Индексы GIN
Введение
GIN расшифровывается как Generalized Inverted Index (обобщенный инвертированный индекс). GIN предназначен для случаев, когда индексируемые значения являются составными, а запросы, на обработку которых рассчитан индекс, ищут значения элементов в этих составных объектах. Например, такими объектами могут быть документы, а запросы могут выполнять поиск документов, содержащих определенные слова.
В этом разделе мы используем термин объект, говоря об индексируемом составном значении, и термин ключ, говоря о включенном в него значении элемента. GIN всегда хранит и ищет ключи, а не значения-объекты как таковые.
Индекс GIN хранит набор пар (ключ, список указателей), где список указателей содержит набор идентификаторов строк, в которых находится данный ключ. Один и тот же идентификатор строки может фигурировать в нескольких списках указателей, поскольку объект может содержать больше одного ключа. Значение каждого ключа хранится только один раз, поэтому индекс GIN очень компактен в случаях, когда один ключ встречается много раз.
GIN является обобщенным в том смысле, что коду метода доступа GIN не нужно знать о конкретных операциях, которые он ускоряет. Вместо этого он применяет специальные стратегии, определенные для конкретных типов данных. Такая стратегия определяет, как ключи извлекаются из индексируемых объектов и условий запросов и как определить, действительно ли строка, содержащая некоторые значения ключей, удовлетворяет запросу.
Одним из преимуществ GIN является то, что он позволяет разрабатывать специальные типы данных с соответствующими методами доступа экспертам в области типов данных, а не экспертам по СУБД. Это практически то же самое преимущество, что есть у GiST.
Встроенные классы операторов
Базовый дистрибутив QHB включает классы операторов GIN, перечисленные в Таблице 1. (Некоторые из специализированных модулей, описанных в разделе Расширения, предоставляют дополнительные классы операторов GIN.)
Таблица 1. Встроенные классы операторов GIN
Имя |
Индексируемые операторы |
|---|---|
| array_ops | && (anyarray,anyarray) |
| @> (anyarray,anyarray) | |
| <@ (anyarray,anyarray) | |
| = (anyarray,anyarray) | |
| jsonb_ops | @> (jsonb,jsonb) |
| @? (jsonb,jsonpath) | |
| @@ (jsonb,jsonpath) | |
| ? (jsonb,text) | |
| ?| (jsonb,text[]) | |
| ?& (jsonb,text[]) | |
| jsonb_path_ops | @> (jsonb,jsonb) |
| @? (jsonb,jsonpath) | |
| @@ (jsonb,jsonpath) | |
| tsvector_ops | @@ (tsvector,tsquery) |
| @@@ (tsvector,tsquery) |
Из двух классов операторов для типа jsonb классом по умолчанию является jsonb_ops. jsonb_path_ops поддерживает меньше операторов, но обеспечивает для них более высокую производительность. Дополнительную информацию см. в подразделе Индексация jsonb.
Расширяемость
Интерфейс GIN имеет высокий уровень абстракции, требующий от разработчика метода доступа только реализации семантики типа данных, к которому производится обращение. Уровень GIN сам занимается параллельным доступом, журналированием и поиском в древовидной структуре.
Все, что требуется для работы метода доступа GIN — это реализовать несколько пользовательских методов, определяющих поведение ключей в дереве и отношения между ключами, индексируемыми объектами и соответствующими запросами. Иначе говоря, GIN сочетает расширяемость с универсальностью, повторным использованием кода и простым интерфейсом.
Существует два метода, которые класс операторов должен предоставить для GIN:
extractValue
Datum *extractValue(Datum itemValue, int32 *nkeys, bool **nullFlags)
Возвращает выделенный с помощью palloc массив ключей индексируемого объекта. Число возвращаемых ключей должно записываться в *nkeys. Если какой-то из ключей может быть NULL, то необходимо также выделить память для массива из *nkeys полей bool, сохранить его адрес в *nullFlags и при необходимости установить эти флаги NULL. Если все ключи отличны от NULL, то можно оставить в *nullFlags значение NULL (это его исходное значение). Возвращаемое значение может быть NULL, если объект вообще не содержит ключей.
