды SQL FETCH, которая допускает только целочисленную константу). Значения direction которые требуют перемещения назад, могут потерпеть неудачу, если курсор не был объявлен или открыт с помощью опции SCROLL.
cursor должен быть именем переменной refcursor которая ссылается на портал открытого курсора.
Примеры:
FETCH curs1 INTO rowvar;
FETCH curs2 INTO foo, bar, baz;
FETCH LAST FROM curs3 INTO x, y;
FETCH RELATIVE -2 FROM curs4 INTO x;
MOVE
MOVE [ direction { FROM | IN } ] cursor;
MOVE перемещает курсор без получения каких-либо данных. MOVE работает точно так же, как команда FETCH, за исключением того, что он только перемещает курсор и не возвращает перемещенную строку. Как и в случае SELECT INTO, специальная переменная FOUND может быть проверена, чтобы увидеть, была ли следующая строка для перемещения.
Примеры:
MOVE curs1;
MOVE LAST FROM curs3;
MOVE RELATIVE -2 FROM curs4;
MOVE FORWARD 2 FROM curs4;
UPDATE/DELETE WHERE CURRENT OF
UPDATE table SET ... WHERE CURRENT OF cursor;
DELETE FROM table WHERE CURRENT OF cursor;
Когда курсор расположен в строке таблицы, эту строку можно обновить или удалить, используя курсор для идентификации строки. Существуют ограничения на то, каким может быть запрос курсора (в частности, нет группировки), и лучше всего использовать FOR UPDATE в курсоре. Для получения дополнительной информации см. Справочную страницу DECLARE.
Пример:
UPDATE foo SET dataval = myval WHERE CURRENT OF curs1;
CLOSE
CLOSE cursor;
CLOSE закрывает портал под открытым курсором. Это может быть использовано для освобождения ресурсов раньше, чем конец транзакции, или для освобождения переменной курсора, которая будет открыта снова.
Пример:
CLOSE curs1;
Возврат курсора
Функции PL/pgSQL могут возвращать курсоры вызывающей стороне. Это полезно для возврата нескольких строк или столбцов, особенно с очень большими результирующими наборами. Для этого функция открывает курсор и возвращает имя курсора вызывающей стороне (или просто открывает курсор, используя имя портала, указанное или иным образом известное вызывающей стороне). Затем вызывающая сторона может извлечь строки из курсора. Курсор может быть закрыт вызывающим абонентом, или он будет закрыт автоматически при закрытии транзакции.
Имя портала, используемое для курсора, может быть указано программистом или сгенерировано автоматически. Чтобы указать имя портала, просто присвойте строку переменной refcursor перед ее открытием. Строковое значение переменной refcursor будет использоваться OPEN в качестве имени базового портала. Однако, если переменная refcursor имеет значение null, OPEN автоматически генерирует имя, которое не конфликтует с каким-либо существующим порталом, и присваивает его переменной refcursor.
Заметка
Связанная переменная курсора инициализируется строковым значением, представляющим его имя, так что имя портала совпадает с именем переменной курсора, если только программист не переопределит его присваиванием перед открытием курсора. Но несвязанная переменная курсора по умолчанию изначально имеет нулевое значение, поэтому она получит автоматически сгенерированное уникальное имя, если оно не будет переопределено.
В следующем примере показан один из способов, которым вызывающее лицо может предоставить имя курсора:
CREATE TABLE test (col text);
INSERT INTO test VALUES ('123');
CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
BEGIN
OPEN $1 FOR SELECT col FROM test;
RETURN $1;
END;
' LANGUAGE plpgsql;
BEGIN;
SELECT reffunc('funccursor');
FETCH ALL IN funccursor;
COMMIT;
В следующем примере используется автоматическая генерация имени курсора:
CREATE FUNCTION reffunc2() RETURNS refcursor AS '
DECLARE
ref refcursor;
BEGIN
OPEN ref FOR SELECT col FROM test;
RETURN ref;
END;
' LANGUAGE plpgsql;
-- need to be in a transaction to use cursors.
BEGIN;
SELECT reffunc2();
reffunc2
--------------------
<unnamed cursor 1>
(1 row)
FETCH ALL IN "<unnamed cursor 1>";
COMMIT;
В следующем примере показан один способ вернуть несколько курсоров из одной функции:
CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
BEGIN
OPEN $1 FOR SELECT * FROM table_1;
RETURN NEXT $1;
OPEN $2 FOR SELECT * FROM table_2;
RETURN NEXT $2;
END;
$$ LANGUAGE plpgsql;
-- need to be in a transaction to use cursors.
BEGIN;
SELECT * FROM myfunc('a', 'b');
FETCH ALL FROM a;
FETCH ALL FROM b;
COMMIT;
Цикл по результату курсора
Существует вариант оператора FOR который позволяет перебирать строки, возвращаемые курсором. Синтаксис:
[ <<label>> ]
FOR recordvar IN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ] LOOP
statements
END LOOP [ label ];
Переменная курсора должна быть привязана к какому-либо запросу, когда она была объявлена, и ее уже нельзя открыть. Оператор FOR автоматически открывает курсор и снова закрывает курсор при выходе из цикла. Список фактических выражений значений аргументов должен появляться тогда и только тогда, когда указывалось, что курсор принимает аргументы. Эти значения будут подставлены в запросе точно так же, как во время OPEN (см. раздел Открытие связанного курсора).
Переменная recordvar автоматически определяется как тип record и существует только внутри цикла (любое существующее определение имени переменной игнорируется в цикле). Каждая строка, возвращаемая курсором, последовательно присваивается этой переменной записи, и выполняется тело цикла.
Управление транзакциями
В процедурах, вызываемых командой CALL, а также в блоках анонимного кода (команда DO ), можно завершать транзакции с помощью команд COMMIT и ROLLBACK. Новая транзакция запускается автоматически после завершения транзакции с использованием этих команд, поэтому отдельной команды START TRANSACTION нет. (Обратите внимание, что BEGIN и END имеют разные значения в PL/pgSQL).
Простой пример:
CREATE PROCEDURE transaction_test1()
LANGUAGE plpgsql
AS $$
BEGIN
FOR i IN 0..9 LOOP
INSERT INTO test1 (a) VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
END
$$;
CALL transaction_test1();
Новая транзакция начинается с характеристик транзакции по умолчанию, таких как уровень изоляции транзакции. В случаях, когда транзакции фиксируются в цикле, может быть желательно автоматически начинать новые транзакции с теми же характеристиками, что и предыдущая. Команды COMMIT AND CHAIN и ROLLBACK AND CHAIN выполняют это.
Управление транзакциями возможно только в CALL или DO из верхнего уровня
или во вложенных CALL или DO без какой-либо другой промежуточной
команды. Например, если стеком вызовов является
CALL proc1() → CALL proc2() → CALL proc3(), то вторая и третья процедуры могут выполнять
действия по управлению транзакциями. Но если стеком вызовов является
CALL proc1() → SELECT func2() → CALL proc3(), то последняя процедура не
может осуществлять управление транзакциями из-за промежуточного SELECT.
Особые соображения применимы к циклам курсора. Рассмотрим этот пример:
CREATE PROCEDURE transaction_test2()
LANGUAGE plpgsql
AS $$
DECLARE
r RECORD;
BEGIN
FOR r IN SELECT * FROM test2 ORDER BY x LOOP
INSERT INTO test1 (a) VALUES (r.x);
COMMIT;
END LOOP;
END;
$$;
CALL transaction_test2();
Обычно курсоры автоматически закрываются при фиксации транзакции. Однако курсор, созданный как часть цикла, подобного этому, автоматически преобразуется в удерживаемый курсор с помощью первого COMMIT или ROLLBACK. Это означает, что курсор полностью вычисляется в первом COMMIT или ROLLBACK а не по строкам. Курсор по-прежнему автоматически удаляется после цикла, поэтому он в большинстве случаев невидим для пользователя.
Команды транзакции не допускаются в циклах курсора, управляемых командами, которые не предназначены только для чтения (например, UPDATE ... RETURNING).
Транзакция не может быть завершена внутри блока с обработчиками исключений.
Ошибки и сообщения
Вывод ошибок и сообщений
Используйте оператор RAISE чтобы выводить расширенные сообщения и обрабатывать ошибки.
RAISE [ level ] 'format' [, expression [, ... ]] [ USING option = expression [, ... ] ];
RAISE [ level ] condition_name [ USING option = expression [, ... ] ];
RAISE [ level ] SQLSTATE 'sqlstate' [ USING option = expression [, ... ] ];
RAISE [ level ] USING option = expression [, ... ];
RAISE ;
Параметр level указывает серьезность ошибки. Допустимые уровни: DEBUG, LOG, INFO, NOTICE, WARNING и EXCEPTION, по умолчанию используется EXCEPTION. EXCEPTION вызывает ошибку (которая обычно прерывает текущую транзакцию); другие уровни генерируют только сообщения с различными уровнями приоритета. Независимо от того, передаются ли сообщения определенного приоритета клиенту, записываются ли они в журнал сервера, или и то, и другое контролируются переменными конфигурации log_min_messages и client_min_messages. См. главу Конфигурация сервера для получения дополнительной информации.
После level если он есть, вы можете написать format (который должен быть простым строковым литералом, а не выражением). Строка формата определяет текст сообщения об ошибке, о которой будет сообщено. За форматной строкой могут следовать необязательные выражения аргумента, которые будут вставлены в сообщение. Внутри строки формата % заменяется строковым представлением значения следующего необязательного аргумента. Напишите %% чтобы получить буквальный %. Количество аргументов должно соответствовать количеству % заполнителей в строке формата, иначе при компиляции функции возникает ошибка.
В этом примере значение v_job_id заменит % в строке:
RAISE NOTICE 'Calling cs_create_job(%)', v_job_id;
Вы можете прикрепить дополнительную информацию к отчету об ошибке, написав USING а затем option = expression items. Каждое expression может быть любым строковым выражением. Допустимые ключевые слова option:
| Option | |
|---|---|
| MESSAGE | Устанавливает текст сообщения об ошибке. Эта опция не может использоваться в форме RAISE которая включает строку формата перед USING. |
| DETAIL | Предоставляет подробное сообщение об ошибке. |
| HINT | Предоставляет подсказку. |
| ERRCODE | Указывает код ошибки (SQLSTATE) для отчета либо по имени условия, как показано в Приложении A], либо непосредственно в виде пятизначного кода SQLSTATE. |
| COLUMN CONSTRAINT DATATYPE TABLE SCHEMA | Предоставляют имя связанного объекта. |
Этот пример прервет транзакцию с данным сообщением об ошибке и подсказкой:
RAISE EXCEPTION 'Nonexistent ID --> %', user_id
USING HINT = 'Please check your user ID';
Эти два примера показывают эквивалентные способы установки SQLSTATE:
RAISE 'Duplicate user ID: %', user_id USING ERRCODE = 'unique_violation';
RAISE 'Duplicate user ID: %', user_id USING ERRCODE = '23505';
Существует второй синтаксис RAISE в котором основным аргументом является имя условия или SQLSTATE, о котором необходимо сообщить, например:
RAISE division_by_zero;
RAISE SQLSTATE '22012';
В этом синтаксисе USING может использоваться для предоставления пользовательского сообщения об ошибке, детализации или подсказки. Другой способ сделать предыдущий пример
RAISE unique_violation USING MESSAGE = 'Duplicate user ID: ' || user_id;
Еще один вариант - написать RAISE USING или RAISE level USING и поместить все остальное в список USING.
Последний вариант RAISE не имеет параметров вообще. Эта форма может использоваться только внутри предложения EXCEPTION блока BEGIN; это приводит к тому, что ошибка, обрабатываемая в данный момент, будет переброшена.
Заметка
До PostgreSQL 9.1 RAISE без параметров интерпретировалось как повторное генерирование ошибки из блока, содержащего активный обработчик исключений. Таким образом, предложение EXCEPTION, вложенное в этот обработчик, не может его перехватить, даже если RAISE находится в блоке вложенного предложения EXCEPTION. Это было сочтено удивительным, а также несовместимым с Oracle PL/SQL.
Если ни имя условия, ни SQLSTATE не указаны в команде RAISE EXCEPTION, по умолчанию используется ERRCODE_RAISE_EXCEPTION ( P0001 ). Если текст сообщения не указан, по умолчанию используется имя условия или SQLSTATE в качестве текста сообщения.
Заметка
При указании кода ошибки с помощью кода SQLSTATE вы не ограничены предварительно определенными кодами ошибок, но можете выбрать любой код ошибки, состоящий из пяти цифр и / или букв ASCII в верхнем регистре, кроме 00000. Рекомендуется избегать выдачи кодов ошибок, которые заканчиваются тремя нулями, потому что это коды категорий, которые могут быть захвачены только путем захвата всей категории.
Проверка утверждений
Оператор ASSERT является удобным сокращением для вставки проверок отладки в функции PL/pgSQL.
ASSERT condition [, message ];
condition является логическим выражением, которое, как ожидается, всегда будет иметь значение true; если это так, оператор ASSERT больше ничего не делает. Если результатом является ложь или ASSERT_FAILURE, то возникает исключение ASSERT_FAILURE. (Если ошибка возникает при оценке condition, она сообщается как нормальная ошибка).
Если предоставляется необязательное message, это выражение, результат которого (если не нулевой) заменяет текст сообщения об ошибке по умолчанию «утверждение не выполнено», если condition не выполнено. Выражение message не оценивается в обычном случае, когда утверждение успешно выполняется.
Тестирование утверждений можно включить или отключить с помощью параметра конфигурации plpgsql.check_asserts, который принимает логическое значение; по умолчанию включено. Если этот параметр off то операторы ASSERT ничего не делают.
Обратите внимание, что ASSERT предназначен для обнаружения программных ошибок, а не для сообщения об обычных ошибках. Для этого используйте оператор RAISE, описанный выше.
Триггерные функции
PL/pgSQL может использоваться для определения триггерных функций при
изменении данных или событий базы данных. Триггерная функция создается с
помощью команды CREATE FUNCTION, объявляющей ее как функцию без
аргументов и возвращаемого типа trigger (для триггеров изменения данных)
или event_trigger (для триггеров событий базы данных). Специальные
локальные переменные с именем *TG_
Триггеры при изменении данных
Триггер изменения данных объявляется как функция без аргументов и возвращаемого типа trigger. Обратите внимание, что функция должна быть объявлена без аргументов, даже если она ожидает получить некоторые аргументы, указанные в CREATE TRIGGER - такие аргументы передаются через TG_ARGV, как описано ниже.
Когда в качестве триггера вызывается функция PL/pgSQL, в блоке верхнего уровня автоматически создаются несколько специальных переменных. Вот они:
| Переменная | |
|---|---|
| NEW | Тип данных RECORD; переменная, содержащая новую строку базы данных для операций INSERT/UPDATE в триггерах уровня строки. Эта переменная равна нулю в триггерах уровня оператора и для операций DELETE. |
| OLD | Тип данных RECORD; переменная, содержащая старую строку базы данных для операций UPDATE / DELETE в триггерах уровня строки. Эта переменная равна нулю в триггерах уровня оператора и для операций INSERT. |
| NEW | Тип данных RECORD; переменная, содержащая новую строку базы данных для операций INSERT/UPDATE в триггерах уровня строки. Эта переменная равна нулю в триггерах уровня оператора и для операций DELETE. |
| OLD | Тип данных RECORD; переменная, содержащая старую строку базы данных для операций UPDATE / DELETE в триггерах уровня строки. Эта переменная равна нулю в триггерах уровня оператора и для операций INSERT. |
| TG_NAME | Тип данных name; переменная, которая содержит имя фактически сработавшего триггера. |
| TG_WHEN | Тип данных text; строка BEFORE, AFTER или INSTEAD OF, в зависимости от определения триггера. |
| TG_LEVEL | Тип данных text; строка ROW или STATEMENT зависимости от определения триггера. |
| TG_OP | Тип данных text; строка INSERT, UPDATE, DELETE или TRUNCATE указывающая, для какой операции сработал триггер. |
| TG_RELID | Тип данных oid; идентификатор объекта таблицы, вызвавшей вызов триггера. |
| TG_RELNAME | Тип данных name; имя таблицы, вызвавшей вызов триггера. Теперь это устарело и может исчезнуть в будущем выпуске. TG_TABLE_NAME этого используйте TG_TABLE_NAME. |
| TG_TABLE_NAME | Тип данных name; имя таблицы, вызвавшей вызов триггера. |
| TG_TABLE_SCHEMA | Тип данных name; имя схемы таблицы, вызвавшей вызов триггера./dd> |
| TG_NARGS | Тип данных integer; количество аргументов, переданных функции триггера в операторе CREATE TRIGGER. |
| TG_ARGV[] | Тип данных массив text; аргументы из оператора CREATE TRIGGER. Индекс отсчитывает от 0. Недопустимые индексы (меньше 0 или больше или равны tg_nargs) приводят к нулевому значению. |
Функция триггера должна возвращать либо NULL либо значение записи/строки, имеющее точно структуру таблицы, для которой был запущен триггер.
Триггеры уровня строки срабатывают до того, как они могут вернуть ноль, чтобы сигнализировать диспетчеру триггеров пропустить оставшуюся часть операции для этой строки (т.е. последующие триггеры не запускаются, и INSERT/UPDATE/DELETE для этой строки не происходит). Если возвращается ненулевое значение, то операция продолжается с этим значением строки. Возвращение значения строки, отличного от исходного значения NEW изменяет строку, которая будет вставлена или обновлена. Таким образом, если триггерная функция хочет, чтобы инициирующее действие успешно выполнялось без изменения значения строки, необходимо вернуть NEW (или равное ему значение). Чтобы изменить строку, подлежащую сохранению, можно заменить отдельные значения непосредственно в NEW и вернуть измененный NEW, или создать полную новую запись / строку для возврата. В случае до-триггера на DELETE, возвращаемое значение не имеет прямого эффекта, но оно должно быть ненулевым, чтобы позволить действию триггера продолжаться. Обратите внимание, что NEW является нулем в триггерах DELETE, поэтому возвращать его обычно не имеет смысла. Обычная идиома в триггерах DELETE - возвращать OLD.
INSTEAD OF (которые всегда являются триггерами уровня строки и могут использоваться только в представлениях) могут возвращать ноль, чтобы указать, что они не выполняли никаких обновлений и что оставшаяся часть операции для этой строки должна быть пропущена (т.е. последующие триггеры не срабатывают, и строка не учитывается в состоянии, затронутом строками для окружающего INSERT/UPDATE/DELETE). В противном случае должно быть возвращено ненулевое значение, чтобы сигнализировать, что триггер выполнил запрошенную операцию. Для операций INSERT и UPDATE возвращаемое значение должно быть NEW, которое триггерная функция может изменить для поддержки INSERT RETURNING и UPDATE RETURNING (это также повлияет на значение строки, передаваемое любым последующим триггерам или передаваемое в специальную ссылку EXCLUDED alias в пределах Оператор INSERT с предложением ON CONFLICT DO UPDATE). Для операций DELETE возвращаемое значение должно быть OLD.
Возвращаемое значение срабатывания триггера уровня строки AFTER или триггера уровня оператора BEFORE или AFTER всегда игнорируется; это также может быть нулевым. Однако любой из этих типов триггеров может все же прервать всю операцию, вызвав ошибку.
Пример 3 показывает вариант функции триггера в PL/pgSQL.
Пример 3. Функция запуска PL/pgSQL
Этот пример триггера гарантирует, что каждый раз, когда строка вставляется или обновляется в таблице, текущее имя пользователя и время указываются в строке. И это проверяет, что имя сотрудника дано и что заработная плата является положительным значением.
CREATE TABLE emp (
empname text,
salary integer,
last_date timestamp,
last_user text
);
CREATE FUNCTION emp_stamp() RETURNS trigger AS $emp_stamp$
BEGIN
-- Check that empname and salary are given
IF NEW.empname IS NULL THEN
RAISE EXCEPTION 'empname cannot be null';
END IF;
IF NEW.salary IS NULL THEN
RAISE EXCEPTION '% cannot have null salary', NEW.empname;
END IF;
-- Who works for us when they must pay for it?
IF NEW.salary < 0 THEN
RAISE EXCEPTION '% cannot have a negative salary', NEW.empname;
END IF;
-- Remember who changed the payroll when
NEW.last_date := current_timestamp;
NEW.last_user := current_user;
RETURN NEW;
END;
$emp_stamp$ LANGUAGE plpgsql;
CREATE TRIGGER emp_stamp BEFORE INSERT OR UPDATE ON emp
FOR EACH ROW EXECUTE FUNCTION emp_stamp();
Другой способ регистрации изменений в таблице заключается в создании новой таблицы, содержащей строку для каждой происходящей вставки, обновления или удаления. Этот подход можно рассматривать как аудит изменений в таблице. Пример 4 показывает вариант функции запуска аудита в PL/pgSQL.
Пример 4. Функция запуска PL/pgSQL для аудита
Этот пример триггера гарантирует, что любая вставка, обновление или удаление строки в таблице emp записано (т.е. проверено) в таблице emp_audit. Текущее время и имя пользователя указываются в строке вместе с типом выполняемой над ней операции.
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- Create a row in emp_audit to reflect the operation performed on emp,
-- making use of the special variable TG_OP to work out the operation.
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit SELECT 'D', now(), user, OLD.*;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit SELECT 'U', now(), user, NEW.*;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit SELECT 'I', now(), user, NEW.*;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$emp_audit$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit
AFTER INSERT OR UPDATE OR DELETE ON emp
FOR EACH ROW EXECUTE FUNCTION process_emp_audit();
Вариант предыдущего примера использует представление, соединяющее основную таблицу с таблицей аудита, чтобы показать, когда каждая запись последний раз изменялась. Этот подход по-прежнему регистрирует полный контрольный журнал изменений таблицы, но также представляет упрощенное представление контрольного журнала, показывая только последнюю измененную временную метку, полученную из контрольного журнала для каждой записи. Пример 5 показывает вариант триггера аудита для представления в PL/pgSQL.
Пример 5. Функция запуска PL/pgSQL View для аудита
В этом примере используется триггер в представлении, чтобы сделать его обновляемым и убедиться, что любая вставка, обновление или удаление строки в представлении записано (т.е. проверено) в таблице emp_audit. Текущее время и имя пользователя записываются вместе с типом выполненной операции, и представление отображает время последнего изменения каждой строки.
CREATE TABLE emp (
empname text PRIMARY KEY,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer,
stamp timestamp NOT NULL
);
CREATE VIEW emp_view AS
SELECT e.empname,
e.salary,
max(ea.stamp) AS last_updated
FROM emp e
LEFT JOIN emp_audit ea ON ea.empname = e.empname
GROUP BY 1, 2;
CREATE OR REPLACE FUNCTION update_emp_view() RETURNS TRIGGER AS $$
BEGIN
--
-- Perform the required operation on emp, and create a row in emp_audit
-- to reflect the change made to emp.
--
IF (TG_OP = 'DELETE') THEN
DELETE FROM emp WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
OLD.last_updated = now();
INSERT INTO emp_audit VALUES('D', user, OLD.*);
RETURN OLD;
ELSIF (TG_OP = 'UPDATE') THEN
UPDATE emp SET salary = NEW.salary WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('U', user, NEW.*);
RETURN NEW;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp VALUES(NEW.empname, NEW.salary);
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('I', user, NEW.*);
RETURN NEW;
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit
INSTEAD OF INSERT OR UPDATE OR DELETE ON emp_view
FOR EACH ROW EXECUTE FUNCTION update_emp_view();
Одним из применений триггеров является ведение сводной таблицы другой таблицы. Результирующая сводка может использоваться вместо исходной таблицы для определенных запросов - часто с значительно сокращенным временем выполнения. Этот метод обычно используется в хранилищах данных, где таблицы измеренных или наблюдаемых данных (так называемые таблицы фактов) могут быть чрезвычайно большими. В примере 6 показан вариант функции триггера в PL/pgSQL, которая поддерживает сводную таблицу для таблицы фактов в хранилище данных.
Пример 6. Функция запуска PL/pgSQL для ведения сводной таблицы
Схема, подробно описанная здесь, частично основана на примере магазина продуктов из набора инструментов хранилища данных Ральфа Кимбалла.
--
-- Main tables - time dimension and sales fact.
--
CREATE TABLE time_dimension (
time_key integer NOT NULL,
day_of_week integer NOT NULL,
day_of_month integer NOT NULL,
month integer NOT NULL,
quarter integer NOT NULL,
year integer NOT NULL
);
CREATE UNIQUE INDEX time_dimension_key ON time_dimension(time_key);
CREATE TABLE sales_fact (
time_key integer NOT NULL,
product_key integer NOT NULL,
store_key integer NOT NULL,
amount_sold numeric(12,2) NOT NULL,
units_sold integer NOT NULL,
amount_cost numeric(12,2) NOT NULL
);
CREATE INDEX sales_fact_time ON sales_fact(time_key);
--
-- Summary table - sales by time.
--
CREATE TABLE sales_summary_bytime (
time_key integer NOT NULL,
amount_sold numeric(15,2) NOT NULL,
units_sold numeric(12) NOT NULL,
amount_cost numeric(15,2) NOT NULL
);
CREATE UNIQUE INDEX sales_summary_bytime_key ON sales_summary_bytime(time_key);
--
-- Function and trigger to amend summarized column(s) on UPDATE, INSERT, DELETE.
--
CREATE OR REPLACE FUNCTION maint_sales_summary_bytime() RETURNS TRIGGER
AS $maint_sales_summary_bytime$
DECLARE
delta_time_key integer;
delta_amount_sold numeric(15,2);
delta_units_sold numeric(12);
delta_amount_cost numeric(15,2);
BEGIN
-- Work out the increment/decrement amount(s).
IF (TG_OP = 'DELETE') THEN
delta_time_key = OLD.time_key;
delta_amount_sold = -1 * OLD.amount_sold;
delta_units_sold = -1 * OLD.units_sold;
delta_amount_cost = -1 * OLD.amount_cost;
ELSIF (TG_OP = 'UPDATE') THEN
-- forbid updates that change the time_key -
-- (probably not too onerous, as DELETE + INSERT is how most
-- changes will be made).
IF ( OLD.time_key != NEW.time_key) THEN
RAISE EXCEPTION 'Update of time_key : % -> % not allowed',
OLD.time_key, NEW.time_key;
END IF;
delta_time_key = OLD.time_key;
delta_amount_sold = NEW.amount_sold - OLD.amount_sold;
delta_units_sold = NEW.units_sold - OLD.units_sold;
delta_amount_cost = NEW.amount_cost - OLD.amount_cost;
ELSIF (TG_OP = 'INSERT') THEN
delta_time_key = NEW.time_key;
delta_amount_sold = NEW.amount_sold;
delta_units_sold = NEW.units_sold;
delta_amount_cost = NEW.amount_cost;
END IF;
-- Insert or update the summary row with the new values.
<<insert_update>>
LOOP
UPDATE sales_summary_bytime
SET amount_sold = amount_sold + delta_amount_sold,
units_sold = units_sold + delta_units_sold,
amount_cost = amount_cost + delta_amount_cost
WHERE time_key = delta_time_key;
EXIT insert_update WHEN found;
BEGIN
INSERT INTO sales_summary_bytime (
time_key,
amount_sold,
units_sold,
amount_cost)
VALUES (
delta_time_key,
delta_amount_sold,
delta_units_sold,
delta_amount_cost
);
EXIT insert_update;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
-- do nothing
END;
END LOOP insert_update;
RETURN NULL;
END;
$maint_sales_summary_bytime$ LANGUAGE plpgsql;
CREATE TRIGGER maint_sales_summary_bytime
AFTER INSERT OR UPDATE OR DELETE ON sales_fact
FOR EACH ROW EXECUTE FUNCTION maint_sales_summary_bytime();
INSERT INTO sales_fact VALUES(1,1,1,10,3,15);
INSERT INTO sales_fact VALUES(1,2,1,20,5,35);
INSERT INTO sales_fact VALUES(2,2,1,40,15,135);
INSERT INTO sales_fact VALUES(2,3,1,10,1,13);
SELECT * FROM sales_summary_bytime;
DELETE FROM sales_fact WHERE product_key = 1;
SELECT * FROM sales_summary_bytime;
UPDATE sales_fact SET units_sold = units_sold * 2;
SELECT * FROM sales_summary_bytime;
Триггеры AFTER также могут использовать таблицы переходов для проверки всего набора строк, измененных оператором запуска. Команда CREATE TRIGGER назначает имена одной или обеим таблицам переходов, а затем функция может ссылаться на эти имена, как если бы они были временными таблицами только для чтения (см. Пример 7).
Пример 7. Аудит с таблицами переходов
Этот пример дает те же результаты, что и Пример 4, но вместо использования триггера, который срабатывает для каждой строки, он использует триггер, который срабатывает один раз для каждого оператора, после сбора соответствующей информации в таблице переходов. Это может быть значительно быстрее, чем подход с триггером строки, когда оператор вызова изменил много строк. Обратите внимание, что мы должны сделать отдельное объявление триггера для каждого типа события, так как предложения REFERENCING должны быть разными для каждого случая. Но это не мешает нам использовать одну функцию триггера, если мы выберем. (На практике может быть лучше использовать три отдельные функции и избегать тестов во время выполнения на TG_OP).
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- Create rows in emp_audit to reflect the operations performed on emp,
-- making use of the special variable TG_OP to work out the operation.
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit
SELECT 'D', now(), user, o.* FROM old_table o;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit
SELECT 'U', now(), user, n.* FROM new_table n;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit
SELECT 'I', now(), user, n.* FROM new_table n;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$emp_audit$ LANGUAGE plpgsql;
CREATE TRIGGER emp_audit_ins
AFTER INSERT ON emp
REFERENCING NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_upd
AFTER UPDATE ON emp
REFERENCING OLD TABLE AS old_table NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_del
AFTER DELETE ON emp
REFERENCING OLD TABLE AS old_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
Триггеры на события
PL/pgSQL может использоваться для определения триггеров событий. QHB требует, чтобы функция, вызываемая как триггер события, была объявлена как функция без аргументов и возвращаемого типа event_trigger.
Когда функция PL/pgSQL вызывается как триггер события, в блоке верхнего уровня автоматически создаются несколько специальных переменных. Они есть:
TG_EVENT
TG_TAG
Пример 8 показывает пример функции триггера событий в PL/pgSQL.
Пример 8. Функция запуска событий PL/pgSQL
Этот пример триггера просто вызывает сообщение NOTICE каждый раз, когда выполняется поддерживаемая команда.
CREATE OR REPLACE FUNCTION snitch() RETURNS event_trigger AS $$
BEGIN
RAISE NOTICE 'snitch: % %', tg_event, tg_tag;
END;
$$ LANGUAGE plpgsql;
CREATE EVENT TRIGGER snitch ON ddl_command_start EXECUTE FUNCTION snitch();
PL/pgSQL под капотом
В этом разделе обсуждаются некоторые детали реализации, которые часто важно знать пользователям PL/pgSQL.
Подстановка переменных
Операторы SQL и выражения в функции PL/pgSQL могут ссылаться на переменные и параметры функции. За кулисами PL/pgSQL заменяет параметры запроса для таких ссылок. Параметры будут заменены только в тех местах, где синтаксически разрешена ссылка на параметр или столбец. В качестве крайнего случая рассмотрим пример плохого стиля программирования:
INSERT INTO foo (foo) VALUES (foo);
Первое вхождение foo должно быть синтаксически именем таблицы, поэтому оно не будет подставлено, даже если функция имеет переменную с именем foo. Второе вхождение должно быть именем столбца таблицы, поэтому оно также не будет подставлено. Только третье вхождение является кандидатом на ссылку на переменную функции.
Поскольку имена переменных синтаксически ничем не отличаются от имен столбцов таблицы, в выражениях, которые также относятся к таблицам, может быть неоднозначность: подразумевается ли данное имя для ссылки на столбец таблицы или переменную? Давайте изменим предыдущий пример на
INSERT INTO dest (col) SELECT foo + bar FROM src;
Здесь dest и src должны быть именами таблиц, а col должен быть столбцом dest, но foo и bar могут быть либо переменными функции, либо столбцами src.
По умолчанию PL/pgSQL сообщит об ошибке, если имя в выражении SQL может ссылаться либо на переменную, либо на столбец таблицы. Вы можете решить эту проблему, переименовав переменную или столбец, или квалифицируя неоднозначную ссылку, или указав PL/pgSQL, какую интерпретацию выбрать.
Самое простое решение - переименовать переменную или столбец. Общим правилом кодирования является использование другого соглашения об именах для переменных PL/pgSQL, чем для имен столбцов. Например, если вы последовательно называете переменные функции v_something, в то время как ни одно из имен столбцов не начинается с v_, никаких конфликтов не будет.
В качестве альтернативы вы можете квалифицировать неоднозначные ссылки, чтобы прояснить их. В приведенном выше примере src.foo будет однозначной ссылкой на столбец таблицы. Чтобы создать однозначную ссылку на переменную, объявите ее в помеченном блоке и используйте метку блока (см. раздел Структура PL/pgSQL). Например,
<<block>>
DECLARE
foo int;
BEGIN
foo := ...;
INSERT INTO dest (col) SELECT block.foo + bar FROM src;
Здесь block.foo означает переменную, даже если в src есть столбец foo. Параметры функции, а также специальные переменные, такие как FOUND, могут быть квалифицированы по имени функции, поскольку они неявно объявляются во внешнем блоке, помеченном именем функции.
Иногда нецелесообразно исправлять все неоднозначные ссылки в большом объеме кода PL/pgSQL. В таких случаях вы можете указать, что PL/pgSQL должен разрешать неоднозначные ссылки как переменную или как столбец таблицы (который совместим с некоторыми другими системами, такими как Oracle),
Чтобы изменить это поведение в масштабе всей системы, установите для параметра конфигурации plpgsql.variable_conflict один из параметров error, use_variable или use_column (где error - заводская настройка по умолчанию). Этот параметр влияет на последующие компиляции операторов в функциях PL/pgSQL, но не на операторы, уже скомпилированные в текущем сеансе. Поскольку изменение этого параметра может привести к неожиданным изменениям в поведении функций PL/pgSQL, его может изменить только суперпользователь.
Вы также можете установить поведение для каждой функции, вставив одну из этих специальных команд в начале текста функции:
#variable_conflict error
#variable_conflict use_variable
#variable_conflict use_column
Эти команды влияют только на функцию, в которой они написаны, и переопределяют настройку plpgsql.variable_conflict. Примером является
CREATE FUNCTION stamp_user(id int, comment text) RETURNS void AS $$
#variable_conflict use_variable
DECLARE
curtime timestamp := now();
BEGIN
UPDATE users SET last_modified = curtime, comment = comment
WHERE users.id = id;
END;
$$ LANGUAGE plpgsql;
В команде UPDATE curtime, comment и id будут ссылаться на переменную функции и параметры независимо от того, есть ли у users столбцы с этими именами. Обратите внимание, что нам нужно было квалифицировать ссылку на users.id в WHERE, чтобы она ссылалась на столбец таблицы. Но нам не нужно было указывать ссылку на comment как цель в списке UPDATE, потому что синтаксически это должен быть столбец users. Мы можем написать одну и ту же функцию, не завися от настройки variable_conflict следующим образом:
CREATE FUNCTION stamp_user(id int, comment text) RETURNS void AS $$
<<fn>>
DECLARE
curtime timestamp := now();
BEGIN
UPDATE users SET last_modified = fn.curtime, comment = stamp_user.comment
WHERE users.id = stamp_user.id;
END;
$$ LANGUAGE plpgsql;
Подстановка переменных не происходит в командной строке, данной EXECUTE или в одном из ее вариантов. Если вам нужно вставить переменное значение в такую команду, сделайте это как часть построения строкового значения или используйте USING, как показано в разделе Выполнение динамических команд.
Подстановка переменных в настоящее время работает только в командах SELECT, INSERT, UPDATE и DELETE, поскольку основной механизм SQL допускает параметры запроса только в этих командах. Чтобы использовать непостоянное имя или значение в других типах операторов (обычно называемых служебными операторами), необходимо создать служебный оператор в виде строки и EXECUTE.
Планирование кеширования
Интерпретатор PL/pgSQL анализирует исходный текст функции и создает внутреннее двоичное дерево инструкций при первом вызове функции (в каждом сеансе). Дерево команд полностью переводит структуру операторов PL/pgSQL, но отдельные выражения SQL и команды SQL, используемые в функции, не переводятся немедленно.
Поскольку каждое выражение и команда SQL сначала выполняются в функции, интерпретатор PL/pgSQL анализирует и анализирует команду, чтобы создать подготовленный оператор, используя функцию SPI_prepare менеджера SPI. Последующие посещения этого выражения или команды повторно используют подготовленное утверждение. Таким образом, функция с условными путями кода, которые редко посещаются, никогда не будет нести затраты на анализ тех команд, которые никогда не выполняются в текущем сеансе. Недостатком является то, что ошибки в определенном выражении или команде не могут быть обнаружены, пока эта часть функции не будет достигнута во время выполнения. (Тривиальные синтаксические ошибки будут обнаружены во время начального этапа анализа, но что-либо более глубокое не будет обнаружено до выполнения).
PL/pgSQL (или, точнее, менеджер SPI) может, кроме того, попытаться кэшировать план выполнения, связанный с любым конкретным подготовленным оператором. Если кэшированный план не используется, то новый план выполнения генерируется при каждом посещении оператора, и текущие значения параметров (то есть значения переменных PL/pgSQL ) можно использовать для оптимизации выбранного плана. Если инструкция не имеет параметров или выполняется много раз, менеджер SPI рассмотрит возможность создания общего плана, который не зависит от конкретных значений параметров, и кэширования его для повторного использования. Обычно это происходит, только если план выполнения не очень чувствителен к значениям переменных PL/pgSQL, на которые есть ссылки. Если это так, генерация плана каждый раз является чистой победой. См. PREPARE для получения дополнительной информации о поведении подготовленных операторов.
Поскольку PL/pgSQL сохраняет подготовленные операторы и иногда планы выполнения таким образом, команды SQL, которые появляются непосредственно в функции PL/pgSQL, должны ссылаться на одни и те же таблицы и столбцы при каждом выполнении; то есть вы не можете использовать параметр в качестве имени таблицы или столбца в команде SQL. Чтобы обойти это ограничение, вы можете создавать динамические команды с помощью оператора PL/pgSQL EXECUTE - ценой выполнения нового анализа синтаксического анализа и создания нового плана выполнения при каждом выполнении.
Изменчивая природа переменных записи представляет другую проблему в этой связи. Когда поля переменной записи используются в выражениях или операторах, типы данных полей не должны изменяться от одного вызова функции к следующему, поскольку каждое выражение будет анализироваться с использованием типа данных, который присутствует, когда выражение является первым достиг. EXECUTE может использоваться, чтобы обойти эту проблему, когда это необходимо.
Если одна и та же функция используется в качестве триггера для нескольких таблиц, PL/pgSQL подготавливает и кэширует операторы независимо для каждой такой таблицы, то есть существует кэш для каждой функции триггера и комбинации таблиц, а не только для каждой функции. Это облегчает некоторые проблемы с различными типами данных; например, триггерная функция сможет успешно работать со столбцом с именем key даже если она имеет разные типы в разных таблицах.
Аналогично, функции, имеющие полиморфные типы аргументов, имеют отдельный кэш операторов для каждой комбинации фактических типов аргументов, для которых они были вызваны, так что различия типов данных не вызывают неожиданных сбоев.
Кэширование операторов иногда может оказать неожиданное влияние на интерпретацию чувствительных ко времени значений. Например, есть разница между тем, что делают эти две функции:
CREATE FUNCTION logfunc1(logtxt text) RETURNS void AS $$
BEGIN
INSERT INTO logtable VALUES (logtxt, 'now');
END;
$$ LANGUAGE plpgsql;
и:
CREATE FUNCTION logfunc2(logtxt text) RETURNS void AS $$
DECLARE
curtime timestamp;
BEGIN
curtime := 'now';
INSERT INTO logtable VALUES (logtxt, curtime);
END;
$$ LANGUAGE plpgsql;
В случае logfunc1 главный анализатор QHB знает, анализируя INSERT что строка ’now’ должна интерпретироваться как timestamp, потому что целевой столбец logtable относится к этому типу. Таким образом, ’now’ будет преобразовано в постоянную timestamp при анализе INSERT, а затем будет использоваться во всех logfunc1 в течение всего времени сеанса. Излишне говорить, что это не то, что хотел программист. Лучшая идея - использовать функцию now() или current_timestamp.
В случае logfunc2 основной анализатор QHB не знает, каким должен быть тип ’now’ и поэтому возвращает значение данных типа text содержащее строку now. Во время последующего присвоения локальной переменной curtime интерпретатор PL/pgSQL преобразует эту строку в тип timestamp , вызывая функции text_out и timestamp_in для преобразования. Таким образом, вычисленная метка времени обновляется при каждом выполнении, как того ожидает программист. Несмотря на то, что это работает должным образом, это не очень эффективно, поэтому использование функции now() все равно было бы лучшей идеей.
Советы по разработке на PL/pgSQL
Хороший способ разработки в PL/pgSQL - использовать выбранный вами текстовый редактор для создания своих функций, а в другом окне использовать qsql для загрузки и тестирования этих функций. Если вы делаете это таким образом, хорошей идеей будет написать функцию, используя CREATE OR REPLACE FUNCTION. Таким образом, вы можете просто перезагрузить файл, чтобы обновить определение функции. Например:
CREATE OR REPLACE FUNCTION testfunc(integer) RETURNS integer AS $$
....
$$ LANGUAGE plpgsql;
Во время работы qsql вы можете загрузить или перезагрузить такой файл определения функции с помощью:
\i filename.sql
а затем немедленно выполните команды SQL для проверки функции.
Еще один хороший способ разработки на PL/pgSQL - это инструмент для доступа к базе данных с графическим интерфейсом, который облегчает разработку на процедурном языке. Одним из примеров такого инструмента является pgAdmin, хотя существуют и другие. Эти инструменты часто предоставляют удобные функции, такие как экранирование одинарных кавычек и упрощение воссоздания и отладки функций.
Обработка кавычек
Код функции PL/pgSQL указывается в CREATE FUNCTION как строковый литерал. Если вы пишете строковый литерал обычным способом с окружающими одинарными кавычками, то любые одинарные кавычки внутри тела функции должны быть удвоены; аналогично, любые обратные слеши должны быть удвоены (при условии использования синтаксиса escape-строки). Удвоение кавычек в лучшем случае утомительно, а в более сложных случаях код может стать совершенно непонятным, потому что вы можете легко найти себе полдюжины или более соседних кавычек. Вместо этого рекомендуется написать тело функции в виде строкового литерала, заключенного в «кавычки» (см. раздел Строковые константы с экранированием знаками доллара). При способе с использованием знаков доллара вы никогда не удваиваете любые кавычки, а вместо этого стараетесь выбирать разные разделители долларовых кавычек для каждого необходимого уровня вложенности. Например, можно написать команду CREATE FUNCTION как:
CREATE OR REPLACE FUNCTION testfunc(integer) RETURNS integer AS $PROC$
....
$PROC$ LANGUAGE plpgsql;
В рамках этого вы можете использовать кавычки для простых литеральных строк в командах SQL и $$ для разделения фрагментов команд SQL, которые вы собираете в виде строк. Если вам нужно заключить в кавычки текст, $$, вы можете использовать $Q$ и так далее.
Следующая таблица показывает, что вы должны делать, когда пишете кавычки без экранирования знаками доллара. Это может быть полезно при переводе пре-долларовых кавычек в нечто более понятное.
одинарные кавычки
CREATE FUNCTION foo() RETURNS integer AS '
....
' LANGUAGE plpgsql;
Везде в теле функции, заключенном в одинарные кавычки, кавычки должны появляться парами.
парные кавычки
a_output := ''Blah'';
SELECT * FROM users WHERE f_name=''foobar'';
При подходе «экранирование знаками доллара» вы просто пишете:
a_output := 'Blah';
SELECT * FROM users WHERE f_name='foobar';
это именно то, что анализатор PL/pgSQL будет видеть в любом случае.
4 кавычки
a_output := a_output || '' AND name LIKE ''''foobar'''' AND xyz''
Значение, добавленное к a_output, будет: AND name LIKE ’foobar’ AND xyz.
В подходе «экранирование знаками доллара» вы написали бы:
a_output := a_output || $$ AND name LIKE 'foobar' AND xyz$$
быть осторожным, что любые разделители долларовых кавычек вокруг этого не просто $$.
6 кавычек
a_output := a_output || '' AND name LIKE ''''foobar''''''
Значение, добавленное к a_output будет: AND name LIKE ’foobar’.
В подходе «экранирование знаками доллара» это становится:
a_output := a_output || $$ AND name LIKE 'foobar'$$
10 кавычек
a_output := a_output || '' if v_'' ||
referrer_keys.kind || '' like ''''''''''
|| referrer_keys.key_string || ''''''''''
then return '''''' || referrer_keys.referrer_type
|| ''''''; end if;'';
Значение a_output тогда будет:
if v_... like ''...'' then return ''...''; end if;
В подходе «экранирование знаками доллара» это становится:
a_output := a_output || $$ if v_$$ || referrer_keys.kind || $$ like '$$
|| referrer_keys.key_string || $$'
then return '$$ || referrer_keys.referrer_type
|| $$'; end if;$$;
где мы предполагаем, что нам нужно только поставить одинарные кавычки в a_output, потому что он будет повторно цитирован перед использованием.
Дополнительные проверки во время компиляции и во время выполнения
Чтобы помочь пользователю найти примеры простых, но распространенных проблем до того, как они причинят вред, PL/pgSQL предоставляет дополнительные checks. Когда они включены, в зависимости от конфигурации они могут использоваться для выдачи WARNING или ERROR во время компиляции функции. Функция, получившая WARNING может быть выполнена без выдачи дополнительных сообщений, поэтому рекомендуется выполнять тестирование в отдельной среде разработки.
При необходимости установка plpgsql.extra_warnings или plpgsql.extra_errors в значение "all" рекомендуется в средах разработки и/или тестирования.
Эти дополнительные проверки включены через переменные конфигурации plpgsql.extra_warnings для предупреждений и plpgsql.extra_errors для ошибок. Оба могут быть установлены в список проверок, разделенных запятыми, "none" или "all". По умолчанию установлено значение "none". В настоящее время список доступных проверок включает в себя:
shadowed_variables
strict_multi_assignment
too_many_rows
В следующем примере показано влияние plpgsql.extra_warnings установленного на shadowed_variables:
SET plpgsql.extra_warnings TO 'shadowed_variables';
CREATE FUNCTION foo(f1 int) RETURNS int AS $$
DECLARE
f1 int;
BEGIN
RETURN f1;
END
$$ LANGUAGE plpgsql;
WARNING: variable "f1" shadows a previously defined variable
LINE 3: f1 int;
^
CREATE FUNCTION
В приведенном ниже примере показаны эффекты установки plpgsql.extra_warnings в значение strict_multi_assignment:
SET plpgsql.extra_warnings TO 'strict_multi_assignment';
CREATE OR REPLACE FUNCTION public.foo()
RETURNS void
LANGUAGE plpgsql
AS $$
DECLARE
x int;
y int;
BEGIN
SELECT 1 INTO x, y;
SELECT 1, 2 INTO x, y;
SELECT 1, 2, 3 INTO x, y;
END;
$$;
SELECT foo();
WARNING: number of source and target fields in assignment does not match
DETAIL: strict_multi_assignment check of extra_warnings is active.
HINT: Make sure the query returns the exact list of columns.
WARNING: number of source and target fields in assignment does not match
DETAIL: strict_multi_assignment check of extra_warnings is active.
HINT: Make sure the query returns the exact list of columns.
foo
-----
(1 row)
Портирование из Oracle PL/SQL
В этом разделе объясняются различия между языком PL/pgSQL QHB и языком PL/SQL Oracle, чтобы помочь разработчикам, которые переносят приложения из Oracle® в QHB.
PL/pgSQL во многом похож на PL/SQL. Это блочно-структурированный императивный язык, и все переменные должны быть объявлены. Присвоения, циклы и условия аналогичны. Основные различия, которые следует учитывать при переносе с PL/SQL на PL/pgSQL:
Примеры портирования
В примере 9 показано, как перенести простую функцию из PL/SQL в PL/pgSQL.
Пример 9. Портирование простой функции из PL/SQL в PL/pgSQL
Вот функция Oracle PL/SQL :
CREATE OR REPLACE FUNCTION cs_fmt_browser_version(v_name varchar2,
v_version varchar2)
RETURN varchar2 IS
BEGIN
IF v_version IS NULL THEN
RETURN v_name;
END IF;
RETURN v_name || '/' || v_version;
END;
/
show errors;
Давайте рассмотрим эту функцию и посмотрим на различия по сравнению с PL/pgSQL :
Вот как будет выглядеть эта функция при портировании на QHB:
CREATE OR REPLACE FUNCTION cs_fmt_browser_version(v_name varchar,
v_version varchar)
RETURNS varchar AS $$
BEGIN
IF v_version IS NULL THEN
RETURN v_name;
END IF;
RETURN v_name || '/' || v_version;
END;
$$ LANGUAGE plpgsql;
В примере 10 показано, как портировать функцию, которая создает другую функцию, и как справиться с возникающими проблемами цитирования.
Пример 10. Портирование функции, которая создает другую функцию из PL/SQL в PL/pgSQL
Следующая процедура извлекает строки из SELECT и строит большую функцию с результатами в операторах IF для эффективности.
Это версия Oracle:
CREATE OR REPLACE PROCEDURE cs_update_referrer_type_proc IS
CURSOR referrer_keys IS
SELECT * FROM cs_referrer_keys
ORDER BY try_order;
func_cmd VARCHAR(4000);
BEGIN
func_cmd := 'CREATE OR REPLACE FUNCTION cs_find_referrer_type(v_host IN VARCHAR2,
v_domain IN VARCHAR2, v_url IN VARCHAR2) RETURN VARCHAR2 IS BEGIN';
FOR referrer_key IN referrer_keys LOOP
func_cmd := func_cmd ||
' IF v_' || referrer_key.kind
|| ' LIKE ''' || referrer_key.key_string
|| ''' THEN RETURN ''' || referrer_key.referrer_type
|| '''; END IF;';
END LOOP;
func_cmd := func_cmd || ' RETURN NULL; END;';
EXECUTE IMMEDIATE func_cmd;
END;
/
show errors;
Вот как эта функция может оказаться в QHB:
CREATE OR REPLACE PROCEDURE cs_update_referrer_type_proc() AS $func$
DECLARE
referrer_keys CURSOR IS
SELECT * FROM cs_referrer_keys
ORDER BY try_order;
func_body text;
func_cmd text;
BEGIN
func_body := 'BEGIN';
FOR referrer_key IN referrer_keys LOOP
func_body := func_body ||
' IF v_' || referrer_key.kind
|| ' LIKE ' || quote_literal(referrer_key.key_string)
|| ' THEN RETURN ' || quote_literal(referrer_key.referrer_type)
|| '; END IF;' ;
END LOOP;
func_body := func_body || ' RETURN NULL; END;';
func_cmd :=
'CREATE OR REPLACE FUNCTION cs_find_referrer_type(v_host varchar,
v_domain varchar,
v_url varchar)
RETURNS varchar AS '
|| quote_literal(func_body)
|| ' LANGUAGE plpgsql;' ;
EXECUTE func_cmd;
END;
$func$ LANGUAGE plpgsql;
Обратите внимание, что тело функции quote_literal отдельно и передается через quote_literal чтобы удвоить любые кавычки в нем. Этот метод необходим, потому что мы не можем безопасно использовать долларовые кавычки для определения новой функции: мы не знаем наверняка, какие строки будут интерполированы из поля referrer_key.key_string. (Здесь мы предполагаем, что referrer_key.kind всегда можно доверять, чтобы он всегда был host, domain или url, но referrer_key.key_string может быть чем угодно, в частности он может содержать знаки доллара). Эта функция на самом деле является улучшением оригинала Oracle, потому что он не будет генерировать неработающий код, когда referrer_key.key_string или referrer_key.referrer_type содержат кавычки.
В примере 11 показано, как перенести функцию с параметрами OUT и обработкой строк. QHB не имеет встроенной функции instr, но вы можете создать ее, используя комбинацию других функций. В разделе Приложение описана реализация instr в PL/pgSQL, которую вы можете использовать для упрощения переноса.
Пример 11. Перенос процедуры с параметрами String Manipulation и OUT из PL/SQL в PL/pgSQL
Следующая процедура Oracle PL/SQL используется для анализа URL-адреса и возврата нескольких элементов (хост, путь и запрос).
Это версия Oracle:
CREATE OR REPLACE PROCEDURE cs_parse_url(
v_url IN VARCHAR2,
v_host OUT VARCHAR2, -- This will be passed back
v_path OUT VARCHAR2, -- This one too
v_query OUT VARCHAR2) -- And this one
IS
a_pos1 INTEGER;
a_pos2 INTEGER;
BEGIN
v_host := NULL;
v_path := NULL;
v_query := NULL;
a_pos1 := instr(v_url, '//');
IF a_pos1 = 0 THEN
RETURN;
END IF;
a_pos2 := instr(v_url, '/', a_pos1 + 2);
IF a_pos2 = 0 THEN
v_host := substr(v_url, a_pos1 + 2);
v_path := '/';
RETURN;
END IF;
v_host := substr(v_url, a_pos1 + 2, a_pos2 - a_pos1 - 2);
a_pos1 := instr(v_url, '?', a_pos2 + 1);
IF a_pos1 = 0 THEN
v_path := substr(v_url, a_pos2);
RETURN;
END IF;
v_path := substr(v_url, a_pos2, a_pos1 - a_pos2);
v_query := substr(v_url, a_pos1 + 1);
END;
/
show errors;
Вот возможный перевод на PL/pgSQL :
CREATE OR REPLACE FUNCTION cs_parse_url(
v_url IN VARCHAR,
v_host OUT VARCHAR, -- This will be passed back
v_path OUT VARCHAR, -- This one too
v_query OUT VARCHAR) -- And this one
AS $$
DECLARE
a_pos1 INTEGER;
a_pos2 INTEGER;
BEGIN
v_host := NULL;
v_path := NULL;
v_query := NULL;
a_pos1 := instr(v_url, '//');
IF a_pos1 = 0 THEN
RETURN;
END IF;
a_pos2 := instr(v_url, '/', a_pos1 + 2);
IF a_pos2 = 0 THEN
v_host := substr(v_url, a_pos1 + 2);
v_path := '/';
RETURN;
END IF;
v_host := substr(v_url, a_pos1 + 2, a_pos2 - a_pos1 - 2);
a_pos1 := instr(v_url, '?', a_pos2 + 1);
IF a_pos1 = 0 THEN
v_path := substr(v_url, a_pos2);
RETURN;
END IF;
v_path := substr(v_url, a_pos2, a_pos1 - a_pos2);
v_query := substr(v_url, a_pos1 + 1);
END;
$$ LANGUAGE plpgsql;
Эту функцию можно использовать так:
SELECT * FROM cs_parse_url('http://foobar.com/query.cgi?baz');
В примере 12 показано, как портировать процедуру, которая использует многочисленные функции, характерные для Oracle.
Пример 12. Портирование процедуры из PL/SQL в PL/pgSQL
Версия Oracle:
CREATE OR REPLACE PROCEDURE cs_create_job(v_job_id IN INTEGER) IS
a_running_job_count INTEGER;
BEGIN
LOCK TABLE cs_jobs IN EXCLUSIVE MODE;
SELECT count(*) INTO a_running_job_count FROM cs_jobs WHERE end_stamp IS NULL;
IF a_running_job_count > 0 THEN
COMMIT; -- free lock
raise_application_error(-20000,
'Unable to create a new job: a job is currently running.');
END IF;
DELETE FROM cs_active_job;
INSERT INTO cs_active_job(job_id) VALUES (v_job_id);
BEGIN
INSERT INTO cs_jobs (job_id, start_stamp) VALUES (v_job_id, now());
EXCEPTION
WHEN dup_val_on_index THEN NULL; -- don't worry if it already exists
END;
COMMIT;
END;
/
show errors
Вот как мы могли бы перенести эту процедуру в PL/pgSQL :
CREATE OR REPLACE PROCEDURE cs_create_job(v_job_id integer) AS $$
DECLARE
a_running_job_count integer;
BEGIN
LOCK TABLE cs_jobs IN EXCLUSIVE MODE;
SELECT count(*) INTO a_running_job_count FROM cs_jobs WHERE end_stamp IS NULL;
IF a_running_job_count > 0 THEN
COMMIT; -- free lock
RAISE EXCEPTION 'Unable to create a new job: a job is currently running'; -- [^1]
END IF;
DELETE FROM cs_active_job;
INSERT INTO cs_active_job(job_id) VALUES (v_job_id);
BEGIN
INSERT INTO cs_jobs (job_id, start_stamp) VALUES (v_job_id, now());
EXCEPTION
WHEN unique_violation THEN -- [^2]
-- don't worry if it already exists
END;
COMMIT;
END;
$$ LANGUAGE plpgsql;
Синтаксис RAISE значительно отличается от оператора Oracle, хотя основной случай RAISE exception_name работает аналогично.
Имена исключений, поддерживаемые PL/pgSQL, отличаются от имен Oracle. Набор встроенных имен исключений намного больше (см. Приложение А). В настоящее время нет способа объявить пользовательские имена исключений, хотя вы можете вместо этого выбрасывать выбранные пользователем значения SQLSTATE.
Другие вещи для наблюдения
В этом разделе объясняются некоторые другие вещи, на которые нужно обратить внимание при портировании функций Oracle PL/SQL на QHB.
Неявный откат после исключений
В PL/pgSQL, когда исключение отлавливается предложением EXCEPTION, все изменения в базе данных, так как блок BEGIN автоматически откатывается. То есть поведение эквивалентно тому, что вы получите в Oracle:
BEGIN
SAVEPOINT s1;
... code here ...
EXCEPTION
WHEN ... THEN
ROLLBACK TO s1;
... code here ...
WHEN ... THEN
ROLLBACK TO s1;
... code here ...
END;
Если вы переводите процедуру Oracle, которая использует SAVEPOINT и ROLLBACK TO в этом стиле, ваша задача проста: просто опустите SAVEPOINT и ROLLBACK TO. Если у вас есть процедура, в которой SAVEPOINT и ROLLBACK TO используются по-разному, вам понадобится определенная мысль.
EXECUTE
Версия EXECUTE для PL/pgSQL работает аналогично версии PL/SQL, но
вы должны помнить, что используйте quote_literal и quote_ident как
описано в разделе Выполнение динамических команд. Конструкции типа EXECUTE 'SELECT * FROM $1';
не будет надежно работать, если вы не используете эти функции.
Оптимизация функций PL/pgSQL
QHB предоставляет вам два модификатора создания функции для оптимизации выполнения: « изменчивость » (всегда ли функция возвращает один и тот же результат, если даны одни и те же аргументы) и «строгость» (возвращает ли функция ноль, если какой-либо аргумент равен нулю). Обратитесь к справочной странице CREATE FUNCTION за подробностями.
При использовании этих атрибутов оптимизации ваш оператор CREATE FUNCTION может выглядеть примерно так:
CREATE FUNCTION foo(...) RETURNS integer AS $$
...
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
Приложение
Этот раздел содержит код для набора Oracle-совместимых функций instr которые вы можете использовать для упрощения процесса переноса.
-
-- instr functions that mimic Oracle's counterpart
-- Syntax: instr(string1, string2 [, n [, m]])
-- where [] denotes optional parameters.
--
-- Search string1, beginning at the nth character, for the mth occurrence
-- of string2. If n is negative, search backwards, starting at the abs(n)'th
-- character from the end of string1.
-- If n is not passed, assume 1 (search starts at first character).
-- If m is not passed, assume 1 (find first occurrence).
-- Returns starting index of string2 in string1, or 0 if string2 is not found.
--
CREATE FUNCTION instr(varchar, varchar) RETURNS integer AS $$
BEGIN
RETURN instr($1, $2, 1);
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
CREATE FUNCTION instr(string varchar, string_to_search_for varchar,
beg_index integer)
RETURNS integer AS $$
DECLARE
pos integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
length integer;
ss_length integer;
BEGIN
IF beg_index > 0 THEN
temp_str := substring(string FROM beg_index);
pos := position(string_to_search_for IN temp_str);
IF pos = 0 THEN
RETURN 0;
ELSE
RETURN pos + beg_index - 1;
END IF;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search_for);
length := char_length(string);
beg := length + 1 + beg_index;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
IF string_to_search_for = temp_str THEN
RETURN beg;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
CREATE FUNCTION instr(string varchar, string_to_search_for varchar,
beg_index integer, occur_index integer)
RETURNS integer AS $$
DECLARE
pos integer NOT NULL DEFAULT 0;
occur_number integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
i integer;
length integer;
ss_length integer;
BEGIN
IF occur_index <= 0 THEN
RAISE 'argument ''%'' is out of range', occur_index
USING ERRCODE = '22003';
END IF;
IF beg_index > 0 THEN
beg := beg_index - 1;
FOR i IN 1..occur_index LOOP
temp_str := substring(string FROM beg + 1);
pos := position(string_to_search_for IN temp_str);
IF pos = 0 THEN
RETURN 0;
END IF;
beg := beg + pos;
END LOOP;
RETURN beg;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search_for);
length := char_length(string);
beg := length + 1 + beg_index;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
IF string_to_search_for = temp_str THEN
occur_number := occur_number + 1;
IF occur_number = occur_index THEN
RETURN beg;
END IF;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
Команды SQL
Эта часть содержит справочную информацию для команд SQL, поддерживаемых QHB. Под «SQL» подразумевается язык в целом; информацию о соответствии стандартам и совместимости каждой команды можно найти на соответствующей справочной странице.
ABORT
ABORT — прервать текущую транзакцию
Синтаксис
ABORT [ WORK | TRANSACTION ] [ AND [ NO ] CHAIN ]
Описание
Команда ABORT откатывает текущую транзакцию и отменяет все внесенные ей изменения.
По своему поведению ABORT идентична стандартной SQL-команде ROLLBACK и
присутствует только по историческим причинам.
Параметры
WORK TRANSACTION
Необязательные ключевые слова, не влияют на результат.
AND CHAIN
Если указывается AND CHAIN, то сразу после окончания текущей транзакции начинается новая с теми же характеристиками, что и только что завершенная (см. раздел SET TRANSACTION). В противном случае новая транзакция не начинается.
Примечания
Для успешного завершения транзакции используйте команду COMMIT.
При выполнении ABORT вне блока транзакций будет выдано предупреждение
и больше ничего не произойдет.
Примеры
Отмена всех изменений:
ABORT;
Совместимость
Команда ABORT является расширением QHB и присутствует по
историческим причинам. Стандартная SQL-команда ROLLBACK идентична ей по своему
поведению.
См. также
ALTER AGGREGATE
ALTER AGGREGATE — изменить определение агрегатной функции
Синтаксис
ALTER AGGREGATE имя ( сигнатура_агрегатной_функции ) RENAME TO новое_имя
ALTER AGGREGATE имя ( сигнатура_агрегатной_функции )
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER AGGREGATE имя ( сигнатура_агрегатной_функции ) SET SCHEMA новая_схема
Где сигнатура_агрегатной_функции:
* |
[ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] |
[ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] ]
ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ]
Описание
Команда ALTER AGGREGATE изменяет определение агрегатной функции.
Чтобы использовать команду ALTER AGGREGATE, нужно быть владельцем соответствующей
агрегатной функции. Чтобы изменить схему агрегатной функции, помимо этого
необходимо иметь право CREATE в новой схеме. Для смены владельца текущий
пользователь также должен быть непосредственным или опосредованным членом новой
роли-владельца, и эта роль должна иметь право CREATE в схеме агрегатной функции.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания агрегатной функции.
Однако суперпользователь всё равно может сменить владельца любой
агрегатной функции.)
Параметры
имя
Имя существующей агрегатной функции (может быть дополнено схемой).
режим_аргумента
Режим аргумента: IN или VARIADIC. Если этот параметр не указан, значением по умолчанию является IN.
имя_аргумента
Название аргумента. Обратите внимание, что ALTER AGGREGATE
фактически не обращает никакого внимания на имена аргументов, поскольку
для определения идентичности агрегатной функции требуются только типы
данных аргументов.
тип_аргумента
Тип входных данных, с которыми работает агрегатная функция. Чтобы сослаться на
агрегатную функцию без аргументов, вместо списка спецификаций аргументов
напишите *. Чтобы сослаться на сортирующую агрегатную функцию, напишите
ORDER BY между спецификациями непосредственных и агрегируемых аргументов.
новое_имя
Новое имя агрегатной функции.
новый_владелец
Новый владелец агрегатной функции.
новая_схема
Новая схема для агрегатной функции.
Примечания
Рекомендуемый синтаксис для ссылки на сортирующую агрегатную функцию — написать
ORDER BY между спецификациями непосредственных и агрегируемых аргументов, как в
CREATE AGGREGATE. Однако команда будет выполнена и без ORDER BY, если просто
перечислить спецификации непосредственных и агрегирующих аргументов в одном списке.
В такой сокращенной форме, если VARIADIC "any" использовалась как в
списке непосредственных, так и в списке агрегирующих аргументов, достаточно указать
VARIADIC "any" только один раз.
Примеры
Переименование агрегатной функции myavg с типом integer в my_average:
ALTER AGGREGATE myavg(integer) RENAME TO my_average;
Смена владельца агрегатной функции myavg с типом integer на joe:
ALTER AGGREGATE myavg(integer) OWNER TO joe;
Перемещение сортирующей агрегатной функции mypercentile с непосредственным аргументом типа float8 и агрегируемым аргументом типа integer в схему myschema:
ALTER AGGREGATE mypercentile(float8 ORDER BY integer) SET SCHEMA myschema;
Так тоже будет работать:
ALTER AGGREGATE mypercentile(float8, integer) SET SCHEMA myschema;
Совместимость
В стандарте SQL нет команды ALTER AGGREGATE.
См. также
CREATE AGGREGATE, DROP AGGREGATE
ALTER COLLATION
ALTER COLLATION — изменить определение правила сортировки
Синтаксис
ALTER COLLATION имя RENAME TO новое_имя
ALTER COLLATION имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER COLLATION имя SET SCHEMA новая_схема
Описание
Команда ALTER COLLATION изменяет определение правила сортировки.
Чтобы использовать команду ALTER COLLATION, нужно быть владельцем соответствующего
правила сортировки. Для смены владельца текущий пользователь также должен быть
непосредственным или опосредованным членом новой роли-владельца, и эта роль
должна иметь право CREATE в схеме правила сортировки. (Эти ограничения
направлены на то, чтобы при смене владельца не происходило ничего, что нельзя было
бы сделать путем удаления и повторного создания правила сортировки. Однако
суперпользователь всё равно может изменить владельца любого правила сортировки.)
Параметры
имя
Имя существующего правила сортировки (может быть дополнено схемой).
новое_имя
Новое имя правила сортировки.
новый_владелец
Новый владелец правила сортировки.
новая_схема
Новая схема для правила сортировки.
REFRESH VERSION
Обновить версию правила сортировки. См. Примечания ниже.
Примечания
Во время применения правил сортировки, которые предоставляются библиотекой ICU, при создании объекта для данного правила в системный каталог будет записана внутренняя версия сортировщика ICU. При использовании правила сортировки текущая версия будет сверяться с записанной, и в случае несоответствия будет выдано предупреждение, например:
WARNING: collation "xx-x-icu" has version mismatch
DETAIL: The collation in the database was created using version 1.2.3.4, but the operating system provides version 2.3.4.5.
HINT: Rebuild all objects affected by this collation and run ALTER COLLATION pg_catalog."xx-x-icu" REFRESH VERSION, or build PostgreSQL with the right library version.
Изменение определений правил сортировки может привести к разрушению индексов и
другим проблемам, поскольку СУБД рассчитывает, что хранимые объекты имеют
определенный порядок сортировки. В целом, подобного следует избегать, но это может
произойти в легитимных обстоятельствах, например при обновлении с помощью команды qhb\_upgrade
двоичных файлов сервера, скомпилированных с более новой версией ICU.
Когда это происходит, все объекты, зависящие от правил
сортировки, должны быть перестроены, например, с помощью REINDEX.
После этого можно обновить версию правил сортировки, выполнив команду
ALTER COLLATION ... REFRESH VERSION. Это обновит системный каталог,
и в него будет записана текущая версия сортировщика,
а предупреждение исчезнет. Обратите внимание, что при выполнении команды фактически не
проверяется, все ли затронутые объекты были перестроены правильно.
Когда применяются правила сортировки, предоставляемые библиотекой libc, а QHB был собран с библиотекой GNU C, в качестве версии правила сортировки используется версия библиотеки C. Поскольку определения правила сортировки обычно изменяются только с новыми версиями библиотеки GNU C, это обеспечивает некоторую (хотя и не в полной мере надежную) защиту от повреждений данных.
В настоящее время версия правила сортировки, по умолчанию установленного для базы данных, не отслеживается.
Для определения всех правил сортировки в текущей базе данных, которые необходимо обновить, и объектов, которые зависят от них, можно использовать следующий запрос:
SELECT pg_describe_object(refclassid, refobjid, refobjsubid) AS "Collation",
pg_describe_object(classid, objid, objsubid) AS "Object"
FROM pg_depend d JOIN pg_collation c
ON refclassid = 'pg_collation'::regclass AND refobjid = c.oid
WHERE c.collversion <> pg_collation_actual_version(c.oid)
ORDER BY 1, 2;
Примеры
Переименование правила сортировки de_DE в german:
ALTER COLLATION "de_DE" RENAME TO german;
Изменение владельца правила сортировки en_US на joe:
ALTER COLLATION "en_US" OWNER TO joe;
Совместимость
В стандарте SQL нет команды ALTER COLLATION.
См. также
CREATE COLLATION, DROP COLLATION
ALTER CONVERSION
ALTER CONVERSION — изменить определение перекодировки
Синтаксис
ALTER CONVERSION имя RENAME TO новое_имя
ALTER CONVERSION имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER CONVERSION имя SET SCHEMA новая_схема
Описание
Команда ALTER CONVERSION изменяет определение перекодировки.
Чтобы использовать команду ALTER CONVERSION, нужно быть владельцем
соответствующей перекодировки. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме перекодировки. (Эти ограничения
направлены на то, чтобы при смене владельца не происходило ничего, что нельзя
было бы сделать путем удаления и повторного создания перекодировки. Однако
суперпользователь всё равно может изменить владельца любой перекодировки.)
Параметры
имя
Имя существующей перекодировки (может быть дополнено схемой).
новое_имя
Новое имя перекодировки.
новый_владелец
Новый владелец перекодировки.
новая_схема
Новая схема для перекодировки.
Примеры
Переименование перекодировки iso_8859_1_to_utf8 в latin1_to_unicode:
ALTER CONVERSION iso_8859_1_to_utf8 RENAME TO latin1_to_unicode;
Смена владельца перекодировки iso_8859_1_to_utf8 на joe:
ALTER CONVERSION iso_8859_1_to_utf8 OWNER TO joe;
Совместимость
В стандарте SQL нет команды ALTER CONVERSION.
См. также
CREATE CONVERSION, DROP CONVERSION
ALTER DATABASE
ALTER DATABASE — изменить базу данных
Синтаксис
ALTER DATABASE имя [ [ WITH ] параметр [ ... ] ]
Где параметр может быть:
ALLOW_CONNECTIONS разрешение_подключения
CONNECTION LIMIT предел_подключений
IS_TEMPLATE это_шаблон
ALTER DATABASE имя RENAME TO новое_имя
ALTER DATABASE имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER DATABASE имя SET TABLESPACE новое_табличное_пространство
ALTER DATABASE имя SET параметр_конфигурации { TO | = } { значение | DEFAULT }
ALTER DATABASE имя SET параметр_конфигурации FROM CURRENT
ALTER DATABASE имя RESET параметр_конфигурации
ALTER DATABASE имя RESET ALL
Описание
Команда ALTER DATABASE изменяет атрибуты базы данных.
Первая форма команды изменяет определенные параметры на уровне базы данных. (Подробное описание см. ниже). Изменять эти параметры может только владелец соответствующей базы данных или суперпользователь.
Вторая форма команды изменяет имя базы данных. Переименовать базу данных может только владелец базы данных или суперпользователь (не суперпользователи должны обладать правом CREATEDB). Переименовать текущую базу данных нельзя. (Если это нужно сделать, подключитесь к другой базе данных.)
Третья форма команды изменяет владельца базы данных. Для смены владельца текущий пользователь должен быть ее владельцем, а также непосредственным или опосредованным членом новой роли-владельца и иметь право CREATEDB. (Обратите внимание, что суперпользователи получают все эти права автоматически.)
Четвертая форма команды изменяет у базы данных табличное пространство по умолчанию. Это может сделать только владелец базы данных или суперпользователь; кроме того, необходимо иметь право на создание нового табличного пространства. Эта команда физически перемещает все таблицы или индексы из старого табличного пространства по умолчанию в новое. Новое табличное пространство по умолчанию должно быть пустым, и никто не должен быть подключен к базе данных. Таблицы и индексы из нестандартных табличных пространств не затрагиваются.
Остальные формы данной команды изменяют сеансовое значение по умолчанию у конфигурационной переменной периода выполнения для базы данных QHB. При последующем запуске нового сеанса в этой базе данных указанное значение становится значением по умолчанию. Заданные для базы данных значения по умолчанию переопределяют любые значения из qhb.conf или полученные из командной строки QHB. Только владелец базы данных и суперпользователь могут изменить для базы данных сеансовые значения по умолчанию. Некоторые переменные таким образом установить нельзя, либо их может установить только суперпользователь.
Параметры
имя
Имя базы данных, атрибуты которой подлежат изменению.
разрешение_подключения
При значении false к этой базе данных никто не сможет подключиться.
предел_подключений
Устанавливает, сколько одновременных подключений может быть сделано к этой базе данных. -1 означает отсутствие ограничений.
это_шаблон
При значении true эта база данных может быть клонирована любым пользователем с правами CREATEDB; при значении false клонировать базу данных могут только суперпользователи или ее владелец.
новое_имя
Новое имя базы данных.
новый_владелец
Новый владелец базы данных.
новое_табличное_пространство
Новое табличное пространство по умолчанию для базы данных.
Эту форму команды нельзя выполнить внутри блока транзакций.
параметр_конфигурации
значение
Устанавливает сеансовое значение по умолчанию для указанного параметра конфигурации. Если указано значение DEFAULT (или его равнозначный вариант RESET), то предыдущее значение параметра удаляется и в новых сеансах будет действовать значение, взятое из системных настроек по умолчанию. Для сброса всех значений параметров базы данных выполните RESET ALL. SET FROM CURRENT устанавливает значение параметра базы данных из его значения в текущем сеансе.
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
Примечания
Также существует возможность привязать параметры сеанса по умолчанию к определенной роли, а не к базе данных; см. раздел ALTER ROLE. При возникновении конфликта ролевые параметры переопределяют параметры для конкретной базы данных.
Примеры
Отключение сканирования индекса по умолчанию в базе данных test:
ALTER DATABASE test SET enable_indexscan TO off;
Совместимость
Команда ALTER DATABASE является расширением QHB.
См. также
CREATE DATABASE, DROP DATABASE, SET, CREATE TABLESPACE
ALTER DEFAULT PRIVILEGES
ALTER DEFAULT PRIVILEGES — определить права доступа по умолчанию
Синтаксис
ALTER DEFAULT PRIVILEGES
[ FOR { ROLE | USER } целевая_роль [, ...] ]
[ IN SCHEMA имя_схемы [, ...] ]
предложение_GRANT_или_REVOKE
Где предложение_GRANT_или_REVOKE может быть следующим:
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON TABLES
TO { [ GROUP ] имя_роли | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { USAGE | SELECT | UPDATE }
[, ...] | ALL [ PRIVILEGES ] }
ON SEQUENCES
TO { [ GROUP ] имя_роли | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTIONS
TO { [ GROUP ] имя_роли | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON TYPES
TO { [ GROUP ] имя_роли | PUBLIC } [, ...] [ WITH GRANT OPTION ]
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON TABLES
FROM { [ GROUP ] имя_роли | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { USAGE | SELECT | UPDATE }
[, ...] | ALL [ PRIVILEGES ] }
ON SEQUENCES
FROM { [ GROUP ] имя_роли | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTIONS
FROM { [ GROUP ] имя_роли | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON TYPES
FROM { [ GROUP ] имя_роли | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
Описание
Команда ALTER DEFAULT PRIVILEGES позволяет задавать права, которые будут применяться
к объектам, создаваемым в будущем. (Это не влияет на права, назначенные уже
существующим объектам.) В настоящее время права можно задавать только для схем,
таблиц (включая представления и сторонние таблицы), последовательностей, функций
и типов (включая домены). Применительно к данной команде функциями считаются
также агрегатные функции и процедуры. Слова FUNCTIONS и ROUTINES в этой
команде равнозначны. (ROUTINES предпочтительнее в перспективе как стандартный
термин, охватывающий и функции, и процедуры. Задать права по умолчанию для
функций и процедур по отдельности нельзя.)
Изменить права по умолчанию можно только для объектов, которые будут созданы текущим пользователем или ролями, членом которых он является. Права доступа могут быть установлены глобально (т. е. для всех объектов, создаваемых в текущей базе данных) или только для объектов, создаваемых в определенных схемах.
Как объяснено в разделе Права, права по умолчанию для любого типа
объекта обычно предоставляют все назначаемые разрешения владельцу
объекта и могут также предоставлять некоторые права роли PUBLIC.
Однако это поведение можно изменить путем смены глобальных прав по умолчанию
командой ALTER DEFAULT PRIVILEGES.
Права по умолчанию на уровне схемы добавляются к любым глобальным правам по умолчанию, применимым к определенному типу объекта. Иными словами, нельзя отозвать права на уровне схемы, если они назначены глобально (либо по умолчанию, либо в соответствии с предыдущей командой ALTER DEFAULT PRIVILEGES, где схема не указана). На уровне схемы команда REVOKE может быть полезна только для того, чтобы отменять действия предыдущей команды GRANT для этой же схемы.
Параметры
целевая_роль
Имя существующей роли, членом которой является текущая роль. Если FOR ROLE не указано, предполагается текущая роль.
имя_схемы
Имя существующей схемы. Если этот параметр указан, то права доступа по умолчанию изменяются для объектов, которые будут создаваться в этой схеме позднее. Если IN SCHEMA не указано, меняются глобальные права по умолчанию. Нельзя указывать IN SCHEMA при установлении прав для схем, так как схемы не могут быть вложенными.
имя_роли
Имя существующей роли, для которой необходимо предоставить или отозвать права. Этот параметр, а также все остальные параметры в предложении_grant_или_revoke действуют как описано в GRANT или REVOKE, за исключением того, что они распространяются не на один конкретный объект, а на целый класс объектов.
Примечания
Для получения информации о текущих назначениях прав по умолчанию, воспользуйтесь командой \ddp в [qsql]. Интерпретация отображения данных о правах такая же, как приведенная в описании команды \dp в разделе Права.
Если вы хотите удалить роль, права по умолчанию для которой были изменены,
необходимо отменить изменения прав по умолчанию
или воспользоваться командой DROP OWNED BY для упразднения
назначенных для этой роли прав по умолчанию.
Примеры
Добавление права SELECT всем пользователям на все таблицы (и представления), которые будут созданы в будущем в схеме myschema, и добавление роли webuser права INSERT для этих же таблиц:
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema GRANT SELECT ON TABLES TO PUBLIC;
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema GRANT INSERT ON TABLES TO webuser;
Отмена предыдущих изменений, чтобы для таблиц, которые будут созданы в будущем, были определены только обычные права, без дополнительных:
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema REVOKE SELECT ON TABLES FROM PUBLIC;
ALTER DEFAULT PRIVILEGES IN SCHEMA myschema REVOKE INSERT ON TABLES FROM webuser;
Отзыв из общего доступа права EXECUTE (которое обычно выдается для функций) для всех функций, которые будут созданы ролью admin:
ALTER DEFAULT PRIVILEGES FOR ROLE admin REVOKE EXECUTE ON FUNCTIONS FROM PUBLIC;
Однако обратите внимание, что тот же эффект нельзя получить с помощью команды,
ограниченной одной схемой. Эта команда будет действовать, только если она отменяет
соответствующую команду GRANT:
ALTER DEFAULT PRIVILEGES IN SCHEMA public REVOKE EXECUTE ON FUNCTIONS FROM PUBLIC;
Это связано с тем, что права по умолчанию на уровне схемы можно только добавить к правам, назначенным глобально, а отозвать последние нельзя.
Совместимость
В стандарте SQL нет команды ALTER DEFAULT PRIVILEGES.
См. также
ALTER DOMAIN
ALTER DOMAIN — изменить определение домена
Синтаксис
ALTER DOMAIN имя
{ SET DEFAULT выражение | DROP DEFAULT }
ALTER DOMAIN имя
{ SET | DROP } NOT NULL
ALTER DOMAIN имя
ADD ограничение_домена [ NOT VALID ]
ALTER DOMAIN имя
DROP CONSTRAINT [ IF EXISTS ] имя_ограничения [ RESTRICT | CASCADE ]
ALTER DOMAIN имя
RENAME CONSTRAINT имя_ограничения TO имя_нового_ограничения
ALTER DOMAIN имя
VALIDATE CONSTRAINT имя_ограничения
ALTER DOMAIN имя
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER DOMAIN имя
RENAME TO новое_имя
ALTER DOMAIN имя
SET SCHEMA новая_схема
Описание
Команда ALTER DOMAIN изменяет определение существующего домена.
Она имеет несколько форм:
SET/DROP DEFAULT
Эти формы устанавливают или удаляют значение по умолчанию для домена.
Обратите внимание, что значения по умолчанию применяются только к
последующим командам INSERT; они не влияют на строки c данным доменом,
уже находящиеся в таблице.
SET/DROP NOT NULL
Эти формы определяют, будут ли разрешены значения NULL. Установить SET NOT NULL можно, только если столбцы, использующие домен, не содержат нулевых значений.
ADD ограничение_домена [ NOT VALID ]
Эта форма добавляет новое ограничение к домену, используя тот же
синтаксис, который описан в CREATE DOMAIN. При добавлении нового ограничения
домена, все столбцы, использующие этот домен, будут проверены на
соответствие вновь добавленному ограничению. Эти проверки можно
пропустить, если добавить указание NOT VALID; а потом активировать ограничение
с помощью ALTER DOMAIN ... VALIDATE CONSTRAINT.
При добавлении и изменении строк они всегда проверяются по всем
ограничениям, даже тем, которые отмечены NOT VALID. NOT VALID принимается
только для ограничений CHECK.
DROP CONSTRAINT [ IF EXISTS ]
Эта форма удаляет ограничения домена. Если указывается IF EXISTS, а ограничение не существует, это не считается ошибкой. В этом случае выдается предупреждение.
RENAME CONSTRAINT
Эта форма изменяет имя ограничения домена.
VALIDATE CONSTRAINT
Эта форма включает проверку ограничения, ранее добавленного как NOT VALID, то есть проверяет, что все значения в табличных столбцах типа домена удовлетворяют указанному ограничению.
OWNER
Эта форма меняет владельца домена на указанного пользователя.
RENAME
Эта форма изменяет имя домена.
SET SCHEMA
Эта форма изменяет схему домена. Все связанные с доменом ограничения также перемещаются в новую схему.
Чтобы использовать команду ALTER DOMAIN, нужно быть владельцем
соответствующего домена. Чтобы изменить схему домена, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме домена.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания домена.
Однако суперпользователь всё равно может сменить владельца любого домена.)
Параметры
имя
Имя существующего домена, подлежащего изменению (может быть дополнено схемой).
ограничение_домена
Новое ограничение домена.
имя_ограничения
Имя существующего ограничения, которое будет удалено или переименовано.
NOT VALID
Не проверять существующие сохраненные данные на соответствие ограничению.
CASCADE
Автоматически удалять объекты, зависящие от ограничения, и в свою очередь все объекты, зависящие от этих объектов (см. Отслеживание зависимостей).
RESTRICT
Запретить удаление ограничения, если есть какие-либо зависимые от него объекты. Это поведение по умолчанию.
новое_имя
Новое имя домена.
имя_нового_ограничения
Новое имя ограничения.
новый_владелец
Имя пользователя, который станет новым владельцем домена.
новая_схема
Новая схема домена.
Примечания
Несмотря на то, что команда ALTER DOMAIN ADD CONSTRAINT пытается проверить, что
существующие данные удовлетворяют новому ограничению, эта проверка не очень
надежна, поскольку команда не может «видеть» строки таблицы, которые были
только что добавлены или изменены и еще не зафиксированы. Если существует
опасность того, что параллельные операции могут добавлять неверные данные,
можно применить следующий подход: создайте ограничения с указанием NOT VALID,
зафиксируйте эту команду, подождите, пока завершатся все начатые до фиксирования
транзакции, а затем выполните ALTER DOMAIN VALIDATE CONSTRAINT для поиска
данных, нарушающих ограничение. Данный метод надежен, так как после фиксирования
ограничения он будет гарантированно действовать на все новые значения типа домена,
вносимые последующими транзакциями.
В настоящее время ALTER DOMAIN ADD CONSTRAINT, ALTER DOMAIN VALIDATE CONSTRAINT
и ALTER DOMAIN SET NOT NULL завершаются ошибкой, если в какой-либо таблице базы
данных указанный домен или любой производный от него домен используется в столбце
контейнерного типа (составном, диапазонном или массиве). В дальнейшем эти команды будут
доработаны, с тем чтобы проверять новое ограничение и для таких вложенных значений.
Примеры
Добавление ограничения NOT NULL к домену:
ALTER DOMAIN zipcode SET NOT NULL;
Удаление ограничения NOT NULL из домена:
ALTER DOMAIN zipcode DROP NOT NULL;
Добавление ограничения-проверки к домену:
ALTER DOMAIN zipcode ADD CONSTRAINT zipchk CHECK (char_length(VALUE) = 5);
Удаление ограничения-проверки из домена:
ALTER DOMAIN zipcode DROP CONSTRAINT zipchk;
Переименование ограничения-проверки в домене:
ALTER DOMAIN zipcode RENAME CONSTRAINT zipchk TO zip_check;
Перемещение домена в другую схему:
ALTER DOMAIN zipcode SET SCHEMA customers;
Совместимость
Команда ALTER DOMAIN соответствует стандарту SQL, за исключением форм
OWNER, RENAME, SET SCHEMA и VALIDATE CONSTRAINT,
которые являются расширениями QHB. Указание NOT VALID формы
ADD CONSTRAINT также является расширением QHB.
См. также
ALTER EVENT TRIGGER
ALTER EVENT TRIGGER — изменить определение событийного триггера
Синтаксис
ALTER EVENT TRIGGER имя DISABLE
ALTER EVENT TRIGGER имя ENABLE [ REPLICA | ALWAYS ]
ALTER EVENT TRIGGER имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER EVENT TRIGGER имя RENAME TO новое_имя
Описание
Команда ALTER EVENT TRIGGER изменяет свойства существующего событийного триггера.
Чтобы изменить событийный триггер, нужно быть суперпользователем.
Параметры
имя
Имя существующего триггера, подлежащего изменению.
новый_владелец
Имя пользователя, который станет новым владельцем событийного триггера.
новое_имя
Новое имя событийного триггера.
DISABLE/ENABLE [ REPLICA | ALWAYS ] TRIGGER
Эти формы настраивают запуск событийного триггера. Отключенный триггер сохраняется в системе, но не выполняется, когда происходит событие, которое его запускает. См. также session_replication_role.
Совместимость
В стандарте SQL нет команды ALTER EVENT TRIGGER.
См. также
CREATE EVENT TRIGGER, DROP EVENT TRIGGER
ALTER EXTENSION
ALTER EXTENSION — изменить определение расширения
Синтаксис
ALTER EXTENSION имя UPDATE [ TO новая_версия ]
ALTER EXTENSION имя SET SCHEMA новая_схема
ALTER EXTENSION имя ADD элемент_объект
ALTER EXTENSION имя DROP элемент_объект
Где элемент_объект может быть:
ACCESS METHOD имя_объекта |
AGGREGATE имя_агрегатной_функции ( сигнатура_агрегатной_функции ) |
CAST (исходный_тип AS целевой_тип) |
COLLATION имя_объекта |
CONVERSION имя_объекта |
DOMAIN имя_объекта |
EVENT TRIGGER имя_объекта |
FOREIGN DATA WRAPPER имя_объекта |
FOREIGN TABLE имя_объекта |
FUNCTION имя_функции [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
MATERIALIZED VIEW имя_объекта |
OPERATOR имя_оператора (тип_слева, тип_справа) |
OPERATOR CLASS имя_объекта USING индексный_метод |
OPERATOR FAMILY имя_объекта USING индексный_метод |
[ PROCEDURAL ] LANGUAGE имя_объекта |
PROCEDURE имя_процедуры [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
ROUTINE имя_подпрограммы [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
SCHEMA имя_объекта |
SEQUENCE имя_объекта |
SERVER имя_объекта |
TABLE имя_объекта |
TEXT SEARCH CONFIGURATION имя_объекта |
TEXT SEARCH DICTIONARY имя_объекта |
TEXT SEARCH PARSER имя_объекта |
TEXT SEARCH TEMPLATE имя_объекта |
TRANSFORM FOR имя_типа LANGUAGE имя_языка |
TYPE имя_объекта |
VIEW имя_объекта
Где сигнатура_агрегатной_функции:
* |
[ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] |
[ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] ] ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ]
Описание
Команда ALTER EXTENSION изменяет определение установленного расширения.
Она имеет несколько форм:
UPDATE
Эта форма обновляет расширение до более новой версии. Расширение должно предоставить подходящий скрипт (или набор скриптов) обновления, который сможет изменить текущую установленную версию на требуемую.
SET SCHEMA
Эта форма перемещает объекты расширения в другую схему. Для успешного выполнения этой команды расширение должно быть перемещаемым.
ADD элемент_объект
Эта форма добавляет к расширению существующий объект. Указание в основном используется в скриптах обновления расширений. Объект впоследствии будет рассматриваться как часть расширения; в частности, он может быть удален только вместе с расширением.
DROP элемент_объект
Эта форма удаляет объект из расширения. Указание в основном используется в скриптах обновления расширений. Объект при этом не удаляется, а только отделяется от расширения.
Дополнительную информацию об этих операциях см. в разделе Упаковка связанных объектов в расширение.
Чтобы использовать команду ALTER EXTENSION, нужно быть владельцем
соответствующего расширения. Для форм ADD/DROP требуется
также быть владельцем добавляемого/удаляемого объекта.
Параметры
имя
Имя установленного расширения.
новая_версия
Запрашиваемая новая версия расширения. Версию можно указать в виде
идентификатора или строки. Если версия не указана,
ALTER EXTENSION UPDATE попытается обновить расширение
до версии по умолчанию в управляющем файле расширения.
новая_схема
Новая схема расширения.
имя_объекта
имя_агрегатной_функции
имя_функции
имя_оператора
имя_процедуры
имя_подпрограммы
Имя объекта, который будет добавлен или удален из расширения. Имена агрегатных функций, доменов, сторонних таблиц, функций, операторов, классов операторов, семейств операторов, процедур, подпрограмм, последовательностей, объектов текстового поиска, типов и представлений могут дополняться именем схемы.
исходный_тип
Имя исходного типа данных для приведения.
целевой_тип
Имя целевого типа данных для приведения.
режим_аргумента
Режим аргумента функции, процедуры или агрегатной функции: IN, OUT, INOUT или VARIADIC.
Если этот параметр опущен, значение по умолчанию равно IN.
Обратите внимание, что фактически ALTER EXTENSION не обращает
никакого внимания на аргументы OUT, так как для определения идентичности
функции требуются только входные аргументы. Поэтому достаточно перечислить
аргументы IN, INOUT и VARIADIC.
имя_аргумента
Имя аргумента функции, процедуры или агрегатной функции. Обратите внимание, что
фактически ALTER EXTENSION не обращает никакого внимания на имена
аргументов, поскольку для определения идентичности функции необходимы
только типы данных аргументов.
тип_аргумента
Тип данных аргумента функции, процедуры или агрегатной функции.
тип_слева
тип_справа
Типы данных аргументов оператора (могут быть дополнены схемой). При отсутствии аргумента префиксного или постфиксного оператора укажите вместо типа NONE.
PROCEDURAL
Не несет смысловой нагрузки.
имя_типа
Имя типа данных, для которого делается трансформация.
имя_языка
Название языка, для которого делается трансформация.
Примеры
Обновление расширения hstore до версии 2.0:
ALTER EXTENSION hstore UPDATE TO '2.0';
Смена схемы расширения hstore на utils:
ALTER EXTENSION hstore SET SCHEMA utils;
Добавление существующей функции в расширение hstore:
ALTER EXTENSION hstore ADD FUNCTION populate_record(anyelement, hstore);
Совместимость
Команда ALTER EXTENSION является расширением QHB.
См. также
CREATE EXTENSION, DROP EXTENSION
ALTER FOREIGN DATA WRAPPER
ALTER FOREIGN DATA WRAPPER — изменить определение обертки сторонних данных
Синтаксис
ALTER FOREIGN DATA WRAPPER имя
[ HANDLER функция_обработчик | NO HANDLER ]
[ VALIDATOR функция_проверки | NO VALIDATOR ]
[ OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ]) ]
ALTER FOREIGN DATA WRAPPER имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER FOREIGN DATA WRAPPER имя RENAME TO новое_имя
Описание
Команда ALTER FOREIGN DATA WRAPPER изменяет определение обертки сторонних данных.
Первая форма команды изменяет вспомогательные функции или общие
параметры обертки сторонних данных (требуется по крайней мере одно
предложение). Вторая форма меняет владельца обертки сторонних данных.
Только суперпользователи могут изменять обертки сторонних данных и быть их владельцами.
Параметры
имя
Имя существующей обертки сторонних данных.
HANDLER функция_обработчик
Задает новую функцию обработчика для обертки сторонних данных.
NO HANDLER
Используется, чтобы указать что обертка сторонних данных больше не имеет функции обработчика. Обратите внимание, что сторонние таблицы, использующие обертки сторонних данных без функции обработчика, не будут доступны при обращении.
VALIDATOR функция_проверки
Задает новую функцию проверки для обертки сторонних данных.
Обратите внимание, что возможна ситуация, когда предыдущие параметры
обертки сторонних данных, зависимых серверов, сопоставлений пользователей
или сторонних таблиц, окажутся недопустимыми для новой функции проверки.
QHB это не проверяет. Пользователь должен самостоятельно
убедиться, что эти параметры являются правильными, прежде чем
использовать измененную обертку сторонних данных. Однако все параметры,
изменяемые в данной команде ALTER FOREIGN DATA WRAPPER, будут проверены
с помощью новой функции проверки.
NO VALIDATOR
Указывает, что обертка сторонних данных больше не имеет функции проверки.
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] )
Эта форма настраивает параметры обертки сторонних данных. ADD, SE и DROP указывают, какое действие будет выполнено (добавление, установка и удаление соответственно). Если явно не указана никакая операция, по умолчанию подразумевается ADD. Имена параметров должны быть уникальными: они вместе со значениями проверяются функцией проверки, если та установлена.
новый_владелец
Имя пользователя, который станет новым владельцем обертки сторонних данных.
новое_имя
Новое имя обертки сторонних данных.
Примеры
Изменение параметров обертки сторонних данных dbi: добавление параметра foo, удаление bar:
ALTER FOREIGN DATA WRAPPER dbi OPTIONS (ADD foo '1', DROP 'bar');
Установление для обертки сторонних данных dbi новой функции проверки bob.myvalidator:
ALTER FOREIGN DATA WRAPPER dbi VALIDATOR bob.myvalidator;
Совместимость
Команда ALTER FOREIGN DATA WRAPPER соответствует стандарту ISO/IEC 9075-9 (SQL/MED),
за исключением указаний HANDLER, VALIDATOR, OWNER TO и RENAME, являющихся расширениями.
См. также
CREATE FOREIGN DATA WRAPPER, DROP FOREIGN DATA WRAPPER
ALTER FOREIGN TABLE
ALTER FOREIGN TABLE — изменить определение сторонней таблицы
Синтаксис
ALTER FOREIGN TABLE [ IF EXISTS ] [ ONLY ] имя [ * ]
действие [, ... ]
ALTER FOREIGN TABLE [ IF EXISTS ] [ ONLY ] имя [ * ]
RENAME [ COLUMN ] имя_столбца TO новое_имя_столбца
ALTER FOREIGN TABLE [ IF EXISTS ] имя
RENAME TO новое_имя
ALTER FOREIGN TABLE [ IF EXISTS ] имя
SET SCHEMA новая_схема
Где действие может быть следующим:
ADD [ COLUMN ] имя_столбца тип_данных [ COLLATE правило_сортировки ] [ ограничение_столбца [ ... ] ]
DROP [ COLUMN ] [ IF EXISTS ] имя_столбца [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] имя_столбца [ SET DATA ] TYPE тип_данных [ COLLATE правило_сортировки ]
ALTER [ COLUMN ] имя_столбца SET DEFAULT выражение
ALTER [ COLUMN ] имя_столбца DROP DEFAULT
ALTER [ COLUMN ] имя_столбца { SET | DROP } NOT NULL
ALTER [ COLUMN ] имя_столбца SET STATISTICS integer
ALTER [ COLUMN ] имя_столбца SET ( атрибут = значение [, ... ] )
ALTER [ COLUMN ] имя_столбца RESET ( атрибут [, ... ] )
ALTER [ COLUMN ] имя_столбца SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ALTER [ COLUMN ] имя_столбца OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ])
ADD ограничение_таблицы [ NOT VALID ]
VALIDATE CONSTRAINT имя_ограничения
DROP CONSTRAINT [ IF EXISTS ] имя_ограничения [ RESTRICT | CASCADE ]
DISABLE TRIGGER [ имя_триггера | ALL | USER ]
ENABLE TRIGGER [ имя_триггера | ALL | USER ]
ENABLE REPLICA TRIGGER имя_триггера
ENABLE ALWAYS TRIGGER имя_триггера
SET WITHOUT OIDS
INHERIT таблица_родитель
NO INHERIT таблица_родитель
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ])
Описание
Команда ALTER FOREIGN TABLE изменяет определение существующей сторонней таблицы.
Существует несколько форм этой команды:
ADD COLUMN
Эта форма добавляет новый столбец в стороннюю таблицу, используя тот же синтаксис, что и CREATE FOREIGN TABLE. В отличие от случая, когда столбец добавляется в обычную таблицу, при данной операции в базовом хранилище ничего не происходит: это действие просто объявляет, что некоторый новый столбец теперь доступен через стороннюю таблицу.
DROP COLUMN [ IF EXISTS ]
Эта форма удаляет столбец из сторонней таблицы. Нужно написать указание CASCADE, если что-то вне таблицы зависит от столбца (например, представление). Если указано IF EXISTS и столбец не существует, ошибка не происходит, вместо этого будет выдано замечание.
SET DATA TYPE
Эта форма изменяет тип столбца сторонней таблицы. Опять же, это не оказывает никакого влияния на базовое хранилище: это действие просто изменяет тип, который, по мнению QHB, имеет этот столбец.
SET/DROP DEFAULT
Эти формы устанавливают или удаляют значение по умолчанию для столбца.
Значения по умолчанию применяются только в последующих командах
INSERT или UPDATE; они не вызывают изменения уже существующих строк в
таблице.
SET/DROP NOT NULL
Устанавливает, будет ли столбец принимать значения NULL или нет.
SET STATISTICS
Эта форма задает цель сбора статистики для каждого столбца для последующих операций ANALYZE. Дополнительную информацию см. в описании аналогичной формы команды ALTER TABLE.
SET ( атрибут = значение [, ... ] )
RESET ( атрибут [, ... ] )
Эта форма устанавливает или сбрасывает значения для атрибута. Дополнительную информацию см. в описании аналогичной формы команды ALTER TABLE.
SET STORAGE
Эта форма задает режим хранения для столбца. Дополнительную информацию см. в описании аналогичной формы команды ALTER TABLE. Обратите внимание, что режим хранения не имеет никакого влияния, если обертка сторонних данных таблицы будет его игнорировать.
ADD ограничение_таблицы [ NOT VALID ]
Эта форма добавляет новое ограничение в стороннюю таблицу, используя тот же синтаксис, что и CREATE FOREIGN TABLE. В настоящее время поддерживаются только ограничения CHECK.
В отличие от случая, когда ограничение добавляется в обычную таблицу, ограничение сторонней таблицы никак не проверяется; скорее, это действие просто объявляет, что некоторое новое условие должно выполняться для всех строк в сторонней таблице. (См. описание в разделе CREATE FOREIGN TABLE) Если ограничение помечено как NOT VALID, то предполагается, что оно не поддерживается, а записывается для возможного использования в будущем.
VALIDATE CONSTRAINT
Эта форма помечает ограничение, которое ранее было помечено NOT VALID, как проверенное. Никаких действий для проверки ограничения не предпринимается, но будущие запросы будут предполагать, что оно поддерживается.
DROP CONSTRAINT [ IF EXISTS ]
Эта форма удаляет указанное ограничение для сторонней таблицы. Если указано IF EXISTS и ограничение не существует, это не считается ошибкой. В этом случае выдается только замечание.
DISABLE/ENABLE [ REPLICA | ALWAYS ] TRIGGER
Эти формы настраивают срабатывание триггера(ов), принадлежащего(их) сторонней таблице. Дополнительную информацию см. в описании аналогичной формы команды ALTER TABLE.
SET WITHOUT OIDS
Синтаксис обратной совместимости для удаления системного столбца oid. Так как добавить системные столбцы oid теперь невозможно, это указание не действует.
INHERIT таблица_родитель
Эта форма добавляет целевую стороннюю таблицу в качестве нового дочернего элемента указанной родительской таблицы. Дополнительную информацию см. в описании аналогичной формы команды ALTER TABLE.
NO INHERIT таблица_родитель
Эта форма удаляет целевую стороннюю таблицу из списка дочерних элементов указанной родительской таблицы.
OWNER
Эта форма меняет владельца сторонней таблицы на указанного пользователя.
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] )
Изменяет параметры для сторонней таблицы или одного из ее столбцов. ADD, SET и DROP указывают на действие, которое необходимо выполнить. Если явно не указана никакая операция, по умолчанию подразумевается ADD. Повторяющиеся имена параметров не допускаются (хотя иметь одно и то же имя для параметра таблицы и параметра столбца нормально). Имена и значения параметров также проверяются с помощью библиотеки обертки сторонних данных.
RENAME
Формы RENAME изменяют имя сторонней таблицы или имя ее столбца.
SET SCHEMA
Эта форма перемещает стороннюю таблицу в другую схему.
Все действия, кроме RENAME и SET SCHEMA, могут быть объединены в один список и выполнены одновременно. Например, в одной команде можно добавить несколько столбцов и/или изменить тип нескольких столбцов.
Если команда написана в виде ALTER FOREIGN TABLE IF EXISTS ...
и сторонняя таблица не существует, это не считается ошибкой.
В этом случае будет выдано замечание.
Чтобы использовать команду ALTER FOREIGN TABLE, нужно быть владельцем
соответствующей сторонней таблицы. Чтобы изменить схему сторонней таблицы, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь
также должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме сторонней таблицы.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания сторонней таблицы.
Однако суперпользователь всё равно может сменить владельца любой
сторонней таблицы.) Чтобы добавить столбец или изменить тип столбца, помимо этого
необходимо иметь право USAGE для его типа данных.
Параметры
имя
Имя существующей сторонней таблицы (может быть дополнено схемой), подлежащей изменению. Если перед именем таблицы указывается ONLY, изменяется только эта таблица. Если ONLY не указано, будут изменены таблица и все ее потомки (если таковые имеются). После имени таблицы можно также добавить необязательное указание *, чтобы явно обозначить, что изменению подлежат все дочерние таблицы.
имя_столбца
Имя нового или существующего столбца.
новое_имя_столбца
Новое имя существующего столбца.
новое_имя
Новое имя таблицы.
тип_данных
Тип данных нового столбца или новый тип данных для существующего столбца.
ограничение_таблицы
Новое ограничение уровня таблицы для сторонней таблицы.
имя_ограничения
Имя существующего ограничения, подлежащего удалению.
CASCADE
Автоматически удалять объекты, зависящие от удаляемого столбца или ограничения (например, ссылающиеся на столбец представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удаление столбца или ограничения, если есть какие-либо зависимые от них объекты. Это поведение по умолчанию.
имя_триггера
Имя одного триггера, который нужно отключить или включить.
ALL
Отключает или включает все триггеры, принадлежащие сторонней таблице. (Если какие-либо из триггеров являются внутрисистемными, то потребуются права суперпользователя. Сама система не добавляет такие триггеры в сторонние таблицы, но дополнительный код может это сделать.)
USER
Отключает или включает все триггеры, принадлежащие сторонней таблице, кроме внутрисистемных
таблица_родитель
Родительская таблица, с которой будет установлена или разорвана связь у этой сторонней таблицы.
новый_владелец
Имя пользователя, который станет новым владельцем таблицы.
новая_схема
Имя схемы, в которую будет перемещена таблица.
Примечания
Ключевое слово COLUMN не несет смысловой нагрузки, и его можно опустить.
Согласованность со сторонним сервером при добавлении или удалении столбца с помощью функции ADD COLUMN/DROP COLUMN, или добавлении ограничений NOT NULL или CHECK, или изменении типа данных SET DATA TYPE не проверяется. Ответственность за то, чтобы определение таблицы соответствовало удаленной стороне, несет пользователь.
Более полное описание допустимых параметров см. в разделе CREATE FOREIGN TABLE.
Примеры
Установление ограничения NOT NULL для столбца:
ALTER FOREIGN TABLE distributors ALTER COLUMN street SET NOT NULL;
Изменение параметров сторонней таблицы:
ALTER FOREIGN TABLE myschema.distributors
OPTIONS (ADD opt1 'value', SET opt2 'value2', DROP opt3 'value3');
Совместимость
Формы ADD, DROP и SET DATA TYPE соответствуют стандарту SQL.
Другие формы являются расширениями QHB. Кроме того, возможность указать в одной
команде ALTER FOREIGN TABLE несколько операций также является расширением.
Команда ALTER FOREIGN TABLE DROP COLUMN позволяет удалить единственный столбец
сторонней таблицы и оставить таблицу без столбцов.
Это является расширением стандарта SQL, который не допускает существование
сторонних таблиц без столбцов.
См. также
CREATE FOREIGN TABLE, DROP FOREIGN TABLE
ALTER FUNCTION
ALTER FUNCTION — изменить определение функции
Синтаксис
ALTER FUNCTION имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
действие [ ... ] [ RESTRICT ]
ALTER FUNCTION имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
RENAME TO новое_имя
ALTER FUNCTION имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER FUNCTION имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
SET SCHEMA новая_схема
ALTER FUNCTION имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
DEPENDS ON EXTENSION имя_расширения
Где действие может быть следующим:
CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
[ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
PARALLEL { UNSAFE | RESTRICTED | SAFE }
COST стоимость_выполнения
ROWS строк_в_результате
SUPPORT вспомогательная_функция
SET параметр_конфигурации { TO | = } { значение | DEFAULT }
SET параметр_конфигурации FROM CURRENT
RESET параметр_конфигурации
RESET ALL
Описание
Команда ALTER FUNCTION изменяет определение функции.
Чтобы использовать команду ALTER FUNCTION, нужно быть владельцем
соответствующей функции. Чтобы изменить схему функции, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме функции.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания функции.
Однако суперпользователь всё равно может сменить владельца любой функции.)
Параметры
имя
Имя существующей функции (может быть дополнено схемой). Если список аргументов не указан, имя должно быть уникальным в своей схеме.
режим_аргумента
Режим аргумента: IN, OUT, INOUT или VARIADIC. По умолчанию равно IN.
Обратите внимание, что ALTER FUNCTION фактически не обращает никакого
внимания на аргументы OUT, так как для определения идентичности функции
нужны только входные аргументы. Поэтому достаточно перечислить аргументы
IN, INOUT и VARIADIC.
имя_аргумента
Название аргумента. Обратите внимание, что ALTER FUNCTION фактически
не обращает никакого внимания на имена аргументов, так как для
определения идентичности функции необходимы только типы данных
аргументов.
тип_аргумента
Типы данных аргументов функции (могут быть дополнены схемой), если таковые имеются.
новое_имя
Новое имя функции.
новый_владелец
Новый владелец функции. Обратите внимание, что если функция помечена как SECURITY DEFINER, в дальнейшем она будет выполняться от имени нового владельца.
новая_схема
Новая схема функции.
имя_расширения
Имя расширения, от которого должна зависеть функция.
CALLED ON NULL INPUT
RETURNS NULL ON NULL INPUT
STRICT
CALLED ON NULL INPUT изменяет функцию таким образом, чтобы она вызывалась, когда некоторые или все ее аргументы равны NULL. RETURNS NULL ON NULL INPUT или STRICT изменяет функцию таким образом, чтобы она не вызывалась, если какой-либо из ее аргументов равен NULL, а вместо этого автоматически предполагался результат NULL. Дополнительную информацию см. в разделе CREATE FUNCTION.
IMMUTABLE
STABLE
VOLATILE
Устанавливает заданный вариант изменчивости функции. Дополнительную информацию см. в разделе CREATE FUNCTION.
[EXTERNAL] SECURITY INVOKER
[EXTERNAL] SECURITY DEFINER
Устанавливает, является ли функция определяющей контекст безопасности. Ключевое слово EXTERNAL игнорируется для соответствия стандарту SQL. Дополнительную информацию об этой возможности см. в разделе CREATE FUNCTION.
PARALLEL
Устанавливает, будет ли функция считаться безопасной для распараллеливания. Дополнительную информацию см. в разделе CREATE FUNCTION.
LEAKPROOF
Устанавливает, будет ли функция рассматриваться как герметичная. Дополнительную информацию об этой возможности см. в разделе CREATE FUNCTION.
COST стоимость_выполнения
Изменяет ориентировочную стоимость выполнения функции. Дополнительную информацию см. в разделе CREATE FUNCTION.
ROWS строк_в_результате
Изменяет ориентировочное число строк в результате функции, возвращающей множество. Дополнительную информацию см. в разделе CREATE FUNCTION.
SUPPORT вспомогательная_функция
Устанавливает или меняет вспомогательную функцию для планировщика, которая будет использоваться с этой функцией. Дополнительную информацию см. в разделе Информация по оптимизации функций. Чтобы использовать эту функцию, нужно быть суперпользователем.
Имя новой вспомогательной функции является обязательным, поэтому данное
указание нельзя использовать для полного удаления вспомогательной функции.
Если понадобится удаление, используйте CREATE OR REPLACE FUNCTION.
параметр_конфигурации
значение
Добавляет или изменяет установку параметра конфигурации, выполняемую при вызове функции.
Если задано значение DEFAULT или равнозначное указание RESET, локальное
переопределение для функции удаляется, вследствие чего функция выполняется со значением,
установленным в окружении. Для удаления всех установок параметров функции
укажите RESET ALL. SET FROM CURRENT устанавливает для последующих вызовов функции
значение параметра, действующее в момент выполнения ALTER FUNCTION.
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
RESTRICT
Игнорируется для соответствия стандарту SQL.
Примеры
Переименование функции sqrt для типа integer в square_root:
ALTER FUNCTION sqrt(integer) RENAME TO square_root;
Смена владельца функции sqrt для типа integer на joe:
ALTER FUNCTION sqrt(integer) OWNER TO joe;
Смена схемы функции sqrt для типа integer на maths:
ALTER FUNCTION sqrt(integer) SET SCHEMA maths;
Обозначение функции sqrt для типа integer как зависимой от расширения mathlib:
ALTER FUNCTION sqrt(integer) DEPENDS ON EXTENSION mathlib;
Изменение пути поиска, который устанавливается автоматически для функции:
ALTER FUNCTION check_password(text) SET search_path = admin, pg_temp;
Отмена автоматического определения search_path для функции:
ALTER FUNCTION check_password(text) RESET search_path;
Теперь функция будет выполняться с тем путем, который задан в момент вызова.
Совместимость
Эта команда частично совместима с командой ALTER FUNCTION в стандарте SQL.
Стандарт позволяет менять больше свойств функции, но не предоставляет возможности
переименовывать функции, переключать контекст безопасности,
связывать с функциями значения параметров конфигурации,
а также менять владельца, схему и тип изменчивости функции.
Стандарт SQL также требует обязательного наличия слова RESTRICT,
тогда как в QHB оно необязательно.
См. также
CREATE FUNCTION, DROP FUNCTION, ALTER PROCEDURE, ALTER ROUTINE
ALTER GROUP
ALTER GROUP — изменить имя роли или членство
Синтаксис
ALTER GROUP указание_роли ADD USER имя_пользователя [, ... ]
ALTER GROUP указание_роли DROP USER имя_пользователя [, ... ]
Где указание_роли может быть:
имя_роли
| CURRENT_USER
| SESSION_USER
ALTER GROUP имя_группы RENAME TO новое_имя
Описание
Команда ALTER GROUP изменяет атрибуты группы пользователей. Это устаревшая
команда, хотя и всё еще поддерживаемая для обратной совместимости, так как
группы (и пользователи тоже) были заменены более общей концепцией ролей.
Первые два варианта команды добавляют пользователей в группу или удаляют их из группы. (При этом любая роль может фигурировать либо как «пользователь», либо как «группа».) Эти варианты практически эквивалентны командам разрешающим/запрещающим членство в роли «группа», поэтому вместо них рекомендуется использовать GRANT и REVOKE.
Третий вариант команды изменяет названия группы. Он полностью аналогичен команде ALTER ROLE, выполняющей переименование роли.
Параметры
имя_группы
Имя группы (роли), подлежащей изменению.
имя_пользователя
Пользователи (роли), которые должны быть добавлены в группу или удалены из нее.
Пользователи уже должны существовать: ALTER GROUP не создает
и не удаляет пользователей.
новое_имя
Новое имя группы.
Примеры
Добавление пользователей в группу:
ALTER GROUP staff ADD USER karl, john;
Удаление пользователей из группы:
ALTER GROUP workers DROP USER beth;
Совместимость
В стандарте SQL нет команды ALTER GROUP.
См. также
ALTER INDEX
ALTER INDEX — изменить определение индекса
Синтаксис
ALTER INDEX [ IF EXISTS ] имя RENAME TO новое_имя
ALTER INDEX [ IF EXISTS ] имя SET TABLESPACE имя_табличного_пространства
ALTER INDEX имя ATTACH PARTITION имя_индекса
ALTER INDEX имя DEPENDS ON EXTENSION имя_расширения
ALTER INDEX [ IF EXISTS ] имя SET ( параметр_хранения = значение [, ... ] )
ALTER INDEX [ IF EXISTS ] имя RESET ( параметр_хранения [, ... ] )
ALTER INDEX [ IF EXISTS ] имя ALTER [ COLUMN ] номер_столбца
SET STATISTICS целое
ALTER INDEX ALL IN TABLESPACE имя [ OWNED BY имя_роли [, ... ] ]
SET TABLESPACE новое_табличное_пространство [ NOWAIT ]
Описание
Команда ALTER INDEX изменяет определение существующего индекса. Она имеет несколько
форм, которые описаны ниже. Обратите внимание, что требуемый
уровень блокировки может отличаться для каждой формы. Если явно не указано, то
по умолчанию запрашивается блокировка ACCESS EXCLUSIVE. Если перечислено несколько подкоманд,
то запрашивается самая строгая блокировка из требуемых подкомандами.
RENAME
Форма RENAME изменяет имя индекса. Если индекс связан с ограничением таблицы (UNIQUE, PRIMARY KEY или EXCLUDE), то ограничение также переименовывается. Это не оказывает никакого влияния на сохраненные данные.
Переименование индекса требует блокировки SHARE UPDATE EXCLUSIVE.
SET TABLESPACE
Эта форма изменяет табличное пространство индекса на указанное и перемещает файл(ы) данных,
связанный с индексом, в новое табличное пространство. Чтобы изменить табличное
пространство индекса, текущий пользователь должен быть владельцем индекса и иметь право CREATE
в новом табличном пространстве. Все индексы в текущей базе данных в табличном пространстве
можно переместить с помощью формы ALL IN TABLESPACE. При этом индексы блокируются для перемещения,
а затем перемещается каждый индекс. Эта форма также поддерживает OWNED BY,
с которым будут перемещены только индексы, принадлежащие заданным ролям.
Если указана опция NOWAIT, то команда завершится ошибкой, если не
сможет сразу получить все необходимые блокировки. Обратите внимание, что
системные каталоги этой командой перемещены не будут; при
необходимости используйте вызов ALTER DATABASE или явный вызов ALTER INDEX.
См. также CREATE TABLESPACE.
ATTACH PARTITION
Эта форма присоединяет указанный индекс к изменяемому. Указанный индекс должен находиться в партиции таблицы, содержащей изменяемый индекс, и иметь эквивалентное определение. Присоединенный индекс не может быть удален сам по себе и будет автоматически удален при удалении родительского индекса.
DEPENDS ON EXTENSION имя_расширения NO DEPENDS ON EXTENSION имя_расширения
Эта форма помечает индекс как зависящий или более не зависящий от данного расширения, если указано NO. Индекс, помеченный как зависящий от расширения, при его удалении также будет автоматически удален.
SET ( параметр_хранения = значение [, ... ] )
Эта форма изменяет один или несколько специфичных для индексного метода параметров хранения. Дополнительную информацию о доступных параметрах см. в разделе CREATE INDEX. Обратите внимание, что содержимое индекса не будет изменено немедленно; в зависимости от параметров, для получения желаемого эффекта может потребоваться перестроить индекс командой REINDEX.
RESET ( параметр_хранения [, ... ] )
Эта форма сбрасывает один или несколько специфичных для индексного метода параметров хранения
к значениям по умолчанию. Как и в случае с SET, для полного обновления индекса
может потребоваться выполнить REINDEX.
ALTER [ COLUMN ] номер_столбца SET STATISTICS целое
Эта форма задает ориентир сбора статистики по столбцу для последующих операций ANALYZE, хотя ее можно использовать только для индексируемых столбцов, определенных как выражение. Поскольку выражения не имеют уникального имени, на них ссылаются, используя порядковый номер столбца в индексе. Ориентир можно задать в диапазоне от 0 до 10000; кроме того, при установке -1 применяется системное значение по умолчанию (default_statistics_target). Дополнительную информацию об использовании статистики планировщиком запросов QHB см. в разделе Статистика, используемая планировщиком.
Параметры
IF EXISTS
Не считать ошибкой, если индекс не существует. В этом случае должно быть выдано замечание.
номер_столбца
Число, указывающее на порядковый номер столбца в индексе (слева направо).
имя
Имя существующего индекса, подлежащего изменению (может быть дополнено схемой).
новое_имя
Новое имя индекса.
имя_табличного_пространства
Табличное пространство, в которое будет перемещен индекс.
имя_расширения
Имя расширения, от которого будет зависеть индекс.
параметр_хранения
Имя специфичного для индексного метода параметра хранения.
значение
Новое значение специфичного для индексного метода параметра хранения. Это может быть число или строка, в зависимости от параметра.
Примечания
Эти операции также можно выполнить с помощью команды ALTER TABLE.
ALTER INDEX фактически является просто синонимом форм команды ALTER TABLE, которые
применяются к индексам.
Ранее существовала форма ALTER INDEX OWNER, но теперь она
игнорируется (с предупреждением). Владелец индекса должен быть и владельцем таблицы.
Смена владельца таблицы автоматически меняет владельца индекса.
Изменение любой части индекса системного каталога не допускается.
Примеры
Переименование существующего индекса:
ALTER INDEX distributors RENAME TO suppliers;
Перемещение индекса в другое табличное пространство:
ALTER INDEX distributors SET TABLESPACE fasttablespace;
Изменение коэффициента заполнения индекса (предполагается, что это поддерживает индексный метод):
ALTER INDEX distributors SET (fillfactor = 75);
REINDEX INDEX distributors;
Установка ориентира сбора статистики для индекса по выражению:
CREATE INDEX coord_idx ON measured (x, y, (z + t));
ALTER INDEX coord_idx ALTER COLUMN 3 SET STATISTICS 1000;
Совместимость
Команда ALTER INDEX является расширением QHB.
См. также
ALTER LANGUAGE
ALTER LANGUAGE — изменить определение процедурного языка
Синтаксис
ALTER [ PROCEDURAL ] LANGUAGE имя RENAME TO новое_имя
ALTER [ PROCEDURAL ] LANGUAGE имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
Описание
Команда ALTER LANGUAGE изменяет определение процедурного языка. Единственная
ее функция — это переименовать язык или назначить нового владельца.
Чтобы использовать команду ALTER LANGUAGE, нужно быть суперпользователем или владельцем соответствующего языка.
Параметры
имя
Название языка
новое_имя
Новое название языка
новый_владелец
Новый владелец языка
Совместимость
В стандарте SQL нет команды ALTER LANGUAGE.
См. также
CREATE LANGUAGE, DROP LANGUAGE
ALTER LARGE OBJECT
ALTER LARGE OBJECT — изменить определение большого объекта
Синтаксис
ALTER LARGE OBJECT oid_большого_объекта OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
Описание
Команда ALTER LARGE OBJECT изменяет определение большого объекта.
Чтобы использовать команду ALTER LARGE OBJECT, нужно быть владельцем
соответствующего большого объекта. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца.
(Однако суперпользователь всё равно может сменить владельца любого
большого объекта.) В настоящее время единственная функция данной команды —
это назначение нового владельца, поэтому всегда действуют оба ограничения.
Параметры
oid_большого_объекта
OID большого объекта, подлежащего изменению
новый_владелец
Новый владелец большого объекта
Совместимость
В стандарте SQL нет команды ALTER LARGE OBJECT.
См. также
ALTER MATERIALIZED VIEW
ALTER MATERIALIZED VIEW — изменить определение материализованного представления
Синтаксис
ALTER MATERIALIZED VIEW [ IF EXISTS ] имя
действие [, ... ]
ALTER MATERIALIZED VIEW имя
DEPENDS ON EXTENSION имя_расширения
ALTER MATERIALIZED VIEW [ IF EXISTS ] имя
RENAME [ COLUMN ] имя_столбца TO новое_имя_столбца
ALTER MATERIALIZED VIEW [ IF EXISTS ] имя
RENAME TO новое_имя
ALTER MATERIALIZED VIEW [ IF EXISTS ] имя
SET SCHEMA новая_схема
ALTER MATERIALIZED VIEW ALL IN TABLESPACE имя [ OWNED BY имя_роли [, ... ] ]
SET TABLESPACE новое_табличное_пространство [ NOWAIT ]
Где действие может быть следующим:
ALTER [ COLUMN ] имя_столбца SET STATISTICS integer
ALTER [ COLUMN ] имя_столбца SET ( атрибут = значение [, ... ] )
ALTER [ COLUMN ] имя_столбца RESET ( атрибут [, ... ] )
ALTER [ COLUMN ] имя_столбца SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
CLUSTER ON имя_индекса
SET WITHOUT CLUSTER
SET ( параметр_хранения = значение [, ... ] )
RESET ( параметр_хранения [, ... ] )
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
Описание
Команда ALTER MATERIALIZED VIEW изменяет различные расширенные свойства
существующего материализованного представления.
Чтобы использовать команду ALTER MATERIALIZED VIEW, нужно быть владельцем
соответствующего материализованного представления. Чтобы изменить схему
материализованного представления, необходимо помимо этого иметь право CREATE в новой схеме.
Для смены владельца текущий пользователь также должен быть непосредственным или опосредованным
членом новой роли, и эта роль должна иметь право CREATE в схеме материализованного представления.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания материализованного представления.
Однако суперпользователь всё равно может сменить владельца любого материализованного представления.)
Форма DEPENDS ON EXTENSION помечает материализованное представление как зависящее от расширения, поэтому материализованное представление будет автоматически удалено при удалении расширения.
Формы и указания, доступные для команды ALTER MATERIALIZED VIEW, являются подмножеством тех,
что доступны для команды ALTER TABLE, и при использовании для материализованных
представлений имеют то же значение. Дополнительную информацию см. в описании
ALTER TABLE.
Параметры
имя
Имя существующего материализованного представления (может быть дополнено схемой).
имя_столбца
Имя нового или существующего столбца.
имя_расширения
Имя расширения, от которого будет зависеть материализованное представление.
новое_имя_столбца
Новое имя существующего столбца.
новый_владелец
Имя пользователя, который станет новым владельцем материализованного представления.
новое_имя
Новое имя материализованного представления.
новая_схема
Новая схема материализованного представления.
Примеры
Переименование материализованного представления foo в bar:
ALTER MATERIALIZED VIEW foo RENAME TO bar;
Совместимость
Команда ALTER MATERIALIZED VIEW является расширением QHB.
См. также
CREATE MATERIALIZED VIEW, DROP MATERIALIZED VIEW, REFRESH MATERIALIZED VIEW
ALTER OPERATOR CLASS
ALTER OPERATOR CLASS — изменить определение класса операторов
Синтаксис
ALTER OPERATOR CLASS имя USING индексный_метод
RENAME TO новое_имя
ALTER OPERATOR CLASS имя USING индексный_метод
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER OPERATOR CLASS имя USING индексный_метод
SET SCHEMA новая_схема
Описание
Команда ALTER OPERATOR CLASS изменяет определение класса операторов.
Чтобы использовать команду ALTER OPERATOR CLASS, нужно быть владельцем
соответствующего класса оператора. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме класса оператора.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания класса оператора.
Однако суперпользователь всё равно может сменить владельца любого класса оператора.)
Параметры
имя
Имя существующего класса операторов (может быть дополнено схемой).
индексный_метод
Имя индексного метода, для которого предназначен этот класс операторов.
новое_имя
Новое имя класса операторов.
новый_владелец
Новый владелец класса операторов.
новая_схема
Новая схема класса операторов.
Совместимость
В стандарте SQL нет команды ALTER OPERATOR CLASS.
См. также
CREATE OPERATOR CLASS, DROP OPERATOR CLASS, ALTER OPERATOR FAMILY
ALTER OPERATOR FAMILY
ALTER OPERATOR FAMILY — изменить определение семейства операторов
Синтаксис
ALTER OPERATOR FAMILY имя USING индексный_метод ADD
{ OPERATOR номер_стратегии имя_оператора ( тип_операнда, тип_операнда )
[ FOR SEARCH | FOR ORDER BY семейство_сортировки ]
| FUNCTION номер_вспомогательной_функции [ ( тип_операнда [ , тип_операнда ] ) ]
имя_функции [ ( тип_аргумента [, ...] ) ]
} [, ... ]
ALTER OPERATOR FAMILY имя USING индексный_метод DROP
{ OPERATOR номер_стратегии ( тип_операнда [ , тип_операнда ] )
| FUNCTION номер_вспомогательной_функции ( тип_операнда [ , тип_операнда ] )
} [, ... ]
ALTER OPERATOR FAMILY имя USING индексный_метод
RENAME TO новое_имя
ALTER OPERATOR FAMILY имя USING индексный_метод
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER OPERATOR FAMILY имя USING индексный_метод
SET SCHEMA новая_схема
Описание
Команда ALTER OPERATOR FAMILY изменяет определение семейства операторов.
Можно добавлять в семейство операторы и вспомогательные функции,
удалять их оттуда, изменять имя или владельца семейства операторов.
Когда операторы и вспомогательные функции добавляются в семейство операторов командой
ALTER OPERATOR FAMILY, они не становятся частью какого-либо
конкретного класса операторов в семействе, а просто считаются «слабосвязанными» с семейством.
Это свидетельствует о том, что данные операторы и функции семантически совместимы с семейством,
но не требуются для правильного функционирования
какого-либо конкретного индекса. (Операторы и функции, которые действительно
требуются для этого, должны быть объявлены как часть класса операторов,
см. CREATE OPERATOR CLASS.) QHB позволяет в любое время
удалить из семейства слабосвязанные члены, но нельзя удалить члены класса
операторов без удаления всего класса и всех зависящих от него
индексов. Как правило, в классы операторов включаются
операторы и функции одного типа данных, поскольку они необходимы
для поддержки индекса для этого конкретного типа данных, тогда как
операторы и функции перекрестных типов данных становятся слабосвязанными
членами семейства.
Чтобы использовать команду ALTER OPERATOR FAMILY, нужно быть суперпользователем.
(Эти ограничения направлены на то, чтобы ошибочное определение семейства операторов
не вызвало нарушение или даже сбой в работе сервера.)
В настоящее время ALTER OPERATOR FAMILY не проверяет, включает
ли определение семейства операторов все операторы и функции, требуемые
для индексного метода, и образуют ли они целостный набор.
Ответственность за определение допустимого семейства операторов несет пользователь.
Дополнительную информацию см. в разделе Интерфейсные расширения для индексов.
Параметры
имя
Имя существующего семейства операторов (может быть дополнено схемой).
индексный_метод
Имя индексного метода, для которого предназначено это семейство операторов.
номер_стратегии
Номер стратегии индексного метода для оператора, связанного с семейством операторов.
имя_оператора
Имя оператора, связанного с семейством операторов (может быть дополнено схемой).
тип_операнда
В предложении OPERATOR указываются типы данных операнда оператора или NONE,
если это левый или правый унарный оператор. В отличие от сопоставимого синтаксиса в
CREATE OPERATOR CLASS, типы данных операнда всегда должны быть указаны.
В предложении ADD FUNCTION указываются типы данных операнда оператора, который должна поддерживать функция, если они отличаются от входных типов данных функции. Для функций сравнения B-деревьев и хэш-функций указывать тип_операнда необязательно, так как их входные типы данных всегда будут верными. Однако для вспомогательных функций сортировки B-деревьев и всех функций в классах операторов GiST, SP-GiST и GIN необходимо указать типы операндов, с которыми будут использоваться эти функции.
В предложении DROP FUNCTION должны быть указаны типы операндов, для поддержки которых предназначена функция.
семейство_сортировки
Имя существующего семейства операторов btree, описывающего порядок сортировки, связанный с оператором сортировки (может быть дополнено схемой).
Если не указано ни FOR SEARCH (для поиска), ни FOR ORDER BY (для сортировки), то значение по умолчанию равно FOR SEARCH.
номер_вспомогательной_функции
Номер вспомогательной функции индексного метода для функции, связанной с данным семейством операторов
имя_функции
Имя функции, являющейся вспомогательной функцией индексного метода для данного семейства операторов (может быть дополнено схемой). Если список аргументов отсутствует, имя функции должно быть уникальным в ее схеме.
тип_аргумента
Тип(ы) данных параметра функции.
новое_имя
Новое имя семейства операторов.
новый_владелец
Новый владелец семейства операторов.
новая_схема
Новая схема для семейства операторов.
Предложения OPERATOR и FUNCTION могут указываться в любом порядке.
Примечания
Обратите внимание, что в синтаксисе DROP указывается только «слот» в семействе операторов (по номеру стратегии или вспомогательной функции) и входные типы данных. Имя оператора или функции, занимающей слот, не упоминается. Кроме того, для DROP FUNCTION необходимо указать тип(ы) входных данных, который должна поддерживать функция; для индексов GiST, SP-GiST и Gin это может не иметь ничего общего с фактическими типами входных аргументов функции.
Поскольку механизм индексирования не проверяет права на доступ к функциям перед их использованием, включение функции или оператора в семейство операторов равносильно предоставлению права на их выполнение. Это обычно не является проблемой для тех видов функций, которые полезны в семействе операторов.
Операторы не должны реализовываться в функциях на языке SQL. SQL-функция, скорее всего, будет встроена в вызывающий запрос, что помешает оптимизатору распознать, что запрос соответствует индексу.
Примеры
Следующий пример добавляет вспомогательные функции и операторы смешанных типов данных в семейство операторов, уже содержащее классы операторов B-дерева для типов данных int4 и int2.
ALTER OPERATOR FAMILY integer_ops USING btree ADD
-- int4 и int2
OPERATOR 1 < (int4, int2) ,
OPERATOR 2 <= (int4, int2) ,
OPERATOR 3 = (int4, int2) ,
OPERATOR 4 >= (int4, int2) ,
OPERATOR 5 > (int4, int2) ,
FUNCTION 1 btint42cmp(int4, int2) ,
-- int2 и int4
OPERATOR 1 < (int2, int4) ,
OPERATOR 2 <= (int2, int4) ,
OPERATOR 3 = (int2, int4) ,
OPERATOR 4 >= (int2, int4) ,
OPERATOR 5 > (int2, int4) ,
FUNCTION 1 btint24cmp(int2, int4) ;
Удаление этих же элементов:
ALTER OPERATOR FAMILY integer_ops USING btree DROP
-- int4 vs int2
OPERATOR 1 (int4, int2) ,
OPERATOR 2 (int4, int2) ,
OPERATOR 3 (int4, int2) ,
OPERATOR 4 (int4, int2) ,
OPERATOR 5 (int4, int2) ,
FUNCTION 1 (int4, int2) ,
-- int2 vs int4
OPERATOR 1 (int2, int4) ,
OPERATOR 2 (int2, int4) ,
OPERATOR 3 (int2, int4) ,
OPERATOR 4 (int2, int4) ,
OPERATOR 5 (int2, int4) ,
FUNCTION 1 (int2, int4) ;
Совместимость
В стандарте SQL нет команды ALTER OPERATOR FAMILY.
