Описание протокола QRAFT
QLuster построен на основе протокола RAFT, но с существенными изменениями:
-
протокол был специализирован под широковещательную сеть (в качестве транспорта выбран udp multicast) — взаимодействие узлов происходит не p2p, а каждый узел видит все сообщения, посланные другими узлами;
- из-за принципиальной ненадежности udp multicast была учтена возможность потери rpc-сообщений;
-
введена pre voting стадия голосования, исключающая появление «мерцаний»;
-
существенно переделаны выборы:
- убран статус узла «кандидат» (узлы могут быть либо лидерами, либо репликами) и соответствующие rpc-сообщения;
- по возможности выбирается узел с самым большим commit index (lsn);
- в случае проваленных выборов нет необходимости в случайной задержке;
-
добавлена защита от split brain (ситуация, когда в кластере одновременно существуют несколько лидеров).
Что осталось неизменным:
-
базовые понятия протокола RAFT: term, commit index, applied index;
-
механизм репликации логов.
Особенности широковещательного транспорта
-
Каждый узел видит все сообщения, посланные другими узлами, но некоторые сообщения могут быть утеряны.
-
Каждый узел кластера следит за связанностью с другими узлами — фиксирует время последнего сообщения от каждого узла, и если это время превышает таймаут, то заносит такой узел в список missing.
-
Во все rpc-сообщение добавляется заголовок, в котором узел сообщает свое состояние:
- term;
- commit index — lsn;
- applied index — первый индекс, который не был применен к машине состояния;
- minimum index — первый индекс лога, который содержится в журнале логов;
- идентификатор лидера кластера;
- список missing.
Такой подход позволяет каждому узлу следить за состоянием всех узлов кластера и принимать более взвешенное решение на стадии голосования за лидера.
Выборы лидера
Рисунок 1. Диаграмма переходов состояний узла кластера
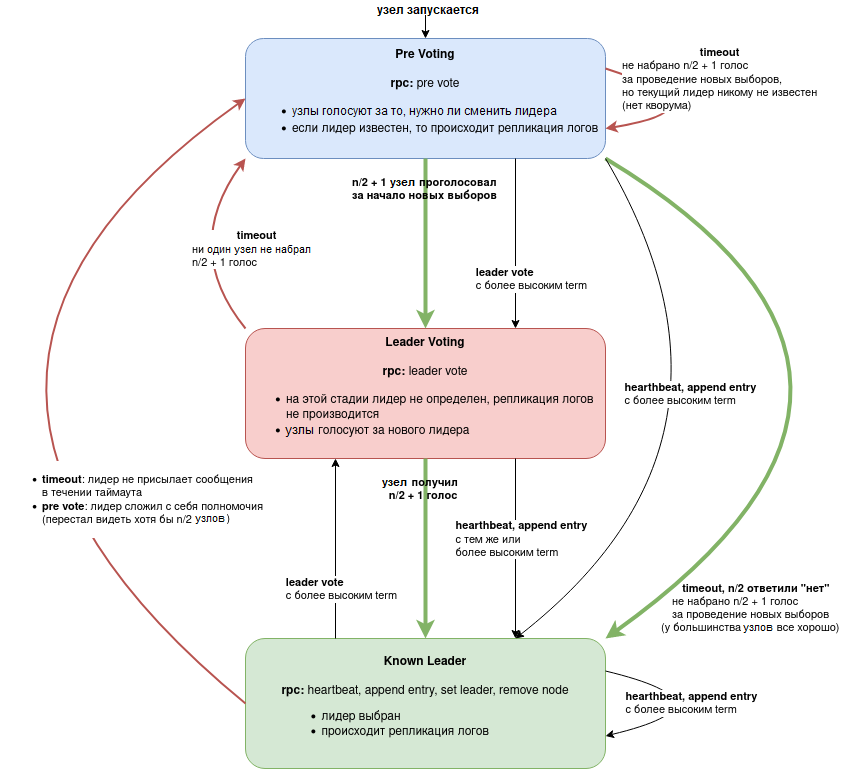
Pre Voting
В оригинальном RAFT существует проблема «мерцаний» — если у одного узла плохая связь, он инициирует выборы лидера и побеждает на них, после чего проблемы начинаются уже у всего кластера.
Чтобы избежать этого сценарии, мы ввели стадию предварительного голосования, на которой узлы голосуют за то, что нужно проводить выборы, или у большинства узлов все хорошо.
На этой стадии term НЕ увеличивается, таким образом работа лидера и репликация не прерываются.