extractQuery
Datum *extractQuery(Datum query, int32 *nkeys, StrategyNumber n, bool **pmatch, Pointer **extra_data, bool **nullFlags, int32 *searchMode)
Возвращает выделенный с помощью palloc массив ключей для запроса; то есть в query* передается значение правого операнда индексируемого оператора, у которого в левом операнде передается индексируемый столбец. В n задается номер стратегии оператора в классе операторов (см. подраздел Стратегии индексного метода). Зачастую функции extractQuery требуется проанализировать n, чтобы определить тип данных query и метод, который нужно использовать для извлечения значений ключей. Число возвращаемых ключей должно сохраняться в *nkeys. Если какой-то из ключей может быть NULL, то необходимо также выделить память для массива из *nkeys полей bool, сохранить его адрес в *nullFlags и при необходимости установить эти флаги NULL. Если все ключи отличны от NULL, то можно оставить в *nullFlags значение NULL (это его исходное значение). Возвращаемое значение может быть NULL, если объект вообще не содержит ключей.
Выходной аргумент searchMode позволяет функции extractQuery выбрать режим, в котором должен выполняться поиск. Если в *searchMode задать GIN_SEARCH_MODE_DEFAULT (это значение устанавливается перед вызовом), подходящими кандидатами считаются объекты, которые соответствуют хотя бы одному из возвращенных ключей. Если в *searchMode задать GIN_SEARCH_MODE_INCLUDE_EMPTY, то в дополнение к объектам с минимум одним совпадением ключа подходящими кандидатами будут считаться и объекты, вообще не содержащие ключей. (Этот режим полезен для реализации, например, операторов «является-подмножеством»). Если в *searchMode задать GIN_SEARCH_MODE_ALL, подходящими кандидатами считаются все отличные от NULL объекты в индексе, независимо от того, соответствуют ли они какому-либо из возвращаемых ключей. (Этот режим намного медленнее других, так как он по сути требует сканирования всего индекса, но он может быть необходим для корректной обработки крайних случаев. Оператор, который часто выбирает этот режим, скорее всего не подходит для реализации в классе операторов GIN).
Выходной аргумент pmatch используется, когда поддерживается частичное соответствие. Чтобы использовать его, extractQuery должна выделить массив из *nkeys элементов типа bool и сохранить его адрес в *pmatch. Если соответствующему ключу требуется частичное соответствие, каждый элемент этого массива должен быть равен true, если нет — false. Если *pmatch равна NULL, GIN предполагает, что частичное соответствие не требуется. В этой переменной NULL устанавливается перед вызовом, поэтому этот аргумент можно просто игнорировать в классах операторов, не поддерживающих частичное соответствие.
Выходной аргумент extra_data позволяет функции extractQuery передать методам consistent и comparePartial дополнительные данные. Чтобы использовать его, extractQuery должна выделить массив из *nkeys указателей и сохранить его адрес в *extra_data, а затем сохранять в отдельные указатели все, что ей нужно. В этой переменной NULL устанавливается перед вызовом, поэтому этот аргумент можно просто игнорировать в классах операторов, которым не требуются дополнительные данные. Если массив *extra_data задан, то он передается в метод consistent целиком, а в comparePartial передается соответствующий его элемент. .
Класс операторов должен также предоставить функцию для проверки, соответствует ли индексированный объект запросу. Поддерживаются два ее варианта: логическая функция consistent и троичная функция triConsistent. triConsistent покрывает функциональность обеих, поэтому достаточно предоставить только ее. Однако если вычисление логического варианта значительно дешевле, имеет смысл предоставить оба варианта. Если предоставлен только логический вариант, некоторые оптимизации, зависящие от отклонения объектов индекса до выборки всех ключей, отключаются.
consistent
bool consistent(bool check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], bool *recheck, Datum queryKeys[], bool nullFlags[])
Возвращает true, если индексированный объект удовлетворяет оператору запроса со стратегией под номером n (или может удовлетворять, если возвращается указание перепроверки). У этой функции нет прямого доступа к значению индексированного объекта, поскольку GIN не хранит объекты явно. Скорее, доступно знание о том, какие значения ключа, извлеченные из запроса, находятся в заданном индексированной объекте. Массив check имеет длину nkeys, равную числу ключей, ранее возвращенных функцией extractQuery для этого значения query. Каждый элемент массива check равен true, если индексированный объект содержит соответствующий ключ запроса, т. е. если (check[i] == true), то i-ый ключ результата массива queryKeys представлен в индексированном объекте. Исходное значение query передается в том случае, если методу consistent нужно его проанализировать, и то же касается массивов queryKeys[] и nullFlags[], ранее возвращенных функцией extractQuery. В extra_data передается массив дополнительных данных, возвращенный функцией extractQuery, или NULL, если такого массива нет.