См. также
CREATE OPERATOR FAMILY, DROP OPERATOR FAMILY, CREATE OPERATOR CLASS, ALTER OPERATOR CLASS, DROP OPERATOR CLASS
ALTER OPERATOR
ALTER OPERATOR — изменить определение оператора
Синтаксис
ALTER OPERATOR имя ( { тип_слева | NONE } , { тип_справа | NONE } )
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER OPERATOR имя ( { тип_слева | NONE } , { тип_справа | NONE } )
SET SCHEMA новая_схема
ALTER OPERATOR имя ( { тип_слева | NONE } , { тип_справа | NONE } )
SET ( { RESTRICT = { процедура_ограничения | NONE }
| JOIN = { процедура_соединения | NONE }
} [, ... ] )
Описание
Команда ALTER OPERATOR изменяет определение оператора.
Чтобы использовать команду ALTER OPERATOR, нужно быть владельцем
соответствующего оператора. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме оператора.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания оператора.
Однако суперпользователь всё равно может сменить владельца любого оператора.)
Параметры
имя
Имя существующего оператора (может быть дополнено схемой).
тип_слева
Тип данных левого операнда оператора; укажите NONE, если у оператора нет левого операнда.
тип_справа
Тип данных правого операнда оператора; укажите NONE, если у оператора нет правого операнда.
новый_владелец
Новый владелец оператора.
новая_схема
Новая схема оператора.
процедура_ограничения
Функция оценки селективности ограничения для этого оператора; чтобы удалить существующую функцию оценки, укажите NONE.
процедура_соединения
Функция оценки селективности соединения для этого оператора; чтобы удалить существующую функцию оценки, укажите NONE.
Примеры
Смена владельца нестандартного оператора a @@ b для типа text:
ALTER OPERATOR @@ (text, text) OWNER TO joe;
Смена функций оценки избирательности ограничения и соединения для нестандартного оператора a && b для типа int[]:
ALTER OPERATOR && (_int4, _int4) SET (RESTRICT = _int_contsel, JOIN = _int_contjoinsel);
Совместимость
В стандарте SQL нет команды ALTER OPERATOR.
См. также
CREATE OPERATOR, DROP OPERATOR
ALTER POLICY
ALTER POLICY — изменить определение политики защиты на уровне строк
Синтаксис
ALTER POLICY имя ON имя_таблицы RENAME TO новое_имя
ALTER POLICY имя ON имя_таблицы
[ TO { имя_роли | PUBLIC | CURRENT_USER | SESSION_USER } [, ...] ]
[ USING ( выражение_использования ) ]
[ WITH CHECK ( выражение_проверки ) ]
Описание
Команда ALTER POLICY изменяет определение существующей политики
защиты на уровне строк. Обратите внимание, что ALTER POLICY
разрешает изменить только набор ролей, к которым применяется политика, а также
выражения USING и WITH CHECK. Чтобы изменить
другие свойства политики, такие как команда, к которой она применяется,
либо параметр разрешительная/ограничительная, политика должна
быть удалена и создана заново.
Чтобы использовать команду ALTER POLICY, нужно быть владельцем таблицы, к которой
применяется политика.
Во второй форме ALTER POLICY список ролей, выражение_использования и выражение_проверки
заменяются независимо, если указаны. Если одно из этих условий опущено, соответствующая часть
политики остается неизменной.
Параметры
имя
Имя существующей политики, подлежащей изменению.
имя_таблицы
Имя таблицы, к которой применяется политика (может быть дополнено схемой).
новое_имя
Новое имя для политики.
имя_роли
Роль(и), на которую(ые) действует политика. Одновременно можно указать несколько ролей. Чтобы применить политику ко всем ролям, используйте PUBLIC.
выражение_использования
Выражение USING для политики. Дополнительную информацию см. в разделе CREATE POLICY.
выражение_проверки
Выражение WITH CHECK для политики. Дополнительную информацию см. в разделе CREATE POLICY.
Совместимость
Команда ALTER POLICY является расширением QHB.
См. также
ALTER PROCEDURE
ALTER PROCEDURE — изменить определение процедуры
Синтаксис
ALTER PROCEDURE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
действие [ ... ] [ RESTRICT ]
ALTER PROCEDURE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
RENAME TO новое_имя
ALTER PROCEDURE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER PROCEDURE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
SET SCHEMA новая_схема
ALTER PROCEDURE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
DEPENDS ON EXTENSION имя_расширения
Где действие может быть следующим:
[ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
SET параметр_конфигурации { TO | = } { значение | DEFAULT }
SET параметр_конфигурации FROM CURRENT
RESET параметр_конфигурации
RESET ALL
Описание
Команда ALTER PROCEDURE изменяет определение процедуры.
Чтобы использовать команду ALTER PROCEDURE, нужно быть владельцем
соответствующей процедуры. Чтобы изменить схему процедуры, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме процедуры.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания процедуры.
Однако суперпользователь всё равно может сменить владельца любой
процедуры.)
Параметры
имя
Имя существующей процедуры (может быть дополнено схемой). Если не указан список аргументов, имя должно быть уникальным в ее схеме.
режим_аргумента
Режим аргумента: IN или VARIADIC. По умолчанию равно IN.
имя_аргумента
Название аргумента. Обратите внимание, что ALTER PROCEDURE фактически
не обращает никакого внимания на имена аргументов, поскольку для
определения идентичности процедуры необходимы только типы данных
аргументов.
тип_аргумента
Тип(ы) данных аргументов процедуры (возможно, дополненный(ые) схемой), если таковые имеются.
новое_имя
Новое имя процедуры.
новый_владелец
Новый владелец функции. Обратите внимание, что если процедура помечена как SECURITY DEFINER, в дальнейшем она будет выполняться от имени нового владельца.
новая_схема
Новая схема для процедуры.
имя_расширения
Имя расширения, от которого будет зависеть процедура.
[EXTERNAL] SECURITY INVOKER
[EXTERNAL] SECURITY DEFINER
Устанавливает, является ли процедура определяющей контекст безопасности. Ключевое слово EXTERNAL игнорируется для соответствия стандарту SQL. Дополнительную информацию об этой возможности см. в разделе CREATE PROCEDURE.
параметр_конфигурации
значение
Добавляет или изменяет установку параметра конфигурации, выполняемую при вызове процедуры.
Если задано значение DEFAULT или равнозначное указание RESET,
локальное переопределение для процедуры удаляется и функция выполняется со значением,
установленным в окружении. Для удаления всех установок параметров процедуры
укажите RESET ALL. SET FROM CURRENT устанавливает для последующих вызовов процедуры
значение параметра, действующее в момент выполнения команды ALTER FUNCTION.
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
RESTRICT
Игнорируется для соответствия стандарту SQL.
Примеры
Переименование процедуры insert_data с двумя аргументами типа integer в insert_record:
ALTER PROCEDURE insert_data(integer, integer) RENAME TO insert_record;
Смена владельца процедуры insert_data с двумя аргументами типа integer на joe:
ALTER PROCEDURE insert_data(integer, integer) OWNER TO joe;
Изменение схемы процедуры insert_data с двумя аргументами типа integer на accounting:
ALTER PROCEDURE insert_data(integer, integer) SET SCHEMA accounting;
Обозначение процедуры insert_data(integer, integer) как зависимой от расширения myext:
ALTER PROCEDURE insert_data(integer, integer) DEPENDS ON EXTENSION myext;
Изменение пути поиска, который устанавливается автоматически для процедуры:
ALTER PROCEDURE check_password(text) SET search_path = admin, pg_temp;
Отмена автоматического определения search_path для процедуры:
ALTER PROCEDURE check_password(text) RESET search_path;
Теперь процедура будет выполняться с тем путем, который задан в момент вызова.
Совместимость
Эта команда частично совместима с командой ALTER PROCEDURE в
стандарте SQL. Стандарт позволяет изменять больше свойств процедуры, но
не предоставляет возможности переименовать процедуру, сделать процедуру
определяющей контекст безопасности, связать с процедурой значения параметров
конфигурации или изменить владельца, схему или характеристику изменчивости
процедуры. Стандарт также требует обязательного наличия слова RESTRICT,
которое является необязательным в QHB.
См. также
CREATE PROCEDURE, DROP PROCEDURE, ALTER FUNCTION, ALTER ROUTINE
ALTER PUBLICATION
ALTER PUBLICATION — изменить определение публикации
Синтаксис
ALTER PUBLICATION имя ADD TABLE [ ONLY ] имя_таблицы [ * ] [, ...]
ALTER PUBLICATION имя SET TABLE [ ONLY ] имя_таблицы [ * ] [, ...]
ALTER PUBLICATION имя DROP TABLE [ ONLY ] имя_таблицы [ * ] [, ...]
ALTER PUBLICATION имя SET ( параметр_публикации [= значение] [, ... ] )
ALTER PUBLICATION имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER PUBLICATION имя RENAME TO новое_имя
Описание
Команда ALTER PUBLICATION может изменять атрибуты публикации.
Первые три варианта команды управляют вхождением таблиц в публикации.
Предложение SET TABLE заменяет список таблиц в публикации заданным.
Предложения ADD TABLE и DROP TABLE добавляют и удаляют таблицы
в публикации. Обратите внимание, что для добавления таблиц
в публикацию, на которую уже оформлена подписка, потребуется выполнить действие
ALTER SUBSCRIPTION ... REFRESH PUBLICATION на стороне подписчика,
чтобы это изменение вступило в силу.
Четвертый указанный в синтаксисе вариант этой команды может изменять все свойства публикации, указанные в разделе CREATE PUBLICATION. Свойства, не упомянутые в команде, сохраняют свои предыдущие значения.
Остальные варианты меняют владельца и название публикации.
Чтобы использовать команду ALTER PUBLICATION, нужно быть владельцем
соответствующей публикации. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в базе данных.
Кроме того, новым владельцем публикации FOR ALL TABLES
должен быть суперпользователь. Однако суперпользователь
может сменить владельца публикации, обходя эти ограничения.
Параметры
имя
Название существующей публикации, определение которой подлежит изменению.
имя_таблицы
Имя существующей таблицы. Если перед именем таблицы указывается ONLY, затрагивается только эта таблица. Если ONLY не указано, затрагиваются и эта таблица, и все ее потомки (если таковые имеются). После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что должны затрагиваться и все дочерние таблицы.
SET ( параметр_публикации [= значение] [, ... ] )
Это предложение изменяет параметры публикации, первоначально заданные командой CREATE PUBLICATION (более подробную информацию см. в описании этой команды).
новый_владелец
Имя пользователя, который станет новым владельцем публикации.
новое_имя
Новое имя для публикации.
Примеры
Изменение публикации, чтобы публиковались только удаления и изменения:
ALTER PUBLICATION noinsert SET (publish = 'update, delete');
Добавление таблиц в публикацию:
ALTER PUBLICATION mypublication ADD TABLE users, departments;
Совместимость
Команда ALTER PUBLICATION является расширением QHB.
См. также
CREATE PUBLICATION, DROP PUBLICATION, CREATE SUBSCRIPTION, ALTER SUBSCRIPTION
ALTER ROLE
ALTER ROLE — изменить роль в базе данных
Синтаксис
ALTER ROLE указание_роли [ WITH ] параметр [ ... ]
Где параметр может быть:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT предел_подключений
| [ ENCRYPTED ] PASSWORD 'пароль' | PASSWORD NULL
| VALID UNTIL 'дата_время'
ALTER ROLE имя RENAME TO новое_имя
ALTER ROLE { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] SET параметр_конфигурации { TO | = } { значение | DEFAULT }
ALTER ROLE { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] SET параметр_конфигурации FROM CURRENT
ALTER ROLE { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] RESET параметр_конфигурации
ALTER ROLE { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] RESET ALL
Где указание_роли может быть:
имя_роли
| CURRENT_USER
| SESSION_USER
Описание
Команда ALTER ROLE изменяет атрибуты роли QHB.
Первый указанный в синтаксисе вариант этой команды может изменить большинство атрибутов роли, которые можно задать в CREATE ROLE. (Покрываются все возможные атрибуты, за исключением возможности добавления/удаления членов роли; для этого нужно использовать команды GRANT и REVOKE.) Атрибуты, не упомянутые в команде, сохраняют свои предыдущие параметры. Суперпользователи базы данных могут изменять любые из этих параметров для любой роли. Роли с правом CREATEROLE могут изменять любые из этих параметров, за исключением SUPERUSER, REPLICATION и BYPASSRLS, но только не для ролей суперпользователя и репликации. Обычные пользователи (роли) могут изменить только свой пароль.
Второй вариант меняет название роли. Суперпользователи базы данных могут переименовать любую роль. Роли с правом CREATEROLE могут переименовывать роли, не являющиеся суперпользователями. Текущий пользователь сеанса не может быть переименован. (Если нужно это сделать, подключитесь как другой пользователь.) Так как в паролях с MD5-шифрованием имя роли используется в качестве криптосоли, то при переименовании роли ее пароль очищается, если он был зашифрован MD5.
Остальные варианты изменяют значение по умолчанию конфигурационной переменной,
которое будет распространятся на сеансы роли либо для всех баз данных, либо,
если указано IN DATABASE, только для сеансов в указанной базе данных.
Если вместо имени роли указывается ALL, то значение переменной
распространяется на все роли. Использование ALL с IN DATABASE по сути
равносильно использованию команды ALTER DATABASE ... SET ....
Когда роль впоследствии запустит новый сеанс, указанное значение станет значением по умолчанию, переопределяя все настройки, присутствующие в qhb.conf или полученные из командной строки QHB. Это происходит только во время входа в систему; выполнение SET ROLE или SET SESSION AUTHORIZATION не вызывает установки новых значений конфигурации. Параметры, заданные для всех баз данных, переопределяются установленными для роли параметрами уровня базы данных. Параметры для конкретных баз данных или ролей могут переопределять только суперпользователи.
Суперпользователи могут менять сеансовые значения по умолчанию для любых ролей. Роли с правом CREATEROLE могут изменять значения по умолчанию для ролей, не являющихся суперпользователями. Обычные пользователи (роли) могут устанавливать значения по умолчанию только для себя. Некоторые переменные конфигурации таким способом установить нельзя или можно установить только в том случае, если команду выполняет суперпользователь. Только суперпользователи могут изменять настройки для всех ролей во всех базах данных.
Параметры
имя
Имя роли, атрибуты которой подлежат изменению.
CURRENT_USER
Изменяет текущего пользователя вместо явно определенной роли.
SESSION_USER
Изменяет текущего пользователя сеанса вместо явно определенной роли.
SUPERUSER
NOSUPERUSER
CREATEDB
NOCREATEDB
CREATEROLE
NOCREATEROLE
INHERIT
NOINHERIT
LOGIN
NOLOGIN
REPLICATION
NOREPLICATION
BYPASSRLS
NOBYPASSRLS
CONNECTION LIMIT предел_подключений
[ ENCRYPTED ] PASSWORD 'пароль'
PASSWORD NULL
VALID UNTIL 'дата_время'
Эти предложения изменяют атрибуты, изначально заданные с помощью команды CREATE ROLE.
Дополнительную информацию см. в разделе CREATE ROLE.
новое_имя
Новое имя роли.
имя_базы_данных
Имя базы данных, в которой должна быть установлена переменная конфигурации.
параметр_конфигурации
значение
Устанавливает заданное значение по умолчанию в сеансах этой роли для указанного параметра конфигурации. Если значение задано как DEFAULT или, что равнозначно, используется указание RESET, настройка переменной на уровне роли удаляется, то есть в новых сеансах роль будет наследовать системную настройку по умолчанию. Чтобы очистить все настройки роли, используйте указание RESET ALL. SET FROM CURRENT сохраняет текущее значение параметра сеанса в качестве значения для роли. Если указано IN DATABASE, параметр конфигурации устанавливается или удаляется только для заданной роли и базы данных.
Настройки переменных для роли применяются только при входе в систему; команды SET ROLE и SET SESSION AUTHORIZATION эти определения не обрабатывают.
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
Примечания
Для добавления новых ролей используйте команду CREATE ROLE, а для удаления — DROP ROLE.
ALTER ROLE не управляет членством роли, для этого применяются команды GRANT и REVOKE.
При указании с помощью этой команды незашифрованного пароля необходимо
соблюдать осторожность. Пароль будет передан на сервер в виде открытого
текста, а также может быть зарегистрирован в журнале команд клиента
или журнале сервера. qsql содержит команду
\\password, которая может быть использована для изменения пароля
роли без предоставления открытого текста пароля.
Кроме того, можно привязать сеанс по умолчанию к определенной базе данных, а не к роли; см. раздел ALTER DATABASE. В случае возникновения конфликта параметры для базы данных и роли переопределяют параметры только для роли, которые в свою очередь переопределяют параметры только для базы данных.
Примеры
Изменение пароля роли:
ALTER ROLE davide WITH PASSWORD 'hu8jmn3';
Удаление пароля роли:
ALTER ROLE davide WITH PASSWORD NULL;
Изменение срока действия пароля указанием, что пароль должен перестать действовать в полдень 4 мая 2015 г. в часовом поясе UTC+1):
ALTER ROLE chris VALID UNTIL 'May 4 12:00:00 2015 +1';
Установка бесконечного срока действия пароля:
ALTER ROLE fred VALID UNTIL 'infinity';
Добавление роли прав на создание других ролей и новых баз данных:
ALTER ROLE miriam CREATEROLE CREATEDB;
Определение нестандартного значения параметра maintenance_work_mem для роли:
ALTER ROLE worker_bee SET maintenance_work_mem = 100000;
Определение нестандартного значения параметра client_min_messages для роли и заданной базы:
ALTER ROLE fred IN DATABASE devel SET client_min_messages = DEBUG;
Совместимость
Команда ALTER ROLE является расширением QHB.
См. также
CREATE ROLE, DROP ROLE, ALTER DATABASE, SET
ALTER ROUTINE
ALTER ROUTINE — изменить определение подпрограммы
Синтаксис
ALTER ROUTINE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
действие [ ... ] [ RESTRICT ]
ALTER ROUTINE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
RENAME TO новое_имя
ALTER ROUTINE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER ROUTINE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
SET SCHEMA новая_схема
ALTER ROUTINE имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ]
DEPENDS ON EXTENSION имя_расширения
Где действие может быть следующим:
IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
[ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
PARALLEL { UNSAFE | RESTRICTED | SAFE }
COST стоимость_выполнения
ROWS строк_в_результате
SET параметр_конфигурации { TO | = } { значение | DEFAULT }
SET параметр_конфигурации FROM CURRENT
RESET параметр_конфигурации
RESET ALL
Описание
Команда ALTER ROUTINE изменяет определение подпрограммы, которая может быть
агрегатной функцией, нормальной функцией или процедурой. Описание параметров,
дополнительные примеры и сведения см. в разделах
ALTER AGGREGATE, ALTER FUNCTION и ALTER PROCEDURE.
Примеры
Переименование подпрограммы foo для типа integer в foobar:
ALTER ROUTINE foo(integer) RENAME TO foobar;
Эта команда будет работать независимо от того, является ли foo процедурой, агрегатной или обычной функцией.
Совместимость
Эта команда частично совместима с командой ALTER ROUTINE в
стандарте SQL. Дополнительную информацию см. в разделах ALTER FUNCTION и ALTER PROCEDURE.
Возможность сослаться по имени подпрограммы на агрегатную функцию является расширением QHB.
См. также
ALTER AGGREGATE, ALTER FUNCTION, ALTER PROCEDURE, DROP ROUTINE
Обратите внимание, что команды CREATE ROUTINE нет.
ALTER RULE
ALTER RULE — изменить определение правила
Синтаксис
ALTER RULE имя ON имя_таблицы RENAME TO новое_имя
Описание
Команда ALTER RULE изменяет свойства существующего правила. В
настоящее время единственным доступным действием является изменение
имени правила.
Чтобы использовать команду ALTER RULE, нужно быть владельцем таблицы или
представления, к которым применяется правило.
Параметры
имя
Имя существующего правила, подлежащего изменению.
имя_таблицы
Имя таблицы или представления, к которым применяется правило (может быть дополнено схемой).
новое_имя
Новое имя правила.
Примеры
Переименование существующего правила:
ALTER RULE notify_all ON emp RENAME TO notify_me;
Совместимость
Команда ALTER RULE является расширением QHB, как и вся система
перезаписи запросов.
См. также
ALTER SCHEMA
ALTER SCHEMA — изменить определение схемы
Синтаксис
ALTER SCHEMA имя RENAME TO новое_имя
ALTER SCHEMA имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
Описание
Команда ALTER SCHEMA изменяет определение схемы.
Чтобы использовать команду ALTER SCHEMA, нужно быть владельцем
соответствующей схемы. Чтобы переименовать схему, необходимо помимо этого
иметь право CREATE в базе данных. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в базы данных.
(Обратите внимание, что суперпользователи имеют все эти права автоматически.)
Параметры
имя
Имя существующей схемы.
новое_имя
Новое имя схемы. Новое имя не может начинаться с pg_, поскольку такие имена зарезервированы для системных схем.
новый_владелец
Новый владелец схемы.
Совместимость
В стандарте SQL нет команды ALTER SCHEMA.
См. также
ALTER SEQUENCE
ALTER SEQUENCE — изменить определение генератора последовательности
Синтаксис
ALTER SEQUENCE [ IF EXISTS ] имя
[ AS тип_данных ]
[ INCREMENT [ BY ] шаг ]
[ MINVALUE мин_значение | NO MINVALUE ] [ MAXVALUE макс_значение | NO MAXVALUE ]
[ START [ WITH ] начало ]
[ RESTART [ [ WITH ] перезапуск ] ]
[ CACHE кэш ] [ [ NO ] CYCLE ]
[ OWNED BY { имя_таблицы.имя_столбца | NONE } ]
ALTER SEQUENCE [ IF EXISTS ] имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER SEQUENCE [ IF EXISTS ] имя RENAME TO новое_имя
ALTER SEQUENCE [ IF EXISTS ] имя SET SCHEMA новая_схема
Описание
Команда ALTER SEQUENCE изменяет параметры существующего генератора
последовательности. Все параметры, не заданные в
ALTER SEQUENCE, сохраняют свои предыдущие настройки.
Чтобы использовать команду ALTER SEQUENCE, нужно быть владельцем
соответствующей последовательности. Чтобы изменить схему последовательности, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь
также должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме последовательности.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания последовательности.
Однако суперпользователь всё равно может сменить владельца любой последовательности.)
Параметры
имя
Имя последовательности, подлежащей изменению (может быть дополнено схемой).
IF EXISTS
Не считать ошибкой, если последовательности не существует. В этом случае будет выдано замечание.
тип_данных
Необязательное предложение AS тип_данных меняет тип данных последовательности. Допустимые типы: smallint, integer и bigint.
Изменение типа данных автоматически изменяет минимальное и максимальное значения последовательности тогда и только тогда, когда предыдущие минимальное и максимальное значения были минимальным или максимальным значением старого типа данных (другими словами, если последовательность была создана с использованием NO MINVALUE или NO MAXVALUE, явно или неявно). В противном случае минимальное и максимальное значения сохраняются, если в рамках этой же команды не заданы новые значения. Если минимальное и максимальное значения не укладываются в новый тип данных, будет выдана ошибка.
шаг
Предложение INCREMENT BY шаг является необязательным. Положительное значение шага генерирует возрастающую последовательность, отрицательное — убывающую. Если не указано, будет сохранено старое значение шага.
мин_значение NO MINVALUE
Необязательное предложение MINVALUE мин_значение определяет минимальное значение, которое может генерировать последовательность. Если указано NO MINVALUE, то для возрастающей последовательности по умолчанию будет использоваться 1, а для убывающей — минимальное число для ее типа данных. Если ничего не указано, будет сохранено текущее минимальное значение.
макс_значение
NO MAXVALUE
Необязательное предложение MAXVALUE макс_значение определяет максимальное значение для последовательности. Если указано NO MAXVALUE, то для возрастающей последовательности по умолчанию будет использоваться максимальное число для ее типа данных, а для убывающей — -1. Если ничего не указано, будет сохранено текущее максимальное значение.
начало
Необязательное предложение *START WITH _начало_8 меняет записанное начальное
значение последовательности. Это не влияет на текущее значение
последовательности; оно просто задает значение, которое будут использовать
будущие команды ALTER SEQUENCE RESTART.
перезапуск
Необязательное предложение RESTART [ WITH перезапуск ] меняет текущее значение
последовательности. Это похоже на вызов функции setval параметром is_called = false:
указанное значение будет возвращено при следующем вызове функции nextval. Если
в предложении RESTART отсутствует значение перезапуск, будет выставлено
начальное значение, которое было указано при выполнении CREATE SEQUENCE или
установлено последним при выполнении ALTER SEQUENCE START WITH.
В отличие от вызова функции setval, операция RESTART над последовательностью является транзакционной и блокирует параллельным транзакциям возможность получать номера из той же последовательности. Если этот режим работы не устраивает, следует воспользоваться функцией setval.
Кэш
Предложение CACHE кэш позволяет заранее распределять и хранить в памяти последовательные номера для быстрого доступа. Минимальное значение равно 1 (за один раз может быть сгенерировано только одно значение, т. е. нет кэша). Если не указано, будет сохранено старое значение кэша.
CYCLE
Необязательный параметр CYCLE можно использовать для того, чтобы зациклить последовательность при достижении макс_значения или мин_значения для возрастающей и убывающей последовательности соответственно. Если предел достигнут, то следующим сгенерированным номером будет мин_значение или макс_значение соответственно.
NO CYCLE
Если указано NO CYCLE, то после того, как последовательность достигнет своего максимального значения, при каждом вызове функции nextval будет возвращена ошибка. Если указания CYCLE и NO CYCLE отсутствуют, сохраняется предыдущее поведение зацикливания.
OWNED BY имя_таблицы.имя_столбца
OWNED BY NONE
Указание OWNED BY связывает последовательность с определенным столбцом таблицы, чтобы при удалении этого столбца (или всей таблицы) последовательность также была автоматически удалена. Это указание заменяет любую ранее установленную связь данной последовательности. Указанная таблица должна иметь того же владельца и находиться в той же схеме, что и последовательность. Указание OWNED BY NONE удаляет все существующие связи, делая последовательность «независимой».
новый_владелец
Имя пользователя нового владельца последовательности.
новое_имя
Новое имя последовательности.
новая_схема
Новая схема последовательности.
Примечания
Команда ALTER SEQUENCE не сразу повлияет на результаты, возвращаемые nextval в серверных процессах,
отличных от текущего, которые могли предварительно сгенерировать
(кэшировать) значения последовательности. Эти процессы заметят изменение параметров
генерации последовательности только после того, как израсходуют все кэшированные значения.
Текущий сервер отреагирует на изменения немедленно.
ALTER SEQUENCE не влияет на статус currval для последовательности.
ALTER SEQUENCE блокирует параллельные вызовы nextval, currval, lastval и setval.
По историческим причинам ALTER TABLE также может работать с
последовательностями, но все разновидности ALTER TABLE, допустимые для
управления последовательностями, равнозначны вышеперечисленным формам.
Примеры
Перезапуск последовательности serial с числа 105:
ALTER SEQUENCE serial RESTART WITH 105;
Совместимость
Команда ALTER SEQUENCE соответствует стандарту SQL, за исключением указаний
AS, START WITH, OWNED BY, OWNER TO, RENAME TO и SET SCHEMA,
которые являются расширениями QHB.
См. также
CREATE SEQUENCE, DROP SEQUENCE
ALTER SERVER
ALTER SERVER — изменить определение стороннего сервера
Синтаксис
ALTER SERVER имя [ VERSION 'новая_версия' ]
[ OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] ) ]
ALTER SERVER имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER SERVER имя RENAME TO новое_имя
Описание
Команда ALTER SERVER изменяет определение стороннего сервера. Первая форма
изменяет строку версии сервера или его общие параметры (требуется по
крайней мере одно предложение). Вторая форма меняет владельца сервера.
Чтобы изменить сервер, нужно быть его владельцем. Кроме того, для смены владельца нужно владеть сервером, а также быть непосредственным или опосредованным членом новой роли-владельца, и эта роль должна иметь право USAGE для обертки сторонних данных сервера. (Обратите внимание, что суперпользователи удовлетворяют всем этим критериям автоматически.)
Параметры
имя
Имя существующего сервера.
новая версия
Новая версия сервера.
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] )
Формы, изменяющие параметры сервера. ADD, SET и DROP указывают действие, которое необходимо выполнить. Если явно не указана ни одна операция, то по умолчанию предполагается AD. Имена параметров должны быть уникальными; имена и значения проверяются с помощью библиотеки обертки сторонних данных сервера.
новый_владелец
Имя пользователя, который станет новым владельцем стороннего сервера.
новое_имя
Новое имя для стороннего сервера.
Примеры
Изменение свойств сервера foo, добавление параметров подключения:
ALTER SERVER foo OPTIONS (host 'foo', dbname 'foodb');
Изменение свойств сервера foo, смена версии, изменение параметра host:
ALTER SERVER foo VERSION '8.4' OPTIONS (SET host 'baz');
Совместимость
Команда ALTER SERVER соответствует стандарту ISO/IEC 9075-9 (SQL/MED). Формы
OWNER TO и RENAME являются расширениями QHB.
См. также
ALTER STATISTICS
ALTER STATISTICS — изменить определение объекта расширенной статистики
Синтаксис
ALTER STATISTICS имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER STATISTICS имя RENAME TO новое_имя
ALTER STATISTICS имя SET SCHEMA новая_схема
ALTER STATISTICS имя SET STATISTICS новый_ориентир
Описание
Команда ALTER STATISTICS изменяет параметры существующего
объекта расширенной статистики. Все параметры, не заданные в
ALTER STATISTICS, сохраняют свои предыдущие значения.
Чтобы использовать команду ALTER STATISTICS, нужно быть владельцем соответствующего объекта
статистики. Чтобы изменить схему объекта статистики, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме объекта статистики.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания объекта статистики.
Однако суперпользователь всё равно может сменить владельца любого
объекта статистики.)
Параметры
имя
Имя объекта статистики, подлежащего изменению (может быть дополнено схемой).
новый_владелец
Имя пользователя, который станет новым владельцем объекта статистики.
новое_имя
Новое имя объекта статистики.
новая_схема
Новая схема объекта статистики.
новый_ориентир Ориентир сбора статистики для данного объекта статистики для последующих операций ANALYZE. Значение ориентира можно задать в диапазоне от 0 до 10 000; также его можно установить равным -1 для возврата к использованию максимального из ориентиров статистики целевых столбцов (если таковые заданы) или к системному ориентиру статистики по умолчанию (default_statistics_target). Более подробную информацию об использовании статистики планировщиком запросов QHB см. в разделе Статистика, используемая планировщиком.
Совместимость
В стандарте SQL нет команды ALTER STATISTICS.
См. также
CREATE STATISTICS, DROP STATISTICS
ALTER SUBSCRIPTION
ALTER SUBSCRIPTION — изменить определение подписки
Синтаксис
ALTER SUBSCRIPTION имя CONNECTION 'строка_подключения'
ALTER SUBSCRIPTION имя SET PUBLICATION имя_публикации [, ...] [ WITH ( параметр_set_publication [= значение] [, ... ] ) ]
ALTER SUBSCRIPTION имя REFRESH PUBLICATION [ WITH ( параметр_обновления [= значение] [, ... ] ) ]
ALTER SUBSCRIPTION имя ENABLE
ALTER SUBSCRIPTION имя DISABLE
ALTER SUBSCRIPTION имя SET ( параметр_подписки [= значение] [, ... ] )
ALTER SUBSCRIPTION имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER SUBSCRIPTION имя RENAME TO новое_имя
Описание
Команда ALTER SUBSCRIPTION может менять большинство свойств подписки,
которые можно указать в команде CREATE SUBSCRIPTION.
Чтобы использовать команду ALTER SUBSCRIPTION, нужно быть владельцем соответствующей подписки.
Для смены владельца текущий пользователь также должен быть непосредственным или опосредованным
членом новой роли-владельца. Новый владелец должен быть суперпользователем.
(В настоящее время все владельцы подписок должны быть суперпользователями, поэтому на практике
проверка владельца будет пропущена. Но в будущем это может измениться.)
Параметры
имя
Имя подписки, свойства которой подлежат изменению.
CONNECTION 'строка_подключения'
Это предложение изменяет свойство соединения, первоначально заданное командой CREATE SUBSCRIPTION. Дополнительную информацию см. в описании этой команды.
SET PUBLICATION имя_публикации
Изменяет список публикаций, на которые оформлена подписка. Дополнительную информацию см. в разделе CREATE SUBSCRIPTION. По умолчанию эта команда также будет действовать как REFRESH PUBLICATION.
В указании параметр_set_publication задаются дополнительные свойства этой операции. Поддерживаемые параметры:
При значении false команда не будет пытаться обновить информацию о таблицах. После этого REFRESH PUBLICATION следует выполнять отдельно. Значение по умолчанию равно true.
Кроме того, здесь могут задаваться параметры обновления, перечисленные в описании REFRESH PUBLICATION.
REFRESH PUBLICATION
Считывает недостающую информацию о таблицах с публикующего сервера. Это приводит к
запуску репликации таблиц, добавленных в публикации, на которые
оформлена подписка, после последнего вызова REFRESH PUBLICATION или CREATE SUBSCRIPTION.
В указании параметр_обновления задаются дополнительные свойства операции обновления. Поддерживаемые параметры:
Указывает, следует ли копировать существующие данные в публикациях, на которые оформляется подписка, после запуска репликации. Значение по умолчанию равно true. (Таблицы, на которые уже оформлена подписка, не копируются.)
ENABLE
Включает ранее отключенную подписку, запуская процесс логической репликации в конце транзакции.
DISABLE
Отключает запущенную подписку, останавливая процесс логической репликации в конце транзакции.
SET ( параметр_подписки [= значение] [, ... ] )
Это предложение изменяет параметры, первоначально заданные с помощью команды CREATE SUBSCRIPTION. Допустимые параметры: slot_name и synchronous_commit
новый_владелец
Имя пользователя, который станет новым владельцем подписки.
новое_имя
Новое имя подписки.
Примеры
Изменение подписки путем подписывания на публикацию insert_only:
ALTER SUBSCRIPTION mysub SET PUBLICATION insert_only;
Отключение (остановка) подписки:
ALTER SUBSCRIPTION mysub DISABLE;
Совместимость
Команда ALTER SUBSCRIPTION является расширением QHB.
См. также
CREATE SUBSCRIPTION, DROP SUBSCRIPTION, CREATE PUBLICATION, ALTER PUBLICATION
ALTER SYSTEM
ALTER SYSTEM — изменить параметр конфигурации сервера
Синтаксис
ALTER SYSTEM SET параметр_конфигурации { TO | = } { значение | 'значение' | DEFAULT }
ALTER SYSTEM RESET параметр_конфигурации
ALTER SYSTEM RESET ALL
Описание
Команда ALTER SYSTEM используется для изменения параметров конфигурации
сервера во всем кластере баз данных. Это может быть более удобным, чем
традиционный метод ручного редактирования файла qhb.conf. ALTER SYSTEM
записывает заданную настройку параметра в файл qhb.auto.conf,
который считывается в дополнение к qhb.conf. При указании в качестве значения параметра DEFAULT
или применении варианта RESET соответствующий элемент конфигурации удаляется из
файла qhb.auto.conf. Указание RESET ALL удаляет все настроенные таким способом параметры.
Значения, установленные с помощью ALTER SYSTEM, будут действовать
после следующей перезагрузки конфигурации сервера или после перезагрузки
сервера (в случае, если параметры можно изменить только при
запуске сервера). Дать команду на перезагрузку конфигурации сервера можно путем
вызова SQL-функции pg\_reload\_conf(), выполнения qhb_ctl reload
или отправки главному серверному процессу сигнала SIGHUP.
Использовать команду ALTER SYSTEM могут только суперпользователи.
Кроме того, поскольку эта команда действует непосредственно на файловую
систему и не может быть отменена, ее нельзя помещать в блок
транзакций или в функцию.
Параметры
параметр_конфигурации
Имя настраиваемого параметра конфигурации. Доступные параметры описаны в главе Конфигурация сервера.
значение
Новое значение параметра. Значения могут быть указаны в виде строковых констант, идентификаторов, чисел или разделенных запятыми списков из них, в зависимости от конкретного параметра. Если в качестве значения указать DEFAULT, параметр и его значение удаляется из qhb.auto.conf.
Примечания
Эту команду нельзя использовать для установки [data_directory] или параметров, которые не допустимы в qhb.conf (например, Предустановленные параметры).
Другие способы задания параметров см. в разделе Настройка параметров.
Примеры
Установка уровня ведения журнала транзакций (wal_level):
ALTER SYSTEM SET wal_level = replica;
Отмена этого изменения, восстановление значения, заданного в qhb.conf:
ALTER SYSTEM RESET wal_level;
Совместимость
Команда ALTER SYSTEM является расширением QHB.
См. также
ALTER TABLESPACE
ALTER TABLESPACE — изменить определение табличного пространства
Синтаксис
ALTER TABLESPACE имя RENAME TO новое_имя
ALTER TABLESPACE имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER TABLESPACE имя SET ( параметр_табличного_пространства = значение [, ... ] )
ALTER TABLESPACE имя RESET ( параметр_табличного_пространства [, ... ] )
Описание
Команда ALTER TABLESPACE изменяет определение табличного пространства.
Чтобы изменить определение табличного пространства, нужно быть владельцем соответствующего табличного пространства. Для смены владельца текущий пользователь также должен быть непосредственным или опосредованным членом новой роли-владельца. (Обратите внимание, что суперпользователи имеют эти права автоматически.)
Параметры
имя
Имя существующего табличного пространства.
новое_имя
Новое имя табличного пространства. Новое имя не может начинаться с pg_, поскольку такие имена зарезервированы для системных табличных пространств.
новый_владелец
Новый владелец табличного пространства.
параметр_табличного_пространства
Параметр табличного пространства, который необходимо установить или сбросить. В настоящее время доступны только следующие параметры: seq_page_cost, random_page_cost, effective_io_concurrency и maintenance_io_concurrency. Установка любого значения для табличного пространства переопределит обычную оценку планировщиком стоимости чтения страниц из таблиц в этом пространстве, установленную параметрами конфигурации с тем же именем (см. seq_page_cost, random_page_cost, effective_io_concurrency, maintenance_io_concurrency). Это может быть полезно, если одно из табличных пространств расположено на диске, который быстрее или медленнее, чем остальная дисковая система.
Примеры
Переименование табличного пространства index_space в fast_raid:
ALTER TABLESPACE index_space RENAME TO fast_raid;
Смена владельца табличного пространства index_space:
ALTER TABLESPACE index_space OWNER TO mary;
Совместимость
В стандарте SQL нет команды ALTER TABLESPACE.
См. также
CREATE TABLESPACE, DROP TABLESPACE
ALTER TABLE
ALTER TABLE — изменить определение таблицы
Синтаксис
ALTER TABLE [ IF EXISTS ] [ ONLY ] имя [ * ]
действие [, ... ]
ALTER TABLE [ IF EXISTS ] [ ONLY ] имя [ * ]
RENAME [ COLUMN ] имя_столбца TO новое_имя_столбца
ALTER TABLE [ IF EXISTS ] [ ONLY ] имя [ * ]
RENAME CONSTRAINT имя_ограничения TO имя_нового_ограничения
ALTER TABLE [ IF EXISTS ] имя
RENAME TO новое_имя
ALTER TABLE [ IF EXISTS ] имя
SET SCHEMA новая_схема
ALTER TABLE ALL IN TABLESPACE имя [ OWNED BY имя_роли [, ... ] ]
SET TABLESPACE новое_табличное_пространство [ NOWAIT ]
ALTER TABLE [ IF EXISTS ] имя
ATTACH PARTITION имя_партиции { FOR VALUES указание_границ_партиции | DEFAULT }
ALTER TABLE [ IF EXISTS ] имя
DETACH PARTITION имя_партиции
Где действие может быть следующим:
ADD [ COLUMN ] [ IF NOT EXISTS ] имя_столбца тип_данных [ COLLATE правило_сортировки ] [ ограничение_столбца [ ... ] ]
DROP [ COLUMN ] [ IF EXISTS ] имя_столбца [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] имя_столбца [ SET DATA ] TYPE тип_данных [ COLLATE правило_сортировки ] [ USING выражение ]
ALTER [ COLUMN ] имя_столбца SET DEFAULT выражение
ALTER [ COLUMN ] имя_столбца DROP DEFAULT
ALTER [ COLUMN ] имя_столбца { SET | DROP } NOT NULL
ALTER [ COLUMN ] имя_столбца DROP EXPRESSION [ IF EXISTS ]
ALTER [ COLUMN ] имя_столбца ADD GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( параметры_последовательности ) ]
ALTER [ COLUMN ] имя_столбца { SET GENERATED { ALWAYS | BY DEFAULT } | SET параметр_последовательности | RESTART [ [ WITH ] перезапуск ] } [...]
ALTER [ COLUMN ] имя_столбца DROP IDENTITY [ IF EXISTS ]
ALTER [ COLUMN ] имя_столбца SET STATISTICS integer
ALTER [ COLUMN ] имя_столбца SET ( атрибут = значение [, ... ] )
ALTER [ COLUMN ] имя_столбца RESET ( атрибут [, ... ] )
ALTER [ COLUMN ] имя_столбца SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ADD ограничение_таблицы [ NOT VALID ]
ADD ограничение_таблицы_по_индексу
ALTER CONSTRAINT имя_ограничения [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
VALIDATE CONSTRAINT имя_ограничения
DROP CONSTRAINT [ IF EXISTS ] имя_ограничения [ RESTRICT | CASCADE ]
DISABLE TRIGGER [ имя_триггера | ALL | USER ]
ENABLE TRIGGER [ имя_триггера | ALL | USER ]
ENABLE REPLICA TRIGGER имя_триггера
ENABLE ALWAYS TRIGGER имя_триггера
DISABLE RULE имя_правила_перезаписи
ENABLE RULE имя_правила_перезаписи
ENABLE REPLICA RULE имя_правила_перезаписи
ENABLE ALWAYS RULE имя_правила_перезаписи
DISABLE ROW LEVEL SECURITY
ENABLE ROW LEVEL SECURITY
FORCE ROW LEVEL SECURITY
NO FORCE ROW LEVEL SECURITY
CLUSTER ON имя_индекса
SET WITHOUT CLUSTER
SET WITHOUT OIDS
SET TABLESPACE новое_табличное_пространство
SET { LOGGED | UNLOGGED }
SET ( параметр_хранения = значение [, ... ] )
RESET ( параметр_хранения [, ... ] )
INHERIT таблица_родитель
NO INHERIT таблица_родитель
OF имя_типа
NOT OF
OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
REPLICA IDENTITY { DEFAULT | USING INDEX имя_индекса | FULL | NOTHING }
Где указание_границ_партиции может быть:
IN ( выражение_границ_партиции [, ...] ) |
FROM ( { выражение_границ_партиции | MINVALUE | MAXVALUE } [, ...] )
TO ( { выражение_границ_партиции | MINVALUE | MAXVALUE } [, ...] ) |
WITH ( MODULUS числовая_константа, REMAINDER числовая_константа )
Где ограничение_столбца может быть:
[ CONSTRAINT имя_ограничения ]
{ NOT NULL |
NULL |
CHECK ( выражение ) [ NO INHERIT ] |
DEFAULT выражение_по_умолчанию |
GENERATED ALWAYS AS ( генерирующее_выражение ) STORED |
GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( параметры_последовательности ) ] |
UNIQUE параметры_индекса |
PRIMARY KEY параметры_индекса |
REFERENCES целевая_таблица [ ( целевой_столбец ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
Где ограничение_таблицы может быть:
[ CONSTRAINT имя_ограничения ]
{ CHECK ( выражение ) [ NO INHERIT ] |
UNIQUE ( имя_столбца [, ... ] ) параметры_индекса |
PRIMARY KEY ( имя_столбца [, ... ] ) параметры_индекса |
EXCLUDE [ USING индексный_метод ] ( элемент_исключения WITH оператор [, ... ] ) параметры_индекса [ WHERE ( предикат ) ] |
FOREIGN KEY ( имя_столбца [, ... ] ) REFERENCES целевая_таблица [ ( целевой_столбец [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
Где ограничение_таблицы_по_индексу может быть:
[ CONSTRAINT имя_ограничения ]
{ UNIQUE | PRIMARY KEY } USING INDEX имя_индекса
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
Где параметры_индекса в ограничениях UNIQUE, PRIMARY KEY и EXCLUDE могут быть:
[ INCLUDE ( имя_столбца [, ... ] ) ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) ]
[ USING INDEX TABLESPACE имя_табличного_пространства ]
Где элемент_исключения в ограничении EXCLUDE может быть:
{ имя_столбца | ( выражение ) } [ класс_операторов ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ]
Описание
Команда ALTER TABLE изменяет определение существующей таблицы. Ниже описано несколько
форм команды. Обратите внимание, что требуемый
уровень блокировки у каждой формы может быть свой. Если явно не отмечено другое,
требуется блокировка ACCESS EXCLUSIVE. При перечислении нескольких подкоманд будет
запрашиваться самая сильная блокировка из требуемых ими.
ADD COLUMN [ IF NOT EXISTS ]
Эта форма добавляет в таблицу новый столбец, используя тот же синтаксис, что и команда CREATE TABLE. Если указано IF NOT EXISTS и столбец с таким именем уже существует, это не будет ошибкой.
DROP COLUMN [ IF EXISTS ]
Эта форма удаляет столбец из таблицы. Связанные со столбцом индексы и ограничения таблицы также будут автоматически удалены. Кроме того, будет удалена охватывающая удаляемый столбец многовариантная статистика, если после его удаления в статистике останутся данные только одного столбца. Чтобы удалить какие-либо зависящие от этого столбца объекты вне таблицы, например ссылки на внешние ключи или представления, необходимо добавить в команду указание CASCADE. Если в команде указано IF EXISTS и удаляемый столбец не существует, это не считается ошибкой, вместо этого просто выдается замечание.
SET DATA TYPE
Эта форма изменяет тип столбца таблицы. Включающие данный столбец индексы и простые табличные ограничения будут автоматически преобразованы для использования нового типа столбца путем повторного разбора изначально определяющего их выражения. Необязательное предложение OLLATE задает правило сортировки для нового столбца; если оно опущено, для нового типа столбца устанавливается правило сортировки по умолчанию. Необязательное предложение USING определяет, как вычислить новое значение столбца из старого; если оно опущено, преобразование по умолчанию выполняется как присваивание значения старого типа данных новому. Предложение USING становится обязательным, если отсутствует неявное приведение или присвоение от старого к новому типу.
SET/DROP DEFAULT
Эти формы устанавливают или удаляют для столбца значение по умолчанию.
Значения по умолчанию применяются только в последующих командах INSERT или UPDATE,
не вызывая изменений уже существующих в таблице строк.
SET/DROP NOT NULL
Эти формы определяют, будет ли столбец принимать значения NULL или нет.
Указание SET NOT NULL можно применять к столбцу, только если ни одна из
записей в таблице не содержит значение NULL. Как правило, это проверяется во время
выполнения команды ALTER TABLE и требует сканирования всей таблицы, однако в случае наличия
у столбца ограничения CHECK, которое гарантирует, что значения NULL отсутствуют, сканирование
таблицы пропускается.
Если таблица является партицией, нельзя выполнить DROP NOT NULL, если столбец помечен NOT NULL в родительской таблице. Для снятия ограничения NOT NULL со всех партиций нужно выполнить DROP NOT NULL у родительской таблицы. При этом, если у родительской таблицы отсутствует ограничение NOT NULL, при желании его всё же можно добавить к отдельным партициям; то есть потомки могут запретить значения NULL, даже если родитель разрешает их, но не наоборот.
DROP EXPRESSION [ IF EXISTS ] Эта форма превращает хранимый генерируемый столбец в обычный. Имеющиеся в столбцах данные сохраняются, но будущие изменения больше не будут вноситься генерирующим выражением.
Если указано DROP EXPRESSION IF EXISTS и столбец не является столбцом идентификации, ошибка не возникает. В этом случае выдается только замечание.
ADD GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY
SET GENERATED { ALWAYS | BY DEFAULT }
DROP IDENTITY [ IF EXISTS ]
Эти формы определяют, является ли столбец столбцом идентификации, и меняют свойства
генерирования значений уже существующего столбца идентификации.
Дополнительную информацию см. в разделе CREATE TABLE. Как и SET DEFAULT, эти формы меняют поведение только последующих команд INSERT или UPDATE и не вызывают изменений уже имеющихся в таблице строк.
Если указывается DROP IDENTITY IF EXISTS и столбец не является столбцом идентификации, ошибка не возникает. В этом случае выдается только замечание.
SET параметр_последовательности
RESTART
Эти формы меняют нижележащую последовательность уже существующего столбца идентификации. Свойство параметр_последовательности поддерживается командой ALTER SEQUENCE, например INCREMENT BY.
SET STATISTICS
Эта форма задает ориентир сбора статистики по столбцу для последующих операций ANALYZE. Значение ориентира можно задать в диапазоне от 0 до 10 000; также его можно установить равным -1 для возврата к использованию системного ориентира статистики по умолчанию (default_statistics_target). Более подробную информацию об использовании статистики планировщиком запросов QHB см. в разделе Статистика, используемая планировщиком.
SET STATISTICS запрашивает блокировку SHARE UPDATE EXCLUSIVE.
SET ( атрибут = значение [, ... ] )
RESET ( атрибут [, ... ] )
Эта форма устанавливает или сбрасывает параметры для каждого атрибута. В
настоящее время единственными параметрами атрибутов
являются n_distinct и n_distinct_inherited, которые переопределяют
оценки числа различных значений, производимые последующими операциями
ANALYZE. n_distinct влияет на статистику для самой таблицы, тогда
как n_distinct_inherited влияет на статистику, собранную и для таблицы,
и для ее потомков. Если установлено положительное значение, ANALYZE будет считать,
что столбец содержит точно указанное число различных значений не NULL. Если установлено
отрицательное значение, которое должно быть больше или равно -1,
ANALYZE будет считать, что число различных значений не NULL
в столбце линейно зависит от размера таблицы; точное число будет вычислено
путем умножения расчетного размера таблицы на абсолютное значение
данного числа. Например, значение -1 подразумевает, что все значения в
столбце различны, а значение -0,5 — что каждое значение повторяется
в среднем дважды. Это может быть полезно, когда размер таблицы изменяется
с течением времени, так как умножение на количество строк в таблице выполняется
только во время планирования запроса. При указании значения 0 количество различных значений оценивается
как обычно. Дополнительную информацию об использовании статистики планировщиком
запросов QHB см. в разделе Статистика, используемая планировщиком.
Для изменения параметров атрибутов запрашивается блокировка SHARE UPDATE EXCLUSIVE.
SET STORAGE
Эта форма задает режим хранения для столбца. Этот параметр определяет, будет ли этот столбец храниться внутри таблицы или в отдельной таблице TOAST, а также следует ли сжимать данные. Режим PLAIN необходимо использовать для значений фиксированной длины, таких как integer; это вариант хранения внутри, без сжатия. Режим MAIN предназначен для хранения внутри, но сжимаемых данных. Режим EXTERNAL предназначен для внешних несжатых данных, а EXTENDED — для внешних сжатых данных. EXTENDED используется по умолчанию для большинства типов данных, которые поддерживают хранение non-PLAIN. Применение EXTERNAL позволяет ускорить операции с подстроками на очень больших значениях text и bytea за счет проигрыша в объеме хранилища. Обратите внимание, что сам по себе SET STORAGE ничего не меняет в таблице, а лишь задает стратегию, которая будет реализована при последующих обновлениях таблицы. Дополнительную информацию см. в разделе TOAST.
ADD ограничение_таблицы [ NOT VALID ]
Эта форма добавляет новое ограничение к таблице, используя тот же синтаксис, что и CREATE TABLE, плюс параметр NOT VALID, который в настоящее время разрешен только для ограничений внешнего ключа и проверки.
Обычно эта форма вызывает сканирование таблицы с целью проверки, что все существующие строки в таблице удовлетворяют новому ограничению. Но если используется параметр NOT VALID, то это потенциально-длительное сканирование пропускается. Ограничение по-прежнему будет применяться к последующим добавлениям или обновлениям (то есть они завершатся ошибкой, если при наличии внешнего ключа в ссылочной таблице нет соответствующей строки или если новая строка не соответствует указанному условию проверки). Но база данных не будет считать, что ограничение выполняется для всех строк в таблице, пока оно не будет проверено с помощью VALIDATE CONSTRAIN. Дополнительную информацию об использовании указания NOT VALID см. ниже, в Примечаниях.
Хотя большинству форм ADD ограничение\_таблицы нужна блокировка ACCESS EXCLUSIVE, вариант ADD FOREIGN KEY требует только блокировку SHARE ROW EXCLUSIVE. Обратите внимание, что ADD FOREIGN KEY запрашивает эту блокировку как
в целевой таблице, так и в таблице, на которую данное ограничение ссылается.
С ограничениями уникальности и первичного ключа, которые добавляются в партиционированные таблицы, связаны дополнительные требования; см. CREATE TABLE. Кроме того, в настоящее время ограничения внешнего ключа для партиционированных таблиц не могут объявляться как непроверенные (NOT VALID).
ADD ограничение_таблицы_по_индексу
Эта форма добавляет в таблицу новое ограничение PRIMARY KEY или UNIQUE, основанное на существующем уникальном индексе. Все столбцы индекса будут включены в ограничение.
Индекс не может быть частичным и включать столбцы-выражения.
Кроме того, это должен быть индекс В-дерева с порядком сортировки по
умолчанию. Эти ограничения гарантируют, что данный индекс эквивалентен тому,
который был бы построен обычными командами ADD PRIMARY KEY или ADD UNIQUE.
Если указывается PRIMARY KEY и столбцы индекса еще не помечены NOT NULL,
то эта команда попытается выполнить ALTER COLUMN SET NOT NULL для каждого такого столбца.
Это потребует полного сканирования таблицы с целью проверки, что столбцы не
содержат нулей. Во всех остальных случаях это быстрая операция.
Если имя ограничения указано, то индекс будет переименован, чтобы соответствовать имени ограничения. В противном случае ограничение будет называться так же, как и индекс.
После выполнения этой команды индекс становится «принадлежащим» ограничению, аналогично
тому, как если бы этот индекс был построен командой ADD PRIMARY KEY или ADD UNIQUE.
В частности, удаление ограничения приведет к удалению индекса.
В настоящее время эта форма не поддерживается для партиционированных таблиц.
Примечание
Добавление ограничения с помощью существующего индекса может быть полезно в ситуациях, когда необходимо добавить новое ограничение, не блокируя обновления таблицы в течение длительного времени. Для этого можно создать индекс, используяCREATE INDEX CONCURRENTLY, а затем задействовать его как полноценное ограничение, используя эту запись. См. пример ниже.
ALTER CONSTRAINT
Эта форма меняет атрибуты созданного ранее ограничения. В настоящее время изменять можно только ограничения внешнего ключа.
VALIDATE CONSTRAINT
Эта форма проверяет ограничение внешнего ключа или проверочное ограничение, которое ранее было создано как NOT VALID, путем сканирования всей таблицы, чтобы убедиться в отсутствии строк, для которых ограничение не выполняется. Если ограничение уже помечено как проверенное, ничего не происходит. (См. Примечания ниже, где объясняется полезность этой команды.)
DROP CONSTRAINT [ IF EXISTS ]
Эта форма удаляет указанное ограничение на таблицу вместе с лежащим в его основе индексом. Если указано IF EXISTS и ограничение не существует, это не считается ошибкой. В таком случае просто выдается уведомление.
DISABLE/ENABLE [ REPLICA | ALWAYS ] TRIGGER
Эти формы настраивают срабатывание принадлежащего таблице триггера(ов). Отключенный триггер сохраняется в системе, но не выполняется, когда происходит его запускающее событие. Для отложенного триггера состояние enable проверяется при наступлении события, а не при фактическом выполнении функции триггера. Можно отключить или включить один триггер, указанный по имени, или все триггеры в таблице, или только пользовательские триггеры (этот параметр исключает внутрисистемные триггеры ограничений, например используемые для реализации ограничений внешнего ключа или отложенных ограничений уникальности и исключения). Отключение или включение сгенерированных внутрисистемных триггеров ограничений требует прав суперпользователя; отключение следует делать с осторожностью, так как, разумеется, при невыполнении триггеров нельзя гарантировать целостность ограничения.
На механизм срабатывания триггера также влияет переменная конфигурации session_replication_role. Включенные без дополнительных указаний триггеры (по умолчанию) будут срабатывать, когда роль репликации является «origin» (по умолчанию) или «local». Триггеры, настроенные с указанием ENABLE REPLICA, будут срабатывать только в том случае, если сеанс находится в режиме «replica», а триггеры, настроенные с указанием ENABLE ALWAYS, будут запущены независимо от текущего режима репликации.
Действие этого механизма заключается в том, что в конфигурации по умолчанию триггеры не срабатывают на репликах. Это полезно, так как если триггер используется в исходной базе для распространения данных между таблицами, то система репликации также будет реплицировать и распределенные данные, и триггер не должен срабатывать во второй раз на реплике, потому что это приведет к дублированию. Однако если триггер используется для другой цели, например для создания внешних оповещений, то его можно задать равным ENABLE ALWAYS, чтобы он срабатывал и в репликах.
Эта команда запрашивает блокировку SHARE ROW EXCLUSIVE.
DISABLE/ENABLE [ REPLICA | ALWAYS ] RULE
Эти формы настраивают запуск принадлежащих таблице правил перезаписи. Отключенное правило сохраняется в системе, но не применяется во время перезаписи запроса. Семантика является такой же, как для отключенных/включенных триггеров. Эта конфигурация игнорируется для правил ON SELECT, которые всегда применяются для поддержания работы представлений, даже в сеансах, исполняющих не основную роль репликации.
Механизм запуска правила также зависит от переменной конфигурации session_replication_role аналогичной вышеописанным триггерам.
DISABLE/ENABLE ROW LEVEL SECURITY
Эти формы управляют применением принадлежащих таблице политик защиты строк. Если защита включена и для таблицы не определены политики, то применяется политика по умолчанию — запретить доступ. Обратите внимание, что политики могут существовать для таблицы, даже если защита на уровне строк отключена — в этом случае политики НЕ применяются и их ограничения игнорируются. См. также CREATE POLICY.
NO FORCE/FORCE ROW LEVEL SECURITY
Эти формы управляют применением принадлежащих таблице политик защиты строк, когда пользователь является владельцем таблицы. Если этот параметр включен, политики защиты на уровне строк будут применяться, когда пользователь является владельцем таблицы. Если этот параметр отключен (по умолчанию), то защита на уровне строк не будет применяться, если пользователь является владельцем таблицы. См. также CREATE POLICY.
CLUSTER ON
Эта форма выбирает индекс по умолчанию для будущих операций кластера CLUSTER. На самом деле это не перекластеризует таблицу.
Для изменения параметров кластеризации запрашивается блокировка SHARE UPDATE EXCLUSIVE.
SET WITHOUT CLUSTER
Эта форма удаляет из таблицы самую последнюю используемую спецификацию индекса кластера CLUSTER. Это влияет на будущие операции кластера, для которых не будет задан индекс.
Для изменения параметров кластеризации запрашивается блокировка SHARE UPDATE EXCLUSIVE.
SET WITHOUT OIDS
Обеспечивающий обратную совместимость синтаксис удаления системного столбца oid. Так как добавить системные столбцы oid теперь невозможно, это указание не действует.
SET TABLESPACE
Эта форма изменяет табличное пространство таблицы на указанное табличное
пространство и перемещает связанные с таблицей файлы данных в новое
табличное пространство. Индексы таблицы, если таковые имеются, не перемещаются,
но их можно перемещать отдельно дополнительными командами SET TABLESPACE.
При применении к партиционированной таблице ничего не перемещается, но все партиции,
созданные позднее с помощью CREATE TABLE PARTITION OF, будут использовать
это табличное пространство, если только оно не будет переопределено предложением
TABLESPACE.
Все таблицы в текущей базе данных в табличном пространстве можно
переместить с помощью формы ALL IN TABLESPACE, которая заблокирует все таблицы,
которые будут перемещены в первую очередь, а затем переместит каждую из них.
Эта форма также поддерживает указание OWNED BY: с которым перемещаются только таблицы
указанных владельцев. Если указана опция NOWAIT, то команда завершится
ошибкой, если не сможет сразу получить все необходимые блокировки.
Обратите внимание, что системные каталоги этой командой не перемещаются;
если требуется переместить их, следует использовать ALTER DATABASE
или явные вызовы ALTER TABLE. Отношения information_schema не считаются частью
системных каталогов и подлежат перемещению. См. также CREATE TABLESPACE.
SET { LOGGED / UNLOGGED }
Эта форма меняет характеристику журналирования таблицы, делает таблицу журналируемой/нежурналируемой соответственно (см. UNLOGGED). Не может быть применена к временной таблице.
SET ( параметр_хранения = значение [, ... ] )
Эта форма изменяет один или несколько параметров хранения таблицы.
Подробную информацию о доступных параметрах см. в разделе Параметры хранения описания команды CREATE TABLE.
Обратите внимание, что содержимое таблицы этой командой не будет изменено
немедленно; в зависимости от параметра может потребоваться переписать таблицы,
чтобы получить желаемый эффект. Это можно сделать с помощью команд
VACUUM FULL, CLUSTER или одной из форм ALTER TABLE, которая принудительно
перезаписывает таблицу. Изменения параметров, связанных с планировщиком,
вступят в силу при следующей блокировке таблицы, поэтому текущие
выполняемые запросы затронуты не будут.
Данная форма запрашивает блокировку SHARE UPDATE EXCLUSIVE для изменения параметров хранения, связанных с коэффициентом заполнения, TOAST и автоочисткой, а также параметра планировщика parallel_workers.
RESET ( параметр_хранения [, ... ] )
Эта форма сбрасывает один или несколько параметров хранения до значений по умолчанию. Как и в случае с SET, для полного обновления таблицы может потребоваться ее перезапись.
INHERIT таблица_родитель
Эта форма добавляет целевую таблицу в качестве нового потомка (дочерней таблицы) указанной родительской таблицы. Впоследствии запросы к родительской таблице будут включать записи целевой таблицы. Чтобы стать потомком, целевая таблица уже должна содержать те же столбцы, что и родительская (она также может содержать и дополнительные столбцы). Столбцы должны иметь соответствующие типы данных, и если они имеют ограничения NOT NULL в родителе, то должны иметь их и в потомке.
Кроме того, в дочерней таблице должны присутствовать все ограничения CHECK родительской
таблицы, за исключением помеченных как ненаследуемые (т. е. созданных с помощью
команды ALTER TABLE ... ADD CONSTRAINT ... NO INHERIT), которые игнорируются;
все соответствующие ограничения дочерней таблицы не должны быть помечены как
ненаследуемые. В настоящий момент ограничения UNIQUE, PRIMARY KEY и
FOREIGN KE не учитываются, но в будущем это может измениться.
NO INHERIT таблица_родитель
Эта форма удаляет целевую таблицу из списка потомков указанной родительской таблицы. Запросы к родительской таблице больше не будут включать записи, полученные из целевой таблицы.
OF имя_типа
Эта форма связывает таблицу с составным типом, как если бы таблица была сформирована
командой CREATE TABLE OF. Список имен и типов столбцов таблицы должен
точно соответствовать списку составного типа. Таблица не должна
быть потомком другой таблицы. Эти ограничения гарантируют, что
CREATE TABLE OF позволит создать таблицу с таким же определением.
NOT OF
Эта форма отделяет типизированную таблицу от ее типа.
OWNER TO
Эта форма меняет владельца таблицы, последовательности, представления, материализованного представления или сторонней таблицы на указанного пользователя.
REPLICA IDENTITY
Эта форма изменяет информацию, которая записывается в журнал предзаписи для идентификации строк, которые обновляются или удаляются. Этот параметр не действует, за исключением случаев, когда используется логическая репликация. В режиме DEFAULT (по умолчанию для несистемных таблиц) записываются старые значения столбцов первичного ключа, если таковые имеются. В режиме USING INDEX записываются старые значения столбцов, составляющих индекс, который должен быть уникальным, не частичным, не отложенным и включать только столбцы, помеченные NOT NULL. В режиме FULL записываются старые значения всех столбцов в строке. В режиме NOTHING не записывается никакой информации о старой строке. (Это значение по умолчанию для системных таблиц.) Во всех случаях старые значения регистрируются, только если хотя бы в одном из столбцов, которые должны быть записаны, имеются различия между старой и новой версиями строки.
RENAME
Форма RENAME изменяет имя таблицы (или индекса, последовательности, представления, материализованного представления или сторонней таблицы), имя отдельного столбца в таблице или имя ограничения таблицы. При переименовании ограничения, имеющего базовый индекс, этот индекс также переименовывается. При этом влияние на сохраненные данные отсутствует.
SET SCHEMA
Эта форма перемещает таблицу в другую схему. Связанные индексы, ограничения и последовательности, принадлежащие столбцам таблицы, также перемещаются.
ATTACH PARTITION имя_партиции { FOR VALUES указание_границ_партиции | DEFAULT }
Эта форма присоединяет существующую таблицу (которая сама может быть
партиционирована) в качестве партиции к целевой таблице. Таблица может быть
присоединена в качестве партиции для конкретных значений с помощью FOR VALUES
или в качестве партиции по умолчанию с помощью DEFAULT. Для
каждого индекса в целевой таблице будет создан соответствующий индекс в
присоединенной таблице, или, если эквивалентный индекс уже существует,
он будет присоединен к индексу целевой таблицы, как при выполнении команды
ALTER INDEX ATTACH PARTITION. Обратите внимание, что если
существующая таблица является сторонней, то в настоящее время ее нельзя
присоединить в качестве партиции целевой таблицы, если в целевой таблице
есть индексы UNIQUE (уникальные). (См. также CREATE FOREIGN TABLE.) Для каждого пользовательского триггера уровня строк, существующего в целевой таблице, будет создан соответствующий триггер в присоединенной таблице.
Для партиции, добавляемой с FOR VALUES, используется то же указание_границ_партиции, что и в CREATE TABLE. Спецификация привязки к партициям должна соответствовать стратегии и ключу разбиения целевой таблицы. Присоединяемая таблица должна содержать те же столбцы, что и целевая таблица, и никаких других; более того, типы столбцов также должны совпадать. Кроме того, присоединяемая таблица должна иметь все ограничения NOT NULL и CHECK целевой таблицы. В настоящий момент ограничения FOREIGN KEY не рассматриваются. Если ограничения UNIQUE и PRIMARY KEY еще не существуют в партиции, они будут созданы в ней из родительской таблицы. Если какое-либо из ограничений CHECK присоединяемой таблицы помечено как NO INHERIT, команда выдаст ошибку; такие ограничения нужно будет пересоздать без предложения NO INHERIT.
Если новая партиция является обычной таблицей, выполняется ее полное сканирование, чтобы проверить, что существующие строки в таблице не нарушают ограничение партиции. Можно избежать этого сканирования, перед выполнением этой команды добавив в таблицу допустимое ограничение CHECK, позволяющее использовать только строки, удовлетворяющие требуемому ограничению партиции. Ограничение CHECK будет использоваться для определения того, что таблицу не нужно сканировать с целью проверки ограничения партиции. Однако это не работает, если какой-либо из ключей разбиения является выражением и раздел не принимает значения NULL. При присоединении партиции по списку, не принимающей значения NULL, также добавьте ограничение NOT NULL в столбец ключа разбиения, если это не выражение.
Если новая партиция является сторонней таблицей, то проверка того, подчиняются ли все строки в сторонней таблице ограничению партиции, не выполняется. (См. рассмотрение ограничений сторонней таблицы в разделе CREATE FOREIGN TABLE.)
Если таблица имеет партицию по умолчанию, добавление новой партиции изменяет ограничение партиции по умолчанию. Партиция по умолчанию не может содержать строк, которые может понадобиться переместить в основную партицию, поэтому она будет просканирована и проверена на предмет их отсутствия. Этого сканирования, как и сканирования новой партиции, можно избежать, если определить подходящее ограничение CHECK. Кроме того, как и сканирование новой партиции, оно всегда пропускается, когда партиция по умолчанию является сторонней таблицей.
Для присоединения партиции наряду с блокировками ACCESS EXCLUSIVE в присоединяемых таблицах и партиции по умолчанию (при наличии) запрашивается блокировка SHARE UPDATE EXCLUSIVE в родительской таблице.
DETACH PARTITION имя_партиции
Эта форма отсоединяет указанную партицию целевой таблицы. Отсоединенная партиция продолжает существовать как отдельная таблица, но больше не имеет никаких связей с таблицей, от которой была отсоединена. Все индексы, присоединенные к индексам целевой таблицы, отсоединяются. Все триггеры, созданные как клоны триггеров целевой таблицы, удаляются.
Все формы ALTER TABLE, которые действуют на одну таблицу, за
исключением RENAME, SET SCHEMA, ATTACH PARTITION и
DETACH PARTITION, могут быть объединены в список из нескольких
изменений, которые будут применяться вместе. Например, можно добавить
несколько столбцов и/или изменить тип нескольких столбцов в одной
команде. Это особенно полезно с большими таблицами, поскольку
вся таблица обрабатывается за один проход.
Чтобы использовать команду ALTER TABLE, нужно быть владельцем соответствующей таблицы.
Чтобы изменить схему или табличное пространство таблицы,
необходимо помимо этого иметь право CREATE в новой схеме или табличном пространстве.
Чтобы добавить таблицу в качестве нового потомка родительской
таблицы, нужно также быть владельцем родительской таблицы.
Кроме того, чтобы присоединить таблицу в качестве новой партиции таблицы, нужно
быть владельцем присоединяемой таблицы. Для смены владельца текущий пользователь
также должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме таблицы.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания таблицы.
Однако суперпользователь всё равно может сменить владельца любой таблицы.)
Чтобы добавить столбец, сменить тип столбца или применить предложение OF,
необходимо помимо этого иметь право USAGE для соответствующего типа данных.
Параметры
IF EXISTS
Не считать ошибкой, если таблица не существует. В этом случае будет выдано замечание.
имя
Имя существующей таблицы, подлежащей изменению (может быть дополнено схемой). Если перед именем таблицы указывается ONLY, изменяется только эта таблица. Если ONLY не указано, будут изменены таблица и все ее потомки (если таковые имеются). После имени таблицы можно также добавить необязательное указание *, чтобы явно обозначить, что изменению подлежат все дочерние таблицы.
имя_столбца
Имя нового или существующего столбца.
новое_имя_столбца
Новое имя существующего столбца.
новое_имя
Новое имя таблицы.
тип_данных
Тип данных нового столбца или новый тип данных для существующего столбца.
ограничение_таблицы
Новое ограничение таблицы.
имя_ограничения
Имя нового или существующего ограничения.
CASCADE
Автоматически удаляются объекты, зависящие от удаляемого столбца или ограничения (например, представления, ссылающиеся на столбец), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удаление столбца или ограничения, если существуют зависящие от них объекты. Это поведение по умолчанию.
имя_триггера
Имя триггера, который нужно отключить или включить.
ALL
Отключить или включить все принадлежащие таблице триггеры. (Если в числе этих триггеров оказываются сгенерированные внутрисистемные триггеры исключений, например используемые для реализации ограничений внешнего ключа или отложенных ограничений уникальности и исключения, то для этого потребуются права суперпользователя.)
USER
Отключить или включить все принадлежащие таблице триггеры, за исключением сгенерированных внутрисистемных триггеров исключений, например используемых для реализации ограничений внешнего ключа или отложенных ограничений уникальности и исключения.
имя_индекса
Имя существующего индекса.
параметр_хранения
Имя параметра хранения таблицы.
значение
Новое значение для параметра хранения таблицы. В зависимости от параметра, это может быть число или строка.
таблица_родитель
Родительская таблица для связывания или отмены связи с этой таблицей.
новый_владелец
Имя пользователя, который станет новым владельцем таблицы.
новое_табличное_пространство
Имя табличного пространства, в которое будет перемещена таблица.
новая_схема
Имя схемы, в которую будет перемещена таблица.
имя_партиции
Имя таблицы, присоединяемой в качестве новой партиции или, наоборот, отсоединяемой от данной таблицы.
указание_границ_партиции
Указание границ для новой партиции. Более подробную информацию о синтаксисе этого указания см. в разделе CREATE TABLE.
Примечания
Ключевое слово COLUMN не несет смысловой нагрузки и может быть опущено.
Когда столбец добавляется с помощью ADD COLUMN и задано неизменчивое выражение DEFAULT, значение по умолчанию вычисляется во время выполнения команды и результат сохраняется в метаданных таблицы. Это значение будет использоваться для столбца во всех существующих строках. Если указание DEFAULT отсутствует, используется значение NULL. Ни в том, ни в другом случае переписывать таблицу не требуется.
Добавление столбца с изменчивым выражением DEFAULT или изменение типа существующего столбца потребует перезаписи всей таблицы и ее индексов. Исключение: если указание USING не изменяет содержимое столбца и старый тип двоично приводится к новому или является неограниченным доменом поверх нового типа, то при изменении типа существующего столбца перезапись таблицы не требуется, но все индексы на затронутых столбцах всё равно должны быть перестроены. Перестройка большой таблицы и/или ее индекса может занять длительное время; при этом временно потребуется вдвое больше места на диске.
Добавление ограничений CHECK или NOT NULL требует сканирования таблицы, чтобы убедиться, что существующие строки соответствуют ограничению, но не требует перезаписи таблицы.
Аналогично при присоединении новой партиции та может быть проверена, чтобы убедиться, что существующие строки соответствуют ограничению партиции.
Основная причина предоставления возможности указать несколько изменений
в одной команде ALTER TABLE заключается в том, что это позволяет совместить
требуемые этим операциям сканирования и перезаписи таблицы и выполнить их за один проход.
Сканирование большой таблицы для проверки нового внешнего ключа или
проверочного ограничения может занять много времени, и другие обновления
таблицы блокируются до тех пор, пока не будет зафиксирована команда
ALTER TABLE ADD CONSTRAINT. Основное предназначение указания NOT VALID
при добавлении ограничения состоит в уменьшении влияния этой операции
на параллельные изменения данных. С указанием NOT VALID команда
ADD CONSTRAINT не сканирует таблицу и может быть немедленно
зафиксирована. После этого можно выполнить команду VALIDATE CONSTRAINT,
чтобы проверить, что существующие строки удовлетворяют
ограничению. Эта команда не будет препятствовать параллельным изменениям,
так как ей известно, что в других транзакциях уже будет действовать ограничение
для добавляемых или изменяемых строк; проверить нужно только уже
существующие строки. Следовательно, проверка запрашивает на изменяемую таблицу
только блокировку SHARE UPDATE EXCLUSIVE. (Если ограничение является внешним
ключом, то в целевой таблице этого ключа также запрашивается блокировка ROW SHARE.)
Помимо оптимизации параллельной работы, может быть полезно использовать
указания NOT VALID и VALIDATE CONSTRAINT в тех случаях, когда заведомо
известно, что в таблице есть строки, нарушающие ограничения. После создания
ограничения добавить новые недопустимые строки будет невозможно, а все существующие
проблемы могут разрешаться в свободное время, пока VALIDATE CONSTRAINT наконец
не будет успешно завершена.
Форма DROP COLUMN не удаляет столбец физически, а просто делает его невидимым для операций SQL. Последующие операции добавления и обновления в таблице будут сохранять нулевое значение для столбца. Как следствие, удаление столбца выполняется быстро, но это не приводит к немедленному уменьшению размера таблицы на диске, поскольку пространство, занимаемое удаляемым столбцом, не восстанавливается. Пространство будет освобождаться с течением времени по мере обновления существующих строк.
Чтобы принудительно освободить место, занимаемое удаляемым
столбцом, можно выполнить одну из форм ALTER TABLE, которая
выполняет перезапись всей таблицы. Это приведет к воссозданию всех строк
с заменой удаленного столбца значением NULL.
Перезаписывающие формы ALTER TABLE небезопасны с точки зрения MVCC. После
перезаписи таблицы та будет казаться пустой для параллельных
транзакций, если они используют снимок, сделанный до этого события.
Более подробную информацию см. в разделе Ограничения.
В указании USING предложения SET DATA TYPE действительно можно указать любое выражение, включающее старые значения строки; то есть оно может ссылаться на другие столбцы, в том числе и на преобразуемый. Это позволяет с помощью SET DATA TYPE выполнять очень общие преобразования. Из-за этой гибкости выражение USING не применяется к значению столбца по умолчанию (если таковое имеется); результат может не быть константным выражением, как это требуется для значения по умолчанию. Это означает, что при отсутствии неявного приведения или присвоения от старого к новому типу SET DATA TYPE, возможно, не удастся преобразовать значение по умолчанию, даже если указано USING. В таких случаях нужно удалить значение по умолчанию с помощью DROP DEFAULT, выполнить ALTER TYPE, а затем использовать SET DEFAULT, чтобы добавить подходящее новое значение по умолчанию. Аналогичные рекомендации применимы к связанным со столбцом индексам и ограничениям.
Если таблица имеет дочерние таблицы, то не разрешается
добавлять, переименовывать или изменять тип столбца в родительской
таблице, не делая то же самое для потомков. Это гарантирует, что у
потомков столбцы всегда соответствуют родительским. Точно так же
нельзя переименовать ограничение CHECK в родительской таблице,
не переименовывая его во всех дочерних таблицах, что тоже гарантирует
соответствие всех ограничений CHECK между родителем и потомком. (Однако
этот запрет не распространяется на ограничения, основанные на
индексах.) Кроме того, поскольку выборка из родительской таблицы также
отбирает из ее потомков, ограничение на родителе не может
быть помечено как действующее, если оно не помечено как действующее
для ее потомков. Во всех этих случаях команда ALTER TABLE ONLY выполнена не будет.
Рекурсивная операция DROP COLUMN удаляет столбец дочерней таблицы
только в том случае, если та не унаследовала данный столбец от каких-то других
родителей и никогда не имела независимое определение столбца.
Нерекурсивная операция DROP COLUMN (т. е. ALTER TABLE ONLY ... DROP COLUMN)
никогда не удаляет унаследованные столбцы, а вместо этого помечает их как
независимо определенные, а не унаследованные. С партиционированной
таблицей нерекурсивная команда DROP COLUMN выдаст ошибку, так как все партиции
таблицы должны содержать те же столбцы, что и главная таблица.
Действия для столбцов идентификации (ADD GENERATED, SET и т. д., DROP IDENTITY), а также действия TRIGGER, CLUSTER, OWNER и TABLESPACE никогда не распространяются рекурсивно на дочерние таблицы; иначе говоря, они всегда действуют так, будто указано ONLY. Добавление ограничения выполняется рекурсивно только для ограничений CHECK, не помеченных как NO INHERIT.
Изменение любой части таблицы системного каталога не допускается.
Более подробное описание допустимых параметров см. в разделе CREATE TABLE. В главе Определение данных содержится дополнительная информация о наследовании.
Примеры
Добавление в таблицу столбца типа varchar:
ALTER TABLE distributors ADD COLUMN address varchar(30);
Удаление столбца из таблицы:
ALTER TABLE distributors DROP COLUMN address RESTRICT;
Изменение типов двух существующих столбцов в одной операции:
ALTER TABLE distributors
ALTER COLUMN address TYPE varchar(80),
ALTER COLUMN name TYPE varchar(100);
Смена типа целочисленного столбца, содержащего время в стиле Unix, на тип timestamp with time zone с применением предложения USING:
ALTER TABLE foo
ALTER COLUMN foo_timestamp SET DATA TYPE timestamp with time zone
USING
timestamp with time zone 'epoch' + foo_timestamp * interval '1 second';
То же самое, но в случае, когда у столбца есть значение по умолчанию, которое не может быть автоматически приведено к новому типу данных:
ALTER TABLE foo
ALTER COLUMN foo_timestamp DROP DEFAULT,
ALTER COLUMN foo_timestamp TYPE timestamp with time zone
USING
timestamp with time zone 'epoch' + foo_timestamp * interval '1 second',
ALTER COLUMN foo_timestamp SET DEFAULT now();
Переименование существующего столбца:
ALTER TABLE distributors RENAME COLUMN address TO city;
Переименование существующей таблицы:
ALTER TABLE distributors RENAME TO suppliers;
Переименование существующего ограничения:
ALTER TABLE distributors RENAME CONSTRAINT zipchk TO zip_check;
Добавление в столбец ограничения NOT NULL:
ALTER TABLE distributors ALTER COLUMN street SET NOT NULL;
Удаление ограничения NOT NULL из столбца:
ALTER TABLE distributors ALTER COLUMN street DROP NOT NULL;
Добавление проверочного ограничения в таблицу и во всех ее потомков:
ALTER TABLE distributors ADD CONSTRAINT zipchk CHECK (char_length(zipcode) = 5);
Добавление проверочного ограничения только в таблицу, но не в ее потомков:
ALTER TABLE distributors ADD CONSTRAINT zipchk CHECK (char_length(zipcode) = 5)
NO INHERIT;
(Данное проверочное ограничение не будет наследоваться и будущими потомками тоже.)
Удаление проверочного ограничения из таблицы и из всех ее потомков:
ALTER TABLE distributors DROP CONSTRAINT zipchk;
Удаление проверочного ограничения только из самой таблицы:
ALTER TABLE ONLY distributors DROP CONSTRAINT zipchk;
(Проверочное ограничение остается во всех дочерних таблицах.)
Добавление в таблицу ограничения внешнего ключа:
ALTER TABLE distributors ADD CONSTRAINT distfk FOREIGN KEY (address)
REFERENCES addresses (address);
Добавление в таблицу ограничения внешнего ключа с наименьшим влиянием на работу других:
ALTER TABLE distributors ADD CONSTRAINT distfk FOREIGN KEY (address)
REFERENCES addresses (address) NOT VALID;
ALTER TABLE distributors VALIDATE CONSTRAINT distfk;
Добавление в таблицу ограничения уникальности (по нескольким столбцам):
ALTER TABLE distributors ADD CONSTRAINT dist_id_zipcode_key UNIQUE (dist_id, zipcode);
Добавление в таблицу первичного ключа с автоматическим именем, учитывая, что в таблице может быть только один первичный ключ:
ALTER TABLE distributors ADD PRIMARY KEY (dist_id);
Перемещение таблицы в другое табличное пространство:
ALTER TABLE distributors SET TABLESPACE fasttablespace;
Перемещение таблицы в другую схему:
ALTER TABLE myschema.distributors SET SCHEMA yourschema;
Пересоздание ограничения первичного ключа без блокировки изменений в процессе перестроения индекса:
CREATE UNIQUE INDEX CONCURRENTLY dist_id_temp_idx ON distributors (dist_id);
ALTER TABLE distributors DROP CONSTRAINT distributors_pkey,
ADD CONSTRAINT distributors_pkey PRIMARY KEY USING INDEX dist_id_temp_idx;
Присоединение партиции к таблице, партиционированной по диапазонам:
ALTER TABLE measurement
ATTACH PARTITION measurement_y2016m07 FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
Присоединение партиции к таблице, партиционированной по списку:
ALTER TABLE cities
ATTACH PARTITION cities_ab FOR VALUES IN ('a', 'b');
Присоединение партиции к таблице, партиционированной по хэшу:
ALTER TABLE orders
ATTACH PARTITION orders_p4 FOR VALUES WITH (MODULUS 4, REMAINDER 3);
Присоединение партиции по умолчанию к партиционированной таблице:
ALTER TABLE cities
ATTACH PARTITION cities_partdef DEFAULT;
Удаление партиции из партиционированной таблицы:
ALTER TABLE measurement
DETACH PARTITION measurement_y2015m12;
Совместимость
Формы ADD (без USING INDEX), DROP [COLUMN], DROP IDENTITY, RESTART,
SET DEFAULT, SET DATA TYPE (без USING), SET GENERATED и
SET параметр_последовательности соответствуют стандарту SQL.
Другие формы являются расширениями стандарта SQL, которые реализованы в QHB.
Кроме того, возможность указать несколько операций изменения
в одной команде ALTER TABLE тоже является расширением.
Команда ALTER TABLE DROP COLUMN позволяет удалить единственный столбец таблицы,
оставляя ее без столбцов. Это расширение стандарта SQL,
который не допускает таблицы без столбцов.
См. также
ALTER TEXT SEARCH CONFIGURATION
ALTER TEXT SEARCH CONFIGURATION — изменить определение конфигурации текстового поиска
Синтаксис
ALTER TEXT SEARCH CONFIGURATION имя
ADD MAPPING FOR тип_фрагмента [, ... ] WITH имя_словаря [, ... ]
ALTER TEXT SEARCH CONFIGURATION имя
ALTER MAPPING FOR тип_фрагмента [, ... ] WITH имя_словаря [, ... ]
ALTER TEXT SEARCH CONFIGURATION имя
ALTER MAPPING REPLACE старый_словарь WITH новый_словарь
ALTER TEXT SEARCH CONFIGURATION имя
ALTER MAPPING FOR тип_фрагмента [, ... ] REPLACE старый_словарь WITH новый_словарь
ALTER TEXT SEARCH CONFIGURATION имя
DROP MAPPING [ IF EXISTS ] FOR тип_фрагмента [, ... ]
ALTER TEXT SEARCH CONFIGURATION имя RENAME TO новое_имя
ALTER TEXT SEARCH CONFIGURATION имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER TEXT SEARCH CONFIGURATION имя SET SCHEMA новая_схема
Описание
Команда ALTER TEXT SEARCH CONFIGURATION изменяет определение
конфигурации текстового поиска. Можно модифицировать его сопоставления
типов фрагментов со словарями или изменить имя или владельца конфигурации.
Чтобы использовать команду ALTER TEXT SEARCH CONFIGURATION, нужно быть владельцем соответствующей конфигурации.
Параметры
имя
Имя существующей конфигурации текстового поиска (может быть дополнено схемой).
тип_фрагмента
Имя типа фрагмента, которое выдается при разборе конфигурации.
имя_словаря
Имя словаря текстового поиска, в котором будет проводиться поиск указанного(ых) типа(ов) фрагмента. Если перечислено несколько словарей, к ним будут обращаться в указанном порядке.
старый_словарь
Имя словаря текстового поиска, который будет заменен в сопоставлении.
новый_словарь
Имя словаря текстового поиска, которое будет подставлено там, где был старый_словарь.
новое_имя
Новое имя конфигурации текстового поиска.
новый_владелец
Новый владелец конфигурации текстового поиска.
новая_схема
Новая схема конфигурации текстового поиска.
Форма ADD MAPPING FOR устанавливает список словарей, которые будут просматриваться в поиске указанных типов фрагментов; если уже существует сопоставление для любого из типов фрагментов, выдается ошибка. Форма ALTER MAPPING FOR делает то же самое, но сначала удаляет все существующие сопоставления для типов фрагментов. Формы ALTER MAPPING REPLACE подставляют новый_словарь вместо старый_словарь везде, где имеется последний. При добавлении FOR это делается только для указанных типов фрагментов, в противном случае — для всех сопоставлений конфигурации. Форма DROP MAPPING удаляет все словари для указанных типов фрагментов, в результате чего фрагменты этих типов игнорируются конфигурацией текстового поиска. Если сопоставлений для заданных типов фрагментов нет, возникает ошибка, если только не добавлено указание IF EXISTS.
Примеры
В следующем примере словарь english заменяется на swedish везде, где использовался english в конфигурации my_config.
ALTER TEXT SEARCH CONFIGURATION my_config
ALTER MAPPING REPLACE english WITH swedish;
Совместимость
В стандарте SQL нет команды ALTER TEXT SEARCH CONFIGURATION.
См. также
CREATE TEXT SEARCH CONFIGURATION, DROP TEXT SEARCH CONFIGURATION
ALTER TEXT SEARCH DICTIONARY
TEXT SEARCH DICTIONARY* — изменить определение словаря текстового поиска
Синтаксис
ALTER TEXT SEARCH DICTIONARY имя (
параметр [ = значение ] [, ... ]
)
ALTER TEXT SEARCH DICTIONARY имя RENAME TO новое_имя
ALTER TEXT SEARCH DICTIONARY имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER TEXT SEARCH DICTIONARY имя SET SCHEMA новая_схема
Описание
Команда ALTER TEXT SEARCH DICTIONARY изменяет определение словаря
текстового поиска. Можно изменить параметры справочника, относящиеся к
определенному шаблону, или изменить имя или владельца справочника.
Чтобы использовать команду ALTER TEXT SEARCH DICTIONARY, нужно быть владельцем соответствующего словаря.
Параметры
имя
Имя существующего словаря текстового поиска (может быть дополнено схемой).
параметр
Имя параметра шаблона, который будет установлен для этого словаря.
значение
Новое значение, используемое для параметра шаблона. Если знак равенства и значение опущены, то любая предыдущая настройка параметра удаляется из справочника, позволяя использовать значение по умолчанию.
новое_имя
Новое имя словаря текстового поиска.
новый_владелец
Новый владелец словаря текстового поиска.
новая_схема
Новая схема словаря текстового поиска.
Параметры настройки шаблона могут указываться в любом порядке.
Примеры
В следующем примере команда меняет список стоп-слов словаря на базе Snowball. Другие параметры остаются неизменными.
ALTER TEXT SEARCH DICTIONARY my_dict ( StopWords = newrussian );
В следующем примере команда меняет параметр, определяющий язык, на dutch и полностью удаляет параметр, задающий список стоп-слов.
ALTER TEXT SEARCH DICTIONARY my_dict ( language = dutch, StopWords );
Следующая команда «изменяет» определение словаря, на самом деле не меняя ничего.
ALTER TEXT SEARCH DICTIONARY my_dict ( dummy );
(Это работает потому, что код удаления параметра не считает ошибкой отсутствие такого параметра.) Этот способ полезен при изменении файлов конфигурации словаря; ALTER принудит все существующие сеансы перечитать файлы конфигурации, что в противном случае они не сделают никогда, если прочитали конфигурацию ранее.
Совместимость
В стандарте SQL нет команды ALTER TEXT SEARCH DICTIONARY.
См. также
CREATE TEXT SEARCH DICTIONARY, DROP TEXT SEARCH DICTIONARY
ALTER TEXT SEARCH PARSER
ALTER TEXT SEARCH PARSER — изменить определение анализатора текстового поиска
Синтаксис
ALTER TEXT SEARCH PARSER имя RENAME TO новое_имя
ALTER TEXT SEARCH PARSER имя SET SCHEMA новая_схема
Описание
Команда ALTER TEXT SEARCH PARSER изменяет определение анализатора текстового
поиска. В настоящее время ее единственной поддерживаемой функциональностью
является изменение имени анализатора текстового поиска.
Чтобы использовать команду ALTER TEXT SEARCH PARSER, нужно быть суперпользователем.
Параметры
имя
Имя существующего анализатора текстового поиска (может быть дополнено схемой).
новое_имя
Новое имя анализатора текстового поиска.
новая_схема
Новая схема анализатора текстового поиска.
Совместимость
В стандарте SQL нет команды ALTER TEXT SEARCH PARSER.
См. также
CREATE TEXT SEARCH PARSER, DROP TEXT SEARCH PARSER
ALTER TEXT SEARCH TEMPLATE
ALTER TEXT SEARCH TEMPLATE — изменить определение шаблона текстового поиска
Синтаксис
ALTER TEXT SEARCH TEMPLATE имя RENAME TO новое_имя
ALTER TEXT SEARCH TEMPLATE имя SET SCHEMA новая_схема
Описание
Команда ALTER TEXT SEARCH TEMPLATE изменяет определение шаблона текстового поиска.
В настоящее время ее единственной поддерживаемой функциональностью является изменение имени шаблона.
Чтобы использовать команду ALTER TEXT SEARCH TEMPLATE, нужно быть суперпользователем.
Параметры
имя
Имя существующего шаблона текстового поиска (может быть дополнено схемой).
новое_имя
Новое имя шаблона текстового поиска.
новая_схема
Новая схема для шаблона текстового поиска.
Совместимость
В стандарте SQL нет команды ALTER TEXT SEARCH TEMPLATE.
См. также
CREATE TEXT SEARCH TEMPLATE, DROP TEXT SEARCH TEMPLATE
ALTER TRIGGER
ALTER TRIGGER — изменить определение триггера
Синтаксис
ALTER TRIGGER имя ON имя_таблицы RENAME TO новое_имя
ALTER TRIGGER имя ON имя_таблицы DEPENDS ON EXTENSION имя_расширения
Описание
Команда ALTER TRIGGER изменяет свойства существующего триггера. Предложение
RENAME изменяет имя данного триггера без изменения определения триггера. Предложение
DEPENDS ON EXTENSION помечает триггер как зависящий от расширения, благодаря чему если
расширение удаляется, триггер также будет автоматически удален.
Только владелец таблицы, на которой работает триггер, имеет возможность изменять его свойства.
Параметры
имя
Имя существующего триггера, свойства которого подлежат изменению.
имя_таблицы
Имя таблицы, на которую действует этот триггер.
новое_имя
Новое имя для триггера.
имя_расширения
Имя расширения, от которого будет зависеть триггер (или больше не будет зависеть, если указано NO). Триггер, помеченный как зависимый от расширения, автоматически удаляется при удалении расширения.
Примечания
Возможность временного включения или отключения триггера предоставляется командой ALTER TABLE,
а не ALTER TRIGGER, поскольку в ALTER TRIGGER нет удобного
способа выразить возможность включения или отключения всех триггеров
таблицы одновременно.
Примеры
Переименование существующего триггера:
ALTER TRIGGER emp_stamp ON emp RENAME TO emp_track_chgs;
Обозначение триггера как зависимого от расширения:
ALTER TRIGGER emp_stamp ON emp DEPENDS ON EXTENSION emplib;
Совместимость
Команда ALTER TRIGGER, реализованная в QHB, является расширением стандарта SQL.
См. также
ALTER TYPE
ALTER TYPE — изменить определение типа
Синтаксис
ALTER TYPE имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER TYPE имя RENAME TO новое_имя
ALTER TYPE имя SET SCHEMA новая_схема
ALTER TYPE имя RENAME ATTRIBUTE имя_атрибута TO новое_имя_атрибута [ CASCADE | RESTRICT ]
ALTER TYPE имя действие [, ... ]
ALTER TYPE имя ADD VALUE [ IF NOT EXISTS ] новое_значение_перечисления [ { BEFORE | AFTER } соседнее_значение_перечисления ]
ALTER TYPE имя RENAME VALUE существующее_значение_перечисления TO новое_значение_перечисления
ALTER TYPE имя SET ( свойство = значение [, ... ] )
Где действие может быть следующим:
ADD ATTRIBUTE имя_атрибута тип_данных [ COLLATE правило_сортировки ] [ CASCADE | RESTRICT ]
DROP ATTRIBUTE [ IF EXISTS ] имя_атрибута [ CASCADE | RESTRICT ]
ALTER ATTRIBUTE имя_атрибута [ SET DATA ] TYPE тип_данных [ COLLATE правило_сортировки ] [ CASCADE | RESTRICT ]
Описание
Команда ALTER TYPE изменяет определение существующего типа. Существует
несколько форм этой команды:
OWNER
Эта форма меняет владельца типа.
RENAME
Эта форма изменяет имя типа.
SET SCHEMA
Эта форма перемещает тип в другую схему.
RENAME ATTRIBUTE
Эта форма применима только к составным типам. Она изменяет имя отдельного атрибута составного типа.
ADD ATTRIBUTE
Эта форма добавляет новый атрибут к составному типу, используя тот же синтаксис, что и CREATE TYPE.
DROP ATTRIBUTE [ IF EXISTS ]
Эта форма удаляет атрибут из составного типа. Если указано IF EXISTS и атрибут не существует, это не считается ошибкой. В этом случае выдается только замечание.
ALTER ATTRIBUTE ... SET DATA TYPE
Эта форма изменяет тип атрибута составного типа.
ADD VALUE [ IF NOT EXISTS ] [ BEFORE | AFTER ]
Эта форма добавляет новое значение в перечислимый тип. Позицию нового значения в перечислении можно указать как BEFORE или AFTER с одним из существующих значений. Без этого указания новый элемент добавляется в конец списка значений.
С указанием IF NOT EXISTS, если тип уже содержит новое значение, ошибки не возникнет: будет выдано замечание, и ничего больше не произойдет. В противном случае, если новое значение уже представлено, возникнет ошибка.
RENAME VALUE
Эта форма переименовывает значение в перечислимом типе. Позиция значения в порядке перечисления не изменяется. Если указанное значение отсутствует или новое имя уже присутствует в перечислимом типе, произойдет ошибка.
SET ( свойство = значение [, ... ] )
Эта форма применима только к базовым типам. Она позволяет настраивать подгруппу свойств типа, которую можно задать в команде CREATE TYPE. В частности, можно изменить следующие свойства:
Более подробную информацию об этих свойствах типа см. в разделе CREATE TYPE. Обратите внимание, что везде, где применимо, изменение этих свойств у базового типа будет автоматически распространяться на основанные на этом типе домены.
Указания ADD ATTRIBUTE, DROP ATTRIBUTE и ALTER ATTRIBUTE можно объединить в список множественных изменений для одновременного выполнения. Например, можно добавить несколько атрибутов и/или изменить тип нескольких атрибутов в одной команде.
Чтобы использовать команду ALTER TYPE, нужно быть владельцем
соответствующего типа. Чтобы изменить схему типа, необходимо помимо этого
иметь право CREATE в новой схеме. Для смены владельца текущий пользователь также
должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме типа.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания типа.
Однако суперпользователь всё равно может сменить владельца любого типа.)
Чтобы добавить атрибут или изменить его тип, необходимо помимо этого иметь право
USAGE для соответствующего типа данных.
Параметры
имя
Имя существующего типа, подлежащего изменению (может быть дополнено схемой).
новое_имя
Новое имя типа.
новый_владелец
Имя пользователя нового владельца типа.
новая_схема
Новая схема типа.
имя атрибута
Имя атрибута, который нужно добавить, изменить или удалить.
новое_имя_атрибута
Новое имя переименовываемого атрибута.
тип_данных
Тип данных добавляемого атрибута либо новый тип данных изменяемого атрибута.
новое_значение_перечисления
Новое значение, которое будет добавлено в список значений перечислимого типа, или новое имя, которое будет присвоено существующему значению. Как и все элементы перечисления, оно должно быть заключено в кавычки.
соседнее_значение_перечисления
Существующие значение в перечислении, непосредственно перед или после которого по порядку перечисления в перечислимом типе будет добавлено новое значение. Как и все элементы перечисления, оно должно быть заключено в кавычки.
существующее_значение_перечисления
Существующее значение в перечислении, которое должно быть переименовано. Как и все элементы перечисления, оно должно быть заключено в кавычки.
свойство
Имя изменяемого свойства базового типа; возможные значения см. выше.
CASCADE
Автоматически распространять операцию на типизированные таблицы изменяемого типа и их потомков.
RESTRICT
Запретить выполнение операции, если изменяемый тип является типом типизированной таблицы. Это поведение по умолчанию.
Примечания
Если ALTER TYPE ... ADD VALUE (форма, которая добавляет новое
значение к типу-перечислению) выполняется внутри блока транзакций, новое
значение не может быть использовано до тех пор, пока транзакция не будет
зафиксирована.
Сравнение, включающее добавленное значение перечисления, иногда происходит медленнее, чем сравнение, включающее только исходные члены перечислимого типа. Это, как правило, происходит только в том случае, если BEFORE или AFTER устанавливает порядковую позицию нового элемента не в конце списка. Однако иногда это наблюдается даже тогда, когда новое значение добавляется в конец списка (это происходит, если счетчик OID «прокручивается» с момента изначального создания перечислимого типа). Замедление обычно незначительно, но если это имеет значение, оптимальная производительность может быть восстановлена путем удаления и повторного создания перечислимого типа или путем выгрузки копии и повторной загрузки базы данных.
Примеры
Переименование типа данных:
ALTER TYPE electronic_mail RENAME TO email;
Смена владельца типа email на joe:
ALTER TYPE email OWNER TO joe;
Смена схемы типа email на customers:
ALTER TYPE email SET SCHEMA customers;
Добавление в тип нового атрибута:
ALTER TYPE compfoo ADD ATTRIBUTE f3 int;
Добавление нового значения в перечислимый тип, в определенную порядковую позицию:
ALTER TYPE colors ADD VALUE 'orange' AFTER 'red';
Переименование значения в перечислении:
ALTER TYPE colors RENAME VALUE 'purple' TO 'mauve';
Создание функций двоичного ввода/вывода для существующего базового типа:
CREATE FUNCTION mytypesend(mytype) RETURNS bytea ...;
CREATE FUNCTION mytyperecv(internal, oid, integer) RETURNS mytype ...;
ALTER TYPE mytype SET (
SEND = mytypesend,
RECEIVE = mytyperecv
);
Совместимость
Варианты добавления и удаления атрибутов являются частью стандарта SQL; другие варианты являются расширениями QHB.
См. также
ALTER USER MAPPING
ALTER USER MAPPING — изменить определение сопоставления пользователей
Синтаксис
ALTER USER MAPPING FOR { имя_пользователя | USER | CURRENT_USER | SESSION_USER | PUBLIC }
SERVER имя_сервера
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] )
Описание
Команда ALTER USER MAPPING изменяет определение сопоставления пользователей.
Владелец стороннего сервера может изменять сопоставления любых пользователей для этого сервера. Кроме того, пользователь может изменить сопоставление для своего собственного имени пользователя, если у него есть право USAGE на сервере.
Параметры
имя_пользователя
Имя пользователя для сопоставления. Значения CURRENT_USER и USER соответствует имени текущего пользователя. PUBLIC используется для сопоставления всех настоящих и будущих имен пользователей в системе.
имя_сервера
Имя сервера, для которого меняется сопоставление пользователей.
OPTIONS ( [ ADD | SET | DROP ] параметр ['значение'] [, ... ] )
Эти формы меняют параметры сопоставления пользователей. Новые параметры переопределяют все ранее указанные параметры. ADD, SET и DROP указывают действие, которое необходимо выполнить. Если операция не указана явно, предполагается ADD. Имена параметров должны быть уникальными; параметры также проверяются оберткой сторонних данных сервера.
Примеры
Изменение пароля в сопоставлении пользователя bob на сервере foo:
ALTER USER MAPPING FOR bob SERVER foo OPTIONS (SET password 'public');
Совместимость
Команда ALTER USER MAPPING соответствует стандарту ISO/IEC 9075-9
(SQL/MED), но существует небольшое синтаксическое различие: в стандарте
ключевое слово FOR опускается. Так как и в CREATE USER MAPPING,
и в DROP USER MAPPING слово FOR находится в аналогичных позициях,
а IBM DB2 (еще одна популярная реализация SQL/MED) требует его наличия
и для команды ALTER USER MAPPING, QHB в этом аспекте отклоняется от стандарта
в целях согласованности и совместимости.
См. также
CREATE USER MAPPING, DROP USER MAPPING
ALTER USER
ALTER USER — изменить роль в базе данных
Синтаксис
ALTER USER указание_роли [ WITH ] параметр [ ... ]
Где параметр может быть:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT предел_подключений
| [ ENCRYPTED ] PASSWORD 'пароль' | PASSWORD NULL
| VALID UNTIL 'дата_время'
ALTER USER имя RENAME TO новое_имя
ALTER USER { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] SET параметр_конфигурации { TO | = } { значение | DEFAULT }
ALTER USER { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] SET параметр_конфигурации FROM CURRENT
ALTER USER { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] RESET параметр_конфигурации
ALTER USER { указание_роли | ALL } [ IN DATABASE имя\_базы\_данных ] RESET ALL
Где указание_роли может быть:
имя_роли
| CURRENT_USER
| SESSION_USER
Описание
Команда ALTER USER теперь стала синонимом команды ALTER ROLE.
Совместимость
Команда ALTER USER является расширением QHB. В стандарте SQL определение
пользователей считается зависимым от реализации.
См. также
ALTER VIEW
ALTER VIEW — изменить определение представления
Синтаксис
ALTER VIEW [ IF EXISTS ] имя ALTER [ COLUMN ] имя_столбца SET DEFAULT выражение
ALTER VIEW [ IF EXISTS ] имя ALTER [ COLUMN ] имя_столбца DROP DEFAULT
ALTER VIEW [ IF EXISTS ] имя OWNER TO { новый_владелец | CURRENT_USER | SESSION_USER }
ALTER VIEW [ IF EXISTS ] имя RENAME TO новое_имя
ALTER VIEW [ IF EXISTS ] имя SET SCHEMA новая_схема
ALTER VIEW [ IF EXISTS ] имя SET ( имя_параметра_представления [= значение_параметра_представления] [, ... ] )
ALTER VIEW [ IF EXISTS ] имя RESET ( имя_параметра_представления [, ... ] )
Описание
Команда ALTER VIEW изменяет различные дополнительные свойства представления.
(Для изменения запроса, определяющего представление, используйте команду CREATE OR REPLACE VIEW.)
Чтобы использовать команду ALTER VIEW, нужно быть владельцем
соответствующего представления. Чтобы изменить схему представления, необходимо
помимо этого иметь право CREATE в новой схеме. Для смены владельца текущий пользователь
также должен быть непосредственным или опосредованным членом новой роли-владельца, и
эта роль должна иметь право CREATE в схеме представления.
(Эти ограничения направлены на то, чтобы при смене владельца не происходило ничего,
что нельзя было бы сделать путем удаления и повторного создания представления.
Однако суперпользователь всё равно может сменить владельца любого представления.)
Параметры
имя
Имя существующего представления (может быть дополнено схемой).
имя_столбца
Имя существующего столбца.
новое_имя_столбца
Новое имя существующего столбца.
IF EXISTS
Не считать ошибкой, если представление не существует. В этом случае будет выдано замечание.
SET/DROP DEFAULT
Эти формы устанавливают или удаляют значение по умолчанию для столбца.
Значение по умолчанию столбца представления подставляется в команды
INSERT или UPDATE, чьей целью является это представление, перед применением к
последнему любых правил или триггеров. Таким образом, значение по умолчанию представления
будет иметь приоритет над любыми значениями по умолчанию в нижележащих отношениях.
новый_владелец
Имя пользователя нового владельца представления.
новое_имя
Новое имя представления.
новая_схема
Новая схема представления.
SET ( имя_параметра_представления [= значение_параметра_представления] [, ... ] ) RESET ( имя_параметра_представления [, ... ] )
Устанавливает или сбрасывает параметр представления. В настоящее время поддерживаются следующие параметры:
Примечания
По историческим причинам команду ALTER TABLE тоже можно использовать с
представлениями; но формы команды ALTER TABLE, которые
разрешены для работы с представлениями, эквивалентны показанным выше.
Примеры
Переименование представления foo в bar:
ALTER VIEW foo RENAME TO bar;
Добавление значения столбца по умолчанию в изменяемое представление:
CREATE TABLE base_table (id int, ts timestamptz);
CREATE VIEW a_view AS SELECT * FROM base_table;
ALTER VIEW a_view ALTER COLUMN ts SET DEFAULT now();
INSERT INTO base_table(id) VALUES(1); -- в ts окажется значение NULL
INSERT INTO a_view(id) VALUES(2); -- в ts окажется текущее время
Совместимость
Команда ALTER VIEW, реализованная в QHB, является расширением стандарта SQL.
См. также
ANALYZE
ANALYZE — собрать статистику о базе данных
Синтаксис
ANALYZE [ ( параметр [, ...] ) ] [ таблица_и_столбцы [, ...] ]
ANALYZE [ VERBOSE ] [ таблица_и_столбцы [, ...] ]
Где параметр может быть:
VERBOSE [ логическое_значение ]
SKIP_LOCKED [ логическое_значение ]
Где таблица_и_столбцы это:
имя_таблицы [ ( имя_столбца [, ...] ) ]
Описание
Команда ANALYZE собирает статистическую информацию о содержании таблиц в базе данных и
сохраняет результаты в системном каталоге pg_statistic. Впоследствии
планировщик запросов использует эти статистические данные для
определения наиболее эффективных планов выполнения запросов.
Без списка таблица_и_столбцы команда ANALYZE обрабатывает
все таблицы и материализованные представления в текущей базе данных,
которые текущий пользователь имеет право анализировать. Со списком ANALYZE обрабатывает
только те таблицы, которые в нем указаны. Кроме того, можно указать список имен столбцов
таблицы; в этом случае собираются статистические данные только для этих столбцов.
Когда список заключается в скобки, параметры могут быть записаны в любом порядке. Написание без скобок считается устаревшим.
Параметры
VERBOSE
Включает отображение сообщений о ходе выполнения.
SKIP_LOCKED
Указывает, что команда ANALYZE не должна ждать освобождения конфликтующих
блокировок при начале работы над отношением: если отношение не может
быть немедленно заблокировано без ожидания, оно пропускается.
Обратите внимание, что даже при использовании этого параметра ANALYZE
по-прежнему может блокироваться при открытии индексов отношения
или при получении выборки строк из партиций, потомков таблиц и некоторых типов сторонних таблиц.
Кроме того, при обычном анализе обрабатываются все партиции указанных партиционированных
таблиц, но эта опция заставит ANALYZE пропустить все партиции при наличии на партиционированной таблице конфликтующей блокировки.
логическое_значение
Указывает, должна ли выбранная функция быть включена или выключена. Для включения функции можно написать TRUE, ON или 1, а для отключения — FALSE, OFF или 0. Если этот параметр опущен, предполагается значение TRUE.
имя_таблицы
Имя конкретной таблицы для анализа (может быть дополнено схемой). Если этот параметр опущен, то анализируются все обычные таблицы, партиционированные таблицы и материализованные представления в текущей базе данных (но не сторонние таблицы). Если указанная таблица является партиционированной таблицей, то обновляется как статистика наследования партиционированной таблицы в целом, так и статистика отдельных партиций.
имя_столбца
Имя конкретного столбца для анализа. По умолчанию анализ проводится для всех столбцов.
Выводимая информация
При указании VERBOSE команда ANALYZE выдает сообщения о ходе выполнения, показывая, какая
таблица обрабатывается в настоящее время. Также печатаются различные статистические данные о
таблицах.
Примечания
Для анализа таблицы обычно необходимо быть владельцем таблицы или
суперпользователем. Однако владельцам баз данных разрешается
анализировать все таблицы в своих базах данных, за исключением общих
каталогов. (Ограничение для общих каталогов означает, что по-настоящему
глобальную команду ANALYZE может выполнить только суперпользователь.)
ANALYZE пропустит все таблицы, для которых вызывающий пользователь не имеет разрешения на анализ.
Сторонние таблицы анализируются только при явном указании. Не все
обертки сторонних данных поддерживают ANALYZE. Если обертка таблицы не
поддерживает ANALYZE, команда выводит предупреждение и ничего не
делает.
В конфигурации QHB по умолчанию процесс «Автовакуум» (см. раздел
Процесс «Автовакуум») запускает автоматический анализ таблиц, когда они впервые
заполняются данными, а также по мере их изменения в ходе штатных операций.
Если функция автоочистки отключена, рекомендуется запускать ANALYZE
периодически или сразу после внесения существенных изменений в
содержимое таблицы. Точная статистика поможет планировщику выбрать
наиболее подходящий план запроса и тем самым повысить скорость
обработки запроса. Общая стратегия для баз данных, где данные преимущественно читаются,
заключается в запуске VACUUM и ANALYZE раз в день во время наименьшей активности.
(Этого будет недостаточно, если данные обновляются активно.)
ANALYZE требуется только блокировка на чтение в целевой таблице,
поэтому команда может выполняться параллельно с другими действиями в таблице.
Статистические данные, собранные методом ANALYZE, обычно включают
список некоторых наиболее распространенных значений в каждом столбце и
гистограмму, показывающую примерное распределение данных в каждом
столбце. Один или оба этих элемента статистики могут быть опущены, если ANALYZE сочтет
их неинтересными (например, в столбце с уникальным ключом нет общих
значений) или если тип данных столбца не поддерживает соответствующие
операторы. Более подробная информация о статистике приведена в главе
Регулярные задачи обслуживания базы данных.
Для больших таблиц ANALYZE берет случайную выборку содержимого
таблицы, а не рассматривает каждую строку. Это позволяет проанализировать
за короткое время даже очень большие таблицы.
Обратите внимание, однако, что статистические данные окажутся
приблизительными и будут незначительно меняться при каждом запуске
ANALYZE, даже если фактическое содержимое таблицы не изменилось. Это
может привести к небольшим изменениям в оценках стоимости запросов,
показанных командой EXPLAIN. В редких случаях этот недетерминизм приведет к
смене выбора планов запросов у планировщика после выполнения ANALYZE.
Чтобы избежать этого, нужно увеличить объем статистики, собранной методом
ANALYZE, как описано ниже.
Количеством статистики можно управлять, настраивая
конфигурационную переменную [default_statistics_target] или на уровне столбцов
устанавливая целевой показатель статистики для каждого столбца командой
ALTER TABLE ... ALTER COLUMN ... SET STATISTICS (см. ALTER TABLE). Целевое
значение задает максимальное количество записей в списке наиболее
распространенных значений и максимальное количество интервалов в гистограмме.
Целевое значение по умолчанию равно 100, но оно может быть
скорректировано вверх или вниз, чтобы компенсировать точность оценок
планировщика относительно времени, затраченного на выполнение ANALYZE, и объема
занимаемого пространства в pg_statistic. В частности, установка
значения целевого показателя статистики равным нулю отключает сбор статистических
данных для этого столбца. Скорее всего, будет полезно сделать это для столбцов,
которые никогда не используются в предложениях WHERE, GROUP BY или ORDER BY,
так как планировщик не будет использовать статистику по таким столбцам.
Число строк таблицы, выбираемых для подготовки статистики, определяется наибольшим
целевым показателем статистики из всех анализируемых столбцов этой таблицы.
Увеличение целевого показателя вызывает пропорциональное увеличение времени
и пространства, необходимого для выполнения ANALYZE.
Один из показателей, оцениваемых командой ANALYZE, — это число различных
значений, встречающихся в каждом столбце. Поскольку рассматривается
только подмножество строк, эта оценка иногда может быть довольно
неточной, даже с максимально возможным целевым показателем статистики. Если эта
неточность приводит к плохим планам запросов, можно вручную определить более
точное значение, а затем задать его командой
ALTER TABLE ... ALTER COLUMN ... SET (n_distinct = ...) (см. ALTER TABLE).
Если анализируемая таблица имеет одну или нескольких дочерних таблиц,
ANALYZE будет собирать статистику дважды: один раз только по
строкам родительской таблицы и второй раз по строкам родительской
таблицы со всеми ее потомками. Этот второй набор
статистических данных необходим при планировании запросов, проходящих
через всё дерево наследования. Процесс «Автовакуум», однако, при принятии решения
о запуске автоматического анализа для этой таблицы будет
рассматривать операции добавления или обновления данных только в самой родительской
таблице. Если эта таблица редко обновляется, наследуемая статистика
не будет обновляться до тех пор, пока не будет вручную запущена команда ANALYZE.
Если какая-либо из дочерних таблиц является сторонней таблицей, чьи
обертки сторонних данных не поддерживают ANALYZE, эти дочерние таблицы
игнорируются при сборе статистики наследования.
Если анализируемая таблица пуста, ANALYZE не будет обновлять статистику для этой таблицы.
Будет сохранена вся существующая статистика.
Совместимость
В стандарте SQL нет команды ANALYZE.
См. также
VACUUM, vacuumdb, Определение предела стоимости работы процесса очистки, Процесс «Автовакуум»
BEGIN
BEGIN — начать блок транзакций
Синтаксис
BEGIN [ AUTONOMOUS ] [ WORK | TRANSACTION ] [ режим_транзакции [, ...] ]
Где режим_транзакции может быть следующим:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE
Описание
Команда BEGIN инициирует блок транзакций, то есть после ее выполнения все операторы будут выполняться в одной транзакции до тех пор, пока
не будет дано явной команды COMMIT или ROLLBACK. По умолчанию
(без BEGIN) QHB выполняет транзакции в режиме «autocommit» (автофиксация),
то есть каждый оператор выполняется в своей собственной транзакции, а
фиксация неявно выполняется в конце оператора (если выполнение было
успешным; в противном случае выполняется откат).
В блоке транзакций операторы выполняются быстрее, потому что запуск/фиксация транзакций требует значительной активности процессора и диска. Также выполнение нескольких операторов внутри транзакции позволяет обеспечить согласованность при внесении нескольких связанных изменений: другие сеансы не смогут увидеть промежуточные состояния, в которых были сделаны не все связанные обновления.
Если указан уровень изоляции, режим чтения/записи или отложенный режим, новая транзакция имеет те же характеристики, что и после выполнения SET TRANSACTION.
Параметры
WORK
TRANSACTION
Необязательные ключевые слова. Они не имеют никакого эффекта.
Информацию о значении других параметров для данного оператора см. в разделе SET TRANSACTION.
Примечания
START TRANSACTION имеет ту же функциональность, что и BEGIN.
Для завершения блока транзакций используйте COMMIT или ROLLBACK.
При попытке выполнить BEGIN внутри уже начатого блока транзакции
будет выдано предупреждение, но на состояние транзакции это не повлияет. Для вложения
подтранзакций внутри блока транзакции используйте точки сохранения (см.
SAVEPOINT).
По соображениям обратной совместимости запятые между последовательными transaction_modes можно не ставить.
Примеры
Начало блока транзакции:
BEGIN;
Совместимость
Команда BEGIN является языковым расширением QHB.
BEGIN равнозначна стандартной SQL команде START TRANSACTION,
справочная страница которой содержит дополнительную информацию о совместимости.
Значение DEFERRABLE параметра режим_транзакции является языковым расширением QHB.
По стечению обстоятельств ключевое слово BEGIN имеет другое значение
во встраиваемом SQL. Поэтому рекомендуется при портировании приложений баз данных
внимательно сверять семантику транзакций.
См. также
COMMIT, ROLLBACK, START TRANSACTION, SAVEPOINT
CALL
CALL — вызвать процедуру
Синтаксис
CALL имя ( [ аргумент ] [, ...] )
Описание
Команда CALL вызывает процедуру.
Если процедура имеет какие-либо выходные параметры, то будет возвращена результирующая строка, содержащая значения этих параметров.
Параметры
имя
Имя процедуры (может быть дополнено схемой).
аргумент
Входной аргумент для вызова процедуры. Полную информацию о синтаксисе вызова функций и процедур, включая использование именованных параметров, см. в разделе Запуск сервера базы данных.
Примечания
Чтобы вызывать процедуру, необходимо иметь для нее право EXECUTE.
Чтобы вызвать функцию (а не процедуру), используйте команду SELECT.
Если CALL выполняется в блоке транзакций, то вызываемая процедура
не может выполнять команды управления транзакциями. Эти команды
допускаются только в том случае, если CALL выполняется в собственной транзакции.
PL/pgSQL обрабатывает выходные параметры в командах вызова по-другому; см. раздел Вызов процедуры.
Примеры
CALL do_db_maintenance();
Совместимость
Команда CALL соответствует стандарту SQL.
См. также
CHECKPOINT
CHECKPOINT — произвести контрольную точку в журнале предзаписи
Синтаксис
CHECKPOINT
Описание
Контрольная точка — это момент в последовательности событий в журнале предзаписи, когда все файлы данных приводятся в актуальное состояние, соответствующее информации в журнале. Все файлы данных сохраняются на диск. Более подробную информацию о том, что происходит во время контрольной точки, см. в разделе Конфигурация WAL.
Команда CHECKPOINT приводит к принудительному выполнению контрольной точки в момент вызова,
не дожидаясь периодической контрольной точки,
запланированной системой (управляется настройками в разделе Контрольные точки).
Команда CHECKPOINT не предназначена для использования в
обычном режиме работы.
Если команда CHECKPOINT будет выполнена во время восстановления, то
вместо записи новой контрольной точки будет принудительно введена точка
перезапуска (см. раздел Конфигурация WAL).
Выполнять команду CHECKPOINT могут только суперпользователи.
Совместимость
Команда CHECKPOINT является языковым расширением QHB.
CLOSE
CLOSE — закрыть курсор
Синтаксис
CLOSE { имя | ALL }
Описание
Команда CLOSE освобождает ресурсы, связанные с открытым курсором. После
закрытия курсора никакие последующие операции на нем не допускаются.
Курсор нужно закрывать, когда он больше не нужен.
Каждый неудерживаемый открытый курсор неявно закрывается, когда
транзакция завершается командами COMMIT или ROLLBACK. Удерживаемый
курсор неявно закрывается, если транзакция, которая его создала,
прерывается командой ROLLBACK. Если создаваемая транзакция успешно
фиксируется, удерживаемый курсор остается открытым до вызова команды CLOSE
или отключения клиента.
Параметры
имя
Имя открытого курсора, подлежащего закрытию.
ALL
Закрыть все открытые курсоры.
Примечания
QHB не имеет явной команды OPEN для курсора; курсор считается
открытым, когда он объявлен. Для объявления курсора используйте команду DECLARE.
Все доступные курсоры можно просмотреть, запросив системное представление pg_cursors.
Если курсор закрывается после точки сохранения, которая позже
откатывается назад, CLOSE не откатывается, то есть курсор
остается закрытым.
Примеры
Закрытие курсора liahona:
CLOSE liahona;
Совместимость
Команда CLOSE полностью соответствует стандарту SQL. Команда CLOSE ALL
является расширением QHB.
См. также
CLUSTER
CLUSTER — кластеризовать таблицу согласно индексу
Синтаксис
CLUSTER [VERBOSE] имя_таблицы [ USING имя_индекса ]
CLUSTER [VERBOSE]
Описание
Команда CLUSTER дает указание QHB кластеризировать таблицу, заданную в параметре
имя_таблицы, основываясь на индексе, заданном в имя_индекса. Индекс уже
должен быть определен в имя_таблицы.
Когда таблица кластеризуется, она физически переупорядочивается на основе данных индекса. Кластеризация является одноразовой операцией: при последующем обновлении таблицы изменения не кластеризуются. То есть не предпринимается никаких попыток сохранить новые или обновленные строки в соответствии с их порядком индексирования. (При желании можно периодически повторять кластеризацию, выполняя команду снова. Кроме того, установка у таблицы параметра FILLFACTOR меньше 100% может помочь сохранить порядок кластеризации во время обновлений, так как обновленные строки останутся на той же странице, если там доступно достаточно места.)
Когда таблица кластеризуется, QHB запоминает, по какому индексу
она была кластеризована. Форма CLUSTER имя\_таблицы повторно кластеризует
таблицу, используя тот же индекс, что и раньше. Для установки индекса,
который будет использоваться в будущих операциях кластеризации,
или очистки предыдущего значения можно также применить команду CLUSTER
или формы SET WITHOUT CLUSTER команды ALTER TABLE.
CLUSTER без какого-либо параметра повторно кластеризует все ранее
кластеризованные таблицы в текущей базе данных, принадлежащей
вызывающему пользователю, или все такие таблицы, если они вызываются
суперпользователем. Эта форма CLUSTER не может быть выполнена
внутри блока транзакций.
Когда таблица кластеризуется, запрашивается блокировка ACCESS EXCLUSIVE.
Это препятствует выполнению любых других операций базы данных (как чтению,
так и записи) над таблицей, пока CLUSTER не будет завершена.
Параметры
имя_таблицы
Имя таблицы (может быть дополнено схемой).
имя_индекса
Имя индекса.
VERBOSE
Выводит отчет о процессе кластеризации по мере обработки таблиц.
Примечания
В случаях, когда происходит обращение к случайным единичным строкам
таблицы, фактический порядок данных в таблице не имеет
значения. Однако если имеется тенденция обращения к одним данным чаще,
чем к другим, и есть индекс, который группирует их вместе, использование
команды CLUSTER дает преимущества. Если запросить из таблицы диапазон
индексированных значений или одно индексированное значение,
имеющее несколько соответствующих строк, CLUSTER поможет,
так как страница таблицы, найденная по индексу для первой искомой строки,
скорее всего, будет содержать и все остальные искомые строки.
Таким образом, кластеризация помогает оптимизировать обращения к диску
и ускорить запросы.
CLUSTER может повторно отсортировать таблицу, используя либо
сканирование по указанному индексу, либо (если индекс является
B-деревом) последовательное сканирование с последующей сортировкой. Она
будет пытаться выбрать более быстрый метод на основе плановых
параметров затрат и доступной статистической информации.
При использовании сканирования индекса создается временная копия таблицы, содержащая данные таблицы в порядке следования индексов. Также создаются временные копии каждого индекса в таблице. Поэтому для данной операции потребуется свободное пространство на диске, по крайней мере равное сумме размера таблицы и размеров индекса.
Когда используется последовательное сканирование и сортировка, также создается временный файл сортировки, так что пиковое требование к временному пространству равно удвоенному размеру таблицы плюс размеры индекса. Этот метод часто работает быстрее, чем метод сканирования индекса, но если требование к дисковому пространству неприемлемо, этот выбор можно отключить, временно установив enable_sort в OFF.
Перед кластеризацией рекомендуется установить значение
maintenance_work_mem достаточно большим (но
не больше, чем объем ОЗУ, который вы можете выделить для операции
CLUSTER).
Поскольку планировщик записывает статистику о порядке таблиц, для новой кластеризованной таблицы рекомендуется выполнить ANALYZE. В противном случае планировщик может сделать неверный выбор планов запросов.
Поскольку CLUSTER запоминает, какие индексы кластеризуются, можно
кластеризировать таблицы, которые требуется кластеризировать вручную в
первый раз, а затем настроить периодический сценарий обслуживания,
который будет выполнять CLUSTER без каких-либо параметров, так что нужные
таблицы будут периодически повторно кластеризоваться.
Примеры
Кластеризация таблицы employees согласно ее индексу employees_ind:
CLUSTER employees USING employees_ind;
Кластеризация таблицы employees согласно уже использовавшемуся индексу:
CLUSTER employees;
Кластеризация всех кластеризованных ранее таблиц в базе данных:
CLUSTER;
Совместимость
В стандарте SQL нет команды CLUSTER.
См. также
COMMENT
COMMENT — задать или изменить комментарий объекта
Синтаксис
COMMENT ON
{
ACCESS METHOD имя_объекта |
AGGREGATE имя_агрегатной_функции ( сигнатура_агрегатной_функции ) |
CAST (исходный_тип AS целевой_тип) |
COLLATION имя_объекта |
COLUMN имя_отношения.имя_столбца |
CONSTRAINT имя_ограничения ON имя_таблицы |
CONSTRAINT имя_ограничения ON DOMAIN имя_домена |
CONVERSION имя_объекта |
DATABASE имя_объекта |
DOMAIN имя_объекта |
EXTENSION имя_объекта |
EVENT TRIGGER имя_объекта |
FOREIGN DATA WRAPPER имя_объекта |
FOREIGN TABLE имя_объекта |
FUNCTION имя_функции [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
INDEX имя_объекта |
LARGE OBJECT oid_большого_объекта |
MATERIALIZED VIEW имя_объекта |
OPERATOR имя_оператора (тип_слева, тип_справа) |
OPERATOR CLASS имя_объекта USING индексный_метод |
OPERATOR FAMILY имя_объекта USING индексный_метод |
POLICY имя_политики ON имя_таблицы |
[ PROCEDURAL ] LANGUAGE имя_объекта |
PROCEDURE имя_процедуры [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
PUBLICATION имя_объекта |
ROLE имя_объекта |
ROUTINE имя_подпрограммы [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
RULE имя_правила ON имя_таблицы |
SCHEMA имя_объекта |
SEQUENCE имя_объекта |
SERVER имя_объекта |
STATISTICS имя_объекта |
SUBSCRIPTION имя_объекта |
TABLE имя_объекта |
TABLESPACE имя_объекта |
TEXT SEARCH CONFIGURATION имя_объекта |
TEXT SEARCH DICTIONARY имя_объекта |
TEXT SEARCH PARSER имя_объекта |
TEXT SEARCH TEMPLATE имя_объекта |
TRANSFORM FOR имя_типа LANGUAGE имя_языка |
TRIGGER имя_триггера ON имя_таблицы |
TYPE имя_объекта |
VIEW имя_объекта
} IS 'текст'
Где сигнатура_агрегатной_функции:
* |
[ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] |
[ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] ] ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ]
Описание
Команда COMMENT хранит комментарий об объекте базы данных.
Для каждого объекта сохраняется только одна строка комментария, поэтому для изменения комментария следует ввести новую команду комментария для того же объекта. Чтобы удалить комментарий, вместо текстовой строки нужно написать NULL. Комментарии автоматически удаляются вместе с объектом.
Для большинства видов объектов установить комментарий может только владелец
объекта. У ролей нет владельцев, поэтому команду COMMENT ON ROLE для
ролей суперпользователей могут выполнять только суперпользователи,
а для обычных ролей — те, кто имеет право CREATEROLE. Кроме того,
методы доступа также не имеют владельцев; чтобы добавлять комментарий для метода доступа,
нужно быть суперпользователем. Разумеется,
суперпользователь может задавать комментарии любым объектам.
Комментарии можно просматривать с помощью семейства команд qsql \D. Другие пользовательские интерфейсы для получения комментариев могут быть построены поверх тех же встроенных функций, которые использует qsql, а именно obj_description, col_description и shobj_description (см. таблицу Comment Information Functions).
Параметры
имя_объекта
имя_отношения.имя_столбца
имя_агрегатной_функции
имя_ограничения
имя_функции
имя_оператора
имя_политики
имя_процедуры
имя_подпрограммы
имя_правила
имя_триггера
Имя объекта, для которого задается комментарий. Имена таблиц, агрегатных функций, правил сортировки, перекодировок, доменов, сторонних таблиц, функций, индексов, операторов, классов операторов, семейств операторов, процедур, подпрограмм, последовательностей, статистики, объектов текстового поиска, типов и представлений могут быть дополнены именем схемы. При комментировании колонки имя_отношения должно ссылаться на таблицу, представление, составной тип или стороннюю таблицу.
имя_таблицы
имя_домена
При создании комментария к ограничению, триггеру, правилу или политике эти параметры задают имя таблицы или домена, в котором этот объект определен.
исходный_тип
Имя исходного типа данных для приведения.
целевой_тип
Имя целевого типа данных для приведения.
режим_аргумента
Режим аргумента функции, процедуры или агрегатной функции: IN, OUT, INOUT или VARIADIC.
Если этот параметр опущен, значение по умолчанию равно IN.
Обратите внимание, что COMMENT на самом деле не обращает
никакого внимания на аргументы OUT, так как для определения идентичности
функции необходимы только входные аргументы. Поэтому достаточно
перечислить аргументы IN, INOUT и VARIADIC.
имя_аргумента
Имя аргумента функции, процедуры или агрегатной функции. Обратите внимание, что
COMMENT фактически не обращает никакого внимания на имена
аргументов, так как для определения идентичности функции необходимы
только типы данных аргумента.
тип_аргумента
Тип данных аргумента функции, процедуры или агрегатной функции.
oid_большого_объекта
OID большого объекта.
тип_слева
тип_справа
Типы данных аргументов оператора (могут быть дополнены именем схемы). В случае отсутствия аргумента оператора укажите вместо типа NONE.
PROCEDURAL
Это слово не несет смысловой нагрузки.
имя_типа
Имя типа данных, для которого предназначена трансформация.
имя_языка
Название языка, для которого предназначена трансформация.
текст
Новый комментарий, написанный в виде строкового литерала, или NULL для удаления комментария.
Примечания
В настоящее время механизм безопасности для просмотра комментариев отсутствует: любой пользователь, подключенный к базе данных, может просматривать все комментарии для объектов в этой базе данных. Для общих объектов, таких как базы данных, роли и табличные пространства, комментарии хранятся глобально, поэтому любой пользователь, подключенный к любой базе данных в кластере, может просматривать все комментарии для общих объектов. Поэтому не следует помещать в комментарии критически важную для безопасности информацию.
