Физическое хранение базы данных
В этой главе представлен обзор формата физического хранения, используемого базами данных QHB.
Структура файлов базы данных
В этом разделе описывается формат хранения на уровне файлов и каталогов.
Как правило, файлы конфигурации и данных, используемые кластером баз данных, хранятся вместе в каталоге данных кластера, обычно называемом PGDATA (по имени переменной среды, которую можно использовать для его определения). Обычно PGDATA располагается в /var/lib/qhb/data. На одной машине могут существовать несколько кластеров, управляемых различными экземплярами сервера.
Каталог PGDATA содержит несколько подкаталогов и управляющих файлов, как показано в Таблице 1. В дополнение к этим необходимым элементам в PGDATA традиционно хранятся файлы конфигурации кластера qhb.conf, qhb_hba.conf, и qhb_ident.conf, хотя их можно разместить и в другом месте.
Таблица 1. Содержимое PGDATA
| Элемент | Описание |
|---|---|
| QHB_VERSION | Файл, содержащий основной номер версии QHB |
| base | Подкаталог, содержащий подкаталоги для каждой базы данных |
| current_logfiles | Файл, содержащий файлы журнала, в которые в настоящее время делает записи сборщик протоколируемых событий |
| global | Подкаталог, содержащий общие таблицы кластера, например pg_database |
| pg_commit_ts | Подкаталог, содержащий данные о времени фиксации транзакций |
| pg_dynshmem | Подкаталог, содержащий файлы, используемые подсистемой динамической разделяемой памяти |
| pg_logical | Подкаталог, содержащий данные состояния для логического декодирования |
| pg_multixact | Подкаталог, содержащий данные о состоянии мультитранзакций (используется для разделяемых блокировок строк) |
| pg_notify | Подкаталог, содержащий данные о состоянии прослушивания/уведомлений (LISTEN/NOTIFY) |
| pg_replslot | Подкаталог, содержащий данные слота репликации |
| pg_serial | Подкаталог, содержащий информацию о зафиксированных сериализуемых транзакциях |
| pg_snapshots | Подкаталог, содержащий экспортированные снимки |
| pg_stat | Подкаталог, содержащий постоянные файлы для подсистемы статистики |
| pg_stat_tmp | Подкаталог, содержащий временные файлы для подсистемы статистики |
| pg_subtrans | Подкаталог, содержащий данные о состоянии субтранзакций |
| pg_tblspc | Подкаталог, содержащий символьные ссылки на табличные пространства |
| pg_twophase | Подкаталог, содержащий файлы состояния для подготовленных транзакций |
| pg_wal | Подкаталог, содержащий файлы WAL (Write Ahead Log, журнал упреждающей записи) |
| pg_xact | Подкаталог, содержащий данные о состоянии фиксации транзакций |
| qhb.auto.conf | Файл, используемый для хранения параметров конфигурации, задаваемых командой ALTER SYSTEM |
| postmaster.opts | Файл, записывающий параметры командной строки, с которыми сервер был запущен в последний раз |
| qhbmaster.pid | Файл блокировки, записывающий идентификатор текущего процесса qhbmaster (PID), путь к каталогу данных кластера, время запуска qhbmaster, номер порта, путь к каталогу сокета домена Unix (может быть пустым), первый допустимый адрес прослушивания (listen_address) (IP-адрес или * либо пустое значение, если нет прослушивания по TCP) и идентификатор сегмента разделяемой памяти (этот файл отсутствует после завершения работы сервера) |
Для каждой базы данных в кластере существует подкаталог внутри PGDATA/base, названный по OID базы данных в pg_database. По умолчанию в этом подкаталоге находятся файлы базы данных; в частности, там хранятся ее системные каталоги.
Обратите внимание, что в следующих разделах описано поведение встроенного табличного метода доступа heap и встроенных индексных методов доступа. Благодаря расширяемой природе QHB другие методы доступа могут работать по-другому.
Каждая таблица и индекс хранятся в отдельном файле. Для обычных отношений эти файлы называются по номеру файлового узла таблицы или индекса, который можно найти в pg_class.relfilenode. Но для временных отношений имя файла имеет вид tBBB_FFF, где BBB — это идентификатор обслуживающего процесса, создавшего этот файл, а FFF — это номер файлового узла номером. В любом случае помимо основного файла (также известного как основная ветвь) у каждой таблицы и индекса имеется карта свободного пространства (см. раздел Карта свободного пространства), где хранится информация о свободном пространстве, доступном в отношении. Карта свободного пространства хранится в файле имя которого состоит из номера файлового узла и суффикса _fsm. Таблицы также имеют карту видимости, хранящуюся в ветви с суффиксом _vm, для отслеживания страниц, не содержащих неиспользуемые кортежи. Карта видимости описывается далее в разделе Карта видимости. У нежурналируемых таблиц и индексов имеется третий файл, называемый ветвью инициализации, который хранится в ветви с суффиксом _init (см. раздел Ветвь инициализации).
