Модуль управления кластерными вычислениями QLUSTER
ВНИМАНИЕ!
В релизе QHB 1.5.3 этот функционал является экспериментальным, его использование в установке на производственной среде не рекомендовано.
Назначение и общая архитектура
QLUSTER — это программный модуль, предназначенный для управления распределенными задачами в кластере. В основе QLUSTER лежит протокол согласования состояний QRaft, который обеспечивает согласованность и отказоустойчивость кластерных операций.
QLUSTER обеспечивает:
- Управление жизненным циклом задач и состояний с помощью QRaft.
- Взаимодействие с внешними системами посредством API-интерфейсов.
- Планирование и маршрутизацию вычислительных задач по узлам кластера.
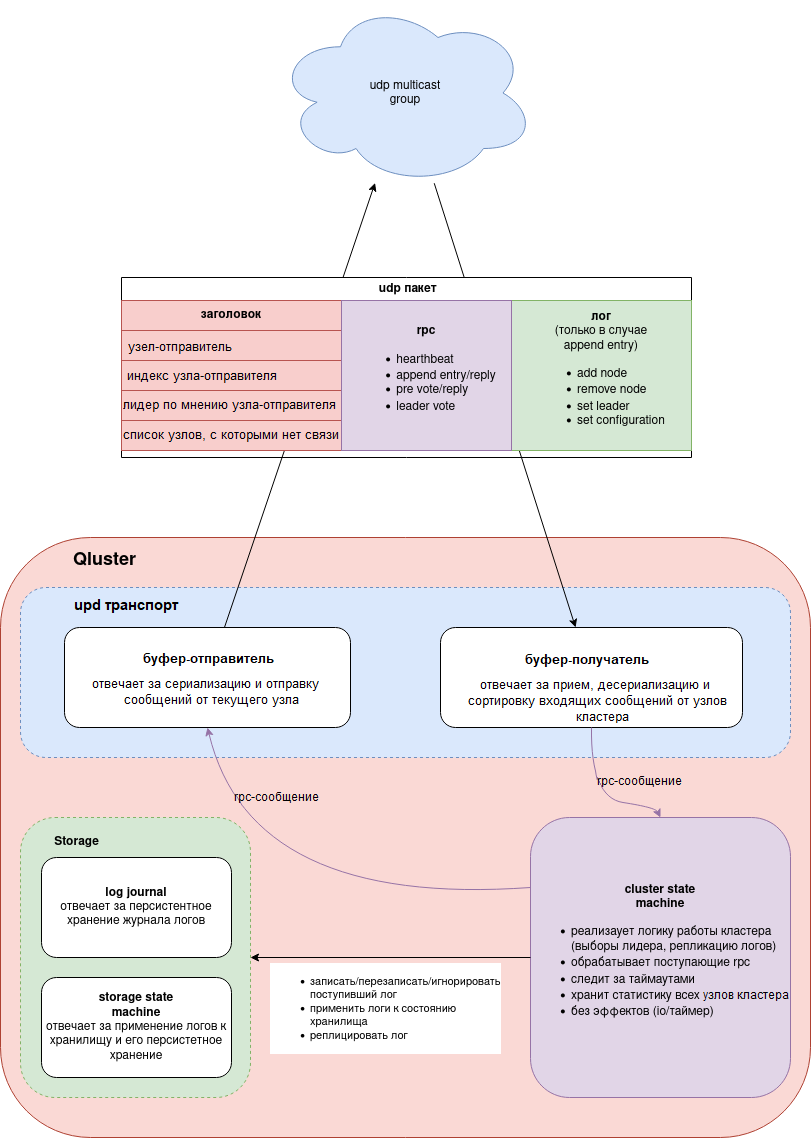
Компоненты:
Рисунок 1. Компоненты кластера
Установка QLUSTER
Для установки QLUSTER необходимо скачать бинарный файл, настроить службу запуска и создать конфигурационный файл config.yaml, который определяет поведение узла в кластерной среде.
Установка бинарного файла
- Скопируйте бинарный файл QLUSTER на сервер, предназначенный для запуска в составе кластера.
- Убедитесь, что бинарный файл доступен пользователю qhb.
Создание службы systemd
Создайте на основе бинарного файла системную службу для управления запуском QLUSTER как демоном. Служба должна работать от имени пользователя qhb.