Примеры
Добавление комментария для таблицы mytable:
COMMENT ON TABLE mytable IS 'Это моя таблица.';
Его удаление:
COMMENT ON TABLE mytable IS NULL;
Еще несколько примеров:
COMMENT ON ACCESS METHOD rtree IS 'Метод доступа R-Tree';
COMMENT ON AGGREGATE my_aggregate (double precision) IS 'Вычисляет дисперсию выборки';
COMMENT ON CAST (text AS int4) IS 'Выполняет приведение строк к int4';
COMMENT ON COLLATION "fr_CA" IS 'Канадский французский';
COMMENT ON COLUMN my_table.my_column IS 'Порядковый номер сотрудника';
COMMENT ON CONVERSION my_conv IS 'Перекодировка в UTF8';
COMMENT ON CONSTRAINT bar_col_cons ON bar IS 'Ограничение столбца col';
COMMENT ON CONSTRAINT dom_col_constr ON DOMAIN dom IS 'Ограничение col для домена';
COMMENT ON DATABASE my_database IS 'База данных разработчиков';
COMMENT ON DOMAIN my_domain IS 'Домен почтового адреса';
COMMENT ON EVENT TRIGGER abort_ddl IS 'Прерывает все команды DDL';
COMMENT ON EXTENSION hstore IS 'Реализует тип данных hstore';
COMMENT ON FOREIGN DATA WRAPPER mywrapper IS 'Моя обертка сторонних данных';
COMMENT ON FOREIGN TABLE my_foreign_table IS 'Информация о сотрудниках в другой БД';
COMMENT ON FUNCTION my_function (timestamp) IS 'Возвращает число римскими цифрами';
COMMENT ON INDEX my_index IS 'Обеспечивает уникальность по коду сотрудника';
COMMENT ON LANGUAGE plpython IS 'Поддержка Python для хранимых процедур';
COMMENT ON LARGE OBJECT 346344 IS 'Документ планирования';
COMMENT ON MATERIALIZED VIEW my_matview IS 'Сводка истории заказов';
COMMENT ON OPERATOR ^ (text, text) IS 'Вычисляет пересечение двух текстов';
COMMENT ON OPERATOR - (NONE, integer) IS 'Унарный минус';
COMMENT ON OPERATOR CLASS int4ops USING btree IS 'Операторы для четырехбайтовых целых (для B-деревьев)';
COMMENT ON OPERATOR FAMILY integer_ops USING btree IS 'Все целочисленные операторы (для B-деревьев)';
COMMENT ON POLICY my_policy ON mytable IS 'Фильтр строк по пользователям';
COMMENT ON PROCEDURE my_proc (integer, integer) IS 'Строит отчет';
COMMENT ON PUBLICATION alltables IS 'Публикует все операции во всех таблицах';
COMMENT ON ROLE my_role IS 'Административная группа для таблиц бухгалтерии';
COMMENT ON ROUTINE my_routine (integer, integer) IS 'Выполняет подпрограмму (функцию или процедуру)';
COMMENT ON RULE my_rule ON my_table IS 'Протоколирует изменения в записях сотрудников';
COMMENT ON SCHEMA my_schema IS 'Данные отдела';
COMMENT ON SEQUENCE my_sequence IS 'Предназначена для генерации первичных ключей';
COMMENT ON SERVER myserver IS 'Мой сторонний сервер';
COMMENT ON STATISTICS my_statistics IS 'Улучшает оценку числа строк для планировщика';
COMMENT ON TABLE my_schema.my_table IS 'Данные сотрудников';
COMMENT ON TABLESPACE my_tablespace IS 'Табличное пространство для индексов';
COMMENT ON TEXT SEARCH CONFIGURATION my_config IS 'Фильтрация специальных слов';
COMMENT ON TEXT SEARCH DICTIONARY swedish IS 'Стеммер Snowball для шведского языка';
COMMENT ON TEXT SEARCH PARSER my_parser IS 'Разделяет текст на слова';
COMMENT ON TEXT SEARCH TEMPLATE snowball IS 'Стеммер Snowball';
COMMENT ON TRANSFORM FOR hstore LANGUAGE plpythonu IS 'Трансформирует данные из hstore в словарь языка Python';
COMMENT ON TRIGGER my_trigger ON my_table IS 'Обеспечивает ссылочную целостность';
COMMENT ON TYPE complex IS 'Тип данных комплексных чисел';
COMMENT ON VIEW my_view IS 'Представление расходов по отделам';
Совместимость
В стандарте SQL нет команды COMMENT.
COMMIT PREPARED
COMMIT PREPARED — зафиксировать транзакцию, которая ранее была подготовлена для двухфазной фиксации
Синтаксис
COMMIT PREPARED id_транзакции
Описание
Команда COMMIT PREPARED фиксирует транзакцию, находящуюся в подготовленном состоянии.
Параметры
id_транзакции
Идентификатор транзакции, подлежащей фиксации.
Примечания
Чтобы зафиксировать подготовленную транзакцию, нужно быть либо пользователем, выполнявшим транзакцию изначально, либо суперпользователем. При этом не обязательно работать в том же сеансе, где выполнялась транзакция.
Эта команда не может быть выполнена внутри блока транзакций. Подготовленная транзакция фиксируется немедленно.
Все доступные в настоящее время подготовленные транзакции перечислены в системном представлении pg_prepared_xacts.
Примеры
Фиксация транзакции, имеющей идентификатор foobar:
COMMIT PREPARED 'foobar';
Совместимость
Команда COMMIT PREPARED является расширением QHB.
Она предназначена для использования внешними системами управления транзакциями, на некоторые из
которых распространяются стандарты (например, X/Open XA), но SQL-сторона этих
систем не стандартизирована.
См. также
PREPARE TRANSACTION, ROLLBACK PREPARED
COMMIT
COMMIT — зафиксировать текущую транзакцию
Синтаксис
COMMIT [ WORK | TRANSACTION ] [ AND [ NO ] CHAIN ]
Описание
Команда COMMIT фиксирует текущую транзакцию. Все внесенные транзакцией изменения
становятся видимыми для других и гарантированно сохранятся, если произойдет сбой.
Параметры
WORK
TRANSACTION
Необязательные ключевые слова. Они не оказывают никакого влияния.
AND CHAIN
Если указывается AND CHAIN, то немедленно запускается новая транзакция с теми же характеристиками (см. раздел SET TRANSACTION), что и только что завершенная. В противном случае новая транзакция не запускается.
Примечания
Для прерывания транзакции используйте команду ROLLBACK.
Выполнение COMMIT вне транзакции не вызовет ошибку, будет выдано только
предупреждающее сообщение. Однако COMMIT AND CHAIN вне транзакции вызовет ошибку.
Примеры
Фиксация текущей транзакции и сохранение всех изменений:
COMMIT;
Совместимость
Команда COMMIT соответствует стандарту SQL. Форма COMMIT TRANSACTION
является расширением QHB.
См. также
COPY
COPY — копировать данные между файлом и таблицей
Синтаксис
COPY имя_таблицы [ ( имя_столбца [, ...] ) ]
FROM { 'имя_файла' | PROGRAM 'команда' | STDIN }
[ [ WITH ] ( параметр [, ...] ) ]
[ WHERE условие ]
COPY { имя_таблицы [ ( имя_столбца [, ...] ) ] | ( запрос ) }
TO { 'имя_файла' | PROGRAM 'команда' | STDOUT }
[ [ WITH ] ( параметр [, ...] ) ]
Где параметр может быть:
FORMAT имя_формата
FREEZE [ boolean ]
DELIMITER 'символ_разделитель'
NULL 'маркер_NULL'
HEADER [ boolean ]
QUOTE 'символ_кавычек'
ESCAPE 'символ_экранирования'
FORCE_QUOTE { ( имя_столбца [, ...] ) | * }
FORCE_NOT_NULL ( имя_столбца [, ...] )
FORCE_NULL ( имя_столбца [, ...] )
ENCODING 'имя_кодировки'
Описание
Команда COPY перемещает данные между таблицами QHB и
стандартными файлами файловой системы. COPY TO копирует
содержимое таблицы в файл, а COPY FROM копирует данные из
файла в таблицу (добавляя данные к тому, что уже находится в таблице).
Команда COPY TO может также копировать результаты запроса SELECT.
Если указан список столбцов, COPY TO будет копировать в файл только данные из
указанных столбцов, а COPY FROM будет по порядку вставлять каждое поле из файла в
указанные столбцы. В столбцы, которых нет в списке, функция COPY FROM добавит их
значения по умолчанию.
COPY с именем файла указывает серверу QHB напрямую
читать или записывать в конкретный файл. Файл должен быть доступен пользователю
QHB (идентификатору пользователя, под которым работает сервер), а
путь к нему указан с точки зрения сервера. Когда указывается PROGRAM,
сервер выполняет заданную команду и считывает данные со
стандартного вывода программы либо записывает их на стандартный вход
программы. Команда должна быть определена с точки зрения сервера и быть
выполнимой пользователем QHB. Когда указывается STDIN или
STDOUT, данные передаются через соединение между клиентом и сервером.
Параметры
имя_таблицы
Имя существующей таблицы (может быть дополнено схемой).
имя_столбца
Необязательный список столбцов для копирования. Если список столбцов не указан, то будут скопированы все столбцы таблицы, кроме сгенерированных.
запрос
Команда SELECT, VALUES, INSERT, UPDATE или DELETE, результаты которой должны быть скопированы. Обратите внимание, что запрос заключается в круглые скобки.
Для запросов INSERT, UPDATE и DELETE должно задаваться предложение RETURNING,
а целевое отношение не должно иметь
ни условного правила, ни правила ALSO, ни правила INSTEAD,
разворачивающегося в несколько операторов.
имя_файла
Путь к входному или выходному файлу. Путь входного файла может быть абсолютным или относительным путем, но путь выходного файла должен быть абсолютным путем. Пользователям Windows может потребоваться использование строки E'' и дублирование каждой обратной черты в пути файла.
PROGRAM
Выполняемая команда. COPY FROM читает стандартный вывод команды, а COPY TO
записывает в ее стандартный ввод
Обратите внимание, что команда вызывается оболочкой, поэтому если вам нужно передать команде оболочки какие-либо аргументы, которые поступают из ненадежного источника, обязательно следует удалить или экранировать любые специальные символы, которые могут иметь особое значение для оболочки. По соображениям безопасности лучше всего использовать фиксированную командную строку или, по крайней мере, избегать передачи в нее любого пользовательского ввода.
STDIN
Указывает, что входные данные поступают из клиентского приложения.
STDOUT
Указывает, что выходные данные передаются в клиентское приложение.
boolean
Указывает, должен ли выбранный параметр быть включен или выключен. Для включения параметра можно написать TRUE, ON или 1, а для отключения — FALSE, OFF или 0. Значение boolean можно опустить; в этом случае подразумевается TRUE.
FORMAT
Выбор формата данных для чтения или записи: text (текстовый), csv (значения, разделенные запятыми (Comma Separated Values)) или binary (двоичный). По умолчанию стоит формат text.
FREEZE
Запрашивает копирование данных с уже замороженными строками, как это
было бы после выполнения команды VACUUM FREEZE. Это позволяет увеличить производительность
для начальной загрузки данных. Строки будут заморожены только в том случае, если загружаемая
таблица была создана или очищена в текущей подтранзакции, нет открытых
курсоров и нет удерживаемых этой транзакцией старых снимков. В
настоящее время невозможно выполнить COPY FREEZE для
партиционированной таблицы.
Обратите внимание, что все остальные сеансы сразу же смогут увидеть данные, как только те будут успешно загружены. Это нарушает обычные правила видимости MVCC, и пользователи, включающие данный режим, должны понимать, какие проблемы это может вызвать.
DELIMITER
Задает символ, который разделяет столбцы в каждой строке файла. По умолчанию используется символ табуляции в текстовом формате, запятая внутри формата CSV. Это должен быть один однобайтовый символ. Для формата binary данный параметр не допускается.
NULL
Задает строку, представляющую собой нулевое значение. Значение по умолчанию: \N (обратная косая черта и N) в текстовом формате и пустая строка без кавычек в формате CSV. Если нет желания различать значения NULL и пустые строки, можно использовать пустую строку даже в текстовом формате. Для формата binary данный параметр не допускается.
Примечание
При использованииCOPY FROMлюбой элемент данных, соответствующий этой строке, будет сохранен как значение NULL, поэтому следует убедиться, что вы используете ту же строку, что и вCOPY TO.
HEADER
Указывает, что файл содержит строку заголовка с именами каждого столбца в файле. На выходе первая строка содержит имена столбцов из таблицы, а на входе первая строка игнорируется. Данный параметр разрешен только при использовании формата CSV.
QUOTE
Задает символ кавычки, который будет использоваться при вводе значения данных в кавычках. По умолчанию используется двойная кавычка. Это должен быть один однобайтовый символ. Данный параметр разрешен только при использовании формата CSV.
ESCAPE
Указывает символ, который должен отображаться перед символом данных, соответствующим значению QUOTE. Значение по умолчанию совпадает с QUOTE (так что если символ кавычки появляется в данных, он удваивается). Это должен быть один однобайтовый символ. Данный параметр разрешен только при использовании формата CSV.
FORCE_QUOTE
Принудительно заключает в кавычки все значения не NULL в указанных столбцах.
Выводимое значение NULL никогда не заключается в кавычки.
Если указана *, значения не NULL будут заключены в
кавычки во всех столбцах. Данный параметр разрешен только в COPY TO и
только при использовании формата CSV.
FORCE_NOT_NULL
Не сопоставлять значения указанных столбцов с маркером NULL. По умолчанию,
когда маркер пуст, это означает, что пустые значения
будут считываться как строки нулевой длины, а не значения NULL, даже
если они не заключены в кавычки. Данный параметр разрешен только в COPY FROM
и только при использовании формата CSV.
FORCE_NULL
Сопоставлять значения указанных столбцов с маркером NULL, даже если те
были заключены в кавычки, и в случае совпадения устанавливать значение NULL.
По умолчанию, когда маркер пуст, пустая строка в кавычках будет преобразовываться в NULL.
Данный параметр разрешен только в COPY FROM и только при использовании формата CSV.
ENCODING
Указывает, что файл имеет кодировку имя_кодировки. Если этот параметр опущен, используется текущая клиентская кодировка. Более подробную информацию см. ниже в примечаниях.
WHERE
Необязательное предложение WHERE имеет общую форму
WHERE условие
где условие — это любое выражение, возвращающее результат типа boolean. Любая строка, которая не удовлетворяет этому условию, не будет добавлена в таблицу. Строка удовлетворяет условию, если она возвращает true при подстановке вместо ссылок на переменные фактических значений из этой строки.
В настоящее время выражения WHERE не могут включать подзапросы,
а при вычислении выражений не видны изменения, которые вносит сама команда COPY
(это имеет значение, когда в них вызываются функции с характеристикой VOLATILE).
Выводимая информация
После успешного завершения команда COPY возвращает метку команды в виде
COPY число
Где число — количество скопированных записей.
Примечание
qsql будет печатать эту метку команды только в том случае, если выполнялась не командаCOPY ... TO STDOUTили ее аналог в qsql, метакоманда\copy ... to stdout. Это сделано для того, чтобы не перепутать метку команды с выведенными перед ней данными.
Примечания
COPY TO можно использовать только с простыми таблицами, но не с
представлениями; также эта команда не копирует строки из дочерних таблиц или партиций. Например, COPY table TO копирует те же строки, что и SELECT * FROM ONLY table. Чтобы выгрузить все строки представления, или таблицы с учетом иерархии наследования, или
партиционированной таблицы, можно написать COPY (SELECT * FROM table) TO ...
COPY FROM можно использовать с простыми, сторонними или
партиционированными таблицами или с представлениями,
в которых установлены триггеры INSTEAD OF INSERT.
Нужно иметь право на выборку заданных для таблицы, значения которой
считываются COPY TO, и право на их добавление для таблицы, в которую
значения добавляются COPY FROM. Однако если в команде перечисляются
выбранные столбцы, достаточно иметь права только для них.
Если для таблицы включена защита на уровне строк, то соответствующие
политики SELECT будут применяться и к операторам COPY таблица TO.
В настоящее время COPY FROM не поддерживается для
таблиц с защитой на уровне строк. Вместо этого используйте
эквивалентные инструкции INSERT.
Файлы, названные в команде COPY, считываются или записываются
непосредственно сервером, а не клиентским приложением. Поэтому они
должны располагаться на сервере или быть доступными серверу, а не клиенту.
Они должны быть доступны на чтение или запись пользователю QHB (идентификатору
пользователя, под которым работает сервер), а не клиенту. Аналогично
команда, указанная параметром PROGRAM, выполняется непосредственно
сервером, а не клиентским приложением и должна быть доступна на выполнение
пользователю QHB. Выполнять COPY с указанием файла или внешней команды
разрешено только суперпользователям базы данных или членам встроенных ролей
pg_read_server_files, pg_write_server_files или pg_execute_server_program,
так как это позволяет читать/записывать любые файлы и запускать
любые программы, к которым имеет доступ сервер.
Не путайте COPY с инструкцией qsql \copy. Метакоманда \\copy
вызывает функцию COPY FROM STDIN или COPY TO STDOUT, а затем
извлекает/сохраняет данные в файле, доступном клиенту qsql. Таким
образом, при использовании \\copy доступность файла и права доступа зависят от
клиента, а не от сервера.
Рекомендуется, чтобы имя файла, используемое в COPY, всегда
указывалось в качестве абсолютного пути. Это обязательное условие для команды
COPY TO, но для COPY FROM есть возможность
чтения из файла, указанного относительным путем. Такой путь будет
интерпретирован относительно рабочего каталога серверного процесса (обычно это
каталог данных кластера), а не рабочего каталога клиента.
Выполнение команды с помощью PROGRAM может быть ограничено механизмами контроля доступа операционной системы, такими как SELinux.
COPY FROM вызовет все триггеры и проверочные ограничения для
целевой таблицы. Однако правила при загрузке данных не вызываются.
Для столбцов идентификации команда COPY FROM всегда будет записывать
значения столбцов, указанные во входных данных,
подобно команде INSERT с указанием OVERRIDING SYSTEM VALUE.
При вводе и выводе данных COPY учитывается DateStyle. Чтобы обеспечить
переносимость на другие установки QHB, которые могут использовать
нестандартные настройки DateStyle, перед использованием COPY TO значение
DateStyle следует установить равным ISO. Также рекомендуется не выгружать данные
с IntervalStyle равным sql_standard, так как сервер с другими настройками IntervalStyle
может неправильно воспринимать значения отрицательных интервалов в таких данных.
Входные данные интерпретируются в соответствии с кодировкой, заданной параметром ENCODING, или текущей клиентской кодировкой, а выходные данные кодируются в кодировке ENCODING или текущую клиентской кодировке, даже если эти данные не проходят через клиент, а считываются или записываются в файл непосредственно сервером.
COPY останавливает работу при первой ошибке. Это не должно
приводить к проблемам в случае COPY TO, но после COPY FROM
в целевой таблице остаются ранее полученные строки. Эти строки не будут
видны или доступны, но по-прежнему будут занимать место на диске. Если сбой
происходит при копировании большого объема данных, это может привести к
значительным потерям дискового пространства. Восстановить потерянное пространство
можно с помощью команды VACUUM.
FORCE_NULL и FORCE_NOT_NULL могут применяться одновременно к одному и тому же столбцу. В результате NULL-значения в кавычках будут преобразованы в NULL, а NULL-значения без кавычек — в пустые строки.
Форматы файлов
Текстовый формат
Когда используется текстовый формат, данные читаются или записываются в виде
текстового файла, строка в котором соответствует строке таблицы. Столбцы в строке
разделяются символом-разделителем. Сами значения столбцов представляют собой
текстовые строки, выдаваемые функцией вывода либо воспринимаемые функцией ввода,
соответствующей типу данных столбца. Заданный маркер NULL используется
вместо столбцов со значением NULL. COPY FROM выдает
ошибку, если какая-либо строка входного файла содержит больше или меньше
столбцов, чем ожидалось.
Конец данных может быть обозначен одной строкой, содержащей только обратную косую черту и точку (\.). Маркер конца данных не является обязательным при чтении из файла, так как его роль вполне выполняет конец файла; он необходим только при копировании данных в клиентские приложения или из клиентских приложений, использующих протокол pre-3.0 client.
Символы обратной косой черты (\) в данных COPY позволяют экранировать символы данных,
которые в противном случае могут быть приняты за разделители строк или столбцов. В
частности, при появлении в качестве части значения столбца обратной косой чертой
должны предваряться следующие символы: сама обратная косая
черта, новая строка, возврат каретки и текущий символ разделителя.
Маркер NULL передается командой COPY TO без добавления
обратной косой черты; в то же время COPY FROM ищет во вводимых данных
маркеры NULL до удаления обратных косых черт. Как следствие, маркер NULL,
например \N, невозможно спутать с настоящим значением \N в данных
(которое должно представляться в виде \\N).
COPY FROM распознает следующие специальные последовательности с обратной косой чертой:
| Последовательность | Представляет |
|---|---|
| \b | Backspace (ASCII 8) |
| \f | Подача формы (ASCII 12)) |
| \n | Новая строка (ASCII 10) |
| \r | Возврат каретки (ASCII 13) |
| \t | Табуляция (ASCII 9) |
| \v | Вертикальная табуляция (ASCII 11) |
| \цифры | Обратная косая черта с последующими 1-3 восьмеричными цифрами представляет символ с заданным числовым кодом |
| \xцифры | Обратная косая черта с последующим x и 1-2 шестнадцатеричными цифрами представляет символ с заданным числовым кодом |
В настоящее время COPY TO никогда не будет выдавать специальные последовательности
с восьмеричными или шестнадцатеричными кодами, однако эта команда
использует для данных управляющих символов другие вышеперечисленные последовательности.
Любой другой символ после обратной косой черты, который не упоминается в приведенной выше таблице, будет принят для представления самого себя. Однако остерегайтесь добавлять обратные косые черты без необходимости, так как это может случайно привести к появлению строки, соответствующей маркеру конца данных (\.) или маркеру NULL (\N по умолчанию). Эти строки будут восприняты раньше, чем обработаются специальные последовательности с обратной косой чертой.
Настоятельно рекомендуется, чтобы приложения, генерирующие данные для COPY,
преобразовывали символы новой строки и возврата каретки в
в последовательности \n и \r соответственно.
В настоящее время возврат каретки в данных можно представить символами
обратная косая черта + возврат каретки, а новую строку — символами
обратная косая черта + новая строка. Однако эти представления могут
быть не приняты в будущих выпусках. Также они крайне уязвимы к искажениям,
если файл с выводом COPY переносится между разными системами
(например, с Unix в Windows и наоборот).
COPY TO завершает каждую строку символом новой строки в стиле Unix
(«\n»). Серверы, работающие на Microsoft Windows, вместо этого выводят
символы возврат каретки/новая строка («\r\n»), но только при выводе COPY
в файл на сервере; для обеспечения согласованности между платформами
COPY TO STDOUT всегда передает «\n» независимо от
платформы сервера. COPY FROM может обрабатывать строки,
заканчивающиеся символами новая строка, возврат каретки или возврат
каретки/новая строка. Чтобы уменьшить риск ошибки из-за отсутствия
обратной косой черты перед символами новой строки и возврата каретки,
которые должны были быть данными, COPY FROM сигнализирует о проблеме,
если концы строк во входных данных различаются.
Формат CSV
Этот формат применяется для импорта и экспорта данных, разделенных запятой (CSV), и используется многими другими программами, такими как электронные таблицы. Вместо правил экранирования, используемых стандартным текстовым форматом QHB, этот формат создает и распознает общий механизм экранирования CSV.
Значения в каждой записи разделяются символом DELIMITER. Если значение содержит символ разделителя, символ QUOTE, маркер NULL, символ возврата каретки или перевода строки, то всё значение будет дополнено спереди и сзади символами QUOTE, а любое вхождение символа QUOTE или спецсимвола (ESCAPE) в данных предваряется спецсимволом. Также можно использовать FORCE_QUOTE, чтобы принудительно заключать в кавычки любые значения не NULL в указанных столбцах.
В формате CSV отсутствует стандартный способ отличить значение NULL от
пустой строки. В QHB команда COPY решает это с помощью кавычек.
Значение NULL выводится в виде строки, задаваемой параметром NULL,
и не заключается в кавычки, тогда как значение не NULL, совпадающее со строкой,
задаваемой параметром NULL, заключается. Например, с
настройками по умолчанию NULL записывается в виде пустой строки без кавычек,
в то время как пустое строковое значение данных записывается с
двойными кавычками (""). Чтение значений следует аналогичным правилам.
Указание FORCE_NOT_NULL позволяет избежать сравнений с NULL во входных
данных в заданных столбцах, а FORCE_NULL — преобразовывать в NULL даже заключенные
в кавычки маркеры NULL.
Так как обратная косая черта не является специальным символом в формате CSV, маркер конца данных \. также может быть значением данных. Чтобы избежать любого неправильного толкования, данные \., отображаемые как одиночная запись в строке, автоматически заключаются в кавычки при выводе, а при вводе этот маркер, заключенный в кавычки, не интерпретируется как маркер конца данных. Если вы загружаете файл, созданный другим приложением, который имеет один столбец без кавычек и может иметь значение \., потребуется дополнительно заключить это значение в кавычки.
Примечание
В формате CSV все символы являются значимыми. Заключенное в кавычки значение, дополненное пробелами или любыми другими символами, кроме DELIMITER, будет включать в себя эти символы. Это может привести к ошибкам при импорте данных из системы, дополняющей строки CSV пробельными символами до некоторой фиксированной ширины. В случае возникновения такой ситуации перед импортом данных в QHB может потребоваться предварительная обработка файла CSV для удаления конечного пробела.
Примечание
Обработчик формата CSV воспринимает и генерирует файлы CSV со значениями в кавычках, которые могут содержать символы возврата каретки и перевода строки. Таким образом, число строк в этих файлах не строго равно числу строк в таблице, как в файлах текстового формата.
Примечание
Многие программы создают странные и иногда неприемлемые файлы CSV, поэтому формат файла является скорее условным, чем стандартным. Как следствие, можно столкнуться с некоторыми файлами, которые нельзя импортировать с помощью этого механизма, иCOPYтакже может создавать файлы, которые другие программы не могут обрабатывать.
Двоичный формат
При выборе формата binary все данные сохраняются/считываются в двоичном, а не текстовом виде. Этот формат может обрабатываться несколько быстрее, чем текстовый и CSV форматы, но файл двоичного формата менее переносим в разных машинных архитектурах и версиях QHB. Кроме того, двоичный формат очень зависит для типа данных; например, он не позволит вывести двоичные данные из столбца smallint а затем прочитать их в столбец integer, хотя с текстовым форматом это вполне возможно.
Формат binary состоит из заголовка файла, нуля или более записей, содержащих данные строк, и окончания файла. Для заголовков и данных принят сетевой порядок байт.
Заголовок файла
Заголовок файла состоит из 15 байт фиксированных полей, за которыми следует область расширения заголовка переменной длины. Фиксированные поля:
Сигнатура
11-байтовая последовательность PGCOPY\n \ 377\r\n\0 — обратите внимание, что нулевой байт является обязательной частью сигнатуры. (Сигнатура предназначена для облегчения идентификации файлов, которые были испорчены при передаче, не сохраняющей все 8 бит данных. Она изменится при прохождении через фильтры, меняющие концы строк, удалении нулевых байтов или старших битов либо при изменениях четности.)
Поле флагов
32-разрядная целочисленная битовая маска для обозначения важных аспектов формата файла. Биты нумеруются от 0 (LSB) до 31 (MSB). Обратите внимание, что это поле хранится в сетевом порядке байтов (наиболее значащий байт первый), как и все целочисленные поля, используемые в данном формате. Биты 16-31 зарезервированы, чтобы обозначить критичные проблемы формата; обработчик должен прервать чтение, встретив неожиданный набор битов в этом диапазоне. Биты 0-15 зарезервированы, чтобы сигнализировать о проблемах формата обратной совместимости; обработчик может просто игнорировать любые неожиданные наборы битов в этом диапазоне. В настоящее время определен только один битовый флаг, остальные должны быть равны 0:
При 1 данные включаются в OID; при 0 — нет. В QHB больше не поддерживаются системные столбцы Oid, но формат всё еще содержит этот индикатор.
Длина области расширения заголовка
32-разрядное целое число, длина в байтах остатка заголовка, не включая само это значение. В настоящее время содержит 0, и сразу за ним следует первая запись. Будущие изменения формата могут привести к появлению дополнительных данных в заголовке. Обработчик должен просто пропустить все данные расширения заголовка, с которыми он не знает, что делать.
Предполагается, что область расширения заголовка будет содержать последовательность самоидентифицирующихся фрагментов. Поле флагов не должно содержать указаний для обработчика о том, что содержится в области расширения. Точное содержимое области расширения может быть определено в будущих версиях.
Эта конструкция позволяет выполнять как обратно-совместимые добавления заголовков (добавлять блоки расширения заголовков или устанавливать младшие биты флагов), так и не обратно-совместимые изменения (устанавливать старшие биты флагов, чтобы сигнализировать о таких изменениях, и при необходимости добавлять вспомогательные данные в область расширения).
Записи
Каждая запись начинается с 16-разрядного целого числа количества полей в записи. (В настоящее время все записи в таблице будут иметь одинаковое количество полей, но это может быть не всегда верно.) Затем для каждого поля в записи указывается 32-битное машинное слово, за которым следует это же количество байт с данными поля. (Машинное слово не включает свой размер и может быть равно нулю.) В качестве особого варианта -1 обозначает, что в поле содержится NULL. В случае с NULL за длиной не следуют байты данных.
Между полями нет выравнивания или каких-либо других дополнительных данных.
В настоящее время все значения данных в файле двоичного формата содержаться в двоичном формате (формате под кодом 1). Предполагается, что в будущем расширении в заголовок может быть добавлено поле, позволяющее задавать другие коды форматов для разных столбцов.
Чтобы определить подходящий двоичный формат для фактических данных, обратитесь к исходному коду QHB, в частности, к функциям send и recv для типов данных каждого столбца (обычно эти функции находятся в каталоге src/backend/utils/adt/ в дереве исходного кода).
Если в файл включается OID, поле OID следует немедленно за числом, определяющим количество полей. Это обычное поле, за исключением того, что оно не учитывается в количестве полей. Обратите внимание, что системные столбцы oid не поддерживаются в текущих версиях QHB.
Окончание файла
Трейлер файла состоит из 16-разрядного целого слова, содержащего -1. Это позволяет легко отличить его от счетчика полей в записи.
Обработчик, читающий файл, должен выдать ошибку, если число полей в записи не равно -1 или ожидаемому числу столбцов. Это обеспечивает дополнительную проверку синхронизации данных.
Примеры
В следующем примере таблица передается клиенту с разделителем полей «вертикальная черта» (|):
COPY country TO STDOUT (DELIMITER '|');
Копирование данных из файла в таблицу country:
COPY country FROM '/usr1/proj/bray/sql/country_data';
Копирование в файл только данных стран, название которых начинается с «A»:
COPY (SELECT * FROM country WHERE country_name LIKE 'A%') TO '/usr1/proj/bray/sql/a_list_countries.copy';
Для копирования данных в сжатый файл можно направить вывод через внешнюю программу сжатия:
COPY country TO PROGRAM 'gzip > /usr1/proj/bray/sql/country_data.gz';
Пример данных, подходящих для копирования в таблицу из STDIN:
AF AFGHANISTAN
AL ALBANIA
DZ ALGERIA
ZM ZAMBIA
ZW ZIMBABWE
Обратите внимание, что пробел в каждой строке фактически является символом табуляции.
Ниже приведены те же данные, но выведенные в двоичном формате. Данные показаны после обработки Unix-утилитой od -c. Таблица содержит три столбца; первый имеет тип char(2), второй — text, а третий — integer. Последний столбец во всех строках содержит NULL.
0000000 P G C O P Y \n 377 \r \n \0 \0 \0 \0 \0 \0
0000020 \0 \0 \0 \0 003 \0 \0 \0 002 A F \0 \0 \0 013 A
0000040 F G H A N I S T A N 377 377 377 377 \0 003
0000060 \0 \0 \0 002 A L \0 \0 \0 007 A L B A N I
0000100 A 377 377 377 377 \0 003 \0 \0 \0 002 D Z \0 \0 \0
0000120 007 A L G E R I A 377 377 377 377 \0 003 \0 \0
0000140 \0 002 Z M \0 \0 \0 006 Z A M B I A 377 377
0000160 377 377 \0 003 \0 \0 \0 002 Z W \0 \0 \0 \b Z I
0000200 M B A B W E 377 377 377 377 377 377
Совместимость
В стандарте SQL нет команды COPY.
CREATE ACCESS METHOD
CREATE ACCESS METHOD — определить новый метод доступа
Синтаксис
CREATE ACCESS METHOD имя
TYPE тип_метода_доступа
HANDLER функция_обработчик
Описание
Команда CREATE ACCESS METHOD создает новый метод доступа.
Имя метода доступа должно быть уникальным в базе данных.
Только суперпользователи могут определять новые методы доступа.
Параметры
имя
Имя создаваемого метода доступа.
тип_метода_доступа
В этом предложении указывается тип определяемого метода доступа. В настоящее время поддерживаются только TABLE и INDEX.
функция_обработчик
В аргументе функция_обработчик указывается имя ранее зарегистрированной функции, представляющей метод доступа (может быть дополнено схемой). Функция-обработчик должна объявляться как принимающая один аргумент типа internal, а тип результата зависит от типа метода доступа; для методов доступа типа TABLE это должен быть table_am_handler, а для INDEX — index_am_handler. API уровня C, который должна реализовывать эта функция-обработчик, меняется в зависимости от типа метода доступа. API табличных методов доступа описаны в главе Определение интерфейса метода доступа к таблице, а индексных — в главе Определение интерфейса метода доступа к индексу
Примеры
Создание метода доступа к индексу heptree с функцией-обработчиком heptree_handler:
CREATE ACCESS METHOD heptree TYPE INDEX HANDLER heptree_handler;
Совместимость
Команда CREATE ACCESS METHOD является расширением QHB.
См. также
DROP ACCESS METHOD, CREATE OPERATOR CLASS, CREATE OPERATOR FAMILY
CREATE AGGREGATE
CREATE AGGREGATE — определить новую агрегатную функцию
Синтаксис
CREATE [ OR REPLACE ] AGGREGATE имя ( [ режим_аргумента ] [ имя_аргумента ] тип_данных_аргумента [ , ... ] ) (
SFUNC = функция_состояния,
STYPE = тип_данных_состояния
[ , SSPACE = размер_данных_состояния ]
[ , FINALFUNC = функция_завершения ]
[ , FINALFUNC_EXTRA ]
[ , FINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE } ]
[ , COMBINEFUNC = комбинирующая_функция ]
[ , SERIALFUNC = функция_сериализации ]
[ , DESERIALFUNC = функция_десериализации ]
[ , INITCOND = начальное_условие ]
[ , MSFUNC = функция_состояния_движ ]
[ , MINVFUNC = обратная_функция_движ ]
[ , MSTYPE = тип_данных_состояния_движ ]
[ , MSSPACE = размер_данных_состояния_движ ]
[ , MFINALFUNC = функция_завершения_движ ]
[ , MFINALFUNC_EXTRA ]
[ , MFINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE } ]
[ , MINITCOND = начальное_условие_движ ]
[ , SORTOP = оператор_сортировки ]
[ , PARALLEL = { SAFE | RESTRICTED | UNSAFE } ]
)
CREATE [ OR REPLACE ] AGGREGATE имя ( [ [ режим_аргумента ] [ имя_аргумента ] тип_данных_аргумента [ , ... ] ]
ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_данных_аргумента [ , ... ] ) (
SFUNC = функция_состояния,
STYPE = тип_данных_состояния
[ , SSPACE = размер_данных_состояния ]
[ , FINALFUNC = функция_завершения ]
[ , FINALFUNC_EXTRA ]
[ , FINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE } ]
[ , INITCOND = начальное_условие ]
[ , PARALLEL = { SAFE | RESTRICTED | UNSAFE } ]
[ , HYPOTHETICAL ]
)
или старый синтаксис:
CREATE [ OR REPLACE ] AGGREGATE имя (
BASETYPE = базовый_тип,
SFUNC = функция_состояния,
STYPE = тип_данных_состояния
[ , SSPACE = размер_данных_состояния ]
[ , FINALFUNC = функция_завершения ]
[ , FINALFUNC_EXTRA ]
[ , FINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE } ]
[ , COMBINEFUNC = комбинирующая_функция ]
[ , SERIALFUNC = функция_сериализации ]
[ , DESERIALFUNC = функция_десериализации ]
[ , INITCOND = начальное_условие ]
[ , MSFUNC = функция_состояния_движ ]
[ , MINVFUNC = обратная_функция_движ ]
[ , MSTYPE = тип_данных_состояния_движ ]
[ , MSSPACE = размер_данных_состояния_движ ]
[ , MFINALFUNC = функция_завершения_движ ]
[ , MFINALFUNC_EXTRA ]
[ , MFINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE } ]
[ , MINITCOND = начальное_условие_движ ]
[ , SORTOP = оператор_сортировки ]
)
Описание
Команда CREATE AGGREGATE определяет новую агрегатную функцию. CREATE OR REPLACE AGGREGATE
либо определяет новую агрегатную функцию, либо заменяет определение уже существующей.
Некоторые основные и часто используемые агрегатные функции включены в дистрибутив;
они описаны в разделе Агрегатные функции. При определении новых типов или возникновении потребности в
агрегатной функции, которая еще не предоставлена, можно получить требуемые объекты,
используя CREATE AGGREGATE.
При замене существующего определения типы аргументов, тип результата и количество аргументов изменить нельзя. Кроме того, новое определение должно быть того же вида (обычный, сортирующий или гипотезирующий агрегат), что и старое.
Если задано имя схемы (например, CREATE AGGREGATE myschema.myagg ...), то
агрегатная функция создается в указанной схеме. В противном случае — в текущей.
Агрегатная функция идентифицируется по имени, а также по типу(ам) входных данных. Два агрегата в одной схеме могут иметь одно и то же имя, если они работают с разными типами входных данных. Имя и тип(ы) входных данных агрегата также должны отличаться от имени и типа(ов) входных данных простых функций в той же схеме. Это поведение идентично перегрузке обычных имен функций (см. CREATE FUNCTION).
Простая агрегатная функция состоит из одной или двух обычных функций: функции перехода состояния функция_состояния, и необязательная функция окончательного вычисления функция_завершения. Они используются следующим образом:
функция_состояния( внутреннее-состояние, следующие-значения-данных ) ---> следующее-внутреннее-состояние
функция_завершения( внутреннее-состояние ) ---> агрегатное-значение
QHB создает временную переменную типа данных тип_данных_состояния, чтобы сохранить текущее внутреннее состояние агрегата. В каждой входной строке вычисляется(ются) значение(я) агрегированных аргументов и вызывается функция перехода состояния с текущим значением состояния и новым(ыми) значением(ями) аргумента для вычисления нового значения внутреннего состояния. После обработки всех строк однократно вызывается завершающая функция для вычисления возвращаемого агрегатом значения. Если нет завершающей функции, то просто возвращается значение конечного состояния.
Агрегатная функция может определить начальное условие, то есть начальное значение для значения внутреннего состояния. Это значение задается и сохраняется в базе данных в виде строки типа text, но оно должно быть допустимым внешним представлением константы типа данных переменной состояния. По умолчанию начальным значением состояния считается NULL.
Если функция перехода состояния объявлена «strict» (строгой), то она не может быть вызвана с входными данными NULL. С такой функцией перехода агрегатное выполнение ведет себя следующим образом. Строки с входными значениями NULL игнорируются (функция не вызывается, а предыдущее значение состояния сохраняется), и если начальное значение состояния равно NULL, то в первой строке со всеми входными значениями не NULL значение первого аргумента заменяется значением состояния, а функция перехода вызывается в каждой последующей строке со всеми входными значениями не NULL. Это удобно для реализации агрегатов, таких как max. Обратите внимание, что это поведение возможно только тогда, когда тип_данных_состояния совпадает с первым типом_данных_аргумента. Если эти типы отличаются, необходимо указать начальное условие не NULL или использовать нестрогую функцию перехода.
Если функция перехода состояния не является строгой, то она будет вызываться безусловно в каждой входной строке и должна сама обрабатывать вводимые значения и переменную состояния, равные NULL. Это позволяет разработчику агрегатной функции полностью управлять тем, как она воспринимает значения NULL.
Если функция завершения объявлена «strict» (строгой), то она не будет вызвана, если значение конечного состояния равно NULL; вместо этого будет автоматически возвращен результат NULL. (Разумеется, это всего лишь обычное поведение строгих функций.) В любом случае функция завершения имеет возможность возвращать результат NULL. Например, функция завершения для avg возвращает NULL, если определяет, что было обработано ноль строк
Иногда бывает полезно объявить функцию завершения как принимающую не
только значение состояния, но и дополнительные параметры,
соответствующие входным значениям агрегата. В основном это имеет смысл, если
функция завершения является полиморфной и типа данных значения состояния
было бы недостаточно, чтобы вывести тип результата.
Эти дополнительные параметры всегда передаются как NULL (поэтому функция
завершения не должна быть строгой, когда применяется опция FINALFUNC_EXTRA),
но в остальном это обычные параметры. Функция завершения может, например,
использовать get\_fn\_expr\_argtype, чтобы определить фактический тип аргумента
в текущем вызове.
Агрегатная функция может дополнительно поддерживать режим движущегося агрегата, как описано в разделе Режим движущегося агрегата. Для этого необходимо указать следующие параметры: MSFUNC, MINVFUNC и MSTYPE, а также выборочно параметры MSSPACE, MFINALFUNC, MFINALFUNC_EXTRA, MFINALFUNC_MODIFY и MINITCOND. За исключением MINVFUNC, эти параметры работают как соответствующие параметры простого агрегата без начальной буквы M; они определяют отдельную реализацию агрегата, включающую функцию обратного перехода.
Если в список параметров добавлено указание ORDER BY, создается особый типа агрегата, называемый сортирующим агрегатом; с указанием HYPOTHETICAL создается гипотезирующий агрегат. Эти агрегаты работают над группами отсортированных значений в зависимости от порядка сортировки, так что спецификация порядка сортировки входных данных является неотъемлемой частью вызова. Кроме того, они могут иметь непосредственные аргументы, которые вычисляются единожды для всей процедуры агрегирования, а не для каждой входной строки. Гипотезирующие агрегаты — это подкласс сортирующих агрегатов, в котором часть непосредственных аргументов должна соответствовать столбцам агрегированных аргументов по количеству и типам данных. Это позволяет добавить значения этих непосредственных аргументов в набор агрегируемых строк в качестве дополнительной «гипотетической» строки.
Агрегатная функция может дополнительно поддерживать частичное агрегирование, как описано в разделе Частичная агрегация. Для этого необходимо задать параметр COMBINEFUNC. Если в качестве типа_данных_состояния выбран internal, обычно также указывают параметры SERIALFUNC и DESERIALFUN, чтобы было возможно параллельное агрегирование. Обратите внимание, что для возможности параллельной агрегации агрегат также должен быть помечен как PARALLEL SAFE .
Агрегаты, работающие подобно MIN и MAX, иногда можно оптимизировать, заменив сканирование каждой входной строки обращением по индексу. Если агрегат подлежит такой оптимизации, обозначьте это, указав оператор сортировки. Основное требование состоит в том, что агрегат должен выдавать первый элемент по порядку сортировки, задаваемому этим оператором, другими словами:
SELECT agg(col) FROM tab;
должно быть эквивалентно:
SELECT col FROM tab ORDER BY col USING sortop LIMIT 1;
Дополнительно предполагается, что агрегат игнорирует значения NULL и возвращает NULL тогда и только тогда, когда строки со значениями не NULL отсутствуют. Обычно оператор < является подходящим оператором сортировки для MIN, а > — для MAX. Обратите внимание, что оптимизация ни на что не повлияет, если указанный оператор не является участником стратегии «меньше, чем» или «больше, чем» в классе операторов индекса типа B-дерево.
Чтобы иметь возможность создать агрегатную функцию, необходимо иметь право USAGE для типов аргументов, типа(ов) состояния и типа результата, а также право EXECUTE для вспомогательных функций.
Параметры
имя
Имя создаваемой агрегатной функции (может быть дополнено схемой).
режим_аргумента
Режим аргумента: IN или VARIADIC (Агрегатные функции не поддерживают выходные аргументы (OUT).) Если этот параметр не указан, значение по умолчанию равно IN. Только последний аргумент может быть помечен как VARIADIC.
имя_аргумента
Название аргумента. В настоящее время используется только для целей документации. Если опущено, соответствующий аргумент будет безымянным.
тип_данных_аргумента
Тип входных данных, с которым работает эта агрегатная функция. Чтобы создать агрегатную функцию без аргументов, вместо списка определений аргументов напишите *. (Примером такого агрегата является count(*).)
базовый_тип
В старом синтаксисе для CREATE AGGREGATE тип входных данных
задается параметром базовый_тип, а не записывается после имени агрегата.
Обратите внимание, что этот синтаксис допускает только один
входной параметр. Чтобы определить агрегатную функцию без
аргументов с помощью этого синтаксиса, в качестве значения базовый_тип нужно указать «ANY»
(не *). Создать сортирующий агрегат старый синтаксис не позволяет.
функция_состояния
Имя функции перехода состояния, вызываемой для каждой входной строки. Для обычных агрегатных функций с N аргументами функция_состояния должна принимать N+1 аргумент, первый должен иметь тип тип_данных_состояния, а остальные — соответствовать заявленному типу входных данных агрегата. Функция должна возвращать значение типа тип_данных_состояния. Эта функция принимает текущее значение состояния и текущее(ие) значение(я) входных данных, а возвращает следующее значение состояния.
В сортирующих (в том числе гипотезирующих) агрегатах функция перехода состояния получает только текущее значение состояния и агрегируемые аргументы, а не непосредственные аргументы. В остальном это одно и то же.
тип_данных_состояния
Тип данных значения состояния агрегатной функции.
размер_данных_состояния
Приблизительный средний размер (в байтах) значения состояния агрегата. Если этот параметр опущен или равен нулю, используется оценка по умолчанию, определяемая по типу тип_данных_состояния. Планировщик использует это значение для оценки памяти, необходимой для агрегатного запроса с группировкой. Планировщик может применить агрегирование по хэшу для такого запроса, только если хэш-таблица, судя по оценке, поместится в work_mem; таким образом, при больших значениях этого параметра агрегирование по хэшу будет менее желательным.
функция_завершения
Имя функции завершения, вызываемой для вычисления результата агрегатной функции после обработки всех входных строк. Для нормального агрегата эта функция должна принимать один аргумент типа тип_данных_состояния. Возвращаемый тип данных агрегата определяется как возвращаемый тип этой функции. Если функция_завершения не указана, то значение конечного состояния используется в качестве результата агрегирования, а типом возвращаемого значения является тип_данных_состояния.
В сортирующих (в том числе гипотезирующих) агрегатах функция завершения получает не только значение конечного состояния, но и значения всех непосредственных аргументов.
Если команда содержит указание FINALFUNC_EXTRA, то в дополнение к конечному значению состояния и всем непосредственным аргументам конечная функция получает дополнительные значения NULL, соответствующие обычным (агрегированным) аргументам агрегата. Это в основном полезно для обеспечения правильного определения типа результата агрегата при определении полиморфной агрегатной функции.
FINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE }
Этот параметр указывает, является ли функция завершения чистой функцией, которая не изменяет свои аргументы. Это свойство функции передает значение READ_ONLY; другие два значения указывают, что она может изменить значение состояния перехода. Подробнее это рассматривается в Примечаниях. По умолчанию значение равно READ_ONLY, за исключением сортирующих агрегатов (для них значение по умолчанию — READ_WRITE).
комбинирующая_функция
Функция комбинирующая_функция может быть дополнительно задана, чтобы разрешить агрегатной функции поддерживать частичную агрегацию. Если задается, комбинирующая_функция должна комбинировать два значения типа_данных_состояния, каждое из которых содержит результат агрегации по некоторому подмножеству входных значений, чтобы получить новое значение типа_данных_состояния, представляющее результат агрегирования по обоим наборам данных. Эту функцию можно рассматривать как функцию_состояния, которая вместо обработки отдельной входной строки и добавления ее данных в текущее агрегируемое состояние включает еще одно агрегированное состояние в текущее.
Указанная комбинирующая_функция должна быть объявлена как принимающая два аргумента с типом тип_данных_состояния и возвращающая значение с типом тип_данных_состояния. Эта функция дополнительно может быть объявлена «строгой». В этом случае функция не будет вызываться, когда одно из входных состояний равно NULL; в качестве корректного результата будет выдано другое состояние.
Для агрегатных функций, у которых тип_данных_состояния — internal, комбинирующая_функция не должна быть «строгой». В этом случае комбинирующая_функция должна проверять, что состояния NULL обрабатываются правильно и что возвращаемое состояние правильно хранится в контексте памяти агрегирования.
функция_сериализации
Агрегатная функция, у которой тип_данных_состояния — internal, может участвовать в параллельном агрегировании только в том случае, если для нее задана функция_сериализации, которая должна сериализовать агрегатное состояние в значение bytea для передачи другому процессу. Эта функция должна принимать один аргумент типа internal и возвращать тип bytea. Также при этом нужно задать соответствующую функцию_десериализации.
функция_десериализации
Десериализует ранее сериализованное агрегатное состояние обратно в тип_данных_состояния. Эта функция должна принимать два аргумента типа bytea и internal и возвращать результат типа internal. (Примечание: второй аргумент internal не используется, но требуется из соображений безопасности для типа)
начальное_условие
Начальное значение переменной состояния. Это должна быть строковая константа в форме, принятой для данного типа данных тип_данных_состояния. Если не указано, то начальным значением состояния будет NULL.
функция_состояния_движ
Имя функции прямого перехода состояния, которая будет вызываться для каждой входной строки в режиме движущегося агрегата. Это такая же функция, как и обычная функция перехода, за исключением того, что ее первый аргумент и результат имеют тип тип_данных_состояния_движ, который может отличаться от типа тип_данных_состояния.
обратная_функция_движ
Имя функции обратного перехода состояния, которая будет использоваться в режиме движущегося агрегата. Эта функция имеет те же типы аргументов и результатов, что и функция_состояния_движ, но используется для удаления значения из текущего состояния агрегата, а не для добавления к нему значения. Функция обратного перехода должна иметь ту же характеристику строгости, что и функция прямого перехода состояния.
тип_данных_состояния_движ
Тип данных для значения состояния агрегата при использовании режима движущегося агрегата.
размер_данных_состояния_движ
Приблизительный средний размер (в байтах) значения состояния агрегата при использовании режима движущегося агрегата. Он имеет то же значение, что и размер_данных_состояния.
функция_завершения_движ
Имя функции завершения, вызываемой для вычисления результата агрегата после обработки всех входных строк при использовании режима движущегося агрегата. Она работает так же, как функция_завершения, за исключением того, что тип ее первого аргумента тип_данных_состояния_движ, а дополнительными пустыми аргументами управляет параметр MFINALFUNC_EXTRA. Тип результата, который определяет функция_завершения_движ или тип_данных_состояния_движ, должен совпадать с типом результата обычной реализации агрегата.
MFINALFUNC_MODIFY = { READ_ONLY | SHAREABLE | READ_WRITE }
Этот параметр подобен FINALFUNC_MODIFY, но описывает поведение функции завершения для движущегося агрегата.
начальное_условие_движ
Начальное значение переменной состояния в режиме движущегося агрегата. Оно применяется так же, как начальное_условие.
оператор_сортировки
Связанный оператор сортировки для реализации агрегатов, подобных MIN или MAX. Это просто имя оператора (может быть дополнено схемой). Предполагается, что оператор имеет те же типы входных данных, что и агрегат (который должен быть обычным и иметь один аргумент).
PARALLEL = { SAFE | RESTRICTED | UNSAFE }
Указания PARALLEL SAFE, PARALLEL RESTRICTED и PARALLEL UNSAFE имеют те же значения, что и в CREATE FUNCTION. Агрегатная функция не будет считаться распараллеливаемой, если она помечена как PARALLEL UNSAFE (что является значением по умолчанию!) или PARALLEL RESTRICTED. Обратите внимание, что планировщик не обращает внимание на допустимость распараллеливания вспомогательных функций агрегата, а учитывает только характеристику самой агрегатной функции.
HYPOTHETICAL
Только для сортирующих агрегатов. Этот флаг указывает, что статистические аргументы должны обрабатываться в соответствии с требованиями для агрегатов с гипотетическими наборами: то есть последние несколько непосредственных аргументов должны соответствовать типам данных агрегатных (WITHIN GROUP) аргументов. Флаг HYPOTHETICAL не влияет на поведение во время выполнения, а учитывается только при разрешении типов данных и правил сортировки для аргументов агрегата во время синтаксического анализа.
Параметры CREATE AGGREGATE могут быть записаны в любом порядке, а не
только в показанном выше.
Примечания
В параметрах, определяющих имена вспомогательных функций, при необходимости
можно записать имя схемы, например SFUNC = public.sum. Однако не
записывайте там типы аргументов — типы аргументов вспомогательных функций
определяются из других параметров.
Обычно предполагается, что функции QHB являются настоящими функциями, которые не изменяют свои входные значения. Тем не менее, функциям агрегатного перехода, используемым в контексте агрегатной функции, разрешено действовать хитрее и изменять аргумент переходного состояния на лету. Это может обеспечить существенные преимущества производительности по сравнению с создаванием каждый раз новой копии переходного состояния.
Подобным образом, хотя функция завершения агрегата обычно не должна изменять свои входные значения, иногда может быть полезно допустить изменение аргумента со значением переходного состояния. Такое поведение должно быть объявлено с помощью параметра FINALFUNC_MODIFY. Его значение READ_WRITE указывает, что функция завершения модифицирует переходное состояние неопределенным образом. Это значение предотвращает использование агрегата в качестве оконной функции, а также предотвращает объединение переходных состояний при вызове агрегатов с одинаковыми входными данными и функциями перехода. Значение SHAREABLE указывает, что функция перехода не может быть применена после функции завершения, но над значением конечного переходного состояния могут быть выполнены несколько вызовов функции завершения. Это значение предотвращает использование агрегата в качестве оконной функции, но позволяет объединять переходные состояния. (То есть оптимизация в данном случае заключается не в многократном применении одной и той же функции завершения, а в применении различных функции завершения к одному и тому же конечному переходному состоянию. Это разрешено до тех пор, пока ни одна из функций завершения не будет отмечена READ_WRITE.)
Если агрегатная функция поддерживает режим движущегося агрегата, это повысит эффективность вычислений, когда агрегат будет использоваться в качестве оконной функции для окна с движущимся началом рамки (то есть когда начало определяется не как UNBOUNDED PRECEDING). По существу, функция прямого перехода добавляет входные значения к состоянию агрегата, когда они появляются в оконной рамке, а функция обратного перехода снова вычитает их, когда они покидают рамку. Поэтому, вычитаются значения в том же порядке, в каком добавлялись. Всякий раз, когда вызывается обратная функция перехода, она, таким образом, получит самое раннее добавленное, но еще не удаленное значение(я) аргумента. Функция обратного перехода может предполагать, что по крайней мере одна строка останется в текущем состоянии после удаления самой старой строки. (В противном случае механизм функции окна просто запускает новую агрегацию, а не использует обратную функцию перехода.)
Функция прямого перехода движущегося агрегата не может возвращать NULL в качестве нового значения состояния. Если функция обратного перехода возвращает значение NULL, это показывает, что обратная функция не может произвести обратное вычисление для этих конкретных данных, и поэтому вычисление агрегата следует выполнить заново от начальной позиции текущей рамки. Это соглашение позволяет использовать режим движущегося агрегата в ситуациях, в которых обратный расчет состояния производить непрактично.
Агрегатную функцию можно использовать с движущимися рамками и без реализации движущегося агрегата, но QHB будет заново агрегировать все данные при каждом перемещении начала рамки. Обратите внимание, что независимо от того, поддерживает ли агрегатная функция режим движущегося агрегата, QHB может обойтись без повторных вычислений при сдвиге конца рамки; это делается путем продолжения добавления новых значений в состояние агрегата. Именно поэтому использование агрегата в качестве оконной функции требует, чтобы функция завершения была только читающей: она не должна повредить значение состояния агрегата, чтобы агрегация могла быть продолжена даже после получения значения результата агрегирования для одного набора строк в определенной рамке.
Синтаксис сортирующих агрегатных функций позволяет указать VARIADIC и в последнем непосредственном параметре, и в последнем агрегатном (WITHIN GROUP). Тем не менее, текущая реализация ограничивает двоякое использование VARIADIC. Во-первых, в сортирующих агрегатных функциях можно использовать только VARIADIC "any", но не другие типы переменных массивов. Во-вторых, если последним непосредственным аргументом является VARIADIC "any", тогда может быть только один агрегированный параметр, и он также должен быть VARIADIC "any". (В представлении, используемом в системных каталогах, эти два параметра объединяются в один пункт VARIADIC "any", так как в pg_proc нельзя представить функцию с несколькими параметрами VARIADIC.) Если агрегат является гипотезирующим, то непосредственные аргументы, соответствующие параметру VARIADIC "any", будут гипотетическими; любые предыдущие параметры представляют дополнительные непосредственные аргументы, которые могут не соответствовать агрегатным.
В настоящее время сортирующие агрегатные функции не поддерживают режим движущегося агрегата, поскольку не могут использоваться в качестве оконных функций.
Частичная (в том числе параллельная) агрегация в настоящее время не поддерживается для сортирующих агрегатных функций. Также она никогда не будет применяться для агрегатных вызовов с предложениями DISTINCT или ORDER BY, так как они по природе своей не могут быть реализованы с частичным агрегированием.
Примеры
См. раздел Пользовательские агрегаты.
Совместимость
Команда CREATE AGGREGATE является расширением QHB. Стандарт SQL не
предусматривает создание пользовательских агрегатных функций.
См. также
ALTER AGGREGATE, DROP AGGREGATE
CREATE CAST
CREATE CAST — определить новое приведение
Синтаксис
CREATE CAST (исходный_тип AS целевой_тип)
WITH FUNCTION имя_функции [ (тип_аргумента [, ...]) ]
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CAST (исходный_тип AS целевой_тип)
WITHOUT FUNCTION
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CAST (исходный_тип AS целевой_тип)
WITH INOUT
[ AS ASSIGNMENT | AS IMPLICIT ]
Описание
Команда CREATE CAST определяет новое приведение. Приведение
указывает, как выполнить преобразование из одного типа в другой.
Например,
SELECT CAST(42 AS float8);
преобразует целочисленную константу 42 в тип float8 путем вызова ранее указанной функции, в данном случае float8(int4). (Если подходящее приведение не было определено, преобразование завершается ошибкой.)
Два типа могут быть двоично-сводимыми, что означает, что преобразование может быть выполнено «бесплатно» без вызова какой-либо функции. Для этого требуется, чтобы соответствующие значения имели одинаковое внутреннее представление. Например, типы text и varchar являются двоично-сводимыми в обе стороны. Отношение двоичной сводимости не обязательно симметрично. Например, приведение типа xml к типу text в настоящей реализации может быть выполнено бесплатно, но обратное направление требует функции, которая выполняет, по крайней мере, проверку синтаксиса. (Два типа, двоично-сводимые в обе стороны, также называются двоично-совместимыми.)
Приведение можно определить как преобразование ввода/вывода, используя указание WITH INOUT. Приведение преобразования ввода-вывода выполняется путем вызова выходной функции исходного типа данных и передачи результирующей строки во входную функцию целевого типа данных. Во многих распространенных случаях эта функция позволяет избежать необходимости писать отдельную функцию приведения для преобразования. Приведение преобразования ввода-вывода действует так же, как и обычное приведение на основе функций; отличается только реализация.
По умолчанию приведение может быть вызвано только явным запросом
приведения, то есть применением конструкции CAST(x AS имя\_типа) или x::имя\_типа.
Если приведение помечено AS ASSIGNMENT, его можно вызывать неявно, присваивая значение столбцу с целевым типом данных. Например, если foo.f1 — столбец типа text, то команда:
INSERT INTO foo (f1) VALUES (42);
будет допустимой, если приведение типа integer к text помечено AS ASSIGNMENT, и не будет в противном случае. (Для описания такого типа приведений обычно используют термин приведение присваивания.)
Если приведение помечено AS IMPLICIT, то оно может быть вызван неявно в любом контексте, будь то присваивание или внутреннее преобразование в выражении. (Для описания такого типа приведений обычно используют термин неявное приведение.) Например, рассмотрим этот запрос:
SELECT 2 + 4.0;
Сначала анализатор помечает константы как относящиеся к типам integer и numeric соответственно. Но в системных каталогах нет оператора integer + numeric, но есть оператор numeric + numeric Поэтому запрос будет выполнен успешно, если доступно преобразование типа integer к numeric с пометкой AS IMPLICIT — что на самом деле так и есть. Анализатор запроса применит неявное приведение и обработает запрос, как если бы тот был записан в виде
SELECT CAST ( 2 AS numeric ) + 4.0;
Надо сказать, что системные каталоги также содержат приведение типа numeric к integer. Если бы это приведение тоже было помечено AS IMPLICIT (на самом деле это не так), то анализатор столкнулся бы с выбором между приведенным выше вариантом и приведением константы numeric к типу integer с последующим применением оператора integer + integer. Не имея никаких знаний о том, какой выбор предпочесть, анализатор объявил бы запрос неоднозначным. Именно потому, что только одно из двух приведений неявно, анализатор приходит к пониманию, что предпочтительным является преобразование выражения numeric-и-integer в numeric; отдельных встроенных сведений об этом нет.
Разумно проявлять консерватизм в отношении того, объявлять ли приведения неявными. Переизбыток неявных способов приведения может привести к тому, что QHB выберет неожиданные интерпретации команд или даже не сможет их выполнить из-за наличия нескольких возможных интерпретаций. Хорошее эмпирическое правило состоит в том, чтобы сделать приведение неявно вызываемым только для сохраняющих информацию преобразований между типами в одной и той же категории типов. Например, приведение int2 к int4 разумно сделать неявным, но приведение float8 к int4, возможно, лучше сделать только приведением присваивания. Приведения типов разных категорий, например text к int4, лучше делать только явными.
Примечание
Иногда по соображениям удобства использования или соответствия стандартам необходимо обеспечить несколько неявных приведений для набора типов, что приводит к неоднозначности, которую нельзя избежать, как указано выше. Чтобы анализатор запроса мог обеспечить желаемое поведение в таких случаях, он дополнительно принимает во внимание категории типов и предпочитаемые типы. Более подробную информацию см. в разделе CREATE TYPE.
Чтобы создать приведение, нужно быть владельцем одного (исходного или целевого) типа данных и иметь право USAGE для другого типа. Чтобы создать двоично-сводимое приведение, нужно быть суперпользователем. (Это ограничение введено потому, что преобразование данных с ошибочным двоичным сведением легко может вызвать сбой сервера.)
Параметры
исходный_тип
Имя исходного типа данных для приведения.
целевой_тип
Имя целевого типа данных для приведения.
имя_функции[(тип_аргумента [, ...])]
Функция, используемая для выполнения приведения. Имя функции может быть дополнено схемой. В ином случае для поиска функции просматривается путь поиска. Тип данных результата функции должен соответствовать целевому типу приведения. Аргументы функции рассматриваются ниже. Если список аргументов не указан, имя функции должно быть уникальным в своей схеме.
WITHOUT FUNCTION
Указывает, что исходный тип является приводимым к целевому на двоичном уровне, так что функция для приведения не требуется.
WITH INOUT
Указывает, что приведение является приведением преобразования ввода-вывода, выполняемым путем вызова выходной функции исходного типа данных и передачи результирующей строки во входную функцию целевого типа данных.
AS ASSIGNMENT
Указывает, что приведение может быть вызвано неявно в контекстах присвоения.
AS IMPLICIT
Указывает, что приведение может быть вызвано неявно в любом контексте.
Функции, реализующие приведение, могут иметь от одного до трех аргументов. Тип первого аргумента должен быть идентичным или двоично-сводимым к исходному типу приведения. Второй аргумент, если он присутствует, должен быть типом integer; он получает модификатор типа, связанный с типом назначения, или -1, если их вообще нет. Третий аргумент, если он присутствует, должен иметь тип boolean; если приведение является явным приведением, в нем передается true; иначе false. (Как ни странно, стандарт SQL требует различного поведения для явных и неявных приведений в некоторых случаях. Этот аргумент предназначен для функций, которые должны реализовывать такие приведения. Однако создавать собственные типы данных, для которых это имело бы значение, не рекомендуется.)
Возвращаемый тип функции приведения должен быть идентичным или двоично-сводимым к целевому типу приведения.
Обычно приведение должно иметь различные типы исходных и целевых данных. Однако разрешается объявлять приведение с одинаковыми исходными и целевыми типами, если функция, реализующая преобразование, имеет более одного аргумента. Это используется для представления в системных каталогах функций, сводящих разные длины типов. Реализующая такое приведение функция используется для сведения значения типа к значению с определенным модификатором, заданному его вторым аргументом.
Если приведение имеет различные исходные и целевые типы, а также функцию, принимающую более одного аргумента, то оно поддерживает преобразование из одного типа в другой и сведение к нужной длине может выполняться за один шаг. Если же соответствующей записи не находится, приведение к типу с определенным модификатором включает два этапа приведения: один для преобразования между типами данных и второй для применения модификатора.
Приведение типа домена или к типу домена в настоящее время не осуществляется. При попытке выполнить такое приведение, вместо этого выполняется приведение, связанное с базовым типом домена.
Примечания
Для удаления приведений, созданных пользователем, применяется DROP CAST.
Помните, что если вы хотите иметь возможность конвертировать типы в обе стороны, вам нужно явно объявить приведение в обе стороны.
Обычно нет необходимости создавать приведения между пользовательскими типами и стандартными строковыми типами (text, varchar и char(n), а также пользовательскими типами, относящимися к категории строковых). QHB предоставляет для этого автоматические преобразования ввода-вывода. Автоматические приведения к строковым типам обрабатываются как приведения присваивания, тогда как автоматические приведения от строковых типов могут быть только явными. Это поведение можно переопределить, объявив свое собственное приведение, чтобы заменить автоматическое, но обычно это нужно, только чтобы сделать вызов более удобным, чем стандартное присваивание или явное указание. Другая возможная причина заключается в желании, чтобы преобразование вело себя иначе, чем функция ввода-вывода; но это выглядит достаточно странным, поэтому стоит дважды подумать, является ли это хорошей идеей. (На самом деле у небольшого количества встроенных типов имеются подобные специфические приведения, в основном, из-за требований стандарта SQL.)
Несмотря на то, что это не обязательно, рекомендуется продолжать следовать старому соглашению именования функций, реализующих приведение, по целевому типу данных. Многие пользователи привыкли иметь возможность приводить типы данных, записывая его в стиле функций, т. е. имя_типа(x). Эта запись на самом деле ни что иное, как вызов функции, реализующей приведение; такой вызов не воспринимается как именно приведение. Если не называть функции преобразования, следуя этому соглашению, это может удивить пользователей. Поскольку QHB позволяет перегружать одно и то же имя функции с различными типами аргументов, ничто не мешает тому, чтобы иметь несколько функций преобразования из разных типов, названных по имени этого целевого типа.
Примечание
На самом деле в предыдущем абзаце содержится некоторое упрощение: есть два случая, в которых конструкция вызова функции будет рассматриваться как запрос приведения без сопоставления его с фактической функцией. Если вызову функции имя(x) в точности не соответствует существующая функция, но имеется тип данных имя и в pg_cast есть двоично-сводимое приведение типа x к этому типу, такой вызов будет воспринят как приведение. Это исключение введено, чтобы двоично-сводимое приведение можно было вызвать, используя синтаксис функций, несмотря на то, что никакой функции преобразования у него нет. Аналогично, если запись приведения в pg_cast отсутствует, но приведение было бы к или от строкового типа, вызов будет истолкован как приведение преобразования ввода-вывода. Это исключение позволяет вызывать приведения преобразования ввода-вывода, используя синтаксис вызова функции.
Примечание
Существует также исключение и из этого исключения: преобразование ввода/вывода из составных типов в строковые нельзя вызвать, используя синтаксис вызова функции; его необходимо записать как явное приведение (используя CAST или запись ::) Это исключение было добавлено, так как после введения автоматически предоставляемых приведений преобразования ввода-вывода было обнаружено, что такое приведение слишком легко вызвать случайно, намереваясь на самом деле дать ссылку на столбец или функцию.
Примеры
Создание приведения присваивания типа bigint к типу int4 с помощью функции int4(bigint):
CREATE CAST (bigint AS int4) WITH FUNCTION int4(bigint) AS ASSIGNMENT;
(Это приведение уже предопределено в системе.)
Совместимость
Команда CREATE CAST соответствует стандарту SQL, за исключением
того, что в стандарте ничего не говорится о двоично-сводимых типах и
дополнительных аргументах реализующих функций. Указание AS IMPLICIT
тоже является расширением QHB.
См. также
CREATE FUNCTION, CREATE TYPE, DROP CAST
CREATE COLLATION
CREATE COLLATION — определить новое правило сортировки
Синтаксис
CREATE COLLATION [ IF NOT EXISTS ] имя (
[ LOCALE = локаль, ]
[ LC_COLLATE = категория_сортировки, ]
[ LC_CTYPE = категория_типов_символов, ]
[ PROVIDER = провайдер, ]
[ DETERMINISTIC = логическое_значение, ]
[ VERSION = версия ]
)
CREATE COLLATION [ IF NOT EXISTS ] имя FROM существующее_правило
Описание
Команда CREATE COLLATION определяет новое правило сортировки,
используя указанные параметры локали операционной системы или
копируя существующие правила сортировки.
Чтобы создать правило сортировки, необходимо иметь право CREATE в целевой схеме.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если правило сортировки с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее правило сортировки как-то соотносится с тем, которое было бы создано.
имя
Имя правила сортировки. Может быть дополнено схемой (если это не так, правило сортировки определяется в текущей схеме). Имя правила сортировки должно быть уникальным в этой схеме. (Системные каталоги могут содержать правила сортировки с тем же именем для других кодировок, но они игнорируются, если кодировка базы данных не соответствует.)
локаль
Это ярлык для одновременной настройки LC_COLLATE и LC_CTYPE. Если задать этот параметр, то нельзя будет указать ни один из этих параметров отдельно.
категория_сортировки
Использовать указанную локаль операционной системы в качестве категории локали LC_COLLATE.
категория_типов_символов
Использовать указанную локаль операционной системы в качестве категории локали LC_CTYPE.
провайдер
Указывает провайдера, который будет использоваться для служб локали, связанных с данным правилом сортировки. Возможные значения: icu, libc. По умолчанию значение равно libc. Доступные варианты зависят от параметров операционной системы и сборки.
DETERMINISTIC
Указывает, должны ли правила сортировки использовать детерминированные сравнения. Значение по умолчанию равно true(использовать детерминированные сравнения). При детерминированном сравнении строки, которые не равны по байтам, считаются неравными, даже если они считаются логически равными при сравнении. QHB решает вопрос их равенства, используя байтовое сравнение. Недетерминированное сравнение может сделать правило, к примеру, независимым от ударения или регистра символов. Для этого нужно выбрать подходящий вариант LC_COLLATE и сделать это правило сортировки недетерминированным.
Недетерминированные правила сортировки поддерживаются только с провайдером ICU.
версия
Указывает строку версии, сохраняемую с правилом сортировки. Обычно
ее не следует задавать, что приведет к вычислению версии из фактической
версии правила сортировки, предоставленного операционной системой. Эта
опция предназначена к использованию qhb\_upgrade для копирования
версии из существующей установки.
Что делать при несовпадении версий правил сортировки, описано в разделе ALTER COLLATION.
существующее_правило
Имя копируемого существующего правила сортировки. Новое правило сортировки будет иметь те же свойства, что и существующее, но будет независимым объектом.
Примечания
CREATE COLLATION устанавливает блокировку SHARE ROW EXCLUSIVE в
системном каталоге pg_collation. Эта блокировка конфликтует с такой же,
поэтому в один момент времени может выполняться только одна команда CREATE COLLATION.
Используйте DROP COLLATION для удаления пользовательских
правил сортировки.
Дополнительную информацию о создании правил сортировки см. в разделе Создание новых правил сортировки.
При использовании провайдера libc для правил сортировки локаль должна быть применима к текущей кодировке базы данных. См. CREATE DATABASE.
Примеры
Создание правила сортировки из локали операционной системы fr_FR.utf8 (предполагается, что кодировка текущей базы данных — UTF8):
CREATE COLLATION french (locale = 'fr_FR.utf8');
Создание правила сортировки с порядком, принятым в Германии для телефонных книг, с использованием провайдера ICU:
CREATE COLLATION german_phonebook (provider = icu, locale = 'de-u-co-phonebk');
Создание правила сортировки из уже существующего:
CREATE COLLATION german FROM "de_DE";
Иногда удобно использовать в приложениях имена правил сортировки, не зависящие от операционной системы.
Совместимость
В стандарте SQL есть команда CREATE COLLATION, но она ограничена
копированием существующих правил сортировки. Синтаксис для создания
новых правил сортировки является расширением QHB.
См. также
ALTER COLLATION, DROP COLLATION
CREATE CONVERSION
CREATE CONVERSION — определить новую перекодировку
Синтаксис
CREATE [ DEFAULT ] CONVERSION имя
FOR исходная_кодировка TO целевая_кодировка FROM имя_функции
Описание
Команда CREATE CONVERSION определяет новую перекодировку набора символов.
Кроме того, перекодировки, отмеченные как DEFAULT, могут использоваться для автоматической
перекодировки между клиентом и сервером. Для этого необходимо определить
две перекодировки — из кодировки A в B и из кодировки B в A.
Чтобы создать перекодировку, необходимо иметь право EXECUTE для реализующей функции и право CREATE в целевой схеме.
Параметры
DEFAULT
Предложение DEFAULT указывает, что эта перекодировка является перекодировкой по умолчанию для заданной исходной кодировки в кодировку назначения. В схеме для пары перекодировок должна быть только одна перекодировка по умолчанию.
имя
Имя перекодировки (может быть дополнено схемой). Если схема не указана, перекодировка создается в текущей схеме. Имя перекодировки должно быть уникальным в пределах схемы.
исходная_кодировка
Имя исходной кодировки.
целевая_кодировка
Имя целевой кодировки.
имя_функции
Функция, используемая для выполнения перекодировки. Имя функции может быть дополнено схемой. Если это не так, для поиска функции просматривается путь поиска.
Функция должна иметь следующую сигнатуру:
conv_proc(
integer, -- идентификатор исходной кодировки
integer, -- идентификатор целевой кодировки
cstring, -- исходная строка (строка, завершающаяся 0, как в C)
internal, -- целевая строка (заполняется строкой, завершающейся 0, как в C)
integer -- длина исходной строки
) RETURNS void;
Примечания
Как исходная, так и конечная кодировки должны отличаться от SQL_ASCII, поскольку поведение сервера в случаях использования «кодировки» SQL_ASCII является аппаратным.
Для удаления пользовательских перекодировок используйте команду
DROP CONVERSION.
Права доступа, необходимые для создания перекодировки, могут быть изменены в будущих версиях.
Примеры
Создание перекодировки из кодировки UTF8 в LATIN1 с использованием функции myfunc:
CREATE CONVERSION myconv FOR 'UTF8' TO 'LATIN1' FROM myfunc;
Совместимость
Команда CREATE CONVERSION является расширением QHB. В стандарте SQL нет
команды CREATE CONVERSION, но есть команда CREATE TRANSLATION,
которая очень похожа по назначению и синтаксису.
См. также
ALTER CONVERSION, CREATE FUNCTION, DROP CONVERSION
CREATE DATABASE
CREATE DATABASE — создать новую базу данных
Синтаксис
CREATE DATABASE имя
[ [ WITH ] [ OWNER [=] имя_пользователя ]
[ TEMPLATE [=] шаблон ]
[ ENCODING [=] кодировка ]
[ LOCALE [=] локаль ]
[ LC_COLLATE [=] категория_сортировки ]
[ LC_CTYPE [=] категория_типов_символов ]
[ TABLESPACE [=] имя_табличного_пространства ]
[ ALLOW_CONNECTIONS [=] разр_подключения ]
[ CONNECTION LIMIT [=] предел_подключений ]
[ IS_TEMPLATE [=] это_шаблон ] ]
Описание
Команда CREATE DATABASE создает новую базу данных QHB.
Чтобы создать базу данных, нужно быть суперпользователем или иметь специальное право CREATEDB. См. раздел CREATE ROLE.
По умолчанию новая база данных будет создана путем клонирования
стандартной системной базы данных template1. Другой шаблон можно задать
указанием TEMPLATE имя. В частности, путем указания TEMPLATE template0
вы можете создать чистую базу данных, содержащую только
стандартные объекты, предопределенные вашей версией QHB. Это
полезно, если вы хотите избежать копирования любых локальных объектов
установки, которые могли быть добавлены к template1.
Параметры
имя
Имя создаваемой базы данных.
имя_пользователя
Имя пользователя (роли), которому будет принадлежать новая база данных, или DEFAULT, чтобы использовать значение по умолчанию (а именно, пользователя, выполняющего команду). Чтобы создать базу данных с другой ролью-владельцем, необходимо быть прямым или косвенным членом этой роли или суперпользователем.
шаблон
Имя шаблона, из которого будет создана новая база данных, или DEFAULT, чтобы использовать шаблон по умолчанию (template1).
кодировка
Кодировка набора символов для использования в новой базе данных. Укажите строковую константу (например, ’SQL_ASCII’), или целочисленный номер кодировки, или DEFAULT, чтобы использовать кодировку по умолчанию (а именно, кодировку шаблона базы данных). Наборы символов, поддерживаемые сервером QHB, описаны в разделе Управление правилами сортировки. Дополнительные ограничения см. ниже.
локаль
Это краткая форма задания двух параметров, LC_COLLATE и LC_TYPE, сразу. При указании этой формы нельзя задать данные параметры по отдельности.
Совет
Другие параметры локали lc_messages, lc_monetary, lc_numeric и lc_time задаются не на уровне базы данных и не устанавливаются этой командой. Если хотите изменить их значения по умолчанию для конкретной базы данных, можно использоватьALTER DATABASE ... SET.
категория_сортировки
Порядок сортировки (LC_COLLATE), который будет использоваться в новой базе данных. Это влияет на порядок сортировки, применяемый к строкам, например, в запросах с ORDER BY, а также на порядок, используемый в индексах текстовых столбцов. По умолчанию используется порядок сортировки шаблона базы данных. Дополнительные ограничения см. ниже.
категория_типов_символов
Классификация символов (LC_CTYPE), которая будет использоваться в новой базе данных. Это влияет на классификацию символов, например: строчные, заглавные, цифры и т. п. По умолчанию используется классификация символов шаблона базы данных. Дополнительные ограничения см. ниже.
имя_табличного_пространства
Имя табличного пространства, которое будет связано с новой базой данных, или DEFAULT, чтобы использовать табличное пространство шаблона базы данных. Это табличное пространство будет табличным пространством по умолчанию, используемым для объектов, созданных в этой базе данных. Дополнительную информацию см. в разделе CREATE TABLESPACE.
разрешение_подключения
Если установлено значение false, то никто не может подключиться к этой базе данных. По умолчанию установлено значение true, разрешающее подключения (за исключением случаев, ограниченных другими механизмами, такими как GRANT/REVOKE CONNECT).
предел_подключений
Предельное число одновременных подключений, которое может быть сделано к этой базе данных. -1 (по умолчанию) означает отсутствие ограничений.
это_шаблон
Если установлено значение true, то эта база данных может быть клонирована любым пользователем с правами CREATEDB; если стоит значение false (по умолчанию), то клонировать базу данных могут только суперпользователи или владелец базы данных.
Дополнительные параметры могут быть записаны в любом порядке, а не только в порядке, показанном выше.
Примечания
Команда CREATE DATABASE не может быть выполнена внутри блока
транзакций.
Ошибки вида «не удалось инициализировать каталог базы данных», скорее всего, связаны с недостаточными разрешениями на каталог данных, переполненным диском или другими проблемами в файловой системе.
Для удаления базы данных используйте команду DROP DATABASE.
Программа createdb является программой-оболочкой этой команды, предусмотренной для удобства.
Параметры конфигурации уровня базы данных (заданные через ALTER DATABASE), а также разрешения уровня базы данных (заданные через GRANT) не копируются из шаблона базы данных.
Хотя можно скопировать не только template1, но и другую базу данных, указав ее имя в
качестве шаблона, данная команда не предназначена (пока) для использования в качестве
универсального средства вроде «COPY DATABASE».
Основное ограничение заключается в том, что во время копирования
никто не должен быть подключен к базе данных, указанной в качестве шаблона.
CREATE DATABASE завершится ошибкой, если при запуске команды есть другие
подключения к этой базе; в противном случае новые
соединения с базой данных шаблона будут заблокированы до завершения
процесса CREATE DATABASE. Дополнительную информацию см. в
разделе Базы данных шаблонов.
Кодировка набора символов, заданная для новой базы данных, должна быть
совместима с выбранными параметрами локали (LC_COLLATE и LC_CTYPE).
Если выбрана локаль С (или POSIX), то разрешены все кодировки,
но для других настроек локали есть только одна кодировка,
которая будет работать должным образом. (В Windows, однако, кодировка
UTF-8 может использоваться с любой локалью.) CREATE DATABASE
позволяет суперпользователям указывать кодировку SQL_ASCII независимо
от настроек локали, но этот вариант устарел и может привести к
неправильному использованию функций символьной строки, если в базе
хранятся данные, не совместимые с кодировкой локали.
Параметры кодировки и локали должны соответствовать параметрам шаблона базы данных, за исключением случаев, когда в качестве шаблона используется template0. Это связано с тем, что другие базы данных могут содержать данные, не соответствующие указанной кодировке, или индексы, порядок сортировки которых зависит от LC_COLLATE и LC_CTYPE. Копирование таких данных может привести к повреждению базы данных в соответствии с новыми настройками. Однако template0, как известно, не содержит никаких данных или индексов, которые могло бы затронуть.
Ограничение CONNECTION LIMIT применяется только приблизительно; если два новых сеанса начинаются примерно в то же время, когда для базы данных остается только один «слот» на подключение, не исключено, что оба сеанса завершатся неудачей. Кроме того, ограничение не применяется к суперпользователям или фоновым рабочим процессам.
Примеры
Создание базы данных:
CREATE DATABASE lusiadas;
Создание базы данных sales, принадлежащей пользователю salesapp, с табличным пространством по умолчанию salesspace:
CREATE DATABASE sales OWNER salesapp TABLESPACE salesspace;
Создание базы данных music с другой локалью:
CREATE DATABASE music
LC_COLLATE 'sv_SE.utf8' LC_CTYPE 'sv_SE.utf8'
TEMPLATE template0;
В этом примере предложение TEMPLATE template0 необходимо, только если указанная локаль
отличается от локали в template1. (В противном случае явное указание локали является избыточным.)
Создание базы данных music2 с другой локалью и другой кодировкой символов:
CREATE DATABASE music2
LC_COLLATE 'sv_SE.iso885915' LC_CTYPE 'sv_SE.iso885915'
ENCODING LATIN9
TEMPLATE template0;
Свойства кодировки должны соответствовать свойствам локали, иначе возникнет ошибка.
Обратите внимание, что имена локалей зависят от операционной системы, поэтому показанные выше команды могут не везде работать одинаково.
Совместимость
В стандарте SQL нет команды CREATE DATABASE.
Базы данных эквивалентны каталогам, создание которых определяется реализацией.
См. также
CREATE DOMAIN
CREATE DOMAIN — определить новый домен
Синтаксис
CREATE DOMAIN имя [ AS ] тип_данных
[ COLLATE правило_сортировки ]
[ DEFAULT выражение ]
[ ограничение [ ... ] ]
Где ограничение может быть:
[ CONSTRAINT имя_ограничения ]
{ NOT NULL | NULL | CHECK (выражение) }
Описание
Команда CREATE DOMAIN создает новый домен. Домен по существу является типом
данных с дополнительными ограничениями (ограничениями на допустимый
набор значений). Пользователь, определяющий домен, становится его
владельцем.
Если задано имя схемы (например, CREATE DOMAIN myschema.mydomain ...), то
домен создается в указанной схеме, в противном случае — в текущей. Имя домена
должно быть уникальным среди имен типов и доменов, существующих в его схеме.
Домены полезны для реферирования общих характеристик разных полей в единое место для упрощения сопровождения. Например, несколько таблиц могут содержать столбцы адресов электронной почты, для проверки синтаксиса которых требуется одно и то же проверочное ограничение CHECK. Определите домен, вместо того чтобы устанавливать ограничение каждой таблицы по отдельности.
Чтобы иметь возможность создать домен, необходимо иметь право USAGE для нижележащего типа.
Параметры
имя
Имя создаваемого домена (может быть дополнено схемой).
тип_данных
Нижележащий тип данных домена. Может включать определение массива с этим типом.
правило_сортировки
Необязательные правила сортировки для домена. Если параметры сортировки не указаны, используются правила сортировки по умолчанию для нижележащего типа данных. Указать COLLATE можно, только если нижележащий тип данных является сортируемым.
DEFAULT выражение
Предложение DEFAULT задает значение по умолчанию для столбцов, типом данных которых является этот домен. Значением является любое выражение без переменной (но подзапросы не разрешены). Тип данных выражения по умолчанию должен соответствовать типу данных домена. Если значение по умолчанию не указано, оно равно NULL.
Выражение по умолчанию будет использоваться в любой операции добавления, которая не задает значение для столбца. Если для конкретного столбца определено значение по умолчанию, оно переопределяет все значения по умолчанию, связанные с доменом. В свою очередь, домен по умолчанию переопределяет любое значение по умолчанию, связанное с нижележащим типом данных.
CONSTRAINT имя_ограничения
Необязательное имя ограничения. Если не указано, система создает имя.
NOT NULL
Значения этого домена не могут быть равны NULL (но см. Примечания ниже).
NULL
Значения этого домена могут быть равны NULL. Это значение по умолчанию.
Это предложение предназначено только для обеспечения совместимости с нестандартными базами данных SQL. В новых приложениях его использование не рекомендуется.
CHECK (выражение)
Предложения CHECK определяют ограничения целостности или проверки, которым должны удовлетворять значения домена. Каждое ограничение должно быть выражением, дающим логический результат. Проверяемое значение в этом выражении должно обозначаться ключевым словом VALUE. Выражения, выдающие значение TRUE или UNKNOWN, успешно выполняются. Если выражение выдает FALSE, появляется сообщение об ошибке и значение не может быть преобразовано в тип домена.
В настоящий момент выражения CHECK не могут содержать вложенные запросы и ссылаться на другие переменные, кроме VALUE.
Когда домен имеет несколько ограничений CHECK, они будут проверены в алфавитном порядке по названию.
Примечания
Ограничения домена, в частности, NOT NULL, проверяются при преобразовании значения в тип домена. Бывает, что даже несмотря на наличие такого ограничения, столбец, который номинально относится к типу домена, всё же можно прочитать как NULL. Например, это может произойти в запросе внешнего соединения, если столбец домена находится на стороне nullable внешнего соединения. Более тонкий пример:
INSERT INTO tab (domcol) VALUES ((SELECT domcol FROM tab WHERE false));
Пустой скалярный SELECT создаст значение NULL, которое считается доменным типом, поэтому к нему не применяется дополнительная проверка ограничений, и добавление будет выполнена успешно.
Очень трудно избежать подобных проблем из-за общего предположения SQL, что значение NULL является допустимым значением каждого типа данных. Поэтому наилучшим решением будет разработать ограничения домена таким образом, чтобы разрешить значение NULL, а затем применить ограничения NOT NULL для столбцов типа домена по мере необходимости, а не непосредственно для типа домена.
QHB предполагает, что условия ограничений CHECK неизменны, то есть они всегда будут давать один и тот же результат для одного и того же входного значения. Именно это предположение объясняет проверку ограничений CHECK только при первом преобразовании значения в тип домена, а не при каждом обращении к нему. (По сути, таким же образом обрабатываются ограничения CHECK для таблиц, как описано в разделе Контрольные ограничения.)
Примером распространенного способа нарушения данного предположения является
ссылка на определяемую пользователем функцию в ограничении CHECK, а
затем изменение поведения этой функции. QHB не запрещает этого, но
и не заметит, если есть сохраненные значения типа домена, которые
теперь нарушают ограничение CHECK. Это может привести к сбою последующего
дампа и перезагрузки базы данных. Рекомендуемый способ обработки такого
изменения состоит в том, чтобы удалить ограничение (используя ALTER DOMAIN),
настроить определение функции и повторно добавить
ограничение, тем самым перепроверив его относительно сохраненных данных.
Примеры
В этом примере создается тип данных us_postal_code (почтовый индекс США), который затем используется в определении таблицы. Для проверки значения на соответствие формату почтовых индексов США применяется проверка с регулярными выражениями:
CREATE DOMAIN us_postal_code AS TEXT
CHECK(
VALUE ~ '^\d{5}$'
OR VALUE ~ '^\d{5}-\d{4}$'
);
CREATE TABLE us_snail_addy (
address_id SERIAL PRIMARY KEY,
street1 TEXT NOT NULL,
street2 TEXT,
street3 TEXT,
city TEXT NOT NULL,
postal us_postal_code NOT NULL
);
Совместимость
Команда CREATE DOMAIN соответствует стандарту SQL.
См. также
CREATE EVENT TRIGGER
CREATE EVENT TRIGGER — определить новый событийный триггер
Синтаксис
CREATE EVENT TRIGGER имя
ON событие
[ WHEN переменная_фильтра IN (filter_value [, ... ]) [ AND ... ] ]
EXECUTE { FUNCTION | PROCEDURE } имя_функции()
Описание
Команда CREATE EVENT TRIGGER создает новый событийный триггер. Всякий раз,
когда происходит назначенное событие и удовлетворяется связанное с
триггером условие WHEN (при наличии), функция триггера будет
выполнена. Общие сведения о событийных триггерах см. в главе Триггеры событий.
Пользователь, создающий событийный триггер, становится его владельцем.
Параметры
имя
Имя, назначаемое новому триггер. Это имя должно быть уникальным в пределах базы данных.
событие
Имя события, которое вызывает срабатывание триггера и вызов функции. Дополнительную информацию об именах событий см. в разделе Поведение триггера событий.
переменная_фильтра
Имя переменной, используемой для фильтрации событий. Это позволяет ограничить запуск триггера подмножеством случаев, в которых он поддерживается. В настоящее время единственным поддерживаемым значением параметра переменная_фильтра является TAG.
значение фильтра
Список значений для связанного параметра переменная_фильтра, для которых должен срабатывать триггер. Для переменной TAG это подразумевает список меток команд (например, 'DROP FUNCTION').
имя_функции
Заданная пользователем функция, которая заявлена как не принимающая аргументов и возвращающая тип event_trigger.
В синтаксисе CREATE EVENT TRIGGER ключевые слова FUNCTION и PROCEDURE
эквивалентны, но указанная функция должна в любом случае быть
функцией, а не процедурой. Использование здесь ключевого слова PROCEDURE
поддерживается по историческим причинам и считается устаревшим.
Примечания
Только суперпользователи могут создавать событийные триггеры.
В однопользовательском режиме событийные триггеры отключены (см. раздел Процесс qhb). Если ошибочный событийный триггер заблокировал базу данных настолько, что его даже невозможно удалить, перезагрузите сервер в однопользовательском режиме, и вы сможете это сделать.
Примеры
Запрет на выполнение любой команды DDL:
CREATE OR REPLACE FUNCTION abort_any_command()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
BEGIN
RAISE EXCEPTION 'command % is disabled', tg_tag;
END;
$$;
CREATE EVENT TRIGGER abort_ddl ON ddl_command_start
EXECUTE FUNCTION abort_any_command();
Совместимость
В стандарте SQL нет команды CREATE EVENT TRIGGER.
См. также
ALTER EVENT TRIGGER, DROP EVENT TRIGGER, CREATE FUNCTION
CREATE EXTENSION
CREATE EXTENSION — установить расширение
Синтаксис
CREATE EXTENSION [ IF NOT EXISTS ] имя_расширения
[ WITH ] [ SCHEMA имя_схемы ]
[ VERSION версия ]
[ CASCADE ]
Описание
Команда CREATE EXTENSION загружает в текущую базу данных новое расширение.
Уже загруженного расширения с тем же именем в базе быть не должно.
Загрузка расширения по существу сводится к запуску файла скрипта
расширения. Скрипт обычно создает новые объекты SQL, например: функции,
типы данных, операторы и методы поддержки индексов. CREATE EXTENSION
дополнительно записывает идентификаторы всех созданных объектов,
так что впоследствии их можно снова удалить, выполнив команду DROP EXTENSION.
Пользователь, запускающий CREATE EXTENSION, становится
владельцем расширения для последующих проверок доступа, а также, как правило,
владельцем всех объектов, созданных скриптом расширения.
Для загрузки расширения требуются те же права доступа, что и для создания составляющих его объектов. Для большинства расширений это означает, что необходимы права суперпользователя или владельца базы данных. Однако если расширение помечено в своем управляющем файле как trusted (доверенное), его может установить любой пользователь с правом CREATE в текущей базе данных. В этом случае сам объект расширения будет принадлежать вызывающему пользователю, но владельцем содержащихся в нем объектов будет первоначальный суперпользователь (если только скрипт расширения явно не назначит их владельцем вызывающего пользователя). Эта конфигурация дает вызывающему пользователю право удалить расширение, но не модифицировать отдельные объекты внутри него.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если расширение с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее расширение как-то соотносится с тем, которое было бы создано из доступного в данный момент скрипта.
имя_расширения
Имя устанавливаемого расширения. QHB создаст расширение, используя сведения из файла SHAREDIR/extension/имя_расширения.control.
имя схемы
Имя схемы, в которой будут устанавливаться объекты расширения (при условии, что расширение позволяет перемещать его содержимое). Названная схема уже должна существовать. Если этот параметр не указан, а в управляющем файле расширения также не указана схема, то используется текущая схема создания объекта по умолчанию.
Если в управляющем файле расширения задается параметр schema, то эту схему нельзя переопределить предложением SCHEMA. Обычно при указании предложения SCHEMA возникает ошибка, если эта схема конфликтует с параметром schema данного расширения. Однако если также задано предложение CASCADE, то в случае конфликта имя_схемы игнорируется. Заданное имя_схемы будет использоваться для установки любых необходимых расширений, если в их управляющем файле не указана schema.
Помните, что само расширение не считается частью какой-либо схемы: расширения имеют неполные имена, которые должны быть уникальными для всей базы данных. Но объекты, принадлежащие расширению, могут находиться внутри схем.
версия
Версия расширения. Ее можно записать в виде идентификатора или строкового значения. Версия по умолчанию указана в управляющем файле расширения.
CASCADE
Автоматически устанавливать все расширения, от которых зависит это расширение и которые еще не установлены. Их зависимости также устанавливаются автоматически, рекурсивно. Предложение SCHEMA (если указано) применяется ко всем расширениями, которые устанавливаются таким образом. Другие параметры инструкции не применяются к автоматически устанавливаемым расширениями; в частности, всегда выбираются их версии по умолчанию.
Примечания
Прежде чем использовать CREATE EXTENSION для загрузки расширения в
базу данных, необходимо установить файлы его поддержки. Информацию об
установке расширений, поставляемых с QHB, можно найти в
разделе Расширения QHB.
Расширения, доступные для загрузки в настоящее время, можно найти в системных представлениях pg_available_extensions или pg_available_extension_versions.
Внимание
Установка расширение от имени суперпользователя требует уверенности в том, что автор расширения написал его установочный скрипт безопасным образом. Для злоумышленного пользователя не составит особого труда создать объекты типа троянского коня, которые впоследствии скомпрометируют выполнение небрежно написанного скрипта расширения, позволив этому пользователю получить права суперпользователя. Однако такие объекты опасны, только если находятся в пути search_path во время выполнения скрипта, то есть если они находятся в схеме, в которую устанавливается расширение, или в схеме, где располагается другое расширение, от которого зависит первое. Таким образом, имея дело с расширениями, скрипты которых не были тщательно проверены, рекомендуется устанавливать их только в те схемы, для которых недоверенные пользователи не имеют и не будут иметь права CREATE. То же самое касается других расширений, от которых они зависят.
Расширения, поставляемые в составе QHB, можно считать защищенными от подобного рода атак времени выполнения, за исключением некоторых, зависящих от других расширений. Как отмечается в документации таких расширений, их следует устанавливать в безопасные схемы и/или в те же схемы, в которые устанавливаются требующиеся им расширения.
Дополнительную информацию о создании новых расширений см. в разделе Упаковка связанных объектов в расширение.
Примеры
Установка расширения hstore в текущую базу данных с размещением его объектов в схеме addons:
CREATE EXTENSION hstore SCHEMA addons;
Еще один способ сделать вышеописанную операцию:
SET search_path = addons;
CREATE EXTENSION hstore;
Совместимость
Команда CREATE EXTENSION является расширением QHB.
См. также
ALTER EXTENSION, DROP EXTENSION
CREATE FOREIGN DATA WRAPPER
CREATE FOREIGN DATA WRAPPER — определить новую обертку сторонних данных
Синтаксис
CREATE FOREIGN DATA WRAPPER имя
[ HANDLER функция_обработчик | NO HANDLER ]
[ VALIDATOR функция_проверки | NO VALIDATOR ]
[ OPTIONS ( параметр 'значение' [, ... ] ) ]
Описание
Команда CREATE FOREIGN DATA WRAPPER создает новую обертку сторонних данных.
Пользователь, определяющий обертку сторонних данных, становится
ее владельцем.
Имя обертки сторонних данных должно быть уникальным в пределах базы данных.
Только суперпользователи могут создавать обертки сторонних данных.
Параметры
имя
Имя создаваемой обертки сторонних данных.
HANDLER функция_обработчик
В аргументе функция_обработчика указывается имя ранее зарегистрированной функции, которая будет вызвана для извлечения функций, реализующих обращения к сторонним таблицам. Функция обработчика должна быть без аргументов, и ее возвращаемый тип должен быть fdw_handler.
Можно создать обертку сторонних данных без функции обработчика, но сторонние таблицы, использующие такую обертку, будут только объявлены, но не доступны.
VALIDATOR функция_проверки
функция_проверки — это имя ранее зарегистрированной функции, которая будет вызвана для проверки общих параметров, передаваемых обертке сторонних данных, а также параметров для сторонних серверов, сопоставлений пользователей и сторонних таблиц, использующих эту обертку сторонних данных. Если нет функции проверки или указано NO VALIDATOR, то во время создания объектов параметры проверяться не будут. (Возможно, обертки сторонних данных будут игнорировать или отклонять недопустимые спецификации параметров во время выполнения, в зависимости от реализации.) Функция проверки должна принимать два аргумента: первый типа text[] (в нем содержится массив параметров, хранящихся в системном каталоге), а второй типа oid (в нем указывается OID системного каталога с этими параметрами). Возвращаемое значение игнорируется; функция должна сообщить о недопустимых параметрах с помощью системной функции ereport(ERROR).
OPTIONS ( параметр 'значение' [, ... ] )
Это предложение задает параметры для новой обертки сторонних данных. Допустимые имена параметров и значения являются специфичными для каждой обертки сторонних данных и проверяются с помощью функции проверки. Имена параметров должны быть уникальными.
Примечания
Функциональность работы QHB со сторонними данными всё еще находится в стадии активного развития. Оптимизация запросов примитивна (и по большей части это тоже делает обертка). Таким образом, имеются широкие возможности для дальнейшего повышения производительности.
Примеры
Создание бесполезной обертки сторонних данных dummy:
CREATE FOREIGN DATA WRAPPER dummy;
Создание обертки сторонних данных file с функцией-обработчиком file_fdw_handler:
CREATE FOREIGN DATA WRAPPER file HANDLER file_fdw_handler;
Создание обертки сторонних данных mywrapper с некими параметрами:
CREATE FOREIGN DATA WRAPPER mywrapper
OPTIONS (debug 'true');
Совместимость
Команда CREATE FOREIGN DATA WRAPPER соответствует стандарту ISO/IEC 9075-9
(SQL/MED), за исключением того, что в QHB предложения
HANDLER и VALIDATOR являются расширениями, а стандартные предложения
LIBRARY и LANGUAGE не реализованы.
Обратите внимание, однако, что соответствие функциональности SQL/MED в комплексе пока не достигнуто.
См. также
ALTER FOREIGN DATA WRAPPER, DROP FOREIGN DATA WRAPPER, CREATE SERVER, CREATE USER MAPPING, CREATE FOREIGN TABLE
CREATE FOREIGN TABLE
CREATE FOREIGN TABLE — определить новую стороннюю таблицу
Синтаксис
CREATE FOREIGN TABLE [ IF NOT EXISTS ] имя_таблицы ( [
{ имя_столбца тип_данных [ OPTIONS ( параметр 'значение' [, ... ] ) ] [ COLLATE правило_сортировки ] [ ограничение_столбца [ ... ] ]
| ограничение_таблицы }
[, ... ]
] )
[ INHERITS ( таблица_родитель [, ... ] ) ]
SERVER имя_сервера
[ OPTIONS ( параметр 'значение' [, ... ] ) ]
CREATE FOREIGN TABLE [ IF NOT EXISTS ] имя_таблицы
PARTITION OF таблица_родитель [ (
{ имя_столбца [ WITH OPTIONS ] [ ограничение_столбца [ ... ] ]
| ограничение_таблицы }
[, ... ]
) ] указание_границ_партиции
SERVER имя_сервера
[ OPTIONS ( параметр 'значение' [, ... ] ) ]
Где ограничение_столбца может быть:
[ CONSTRAINT имя_ограничения ]
{ NOT NULL |
NULL |
CHECK ( выражение ) [ NO INHERIT ] |
DEFAULT выражение_по_умолчанию |
GENERATED ALWAYS AS ( генерирующее_выражение ) STORED }
Где ограничение_таблицы может быть:
[ CONSTRAINT имя_ограничения ]
CHECK ( выражение ) [ NO INHERIT ]
Описание
Команда CREATE FOREIGN TABLE создает в текущей базе данных новую стороннюю таблицу.
Таблица будет принадлежать пользователю, выполнившему эту команду.
Если задано имя схемы (например, CREATE FOREIGN TABLE myschema.mytable ...),
то таблица создается в указанной схеме, в противном случае — в текущей.
Имя сторонней таблицы должно отличаться от имени любой другой сторонней таблицы,
а также таблицы, последовательности, индекса, представления или материализованного
представления в той же схеме.
CREATE FOREIGN TABLE также автоматически создает тип данных, который представляет
собой составной тип, соответствующий одной строке сторонней таблицы. По этой причине
сторонние таблицы не могут иметь то же имя, что и любой существующий тип данных в той же схеме.
Если указано предложение PARTITION OF, таблица создается в виде партиции parent_table с заданными границами.
Чтобы создать стороннюю таблицу, необходимо иметь право USAGE для стороннего сервера, а также право USAGE для всех типов столбцов, содержащихся в таблице.
Параметры
IF NOT EXISTS
Не считать ошибкой, если отношение с таким именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее отношение как-то соотносится с тем, которое было бы создано.
имя_таблицы
Имя создаваемой таблицы (может быть дополнено схемой).
имя_столбца
Имя столбца, который будет создан в новой таблице.
тип_данных
Тип данных столбца. Может включать спецификаторы массива с этим типом. Более подробную информацию о типах данных, поддерживаемых QHB, см. в главе Типы данных.
COLLATE правило_сортировки
Предложение COLLATE назначает правило сортировки для столбца (который должен иметь сопоставимый тип данных). Если параметр не указан, используются правила сортировки по умолчанию для типа данных столбца.
INHERITS ( таблица_родитель [, ... ] )
Необязательное предложение INHERITS задает список таблиц, из которых новая сторонняя таблица автоматически наследует все столбцы. Родительские таблицы могут быть простыми или сторонними таблицами. Более подробную информацию см. в аналогичной форме команды CREATE TABLE.
PARTITION OF таблица_родитель FOR VALUES указание_границ_партиции
Эта форма может быть использована для создания сторонней таблицы в качестве партиции указанной родительской таблицы с заданными граничными значениями. Более подробную информацию см. в аналогичной форме команды CREATE TABLE. Обратите внимание, что в настоящее время не разрешается создавать стороннюю таблицу в качестве партиции родительской таблицы, если в последней есть индексы UNIQUE (уникальные). (См. также раздел ALTER TABLE ATTACH PARTITION.)
CONSTRAINT имя_ограничения
Необязательное имя столбца или ограничения таблицы. Если ограничение нарушается, имя ограничения присутствует в сообщениях об ошибках, поэтому имена ограничений, например столбец должен быть положительным, могут использоваться для передачи клиентским приложениям полезной информации об ограничениях. (Имена ограничений, содержащие пробелы, необходимо заключать в двойные кавычки.) Если имя ограничения не указано, система генерирует имя автоматически.
NOT NULL
Столбец не может содержать значения NULL.
NULL
Столбец может содержать значения NULL. Это значение по умолчанию.
Это предложение предусмотрено только для обеспечения совместимости с нестандартными базами данных SQL. В новых приложениях его использование не рекомендуется.
CHECK ( выражение ) [ NO INHERIT ]
Предложение CHECK задает выражение, производящее логический результат, которому должна удовлетворять каждая строка в сторонней таблице; то есть выражение должно выдавать TRUE или UNKNOWN, но не FALSE для всех строк в сторонней таблице. Проверочное ограничение, указанное в качестве ограничения столбца, должно ссылаться только на значение этого столбца, тогда как выражение, указанное в ограничении таблицы, может ссылаться на несколько столбцов.
В настоящий момент выражения CHECK не могут содержать вложенные запросы и ссылаться на переменные, отличные от столбцов текущей строки. Также допустима ссылка на системный столбец tableoid, но не на другие системные столбцы.
Ограничение с пометкой NO INHERIT не будет наследоваться дочерними таблицами.
DEFAULT выражение_по_умолчанию
Предложение DEFAULT задает значение по умолчанию для столбца, в определении которого оно присутствует. Значением является любое выражение без переменных (подзапросы и перекрестные ссылки на другие столбцы текущей таблицы запрещены). Тип данных выражения по умолчанию должен соответствовать типу данных столбца.
Выражение по умолчанию будет использоваться в любой операции добавления, в которой не задано значение для столбца. Если для столбца не задано значение по умолчанию, то значение по умолчанию равно NULL.
GENERATED ALWAYS AS ( генерирующее_выражение ) STORED
Это предложение создает столбец как генерируемый. В такой столбец нельзя записать данные, а при чтении его возвращается результат указанного выражения
Ключевое слово STORED требуется для обозначения того, что столбец будет вычисляться при записи. (Вычисленное значение будет передаваться обертке сторонних данных для сохранения и должно быть возвращено оберткой при чтении.)
Генерирующее выражение может ссылаться на другие столбцы в таблице, но не на другие генерируемые столбцы. Все функции и операторы в нем должны быть постоянными. Ссылки на другие таблицы не допускаются.
имя_сервера
Имя существующего стороннего сервера, используемого для сторонней таблицы. Дополнительную информацию об определении сервера см. в разделе CREATE SERVER.
OPTIONS ( параметр 'значение' [, ...] )
Параметры, которые будут связаны с новой сторонней таблицей или одним из ее столбцов. Допустимые имена параметров и их значений являются специфичными для каждой обертки сторонних данных и проверяются с помощью функции проверки. Имена параметров не должны повторяться (хотя параметр таблицы и параметр столбца могут иметь одно и то же имя).
Примечания
Ограничения сторонних таблицы (такие как CHECK или NOT NULL) не контролируются ядром системы QHB, и большинство оберток сторонних данных также не пытаются их контролировать; то есть система просто предполагает, что ограничение выполняется. Подобный контроль был бы нецелесообразен, поскольку применялся бы только к строкам, добавленным или обновленным через стороннюю таблицу, а не к строкам, измененным другими способами, например непосредственно на удаленном сервере. Вместо этого ограничение, связанное со сторонней таблицей, должно представлять собой ограничение, контролируемое удаленным сервером.
Некоторые специальные обертки сторонних данных могут быть единственным механизмом доступа к данным, к которым они обращаются, и в этом случае может быть уместно выполнение контроля ограничений самой оберткой сторонних данных. Но не следует полагать, что какая-либо обертка ведет себя так, если об этом не сказано явно в ее документации.
Хотя QHB не пытается контролировать ограничения для сторонних таблиц, она предполагает, что они выполняются для целей оптимизации запросов. Если есть строки, видимые в сторонней таблице, которые не удовлетворяют объявленному ограничению, запросы к таблице могут выдавать некорректные результаты. Ответственность за то, чтобы выполнялись условия ограничения, несет пользователь.
Подобные соображения распространяются и на генерируемые столбцы. Сохраненные генерируемые столбцы вычисляются при добавлении или обновлении на локальном сервере QHB и передаются обертке сторонних данных для записи в стороннее хранилище данных. При этом сервер не требует, чтобы запросы сторонней таблицы возвращали значения сохраненных генерируемых столбцов, соответствующие генерирующему выражению. Опять же, это может привести к неверным результатам запроса.
Хотя строки можно переместить из локальных партиций в партицию сторонней таблицы (при условии, что обертка сторонних данных поддерживает маршрутизацию кортежей), их нельзя переместить из партиции сторонней таблицы в другую партицию.
Примеры
Создание сторонней таблицы films, которая будет доступна через сервер film_server:
CREATE FOREIGN TABLE films (
code char(5) NOT NULL,
title varchar(40) NOT NULL,
did integer NOT NULL,
date_prod date,
kind varchar(10),
len interval hour to minute
)
SERVER film_server;
Создание сторонней таблицы measurement_y2016m07, которая будет доступна через сервер server_07, в виде партиции таблицы measurement, партиционированной по диапазонам:
CREATE FOREIGN TABLE measurement_y2016m07
PARTITION OF measurement FOR VALUES FROM ('2016-07-01') TO ('2016-08-01')
SERVER server_07;
Совместимость
Команда CREATE FOREIGN TABLE в значительной степени соответствует
стандарту SQL, однако, так же, как и CREATE TABLE, допускает
ограничения NULL и сторонние таблицы без столбцов.
Возможность указать значения столбца по умолчанию также является расширением QHB.
Наследование таблиц в форме, определенной QHB, не соответствует стандарту.
См. также
ALTER FOREIGN TABLE, DROP FOREIGN TABLE, CREATE TABLE, CREATE SERVER, IMPORT FOREIGN SCHEMA
CREATE FUNCTION
CREATE FUNCTION — определить новую функцию
Синтаксис
CREATE [ OR REPLACE ] FUNCTION
имя ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ { DEFAULT | = } выражение_по_умолчанию ] [, ...] ] )
[ RETURNS тип_результата
| RETURNS TABLE ( имя_столбца тип_столбца [, ...] ) ]
{ LANGUAGE имя_языка
| TRANSFORM { FOR TYPE имя_типа } [, ... ]
| WINDOW
| IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST стоимость_выполнения
| ROWS строк_в_результате
| SUPPORT вспомогательная_функция
| SET параметр_конфигурации { TO значение | = значение | FROM CURRENT }
| AS 'определение'
| AS 'объектный_файл', 'объектный_символ'
} ...
Описание
Команда CREATE FUNCTION определяет новую функцию. CREATE OR REPLACE FUNCTION
будет либо создавать новую функцию, либо заменять определение
существующей. Чтобы определить функцию, необходимо иметь право USAGE
для соответствующего языка.
Если указано имя схемы, то функция создается в указанной схеме, в противном случае — в текущей. Имя новой функции не должно совпадать ни с одной существующей функцией или процедурой с теми же типами входных аргументов в этой же схеме. Однако функции и процедуры с различными типами аргументов могут иметь одно имя (это называется перегрузкой ).
Чтобы заменить текущее определение существующей функции, используйте
CREATE OR REPLACE FUNCTION. Однако таким способом невозможно
изменить имя или типы аргументов функции (если вы попытаетесь, то
фактически создадите новую, независимую функцию). Кроме того,
CREATE OR REPLACE FUNCTION не позволит изменить тип возвращаемого значения
существующей функции. Для этого необходимо удалить и заново создать
функцию. (В случае использования параметров OUT (выходных) это означает,
что изменить типы параметров OUT можно, только удалив функцию.)
Когда CREATE OR REPLACE FUNCTION используется для замены
существующей функции, владелец и права доступа функции не
изменяются. Всем остальным свойствам функции присваиваются значения, указанные
в команде, или значения по умолчанию. Чтобы заменить функцию, необходимо
быть ее владельцем (или быть членом роли-владельца).
Если вы удалите и снова создадите функцию, новая функция будет другой
сущностью; вам придется удалить существующие правила, представления,
триггеры и т. д. — всё, что относится к старой функции.
Поэтому чтобы изменить определение функции, не нарушая ссылающиеся на нее объекты,
используйте команду CREATE OR REPLACE FUNCTION.
Кроме того, многие дополнительные свойства существующей функции
можно изменить с помощью ALTER FUNCTION.
Пользователь, создавший функцию, становится ее владельцем.
Чтобы создать функцию, необходимо иметь право USAGE для типов ее аргументов и возвращаемого типа.
Параметры
имя
Имя создаваемой функции (может быть дополнено схемой).
режим_аргумента
Режим аргумента: IN (входной), OUT (выходной), INOUT (входной и выходной) или VARIADIC (переменный). Если этот параметр опущен, значение по умолчанию равно IN. За аргументом VARIADIC могут следовать только аргументы OUT. Также аргументы OUT и INOUT нельзя использовать с предложением RETURNS TABLE.
имя_аргумента
Имя аргумента. Некоторые языки (включая SQL и PL/pgSQL) позволяют использовать это имя в теле функции. Для других языков имя входного аргумента является просто дополнительным описанием, если говорить о самой функции; но имена входных аргументов при вызове функции можно использовать для улучшения читаемости (см. раздел Вызов функции). В любом случае имя выходного аргумента является значимым, поскольку оно определяет имя столбца в типе результата. (Если вы опустите имя для выходного аргумента, система выберет имя столбца по умолчанию.)
тип_аргумента
Тип(ы) данных аргументов функции (может быть дополнен схемой), если таковой имеется. Типы аргументов могут быть базовыми, составными или доменными типами, а также могут ссылаться на тип столбца таблицы.
В зависимости от языка реализации также может быть разрешено указывать «псевдотипы», такие как cstring. Псевдотипы свидетельствуют о том, что фактический тип аргумента либо указан не полностью, либо находится вне набора обычных типов данных SQL.
Ссылка на тип столбца записывается в виде имя_таблицы.имя_столбца%TYPE. Использование такой записи иногда может помочь сделать функцию независимой от изменений в определении таблицы.
выражение_по_умолчанию
Выражение, которое будет использоваться в качестве значения по умолчанию, если параметр не указан. Результат выражения должен сводиться к типу соответствующего параметра. Только входные параметры (включая INOUT) могут иметь значение по умолчанию. Все входные параметры, следующие за параметром со значением по умолчанию, также должны иметь значения по умолчанию.
тип_результата
Возвращаемый тип данных (может быть дополнен схемой). Тип возвращаемого значения может быть базовым, составным или доменным, а также может ссылаться на тип столбца таблицы. В зависимости от языка реализации также может быть разрешено указывать «псевдотипы», например cstring. Если функция не должна возвращать значение, в качестве возвращаемого типа укажите void.
В случае наличия параметров OUT или INOUT предложение RETURNS можно опустить. Если оно присутствует, то должно быть согласовано с типом результата, подразумеваемым выходными параметрами: RECORD, если выходных параметров несколько, либо тем же типом, что и у единственного выходного параметра.
Указание SETOF показывает, что функция возвращает множество, а не единственный элемент.
Ссылка на тип столбца записывается в виде имя_таблицы.имя_столбца%TYPE.
имя_столбца
Имя выходного столбца в записи RETURNS TABLE. Это фактически еще один способ объявления именованного выходного параметра (OUT), но RETURNS TABLE также подразумевает и RETURNS SETOF.
тип_столбца
Тип данных выходного столбца в записи RETURNS TABLE.
имя_языка
Имя языка, на котором реализована функция. Это может быть sql, c, internal, или имя определяемого пользователем процедурного языка, например plpgsql. Заключать имя в одинарные кавычки не рекомендуется и требует соответствующего регистра.
TRANSFORM { FOR TYPE имя_типа } [, ... ] }
Устанавливает список трансформаций, которые должны применяться при вызове функции. Трансформации выполняют преобразования между типами SQL и языковыми типами данных; см. раздел CREATE TRANSFORM. Преобразования встроенных типов обычно жестко предопределены в реализациях процедурных языков, так что их здесь указывать не нужно. Если реализация процедурного языка не знает, как обрабатывать тип, и трансформация не предоставляется, будет выполнено преобразование типов данных по умолчанию, но это зависит от реализации.
WINDOW
WINDOW указывает, что функция является не простой, а оконной функцией. В настоящее время имеет смысл только для функций, написанных на языке C. Указание WINDOW не может быть изменено при изменении существующего определения функции.
IMMUTABLE
STABLE
VOLATILE
Эти атрибуты информируют оптимизатор запросов о поведении функции. Одновременно можно указать не более одного атрибута. Если ни один из них не указан, по умолчанию предполагается VOLATILE.
IMMUTABLE (постоянная) указывает, что функция не может изменять базу данных и всегда возвращает один и тот же результат при одинаковых заданных значениях аргумента; т. е. она не выполняет поиск в базе данных и не использует иным образом информацию, не представленную непосредственно в ее списке аргументов. Если задана эта опция, то любой вызов функции со всеми постоянными аргументами может быть немедленно заменен значением функции.
STABLE (стабильная) указывает, что функция не может изменять базу данных и что в рамках одного сканирования таблицы она будет последовательно возвращать один и тот же результат для одних и тех же значений аргумента, но при этом его результат может изменяться в разных инструкциях SQL. Это подходящий выбор для функций, результаты которых зависят от содержимого базы данных и настраиваемых параметров (таких как текущий часовой пояс) и т. д. (Но этот вариант не подходит для триггеров AFTER, желающих сделать запрос на строки, измененные текущей командой.) Также обратите внимание, что функции семейства current_timestamp считаются стабильными, так как их результаты не изменяются в рамках транзакции.
VOLATILE (изменчивая) указывает, что значение функции может изменяться даже в пределах одного сканирования таблицы, поэтому ее вызовы нельзя оптимизировать. Относительно немногие функции базы данных являются изменчивыми в этом смысле, например: random(), currval() и timeofday(). Но обратите внимание, что любая функция, которая имеет побочные эффекты, должна быть классифицирована как VOLATILE, даже если ее результат вполне предсказуем, чтобы предотвратить оптимизацию вызовов; примером является setval().
Дополнительную информацию см. в разделе Категории изменчивости функций.
LEAKPROOF
LEAKPROOF (герметичная) указывает, что функция не имеет никаких побочных эффектов. Она не раскрывает никакой информации о своих аргументах, кроме своего возвращаемого значения. Например, функция, которая выдает сообщение об ошибке только для некоторых значений аргументов или которая включает значения аргументов в каждое сообщение об ошибке, не является герметичной. Это влияет на то, как система выполняет запросы к представлениям, созданным с барьером безопасности security_barrier, или таблицам с включенной защитой на уровне строк. Система будет принудительно применять условия из политик защиты и представлений с барьерами безопасности перед любыми условиями, которые пользователь задает в запросе и в которых задействуются негерметичные функции, чтобы предотвратить непреднамеренное раскрытие данных. Функции и операторы, помеченные как герметичные, считаются надежными и могут выполняться до выполнения условий из политик защиты и представлений с барьерами безопасности. Кроме того, функции, которые не имеют аргументов или которым не передаются никакие аргументы из представления с барьером безопасности или таблицы, не требуется помечать как герметичные, чтобы они выполнялись до условий, связанных с безопасностью. См. разделы CREATE VIEW и Система правил QHB. Этот параметр может быть установлен только суперпользователем.
CALLED ON NULL INPUT
RETURNS NULL ON NULL INPUT
STRICT
CALLED ON NULL INPUT (по умолчанию) указывает, что функция будет вызываться как обычно, когда некоторые из ее аргументов равны NULL. В этом случае ответственность за проверку (при необходимости) значений NULL и соответствующую их обработку несет автор функции.
RETURNS NULL ON NULL INPUT или STRICT указывает, что функция всегда возвращает значение NULL, когда любой из ее аргументов равен NULL. Если этот параметр указан, функция не выполняется при наличии NULL аргументов; вместо этого автоматически принимается результат NULL.
[EXTERNAL] SECURITY INVOKER
[EXTERNAL] SECURITY DEFINER
Характеристика SECURITY INVOKER (безопасность вызывающего) указывает, что функция должна выполняться с правами вызывающего ее пользователя. Это значение по умолчанию. Вариант SECURITY DEFINER (безопасность определившего) указывает, что функция должна выполняться с правами пользователя, которому она принадлежит (владельца).
Ключевое слово EXTERNAL (внешняя) допускается для соответствия стандарту SQL, но является необязательным, так как, в отличие от SQL, эта характеристика распространяется на все функции, а не только внешние.
PARALLEL
Указание PARALLEL UNSAFE означает, что функция не может быть выполнена в параллельном режиме и наличие такой функции в инструкции SQL приводит к последовательному плану выполнения. Это значение по умолчанию. Указание PARALLEL RESTRICTED означает, что функция может выполняться в параллельном режиме, но только в ведущем процессе параллельной группы. PARALLEL SAFE указывает, что функция безопасна для работы в параллельном режиме без ограничений.
Функции должны быть помечены как небезопасные для параллельного выполнения (PARALLEL UNSAFE), если они изменяют состояние базы данных, или вносят изменения в транзакцию, например используя подтранзакции, или обращаются к последовательностям или пытаются сохранять настройки параметров (например, используя setval). Функции должны быть помечены как ограниченно параллельные (PARALLEL RESTRICTED), если они обращаются к временным таблицам, состоянию клиентского подключения, курсорам, подготовленным операторам или разнообразному состоянию обслуживающего процесса, которые система не может синхронизировать в параллельном режиме (например, setseed может выполнять только ведущий процесс группы, так как изменения, внесенные другим процессом, не передаются ведущему). В целом, если функция помечена как безопасная (PARALLEL SAFE), являясь на самом деле ограниченной или небезопасной, либо помечена как ограниченно безопасная, не являясь безопасной, она может выдавать ошибки или давать неправильные результаты при использовании в параллельном запросе. Функции на языке C теоретически могут демонстрировать совершенно неопределенное поведение при неправильной маркировке, поскольку система не может защитить себя от произвольного кода на C, но в большинстве случаев результат будет не хуже, чем для любой другой функции. При возникновении сомнений функции следует помечать как UNSAFE, что является значением по умолчанию.
COST стоимость_выполнения
Положительное число, задающее примерную стоимость выполнения функции в единицах cpu_operator_cost. Если функция возвращает множество, то это стоимость за возвращенную строку. Если стоимость не указана, то для функций языка C и внутренних функций она считается равной 1 единице, а для функций на всех других языках — 100 единицам. Более высокие значения заставляют планировщик пытаться избегать оценки функции чаще необходимого.
ROWS строк_в_результате
Положительное число, задающее примерное количество строк, которое планировщик должен ожидать от функции на выходе. Это указание допустимо только в том случае, если функция объявлена возвращающей множество. Предполагаемое по умолчанию значение — 1000 строк.
SUPPORT вспомогательная_функция
Имя вспомогательной функции для планировщика, используемое для этой функции (может быть дополнено схемой). Дополнительную информацию см. в разделе Информация по оптимизации функций. Чтобы использовать эту опцию, нужно быть суперпользователем.
параметр_конфигурации
значение
Предложение SET определяет, что при вызове функции указанный параметр
конфигурации должен принять заданное значение, а затем восстановить свое
предыдущее значение по завершении функции.
Предложение SET FROM CURRENT сохраняет значение параметра, действующее при
выполнении CREATE FUNCTION, в качестве значения, которое будет применено
при входе в функцию.
Если в определение функции добавлено предложение SET, то действие команды SET LOCAL,
выполняемой внутри функции для той же переменной, ограничивается этой функцией:
предыдущее значение параметра конфигурации восстанавливается по завершении
функции. Однако обычная команда SET (без LOCAL) переопределяет предложение
SET, как сделало бы и для предыдущей команды SET LOCAL: эффекты такой команды
сохранятся после завершения функции, если не случится откат текущей транзакции.
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
определение
Строковая константа, определяющая функцию; значение зависит от языка. Это может быть имя внутренней функции, путь к объектному файлу, команда SQL или текст на процедурном языке.
Часто бывает полезно заключать определение функции в знаки доллара (см. раздел Строковые константы с экранированием знаками доллара), а не в традиционные апострофы. Если не использовать знаки доллара, то любые одиночные кавычки или обратные косые черты в определении функции должны быть экранированы путем удвоения.
объектный_файл, объектный_символ
Эта форма предложения AS используется для динамически загружаемых функций языка C, когда имя функции в исходном коде языка C не совпадает с именем функции SQL. Строка объектный_файл является именем файла разделяемой библиотеки, содержащего скомпилированную функцию C, и интерпретируется как параметр команды LOAD. Строка объектный_символ задает скомпонованный символ функции, то есть имя функции в исходном коде языка C. Если объектный символ опущен, предполагается, что он совпадает с именем определяемой функции SQL. В C имена всех функций должны быть разными, поэтому следует давать перегруженным функциям C разные имена (например, включать в имена C обозначения типов аргументов).
При повторных вызовах CREATE FUNCTION ссылается на один и тот же
объектный файл, который загружается только один раз за сеанс. Чтобы
выгрузить и перезагрузить файл (скажем, во время разработки),
запустите новый сеанс.
Дополнительную информацию о функциях записи см. в разделе Пользовательские функции.
Перегрузка
QHB допускает перегрузку функций; то есть одно и то же имя может использоваться для нескольких различных функций, если они имеют различные типы входных аргументов. Независимо от того, используете вы эту возможность или нет, она требует предосторожности при вызове функций в базах данных, где одни пользователи не доверяют другим пользователям (см. раздел Перегрузка функций).
Две функции считаются одинаковыми, если они имеют одинаковые имена и типы входных аргументов, игнорируя параметры OUT. Так, например, эти декларации конфликтуют:
CREATE FUNCTION foo(int) ...
CREATE FUNCTION foo(int, out text) ...
Функции, которые имеют разные списки типов аргументов, не будут считаться конфликтующими во время создания, но предоставленные для них значения по умолчанию могут вызвать конфликт в момент использования. Например, рассмотрим
CREATE FUNCTION foo(int) ...
CREATE FUNCTION foo(int, int default 42) ...
Вызов foo(10) завершится ошибкой из-за неоднозначности в выборе вызываемой функции.
Примечания
В объявлении аргументов функции и возвращаемого значения допускается полный
синтаксис описания типа SQL. Однако заключенные в скобки модификаторы типа
(например, поле точности для типа numeric) команда CREATE FUNCTION не учитывает.
Так, например, CREATE FUNCTION foo (varchar(10)) ... — это ровно то же
самое, что и CREATE FUNCTION foo (varchar) ....
При замене существующей функции с помощью CREATE OR REPLACE FUNCTION
существуют ограничения на изменение имен параметров. Нельзя
изменить имя, уже присвоенное какому-либо входному параметру (хотя
можно добавить имена к параметрам, которые ранее не имели имени).
Если существует несколько выходных параметров, нельзя изменить их имена,
поскольку это приведет к изменению имен
столбцов анонимного составного типа, описывающего результат функции. Эти
ограничения применяются для того, чтобы существующие вызовы
функции гарантированно не прекращали работу после ее замены.
Если функция объявлена как STRICT с аргументом VARIADIC, то при оценке строгости проверяется, чтобы весь переменный массив в целом не был NULL. Если же массив содержит элементы NULL, функция будет по-прежнему вызываться.
Примеры
Ниже приведено несколько простых вводных примеров. Дополнительную информацию и примеры см. в разделе Написание триггерных функций на C.
CREATE FUNCTION add(integer, integer) RETURNS integer
AS 'select $1 + $2;'
LANGUAGE SQL
IMMUTABLE
RETURNS NULL ON NULL INPUT;
Функция увеличения целого числа, использующая именованный аргумент, на языке PL/pgSQL:
CREATE OR REPLACE FUNCTION increment(i integer) RETURNS integer AS $$
BEGIN
RETURN i + 1;
END;
$$ LANGUAGE plpgsql;
Функция, возвращающая запись с несколькими выходными параметрами:
CREATE FUNCTION dup(in int, out f1 int, out f2 text)
AS $$ SELECT $1, CAST($1 AS text) || ' is text' $$
LANGUAGE SQL;
SELECT * FROM dup(42);
То же самое можно сделать более развернуто, явно объявив составной тип:
CREATE TYPE dup_result AS (f1 int, f2 text);
CREATE FUNCTION dup(int) RETURNS dup_result
AS $$ SELECT $1, CAST($1 AS text) || ' is text' $$
LANGUAGE SQL;
SELECT * FROM dup(42);
Еще один способ вернуть несколько столбцов — применить функцию TABLE:
CREATE FUNCTION dup(int) RETURNS TABLE(f1 int, f2 text)
AS $$ SELECT $1, CAST($1 AS text) || ' is text' $$
LANGUAGE SQL;
SELECT * FROM dup(42);
Однако пример с TABLE отличается от предыдущих, так как в нем функция на самом деле возвращает не одну, а набор записей.
Разработка защищенных функций SECURITY DEFINER
Так как функция SECURITY DEFINER выполняется с правами владеющего ей пользователя, необходимо позаботиться о том, чтобы функцию невозможно было использовать не по назначению. В целях обеспечения безопасности следует установить search_path, чтобы исключить любые схемы, доступные для записи ненадежными пользователями. Это предотвращает создание злоумышленниками объектов (например, таблиц, функций и операторов), маскирующих объекты, предназначенные для использования функцией. Особенно важной в этом отношении является схема временной таблицы, которая по умолчанию ищется первой и обычно доступна для записи любым пользователям. Соответствующую защиту можно организовать, поместив временную схему в конец списка поиска. Для этого нужно сделать pg_temp последней записью в search_path. Эта функция иллюстрирует безопасное использование:
CREATE FUNCTION check_password(uname TEXT, pass TEXT)
RETURNS BOOLEAN AS $$
DECLARE passed BOOLEAN;
BEGIN
SELECT (pwd = $2) INTO passed
FROM pwds
WHERE username = $1;
RETURN passed;
END;
$$ LANGUAGE plpgsql
SECURITY DEFINER
-- Установить безопасный путь поиска: сначала доверенная(ые) схема(ы), затем 'pg_temp'.
SET search_path = admin, pg_temp;
Эта функция должна обращаться к таблице admin.pwds, но без предложения SET или с предложением SET, включающим только admin; ее можно «обмануть», создав временную таблицу с именем pwds.
Еще один момент, который следует иметь в виду, — это то, что по умолчанию право выполнения для создаваемых функций имеет роль PUBLIC (см. дополнительную информацию в разделе Права). Однако зачастую требуется разрешить доступ к функции, работающей в контексте безопасности определившего, только некоторым пользователям. Для этого необходимо отозвать стандартные права PUBLIC, а затем предоставить права выполнения выборочно. Чтобы избежать появления окна, в котором новая функция доступна для всех, создайте ее и установите права доступа в рамках одной транзакции. Например:
BEGIN;
CREATE FUNCTION check_password(uname TEXT, pass TEXT) ... SECURITY DEFINER;
REVOKE ALL ON FUNCTION check_password(uname TEXT, pass TEXT) FROM PUBLIC;
GRANT EXECUTE ON FUNCTION check_password(uname TEXT, pass TEXT) TO admins;
COMMIT;
Совместимость
Команда CREATE FUNCTION определена в стандарте SQL. Реализация в QHB
аналогична, но совместима не полностью. К отличиям относятся
непереносимые атрибуты, а также поддержка различных языков.
Для обеспечения совместимости с некоторыми другими системами баз данных режим_аргумента можно записать после имени_аргумента или перед ним. Но только первый способ соответствует стандартам.
Для определения значений параметров по умолчанию стандарт SQL поддерживает только синтаксис с помощью ключевого слова DEFAULT. Синтаксис со знаком = используется в T-SQL и Firebird.
См. также
ALTER FUNCTION, DROP FUNCTION, GRANT, LOAD, REVOKE
CREATE GROUP
CREATE GROUP — определить новую роль в базе данных
Синтаксис
CREATE GROUP имя [ [ WITH ] параметр [ ... ] ]
Где параметр может быть:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT предел_подключений
| [ ENCRYPTED ] PASSWORD 'пароль' | PASSWORD NULL
| VALID UNTIL 'дата_время'
| IN ROLE имя_роли [, ...]
| IN GROUP имя_роли [, ...]
| ROLE имя_роли [, ...]
| ADMIN имя_роли [, ...]
| USER имя_роли [, ...]
| SYSID uid
Описание
Команда CREATE GROUP теперь является синонимом команды CREATE ROLE.
Совместимость
В стандарте SQL нет команды CREATE GROUP.