ВНИМАНИЕ!
Обратите внимание, что хотя файловый узел таблицы часто совпадает с ее OID, это бывает не всегда. Некоторые операции, напримерTRUNCATE,REINDEX,CLUSTERи некоторые формыALTER TABLE, могут изменить файловый узел, сохранив при этом OID. Старайтесь не рассчитывать, что файловый узел и OID таблицы — это одно и то же. Кроме того, для некоторых системных каталогов, включая сам pg_class, pg_class.relfilenode содержит ноль. Фактические номера файловых узлов этих каталогов хранятся в структуре данных более низкого уровня и могут быть получены с помощью функции pg_relation_filenode().
Когда объем таблицы или индекса превышает 1 ГБ, они делятся на сегменты размером в гигабайт. Имя файла первого сегмента совпадает с номером файлового узла (filenode); последующие сегменты получают имена filenode.1, filenode.2, и т. д. Такая компоновка позволяет избежать проблем на платформах, имеющих ограничения по размеру файлов. (На самом деле, 1 ГБ — всего лишь размер сегмента по умолчанию. Этот размер можно регулировать с помощью параметра конфигурации --with-segsize при сборке QHB.) Теоретически для карт свободного пространства и карт видимости тоже может потребоваться несколько сегментов, хотя на практике это вряд ли произойдет.
Таблица, содержащая столбцы с потенциально большими записями, будет иметь связанную с ней таблицу TOAST, предназначенную для отдельного хранения полей, которые слишком велики, чтобы хранить их непосредственно в строках таблицы. Поле pg_class.reltoastrelid связывает таблицу с ее таблицей TOAST, если таковая имеется. Более подробную информацию см. в разделе TOAST.
Содержание таблиц и индексов рассматривается ниже в разделе Внутренняя структура страницы базы данных.
Табличные пространства делают сценарий более сложным. Каждое пользовательское
табличное пространство имеет символьную ссылку в каталоге PGDATA/pg_tblspc,
указывающую на физический каталог табличного пространства (т. е. расположение,
указанное в команде CREATE TABLESPACE данного табличного пространства). Эта
символьная ссылка получает имя по OID табличного пространства. Внутри физического
каталога табличных пространств есть подкаталог с именем, зависящим от версии
сервера QHB, например: QHB_1.4_201008051.
(Этот подкаталог необходим для того, чтобы последующие версии базы данных могли
бесконфликтно использовать одно и тоже расположение, заданное в CREATE TABLESPACE.)
В подкаталоге конкретной версии для каждой базы данных, имеющей элементы в
табличном пространстве, существует подкаталог, названный по OID этой базы. Таблицы
и индексы хранятся в этом каталоге, используя схему именования файловых узлов.
Табличное пространство pg_default недоступно через pg_tblspc, но
соответствует PGDATA/base. Аналогично табличное пространство pg_global
недоступно через pg_tblspc, но соответствует PGDATA/global.
Функция pg_relation_filepath() показывает весь путь (относительно PGDATA) любого отношения. Это зачастую удобнее, чем запоминать множество вышеперечисленных правил. Но имейте в виду, что эта функция просто выдает имя первого сегмента основной ветви отношения — чтобы найти все файлы, связанные с этим отношением, вам может понадобиться добавить номер сегмента и/или _fsm, _vm или _init .
Временные файлы (для операций вроде сортировки данных большего объема, чем может поместиться в памяти) создаются внутри PGDATA/base/pgsql_tmp, или в подкаталоге pgsql_tmp каталога табличного пространства, если для них задано табличное пространство, отличное от pg_default. Имя временного файла имеет вид pgsql_tmpPPP.NNN, где PPP — это PID обслуживающего процесса-владельца, а NNN служит для разделения различных временных файлов этого обслуживающего процесса.
TOAST
В этом разделе представлен обзор TOAST (The Oversized-Attribute Storage Technique, методика хранения сверхбольших атрибутов).