Когда extractQuery возвращает ключ NULL в queryKeys[], соответствующий элемент check[] равен true, если индексированный объект содержит ключ NULL; то есть семантика check[] подобна IS NOT DISTINCT FROM. Функция consistent может проверить соответствующий элемент nullFlags[], если ей нужно различать соответствие с обычным значением и соответствие с NULL.
В случае успеха в *recheck следует установить true, если кортеж кучи нужно перепроверить с оператором запроса, или false, если проверка по индексу точная. То есть возвращенное значение false гарантирует, что кортеж кучи не соответствует запросу; возвращенное значение true вместе с *recheck, установленным в false, означает, кортеж кучи может соответствовать запросу, поэтому его нужно выбрать и перепроверить путем вычисления оператора запроса напрямую по исходному индексированному объекту.
triConsistent
GinTernaryValue triConsistent(GinTernaryValue check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], Datum queryKeys[], bool nullFlags[])
Функция triConsistent подобна consistent, но вместо логических значений в векторе check ей передаются три возможных значения для каждого ключа: GIN_TRUE, GIN_FALSE и GIN_MAYBE. У GIN_FALSE и GIN_TRUE тот же смысл, что и у обычных логических значений, тогда как GIN_MAYBE означает, что присутствие этого ключа неизвестно. Когда присутствуют значения GIN_MAYBE, эта функция должна возвращать GIN_TRUE, только если объект точно удовлетворяет запросу, независимо от того, содержит ли объект индекса соответствующие ключи запроса. Аналогичным образом, функция должна возвращать GIN_FALSE, только если объект точно не удовлетворяет запросу, независимо того, содержи ли он ключи GIN_MAYBE. Если результат зависит от записей GIN_MAYBE, т. е. соответствие нельзя подтвердить или опровергнуть, основываясь на известных ключах запроса, функция должна вернуть GIN_MAYBE.
Когда в векторе check нет значений GIN_MAYBE, возвращаемое значение GIN_MAYBE равнозначно установке флага recheck в логической функции consistent. .
Кроме того, GIN должен иметь способ сортировки значений ключей, хранящихся в индексе. Класс операторов может определить порядок сортировки, указав метод сравнения.
compare
int compare(Datum a, Datum b)
Сравнивает два ключа (не индексированные объекты!) и возвращает целое меньше нуля, ноль или целое больше нуля, показывая, что первый ключ меньше, равен или больше второго. Ключи NULL этой функции никогда не передаются.
Или же, если класс операторов не предоставляет метод compare, GIN будет искать
класс операторов B-дерева по умолчанию для типа данных ключа индекса и
воспользуется его функцией сравнения. Рекомендуется указывать функцию сравнения в
классе операторов GIN, предназначенном только для одного типа данных, поскольку
поиск класса операторов B-дерева занимает несколько циклов. Однако для полиморфных
классов операторов GIN (например для array_ops) обычно нельзя указать одну
функцию сравнения.
.
Дополнительно класс операторов для GIN может предоставить следующие методы:
comparePartial
int comparePartial(Datum partial_key, Datum key, StrategyNumber n, Pointer extra_data)
Сравнивает ключ запроса с частичным соответствием с ключом индекса. Возвращает целое, знак которого отражает результат: отрицательное число означает, что ключ индекса не соответствует запросу, но сканирование индекса должно продолжаться; ноль означает, что ключ индекса не соответствует запросу; положительное число указывает на то, что сканирование индекса должно остановиться, потому что больше соответствий не будет. Функции предоставляется номер стратегии n оператора, сгенерировавшего запрос частичного соответствия, на случай, если его семантика понадобится, чтобы определить, когда прекратить сканирование. Кроме того, в extra_data передается соответствующий элемент массива дополнительных данных, созданного функцией extractQuery, или NULL, если такого массива нет. Ключи NULL этой функции никогда не передаются.
options
void options(local_relopts *relopts)
Определяет набор видимых пользователю параметров, контролирующих поведение класса операторов.