См. также
CREATE INDEX
CREATE INDEX — определить новый индекс
Синтаксис
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] имя ] ON [ ONLY ] имя_таблицы [ USING метод ]
( { имя_столбца | ( выражение ) } [ COLLATE правило_сортировки ] [ класс_операторов [ ( параметр_класса_операторов = значение [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( имя_столбца [, ...] ) ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) ]
[ TABLESPACE имя_табличного_пространства ]
[ WHERE предикат ]
Описание
Команда CREATE INDEX строит индекс по указанному(ым) столбцу(ам) заданного
отношения, которое может быть таблицей или материализованным
представлением. Индексы в основном используются для повышения
производительности базы данных (хотя неправильное использование может
привести к ее снижению).
Ключевое(ые) поле(я) для индекса указывается в виде имен столбцов или же в виде выражений, заключенных в круглые скобки. Если индексный метод поддерживает составные индексы, можно указать несколько полей.
Поле индекса может быть выражением, вычисленным из значений одного или нескольких столбцов строки таблицы. Эту функцию можно использовать для быстрого доступа к данным на основе некоторого преобразования исходных данных. Например, индекс, построенный по выражению upper(col), позволит использовать поиск по индексу в предложении WHERE upper(col) = 'JIM'.
QHB предоставляет следующие методы индексов: B-дерево, хэш, GiST, SP-GiST, GIN и BRIN. Пользователи также могут определять свои собственные методы индексирования, но это довольно сложно.
Когда в команде присутствует предложение WHERE, создается частичный индекс. Частичный индекс — это индекс, содержащий записи только для части таблицы, обычно более полезной для индексации, чем остальная часть таблицы. Например, если у вас есть таблица, которая содержит выставленные и неоплаченные счета за заказы, и неоплаченные заказы занимают малую часть общей таблицы, но запрашиваются чаще, можно улучшить производительность, создав индекс только для этой части. Еще одним возможным применением является указание WHERE вместе с UNIQUE для обеспечения уникальности по подмножеству таблицы. Дополнительную информацию см. в разделе Частичные индексы.
Выражение, используемое в предложении WHERE, может ссылаться только на столбцы нижележащей таблицы, но при этом использовать все столбцы, а не только индексируемые. В настоящее время подзапросы и агрегатные выражения в WHERE тоже запрещены. Такие же ограничения применяются к выражениями в полях индексов.
Все функции и операторы, используемые в определении индекса, должны быть «постоянными», то есть их результаты должны зависеть только от их аргументов, а не от какого-либо внешнего влияния (например, содержимого другой таблицы или текущего времени). Это ограничение гарантирует, что поведение индекса четко определено. Чтобы использовать определяемую пользователем функцию в выражении индекса или предложении WHERE, не забудьте при создании отметить функцию как IMMUTABLE (постоянную).
Параметры
UNIQUE
Указывает, что система должна проверять наличие повторяющихся значений в таблице при создании индекса (если данные уже существуют) и при каждом добавлении данных. Попытки добавить или обновить данные, которые вызовут дублирование записей, приведут к ошибке.
Дополнительные ограничения действуют при применении уникальных индексов к партиционированным таблицам; см. раздел CREATE TABLE.
CONCURRENTLY
Если используется этот параметр, QHB будет строить индекс без установления каких-либо блокировок, предотвращающих параллельные добавления, изменения или удаление записей в таблице, тогда как стандартная операция построения индекса блокирует запись (но не чтение) в таблице до своего завершения. Существует несколько особенностей, которые следует учитывать при использовании этого параметра — см. ниже Неблокирующее построение индексов.
IF NOT EXISTS
Не считать ошибкой, если индекс с таким именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующий индекс как-то соотносится с тем, который был бы создан. Если указано IF NOT EXISTS, то имя индекса является обязательным.
INCLUDE
Необязательное предложение INCLUDE указывает список столбцов, которые будут включены в индекс в качестве неключевых столбцов. Неключевой столбец не будет использоваться в условии поиска для сканирования по индексу; также он игнорируется при анализе ограничения уникальности или исключения, применяемого индексом. Однако при сканировании только индекса может возвращаться содержимое неключевых столбцов без необходимости обращения к таблице, поскольку они доступны непосредственно из записи индекса. Таким образом, добавление неключевых столбцов позволяет использовать сканирование только индекса в тех запросах, где иначе оно было бы неприменимо.
В отношении добавления неключевых столбцов в индекс разумно проявлять консерватизм, особенно для широких столбцов. Если кортеж индекса превысит максимальный размер, разрешенный для типа индекса, добавление данных завершится ошибкой. В любом случае, неключевые столбцы дублируют данные из таблицы и раздувают размер индекса, что потенциально замедляет поиск. Более того, в индексе B-дерево, содержащем неключевой столбец, не будет работать исключение дубликатов
Столбцы, перечисленные в предложении INCLUDE, не нуждаются в соответствующих классах операторов; предложение может включать столбцы, типы данных которых не имеют классов операторов, определенных для данного метода доступа.
Выражения во включаемых столбцах не поддерживаются, так как они не могут использоваться при сканировании индекса.
В настоящее время эту возможность поддерживают только методы доступа индексов B-дерево и GiST. В таких индексах значения столбцов, перечисленных в предложении INCLUDE, включаются в кортежи на уровне листьев, которые соответствуют кортежам кучи, но не включены в записи индекса верхнего уровня, используемые для навигации по деревьям.
имя
Имя создаваемого индекса. Имя схемы здесь не может быть включено: индекс всегда создается в той же схеме, что и его родительская таблица. Если имя опущено, QHB выбирает подходящее имя на основе имени родительской таблицы и индексированных имен столбцов.
ONLY
Указывает, что индексы не должны рекурсивно создаваться на партициях, если таблица партиционирована. По умолчанию используется рекурсивно.
имя_таблицы
Имя индексируемой таблицы (может быть дополнено схемой).
метод
Имя используемого индексного метода. Возможные варианты: btree, hash, gist, spgist, gin и brin. По умолчанию используется метод btree.
имя_столбца
Имя столбца таблицы.
выражение
Выражение, основанное на одном или нескольких столбцах таблицы. Обычно выражение должно быть записано в скобках, как показано в синтаксисе. Однако если выражение записано в виде вызова функции, круглые скобки могут быть опущены.
правило_сортировки
Имя правила сортировки, используемого для индекса. По умолчанию индекс использует правило сортировки, объявленное для подлежащего индексированию столбца, или результирующее правило подлежащего индексированию выражения. Индексы с нестандартными правилами сортировки могут быть полезны для запросов, содержащих выражения, использующие такие правила.
класс_операторов
Имя класса оператора. Дополнительную информацию см. ниже.
параметр_класса_операторов
Имя параметра класса операторов. Дополнительную информацию см. ниже.
ASC
Задает порядок сортировки по возрастанию (который является порядком сортировки по умолчанию).
DESC
Задает порядок сортировки по убыванию.
NULLS FIRST
Указывает, что значения NULL после сортировки оказываются перед остальными. Это значение по умолчанию, когда задано DESC.
NULLS LAST
Указывает, что значения NULL после сортировки оказываются после остальных. Это значение по умолчанию, когда задано ASC.
параметр_хранения
Имя параметра хранения, зависящего от индексного метода. Дополнительную информацию см. в разделе Параметры хранения индекса.
имя_табличного_пространства
Табличное пространство, в котором будет создан индекс. Если этот параметр не указан, выполняется обращение к default_tablespace или temp_tablespaces для индексов временных таблиц.
предикат
Выражение ограничения для частичного индекса.
Параметры хранения индекса
Необязательное предложение WITH задает параметры хранения для индекса. Каждый индексный метод имеет свой собственный набор допустимых параметров хранения. Индексные методы B-tree, hash, GiST и SP-GiST принимают этот параметр:
fillfactor (integer)
Коэффициент заполнения для индекса выражается в процентах и определяет, насколько плотно индексный метод будет пытаться заполнить страницы индекса. Для B-деревьев страницы уровня листьев заполняются до этого процента во время первоначального построения индекса, а также при расширении индекса вправо (добавление новых наибольших значений ключей). Если впоследствии страницы будут полностью заполнены, они будут разделены, что приведет к постепенному снижению эффективности индекса. По умолчанию B-деревья используют коэффициент заполнения 90, но можно выбрать любое целочисленное значение от 10 до 100. Если таблица статична, то коэффициент заполнения, равный 100, помогает уменьшить физический размер таблицы, но для интенсивно изменяемых таблиц лучше использовать меньшее значение коэффициента заполнения, чтобы минимизировать необходимость разбиения страниц. С другими индексными методами коэффициент заполнения действует по-другому, но примерно в том же ключе; значение коэффициента заполнения по умолчанию для разных методов разное.
Индексы B-дерево также принимают эти параметры:
deduplicate_items (boolean)
Контролирует использование техники исключения дубликатов, описанной в подразделе Дедупликация. Устанавливается на значения ON или OFF для включения или выключения соответственно. (Допустимые варианты написания ON и OFF описаны в разделе Настройка параметров.) Значение по умолчанию равно ON.
Примечание
После выключения deduplicate_items во время выполнения командыALTER INDEXв будущем при операциях добавления элементов автоматическая дедупликация срабатывать не будет, но представление существующих кортежей со списком идентификаторов на стандартное не поменяется.
vacuum_cleanup_index_scale_factor (floating point)
Значение vacuum_cleanup_index_scale_factor для индекса.
Индексы GiST дополнительно принимают этот параметр:
buffering (enum)
Определяет, используется ли для построения индекса метод буферизации, описанный в разделе Индексы GiST. Реализация. Со значением OFF он отключен, с ON — включен, а с AUTO — вначале отключен, но включается на лету, как только размер индекса достигает effective_cache_size. Значение по умолчанию равно AUTO.
Индексы GIN принимают другие параметры:
fastupdate (boolean)
Этот параметр управляет использованием механизма быстрого обновления, описанного в разделе Быстрое обновление GIN. Это логический параметр: ON включает быстрое обновление, OFF отключает его. (Допустимые варианты написания ON и OFF описаны в разделе Настройка параметров.) Значение по умолчанию равно ON.
Примечание
Выключение fastupdate вALTER INDEXпредотвращает помещение добавляемых в дальнейшем строк в список записей, ожидающих индексации, но записи, добавленные в этот список ранее, в нем остаются. Чтобы очистить очередь операций, надо затем выполнить для этой таблицыVACUUMили вызвать функцию gin_clean_pending_list.
gin_pending_list_limit (integer)
Пользовательский параметр gin_pending_list_limit. Это значение указывается в килобайтах.
Индексы BRIN принимают другие параметры:
pages_per_range (integer)
Определяет количество блоков таблицы, которые составляют один диапазон блоков для каждой записи индекса BRIN (более подробную информацию см. в разделе Индексы BRIN). Значение по умолчанию равно 128.
autosummarize (boolean)
Определяет, нужно ли вычислять сводное значение для диапазона предыдущей страницы, когда происходит добавление на следующей странице.
Неблокирующее построение индексов
Создание индекса может помешать обычной работе базы данных. Как правило, QHB блокирует для записи предназначенную к индексированию таблицу и полностью выполняет построение индекса за одно сканирование таблицы. Другие транзакции по-прежнему могут читать из таблицы, но при попытке добавления, изменения или удаления строки в таблице они будут блокироваться до завершения построения индекса. Это может иметь серьезные последствия, если система является производственной базой данных в реальном времени. Индексация очень больших таблиц может занять много часов, и даже у таблиц меньшего размера построение индекса может блокировать записи на время, неприемлемое для производственной системы.
QHB поддерживает построение индексов без блокировки записи. Этот
метод вызывается путем указания CONCURRENTLY команды CREATE INDEX.
Если используется этот параметр, QHB должен выполнить два
сканирования таблицы и помимо этого дождаться завершения всех
существующих транзакций, которые потенциально могут изменить или
использовать индекс. Таким образом, данный метод требует проделать в
сумме больше действий, чем стандартное построение индекса, и занимает значительно
больше времени. Однако поскольку он позволяет продолжать
обычную работу во время построения индекса, этот метод удобен для
добавления новых индексов в производственной среде. Разумеется, дополнительная
нагрузка на процессор и подсистему ввода/вывода, вызванная созданием индекса,
может замедлить другие операции.
При неблокирующем построении индекса он действительно попадает в системный каталог в
одной транзакции, а затем в еще двух транзакциях происходят два
сканирования таблиц. Перед каждым сканированием операция
построения индекса должна ожидать завершения существующих транзакций, которые
модифицируют таблицу. После второго сканирования этой операции также необходимо
дождаться завершения всех транзакций, которые получили снимок таблицы
(см. главу Параллельный контроль) перед вторым сканированием.
Затем индекс наконец может быть помечен как готовый к использованию,
и команда CREATE INDEX завершается. Однако даже в этом случае индекс может не
сразу стать пригодным для запросов: в худшем случае его нельзя
применять до тех пор, пока существуют транзакции, запущенные до
начала построения индекса.
Если при сканировании таблицы возникает проблема, например
взаимоблокировка или нарушение уникальности в уникальном индексе,
команда CREATE INDEX завершится ошибкой, но оставит «нерабочий»
индекс. Этот индекс будет игнорироваться при запросах, поскольку он
может быть неполным; однако он всё равно будет потреблять ресурсы при
обновлениях. Команда qsql \d сообщит о таком индексе, пометив его как
INVALID:
qhb=# \d tab
Table "public.tab"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
col | integer | | |
Indexes:
"idx" btree (col) INVALID
Рекомендуемый метод восстановления в таких случаях заключается в том,
чтобы удалить индекс и попытаться снова выполнить CREATE INDEX CONCURRENTLY.
(Другая возможность состоит в том, чтобы
перестроить индекс с помощью команды REINDEX INDEX CONCURRENTLY.)
Еще одна сложность, с которой можно столкнуться при неблокирующем построении уникального индекса, в том, что когда начинается второе сканирование таблицы, ограничение уникальности уже применяется к другим транзакциям. Это означает, что нарушения ограничений могут быть зарегистрированы в других запросах раньше, чем индекс станет доступным для использования, или даже в тех случаях, когда построение индекса в конечном итоге завершится неудачей. Кроме того, если во время второго сканирования происходит сбой, то «нерабочий» индекс все равно продолжает после этого применять свое ограничение уникальности.
Метод неблокирующего построения поддерживает также индексы выражений и частичные индексы. Ошибки, возникающие при вычислении этих выражений, могут привести к поведению, описанному выше для случаев с нарушением ограничений уникальности.
Обычное построение индекса допускает одновременное построение других
индексов для таблицы обычным методом, но неблокирующее построение
для конкретной таблицы в один момент времени допускается только одно.
В любом случае никакие другие изменения схемы таблицы во время построения
индекса не допускаются. Другое отличие состоит в том,
что обычная команда CREATE INDEX может быть выполнена в блоке
транзакций, а CREATE INDEX CONCURRENTLY — нет.
Метод неблокирующего построения для индексов в партиционированных таблицах в настоящее время не поддерживаются. Однако можно использовать этот метод для каждой партиции отдельно, а затем создать индекс партиции в обычном режиме, чтобы сократить время блокировки записи в партиционированную таблицу. В этом случае построение индекса партиции будет заключаться только в изменении метаданных.
Примечания
Информацию о том, когда можно использовать индексы, когда они не используются и в каких конкретных ситуациях они могут быть полезны, см. в главе Индексы.
В настоящее время только методы B-tree, GiST, GIN и BRIN поддерживают составные индексы. По умолчанию можно указать до 32 полей. (Это ограничение можно изменить при пересборке QHB.) В настоящее время только B-tree поддерживает уникальные индексы.
Для каждого столбца индекса можно указать класс операторов. Класс операторов определяет операторов, которые будут использоваться индексом для этого столбца. Например, индекс B-дерева для четырехбайтовых целых чисел будет использовать класс int4_ops; этот класс операторов включает функции сравнения для четырехбайтовых целых чисел. На практике класс операторов по умолчанию для типа данных столбца обычно является достаточным. Основной смысл наличия классов операторов состоит в том, что для некоторых типов данных может существовать больше одного осмысленного порядка сортировки. Например, мы можем захотеть отсортировать комплексные числа как по абсолютному значению, так и по вещественной части. Мы могли бы сделать это, определив два класса операторов для типа данных и затем при создании индекса выбрав подходящий. Более подробная информация о классах операторов находится в разделах Классы операторов и семейства операторов и Интерфейсные расширения для индексов.
Когда команда CREATE INDEX вызывается для партиционированной таблицы,
поведение по умолчанию — это рекурсивно распространить ее действие
на все партиции, чтобы убедиться, что все они имеют соответствующие
индексы. Сначала каждая партиция проверяется на наличие равнозначного индекса,
и если таковой имеется, он будет присоединен в качестве индекса партиции к создаваемому
индексу, который станет его родительским индексом. Если соответствующий
индекс не существует, он будет создан и автоматически присоединен;
имя индекса для каждой партиции выбирается так же, как и при выполнении
этой команды без имени индекса. С указанием ONLY рекурсия не производится
и индекс помечается как нерабочий. (Команда ALTER INDEX ... ATTACH PARTITION
пометит его как рабочий, когда все партиции получат соответствующие индексы.)
Обратите внимание, что для любой партиции, которая будет создана в будущем с помощью
CREATE TABLE ... PARTITION OF, соответствующий индекс будет создан автоматически,
независимо от того, задано ли ONLY.
Для индексных методов, поддерживающих сканирование по порядку (в
настоящее время это поддерживает только В-дерево), можно изменить
порядок сортировки индекса, указав необязательные предложения AS,
DESC, NULLS FIRST или NULLS LAST. Поскольку упорядоченный индекс
можно сканировать как вперед, так и назад, обычно не рекомендуется
создавать индекс по убыванию (DESC) для одного столбца — этот порядок сортировки
уже доступен с обычным индексом. Ценность этих параметров состоит в возможности
создать составные индексы, которые будут соответствовать порядку
сортировки, указанному в запросе со смешанным порядком сортировки, например
SELECT ... ORDER BY x ASC, y DESC. Параметры NULLS полезны,
когда в запросах, зависящих от индексов, требуется вместо стандартного «NULL вверху»
реализовать поведение «NULL внизу», чтобы избежать этапов сортировки.
Система регулярно собирает статистику со всех столбцов таблицы. Новые индексы, созданные без применения выражений, могут сразу использовать эту статистику, чтобы определить полезность индекса. Для тех же новых индексов, что были построены с применением выражений, нужно выполнить команду ANALYZE или подождать, пока процесс «Автовакуум» не проанализирует таблицу и не сформирует статистику для этих индексов.
Для большинства методов индексов скорость создания индекса зависит от параметра maintenance_work_mem. Более высокие значения этого параметра сократят время, необходимое для создания индекса (если только заданное значение не превышает объем действительно доступной памяти, что влечет за собой использование подкачки).
QHB может создавать индексы, используя несколько процессоров, чтобы быстрее обрабатывать строки таблицы. Эта функция называется параллельным построением индекса. Для индексных методов, поддерживающих параллельное построение индексов (в настоящее время только В-дерево), maintenance_work_mem задает максимальный объем памяти, который может использовать каждая операция построения индекса в целом, независимо от количества запущенных рабочих процессов. Целесообразность использования параллельных процессов и их оптимальное количество обычно автоматически определяется моделью стоимости.
Параллельное построение индексов может выиграть от увеличения maintenance_work_mem там, где для аналогичного последовательного построения индекса выигрыша не будет или он будет минимальным. Обратите внимание, что maintenance_work_mem может влиять на количество запрашиваемых рабочих процессов, так как параллельные рабочие процессы должны иметь не менее 32MB из общего бюджета maintenance_work_mem. Кроме того, еще 32MB должно остаться для ведущего процесса. Увеличение max_parallel_maintenance_workers может позволить использовать больше исполнителей, что сократит время, необходимое для создания индекса (если только создание индекса уже не упирается в скорость ввода/вывода). Конечно, для этого должно быть достаточно процессорных ресурсов, которые иначе бы простаивали.
Если в команде ALTER TABLE задается значение для parallel_workers, это напрямую
определяет, сколько параллельных рабочих процессов будет запрашивать для таблицы
команда CREATE INDEX. При этом полностью игнорируется модель
стоимости, и maintenance_work_mem не влияет на определение количества
параллельных исполнителей. Если в ALTER TABLE параметр parallel_workers
установлен равным 0, это полностью отключает параллельное построение индексов для этой
таблицы.
Совет
Имеет смысл сбросить настройки parallel_workers после выполнения построения индекса. Это позволит избежать нежелательных изменений планов запросов, так как parallel_workers влияет на все параллельные сканирования таблицы.
Хотя CREATE INDEX с указанием CONCURRENTLY
поддерживает параллельное построение без специальных ограничений, только
первое сканирование таблицы на самом деле выполняется параллельно.
Для удаления индекса используйте DROP INDEX.
Как и любая другая длительная транзакция, операция CREATE INDEX с таблицей может повлиять на то, какие кортежи может удалить параллельная операция VACUUM с какой-либо другой таблицей
Предыдущие выпуски системы также поддерживали индексный метод R-дерево. Этот
метод был удален, поскольку не имел существенных преимуществ по
сравнению с методом GiST. Указание USING rtree в CREATE INDEX
будет интерпретироваться как USING GiST, чтобы
упростить преобразование старых баз данных в GiST.
Примеры
Создание уникального индекса B-дерева по столбцу title в таблице films:
CREATE UNIQUE INDEX title_idx ON films (title);
Создание уникального индекса B-дерева по столбцу title, а также включенным столбцам director и rating в таблице films:
CREATE UNIQUE INDEX title_idx ON films (title) INCLUDE (director, rating);
Создание индекса B-дерева с отключенным механизмом дедупликации:
CREATE INDEX title_idx ON films (title) WITH (deduplicate_items = off);
Создание индекса по выражению lower(title), позволяющего эффективно выполнять поиск без учета регистра:
CREATE INDEX ON films ((lower(title)));
(В этом примере мы решили опустить имя индекса, чтобы его выбрала система; обычно это films_lower_idx.)
Создание индекса с нестандартным правилом сортировки:
CREATE INDEX title_idx_german ON films (title COLLATE "de_DE");
Создание индекса с нестандартным порядком сортировки значений NULL:
CREATE INDEX title_idx_nulls_low ON films (title NULLS FIRST);
Создание индекса с нестандартным коэффициентом заполнения:
CREATE UNIQUE INDEX title_idx ON films (title) WITH (fillfactor = 70);
Создание индекса GIN с отключенным механизмом быстрого обновления:
CREATE INDEX gin_idx ON documents_table USING GIN (locations) WITH (fastupdate = off);
Создание индекса по столбцу code в таблице films и размещение его в табличном пространстве indexspace:
CREATE INDEX code_idx ON films (code) TABLESPACE indexspace;
Создание индекса GiST по координатам точек, позволяющего эффективно использовать операторы box с результатом функции преобразования:
CREATE INDEX pointloc
ON points USING gist (box(location,location));
SELECT * FROM points
WHERE box(location,location) && '(0,0),(1,1)'::box;
Создание индекса без блокировки записи в таблицу:
CREATE INDEX CONCURRENTLY sales_quantity_index ON sales_table (quantity);
Совместимость
Команда CREATE INDEX является расширением QHB. В стандарте SQL нет положений для индексов.
См. также
ALTER INDEX, DROP INDEX, REINDEX
CREATE LANGUAGE
CREATE LANGUAGE — определить новый процедурный язык
Синтаксис
CREATE [ OR REPLACE ] [ PROCEDURAL ] LANGUAGE имя
CREATE [ OR REPLACE ] [ TRUSTED ] [ PROCEDURAL ] LANGUAGE имя
HANDLER обработчик_вызова [ INLINE обработчик_внедренного_кода ] [ VALIDATOR функция_проверки ]
Описание
Команда CREATE LANGUAGE регистрирует в базе данных QHB новый
процедурный язык. Впоследствии на этом новом языке могут быть определены функции и процедуры.
В сущности, CREATE LANGUAGE связывает имя языка с функциями-обработчиками,
которые отвечают за выполнение функций, написанных на этом
языке. Дополнительную информацию о языковых обработчиках см. в главе Процедурные языки.
Команда CREATE OR REPLACE LANGUAGE приведет либо к созданию нового языка,
либо к замене существующего определения. Если язык уже существует, его
параметры обновляются в соответствии со значениями, указанными в команде, но при этом владелец языка и права доступа не меняются,
а все существующие функции, написанные на этом языке,
считаются по-прежнему действительными.
Чтобы зарегистрировать новый язык или изменить параметры существующего языка, нужно иметь права суперпользователя QHB. Однако после создания языка его владельцем можно назначить и обычного пользователя, который затем может его удалить или переименовать, изменить права доступа к нему или назначить нового владельца. (Однако нельзя назначить обычного пользователя владельцем нижележащих функций на С, поскольку это откроет перед ним возможность повысить свои права.)
Форма CREATE LANGUAGE, которая не задает никакую функцию-обработчик, является устаревшей. Для обратной совместимости со старыми файлами дампа она интерпретируется как CREATE EXTENTION. Это сработает, если язык был упакован в расширение с тем же именем — как обычно и устанавливаются процедурные языки.
Параметры
TRUSTED
TRUSTED (доверенный) указывает, что язык не предоставляет доступ к данным, к которым пользователь не имел бы доступа без него. Если при регистрации языка это ключевое слово опущено, только пользователи с правами суперпользователя QHB смогут использовать этот язык для создания новых функций.
PROCEDURAL
Это слово не несет смысловой нагрузки.
имя
Имя нового процедурного языка. Оно должно быть уникальным среди всех языков в базе данных.
Для обратной совместимости имя может быть заключено в одинарные кавычки.
HANDLER обработчик_вызова
обработчик_вызова — это имя ранее зарегистрированной функции, которая будет вызвана для выполнения функций на этом процедурном языке. Обработчик вызовов для процедурного языка должен быть написан на компилируемом языке, например C с соглашениями о вызовах версии 1, и зарегистрирован в QHB как функция, не принимающая аргументы и возвращающая фиктивный тип language_handler, который просто используется для идентификации функции в качестве обработчика вызовов.
INLINE обработчик_внедренного_кода
обработчик_внедренного_кода — это имя ранее зарегистрированной функции, которая
будет вызвана для выполнения анонимного блока кода (команды DO) на этом
языке. Если функция обработчика_внедренного_кода не указана, язык не будет поддерживать
анонимные блоки кода. Функция обработчика должна принимать один аргумент
типа internal, который будет внутренним представлением команды DO, и
он, как правило, возвращает тип void. Возвращаемое значение обработчика
игнорируется.
VALIDATOR функция_проверки
функция_проверки — это имя ранее зарегистрированной функции, которая будет вызываться при создании новой функции на языке, чтобы ее проверить. Если функция проверки не указана, то новая функция при создании проверяться не будет. Функция проверки должна принимать один аргумент типа oid, который станет идентификатором создаваемой функции и обычно будет возвращать void.
Функция проверки обычно проверяет синтаксическую корректность тела функции, но также может анализировать и другие свойства функции, например поддержку определенных типов аргументов этим языком. Чтобы сигнализировать об ошибке, функция проверки должна использовать функцию ereport(). Возвращаемое значение функции игнорируется.
Примечания
Для удаления процедурных языков используйте DROP LANGUAGE.
Информация о текущих установленных языках содержится в системном
каталоге pg_language. Кроме того, команда qsql
\dL показывает список установленных языков.
Чтобы создавать функции на процедурном языке, необходимо иметь право USAGE для языка. По умолчанию для доверенных языков право USAGE предоставляется роли PUBLIC (т.е. для всех), но при желании это можно отменить.
Процедурные языки являются локальными для отдельных баз данных. Тем не менее, язык может быть установлен в базу данных template1, вследствие чего язык будет автоматически доступен во всех созданных после этого базах данных.
Примеры
Минимальная запись для создания нового процедурного языка:
CREATE FUNCTION plsample_call_handler() RETURNS language_handler
AS '$libdir/plsample'
LANGUAGE C;
CREATE LANGUAGE plsample
HANDLER plsample_call_handler;
Обычно эти команды записываются в скрипте установки расширения, и пользователи устанавливают его так:
CREATE EXTENSION plsample;
Совместимость
Команда CREATE LANGUAGE является расширением QHB.
См. также
ALTER LANGUAGE, CREATE FUNCTION, DROP LANGUAGE, GRANT, REVOKE
CREATE MATERIALIZED VIEW
CREATE MATERIALIZED VIEW — определить новое материализованное представление
Синтаксис
CREATE MATERIALIZED VIEW [ IF NOT EXISTS ] имя_таблицы
[ (имя_столбца [, ...] ) ]
[ USING метод ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) ]
[ TABLESPACE имя_табличного_пространства ]
AS запрос
[ WITH [ NO ] DATA ]
Описание
Команда CREATE MATERIALIZED VIEW определяет материализованное
представление запроса. Запрос выполняется и используется для заполнения
представления во время выполнения команды (если только не указано WITH NO DATA).
Обновить представление позже можно, выполнив REFRESH MATERIALIZED VIEW.
Команда CREATE MATERIALIZED VIEW подобна CREATE TABLE AS, за
исключением того, что она еще и запоминает запрос, используемый для
инициализации представления, чтобы его можно было обновить позже по
требованию. Материализованное представление по многим свойствам сходно с таблицей,
но в нём не поддерживаются временные материализованные представления.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если материализованное представление с таким же именем уже существует. В этом случае выдается соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее материализованное представление как-то соотносится с тем, которое было бы создано.
имя_таблицы
Имя создаваемого материализованного представления (может быть дополнено схемой).
имя_столбца
Имя столбца в новом материализованном представлении. Если имена столбцов не указаны, они берутся из имен столбцов результата запроса.
USING метод
Это необязательное предложение определяет метод доступа к таблице, используемый для хранения содержимого для нового материализованного представления; этот метод должен быть типа TABLE. Дополнительную информацию см. в главе Определение интерфейса метода доступа к таблице. Если этот параметр не указан, то для нового материализованного представления выбирается метод доступа к таблице по умолчанию. Дополнительную информацию см. в разделе default_table_access_method.
WITH ( параметр_хранения [= значение] [, ... ] )
В этом предложении указываются необязательные параметры хранения для
нового материализованного представления; дополнительную информацию см. в
разделе Параметры хранения описания команды CREATE TABLE. Все параметры, которые поддерживает CREATE TABLE, поддерживает и
CREATE MATERIALIZED VIEW. Дополнительную информацию см. в разделе CREATE TABLE.
TABLESPACE имя_табличного_пространства
имя_табличного_пространства — это имя табличного пространства, в котором будет создано новое материализованное представление. Если не указано, то выбирается default_tablespace.
запрос
Команда SELECT, TABLE или VALUES. Этот запрос будет выполняться в рамках операции с ограничениями безопасности; в частности, вызовы функций, которые сами создают временные таблицы, завершатся ошибкой.
WITH [ NO ] DATA
Это предложение указывает, следует ли заполнять материализованное
представление во время его создания. Если материализованное представление
не наполняется, оно помечается как нечитаемое, так что к нему нельзя
будет обращаться до выполнения REFRESH MATERIALIZED VIEW.
Совместимость
Команда CREATE MATERIALIZED VIEW является расширением QHB.
См. также
ALTER MATERIALIZED VIEW, CREATE TABLE AS, CREATE VIEW, DROP MATERIALIZED VIEW, REFRESH MATERIALIZED VIEW
CREATE OPERATOR CLASS
CREATE OPERATOR CLASS — определить новый класс операторов
Синтаксис
CREATE OPERATOR CLASS имя [ DEFAULT ] FOR TYPE тип_данных
USING индексный_метод [ FAMILY имя_семейства ] AS
{ OPERATOR номер_стратегии имя_оператора [ ( тип_операнда, тип_операнда ) ] [ FOR SEARCH | FOR ORDER BY имя_семейства_сортировки ]
| FUNCTION номер_вспомогательной_функции [ ( тип_операнда [ , тип_операнда ] ) ] имя_функции ( тип_аргумента [, ...] )
| STORAGE тип_хранения
} [, ... ]
Описание
Команда CREATE OPERATOR CLASS создает новый класс операторов. Класс операторов
определяет, как конкретный тип данных может использоваться с индексом.
Класс операторов указывает, что некоторые операторы будут заполнять для этого типа
данных и этого индексного метода определенные роли или «стратегии».
Класс операторов также определяет вспомогательные функции,
которые будут использоваться индексным методом при выборе
класса операторов для столбца индекса. Все операторы и функции,
используемые классом операторов, должны быть определены еще до появления возможности
его создать.
Если задано имя схемы, то класс операторов создается в указанной схеме, в противном случае — в текущей схеме. Два класса операторов в одной схеме могут иметь одинаковое имя только в том случае, если они предназначены для разных индексных методов.
Пользователь, определяющий класс операторов, становится его владельцем. В настоящее время создавать классы операторов могут только суперпользователи. (Причина этого ограничения в том, что ошибочное определение класса операторов может вызвать нарушения или даже сбой в работе сервера.)
В настоящее время CREATE OPERATOR CLASS не проверяет, включает ли
определение класса оператора все операторы и функции, требуемые
индексным методом, и образуют ли операторы и функции целостный
набор. Ответственность за определение корректного класса операторов
лежит на пользователе.
Связанные классы операторов можно сгруппировать в семейства операторов.
Чтобы добавить новый класс оператора в существующее семейство, укажите
параметр FAMILY в команде CREATE OPERATOR CLASS. Без этого параметра новый
класс помещается в семейство с тем же именем, что и класс
(если такое семейство не существует, оно создается).
Дополнительную информацию см. в разделе Интерфейсные расширения для индексов.
Параметры
имя
Имя создаваемого класса операторов (может быть дополнено схемой).
DEFAULT
При наличии этого указания класс операторов становится классом по умолчанию для своего типа данных. У конкретного типа данных и индексного метода не может быть более одного класса операторов по умолчанию.
тип_данных
Тип данных столбца, для которого предназначен этот класс операторов.
индексный метод
Имя индексного метода, для которого предназначен этот класс операторов.
имя_семейства
Имя существующего семейства операторов, в которое будет добавлен этот класс. Если не указано, используется семейство с тем же именем, что и у класса оператора (если такое семейство не существует, оно создается).
номер_стратегии
Номер стратегии индексного метода для оператора, связанного с классом оператора.
имя_оператора
Имя оператора, связанного с данным классом оператора (может быть дополнено схемой).
тип_операнда
В предложении OPERATOR это тип(ы) данных операнда (либо ключевое слово NONE), характеризующий левый унарный или правый унарный оператор. В нормальных условиях, когда типы данных операнда совпадают с типом данных класса оператора, их можно опустить.
В предложении FUNCTION это тип(ы) данных операнда, для поддержки которого предназначена эта функция, если тот отличается от типа(ов) входных данных функции (для функций сравнения B-дерева и хэш-функций) или типа данных класса (для вспомогательных функций сортировки B-дерева и всех функций в классах операторов GiST, SP-GiST, GIN и BRIN). Обычно предполагаемые по умолчанию типы оказываются верными, так что тип_операнда указывать в FUNCTION не нужно (исключение составляют функции сортировки B-дерева, предназначенные для сравнений разных типов данных).
имя_семейства_сортировки
Имя существующего семейства операторов В-деревьев, описывающего порядок сортировки, связанный с оператором сортировки (может быть дополнено схемой).
Если не указано ни FOR SEARCH (для поиска), ни FOR ORDER BY (для сортировки), по умолчанию подразумевается FOR SEARCH.
номер_вспомогательной_функции
Номер вспомогательной функции индексного метода для функции, связанной с классом операторов.
имя_функции
Имя функции, которая является вспомогательной функцией индексного метода для класса операторов (может быть дополнено схемой).
тип_аргумента
Тип(ы) данных параметра функции.
тип_хранения
Тип данных, фактически сохраненных в индексе. Обычно это то же самое, что и тип данных столбца, но некоторые индексные методы (в настоящее время GiST, GIN и BRIN) могут работать с отличающимся типом. Если тип_данных столбца задан как anyarray, тип_хранения может быть объявлен как anyelement, чтобы показать, что записи в индексе являются членами типа элемента, принадлежащего к фактическому типу массива, для которого создается конкретный индекс.
Предложения OPERATOR, FUNCTION и STORAGE могут появляться в любом порядке.
Примечания
Поскольку механизм индексирования не проверяет разрешения на доступ к функциям перед их использованием, включение функции или оператора в класс операторов равносильно предоставлению общедоступного разрешения на их выполнение. Обычно это не проблема для разновидностей функций, которые бывают полезны в классе операторов.
Операторы не должны определяться функциями SQL. Функция SQL, скорее всего, будет встроена в вызывающий запрос, что помешает оптимизатору распознать, что запрос соответствует индексу.
Примеры
Команда в следующем примере определяет класс операторов индекса GiST для типа данных _int4 (массива из int4).
CREATE OPERATOR CLASS gist__int_ops
DEFAULT FOR TYPE _int4 USING gist AS
OPERATOR 3 &&,
OPERATOR 6 = (anyarray, anyarray),
OPERATOR 7 @>,
OPERATOR 8 <@,
OPERATOR 20 @@ (_int4, query_int),
FUNCTION 1 g_int_consistent (internal, _int4, smallint, oid, internal),
FUNCTION 2 g_int_union (internal, internal),
FUNCTION 3 g_int_compress (internal),
FUNCTION 4 g_int_decompress (internal),
FUNCTION 5 g_int_penalty (internal, internal, internal),
FUNCTION 6 g_int_picksplit (internal, internal),
FUNCTION 7 g_int_same (_int4, _int4, internal);
Совместимость
Команда CREATE OPERATOR CLASS является расширением
QHB. В стандарте SQL такой команды нет.
См. также
ALTER OPERATOR CLASS, DROP OPERATOR CLASS, CREATE OPERATOR FAMILY, ALTER OPERATOR FAMILY
CREATE OPERATOR FAMILY
CREATE OPERATOR FAMILY — определить новое семейство операторов
Синтаксис
CREATE OPERATOR FAMILY имя USING индексный_метод
Описание
Команда CREATE OPERATOR FAMILY создает новое семейство операторов. Семейство
операторов определяет набор связанных классов операторов и, возможно,
некоторые дополнительные операторы и вспомогательные функции,
совместимые с этими классами операторов, но несущественные
для функционирования любого отдельного индекса. (Операторы и функции,
которые важны для индексов, следует сгруппировать в пределах
соответствующего класса операторов, а не «слабо связывать» в семействе
операторов. Как правило, операторы с одним типом данных привязаны к
классам операторов, тогда как операторы с перекрестными типами
данных могут быть слабо связаны в семействе операторов, содержащем классы
операторов для обоих типов данных.)
Новое семейство операторов изначально пустое. Его нужно заполнить
командами CREATE OPERATOR CLASS, которые добавят в него классы операторов, и,
возможно, командами ALTER OPERATOR FAMILY, которые добавят «слабосвязанные»
операторы и соответствующие вспомогательные функции.
Если задано имя схемы, то семейство операторов создается в указанной схеме, в противном случае — в текущей схеме. Два семейства операторов в одной схеме могут иметь одинаковое имя только в том случае, если они предназначены для разных индексных методов.
Пользователь, определяющий семейство операторов, становится его владельцем. В настоящее время для создания семейства операторов нужно быть суперпользователем. (Причина этого ограничения в том, что ошибочное определение семейства операторов может вызвать нарушения или даже сбой в работе сервера.)
Дополнительную информацию см. в разделе Интерфейсные расширения для индексов.
Параметры
имя
Имя создаваемого семейства операторов (может быть дополнено схемой).
индексный метод
Имя индексного метода, для которого предназначено это семейство операторов.
Совместимость
Команда CREATE OPERATOR FAMILY является расширением
QHB. В стандарте SQL такой команды нет.
См. также
ALTER OPERATOR FAMILY, DROP OPERATOR FAMILY, CREATE OPERATOR CLASS, ALTER OPERATOR CLASS, DROP OPERATOR CLASS
CREATE OPERATOR
CREATE OPERATOR — определить новый оператор
Синтаксис
CREATE OPERATOR имя (
{FUNCTION|PROCEDURE} = имя_функции
[, LEFTARG = тип_слева ] [, RIGHTARG = тип_справа ]
[, COMMUTATOR = коммут_оператор ] [, NEGATOR = обратный_оператор ]
[, RESTRICT = процедура_ограничения ] [, JOIN = процедура_соединения ]
[, HASHES ] [, MERGES ]
)
Описание
Команда CREATE OPERATOR определяет новый оператор, имя. Пользователь,
создавший оператор, становится его владельцем. Если задано имя
схемы, то оператор создается в указанной схеме, если нет — в текущей.
Имя оператора представляет собой последовательность из нескольких символов (не более чем NAMEDATALEN-1, по умолчанию 63) из следующего списка:
+ - * / < > = ~ ! @ # % ^ & | ` ?
Есть несколько ограничений на выбор имени:
~ ! @ \# % ^ & ‘ ?
Например, @- является допустимым именем оператора, а *- не является. Это ограничение позволяет QHB анализировать SQL-совместимые команды, не требуя пробелов между токенами.
Оператор != при вводе отображается в <>, так что эти два имени всегда равнозначны.
Необходимо обязательно определить LEFTARG либо RIGHTARG, а для бинарных операторов — оба аргумента. Для правых унарных операторов должно быть определено только LEFTARG, тогда как для левых унарных операторов — только RIGHTARG.
Примечание
Правые унарные операторы, также называемые постфиксными, являются устаревшими и будут удалены в следующей версии QHB.
Функция имя_функции должна быть заранее определена с помощью
CREATE FUNCTION и таким образом, чтобы принимать правильное
числа аргументов (одного или двух) из указанных типов.
В синтаксисе CREATE OPERATOR ключевые слова FUNCTION и PROCEDURE
равнозначны, но указанная функция должна в любом случае быть функцией,
а не процедурой. Использование ключевого слова PROCEDURE здесь поддерживается
по историческим причинам и считается устаревшим.
В других предложениях указываются необязательные параметры оптимизации оператора. Их значение подробно описано в разделе Информация по оптимизации оператора.
Чтобы создать оператор, необходимо иметь право USAGE для типов аргументов и результата, а также право EXECUTE для нижележащей функции. Если указывается коммутативный или обратный оператор, нужно быть его владельцем.
Параметры
имя
Имя определяемого оператора. Допустимые символы см. выше. Имя может быть
дополнено схемой, например, так: CREATE OPERATOR myschema.+ (...). Если
схема не указана, то оператор создается в текущей схеме. Если два оператора в одной схеме
работают с разными типами данных, они могут иметь одинаковое имя.
Это называется перегрузкой.
имя_функции
Функция, используемая для реализации этого оператора.
тип_слева
Тип данных левого операнда оператора, если таковой имеется. Этот параметр будет опущен для левых унарных операторов.
тип_справа
Тип данных правого операнда оператора, если таковой имеется. Этот параметр будет опущен для правых унарных операторов.
коммут_оператор
Оператор, коммутирующий для данного.
обратный_оператор
Оператор, обратный для данного.
процедура_ограничения
Функция оценки селективности ограничения для этого оператора.
процедура_соединения
Функция оценки селективности соединения для этого оператора.
HASHES
Указывает, что этот оператор может поддерживать хэш-соединение.
MERGES
Указывает, что этот оператор может поддерживать соединение слиянием.
Чтобы задать имя оператора с указанием схемы в коммут_оператор или другом
дополнительном аргументе, применяется синтаксис OPERATOR(), например:
COMMUTATOR = OPERATOR(myschema.===) ,
Примечания
Указать лексический приоритет оператора в команде CREATE OPERATOR невозможно,
поскольку поведение приоритета синтаксического анализатора реализовано
аппаратно. См. раздел Приоритет оператора.
Устаревшие опции SORT1, SORT2, LTCMP и GTCMP ранее использовались для указания имен операторов сортировки, связанных с оператором, применяемым при соединении слиянием. В этом больше нет необходимости, так как сведения о связанных операторах можно найти, обратившись вместо этого к семействам операторов B-деревьев. Если в команде отсутствует явное указание MERGES, все эти параметры игнорируются.
Для удаления из базы данных пользовательских операторов используйте DROP OPERATOR, а для изменения их свойств — ALTER OPERATOR.
Примеры
Следующая команда определяет новый оператор, проверяющий равенство площадей, для типа данных box:
CREATE OPERATOR === (
LEFTARG = box,
RIGHTARG = box,
FUNCTION = area_equal_function,
COMMUTATOR = ===,
NEGATOR = !==,
RESTRICT = area_restriction_function,
JOIN = area_join_function,
HASHES, MERGES
);
Совместимость
Команда CREATE OPERATOR является расширением QHB. В стандарте SQL нет
определения для пользовательских операторов.
См. также
ALTER OPERATOR, CREATE OPERATOR CLASS, DROP OPERATOR
CREATE POLICY
CREATE POLICY — определить для таблицы новую политику защиты на уровне строк
Синтаксис
CREATE POLICY имя ON имя_таблицы
[ AS { PERMISSIVE | RESTRICTIVE } ]
[ FOR { ALL | SELECT | INSERT | UPDATE | DELETE } ]
[ TO { имя_роли | PUBLIC | CURRENT_USER | SESSION_USER } [, ...] ]
[ USING ( выражение_USING ) ]
[ WITH CHECK ( выражение_CHECK ) ]
Описание
Команда CREATE POLICY определяет для таблицы новую политику защиты на
уровне строк. Обратите внимание, что для применения созданных политик нужно
включить для таблицы защиту на уровне строк
(используя ALTER TABLE ... ENABLE ROW LEVEL SECURITY).
Политика предоставляет разрешение на выбор, добавление, обновление или удаление строк, удовлетворяющих соответствующему выражению политики. Существующие строки таблицы сравниваются с выражением, указанным в в USING, в то время как новые строки, которые будут созданы с помощью INSERT или UPDATE, проверяются на соответствие выражению, указанному в WITH CHECK. Когда выражение USING возвращает для данной строки true, эта строка видна пользователю, а если возвращается false или NULL, то не видна. Когда выражение WITH CHECK возвращает для строки значение true, эта строка добавляется или обновляется, а если возвращается значение false или NULL, то возникает ошибка.
Для операторов INSERT и UPDATE выражения WITH CHECK применяются после того, как срабатывают триггеры *BEFORE, и прежде, чем будут сделаны какие-либо фактические изменения данных. Таким образом, триггер BEFORE ROW может изменять добавляемые данные, влияя на результат проверки политики защиты. Выражения WITH CHECK применяются перед любыми другими ограничениями.
Имена политик указаны на уровне таблицы. Поэтому одно имя политики может использоваться для нескольких разных таблиц и в каждой дать отдельное определение политики, подходящее этой конкретной таблице.
Политики могут применяться для определенных команд или для определенных ролей. По умолчанию для вновь созданных политик они применяются для всех команд и ролей, если не указано иное. К одной команде может применяться несколько политик; дополнительную информацию см. ниже. Ниже в таблице 256 показано, как различные типы политик применяются к определенным командам.
Для политик, которые могут иметь и выражения USING, и выражения WITH CHECK (ALL и UPDATE), в случае отсутствия выражения WITH CHECK выражение USING будет использоваться для определения того, какие строки будут видимыми (обычное назначение USING) и какие новые строки будет разрешено добавить (назначение WITH CHECK)
Если для таблицы включена защита на уровне строк, но применимые политики отсутствуют, то предполагается политика «по умолчанию запретить», чтобы никакие строки не были видны или доступны для обновления.
Параметры
имя
Имя создаваемой политики. Должно отличаться от имени любой другой политики для таблицы.
имя_таблицы
Имя таблицы, к которой применяется политика (может быть дополнено схемой).
PERMISSIVE
Указывает, что политика должна быть создана как разрешительная. Все разрешительные политики, применимые к данному запросу, будут объединены с помощью логического оператора «ИЛИ». Создавая разрешительные политики, администраторы могут расширить множество записей, к которым можно обращаться. По умолчанию политики являются разрешительными.
RESTRICTIVE
Указывает, что политика должна быть создана как ограничительная. Все ограничительные политики, применимые к данному запросу, будут объединены с помощью логического оператора «И». Создавая ограничительные политики, администраторы могут сократить множество записей, к которым можно обращаться, так как для каждой записи должны удовлетворяться все ограничительные политики.
Обратите внимание, что для предоставления доступа к записям необходима хотя бы одна разрешительная политика, и только после этого возможно успешное использование ограничительных политик для сокращения этого доступа. Если существуют только ограничительные политики, то никакие записи не будут доступны. При наличии сочетания разрешительных и ограничительных политик запись доступна только в том случае, если кроме всех ограничительных политик удовлетворяется как минимум одна из разрешительных.
команда
Команда, к которой применяется политика. Допустимые варианты: ALL, SELECT, INSERT, UPDATE и DELETE. По умолчанию подразумевается ALL (все). Особенности их применения описаны ниже.
имя_роли
Роль(и), к которой(ым) будет применяться политика. Значение по умолчанию равно PUBLIC, то есть политика применяется ко всем ролям.
выражение_USING
Произвольное условное выражение SQL (возвращающее boolean). Условное выражение не может содержать никаких агрегатных или оконных функций. Это выражение будет добавлено в запросы, обращающиеся к данной таблице, если включена защита на уровне строк. Строки, для которых выражение возвращает true, будут видны. Любые строки, для которых выражение возвращает значение false или NULL, не будут видны пользователю (в запросе SELECT) и не будут доступны для изменения (в запросе UPDATE или DELETE). Такая строка просто пропускается, ошибка при этом не выдается.
выражение_CHECK
Произвольное условное выражение SQL (возвращающее boolean). Условное выражение не может содержать никаких агрегатных или оконных функций. Это выражение будет использоваться в запросах INSERT и UPDATE к таблице, если включена защита на уровне строк, так что в них принимаются только те строки, для которых оно выдает true. Если это выражение выдает false или NULL для любой из добавляемых записей или записей, получаемых при изменении, выдается ошибка. Обратите внимание, что выражение_CHECK вычисляется для предлагаемого нового содержимого строки, а не для существующих данных.
Политики по командам
ALL
Указание ALL для политики означает, что она будет применяться ко всем командам, независимо от типа последних. Если существует политика ALL и другие более детализированные политики, то будут применяться и политика ALL, и более детализированные политики. Вдобавок политики ALL будут применяться как к стороне выборки, так и к стороне изменения данных в запросе, используя в обоих случаях выражение USING, если определено только оно.
Например, когда выполняется UPDATE, политика ALL будет фильтровать
и строки, которые UPDATE сможет выбрать для изменения (применяя выражение USING),
и итоговые измененные строки, проверяя, разрешено ли записать их в таблицу
(применяя выражение WITH CHECK, если оно определено, или, в противном случае,
USING). Если команда INSERT или UPDATE пытается добавить в таблицу строки,
не удовлетворяющие выражению WITH CHECK политики ALL, вся команда будет прервана.
SELECT
Указание SELECT для политики означает, что она будет применяться к
запросам SELECT всякий раз, когда при обращении к отношению, для
которого определена политика, требуется право SELECT.
Результатом является то, что запрос SELECT выдаст только те записи
из отношения, которые удовлетворят политике SELECT, и запросы, использующие
право SELECT, например запрос UPDATE, увидят только записи,
разрешенные политикой SELECT. Для политики SELECT не может задаваться
выражение WITH CHECK, так как оно действует, только когда записи
читаются из отношения.
INSERT
Указание INSERT для политики означает, что она будет применяться к
командам INSERT. Попытка добавления строк, которые не удовлетворят этой политике,
приведет к ошибке нарушения политики, и вся команда INSERT
будет прервана. Для политики INSERT не может задаваться выражение USING,
так как она действует, только когда в отношение добавляются записи.
Обратите внимание, что INSERT с указанием ON CONFLICT DO UPDATE
проверяет выражения WITH CHECK политик INSERT только для строк,
добавляемых в отношение по пути INSERT.
UPDATE
Указание UPDATE для политики означает, что она будет применяться к
командам UPDATE, SELECT FOR UPDATE и SELECT FOR SHARE,
а также к дополнительным предложениям ON CONFLICT DO UPDATE команд INSERT.
Так как UPDATE подразумевает извлечение существующей
записи и замену ее новой измененной записью, политики UPDATE принимают
оба выражения: и USING, и WITH CHECK. Выражение USING
определяет, какие записи команда UPDATE будет видеть для последующего изменения,
в то время как выражение WITH CHECK определяет, какие
измененные строки могут быть сохранены в отношении.
Любые строки, обновленные значения которых не будут удовлетворять выражению WITH CHECK, вызовут ошибку, и вся команда будет прервана. Если указывается только предложение USING, оно будет применяться и в качестве собственно USING, и в качестве выражения WITH CHECK.
Как правило, команда UPDATE также должна считывать данные из
столбцов подлежащего изменению отношения (например, в предложении WHERE
или RETURNING либо в выражении в правой части предложения SET).
В этом случае также требуется иметь права SELECT в изменяемом отношении,
а в дополнение к политикам UPDATE будут применяться соответствующие политики
SELECT или ALL. Таким образом, пользователь должен иметь доступ к изменяемой(ым)
строке(ам) через политику UPDATE или ALL, а также разрешение на изменение этой(их)
строк(и) от политики *SELECT или ALL.
Если команда INSERT указана со вспомогательным предложением ON CONFLICT DO UPDATE,
то при выборе пути UPDATE сначала подлежащая изменению строка
проверяется по выражениям USING всех политик UPDATE,
а затем новая обновленная строка проверяется по выражениям WITH CHECK.
Обратите внимание, однако, что, в отличие от отдельной команды UPDATE,
если существующая строка не удовлетворяет выражениям USING, будет выдаваться ошибка
(путь UPDATE никогда не пропускается неявно).
DELETE
Указание DELETE для политики означает, что она будет применяться к
командам DELETE. Команде DELETE будут видны только те строки, которые разрешит
эта команда. При этом среди них могут быть строки, которые видны через SELECT,
но если они не удовлетворяют выражению USING политики DELETE, то
удалить их будет нельзя.
В большинстве случаев команде DELETE также требуется считывать данные из
столбцов в отношении, из которого осуществляется удаление
(например, в предложении WHERE или RETURNING). В этом случае также требуются
права SELECT на отношения, и в дополнение к политикам DELETE будут применяться
соответствующие политики SELECT или ALL. Таким образом, пользователь
должен иметь доступ к удаляемой(ым) строке(ам) через политику SELECT или ALL, а
также разрешение на удаление этой(их) строк(и) от политики DELETE или ALL.
Для политики DELETE не может задаваться выражение WITH CHECK, так как она применяется только тогда, когда записи удаляются из отношения, а в этом случае новые строки, подлежащие проверке, отсутствуют.
Таблица 256. Политики, применяемые по типу команды
| Команда | Политика SELECT/ALL Выражение USING | Политика INSERT/ALL Выражение WITH CHECK | Политика UPDATE/ALL Выражение USING | Политика UPDATE/ALL Выражение WITH CHECK | Политика DELETE/ALL |
|---|---|---|---|---|---|
| SELECT | Существующая строка | - | - | - | - |
| SELECT FOR UPDATE/SHARE | Существующая строка | - | Существующая строка | - | - |
| INSERT | - | Новая строка | - | - | - |
| INSERT ... RETURNING | Новая строка [(a)] | Новая строка | - | - | - |
| UPDATE | Существующие и новые строки [(a)] | - | Существующая строка | Новая строка | - |
| DELETE | Существующая строка [(a)] | - | - | - | Существующая строка |
| ON CONFLICT DO UPDATE | Существующие и новые строки | - | Существующая строка | Новая строка | - |
Если для существующей или новой строки требуется доступ на чтение (например, предложения WHERE или RETURNING, обращающиеся к столбцам отношения).
Применение нескольких политик
Если к одной команде применяются несколько политик различных типов
команд (например, политики SELECT и UPDATE применяются к команде UPDATE),
пользователь должен иметь оба типа разрешений
(например, разрешение на выбор строк из отношения и разрешение на
их обновление). Таким образом, выражения для одного типа политики
комбинируются с выражениями для другого типа политики с помощью оператора И.
Если к одной команде применяется несколько политик одного и того же типа команд, то должна быть хотя бы одна политика PERMISSIVE (разрешительная), предоставляющая доступ к отношению, а также должны удовлетворяться все политики RESTRICTIVE (ограничительные). Таким образом, выражения всех политик PERMISSIVE объединяются с помощью ИЛИ, выражения всех политик RESTRICTIVE объединяются при помощи И и полученные результаты также объединяются при помощи И. Если политики PERMISSIVE отсутствуют, доступ запрещается.
Обратите внимание, что в целях объединения нескольких политик политики ALL рассматриваются как политики любого применимого в данном случае типа.
Например, в команде UPDATE, требующей разрешения и для SELECT,
и для UPDATE, в случае существования нескольких применимых политик
каждого типа они будут объединяться следующим образом:
выражение from RESTRICTIVE SELECT/ALL policy 1
AND
выражение from RESTRICTIVE SELECT/ALL policy 2
AND
...
AND
(
выражение from PERMISSIVE SELECT/ALL policy 1
OR
выражение from PERMISSIVE SELECT/ALL policy 2
OR
...
)
AND
выражение from RESTRICTIVE UPDATE/ALL policy 1
AND
выражение from RESTRICTIVE UPDATE/ALL policy 2
AND
...
AND
(
выражение from PERMISSIVE UPDATE/ALL policy 1
OR
выражение from PERMISSIVE UPDATE/ALL policy 2
OR
...
)
Примечания
Чтобы создавать или изменять политики для таблицы, нужно быть ее владельцем.
Хотя политики будут применяться для явных запросов к таблицам в базе данных, они не применяются, когда система выполняет внутренние проверки целостности ссылок или проверяет ограничения. Это означает, что существуют косвенные способы определить, что данное значение существует. Примером этого является попытка добавить повторяющееся значение в столбец, образующий первичный ключ или имеющий ограничение уникальности. Если добавление завершается неудачно, то пользователь может сделать вывод, что значение уже существует. (В этом примере предполагается, что пользователю разрешено политикой добавлять записи, которые он не может видеть.) Другой пример — это когда пользователю разрешено добавлять записи в таблицу, которая ссылается на другую, иным образом не видимую. Существование значения может быть определено пользователем, который добавляет значения в подчиненную таблицу, где успешный результат операции будет признаком того, что значение существует в главной таблице. Эти проблемы могут быть решены путем тщательной разработки политик, чтобы полностью запретить пользователям добавлять, удалять или обновлять записи, которые могут указывать на не видимое иным образом значение, либо путем использования генерируемых значений (например, суррогатных ключей) вместо ключей с внешними значениями.
Как правило, система будет применять условия фильтрации, введенные с помощью политик безопасности, до условий в запросах пользователя, чтобы предотвратить нежелательную утечку защищаемых данных через пользовательские функции, которые могут не быть доверенными. Однако функции и операторы, помеченные системой (или системным администратором) как LEAKPROOF, могут вычисляться до условий политики, так как они считаются доверенными.
Поскольку выражения политики добавляются непосредственно в запрос пользователя, они будут выполняться с правами пользователя, выполняющего запрос. Таким образом, пользователи, на которых распространяется заданная политика, должны иметь доступ ко всем таблицам или функциям, на которые ссылается выражение, иначе при попытке обращения к таблице, у которой включена защита на уровне строк, они просто получат ошибку «отказано в доступе». Однако это не меняет способ работы представлений. Как и с обычными запросами и представлениями, проверки разрешений и политики для таблиц, на которые ссылается представление, будут использовать права владельца представления и все политики, распространяющиеся на этого владельца.
Дополнительное описание и практические примеры можно найти в разделе Политики безопасности строк.
Совместимость
Команда CREATE POLICY является расширением QHB.
См. также
ALTER POLICY, DROP POLICY, ALTER TABLE
CREATE PROCEDURE
CREATE PROCEDURE — определить новую процедуру
Синтаксис
CREATE [ OR REPLACE ] PROCEDURE
имя ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ { DEFAULT | = } выражение_по_умолчанию ] [, ...] ] )
{ LANGUAGE имя_языка
| TRANSFORM { FOR TYPE имя_типа } [, ... ]
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| SET параметр_конфигурации { TO значение | = значение | FROM CURRENT }
| AS 'определение'
| AS 'объектный_файл', 'объектный_символ'
} ...
Описание
Команда CREATE PROCEDURE определяет новую процедуру.
CREATE OR REPLACE PROCEDURE будет либо создавать новую процедуру, либо заменять
существующее определение. Чтобы иметь возможность определить процедуру,
необходимо иметь право USAGE для соответствующего языка.
Если указано имя схемы, то процедура создается в указанной схеме, в противном случае — в текущей. Имя новой процедуры не должно совпадать ни с одной существующей процедурой или функцией с теми же типами входных аргументов в той же схеме. Однако процедуры и функции с различными типами аргументов могут иметь одинаковое имя (это называется перегрузкой ).
Чтобы заменить текущее определение существующей процедуры, используйте
CREATE OR REPLACE PROCEDURE. Таким способом невозможно
изменить имя или типы аргументов процедуры (если вы попытаетесь, то
фактически создадите новую, отличную процедуру).
Если CREATE OR REPLACE PROCEDURE используется для замены
существующей процедуры, владелец и права доступа к этой процедуре не
меняются. Всем остальным свойствам процедуры присваиваются значения,
указанные в команде явно или подразумеваемые по умолчанию. Чтобы заменить
процедуру, нужно быть ее владельцем (или быть членом роли-владельца).
Пользователь, создающий процедуру, становится ее владельцем.
Чтобы создать процедуру, необходимо иметь право USAGE для типов ее аргументов.
Параметры
имя
Имя создаваемой процедуры (может быть дополнено схемой).
режим_аргумента
Режим аргумента: IN, INOUT или VARIADIC. Если этот параметр опущен, значение по умолчанию равно IN. (Аргументы OUT в настоящее время для процедур не поддерживаются. Вместо них можно воспользоваться INOUT.)
имя_аргумента
Имя аргумента.
тип_аргумента
Тип(ы) данных аргументов процедуры (при необходимости дополненный схемой), если таковой имеется. Типы аргументов могут быть базовыми, составными или доменными типами, а также могут ссылаться на тип столбца таблицы.
В зависимости от языка реализации также может быть разрешено указывать «псевдотипы», такие как cstring. Псевдотипы показывают, что фактический тип аргумента либо указан не полностью, либо находится вне набора обычных типов данных SQL.
Ссылка на тип столбца записывается в виде имя_таблицы.имя_столбца%TYPE.
Использование этой функции иногда может помочь сделать процедуру
независимой от изменений в определении таблицы.
выражение_по_умолчанию
Выражение, которое будет использоваться в качестве значения по умолчанию, если параметр не указан. Выражение должно быть приведено к типу аргумента параметра. Все входные параметры, следующие за параметром со значением по умолчанию, также должны иметь значения по умолчанию.
имя_языка
Имя языка, на котором реализована процедура. Это может быть sql, c, internal или имя определяемого пользователем процедурного языка, например plpgsql. Стиль написания этого имени в апострофах считается устаревшим и требует точного совпадения регистра.
TRANSFORM { FOR TYPE имя_типа } [, ... ] }
Устанавливает список трансформаций, которые должны применяться при вызове процедуры. Трансформации выполняют преобразования между типами SQL и языковыми типами данных; см. раздел CREATE TRANSFORM. Преобразования встроенных типов обычно жестко предопределены в реализациях процедурных языков, так что их здесь указывать не нужно. Если реализация процедурного языка не знает, как обрабатывать тип, и трансформация не предоставляется, будет выполнено преобразование типов данных по умолчанию, но это зависит от реализации.
[EXTERNAL] SECURITY INVOKER
[EXTERNAL] SECURITY DEFINER
Характеристика SECURITY INVOKER (безопасность вызывающего) указывает, что процедура должна выполняться с правами вызывающего ее пользователя. Это значение по умолчанию. Вариант SECURITY DEFINER (безопасность определившего) указывает, что процедура должна выполняться с правами пользователя, которому она принадлежит (владельца).
Ключевое слово EXTERNAL (внешняя) допускается для соответствия стандарту SQL, но является необязательным, так как, в отличие от SQL, эта характеристика распространяется на все процедуры, а не только внешние.
В процедуре с характеристикой SECURITY DEFINER не могут выполняться
операторы управления транзакциями (например, COMMIT и ROLLBACK в некоторых языках).
параметр_конфигурации
значение
Предложение SET определяет, что при вызове процедуры указанный параметр конфигурации должен принять заданное значение, а затем, по завершении процедуры, восстановить свое предыдущее значение. Предложение SET FROM CURRENT сохраняет значение параметра, действующее при выполнении CREATE PROCEDURE, в качестве значения, которое будет применено при входе в процедуру.
Если в определение процедуры добавлено SET, то действие команды SET LOCAL,
выполняемой внутри процедуры для той же переменной, ограничивается процедурой:
предыдущее значение параметра конфигурации восстанавливается по завершении
процедуры. Однако обычная команда SET (без LOCAL) переопределяет значение
SET, как и предыдущую команду SET LOCAL: эффекты команды сохраняются
после завершения процедуры, если не случится откат текущей транзакции.
Если к определению процедуры добавлено SET, то в этой процедуре не
смогут выполняться операторы управления транзакциями (например,
COMMIT и ROLLBACK в некоторых языках).
Дополнительную информацию о допустимых именах и значениях параметров см. в разделе SET и главе Конфигурация сервера.
определение
Строковая константа, определяющая процедуру; значение зависит от языка. Это может быть имя внутренней процедуры, путь к объектному файлу, команда SQL или код на процедурном языке.
Часто бывает полезно заключать определение процедуры в знаки доллара (см. раздел Строковые константы с экранированием знаками доллара), а не в традиционные апострофы. Если не использовать знаки доллара, то любые одиночные кавычки или обратные косые черты в определении процедуры должны быть экранированы путем удвоения.
объектный_файл, объектный_символ
Это форма предложения AS используется для динамически загружаемых процедур на языке C, когда имя процедуры в исходном коде языка C не совпадает с именем процедуры SQL. Строка объектный_файл является именем файла разделяемой библиотеки, содержащего скомпилированную процедуру на C, и интерпретируется как параметр команды LOAD. Строка объектный_символ задает скомпонованный символ процедуры, то есть имя процедуры в исходном коде языка C. Если объектный символ опущен, предполагается, что он совпадает с именем определяемой процедуры SQL.
При повторных вызовах CREATE PROCEDURE ссылается на один и тот же
объектный файл, который загружается только один раз за сеанс. Чтобы
выгрузить и перезагрузить файл (возможно, во время разработки),
запустите новый сеанс.
Примечания
Дополнительную информацию о создании функций, которые также применяются к процедурам, см. в разделе CREATE FUNCTION.
Чтобы выполнить процедуру, используйте команду CALL.
Примеры
CREATE PROCEDURE insert_data(a integer, b integer)
LANGUAGE SQL
AS $$
INSERT INTO tbl VALUES (a);
INSERT INTO tbl VALUES (b);
$$;
CALL insert_data(1, 2);
Совместимость
Команда CREATE PROCEDURE определена в стандарте SQL. Реализация
QHB близка к стандартизированной, но совместима с ней не
полностью. Дополнительную информацию см. в разделе CREATE FUNCTION.
См. также
ALTER PROCEDURE, DROP PROCEDURE, CALL, CREATE FUNCTION
CREATE PUBLICATION
CREATE PUBLICATION — определить новую публикацию
Синтаксис
CREATE PUBLICATION имя
[ FOR TABLE [ ONLY ] имя_таблицы [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( параметр_публикации [= значение] [, ... ] ) ]
Описание
Команда CREATE PUBLICATION добавляет новую публикацию в текущую базу данных.
Имя публикации должно отличаться от имени других существующих публикаций
в текущей базе данных.
Публикация — это, по существу, группа таблиц, изменения данных которых подлежат логической репликации.
Параметры
имя
Имя новой публикации.
FOR TABLE
Указывает список таблиц для добавления в публикацию. Если перед именем таблицы указано ONLY, в публикацию добавляется только заданная таблица. Без ONLY добавляется и заданная таблица, и все ее потомки (если таковые имеются). После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что включены дочерние таблицы.
Только постоянные базовые таблицы могут быть частью публикации. Временные, нежурналируемые, сторонние и партиционированные таблицы, а также материализованные и обычные представления не могут быть частью публикации. Чтобы реплицировать партиционированную таблицу, добавьте в публикацию ее отдельные партиции.
FOR ALL TABLES
Отмечает публикацию как реплицирующую изменения для всех таблиц в базе данных, включая таблицы, созданные в будущем.
WITH ( параметр_публикации [= значение] [, ... ] )
В этом предложении указываются необязательные параметры для публикации. Поддерживаются следующие параметры:
Этот параметр определяет, какие операции DML будут опубликованы новой публикацией для подписчиков. В качестве его значения через запятую задается список операций. Разрешены следующие операции: insert, update, delete и truncate. По умолчанию публикуются все действия, поэтому значение по умолчанию для этого параметра равно 'insert, update, delete, truncate'.
Этот параметр определяет, будут ли изменения во включенной в публикацию партиционированной таблице (или в ее партициях) опубликованы с именем и схемой этой партиционированной таблицы, а не ее отдельных партиций, где эти изменения на самом деле произошли (второе — поведение по умолчанию). Включение этого параметра позволяет реплицировать изменения в непартиционированную таблицу или в партиционированную таблицу, состоящую из другого набора партиций.
Если этот параметр включен, операции TRUNCATE, выполняемые непосредственно с партициями, не реплицируются.
Примечания
Если не задано ни FOR TABLE, ни FOR ALL TABLES, публикация создается с пустым набором таблиц. Это удобно, если таблицы будут добавлены позже.
Создание публикации не запускает репликацию. Оно лишь определяет логику группировки и фильтрации для будущих подписчиков.
Чтобы создать публикацию, необходимо иметь право CREATE в текущей базе данных. (Разумеется, суперпользователи эту проверку проходят.)
Чтобы добавить таблицу в публикацию, нужно быть владельцем таблицы. Предложение FOR ALL TABLES требует, чтобы вызывающий его пользователь был суперпользователем.
Таблицы, добавленные в публикацию, которая публикует
операции UPDATE и/или DELETE, должны иметь свойство REPLICA IDENTITY.
В противном случае данные операции для этих таблиц будут запрещены.
Для команды INSERT ... ON CONFLICT публикация
выдает операцию, которая фактически является результатом выполнения
этой команды. Таким образом, в зависимости от результата, она может быть
опубликована как INSERT или UPDATE или не быть опубликована вовсе.
Команды COPY ... FROM публикуются в виде операций INSERT.
Операции DDL не публикуются.
Примеры
Создание публикации, охватывающей изменения в двух таблицах:
CREATE PUBLICATION mypublication FOR TABLE users, departments;
Создание публикации, охватывающей все изменения во всех таблицах:
CREATE PUBLICATION alltables FOR ALL TABLES;
Создание публикации, охватывающей только операции INSERT в одной таблице:
CREATE PUBLICATION insert_only FOR TABLE mydata
WITH (publish = 'insert');
Совместимость
Команда CREATE PUBLICATION является расширением QHB.
См. также
ALTER PUBLICATION, DROP PUBLICATION
CREATE ROLE
CREATE ROLE — определить новую роль в базе данных
Синтаксис
CREATE ROLE имя [ [ WITH ] параметр [ ... ] ]
Где параметр:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT предел_подключений
| [ ENCRYPTED ] PASSWORD 'пароль' | PASSWORD NULL
| VALID UNTIL 'дата_время'
| IN ROLE имя_роли [, ...]
| IN GROUP имя_роли [, ...]
| ROLE имя_роли [, ...]
| ADMIN имя_роли [, ...]
| USER имя_роли [, ...]
| SYSID uid
Описание
Команда CREATE ROLE добавляет новую роль в кластер баз данных QHB.
Роль — это логический объект, который может владеть объектами базы данных и иметь
права доступа к ней; роль может рассматриваться как
«пользователь», «группа» или и то, и другое в зависимости от того, как
она используется. Дополнительную информацию об управлении пользователями
и проверке подлинности см. в главе Роли в базе данных.
Чтобы выполнить эту команду, нужно быть суперпользователем базы данных или иметь право CREATEROLE.
Обратите внимание, что роли определяются на уровне кластера баз данных и поэтому допустимы во всех базах данных в кластере.
Параметры
имя
Имя новой роли.
SUPERUSER
NOSUPERUSER
Эти предложения определяют, является ли новая роль «суперпользователем», который может переопределить все ограничения доступа в базе данных. Статус суперпользователя опасен и должен использоваться только тогда, когда это действительно необходимо. Чтобы создать нового суперпользователя нужно самому быть суперпользователем. Если ничего не указано, значение по умолчанию равно NOSUPERUSER.
CREATEDB
NOCREATEDB
Эти предложения определяют способность роли создавать базы данных. Если указывается CREATEDB, то определяемой роли будет разрешено создавать новые базы данных. NOCREATEDB лишит роль возможности создавать базы данных. Если ничего не указано, значение по умолчанию равно NOCREATEDB.
CREATEROLE
NOCREATEROLE
Эти предложения определяют, будет ли разрешено роли создавать новые
роли (то есть выполнять CREATE ROLE). Роль с правом CREATEROLE
может также изменять и удалять другие роли. Если ничего не указано, значение по умолчанию равно NOCREATEROLE.
INHERIT
NOINHERIT
Эти предложения определяют, «наследует» ли роль права ролей, членом
которых является. Роль с атрибутом INHERIT может
автоматически использовать любые права в базе данных, предоставленные
всем ролям, в которые она непосредственно или опосредованно входит.
Без INHERIT членство в другой роли позволяет только выполнить SET ROLE
и переключиться на эту роль; права, назначенные другой роли, будут доступны
только после этого. Значение по умолчанию равно INHERIT.
LOGIN
NOLOGIN
Эти предложения определяют, разрешен ли роли вход на сервер; то
есть может ли роль быть задана в качестве начального авторизованного
имени при подключении клиента. Роль с атрибутом LOGIN
может рассматриваться как пользователь. Роли без этого атрибута полезны
для управления правами доступа к базе данных, но не являются
пользователями в обычном смысле этого слова. Если ничего не указано, значение по
умолчанию равно NOLOGIN, за исключением случаев, когда CREATE ROLE вызывается
через альтернативное написание CREATE USER.
REPLICATION
NOREPLICATION
Эти предложения определяют, является ли роль ролью репликации. Роль должна иметь этот атрибут (или быть суперпользователем), чтобы иметь возможность подключаться к серверу в режиме репликации (физической или логической), а также создавать или удалять слоты репликации. Роль с атрибутом REPLICATION обладает очень большими правами и должна использоваться только в ролях, фактически используемых для репликации. Если ничего не указано, значение по умолчанию равно NOREPLICATION. Чтобы создать новую роль с атрибутом REPLICATION, нужно быть суперпользователем.
BYPASSRLS
NOBYPASSRLS
Эти предложения определяют, будут ли для роли игнорироваться все
политики защиты на уровне строк (row-level security, RLS). Значение по умолчанию равно NOBYPASSRLS.
Чтобы создать новую роль с атрибутом BYPASSRLS, нужно быть суперпользователем.
Обратите внимание, что qhb_dump по умолчанию установит для row_security
значение OFF для гарантии, что всё содержимое таблицы выгружается. Если
пользователь, выполняющий qhb_dump, не имеет соответствующих прав,
будет возвращена ошибка. Суперпользователь и владелец выгружаемой
таблицы всегда обходят RLS.
CONNECTION LIMIT предел_подключений
Если роли разрешен вход, параметр указывает, сколько одновременных подключений она может выполнить. Значение -1 (по умолчанию) означает отсутствие ограничений. Обратите внимание, что под это ограничение подпадают только обычные соединения. Ни подготовленные транзакции, ни фоновые рабочие соединения не учитываются.
[ ENCRYPTED ] PASSWORD 'пароль'
PASSWORD NULL
Задает пароль роли. (Пароль используется только для ролей с атрибутом LOGIN, но тем не менее вы можете определить его для ролей без него.) Если вы не планируете использовать аутентификацию паролем, можете опустить эту опцию. Если пароль не указан, он будет установлен в значение NULL, и проверка подлинности пароля для этого пользователя всегда завершится ошибкой. При желании пароль NULL можно установить явно, указав PASSWORD NULL.
Примечание
При указании пустой строки пароль также будет иметь значение NULL. Чтобы избежать двусмысленности, следует избегать указания пустой строки.
Пароль всегда хранится зашифрованным в системных каталогах. Ключевое слово ENCRYPTED не имеет эффекта, но принимается для обратной совместимости. Способ шифрования определяется параметром конфигурации password_encryption. Если представленная строка пароля уже зашифрована в формате MD5 или SCRAM, она сохраняется как есть независимо от password_encryption (поскольку система не может расшифровать указанную зашифрованную строку пароля, чтобы зашифровать ее в другом формате). Это позволяет перезагрузить зашифрованные пароли во время выгрузки/восстановления.
VALID UNTIL ’дата_время’
Предложение VALID UNTIL устанавливает дату и время, после которых пароль роли становится недействительным. Если это предложение пропущено пароль будет действителен в течение всего времени.
IN ROLE имя_роли
В предложении IN ROLE перечислены одна или несколько существующих ролей, к которым новая роль будет немедленно добавлена в качестве нового члена. (Обратите внимание, что нет возможности добавить новую роль в качестве администратора; для этого используйте отдельную команду GRANT).
IN GROUP имя_роли
IN GROUP — это устаревшее написание предложения IN ROLE.
ROLE имя_роли
В предложении ROLE перечислены одна или несколько существующих ролей, которые автоматически добавляются в качестве членов новой роли. (Это фактически делает новую роль «группой».)
ADMIN имя_роли
Предложение ADMIN подобно ROLE, но перечисленные роли добавляются в новую роль с атрибутом WITH ADMIN OPTION, давая им право предоставлять членство в этой роли другим ролям.
USER имя_роли
Предложение USER является устаревшим написанием предложения ROLE.
SYSID uid
Предложение SYSID игнорируется, но принимается для обратной совместимости.
Примечания
Используйте команду ALTER ROLE, чтобы изменить атрибуты роли, и
DROP ROLE, чтобы ее удалить. Все атрибуты, указанные в CREATE ROLE,
могут быть позднее изменены командами ALTER ROLE.
Предпочтительным способом добавления и удаления членов ролей, используемых в качестве групп, является использование функций GRANT и REVOKE.
Предложение VALID UNTIL определяет срок действия только для пароля, а не для роли как таковой. В частности, при входе в систему с помощью метода проверки подлинности без пароля время истечения срока действия не проверяется.
Атрибут INHERIT управляет наследованием предоставленных прав (т. е. прав доступа
для объектов базы данных и членства в ролях). Он не
применяется к специальным атрибутам роли, заданным с помощью
CREATE ROLE и ALTER ROLE. Например, членство в роли с правом CREATEDB
недостаточно для получения права создавать базы данных, даже если
установлен атрибут INHERIT; перед тем, как создать базу данных,
необходимо будет переключиться на эту роль, выполнив SET ROLE.
Хотя по умолчанию установлено INHERIT, но значение NOINHERIT больше подходит по смыслу к тому, что описано в стандарте SQL.
Будьте осторожны с правом CREATEROLE, т. к. на роли с этим правом не распространяется концепция наследования прав. Это означает, что даже если у роли нет определенных прав, ей всё равно разрешено создавать другие роли, и она может легко создать другую роль с правами, отличными от тех, что есть у нее самой (за исключением создания ролей с правами суперпользователя). Например, если роль «user» имеет право CREATEROLE, но не CREATEDB, она, тем не менее, может создать новую роль с правом CREATEDB. Поэтому роль с правом CREATEROLE следует воспринимать почти как роль суперпользователя.
QHB включает в себя программу createuser, которая имеет ту же
функциональность, что и команда CREATE ROLE (на самом деле она вызывает эту команду),
но может запускаться в командной оболочке.
Ограничение CONNECTION LIMIT действует приблизительно; если одновременно запускаются два сеанса, в то время как для этой роли остается только один «слот», может так случиться, что будут отклонены оба подключения. Кроме того, это ограничение не распространяется на суперпользователей.
При указании незашифрованного пароля с помощью этой команды следует
соблюдать осторожность. Пароль будет передан на сервер в виде открытого
текста, и он также может быть зарегистрирован в журнале команд клиента
или журнале сервера. Команда createuser, однако, передает
зашифрованный пароль. Кроме того, qsql содержит команду
\password, которую можно использовать для последующего безопасного
изменения пароля.
Примеры
Создание роли, для которой разрешен вход, но не задан пароль:
CREATE ROLE jonathan LOGIN;
Создание роли с паролем:
CREATE USER davide WITH PASSWORD 'jw8s0F4';
(CREATE USER действует так же, как CREATE ROLE, но подразумевает еще и атрибут LOGIN.)
Создание роли с паролем, действующим до конца 2004 г., то есть пароль перестает действовать в первую же секунду 2005 г.
CREATE ROLE miriam WITH LOGIN PASSWORD 'jw8s0F4' VALID UNTIL '2005-01-01';
Создание роли, которая может создавать базы данных и управлять ролями:
CREATE ROLE admin WITH CREATEDB CREATEROLE;
Совместимость
Команда CREATE ROLE описана в стандарте SQL, но стандарт требует поддержки только
следующего синтаксиса:
CREATE ROLE имя [ WITH ADMIN имя_роли ]
Возможность создавать множество начальных администраторов и все
другие параметры CREATE ROLE относятся к расширениям QHB.
Стандарт SQL определяет понятия пользователей и ролей, но рассматривает их как отдельные понятия и оставляет на усмотрение каждой реализации СУБД самостоятельно указывать все команды, определяющие пользователей. В QHB мы решили объединить пользователей и роли в единый вид логического объекта. Таким образом, роли имеют гораздо больше дополнительных атрибутов, чем в стандарте.
Поведение, заданное стандартом SQL, с наибольшей достоверностью можно получить, если создавать пользователей с атрибутом NOINHERIT, а роли — с атрибутом INHERIT.
См. также
SET ROLE, ALTER ROLE, DROP ROLE, GRANT, REVOKE, createuser
CREATE RULE
CREATE RULE — определение нового правила перезаписи
Синтаксис
CREATE [ OR REPLACE ] RULE имя AS ON событие
TO имя_таблицы [ WHERE условие ]
DO [ ALSO | INSTEAD ] { NOTHING | команда | ( команда ; команда ... ) }
Где событие может быть:
SELECT | INSERT | UPDATE | DELETE
Описание
Команда CREATE RULE определяет новое правило, применяемое к указанной
таблице или представлению. CREATE OR REPLACE RULE будет либо
создавать новое правило, либо заменять существующее правило с тем же
именем для той же таблицы.
Система правил QHB позволяет определить альтернативное действие, которое будет выполняться при добавлении, изменении или удалении в таблицах базы данных. Грубо говоря, когда выполняется данная команда на данной таблице, правило вызывает выполнение дополнительных команд. В качестве альтернативы правило INSTEAD может заменить данную команду другой или привести к тому, что команда не будет выполняться вообще. Правила также используются для реализации представлений SQL. Важно понимать, что правило — это действительно механизм преобразования команд, или командный макрос. Преобразование происходит до начала выполнения команды. Если вам действительно нужна операция, которая срабатывает независимо для каждой физической строки, вы, вероятно, захотите использовать триггер, а не правило.
На данный момент правила ON SELECT должны быть безусловными,
с указанием INSTEAD, и их действия должны состоять из единственной команды SELECT.
Таким образом, правило ON SELECT эффективно превращает таблицу в
представление, видимым содержимым которого являются строки, возвращаемые
заданной в правиле командой SELECT, а не данные,
хранящиеся в таблице (если они есть). Считается всё же, что для этой цели
лучше пользоваться командой CREATE VIEW, а не создавать реальную таблицу
и затем определять для нее правило ON SELECT.
Вы можете создать иллюзию изменяемого представления путем определения правил ON INSERT, ON UPDATE и ON DELETE (или любого подмножество правил, достаточного для ваших целей), чтобы заменить операции изменения в представлении соответствующими изменениями в других таблицах. Если хотите поддержать операторы вроде INSERT RETURNING и и пр., то не забудьте поместить в каждое из этих правил подходящее предложение RETURNING.
При попытке использовать условные правила для изменения сложных представлений возникает одна загвоздка: для каждого действия, которое вы хотите разрешить для представления, необходимо определить безусловное правило INSTEAD. Если правило условное или не типа INSTEAD, система отвергнет попытки выполнить изменения, предполагая, что в некоторых случаях они могут свестись к попыткам провести операцию с фиктивной таблицей представления. Если вы хотите обрабатывать все полезные случаи изменений в условных правилах, добавьте безусловное правило DO INSTEAD NOTHING, гарантирующее, что система поймет, что ей никогда не придется изменять фиктивную таблицу. Затем создайте условные правила без свойства INSTEAD; в тех случаях, когда они будут применяться, их действия будут добавлены к действию по умолчанию INSTEAD NOTHING. (Однако в настоящее время этот способ не подходит для реализации запросов RETURNING.)
Примечание
Представление, которое достаточно просто, чтобы быть автоматически изменяемым (см. CREATE VIEW), не требует для изменения созданного пользователем правила. Хотя всё равно можно создать явное правило, но автоматическое преобразование изменения в общем и целом его превзойдет.
Еще одна альтернатива, которую стоит рассмотреть, — это использование вместо правил триггеров INSTEAD OF (см. раздел CREATE TRIGGER).
Параметры
имя
Имя создаваемого правила. Должно отличаться от имени любого другого правила для той же таблицы. Несколько правил для одной и той же таблицы и одного и того же типа событий применяются в алфавитном порядке имен.
событие
Тип события: SELECT, INSERT, UPDATE или DELETE. Обратите внимание, что INSERT с предложением ON CONFLICT не может быть использовано в таблицах, для которых определено правило INSERT или UPDATE. Вместо этого рассмотрите возможность использования изменяемого представления.
имя_таблицы
Имя таблицы или представления, к которым будет применяться правило (может быть дополнено схемой).
условие
Любое выражение условия SQL (возвращающее boolean). Выражение условия не может ссылаться ни на какие таблицы, кроме NEW и OLD, и не может содержать агрегатных функций.
INSTEAD
INSTEAD указывает, что команды должны выполняться вместо исходной команды.
ALSO
ALSO указывает, что команды должны выполняться в дополнение к исходной команде.
Если ни INSTEAD, ни ALSO не заданы, по умолчанию применяется ALSO.
команда
Команда или команды, составляющие действие правила. Допустимыми
командами являются SELECT, INSERT , UPDATE , DELETE и
NOTIFY.
В параметрах условие и команда для обращения к значениям в соответствующей таблице могут использоваться имена специальных таблиц NEW и OLD. NEW действительна в правилах ON INSERT и ON UPDATE для ссылки на новую добавляемую или изменяемую строку. OLD действительна в правилах ON UPDATE и ON DELETE для ссылки на существующую строку, которая изменяется или удаляется.
Примечания
Чтобы создавать или изменять правила для таблицы, нужно быть ее владельцем.
В правила для INSERT, UPDATE или DELETE для представления можно
добавить предложение RETURNING, которое выдает столбцы
представления. Это предложение будет использоваться для вычисления
выходных данных, если правило инициируется командой INSERT RETURNING,
UPDATE RETURNING или DELETE RETURNING. Когда
правило запускается командой без RETURNING, его собственное предложение
RETURNING будет проигнорировано. Текущая реализация позволяет содержать
RETURNING только безусловным правилам INSTEAD; более того, среди всех правил
для одного события может быть не более одного предложения RETURNING.
(Это гарантирует, что существует только одно подходящее предложение RETURNING,
которое и будет использоваться для вычисления результатов.) Запросы с RETURNING к
представлению будут отклонены, если в его правилах нет ни одного предложения RETURNING.
Очень важно позаботиться о том, чтобы правила не зацикливались.
Например, хотя каждое из следующих двух определений правил принимается
QHB, команда SELECT приведет к тому, что QHB сообщит
об ошибке из-за рекурсивного расширения правила:
CREATE RULE "_RETURN" AS
ON SELECT TO t1
DO INSTEAD
SELECT * FROM t2;
CREATE RULE "_RETURN" AS
ON SELECT TO t2
DO INSTEAD
SELECT * FROM t1;
SELECT * FROM t1;
В настоящее время если действие правила содержит команду NOTIFY,
та будет выполняться безоговорочно, то есть уведомление
будет выдано, даже если нет строк, к которым должно применяться
правило. Например, в:
CREATE RULE notify_me AS ON UPDATE TO mytable DO ALSO NOTIFY mytable;
UPDATE mytable SET name = 'foo' WHERE id = 42;
событие NOTIFY будет отправлено во время выполнения UPDATE
независимо от того, есть ли строки, соответствующие условию id = 42. Это
ограничение реализации, которое может быть исправлено в будущих
выпусках.
Совместимость
Команда CREATE RULE является языковым расширением QHB, как и вся система
перезаписи запросов.
См. также
CREATE SCHEMA
CREATE SCHEMA — определить новую схему
Синтаксис
CREATE SCHEMA имя_схемы [ AUTHORIZATION указание_роли ] [ элемент_схемы [ ... ] ]
CREATE SCHEMA AUTHORIZATION указание_роли [ элемент_схемы [ ... ] ]
CREATE SCHEMA IF NOT EXISTS имя_схемы [ AUTHORIZATION указание_роли ]
CREATE SCHEMA IF NOT EXISTS AUTHORIZATION указание_роли
Где указание_роли может быть:
имя_пользователя
| CURRENT_USER
| SESSION_USER
Описание
Команда CREATE SCHEMA вносит новую схему в текущую базу данных. Имя схемы
должно отличаться от имени любой существующей схемы в текущей базе
данных.
Схема по существу является пространством имен: она содержит именованные
объекты (таблицы, типы данных, функции и операторы), имена которых могут
дублировать имена других объектов, существующих в других схемах. Доступ
к именованным объектам осуществляется либо путем «дополнения» их имен
именем схемы в качестве префикса, либо путем задания пути поиска,
включающего требуемую(ые) схему(ы). Команда CREATE, в которой указывается
неполное имя объекта, создает объект в текущей схеме (той, что стоит в пути поиска
первой; узнать ее позволяет функция current_schema).
При необходимости CREATE SCHEMA может включать подкоманды для
создания объектов в новой схеме. В целом, подкоманды обрабатываются
так же, как и отдельные команды, выполняемые после создания схемы, за
исключением того, что при использовании предложения AUTHORIZATION все
созданные объекты будут принадлежать указанному пользователю.
Параметры
имя_схемы
Имя создаваемой схемы. Если этот параметр опущен, то в качестве имени схемы используется имя_пользователя. Имя не может начинаться с pg_, поскольку такие имена зарезервированы для системных схем.
имя_пользователя
Имя пользователя (роли), которому будет принадлежать новая схема. Если этот параметр опущен, по умолчанию владельцем становится пользователь, выполняющий команду. Чтобы создать схему, принадлежащую другой роли, необходимо быть непосредственным или опосредованным членом этой роли или суперпользователем.
элемент_схемы
Оператор SQL, определяющий объект, который должен быть создан в схеме. В
настоящее время CREATE SCHEMA может содержать только подкоманды
CREATE TABLE, CREATE VIEW, CREATE INDEX, CREATE SEQUENCE,
CREATE TRIGGER и GRANT. Другие виды объектов должны быть созданы
в отдельных командах после создания схемы.
IF NOT EXISTS
Не делать ничего (кроме выдачи уведомления), если схема с тем же именем уже существует. Когда используется это указание, такая команда не может содержать подкоманды элемент_схемы.
Примечания
Чтобы создать схему, необходимо иметь право CREATE в текущей базе данных. (Разумеется, на суперпользователей это условие не распространяется.)
Примеры
Создание схемы:
CREATE SCHEMA myschema;
Создание схемы для пользователя joe; схема получит имя joe:
CREATE SCHEMA AUTHORIZATION joe;
Создание схемы с именем test, владельцем которой будет пользователь joe, если только схема test еще не существует. (Является ли пользователь joe владельцем существующей схемы, значения не имеет.)
CREATE SCHEMA IF NOT EXISTS test AUTHORIZATION joe;
Создание схемы, в которой сразу создаются таблица и представление:
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;
Обратите внимание, что отдельные подкоманды не завершаются точкой с запятой.
Следующие команды приводят к тому же результату другим способом:
CREATE SCHEMA hollywood;
CREATE TABLE hollywood.films (title text, release date, awards text[]);
CREATE VIEW hollywood.winners AS
SELECT title, release FROM hollywood.films WHERE awards IS NOT NULL;
Совместимость
Стандарт SQL допускает в команде CREATE SCHEMA предложение DEFAULT CHARACTER SET
и дополнительные типы подкоманд, которые QHB в настоящее время не принимает.
Стандарт SQL указывает, что подкоманды CREATE SCHEMA могут быть указаны
в любом порядке. Настоящая реализация QHB не обрабатывает все случаи
порядка указания подкоманд; иногда может потребоваться изменить порядок
подкоманд, чтобы избежать ссылок вперед.
Согласно стандарту SQL, владелец схемы всегда владеет всеми объектами внутри нее. QHB позволяет схемам содержать объекты, принадлежащие пользователям, отличным от владельца схемы. Это может произойти, только если владелец схемы предоставляет право CREATE на своей схеме кому-то другому либо объекты в ней будет создавать суперпользователь.
Указание IF NOT EXISTS является расширением QHB.
См. также
CREATE SEQUENCE
CREATE SEQUENCE — определить новый генератор последовательности
Синтаксис
CREATE [ TEMPORARY | TEMP ] SEQUENCE [ IF NOT EXISTS ] имя
[ AS тип_данных ]
[ INCREMENT [ BY ] шаг ]
[ MINVALUE мин_значение | NO MINVALUE ] [ MAXVALUE макс_значение | NO MAXVALUE ]
[ START [ WITH ] начало ] [ CACHE кэш ] [ [ NO ] CYCLE ]
[ OWNED BY { имя_таблицы.имя_столбца | NONE } ]
Описание
Команда CREATE SEQUENCE создает новый генератор порядковых
номеров. Это включает в себя создание и инициализацию новой специальной
однострочной таблицы с именем имя. Генератор будет принадлежать
пользователю, выдавшему команду.
Если задано имя схемы, то последовательность создается в указанной схеме, в противном случае — в текущей. Временные последовательности существуют в специальной схеме, поэтому при создании временной последовательности имя схемы не может быть задано. Имя последовательности должно отличаться от имени любой другой последовательности, таблицы, индекса, представления или сторонней таблицы в той же схеме.
После того как последовательность создана, с ней можно работать, используя функции nextval, currval и setval. Эти функции описаны в разделе Функции управления последовательностями.
Хотя обновить последовательность напрямую нельзя, можно использовать запрос наподобие этого:
SELECT * FROM name;
чтобы изучить ее параметры и текущее состояние. В частности, поле last_value последовательности показывает последнее значение, выделенное для какого-либо сеанса. (Разумеется, если другие сеансы активно вызывают nextval, то к моменту печати это значение может устареть.)
Параметры
TEMPORARY или TEMP
Если этот параметр указан, объект последовательности создается только для этого сеанса и автоматически удаляется при выходе из сеанса. Существующие постоянные последовательности с одинаковым именем не видны (в этом сеансе), пока существует временная последовательность, если только они не связаны с именами, определенными схемой.
IF NOT EXISTS
Не считать ошибкой, если связь с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее отношение как-то соотносится с последовательностью, которая была бы создана — это может даже не быть последовательностью.
имя
Имя создаваемой последовательности (может быть дополнено схемой).
тип_данных
Необязательное предложение AS тип_данных задает тип данных последовательности. Допустимые типы: smallint, integer и bigint. Значение по умолчанию равно bigint. Тип данных определяет минимальные и максимальные значения последовательности по умолчанию.
шаг
Необязательное предложение INCREMENT BY шаг указывает, какое значение добавляется к текущему значению последовательности для создания нового значения. Положительное значение сделает восходящую последовательность, отрицательное — нисходящую. Значение по умолчанию равно 1.
мин_значение NO MINVALUE
Необязательное предложение MINVALUE мин_значение определяет минимальное значение, которое может генерировать последовательность. Если это условие не указано или не указано значение NO MINVALUE, будут использоваться значения по умолчанию. Значение по умолчанию для восходящей последовательности равно 1. Значение по умолчанию для нисходящей последовательности равно минимальному значению типа данных.
макс_значение NO MAXVALUE
Необязательное предложение MAXVALUE макс_значение определяет максимальное значение для последовательности. Если это условие не указано или указано значение NO MAXVALUE, будут использоваться значения по умолчанию. Значение по умолчанию для восходящей последовательности равно максимальному значению типа данных. Значение по умолчанию для нисходящей последовательности равно -1.
начало
Необязательное предложение START WITH начало позволяет последовательности начинаться в любом месте. Начальное значение по умолчанию равно мин_значение для восходящих последовательностей и макс_значение для нисходящих.
кэш
Необязательное предложение CACHE кэш указывает, сколько порядковых номеров должно быть предварительно выделено и сохранено в памяти для быстрого доступа. Минимальное значение равно 1 (за один раз может быть сгенерировано только одно значение, т. е. кэша нет), и оно же значение по умолчанию.
CYCLE NO CYCLE
Параметр CYCLE позволяет последовательности зацикливаться, когда восходящей или нисходящей последовательностью было достигнуто макс_значение или мин_значение соответственно. Если предел достигнут, то следующим сгенерированным номером будет мин_значение или макс_значение соответственно.
Если указано NO CYCLE, любые вызовы nextval после достижения последовательностью максимального значения будут возвращать ошибку. Если не указано ни CYCLE, ни NO CYCLE, значение по умолчанию равно NO CYCLE.
OWNED BY имя_таблицы.имя_столбца
OWNED BY NONE
Параметр OWNED BY заставляет последовательность связываться с определенным столбцом таблицы таким образом, что если этот столбец (или вся его таблица) удаляется, последовательность будет также автоматически удалена. Указанная таблица должна иметь того же владельца и находиться в той же схеме, что и последовательность. Значение по умолчанию OWNED BY NONE указывает, что такой связи не существует.
Примечания
Чтобы удалить последовательность, используйте DROP SEQUENCE.
Последовательности основаны на арифметике bigint, поэтому диапазон не может превышать диапазон восьмибайтного целого числа (от -9223372036854775808 до 9223372036854775807).
Поскольку вызовы nextval и setval никогда не откатываются, объекты последовательности нельзя использовать, если требуется непрерывное присвоение порядковых номеров. Такое присвоение можно устроить с помощью исключительной блокировки таблицы, содержащей счетчик, но это решение гораздо дороже, чем объекты последовательности, особенно если сразу много транзакций одновременно затребует порядковые номера.
Если для объекта последовательности, который будет использоваться одновременно несколькими сеансами, значение кэш установлено больше единицы, это может привести к неожиданным результатам. Каждый сеанс будет выделять и кэшировать следующие друг за другом значения последовательности во время одного обращения к объекту последовательности и, соответственно, увеличивать последнее_значение объекта последовательности. Затем следующие кэш-1 вызовы nextval в этом сеансе будут просто возвращать предварительно выделенные значения, не касаясь объекта последовательности. В результате любые номера, выделенные, но не используемые в сеансе, по его окончании будут потеряны, что приведет к «прорехам» в последовательности.
Более того, хотя несколько сеансов гарантированно выделяют отдельные значения последовательности, последние могут быть сгенерированы из последовательности, когда рассматриваются все сеансы. Например, когда значение кэш равно 10, сеанс A может резервировать значения от 1 до 10 и возвращать nextval=1, затем сеанс B может зарезервировать значения от 11 до 20 и возвращать nextval=11 до того, как сеанс А сгенерирует nextval=2. Таким образом, при значении кэш, равном единице, можно с уверенностью предположить, что значения nextval генерируются последовательно, но при значении кэш выше единицы следует предполагать лишь, что все значения nextval различны, а не исключительную последовательность их генерации. Кроме того, последнее_значение будет отражать самое последнее значение, зарезервированное любым сеансом, независимо от того, было ли оно уже возвращено nextval.
Также следует учесть, что действие функции setval, выполненное в такой последовательности, не будет замечено другими сеансами, пока те не используют все предварительно выделенные значения, которые они кэшировали.
Примеры
Создание восходящей последовательности с именем serial с начальным значением 101:
CREATE SEQUENCE serial START 101;
Выбор следующего номера из этой последовательности:
SELECT nextval('serial');
nextval
---------
101
Выбор следующего номера из этой последовательности:
SELECT nextval('serial');
nextval
---------
102
Использование этой последовательности в команде INSERT:
INSERT INTO distributors VALUES (nextval('serial'), 'nothing');
Изменение значения последовательности после COPY FROM:
BEGIN;
COPY distributors FROM 'input_file';
SELECT setval('serial', max(id)) FROM distributors;
END;
Совместимость
Команда CREATE SEQUENCE соответствует стандарту SQL, за следующими
исключениями:
См. также
CREATE SERVER
CREATE SERVER — определить новый сторонний сервер
Синтаксис
CREATE SERVER [ IF NOT EXISTS ] имя_сервера [ TYPE 'тип_сервера' ] [ VERSION 'версия_сервера' ]
FOREIGN DATA WRAPPER имя_обертки_сторонних_данных
[ OPTIONS ( параметр 'значение' [, ... ] ) ]
Описание
Команда CREATE SERVER определяет новый сторонний сервер. Пользователь,
создавший сервер, становится его владельцем.
Определение стороннего сервера обычно включает информацию о подключении, которую обертка сторонних данных использует для доступа к внешнему ресурсу данных. Дополнительную информацию о соединении можно задать с помощью сопоставлений пользователей.
Имя сервера должно быть уникальным в пределах базы данных.
Для создания сервера требуется право USAGE на используемую обертку сторонних данных.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если сервер с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующий сервер как-то соотносится с тем, который был бы создан.
имя_сервера
Имя создаваемого стороннего сервера.
тип_сервера
Необязательный тип сервера, потенциально полезный для оберток сторонних данных.
версия_сервера
Необязательная версия сервера, потенциально полезная для оберток сторонних данных.
имя_обертки_сторонних_данных
Имя обертки сторонних данных, управляющей сервером.
OPTIONS ( параметр 'значение' [, ... ] )
Это предложение задает параметры для сервера. Параметры обычно определяют характеристики соединения сервера, но фактические имена и значения зависят от обертки сторонних данных сервера.
Примечания
При использовании модуля dblink имя стороннего сервера можно использовать в качестве аргумента функции dblink_connect для указания параметров соединения. Необходимо иметь право USAGE для стороннего сервера, чтобы иметь возможность использовать его таким образом.
Примеры
Создание сервера myserver, который использует обертку сторонних данных qhb_fdw:
CREATE SERVER myserver FOREIGN DATA WRAPPER qhb_fdw OPTIONS (host 'foo', dbname 'foodb', port '5432');
Совместимость
Команда CREATE SERVER соответствует стандарту ISO/IEC 9075-9 (SQL/MED).
См. также
ALTER SERVER, DROP SERVER, CREATE FOREIGN DATA WRAPPER, CREATE FOREIGN TABLE, CREATE USER MAPPING
CREATE STATISTICS
CREATE STATISTICS — определить расширенную статистику
Синтаксис
CREATE STATISTICS [ IF NOT EXISTS ] имя_статистики
[ ( вид_статистики [, ... ] ) ]
ON имя_столбца, имя_столбца [, ...]
FROM имя_таблицы
Описание
Команда CREATE STATISTICS создаст новый расширенный объект статистики,
отслеживающий данные о заданной таблице, сторонней таблице или
материализованном представлении. Объект статистики будет создан в
текущей базе данных и будет принадлежать пользователю, выдавшему
команду.
Если задано имя схемы (например, CREATE STATISTICS myschema.mystat ...), то
объект статистики создается в указанной схеме, в противном случае — в текущей.
Имя объекта статистики должно отличаться
от имени любого другого объекта статистики в той же схеме.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если объект статистики с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что здесь рассматривается только имя объекта статистики, а не детали его определения.
имя_статистики
Имя создаваемого объекта статистики (может быть дополнено схемой).
вид_статистики
Вид статистики, который будет вычисляться в этом объекте статистики. В настоящее время поддерживаются следующие виды: ndistinct, который активирует n-различную статистику, dependencies, который активирует статистику функциональных зависимостей, и mcv, который активирует списки наиболее распространенных значений. Если это предложение опущено, в объект статистики включаются все поддерживаемые виды статистики. Дополнительную информацию см. в разделах Расширенная статистика и Примеры многомерной статистики.
имя_столбца
Имя столбца таблицы, который будет покрыт вычисляемой статистикой. Должно быть задано не менее двух имен столбцов; порядок имен столбцов значения не имеет.
имя_таблицы
Имя таблицы, содержащей столбец(цы), по которому(ым) вычисляются статистические данные (может быть дополнено схемой).
Примечания
Чтобы создать считывающий таблицу объект статистики, нужно быть владельцем этой таблицы. Однако после создания объекта статистики его владелец определяется независимо от нижележащих таблиц.
Примеры
Создание таблицы t1 с двумя функционально зависимыми столбцами, т. е. знания значения в первом столбце достаточно для определения значения в другом столбце. Затем на этих столбцах строится статистика функциональной зависимости:
CREATE TABLE t1 (
a int,
b int
);
INSERT INTO t1 SELECT i/100, i/500
FROM generate_series(1,1000000) s(i);
ANALYZE t1;
-- число совпадающих строк будет существенно недооценено:
EXPLAIN ANALYZE SELECT * FROM t1 WHERE (a = 1) AND (b = 0);
CREATE STATISTICS s1 (dependencies) ON a, b FROM t1;
ANALYZE t1;
-- теперь оценка числа строк стала точнее:
EXPLAIN ANALYZE SELECT * FROM t1 WHERE (a = 1) AND (b = 0);
Без статистики функциональной зависимости планировщик предположил бы, что эти два условия WHERE независимы, и перемножил бы их избирательности вместе, получив при этом слишком маленькую оценку количества строк. С такой статистикой планировщик признает, что условия WHERE являются избыточными, и не занижает количество строк.
Создание таблицы t2 с двумя идеально коррелирующими столбцами (содержащими идентичные данные) и списком MCV на этих столбцах:
CREATE TABLE t2 (
a int,
b int
);
INSERT INTO t2 SELECT mod(i,100), mod(i,100)
FROM generate_series(1,1000000) s(i);
CREATE STATISTICS s2 (mcv) ON a, b FROM t2;
ANALYZE t2;
-- подходящая комбинация (входит в MCV)
EXPLAIN ANALYZE SELECT * FROM t2 WHERE (a = 1) AND (b = 1);
-- неподходящая комбинация (не входит в MCV)
EXPLAIN ANALYZE SELECT * FROM t2 WHERE (a = 1) AND (b = 2);
Список MCV предоставляет планировщику более подробную информацию о конкретных значениях, которые обычно отображаются в таблице, а также верхнюю границу избирательности комбинаций значений, которые не отображаются в таблице, что позволяет ему генерировать лучшие оценки в обоих случаях.
Совместимость
В стандарте SQL нет команды CREATE STATISTICS.
См. также
ALTER STATISTICS, DROP STATISTICS
CREATE SUBSCRIPTION
CREATE SUBSCRIPTION — определить новую подписку
Синтаксис
CREATE SUBSCRIPTION имя_подписки
CONNECTION 'строка_подключения'
PUBLICATION имя_публикации [, ...]
[ WITH ( параметр_подписки [= значение] [, ... ] ) ]
Описание
Команда CREATE SUBSCRIPTION добавляет новую подписку для текущей базы данных.
Имя подписки должно отличаться от имени любой существующей подписки в
базе данных.
Подписка представляет собой подключение репликации к публикующему серверу. Таким образом, эта команда не только добавляет определения в локальные каталоги, но и создает слот репликации на публикующем сервере.
При фиксации транзакции, в которой выполняется эта команда, будет запущен модуль логической репликации, который будет реплицировать данные для новой подписки.
Параметры
имя_подписки
Имя новой подписки.
CONNECTION 'строка_подключения'
Строка подключения к публикующему серверу..
PUBLICATION имя_публикации
Имена публикаций на публикующем сервере, на которые производится подписка.
WITH ( параметр_подписки [= значение] [, ... ] )
В этом предложении указываются необязательные параметры для подписки. Поддерживаются следующие параметры:
copy_data (boolean)
Указывает, должны ли копироваться существующие данные в публикациях, на которые выполняется подписка, сразу после запуска репликации. Значение по умолчанию равно true.
create_slot (boolean)
Указывает, должна ли команда создать слот репликации на публикующем сервере. Значение по умолчанию равно true.
enabled (boolean)
Указывает, следует ли активировать репликацию подписки или ее нужно только настроить, но пока не запускать. Значение по умолчанию равно true.
slot_name (string)
Имя используемого слота репликации. Поведение по умолчанию заключается в использовании имени подписки для имени слота.
Когда значение slot_name задается как NONE, с подпиской не будет связан никакой слот репликации. Это можно использовать, если слот репликации будет создан позже вручную. В таких подписках также должны быть установлены значения false для параметров enabled и create_slot.
synchronous_commit (enum)
Значение этого параметра переопределяет параметр synchronous_commit. Значение по умолчанию равно off.
Использование значения off безопасно для логической репликации: если подписчик потеряет транзакции из-за отсутствия синхронизации, данные будут повторно отправлены с публикующего сервера.
При выполнении синхронной логической репликации может потребоваться
другой параметр. Модули логической репликации передают на публикующий сервер
позиции записанных и сохраненных на диске данных, и при использовании синхронной
репликации тот будет ожидать фактического сохранения. Следовательно,
значение off параметра synchronous_commit для подписчика при использовании
подписки для синхронной репликации может увеличить задержку выполнения COMMIT
на публикующем сервере. При таком сценарии может быть выгодно установить для
synchronous_commit значение local или выше.
connect (boolean)
Указывает, должна ли CREATE SUBSCRIPTION вообще подключаться к публикующему
серверу. При установке для этого параметра значения false значения по умолчанию
параметров enabled, create_slot и copy_data также сменятся на false.
Не допускается совмещение значения false для параметра connect и значения true для параметров enabled,create_slot или copy_data.
Так как при значении false для этого параметра соединение не устанавливается,
подписка на таблицы не производится, и поэтому после включения подписки ничего
реплицироваться не будет. Чтобы запустить подписку на таблицы, нужно выполнить
команду ALTER SUBSCRIPTION ... REFRESH PUBLICATION.
Примечания
.При создании слота репликации (поведение по умолчанию) команду
CREATE SUBSCRIPTION нельзя выполнить внутри блока транзакций.
Создание подписки, которая подключается к одному и тому же кластеру баз
данных (например, для репликации между базами данных в одном и том же
кластере или для репликации в одной и той же базе данных), будет
успешным только в том случае, если слот репликации не создается в рамках
той же команды. В противном случае вызов CREATE SUBSCRIPTION будет зависать.
Чтобы выполнить эту работу, создайте слот репликации отдельно (с помощью
функции pg_create_logical_replication_slot с именем плагина
pgoutput) и создайте подписку с помощью параметра create_slot = false.
Это ограничение реализации, которое может быть снято в будущем выпуске.
Примеры
Создание подписки на удаленный сервер, который реплицирует таблицы в публикациях mypublication и insert_only с немедленным запуском репликации при фиксации транзакции:
CREATE SUBSCRIPTION mysub
CONNECTION 'host=192.168.1.50 port=5432 user=foo dbname=foodb'
PUBLICATION mypublication, insert_only;
Создание подписки на удаленный сервер, который реплицирует таблицы в публикацию insert_only с отложенным запуском репликации.
CREATE SUBSCRIPTION mysub
CONNECTION 'host=192.168.1.50 port=5432 user=foo dbname=foodb'
PUBLICATION insert_only
WITH (enabled = false);
Совместимость
Команда CREATE SUBSCRIPTION является расширением QHB.
См. также
ALTER SUBSCRIPTION, DROP SUBSCRIPTION, CREATE PUBLICATION, ALTER PUBLICATION
CREATE TABLE AS
CREATE TABLE AS — определить новую таблицу из результатов запроса
Синтаксис
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] имя_таблицы
[ (имя_столбца [, ...] ) ]
[ USING метод ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE имя_табличного_пространства ]
AS запрос
[ WITH [ NO ] DATA ]
Описание
Команда CREATE TABLE AS создает таблицу и заполняет ее данными,
вычисленными командой SELECT. Столбцы таблицы имеют имена и типы
данных, связанные с выходными столбцами SELECT (за исключением того,
что можно переопределить имена столбцов, предоставив явный список новых
имен столбцов).
Команда CREATE TABLE AS имеет некоторое сходство с созданием представления,
но на самом деле это совсем другое: она создает новую таблицу и оценивает
запрос только один раз, чтобы заполнить новую таблицу изначально. Новая
таблица не будет отслеживать последующие изменения исходных таблиц
запроса. Напротив, представление повторно оценивает определяющую его
команду SELECT при каждом запросе к нему.
Параметры
GLOBAL или LOCAL
Игнорируется для совместимости. Использование этих ключевых слов не рекомендуется; дополнительную информацию см. в разделе CREATE TABLE.
TEMPORARY или TEMP
Если этот параметр указан, таблица создается как временная таблица. Дополнительную информацию см. в разделе CREATE TABLE.
UNLOGGED
Если этот параметр указан, таблица создается как незарегистрированная таблица. Дополнительную информацию см. в разделе CREATE TABLE.
IF NOT EXISTS
Не считать ошибкой, если связь с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Дополнительную информацию см. в разделе CREATE TABLE.
имя_таблицы
Имя создаваемой таблицы (может быть дополнено схемой).
имя_столбца
Имя столбца в новой таблице. Если имена столбцов не предоставлены, они берутся из имен выходных столбцов запроса.
USING метод
Это необязательное предложение определяет метод доступа к таблице,
который будет использоваться для хранения содержимого для новой таблицы; этот метод должен быть типа TABLE.
Дополнительную информацию см. в главе Определение интерфейса метода доступа к таблице.
Если этот параметр не указан, то для новой таблицы выбирается метод доступа к таблице по умолчанию.
Дополнительную информацию см. в разделе default_table_access_method.
В QHB есть встроенный метод доступа к таблице qss, при указании которого данные таблицы,
ее индексов и журнала будут записываться на диск в зашифрованном виде.
Дополнительную информацию см. в разделе Модуль безопасного хранения QSS.
Также в QHB реализован встроенный метод доступа, реализующий хранилище append_only, для которого характерны следующие свойства:
Дополнительную информацию см. в разделе Таблицы APPEND_ONLY.
WITH ( параметр_хранения [= значение] [, ... ] )
В этом предложении указываются необязательные параметры хранения для новой таблицы. Дополнительную информацию см. в подразделе Параметры хранения в описании команды CREATE TABLE. В целях обратной совместимости предложение WITH для таблицы также может включать в себя OIDS=FALSE, чтобы указать, что строки новой таблицы не должны содержать OID (идентификаторы объектов); OIDS=TRUE не поддерживается.
WITHOUT OIDS
Это синтаксис обратной совместимости для объявления таблицы WITHOUT OIDS; создание таблицы WITH OIDS не поддерживается.
ON COMMIT
Поведение временных таблиц в конце блока транзакций можно контролировать с помощью ON COMMIT. Есть три варианта::
TABLESPACE имя_табличного_пространства
имя_табличного_пространства — это имя табличного пространства, в котором будет создана новая таблица. Если этот параметр не указан, выполняется запрос default_tablespace или temp_tablespaces (если таблица временная).
запрос
Команда SELECT, TABLE или VALUES либо команда EXECUTE, которая
выполняет подготовленный запрос SELECT, TABLE или VALUES.
WITH [NO ] DATA
Это предложение указывает, следует ли копировать данные, созданные запросом, в новую таблицу. Если нет, то копируется только структура таблицы. По умолчанию выполняется копирование данных.
Примечания
Эта команда функционально похожа на SELECT INTO, но она
предпочтительнее, так как ее менее вероятно спутать с другими вариантами
использования синтаксиса SELECT INTO. Кроме того,
набор функций у CREATE TABLE AS больше, чем у SELECT INTO.
Примеры
Создание новой таблицы films_recent, состоящей только из последних записей из таблицы films:
CREATE TABLE films_recent AS
SELECT * FROM films WHERE date_prod >= '2002-01-01';
Чтобы скопировать таблицу полностью, также можно использовать короткую форму с
помощью команды TABLE:
CREATE TABLE films2 AS
TABLE films;
Создание новой временной таблицы films_recent, состоящей только из последних записей таблицы films, используя подготовленный оператор. Новая таблица будет удалена при фиксации транзакции:
PREPARE recentfilms(date) AS
SELECT * FROM films WHERE date_prod > $1;
CREATE TEMP TABLE films_recent ON COMMIT DROP AS
EXECUTE recentfilms('2002-01-01');
Совместимость
Команда CREATE TABLE AS соответствует стандарту SQL. Ниже приведены
нестандартные расширения:
См. также
CREATE MATERIALIZED VIEW, CREATE TABLE, EXECUTE, SELECT, SELECT INTO, VALUES
CREATE TABLESPACE
CREATE TABLESPACE — определить новое табличное пространство
Синтаксис
CREATE TABLESPACE имя_табличного_пространства
[ OWNER { новый_владелец | CURRENT_USER | SESSION_USER } ]
LOCATION 'каталог'
[ WITH ( параметр_табличного_пространства = значение [, ... ] ) ]
Описание
Команда CREATE TABLESPACE регистрирует новое табличное
пространство в масштабе кластера. Имя табличного пространства должно
отличаться от имени любого существующего табличного пространства в
кластере баз данных.
Табличное пространство позволяет суперпользователям определять альтернативное расположение в файловой системе, в котором могут находиться файлы данных, содержащие объекты базы данных (такие как таблицы и индексы).
Пользователь с соответствующими правами может передать параметр
имя_табличного_пространства команде CREATE DATABASE, CREATE TABLE,
CREATE INDEX или ADD CONSTRAINT, чтобы файлы данных для
этих объектов хранились в указанном табличном пространстве.
Предупреждение!
Табличное пространство не может использоваться независимо от кластера, в котором оно определено; см. раздел Табличные пространства.
Параметры
имя_табличного_пространства
Имя создаваемого табличного пространства. Имя не может начинаться с pg_, поскольку такие имена зарезервированы для системных табличных пространств.
имя_пользователя
Имя пользователя, которому будет принадлежать табличное пространство. Если этот параметр опущен, по умолчанию владельцем станет пользователь, выполняющий команду. Только суперпользователи могут создавать табличные пространства, но они могут назначать владение табличными пространствами не суперпользователям.
каталог
Каталог, который будет использоваться для табличного пространства.
Каталог должен существовать (CREATE TABLESPACE не будет его
создавать), быть пустым и принадлежать системному пользователю
QHB. Каталог должен быть задан абсолютным именем пути.
параметр_табличного_пространства
Параметр табличного пространства, который необходимо установить или сбросить. В настоящее время доступны только следующие параметры: seq_page_cost, random_page_cost, effective_io_concurrency и maintenance_io_concurrency. Установка любого значения для конкретного табличного пространства переопределит обычную оценку планировщиком стоимости чтения страниц из таблиц в этом табличном пространстве, установленную параметрами конфигурации с тем же именем (см. подразделы seq_page_cost, random_page_cost, effective_io_concurrency, maintenance_io_concurrency). Это может быть полезно, если одно табличное пространство расположено на диске, который быстрее или медленнее, чем остальная часть подсистемы ввода-вывода.
Примечания
Табличные пространства поддерживаются только в системах, поддерживающих символьные ссылки.
Команда CREATE TABLESPACE не может быть выполнена внутри
блока транзакций.
Примеры
Чтобы создать табличное пространство dbspace в расположении файловой системы /data/dbs, сначала создайте каталог с помощью средств операционной системы и установите правильное владение:
mkdir /data/dbs
chown qhb:qhb /data/dbs
Затем выполните команду создания табличного пространства внутри QHB:
CREATE TABLESPACE dbspace LOCATION '/data/dbs';
Чтобы создать табличное пространство, принадлежащее другому пользователю базы данных, используйте следующую команду:
CREATE TABLESPACE indexspace OWNER genevieve LOCATION '/data/indexes';
Совместимость
Команда CREATE TABLESPACE является расширением QHB.
См. также
CREATE DATABASE, CREATE TABLE, CREATE INDEX, DROP TABLESPACE, ALTER TABLESPACE
CREATE TABLE
CREATE TABLE — определить новую таблицу
Синтаксис
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] имя_таблицы ( [
{ имя_столбца тип_данных [ COLLATE правило_сортировки ] [ ограничение_столбца [ ... ] ]
| ограничение_таблицы
| LIKE исходная_таблица [ вариант_копирования ... ] }
[, ... ]
] )
[ INHERITS ( таблица_родитель [, ... ] ) ]
[ PARTITION BY { RANGE | LIST | HASH } ( { имя_столбца | ( выражение ) } [ COLLATE правило_сортировки ] [ класс_операторов ] [, ... ] ) ]
[ USING метод ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE имя_табличного_пространства ]
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] имя_таблицы
OF имя_типа [ (
{ имя_столбца [ WITH OPTIONS ] [ ограничение_столбца [ ... ] ]
| ограничение_таблицы }
[, ... ]
) ]
[ PARTITION BY { RANGE | LIST | HASH } ( { имя_столбца | ( выражение ) } [ COLLATE правило_сортировки ] [ класс_операторов ] [, ... ] ) ]
[ USING метод ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE имя_табличного_пространства ]
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] имя_таблицы
PARTITION OF таблица_родитель [ (
{ имя_столбца [ WITH OPTIONS ] [ ограничение_столбца [ ... ] ]
| ограничение_таблицы }
[, ... ]
) ] { FOR VALUES указание_границ_партиции | DEFAULT }
[ PARTITION BY { RANGE | LIST | HASH } ( { имя_столбца | ( выражение ) } [ COLLATE правило_сортировки ] [ класс_операторов ] [, ... ] ) ]
[ USING метод ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE имя_табличного_пространства ]
Где ограничение_столбца может быть:
[ CONSTRAINT имя_ограничения ]
{ NOT NULL |
NULL |
CHECK ( выражение ) [ NO INHERIT ] |
DEFAULT выражение_по_умолчанию |
GENERATED ALWAYS AS ( выражение_генерации ) STORED |
GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( параметры_последовательности ) ] |
UNIQUE параметры_индекса |
PRIMARY KEY параметры_индекса |
REFERENCES ссылочная_таблица [ ( ссылочный_столбец ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
Где ограничение_таблицы может быть:
[ CONSTRAINT имя_ограничения ]
{ CHECK ( выражение ) [ NO INHERIT ] |
UNIQUE ( имя_столбца [, ... ] ) параметры_индекса |
PRIMARY KEY ( имя_столбца [, ... ] ) параметры_индекса |
EXCLUDE [ USING индексный_метод ] ( элемент_исключения WITH оператор [, ... ] ) параметры_индекса [ WHERE ( предикат ) ] |
FOREIGN KEY ( имя_столбца [, ... ] ) REFERENCES целевая_таблица [ ( целевой_столбец [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
Где вариант_копирования может быть::
{ INCLUDING | EXCLUDING } { COMMENTS | CONSTRAINTS | DEFAULTS | GENERATED | IDENTITY | INDEXES | STATISTICS | STORAGE | ALL }
Где указание_границ_партиции может быть:
IN ( выражение_границ_партиции [, ...] ) |
FROM ( { выражение_границ_партиции | MINVALUE | MAXVALUE } [, ...] )
TO ( { выражение_границ_партиции | MINVALUE | MAXVALUE } [, ...] ) |
WITH ( MODULUS числовая_константа, REMAINDER числовая_константа )
Где параметр_индекса в ограничениях UNIQUE, PRIMARY KEY и EXCLUDE может быть:
[ INCLUDE ( имя_столбца [, ... ] ) ]
[ WITH ( параметр_хранения [= значение] [, ... ] ) ]
[ USING INDEX TABLESPACE имя_табличного_пространства ]
Где элемент_исключения в ограничении EXCLUDE может быть:
{ имя_столбца | ( выражение ) } [ класс_операторов ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ]
Описание
Команда CREATE TABLE создаст новую, изначально пустую таблицу в текущей базе
данных. Таблица будет принадлежать пользователю, выполнившему эту команду.
Если задано имя схемы (например, CREATE TABLE myschema.mytable ...), то
таблица создается в указанной схеме, в противном случае — в текущей.
Временные таблицы существуют в специальной схеме, поэтому при их создании не
может быть задано имя схемы. Имя таблицы должно отличаться от имени любой другой
таблицы, последовательности, индекса, представления или сторонней таблицы
в той же схеме.
Также команда CREATE TABLE автоматически создает тип данных, представляющий
составной тип, соответствующий одной строке таблицы. Поэтому таблицы не
могут иметь то же имя, что и любой существующий тип данных в той же
схеме.
Необязательные предложения ограничений определяют ограничения (тесты), которым новые или измененные строки должны удовлетворять для успешного выполнения операции добавления или изменения. Ограничение — это объект SQL, который помогает различными способами определить набор допустимых значений в таблице.
Существует два способа определения ограничений: ограничения таблицы и ограничения столбца. Ограничение столбца определяется как часть определения столбца. Определение ограничения таблицы не привязано к определенному столбцу и может охватывать несколько столбцов. Каждое ограничение столбца также может быть записано как ограничение таблицы; ограничение столбца — это только удобство обозначений для использования, когда ограничение затрагивает только один столбец.
Чтобы иметь возможность создать таблицу, необходимо иметь право USAGE на все типы столбцов или тип в предложении OF соответственно.
Параметры
TEMPORARY или TEMP
Если указан этот параметр, таблица создается как временная таблица. Временные таблицы автоматически удаляются в конце сеанса или, при необходимости, в конце текущей транзакции (см. подраздел ON COMMIT ниже). Существующие постоянные таблицы с одинаковыми именами не видны текущему сеансу, пока существует временная таблица, если только они не связаны с именами, определенными схемой. Все индексы, созданные во временной таблице, также автоматически являются временными.
Процесс «Автовакуум» не может получить доступ и,
следовательно, не может очищать или анализировать временные
таблицы. По этой причине соответствующие операции очистки и
анализа должны выполняться с помощью команд сеанса SQL. Например, если
временная таблица будет использоваться в сложных запросах, целесообразно
после ее заполнения запустить ANALYZE для временной таблицы.
При желании перед TEMPORARY или *TEMP можно написать GLOBAL или LOCAL. В настоящее время в QHB это не имеет никакого значения и является устаревшей опцией; см. раздел Cовместимость.
Если указан этот параметр, таблица создается как нерегистрируемая таблица. Данные, записанные в нерегистрируемые таблицы, не записываются в журнал предварительной записи (см. главу Надежность и журнал записи), что делает их значительно быстрее, чем обычные таблицы. Однако они не защищены от сбоев: нерегистрируемая таблица автоматически усекается после сбоя или небезопасного завершения работы. Кроме того, содержимое нерегистрируемой таблицы не реплицируется на резервные серверы. Все индексы, созданные в незарегистрированной таблице, тоже автоматически становятся нерегистрируемыми.
IF NOT EXISTS
Не считать ошибкой, если отношение с тем же именем уже существует. В этом случае будет выдано соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее отношение как-то соотносится с тем, которое было бы создано.
имя_таблицы
Имя создаваемой таблицы (может быть дополнено схемой).
OF имя_типа
Создает типизированную таблицу, которая берет свою структуру из
указанного составного типа (имя может быть дополнено схемой).
Типизированная таблица привязывается к своему типу: например, таблица
будет удалена, если тип будет удален (с DROP TYPE ... CASCADE).
При создании типизированной таблицы типы данных столбцов определяются
базовым составным типом и не определяются командой CREATE TABLE.
Но CREATE TABLE может добавлять в таблицу значения по умолчанию и ограничения,
а также указывать параметры хранения.
имя_столбца
Имя столбца, который будет создан в новой таблице.
тип_данных
Тип данных столбца. Может включать в себя спецификаторы массива. Дополнительную информацию о типах данных, поддерживаемых QHB, см. в главе Типы данных.
COLLATE правило_сортировки
Предложение COLLATE назначает правило сортировки для столбца (который должен иметь сопоставимый тип данных). Если параметр не указан, используется правило сортировки по умолчанию для типа данных столбца.
INHERITS ( таблица_родитель [, ... ] )
Необязательное предложение INHERITS задает список таблиц, из которых новая таблица автоматически наследует все столбцы. Родительские таблицы могут быть простыми или сторонними таблицами.
Использование INHERITS создает постоянную связь между новой дочерней таблицей и ее родительской(ими) таблицей(ами). Изменения схемы в родительской(их) таблице(ах) обычно распространяются также и на дочерние, и по умолчанию данные дочерней таблицы включаются в сканы родительской(их).
Если одно и то же имя столбца существует в более чем одной родительской таблице, то появляется сообщение об ошибке, если только типы данных столбцов не совпадают в каждой из родительских таблиц. В этом случае повторяющиеся столбцы объединяются, чтобы сформировать один столбец в новой таблице. Если список имен столбцов новой таблицы содержит имя столбца, которое тоже наследуется, тип данных аналогичным образом должен соответствовать унаследованному(ым) столбцу(ам), и определения столбцов объединяются в одно. Если новая таблица явно указывает значение по умолчанию для столбца, оно переопределяет любые значения по умолчанию из унаследованных объявлений столбца. В противном случае все родительские таблицы, указывающие значения по умолчанию для столбца, должны указывать одно и то же значение по умолчанию, иначе будет сообщено об ошибке.
Ограничения CHECK объединяются, по сути, так же, как и столбцы: если несколько родительских таблиц и/или новое определение таблицы содержат ограничения CHECK с идентичными именами, то все эти ограничения должны иметь одно и то же выражение проверки, иначе появится сообщение об ошибке. Ограничения, имеющие одинаковое имя и выражение, будут объединены в одну копию. Ограничение, помеченное в родительской таблице как NO INHERIT, рассматриваться не будет. Обратите внимание, что безымянное ограничение CHECK в новой таблице никогда не будет объединено, так как для него всегда будет выбираться уникальное имя.
Параметры STORAGE для столбца также копируются из родительских таблиц.
Если столбец в родительской таблице является столбцом идентификаторов, это свойство не наследуется. При желании столбец в дочерней таблице можно объявить столбцом идентификаторов.
PARTITION BY { RANGE | LIST | HASH } ( { имя_столбца | ( выражение ) } [ класс_операторов ] [, ...] )
Необязательное предложение PARTITION BY задает стратегию разбиения таблицы. Созданная таким образом таблица называется партиционированной таблицей. Заключенный в скобки список столбцов или выражений формирует ключ разбиения для таблицы. При использовании партиционирования по диапазонам или по хэшу ключ разбиения может включать несколько столбцов или выражений (до 32, но это ограничение может быть изменено при создании QHB), но для партиционирования по списку ключ разбиения должен состоять из одного столбца или выражения.
Для партиционирования по диапазонам и по списку требуется класс операторов В-дерева, а для партиционирования по хэшу — класс операторов хэширования. Если класс операторов не указан явно, будет использоваться класс операторов по умолчанию соответствующего типа; если класс операторов по умолчанию отсутствует, будет вызвана ошибка. При использовании хэш-партиционирования применяемый класс операторов должен реализовывать вспомогательную функцию 2 (более подробную информацию см. в разделе Процедуры поддержки индексного метода).
Партиционированная таблица делится на подтаблицы (называемые партициями),
которые создаются с помощью отдельных команд CREATE TABLE.
Партиционированная таблица сама по себе пуста. Добавленная в таблицу строка данных
направляется в партицию на основании значения столбцов
или выражений в ключе разбиения. Если ни одна существующая партиция не
соответствует значениям в новой строке, будет сообщено об ошибке.
Партиционированные таблицы не поддерживают ограничение EXCLUDE, однако эти ограничения можно определить для отдельных партиций.
Дополнительную информацию о партиционировании таблиц см. в разделе Партиционирование таблиц.
PARTITION OF таблица_родитель { FOR VALUES указание_границ_партиции | DEFAULT }
Создает таблицу как партицию указанной родительской таблицы. Таблица может быть создана либо как партиция для конкретных значений (с помощью FOR VALUES), либо в качестве партиции по умолчанию (с помощью DEFAULT). Все индексы, ограничения и пользовательские триггеры уровня строк, которые имеются в родительской таблице, клонируются в новую партицию.
указание_границ_партиции должно соответствовать методу и ключу разбиения родительской таблицы и не должно перекрываться ни с какой существующей партицией этого родителя. Форма с IN используется для партиционирования по списку, форма с FROM и TO — для партиционирования по диапазонам, а форма с WITH — для партиционирования по хэшу.
выражение_границ_партиции — это любое выражение без переменных (подзапросы, оконные функции, агрегатные функции и функции возврата набора не допускаются). Его тип данных должен соответствовать типу данных соответствующего столбца ключа разбиения. Выражение вычисляется один раз во время создания таблицы, поэтому может даже содержать изменчивые выражения, такие как CURRENT_TIMESTAMP.