QHB использует фиксированный размер страницы (обычно 8 Кб) и не позволяет кортежам занимать несколько страниц. Поэтому нельзя напрямую хранить очень большие значения полей. Чтобы преодолеть это ограничение, большие значения полей сжимаются и/или разбиваются на несколько физических строк. Это происходит прозрачно для пользователя и на большую часть внутреннего кода влияет мало. Эту методику называют TOAST (шутл. омоним тоста, или «лучшего, что изобрели после хлеба в нарезке»). Инфраструктура TOAST также используется для улучшения обработки больших значений данных в памяти.
Только некоторые типы данных поддерживают TOAST — нет необходимости тратить ресурсы на типы данных, которые не могут создавать большие значения полей. Для поддержки TOAST тип данных должен иметь представление переменной длины (varlena), в котором, как правило, первое четырехбайтовое слово любого хранящегося значения содержит общую длину значения в байтах (включая само это слово). TOAST не ограничивает остальную часть представления типа данных. Специальные представления, совокупно именуемые значениями в формате TOAST, работают путем изменения или переосмысления этого начального слова длины. Поэтому функции уровня C/RUST, поддерживающие типы данных, подходящие для TOAST, должны аккуратно обрабатывать входные значения, которые потенциально могут быть в формате TOAST: входные данные могут на самом деле и не состоять из четырехбайтового слова длины и содержимого, пока не будут распакованы. (Обычно это делают, вызывая макрос PG_DETOAST_DATUM прежде, чем что-то делать с входным значением, но в некоторых случаях возможны более эффективные подходы. Более подробную информацию см. в подразделе Особенности TOAST.)
TOAST забирает два бита из слова длины varlena (старшие биты на машинах с обратным порядком байтов и младшие биты на машинах с прямым порядком байтов), тем самым ограничивая логический размер любого значения типа данных, подходящих для TOAST, до 1 ГБ (230 - 1 байт). Когда оба бита равны нулю, значение является обычным, не в формате TOAST, значением соответствующего типа данных, а оставшиеся биты слова длины задают общий размер данных (включая слово длины) в байтах. Когда установлен самый старший или самый младший бит, значение имеет только однобайтовый заголовок вместо обычного четырехбайтового, а оставшиеся биты этого байта задают общий размер данных (включая байт длины) в байтах. Этот альтернативный подход обеспечивает экономичное хранение значений размером менее 127 байт, при этом позволяя при необходимости увеличить значение типа данных до 1 ГБ. Значения с однобайтовыми заголовками не выравниваются по какой-либо конкретной границе, тогда как значения с четырехбайтовыми заголовками выравниваются как минимум по четырехбайтовой границе; это отсутствие необходимости в заполнении для выравнивания обеспечивает дополнительную экономию места, что ощутимо для коротких значений. В особом случае, если все оставшиеся биты однобайтового заголовка равны нулю (что потенциально невозможно с учетом включения размера длины), значение является указателем на отделенные данные с несколькими возможными альтернативами, как описывается ниже. Тип и размер такого указателя TOAST определяется кодом, хранящимся во втором байте данных. Наконец, когда самый старший или самый младший бит очищен, но соседний бит установлен, значит, содержимое данных было сжато и должно быть распаковано перед использованием. В этом случае оставшиеся биты четырехбайтового слова длины задают общий размер сжатых, а не исходных данных. Обратите внимание, что сжатие также возможно для отделенных данных, но заголовок varlena не говорит, произошло ли оно, — на это указывает содержимое указателя TOAST.
Методику, которая будет использоваться для сжатия внутренних или отделенных данных,
можно выбрать для каждого столбца по отдельности, установив параметр столбца
COMPRESSION в команде CREATE TABLE или ALTER TABLE. По умолчанию для
столбцов, у которых методика не задана явно, во время добавления данных используется
метод из параметра default_toast_compression.
Как уже упоминалось, существует несколько типов указателя данных TOAST. Старейший и самый распространенный тип — это указатель на отделенные данные, хранящиеся в таблице TOAST, которая отделена от таблицы, содержащей указатель TOAST, но связана с ней. Такие указатели на диске создаются с помощью кода управления TOAST (в access/heap/tuptoaster.c), когда кортеж, сохраняемый на диск, слишком велик, чтобы храниться как есть. Более подробная информация приводится в подразделе Отдельное хранение TOAST на диске. Как вариант, указатель TOAST может содержать указатель на отделенные данные, находящиеся в другом месте в памяти. Такие данные обязательно временные и никогда не оказываются на диске, но они очень полезны для предотвращения копирования и избыточной обработки больших значений данных. Более подробная информация приводится в подразделе Отдельное хранение TOAST в памяти.