Функции options передается указатель на структуру local_relopts, которую нужно заполнить набором параметров, специфичных для класса операторов.К этим параметрам можно обратиться из других вспомогательных функций с помощью макросов PG_HAS_OPCLASS_OPTIONS() и PG_GET_OPCLASS_OPTIONS().
Поскольку в GIN извлечение ключа из индексированных значений и представление ключа гибкие, они могут зависеть от параметров, заданных пользователем. .
Для поддержки запросов на «частичное соответствие» класс операторов должен предоставить метод comparePartial, а его метод extractQuery должен устанавливать параметр pmatch, когда встречается запрос на частичное соответствие. Дополнительную информацию см. в подразделе Алгоритм частичного соответствия.
Фактические типы данных различных значений Datum, упоминаемых выше, варьируются в зависимости от класса операторов. Значения объектов, передаваемые функции extractValue, всегда имеет входной тип класса операторов, а все значения ключей имеют тип, заданный параметром STORAGE для этого класса. Тип аргумента query, передаваемого функциям extractQuery, consistent и triConsistent, будет совпадать с входным типом правого операнда оператора-члена класса, определяемого по номеру стратегии. Он не обязательно должен совпадать с индексируемым типом, главное, чтобы из него можно было извлечь значения ключей правильного типа. Однако в SQL-объявлениях этих трех вспомогательных функций рекомендуется использовать для аргумента query индексируемый тип данных класса операторов, даже если фактический тип может быть другим, в зависимости от оператора.
Реализация
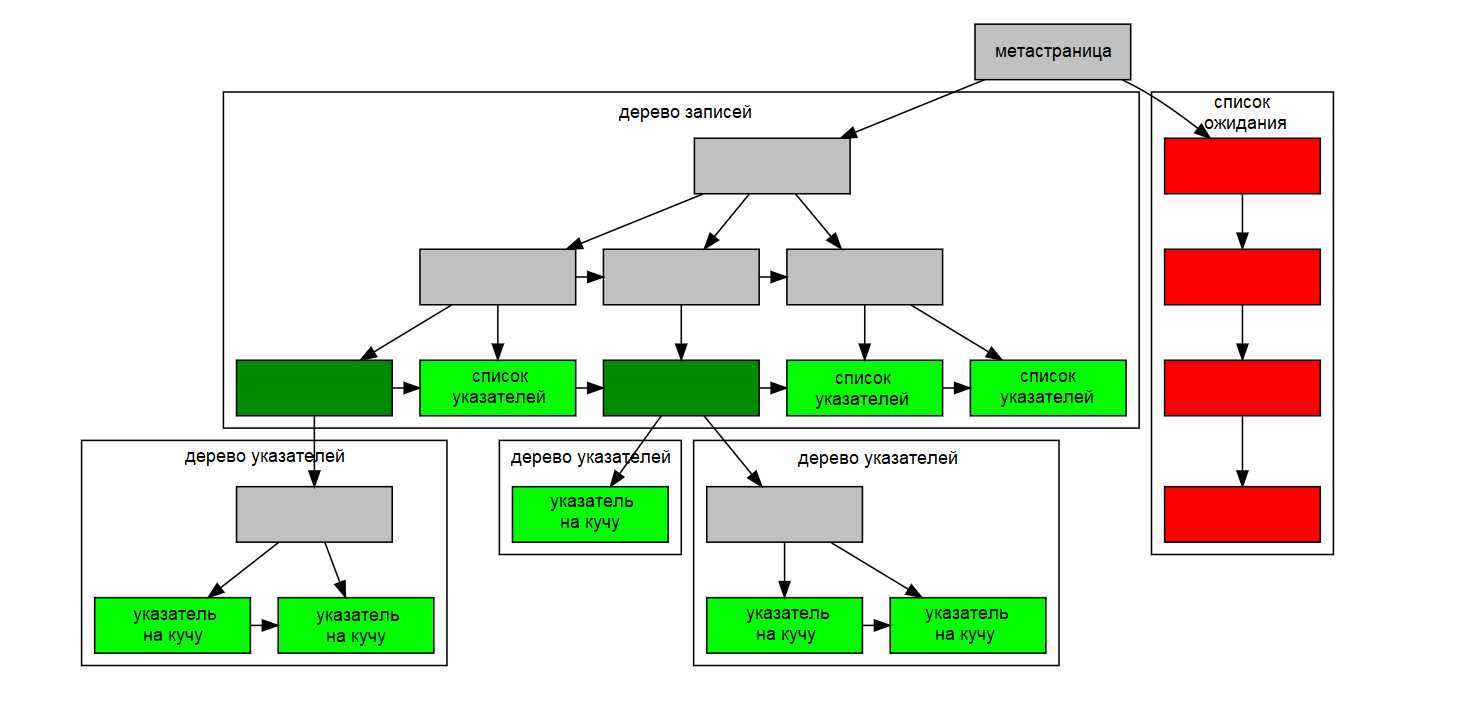
Внутри индекс GIN содержит индекс B-дерево, построенный по ключам, где каждый ключ является элементом одного или нескольких индексированных объектов (например членом массива), и где каждый кортеж в листовой странице содержит либо указатель на B-дерево указателей на кучу («дерево указателей»), либо простой список указателей на кучу («список указателей»), когда этот список достаточно мал, чтобы поместиться в одном кортеже индекса вместе со значением ключа. На Рисунке 1 показаны эти компоненты индекса GIN.