При создании списочной партиции можно указать в этом списке NULL, чтобы обозначить, что столбец ключа разбиения может содержать NULL. Однако у отдельно взятой родительской таблицы не может быть более одной такой списочной партиции. Нельзя указывать NULL для диапазонных партиций.
При создании диапазонной партиции нижняя граница, заданная с помощью FROM,
является включающей границей, тогда как верхняя граница, заданная с помощью
TO, является исключающей границей. То есть значения, указанные в списке FROM, —
это допустимые значения соответствующих столбцов ключа разбиения
для данной партиции, тогда как значения в списке TO таковыми не являются.
Обратите внимание, что это утверждение следует понимать в
соответствии с правилами сравнения строк (см. раздел Сравнение конструкторов строк).
Например, с разделением PARTITION BY RANGE (x,y) партиция с границами
FROM (1, 2) TO (3, 4) примет x=1 с любым значением y>=2, x=2 — с любым
значением y, отличным от NULL, и x=3 — с любым y<4.
При создании диапазонной партиции можно использовать особые значения MINVALUE и
MAXVALUE, чтобы указать, что нет нижней или верхней границы значения
столбца. Например, партиция, определенная с помощью FROM (MINVALUE) TO (10) принимает любые значения меньше 10, а партиция,
определенная с помощью FROM (10) TO (MAXVALUE), принимает любые значения,
превышающие или равные 10.
При создании диапазонной партиции, включающей более одного столбца,
также может иметь смысл использовать MAXVALUE как часть нижней границы
и MINVALUE как часть верхней границы. Например, партиция, определенная с
помощью FROM (0, MAXVALUE) TO (10, MAXVALUE), принимает любые строки, в
которых первый столбец ключа разбиения больше 0 и меньше или равен 10.
Аналогично, партиция, определенная с помощью FROM (’a’, MINVALUE) TO (’b’, MINVALUE), принимает любые строки, в которых первый столбец ключа разбиения
начинается с «a».
Обратите внимание, что если MINVALUE или MAXVALUE используется для
одного столбца границы партиции, то это же значение должно
использоваться для всех последующих столбцов. Например, (10, MINVALUE, 0) не является допустимой границей; следует написать (10, MINVALUE, MINVALUE).
Также обратите внимание, что у некоторых типов элементов, таких как timestamp
(отметка времени), есть понятие «infinity» (бесконечность), которое является
просто еще одним сохраняемым значением. Оно отличается от MINVALUE и
MAXVALUE, являющимися не реальными значениями, которые могут быть
сохранены, а скорее способами сказать, что значение
безгранично. MAXVALUE можно рассматривать как значение, превышающее любое другое,
включая «бесконечность», а MINVALUE — как значение меньше любого другого,
включая «минус бесконечность». Таким образом, диапазон
FROM ('infinity') TO (MAXVALUE) — это не пустой диапазон; он позволяет хранить
ровно одно значение — «infinity».
Если указывается DEFAULT, то таблица будет создана как партиция по умолчанию родительской таблицы. Этот параметр недоступен для хэш-партиционированных таблиц. Значение ключа разбиения, не вписывающееся в любую другую партицию данного родительского объекта, будет перенаправлено в партицию по умолчанию.
Когда таблица уже имеет партицию по умолчанию (DEFAULT) и к нему добавляется новая партиция, нужно просканировать партицию по умолчанию, чтобы убедиться, что она не содержит строк, которые точно подходят для новой партиции. Если партиция по умолчанию содержит большое количество строк, этот процесс может быть медленным. Проверка будет пропущена, если партиция по умолчанию является сторонней таблицей или имеет ограничение, которое доказывает, что она не может содержать строки, которые должны быть размещены в новой партиции.
При создании хэш-партиции необходимо указать модуль и остаток. Модуль должен быть положительным целым числом, а остаток — неотрицательным целым числом меньше модуля. Как правило, при первоначальной настройке хэш-партиционированной таблицы следует выбрать модуль, равный числу партиций, и назначить каждой таблице этот модуль и разные остатки (см. примеры ниже). Однако партициям необязательно иметь одинаковый модуль, достаточно чтобы каждый модуль, который встречается среди партиций хэш-партиционированной таблицы, был кратным следующего большего модуля. Это позволяет постепенно увеличивать число партиций без необходимости перемещать все данные одновременно. Например, предположим, что у вас есть хэш-партиционированная таблица с 8 партициями, каждая из которых имеет модуль 8, но необходимо увеличить число партиций до 16. Можно отсоединить одну из партиций по модулю 8, создать две новые партиции по модулю 16, охватывающие ту же часть пространства ключей (одну с остатком, равным остатку отсоединенной партиции, а другую с остатком, равным этому значению плюс 8), и повторно заполнить их данными. Затем этот процесс можно повторить — возможно, позднее — для каждой партиции по модулю 8, пока ни одной из них не останется. Хотя такой способ по-прежнему может включать в себя большой объем перемещения данных на каждом этапе, это всё же лучше, чем создавать целую новую таблицу и перемещать все данные сразу.
Партиция должна содержать те же имена и типы столбцов, что и партиционированная таблица, к которой она принадлежит. Изменения имен или типов столбцов партиционированной таблицы будут автоматически распространяться на все партиции. Ограничения CHECK будут наследоваться автоматически каждой партицией, но для отдельных партиций можно указать дополнительные ограничения CHECK; дополнительные ограничения с теми же именами и условиями, что и в родительском элементе, будут объединены с родительским ограничением. Значения по умолчанию могут быть указаны отдельно для каждой партиции. Однако обратите внимание, что значение по умолчанию, заданное для партиции, не будет применяться при добавлении кортежа через партиционированную таблицу.
Строки, добавленные в партиционированную таблицу, будут автоматически перенаправлены в нужную партицию. Если подходящей партиции не существует, произойдет ошибка.
Такие операции, как TRUNCATE, которые обычно влияют на таблицу и все ее
дочерние элементы, будут распространяться на все партиции, но
также могут выполняться на отдельной партиции. Обратите внимание, что
удаление партиции с помощью DROP TABLE требует запрашивать блокировку
ACCESS EXCLUSIVE на родительской таблице.
LIKE исходная_таблица [ вариант_копирования ... ]
Предложение LIKE указывает таблицу, из которой новая таблица автоматически копирует все имена столбцов, их типы данных и их ограничения на значение NULL.
В отличие от INHERITS, новая и исходная таблицы полностью разъединяются после завершения создания. Изменения исходной таблицы не будут применены к новой таблице, и нет возможности включить данные новой таблицы в сканы исходной таблицы.
Также, в отличие от INHERITS, столбцы и ограничения, скопированные при помощи LIKE, не объединяются с одноименными столбцами и ограничениями. Если одно и то же имя указано явно или содержится в другом предложении LIKE, будет выдана ошибка.
Необязательные предложения вариант_копирования указывают, какие дополнительные свойства исходной таблицы следует скопировать. Указание INCLUDING копирует свойство, указание EXCLUDING опускает свойство. EXCLUDING — это значение по умолчанию. Если для одного и того же типа объекта создается несколько спецификаций, то используется последняя из них. Доступные варианты:
INCLUDING COMMENTS
Будут скопированы комментарии для скопированных столбцов, ограничений и индексов. Поведение по умолчанию заключается в исключении комментариев, в результате чего скопированные столбцы и ограничения в новой таблице их не имеют.
INCLUDING CONSTRAINTS
Будут скопированы ограничения CHECK. Между ограничениями столбцов и таблиц никакого различия не делается. Ограничения на NULL всегда копируются в новую таблицу.
INCLUDING DEFAULTS
Будут скопированы выражения по умолчанию для скопированных определений столбцов. В противном случае выражения по умолчанию не копируются, в результате чего скопированные столбцы в новой таблице имеют значения по умолчанию NULL. Обратите внимание, что копирование значений по умолчанию, которые вызывают функции изменения базы данных, такие как nextval, может создать функциональную связь между исходной и новой таблицами.
INCLUDING GENERATED
Будут скопированы все выражения генерации скопированных определений столбцов. По умолчанию новые столбцы будут обычными базовыми столбцами.
INCLUDING IDENTITY
Будут скопированы все спецификации идентификаторов скопированных определений столбцов. Новая последовательность создается для каждого столбца идентификаторов новой таблицы отдельно от последовательностей, связанных со старой таблицей.
INCLUDING INDEXES
Индексы и ограничения PRIMARY KEY, UNIQUE и EXCLUDE для исходной таблицы будут созданы для новой таблицы. Имена для новых индексов и ограничений выбираются в соответствии с правилами по умолчанию, независимо от того, как были названы оригиналы. (Это поведение позволяет избежать возможных ошибок повторяющихся имен для новых индексов.)
INCLUDING STATISTICS
Расширенная статистика копируется в новую таблицу.
INCLUDING STORAGE
Будут скопированы параметры STORAGE для скопированных определений столбцов. Поведением по умолчанию является исключение параметров STORAGE, в результате чего скопированные столбцы в новой таблице имеют параметры по умолчанию для конкретного типа. Дополнительную информацию о параметрах STORAGE см. в разделе TOAST.
INCLUDING ALL
INCLUDING ALL — это сокращенная форма выбора всех доступных индивидуальных настроек. (Может быть удобно после применения INCLUDING ALL написать отдельные предложения EXCLUDING, чтобы выбрать все, кроме некоторых конкретных параметров.)
Предложение LIKE также можно использовать для копирования определений столбцов из представлений, сторонних таблиц или составных типов. Неприменимые настройки (например, INCLUDING INDEXES из представления) игнорируются.
CONSTRAINT имя_ограничения
Необязательное имя для ограничения столбца или таблицы. Если ограничение нарушается, имя ограничения присутствует в сообщениях об ошибках, поэтому имена ограничений, такие как столбец должен быть положительным, можно использовать для передачи полезной информации об ограничениях клиентским приложениям. (Для указания имен ограничений, содержащих пробелы, необходимы двойные кавычки.) Если имя ограничения не указано, система создает его автоматически.
NOT NULL
Столбец не может содержать значения NULL.
NULL
Столбец может содержать значения NULL. Это значение по умолчанию.
Это предложение предусмотрено только для обеспечения совместимости с нестандартными базами данных SQL. Его использование не рекомендуется в новых приложениях.
CHECK ( выражение ) [ NO INHERIT ]
Предложение CHECK задает выражение, создающее логический результат, которому должны удовлетворять новые или измененные строки для успешного выполнения операции добавления или изменения. Выражения, результат которых равен TRUE или UNKNOWN, успешно выполняются. Если какая-либо строка операции добавления или изменения приводит к результату FALSE, возникает ошибка и эта операция не изменяет базу данных. Проверочное ограничение, указанное как ограничение столбца, должно ссылаться только на значение этого столбца, тогда как выражение, расположенное в ограничении таблицы, может ссылаться на несколько столбцов.
В настоящий момент выражения CHECK не могут содержать вложенные запросы и ссылаться на переменные, отличные от столбцов текущей строки (см. раздел Контрольные ограничения). Допустима ссылка на системный столбец tableoid, но не на другие системные столбцы.
Ограничение с пометкой NO INHERIT не будет распространяться на дочерние таблицы.
Когда таблица имеет несколько ограничений CHECK, они будут проверяться для каждой строки в алфавитном порядке по имени после проверки ограничений NOT NULL.
DEFAULT выражение_по_умолчанию
Предложение DEFAULT присваивает значение данных по умолчанию для столбца, в определении которого оно отображается. Значением является любое выражение без переменной (в частности, перекрестные ссылки на другие столбцы в текущей таблице не допускаются). Подзапросы также не допускаются. Тип данных выражения по умолчанию должен соответствовать типу данных столбца.
Выражение по умолчанию будет использоваться в любой операции добавления, которая не задает значение для столбца. Если для столбца нет значения по умолчанию, то оно будет равно NULL.
GENERATED ALWAYS AS ( выражение_генерации ) STORED
Это предложение создает столбец как генерируемый столбец. Столбец не может быть записан, и при его чтении будет возвращен результат указанного выражения.
Ключевое слово STORED требуется для обозначения того, что столбец будет вычислен при записи и сохранен на диске.
Выражение генерации может ссылаться на другие столбцы в таблице, но не на другие генерируемые столбцы. Любые используемые функции и операторы должны быть неизменяемыми. Ссылки на другие таблицы не допускаются.
GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( параметры_последовательности ) ]
Это предложение создает столбец как столбец идентификации. К нему будет прикреплена неявная последовательность, и в новых строках такой столбец будет автоматически получать значения из назначенной ему последовательности.
Предложения ALWAYS и BY DEFAULT определяют, каким образом значение
последовательности имеет приоритет над пользовательским значением
в операторе INSERT. Если задано значение ALWAYS, пользовательское значение
принимается только в том случае, если в операторе INSERT указано
VERRIDING SYSTEM VALUE. Если указано BY DEFAULT, то пользовательское
значение имеет приоритет. Дополнительную информацию см. в разделе INSERT.
(В команде COPY всегда используются пользовательские
значения, независимо от этого параметра.)
Необязательное предложение параметры_последовательности можно использовать для переопределения параметров последовательности. Дополнительную информацию см. в разделе CREATE SEQUENCE.
UNIQUE (ограничение столбца) UNIQUE ( имя_столбца [, ... ] ) [ INCLUDE ( имя_столбца [, ...]) ] (ограничение таблицы)
Ограничение UNIQUE указывает, что группа из одного или нескольких столбцов таблицы может содержать только уникальные значения. Поведение ограничения уникальности для таблицы такое же, как и для столбцов, с дополнительной возможностью охватывать несколько столбцов.
При проверке ограничения уникальности значения NULL не считаются равными.
Каждое ограничение уникальности для таблицы должно содержать имя набора столбцов, отличного от набора столбцов, названных любым другим ограничением уникального или первичного ключа, определенным для таблицы. (В противном случае это будет просто одно и то же ограничение, указанное дважды.)
При установлении ограничения уникальности для многоуровневой иерархии партиций в определение ограничения должны быть включены все столбцы в ключе разбиения целевой партиционированной таблицы, а также столбцы всех ее дочерних партиционированных таблиц.
Добавление ограничения уникальности автоматически создаст уникальный
индекс типа В-дерево для столбца или группы столбцов, используемых в
ограничении. Необязательное предложение INCLUDE добавляет к этому
индексу один или несколько столбцов, для которых не применяется
уникальность. Обратите внимание, что хотя ограничение не применяется к
включенным столбцам, оно всё равно зависит от них. Следовательно,
некоторые операции над этими столбцами (например, DROP COLUMN)
могут вызвать каскадное ограничение и удаление индекса.
PRIMARY KEY (ограничение столбца) PRIMARY KEY ( имя_столбца [, ... ] ) [ INCLUDE ( имя_столбца [, ...]) ] (ограничение таблицы)
Ограничение PRIMARY KEY указывает, что столбец или столбцы таблицы могут содержать только уникальные (не повторяющиеся) значения, отличные от NULL. Для таблицы можно указать только один первичный ключ, будь то ограничение столбца или ограничение таблицы.
Ограничение первичного ключа должно содержать имя набора столбцов, отличного от набора столбцов, названных любым ограничением уникальности, определенным для той же таблицы. (В противном случае ограничение уникальности является избыточным и будет отброшено.)
PRIMARY KEY принудительно применяет те же ограничения данных, что и комбинация UNIQUE и NOT NULL, но указание набора столбцов в качестве первичного ключа также предоставляет метаданные о конструкции схемы, поскольку первичный ключ подразумевает, что другие таблицы могут полагаться на этот набор столбцов в качестве уникального идентификатора для строк.
Ограничения PRIMARY KEY разделяют условия, которые имеют ограничения UNIQUE при размещении в партиционированных таблицах.
Добавление ограничения PRIMARY KEY автоматически создаст уникальный
индекс типа B-дерево для столбца или группы столбцов, используемых в
ограничении. Необязательное предложение INCLUDE позволяет
указать список столбцов, которые будут включены в неключевую часть
индекса. Хотя уникальность не применяется к включенным столбцам,
ограничение всё равно зависит от них. Следовательно, некоторые операции
над включенными столбцами (например, DROP COLUMN) могут вызвать
каскадное ограничение и удаление индекса.
EXCLUDE [ USING индексный_метод ] ( элемент_исключения WITH оператор [, ... ] ) параметры_индекса [ WHERE ( предикат ) ]
Предложение EXCLUDE определяет ограничение исключения, которое гарантирует, что если любые две строки сравниваются на указанном столбце(ах) или выражении(ях) с использованием указанного оператора(ов), не все эти сравнения вернут значение TRUE. Если все указанные операторы проверяются на равенство, это эквивалентно ограничению UNIQUE, хотя обычное ограничение уникальности будет быстрее. Однако ограничения исключения могут указывать на ограничения, которые являются более общими, чем простое равенство. Например, можно указать ограничение, что никакие две строки в таблице не содержат перекрывающихся кругов (см. Геометрические типы), используя оператор &&.
Ограничения исключения реализуются с помощью индекса, поэтому каждый указанный оператор должен быть связан с соответствующим классом оператора (см. раздел Классы операторов и семейства операторов) для метода доступа к индексу индексный_метод. Операторы должны быть коммутативными. В каждом элементе_исключения можно дополнительно указать класс оператора и/или параметры сортировки; они полностью описаны в разделе CREATE INDEX.
Метод доступа должен поддерживать amgettuple (см. главу Определение интерфейса метода доступа к индексу); в настоящее время это означает, что GIN использовать нельзя. Хотя это разрешено, нет особого смысла в использовании с ограничением исключения B-дерева или хэш-индексов, потому что это ничуть не лучше, чем обычное ограничение уникальности. Поэтому на практике метод доступа всегда будет GiST или SP-GiST.
Параметр предикат позволяет задать ограничение исключения для подмножества таблицы; внутри он создает частичный индекс. Обратите внимание, что вокруг предиката требуются круглые скобки.
REFERENCES ссылочная_таблица [ ( ссылочный_столбец ) ] [ MATCH тип_совпадения ] [ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] (ограничение столбца) FOREIGN KEY ( имя_столбца [, ...\ ] ) REFERENCES ссылочная_таблица [ ( ссылочный_столбец [, ... ] ) ] [ MATCH тип_совпадения ] [ ON DELETE ссылочное_действие ] [ ON UPDATE ссылочное_действие ] (ограничение таблицы)
Эти предложения задают ограничение внешнего ключа, которое требует, чтобы группа из одного или нескольких столбцов новой таблицы содержала только значения, соответствующие значениям в ссылочном(ых) столбце(ах) некоторых строк ссылочной таблицы. Если список ссылочных_столбцов опущен, в качестве него будет использован первичный ключ ссылочной_таблицы. Ссылочные столбцы должны быть столбцами неоткладываемого ограничения уникальности или первичного ключа в ссылочной таблице. Необходимо иметь разрешение REFERENCES на эту ссылочную таблицу (либо на всю таблицу, либо на конкретные ссылочные столбцы). Добавление ограничения внешнего ключа требует блокировки SHARE ROW EXCLUSIVE соответствующей ссылочной таблицы. Обратите внимание, что ограничения внешнего ключа нельзя определить между временными и постоянными таблицами.
Значение, добавленное в ссылочный(ые) столбец(цы), сопоставляется со значениями ссылочной таблицы и ссылочных столбцов с использованием заданного типа соответствия. Существует три типа соответствия: MATCH FULL, MATCH PARTIAL и MATCH SIMPLE (что является значением по умолчанию). MATCH FULL не допускает, чтобы один столбец многоколоночного внешнего ключа имел значение NULL, если только все столбцы внешнего ключа не имеют значения NULL; если все они имеют значение NULL, то строка не обязательно должна совпадать в указанной таблице. MATCH SIMPLE позволяет любому из столбцов внешнего ключа иметь значение NULL; если какой-либо из них имеет значение NULL, строка не обязательно должна совпадать в ссылочной таблице. MATCH PARTIAL пока не реализовано. (Разумеется, для предотвращения возникновения подобных случаев к ссылочному(ым) столбцу(ам) могут быть применены ограничения NOT NULL.)
Кроме того, при изменении данных в ссылочных столбцах выполняются определенные действия с данными в столбцах этой таблицы. Предложение ON DELETE указывает действие, которое необходимо выполнить при удалении ссылочной строки в ссылочной таблице. Аналогичным образом предложение ON UPDATE указывает действие, которое необходимо выполнить, когда ссылочный столбец в ссылочной таблице обновляется до нового значения. Если строка обновляется, но ссылочный столбец фактически не изменяется, никакие действия не выполняются. Ссылочные действия, отличные от NO ACTION, нельзя сделать откладываемыми, даже если ограничение объявлено отложенным. Для каждого предложения возможны следующие действия:
NO ACTION
Выдать ошибку, указывающую на то, что удаление или обновление приведет к нарушению ограничения внешнего ключа. Если ограничение отложено, эта ошибка произойдет во время проверки ограничения, если всё еще существуют какие-либо ссылочные строки. Это действие по умолчанию.
RESTRICT
Выдать ошибку, указывающую на то, что удаление или обновление приведет к нарушению ограничения внешнего ключа. Это то же самое, что и NO ACTION, за исключением того, что проверка не откладывается.
CASCADE
Удалить все строки, ссылающиеся на удаленную строку, или обновить значения ссылочного(ых) столбца(ов) до новых значений ссылочных столбцов соответственно.
SET NULL
Установить для ссылочных столбцов значение NULL.
SET DEFAULT
Установить для ссылочного(ых) столбца(ов) значения по умолчанию. (В ссылочной таблице должна быть строка, соответствующая значениям по умолчанию, если их значение не NULL, иначе операция завершится ошибкой.)
Если ссылочные столбцы часто изменяются, возможно, целесообразно будет добавить ним индекс, чтобы ссылочные действия, связанные с ограничением внешнего ключа, могли выполняться более эффективно.
DEFERRABLE NOT DEFERRABLE
Это предложение определяет, может ли ограничение быть отложено. Неоткладываемое
ограничение будет проверяться сразу же после выполнения каждой команды.
Проверка откладываемых ограничений может быть отсрочена до окончания
транзакции (с помощью команды SET CONSTRAINTS). NOT DEFERRABLE является
значением по умолчанию. В настоящее время только ограничения
UNIQU, PRIMARY KEY, EXCLUDE и REFERENCES (внешний ключ)
принимают это предложение. Ограничения NOT NULL и CHECK являются
неоткладываемыми. Обратите внимание, что откладываемые ограничения нельзя
использовать в качестве арбитраторов конфликтов в операторе INSERT,
который включает в себя предложение ON CONFLICT DO UPDATE.
INITIALLY IMMEDIATE INITIALLY DEFERRED
Если ограничение является откладываемым, это предложение указывает время по умолчанию для проверки ограничения. Ограничение с характеристикой INITIALLY IMMEDIATE проверяется после каждого оператора. Это значение по умолчанию. Ограничение с характеристикой INITIALLY DEFERRED проверяется только в конце транзакции. Время проверки ограничений можно изменить с помощью команды SET CONSTRAINTS.
USING метод
Это необязательное предложение определяет метод доступа к таблице,
который будет использоваться для хранения содержимого для новой таблицы; этот метод должен быть типа TABLE.
Дополнительную информацию см. в главе Определение интерфейса метода доступа к таблице.
Если этот параметр не указан, то для новой таблицы выбирается метод доступа к таблице по умолчанию.
Дополнительную информацию см. в разделе default_table_access_method.
В QHB есть встроенный метод доступа к таблице qss, при указании которого данные таблицы,
ее индексов и журнала будут записываться на диск в зашифрованном виде.
Дополнительную информацию см. в разделе Модуль безопасного хранения QSS.
Также в QHB реализован встроенный метод доступа, реализующий хранилище append_only, для которого характерны следующие свойства:
Дополнительную информацию см. в разделе Таблицы APPEND_ONLY.
WITH ( параметр_хранения [= значение] [, ... ] )
В этом предложении указываются необязательные параметры хранения для таблицы или индекса; дополнительную информацию см. в подразделе Параметры хранения. Для обратной совместимости предложение WITH для таблицы также может включать в себя условие OIDS=FALSE, чтобы указать, что строки новой таблицы не должны содержать OID (идентификаторы объектов); OIDS=TRUE не поддерживается.
WITHOUT OIDS
Это синтаксис обратной совместимости для объявления таблицы WITHOUT OIDS; создание таблицы WITH OIDS не поддерживается.
ON COMMIT
Поведение временных таблиц в конце блока транзакций можно контролировать с помощью ON COMMIT. Есть три варианта:
Никаких специальных действий по завершению транзакций не предпринимается. Это поведение по умолчанию.
Все строки во временной таблице будут удалены в конце каждого блока транзакций. По существу, при каждой фиксации автоматически выполняется TRUNCATE. При использовании в партиционированной таблице это не распространяется на ее партиции.
Временная таблица будет удалена в конце текущего блока транзакций. При использовании в партиционированной таблице это действие удаляет ее партиции, а при использовании в таблицах с дочерними элементами в иерархии наследования — зависимые дочерние элементы.
TABLESPACE имя_табличного_пространства
имя_табличного_пространства — это имя табличного пространства, в котором будет создана новая таблица. Если этот параметр не указан, выполняется запрос default_tablespace или temp_tablespaces (если таблица временная). Для партиционированных таблиц, поскольку для самой таблицы хранение не требуется, указанное табличное пространство переопределяет default_tablespace как табличное пространство по умолчанию, используемое для любых вновь созданных партиций, когда никакое другое табличное пространство явно не указано.
USING INDEX TABLESPACE имя_табличного_пространства
Это предложение позволяет выбрать табличное пространство, в котором будет создан индекс, связанный с ограничением UNIQUE, PRIMARY KEY или EXCLUDE. Если этот параметр не указан, выполняется запрос default_tablespace или temp_tablespaces (если таблица временная).
Параметры хранения
Предложение WITH может указывать параметры хранения для таблиц, а также для индексов, связанных с ограничениями UNIQUE, PRIMARY KEY или EXCLUDE. Параметры хранения для индексов описаны в разделе CREATE INDEX. Ниже перечислены параметры хранения, доступные в настоящее время для таблиц. Для многих из этих параметров, как показано, существует дополнительный параметр с тем же именем, префиксом которого является toast., который управляет поведением вторичной таблицы TOAST, если таковая имеется (дополнительную информацию о таких таблицах см. в разделе TOAST). Если установлено значение параметра таблицы, а и аналогичный параметр toast. не определен, таблица TOAST будет использовать значение параметра таблицы. Указание этих параметров для партиционированных таблиц не поддерживается, но их можно задать для отдельных конечных партиций.
fillfactor (integer)
Коэффициент заполнения для таблицы, задается в процентах от 10 до 100. Значение по умолчанию равно 100 (полное заполнение). Если указан меньший коэффициент заполнения, то операции добавления упаковывают страницы таблицы только до указанного процента; оставшееся пространство на каждой странице зарезервировано для изменения строк на этой странице. Это дает UPDATE возможность разместить измененную копию строки на той же странице, что и оригинал, что более эффективно, чем размещение его на другой странице. Для таблицы, записи которой никогда не обновляются, лучшим выбором является полное заполнение, но в активно обновляемых таблицах целесообразнее использовать более мелкие коэффициенты заполнения. Этот параметр нельзя задать для таблиц TOAST.
toast_tuple_target (integer)
toast_tuple_target задает минимальную необходимую длину кортежа, после превышения которой мы попытаемся сжать и/или переместить значения длинных столбцов в таблицы TOAST, а также целевое значение, до которого мы попытаемся уменьшить нижележащую длину после перехода к TOAST. Это касается столбцов, помеченных как External (внешние, которые могут переноситься), Main (основные, которые могут сжиматься) или Extended (расширенные, которые могут как сжиматься, так и просто переноситься) и применяется только к новым кортежам. На существующие строки это не влияет. По умолчанию значение этого параметра допускает размещение не менее 4 кортежей на блок, что при стандартном размере блока составляет 2040 байт. Допустимые значения находятся в диапазоне от 128 байт до (размер блока — заголовок), по умолчанию 8160 байт. Изменение этого значения может быть не очень полезно для слишком коротких или слишком длинных строк. Обратите внимание, что настройка по умолчанию часто близка к оптимальной, и вполне возможно, что перенастройка этого параметра в некоторых случаях может иметь негативные последствия. Этот параметр нельзя задать для таблиц TOAST.
parallel_workers (integer)
Этот параметр задает число процессов, которые должны использоваться для поддержки параллельного сканирования данной таблицы. Если этот параметр не задан, система определит значение на основе размера отношения. Фактическое число процессов, выбранных планировщиком или служебными операторами, использующими параллельное сканирование, может быть меньше, например, из-за установки ограничения max_worker_processes.
autovacuum_enabled, toast.autovacuum_enabled (boolean)
Включает или отключает процесс «Автовакуум» для определенной таблицы. Если
задано значение true, то процесс «Автовакуум» будет выполнять в этой таблице
автоматические операции VACUUM и/или ANALYZE, следуя
правилам, описанным в разделе Процесс «Автовакуум». Если значение
равно false, эта таблица не будет подвергнута автоочистке, за
исключением случаев, когда необходимо предотвратить зацикливание идентификатора
транзакции. Дополнительную информацию о предотвращении зацикливания см. в
разделе Предотвращение ошибок зацикливания идентификатора транзакции. Обратите внимание,
что процесс «Автовакуум» не запускается вообще (кроме как для предотвращения
обхода идентификатора транзакции), если параметр autovacuum имеет
значение false; установка параметров хранения для отдельных таблиц это не
переопределяет. Поэтому явно задавать этому параметру хранения значение true
не имеет особого смысла — полезно только значение false.
vacuum_index_cleanup, toast.vacuum_index_cleanup (boolean)
Включает или отключает очистку индекса при выполнении команды VACUUM в этой
таблице. Значение по умолчанию равно true. Отключение очистки индекса
может значительно ускорить выполнение VACUUM, но также может привести к
появлению сильно «раздутых» индексов, если изменения таблицы происходят часто.
Параметр INDEX_CLEANUP команды VACUUM, если он указан,
переопределяет значение этого параметра.
vacuum_truncate, toast.vacuum_truncate (boolean)
Включает или отключает очистку, чтобы попытаться провести усечение всех пустых
страниц в конце этой таблицы. Значение по умолчанию равно true. При значении
true VACUUM и автоочистка делают усечение, и дисковое
пространство для усеченных страниц возвращается в операционную систему.
Обратите внимание, что для усечения требуется блокировка ACCESS EXCLUSIVE
для таблицы. Явно указанный параметр TRUNCATE команды VACUUM
переопределяет значение этого параметра.
autovacuum_vacuum_threshold, toast.autovacuum_vacuum_threshold (integer)
Значение параметра autovacuum_vacuum_threshold для таблицы.
autovacuum_vacuum_scale_factor, toast.autovacuum_vacuum_scale_factor (floating point)
Значение параметра autovacuum_vacuum_scale_factor для таблицы.
autovacuum_vacuum_insert_threshold, toast.autovacuum_vacuum_insert_threshold (integer)
Значение параметра autovacuum_vacuum_insert_threshold для таблицы. Для отключения очистки, вызываемой добавлением данных в таблицу, можно применить специальное значение -1.
autovacuum_vacuum_insert_scale_factor, toast.autovacuum_vacuum_insert_scale_factor (floating point)
Значение параметра autovacuum_vacuum_insert_scale_factor для таблицы.
autovacuum_analyze_threshold (integer)
Значение параметра autovacuum_analyze_threshold для таблицы.
autovacuum_analyze_scale_factor (floating point)
Значение параметра autovacuum_analyze_scale_factor для таблицы.
autovacuum_vacuum_cost_delay, toast.autovacuum_vacuum_cost_delay (floating point)
Значение параметра autovacuum_vacuum_cost_delay для таблицы.
autovacuum_vacuum_cost_limit, toast.autovacuum_vacuum_cost_limit (integer)
Значение параметра autovacuum_vacuum_cost_limit для таблицы.
autovacuum_freeze_min_age, toast.autovacuum_freeze_min_age (integer)
Значение параметра [vacuum_freeze_min_age] для таблицы. Обратите внимание, что автоочистка будет игнорировать табличные параметры autovacuum_freeze_min_age, превышающие половину значения общесистемного параметра autovacuum_freeze_max_age.
autovacuum_freeze_max_age, toast.autovacuum_freeze_max_age (integer)
Значение параметра autovacuum_freeze_max_age для таблицы. Обратите внимание, что автоочистка будет игнорировать табличные параметры autovacuum_freeze_max_age, превышающие значение общесистемного параметра (они могут быть установлены только меньше).
autovacuum_freeze_table_age, toast.autovacuum_freeze_table_age (integer)
Значение параметра [vacuum_freeze_table_age] для таблицы.
autovacuum_multixact_freeze_min_age, toast.autovacuum_multixact_freeze_min_age (integer)
Значение параметра vacuum_multixact_freeze_min_age для таблицы. Обратите внимание, что автоочистка будет игнорировать табличные параметры autovacuum_multixact_freeze_min_age, превышающие половину значения общесистемного параметра autovacuum_multixact_freeze_max_age.
autovacuum_multixact_freeze_max_age, toast.autovacuum_multixact_freeze_max_age (integer)
Значение параметра autovacuum_multixact_freeze_max_age для таблицы. Обратите внимание, что автоочистка будет игнорировать табличные параметры autovacuum_multixact_freeze_max_age, превышающие значение общесистемного параметра (они могут быть установлены только меньше).
autovacuum_multixact_freeze_table_age, toast.autovacuum_multixact_freeze_table_age (integer)
Значение параметра vacuum_multixact_freeze_table_age для таблицы.
log_autovacuum_min_duration, toast.log_autovacuum_min_duration (integer)
Значение параметра log_autovacuum_min_duration для таблицы.
user_catalog_table (boolean)
Объявить таблицу дополнительной таблицей каталога в целях логической репликации. Этот параметр нельзя задать для таблиц TOAST.
holdmem (OFF, POSSIBLY, ONLY)
Параметр указывающий что для таблицы будет использоваться особый кеш дисковых блоков. Подробнее см. Параметр HOLDMEM и дополнительные кешы дисковых блоков.
Примечания
QHB автоматически создает индекс, обеспечивающий уникальность для каждого ограничения уникальности и ограничения первичного ключа. Таким образом, нет необходимости явно создавать индекс для столбцов первичного ключа. (Дополнительную информацию см. в разделе CREATE INDEX.)
Ограничения уникальности и первичные ключи в текущей реализации не наследуются. Поэтому сочетание наследования и ограничений уникальности довольно дисфункционально.
Таблица не может иметь более 1600 столбцов. (На практике эффективный предел обычно ниже из-за ограничений длины кортежа.)
Примеры
Создание таблиц films и distributors:
CREATE TABLE films (
code char(5) CONSTRAINT firstkey PRIMARY KEY,
title varchar(40) NOT NULL,
did integer NOT NULL,
date_prod date,
kind varchar(10),
len interval hour to minute
);
CREATE TABLE distributors (
did integer PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
name varchar(40) NOT NULL CHECK (name<> '')
);
Создание таблицы с двумерным массивом:
CREATE TABLE array_int (
vector int[][]
);
Определение ограничения уникальности таблицы для таблицы films. Ограничения уникальности таблицы могут быть определены для одного или нескольких столбцов таблицы:
CREATE TABLE films (
code char(5),
title varchar(40),
did integer,
date_prod date,
kind varchar(10),
len interval hour to minute,
CONSTRAINT production UNIQUE(date_prod)
);
Определение ограничения-теста для столбца:
CREATE TABLE distributors (
did integer CHECK (did > 100),
name varchar(40)
);
Определение ограничения-теста для таблицы:
CREATE TABLE distributors (
did integer,
name varchar(40),
CONSTRAINT con1 CHECK (did > 100 AND name<> '')
);
Определение ограничения первичного ключа для таблицы films:
CREATE TABLE films (
code char(5),
title varchar(40),
did integer,
date_prod date,
kind varchar(10),
len interval hour to minute,
CONSTRAINT code_title PRIMARY KEY(code,title)
);
Определение ограничения первичного ключа для таблицы distributors. Следующие два примера равнозначны: первый использует синтаксис ограничения для таблицы, а второй — для столбца:
CREATE TABLE distributors (
did integer,
name varchar(40),
PRIMARY KEY(did)
);
CREATE TABLE distributors (
did integer PRIMARY KEY,
name varchar(40)
);
Установка значений по умолчанию: для столбца name это литерная константа, для столбца did оно генерируется путем выбора следующего значения объекта последовательности, для modtime это время добавления строки:
CREATE TABLE distributors (
name varchar(40) DEFAULT 'Luso Films',
did integer DEFAULT nextval('distributors_serial'),
modtime timestamp DEFAULT current_timestamp
);
Определение двух ограничений NOT NULL для столбцов в таблице distributors, одному из которых явно дано имя:
CREATE TABLE distributors (
did integer CONSTRAINT no_null NOT NULL,
name varchar(40) NOT NULL
);
Определение ограничения уникальности для столбца name:
CREATE TABLE distributors (
did integer,
name varchar(40) UNIQUE
);
То же самое, указанное в качестве ограничения для таблицы:
CREATE TABLE distributors (
did integer,
name varchar(40),
UNIQUE(name)
);
Создание той же таблицы с указанием коэффициента заполнения 70% как для самой таблицы, так и для ее уникального индекса:
CREATE TABLE distributors (
did integer,
name varchar(40),
UNIQUE(name) WITH (fillfactor=70)
)
WITH (fillfactor=70);
Создание таблицы circles с ограничением исключения, которое предотвращает перекрытие любых двух кругов:
CREATE TABLE circles (
c circle,
EXCLUDE USING gist (c WITH &&)
);
Создание таблицы cinemas в табличном пространстве diskvol1:
CREATE TABLE cinemas (
id serial,
name text,
location text
) TABLESPACE diskvol1;
Создание составного типа и типизированной таблицы:
CREATE TYPE employee_type AS (name text, salary numeric);
CREATE TABLE employees OF employee_type (
PRIMARY KEY (name),
salary WITH OPTIONS DEFAULT 1000
);
Создание таблицы, партиционированной по диапазонам:
CREATE TABLE measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
Создание таблицы, партиционированной по диапазонам, с несколькими столбцами в ключе разбиения:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
Создание таблицы, партиционированной по списку:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
Создание хэш-партиционированной таблицы:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
Создание партиции таблицы, партиционированной по диапазонам:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
Создание нескольких партиций таблицы, партиционированной по диапазонам, с несколькими столбцами в ключе разбиения:
CREATE TABLE measurement_ym_older
PARTITION OF measurement_year_month
FOR VALUES FROM (MINVALUE, MINVALUE) TO (2016, 11);
CREATE TABLE measurement_ym_y2016m11
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 11) TO (2016, 12);
CREATE TABLE measurement_ym_y2016m12
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 12) TO (2017, 01);
CREATE TABLE measurement_ym_y2017m01
PARTITION OF measurement_year_month
FOR VALUES FROM (2017, 01) TO (2017, 02);
Создание партиции таблицы со списочным партиционированием:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b');
Создание партиции таблицы со списочным партиционированием, которая сама в дальнейшем партиционируется, а затем добавление в нее партиции:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b') PARTITION BY RANGE (population);
CREATE TABLE cities_ab_10000_to_100000
PARTITION OF cities_ab FOR VALUES FROM (10000) TO (100000);
Создание партиций хэш-партиционированной таблицы:
CREATE TABLE orders_p1 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
Создание партиции по умолчанию:
CREATE TABLE cities_partdef
PARTITION OF cities DEFAULT;
Совместимость
Команда CREATE TABLE соответствует стандарту SQL с исключениями,
указанными ниже.
Временная таблица
Хотя синтаксис CREATE TEMPORARY TABLE похож на тот, что имеется в
стандарте SQL, их действие неодинаково. В стандарте временные
таблицы определяются только один раз и автоматически существуют (начиная
с пустого содержимого) в каждом сеансе, который нуждается в них.
QHB вместо этого требует, чтобы каждый сеанс выдавал для каждой
используемой временной таблицы свою собственную команду CREATE TEMPORARY TABLE.
Это позволяет различным сеансам использовать одно и
то же имя временной таблицы для различных целей, в то время как подход
стандарта ограничивает все экземпляры данного имени временной таблицы
одной и той же структурой таблицы.
Стандартное определение поведения временных таблиц по большей части игнорируется. Поведение QHB на этом этапе аналогично поведению нескольких других баз данных SQL.
Стандарт SQL также различает глобальные и локальные временные таблицы, где локальная временная таблица имеет отдельный набор содержимого для каждого модуля SQL в каждом сеансе, хотя его определение всё еще является общим для всех сеансов. Поскольку QHB не поддерживает модули SQL, это различие в QHB отсутствует.
Для обеспечения совместимости QHB принимает в объявлении временной таблицы ключевые слова GLOBAL и LOCAL, но в настоящее время они не имеют никакого эффекта. Использование этих ключевых слов не рекомендуется, так как будущие версии QHB могут принять более стандартную интерпретацию их значения.
Предложение ON COMMIT для временных таблиц также напоминает стандарт SQL, но имеет некоторые отличия. Если предложение ON COMMIT опущено, SQL указывает, что поведением по умолчанию является ON COMMIT DELETE ROWS. Однако в QHB поведением по умолчанию является ON COMMIT PRESERVE ROWS. Параметра ON COMMIT DROP в SQL не существует.
Неотложные ограничения уникальности
Когда ограничение UNIQUE или PRIMARY KEY не является откладываемым, QHB проверяет уникальность непосредственно в момент добавления или изменения строки. Стандарт SQL говорит, что уникальность должна быть применена только в конце оператора; это имеет значение, когда, например, одна команда изменяет множество ключевых значений. Чтобы получить поведение, соответствующее стандарту, объявите ограничение как DEFERRABLE (откладываемое), но не отложенное (т. е. INITIALLY IMMEDIATE). Имейте в виду, что это может быть значительно медленнее, чем немедленная проверка уникальности.
Ограничения-тесты для столбцов
В стандарте SQL говорится, что ограничения CHECK для столбца могут ссылаться только на столбец, к которому они применяются; только ограничения CHECK для таблицы могут ссылаться на множество столбцов. QHB не применяет это условие; он обрабатывает ограничения-тесты столбцов и таблиц одинаково.
Ограничение EXCLUDE
Ограничение EXCLUDE является расширением QHB.
«Ограничение» NULL
«Ограничение» NULL (на самом деле не является ограничением) является расширением QHB для стандарта SQL, которое включено для совместимости с некоторыми другими системами баз данных (и для симметрии с ограничением NOT NULL). Поскольку это поведение по умолчанию для любого столбца, присутствие данного слова не несет смысловой нагрузки.
Ограничение именования
Стандарт SQL говорит, что ограничения таблицы и домена должны иметь имена, которые являются уникальными в схеме, содержащей таблицу или домен. QHB в этом плане либеральнее: он требует только, чтобы имена были уникальными среди ограничений, прикрепленных к определенной таблице или домену. Однако эта дополнительная свобода не существует для ограничений на основе индексов (ограничения UNIQUE, PRIMARY KEY и EXCLUDE), поскольку связанный индекс имеет то же имя, что и ограничение, а имена индексов должны быть уникальными во всех отношениях в пределах одной схемы.
В настоящее время QHB вообще не записывает имена для ограничения NOT NULL, поэтому они не подлежат ограничению уникальности. Это может измениться в будущем выпуске.
Наследование
Множественное наследование через предложение INHERITS является языковым расширением QHB. SQL:1999 и более поздние версии определяют одиночное наследование, используя другой синтаксис и другую семантику. Наследование стиля SQL:1999 в QHB пока еще не поддерживается.
Таблицы с нулевыми столбцами
QHB позволяет создавать таблицу без столбцов (например,
CREATE TABLE foo();). Это расширение от стандарта SQL, который не позволяет
таблицы с нулевыми столбцами. Таблицы с нулевыми столбцами сами по себе
не очень полезны, но их запрещение создает специальные случаи
для ALTER TABLE DROP COLUMN, поэтому кажется более правильным
игнорировать это ограничение стандарта.
Множество столбцов идентификаторов
QHB позволяет таблице иметь более одного столбца идентификаторов.
Стандарт же указывает, что таблица может иметь не более одного столбца
идентификаторов. Это ограничение смягчено главным образом для обеспечения большей
гибкости при выполнении изменений схемы или миграции. Обратите внимание,
что команда INSERT поддерживает только одно предложение переопределения,
которое применяется ко всему оператору, поэтому наличие нескольких
столбцов идентификаторов с различным поведением поддерживается не очень хорошо.
Генерируемые столбцы
Вариант STORED не является стандартным, но также используется другими реализациями SQL. Стандарт SQL не определяет хранение генерируемых столбцов.
Предложение LIKE
Хотя предложение LIKE и существует в стандарте SQL, многие параметры, которые принимает для него QHB, не входят в стандарт, и наоборот, некоторые параметры стандарта не реализуются в QHB.
Предложение USING qss
Предложение USING с методом qss. является расширением QHB.
Предложение USING append_only
Предложение USING с методом append_only является расширением QHB.
Предложение WITH
Предложение WITH является расширением QHB; параметры хранения не входят в стандарт.
TABLESPACE
Концепция табличных пространств QHB не является частью стандарта. Следовательно, пункты TABLESPACE и USING INDEX TABLESPACE являются расширениями.
Типизированная таблица
Типизированные таблицы реализуют подмножество стандарта SQL. Согласно стандарту, типизированная таблица имеет столбцы, соответствующие базовому составному типу, а также еще один столбец, который является «самоссылающимся столбцом». QHB явно не поддерживает столбцы, ссылающиеся на себя.
Предложение PARTITION BY
Предложение PARTITION BY является расширением QHB.
Предложение PARTITION OF
Предложение PARTITION OF является расширением QHB.
См. также
ALTER TABLE, DROP TABLE, CREATE TABLE AS, CREATE TABLESPACE, CREATE TYPE
CREATE TEXT SEARCH CONFIGURATION
CREATE TEXT SEARCH CONFIGURATION — определить новую конфигурацию текстового поиска
Синтаксис
CREATE TEXT SEARCH CONFIGURATION имя (
PARSER = имя_анализатора |
COPY = исходная_конфигурация
)
Описание
Команда CREATE TEXT SEARCH CONFIGURATION создает новую конфигурацию
текстового поиска. Конфигурация текстового поиска задает синтаксический
анализатор текстового поиска, который может разделить строку на фрагменты,
а также словари, которые могут использоваться для определения, какие из
фрагментов представляют интерес для поиска.
Если указан только синтаксический анализатор, то новая конфигурация
текстового поиска изначально не имеет сопоставлений между типами фрагментов
и словарями и поэтому будет игнорировать все слова. Для создания сопоставлений и
извлечения пользы из конфигурации следом необходимо использовать команду
ALTER TEXT SEARCH CONFIGURATION. Или же можно скопировать существующую конфигурацию текстового поиска.
Если задано имя схемы, то конфигурация текстового поиска создается в указанной схеме, в противном случае — в текущей.
Пользователь, определивший конфигурацию текстового поиска, становится ее владельцем.
Параметры
имя
Имя создаваемой конфигурации текстового поиска (может быть дополнено схемой).
имя_анализатора
Имя синтаксического анализатора текстового поиска, используемого для этой конфигурации.
исходная_конфигурация
Имя существующей конфигурации текстового поиска для копирования.
Примечания
Параметры PARSER и COPY являются взаимоисключающими, поскольку при копировании существующей конфигурации копируется и выбранный в ней анализатор.
Совместимость
В стандарте SQL нет команды CREATE TEXT SEARCH CONFIGURATION.
См. также
ALTER TEXT SEARCH CONFIGURATION, DROP TEXT SEARCH CONFIGURATION
CREATE TEXT SEARCH DICTIONARY
CREATE TEXT SEARCH DICTIONARY — определить новый словарь текстового поиска
Синтаксис
CREATE TEXT SEARCH DICTIONARY имя (
TEMPLATE = шаблон
[, параметр = значение [, ... ]]
)
Описание
Команда CREATE TEXT SEARCH DICTIONARY создает новый словарь текстового
поиска. Словарь текстового поиска задает способ распознавания
интересных или неинтересных для поиска слов. Словарь зависит от шаблона
текстового поиска, который определяет функции, фактически выполняющие
эту работу. Обычно словарь предоставляет некоторые параметры, которые
управляют подробным поведением функций шаблона.
Если задано имя схемы, то словарь текстового поиска создается в указанной схеме, в противном случае — в текущей.
Пользователь, определивший словарь текстового поиска, становится его владельцем.
Параметры
имя
Имя создаваемого словаря текстового поиска (может быть дополнено схемой).
шаблон
Имя шаблона текстового поиска, который будет определять основное поведение этого словаря.
параметр
Имя привязанного к шаблону параметра, устанавливаемого для этого словаря.
значение
Значение, используемое для привязанного к шаблону параметра. Если значение не является простым идентификатором или числом, оно должно быть заключено в кавычки (при желании его можно заключать в кавычки всегда).
Параметры могут отображаться в любом порядке.
Примеры
В следующем примере команда создает словарь на основе Snowball с нестандартным списком стоп-слов.
CREATE TEXT SEARCH DICTIONARY my_russian (
template = snowball,
language = russian,
stopwords = myrussian
);
Совместимость
В стандарте SQL нет команды CREATE TEXT SEARCH DICTIONARY.
См. также
ALTER TEXT SEARCH DICTIONARY, DROP TEXT SEARCH DICTIONARY
CREATE TEXT SEARCH PARSER
CREATE TEXT SEARCH PARSER — определить новый синтаксический анализатор текстового поиска
Синтаксис
CREATE TEXT SEARCH PARSER имя (
START = функция_начала ,
GETTOKEN = функция_выдачи_фрагмента ,
END = функция_окончания ,
LEXTYPES = функция_лекс_типов
[, HEADLINE = функция_выдержек ]
)
Описание
Команда CREATE TEXT SEARCH PARSER создает новый анализатор текстового
поиска. Синтаксический анализатор текстового поиска определяет способ
разбиения текстовой строки на фрагменты и назначения фрагментам типов
(категорий). Синтаксический анализатор сам по себе не особенно полезен,
но должен быть привязан к конфигурации текстового поиска вместе с
некоторыми словарями текстового поиска, которые будут использоваться для
поиска.
Если задано имя схемы, то анализатор текстового поиска создается в указанной схеме, в противном случае — в текущей.
Чтобы использовать команду CREATE TEXT SEARCH PARSER, нужно быть
суперпользователем. (Это ограничение сделано потому, что ошибочное
определение синтаксического анализатора текстового поиска может нарушить
или даже аварийно завершеть работу сервера.)
Параметры
имя
Имя создаваемого анализатора текстового поиска (может быть дополнено схемой).
функция_начала
Имя функции запуска для синтаксического анализатора.
функция_выдачи_фрагмента
Имя функции, выдающей следующий фрагмент для синтаксического анализатора.
функция_окончания
Имя конечной функции для синтаксического анализатора.
функция_лекс_типов
Имя функции перечисления лексических типов для синтаксического анализатора (функция, которая возвращает информацию о производимом ей наборе типов фрагментов).
функция_выдержек
Имя функции извлечения выдержек (функция, которая выделяет краткое содержание для набора фрагментов).
При необходимости имена функций могут быть дополнены схемой. Типы аргументов не задаются, так как список аргументов для каждого типа функции предопределен. Все функции, кроме функции выдержек, являются обязательными.
Аргументы могут появляться в любом порядке, а не только в показанном выше.
Совместимость
В стандарте SQL нет команды CREATE TEXT SEARCH PARSER.
См. также
ALTER TEXT SEARCH PARSER, DROP TEXT SEARCH PARSER
CREATE TEXT SEARCH TEMPLATE
CREATE TEXT SEARCH TEMPLATE — определить новый шаблон текстового поиска
Синтаксис
CREATE TEXT SEARCH TEMPLATE имя (
[ INIT = функция_инициализации , ]
LEXIZE = функция_выделения_лексем
)
Описание
Команда CREATE TEXT SEARCH TEMPLATE создает новый шаблон текстового
поиска. Шаблоны текстового поиска определяют функции, реализующие
словари текстового поиска. Сам по себе шаблон бесполезен, но его нужно
установить как словарь для будущего использования. В
словаре обычно указываются параметры, которые должны быть заданы
функциям шаблона.
Если задано имя схемы, то шаблон текстового поиска создается в указанной схеме, в противном случае — в текущей.
Чтобы использовать команду CREATE TEXT SEARCH TEMPLATE, нужно быть суперпользователем.
Это ограничение сделано из-за того, что ошибочное
определение шаблона текстового поиска может нарушить или даже аварийно
завершить работу сервера. Причина отделения шаблонов от словарей
заключается в том, что шаблон инкапсулирует «небезопасные» аспекты
определения словаря. Параметры, которые можно задать при определении словаря,
не могут причинить вред, поэтому создание словаря не требует особых прав.
Параметры
имя
Имя создаваемого шаблона текстового поиска (может быть дополнено схемой).
функция_инициализации
Имя функции инициализации для шаблона.
функция_выделения_лексем
Имя функции выделения лексем для шаблона.
При необходимости имена функций могут быть определены схемой. Типы аргументов не задаются, так как список аргументов для каждого типа функции предопределен. Функция выделения лексем является необходимой, но функция инициализации необязательна.
Аргументы могут появляться в любом порядке, а не только в показанном выше.
Совместимость
В стандарте SQL нет команды CREATE TEXT SEARCH TEMPLATE.
См. также
ALTER TEXT SEARCH TEMPLATE, DROP TEXT SEARCH TEMPLATE
CREATE TRANSFORM
CREATE TRANSFORM — определить новую трансформацию
Синтаксис
CREATE [ OR REPLACE ] TRANSFORM FOR имя_типа LANGUAGE имя_языка (
FROM SQL WITH FUNCTION имя_функции_из_sql [ (тип_аргумента [, ...]) ],
TO SQL WITH FUNCTION имя_функции_в_sql [ (тип_аргумента [, ...]) ]
);
Описание
Команда CREATE TRANSFORM определяет новую трансформацию. CREATE OR REPLACE TRANSFORM
будет либо создавать новую трансформацию, либо заменять существующее определение.
Трансформация указывает, как адаптировать тип данных к процедурному языку. Например, при написании функции на языке PL/Python с использованием типа hstore PL/Python заранее не знает, как представить значения hstore в среде Python. Языковые реализации обычно по умолчанию используют текстовое представление, но это неудобно, когда, например, более подходящими были бы ассоциативный массив или список.
Трансформация определяет две функции:
Нет необходимости предоставлять обе эти функции одновременно. Если одна из них не указана, при необходимости будет использоваться поведение по умолчанию для конкретного языка. (Чтобы полностью исключить возможность трансформации в одном направлении, можно написать функцию трансформации, которая будет всегда выдавать ошибку.)
Чтобы иметь возможность создать трансформацию, нужно быть владельцем и иметь право USAGE для типа, иметь право USAGE для языка и быть владельцем и иметь право EXECUTE для функций из-SQL и в-SQL, если те заданы.
Параметры
имя_типа
Имя типа данных, для которого предназначена трансформация.
имя_языка
Имя языка, для которого предназначена трансформация.
имя_функции_из_sql[(тип_аргумента [, ...])]
Имя функции для преобразования типа из среды SQL в среду языка. Она должна принимать один аргумент типа internal и возвращать тип internal. Фактический аргумент будет иметь тип, предназначенный для трансформирования, и функция должна быть закодирована под это. (Но нельзя объявить функцию, возвращающую тип internal, на уровне SQL без как минимум одного входного аргумента типа internal.) Фактическое возвращаемое значение будет определяться реализацией языка. Если не указан список аргументов, имя функции должно быть уникальным в схеме.
имя_функции_в_sql[(тип_аргумента [, ...])]
Имя функции для преобразования типа из среды языка в среду SQL. Она должна принимать один аргумент типа internal и возвращать тип, который и предназначен для трансформации. Фактическое значение аргумента будет определяться реализацией языка. Если не указан список аргументов, имя функции должно быть уникальным в схеме.
Примечания
Для удаления трансформации используйте DROP TRANSFORM.
Примеры
Чтобы создать трансформацию для типа hstore и языка plpythonu, сначала нужно создать тип и язык:
CREATE TYPE hstore ...;
CREATE EXTENSION plpythonu;
Затем создать необходимые функции:
CREATE FUNCTION hstore_to_plpython(val internal) RETURNS internal
LANGUAGE C STRICT IMMUTABLE
AS ...;
CREATE FUNCTION plpython_to_hstore(val internal) RETURNS hstore
LANGUAGE C STRICT IMMUTABLE
AS ...;
И наконец создать трансформацию, чтобы соединить их вместе:
CREATE TRANSFORM FOR hstore LANGUAGE plpythonu (
FROM SQL WITH FUNCTION hstore_to_plpython(internal),
TO SQL WITH FUNCTION plpython_to_hstore(internal)
);
На практике эти команды будут помещены в расширение.
Раздел contrib содержит ряд расширений, предоставляющих трансформации, которые могут служить в качестве реальных примеров.
Совместимость
Команда CREATE TRANSFORM является расширением QHB.
В стандарте SQL существует команда CREATE TRANSFORM, но она
предназначена для адаптации типов данных к языкам на стороне клиента.
Такой вариант использования QHB не поддерживается.
См. также
CREATE FUNCTION, CREATE LANGUAGE, CREATE TYPE, DROP TRANSFORM
CREATE TRIGGER
CREATE TRIGGER — определить новый триггер
Синтаксис
CREATE [ CONSTRAINT ] TRIGGER имя { BEFORE | AFTER | INSTEAD OF } { событие [ OR ... ] }
ON имя_таблицы
[ FROM имя_ссылочной_таблицы ]
[ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ]
[ REFERENCING { { OLD | NEW } TABLE [ AS ] имя_переходного_отношения } [ ... ] ]
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN ( условие ) ]
EXECUTE { FUNCTION | PROCEDURE } имя_функции ( аргументы )
Где событием может быть:
INSERT
UPDATE [ OF имя_столбца [, ... ] ]
DELETE
TRUNCATE
Описание
Команда CREATE TRIGGER создает новый триггер. Триггер будет связан с
заданной таблицей, представлением или сторонней таблицей и будет выполнять
указанную функцию имя_функции при выполнении определенных типов операций с таблицей.
Триггер может быть настроен так, чтобы срабатывать до попытки выполнения операции со
строкой (до проверки ограничений и попытки выполнить INSERT, UPDATE
или DELETE), или после завершения операции (после проверки
ограничений и завершения INSERT, UPDATE или DELETE),
или вместо операции (в случае добавления, обновления или удаления строк в
представлении). Если триггер срабатывает до или вместо события, он
может пропустить операцию с текущей строкой или изменить добавляемую
строку (только для операций INSERT и UPDATE). Если триггер
срабатывает после события, все изменения, включая результаты действия других
триггеров, будут для него «видимыми».
Триггер с указанием FOR EACH ROW вызывается один раз для
каждой строки, которая изменяется в результате операции. Например, операция DELETE, которая
затрагивает(удаляет) 10 строк, вызовет срабатывание всех триггеров с событием ON DELETE для целевого
отношения 10 раз подряд: по одному разу для каждой удаляемой строки. И наоборот, триггер с указанием
FOR EACH STATEMENT срабатывает только один раз для любой заданной операции,
независимо от того, сколько строк она изменяет (в частности, выполнение операции,
которая не изменит ни одной строки, всё равно приведет к вызову
всех применимых триггеров FOR EACH STATEMENT).
Триггеры, предназначенные для запуска вместо события, т. е. INSTEAD OF, должны быть помечены как FOR EACH ROW и могут быть определены только для представлений. Триггеры с режимами BEFORE и AFTER для представления должны быть помечены как FOR EACH STATEMENT.
Кроме того, триггеры могут быть определены для операции TRUNCATE,
но только с указанием FOR EACH STATEMENT.
В следующей таблице перечислены типы триггеров, которые могут использоваться для таблиц, представлений и сторонних таблиц:
| Когда | Событие | На уровне строк | На уровне оператора |
|---|---|---|---|
| BEFORE | INSERT/UPDATE/DELETE | Таблицы и сторонние таблицы | Таблицы, представления и сторонние таблицы |
| BEFORE | TRUNCATE | — | Таблицы |
| AFTER | INSERT/UPDATE/DELETE | Таблицы и сторонние таблицы | Таблицы, Представления и сторонние таблицы |
| AFTER | TRUNCATE | — | Таблицы |
| INSTEAD OF | INSERT/UPDATE/DELETE | Представления | — |
| INSTEAD OF | TRUNCATE | — | — |
Кроме того, в определении триггера можно указать логическое условие WHEN, после проверки которого определяется, должен ли срабатывать триггер. В триггерах на уровне строк условие WHEN может проверять старые и/или новые значения столбцов строки. Триггеры на уровне оператора также могут содержать условия WHEN, хотя для них эта функциональность не так полезна, так как в условии нельзя сослаться на какие-либо значения в таблице.
Если для одного и того же события определено несколько триггеров одного типа, они будут срабатывать в алфавитном порядке их имен.
Если указан параметр CONSTRAINT, команда создает триггер ограничения.
Он такой же, как и обычный триггер, за исключением того, что время его срабатывания
можно регулировать с помощью команды SET CONSTRAINTS. Триггеры ограничений должны быть созданы
с указанием AFTER ROW для обычных таблиц (не для сторонних). Они могут
срабатывать либо в конце оператора, вызывающего целевое событие,
либо в конце содержащей оператор транзакции; в последнем случае они считаются отложенными.
Срабатывание ожидающего отложенного запуска триггера также может быть принудительно вызвано
с помощью команды SET CONSTRAINTS. Ожидается, что триггеры ограничений должны генерировать исключение,
когда нарушаются реализуемые ими ограничения.
Если указан параметр REFERENCING, для триггера собираются переходные отношения,
которые представляют собой наборы строк, включающие все строки, которые были
добавлены, удалены или изменены текущим оператором SQL. Эта функциональность позволяет
триггеру иметь глобальное представление о том, что сделал оператор, а не
только об одной строке за раз. Это указание разрешено только для
триггера с режимом AFTER, который не является триггером ограничения; также, если
такой триггер является триггером для операций UPDATE, у него должен отсутствовать список имен_столбцов.
Указание OLD TABLE может быть задано только один раз и
только для триггера, который срабатывает для операций UPDATE или DELETE; это указание
создает переходное отношение, которое содержит образы до изменения всех
строк, обновленных или удаленных оператором. Аналогично указание NEW TABLE
может быть задано только один раз и только для триггера, который срабатывает для операций UPDATE
или INSERT; это указание создает переходное отношение,
которое содержит образы после изменения всех строк, обновленных или добавленных
оператором.
Операция SELECT не изменяет строки, поэтому нельзя создать триггеры SELECT.
Для решения проблем, в которых, видимо, требуются такие триггеры, могут подойти правила и представления
Дополнительную информацию о триггерах см. в главе Триггеры.
Параметры
имя
Имя, задаваемое новому триггеру. Оно должно отличаться от имени любого
другого триггера для той же таблицы. Имя триггера не может быть дополнено
схемой, так как тот наследует схему своей таблицы. Для триггера ограничения
это имя также используется для изменения поведения триггера с помощью команды
SET CONSTRAINTS.
BEFORE
AFTER
INSTEAD OF
Определяет, вызывается ли функция до, после или вместо события. Для триггера ограничения можно задать только значение AFTER.
событие
Принимает одно из значений: INSERT, UPDATE, DELETE или TRUNCATE; параметр указывает на событие, которое приведет к срабатыванию триггера. Можно указать несколько событий с помощью слова OR, за исключением случаев, когда запрашиваются переходные отношения.
Для событий UPDATE можно указать список столбцов, используя следующий синтаксис:
UPDATE OF имя_столбца1 [, имя_столбца2 ... ]
Триггер будет срабатывать только в том случае, если хотя бы один из
перечисленных столбцов указан как цель команды UPDATE или
является генерируемым и при этом зависящим от столбца, который фигурирует в UPDATE.
Для событий INSTEAD OF UPDATE не допускается использование списка столбцов. Список столбцов также не может быть указан при запросе переходных отношений.
имя_таблицы
Имя таблицы, представления или сторонней таблицы, для которой предназначен триггер (может быть дополнено схемой).
имя_ссылающейся_таблицы
Имя другой таблицы, на которую ссылается ограничение (может быть дополнено схемой). Этот параметр используется для ограничений внешнего ключа и не рекомендуется для обычного использования. Параметр может быть указан только для триггеров ограничений.
DEFERRABLE
NOT DEFERRABLE
INITIALLY IMMEDIATE
INITIALLY DEFERRED
Время срабатывания триггера по умолчанию. Подробную информацию об этих параметрах см. в разделе CREATE TABLE. Параметр может быть указан только для триггеров ограничений.
REFERENCING
Это ключевое слово непосредственно предшествует объявлению одного или двух имен отношений, обеспечивают доступ к переходным отношениям при выполнении операторов, вызванных триггером.
OLD TABLE NEW TABLE
Это предложение указывает, относится ли следующее имя к отношению перехода исходного образа записи или к отношению перехода преобразованного образа записи.
имя_переходного_отношения
Имя (без указания схемы), которое будет использоваться в триггере для этого переходного отношения.
FOR EACH ROW FOR EACH STATEMENT
Этот параметр указывает, запускать ли функцию триггера по одному разу для каждой строки, на которую влияет событие триггера, или только один раз для оператора SQL. Если ничего не указано, по умолчанию подразумевается FOR EACH STATEMENT. Для триггеров ограничений можно указать только FOR EACH ROW.
условие
Логическое выражение, определяющее, будет ли фактически выполняться функция триггера. Если указано WHEN, функция будет вызываться только в том случае, если условие вернет true. В триггерах FOR EACH ROW условие WHEN может ссылаться на столбцы старых и/или новых значений строк в виде записи OLD.имя_столбца или NEW.имя_столбца соответственно. Конечно, триггеры INSERT не могут ссылаться на OLD, а триггеры DELETE не могут ссылаться на NEW.
Триггеры INSTEAD OF не поддерживают условия WHEN.
В настоящий момент выражения WHEN не могут содержать вложенные запросы.
Обратите внимание, что для триггеров ограничений вычисление условия WHEN не откладывается, а выполняется сразу после операции изменения строки. Если результат проверки условия не true, то триггер не помещается в очередь для отложенного выполнения.
имя_функции
Функция, заданная пользователем, которая объявляется как функция без аргументов и возвращающая тип trigger и которая выполняется при срабатывании триггера.
В синтаксисе команды CREATE TRIGGER ключевые слова FUNCTION и PROCEDURE
равнозначны, но указанная функция должна в любом случае быть функцией,
а не процедурой. Ключевое слово PROCEDURE оставлено по историческим причинам и является устаревшим.
аргументы
Необязательный список аргументов, разделенных запятыми, которые будут переданы функции при срабатывании триггера. Аргументы являются строковыми константами. Также в качестве аргументов можно указать простые имена и числовые константы, но все они будут преобразованы в строки. Следует проверить описание языка реализации триггерной функции, чтобы точно знать порядок обращения к таким аргументам внутри функции, так как он может отличаться от обычных аргументов функции.
Примечания
Чтобы создать триггер, необходимо иметь право TRIGGER для таблицы, а также право EXECUTE для функции триггера.
Для удаления триггера используйте команду DROP TRIGGER.
Триггер для определенных столбцов (созданный с помощью синтаксиса
UPDATE OF имя_столбца) будет срабатывать, когда любой из его столбцов
перечислен в качестве целевого в списке SET команды UPDATE.
Значение столбца можно изменить, даже когда триггер не работает,
потому что изменения содержимого строки, внесенные с помощью триггеров BEFORE UPDATE, не рассматриваются. И
наоборот, команда вроде UPDATE ... SET x = x ... запустит
триггер по колонке x, даже если значение столбца не изменилось.
Существует несколько встроенных триггерных функций, которые можно использовать для решения распространенных задач без необходимости написания собственного триггерного кода; см. раздел Триггерные функции.
В триггере BEFORE условие WHEN вычисляется непосредственно перед фактическим или возможным выполнением функции, поэтому использование WHEN существенно не отличается от проверки того же условия в начале триггерной функции. В частности, обратите внимание, что строка NE, рассматриваемая условием, содержит текущее значение, которое, возможно, было изменено предыдущими триггерами. Кроме того, условие WHEN триггера BEFORE не сможет проверять системные столбцы строк NEW (такие как ctid), потому что они еще не будут установлены.
В триггере AFTER условие WHEN вычисляется сразу после того, как происходит изменение строки, и это определяет, помещается ли событие в очередь для запуска триггера в конце оператора. Поэтому когда условие WHE триггера AFTER не возвращает true, нет необходимости ставить событие в очередь или повторно считывать строку в конце оператора. Это может привести к значительному ускорению операторов, изменяющих много строк, если триггер должен срабатывать только для нескольких из них.
В некоторых случаях одна команда SQL может запустить несколько
видов триггеров. Например, команда INSERT с предложением ON CONFLICT DO UPDATE
может вызвать как операции добавления, так и операции изменения, поэтому она
будет запускать оба типа триггеров по мере необходимости. Отношения перехода,
предоставляемые триггерам, являются специфичными для их типа событий;
таким образом, триггер INSERT будет видеть только добавленные строки,
в то время как триггер UPDATE будет видеть только измененные строки.
Изменения или удаления строк, вызванные принудительными действиями внешнего ключа, такими как ON UPDATE CASCADE или ON DELETE SET NULL, рассматриваются как часть команды SQL, которая вызвала их (обратите внимание, что такие действия никогда не откладываются). В затрагиваемой таблице будут запущены соответствующие триггеры, так что это дает команде SQL еще один способ запускать триггеры, не вполне соответствующие их типу. В простых случаях триггеры, которые запрашивают отношения перехода, будут видеть все изменения, сделанные в их таблице одной исходной командой SQL, в виде одного отношения перехода. Однако существуют случаи, в которых наличие триггера AFTER ROW, который запрашивает отношения перехода, приведет к тому, что действия принудительного применения внешнего ключа, инициированные одной командой SQL, будут разделены на несколько этапов, каждый со своим(и) собственным(ми) отношением(ями) перехода. В таких случаях любые имеющиеся триггеры уровня оператора будут вызваны один раз при создании отношения перехода, гарантируя, что триггеры будут видеть каждую затронутую строку в отношения перехода один и только один раз.
Триггеры уровня операторов для представления срабатывают только в том случае, если операция с представлением обрабатывается триггером уровня строк INSTEAD OF. Если операция обрабатывается по правилу INSTEAD, то все генерируемые им операторы выполняются вместо исходного оператора, обращающегося к этому представлению, так что триггеры, которые будут запущены, являются триггерами для таблиц, к которым обращаются заменяющие операторы. Аналогично, если представление автоматически обновляется, то операция обрабатывается путем автоматического переписывания оператора в виде операции с базовой таблицей представления, так что запускаются триггеры уровня операторов базовой таблицы.
Создание триггера уровня строки в партиционированной таблице приведет к созданию идентичных триггеров во всех ее партициях; и все партиции, созданные или присоединенные позже, также будут содержать идентичный триггер. Если партиция отсоединяется от таблицы-родителя, триггер удаляется. Триггеры для партиционированных таблиц могут быть только с режимом AFTER.
Изменение данных в партиционированной таблице или таблице, у которой есть потомки, запускает триггеры уровня оператора, связанные с явно задействованной таблицей, но не триггеры уровня оператора для ее партиций или дочерних таблиц. Напротив, триггеры уровня строк запускаются для строк в затронутых партициях или дочерних таблицах, даже если они явно не присутствуют в запросе. Если триггер уровня оператора был определен с отношениями перехода, указанными в предложении REFERENCING, то в них будут видны исходные и преобразованные образы строк из всех затронутых партиций или дочерних таблиц. В случае дочерних таблиц в иерархии наследования образы строк включают только столбцы, которые присутствуют в таблице, связанной с триггером. В настоящее время триггеры уровня строк с отношениями перехода нельзя определить для партиций или дочерних таблиц в иерархии наследования.
Примеры
Выполнение функции check_account_update всякий раз перед изменением строк таблицы accounts:
CREATE TRIGGER check_update
BEFORE UPDATE ON accounts
FOR EACH ROW
EXECUTE FUNCTION check_account_update();
То же самое, но функция будет выполняться, если столбец balance указан в
списке целевых столбцов команды UPDATE:
CREATE TRIGGER check_update
BEFORE UPDATE OF balance ON accounts
FOR EACH ROW
EXECUTE FUNCTION check_account_update();
В этом примере функция будет выполняться, если значение столбца balance действительно изменилось:
CREATE TRIGGER check_update
BEFORE UPDATE ON accounts
FOR EACH ROW
WHEN (OLD.balance IS DISTINCT FROM NEW.balance)
EXECUTE FUNCTION check_account_update();
Вызов функции, ведущей журнал изменений в accounts, но только если что-то изменилось:
CREATE TRIGGER log_update
AFTER UPDATE ON accounts
FOR EACH ROW
WHEN (OLD.* IS DISTINCT FROM NEW.*)
EXECUTE FUNCTION log_account_update();
Выполнение для каждой строки функции view_insert_row, которая будет добавлять строки в нижележащие таблицы представления:
CREATE TRIGGER view_insert
INSTEAD OF INSERT ON my_view
FOR EACH ROW
EXECUTE FUNCTION view_insert_row();
Выполнение функции check_transfer_balances_to_zero для каждого оператора, чтобы убедиться, что строки таблицы transfer в совокупности дают нулевой баланс:
CREATE TRIGGER transfer_insert
AFTER INSERT ON transfer
REFERENCING NEW TABLE AS inserted
FOR EACH STATEMENT
EXECUTE FUNCTION check_transfer_balances_to_zero();
Выполнение функции check_matching_pairs для каждой строки, чтобы убедиться, что соответствующие пары пунктов изменены синхронно (одним оператором):
CREATE TRIGGER paired_items_update
AFTER UPDATE ON paired_items
REFERENCING NEW TABLE AS newtab OLD TABLE AS oldtab
FOR EACH ROW
EXECUTE FUNCTION check_matching_pairs();
Раздел Полный пример запуска содержит полный пример триггерной функции, написанной на языке C.
Совместимость
Команда CREATE TRIGGER в QHB реализует подмножество
возможностей, описанных в стандарте SQL. В настоящее время отсутствуют
следующие функциональные возможности:
В стандарте SQL определено, что несколько триггеров должны срабатывать в том порядке, в каком они были созданы. QHB использует порядок имен, который был сочтен более удобным.
В стандарте SQL указано, что триггеры BEFORE DELETE для каскадного удаления запускаются
после завершения каскадного DELETE. В QHB
триггеры BEFORE DELETE всегда запускаются перед операцией удаления,
даже каскадной. Это поведение выбрано как более логичное. Существует еще одно отклонение
от стандарта, если триггеры BEFORE изменяют строки или препятствуют обновлениям
во время обновления, вызванного ссылочной операцией. Это может привести к нарушениям
ограничений или сохранению данных, которые не соблюдают ссылочную целостность.
Возможность задать несколько действий для одного триггера с помощью слова OR является расширением стандарта SQL, реализованным в QHB.
Возможность вызова триггеров для операции TRUNCATE является расширением стандарта SQL,
реализованным в QHB, так же как и возможность определять триггеры
уровне оператора для представлений.
Вариант команды CREATE CONSTRAINT TRIGGER является расширением стандарта SQL,
реализованным в QHB.
См. также
ALTER TRIGGER, DROP TRIGGER, CREATE FUNCTION, SET CONSTRAINTS
CREATE TYPE
CREATE TYPE — определить новый тип данных
Синтаксис
CREATE TYPE имя AS
( [ имя_атрибута тип_данных [ COLLATE правило_сортировки ] [, ... ] ] )
CREATE TYPE имя AS ENUM
( [ 'метка' [, ... ] ] )
CREATE TYPE имя AS RANGE (
SUBTYPE = подтип
[ , SUBTYPE_OPCLASS = класс_оператора_подтипа ]
[ , COLLATION = правило_сортировки ]
[ , CANONICAL = каноническая_функция ]
[ , SUBTYPE_DIFF = функция_разницы_подтипа ]
)
CREATE TYPE имя (
INPUT = функция_ввода,
OUTPUT = функция_вывода
[ , RECEIVE = функция_получения ]
[ , SEND = функция_отправки ]
[ , TYPMOD_IN = функция_ввода_модификатора_типа ]
[ , TYPMOD_OUT = функция_вывода_модификатора_типа ]
[ , ANALYZE = функция_анализа ]
[ , INTERNALLENGTH = { внутренняя_длина | VARIABLE } ]
[ , PASSEDBYVALUE ]
[ , ALIGNMENT = выравнивание ]
[ , STORAGE = хранение ]
[ , LIKE = тип_образец ]
[ , CATEGORY = категория ]
[ , PREFERRED = предпочитаемый ]
[ , DEFAULT = по_умолчанию ]
[ , ELEMENT = элемент ]
[ , DELIMITER = разделитель ]
[ , COLLATABLE = сортируемый ]
)
CREATE TYPE имя
Описание
Команда CREATE TYPE регистрирует новый тип данных для использования в
текущей базе данных. Пользователь, определивший тип, становится его
владельцем.
Если задано имя схемы, то тип будет создан в указанной схеме, в противном случае — в текущей. Имя типа должно отличаться от имени любого существующего типа или домена в той же схеме. (Поскольку таблицы связаны с типами данных, имя типа также должно отличаться от имени любой существующей таблицы в той же схеме.)
Существует пять форм команды CREATE TYPE, как показано выше в блоке синтаксис.
Они создают соответственно: составной тип, перечисляемый тип,
диапазонный тип, базовый тип или тип-оболочку.
Первые четыре из них рассматриваются ниже. Тип-оболочка представляет собой просто заготовку для типа,
который будет определен позже; он создается командой CREATE TYPE без параметров, только с указанием имени типа.
Типы-оболочки необходимы в качестве прямых ссылок при создании диапазонных и базовых типов,
как это описано в соответствующих разделах.
Составные типы
Первая форма CREATE TYPE создает составной тип. Составной тип
определяется списком имен атрибутов и типов данных. Для атрибута может быть также указано
правило сортировки, если тип данных является сортируемым. Составной тип по существу совпадает с типом строки
таблицы, но использование CREATE TYPE позволяет избежать
необходимости создавать настоящую таблицу, когда требуется всего лишь
определить тип. Отдельный составной тип может быть полезен, например, в качестве
аргумента или возвращаемого типа функции.
Чтобы создать составной тип, необходимо иметь право USAGE для всех типов его атрибутов.
Перечисляемые типы
Вторая форма CREATE TYPE создает перечисляемый тип, как
описано в разделе Перечисляемые типы. Перечисляемые типы принимают список заключенных в кавычки меток,
каждая из которых может иметь длину не больше NAMEDATALEN байт (64
байта в стандартной сборке QHB). (Можно создать перечислимый тип
без меток, но такой тип нельзя использовать для хранения
значений, пока хотя бы одна метка не будет добавлена с помощью команды
ALTER TYPE.)
Диапазонные типы
Третья форма CREATE TYPE создает новый диапазонный тип, как описано в
разделе Диапазонные типы.
Подтип диапазонного типа может быть любым типом со связанным классом операторов B-дерева (для определения порядка значений в диапазоне). Обычно для определения порядка используется класс операторов B-дерева по умолчанию; чтобы изменить класс оператора, укажите его имя в параметре класс_операторов_подтипа. Если подтип поддерживает сортировку и вы хотите использовать правила сортировки, отличные от заданных по умолчанию, укажите нужные правила сортировки в параметре правило_сортировки.
Необязательная каноническая_функция должна принимать один
аргумент определяемого диапазонного типа и возвращать значение того же
типа. Эта настройка используется для преобразования значений диапазона в
каноническую форму, когда это применимо. Дополнительную информацию
см. в разделе Определение новых диапазонных типов. Создание канонической_функции
сложнее, так как она должна быть определена до того, как диапазонный тип
может быть объявлен. Для этого необходимо сначала создать тип-оболочку,
который является заглушкой, не имеющей никаких свойств, кроме имени и владельца.
Это делается путем выполнения команды CREATE TYPE имя без дополнительных параметров.
Затем может быть объявлена функция с использованием типа-оболочки в качестве аргумента
и результата, и наконец диапазонный тип может быть объявлен с использованием того же
имени. Последнее действие автоматически заменяет тип-оболочку допустимым
диапазонным типом.
Необязательная функция_разницы_подтипа должна принимать в качестве аргументов два значения типа подтип и возвращать значение double precision, представляющее собой разницу между двумя первыми значениями. Хотя эта функция необязательная, с помощью нее можно кардинально увеличить эффективность индексов GiST для столбцов диапазонного типа. Дополнительную информацию см. в разделе Определение новых диапазонных типов.
Базовые типы
Четвертая форма CREATE TYPE создает новый базовый тип (скалярный
тип). Чтобы создать новый базовый тип, нужно быть
суперпользователем. (Это ограничение сделано потому, что ошибочное
определение типа может вызвать нарушения или даже сбой в работе сервера.)
Параметры могут перечисляться в любом порядке, а не только в том, который
показан выше, и большинство из них являются необязательными. Перед
определением типа необходимо зарегистрировать две или более функций (с
помощью CREATE FUNCTION). Обязательными функциями являются функция_ввода и
функция_вывода, а функции функция_получения,
функция_отправки, функция_модификатора_типа,
функция_вывода_модификатора_типа и функция_анализа можно не
указывать. Как правило, эти функции должны быть написаны на C/RUST
или другом языке низкого уровня.
Функция_ввода преобразует внешнее текстовое представление типа во внутреннее, используемое операторами и функциями, определенными для данного типа. Функция_вывода выполняет обратное преобразование. Функция ввода может быть объявлена как принимающая один аргумент типа cstring или как принимающая три аргумента с типами cstring, oid, integer. Первый аргумент — это вводимый текст в виде строки в стиле C, второй аргумент — собственный OID типа (за исключением типов массивов, для которых передается OID типа элемента), а третий — это модификатор_типа для целевого столбца, если он известен (и -1, если нет). Функция ввода должна возвращать значение нового типа данных. Обычно функция ввода должна быть объявлена строгой (STRICT); если это не так, при получении на вход значения NULL она будет вызываться с первым параметром NULL. В этом случае функция всё равно должна возвращать значение NULL, иначе будет вызвана ошибка. (Этот случай в основном предназначен для поддержки функций ввода доменных типов, которые не должны принимать значения NULL). Функция вывода должна быть объявлена как принимающая один аргумент нового типа данных, а возвращать должна тип cstring. Функции вывода не вызываются для значений NULL.
Необязательная функция_получения преобразует внешнее двоичное представление типа во внутреннее представление. Если эта функция не указана, тип не может участвовать в двоичном вводе. Двоичное представление должно быть выбрано так, чтобы оно легко преобразовывалось во внутреннюю форму, будучи при этом достаточно переносимым. (Например, для стандартных целочисленных типов данных в качестве внешнего двоичного представления используют сетевой порядок байтов, в то время как внутреннее представление определяется порядком байтов в процессоре.) Функция получения должна выполнять адекватную проверку, чтобы убедиться, что значение является допустимым. Функция получения может быть объявлена как принимающая один аргумент типа internal либо как принимающая три аргумента с типами internal, oid, integer. Первый аргумент — это указатель на буфер StringInfo, содержащий полученную байтовую строку; а остальные аргументы такие же, как и для функции ввода текста. Функция получения должна возвращать значение нового типа данных. Обычно функция получения должна быть объявлена строгой (STRICT); если это не так, при прочтении входного значения NULL, она будет вызываться с первым параметром NULL. В этом случае функция всё равно должна возвращать значение NULL, иначе будет вызвана ошибка. (Этот случай в основном предназначен для поддержки функций ввода доменных типов, которые не должны принимать значения NULL.) Аналогично, необязательная функция_отправки преобразует данные из внутреннего представления во внешнее двоичное представление. Если эта функция не указана, тип не может участвовать в двоичном выводе. Функция отправки должна быть объявлена как принимающая один аргумент нового типа данных, а возвращать тип bytea. Функции отправки не вызываются для значений NULL.
На этом этапе может возникнуть вопрос, как функции ввода и вывода
могут быть объявлены принимающими или возвращающими значения нового типа, если
они должны быть созданы до того, как новый тип объявлен. Ответ прост:
тип сначала должен быть определен как тип-оболочка,
который является заготовкой и не имеет никаких
свойств, кроме имени и владельца. Он объявляется командой
CREATE TYPE имя без дополнительных параметров. Тогда функции ввода/вывода на C/RUST
могут быть определены, ссылаясь на этот пустой тип. Затем команда CREATE TYPE с полным
определением заменит тип-оболочку на полное, допустимое определение типа, после чего новый тип
можно будет использовать как обычно.
Необязательные функции функция_ввода_модификатора_типа и функция_вывода_модификатора_типа необходимы, если тип поддерживает модификаторы, то есть дополнительные ограничения, связанные с объявлением типа, такие как char(5) или numeric(30,2). QHB позволяет создавать типы, которые могут принимать одну или несколько простых констант или идентификаторов в качестве модификаторов. Однако эта информация должна быть упакована в одно неотрицательное целочисленное значение для хранения в системных каталогах. Функция_ввода_модификатора_типа получает объявленный(ые) модификатор(ы) в виде строки cstring. Функция должна проверить значения на допустимость (и вызвать ошибку, если они неверны) и, если они верны, выдать одно неотрицательное значение integer, которое будет сохранено в столбце «typmod». Модификаторы типа не будут приниматься, если функция_ввода_модификатора_типа для типа не указана. Функция_вывода_модификатора_типа преобразует внутреннее целочисленное значение typmod обратно в понятную форму для отображения пользователю. Она должна вернуть значение cstring, которое является строкой для добавления к имени типа; например, функция numeric должна вернуть (30,2). Функция_вывода_модификатора_типа, может быть не указана; в этом случае отображением по умолчанию будет сохраненное целочисленное значение typmod, заключенное в круглые скобки.
Необязательная функция_анализа выполняет сбор специфичной
для типа статистики по столбцам с этим типом данных. По умолчанию команда ANALYZE
попытается собрать статистику, используя операторы «равно» и
«меньше, чем», если для типа определен класс операторов B-дерева по
умолчанию. Для нескалярных типов такое поведение в большинстве случаев не
подходит, поэтому его можно переопределить, указав собственную
функцию анализа. Функция анализа должна быть объявлена как принимающая
один аргумент типа internal, и возвращающая результат boolean.
Подробно API функций анализа описан в разделе src/include/commands/vacuum.h.
Хотя сведения о внутреннем представлении нового типа известны только функциям ввода-вывода и другим функциям, созданным для работы с типом, существует еще несколько свойств внутреннего представления, которые должны быть объявлены в QHB. Прежде всего, это внутренняя_длина. Если базовый тип данных фиксированной длины, то внутренняя_длина указывается в виде положительного числа, а если тип переменной длины, во внутренней_длине задается значение VARIABLE. (Внутри же typlen принимает значение -1.) Внутреннее представление всех типов переменной длины должно начинаться с 4-байтового целого числа, задающего общую длину значения типа. (Обратите внимание, что поле длины часто кодируется, как описано в разделе TOAST; неразумно обращаться к нему напрямую.)
Необязательный флаг PASSEDBYVALUE указывает, что значения создаваемого типа данных передаются по значению, а не по ссылке. Типы, передаваемые по значению, должны быть фиксированной длины, и их внутреннее представление не может быть больше размера типа Datum (4 байта на одних машинах, 8 байт на других).
Параметр выравнивание указывает, как требуется выравнивать данные этого типа. Допустимые значения выравнивания по границам 1, 2, 4 или 8 байт. Обратите внимание, что типы переменной длины должны иметь выравнивание не менее 4 байт, так как они обязательно содержат своим первым компонентом int4.
Параметр хранение позволяет выбирать стратегии хранения для типов данных переменной длины. (Для типов фиксированной длины допускается только вариант plain.) Вариант plain указывает, что данные этого типа всегда будут храниться внутри и не будут сжаты. Вариант extended указывает, что система сначала попытается сжать большое значение данных, а затем, если оно и после сжатия окажется слишком большим, переместит его из строки основной таблицы. Вариант external позволяет переместить значение из основной таблицы, но система не будет пытаться сжать его. Вариант main разрешает сжатие, но препятствует перемещению значения из основной таблицы. (Элементы данных с этим вариантом хранения всё равно могут быть перемещены из основной таблицы, если нет другого способа уместить их в строке, но предпочтение будет отдано сохранению в основной таблице, в отличие от вариантов extended и external.)
Все значения параметра хранение, кроме plain, подразумевают, что
функции типа данных могут принимать значения в формате toast, как описано в разделах TOAST
и Использование TOAST. Такое значение просто определяет
вариант хранения TOAST по умолчанию для столбцов отделяемого в TOAST типа данных;
другие варианты для отдельных столбцов можно выбирать
с помощью команды ALTER TABLE SET STORAGE.
Параметр тип_образец предоставляет альтернативный метод для указания основных свойств представления типа данных: скопировать их из другого существующего типа. Из указанного типа будут скопированы значения свойств внутренняя_длина, передача_по_значению, выравнивание и хранение. (Можно, хотя обычно это нежелательно, переопределить некоторые из этих значений, указав их вместе с предложением LIKE) Указывать представление типа таким образом особенно удобно при низкоуровневой реализации нового типа, которая некоторым образом «опирается» на существующий тип.
Параметры категория и предпочитаемый могут использоваться для поддержки в управлении тем, какое неявное приведение будет применяться в неоднозначных ситуациях. Каждый тип данных относится к категории, обозначаемой одним символом ASCII, и каждый тип в этой категории является либо «предпочтительным» либо нет. Анализатор запроса постарается выбрать приведение к предпочтительному типу (но только из других типов в той же категории); это правило полезно при разрешении перегруженных функций или операторов. Более подробную информацию см. в главе PL/pgSQL. Для типов, которые не имеют неявных приведений к какому-либо другому типу или из них, достаточно оставить значения по умолчанию. Однако для группы связанных типов, которые имеют неявные приведения, часто бывает полезно пометить их все как принадлежащие к категории и выбрать один или два «наиболее общих» типа как предпочтительные в категории. Параметр категория особенно полезен при добавлении пользовательского типа в существующую встроенную категорию, например, числовые или строковые типы. Однако также можно создавать новые, полностью пользовательские категории типов. В качестве имени такой категории можно выбрать любой ASCII-символ, кроме латинской заглавной буквы.
При желании можно назначить столбцам с этим типом данных значение по умолчанию, отличное от NULL, указав его после ключевого слова DEFAULT в этой команде. (Такое значение по умолчанию может быть переопределено явным предложением DEFAULT, добавленным при создании определенного столбца.)
Чтобы указать, что тип является массивом, задайте тип элементов массива
с помощью ключевого слова ELEMENT. Например, чтобы определить массив
4-байтовых целых чисел (int4), задайте ELEMENT = int4. Ниже приведены
дополнительные сведения о типах массивов.
Для указания разделителя, который будет использоваться между значениями во внешнем представлении массива с элементами этого типа, можно задать параметру delimiter определенный символ. Разделителем по умолчанию является запятая (,). Обратите внимание, что разделитель связан с типом элементов массива, а не с самим типом массива.
Если у необязательного логического параметра сортируемый установлено значение true, определения столбцов и выражения этого типа могут содержать информацию о правилах сортировки с помощью предложения COLLATE. Получение фактической пользы от этих правил зависит от реализаций функций, работающих с типом; просто от того, что тип помечен как сортируемый, эти правила действовать не будут.
Типы массивов
Каждый раз при создании пользовательского типа QHB автоматически создает связанный тип массива, имя которого состоит из имени типа элемента и знака подчеркивания перед ним. Полученное имя усекается, если это его длина превышает NAMEDATALEN байт. (Если имя, созданное таким образом, конфликтует с существующим именем типа, процесс повторяется до тех пор, пока не будет найдено непротиворечивое имя.) Этот неявно созданный тип массива имеет переменную длину и использует встроенные функции ввода и вывода array_in и array_out. Тип массива отражает любые изменения владельца или схемы его типа элемента и удаляется, если удаляется тип элемента.
Вы можете задать вопрос, зачем существует параметр ELEMENT, если система создает правильный тип массива автоматически. Единственный случай, когда полезно использовать ELEMENT, это когда вы создаете тип фиксированной длины, который оказывается массивом нескольких одинаковых элементов, и вы хотите, чтобы эти элементы были доступны при обращению по индексу, в дополнение к любым операциям, которые вы планируете реализовать для типа в целом. Например, тип point представляется в виде двух чисел с плавающей запятой, доступ к которым можно получить с помощью point[0] и point[1]. Обратите внимание, что эта функция работает только для типов фиксированной длины, внутренняя форма которых представляет собой точную последовательность одинаковых полей фиксированной длины. Тип массива переменной длины должен иметь обобщенное внутреннее представление, с которым умеют работать array_in и array_out. По историческим причинам (т.е. это определенно некорректно, но слишком поздно это менять), индексы в массивах фиксированной длины начинаются с нуля, а не с единицы, как для массивов переменной длины.
Параметры
имя
Имя создаваемого типа (может быть дополнено схемой).
имя_атрибута
Имя атрибута (столбца) для составного типа.
тип_данных
Имя существующего типа данных, который должен стать столбцом составного типа.
правило_сортировки
Имя существующего правила сортировки, которое должно быть связано со столбцом составного или диапазонного типа.
метка
Строковый литерал, представляющий текстовую метку, связанную с одним значением перечисляемого типа.
подтип
Имя типа элемента, для которого диапазонный тип будет представлять множество значений.
класс_оператора_подтипа
Имя класса операторов B-дерева для подтипа.
каноническая_функция
Имя функции канонизации для диапазонного типа.
функция_разницы_подтипа
Имя функции разницы для данного подтипа.
функция_ввода
Имя функции, преобразующей данные из внешней текстовой формы (представления) типа в его внутреннюю форму.
функция_вывода
Имя функции, преобразующей данные из внутренней формы (представления) типа во внешнюю текстовую форму.
функция_получения
Имя функции, преобразующей данные из внешней двоичной формы (представления) типа в его внутреннюю форму.
функция_отправки
Имя функции, преобразующей данные из внутренней формы типа во внешнюю двоичную форму типа.
функция_ввода_модификатора_типа
Имя функции, преобразующей массив модификаторов для данного типа во внутреннюю форму.
функция_вывода_модификатора_типа
Имя функции, преобразующей внутреннюю форму модификатора(ов) типа во внешнюю текстовую форму.
функция_анализа
Имя функции, выполняющей статистический анализ для данного типа данных.
внутренняя_длина
Числовая константа, указывающая длину внутреннего представления нового типа в байтах. По умолчанию предполагается, что тип имеет переменную длину.
выравнивание
Требуемое выравнивание для типа данных. Допустимые значения: char, int2, int4 или double; значение по умолчанию равно int4.
хранение
Стратегия хранения для данного типа данных. Допустимые значения: plain, external, extended или main; значение по умолчанию равно plain.
тип_образец
Имя существующего типа данных, от которого получит свойства представления
новый тип. Будут скопированы значения следующих параметров этого типа: внутренняя_длина,
передача_по_значению, выравнивание и хранение,
если только они не будут переопределены явными указаниями в команде CREATE TYPE.
категория
Код категории (один символ ASCII) для этого типа. Значение по умолчанию: 'U', что означает «пользовательский тип» (user-defined). Другие коды категорий можно найти в разделе Таблица кодов категорий. Вы также можете выбрать другие символы ASCII для создания пользовательских категорий.
предпочитаемый
Если значение равно true, то этот тип является предпочтительным типом в своей категории типов. Значение по умолчанию равно false. Будьте очень осторожны при создании нового предпочтительного типа в рамках существующей категории типов, так как это может вызвать неожиданные изменения в поведении.
по_умолчанию
Значение по умолчанию для данного типа данных. Если этот параметр не задан, будет использовано значение по умолчанию, равное NULL.
элемент
Указывает что создаваемый тип является массивом; это параметр определяет тип элементов массива.
разделитель
Символ-разделитель, используемый между значениями в массивах, образованных из значений создаваемого типа.
сортируемый
Если значение равно true, в операциях с этим типом может учитываться информация о параметрах сортировки. Значение по умолчанию равно false.
Примечания
Поскольку нет никаких ограничений на использование типа данных после его создания, создание базового или диапазонного типа равносильно предоставлению права на выполнение функций, упомянутых в определении типа. Это обычно не является проблемой для тех функций, которые используются в определении типа. Но стоит подумать дважды, прежде чем создавать тип, преобразование которого во внешнюю форму и обратно потребует использования «секретной» информации.
Рекомендуется избегать использования имен типов и таблиц, начинающихся с символа подчеркивания(_). Хотя сервер сможет сгенерировать другое имя, чтобы избежать конфликтов с пользовательскими именами, по-прежнему существует риск возникновения путаницы, особенно со старыми клиентскими приложениями, которые могут предположить, что имена типов, начинающиеся с подчеркивания, относится к типу массива.
Примеры
В этом примере создается составной тип, который затем используется в определении функции:
CREATE TYPE compfoo AS (f1 int, f2 text);
CREATE FUNCTION getfoo() RETURNS SETOF compfoo AS $$
SELECT fooid, fooname FROM foo
$$ LANGUAGE SQL;
В этом примере создается перечисляемый тип, который затем используется в определении таблицы:
CREATE TYPE bug_status AS ENUM ('new', 'open', 'closed');
CREATE TABLE bug (
id serial,
description text,
status bug_status
);
В этом примере создается диапазонный тип:
CREATE TYPE float8_range AS RANGE (subtype = float8, subtype_diff = float8mi);
В этом примере создается базовый тип данных box, который затем используется в определении таблицы:
CREATE TYPE box;
CREATE FUNCTION my_box_in_function(cstring) RETURNS box AS ... ;
CREATE FUNCTION my_box_out_function(box) RETURNS cstring AS ... ;
CREATE TYPE box (
INTERNALLENGTH = 16,
INPUT = my_box_in_function,
OUTPUT = my_box_out_function
);
CREATE TABLE myboxes (
id integer,
description box
);
Если бы внутренняя структура box была массивом из четырех элементов float4, можно было бы вместо этого использовать:
CREATE TYPE box (
INTERNALLENGTH = 16,
INPUT = my_box_in_function,
OUTPUT = my_box_out_function,
ELEMENT = float4
);
В этом случае к числам, составляющим значение этого типа, можно было бы обращаться по индексу. В остальном поведение этого типа будет таким же.
В этом примере создается тип большого объекта и используется в определении таблицы:
CREATE TYPE bigobj (
INPUT = lo_filein, OUTPUT = lo_fileout,
INTERNALLENGTH = VARIABLE
);
CREATE TABLE big_objs (
id integer,
obj bigobj
);
Дополнительные примеры, включая соответствующие функции ввода и вывода, приведены в разделе Пользовательские типы.
Совместимость
Первая форма команды CREATE TYPE, которая создает составной тип,
соответствует стандарту SQL. Другие формы являются расширением QHB.
Команда CREATE TYPE в стандарте SQL также имеет другие
формы, которые не реализованы в QHB.
Возможность создания составного типа без атрибутов является
специфическим для QHB отклонением от стандарта (аналогично
CREATE TABLE).
См. также
ALTER TYPE, CREATE DOMAIN, CREATE FUNCTION, DROP TYPE
CREATE USER MAPPING
CREATE USER MAPPING — определить новое сопоставление пользователя для стороннего сервера
Синтаксис
CREATE USER MAPPING [ IF NOT EXISTS ] FOR { имя_пользователя | USER | CURRENT_USER | PUBLIC }
SERVER имя_сервера
[ OPTIONS ( параметр 'значение' [ , ... ] ) ]
Описание
Команда CREATE USER MAPPING определяет сопоставление
пользователя на стороннем сервере. Пользовательское сопоставление обычно
содержит информацию о соединении, которую обертка сторонних данных
будет использовать вместе с информацией, инкапсулированной сторонним сервером, для
доступа к внешнему ресурсу данных.
Владелец стороннего сервера может создавать сопоставления для любых пользователей на этом сервере. Кроме того, пользователь может создавать сопоставление пользователей для своего собственного имени, если у него есть право USAGE на данном сервере.
Параметры
IF NOT EXISTS
Не выдавать ошибку, если сопоставление данного пользователя с данным сторонним сервером уже существует. В этом случае выдается соответствующее уведомление. Обратите внимание, что нет никакой гарантии, что существующее пользовательское сопоставление как-то соотносится с тем, которое было бы создано.
имя_пользователя
Имя существующего пользователя, для которого создается сопоставление на стороннем сервере. Ключевые слова CURRENT_USER и USER обозначают имя текущего пользователя. Если указывается PUBLIC, то создается так называемое общедоступное сопоставление, которое используется, когда не применяется никакое пользовательское сопоставление.
имя_сервера
Имя существующего сервера, для которого создается сопоставление пользователя.
OPTIONS ( параметр 'значение' [, ... ] )
В этом предложении задаются параметры сопоставления. Эти параметры обычно определяют фактическое имя и пароль пользователя на целевом сервере. Имена параметров должны быть уникальными. Набор допустимых имен и значений параметров определяется оберткой сторонних данных внешнего сервера.
Примеры
Создание пользовательского сопоставления для пользователя bob, сервер foo:
CREATE USER MAPPING FOR bob SERVER foo OPTIONS (user 'bob', password 'secret');
Совместимость
Команда CREATE USER MAPPING соответствует стандарту ISO/IEC 9075-9 (SQL/MED).
См. также
ALTER USER MAPPING, DROP USER MAPPING, CREATE FOREIGN DATA WRAPPER, CREATE SERVER
CREATE USER
CREATE USER — определить новую роль в базе данных
Синтаксис
CREATE USER имя [ [ WITH ] параметр [ ... ] ]
Где параметр может быть:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| BYPASSRLS | NOBYPASSRLS
| CONNECTION LIMIT предел_подключений
| [ ENCRYPTED ] PASSWORD 'пароль' | PASSWORD NULL
| VALID UNTIL 'дата_время'
| IN ROLE имя_роли [, ...]
| IN GROUP имя_роли [, ...]
| ROLE имя_роли [, ...]
| ADMIN имя_роли [, ...]
| USER имя_роли [, ...]
| SYSID uid
Описание
Сейчас команда CREATE USER является псевдонимом для CREATE ROLE.
Единственное отличие заключается в том, что в команде CREATE USER
по умолчанию подразумевается параметр LOGIN, в то время как в команде
CREATE ROLE по умолчанию подразумевается параметр NOLOGIN.
Совместимость
Команда CREATE USER является расширением QHB. Стандарт SQL
оставляет определение пользователей на усмотрение реализации.
См. также
CREATE VIEW
CREATE VIEW — определить новое представление
Синтаксис
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] [ RECURSIVE ] VIEW имя [ ( имя_столбца [, ...] ) ]
[ WITH ( имя_параметра_представления [= значение_параметра_представления] [, ... ] ) ]
AS запрос
[ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
Описание
Команда CREATE VIEW определяет представление запроса. Так как это
представление физически не материализуется, то указанный запрос будет
выполняться при каждом обращении к представлению.
CREATE OR REPLACE VIEW действует аналогичным образом,
но если представление с тем же именем уже существует, оно будет заменено.
Новый запрос должен выдавать те же столбцы, что и существующий запрос
представления (то есть те же имена столбцов в том же порядке и с теми же
типами данных), но также он может добавлять дополнительные столбцы в конец списка.
Вычисления, в результате которых формируются столбцы представления,
могут быть совершенно другими.
Если задано имя схемы (см. раздел Схемы) (например, CREATE VIEW myschema.myview ...), то
представление создается в указанной схеме, в противном случае — в текущей.
Временные представления существуют в специальной схеме, поэтому при
создании таких представлений имя схемы задать нельзя. Имя представления
должно отличаться от имен других представлений, таблиц, последовательностей,
индексов или сторонних таблиц в этой схеме.
Параметры
TEMPORARY или TEMP
Если этот параметр указан, то представление создается как временное представление. Временные представления автоматически удаляются в конце сеанса. Существующее постоянное представление с тем же именем не будет видно в текущем сеансе, пока существует временное, однако к нему можно обратиться, дополнив имя указанием схемы.
Если в определении представления задействованы временные таблицы, то такое представление создается как временное вне зависимости от явного указания TEMPORARY.
RECURSIVE
Создает рекурсивное представление. Синтаксис
CREATE RECURSIVE VIEW [ схема . ] имя_представления (имена_столбцов) AS SELECT ...;
равнозначен
CREATE VIEW [ схема . ] имя_представления AS WITH RECURSIVE имя_представления (имена_столбцов) AS (SELECT ...) SELECT имена_столбцов FROM имя_представления;
Для рекурсивного представления обязательно должен задаваться список с именами столбцов.
имя
Имя создаваемого представления (может быть дополнено схемой).
имя_столбца
Необязательный список имен, назначаемых столбцам представления. При его отсутствии имена столбцов формируются из результатов запроса.
WITH ( имя_параметра_представления [= значение_параметра_представления] [, ... ] )
В этом предложении указываются необязательные параметры для представления. Поддерживаются следующие параметры:
check_option (enum)
Этот параметр может принимать значение local (локально) или cascaded (каскадно) и равнозначен указанию WITH [ CASCADED | LOCAL ] CHECK OPTION (см. ниже). На существующих представлениях этот параметр можно изменить с помощью команды ALTER VIEW.
security_barrier (boolean)
Этот параметр следует использовать, если представление должно обеспечивать защиту на уровне строк. Дополнительную информацию см. в разделе Политики безопасности строк.
запрос
Команда SELECT или VALUES, которая предоставляет столбцы и строки представления.
WITH [ CASCADED | LOCAL ] CHECK OPTION
Этот параметр управляет поведением автоматически обновляемых
представлений. Если этот параметр указан, то команды INSERT и
UPDATE в представлении будут проверяться на предмет того, удовлетворяют ли новые
строки условию, определяющему представление (то есть будет выполнена проверка
новых строк на видимость через это представление). Если строки не видны,
обновление будет отклонено. Если параметр CHECK OPTION не указан,
то командам INSERT и UPDATE в представлении разрешается
создавать строки, которые не будут видны через это представление.
Поддерживаются следующие варианты проверки:
LOCAL
Новые строки проверяются только на соответствие условиям, определенным непосредственно в самом представлении. Любые условия, определенные на нижележащих базовых представлениях, не проверяются (если только в них тоже нет указания CHECK OPTION).
CASCADED
Новые строки проверяются на соответствие условиям представления и всех нижележащих базовых представлений. Если указано CHECK OPTION, а *LOCAL и CASCADED опущены, то предполагается значение CASCADED.
Не допускается использование CHECK OPTION с представлениями RECURSIVE.
Обратите внимание, что CHECK OPTION поддерживается только для
автоматически изменяемых представлений, не имеющих
триггеров INSTEAD OF или правил INSTEAD. Если автоматически изменяемое
представление определено поверх базового представления с триггерами INSTEAD OF,
то параметр LOCAL CHECK OPTION можно использовать для проверки ограничений
автоматически изменяемого представления, но условия базового представления
с триггером INSTEAD OF проверяться не будут (каскадная опция проверки
не будет спускаться ниже к представлению, модифицируемому
триггером, и любые параметры проверки, определенные напрямую для такого
представления, будут игнорироваться). Если для представления или любого из его базовых
отношений определено правило INSTEAD (которое приводит к перезаписи команды
INSERT или UPDATE), то все параметры проверки в перезаписанном запросе будут
проигнорированы, в том числе проверки из автоматически обновляемых представлений,
определенных поверх отношения с правилом INSTEAD.
Примечания
Для удаления представлений применяется команда DROP VIEW.
Позаботьтесь о том, чтобы столбцы представления получили желаемые имена и типы. Например, такая команда:
CREATE VIEW vista AS SELECT 'Hello World';
плоха тем, что по умолчанию именем столбца будет ?column?, а типом данных — text, а это может быть совсем не тем, что вы хотели. Лучше записывать строковую константу в результате представления примерно так:
CREATE VIEW vista AS SELECT text 'Hello World' AS hello;
Доступ к таблицам, задействованным в представлении, определяется правами владельца представления. В некоторых случаях это позволяет организовать безопасный, но ограниченный доступ к нижележащим таблицам. Однако учтите, что не все представления могут быть защищенными (подробную информацию см. в разделе Система правил QHB). Функции, вызываемые в представлении, выполняются так, будто они вызываются непосредственно из запроса, обращающегося к представлению. Поэтому пользователь представления должен иметь права, необходимые для вызова всех функций, задействованных в представлении.
При выполнении CREATE OR REPLACE VIEW для существующего
представления изменяется только правило SELECT, определяющее
представление. Другие свойства представления, включая владельца,
права и правила (кроме SELECT), остаются неизменными. Чтобы
изменить определение представления, необходимо быть его владельцем
(или членом роли-владельца).
Изменяемые представления
Простые представления становятся изменяемыми автоматически: система
позволит выполнять команды INSERT, UPDATE и DELETE с таким
представлением так же, как и с обычной таблицей. Представление будет
автоматически изменяемым, если оно удовлетворяет одновременно всем
следующим условиям:
Автоматически обновляемое представление может содержать как изменяемые,
так и неизменяемые столбцы. Столбец является изменяемым, если это
простая ссылка на изменяемый столбец нижележащего базового отношения;
в противном случае этот столбец будет доступен только для чтения,
и если команда INSERT или UPDATE попытается записать в него значение,
то возникнет ошибка.
Если представление автоматически изменяемое, то система будет преобразовывать
обращающиеся к нему команды INSERT, UPDATE и DELETE в соответствующие
операторы, обращающиеся к нижележащему базовому отношению.
При этом в полной мере поддерживаются команды INSERT с параметром
ON CONFLICT UPDATE.
Если автоматически изменяемое представление содержит условие WHERE, то
это условие ограничивает набор строк базового отношения, которые могут быть изменены командой
UPDATE и удалены командой DELETE в этом представлении.
Однако UPDATE может изменить строку так, что она перестанет
соответствовать условию WHERE и, как следствие, больше не будет видна
через представление. Команда INSERT подобным образом может добавить
в базовое отношение строки, которые не удовлетворят условию WHERE и поэтому
не будут видны через представление (ON CONFLICT UPDATE может подобным
образом воздействовать на существующую строку, не видимую через представление).
Чтобы предотвратить создание подобных строк командами INSERT и UPDATE,
можно воспользоваться указанием CHECK OPTION.
Если автоматически изменяемое представление имеет свойство security_barrier
(барьер безопасности), то все условия WHERE этого представления
(и все условия с герметичными операторами (LEAKPROOF)) будут всегда
вычисляться перед условиями, добавленными пользователем представления.
Подробную информацию см. в разделе Система правил QHB.
Обратите внимание, что по этой причине строки, которые в итоге не были возвращены
(потому что не прошли проверку в пользовательском условии WHERE), могут всё
же остаться заблокированными. Чтобы определить, какие условия применяются
на уровне отношения (и, как следствие, избавляют часть строк от блокировки),
можно воспользоваться командой EXPLAIN.
Более сложные представления, не удовлетворяющие этим условиям, по умолчанию доступны только для чтения: система не позволит выполнить операции добавления, изменения или удаления строк в таком представлении. Создать эффект изменяемого представления для них можно, определив триггеры INSTEAD OF, которые будут преобразовывать запросы на изменение данных в соответствующие действия с другими таблицами. Подробную информацию см. в разделе CREATE TRIGGER. Также есть возможность создавать правила (см. CREATE RULE), но на практике триггеры проще для понимания и применения.
Учтите, что пользователь, выполняющий операции добавления, изменения или удаления данных в представлении, должен иметь соответствующие права для этого представления. Кроме того, владелец представления должен иметь сопутствующие права в нижележащих базовых отношениях, хотя пользователь, выполняющий эти операции, может таких прав не иметь (см. Система правил QHB).
Примеры
Создание представления, содержащего все комедийные фильмы:
CREATE VIEW comedies AS
SELECT *
FROM films
WHERE kind = 'Comedy';
Эта команда создаст представление со столбцами, которые содержались в таблице film в момент выполнения команды. Хотя при создании представления было указано *, столбцы, добавляемые в таблицу позже, не будут являться частью представления.
Создание представления с указанием LOCAL CHECK OPTION:
CREATE VIEW universal_comedies AS
SELECT *
FROM comedies
WHERE classification = 'U'
WITH LOCAL CHECK OPTION;
Эта команда создаст представление на базе представления comedies,
выдающее только комедии (kind = 'Comedy') универсальной возрастной
категории classification = 'U'. Любая попытка выполнить в
представлении INSERT или UPDATE со строкой, не удовлетворяющей
условию classification = 'U', будет отвергнута, но ограничение
по полю kind (тип фильма) проверяться не будет.
Создание представления с указанием CASCADED CHECK OPTION:
CREATE VIEW pg_comedies AS
SELECT *
FROM comedies
WHERE classification = 'PG'
WITH CASCADED CHECK OPTION;
Это представление будет проверять, удовлетворяют ли новые строки обоим условиям: по столбцу kind и по столбцу classification.
Создание представления с изменяемыми и неизменяемыми столбцами:
CREATE VIEW comedies AS
SELECT f.*,
country_code_to_name(f.country_code) AS country,
(SELECT avg(r.rating)
FROM user_ratings r
WHERE r.film_id = f.id) AS avg_rating
FROM films f
WHERE f.kind = 'Comedy';
Это представление будет поддерживать операции INSERT, UPDATE и DELETE.
Изменяемыми будут все столбцы из таблицы films, тогда как вычисляемые
столбцы country и avg_rating будут доступны только для чтения.
Создание рекурсивного представления, состоящего из чисел от 1 до 100:
CREATE RECURSIVE VIEW public.nums_1_100 (n) AS
VALUES (1)
UNION ALL
SELECT n+1 FROM nums_1_100 WHERE n < 100;
Обратите внимание, что несмотря на то, что имя рекурсивного представления
дополнено схемой в этой команде CREATE, внутренняя ссылка представления
на себя же схемой не дополняется. Это связано с тем, что имя неявно
создаваемого общего табличного выражения (ОТВ) не может дополняться схемой.
Совместимость
Команда CREATE OR REPLACE VIEW является языковым расширением QHB.
Также расширением является предложение WITH ( ... ) и концепция
временного представления.
См. также
ALTER VIEW, DROP VIEW, CREATE MATERIALIZED VIEW
DEALLOCATE
DEALLOCATE — освободить подготовленный оператор
Синтаксис
DEALLOCATE [ PREPARE ] { имя | ALL }
Описание
Команда DEALLOCATE используется для освобождения заранее подготовленного
оператора SQL. Если не освободить подготовленный оператор явно, он
освобождается по окончании сеанса.
Дополнительную информацию о подготовленных инструкциях см. в разделе PREPARE.
Параметры
PREPARE
Это ключевое слово игнорируется.
имя
Имя подготовленного оператора для освобождения.
ALL
Освобождает все подготовленные операторы.
Совместимость
Стандарт SQL включает в себя команду DEALLOCATE, но она предназначена
только для использования во встраиваемом SQL.
См. также
DECLARE
DECLARE — определить курсор
Синтаксис
DECLARE имя [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR запрос
Описание
Команда DECLARE позволяет пользователю создавать курсоры, которые могут
использоваться для извлечения небольшого количества строк за один раз из
большего запроса. После создания курсора строки извлекаются из него с
помощью команды FETCH.
Примечание
Эта страница описывает использование курсоров на уровне команд SQL. Если вы пытаетесь использовать курсоры внутри функции PL/pgSQL, правила будут другими — см. раздел Структура PL/pgSQL.
Параметры
имя
Имя создаваемого курсора.
BINARY
Курсор будет возвращать данные в двоичном, а не в текстовом формате.
INSENSITIVE
Указывает, что данные, извлеченные из курсора, не должны быть затронуты обновлениями таблиц(ы), лежащей(их) в основе курсора, которые происходят после его создания. В QHB это поведение по умолчанию, поэтому данное ключевое слово не имеет никакого эффекта и принимается только для совместимости со стандартом SQL.
SCROLL
NO SCROLL
SCROLL указывает, что курсор можно использовать для получения строк непоследовательно (например, в обратном порядке). В зависимости от сложности плана выполнения запроса, указание SCROLL может привести к снижению производительности во время выполнения запроса. NO SCROLL указывает, что курсор не может быть использован для получения строк неупорядоченным образом. По умолчанию прокрутка в некоторых случаях разрешается, но это не равнозначно эффекту указания SCROLL. Дополнительную информацию см. в Примечаниях ниже.
WITH HOLD
WITHOUT HOLD
WITH HOLD указывает, что курсор можно продолжать использовать после успешной фиксации транзакции, которая его создала. WITHOUT HOLD указывает, что курсор не может использоваться вне транзакции, которая его создала. Если не указано ни WITHOUT HOLD, ни WITH HOLD, значением по умолчанию является WITHOUT HOLD.
запрос
Команды SELECT или VALUES, которые предоставляют строки, возвращаемые курсором.
Ключевые слова BINARY, INSENSITIVE и SCROLL могут быть указаны в любом порядке.
Примечания
Обычные курсоры возвращают данные в текстовом формате, в каком
их выдает SELECT. Опция BINARY указывает, что курсор должен возвращать
данные в двоичном формате. Это упрощает операции преобразования данных
для сервера и клиента за счет дополнительных усилий программиста по
работе с зависимыми от платформы двоичными форматами данных. Например,
если запрос возвращает значение единица из целочисленного столбца, с курсором по умолчанию вы
получите строку, содержащую 1, тогда как с двоичным
курсором вы получите 4-байтовое поле, содержащее внутреннее
представление значения (с сетевым порядком байтов).
Двоичные курсоры следует использовать осторожно. Многие приложения, включая qsql, не готовы обрабатывать двоичные курсоры и ожидают, что данные вернутся в текстовом формате.
Примечание
Когда клиентское приложение использует протокол «расширенный запрос» для выполнения командыFETCH, сообщение протокола Bind указывает, следует ли извлекать данные в текстовом или двоичном формате. Этот выбор переопределяет свойство курсора, заданное в его определении. Таким образом, понятие двоичного курсора как такового устарело при использовании расширенного протокола запросов — любой курсор может рассматриваться как текстовый или двоичный.
Если в команде объявления курсора не указано WITH HOLD, созданный этой
командой курсор может использоваться только в рамках текущей транзакции.
Таким образом, оператор DECLARE без WITH HOLD бесполезен вне блока транзакций: курсор
сохранится только до завершения оператора. Поэтому QHB сообщает
об ошибке, если такая команда используется вне блока транзакций.
Для определения блока транзакций используйте команды BEGIN и COMMIT
(или ROLLBACK).
Если в объявлении курсора WITH HOLD указывается и транзакция, создавшая курсор,
успешно фиксируется, курсор может и далее быть доступным для
последующих транзакций в том же сеансе. (Но если создание транзакции
прерывается, курсор удаляется.) Курсор со свойством WITH HOLD
закрывается, когда явно задается команда CLOSE или по завершении сеанса.
В текущей реализации строки, представленные удерживаемым
курсором, копируются во временный файл или область памяти, чтобы
оставаться доступными для последующих транзакций.
Свойство WITH HOLD можно не указывать, если запрос включает в себя указания FOR UPDATE или FOR SHARE.
Опция SCROLL должна быть указана при определении курсора, который будет использоваться для выборки данных в обратном порядке. Это требуется стандартом SQL. Однако для совместимости с более ранними версиями в QHB разрешается выборка в обратном направлении и без указания SCROLL*, если план запроса курсора достаточно прост и для его поддержки не требуются никакие дополнительные накладные расходы. Однако разработчикам приложений рекомендуется не полагаться на использование выборки в обратном порядке из курсора, который не был создан с помощью SCROLL. С указанием NO SCROLL прокрутка назад запрещается в любом случае.
Выборка в обратном направлении также запрещается, если запрос включает в себя указания FOR UPDATE и FOR SHARE; в этом случае указание SCROLL не принимается.
Внимание!!!
Прокручиваемые и удерживаемые (WITH HOLD) курсоры могут давать неожиданные результаты, если они вызывают любые изменчивые функции (см. раздел Категории изменчивости функций). Когда ранее извлеченная строка выбирается повторно, функции также могут выполниться повторно, возможно, приведя к результатам, отличным от полученных в первый раз. Одним из обходных путей для таких случаев является объявление курсора с указанием WITH HOLD и фиксация транзакции перед чтением любых строк из него. В этом случае весь набор данных курсора будет материализован во временном хранилище, так что изменчивые функции будут выполнены для каждой строки лишь единожды.
Если запрос в определении курсора включает указания FOR UPDATE или FOR SHARE, возвращаемые
курсором строки блокируются в момент первой выборки, аналогично происходящему при
выполнении обычной команды SELECT с этими указаниями. Кроме того, возвращаемые
строки будут самыми актуальными версиями; поэтому эти параметры
обеспечивают эквивалент того, что стандарт SQL называет «чувствительным
курсором». (Указание INSENSITIVE для курсора с запросом FOR UPDATE или FOR SHARE является ошибкой.)
Внимание!!!
Обычно рекомендуется использовать FOR UPDATE, если курсор предназначен для использования в командахUPDATE ... WHERE CURRENT OFиDELETE ... WHERE CURRENT OF. Указание FOR UPDATE запрещает другим сеансам изменять строки между моментом их извлечения и моментом их обновления. Без указания FOR UPDATE последующая команда с WHERE CURRENT OF не сработает, если строка была изменена с момента создания курсора.
Еще одна причина использовать FOR UPDATE в том, что без него при выполнении последующих команд с WHERE CURRENT OF может произойти сбой, если запрос курсора не удовлетворяет оговоренному в стандарте SQL критерию «простой изменяемости» (в частности, курсор должен ссылаться только на одну таблицу и не должен использовать группировку и сортировку (ORDER BY).) Курсоры, не удовлетворяющие этому критерию, могут работать либо не работать, в зависимости от конкретного выбранного плана; так что в худшем случае приложение может работать в тестовой, но сломается в производственной среде. С указанием FOR UPDATE курсор гарантированно будет изменяемым.
Главная причина не использовать FOR UPDATE вместе с WHERE CURRENT OF возникает, если требуется получить прокручиваемый курсор или курсор, не отражающий последующие изменения (то есть продолжающий показывать старые данные). Если это действительно необходимо, обязательно учтите при реализации приведенные выше замечания.
Стандарт SQL содержит только положения для курсоров во встраиваемом SQL. Сервер QHB не реализует инструкцию OPEN для курсоров; курсор считается открытым при его объявлении. Однако ECPG, встроенный препроцессор SQL для QHB, поддерживает стандартные соглашения о курсорах SQL, в том числе включающие инструкции DECLARE и OPEN. Вы можете просмотреть все доступные курсоры, запросив системное представление pg_cursors.
Примеры
Чтобы объявить курсор:
DECLARE liahona CURSOR FOR SELECT * FROM films;
Дополнительные примеры использования курсора см. в разделе FETCH.
Совместимость
Стандарт SQL говорит, что чувствительность курсоров к параллельному обновлению нижележащих данных по умолчанию определяется реализацией. В QHB курсоры по умолчанию нечувствительны и могут быть сделаны чувствительными путем указания FOR UPDATE. Другие СУБД могут работать по-другому.
Стандарт SQL позволяет использовать курсоры только во встраиваемом SQL и в модулях. QHB позволяет использовать курсоры в интерактивном режиме.
Бинарные курсоры являются расширением QHB.
См. также
DELETE
DELETE — удалить строки таблицы
Синтаксис
[ WITH [ RECURSIVE ] запрос_WITH [, ...] ]
DELETE FROM [ ONLY ] имя_таблицы [ * ] [ [ AS ] псевдоним ]
[ USING элемент_FROM [, ...] ]
[ WHERE условие | WHERE CURRENT OF имя_курсора ]
[ RETURNING * | выражение_результата [ [ AS ] имя_результата ] [, ...] ]
Описание
Команда DELETE удаляет строки из указанной таблицы, удовлетворяющие требованиям предложения WHERE.
Если предложение WHERE отсутствует, результат будет
заключаться в удалении всех строк таблицы. Итогом станет
действительная, но пустая таблица.
Совет
КомандаTRUNCATEобеспечивает более быстрый механизм для удаления всех строк из таблицы.
Существует два способа удаления строк в таблице с помощью информации, содержащейся в других таблицах базы данных: с помощью подзапросов или путем указания дополнительных таблиц в предложении USING. Какой метод является более подходящим, зависит от конкретных обстоятельств.
Необязательное предложение RETURNING указывает, что команда DELETE должна вычислить
и возвратить значение(я) для каждой фактически удаленной строки.
Вычислить в нем можно любое выражение со столбцами целевой таблицы
и/или столбцами других таблиц, упомянутых в USING. Список RETURNING
имеет тот же синтаксис, что и список результатов SELECT.
Чтобы удалять данные из таблицы, необходимо иметь право DELETE для нее, а также право SELECT для всех таблиц, перечисленных в предложении USING, и таблиц, данные которых считываются в условии.
Параметры
запрос_WITH
Предложение WITH позволяет указать один или несколько вложенных запросов, на которые можно ссылаться по имени в запросе на удаление. Дополнительную информацию см. в разделах Запросы WITH и SELECT.
имя_таблицы
Имя таблицы, из которой будут удалены строки (может быть дополнено схемой). Если перед именем таблицы указывается ONLY, совпадающие строки удаляются только из указанной таблицы. Если ONLY не указано, совпадающие строки также удаляются из всех таблиц, наследуемых от указанной таблицы. После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что операция затрагивает все дочерние таблицы.
псевдоним
Альтернативное имя целевой таблицы. Когда предоставляется псевдоним, он
полностью скрывает фактическое имя таблицы. Например, в запросе DELETE FROM foo AS f
остальная часть инструкции DELETE должна ссылаться на эту
таблицу по имени f, а не foo.
элемент_FROM
Табличное выражение, позволяющее добавить в условие WHERE столбцы
из других таблиц. В этом выражении используется тот же синтаксис,
что и в предложении FROM команды SELECT;
например, в нем можно определить псевдоним для таблицы. Повторять в нем имя целевой таблицы нужно,
только если требуется определить замкнутое соединение
(в этом случае для данного имени должен определяться псевдоним).
условие
Выражение, которое возвращает значение типа boolean. Будут удалены только те строки, для которых это выражение возвращает true.
имя_курсора
Имя курсора, который будет использоваться в условии WHERE CURRENT OF. Строка,
подлежащая удалению, является самой последней извлеченной из этого
курсора. Курсор должен быть образован запросом без группировки по целевой таблице
команды DELETE. Обратите внимание, что WHERE CURRENT OF не может быть указано
вместе с логическим условием. Дополнительную информацию об использовании
курсоров с WHERE CURRENT OF см. в описании команды DECLARE.
выражение_результата
Выражение, вычисляемое и возвращаемое командой DELETE после удаления каждой
строки. Выражение может использовать любые имена столбцов
таблицы имя_таблицы или таблиц, перечисленных в списке USING.
Чтобы получить все столбцы, достаточно написать *.
имя_результата
Имя, используемое для возвращаемого столбца.
Выводимая информация
После успешного завершения команда DELETE возвращает метку команды в виде
DELETE число
Где число — количество удаленных строк. Обратите внимание, что это число может быть меньше, чем число строк, которые соответствуют условию, если удаления были подавлены триггером BEFORE DELETE. Если число равно 0, ни одна строка не была удалена запросом (это не считается ошибкой).
Если команда DELETE содержит предложение RETURNING, результат
будет похож на результат команды SELECT (с теми же столбцами и значениями,
что содержатся в списке RETURNING), полученный для строк, удаленных этой командой.
Примечания
QHB позволяет ссылаться на столбцы других таблиц в условии WHERE, когда эти таблицы перечисляются в предложении USING. Например, чтобы удалить все фильмы, произведенные определенным производителем, можно сделать:
DELETE FROM films USING producers
WHERE producer_id = producers.id AND producers.name = 'foo';
По существу происходит соединение таблиц films и producers, причем все успешно включенные в соединение строки в films помечаются для удаления. Этот синтаксис не является стандартным. Более стандартный способ сделать это:
DELETE FROM films
WHERE producer_id IN (SELECT id FROM producers WHERE name = 'foo');
В некоторых случаях запрос в стиле соединения легче написать и он может выполняться быстрее, чем запрос в стиле вложенного запроса.
Примеры
Удаление всех фильмов, кроме мюзиклов:
DELETE FROM films WHERE kind <> 'Musical';
Очистка таблицы films:
DELETE FROM films;
Удаление завершенных задач с получением всех данных удаленных строк:
DELETE FROM tasks WHERE status = 'DONE' RETURNING *;
Удаление из tasks строки, на которой в текущий момент располагается курсор c_tasks:
DELETE FROM tasks WHERE CURRENT OF c_tasks;
Совместимость
Команда DELETE соответствует стандарту SQL, за исключением того,
что предложения USING и RETURNING являются расширениями QHB,
так же как и возможность использовать WITH с этой командой.
См. также
DISCARD
DISCARD — очистить состояние сеанса
Синтаксис
DISCARD { ALL | PLANS | SEQUENCES | TEMPORARY | TEMP }
Описание
Команда DISCARD освобождает внутренние ресурсы, связанные с сеансом использования базы
данных. Эта команда полезна для частичного или полного сброса состояния
сеанса. Существует несколько подкоманд для освобождения различных типов
ресурсов; вариант DISCARD ALL объединяет все остальные,
а также сбрасывает дополнительное состояние.
Параметры
PLANS
Освобождает все кэшированные планы запросов, заставляя сервер провести повторное планирование при следующем использовании связанного подготовленного оператора.
SEQUENCES
Сбрасывает все кэшированные состояния, связанные с последовательностями, включая информацию currval()/lastval() и любые предварительно выделенные значения последовательности, которые еще не были возвращены nextval(). (Описание предварительно выделенных значений последовательности см. в разделе CREATE SEQUENCE).
TEMPORARY или TEMP
Удаляет все временные таблицы, созданные в текущем сеансе.
ALL
Освобождает все временные ресурсы, связанные с текущим сеансом, и возвращает сеанс в исходное состояние. В настоящее время это имеет тот же эффект, что и выполнение следующей последовательности операторов:
CLOSE ALL;
SET SESSION AUTHORIZATION DEFAULT;
RESET ALL;
DEALLOCATE ALL;
UNLISTEN *;
SELECT pg_advisory_unlock_all();
DISCARD PLANS;
DISCARD TEMP;
DISCARD SEQUENCES;
Примечания
DISCARD ALL не может быть выполнена внутри блока транзакций.
Совместимость
Команда DISCARD ALL является расширением QHB.
DO
DO — выполнить анонимный блок кода
Синтаксис
DO [ LANGUAGE имя_языка ] код
Описание
Команда DO выполняет анонимный блок кода или, другими словами, временную
анонимную функцию на процедурном языке.
Блок кода обрабатывается так, как если бы это было тело функции без параметров, возвращающее значение void. Этот код анализируется и выполняется один раз.
Необязательное предложение LANGUAGE может быть написано как до, так и после блока кода.
Параметры
код
Выполняемый код на процедурном языке. Он должен задаваться в
виде текстовой строки (ее рекомендуется заключать в знаки доллара),
как и код в CREATE FUNCTION.
имя_языка
Название процедурного языка, на котором написан код. Если этот параметр опущен, значение по умолчанию равно plpgsql.
Примечания
Используемый процедурный язык должен быть уже установлен в текущую базу
данных с помощью команды CREATE EXTENSION. plpgsql устанавливается по
умолчанию, но другие языки — нет.
Необходимо иметь право USAGE для данного процедурного языка либо быть суперпользователем, если язык недоверенный. Такие же права требуются и при создании функции на этом языке.
Если команда DO выполняется в блоке транзакций, то код процедуры не может
вызывать операторы управления транзакциями. Такие операторы допускаются
только в том случае, если DO выполняется в собственной транзакции.
Примеры
Предоставление роли webuser всех прав доступа на все представления в схеме public:
DO $$DECLARE r record;
BEGIN
FOR r IN SELECT table_schema, table_name FROM information_schema.tables
WHERE table_type = 'VIEW' AND table_schema = 'public'
LOOP
EXECUTE 'GRANT ALL ON ' || quote_ident(r.table_schema) || '.' || quote_ident(r.table_name) || ' TO webuser';
END LOOP;
END$$;
Совместимость
В стандарте SQL нет команды DO.
См. также
DROP ACCESS METHOD
DROP ACCESS METHOD — удалить метод доступа
Синтаксис
DROP ACCESS METHOD [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP ACCESS METHOD удаляет существующий метод доступа.
Удалять методы доступа могут только суперпользователи.
Параметры
IF EXISTS
Не считать ошибкой, если метод доступа не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего метода доступа.
CASCADE
Автоматически удалять объекты, зависящие от метода доступа (такие как классы операторов, семейства операторов и индексы), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять метод доступа, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление метода доступа heptree:
DROP ACCESS METHOD heptree;
Совместимость
Команда DROP ACCESS METHOD является расширением QHB.