Отдельное хранение TOAST на диске
Если любой из столбцов таблицы подходит для TOAST, таблица будет иметь связанную таблицу TOAST, OID которой хранится в записи таблицы pg_class.reltoastrelid. На диске значения в формате TOAST содержатся в таблице TOAST, что подробнее описывается ниже.
Отделенные значения делятся (после сжатия, если оно применяется) на фрагменты размером не более TOAST_MAX_CHUNK_SIZE байт (по умолчанию это значение выбирается таким образом, чтобы на странице помещались четыре строки фрагмента, то есть размер одного фрагмента составляет около 2000 байт). Каждый фрагмент хранится в виде отдельной строки в таблице TOAST, принадлежащей таблице-владельцу. У каждой таблицы TOAST есть столбцы chunk_id (OID, определяющий конкретное значение в формате TOAST), chunk_seq (порядковый номер для фрагмента в пределах его значения) и chunk_data (фактические данные фрагмента). Уникальный индекс по chunk_id и chunk_seq обеспечивает быстрое получение значений. Таким образом, в указателе на данные, представляющем отделенное значение TOAST на диске, должен храниться OID таблицы TOAST, в которой нужно искать, и OID конкретного значения (его chunk_id). Для удобства указатели на данные также хранят логический размер данных (исходную несжатую длину), физический сохраненный размер (отличается, если применялось сжатие) и использованный метод сжатия, если он задан. Учитывая байты заголовка varlena, общий размер указателя данных TOAST на диске составляет 18 байт независимо от фактического размера представляемого значения.
Код обработки TOAST запускается, только когда значение строки, подлежащее хранению
в таблице, больше TOAST_TUPLE_THRESHOLD байт (обычно 2 КБ). Код TOAST будет
сжимать и/или перемещать значения полей за пределы таблицы, пока значение строки
не станет короче TOAST_TUPLE_TARGET байт (по умолчанию тоже 2 КБ) или пока
дальнейшее уменьшение станет невозможным. Во время операции UPDATE значения
неизмененных полей обычно сохраняются как есть; поэтому изменение строки с
отделенными значениями не несет затрат, связанных с TOAST, если ни одно из таких
значений не изменилось.
Код обработки TOAST распознает четыре различные стратегии для хранения столбцов с поддержкой TOAST на диске:
-
PLAIN предотвращает сжатие или хранение вне таблицы; кроме того, она выключает использование однобайтовых заголовков для типов varlena. Это единственно возможная стратегия для столбцов типов данных, не допускающих TOAST.
-
EXTENDED позволяет как сжатие, так и хранение вне таблицы. Это стратегия по умолчанию для большинства типов данных с поддержкой TOAST. Сначала будет предпринята попытка сжатия, затем, если строка все еще слишком велика, сохранение отдельно.
-
EXTERNAL допускает хранение вне таблицы, но не сжатие. Использование EXTERNAL ускорит операции с подстрокой в больших столбцах text и bytea (ценой увеличения объема памяти для хранения), потому что такие операции оптимизированы для выборки только необходимых частей отделенного значения, когда оно не сжато.
-
MAIN позволяет сжатие, но не хранение вне таблицы. (На самом деле для таких столбцов по-прежнему будет выполняться хранение вне таблицы, но только в крайнем случае, когда нет другого способа сделать строку достаточно маленькой, чтобы уместить на странице.)
Каждый тип данных с поддержкой TOAST задает стратегию по умолчанию для столбцов
этого типа данных. Кроме того, стратегию для указанного столбца таблицы можно
изменить с помощью ALTER TABLE ... SET STORAGE.
TOAST_TUPLE_TARGET можно настроить для каждой таблицы с помощью
ALTER TABLE ... SET (toast_tuple_target = N)
По сравнению с более простым подходом, который позволяет значениям строк занимать несколько страниц, эта схема имеет ряд преимуществ. Предполагая, что обычно запросы уточняются путем сравнения с относительно маленькими значениями ключей, большая часть работы будет выполнена с использованием основной записи строки. Большие значения атрибутов в формате TOAST будут извлекаться (если вообще будут выбраны) только во время отправки результата клиенту. Таким образом, основная таблица оказывается намного меньше, а значит, в кэш разделяемого буфера помещается больше ее строк, чем их было бы без отдельного хранения. Наборы данных для сортировки тоже уменьшаются, и сортировка чаще будет выполняться полностью в памяти. Небольшой тест показал, что таблица, содержащая типичные HTML-страницы и их URL, после сохранения занимала половину объема исходных данных, включая таблицу TOAST, и что основная таблица содержала только около 10% всех данных (URL и некоторые небольшие HTML-страницы). При этом не было никакой разницы по времени выполнения по сравнению с таблицей без использования TOAST, в которой все HTML-страницы были уменьшены до 7 КБ, чтобы поместиться в строках.