В индекс могут быть явно включены ключи со значением NULL. Кроме того, значения- заполнители NULL включаются в индекс для индексированных объектов, равных NULL или не содержащих ключей согласно функции ExtractValue. Это позволяет находить пустые объекты, когда это нужно сделать.
Многостолбцовые индексы GIN реализуются путем построения одного B-дерева по составным значениям (номер столбца, значение ключа). Значения ключей для разных столбцов могут быть разных типов.
Рисунок 1. Внутренняя структура GIN
Методика быстрого обновления GIN
Обновление индекса GIN, как правило, происходит медленно вследствие естественных свойств инвертированных индексов: добавление или изменение одной строки кучи может повлечь множество добавлений в индекс (по одному для каждого ключа, извлеченного из индексируемого объекта). GIN способен отложить большую часть этой работы, вставляя новые кортежи во временный, несортированный список ожидающих записей. Когда таблица очищается или автоматически анализируется, или когда вызывается функция gin_clean_pending_list, или когда длина списка ожидания превышает значение параметра gin_pending_list_limit, эти записи перемещаются в основную структуру данных GIN с помощью той же методики группового добавления, что и при начальном создании индекса. Это значительно увеличивает скорость обновления индекса GIN, даже с учетом дополнительных затрат на очистку. Более того, эту затратную работу можно сделать в фоновом процессе, а не в приоритетном процессе, выполняющем запросы.
Главный недостаток этого подхода состоит в том, что при поиске приходится, помимо обычного индекса, сканировать список ожидающих записей, и поэтому большие списки значительно замедлят поиск. Еще один недостаток заключается в том, что, хотя большинство изменений производятся быстро, изменение, из-за которого список ожидания становится «слишком большим», повлечет за собой немедленную очистку и таким образом будет выполняться гораздо медленнее других изменений. Обе эти проблемы можно свести к минимуму, правильно настроив автоочистку.
Если согласуемое время отклика важнее, чем скорость изменений, использование
отложенных записей можно отключить, выключив параметр хранения fastupdate
индекса GIN. Дополнительную информацию см. в описании команды CREATE INDEX.