См. также
DROP AGGREGATE
DROP AGGREGATE — удалить агрегатную функции
Синтаксис
DROP AGGREGATE [ IF EXISTS ] имя ( сигнатура_агрегатной_функции ) [ CASCADE | RESTRICT ]
Где сигнатура_агрегатной_функции:
* |
[ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] |
[ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] ] ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ]
Описание
Команда DROP AGGREGATE удаляет существующую агрегатную функцию. Для
выполнения этой команды нужно быть владельцем соответствующей агрегатной функции.
Параметры
IF EXISTS
Не считать ошибкой, если агрегатная функция не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей агрегатной функции (может быть дополнено схемой).
режим_аргумента
Режим аргумента: IN или VARIADIC. Значение по умолчанию равно IN.
имя_аргумента
Имя аргумента. Обратите внимание, что DROP AGGREGATE фактически
не обращает внимания на имена аргументов, поскольку для идентификации
агрегатной функции необходимы только типы данных ее аргументов.
тип_аргумента
Тип входных данных, с которыми работает агрегатная функция. Чтобы сослаться на агрегатную функцию без аргументов, напишите вместо списка аргументов *. Чтобы сослаться на сортирующую агрегатную функцию, напишите ORDER BY между непосредственными и агрегированными аргументами.
CASCADE
Автоматически удалять объекты, зависящие от агрегатной функции (например, использующие ее представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять агрегатную функцию, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примечания
Альтернативные синтаксисы для указания сортирующих агрегатных функций описаны в разделе ALTER AGGREGATE.
Примеры
Удалить агрегатную функцию myavg для типа integer:
DROP AGGREGATE myavg(integer);
Удалить гипотезирующую агрегатную функцию myrank, которая принимает произвольный список сортируемых столбцов и соответствующий список непосредственных аргументов:
DROP AGGREGATE myrank(VARIADIC "any" ORDER BY VARIADIC "any");
Удалить несколько агрегатных функций в одной команде:
DROP AGGREGATE myavg (integer), myavg (bigint);
Совместимость
В стандарте SQL нет команды DROP AGGREGATE.
См. также
ALTER AGGREGATE, CREATE AGGREGATE
DROP CAST
DROP CAST — удалить приведение типа
Синтаксис
DROP CAST [ IF EXISTS ] (исходный_тип AS целевой_тип) [ CASCADE | RESTRICT ]
Описание
Команда DROP CAST удаляет ранее определенное приведение типа.
Чтобы удалить приведение типа, нужно быть владельцем исходного или целевого типа данных. Эти же требования действуют и при создании приведения.
Параметры
IF EXISTS
Не считать ошибкой, если приведение не существует. В этом случае будет выдано соответствующее уведомление.
исходный_тип
Имя исходного типа данных для приведения.
целевой_тип
Имя целевого типа данных для приведения.
CASCADE RESTRICT
Эти ключевые слова не имеют эффекта, так как нет объектов, зависящих от приведений.
Примеры
Удалить приведение типа text к типу int:
DROP CAST (text AS int);
Совместимость
Команда DROP CAST соответствует стандарту SQL.
См. также
DROP COLLATION
DROP COLLATION — удалить правило сортировки
Синтаксис
DROP COLLATION [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP COLLATION удаляет ранее определенное правило сортировки.
Чтобы удалить правило сортировки, нужно быть его владельцем.
Параметры
IF EXISTS
Не считать ошибкой, если правило сортировки не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя правила сортировки (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от правила сортировки, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять правила сортировки, если от них зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удалить правило сортировки с именем german:
DROP COLLATION german;
Совместимость
Команда DROP COLLATION соответствует стандарту SQL, за исключением параметра
IF EXISTS, который является расширением QHB.
См. также
ALTER COLLATION, CREATE COLLATION
DROP CONVERSION
DROP CONVERSION — удалить преобразование
Синтаксис
DROP CONVERSION [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP CONVERSION удаляет ранее определенное преобразование. Чтобы
иметь возможность удалить преобразование, нужно быть его владельцем.
Параметры
IF EXISTS
Не считать ошибкой, если преобразование не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя преобразования (может быть дополнено схемой).
CASCADE
RESTRICT
Эти ключевые слова не имеют эффекта, так как нет объектов, зависящих от преобразований.
Примеры
Удалить преобразование с именем myname:
DROP CONVERSION myname;
Совместимость
В стандарте SQL нет команды DROP CONVERSION, но есть команда
DROP TRANSLATION, сопутствующая команде CREATE TRANSLATION, которая,
в свою очередь, подобна команде CREATE CONVERSION в QHB.
См. также
ALTER CONVERSION, CREATE CONVERSION
DROP DATABASE
DROP DATABASE — удалить базу данных
Синтаксис
DROP DATABASE [ IF EXISTS ] имя [ [ WITH ] ( параметр [, ...] ) ]
Где параметр может быть:
FORCE
Описание
Команда DROP DATABASE удаляет базу данных. Она удаляет записи из каталогов,
которые относятся к базе данных, и удаляет каталог, содержащий данные. Выполнить
команду может только владелец базы данных. Кроме того, команда не может быть
выполнена, пока вы или кто-либо другой подключен к целевой базе данных.
(Чтобы выполнить эту команду, подключитесь к QHB или любой
другой базе данных.)
Действие команды DROP DATABASE нельзя отменить. Используйте ее с
осторожностью!
Параметры
IF EXISTS
Не считать ошибкой, если база данных не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя базы данных, подлежащей удалению.
FORCE
Попытаться завершить все существующие подключения к целевой базе данных. Подключения не завершаются, если в целевой базе данных находятся подготовленные транзакции, активные слоты логической репликации или подписки.
Данная операция завершится ошибкой, если у текущего пользователя нет прав завершать другие подключения (это те же права, что требуются для выполнения pg_terminate_backend; они описаны в разделе Функции сигнализации сервера). Также ошибка произойдет, если завершить подключения не удастся.
Примечания
Команда DROP DATABASE не может быть выполнена внутри блока транзакций.
Эта команда не может быть выполнена, если установлено подключение к целевой базе данных. Таким образом, возможно, будет удобнее использовать вместо нее программу dropdb, которая является ее оболочкой.
Совместимость
В стандарте SQL нет команды DROP DATABASE.
См. также
DROP DOMAIN
DROP DOMAIN — удалить домен
Синтаксис
DROP DOMAIN [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP DOMAIN удаляет домен. Только владелец домена может его удалить.
Параметры
IF EXISTS
Не считать ошибкой, если домен не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего домена (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от домена (например, столбцы таблицы), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять домен, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удалить домен box:
DROP DOMAIN box;
Совместимость
Команда DROP DOMAIN соответствует стандарту SQL, за исключением параметра
IF EXISTS, который является расширением QHB.
См. также
DROP EVENT TRIGGER
DROP EVENT TRIGGER — удалить событийный триггер
Синтаксис
DROP EVENT TRIGGER [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP EVENT TRIGGER удаляет существующий событийный триггер. Для
выполнения этой команды нужно быть владельцем соответствующего событийного триггера.
Параметры
IF EXISTS
Не считать ошибкой, если событийный триггер не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя событийного триггера, подлежащего удалению.
CASCADE
Автоматически удалять объекты, зависящие от триггера, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять триггер, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление триггера snitch:
DROP EVENT TRIGGER snitch;
Совместимость
В стандарте SQL нет команды DROP EVENT TRIGGER.
См. также
CREATE EVENT TRIGGER, ALTER EVENT TRIGGER
DROP EXTENSION
DROP EXTENSION — удалить расширение
Синтаксис
DROP EXTENSION [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP EXTENSION удаляет расширения из базы данных. Удаление
расширения также приводит к удалению составляющих его объектов.
Для выполнения команды DROP EXTENSION нужно быть владельцем соответствующего расширения.
Параметры
IF EXISTS
Не считать ошибкой, если расширение не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя установленного расширения.
CASCADE
Автоматически удалять объекты, зависящие от расширения, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять расширение, если от него зависят какие-либо
объекты (кроме его собственных объектов и других расширений,
перечисленных в той же команде DROP). Это поведение по умолчанию.
Примеры
Удаление расширения hstore из текущей базы данных:
DROP EXTENSION hstore;
Эта команда не будет выполнена, если какой-либо объект из hstore используется в базе данных, например, если в какой-либо таблице есть столбец с типом hstore. Добавив указание CASCADE, можно принудительно удалить и все зависимые объекты.
Совместимость
Команда DROP EXTENSION является расширением QHB.
См. также
CREATE EXTENSION, ALTER EXTENSION
DROP FOREIGN DATA WRAPPER
DROP FOREIGN DATA WRAPPER — удалить обертку сторонних данных
Синтаксис
DROP FOREIGN DATA WRAPPER [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP FOREIGN DATA WRAPPER удаляет существующую обертку сторонних данных.
Для выполнения этой команды нужно быть владельцем соответствующей обертки сторонних данных.
Параметры
IF EXISTS
Не считать ошибкой, если обертка сторонних данных не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей обертки сторонних данных.
CASCADE
Автоматически удалять объекты, зависящие от обертки сторонних данных (например, сторонние таблицы и серверы), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять обертку сторонних данных, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление обертки сторонних данных dbi:
DROP FOREIGN DATA WRAPPER dbi;
Совместимость
Команда DROP FOREIGN DATA WRAPPER соответствует стандарту ISO/IEC 9075-9 (SQL/MED).
Предложение IF EXISTS является расширением QHB.
См. также
CREATE FOREIGN DATA WRAPPER, ALTER FOREIGN DATA WRAPPER
DROP FOREIGN TABLE
DROP FOREIGN TABLE — удалить стороннюю таблицу
Синтаксис
DROP FOREIGN TABLE [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP FOREIGN TABLE удаляет стороннюю таблицу. Только владелец сторонней
таблицы может ее удалить.
Параметры
IF EXISTS
Не считать ошибкой, если сторонняя таблица не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя сторонней таблицы, подлежащей удалению (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от сторонней таблицы (например, представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять стороннюю таблицу, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление двух сторонних таблиц, films и distributors:
DROP FOREIGN TABLE films, distributors;
Совместимость
Команда DROP FOREIGN TABLE соответствует стандарту ISO/IEC 9075-9 (SQL/MED), за
исключением возможности удалять несколько сторонних
таблиц в одной команде, а также параметра IF EXISTS,
которые являются расширением QHB.
См. также
ALTER FOREIGN TABLE, CREATE FOREIGN TABLE
DROP FUNCTION
DROP FUNCTION — удалить функцию
Синтаксис
DROP FUNCTION [ IF EXISTS ] имя ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] )
[ CASCADE | RESTRICT ]
Описание
Команда DROP FUNCTION удаляет определение существующей функции. Для
выполнения этой команды нужно быть владельцем соответствующей функции.
Кроме имени функции должны быть еще указаны типы ее аргументов, так как могут существовать
несколько различных функций с одинаковым именем и разными
списками аргументов.
Параметры
IF EXISTS
Не считать ошибкой, если функция не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей функции (может быть дополнено схемой). Если список аргументов не указан, имя должно быть уникальным в своей схеме.
режим_аргумента
Режим аргумента: IN, OUT, INOUT или VARIADIC. Значением по умолчанию является IN.
Обратите внимание, что команда DROP FUNCTION на самом деле не обращает внимания на аргументы
с режимом OUT, поскольку для идентификации функции нужны только аргументы с режимом IN.
Так что достаточно перечислить аргументы с режимами IN, INOUT и VARIADIC.
имя_аргумента
Имя аргумента. Обратите внимание, что команда DROP FUNCTION фактически
не обращает внимания на имена аргументов, поскольку для идентификации функции нужны
только типы данных ее аргументов.
тип_аргумента
Тип(ы) данных аргументов функции (могут быть дополнены схемой), если таковые имеются.
CASCADE
Автоматически удалять объекты, зависящие от функции (например, операторы или триггеры), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять функцию, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Эта команда удаляет функцию, вычисляющую квадратный корень:
DROP FUNCTION sqrt(integer);
Удаление нескольких функций одной командой:
DROP FUNCTION sqrt(integer), sqrt(bigint);
Если имя функции уникально в ее схеме, на нее можно указать без списка аргументов:
DROP FUNCTION update_employee_salaries;
Обратите внимание, что это отличается от
DROP FUNCTION update_employee_salaries();
Данная форма ссылается на функцию без аргументов, тогда как первый вариант подходит для функции с любым числом аргументов (в том числе и совсем без них), если имя функции уникально.
Совместимость
Команда DROP FUNCTION соответствует стандарту SQL, со следующими расширениями
QHB:
См. также
CREATE FUNCTION, ALTER FUNCTION, DROP PROCEDURE, DROP ROUTINE
DROP GROUP
DROP GROUP — удалить роль в базе данных
Синтаксис
DROP GROUP [ IF EXISTS ] имя [, ...]
Описание
Команда DROP GROUP является синонимом команды DROP ROLE.
Совместимость
В стандарте SQL нет команды DROP GROUP.
См. также
DROP INDEX
DROP INDEX — удалить индекс
Синтаксис
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP INDEX удаляет существующий индекс из базы данных. Для
выполнения этой команды нужно быть владельцем соответствующего индекса.
Параметры
CONCURRENTLY
Это указание позволяет удалить индекс без блокировки одновременных операций отбора, добавления,
изменения и удаления данных в таблице индекса. Обычная команда
DROP INDEX запрашивает исключительную блокировку на таблицу, блокируя другие обращения к ней до
тех пор, пока удаление индекса не будет завершено. При использовании же данного параметра
команда вместо этого будет ожидать завершения конфликтующих транзакций.
Есть несколько особенностей, которые следует учитывать при
использовании этого параметра. В команде можно указать только одно имя индекса; также
не поддерживается указание CASCADE. (Следовательно, индекс, поддерживающий
ограничение UNIQUE или PRIMARY KEY, не может быть удален таким способом.)
Кроме того, обычные команды DROP INDEX могут выполняться в
блоке транзакций, а DROP INDEX CONCURRENTLY не может. И наконец, с помощью этого параметра нельзя удалить индексы партиционированных таблиц.
На временных таблицах команда DROP INDEX всегда выполняется менее затратным неблокирующим способом, так как они не могут использоваться другими сеансами.
IF EXISTS
Не считать ошибкой, если индекс не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя индекса, подлежащего удалению (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от индекса, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять индекс, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Эта команда удалит индекс title_idx:
DROP INDEX title_idx;
Совместимость
Команда DROP INDEX является расширением QHB. В стандарте SQL нет
положений для индексов.
См. также
DROP LANGUAGE
DROP LANGUAGE — удалить процедурный язык
Синтаксис
DROP [ PROCEDURAL ] LANGUAGE [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP LANGUAGE удаляет определение ранее зарегистрированного
процедурного языка. Чтобы использовать команду DROP LANGUAGE, нужно быть суперпользователем
или владельцем соответствующего языка.
Примечание
Большинство процедурных языков были преобразованы в «расширения», поэтому теперь их следует удалять командой DROP EXTENSION, а неDROP LANGUAGE.
Параметры
IF EXISTS
Не считать ошибкой, если процедурный язык не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего процедурного языка. Для обратной совместимости может быть заключено в одинарные кавычки.
CASCADE
Автоматически удалять объекты, зависящие от процедурного языка (например, функции в языке), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять процедурный язык, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Эта команда удаляет процедурный язык plsample:
DROP LANGUAGE plsample;
Совместимость
В стандарте SQL нет команды DROP LANGUAGE.
См. также
ALTER LANGUAGE, CREATE LANGUAGE
DROP MATERIALIZED VIEW
DROP MATERIALIZED VIEW — удалить материализованное представление
Синтаксис
DROP MATERIALIZED VIEW [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP MATERIALIZED VIEW удаляет существующее материализованное представление.
Для выполнения этой команды нужно быть владельцем соответствующего
материализованного представления.
Параметры
IF EXISTS
Не считать ошибкой, если материализованное представление не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя материализованного представления, подлежащего удалению (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от материализованного представления (например, другие материализованные представления или обычные представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять материализованное представление, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Эта команда удаляет материализованное представление с именем order_summary:
DROP MATERIALIZED VIEW order_summary;
Совместимость
Команда DROP MATERIALIZED VIEW является расширением QHB.
См. также
CREATE MATERIALIZED VIEW, ALTER MATERIALIZED VIEW, REFRESH MATERIALIZED VIEW
DROP OPERATOR CLASS
DROP OPERATOR CLASS — удалить класс операторов
Синтаксис
DROP OPERATOR CLASS [ IF EXISTS ] имя USING индексный_метод [ CASCADE | RESTRICT ]
Описание
Команда DROP OPERATOR CLASS удаляет существующий класс
операторов. Для выполнения этой команды нужно быть владельцем
соответствующего класса операторов.
DROP OPERATOR CLASS не удаляет операторы и функции, связанные с этим классом.
Если есть какие-либо индексы, зависящие от этого класса оператора, необходимо
будет указать CASCADE, чтобы удаление было успешно завершено.
Параметры
IF EXISTS
Не считать ошибкой, если класс операторов не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего класса операторов (может быть дополнено схемой).
индексный_метод
Имя метода доступа к индексу, для которого предназначен класс операторов.
CASCADE
Автоматически удалять объекты, зависящие от класса операторов (например, индексы), и в свою очередь все объекты, зависящие от этих объектов (см.раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять класс операторов, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примечания
DROP OPERATOR CLASS не удаляет семейство операторов, содержащее
класс, даже если в семействе больше ничего не останется (в частности, в
том случае, когда семейство было неявно создано с помощью команды CREATE OPERATOR CLASS). Пустое семейство операторов безвредно, но из
соображений аккуратности его можно удалить командой DROP OPERATOR FAMILY. Или,
возможно, лучше изначально использовать DROP OPERATOR FAMILY.
Примеры
Удаление класса операторов B-дерева с именем widget_ops:
DROP OPERATOR CLASS widget_ops USING btree;
Эта команда не будет выполнена, если существуют какие-либо индексы, использующие этот класс операторов. Чтобы удалить такие индексы вместе с классом оператора, нужно добавить в команду указание CASCADE.
Совместимость
В стандарте SQL нет команды DROP OPERATOR CLASS.
См. также
ALTER OPERATOR CLASS, CREATE OPERATOR CLASS, DROP OPERATOR FAMILY
DROP OPERATOR FAMILY
DROP OPERATOR FAMILY — удалить семейство операторов
Синтаксис
DROP OPERATOR FAMILY [ IF EXISTS ] имя USING индексный_метод [ CASCADE | RESTRICT ]
Описание
Команда DROP OPERATOR FAMILY удаляет существующее семейство
операторов. Для выполнения этой команды нужно быть владельцем соответствующего
семейства операторов.
Команда DROP OPERATOR FAMILY удаляет также и все классы операторов,
содержащиеся в семействе, но не удаляет связанные с семейством операторы и
функции. Если внутри семейства существуют какие-либо индексы, зависящие от
классов операторов, для успешного завершения команды необходимо будет
указать CASCADE.
Параметры
IF EXISTS
Не считать ошибкой, если семейство операторов не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего семейства операторов (может быть дополнено схемой).
индексный_метод
Имя метода доступа к индексу, для которого предназначено семейство операторов.
CASCADE
Автоматически удалять объекты, зависящие от семейства операторов, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять семейство операторов, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление семейства операторов B-дерева с именем float_ops:
DROP OPERATOR FAMILY float_ops USING btree;
Эта команда не будет выполнена, если внутри данного семейства существуют какие-либо индексы, использующие классы операторов. Чтобы удалить такие индексы вместе с семейством операторов, нужно добавить указание CASCADE.
Совместимость
В стандарте SQL нет команды DROP OPERATOR FAMILY.
См. также
ALTER OPERATOR FAMILY, CREATE OPERATOR FAMILY, ALTER OPERATOR CLASS CREATE OPERATOR CLASS, DROP OPERATOR CLASS
DROP OPERATOR
DROP OPERATOR — удалить оператор
Синтаксис
DROP OPERATOR [ IF EXISTS ] имя ( { тип_слева | NONE } , { тип_справа | NONE } ) [, ... ] [ CASCADE | RESTRICT ]
Описание
Команда DROP OPERATOR удаляет существующий оператор из базы данных.
Для выполнения этой команды нужно быть владельцем соответствующего оператора.
Параметры
IF EXISTS
Не считать ошибкой, если оператор не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего оператора (может быть дополнено схемой).
тип_слева
Тип данных левого операнда оператора; если у оператора нет левого операнда, укажите NONE.
тип_справа
Тип данных правого операнда оператора; если у оператора нет правого операнда, укажите NONE.
CASCADE
Автоматически удалять объекты, зависящие от оператора (например, использующие его представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять оператор, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление оператора возведения в степень a^b для типа integer:
DROP OPERATOR ^ (integer, integer);
Удаление левого унарного оператора двоичного дополнения ~b для типа bit:
DROP OPERATOR ~ (none, bit);
Удаление правого унарного оператора вычисления факториала x! для типа bigint:
DROP OPERATOR ! (bigint, none);
Удаление нескольких операторов одной командой:
DROP OPERATOR ~ (none, bit), ! (bigint, none);
Совместимость
В стандарте SQL нет команды DROP OPERATOR.
См. также
CREATE OPERATOR, ALTER OPERATOR
DROP OWNED
DROP OWNED — удалить объекты базы данных, принадлежащие роли
Синтаксис
DROP OWNED BY { имя | CURRENT_USER | SESSION_USER } [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP OWNED удаляет все объекты в текущей базе данных,
принадлежащие указанным ролям. Все права, предоставленные данным ролям для
объектов в текущей базе данных или для общих объектов (баз данных, табличных
пространств), также будут отозваны.
Параметры
имя
Имя роли, объекты которой будут удалены и права которой будут отозваны.
CASCADE
Автоматически удалять объекты, зависящие от затронутых объектов, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять объекты, принадлежащие роли, если любые другие объекты базы данных зависят от одного из затронутых объектов. Это поведение по умолчанию.
Примечания
Команда DROP OWNED часто используется для подготовки к удалению одной или
нескольких ролей. Поскольку DROP OWNED влияет только на объекты в
текущей базе данных, обычно необходимо выполнить эту команду в каждой
базе данных, содержащей объекты, принадлежащие удаляемой роли.
С указанием CASCADE эта команда рекурсивно удалит объекты, принадлежащие и другим пользователям.
Команда REASSIGN OWNED является альтернативой DROP OWNED: она
переназначает владельца всех объектов базы данных, принадлежащих одной
или нескольким ролям. Однако REASSIGN OWNED не затрагивает никакие права
для других объектов.
Базы данных и табличные пространства, принадлежащие роли(ям), удалены не будут.
Дополнительную информацию см. в разделе Удаление ролей.
Совместимость
Команда DROP OWNED является расширением QHB.
См. также
DROP POLICY
DROP POLICY — удалить политику защиты на уровне строк для таблицы
Синтаксис
DROP POLICY [ IF EXISTS ] имя ON имя_таблицы [ CASCADE | RESTRICT ]
Описание
Команда DROP POLICY удаляет указанную политику из таблицы. Обратите внимание,
что если из таблицы удаляется последняя политика и для таблицы
по-прежнему включена защита на уровне строк (с помощью ALTER TABLE),
то использоваться будет политика запрета по умолчанию. Для отключения защиты
строк для таблицы, независимо от того, существуют ли политики для таблицы или нет,
можно использовать команду ALTER TABLE ... DISABLE ROW LEVEL SECURITY.
Параметры
IF EXISTS
Не считать ошибкой, если политика не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя политики, подлежащей удалению.
имя_таблицы
Имя таблицы, для которой включена политика (может быть дополнено схемой).
CASCADE
RESTRICT
Эти ключевые слова не имеют эффекта, так как у политик отсутствуют зависимые объекты.
Примеры
Удаление политики p1 из таблицы my_table:
DROP POLICY p1 ON my_table;
Совместимость
Команда DROP POLICY является расширением QHB.
См. также
DROP PROCEDURE
DROP PROCEDURE — удалить процедуру
Синтаксис
DROP PROCEDURE [ IF EXISTS ] имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] [, ...]
[ CASCADE | RESTRICT ]
Описание
Команда DROP PROCEDURE удаляет определение существующей процедуры. Для
выполнения этой команды нужно быть владельцем соответствующей процедуры.
Должны быть указаны типы аргументов процедуры, так как может существовать несколько
различных процедур с одинаковыми именами и разными списками аргументов.
Параметры
IF EXISTS
Не считать ошибкой, если процедура не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей процедуры (может быть дополнено схемой). Если список аргументов не указан, имя должно быть уникальным в своей схеме.
режим_аргумента
Режим аргумента: IN или VARIADIC. Значение по умолчанию равно IN.
имя_аргумента
Имя аргумента. Обратите внимание, что команда DROP PROCEDURE фактически
не обращает внимания на имена аргументов, поскольку для
идентификации процедуры необходимы только типы данных ее аргументов.
тип_аргумента
Тип(ы) данных аргументов процедуры (могут быть дополнены схемой), если таковые имеются.
CASCADE
Автоматически удалять объекты, зависящие от процедуры, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять процедуру, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
DROP PROCEDURE do_db_maintenance();
Совместимость
Команда DROP PROCEDURE соответствует стандарту SQL и имеет следующие расширения
QHB:
См. также
CREATE PROCEDURE, ALTER PROCEDURE, DROP FUNCTION, DROP ROUTINE
DROP PUBLICATION
DROP PUBLICATION — удалить публикацию
Синтаксис
DROP PUBLICATION [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP PUBLICATION удаляет существующую публикацию из базы данных.
Публикацию может удалить только ее владелец или суперпользователь.
Параметры
IF EXISTS
Не считать ошибкой, если публикация не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей публикации.
CASCADE
RESTRICT
Эти ключевые слова не имеют эффекта, так как у публикаций нет зависимых объектов.
Примеры
Удаление публикации:
DROP PUBLICATION mypublication;
Совместимость
Команда DROP PUBLICATION является расширением QHB.
См. также
CREATE PUBLICATION, ALTER PUBLICATION
DROP ROLE
DROP ROLE — удалить роль в базе данных
Синтаксис
DROP ROLE [ IF EXISTS ] имя [, ...]
Описание
Команда DROP ROLE удаляет указанную(ые) роль(и). Чтобы удалить роль
суперпользователя, нужно самому быть суперпользователем; чтобы удалять
обычные роли, необходимо иметь право CREATEROLE.
Роль нельзя удалить, если на нее всё еще есть ссылки в любой базе данных кластера; в этом случае возникнет ошибка и роль не будет удалена. Перед удалением роли необходимо удалить все принадлежащие ей объекты (или сменить их владельца) и отозвать все права, предоставленные этой роли для других объектов. Для этой цели могут быть применены команды REASSIGN OWNED и DROP OWNED; дополнительную информацию см. в разделе Удаление ролей.
Тем не менее, нет необходимости удалять членство в ролях, включающее
роль; DROP ROLE автоматически отменяет любое членство целевой роли в
других ролях и каких-либо других ролей в целевой роли. Нецелевые роли при этом не
удаляются и не затрагиваются иным образом.
Параметры
IF EXISTS
Не считать ошибкой, если роль не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя роли, подлежащей удалению.
Примечания
QHB включает в себя программу dropuser, которая имеет ту же функциональность, что и эта команда (фактически она вызывает эту команду), но может быть запущена из командной оболочки.
Примеры
Удаление роли:
DROP ROLE jonathan;
Совместимость
В стандарте SQL описана команда DROP ROLE, но он позволяет
удалять командой только одну роль и определяет требования к
правам, отличные от требований QHB.
См. также
CREATE ROLE, ALTER ROLE, SET ROLE
DROP ROUTINE
DROP ROUTINE — удалить подпрограмму
Синтаксис
DROP ROUTINE [ IF EXISTS ] имя [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] [, ...]
[ CASCADE | RESTRICT ]
Описание
Команда DROP ROUTINE удаляет определение существующей подпрограммы,
которая может быть агрегатной функцией, обычной функцией или
процедурой. Описание параметров, а также дополнительные примеры и
сведения см. в разделах DROP AGGREGATE, DROP FUNCTION и DROP PROCEDURE.
Примеры
Удаление подпрограммы foo для типа integer:
DROP ROUTINE foo(integer);
Эта команда будет работать, независимо от того, является ли foo агрегатной функцией, обычной функцией или процедурой.
Совместимость
Команда DROP ROUTINE соответствует стандарту SQL и имеет следующие расширения
QHB:
См. также
DROP AGGREGATE, DROP FUNCTION, DROP PROCEDURE, ALTER ROUTINE
Обратите внимание, что команды CREATE ROUTINE нет.
DROP RULE
DROP RULE — удалить правило перезаписи
Синтаксис
DROP RULE [ IF EXISTS ] имя ON имя_таблицы [ CASCADE | RESTRICT ]
Описание
Команда DROP RULE удаляет правило перезаписи.
Параметры
IF EXISTS
Не считать ошибкой, если правило не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя правила, подлежащего удалению.
имя_таблицы
Имя таблицы или представления, к которым применяется правило (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от правила, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять правило, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление правила перезаписи newrule:
DROP RULE newrule ON mytable;
Совместимость
Команда DROP RULE является языковым расширением QHB, как и вся
система перезаписи запросов.
См. также
DROP SCHEMA
DROP SCHEMA — удалить схему
Синтаксис
DROP SCHEMA [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP SCHEMA удаляет схемы из базы данных.
Схему может удалить только ее владелец или суперпользователь. Обратите внимание, что владелец может удалить схему (и, как следствие, все содержащиеся в ней объекты), даже если он не владеет некоторыми объектами внутри схемы.
Параметры
IF EXISTS
Не считать ошибкой, если схема не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя схемы.
CASCADE
Автоматически удалять объекты (таблицы, функции и т. д.), которые содержатся в схеме, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять схему, если она содержит какие-либо объекты. Это поведение по умолчанию.
Примечания
С указанием CASCADE команда может удалить объекты и в других схемах помимо целевой.
Примеры
Удаление схемы mystuff из базы данных вместе со всем, что в ней содержится:
DROP SCHEMA mystuff CASCADE;
Совместимость
Команда DROP SCHEMA полностью соответствует стандарту SQL, за исключением того, что
стандарт позволяет удалять в одной команде только одну схему, а также указания
IF EXISTS, которое является расширением QHB.
См. также
DROP SEQUENCE
DROP SEQUENCE — удалить последовательность
Синтаксис
DROP SEQUENCE [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP SEQUENCE удаляет генераторы числовых последовательностей.
Последовательность может удалить только ее владелец или суперпользователь.
Параметры
IF EXISTS
Не считать ошибкой, если последовательность не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя последовательности (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от последовательности, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять последовательность, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление последовательности serial:
DROP SEQUENCE serial;
Совместимость
Команда DROP SEQUENCE соответствует стандарту SQL, за исключением того, что стандарт
позволяет удалять в одной команде только одну последовательность, а также указания
IF EXISTS, которое является расширением QHB.
См. также
CREATE SEQUENCE, ALTER SEQUENCE
DROP SERVER
DROP SERVER — удалить описание стороннего сервера
Синтаксис
DROP SERVER [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP SERVER удаляет существующее описание стороннего сервера. Для
выполнения этой команды нужно быть владельцем соответствующего стороннего сервера.
Параметры
IF EXISTS
Не считать ошибкой, если сервер не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего сервера.
CASCADE
Автоматически удалять объекты, зависящие от сервера (например, пользовательские сопоставления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять сервер, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление определения сервера foo, если оно существует:
DROP SERVER IF EXISTS foo;
Совместимость
Команда DROP SERVER соответствует стандарту ISO/IEC 9075-9 (SQL/MED).
Предложение IF EXISTS является расширением QHB.
См. также
DROP STATISTICS
DROP STATISTICS — удалить расширенную статистику
Синтаксис
DROP STATISTICS [ IF EXISTS ] имя [, ...]
Описание
Команда DROP STATISTICS удаляет объект(ы) статистики из базы данных. Только
владелец соответствующего объекта статистики, владелец схемы или суперпользователь
могут удалить объект статистики.
Параметры
IF EXISTS
Не считать ошибкой, если объект статистики не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя объекта статистики, подлежащего удалению (может быть дополнено схемой).
Примеры
Удаление двух объектов статистики в разных схемах (если эти объекты отсутствуют, ошибки не будет):
DROP STATISTICS IF EXISTS
accounting.users_uid_creation,
public.grants_user_role;
Совместимость
В стандарте SQL нет команды DROP STATISTICS.
См. также
ALTER STATISTICS, CREATE STATISTICS
DROP SUBSCRIPTION
DROP SUBSCRIPTION — удалить подписку
Синтаксис
DROP SUBSCRIPTION [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP SUBSCRIPTION удаляет подписку из кластера базы данных.
Подписку может удалить только суперпользователь.
DROP SUBSCRIPTION не может быть выполнена внутри блока транзакций,
если подписка связана с слотом репликации. (Для освобождения слота можно
использовать ALTER SUBSCRIPTION.)
Параметры
имя
Имя подписки, подлежащей удалению.
CASCADE
RESTRICT
Эти ключевые слова не имеют эффекта, так как подписки не имеют зависимых объектов.
Примечания
При удалении подписки, связанной со слотом репликации на удаленном узле
(типичная ситуация), команда DROP SUBSCRIPTION подключится к удаленному узлу
и попытается удалить слот репликации как часть этой операции. Это
необходимо для того, чтобы освободить ресурсы, выделенные для подписки
на удаленном узле. Если при этом происходит сбой — либо из-за недоступности
удаленного узла, либо из-за ошибки при удалении слота репликации,
либо вообще из-за его отсутствия, — команда DROP SUBSCRIPTION прерывается.
Чтобы продолжить работу в такой ситуации, отключите подписку от слота репликации
путем выполнения ALTER SUBSCRIPTION ... SET (slot_name = NONE).
После этого DROP SUBSCRIPTION больше не будет пытаться выполнять какие-либо
действия на удаленном узле. Примите к сведению, что если удаленный слот репликации
всё еще существует, его следует удалить вручную; в противном случае он
будет продолжать резервировать WAL, что может в конечном итоге привести к
переполнению диска.
Если подписка связана со слотом репликации, то команда DROP SUBSCRIPTION не
может быть выполнена внутри блока транзакций.
Примеры
Удаление подписки:
DROP SUBSCRIPTION mysub;
Совместимость
Команда DROP SUBSCRIPTION является расширением QHB.
См. также
CREATE SUBSCRIPTION, ALTER SUBSCRIPTION
DROP TABLESPACE
DROP TABLESPACE — удалить табличное пространство
Синтаксис
DROP TABLESPACE [ IF EXISTS ] имя
Описание
Команда DROP TABLESPACE удаляет табличное пространство из системы.
Табличное пространство может быть удалено только его владельцем или
суперпользователем. Перед удалением табличное пространство необходимо очистить от всех
объектов базы данных. Необходимо также учесть, что если в текущей базе данных не будет ни одного
объекта, находящегося в этом пространстве, в нём вполне могут оставаться
объекты других баз данных. Кроме того, если табличное пространство,
указано в списке temp_tablespaces любого активного сеанса, в этом пространстве
окажутся временные файлы, из-за чего команда DROP может завершиться ошибкой.
Параметры
IF EXISTS
Не считать ошибкой, если табличное пространство не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя табличного пространства.
Примечания
Команда DROP TABLESPACE не может быть выполнена внутри блока транзакций.
Примеры
Удаление табличного пространства mystuff:
DROP TABLESPACE mystuff;
Совместимость
Команда DROP TABLESPACE является расширением QHB.
См. также
CREATE TABLESPACE, ALTER TABLESPACE
DROP TABLE
DROP TABLE — удалить таблицу
Синтаксис
DROP TABLE [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP TABLE удаляет таблицы из базы данных. Только владелец соответствующей таблицы,
владелец схемы или суперпользователь могут удалить таблицу. Чтобы удалить содержимое таблицы,
не удаляя ее саму, используйте команды DELETE или TRUNCATE.
Команда DROP TABLE также удаляет все индексы, правила, триггеры и
ограничения, которые существуют для целевой таблицы. Однако для удаления
таблицы, на которую ссылается представление или ограничение внешнего
ключа другой таблицы, должно быть дополнительно указано CASCADE. (CASCADE полностью
удалит зависимое представление, но в случае внешнего ключа будет
удалено только ограничение внешнего ключа, а не вся таблица, с которой он связан.)
Параметры
IF EXISTS
Не считать ошибкой, если таблица не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя удаляемой таблицы (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от таблицы (например, представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять таблицу, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление таблиц films и distributors:
DROP TABLE films, distributors;
Совместимость
Команда DROP TABLE соответствует стандарту SQL, за исключением того, что стандарт
позволяет удалять в одной команде только одну таблицу, а также параметра
IF EXISTS, который является расширением QHB.
См. также
DROP TEXT SEARCH CONFIGURATION
DROP TEXT SEARCH CONFIGURATION — удалить конфигурацию текстового поиска
Синтаксис
DROP TEXT SEARCH CONFIGURATION [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP TEXT SEARCH CONFIGURATION удаляет существующую конфигурацию
текстового поиска. Для выполнения этой команды нужно быть владельцем
соответствующей конфигурации.
Параметры
IF EXISTS
Не считать ошибкой, если конфигурация текстового поиска не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующей конфигурации текстового поиска (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от конфигурации текстового поиска, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять конфигурацию текстового поиска, если от нее зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление конфигурации текстового поиска my_english:
DROP TEXT SEARCH CONFIGURATION my_english;
Эта команда не будет выполнена, если существуют какие-либо индексы, ссылающиеся на конфигурацию в вызовах to_tsvector. Чтобы удалить такие индексы вместе с конфигурацией текстового поиска, нужно дополнительно указать CASCADE.
Совместимость
В стандарте SQL нет команды DROP TEXT SEARCH CONFIGURATION.
См. также
ALTER TEXT SEARCH CONFIGURATION, CREATE TEXT SEARCH CONFIGURATION
DROP TEXT SEARCH DICTIONARY
DROP TEXT SEARCH DICTIONARY — удалить словарь текстового поиска
Синтаксис
DROP TEXT SEARCH DICTIONARY [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP TEXT SEARCH DICTIONARY удаляет существующий словарь текстового
поиска. Для выполнения этой команды нужно быть владельцем соответствующего словаря.
Параметры
IF EXISTS
Не считать ошибкой, если словарь текстового поиска не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего словаря текстового поиска (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от словаря текстового поиска, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять словарь текстового поиска, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление словаря текстового поиска english:
DROP TEXT SEARCH DICTIONARY english;
Эта команда не будет выполнена, если существуют какие-либо конфигурации текстового поиска, использующие этот словарь. Чтобы удалить такие конфигурации вместе со словарем, нужно дополнительно указать CASCADE.
Совместимость
В стандарте SQL нет команды DROP TEXT SEARCH DICTIONARY.
См. также
ALTER TEXT SEARCH DICTIONARY, CREATE TEXT SEARCH DICTIONARY
DROP TEXT SEARCH PARSER
DROP TEXT SEARCH PARSER — удалить анализатор текстового поиска
Синтаксис
DROP TEXT SEARCH PARSER [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP TEXT SEARCH PARSER удаляет существующий анализатор текстового поиска.
Чтобы выполнить эту команду, нужно быть суперпользователем.
Параметры
IF EXISTS
Не считать ошибкой, если анализатор текстового поиска не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего анализатора текстового поиска (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от анализатора текстового поиска, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять анализатор текстового поиска, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление анализатора текстового поиска my_parser:
DROP TEXT SEARCH PARSER my_parser;
Эта команда не будет выполнена, если существуют какие-либо конфигурации текстового поиска, использующие этот анализатор. Чтобы удалить такие конфигурации вместе с анализатором, нужно дополнительно указать CASCADE.
Совместимость
В стандарте SQL нет команды DROP TEXT SEARCH PARSER.
См. также
ALTER TEXT SEARCH PARSER, CREATE TEXT SEARCH PARSER
DROP TEXT SEARCH TEMPLATE
DROP TEXT SEARCH TEMPLATE — удалить шаблон текстового поиска
Синтаксис
DROP TEXT SEARCH TEMPLATE [ IF EXISTS ] имя [ CASCADE | RESTRICT ]
Описание
Команда DROP TEXT SEARCH TEMPLATE удаляет существующий шаблон
текстового поиска. Чтобы выполнить эту команду, нужно быть суперпользователем.
Параметры
IF EXISTS
Не считать ошибкой, если шаблон текстового поиска не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя существующего шаблона текстового поиска (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от шаблона текстового поиска, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять шаблон текстового поиска, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление шаблона текстового поиска thesaurus:
DROP TEXT SEARCH TEMPLATE thesaurus;
Эта команда не будет выполнена, если существуют какие-либо словари текстового поиска, использующие этот шаблон. Чтобы удалить такие словари вместе с шаблоном, нужно дополнительно указать CASCADE.
Совместимость
В стандарте SQL нет команды DROP TEXT SEARCH TEMPLATE.
См. также
ALTER TEXT SEARCH TEMPLATE, CREATE TEXT SEARCH TEMPLATE
DROP TRANSFORM
DROP TRANSFORM — удалить трансформацию
Синтаксис
DROP TRANSFORM [ IF EXISTS ] FOR имя_типа LANGUAGE имя_языка [ CASCADE | RESTRICT ]
Описание
Команда DROP TRANSFORM удаляет ранее определенную трансформацию.
Чтобы удалить трансформацию, нужно быть владельцем соответствующих типа и языка. Такие же требования действуют и при создании трансформации.
Параметры
IF EXISTS
Не считать ошибкой, если трансформация не существует. В этом случае будет выдано соответствующее уведомление.
имя_типа
Имя типа данных трансформации.
имя_языка
Имя языка трансформации.
CASCADE
Автоматически удалять объекты, зависящие от трансформации, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять трансформацию, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление трансформации для типа hstore и языка plpythonu:
DROP TRANSFORM FOR hstore LANGUAGE plpythonu;
Совместимость
Команда DROP TRANSFORM является расширением QHB.
Дополнительную информацию см. в разделе CREATE TRANSFORM.
См. также
DROP TRIGGER
DROP TRIGGER — удалить триггер
Синтаксис
DROP TRIGGER [ IF EXISTS ] имя ON имя_таблицы [ CASCADE | RESTRICT ]
Описание
Команда DROP TRIGGER удаляет существующее определение триггера. Для выполнения
этой команды нужно быть владельцем таблицы, для которой определен триггер.
Параметры
IF EXISTS
Не считать ошибкой, если триггер не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя триггера, подлежащего удалению.
имя_таблицы
Имя таблицы, для которой определен триггер (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от триггера, и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять триггер, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление триггера if_dist_exists в таблице films:
DROP TRIGGER if_dist_exists ON films;
Совместимость
Команда DROP TRIGGER в QHB несовместима со стандартом SQL.
В стандарте SQL имена триггеров не являются локальными для таблиц,
поэтому синтаксис команды проще: DROP TRIGGER имя.
См. также
DROP TYPE
DROP TYPE — удалить тип данных
Синтаксис
DROP TYPE [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP TYPE удаляет созданный пользователем тип данных. Только
владелец типа может его удалить.
Параметры
IF EXISTS
Не считать ошибкой, если тип не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя типа данных, подлежащего удалению (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от типа (например, столбцы таблицы, функции и операторы), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять тип, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Удаление типа данных box:
DROP TYPE box;
Совместимость
Эта команда аналогична соответствующей команде в стандарте SQL, но параметр
IF EXISTS является расширением QHB. Обратите внимание,
что команда CREATE TYPE и механизмы расширения типов в QHB отличаются от
стандарта SQL.
См. также
DROP USER MAPPING
DROP USER MAPPING — удалить сопоставление пользователей для стороннего сервера
Синтаксис
DROP USER MAPPING [ IF EXISTS ] FOR { имя_пользователя | USER | CURRENT_USER | PUBLIC } SERVER имя_сервера
Описание
Команда DROP USER MAPPING удаляет существующее сопоставление пользователя
для стороннего сервера.
Владелец стороннего сервера может удалять заданные для этого сервера сопоставления любых пользователей. Кроме того, обычный пользователь может удалить сопоставление для собственного имени, если у него есть право USAGE для соответствующего сервера.
Параметры
IF EXISTS
Не считать ошибкой, если сопоставление не существует. В этом случае будет выдано соответствующее уведомление.
имя_пользователя
Имя пользователя для сопоставления. Значения CURRENT_USER и USER соответствуют имени текущего пользователя. Значение PUBLIC используется для сопоставления всех текущих и будущих имен пользователей в системе.
имя_сервера
Имя сервера, в котором задано сопоставление пользователей.
Примеры
Удаление сопоставления пользователя bob для сервера foo, если оно существует:
DROP USER MAPPING IF EXISTS FOR bob SERVER foo;
Совместимость
Команда DROP USER MAPPING соответствует стандарту ISO/IEC 9075-9 (SQL/MED).
Предложение IF EXISTS является расширением QHB.
См. также
CREATE USER MAPPING, ALTER USER MAPPING
DROP USER
DROP USER — удалить роль в базе данных
Синтаксис
DROP USER [ IF EXISTS ] имя [, ...]
Описание
Команда DROP USER — это просто альтернативное написание команды DROP ROLE.
Совместимость
Команда DROP USER является расширением QHB. В стандарте SQL
определение пользователей считается зависимым от реализации.
См. также
DROP VIEW
DROP VIEW — удалить представление
Синтаксис
DROP VIEW [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
Описание
Команда DROP VIEW удаляет существующее представление. Для выполнения этой
команды нужно быть владельцем соответствующего представления.
Параметры
IF EXISTS
Не считать ошибкой, если представление не существует. В этом случае будет выдано соответствующее уведомление.
имя
Имя представления, подлежащего удалению (может быть дополнено схемой).
CASCADE
Автоматически удалять объекты, зависящие от представления (например, другие представления), и в свою очередь все объекты, зависящие от этих объектов (см. раздел Отслеживание зависимостей).
RESTRICT
Запретить удалять представление, если от него зависят какие-либо объекты. Это поведение по умолчанию.
Примеры
Эта команда удалит представление с именем kinds:
DROP VIEW kinds;
Совместимость
Команда DROP VIEW соответствует стандарту SQL, за исключением того, что стандарт
позволяет удалять в одной команде только одно представление, а также параметра
IF EXISTS, который является расширением QHB.
См. также
END
END — фиксация текущей транзакции
Синтаксис
END [ WORK | TRANSACTION ] [ AND [ NO ] CHAIN ]
Описание
Команда END фиксирует текущую транзакцию. Все изменения, внесенные
транзакцией, становятся видимыми для других и гарантированно будут
сохранены, если произойдет сбой. Эта команда является расширением
QHB и эквивалентна команде COMMIT.
Параметры
WORK
TRANSACTION
Необязательные ключевые слова. Не имеют эффекта.
AND CHAIN
Если указывается AND CHAIN, то сразу после окончания текущей транзакции начинается новая с теми же характеристиками (см. раздел SET TRANSACTION), что и только что завершенная. В противном случае новая транзакция не запускается.
Примечания
Для прерывания транзакции используйте команду ROLLBACK.
Попытка выполнить команду END вне транзакции не вызовет
ошибки, но будет выдано предупреждающее сообщение.
Примеры
Фиксация текущей транзакции и сохранение всех изменений:
END;
Совместимость
Команда END является расширением QHB и предоставляет
функциональные возможности, эквивалентные команде COMMIT, которые указаны в стандарте SQL.
См. также
EXECUTE
EXECUTE — выполнить подготовленный оператор
Синтаксис
EXECUTE имя [ ( параметр [, ...] ) ]
Описание
Команда EXECUTE используется для выполнения ранее подготовленного оператора.
Поскольку подготовленные операторы существуют только в течение сеанса,
они должны создаваться командой PREPARE, выполненной в текущем сеансе ранее.
Если в команде PREPARE, создавшей оператор, указаны некоторые
параметры, то в команду EXECUTE должен быть передан совместимый набор
параметров, иначе возникает ошибка. Обратите внимание, что (в отличие от
функций) подготовленные операторы не перегружаются на основе типа или
числа их параметров; имя подготовленного оператора должно быть
уникальным в рамках текущего сеанса.
Дополнительную информацию о создании и использовании подготовленных операторов см. в разделе PREPARE.
Параметры
имя
Имя подготовленного оператора, подлежащего выполнению.
параметр
Фактическое значение параметра для подготовленного оператора. Это должно быть выражение, возвращающее значение, совместимое с типом данных этого параметра, как было определено при создании подготовленного оператора.
Выводимая информация
Метка команды, возвращаемая EXECUTE, соответствует
подготовленному оператору, а не оператору EXECUTE.
Примеры
Примеры приведены в разделе «Примеры» документации по команде PREPARE.
Совместимость
Стандарт SQL включает команду EXECUTE, но она предназначена только
для использования во встраиваемом SQL. Кроме того, данная версия команды EXECUTE
имеет несколько другой синтаксис.
См. также
EXPLAIN
EXPLAIN — показать план выполнения оператора
Синтаксис
EXPLAIN [ ( параметр [, ...] ) ] оператор
EXPLAIN [ ANALYZE ] [ VERBOSE ] оператор
Где параметр может быть:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
SETTINGS [ boolean ]
BUFFERS [ boolean ]
WAL [ boolean ]
TIMING [ boolean ]
SUMMARY [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
Описание
Команда EXPLAIN отображает план выполнения, который планировщик
QHB создает для заданного оператора. План выполнения показывает,
как таблица(ы), на которую(ые) ссылается оператор, будет сканироваться:
простым последовательным сканированием, индексным сканированием и т. д.
— и если имеется ссылка на несколько таблиц, то какие алгоритмы
объединения будут использоваться для объединения необходимых строк из
каждой входной таблицы.
Наиболее важной частью выводимой информации является расчетная стоимость выполнения оператора, которая представляет собой предположение планировщика о том, сколько времени потребуется для выполнения оператора (это значение измеряется в единицах стоимости, которые не имеют точного определения, но обычно это обращение к странице на диске). На самом деле выводятся два числа: начальная стоимость до выдачи первой строки и общая стоимость выдачи всех строк. Для большинства запросов важна общая стоимость, но в таких контекстах, как подзапрос в EXISTS, планировщик выбирает вместо нее наименьшую стартовую стоимость (так как исполнение запроса всё равно завершится сразу после получения одной строки). Кроме того, если ограничить число строк предложением LIMIT, то планировщик делает соответствующую интерполяцию между двумя этими числами, выбирая наиболее выгодный план.
С параметром ANALYZE оператор будет выполнен, а не только запланирован. При этом в вывод добавляются фактические статистические данные времени выполнения, включая общее затраченное время в каждом узле плана (в миллисекундах) и общее количество строк, которые он фактически вернул. Это помогает проверить, близки ли оценки планировщика к реальности.
Важно!
Имейте в виду, что с указанием ANALYZE оператор действительно выполняется.
Хотя EXPLAIN отбрасывает результат, который вернул бы SELECT, в остальном
все действия выполняются как обычно. Если вы хотите выполнить EXPLAIN ANALYZE
с командой INSERT, UPDATE, DELETE, CREATE TABLE AS или EXECUTE, не
допуская изменения данных этой командой, используйте:
BEGIN;
EXPLAIN ANALYZE ...;
ROLLBACK;
Без скобок для этого оператора можно указать только параметры ANALYZE и VERBOSE, и только в таком порядке.
Параметры
ANALYZE
Выполнить команду и показать фактическое время выполнения и другую статистику. По умолчанию этот параметр имеет значение FALSE.
VERBOSE
Вывести дополнительную информацию о плане. В частности, включить список выходных столбцов для каждого узла в дереве плана, имена таблиц и функций, отвечающих требованиям схемы, всегда указывать для переменных в выражениях псевдоним их таблицы, а также выводить имена всех триггеров, для которых отображается статистика. По умолчанию этот параметр имеет значение FALSE.
COSTS
Вывести информацию о рассчитанной стоимости запуска и общей стоимости каждого узла плана, а также информацию о предполагаемом количестве строк и предполагаемой ширине каждой строки. По умолчанию этот параметр имеет значение TRUE.
SETTINGS
Вывести информацию о параметрах конфигурации. В частности, вывести параметры, влияющие на планирование запроса со значением, отличным от стандартного значения по умолчанию. По умолчанию этот параметр имеет значение FALSE.
BUFFERS
Вывести информацию об использовании буфера. В частности, вывести число попаданий, блоков прочитанных, загрязненных и записанных в разделяемом и локальном буфере, число прочитанных и записанных временных блоков, а также время, потраченное на чтение и запись блоков файлов данных (в миллисекундах), если включен track_io_timing. Попаданием (hit) считается ситуация, когда требуемый блок уже находится в кэше и чтения с диска удается избежать. Блоки в общем буфере содержат данные из обычных таблиц и индексов, в локальном — данные из временных таблиц и индексов, тогда как временные блоки предназначены для краткосрочного использования при выполнении сортировки, хэширования, материализации и тому подобных узлов плана. Количество загрязненных блоков (dirtied) показывает, сколько ранее не модифицированных блоков изменила данная операция; в то время как количество записанных блоков (written) показывает, сколько ранее загрязненных блоков вытеснило из кэша этим серверным модулем во время обработки запроса. Количество блоков, показанных для узла верхнего уровня, включает блоки, используемые всеми его дочерними узлами. В текстовом формате печатаются только ненулевые значения. По умолчанию имеет значение FALSE.
WAL
Вывести информацию о генерировании записей WAL. В частности, вывести число записей, число полных образов страниц (full page images, fpi) и число сгенерированных WAL в байтах. В текстовом формате печатаются только ненулевые значения. Этот параметр можно использовать только при включенном режиме ANALYZE. По умолчанию имеет значение FALSE.
TIMING
Вывести фактическое время запуска и время, затраченное в каждом узле на выходе. Накладные расходы многократного чтения системных часов могут значительно замедлить запрос в некоторых системах, поэтому когда требуется только фактическое количество строк, а не точное время, может быть полезно установить этот параметр в FALSE. Время выполнения всего оператора всегда измеряется, даже если синхронизация на уровне узла отключена с помощью этого параметра. Этот параметр можно использовать только при включенном режиме ANALYZE. По умолчанию имеет значение TRUE.
SUMMARY
Вывести сводку (например, суммарное время) после плана запроса.
При использовании ANALYZE сводная информация выводится по умолчанию,
но этот параметр позволяет получить ее
и с другими вариантами команды. В EXPLAIN EXECUTE
время планирования включает в себя время, требуемое для извлечения
плана из кэша, и, при необходимости, время, требуемое для повторного
планирования.
FORMAT
Установить формат вывода, который может быть TEXT, XML, JSON или YAML. Нетекстовые форматы содержат ту же информацию, что и TEXT, но больше подходят для программного разбора. По умолчанию этот параметр имеет значение TEXT.
boolean
Указывает, должен ли выбранный параметр быть включен или выключен. Для включения параметра можно написать: TRUE, ON или 1, а для отключения — FALSE, OFF или 0. Значение boolean также может быть опущено; в этом случае предполагается TRUE.
оператор
Любой оператор SELECT, INSERT, UPDATE, DELETE, VALUES,
EXECUTE, DECLARE, CREATE TABLE AS или CREATE MATERIALIZED VIEW AS, план выполнения которого вы хотите видеть.
Выводимая информация
Результатом выполнения команды является текстовое описание выбранного для оператора плана, при необходимости дополненное статистикой выполнения. Раздел Использование EXPLAIN описывает предоставленную информацию.
Примечания
Чтобы планировщик запросов QHB мог принимать обоснованные решения при оптимизации запросов, данные в pg_statistic должны быть актуальными для всех таблиц, используемых в запросе. Обычно это автоматически обеспечивает Процесс «Автовакуум». Но если в содержимом таблицы недавно произошли существенные изменения, может потребоваться вручную выполнить ANALYZE, не дожидаясь, пока до них доберется автоочистка.
Чтобы измерить затраты времени на выполнение каждого узла в плане
выполнения, текущая реализация EXPLAIN ANALYZE добавляет в выполнение запроса
накладные расходы профилирования. В результате выполнение запроса с
EXPLAIN ANALYZE иногда может занять значительно больше
времени, чем обычное выполнение запроса. Объем накладных расходов зависит
от характера запроса, а также от используемой платформы. Наихудший случай
возникает в узлах плана, которые сами по себе требуют очень мало
времени на выполнение, и в операционных системах, где получение
текущего времени является относительно длительной операцией.
Примеры
Получение плана простого запроса для таблицы, содержащей единственный столбец типа integer и 10 000 строк:
EXPLAIN SELECT * FROM foo;
QUERY PLAN
---------------------------------------------------------
Seq Scan on foo (cost=0.00..155.00 rows=10000 width=4)
(1 row)
План того же запроса, но выведенный в формате JSON:
EXPLAIN (FORMAT JSON) SELECT * FROM foo;
QUERY PLAN
--------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Seq Scan",+
"Relation Name": "foo", +
"Alias": "foo", +
"Startup Cost": 0.00, +
"Total Cost": 155.00, +
"Plan Rows": 10000, +
"Plan Width": 4 +
} +
} +
]
(1 row)
Если в таблице есть индекс, а в запросе присутствует условие WHERE,
для которого полезен этот индекс, EXPLAIN может показать другой план:
EXPLAIN SELECT * FROM foo WHERE i = 4;
QUERY PLAN
--------------------------------------------------------------
Index Scan using fi on foo (cost=0.00..5.98 rows=1 width=4)
Index Cond: (i = 4)
(2 rows)
План того же запроса, но в формате YAML:
EXPLAIN (FORMAT YAML) SELECT * FROM foo WHERE i='4';
QUERY PLAN
-------------------------------
- Plan: +
Node Type: "Index Scan" +
Scan Direction: "Forward"+
Index Name: "fi" +
Relation Name: "foo" +
Alias: "foo" +
Startup Cost: 0.00 +
Total Cost: 5.98 +
Plan Rows: 1 +
Plan Width: 4 +
Index Cond: "(i = 4)"
(1 row)
Рассмотрение формата XML оставлено в качестве упражнения для читателя.
План того же запроса без вывода оценок стоимости:
EXPLAIN (COSTS FALSE) SELECT * FROM foo WHERE i = 4;
QUERY PLAN
----------------------------
Index Scan using fi on foo
Index Cond: (i = 4)
(2 rows)
Пример плана для запроса с агрегатной функцией:
EXPLAIN SELECT sum(i) FROM foo WHERE i < 10;
QUERY PLAN
---------------------------------------------------------------------
Aggregate (cost=23.93..23.93 rows=1 width=4)
-> Index Scan using fi on foo (cost=0.00..23.92 rows=6 width=4)
Index Cond: (i < 10)
(3 rows)
Пример использования EXPLAIN EXECUTE для отображения плана
выполнения подготовленного запроса:
PREPARE query(int, int) AS SELECT sum(bar) FROM test
WHERE id > $1 AND id < $2
GROUP BY foo;
EXPLAIN ANALYZE EXECUTE query(100, 200);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=9.54..9.54 rows=1 width=8) (actual time=0.156..0.161 rows=11 loops=1)
Group Key: foo
-> Index Scan using test_pkey on test (cost=0.29..9.29 rows=50 width=8) (actual time=0.039..0.091 rows=99 loops=1)
Index Cond: ((id > $1) AND (id < $2))
Planning time: 0.197 ms
Execution time: 0.225 ms
(6 rows)
Конечно, показанные здесь конкретные цифры зависят от фактического
содержания соответствующих таблиц. Также обратите внимание, что номера и
даже выбранная стратегия запроса могут отличаться в разных выпусках
QHB из-за улучшений планировщика. Кроме того, команда ANALYZE
использует случайную выборку для оценки статистики данных, поэтому
оценки затрат могут измениться после нового запуска ANALYZE, даже
если фактическое распределение данных в таблице не изменилось.
Совместимость
В стандарте SQL нет команды EXPLAIN.
См. также
FETCH
FETCH — получить результат запроса через курсор
Синтаксис
FETCH [ направление [ FROM | IN ] ] имя_курсора
Где направление может быть не задано или принимать одно из значений:
NEXT
PRIOR
FIRST
LAST
ABSOLUTE число
RELATIVE число
число
ALL
FORWARD
FORWARD число
FORWARD ALL
BACKWARD
BACKWARD число
BACKWARD ALL
Описание
Команда FETCH извлекает строки с помощью ранее созданного курсора.
Курсор связан с определенным положением, что и использует FETCH.
Положение курсора может быть перед первой строкой результата запроса,
на любой конкретной строке результата или после последней строки
результата. При создании курсор располагается перед первой строкой.
После выборки нескольких строк курсор будет расположен на последней
полученной строке. Если FETCH выполняется до конца доступных строк,
то курсор остается расположенным после последней строки, если выборка выполняется
назад, то перед первой строкой. Команды FETCH ALL
и FETCH BACKWARD ALL всегда будут оставлять курсор после последней
строки или перед первой строкой соответственно.
Формы NEXT, PRIOR, FIRST, LAST, ABSOLUTE и RELATIVE выбирают одну строку после соответствующего перемещения курсора. Если такой строки нет, то возвращается пустой результат и курсор остается расположенным перед первой строкой или после последней строки, в зависимости от ситуации.
Формы с использованием FORWARD и BACKWARD извлекают указанное число строк, сдвигаясь соответственно вперед или назад; в результате курсор оказывается на последней выданной строке (или перед/после всех строк, если число превышает количество доступных строк).
Формы RELATIVE 0, FORWARD 0 и BACKWARD 0 действуют одинаково — запрашивают выборку текущей строки без перемещения курсора, то есть повторно выбирая строку, которая была извлечена последней. Это произойдет успешно, если курсор не будет расположен перед первой строкой или после последней строки; в этом случае строка не возвращается.
Примечание
На этой странице описывается использование курсоров на уровне команд SQL. Если вы пытаетесь использовать курсоры внутри функции PL/pgSQL, правила будут отличаться — см. раздел Курсоры.
Параметры
направление
Параметр направление определяет направление движения и число выбираемых строк. Может быть один из следующих вариантов:
NEXT
Извлечь следующую строку. Это действие подразумевается по умолчанию, если направление опущено.
PRIOR
Извлечь предыдущую строку.
FIRST
Извлечь первую строку запроса (аналогично ABSOLUTE 1).
LAST
Извлечь последнюю строку запроса (аналогично ABSOLUTE -1).
ABSOLUTE число
Извлечь строку под номером число с начала либо под номером abs(число) с конца, если число отрицательно. Если число выходит за границы набора строк, курсор размещается перед первой или после последней строки; в частности, с ABSOLUTE 0 курсор оказывается перед первой строкой.
RELATIVE число
Извлечь строку под номером число, считая со следующей вперед, либо под номером abs(число), считая с предыдущей назад, если число отрицательно. RELATIVE 0 повторно считывает текущую строку, если таковая имеется.
число
Извлечь следующее число строк (аналогично FORWARD число).
ALL
Извлечь все оставшиеся строки (аналогично FORWARD ALL).
FORWARD
Извлечь следующую строку (аналогично NEXT).
FORWARD число
Извлечь следующее число строк. FORWARD 0 повторно выбирает текущую строку.
FORWARD ALL
Извлечь все оставшиеся строки.
BACKWARD
Извлечь предыдущую строку (аналогично PRIOR).
BACKWARD число
Извлечь предыдущее число строк (перемещение назад). BACKWARD 0 повторно извлекает текущую строку.
BACKWARD ALL
Извлечь все предыдущие строки (перемещение назад).
число
Здесь число — это целочисленная константа, возможно, со знаком, определяющая положение или количество выбираемых строк. Для вариантов *FORWARD и BACKWARD указание отрицательного числа равнозначно смене направления FORWARD на BACKWARD и наоборот.
имя_курсора
Имя открытого курсора.
Выводимая информация
При успешном выполнении FETCH возвращает метку команды вида
FETCH число
Где число — количество извлеченных строк (возможно, ноль). Обратите внимание, что в qsql метка команды на самом деле не выдается, так как qsql отображает вместо этого извлеченные строки.
Примечания
Если перемещение курсора в FETCH не ограничивается вариантами
FETCH NEXT или FETCH FORWARD с положительным числом, курсор
должен быть объявлен с указанием SCROLL. Для простых запросов QHB
позволит выполнять обратное перемещение курсора, объявленного без SCROLL,
но на такое поведение лучше не полагаться. Если курсор
объявлен с указанием NO SCROLL, обратное перемещение не
допускается.
Вариант ABSOLUTE нисколько не быстрее, чем переход к нужной
строке с относительным перемещением: базовая реализация в любом случае
должна пройти все промежуточные строки. Отрицательные абсолютные
выборки еще хуже: запрос должен быть прочитан до конца, чтобы найти
последнюю строку, а затем вернуться назад к указанной строке. Тем не менее, перемотка
к началу запроса (FETCH ABSOLUTE 0) идет быстро.
Определить курсор позволяет команда DECLARE, а переместить его, не читая данные, — команда MOVE.
Примеры
Следующий пример демонстрирует перемещение курсора в таблице:
BEGIN WORK;
-- Создание курсора:
DECLARE liahona SCROLL CURSOR FOR SELECT * FROM films;
-- Получение первых 5 строк через курсор liahona:
FETCH FORWARD 5 FROM liahona;
code | title | did | date_prod | kind | len
-------+-------------------------+-----+------------+----------+-------
BL101 | The Third Man | 101 | 1949-12-23 | Drama | 01:44
BL102 | The African Queen | 101 | 1951-08-11 | Romantic | 01:43
JL201 | Une Femme est une Femme | 102 | 1961-03-12 | Romantic | 01:25
P_301 | Vertigo | 103 | 1958-11-14 | Action | 02:08
P_302 | Becket | 103 | 1964-02-03 | Drama | 02:28
-- Получение предыдущей строки:
FETCH PRIOR FROM liahona;
code | title | did | date_prod | kind | len
-------+---------+-----+------------+--------+-------
P_301 | Vertigo | 103 | 1958-11-14 | Action | 02:08
-- Закрытие курсора и завершение транзакции:
CLOSE liahona;
COMMIT WORK;
Совместимость
Стандарт SQL определяет команду FETCH для использования только для
встраиваемого SQL. Вариант FETCH, описанный здесь, возвращает данные
подобно оператору SELECT, а не помещает их в переменные исполняющей среды.
В остальном FETCH имеет полную прямую совместимость со стандартом SQL.
Формы FETCH с указанием FORWARD и BACKWARD, а также формы FETCH число
и FETCH ALL (в которых FORWARD подразумевается) являются расширениями
QHB.
В стандарте SQL перед именем курсора допускается только указание FROM; возможность указать IN или опустить оба указания является расширением.
См. также
GRANT
GRANT — определить права доступа
Синтаксис
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] имя_таблицы [, ...]
| ALL TABLES IN SCHEMA имя_схемы [, ...] }
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { { SELECT | INSERT | UPDATE | REFERENCES } ( имя_столбца [, ...] )
[, ...] | ALL [ PRIVILEGES ] ( имя_столбца [, ...] ) }
ON [ TABLE ] имя_таблицы [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { { USAGE | SELECT | UPDATE }
[, ...] | ALL [ PRIVILEGES ] }
ON { SEQUENCE имя_последовательности [, ...]
| ALL SEQUENCES IN SCHEMA имя_схемы [, ...] }
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | CONNECT | TEMPORARY | TEMP } [, ...] | ALL [ PRIVILEGES ] }
ON DATABASE имя_базы_данных [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON DOMAIN имя_домена [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON FOREIGN DATA WRAPPER имя_обертки_сторонних_данных [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON FOREIGN SERVER имя_сервера [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON { { FUNCTION | PROCEDURE | ROUTINE } имя_подпрограммы [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] [, ...]
| ALL { FUNCTIONS | PROCEDURES | ROUTINES } IN SCHEMA имя_схемы [, ...] }
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE имя_языка [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { { SELECT | UPDATE } [, ...] | ALL [ PRIVILEGES ] }
ON LARGE OBJECT oid_БО [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | USAGE } [, ...] | ALL [ PRIVILEGES ] }
ON SCHEMA имя_схемы [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE имя_табличного_пространства [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON TYPE имя_типа [, ...]
TO указание_роли [, ...] [ WITH GRANT OPTION ]
GRANT имя_роли [, ...] TO указание_роли [, ...]
[ WITH ADMIN OPTION ]
[ GRANTED BY указание_роли ]
Где указание_роли:
[ GROUP ] имя_роли
| PUBLIC
| CURRENT_USER
| SESSION_USER
Описание
Команда GRANT имеет два основных варианта: один, предоставляющий
права доступа к объектам базы данных (таблице, столбцу, представлению,
сторонней таблице, последовательности, базе данных, обертке сторонних
данных, стороннему серверу, функции, процедуре, процедурному языку, схеме или
табличному пространству), и второй, предоставляющий членство в роли. Эти
варианты во многом похожи, но и имеют достаточно отличий, чтобы быть
описанными отдельно.
GRANT для объектов баз данных
Этот вариант команды GRANT предоставляет определенные права доступа
к объекту базы данных для одной или нескольких ролей. Эти права
добавляются к уже предоставленным, если таковые имеются.
Ключевое слово PUBLIC указывает, что права должны быть предоставлены всем ролям, включая те, что могут быть созданы позже. PUBLIC может рассматриваться как неявно определенная группа, которая всегда включает все роли. Любая конкретная роль будет иметь сумму прав, предоставленных непосредственно ей, прав, предоставленных любой роли, членом которой она в настоящее время является, и прав, предоставленных PUBLIC.
Если указано WITH GRANT OPTION, получатель права может в свою очередь предоставить его другим лицам. Без этого указания получатель не может этого сделать. Группе PUBLIC право передачи права дать нельзя.
Нет необходимости предоставлять права доступа владельцу объекта (как правило, пользователю, который его создал), так как владелец имеет все права доступа по умолчанию. (Однако в целях обеспечения безопасности владелец может отказаться от некоторых своих прав.)
Право удалить объект или каким-либо образом изменить его определение в качестве предоставляемого права не рассматривается; оно присуще владельцу и не может быть предоставлено или отозвано. (Однако аналогичный эффект можно получить, предоставив или отозвав членство в роли, которой принадлежит объект; см. ниже.) Также владелец неявно имеет право распоряжения всеми правами для своего объекта.
Возможные права:
Особые типы прав, определенные в разделе Права.
TEMP
Альтернативное написание для TEMPORARY.
ALL PRIVILEGES
Предоставление всех права доступа, применимых для типа объекта. В QHB ключевое слово PRIVILEGES является необязательным, хотя оно и обязательно в стандарте SQL.
Синтаксис FUNCTION распространяется для простых, агрегатных и оконных функций, но не для процедур; для последних предназначен синтаксис PROCEDURE. В качестве альтернативы используйте ROUTINE, чтобы ссылаться на функцию, агрегатную функцию, оконную функцию или процедуру, независимо от ее точного типа.
Существует также возможность предоставления прав на все объекты
одного типа в рамках одной или нескольких схем. В настоящее
время эта функция поддерживается только для таблиц, последовательностей,
функций и процедур. ALL TABLES также влияет на представления и сторонние
таблицы, аналогично команде GRANT для конкретного объекта. ALL FUNCTIONS также
влияет на агрегатные и оконные функции, но не на процедуры — опять же аналогично
GRANT для конкретного объекта. Чтобы включить процедуры,
воспользуйтесь формой ALL ROUTINES.
GRANT для ролей
Этот вариант команды GRANT предоставляет членство в роли для одной
или нескольких других ролей. Членство в роли имеет важное значение,
поскольку оно передает предоставленные роли права каждому из ее членов.
Участник, получивший членство в роли с указанием WITH ADMIN OPTION, может, в свою очередь, предоставлять членство в роли другим пользователям, а также отменять членство в роли. Без WITH ADMIN OPTION обычные пользователи не могут этого сделать. Роль не имеет права WITH ADMIN OPTION для самой себя, но может предоставить или отозвать членство в роли в сеансе базы данных, в котором пользователь сеанса соответствует роли. Суперпользователи баз данных могут предоставлять или отменять членство в любой роли кому угодно. Роли с правом CREATEROLE могут предоставлять или отменять членство в любой роли, которая не является суперпользователем.
При указании GRANTED BY предоставление права записывается как совершенное конкретной ролью. Этой возможностью могут пользоваться только суперпользователи, за исключением тех случаев, когда она называет ту же роль при выполнении команды.
В отличие от прав, членство в роли не может быть предоставлено группе PUBLIC. Обратите также внимание, что эта форма команды не допускает избыточное слово GROUP в указании_роли.
Примечания
Для отмены прав доступа используется команда REVOKE.
Понятия пользователей и групп были объединены в единый вид сущности, называемый ролью. Поэтому больше нет необходимости использовать ключевое слово GROUP, чтобы определить, является ли участник пользователем или группой. Слово GROUP по-прежнему разрешено в команде, но лишено смысловой нагрузки.
Пользователь может выполнить команды SELECT, INSERT и подобные им
со столбцом таблицы, если обладает этим правом для конкретного столбца
или для всей таблицы. Предоставление права на уровне таблицы, а затем
отмена права для одного из столбцов этой таблицы не даст желаемого эффекта:
операция с правами на уровне столбцов не затронет право на уровне таблицы.
Если пользователь, не являющийся владельцем объекта, попытается
назначить право доступа к объекту (с помощью GRANT), то эта команда
завершится ошибкой, если у пользователя нет никаких прав доступа к объекту.
Если же пользователь имеет некоторые права, команда будет выполнена, но
предоставит только те права, которые даны ему с правом передачи.
Формы GRANT ALL PRIVILEGES выдадут предупреждающее сообщение,
если у пользователя вообще нет никаких прав передачи, тогда как другие формы выдадут предупреждение,
если пользователь не имеет прав распоряжаться конкретными правами, указанными в команде.
(В принципе, эти утверждения применимы и к владельцу объекта, но поскольку владелец всегда
рассматривается как обладатель всех прав, такие ситуации невозможны.)
Следует отметить, что суперпользователи баз данных могут обращаться ко всем объектам, независимо от настроек прав объекта. Это сравнимо с правами пользователя root в системе Unix. Как и в случае с root, неразумно работать под суперпользователем, за исключением тех случаев, когда это абсолютно необходимо.
Если суперпользователь решает выполнить команду GRANT или REVOKE,
команда выполняется так, как если бы она выполнялась владельцем
объекта воздействия. В частности, права, предоставленные с помощью
такой команды, проявятся как права, назначенные владельцем объекта.
(Для членства в роли членство будет представлено как назначенное самой ролью.)
GRANT и REVOKE также могут выполняться ролью, которая не
является владельцем объекта воздействия, но является членом роли,
которая владеет объектом, или членом роли, которая обладает правами
доступа WITH GRANT OPTION для этого объекта. В этом случае права будут
записаны как предоставленные ролью, которая фактически владеет объектом
или владеет правами доступа WITH GRANT OPTION. Например, если таблица t1
принадлежит роли g1, членом которой является u1, то u1 может
предоставлять права на t1 роли u2, но эти права будут предоставлены
как назначенные непосредственно ролью g1. Любой другой член
роли g1 сможет позже отозвать их.
Если роль, выполняющая команду GRANT, получила на это необходимые права косвенно
через несколько путей членства в роли, то не будет определено,
какая именно роль назначила право. В таких случаях рекомендуется
использовать SET ROLE, чтобы переключиться на конкретную роль, которую
вы хотите назначить в качестве выполняющей команду GRANT.
Предоставление прав на таблицу не означает автоматического расширения прав на любые используемые таблицей последовательности, включая те из них, что связаны со столбцами SERIAL. Разрешения на последовательности должны быть установлены отдельно.
Дополнительную информацию о конкретных типах прав, а также о том, как просмотреть права объектов, см. в разделе Права.
Примеры
Разрешить всем добавлять записи в таблицу films:
GRANT INSERT ON films TO PUBLIC;
Дать пользователю manuel все права для представления kinds:
GRANT ALL PRIVILEGES ON kinds TO manuel;
Учтите, что если ее выполнит суперпользователь или владелец представления kinds, эта команда действительно даст субъекту все права, но если ее выполнит обычный пользователь, субъект получит только те права, которые даны этому пользователю с правом передачи.
Включение в роль admins пользователя joe:
GRANT admins TO joe;
Совместимость
Согласно стандарту SQL, слово PRIVILEGES в указании ALL PRIVILEGES является обязательным. Стандарт SQL не поддерживает установку прав для более чем одного объекта на команду.
QHB позволяет владельцу объекта отозвать свои обычные права: например, владелец таблицы может сделать таблицу доступной только для чтения для себя, отозвав свои собственные права INSERT, UPDATE, DELETE и TRUNCATE. В соответствии со стандартом SQL, это невозможно. Причина заключается в том, что QHB рассматривает права владельца как предоставленные им самому себе, поэтому владелец также может и отозвать их. В стандарте SQL права владельца предоставляются предполагаемой сущностью «_SYSTEM». Так как владелец объекта отличается от «_SYSTEM», лишить себя этих прав он не может.
В соответствии со стандартом SQL, право с правом передачи можно дать субъекту PUBLIC; QHB поддерживает его только при предоставлении ролям права передачи прав.
Стандарт SQL позволяет использовать указание GRANTED BY во всех формах GRANT.
QHB поддерживает его только при назначении членства ролей,
и даже в этом случае только суперпользователи могут использовать его нетривиальным образом.
Стандарт SQL предусматривает распространение права USAGE на другие виды объектов: наборы символов, правила сортировки, переводы, преобразования.
В стандарте SQL последовательности имеют лишь право USAGE, которое контролирует использование выражения NEXT VALUE FOR, эквивалентное функции nextval в QHB. Права SELECT и UPDATE для последовательностей являются расширениями QHB. Применение права USAGE для последовательностей к функции currval также относится к расширениям QHB (как и сама функция).
Права доступа к базам данных, табличным пространствам, схемам и языкам являются расширениями QHB.
См. также
REVOKE, ALTER DEFAULT PRIVILEGES
IMPORT FOREIGN SCHEMA
IMPORT FOREIGN SCHEMA — импортировать определения таблиц со стороннего сервера
Синтаксис
IMPORT FOREIGN SCHEMA удаленная_схема
[ { LIMIT TO | EXCEPT } ( имя_таблицы [, ...] ) ]
FROM SERVER имя_сервера
INTO локальная_схема
[ OPTIONS ( параметр 'значение' [, ... ] ) ]
Описание
Команда IMPORT FOREIGN SCHEMA создает сторонние таблицы, которые представляют
таблицы, существующие на стороннем сервере. Новые сторонние таблицы будут
принадлежать пользователю, выполнившему команду, и будут созданы с
правильными определениями столбцов и параметров, соответствующих
удаленным таблицам.
По умолчанию импортируются все таблицы и представления, существующие в определенной схеме на стороннем сервере. При необходимости список таблиц можно ограничить указанным подмножеством или исключить определенные таблицы. Все новые сторонние таблицы создаются в целевой схеме, которая уже должна существовать.
Чтобы использовать IMPORT FOREIGN SCHEMA, необходимо иметь
право USAGE на стороннем сервере, а также право CREATE в целевой схеме.
Параметры
удаленная_схема
Удаленная схема, предназначенная для импорта из нее. Что именно представляет собой удаленная схема, зависит от применяемой обертки сторонних данных.
LIMIT TO ( имя_таблицы [, ...] )
Импортировать только сторонние таблицы, соответствующие одному из указанных имен таблиц. Другие таблицы, существующие в сторонней схеме, будут игнорироваться.
EXCEPT ( имя_таблицы [, ...] )
Исключить указанные сторонние таблицы из импорта. Все существующие в сторонней схеме таблицы, за исключением перечисленных, будут импортированы.
имя_сервера
Сторонний сервер, предназначенный для импорта из него.
локальная_схема
Схема, в которой будут созданы импортируемые сторонние таблицы.
OPTIONS ( параметр 'значение' [, ...] )
Параметры, которые будут использоваться во время импорта. Допустимые имена и значения параметров являются специфичными для каждой обертки сторонних данных.
Примеры
Импорт определений таблиц из удаленной схемы foreign_films на сервере film_server с созданием сторонних таблиц в локальной схеме films:
IMPORT FOREIGN SCHEMA foreign_films
FROM SERVER film_server INTO films;
Та же операция, но импортируются только таблицы actors и directors (если они существуют):
IMPORT FOREIGN SCHEMA foreign_films LIMIT TO (actors, directors)
FROM SERVER film_server INTO films;
Совместимость
Команда IMPORT FOREIGN SCHEMA соответствует стандарту SQL, за
исключением параметра OPTIONS, являющегося расширением QHB.
См. также
CREATE FOREIGN TABLE, CREATE SERVER
INSERT
INSERT — добавить новые строки в таблицу
Синтаксис
[ WITH [ RECURSIVE ] запрос_WITH [, ...] ]
INSERT INTO имя_таблицы [ AS псевдоним ] [ ( имя_столбца [, ...] ) ]
[ OVERRIDING { SYSTEM | USER } VALUE ]
{ DEFAULT VALUES | VALUES ( { выражение | DEFAULT } [, ...] ) [, ...] | запрос }
[ ON CONFLICT [ объект_конфликта ] действие_при_конфликте ]
[ RETURNING * | выражение_результата [ [ AS ] имя_результата ] [, ...] ]
где объект_конфликта может быть:
( { имя_столбца_индекса | ( выражение_индекса ) } [ COLLATE правило_сортировки ] [ класс_операторов ] [, ...] ) [ WHERE предикат_индекса ]
ON CONSTRAINT имя_ограничения
и действие_при_конфликте может быть:
DO NOTHING
DO UPDATE SET { имя_столбца = { выражение | DEFAULT } |
( имя_столбца [, ...] ) = [ ROW ] ( { выражение | DEFAULT } [, ...] ) |
( имя_столбца [, ...] ) = ( вложенный_SELECT )
} [, ...]
[ WHERE условие ]
Описание
Команда INSERT добавляет новые строки в таблицу. Можно добавить одну и
более строк, заданных выражениями значений, или ноль и более
строк, полученных в результате запроса.
Имена целевых столбцов могут быть перечислены в любом порядке. Если список имен столбцов вообще не задан, то по умолчанию используются все столбцы таблицы в их объявленном порядке; либо первые N из них, если от предложения VALUES или запроса поступает только N столбцов. Значения, получаемые от предложения VALUES или запроса, связываются с явно или неявно определенным списком столбцов слева направо.
Каждый столбец, не присутствующий в явном или неявном списке столбцов, будет заполнен значением по умолчанию, если оно задано, либо, в противном случае, значением NULL.
Если выражение для любого столбца выдает неправильный тип данных, будет предпринята попытка автоматического преобразования типа.
Можно использовать предложение ON CONFLICT для указания альтернативного действия, заменяющего возникновение ошибки при нарушении ограничения уникальности или ограничения-исключения. (См. Предложение ON CONFLICT ниже).
С необязательным предложением RETURNING команда INSERT
вычислит и возвратит значения каждой строки, фактически добавленной
(или измененной, если было использовано предложение ON CONFLICT DO UPDATE).
Это в первую очередь полезно для получения значений,
присвоенных по умолчанию, таких как последовательный номер записи.
Однако в этом предложении можно задать любое выражение со столбцами
таблицы. Список RETURNING идентичен синтаксису списка результатов SELECT.
Будут возвращены только строки, которые были успешно добавлены или
изменены. Например, если строка была заблокирована, но не изменена
из-за того, что условие в предложении ON CONFLICT DO UPDATE ... WHERE
не удовлетворено, строка не будет возвращена.
Чтобы добавлять строки в таблицу, необходимо иметь для нее право INSERT. Если присутствует предложение ON CONFLICT DO UPDATE, для такой таблицы также потребуется право UPDATE.
Если указан список столбцов, достаточно иметь право INSERT только для перечисленных столбцов. По аналогии предложению ON CONFLICT DO UPDATE требуется право UPDATE только для столбца(ов), который(ые) будет(ут) обновлен(ы). Однако помимо этого предложение ON CONFLICT DO UPDATE требует наличия права SELECT для всех столбцов, значения которых считываются в выражениях ON CONFLICT DO UPDATE или в условии.
Для использования предложения RETURNING требуется право SELECT для всех упомянутых в RETURNING столбцов. Если для добавления строк используется запрос, то, разумеется, нужно иметь право SELECT для всех перечисленных в данном запросе таблиц или столбцов.
Параметры
Добавление
В этом разделе описываются параметры, которые могут использоваться только при добавлении новых строк. Параметры, используемые исключительно с предложением ON CONFLICT, описываются отдельно.
запрос_WITH
Предложение WITH позволяет указать один или несколько вложенных
запросов, на которые можно ссылаться по имени в запросе INSERT.
Дополнительную информацию см. в разделах Запросы WITH и SELECT.
Сам заданный запрос (оператор SELECT) также может содержать предложение WITH.
В этом случае в запросе можно обращаться к обоим наборам запрос_WITH, но у второго будет
приоритет, так как он вложен ближе.
имя_таблицы
Имя существующей таблицы (может быть дополнено схемой).
псевдоним
Альтернативное имя для имени_таблицы. При указании псевдонима тот полностью скрывает фактическое имя таблицы. Это особенно полезно, когда в предложении ON CONFLICT DO UPDATE фигурирует таблица с именем excluded, поскольку в противном случае это имя будет присвоено специальной таблице, представляющей строки, которые предназначены для добавления.
имя_столбца
Имя столбца в таблице с именем имя_таблицы. При необходимости имя столбца может быть
дополнено именем вложенного поля или индексом в массиве.
(Когда данные добавляются только в некоторые поля столбца
составного типа, в другие поля записывается значение NULL.) Обращаясь к столбцу в
предложении ON CONFLICT DO UPDATE, не следует включать в ссылку на
целевой столбец имя таблицы. Например, запись
INSERT INTO table_name ... ON CONFLICT DO UPDATE SET table_name.col = 1
недопустима (это соответствует общему поведению команды UPDATE ).
OVERRIDING SYSTEM VALUE
При указании этого предложения все значения, предоставляемые для столбцов идентификации, будут переопределять значения, выдаваемые последовательностью по умолчанию.
Для столбца идентификации, определенного как GENERATED ALWAYS, добавление явного значения (кроме DEFAULT) является ошибкой, если не указано OVERRIDING SYSTEM VALUE или OVERRIDING USER VALUE. (Для столбца идентификации, определенного как GENERATED BY DEFAULT, OVERRIDING SYSTEM VALUE является обычным поведением, поэтому его указание ни на что не влияет, но QHB допускает его в качестве расширения.)
OVERRIDING USER VALUE
При указании этого предложения игнорируются любые значения, предоставляемые для столбцов идентификаторов, и применяются значения, выдаваемые последовательностью по умолчанию.
Это предложение полезно, например, при копировании значений между
таблицами. Команда
INSERT INTO tbl2 OVERRIDING USER VALUE SELECT \* FROM tbl1 скопирует из tbl1
все столбцы, которые не являются столбцами идентификаторами в tbl2, тогда как
значения для столбцов идентификаторов в tbl2 будут генерироваться
последовательностями, связанными с tbl2.
DEFAULT VALUES
Все столбцы будут заполнены значениями по умолчанию, как при для явном указании DEFAULT для каждого столбца. (Предложение OVERRIDING в этой форме не допускается.)
выражение
Выражение или значение для присвоения соответствующему столбцу.
DEFAULT
Соответствующий столбец получит значение по умолчанию. Столбец идентификации получит новое значение, выданное связанной последовательностью. Для генерируемого столбца указание этого параметра допустимо, но он всего лишь описывает обычное поведение при вычислении значения столбца из генерирующего его выражения.
запрос
Запрос (оператор SELECT), который выдаст строки для добавления в таблицу.
Описание его синтаксиса см. в разделе SELECT.
выражение_результата
Выражение, вычисляемое и возвращаемое командой INSERT после каждой
строки, которая добавляется или изменяется. В этом выражении могут использоваться любые
имена столбцов таблицы с именем имя_таблицы. Чтобы
вернуть все столбцы добавленных или измененных строк, достаточно написать *.
имя_результата
Имя, используемое для возвращаемого столбца.
Предложение ON CONFLICT
Необязательное предложение ON CONFLICT указывает альтернативное действие, заменяющее возникновение ошибки при нарушении ограничения уникальности или ограничения-исключения. Для каждой отдельной предложенной для добавления строки добавление либо продолжается, либо, если нарушается решающее ограничение или индекс, указанный как объект_конфликта, выполняется альтернативное действие_при_конфликте. Вариант ON CONFLICT DO NOTHING в качестве альтернативного действия просто отменяет добавление строки. Вариант ON CONFLICT DO UPDATE обновляет существующую строку, которая конфликтует со строкой, предложенной для добавления.
Задаваемый объект_конфликта может выбирать уникальный индекс. Определение объекта, позволяющее выбрать индекс, включает один или несколько столбцов (их определяет имя_столбца_индекса) и/или выражение_индекса и необязательный предикат_индекса. В качестве решающих индексов выводятся (выбираются) все уникальные индексы в таблице имя_таблицы, которые, без учета порядка столбцов, содержат именно те столбцы/выражения, что определяют объект_конфликта. Если указывается предикат_индекса, он должен, в качестве дополнительного требования выбора, удовлетворять уникальным индексам. Обратите внимание: это означает, что не частичный уникальный индекс (уникальный индекс без предиката) будет выбран (и, следовательно, будет использован в ON CONFLICT), если он удовлетворяет всем остальным критериям. Если попытка выбора неудачна, выдается ошибка.
ON CONFLICT DO UPDATE гарантирует атомарный результат
команды INSERT или UPDATE; при отсутствии внешней ошибки даже при высокой
параллельной активности гарантируется один из этих двух результатов. Эта операция также известна как
UPSERT — «UPDATE или INSERT».
объект_конфликта
Указывает, какие именно конфликты в ON CONFLICT будут решаться альтернативным действием, устанавливая решающие индексы. Это указание позволяет выполнять выбор уникального индекса либо явно задает имя ограничения. Для ON CONFLICT DO NOTHING необязательно указывать объект_конфликта; в этом случае игнорироваться будут все конфликты с любыми ограничениями (и уникальными индексами). Для ON CONFLICT DO UPDATE объект_конфликта должен указываться.
действие_при_конфликте
Параметр действие_при_конфликте задает альтернативное действие в случае конфликта. Это может быть предложение DO NOTHING (не делать ничего) или DO UPDATE (произвести обновление), где указываются точные детали операции UPDATE, выполняемой в случае возникновения конфликта. Предложения SET и WHERE в ON CONFLICT DO UPDATE могут обращаться к существующей строке с использованием имени таблицы (или псевдонима), а также к строкам, предложенным для добавления с помощью специальной таблицы excluded. Для чтения столбцов excluded необходимо иметь право SELECT для соответствующих столбцов в целевой таблице.
Обратите внимание, что эффекты действий всех триггеров уровня строк BEFORE INSERT отражаются в значениях excluded, так как эти эффекты могут привести к исключению строки из добавления.
имя_столбца_индекса
Имя столбца в таблице имя_таблицы. Используется для выбора решающих индексов.
Задается в формате CREATE INDEX. Чтобы запрос выполнился, для столбца
имя_столбца_индекса требуется право SELECT.
выражение_индекса
Подобно указанию имя_столбца_индекса, но используется для выбора индекса
по выражениям со столбцами таблицы имя_таблицы, обозначенными в определениях индексов
(а не по простым столбцам). Задается в формате CREATE INDEX. Для всех столбцов,
к которым обращается выражение_индекса, требуется право SELECT.
правило_сортировки
При указании устанавливает, что соответствующий столбец имя_столбца_индекса
или выражение_индекса должен использовать определенный порядок сортировки для
сопоставления во время выбора индекса. Обычно это указание опущено, так как правила
сортировки в большинстве случаев не влияют на то, произойдет ли нарушение ограничений.
Задается в формате CREATE INDEX.
класс_операторов
При указании устанавливает, что соответствующий столбец имя_столбца_индекса или
выражение_индекса должен использовать определенный класс оператора для
сопоставления во время выбора индекса. Обычно это указание опущено, поскольку
семантика равенства все равно часто эквивалентна в разных классах операторов типа
либо поскольку достаточно полагаться на то, что заданные уникальные индексы
имеют адекватное определение равенства. Задается в формате CREATE INDEX.
предикат_индекса
Используется для разрешения выбора частичных уникальных индексов. Могут быть выбраны любые
индексы, удовлетворяющие предикату (причем в действительности им необязательно быть
частичными индексами). Задается в формате CREATE INDEX.
Для всех столбцов, задействованных в предикате_индекса, требуется право SELECT.
имя_ограничения
Явно указывает решающее ограничение по имени, что заменяет неявный выбор ограничения или индекса.
условие
Выражение, которое выдает значение типа boolean. Будут обновлены только те строки, для которых это выражение выдает true, хотя при выборе операции ON CONFLICT DO UPDATE все строки будут заблокированы. Обратите внимание, что условие оценивается последним, после определения конфликта в качестве кандидата на обновление.
Примите к сведению, что ограничения-исключения не могут быть решающими в ON CONFLICT DO UPDATE. Во всех случаях в качестве решающих поддерживаются только неоткладываемые (NOT DEFERRABLE) ограничения и уникальные индексы.
Команда INSERT с предложением ON CONFLICT DO UPDATE является «детерминированной».
Это означает, что команде не разрешено влиять на одну существующую строку более
одного раза; в случае такой ситуации возникнет ошибка нарушения мощности множества.
Строки, предлагаемые для добавления, не должны дублировать
друг друга с точки зрения атрибутов, ограниченных решающим индексом или
ограничением.
Обратите внимание, что в настоящее время это не работает для предложения
ON CONFLICT DO UPDATE команды INSERT, применяемой к партиционированной таблице
с целью обновления ключа разбиения в конфликтующей строке таким образом,
что эта строка должна быть перенесена в новую партицию.
Совет
Часто предпочтительнее вместо непосредственного указания ограничения в виде ON CONFLICT ON CONSTRAINT имя_ограничения использовать неявный выбор уникального индекса. Выбор продолжит работать правильно, когда нижележащий индекс будет заменен другим более или менее эквивалентным индексом методом наложения, например при использованииCREATE UNIQUE INDEX ... CONCURRENTLYс последующим удалением заменяемого индекса.
Выводимая информация
После успешного завершения команда INSERT возвращает метку команды в виде
INSERT oid число
Здесь число представляет количество добавленных или обновленных строк. Поле oid всегда содержит 0 (раньше это был OID, назначенный добавленной строке, если число равнялось 1 и целевая таблица была объявлена указанием WITH OIDS, и 0 в противном случае, но создание таблицы с характеристикой WITH OIDS больше не поддерживается).
Если команда INSERT содержит предложение RETURNING, результат
будет похож на результат команды SELECT (с теми же столбцами и значениями,
что содержатся в списке RETURNING), полученный для строк, добавленных или
обновленных этой командой.
Примечания
Если указанная таблица является партиционированной таблицей, то каждая строка направляется в соответствующую партицию и добавляется в нее. Если указанная таблица является партицией и какая-либо из входных строк нарушает ограничение этой партиции, происходит ошибка.
Примеры
Добавление одной строки в таблицу films:
INSERT INTO films VALUES
('UA502', 'Bananas', 105, '1971-07-13', 'Comedy', '82 minutes');
В этом примере столбец len опускается и, как следствие, получает значение по умолчанию:
INSERT INTO films (code, title, did, date_prod, kind)
VALUES ('T_601', 'Yojimbo', 106, '1961-06-16', 'Drama');
В этом примере для столбца с датой задается указание DEFAULT, а не явное значение:
INSERT INTO films VALUES
('UA502', 'Bananas', 105, DEFAULT, 'Comedy', '82 minutes');
INSERT INTO films (code, title, did, date_prod, kind)
VALUES ('T_601', 'Yojimbo', 106, DEFAULT, 'Drama');
Добавление строки, полностью состоящей из значений по умолчанию:
INSERT INTO films DEFAULT VALUES;
Добавление нескольких строк с использованием многострочного синтаксиса VALUES:
INSERT INTO films (code, title, did, date_prod, kind) VALUES
('B6717', 'Tampopo', 110, '1985-02-10', 'Comedy'),
('HG120', 'The Dinner Game', 140, DEFAULT, 'Comedy');
В этом примере в таблицу films добавляются некоторые строки из таблицы tmp_films, имеющей ту же структуру столбцов, что и films:
INSERT INTO films SELECT * FROM tmp_films WHERE date_prod < '2004-05-07';
Этот пример демонстрирует добавление данных в столбцы с типом массива:
-- Создание пустого поля 3x3 для игры в крестики-нолики
INSERT INTO tictactoe (game, board[1:3][1:3])
VALUES (1, '{{" "," "," "},{" "," "," "},{" "," "," "}}');
-- Указания индексов в предыдущей команде могут быть опущены
INSERT INTO tictactoe (game, board)
VALUES (2, '{{X," "," "},{" ",O," "},{" ",X," "}}');
Добавление одной строки в таблицу distributors и получение последовательного номера, сгенерированного благодаря указанию DEFAULT:
INSERT INTO distributors (did, dname) VALUES (DEFAULT, 'XYZ Widgets')
RETURNING did;
Увеличение счетчика продаж для продавца, занимающегося компанией Acme Corporation, и сохранение всей обновленной строки вместе с текущим временем в таблице журнала:
WITH upd AS (
UPDATE employees SET sales_count = sales_count + 1 WHERE id =
(SELECT sales_person FROM accounts WHERE name = 'Acme Corporation')
RETURNING *
)
INSERT INTO employees_log SELECT *, current_timestamp FROM upd;
Добавить дистрибьюторов или обновить существующие данные должным образом. Предполагается, что в таблице определен уникальный индекс, ограничивающий значения в столбце did. Обратите внимание, что для обращения к значениям, изначально предлагаемым для добавления, используется специальная таблица excluded:
INSERT INTO distributors (did, dname)
VALUES (5, 'Gizmo Transglobal'), (6, 'Associated Computing, Inc')
ON CONFLICT (did) DO UPDATE SET dname = EXCLUDED.dname;
Добавить дистрибьютора или не делать ничего для строк, предложенных для добавления, если уже есть существующая исключающая строка (строка, содержащая конфликтующие значения в столбце или столбцах после срабатывания триггеров перед добавлением строки). В данном примере предполагается, что определен уникальный индекс, ограничивающий значения в столбце did:
INSERT INTO distributors (did, dname) VALUES (7, 'Redline GmbH')
ON CONFLICT (did) DO NOTHING;
Добавить дистрибьюторов или обновить существующие данные должным образом. В данном примере предполагается, что в таблице определен уникальный индекс, ограничивающий значения в столбце did. Предложение WHERE позволяет ограничить набор фактически обновляемых строк (однако любая существующая строка, не подлежащая обновлению, всё равно будет заблокирована):
-- Не менять данные существующих дистрибьюторов в зависимости от почтового индекса
INSERT INTO distributors AS d (did, dname) VALUES (8, 'Anvil Distribution')
ON CONFLICT (did) DO UPDATE
SET dname = EXCLUDED.dname || ' (formerly ' || d.dname || ')'
WHERE d.zipcode <> '21201';
-- Указать имя ограничения непосредственно в операторе (связанный индекс
-- применяется для принятия решения о выполнении действия DO NOTHING)
INSERT INTO distributors (did, dname) VALUES (9, 'Antwerp Design')
ON CONFLICT ON CONSTRAINT distributors_pkey DO NOTHING;
Добавить дистрибьютора, если возможно; в противном случае не делать ничего (DO NOTHING). В данном примере предполагается, что в таблице определен уникальный индекс, ограничивающий значения в столбце did по подмножеству строк, в котором логический столбец is_active содержит true:
-- Этот оператор может выбрать частичный уникальный индекс по "did"
-- с предикатом "WHERE is_active", а может, просто использовать
-- обычное ограничение уникальности по столбцу "did"
INSERT INTO distributors (did, dname) VALUES (10, 'Conrad International')
ON CONFLICT (did) WHERE is_active DO NOTHING;
Совместимость
Команда INSERT соответствует стандарту SQL, за исключением того, что
предложение RETURNING является расширением QHB, как и
возможность использовать WITH с INSERT, а также возможность
указать альтернативное действие с помощью ON CONFLICT. Кроме того,
ситуация, при которой список имен столбцов опущен, но не все столбцы
получают значения из предложения VALUES или запроса, стандартом не допускается.
Стандарт SQL определяет, что предложение OVERRIDING SYSTEM VALUE может быть указано только в том случае, если существует столбец идентификации, для которого всегда генерируется значение. QHB разрешает это предложение в любом случае и игнорирует его, если оно не применимо.
Возможные ограничения по использованию предложения запрос описаны в разделе SELECT.
LISTEN
LISTEN — прослушивать уведомления
Синтаксис
LISTEN канал
Описание
Команда LISTEN регистрирует текущий сеанс в качестве прослушивателя
на канале уведомлений с именем канал. Если текущий сеанс уже
зарегистрирован в качестве прослушивателя для этого канала уведомлений,
ничего не происходит.
Всякий раз, когда вызывается команда NOTIFY канал (в этом
сеансе или в другом, подключенном к той же базе данных), все сеансы,
которые в настоящий момент прослушивают этот канал уведомлений,
получают уведомление и в свою очередь передают его своему подключенному
клиентскому приложению.
Сеанс может быть отменен для данного канала уведомлений с помощью
команды UNLISTEN. Регистрация прослушивания канала автоматически
очищается по окончании сеанса.
Метод, который клиентское приложение должно использовать для обнаружения
событий уведомления, зависит от того, какой программный интерфейс
приложения QHB оно использует. С библиотекой libpq приложение
выполняет команду LISTEN как обычную команду SQL, а затем должно
периодически вызывать функцию PQnotifies, чтобы узнать, были ли получены
какие-либо уведомления. Другие интерфейсы, например libpgtcl,
предоставляют более высокоуровневые методы для обработки событий уведомлений;
более того, с libpgtcl программисту приложения даже не нужно запускать
LISTEN или UNLISTEN напрямую. Дополнительную информацию см.
в документации по используемому интерфейсу.
Параметры
канал
Наименование канала уведомления (любой идентификатор).
Примечания
Команда LISTEN вступает в силу при фиксации транзакции. Если LISTEN или
UNLISTEN выполняется в транзакции, которая позже откатывается, набор
прослушиваемых каналов уведомлений остается неизменным.
Транзакция, которая выполнила LISTEN, не может быть подготовлена к
двухфазной фиксации.
При первой настройке сеанса на прослушивание существует условие гонки: если параллельно фиксирующиеся транзакции посылают уведомления о событии, какое из них получит свежеподписавшийся сеанс? Ответ: сеанс получит все события, зафиксированные после момента фиксации транзакции, регистрирующей подписку. Но эти уведомления будут отражать состояния базы данных с некоторым запозданием по сравнению с тем, которое эта транзакция могла бы наблюдать в своих запросах. Это приводит к следующему правилу использования LISTEN: сначала выполнить (и зафиксировать!) эту команду, затем в новой транзакции проверить состояние базы данных согласно требованиям логики приложения, затем воспользоваться уведомлениями для выявления последующих изменений состояния базы данных. Первые несколько уведомлений могут относиться к изменениям, которые уже наблюдались при исходной проверке базы данных, но обычно в этом нет вреда.
В разделе NOTIFY можно найти более подробный разбор использования команд LISTEN and NOTIFY.
Примеры
Настройка и выполнение последовательности listen/notify от qsql:
LISTEN virtual;
NOTIFY virtual;
Asynchronous notification "virtual" received from server process with PID 8448.
Совместимость
В стандарте SQL нет команды LISTEN.
См. также
LOAD
LOAD — загрузить файл разделяемой библиотеки
Синтаксис
LOAD 'имя_файла'
Описание
Команда LOAD загружает файл разделяемой библиотеки в адресное пространство
сервера QHB. Если файл уже загружен, команда ничего не делает.
Файлы разделяемой библиотеки, содержащие функции на C, автоматически загружаются
при первом вызове одной из их функций. Поэтому явно выполнять LOAD обычно
требуется только для загрузки библиотек, которые изменяют поведение
сервера, внедряя свои обработчики, а не предоставляют набор функций.
Имя файла библиотеки обычно задается как простое имя файла, которое ищется в пути поиска библиотек сервера (задается параметром dynamic_library_path). Кроме того, он может быть задан в качестве полного имени пути. В любом случае стандартное расширение имени файла разделяемой библиотеки платформы может быть опущено.
Не суперпользователи могут применять LOAD только для загрузки файлов
библиотек, расположенных в $libdir/plugins/ — указанное имя_файла
должно начинаться именно с этой строки. (Ответственность за установку только
«безопасных» библиотек лежит на администраторе базы данных.)
Совместимость
LOAD является расширением QHB.
См. также
LOCK
LOCK — заблокировать таблицу
Синтаксис
LOCK [ TABLE ] [ ONLY ] имя [ * ] [, ...][ IN режим_блокировки ] [ NOWAIT ]
где режим_блокировки является одним из следующих:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE
| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
Описание
LOCK TABLE получает блокировку уровня таблицы, при необходимости ожидая
освобождения всех конфликтующих блокировок. Если указывается NOWAIT,
LOCK TABLE не ожидает освобождения таблицы: если блокировку нельзя получить немедленно, команда
прерывается и выдается ошибка. После получения блокировка удерживается до конца
текущей транзакции. (Команды UNLOCK TABLE не существует; блокировки всегда
освобождаются в конце транзакции.)
Когда блокируется представление, все отношения, появляющиеся в запросе определения представления, также рекурсивно блокируются с тем же режимом блокировки.
При автоматическом получении блокировок для команд, ссылающихся на
таблицы, QHB всегда использует наименее ограничительный режим
блокировки. Команда LOCK TABLE предназначена для случаев, когда
может потребоваться более строгая блокировка. Например, предположим, что
приложение выполняет транзакцию на уровне изоляции READ COMMITTED
и должно обеспечить неизменность данных в таблице на протяжении всей транзакции.
Для этого можно перед запросом получить над таблицей блокировку в режиме SHARE.
Это предотвратит одновременные изменения данных и обеспечит стабильное представление зафиксированных данных при последующем
чтении таблицы, потому что режим блокировки SHARE конфликтует с запрашиваемой при записи
блокировкой ROW EXCLUSIVE, а команда LOCK TABLE имя IN SHARE MODE будет ждать, пока
все параллельные транзакции с блокировкой ROW EXCLUSIVE не будут зафиксированы или отменены.
Таким образом, в момент получения такой блокировки
не останется никаких открытых незафиксированных операций записи; более
того, до снятия блокировки никто не сможет записывать в таблицу.
Для достижения аналогичного эффекта при выполнении транзакции на
уровнях изоляции REPEATABLE READ или SERIALIZABLE нужно
выполнить команду LOCK TABLE перед выполнением первой команды
SELECT или команды, изменяющей данные.
Представление данных для транзакции уровня REPEATABLE READ или
SERIALIZABLE будет заморожено в момент, когда начнет выполняться этот запрос.
Если команда LOCK TABLE выполняется в транзакции позже, она также исключает
параллельную запись, но не гарантирует, что транзакция будет считывать
последние зафиксированные значения.
Если транзакция такого рода будет изменять данные в таблице, следует использовать режим блокировки SHARE ROW EXCLUSIVE вместо SHARE. Это гарантирует, что в один момент времени будет выполняться только одна транзакция такого типа. Без этого ограничения возможна взаимная блокировка: обе транзакции могут получить блокировки SHARE, после чего не смогут получить блокировку ROW EXCLUSIVE, чтобы выполнить изменения. (Обратите внимание, что собственные блокировки транзакции никогда не конфликтуют, поэтому транзакция может получить блокировку ROW EXCLUSIVE, когда владеет блокировкой SHARE — но не тогда, когда блокировку SHARE удерживает другая транзакция.) Чтобы избежать взаимоблокировок, убедитесь, что все транзакции запрашивают блокировки одних и тех же объектов в одном и том же порядке, и если для одного объекта запрашиваются блокировки с разными режимами, то транзакции всегда должны сначала запрашивать наиболее строгую блокировку.
Дополнительную информацию о режимах и стратегиях блокировки можно найти в разделе Явная блокировка.
Параметры
имя
Имя существующей таблицы, подлежащей блокировке (может быть дополнено схемой). Если перед именем таблицы указывается ONLY, то блокируется только эта таблица. Если ONLY не указан, то блокируются таблица и все ее потомки (если таковые имеются). После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что включены и все дочерние таблицы.
Команда LOCK TABLE a, b; эквивалентна LOCK TABLE a; LOCK TABLE b;. Таблицы блокируются одна за другой
в порядке, указанном в команде LOCK TABLE.
режим блокировки
Режим блокировки определяет, с какими блокировками эта блокировка конфликтует. Режимы блокировки описаны в разделе Явная блокировка.
Если режим блокировки не указан, то применяется самый строгий режим ACCESS EXCLUSIVE.
NOWAIT
Указывает, что LOCK TABLE не должна ожидать освобождения
конфликтующих блокировок: если указанные блокировки не могут быть
получены немедленно без ожидания, транзакция прерывается.
Примечания
Команда LOCK TABLE ... IN ACCESS SHARE MODE требует права SELECT к целевой таблице.
Команда LOCK TABLE ... IN ROW EXCUSIVE MODE требует прав INSERT, UPDATE,
DELETE или TRUNCATE к целевой таблице. Все другие формы LOCK требуют
прав UPDATE, DELETE или TRUNCATE к целевой таблице.
Пользователь, выполняющий блокировку представления, должен иметь соответствующие права для этого представления. Кроме того, владелец представления должен иметь соответствующие права доступа к нижележащим базовым отношениям, но пользователь, выполняющий блокировку, не нуждается в каких-либо правах на базовые отношения.
LOCK TABLE бесполезна вне блока транзакций: блокировка будет
удерживаться только до завершения операции. Поэтому если LOCK используется вне блока
транзакций, QHB сообщает об ошибке.
Для определения блока транзакций используйте команды BEGIN и COMMIT (или ROLLBACK).
LOCK TABLE имеет дело только с блокировками уровня таблицы, и
поэтому имена режимов, включающие ROW, не вполне корректны.
Эти имена режимов обычно следует рассматривать как указывающие на намерение
пользователя получить блокировки на уровне строк в заблокированной
таблице. Кроме того, ROW EXCLUSIVE — это разделяемая блокировка
таблицы. Имейте в виду, что для LOCK TABLE все режимы блокировки имеют одинаковую
семантику, отличаясь только правилами, определяющими, какие режимы конфликтуют друг с другом.
Информацию о том, как получить фактическую блокировку уровня
строки, см. в разделах Блокировка на уровне строк
и Предложение блокировки в справочной документации по команде SELECT.
Примеры
Получение блокировки SHARE для первичного ключа таблицы при выполнении операций добавления в подчиненную таблицу:
BEGIN WORK;
LOCK TABLE films IN SHARE MODE;
SELECT id FROM films
WHERE name = 'Star Wars: Episode I - The Phantom Menace';
-- Будет выполнен откат, если запись не будет возвращена
INSERT INTO films_user_comments VALUES
(id, 'GREAT! I was waiting for it for so long!');
COMMIT WORK;
Установка блокировки SHARE ROW EXCLUSIVE в таблице первичного ключа перед выполнением операции удаления:
BEGIN WORK;
LOCK TABLE films IN SHARE ROW EXCLUSIVE MODE;
DELETE FROM films_user_comments WHERE id IN
(SELECT id FROM films WHERE rating < 5);
DELETE FROM films WHERE rating < 5;
COMMIT WORK;
Совместимость
В стандарте SQL нет команды LOCK TABLE; вместо этого для указания уровней изоляции в транзакциях
в нём используется команда SET TRANSACTION.
QHB поддерживает и этот вариант; дополнительную информацию см. в
разделе SET TRANSACTION.
За исключением ACCESS SHARE, ACCESS EXCLUSIVE и SHARE UPDATE EXCLUSIVE,
режимы блокировки и синтаксис команды LOCK TABLE в QHB
совместимы с имеющимися в СУБД Oracle.
MOVE
MOVE — переместить курсор
Синтаксис
MOVE [ направление [ FROM | IN ] ] имя_курсора
Где направление может быть пустым или принимать одно из значений:
NEXT
PRIOR
FIRST
LAST
ABSOLUTE число
RELATIVE число
число
ALL
FORWARD
FORWARD число
FORWARD ALL
BACKWARD
BACKWARD число
BACKWARD ALL
Описание
Команда MOVE перемещает курсор без извлечения каких-либо данных.
MOVE работает точно так же, как команда FETCH, за
исключением того, что она только позиционирует курсор и не возвращает
строки.
Параметры команды MOVE идентичны параметрам команды FETCH; подробную
информацию о синтаксисе и использовании см. в разделе FETCH.
Выводимая информация
После успешного завершения команда MOVE возвращает метку
команды в виде
MOVE число
Где число — это число строк, которое вернула бы команда FETCH с теми же
параметрами (возможно, ноль).
Примеры
BEGIN WORK;
DECLARE liahona CURSOR FOR SELECT * FROM films;
-- Пропустить первые 5 строк:
MOVE FORWARD 5 IN liahona;
MOVE 5
-- Выбрать 6-ю строку из курсора liahona:
FETCH 1 FROM liahona;
code | title | did | date_prod | kind | len
-------+--------+-----+------------+--------+-------
P_303 | 48 Hrs | 103 | 1982-10-22 | Action | 01:37
(1 row)
-- Закрыть курсор liahona и завершить транзакцию:
CLOSE liahona;
COMMIT WORK;
Совместимость
В стандарте SQL нет команды MOVE.
См. также
NOTIFY
NOTIFY — сгенерировать уведомление
Синтаксис
NOTIFY канал [ , полезная_информация ]
Описание
Команда NOTIFY отправляет событие уведомления вместе с необязательной строкой «полезная информация» каждому клиентскому
приложению, которое ранее выполнило команду LISTEN канал для указанного имени канала в текущей базе данных.
Уведомления отображаются для всех пользователей.
NOTIFY предоставляет простой механизм межпроцессной связи для набора процессов, обращающихся к одной и той же
базе данных QHB. Строка полезной информации может быть отправлена вместе с уведомлением, а при использовании
таблиц в базе данных для передачи дополнительных данных от уведомителя к прослушивателю(ям) можно создать
механизмы более высокого уровня для передачи структурированных данных.
Информация, передаваемая клиенту для события уведомления, включает имя канала уведомления, идентификатор PID серверного процесса сеанса уведомления и строку полезной информации, которая остается пустой, если не задать сообщение.
Выбор подходящих имен каналов и их назначения остается на усмотрение проектировщика базы данных. Обычно имя канала совпадает
с именем некоторой таблицы в базе данных, и событие, по существу, означает: «я изменил эту таблицу, взгляните на нее,
чтобы увидеть, что нового». Но командами NOTIFY и LISTEN подобная ассоциация не навязывается.
Например, проектировщик базы данных может использовать несколько различных имен каналов для передачи сигналов
о различных видах изменений в одной таблице. Кроме того, строка полезной информации может использоваться для
дифференциации различных случаев.
Когда NOTIFY используется для сигнализации о появлении изменений в определенной таблице, полезным методом
программирования является помещение NOTIFY в триггер команды, который запускается обновлениями таблицы.
Таким образом, уведомление происходит автоматически при изменении таблицы, и программист приложения не может
случайно забыть это сделать.
NOTIFY взаимодействует с транзакциями SQL несколькими важными способами. Во-первых, если NOTIFY выполняется
внутри транзакции, уведомляющие события не доставляются до тех пор, пока транзакция не будет зафиксирована.
Это целесообразно, так как при прерывании транзакции действие всех команд внутри нее, включая NOTIFY, аннулируется.
Но это может привести в замешательство, если пользователь ожидает, что события уведомления будут доставлены немедленно.
Во-вторых, если во время нахождения в транзакции сеанс прослушивания получает сигнал уведомления,
это событие не будет доставлено своему подключенному клиенту сразу после завершения (фиксации или прерывания)
транзакции. Опять же, смысл в том, что если уведомление было доставлено в рамках транзакции,
которая позже была прервана, кто-нибудь может захотеть как-то отменить его — но
сервер не может «забрать» уведомление, которое уже отправлено клиенту.
Поэтому события уведомлений доставляются только между транзакциями. Подводя итог вышесказанному,
приложениям, использующим NOTIFY для сигнализации в режиме реального времени, следует по возможности
максимально сокращать размер своих транзакций.
Если из одной транзакции несколько раз сигнализируется одно и то же имя канала с одинаковыми строками полезной информации,
сервер баз данных может принять решение о доставке только одного уведомления. С другой стороны, уведомления
с различными строками полезной информации всегда будут доставляться по отдельности.
Аналогично никогда не будут объединены и уведомления от различных транзакций.
За исключением удаления более поздних экземпляров повторяющихся уведомлений, NOTIFY гарантирует,
что уведомления от одной и той же транзакции будут доставлены в том же порядке, в котором были отправлены.
Также гарантируется, что сообщения от различных транзакций доставляются в том же порядке, в котором были совершены.
Часто бывает, что клиент, выполнивший NOTIFY, ожидает уведомления на том же канале. В этом случае он получит
свое же событие уведомления, как и любой другой сеанс прослушивания.
В зависимости от логики приложения, это может привести к бесполезной работе, например чтению таблицы базы данных
для поиска тех же обновлений, которые только что были записаны в этом сеансе. Подобной дополнительной работы
можно избежать, отследив, не совпадает ли PID процесса сервера уведомляющего сеанса (предоставленный в сообщении о событии
уведомления) с PID собственного сеанса (доступным из libpq). Если они одинаковы, значит, это вернувшееся событие
уведомления о ваших собственных действиях и его можно игнорировать.
Параметры
канал
Название канала уведомлений, который будет оповещен (любой идентификатор).
полезная_информация
Строка «полезной информации», передаваемая вместе с уведомлением. Она должна задаваться простой текстовой константой. В стандартной конфигурации ее длина должна быть меньше 8000 байт. (Если требуется передать двоичные данные или большой объем информации, лучше поместить их в таблицу базы данных и передать ключ этой записи.)
Примечания
Существует очередь, содержащая уведомления, которые были отправлены, но еще не обработаны всеми
сеансами прослушивания. Если эта очередь переполняется, транзакции, вызывающие NOTIFY, не
смогут выполнить фиксацию. Очередь довольно большая (8 ГБ в стандартной установке), так что ее должно хватать
для почти каждого случая использования. Однако если в сеансе выполняется LISTEN, а затем продолжается
очень длительная транзакция, очередь не очищается. Как только эта очередь заполняется наполовину,
в журнал записываются предупреждения, где указывается, какой сеанс препятствует очистке очереди.
В этом случае следует добиться завершения текущей транзакции в указанном сеансе, чтобы очередь была очищена.
Функция pg_notification_queue_usage возвращает долю очереди, которая в настоящее время занята ожидающими уведомлениями. Дополнительную информацию см. в разделе Расширенные функции SQL.
Транзакция, которая выполнила NOTIFY, не может быть подготовлена к
двухфазной фиксации.
pg_notify
Чтобы отправить уведомление, также можно использовать функцию pg_notify(text, text).
Функция принимает имя канала в качестве первого аргумента, а полезные данные — в качестве второго.
Эта функция намного проще в использовании, чем команда NOTIFY, если нужно работать с изменяемыми именами
каналов и полезными нагрузками.
Примеры
Настройка и выполнение последовательности ожидания/получения уведомления от qsql:
LISTEN virtual;
NOTIFY virtual;
Asynchronous notification "virtual" received from server process with PID 8448.
NOTIFY virtual, 'This is the payload';
Asynchronous notification "virtual" with payload "This is the payload" received
from server process with PID 8448.
LISTEN foo;
SELECT pg_notify('fo' || 'o', 'pay' || 'load');
Asynchronous notification "foo" with payload "payload" received from server
process with PID 14728.
Совместимость
В стандарте SQL нет команды NOTIFY.
См. также
PREPARE
PREPARE — подготовить оператор для исполнения
Синтаксис
PREPARE имя [ ( тип_данных [, ...] ) ] AS оператор
Описание
Команда PREPARE создает подготовленный оператор. Подготовленный оператор —
это объект на стороне сервера, который можно использовать для
оптимизации производительности. При выполнении команды PREPARE
указанный оператор разбирается, анализируется и перезаписывается. При
последующем выполнении команды EXECUTE подготовленный оператор
планируется и исполняется. Это разделение труда предотвращает
повторный синтаксический анализ запроса, при этом позволяя
выбрать наилучший план выполнения в зависимости от определенных значений параметров.
Подготовленные операторы могут принимать параметры: значения, которые
подставляются в оператор при его выполнении. При создании
подготовленного оператора к этим параметрам можно обращаться по порядковому номеру,
используя запись $1, $2 и т. д. При необходимости можно указать соответствующий список
типов данных параметров. Если тип данных параметра не указан или
объявлен как unknown (неизвестный), тип выводится из контекста, в котором произошло
первое обращение к данному параметру (если это возможно). При выполнении оператора
укажите команде EXECUTE фактические значения этих параметров.
Дополнительную информацию об этом см. в разделе EXECUTE.
Подготовленные операторы существуют только в течение текущего сеанса работы с базой данных. По окончании сеанса система забывает подготовленный оператор, поэтому перед повторным использованием его необходимо воссоздать. Это также означает, что один подготовленный оператор не может использоваться одновременно несколькими клиентами базы данных; тем не менее каждый клиент может создать свой собственный подготовленный оператор для использования. Подготовленные операторы можно очистить вручную с помощью команды DEALLOCATE.
Подготовленные операторы потенциально обладают наибольшим преимуществом производительности, когда один сеанс используется для выполнения большого количества однотипных операторов. Разница в производительности будет особенно существенной, если операторы сложны для планирования или перезаписи, например если запрос включает соединение многих таблиц или требует применения нескольких правил. Если оператор относительно прост в планировании и переписывании, но относительно дорог в выполнении, преимущество производительности подготовленных операторов будет менее заметным.
Параметры
имя
Произвольное имя, данное этому конкретному подготовленному оператору. Оно должно быть уникальным в пределах одного сеанса и впоследствии используется для выполнения или освобождения ранее подготовленного оператора.
тип_данных
Тип данных параметра для подготовленного оператора. Если тип данных конкретного параметра не определен или указан как unknown, он будет выведен из контекста, в котором произошло первое обращение к этому параметру. Для обращения к параметрам в самом подготовленном операторе используйте запись $1, $2 и т. д.
оператор
Любой оператор SELECT, INSERT, UPDATE, DELETE или VALUES.
Примечания
Подготовленный оператор может быть выполнен либо с общим планом, либо со специализированным планом. Общий план является одинаковым для всех выполнений, тогда как специализированный создается для конкретного выполнения с использованием значений параметров, заданных в этом вызове. Использование общего плана позволяет избежать накладных расходов на планирование, но в некоторых ситуациях выполнение специализированного плана будет гораздо более эффективным, поскольку планировщик может подстроиться под значения параметров. (Конечно, если подготовленный оператор не имеет параметров, это неактуально и всегда используется общий план.)
По умолчанию (то есть когда plan_cache_mode установлен в auto), сервер автоматически выберет, какой план использовать для подготовленного оператора с параметрами: общий или специализированный. Текущее правило состоит в том, что первые пять исполнений выполняются со специализированными планами, и рассчитывается средняя расчетная стоимость этих планов. Затем создается общий план, и его расчетная стоимость сравнивается со средней стоимостью специализированного плана. Последующие выполнения используют общий план, если его стоимость по сравнению со стоимостью специализированных не настолько велика, чтобы делать повторное перепланирование.
Эту логику можно переопределить, заставляя сервер использовать либо только общие, либо специализированные планы, установив для параметра plan_cache_mode значение force_generic_plan или force_custom_plan соответственно. Этот параметр в первую очередь полезен, если по какой-то причине плохо работает оценка общего плана, так как позволяет выбрать его, даже если его фактическая стоимость намного больше, чем у специализированного плана.
Чтобы узнать план запроса, который QHB выбирает для подготовленного оператора, используйте команду EXPLAIN, например:
EXPLAIN EXECUTE имя(значения_параметров);
Если используется общий план, он будет содержать символы параметров $n, в то время как специализированный план будет иметь подставленные в него фактические значения параметров.
Дополнительную информацию о планировании запросов и статистике, собранной QHB для этой цели, см. в документации по команде ANALYZE.
Хотя основной целью подготовленных операторов является предотвращение повторного разбора и планирования оператора, QHB будет принудительно заново анализировать и планировать выполнение оператора всякий раз, когда используемые в операторе объекты базы данных подвергаются изменениям определения (DDL) с момента предыдущего использования подготовленного оператора. Кроме того, если значение search_path изменяется от одного использования к другому, оператор будет повторно разобран с новым search_path. С этими правилами использование подготовленного оператора по сути почти не отличается от выполнения одного и того же запроса снова и снова, но с преимуществом производительности, если определения объектов не меняются (особенно если оптимальный план из раза в раз остается неизменным). Примером случая, когда различия всё же могут проявиться, служит то, что если оператор обращается к таблице по неполному имени, а затем новая таблица с таким же именем создается в схеме, стоящей в пути search_path раньше, автоматический пересмотр запроса не происходит, так как ни один используемый в операторе объект не изменился. Однако если какое-то другое изменение вызывает повторный анализ, при последующем выполнении запроса будет задействована новая таблица.
Получить список всех доступных в сеансе подготовленных операторов можно, обратившись к системному представлению pg_prepared_statements.
Примеры
Создание подготовленного оператора для команды INSERT, который затем выполняется:
PREPARE fooplan (int, text, bool, numeric) AS
INSERT INTO foo VALUES($1, $2, $3, $4);
EXECUTE fooplan(1, 'Hunter Valley', 't', 200.00);
Создание подготовленного оператора для команды SELECT, который затем выполняется:
PREPARE usrrptplan (int) AS
SELECT * FROM users u, logs l WHERE u.usrid=$1 AND u.usrid=l.usrid
AND l.date = $2;
EXECUTE usrrptplan(1, current_date);
В этом примере тип данных второго параметра не указывается, поэтому он выводится из контекста, в котором используется $2.
Совместимость
Стандарт SQL включает команду PREPARE, но она предназначена только
для использования во встраиваемом SQL. Эта версия команды PREPARE также
использует несколько иной синтаксис.
См. также
PREPARE TRANSACTION
PREPARE TRANSACTION — подготовить текущую транзакцию к двухфазной фиксации
Синтаксис
PREPARE TRANSACTION id_транзакции
Описание
Команда PREPARE TRANSACTION подготавливает текущую транзакцию к двухфазной
фиксации. После выполнения этой команды транзакция лишается связи с
текущим сеансом; вместо этого ее состояние полностью сохраняется на
диске, и она с очень большой вероятностью будет успешно
зафиксирована, даже если сбой базы данных произойдет до запроса
фиксации.
После подготовки транзакцию можно впоследствии зафиксировать или откатить с помощью COMMIT PREPARED или ROLLBACK PREPARED соответственно. Эти команды могут быть выполнены из любого сеанса, а не только из того, в котором эта транзакция создавалась.
С точки зрения сеанса, выполняющего команду, PREPARE TRANSACTION не отличается
от команды ROLLBACK: после ее выполнения нет активной текущей транзакции,
и эффекты подготовленной транзакции больше не видны. (Последствия снова
станут видимыми, если транзакция зафиксирована.)
Если команда PREPARE TRANSACTION по какой-либо причине
завершается неудачно, то она действует как ROLLBACK: текущая транзакция
отменяется.
Параметры
id_транзакции
Произвольный идентификатор, который позже идентифицирует эту транзакцию
для COMMIT PREPARED или ROLLBACK PREPARED. Идентификатор должен
быть записан в виде строковой константы и иметь длину менее 200 байт. Он
не должен совпадать с идентификатором, используемым для любой текущей
подготовленной транзакции.
Примечания
Команда PREPARE TRANSACTION не предназначена для использования в
приложениях или интерактивных сеансах. Ее цель — позволить
внешнему менеджеру транзакций выполнять атомарные глобальные
транзакции, охватывающие несколько баз данных или других транзакционных
ресурсов. Если вы не разрабатываете собственный менеджер транзакций, вероятно,
вам не стоит использовать PREPARE TRANSACTION.
Эта команда должна применяться внутри блока транзакций. Чтобы его начать, используйте команду BEGIN.
В настоящее время команда PREPARE не способна подготавливать транзакцию,
в которой выполнялись какие-либо операции с временными таблицами или временным пространством
имен сеанса, создавались какие-либо курсоры WITH HOLD или выполнялись команды
LISTEN, UNLISTEN или NOTIFY. Эти функции слишком тесно
связаны с текущим сеансом, чтобы быть полезными в транзакции, подлежащей
подготовке.
Если транзакция изменила какие-либо параметры времени выполнения
командой SET (без указания LOCAL), их значения сохраняются
после PREPARE TRANSACTION и не будут затронуты более
поздним выполнением команд COMMIT PREPARED или ROLLBACK PREPARED.
То есть в этом отношении PREPARE TRANSACTION действует скорее
как COMMIT, чем как ROLLBACK.
Все доступные в настоящее время подготовленные транзакции перечислены в системном представлении pg_prepared_xacts.
Внимание
Оставлять транзакции в подготовленном состоянии на длительное время неразумно. Это будет препятствовать способности команды
VACUUMвысвобождать пространство и в крайних случаях может привести к отключению базы данных для предотвращения зацикливания ID транзакций (см. раздел Предотвращение ошибок зацикливания идентификатора транзакции). Также имейте в виду, что транзакция продолжает удерживать все свои блокировки. Предполагаемое использование этой функции заключается в том, что подготовленная транзакция обычно фиксируется или откатывается, как только внешний менеджер транзакций убедится, что другие базы данных также готовы к фиксации.
Если вы не настроили внешний менеджер транзакций для отслеживания подготовленных транзакций и обеспечения их своевременного закрытия, лучше всего отключить функцию подготовки транзакций, установив значение max_prepared_transactions равным нулю. Это предотвратит случайное создание подготовленных транзакций, которые затем могут быть забыты и в конечном итоге вызвать проблемы.
Примеры
Подготовка текущей транзакции для двухфазной фиксации, при этом ей назначается идентификатор foobar:
PREPARE TRANSACTION 'foobar';
Совместимость
Команда PREPARE TRANSACTION является расширением QHB. Она предназначена для
использования внешними системами управления транзакциями, некоторые из
которых включены в стандарты (например, X/Open XA), но сторона SQL этих
систем не стандартизирована.
См. также
COMMIT PREPARED, ROLLBACK PREPARED
REASSIGN OWNED
REASSIGN OWNED — сменить владельца объектов базы данных, принадлежащих роли базы данных
Синтаксис
REASSIGN OWNED BY { старая_роль | CURRENT_USER | SESSION_USER } [, ...]
TO { новая_роль | CURRENT_USER | SESSION_USER }
Описание
Команда REASSIGN OWNED дает системе указание сменить владельца
объектов базы данных, принадлежащих одной из старых_ролей,
на новую роль.
Параметры
старая_роль
Название роли. Права собственности на все объекты в текущей базе данных и на все общие объекты (базы данных, табличные пространства), принадлежащие этой роли, будут переназначены на новую_роль.
новая_роль
Имя роли, которая будет сделана новым владельцем затронутых объектов.
Примечания
Команда REASSIGN OWNED часто используется для подготовки к удалению
одной или нескольких ролей. Поскольку REASSIGN OWNED не влияет
на объекты в других базах данных, обычно необходимо выполнить эту
команду в каждой базе данных, которая содержит объекты, принадлежащие
удаляемой роли.
Для выполнения команды REASSIGN OWNED требуется членство как в
исходной(ых), так и в целевой ролях.
Альтернативой является команда DROP OWNED, которая просто удаляет все объекты базы данных, принадлежащие одной или нескольким ролям.
Команда REASSIGN OWNED не влияет ни на какие права,
предоставленные старым_ролям на объекты, которые им не
принадлежат. Кроме того, она не влияет на права по умолчанию,
созданные с помощью команды ALTER DEFAULT PRIVILEGES. Отозвать эти права можно,
воспользовавшись командой DROP OWNED.
Дополнительную информацию см. в разделе Удаление ролей.
Совместимость
Команда REASSIGN OWNED является расширением QHB.
См. также
DROP OWNED, DROP ROLE, ALTER DATABASE
REFRESH MATERIALIZED VIEW
REFRESH MATERIALIZED VIEW — заменить содержимое материализованного представления
Синтаксис
REFRESH MATERIALIZED VIEW [ CONCURRENTLY ] имя
[ WITH [ NO ] DATA ]
Описание
Команда REFRESH MATERIALIZED VIEW полностью заменяет
содержимое материализованного представления. Для выполнения этой команды
нужно быть владельцем соответствующего материализованного представления. Старое
содержимое удаляется. Если указывается WITH DATA (или по умолчанию), то
для предоставления новых данных выполняется нижележащий запрос, а
материализованное представление остается в состоянии сканирования. Если
указывается WITH NO DATA, то новые данные не выдаются, а
материализованное представление остается в несканируемом состоянии.
Параметр WITH NO DATA нельзя задавать вместе с параметром CONCURRENTLY.