Отдельное хранение TOAST в памяти
Указатели TOAST могут указывать на данные, находящиеся не на диске, а в другом месте в памяти текущего серверного процесса. Очевидно, что такие указатели не могут быть долговечными, но тем не менее они полезны. В настоящее время существует два подвида: указатели на косвенные данные и указатели на развернутые данные.
Косвенные указатели TOAST просто указывают на непосредственное значение varlena, хранящееся где-то в памяти. Изначально этот подвид был создан просто как доказательство концепции, но в настоящее время он используется при логическом декодировании во избежание потенциальной необходимости создания физических кортежей больше 1 гб (что может произойти при сведении всех отделенных значений полей в один кортеж). У такого способа весьма ограниченное применение, поскольку владелец такого указателя должен в полной мере осознавать, что ссылочные данные существуют, только пока существует указатель, и никакая инфраструктура этого не изменит.
Развернутые указатели TOAST полезны для сложных типов данных, представление которых на диске не особенно подходит для вычислительных целей. Например, стандартное представление varlena массива QHB включает информацию о размерности, битовую карту элементов NULL, если таковые имеются, а затем значения всех элементов по порядку. Когда сам тип элемента имеет переменную длину, единственный способ найти N-й элемент — это просканировать все предыдущие элементы. Такое представление подходит для хранения на диске из-за его компактности, но для вычислений с массивом гораздо удобнее иметь «развернутое» или «деконструированное» представление, в котором были определены начальные местоположения всех элементов. Механизм указателя TOAST поддерживает эту потребность, позволяя переданному по ссылке элементу Datum указывать либо на стандартное значение varlena (представление на диске), либо на указатель TOAST, указывающий на развернутое представление где-то в памяти. Детали этого развернутого представления зависят от типа данных, но он должен иметь стандартный заголовок и соответствовать также другим требованиям API.
Функции уровня C/RUST, работающие с таким типом данных, могут выбрать для обработки любое представление. Функции, которые не знают о развернутом представлении, а просто применяют к своим входным данным PG_DETOAST_DATUM, будут автоматически получать традиционное представление varlena, поэтому поддержку развернутого представления можно вводить постепенно, по одной функции за раз.
Указатели TOAST на развернутые значения далее делятся на указатели для чтения-записи и только для чтения. Представление, на которое они указывают, в любом случае будет одинаковым, но функция, получающая указатель для чтения-записи, может изменять ссылочное значение сразу на месте, тогда как функция, получающая указатель только для чтения, не должна этого делать; если она хочет получить измененную версию значения, сначала она должна создать копию. Это различие и некоторые связанные с ним соглашения позволяют избежать ненужного копирования развернутых значений при выполнении запроса.
Для всех типов указателей TOAST в памяти код обработки TOAST гарантирует, что подобные данные указателей не могут случайно сохраниться на диске. Указатели TOAST в памяти автоматически разворачиваются в обычные внутренние значения varlena перед сохранением, а затем могут преобразоваться в указатели TOAST на диске, если иначе содержащий их кортеж был бы слишком большим.
Карта свободного пространства
Каждое отношение кучи и индекса, за исключением хеш-индексов, имеет карту свободного пространства (Free Space Map, FSM) для отслеживания доступного пространства в отношении. Она хранится вместе с основными данными отношения в отдельной ветви отношений, называемой по номеру файлового узла отношения с суффиксом _fsm. Например, если номер файлового узла отношения равен 12345, то FSM хранится в файле с именем 12345_fsm, в том же каталоге, что и основной файл отношения.
Карта свободного пространства организована в виде дерева страниц FSM. Страницы FSM нижнего уровня хранят информацию о свободном пространстве, доступном на каждой странице кучи (или индекса), используя один байт для представления каждой такой страницы. Верхние уровни агрегируют информацию с нижних уровней.
Внутри каждой страницы FSM находится двоичное дерево, хранящееся в массиве, где на каждый узел приходится один байт. Каждый листовой узел представляет страницу кучи или страницу FSM более низкого уровня. В каждом не листовом узле хранится наивысшее из его дочерних значений. Поэтому максимальное из значений листовых узлов хранится в корне.
Для изучения информации, хранящейся на картах свободногопространства, можно воспользоваться модулем pg_freespacemap.