Алгоритм частичного соответствия
GIN может поддерживать проверки «частичного соответствия», в которых запрос выявляет не точное соответствие одному и более ключам, а возможные соответствия, попадающие в достаточно узкий диапазон значений ключей (при порядке сортировки ключей, определенном вспомогательным методом compare). Метод extractQuery, вместо того, чтобы вернуть значение ключа, которое соответствует точно, возвращает значение ключа, равное нижней границе сканируемого диапазона, и устанавливает флаг pmatch. Затем этот диапазон ключей сканируется методом comparePartial. Метод comparePartial должен вернуть ноль для соответствующего ключа индекса, отрицательное значение, если соответствия нет, но оно все еще внутри диапазона, поэтому нужно продолжать поиск, или положительное значение, если ключ индекса выходит за пределы диапазона, в котором может быть соответствие.
Советы и приемы для индексов GIN
Создание или добавление
Добавление в индекс GIN может выполняться медленно из-за того, что для каждого объекта почти наверняка понадобится добавлять много ключей. Поэтому при массовом добавлении в таблицу рекомендуется удалить индекс GIN и пересоздать его после завершения массового добавления.
Когда для GIN включен режим fastupdate (подробную информацию см. в подразделе Методика быстрого обновления GIN), издержки меньше, чем когда он выключен. Но для очень больших объемов изменений, возможно, все же будет лучше удалить и пересоздать индекс.
Время построения индекса GIN сильно зависит от параметра maintenance_work_mem; не стоит экономить на рабочей памяти во время создания индекса.
Во время последовательных добавлений в существующий индекс GIN, у которого включен fastupdate, система будет очищать список ожидания, когда его размер превысит gin_pending_list_limit. Во избежание колебаний в наблюдаемом времени отклика желательно проводить очистку списка ожидания в фоновом режиме (т. е. посредством автоочистки). Операций очистки на переднем плане можно избежать, увеличив значение gin_pending_list_limit или сделав автоочистку более интенсивной. Однако увеличение порога операции очистки означает, что если все-таки случится очистка на переднем плане, она займет еще больше времени.
Настройку параметра gin_pending_list_limit можно переопределить для отдельных индексов GIN, изменив параметры хранения, которые позволяют каждому индексу GIN иметь собственный порог очистки. Например, можно увеличить порог очистки только для индекса GIN, который может часто обновляться, и снизить его для всех остальных.
Основной целью разработки индексов GIN было создать поддержку отлично расширяемого полнотекстового поиска в QHB, и при этом нередко возникают ситуации, когда полнотекстовый поиск возвращает очень большой набор результатов. Более того, это зачастую происходит, когда запрос содержит очень часто встречающиеся слова, так что огромный результат даже не будет полезен. Поскольку чтение множества кортежей с диска и их сортировка могут занять много времени, это неприемлемо в среде промышленной эксплуатации. (Обратите внимание, что сам по себе поиск по индексу крайне быстрый.)
Чтобы облегчить управляемое выполнение таких запросов, у GIN имеется настраиваемый мягкий верхний предел числа возвращаемых строк: параметр конфигурации gin_fuzzy_search_limit. По умолчанию он равен 0 (то есть предела нет). Если установлено ненулевое значение, то возвращаемый набор является случайно выбранным подмножеством общего результирующего набора.
«Мягкий» означает, что фактическое число возвращаемых результатов может немного отличаться от заданного предела, в зависимости от запроса и качества системного генератора случайных чисел.
Из опыта: значения в несколько тысяч (например 5000 — 20000) работают нормально.
Ограничения
GIN предполагает, что индексируемые операторы являются строгими. Это означает, что функция extractValue вообще не будет вызываться для объектов NULL (вместо этого в индексе автоматически создается запись-заполнитель), а функция extractQuery аналогично не будет вызываться для поисковых значений NULL (вместо этого запрос будет считаться предположительно неудовлетворяемым). Однако обратите внимание, что ключи NULL, содержащиеся в отличном от NULL составном объекте или поисковом значении, при этом поддерживаются.
Примеры
Основной дистрибутив QHB включает классы операторов GIN, ранее перечисленные в таблице в разделе Встроенные классы операторов. Классы операторов GIN также содержат следующие модули из share/extension:
btree_gin
Функциональность, равнозначная B-дереву, для некоторых типов данных
hstore
Модуль для хранения пар (ключ, значение)
intarray
Расширенная поддержка для int[ ]
pg_trgm
Похожесть текста, основанная на сопоставлении триграмм