Параметры
CONCURRENTLY
Обновить материализованное представление, не блокируя параллельные выборки из него. Без этого параметра обновление, влияющее на значительное количество строк, в большинстве случаев будет использовать меньше ресурсов и завершаться быстрее, но может блокировать другие соединения, которые пытаются читать из материализованного представления. Этот режим может быть быстрее, если затрагивается небольшое количество строк.
Данный параметр разрешен только в том случае, если в материализованном представлении имеется хотя бы один индекс UNIQUE, который использует только имена столбцов и включает все строки, то есть он не должен быть индексом выражения или включать предложение WHERE.
Этот параметр нельзя использовать, если материализованное представление еще не заполнено.
Даже с этим параметром в один момент времени допускается только одно обновление (REFRESH) материализованного представления.
имя
Имя материализованного представления, подлежащего обновлению (может быть дополнено схемой).
Примечания
Хотя индекс по умолчанию для будущих операций CLUSTER сохраняется, команда
REFRESH MATERIALIZED VIEW не упорядочивает по нему генерируемые строки. Если
вы хотите, чтобы данные были упорядочены при создании, в определяющем запросе следует
использовать предложение ORDER BY.
Примеры
Эта команда заменит содержимое материализованного представления order_summary, используя запрос из определения материализованного представления, и оставит его в сканируемом состоянии:
REFRESH MATERIALIZED VIEW order_summary;
Эта команда освободит пространство, связанное с материализованным представлением annual_statistics_basis, и оставит это представление в несканируемом состоянии:
REFRESH MATERIALIZED VIEW annual_statistics_basis WITH NO DATA;
Совместимость
Команда REFRESH MATERIALIZED VIEW является расширением QHB.
См. также
CREATE MATERIALIZED VIEW, ALTER MATERIALIZED VIEW, DROP MATERIALIZED VIEW
REINDEX
REINDEX — перестроить индексы
Синтаксис
RREINDEX [ ( параметр [, ...] ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } [ CONCURRENTLY ] имя
Где параметр может быть:
VERBOSE
Описание
Команда REINDEX перестраивает индекс, обрабатывая данные, хранящиеся в
таблице индекса, и заменяя его старую копию. Существует несколько
сценариев, в которых можно использовать команду REINDEX:
Параметры
INDEX
Перестраивает указанный индекс.
TABLE
Перестраивает все индексы указанной таблицы. Если таблица имеет дополнительную таблицу «TOAST», то она также будет переиндексирована.
SCHEMA
Перестраивает все индексы указанной схемы. Если таблица этой схемы
имеет дополнительную таблицу «TOAST», то она также будет переиндексирована. Также
обрабатываются индексы в общих системных каталогах. Эта форма
REINDEX не может быть выполнена внутри блока транзакций.
DATABASE
Перестраивает все индексы в текущей базе данных. Также обрабатываются
индексы в общих системных каталогах. Эта форма REINDEX не
может быть выполнена внутри блока транзакций.
SYSTEM
Перестраивает все индексы в системных каталогах в текущей базе данных.
Индексы в общих системных каталогах также будут обработаны. Индексы в пользовательских
таблицах не обрабатываются. Эта форма REINDEX не может быть
выполнена внутри блока транзакций.
имя
Имя конкретного индекса, таблицы или базы данных, подлежащих переиндексации.
Имена индексов и таблиц могут быть дополнены схемой. В
настоящее время REINDEX DATABASE и REINDEX SYSTEM могут переиндексировать
только текущую базу данных, поэтому параметр должен соответствовать имени
текущей базы данных.
CONCURRENTLY
Если используется этот параметр, QHB будет перестраивать индекс, не устанавливая никаких блокировок, которые предотвращают параллельные добавления, изменения или удаления в таблице; тогда как стандартное перестроение индекса блокирует запись (но не чтение) в таблице вплоть до своего завершения. Существует несколько предупреждений, которые следует учитывать при использовании этого параметра, — см. подраздел Неблокирующее перестроение индексов ниже.
Для временных таблиц REINDEX всегда выполняется в неблокирующем режиме, поскольку никакие другие сеансы не могут их использовать, а этот способ переиндексации менее затратен.
VERBOSE
Выводит отчет о ходе работы по мере переиндексации каждого индекса.
Примечания
При подозрении на повреждение индекса в пользовательской таблице
можно просто перестроить этот индекс или все индексы в таблице,
используя REINDEX INDEX или REINDEX TABLE.
Все становится сложнее, если нужно восстановить поврежденный индекс в системной таблице. В этом случае важно, чтобы система сама не использовала подозрительные индексы. (В действительности при таком сценарии можно обнаружить, что серверные процессы отказывают при запуске из-за зависимости от поврежденных индексов.) Для безопасного восстановления сервер должен быть запущен с параметром -P, который отключает использование индексов при поиске в системных каталогах.
Один из способов сделать это — выключить сервер и запустить
QHB в однопользовательском режиме с параметром -P
в командной строке. Затем можно выполнить REINDEX DATABASE,
REINDEX SYSTEM, REINDEX TABLE или REINDEX INDEX, в зависимости
от того, что вы хотите восстановить. Если сомневаетесь, используйте
команду REINDEX SYSTEM, чтобы перестроить все системные индексы в базе данных. После этого
завершите однопользовательский сеанс сервера и перезапустите сервер в обычном режиме.
Дополнительную информацию о том, как работать с
сервером в однопользовательском интерфейсе, см. в разделе
Процесс qhb.
Как вариант, можно запустить обычный экземпляр сервера, но добавить в параметры командной строки -P. В разных клиентах это может делаться по-разному, но во всех клиентах на базе libpq можно установить для переменной окружения PGOPTIONS значение -P до запуска клиента. Обратите внимание, что хотя этот метод не требует блокировки других клиентов, всё же было бы разумно запретить другим пользователям подключаться к поврежденной базе данных до завершения восстановления.
Действие REINDEX подобно удалению и повторному созданию индекса в том, что
содержимое индекса перестраивается с нуля. Тем не менее,
блокировки при этом устанавливаются другие. Команда REINDEX блокирует операции
записи, но не чтение из родительской таблицы индекса. Она также устанавливает
исключительную блокировку на обрабатываемый индекс, которая
блокирует чтение, задействующее этот индекс. DROP INDEX, напротив,
мгновенно устанавливает исключительную блокировку на
родительской таблице, блокируя как запись, так и чтение. Последующая
CREATE INDEX блокирует запись, но не чтение; поскольку индекс
отсутствует, при чтении не будет попыток обращения к нему, а это
значит, что не будет никакой блокировки, но чтение может непроизвольно превратиться в
дорогостоящее последовательное сканирование.
Для перестраивания одного индекса или таблицы нужно быть
владельцем этого индекса или таблицы. Для переиндексирования схемы или
базы данных нужно быть владельцем этой схемы или базы данных.
Обратите внимание, что из-за этого в ряде случаев не только суперпользователи могут перестраивать
индексы таблиц, принадлежащих другим пользователям. Однако из этих правил есть
исключение: когда команду REINDEX DATABASE, REINDEX SCHEMA или REINDEX SYSTEM
выполняет не суперпользователь, индексы общих каталогов будут пропущены,
если только пользователь не владеет каталогом (как правило, это не так).
Конечно, суперпользователи всегда могут переиндексировать всё без ограничений.
Переиндексирование партиционированных таблиц или партиционированных индексов не поддерживается. Вместо этого каждую партицию можно переиндексировать отдельно.
Неблокирующее перестроение индексов
Перестроение индекса может помешать регулярной работе базы данных. Обычно QHB блокирует на запись таблицу, индекс которой перестраивается, и выполняет всю операцию перестройки индекса за одно сканирование таблицы. Другие транзакции по-прежнему могут читать таблицу, но при попытке добавления, изменения или удаления строк в таблице они будут блокироваться до завершения перестроения индекса. Это может иметь серьезные последствия, если система является производственной базой данных. Индексирование очень больших таблиц может занять много часов, и даже у таблиц меньшего размера перестройка индекса может заблокировать запись в таблицы на неприемлемо долгий для производственной системы период.
QHB поддерживает перестроение индексов с минимальной блокировкой
записи. Этот режим вызывается путем указания CONCURRENTLY
команды REINDEX. При использовании этого параметра QHB должна
выполнить два сканирования таблицы для каждого индекса, который
необходимо перестроить, и дождаться завершения всех существующих
транзакций, которые потенциально могут использовать индекс. Этот метод
требует, в целом, большего количества действий, чем стандартное перестроение индекса, и
весь процесс занимает значительно больше времени, поскольку нужно
дождаться незавершенных транзакций, которые могут изменить индекс.
Однако поскольку он позволяет продолжить обычные операции во время
перестроения индекса, этот метод полезен для перестроения индексов в
производственной среде. Разумеется, дополнительная загрузка процессора, памяти и
ввода-вывода, продиктованная перестроением индекса, может замедлить другие
операции.
При неблокирующем переиндексировании выполняются следующие шаги. Каждый шаг выполняется в отдельной транзакции. Если необходимо перестроить несколько индексов, то каждый шаг выполняется для всех индексов, прежде чем перейти к следующему шагу.
Если при перестроении индексов возникает проблема, например нарушение
уникальности в уникальном индексе, команда REINDEX завершится ошибкой,
но оставит после себя «нерабочий» новый индекс в дополнение к уже существующему.
Этот индекс будет игнорироваться запросами, поскольку может
быть неполным; однако он всё равно будет обновляться при изменении данных,
что повлечет дополнительные издержки. Команда qsql \d сообщит о таком индексе как об
INVALID:
qhb=# \d tab
Table "public.tab"
Column | Type | Modifiers
--------+---------+-----------
col | integer |
Indexes:
"idx" btree (col)
"idx_ccnew" btree (col) INVALID
Если индекс, отмеченный INVALID, имеет имя с окончанием ccnew, то он соответствует временному индексу,
созданному во время совмещенной операции, и рекомендуемый метод восстановления состоит в удалении такого индекса
при помощи команды DROP INDEX и повторной попытке выполнить REINDEX CONCURRENTLY.
Если нерабочий индекс имеет окончание ccold, то он соответствует исходному индексу, который удалить нельзя;
рекомендуемый метод восстановления состоит в простом удалении нерабочего индекса,
раз уж перестроение индекса прошло успешно.
Обычные построения индексов позволяют другим построениям
индексов в одной и той же таблице выполняться одновременно, но неблокирующее
построение индексов в таблице может выполняться только одно за раз.
В обоих случаях никакие другие изменения схемы
таблицы в это время не разрешаются. Другое отличие состоит в том, что
обычные команды REINDEX TABLE или REINDEX INDEX могут выполняться в
блоке транзакций, а REINDEX CONCURRENTLY — нет.
REINDEX SYSTEM не поддерживает указание CONCURRENTLY, так как
системные каталоги нельзя переиндексировать в неблокирующем режиме.
Более того, индексы, связанные с ограничениями-исключениями, тоже нельзя переиндексировать в неблокирующем режиме. Если явно указать имя такого индекса в этой команде, будет выдана ошибка. Если таблица или база данных с с такими индексами переиндексируются в неблокирующем режиме, эти индексы будут пропущены. (Можно переиндексировать такие индексы без параметра CONCURRENTLY.)
Примеры
Перестроение одного индекса:
REINDEX INDEX my_index;
Перестроение всех индексов таблицы my_table:
REINDEX TABLE my_table;
Перестроение всех индексов в определенной базе данных исходя из предположения, что целостность системных индексов под сомнением:
$ export PGOPTIONS="-P"
$ psql broken_db
...
broken_db=> REINDEX DATABASE broken_db;
broken_db=> \q
Перестроение индексов таблицы без блокировки операций чтения и записи в затрагиваемых процессом отношениях:
REINDEX TABLE CONCURRENTLY my_broken_table;
Совместимость
В стандарте SQL нет команды REINDEX.
См. также
CREATE INDEX, DROP INDEX, reindexdb
RELEASE SAVEPOINT
RELEASE SAVEPOINT — уничтожить ранее определенную точку сохранения
Синтаксис
RELEASE [ SAVEPOINT ] имя_точки_сохранения
Описание
Команда RELEASE SAVEPOINT уничтожает точку сохранения, ранее
определенную в текущей транзакции.
Уничтожение точки сохранения делает ее неприменимой в качестве точки отката, но никаких других видимых для пользователя проявлений эта команда не имеет. Она не отменяет действие команд, выполненных после установки точки сохранения. (Для этого предназначена команда ROLLBACK TO SAVEPOINT.) Уничтожение ставшей ненужной точки сохранения позволяет системе восстановить некоторые ресурсы до завершения транзакции.
RELEASE SAVEPOINT также уничтожает все точки сохранения, которые
были установлены после указанной.
Параметры
имя_точки_сохранения
Имя точки сохранения, подлежащей уничтожению.
Примечания
Указание имени точки сохранения, которая ранее не была определена, является ошибкой.
Невозможно уничтожить точку сохранения, когда транзакция находится в прерванном состоянии.
Если несколько точек сохранения имеют одинаковое имя, уничтожается только та, которая была определена последней.
Примеры
Установка и последующее уничтожение точки сохранения:
BEGIN;
INSERT INTO table1 VALUES (3);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (4);
RELEASE SAVEPOINT my_savepoint;
COMMIT;
Данная транзакция добавит значения 3 и 4.
Совместимость
Команда RELEASE SAVEPOINT соответствует стандарту SQL. Стандарт указывает, что
ключевое слово SAVEPOINT является обязательным, но QHB
позволяет его опустить.
См. также
BEGIN, COMMIT, ROLLBACK, ROLLBACK TO SAVEPOINT, SAVEPOINT
RESET
RESET — восстановить значение параметра времени выполнения до значения по умолчанию
Синтаксис
RESET параметр_конфигурации
RESET ALL
Описание
Команда RESET восстанавливает параметры времени выполнения до их значений по
умолчанию. RESET — это альтернативное написание команды
SET параметр_конфигурации TO DEFAULT
Дополнительную информацию см. в разделе SET.
Значение по умолчанию определяется как значение, которое имел бы
параметр, если бы для него в текущем сеансе не выполнялась команда SET.
Фактическим источником этого значения может быть
скомпилированное значение по умолчанию, файл конфигурации, параметры
командной строки или параметры по умолчанию для каждой базы данных или
для каждого пользователя. Это немного отличается от определения его как
«значение, которое параметр имел при запуске сеанса», потому что если
значение пришло из файла конфигурации, оно будет сброшено к тому, что
указано в файле конфигурации в настоящий момент. См. дополнительную информацию
в главе Конфигурация сервера.
Транзакционное поведение команды RESET совпадает с SET: ее действия
будут отменены откатом транзакции.
Параметры
параметр_конфигурации
Имя настраиваемого параметра времени выполнения. Доступные параметры описаны в главе Конфигурация сервера и в разделе SET.
ALL
Сбрасывает все настраиваемые параметры времени выполнения до значений по умолчанию.
Примеры
Установить переменную конфигурации timezone в значение по умолчанию:
RESET timezone;
Совместимость
Команда RESET является расширением QHB.
См. также
REVOKE
REVOKE — отозвать права доступа
Синтаксис
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[, ...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] имя_таблицы [, ...]
| ALL TABLES IN SCHEMA имя_схемы [, ...] }
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | REFERENCES } ( имя_столбца [, ...] )
[, ...] | ALL [ PRIVILEGES ] ( имя_столбца [, ...] ) }
ON [ TABLE ] имя_таблицы [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { USAGE | SELECT | UPDATE }
[, ...] | ALL [ PRIVILEGES ] }
ON { SEQUENCE имя_последовательности [, ...]
| ALL SEQUENCES IN SCHEMA имя_схемы [, ...] }
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | CONNECT | TEMPORARY | TEMP } [, ...] | ALL [ PRIVILEGES ] }
ON DATABASE имя_базы_данных [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON DOMAIN имя_домена [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON FOREIGN DATA WRAPPER имя_обертки_сторонних_данных [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON FOREIGN SERVER имя_сервера [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON { { FUNCTION | PROCEDURE | ROUTINE } имя_функции [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] [, ...]
| ALL { FUNCTIONS | PROCEDURES | ROUTINES } IN SCHEMA имя_схемы [, ...] }
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE имя_языка [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | UPDATE } [, ...] | ALL [ PRIVILEGES ] }
ON LARGE OBJECT oid_БО [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | USAGE } [, ...] | ALL [ PRIVILEGES ] }
ON SCHEMA имя_схемы [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE имя_табличного_пространства [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON TYPE имя_типа [, ...]
FROM указание_роли [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ ADMIN OPTION FOR ]
имя_роли [, ...] FROM указание_роли [, ...]
[ GRANTED BY указание_роли ]
[ CASCADE | RESTRICT ]
Где указание_роли:
[ GROUP ] имя_роли
| PUBLIC
| CURRENT_USER
| SESSION_USER
Описание
Команда REVOKE отменяет ранее предоставленные права доступа для
одной или нескольких ролей. Ключевое слово PUBLIC обозначает неявно
определенную группу всех ролей.
Определение типов прав см. в описании команды GRANT.
Обратите внимание, что любая конкретная роль будет иметь сумму прав, предоставленных непосредственно ей, прав, предоставленных любой роли, членом которой она в настоящее время является, и прав, предоставленных группе PUBLIC. Таким образом, например, удаление у роли PUBLIC права SELECT не обязательно означает, что все роли потеряют права SELECT для объекта: те, кто получил право непосредственно или через другую роль, всё равно будут иметь право SELECT. Аналогично удаление у пользователя права SELECT может не повлиять на его возможность пользоваться этим правом, если оно выдано группе PUBLIC или другой роли, в которую включен пользователь.
Если указано GRANT OPTION FOR, отзывается только право передачи права, а не само право. В противном случае будут отменены и право, и возможность передачи.
Если пользователь имеет право с правом передачи и предоставил право
другим пользователям, то такие права называются зависимыми.
Если при отмене у первого пользователя самого права или права его передачи
указано CASCADE, то зависимые права (если таковые существуют) тоже
отменяются; в противном случае операция завершается
ошибкой. Это рекурсивное аннулирование прав влияет только на
права, предоставленные через цепочку пользователей,
которая отслеживается до пользователя, являющегося субъектом команды REVOKE.
Таким образом, пользователи могут в итоге сохранить это право, если оно
было также получено через других пользователей.
При отмене прав на таблицу соответствующие права для столбца (если таковые имеются) также автоматически отменяются для каждого столбца таблицы. С другой стороны, если роли были предоставлены права на таблицу, то отзыв тех же прав для отдельных столбцов не будет иметь никакого эффекта.
При отзыве членства в роли указание GRANT OPTION меняется на ADMIN OPTION, но поведение очень похоже. Эта форма команды также принимает указание GRANTED BY, но в настоящее время оно игнорируется (за исключением проверки указанной в нем роли). Также обратите внимание, что эта форма команды не принимает избыточное слово GROUP в указании_роли.
Примечания
Пользователь может отозвать только те права, которые были предоставлены непосредственно им. Если, например, пользователь A предоставил право с правом передачи пользователю B, а пользователь B в свою очередь предоставил его пользователю C, то пользователь A не может напрямую отозвать право у пользователя C. Вместо этого пользователь A может отозвать право передачи у пользователя B и применить параметр CASCADE, чтобы право в свою очередь было отозвано у пользователя C. Другой пример: если и A, и B предоставили одно и то же право C, A может отозвать только то право, которое предоставил он сам, но не В, поэтому в итоге C всё равно будет иметь это право.
Если команду REVOKE пытается выполнить не владелец заданного объекта,
она завершится ошибкой, если у пользователя нет никаких прав
доступа к этому объекту. Если же у пользователя есть некоторые права,
команда будет выполняться, но отменит только те права, которые пользователь
может передавать. Формы REVOKE ALL PRIVILEGES будут выдавать
предупреждающее сообщение, если у пользователя нет никаких прав на передачу, тогда
как другие формы выдадут предупреждение, если пользователь не имеет права
распоряжаться именно теми правами, которые указаны в команде. (В принципе, эти утверждения
применимы и к владельцу объекта, но поскольку всегда считается, что ему
разрешено распоряжаться всем правами, такие ситуации невозможны.)
Если суперпользователь запускает команду GRANT или REVOKE,
она выполняется так, как если бы была запущена владельцем
заданного объекта. Поскольку все права в конечном счете исходят
от владельца объекта (возможно, косвенно через цепочки или через право
распоряжением правом), суперпользователь может отозвать все права, но это
может потребовать использования CASCADE, как уже говорилось выше.
Команда REVOKE также может быть выполнена ролью, которая не является
владельцем заданного объекта, но является членом роли, которой
принадлежит объект, или членом роли, обладающей правами доступа
WITH GRANT OPTION для объекта. В этом случае команда выполняется так, как если бы
ее задала содержащая роль, которая фактически владеет объектом
или имеет права доступа WITH GRANT OPTION. Например, если таблица t1
принадлежит роли g1, членом которой является роль u1, то u1 может
отзывать права на t1, которые записаны как предоставленные
ролью g1. Это могут быть как права, данные ролью u1, так и предоставленные
другими членами роли g1.
Если роль, выполняющая команду REVOKE, получила права косвенно через
несколько путей членства в ролях, то не определено, какая именно роль
будет выбрана для выполнения команды. В таких случаях
рекомендуется использовать команду SET ROLE, чтобы переключиться на конкретную
роль, от имени которой вы хотите выполнить команду REVOKE. Невыполнение этого требования
может привести к отмене совсем не тех прав, которые были запланированы,
или вообще ничего не отменить.
Дополнительную информацию о конкретных типах прав, а также о том, как проверять права объектов, см. в разделе Права.
Примеры
Удаление у группы public права добавлять данные в таблицу films:
REVOKE INSERT ON films FROM PUBLIC;
Удаление у пользователя manuel всех прав для представления kinds:
REVOKE ALL PRIVILEGES ON kinds FROM manuel;
Обратите внимание, что на самом деле это означает «Удаление всех прав, которые были выданы мной».
Исключение из членов роли admins пользователя joe:
REVOKE admins FROM joe;
Совместимость
Примечания по совместимости команды GRANT аналогично применимы и для команды
REVOKE. В соответствии со стандартом требуется ключевое слово RESTRICT или
CASCADE, но QHB предполагает RESTRICT по умолчанию.
См. также
GRANT, ALTER DEFAULT PRIVILEGES
ROLLBACK
ROLLBACK — прервать текущую транзакцию
Синтаксис
ROLLBACK [ WORK | TRANSACTION ] [ AND [ NO ] CHAIN ]
Описание
Команда ROLLBACK откатывает текущую транзакцию и приводит к отмене всех
изменений, произведенных этой транзакцией.
Параметры
WORK
TRANSACTION
Необязательные ключевые слова. Не имеют никакого эффекта.
AND CHAIN
Если указывается AND CHAIN, то сразу после окончания текущей транзакции начинается новая с теми же характеристиками (см. раздел SET TRANSACTION), что и только что завершенная. В противном случае новая транзакция не начинается.
Примечания
Для успешного завершения и фиксации транзакции используйте команду COMMIT.
При выполнении ROLLBACK вне блока транзакций будет выдано предупреждение
и больше ничего не произойдет. Однако выполнение ROLLBACK AND CHAIN
вне блока транзакции вызывает ошибку.
Примеры
Отмена всех изменений:
ROLLBACK;
Совместимость
Команда ROLLBACK соответствует стандарту SQL. Форма
ROLLBACK TRANSACTION является расширением QHB.
См. также
BEGIN, COMMIT, ROLLBACK TO SAVEPOINT
ROLLBACK PREPARED
ROLLBACK PREPARED — отменить транзакцию, которая ранее была подготовлена для двухфазной фиксации
Синтаксис
ROLLBACK PREPARED id_транзакции
Описание
Команда ROLLBACK PREPARED откатывает транзакцию, которая находится в
подготовленном состоянии.
Параметры
id_транзакции
Идентификатор транзакции, которую нужно откатить.
Примечания
Чтобы откатить подготовленную транзакцию, нужно быть тем же пользователем, который выполнял транзакцию изначально, либо суперпользователем. Но при этом не обязательно работать в том же сеансе, где выполнялась транзакция.
Эта команда не может быть выполнена внутри блока транзакций. Подготовленная транзакция откатывается немедленно.
Все доступные в настоящее время подготовленные транзакции перечислены в системном представлении pg_prepared_xacts.
Примеры
Откат транзакции, имеющей идентификатор foobar:
ROLLBACK PREPARED 'foobar';
Совместимость
Команда ROLLBACK PREPARED является расширением QHB. Она предназначена
для использования внешними системами управления транзакциями, некоторые
из которых охватываются стандартами (например, X/Open XA), но сторона SQL
этих систем не стандартизирована.
См. также
PREPARE TRANSACTION, COMMIT PREPARED
ROLLBACK TO SAVEPOINT
ROLLBACK TO SAVEPOINT — откатить к точке сохранения
Синтаксис
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] имя_точки_сохранения
Описание
Откат всех команд, выполненных после установки точки сохранения. Точка сохранения остается действительной, и при необходимости позже можно снова к ней откатиться.
Команда ROLLBACK TO SAVEPOINT неявно уничтожает все точки сохранения,
которые были установлены после указанной.
Параметры
имя_точки_сохранения
Точка сохранения, к которой нужно откатиться.
Примечания
Чтобы уничтожить точку сохранения, не отменяя действия команд, выполненных после ее установки, используйте команду RELEASE SAVEPOINT.
Указание имени точки сохранения, которое не было установлено, является ошибкой.
Курсоры имеют несколько нетранзакционное поведение по отношению к точкам
сохранения. Любой курсор, открытый внутри точки сохранения, будет закрыт
при ее откате. Если команда FETCH или MOVE перемещает ранее открытый курсор
внутри точки сохранения, которая затем откатывается назад, то этот курсор
остается в том положении, в котором оказался после выполнения FETCH
(т. е. движение курсора, вызванное FETCH, не откатывается).
Также при откате не отменяется и закрытие курсора. Однако другие побочные эффекты,
вызванные запросом курсора (например, побочные действия вызываемых запросом
изменчивых функций) отменяются, если они происходят после точки сохранения,
к которой затем происходит откат. Курсор, выполнение которого
приводит к прерыванию транзакции, переводится в нерабочее состояние,
поэтому, хотя транзакцию можно восстановить с помощью
ROLLBACK TO SAVEPOINT, такой курсор больше использовать нельзя.
Примеры
Отмена действия команд, выполненных после установки точки сохранения my_savepoint:
ROLLBACK TO SAVEPOINT my_savepoint;
Откат к точке сохранения не отражается на положении курсора:
BEGIN;
DECLARE foo CURSOR FOR SELECT 1 UNION SELECT 2;
SAVEPOINT foo;
FETCH 1 FROM foo;
?column?
----------
1
ROLLBACK TO SAVEPOINT foo;
FETCH 1 FROM foo;
?column?
----------
2
COMMIT;
Совместимость
Стандарт SQL указывает, что ключевое слово SAVEPOINT является
обязательным, но QHB и Oracle позволяют его опустить. SQL
позволяет в качестве избыточного слова после ROLLBACK только WORK,
но не TRANSACTION. Кроме того, в SQL есть необязательное предложение
AND [ NO ] CHAIN, которое в настоящее время не поддерживается QHB.
В остальном эта команда соответствует стандарту SQL.
Смотрите также
BEGIN, COMMIT, RELEASE SAVEPOINT, ROLLBACK, SAVEPOINT
SAVEPOINT
SAVEPOINT — определить новую точку сохранения в текущей транзакции
Синтаксис
SAVEPOINT имя_точки_сохранения
Описание
Команда SAVEPOINT устанавливает новую точку сохранения в текущей транзакции.
Точка сохранения — это специальная метка внутри транзакции, которая позволяет откатить действие всех команд, выполненных после того, как она была установлена, восстанавливая транзакцию до того состояния, каким оно было на момент установки этой точки.
Параметры
имя_точки_сохранения
Имя, присваиваемое новой точке сохранения.
Примечания
Для отката к точке сохранения используйте команду ROLLBACK TO SAVEPOINT. Для уничтожения точки сохранения с сохранением изменений, произведенных командами после того, как она была установлена, используйте RELEASE SAVEPOINT.
Точки сохранения можно установить только внутри блока транзакции. В транзакции может быть определено несколько точек сохранения.
Примеры
Установка точки сохранения с последующей отменой действий всех команд, выполненных после ее создания:
BEGIN;
INSERT INTO table1 VALUES (1);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (2);
ROLLBACK TO SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (3);
COMMIT;
Вышеуказанная транзакция добавит в таблицу значения 1 и 3, но не 2.
Установка и последующее уничтожение точки сохранения:
BEGIN;
INSERT INTO table1 VALUES (3);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (4);
RELEASE SAVEPOINT my_savepoint;
COMMIT;
Данная транзакция добавит значения 3 и 4.
Совместимость
Стандарт SQL требует, чтобы точка сохранения уничтожалась автоматически при
установке другой точки сохранения с тем же именем. В QHB
сохраняется и старая точка сохранения, хотя при откате и освобождении
будет использоваться только самая последняя точка.
(Освобождение новой точки сохранения с помощью RELEASE SAVEPOINT
приведет к тому, что старая точка сохранения снова станет доступной для
команд ROLLBACK TO SAVEPOINT и RELEASE SAVEPOINT.) В остальном команда
SAVEPOINT полностью соответствует стандарту.
См. также
BEGIN, COMMIT, RELEASE SAVEPOINT, ROLLBACK, ROLLBACK TO SAVEPOINT
SECURITY LABEL
SECURITY LABEL — определить или изменить метку безопасности, примененную к объекту
Синтаксис
SECURITY LABEL [ FOR провайдер ] ON
{
TABLE имя_объекта |
COLUMN имя_таблицы.имя_столбца |
AGGREGATE имя_агрегатной_функции ( сигнатура_агрегатной_функции ) |
DATABASE имя_объекта |
DOMAIN имя_объекта |
EVENT TRIGGER имя_объекта |
FOREIGN TABLE имя_объекта
FUNCTION имя_функции [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
LARGE OBJECT oid_большого_объекта |
MATERIALIZED VIEW имя_объекта |
[ PROCEDURAL ] LANGUAGE имя_объекта |
PROCEDURE имя_процедуры [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
PUBLICATION имя_объекта |
ROLE имя_объекта |
ROUTINE имя_подпрограммы [ ( [ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [, ...] ] ) ] |
SCHEMA имя_объекта |
SEQUENCE имя_объекта |
SUBSCRIPTION имя_объекта |
TABLESPACE имя_объекта |
TYPE имя_объекта |
VIEW имя_объекта
} IS 'метка'
Где сигнатура_агрегатной_функции это:
* |
[ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] |
[ [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ] ] ORDER BY [ режим_аргумента ] [ имя_аргумента ] тип_аргумента [ , ... ]
Описание
Команда SECURITY LABEL применяет метку безопасности к объекту базы
данных. С объектом базы данных можно связать произвольное количество
меток безопасности, по одной на каждого провайдера. Провайдеры меток — это
загружаемые модули, которые регистрируются с помощью функции
register_label_provider.
Примечание
register_label_provider не является SQL-функцией; она может быть вызвана только из кода C, загруженного в серверную часть.
Провайдер меток определяет, является ли данная метка допустимой и разрешено ли присвоить эту метку данному объекту. Смысл заданной метки тоже определяет провайдер меток. QHB не накладывает никаких ограничений на то, как провайдер меток должен интерпретировать метки безопасности; он просто предоставляет механизм их хранения. На практике это средство предназначено для обеспечения интеграции с системами обязательного контроля доступа на основе меток (MAC), такими как SELinux. Такие системы принимают все решения по управлению доступом на основе меток объектов, а не на традиционных концепциях избирательного управления доступом (discretionary access control, DAC), таких как пользователи и группы.
Параметры
имя_объекта
имя_таблицы.имя_столбца
имя_агрегатной_функции
имя_функции
имя_процедуры
имя_подпрограммы
Имя маркируемого объекта. Имена таблиц, агрегатных и обычных функций, доменов, сторонних таблиц, процедур, подпрограмм, последовательностей, типов и представлений могут быть дополнены схемой.
провайдер
Имя провайдера, с которым должна быть связана эта метка. Указанный провайдер должен быть загружен и быть готов к предложенной операции маркировки. Если загружен только один провайдер, имя провайдера может быть опущено для краткости.
режим_аргумента
Режим аргумента функции, процедуры или агрегатной функции: IN, OUT, INOUT
или VARIADIC. Если этот параметр опущен, значение по умолчанию равно IN.
Обратите внимание, что SECURITY LABEL на самом деле не
обращает никакого внимания на аргументы OUT, так как для определения
идентичности функции необходимы только входные аргументы. Так что
достаточно перечислить аргументы IN, INOUT и VARIADIC.
имя_аргумента
Имя аргумента функции, процедуры или агрегатной функции. Обратите внимание, что
SECURITY LABEL на самом деле не обращает никакого внимания на имена
аргументов, поскольку для определения идентификатора функции необходимы
только типы данных аргументов.
тип_аргумента
Тип данных аргумента функции, процедуры или агрегата.
oid_большого_объекта
OID большого объекта.
PROCEDURAL
Это слово не несет смысловой нагрузки.
метка
Новая метка безопасности, записанная как строковая константа, либо NULL чтобы удалить метку безопасности.
Примеры
Следующий пример показывает, как можно изменить метку безопасности для таблицы.
SECURITY LABEL FOR selinux ON TABLE mytable IS 'system_u:object_r:sepgsql_table_t:s0';
Совместимость
В стандарте SQL нет команды SECURITY LABEL.
SELECT INTO
SELECT INTO — определить новую таблицу из результатов запроса
Синтаксис
[ WITH [ RECURSIVE ] запрос_WITH [, ...] ]
SELECT [ ALL | DISTINCT [ ON ( выражение [, ...] ) ] ]
* | выражение [ [ AS ] имя_результата ] [, ...]
INTO [ TEMPORARY | TEMP | UNLOGGED ] [ TABLE ] новая_таблица
[ FROM элемент_FROM [, ...] ]
[ WHERE условие ]
[ GROUP BY выражение [, ...] ]
[ HAVING условие [, ...] ]
[ WINDOW имя_окна AS ( определение_окна ) [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select ]
[ ORDER BY выражение [ ASC | DESC | USING оператор ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ LIMIT { число | ALL } ]
[ OFFSET начало [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ число ] { ROW | ROWS } ONLY ]
[ FOR { UPDATE | SHARE } [ OF имя_таблицы [, ...] ] [ NOWAIT ] [...] ]
Описание
Команда SELECT INTO создает новую таблицу и заполняет ее данными,
вычисленными с помощью запроса. Данные не возвращаются клиенту, как это
происходит с обычным SELECT. Столбцы новой таблицы имеют имена и
типы данных, связанные с выходными столбцами SELECT.
Параметры
TEMPORARY или TEMP
Если этот параметр указан, таблица создается как временная таблица. Дополнительную информацию см. в разделе CREATE TABLE.
UNLOGGED
Если этот параметр указан, таблица создается как нежурналируемая таблица. Дополнительную информацию см. в разделе CREATE TABLE.
новая_таблица
Имя создаваемой таблицы (может быть дополнено схемой).
Все остальные параметры подробно описаны в разделе SELECT.
Примечания
Команда SELECT INTO функционально аналогична команде CREATE TABLE AS. Однако
рекомендуется использовать CREATE TABLE AS, так как форма SELECT INTO
в ECPG или PL/pgSQL не поддерживается, поскольку они интерпретируют
предложение INTO по-своему. Кроме того, CREATE TABLE AS, предлагает
больший набор функций, чем SELECT INTO.
В отличие от CREATE TABLE AS, команда SELECT INTO не позволяет указывать некоторые
свойства, например, метод доступа к таблице с помощью USING метод или
табличное пространство таблицы с помощью TABLESPACE имя_табличного_пространства.
Поэтому при возникновении такой необходимости лучше использовать команду CREATE TABLE AS.
Таким образом, для новой таблицы выбирается метод доступа к таблице по
умолчанию. Дополнительную информацию см. в разделе
default_table_access_method.
Примеры
Создание таблицы films_recent, содержащей только последние записи из таблицы films:
SELECT * INTO films_recent FROM films WHERE date_prod >= '2002-01-01';
Совместимость
Стандарт SQL применяет команду SELECT INTO для передачи скалярных значений
клиентской программе, а не для создания новой таблицы. Именно это
применение описано в ECPG и PL/pgSQL (см. PL/pgSQL).
В QHB применение SELECT INTO для создания таблиц имеет
исторические причины. В новом коде для этой цели лучше всего использовать
CREATE TABLE AS.
См. также
SELECT
SELECT, TABLE, WITH — получить строки из таблицы или представления
Синтаксис
[ WITH [ RECURSIVE ] запрос_WITH [, ...] ]
SELECT [ ALL | DISTINCT [ ON ( выражение [, ...] ) ] ]
[ * | выражение [ [ AS ] имя_результата ] [, ...] ]
[ FROM элемент_FROM [, ...] ]
[ WHERE условие ]
[ GROUP BY элемент_группирования [, ...] ]
[ HAVING условие ]
[ WINDOW имя_окна AS ( определение_окна ) [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] выборка ]
[ ORDER BY выражение [ ASC | DESC | USING оператор ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ LIMIT { число | ALL } ]
[ OFFSET начало [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ число ] { ROW | ROWS } { ONLY | WITH TIES } ]
[ FOR { UPDATE | NO KEY UPDATE | SHARE | KEY SHARE } [ OF имя_таблицы [, ...] ] [ NOWAIT | SKIP LOCKED ] [...] ]
Где элемент_FROM может быть:
[ ONLY ] имя_таблицы [ * ] [ [ AS ] псевдоним [ ( псевдоним_столбца [, ...] ) ] ]
[ TABLESAMPLE метод_выборки ( аргумент [, ...] ) [ REPEATABLE ( затравка ) ] ]
[ LATERAL ] ( выборка ) [ AS ] псевдоним [ ( псевдоним_столбца [, ...] ) ]
имя_запроса_WITH [ [ AS ] псевдоним [ ( псевдоним_столбца [, ...] ) ] ]
[ LATERAL ] имя_функции ( [ аргумент [, ...] ] )
[ WITH ORDINALITY ] [ [ AS ] псевдоним [ ( псевдоним_столбца [, ...] ) ] ]
[ LATERAL ] имя_функции ( [ аргумент [, ...] ] ) [ AS ] псевдоним ( определение_столбца [, ...] )
[ LATERAL ] имя_функции ( [ аргумент [, ...] ] ) AS ( определение_столбца [, ...] )
[ LATERAL ] ROWS FROM( имя_функции ( [ аргумент [, ...] ] ) [ AS ( определение_столбца [, ...] ) ] [, ...] )
[ WITH ORDINALITY ] [ [ AS ] псевдоним [ ( псевдоним_столбца [, ...] ) ] ]
элемент_FROM [ NATURAL ] тип_соединения элемент_FROM [ ON условие_соединения | USING ( столбец_соединения [, ...] ) ]
Где элемент_группирования может быть:
( )
выражение
( выражение [, ...] )
ROLLUP ( { выражение | ( выражение [, ...] ) } [, ...] )
CUBE ( { выражение | ( выражение [, ...] ) } [, ...] )
GROUPING SETS ( элемент_группирования [, ...] )
Где запрос_WITH может быть:
имя_запроса_WITH [ ( имя_столбца [, ...] ) ] AS [ [ NOT ] MATERIALIZED ] ( select | values | insert | update | delete )
TABLE [ ONLY ] имя_таблицы [ * ]
Описание
Команда SELECT извлекает строки из перечня таблиц, возможно, пустого.
Общая обработка при помощи SELECT выглядит следующим образом:
Для всех столбцов, задействованных в команде SELECT, необходимо иметь
право SELECT. Использование блокировок FOR NO KEY UPDATE, FOR UPDATE,
FOR SHARE и FOR KEY SHARE требует права UPDATE (по меньшей мере
для одного столбца каждой таблицы, выбранной для блокировки таким образом).
Параметры
Предложение WITH
Предложение WITH позволяет указать один или несколько подзапросов,
на которые можно ссылаться по имени в основном запросе.
Подзапросы в сущности действуют как временные таблицы или представления на протяжении
выполнения всего основного запроса. Каждый подзапрос может представлять
собой оператор SELECT, TABLE, VALUES, INSERT, UPDATE или DELETE.
При использовании в WITH операторов, изменяющих данные (INSERT, UPDATE или DELETE), обычно добавляется предложение RETURNING.
Именно результат RETURNING, а не нижележащая таблица, изменяемая запросом,
формирует временную таблицу, которую затем читает основной запрос. Если
RETURNING опущено, оператор всё равно выполняется, но не выдает
никаких выходных данных, поэтому на него нельзя ссылаться
в качестве таблицы в основном запросе.
Имя (без схемы) должно быть указано для каждого запроса WITH. При необходимости можно указать список имен столбцов; если этот список опущен, имена столбцов выводятся из подзапроса.
Если указано RECURSIVE, подзапрос SELECT может ссылаться сам на себя
по имени. Такой подзапрос должен иметь вид
нерекурсивная_часть UNION [ ALL | DISTINCT ] рекурсивная_часть
где рекурсивная_часть должна появиться в правой части от UNION.
Для каждого запроса допускается только одна рекурсивная ссылка.
Операторы изменения данных не могут быть рекурсивными, но в них можно
использовать результаты рекурсивного запроса SELECT. Пример см. в разделе Запросы WITH.
Еще одна особенность RECURSIVE заключается в том, что запросы WITH не должны быть упорядоченными: один запрос может ссылаться на другой, который находится в списке после него. (Однако циклические ссылки или взаимная рекурсия не поддерживаются.) Без RECURSIVE запросы в WITH могут ссылаться только на запросы того же уровня в WITH, предшествующие им в списке WITH.
Когда в предложении WITH содержится несколько запросов, RECURSIVE нужно написать только один раз, сразу после WITH. Этот параметр будет действовать на все запросы в предложении WITH, кроме тех, которые не используют рекурсию или ссылки на последующие запросы.
Основной запрос и запросы WITH, условно говоря, выполняются одновременно. Это означает, что действие оператора, изменяющего данные в WITH, не будет видно из других частей запроса, кроме как при чтении его вывода в RETURNING. Если два таких оператора изменения данных пытаются изменить одну и ту же строку, результат будет неопределенным.
Ключевое свойство запросов WITH состоит в том, что обычно они вычисляются только один раз для всего основного запроса, даже если тот ссылается на них более одного раза. В частности, операторы изменения данных гарантированно выполняются один и только один раз, независимо от того, будет ли их результат прочитан основным запросом и в каком объеме.
Однако, добавив для запроса WITH пометку NOT MATERIALIZED, можно отказаться от
этой гарантии. В таком случае запрос WITH может быть свернут в основной
запрос так же, как если бы это был простой подзапрос SELECT внутри предложения FROM
основного запроса. Это приводит к дублированию вычислений, если основной
запрос ссылается на запрос в WITH более одного раза; но если
для каждого такого использования требуется только несколько строк из всего
результата запроса WITH, указание NOT MATERIALIZED, позволяющее
оптимизировать запросы совместно, в целом, может оказаться выгодным.
NOT MATERIALIZED игнорируется в запросе WITH, если тот является
рекурсивным или не свободен от побочных эффектов (т. е. когда не
является простым SELECT без изменчивых функций).
По умолчанию запрос WITH без побочных эффектов включается в основной запрос, если в своем предложении FROM тот используется ровно один раз. Это позволяет совместно оптимизировать два уровня запросов в ситуациях, когда это должно быть семантически незаметно. Однако такое сворачивание можно предотвратить, если пометить запрос WITH как MATERIALIZED. Это может быть полезно, например, если предложение WITH используется в качестве преграды для оптимизатора, чтобы предотвратить выбор планировщиком плохого плана.
Дополнительную информацию см. в разделе Запросы WITH.
Предложение FROM
Предложение FROM указывает одну или несколько исходных таблиц, служащих
источником данных для SELECT. Если указано несколько источников, результатом является
декартово произведение (перекрестное соединение) всех строк. Но
обычно в запрос добавляются уточняющие условия (через WHERE), чтобы ограничить
возвращаемый набор строк небольшим подмножеством декартова произведения.
Предложение FROM может содержать следующие элементы:
имя_таблицы
Имя существующей таблицы или представления (может быть дополнено схемой). Если перед именем таблицы указывается ONLY, сканируется только эта таблица. Если ONLY не указано, сканируются таблица и все ее потомки (если таковые имеются). После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что блокировка затрагивает и все дочерние таблицы.
псевдоним
Псевдоним, заменяющий имя для элемента списка FROM. Используется для
краткости или для устранения неоднозначности с замкнутыми соединениями
(где одна и та же таблица сканируется несколько раз).
Когда задается псевдоним, он полностью скрывает фактическое имя
таблицы или функции; например, задано FROM foo AS f, остальная часть
запроса SELECT должна обращаться к этому элементу FROM по имени f,
а не foo. Если задан псевдоним таблицы, то в целях обеспечения замены имени
для одного или нескольких столбцов таблицы также может быть записан список
псевдонимов.
TABLESAMPLE метод_выборки ( аргумент [, ...] ) [ REPEATABLE ( затравка ) ]
Предложение TABLESAMPLE после имени_таблицы указывает на то, что для получения подмножества строк в этой таблице должен использоваться заданный метод_выборки. Этот метод_выборки предшествует применению любых других фильтров, например, предложения WHERE. Стандартный дистрибутив QHB включает два метода выборки, BERNOULLI и SYSTEM, а другие методы выборки могут быть установлены в базе данных с помощью расширений.
Методы выборки BERNOULLI и SYSTEM принимают единственный аргумент, который определяет, какой процент таблицы должен попасть в выборку в диапазоне от 0 до 100. Этот аргумент может быть любым выражением со значением типа real. (Другие методы выборки могут принимать большее число аргументов или другие аргументы.) Эти два метода возвращают случайную выборку таблицы, которая будет содержать приблизительно указанный процент строк таблицы. Метод BERNOULLI сканирует всю таблицу и выбирает или игнорирует отдельные строки независимо с заданной вероятностью. Метод SYSTEM делает выборку на уровне блоков, для каждого блока определяя шанс его задействовать; возвращаются все строки в каждом выбранном блоке. Метод SYSTEM значительно быстрее метода BERNOULLI, когда выбирается небольшой процент строк, но в результате эффектов кучности он может возвращать менее случайную выборку таблицы.
В необязательном предложении REPEATABLE определяется аргумент затравка — число или выражение, используемое для генерации случайных чисел в рамках метода выборки. Значением затравки может быть любое отличное от NULL число с плавающей запятой. Два запроса, в которых указаны одинаковые значения затравки и аргумента, выдадут одну и ту же выборку таблицы при условии неизменности содержимого последней. Но разные значения затравки обычно создают разные выборки. В отсутствие предложения REPEATABLE для каждого запроса выбирается новая случайная выборка, основанная на затравке, сгенерированной системой. Обратите внимание, что некоторые дополнительные методы выборки не принимают предложение REPEATABLE и выдают разные выборки при каждом использовании.
выборка
Предложение FROM может содержать подзапрос SELECT. Это
действует так, словно на время выполнения основной команды SELECT
его выходные данные были созданы в виде временной таблицы.
Обратите внимание, что подзапрос SELECT должен быть заключен
в круглые скобки и для него должен быть задан псевдоним. Здесь
также можно использовать команду VALUES.
имя_запроса_WITH
На запрос WITH можно ссылаться по имени, как если бы имя запроса было именем таблицы. (На самом деле запрос WITH скрывает любую реальную таблицу с тем же именем для целей основного запроса. При необходимости можно обратиться к реальной таблице с тем же именем, указав имя таблицы в схеме.) Так же, как и для имени таблицы, для этого имени можно задать псевдоним.
имя_функции
В предложении FROM могут содержаться вызовы функций. (Это особенно полезно
для функций, возвращающих результирующие множества, но можно использовать
любую функцию.) Это действует так, как если бы выходные данные функции
были созданы как временная таблица на время выполнения основной команды
SELECT. Когда к вызову функции добавляется необязательное предложение
WITH ORDINALITY, после всех выдаваемых функцией столбцов
функции добавляется новый столбец с номерами строк.
Так же, как и для таблицы, для функции можно задать псевдоним. Если псевдоним задан, то также можно задать список псевдонимов столбцов, чтобы предоставить альтернативные имена для одного или нескольких атрибутов составного типа результата функции, включая имя столбца, добавленного предложением ORDINALITY, если оно присутствует.
Несколько вызовов функций могут быть объединены в одном элементе предложения FROM, если заключить их в конструкцию ROWS FROM( ... ). Результатом такого элемента будет сцепление первых строк из каждой функции, затем вторых строк из каждой функции и т. д. Если какие-то функции выдают меньше строк, чем другие, то отсутствующие данные заменяются значением NULL, так что общее количество возвращаемых строк всегда такое же, как для функции, которая выдала наибольшее количество строк.
Если функция была определена как возвращающая тип данных record, для нее нужно указать псевдоним или ключевое слово AS, а затем список определений столбцов в форме ( имя_столбца тип_данных [, ... ]). Список определений столбцов должен соответствовать фактическому количеству и типам столбцов, возвращаемых функцией.
Если при использовании синтаксиса ROWS FROM( ... ) одной из функций требуется список определений столбцов, предпочтительно поместить список определений столбцов после вызова функции внутри ROWS FROM( ... ). Список определений столбцов можно поместить после конструкции ROWS FROM( ... ), только если вызывается всего одна функция, а предложение WITH ORDINALITY отсутствует.
Для того чтобы использовать WITH ORDINALITY вместе со списком определений столбцов, необходимо использовать запись ROWS FROM( ... ) и поместить список определений столбцов внутрь ROWS FROM( ... ).
тип_соединения
Один из
Для типов соединений INNER и OUTER должно быть указано условие соединения, а именно одно из предложений NATURAL, ON условие_соединения или USING (столбец_соединения [, ...]). См. их описания ниже. Для CROSS JOIN ни одно из этих предложений не допускается.
Предложение JOIN объединяет в себе два элемента списка FROM, которые для удобства будем называть «таблицами», хотя на самом деле они могут быть любого типа, допустимого в качестве элемента FROM. При необходимости используйте круглые скобки для определения порядка вложенности. При отсутствии круглых скобок предложение JOIN обрабатывается слева направо. В любом случае, JOIN связывает элементы сильнее, чем разделяющие запятые в списке FROM.
CROSS JOIN и INNER JOIN формируют простое декартово произведение — такой же результат, какой можно получить, указав две таблицы на верхнем уровне FROM, но ограниченный возможным условием соединения (если таковое имеется). Предложение CROSS JOIN эквивалентно INNER JOIN ON (TRUE), то есть никакие строки не удаляются по условию. Эти типы соединения введены исключительно для удобства записи, так как они не делают ничего, что нельзя было бы сделать с помощью простого FROM и WHERE.
LEFT OUTER JOIN возвращает все строки ограниченного декартова произведения (т. е. все объединенные строки, попадающие под условие соединения) плюс все строки в таблице слева, для которых не находится строк в таблице справа, удовлетворяющих условию соединения. Левая строка дополняется значениями NULL справа до полной ширины объединенной таблицы. Обратите внимание, что только условие самого предложения JOIN учитывается при принятии решения о том, какие строки двух таблиц соответствуют друг другу. И только затем применяются внешние условия.
Напротив, RIGHT OUTER JOIN возвращает все соединенные строки, а также одну строку для каждой строки справа, не имеющей соответствия слева (дополненные значениями NULL слева). Это предложение введено для удобства, так как его можно преобразовать в LEFT OUTER JOIN, изменив положение левой и правой таблиц.
FULL OUTER JOIN возвращает все соединенные строки плюс все строки слева, не имеющие соответствия справа (дополненные значениями NULL справа), плюс все строки справа, не имеющие соответствия слева (дополненные значениями NULL слева).
ON условие_соединения
Аргумент условие_соединения является выражением, возвращающим значение типа boolean (как в предложении WHERE) и указывающим, какие строки при соединении считаются сопоставимыми.
USING ( столбец_соединения [, ...] )
Предложение вида USING ( a, b, ... ) представляет собой сокращенную форму записи
ON таблица_слева.a = таблица_справа.a AND таблица_слева.b = таблица_справа.b ....
Также USING подразумевает, что только один из каждой пары эквивалентных
столбцов будет включен в результат соединения, а не оба.
NATURAL
NATURAL является сокращенной формой USING со списком, который содержит все столбцы в двух таблицах, имеющие одинаковые имена. Если нет одинаковых имен столбцов, NATURAL эквивалентно ON TRUE.
LATERAL
Ключевое слово LATERAL может предшествовать подзапросу SELECT
в списке FROM. Оно позволяет в этом вложенном SELECT обращаться к столбцам
элементов FROM, которые появляются перед ним в списке FROM. (Без LATERAL
каждый вложенный SELECT обрабатывается независимо и поэтому не может
перекрестно ссылаться на другие элементы списка FROM.)
LATERAL может также предшествовать вызову функции в списке FROM, но в данном случае оно будет избыточным, потому что выражения с функциями в любом случае могут ссылаться на предыдущие элементы списка FROM.
Элемент LATERAL может быть указан и в верхнем уровне списка FROM, и в дереве JOIN. В последнем случае он может ссылаться на любые элементы, находящиеся в левой части JOIN, от которого он находится справа.
Когда элемент FROM содержит ссылки LATERAL, запрос будет выполнен следующим образом: для каждой строки элемента FROM, предоставляющего столбец(цы) с перекрестной ссылкой, или набора строк из нескольких элементов FROM, предоставляющих столбцы, элемент LATERAL вычисляется с использованием этой строки или значений набора строк столбцов. Результирующие строки, как обычно, объединяются со строками, из которых они были вычислены. Эта процедура повторяется для каждой строки или набора строк из исходной(ых) таблиц(ы).
Исходная(ые) таблица(ы) столбца должна быть связана с элементом LATERAL
соединением INNER или LEFT, иначе не образуется однозначно
определенного набора строк, из которого можно было бы вычислить
набор строк для LATERAL. Таким образом, хотя такая конструкция,
как X RIGHT JOIN LATERAL Y, является синтаксически допустимой,
фактически Y не может обращаться к X.
Предложение WHERE
Необязательное предложение WHERE
WHERE условие
где условие — это любое выражение, которое выдает результат типа boolean. Любая строка, которая не удовлетворяет этому условию, будет исключена из результата. Строка удовлетворяет условию, если возвращает true, когда вместо ссылок на переменные подставляются фактические значения строки.
Предложение GROUP BY
Необязательное предложение GROUP BY имеет общую форму
GROUP BY элемент_группирования [, ...]
GROUP BY собирает в одну строку все выбранные строки, имеющие
одинаковые значения для выражений группировки. Таким выражением,
использованным внутри элемента_группирования, может быть имя входного
столбца, либо имя или порядковый номер выходного столбца (из списка
элементов SELECT), либо произвольное выражение, сформированное из значений входных
столбцов. В случае неоднозначности имя в GROUP BY будет интерпретироваться
как имя входного, а не выходного столбца.
Если в элементе группирования задается GROUPING SETS, ROLLUP или CUBE, то предложение GROUP BY в целом определяет некоторое количество независимых наборов группирования. Эффект от этого равнозначен объединению подзапросов (с UNION ALL) с отдельными наборами группирования в качестве их предложений GROUP BY. Дополнительную информацию об обработке наборов группирования см. в разделе GROUPING SETS, CUBE и ROLLUP.
Агрегатные функции, если они используются, вычисляются по всем строкам, составляющим каждую группу, выдавая отдельное значение для каждой группы. (Если указаны агрегатные функции, но нет предложения GROUP BY, запрос выполняется как если бы была одна группа, содержащая все выбранные строки.) Набор строк, подаваемых в каждую агрегатную функцию, может быть дополнительно отфильтрован путем добавления предложения FILTER к вызову агрегатной функции; дополнительную информацию см. в разделе Агрегатные выражения. С предложением FILTER на вход агрегатной функции будут поступать только строки, соответствующие фильтру.
Когда указано предложение GROUP BY или какая-либо агрегатная функция,
выражения в списке SELECT не могут обращаться к негруппируемым столбцам,
кроме как в агрегатных функциях или если негруппируемый столбец функционально
зависит от группируемых столбцов, поскольку в противном случае в негруппируемом
столбце вернулось бы более одного возможного значения. Функциональная
зависимость появляется, если группируемые столбцы (или их
подмножество) являются первичным ключом таблицы, содержащей
негруппируемый столбец.
Имейте в виду, что все агрегатные функции вычисляются перед вычислением
любых «скалярных» выражений в предложении HAVING или списке SELECT.
Это означает, что, например, нельзя использовать выражение CASE, чтобы пропустить
вычисление агрегатной функции; см. раздел Правила вычисления выражений.
В настоящий момент вместе с GROUP BY нельзя задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение HAVING
Необязательное предложение HAVING имеет общую форму
HAVING условие
где условие задается так же, как и в предложении WHERE.
Предложение HAVING исключает из результата не удовлетворяющие условию строки групп. HAVING отличается от WHERE: WHERE фильтрует отдельные строки перед применением GROUP BY, тогда как HAVING фильтрует группы строк, созданные с помощью GROUP BY. Каждый столбец, указанный в условии, должен однозначно ссылаться на группируемый столбец, если только ссылка не находится внутри агрегатной функции или негруппируемый столбец функционально зависит от группируемых.
Наличие предложения HAVING превращает запрос в группируемый, даже если
отсутствует предложение GROUP BY. То же самое происходит, когда запрос
содержит агрегатные функции, но нет предложения GROUP BY. Все выбранные
строки считаются образующими одну группу, а в списке SELECT и предложении
HAVING можно обращаться к столбцам таблицы только из числа агрегатных функций.
Такой запрос будет выдавать одну строку, если результат условия HAVING
является true, и ноль строк в противном случае.
В настоящий момент вместе с HAVING нельзя задать указания FOR NO KEY UPDATE, *FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение WINDOW
Необязательное предложение WINDOW имеет общую форму
WINDOW имя_окна AS ( определение_окна ) [, ...]
где имя_окна — это имя, на которое можно ссылаться из предложения OVER или последующих определений окна, а определение_окна — это:
[ имя_существующего_окна ]
[ PARTITION BY выражение [, ...] ]
[ ORDER BY выражение [ ASC | DESC | USING оператор ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ предложение_рамки ]
Если имя_существующего_окна указано, оно должно ссылаться на предшествующую запись в списке WINDOW; новое окно копирует предложение разбиения из этой записи, а также предложение сортировки, если таковое имеется. В этом случае для нового окна нельзя указать свое собственное предложение PARTITION BY, а предложение ORDER BY можно определить, только если его не было у копируемого окна. Новое окно всегда использует свое собственное предложение рамки; в копируемом окне предложение рамки не должно быть указано.
Элементы списка PARTITION BY интерпретируется во многом так же, как элементы предложения GROUP BY, за исключением того, что они всегда являются простыми выражениями и никогда не являются именем или номером выходного столбца. Другое отличие заключается в том, что эти выражения могут содержать вызовы агрегатных функций, которые не разрешены в обычном предложении GROUP BY. Они разрешены здесь, потому что формирование окна происходит после группировки и агрегации.
Аналогично элементы списка ORDER BY интерпретируется во многом так же, как элементы предложения ORDER BY, за исключением того, что выражения всегда принимаются как простые выражения и никогда как имя или номер выходного столбца.
Необязательное предложение_рамки определяет рамку окна для оконных функций, которые зависят от рамки (не все они зависят). Рамка окна представляет собой набор связанных строк для каждой строки запроса (называемой текущей строкой ). предложение_рамки может быть:
{ RANGE | ROWS | GROUPS } начало_рамки [ исключение_рамки ]
{ RANGE | ROWS | GROUPS } BETWEEN начало_рамки AND конец_рамки [ исключение_рамки ]
где начало_рамки и конец_рамки может быть:
UNBOUNDED PRECEDING
смещение PRECEDING
CURRENT ROW
смещение FOLLOWING
UNBOUNDED FOLLOWING
и исключение_рамки может быть:
EXCLUDE CURRENT ROW
EXCLUDE GROUP
EXCLUDE TIES
EXCLUDE NO OTHERS
Если конец_рамки не указан, то по умолчанию подразумевается CURRENT ROW. Ограничения заключаются в том, что в качестве начала_рамки не может быть указано UNBOUNDED FOLLOWING, а конец_рамки не может быть указан как UNBOUNDED PRECEDING и не может появиться перед началом_рамки в приведенном выше списке параметров начала_рамки и конца_рамки — например, синтаксис RANGE BETWEEN CURRENT ROW AND смещение PRECEDING не допускается.
Рамка окна образуется по умолчанию предложением RANGE UNBOUNDED PRECEDING, которое равнозначно RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW; оно устанавливает рамку так, чтобы та включала все строки от начала раздела до последней строки, родственной текущей (строка, которая, согласно указанному для окна предложению ORDER BY, считается эквивалентной текущей; если предложение ORDER BY отсутствует, все строки являются родственными). В целом, UNBOUNDED PRECEDING означает, что рамка начинается с первой строки раздела, и подобным же образом UNBOUNDED FOLLOWING означает, что рамка заканчивается последней строкой раздела, независимо от того, какой установлен режим: RANGE, ROWS или GROUPS. В режиме ROWS указание CURRENT ROW означает, что рамка начинается или заканчивается текущей строкой; но в режиме RANGE или GROUPS это означает, что рамка начинается или заканчивается первой или последней строкой, родственной текущей, согласно порядку ORDER BY. Параметры смещение PRECEDING и смещение FOLLOWING различаются по значению в зависимости от режима рамки. В режиме ROWS смещение является целым числом, показывающим количество строк, на которое начало или конец рамки смещается от текущей строки (вверх или вниз соответственно). В режиме GROUPS смещение является целым числом, показывающим, количество групп родственных строк, на которое начало или конец рамки смещается от текущей строки (вверх или вниз соответственно), где группа родственных строк — это группа строк, эквивалентных в соответствии с предложением ORDER BY для данного окна. В режиме RANGE для указания смещения требуется, чтобы в определении окна присутствовал ровно один столбец ORDER BY. Тогда рамка содержит те строки, где значение упорядочивающего столбца не более чем на смещение меньше (для PRECEDING) или больше (для FOLLOWING) значения упорядочивающего столбца текущей строки. В этих случаях тип данных выражения смещение зависит от типа данных упорядочивающего столбца. Для числовых столбцов это обычно тот же числовой тип, а для столбцов с типом дата/время — тип interval. Во всех этих случаях значение смещения должно быть отличным от NULL и неотрицательным. Кроме того, несмотря на то, что смещение не обязательно должно быть простой константой, оно не может содержать переменные, агрегатные или оконные функции.
Параметр исключение_рамки позволяет исключать из рамки строки, окружающие текущую строку, даже если они должны быть включены в соответствии с параметрами начала и конца рамки. Предложение EXCLUDE CURRENT ROW исключает текущую строку из рамки. EXCLUDE GROUP исключает из рамки текущую строку и родственные ей согласно порядку сортировки. EXCLUDE TIES исключает из рамки только строки, родственные текущей строке, но не саму текущую строку. EXCLUDE NO OTHERS просто указывает явно поведение по умолчанию: не исключать ни текущую строку, ни родственные ей.
Будьте осторожны: в режиме ROWS могут выдаваться непредсказуемые результаты, если согласно порядку, указанному в ORDER BY, строки сортируются неоднозначно. Режимы RANGE и GROUPS предназначены для обеспечения того, чтобы строки, являющиеся родственными в порядке ORDER BY, обрабатывались одинаково: все строки данной родственной группы попадут в одну рамку или будут исключены из нее.
Назначение предложения WINDOW — управление поведением оконных функций, фигурирующих в параметрах списка SELECT или предложения ORDER BY запроса. Эти функции могут ссылаться на элементы WINDOW по имени в своих предложениях OVER. Однако элемент WINDOW не обязательно задействовать в запросе: если он не используется в запросе, то просто игнорируется. Можно использовать оконные функции вообще без предложения WINDOW, так как в вызове оконной функции можно указать ее определение окна непосредственно в предложении OVER. Тем не менее, предложение WINDOW позволяет сократить текст запроса, когда одно и то же определение окна требуется для более чем одной оконной функции.
В настоящий момент вместе с WINDOW нельзя задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Функции окон подробно описаны в разделах Руководство по оконным функциям, Вызовы оконных функций и Обработка оконных функций.
Список SELECT
Список SELECT (между ключевыми словами SELECT и FROM) задает
выражения, которые формируют выходные строки команды SELECT.
Выражения могут (и обычно это делают) ссылаться на столбцы, вычисленные
в предложении FROM.
Так же, как и в таблице, каждый выходной столбец SELECT имеет имя. В
простом SELECT это имя используется только для обозначения столбца
для отображения, но когда SELECT является подзапросом большего
запроса, имя рассматривается большим запросом как имя столбца
виртуальной таблицы, созданной подзапросом. Чтобы указать имя,
используемое для выходного столбца, нужно написать AS выходное_имя после
выражения столбца. (Можно не указывать слово AS, но только если желаемое
выходное имя не совпадает с ключевыми словами QHB (см. раздел
Ключевые слова SQL). Для защиты от возможных будущих добавлений ключевых
слов рекомендуется всегда либо писать AS, либо заключать имя в двойные кавычки.)
Если не задать имя столбца, QHB выберет его автоматически.
Если выражение столбца является простой ссылкой на
столбец, то выбранное имя совпадет с именем этого столбца. В более
сложных случаях может использоваться имя функции или типа, либо система
может сгенерировать имя, например ?column?.
Имя выходного столбца может использоваться для обращения к его значению в предложениях ORDER BY и GROUP BY, но не в предложениях WHERE или HAVING; там следует написать вместо имени всё выражение.
Вместо выражения в выходной список можно записать * в качестве краткого обозначения всех столбцов выбранных строк. Кроме того, можно написать имя_таблицы.* как краткое обозначение для столбцов, получаемых из этой таблицы. В этих случаях невозможно указать новые имена с помощью AS; имена выходных столбцов будут совпадать с именами столбцов таблицы.
Согласно стандарту SQL, выражения в выходном списке должны быть
вычислены перед применением DISTINCT, ORDER BY или LIMIT. Это
безусловно необходимо при использовании DISTINCT, так как иначе
неясно, какие значения должны выдаваться как уникальные. Однако во
многих случаях удобнее, если выходные выражения вычисляются после
ORDER BY и LIMIT; особенно если выходной список содержит какие-либо
изменчивые или дорогостоящие функции. В этом случае порядок вычисления функций
является более интуитивным, а для строк, которые не попадут в результат, не
будут производиться вычисления. QHB будет
фактически вычислять выходные выражения после сортировки и ограничения,
если эти выражения не фигурируют в DISTINCT, ORDER BY или
GROUP BY. (В качестве примера, в запросе SELECT f(x) FROM tab ORDER BY 1
функция f(x), несомненно, должна вычисляться перед сортировкой.) Выходные
выражения, содержащие возвращающие множества функции, фактически вычисляются
после сортировки и перед ограничением количества строк, так что LIMIT будет
отбрасывать строки, выдаваемые функцией, возвращающей множество.
Предложение DISTINCT
Если указывается SELECT DISTINCT, то все повторяющиеся строки
исключаются из результирующего набора (сохраняется одна строка из каждой
группы дубликатов). SELECT ALL указывает на обратное: все строки
сохраняются; это поведение по умолчанию.
SELECT DISTINCT ON ( выражение [, ...] ) сохраняет только первую строку каждого набора строк, в котором заданные выражения дают одинаковые значения. Выражения DISTINCT ON интерпретируются с использованием тех же правил, что и ORDER BY (см. выше). Обратите внимание, что «первая строка» каждого набора непредсказуема, если для обеспечения того, чтобы нужная строка появилась первой, не указано ORDER BY. Например:
SELECT DISTINCT ON (location) location, time, report
FROM weather_reports
ORDER BY location, time DESC;
извлекает самый последний отчет о погоде для каждого местоположения. Но если бы мы не воспользовались ORDER BY, чтобы принудительно установить нисходящий порядок значений времени для каждого местоположения, мы бы получили для каждого местоположения отчет от непредсказуемого времени.
Выражение(я) DISTINCT ON должно(ы) соответствовать самому левому выражению в ORDER BY. Предложение ORDER BY обычно содержит дополнительное(ые) выражение(я), определяющее(ие) желаемый приоритет строк внутри каждой группы DISTINCT ON.
В настоящий момент вместе с DISTINCT нельзя задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение UNION
Предложение UNION имеет общую форму:
оператор_SELECT UNION [ ALL | DISTINCT ] оператор_SELECT
Где оператор_SELECT — это любой подзапрос SELECT без предложений ORDER BY,
LIMIT, FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE или FOR KEY SHARE.
(ORDER BY и LIMIT можно присоединить к вложенному выражению, если оно
заключено в круглые скобки. Без скобок эти предложения будут восприняты для
применения к результату UNION, а не к выражению в его правой части.)
Оператор UNION вычисляет объединение набора строк, возвращенных
указанными запросами SELECT. Строка находится в объединении двух
результирующих наборов, если появляется по крайней мере
в одном из них. Два оператора SELECT, представляющие
прямые операнды объекта UNION, должны выдавать одинаковое количество
столбцов, а соответствующие столбцы должны иметь совместимые типы
данных.
Результат UNION не будет содержать повторяющихся строк, если не указан параметр ALL. ALL предотвращает устранение дубликатов. (Следовательно, UNION ALL обычно значительно быстрее, чем UNION, поэтому по возможности следует использовать ALL.) Можно написать DISTINCT, чтобы явно указать, что повторяющиеся строки должны быть удалены (это поведение по умолчанию).
Несколько операторов UNION в одном запросе SELECT вычисляются слева
направо, если круглыми скобками не определен иной порядок.
В настоящий момент ни для результата с UNION, ни для любого из подзапросов UNION невозможно задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение INTERSECT
Предложение INTERSECT имеет общую форму:
оператор_SELECT INTERSECT [ ALL | DISTINCT ] оператор_SELECT
Где оператор_SELECT — это любой подзапрос SELECT без предложений ORDER BY,
LIMIT, FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE или FOR KEY SHARE.
Оператор INTERSECT вычисляет пересечение набора строк,
возвращаемых соответствующими запросами SELECT. Строка находится в
пересечении двух результирующих наборов, если присутствует в них обоих.
Результат INTERSECT не будет содержать повторяющихся строк, если не указан параметр ALL. С ALL строка, повторяющаяся m раз в левой таблице и n раз в правой, будет выдана в результирующем наборе min(m,n) раз. Можно написать DISTINCT, чтобы явно указать, что повторяющиеся строки должны быть удалены (это поведение по умолчанию).
Несколько операторов INTERSECT в одном запросе SELECT вычисляются слева
направо, если круглыми скобками не определен иной порядок.
INTERSECT связывает свои подзапросы сильнее, чем UNION. Иными словами,
A UNION B INTERSECT C будет восприниматься как A UNION (B INTERSECT C).
В настоящий момент ни для результата с INTERSECT, ни для любого из подзапросов INTERSECT нельзя задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение EXCEPT
Предложение EXCEPT имеет общую форму:
оператор_SELECT EXCEPT [ ALL | DISTINCT ] оператор_SELECT
Где оператор_SELECT — это любой подзапрос SELECT без предложений ORDER BY,
LIMIT, FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE или FOR KEY SHARE.
Оператор EXCEPT вычисляет набор строк, которые находятся в результате
выполнения левого запроса SELECT, но не в результате выполнения
правого.
Результат EXCEPT не будет содержать каких-либо повторяющихся строк, если не указан параметр ALL. С ALL строка, повторяющаяся m раз в левой таблице и n раз в правой, будет выдана в результирующем наборе max(m-n,0) раз. Можно написать DISTINCT, чтобы явно указать, что повторяющиеся строки должны быть удалены (это поведение по умолчанию).
Несколько операторов EXCEPT в одном запросе SELECT вычисляются слева
направо, если круглыми скобками не определен иной порядок.
EXCEPT связывает свои подзапросы так же сильно, как UNION.
В настоящий момент ни для результата с EXCEPT, ни для любого из подзапросов EXCEPT нельзя задать указания FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE и FOR KEY SHARE.
Предложение ORDER BY
Необязательное предложение ORDER BY имеет общую форму:
ORDER BY выражение [ ASC | DESC | USING оператор ] [ NULLS { FIRST | LAST } ] [, ...]
Предложение ORDER BY указывает, что результирующие строки запроса должны быть отсортированы в соответствии с указанным(и) выражением(ями). Если значения двух строк равны по самому левому выражению, то они сравниваются по следующему выражению и т. д. Если их значения равны по всем указанным выражениям, строки возвращаются в порядке, определяемом реализацией.
В качестве выражения может быть указано имя или порядковый номер выходного
столбца (элемент списка SELECT) либо произвольное выражение,
сформированное из значений входного столбца.
Порядковый номер означает последовательный номер (нумерация слева направо) позиции выходного столбца. Эта функция позволяет определить порядок сортировки по столбцу, который не имеет уникального имени. В этом нет абсолютной необходимости, потому что имя выходному столбцу всегда можно назначить с помощью предложения AS.
Также в предложении ORDER BY можно использовать произвольные выражения,
в том числе столбцы, которые не отображаются в списке результатов SELECT.
Таким образом, следующий запрос вполне корректен:
SELECT name FROM distributors ORDER BY code;
Однако здесь есть ограничение: если предложение ORDER BY применяется к результату предложений UNION, INTERSECT или EXCEPT, в нем можно указывать только имя или номер выходного столбца, но не выражение.
Если выражение ORDER BY — простое имя, которое соответствует имени как выходного, так и входного столбца,ORDER BY будет интерпретировать его как имя выходного столбца. Это противоположно выбору, который в такой же ситуации сделает GROUP BY. Данное несоответствие допущено для совместимости со стандартом SQL.
Дополнительно можно добавить ключевое слово ASC (по возрастанию) или DESC (по убыванию) после любого выражения в предложении ORDER BY. Если ничего не указано, по умолчанию предполагается ASC. Кроме того, можно указать имя специфического оператора сортировки в предложении USING. Оператор сортировки должен быть членом «меньше» или «больше» некоторого семейства операторов B-дерева. ASC обычно эквивалентно USING <, а DESC эквивалентно USING >. (Но создатель пользовательского типа данных может точно определить порядок сортировки по умолчанию, который может соответствовать операторам с другими именами.)
Если указывается NULLS LAST, значения NULL будут отсортированы после всех значений не NULL; если указывается NULLS FIRST, значения NULL будут отсортированы перед всеми значениями не NULL. Если ни то, ни другое не указано, то при явном или косвенном выборе порядка ASC по умолчанию подразумевается NULLS LAST, и наоборот, при явном или косвенном выборе порядка DESC по умолчанию подразумевается NULLS FIRST (следовательно, по умолчанию считается, что значения NULL больше значений не NULL). С предложением USING порядок NULL по умолчанию зависит от того, является ли заданный оператор оператором «меньше» или «больше».
Обратите внимание, что параметры сортировки применяются только к
выражению, за которым они следуют: например, ORDER BY x, y DESC не
то же самое, что ORDER BY x DESC, y DESC.
Данные символьных строк сортируются в соответствии с правилом
сортировки, установленным для сортируемого столбца. При необходимости это поведение
можно переопределить путем включения в выражение предложения COLLATE,
например, так: ORDER BY mycolumn COLLATE "en_US".
Дополнительную информацию см. в разделах Применение правил сортировки
и Поддержка правил сортировки.
Предложение LIMIT
Предложение LIMIT состоит из двух независимых вложенных предложений:
LIMIT { число | ALL }
OFFSET начало
Где число задает максимальное количество строк, которое должно быть выдано, в то время как начало указывает количество строк, которые необходимо пропустить, прежде чем начать выдавать строки. Если указаны оба значения, сначала строки пропускаются в количестве, заданном значением начало, а потом отсчитывается заданное значением число количество следующих строк, которые будут выданы.
Если в результате вычисления выражения число оказывается NULL, предложение обрабатывается как LIMIT ALL, то есть без ограничения числа строк. Если начало принимает значение NULL, оно обрабатывается так же, как OFFSET 0.
SQL:2008 представил другой синтаксис для получения того же результата, который также поддерживает QHB. Это:
OFFSET начало { ROW | ROWS }
FETCH { FIRST | NEXT } [ число ] { ROW | ROWS } ONLY
В этом синтаксисе стандарт требует, чтобы значение начало или число было буквальной константой, параметром или именем переменной; QHB разрешает использовать другие выражения, но они обычно должны быть заключены в круглые скобки, чтобы избежать неоднозначности. Если в предложении FETCH число опускается, то по умолчанию принимается значение 1. Слова ROW и ROWS, а также FIRST и NEXT являются незначащими и не влияют на поведение этих предложений. Согласно стандарту, предложение OFFSET должно предшествовать предложению FETCH, если присутствуют оба; но QHB менее строг и позволяет любой порядок.
При использовании LIMIT имеет смысл использовать и предложение ORDER BY, чтобы результирующие строки выдавались в определенном порядке. В противном случае вы получите непредсказуемое подмножество строк запроса — можно запросить строки с десятой по двадцатую, но в каком порядке? Порядок будет неизвестен, если не указать ORDER BY.
Планировщик запросов учитывает ограничение LIMIT при создании плана запроса, поэтому высока вероятность, что вы получите разные планы (и разный же порядок строк) в зависимости от того, какие значения указаны для LIMIT и OFFSET. Таким образом, различные значения LIMIT/OFFSET при выборе различных подмножеств результата запроса приведут к несогласованным результатам, если не установить предсказуемый порядок сортировки результатов с помощью ORDER BY. Это не ошибка, а неотъемлемое следствие того факта, что SQL не гарантирует вывод результатов запроса в каком-то конкретном порядке, если тот не задан предложением ORDER BY.
Возможно даже, что без предложения ORDER BY, принудительно выбирающего детерминированное подмножество, при повторном выполнении одного и того же запроса с LIMIT будут получены разные подмножества строк таблицы. Это опять же не ошибка; в подобном случае детерминированность результатов просто не гарантируется.
Предложение блокировки
Предложениями блокировки являются операторы FOR UPDATE,
FOR NO KEY UPDATE, FOR SHARE и FOR KEY SHARE; они влияют на то,
как SELECT блокирует строки по мере их получения из таблицы.
Блокирующее предложение имеет общую форму
FOR вариант_блокировки [ OF имя_таблицы [, ...] ] [ NOWAIT | SKIP LOCKED ]
где вариант_блокировки может быть одним из
UPDATE
NO KEY UPDATE
SHARE
KEY SHARE
Для получения дополнительной информации о каждом режиме блокировки на уровне строк см. раздел Блокировка на уровне строк.
Чтобы операция не ожидала фиксации других транзакций, используйте указание NOWAIT или SKIP LOCKED. С NOWAIT оператор сообщает об ошибке, а не ждет, если выбранную строку нельзя заблокировать немедленно. С указанием SKIP LOCKED все выбранные строки, которые нельзя немедленно заблокировать, пропускаются. Пропуск заблокированных строк формирует несогласованное представление данных, поэтому этот вариант не подходит для общего применения, но может быть использован для предотвращения конфликта блокировок при обращении множества потребителей к таблице типа очереди. Обратите внимание, что указания NOWAIT и SKIP LOCKED можно применить только к блокировке(ам) уровня строк — необходимая блокировка ROW SHARE уровня таблицы по-прежнему запрашивается обычным способом (см. главу Параллельный контроль). Если нужно запросить блокировку уровня таблицы без ожидания, можно использовать команду LOCK с указанием NOWAIT.
Если в предложении блокировки заданы определенные имена таблиц, то
будут блокироваться только строки, поступающие из этих таблиц; любые другие
таблицы, указанные в SELECT, будут прочитаны как обычно.
Предложение блокировки без списка таблиц влияет на все таблицы,
указанные в операторе. Если предложение блокировки применяется к
представлению или подзапросу, оно влияет на все таблицы, используемые в
представлении или подзапросе. Но эти предложения не применяются к
запросам WITH, на которые ссылается основной запрос. Если вы хотите, чтобы
блокировка строк происходила в пределах запроса WITH, укажите предложение
блокировки непосредственно в этом запросе WITH.
Можно указать в запросе несколько предложений блокировки, если необходимо указать различное поведение блокировки для разных таблиц. При этом если одна и та же таблица упоминается (или неявно затрагивается) более чем в одном предложении блокировки, то блокировка устанавливается так, как если бы было указано только самое сильное из них. Аналогично таблица обрабатывается в режиме NOWAIT, если тот указан в любом из затрагивающих ее предложений. В противном случае таблица обрабатывается в режиме SKIP LOCKED, если тот указан в любом из затрагивающих ее предложений.
Предложения блокировки нельзя использовать в контекстах, где возвращаемые строки невозможно четко связать с отдельными строками таблицы; например, они не могут использоваться при агрегировании.
Когда предложение блокировки появляется на верхнем уровне запроса
SELECT, блокируются именно те строки, которые возвращаются запросом; в
случае запроса объединения блокируются те строки, которые участвуют в
возвращаемых строках объединения. Кроме того, строки, удовлетворяющие условиям
запроса на момент создания снимка запроса, будут заблокированы, хотя
и не будут возвращены, если были обновлены с момента снимка и
больше не удовлетворяют условиям запроса. Если используется LIMIT,
блокировка остановится, как только будет возвращено достаточное
количество строк, чтобы удовлетворить пределу (но обратите внимание, что
строки, пропускаемые указанием OFFSET, будут блокироваться). Аналогично
если предложение блокировки используется в запросе курсора, то
блокируются только строки, фактически извлеченные или пройденные
курсором.
Когда предложение блокировки появляется в подзапросе SELECT,
блокируются те строки, которые будут возвращены внешним запросом от
подзапроса. Этих строк может оказаться меньшее количество, чем
предполагает анализ только подзапроса, поскольку условия из внешнего
запроса могут способствовать оптимизации выполнения подзапроса.
Например,
SELECT * FROM (SELECT * FROM mytable FOR UPDATE) ss WHERE col1 = 5;
будет блокировать только строки c col1 = 5, хотя в такой записи условие не относится к подзапросу.
В предыдущих версиях не удавалось сохранить блокировку, которая была обновлена более поздней точкой сохранения. Например, этому коду:
BEGIN;
SELECT * FROM mytable WHERE key = 1 FOR UPDATE;
SAVEPOINT s;
UPDATE mytable SET ... WHERE key = 1;
ROLLBACK TO s;
не удалось бы сохранить блокировку FOR UPDATE после ROLLBACK TO.
Внимание
Команда
SELECT, запущенная с уровнем изоляции транзакций READ COMMITTED с использованием ORDER BY и предложением блокировки, возможно, будет возвращать строки не по порядку. Это связано с тем, что ORDER BY применяется в первую очередь. Команда сортирует результат, но затем может быть заблокирована при попытке получить блокировку одной или нескольких строк. Как только блокировка сSELECTбудет снята, некоторые значения сортируемых столбцов могут быть изменены, что приведет к тому, что порядок может быть нарушен (хотя они были упорядочены с точки зрения исходных значений столбцов). При необходимости можно обойти эту проблему, поместив FOR UPDATE/SHARE в подзапрос, например:
SELECT * FROM (SELECT * FROM mytable FOR UPDATE) SS ORDER BY column1;
Обратите внимание, что этот запрос приведет к блокировке всех строк таблицы mytable, но если бы предложение FOR UPDATE было указано на верхнем уровне, были бы заблокированы только фактически возвращенные строки. Это может значительно влиять на производительность, особенно если ORDER BY совмещено с LIMIT или другими ограничениями. Таким образом, этот метод рекомендуется только в том случае, если ожидаются параллельные обновления сортируемых столбцов и требуется строго отсортированный результат.
На уровнях изоляции транзакций REPEATABLE READ и SERIALIZABLE это приведет к ошибке сериализации (с SQLSTATE '40001'), поэтому на этих уровнях изоляции нет никакой возможности получения строк не по порядку.
Команда TABLE
Команда
TABLE имя
равнозначна
SELECT * FROM имя
Команда TABLE может использоваться как команда верхнего уровня или как
вариант более краткой записи внутри сложных запросов. С командой TABLE могут
быть использованы только предложения WITH, UNION, INTERSECT, EXCEPT,
ORDER BY, LIMIT, OFFSET, FETCH и предложения блокировки FOR;
предложение WHERE и любые формы агрегирования использовать нельзя.
Примеры
Соединение таблицы films с таблицей distributors:
SELECT f.title, f.did, d.name, f.date_prod, f.kind
FROM distributors d, films f
WHERE f.did = d.did
title | did | name | date_prod | kind
-------------------+-----+--------------+------------+----------
The Third Man | 101 | British Lion | 1949-12-23 | Drama
The African Queen | 101 | British Lion | 1951-08-11 | Romantic
...
Суммирование значений столбца len (продолжительность) для всех фильмов и группирование результатов по столбцу kind (тип фильма):
SELECT kind, sum(len) AS total FROM films GROUP BY kind;
kind | total
----------+-------
Action | 07:34
Comedy | 02:58
Drama | 14:28
Musical | 06:42
Romantic | 04:38
Суммирование значений столбца len для всех фильмов, группирование результатов по столбцу kind и вывод только тех групп, общая продолжительность которых меньше 5 часов:
SELECT kind, sum(len) AS total
FROM films
GROUP BY kind
HAVING sum(len) < interval '5 hours';
kind | total
----------+-------
Comedy | 02:58
Romantic | 04:38
Следующие два примера демонстрируют равнозначные способы сортировки результатов по содержимому второго столбца (name):
SELECT * FROM distributors ORDER BY name;
SELECT * FROM distributors ORDER BY 2;
did | name
-----+------------------
109 | 20th Century Fox
110 | Bavaria Atelier
101 | British Lion
107 | Columbia
102 | Jean Luc Godard
113 | Luso films
104 | Mosfilm
103 | Paramount
106 | Toho
105 | United Artists
111 | Walt Disney
112 | Warner Bros.
108 | Westward
Следующий пример показывает объединение таблиц distributors и actors, ограниченное именами, начинающимися с буквы W в каждой таблице. Интерес представляют только неповторяющиеся строки, поэтому ключевое слово ALL опущено.
distributors: actors:
did | name id | name
-----+-------------- ----+----------------
108 | Westward 1 | Woody Allen
111 | Walt Disney 2 | Warren Beatty
112 | Warner Bros. 3 | Walter Matthau
... ...
SELECT distributors.name
FROM distributors
WHERE distributors.name LIKE 'W%'
UNION
SELECT actors.name
FROM actors
WHERE actors.name LIKE 'W%';
name
----------------
Walt Disney
Walter Matthau
Warner Bros.
Warren Beatty
Westward
Woody Allen
Этот пример показывает, как использовать функцию в предложении FROM, со списком определений столбцов и без него:
CREATE FUNCTION distributors(int) RETURNS SETOF distributors AS $$
SELECT * FROM distributors WHERE did = $1;
$$ LANGUAGE SQL;
SELECT * FROM distributors(111);
did | name
-----+-------------
111 | Walt Disney
CREATE FUNCTION distributors_2(int) RETURNS SETOF record AS $$
SELECT * FROM distributors WHERE did = $1;
$$ LANGUAGE SQL;
SELECT * FROM distributors_2(111) AS (f1 int, f2 text);
f1 | f2
-----+-------------
111 | Walt Disney
Пример функции с добавленным столбцом нумерации:
SELECT * FROM unnest(ARRAY['a','b','c','d','e','f']) WITH ORDINALITY;
unnest | ordinality
--------+----------
a | 1
b | 2
c | 3
d | 4
e | 5
f | 6
(6 rows)
Этот пример показывает, как использовать простое предложение WITH:
WITH t AS (
SELECT random() as x FROM generate_series(1, 3)
)
SELECT * FROM t
UNION ALL
SELECT * FROM t
x
--------------------
0.534150459803641
0.520092216785997
0.0735620250925422
0.534150459803641
0.520092216785997
0.0735620250925422
Обратите внимание, что запрос WITH выполняется всего один раз, поэтому мы получаем два одинаковых набора по три случайных значения.
В этом примере WITH RECURSIVE применяется для поиска всех подчиненных Мэри (непосредственных или косвенных) и вывода их уровня косвенности в таблице с информацией только о непосредственных подчиненных:
WITH RECURSIVE employee_recursive(distance, employee_name, manager_name) AS (
SELECT 1, employee_name, manager_name
FROM employee
WHERE manager_name = 'Mary'
UNION ALL
SELECT er.distance + 1, e.employee_name, e.manager_name
FROM employee_recursive er, employee e
WHERE er.employee_name = e.manager_name
)
SELECT distance, employee_name FROM employee_recursive;
Обратите внимание, что это типичная форма рекурсивных запросов: начальное условие, последующий UNION, а затем рекурсивная часть запроса. Убедитесь в том, что рекурсивная часть запроса в конце концов перестанет возвращать строки, иначе запрос окажется в бесконечном цикле. (Другие примеры см. в разделе Запросы WITH.)
В этом примере используется LATERAL для применения возвращающей множество функции get_product_names() для каждой строки таблицы manufacturers:
SELECT m.name AS mname, pname
FROM manufacturers m, LATERAL get_product_names(m.id) pname;
Производители, с которыми в данный момент не связаны никакие продукты, не попадут в результат, так как это внутреннее соединение. Если бы мы захотели включить названия и этих производителей, можно сделать так:
SELECT m.name AS mname, pname
FROM manufacturers m LEFT JOIN LATERAL get_product_names(m.id) pname ON true;
Совместимость
Разумеется, команда SELECT совместима со стандартом SQL. Но есть некоторые
расширения и некоторые отсутствующие функции.
Необязательное предложение FROM
QHB позволяет опустить предложение FROM. Это упрощает вычисление результатов простых выражений:
SELECT 2+2;
?column?
----------
4
Некоторые другие базы данных SQL могут сделать это только путем
введения фиктивной таблицы с одной строкой, из которой нужно сделать
SELECT.
Обратите внимание, что если предложение FROM не указано, запрос не может ссылаться ни на какие таблицы базы данных. Например, недопустим следующий запрос:
SELECT distributors.* WHERE distributors.name = 'Westward';
Пустые списки SELECT
Список выходных выражений после SELECT может быть пустым, создавая
таблицу результатов без столбцов. Согласно стандарту SQL это недопустимый
синтаксис. QHB допускает его, так как это согласуется с
возможностью иметь таблицы без столбцов. Однако при использовании DISTINCT
пустой список не допускается.
Необязательное ключевое слово AS
В стандарте SQL необязательное ключевое слово AS может быть опущено перед именем выходного столбца, когда новое имя столбца является допустимым именем столбца (то есть отличающимся от всех зарезервированных ключевых слов). QHB более строг: AS требуется, если новое имя столбца соответствует любому ключевому слову вообще, независимо от того, зарезервировано оно или нет. Рекомендуемая практика заключается в использовании AS или заключении имен выходных столбцов в кавычки, чтобы предотвратить любой возможный конфликт в будущем при добавлении ключевых слов.
В списке FROM как стандарт SQL, так и QHB позволяют пропускать AS перед псевдонимом, который является незарезервированным ключевым словом. Но это нецелесообразно для имен выходных столбцов из-за синтаксической неоднозначности.
ONLY и наследование
Стандарт SQL требует заключать имя таблицы в круглые скобки при написании
ONLY, например SELECT * FROM ONLY (tab1), ONLY (tab2) WHERE ....
QHB считает эти скобки необязательными.
QHB допускает добавлять в конце *, чтобы явно указать
что дочерние таблицы включаются в рассмотрение, в отличие от поведения
с ONLY. Стандарт SQL этого не допускает.
(Эти соображения применяются ко всем командам SQL, поддерживающим параметр ONLY.)
Ограничения предложения TABLESAMPLE
Предложение TABLESAMPLE в настоящее время принимается только для обычных таблиц и материализованных представлений. Согласно стандарту SQL должна быть возможность применить его к любым элементам списка FROM.
Вызовы функций в предложении FROM
QHB позволяет записывать вызов функции непосредственно в
качестве элемента списка FROM. В стандарте SQL было бы необходимо обернуть
такой вызов функции в подзапрос SELECT; то есть запись
FROM функция(...) псевдоним примерно равнозначна записи
FROM LATERAL (SELECT функция(...)) псевдоним. Обратите внимание, что
указание LATERAL считается неявным; это связано с тем, что стандарт требует
поведения LATERAL для элемента UNNEST() в предложении FROM. QHB
обрабатывает UNNEST() так же, как и другие функции, возвращающие множества.
Пространства имен в GROUP BY и ORDER BY
В стандарте SQL-92 предложение ORDER BY может ссылаться только на имена или номера выходных столбцов, в то время как предложение GROUP BY может ссылаться только на выражения, основанные на именах входных столбцов. QHB расширяет оба предложения, позволяя также применять другие варианты (но он использует интерпретацию стандарта, если есть неоднозначность). QHB также позволяет указывать произвольные выражения в обоих предложениях. Обратите внимание, что имена, фигурирующие в выражениях, всегда будут приниматься как имена входных столбцов, а не выходных.
В SQL:1999 и более поздних стандартах введено немного другое определение, которое не полностью совместимо с SQL-92. В большинстве случаев, однако, QHB будет интерпретировать выражение ORDER BY или GROUP BY так, как требует SQL:1999.
Функциональные зависимости
QHB распознает функциональную зависимость (позволяет пропускать столбцы из GROUP BY) только в том случае, если первичный ключ таблицы включен в список GROUP BY. Стандарт SQL задает дополнительные условия, которые должны быть учтены.
LIMIT и OFFSET
Предложения LIMIT и OFFSET являются специфичным синтаксисом QHB, также используемым в MySQL. Стандарт SQL:2008 для той же цели вводит предложения OFFSET ... FETCH {FIRST|NEXT} ..., рассмотренные ранее в подразделе Предложение LIMIT. Этот синтаксис также используется IBM DB2. (Приложения, написанные для Oracle, часто используют обходной путь, включая автоматически генерируемый столбец rownum, который отсутствует в QHB, чтобы реализовать эффект этих предложений.)
FOR NO KEY UPDATE, FOR UPDATE, FOR SHARE, FOR KEY SHARE
Хотя в стандарте SQL есть предложение блокировки FOR UPDATE, стандарт
позволяет использовать его только в предложении DECLARE CURSOR. QHB
же позволяет его использовать в любом запросе SELECT, а также подзапросах
SELECT, но это является расширением. Варианты FOR NO KEY UPDATE,
FOR SHARE и FOR KEY SHARE, а также NOWAIT и SKIP LOCKED не отображены
в стандарте.
Изменение данных в WITH
QHB позволяет использовать INSERT, UPDATE и DELETE в
в качестве запросов WITH. Этого нет в стандарте SQL.
Нестандартные предложения
DISTINCT ON ( ... ) является расширением стандарта SQL.
ROWS FROM( ... ) является расширением стандарта SQL.
Указания MATERIALIZED и NOT MATERIALIZED предложения WITH также относятся к расширениям стандарта SQL.
SET CONSTRAINTS
SET CONSTRAINTS — установить время проверки ограничений для текущей транзакции
Синтаксис
SET CONSTRAINTS { ALL | имя [, ...] } { DEFERRED | IMMEDIATE }
Описание
Команда SET CONSTRAINTS задает поведение при проверке ограничений в рамках
текущей транзакции. Ограничения IMMEDIATE проверяются в конце каждого
оператора. Ограничения DEFERRED откладываются до фиксации
транзакции. Каждое из ограничений IMMEDIATE или DEFERRED задается
независимо.
При создании ограничения задается одна из трех характеристик:
DEFERRABLE INITIALLY DEFERRED, DEFERRABLE INITIALLY IMMEDIATE или
NOT DEFERRABLE. Третий вариант всегда подразумевает IMMEDIATE и не
зависит от команды SET CONSTRAINTS. Первые два вариант запускаются
в каждой транзакции в указанном режиме, но их поведение может быть
изменено в рамках транзакции командой SET CONSTRAINTS.
SET CONSTRAINTS со списком имен ограничений изменяет режим только
этих ограничений (которые все должны быть откладываемыми). Каждое имя
ограничения может быть дополнено схемой. Если имя схемы не
указано, для поиска первого совпадающего имени используется текущий путь поиска
схемы. SET CONSTRAINTS ALL изменяет режим всех откладываемых
ограничений.
Когда SET CONSTRAINTS меняет режим ограничения с DEFERRED на
IMMEDIATE, новый режим начинает действовать в обратную сторону:
все изменения данных, которые были бы проверены в конце транзакции, вместо
этого проверяются во время выполнения команды SET CONSTRAINTS. Если
какое-либо такое ограничение нарушается, при выполнении SET CONSTRAINTS
происходит ошибка (и не изменяется режим ограничения). Таким образом,
SET CONSTRAINTS можно использовать для принудительной проверки
ограничений в определенной точке транзакции.
В настоящее время такое поведение распространяется только на ограничения UNIQUE, PRIMARY KEY, REFERENCES (внешний ключ) и EXCLUDE. Ограничения NOT NULL и CHECK всегда проверяются немедленно, в момент, когда строка добавляется или изменяется (не в конце оператора). Ограничения уникальности и исключения, которые не были объявлены как EFERRABLE, также проверяются немедленно.
Запуск триггеров, объявленных как «триггеры ограничений», также контролируется этой командой — они срабатывают в то время, когда должна произойти проверка связанного ограничения.
Примечания
Поскольку QHB не требует, чтобы имена ограничений были
уникальными в схеме (только в своей таблице), возможно
существование нескольких соответствующих ограничений для указанного имени
ограничения. В этом случае SET CONSTRAINTS будет действовать на все
эти ограничения. Для имен без указания схемы действие команды будет
распространяться только на ограничение, найденное в первой из схем в пути
поиска, остальные схемы просматриваться не будут.
Эта команда изменяет только поведение ограничений в рамках текущей транзакции. При выполнении вне блока транзакций будет выдано предупреждение и больше ничего не произойдет.
Совместимость
Эта команда соответствует поведению, определенному в стандарте SQL, за исключением того, что QHB не влияет на проверку ограничения NOT NULL и CHECK. Кроме того, QHB проверяет неоткладываемые ограничения уникальности сразу же, а не в конце оператора, как предполагает стандарт.
SET ROLE
SET ROLE — установить идентификатор текущего пользователя для активного сеанса
Синтаксис
SET [ SESSION | LOCAL ] ROLE имя_роли
SET [ SESSION | LOCAL ] ROLE NONE
RESET ROLE
Описание
Эта команда задает идентификатор текущего пользователя для активного
сеанса SQL как имя_роли. Имя роли может быть записано
как идентификатор или строковая константа. После SET ROLE
проверка права доступа для команд SQL выполняется так, как если бы
сеанс изначально был установлен с этим именем роли.
Указанное имя_роли должно быть ролью, членом которой является пользователь активного сеанса. (Если пользователь сеанса является суперпользователем, он может выбрать любую роль.)
Модификаторы SESSION и LOCAL действуют так же, как и для обычной команды SET.
Формы NONE и RESET сбрасывают идентификатор текущего пользователя, в результате чего активным становится идентификатор пользователя активного сеанса. Эти формы может выполнить любой пользователь.
Примечания
С помощью этой команды можно как добавить права, так и ограничить их. Если роль
пользователя сеанса имеет атрибут INHERIT, она автоматически получает
права всех ролей, на которые может переключиться с помощью SET ROLE;
в этом случае SET ROLE по сути удаляет все права, назначенные непосредственно
пользователю сеанса и другим ролям, членом которых он является, оставляя только
права, доступные для указанной роли. С другой стороны, если роль
пользователя сеанса имеет атрибут NOINHERIT, то SET ROLE
удаляет права, назначенные непосредственно пользователю сеанса,
и вместо этого назначает права, доступные для указанной роли.
В частности, когда суперпользователь переключается через SET ROLE на роль,
не являющуюся суперпользователем, он теряет свои права суперпользователя.
SET ROLE оказывает действие, сравнимое с SET SESSION AUTHORIZATION, но
проверки прав при этом совсем другие. Кроме того, SET SESSION AUTHORIZATION
определяет, какие роли допустимы для последующей SET ROLE, тогда как
изменение ролей с помощью SET ROLE не изменяет набор ролей, допустимых для
последующей команды SET ROLE.
SET ROLE не обрабатывает переменные сеанса, заданные в свойствах команды ALTER ROLE для данной роли;
они устанавливаются только во время входа в систему.
Команду SET ROLE нельзя использовать в пределах функций с характеристикой SECURITY DEFINER.
Примеры
SELECT SESSION_USER, CURRENT_USER;
session_user | current_user
--------------+--------------
peter | peter
SET ROLE 'paul';
SELECT SESSION_USER, CURRENT_USER;
session_user | current_user
--------------+--------------
peter | paul
Совместимость
QHB допускает синтаксис идентификаторов (параметр «имя_роли»), в то время как стандарт SQL требует, чтобы имя роли было записано как строковая константа. Стандарт SQL не разрешает выполнять эту команду во время транзакции; в QHB такого ограничения нет, потому что для него нет никаких причин. Указания SESSION и LOCAL являются расширением QHB, так же, как и синтаксис RESET.
См. также
SET SESSION AUTHORIZATION
SET SESSION AUTHORIZATION — установить идентификатор пользователя сеанса и идентификатор текущего пользователя для активного сеанса
Синтаксис
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION имя_пользователя
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT
RESET SESSION AUTHORIZATION
Описание
Эта команда устанавливает идентификатор пользователя сеанса и идентификатор текущего пользователя активного сеанса SQL как имя_пользователя. Имя пользователя может быть записано как идентификатор или строковая константа. Используя эту команду, можно, например, временно переключиться на непривилегированного пользователя, а затем снова переключиться на суперпользователя.
Идентификатор пользователя сеанса изначально задается как имя пользователя (возможно, прошедшего проверку подлинности), введенное клиентом. Идентификатор текущего пользователя обычно равен идентификатору пользователя сеанса, но может временно измениться в рамках функций с характеристикой SECURITY DEFINER и других схожих механизмов; также его можно изменить с помощью SET ROLE. Идентификатор текущего пользователя принимается во внимание при проверке разрешений.
Идентификатор пользователя сеанса может быть изменен, только если исходный пользователь сеанса (аутентифицированный пользователь) имел право суперпользователя. В противном случае команда принимается, только если в ней указано имя аутентифицированного пользователя.
Указания SESSION и LOCAL действуют так же, как и для обычной команды SET.
Формы DEFAULT и RESET сбрасывают идентификаторы текущего пользователя и пользователя сеанса, так что текущим становится изначально аутентифицированный пользователь. Эти формы может выполнить любой пользователь.
Примечания
Команду SET SESSION AUTHORIZATION нельзя использовать в функциях с характеристикой
SECURITY DEFINER.
Примеры
SELECT SESSION_USER, CURRENT_USER;
session_user | current_user
--------------+--------------
peter | peter
SET SESSION AUTHORIZATION 'paul';
SELECT SESSION_USER, CURRENT_USER;
session_user | current_user
--------------+--------------
paul | paul
Совместимость
Стандарт SQL позволяет вместо строковой константы имя_пользователя указывать некоторые другие выражения, но эти варианты не важны на практике. QHB допускает синтаксис идентификаторов (параметр «имя_пользователя»), а стандарт SQL — нет. SQL не разрешает выполнять эту команду во время транзакции; в QHB этого ограничения нет, потому что для него нет никаких причин. Указания SESSION и LOCAL являются расширением QHB, как и синтаксис RESET.
Права доступа, необходимые для выполнения этой команды, согласно стандарту, определяются реализацией.
См. также
SET TRANSACTION
SET TRANSACTION — установить характеристики текущей транзакции
Синтаксис
SET TRANSACTION режим_транзакции [, ...]
SET TRANSACTION SNAPSHOT id_снимка
SET SESSION CHARACTERISTICS AS TRANSACTION режим_транзакции [, ...]
где режим_транзакции является одним из следующих:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE
Описание
Команда SET TRANSACTION задает характеристики текущей транзакции. Она не
влияет на последующие транзакции. SET SESSION CHARACTERISTICS
задает характеристики транзакции по умолчанию для последующих транзакций
сеанса. Затем эти характеристики по умолчанию можно переопределить для отдельной
транзакции командой SET TRANSACTION.
Доступные характеристики транзакции — это уровень изоляции транзакции, режим доступа к транзакции (чтение/запись или только чтение) и режим отложенного доступа. Кроме того, можно выбрать снимок, но только для текущей транзакции, а не для сеанса по умолчанию.
Уровень изоляции транзакции определяет, какие данные транзакция может видеть, когда параллельно выполняются другие транзакции:
READ COMMITTED
Оператор может видеть только строки, зафиксированные до начала выполнения транзакции. Это значение по умолчанию.
REPEATABLE READ
Все операторы текущей транзакции могут видеть только строки, зафиксированные до выполнения первого запроса или оператора изменения данных в этой транзакции.
SERIALIZABLE
Все операторы текущей транзакции могут видеть только строки, зафиксированные до выполнения первого запроса или оператора изменения данных в этой транзакции. Если наложение операций чтения и записи среди параллельных сериализуемых транзакций создаст ситуацию, невозможную при однопоточном (поочередном) их выполнении, произойдет откат одной из транзакций с ошибкой serialization_failure (сбой сериализации).
Стандарт SQL определяет один дополнительный уровень, READ UNCOMMITTED. В QHB READ UNCOMMITTED трактуется как READ COMMITTED.
Уровень изоляции транзакции не может быть изменен после выполнения
первого запроса или оператора изменения данных (SELECT,
INSERT, DELETE, UPDATE, FETCH или COPY) в текущей транзакции.
Дополнительную информацию об изоляции транзакции см. в главе
Управление параллельным доступом.
Режим доступа к транзакции определяет, является ли транзакция доступной
для чтения/записи или только для чтения. Чтение/запись — это поведение по умолчанию.
Когда транзакция доступна только для чтения, запрещены следующие команды SQL:
INSERT, UPDATE, DELETE и COPY FROM (если таблица, в
которую будут писать, не является временной таблицей), любые команды CREATE,
ALTER и DROP, а также COMMENT, GRANT, REVOKE, TRUNCATE;
EXPLAIN ANALYZE и EXECUTE запрещаются, если команда, которую они будут
выполнять, находится в числе вышеперечисленных. Это высокоуровневое определение
режима только для чтения, которое не препятствует записи на диск.
Свойство DEFERRABLE транзакции не имеет эффекта, если транзакция не находится в режиме SERIALIZABLE и READ ONLY. Если для транзакции выбраны все три этих свойства, она может быть заблокирована при первой попытке получить свой снимок данных, после чего сможет выполняться без обычных для режима SERIALIZABLE накладных расходов и без какого-либо риска пострадать или быть отмененной из-за сбоя сериализации. Этот режим хорошо подходит для длительных построений отчетов или выполнения резервных копий.
Команда SET TRANSACTION SNAPSHOT позволяет выполнить новую транзакцию с тем
же снимком данных, что и существующая транзакция. Ранее существовавшая
транзакция должна экспортировать этот снимок с помощью функции
pg_export_snapshot (см. раздел Функции синхронизации снимков). Эта функция
возвращает идентификатор снимка, который необходимо передать команде
SET TRANSACTION SNAPSHOT, чтобы указать, какой снимок будет импортирован.
Идентификатор должен быть записан в виде строковой константы, например
’000003A1-1’. SET TRANSACTION SNAPSHOT может выполняться только в начале
транзакции, до выполнения первого запроса или оператора изменения данных
(SELECT, INSERT, DELETE, UPDATE, FETCH или COPY) этой транзакции.
Более того, в транзакции уже должен быть установлен уровень изоляции
SERIALIZABLE или REPEATABLE READ (иначе снимок будет
немедленно удален, так как на уровне READ COMMITTED создается новый снимок
для каждой команды). Если импортирующая транзакция имеет уровне изоляции
SERIALIZABLE, то транзакция, экспортировавшая снимок, тоже должна
использовать этот уровень изоляции. Кроме того, сериализуемая транзакция в режиме чтение/запись
не может импортировать снимок из транзакции в режиме «только чтение».
Примечания
При выполнении команды SET TRANSACTION без предварительного выполнения
START TRANSACTION или BEGIN будет выдано предупреждение и больше ничего
не произойдет.
Можно обойтись без SET TRANSACTION, указав вместо нее желаемый
режим_транзакции в операторах BEGIN или START TRANSACTION.
Но такой возможности не предусмотрено для SET TRANSACTION SNAPSHOT.
Режимы транзакций сеанса по умолчанию также можно задать в
параметрах конфигурации default_transaction_isolation,
default_transaction_read_only и default_transaction_deferrable.
(На самом деле SET SESSION CHARACTERISTICS — это более многословная
альтернатива для установки этих переменных с помощью команды SET.) Это
означает, что значения по умолчанию могут быть установлены в файле
конфигурации, через ALTER DATABASE и т.д. Дополнительную информацию см.
в главе Конфигурация сервера.
Примеры
Чтобы начать новую транзакцию со снимком данных, который получила уже существующая транзакция, его нужно сначала экспортировать из первой транзакции. При этом будет получен идентификатор снимка, например:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT pg_export_snapshot();
pg_export_snapshot
---------------------
00000003-0000001B-1
(1 строка)
Затем этот идентификатор нужно передать команде
SET TRANSACTION SNAPSHOT в начале новой транзакции:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET TRANSACTION SNAPSHOT '00000003-0000001B-1';
Совместимость
Эти команды определены в стандарте SQL, за исключением режима транзакции
DEFERRABLE и формы SET TRANSACTION SNAPSHOT, которые являются
расширениями QHB.
В стандарте уровнем изоляции транзакции по умолчанию является SERIALIZABLE. В QHB обычно используется значение по умолчанию READ COMMITTED, но, как упоминалось выше, его можно изменить.
В стандарте SQL есть еще одна характеристика транзакции, которую нельзя задать с помощью этих команд: размер диагностической области. Эта концепция специфична для встраиваемого SQL и поэтому не реализована в сервере QHB.
Стандарт SQL требует запятых между последовательными режимами_транзакции, но по историческим причинам QHB позволяет опустить запятые.
SET
SET — изменить параметр времени выполнения
Синтаксис
SET [ SESSION | LOCAL ] параметр_конфигурации { TO | = } { значение | 'значение' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { часовой_пояс | LOCAL | DEFAULT }
Описание
Команда SET изменяет параметры конфигурации времени выполнения.
С помощью SET можно динамически изменить многие из параметров времени
выполнения, перечисленных в главе Конфигурация сервера.
(Но некоторые из них требуют для изменения прав суперпользователя, а другие
нельзя изменить после запуска сервера или сеанса.) Команда SET влияет
только на значение, используемое в текущем сеансе.
Если команда SET (или эквивалентная ей SET SESSION) выполняется внутри
транзакции, которая позже прерывается, при откате транзакции эффекты команды
SET исчезают. Если же окружающая транзакция фиксируется, эффекты
сохранятся до конца сеанса, если их не переопределит другая команда SET.
Эффекты от выполнения SET LOCAL сохраняются только до конца текущей
транзакции, независимо от того, фиксируется она или нет. Особый случай
представляет использование SET с последующей SET LOCAL в пределах одной
транзакции: значение SET LOCAL будет сохраняться до конца
транзакции, но после этого (если транзакция зафиксирована)
восстановится значение, заданное командой SET.
Эффекты от выполнения SET или SET LOCAL также отменяются при откате к точке
сохранения, которая установлена до выполнения команды.
Если SET LOCAL используется в функции, где параметр SET
устанавливает значение той же переменной (см. CREATE FUNCTION), эффекты
действия SET LOCAL при выходе из функции исчезают, то есть в любом случае
восстанавливается значение, действующее при вызове функции. Это позволяет
устанавливать значение SET LOCAL для динамических или неоднократных
изменений параметра внутри функции, при этом благодаря SET имея
возможность сохранить и восстановить значение, полученное извне. Однако
обычная команда SET переопределяет любой параметр SET окружающей функции;
ее эффект будет сохраняться, если не произойдет откат транзакции.
Параметры
SESSION
Указывает, что команда вступает в силу для текущего сеанса. (Это значение по умолчанию, если не указано SESSION или LOCAL.)
LOCAL
Указывает, что команда вступает в силу только для текущей транзакции.
После выполнения COMMIT или ROLLBACK снова вступают в силу настройки
уровня сеанса. При выполнении такой команды вне блока транзакций будет выдано
предупреждение и больше ничего не произойдет.
параметр_конфигурации
Имя настраиваемого параметра времени выполнения. Доступные параметры описаны в главе Конфигурация сервера и ниже.
значение
Новое значение параметра. Значения можно указывать в виде строковых
констант, идентификаторов, чисел или разделенных запятыми списков из
них, в зависимости от конкретного параметра. Можно записать указание DEFAULT,
чтобы сбросить параметр к значению по умолчанию (то
есть к тому значению, которое он имел бы, если бы в текущем сеансе не
выполнялись команды SET).
Помимо параметров конфигурации, описанных в главе Конфигурация сервера,
есть несколько параметров, которые можно настроить только с помощью команды
SET или которые имеют специальный синтаксис:
SCHEMA
SET SCHEMA 'значение' является альтернативным написанием команды SET search_path TO значение. С помощью этого синтаксиса можно указать только одну схему.
NAMES
SET NAMES значение является альтернативным написанием команды SET client_encoding TO значение.
SEED
Задает внутреннее начальное значение для генератора случайных чисел (функции random). Допустимые значения — это числа с плавающей запятой от -1 до 1, которые затем умножаются на 231-1.
Начальное значение также может быть установлено путем вызова функции setseed:
SELECT setseed(значение);
TIME ZONE
SET TIME ZONE значение является альтернативным написанием команды SET timezone TO значение. Синтаксис SET TIME ZONE позволяет использовать специальный синтаксис для указания часового пояса. Вот примеры допустимых значений:
'PST8PDT'
Часовой пояс для города Беркли, штат Калифорния.
'Europe / Rome'
Часовой пояс для Италии.
-7
Часовой пояс, сдвинутый от UTC на 7 часов к западу (эквивалент PDT). Положительные значения означают сдвиг от UTC к востоку.
INTERVAL '-08:00' HOUR TO MINUTE
Часовой пояс, сдвинутый от UTC на 8 часов к западу (эквивалент PST).
LOCAL
DEFAULT
Устанавливает в качестве часового пояса местный часовой пояс (т. е. значение по умолчанию серверного параметра timezone).
Значения часового пояса, заданные в виде чисел или интервалов,
преобразуются внутри в формат часового пояса POSIX. Например,
после SET TIME ZONE -7 команда SHOW TIME ZONE покажет <-07>+07.
Дополнительную информацию о часовых поясах см. в разделе Часовые пояса.
Примечания
Изменить значение параметра можно также с помощью функции set_config; см.
раздел Функции системного администрирования. Кроме того, системное
представление pg_settings можно обновить командой UPDATE, что является
эквивалентом SET.
Примеры
Установка пути поиска схем:
SET search_path TO my_schema, public;
Установка традиционного стиля даты POSTGRES с форматом ввода «день, месяц, год»:
SET datestyle TO postgres, dmy;
Установка часового пояса для Беркли, штат Калифорния:
SET TIME ZONE 'PST8PDT';
Установка часового пояса Италии:
SET TIME ZONE 'Europe/Rome';
Совместимость
КомандаSET TIME ZONE расширяет синтаксис, определенный в стандарте
SQL. Стандарт допускает только числовые смещения часовых поясов, в то
время как QHB допускает для последних более гибкие спецификации.
Все остальные функции SET являются расширениями QHB.
См. также
SHOW
SHOW — показать значение параметра времени выполнения
Синтаксис
SHOW имя
SHOW ALL
Описание
Команда SHOW отображает текущую настройку параметров времени выполнения. Эти
переменные можно установить с помощью команды SET, путем
редактирования конфигурационного файла qhb.conf, через переменную
окружения PGOPTIONS (при использовании libpq или приложений на основе
libpq) или через параметры командной строки при запуске сервера QHB.
Дополнительную информацию см. в главе Конфигурация сервера.
Параметры
имя
Имя параметра времени выполнения. Доступные параметры описаны в главе Конфигурация сервера и в справочном разделе по команде SET. Кроме того, есть несколько параметров, которые могут быть показаны, но не установлены:
SERVER_VERSION
Показывает номер версии сервера.
SERVER_ENCODING
Показывает кодировку набора символов на стороне сервера. В настоящее время этот параметр может быть показан, но не задан, поскольку кодировка определяется во время создания базы данных.
LC_COLLATE
Показывает параметр локали базы данных для правил сортировки (упорядочение текста). В настоящее время этот параметр можно отобразить, но не задать, так как он определяется во время создания базы данных.
LC_CTYPE
Показывает параметр локали базы данных для классификации символов. В настоящее время этот параметр можно отобразить, но не задать, так как он определяется во время создания базы данных.
IS_SUPERUSER
Возвращает true, если текущая роль имеет права суперпользователя.
ALL
Показать значения всех параметров конфигурации с описаниями.
Примечания
Ту же информацию выдает функция current_setting; см. раздел Функции системного администрирования. Также эту информацию содержит системное представление pg_settings.
Примеры
Просмотр текущего значения параметра DateStyle:
SHOW DateStyle;
DateStyle
-----------
ISO, MDY
(1 row)
Просмотр текущего значения параметра geqo:
SHOW geqo;
geqo
------
on
(1 row)
Просмотр всех параметров:
SHOW ALL;
name | setting | description
-------------------------+---------+-------------------------------------------------
allow_system_table_mods | off | Allows modifications of the structure of ...
.
.
.
xmloption | content | Sets whether XML data in implicit parsing ...
zero_damaged_pages | off | Continues processing past damaged page headers.
(196 rows)
Совместимость
Команда SHOW является расширением QHB.
См. также
START TRANSACTION
START TRANSACTION — начать блок транзакции
Синтаксис
START TRANSACTION [ режим_транзакции [, ...] ]
где режим_транзакции может быть одним из следующих:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE
Описание
Эта команда начинает новый блок транзакции. Если указан уровень изоляции, режим чтения/записи или отложенный режим, то новая транзакция имеет те же характеристики, как если бы была выполнена команда SET TRANSACTION. Данная команда равнозначна команде BEGIN.
Параметры
Информацию о значении параметров для данной команды см. в описании SET TRANSACTION.
Совместимость
Согласно стандарту, необязательно выполнять команду START TRANSACTION,
чтобы начать блок транзакции: любая команда SQL неявно начинает блок.
Поведение QHB можно рассматривать как неявное выполнение
COMMIT после каждой команды, которая не следует за START TRANSACTION
(или BEGIN), и поэтому его часто называют «автоматической фиксацией». Другие системы
реляционных баз данных могут предлагать функцию автоматической фиксации в
качестве удобной возможности.
Значение DEFERRABLE параметра режим_транзакции является расширением языка QHB.
Стандарт SQL требует разделения последовательных режимов_транзакции запятыми, но по историческим причинам QHB позволяет их опустить.
Также сведения о совместимости см. в описании SET TRANSACTION.
См. также
BEGIN, COMMIT, ROLLBACK, SAVEPOINT, SET TRANSACTION
TRUNCATE
TRUNCATE — очистить таблицу или набор таблиц
Синтаксис
TRUNCATE [ TABLE ] [ ONLY ] имя [ * ] [, ... ]
[ RESTART IDENTITY | CONTINUE IDENTITY ] [ CASCADE | RESTRICT ]
Описание
Команда TRUNCATE быстро удаляет все строки из набора таблиц (очищает
таблицу). Она действует так же, как и выполненная без условий команда DELETE
для каждой заданной таблицы, но поскольку команда TRUNCATE фактически не
сканирует таблицы, она быстрее. Более того, она сразу же освобождает место
на диске и не требует последующей операции VACUUM. Это наиболее удобно
на больших таблицах.
Параметры
имя
Имя таблицы для очищения (может быть дополнено схемой). Если перед именем таблицы указывается ONLY, то очищается только эта таблица. Если ONLY не указано, очищаются таблица и все ее потомки (если таковые имеются). После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что включены дочерние таблицы.
RESTART IDENTITY
Автоматически перезапускать последовательности, принадлежащие столбцам очищаемой(ых) таблиц(ы).
CONTINUE IDENTITY
Не изменять значения последовательностей. Это поведение по умолчанию.
CASCADE
Автоматически выполнять TRUNCATE для всех таблиц, имеющих ссылки по
внешнему ключу на любую из заданных таблиц или на любые таблицы,
затронутые в результате действия CASCADE.
RESTRICT
Запретить очищение, если какая-либо таблица имеет ссылки по внешнему ключу из таблиц, которые не перечислены в команде. Это поведение по умолчанию.
Примечания
Чтобы очистить таблицу, необходимо иметь право TRUNCATE для этой таблицы.
Команда TRUNCATE запрашивает блокировку ACCESS EXCLUSIVE для каждой
таблицы, которую обрабатывает, тем самым блокируя все другие параллельные
операции на таблице. Когда указано RESTART IDENTITY, все последовательности,
которые должны быть перезапущены, также блокируются. Если требуется
параллельный доступ к таблице, следует использовать команду DELETE.
TRUNCATE нельзя использовать для таблицы, имеющей ссылки по внешним
ключам из других таблиц, если только все эти таблицы не очищаются в той
же команде. В таких случаях проверка допустимости операции потребует
сканирования таблиц, а весь смысл команды заключается в том, чтобы этого не
делать. Можно использовать CASCADE для автоматической обработки всех
зависимых таблиц — но будьте очень осторожны при использовании этого указания,
иначе можете потерять данные, которые не собирались удалять! В частности, следует отметить, что когда таблица, предназначенная к очищению, является партицией, родственные партиции остаются нетронутыми, но все без исключения связанные таблицы и их партиции подвергаются каскадному очищению.
При выполнении TRUNCATE не будут срабатывать триггеры ON DELETE, которые
могут существовать для таблиц. Но будут срабатывать триггеры ON TRUNCATE.
Если триггеры ON TRUNCATE определены для любой из таблиц, то все триггеры
BEFORE TRUNCATE срабатывают до того, как произойдет очищение, а все триггеры
AFTER TRUNCATE срабатывают после очищения последней таблицы из
списка и сброса всех последовательностей. Триггеры будут срабатывать в том же
порядке, в каком таблицы должны быть обработаны (сначала те, которые
перечислены в команде, а затем те, которые затрагиваются каскадно).
Команда TRUNCATE не является безопасной с точки зрения MVCC. После очищения
таблица будет выглядеть пустой для параллельных транзакций, если они используют снимок,
сделанный до того, как произошло очищение. Более подробную информацию см.
в разделе Ограничения.
TRUNCATE является безопасной транзакционной операцией по отношению к данным
в таблицах: если окружающая транзакция не будет зафиксирована,
очищение будет безопасно отменено.
Когда указывается RESTART IDENTITY, подразумеваемые команды
ALTER SEQUENCE RESTART также выполняются транзакционно, то есть они будут
отменены, если окружающая транзакция не будет зафиксирована. Обратите внимание,
что если перед откатом транзакции на повторно запущенных последовательностях выполняются какие-либо дополнительные операции,
эффект этих операций также будет отменен, но не их влияние на currval();
то есть после завершения транзакции currval() будет продолжать возвращать
последнее значение последовательности, полученное внутри неудачной транзакции,
даже если сама последовательность уже может быть не согласованной с ним.
Обычно подобным образом currval() ведет себя и после сбоя транзакции.
В настоящее время TRUNCATE не поддерживается для сторонних таблиц. Это
означает, что если у указанной таблицы есть какие-либо дочерние таблицы,
которые являются сторонними, команда завершится ошибкой.
Примеры
Очищение таблиц bigtable и fattable:
TRUNCATE bigtable, fattable;
Та же операция и сброс любых связанных генераторов последовательностей:
TRUNCATE bigtable, fattable RESTART IDENTITY;
Очищение таблицы othertable и каскадная обработка таблиц, которые ссылаются на othertable через ограничения внешнего ключа:
TRUNCATE othertable CASCADE;
Совместимость
Стандарт SQL:2008 включает команду TRUNCATE с синтаксисом
TRUNCATE TABLE имя_таблицы. Предложения CONTINUE IDENTITY/RESTART IDENTITY
также включены в стандарт, но имеют несколько другое, хотя и похожее назначение.
Согласно стандарту, поведение этой команды при параллельных операциях
определяется реализацией, поэтому при необходимости вышеуказанные примечания
следует рассматривать и сопоставлять с другими реализациями.
См. также
UNLISTEN
UNLISTEN — остановить прослушивание уведомления
Синтаксис
UNLISTEN { канал | * }
Описание
Команда UNLISTEN используется для удаления существующей подписки на события
NOTIFY. UNLISTEN отменяет любую существующую подписку текущего сеанса
QHB на канал уведомлений с именем канал. Специальный
знак * отменяет все подписки текущего сеанса.
Страница NOTIFY содержит более подробное описание команд LISTEN и NOTIFY.
Параметры
канал
Имя канала уведомления (любой идентификатор).
*
Все текущие подписки на уведомления для этого сеанса отменяются.
Примечания
Вы можете отменить подписку на канал, на который не подписаны; при этом не появится никакого предупреждения или ошибки.
В конце каждого сеанса UNLISTEN * выполняется автоматически.
Транзакцию, которая выполняла UNLISTEN, нельзя подготовить к
двухфазной фиксации.
Примеры
Подписка на получение события:
LISTEN virtual;
NOTIFY virtual;
Asynchronous notification "virtual" received from server process with PID 8448.
После того, как UNLISTEN была выполнена, дальнейшие сообщения NOTIFY будут
игнорироваться:
UNLISTEN virtual;
NOTIFY virtual;
-- событие NOTIFY не поступает
Совместимость
В стандарте SQL нет команды UNLISTEN.
См. также
UPDATE
UPDATE — изменить строки таблицы
Синтаксис
[ WITH [ RECURSIVE ] запрос_WITH [, ...] ]
UPDATE [ ONLY ] имя_таблицы [ * ] [ [ AS ] псевдоним ]
SET { имя_столбца = { выражение | DEFAULT } |
( имя_столбца [, ...] ) = [ ROW ] ( { выражение | DEFAULT } [, ...] ) |
( имя_столбца [, ...] ) = ( вложенный_SELECT )
} [, ...]
[ FROM элемент_FROM [, ...] ]
[ WHERE условие | WHERE CURRENT OF имя_курсора ]
[ RETURNING * | выражение_результата [ [ AS ] имя_результата ] [, ...] ]
Описание
Команда UPDATE изменяет значения указанных столбцов во всех строках,
удовлетворяющих условию. В предложении SET следует указывать только те столбцы,
которые необходимо изменить; столбцы, явно не измененные,
сохраняют свои предыдущие значения.
Существует два способа изменить строки в таблице, используя информацию, содержащуюся в других таблицах базы данных: с помощью подзапросов или указав дополнительные таблицы в предложении FROM. Какой метод является более подходящим, зависит от конкретных обстоятельств.
Необязательное предложение RETURNING указывает, что UPDATE должна
вычислить и возвратить значение(я) каждой фактически обновленной
строки. Можно вычислить любое выражение, использующее столбцы данной
таблицы и/или столбцы других таблиц, упомянутых в списке FROM. При этом
при вычислении используются новые (после обновления) значения столбцов таблицы.
Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Нужно иметь право UPDATE для таблицы или, по крайней мере, для столбцов, которые перечислены для обновления. Также необходимо иметь право SELECT для всех столбцов, значения которых считываются в выражениях или условии.
Параметры
запрос_WITH
Предложение WITH позволяет указать один или несколько вложенных
запросов, на которые можно ссылаться по имени в запросе UPDATE.
Дополнительную информацию см. в разделах Запросы WITH и SELECT.
имя_таблицы
Имя таблицы, подлежащей обновлению (может быть дополнено схемой). Если перед именем таблицы добавлено ONLY, соответствующие строки обновятся только в указанной таблице. Если ONLY не указано, строки также обновятся в любых таблицах, наследуемых от указанной. После имени таблицы можно добавить необязательное указание *, чтобы явно обозначить, что в операцию включены и дочерние таблицы.
псевдоним
Альтернативное имя целевой таблицы. Когда указывается псевдоним, он
полностью скрывает фактическое имя таблицы. Например, в запросе
UPDATE foo AS f остальная часть инструкции UPDATE должна ссылаться
на таблицу по имени f, а не foo.
имя_столбца
Имя столбца в таблице с именем имя_таблицы. При необходимости имя столбца можно
определить с помощью имени вложенного поля или индекса массива.
Имя таблицы добавлять к имени целевого столбца не нужно —
например, UPDATE table_name SET table_name.col = 1 является недопустимой командой.
выражение
Выражение, результат которого присваивается столбцу. Выражение может использовать предыдущие значения этого и других столбцов в таблице.
DEFAULT
Установить для столбца значение по умолчанию (которое будет равно NULL, если ему не было присвоено никакого конкретного выражения по умолчанию).
вложенный_SELECT
Подзапрос SELECT, который создает столько выходных столбцов, сколько перечислено в предшествующем ему списке столбцов, заключенном в скобки. Подзапрос должен выдавать не более одной строки. Если он выдает одну строку, значения его столбцов назначаются целевым столбцам; если он не возвращает строк, целевым столбцам назначаются значения NULL. Подзапрос может ссылаться на предыдущие значения текущей обновляемой строки таблицы.
элемент_FROM
Табличное выражение, позволяющее столбцам из других таблиц появляться в условии
WHERE и в обновленных выражениях. В нем используется тот же
синтаксис, что и в предложении FROM команды SELECT. Не повторяйте имя
целевой таблицы в предложении FROM, если не собираетесь определить замкнутое
соединение (в этом случае для данного имени в элемент_FROM должен появиться
псевдоним).
условие
Выражение, которое возвращает значение типа boolean. Будут обновлены только те строки, для которых это выражение возвращает true.
имя_курсора
Имя курсора, который будет использован в условии WHERE CURRENT OF.
С таким условием будет изменена строка, выбранная из этого курсора последней.
Курсор должен образовываться негруппирующим запросом к целевой таблице команды UPDATE. Обратите внимание, что WHERE CURRENT OF нельзя указывать
вместе с логическим условием. Дополнительную информацию об использовании
курсоров с помощью WHERE CURRENT OF см. в разделе DECLARE.
выражение_результата
Выражение, которое вычисляется и возвращается командой UPDATE после
обновления каждой строки. Выражение может использовать любые имена
столбцов таблицы имя_таблицы или таблиц, перечисленных в списке FROM.
Чтобы вернуть все столбцы, напишите *.
имя_результата
Имя, используемое для возвращаемого столбца.
Выводимая информация
После успешного завершения команда UPDATE возвращает метку команды
в форме
UPDATE число
Где число — это число обновленных строк, включая соответствующие строки, значения которых не изменились. Обратите внимание, что это число может быть меньше, чем число строк, которые соответствуют условию, когда обновления были подавлены триггером BEFORE UPDATE. Если число равно 0, значит, ни одна строка не была обновлена запросом (это не считается ошибкой).
Если команда UPDATE содержит предложение RETURNING, результат
будет похож на тот, что возвращает команда SELECT (содержащий столбцы и
значения, определенные в списке RETURNING), полученный для измененных этой
командой строк.
Примечания
Когда присутствует предложение FROM, целевая таблица, по сути, соединяется с таблицами из списка элемент_FROM, и каждая выходная строка соединения представляет собой операцию обновления для целевой таблицы. При использовании FROM необходимо убедиться, что соединение создает не более одной выходной строки для каждой строки, подлежащей изменению. Другими словами, целевая строка должна соединяться максимум с одной строкой из других таблиц. При нарушении данного условия для обновления целевой строки будет использоваться только одна из присоединенных строк, но какая именно, предсказать трудно.
Из-за этой неопределенности безопаснее ссылаться на другие таблицы только в пределах подзапросов, хотя такие конструкции зачастую труднее читаются и работают медленнее, чем при использовании соединения.
Применительно к партиционированной таблице обновление строки может привести к
тому, что она перестанет удовлетворять ограничению
содержащей ее партиции. В таком случае если в дереве партиционирования есть
какая-либо другая партиция, ограничению которой удовлетворяет эта строка,
последняя перемещается в эту партицию. Если такая
партиция отсутствует, произойдет ошибка. На самом деле движение строки
фактически является операцией DELETE и INSERT.
Существует вероятность того, что одновременное выполнение команд UPDATE или
DELETE перемещаемой строки приведет к ошибке сериализации.
Предположим, что сеанс 1 выполняет UPDATE ключа разбиения, и в это
же время параллельный сеанс 2, для которого эта строка видна, выполняет
операцию UPDATE или DELETE этой строки. В этом случае
UPDATE или DELETE сеанса 2 обнаружит перемещение строки и
вызовет ошибку сбоя сериализации (которая всегда возвращается с кодом
SQLSTATE ’40001’). Если это произойдет, приложения могут попытаться повторить
транзакцию. В обычных условиях, когда таблица не партиционирована или
нет никакого перемещения строки, сеанс 2 определил бы недавно
обновленную строку и выполнил бы UPDATE/DELETE на этой
новой версии строки.