Карта видимости
Каждое отношение кучи имеет карту видимости (Visibility Map, VM) для отслеживания того, какие страницы содержат только те кортежи, которые считаются видимыми для всех активных транзакций; также она отслеживает, какие страницы содержат только замороженные кортежи. Она хранится вместе с основными данными отношения в отдельной ветви отношения, называемой по номеру файлового узла отношения с суффиксом _vm. Например, если номер файлового узла отношения равен 12345, то VM хранится в файле с именем 12345_vm, в том же каталоге, что и основной файл отношения. Обратите внимание, что индексы не имеют карту видимости.
Карта видимости хранит по два бита на каждую страницу кучи. Первый бит, если он установлен, указывает, что страница является полностью видимой, или, другими словами, что страница не содержит никаких кортежей, которые необходимо очистить. Эта информация также может использоваться сканированиями только по индексу для ответа на запросы, использующие только кортеж индекса. Второй бит, если он установлен, означает, что все кортежи на странице были заморожены. Это означает, что даже очистке с защитой от зацикливания счетчиков транзакций не нужно повторно просматривать эту страницу.
Карта является консервативной в том смысле, что мы уверены, что когда бит установлен, нам известно, что условие истинно, но когда бит не установлен, оно может быть как истинным, так и ложным. Биты карты видимости устанавливаются только очисткой, но зато сбрасываются любыми операциями, изменяющими данные на странице.
Для изучения информации, хранящейся в карте видимости, можно воспользоваться модулем pg_visibility.
Ветвь инициализации
Каждая нежурналируемая таблица и каждый индекс нежурналируемой таблицы имеют ветвь инициализации. Ветвь инициализации — это пустая таблица или индекс соответствующего типа. Когда нежурналируемую таблицу нужно сбросить до пустого состояния из-за сбоя, ветвь инициализации копируется поверх основной ветви, а все остальные ветви стираются (они будут автоматически воссоздаваться по мере необходимости).
Внутренняя структура страницы базы данных
В этом разделе представлен обзор формата страницы, используемого в таблицах и индексах QHB1. Последовательности и таблицы TOAST форматируются так же, как обычная таблица.
В следующем объяснении предполагается, что байт содержит 8 бит. Кроме того, термин элемент относится к индивидуальному значению данных, хранящемуся на странице. В таблице элемент — строка; в индексе — запись индекса.
Каждая таблица и индекс хранятся в виде массива страниц фиксированного размера (обычно 8 КБ, хотя при компиляции сервера можно выбрать другой размер страницы). В таблице все страницы логически равнозначны, поэтому определенный элемент (строка) может храниться на любой странице. В индексах первая страница обычно резервируется как метастраница, содержащая управляющую информацию, и в индексе могут быть разные типы страниц, в зависимости от индексного метода доступа.
В Таблице 2 показана общая структура страницы. Каждая страница состоит из пяти частей.
Таблица 2. Общая структура страницы
| Элемент | Описание |
|---|---|
| PageHeaderData | Длина 24 байта. Содержит общую информацию о странице, включая указатели на свободное пространство. |
| ItemIdData | Массив идентификаторов элементов, указывающих на фактические элементы. Каждая запись является парой (смещение,длина). По 4 байта на элемент. |
| Free space | Свободное пространство. Новые идентификаторы элементов выделяются с начала этой области, новые элементы — с конца. |
| Items | Собственно сами элементы. |
| Special space | Данные, специфичные для индексного метода доступа. Различные методы хранят различные данные. Для обычных таблиц это пустое поле. |
Первые 24 байта каждой страницы состоят из заголовка страницы (PageHeaderData). Его формат подробно описан в Таблице 3. В первом поле отслеживается самая последняя запись WAL, связанная с этой страницей. Второе поле содержит контрольную сумму страницы, если включен расчет контрольных сумм. Далее идет 2-байтовое поле, содержащее биты флагов. За ним следуют три 2-байтовых целочисленных поля (pd_lower, pd_upper, и pd_special). Они содержат смещения в байтах от начала страницы до начала свободного пространства, до конца свободного пространства и до начала специального пространства. Следующие 2 байта заголовка страницы, pd_pagesize_version, содержат размер страницы и индикатор версии. Размер страницы в основном присутствует только в качестве перекрестной проверки; в установке нет поддержки страниц разных размеров. Последнее поле служит подсказкой, показывающей, будет ли выгодно очистить страницу: она отслеживает самый старый неочищенный XMAX на странице.