Если нужное количество голосов не набирается в течении prevoting timeout, начавший голосование узел принимает текущего лидера (узел с максимальным числом упоминаний в качестве лидера в заголовках rpc-сообщений).
Если n/2 + 1 узел голосуют за то, что нужны новые выборы, то все узлы увеличивают свой term и переходят в состояние Leader Voting.
Leader Voting
-
На стадии Pre Voting все узлы актуализируют свои commit index и список missing.
-
Каждый узел сортирует список всех узлов кластера по убыванию, по значениям:
- commit index,
- идентификатор узла;
-
отфильтровываются узлы, которые не видит голосующий узел;
-
отфильтровываются узлы, которых не видит половина кластера или больше;
-
голос отдается за первый узлы в списке, если список пуст, то узел голосует за себя.
Такой подход утилизирует преимущества широковещательного транспорта и позволяет отказаться от «кандидатов» и случайных задержек.
Особенности работы лидера
Репликация логов
Механизм репликации логов полностью взят из RAFT без изменений.
В нашей реализации есть поддержка как слабой, так и сильной репликации, для чего используется параметр replication factor — на какое количество узлов должен быть реплицирован лог, прежде чем его можно применить к состоянию и увеличить значение applied index.
Сердцебиение
Если у лидера нет логов, которые требуется реплицировать, то он рассылает rpc Hearthbeat, чтобы передать текущий статус и показать, что он жив.
Узлы, получившие Hearthbeat от лидера, тоже отправляют Hearthbeat.
Уход в отставку
Без преемника
Если список missing лидера, содержит больше половины узлов кластера, то лидер добровольно снимает с себя полномочия. При этом он посылает rpc PreVote, чтобы уведомить об этом остальные узлы кластера. При получении PreVote от лидера узлы тут же начинают голосование за нового лидера.
С преемником
Если администратор планирует вручную переключить лидера в кластере, лидер формирует лог SetLeader с указанием узла-преемника.
Автоматический вывод узлов из кластера
Если некий узел кластера попал в список missing у n/2 + 1 узлов в кластере, то лидер автоматически формирует лог RemoveNode для его удалении из кластера.
При этом в настройках можно указать минимальное количество узлов в кластере (по умолчанию 5), при котором автоудаление перестает работать.
RPC-сообщения
Hearthbeat
Сердцебиение для наглядности и удобства выделано в отдельное rpc (в RAFT это AppendEntry без лога).
Разделение на request/reply нет, приемники имеют возможность определить, что сообщение отправлено лидером и на него требуется ответить.
AppendEntry/AppendEntryReply
Лидер отправляет AppendEntry, для того чтобы реплицировать лог на остальные узлы. Узлы, получившие это сообщение, пытаются реплицировать лог и отвечают статусом.
Параметры AppendEntry:
- prev log index;
- prev log term;
- log term;
- log.
Параметры AppendEntryReply:
- log index;
- success (да/нет).
PreVote/PreVoteReply
PreVote отправляет узел, который не видит сообщений от лидера в течении таймаута. При этом он не переключает term.
Каждый узел, получивший PreVote, отвечает PreVoteReply.
Параметры PreVoteReply:
- agree (да/нет) — голос за или против проведения выборов лидера.
LeaderVote
Отправляя это сообщение, узел голосует за нового лидера.
В RAFT это RequestVote/RequestVoteReply, но поскольку у нас нет кандидатов, то разделение на request/reply не требуется.
Параметры:
- candidate — идентификатор узла, за который проводится голосование.
Логи кластера
AddNode
Ввод в кластер нового узла.
RemoveNode
Отправляется лидером, если нужно вывести узел из кластера.
Параметры:
- id — идентификатор узла, удаляемого из кластера.
SetLeader
Смена лидера в кластере.
Параметры:
- leader — узел-преемник, который станет новым лидером.
SetConfiguration
Обновление настроек кластера. Все настройки отправляются в одном логе.
QhbReady/QhbDown
Отправляется узлом, сигнализирует о состоянии базы данных узла.
LeaderReady
Отправляется новым лидером после приведения базы данных в работоспособное состояние мастера.
Смена лидера вручную
-
Отправляется лог SetLeader с указанием идентификатора нового лидера.
-
Текущий (старый) лидер входит в режим смены лидера и больше не принимает новые логи.
-
Текущий лидер продолжает репликацию логов и ждет от нового лидера сердцебиение с увеличенным term.
-
Если в течении таймаута переключение лидера не происходит, старый лидер увеличивает term на 2 и остается лидером.