Пример (/etc/systemd/system/qluster.service):
[Unit]
Description=QLUSTER service
After=network.target
[Service]
User=qhb
ExecStart=/usr/local/bin/qluster --config /etc/qluster/config.yaml
Restart=always
[Install]
WantedBy=multi-user.target
Активируйте службу:
sudo systemctl daemon-reexec
sudo systemctl enable qluster
sudo systemctl start qluster
Настройка конфигурационного файла
Конфигурация узла QLUSTER задается через файл config.yaml, который должен лежать рядом с бинарным файлом или по указанному пути. Пример содержимого:
ip: "ip адрес сервера"
api-port: 8080
udp:
socket:
group: "udp мультикаст адрес:порт должен быть одинаковый на всех узлах"
interface: "имя сетевого интерфейса для udp multicast"
pacing-rate: 268435456
loopback: false
send-buffer-size: 1048576
recv-buffer-size: 1048576
max-log-size: 64000
send-buffer-capacity: 256
recv-buffer-capacity: 256
cluster:
node-timeout: 30s
heartbeat-interval: 10s
pre-voting-timeout: 10s
leader-voting-timeout: 10s
quorum-replication: true
replication-factor: 0
replication-retry-interval: 1s
autoremove-enabled: false
autoremove-minimum: 3
remove-interval: 1m
hello-retry-interval: 1s
Примечание
Значения параметров должны быть синхронизированы между всеми узлами кластера, особенно поля udp.socket.group, interface и pacing-rate.
Ключевые параметры:
- node-timeout — максимальное время ожидания ответа от текущего лидера до начала процедуры предвыборов.
- pre-voting-timeout — продолжительность стадии предвыборов (pre-vote), на которой узлы оценивают возможность начала выборов.
- leader-voting-timeout — максимальное время, отведенное на проведение выборов лидера (vote round).
- heartbeat-interval — интервал между heartbeat-сигналами, которые рассылает лидер для подтверждения активности.
- replication-factor — количество реплик (узлов), которым необходимо доставить запись лога перед ее фиксацией (по умолчанию 0 — используется значение по кворуму).
- quorum-replication — включение репликации по кворуму: запись считается подтвержденной, если доставлена хотя бы n/2 + 1 узлам.
- replication-retry-interval — интервал, через который производится повторная попытка репликации лога в случае сбоя.
- autoremove-enabled — автоматическое исключение узлов из кластера, если они недоступны для большинства (кворума).
- autoremove-minimum — минимальное количество узлов в кластере, при котором допускается срабатывание механизма автоудаления.
Переинициализация кластера под управлением QLUSTER
Иногда требуется полностью переинициализировать кластер. Для этого нужно выполнить следующие действия:
- Остановить службы (qluster, qcp):
systemctl stop qluster
systemctl stop qcp
- Очистить каталоги баз данных командой:
rm -rf /opt/qhb-data/*
- На ведущем узле удалить файл /qluster/add_node:
rm /qluster/add_node
- Удалить содержимое сетевого каталога для архива WAL:
rm /opt/qhb-backup/wal/*
Можно объединить эти действия в две команды для основного узла и для других узлов:
systemctl stop qluster && rm /opt/qhb-backup/wal/* && rm /qluster/add_node && rm -rf /opt/qhb-data/* # для основного узла-лидера
systemctl stop qluster && rm -rf /opt/qhb-data/* # для узлов-реплик qhb
Далее нужно последовательно с небольшими паузами поднять службу qluster на всех трех узлах с QHB, начиная с узла-лидера, где был удален файл /qluster/add_node:
systemctl start qluster
При этом на узле-лидере будет автоматически проинициализирован каталог баз данных, а на узлах-репликах будут автоматически созданы реплики. Используются временные слоты репликации, которые создаются автоматически при необходимости.
Если при тестировании используется QCP, необходимо поднять на четвертом хосте службу qcp:
systemctl start qcp
Список команд
- Запуск службы QLUSTER:
systemctl start qluster
- Остановка службы QLUSTER:
systemctl stop qluster
- Перезапуск службы QLUSTER:
systemctl restart qluster
- Проверка статуса службы:
systemctl status qluster
- Чтение логов QLUSTER:
journalctl -u qluster --since "2025-08-12 15:12:00"
Некоторые данные можно также получать через Swagger или напрямую через REST-интерфейс.
Важные особенности
В случае остановки QHB при работающей qcp та начинает интенсивно пытаться установить связь с неработающим QHB, и в скором времени системный лог очень сильно увеличивается в размерах, что приводит к заполнению всего доступного пространства. После устранения причин генерации логов (запуск QHB или остановка qcp) нужно очистить системный журнал от имени пользователя root следующей командой:
truncate -s 0 /var/log/syslog # Очистка системного журнала в Ubuntu