Таблица 3. Структура PageHeaderData
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| pd_lsn | PageXLogRecPtr | 8 байт | LSN: следующий байт после последнего байта WAL-записи для последнего изменения на этой странице |
| pd_checksum | uint16 | 2 байта | Контрольная сумма страницы |
| pd_flags | uint16 | 2 байта | Биты флагов |
| pd_lower | LocationIndex | 2 байта | Смещение до начала свободного места |
| pd_upper | LocationIndex | 2 байта | Смещение до конца свободного пространства |
| pd_special | LocationIndex | 2 байта | Смещение до начала специального пространства |
| pd_pagesize_version | uint16 | 2 байта | Размер страницы и номер версии макета информация |
| pd_prune_xid | TransactionId | 4 байта | Самый старый неочищенный XMAX на странице, или ноль, если отсутствует |
После заголовка страницы идут идентификаторы элементов (ItemIdData), каждый из которых занимает четыре байта. Идентификатор элемента содержит смещение в байтах до начала элемента, его длину в байтах и несколько битов атрибутов, влияющих на его интерпретацию. Новые идентификаторы элементов выделяются по мере надобности с начала свободного пространства. Количество наличествующих идентификаторов элементов можно определить, просмотрев поле pd_lower, значение которого увеличивается при выделении нового идентификатора. Поскольку до своего освобождения идентификатор элемента никогда не перемещается, его индекс можно использовать для ссылки на элемент в течение длительного времени, даже если сам элемент перемещается по странице для уплотнения свободного пространства. На самом деле, каждый указатель на элемент (ItemPointer, также известный как CTID), созданный QHB, состоит из номера страницы и индекса идентификатора элемента.
Сами элементы хранятся в пространстве, выделенном с конца свободного пространства. Точная структура меняется в зависимости от того, что будет содержать таблица. В таблицах и последовательностях используется структура с именем HeapTupleHeaderData, описанная ниже.
Последний раздел — это «специальный раздел», который может содержать все, что метод доступа желает сохранить. Например, индексы B-деревья хранят ссылки на левый и правый родственные элементы страницы, а также некоторые другие данные, относящиеся к структуре индекса. Обычные таблицы вообще не используют специальный раздел (что указывается установкой в pd_special значения, равного размеру страницы).
На Рисунке 1 показано, как эти части располагаются на странице.
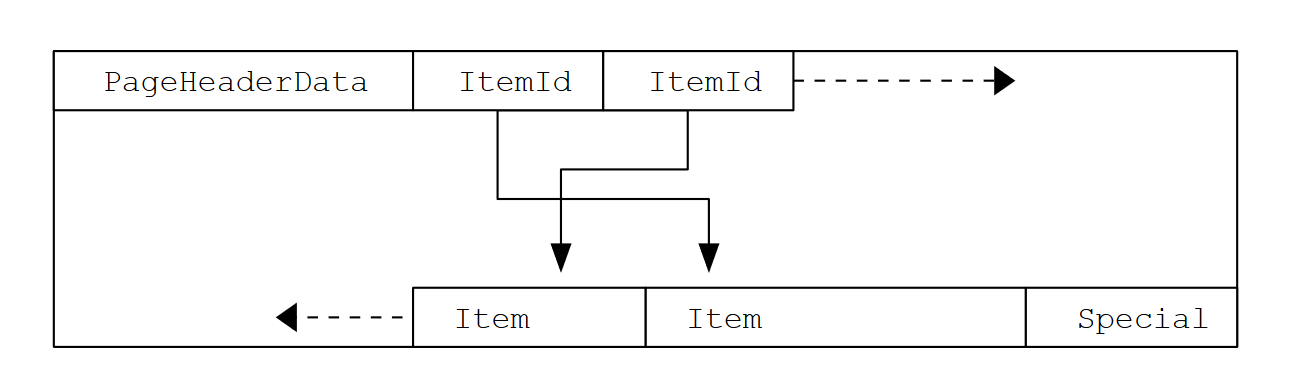
Структура строк таблицы
Все строки таблицы обладают схожей структурой. Они состоят из заголовка фиксированного размера (занимающего 23 байта на большинстве машин), за которым следует необязательная битовая карта пустых значений, необязательное поле идентификатора объекта и пользовательские данные. Заголовок подробно описывается в Таблице 4. Собственно пользовательские данные (столбцы строки) начинаются со смещения, указанного в t_hoff, которое всегда должно быть кратно расстоянию MAXALIGN для платформы. Битовая карта пустых значений присутствует только в том случае, если бит HEAP_HASNULL установлен в t_infomask. Если она присутствует, то начинается сразу после фиксированного заголовка и занимает столько байт, чтобы на каждый столбец данных приходилось по одному биту (т. е. количество битов равно числу атрибутов, указанному в t_infomask2). В этом списке битов бит 1 обозначает элемент, отличный от NULL, бит 0 — NULL. Когда битовой карты нет, все столбцы считаются отличными от NULL. Идентификатор объекта присутствует только в том случае, если бит HEAP_HASOID_OLD установлен в t_infomask. Если он присутствует, то находится сразу перед границей t_hoff. Любое заполнение, требуемое для того, чтобы сделать t_hoff кратным MAXALIGN, будет находиться между битовой картой пустых значений и идентификатором объекта. (Это в свою очередь гарантирует, что идентификатор объекта тоже выровнен соответствующим образом.)