Обратите внимание, что хотя строки могут быть перемещены из локальных партиций в партицию сторонней таблицы (при условии, что обертка сторонних данных поддерживает маршрутизацию кортежей), их нельзя переместить из партиции сторонней таблицы в другую партицию.
Примеры
Изменение слова Drama на Dramatic в столбце kind таблицы films:
UPDATE films SET kind = 'Dramatic' WHERE kind = 'Drama';
Изменение значений температуры и сброс уровня осадков к значению по умолчанию в одной строке таблицы weather:
UPDATE weather SET temp_lo = temp_lo+1, temp_hi = temp_lo+15, prcp = DEFAULT
WHERE city = 'San Francisco' AND date = '2003-07-03';
Выполнение той же операции с получением измененных записей:
UPDATE weather SET temp_lo = temp_lo+1, temp_hi = temp_lo+15, prcp = DEFAULT
WHERE city = 'San Francisco' AND date = '2003-07-03'
RETURNING temp_lo, temp_hi, prcp;
Такое же изменение с применением альтернативного синтаксиса со списком столбцов:
UPDATE weather SET (temp_lo, temp_hi, prcp) = (temp_lo+1, temp_lo+15, DEFAULT)
WHERE city = 'San Francisco' AND date = '2003-07-03';
Увеличение счетчика продаж для менеджера, занимающегося компанией Acme Corporation, с применением предложения FROM:
UPDATE employees SET sales_count = sales_count + 1 FROM accounts
WHERE accounts.name = 'Acme Corporation'
AND employees.id = accounts.sales_person;
Выполнение той же операции с подзапросом в предложении WHERE:
UPDATE employees SET sales_count = sales_count + 1 WHERE id =
(SELECT sales_person FROM accounts WHERE name = 'Acme Corporation');
Изменение имени контакта в таблице счетов (это должно быть имя назначенного менеджера по продажам):
UPDATE accounts SET (contact_first_name, contact_last_name) =
(SELECT first_name, last_name FROM salesmen
WHERE salesmen.id = accounts.sales_id);
Подобный результат можно получить, применив соединение:
UPDATE accounts SET contact_first_name = first_name,
contact_last_name = last_name
FROM salesmen WHERE salesmen.id = accounts.sales_id;
Однако если salesmen.id — не уникальный ключ, второй запрос может давать непредсказуемые результаты, тогда как первый запрос гарантированно выдаст ошибку, если найдется несколько записей с одним id. Кроме того, если не найдется запись, соответствующая запросу accounts.sales_id, первый запрос запишет в поля имени NULL, а второй вовсе не изменит строку.
Обновление статистики в сводной таблице в соответствии с текущими данными:
UPDATE summary s SET (sum_x, sum_y, avg_x, avg_y) =
(SELECT sum(x), sum(y), avg(x), avg(y) FROM data d
WHERE d.group_id = s.group_id);
Попытка добавить новый продукт вместе с количеством. Если такая запись уже существует, то вместо этого увеличить количество данного продукта в существующей записи. Чтобы реализовать этот подход, не откатывая всю транзакцию, можно использовать точки сохранения:
BEGIN;
-- другие операции
SAVEPOINT sp1;
INSERT INTO wines VALUES('Chateau Lafite 2003', '24');
-- Предполагая, что здесь возникает ошибка из-за нарушения уникальности ключа,
-- мы выполняем следующие команды:
ROLLBACK TO sp1;
UPDATE wines SET stock = stock + 24 WHERE winename = 'Chateau Lafite 2003';
-- Продолжение других операций и в завершение...
COMMIT;
Изменение значения столбца kind таблицы films в строке, на которой в данный момент находится курсор c_films:
UPDATE films SET kind = 'Dramatic' WHERE CURRENT OF c_films;
Совместимость
Команда UPDATE соответствует стандарту SQL, за исключением предложений FROM
и RETURNING, которые являются расширениями QHB, как
и возможность применять WITH с UPDATE.
В некоторых других СУБД также поддерживается дополнительное предложение FROM, но предполагается, что целевая таблица должна еще раз упоминаться в этом предложении. QHB интерпретирует FROM не так. Будьте осторожны при портировании приложений, которые используют это расширение.
Согласно стандарту, исходным значением для вложенного списка имен
целевых столбцов, данного в скобках, может быть любое строковое выражение,
возвращающее строку с правильным числом столбцов. QHB принимает в
качестве этого значения только конструктор строк или подзапрос SELECT.
Изменяемое значение отдельного столбца можно указать как DEFAULT в
конструкторе строки, но не внутри подзапроса SELECT.
VACUUM
VACUUM — почистить память и при необходимости проанализировать базу данных
Синтаксис
VACUUM [ ( параметр [, ...] ) ] [ таблица_и_столбцы [, ...] ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ ANALYZE ] [ таблица_и_столбцы [, ...] ]
Где параметр может быть следующим:
FULL [ логическое_значение ]
FREEZE [ логическое_значение ]
VERBOSE [ логическое_значение ]
ANALYZE [ логическое_значение ]
DISABLE_PAGE_SKIPPING [ логическое_значение ]
SKIP_LOCKED [ логическое_значение ]
INDEX_CLEANUP [ логическое_значение ]
TRUNCATE [ логическое_значение ]
PARALLEL целое_число
Где таблица_и_столбцы это:
имя_таблицы [ ( имя_столбца [, ...] ) ]
Описание
Команда VACUUM освобождает пространство, занятое «мертвыми» кортежами. В
обычной работе QHB удаленные или устаревшие из-за обновления
кортежи физически не удаляются из своей таблицы, а остаются в ней до
тех пор, пока не будет вызвана команда VACUUM. Поэтому VACUUM нужно периодически
запускать, особенно на часто обновляемых таблицах.
Без списка таблица_и_столбцы команда VACUUM обрабатывает каждую
таблицу и материализованное представление в текущей базе данных, на очистку
которых текущий пользователь имеет разрешение. При наличии списка
VACUUM обрабатывает только заданную таблицу(ы).
VACUUM ANALYZE выполняет VACUUM (очистку), а затем ANALYZE (анализ) для каждой
выбранной таблицы. Это удобная комбинированная форма для сценариев
регламентного обслуживания. Дополнительную информацию о его обработке
см. в разделе ANALYZE.
Обычный VACUUM (без FULL) просто восстанавливает пространство и
делает его доступным для повторного использования. Эта форма команды
может работать параллельно с обычным чтением и записью таблицы, так как
исключительная блокировка не возникает. Однако дополнительное
пространство не возвращается в операционную систему (в большинстве
случаев); оно просто остается доступным для повторного использования в
той же таблице. VACUUM FULL перезаписывает всё содержимое таблицы в
новый дисковый файл без дополнительного места, позволяя возвращать
неиспользуемое пространство в операционную систему. Эта форма работает
намного медленнее и при обработке требует исключительной блокировки для
каждой таблицы.
Когда список параметров заключен в скобки, эти параметры могут быть записаны в любом порядке. Без скобок параметры следует указывать точно в продемонстрированном выше порядке. Синтаксис без скобок является устаревшим.
Параметры
FULL
Выбирает «полную» очистку, которая может освободить больше места, но занимает гораздо больше времени и исключительно блокирует таблицы. Этот метод также требует дополнительного дискового пространства, так как он записывает новую копию таблицы и не освобождает старую копию до завершения операции. Обычно это следует использовать только тогда, когда требуется освободить значительное пространство внутри таблицы.
FREEZE
Выбирает агрессивное «замораживание» кортежей. Указание FREEZE
эквивалентно выполнению VACUUM с параметрами
vacuum_freeze_min_age и vacuum_freeze_table_age, установленными
в ноль. Агрессивное замораживание всегда выполняется при перезаписи
таблицы, поэтому при указании FULL этот параметр избыточен.
VERBOSE
Печатает подробный отчет о процедуре очистки для каждой таблицы.
ANALYZE
Обновляет статистику, используемую планировщиком для определения наиболее эффективного способа выполнения запроса.
DISABLE_PAGE_SKIPPING
Обычно VACUUM пропускает страницы, основанные на карте видимости.
Страницы, где все кортежи значатся замороженными, всегда можно
пропустить, а те, где все кортежи будут видны для всех
транзакций, можно пропустить, за исключением случаев, когда выполняется агрессивная
очистка. Кроме того, за тем же исключением, можно пропустить и некоторые страницы,
чтобы не ждать, когда их закончат использовать другие сеансы. Этот параметр
отключает все операции пропуска страниц и предназначен для использования
только в том случае, если содержимое карты видимости является
подозрительным, что должно происходить, только когда
существует аппаратная или программная проблема, вызывающая повреждение
базы данных.
SKIP_LOCKED
Указывает, что при начале работы над таблицей VACUUM не должен ждать
освобождения конфликтующих блокировок: если таблицу нельзя
немедленно заблокировать без ожидания, она пропускается.
Обратите внимание, что даже при использовании этого параметра VACUUM
по-прежнему может блокироваться при открытии индексов. Также
VACUUM ANALYZE может блокироваться при получении выборочных
строк из партиций, дочерних элементов наследования таблиц и некоторых
типов сторонних таблиц. Кроме того, хотя обычно VACUUM обрабатывает
все партиции указанных партиционированных таблиц, этот параметр позволит
VACUUM пропустить их, если на партиционированной таблице
имеется конфликтующая блокировка.
INDEX_CLEANUP
Указывает, что VACUUM должен пытаться удалить записи индекса,
указывающие на мертвые кортежи. Обычно это желаемое поведение
и значение по умолчанию, если только параметр vacuum_index_cleanup
подлежащей очистке таблицы не был установлен в значение false.
Установка этого параметра в значение false может быть полезна при
необходимости как можно сильнее ускорить процесс очистки, например, чтобы
избежать предстоящего обхода идентификатора транзакции
(см. раздел Предотвращение ошибок зацикливания идентификатора транзакции).
Однако без регулярной очистки индекса производительность
может пострадать, потому что при изменении таблицы
индексы будут накапливать мертвые кортежи, а сама таблица будет
накапливать указатели мертвых строк, которые нельзя удалить до
завершения очистки индекса. Данный параметр не действует для таблиц,
которые не имеют индекса, и игнорируется при использовании VACUUM FULL.
TRUNCATE
Указывает, что VACUUM должен попытаться обрезать любые пустые
страницы в конце таблицы и освободить дисковое пространство для усеченных
страниц, которые будут возвращены в операционную систему. Обычно это
желаемое поведение и значение по умолчанию, если только параметр
vacuum_truncate подлежащей очистке таблицы не был установлен
в значение false. Установка этого параметра в false может быть полезна,
чтобы избежать блокировки ACCESS EXCLUSIVE таблицы, которая требуется
для усечения. Этот параметр игнорируется при использовании FULL.
PARALLEL
Осуществляет фазы очистки и уборки индексов при параллельном выполнении VACUUM, используя целое_число фоновых рабочих процессов (подробную информацию о каждой фазе очистки см. в таблице Фазы VACUUM). Число рабочих процессов, используемых для этой операции, равно числу индексов в отношении, подходящих для параллельной очистки. Это число ограничено числом рабочих процессов, заданных с помощью параметра PARALLEL (если он указан), которые дополнительно ограничены параметром max_parallel_maintenance_workers. Индекс может обрабатываться в режиме параллельной очистки только в том случае, если размер этого индекса больше указанного в параметре min_parallel_index_scan_size. Пожалуйста, учтите, что это не гарантирует, что при выполнении данной операции будет задействовано столько параллельных рабочих процессов, сколько задано параметром целое_число. Вполне возможно, что в процессе очистки рабочие процессы будут использоваться в меньшем количестве или не будут использоваться вовсе. На обработку каждого индекса может быть задействован только один рабочий процесс, поэтому параллельные рабочие процессы запускаются, только если в таблице имеется как минимум 2 индекса. Рабочие процессы очистки запускаются до начала каждой фазы и завершаются после ее окончания. В будущих релизах это поведение может измениться. Данный параметр нельзя использовать вместе с FULL.
логическое_значение
Указывает, должен ли выбранный параметр быть включен или выключен. Можно написать TRUE, ON или 1, чтобы включить этот параметр, и FALSE, OFF или 0, чтобы отключить. логическое_значение может быть опущено, в этом случае предполагается TRUE.
целое_число
Указывает неотрицательное целое значение, передаваемое выбранному параметру.
имя_таблицы
Имя конкретной таблицы или материализованного представления, подлежащего очистке (может быть дополнено схемой). Если указанная таблица является партиционированной, все ее конечные партиции также очищаются.
имя_столбца
Имя конкретного столбца для анализа. По умолчанию производится анализ всех столбцов. Если указан список столбцов, также должно быть указано ANALYZE.
Вывод на консоль
Когда указывается VERBOSE, команда VACUUM выдает сообщения о том,
какая таблица обрабатывается в настоящее время. Также печатаются различные
статистические данные о таблицах.
Примечания
Чтобы очистить таблицу, обычно нужно быть ее владельцем или
суперпользователем. Однако владельцам баз данных разрешено очищать все
таблицы в своих базах данных, за исключением общих каталогов.
(Ограничение для общих каталогов означает, что истинную очистку всей
базы данных может выполнить только суперпользователь.) VACUUM будет
пропускать все таблицы, которые вызывающий пользователь не имеет права очищать.
Команду VACUUM нельзя выполнить внутри блока транзакций.
Для таблиц с индексами GIN VACUUM (в любой форме) также завершает
все отложенные добавления индекса, перемещая отложенные записи индекса в
соответствующие места в основной структуре индекса GIN. Дополнительную
информацию см. в разделе Быстрое обновление GIN.
Для удаления мертвых строк рекомендуется часто (хотя бы каждую ночь)
очищать активные промышленные базы данных. После добавления
или удаления большого количества строк может быть полезно выполнить
для обработанной таблицы команду VACUUM ANALYZE. Это позволит
обновить системные каталоги с результатами всех последних изменений, а
также позволит планировщику запросов QHB принимать лучшие решения
при планировании запросов.
Параметр FULL не рекомендуется для рутинного использования, но может
быть полезен в особых случаях. Например, если вы удалили или изменили
большую часть строк в таблице и хотели бы, чтобы таблица физически
уменьшилась, стала занимать меньше места на диске и позволила бы проводить более
быстрое сканирование таблицы. Обычно VACUUM FULL сжимает
таблицу более эффективно, чем простой VACUUM.
Параметр PARALLEL используется только в целях очистки. Если этот параметр указан вместе с ANALYZE, на работу ANALYZE он не влияет.
Команда VACUUM вызывает значительное увеличение трафика ввода/вывода, что
может привести к низкой производительности для других активных сеансов.
Поэтому иногда рекомендуется использовать функцию задержки очистки на
основе затрат. При параллельной очистке каждый рабочий процесс переходит в неактивный режим на время, пропорциональное объему произведенной им работы. Подробную информацию см. в разделе
Определение предела стоимости работы процесса очистки.
QHB включает в себя установку «autovacuum» (автоочистка), которая может автоматизировать регулярную очистку. Дополнительную информацию об автоматической и ручной очистке см. в разделе Регулярная очистка.
Примеры
Очистить одну таблицу onek, проанализировать ее для оптимизатора и распечатать подробный отчет о вакуумной активности:
VACUUM (VERBOSE, ANALYZE) onek;
Совместимость
В стандарте SQL нет команды VACUUM.
См. также
vacuumdb, Определение предела стоимости работы процесса очистки, Процесс «Автовакуум»
VALUES
VALUES — вычислить набор строк
Синтаксис
VALUES ( выражение [, ...] ) [, ...]
[ ORDER BY выражение_сортировки [ ASC | DESC | USING оператор ] [, ...] ]
[ LIMIT { число | ALL } ]
[ OFFSET начало [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ число ] { ROW | ROWS } ONLY ]
Описание
Команда VALUES вычисляет значение или набор значений строки, заданных
выражениями значений. Чаще всего она используется для формирования
«таблицы констант» в рамках более крупной команды, но может быть
использована и самостоятельно.
Если указано более одной строки, то все строки должны иметь одинаковое количество элементов. Типы данных столбцов результирующей таблицы определяются путем объединения явных и неявных типов выражений, заданных для этих столбцов, с использованием тех же правил, что и для UNION.
В составе других команд синтаксис допускает использование VALUES везде,
где допускается SELECT. Так как грамматически она воспринимается как SELECT,
с командой VALUES можно использовать предложения ORDER BY, LIMIT
(или равнозначное FETCH FIRST) и OFFSET.
Параметры
выражение
Константа или выражение, подлежащее для вычислению и добавлению в указанное место
в результирующей таблице (наборе строк). В списке VALUES, отображаемом
на верхнем уровне INSERT, выражение можно заменить на значение DEFAULT,
указывая, что должно быть добавлено значение по умолчанию столбца-получателя. DEFAULT
нельзя использовать, когда VALUES употребляется в других контекстах.
выражение_сортировки
Выражение или целочисленная константа, указывающая, как сортировать
результирующие строки. Это выражение может ссылаться на столбцы
результата VALUES по именам column1, column2 и т. д. Дополнительную
информацию см. в описании предложения ORDER BY команды SELECT.
оператор
Оператор сортировки. Дополнительную информацию см. в описании предложения ORDER BY команды SELECT.
число
Максимальное количество строк, которое должно быть возвращено. Дополнительную информацию см. в описании предложения LIMIT команды SELECT.
начало
Число строк, которые необходимо пропустить перед началом возврата строк. Дополнительную информацию см. в описании предложения LIMIT команды SELECT.
Примечания
Следует избегать списков VALUES с очень большим количеством строк, так
как можно столкнуться с нехваткой памяти или низкой производительностью.
Применение VALUES в команде INSERT является особым случаем
(поскольку нужные типы столбцов известны из целевой таблицы INSERT, и их
не надо вычислять, сканируя весь список VALUES), поэтому может обрабатывать
более объемные списки, чем это практично в других контекстах.
Примеры
Простая команда VALUES:
VALUES (1, 'one'), (2, 'two'), (3, 'three');
Эта команда выдаст таблицу из двух столбцов и трех строк. По сути она равнозначна запросу:
SELECT 1 AS column1, 'one' AS column2
UNION ALL
SELECT 2, 'two'
UNION ALL
SELECT 3, 'three';
Более часто VALUES используют в составе другой команды SQL.
Чаще всего она применяется в INSERT:
INSERT INTO films (code, title, did, date_prod, kind)
VALUES ('T_601', 'Yojimbo', 106, '1961-06-16', 'Drama');
В контексте INSERT список VALUES может содержать слово DEFAULT,
указывающее, что здесь вместо некоторого значения должно
использоваться значение столбца по умолчанию:
INSERT INTO films VALUES
('UA502', 'Bananas', 105, DEFAULT, 'Comedy', '82 minutes'),
('T_601', 'Yojimbo', 106, DEFAULT, 'Drama', DEFAULT);
VALUES также можно применять там, где есть возможность написать подзапрос SELECT, например,
в предложении FROM:
SELECT f.*
FROM films f, (VALUES('MGM', 'Horror'), ('UA', 'Sci-Fi')) AS t (studio, kind)
WHERE f.studio = t.studio AND f.kind = t.kind;
UPDATE employees SET salary = salary * v.increase
FROM (VALUES(1, 200000, 1.2), (2, 400000, 1.4)) AS v (depno, target, increase)
WHERE employees.depno = v.depno AND employees.sales >= v.target;
Обратите внимание, что когда VALUES используется в предложении FROM,
требуется предложение AS, как и для SELECT. При этом имена всех столбцов
указывать в AS не обязательно, но рекомендуется. (В QHB именами столбцов по умолчанию являются column1, column2 и т. д., но в других СУБД эти имена могут быть другими.)
Когда VALUES используется в команде INSERT, значения автоматически будут приведены
к типу данных соответствующего целевого столбца. Когда же она используется в других контекстах,
может потребоваться указать нужный тип данных. Если все записи представлены строковыми константами
в кавычках, достаточно привести к нужному типу значения в первой строке, чтобы задать тип для всех строк:
SELECT * FROM machines
WHERE ip_address IN (VALUES('192.168.0.1'::inet), ('192.168.0.10'), ('192.168.1.43'));
Совет
Для проверок на включение IN лучше полагаться на форму IN со списком скаляров, чем писать запрос VALUES, как показано выше. Метод со списком скаляров проще для записи и зачастую более эффективен.
Совместимость
Команда VALUES соответствует стандарту SQL. Параметры LIMIT и OFFSET являются
расширениями QHB; см. также раздел SELECT.
См. также
Приложения
Для данного раздела документация на русском языке пока присутствует не полностью, но мы над ней работаем.
Вы можете обратиться к официальной документации PostgreSQL по адресу https://www.postgresql.org/docs/
Коды ошибок QHB
Всем сообщениям, которые выдаёт сервер QHB, назначены пятисимвольные коды ошибок, соответствующие кодам «SQLSTATE», описанным в стандарте SQL. Приложения, которые должны знать, какое условие ошибки имело место, обычно проверяют код ошибки и только потом обращаются к текстовому сообщению об ошибке. Коды ошибок, скорее всего, не изменятся от выпуска к выпуску QHB, и они не меняются при локализации как сообщения об ошибках. Заметьте, что некоторые, но не все коды ошибок, которые выдаёт QHB, определены стандартом SQL; некоторые дополнительные коды ошибок для условий, не описанных стандартом, были добавлены независимо или позаимствованы из других баз данных.
Согласно стандарту, первые два символа кода ошибки обозначают класс ошибок, а последние три символа обозначают определённое условие в этом классе. Таким образом, приложение, не знающее значение определённого кода ошибки, всё же может понять, что делать, по классу ошибки.
В Таблице 1 перечислены все коды ошибок, определённые в QHB. (Некоторые из них в настоящее время не используются, хотя они определены в стандарте SQL.) Также показаны классы ошибок. Для каждого класса ошибок имеется «стандартный» код ошибки с последними тремя символами 000. Этот код выдаётся только для таких условий ошибок, которые относятся к некоторому классу, но у них нет более определённого кода.
Символ, указанный во втором столбце - имя условия в PL/pgSQL. Имена условий могут записываться в верхнем или нижнем регистре. (Заметьте, что PL/pgSQL, в отличие от ошибок, не распознаёт предупреждения; то есть классы 00, 01 и 02.)
Для некоторых типов ошибок сервер сообщает имя объекта базы данных (таблицу, столбец таблицы, тип данных или ограничение), связанного с ошибкой; например, имя уникального ограничения, вызвавшего ошибку unique_violation. Такие имена передаются в отдельных полях сообщения об ошибке, чтобы приложениям не пришлось извлекать его из возможно локализованного текста ошибки для человека. На момент выхода PostgreSQL 9.3 полностью покрывались этой особенностью только ошибки класса SQLSTATE 23 (нарушения ограничений целостности), но в будущем вероятно будут охвачены и другие классы.
Таблица 1. Коды ошибок QHB
| Код ошибки | Имя условия |
|---|---|
| Класс 00 — Успешное завершение | |
| 00000 | successful_completion |
| Класс 01 — Предупреждение | |
| 01000 | warning |
| 0100C | dynamic_result_sets_returned |
| 01008 | implicit_zero_bit_padding |
| 01003 | null_value_eliminated_in_set_function |
| 01007 | privilege_not_granted |
| 01006 | privilege_not_revoked |
| 01004 | string_data_right_truncation |
| 01P01 | deprecated_feature |
| Класс 02 — Нет данных (это также класс предупреждений согласно стандарту SQL) | |
| 02000 | no_data |
| 02001 | no_additional_dynamic_result_sets_returned |
| Класс 03 — SQL-оператор ещё не завершён | |
| 03000 | sql_statement_not_yet_complete |
| Класс 08 — Исключение, связанное с подключением | |
| 08000 | connection_exception |
| 08003 | connection_does_not_exist |
| 08006 | connection_failure |
| 08001 | sqlclient_unable_to_establish_sqlconnection |
| 08004 | sqlserver_rejected_establishment_of_sqlconnection |
| 08007 | transaction_resolution_unknown |
| 08P01 | protocol_violation |
| Класс 09 — Исключение с действием триггера | |
| 09000 | triggered_action_exception |
| Класс 0A — Неподдерживаемая функциональность | |
| 0A000 | feature_not_supported |
| Класс 0B — Неверное начало транзакции | |
| 0B000 | invalid_transaction_initiation |
| Класс 0F — Исключение с указателем на данные | |
| 0F000 | locator_exception |
| 0F001 | invalid_locator_specification |
| Класс 0L — Неверный праводатель | |
| 0L000 | invalid_grantor |
| 0LP01 | invalid_grant_operation |
| Класс 0P — Неверное указание роли | |
| 0P000 | invalid_role_specification |
| Класс 0Z — Исключение диагностики | |
| 0Z000 | diagnostics_exception |
| 0Z002 | stacked_diagnostics_accessed_without_active_handler |
| Класс 20 — Case не найден | |
| 20000 | case_not_found |
| Класс 21 — Нарушение количества | |
| 21000 | cardinality_violation |
| Класс 22 — Исключение в данных | |
| 22000 | data_exception |
| 2202E | array_subscript_error |
| 22021 | character_not_in_repertoire |
| 22008 | datetime_field_overflow |
| 22012 | division_by_zero |
| 22005 | error_in_assignment |
| 2200B | escape_character_conflict |
| 22022 | indicator_overflow |
| 22015 | interval_field_overflow |
| 2201E | invalid_argument_for_logarithm |
| 22014 | invalid_argument_for_ntile_function |
| 22016 | invalid_argument_for_nth_value_function |
| 2201F | invalid_argument_for_power_function |
| 2201G | invalid_argument_for_width_bucket_function |
| 22018 | invalid_character_value_for_cast |
| 22007 | invalid_datetime_format |
| 22019 | invalid_escape_character |
| 2200D | invalid_escape_octet |
| 22025 | invalid_escape_sequence |
| 22P06 | nonstandard_use_of_escape_character |
| 22010 | invalid_indicator_parameter_value |
| 22023 | invalid_parameter_value |
| 22013 | invalid_preceding_or_following_size |
| 2201B | invalid_regular_expression |
| 2201W | invalid_row_count_in_limit_clause |
| 2201X | invalid_row_count_in_result_offset_clause |
| 2202H | invalid_tablesample_argument |
| 2202G | invalid_tablesample_repeat |
| 22009 | invalid_time_zone_displacement_value |
| 2200C | invalid_use_of_escape_character |
| 2200G | most_specific_type_mismatch |
| 22004 | null_value_not_allowed |
| 22002 | null_value_no_indicator_parameter |
| 22003 | numeric_value_out_of_range |
| 2200H | sequence_generator_limit_exceeded |
| 22026 | string_data_length_mismatch |
| 22001 | string_data_right_truncation |
| 22011 | substring_error |
| 22027 | trim_error |
| 22024 | unterminated_c_string |
| 2200F | zero_length_character_string |
| 22P01 | floating_point_exception |
| 22P02 | invalid_text_representation |
| 22P03 | invalid_binary_representation |
| 22P04 | bad_copy_file_format |
| 22P05 | untranslatable_character |
| 2200L | not_an_xml_document |
| 2200M | invalid_xml_document |
| 2200N | invalid_xml_content |
| 2200S | invalid_xml_comment |
| 2200T | invalid_xml_processing_instruction |
| 22030 | duplicate_json_object_key_value |
| 22032 | invalid_json_text |
| 22033 | invalid_sql_json_subscript |
| 22034 | more_than_one_sql_json_item |
| 22035 | no_sql_json_item |
| 22036 | non_numeric_sql_json_item |
| 22037 | non_unique_keys_in_a_json_object |
| 22038 | singleton_sql_json_item_required |
| 22039 | sql_json_array_not_found |
| 2203A | sql_json_member_not_found |
| 2203B | sql_json_number_not_found |
| 2203C | sql_json_object_not_found |
| 2203D | too_many_json_array_elements |
| 2203E | too_many_json_object_members |
| 2203F | sql_json_scalar_required |
| Класс 23 — Нарушение ограничения целостности | |
| 23000 | integrity_constraint_violation |
| 23001 | restrict_violation |
| 23502 | not_null_violation |
| 23503 | foreign_key_violation |
| 23505 | unique_violation |
| 23514 | check_violation |
| 23P01 | exclusion_violation |
| Класс 24 — Неверное состояние курсора | |
| 24000 | invalid_cursor_state |
| Класс 25 — Неверное состояние транзакции | |
| 25000 | invalid_transaction_state |
| 25001 | active_sql_transaction |
| 25002 | branch_transaction_already_active |
| 25008 | held_cursor_requires_same_isolation_level |
| 25003 | inappropriate_access_mode_for_branch_transaction |
| 25004 | inappropriate_isolation_level_for_branch_transaction |
| 25005 | no_active_sql_transaction_for_branch_transaction |
| 25006 | read_only_sql_transaction |
| 25007 | schema_and_data_statement_mixing_not_supported |
| 25P01 | no_active_sql_transaction |
| 25P02 | in_failed_sql_transaction |
| 25P03 | idle_in_transaction_session_timeout |
| Класс 26 — Неверное имя SQL-оператора | |
| 26000 | invalid_sql_statement_name |
| Класс 27 — Нарушение при изменении данных в триггере | |
| 27000 | triggered_data_change_violation |
| Класс 28 — Неверное указание авторизации | |
| 28000 | invalid_authorization_specification |
| 28P01 | invalid_password |
| Класс 2B — Зависимые описания привилегий всё ещё существуют | |
| 2B000 | dependent_privilege_descriptors_still_exist |
| 2BP01 | dependent_objects_still_exist |
| Класс 2D — Неверное завершение транзакции | |
| 2D000 | invalid_transaction_termination |
| Класс 2F — Исключение в подпрограмме SQL | |
| 2F000 | sql_routine_exception |
| 2F005 | function_executed_no_return_statement |
| 2F002 | modifying_sql_data_not_permitted |
| 2F003 | prohibited_sql_statement_attempted |
| 2F004 | reading_sql_data_not_permitted |
| Класс 34 — Неверное имя курсора | |
| 34000 | invalid_cursor_name |
| Класс 38 — Исключение во внешней подпрограмме | |
| 38000 | external_routine_exception |
| 38001 | containing_sql_not_permitted |
| 38002 | modifying_sql_data_not_permitted |
| 38003 | prohibited_sql_statement_attempted |
| 38004 | reading_sql_data_not_permitted |
| Класс 39 — Исключение при вызове внешней подпрограммы | |
| 39000 | external_routine_invocation_exception |
| 39001 | invalid_sqlstate_returned |
| 39004 | null_value_not_allowed |
| 39P01 | trigger_protocol_violated |
| 39P02 | srf_protocol_violated |
| 39P03 | event_trigger_protocol_violated |
| Класс 3B — Исключение точки сохранения | |
| 3B000 | savepoint_exception |
| 3B001 | invalid_savepoint_specification |
| Класс 3D — Неверное имя каталога | |
| 3D000 | invalid_catalog_name |
| Класс 3F — Неверное имя схемы | |
| 3F000 | invalid_schema_name |
| Класс 40 — Откат транзакции | |
| 40000 | transaction_rollback |
| 40002 | transaction_integrity_constraint_violation |
| 40001 | serialization_failure |
| 40003 | statement_completion_unknown |
| 40P01 | deadlock_detected |
| Класс 42 — Ошибка синтаксиса или нарушение правила доступа | |
| 42000 | syntax_error_or_access_rule_violation |
| 42601 | syntax_error |
| 42501 | insufficient_privilege |
| 42846 | cannot_coerce |
| 42803 | grouping_error |
| 42P20 | windowing_error |
| 42P19 | invalid_recursion |
| 42830 | invalid_foreign_key |
| 42602 | invalid_name |
| 42622 | name_too_long |
| 42939 | reserved_name |
| 42804 | datatype_mismatch |
| 42P18 | indeterminate_datatype |
| 42P21 | collation_mismatch |
| 42P22 | indeterminate_collation |
| 42809 | wrong_object_type |
| 428C9 | generated_always |
| 42703 | undefined_column |
| 42883 | undefined_function |
| 42P01 | undefined_table |
| 42P02 | undefined_parameter |
| 42704 | undefined_object |
| 42701 | duplicate_column |
| 42P03 | duplicate_cursor |
| 42P04 | duplicate_database |
| 42723 | duplicate_function |
| 42P05 | duplicate_prepared_statement |
| 42P06 | duplicate_schema |
| 42P07 | duplicate_table |
| 42712 | duplicate_alias |
| 42710 | duplicate_object |
| 42702 | ambiguous_column |
| 42725 | ambiguous_function |
| 42P08 | ambiguous_parameter |
| 42P09 | ambiguous_alias |
| 42P10 | invalid_column_reference |
| 42611 | invalid_column_definition |
| 42P11 | invalid_cursor_definition |
| 42P12 | invalid_database_definition |
| 42P13 | invalid_function_definition |
| 42P14 | invalid_prepared_statement_definition |
| 42P15 | invalid_schema_definition |
| 42P16 | invalid_table_definition |
| 42P17 | invalid_object_definition |
| Класс 44 — Нарушение WITH CHECK OPTION | |
| 44000 | with_check_option_violation |
| Класс 53 — Нехватка ресурсов | |
| 53000 | insufficient_resources |
| 53100 | disk_full |
| 53200 | out_of_memory |
| 53300 | too_many_connections |
| 53400 | configuration_limit_exceeded |
| Класс 54 — Превышение ограничения программы | |
| 54000 | program_limit_exceeded |
| 54001 | statement_too_complex |
| 54011 | too_many_columns |
| 54023 | too_many_arguments |
| Класс 55 — Объект не в требуемом состоянии | |
| 55000 | object_not_in_prerequisite_state |
| 55006 | object_in_use |
| 55P02 | cant_change_runtime_param |
| 55P03 | lock_not_available |
| 55P04 | unsafe_new_enum_value_usage |
| Класс 57 — Вмешательство оператора | |
| 57000 | operator_intervention |
| 57014 | query_canceled |
| 57P01 | admin_shutdown |
| 57P02 | crash_shutdown |
| 57P03 | cannot_connect_now |
| 57P04 | database_dropped |
| Класс 58 — Ошибка системы (ошибка, внешняя по отношению к PostgreSQL) | |
| 58000 | system_error |
| 58030 | io_error |
| 58P01 | undefined_file |
| 58P02 | duplicate_file |
| Класс 72 — Ошибка снимка | |
| 72000 | snapshot_too_old |
| Класс F0 — Ошибка файла конфигурации | |
| F0000 | config_file_error |
| F0001 | lock_file_exists |
| Класс HV — Ошибка обёртки сторонних данных (SQL/MED) | |
| HV000 | fdw_error |
| HV005 | fdw_column_name_not_found |
| HV002 | fdw_dynamic_parameter_value_needed |
| HV010 | fdw_function_sequence_error |
| HV021 | fdw_inconsistent_descriptor_information |
| HV024 | fdw_invalid_attribute_value |
| HV007 | fdw_invalid_column_name |
| HV008 | fdw_invalid_column_number |
| HV004 | fdw_invalid_data_type |
| HV006 | fdw_invalid_data_type_descriptors |
| HV091 | fdw_invalid_descriptor_field_identifier |
| HV00B | fdw_invalid_handle |
| HV00C | fdw_invalid_option_index |
| HV00D | fdw_invalid_option_name |
| HV090 | fdw_invalid_string_length_or_buffer_length |
| HV00A | fdw_invalid_string_format |
| HV009 | fdw_invalid_use_of_null_pointer |
| HV014 | fdw_too_many_handles |
| HV001 | fdw_out_of_memory |
| HV00P | fdw_no_schemas |
| HV00J | fdw_option_name_not_found |
| HV00K | fdw_reply_handle |
| HV00Q | fdw_schema_not_found |
| HV00R | fdw_table_not_found |
| HV00L | fdw_unable_to_create_execution |
| HV00M | fdw_unable_to_create_reply |
| HV00N | fdw_unable_to_establish_connection |
| Класс P0 — Ошибка PL/pgSQL | |
| P0000 | plpgsql_error |
| P0001 | raise_exception |
| P0002 | no_data_found |
| P0003 | too_many_rows |
| P0004 | assert_failure |
| Класс XX — Внутренняя ошибка | |
| XX000 | internal_error |
| XX001 | data_corrupted |
| XX002 | index_corrupted |
Расширения QHB
Для данного раздела пока отсутствует документация на русском языке.
Вы можете обратиться к официальной документации PostgreSQL по адресу https://www.postgresql.org/docs/
Ключевые слова SQL
В таблице перечислены все токены, которые являются ключевыми словами в стандарте SQL и в QHB. Исходную информацию можно найти в разделе Лексическая-структура (для исторического сравнения включены только две последние версии стандарта SQL и SQL-92. Различия между этими и другими промежуточными стандартными версиями невелики).
SQL различает зарезервированные и незарезервированные ключевые слова. Согласно стандарту, зарезервированные ключевые слова являются полноценными ключевыми словами; они никогда не допускаются в качестве идентификаторов. Незарезервированные ключевые слова имеют особое значение только в определенных контекстах и могут использоваться в качестве идентификаторов в других контекстах. Большинство незарезервированных ключевых слов на самом деле являются именами встроенных таблиц и функций, определенных SQL. Концепция незарезервированных ключевых слов, существует только для того, чтобы объявить, что в некоторых контекстах слову сопоставляется какое-то предопределенное значение.
В парсере QHB существует несколько различных классов токенов, начиная от
тех, которые никогда не могут использоваться в качестве идентификатора,
до тех, которые не имеют никакого специального статуса в
анализаторе по сравнению с обычным идентификатором. (Последнее обычно
имеет место для функций, определенных SQL.) Даже зарезервированные
ключевые слова не могут
использоваться в качестве меток столбцов (например, SELECT 55 AS CHECK,
даже если CHECK является зарезервированным ключевым словом).
В таблице в столбце для QHB как «non-reserved» определяются те ключевые слова, которые явно известны синтаксическому анализатору, но допускаются как имена столбцов или таблиц. Некоторые ключевые слова, которые в противном случае являются незарезервированными, не могут использоваться в качестве имен функций или типов данных и помечаются соответствующим образом. (Большинство этих слов представляют собой встроенные функции или типы данных со специальным синтаксисом. Функция или тип все еще доступны, но уже не могут быть переопределены пользователем.) Пометкой «reserved» обозначаются те токены, которые не допускаются в качестве имен столбцов или таблиц. Некоторые зарезервированные ключевые слова допустимы в качестве имен для функций или типов данных; это также показано в таблице. Если не отмечено, зарезервированное ключевое слово допускается только в качестве имени метки столбца «AS».
Как правило, если вы получаете ложные ошибки синтаксического анализатора для команд, которые содержат любое из перечисленных ключевых слов в качестве идентификатора, вы должны попытаться заключить в кавычки идентификатор, чтобы увидеть, исчезнет ли проблема.
Перед изучением таблицы важно понять, что тот факт, что ключевое слово не зарезервировано в QHB, не означает, что функция, связанная со словом, не реализована. И наоборот, наличие ключевого слова не указывает на наличие функции.
Таблица Ключевые слова SQL
| Ключевое слово | QHB/PostreSQL | SQL: 2016 | SQL: 2011 | SQL-92 |
|---|---|---|---|---|
| A | non-reserved | non-reserved | ||
| ABORT | non-reserved | |||
| ABS | reserved | reserved | ||
| ABSENT | non-reserved | non-reserved | ||
| ABSOLUTE | non-reserved | non-reserved | non-reserved | reserved |
| ACCESS | non-reserved | |||
| ACCORDING | non-reserved | non-reserved | ||
| ACOS | reserved | |||
| ACTION | non-reserved | non-reserved | non-reserved | reserved |
| ADA | non-reserved | non-reserved | non-reserved | |
| ADD | non-reserved | non-reserved | non-reserved | reserved |
| ADMIN | non-reserved | non-reserved | non-reserved | |
| AFTER | non-reserved | non-reserved | non-reserved | |
| AGGREGATE | non-reserved | |||
| ALL | reserved | reserved | reserved | reserved |
| ALLOCATE | reserved | reserved | reserved | |
| ALSO | non-reserved | |||
| ALTER | non-reserved | reserved | reserved | reserved |
| ALWAYS | non-reserved | non-reserved | non-reserved | |
| ANALYSE | reserved | |||
| ANALYZE | reserved | |||
| AND | reserved | reserved | reserved | reserved |
| ANY | reserved | reserved | reserved | reserved |
| APPEND_ONLY | reserved (может быть функцией или типом) | non-reserved | non-reserved | non-reserved |
| ARE | reserved | reserved | reserved | |
| ARRAY | reserved | reserved | reserved | |
| ARRAY_AGG | reserved | reserved | ||
| ARRAY_MAX_CARDINALITY | reserved | reserved | ||
| AS | reserved | reserved | reserved | reserved |
| ASC | reserved | non-reserved | non-reserved | reserved |
| ASENSITIVE | reserved | reserved | ||
| ASIN | reserved | |||
| ASSERTION | non-reserved | non-reserved | non-reserved | reserved |
| ASSIGNMENT | non-reserved | non-reserved | non-reserved | |
| ASYMMETRIC | reserved | reserved | reserved | |
| AT | non-reserved | reserved | reserved | reserved |
| ATAN | reserved | |||
| ATOMIC | reserved | reserved | ||
| ATTACH | non-reserved | |||
| ATTRIBUTE | non-reserved | non-reserved | non-reserved | |
| ATTRIBUTES | non-reserved | non-reserved | ||
| AUTHORIZATION | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| AVG | reserved | reserved | reserved | |
| BACKWARD | non-reserved | |||
| BASE64 | non-reserved | non-reserved | ||
| BEFORE | non-reserved | non-reserved | non-reserved | |
| BEGIN | non-reserved | reserved | reserved | reserved |
| BEGIN_FRAME | reserved | reserved | ||
| BEGIN_PARTITION | reserved | reserved | ||
| BERNOULLI | non-reserved | non-reserved | ||
| BETWEEN | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| BIGINT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| BINARY | reserved (может быть функцией или типом) | reserved | reserved | |
| BIT | non-reserved (не может быть функцией или типом) | reserved | ||
| BIT_LENGTH | reserved | |||
| BLOB | reserved | reserved | ||
| BLOCKED | non-reserved | non-reserved | ||
| BOM | non-reserved | non-reserved | ||
| BOOLEAN | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| BOTH | reserved | reserved | reserved | reserved |
| BREADTH | non-reserved | non-reserved | ||
| BY | non-reserved | reserved | reserved | reserved |
| C | non-reserved | non-reserved | non-reserved | |
| CACHE | non-reserved | |||
| CALL | non-reserved | reserved | reserved | |
| CALLED | non-reserved | reserved | reserved | |
| CARDINALITY | reserved | reserved | ||
| CASCADE | non-reserved | non-reserved | non-reserved | reserved |
| CASCADED | non-reserved | reserved | reserved | reserved |
| CASE | reserved | reserved | reserved | reserved |
| CAST | reserved | reserved | reserved | reserved |
| CATALOG | non-reserved | non-reserved | non-reserved | reserved |
| CATALOG_NAME | non-reserved | non-reserved | non-reserved | |
| CEIL | reserved | reserved | ||
| CEILING | reserved | reserved | ||
| CHAIN | non-reserved | non-reserved | non-reserved | |
| CHAINING | non-reserved | |||
| CHAR | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| CHARACTER | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| CHARACTERISTICS | non-reserved | non-reserved | non-reserved | |
| CHARACTERS | non-reserved | non-reserved | ||
| CHARACTER_LENGTH | reserved | reserved | reserved | |
| CHARACTER_SET_CATALOG | non-reserved | non-reserved | non-reserved | |
| CHARACTER_SET_NAME | non-reserved | non-reserved | non-reserved | |
| CHARACTER_SET_SCHEMA | non-reserved | non-reserved | non-reserved | |
| CHAR_LENGTH | reserved | reserved | reserved | |
| CHECK | reserved | reserved | reserved | reserved |
| CHECKPOINT | non-reserved | |||
| CLASS | non-reserved | |||
| CLASSIFIER | reserved | |||
| CLASS_ORIGIN | non-reserved | non-reserved | non-reserved | |
| CLOB | reserved | reserved | ||
| CLOSE | non-reserved | reserved | reserved | reserved |
| CLUSTER | non-reserved | |||
| COALESCE | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| COBOL | non-reserved | non-reserved | non-reserved | |
| COLLATE | reserved | reserved | reserved | reserved |
| COLLATION | reserved (может быть функцией или типом) | non-reserved | non-reserved | reserved |
| COLLATION_CATALOG | non-reserved | non-reserved | non-reserved | |
| COLLATION_NAME | non-reserved | non-reserved | non-reserved | |
| COLLATION_SCHEMA | non-reserved | non-reserved | non-reserved | |
| COLLECT | reserved | reserved | ||
| COLUMN | reserved | reserved | reserved | reserved |
| COLUMNS | non-reserved | non-reserved | non-reserved | |
| COLUMN_NAME | non-reserved | non-reserved | non-reserved | |
| COMMAND_FUNCTION | non-reserved | non-reserved | non-reserved | |
| COMMAND_FUNCTION_CODE | non-reserved | non-reserved | ||
| COMMENT | non-reserved | |||
| COMMENTS | non-reserved | |||
| COMMIT | non-reserved | reserved | reserved | reserved |
| COMMITTED | non-reserved | non-reserved | non-reserved | non-reserved |
| CONCURRENTLY | reserved (может быть функцией или типом) | |||
| CONDITION | reserved | reserved | ||
| CONDITIONAL | non-reserved | |||
| CONDITION_NUMBER | non-reserved | non-reserved | non-reserved | |
| CONFIGURATION | non-reserved | |||
| CONFLICT | non-reserved | |||
| CONNECT | reserved | reserved | reserved | |
| CONNECTION | non-reserved | non-reserved | non-reserved | reserved |
| CONNECTION_NAME | non-reserved | non-reserved | non-reserved | |
| CONSTRAINT | reserved | reserved | reserved | reserved |
| CONSTRAINTS | non-reserved | non-reserved | non-reserved | reserved |
| CONSTRAINT_CATALOG | non-reserved | non-reserved | non-reserved | |
| CONSTRAINT_NAME | non-reserved | non-reserved | non-reserved | |
| CONSTRAINT_SCHEMA | non-reserved | non-reserved | non-reserved | |
| CONSTRUCTOR | non-reserved | non-reserved | ||
| CONTAINS | reserved | reserved | ||
| CONTENT | non-reserved | non-reserved | non-reserved | |
| CONTINUE | non-reserved | non-reserved | non-reserved | reserved |
| CONTROL | non-reserved | non-reserved | ||
| CONVERSION | non-reserved | |||
| CONVERT | reserved | reserved | reserved | |
| COPY | non-reserved | reserved | ||
| CORR | reserved | reserved | ||
| CORRESPONDING | reserved | reserved | reserved | |
| COS | reserved | |||
| COSH | reserved | |||
| COST | non-reserved | |||
| COUNT | reserved | reserved | reserved | |
| COVAR_POP | reserved | reserved | ||
| COVAR_SAMP | reserved | reserved | ||
| CREATE | reserved | reserved | reserved | reserved |
| CROSS | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| CSV | non-reserved | |||
| CUBE | non-reserved | reserved | reserved | |
| CUME_DIST | reserved | reserved | ||
| CURRENT | non-reserved | reserved | reserved | reserved |
| CURRENT_CATALOG | reserved | reserved | reserved | |
| CURRENT_DATE | reserved | reserved | reserved | reserved |
| CURRENT_DEFAULT_TRANSFORM_GROUP | reserved | reserved | ||
| CURRENT_PATH | reserved | reserved | ||
| CURRENT_ROLE | reserved | reserved | reserved | |
| CURRENT_ROW | reserved | reserved | ||
| CURRENT_SCHEMA | reserved (может быть функцией или типом) | reserved | reserved | |
| CURRENT_TIME | reserved | reserved | reserved | reserved |
| CURRENT_TIMESTAMP | reserved | reserved | reserved | reserved |
| CURRENT_TRANSFORM_GROUP_FOR_TYPE | reserved | reserved | ||
| CURRENT_USER | reserved | reserved | reserved | reserved |
| CURSOR | non-reserved | reserved | reserved | reserved |
| CURSOR_NAME | non-reserved | non-reserved | non-reserved | |
| CYCLE | non-reserved | reserved | reserved | |
| DATA | non-reserved | non-reserved | non-reserved | non-reserved |
| DATABASE | non-reserved | |||
| DATALINK | reserved | reserved | ||
| DATE | reserved | reserved | reserved | |
| DATETIME_INTERVAL_CODE | non-reserved | non-reserved | non-reserved | |
| DATETIME_INTERVAL_PRECISION | non-reserved | non-reserved | non-reserved | |
| DAY | non-reserved | reserved | reserved | reserved |
| DB | non-reserved | non-reserved | ||
| DEALLOCATE | non-reserved | reserved | reserved | reserved |
| DEC | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| DECFLOAT | reserved | |||
| DECIMAL | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| DECLARE | non-reserved | reserved | reserved | reserved |
| DEFAULT | reserved | reserved | reserved | reserved |
| DEFAULTS | non-reserved | non-reserved | non-reserved | |
| DEFERRABLE | reserved | non-reserved | non-reserved | reserved |
| DEFERRED | non-reserved | non-reserved | non-reserved | reserved |
| DEFINE | reserved | |||
| DEFINED | non-reserved | non-reserved | ||
| DEFINER | non-reserved | non-reserved | non-reserved | |
| DEGREE | non-reserved | non-reserved | ||
| DELETE | non-reserved | reserved | reserved | reserved |
| DELIMITER | non-reserved | |||
| DELIMITERS | non-reserved | |||
| DENSE_RANK | reserved | reserved | ||
| DEPENDS | non-reserved | |||
| DEPTH | non-reserved | non-reserved | ||
| DEREF | reserved | reserved | ||
| DERIVED | non-reserved | non-reserved | ||
| DESC | reserved | non-reserved | non-reserved | reserved |
| DESCRIBE | reserved | reserved | reserved | |
| DESCRIPTOR | non-reserved | non-reserved | reserved | |
| DETACH | non-reserved | |||
| DETERMINISTIC | reserved | reserved | ||
| DIAGNOSTICS | non-reserved | non-reserved | reserved | |
| DICTIONARY | non-reserved | |||
| DISABLE | non-reserved | |||
| DISCARD | non-reserved | |||
| DISCONNECT | reserved | reserved | reserved | |
| DISPATCH | non-reserved | non-reserved | ||
| DISTINCT | reserved | reserved | reserved | reserved |
| DLNEWCOPY | reserved | reserved | ||
| DLPREVIOUSCOPY | reserved | reserved | ||
| DLURLCOMPLETE | reserved | reserved | ||
| DLURLCOMPLETEONLY | reserved | reserved | ||
| DLURLCOMPLETEWRITE | reserved | reserved | ||
| DLURLPATH | reserved | reserved | ||
| DLURLPATHONLY | reserved | reserved | ||
| DLURLPATHWRITE | reserved | reserved | ||
| DLURLSCHEME | reserved | reserved | ||
| DLURLSERVER | reserved | reserved | ||
| DLVALUE | reserved | reserved | ||
| DO | reserved | |||
| DOCUMENT | non-reserved | non-reserved | non-reserved | |
| DOMAIN | non-reserved | non-reserved | non-reserved | reserved |
| DOUBLE | non-reserved | reserved | reserved | reserved |
| DROP | non-reserved | reserved | reserved | reserved |
| DYNAMIC | reserved | reserved | ||
| DYNAMIC_FUNCTION | non-reserved | non-reserved | non-reserved | |
| DYNAMIC_FUNCTION_CODE | non-reserved | non-reserved | ||
| EACH | non-reserved | reserved | reserved | |
| ELEMENT | reserved | reserved | ||
| ELSE | reserved | reserved | reserved | reserved |
| EMPTY | reserved | non-reserved | ||
| ENABLE | non-reserved | |||
| ENCODING | non-reserved | non-reserved | non-reserved | |
| ENCRYPTED | non-reserved | |||
| END | reserved | reserved | reserved | reserved |
| END-EXEC | reserved | reserved | reserved | |
| END_FRAME | reserved | reserved | ||
| END_PARTITION | reserved | reserved | ||
| ENFORCED | non-reserved | non-reserved | ||
| ENUM | non-reserved | |||
| EQUALS | reserved | reserved | ||
| ERROR | non-reserved | |||
| ESCAPE | non-reserved | reserved | reserved | reserved |
| EVENT | non-reserved | |||
| EVERY | reserved | reserved | ||
| EXCEPT | reserved | reserved | reserved | reserved |
| EXCEPTION | reserved | |||
| EXCLUDE | non-reserved | non-reserved | non-reserved | |
| EXCLUDING | non-reserved | non-reserved | non-reserved | |
| EXCLUSIVE | non-reserved | |||
| EXEC | reserved | reserved | reserved | |
| EXECUTE | non-reserved | reserved | reserved | reserved |
| EXISTS | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| EXP | reserved | reserved | ||
| EXPLAIN | non-reserved | |||
| EXPRESSION | non-reserved | non-reserved | ||
| EXTENSION | non-reserved | |||
| EXTERNAL | non-reserved | reserved | reserved | reserved |
| EXTRACT | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| FALSE | reserved | reserved | reserved | reserved |
| FAMILY | non-reserved | |||
| FETCH | reserved | reserved | reserved | reserved |
| FILE | non-reserved | non-reserved | ||
| FILTER | non-reserved | reserved | reserved | |
| FINAL | non-reserved | non-reserved | ||
| FINISH | non-reserved | |||
| FIRST | non-reserved | non-reserved | non-reserved | reserved |
| FIRST_VALUE | reserved | reserved | ||
| FLAG | non-reserved | non-reserved | ||
| FLOAT | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| FLOOR | reserved | reserved | ||
| FOLLOWING | non-reserved | non-reserved | non-reserved | |
| FOR | reserved | reserved | reserved | reserved |
| FORCE | non-reserved | |||
| FOREIGN | reserved | reserved | reserved | reserved |
| FORMAT | non-reserved | |||
| FORTRAN | non-reserved | non-reserved | non-reserved | |
| FORWARD | non-reserved | |||
| FOUND | non-reserved | non-reserved | reserved | |
| FRAME_ROW | reserved | reserved | ||
| FREE | reserved | reserved | ||
| FREEZE | reserved (может быть функцией или типом) | |||
| FROM | reserved | reserved | reserved | reserved |
| FS | non-reserved | non-reserved | ||
| FULFILL | non-reserved | |||
| FULL | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| FUNCTION | non-reserved | reserved | reserved | |
| FUNCTIONS | non-reserved | |||
| FUSION | reserved | reserved | ||
| G | non-reserved | non-reserved | ||
| GENERAL | non-reserved | non-reserved | ||
| GENERATED | non-reserved | non-reserved | non-reserved | |
| GET | reserved | reserved | reserved | |
| GLOBAL | non-reserved | reserved | reserved | reserved |
| GO | non-reserved | non-reserved | reserved | |
| GOTO | non-reserved | non-reserved | reserved | |
| GRANT | reserved | reserved | reserved | reserved |
| GRANTED | non-reserved | non-reserved | non-reserved | |
| GREATEST | non-reserved (не может быть функцией или типом) | |||
| GROUP | reserved | reserved | reserved | reserved |
| GROUPING | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| GROUPS | non-reserved | reserved | reserved | |
| HANDLER | non-reserved | |||
| HAVING | reserved | reserved | reserved | reserved |
| HEADER | non-reserved | |||
| HEX | non-reserved | non-reserved | ||
| HIERARCHY | non-reserved | non-reserved | ||
| HOLD | non-reserved | reserved | reserved | |
| HOUR | non-reserved | reserved | reserved | reserved |
| ID | non-reserved | non-reserved | ||
| IDENTITY | non-reserved | reserved | reserved | reserved |
| IF | non-reserved | |||
| IGNORE | non-reserved | non-reserved | ||
| ILIKE | reserved (может быть функцией или типом) | |||
| IMMEDIATE | non-reserved | non-reserved | non-reserved | reserved |
| IMMEDIATELY | non-reserved | non-reserved | ||
| IMMUTABLE | non-reserved | |||
| IMPLEMENTATION | non-reserved | non-reserved | ||
| IMPLICIT | non-reserved | |||
| IMPORT | non-reserved | reserved | reserved | |
| IN | reserved | reserved | reserved | reserved |
| INCLUDE | non-reserved | |||
| INCLUDING | non-reserved | non-reserved | non-reserved | |
| INCREMENT | non-reserved | non-reserved | non-reserved | |
| INDENT | non-reserved | non-reserved | ||
| INDEX | non-reserved | |||
| INDEXES | non-reserved | |||
| INDICATOR | reserved | reserved | reserved | |
| INHERIT | non-reserved | |||
| INHERITS | non-reserved | |||
| INITIAL | reserved | |||
| INITIALLY | reserved | non-reserved | non-reserved | reserved |
| INLINE | non-reserved | |||
| INNER | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| INOUT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| INPUT | non-reserved | non-reserved | non-reserved | reserved |
| INSENSITIVE | non-reserved | reserved | reserved | reserved |
| INSERT | non-reserved | reserved | reserved | reserved |
| INSTANCE | non-reserved | non-reserved | ||
| INSTANTIABLE | non-reserved | non-reserved | ||
| INSTEAD | non-reserved | non-reserved | non-reserved | |
| INT | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| INTEGER | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| INTEGRITY | non-reserved | non-reserved | ||
| INTERSECT | reserved | reserved | reserved | reserved |
| INTERSECTION | reserved | reserved | ||
| INTERVAL | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| INTO | reserved | reserved | reserved | reserved |
| INVOKER | non-reserved | non-reserved | non-reserved | |
| IS | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| ISNULL | reserved (может быть функцией или типом) | |||
| ISOLATION | non-reserved | non-reserved | non-reserved | reserved |
| JOIN | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| JSON | non-reserved | |||
| JSON_ARRAY | reserved | |||
| JSON_ARRAYAGG | reserved | |||
| JSON_EXISTS | reserved | |||
| JSON_OBJECT | reserved | |||
| JSON_OBJECTAGG | reserved | |||
| JSON_QUERY | reserved | |||
| JSON_TABLE | reserved | |||
| JSON_TABLE_PRIMITIVE | reserved | |||
| JSON_VALUE | reserved | |||
| K | non-reserved | non-reserved | ||
| KEEP | non-reserved | |||
| KEY | non-reserved | non-reserved | non-reserved | reserved |
| KEYS | non-reserved | |||
| KEY_MEMBER | non-reserved | non-reserved | ||
| KEY_TYPE | non-reserved | non-reserved | ||
| LABEL | non-reserved | |||
| LAG | reserved | reserved | ||
| LANGUAGE | non-reserved | reserved | reserved | reserved |
| LARGE | non-reserved | reserved | reserved | |
| LAST | non-reserved | non-reserved | non-reserved | reserved |
| LAST_VALUE | reserved | reserved | ||
| LATERAL | reserved | reserved | reserved | |
| LEAD | reserved | reserved | ||
| LEADING | reserved | reserved | reserved | reserved |
| LEAKPROOF | non-reserved | |||
| LEAST | non-reserved (не может быть функцией или типом) | |||
| LEFT | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| LENGTH | non-reserved | non-reserved | non-reserved | |
| LEVEL | non-reserved | non-reserved | non-reserved | reserved |
| LIBRARY | non-reserved | non-reserved | ||
| LIKE | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| LIKE_REGEX | reserved | reserved | ||
| LIMIT | reserved | non-reserved | non-reserved | |
| LINK | non-reserved | non-reserved | ||
| LISTAGG | reserved | |||
| LISTEN | non-reserved | |||
| LN | reserved | reserved | ||
| LOAD | non-reserved | |||
| LOCAL | non-reserved | reserved | reserved | reserved |
| LOCALTIME | reserved | reserved | reserved | |
| LOCALTIMESTAMP | reserved | reserved | reserved | |
| LOCATION | non-reserved | non-reserved | non-reserved | |
| LOCATOR | non-reserved | non-reserved | ||
| LOCK | non-reserved | |||
| LOCKED | non-reserved | |||
| LOG | reserved | |||
| LOG10 | reserved | |||
| LOGGED | non-reserved | |||
| LOWER | reserved | reserved | reserved | |
| M | non-reserved | non-reserved | ||
| MAP | non-reserved | non-reserved | ||
| MAPPING | non-reserved | non-reserved | non-reserved | |
| MATCH | non-reserved | reserved | reserved | reserved |
| MATCHED | non-reserved | non-reserved | ||
| MATCHES | reserved | |||
| MATCH_NUMBER | reserved | |||
| MATCH_RECOGNIZE | reserved | |||
| MATERIALIZED | non-reserved | |||
| MAX | reserved | reserved | reserved | |
| MAXVALUE | non-reserved | non-reserved | non-reserved | |
| MEASURES | reserved | |||
| MEMBER | reserved | reserved | ||
| MERGE | reserved | reserved | ||
| MESSAGE_LENGTH | non-reserved | non-reserved | non-reserved | |
| MESSAGE_OCTET_LENGTH | non-reserved | non-reserved | non-reserved | |
| MESSAGE_TEXT | non-reserved | non-reserved | non-reserved | |
| METHOD | non-reserved | reserved | reserved | |
| MIN | reserved | reserved | reserved | |
| MINUTE | non-reserved | reserved | reserved | reserved |
| MINVALUE | non-reserved | non-reserved | non-reserved | |
| MOD | reserved | reserved | ||
| MODE | non-reserved | |||
| MODIFIES | reserved | reserved | ||
| MODULE | reserved | reserved | reserved | |
| MONTH | non-reserved | reserved | reserved | reserved |
| MORE | non-reserved | non-reserved | non-reserved | |
| MOVE | non-reserved | |||
| MULTISET | reserved | reserved | ||
| MUMPS | non-reserved | non-reserved | non-reserved | |
| NAME | non-reserved | non-reserved | non-reserved | non-reserved |
| NAMES | non-reserved | non-reserved | non-reserved | reserved |
| NAMESPACE | non-reserved | non-reserved | ||
| NATIONAL | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| NATURAL | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| NCHAR | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| NCLOB | reserved | reserved | ||
| NESTED | non-reserved | |||
| NESTING | non-reserved | non-reserved | ||
| NEW | non-reserved | reserved | reserved | |
| NEXT | non-reserved | non-reserved | non-reserved | reserved |
| NFC | non-reserved | non-reserved | ||
| NFD | non-reserved | non-reserved | ||
| NFKC | non-reserved | non-reserved | ||
| NFKD | non-reserved | non-reserved | ||
| NIL | non-reserved | non-reserved | ||
| NO | non-reserved | reserved | reserved | reserved |
| NONE | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| NORMALIZE | reserved | reserved | ||
| NORMALIZED | non-reserved | non-reserved | ||
| NOT | reserved | reserved | reserved | reserved |
| NOTHING | non-reserved | |||
| NOTIFY | non-reserved | |||
| NOTNULL | reserved (может быть функцией или типом) | |||
| NOWAIT | non-reserved | |||
| NTH_VALUE | reserved | reserved | ||
| NTILE | reserved | reserved | ||
| NULL | reserved | reserved | reserved | reserved |
| NULLABLE | non-reserved | non-reserved | non-reserved | |
| NULLIF | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| NULLS | non-reserved | non-reserved | non-reserved | |
| NUMBER | non-reserved | non-reserved | non-reserved | |
| NUMERIC | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| OBJECT | non-reserved | non-reserved | non-reserved | |
| OCCURRENCES_REGEX | reserved | reserved | ||
| OCTETS | non-reserved | non-reserved | ||
| OCTET_LENGTH | reserved | reserved | reserved | |
| OF | non-reserved | reserved | reserved | reserved |
| OFF | non-reserved | non-reserved | non-reserved | |
| OFFSET | reserved | reserved | reserved | |
| OIDS | non-reserved | |||
| OLD | non-reserved | reserved | reserved | |
| OMIT | reserved | |||
| ON | reserved | reserved | reserved | reserved |
| ONE | reserved | |||
| ONLY | reserved | reserved | reserved | reserved |
| OPEN | reserved | reserved | reserved | |
| OPERATOR | non-reserved | |||
| OPTION | non-reserved | non-reserved | non-reserved | reserved |
| OPTIONS | non-reserved | non-reserved | non-reserved | |
| OR | reserved | reserved | reserved | reserved |
| ORDER | reserved | reserved | reserved | reserved |
| ORDERING | non-reserved | non-reserved | ||
| ORDINALITY | non-reserved | non-reserved | non-reserved | |
| OTHERS | non-reserved | non-reserved | non-reserved | |
| OUT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| OUTER | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| OUTPUT | non-reserved | non-reserved | reserved | |
| OVER | non-reserved | reserved | reserved | |
| OVERFLOW | non-reserved | |||
| OVERLAPS | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| OVERLAY | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| OVERRIDING | non-reserved | non-reserved | non-reserved | |
| OWNED | non-reserved | |||
| OWNER | non-reserved | |||
| P | non-reserved | non-reserved | ||
| PAD | non-reserved | non-reserved | reserved | |
| PARALLEL | non-reserved | |||
| PARAMETER | reserved | reserved | ||
| PARAMETER_MODE | non-reserved | non-reserved | ||
| PARAMETER_NAME | non-reserved | non-reserved | ||
| PARAMETER_ORDINAL_POSITION | non-reserved | non-reserved | ||
| PARAMETER_SPECIFIC_CATALOG | non-reserved | non-reserved | ||
| PARAMETER_SPECIFIC_NAME | non-reserved | non-reserved | ||
| PARAMETER_SPECIFIC_SCHEMA | non-reserved | non-reserved | ||
| PARSER | non-reserved | |||
| PARTIAL | non-reserved | non-reserved | non-reserved | reserved |
| PARTITION | non-reserved | reserved | reserved | |
| PASCAL | non-reserved | non-reserved | non-reserved | |
| PASS | non-reserved | |||
| PASSING | non-reserved | non-reserved | non-reserved | |
| PASSTHROUGH | non-reserved | non-reserved | ||
| PASSWORD | non-reserved | |||
| PAST | non-reserved | |||
| PATH | non-reserved | non-reserved | ||
| PATTERN | reserved | |||
| PER | reserved | |||
| PERCENT | reserved | reserved | ||
| PERCENTILE_CONT | reserved | reserved | ||
| PERCENTILE_DISC | reserved | reserved | ||
| PERCENT_RANK | reserved | reserved | ||
| PERIOD | reserved | reserved | ||
| PERMISSION | non-reserved | non-reserved | ||
| PERMUTE | reserved | |||
| PLACING | reserved | non-reserved | non-reserved | |
| PLAN | non-reserved | |||
| PLANS | non-reserved | |||
| PLI | non-reserved | non-reserved | non-reserved | |
| POLICY | non-reserved | |||
| PORTION | reserved | reserved | ||
| POSITION | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| POSITION_REGEX | reserved | reserved | ||
| POWER | reserved | reserved | ||
| PRECEDES | reserved | reserved | ||
| PRECEDING | non-reserved | non-reserved | non-reserved | |
| PRECISION | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| PREPARE | non-reserved | reserved | reserved | reserved |
| PREPARED | non-reserved | |||
| PRESERVE | non-reserved | non-reserved | non-reserved | reserved |
| PRIMARY | reserved | reserved | reserved | reserved |
| PRIOR | non-reserved | non-reserved | non-reserved | reserved |
| PRIVATE | non-reserved | |||
| PRIVILEGES | non-reserved | non-reserved | non-reserved | reserved |
| PROCEDURAL | non-reserved | |||
| PROCEDURE | non-reserved | reserved | reserved | reserved |
| PROCEDURES | non-reserved | |||
| PROGRAM | non-reserved | |||
| PRUNE | non-reserved | |||
| PTF | reserved | |||
| PUBLIC | non-reserved | non-reserved | reserved | |
| PUBLICATION | non-reserved | |||
| QUOTE | non-reserved | |||
| QUOTES | non-reserved | |||
| RANGE | non-reserved | reserved | reserved | |
| RANK | reserved | reserved | ||
| READ | non-reserved | non-reserved | non-reserved | reserved |
| READS | reserved | reserved | ||
| REAL | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| REASSIGN | non-reserved | |||
| RECHECK | non-reserved | |||
| RECOVERY | non-reserved | non-reserved | ||
| RECURSIVE | non-reserved | reserved | reserved | |
| REF | non-reserved | reserved | reserved | |
| REFERENCES | reserved | reserved | reserved | reserved |
| REFERENCING | non-reserved | reserved | reserved | |
| REFRESH | non-reserved | |||
| REGR_AVGX | reserved | reserved | ||
| REGR_AVGY | reserved | reserved | ||
| REGR_COUNT | reserved | reserved | ||
| REGR_INTERCEPT | reserved | reserved | ||
| REGR_R2 | reserved | reserved | ||
| REGR_SLOPE | reserved | reserved | ||
| REGR_SXX | reserved | reserved | ||
| REGR_SXY | reserved | reserved | ||
| REGR_SYY | reserved | reserved | ||
| REINDEX | non-reserved | |||
| RELATIVE | non-reserved | non-reserved | non-reserved | reserved |
| RELEASE | non-reserved | reserved | reserved | |
| RENAME | non-reserved | |||
| REPEATABLE | non-reserved | non-reserved | non-reserved | non-reserved |
| REPLACE | non-reserved | |||
| REPLICA | non-reserved | |||
| REQUIRING | non-reserved | non-reserved | ||
| RESET | non-reserved | |||
| RESPECT | non-reserved | non-reserved | ||
| RESTART | non-reserved | non-reserved | non-reserved | |
| RESTORE | non-reserved | non-reserved | ||
| RESTRICT | non-reserved | non-reserved | non-reserved | reserved |
| RESULT | reserved | reserved | ||
| RETURN | reserved | reserved | ||
| RETURNED_CARDINALITY | non-reserved | non-reserved | ||
| RETURNED_LENGTH | non-reserved | non-reserved | non-reserved | |
| RETURNED_OCTET_LENGTH | non-reserved | non-reserved | non-reserved | |
| RETURNED_SQLSTATE | non-reserved | non-reserved | non-reserved | |
| RETURNING | reserved | non-reserved | non-reserved | |
| RETURNS | non-reserved | reserved | reserved | |
| REVOKE | non-reserved | reserved | reserved | reserved |
| RIGHT | reserved (может быть функцией или типом) | reserved | reserved | reserved |
| ROLE | non-reserved | non-reserved | non-reserved | |
| ROLLBACK | non-reserved | reserved | reserved | reserved |
| ROLLUP | non-reserved | reserved | reserved | |
| ROUTINE | non-reserved | non-reserved | non-reserved | |
| ROUTINES | non-reserved | |||
| ROUTINE_CATALOG | non-reserved | non-reserved | ||
| ROUTINE_NAME | non-reserved | non-reserved | ||
| ROUTINE_SCHEMA | non-reserved | non-reserved | ||
| ROW | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| ROWS | non-reserved | reserved | reserved | reserved |
| ROW_COUNT | non-reserved | non-reserved | non-reserved | |
| ROW_NUMBER | reserved | reserved | ||
| RULE | non-reserved | |||
| RUNNING | reserved | |||
| SAVEPOINT | non-reserved | reserved | reserved | |
| SCALAR | non-reserved | |||
| SCALE | non-reserved | non-reserved | non-reserved | |
| SCHEMA | non-reserved | non-reserved | non-reserved | reserved |
| SCHEMAS | non-reserved | |||
| SCHEMA_NAME | non-reserved | non-reserved | non-reserved | |
| SCOPE | reserved | reserved | ||
| SCOPE_CATALOG | non-reserved | non-reserved | ||
| SCOPE_NAME | non-reserved | non-reserved | ||
| SCOPE_SCHEMA | non-reserved | non-reserved | ||
| SCROLL | non-reserved | reserved | reserved | reserved |
| SEARCH | non-reserved | reserved | reserved | |
| SECOND | non-reserved | reserved | reserved | reserved |
| SECTION | non-reserved | non-reserved | reserved | |
| SECURITY | non-reserved | non-reserved | non-reserved | |
| SEEK | reserved | |||
| SELECT | reserved | reserved | reserved | reserved |
| SELECTIVE | non-reserved | non-reserved | ||
| SELF | non-reserved | non-reserved | ||
| SENSITIVE | reserved | reserved | ||
| SEQUENCE | non-reserved | non-reserved | non-reserved | |
| SEQUENCES | non-reserved | |||
| SERIALIZABLE | non-reserved | non-reserved | non-reserved | non-reserved |
| SERVER | non-reserved | non-reserved | non-reserved | |
| SERVER_NAME | non-reserved | non-reserved | non-reserved | |
| SESSION | non-reserved | non-reserved | non-reserved | reserved |
| SESSION_USER | reserved | reserved | reserved | reserved |
| SET | non-reserved | reserved | reserved | reserved |
| SETOF | non-reserved (не может быть функцией или типом) | |||
| SETS | non-reserved | non-reserved | non-reserved | |
| SHARE | non-reserved | |||
| SHOW | non-reserved | reserved | ||
| SIMILAR | reserved (может быть функцией или типом) | reserved | reserved | |
| SIMPLE | non-reserved | non-reserved | non-reserved | |
| SIN | reserved | |||
| SINH | reserved | |||
| SIZE | non-reserved | non-reserved | reserved | |
| SKIP | non-reserved | reserved | ||
| SMALLINT | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| SNAPSHOT | non-reserved | |||
| SOME | reserved | reserved | reserved | reserved |
| SOURCE | non-reserved | non-reserved | ||
| SPACE | non-reserved | non-reserved | reserved | |
| SPECIFIC | reserved | reserved | ||
| SPECIFICTYPE | reserved | reserved | ||
| SPECIFIC_NAME | non-reserved | non-reserved | ||
| SQL | non-reserved | reserved | reserved | reserved |
| SQLCODE | reserved | |||
| SQLERROR | reserved | |||
| SQLEXCEPTION | reserved | reserved | ||
| SQLSTATE | reserved | reserved | reserved | |
| SQLWARNING | reserved | reserved | ||
| SQRT | reserved | reserved | ||
| STABLE | non-reserved | |||
| STANDALONE | non-reserved | non-reserved | non-reserved | |
| START | non-reserved | reserved | reserved | |
| STATE | non-reserved | non-reserved | ||
| STATEMENT | non-reserved | non-reserved | non-reserved | |
| STATIC | reserved | reserved | ||
| STATISTICS | non-reserved | |||
| STDDEV_POP | reserved | reserved | ||
| STDDEV_SAMP | reserved | reserved | ||
| STDIN | non-reserved | |||
| STDOUT | non-reserved | |||
| STORAGE | non-reserved | |||
| STORED | non-reserved | |||
| STRICT | non-reserved | |||
| STRING | non-reserved | |||
| STRIP | non-reserved | non-reserved | non-reserved | |
| STRUCTURE | non-reserved | non-reserved | ||
| STYLE | non-reserved | non-reserved | ||
| SUBCLASS_ORIGIN | non-reserved | non-reserved | non-reserved | |
| SUBMULTISET | reserved | reserved | ||
| SUBSCRIPTION | non-reserved | |||
| SUBSET | reserved | |||
| SUBSTRING | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| SUBSTRING_REGEX | reserved | reserved | ||
| SUCCEEDS | reserved | reserved | ||
| SUM | reserved | reserved | reserved | |
| SUPPORT | non-reserved | |||
| SYMMETRIC | reserved | reserved | reserved | |
| SYSID | non-reserved | |||
| SYSTEM | non-reserved | reserved | reserved | |
| SYSTEM_TIME | reserved | reserved | ||
| SYSTEM_USER | reserved | reserved | reserved | |
| T | non-reserved | non-reserved | ||
| TABLE | reserved | reserved | reserved | reserved |
| TABLES | non-reserved | |||
| TABLESAMPLE | reserved (может быть функцией или типом) | reserved | reserved | |
| TABLESPACE | non-reserved | |||
| TABLE_NAME | non-reserved | non-reserved | non-reserved | |
| TAN | reserved | |||
| TANH | reserved | |||
| TEMP | non-reserved | |||
| TEMPLATE | non-reserved | |||
| TEMPORARY | non-reserved | non-reserved | non-reserved | reserved |
| TEXT | non-reserved | |||
| THEN | reserved | reserved | reserved | reserved |
| THROUGH | non-reserved | |||
| TIES | non-reserved | non-reserved | non-reserved | |
| TIME | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| TIMESTAMP | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| TIMEZONE_HOUR | reserved | reserved | reserved | |
| TIMEZONE_MINUTE | reserved | reserved | reserved | |
| TO | reserved | reserved | reserved | reserved |
| TOKEN | non-reserved | non-reserved | ||
| TOP_LEVEL_COUNT | non-reserved | non-reserved | ||
| TRAILING | reserved | reserved | reserved | reserved |
| TRANSACTION | non-reserved | non-reserved | non-reserved | reserved |
| TRANSACTIONS_COMMITTED | non-reserved | non-reserved | ||
| TRANSACTIONS_ROLLED_BACK | non-reserved | non-reserved | ||
| TRANSACTION_ACTIVE | non-reserved | non-reserved | ||
| TRANSFORM | non-reserved | non-reserved | non-reserved | |
| TRANSFORMS | non-reserved | non-reserved | ||
| TRANSLATE | reserved | reserved | reserved | |
| TRANSLATE_REGEX | reserved | reserved | ||
| TRANSLATION | reserved | reserved | reserved | |
| TREAT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| TRIGGER | non-reserved | reserved | reserved | |
| TRIGGER_CATALOG | non-reserved | non-reserved | ||
| TRIGGER_NAME | non-reserved | non-reserved | ||
| TRIGGER_SCHEMA | non-reserved | non-reserved | ||
| TRIM | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| TRIM_ARRAY | reserved | reserved | ||
| TRUE | reserved | reserved | reserved | reserved |
| TRUNCATE | non-reserved | reserved | reserved | |
| TRUSTED | non-reserved | |||
| TYPE | non-reserved | non-reserved | non-reserved | non-reserved |
| TYPES | non-reserved | |||
| UESCAPE | reserved | reserved | ||
| UNBOUNDED | non-reserved | non-reserved | non-reserved | |
| UNCOMMITTED | non-reserved | non-reserved | non-reserved | non-reserved |
| UNCONDITIONAL | non-reserved | |||
| UNDER | non-reserved | non-reserved | ||
| UNENCRYPTED | non-reserved | |||
| UNION | reserved | reserved | reserved | reserved |
| UNIQUE | reserved | reserved | reserved | reserved |
| UNKNOWN | non-reserved | reserved | reserved | reserved |
| UNLINK | non-reserved | non-reserved | ||
| UNLISTEN | non-reserved | |||
| UNLOGGED | non-reserved | |||
| UNMATCHED | reserved | |||
| UNNAMED | non-reserved | non-reserved | non-reserved | |
| UNNEST | reserved | reserved | ||
| UNTIL | non-reserved | |||
| UNTYPED | non-reserved | non-reserved | ||
| UPDATE | non-reserved | reserved | reserved | reserved |
| UPPER | reserved | reserved | reserved | |
| URI | non-reserved | non-reserved | ||
| USAGE | non-reserved | non-reserved | reserved | |
| USER | reserved | reserved | reserved | reserved |
| USER_DEFINED_TYPE_CATALOG | non-reserved | non-reserved | ||
| USER_DEFINED_TYPE_CODE | non-reserved | non-reserved | ||
| USER_DEFINED_TYPE_NAME | non-reserved | non-reserved | ||
| USER_DEFINED_TYPE_SCHEMA | non-reserved | non-reserved | ||
| USING | reserved | reserved | reserved | reserved |
| UTF16 | non-reserved | |||
| UTF32 | non-reserved | |||
| UTF8 | non-reserved | |||
| VACUUM | non-reserved | |||
| VALID | non-reserved | non-reserved | non-reserved | |
| VALIDATE | non-reserved | |||
| VALIDATOR | non-reserved | |||
| VALUE | non-reserved | reserved | reserved | reserved |
| VALUES | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| VALUE_OF | reserved | reserved | ||
| VARBINARY | reserved | reserved | ||
| VARCHAR | non-reserved (не может быть функцией или типом) | reserved | reserved | reserved |
| VARIADIC | reserved | |||
| VARYING | non-reserved | reserved | reserved | reserved |
| VAR_POP | reserved | reserved | ||
| VAR_SAMP | reserved | reserved | ||
| VERBOSE | reserved (может быть функцией или типом) | |||
| VERSION | non-reserved | non-reserved | non-reserved | |
| VERSIONING | reserved | reserved | ||
| VIEW | non-reserved | non-reserved | non-reserved | reserved |
| VIEWS | non-reserved | |||
| VOLATILE | non-reserved | |||
| WHEN | reserved | reserved | reserved | reserved |
| WHENEVER | reserved | reserved | reserved | |
| WHERE | reserved | reserved | reserved | reserved |
| WHITESPACE | non-reserved | non-reserved | non-reserved | |
| WIDTH_BUCKET | reserved | reserved | ||
| WINDOW | reserved | reserved | reserved | |
| WITH | reserved | reserved | reserved | reserved |
| WITHIN | non-reserved | reserved | reserved | |
| WITHOUT | non-reserved | reserved | reserved | |
| WORK | non-reserved | non-reserved | non-reserved | reserved |
| WRAPPER | non-reserved | non-reserved | non-reserved | |
| WRITE | non-reserved | non-reserved | non-reserved | reserved |
| XML | non-reserved | reserved | reserved | |
| XMLAGG | reserved | reserved | ||
| XMLATTRIBUTES | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLBINARY | reserved | reserved | ||
| XMLCAST | reserved | reserved | ||
| XMLCOMMENT | reserved | reserved | ||
| XMLCONCAT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLDECLARATION | non-reserved | non-reserved | ||
| XMLDOCUMENT | reserved | reserved | ||
| XMLELEMENT | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLEXISTS | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLFOREST | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLITERATE | reserved | reserved | ||
| XMLNAMESPACES | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLPARSE | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLPI | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLQUERY | reserved | reserved | ||
| XMLROOT | non-reserved (не может быть функцией или типом) | |||
| XMLSCHEMA | non-reserved | non-reserved | ||
| XMLSERIALIZE | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLTABLE | non-reserved (не может быть функцией или типом) | reserved | reserved | |
| XMLTEXT | reserved | reserved | ||
| XMLVALIDATE | reserved | reserved | ||
| YEAR | non-reserved | reserved | reserved | reserved |
| YES | non-reserved | non-reserved | non-reserved | |
| ZONE | non-reserved | non-reserved | non-reserved | reserved |
Поддерживаемые платформы
Платформа (то есть комбинация архитектуры процессора и операционной системы) считается поддерживаемой сообществом разработчиков QHB, если код адаптирован для работы на этой платформе, и он в настоящее время успешно собирается и проходит регрессионные тесты на ней.
В настоящее время тестирование совместимости в основном выполняется автоматически силами сообщества разработчиков QHB.
Если вы заинтересованы в использовании QHB на платформе, ещё не представленной в данном разделе, но уверены, что код на ней работает или может работать, сообщите нам по адресу qhb.support@granit-concern.ru.
В текущей версии QHB 1.3.0 поддерживаются процессоры следующих архитектур:
Cервер QHB собирается и будет работать в следующих операционных системах:
Если вы столкнулись с проблемами установки на поддерживаемой платформе, пожалуйста, сообщите о них по адресу qhb.support@granit-concern.ru.
Страница загрузки
Бинарные дистрибутивы для поддерживаемых платформ можно получить в репозитории QHB.
QHB для CentOs 7 и 8
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
rpm --import https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb
и далее, для CentOs 7:
yum-config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/centos/7/x86_64/qhb.repo
или для CentOs 8:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/centos/8/x86_64/qhb.repo
Установите бинарные пакеты командой:
yum install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
yum install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
QHB для Альт Сервер 9
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Для установки потребуется дополнительная библиотека libicu.
Скачайте библиотеку (подходит версия 60.3-2) в любую локальную папку:
wget -c http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/libicu-60.3-2.el8_1.x86_64.rpm
Скачайте в эту же папку пакеты программного продукта СУБД «Квант-Гибрид» из репозитория командой:
wget -c -r -l1 -A '*.rpm' -nd -np https://repo.granit-concern.ru/qhb/std-1/centos/8/x86_64/
Обновите описания пакетов:
apt-get update
Находясь в этой же локальной папке, установите бинарные пакеты командой, например:
apt-get install *.rpm
Вы можете установить не все пакеты QHB, а только необходимые вам. В этом случае вы можете перечислить в команде нужные вам пакеты rpm через пробел. Выбирайте последние версии из rpm пакетов, которые скачались.
Библиотека libicu и пакет qhb-core - обязательны.
В результате установки пакета ядра QHB будет создан пользователь qhb,
ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
QHB для Fedora 32 и 33
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
rpm --import https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb
и далее, для Fedora 32:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/fedora/32/x86_64/qhb.repo
или для Fedora 33:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/fedora/33/x86_64/qhb.repo
Установите бинарные пакеты командой:
dnf install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
dnf install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
QHB для Debian 9 и Astra Linux Special Edition «Смоленск» 1.6
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Для подключения к репозиторию выполните следующую команду:
apt install gnupg2 apt-transport-https wget
Для Astra требуется установка корневых сертификатов. Установите их с помощью команды:
apt-get install ca-certificates
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
wget -qO - https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb | apt-key add -
Далее выполните команды:
echo 'deb https://repo.granit-concern.ru/qhb/std-1/debian stretch main' >> /etc/apt/sources.list
и
apt update
Установите бинарные пакеты командой:
apt install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
apt install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
QHB в виде docker контейнера
Предлагается конфигурация: сервер СУБД «Квант-Гибрид» с расширениями и пул соединений QCP.
Получение Dockerfile и конфигураций
Создайте локальный каталог и разверните в нём скрипты docker из репозитория СУБД «Квант-Гибрид»:
wget https://repo.granit-concern.ru/qhb/std-1/docker/qhb-docker-image.tar.gz -O - | tar -xz
Создание образов
Внимание!
Потребуется docker-compose. Здесь и далее, запускать docker-compose следует из-под обычного пользователя (не root). Возможно, для этого надо будет выполнить рекомендации по настройке docker.
Как правило, не требуется вручную создавать образ, т.к. он автоматически создаётся при первом запуске. Однако это можно сделать и явным образом:
docker-compose build
Замечание.
Если возникают проблемы с построением образа, связанные с недоступностью репозитория centos, нужно проверить сетевые разрешения. Иногда, перед построением, просто помогает выполнение таких команд:sudo firewall-cmd --zone=public --add-masquerade --permanent sudo firewall-cmd --reload
Запуск контейнера
Для запуска контейнеров СУБД «Квант-Гибрид» и QCP с настройками по умолчанию, выполните в текущем каталоге:
docker-compose up
Прервать выполнение можно с помощью Ctrl+C, или же выполнив из другой консоли в текущем каталоге:
docker-compose down
Для запуска контейнеров в режиме "демона", выполните:
docker-compose up -d
При первом запуске база данных будет автоматически инициализирована.
Посмотреть логи можно с помощью команды:
docker-compose logs
По умолчанию, база данных сохраняется на диске в каталоге qhb/pgdata.
Остановка контейнеров
Если контейнеры были запущен посредством docker-compose up, то для остановки достаточно нажать Ctrl+C.
Если же контейнеры были запущены в режиме "демона", т.е. посредством docker-compose up -d, то для остановки контейнеров выполните (из любой консоли) в текущем каталоге:
docker-compose down. Эту команду также можно выполнять и при остановленных контейнерах.
Настройка QCP
По умолчанию, сервис QCP отключён. Для его запуска необходимо в файле docker-compose.yaml убрать (закомментировать) запись
entrypoint: ["echo", "Service qcp disabled"]
из раздела services: -> qcp:, а также настроить сервис, в частности, параметры подключения к серверу.
Настройка QCP осуществляется посредством редактирования файла ./qcp/config.yaml.
Обязательно замените в разделе servers:
%USER% - на имя пользователя, от имени которого запускается docker-compose, и
%DATABASE% - на имя базы данных, в простейшем случае база создается с именем, совпадающим с именем пользователя.
В дальнейшем, если вы создадите другую базу данных, этот параметр может потребоваться изменить. По умолчанию сервис QCP работает на порту 8080, при необходимости переопределите этот параметр. Обратите внимание, что настройки применяются только при запуске.
Отредактируйте файл docker-compose.yaml следующим образом:
В разделе services: -> qhb: -> volumes: замените
- ./qhb/pgdata:/qhb-data/
на
- /path/to/pgdata:/qhb-data/
где /path/to/pgdata — абсолютный путь до каталога базы данных с существующей базой данных.
В разделе services: -> qhb: -> environment: замените - USER на - USER=USERNAME
Запустите контейнер с помощью команды
docker-compose -e USER="USERNAME" up
где USERNAME — имя пользователя, владеющего каталогом /path/to/pgdata.
Пример отредактированного файла docker-compose.yaml:
version: "3.3"
services:
qhb:
build: qhb
image: qhb
network_mode: "host"
environment:
- USER=qhb
volumes:
- ./qhb/pgdata:/qhb-data/
qcp:
build: qcp
image: qcp
network_mode: "host"
entrypoint: ["echo", "Service qcp disabled"] # Comment this line if will use QCP
volumes:
- ./qcp/config.yaml:/config.yaml:ro
Поддержка прикладных платформ
2B: Поддержка решений 1С
Поддерживается платформа «1С:Предприятие», начиная с версии 8.3.18.
Дополнительные типы данных для совместимости с Microsoft SQL Server
В версии QHB 1.2.0 добавлены типы данных mchar и mvarchar, являющиеся аналогами типов char и varchar, но имеющие ряд особенностей поведения, повторяющих поведение типов nchar и nvarchar в Microsoft SQL Server.
Отличия от стандартных типов char и varchar в QHB:
Отличия от поведения nchar и nvarchar в Microsoft SQL Server:
Для типов данных mchar и mvarchar поддерживаются индексы B-Tree и Hash.
Дополнительный оператор равенства для совместимости с Microsoft SQL Server
В версии QHB 1.2.0 добавлен оператор полного равенства == для совместимости с Microsoft SQL Server.
Оператор "полного" равенства (==), отличается от обычного (=) тем,
что возвращает TRUE при сравнении двух NULL значений
(обычное равенство возвращает NULL согласно стандарту ANSI SQL).
Такое поведение принято в СУБД семейства Microsoft SQL.
Оператор == определён для следующих типов данных:
Быстрое усечение временных таблиц
В QHB операция TRUNCATE транзакционная: её можно откатить. Из-за этого она более дорогая, чем в других СУБД.
В версии 1.2.0 добавлена функция fasttruncate, которая очищает таблицу быстрее и предотвращает разрастание системного каталога pg_class. Применять её можно пока только ко временным таблицам, благо усечение временной таблицы не может вызвать конфликта с другим пользователем. Функция fasttruncate является внетранзакционной: при откате транзакции очистка таблицы не будет отменена!
Пример использования:
select fasttruncate ('pg_temp.tmp3')
Немедленное обновление статистики отдельных таблиц
Для сильно меняющихся таблиц, например, временных таблиц, стандартные средства сбора статистики могут быть неэффективны. В версии QHB 1.2.0 появилась возможность немедленного обновления статистики таблицы после её изменения, т.н. немедленный анализ (online analyze).
Сбор статистики вызывается после фиксации транзакции, модифицировавшей таблицу, при выполнении определённых условий. Настройка этого поведения осуществляется с помощью конфигурационных параметров, перечисленных ниже.
Если не включить, то немедленный анализ вообще не будет происходить:
online_analyze.enable = on
Писать в лог при сборе статистики аналогично ANALYZE VERBOSE:
online_analyze.verbose = off
Параметры, задающие таблицы, для которых следует применять немедленный анализ.
Типы таблиц, для которых выполняется немедленный анализ: all (все), persistent (постоянные), temporary (временные), none (никакие):
online_analyze.table_type = "temporary"
Список таблиц, исключаемых из немедленного анализа:
online_analyze.exclude_tables = ""
Список таблиц, подлежащих немедленному анализу, перекрывает online_analyze.exclude_tables:
online_analyze.include_tables = ""
Параметры, касающиеся хранения статистики временных таблиц (по умолчанию используется системная статистика, но имеет смысл хранить её в локальном кеше процесса, обслуживающего сессию):
Включает хранение статистике временных таблиц в локальном кеше:
online_analyze.local_tracking = on
Максимальное число временных таблиц, сохраняемых в локальном кеше:
online_analyze.capacity_threshold = 100000
Параметры, задающие события, при которых происходит сбор статистики.
Процент изменённых строк от всей таблицы, при котором начинается немедленный анализ:
online_analyze.scale_factor = 0.1
Минимальное число изменённых строк, после которого может начаться немедленный анализ:
online_analyze.threshold = 50
Минимальное число строк в таблице, при котором может начаться немедленный анализ:
online_analyze.lower_limit = 0
Минимальный интервал времени между вызовами ANALYZE для конкретной таблицы (в миллисекундах):
online_analyze.min_interval = 10000
Поддержка указаний для планировщика, позволяющих отключать или подключать определённые индексы при выполнении запроса
В версии QHB 1.2.0 добавлены конфигурационные параметры для управления использованием индексов. С их помощью можно просить планировщик не использовать определённые индексы. Если вы хотите, чтобы конкретный индекс использовался, этих параметров недостаточно, одновременно с ними можно использовать параметр enable_seqscan и другие.
Эти новые параметры относятся к настройкам планирования. Как и для других настроек планирования, основной сценарий использования — менять эти параметры на уровне транзакции, перед выполнением конкретного запроса. Технически возможно использование параметров на уровне базы данных или сервера, но если вы отключаете использование индекса на уровне базы данных, то может лучше его удалить?
Список индексов, которые нельзя использовать:
plantuner.disable_index = 'index1, sch.index2'
Список индексов, которые всё-таки можно использовать, перекрывает plantuner.disable_index:
plantuner.enable_index = 'scheme2.index4, index1'
Точный список индексов, которые можно использовать, перекрывает plantuner.disable_index и plantuner.enable_index:
plantuner.only_index = 'index5, sch.index2'
Значения этих 3-х параметров — список имён индексов через запятую. Разрешение имени индекса происходит для конкретного пользователя, даже если параметр задан на уровне сервера. Если индекс не найден по имени, например, когда индекс вообще не существует, он игнорируется.
Этот параметр меняет оценку совсем пустых таблиц планировщиком (свежесозданных или оттранкированных):
plantuner.fix_empty_table = true
Если параметр выключен, то поведение QHB по умолчанию — считать их содержащими пару десятков записей. Если параметр включен, то QHB планирует в предположении, что эти таблицы так и будут оставаться пустыми.
Краткие инструкции
Предоставляются краткие инструкции по различным задачам при использовании QHB.
Они не глубоко раскрывают различные тонкости и параметры, но предоставляют собой примерные, ознакомительные и наиболее употребительные сценарии.
Пошаговая инструкция по начальной загрузке, установке и запуску
Описывается сценарий установки СУБД «Квант-Гибрид» в первый раз, или установки и обновления при начальной инициализации кластера базы данных, если есть возможность произвести бэкап и восстановление данных во вновь создаваемый кластер.
Внимание!
В случаях, когда
обратитесь к разделу документации Краткая инструкция по обновлению.
Также настоятельно рекомендуется использовать процедуры Резервного копирования и восстановления.
Загрузка и установка бинарных пакетов
Обратите внимание
При установке команды должны выполняться от пользователя с правами суперпользователя. Если пользователь не обладает правами суперпользователя, выполните в терминале команду (понадобится ввести пароль суперпользователя)su -или временно повысьте привилегии пользователя до суперпользователя командой
sudo -i
Загрузка и установка бинарных пакетов производится из репозитория СУБД «Квант-Гибрид». Обратитесь к разделу документации Поддерживаемые платформы для уточнения, какие именно платформы поддерживаются СУБД «Квант-Гибрид».
Для Centos 7 и 8
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
rpm --import https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb
и далее, для CentOs 7:
yum-config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/centos/7/x86_64/qhb.repo
или для CentOs 8:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/centos/8/x86_64/qhb.repo
Установите бинарные пакеты командой:
yum install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
yum install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
Смотрите дополнительно: Состав поставки, Страница загрузки
Для Альт Сервер 9
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Для установки потребуется дополнительная библиотека libicu.
Скачайте библиотеку (подходит версия 60.3-2) в любую локальную папку:
wget -c http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/libicu-60.3-2.el8_1.x86_64.rpm
Скачайте в эту же папку пакеты программного продукта СУБД «Квант-Гибрид» из репозитория командой:
wget -c -r -l1 -A '*.rpm' -nd -np https://repo.granit-concern.ru/qhb/std-1/centos/8/x86_64/
Обновите описания пакетов:
apt-get update
Находясь в этой же локальной папке, установите бинарные пакеты командой, например:
apt-get install *.rpm
Вы можете установить не все пакеты QHB, а только необходимые вам. В этом случае вы можете перечислить в команде нужные вам пакеты rpm через пробел. Выбирайте последние версии из rpm пакетов, которые скачались.
Библиотека libicu и пакет qhb-core - обязательны.
В результате установки пакета ядра QHB будет создан пользователь qhb,
ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
Смотрите дополнительно: Состав поставки, Страница загрузки
Для Fedora 32 и 33
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
rpm --import https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb
и далее, для Fedora 32:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/fedora/32/x86_64/qhb.repo
или для Fedora 33:
dnf config-manager --add-repo https://repo.granit-concern.ru/qhb/std-1/fedora/33/x86_64/qhb.repo
Установите бинарные пакеты командой:
dnf install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
dnf install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
Смотрите дополнительно: Состав поставки, Страница загрузки
Для Debian и Astra
Обратите внимание, что команды должны выполняться от пользователя с правами суперпользователя.
Для подключения к репозиторию выполните следующую команду:
apt install gnupg2 apt-transport-https wget
Для Astra требуется установка корневых сертификатов. Установите их с помощью команды:
apt-get install ca-certificates
Установите репозиторий программного продукта СУБД «Квант-Гибрид» командой:
wget -qO - https://repo.granit-concern.ru/qhb/keys/RPM-GPG-KEY-qhb | apt-key add -
Далее выполните команды:
echo 'deb https://repo.granit-concern.ru/qhb/std-1/debian stretch main' >> /etc/apt/sources.list
и
apt update
Установите бинарные пакеты командой:
apt install qhb-core [qhb-contrib] [qcp] [qdl] [qbackup] [metricsd]
Например:
apt install qhb-core
В результате установки пакета ядра QHB будет создан пользователь qhb.
Ядро QHB, по умолчанию, установится в каталог /usr/local/qhb.
Многие утилиты QHB устанавливаются в каталог /usr/local/qhb/bin.
Если этот каталог указать в переменной окружения $PATH, это облегчит их запуск.
Смотрите дополнительно: Состав поставки, Страница загрузки
В виде docker контейнера
Предлагается конфигурация: сервер СУБД «Квант-Гибрид» с расширениями и пул соединений QCP.
Получение Dockerfile и конфигураций
Создайте локальный каталог и разверните в нём скрипты docker из репозитория СУБД «Квант-Гибрид»:
wget https://repo.granit-concern.ru/qhb/std-1/docker/qhb-docker-image.tar.gz -O - | tar -xz
Создание образов
Внимание!
Потребуется docker-compose. Здесь и далее, запускать docker-compose следует из-под обычного пользователя (не root). Возможно, для этого надо будет выполнить рекомендации по настройке docker.
Как правило, не требуется вручную создавать образ, т.к. он автоматически создаётся при первом запуске. Однако это можно сделать и явным образом:
docker-compose build
Замечание.
Если возникают проблемы с построением образа, связанные с недоступностью репозитория centos, нужно проверить сетевые разрешения. Иногда, перед построением, просто помогает выполнение таких команд:sudo firewall-cmd --zone=public --add-masquerade --permanent sudo firewall-cmd --reload
Запуск контейнера
Для запуска контейнеров СУБД «Квант-Гибрид» и QCP с настройками по умолчанию, выполните в текущем каталоге:
docker-compose up
Прервать выполнение можно с помощью Ctrl+C, или же выполнив из другой консоли в текущем каталоге:
docker-compose down
Для запуска контейнеров в режиме "демона", выполните:
docker-compose up -d
При первом запуске база данных будет автоматически инициализирована.
Посмотреть логи можно с помощью команды:
docker-compose logs
По умолчанию, база данных сохраняется на диске в каталоге qhb/pgdata.
Остановка контейнеров
Если контейнеры были запущен посредством docker-compose up, то для остановки достаточно нажать Ctrl+C.
Если же контейнеры были запущены в режиме "демона", т.е. посредством docker-compose up -d, то для остановки контейнеров выполните (из любой консоли) в текущем каталоге:
docker-compose down. Эту команду также можно выполнять и при остановленных контейнерах.
Настройка QCP
По умолчанию, сервис QCP отключён. Для его запуска необходимо в файле docker-compose.yaml убрать (закомментировать) запись
entrypoint: ["echo", "Service qcp disabled"]
из раздела services: -> qcp:, а также настроить сервис, в частности, параметры подключения к серверу.
Настройка QCP осуществляется посредством редактирования файла ./qcp/config.yaml.
Обязательно замените в разделе servers:
%USER% - на имя пользователя, от имени которого запускается docker-compose, и
%DATABASE% - на имя базы данных, в простейшем случае база создается с именем, совпадающим с именем пользователя.
В дальнейшем, если вы создадите другую базу данных, этот параметр может потребоваться изменить. По умолчанию сервис QCP работает на порту 8080, при необходимости переопределите этот параметр. Обратите внимание, что настройки применяются только при запуске.
Отредактируйте файл docker-compose.yaml следующим образом:
В разделе services: -> qhb: -> volumes: замените
- ./qhb/pgdata:/qhb-data/
на
- /path/to/pgdata:/qhb-data/
где /path/to/pgdata — абсолютный путь до каталога базы данных с существующей базой данных.
В разделе services: -> qhb: -> environment: замените - USER на - USER=USERNAME
Запустите контейнер с помощью команды
docker-compose -e USER="USERNAME" up
где USERNAME — имя пользователя, владеющего каталогом /path/to/pgdata.
Пример отредактированного файла docker-compose.yaml:
version: "3.3"
services:
qhb:
build: qhb
image: qhb
network_mode: "host"
environment:
- USER=qhb
volumes:
- ./qhb/pgdata:/qhb-data/
qcp:
build: qcp
image: qcp
network_mode: "host"
entrypoint: ["echo", "Service qcp disabled"] # Comment this line if will use QCP
volumes:
- ./qcp/config.yaml:/config.yaml:ro
В данном сценарии уже подготовлены и при запуске будут проделаны шаги по инициализации кластера, запуску сервера и созданию базы данных.
Поэтому, следующие шаги в данной инструкции могут быть пропущены. Может оказаться полезным раздел Доступ к базе данных.
Инициализация кластера базы данных
Создайте каталог для размещения базы данных командой
sudo mkdir <путь/имя каталога>
Например:
sudo mkdir /usr/local/qhb/data
Разрешите доступ к нему пользователю qhb командой
sudo chown qhb <путь/имя каталога>
В нашем случае:
sudo chown qhb /usr/local/qhb/data
Далее рекомендуется переключиться на пользователя qhb и выполнять команды от его имени.
В ином случае необходимо использовать sudo -u qhb для всех последующих команд, если вы работаете от пользователя с правами sudo.
Инициализируйте кластер базы данных при помощи утилиты initdb или qhb_bootstrap
<путь к бинарным утилитам QHB>/initdb -D <путь/имя каталога> -U qhb
В нашем случае:
/usr/local/qhb/bin/initdb -D /usr/local/qhb/data -U qhb
или, если установлена переменная окружения $PATH:
initdb -D /usr/local/qhb/data -U qhb
В дальнейшем, данный каталог будет использоваться при запуске и остановке сервера QHB.
Его можно указать в переменной окружения $PGDATA, что облегчит запуск следующих утилит - можно будет не указывать каталог в параметре -D.
Смотрите дополнительно: Создание кластера базы данных, initdb, qhb_bootstrap
Запуск и остановка сервера
Рекомендуется переключиться на пользователя qhb и выполнять команды от его имени.
В ином случае необходимо использовать sudo -u qhb для всех последующих команд если вы работаете от пользователя с правами sudo.
Для запуска сервера используйте команду:
<путь к бинарным утилитам QHB>/qhb_ctl -D <путь/имя каталога> start
В нашем случае:
/usr/local/qhb/bin/qhb_ctl -D /usr/local/qhb/data start
Или, если установлены переменные окружения $PGDATA и $PATH:
qhb_ctl start
Для остановки сервера используйте команду:
<путь к бинарным утилитам QHB>/qhb_ctl -D <путь/имя каталога> stop
В нашем случае:
/usr/local/qhb/bin/qhb_ctl -D /usr/local/qhb/data stop
Или, если установлена переменная окружения $PGDATA:
qhb_ctl stop
Смотрите дополнительно: Запуск сервера базы данных, Завершение работы сервера
Запуск и остановка сервера с помощью сервиса systemd
Замечание.
Описывается запуск QHB сервиса через подсистему инициализации и управления службамиsystemd. Уточните, что она установлена в вашем дистрибутиве Linux.
При установке из пакета rpm, имеется возможность использовать сервис systemd для автоматического запуска сервера БД при старте системы. Для этого, необходимо уточнить предварительно установленный скрипт запуска сервиса. Если необходимо поменять расположение каталога базы данных, задаваемое по умолчанию, выполните:
sudo systemctl edit qhb
Далее, в открывшемся редакторе (файл изначально пуст) укажите нужный путь:
[Service]
Environment=PGDATA=/opt/qhb/data
Сохраните изменения и завершите работу редактора.
Перестройте сервис и, если необходимо, разрешите ему запускаться при перезагрузке ОС:
sudo systemctl daemon-reload
sudo systemctl enable qhb
В дальнейшем, после начальной настройки (см. Начало работы), запускать сервис нужно будет командой:
sudo systemctl start qhb
А останавливать командой:
sudo systemctl stop qhb
Создание базы данных
Первый тест, чтобы увидеть, можете ли вы получить доступ к серверу базы данных - попытаться создать базу данных. Работающий сервер QHB может управлять многими базами данных. Как правило, отдельная база данных используется для каждого проекта или для каждого пользователя.
Возможно, ваш администратор уже создал базу данных для вашего использования. В этом случае вы можете пропустить этот шаг и перейти к следующему разделу.
Чтобы создать новую базу данных, в этом примере с именем mydb, вы используете следующую команду:
createdb mydb -h localhost
Если в ответ на такой запуск нет ошибки, то этот шаг был успешным, и вы можете пропустить оставшуюся часть этого раздела.
Если вы видите сообщение, похожее на:
createdb: command not found
тогда QHB не был установлен должным образом. Либо он вообще не был установлен, либо путь поиска вашей оболочки не был настроен на его включение. Попробуйте вместо этого вызвать команду с абсолютным путем:
/usr/local/qhb/bin/createdb mydb
Ваш путь может быть другим. Обратитесь к вашему администратору или ознакомьтесь с инструкциями по установке, чтобы исправить ситуацию.
Другой ответ может быть таким:
createdb: could not connect to database qhb: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
Это означает, что сервер не был запущен или не был запущен там, где
ожидал createdb. Снова, проверьте инструкции по установке или
проконсультируйтесь с администратором.
Другой ответ может быть таким:
createdb: could not connect to database qhb: FATAL: role "joe" does not exist
где упоминается ваше имя пользователя. Это произойдет, если администратор не создал для вас учетную запись пользователя QHB. (Учетные записи пользователей QHB отличаются от учетных записей пользователей операционной системы). Если вы являетесь администратором, обратитесь к главе Роли в базе данных за помощью в создании учетных записей. Вам нужно стать пользователем операционной системы, под которой был установлен QHB (обычно qhb), чтобы создать первую учетную запись пользователя. Возможно также, что вам было присвоено имя пользователя QHB, отличающееся от имени пользователя вашей операционной системы; в этом случае вам нужно использовать ключ -U или установить окружение PGUSER, чтобы указать свое имя пользователя в QHB.
Если у вас есть учетная запись пользователя, но у нее нет прав, необходимых для создания базы данных, вы увидите следующее:
createdb: database creation failed: ERROR: permission denied to create database
Не каждый пользователь имеет право создавать новые базы данных. Если QHB отказывается создавать базы данных для вас, ваш администратор должен предоставить вам разрешение на создание баз данных. Обратитесь к вашему администратору, если это произойдет. Если вы установили QHB самостоятельно, вы должны войти в систему в целях данного руководства под учетной записью пользователя, с которой вы запустили сервер1.
Вы также можете создавать базы данных с другими именами. QHB позволяет создавать любое количество баз данных. Имена баз данных должны иметь алфавитный первый символ и иметь длину не более 63 байтов. Удобный выбор - создать базу данных с тем же именем, что и ваше текущее имя пользователя. Многие инструменты предполагают, что имя базы данных используется как имя по умолчанию, поэтому оно поможет вам сэкономить время при наборе текста. Чтобы создать эту базу данных, просто введите:
createdb
Если вы больше не хотите использовать свою базу данных, вы можете удалить ее. Например, если вы являетесь владельцем (создателем) базы данных mydb, вы можете уничтожить ее, используя следующую команду:
dropdb mydb
(Для этой команды имя базы данных по умолчанию не совпадает с именем учетной записи пользователя. Вы всегда должны указывать его.) Это действие физически удаляет все файлы, связанные с базой данных, и не может быть отменено, так что это должно быть сделано только с большим количеством предусмотрительности.
Больше информации по командам createdb и dropdb можно найти в соответствующих разделах.
В качестве объяснения того, почему это работает: имена пользователей QHB отделены от учетных записей пользователей операционной системы. Когда вы подключаетесь к базе данных, вы можете выбрать, какое имя пользователя QHB будет подключаться; если вы этого не сделаете, по умолчанию будет использоваться то же имя, что и ваша текущая учетная запись операционной системы. Как это бывает, всегда будет учетная запись пользователя QHB, имя которой совпадает с именем пользователя операционной системы, запустившего сервер, и также бывает, что этот пользователь всегда имеет разрешение на создание баз данных. Вместо входа в систему под этим пользователем вы также можете указать опцию -U везде, чтобы выбрать имя пользователя QHB для подключения.
Доступ к базе данных
Создав базу данных, вы можете получить к ней доступ одним из следующих способов:
Возможно, вы захотите запустить qsql, чтобы попробовать примеры из этого урока. Его можно запустить для базы данных mydb, набрав команду:
$ qsql -h localhost -d mydb
Если вы не укажете имя базы данных, по умолчанию будет использоваться имя вашей учетной записи. Мы уже сталкивались с этой схемой в предыдущем разделе, при работе с createdb.
Внутри qsql вы увидите следующее сообщение:
qsql - Interactive terminal qhb (1.2.0)
Enter "\help" in order to get help
mydb(username)=#
Это будет означать, что вы являетесь суперпользователем базы данных, что наиболее вероятно, если вы установили экземпляр QHB самостоятельно. Суперпользователь имеет неограниченный доступ к базе данных; впрочем, для целей урока это не имеет значения.
Если вы столкнулись с проблемами при запуске qsql, вернитесь к предыдущему разделу. Диагностика createdb и qsql схожи, и если первый сработал, последний также должен сработать.
Последняя строка, напечатанная qsql является приглашением и указывает, что qsql ожидает ввод, то есть вы можете вводить запросы SQL в рабочее пространство. Попробуйте эти команды:
mydb(username)=# select version();
version
----------
QHB 1.2.0
(1 строка)
mydb(username)=# SELECT current_date;
date
------------
2020-10-07
mydb(username)=# SELECT 2 + 2;
?column?
----------
4
(1 строка)
Программа qsql имеет ряд внутренних команд, которые не являются
командами SQL. Они начинаются с символа обратной косой черты "\".
Например, чтобы выйти из qsql, введите:
mydb(username)=# \q
и qsql завершит работу и вернёт вас в командную оболочку.
Все возможности qsql описаны в соответствующем разделе: qsql.
Краткая инструкция по обновлению
Описывается базовый сценарий обновления QHB с помощью утилиты qhb_upgrade. Для получения более подробной информации вы можете обратиться к соответствующему разделу документации (см. qhb_upgrade)
В случае, если ваш сервер уже остановлен, первый шаг можно пропустить.
Для остановки сервера БД введите:
qhb_ctl -D $PGDATA stop
или, если он запускался через сервис:
sudo systemctl stop qhb
Примечание.
Файлы конфигурации и данных, используемые СУБД, обычно хранятся в одном каталоге называемом PGDATA (аналогично имени переменной среды). В наших примерах мы будем использовать /opt/qhb/data.old как путь к данным старого каталога кластера БД и /opt/qhb/data как путь к данным нового каталога кластера БД. Каталог /usr/local/qhb.old/bin это место хранения исполняемых файлов старой версии QHB, а каталог /usr/local/qhb/bin это место хранения исполняемых файлов новой версии QHB.
Переместите старый кластер:
sudo mv /opt/qhb/data /opt/qhb/data.old
Переместите текущий установочный каталог QHB, чтобы он не мешал новой установке QHB:
sudo mv /usr/local/qhb /usr/local/qhb.old
Установите новые пакеты QHB командой от пользователя с правами суперпользователя:
yum [ install | upgrade ] <путь до каталога c пакетами/названия пакетов>
Примечание.
В зависимости от ОС команда для установки может меняться. Если вы устанавливаете пакеты из репозитория QHB, то вы можете воспользоваться инструкцией (см. Краткая инструкция по начальной загрузке и установке).
Вновь создайте папку для БД:
sudo mkdir -p /opt/qhb/data
Разрешите пользователю qhb доступ к ней:
sudo chown -R qhb /opt/qhb/data
Далее рекомендуется переключиться на пользователя qhb и выполнять команды от его имени.
В ином случае необходимо использовать sudo -u qhb для всех последующих команд если вы работаете от пользователя с правами sudo.
Инициализируйте кластер БД командой:
initdb -D /opt/qhb/data
Выполните обновление QHB через утилиту qhb_upgrade:
qhb_upgrade \
--old-bindir=/usr/local/qhb.old/bin/ \
--new-bindir=/usr/local/qhb/bin/ \
--old-datadir=/opt/qhb/data.old \
--new-datadir=/opt/qhb/data --verbose
Примечание.
В случае ошибки обновления необходимо убедиться, что пользователь qhb имеет права доступа ко всем указанным каталогам.
Ожидаемый результат:
Upgrade Complete
Для старта сервера БД введите:
qhb_ctl -D /opt/qhb/data start
или
sudo systemctl start qhb
Запуск и остановка сервера с помощью сервиса systemd
Замечание.
Описывается запуск QHB сервиса через подсистему инициализации и управления службамиsystemd. Уточните, что она установлена в вашем дистрибутиве Linux.
При установке из пакета rpm, имеется возможность использовать сервис systemd для автоматического запуска сервера БД при старте системы. Для этого, необходимо уточнить предварительно установленный скрипт запуска сервиса. Если необходимо поменять расположение каталога базы данных, задаваемое по умолчанию, выполните:
sudo systemctl edit qhb
Далее, в открывшемся редакторе (файл изначально пуст) укажите нужный путь:
[Service]
Environment=PGDATA=/opt/qhb/data
Сохраните изменения и завершите работу редактора.
Перестройте сервис и, если необходимо, разрешите ему запускаться при перезагрузке ОС:
sudo systemctl daemon-reload
sudo systemctl enable qhb
В дальнейшем, после начальной настройки (см. Начало работы), запускать сервис нужно будет командой:
sudo systemctl start qhb
А останавливать командой:
sudo systemctl stop qhb
Пример настройки синхронной реплики
Внимание!
В данном разделе приводится конечный пример настройки кластера баз данных с синхронной репликации. Обратите внимание, что здесь приводятся некоторые параметры, такие как ip адреса хостов или каталоги баз данных, которые могут не соответствовать вашим.
Начальные условия
Операционная система на серверах - CentOS 7.
172.31.101.70 - IP сервера, назначенного как Master.
172.31.101.71 - Соответсвенно IP Standby сервера.
СУБД установлена из RPM пакетов (см. Страница загрузки. QHB для Centos 7 и 8).
Каталог размещения БД - PG_DATA = /u01/qhb/db
/usr/local/qhb/ - путь установки QHB (по умолчанию)
Сервисы systemd сконфигурированы с учётом вышеперечисленного.
Настройка Master
create user repluser replication password 'repluser';
listen_addresses = '*'
wal_level = hot_standby
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
logging_collector = on
log_directory = './log'
synchronous_commit = on
synchronous_standby_names = '*'
vi /u01/qhb/db/qhb_hba.conf
host replication repluser 172.31.101.70/32 md5
host replication repluser 172.31.101.71/32 md5
Существующую запись
host replicationне изменяем
systemctl restart qhb && systemctl status qhb
Настройка Standby
systemctl stop qhb && systemctl status qhb
Внимание !: Удаляя директорию, вы должны полностью осознавать необратимость данного действия, и тот факт что все данные, файлы конфигурации и логи будут утеряны без возможности восстановления.
rm -rf /u01/qhb/db/* # Я понимаю что делает эта команда
Восстановление через утилиту бэкапирования, запускается от системного пользователя QHB:
sudo -u qhb \#
/usr/local/qhb/bin/qhb_basebackup \#Утилита бэкапа
-h 172.31.101.70 \ # IP адрес мастер сервера
-p 5432 \ # Порт по умолчанию, сменить если меняли конфигурацию
-U repluser \ # созданный на мастере ранее пользователь с правами репликации
-D /u01/qhb/db/ \ # директория размещения СУБД
-Fp -Xs -P -R # Набор ключей необходимы для репликации
Для лучшего понимания, следует ознакомиться с функционированием ключей
-Fp -Xs -P -R утилиты, описанных в Параметры qhb_basebackup.
Если делается копия при помощи qhb_basebackup, параметры подключения для
реплики будут указаны в файле qhb.auto.conf.
Следует удостовериться в корректности заданной строки подключения.
Если копия БД была развёрнута через файл (или иной корректный способ, не указанный в данной инструкции), то до старта необходимо скорректировать несколько параметров:
sudo -u qhb touch /u01/qhb/db/standby.signal
ls -la standby.signal
#-rw------- 1 qhb qhb 0 Nov 25 15:34 standby.signal
primary_conninfo = 'user=repluser password=repluser host=172.31.101.70 port=5432 sslmode=disable sslcompression=0 gssencmode=disable krbsrvname=postgres target_session_attrs=any'
Строка подключения длинная, и некоторые консольные редакторы могут применить опцию word-wrap, нарушая визуальную целостность строки.
vi /u01/qhb/db/qhb.conf
listen_addresses = '*'
logging_collector = on
log_directory = 'log' # удостоверьтесь в существовани директории и наличии необходимых прав.
systemctl start qhb && systemctl status qhb
Проверка
/usr/local/qhb/bin/psql -x -c "select * from pg_stat_replication"
Должен высветится один слот:
pid | 15566
usesysid | 16385
usename | repluser
application_name | walreceiver
client_addr | 172.31.101.71
client_hostname |
client_port | 40516
backend_start | 2020-11-25 09:45:22.249802-03
backend_xmin |
state | streaming
sent_lsn | 0/30001F8
write_lsn | 0/30001F8
flush_lsn | 0/30001F8
replay_lsn | 0/30001F8
write_lag |
flush_lag |
replay_lag |
sync_priority | 1
sync_state | sync
^^^^^^^
reply_time | 2020-11-25 09:47:22.710523-03
Причём sync_state должен быть sync (репликация синхронная)
CREATE TABLE rtest (vname VARCHAR(40));
insert into rtest select substr(md5(random()::text), 0, 40) from generate_series(1,1000000);
qhb=# select count(*) from rtest;
count
---------
1000000
(1 row)
Дополнительные настройки
В некоторых вариантах рекомендовано прописать явное указание слота репликации.
На реплике в файл qhb.auto.conf добавить параметр primary_slot_name = 'standby_slot2_qhb'.
На мастере выполнить SQL
SELECT pg_create_physical_replication_slot('standby_slot2_qhb');
Запрос по активным слотам репликации должен показывать на мастере нашу реплику
select * from pg_replication_slots where active=true;
Смотрите Также
Внешний гайд с инструкциями и пояснениями
Инструкция по использованию QSS в режиме хранения пользовательского ключа на USB носителе
В данной инструкции представлены рекомендации по использованию модуля безопасного хранения QHB (Quantum Secure Storage, QSS), а так же сценарий инициализации QSS c помощью утилиты qss_mgr и последующий запуск сервера БД. Для получения более подробной информации вы можете обратиться к соответствующему разделу документации (см. qss)
Для начала работы с QSS требуется установить QHB на ваш компьютер и инициализировать кластер БД (обычно путь к данным кластера экспортируется в переменную среды PGDATA). Если вы устанавливаете пакеты из репозитория QHB, то вы можете воспользоваться инструкцией (см. Краткая инструкция по начальной загрузке и установке).
Сервер БД должен остаться выключенным.
Подключите USB носители к компьютеру для генерации мастер ключа и ключа Пользователя который имеет право запускать сервер БД (далее Админ)
Примечание.
USB носитель должен всегда подключаться по одному и тому-же пути (здесь используется путь /mtn/flash для флешки Админа, /mtn/flash_master для флешки с мастер ключем). Мастер ключ не должен копироваться на компьютер. USB носитель с мастер ключем (или сам файл мастер-ключа) нужен только при инициализации QSS и потом должен храниться в защищенном месте.
Выполните генерацию мастер ключа (данную операцию не обязательно производить на сервере c qhb, выполнение возможно на любой другой машине):
head -c 32 /dev/random > /mnt/flash_master/master.bin
Выполните генерацию пользовательского ключа:
head -c 32 /dev/random > /mnt/flash/user1.bin
Добавьте ключи в QSS с помощью утилиты qss_mgr (здесь и далее не указаны пути до места хранения исполняемых файлов QHB). Данная командная строка требует установленной переменной среды PGDATA. В случае если PGDATA не установлена, следует использовать параметр -d либо --data-dir для указания пути до папки БД:
qss_mgr init --module=/usr/lib64/librtpkcs11ecp.so \
-m fs \
-k \
/mnt/flash/user1.bin \
/mnt/flash_master/master.bin
Для добавления в QSS ключа другого Админа необходимо, кроме флешки добавляемого Админа, подключить флешку уже добавленного Админа.
Примечание.
Если Владельцев ключа несколько, USB носители должны монтироваться по уникальным путям, например, /mnt/flash2, /mnt/flash3 и т.п.
Для добавления в QSS дополнительного ключа введите:
qss_mgr add
-m fs \
-n 0 \ # номер ключа уже добавленного Админа (при инициализации добавляется ключ с номером 0)
/mnt/flash2/user2.bin
Включите шифрование путем добавления значения qss_mode = 1 в файл qhb.conf:
echo qss_mode = 1 >> $PGDATA/qhb.conf
Для запуска сервера БД в режиме работы модуля безопасного хранения QSS порядок действий будет следующий:
qhb_ctl start
Инструкция по использованию QSS в режиме хранения пользовательского ключа на крипто-токене
В данной инструкции представлены рекомендации по использованию модуля безопасного хранения QHB (Quantum Secure Storage, QSS), сценарий инициализации QSS c помощью утилит qss_mgr и qss_pinpad. Так же здесь представлена информация об использовании Рутокена, как средства безопасной двухфакторной аутентификации пользователей, генерации и защищенного хранения ключей шифрования. Для получения более подробной информации вы можете обратиться к соответствующему разделу документации (см. qss).
В QHB допускается использование токенов поддерживающих аппаратное шифрование с использованием алгоритма Магма ГОСТ 34.12-2018 (ГОСТ 28147-89) и поддерживающих стандарт PKCS#11. Шифрование проверялось на следующих токенах: Рутокен ЭЦП 2.0, Рутокен ЭЦП 2.0 сертифицированный ФСБ, Рутокен ЭЦП 2.0 3000, сертифицированный ФСБ (более подробную информацию о токенах можно найти на официальном сайте www.rutoken.ru или по ссылке https://www.rutoken.ru/products/all/rutoken-ecp/.
Для начала работы с QSS требуется установить QHB на ваш компьютер и инициализировать кластер БД (обычно путь к данным кластера экспортируется в переменную среды PGDATA). Если вы устанавливаете пакеты из репозитория QHB, то вы можете воспользоваться инструкцией (см. Краткая инструкция по начальной загрузке и установке).
Так же для работы требуется установленный модуль PKCS#12. Для Рутокен его можно скачать по ссылке https://www.rutoken.ru/support/download/pkcs/. Токен устанавливается по пути /usr/lib64/librtpkcs11ecp.so или /usr/lib/librtpkcs11ecp.so в зависимости от операционной системы.
Иницализации ключей
Сервер БД должен остаться выключенным.
Подключите USB носитель к компьютеру для генерации мастер ключа.
Примечание.
USB носитель должен всегда подключаться по одному и тому-же пути (здесь используется путь /mtn/flash_master для флешки с мастер ключем). Мастер ключ не должен копироваться на компьютер. USB носитель с мастер ключем (или сам файл мастер-ключа) нужен только при инициализации QSS и потом, как и носитель с токеном, должен храниться в защищенном месте.
Выполните генерацию мастер ключа (данную операцию не обязательно производить на сервере c qhb, выполнение возможно на любой другой машине):
head -c 32 /dev/random > /mnt/flash_master/master.bin
Пользовательский ключ (далее токен) генерируется внешними программно-аппаратными средствами или утилитой magma_key_gen, которая поставляется в пакете qhb-contrib.
Проверить токен можно с помощью утилиты из пакета opensc. Если данного пакета у вас нет, вы можете скачать его выполнив в терминале команду (для centos/fedora):
sudo dnf install opensc
для дебиан/астра:
sudo apt-get install opensc
Для проверки ключа введите в своем терминале:
pkcs11-tool --module /usr/lib64/librtpkcs11ecp.so -T
Пример вывода:
Available slots:
Slot 0 (0x0): Aktiv Rutoken ECP 00 00
token label : test_label
token manufacturer : Aktiv Co.
token model : Rutoken ECP
token flags : login required, rng, SO PIN to be changed, token initialized, PIN initialized, user PIN to be changed
hardware version : 20.5
firmware version : 23.2
serial num : 3c4c6444
pin min/max : 6/32
"serial num" это уникальный серийный номер токена, нужен для добавления токена в QSS.
Также необходимо проверить список ключей на токене. Для этого введите в своем терминале:
pkcs11-tool --module /usr/lib64/librtpkcs11ecp.so -Ol
Пример вывода:
Using slot 0 with a present token (0x0)
Logging in to "test_label".
WARNING: user PIN to be changed
Please enter User PIN:
Secret Key Object; unknown key algorithm 50
label:
ID: 3132333435
Usage: encrypt, decrypt, verify
Запись "unknown key algorithm 50" означает, что используется тип ключа Магма. ID отображен в шестнадцатеричном виде, в данном случае это строка "3132333435", что соответствует строке "12345", также нужен для добавления токена в QSS. В строке "Usage" должны быть "encrypt, decrypt"
Описание иницализации QSS
В отдельном терминале запустите утилиту qss_pinpad, она требуется для ввода пин-кода токена. Запуск должен производиться от пользователя, который будет добавлять ключи в QSS.
Подключите USB носители с Мастер ключем и пользовательским ключем (токеном)
Добавьте ключи в QSS с помощью утилиты qss_mgr (здесь и далее не указаны пути до места хранения исполняемых файлов QHB). Данная командная строка требует установленной переменной среды PGDATA. В случае если PGDATA не установлена, следует использовать параметр -d либо --data-dir для указания пути до папки БД:
qss_mgr init \
--module=/usr/lib64/librtpkcs11ecp.so \
-m pkcs11 \
--token-serial-number 3c4c6444 \
--token-key-id 12345 \
/mnt/flash_master/master.bin
Введите пин-код токена, запрос которого будет выдан в терминале с qss_pinpad в процессе работы.
Отключите USB носитель с мастер-ключем и токен.
Примечание.
Токеном должен "владеть" пользователь, имеющий право запускать сервер (далее Админ). Если таких Админов несколько, то у каждого должна быть свой токен.
Далее рассмотрим пример добавления в QSS дополнительного ключа (если Админ один - можете пропустить этот пункт):
В отдельном терминале запустите qss_pinpad.
Подключите токен нового Админа и токен уже зарегистрированного Админа
Для добавления в QSS дополнительного ключа введите:
qss_mgr add
-m pkcs11 \
--token-serial-number 3c4c6444 \
--token-key-id 3132333435 \
-n 0 \ # номер ключа уже добавленного Админа (при инициализации добавляется ключ с номером 0)
Включение режима работы сервера с QSS
Для использования QSS при работы с вашей БД включите шифрование путем добавления значения qss_mode = 1 в файл qhb.conf:
echo qss_mode = 1 >> $PGDATA/qhb.conf
Запуск сервера
Для запуска сервера БД в режиме работы модуля безопасного хранения QSS (вариант хранения пользовательского ключа на крипто-токене) порядок действий будет следующий:
qhb_ctl start
Инструкция по установке и использованию QCP
В данной инструкции представлены простые шаги по установке пулера соединений QCP, а так же базовая настройка сервиса systemd. Для получения более подробной информации вы можете обратиться к соответствующему разделу документации (см. qcp).
Для начала использования QCP, необходимо установить поставляемый пакет в систему. Если вы устанавливаете пакеты из репозитория QHB, то вы можете воспользоваться инструкцией (см. Краткая инструкция по начальной загрузке и установке). После подключения к репозиторию установить пакет, например для Centos 7, можно следующим образом:
sudo yum install qcp
После установки будет создан файл с примером конфигурации в /etc/qcp/config-example.yaml. Его необходимо скопировать в /etc/qcp/config.yaml и отредактировать под свои нужды, выставив необходимы параметры подключения к СУБД.
Управление сервисом осуществляется через поставляемый юнит systemd:
Перед первым запуском, после установки QCP, необходимо выполнить перезагрузку демона systemd, для того чтобы изменения вступили в силу:
systemctl daemon-reload
Запуск QCP:
sudo systemctl start qcp
Остановка QCP:
sudo systemctl stop qcp
Для того, чтобы QCP запускался автоматически при старте системы, выполните следующую команду:
sudo systemctl enable qcp
-----------------------------
-- Наследование:
-- Таблица может наследоваться от нескольких таблиц. Запрос может получить как записи из таблицы
-- так дополнительно и записи из всех её наследников.
-----------------------------
-- Для примера, таблица capitals (столицы) наследуется от таблицы cities (города), будут унаследованы все поля
CREATE TABLE cities (
name text,
population float8,
altitude int -- (in ft)
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
-- Теперь заполним таблицы.
INSERT INTO cities VALUES ('San Francisco', 7.24E+5, 63);
INSERT INTO cities VALUES ('Las Vegas', 2.583E+5, 2174);
INSERT INTO cities VALUES ('Mariposa', 1200, 1953);
INSERT INTO capitals VALUES ('Sacramento', 3.694E+5, 30, 'CA');
INSERT INTO capitals VALUES ('Madison', 1.913E+5, 845, 'WI');
SELECT * FROM cities;
SELECT * FROM capitals;
-- Можно найти все города включая столицы которые расположены на высоте 500 футов и выше
SELECT c.name, c.altitude
FROM cities c
WHERE c.altitude > 500;
-- Для того что бы в запросе участвовала только родительская таблица используйте ключевое слово ONLY:
SELECT name, altitude
FROM ONLY cities
WHERE altitude > 500;
-- Очистка таблиц (сначала надо удалить дочерние таблицы)
DROP TABLE capitals;
DROP TABLE cities;
Замечания к релизу QHB версии 1.3.0
Добавлено
Улучшено
Исправлено
Замечания к релизу QHB версии 1.2.0
QHB 2B
Расширения QHB для поддержки 1С. Поддерживается платформа «1С:Предприятие», начиная с версии 8.3.18.
Новая функция
qhb_upgrade
Подготовлена и включена в релиз утилита миграции базы данных из предыдущих версий QHB и версии PostgreSQL 12.
Добавлено
Прочие улучшения
Замечания к релизу QHB версии 1.1.0
QHB Plan Cache
Экспериментальная функция выключена по умолчанию, добавлена для проверки стабильности и работоспособности.
Новая функция
QHB Bootstrap
Система инициализации базы, функциональный аналог initdb полностью переделан для учёта особенностей QHB.
Новая функция
QSS
Модуль безопасного хранения (шифрования с поддержкой криптоалгоритма "Кузнечик").
QSQL
Пользовательская интерактивная утилита для работы из командной строки.
Append Only Storage
Данное хранилище позволяет только добавлять записи, но делает это с максимальной скоростью, т.к. не выполняется полноценного MVCC анализа.
Предназначено для таблиц, с которыми не производятся модификации, например журналы, данные с датчиков и т.п.
Новая функция
QBackup
Добавлена новая подсистема резервного копирования и восстановления с поддержкой каталога, архивации резервных копий и сохранения "разности" вместо полной резервной копии.
QDL
Добавлено
Изменено
Исправлено
Утилиты
Метрики
Подсистема сбора и предоставления для внешнего отображения системных метрик. Предоставление пока только в grafana.