Таблица 4. Структура Heaptupleheaderdata
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| t_xmin | TransactionId | 4 байта | метка XID добавления |
| t_xmax | TransactionId | 4 байта | метка XID удаления |
| t_cid | CommandId | 4 байта | метка CID добавления и/или удаление (пересекается с t_xvac) |
| t_xvac | TransactionId | 4 байта | XID для операции VACUUM при перемещении версии строки |
| t_ctid | ItemPointerData | 6 байт | текущий TID этой или более новой версии строки |
| t_infomask2 | uint16 | 2 байта | количество атрибутов плюс различные биты флагов |
| t_infomask | uint16 | 2 байта | различные биты флагов |
| t_hoff | uint8 | 1 байт | смещение до пользовательских данных |
Интерпретация фактических данных может быть выполнена только с помощью информации, полученной из других таблиц, в основном из pg_attribute. Ключевые значения, необходимые для определения местоположения полей: attlen и attalign. Не существует способа напрямую получить конкретный атрибут, за исключением случая, когда все поля имеют фиксированную длину и нет значений NULL. Все эти особенности охвачены в функциях heap_getattr, fastgetattr и heap_getsysattr.
Чтобы прочитать данные, требуется просмотреть каждый атрибут по очереди. Первым делом нужно проверить, содержит ли поле NULL согласно битовой карте пустых значений. Если это так, следует перейти к следующему полю. После этого необходимо убедиться в правильности выравнивания. Если поле имеет фиксированную ширину, то все байты просто отдаются. Если же это поле переменной длины (attlen = -1), то все становится немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка struct varlena, включающую в себя общую длину хранимого значения и некоторые биты флагов. В зависимости от этих флагов, данные могут храниться либо внутри, либо в таблице TOAST; кроме того, они могут быть сжатыми (см. раздел TOAST).
На самом деле, использование этого формата страницы не требуется ни для табличных, ни для индексных методов доступа. Табличный метод доступа heap всегда использует этот формат. Все существующие индексные методы тоже используют базовый формат, но данные, хранящиеся на метастраницах индекса, обычно не следуют правилам компоновки элементов.
Кортежи только в куче (Heap-Only Tuples, HOT)
Для обеспечения параллелизма высокой степени QHB использует для сохранения строк многоверсионное управление параллельным доступом (MVCC). Однако у MVCC имеется несколько побочных эффектов, когда дело касается запросов на изменение данных. В частности, при изменении требуется, чтобы в таблицы добавлялись новые версии строк. Кроме того, для каждой измененной строки в индекс должны добавляться новые записи, а удаление старых версий строк и их записей в индексе может быть затратным.
Для снижения издержек на изменения данных в QHB имеется оптимизация, называемая «кортежи только в куче» (HOT). Эта оптимизация возможна в следующих случаях:
-
Изменение не модифицирует столбцы, на которые ссылаются индексы таблицы, включая индексы по выражениям и частичные индексы.
-
На странице, содержащей старую строку, имеется достаточно свободного места для измененной строки.
В таких случаях принцип «кортежи только в куче» предоставляет две оптимизации:
-
Для представления измененных строк не нужны новые записи индекса.
-
Старые версии измененных строк могут быть полностью удалены во время обычной операции, включая
SELECT, и не требуют периодического выполнение операций очистки. (Это возможно, поскольку индексы не ссылаются на свои идентификаторы элементов страниц.)
Подводя итог вышесказанному, изменения кортежей только в куче могут выполняться, только если не изменяются столбцы, задействованные в индексах. Можно поспособствовать появлению достаточного места для изменений HOT, уменьшив фактор заполнения таблицы. Даже если этого не делать, изменения HOT все равно произойдут, поскольку новые строки будут естественным образом мигрировать на новые страницы и существующие страницы, где достаточно свободного места для новых версий строк. Системное представление pg_stat_all_tables позволяет мониторить изменения в режиме HOT и в обычном режиме.